Note: DocumentLab is only built for x64.
To configure a project to build in x64
- Click the solution platform dropdown (Any CPU) -> Configuration Manager -> Active solution platform -> New -> Platform -> x64 -> Click ok
- Right click your C# project -> Properties -> Build -> Platform target -> set to x64
- Make sure the selected solution platform is x64 and not Any CPU
The OCR step in DocumentLab is optimized for parallel processing, the following diagram represents the conceptual implementation of the load-balancing and parallelization. It's not necessarily a 1-1 representation of the implementation but it suffices to show the steps taken to distribute the load appropriately,
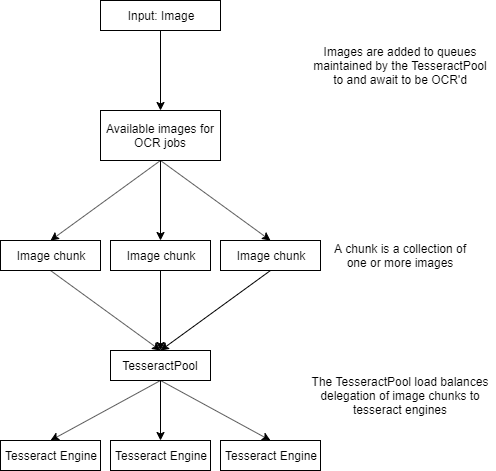
In Data\Configuration\OcrConfiguration.json we have a number of configuration parameters. The intent of which allow us to optimize OCR processing, namely, Tesseract specifically to our host system hardware .
- NumberOfThreads - Maximum number of parallel threads we'll allow DocumentLab to instantiate
- This is independent of how many engines we have available, i.e., even if an engine becomes available we can't assign a new OCR job to it if we're exceeding maximum thread count
- When adjusting this parameter, pay attention to how many cores/threads your host CPU provides
- Setting this one too high can bottleneck your system, setting it too low will limit otherwise available excess computational power
- TesseractEnginePoolSize - How many Tesseract engines we want our threads to have access to
- The TesseractPool in the diagram represents how OCR jobs are distributed between Tesseract Engines. This parameter sets the number of Tesseract Engines the TesseractPool has at its disposal when distributing jobs
- Ideally, this parameter should be around half or slightly less than half of the maximum number of threads you allow (according to my not-so scientific tests)
- Setting this one too high wastes memory but has little impact on overall performance, setting it too low will bottleneck your threads
- ResultChunkSize
- Each OCR job assigned to a tesseract engine includes a set of images, referred to as chunks. These chunks of images are processed sequentially by each TesseractEngine job
- The reason for processing more than one image in a job sequentially is that it can offload the context switching/thread management overhead a bit
- The default setting is to chunk together two images, playing with this parameter may yield different results on different hardware
To set the language used by DocumentLab, you can adjust the parameter named Language in Data\Configuration\GlobalConfiguration.json
Note: In v. <= 1.2.0 the file containing this parameter is OcrConfiguration.json
- It requires a corresponding .traineddata file under the tessdata directory
- The Language parameter should correspond to the file name without the post-fix file type
- See Tesseract-OCR traineddata downloads page for prepared trained language files
- Contextual files are language dependant, if you switch to for example 'nor', the files in context\swe* won't be used in the text analyzer
The following are the standard text types that are included in DocumentLab. Additional text types include those defined in contextual files and custom text type definitions.
- AmountOrNumber
- Amount
- Date
- InvoiceNumber
- Letters
- Number
- PageNumber
- Percentage
- Text
- WebAddress
How we write amounts and dates varies between countries. The analysis of which are defined with regular expressions in Data/Configuration/TextAnalysis.json. Comma and decimal point separated numbers are classified as amounts. Dates follow the ISO 8601 standard. You'll need to define regular expressions for your own needs if your documents have different representations.
Defining custom text types using regular expressions and some common operations is possible in TextTypeDefinitions.json.
Opening that file shows an example of one such definition. The InvoiceNumber text type is defined in such a way.
[
{
"Name": "InvoiceNumber",
"Text": {
"GetAs": "Text",
"Replace": [
{
"Find": [ "\\-" ],
"Replace": ""
}
],
"Regexes": [
"((?<!\\w)\\w+\\d+)"
]
}
}
]The custom definition analyzer expects to find at least a name and regexes properties for each definition. The text definition can be omitted for default handling.
The GetAs field can be set to Text or Continuous and the Replace definitions are helpful to standardizing raw text to something that you can easier match with regular expressions.
- Text - Means that the ocr result under analysis will be treated as a normal string, spaces instead of newlines.
- Continuous - Removes any space or newline character, result will be matched to the regex in one clump of text
- For instance, you might get a result like "InterestingData: 999 333 555", it would be easier to write a regex for "InterestingData:9993355"
DocumentLab comes packaged with country specific configuration files by default, the following files under Data\Context are specifically for documents originating from Swedish/Nordic countries,
- PostalCode.txt
- StreetAddress.txt
- Town.txt
These files contain information separated by newline. These files are used during the text classification process.
By using these kind of files we can let DocumentLab know what a StreetAddress is as opposed to just Some piece of text. This is especially useful to expand the context we can specify when we write patterns for our queries. It is way more specific to be able to say capture the [StreetAddress] instead of capture the [Text] which might result in more faulty results.
The default provided files specified above can be deleted from the context folder if they're not going to be used without issue.
If you need DocumentLab to understand custom contextual information you can achieve that by providing your own newline separated text files in the context folder. These files are loaded dynamically upon DocumentLab startup and you should be able to use them directly without further configuration.
When DocumentLab starts, it loads the contents of these files into memory. It uses a binary search algorithm that allows a certain degree of fuzzy-matching. Search time is O(log n) so the files can contain quite a lot of information before performance becomes an issue.
Note: There is a configuration parameter specifically intended for configuring street address information files in Data\Configuration\FromFileConfiguration.json. There aren't further configuration options available for dynamically loaded contextual files at the moment.
I'll find a better place to write this down later.
Adjusting image analysis process
One of the things DocumentLab already does to improve performance during the image analysis phase is to scale down the input image to 25% of its original size, performing area detection on the scaled down image and then scaling up the results to match the original image size.
In order to squeeze more performance out of DocumentLab it is possible to modify the scale percentage used and the highlight intensity value used for area detection. Namely,
You could theoretically lower the scale percentage value to, let's say, 15%
/Libraries/DocumentLab.ImageProcessing/Strategies/ProcessImageStrategies/DownsampleStrategy.cs
Then you'd want to lower the highlight intensity used for area detection since we have fewer pixels, I've tried lowering it to 2 - 3 with good results,
/Libraries/DocumentLab.ImageProcessing/Data/Configuration/ImageProcessorConfiguration.json
From some tests I've done this yields equal results but the total execution time DocumentLab takes is halved. But it may depend on the fuzziness and quality of images we're working with.