\n",
+ "\n",
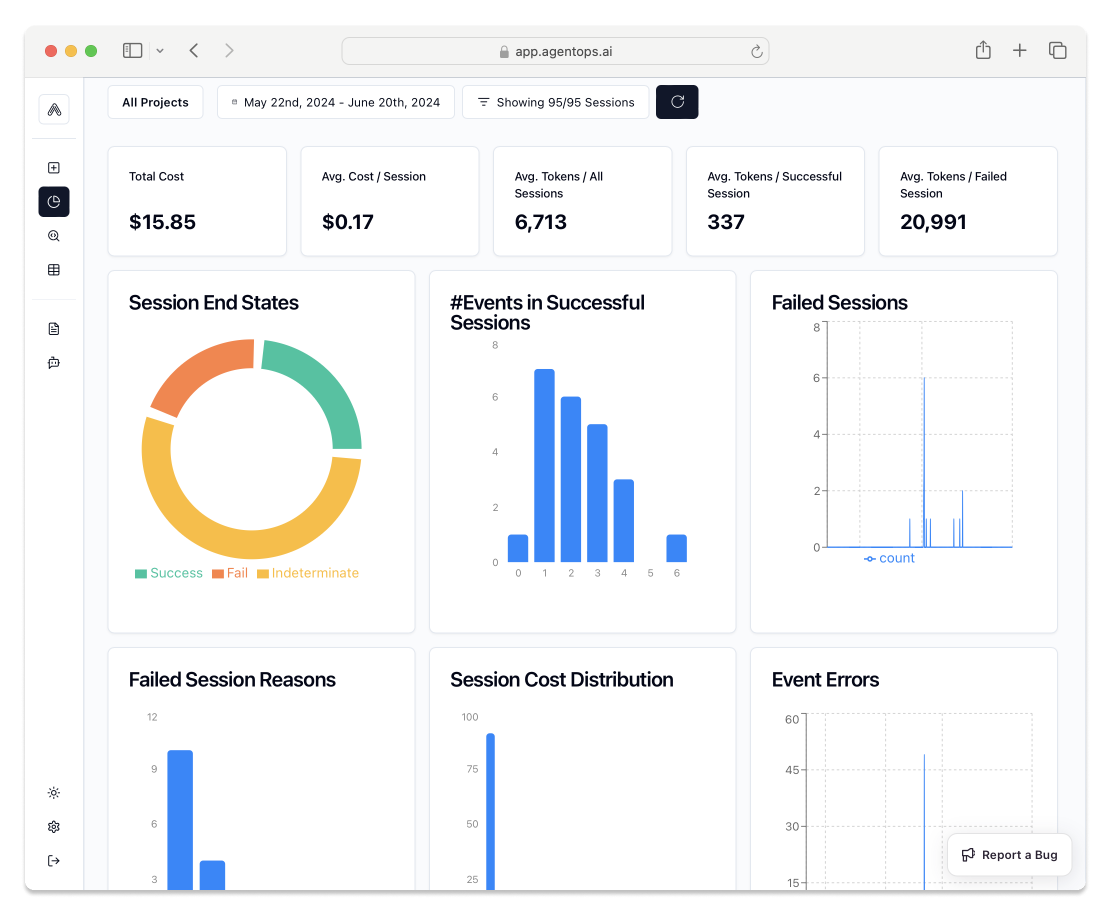
+ "### Session Replays\n",
+ "
\n",
+ "\n",
+ "### Session Replays\n",
+ " "
]
},
{
@@ -39,7 +42,7 @@
"## Adding AgentOps to an existing Autogen service.\n",
"To get started, you'll need to install the AgentOps package and set an API key.\n",
"\n",
- "AgentOps automatically configures itself when it's initialized. This means your agents will be tracked and logged to your AgentOps account right away."
+ "AgentOps automatically configures itself when it's initialized meaning your agent run data will be tracked and logged to your AgentOps account right away."
]
},
{
@@ -69,7 +72,7 @@
"\n",
"By default, the AgentOps `init()` function will look for an environment variable named `AGENTOPS_API_KEY`. Alternatively, you can pass one in as an optional parameter.\n",
"\n",
- "Create an account and API key at [AgentOps.ai](https://agentops.ai/)"
+ "Create an account and obtain an API key at [AgentOps.ai](https://agentops.ai/settings/projects)"
]
},
{
@@ -87,12 +90,14 @@
"name": "stderr",
"output_type": "stream",
"text": [
- "🖇 AgentOps: \u001B[34m\u001B[34mSession Replay: https://app.agentops.ai/drilldown?session_id=8bfaeed1-fd51-4c68-b3ec-276b1a3ce8a4\u001B[0m\u001B[0m\n"
+ "🖇 AgentOps: \u001b[34m\u001b[34mSession Replay: https://app.agentops.ai/drilldown?session_id=8bfaeed1-fd51-4c68-b3ec-276b1a3ce8a4\u001b[0m\u001b[0m\n"
]
},
{
"data": {
- "text/plain": "UUID('8bfaeed1-fd51-4c68-b3ec-276b1a3ce8a4')"
+ "text/plain": [
+ "UUID('8bfaeed1-fd51-4c68-b3ec-276b1a3ce8a4')"
+ ]
},
"execution_count": 1,
"metadata": {},
@@ -105,6 +110,7 @@
"from autogen import ConversableAgent, UserProxyAgent, config_list_from_json\n",
"\n",
"agentops.init(api_key=\"7c94212b-b89d-47a6-a20c-23b2077d3226\") # or agentops.init(api_key=\"...\")"
+ "agentops.init(api_key=\"...\")"
]
},
{
@@ -144,19 +150,19 @@
"name": "stdout",
"output_type": "stream",
"text": [
- "\u001B[33magent\u001B[0m (to user):\n",
+ "\u001b[33magent\u001b[0m (to user):\n",
"\n",
"How can I help you today?\n",
"\n",
"--------------------------------------------------------------------------------\n",
- "\u001B[33muser\u001B[0m (to agent):\n",
+ "\u001b[33muser\u001b[0m (to agent):\n",
"\n",
"2+2\n",
"\n",
"--------------------------------------------------------------------------------\n",
- "\u001B[31m\n",
- ">>>>>>>> USING AUTO REPLY...\u001B[0m\n",
- "\u001B[33magent\u001B[0m (to user):\n",
+ "\u001b[31m\n",
+ ">>>>>>>> USING AUTO REPLY...\u001b[0m\n",
+ "\u001b[33magent\u001b[0m (to user):\n",
"\n",
"2 + 2 equals 4.\n",
"\n",
@@ -168,7 +174,7 @@
"output_type": "stream",
"text": [
"🖇 AgentOps: This run's cost $0.000960\n",
- "🖇 AgentOps: \u001B[34m\u001B[34mSession Replay: https://app.agentops.ai/drilldown?session_id=8bfaeed1-fd51-4c68-b3ec-276b1a3ce8a4\u001B[0m\u001B[0m\n"
+ "🖇 AgentOps: \u001b[34m\u001b[34mSession Replay: https://app.agentops.ai/drilldown?session_id=8bfaeed1-fd51-4c68-b3ec-276b1a3ce8a4\u001b[0m\u001b[0m\n"
]
}
],
@@ -185,7 +191,7 @@
"# Create the agent that represents the user in the conversation.\n",
"user_proxy = UserProxyAgent(\"user\", code_execution_config=False)\n",
"\n",
- "# Let the assistant start the conversation. It will end when the user types exit.\n",
+ "# Let the assistant start the conversation. It will end when the user types \"exit\".\n",
"assistant.initiate_chat(user_proxy, message=\"How can I help you today?\")\n",
"\n",
"# Close your AgentOps session to indicate that it completed.\n",
@@ -204,13 +210,13 @@
},
{
"cell_type": "markdown",
- "source": [
- ""
- ],
+ "id": "cbd689b0f5617013",
"metadata": {
"collapsed": false
},
- "id": "cbd689b0f5617013"
+ "source": [
+ ""
+ ]
},
{
"cell_type": "markdown",
@@ -236,70 +242,70 @@
"name": "stderr",
"output_type": "stream",
"text": [
- "🖇 AgentOps: \u001B[34m\u001B[34mSession Replay: https://app.agentops.ai/drilldown?session_id=880c206b-751e-4c23-9313-8684537fc04d\u001B[0m\u001B[0m\n"
+ "🖇 AgentOps: \u001b[34m\u001b[34mSession Replay: https://app.agentops.ai/drilldown?session_id=880c206b-751e-4c23-9313-8684537fc04d\u001b[0m\u001b[0m\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\u001B[33mUser\u001B[0m (to Assistant):\n",
+ "\u001b[33mUser\u001b[0m (to Assistant):\n",
"\n",
"What is (1423 - 123) / 3 + (32 + 23) * 5?\n",
"\n",
"--------------------------------------------------------------------------------\n",
- "\u001B[31m\n",
- ">>>>>>>> USING AUTO REPLY...\u001B[0m\n",
- "\u001B[33mAssistant\u001B[0m (to User):\n",
+ "\u001b[31m\n",
+ ">>>>>>>> USING AUTO REPLY...\u001b[0m\n",
+ "\u001b[33mAssistant\u001b[0m (to User):\n",
"\n",
- "\u001B[32m***** Suggested tool call (call_aINcGyo0Xkrh9g7buRuhyCz0): calculator *****\u001B[0m\n",
+ "\u001b[32m***** Suggested tool call (call_aINcGyo0Xkrh9g7buRuhyCz0): calculator *****\u001b[0m\n",
"Arguments: \n",
"{\n",
" \"a\": 1423,\n",
" \"b\": 123,\n",
" \"operator\": \"-\"\n",
"}\n",
- "\u001B[32m***************************************************************************\u001B[0m\n",
+ "\u001b[32m***************************************************************************\u001b[0m\n",
"\n",
"--------------------------------------------------------------------------------\n",
- "\u001B[35m\n",
- ">>>>>>>> EXECUTING FUNCTION calculator...\u001B[0m\n",
- "\u001B[33mUser\u001B[0m (to Assistant):\n",
+ "\u001b[35m\n",
+ ">>>>>>>> EXECUTING FUNCTION calculator...\u001b[0m\n",
+ "\u001b[33mUser\u001b[0m (to Assistant):\n",
"\n",
- "\u001B[33mUser\u001B[0m (to Assistant):\n",
+ "\u001b[33mUser\u001b[0m (to Assistant):\n",
"\n",
- "\u001B[32m***** Response from calling tool (call_aINcGyo0Xkrh9g7buRuhyCz0) *****\u001B[0m\n",
+ "\u001b[32m***** Response from calling tool (call_aINcGyo0Xkrh9g7buRuhyCz0) *****\u001b[0m\n",
"1300\n",
- "\u001B[32m**********************************************************************\u001B[0m\n",
+ "\u001b[32m**********************************************************************\u001b[0m\n",
"\n",
"--------------------------------------------------------------------------------\n",
- "\u001B[31m\n",
- ">>>>>>>> USING AUTO REPLY...\u001B[0m\n",
- "\u001B[33mAssistant\u001B[0m (to User):\n",
+ "\u001b[31m\n",
+ ">>>>>>>> USING AUTO REPLY...\u001b[0m\n",
+ "\u001b[33mAssistant\u001b[0m (to User):\n",
"\n",
- "\u001B[32m***** Suggested tool call (call_prJGf8V0QVT7cbD91e0Fcxpb): calculator *****\u001B[0m\n",
+ "\u001b[32m***** Suggested tool call (call_prJGf8V0QVT7cbD91e0Fcxpb): calculator *****\u001b[0m\n",
"Arguments: \n",
"{\n",
" \"a\": 1300,\n",
" \"b\": 3,\n",
" \"operator\": \"/\"\n",
"}\n",
- "\u001B[32m***************************************************************************\u001B[0m\n",
+ "\u001b[32m***************************************************************************\u001b[0m\n",
"\n",
"--------------------------------------------------------------------------------\n",
- "\u001B[35m\n",
- ">>>>>>>> EXECUTING FUNCTION calculator...\u001B[0m\n",
- "\u001B[33mUser\u001B[0m (to Assistant):\n",
+ "\u001b[35m\n",
+ ">>>>>>>> EXECUTING FUNCTION calculator...\u001b[0m\n",
+ "\u001b[33mUser\u001b[0m (to Assistant):\n",
"\n",
- "\u001B[33mUser\u001B[0m (to Assistant):\n",
+ "\u001b[33mUser\u001b[0m (to Assistant):\n",
"\n",
- "\u001B[32m***** Response from calling tool (call_prJGf8V0QVT7cbD91e0Fcxpb) *****\u001B[0m\n",
+ "\u001b[32m***** Response from calling tool (call_prJGf8V0QVT7cbD91e0Fcxpb) *****\u001b[0m\n",
"433\n",
- "\u001B[32m**********************************************************************\u001B[0m\n",
+ "\u001b[32m**********************************************************************\u001b[0m\n",
"\n",
"--------------------------------------------------------------------------------\n",
- "\u001B[31m\n",
- ">>>>>>>> USING AUTO REPLY...\u001B[0m\n"
+ "\u001b[31m\n",
+ ">>>>>>>> USING AUTO REPLY...\u001b[0m\n"
]
},
{
@@ -316,94 +322,94 @@
"name": "stdout",
"output_type": "stream",
"text": [
- "\u001B[33mAssistant\u001B[0m (to User):\n",
+ "\u001b[33mAssistant\u001b[0m (to User):\n",
"\n",
- "\u001B[32m***** Suggested tool call (call_CUIgHRsySLjayDKuUphI1TGm): calculator *****\u001B[0m\n",
+ "\u001b[32m***** Suggested tool call (call_CUIgHRsySLjayDKuUphI1TGm): calculator *****\u001b[0m\n",
"Arguments: \n",
"{\n",
" \"a\": 32,\n",
" \"b\": 23,\n",
" \"operator\": \"+\"\n",
"}\n",
- "\u001B[32m***************************************************************************\u001B[0m\n",
+ "\u001b[32m***************************************************************************\u001b[0m\n",
"\n",
"--------------------------------------------------------------------------------\n",
- "\u001B[35m\n",
- ">>>>>>>> EXECUTING FUNCTION calculator...\u001B[0m\n",
- "\u001B[33mUser\u001B[0m (to Assistant):\n",
+ "\u001b[35m\n",
+ ">>>>>>>> EXECUTING FUNCTION calculator...\u001b[0m\n",
+ "\u001b[33mUser\u001b[0m (to Assistant):\n",
"\n",
- "\u001B[33mUser\u001B[0m (to Assistant):\n",
+ "\u001b[33mUser\u001b[0m (to Assistant):\n",
"\n",
- "\u001B[32m***** Response from calling tool (call_CUIgHRsySLjayDKuUphI1TGm) *****\u001B[0m\n",
+ "\u001b[32m***** Response from calling tool (call_CUIgHRsySLjayDKuUphI1TGm) *****\u001b[0m\n",
"55\n",
- "\u001B[32m**********************************************************************\u001B[0m\n",
+ "\u001b[32m**********************************************************************\u001b[0m\n",
"\n",
"--------------------------------------------------------------------------------\n",
- "\u001B[31m\n",
- ">>>>>>>> USING AUTO REPLY...\u001B[0m\n",
- "\u001B[33mAssistant\u001B[0m (to User):\n",
+ "\u001b[31m\n",
+ ">>>>>>>> USING AUTO REPLY...\u001b[0m\n",
+ "\u001b[33mAssistant\u001b[0m (to User):\n",
"\n",
- "\u001B[32m***** Suggested tool call (call_L7pGtBLUf9V0MPL90BASyesr): calculator *****\u001B[0m\n",
+ "\u001b[32m***** Suggested tool call (call_L7pGtBLUf9V0MPL90BASyesr): calculator *****\u001b[0m\n",
"Arguments: \n",
"{\n",
" \"a\": 55,\n",
" \"b\": 5,\n",
" \"operator\": \"*\"\n",
"}\n",
- "\u001B[32m***************************************************************************\u001B[0m\n",
+ "\u001b[32m***************************************************************************\u001b[0m\n",
"\n",
"--------------------------------------------------------------------------------\n",
- "\u001B[35m\n",
- ">>>>>>>> EXECUTING FUNCTION calculator...\u001B[0m\n",
- "\u001B[33mUser\u001B[0m (to Assistant):\n",
+ "\u001b[35m\n",
+ ">>>>>>>> EXECUTING FUNCTION calculator...\u001b[0m\n",
+ "\u001b[33mUser\u001b[0m (to Assistant):\n",
"\n",
- "\u001B[33mUser\u001B[0m (to Assistant):\n",
+ "\u001b[33mUser\u001b[0m (to Assistant):\n",
"\n",
- "\u001B[32m***** Response from calling tool (call_L7pGtBLUf9V0MPL90BASyesr) *****\u001B[0m\n",
+ "\u001b[32m***** Response from calling tool (call_L7pGtBLUf9V0MPL90BASyesr) *****\u001b[0m\n",
"275\n",
- "\u001B[32m**********************************************************************\u001B[0m\n",
+ "\u001b[32m**********************************************************************\u001b[0m\n",
"\n",
"--------------------------------------------------------------------------------\n",
- "\u001B[31m\n",
- ">>>>>>>> USING AUTO REPLY...\u001B[0m\n",
- "\u001B[33mAssistant\u001B[0m (to User):\n",
+ "\u001b[31m\n",
+ ">>>>>>>> USING AUTO REPLY...\u001b[0m\n",
+ "\u001b[33mAssistant\u001b[0m (to User):\n",
"\n",
- "\u001B[32m***** Suggested tool call (call_Ygo6p4XfcxRjkYBflhG3UVv6): calculator *****\u001B[0m\n",
+ "\u001b[32m***** Suggested tool call (call_Ygo6p4XfcxRjkYBflhG3UVv6): calculator *****\u001b[0m\n",
"Arguments: \n",
"{\n",
" \"a\": 433,\n",
" \"b\": 275,\n",
" \"operator\": \"+\"\n",
"}\n",
- "\u001B[32m***************************************************************************\u001B[0m\n",
+ "\u001b[32m***************************************************************************\u001b[0m\n",
"\n",
"--------------------------------------------------------------------------------\n",
- "\u001B[35m\n",
- ">>>>>>>> EXECUTING FUNCTION calculator...\u001B[0m\n",
- "\u001B[33mUser\u001B[0m (to Assistant):\n",
+ "\u001b[35m\n",
+ ">>>>>>>> EXECUTING FUNCTION calculator...\u001b[0m\n",
+ "\u001b[33mUser\u001b[0m (to Assistant):\n",
"\n",
- "\u001B[33mUser\u001B[0m (to Assistant):\n",
+ "\u001b[33mUser\u001b[0m (to Assistant):\n",
"\n",
- "\u001B[32m***** Response from calling tool (call_Ygo6p4XfcxRjkYBflhG3UVv6) *****\u001B[0m\n",
+ "\u001b[32m***** Response from calling tool (call_Ygo6p4XfcxRjkYBflhG3UVv6) *****\u001b[0m\n",
"708\n",
- "\u001B[32m**********************************************************************\u001B[0m\n",
+ "\u001b[32m**********************************************************************\u001b[0m\n",
"\n",
"--------------------------------------------------------------------------------\n",
- "\u001B[31m\n",
- ">>>>>>>> USING AUTO REPLY...\u001B[0m\n",
- "\u001B[33mAssistant\u001B[0m (to User):\n",
+ "\u001b[31m\n",
+ ">>>>>>>> USING AUTO REPLY...\u001b[0m\n",
+ "\u001b[33mAssistant\u001b[0m (to User):\n",
"\n",
"The result of the calculation is 708.\n",
"\n",
"--------------------------------------------------------------------------------\n",
- "\u001B[33mUser\u001B[0m (to Assistant):\n",
+ "\u001b[33mUser\u001b[0m (to Assistant):\n",
"\n",
"\n",
"\n",
"--------------------------------------------------------------------------------\n",
- "\u001B[31m\n",
- ">>>>>>>> USING AUTO REPLY...\u001B[0m\n",
- "\u001B[33mAssistant\u001B[0m (to User):\n",
+ "\u001b[31m\n",
+ ">>>>>>>> USING AUTO REPLY...\u001b[0m\n",
+ "\u001b[33mAssistant\u001b[0m (to User):\n",
"\n",
"TERMINATE\n",
"\n",
@@ -415,7 +421,7 @@
"output_type": "stream",
"text": [
"🖇 AgentOps: This run's cost $0.001800\n",
- "🖇 AgentOps: \u001B[34m\u001B[34mSession Replay: https://app.agentops.ai/drilldown?session_id=880c206b-751e-4c23-9313-8684537fc04d\u001B[0m\u001B[0m\n"
+ "🖇 AgentOps: \u001b[34m\u001b[34mSession Replay: https://app.agentops.ai/drilldown?session_id=880c206b-751e-4c23-9313-8684537fc04d\u001b[0m\u001b[0m\n"
]
}
],
@@ -474,7 +480,7 @@
" description=\"A simple calculator\", # A description of the tool.\n",
")\n",
"\n",
- "# Let the assistant start the conversation. It will end when the user types exit.\n",
+ "# Let the assistant start the conversation. It will end when the user types \"exit\".\n",
"user_proxy.initiate_chat(assistant, message=\"What is (1423 - 123) / 3 + (32 + 23) * 5?\")\n",
"\n",
"agentops.end_session(\"Success\")"
@@ -493,13 +499,13 @@
},
{
"cell_type": "markdown",
- "source": [
- ""
- ],
+ "id": "a922a52ab5fce31",
"metadata": {
"collapsed": false
},
- "id": "a922a52ab5fce31"
+ "source": [
+ ""
+ ]
}
],
"metadata": {
diff --git a/notebook/agentchat_nested_chats_chess_altmodels.ipynb b/notebook/agentchat_nested_chats_chess_altmodels.ipynb
new file mode 100644
index 000000000000..69d3edbcfb50
--- /dev/null
+++ b/notebook/agentchat_nested_chats_chess_altmodels.ipynb
@@ -0,0 +1,584 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Conversational Chess using non-OpenAI clients\n",
+ "\n",
+ "This notebook provides tips for using non-OpenAI models when using functions/tools.\n",
+ "\n",
+ "The code is based on [this notebook](/docs/notebooks/agentchat_nested_chats_chess),\n",
+ "which provides a detailed look at nested chats for tool use. Please refer to that\n",
+ "notebook for more on nested chats as this will be concentrated on tweaks to\n",
+ "improve performance with non-OpenAI models.\n",
+ "\n",
+ "The notebook represents a chess game between two players with a nested chat to\n",
+ "determine the available moves and select a move to make.\n",
+ "\n",
+ "This game contains a couple of functions/tools that the LLMs must use correctly by the\n",
+ "LLMs:\n",
+ "- `get_legal_moves` to get a list of current legal moves.\n",
+ "- `make_move` to make a move.\n",
+ "\n",
+ "Two agents will be used to represent the white and black players, each associated with\n",
+ "a different LLM cloud provider and model:\n",
+ "- Anthropic's Sonnet 3.5 will be Player_White\n",
+ "- Mistral's Mixtral 8x7B (using Together.AI) will be Player_Black\n",
+ "\n",
+ "As this involves function calling, we use larger, more capable, models from these providers.\n",
+ "\n",
+ "The nested chat will be supported be a board proxy agent who is set up to execute\n",
+ "the tools and manage the game.\n",
+ "\n",
+ "Tips to improve performance with these non-OpenAI models will be noted throughout **in bold**."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Installation\n",
+ "\n",
+ "First, you need to install the `pyautogen` and `chess` packages to use AutoGen. We'll include Anthropic and Together.AI libraries."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 1,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "! pip install -qqq pyautogen[anthropic,together] chess"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Setting up LLMs\n",
+ "\n",
+ "We'll use the Anthropic (`api_type` is `anthropic`) and Together.AI (`api_type` is `together`) client classes, with their respective models, which both support function calling."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 5,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "\n",
+ "import chess\n",
+ "import chess.svg\n",
+ "from IPython.display import display\n",
+ "from typing_extensions import Annotated\n",
+ "\n",
+ "from autogen import ConversableAgent, register_function\n",
+ "\n",
+ "# Let's set our two player configs, specifying clients and models\n",
+ "\n",
+ "# Anthropic's Sonnet for player white\n",
+ "player_white_config_list = [\n",
+ " {\n",
+ " \"api_type\": \"anthropic\",\n",
+ " \"model\": \"claude-3-5-sonnet-20240620\",\n",
+ " \"api_key\": os.getenv(\"ANTHROPIC_API_KEY\"),\n",
+ " \"cache_seed\": None,\n",
+ " },\n",
+ "]\n",
+ "\n",
+ "# Mistral's Mixtral 8x7B for player black (through Together.AI)\n",
+ "player_black_config_list = [\n",
+ " {\n",
+ " \"api_type\": \"together\",\n",
+ " \"model\": \"mistralai/Mixtral-8x7B-Instruct-v0.1\",\n",
+ " \"api_key\": os.environ.get(\"TOGETHER_API_KEY\"),\n",
+ " \"cache_seed\": None,\n",
+ " },\n",
+ "]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We'll setup game variables and the two functions for getting the available moves and then making a move."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 3,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Initialize the board.\n",
+ "board = chess.Board()\n",
+ "\n",
+ "# Keep track of whether a move has been made.\n",
+ "made_move = False\n",
+ "\n",
+ "\n",
+ "def get_legal_moves() -> Annotated[\n",
+ " str,\n",
+ " \"Call this tool to list of all legal chess moves on the board, output is a list in UCI format, e.g. e2e4,e7e5,e7e8q.\",\n",
+ "]:\n",
+ " return \"Possible moves are: \" + \",\".join([str(move) for move in board.legal_moves])\n",
+ "\n",
+ "\n",
+ "def make_move(\n",
+ " move: Annotated[\n",
+ " str,\n",
+ " \"Call this tool to make a move after you have the list of legal moves and want to make a move. Takes UCI format, e.g. e2e4 or e7e5 or e7e8q.\",\n",
+ " ]\n",
+ ") -> Annotated[str, \"Result of the move.\"]:\n",
+ " move = chess.Move.from_uci(move)\n",
+ " board.push_uci(str(move))\n",
+ " global made_move\n",
+ " made_move = True\n",
+ " # Display the board.\n",
+ " display(\n",
+ " chess.svg.board(board, arrows=[(move.from_square, move.to_square)], fill={move.from_square: \"gray\"}, size=200)\n",
+ " )\n",
+ " # Get the piece name.\n",
+ " piece = board.piece_at(move.to_square)\n",
+ " piece_symbol = piece.unicode_symbol()\n",
+ " piece_name = (\n",
+ " chess.piece_name(piece.piece_type).capitalize()\n",
+ " if piece_symbol.isupper()\n",
+ " else chess.piece_name(piece.piece_type)\n",
+ " )\n",
+ " return f\"Moved {piece_name} ({piece_symbol}) from {chess.SQUARE_NAMES[move.from_square]} to {chess.SQUARE_NAMES[move.to_square]}.\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Creating agents\n",
+ "\n",
+ "Our main player agents are created next, with a few tweaks to help our models play:\n",
+ "\n",
+ "- Explicitly **telling agents their names** (as the name field isn't sent to the LLM).\n",
+ "- Providing simple instructions on the **order of functions** (not all models will need it).\n",
+ "- Asking the LLM to **include their name in the response** so the message content will include their names, helping the LLM understand who has made which moves.\n",
+ "- Ensure **no spaces are in the agent names** so that their name is distinguishable in the conversation.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 6,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "player_white = ConversableAgent(\n",
+ " name=\"Player_White\",\n",
+ " system_message=\"You are a chess player and you play as white, your name is 'Player_White'. \"\n",
+ " \"First call the function get_legal_moves() to get list of legal moves. \"\n",
+ " \"Then call the function make_move(move) to make a move. \"\n",
+ " \"Then tell Player_Black you have made your move and it is their turn. \"\n",
+ " \"Make sure you tell Player_Black you are Player_White.\",\n",
+ " llm_config={\"config_list\": player_white_config_list, \"cache_seed\": None},\n",
+ ")\n",
+ "\n",
+ "player_black = ConversableAgent(\n",
+ " name=\"Player_Black\",\n",
+ " system_message=\"You are a chess player and you play as black, your name is 'Player_Black'. \"\n",
+ " \"First call the function get_legal_moves() to get list of legal moves. \"\n",
+ " \"Then call the function make_move(move) to make a move. \"\n",
+ " \"Then tell Player_White you have made your move and it is their turn. \"\n",
+ " \"Make sure you tell Player_White you are Player_Black.\",\n",
+ " llm_config={\"config_list\": player_black_config_list, \"cache_seed\": None},\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Now we create a proxy agent that will be used to move the pieces on the board."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 7,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Check if the player has made a move, and reset the flag if move is made.\n",
+ "def check_made_move(msg):\n",
+ " global made_move\n",
+ " if made_move:\n",
+ " made_move = False\n",
+ " return True\n",
+ " else:\n",
+ " return False\n",
+ "\n",
+ "\n",
+ "board_proxy = ConversableAgent(\n",
+ " name=\"Board_Proxy\",\n",
+ " llm_config=False,\n",
+ " # The board proxy will only terminate the conversation if the player has made a move.\n",
+ " is_termination_msg=check_made_move,\n",
+ " # The auto reply message is set to keep the player agent retrying until a move is made.\n",
+ " default_auto_reply=\"Please make a move.\",\n",
+ " human_input_mode=\"NEVER\",\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Our functions are then assigned to the agents so they can be passed to the LLM to choose from.\n",
+ "\n",
+ "We have tweaked the descriptions to provide **more guidance on when** to use it."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "register_function(\n",
+ " make_move,\n",
+ " caller=player_white,\n",
+ " executor=board_proxy,\n",
+ " name=\"make_move\",\n",
+ " description=\"Call this tool to make a move after you have the list of legal moves.\",\n",
+ ")\n",
+ "\n",
+ "register_function(\n",
+ " get_legal_moves,\n",
+ " caller=player_white,\n",
+ " executor=board_proxy,\n",
+ " name=\"get_legal_moves\",\n",
+ " description=\"Call this to get a legal moves before making a move.\",\n",
+ ")\n",
+ "\n",
+ "register_function(\n",
+ " make_move,\n",
+ " caller=player_black,\n",
+ " executor=board_proxy,\n",
+ " name=\"make_move\",\n",
+ " description=\"Call this tool to make a move after you have the list of legal moves.\",\n",
+ ")\n",
+ "\n",
+ "register_function(\n",
+ " get_legal_moves,\n",
+ " caller=player_black,\n",
+ " executor=board_proxy,\n",
+ " name=\"get_legal_moves\",\n",
+ " description=\"Call this to get a legal moves before making a move.\",\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Almost there, we now create nested chats between players and the board proxy agent to work out the available moves and make the move."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 9,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "player_white.register_nested_chats(\n",
+ " trigger=player_black,\n",
+ " chat_queue=[\n",
+ " {\n",
+ " # The initial message is the one received by the player agent from\n",
+ " # the other player agent.\n",
+ " \"sender\": board_proxy,\n",
+ " \"recipient\": player_white,\n",
+ " # The final message is sent to the player agent.\n",
+ " \"summary_method\": \"last_msg\",\n",
+ " }\n",
+ " ],\n",
+ ")\n",
+ "\n",
+ "player_black.register_nested_chats(\n",
+ " trigger=player_white,\n",
+ " chat_queue=[\n",
+ " {\n",
+ " # The initial message is the one received by the player agent from\n",
+ " # the other player agent.\n",
+ " \"sender\": board_proxy,\n",
+ " \"recipient\": player_black,\n",
+ " # The final message is sent to the player agent.\n",
+ " \"summary_method\": \"last_msg\",\n",
+ " }\n",
+ " ],\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Playing the game\n",
+ "\n",
+ "Now the game can begin!"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 10,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\u001b[33mPlayer_Black\u001b[0m (to Player_White):\n",
+ "\n",
+ "Let's play chess! Your move.\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[31m\n",
+ ">>>>>>>> USING AUTO REPLY...\u001b[0m\n",
+ "\u001b[34m\n",
+ "********************************************************************************\u001b[0m\n",
+ "\u001b[34mStarting a new chat....\u001b[0m\n",
+ "\u001b[34m\n",
+ "********************************************************************************\u001b[0m\n",
+ "\u001b[33mBoard_Proxy\u001b[0m (to Player_White):\n",
+ "\n",
+ "Let's play chess! Your move.\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[31m\n",
+ ">>>>>>>> USING AUTO REPLY...\u001b[0m\n",
+ "\u001b[33mPlayer_White\u001b[0m (to Board_Proxy):\n",
+ "\n",
+ "Certainly! I'd be happy to play chess with you. As White, I'll make the first move. Let me start by checking the legal moves available to me.\n",
+ "\u001b[32m***** Suggested tool call (toolu_015sLMucefMVqS5ZNyWVGjgu): get_legal_moves *****\u001b[0m\n",
+ "Arguments: \n",
+ "{}\n",
+ "\u001b[32m*********************************************************************************\u001b[0m\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[35m\n",
+ ">>>>>>>> EXECUTING FUNCTION get_legal_moves...\u001b[0m\n",
+ "\u001b[33mBoard_Proxy\u001b[0m (to Player_White):\n",
+ "\n",
+ "\u001b[33mBoard_Proxy\u001b[0m (to Player_White):\n",
+ "\n",
+ "\u001b[32m***** Response from calling tool (toolu_015sLMucefMVqS5ZNyWVGjgu) *****\u001b[0m\n",
+ "Possible moves are: g1h3,g1f3,b1c3,b1a3,h2h3,g2g3,f2f3,e2e3,d2d3,c2c3,b2b3,a2a3,h2h4,g2g4,f2f4,e2e4,d2d4,c2c4,b2b4,a2a4\n",
+ "\u001b[32m***********************************************************************\u001b[0m\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[31m\n",
+ ">>>>>>>> USING AUTO REPLY...\u001b[0m\n",
+ "\u001b[33mPlayer_White\u001b[0m (to Board_Proxy):\n",
+ "\n",
+ "Thank you for initiating a game of chess! As Player_White, I'll make the first move. After analyzing the legal moves, I've decided to make a classic opening move.\n",
+ "\u001b[32m***** Suggested tool call (toolu_01VjmBhHcGw5RTRKYC4Y5MeV): make_move *****\u001b[0m\n",
+ "Arguments: \n",
+ "{\"move\": \"e2e4\"}\n",
+ "\u001b[32m***************************************************************************\u001b[0m\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[35m\n",
+ ">>>>>>>> EXECUTING FUNCTION make_move...\u001b[0m\n"
+ ]
+ },
+ {
+ "data": {
+ "image/svg+xml": [
+ ""
+ ],
+ "text/plain": [
+ "''"
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\u001b[33mBoard_Proxy\u001b[0m (to Player_White):\n",
+ "\n",
+ "\u001b[33mBoard_Proxy\u001b[0m (to Player_White):\n",
+ "\n",
+ "\u001b[32m***** Response from calling tool (toolu_01VjmBhHcGw5RTRKYC4Y5MeV) *****\u001b[0m\n",
+ "Moved pawn (♙) from e2 to e4.\n",
+ "\u001b[32m***********************************************************************\u001b[0m\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[31m\n",
+ ">>>>>>>> USING AUTO REPLY...\u001b[0m\n",
+ "\u001b[33mPlayer_White\u001b[0m (to Board_Proxy):\n",
+ "\n",
+ "Hello, Player_Black! I'm Player_White, and I've just made my move. I've chosen to play the classic opening move e2e4, moving my king's pawn forward two squares. This opens up lines for both my queen and king's bishop, and stakes a claim to the center of the board. It's now your turn to make a move. Good luck!\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[33mPlayer_White\u001b[0m (to Player_Black):\n",
+ "\n",
+ "Hello, Player_Black! I'm Player_White, and I've just made my move. I've chosen to play the classic opening move e2e4, moving my king's pawn forward two squares. This opens up lines for both my queen and king's bishop, and stakes a claim to the center of the board. It's now your turn to make a move. Good luck!\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[31m\n",
+ ">>>>>>>> USING AUTO REPLY...\u001b[0m\n",
+ "\u001b[34m\n",
+ "********************************************************************************\u001b[0m\n",
+ "\u001b[34mStarting a new chat....\u001b[0m\n",
+ "\u001b[34m\n",
+ "********************************************************************************\u001b[0m\n",
+ "\u001b[33mBoard_Proxy\u001b[0m (to Player_Black):\n",
+ "\n",
+ "Hello, Player_Black! I'm Player_White, and I've just made my move. I've chosen to play the classic opening move e2e4, moving my king's pawn forward two squares. This opens up lines for both my queen and king's bishop, and stakes a claim to the center of the board. It's now your turn to make a move. Good luck!\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[31m\n",
+ ">>>>>>>> USING AUTO REPLY...\u001b[0m\n",
+ "\u001b[33mPlayer_Black\u001b[0m (to Board_Proxy):\n",
+ "\n",
+ "\u001b[32m***** Suggested tool call (call_z6jagiqn59m784w1n0zhmiop): get_legal_moves *****\u001b[0m\n",
+ "Arguments: \n",
+ "{}\n",
+ "\u001b[32m********************************************************************************\u001b[0m\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[35m\n",
+ ">>>>>>>> EXECUTING FUNCTION get_legal_moves...\u001b[0m\n",
+ "\u001b[33mBoard_Proxy\u001b[0m (to Player_Black):\n",
+ "\n",
+ "\u001b[33mBoard_Proxy\u001b[0m (to Player_Black):\n",
+ "\n",
+ "\u001b[32m***** Response from calling tool (call_z6jagiqn59m784w1n0zhmiop) *****\u001b[0m\n",
+ "Possible moves are: g8h6,g8f6,b8c6,b8a6,h7h6,g7g6,f7f6,e7e6,d7d6,c7c6,b7b6,a7a6,h7h5,g7g5,f7f5,e7e5,d7d5,c7c5,b7b5,a7a5\n",
+ "\u001b[32m**********************************************************************\u001b[0m\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[31m\n",
+ ">>>>>>>> USING AUTO REPLY...\u001b[0m\n",
+ "\u001b[33mPlayer_Black\u001b[0m (to Board_Proxy):\n",
+ "\n",
+ "\u001b[32m***** Suggested tool call (call_59t20pl0ab68z4xx2workgbc): make_move *****\u001b[0m\n",
+ "Arguments: \n",
+ "{\"move\":\"g8h6\"}\n",
+ "\u001b[32m**************************************************************************\u001b[0m\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[35m\n",
+ ">>>>>>>> EXECUTING FUNCTION make_move...\u001b[0m\n"
+ ]
+ },
+ {
+ "data": {
+ "image/svg+xml": [
+ ""
+ ],
+ "text/plain": [
+ "''"
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\u001b[33mBoard_Proxy\u001b[0m (to Player_Black):\n",
+ "\n",
+ "\u001b[33mBoard_Proxy\u001b[0m (to Player_Black):\n",
+ "\n",
+ "\u001b[32m***** Response from calling tool (call_59t20pl0ab68z4xx2workgbc) *****\u001b[0m\n",
+ "Moved knight (♞) from g8 to h6.\n",
+ "\u001b[32m**********************************************************************\u001b[0m\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[31m\n",
+ ">>>>>>>> USING AUTO REPLY...\u001b[0m\n",
+ "\u001b[33mPlayer_Black\u001b[0m (to Board_Proxy):\n",
+ "\n",
+ "\u001b[32m***** Suggested tool call (call_jwv1d86srs1fnvu33cky9tgv): make_move *****\u001b[0m\n",
+ "Arguments: \n",
+ "{\"move\":\"g8h6\"}\n",
+ "\u001b[32m**************************************************************************\u001b[0m\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[33mPlayer_Black\u001b[0m (to Player_White):\n",
+ "\n",
+ "\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[31m\n",
+ ">>>>>>>> USING AUTO REPLY...\u001b[0m\n",
+ "\u001b[31m\n",
+ ">>>>>>>> USING AUTO REPLY...\u001b[0m\n"
+ ]
+ }
+ ],
+ "source": [
+ "# Clear the board.\n",
+ "board = chess.Board()\n",
+ "\n",
+ "chat_result = player_black.initiate_chat(\n",
+ " player_white,\n",
+ " message=\"Let's play chess! Your move.\",\n",
+ " max_turns=10,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "At this stage, it's hard to tell who's going to win, but they're playing well and using the functions correctly."
+ ]
+ }
+ ],
+ "metadata": {
+ "front_matter": {
+ "description": "LLM-backed agents playing chess with each other using nested chats.",
+ "tags": [
+ "nested chat",
+ "tool use",
+ "orchestration"
+ ]
+ },
+ "kernelspec": {
+ "display_name": "autogen",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.9"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 2
+}
diff --git a/notebook/autogen_uniformed_api_calling.ipynb b/notebook/autogen_uniformed_api_calling.ipynb
new file mode 100644
index 000000000000..08f747e1722f
--- /dev/null
+++ b/notebook/autogen_uniformed_api_calling.ipynb
@@ -0,0 +1,398 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# A Uniform interface to call different LLMs\n",
+ "\n",
+ "Autogen provides a uniform interface for API calls to different LLMs, and creating LLM agents from them.\n",
+ "Through setting up a configuration file, you can easily switch between different LLMs by just changing the model name, while enjoying all the [enhanced features](https://microsoft.github.io/autogen/docs/topics/llm-caching) such as [caching](https://microsoft.github.io/autogen/docs/Use-Cases/enhanced_inference/#usage-summary) and [cost calculation](https://microsoft.github.io/autogen/docs/Use-Cases/enhanced_inference/#usage-summary)!\n",
+ "\n",
+ "In this notebook, we will show you how to use AutoGen to call different LLMs and create LLM agents from them.\n",
+ "\n",
+ "Currently, we support the following model families:\n",
+ "- [OpenAI](https://platform.openai.com/docs/overview)\n",
+ "- [Azure OpenAI](https://azure.microsoft.com/en-us/products/ai-services/openai-service/?ef_id=_k_CjwKCAjwps-zBhAiEiwALwsVYdbpVkqA3IbY7WnxtrjNSefBnTfrijwRAFaYd8uuLCjeWsPdfZmxUBoC_ZAQAvD_BwE_k_&OCID=AIDcmm5edswduu_SEM__k_CjwKCAjwps-zBhAiEiwALwsVYdbpVkqA3IbY7WnxtrjNSefBnTfrijwRAFaYd8uuLCjeWsPdfZmxUBoC_ZAQAvD_BwE_k_&gad_source=1&gclid=CjwKCAjwps-zBhAiEiwALwsVYdbpVkqA3IbY7WnxtrjNSefBnTfrijwRAFaYd8uuLCjeWsPdfZmxUBoC_ZAQAvD_BwE)\n",
+ "- [Anthropic Claude](https://docs.anthropic.com/en/docs/welcome)\n",
+ "- [Google Gemini](https://ai.google.dev/gemini-api/docs)\n",
+ "- [Mistral](https://docs.mistral.ai/) (API to open and closed-source models)\n",
+ "- [DeepInfra](https://deepinfra.com/) (API to open-source models)\n",
+ "- [TogetherAI](https://www.together.ai/) (API to open-source models)\n",
+ "\n",
+ "... and more to come!\n",
+ "\n",
+ "You can also [plug in your local deployed LLM](https://microsoft.github.io/autogen/blog/2024/01/26/Custom-Models) into AutoGen if needed."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Install required packages\n",
+ "\n",
+ "You may want to install AutoGen with options to different LLMs. Here we install AutoGen with all the supported LLMs.\n",
+ "By default, AutoGen is installed with OpenAI support.\n",
+ " \n",
+ "```bash\n",
+ "pip install pyautogen[gemini,anthropic,mistral,together]\n",
+ "```\n",
+ "\n",
+ "\n",
+ "## Config list setup\n",
+ "\n",
+ "\n",
+ "First, create a `OAI_CONFIG_LIST` file to specify the api keys for the LLMs you want to use.\n",
+ "Generally, you just need to specify the `model`, `api_key` and `api_type` from the provider.\n",
+ "\n",
+ "```python\n",
+ "[\n",
+ " { \n",
+ " # using OpenAI\n",
+ " \"model\": \"gpt-35-turbo-1106\", \n",
+ " \"api_key\": \"YOUR_API_KEY\"\n",
+ " # default api_type is openai\n",
+ " },\n",
+ " {\n",
+ " # using Azure OpenAI\n",
+ " \"model\": \"gpt-4-turbo-1106\",\n",
+ " \"api_key\": \"YOUR_API_KEY\",\n",
+ " \"api_type\": \"azure\",\n",
+ " \"base_url\": \"YOUR_BASE_URL\",\n",
+ " \"api_version\": \"YOUR_API_VERSION\"\n",
+ " },\n",
+ " { \n",
+ " # using Google gemini\n",
+ " \"model\": \"gemini-1.5-pro-latest\",\n",
+ " \"api_key\": \"YOUR_API_KEY\",\n",
+ " \"api_type\": \"google\"\n",
+ " },\n",
+ " {\n",
+ " # using DeepInfra\n",
+ " \"model\": \"meta-llama/Meta-Llama-3-70B-Instruct\",\n",
+ " \"api_key\": \"YOUR_API_KEY\",\n",
+ " \"base_url\": \"https://api.deepinfra.com/v1/openai\" # need to specify the base_url\n",
+ " },\n",
+ " {\n",
+ " # using Anthropic Claude\n",
+ " \"model\": \"claude-1.0\",\n",
+ " \"api_type\": \"anthropic\",\n",
+ " \"api_key\": \"YOUR_API_KEY\"\n",
+ " },\n",
+ " {\n",
+ " # using Mistral\n",
+ " \"model\": \"mistral-large-latest\",\n",
+ " \"api_type\": \"mistral\",\n",
+ " \"api_key\": \"YOUR_API_KEY\"\n",
+ " },\n",
+ " {\n",
+ " # using TogetherAI\n",
+ " \"model\": \"google/gemma-7b-it\",\n",
+ " \"api_key\": \"YOUR_API_KEY\",\n",
+ " \"api_type\": \"together\"\n",
+ " }\n",
+ " ...\n",
+ "]\n",
+ "```\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Uniform Interface to call different LLMs\n",
+ "We first demonstrate how to use AutoGen to call different LLMs with the same wrapper class.\n",
+ "\n",
+ "After you install relevant packages and setup your config list, you only need three steps to call different LLMs:\n",
+ "1. Extract the config with the model name you want to use.\n",
+ "2. create a client with the model name.\n",
+ "3. call the client `create` to get the response.\n",
+ "\n",
+ "Below, we define a helper function `model_call_example_function` to implement the above steps."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 15,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import autogen\n",
+ "from autogen import OpenAIWrapper\n",
+ "\n",
+ "\n",
+ "def model_call_example_function(model: str, message: str, cache_seed: int = 41, print_cost: bool = False):\n",
+ " \"\"\"\n",
+ " A helper function that demonstrates how to call different models using the OpenAIWrapper class.\n",
+ " Note the name `OpenAIWrapper` is not accurate, as now it is a wrapper for multiple models, not just OpenAI.\n",
+ " This might be changed in the future.\n",
+ " \"\"\"\n",
+ " config_list = autogen.config_list_from_json(\n",
+ " \"OAI_CONFIG_LIST\",\n",
+ " filter_dict={\n",
+ " \"model\": [model],\n",
+ " },\n",
+ " )\n",
+ " client = OpenAIWrapper(config_list=config_list)\n",
+ " response = client.create(messages=[{\"role\": \"user\", \"content\": message}], cache_seed=cache_seed)\n",
+ "\n",
+ " print(f\"Response from model {model}: {response.choices[0].message.content}\")\n",
+ "\n",
+ " # Print the cost of the API call\n",
+ " if print_cost:\n",
+ " client.print_usage_summary()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 2,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Response from model gpt-35-turbo-1106: Why couldn't the bicycle stand up by itself?\n",
+ "\n",
+ "Because it was two-tired!\n"
+ ]
+ }
+ ],
+ "source": [
+ "model_call_example_function(model=\"gpt-35-turbo-1106\", message=\"Tell me a joke.\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 3,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Response from model gemini-1.5-pro-latest: Why don't scientists trust atoms? \n",
+ "\n",
+ "Because they make up everything! \n",
+ " \n",
+ "Let me know if you'd like to hear another one! \n",
+ "\n"
+ ]
+ }
+ ],
+ "source": [
+ "model_call_example_function(model=\"gemini-1.5-pro-latest\", message=\"Tell me a joke.\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 4,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Response from model meta-llama/Meta-Llama-3-70B-Instruct: Here's one:\n",
+ "\n",
+ "Why couldn't the bicycle stand up by itself?\n",
+ "\n",
+ "(wait for it...)\n",
+ "\n",
+ "Because it was two-tired!\n",
+ "\n",
+ "How was that? Do you want to hear another one?\n"
+ ]
+ }
+ ],
+ "source": [
+ "model_call_example_function(model=\"meta-llama/Meta-Llama-3-70B-Instruct\", message=\"Tell me a joke. \")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 18,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Response from model mistral-large-latest: Sure, here's a light-hearted joke for you:\n",
+ "\n",
+ "Why don't scientists trust atoms?\n",
+ "\n",
+ "Because they make up everything!\n",
+ "----------------------------------------------------------------------------------------------------\n",
+ "Usage summary excluding cached usage: \n",
+ "Total cost: 0.00042\n",
+ "* Model 'mistral-large-latest': cost: 0.00042, prompt_tokens: 9, completion_tokens: 32, total_tokens: 41\n",
+ "\n",
+ "All completions are non-cached: the total cost with cached completions is the same as actual cost.\n",
+ "----------------------------------------------------------------------------------------------------\n"
+ ]
+ }
+ ],
+ "source": [
+ "model_call_example_function(model=\"mistral-large-latest\", message=\"Tell me a joke. \", print_cost=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Using different LLMs in agents\n",
+ "Below we give a quick demo of using different LLMs agents in a groupchat. \n",
+ "\n",
+ "We mock a debate scenario where each LLM agent is a debater, either in affirmative or negative side. We use a round-robin strategy to let each debater from different teams to speak in turn."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 10,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def get_llm_config(model_name):\n",
+ " return {\n",
+ " \"config_list\": autogen.config_list_from_json(\"OAI_CONFIG_LIST\", filter_dict={\"model\": [model_name]}),\n",
+ " \"cache_seed\": 41,\n",
+ " }\n",
+ "\n",
+ "\n",
+ "affirmative_system_message = \"You are in the Affirmative team of a debate. When it is your turn, please give at least one reason why you are for the topic. Keep it short.\"\n",
+ "negative_system_message = \"You are in the Negative team of a debate. The affirmative team has given their reason, please counter their argument. Keep it short.\"\n",
+ "\n",
+ "gpt35_agent = autogen.AssistantAgent(\n",
+ " name=\"GPT35\", system_message=affirmative_system_message, llm_config=get_llm_config(\"gpt-35-turbo-1106\")\n",
+ ")\n",
+ "\n",
+ "llama_agent = autogen.AssistantAgent(\n",
+ " name=\"Llama3\",\n",
+ " system_message=negative_system_message,\n",
+ " llm_config=get_llm_config(\"meta-llama/Meta-Llama-3-70B-Instruct\"),\n",
+ ")\n",
+ "\n",
+ "mistral_agent = autogen.AssistantAgent(\n",
+ " name=\"Mistral\", system_message=affirmative_system_message, llm_config=get_llm_config(\"mistral-large-latest\")\n",
+ ")\n",
+ "\n",
+ "gemini_agent = autogen.AssistantAgent(\n",
+ " name=\"Gemini\", system_message=negative_system_message, llm_config=get_llm_config(\"gemini-1.5-pro-latest\")\n",
+ ")\n",
+ "\n",
+ "claude_agent = autogen.AssistantAgent(\n",
+ " name=\"Claude\", system_message=affirmative_system_message, llm_config=get_llm_config(\"claude-3-opus-20240229\")\n",
+ ")\n",
+ "\n",
+ "user_proxy = autogen.UserProxyAgent(\n",
+ " name=\"User\",\n",
+ " code_execution_config=False,\n",
+ ")\n",
+ "\n",
+ "# initilize the groupchat with round robin speaker selection method\n",
+ "groupchat = autogen.GroupChat(\n",
+ " agents=[claude_agent, gemini_agent, mistral_agent, llama_agent, gpt35_agent, user_proxy],\n",
+ " messages=[],\n",
+ " max_round=8,\n",
+ " speaker_selection_method=\"round_robin\",\n",
+ ")\n",
+ "manager = autogen.GroupChatManager(groupchat=groupchat)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 12,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\u001b[33mUser\u001b[0m (to chat_manager):\n",
+ "\n",
+ "Debate Topic: Should vaccination be mandatory?\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[32m\n",
+ "Next speaker: Claude\n",
+ "\u001b[0m\n",
+ "\u001b[33mClaude\u001b[0m (to chat_manager):\n",
+ "\n",
+ "As a member of the Affirmative team, I believe that vaccination should be mandatory for several reasons:\n",
+ "\n",
+ "1. Herd immunity: When a large percentage of the population is vaccinated, it helps protect those who cannot receive vaccines due to medical reasons or weakened immune systems. Mandatory vaccination ensures that we maintain a high level of herd immunity, preventing the spread of dangerous diseases.\n",
+ "\n",
+ "2. Public health: Vaccines have been proven to be safe and effective in preventing the spread of infectious diseases. By making vaccination mandatory, we prioritize public health and reduce the risk of outbreaks that could lead to widespread illness and loss of life.\n",
+ "\n",
+ "3. Societal benefits: Mandatory vaccination not only protects individuals but also benefits society as a whole. It reduces healthcare costs associated with treating preventable diseases and minimizes the economic impact of disease outbreaks on businesses and communities.\n",
+ "\n",
+ "In summary, mandatory vaccination is a critical tool in protecting public health, maintaining herd immunity, and promoting the well-being of our society.\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[32m\n",
+ "Next speaker: Gemini\n",
+ "\u001b[0m\n",
+ "\u001b[33mGemini\u001b[0m (to chat_manager):\n",
+ "\n",
+ "While we acknowledge the importance of herd immunity and public health, mandating vaccinations infringes upon individual autonomy and medical freedom. Blanket mandates fail to consider individual health circumstances and potential vaccine risks, which are often overlooked in favor of a one-size-fits-all approach. \n",
+ "\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[32m\n",
+ "Next speaker: Mistral\n",
+ "\u001b[0m\n",
+ "\u001b[33mMistral\u001b[0m (to chat_manager):\n",
+ "\n",
+ "I understand your concerns and the value of individual autonomy. However, it's important to note that mandatory vaccination policies often include exemptions for medical reasons. This allows for individual health circumstances to be taken into account, ensuring that those who cannot safely receive vaccines are not put at risk. The goal is to strike a balance between protecting public health and respecting individual choices, while always prioritizing the well-being and safety of all members of society.\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[32m\n",
+ "Next speaker: Llama3\n",
+ "\u001b[0m\n",
+ "\u001b[33mLlama3\u001b[0m (to chat_manager):\n",
+ "\n",
+ "I understand your point, but blanket exemptions for medical reasons are not sufficient to address the complexities of individual health circumstances. What about those who have experienced adverse reactions to vaccines in the past or have a family history of such reactions? What about those who have compromised immune systems or are taking medications that may interact with vaccine components? A one-size-fits-all approach to vaccination ignores the nuances of individual health and puts some people at risk of harm. Additionally, mandating vaccination undermines trust in government and healthcare institutions, leading to further divides and mistrust. We need to prioritize informed consent and individual autonomy in medical decisions, rather than relying solely on a blanket mandate.\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[32m\n",
+ "Next speaker: GPT35\n",
+ "\u001b[0m\n",
+ "\u001b[33mGPT35\u001b[0m (to chat_manager):\n",
+ "\n",
+ "I understand your point, but mandatory vaccination policies can still allow for exemptions based on medical history, allergic reactions, and compromised immunity. This would address the individual circumstances you mentioned. Furthermore, mandating vaccination can also help strengthen trust in public health measures by demonstrating a commitment to protecting the entire community. Informed consent is important, but it is also essential to consider the potential consequences of not being vaccinated on public health and the well-being of others.\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[32m\n",
+ "Next speaker: User\n",
+ "\u001b[0m\n"
+ ]
+ }
+ ],
+ "source": [
+ "chat_history = user_proxy.initiate_chat(recipient=manager, message=\"Debate Topic: Should vaccination be mandatory?\")"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "autodev",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.12.4"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 2
+}
diff --git a/setup.py b/setup.py
index da87d263b0ca..9117ed45ceac 100644
--- a/setup.py
+++ b/setup.py
@@ -72,15 +72,13 @@
"mathchat": ["sympy", "pydantic==1.10.9", "wolframalpha"],
"retrievechat": retrieve_chat,
"retrievechat-pgvector": retrieve_chat_pgvector,
- "retrievechat-qdrant": [
- *retrieve_chat,
- "qdrant_client[fastembed]<1.9.2",
- ],
+ "retrievechat-qdrant": [*retrieve_chat, "qdrant_client", "fastembed>=0.3.1"],
"autobuild": ["chromadb", "sentence-transformers", "huggingface-hub", "pysqlite3"],
"teachable": ["chromadb"],
"lmm": ["replicate", "pillow"],
"graph": ["networkx", "matplotlib"],
"gemini": ["google-generativeai>=0.5,<1", "google-cloud-aiplatform", "google-auth", "pillow", "pydantic"],
+ "together": ["together>=1.2"],
"websurfer": ["beautifulsoup4", "markdownify", "pdfminer.six", "pathvalidate"],
"redis": ["redis"],
"cosmosdb": ["azure-cosmos>=4.2.0"],
@@ -90,6 +88,8 @@
"long-context": ["llmlingua<0.3"],
"anthropic": ["anthropic>=0.23.1"],
"mistral": ["mistralai>=0.2.0"],
+ "groq": ["groq>=0.9.0"],
+ "cohere": ["cohere>=5.5.8"],
}
setuptools.setup(
diff --git a/test/oai/test_cohere.py b/test/oai/test_cohere.py
new file mode 100644
index 000000000000..83ef56b17087
--- /dev/null
+++ b/test/oai/test_cohere.py
@@ -0,0 +1,69 @@
+#!/usr/bin/env python3 -m pytest
+
+import os
+
+import pytest
+
+try:
+ from autogen.oai.cohere import CohereClient, calculate_cohere_cost
+
+ skip = False
+except ImportError:
+ CohereClient = object
+ skip = True
+
+
+reason = "Cohere dependency not installed!"
+
+
+@pytest.fixture()
+def cohere_client():
+ return CohereClient(api_key="dummy_api_key")
+
+
+@pytest.mark.skipif(skip, reason=reason)
+def test_initialization_missing_api_key():
+ os.environ.pop("COHERE_API_KEY", None)
+ with pytest.raises(
+ AssertionError,
+ match="Please include the api_key in your config list entry for Cohere or set the COHERE_API_KEY env variable.",
+ ):
+ CohereClient()
+
+ CohereClient(api_key="dummy_api_key")
+
+
+@pytest.mark.skipif(skip, reason=reason)
+def test_intialization(cohere_client):
+ assert cohere_client.api_key == "dummy_api_key", "`api_key` should be correctly set in the config"
+
+
+@pytest.mark.skipif(skip, reason=reason)
+def test_calculate_cohere_cost():
+ assert (
+ calculate_cohere_cost(0, 0, model="command-r") == 0.0
+ ), "Cost should be 0 for 0 input_tokens and 0 output_tokens"
+ assert calculate_cohere_cost(100, 200, model="command-r-plus") == 0.0033
+
+
+@pytest.mark.skipif(skip, reason=reason)
+def test_load_config(cohere_client):
+ params = {
+ "model": "command-r-plus",
+ "stream": False,
+ "temperature": 1,
+ "p": 0.8,
+ "max_tokens": 100,
+ }
+ expected_params = {
+ "model": "command-r-plus",
+ "temperature": 1,
+ "p": 0.8,
+ "seed": None,
+ "max_tokens": 100,
+ "frequency_penalty": 0,
+ "presence_penalty": 0,
+ "k": 0,
+ }
+ result = cohere_client.parse_params(params)
+ assert result == expected_params, "Config should be correctly loaded"
diff --git a/test/oai/test_groq.py b/test/oai/test_groq.py
new file mode 100644
index 000000000000..f55edbd8c7a6
--- /dev/null
+++ b/test/oai/test_groq.py
@@ -0,0 +1,249 @@
+from unittest.mock import MagicMock, patch
+
+import pytest
+
+try:
+ from autogen.oai.groq import GroqClient, calculate_groq_cost
+
+ skip = False
+except ImportError:
+ GroqClient = object
+ InternalServerError = object
+ skip = True
+
+
+# Fixtures for mock data
+@pytest.fixture
+def mock_response():
+ class MockResponse:
+ def __init__(self, text, choices, usage, cost, model):
+ self.text = text
+ self.choices = choices
+ self.usage = usage
+ self.cost = cost
+ self.model = model
+
+ return MockResponse
+
+
+@pytest.fixture
+def groq_client():
+ return GroqClient(api_key="fake_api_key")
+
+
+skip_reason = "Groq dependency is not installed"
+
+
+# Test initialization and configuration
+@pytest.mark.skipif(skip, reason=skip_reason)
+def test_initialization():
+
+ # Missing any api_key
+ with pytest.raises(AssertionError) as assertinfo:
+ GroqClient() # Should raise an AssertionError due to missing api_key
+
+ assert "Please include the api_key in your config list entry for Groq or set the GROQ_API_KEY env variable." in str(
+ assertinfo.value
+ )
+
+ # Creation works
+ GroqClient(api_key="fake_api_key") # Should create okay now.
+
+
+# Test standard initialization
+@pytest.mark.skipif(skip, reason=skip_reason)
+def test_valid_initialization(groq_client):
+ assert groq_client.api_key == "fake_api_key", "Config api_key should be correctly set"
+
+
+# Test parameters
+@pytest.mark.skipif(skip, reason=skip_reason)
+def test_parsing_params(groq_client):
+ # All parameters
+ params = {
+ "model": "llama3-8b-8192",
+ "frequency_penalty": 1.5,
+ "presence_penalty": 1.5,
+ "max_tokens": 1000,
+ "seed": 42,
+ "stream": False,
+ "temperature": 1,
+ "top_p": 0.8,
+ }
+ expected_params = {
+ "model": "llama3-8b-8192",
+ "frequency_penalty": 1.5,
+ "presence_penalty": 1.5,
+ "max_tokens": 1000,
+ "seed": 42,
+ "stream": False,
+ "temperature": 1,
+ "top_p": 0.8,
+ }
+ result = groq_client.parse_params(params)
+ assert result == expected_params
+
+ # Only model, others set as defaults
+ params = {
+ "model": "llama3-8b-8192",
+ }
+ expected_params = {
+ "model": "llama3-8b-8192",
+ "frequency_penalty": None,
+ "presence_penalty": None,
+ "max_tokens": None,
+ "seed": None,
+ "stream": False,
+ "temperature": 1,
+ "top_p": None,
+ }
+ result = groq_client.parse_params(params)
+ assert result == expected_params
+
+ # Incorrect types, defaults should be set, will show warnings but not trigger assertions
+ params = {
+ "model": "llama3-8b-8192",
+ "frequency_penalty": "1.5",
+ "presence_penalty": "1.5",
+ "max_tokens": "1000",
+ "seed": "42",
+ "stream": "False",
+ "temperature": "1",
+ "top_p": "0.8",
+ }
+ result = groq_client.parse_params(params)
+ assert result == expected_params
+
+ # Values outside bounds, should warn and set to defaults
+ params = {
+ "model": "llama3-8b-8192",
+ "frequency_penalty": 5000,
+ "presence_penalty": -500,
+ "temperature": 3,
+ }
+ result = groq_client.parse_params(params)
+ assert result == expected_params
+
+ # No model
+ params = {
+ "frequency_penalty": 1,
+ }
+
+ with pytest.raises(AssertionError) as assertinfo:
+ result = groq_client.parse_params(params)
+
+ assert "Please specify the 'model' in your config list entry to nominate the Groq model to use." in str(
+ assertinfo.value
+ )
+
+
+# Test cost calculation
+@pytest.mark.skipif(skip, reason=skip_reason)
+def test_cost_calculation(mock_response):
+ response = mock_response(
+ text="Example response",
+ choices=[{"message": "Test message 1"}],
+ usage={"prompt_tokens": 500, "completion_tokens": 300, "total_tokens": 800},
+ cost=None,
+ model="llama3-70b-8192",
+ )
+ assert (
+ calculate_groq_cost(response.usage["prompt_tokens"], response.usage["completion_tokens"], response.model)
+ == 0.000532
+ ), "Cost for this should be $0.000532"
+
+
+# Test text generation
+@pytest.mark.skipif(skip, reason=skip_reason)
+@patch("autogen.oai.groq.GroqClient.create")
+def test_create_response(mock_chat, groq_client):
+ # Mock GroqClient.chat response
+ mock_groq_response = MagicMock()
+ mock_groq_response.choices = [
+ MagicMock(finish_reason="stop", message=MagicMock(content="Example Groq response", tool_calls=None))
+ ]
+ mock_groq_response.id = "mock_groq_response_id"
+ mock_groq_response.model = "llama3-70b-8192"
+ mock_groq_response.usage = MagicMock(prompt_tokens=10, completion_tokens=20) # Example token usage
+
+ mock_chat.return_value = mock_groq_response
+
+ # Test parameters
+ params = {
+ "messages": [{"role": "user", "content": "Hello"}, {"role": "assistant", "content": "World"}],
+ "model": "llama3-70b-8192",
+ }
+
+ # Call the create method
+ response = groq_client.create(params)
+
+ # Assertions to check if response is structured as expected
+ assert (
+ response.choices[0].message.content == "Example Groq response"
+ ), "Response content should match expected output"
+ assert response.id == "mock_groq_response_id", "Response ID should match the mocked response ID"
+ assert response.model == "llama3-70b-8192", "Response model should match the mocked response model"
+ assert response.usage.prompt_tokens == 10, "Response prompt tokens should match the mocked response usage"
+ assert response.usage.completion_tokens == 20, "Response completion tokens should match the mocked response usage"
+
+
+# Test functions/tools
+@pytest.mark.skipif(skip, reason=skip_reason)
+@patch("autogen.oai.groq.GroqClient.create")
+def test_create_response_with_tool_call(mock_chat, groq_client):
+ # Mock `groq_response = client.chat(**groq_params)`
+ mock_function = MagicMock(name="currency_calculator")
+ mock_function.name = "currency_calculator"
+ mock_function.arguments = '{"base_currency": "EUR", "quote_currency": "USD", "base_amount": 123.45}'
+
+ mock_function_2 = MagicMock(name="get_weather")
+ mock_function_2.name = "get_weather"
+ mock_function_2.arguments = '{"location": "Chicago"}'
+
+ mock_chat.return_value = MagicMock(
+ choices=[
+ MagicMock(
+ finish_reason="tool_calls",
+ message=MagicMock(
+ content="Sample text about the functions",
+ tool_calls=[
+ MagicMock(id="gdRdrvnHh", function=mock_function),
+ MagicMock(id="abRdrvnHh", function=mock_function_2),
+ ],
+ ),
+ )
+ ],
+ id="mock_groq_response_id",
+ model="llama3-70b-8192",
+ usage=MagicMock(prompt_tokens=10, completion_tokens=20),
+ )
+
+ # Construct parameters
+ converted_functions = [
+ {
+ "type": "function",
+ "function": {
+ "description": "Currency exchange calculator.",
+ "name": "currency_calculator",
+ "parameters": {
+ "type": "object",
+ "properties": {
+ "base_amount": {"type": "number", "description": "Amount of currency in base_currency"},
+ },
+ "required": ["base_amount"],
+ },
+ },
+ }
+ ]
+ groq_messages = [
+ {"role": "user", "content": "How much is 123.45 EUR in USD?"},
+ {"role": "assistant", "content": "World"},
+ ]
+
+ # Call the create method
+ response = groq_client.create({"messages": groq_messages, "tools": converted_functions, "model": "llama3-70b-8192"})
+
+ # Assertions to check if the functions and content are included in the response
+ assert response.choices[0].message.content == "Sample text about the functions"
+ assert response.choices[0].message.tool_calls[0].function.name == "currency_calculator"
+ assert response.choices[0].message.tool_calls[1].function.name == "get_weather"
diff --git a/test/oai/test_together.py b/test/oai/test_together.py
new file mode 100644
index 000000000000..0581d19f0f73
--- /dev/null
+++ b/test/oai/test_together.py
@@ -0,0 +1,264 @@
+from unittest.mock import MagicMock, patch
+
+import pytest
+
+try:
+ from openai.types.chat.chat_completion import ChatCompletionMessage, Choice
+
+ from autogen.oai.together import TogetherClient, calculate_together_cost
+
+ skip = False
+except ImportError:
+ TogetherClient = object
+ InternalServerError = object
+ skip = True
+
+
+# Fixtures for mock data
+@pytest.fixture
+def mock_response():
+ class MockResponse:
+ def __init__(self, text, choices, usage, cost, model):
+ self.text = text
+ self.choices = choices
+ self.usage = usage
+ self.cost = cost
+ self.model = model
+
+ return MockResponse
+
+
+@pytest.fixture
+def together_client():
+ return TogetherClient(api_key="fake_api_key")
+
+
+# Test initialization and configuration
+@pytest.mark.skipif(skip, reason="Together.AI dependency is not installed")
+def test_initialization():
+
+ # Missing any api_key
+ with pytest.raises(AssertionError) as assertinfo:
+ TogetherClient() # Should raise an AssertionError due to missing api_key
+
+ assert (
+ "Please include the api_key in your config list entry for Together.AI or set the TOGETHER_API_KEY env variable."
+ in str(assertinfo.value)
+ )
+
+ # Creation works
+ TogetherClient(api_key="fake_api_key") # Should create okay now.
+
+
+# Test standard initialization
+@pytest.mark.skipif(skip, reason="Together.AI dependency is not installed")
+def test_valid_initialization(together_client):
+ assert together_client.api_key == "fake_api_key", "Config api_key should be correctly set"
+
+
+# Test parameters
+@pytest.mark.skipif(skip, reason="Together.AI dependency is not installed")
+def test_parsing_params(together_client):
+ # All parameters
+ params = {
+ "model": "Qwen/Qwen2-72B-Instruct",
+ "max_tokens": 1000,
+ "stream": False,
+ "temperature": 1,
+ "top_p": 0.8,
+ "top_k": 50,
+ "repetition_penalty": 0.5,
+ "presence_penalty": 1.5,
+ "frequency_penalty": 1.5,
+ "min_p": 0.2,
+ "safety_model": "Meta-Llama/Llama-Guard-7b",
+ }
+ expected_params = {
+ "model": "Qwen/Qwen2-72B-Instruct",
+ "max_tokens": 1000,
+ "stream": False,
+ "temperature": 1,
+ "top_p": 0.8,
+ "top_k": 50,
+ "repetition_penalty": 0.5,
+ "presence_penalty": 1.5,
+ "frequency_penalty": 1.5,
+ "min_p": 0.2,
+ "safety_model": "Meta-Llama/Llama-Guard-7b",
+ }
+ result = together_client.parse_params(params)
+ assert result == expected_params
+
+ # Only model, others set as defaults
+ params = {
+ "model": "mistralai/Mixtral-8x7B-Instruct-v0.1",
+ }
+ expected_params = {
+ "model": "mistralai/Mixtral-8x7B-Instruct-v0.1",
+ "max_tokens": 512,
+ "stream": False,
+ "temperature": None,
+ "top_p": None,
+ "top_k": None,
+ "repetition_penalty": None,
+ "presence_penalty": None,
+ "frequency_penalty": None,
+ "min_p": None,
+ "safety_model": None,
+ }
+ result = together_client.parse_params(params)
+ assert result == expected_params
+
+ # Incorrect types, defaults should be set, will show warnings but not trigger assertions
+ params = {
+ "model": "mistralai/Mixtral-8x7B-Instruct-v0.1",
+ "max_tokens": "512",
+ "stream": "Yes",
+ "temperature": "0.5",
+ "top_p": "0.8",
+ "top_k": "50",
+ "repetition_penalty": "0.5",
+ "presence_penalty": "1.5",
+ "frequency_penalty": "1.5",
+ "min_p": "0.2",
+ "safety_model": False,
+ }
+ result = together_client.parse_params(params)
+ assert result == expected_params
+
+ # Values outside bounds, should warn and set to defaults
+ params = {
+ "model": "mistralai/Mixtral-8x7B-Instruct-v0.1",
+ "max_tokens": -200,
+ "presence_penalty": -5,
+ "frequency_penalty": 5,
+ "min_p": -0.5,
+ }
+ result = together_client.parse_params(params)
+ assert result == expected_params
+
+
+# Test cost calculation
+@pytest.mark.skipif(skip, reason="Together.AI dependency is not installed")
+def test_cost_calculation(mock_response):
+ response = mock_response(
+ text="Example response",
+ choices=[{"message": "Test message 1"}],
+ usage={"prompt_tokens": 10, "completion_tokens": 5, "total_tokens": 15},
+ cost=None,
+ model="mistralai/Mixtral-8x22B-Instruct-v0.1",
+ )
+ assert (
+ calculate_together_cost(response.usage["prompt_tokens"], response.usage["completion_tokens"], response.model)
+ == 0.000018
+ ), "Cost for this should be $0.000018"
+
+
+# Test text generation
+@pytest.mark.skipif(skip, reason="Together.AI dependency is not installed")
+@patch("autogen.oai.together.TogetherClient.create")
+def test_create_response(mock_create, together_client):
+ # Mock TogetherClient.chat response
+ mock_together_response = MagicMock()
+ mock_together_response.choices = [
+ MagicMock(finish_reason="stop", message=MagicMock(content="Example Llama response", tool_calls=None))
+ ]
+ mock_together_response.id = "mock_together_response_id"
+ mock_together_response.model = "meta-llama/Llama-3-8b-chat-hf"
+ mock_together_response.usage = MagicMock(prompt_tokens=10, completion_tokens=20) # Example token usage
+
+ mock_create.return_value = mock_together_response
+
+ # Test parameters
+ params = {
+ "messages": [{"role": "user", "content": "Hello"}, {"role": "assistant", "content": "World"}],
+ "model": "meta-llama/Llama-3-8b-chat-hf",
+ }
+
+ # Call the create method
+ response = together_client.create(params)
+
+ # Assertions to check if response is structured as expected
+ assert (
+ response.choices[0].message.content == "Example Llama response"
+ ), "Response content should match expected output"
+ assert response.id == "mock_together_response_id", "Response ID should match the mocked response ID"
+ assert response.model == "meta-llama/Llama-3-8b-chat-hf", "Response model should match the mocked response model"
+ assert response.usage.prompt_tokens == 10, "Response prompt tokens should match the mocked response usage"
+ assert response.usage.completion_tokens == 20, "Response completion tokens should match the mocked response usage"
+
+
+# Test functions/tools
+@pytest.mark.skipif(skip, reason="Together.AI dependency is not installed")
+@patch("autogen.oai.together.TogetherClient.create")
+def test_create_response_with_tool_call(mock_create, together_client):
+
+ # Define the mock response directly within the patch
+ mock_function = MagicMock(name="currency_calculator")
+ mock_function.name = "currency_calculator"
+ mock_function.arguments = '{"base_currency": "EUR", "quote_currency": "USD", "base_amount": 123.45}'
+
+ # Define the mock response directly within the patch
+ mock_create.return_value = MagicMock(
+ choices=[
+ MagicMock(
+ finish_reason="tool_calls",
+ message=MagicMock(
+ content="", # Message is empty for tool responses
+ tool_calls=[MagicMock(id="gdRdrvnHh", function=mock_function)],
+ ),
+ )
+ ],
+ id="mock_together_response_id",
+ model="meta-llama/Llama-3-8b-chat-hf",
+ usage=MagicMock(prompt_tokens=10, completion_tokens=20),
+ )
+
+ # Test parameters
+ converted_functions = [
+ {
+ "type": "function",
+ "function": {
+ "description": "Currency exchange calculator.",
+ "name": "currency_calculator",
+ "parameters": {
+ "type": "object",
+ "properties": {
+ "base_amount": {"type": "number", "description": "Amount of currency in base_currency"},
+ "base_currency": {
+ "enum": ["USD", "EUR"],
+ "type": "string",
+ "default": "USD",
+ "description": "Base currency",
+ },
+ "quote_currency": {
+ "enum": ["USD", "EUR"],
+ "type": "string",
+ "default": "EUR",
+ "description": "Quote currency",
+ },
+ },
+ "required": ["base_amount"],
+ },
+ },
+ }
+ ]
+
+ together_messages = [
+ {
+ "role": "user",
+ "content": "How much is 123.45 EUR in USD?",
+ "name": None,
+ "tool_calls": None,
+ "tool_call_id": None,
+ },
+ ]
+
+ # Call the create method (which is now mocked)
+ response = together_client.create(
+ {"messages": together_messages, "tools": converted_functions, "model": "meta-llama/Llama-3-8b-chat-hf"}
+ )
+
+ # Assertions to check if response is structured as expected
+ assert response.choices[0].message.content == ""
+ assert response.choices[0].message.tool_calls[0].function.name == "currency_calculator"
diff --git a/website/blog/2023-06-28-MathChat/index.mdx b/website/blog/2023-06-28-MathChat/index.mdx
index 4c1007c611b8..be2423de9eed 100644
--- a/website/blog/2023-06-28-MathChat/index.mdx
+++ b/website/blog/2023-06-28-MathChat/index.mdx
@@ -75,7 +75,7 @@ We found that compared to basic prompting, which demonstrates the innate capabil
For categories like Algebra and Prealgebra, PoT and PS showed little improvement, and in some instances, even led to a decrease in accuracy. However, MathChat was able to enhance total accuracy by around 6% compared to PoT and PS, showing competitive performance across all categories. Remarkably, MathChat improved accuracy in the Algebra category by about 15% over other methods. Note that categories like Intermediate Algebra and Precalculus remained challenging for all methods, with only about 20% of problems solved accurately.
-The code for experiments can be found at this [repository](https://github.com/kevin666aa/FLAML/tree/gpt_math_solver/flaml/autogen/math).
+The code for experiments can be found at this [repository](https://github.com/yiranwu0/FLAML/tree/gpt_math_solver/flaml/autogen/math).
We now provide an implementation of MathChat using the interactive agents in AutoGen. See this [notebook](https://github.com/microsoft/autogen/blob/main/notebook/agentchat_MathChat.ipynb) for example usage.
## Future Directions
diff --git a/website/blog/2023-11-13-OAI-assistants/index.mdx b/website/blog/2023-11-13-OAI-assistants/index.mdx
index e73e31ad591f..07216a25969c 100644
--- a/website/blog/2023-11-13-OAI-assistants/index.mdx
+++ b/website/blog/2023-11-13-OAI-assistants/index.mdx
@@ -112,6 +112,6 @@ Checkout more examples [here](https://github.com/microsoft/autogen/tree/main/not
`GPTAssistantAgent` was made possible through collaboration with
[@IANTHEREAL](https://github.com/IANTHEREAL),
[Jiale Liu](https://leoljl.github.io),
-[Yiran Wu](https://github.com/kevin666aa),
+[Yiran Wu](https://github.com/yiranwu0),
[Qingyun Wu](https://qingyun-wu.github.io/),
[Chi Wang](https://www.microsoft.com/en-us/research/people/chiw/), and many other AutoGen maintainers.
diff --git a/website/blog/2024-06-21-AgentEval/img/agenteval_ov_v3.png b/website/blog/2024-06-21-AgentEval/img/agenteval_ov_v3.png
new file mode 100644
index 000000000000..fe31283d72d0
--- /dev/null
+++ b/website/blog/2024-06-21-AgentEval/img/agenteval_ov_v3.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:e17aebbc38a8ba55e4b18b9352a680edcca4b3d6625b16f6d1ab3131da799b63
+size 236624
diff --git a/website/blog/2024-06-21-AgentEval/index.mdx b/website/blog/2024-06-21-AgentEval/index.mdx
new file mode 100644
index 000000000000..87ffc857e839
--- /dev/null
+++ b/website/blog/2024-06-21-AgentEval/index.mdx
@@ -0,0 +1,202 @@
+---
+title: "AgentEval: A Developer Tool to Assess Utility of LLM-powered Applications"
+authors:
+ - jluey
+ - julianakiseleva
+tags: [LLM, GPT, evaluation, task utility]
+---
+
+
+
+
+
"
]
},
{
@@ -39,7 +42,7 @@
"## Adding AgentOps to an existing Autogen service.\n",
"To get started, you'll need to install the AgentOps package and set an API key.\n",
"\n",
- "AgentOps automatically configures itself when it's initialized. This means your agents will be tracked and logged to your AgentOps account right away."
+ "AgentOps automatically configures itself when it's initialized meaning your agent run data will be tracked and logged to your AgentOps account right away."
]
},
{
@@ -69,7 +72,7 @@
"\n",
"By default, the AgentOps `init()` function will look for an environment variable named `AGENTOPS_API_KEY`. Alternatively, you can pass one in as an optional parameter.\n",
"\n",
- "Create an account and API key at [AgentOps.ai](https://agentops.ai/)"
+ "Create an account and obtain an API key at [AgentOps.ai](https://agentops.ai/settings/projects)"
]
},
{
@@ -87,12 +90,14 @@
"name": "stderr",
"output_type": "stream",
"text": [
- "🖇 AgentOps: \u001B[34m\u001B[34mSession Replay: https://app.agentops.ai/drilldown?session_id=8bfaeed1-fd51-4c68-b3ec-276b1a3ce8a4\u001B[0m\u001B[0m\n"
+ "🖇 AgentOps: \u001b[34m\u001b[34mSession Replay: https://app.agentops.ai/drilldown?session_id=8bfaeed1-fd51-4c68-b3ec-276b1a3ce8a4\u001b[0m\u001b[0m\n"
]
},
{
"data": {
- "text/plain": "UUID('8bfaeed1-fd51-4c68-b3ec-276b1a3ce8a4')"
+ "text/plain": [
+ "UUID('8bfaeed1-fd51-4c68-b3ec-276b1a3ce8a4')"
+ ]
},
"execution_count": 1,
"metadata": {},
@@ -105,6 +110,7 @@
"from autogen import ConversableAgent, UserProxyAgent, config_list_from_json\n",
"\n",
"agentops.init(api_key=\"7c94212b-b89d-47a6-a20c-23b2077d3226\") # or agentops.init(api_key=\"...\")"
+ "agentops.init(api_key=\"...\")"
]
},
{
@@ -144,19 +150,19 @@
"name": "stdout",
"output_type": "stream",
"text": [
- "\u001B[33magent\u001B[0m (to user):\n",
+ "\u001b[33magent\u001b[0m (to user):\n",
"\n",
"How can I help you today?\n",
"\n",
"--------------------------------------------------------------------------------\n",
- "\u001B[33muser\u001B[0m (to agent):\n",
+ "\u001b[33muser\u001b[0m (to agent):\n",
"\n",
"2+2\n",
"\n",
"--------------------------------------------------------------------------------\n",
- "\u001B[31m\n",
- ">>>>>>>> USING AUTO REPLY...\u001B[0m\n",
- "\u001B[33magent\u001B[0m (to user):\n",
+ "\u001b[31m\n",
+ ">>>>>>>> USING AUTO REPLY...\u001b[0m\n",
+ "\u001b[33magent\u001b[0m (to user):\n",
"\n",
"2 + 2 equals 4.\n",
"\n",
@@ -168,7 +174,7 @@
"output_type": "stream",
"text": [
"🖇 AgentOps: This run's cost $0.000960\n",
- "🖇 AgentOps: \u001B[34m\u001B[34mSession Replay: https://app.agentops.ai/drilldown?session_id=8bfaeed1-fd51-4c68-b3ec-276b1a3ce8a4\u001B[0m\u001B[0m\n"
+ "🖇 AgentOps: \u001b[34m\u001b[34mSession Replay: https://app.agentops.ai/drilldown?session_id=8bfaeed1-fd51-4c68-b3ec-276b1a3ce8a4\u001b[0m\u001b[0m\n"
]
}
],
@@ -185,7 +191,7 @@
"# Create the agent that represents the user in the conversation.\n",
"user_proxy = UserProxyAgent(\"user\", code_execution_config=False)\n",
"\n",
- "# Let the assistant start the conversation. It will end when the user types exit.\n",
+ "# Let the assistant start the conversation. It will end when the user types \"exit\".\n",
"assistant.initiate_chat(user_proxy, message=\"How can I help you today?\")\n",
"\n",
"# Close your AgentOps session to indicate that it completed.\n",
@@ -204,13 +210,13 @@
},
{
"cell_type": "markdown",
- "source": [
- ""
- ],
+ "id": "cbd689b0f5617013",
"metadata": {
"collapsed": false
},
- "id": "cbd689b0f5617013"
+ "source": [
+ ""
+ ]
},
{
"cell_type": "markdown",
@@ -236,70 +242,70 @@
"name": "stderr",
"output_type": "stream",
"text": [
- "🖇 AgentOps: \u001B[34m\u001B[34mSession Replay: https://app.agentops.ai/drilldown?session_id=880c206b-751e-4c23-9313-8684537fc04d\u001B[0m\u001B[0m\n"
+ "🖇 AgentOps: \u001b[34m\u001b[34mSession Replay: https://app.agentops.ai/drilldown?session_id=880c206b-751e-4c23-9313-8684537fc04d\u001b[0m\u001b[0m\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\u001B[33mUser\u001B[0m (to Assistant):\n",
+ "\u001b[33mUser\u001b[0m (to Assistant):\n",
"\n",
"What is (1423 - 123) / 3 + (32 + 23) * 5?\n",
"\n",
"--------------------------------------------------------------------------------\n",
- "\u001B[31m\n",
- ">>>>>>>> USING AUTO REPLY...\u001B[0m\n",
- "\u001B[33mAssistant\u001B[0m (to User):\n",
+ "\u001b[31m\n",
+ ">>>>>>>> USING AUTO REPLY...\u001b[0m\n",
+ "\u001b[33mAssistant\u001b[0m (to User):\n",
"\n",
- "\u001B[32m***** Suggested tool call (call_aINcGyo0Xkrh9g7buRuhyCz0): calculator *****\u001B[0m\n",
+ "\u001b[32m***** Suggested tool call (call_aINcGyo0Xkrh9g7buRuhyCz0): calculator *****\u001b[0m\n",
"Arguments: \n",
"{\n",
" \"a\": 1423,\n",
" \"b\": 123,\n",
" \"operator\": \"-\"\n",
"}\n",
- "\u001B[32m***************************************************************************\u001B[0m\n",
+ "\u001b[32m***************************************************************************\u001b[0m\n",
"\n",
"--------------------------------------------------------------------------------\n",
- "\u001B[35m\n",
- ">>>>>>>> EXECUTING FUNCTION calculator...\u001B[0m\n",
- "\u001B[33mUser\u001B[0m (to Assistant):\n",
+ "\u001b[35m\n",
+ ">>>>>>>> EXECUTING FUNCTION calculator...\u001b[0m\n",
+ "\u001b[33mUser\u001b[0m (to Assistant):\n",
"\n",
- "\u001B[33mUser\u001B[0m (to Assistant):\n",
+ "\u001b[33mUser\u001b[0m (to Assistant):\n",
"\n",
- "\u001B[32m***** Response from calling tool (call_aINcGyo0Xkrh9g7buRuhyCz0) *****\u001B[0m\n",
+ "\u001b[32m***** Response from calling tool (call_aINcGyo0Xkrh9g7buRuhyCz0) *****\u001b[0m\n",
"1300\n",
- "\u001B[32m**********************************************************************\u001B[0m\n",
+ "\u001b[32m**********************************************************************\u001b[0m\n",
"\n",
"--------------------------------------------------------------------------------\n",
- "\u001B[31m\n",
- ">>>>>>>> USING AUTO REPLY...\u001B[0m\n",
- "\u001B[33mAssistant\u001B[0m (to User):\n",
+ "\u001b[31m\n",
+ ">>>>>>>> USING AUTO REPLY...\u001b[0m\n",
+ "\u001b[33mAssistant\u001b[0m (to User):\n",
"\n",
- "\u001B[32m***** Suggested tool call (call_prJGf8V0QVT7cbD91e0Fcxpb): calculator *****\u001B[0m\n",
+ "\u001b[32m***** Suggested tool call (call_prJGf8V0QVT7cbD91e0Fcxpb): calculator *****\u001b[0m\n",
"Arguments: \n",
"{\n",
" \"a\": 1300,\n",
" \"b\": 3,\n",
" \"operator\": \"/\"\n",
"}\n",
- "\u001B[32m***************************************************************************\u001B[0m\n",
+ "\u001b[32m***************************************************************************\u001b[0m\n",
"\n",
"--------------------------------------------------------------------------------\n",
- "\u001B[35m\n",
- ">>>>>>>> EXECUTING FUNCTION calculator...\u001B[0m\n",
- "\u001B[33mUser\u001B[0m (to Assistant):\n",
+ "\u001b[35m\n",
+ ">>>>>>>> EXECUTING FUNCTION calculator...\u001b[0m\n",
+ "\u001b[33mUser\u001b[0m (to Assistant):\n",
"\n",
- "\u001B[33mUser\u001B[0m (to Assistant):\n",
+ "\u001b[33mUser\u001b[0m (to Assistant):\n",
"\n",
- "\u001B[32m***** Response from calling tool (call_prJGf8V0QVT7cbD91e0Fcxpb) *****\u001B[0m\n",
+ "\u001b[32m***** Response from calling tool (call_prJGf8V0QVT7cbD91e0Fcxpb) *****\u001b[0m\n",
"433\n",
- "\u001B[32m**********************************************************************\u001B[0m\n",
+ "\u001b[32m**********************************************************************\u001b[0m\n",
"\n",
"--------------------------------------------------------------------------------\n",
- "\u001B[31m\n",
- ">>>>>>>> USING AUTO REPLY...\u001B[0m\n"
+ "\u001b[31m\n",
+ ">>>>>>>> USING AUTO REPLY...\u001b[0m\n"
]
},
{
@@ -316,94 +322,94 @@
"name": "stdout",
"output_type": "stream",
"text": [
- "\u001B[33mAssistant\u001B[0m (to User):\n",
+ "\u001b[33mAssistant\u001b[0m (to User):\n",
"\n",
- "\u001B[32m***** Suggested tool call (call_CUIgHRsySLjayDKuUphI1TGm): calculator *****\u001B[0m\n",
+ "\u001b[32m***** Suggested tool call (call_CUIgHRsySLjayDKuUphI1TGm): calculator *****\u001b[0m\n",
"Arguments: \n",
"{\n",
" \"a\": 32,\n",
" \"b\": 23,\n",
" \"operator\": \"+\"\n",
"}\n",
- "\u001B[32m***************************************************************************\u001B[0m\n",
+ "\u001b[32m***************************************************************************\u001b[0m\n",
"\n",
"--------------------------------------------------------------------------------\n",
- "\u001B[35m\n",
- ">>>>>>>> EXECUTING FUNCTION calculator...\u001B[0m\n",
- "\u001B[33mUser\u001B[0m (to Assistant):\n",
+ "\u001b[35m\n",
+ ">>>>>>>> EXECUTING FUNCTION calculator...\u001b[0m\n",
+ "\u001b[33mUser\u001b[0m (to Assistant):\n",
"\n",
- "\u001B[33mUser\u001B[0m (to Assistant):\n",
+ "\u001b[33mUser\u001b[0m (to Assistant):\n",
"\n",
- "\u001B[32m***** Response from calling tool (call_CUIgHRsySLjayDKuUphI1TGm) *****\u001B[0m\n",
+ "\u001b[32m***** Response from calling tool (call_CUIgHRsySLjayDKuUphI1TGm) *****\u001b[0m\n",
"55\n",
- "\u001B[32m**********************************************************************\u001B[0m\n",
+ "\u001b[32m**********************************************************************\u001b[0m\n",
"\n",
"--------------------------------------------------------------------------------\n",
- "\u001B[31m\n",
- ">>>>>>>> USING AUTO REPLY...\u001B[0m\n",
- "\u001B[33mAssistant\u001B[0m (to User):\n",
+ "\u001b[31m\n",
+ ">>>>>>>> USING AUTO REPLY...\u001b[0m\n",
+ "\u001b[33mAssistant\u001b[0m (to User):\n",
"\n",
- "\u001B[32m***** Suggested tool call (call_L7pGtBLUf9V0MPL90BASyesr): calculator *****\u001B[0m\n",
+ "\u001b[32m***** Suggested tool call (call_L7pGtBLUf9V0MPL90BASyesr): calculator *****\u001b[0m\n",
"Arguments: \n",
"{\n",
" \"a\": 55,\n",
" \"b\": 5,\n",
" \"operator\": \"*\"\n",
"}\n",
- "\u001B[32m***************************************************************************\u001B[0m\n",
+ "\u001b[32m***************************************************************************\u001b[0m\n",
"\n",
"--------------------------------------------------------------------------------\n",
- "\u001B[35m\n",
- ">>>>>>>> EXECUTING FUNCTION calculator...\u001B[0m\n",
- "\u001B[33mUser\u001B[0m (to Assistant):\n",
+ "\u001b[35m\n",
+ ">>>>>>>> EXECUTING FUNCTION calculator...\u001b[0m\n",
+ "\u001b[33mUser\u001b[0m (to Assistant):\n",
"\n",
- "\u001B[33mUser\u001B[0m (to Assistant):\n",
+ "\u001b[33mUser\u001b[0m (to Assistant):\n",
"\n",
- "\u001B[32m***** Response from calling tool (call_L7pGtBLUf9V0MPL90BASyesr) *****\u001B[0m\n",
+ "\u001b[32m***** Response from calling tool (call_L7pGtBLUf9V0MPL90BASyesr) *****\u001b[0m\n",
"275\n",
- "\u001B[32m**********************************************************************\u001B[0m\n",
+ "\u001b[32m**********************************************************************\u001b[0m\n",
"\n",
"--------------------------------------------------------------------------------\n",
- "\u001B[31m\n",
- ">>>>>>>> USING AUTO REPLY...\u001B[0m\n",
- "\u001B[33mAssistant\u001B[0m (to User):\n",
+ "\u001b[31m\n",
+ ">>>>>>>> USING AUTO REPLY...\u001b[0m\n",
+ "\u001b[33mAssistant\u001b[0m (to User):\n",
"\n",
- "\u001B[32m***** Suggested tool call (call_Ygo6p4XfcxRjkYBflhG3UVv6): calculator *****\u001B[0m\n",
+ "\u001b[32m***** Suggested tool call (call_Ygo6p4XfcxRjkYBflhG3UVv6): calculator *****\u001b[0m\n",
"Arguments: \n",
"{\n",
" \"a\": 433,\n",
" \"b\": 275,\n",
" \"operator\": \"+\"\n",
"}\n",
- "\u001B[32m***************************************************************************\u001B[0m\n",
+ "\u001b[32m***************************************************************************\u001b[0m\n",
"\n",
"--------------------------------------------------------------------------------\n",
- "\u001B[35m\n",
- ">>>>>>>> EXECUTING FUNCTION calculator...\u001B[0m\n",
- "\u001B[33mUser\u001B[0m (to Assistant):\n",
+ "\u001b[35m\n",
+ ">>>>>>>> EXECUTING FUNCTION calculator...\u001b[0m\n",
+ "\u001b[33mUser\u001b[0m (to Assistant):\n",
"\n",
- "\u001B[33mUser\u001B[0m (to Assistant):\n",
+ "\u001b[33mUser\u001b[0m (to Assistant):\n",
"\n",
- "\u001B[32m***** Response from calling tool (call_Ygo6p4XfcxRjkYBflhG3UVv6) *****\u001B[0m\n",
+ "\u001b[32m***** Response from calling tool (call_Ygo6p4XfcxRjkYBflhG3UVv6) *****\u001b[0m\n",
"708\n",
- "\u001B[32m**********************************************************************\u001B[0m\n",
+ "\u001b[32m**********************************************************************\u001b[0m\n",
"\n",
"--------------------------------------------------------------------------------\n",
- "\u001B[31m\n",
- ">>>>>>>> USING AUTO REPLY...\u001B[0m\n",
- "\u001B[33mAssistant\u001B[0m (to User):\n",
+ "\u001b[31m\n",
+ ">>>>>>>> USING AUTO REPLY...\u001b[0m\n",
+ "\u001b[33mAssistant\u001b[0m (to User):\n",
"\n",
"The result of the calculation is 708.\n",
"\n",
"--------------------------------------------------------------------------------\n",
- "\u001B[33mUser\u001B[0m (to Assistant):\n",
+ "\u001b[33mUser\u001b[0m (to Assistant):\n",
"\n",
"\n",
"\n",
"--------------------------------------------------------------------------------\n",
- "\u001B[31m\n",
- ">>>>>>>> USING AUTO REPLY...\u001B[0m\n",
- "\u001B[33mAssistant\u001B[0m (to User):\n",
+ "\u001b[31m\n",
+ ">>>>>>>> USING AUTO REPLY...\u001b[0m\n",
+ "\u001b[33mAssistant\u001b[0m (to User):\n",
"\n",
"TERMINATE\n",
"\n",
@@ -415,7 +421,7 @@
"output_type": "stream",
"text": [
"🖇 AgentOps: This run's cost $0.001800\n",
- "🖇 AgentOps: \u001B[34m\u001B[34mSession Replay: https://app.agentops.ai/drilldown?session_id=880c206b-751e-4c23-9313-8684537fc04d\u001B[0m\u001B[0m\n"
+ "🖇 AgentOps: \u001b[34m\u001b[34mSession Replay: https://app.agentops.ai/drilldown?session_id=880c206b-751e-4c23-9313-8684537fc04d\u001b[0m\u001b[0m\n"
]
}
],
@@ -474,7 +480,7 @@
" description=\"A simple calculator\", # A description of the tool.\n",
")\n",
"\n",
- "# Let the assistant start the conversation. It will end when the user types exit.\n",
+ "# Let the assistant start the conversation. It will end when the user types \"exit\".\n",
"user_proxy.initiate_chat(assistant, message=\"What is (1423 - 123) / 3 + (32 + 23) * 5?\")\n",
"\n",
"agentops.end_session(\"Success\")"
@@ -493,13 +499,13 @@
},
{
"cell_type": "markdown",
- "source": [
- ""
- ],
+ "id": "a922a52ab5fce31",
"metadata": {
"collapsed": false
},
- "id": "a922a52ab5fce31"
+ "source": [
+ ""
+ ]
}
],
"metadata": {
diff --git a/notebook/agentchat_nested_chats_chess_altmodels.ipynb b/notebook/agentchat_nested_chats_chess_altmodels.ipynb
new file mode 100644
index 000000000000..69d3edbcfb50
--- /dev/null
+++ b/notebook/agentchat_nested_chats_chess_altmodels.ipynb
@@ -0,0 +1,584 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Conversational Chess using non-OpenAI clients\n",
+ "\n",
+ "This notebook provides tips for using non-OpenAI models when using functions/tools.\n",
+ "\n",
+ "The code is based on [this notebook](/docs/notebooks/agentchat_nested_chats_chess),\n",
+ "which provides a detailed look at nested chats for tool use. Please refer to that\n",
+ "notebook for more on nested chats as this will be concentrated on tweaks to\n",
+ "improve performance with non-OpenAI models.\n",
+ "\n",
+ "The notebook represents a chess game between two players with a nested chat to\n",
+ "determine the available moves and select a move to make.\n",
+ "\n",
+ "This game contains a couple of functions/tools that the LLMs must use correctly by the\n",
+ "LLMs:\n",
+ "- `get_legal_moves` to get a list of current legal moves.\n",
+ "- `make_move` to make a move.\n",
+ "\n",
+ "Two agents will be used to represent the white and black players, each associated with\n",
+ "a different LLM cloud provider and model:\n",
+ "- Anthropic's Sonnet 3.5 will be Player_White\n",
+ "- Mistral's Mixtral 8x7B (using Together.AI) will be Player_Black\n",
+ "\n",
+ "As this involves function calling, we use larger, more capable, models from these providers.\n",
+ "\n",
+ "The nested chat will be supported be a board proxy agent who is set up to execute\n",
+ "the tools and manage the game.\n",
+ "\n",
+ "Tips to improve performance with these non-OpenAI models will be noted throughout **in bold**."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Installation\n",
+ "\n",
+ "First, you need to install the `pyautogen` and `chess` packages to use AutoGen. We'll include Anthropic and Together.AI libraries."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 1,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "! pip install -qqq pyautogen[anthropic,together] chess"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Setting up LLMs\n",
+ "\n",
+ "We'll use the Anthropic (`api_type` is `anthropic`) and Together.AI (`api_type` is `together`) client classes, with their respective models, which both support function calling."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 5,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "\n",
+ "import chess\n",
+ "import chess.svg\n",
+ "from IPython.display import display\n",
+ "from typing_extensions import Annotated\n",
+ "\n",
+ "from autogen import ConversableAgent, register_function\n",
+ "\n",
+ "# Let's set our two player configs, specifying clients and models\n",
+ "\n",
+ "# Anthropic's Sonnet for player white\n",
+ "player_white_config_list = [\n",
+ " {\n",
+ " \"api_type\": \"anthropic\",\n",
+ " \"model\": \"claude-3-5-sonnet-20240620\",\n",
+ " \"api_key\": os.getenv(\"ANTHROPIC_API_KEY\"),\n",
+ " \"cache_seed\": None,\n",
+ " },\n",
+ "]\n",
+ "\n",
+ "# Mistral's Mixtral 8x7B for player black (through Together.AI)\n",
+ "player_black_config_list = [\n",
+ " {\n",
+ " \"api_type\": \"together\",\n",
+ " \"model\": \"mistralai/Mixtral-8x7B-Instruct-v0.1\",\n",
+ " \"api_key\": os.environ.get(\"TOGETHER_API_KEY\"),\n",
+ " \"cache_seed\": None,\n",
+ " },\n",
+ "]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We'll setup game variables and the two functions for getting the available moves and then making a move."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 3,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Initialize the board.\n",
+ "board = chess.Board()\n",
+ "\n",
+ "# Keep track of whether a move has been made.\n",
+ "made_move = False\n",
+ "\n",
+ "\n",
+ "def get_legal_moves() -> Annotated[\n",
+ " str,\n",
+ " \"Call this tool to list of all legal chess moves on the board, output is a list in UCI format, e.g. e2e4,e7e5,e7e8q.\",\n",
+ "]:\n",
+ " return \"Possible moves are: \" + \",\".join([str(move) for move in board.legal_moves])\n",
+ "\n",
+ "\n",
+ "def make_move(\n",
+ " move: Annotated[\n",
+ " str,\n",
+ " \"Call this tool to make a move after you have the list of legal moves and want to make a move. Takes UCI format, e.g. e2e4 or e7e5 or e7e8q.\",\n",
+ " ]\n",
+ ") -> Annotated[str, \"Result of the move.\"]:\n",
+ " move = chess.Move.from_uci(move)\n",
+ " board.push_uci(str(move))\n",
+ " global made_move\n",
+ " made_move = True\n",
+ " # Display the board.\n",
+ " display(\n",
+ " chess.svg.board(board, arrows=[(move.from_square, move.to_square)], fill={move.from_square: \"gray\"}, size=200)\n",
+ " )\n",
+ " # Get the piece name.\n",
+ " piece = board.piece_at(move.to_square)\n",
+ " piece_symbol = piece.unicode_symbol()\n",
+ " piece_name = (\n",
+ " chess.piece_name(piece.piece_type).capitalize()\n",
+ " if piece_symbol.isupper()\n",
+ " else chess.piece_name(piece.piece_type)\n",
+ " )\n",
+ " return f\"Moved {piece_name} ({piece_symbol}) from {chess.SQUARE_NAMES[move.from_square]} to {chess.SQUARE_NAMES[move.to_square]}.\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Creating agents\n",
+ "\n",
+ "Our main player agents are created next, with a few tweaks to help our models play:\n",
+ "\n",
+ "- Explicitly **telling agents their names** (as the name field isn't sent to the LLM).\n",
+ "- Providing simple instructions on the **order of functions** (not all models will need it).\n",
+ "- Asking the LLM to **include their name in the response** so the message content will include their names, helping the LLM understand who has made which moves.\n",
+ "- Ensure **no spaces are in the agent names** so that their name is distinguishable in the conversation.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 6,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "player_white = ConversableAgent(\n",
+ " name=\"Player_White\",\n",
+ " system_message=\"You are a chess player and you play as white, your name is 'Player_White'. \"\n",
+ " \"First call the function get_legal_moves() to get list of legal moves. \"\n",
+ " \"Then call the function make_move(move) to make a move. \"\n",
+ " \"Then tell Player_Black you have made your move and it is their turn. \"\n",
+ " \"Make sure you tell Player_Black you are Player_White.\",\n",
+ " llm_config={\"config_list\": player_white_config_list, \"cache_seed\": None},\n",
+ ")\n",
+ "\n",
+ "player_black = ConversableAgent(\n",
+ " name=\"Player_Black\",\n",
+ " system_message=\"You are a chess player and you play as black, your name is 'Player_Black'. \"\n",
+ " \"First call the function get_legal_moves() to get list of legal moves. \"\n",
+ " \"Then call the function make_move(move) to make a move. \"\n",
+ " \"Then tell Player_White you have made your move and it is their turn. \"\n",
+ " \"Make sure you tell Player_White you are Player_Black.\",\n",
+ " llm_config={\"config_list\": player_black_config_list, \"cache_seed\": None},\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Now we create a proxy agent that will be used to move the pieces on the board."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 7,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Check if the player has made a move, and reset the flag if move is made.\n",
+ "def check_made_move(msg):\n",
+ " global made_move\n",
+ " if made_move:\n",
+ " made_move = False\n",
+ " return True\n",
+ " else:\n",
+ " return False\n",
+ "\n",
+ "\n",
+ "board_proxy = ConversableAgent(\n",
+ " name=\"Board_Proxy\",\n",
+ " llm_config=False,\n",
+ " # The board proxy will only terminate the conversation if the player has made a move.\n",
+ " is_termination_msg=check_made_move,\n",
+ " # The auto reply message is set to keep the player agent retrying until a move is made.\n",
+ " default_auto_reply=\"Please make a move.\",\n",
+ " human_input_mode=\"NEVER\",\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Our functions are then assigned to the agents so they can be passed to the LLM to choose from.\n",
+ "\n",
+ "We have tweaked the descriptions to provide **more guidance on when** to use it."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "register_function(\n",
+ " make_move,\n",
+ " caller=player_white,\n",
+ " executor=board_proxy,\n",
+ " name=\"make_move\",\n",
+ " description=\"Call this tool to make a move after you have the list of legal moves.\",\n",
+ ")\n",
+ "\n",
+ "register_function(\n",
+ " get_legal_moves,\n",
+ " caller=player_white,\n",
+ " executor=board_proxy,\n",
+ " name=\"get_legal_moves\",\n",
+ " description=\"Call this to get a legal moves before making a move.\",\n",
+ ")\n",
+ "\n",
+ "register_function(\n",
+ " make_move,\n",
+ " caller=player_black,\n",
+ " executor=board_proxy,\n",
+ " name=\"make_move\",\n",
+ " description=\"Call this tool to make a move after you have the list of legal moves.\",\n",
+ ")\n",
+ "\n",
+ "register_function(\n",
+ " get_legal_moves,\n",
+ " caller=player_black,\n",
+ " executor=board_proxy,\n",
+ " name=\"get_legal_moves\",\n",
+ " description=\"Call this to get a legal moves before making a move.\",\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Almost there, we now create nested chats between players and the board proxy agent to work out the available moves and make the move."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 9,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "player_white.register_nested_chats(\n",
+ " trigger=player_black,\n",
+ " chat_queue=[\n",
+ " {\n",
+ " # The initial message is the one received by the player agent from\n",
+ " # the other player agent.\n",
+ " \"sender\": board_proxy,\n",
+ " \"recipient\": player_white,\n",
+ " # The final message is sent to the player agent.\n",
+ " \"summary_method\": \"last_msg\",\n",
+ " }\n",
+ " ],\n",
+ ")\n",
+ "\n",
+ "player_black.register_nested_chats(\n",
+ " trigger=player_white,\n",
+ " chat_queue=[\n",
+ " {\n",
+ " # The initial message is the one received by the player agent from\n",
+ " # the other player agent.\n",
+ " \"sender\": board_proxy,\n",
+ " \"recipient\": player_black,\n",
+ " # The final message is sent to the player agent.\n",
+ " \"summary_method\": \"last_msg\",\n",
+ " }\n",
+ " ],\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Playing the game\n",
+ "\n",
+ "Now the game can begin!"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 10,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\u001b[33mPlayer_Black\u001b[0m (to Player_White):\n",
+ "\n",
+ "Let's play chess! Your move.\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[31m\n",
+ ">>>>>>>> USING AUTO REPLY...\u001b[0m\n",
+ "\u001b[34m\n",
+ "********************************************************************************\u001b[0m\n",
+ "\u001b[34mStarting a new chat....\u001b[0m\n",
+ "\u001b[34m\n",
+ "********************************************************************************\u001b[0m\n",
+ "\u001b[33mBoard_Proxy\u001b[0m (to Player_White):\n",
+ "\n",
+ "Let's play chess! Your move.\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[31m\n",
+ ">>>>>>>> USING AUTO REPLY...\u001b[0m\n",
+ "\u001b[33mPlayer_White\u001b[0m (to Board_Proxy):\n",
+ "\n",
+ "Certainly! I'd be happy to play chess with you. As White, I'll make the first move. Let me start by checking the legal moves available to me.\n",
+ "\u001b[32m***** Suggested tool call (toolu_015sLMucefMVqS5ZNyWVGjgu): get_legal_moves *****\u001b[0m\n",
+ "Arguments: \n",
+ "{}\n",
+ "\u001b[32m*********************************************************************************\u001b[0m\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[35m\n",
+ ">>>>>>>> EXECUTING FUNCTION get_legal_moves...\u001b[0m\n",
+ "\u001b[33mBoard_Proxy\u001b[0m (to Player_White):\n",
+ "\n",
+ "\u001b[33mBoard_Proxy\u001b[0m (to Player_White):\n",
+ "\n",
+ "\u001b[32m***** Response from calling tool (toolu_015sLMucefMVqS5ZNyWVGjgu) *****\u001b[0m\n",
+ "Possible moves are: g1h3,g1f3,b1c3,b1a3,h2h3,g2g3,f2f3,e2e3,d2d3,c2c3,b2b3,a2a3,h2h4,g2g4,f2f4,e2e4,d2d4,c2c4,b2b4,a2a4\n",
+ "\u001b[32m***********************************************************************\u001b[0m\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[31m\n",
+ ">>>>>>>> USING AUTO REPLY...\u001b[0m\n",
+ "\u001b[33mPlayer_White\u001b[0m (to Board_Proxy):\n",
+ "\n",
+ "Thank you for initiating a game of chess! As Player_White, I'll make the first move. After analyzing the legal moves, I've decided to make a classic opening move.\n",
+ "\u001b[32m***** Suggested tool call (toolu_01VjmBhHcGw5RTRKYC4Y5MeV): make_move *****\u001b[0m\n",
+ "Arguments: \n",
+ "{\"move\": \"e2e4\"}\n",
+ "\u001b[32m***************************************************************************\u001b[0m\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[35m\n",
+ ">>>>>>>> EXECUTING FUNCTION make_move...\u001b[0m\n"
+ ]
+ },
+ {
+ "data": {
+ "image/svg+xml": [
+ ""
+ ],
+ "text/plain": [
+ "''"
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\u001b[33mBoard_Proxy\u001b[0m (to Player_White):\n",
+ "\n",
+ "\u001b[33mBoard_Proxy\u001b[0m (to Player_White):\n",
+ "\n",
+ "\u001b[32m***** Response from calling tool (toolu_01VjmBhHcGw5RTRKYC4Y5MeV) *****\u001b[0m\n",
+ "Moved pawn (♙) from e2 to e4.\n",
+ "\u001b[32m***********************************************************************\u001b[0m\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[31m\n",
+ ">>>>>>>> USING AUTO REPLY...\u001b[0m\n",
+ "\u001b[33mPlayer_White\u001b[0m (to Board_Proxy):\n",
+ "\n",
+ "Hello, Player_Black! I'm Player_White, and I've just made my move. I've chosen to play the classic opening move e2e4, moving my king's pawn forward two squares. This opens up lines for both my queen and king's bishop, and stakes a claim to the center of the board. It's now your turn to make a move. Good luck!\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[33mPlayer_White\u001b[0m (to Player_Black):\n",
+ "\n",
+ "Hello, Player_Black! I'm Player_White, and I've just made my move. I've chosen to play the classic opening move e2e4, moving my king's pawn forward two squares. This opens up lines for both my queen and king's bishop, and stakes a claim to the center of the board. It's now your turn to make a move. Good luck!\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[31m\n",
+ ">>>>>>>> USING AUTO REPLY...\u001b[0m\n",
+ "\u001b[34m\n",
+ "********************************************************************************\u001b[0m\n",
+ "\u001b[34mStarting a new chat....\u001b[0m\n",
+ "\u001b[34m\n",
+ "********************************************************************************\u001b[0m\n",
+ "\u001b[33mBoard_Proxy\u001b[0m (to Player_Black):\n",
+ "\n",
+ "Hello, Player_Black! I'm Player_White, and I've just made my move. I've chosen to play the classic opening move e2e4, moving my king's pawn forward two squares. This opens up lines for both my queen and king's bishop, and stakes a claim to the center of the board. It's now your turn to make a move. Good luck!\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[31m\n",
+ ">>>>>>>> USING AUTO REPLY...\u001b[0m\n",
+ "\u001b[33mPlayer_Black\u001b[0m (to Board_Proxy):\n",
+ "\n",
+ "\u001b[32m***** Suggested tool call (call_z6jagiqn59m784w1n0zhmiop): get_legal_moves *****\u001b[0m\n",
+ "Arguments: \n",
+ "{}\n",
+ "\u001b[32m********************************************************************************\u001b[0m\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[35m\n",
+ ">>>>>>>> EXECUTING FUNCTION get_legal_moves...\u001b[0m\n",
+ "\u001b[33mBoard_Proxy\u001b[0m (to Player_Black):\n",
+ "\n",
+ "\u001b[33mBoard_Proxy\u001b[0m (to Player_Black):\n",
+ "\n",
+ "\u001b[32m***** Response from calling tool (call_z6jagiqn59m784w1n0zhmiop) *****\u001b[0m\n",
+ "Possible moves are: g8h6,g8f6,b8c6,b8a6,h7h6,g7g6,f7f6,e7e6,d7d6,c7c6,b7b6,a7a6,h7h5,g7g5,f7f5,e7e5,d7d5,c7c5,b7b5,a7a5\n",
+ "\u001b[32m**********************************************************************\u001b[0m\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[31m\n",
+ ">>>>>>>> USING AUTO REPLY...\u001b[0m\n",
+ "\u001b[33mPlayer_Black\u001b[0m (to Board_Proxy):\n",
+ "\n",
+ "\u001b[32m***** Suggested tool call (call_59t20pl0ab68z4xx2workgbc): make_move *****\u001b[0m\n",
+ "Arguments: \n",
+ "{\"move\":\"g8h6\"}\n",
+ "\u001b[32m**************************************************************************\u001b[0m\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[35m\n",
+ ">>>>>>>> EXECUTING FUNCTION make_move...\u001b[0m\n"
+ ]
+ },
+ {
+ "data": {
+ "image/svg+xml": [
+ ""
+ ],
+ "text/plain": [
+ "''"
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\u001b[33mBoard_Proxy\u001b[0m (to Player_Black):\n",
+ "\n",
+ "\u001b[33mBoard_Proxy\u001b[0m (to Player_Black):\n",
+ "\n",
+ "\u001b[32m***** Response from calling tool (call_59t20pl0ab68z4xx2workgbc) *****\u001b[0m\n",
+ "Moved knight (♞) from g8 to h6.\n",
+ "\u001b[32m**********************************************************************\u001b[0m\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[31m\n",
+ ">>>>>>>> USING AUTO REPLY...\u001b[0m\n",
+ "\u001b[33mPlayer_Black\u001b[0m (to Board_Proxy):\n",
+ "\n",
+ "\u001b[32m***** Suggested tool call (call_jwv1d86srs1fnvu33cky9tgv): make_move *****\u001b[0m\n",
+ "Arguments: \n",
+ "{\"move\":\"g8h6\"}\n",
+ "\u001b[32m**************************************************************************\u001b[0m\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[33mPlayer_Black\u001b[0m (to Player_White):\n",
+ "\n",
+ "\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[31m\n",
+ ">>>>>>>> USING AUTO REPLY...\u001b[0m\n",
+ "\u001b[31m\n",
+ ">>>>>>>> USING AUTO REPLY...\u001b[0m\n"
+ ]
+ }
+ ],
+ "source": [
+ "# Clear the board.\n",
+ "board = chess.Board()\n",
+ "\n",
+ "chat_result = player_black.initiate_chat(\n",
+ " player_white,\n",
+ " message=\"Let's play chess! Your move.\",\n",
+ " max_turns=10,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "At this stage, it's hard to tell who's going to win, but they're playing well and using the functions correctly."
+ ]
+ }
+ ],
+ "metadata": {
+ "front_matter": {
+ "description": "LLM-backed agents playing chess with each other using nested chats.",
+ "tags": [
+ "nested chat",
+ "tool use",
+ "orchestration"
+ ]
+ },
+ "kernelspec": {
+ "display_name": "autogen",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.9"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 2
+}
diff --git a/notebook/autogen_uniformed_api_calling.ipynb b/notebook/autogen_uniformed_api_calling.ipynb
new file mode 100644
index 000000000000..08f747e1722f
--- /dev/null
+++ b/notebook/autogen_uniformed_api_calling.ipynb
@@ -0,0 +1,398 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# A Uniform interface to call different LLMs\n",
+ "\n",
+ "Autogen provides a uniform interface for API calls to different LLMs, and creating LLM agents from them.\n",
+ "Through setting up a configuration file, you can easily switch between different LLMs by just changing the model name, while enjoying all the [enhanced features](https://microsoft.github.io/autogen/docs/topics/llm-caching) such as [caching](https://microsoft.github.io/autogen/docs/Use-Cases/enhanced_inference/#usage-summary) and [cost calculation](https://microsoft.github.io/autogen/docs/Use-Cases/enhanced_inference/#usage-summary)!\n",
+ "\n",
+ "In this notebook, we will show you how to use AutoGen to call different LLMs and create LLM agents from them.\n",
+ "\n",
+ "Currently, we support the following model families:\n",
+ "- [OpenAI](https://platform.openai.com/docs/overview)\n",
+ "- [Azure OpenAI](https://azure.microsoft.com/en-us/products/ai-services/openai-service/?ef_id=_k_CjwKCAjwps-zBhAiEiwALwsVYdbpVkqA3IbY7WnxtrjNSefBnTfrijwRAFaYd8uuLCjeWsPdfZmxUBoC_ZAQAvD_BwE_k_&OCID=AIDcmm5edswduu_SEM__k_CjwKCAjwps-zBhAiEiwALwsVYdbpVkqA3IbY7WnxtrjNSefBnTfrijwRAFaYd8uuLCjeWsPdfZmxUBoC_ZAQAvD_BwE_k_&gad_source=1&gclid=CjwKCAjwps-zBhAiEiwALwsVYdbpVkqA3IbY7WnxtrjNSefBnTfrijwRAFaYd8uuLCjeWsPdfZmxUBoC_ZAQAvD_BwE)\n",
+ "- [Anthropic Claude](https://docs.anthropic.com/en/docs/welcome)\n",
+ "- [Google Gemini](https://ai.google.dev/gemini-api/docs)\n",
+ "- [Mistral](https://docs.mistral.ai/) (API to open and closed-source models)\n",
+ "- [DeepInfra](https://deepinfra.com/) (API to open-source models)\n",
+ "- [TogetherAI](https://www.together.ai/) (API to open-source models)\n",
+ "\n",
+ "... and more to come!\n",
+ "\n",
+ "You can also [plug in your local deployed LLM](https://microsoft.github.io/autogen/blog/2024/01/26/Custom-Models) into AutoGen if needed."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Install required packages\n",
+ "\n",
+ "You may want to install AutoGen with options to different LLMs. Here we install AutoGen with all the supported LLMs.\n",
+ "By default, AutoGen is installed with OpenAI support.\n",
+ " \n",
+ "```bash\n",
+ "pip install pyautogen[gemini,anthropic,mistral,together]\n",
+ "```\n",
+ "\n",
+ "\n",
+ "## Config list setup\n",
+ "\n",
+ "\n",
+ "First, create a `OAI_CONFIG_LIST` file to specify the api keys for the LLMs you want to use.\n",
+ "Generally, you just need to specify the `model`, `api_key` and `api_type` from the provider.\n",
+ "\n",
+ "```python\n",
+ "[\n",
+ " { \n",
+ " # using OpenAI\n",
+ " \"model\": \"gpt-35-turbo-1106\", \n",
+ " \"api_key\": \"YOUR_API_KEY\"\n",
+ " # default api_type is openai\n",
+ " },\n",
+ " {\n",
+ " # using Azure OpenAI\n",
+ " \"model\": \"gpt-4-turbo-1106\",\n",
+ " \"api_key\": \"YOUR_API_KEY\",\n",
+ " \"api_type\": \"azure\",\n",
+ " \"base_url\": \"YOUR_BASE_URL\",\n",
+ " \"api_version\": \"YOUR_API_VERSION\"\n",
+ " },\n",
+ " { \n",
+ " # using Google gemini\n",
+ " \"model\": \"gemini-1.5-pro-latest\",\n",
+ " \"api_key\": \"YOUR_API_KEY\",\n",
+ " \"api_type\": \"google\"\n",
+ " },\n",
+ " {\n",
+ " # using DeepInfra\n",
+ " \"model\": \"meta-llama/Meta-Llama-3-70B-Instruct\",\n",
+ " \"api_key\": \"YOUR_API_KEY\",\n",
+ " \"base_url\": \"https://api.deepinfra.com/v1/openai\" # need to specify the base_url\n",
+ " },\n",
+ " {\n",
+ " # using Anthropic Claude\n",
+ " \"model\": \"claude-1.0\",\n",
+ " \"api_type\": \"anthropic\",\n",
+ " \"api_key\": \"YOUR_API_KEY\"\n",
+ " },\n",
+ " {\n",
+ " # using Mistral\n",
+ " \"model\": \"mistral-large-latest\",\n",
+ " \"api_type\": \"mistral\",\n",
+ " \"api_key\": \"YOUR_API_KEY\"\n",
+ " },\n",
+ " {\n",
+ " # using TogetherAI\n",
+ " \"model\": \"google/gemma-7b-it\",\n",
+ " \"api_key\": \"YOUR_API_KEY\",\n",
+ " \"api_type\": \"together\"\n",
+ " }\n",
+ " ...\n",
+ "]\n",
+ "```\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Uniform Interface to call different LLMs\n",
+ "We first demonstrate how to use AutoGen to call different LLMs with the same wrapper class.\n",
+ "\n",
+ "After you install relevant packages and setup your config list, you only need three steps to call different LLMs:\n",
+ "1. Extract the config with the model name you want to use.\n",
+ "2. create a client with the model name.\n",
+ "3. call the client `create` to get the response.\n",
+ "\n",
+ "Below, we define a helper function `model_call_example_function` to implement the above steps."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 15,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import autogen\n",
+ "from autogen import OpenAIWrapper\n",
+ "\n",
+ "\n",
+ "def model_call_example_function(model: str, message: str, cache_seed: int = 41, print_cost: bool = False):\n",
+ " \"\"\"\n",
+ " A helper function that demonstrates how to call different models using the OpenAIWrapper class.\n",
+ " Note the name `OpenAIWrapper` is not accurate, as now it is a wrapper for multiple models, not just OpenAI.\n",
+ " This might be changed in the future.\n",
+ " \"\"\"\n",
+ " config_list = autogen.config_list_from_json(\n",
+ " \"OAI_CONFIG_LIST\",\n",
+ " filter_dict={\n",
+ " \"model\": [model],\n",
+ " },\n",
+ " )\n",
+ " client = OpenAIWrapper(config_list=config_list)\n",
+ " response = client.create(messages=[{\"role\": \"user\", \"content\": message}], cache_seed=cache_seed)\n",
+ "\n",
+ " print(f\"Response from model {model}: {response.choices[0].message.content}\")\n",
+ "\n",
+ " # Print the cost of the API call\n",
+ " if print_cost:\n",
+ " client.print_usage_summary()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 2,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Response from model gpt-35-turbo-1106: Why couldn't the bicycle stand up by itself?\n",
+ "\n",
+ "Because it was two-tired!\n"
+ ]
+ }
+ ],
+ "source": [
+ "model_call_example_function(model=\"gpt-35-turbo-1106\", message=\"Tell me a joke.\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 3,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Response from model gemini-1.5-pro-latest: Why don't scientists trust atoms? \n",
+ "\n",
+ "Because they make up everything! \n",
+ " \n",
+ "Let me know if you'd like to hear another one! \n",
+ "\n"
+ ]
+ }
+ ],
+ "source": [
+ "model_call_example_function(model=\"gemini-1.5-pro-latest\", message=\"Tell me a joke.\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 4,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Response from model meta-llama/Meta-Llama-3-70B-Instruct: Here's one:\n",
+ "\n",
+ "Why couldn't the bicycle stand up by itself?\n",
+ "\n",
+ "(wait for it...)\n",
+ "\n",
+ "Because it was two-tired!\n",
+ "\n",
+ "How was that? Do you want to hear another one?\n"
+ ]
+ }
+ ],
+ "source": [
+ "model_call_example_function(model=\"meta-llama/Meta-Llama-3-70B-Instruct\", message=\"Tell me a joke. \")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 18,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Response from model mistral-large-latest: Sure, here's a light-hearted joke for you:\n",
+ "\n",
+ "Why don't scientists trust atoms?\n",
+ "\n",
+ "Because they make up everything!\n",
+ "----------------------------------------------------------------------------------------------------\n",
+ "Usage summary excluding cached usage: \n",
+ "Total cost: 0.00042\n",
+ "* Model 'mistral-large-latest': cost: 0.00042, prompt_tokens: 9, completion_tokens: 32, total_tokens: 41\n",
+ "\n",
+ "All completions are non-cached: the total cost with cached completions is the same as actual cost.\n",
+ "----------------------------------------------------------------------------------------------------\n"
+ ]
+ }
+ ],
+ "source": [
+ "model_call_example_function(model=\"mistral-large-latest\", message=\"Tell me a joke. \", print_cost=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Using different LLMs in agents\n",
+ "Below we give a quick demo of using different LLMs agents in a groupchat. \n",
+ "\n",
+ "We mock a debate scenario where each LLM agent is a debater, either in affirmative or negative side. We use a round-robin strategy to let each debater from different teams to speak in turn."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 10,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def get_llm_config(model_name):\n",
+ " return {\n",
+ " \"config_list\": autogen.config_list_from_json(\"OAI_CONFIG_LIST\", filter_dict={\"model\": [model_name]}),\n",
+ " \"cache_seed\": 41,\n",
+ " }\n",
+ "\n",
+ "\n",
+ "affirmative_system_message = \"You are in the Affirmative team of a debate. When it is your turn, please give at least one reason why you are for the topic. Keep it short.\"\n",
+ "negative_system_message = \"You are in the Negative team of a debate. The affirmative team has given their reason, please counter their argument. Keep it short.\"\n",
+ "\n",
+ "gpt35_agent = autogen.AssistantAgent(\n",
+ " name=\"GPT35\", system_message=affirmative_system_message, llm_config=get_llm_config(\"gpt-35-turbo-1106\")\n",
+ ")\n",
+ "\n",
+ "llama_agent = autogen.AssistantAgent(\n",
+ " name=\"Llama3\",\n",
+ " system_message=negative_system_message,\n",
+ " llm_config=get_llm_config(\"meta-llama/Meta-Llama-3-70B-Instruct\"),\n",
+ ")\n",
+ "\n",
+ "mistral_agent = autogen.AssistantAgent(\n",
+ " name=\"Mistral\", system_message=affirmative_system_message, llm_config=get_llm_config(\"mistral-large-latest\")\n",
+ ")\n",
+ "\n",
+ "gemini_agent = autogen.AssistantAgent(\n",
+ " name=\"Gemini\", system_message=negative_system_message, llm_config=get_llm_config(\"gemini-1.5-pro-latest\")\n",
+ ")\n",
+ "\n",
+ "claude_agent = autogen.AssistantAgent(\n",
+ " name=\"Claude\", system_message=affirmative_system_message, llm_config=get_llm_config(\"claude-3-opus-20240229\")\n",
+ ")\n",
+ "\n",
+ "user_proxy = autogen.UserProxyAgent(\n",
+ " name=\"User\",\n",
+ " code_execution_config=False,\n",
+ ")\n",
+ "\n",
+ "# initilize the groupchat with round robin speaker selection method\n",
+ "groupchat = autogen.GroupChat(\n",
+ " agents=[claude_agent, gemini_agent, mistral_agent, llama_agent, gpt35_agent, user_proxy],\n",
+ " messages=[],\n",
+ " max_round=8,\n",
+ " speaker_selection_method=\"round_robin\",\n",
+ ")\n",
+ "manager = autogen.GroupChatManager(groupchat=groupchat)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 12,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\u001b[33mUser\u001b[0m (to chat_manager):\n",
+ "\n",
+ "Debate Topic: Should vaccination be mandatory?\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[32m\n",
+ "Next speaker: Claude\n",
+ "\u001b[0m\n",
+ "\u001b[33mClaude\u001b[0m (to chat_manager):\n",
+ "\n",
+ "As a member of the Affirmative team, I believe that vaccination should be mandatory for several reasons:\n",
+ "\n",
+ "1. Herd immunity: When a large percentage of the population is vaccinated, it helps protect those who cannot receive vaccines due to medical reasons or weakened immune systems. Mandatory vaccination ensures that we maintain a high level of herd immunity, preventing the spread of dangerous diseases.\n",
+ "\n",
+ "2. Public health: Vaccines have been proven to be safe and effective in preventing the spread of infectious diseases. By making vaccination mandatory, we prioritize public health and reduce the risk of outbreaks that could lead to widespread illness and loss of life.\n",
+ "\n",
+ "3. Societal benefits: Mandatory vaccination not only protects individuals but also benefits society as a whole. It reduces healthcare costs associated with treating preventable diseases and minimizes the economic impact of disease outbreaks on businesses and communities.\n",
+ "\n",
+ "In summary, mandatory vaccination is a critical tool in protecting public health, maintaining herd immunity, and promoting the well-being of our society.\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[32m\n",
+ "Next speaker: Gemini\n",
+ "\u001b[0m\n",
+ "\u001b[33mGemini\u001b[0m (to chat_manager):\n",
+ "\n",
+ "While we acknowledge the importance of herd immunity and public health, mandating vaccinations infringes upon individual autonomy and medical freedom. Blanket mandates fail to consider individual health circumstances and potential vaccine risks, which are often overlooked in favor of a one-size-fits-all approach. \n",
+ "\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[32m\n",
+ "Next speaker: Mistral\n",
+ "\u001b[0m\n",
+ "\u001b[33mMistral\u001b[0m (to chat_manager):\n",
+ "\n",
+ "I understand your concerns and the value of individual autonomy. However, it's important to note that mandatory vaccination policies often include exemptions for medical reasons. This allows for individual health circumstances to be taken into account, ensuring that those who cannot safely receive vaccines are not put at risk. The goal is to strike a balance between protecting public health and respecting individual choices, while always prioritizing the well-being and safety of all members of society.\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[32m\n",
+ "Next speaker: Llama3\n",
+ "\u001b[0m\n",
+ "\u001b[33mLlama3\u001b[0m (to chat_manager):\n",
+ "\n",
+ "I understand your point, but blanket exemptions for medical reasons are not sufficient to address the complexities of individual health circumstances. What about those who have experienced adverse reactions to vaccines in the past or have a family history of such reactions? What about those who have compromised immune systems or are taking medications that may interact with vaccine components? A one-size-fits-all approach to vaccination ignores the nuances of individual health and puts some people at risk of harm. Additionally, mandating vaccination undermines trust in government and healthcare institutions, leading to further divides and mistrust. We need to prioritize informed consent and individual autonomy in medical decisions, rather than relying solely on a blanket mandate.\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[32m\n",
+ "Next speaker: GPT35\n",
+ "\u001b[0m\n",
+ "\u001b[33mGPT35\u001b[0m (to chat_manager):\n",
+ "\n",
+ "I understand your point, but mandatory vaccination policies can still allow for exemptions based on medical history, allergic reactions, and compromised immunity. This would address the individual circumstances you mentioned. Furthermore, mandating vaccination can also help strengthen trust in public health measures by demonstrating a commitment to protecting the entire community. Informed consent is important, but it is also essential to consider the potential consequences of not being vaccinated on public health and the well-being of others.\n",
+ "\n",
+ "--------------------------------------------------------------------------------\n",
+ "\u001b[32m\n",
+ "Next speaker: User\n",
+ "\u001b[0m\n"
+ ]
+ }
+ ],
+ "source": [
+ "chat_history = user_proxy.initiate_chat(recipient=manager, message=\"Debate Topic: Should vaccination be mandatory?\")"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "autodev",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.12.4"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 2
+}
diff --git a/setup.py b/setup.py
index da87d263b0ca..9117ed45ceac 100644
--- a/setup.py
+++ b/setup.py
@@ -72,15 +72,13 @@
"mathchat": ["sympy", "pydantic==1.10.9", "wolframalpha"],
"retrievechat": retrieve_chat,
"retrievechat-pgvector": retrieve_chat_pgvector,
- "retrievechat-qdrant": [
- *retrieve_chat,
- "qdrant_client[fastembed]<1.9.2",
- ],
+ "retrievechat-qdrant": [*retrieve_chat, "qdrant_client", "fastembed>=0.3.1"],
"autobuild": ["chromadb", "sentence-transformers", "huggingface-hub", "pysqlite3"],
"teachable": ["chromadb"],
"lmm": ["replicate", "pillow"],
"graph": ["networkx", "matplotlib"],
"gemini": ["google-generativeai>=0.5,<1", "google-cloud-aiplatform", "google-auth", "pillow", "pydantic"],
+ "together": ["together>=1.2"],
"websurfer": ["beautifulsoup4", "markdownify", "pdfminer.six", "pathvalidate"],
"redis": ["redis"],
"cosmosdb": ["azure-cosmos>=4.2.0"],
@@ -90,6 +88,8 @@
"long-context": ["llmlingua<0.3"],
"anthropic": ["anthropic>=0.23.1"],
"mistral": ["mistralai>=0.2.0"],
+ "groq": ["groq>=0.9.0"],
+ "cohere": ["cohere>=5.5.8"],
}
setuptools.setup(
diff --git a/test/oai/test_cohere.py b/test/oai/test_cohere.py
new file mode 100644
index 000000000000..83ef56b17087
--- /dev/null
+++ b/test/oai/test_cohere.py
@@ -0,0 +1,69 @@
+#!/usr/bin/env python3 -m pytest
+
+import os
+
+import pytest
+
+try:
+ from autogen.oai.cohere import CohereClient, calculate_cohere_cost
+
+ skip = False
+except ImportError:
+ CohereClient = object
+ skip = True
+
+
+reason = "Cohere dependency not installed!"
+
+
+@pytest.fixture()
+def cohere_client():
+ return CohereClient(api_key="dummy_api_key")
+
+
+@pytest.mark.skipif(skip, reason=reason)
+def test_initialization_missing_api_key():
+ os.environ.pop("COHERE_API_KEY", None)
+ with pytest.raises(
+ AssertionError,
+ match="Please include the api_key in your config list entry for Cohere or set the COHERE_API_KEY env variable.",
+ ):
+ CohereClient()
+
+ CohereClient(api_key="dummy_api_key")
+
+
+@pytest.mark.skipif(skip, reason=reason)
+def test_intialization(cohere_client):
+ assert cohere_client.api_key == "dummy_api_key", "`api_key` should be correctly set in the config"
+
+
+@pytest.mark.skipif(skip, reason=reason)
+def test_calculate_cohere_cost():
+ assert (
+ calculate_cohere_cost(0, 0, model="command-r") == 0.0
+ ), "Cost should be 0 for 0 input_tokens and 0 output_tokens"
+ assert calculate_cohere_cost(100, 200, model="command-r-plus") == 0.0033
+
+
+@pytest.mark.skipif(skip, reason=reason)
+def test_load_config(cohere_client):
+ params = {
+ "model": "command-r-plus",
+ "stream": False,
+ "temperature": 1,
+ "p": 0.8,
+ "max_tokens": 100,
+ }
+ expected_params = {
+ "model": "command-r-plus",
+ "temperature": 1,
+ "p": 0.8,
+ "seed": None,
+ "max_tokens": 100,
+ "frequency_penalty": 0,
+ "presence_penalty": 0,
+ "k": 0,
+ }
+ result = cohere_client.parse_params(params)
+ assert result == expected_params, "Config should be correctly loaded"
diff --git a/test/oai/test_groq.py b/test/oai/test_groq.py
new file mode 100644
index 000000000000..f55edbd8c7a6
--- /dev/null
+++ b/test/oai/test_groq.py
@@ -0,0 +1,249 @@
+from unittest.mock import MagicMock, patch
+
+import pytest
+
+try:
+ from autogen.oai.groq import GroqClient, calculate_groq_cost
+
+ skip = False
+except ImportError:
+ GroqClient = object
+ InternalServerError = object
+ skip = True
+
+
+# Fixtures for mock data
+@pytest.fixture
+def mock_response():
+ class MockResponse:
+ def __init__(self, text, choices, usage, cost, model):
+ self.text = text
+ self.choices = choices
+ self.usage = usage
+ self.cost = cost
+ self.model = model
+
+ return MockResponse
+
+
+@pytest.fixture
+def groq_client():
+ return GroqClient(api_key="fake_api_key")
+
+
+skip_reason = "Groq dependency is not installed"
+
+
+# Test initialization and configuration
+@pytest.mark.skipif(skip, reason=skip_reason)
+def test_initialization():
+
+ # Missing any api_key
+ with pytest.raises(AssertionError) as assertinfo:
+ GroqClient() # Should raise an AssertionError due to missing api_key
+
+ assert "Please include the api_key in your config list entry for Groq or set the GROQ_API_KEY env variable." in str(
+ assertinfo.value
+ )
+
+ # Creation works
+ GroqClient(api_key="fake_api_key") # Should create okay now.
