diff --git a/.github/workflows/main.yml b/.github/workflows/main.yml
deleted file mode 100644
index f858af1bc72..00000000000
--- a/.github/workflows/main.yml
+++ /dev/null
@@ -1,33 +0,0 @@
-name: CI
-on: [push, pull_request]
-jobs:
- build:
- runs-on: ubuntu-latest
- steps:
- - uses: actions/checkout@v1
- - uses: actions/setup-python@v1
- with:
- python-version: '3.6'
- architecture: 'x64'
- - name: Install the library
- run: |
- pip install nbdev jupyter
- pip install -e .
- - name: Read all notebooks
- run: |
- nbdev_read_nbs
- - name: Check if all notebooks are cleaned
- run: |
- echo "Check we are starting with clean git checkout"
- if [ -n "$(git status -uno -s)" ]; then echo "git status is not clean"; false; fi
- echo "Trying to strip out notebooks"
- nbdev_clean_nbs
- echo "Check that strip out was unnecessary"
- git status -s # display the status to see which nbs need cleaning up
- if [ -n "$(git status -uno -s)" ]; then echo -e "!!! Detected unstripped out notebooks\n!!!Remember to run nbdev_install_git_hooks"; false; fi
- - name: Check if there is no diff library/notebooks
- run: |
- if [ -n "$(nbdev_diff_nbs)" ]; then echo -e "!!! Detected difference between the notebooks and the library"; false; fi
- - name: Run tests
- run: |
- nbdev_test_nbs --fname 'nbs/[!03|!04|!05|]*.ipynb'
diff --git a/README.md b/README.md
index b4cb1b955cd..3e4794ebd62 100644
--- a/README.md
+++ b/README.md
@@ -21,7 +21,7 @@ This process is illustrated in the sketch below:
-
+
Figure: Sketch of the workflow.
@@ -94,7 +94,7 @@ train_stats = ppo_trainer.step([query_tensor[0]], [response_tensor[0]], reward)
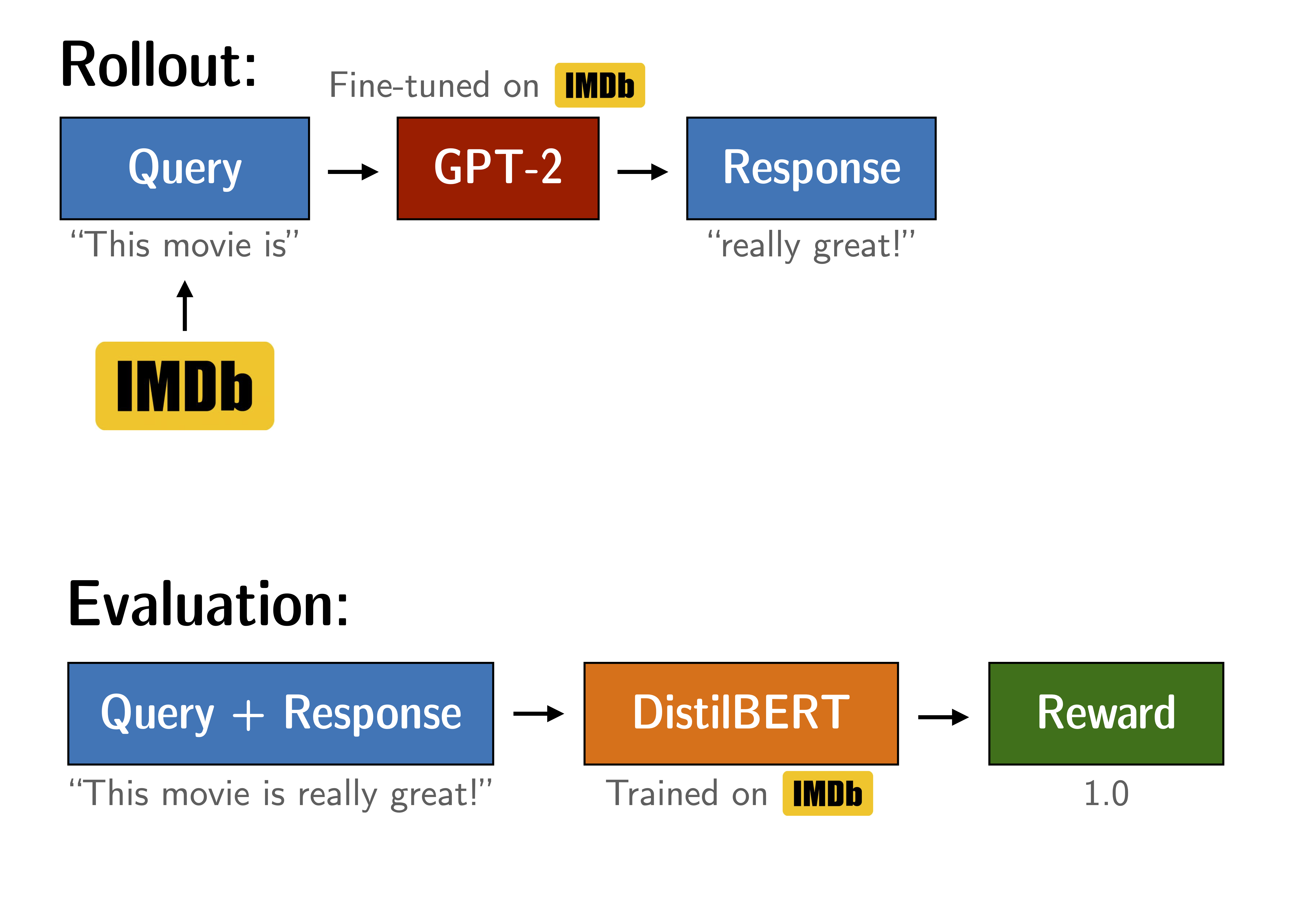
For a detailed example check out the notebook `04-gpt2-sentiment-ppo-training.ipynb`, where GPT2 is fine-tuned to generate positive movie reviews. An few examples from the language models before and after optimisation are given below:
-
+
Figure: A few review continuations before and after optimisation.
diff --git a/nbs/03-distilbert-imdb-training.ipynb b/examples/notebooks/distilbert-imdb-training.ipynb
similarity index 100%
rename from nbs/03-distilbert-imdb-training.ipynb
rename to examples/notebooks/distilbert-imdb-training.ipynb
diff --git a/nbs/05-gpt2-sentiment-control.ipynb b/examples/notebooks/gpt2-sentiment-control.ipynb
similarity index 99%
rename from nbs/05-gpt2-sentiment-control.ipynb
rename to examples/notebooks/gpt2-sentiment-control.ipynb
index ddd86eecdea..7e8123cc9bf 100644
--- a/nbs/05-gpt2-sentiment-control.ipynb
+++ b/examples/notebooks/gpt2-sentiment-control.ipynb
@@ -20,7 +20,7 @@
"metadata": {},
"source": [
"
\n",
- "\n",
+ "\n",
"
Figure: Experiment setup to tune GPT2. The yellow arrows are outside the scope of this notebook, but the trained models are available through Hugging Face.
\n",
"
\n",
"\n",
@@ -812,7 +812,7 @@
"If you are tracking the training progress with Weights&Biases you should see a plot similar to the following:\n",
"\n",
"
\n",
- "\n",
+ "\n",
"
Figure: Reward mean and distribution evolution during training.
Figure: Experiment setup to tune GPT2. The yellow arrows are outside the scope of this notebook, but the trained models are available through Hugging Face.
Figure: Reward mean and distribution evolution during training.
\n",
"
\n",
"\n",
@@ -604,7 +676,11 @@
{
"cell_type": "code",
"execution_count": null,
- "metadata": {},
+ "metadata": {
+ "vscode": {
+ "languageId": "python"
+ }
+ },
"outputs": [
{
"name": "stderr",
@@ -901,7 +977,11 @@
{
"cell_type": "code",
"execution_count": null,
- "metadata": {},
+ "metadata": {
+ "vscode": {
+ "languageId": "python"
+ }
+ },
"outputs": [
{
"name": "stdout",
@@ -960,7 +1040,11 @@
{
"cell_type": "code",
"execution_count": null,
- "metadata": {},
+ "metadata": {
+ "vscode": {
+ "languageId": "python"
+ }
+ },
"outputs": [
{
"name": "stderr",
@@ -1025,7 +1109,11 @@
{
"cell_type": "code",
"execution_count": null,
- "metadata": {},
+ "metadata": {
+ "vscode": {
+ "languageId": "python"
+ }
+ },
"outputs": [],
"source": []
}
diff --git a/examples/scripts/04-ppo-sentiment.py b/examples/scripts/04-ppo-sentiment.py
new file mode 100644
index 00000000000..b6a17b5909f
--- /dev/null
+++ b/examples/scripts/04-ppo-sentiment.py
@@ -0,0 +1,139 @@
+import torch
+import wandb
+import time
+import os
+from tqdm import tqdm
+import numpy as np
+import pandas as pd
+tqdm.pandas()
+
+from datasets import load_dataset
+
+from transformers import AutoTokenizer, pipeline
+
+from trl.gpt2 import GPT2HeadWithValueModel, respond_to_batch
+from trl.ppo import PPOTrainer
+from trl.core import build_bert_batch_from_txt, listify_batch
+
+config = {
+ "model_name": "lvwerra/gpt2-imdb",
+ "cls_model_name": "lvwerra/distilbert-imdb",
+ "steps": 20000,
+ "batch_size": 256,
+ "forward_batch_size": 16,
+ "ppo_epochs": 4,
+ "txt_in_min_len": 2,
+ "txt_in_max_len": 8,
+ "txt_out_min_len": 4,
+ "txt_out_max_len": 16,
+ "lr": 1.41e-5,
+ "init_kl_coef":0.2,
+ "target": 6,
+ "horizon":10000,
+ "gamma":1,
+ "lam":0.95,
+ "cliprange": .2,
+ "cliprange_value":.2,
+ "vf_coef":.1,
+}
+
+device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
+pipe_device = 0 if torch.cuda.is_available() else -1
+
+wandb.init(name='run-42', project='gpt2-test', config=config)
+
+# load imdb with datasets
+ds = load_dataset('imdb', split='train')
+ds = ds.rename_columns({'text': 'review', 'label': 'sentiment'})
+ds = ds.filter(lambda x: len(x["review"])>200, batched=False)
+
+sent_kwargs = {
+ "return_all_scores": True,
+ "function_to_apply": "none",
+ "batch_size": config["forward_batch_size"]
+}
+
+sentiment_pipe = pipeline("sentiment-analysis","lvwerra/distilbert-imdb", device=pipe_device)
+
+gpt2_model = GPT2HeadWithValueModel.from_pretrained(config['model_name'])
+gpt2_model_ref = GPT2HeadWithValueModel.from_pretrained(config['model_name'])
+
+gpt2_tokenizer = AutoTokenizer.from_pretrained(config['model_name'])
+gpt2_tokenizer.pad_token = gpt2_tokenizer.eos_token
+
+wandb.watch(gpt2_model, log='all')
+
+gpt2_model.to(device)
+gpt2_model_ref.to(device)
+
+class LengthSampler:
+ def __init__(self, min_value, max_value):
+ self.values = list(range(min_value, max_value))
+ def __call__(self):
+ return np.random.choice(self.values)
+
+input_size = LengthSampler(config["txt_in_min_len"], config["txt_in_max_len"])
+output_size = LengthSampler(config["txt_out_min_len"], config["txt_out_max_len"])
+
+def tokenize(sample):
+ sample["tokens"] = gpt2_tokenizer.encode(sample["review"])[:input_size()]
+ sample["query"] = gpt2_tokenizer.decode(sample["tokens"])
+ return sample
+
+ds = ds.map(tokenize, batched=False)
+
+gen_kwargs = {
+ "min_length":-1,
+ "top_k": 0.0,
+ "top_p": 1.0,
+ "do_sample": True,
+ "pad_token_id": gpt2_tokenizer.eos_token_id
+}
+
+def collater(data):
+ return dict((key, [d[key] for d in data]) for key in data[0])
+
+dataloader = torch.utils.data.DataLoader(ds, batch_size=config['batch_size'], collate_fn=collater)
+
+ppo_trainer = PPOTrainer(gpt2_model, gpt2_model_ref, gpt2_tokenizer, **config)
+
+total_ppo_epochs = int(np.ceil(config["steps"]/config['batch_size']))
+
+for epoch, batch in tqdm(zip(range(total_ppo_epochs), iter(dataloader))):
+ logs, timing = dict(), dict()
+ t0 = time.time()
+ query_tensors = [torch.tensor(t).long().to(device) for t in batch["tokens"]]
+
+ #### Get response from gpt2
+ t = time.time()
+ response_tensors = []
+ for i in range(config['batch_size']):
+ gen_len = output_size()
+ response = gpt2_model.generate(query_tensors[i].unsqueeze(dim=0),
+ max_new_tokens=gen_len, **gen_kwargs)
+ response_tensors.append(response.squeeze()[-gen_len:])
+ batch['response'] = [gpt2_tokenizer.decode(r.squeeze()) for r in response_tensors]
+ timing['time/get_response'] = time.time()-t
+
+ #### Compute sentiment score
+ t = time.time()
+ texts = [q + r for q,r in zip(batch['query'], batch['response'])]
+ pipe_outputs = sentiment_pipe(texts, **sent_kwargs)
+ rewards = torch.tensor([output[1]["score"] for output in pipe_outputs]).to(device)
+ timing['time/get_sentiment_preds'] = time.time()-t
+
+ #### Run PPO step
+ t = time.time()
+ stats = ppo_trainer.step(query_tensors, response_tensors, rewards)
+ timing['time/optimization'] = time.time()-t
+
+ #### Log everything
+ timing['time/epoch'] = time.time()-t0
+ table_rows = [list(r) for r in zip(batch['query'], batch['response'], rewards.cpu().tolist())]
+ logs.update({'game_log': wandb.Table(columns=['query', 'response', 'reward'], rows=table_rows)})
+ logs.update(timing)
+ logs.update(stats)
+ logs['env/reward_mean'] = torch.mean(rewards).cpu().numpy()
+ logs['env/reward_std'] = torch.std(rewards).cpu().numpy()
+ logs['env/reward_dist'] = rewards.cpu().numpy()
+ wandb.log(logs)
\ No newline at end of file
diff --git a/nbs/00-core.ipynb b/nbs/00-core.ipynb
deleted file mode 100644
index e25841e9e9f..00000000000
--- a/nbs/00-core.ipynb
+++ /dev/null
@@ -1,230 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "# default_exp core"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "# Utility functions\n",
- "> A set of utility functions used throughout the library."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "# export\n",
- "import torch\n",
- "import torch.nn.functional as F\n",
- "from torch.nn.utils.rnn import pad_sequence\n",
- "\n",
- "import collections\n",
- "import numpy as np"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Constants"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "# export\n",
- "WANDB_PADDING = -1"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## General utils"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "# exports\n",
- "\n",
- "def flatten_dict(nested, sep='/'):\n",
- " \"\"\"Flatten dictionary and concatenate nested keys with separator.\"\"\"\n",
- " def rec(nest, prefix, into):\n",
- " for k, v in nest.items():\n",
- " if sep in k:\n",
- " raise ValueError(f\"separator '{sep}' not allowed to be in key '{k}'\")\n",
- " if isinstance(v, collections.Mapping):\n",
- " rec(v, prefix + k + sep, into)\n",
- " else:\n",
- " into[prefix + k] = v\n",
- " flat = {}\n",
- " rec(nested, '', flat)\n",
- " return flat\n",
- "\n",
- "def stack_dicts(stats_dicts):\n",
- " \"\"\"Stack the values of a dict.\"\"\"\n",
- " results = dict()\n",
- " for k in stats_dicts[0]:\n",
- " stats_list = [torch.flatten(d[k]) for d in stats_dicts]\n",
- " results[k] = pad_sequence(stats_list, batch_first=True, padding_value=WANDB_PADDING)\n",
- " return results\n",
- "\n",
- "def add_suffix(input_dict, suffix):\n",
- " \"\"\"Add suffix to dict keys.\"\"\"\n",
- " return dict((k + suffix, v) for k,v in input_dict.items())"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Torch utils"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "# exports\n",
- "\n",
- "def pad_to_size(tensor, size, dim=1, padding=50256):\n",
- " \"\"\"Pad tensor to size.\"\"\"\n",
- " t_size = tensor.size()[dim]\n",
- " if t_size==size:\n",
- " return tensor\n",
- " else:\n",
- " return torch.nn.functional.pad(tensor, (0,size-t_size), 'constant', padding)\n",
- "\n",
- "def logprobs_from_logits(logits, labels):\n",
- " \"\"\"\n",
- " See: https://github.com/pytorch/pytorch/issues/563#issuecomment-330103591\n",
- " \"\"\"\n",
- " logp = F.log_softmax(logits, dim=2)\n",
- " logpy = torch.gather(logp, 2, labels.unsqueeze(2)).squeeze(-1)\n",
- " return logpy\n",
- "\n",
- "\n",
- "def whiten(values, shift_mean=True):\n",
- " \"\"\"Whiten values.\"\"\"\n",
- " mean, var = torch.mean(values), torch.var(values)\n",
- " whitened = (values - mean) * torch.rsqrt(var + 1e-8)\n",
- " if not shift_mean:\n",
- " whitened += mean\n",
- " return whitened\n",
- "\n",
- "def clip_by_value(x, tensor_min, tensor_max):\n",
- " \"\"\"\n",
- " Tensor extenstion to torch.clamp\n",
- " https://github.com/pytorch/pytorch/issues/2793#issuecomment-428784713\n",
- " \"\"\"\n",
- " clipped = torch.max(torch.min(x, tensor_max), tensor_min)\n",
- " return clipped\n",
- "\n",
- "def entropy_from_logits(logits):\n",
- " \"\"\"Calculate entropy from logits.\"\"\"\n",
- " pd = torch.nn.functional.softmax(logits, dim=-1)\n",
- " entropy = torch.logsumexp(logits, axis=-1) - torch.sum(pd*logits, axis=-1)\n",
- " return entropy\n",
- "\n",
- "\n",
- "def average_torch_dicts(list_of_dicts):\n",
- " \"\"\"Average values of a list of dicts wiht torch tensors.\"\"\"\n",
- " average_dict = dict()\n",
- " for key in list_of_dicts[0].keys():\n",
- " average_dict[key] = torch.mean(torch.stack([d[key] for d in list_of_dicts]), axis=0)\n",
- " return average_dict\n",
- "\n",
- "def stats_to_np(stats_dict):\n",
- " \"\"\"Cast all torch.tensors in dict to numpy arrays.\"\"\"\n",
- " new_dict = dict()\n",
- " for k, v in stats_dict.items():\n",
- " if isinstance(v, torch.Tensor):\n",
- " new_dict[k] = v.detach().cpu().numpy()\n",
- " else:\n",
- " new_dict[k] = v\n",
- " if np.isscalar(new_dict[k]):\n",
- " new_dict[k] = float(new_dict[k])\n",
- " return new_dict\n",
- "\n",
- "def listify_batch(tensor):\n",
- " \"\"\"Turns the first dimension of a tensor into a list.\"\"\"\n",
- " return [tensor[i] for i in range(tensor.shape[0])]"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## BERT utils"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "# exports\n",
- "\n",
- "def build_bert_batch_from_txt(text_list, tokenizer, device):\n",
- " \"\"\"Create token id and attention mask tensors from text list for BERT classification.\"\"\"\n",
- " \n",
- " # tokenize\n",
- " tensors = [tokenizer.encode(txt, return_tensors=\"pt\").to(device) for txt in text_list]\n",
- " \n",
- " # find max length to pad to\n",
- " max_len = max([t.size()[1] for t in tensors])\n",
- " \n",
- " # get padded tensors and attention masks\n",
- " # (attention masks make bert ignore padding)\n",
- " padded_tensors = []\n",
- " attention_masks = []\n",
- " for tensor in tensors:\n",
- " attention_mask = torch.ones(tensor.size(), device=device)\n",
- " padded_tensors.append(pad_to_size(tensor, max_len, padding=0))\n",
- " attention_masks.append(pad_to_size(attention_mask, max_len, padding=0))\n",
- " \n",
- " # stack all tensors\n",
- " padded_tensors = torch.cat(padded_tensors)\n",
- " attention_masks = torch.cat(attention_masks) \n",
- " \n",
- " return padded_tensors, attention_masks"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": []
- }
- ],
- "metadata": {
- "kernelspec": {
- "display_name": "Python 3 (ipykernel)",
- "language": "python",
- "name": "python3"
- }
- },
- "nbformat": 4,
- "nbformat_minor": 4
-}
diff --git a/nbs/01-gpt2-with-value-head.ipynb b/nbs/01-gpt2-with-value-head.ipynb
deleted file mode 100644
index 6cb3da00ad3..00000000000
--- a/nbs/01-gpt2-with-value-head.ipynb
+++ /dev/null
@@ -1,519 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "# GPT2 with value head\n",
- "> A GPT2 model with a value head built on the `transformer` library by Hugging Face."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Why a value head?\n",
- "Optimisation through PPO requires estimates on the current states value. The value can be estimated by adding a second head to the GPT2 model which outputs a scalar for each output token."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Detach head\n",
- "I experimented with detaching the head from the body when optimizing the model. This means that only the head is trained and the gradients are not passed through the body. Although I did not use it in the end it is still possible to detach the head by calling `model.detach_head()`."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "# default_exp gpt2"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "# export\n",
- "\n",
- "from transformers import GPT2LMHeadModel, GPT2Tokenizer, GPT2Model, GPT2PreTrainedModel\n",
- "from transformers import top_k_top_p_filtering\n",
- "from transformers.modeling_outputs import ModelOutput\n",
- "from torch import nn\n",
- "from torch.nn import Identity\n",
- "import torch.nn.functional as F\n",
- "import torch\n",
- "from dataclasses import dataclass\n",
- "from typing import Optional, Tuple"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "# exports\n",
- "@dataclass\n",
- "class CausalLMOutputWithCrossAttentions(ModelOutput):\n",
- " loss: Optional[torch.FloatTensor] = None\n",
- " logits: torch.FloatTensor = None\n",
- " past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None\n",
- " hidden_states: Optional[Tuple[torch.FloatTensor]] = None\n",
- " attentions: Optional[Tuple[torch.FloatTensor]] = None\n",
- " cross_attentions: Optional[Tuple[torch.FloatTensor]] = None\n",
- " value: Optional[torch.FloatTensor] = None"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "# exports\n",
- "\n",
- "class ValueHead(nn.Module):\n",
- " \"\"\"The ValueHead class implements a head for GPT2 that returns a scalar for each output token.\"\"\"\n",
- " def __init__(self, config):\n",
- " super().__init__()\n",
- " self.detach_head = False\n",
- " self.summary_type = config.summary_type if hasattr(config, \"summary_type\") else \"last\"\n",
- " if self.summary_type == \"attn\":\n",
- " raise NotImplementedError\n",
- "\n",
- " self.summary = Identity()\n",
- " if hasattr(config, \"summary_use_proj\") and config.summary_use_proj:\n",
- " if hasattr(config, \"summary_proj_to_labels\") and config.summary_proj_to_labels and config.num_labels > 0:\n",
- " num_classes = config.num_labels\n",
- " else:\n",
- " num_classes = config.hidden_size\n",
- " self.summary = nn.Linear(config.hidden_size, num_classes)\n",
- "\n",
- " self.activation = Identity()\n",
- " if hasattr(config, \"summary_activation\") and config.summary_activation == \"tanh\":\n",
- " self.activation = nn.Tanh()\n",
- "\n",
- " self.first_dropout = Identity()\n",
- " if hasattr(config, \"summary_first_dropout\") and config.summary_first_dropout > 0:\n",
- " self.first_dropout = nn.Dropout(config.summary_first_dropout)\n",
- "\n",
- " self.last_dropout = Identity()\n",
- " if hasattr(config, \"summary_last_dropout\") and config.summary_last_dropout > 0:\n",
- " self.last_dropout = nn.Dropout(config.summary_last_dropout)\n",
- " \n",
- " self.flatten = nn.Flatten()\n",
- "\n",
- " def forward(self, hidden_states, cls_index=None):\n",
- " if self.detach_head:\n",
- " output = hidden_states.detach()\n",
- " else:\n",
- " output = hidden_states\n",
- " output = self.first_dropout(output)\n",
- " output = self.summary(output)\n",
- " output = self.activation(output)\n",
- " output = self.last_dropout(output)\n",
- "\n",
- " return output"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "# exports\n",
- "\n",
- "class GPT2HeadWithValueModel(GPT2PreTrainedModel):\n",
- " \"\"\"The GPT2HeadWithValueModel class implements a GPT2 language model with a secondary, scalar head.\"\"\"\n",
- " def __init__(self, config):\n",
- " super().__init__(config)\n",
- " config.num_labels = 1\n",
- " self.transformer = GPT2Model(config)\n",
- " self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)\n",
- " self.v_head = ValueHead(config)\n",
- "\n",
- " self.init_weights()\n",
- "\n",
- " def get_output_embeddings(self):\n",
- " return self.lm_head\n",
- "\n",
- " def detach_value_head(self):\n",
- " self.v_head.detach_head = True\n",
- "\n",
- " def forward(\n",
- " self,\n",
- " input_ids=None,\n",
- " past_key_values=None,\n",
- " attention_mask=None,\n",
- " token_type_ids=None,\n",
- " position_ids=None,\n",
- " head_mask=None,\n",
- " inputs_embeds=None,\n",
- " mc_token_ids=None,\n",
- " lm_labels=None,\n",
- " mc_labels=None,\n",
- " return_dict=False,\n",
- " output_attentions=False,\n",
- " output_hidden_states=False,\n",
- " ):\n",
- " loss=None\n",
- " transformer_outputs = self.transformer(\n",
- " input_ids,\n",
- " past_key_values=past_key_values,\n",
- " attention_mask=attention_mask,\n",
- " token_type_ids=token_type_ids,\n",
- " position_ids=position_ids,\n",
- " head_mask=head_mask,\n",
- " inputs_embeds=inputs_embeds,\n",
- " )\n",
- "\n",
- " hidden_states = transformer_outputs[0]\n",
- "\n",
- " lm_logits = self.lm_head(hidden_states)\n",
- " value = self.v_head(hidden_states).squeeze(-1)\n",
- "\n",
- " \n",
- " if not return_dict:\n",
- " outputs = (lm_logits,) + transformer_outputs[1:] + (value,)\n",
- " return outputs\n",
- "\n",
- " return CausalLMOutputWithCrossAttentions(\n",
- " loss=loss,\n",
- " logits=lm_logits,\n",
- " past_key_values=transformer_outputs.past_key_values,\n",
- " hidden_states=transformer_outputs.hidden_states,\n",
- " attentions=transformer_outputs.attentions,\n",
- " cross_attentions=transformer_outputs.cross_attentions,\n",
- " value=value,\n",
- " ) \n",
- " return outputs"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Load a pre-trained language model\n",
- "Loading a pretrained language model works like loading it with a model from the `transformer` library."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "Some weights of GPT2HeadWithValueModel were not initialized from the model checkpoint at gpt2 and are newly initialized: ['h.6.attn.masked_bias', 'h.10.attn.masked_bias', 'h.0.attn.masked_bias', 'h.3.attn.masked_bias', 'h.7.attn.masked_bias', 'h.5.attn.masked_bias', 'h.11.attn.masked_bias', 'h.9.attn.masked_bias', 'h.8.attn.masked_bias', 'lm_head.weight', 'h.4.attn.masked_bias', 'v_head.summary.weight', 'h.2.attn.masked_bias', 'v_head.summary.bias', 'h.1.attn.masked_bias']\n",
- "You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.\n"
- ]
- }
- ],
- "source": [
- "model = GPT2HeadWithValueModel.from_pretrained('gpt2')\n",
- "tokenizer = GPT2Tokenizer.from_pretrained('gpt2')"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Forward pass"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "input_txt = \"I liked the movie Transformers!\" + tokenizer.eos_token\n",
- "input_ids = tokenizer.encode(input_txt, add_special_tokens=True, return_tensors=\"pt\")\n",
- "logits, transformer_outputs, values = model(input_ids)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Model outputs"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "We input a batch of `1` with `7` tokens."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [
- {
- "data": {
- "text/plain": [
- "torch.Size([1, 7])"
- ]
- },
- "execution_count": null,
- "metadata": {},
- "output_type": "execute_result"
- }
- ],
- "source": [
- "input_ids.shape"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "The logits tensor is of shape `[batch_size, num_input_tokens, vocab_size]`:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [
- {
- "data": {
- "text/plain": [
- "torch.Size([1, 7, 50257])"
- ]
- },
- "execution_count": null,
- "metadata": {},
- "output_type": "execute_result"
- }
- ],
- "source": [
- "logits.shape"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "The value tensor is of shape `[batch_size, num_input_tokens]`:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [
- {
- "data": {
- "text/plain": [
- "torch.Size([1, 7])"
- ]
- },
- "execution_count": null,
- "metadata": {},
- "output_type": "execute_result"
- }
- ],
- "source": [
- "values.shape"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "We can greedy decode the next token predictions from the logits:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "pred_ids = torch.argmax(logits, dim=-1)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "I --> .\n",
- " liked --> the\n",
- " the --> idea\n",
- " movie --> ,\n",
- " Transformers --> ,\n",
- "! --> I\n",
- "<|endoftext|> --> The\n"
- ]
- }
- ],
- "source": [
- "for i in range(input_ids.shape[1]):\n",
- " current_id = tokenizer.decode(input_ids[:, i])\n",
- " next_id = tokenizer.decode(pred_ids[:, i])\n",
- " print(current_id, '-->', next_id)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Batched response to queries\n",
- "To speed up computations it helps to process queries in a batched fashion."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "# exports\n",
- "\n",
- "def respond_to_batch(model, queries, txt_len=20, top_k=0, top_p=1.0):\n",
- " \"\"\"Sample text from language model.\"\"\"\n",
- " input_ids = queries\n",
- " for i in range(txt_len):\n",
- " # Get Logits\n",
- " outputs = model(input_ids)\n",
- " next_token_logits = outputs[0][:, -1, :]\n",
- " next_token_logits = top_k_top_p_filtering(next_token_logits, top_k=top_k, top_p=top_p)\n",
- " # Sample\n",
- " probs = F.softmax(next_token_logits, dim=-1)\n",
- " next_token = torch.multinomial(probs, num_samples=1).squeeze(1)\n",
- " input_ids = torch.cat([input_ids, next_token.unsqueeze(-1)], dim=-1)\n",
- " return input_ids[:, -txt_len:]"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "We have the model respond to two queries in parallel:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "[torch.Size([1, 5]), torch.Size([1, 5])]\n"
- ]
- }
- ],
- "source": [
- "query_txt_1 = \"My most favourite movie is\"\n",
- "query_txt_2 = \"My least favourite movie is\"\n",
- "queries_txt = [query_txt_1, query_txt_2]\n",
- "\n",
- "queries = [tokenizer.encode(query_txt, return_tensors=\"pt\") for query_txt in queries_txt]\n",
- "print([q.shape for q in queries])\n",
- "queries = torch.cat(queries)\n",
- "\n",
- "responses = respond_to_batch(model, queries, txt_len=10)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "**Note:** This only works because both queries have the same number of tokens. If that is not the case one must pad the tensors before stacking them in `torch.cat(queries)`.\n",
- "\n",
- "Then we can decode the responses:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "My most favourite movie is Captain America: Civil War, which moved into the\n",
- "My least favourite movie is Jon Favreau's Log Horizon, complete with psychedelic\n"
- ]
- }
- ],
- "source": [
- "for i in range(responses.shape[0]):\n",
- " response_txt = tokenizer.decode(responses[i])\n",
- " query_txt = queries_txt[i]\n",
- " print(query_txt + response_txt)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Why the custom response function?\n",
- "The models in the `transformer` library come with a very useful and optimised generation function `model.generate()`. In the beginning this function was indeed used to generate text but after lengthy debugging it turned out that PPO was exploiting some aspects that are generally useful for text generation but allowed the model to abuse it and gain extra rewards.\n",
- "\n",
- "### The model reward\n",
- "To understand how the model was able to exploit the generation function it is worth looking at the reward function for language modeling with PPO. The reward consists of an arbitrary score (any scalar to indicate whether the model output was good or bad) and the KL-divergence from the untrained model:\n",
- "\n",
- "$$reward = score - \\beta \\times KL$$\n",
- "\n",
- "where $\\beta$ is some positive factor. The KL divergence is calculate with:\n",
- "\n",
- "$$ KL = \\mathbb{E}_{x \\sim p_{model}} [\\log p_{model}(x) - \\log p_{refmodel}(x)]$$\n",
- "\n",
- "Since $x$ is sampled from $p_{model}$ the KL-divergence is always positive. However, if the model found a way to get negative KL-divergence it would achieve a positive reward. This is what happened twice with in the experiment and both times a quirk of the text generation was abused to avoid proper sampling from the probability distribution.\n",
- "\n",
- "### Case 1: `min_length=None`\n",
- "When no `min_length` is specified in the `model.generate()` function the model probability distribution is normally sampled until the first `` token appears. Then the rest of the sequence is padded with a padding token until `max_length` is reached (for GPT2 this is also the `` token). If that sequence is again passed through the model to evaluate the log-probabilities everything is normal until after the first `` token, since multiple `` tokens are very unlikely. The model exploited this by decreasing the probability for the `` token after the first appearence even further below the probability of the reference model, thus achieving negative KL-divergence. Additionally, it inserted the first `` earlier and earlier in the sentences to minimize the KL-divergence and thus maximise the reward. This only worked because the sequence after the first `` token wasn't properly sampled but padded, otherwise the low probabilities would have lead to other tokens with higher probability being sampled.\n",
- "\n",
- "\n",
- "### Case 2: `min_length=max_length`\n",
- "I thought this could be easily fixed: just set the `min_length=max_length`. This seemed to work fine for a few experiments until the training failed again due to negative KL-divergences. Finding the problem was harder than before, since it only happened rarely after several training steps. In addition the generated sentences deteriorated quickly to complete gibberish. After some investigation it turned out that the model was again exploiting the sampling function. Up to this point I was not aware that the model was also not allowed to produce an `` token before `min_length` is reached. In practice this is achieved by setting the next token logit to -infinity:\n",
