Deep Q Learning #2811
Comments
|
UE can sometimes fail to render the image, and in that case, the image would be empty. You'll have to handle this case, maybe call the API again if the image is empty? Since the RPC problem has been fixed, I think the workaround in AirSim can be removed now A discussion could be had whether an empty image should be handled by Airsim internally or by the user |
|
@rajat2004 An another question if possible. Is there a way, in AirSim, to reset position of 1 drone only. For example if I try to use DQL or RL for several multirators ? |
|
Hmm, the current |
Hi.
I made a code for obstacle avoidance, but there is an error that I can't understand the origin.
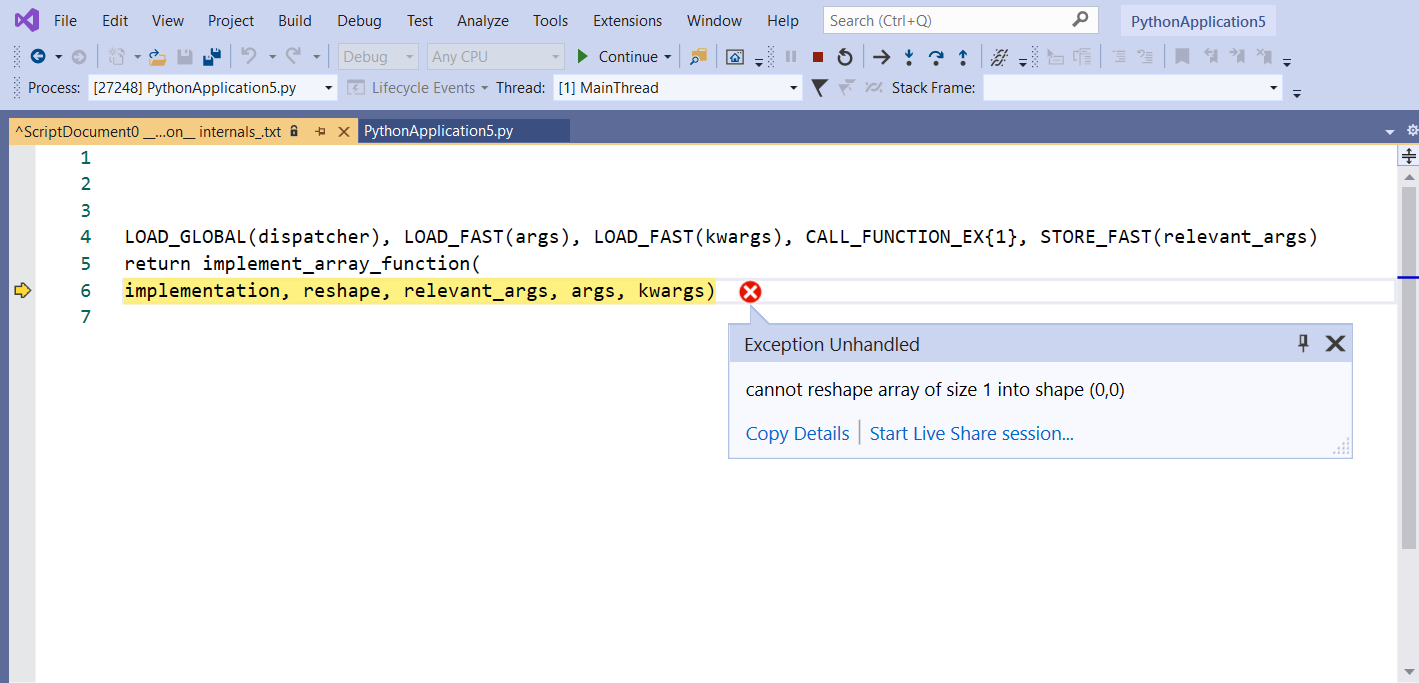
At a random iteration (example : 400, 1208,...) VS2019 interrupt the training, and returns me the following error.
There is the full code. As I'm new with RL, it's not a complexe code. And where there are variables inside tim.sleep(x), that are divided by 300, it's because I've accelerated the time of UE4.
Thak you for help.
`
import numpy as np
import airsim
import time
import math
import tensorflow as tf
import keras
from airsim.utils import to_eularian_angles
from airsim.utils import to_quaternion
from keras.layers import Conv2D,Dense
from keras.layers import Activation
from keras.layers import MaxPool2D
from keras.layers import Dropout
from keras.layers import Input
import keras.backend as K
from keras.models import load_model
from keras import Input
from keras.layers import Flatten
from keras.activations import softmax,elu,relu
from keras.optimizers import Adam
from keras.optimizers import adam
from keras.models import Sequential
from keras.optimizers import Adam, RMSprop
from keras.models import Model
#tf.compat.v1.disable_eager_execution()
import random
from collections import deque
client=airsim.MultirotorClient()
z=-5
memory_size=10000000
#pos_0=client.getMultirotorState().kinematics_estimated.position
#state_space=[84, 84]
#action_size=3
def OurModel(state_size,action_space):
class MemoryClass():
def init(self,memory_size):
self.memory_size=memory_size
self.buffer=deque(maxlen=memory_size)
self.batch_size=64
#self.start_training=20
class Agent():
def init(self):
self.state_size=(84, 84,1)
self.action_space=3
#self.DQNNetwork=DQNN(state_size,action_space)
self.model1=OurModel(self.state_size,self.action_space)
self.memory_size=10000000
self.memory=MemoryClass(memory_size)
self.gamma=0.75
self.epsilon_min=0.001
self.epsilon=1.0
self.epsilon_decay=0.995
self.episodes=120
self.max_step=120
self.step=0
self.count=0
self.pos0=client.getMultirotorState().kinematics_estimated.position
self.z=-5
self.goal_pos=[50,50]
self.initial_position=[0,0]
self.initial_distance=np.sqrt((self.initial_position[0]-self.goal_pos[0])**2+(self.initial_position[1]-self.goal_pos[1])**2)
self.batch_size=30
agent=Agent()
agent.train()
`
The text was updated successfully, but these errors were encountered: