diff --git a/README.md b/README.md
index 7e79f1d956..2d1404bdb3 100644
--- a/README.md
+++ b/README.md
@@ -32,7 +32,7 @@ Trinity-RFT is a flexible, general-purpose framework for reinforcement fine-tuni
* 📊 For data engineers. [[tutorial]](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/develop_operator.html)
- Create datasets and build data pipelines for cleaning, augmentation, and human-in-the-loop scenarios.
- - Example: [Data Processing](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_data_functionalities.html)
+ - Example: [Data Processing Foundations](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_data_functionalities.html), [Online Task Curriculum](https://github.com/modelscope/Trinity-RFT/tree/main/examples/bots)
## 🌟 Key Features
@@ -67,13 +67,13 @@ Trinity-RFT is a flexible, general-purpose framework for reinforcement fine-tuni
## 🔨 Tutorials and Guidelines
-| Category | Tutorial / Guideline |
-| --- | --- |
-| Run diverse RFT modes | + [Quick example: GRPO on GSM8k](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_reasoning_basic.html)
+ [Off-policy RFT](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_reasoning_advanced.html)
+ [Fully asynchronous RFT](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_async_mode.html)
+ [Offline learning by DPO or SFT](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_dpo.html) |
-| Multi-step agentic scenarios | + [Concatenated multi-turn workflow](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_multi_turn.html)
+ [General multi-step workflow](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_step_wise.html)
+ [ReAct workflow with an agent framework](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_react.html) |
-| Advanced data pipelines | + [Rollout task mixing and selection](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/develop_selector.html)
+ [Experience replay](https://github.com/modelscope/Trinity-RFT/tree/main/examples/ppo_countdown_exp_replay)
+ [Advanced data processing & human-in-the-loop](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_data_functionalities.html) |
-| Algorithm development / research | + [RL algorithm development with Trinity-RFT](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_mix_algo.html) ([paper](https://arxiv.org/pdf/2508.11408))
+ Non-verifiable domains: [RULER](https://github.com/modelscope/Trinity-RFT/tree/main/examples/grpo_gsm8k_ruler), [trainable RULER](https://github.com/modelscope/Trinity-RFT/tree/main/examples/grpo_gsm8k_trainable_ruler), [rubric-as-reward](https://github.com/modelscope/Trinity-RFT/tree/main/examples/grpo_rubric_as_reward)
+ [Research project: group-relative REINFORCE](https://github.com/modelscope/Trinity-RFT/tree/main/examples/rec_gsm8k) ([paper](https://arxiv.org/abs/2509.24203))|
-| Going deeper into Trinity-RFT | + [Full configurations](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/trinity_configs.html)
+ [Benchmark toolkit for quick verification and experimentation](./benchmark/README.md)
+ [Understand the coordination between explorer and trainer](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/synchronizer.html) |
+| Category | Tutorial / Guideline |
+| --- |------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+| Run diverse RFT modes | + [Quick example: GRPO on GSM8k](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_reasoning_basic.html)
+ [Off-policy RFT](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_reasoning_advanced.html)
+ [Fully asynchronous RFT](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_async_mode.html)
+ [Offline learning by DPO or SFT](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_dpo.html) |
+| Multi-step agentic scenarios | + [Concatenated multi-turn workflow](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_multi_turn.html)
+ [General multi-step workflow](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_step_wise.html)
+ [ReAct workflow with an agent framework](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_react.html) |
+| Advanced data pipelines | + [Rollout task mixing and selection](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/develop_selector.html)
+ [Online task curriculum](https://github.com/modelscope/Trinity-RFT/tree/main/examples/bots) ([paper](https://arxiv.org/pdf/2510.26374))
+ [Experience replay](https://github.com/modelscope/Trinity-RFT/tree/main/examples/ppo_countdown_exp_replay)
+ [Advanced data processing & human-in-the-loop](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_data_functionalities.html) |
+| Algorithm development / research | + [RL algorithm development with Trinity-RFT](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_mix_algo.html) ([paper](https://arxiv.org/pdf/2508.11408))
+ Non-verifiable domains: [RULER](https://github.com/modelscope/Trinity-RFT/tree/main/examples/grpo_gsm8k_ruler), [trainable RULER](https://github.com/modelscope/Trinity-RFT/tree/main/examples/grpo_gsm8k_trainable_ruler), [rubric-as-reward](https://github.com/modelscope/Trinity-RFT/tree/main/examples/grpo_rubric_as_reward)
+ [Research project: group-relative REINFORCE](https://github.com/modelscope/Trinity-RFT/tree/main/examples/rec_gsm8k) ([paper](https://arxiv.org/abs/2509.24203)) |
+| Going deeper into Trinity-RFT | + [Full configurations](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/trinity_configs.html)
+ [Benchmark toolkit for quick verification and experimentation](./benchmark/README.md)
+ [Understand the coordination between explorer and trainer](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/synchronizer.html) |
> [!NOTE]
@@ -82,6 +82,7 @@ Trinity-RFT is a flexible, general-purpose framework for reinforcement fine-tuni
## 🚀 News
+* [2025-11] Introducing [BOTS](https://github.com/modelscope/Trinity-RFT/tree/main/examples/bots): online RL task selection for efficient LLM fine-tuning ([paper](https://arxiv.org/pdf/2510.26374)).
* [2025-10] [[Release Notes](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.3.2)] Trinity-RFT v0.3.2 released: bug fixes and advanced task selection & scheduling.
* [2025-10] [[Release Notes](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.3.1)] Trinity-RFT v0.3.1 released: multi-stage training support, improved agentic RL examples, LoRA support, debug mode and new RL algorithms.
* [2025-09] [[Release Notes](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.3.0)] Trinity-RFT v0.3.0 released: enhanced Buffer, FSDP2 & Megatron support, multi-modal models, and new RL algorithms/examples.
diff --git a/README_zh.md b/README_zh.md
index a54b2389b6..e8700d83ea 100644
--- a/README_zh.md
+++ b/README_zh.md
@@ -32,7 +32,7 @@ Trinity-RFT 是一个灵活、通用的大语言模型(LLM)强化微调(RF
* 📊 面向数据工程师。[[教程]](https://modelscope.github.io/Trinity-RFT/zh/main/tutorial/develop_operator.html)
- 设计针对任务定制的数据集,构建处理流水线以支持数据清洗、增强以及人类参与场景
- - 示例:[数据处理](https://modelscope.github.io/Trinity-RFT/zh/main/tutorial/example_data_functionalities.html)
+ - 示例:[数据处理基础](https://modelscope.github.io/Trinity-RFT/zh/main/tutorial/example_data_functionalities.html),[在线任务选择](https://github.com/modelscope/Trinity-RFT/tree/main/examples/bots)
# 🌟 核心特性
@@ -67,13 +67,13 @@ Trinity-RFT 是一个灵活、通用的大语言模型(LLM)强化微调(RF
## 🔨 教程与指南
-| Category | Tutorial / Guideline |
-| --- | --- |
-| 运行各种 RFT 模式 | + [快速开始:在 GSM8k 上运行 GRPO](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_reasoning_basic.html)
+ [Off-policy RFT](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_reasoning_advanced.html)
+ [全异步 RFT](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_async_mode.html)
+ [通过 DPO 或 SFT 进行离线学习](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_dpo.html) |
-| 多轮智能体场景 | + [拼接多轮任务](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_multi_turn.html)
+ [通用多轮任务](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_step_wise.html)
+ [调用智能体框架中的 ReAct 工作流](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_react.html) |
-| 数据流水线进阶能力 | + [Rollout 任务混合与选取](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/develop_selector.html)
+ [经验回放](https://github.com/modelscope/Trinity-RFT/tree/main/examples/ppo_countdown_exp_replay)
+ [高级数据处理能力 & Human-in-the-loop](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_data_functionalities.html) |
+| Category | Tutorial / Guideline |
+| --- |-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+| 运行各种 RFT 模式 | + [快速开始:在 GSM8k 上运行 GRPO](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_reasoning_basic.html)
+ [Off-policy RFT](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_reasoning_advanced.html)
+ [全异步 RFT](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_async_mode.html)
+ [通过 DPO 或 SFT 进行离线学习](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_dpo.html) |
+| 多轮智能体场景 | + [拼接多轮任务](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_multi_turn.html)
+ [通用多轮任务](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_step_wise.html)
+ [调用智能体框架中的 ReAct 工作流](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_react.html) |
+| 数据流水线进阶能力 | + [Rollout 任务混合与选取](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/develop_selector.html)
+ [在线任务选择](https://github.com/modelscope/Trinity-RFT/tree/main/examples/bots) ([论文](https://arxiv.org/pdf/2510.26374))
+ [经验回放](https://github.com/modelscope/Trinity-RFT/tree/main/examples/ppo_countdown_exp_replay)
+ [高级数据处理能力 & Human-in-the-loop](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_data_functionalities.html) |
| RL 算法开发/研究 | + [使用 Trinity-RFT 进行 RL 算法开发](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_mix_algo.html) ([论文](https://arxiv.org/pdf/2508.11408))
+ 不可验证的领域:[RULER](https://github.com/modelscope/Trinity-RFT/tree/main/examples/grpo_gsm8k_ruler), [可训练 RULER](https://github.com/modelscope/Trinity-RFT/tree/main/examples/grpo_gsm8k_trainable_ruler), [rubric-as-reward](https://github.com/modelscope/Trinity-RFT/tree/main/examples/grpo_rubric_as_reward)
+ [研究项目: group-relative REINFORCE](https://github.com/modelscope/Trinity-RFT/tree/main/examples/rec_gsm8k) ([论文](https://arxiv.org/abs/2509.24203)) |
-| 深入认识 Trinity-RFT | + [完整配置指南](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/trinity_configs.html)
+ [用于快速验证和实验的 Benchmark 工具](./benchmark/README.md)
+ [理解 explorer-trainer 同步逻辑](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/synchronizer.html) |
+| 深入认识 Trinity-RFT | + [完整配置指南](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/trinity_configs.html)
+ [用于快速验证和实验的 Benchmark 工具](./benchmark/README.md)
+ [理解 explorer-trainer 同步逻辑](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/synchronizer.html) |
> [!NOTE]
@@ -83,6 +83,7 @@ Trinity-RFT 是一个灵活、通用的大语言模型(LLM)强化微调(RF
## 🚀 新闻
+* [2025-11] 推出 [BOTS](https://github.com/modelscope/Trinity-RFT/tree/main/examples/bots):在线RL任务选择,实现高效LLM微调([论文](https://arxiv.org/pdf/2510.26374))。
* [2025-10] [[发布说明](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.3.2)] Trinity-RFT v0.3.2 发布:修复若干 Bug 并支持进阶的任务选择和调度。
* [2025-10] [[发布说明](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.3.1)] Trinity-RFT v0.3.1 发布:多阶段训练支持、改进的智能体 RL 示例、LoRA 支持、调试模式和全新 RL 算法。
* [2025-09] [[发布说明](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.3.0)] Trinity-RFT v0.3.0 发布:增强的 Buffer、FSDP2 & Megatron 支持,多模态模型,以及全新 RL 算法/示例。
diff --git a/docs/sphinx_doc/source/main.md b/docs/sphinx_doc/source/main.md
index 9c6857e237..c44ff90401 100644
--- a/docs/sphinx_doc/source/main.md
+++ b/docs/sphinx_doc/source/main.md
@@ -12,7 +12,7 @@ Trinity-RFT is a flexible, general-purpose framework for reinforcement fine-tuni
* 📊 For data engineers. [[tutorial]](/tutorial/develop_operator.md)
- Create datasets and build data pipelines for cleaning, augmentation, and human-in-the-loop scenarios.