+
+
+# Test standard initialization
+@pytest.mark.skipif(skip, reason=skip_reason)
+def test_valid_initialization(groq_client):
+ assert groq_client.api_key == "fake_api_key", "Config api_key should be correctly set"
+
+
+# Test parameters
+@pytest.mark.skipif(skip, reason=skip_reason)
+def test_parsing_params(groq_client):
+ # All parameters
+ params = {
+ "model": "llama3-8b-8192",
+ "frequency_penalty": 1.5,
+ "presence_penalty": 1.5,
+ "max_tokens": 1000,
+ "seed": 42,
+ "stream": False,
+ "temperature": 1,
+ "top_p": 0.8,
+ }
+ expected_params = {
+ "model": "llama3-8b-8192",
+ "frequency_penalty": 1.5,
+ "presence_penalty": 1.5,
+ "max_tokens": 1000,
+ "seed": 42,
+ "stream": False,
+ "temperature": 1,
+ "top_p": 0.8,
+ }
+ result = groq_client.parse_params(params)
+ assert result == expected_params
+
+ # Only model, others set as defaults
+ params = {
+ "model": "llama3-8b-8192",
+ }
+ expected_params = {
+ "model": "llama3-8b-8192",
+ "frequency_penalty": None,
+ "presence_penalty": None,
+ "max_tokens": None,
+ "seed": None,
+ "stream": False,
+ "temperature": 1,
+ "top_p": None,
+ }
+ result = groq_client.parse_params(params)
+ assert result == expected_params
+
+ # Incorrect types, defaults should be set, will show warnings but not trigger assertions
+ params = {
+ "model": "llama3-8b-8192",
+ "frequency_penalty": "1.5",
+ "presence_penalty": "1.5",
+ "max_tokens": "1000",
+ "seed": "42",
+ "stream": "False",
+ "temperature": "1",
+ "top_p": "0.8",
+ }
+ result = groq_client.parse_params(params)
+ assert result == expected_params
+
+ # Values outside bounds, should warn and set to defaults
+ params = {
+ "model": "llama3-8b-8192",
+ "frequency_penalty": 5000,
+ "presence_penalty": -500,
+ "temperature": 3,
+ }
+ result = groq_client.parse_params(params)
+ assert result == expected_params
+
+ # No model
+ params = {
+ "frequency_penalty": 1,
+ }
+
+ with pytest.raises(AssertionError) as assertinfo:
+ result = groq_client.parse_params(params)
+
+ assert "Please specify the 'model' in your config list entry to nominate the Groq model to use." in str(
+ assertinfo.value
+ )
+
+
+# Test cost calculation
+@pytest.mark.skipif(skip, reason=skip_reason)
+def test_cost_calculation(mock_response):
+ response = mock_response(
+ text="Example response",
+ choices=[{"message": "Test message 1"}],
+ usage={"prompt_tokens": 500, "completion_tokens": 300, "total_tokens": 800},
+ cost=None,
+ model="llama3-70b-8192",
+ )
+ assert (
+ calculate_groq_cost(response.usage["prompt_tokens"], response.usage["completion_tokens"], response.model)
+ == 0.000532
+ ), "Cost for this should be $0.000532"
+
+
+# Test text generation
+@pytest.mark.skipif(skip, reason=skip_reason)
+@patch("autogen.oai.groq.GroqClient.create")
+def test_create_response(mock_chat, groq_client):
+ # Mock GroqClient.chat response
+ mock_groq_response = MagicMock()
+ mock_groq_response.choices = [
+ MagicMock(finish_reason="stop", message=MagicMock(content="Example Groq response", tool_calls=None))
+ ]
+ mock_groq_response.id = "mock_groq_response_id"
+ mock_groq_response.model = "llama3-70b-8192"
+ mock_groq_response.usage = MagicMock(prompt_tokens=10, completion_tokens=20) # Example token usage
+
+ mock_chat.return_value = mock_groq_response
+
+ # Test parameters
+ params = {
+ "messages": [{"role": "user", "content": "Hello"}, {"role": "assistant", "content": "World"}],
+ "model": "llama3-70b-8192",
+ }
+
+ # Call the create method
+ response = groq_client.create(params)
+
+ # Assertions to check if response is structured as expected
+ assert (
+ response.choices[0].message.content == "Example Groq response"
+ ), "Response content should match expected output"
+ assert response.id == "mock_groq_response_id", "Response ID should match the mocked response ID"
+ assert response.model == "llama3-70b-8192", "Response model should match the mocked response model"
+ assert response.usage.prompt_tokens == 10, "Response prompt tokens should match the mocked response usage"
+ assert response.usage.completion_tokens == 20, "Response completion tokens should match the mocked response usage"
+
+
+# Test functions/tools
+@pytest.mark.skipif(skip, reason=skip_reason)
+@patch("autogen.oai.groq.GroqClient.create")
+def test_create_response_with_tool_call(mock_chat, groq_client):
+ # Mock `groq_response = client.chat(**groq_params)`
+ mock_function = MagicMock(name="currency_calculator")
+ mock_function.name = "currency_calculator"
+ mock_function.arguments = '{"base_currency": "EUR", "quote_currency": "USD", "base_amount": 123.45}'
+
+ mock_function_2 = MagicMock(name="get_weather")
+ mock_function_2.name = "get_weather"
+ mock_function_2.arguments = '{"location": "Chicago"}'
+
+ mock_chat.return_value = MagicMock(
+ choices=[
+ MagicMock(
+ finish_reason="tool_calls",
+ message=MagicMock(
+ content="Sample text about the functions",
+ tool_calls=[
+ MagicMock(id="gdRdrvnHh", function=mock_function),
+ MagicMock(id="abRdrvnHh", function=mock_function_2),
+ ],
+ ),
+ )
+ ],
+ id="mock_groq_response_id",
+ model="llama3-70b-8192",
+ usage=MagicMock(prompt_tokens=10, completion_tokens=20),
+ )
+
+ # Construct parameters
+ converted_functions = [
+ {
+ "type": "function",
+ "function": {
+ "description": "Currency exchange calculator.",
+ "name": "currency_calculator",
+ "parameters": {
+ "type": "object",
+ "properties": {
+ "base_amount": {"type": "number", "description": "Amount of currency in base_currency"},
+ },
+ "required": ["base_amount"],
+ },
+ },
+ }
+ ]
+ groq_messages = [
+ {"role": "user", "content": "How much is 123.45 EUR in USD?"},
+ {"role": "assistant", "content": "World"},
+ ]
+
+ # Call the create method
+ response = groq_client.create({"messages": groq_messages, "tools": converted_functions, "model": "llama3-70b-8192"})
+
+ # Assertions to check if the functions and content are included in the response
+ assert response.choices[0].message.content == "Sample text about the functions"
+ assert response.choices[0].message.tool_calls[0].function.name == "currency_calculator"
+ assert response.choices[0].message.tool_calls[1].function.name == "get_weather"
diff --git a/test/oai/test_together.py b/test/oai/test_together.py
new file mode 100644
index 000000000000..0581d19f0f73
--- /dev/null
+++ b/test/oai/test_together.py
@@ -0,0 +1,264 @@
+from unittest.mock import MagicMock, patch
+
+import pytest
+
+try:
+ from openai.types.chat.chat_completion import ChatCompletionMessage, Choice
+
+ from autogen.oai.together import TogetherClient, calculate_together_cost
+
+ skip = False
+except ImportError:
+ TogetherClient = object
+ InternalServerError = object
+ skip = True
+
+
+# Fixtures for mock data
+@pytest.fixture
+def mock_response():
+ class MockResponse:
+ def __init__(self, text, choices, usage, cost, model):
+ self.text = text
+ self.choices = choices
+ self.usage = usage
+ self.cost = cost
+ self.model = model
+
+ return MockResponse
+
+
+@pytest.fixture
+def together_client():
+ return TogetherClient(api_key="fake_api_key")
+
+
+# Test initialization and configuration
+@pytest.mark.skipif(skip, reason="Together.AI dependency is not installed")
+def test_initialization():
+
+ # Missing any api_key
+ with pytest.raises(AssertionError) as assertinfo:
+ TogetherClient() # Should raise an AssertionError due to missing api_key
+
+ assert (
+ "Please include the api_key in your config list entry for Together.AI or set the TOGETHER_API_KEY env variable."
+ in str(assertinfo.value)
+ )
+
+ # Creation works
+ TogetherClient(api_key="fake_api_key") # Should create okay now.
+
+
+# Test standard initialization
+@pytest.mark.skipif(skip, reason="Together.AI dependency is not installed")
+def test_valid_initialization(together_client):
+ assert together_client.api_key == "fake_api_key", "Config api_key should be correctly set"
+
+
+# Test parameters
+@pytest.mark.skipif(skip, reason="Together.AI dependency is not installed")
+def test_parsing_params(together_client):
+ # All parameters
+ params = {
+ "model": "Qwen/Qwen2-72B-Instruct",
+ "max_tokens": 1000,
+ "stream": False,
+ "temperature": 1,
+ "top_p": 0.8,
+ "top_k": 50,
+ "repetition_penalty": 0.5,
+ "presence_penalty": 1.5,
+ "frequency_penalty": 1.5,
+ "min_p": 0.2,
+ "safety_model": "Meta-Llama/Llama-Guard-7b",
+ }
+ expected_params = {
+ "model": "Qwen/Qwen2-72B-Instruct",
+ "max_tokens": 1000,
+ "stream": False,
+ "temperature": 1,
+ "top_p": 0.8,
+ "top_k": 50,
+ "repetition_penalty": 0.5,
+ "presence_penalty": 1.5,
+ "frequency_penalty": 1.5,
+ "min_p": 0.2,
+ "safety_model": "Meta-Llama/Llama-Guard-7b",
+ }
+ result = together_client.parse_params(params)
+ assert result == expected_params
+
+ # Only model, others set as defaults
+ params = {
+ "model": "mistralai/Mixtral-8x7B-Instruct-v0.1",
+ }
+ expected_params = {
+ "model": "mistralai/Mixtral-8x7B-Instruct-v0.1",
+ "max_tokens": 512,
+ "stream": False,
+ "temperature": None,
+ "top_p": None,
+ "top_k": None,
+ "repetition_penalty": None,
+ "presence_penalty": None,
+ "frequency_penalty": None,
+ "min_p": None,
+ "safety_model": None,
+ }
+ result = together_client.parse_params(params)
+ assert result == expected_params
+
+ # Incorrect types, defaults should be set, will show warnings but not trigger assertions
+ params = {
+ "model": "mistralai/Mixtral-8x7B-Instruct-v0.1",
+ "max_tokens": "512",
+ "stream": "Yes",
+ "temperature": "0.5",
+ "top_p": "0.8",
+ "top_k": "50",
+ "repetition_penalty": "0.5",
+ "presence_penalty": "1.5",
+ "frequency_penalty": "1.5",
+ "min_p": "0.2",
+ "safety_model": False,
+ }
+ result = together_client.parse_params(params)
+ assert result == expected_params
+
+ # Values outside bounds, should warn and set to defaults
+ params = {
+ "model": "mistralai/Mixtral-8x7B-Instruct-v0.1",
+ "max_tokens": -200,
+ "presence_penalty": -5,
+ "frequency_penalty": 5,
+ "min_p": -0.5,
+ }
+ result = together_client.parse_params(params)
+ assert result == expected_params
+
+
+# Test cost calculation
+@pytest.mark.skipif(skip, reason="Together.AI dependency is not installed")
+def test_cost_calculation(mock_response):
+ response = mock_response(
+ text="Example response",
+ choices=[{"message": "Test message 1"}],
+ usage={"prompt_tokens": 10, "completion_tokens": 5, "total_tokens": 15},
+ cost=None,
+ model="mistralai/Mixtral-8x22B-Instruct-v0.1",
+ )
+ assert (
+ calculate_together_cost(response.usage["prompt_tokens"], response.usage["completion_tokens"], response.model)
+ == 0.000018
+ ), "Cost for this should be $0.000018"
+
+
+# Test text generation
+@pytest.mark.skipif(skip, reason="Together.AI dependency is not installed")
+@patch("autogen.oai.together.TogetherClient.create")
+def test_create_response(mock_create, together_client):
+ # Mock TogetherClient.chat response
+ mock_together_response = MagicMock()
+ mock_together_response.choices = [
+ MagicMock(finish_reason="stop", message=MagicMock(content="Example Llama response", tool_calls=None))
+ ]
+ mock_together_response.id = "mock_together_response_id"
+ mock_together_response.model = "meta-llama/Llama-3-8b-chat-hf"
+ mock_together_response.usage = MagicMock(prompt_tokens=10, completion_tokens=20) # Example token usage
+
+ mock_create.return_value = mock_together_response
+
+ # Test parameters
+ params = {
+ "messages": [{"role": "user", "content": "Hello"}, {"role": "assistant", "content": "World"}],
+ "model": "meta-llama/Llama-3-8b-chat-hf",
+ }
+
+ # Call the create method
+ response = together_client.create(params)
+
+ # Assertions to check if response is structured as expected
+ assert (
+ response.choices[0].message.content == "Example Llama response"
+ ), "Response content should match expected output"
+ assert response.id == "mock_together_response_id", "Response ID should match the mocked response ID"
+ assert response.model == "meta-llama/Llama-3-8b-chat-hf", "Response model should match the mocked response model"
+ assert response.usage.prompt_tokens == 10, "Response prompt tokens should match the mocked response usage"
+ assert response.usage.completion_tokens == 20, "Response completion tokens should match the mocked response usage"
+
+
+# Test functions/tools
+@pytest.mark.skipif(skip, reason="Together.AI dependency is not installed")
+@patch("autogen.oai.together.TogetherClient.create")
+def test_create_response_with_tool_call(mock_create, together_client):
+
+ # Define the mock response directly within the patch
+ mock_function = MagicMock(name="currency_calculator")
+ mock_function.name = "currency_calculator"
+ mock_function.arguments = '{"base_currency": "EUR", "quote_currency": "USD", "base_amount": 123.45}'
+
+ # Define the mock response directly within the patch
+ mock_create.return_value = MagicMock(
+ choices=[
+ MagicMock(
+ finish_reason="tool_calls",
+ message=MagicMock(
+ content="", # Message is empty for tool responses
+ tool_calls=[MagicMock(id="gdRdrvnHh", function=mock_function)],
+ ),
+ )
+ ],
+ id="mock_together_response_id",
+ model="meta-llama/Llama-3-8b-chat-hf",
+ usage=MagicMock(prompt_tokens=10, completion_tokens=20),
+ )
+
+ # Test parameters
+ converted_functions = [
+ {
+ "type": "function",
+ "function": {
+ "description": "Currency exchange calculator.",
+ "name": "currency_calculator",
+ "parameters": {
+ "type": "object",
+ "properties": {
+ "base_amount": {"type": "number", "description": "Amount of currency in base_currency"},
+ "base_currency": {
+ "enum": ["USD", "EUR"],
+ "type": "string",
+ "default": "USD",
+ "description": "Base currency",
+ },
+ "quote_currency": {
+ "enum": ["USD", "EUR"],
+ "type": "string",
+ "default": "EUR",
+ "description": "Quote currency",
+ },
+ },
+ "required": ["base_amount"],
+ },
+ },
+ }
+ ]
+
+ together_messages = [
+ {
+ "role": "user",
+ "content": "How much is 123.45 EUR in USD?",
+ "name": None,
+ "tool_calls": None,
+ "tool_call_id": None,
+ },
+ ]
+
+ # Call the create method (which is now mocked)
+ response = together_client.create(
+ {"messages": together_messages, "tools": converted_functions, "model": "meta-llama/Llama-3-8b-chat-hf"}
+ )
+
+ # Assertions to check if response is structured as expected
+ assert response.choices[0].message.content == ""
+ assert response.choices[0].message.tool_calls[0].function.name == "currency_calculator"
diff --git a/website/blog/2023-06-28-MathChat/index.mdx b/website/blog/2023-06-28-MathChat/index.mdx
index 4c1007c611b8..be2423de9eed 100644
--- a/website/blog/2023-06-28-MathChat/index.mdx
+++ b/website/blog/2023-06-28-MathChat/index.mdx
@@ -75,7 +75,7 @@ We found that compared to basic prompting, which demonstrates the innate capabil
For categories like Algebra and Prealgebra, PoT and PS showed little improvement, and in some instances, even led to a decrease in accuracy. However, MathChat was able to enhance total accuracy by around 6% compared to PoT and PS, showing competitive performance across all categories. Remarkably, MathChat improved accuracy in the Algebra category by about 15% over other methods. Note that categories like Intermediate Algebra and Precalculus remained challenging for all methods, with only about 20% of problems solved accurately.
-The code for experiments can be found at this [repository](https://github.com/kevin666aa/FLAML/tree/gpt_math_solver/flaml/autogen/math).
+The code for experiments can be found at this [repository](https://github.com/yiranwu0/FLAML/tree/gpt_math_solver/flaml/autogen/math).
We now provide an implementation of MathChat using the interactive agents in AutoGen. See this [notebook](https://github.com/microsoft/autogen/blob/main/notebook/agentchat_MathChat.ipynb) for example usage.
## Future Directions
diff --git a/website/blog/2023-11-13-OAI-assistants/index.mdx b/website/blog/2023-11-13-OAI-assistants/index.mdx
index e73e31ad591f..07216a25969c 100644
--- a/website/blog/2023-11-13-OAI-assistants/index.mdx
+++ b/website/blog/2023-11-13-OAI-assistants/index.mdx
@@ -112,6 +112,6 @@ Checkout more examples [here](https://github.com/microsoft/autogen/tree/main/not
`GPTAssistantAgent` was made possible through collaboration with
[@IANTHEREAL](https://github.com/IANTHEREAL),
[Jiale Liu](https://leoljl.github.io),
-[Yiran Wu](https://github.com/kevin666aa),
+[Yiran Wu](https://github.com/yiranwu0),
[Qingyun Wu](https://qingyun-wu.github.io/),
[Chi Wang](https://www.microsoft.com/en-us/research/people/chiw/), and many other AutoGen maintainers.
diff --git a/website/blog/2024-06-21-AgentEval/img/agenteval_ov_v3.png b/website/blog/2024-06-21-AgentEval/img/agenteval_ov_v3.png
new file mode 100644
index 000000000000..fe31283d72d0
--- /dev/null
+++ b/website/blog/2024-06-21-AgentEval/img/agenteval_ov_v3.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:e17aebbc38a8ba55e4b18b9352a680edcca4b3d6625b16f6d1ab3131da799b63
+size 236624
diff --git a/website/blog/2024-06-21-AgentEval/index.mdx b/website/blog/2024-06-21-AgentEval/index.mdx
new file mode 100644
index 000000000000..87ffc857e839
--- /dev/null
+++ b/website/blog/2024-06-21-AgentEval/index.mdx
@@ -0,0 +1,202 @@
+---
+title: "AgentEval: A Developer Tool to Assess Utility of LLM-powered Applications"
+authors:
+ - jluey
+ - julianakiseleva
+tags: [LLM, GPT, evaluation, task utility]
+---
+
+
+
+
+Fig.1 illustrates the general flow of AgentEval with verification step
+ + + +TL;DR: +* As a developer, how can you assess the utility and effectiveness of an LLM-powered application in helping end users with their tasks? +* To shed light on the question above, we previously introduced [`AgentEval`](https://microsoft.github.io/autogen/blog/2023/11/20/AgentEval/) — a framework to assess the multi-dimensional utility of any LLM-powered application crafted to assist users in specific tasks. We have now embedded it as part of the AutoGen library to ease developer adoption. +* Here, we introduce an updated version of AgentEval that includes a verification process to estimate the robustness of the QuantifierAgent. More details can be found in [this paper](https://arxiv.org/abs/2405.02178). + + +## Introduction + +Previously introduced [`AgentEval`](https://microsoft.github.io/autogen/blog/2023/11/20/AgentEval/) is a comprehensive framework designed to bridge the gap in assessing the utility of LLM-powered applications. It leverages recent advancements in LLMs to offer a scalable and cost-effective alternative to traditional human evaluations. The framework comprises three main agents: `CriticAgent`, `QuantifierAgent`, and `VerifierAgent`, each playing a crucial role in assessing the task utility of an application. + +**CriticAgent: Defining the Criteria** + +The CriticAgent's primary function is to suggest a set of criteria for evaluating an application based on the task description and examples of successful and failed executions. For instance, in the context of a math tutoring application, the CriticAgent might propose criteria such as efficiency, clarity, and correctness. These criteria are essential for understanding the various dimensions of the application's performance. It’s highly recommended that application developers validate the suggested criteria leveraging their domain expertise. + +**QuantifierAgent: Quantifying the Performance** + +Once the criteria are established, the QuantifierAgent takes over to quantify how well the application performs against each criterion. This quantification process results in a multi-dimensional assessment of the application's utility, providing a detailed view of its strengths and weaknesses. + +**VerifierAgent: Ensuring Robustness and Relevance** + +VerifierAgent ensures the criteria used to evaluate a utility are effective for the end-user, maintaining both robustness and high discriminative power. It does this through two main actions: + +1. Criteria Stability: + * Ensures criteria are essential, non-redundant, and consistently measurable. + * Iterates over generating and quantifying criteria, eliminating redundancies, and evaluating their stability. + * Retains only the most robust criteria. + +2. Discriminative Power: + + * Tests the system's reliability by introducing adversarial examples (noisy or compromised data). + * Assesses the system's ability to distinguish these from standard cases. + * If the system fails, it indicates the need for better criteria to handle varied conditions effectively. + +## A Flexible and Scalable Framework + +One of AgentEval's key strengths is its flexibility. It can be applied to a wide range of tasks where success may or may not be clearly defined. For tasks with well-defined success criteria, such as household chores, the framework can evaluate whether multiple successful solutions exist and how they compare. For more open-ended tasks, such as generating an email template, AgentEval can assess the utility of the system's suggestions. + +Furthermore, AgentEval allows for the incorporation of human expertise. Domain experts can participate in the evaluation process by suggesting relevant criteria or verifying the usefulness of the criteria identified by the agents. This human-in-the-loop approach ensures that the evaluation remains grounded in practical, real-world considerations. + +## Empirical Validation + +To validate AgentEval, the framework was tested on two applications: math problem solving and ALFWorld, a household task simulation. The math dataset comprised 12,500 challenging problems, each with step-by-step solutions, while the ALFWorld dataset involved multi-turn interactions in a simulated environment. In both cases, AgentEval successfully identified relevant criteria, quantified performance, and verified the robustness of the evaluations, demonstrating its effectiveness and versatility. + +## How to use `AgentEval` + +AgentEval currently has two main stages; criteria generation and criteria quantification (criteria verification is still under development). Both stages make use of sequential LLM-powered agents to make their determinations. + +**Criteria Generation:** + +During criteria generation, AgentEval uses example execution message chains to create a set of criteria for quantifying how well an application performed for a given task. + +``` +def generate_criteria( + llm_config: Optional[Union[Dict, Literal[False]]] = None, + task: Task = None, + additional_instructions: str = "", + max_round=2, + use_subcritic: bool = False, +) +``` + +Parameters: +* llm_config (dict or bool): llm inference configuration. +* task ([Task](https://github.com/microsoft/autogen/tree/main/autogen/agentchat/contrib/agent_eval/task.py)): The task to evaluate. +* additional_instructions (str, optional): Additional instructions for the criteria agent. +* max_round (int, optional): The maximum number of rounds to run the conversation. +* use_subcritic (bool, optional): Whether to use the Subcritic agent to generate subcriteria. The Subcritic agent will break down a generated criteria into smaller criteria to be assessed. + +Example code: +``` +config_list = autogen.config_list_from_json("OAI_CONFIG_LIST") +task = Task( + **{ + "name": "Math problem solving", + "description": "Given any question, the system needs to solve the problem as consisely and accurately as possible", + "successful_response": response_successful, + "failed_response": response_failed, + } +) + +criteria = generate_criteria(task=task, llm_config={"config_list": config_list}) +``` + +Note: Only one sample execution chain (success/failure) is required for the task object but AgentEval will perform better with an example for each case. + + +Example Output: +``` +[ + { + "name": "Accuracy", + "description": "The solution must be correct and adhere strictly to mathematical principles and techniques appropriate for the problem.", + "accepted_values": ["Correct", "Minor errors", "Major errors", "Incorrect"] + }, + { + "name": "Conciseness", + "description": "The explanation and method provided should be direct and to the point, avoiding unnecessary steps or complexity.", + "accepted_values": ["Very concise", "Concise", "Somewhat verbose", "Verbose"] + }, + { + "name": "Relevance", + "description": "The content of the response must be relevant to the question posed and should address the specific problem requirements.", + "accepted_values": ["Highly relevant", "Relevant", "Somewhat relevant", "Not relevant"] + } +] +``` + + + +**Criteria Quantification:** + +During the quantification stage, AgentEval will use the generated criteria (or user defined criteria) to assess a given execution chain to determine how well the application performed. + +``` +def quantify_criteria( + llm_config: Optional[Union[Dict, Literal[False]]], + criteria: List[Criterion], + task: Task, + test_case: str, + ground_truth: str, +) +``` + +Parameters: +* llm_config (dict or bool): llm inference configuration. +* criteria ([Criterion](https://github.com/microsoft/autogen/tree/main/autogen/agentchat/contrib/agent_eval/criterion.py)): A list of criteria for evaluating the utility of a given task. This can either be generated by the `generate_criteria` function or manually created. +* task ([Task](https://github.com/microsoft/autogen/tree/main/autogen/agentchat/contrib/agent_eval/task.py)): The task to evaluate. It should match the one used during the `generate_criteria` step. +* test_case (str): The execution chain to assess. Typically this is a json list of messages but could be any string representation of a conversation chain. +* ground_truth (str): The ground truth for the test case. + +Example Code: +``` +test_case="""[ + { + "content": "Find $24^{-1} \\pmod{11^2}$. That is, find the residue $b$ for which $24b \\equiv 1\\pmod{11^2}$.