

This is a collection of simple PyTorch implementations of neural networks and related algorithms. These implementations are documented with explanations,
The website renders these as side-by-side formatted notes. We believe these would help you understand these algorithms better.
We are actively maintaining this repo and adding new
implementations almost weekly.
- Multi-headed attention
- Transformer building blocks
- Transformer XL
- Rotary Positional Embeddings
- Attention with Linear Biases (ALiBi)
- RETRO
- Compressive Transformer
- GPT Architecture
- GLU Variants
- kNN-LM: Generalization through Memorization
- Feedback Transformer
- Switch Transformer
- Fast Weights Transformer
- FNet
- Attention Free Transformer
- Masked Language Model
- MLP-Mixer: An all-MLP Architecture for Vision
- Pay Attention to MLPs (gMLP)
- Vision Transformer (ViT)
- Primer EZ
- Hourglass
- Denoising Diffusion Probabilistic Models (DDPM)
- Denoising Diffusion Implicit Models (DDIM)
- Latent Diffusion Models
- Stable Diffusion
- Original GAN
- GAN with deep convolutional network
- Cycle GAN
- Wasserstein GAN
- Wasserstein GAN with Gradient Penalty
- StyleGAN 2
✨ LSTM
✨ ResNet
✨ U-Net
Solving games with incomplete information such as poker with CFR.
- Proximal Policy Optimization with Generalized Advantage Estimation
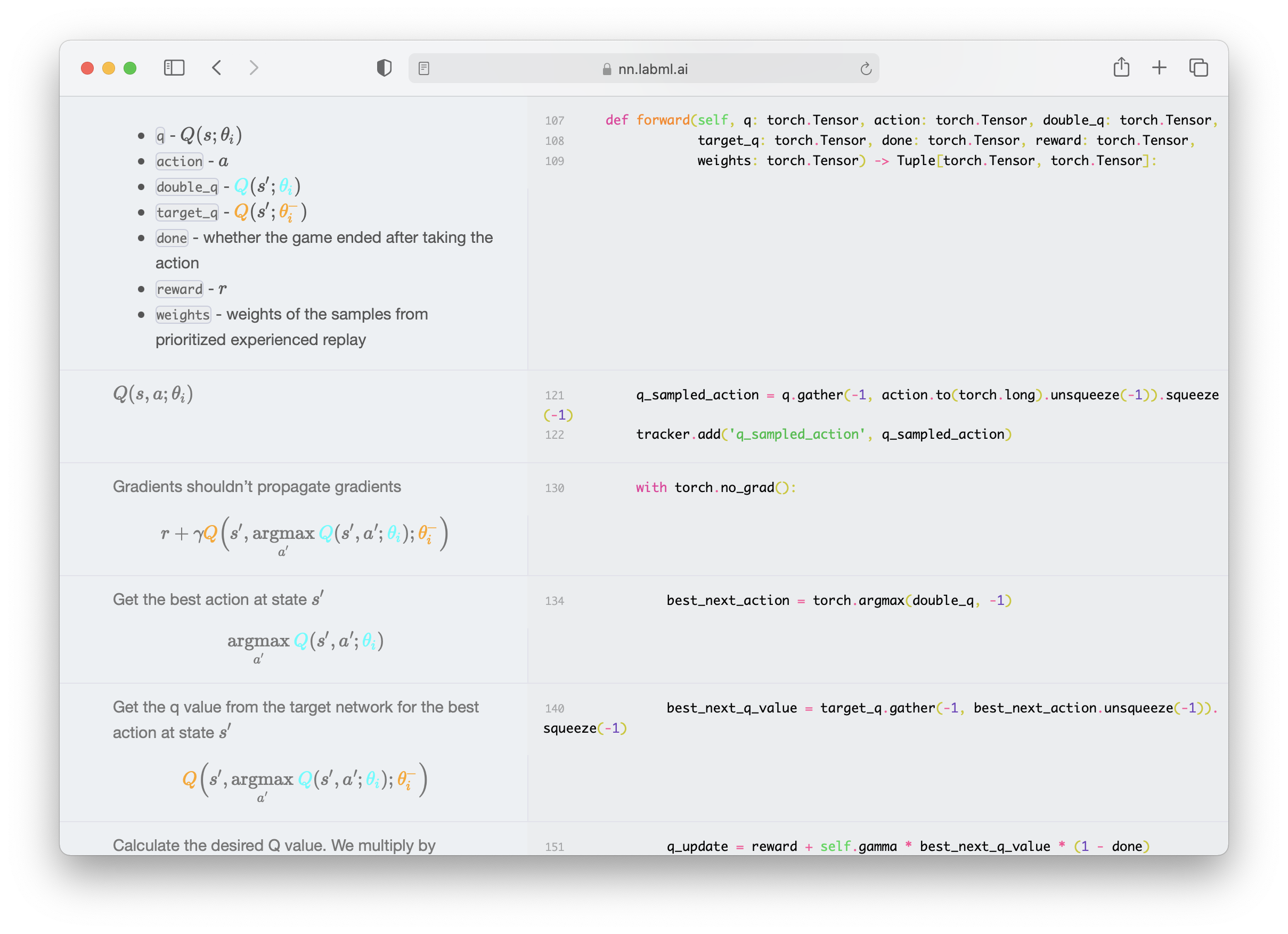
- Deep Q Networks with with Dueling Network, Prioritized Replay and Double Q Network.
- Adam
- AMSGrad
- Adam Optimizer with warmup
- Noam Optimizer
- Rectified Adam Optimizer
- AdaBelief Optimizer
- Sophia-G Optimizer
- Batch Normalization
- Layer Normalization
- Instance Normalization
- Group Normalization
- Weight Standardization
- Batch-Channel Normalization
- DeepNorm
pip install labml-nn