Node crashes can lead to the loss of inserted triples #2290
Comments
|
@aphyr Is the client client being used after restart here ? |
|
Yes, we continue to use the same clients through restart, at least until the client gives us an indeterminate error, at which point we generate a new one. |
|
This can happen when using client side sequential mode. If server crashes before the data is persisted to disk, on restart a new client can read the data before the WAL is replayed. |
|
It's not a loss but you would see it eventually with client side sequential mode. If we use server side sequential mode then the read would wait till everything is replayed. |
|
Ahh, okay. Do you know how long you'd have to wait for recovery to complete? |
|
Depends on when snapshot happened and how many entries needs to be replayed. |
|
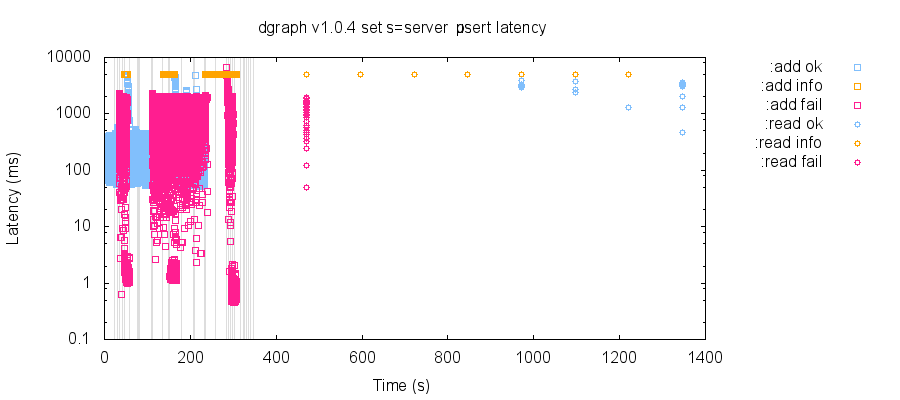
It looks it might be hundreds of times longer than that?
In this test I allow two minutes for the first recovery, but some records are still missing until a thousand seconds later, when other nodes finally come back online. And there's still that weird issue with returning records for an index query that don't have any associated |
|
@aphyr It's not expected behaviour. Are you using latest nightly build ? |
|
I'm looking at 1.0.4--the nightlies were deadlocking in this test on Friday, but that may be fixed now! |
|
Server side sequential mode is not there in 1.0.4. Can you please try with this build. It has the fix for deadlocking. |
|
So, uh, Z5CTJ with server-side sequencing did this incredibly interesting thing:
After a series of alpha and zero crashes and restarts, it took about 400 seconds to recover, then failed to return all but one of the 29662 acknowledged inserts. Instead, it gave a sequence of a whole boatload of value-less responses (that's the 190 :ok :read (nil nil nil nil ... nil nil nil 133143)You can reproduce this with Jepsen 0ef6e711dfb07aad4afc84f7f9c3348961afa9d7: lein run test --package-url https://transfer.sh/Z5CTJ/dgraph-linux-amd64.tar.gz --time-limit 300 --concurrency 100 --nemesis kill-alpha,fix-alpha,kill-zero --test-count 20 --workload set --final-recovery-time 200Since we only insert records with a numeric |

|
To make sure this wasn't something to do with the recovery process itself--like maybe servers could only expose these results immediately after coming back online--I ran another test with a 2000-second pause before we perform any read queries, and it exhibited the same losing-all-but-one-write behavior:
{:valid? false,
:lost
"#{0..16982 16984..16987 16989..16999 17001 ... 63839..63840 63844}",
:recovered "#{63845}",
:ok "#{63845}",
:recovered-frac 1/65624,
:unexpected-frac 1/65624,
:unexpected "#{nil}",
:lost-frac 39115/65624,
:ok-frac 1/65624},
:valid? false} |

|
Test no longer fails with |
In a five node cluster, with a mix of crashes and restarts of both zero and alpha nodes, it appears that the crash of multiple Alpha nodes can cause the loss of successfully inserted documents just prior to the crash. Moreover, nodes can disagree on the records that should be returned for a query for all records of a given type, and some nodes can have objects which match the type predicate, but have a missing value for the
valuefield. This is on versionOur schema is
We perform single mutations in transactions, inserting objects with type "element" and a unique integer value. In this test run, we lose three acknowledged inserts when Alpha crashes: 20180331T020118.000-0500.zip
From Jepsen's log just prior to the crash (read "process 8 invoked an add of element 641"...):
Note that there are three missing inserts (641, 643, 644), which occurred just prior to the crash of n1, n2, n3, and n5. There are also five
nilvalues that matched our query for all records matchingeq(type "element"), which suggests that perhaps UIDs were created for these objects (and perhaps two others which timed out or failed?), but those UIDs weren't linked to the :value fields correctly?Note that process numbers (the first column) are striped over nodes, so processes 0, 5, 10, ... talk to node
n1. From this we can infer also odd that those value-less objects are present on one node (n2), whereas n1, n3,and n4 don't show them! n5 did not respond to either of 2 clients for its final read.You can reproduce this with Jepsen fd875fa9f3c248f6715e1056a504392bfa3963d3 by running:
The text was updated successfully, but these errors were encountered: