{kind=link}
{kind=link}
{kind=link}
{kind=link}
🛠️ A Vite + React-based setup that allows users to upload audio recordings and retrieve its text content. Note: For simplicity, this setup only accounts for 'English' transcription..
Based on whisper-webgpu.
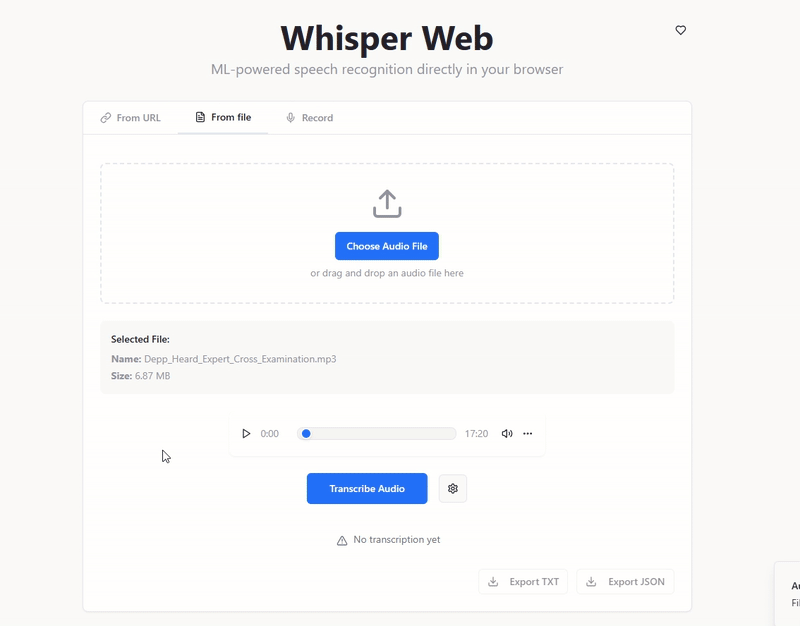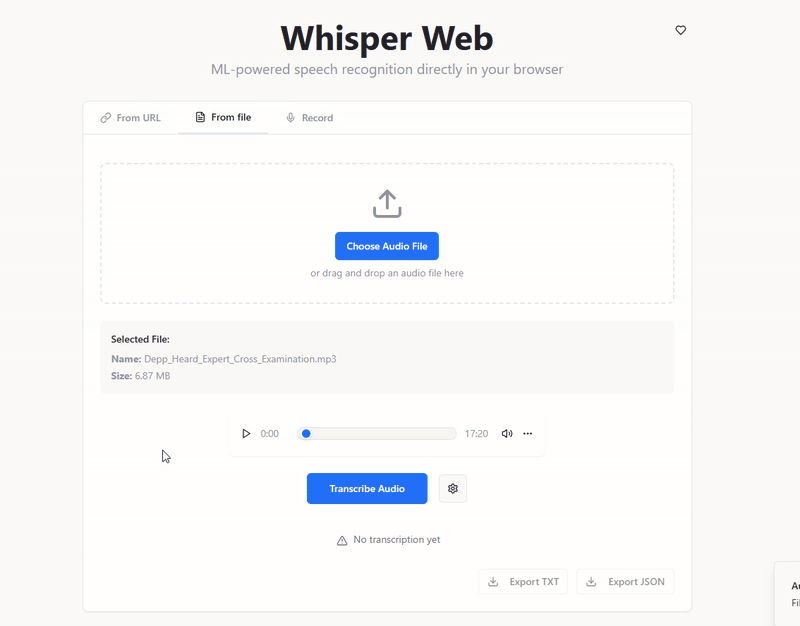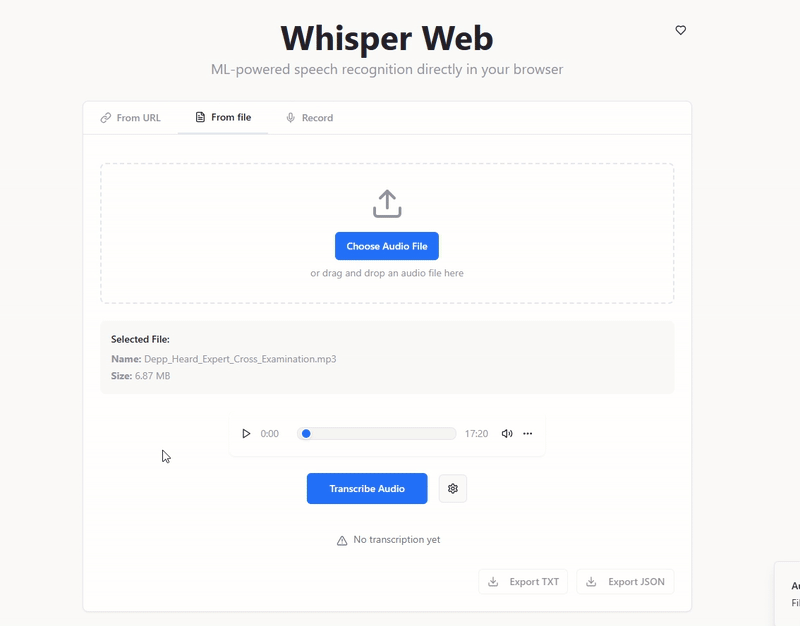
Article :: Link :: Implementing Whisper OpenAI In-Browser for Offline Audio Transcription
- 📄 Upload audio clips (.mp3 .webm .wav files)
- 💬 Audio conversion to WAV via FFMPEG
- 🤖 AI-powered Speech Recognition using Whisper OpenAI local models
- 📱 Mobile-responsive design
- 🔒 Complete offline functionality
- 💾 Export transcription results
