What about support for data-* attributes? #727
Comments
|
Nevermind, it doesn't work as I expected with React and Inferno, as the object would be converted to an string. |
|
Hmm - this should work in Preact, not sure what you're running into. let div = render(<div data-foo="bar" />, document.body)
// is identical to doing:
let div = document.createElement('div');
div.setAttribute('data-foo', 'bar');
document.body.appendChild(div); |
|
I tried something like |
|
Ah yeah, they all use setAttribute so it'll be serialized to a String. For efficient lists, I would strongly recommend using a windowing technique rather than trying to reduce overhead of 1000 items. There are a few out there to study, the most notable being React-Virtualized. There are two simple ones for Preact as well: preact-scroll-viewport and preact-virtual-list. Both can handle rendering a million rows easily, beyond that the browser's scrollbar becomes unreliable. |
|
Since this is a problem space I'm particularly fond of, I couldn't help but make a little jsfiddle showing an autosuggest-like setup doing live search over 100,000 results using https://jsfiddle.net/3yhqvk9L/ |
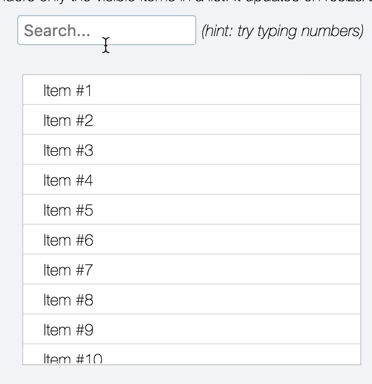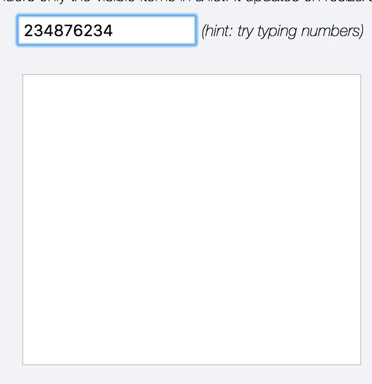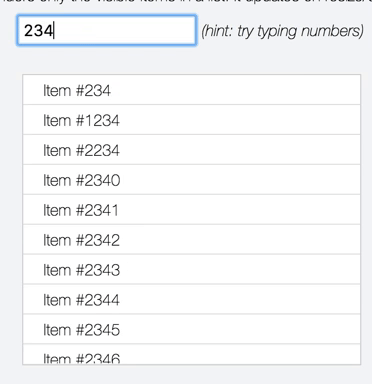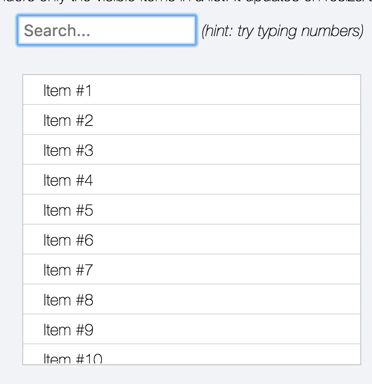
|
That's great, I'll certainly take a look at it next week. Here's how we currently handle it with jQuery. We generate a tree with possibly a thousand of autocomplete inputs, but we don't initialize them until they get focus. Hardly a user would focus on many of them, so this is lightweight (but for other components, such as sliders, that need to be initialized, we have a performance issue if we have many of them). Maintaining the DOM state by hand makes the app larger, harder to understand and more bug prone, that's why I'm interested in virtual DOM solutions since I'd usually only be concerned about the initial rendering and storing a few states. I have many ideas to optimize our code. For example, currently we render all tree items, even for collapsed sections, which are most of them. My idea is to only create those items once the sections are expanded, which should help reducing the memory usage. In addition to that, my plan is to avoid registering many event handlers, by using global handlers rather than per component handler, which should also help with memory savings. You're talking about dealing with tons of suggestions, which is also an interesting problem, and one we have to handle with for a few fields, but I'm mostly concerning about having a thousand of autocomplete components, like one per section item. Ideally, I wouldn't render those components in place, but click on the item to expand the components, but this decision is not mine to make and they didn't accept my approach. So, I'm trying to improve things without changing the current design. Our application is currently already fast, so I'm not in a hurry and have some time to think carefully about this. My goal is to make it more readable and maybe reduce the bundle size to make it load faster (it already loads fast, but I believe I can make it load even faster). As for the autocomplete presenting too many fields, when it becomes a performance issue, we can always resort to limit the amount of items in the server instead of showing all of them. |
|
Regarding your last jsfiddle, I didn't quite understand what you meant. Are you suggesting some libraries would render items that don't match and hide them? |
|
No - just you were talking about rendering thousands of items, so I figured that was the "visible" set. FWIW, in VDOM libs if you render 20 components and then re-render with 20 "different" components (different instances+data), the instances will simply be updated in-place without much cost. Your jQuery comparison is apt, and shows one of the strengths of Virtual DOM components in general. The ability to conditionally render totally changes how DOM interaction performs. Sounds like you're on an interesting path! :) |
|