- "\n",
- "```\n",
- "next_token_logits[:, eos_token_id] = -float(\"inf\")\n",
- "```\n",
- "\n",
- "This makes sure that after the softmax function the probability for the `` token is zero, no matter the model output. The model exploited this by maximizing the logit output for that token and thus setting all other logits to increasingly small numbers. Since, I did not apply the same step when evaluating the generated sequence (calculating softmax without the -inf trick) the probabilities for the generated sequences were extremely small and in fact smaller than the probabilities of the reference model. This lead again to negative KL-divergence.\n",
- "\n",
- "### Conclusion\n",
- "In both cases $x \\sim p_{model}$ in the KL-divergence equation was not satisfied, but this was hidden in the sequence generating function. Reinforcement Learning is very effective in finding and exploiting environment quirks as others have pointed out for other environments such as ATARI games. The solution was to go back to a simpler sequence sampler to avoid this exploits. Alternatively, I could have applied the same tricks and some masking to the model outputs when evaluating the sequences, but I didn't feel confident enough that there would not be other sequence generation tricks the model could abuse."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": []
- }
- ],
- "metadata": {
- "kernelspec": {
- "display_name": "Python 3 (ipykernel)",
- "language": "python",
- "name": "python3"
- }
- },
- "nbformat": 4,
- "nbformat_minor": 4
-}
diff --git a/nbs/02-ppo.ipynb b/nbs/02-ppo.ipynb
deleted file mode 100644
index 8173f4308be..00000000000
--- a/nbs/02-ppo.ipynb
+++ /dev/null
@@ -1,426 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "# PPO for transformer models\n",
- "> A Pytorch implementation of Proximal Policy Optimization for transfomer models."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "This follows the language model approach proposed in paper [\"Fine-Tuning Language Models from Human Preferences\"](\n",
- "https://arxiv.org/pdf/1909.08593.pdf) and is similar to the [original implementation](https://github.com/openai/lm-human-preferences). The two main differences are 1) the method is implemented in Pytorch and 2) works with the `transformer` library by Hugging Face."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "# default_exp ppo"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "# export\n",
- "import numpy as np\n",
- "import torch.nn.functional as F\n",
- "from torch.optim import Adam\n",
- "import torch\n",
- "import collections\n",
- "import time\n",
- "import random\n",
- "\n",
- "from transformers import DataCollatorForLanguageModeling\n",
- "\n",
- "from trl.core import (logprobs_from_logits,\n",
- " whiten,\n",
- " clip_by_value,\n",
- " entropy_from_logits,\n",
- " flatten_dict,\n",
- " average_torch_dicts,\n",
- " stats_to_np,\n",
- " stack_dicts,\n",
- " add_suffix,\n",
- " WANDB_PADDING)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## KL-controllers\n",
- "To ensure that the learned policy does not deviate to much from the original language model the KL divergence between the policy and a reference policy (the language model before PPO training) is used as an additional reward signal. Large KL-divergences are punished and staying close to the reference is rewarded.\n",
- "\n",
- "Two controllers are presented in the paper: an adaptive log-space proportional controller and a fixed controller."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "# exports\n",
- "\n",
- "class AdaptiveKLController:\n",
- " \"\"\"\n",
- " Adaptive KL controller described in the paper:\n",
- " https://arxiv.org/pdf/1909.08593.pdf\n",
- " \"\"\"\n",
- " def __init__(self, init_kl_coef, target, horizon):\n",
- " self.value = init_kl_coef\n",
- " self.target = target\n",
- " self.horizon = horizon\n",
- "\n",
- " def update(self, current, n_steps):\n",
- " target = self.target\n",
- " proportional_error = np.clip(current / target - 1, -0.2, 0.2)\n",
- " mult = 1 + proportional_error * n_steps / self.horizon\n",
- " self.value *= mult"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "# exports \n",
- "\n",
- "class FixedKLController:\n",
- " \"\"\"Fixed KL controller.\"\"\"\n",
- " def __init__(self, kl_coef):\n",
- " self.value = kl_coef\n",
- "\n",
- " def update(self, current, n_steps):\n",
- " pass"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "# exports \n",
- "\n",
- "class PPOTrainer:\n",
- " \"\"\"\n",
- " The PPO_trainer uses Proximal Policy Optimization to optimise language models.\n",
- " \"\"\"\n",
- " \n",
- " default_params = {\n",
- " \"lr\": 1.41e-5,\n",
- " \"adap_kl_ctrl\": True, \n",
- " \"init_kl_coef\":0.2,\n",
- " \"target\": 6,\n",
- " \"horizon\":10000,\n",
- " \"gamma\":1,\n",
- " \"lam\":0.95,\n",
- " \"cliprange\": .2,\n",
- " \"cliprange_value\":.2,\n",
- " \"vf_coef\":.1,\n",
- " \"batch_size\": 256,\n",
- " \"forward_batch_size\": 16,\n",
- " \"ppo_epochs\": 4, \n",
- " } \n",
- " \n",
- " def __init__(self, model, ref_model, tokenizer, **ppo_params):\n",
- " \"\"\"\n",
- " Initialize PPOTrainer.\n",
- " \n",
- " Args:\n",
- " model (torch.model): Hugging Face transformer GPT2 model with value head\n",
- " ref_model (torch.model): Hugging Face transformer GPT2 refrence model used for KL penalty\n",
- " tokenizer (tokenizer): Hugging Face tokenizer\n",
- " ppo_params (dict or None): PPO parameters for training. Can include following keys:\n",
- " 'lr' (float): Adam learning rate, default: 1.41e-5\n",
- " 'batch_size' (int): Number of samples per optimisation step, default: 256\n",
- " 'forward_batch_size' (int): Number of samples forward passed through model at a time, default: 16\n",
- " 'ppo_epochs' (int): Number of optimisation epochs per batch of samples, default: 4\n",
- " 'gamma' (float)): Gamma parameter for advantage calculation, default: 1.\n",
- " 'lam' (float): Lambda parameter for advantage calcualation, default: 0.95\n",
- " 'cliprange_value' (float): Range for clipping values in loss calculation, default: 0.2\n",
- " 'cliprange' (float): Range for clipping in PPO policy gradient loss, default: 0.2\n",
- " 'vf_coef' (float): Scaling factor for value loss, default: 0.1\n",
- " 'adap_kl_ctrl' (bool): Use adaptive KL control, otherwise linear, default: True\n",
- " 'init_kl_coef' (float): Initial KL penalty coefficient (used for adaptive and linear control), default: 0.2\n",
- " 'target' (float): Target KL value for adaptive KL control, default: 6.0\n",
- " 'horizon' (float): Horizon for adaptive KL control, default: 10000\n",
- " \n",
- " \"\"\"\n",
- " self.ppo_params = self.default_params\n",
- " self.ppo_params.update(ppo_params)\n",
- " \n",
- " self.ref_model = ref_model\n",
- " self.model = model\n",
- " self.tokenizer = tokenizer\n",
- " self.data_collator = DataCollatorForLanguageModeling(tokenizer, mlm=False)\n",
- " \n",
- " self.optimizer = Adam(model.parameters(), lr=self.ppo_params['lr'])\n",
- " \n",
- " if self.ppo_params['adap_kl_ctrl']:\n",
- " self.kl_ctl = AdaptiveKLController(self.ppo_params['init_kl_coef'],\n",
- " self.ppo_params['target'],\n",
- " self.ppo_params['horizon'])\n",
- " else:\n",
- " self.kl_ctl = FixedKLController(self.ppo_params['init_kl_coef'])\n",
- "\n",
- "\n",
- " def step(self, queries, responses, scores):\n",
- " \"\"\"\n",
- " Run a PPO optimisation step.\n",
- " \n",
- " args:\n",
- " queries (List): List of tensors containing the encoded queries, shape [query_length]\n",
- " responses (List): List of tensors containing the encoded responses, shape [response_length]\n",
- " scores (List): tensor containing the scores, shape [batch_size]\n",
- " \n",
- " returns:\n",
- " train_stats (dict): a summary of the training statistics\n",
- " \"\"\"\n",
- "\n",
- " bs = self.ppo_params['batch_size']\n",
- " assert bs == len(queries), f\"Batch size ({bs}) does not match number of examples ({len(queries)})\"\n",
- " \n",
- " timing = dict()\n",
- " t0 = time.time()\n",
- " \n",
- " response_lengths = [len(r) for r in responses]\n",
- " \n",
- " t = time.time()\n",
- " logprobs, ref_logprobs, values = self.batched_forward_pass(queries, responses)\n",
- " timing['time/ppo/forward_pass'] = time.time()-t\n",
- "\n",
- " t = time.time()\n",
- " rewards, non_score_reward = self.compute_rewards(scores, logprobs, ref_logprobs)\n",
- " timing['time/ppo/compute_rewards'] = time.time()-t \n",
- " \n",
- " t = time.time() \n",
- " all_stats = []\n",
- " idxs = list(range(bs))\n",
- " for _ in range(self.ppo_params['ppo_epochs']):\n",
- " random.shuffle(idxs)\n",
- " for i in range(bs):\n",
- " idx = idxs[i]\n",
- " train_stats = self.train_minibatch(logprobs[idx].unsqueeze(0), values[idx].unsqueeze(0),\n",
- " rewards[idx].unsqueeze(0), queries[idx].unsqueeze(0),\n",
- " responses[idx].unsqueeze(0),\n",
- " torch.cat([queries[idx],responses[idx]]).unsqueeze(0))\n",
- " all_stats.append(train_stats)\n",
- " timing['time/ppo/optimize_step'] = time.time()-t\n",
- " \n",
- " t = time.time()\n",
- " train_stats = stack_dicts(all_stats)\n",
- " \n",
- " # reshape advantages/ratios such that they are not averaged.\n",
- " train_stats['policy/advantages'] = torch.flatten(train_stats['policy/advantages']).unsqueeze(0)\n",
- " train_stats['policy/advantages'] = torch.nan_to_num(train_stats['policy/advantages'], WANDB_PADDING)\n",
- " train_stats['policy/ratio'] = torch.flatten(train_stats['policy/ratio']).unsqueeze(0)\n",
- " \n",
- " stats = self.record_step_stats(scores=scores, logprobs=logprobs, ref_logprobs=ref_logprobs,\n",
- " non_score_reward=non_score_reward, train_stats=train_stats,\n",
- " kl_coef=self.kl_ctl.value)\n",
- " stats = stats_to_np(stats)\n",
- " timing['time/ppo/calc_stats'] = time.time()-t\n",
- "\n",
- " self.kl_ctl.update(stats['objective/kl'], self.ppo_params['batch_size'])\n",
- "\n",
- " timing['time/ppo/total'] = time.time()-t0\n",
- " stats.update(timing)\n",
- " return stats\n",
- "\n",
- " def batched_forward_pass(self, queries, responses):\n",
- " \"\"\"Calculate model outputs in multiple batches.\"\"\"\n",
- " bs = self.ppo_params['batch_size']\n",
- " fbs = self.ppo_params['forward_batch_size']\n",
- " all_logprobs = []\n",
- " all_ref_logprobs = []\n",
- " all_values = []\n",
- " \n",
- " for i in range(int(bs/fbs)):\n",
- " query_batch = queries[i*fbs:(i+1)*fbs]\n",
- " response_batch = responses[i*fbs:(i+1)*fbs]\n",
- " input_ids = self.data_collator([torch.cat([q, r]) for q, r in zip(query_batch, response_batch)])[\"input_ids\"]\n",
- " with torch.no_grad():\n",
- " logits, _, v = self.model(input_ids)\n",
- " ref_logits, _, _ = self.ref_model(input_ids)\n",
- " logprobs = logprobs_from_logits(logits[:,:-1,:], input_ids[:,1:])\n",
- " ref_logprobs = logprobs_from_logits(ref_logits[:,:-1,:], input_ids[:,1:])\n",
- " for j in range(fbs):\n",
- " start = len(query_batch[j])-1\n",
- " end = len(query_batch[j]) + len(response_batch[j])-1\n",
- " all_values.append(v[j, start-1:end-1])\n",
- " all_logprobs.append(logprobs[j, start:end])\n",
- " all_ref_logprobs.append(ref_logprobs[j, start:end])\n",
- " return all_logprobs, all_ref_logprobs, all_values\n",
- " \n",
- " def train_minibatch(self, logprobs, values, rewards, query, response, model_input):\n",
- " \"\"\"Train one PPO minibatch\"\"\"\n",
- " loss_p, loss_v, train_stats = self.loss(logprobs, values, rewards, query, response, model_input)\n",
- " loss = loss_p + loss_v\n",
- " self.optimizer.zero_grad()\n",
- " loss.backward()\n",
- " self.optimizer.step()\n",
- " return train_stats\n",
- " \n",
- " def compute_rewards(self, scores, logprobs, ref_logprobs):\n",
- " \"\"\"Compute per token rewards from scores and KL-penalty.\"\"\"\n",
- " rewards, non_score_rewards = [], []\n",
- " for score, logprob, ref_logprob in zip(scores, logprobs, ref_logprobs):\n",
- " kl = logprob - ref_logprob\n",
- " non_score_reward = -self.kl_ctl.value * kl\n",
- " non_score_rewards.append(non_score_reward)\n",
- " reward = non_score_reward.clone()\n",
- " reward[-1] += score\n",
- " rewards.append(reward)\n",
- " return rewards, non_score_rewards\n",
- "\n",
- " def loss(self, old_logprobs, values, rewards, query, response, model_input):\n",
- " \"\"\"Calculate policy and value losses.\"\"\"\n",
- " lastgaelam = 0\n",
- " advantages_reversed = []\n",
- " gen_len = response.shape[1]\n",
- " \n",
- " for t in reversed(range(gen_len)):\n",
- " nextvalues = values[:, t + 1] if t < gen_len - 1 else 0.0\n",
- " delta = rewards[:, t] + self.ppo_params['gamma'] * nextvalues - values[:, t]\n",
- " lastgaelam = delta + self.ppo_params['gamma'] * self.ppo_params['lam'] * lastgaelam\n",
- " advantages_reversed.append(lastgaelam)\n",
- " advantages = torch.stack(advantages_reversed[::-1]).transpose(0, 1)\n",
- "\n",
- " returns = advantages + values\n",
- " advantages = whiten(advantages)\n",
- " advantages = advantages.detach()\n",
- "\n",
- " logits, _, vpred = self.model(model_input)\n",
- " logprob = logprobs_from_logits(logits[:,:-1,:], model_input[:, 1:])\n",
- " \n",
- " #only the generation part of the values/logprobs is needed\n",
- " logprob, vpred = logprob[:, -gen_len:], vpred[:,-gen_len-1:-1]\n",
- "\n",
- " vpredclipped = clip_by_value(vpred,\n",
- " values - self.ppo_params[\"cliprange_value\"],\n",
- " values + self.ppo_params[\"cliprange_value\"])\n",
- "\n",
- " vf_losses1 = (vpred - returns)**2\n",
- " vf_losses2 = (vpredclipped - returns)**2\n",
- " vf_loss = .5 * torch.mean(torch.max(vf_losses1, vf_losses2))\n",
- " vf_clipfrac = torch.mean(torch.gt(vf_losses2, vf_losses1).double())\n",
- "\n",
- " ratio = torch.exp(logprob - old_logprobs)\n",
- " \n",
- " pg_losses = -advantages * ratio\n",
- " pg_losses2 = -advantages * torch.clamp(ratio,\n",
- " 1.0 - self.ppo_params['cliprange'],\n",
- " 1.0 + self.ppo_params['cliprange'])\n",
- "\n",
- " pg_loss = torch.mean(torch.max(pg_losses, pg_losses2))\n",
- " pg_clipfrac = torch.mean(torch.gt(pg_losses2, pg_losses).double())\n",
- " \n",
- " loss = pg_loss + self.ppo_params['vf_coef'] * vf_loss\n",
- "\n",
- " entropy = torch.mean(entropy_from_logits(logits))\n",
- " approxkl = .5 * torch.mean((logprob - old_logprobs)**2)\n",
- " policykl = torch.mean(logprob - old_logprobs)\n",
- " return_mean, return_var = torch.mean(returns), torch.var(returns)\n",
- " value_mean, value_var = torch.mean(values), torch.var(values)\n",
- "\n",
- " stats = dict(\n",
- " loss=dict(policy=pg_loss, value=vf_loss, total=loss),\n",
- " policy=dict(entropy=entropy, approxkl=approxkl,policykl=policykl, clipfrac=pg_clipfrac,\n",
- " advantages=advantages, advantages_mean=torch.mean(advantages), ratio=ratio),\n",
- " returns=dict(mean=return_mean, var=return_var),\n",
- " val=dict(vpred=torch.mean(vpred), error=torch.mean((vpred - returns) ** 2),\n",
- " clipfrac=vf_clipfrac, mean=value_mean, var=value_var),\n",
- " )\n",
- " return pg_loss, self.ppo_params['vf_coef'] * vf_loss, flatten_dict(stats)\n",
- "\n",
- "\n",
- " def record_step_stats(self, kl_coef, **data):\n",
- " \"\"\"Record training step statistics.\"\"\"\n",
- " kl_list = [logprobs-ref_logprobs for logprobs, ref_logprobs in zip(data['logprobs'], data['ref_logprobs'])] \n",
- " mean_kl = torch.mean(torch.stack([torch.sum(kl) for kl in kl_list]))\n",
- " mean_entropy = torch.mean(torch.stack([torch.sum(-log_probs) for log_probs in data['logprobs']]))\n",
- " mean_non_score_reward =torch.mean(torch.stack([torch.sum(non_score_reward) for non_score_reward in data['non_score_reward']]))\n",
- " stats = {\n",
- " 'objective/kl': mean_kl,\n",
- " 'objective/kl_dist': kl_list,\n",
- " 'objective/logprobs': data['logprobs'],\n",
- " 'objective/ref_logprobs': data['ref_logprobs'],\n",
- " 'objective/kl_coef': kl_coef,\n",
- " 'objective/entropy': mean_entropy,\n",
- " 'ppo/mean_non_score_reward': mean_non_score_reward,\n",
- " }\n",
- "\n",
- " for k, v in data['train_stats'].items():\n",
- " stats[f'ppo/{k}'] = torch.mean(v, axis=0)\n",
- " stats['ppo/val/var_explained'] = 1 - stats['ppo/val/error'] / stats['ppo/returns/var']\n",
- " return stats\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Tensor shapes and contents"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "Debugging tensor shapes and contents usually involves inserting a lot of print statements in the code. To avoid this in the future I add a list of the tensor shapes and contents for reference. If the tensors are sliced or reshaped I list the last shape.\n",
- "\n",
- "| Name | Shape | Content |\n",
- "|-------|---------|---------|\n",
- "| `query` | `[batch_size, query_length]`| contains token ids of query|\n",
- "| `response`| `[batch_size, response_length]`| contains token ids of responses|\n",
- "| `scores`| `[batch_size]`| rewards of each query/response pair|\n",
- "| `model_input`| `[batch_size, query_length + response_length]`| combined query and response tokens|\n",
- "| `m_input`|`[forward_batch_size, query_length + response_length]`| small forward batch of model_input|\n",
- "| `logits` | `[forward_batch_size, query_length + response_length, vocab_size]`| logits from model outputs|\n",
