- Introduction: The Protein Folding Problem (predicting a protein structure from its sequence) is an interesting one since DNA sequence data available is becoming cheaper and cheaper at an unprecedented rate, even faster than Moore's law 1. Recent research has applied Deep Learning techniques in order to accurately predict the structure of polypeptides [2, 3].
- Methods: In this work, we present an attempt to imitate the AlphaFold system for protein prediction architecture [3]. We use 1-D Residual Networks (ResNets) to predict dihedral torsion angles and 2-D ResNets to predict distance maps between the protein amino-acids[4]. We use the CASP7 ProteinNet dataset section for training and evaluation of the model [5]. An open-source implementation of the system described can be found here.
- Results: We are able to obtain distance maps and torsion angle predictions for a protein given it's sequence and PSSM. Our angle prediction model scores a 0.39 of MAE (Mean Absolute Error), and 0.39 and 0.43 R^2 coefficients for Phi and Psi respectively, whereas SoTA is around 0.69 (Phi) and 0.73 (Psi). Our methods do not include post-processing of Deep Learning outputs, which can be very noisy.
- Conclusion: We have shown the potential of Deep Learning methods and its possible application to solve the Protein Folding Problem. Despite technical limitations, Neural Networks are able to capture relations between the data. Although our visually pleasant results, our system lacks components such as the protein structure prediction from both dihedral torsion angles and the distance map of a given protein and the post-processing of our predictions in order to reduce noise.
@misc{ericalcaide2019
title = {MiniFold: a DeepLearning-based Mini Protein Folding Engine},
publisher = {GitHub},
journal = {GitHub repository},
author = {Alcaide, Eric},
year = {2019},
howpublished = {\url{https://github.com/EricAlcaide/MiniFold/}},
doi = {10.5281/zenodo.3774491},
url = {https://doi.org/10.5281/zenodo.3774491}
}
DeepMind, a company affiliated with Google and specialized in AI, presented a novel algorithm for Protein Structure Prediction at CASP13 (a competition which goal is to find the best algorithms that predict protein structures in different categories).
The Protein Folding Problem is an interesting one since there's tons of DNA sequence data available and it's becoming cheaper and cheaper at an unprecedented rate (faster than Moore's law). The cells build the proteins they need through transcription (from DNA to RNA) and translation (from RNA to Aminocids (AAs)). However, the function of a protein does not depend solely on the sequence of AAs that form it, but also their spatial 3D folding. Thus, it's hard to predict the function of a protein from its DNA sequence. AI can help solve this problem by learning the relations that exist between a determined sequence and its spatial 3D folding.
The DeepMind work presented @ CASP was not a technological breakthrough (they did not invent any new type of AI) but an engineering one: they applied well-known AI algorithms to a problem along with lots of data and computing power and found a great solution through model design, feature engineering, model ensembling and so on. DeepMind has no plan to open source the code of their model nor set up a prediction server.
Based on the premise exposed before, the aim of this project is to build a model suitable for protein 3D structure prediction inspired by AlphaFold and many other AI solutions that may appear and achieve SOTA results.
The methods implemented are inspired by DeepMind's original post. Two different residual neural networks (ResNets) are used to predict angles between adjacent aminoacids (AAs) and distance between every pair of AAs of a protein. For distance prediction a 2D Resnet was used while for angles prediction a 1D Resnet was used.
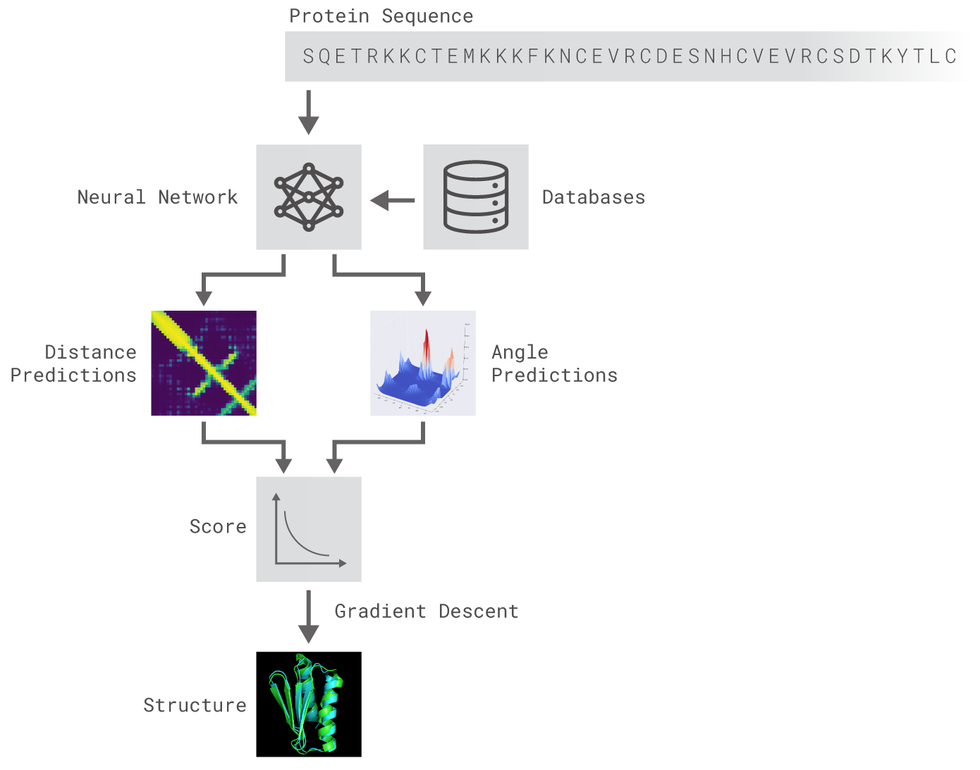
Image from DeepMind's original blogpost.
The ResNet for distance prediction is built as a 2D-ResNet and takes as input tensors of shape LxLxN (a normal image would be LxLx3). The window length is set to 200 (we only train and predict proteins of less than 200 AAs) and smaller proteins are padded to match the window size. No larger proteins nor crops of larger proteins are used.
The 41 channels of the input are distributed as follows: 20 for AAs in one-hot encoding (LxLx20), 1 for the Van der Waals radius of the AA encoded previously and 20 channels for the Position Specific Scoring Matrix).
The network is comprised of packs of residual blocks with the architecture below illustrated with blocks cycling through 1,2,4 and 8 strides plus a first normal convolutional layer and the last convolutional layer where a Softmax activation function is applied to get an output of LxLx7 (6 classes for different distance + 1 trash class for the padding that is less penalized).

Architecture of the residual block used. A mini version of the block in this description
The network has been trained with 134 proteins and evaluated with 16 more. Clearly unsufficient data, but memory constraints didn't allow for more. Comparably, AlphaFold was trained with 29k proteins.
The output of the network is, then, a classification among 6 classes wich are ranges of distances between a pair of AAs. Here there's an example of AlphaFold predicted distances and the distances predicted by our model:


The architecture of the Residual Network for distance prediction is very simmilar, the main difference being that the model here described was trained with windows of 200x200 AAs while AlphaFold was trained with crops of 64x64 AAs. When it comes to prediction, AlphaFold used the smaller window size to average across different outputs and achieve a smoother result. Our prediction, however, is a unique window, so there's no average (noisier predictions).
The ResNet for angles prediction is built as a 1D-ResNet and takes as input tensors of shape LxN. The window length is set to 34 and we only train and predict aangles of proteins with less than 200 (L) AAs. No larger proteins nor crops of larger proteins are used.
The 42 (N) channels of the input are distributed as follows: 20 for AAs in one-hot encoding (Lx20), 2 for the Van der Waals radius and the surface accessibility of the AA encoded previously and 20 channels for the Position Specific Scoring Matrix).
We followed the ResNet20 architecture but replaced the 2D Convolutions by 1D convolutions. The network output consists of a vector of 4 numbers that represent the sin and cos of the 2 dihedral angles between two AAs (Phi and Psi).
Dihedral angles were extracted from raw coordinates of the protein backbone atoms (N-terminus, C-alpha and C-terminus of each AA). The plot of Phi and Psi recieves the name of Ramachandran plot:

The results of the model when making predictions can be observed below:

The network has been trained with crops 38,7k crops from 600 different proteins and evaluated with some 4,3k more.
The architecture of the Residual Network is different from the one implemented in AlphaFold. The model here implemented was inspired by this paper and this one.
While the architectures implemented in this first preliminary version of the project are inspired by papers with great results, the results here obtained are not as good as they could be. It's likely that the lack of Multiple Alignmnent (MSA), MSA-based features, Physicochemichal properties of AAs (beyond Van der Waals radius) or the lack of both model and feature engineering have affected the models negatively, as well as the little data that they have been trained on.
For that reason, we can conclude that it has been a somehow naive approach and we expect to further implement some ideas/improvements to these models. As the DeepMind team says: "With few or no alignments accuracy is much worse". It would be interesting to use the predictions made by the models as constraints to a folding algorithm (ie. Rosetta) in order to visualize our results.
Here are the following steps in order to run the code locally or in the cloud:
- Clone the repo:
git clone https://github.com/EricAlcaide/MiniFold - Install dependencies:
pip install -r requirements.txt - Get & format the data
- Download data here (select CASP7 text-based format)
- Extract/Decompress the data in any directory
- Create the
/datafolder inside theMiniFolddirectory and copy thetraining_30, training_70 and training90files to it. Change extensions to.txt.
- Execute data preprocessing notebooks (
preprocessingfolder) in the following order (we plan to release simple scripts instead of notebooks very soon):get_proteins_under_200aa.jl *source_path* *destin_path*: - selects proteins under 200 residues from the source_path file (alternatively can be declared in the script itself) - (you will need the Julia programming language v1.0 in order to run it)- Alternatively:
julia_get_proteins_under_200aa.ipynb(you will need Julia as well as iJulia)
- Alternatively:
get_angles_from_coords_py.ipynb- calculates dihedral angles from raw coordinatesangle_data_preparation_py.ipynb
- Run the models!
- For angles prediction:
models/predicting_angles.ipynb - For distance prediction:
models/distance_pipeline/pretrain_model_pssm_l_x_l.ipynbmodels/distance_pipeline/pipeline_caller.py
- For angles prediction:
- 3D structure modelling from predicted results
- For RR format conversion and 3D structure modelling follow the steps given in
models/distance_pipeline/Tutorials/README.pdf
- For RR format conversion and 3D structure modelling follow the steps given in
If you encounter any errors during installation, don't hesitate and open an issue.
Presently the post processing of the predictions is done using a python script which converts the predicted results into RR format known as Residue-Residue contact prediction format. This format represents the probability of contact between pairwise residues. Data in this format are inserted between MODEL and END records of the submission file. The prediction starts with the sequence of the predicted target splitted.The sequence is followed by the list of contacts in the five-column format as represented below :
PFRMAT RR
TARGET T0999
AUTHOR 1234-5678-9000
REMARK Predictor remarks
METHOD Description of methods used
METHOD Description of methods used
MODEL 1
HLEGSIGILLKKHEIVFDGC # <- entire target sequence (up to 50
HDFGRTYIWQMSDASHMD # residues per line)
1 8 0 8 0.720
1 10 0 8 0.715 # <- i=1 j=10: indices of residues (integers),
31 38 0 8 0.710
10 20 0 8 0.690 # <- d1=0 d2=8: the range of Cb-Cb distance
30 37 0 8 0.678 # predicted for the residue pair (i,j)
11 29 0 8 0.673
1 9 0 8 0.63 # <- p=0.63: probability of the residues i=1 and j=9
21 37 0 8 0.502 # being in contact (in descending order)
8 15 0 8 0.401
3 14 0 8 0.400
5 15 0 8 0.307
7 14 0 8 0.30
END
The predictions in this format can then be utilised as input to build 3D models using structure modelling softwares.
There is plenty of ideas that could not be tried in this project due to computational and time constraints. In a brief way, some promising ideas or future directions are listed below:
- Train with crops of 64x64 AAs, not windows of 200x200 AAs and average at prediction time.
- Use data from Multiple Sequence Alignments (MSA) such as paired changes bewteen AAs.
- Use distance map as potential input for angle prediction or vice versa.
- Train with more data
- Use predictions as constraints to a Protein Structure Prediction pipeline (CNS, Rosetta Solve or others).
- Set up a prediction script/pipeline from raw text/FASTA file
This project has been developed mainly during 3 weeks by 1 person and, therefore, many limitations have appeared. They will be listed below in order to give a sense about what this project is and what it's not.
- No usage of Multiple Sequence Alignments (MSA): The methods developed in this project don't use MSA nor MSA-based features as input.
- Computing power/memory: Development of the project has taken part in a computer with the following specifications: Intel i7-6700k, 8gb RAM, NVIDIA GTX-1060Ti 6gb and 256gb of storage. The capacity for data exploration, processing, training and evaluating the models is limited.
- GPU/TPUs for training: The models were trained and evaluated on a single GPU. No cloud servers were used.
- Time: Three weeks of development during spare time.
- Domain expertise: No experts in the field of genomics, proteomics or bioinformatics. The author knows the basics of Biochemistry and Deep Learning.
- Data: The average paper about Protein Structure Prediction uses a personalized dataset acquired from the Protein Data Bank (PDB). No such dataset was used. Instead, we used a subset of the ProteinNet dataset from CASP7. Our models are trained with just 150 proteins (distance prediction) and 600 proteins (angles prediction) due to memory constraints.
Due to these limitations and/or constraints, the precission/accuracy the methods here developed can achieve is limited when compared against State Of The Art algorithms.
- DeepMind original blog post
- AlphaFold @ CASP13: “What just happened?”
- Siraj Raval's YT video on AlphaFold
- ProteinNet dataset
- Accurate De Novo Prediction of Protein Contact Map by Ultra-Deep Learning Model
- AlphaFold slides
- De novo protein structure prediction using ultra-fast molecular dynamics simulation
Hey there! New ideas are welcome: open/close issues, fork the repo and share your code with a Pull Request. Clone this project to your computer:
git clone https://github.com/EricAlcaide/MiniFold
By participating in this project, you agree to abide by the thoughtbot code of conduct
- Author's GitHub Profile: Eric Alcaide
- Twitter: @eric_alcaide
- Email: [email protected]