The main problem I see with virtual DOM components is that it's hard to integrate with existing components, and, specially, replacing parts of the application one at a time. This is the same problem I noticed with Knockout.js some years ago. Ultimately I found that it seems a bit easier to write components with JSX/ES6 rather than with Knockout.js and similar solutions such as Vue and Angular. Also, it seems the initial rendering has the potential to be faster than the MVVM approach, and it's the most important time for most applications since it's okay if an update would take 300ms with virtual DOM implementations and only 1ms with Angular or KO, while taking 2s for the initial rendering with KO is significantly slower than taking 900ms with React.js for example. This is just the idea, I didn't measure those times myself yet because it takes a lot of time to make those experiments. Two days ago I spent several hours comparing how different design choices lead to different bundle sizes and build time: https://github.com/rosenfeld/minjs But I felt I should do it because since I'll start to port my code from CoffeeScript/(jQuery + KO mix) to JSX/Babel, I wanted to know what are the consequences for the code styling I decide to adopt. One of the most expensive operations during the boot time is to render a recursive tree that, for some deal types, will render over a thousand separate fields with components attached to them such as autocomplete, sliders and datepickers. When we created this code we had to support IE8 and it was painfully slow to create elements in IE8 with document.createElement. So, we had to generate the tree in pure HTML and basically set it to the tree element using innerHTML (actually there's more behind $().html() to avoid memory leaks). This part of the code didn't change much since then. We generate all HTML, set it to the tree and then we'll set up the date pickers, autocompletes and sliders. For date pickers and autocomplete I was able to lazily load them with little effort, and that improved a lot the initial load time for the application. However, it would be much more effort to try to mimic sliders and then replace them with actual sliders as someone would try to use it. So, I asked them to avoid using sliders for all numeric fields, but that would be ideal from a UX point of view. Now that I have some free time to try different things and now that our analytics tell us that no one is using IE8 these days, I can finally experiment with things such as React, Preact and Inferno. So, I'm trying to get a proof of concept on whether using them would allow me to get a similar boot time as we currently have, while improving the readability and maintainability and maybe the bundle sizes or build time. Since I started to learn about how to use virtual DOM implementations this week, I decided to implement a simple but performant autocomplete component, as we'll need a custom auto-completer anyway. Currently we built ours on top of jQuery UI autocomplete, but it behaves very differently from the original implementation. The basic version is mostly finished. Then I'll try to implement other alternatives, such as integrating an existing component lazily and compare the initial rendering performance as well as the impact on updates. This autocomplete component seems to be pretty lightweight, so I'm planning on using it for the other approach: http://leaverou.github.io/awesomplete/ Finally, I'll try another approach using pure JS and the awesomplete lazily initialized. I'm mostly interested on the overhead of solutions such as Preact, Inferno and React in the initial load time. I already noticed a problem with the Preact diffing algorithm and reported it a few days ago (issue #725). If you're interested, I'll let you know once I finish this experiment, which I intend to do next week unless I get some items in my backlog. |
the fast vdom libs have very low overhead [1]. most of the slowdown will be from the fact that you have a huge DOM for the browser to render rather than a huge backing vtree. "over one thousand" is peanuts :) [1] https://rawgit.com/krausest/js-framework-benchmark/master/webdriver-ts/table.html |
|
I'd definitely be curious to see how your experiments progress - in my performance testing over the past 2 years I've consistently seen updates take a fraction of the time an initial render takes - most of the cost is in atomic DOM operations. In order to combat initial render cost, people often server-render their (p)react applications as static HTML (codepen example), and then boot them on the client, which diffs against the static HTML. There is an interesting demo here where you can compare SSR (statically pre-rendered HTML) VS a cold boot. On my machine rendering the 4000 elements takes 30ms with SSR or 40ms without. |
|