\n\nExpress your answer as an integer from $0$ to $11^2-1$, inclusive.", + "role": "user" + }, + { + "content": "To find the modular inverse of 24 modulo 11^2, we can use the Extended Euclidean Algorithm. Here is a Python function to compute the modular inverse using this algorithm:\n\n```python\ndef mod_inverse(a, m):\n..." + "role": "assistant" + } + ]""" + +quantifier_output = quantify_criteria( + llm_config={"config_list": config_list}, + criteria=criteria, + task=task, + test_case=test_case, + ground_truth="true", +) +``` + +The output will be a json object consisting of the ground truth and a dictionary mapping each criteria to it's score. + +``` +{ + "actual_success": true, + "estimated_performance": { + "Accuracy": "Correct", + "Conciseness": "Concise", + "Relevance": "Highly relevant" + } +} +``` + +## What is next? +* Enabling AgentEval in AutoGen Studio for a nocode solution. +* Fully implementing VerifierAgent in the AgentEval framework. + +## Conclusion + +AgentEval represents a significant advancement in the evaluation of LLM-powered applications. By combining the strengths of CriticAgent, QuantifierAgent, and VerifierAgent, the framework offers a robust, scalable, and flexible solution for assessing task utility. This innovative approach not only helps developers understand the current performance of their applications but also provides valuable insights that can drive future improvements. As the field of intelligent agents continues to evolve, frameworks like AgentEval will play a crucial role in ensuring that these applications meet the diverse and dynamic needs of their users. + + +## Further reading + +Please refer to our [paper](https://arxiv.org/abs/2405.02178) and [codebase](https://github.com/microsoft/autogen/tree/main/autogen/agentchat/contrib/agent_eval) for more details about AgentEval. + +If you find this blog useful, please consider citing: +```bobtex +@article{arabzadeh2024assessing, + title={Assessing and Verifying Task Utility in LLM-Powered Applications}, + author={Arabzadeh, Negar and Huo, Siging and Mehta, Nikhil and Wu, Qinqyun and Wang, Chi and Awadallah, Ahmed and Clarke, Charles LA and Kiseleva, Julia}, + journal={arXiv preprint arXiv:2405.02178}, + year={2024} +} +``` diff --git a/website/blog/2024-06-24-AltModels-Classes/img/agentstogether.jpeg b/website/blog/2024-06-24-AltModels-Classes/img/agentstogether.jpeg new file mode 100644 index 000000000000..fd859fc62076 --- /dev/null +++ b/website/blog/2024-06-24-AltModels-Classes/img/agentstogether.jpeg @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:964628601b60ddbab8940fea45014dcd841b89783bb0b7e9ac9d3690f1c41798 +size 659594 diff --git a/website/blog/2024-06-24-AltModels-Classes/index.mdx b/website/blog/2024-06-24-AltModels-Classes/index.mdx new file mode 100644 index 000000000000..9c94094e7e4c --- /dev/null +++ b/website/blog/2024-06-24-AltModels-Classes/index.mdx @@ -0,0 +1,393 @@ +--- +title: Enhanced Support for Non-OpenAI Models +authors: + - marklysze + - Hk669 +tags: [mistral ai,anthropic,together.ai,gemini] +--- + + + +## TL;DR + +- **AutoGen has expanded integrations with a variety of cloud-based model providers beyond OpenAI.** +- **Leverage models and platforms from Gemini, Anthropic, Mistral AI, Together.AI, and Groq for your AutoGen agents.** +- **Utilise models specifically for chat, language, image, and coding.** +- **LLM provider diversification can provide cost and resilience benefits.** + +In addition to the recently released AutoGen [Google Gemini](https://ai.google.dev/) client, new client classes for [Mistral AI](https://mistral.ai/), [Anthropic](https://www.anthropic.com/), [Together.AI](https://www.together.ai/), and [Groq](https://groq.com/) enable you to utilize over 75 different large language models in your AutoGen agent workflow. + +These new client classes tailor AutoGen's underlying messages to each provider's unique requirements and remove that complexity from the developer, who can then focus on building their AutoGen workflow. + +Using them is as simple as installing the client-specific library and updating your LLM config with the relevant `api_type` and `model`. We'll demonstrate how to use them below. + +The community is continuing to enhance and build new client classes as cloud-based inference providers arrive. So, watch this space, and feel free to [discuss](https://discord.gg/pAbnFJrkgZ) or [develop](https://github.com/microsoft/autogen/pulls) another one. + +## Benefits of choice + +The need to use only the best models to overcome workflow-breaking LLM inconsistency has diminished considerably over the last 12 months. + +These new classes provide access to the very largest trillion-parameter models from OpenAI, Google, and Anthropic, continuing to provide the most consistent +and competent agent experiences. However, it's worth trying smaller models from the likes of Meta, Mistral AI, Microsoft, Qwen, and many others. Perhaps they +are capable enough for a task, or sub-task, or even better suited (such as a coding model)! + +Using smaller models will have cost benefits, but they also allow you to test models that you could run locally, allowing you to determine if you can remove cloud inference costs +altogether or even run an AutoGen workflow offline. + +On the topic of cost, these client classes also include provider-specific token cost calculations so you can monitor the cost impact of your workflows. With costs per million +tokens as low as 10 cents (and some are even free!), cost savings can be noticeable. + +## Mix and match + +How does Google's Gemini 1.5 Pro model stack up against Anthropic's Opus or Meta's Llama 3? + +Now you have the ability to quickly change your agent configs and find out. If you want to run all three in the one workflow, +AutoGen's ability to associate specific configurations to each agent means you can select the best LLM for each agent. + +## Capabilities + +The common requirements of text generation and function/tool calling are supported by these client classes. + +Multi-modal support, such as for image/audio/video, is an area of active development. The [Google Gemini](https://microsoft.github.io/autogen/docs/topics/non-openai-models/cloud-gemini) client class can be +used to create a multimodal agent. + +## Tips + +Here are some tips when working with these client classes: + +- **Most to least capable** - start with larger models and get your workflow working, then iteratively try smaller models. +- **Right model** - choose one that's suited to your task, whether it's coding, function calling, knowledge, or creative writing. +- **Agent names** - these cloud providers do not use the `name` field on a message, so be sure to use your agent's name in their `system_message` and `description` fields, as well as instructing the LLM to 'act as' them. This is particularly important for "auto" speaker selection in group chats as we need to guide the LLM to choose the next agent based on a name, so tweak `select_speaker_message_template`, `select_speaker_prompt_template`, and `select_speaker_auto_multiple_template` with more guidance. +- **Context length** - as your conversation gets longer, models need to support larger context lengths, be mindful of what the model supports and consider using [Transform Messages](https://microsoft.github.io/autogen/docs/topics/handling_long_contexts/intro_to_transform_messages) to manage context size. +- **Provider parameters** - providers have parameters you can set such as temperature, maximum tokens, top-k, top-p, and safety. See each client class in AutoGen's [API Reference](https://microsoft.github.io/autogen/docs/reference/oai/gemini) or [documentation](https://microsoft.github.io/autogen/docs/topics/non-openai-models/cloud-gemini) for details. +- **Prompts** - prompt engineering is critical in guiding smaller LLMs to do what you need. [ConversableAgent](https://microsoft.github.io/autogen/docs/reference/agentchat/conversable_agent), [GroupChat](https://microsoft.github.io/autogen/docs/reference/agentchat/groupchat), [UserProxyAgent](https://microsoft.github.io/autogen/docs/reference/agentchat/user_proxy_agent), and [AssistantAgent](https://microsoft.github.io/autogen/docs/reference/agentchat/assistant_agent) all have customizable prompt attributes that you can tailor. Here are some prompting tips from [Anthropic](https://docs.anthropic.com/en/docs/build-with-claude/prompt-engineering/overview)([+Library](https://docs.anthropic.com/en/prompt-library/library)), [Mistral AI](https://docs.mistral.ai/guides/prompting_capabilities/), [Together.AI](https://docs.together.ai/docs/examples), and [Meta](https://llama.meta.com/docs/how-to-guides/prompting/). +- **Help!** - reach out on the AutoGen [Discord](https://discord.gg/pAbnFJrkgZ) or [log an issue](https://github.com/microsoft/autogen/issues) if you need help with or can help improve these client classes. + +Now it's time to try them out. + +## Quickstart + +### Installation + +Install the appropriate client based on the model you wish to use. + +```sh +pip install pyautogen["mistral"] # for Mistral AI client +pip install pyautogen["anthropic"] # for Anthropic client +pip install pyautogen["together"] # for Together.AI client +pip install pyautogen["groq"] # for Groq client +``` + +### Configuration Setup + +Add your model configurations to the `OAI_CONFIG_LIST`. Ensure you specify the `api_type` to initialize the respective client (Anthropic, Mistral, or Together). + +```yaml +[ + { + "model": "your anthropic model name", + "api_key": "your Anthropic api_key", + "api_type": "anthropic" + }, + { + "model": "your mistral model name", + "api_key": "your Mistral AI api_key", + "api_type": "mistral" + }, + { + "model": "your together.ai model name", + "api_key": "your Together.AI api_key", + "api_type": "together" + }, + { + "model": "your groq model name", + "api_key": "your Groq api_key", + "api_type": "groq" + } +] +``` + +### Usage + +The `[config_list_from_json](https://microsoft.github.io/autogen/docs/reference/oai/openai_utils/#config_list_from_json)` function loads a list of configurations from an environment variable or a json file. + +```py +import autogen +from autogen import AssistantAgent, UserProxyAgent + +config_list = autogen.config_list_from_json( + "OAI_CONFIG_LIST" +) +``` + +### Construct Agents + +Construct a simple conversation between a User proxy and an Assistant agent + +```py +user_proxy = UserProxyAgent( + name="User_proxy", + code_execution_config={ + "last_n_messages": 2, + "work_dir": "groupchat", + "use_docker": False, # Please set use_docker = True if docker is available to run the generated code. Using docker is safer than running the generated code directly. + }, + human_input_mode="ALWAYS", + is_termination_msg=lambda msg: not msg["content"] +) + +assistant = AssistantAgent( + name="assistant", + llm_config = {"config_list": config_list} +) +``` + +### Start chat + +```py + +user_proxy.intiate_chat(assistant, message="Write python code to print Hello World!") + +``` + +**NOTE: To integrate this setup into GroupChat, follow the [tutorial](https://microsoft.github.io/autogen/docs/notebooks/agentchat_groupchat) with the same config as above.** + + +## Function Calls + +Now, let's look at how Anthropic's Sonnet 3.5 is able to suggest multiple function calls in a single response. + +This example is a simple travel agent setup with an agent for function calling and a user proxy agent for executing the functions. + +One thing you'll note here is Anthropic's models are more verbose than OpenAI's and will typically provide chain-of-thought or general verbiage when replying. Therefore we provide more explicit instructions to `functionbot` to not reply with more than necessary. Even so, it can't always help itself! + +Let's start with setting up our configuration and agents. + +```py +import os +import autogen +import json +from typing import Literal +from typing_extensions import Annotated + +# Anthropic configuration, using api_type='anthropic' +anthropic_llm_config = { + "config_list": + [ + { + "api_type": "anthropic", + "model": "claude-3-5-sonnet-20240620", + "api_key": os.getenv("ANTHROPIC_API_KEY"), + "cache_seed": None + } + ] +} + +# Our functionbot, who will be assigned two functions and +# given directions to use them. +functionbot = autogen.AssistantAgent( + name="functionbot", + system_message="For currency exchange tasks, only use " + "the functions you have been provided with. Do not " + "reply with helpful tips. Once you've recommended functions " + "reply with 'TERMINATE'.", + is_termination_msg=lambda x: x.get("content", "") and (x.get("content", "").rstrip().endswith("TERMINATE") or x.get("content", "") == ""), + llm_config=anthropic_llm_config, +) + +# Our user proxy agent, who will be used to manage the customer +# request and conversation with the functionbot, terminating +# when we have the information we need. +user_proxy = autogen.UserProxyAgent( + name="user_proxy", + system_message="You are a travel agent that provides " + "specific information to your customers. Get the " + "information you need and provide a great summary " + "so your customer can have a great trip. If you " + "have the information you need, simply reply with " + "'TERMINATE'.", + is_termination_msg=lambda x: x.get("content", "") and (x.get("content", "").rstrip().endswith("TERMINATE") or x.get("content", "") == ""), + human_input_mode="NEVER", + max_consecutive_auto_reply=10, +) +``` + +We define the two functions. +```py +CurrencySymbol = Literal["USD", "EUR"] + +def exchange_rate(base_currency: CurrencySymbol, quote_currency: CurrencySymbol) -> float: + if base_currency == quote_currency: + return 1.0 + elif base_currency == "USD" and quote_currency == "EUR": + return 1 / 1.1 + elif base_currency == "EUR" and quote_currency == "USD": + return 1.1 + else: + raise ValueError(f"Unknown currencies {base_currency}, {quote_currency}") + +def get_current_weather(location, unit="fahrenheit"): + """Get the weather for some location""" + if "chicago" in location.lower(): + return json.dumps({"location": "Chicago", "temperature": "13", "unit": unit}) + elif "san francisco" in location.lower(): + return json.dumps({"location": "San Francisco", "temperature": "55", "unit": unit}) + elif "new york" in location.lower(): + return json.dumps({"location": "New York", "temperature": "11", "unit": unit}) + else: + return json.dumps({"location": location, "temperature": "unknown"}) +``` + +And then associate them with the `user_proxy` for execution and `functionbot` for the LLM to consider using them. + +```py +@user_proxy.register_for_execution() +@functionbot.register_for_llm(description="Currency exchange calculator.") +def currency_calculator( + base_amount: Annotated[float, "Amount of currency in base_currency"], + base_currency: Annotated[CurrencySymbol, "Base currency"] = "USD", + quote_currency: Annotated[CurrencySymbol, "Quote currency"] = "EUR", +) -> str: + quote_amount = exchange_rate(base_currency, quote_currency) * base_amount + return f"{quote_amount} {quote_currency}" + +@user_proxy.register_for_execution() +@functionbot.register_for_llm(description="Weather forecast for US cities.") +def weather_forecast( + location: Annotated[str, "City name"], +) -> str: + weather_details = get_current_weather(location=location) + weather = json.loads(weather_details) + return f"{weather['location']} will be {weather['temperature']} degrees {weather['unit']}" +``` + +Finally, we start the conversation with a request for help from our customer on their upcoming trip to New York and the Euro they would like exchanged to USD. + +Importantly, we're also using Anthropic's Sonnet to provide a summary through the `summary_method`. Using `summary_prompt`, we guide Sonnet to give us an email output. + +```py +# start the conversation +res = user_proxy.initiate_chat( + functionbot, + message="My customer wants to travel to New York and " + "they need to exchange 830 EUR to USD. Can you please " + "provide them with a summary of the weather and " + "exchanged currently in USD?", + summary_method="reflection_with_llm", + summary_args={ + "summary_prompt": """Summarize the conversation by + providing an email response with the travel information + for the customer addressed as 'Dear Customer'. Do not + provide any additional conversation or apologise, + just provide the relevant information and the email.""" + }, +) +``` + +After the conversation has finished, we'll print out the summary. + +```py +print(f"Here's the LLM summary of the conversation:\n\n{res.summary['content']}") +``` + +Here's the resulting output. + +```text +user_proxy (to functionbot): + +My customer wants to travel to New York and they need to exchange 830 EUR +to USD. Can you please provide them with a summary of the weather and +exchanged currently in USD? + +-------------------------------------------------------------------------------- +functionbot (to user_proxy): + +Certainly! I'd be happy to help your customer with information about the +weather in New York and the currency exchange from EUR to USD. Let's use +the available tools to get this information. + +***** Suggested tool call (toolu_016wBUKVX2TToBaMqmiGvhav): weather_forecast ***** +Arguments: +{"location": "New York"} +********************************************************************************** +***** Suggested tool call (toolu_01Nxjeew2BspfKdZ85on3XkP): currency_calculator ***** +Arguments: +{"base_amount": 830, "base_currency": "EUR", "quote_currency": "USD"} +************************************************************************************* + +-------------------------------------------------------------------------------- + +>>>>>>>> EXECUTING FUNCTION weather_forecast... + +>>>>>>>> EXECUTING FUNCTION currency_calculator... +user_proxy (to functionbot): + +user_proxy (to functionbot): + +***** Response from calling tool (toolu_016wBUKVX2TToBaMqmiGvhav) ***** +New York will be 11 degrees fahrenheit +*********************************************************************** + +-------------------------------------------------------------------------------- +user_proxy (to functionbot): + +***** Response from calling tool (toolu_01Nxjeew2BspfKdZ85on3XkP) ***** +913.0000000000001 USD +*********************************************************************** + +-------------------------------------------------------------------------------- +functionbot (to user_proxy): + +Thank you for providing the information. I can now give your customer a +summary of the weather in New York and the currency exchange from EUR to USD. + +Weather in New York: +The current forecast for New York indicates that it will be 11 degrees +Fahrenheit. This is quite cold, so your customer should be prepared with +warm clothing for their trip. + +Currency Exchange: +For 830 EUR, your customer will receive approximately 913 USD. This is based +on the current exchange rate provided by our currency calculator. + +To summarize: +1. Weather in New York: 11°F (very cold) +2. Currency exchange: 830 EUR = 913 USD + +Your customer should pack warm clothes for the cold weather in New York and +can expect to have about 913 USD for their trip after exchanging 830 EUR. + +TERMINATE + +-------------------------------------------------------------------------------- +Here's the LLM summary of the conversation: + +Certainly. I'll provide an email response to the customer with the travel +information as requested. + +Dear Customer, + +We are pleased to provide you with the following information for your +upcoming trip to New York: + +Weather Forecast: +The current forecast for New York indicates a temperature of 11 degrees +Fahrenheit. Please be prepared for very cold weather and pack appropriate +warm clothing. + +Currency Exchange: +We have calculated the currency exchange for you. Your 830 EUR will be +equivalent to approximately 913 USD at the current exchange rate. + +We hope this information helps you prepare for your trip to New York. Have +a safe and enjoyable journey! + +Best regards, +Travel Assistance Team +``` + +So we can see how Anthropic's Sonnet is able to suggest multiple tools in a single response, with AutoGen executing them both and providing the results back to Sonnet. Sonnet then finishes with a nice email summary that can be the basis for continued real-life conversation with the customer. + +## More tips and tricks + +For an interesting chess game between Anthropic's Sonnet and Mistral's Mixtral, we've put together a sample notebook that highlights some of the tips and tricks for working with non-OpenAI LLMs. [See the notebook here](https://microsoft.github.io/autogen/docs/notebooks/agentchat_nested_chats_chess_altmodels). diff --git a/website/blog/authors.yml b/website/blog/authors.yml index 302bb8fceaaf..0e023514465d 100644 --- a/website/blog/authors.yml +++ b/website/blog/authors.yml @@ -13,8 +13,8 @@ qingyunwu: yiranwu: name: Yiran Wu title: PhD student at Pennsylvania State University - url: https://github.com/kevin666aa - image_url: https://github.com/kevin666aa.png + url: https://github.com/yiranwu0 + image_url: https://github.com/yiranwu0.png jialeliu: name: Jiale Liu @@ -123,3 +123,20 @@ yifanzeng: title: PhD student at Oregon State University url: https://xhmy.github.io/ image_url: https://xhmy.github.io/assets/img/photo.JPG + +jluey: + name: James Woffinden-Luey + title: Senior Research Engineer at Microsoft Research + url: https://github.com/jluey1 + +Hk669: + name: Hrushikesh Dokala + title: CS Undergraduate Based in India + url: https://github.com/Hk669 + image_url: https://github.com/Hk669.png + +marklysze: + name: Mark Sze + title: AI Freelancer + url: https://github.com/marklysze + image_url: https://github.com/marklysze.png diff --git a/website/docs/Examples.md b/website/docs/Examples.md index 2ec83d1e0f21..3b71dd682e97 100644 --- a/website/docs/Examples.md +++ b/website/docs/Examples.md @@ -80,6 +80,9 @@ Links to notebook examples: - OpenAI Assistant in a Group Chat - [View Notebook](https://github.com/microsoft/autogen/blob/main/notebook/agentchat_oai_assistant_groupchat.ipynb) - GPTAssistantAgent based Multi-Agent Tool Use - [View Notebook](https://github.com/microsoft/autogen/blob/main/notebook/gpt_assistant_agent_function_call.ipynb) +### Non-OpenAI Models +- Conversational Chess using non-OpenAI Models - [View Notebook](/docs/notebooks/agentchat_nested_chats_chess_altmodels) + ### Multimodal Agent - Multimodal Agent Chat with DALLE and GPT-4V - [View Notebook](https://github.com/microsoft/autogen/blob/main/notebook/agentchat_dalle_and_gpt4v.ipynb) diff --git a/website/docs/Getting-Started.mdx b/website/docs/Getting-Started.mdx index 0f8c7322411d..3e162a098327 100644 --- a/website/docs/Getting-Started.mdx +++ b/website/docs/Getting-Started.mdx @@ -3,11 +3,12 @@ import TabItem from "@theme/TabItem"; # Getting Started -AutoGen is a framework that enables development of LLM applications using -multiple agents that can converse with each other to solve tasks. AutoGen agents -are customizable, conversable, and seamlessly allow human participation. They -can operate in various modes that employ combinations of LLMs, human inputs, and -tools. +AutoGen is an open-source programming framework for building AI agents and facilitating +cooperation among multiple agents to solve tasks. AutoGen aims to provide an easy-to-use +and flexible framework for accelerating development and research on agentic AI, +like PyTorch for Deep Learning. It offers features such as agents that can converse +with other agents, LLM and tool use support, autonomous and human-in-the-loop workflows, +and multi-agent conversation patterns.  diff --git a/website/docs/contributor-guide/contributing.md b/website/docs/contributor-guide/contributing.md index b90d81f227c8..b1b6b848f667 100644 --- a/website/docs/contributor-guide/contributing.md +++ b/website/docs/contributor-guide/contributing.md @@ -1,6 +1,6 @@ # Contributing to AutoGen -This project welcomes and encourages all forms of contributions, including but not limited to: +The project welcomes contributions from developers and organizations worldwide. Our goal is to foster a collaborative and inclusive community where diverse perspectives and expertise can drive innovation and enhance the project's capabilities. Whether you are an individual contributor or represent an organization, we invite you to join us in shaping the future of this project. Together, we can build something truly remarkable. Possible contributions include but not limited to: - Pushing patches. - Code review of pull requests. @@ -32,3 +32,7 @@ To see what we are working on and what we plan to work on, please check our ## Becoming a Reviewer There is currently no formal reviewer solicitation process. Current reviewers identify reviewers from active contributors. If you are willing to become a reviewer, you are welcome to let us know on discord. + +## Contact Maintainers + +The project is currently maintained by a [dynamic group of volunteers](https://butternut-swordtail-8a5.notion.site/410675be605442d3ada9a42eb4dfef30?v=fa5d0a79fd3d4c0f9c112951b2831cbb&pvs=4) from several different organizations. Contact project administrators Chi Wang and Qingyun Wu via auto-gen@outlook.com if you are interested in becoming a maintainer. diff --git a/website/docs/ecosystem/agentops.md b/website/docs/ecosystem/agentops.md index 76995b6eb5e4..581fb2671e97 100644 --- a/website/docs/ecosystem/agentops.md +++ b/website/docs/ecosystem/agentops.md @@ -1,29 +1,37 @@ -# AgentOps 🖇️ +# Agent Monitoring and Debugging with AgentOps - +