- "| `ref_logits`|`[forward_batch_size, query_length + response_length, vocab_size]`| logits from ref_model outputs|\n",
- "| `logprobs`| `[batch_size, response_length]`| log-probabilities of response tokens |\n",
- "| `ref_logprobs`| `[batch_size, response_length]`| reference log-probabilities of response tokens |\n",
- "| `rewards`| `[batch_size, response_length]`| the model rewards incl. kl-score for each token|\n",
- "| `non_score_reward`| `[batch_size, response_length]`| the model kl-score for each token|"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Model output alignments\n",
- "Some notes on output alignments, since I spent a considerable time debugging this. All model outputs are shifted by 1 to the model inputs. That means that the logits are shifted by one as well as values. For this reason the logits and values are always shifted one step to the left. This also means we don't have logits for the first input element and so we delete the first input token when calculating the softmax, since we don't have logits predictions. The same applies for the values and we shift them by index one to the left."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## KL-divergence\n",
- "One question that came up during the implementation was \"Why is the KL-divergence just the difference of the log-probs? Where is the probability in front of the log term?\". The answer can be found in Sergey Levine's [lecture slides](http://rll.berkeley.edu/deeprlcourse/docs/week_3_lecture_1_dynamics_learning.pdf): To calculate the KL divergence we calculate the expected value of the log term. The probability usually in front of the log-term comes from that expected value and for a set of trajectories we can simply take the mean over the sampled trajectories."
- ]
- }
- ],
- "metadata": {
- "kernelspec": {
- "display_name": "Python 3 (ipykernel)",
- "language": "python",
- "name": "python3"
- }
- },
- "nbformat": 4,
- "nbformat_minor": 4
-}
diff --git a/nbs/images/gpt2-ctrl-training-setup.png b/nbs/images/gpt2-ctrl-training-setup.png
deleted file mode 100644
index b66cf54755c..00000000000
Binary files a/nbs/images/gpt2-ctrl-training-setup.png and /dev/null differ
diff --git a/nbs/images/gpt2-ctrl-training-stats.png b/nbs/images/gpt2-ctrl-training-stats.png
deleted file mode 100644
index 9ba32a81a0a..00000000000
Binary files a/nbs/images/gpt2-ctrl-training-stats.png and /dev/null differ
diff --git a/nbs/images/gpt2_bert_training.png b/nbs/images/gpt2_bert_training.png
deleted file mode 100644
index 76dd8954374..00000000000
Binary files a/nbs/images/gpt2_bert_training.png and /dev/null differ
diff --git a/nbs/images/gpt2_tuning_progress.png b/nbs/images/gpt2_tuning_progress.png
deleted file mode 100644
index 839ddd73701..00000000000
Binary files a/nbs/images/gpt2_tuning_progress.png and /dev/null differ
diff --git a/nbs/images/table_imdb_preview.png b/nbs/images/table_imdb_preview.png
deleted file mode 100644
index 5de077d794e..00000000000
Binary files a/nbs/images/table_imdb_preview.png and /dev/null differ
diff --git a/nbs/images/trl_overview.png b/nbs/images/trl_overview.png
deleted file mode 100644
index f383157ce30..00000000000
Binary files a/nbs/images/trl_overview.png and /dev/null differ
diff --git a/nbs/index.ipynb b/nbs/index.ipynb
deleted file mode 100644
index 47a72b64c9a..00000000000
--- a/nbs/index.ipynb
+++ /dev/null
@@ -1,196 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "# Welcome to Transformer Reinforcement Learning (trl)\n",
- "\n",
- "> Train transformer language models with reinforcement learning."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## What is it?\n",
- "With `trl` you can train transformer language models with Proximal Policy Optimization (PPO). The library is built on top of the [`transformer`](https://github.com/huggingface/transformers) library by 🤗 Hugging Face. Therefore, pre-trained language models can be directly loaded via `transformers`. At this point only decoder architectures such as GTP2 are implemented.\n",
- "\n",
- "**Highlights:**\n",
- "- PPOTrainer: A PPO trainer for language models that just needs (query, response, reward) triplets to optimise the language model.\n",
- "- GPT2 model with a value head: A transformer model with an additional scalar output for each token which can be used as a value function in reinforcement learning.\n",
- "- Example: Train GPT2 to generate positive movie reviews with a BERT sentiment classifier."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## How it works\n",
- "Fine-tuning a language model via PPO consists of roughly three steps:\n",
- "\n",
- "1. **Rollout**: The language model generates a response or continuation based on query which could be the start of a sentence.\n",
- "2. **Evaluation**: The query and response are evaluated with a function, model, human feedback or some combination of them. The important thing is that this process should yield a scalar value for each query/response pair.\n",
- "3. **Optimization**: This is the most complex part. In the optimisation step the query/response pairs are used to calculate the log-probabilities of the tokens in the sequences. This is done with the model that is trained and and a reference model, which is usually the pre-trained model before fine-tuning. The KL-divergence between the two outputs is used as an additional reward signal to make sure the generated responses don't deviate to far from the reference language model. The active language model is then trained with PPO.\n",
- "\n",
- "This process is illustrated in the sketch below:\n",
- "\n",
- "\n",
- "
\n",
- "\n",
- "
Figure: Sketch of the workflow.
\n",
- "
"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Installation"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### Python package\n",
- "Install the library with pip:\n",
- "```bash\n",
- "pip install trl\n",
- "```\n",
- "\n",
- "### From source\n",
- "If you want to run the examples in the repository a few additional libraries are required. Clone the repository and install it with pip:\n",
- "```bash\n",
- "git clone https://github.com/lvwerra/trl.git\n",
- "cd tlr/\n",
- "pip install -r requirements.txt\n",
- "```\n",
- "### Jupyter notebooks\n",
- "\n",
- "If you run Jupyter notebooks you might need to run the following:\n",
- "```bash\n",
- "jupyter nbextension enable --py --sys-prefix widgetsnbextension\n",
- "```\n",
- "\n",
- "For Jupyterlab additionally this command:\n",
- "\n",
- "```bash\n",
- "jupyter labextension install @jupyter-widgets/jupyterlab-manager\n",
- "```"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## How to use"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### Example\n",
- "This is a basic example on how to use the library. Based on a query the language model creates a response which is then evaluated. The evaluation could be a human in the loop or another model's output."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "# imports\n",
- "import torch\n",
- "from transformers import GPT2Tokenizer\n",
- "from trl.gpt2 import GPT2HeadWithValueModel, respond_to_batch\n",
- "from trl.ppo import PPOTrainer\n",
- "\n",
- "# get models\n",
- "gpt2_model = GPT2HeadWithValueModel.from_pretrained('gpt2')\n",
- "gpt2_model_ref = GPT2HeadWithValueModel.from_pretrained('gpt2')\n",
- "gpt2_tokenizer = GPT2Tokenizer.from_pretrained('gpt2')\n",
- "\n",
- "# initialize trainer\n",
- "ppo_config = {'batch_size': 1, 'forward_batch_size': 1}\n",
- "ppo_trainer = PPOTrainer(gpt2_model, gpt2_model_ref, gpt2_tokenizer, **ppo_config)\n",
- "\n",
- "# encode a query\n",
- "query_txt = \"This morning I went to the \"\n",
- "query_tensor = gpt2_tokenizer.encode(query_txt, return_tensors=\"pt\")\n",
- "\n",
- "# get model response\n",
- "response_tensor = respond_to_batch(gpt2_model, query_tensor)\n",
- "response_txt = gpt2_tokenizer.decode(response_tensor[0,:])\n",
- "\n",
- "# define a reward for response\n",
- "# (this could be any reward such as human feedback or output from another model)\n",
- "reward = [torch.tensor(1.0)]\n",
- "\n",
- "# train model with ppo\n",
- "train_stats = ppo_trainer.step([query_tensor[0]], [response_tensor[0]], reward)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### Advanced example: IMDB sentiment\n",
- "For a detailed example check out the notebook `04-gpt2-sentiment-ppo-training.ipynb`, where GPT2 is fine-tuned to generate positive movie reviews. An few examples from the language models before and after optimisation are given below:\n",
- "\n",
- "
\n",
- "\n",
- "
Figure: A few review continuations before and after optimisation.
\n",
- "
\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Notebooks\n",
- "This library is built with `nbdev` and as such all the library code as well as examples are in Jupyter notebooks. The following list gives an overview:\n",
- "\n",
- "- `index.ipynb`: Generates the README and the overview page.\n",
- "- `00-core.ipynb`: Contains the utility functions used throughout the library and examples.\n",
- "- `01-gpt2-with-value-head.ipynb`: Implementation of a `transformer` compatible GPT2 model with an additional value head as well as a function to generate sequences.\n",
- "- `02-ppo.ipynb`: Implementation of the PPOTrainer used to train language models.\n",
- "- `03-bert-imdb-training.ipynb`: Training of DistilBERT to classify sentiment on the IMDB dataset.\n",
- "- `04-gpt2-sentiment-ppo-training.ipynb`: Fine-tune GPT2 with the BERT sentiment classifier to produce positive movie reviews.\n",
- "\n",
- "Currently using `trl==0.0.3`:\n",
- "- `05-gpt2-sentiment-control.ipynb`: Fine-tune GPT2 with the BERT sentiment classifier to produce movie reviews with controlled sentiment."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## References\n",
- "\n",
- "### Proximal Policy Optimisation\n",
- "The PPO implementation largely follows the structure introduced in the paper **\"Fine-Tuning Language Models from Human Preferences\"** by D. Ziegler et al. \\[[paper](https://arxiv.org/pdf/1909.08593.pdf), [code](https://github.com/openai/lm-human-preferences)].\n",
- "\n",
- "### Language models\n",
- "The language models utilize the `transformers` library by 🤗 Hugging Face."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": []
- }
- ],
- "metadata": {
- "kernelspec": {
- "display_name": "Python 3 (ipykernel)",
- "language": "python",
- "name": "python3"
- }
- },
- "nbformat": 4,
- "nbformat_minor": 4
-}
diff --git a/requirements.txt b/requirements.txt
index 1d2a185b5c1..dccba71ddd4 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -1,10 +1,9 @@
-e .
pandas==1.3.5
jupyterlab==2.2.10
-nbdev==0.2.16
datasets==1.17.0
torch>=1.4.0
tqdm
-transformers==4.15.0
+transformers
wandb==0.10.20
matplotlib==3.5.1
diff --git a/trl/_nbdev.py b/trl/_nbdev.py
deleted file mode 100644
index af304e114b5..00000000000
--- a/trl/_nbdev.py
+++ /dev/null
@@ -1,34 +0,0 @@
-# AUTOGENERATED BY NBDEV! DO NOT EDIT!
-
-__all__ = ["index", "modules", "custom_doc_links", "git_url"]
-
-index = {"WANDB_PADDING": "00-core.ipynb",
- "flatten_dict": "00-core.ipynb",
- "stack_dicts": "00-core.ipynb",
- "add_suffix": "00-core.ipynb",
- "pad_to_size": "00-core.ipynb",
- "logprobs_from_logits": "00-core.ipynb",
- "whiten": "00-core.ipynb",
- "clip_by_value": "00-core.ipynb",
- "entropy_from_logits": "00-core.ipynb",
- "average_torch_dicts": "00-core.ipynb",
- "stats_to_np": "00-core.ipynb",
- "listify_batch": "00-core.ipynb",
- "build_bert_batch_from_txt": "00-core.ipynb",
- "CausalLMOutputWithCrossAttentions": "01-gpt2-with-value-head.ipynb",
- "ValueHead": "01-gpt2-with-value-head.ipynb",
- "GPT2HeadWithValueModel": "01-gpt2-with-value-head.ipynb",
- "respond_to_batch": "01-gpt2-with-value-head.ipynb",
- "AdaptiveKLController": "02-ppo.ipynb",
- "FixedKLController": "02-ppo.ipynb",
- "PPOTrainer": "02-ppo.ipynb"}
-
-modules = ["core.py",
- "gpt2.py",
- "ppo.py"]
-
-doc_url = "https://lvwerra.github.io/trl/"
-
-git_url = "https://github.com/lvwerra/trl/tree/master/"
-
-def custom_doc_links(name): return None
diff --git a/trl/core.py b/trl/core.py
index 38c36b1e8b6..30ca719a1ab 100644
--- a/trl/core.py
+++ b/trl/core.py
@@ -1,10 +1,3 @@
-# AUTOGENERATED! DO NOT EDIT! File to edit: nbs/00-core.ipynb (unless otherwise specified).
-
-__all__ = ['WANDB_PADDING', 'flatten_dict', 'stack_dicts', 'add_suffix', 'pad_to_size', 'logprobs_from_logits',
- 'whiten', 'clip_by_value', 'entropy_from_logits', 'average_torch_dicts', 'stats_to_np', 'listify_batch',
- 'build_bert_batch_from_txt']
-
-# Cell
import torch
import torch.nn.functional as F
from torch.nn.utils.rnn import pad_sequence
@@ -12,10 +5,9 @@
import collections
import numpy as np
-# Cell
+
WANDB_PADDING = -1
-# Cell
def flatten_dict(nested, sep='/'):
"""Flatten dictionary and concatenate nested keys with separator."""
@@ -43,7 +35,6 @@ def add_suffix(input_dict, suffix):
"""Add suffix to dict keys."""
return dict((k + suffix, v) for k,v in input_dict.items())
-# Cell
def pad_to_size(tensor, size, dim=1, padding=50256):
"""Pad tensor to size."""
@@ -108,7 +99,6 @@ def listify_batch(tensor):
"""Turns the first dimension of a tensor into a list."""
return [tensor[i] for i in range(tensor.shape[0])]
-# Cell
def build_bert_batch_from_txt(text_list, tokenizer, device):
"""Create token id and attention mask tensors from text list for BERT classification."""
diff --git a/trl/gpt2.py b/trl/gpt2.py
index 707361e6d88..827c1031720 100644
--- a/trl/gpt2.py
+++ b/trl/gpt2.py
@@ -104,6 +104,7 @@ def forward(
return_dict=False,
output_attentions=False,
output_hidden_states=False,
+ use_cache=True,
):
loss=None
transformer_outputs = self.transformer(
@@ -114,6 +115,7 @@ def forward(
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
)
hidden_states = transformer_outputs[0]
@@ -123,7 +125,7 @@ def forward(
if not return_dict:
- outputs = (lm_logits,) + transformer_outputs[1:] + (value,)
+ outputs = (lm_logits, loss, value,)
return outputs
return CausalLMOutputWithCrossAttentions(
@@ -135,7 +137,34 @@ def forward(
cross_attentions=transformer_outputs.cross_attentions,
value=value,
)
- return outputs
+
+ def prepare_inputs_for_generation(self, input_ids, past=None, **kwargs):
+ token_type_ids = kwargs.get("token_type_ids", None)
+ # only last token for inputs_ids if past is defined in kwargs
+ if past:
+ input_ids = input_ids[:, -1].unsqueeze(-1)
+ if token_type_ids is not None:
+ token_type_ids = token_type_ids[:, -1].unsqueeze(-1)
+
+ attention_mask = kwargs.get("attention_mask", None)
+ position_ids = kwargs.get("position_ids", None)
+
+ if attention_mask is not None and position_ids is None:
+ # create position_ids on the fly for batch generation
+ position_ids = attention_mask.long().cumsum(-1) - 1
+ position_ids.masked_fill_(attention_mask == 0, 1)
+ if past:
+ position_ids = position_ids[:, -1].unsqueeze(-1)
+ else:
+ position_ids = None
+ return {
+ "input_ids": input_ids,
+ "past_key_values": past,
+ "use_cache": kwargs.get("use_cache"),
+ "position_ids": position_ids,
+ "attention_mask": attention_mask,
+ "token_type_ids": token_type_ids,
+ }
# Cell
 +
+
 +
+
 \n",
+ "
\n",
+ " \n",
"
\n",
" \n",
+ "
\n",
+ " \n",
"
\n",
" \n",
+ "
\n",
+ " \n",
"
\n",
" \n",
+ "
\n",
+ " \n",
"
\n",
" \n",
- "
\n",
- " \n",
- "
\n",
- "