I've been researching about ways to improve the initial page load time for several years now. About 4 or 5 years ago, we signed a contract in which we should load the application in under 5s (I wasn't consulted about that clause by that time, I've just been informed about it). Since then I've been working hard to meet that constraint but it consistently fails for about 5-10% of our views for quite a while, but it was about the opposite about 4 or 5 years ago, when only 5-10% would load it in under 5s ;) I was able to improve the server-side design so much that currently it takes only about 50ms at most of total server time to generate the data. I've also made several changes to the front-end to make it load as fast as I could and that was the main reason why I switched from Sprockets to Webpack a few years ago when I wanted to lazily load our code to reduce the initial bundle size. Years ago, during my experiments, I tried to render the fields tree in the server-side rather than in the client-side and couldn't notice any significant difference in the total load time, and this was in my development machine running with production settings. When I tried that in the collocation servers we had by that time, things got a bit worse actually because even after gzip the HTML response would be bigger with the pre-rendered tree, while it was smaller when I embedded the tree as JSON and rendered in the client. Since then I've changed how the page load works, so I can't repeat this comparison. Since our CSRF token is served with the page and since it's always different for each page load, we can't cache it, from a client-point of view (returning 304, for example). So, we try to make it trivially small and render everything in the client-side because our bundles are cached and the fields tree JSON can also be cached. Instead of requesting the fields tree JSON with XHR, which wouldn't use the browser caching, we actually serve it as a separate JS file we refer to in the main page head section. I won't go into the details since there's a lot to say about it. The fact is that most of the time all of our JS files will be cached. Even when they aren't they should load fast. They are all declared soon in the head and marked as async. The main page is pretty small. I haven't measured but I suspect SSR would make the total load time usually worse, not better. If you are curious on the subject, I'm available to give more details about my researches so far. Since I wasn't happy with NewRelic's Browser available information by the time it was a beta product, I created my own simple performance analytics tool that would store all data from the Also, since it's a Ruby application, if I was going to render it in the server-side I'd have to probably call an external process to do that for me, which means more complexity in the back-end. Since I'm not convinced this could improve things and I suspect it could actually make things worse, I'm currently not much interested in SSR, since I already know I can improve other parts that would give me better results than SSR. I'm particularly interested in your suggestion of creating elements that would be in the view port, although I have no idea on how to implement that in a reliable way, that would work well with the scrollbar. But I don't think this is the time for this kind of optimizations because it would be premature. I have a much simpler idea for now, since only the first section is usually expanded, which would already reduce significantly the amount of elements to create with a new approach I intend to use. Maybe that will be enough optimization for me to stop worrying about this field tree. That's why I'm currently focusing on supporting autocomplete, sliders and date pickers, which will allow me to replace the fields tree with Preact in the main application and give it a try on the real thing so that I can compare to the current solution. |
|
here's a 50x50 https://jsfiddle.net/2g5pze4b/ you can see from the screenshot that the vast majority of the time spent is just the browser actually doing layout and painting. the vdom lib overhead is ~125ms of scripting time, which includes parsing the lib, generating the fake data and building the vtree. (this is not on a fast machine, my laptop can do 2x-3x faster). all other aspects of performance are orthogonal to this - things like network optimizations, TTFB, code minification & bundling (i recommend Closure Compiler). you can get really far before code splitting adds measurable value and justifies its complexity (similar to SSR); personally, i've never had an app that needed it.
|

|
Lazy loading is very important when you are worried about the total bundle size for non cached requests. I noticed a while back that the main reason why some people were taking over 5s to render the initial page is because they were waiting a few seconds downloading about 500KB or so of minified and gzipped bundled JS containing the entire application. Only part of that JS is really required for the initial page load, so the lazy load approach allowed us to get significantly better results for clients with low bandwidth. TTFB is usually out of our control when the back-end request takes basically no time, so what I can really act upon is on the bundle size, code run speed and server processing time. There's no way I can significantly improve things in the server-side as it would save me only about 50ms or so in the worst scenario. That's why I focus on the bundle size for the initial page rendering and reducing the total time spent in JS. My main concern with integrating Google Closure Compiler with webpack is that I suspect the builds would become significantly slower since it doesn't provide a daemon based mode to skip the JVM startup overhead. In some quick experiments I've done these days, GCC would take about the same time as UglifyJS 3 while resulting in basically the same bundle size after gzip, so I'm not that much impressed with it. 50% of all views happen in less than 1s in our application, so I don't need to further optimize towards them. I do need to focus on the extra 5-10% that take over 5s and in many of those cases, the bundle size seems to have a big impact. For the other cases I don't think there's anything I could do since they are related to TTFB factors that are out of my control... |
|
nice - this is a good example of where app design + things like windowing can entirely change the way the browser performs. If we can push some of the complexity of layout and clipping into a layer we control that can make more specific assumptions, we can avoid relying on the browser to do things for us. For me, there is a balance though - moving rendering and layout out of the DOM and into a library risks giving up things the DOM does well like accessibility and extensibility. To your comment @rosenfeld - I feel like caching could probably mitigate most of the effects of those performance factors, right? First hit does all the warmup and computation, but thereafter its really just static. |
|
Not just that. It's not simple to decide whether or not we should render a component based on the view port. Even if we can do that in a reliable way, I don't think there would be a reliable way to properly calculate the padding in such a way the scroll bar would simulate as all items have been rendered, unless you know for sure the height of each item (they are not uniform in our fields tree). And even if you could do that, there's a chance you increased the size bundle in a few KB after min.gz to do that, which also affects the time to download. So, it should be used as a last resource. Particularly for this application I don't think I'll need such optimizations because only the first section containing some few popular fields is expanded upon load, which allows me to lazily generate the other fields as the user expands the other sections. There are usually less than 20 sections and we typically only display the section names in the fields tree in the initial load, so it should be able to quickly render the initial state of the fields tree without resorting to complex algorithms that would try to optimize towards rendering components in the view port only. As I told you, the most painful part in this process is to have to rewrite a lot of stuff to work well with the virtual DOM. Preact will compare to the real DOM, so it's less than a problem to use external libraries with Preact than it would be with Inferno or React since they compare to the previous vdom and things could go wrong if the components act directly in the DOM. I'm trying to write the application so that it works equally well with whatever React-like solution so that I can always switch them and compare which ones gives me the best results without changing the code. Another reason is that I wouldn't rely on a single vendor, which is important to me in case some project changes radically the way components should be written and I would be forced to update all my components or if the libraries stop to be maintained for any reasons... I'd love to be able to more quickly replace parts of the application with Preact while still being able to use the other code that relies on DOM modifications, but I understand that it can't be the case with vdom solutions while still getting good performance. Also, when such solutions are intermixed, the chances of memory leaking are pretty high. jQuery won't call componentWillUnmount and vdom solutions won't call jQuery().remove() on the nodes to make sure any associated data would be cleared, resulting in memory leak. That's why I should completely implement the fields tree component as a whole before I replace the current implementation... |
|
500KB gz is a very large app, assuming most of it isn't data and your app framework & datastore isn't 50% of it. even so, as @developit points out, after initial load it's all cached.