- - Example: [Data Processing](/tutorial/example_data_functionalities.md)
+ - Example: [Data Processing Foundations](/tutorial/example_data_functionalities.md), [Online Task Curriculum](https://github.com/modelscope/Trinity-RFT/tree/main/examples/bots)
## 🌟 Key Features
@@ -52,7 +52,7 @@ Trinity-RFT is a flexible, general-purpose framework for reinforcement fine-tuni
| --- | --- |
| Run diverse RFT modes | + [Quick example: GRPO on GSM8k](/tutorial/example_reasoning_basic.md)
+ [Off-policy RFT](/tutorial/example_reasoning_advanced.md)
+ [Fully asynchronous RFT](/tutorial/example_async_mode.md)
+ [Offline learning by DPO or SFT](/tutorial/example_dpo.md) |
| Multi-step agentic scenarios | + [Concatenated multi-turn workflow](/tutorial/example_multi_turn.md)
+ [General multi-step workflow](/tutorial/example_step_wise.md)
+ [ReAct workflow with an agent framework](/tutorial/example_react.md) |
-| Advanced data pipelines | + [Rollout task mixing and selection](/tutorial/develop_selector.md)
+ [Experience replay](https://github.com/modelscope/Trinity-RFT/tree/main/examples/ppo_countdown_exp_replay)
+ [Advanced data processing & human-in-the-loop](/tutorial/example_data_functionalities.md) |
+| Advanced data pipelines | + [Rollout task mixing and selection](/tutorial/develop_selector.md)
+ [Online task curriculum](https://github.com/modelscope/Trinity-RFT/tree/main/examples/bots) ([paper](https://arxiv.org/pdf/2510.26374))
+ [Experience replay](https://github.com/modelscope/Trinity-RFT/tree/main/examples/ppo_countdown_exp_replay)
+ [Advanced data processing & human-in-the-loop](/tutorial/example_data_functionalities.md) |
| Algorithm development / research | + [RL algorithm development with Trinity-RFT](/tutorial/example_mix_algo.md) ([paper](https://arxiv.org/pdf/2508.11408))
+ Non-verifiable domains: [RULER](https://github.com/modelscope/Trinity-RFT/tree/main/examples/grpo_gsm8k_ruler), [trainable RULER](https://github.com/modelscope/Trinity-RFT/tree/main/examples/grpo_gsm8k_trainable_ruler), [rubric-as-reward](https://github.com/modelscope/Trinity-RFT/tree/main/examples/grpo_rubric_as_reward)
+ [Research project: group-relative REINFORCE](https://github.com/modelscope/Trinity-RFT/tree/main/examples/rec_gsm8k) ([paper](https://arxiv.org/abs/2509.24203))|
| Going deeper into Trinity-RFT | + [Full configurations](/tutorial/trinity_configs.md)
+ [Benchmark toolkit for quick verification and experimentation](https://github.com/modelscope/Trinity-RFT/tree/main/benchmark/README.md)
+ [Understand the coordination between explorer and trainer](/tutorial/synchronizer.md) |
diff --git a/docs/sphinx_doc/source_zh/main.md b/docs/sphinx_doc/source_zh/main.md
index e982516020..7f1c871998 100644
--- a/docs/sphinx_doc/source_zh/main.md
+++ b/docs/sphinx_doc/source_zh/main.md
@@ -12,7 +12,7 @@ Trinity-RFT 是一个灵活、通用的大语言模型(LLM)强化微调(RF
* 📊 面向数据工程师。[[教程]](/tutorial/develop_operator.md)
- 设计针对任务定制的数据集,构建处理流水线以支持数据清洗、增强以及人类参与场景
- - 示例:[数据处理](/tutorial/example_data_functionalities.md)
+ - 示例:[数据处理基础](/tutorial/example_data_functionalities.md),[在线任务选择](https://github.com/modelscope/Trinity-RFT/tree/main/examples/bots)
# 🌟 核心特性
@@ -48,13 +48,13 @@ Trinity-RFT 是一个灵活、通用的大语言模型(LLM)强化微调(RF
## 🔨 教程与指南
-| Category | Tutorial / Guideline |
-| --- | --- |
-| 运行各种 RFT 模式 | + [快速开始:在 GSM8k 上运行 GRPO](/tutorial/example_reasoning_basic.md)
+ [Off-policy RFT](/tutorial/example_reasoning_advanced.md)
+ [全异步 RFT](/tutorial/example_async_mode.md)
+ [通过 DPO 或 SFT 进行离线学习](/tutorial/example_dpo.md) |
-| 多轮智能体场景 | + [拼接多轮任务](/tutorial/example_multi_turn.md)
+ [通用多轮任务](/tutorial/example_step_wise.md)
+ [调用智能体框架中的 ReAct 工作流](/tutorial/example_react.md) |
-| 数据流水线进阶能力 | + [Rollout 任务混合与选取](/tutorial/develop_selector.md)
+ [经验回放](https://github.com/modelscope/Trinity-RFT/tree/main/examples/ppo_countdown_exp_replay)
+ [高级数据处理能力 & Human-in-the-loop](/tutorial/example_data_functionalities.md) |
+| Category | Tutorial / Guideline |
+| --- |---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+| 运行各种 RFT 模式 | + [快速开始:在 GSM8k 上运行 GRPO](/tutorial/example_reasoning_basic.md)
+ [Off-policy RFT](/tutorial/example_reasoning_advanced.md)
+ [全异步 RFT](/tutorial/example_async_mode.md)
+ [通过 DPO 或 SFT 进行离线学习](/tutorial/example_dpo.md) |
+| 多轮智能体场景 | + [拼接多轮任务](/tutorial/example_multi_turn.md)
+ [通用多轮任务](/tutorial/example_step_wise.md)
+ [调用智能体框架中的 ReAct 工作流](/tutorial/example_react.md) |
+| 数据流水线进阶能力 | + [Rollout 任务混合与选取](/tutorial/develop_selector.md)
+ [在线任务选择](https://github.com/modelscope/Trinity-RFT/tree/main/examples/bots) ([论文](https://arxiv.org/pdf/2510.26374))
+ [经验回放](https://github.com/modelscope/Trinity-RFT/tree/main/examples/ppo_countdown_exp_replay)
+ [高级数据处理能力 & Human-in-the-loop](/tutorial/example_data_functionalities.md) |
| RL 算法开发/研究 | + [使用 Trinity-RFT 进行 RL 算法开发](/tutorial/example_mix_algo.md) ([论文](https://arxiv.org/pdf/2508.11408))
+ 不可验证的领域:[RULER](https://github.com/modelscope/Trinity-RFT/tree/main/examples/grpo_gsm8k_ruler), [可训练 RULER](https://github.com/modelscope/Trinity-RFT/tree/main/examples/grpo_gsm8k_trainable_ruler), [rubric-as-reward](https://github.com/modelscope/Trinity-RFT/tree/main/examples/grpo_rubric_as_reward)
+ [研究项目: group-relative REINFORCE](https://github.com/modelscope/Trinity-RFT/tree/main/examples/rec_gsm8k) ([论文](https://arxiv.org/abs/2509.24203)) |
-| 深入认识 Trinity-RFT | + [完整配置指南](/tutorial/trinity_configs.md)
+ [用于快速验证和实验的 Benchmark 工具](https://github.com/modelscope/Trinity-RFT/tree/main/benchmark/README.md)
+ [理解 explorer-trainer 同步逻辑](/tutorial/synchronizer.md) |
+| 深入认识 Trinity-RFT | + [完整配置指南](/tutorial/trinity_configs.md)
+ [用于快速验证和实验的 Benchmark 工具](https://github.com/modelscope/Trinity-RFT/tree/main/benchmark/README.md)
+ [理解 explorer-trainer 同步逻辑](/tutorial/synchronizer.md) |
diff --git a/examples/bots/README.md b/examples/bots/README.md
new file mode 100644
index 0000000000..63fd2345ca
--- /dev/null
+++ b/examples/bots/README.md
@@ -0,0 +1,71 @@
+# 🤖🤖🤖 BOTS: A Unified Framework for Bayesian Online Task Selection in LLM Reinforcement Finetuning
+
+
+
+  +
+
+
+
+
+### Overview
+
+BOTS is a unified framework for **B**ayesian **O**nline **T**ask **S**election in LLM reinforcement finetuning.
+
+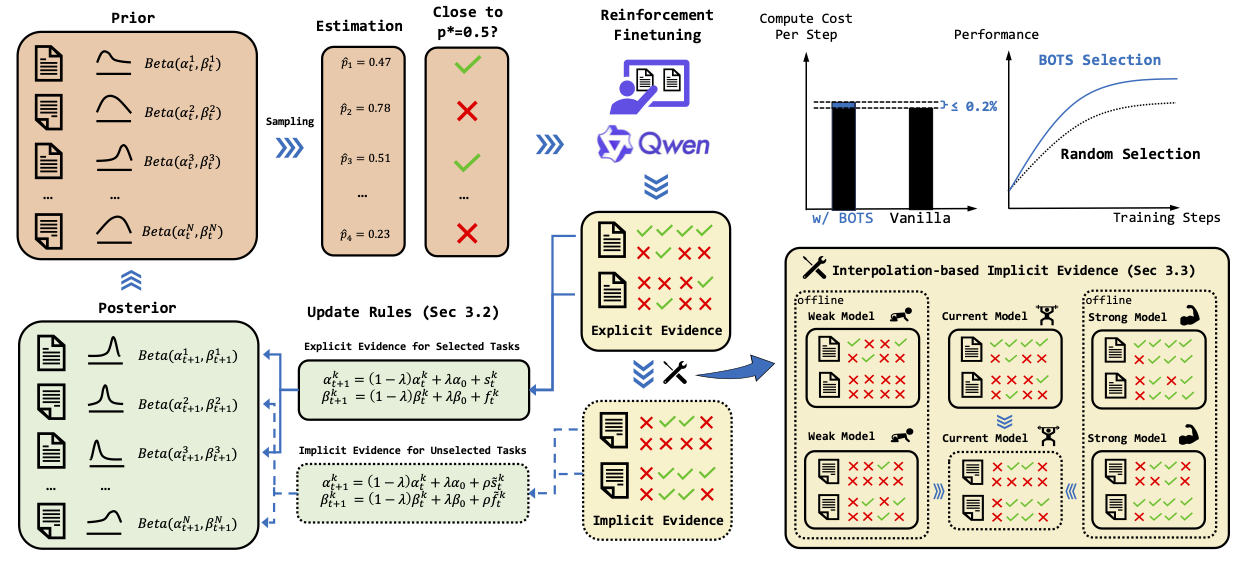 +
+BOTS operates in a continuous loop of task selection, model training, and posterior updating.
+(1) **Selection**: Thompson sampling from the posterior beliefs selects a batch of tasks whose estimated success probabilities are near a target difficulty (e.g., $p^*=0.5$).
+(2) **Training \& Evidence Collection**: The LLM is finetuned, yielding direct success/failure counts (_explicit evidence_) for the selected batch.
+For unselected tasks, predicted counts (_implicit evidence_) are produced by a plug-in; We introduce an ultra-lightweight interpolation-based variant with negligible overhead.
+(3) **Posterior Updating**: Explicit and implicit evidence are fused using our generalized Bayesian update rule.
+
+### Usage
+
+##### Step 1: Environment Preparation
+
+Ensure Trinity-RFT is well installed ([Installation Guide](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/trinity_installation.html)). No extra dependence is required.
+
+##### Step 2: Model & Dataset Preparation
+
+Download the model your want to train (e.g., [Qwen2.5-1.5B-Instruct](https://www.modelscope.cn/models/Qwen/Qwen2.5-1.5B-Instruct)).
+
+Download the [GURU](https://huggingface.co/datasets/LLM360/guru-RL-92k) dataset.
+Also refer to the [Data Preparation Guide](https://github.com/LLM360/Reasoning360?tab=readme-ov-file#data-preparation) and the [Tech Report](https://www.arxiv.org/pdf/2506.14965) provided by the LLM360 team.
+
+Remember to modify the model/data path in `bots.yaml` and `random.yaml` accordingly.
+
+##### Step 3: Training
+Launch training by executing:
+```bash
+trinity run --config examples/bots/bots.yaml --plugin-dir examples/bots/workflow
+```
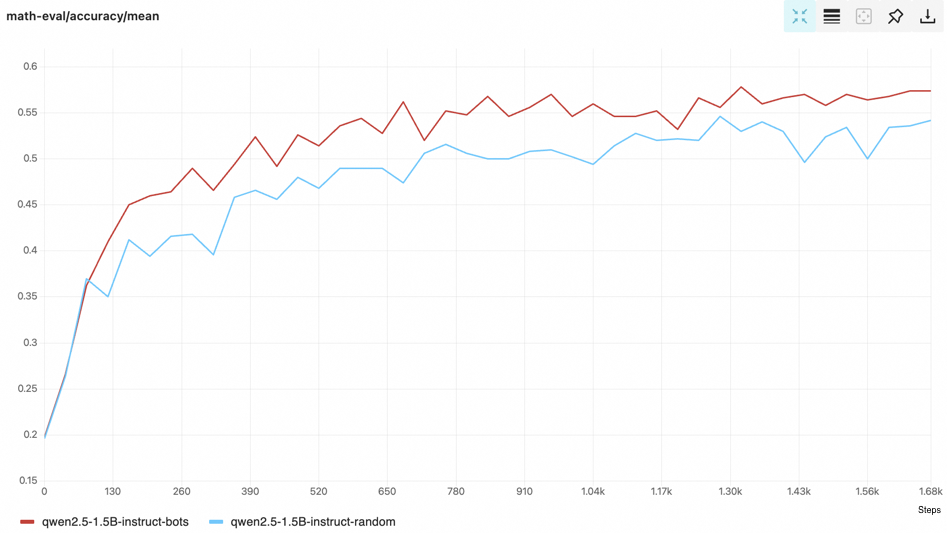
+The improvement over random selection baseline can be stably obtained 🤖🤖🤖.
+
+
+
+BOTS operates in a continuous loop of task selection, model training, and posterior updating.
+(1) **Selection**: Thompson sampling from the posterior beliefs selects a batch of tasks whose estimated success probabilities are near a target difficulty (e.g., $p^*=0.5$).
+(2) **Training \& Evidence Collection**: The LLM is finetuned, yielding direct success/failure counts (_explicit evidence_) for the selected batch.
+For unselected tasks, predicted counts (_implicit evidence_) are produced by a plug-in; We introduce an ultra-lightweight interpolation-based variant with negligible overhead.
+(3) **Posterior Updating**: Explicit and implicit evidence are fused using our generalized Bayesian update rule.
+
+### Usage
+
+##### Step 1: Environment Preparation
+
+Ensure Trinity-RFT is well installed ([Installation Guide](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/trinity_installation.html)). No extra dependence is required.
+
+##### Step 2: Model & Dataset Preparation
+
+Download the model your want to train (e.g., [Qwen2.5-1.5B-Instruct](https://www.modelscope.cn/models/Qwen/Qwen2.5-1.5B-Instruct)).
+
+Download the [GURU](https://huggingface.co/datasets/LLM360/guru-RL-92k) dataset.
+Also refer to the [Data Preparation Guide](https://github.com/LLM360/Reasoning360?tab=readme-ov-file#data-preparation) and the [Tech Report](https://www.arxiv.org/pdf/2506.14965) provided by the LLM360 team.
+
+Remember to modify the model/data path in `bots.yaml` and `random.yaml` accordingly.
+
+##### Step 3: Training
+Launch training by executing:
+```bash
+trinity run --config examples/bots/bots.yaml --plugin-dir examples/bots/workflow
+```
+The improvement over random selection baseline can be stably obtained 🤖🤖🤖.
+
+ +
+### Complete Reproduction
+
+For complete reproduction of the results in our paper, please use the verl version implementation available [here](https://dail-wlcb.oss-cn-wulanchabu.aliyuncs.com/public/BOTS_verl_version.zip).
+
+### Citation
+If you find the repo helpful, please cite:
+```
+@misc{TrinityRFT,
+ title={Trinity-RFT: A General-Purpose and Unified Framework for Reinforcement Fine-Tuning of Large Language Models},
+ author={Xuchen Pan and Yanxi Chen and Yushuo Chen and Yuchang Sun and Daoyuan Chen and Wenhao Zhang and Yuexiang Xie and Yilun Huang and Yilei Zhang and Dawei Gao and Weijie Shi and Yaliang Li and Bolin Ding and Jingren Zhou},
+ year={2025},
+ eprint={2505.17826},
+ archivePrefix={arXiv},
+ primaryClass={cs.LG},
+ url={https://arxiv.org/abs/2505.17826},
+}
+
+@misc{BOTS,
+ title={BOTS: A Unified Framework for Bayesian Online Task Selection in LLM Reinforcement Finetuning},
+ author={Qianli Shen and Daoyuan Chen and Yilun Huang and Zhenqing Ling and Yaliang Li and Bolin Ding and Jingren Zhou},
+ year={2025},
+ eprint={2510.26374},
+ archivePrefix={arXiv},
+ primaryClass={cs.AI},
+ url={https://arxiv.org/abs/2510.26374},
+}
+```
diff --git a/examples/bots/README_zh.md b/examples/bots/README_zh.md
new file mode 100644
index 0000000000..9f20ba0e4b
--- /dev/null
+++ b/examples/bots/README_zh.md
@@ -0,0 +1,68 @@
+# 🤖🤖🤖 BOTS: A Unified Framework for Bayesian Online Task Selection in LLM Reinforcement Finetuning
+
+
+
+### Complete Reproduction
+
+For complete reproduction of the results in our paper, please use the verl version implementation available [here](https://dail-wlcb.oss-cn-wulanchabu.aliyuncs.com/public/BOTS_verl_version.zip).
+
+### Citation
+If you find the repo helpful, please cite:
+```
+@misc{TrinityRFT,
+ title={Trinity-RFT: A General-Purpose and Unified Framework for Reinforcement Fine-Tuning of Large Language Models},
+ author={Xuchen Pan and Yanxi Chen and Yushuo Chen and Yuchang Sun and Daoyuan Chen and Wenhao Zhang and Yuexiang Xie and Yilun Huang and Yilei Zhang and Dawei Gao and Weijie Shi and Yaliang Li and Bolin Ding and Jingren Zhou},
+ year={2025},
+ eprint={2505.17826},
+ archivePrefix={arXiv},
+ primaryClass={cs.LG},
+ url={https://arxiv.org/abs/2505.17826},
+}
+
+@misc{BOTS,
+ title={BOTS: A Unified Framework for Bayesian Online Task Selection in LLM Reinforcement Finetuning},
+ author={Qianli Shen and Daoyuan Chen and Yilun Huang and Zhenqing Ling and Yaliang Li and Bolin Ding and Jingren Zhou},
+ year={2025},
+ eprint={2510.26374},
+ archivePrefix={arXiv},
+ primaryClass={cs.AI},
+ url={https://arxiv.org/abs/2510.26374},
+}
+```
diff --git a/examples/bots/README_zh.md b/examples/bots/README_zh.md
new file mode 100644
index 0000000000..9f20ba0e4b
--- /dev/null
+++ b/examples/bots/README_zh.md
@@ -0,0 +1,68 @@
+# 🤖🤖🤖 BOTS: A Unified Framework for Bayesian Online Task Selection in LLM Reinforcement Finetuning
+
+
+
+
+
+
+
+### 概览
+
+BOTS是一个统一的LLM强化微调的**贝叶斯在线任务选择**框架。
+
+
+
+BOTS 以任务选择、模型训练和后验概率更新的连续循环运行。
+(1) **任务选择**:从后验概率信念中采用汤普森采样选择一批估计成功概率接近目标难度(例如,$p^*=0.5$)的任务。
+(2) **模型训练和证据收集**:对 LLM 模型进行微调,从而获得所选任务批次的直接成功/失败计数(显式证据)。
+对于未选择的任务,预测计数(隐式证据)由插件生成;我们引入了一种基于插值的超轻量级变体,其开销可忽略不计。
+(3) **后验概率更新**:使用我们提出的广义贝叶斯更新规则融合显式和隐式证据。
+### 使用
+
+##### 第一步:环境准备
+
+确保Trinity-RFT安装好了([安装指南](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/trinity_installation.html))。不需要额外的依赖。
+
+##### 第二步:模型和数据准备
+
+下载你想要训练的模型(例如:[Qwen2.5-1.5B-Instruct](https://www.modelscope.cn/models/Qwen/Qwen2.5-1.5B-Instruct))。
+下载[GURU](https://huggingface.co/datasets/LLM360/guru-RL-92k)数据集,
+请参考LLM360提供的[数据准备指南](https://github.com/LLM360/Reasoning360?tab=readme-ov-file#data-preparation)和[技术报告](https://www.arxiv.org/pdf/2506.14965)。
+请修改`bots.yaml`和`random.yaml`中相应的模型/数据路径。
+
+##### 第三步:训练
+执行以下命令启动训练:
+```bash
+trinity run --config examples/bots/bots.yaml --plugin-dir examples/bots/workflow
+```
+相比随机选择基线的提升可以被稳定地观察到🤖🤖🤖.
+
+
+
+### 完整复现
+
+想要完整复现我们论文中的结果,请从[这里](https://dail-wlcb.oss-cn-wulanchabu.aliyuncs.com/public/BOTS_verl_version.zip)下载verl版本的框架。
+
+### 引用
+如果你觉得这个代码仓库有帮助,请引用:
+```
+@misc{TrinityRFT,
+ title={Trinity-RFT: A General-Purpose and Unified Framework for Reinforcement Fine-Tuning of Large Language Models},
+ author={Xuchen Pan and Yanxi Chen and Yushuo Chen and Yuchang Sun and Daoyuan Chen and Wenhao Zhang and Yuexiang Xie and Yilun Huang and Yilei Zhang and Dawei Gao and Weijie Shi and Yaliang Li and Bolin Ding and Jingren Zhou},
+ year={2025},
+ eprint={2505.17826},
+ archivePrefix={arXiv},
+ primaryClass={cs.LG},
+ url={https://arxiv.org/abs/2505.17826},
+}
+
+@misc{BOTS,
+ title={BOTS: A Unified Framework for Bayesian Online Task Selection in LLM Reinforcement Finetuning},
+ author={Qianli Shen and Daoyuan Chen and Yilun Huang and Zhenqing Ling and Yaliang Li and Bolin Ding and Jingren Zhou},
+ year={2025},
+ eprint={2510.26374},
+ archivePrefix={arXiv},
+ primaryClass={cs.AI},
+ url={https://arxiv.org/abs/2510.26374},
+}
+```
diff --git a/examples/bots/bots.yaml b/examples/bots/bots.yaml
new file mode 100644
index 0000000000..e3a948fee3
--- /dev/null
+++ b/examples/bots/bots.yaml
@@ -0,0 +1,79 @@
+project: "BOTS-Selector"
+name: "qwen2.5-1.5B-instruct-bots"
+checkpoint_root_dir: ${oc.env:TRINITY_CHECKPOINT_ROOT_DIR,./checkpoints}
+data_processor:
+ experience_pipeline:
+ operators:
+ - name: pass_rate_calculator
+algorithm:
+ algorithm_type: grpo
+ repeat_times: 16
+ optimizer:
+ lr: 1e-6
+model:
+ model_path: ${oc.env:TRINITY_MODEL_PATH,Qwen/Qwen2.5-1.5B-Instruct}
+ max_prompt_tokens: 4096
+ max_response_tokens: 8192
+cluster:
+ node_num: 1
+ gpu_per_node: 8
+buffer:
+ total_epochs: 1
+ batch_size: 32
+ explorer_input:
+ taskset:
+ name: math-train
+ storage_type: file
+ path: '/LLM360/guru-RL-92k/train/math__combined_54.4k.parquet'
+ split: 'train'
+ format:
+ prompt_key: 'prompt'
+ response_key: 'reward_model.ground_truth'
+ rollout_args:
+ temperature: 1.0
+ task_selector:
+ selector_type: difficulty_based
+ feature_keys: [ "qwen2.5_7b_pass_rate", "qwen3_30b_pass_rate" ]
+ kwargs:
+ m: 16
+ lamb: 0.1
+ rho: 0.1
+ target_reward: 0.5
+ tau: 0
+ do_sample: true
+ eval_tasksets:
+ - name: math-eval
+ storage_type: file
+ path: '/LLM360/guru-RL-92k/online_eval/math__math_500.parquet'
+ format:
+ prompt_key: 'prompt'
+ response_key: 'reward_model.ground_truth'
+ rollout_args:
+ temperature: 1.0
+ default_workflow_type: 'bots_math_boxed_workflow'
+ trainer_input:
+ experience_buffer:
+ name: exp_buffer
+ storage_type: queue
+ path: 'sqlite:///bots_trainer_buffer.db'
+explorer:
+ eval_interval: 40
+ runner_per_model: 8
+ rollout_model:
+ engine_num: 4
+ tensor_parallel_size: 1
+ enable_prefix_caching: false
+ enforce_eager: true
+ dtype: bfloat16
+ seed: 42
+synchronizer:
+ sync_method: 'nccl'
+ sync_interval: 8
+ sync_timeout: 1200
+trainer:
+ trainer_type: 'verl'
+ save_interval: 800
+ grad_clip: 1.0
+ use_dynamic_bsz: true
+ max_token_len_per_gpu: 24576
+ ulysses_sequence_parallel_size: 1
diff --git a/examples/bots/random.yaml b/examples/bots/random.yaml
new file mode 100644
index 0000000000..4fa2e3978a
--- /dev/null
+++ b/examples/bots/random.yaml
@@ -0,0 +1,67 @@
+project: "BOTS-Selector"
+name: "qwen2.5-1.5B-instruct-random"
+checkpoint_root_dir: ${oc.env:TRINITY_CHECKPOINT_ROOT_DIR,./checkpoints}
+algorithm:
+ algorithm_type: grpo
+ repeat_times: 16
+ optimizer:
+ lr: 1e-6
+model:
+ model_path: ${oc.env:TRINITY_MODEL_PATH,Qwen/Qwen2.5-1.5B-Instruct}
+ max_prompt_tokens: 4096
+ max_response_tokens: 8192
+cluster:
+ node_num: 1
+ gpu_per_node: 8
+buffer:
+ total_epochs: 1
+ batch_size: 32
+ explorer_input:
+ taskset:
+ name: math-train
+ storage_type: file
+ path: '/LLM360/guru-RL-92k/train/math__combined_54.4k.parquet'
+ split: 'train'
+ format:
+ prompt_key: 'prompt'
+ response_key: 'reward_model.ground_truth'
+ rollout_args:
+ temperature: 1.0
+ task_selector:
+ selector_type: random
+ eval_tasksets:
+ - name: math-eval
+ storage_type: file
+ path: '/LLM360/guru-RL-92k/online_eval/math__math_500.parquet'
+ format:
+ prompt_key: 'prompt'
+ response_key: 'reward_model.ground_truth'
+ rollout_args:
+ temperature: 1.0
+ default_workflow_type: 'bots_math_boxed_workflow'
+ trainer_input:
+ experience_buffer:
+ name: exp_buffer
+ storage_type: queue
+ path: 'sqlite:///random_trainer_buffer.db'
+explorer:
+ eval_interval: 40
+ runner_per_model: 8
+ rollout_model:
+ engine_num: 4
+ tensor_parallel_size: 1
+ enable_prefix_caching: false
+ enforce_eager: true
+ dtype: bfloat16
+ seed: 42
+synchronizer:
+ sync_method: 'nccl'
+ sync_interval: 8
+ sync_timeout: 1200
+trainer:
+ trainer_type: 'verl'
+ save_interval: 800
+ grad_clip: 1.0
+ use_dynamic_bsz: true
+ max_token_len_per_gpu: 24576
+ ulysses_sequence_parallel_size: 1
diff --git a/examples/bots/workflow/bots_math_boxed_reward.py b/examples/bots/workflow/bots_math_boxed_reward.py
new file mode 100644
index 0000000000..335f72378d
--- /dev/null
+++ b/examples/bots/workflow/bots_math_boxed_reward.py
@@ -0,0 +1,33 @@
+from typing import Optional
+
+from trinity.common.rewards.reward_fn import REWARD_FUNCTIONS, RewardFn
+from trinity.utils.eval_utils import validate_think_pattern
+
+from .bots_reward import compute_score
+
+
+@REWARD_FUNCTIONS.register_module("bots_math_boxed_reward")
+class BOTSMathBoxedRewardFn(RewardFn):
+ """A reward function that rewards for math task for BOTS."""
+
+ def __init__(
+ self,
+ **kwargs,
+ ) -> None:
+ pass
+
+ def __call__( # type: ignore
+ self,
+ response: str,
+ truth: Optional[str] = None,
+ with_think: Optional[bool] = False,
+ format_score_coef: Optional[float] = 0.1,
+ **kwargs,
+ ) -> dict[str, float]:
+ accuracy_score = compute_score(response, truth)
+
+ format_score = 0.0
+ if with_think and not validate_think_pattern(response):
+ format_score = (format_score_coef or 0.1) * -1.0
+
+ return {"accuracy": accuracy_score, "format_score": format_score}
diff --git a/examples/bots/workflow/bots_math_boxed_workflow.py b/examples/bots/workflow/bots_math_boxed_workflow.py
new file mode 100644
index 0000000000..1596aa87f6
--- /dev/null
+++ b/examples/bots/workflow/bots_math_boxed_workflow.py
@@ -0,0 +1,46 @@
+from typing import Union
+
+from trinity.common.workflows.customized_math_workflows import MathBoxedWorkflow, Task
+from trinity.common.workflows.workflow import WORKFLOWS
+
+from .bots_math_boxed_reward import BOTSMathBoxedRewardFn
+
+
+@WORKFLOWS.register_module("bots_math_boxed_workflow")
+class BOTSMathBoxedWorkflow(MathBoxedWorkflow):
+ """A workflow for math tasks that give answers in boxed format for BOTS."""
+
+ def reset(self, task: Task):
+ super().reset(task)
+ self.reward_fn = BOTSMathBoxedRewardFn(**self.reward_fn_args)
+
+ def format_messages(self):
+ # the prompts are already in message format
+ return self.task_desc
+
+ @property
+ def task_desc(self) -> Union[str, None]:
+ prompt_key = self.format_args.prompt_key
+ return nested_query(prompt_key, self.raw_task) # type: ignore
+
+ @property
+ def truth(self) -> Union[str, None]:
+ response_key = self.format_args.response_key
+ return nested_query(response_key, self.raw_task)
+
+
+def nested_query(query_key: str, query_obj: Union[dict, None]):
+ # support nested query for a dict given query_keys split by '.'
+ if query_obj is None:
+ return None
+ if "." in query_key:
+ query_keys = query_key.split(".")
+ else:
+ query_keys = [query_key]
+ ret = query_obj
+ for key in query_keys:
+ if isinstance(ret, dict) and key in ret:
+ ret = ret[key]
+ else:
+ return None
+ return ret
diff --git a/examples/bots/workflow/bots_reward.py b/examples/bots/workflow/bots_reward.py
new file mode 100644
index 0000000000..61ea7789ed
--- /dev/null
+++ b/examples/bots/workflow/bots_reward.py
@@ -0,0 +1,909 @@
+# Adapted from Reasoning360: https://github.com/LLM360/Reasoning360/blob/main/verl/utils/reward_score/naive_dapo.py
+
+import contextlib
+import math
+import re
+from math import isclose
+from typing import Optional, Union
+
+import sympy
+from pylatexenc import latex2text
+from sympy import N, simplify
+from sympy.parsing import sympy_parser
+from sympy.parsing.latex import parse_latex
+from sympy.parsing.sympy_parser import parse_expr
+from verl.utils.py_functional import timeout_limit
+
+
+def handle_base(x):
+ if isinstance(x, str) and "_" in x:
+ # Due to base
+ x = x.split("_")[0]
+ x = float(x)
+ return int(x)
+ return x
+
+
+def handle_pi(string, pi):
+ if isinstance(string, str) and "\\pi" in string:
+ # Find the first occurrence of "\pi"
+ idx = string.find("\\pi")
+
+ # Iterate over the string and find all occurrences of "\pi" with a valid previous character
+ while idx != -1:
+ if idx > 0 and string[idx - 1].isdigit():
+ # Replace "\pi" with "*math.pi" if the previous character is a digit
+ string = string[:idx] + f"*{pi}" + string[idx + 3 :]
+ else:
+ # Replace "\pi" with "1*math.pi" if the previous character is not a digit
+ string = string[:idx] + f"1*{pi}" + string[idx + 3 :]
+
+ # Find the next occurrence of "\pi"
+ idx = string.find("\\pi", idx + 1)
+
+ # Evaluate the expression using eval() function
+ with contextlib.suppress(Exception):
+ string = eval(string)
+
+ return string
+
+
+def normalize(answer, pi) -> str:
+ # checking if answer is $ and removing $ in that case to compare
+ if isinstance(answer, str) and bool(re.match(r"\$\d+(\.\d+)?", answer)):
+ return answer[1:]
+
+ # checking if answer is % or \\% and removing %
+ if isinstance(answer, str) and (
+ bool(re.match(r"^\d+(\.\d+)?%$", answer)) or bool(re.match(r"^\d+(\.\d+)?\\%$", answer))
+ ):
+ return answer.replace("\\%", "").replace("%", "")
+
+ # handle base
+ answer = handle_base(answer)
+
+ # handle pi
+ answer = handle_pi(answer, pi)
+
+ return answer
+
+
+def is_digit(s):
+ try:
+ if "{,}" in str(s):
+ num = float(str(s).replace("{,}", ""))
+ return True, num
+
+ num = float(str(s).replace(",", ""))
+ return True, num
+ except ValueError:
+ return False, 0.0
+
+
+def format_intervals(prediction) -> str:
+ patterns = {
+ "Interval(": r"^Interval\((.*)\)$",
+ "Interval.Ropen(": r"^Interval\.Ropen\((.*)\)$",
+ "Interval.Lopen(": r"^Interval\.Lopen\((.*)\)$",
+ "Interval.open(": r"^Interval\.open\((.*)\)$",
+ }
+
+ for key, pattern in patterns.items():
+ match = re.match(pattern, prediction)
+ if match:
+ inner_content = match.group(1)
+
+ if key == "Interval(": # Intarval(a, b) == [a, b]
+ return f"[{inner_content}]"
+ elif key == "Interval.Ropen(": # Intarval.Ropen(a, b) == [a, b)
+ return f"[{inner_content})"
+ elif key == "Interval.Lopen(": # Intarval.Lopen(a, b) == (a, b]
+ return f"({inner_content}]"
+ elif key == "Interval.open(": # Intarval.open(a, b) == (a, b)
+ return f"({inner_content})"
+
+ return str(prediction)
+
+
+def symbolic_equal(a, b, tolerance, timeout=10.0):
+ def _parse(s):
+ for f in [parse_expr, parse_latex]:
+ try:
+ with timeout_limit(seconds=timeout):
+ return f(s)
+ except TimeoutError:
+ print(f"Parsing timed out for {s}")
+ continue
+ except Exception:
+ continue
+ return s
+
+ a = _parse(a)
+ b = _parse(b)
+
+ try:
+ with timeout_limit(seconds=timeout):
+ if simplify(a - b) == 0:
+ return True
+ except TimeoutError:
+ print(f"Simplification timed out for {a} - {b}")
+ pass
+ except Exception:
+ pass
+
+ try:
+ with timeout_limit(seconds=timeout):
+ if isclose(N(a), N(b), rel_tol=tolerance):
+ return True
+ except TimeoutError:
+ print(f"Numerical evaluation timed out for {a}, {b}")
+ pass
+ except Exception:
+ pass
+ return False
+
+
+def math_equal( # noqa
+ prediction: Union[bool, float, str],
+ reference: Union[float, str],
+ include_percentage: bool = True,
+ tolerance: float = 1e-4,
+ timeout: float = 10.0,
+ pi: float = math.pi,
+) -> bool:
+ """
+ Exact match of math if and only if:
+ 1. numerical equal: both can convert to float and are equal
+ 2. symbolic equal: both can convert to sympy expression and are equal
+ """
+
+ prediction = normalize(prediction, pi)
+ reference = normalize(reference, pi)
+
+ if isinstance(prediction, str) and len(prediction) > 1000: # handling weird corner-cases
+ prediction = prediction[:1000]
+
+ # 0. string comparison
+ if isinstance(prediction, str) and isinstance(reference, str):
+ if prediction.strip().lower() == reference.strip().lower():
+ return True
+ if prediction.replace(" ", "") == reference.replace(" ", ""):
+ return True
+
+ try: # 1. numerical equal
+ if is_digit(prediction)[0] and is_digit(reference)[0]:
+ prediction = is_digit(prediction)[1]
+ reference = is_digit(reference)[1]
+ # number questions
+ gt_result = (
+ [float(reference) / 100.0, float(reference), float(reference) * 100.0]
+ if include_percentage
+ else [float(reference)]
+ )
+ for item in gt_result:
+ try:
+ if isclose(float(item), float(prediction), rel_tol=tolerance):
+ return True
+ except Exception:
+ continue
+ return False
+ except Exception:
+ pass
+
+ if not prediction and prediction not in [0, False]:
+ return False
+
+ # 2. symbolic equal
+ reference = str(reference).strip()
+ prediction = str(prediction).strip()
+
+ ## deal with [], (), {}
+ prediction = format_intervals(prediction)
+
+ pred_str, ref_str = prediction, reference
+ if (
+ prediction.startswith("[") and prediction.endswith("]") and not reference.startswith("(")
+ ) or (
+ prediction.startswith("(") and prediction.endswith(")") and not reference.startswith("[")
+ ):
+ pred_str = pred_str.strip("[]()")
+ ref_str = ref_str.strip("[]()")
+ for s in ["{", "}", "(", ")"]:
+ ref_str = ref_str.replace(s, "")
+ pred_str = pred_str.replace(s, "")
+ if pred_str == ref_str:
+ return True
+
+ ## [a, b] vs. [c, d], return a==c and b==d
+ if (
+ prediction
+ and reference
+ and prediction[0] in "(["
+ and prediction[-1] in ")]"
+ and prediction[0] == reference[0]
+ and prediction[-1] == reference[-1]
+ ):
+ pred_parts = prediction[1:-1].split(",")
+ ref_parts = reference[1:-1].split(",")
+ if len(pred_parts) == len(ref_parts) and all(
+ [
+ math_equal(pred_pt, ref_pt, include_percentage, tolerance)
+ for pred_pt, ref_pt in zip(pred_parts, ref_parts)
+ ]
+ ):
+ return True
+
+ if "," in prediction and "," in reference:
+ pred_parts = [item.strip() for item in prediction.split(",")]
+ ref_parts = [item.strip() for item in reference.split(",")]
+
+ if len(pred_parts) == len(ref_parts):
+ return bool(
+ all(
+ [
+ math_equal(pred_parts[i], ref_parts[i], include_percentage, tolerance)
+ for i in range(len(pred_parts))
+ ]
+ )
+ )
+
+ # if we have point == tuple of values
+ if prediction.startswith("Point") and reference[0] == "(" and reference[-1] == ")":
+ pred_parts = prediction[prediction.find("(") + 1 : -1].split(",")
+ ref_parts = reference[1:-1].split(",")
+ if len(pred_parts) == len(ref_parts) and all(
+ [
+ math_equal(pred_pt, ref_pt, include_percentage, tolerance)
+ for pred_pt, ref_pt in zip(pred_parts, ref_parts)
+ ]
+ ):
+ return True
+
+ # if reference is a matrix
+ if "\begin{pmatrix}" in reference and prediction.startswith("Matrix"):
+ try:
+ pred_matrix = parse_expr(prediction)
+ ref_matrix_items = reference.split()[1:-1:2]
+ if len(pred_matrix) == len(ref_matrix_items) and all(
+ [
+ math_equal(pred, ref, include_percentage, tolerance)
+ for ref, pred in zip(ref_matrix_items, pred_matrix)
+ ]
+ ):
+ return True
+ except Exception:
+ pass
+ elif "\begin{pmatrix}" in reference and prediction.startswith("[") and prediction.endswith("]"):
+ if isinstance(eval(prediction), list):
+ try:
+ pred_matrix = eval(prediction)
+ # ref_matrix_items = reference.split()[1:-1:2]
+ ref_matrix_items = (
+ reference.lstrip("\\begin{pmatrix}")
+ .lstrip("\begin{pmatrix}")
+ .rstrip("\\end{pmatrix}")
+ .rstrip("\\end{pmatrix}")
+ ) # noqa: B005
+ ref_matrix_items = ref_matrix_items.split("\\")
+ # ref_matrix_items = [
+ # row.split("&") if "&" in row else row for row in ref_matrix_items
+ # ]
+ if len(pred_matrix) == len(ref_matrix_items) and all(
+ [
+ math_equal(pred, ref, include_percentage, tolerance)
+ for ref, pred in zip(ref_matrix_items, pred_matrix)
+ ]
+ ):
+ return True
+ except Exception:
+ pass
+
+ return symbolic_equal(prediction, reference, tolerance, timeout)
+
+
+# Constants for normalization
+SUBSTITUTIONS = [
+ ("an ", ""),
+ ("a ", ""),
+ (".$", "$"),
+ ("\\$", ""),
+ (r"\ ", ""),
+ (" ", ""),
+ ("mbox", "text"),
+ (",\\text{and}", ","),
+ ("\\text{and}", ","),
+ ("\\text{m}", "\\text{}"),
+]
+
+REMOVED_EXPRESSIONS = [
+ "square",
+ "ways",
+ "integers",
+ "dollars",
+ "mph",
+ "inches",
+ "hours",
+ "km",
+ "units",
+ "\\ldots",
+ "sue",
+ "points",
+ "feet",
+ "minutes",
+ "digits",
+ "cents",
+ "degrees",
+ "cm",
+ "gm",
+ "pounds",
+ "meters",
+ "meals",
+ "edges",
+ "students",
+ "childrentickets",
+ "multiples",
+ "\\text{s}",
+ "\\text{.}",
+ "\\text{\ns}",
+ "\\text{}^2",
+ "\\text{}^3",
+ "\\text{\n}",
+ "\\text{}",
+ r"\mathrm{th}",
+ r"^\circ",
+ r"^{\circ}",
+ r"\;",
+ r",\!",
+ "{,}",
+ '"',
+ "\\dots",
+]
+
+
+def normalize_final_answer(final_answer: str) -> str:
+ """Normalize a final answer to a quantitative reasoning question.
+
+ Args:
+ final_answer: The answer string to normalize
+
+ Returns:
+ Normalized answer string
+ """
+ final_answer = final_answer.split("=")[-1]
+
+ # Apply substitutions and removals
+ for before, after in SUBSTITUTIONS:
+ final_answer = final_answer.replace(before, after)
+ for expr in REMOVED_EXPRESSIONS:
+ final_answer = final_answer.replace(expr, "")
+
+ # Extract and normalize LaTeX math
+ final_answer = re.sub(r"(.*?)(\$)(.*?)(\$)(.*)", "$\\3$", final_answer)
+ final_answer = re.sub(r"(\\text\{)(.*?)(\})", "\\2", final_answer)
+ final_answer = re.sub(r"(\\textbf\{)(.*?)(\})", "\\2", final_answer)
+ final_answer = re.sub(r"(\\overline\{)(.*?)(\})", "\\2", final_answer)
+ final_answer = re.sub(r"(\\boxed\{)(.*)(\})", "\\2", final_answer)
+
+ # Normalize shorthand TeX:
+ # \fracab -> \frac{a}{b}
+ # \frac{abc}{bef} -> \frac{abc}{bef}
+ # \fracabc -> \frac{a}{b}c
+ # \sqrta -> \sqrt{a}
+ # \sqrtab -> sqrt{a}b
+ final_answer = re.sub(r"(frac)([^{])(.)", "frac{\\2}{\\3}", final_answer)
+ final_answer = re.sub(r"(sqrt)([^{])", "sqrt{\\2}", final_answer)
+ final_answer = final_answer.replace("$", "")
+
+ # Normalize numbers
+ if final_answer.replace(",", "").isdigit():
+ final_answer = final_answer.replace(",", "")
+
+ return final_answer.strip()
+
+
+# sympy might hang -- we don't care about trying to be lenient in these cases
+BAD_SUBSTRINGS = ["^{", "^("]
+BAD_REGEXES = [r"\^[0-9]+\^", r"\^[0-9][0-9]+"]
+TUPLE_CHARS = "()[]"
+
+
+def _sympy_parse(expr: str):
+ """Parses an expression with sympy."""
+ py_expr = expr.replace("^", "**")
+ return sympy_parser.parse_expr(
+ py_expr,
+ transformations=(
+ sympy_parser.standard_transformations
+ + (sympy_parser.implicit_multiplication_application,)
+ ),
+ )
+
+
+def _parse_latex(expr: str) -> str:
+ """Attempts to parse latex to an expression sympy can read."""
+ expr = expr.replace("\\tfrac", "\\frac")
+ expr = expr.replace("\\dfrac", "\\frac")
+ expr = expr.replace("\\frac", " \\frac") # Play nice with mixed numbers.
+ expr = latex2text.LatexNodes2Text().latex_to_text(expr)
+
+ # Replace the specific characters that this parser uses.
+ expr = expr.replace("√", "sqrt")
+ expr = expr.replace("π", "pi")
+ expr = expr.replace("∞", "inf")
+ expr = expr.replace("∪", "U")
+ expr = expr.replace("·", "*")
+ expr = expr.replace("×", "*")
+
+ return expr.strip()
+
+
+def _is_float(num: str) -> bool:
+ try:
+ float(num)
+ return True
+ except ValueError:
+ return False
+
+
+def _is_int(x: float) -> bool:
+ try:
+ return abs(x - int(round(x))) <= 1e-7
+ except Exception:
+ return False
+
+
+def _is_frac(expr: str) -> bool:
+ return bool(re.search(r"^-?[0-9]+.?/0*[1-9][0-9]*.?$", expr))
+
+
+def _str_is_int(x: str) -> bool:
+ try:
+ x = _strip_properly_formatted_commas(x)
+ return abs(float(x) - int(round(float(x)))) <= 1e-7
+ except Exception:
+ return False
+
+
+def _str_to_int(x: str) -> int:
+ x = x.replace(",", "")
+ x = float(x)
+ return int(x)
+
+
+def _inject_implicit_mixed_number(step: str):
+ """
+ Automatically make a mixed number evalable
+ e.g. 7 3/4 => 7+3/4
+ """
+ p1 = re.compile("([0-9]) +([0-9])")
+ step = p1.sub("\\1+\\2", step) # implicit mults
+ return step
+
+
+def _strip_properly_formatted_commas(expr: str):
+ # We want to be careful because we don't want to strip tuple commas
+ p1 = re.compile(r"(\d)(,)(\d\d\d)($|\D)")
+ while True:
+ next_expr = p1.sub("\\1\\3\\4", expr)
+ if next_expr == expr:
+ break
+ expr = next_expr
+ return next_expr
+
+
+def _normalize(expr: str) -> str:
+ """Normalize answer expressions."""
+ if expr is None:
+ return None
+
+ # Remove enclosing `\text{}`.
+ m = re.search(r"^\\\\text\{(?P.+?)\}$", expr)
+ if m is not None:
+ expr = m.group("text")
+
+ expr = expr.replace("\\%", "%")
+ expr = expr.replace("\\$", "$")
+ expr = expr.replace("$", "")
+ expr = expr.replace("%", "")
+ expr = expr.replace(" or ", " , ")
+ expr = expr.replace(" and ", " , ")
+
+ expr = expr.replace("million", "*10^6")
+ expr = expr.replace("billion", "*10^9")
+ expr = expr.replace("trillion", "*10^12")
+
+ for unit in [
+ "degree",
+ "cm",
+ "centimeter",
+ "meter",
+ "mile",
+ "second",
+ "minute",
+ "hour",
+ "day",
+ "week",
+ "month",
+ "year",
+ "foot",
+ "feet",
+ "inch",
+ "yard",
+ "liter",
+ ]:
+ expr = re.sub(r"{}(es)?(s)? *(\^[0-9]+)?".format(unit), "", expr)
+ expr = re.sub(r"\^ *\\\\circ", "", expr)
+
+ if len(expr) > 0 and expr[0] == "{" and expr[-1] == "}":
+ expr = expr[1:-1]
+
+ expr = re.sub(",\\\\! *", "", expr)
+ if _is_float(expr) and _is_int(float(expr)):
+ expr = str(int(round(float(expr))))
+ if "\\" in expr:
+ try:
+ expr = _parse_latex(expr)
+ except Exception:
+ pass
+
+ # edge case with mixed numbers and negative signs
+ expr = re.sub("- *", "-", expr)
+
+ expr = _inject_implicit_mixed_number(expr)
+
+ # don't be case sensitive for text answers
+ expr = expr.lower()
+
+ if _str_is_int(expr):
+ expr = str(_str_to_int(expr))
+
+ return expr
+
+
+def count_unknown_letters_in_expr(expr: str):
+ expr = expr.replace("sqrt", "")
+ expr = expr.replace("frac", "")
+ letters_in_expr = set([x for x in expr if x.isalpha()])
+ return len(letters_in_expr)
+
+
+def should_allow_eval(expr: str):
+ # we don't want to try parsing unknown text or functions of more than two variables
+ if count_unknown_letters_in_expr(expr) > 2:
+ return False
+
+ for bad_string in BAD_SUBSTRINGS:
+ if bad_string in expr:
+ return False
+
+ for bad_regex in BAD_REGEXES:
+ if re.search(bad_regex, expr) is not None:
+ return False
+
+ return True
+
+
+# @timeout(timeout_seconds=10)
+def are_equal_under_sympy(ground_truth_normalized: str, given_normalized: str):
+ are_equal = False
+ try:
+ expr = f"({ground_truth_normalized})-({given_normalized})"
+ if should_allow_eval(expr):
+ sympy_diff = _sympy_parse(expr)
+ simplified = sympy.simplify(sympy_diff)
+ if simplified == 0:
+ are_equal = True
+ except Exception:
+ pass
+ return are_equal
+
+
+def split_tuple(expr: str):
+ """
+ Split the elements in a tuple/interval, while handling well-formatted commas in large numbers
+ """
+ expr = _strip_properly_formatted_commas(expr)
+ if len(expr) == 0:
+ return []
+ if (
+ len(expr) > 2
+ and expr[0] in TUPLE_CHARS
+ and expr[-1] in TUPLE_CHARS
+ and all([ch not in expr[1:-1] for ch in TUPLE_CHARS])
+ ):
+ elems = [elem.strip() for elem in expr[1:-1].split(",")]
+ else:
+ elems = [expr]
+ return elems
+
+
+def _fix_fracs(string):
+ substrs = string.split("\\frac")
+ new_str = substrs[0]
+ if len(substrs) > 1:
+ substrs = substrs[1:]
+ for substr in substrs:
+ new_str += "\\frac"
+ if substr[0] == "{":
+ new_str += substr
+ else:
+ try:
+ assert len(substr) >= 2
+ except: # noqa: E722
+ return string
+ a = substr[0]
+ b = substr[1]
+ if b != "{":
+ if len(substr) > 2:
+ post_substr = substr[2:]
+ new_str += "{" + a + "}{" + b + "}" + post_substr
+ else:
+ new_str += "{" + a + "}{" + b + "}"
+ else:
+ if len(substr) > 2:
+ post_substr = substr[2:]
+ new_str += "{" + a + "}" + b + post_substr
+ else:
+ new_str += "{" + a + "}" + b
+ string = new_str
+ return string
+
+
+def _fix_a_slash_b(string):
+ if len(string.split("/")) != 2:
+ return string
+ a = string.split("/")[0]
+ b = string.split("/")[1]
+ try:
+ a = int(a)
+ b = int(b)
+ assert string == "{}/{}".format(a, b)
+ new_string = "\\frac{" + str(a) + "}{" + str(b) + "}"
+ return new_string
+ except: # noqa: E722
+ return string
+
+
+def _remove_right_units(string):
+ # "\\text{ " only ever occurs (at least in the val set) when describing units
+ if "\\text{ " in string:
+ splits = string.split("\\text{ ")
+ assert len(splits) == 2
+ return splits[0]
+ else:
+ return string
+
+
+def _fix_sqrt(string):
+ if "\\sqrt" not in string:
+ return string
+ splits = string.split("\\sqrt")
+ new_string = splits[0]
+ for split in splits[1:]:
+ if split[0] != "{":
+ a = split[0]
+ new_substr = "\\sqrt{" + a + "}" + split[1:]
+ else:
+ new_substr = "\\sqrt" + split
+ new_string += new_substr
+ return new_string
+
+
+def _strip_string(string):
+ # linebreaks
+ string = string.replace("\n", "")
+
+ # remove inverse spaces
+ string = string.replace("\\!", "")
+
+ # replace \\ with \
+ string = string.replace("\\\\", "\\")
+
+ # replace tfrac and dfrac with frac
+ string = string.replace("tfrac", "frac")
+ string = string.replace("dfrac", "frac")
+
+ # remove \left and \right
+ string = string.replace("\\left", "")
+ string = string.replace("\\right", "")
+
+ # Remove circ (degrees)
+ string = string.replace("^{\\circ}", "")
+ string = string.replace("^\\circ", "")
+
+ # remove dollar signs
+ string = string.replace("\\$", "")
+
+ # remove units (on the right)
+ string = _remove_right_units(string)
+
+ # remove percentage
+ string = string.replace("\\%", "")
+ string = string.replace("\\%", "")
+
+ # " 0." equivalent to " ." and "{0." equivalent to "{." Alternatively, add "0" if "." is the start of the string
+ string = string.replace(" .", " 0.")
+ string = string.replace("{.", "{0.")
+ # if empty, return empty string
+ if len(string) == 0:
+ return string
+ if string[0] == ".":
+ string = "0" + string
+
+ # to consider: get rid of e.g. "k = " or "q = " at beginning
+ if len(string.split("=")) == 2 and len(string.split("=")[0]) <= 2:
+ string = string.split("=")[1]
+
+ # fix sqrt3 --> sqrt{3}
+ string = _fix_sqrt(string)
+
+ # remove spaces
+ string = string.replace(" ", "")
+
+ # \frac1b or \frac12 --> \frac{1}{b} and \frac{1}{2}, etc. Even works with \frac1{72} (but not \frac{72}1). Also does a/b --> \\frac{a}{b}
+ string = _fix_fracs(string)
+
+ # manually change 0.5 --> \frac{1}{2}
+ if string == "0.5":
+ string = "\\frac{1}{2}"
+
+ # NOTE: X/Y changed to \frac{X}{Y} in dataset, but in simple cases fix in case the model output is X/Y
+ string = _fix_a_slash_b(string)
+
+ return string
+
+
+def normalize_answer(answer: Optional[str]) -> str:
+ if answer is None:
+ return ""
+ answer = answer.strip()
+ try:
+ # Remove enclosing `\text{}`.
+ m = re.search("^\\\\text\\{(?P.+?)\\}$", answer)
+ if m is not None:
+ answer = m.group("text").strip()
+ return _strip_string(answer)
+ except: # noqa: E722
+ return answer
+
+
+def grade_answer(given_answer: str, ground_truth: str) -> tuple[bool, str]:
+ """
+ The answer will be considered correct if:
+ (a) it normalizes to the same string as the ground truth answer
+ OR
+ (b) sympy can simplify the difference between the expressions to 0
+ """
+ if given_answer is None:
+ return False
+
+ ground_truth_normalized_mathd = normalize_answer(ground_truth)
+ given_answer_normalized_mathd = normalize_answer(given_answer)
+
+ # be at least as lenient as mathd
+ if ground_truth_normalized_mathd == given_answer_normalized_mathd:
+ return True, given_answer_normalized_mathd
+
+ ground_truth_normalized = _normalize(ground_truth)
+ given_normalized = _normalize(given_answer)
+
+ if ground_truth_normalized is None:
+ return False, given_normalized
+
+ if ground_truth_normalized == given_normalized:
+ return True, given_normalized
+
+ if len(given_normalized) == 0:
+ return False, given_normalized
+
+ ground_truth_elems = split_tuple(ground_truth_normalized)
+ given_elems = split_tuple(given_normalized)
+
+ if len(ground_truth_elems) > 1 and (
+ ground_truth_normalized[0] != given_normalized[0]
+ or ground_truth_normalized[-1] != given_normalized[-1]
+ ):
+ is_correct = False
+ elif len(ground_truth_elems) != len(given_elems):
+ is_correct = False
+ else:
+ for ground_truth_elem, given_elem in zip(ground_truth_elems, given_elems):
+ if _is_frac(ground_truth_elem) and _is_frac(given_elem):
+ # if fractions aren't reduced, then shouldn't be marked as correct
+ # so, we don't want to allow sympy.simplify in this case
+ is_correct = ground_truth_elem == given_elem
+ elif _str_is_int(ground_truth_elem) != _str_is_int(given_elem):
+ # if the ground truth answer is an integer, we require the given answer to be a strict match (no sympy.simplify)
+ is_correct = False
+ else:
+ is_correct = are_equal_under_sympy(ground_truth_elem, given_elem)
+ if not is_correct:
+ break
+
+ return is_correct, given_normalized
+
+
+def _last_boxed_only_string(string):
+ idx = string.rfind("\\boxed")
+ if idx < 0:
+ idx = string.rfind("\\fbox")
+ if idx < 0:
+ return None
+
+ i = idx
+ left_brace_idx = None
+ right_brace_idx = None
+ num_left_braces_open = 0
+ while i < len(string):
+ if string[i] == "{":
+ num_left_braces_open += 1
+ if left_brace_idx is None:
+ left_brace_idx = i
+ elif string[i] == "}":
+ num_left_braces_open -= 1
+ if num_left_braces_open == 0:
+ right_brace_idx = i
+ break
+
+ i += 1
+
+ if left_brace_idx is None or right_brace_idx is None:
+ return None
+
+ return string[left_brace_idx + 1 : right_brace_idx].strip()
+
+
+def match_answer(response):
+ is_matched = False
+ response = response.split("")[-1]
+
+ # Find boxed
+ ans_boxed = _last_boxed_only_string(response)
+ if ans_boxed:
+ is_matched = True
+ response = ans_boxed
+
+ return is_matched, response
+
+
+def compute_score(solution_str: str, ground_truth: Optional[str]) -> float:
+ """Compute the reward score for a solution. This draws heavily from the LLM-as-judge and PRIME reward functions
+
+ Args:
+ solution_str: The solution string
+ ground_truth: The ground truth answer
+ extra_info: dict with additional info for the score computation
+
+ Returns:
+ Reward score (1.0 for correct, -1.0 for incorrect)
+ """
+ # First assert intended generation and gt type
+ model_output = str(solution_str)
+ ground_truth = str(ground_truth)
+
+ # Extract answer from generated output
+ is_matched, extracted_model_output = match_answer(model_output)
+
+ # TWK NOTE: WE REMOVED THE RESPONSE TRUNCATION FROM math_dapo.compute_score
+
+ # Verify the solution, first check simple comparisons.
+ correct, pred = grade_answer(extracted_model_output, ground_truth)
+
+ if not correct:
+ try:
+ if "\\pi" in extracted_model_output or "\\pi" in ground_truth:
+ equivs = []
+ for pi in [math.pi, 3.14]:
+ equivs.append(
+ math_equal(extracted_model_output, ground_truth, timeout=True, pi=pi)
+ )
+ correct = any(equivs)
+ else:
+ correct = math_equal(extracted_model_output, ground_truth, timeout=True)
+ except Exception:
+ correct = False
+
+ # reward = 1.0 if correct else -1.0
+ reward = 1.0 if correct else 0.0
+
+ return reward
diff --git a/trinity/buffer/operators/mappers/pass_rate_calculator.py b/trinity/buffer/operators/mappers/pass_rate_calculator.py
index 38ff5627c5..a743c9c122 100644
--- a/trinity/buffer/operators/mappers/pass_rate_calculator.py
+++ b/trinity/buffer/operators/mappers/pass_rate_calculator.py
@@ -24,6 +24,7 @@ def process(self, exps: List[Experience]) -> Tuple[List[Experience], Dict]:
assert "index" in task_index
raw_metric[task_index["taskset_id"]][task_index["index"]].append(exp.reward)
metric = {}
+ ref_pass_rates = []
for taskset_id, taskset_metric in raw_metric.items():
indices = []
reward_means = []
@@ -34,4 +35,30 @@ def process(self, exps: List[Experience]) -> Tuple[List[Experience], Dict]:
"indices": indices,
"values": reward_means,
}
- return exps, {SELECTOR_METRIC: metric}
+ ref_pass_rates.extend(reward_means)
+ ret_metric = {SELECTOR_METRIC: metric}
+
+ valid_ratio = np.mean([1 if 0 < pr < 1 else 0 for pr in ref_pass_rates])
+ strict_valid_ratio = np.mean(
+ [1 if 1 / 16 + 1e-3 < pr < 15 / 16 - 1e-3 else 0 for pr in ref_pass_rates]
+ )
+ less_than_one_ratio = np.mean([1 if pr < 1 else 0 for pr in ref_pass_rates])
+ larger_than_zero_ratio = np.mean([1 if pr > 0 else 0 for pr in ref_pass_rates])
+ less_than_15_over_16_ratio = np.mean(
+ [1 if pr < 15 / 16 - 1e-3 else 0 for pr in ref_pass_rates]
+ )
+ larger_than_1_over_16_ratio = np.mean(
+ [1 if pr > 1 / 16 + 1e-3 else 0 for pr in ref_pass_rates]
+ )
+ ret_metric.update(
+ {
+ "selection/valid_ratio": valid_ratio,
+ "selection/strict_valid_ratio": strict_valid_ratio,
+ "selection/<1_ratio": less_than_one_ratio,
+ "selection/>0_ratio": larger_than_zero_ratio,
+ "selection/<15_16_ratio": less_than_15_over_16_ratio,
+ "selection/>1_16_ratio": larger_than_1_over_16_ratio,
+ }
+ )
+
+ return exps, ret_metric
diff --git a/trinity/buffer/task_scheduler.py b/trinity/buffer/task_scheduler.py
index 495af95bf7..7619a3702f 100644
--- a/trinity/buffer/task_scheduler.py
+++ b/trinity/buffer/task_scheduler.py
@@ -190,7 +190,7 @@ def update(self, pipeline_metrics: Dict) -> None:
"""
if SELECTOR_METRIC not in pipeline_metrics:
return
- selector_metric = pipeline_metrics[SELECTOR_METRIC]
+ selector_metric = pipeline_metrics.pop(SELECTOR_METRIC, {})
for taskset_id, taskset_kwargs in selector_metric.items():
selector = self.selectors[taskset_id]
selector.update(**taskset_kwargs)
diff --git a/trinity/common/experience.py b/trinity/common/experience.py
index 6847d8e655..42af635873 100644
--- a/trinity/common/experience.py
+++ b/trinity/common/experience.py
@@ -238,7 +238,7 @@ def deserialize(cls, data: bytes) -> Experience:
def to_dict(self) -> dict:
"""Convert the experience to a dictionary."""
res = {
- "eid": self.eid,
+ "eid": self.eid.to_dict(),
"type": self.experience_type,
"prompt_length": self.prompt_length,
"response_length": len(self.tokens) - self.prompt_length, # type: ignore [arg-type]
diff --git a/trinity/common/workflows/workflow.py b/trinity/common/workflows/workflow.py
index 8a493e161f..38881f22a7 100644
--- a/trinity/common/workflows/workflow.py
+++ b/trinity/common/workflows/workflow.py
@@ -60,18 +60,6 @@ def to_workflow(
auxiliary_models=auxiliary_models,
)
- # Deprecated property, will be removed in the future
- @property
- def task_desc(self) -> Union[str, None]:
- prompt_key = self.format_args.prompt_key
- return self.raw_task[prompt_key] if prompt_key in self.raw_task else None # type: ignore
-
- # Deprecated property, will be removed in the future
- @property
- def truth(self) -> Union[str, None]:
- response_key = self.format_args.response_key
- return self.raw_task[response_key] if response_key in self.raw_task else None # type: ignore
-
def to_dict(self) -> dict:
return self.raw_task # type: ignore