Replies: 18 comments 61 replies
-
|
That's not a bug, that is exactly what is expected.
You need to design you code to work another way, or use SSE or websockets. |
Beta Was this translation helpful? Give feedback.
-
Like I said earlier, and also on another issue, you must not stall the async_tcp response callback so much. The callback at this point is is the context of a tcp com, called to fill the pcb client space and send the buffer. If you write blocking code there, you will stall the ESP execution of remaining tasks and the watchdog triggers hopefully to tell you that. You need to re-design the way you communicate the data. The problem is that a SD card is really slow. You could do that through websocket, or SSE, this would be more efficient and won't stall. The idea is to receive the list request from the UI, display a spinning icon, and trigger a task somewhere in the ESP (or a flag read from the loop) to start listing and each time you have a batch of files to send, you send it. Decouple the heavy processing of the request from the request itself by using async responses (ws or sse). |
Beta Was this translation helpful? Give feedback.
-
|
Mathieu, I totally am on board with you regarding list of files, but am still clueless for downloading files. See, if the download takes more than 30sec, because the SD is slow, the esp crashes on the watchdog. That's what a slowed down 160k dummy chunk handler looks like. I find it weird that the whole process hangs when the watchdog is disabled, the chunk callback isn't called anymore, after 30 seconds, even when the client disconnects. While before those 30sec, I can handle any other requests just fine, simply because each chunk takes about 1.5ms and yields. Am gonna repeat myself, but I expect the async library to do that for me. After reading its code yesterday, I found out that there is no busy loop under the hood, each chunk is treated as one small bit of the request, disables the watchdog and moves on, as far as I could tell. To me, something else is cutting the wire. I don't have full understanding yet as to where things operate between asynctcp and espasync. The way I was testing was with the 160k dummy chunked handler and commented out the code that enables the wdt in asynctcp. I really hope it's something that can be addressed, and I hope you understand my POV. |
Beta Was this translation helpful? Give feedback.
-
|
Yes, I do understand, but do not have any solution either for now. What do you mean by that ?
To me this is normal if the client disconnects to stop the processing ? |
Beta Was this translation helpful? Give feedback.
-
|
Also did you try to put the ESP in verbose mode to see if you have some logs from espasyncWs or async tcp ? |
Beta Was this translation helpful? Give feedback.
-
|
I pushed an example in main: // time curl -N -v -X GET http://192.168.4.1/slow.html --output -
server.on("/slow.html", HTTP_GET, [](AsyncWebServerRequest* request) {
request->client()->setRxTimeout(2000);
AsyncWebServerResponse* response = request->beginChunkedResponse("text/html", [](uint8_t* buffer, size_t maxLen, size_t index) -> size_t {
Serial.printf("%u\n", index);
// finished ?
if (index >= 160000)
return 0;
// slow down the task by 2 seconds
// to simulate some heavy processing, like SD card reading
delay(100);
memset(buffer, characters[charactersIndex], 256);
charactersIndex = (charactersIndex + 1) % sizeof(characters);
return 256;
});
request->send(response);
});called with: time curl -N -v -X GET http://192.168.4.1/slow.html --output -The request works fine and lasts 1 min: Are you sure this is not the browser that is timing out your request ? |
Beta Was this translation helpful? Give feedback.
-
I meant that, after 30 seconds, the ESP stalls indefinitely, even if the client (chrome or
I did, nothing new is printed at the point of the stall.
Yeah! That's exactly what I'm doing.
I am testing with Thank you for trying on your end! |
Beta Was this translation helpful? Give feedback.
-
|
If I put I added a dummy counter when pushing/popping elements from If I increase the delay from 100 to 1500ms (closer to my usecase with a slow SD), it still rises at 3.2/1.5sec ~ 2/sec, except it's 10 times slower, hence never reaches the end. Crashes when index is 20k. To play around, I added a GET parameter to change the time each chunk takes, and see how the number of elements in the Surprisingly, the default value of I found this post that looks very similar to this issue I'm having. |
Beta Was this translation helpful? Give feedback.
-
|
@Levak : wow! Thanks for all this deeper analysis this will definitely help! Did you try also playing with the ack timeout of async tcp and increase it ? It defaults to 5 sec but maybe it can have an effect here ? I don't know if you have reduced it to 3 sec like I used to in my app. Maybe try to increase it to 10 sec just to see ? |
Beta Was this translation helpful? Give feedback.
-
You mean this? If yes, then, yes, I was testing all along with 200sec. |
Beta Was this translation helpful? Give feedback.
-
No I was talking about this one: It defaults to 5 sec... I don't know if the ack timeout can have an effect. The |
Beta Was this translation helpful? Give feedback.
-
Tested with 10 sec, no difference in the rate at which the queue fills up. |
Beta Was this translation helpful? Give feedback.
-
|
interesting. |
Beta Was this translation helpful? Give feedback.
-
|
So... I was able to fix this. Or more like enforce some safety, anyone dare to try? do not consider this as a final solution, but at least it allows me to pass this slow test with default values |
Beta Was this translation helpful? Give feedback.
-
|
@vortigont : the problem is more the ack that is not coming faster, right ? So by doing that, you give more time to receive the onAck event ? |
Beta Was this translation helpful? Give feedback.
-
|
I'm still digging this code. It's so low level and error prone. Everything goes via a single queue of messages and all code is blocking on this queue, so it's just a matter of chance and time when it will gets stuck. We might need some heavy refactoring there. |
Beta Was this translation helpful? Give feedback.
-
That was also a complain from @yubox-node-org and one of the reason why he created AsyncTCPSock. But strangely, @Levak : did you also try swapping AsyncTCP by AsyncTCPSock as described in the README ? |
Beta Was this translation helpful? Give feedback.
-
|
Nice one @vortigont ! So, I confirm that this commit does prevent the queue from filling up from poll requests on my end as long as there is less than 1/4 of space left in it. Now, I understand that this fix isn't really pretty. I see one immediate effect to it: Now, AsyncTCP does not like any new connection when it reaches that far (I see the message is queued) until the full chunk response finished. When another "slow" request is queued, it seems to perform 1 or 2 chunks, and just drops when the first "slow" request finishes (meaning, we don't get the full answer of the second "slow" request).
Well, with 3 "slow" in parallel, it was doing pretty fine (slowed down, of course, but still processing all requests), up until one of them finished and made the board crash on "watchdog timeout" 🤣. I may be wrong, but I don't see any limit to his write queue, so it was probably allocating too much RAM. I also tried with 1 "fast" 160k, which also crashes at the end but for a different reason: |
Beta Was this translation helpful? Give feedback.
-
|
@vortigont @Levak : fyi i have updated the sample to be able to control the delay + total payload length:
I am finally able to reproduce. |
Beta Was this translation helpful? Give feedback.
-
|
@Levak : fyi, I use to run AsyncTCP with using using |
Beta Was this translation helpful? Give feedback.
-
|
I guess I have a solution. Separate the I will need to make a fork to commit the changes a bit later tonight. For now, here is a preview: static void _async_service_task(void *pvParameters){
lwip_event_packet_t * packet = NULL;
for (;;) {
- if(_get_async_event(&packet)){
+ if(_get_async_event(&packet) || _get_async_poll(&packet)){
#if CONFIG_ASYNC_TCP_USE_WDTQueueHandle_t _async_queue;
+QueueHandle_t _poll_queue;
+static inline bool _init_poll_queue(){
+ if(!_poll_queue){
+ _poll_queue = xQueueCreate(CONFIG_ASYNC_TCP_POLL_QUEUE_SIZE, sizeof(lwip_event_packet_t *));
+ if(!_poll_queue){
+ return false;
+ }
+ }
+ return true;
+}
+static inline bool _send_async_poll(lwip_event_packet_t ** e){
+ return _async_queue && xQueueSend(_poll_queue, e, portMAX_DELAY) == pdPASS;
+}
+static inline bool _get_async_poll(lwip_event_packet_t ** e){
+ return _async_queue && xQueueReceive(_poll_queue, e, portMAX_DELAY) == pdPASS;
+} } else if(e->event == LWIP_TCP_CLEAR){
- _remove_events_with_arg(e->arg);
+ _remove_events_with_arg(_async_queue, e->arg);
+ _remove_events_with_arg(_poll_queue, e->arg); static int8_t _tcp_poll(void * arg, struct tcp_pcb * pcb) {
+ // inhibit polling when event queue is getting filled up, let it handle _onack's
+ if (uxQueueMessagesWaiting(_poll_queue) > CONFIG_ASYNC_TCP_POLL_QUEUE_SIZE - 1)
+ return ERR_OK;
//ets_printf("+P: 0x%08x\n", pcb);
lwip_event_packet_t * e = (lwip_event_packet_t *)malloc(sizeof(lwip_event_packet_t));
e->event = LWIP_TCP_POLL;
e->arg = arg;
e->poll.pcb = pcb;
- if (!_send_async_event(&e)) {
+ if (!_send_async_poll(&e)) {
free((void*)(e));
}
return ERR_OK;
} |
Beta Was this translation helpful? Give feedback.
-
|
Wow! thanks ! I am applying them to check in both projects the tests and perf tests |
Beta Was this translation helpful? Give feedback.
-
|
@Levak : I've reproduced and adapted your fix in PR: mathieucarbou/AsyncTCP#31 I tested it in the project. The SSE perf test is 12% faster at now around 530 events / second with 10 concurrent connections But the HTTP tests is horribly slow: 
compared to without the patch: I suspect that the change helps improves the data flow on long lived connections but something broke concurrency for http requests. |
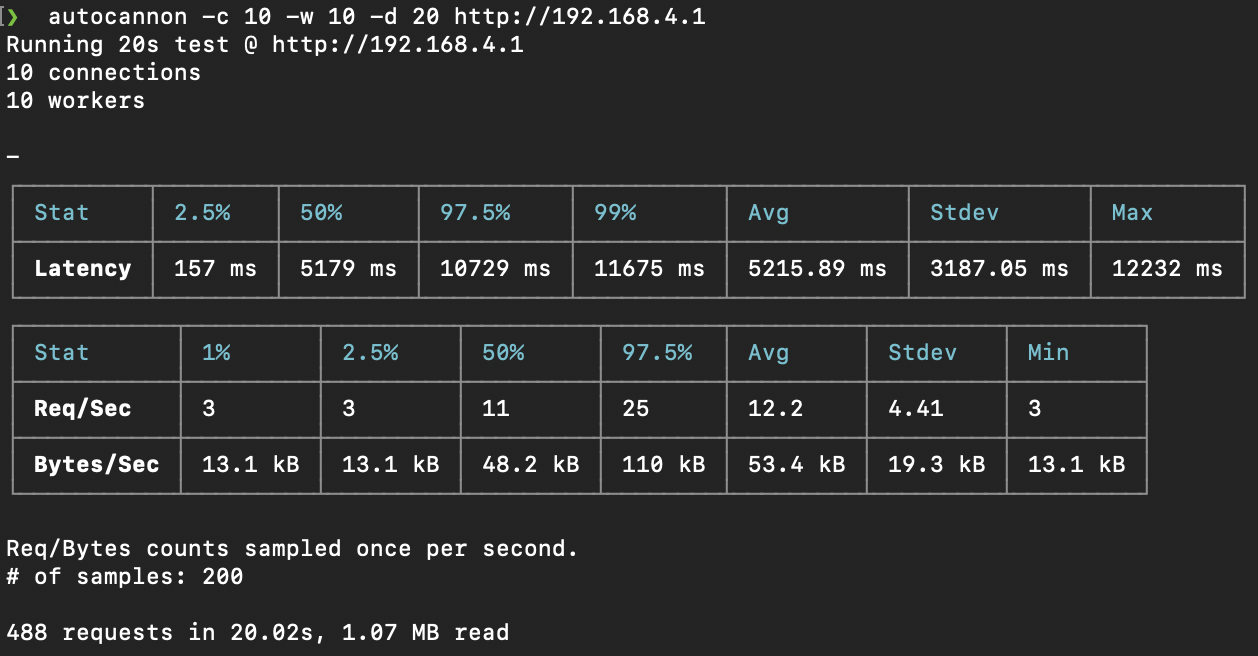
Beta Was this translation helpful? Give feedback.
-
That is not good news. On my end I was able to fire 3 parallel chunk requests, started with a small interval. Tho I noticed the poll queue was full, but not affecting my test. There is still some digging to do! |
Beta Was this translation helpful? Give feedback.
-
|
@Levak :
I definitely think you should use websocket or sse for that because your SD reading would be done outside of the async_tcp callbacks and you would just need to send events / ws messages after having read a batch or files, folder or whatever. Also, if you have a TWDT in your app (like i use to) you can apply a TWDT to only some specific tasks., not the SD reading task. That's what I do in my apps with my TaskManager lib (https://github.com/mathieucarbou/MycilaTaskManager). I am splitting my app parts in tasks (once or recurrent) associate them to managers, which can be started async or not, linked to a TWDT or not. Typically for long running tasks like MQTT publishing I do not activate the TWDT. |
Beta Was this translation helpful? Give feedback.
-
That was my goal. Did you try swapping them, instead of splitting them? |
Beta Was this translation helpful? Give feedback.
-
yes, swapping them in the if is worse: html page do not open... no data. |
Beta Was this translation helpful? Give feedback.
-
|
By splitting i meant: if(_get_async_event(&packet)){
#if CONFIG_ASYNC_TCP_USE_WDT
if(esp_task_wdt_add(NULL) != ESP_OK){
log_e("Failed to add async task to WDT");
}
#endif
_handle_async_event(packet);
#if CONFIG_ASYNC_TCP_USE_WDT
if(esp_task_wdt_delete(NULL) != ESP_OK){
log_e("Failed to remove loop task from WDT");
}
#endif
}
if(_get_async_poll(&packet)){
#if CONFIG_ASYNC_TCP_USE_WDT
if(esp_task_wdt_add(NULL) != ESP_OK){
log_e("Failed to add async task to WDT");
}
#endif
_handle_async_event(packet);
#if CONFIG_ASYNC_TCP_USE_WDT
if(esp_task_wdt_delete(NULL) != ESP_OK){
log_e("Failed to remove loop task from WDT");
}
#endif
} |
Beta Was this translation helpful? Give feedback.
-
|
I am trying to download 4 files in parallel from SD using this command (specific to my project, but you should get the idea of what it's doing) : I see no issue, all files downloaded, no crash. Windows reports I'm downloading at 5Mbps average. Each file ranges from 1MB to 40MB. Those requests are with I don't know how to reproduce your case then. |
Beta Was this translation helpful? Give feedback.
-
|
@Levak : with which flavor ? The original one in the PR ? |
Beta Was this translation helpful? Give feedback.
-
|
Wow, you had quite productive discussion here, guys.
yeah, that was just a PoC as I told
that could be a solution but not that simple, having two queues brings you an execution ordering problem that might pop out randomly. Some of the messages should be processed in order for a specific connection or a special care should be taken for cases like closing/timeouting etc.. Another side effect is that high polling rate could give you a very low latency but quite slow connections. Which is what Mathieu hit with his benchmark as I see later on. A very simple, but not perfect, solution is to use probability-based throttling as I mentioned. I've updated my [branch](https:// Very simple and cheap in terms of memory/resources but it works OK for multiple slow connections too, 'cause it allows poll events from other connections to enter the queue. It distributes unfair and make new connections to start really slow but it would catch up eventually. In general it needs a more deep refactoring here. I'm not that good at this level but some old networking skills working with traffic shapers rings some bells in my head :) Will try to optimize it a bit more (with a help of testing) :) Here what it gives me with Mathieu's cannon (I had to comment out rate-limit midware, btw) |
Beta Was this translation helpful? Give feedback.
-
There is a perf environment in the Pio file: one for AsyncTCPSock and one for AsyncTCP |
Beta Was this translation helpful? Give feedback.
-
|
@Levak : could you please test this branch also ? |
Beta Was this translation helpful? Give feedback.
-
|
@vortigont : I updated your code to add a debug line: I am running with: -D CONFIG_ASYNC_TCP_MAX_ACK_TIME=5000 // (keep default)
-D CONFIG_ASYNC_TCP_PRIORITY=10 // (keep default)
-D CONFIG_ASYNC_TCP_QUEUE_SIZE=64 // (keep default)
-D CONFIG_ASYNC_TCP_RUNNING_CORE=1 // force async_tcp task to be on same core as the app (default is core 0)
-D CONFIG_ASYNC_TCP_STACK_SIZE=4096 // reduce the stack size (default is 16K)http perf test is what you saw and also match the one from main: 
SSE perf tests: // With AsyncTCP, with 16 workers: some "Event message queue overflow: discard message", but no crash with a queue size of 64 (128 is too big - especially crashes)
//
// Total: 1711 events, 427.75 events / second
// Total: 1711 events, 427.75 events / second
// Total: 1626 events, 406.50 events / second
// Total: 1562 events, 390.50 events / second
// Total: 1706 events, 426.50 events / second
// Total: 1659 events, 414.75 events / second
// Total: 1624 events, 406.00 events / second
// Total: 1706 events, 426.50 events / second
// Total: 1487 events, 371.75 events / second
// Total: 1573 events, 393.25 events / second
// Total: 1569 events, 392.25 events / second
// Total: 1559 events, 389.75 events / second
// Total: 1560 events, 390.00 events / second
// Total: 1562 events, 390.50 events / second
// Total: 1626 events, 406.50 events / second
//
// With AsyncTCP, with 10 workers:
//
// Total: 2038 events, 509.50 events / second
// Total: 2120 events, 530.00 events / second
// Total: 2119 events, 529.75 events / second
// Total: 2038 events, 509.50 events / second
// Total: 2037 events, 509.25 events / second
// Total: 2119 events, 529.75 events / second
// Total: 2119 events, 529.75 events / second
// Total: 2120 events, 530.00 events / second
// Total: 2038 events, 509.50 events / second
// Total: 2038 events, 509.50 events / secondSlow test: Finishes in 2 minutes In the output, we can see the random throttling In conclusion, so far so good, thanks @vortigont ! I will wait for some more test from @Levak of this PR mathieucarbou/AsyncTCP#32 and once I have your GO, I merge and release. Note: I also tested Websocket, no issue. |
Beta Was this translation helpful? Give feedback.
-
|
Kudos for all of us participating in this discussion! |
Beta Was this translation helpful? Give feedback.
-
|
looks not bad as for me. Could be considered as minimal acceptable solution, other more deeper changes (if required) we could suggest/estimate separately? |
Beta Was this translation helpful? Give feedback.
-
|
Yes, definitely. |
Beta Was this translation helpful? Give feedback.
-
|
I tested few things,
Overall, it's better than nothing. But as @vortigont said, it's not a definitive solution. Thanks all 👍 |
Beta Was this translation helpful? Give feedback.
-
|
Thanks! I will issue releases late this evening then. |
Beta Was this translation helpful? Give feedback.
-
@Levak : I think for this use case you could implement a middleware to allow some download permits: there is an exemple in the project of a rate limiting middleware, so this could be something similar, making sure you limit the number of concurrent downloads with at the same time the number of requests. |
Beta Was this translation helpful? Give feedback.
-
|
Released! |
Beta Was this translation helpful? Give feedback.
-
|
Nice done, team!
Not at all, actually it's not a proper fix for chunked responses as I think, but more of a things that must be there for other cases, like massive SSE's or overloaded websockets which relies on polls a lot. For chunked responses it should be other approach and I'm already have some ideas where to look into. Will keep you in touch in this thread. And another thing - AsycnTCPSock's implementation is definitely worth a closer look in the light of modern IDF's API. I like its being more abstracted. Let's keep it in mind for upcoming no-8266 option. |
Beta Was this translation helpful? Give feedback.
-
|
About esp-idf: I am also one of the collaborator in Psychichttp project which is based on esp-idf. The perf is definitely better when using the esp-idf API, but some features are not possible, like getting all headers. On my spare time I try to improve Psychic also and do a ESPAsyncWebServer - psychic bridge, but this is very low priority for me since I only use ESPAsyncWS. For next version 4 of ESPAsyncWS, we also have the choice of dropping AsyncTCP if we want because it was done in the purpose of being swapped by another lib depending on the platform. But something I would like is that we try to keep the API as close as possible as today, so that users could easily migrate by just doing some search and replace if needs to. And if we do a v4, I will consider detaching the fork ;-) |
Beta Was this translation helpful? Give feedback.
-
|
I've found out how deep this rabbit hole is :) One thing is in-flight buffer credits - it intended to throttle refill (user callback) calls for long lived connections for a constantly incoming poll events if there is already enough chunks being transmitted. Another is buffer refill moderation - it tries to reduce refill (user callback) calls from being called too often when socket buff space is small compared to in-flight data size. This effectively drops ack events and reduces queue size while making sure to have a buffer at leat 50% loaded. And from the AsyncTCP side it tries to coalesce consecutive poll events into one, it evicts the queue from excessive polls and allows other connections to get more chance to get task's time. I've done some basic testing with downloading static file from LittleFS and running that ugly
Origin: crash by watchdog I do not have SD card setup currently to test, so would appreciate some feedback from @Levak |
Beta Was this translation helpful? Give feedback.
-
|
Thanks! Let me know when this is ready to review, I will do some perf tests. For what I understand from te AsyncTCP change, any way, it could be merged as-is right ? The queue cleanup that you do is already beneficial, even without the ESAsyncWS change right ? |
Beta Was this translation helpful? Give feedback.
-
|
Any kind of tests are welcome.
yes, it could be beneficial but in some corner cases like one ugly slow callback or some spike delays. I'm thinking about improving it to also handle interleaved events. But on the other hand I do not want to make it a chase of mitigating all kind of improperly designed code. |
Beta Was this translation helpful? Give feedback.
-
|
Hey! Thank you for your solution @vortigont ! Putting that aside, this allowed me to focus more on a more serious problem on the "user code". TL;DR, listing files from an SD card formatted with FAT makes every single So, thanks to the limitation in ESP-IDF about SD/FAT, we were able to trigger very long chunk handlers in ESPAsyncWebserver and find a limitation in AsyncTCP, what a journey :D The way I'll be doing the Chunk handler for now, is to put both a limit on size (max_len) but also a limit on how much time each chunk takes, capped at 2 sec. That way, the watchdog that seems to trigger at 5 sec will never trigger, and it's also a good middle ground between browsing lots of files and not being too "hangy". Thanks all! |
Beta Was this translation helpful? Give feedback.
-
|
Note that you also can control the watchdog timeout ;-) bool Mycila::TaskManager::configureWDT(uint32_t timeoutSeconds, bool panic) {
LOGI(TAG, "Configuring Task Watchdog Timer (TWDT) to %" PRIu32 " seconds", timeoutSeconds);
#if ESP_IDF_VERSION_MAJOR < 5
return esp_task_wdt_init(timeoutSeconds, panic) == ESP_OK;
#else
esp_task_wdt_config_t config = {
.timeout_ms = timeoutSeconds * 1000,
.idle_core_mask = (1 << SOC_CPU_CORES_NUM) - 1, // Bitmask of all cores
.trigger_panic = panic,
};
return esp_task_wdt_init(&config) == ESP_OK || esp_task_wdt_reconfigure(&config) == ESP_OK;
#endif
} |
Beta Was this translation helpful? Give feedback.
-
|
another testcase:
Origin: crash by watchdog |
Beta Was this translation helpful? Give feedback.
-
|
Awesome! I will test that today! |
Beta Was this translation helpful? Give feedback.
-
|
@vortigont here are some results: SSE Perf test:
=> OK, same as main
=> Wow !!! No messages discarded anymore! This is better! WS tests => OK HTTP perf test 10 workers: same as main ( 
16 workers ( 
slow test
ends correctly with: I see a bunch of debug logs (expected): Now, I am combining:
I see a lot of : 
Maybe too much... So I am now trying:

So concurrent requests are still served, but slower. And the more we have concurrent req, the more the req/sec number increasses. But what I do not understand is why it takes about 5 sec on average to serve 2 requests... The delay in my slow test is 3 sec, which is pausing the chunk process for a very long time. But I a wondering if there is a way to give a priority over serving slower requests... This might be a little complicated because it would require probably to save some states (counters) and be able to re-order thee queue to process events with lower counter values... Any way... I will merge all that and release. Thanks! |
Beta Was this translation helpful? Give feedback.
-
|
thanks for that issues links, @Levak. I never know that this problem exists in fatfs code actially. Maybe because I have never used it yet? :)
sorry to say but that is not the right way to do this also :( By doing this you would suffocate all other webserver operations also including websockets if you would switch to this approach. Something like:
That's not simple piece of code but "this is the way" :) |
Beta Was this translation helpful? Give feedback.
-
|
File downloads (even very large ones) should no longer be affected with a recent in-flight credits control. |
Beta Was this translation helpful? Give feedback.
-
|
You would not believe me, but I found a way to speed up SD directory listing by more than 300 times! I looked up a lot of existing threads of ppl sad that SD listing is slow on ESP32. The root of the issue is first because FATFS is a linked list of sectors and blocks, so listing a directory is sure straightforward, but using functions like One "optimisation" found by some other community members was to introduce Then I dug at the lowlevel implementation of The implementation becomes trivial: Before: After: Logs: So, out of the 481ms, really the handler ran for 155ms! I'm shocked. |
Beta Was this translation helpful? Give feedback.
-
|
Wow! Nice improvement! Is that similar to what was proposing @chipweinberger who opened espressif/esp-idf#10220 ? He seems to also use |
Beta Was this translation helpful? Give feedback.
-
Yes, I only found about it when closing all my tabs :p Furthermore, from my understanding, the IDF v5.4 may add caching to |
Beta Was this translation helpful? Give feedback.
-
Did just now. I tried to download the same file of 41MB.
|
Beta Was this translation helpful? Give feedback.
-
|
thanks for the tests @mathieucarbou
yes, that is exactly what
all my changes so far to asynctcp was to try minimize the impact of long callbacks to the queue itself were pure math, so very cheap, costs no memory and does not do any intermediate mallocs. But in the end all does come to the same thing - if a single event takes the task for too long - all other events (i.e. connections) are blocked. Even if the q could reorder it somehow it will anyway stall eventually on slowest ones. The only way here is to create a pool of worker threads and somehow manage it. Won't be that easy and cheap and also won't work for single core boards at all. Have some other idea in mind though... |
Beta Was this translation helpful? Give feedback.
-
|
sharing other ideas in #173 |
Beta Was this translation helpful? Give feedback.
-
|
I've tested downloading of files from SDCARD. Work perfectly. Two large files in parallel with multiple small reqs is also fine. Large files are not affecting small downloads at all. |
Beta Was this translation helpful? Give feedback.
-
|
Right, this is because the chunk callback executes fast. Probably that file listing is slower than downloading in terms of chunk callback execution time because sequential reading is faster than querying the file system. Which means that @Levak should definitely think about moving the listing part outside of the async_tcp task, by using SSE or websocket, and only keep file download through the chunk mechanism. |
Beta Was this translation helpful? Give feedback.
-
|
that's a nice catch with
|
Beta Was this translation helpful? Give feedback.
-
Hi there!
Description
When the ESPAsyncWebServer sends a very long chunked response (over 30 seconds), the ESP32 crashes on a watchdog timeout in AsyncTCP. I can see in Chrome DevTools that the chunked answer is being sent correctly, one chunk at a time, but when the 30 seconds mark hits, the ESP32 resets.
In my code, I am trying to traverse a list of files from an SD card. After roughly 300 files (700 in this particular test) sent, aka 30 seconds, the problem appears.
Pagination can be implemented, but we are trying to stay retro-compatible with an official WebUI that lacks such feature. This is sadly a regression compared to a basic WebServer app, where the timeout can be as long as one wants, as long as the client doesn't disconnect.
Link: https://github.com/Levak/sdwifi/blob/async/sdwifi.ino#L714
Board: esp32-pico-d4 (Fysetc SD WIFI PRO)
Stack trace
E (809882) task_wdt: Task watchdog got triggered. The following tasks/users did not reset the watchdog in time:
E (809882) task_wdt: - async_tcp (CPU 0/1)
E (809882) task_wdt: Tasks currently running:
E (809882) task_wdt: CPU 0: IDLE0
E (809882) task_wdt: CPU 1: loopTask
Additional notes
Old discussion about this code
Beta Was this translation helpful? Give feedback.
All reactions