personally, i aim for 250ms worst case and ~100ms typical case. keeping the DOM size manageable and css complexity under control is instrumental to this. 1,000 fields in a single view (or 1000-long autocomplete list) is recipe for slowness [and, frankly, sub-optimal ux] no matter which framework you use. the only time when it may be difficult to avoid is if you absolutely must render a grid of data where [as you pointed out] the cell size cannot be pre-determined without rendering which makes occlusion culling fall over. |
so you're not initially rendering thousands of fields. then i assume the slowness comes purely from your UI framework or app code and not from DOM size. even the slowest frameworks can render 100-200 fields quickly (ms, not s) and render the rest upon interaction/expansion, so i'm pretty confused. |
|
Progressive boot would give you the effect you describe with the lazy upgrade of jQuery plugins, but in a completely automated way. Paul Lewis submitted a PR to add it to Preact a while ago that I've been toying with since then, #409, that might be worth a look. Viewport doesn't have to just be flat lists or anything - we have a component at work that we use to completely skip rendering of obscured components that uses the browser's own calculations. No need for custom layout calculations or visibility checks, it sortof "just works". We wrap our split points in it too, so we don't even load code for out of view components until they are needed. |
|
Exactly, @leeoniya. That's why I asked many times to remove some features from the interface like the "Expand All Sections" button which would force me to render all of them. Eventually I was able to get rid of this button for other UX related issues since the client asked for it and I celebrated because they weren't listening to my technical complaints regarding performance. I always wanted to be able to render the tree lazily, as the user expanded the sections and subsections, but the Expand All buttons would make this approach extremely slow. Now things are a bit different and I can test new approaches. If I would be able to load that tree lazily, I would save about 30KB of JSON data after gzip, which should help to improve the load time even more. This tree is usually cached in the server-side and the JSON usually generated in under 100ms when needed, but it wouldn't be necessary to do that if everything happened in a lazy way.
It's indeed a large app. It was already large and I took this project about 6 years ago and it keeps growing. Definitely this is not data store, but a lot of it used to be used by dependencies which I have been removed in the past years, so I guess it wouldn't be that big today if I bundled everything together. jQuery UI is the biggest dependency after gzip and minify. The other large ones that I remember are jQuery and Knockout.js. The Datepicker is one of the biggest dependencies in jQuery UI. Most of our code is currently written as CoffeeScript classes, which means the minifier is not able to compact the method names, unless we use some sort of conventions for private methods, which is something I've been considering since we already use a convention for most cases. That's why I created the minjs repository so that I could test the impact on the bundle size and in the build time when using classes with ES6 or pure functions. Our Search CoffeeScript class is our largest dependency among the non-vendor code. It's a big CoffeeScript class today, asking for a big refactoring to split it furthermore (this work has started a while ago, but there's much more to be done). When I took this code base, it was a Grails application and all JS was embedded in the GSP as huge functions. At some point I splitted those functions and converted that code to use CoffeeScript classes and the functions became methods and most function arguments become properties of the class instance. The code became way more maintanable then it used to be, but I really want to split it furthermore into smaller components that would be easier to test separately. The Search responds for the main application's tab, but we have others. Viewing and editing a transaction is also another big part of it but it's not required for the initial page load, so it's loaded lazily. Currently, just rendering the fields tree without initializing the sliders (datepickers and autocomplete are already just initialized in a lazy way), take about 180ms to generate all fields (most are initially hidden though, so they are not rendered by the browser, but the elements were created). We enabled the slider for just two fields and it takes another 30ms just to render those two sliders using jQuery UI. We have hundreds of numeric fields and they asked me once to enable the slider for all of them but as you can see, it would be pretty slow if I did that. But it might be possible if I render those sections on demand or if I write my own slider component. We display an initial state in usually less than 0.5s with a "loading indication" which I can't really see in my local environment even without cache, but it's important for those that take 5s to load it. In my development enviroment, enabling the filmstrip feature in Chrome DevTools, it takes about 1.7s to render the full initial state for an uncached request simulating a 4G regular connection. The loading page is displayed in about 300ms (first snapshot). For cached requests it goes to about 1.1s. This is for a total of 848 fields for this deal type. Profiling the page loading shows that we currently use 1.2s of scripting vs 110ms of actual rendering and only 4ms for Painting. So, there's quite some space to improve the scripting part. |
probably worth starting a gradual migration to ES2015 :)