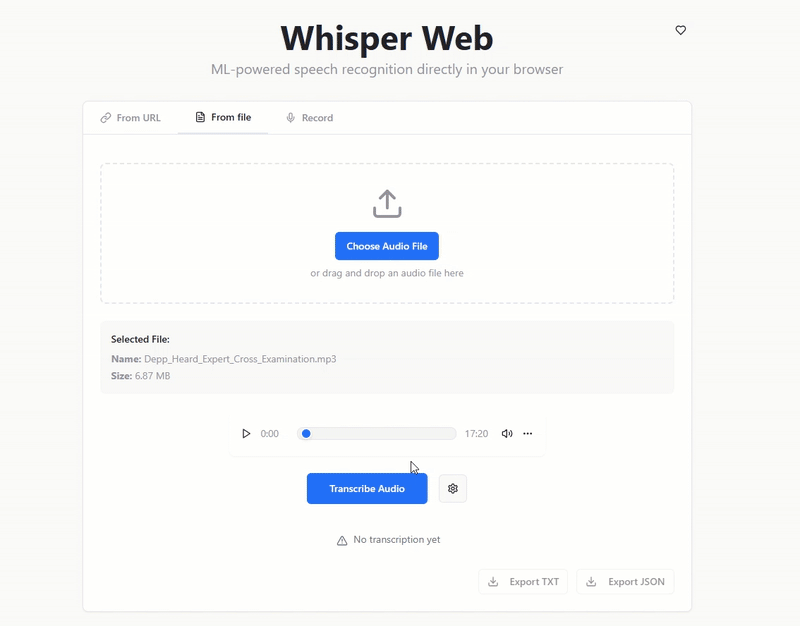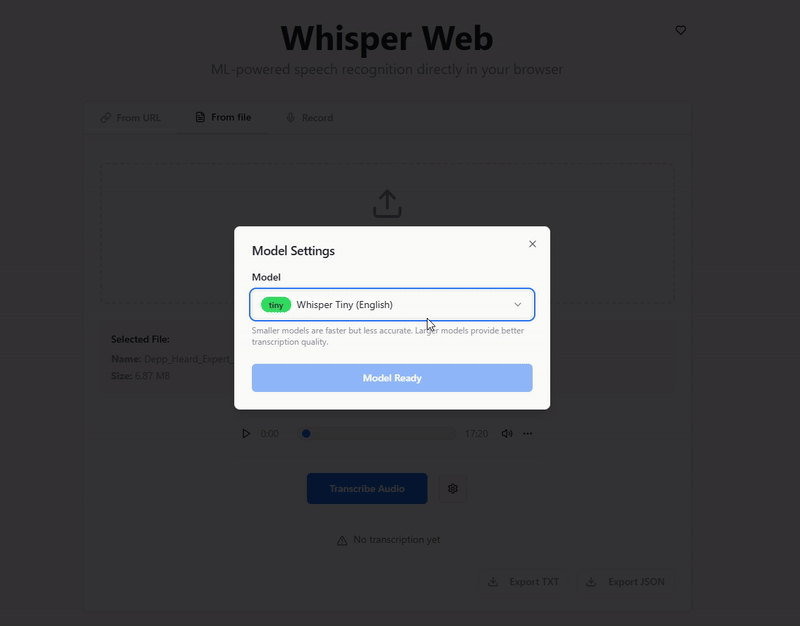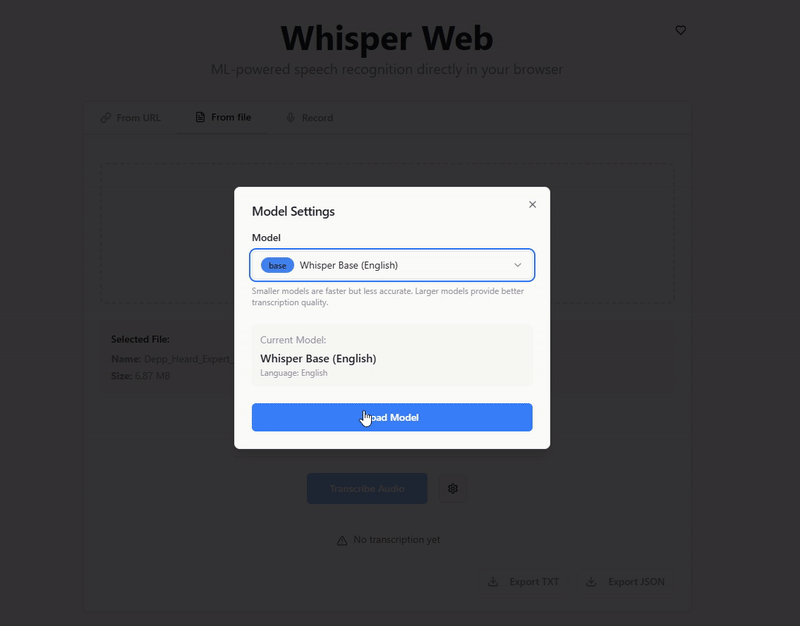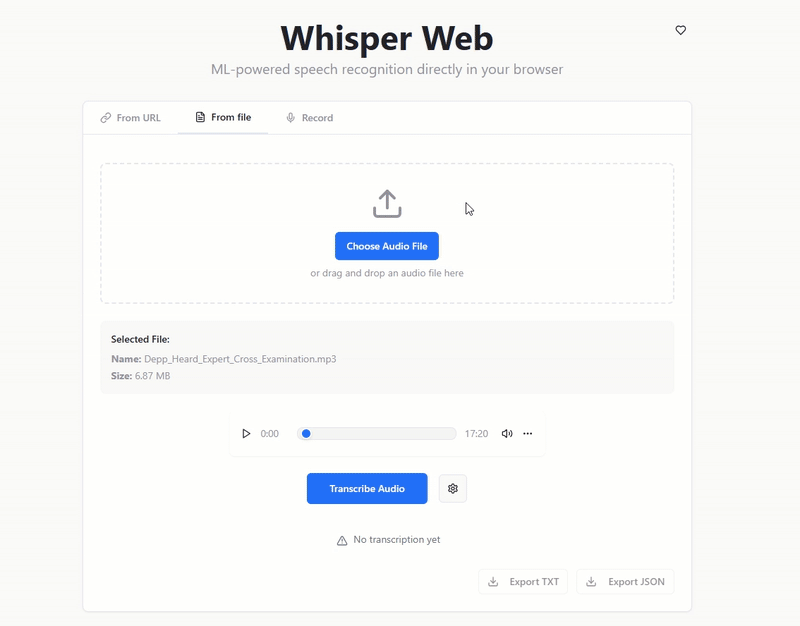
For complete offline functionality, download the following model files to the public/models/ directory:
Whisper Tiny (en) Model (whisper-tiny.en)
Download these files to public/models/Xenova/whisper-tiny.en/:
added_tokens.jsonconfig.jsongeneration_config.jsonmerges.txtnormalizer.jsonpreprocessor_config.jsonquant_config.jsonquantize_config.jsonspecial_tokens_map.jsontokenizer.jsontokenizer_config.jsonvocab.jsononnx/decoded_model_merged_fp16.onnxonnx/encoder_model_fp16.onnx
Whisper Base (en) Model (whisper-base.en)
Download these files to public/models/Xenova/whisper-base.en/:
added_tokens.jsonconfig.jsongeneration_config.jsonmerges.txtnormalizer.jsonpreprocessor_config.jsonquant_config.jsonquantize_config.jsonspecial_tokens_map.jsontokenizer.jsontokenizer_config.jsonvocab.jsononnx/decoded_model_merged_fp16.onnxonnx/encoder_model_fp16.onnx
- Clone the repository
- Install dependencies:
npm install - Download the required model files (refer to above)
- Build and start the server:
npm run build && npm run preview
- React 18 with TypeScript
- Vite for build tooling
- Tailwind CSS for styling
- @huggingface/transformers for AI model inference
- WebGPU acceleration (with WASM fallback)
— Join me on 📝 Medium at ~ ξ(🎀˶❛◡❛) @geek-cc