a basic datepicker can be had in < 1k gz ;) it sounds like the majority of your app can be refactored away and you'd end up with < 200k gz. i'll bet you a large sum of money that you will not need SSR, progressive/lazy loading, occlusion culling, code splitting or any obscure optimization tricks if the app is simply rewritten properly on top of any fast vdom lib. |
|
Yes, exactly, I'm writing the new autocomplete component with ES6 (ES2015, is there any difference?). The minjs repository was to see whether I should use ES6 classes or avoid them and prefer pure functions when possible. As for the datepicker, I was evaluating Pickaday: https://github.com/dbushell/Pikaday Does your datepicker have a related project with documentation, license and so on, or is it just for internal usage or a toy? I'm pretty happy with lazy loading, it's pretty simple to implement with webpack and it helps a lot. I don't think I'll stop using it at any point... I'm also not yet convinced SSR would help with our application. But I agree that our code should become much smaller, not only by replacing big UI libraries with small ones, but also because I'd be able to remove tons of code to manage the DOM and only caring about the initial rendering, handling everything else with pure JS controlling the states... I just have that feeling that it will be a long time before I can finish converting to vdom :) |
the datepicker is a demo component built with domvm. so you cannot just take it without inheriting that vdom dependency (~6k gz). i would not recommend that you use it if the rest of your app is built using another ui lib. is it a toy? well, it probably lacks 95% of options you would find in datepickers that support i18n, a11y, and hundreds of other things. it's written as bare-bones example to be modified and tweaked as needed by the end user. the only options it really has is being able to configure the start of the week. if what you need is simple, then it may very well suffice, otherwise you may need to add a lot more stuff to it. the goal was to just build out the core logic for calendar display. the license is the same as the domvm repo, it's MIT. if you want to build your own picker, feel free to take the cell computation logic and use it within your own ui lib to code a picker. |
|
I just opened the production site as a regular client rather than as an admin. The first screenshot took about 250ms to display the "loading page" and 1.1s to display the final state. The main page is 6.7 KB gzipped, the theme CSS is 3 KB, the vendor bundle is 187 KB and the client bundle is 66.5 KB. There are 3 other dynamic JS (2 of them cacheable) with 4.3 KB, 3.7 KB and 18.4 KB (the last two bring data from the database and are cacheable). The main sprite image is about 11.8 KB. Just after the page is rendered we ask for some other common bundles, so that they would be already available the moment the user requests to open some transaction, which is a common operation, allowing them to load faster. We preload two bundles after the initial rendering of 71.6 KB and another of 12.7 KB... |
|
The total transferred amount reported by the Network tab of the Chrome Devtools is 412KB (22 requests, most of them are images), including some third-party tracking JS... DOMContentLoaded happens at 245ms and Load event in 686ms. All of this for an uncached request. |
|
those metrics are not nightmarish; seems like you just have a ton of legacy js baggage and some slow dependencies. |
|
We don't need a fancy datepicker. It just needs to work, provide some simple callbacks when a date is picked and allow me to specify a valid date range. I may try to use your sample datepicker and adapt to my needs but if it gets bigger than Pickaday, maybe I'd use the latter :) |
|
They are not legacy JS (except for the vendored dependencies) in the sense I could get rid of lots of it. We actually use all that JS, but we need a better way to split them in smaller components so that we could test them in isolation. Also, it would be much better if we didn't have to manually perform DOM operations and only care about logic and updating the data. That's why I was interested in Knockout.js. However, it seems things can get much simpler and with a faster initial rendering time by using some vdom tech and JSX instead of KO. |
|
if Pikaday is 5kb, then you'd already be over by ingesting domvm (~6kb) and have none of Pikaday's features to show for it :) so, again: not recommended unless you're already using domvm for the rest of your app. |
|
I was assuming that domvm wouldn't be required and the code could be adapted to use Preact/React/Inferno, so the code itself isn't 6kb, right? :) |
|
sure :) also, 2.5K: https://github.com/chrisdavies/tiny-date-picker |
|
Great, thanks! |
|
Also, we don't need to handle i18n in the calendar. We just need to localize the date format a bit different for our UK users which use dd/mm/yyyy rather than Canadian and US users which use mm/dd/yyyy. But all clients use the interface in English. |
|
A lot of the complexity and size in datepickers comes from those edge cases as @leeoniya pointed out. If you can skip them, skip them. The Canadian VS US dates you can probably do as a display mechanism if you're using VDOM (data doesn't have to be displayed in the same format as it is held/edited). I agree the numbers you're looking at actually aren't that bad, and Code Splitting seems like an easy bit of low-hanging fruit. |
I noticed I can add data-* attributes to the virtual dom and they work as expected both with React and Inferno. I'm curious about why this doesn't work with Preact. Is that on purpose. What would be the reason for that? I just get an empty
datasetwith Preact.The text was updated successfully, but these errors were encountered: