diff --git a/README.md b/README.md
index 98cfe0e30b4..88c6db10fc9 100644
--- a/README.md
+++ b/README.md
@@ -113,18 +113,13 @@ trainer.train()
```python
from datasets import load_dataset
-from transformers import AutoModelForCausalLM, AutoTokenizer
-from trl import DPOConfig, DPOTrainer
+from trl import DPOTrainer
-model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-0.5B-Instruct")
-tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-0.5B-Instruct")
dataset = load_dataset("trl-lib/ultrafeedback_binarized", split="train")
-training_args = DPOConfig(output_dir="Qwen2.5-0.5B-DPO")
+
trainer = DPOTrainer(
- model=model,
- args=training_args,
+ model="Qwen3/Qwen-0.6B",
train_dataset=dataset,
- processing_class=tokenizer
)
trainer.train()
```
diff --git a/docs/source/bema_for_reference_model.md b/docs/source/bema_for_reference_model.md
index 832acfc932c..896e642a347 100644
--- a/docs/source/bema_for_reference_model.md
+++ b/docs/source/bema_for_reference_model.md
@@ -7,26 +7,16 @@ This feature implements the BEMA algorithm to update the reference model during
```python
from trl.experimental.bema_for_ref_model import BEMACallback, DPOTrainer
from datasets import load_dataset
-from transformers import AutoModelForCausalLM, AutoTokenizer
-
-pref_dataset = load_dataset("trl-internal-testing/zen", "standard_preference", split="train")
-ref_model = AutoModelForCausalLM.from_pretrained("trl-internal-testing/tiny-Qwen2ForCausalLM-2.5")
+dataset = load_dataset("trl-internal-testing/zen", "standard_preference", split="train")
bema_callback = BEMACallback(update_ref_model=True)
-model = AutoModelForCausalLM.from_pretrained("trl-internal-testing/tiny-Qwen2ForCausalLM-2.5")
-tokenizer = AutoTokenizer.from_pretrained("trl-internal-testing/tiny-Qwen2ForCausalLM-2.5")
-tokenizer.pad_token = tokenizer.eos_token
-
trainer = DPOTrainer(
- model=model,
- ref_model=ref_model,
- train_dataset=pref_dataset,
- processing_class=tokenizer,
+ model="trl-internal-testing/tiny-Qwen2ForCausalLM-2.5",
+ train_dataset=dataset,
callbacks=[bema_callback],
)
-
trainer.train()
```
diff --git a/docs/source/customization.md b/docs/source/customization.md
index 19ba1088fd1..7ae44d0e51d 100644
--- a/docs/source/customization.md
+++ b/docs/source/customization.md
@@ -1,32 +1,27 @@
# Training customization
-TRL is designed with modularity in mind so that users are able to efficiently customize the training loop for their needs. Below are examples on how you can apply and test different techniques.
+TRL is designed with modularity in mind so that users are able to efficiently customize the training loop for their needs. Below are examples on how you can apply and test different techniques.
> [!NOTE]
> Although these examples use the [`DPOTrainer`], these customization methods apply to most (if not all) trainers in TRL.
## Use different optimizers and schedulers
-By default, the `DPOTrainer` creates a `torch.optim.AdamW` optimizer. You can create and define a different optimizer and pass it to `DPOTrainer` as follows:
+By default, the [`DPOTrainer`] creates a `torch.optim.AdamW` optimizer. You can create and define a different optimizer and pass it to [`DPOTrainer`] as follows:
```python
from datasets import load_dataset
-from transformers import AutoModelForCausalLM, AutoTokenizer
from torch import optim
-from trl import DPOConfig, DPOTrainer
+from transformers import AutoModelForCausalLM
+from trl import DPOTrainer
-model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-0.5B-Instruct")
-tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-0.5B-Instruct")
dataset = load_dataset("trl-lib/ultrafeedback_binarized", split="train")
-training_args = DPOConfig(output_dir="Qwen2.5-0.5B-DPO")
-
-optimizer = optim.SGD(model.parameters(), lr=training_args.learning_rate)
+model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-0.5B-Instruct")
+optimizer = optim.SGD(model.parameters(), lr=1e-6)
trainer = DPOTrainer(
model=model,
- args=training_args,
train_dataset=dataset,
- tokenizer=tokenizer,
optimizers=(optimizer, None),
)
trainer.train()
@@ -39,7 +34,7 @@ You can also add learning rate schedulers by passing both optimizer and schedule
```python
from torch import optim
-optimizer = optim.AdamW(model.parameters(), lr=training_args.learning_rate)
+optimizer = optim.AdamW(model.parameters(), lr=1e-6)
lr_scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
trainer = DPOTrainer(..., optimizers=(optimizer, lr_scheduler))
@@ -50,7 +45,7 @@ trainer = DPOTrainer(..., optimizers=(optimizer, lr_scheduler))
Another tool you can use for more memory efficient fine-tuning is to share layers between the reference model and the model you want to train.
```python
-from trl import create_reference_model
+from trl.experimental.utils import create_reference_model
ref_model = create_reference_model(model, num_shared_layers=6)
diff --git a/docs/source/dpo_trainer.md b/docs/source/dpo_trainer.md
index 2d618c7a96b..fc7fb3d1a64 100644
--- a/docs/source/dpo_trainer.md
+++ b/docs/source/dpo_trainer.md
@@ -1,148 +1,162 @@
# DPO Trainer
-[](https://huggingface.co/models?other=dpo,trl) [](https://github.com/huggingface/smol-course/tree/main/2_preference_alignment)
+[](https://huggingface.co/models?other=dpo,trl) [](https://github.com/huggingface/smol-course/tree/main/2_preference_alignment)
## Overview
-TRL supports the DPO Trainer for training language models from preference data, as described in the paper [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://huggingface.co/papers/2305.18290) by [Rafael Rafailov](https://huggingface.co/rmrafailov), Archit Sharma, Eric Mitchell, [Stefano Ermon](https://huggingface.co/ermonste), [Christopher D. Manning](https://huggingface.co/manning), [Chelsea Finn](https://huggingface.co/cbfinn).
+TRL supports the Direct Preference Optimization (DPO) Trainer for training language models, as described in the paper [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://huggingface.co/papers/2305.18290) by [Rafael Rafailov](https://huggingface.co/rmrafailov), Archit Sharma, Eric Mitchell, [Stefano Ermon](https://huggingface.co/ermonste), [Christopher D. Manning](https://huggingface.co/manning), [Chelsea Finn](https://huggingface.co/cbfinn).
The abstract from the paper is the following:
> While large-scale unsupervised language models (LMs) learn broad world knowledge and some reasoning skills, achieving precise control of their behavior is difficult due to the completely unsupervised nature of their training. Existing methods for gaining such steerability collect human labels of the relative quality of model generations and fine-tune the unsupervised LM to align with these preferences, often with reinforcement learning from human feedback (RLHF). However, RLHF is a complex and often unstable procedure, first fitting a reward model that reflects the human preferences, and then fine-tuning the large unsupervised LM using reinforcement learning to maximize this estimated reward without drifting too far from the original model. In this paper we introduce a new parameterization of the reward model in RLHF that enables extraction of the corresponding optimal policy in closed form, allowing us to solve the standard RLHF problem with only a simple classification loss. The resulting algorithm, which we call Direct Preference Optimization (DPO), is stable, performant, and computationally lightweight, eliminating the need for sampling from the LM during fine-tuning or performing significant hyperparameter tuning. Our experiments show that DPO can fine-tune LMs to align with human preferences as well as or better than existing methods. Notably, fine-tuning with DPO exceeds PPO-based RLHF in ability to control sentiment of generations, and matches or improves response quality in summarization and single-turn dialogue while being substantially simpler to implement and train.
-The first step is to train an SFT model, to ensure the data we train on is in-distribution for the DPO algorithm.
-
-Then, fine-tuning a language model via DPO consists of two steps and is easier than [PPO](ppo_trainer):
-
-1. **Data collection**: Gather a [preference dataset](dataset_formats#preference) with positive and negative selected pairs of generation, given a prompt.
-2. **Optimization**: Maximize the log-likelihood of the DPO loss directly.
-
-This process is illustrated in the sketch below (from [Figure 1 of the DPO paper](https://huggingface.co/papers/2305.18290)):
-
-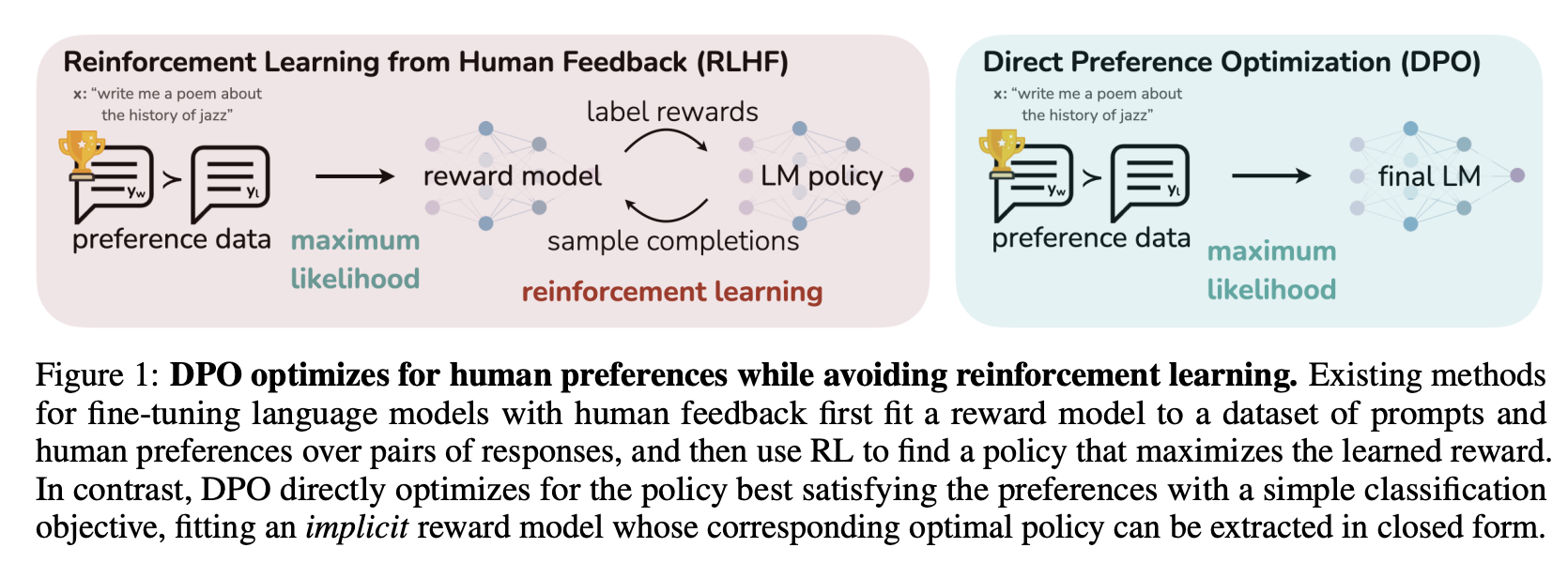
-
-Read more about DPO algorithm in the [original paper](https://huggingface.co/papers/2305.18290).
+This post-training method was contributed by [Kashif Rasul](https://huggingface.co/kashif) and later refactored by [Quentin Gallouédec](https://huggingface.co/qgallouedec).
## Quick start
-This example demonstrates how to train a model using the DPO method. We use the [Qwen 0.5B model](https://huggingface.co/Qwen/Qwen2-0.5B-Instruct) as the base model. We use the preference data from the [UltraFeedback dataset](https://huggingface.co/datasets/openbmb/UltraFeedback). You can view the data in the dataset here:
-
-
-
-Below is the script to train the model:
+This example demonstrates how to train a language model using the [`DPOTrainer`] from TRL. We train a [Qwen 3 0.6B](https://huggingface.co/Qwen/Qwen3-0.6B) model on the [UltraFeedback dataset](https://huggingface.co/datasets/openbmb/UltraFeedback).
```python
-# train_dpo.py
+from trl import DPOTrainer
from datasets import load_dataset
-from trl import DPOConfig, DPOTrainer
-from transformers import AutoModelForCausalLM, AutoTokenizer
-model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
-tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
-train_dataset = load_dataset("trl-lib/ultrafeedback_binarized", split="train")
-
-training_args = DPOConfig(output_dir="Qwen2-0.5B-DPO")
-trainer = DPOTrainer(model=model, args=training_args, processing_class=tokenizer, train_dataset=train_dataset)
+trainer = DPOTrainer(
+ model="Qwen/Qwen3-0.6B",
+ train_dataset=load_dataset("trl-lib/ultrafeedback_binarized", split="train"),
+)
trainer.train()
```
-Execute the script using the following command:
-
-```bash
-accelerate launch train_dpo.py
-```
-
-Distributed across 8 GPUs, the training takes approximately 3 minutes. You can verify the training progress by checking the reward graph. An increasing trend in the reward margin indicates that the model is improving and generating better responses over time.
-
-
+
-To see how the [trained model](https://huggingface.co/trl-lib/Qwen2-0.5B-DPO) performs, you can use the [Transformers Chat CLI](https://huggingface.co/docs/transformers/quicktour#chat-with-text-generation-models).
+## Expected dataset type and format
-$ transformers chat trl-lib/Qwen2-0.5B-DPO
-<shirin_yamani>:
-What is Huggingface?
+DPO requires a [preference](dataset_formats#preference) dataset. The [`DPOTrainer`] is compatible with both [standard](dataset_formats#standard) and [conversational](dataset_formats#conversational) dataset formats. When provided with a conversational dataset, the trainer will automatically apply the chat template to the dataset.
-<trl-lib/Qwen2-0.5B-DPO>:
-Huggingface is a platform that allows users to access a variety of open-source machine learning resources such as pre-trained models and datasets Huggingface is a platform that allows users to access a variety of open-source machine learning resources such as pre-trained models and datasets for the development of machine learning models and applications. It provides a repository of over 300, 000 pre-trained models in Huggingface is a platform that allows users to access a variety of open-source machine learning resources such as pre-trained models and datasets for the development of machine learning models and applications. It provides a repository of over 300, 000 pre-trained models in a variety of languages, enabling users to explore and utilize the latest techniques and technologies in the field of machine learning.
-
-
-## Expected dataset type
+```python
+# Standard format
+## Explicit prompt (recommended)
+preference_example = {"prompt": "The sky is", "chosen": " blue.", "rejected": " green."}
+# Implicit prompt
+preference_example = {"chosen": "The sky is blue.", "rejected": "The sky is green."}
+
+# Conversational format
+## Explicit prompt (recommended)
+preference_example = {"prompt": [{"role": "user", "content": "What color is the sky?"}],
+ "chosen": [{"role": "assistant", "content": "It is blue."}],
+ "rejected": [{"role": "assistant", "content": "It is green."}]}
+## Implicit prompt
+preference_example = {"chosen": [{"role": "user", "content": "What color is the sky?"},
+ {"role": "assistant", "content": "It is blue."}],
+ "rejected": [{"role": "user", "content": "What color is the sky?"},
+ {"role": "assistant", "content": "It is green."}]}
+```
-DPO requires a [preference dataset](dataset_formats#preference). The [`DPOTrainer`] supports both [conversational](dataset_formats#conversational) and [standard](dataset_formats#standard) dataset formats. When provided with a conversational dataset, the trainer will automatically apply the chat template to the dataset.
+If your dataset is not in one of these formats, you can preprocess it to convert it into the expected format. Here is an example with the [Vezora/Code-Preference-Pairs](https://huggingface.co/datasets/Vezora/Code-Preference-Pairs) dataset:
-Although the [`DPOTrainer`] supports both explicit and implicit prompts, we recommend using explicit prompts. If provided with an implicit prompt dataset, the trainer will automatically extract the prompt from the `"chosen"` and `"rejected"` columns. For more information, refer to the [preference style](dataset_formats#preference) section.
+```python
+from datasets import load_dataset
-### Special considerations for vision-language models
+dataset = load_dataset("Vezora/Code-Preference-Pairs")
-The [`DPOTrainer`] supports fine-tuning vision-language models (VLMs). For these models, a vision dataset is required. To learn more about the specific format for vision datasets, refer to the [Vision dataset format](dataset_formats#vision-datasets) section.
-Additionally, unlike standard text-based models where a `tokenizer` is used, for VLMs, you should replace the `tokenizer` with a `processor`.
+def preprocess_function(example):
+ return {
+ "prompt": [{"role": "user", "content": example["input"]}],
+ "chosen": [{"role": "assistant", "content": example["accepted"]}],
+ "rejected": [{"role": "assistant", "content": example["rejected"]}],
+ }
-```diff
-- model = AutoModelForCausalLM.from_pretrained(model_id)
-+ model = AutoModelForImageTextToText.from_pretrained(model_id)
-- tokenizer = AutoTokenizer.from_pretrained(model_id)
-+ processor = AutoProcessor.from_pretrained(model_id)
+dataset = dataset.map(preprocess_function, remove_columns=["instruction", "input", "accepted", "ID"])
+print(next(iter(dataset["train"])))
+```
- trainer = DPOTrainer(
- model,
- args=training_args,
- train_dataset=train_dataset,
-- processing_class=tokenizer,
-+ processing_class=processor,
-)
+```json
+{
+ "prompt": [{"role": "user", "content": "Create a nested loop to print every combination of numbers [...]"}],
+ "chosen": [{"role": "assistant", "content": "Here is an example of a nested loop in Python [...]"}],
+ "rejected": [{"role": "assistant", "content": "Here is an example of a nested loop in Python [...]"}],
+}
```
-For a complete example of fine-tuning a vision-language model, refer to the script in [`examples/scripts/dpo_vlm.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/dpo_vlm.py).
+## Looking deeper into the DPO method
-## Example script
+Direct Preference Optimization (DPO) is a training method designed to align a language model with preference data. Instead of supervised input–output pairs, the model is trained on pairs of completions to the same prompt, where one completion is preferred over the other. The objective directly optimizes the model to assign higher likelihood to preferred completions than to dispreferred ones, relative to a reference model, without requiring an explicit reward model.
-We provide an example script to train a model using the DPO method. The script is available in [`trl/scripts/dpo.py`](https://github.com/huggingface/trl/blob/main/trl/scripts/dpo.py)
+This section breaks down how DPO works in practice, covering the key steps: **preprocessing** and **loss computation**.
-To test the DPO script with the [Qwen2 0.5B model](https://huggingface.co/Qwen/Qwen2-0.5B-Instruct) on the [UltraFeedback dataset](https://huggingface.co/datasets/trl-lib/ultrafeedback_binarized), run the following command:
+### Preprocessing and tokenization
-```bash
-accelerate launch trl/scripts/dpo.py \
- --model_name_or_path Qwen/Qwen2-0.5B-Instruct \
- --dataset_name trl-lib/ultrafeedback_binarized \
- --num_train_epochs 1 \
- --output_dir Qwen2-0.5B-DPO
-```
+During training, each example is expected to contain a prompt along with a preferred (`chosen`) and a dispreferred (`rejected`) completion. For more details on the expected formats, see [Dataset formats](dataset_formats).
+The [`DPOTrainer`] tokenizes each input using the model's tokenizer.
-## Logged metrics
+### Computing the loss
-While training and evaluating, we record the following reward metrics:
+
-- `rewards/chosen`: the mean difference between the log probabilities of the policy model and the reference model for the chosen responses scaled by beta
-- `rewards/rejected`: the mean difference between the log probabilities of the policy model and the reference model for the rejected responses scaled by beta
-- `rewards/accuracies`: mean of how often the chosen rewards are > than the corresponding rejected rewards
-- `rewards/margins`: the mean difference between the chosen and corresponding rejected rewards
+The loss used in DPO is defined as follows:
+$$
+\mathcal{L}_{\mathrm{DPO}}(\theta) = -\mathbb{E}_{(x,y^{+},y^{-})}\!\left[\log \sigma\!\left(\beta\Big(\log\frac{{\pi_{\theta}(y^{+}\!\mid x)}}{{\pi_{\mathrm{ref}}(y^{+}\!\mid x)}}-\log \frac{{\pi_{\theta}(y^{-}\!\mid x)}}{{\pi_{\mathrm{ref}}(y^{-}\!\mid x)}}\Big)\right)\right]
+$$
+
+where \\( x \\) is the prompt, \\( y^+ \\) is the preferred completion and \\( y^- \\) is the dispreferred completion. \\( \pi_{\theta} \\) is the policy model being trained, \\( \pi_{\mathrm{ref}} \\) is the reference model, \\( \sigma \\) is the sigmoid function, and \\( \beta > 0 \\) is a hyperparameter that controls the strength of the preference signal.
-## Loss functions
+#### Loss Types
-The DPO algorithm supports several loss functions. The loss function can be set using the `loss_type` parameter in the [`DPOConfig`]. The following loss functions are supported:
+Several formulations of the objective have been proposed in the literature. Initially, the objective of DPO was defined as presented above.
| `loss_type=` | Description |
| --- | --- |
| `"sigmoid"` (default) | Given the preference data, we can fit a binary classifier according to the Bradley-Terry model and in fact the [DPO](https://huggingface.co/papers/2305.18290) authors propose the sigmoid loss on the normalized likelihood via the `logsigmoid` to fit a logistic regression. |
| `"hinge"` | The [RSO](https://huggingface.co/papers/2309.06657) authors propose to use a hinge loss on the normalized likelihood from the [SLiC](https://huggingface.co/papers/2305.10425) paper. In this case, the `beta` is the reciprocal of the margin. |
-| `"ipo"` | The [IPO](https://huggingface.co/papers/2310.12036) authors provide a deeper theoretical understanding of the DPO algorithms and identify an issue with overfitting and propose an alternative loss. In this case, the `beta` is the reciprocal of the gap between the log-likelihood ratios of the chosen vs the rejected completion pair and thus the smaller the `beta` the larger this gaps is. As per the paper the loss is averaged over log-likelihoods of the completion (unlike DPO which is summed only). |
-| `"exo_pair"` | The [EXO](https://huggingface.co/papers/2402.00856) authors propose to minimize the reverse KL instead of the negative log-sigmoid loss of DPO which corresponds to forward KL. Setting non-zero `label_smoothing` (default `1e-3`) leads to a simplified version of EXO on pair-wise preferences (see Eqn. (16) of the [EXO paper](https://huggingface.co/papers/2402.00856)). The full version of EXO uses `K>2` completions generated by the SFT policy, which becomes an unbiased estimator of the PPO objective (up to a constant) when `K` is sufficiently large. |
+| `"ipo"` | The [IPO](https://huggingface.co/papers/2310.12036) authors argue the logit transform can overfit and propose the identity transform to optimize preferences directly; TRL exposes this as `loss_type="ipo"`. |
+| `"exo_pair"` | The [EXO](https://huggingface.co/papers/2402.00856) authors propose reverse-KL preference optimization. `label_smoothing` must be strictly greater than `0.0`; a recommended value is `1e-3` (see Eq. 16 for the simplified pairwise variant). The full method uses `K>2` SFT completions and approaches PPO as `K` grows. |
| `"nca_pair"` | The [NCA](https://huggingface.co/papers/2402.05369) authors shows that NCA optimizes the absolute likelihood for each response rather than the relative likelihood. |
-| `"robust"` | The [Robust DPO](https://huggingface.co/papers/2403.00409) authors propose an unbiased estimate of the DPO loss that is robust to preference noise in the data. Like in cDPO, it assumes that the preference labels are noisy with some probability. In this approach, the `label_smoothing` parameter in the [`DPOConfig`] is used to model the probability of existing label noise. To apply this conservative loss, set `label_smoothing` to a value greater than 0.0 (between 0.0 and 0.5; the default is 0.0) |
+| `"robust"` | The [Robust DPO](https://huggingface.co/papers/2403.00409) authors propose an unbiased DPO loss under noisy preferences. Use `label_smoothing` in [`DPOConfig`] to model label-flip probability; valid values are in the range `[0.0, 0.5)`. |
| `"bco_pair"` | The [BCO](https://huggingface.co/papers/2404.04656) authors train a binary classifier whose logit serves as a reward so that the classifier maps {prompt, chosen completion} pairs to 1 and {prompt, rejected completion} pairs to 0. For unpaired data, we recommend the dedicated [`experimental.bco.BCOTrainer`]. |
| `"sppo_hard"` | The [SPPO](https://huggingface.co/papers/2405.00675) authors claim that SPPO is capable of solving the Nash equilibrium iteratively by pushing the chosen rewards to be as large as 1/2 and the rejected rewards to be as small as -1/2 and can alleviate data sparsity issues. The implementation approximates this algorithm by employing hard label probabilities, assigning 1 to the winner and 0 to the loser. |
-| `"aot"` or `loss_type="aot_unpaired"` | The [AOT](https://huggingface.co/papers/2406.05882) authors propose to use Distributional Preference Alignment Via Optimal Transport. Traditionally, the alignment algorithms use paired preferences at a sample level, which does not ensure alignment on the distributional level. AOT, on the other hand, can align LLMs on paired or unpaired preference data by making the reward distribution of the positive samples stochastically dominant in the first order on the distribution of negative samples. Specifically, `loss_type="aot"` is appropriate for paired datasets, where each prompt has both chosen and rejected responses; `loss_type="aot_unpaired"` is for unpaired datasets. In a nutshell, `loss_type="aot"` ensures that the log-likelihood ratio of chosen to rejected of the aligned model has higher quantiles than that ratio for the reference model. `loss_type="aot_unpaired"` ensures that the chosen reward is higher on all quantiles than the rejected reward. Note that in both cases quantiles are obtained via sorting. To fully leverage the advantages of the AOT algorithm, it is important to maximize the per-GPU batch size. |
-| `"apo_zero"` or `loss_type="apo_down"` | The [APO](https://huggingface.co/papers/2408.06266) method introduces an "anchored" version of the alignment objective. There are two variants: `apo_zero` and `apo_down`. The `apo_zero` loss increases the likelihood of winning outputs while decreasing the likelihood of losing outputs, making it suitable when the model is less performant than the winning outputs. On the other hand, `apo_down` decreases the likelihood of both winning and losing outputs, but with a stronger emphasis on reducing the likelihood of losing outputs. This variant is more effective when the model is better than the winning outputs. |
+| `"aot"` or `loss_type="aot_unpaired"` | The [AOT](https://huggingface.co/papers/2406.05882) authors propose Distributional Preference Alignment via Optimal Transport. `loss_type="aot"` is for paired data; `loss_type="aot_unpaired"` is for unpaired data. Both enforce stochastic dominance via sorted quantiles; larger per-GPU batch sizes help. |
+| `"apo_zero"` or `loss_type="apo_down"` | The [APO](https://huggingface.co/papers/2408.06266) method introduces an anchored objective. `apo_zero` boosts winners and downweights losers (useful when the model underperforms the winners). `apo_down` downweights both, with stronger pressure on losers (useful when the model already outperforms winners). |
| `"discopop"` | The [DiscoPOP](https://huggingface.co/papers/2406.08414) paper uses LLMs to discover more efficient offline preference optimization losses. In the paper the proposed DiscoPOP loss (which is a log-ratio modulated loss) outperformed other optimization losses on different tasks (IMDb positive text generation, Reddit TLDR summarization, and Alpaca Eval 2.0). |
| `"sft"` | SFT (Supervised Fine-Tuning) loss is the negative log likelihood loss, used to train the model to generate preferred responses. |
+## Logged metrics
+
+While training and evaluating we record the following reward metrics:
+
+* `global_step`: The total number of optimizer steps taken so far.
+* `epoch`: The current epoch number, based on dataset iteration.
+* `num_tokens`: The total number of tokens processed so far.
+* `loss`: The average cross-entropy loss computed over non-masked tokens in the current logging interval.
+* `entropy`: The average entropy of the model's predicted token distribution over non-masked tokens.
+* `mean_token_accuracy`: The proportion of non-masked tokens for which the model’s top-1 prediction matches the token from the chosen completion.
+* `learning_rate`: The current learning rate, which may change dynamically if a scheduler is used.
+* `grad_norm`: The L2 norm of the gradients, computed before gradient clipping.
+* `logits/chosen`: The average logit values assigned by the model to the tokens in the chosen completion.
+* `logits/rejected`: The average logit values assigned by the model to the tokens in the rejected completion.
+* `logps/chosen`: The average log-probability assigned by the model to the tokens in the chosen completion.
+* `logps/rejected`: The average log-probability assigned by the model to the tokens in the rejected completion.
+* `rewards/chosen`: The average implicit reward computed for the chosen completion, computed as \\( \beta \log \frac{{\pi_{\theta}(y^{+}\!\mid x)}}{{\pi_{\mathrm{ref}}(y^{+}\!\mid x)}} \\).
+* `rewards/rejected`: The average implicit reward computed for the rejected completion, computed as \\( \beta \log \frac{{\pi_{\theta}(y^{-}\!\mid x)}}{{\pi_{\mathrm{ref}}(y^{-}\!\mid x)}} \\).
+* `rewards/margins`: The average implicit reward margin between the chosen and rejected completions.
+* `rewards/accuracies`: The proportion of examples where the implicit reward for the chosen completion is higher than that for the rejected completion.
+
+## Customization
+
+### Compatibility and constraints
+
+Some argument combinations are intentionally restricted in the current [`DPOTrainer`] implementation:
+
+* `use_weighting=True` is not supported with `loss_type="aot"` or `loss_type="aot_unpaired"`.
+* With `use_liger_kernel=True`:
+ * only a single `loss_type` is supported,
+ * `compute_metrics` is not supported,
+ * `precompute_ref_log_probs=True` is not supported.
+* `sync_ref_model=True` is not supported when training with PEFT models that do not keep a standalone `ref_model`.
+* `sync_ref_model=True` cannot be combined with `precompute_ref_log_probs=True`.
+* `precompute_ref_log_probs=True` is not supported with `IterableDataset` (train or eval).
+
### Multi-loss combinations
The DPO trainer supports combining multiple loss functions with different weights, enabling more sophisticated optimization strategies. This is particularly useful for implementing algorithms like MPO (Mixed Preference Optimization). MPO is a training approach that combines multiple optimization objectives, as described in the paper [Enhancing the Reasoning Ability of Multimodal Large Language Models via Mixed Preference Optimization](https://huggingface.co/papers/2411.10442).
@@ -152,141 +166,123 @@ To combine multiple losses, specify the loss types and corresponding weights as
```python
# MPO: Combines DPO (sigmoid) for preference and BCO (bco_pair) for quality
training_args = DPOConfig(
- loss_type=["sigmoid", "bco_pair", "sft"], # Loss types to combine
- loss_weights=[0.8, 0.2, 1.0] # Corresponding weights, as used in the MPO paper
+ loss_type=["sigmoid", "bco_pair", "sft"], # loss types to combine
+ loss_weights=[0.8, 0.2, 1.0] # corresponding weights, as used in the MPO paper
)
```
-If `loss_weights` is not provided, all loss types will have equal weights (1.0 by default).
-
-### Label smoothing
-
-The [cDPO](https://ericmitchell.ai/cdpo.pdf) is a tweak on the DPO loss where we assume that the preference labels are noisy with some probability. In this approach, the `label_smoothing` parameter in the [`DPOConfig`] is used to model the probability of existing label noise. To apply this conservative loss, set `label_smoothing` to a value greater than 0.0 (between 0.0 and 0.5; the default is 0.0).
+### Model initialization
-### Syncing the reference model
+You can directly pass the kwargs of the [`~transformers.AutoModelForCausalLM.from_pretrained()`] method to the [`DPOConfig`]. For example, if you want to load a model in a different precision, analogous to
-The [TR-DPO](https://huggingface.co/papers/2404.09656) paper suggests syncing the reference model weights after every `ref_model_sync_steps` steps of SGD with weight `ref_model_mixup_alpha` during DPO training. To toggle this callback use the `sync_ref_model=True` in the [`DPOConfig`].
-
-### RPO loss
-
-The [RPO](https://huggingface.co/papers/2404.19733) paper implements an iterative preference tuning algorithm using a loss related to the RPO loss in this [paper](https://huggingface.co/papers/2405.16436) that essentially consists of a weighted SFT loss on the chosen preferences together with the DPO loss. To use this loss, include `"sft"` in the `loss_type` list in the [`DPOConfig`] and set its weight in `loss_weights`.
+```python
+model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen3-0.6B", dtype=torch.bfloat16)
+```
-> [!WARNING]
-> The old implementation of RPO loss in TRL used the `rpo_alpha` parameter. This parameter is deprecated and will be removed in 0.29.0; instead.
+you can do so by passing the `model_init_kwargs={"dtype": torch.bfloat16}` argument to the [`DPOConfig`].
-### WPO loss
+```python
+from trl import DPOConfig
-The [WPO](https://huggingface.co/papers/2406.11827) paper adapts off-policy data to resemble on-policy data more closely by reweighting preference pairs according to their probability under the current policy. To use this method, set the `use_weighting` flag to `True` in the [`DPOConfig`].
+training_args = DPOConfig(
+ model_init_kwargs={"dtype": torch.bfloat16},
+)
+```
-### LD-DPO loss
+Note that all keyword arguments of [`~transformers.AutoModelForCausalLM.from_pretrained()`] are supported.
-The [LD-DPO](https://huggingface.co/papers/2409.06411) paper decomposes the portion of the response that exceeds the desired length into two components — human-like preferences and verbosity preference — based on a mixing coefficient \\( \alpha \\). To use this method, set the `ld_alpha` in the [`DPOConfig`] to an appropriate value. The paper suggests setting this value between `0.0` and `1.0`.
+### Train adapters with PEFT
-### For Mixture of Experts Models: Enabling the auxiliary loss
+We support tight integration with 🤗 PEFT library, allowing any user to conveniently train adapters and share them on the Hub, rather than training the entire model.
-MOEs are the most efficient if the load is about equally distributed between experts.
-To ensure that we train MOEs similarly during preference-tuning, it is beneficial to add the auxiliary loss from the load balancer to the final loss.
+```python
+from datasets import load_dataset
+from trl import DPOTrainer
+from peft import LoraConfig
-This option is enabled by setting `output_router_logits=True` in the model config (e.g. [`~transformers.MixtralConfig`]).
-To scale how much the auxiliary loss contributes to the total loss, use the hyperparameter `router_aux_loss_coef=...` (default: `0.001`) in the model config.
+dataset = load_dataset("trl-lib/ultrafeedback_binarized", split="train")
-### Rapid Experimentation for DPO
+trainer = DPOTrainer(
+ "Qwen/Qwen3-0.6B",
+ train_dataset=dataset,
+ peft_config=LoraConfig(),
+)
-RapidFire AI is an open-source experimentation engine that sits on top of TRL and lets you launch multiple DPO configurations at once, even on a single GPU. Instead of trying configurations sequentially, RapidFire lets you **see all their learning curves earlier, stop underperforming runs, and clone promising ones with new settings in flight** without restarting. For more information, see [RapidFire AI Integration](rapidfire_integration).
+trainer.train()
+```
-## Accelerate DPO fine-tuning using `unsloth`
+You can also continue training your [`~peft.PeftModel`]. For that, first load a `PeftModel` outside [`DPOTrainer`] and pass it directly to the trainer without the `peft_config` argument being passed.
-You can further accelerate QLoRA / LoRA (2x faster, 60% less memory) using the [`unsloth`](https://github.com/unslothai/unsloth) library that is fully compatible with `SFTTrainer`. Currently `unsloth` supports only Llama (Yi, TinyLlama, Qwen, Deepseek etc) and Mistral architectures. Some benchmarks for DPO listed below:
+```python
+from datasets import load_dataset
+from trl import DPOTrainer
+from peft import AutoPeftModelForCausalLM
-| GPU | Model | Dataset | 🤗 | 🤗 + FlashAttention 2 | 🦥 Unsloth | 🦥 VRAM saved |
-| --- | --- | --- | --- | --- | --- | --- |
-| A100 40G | Zephyr 7b | Ultra Chat | 1x | 1.24x | **1.88x** | -11.6% |
-| Tesla T4 | Zephyr 7b | Ultra Chat | 1x | 1.09x | **1.55x** | -18.6% |
+model = AutoPeftModelForCausalLM.from_pretrained("trl-lib/Qwen3-4B-LoRA", is_trainable=True)
+dataset = load_dataset("trl-lib/ultrafeedback_binarized", split="train")
-First install `unsloth` according to the [official documentation](https://github.com/unslothai/unsloth). Once installed, you can incorporate unsloth into your workflow in a very simple manner; instead of loading `AutoModelForCausalLM`, you just need to load a `FastLanguageModel` as follows:
+trainer = DPOTrainer(
+ model=model,
+ train_dataset=dataset,
+)
-```diff
- from datasets import load_dataset
- from trl import DPOConfig, DPOTrainer
-- from transformers import AutoModelForCausalLM, AutoTokenizer
-+ from unsloth import FastLanguageModel
+trainer.train()
+```
-- model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
-- tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
-+ model, tokenizer = FastLanguageModel.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
-+ model = FastLanguageModel.get_peft_model(model)
- train_dataset = load_dataset("trl-lib/ultrafeedback_binarized", split="train")
+> [!TIP]
+> When training adapters, you typically use a higher learning rate (≈1e‑5) since only new parameters are being learned.
+>
+> ```python
+> DPOConfig(learning_rate=1e-5, ...)
+> ```
-- training_args = DPOConfig(output_dir="Qwen2-0.5B-DPO")
-+ training_args = DPOConfig(output_dir="Qwen2-0.5B-DPO", bf16=True)
- trainer = DPOTrainer(model=model, args=training_args, processing_class=tokenizer, train_dataset=train_dataset)
- trainer.train()
+### Train with Liger Kernel
-```
+Liger Kernel is a collection of Triton kernels for LLM training that boosts multi-GPU throughput by 20%, cuts memory use by 60% (enabling up to 4× longer context), and works seamlessly with tools like FlashAttention, PyTorch FSDP, and DeepSpeed. For more information, see [Liger Kernel Integration](liger_kernel_integration).
-The saved model is fully compatible with Hugging Face's transformers library. Learn more about unsloth in their [official repository](https://github.com/unslothai/unsloth).
+### Rapid Experimentation for DPO
-## Reference model considerations with PEFT
+RapidFire AI is an open-source experimentation engine that sits on top of TRL and lets you launch multiple DPO configurations at once, even on a single GPU. Instead of trying configurations sequentially, RapidFire lets you **see all their learning curves earlier, stop underperforming runs, and clone promising ones with new settings in flight** without restarting. For more information, see [RapidFire AI Integration](rapidfire_integration).
-You have three main options (plus several variants) for how the reference model works when using PEFT, assuming the model that you would like to further enhance with DPO was tuned using (Q)LoRA.
+### Train with Unsloth
-1. Simply create two instances of the model, each loading your adapter - works fine but is very inefficient.
-2. Merge the adapter into the base model, create another adapter on top, then leave the `ref_model` param null, in which case DPOTrainer will unload the adapter for reference inference - efficient, but has potential downsides discussed below.
-3. Load the adapter twice with different names, then use `set_adapter` during training to swap between the adapter being DPO'd and the reference adapter - slightly less efficient compared to 2 (~adapter size VRAM overhead), but avoids the pitfalls.
+Unsloth is an open‑source framework for fine‑tuning and reinforcement learning that trains LLMs (like Llama, Mistral, Gemma, DeepSeek, and more) up to 2× faster with up to 70% less VRAM, while providing a streamlined, Hugging Face–compatible workflow for training, evaluation, and deployment. For more information, see [Unsloth Integration](unsloth_integration).
-### Downsides to merging QLoRA before DPO (approach 2)
+## Tool Calling with DPO
-As suggested by [Benjamin Marie](https://medium.com/@bnjmn_marie/dont-merge-your-lora-adapter-into-a-4-bit-llm-65b6da287997), the best option for merging QLoRA adapters is to first dequantize the base model, then merge the adapter. Something similar to [this script](https://github.com/jondurbin/qlora/blob/main/qmerge.py).
+The [`DPOTrainer`] fully supports fine-tuning models with _tool calling_ capabilities. In this case, each dataset example should include:
-However, after using this approach, you will have an unquantized base model. Therefore, to use QLoRA for DPO, you will need to re-quantize the merged model or use the unquantized merge (resulting in higher memory demand).
+* The conversation messages (prompt, chosen and rejected), including any tool calls (`tool_calls`) and tool responses (`tool` role messages)
+* The list of available tools in the `tools` column, typically provided as JSON `str` schemas
-### Using option 3 - load the adapter twice
+For details on the expected dataset structure, see the [Dataset Format — Tool Calling](dataset_formats#tool-calling) section.
-To avoid the downsides with option 2, you can load your fine-tuned adapter into the model twice, with different names, and set the model/ref adapter names in [`DPOTrainer`].
+## Training Vision Language Models
-For example:
+[`DPOTrainer`] fully supports training Vision-Language Models (VLMs). To train a VLM, provide a dataset with either an `image` column (single image per sample) or an `images` column (list of images per sample). For more information on the expected dataset structure, see the [Dataset Format — Vision Dataset](dataset_formats#vision-dataset) section.
+An example of such a dataset is the [RLAIF-V Dataset](https://huggingface.co/datasets/HuggingFaceH4/rlaif-v_formatted) dataset.
```python
-# Load the base model.
-bnb_config = BitsAndBytesConfig(
- load_in_4bit=True,
- llm_int8_threshold=6.0,
- llm_int8_has_fp16_weight=False,
- bnb_4bit_compute_dtype=torch.bfloat16,
- bnb_4bit_use_double_quant=True,
- bnb_4bit_quant_type="nf4",
-)
-model = AutoModelForCausalLM.from_pretrained(
- "mistralai/mixtral-8x7b-v0.1",
- load_in_4bit=True,
- quantization_config=bnb_config,
- attn_implementation="kernels-community/flash-attn2",
- dtype=torch.bfloat16,
- device_map="auto",
-)
-
-# Load the adapter.
-model = PeftModel.from_pretrained(
- model,
- "/path/to/peft",
- is_trainable=True,
- adapter_name="train",
-)
-# Load the adapter a second time, with a different name, which will be our reference model.
-model.load_adapter("/path/to/peft", adapter_name="reference")
+from trl import DPOConfig, DPOTrainer
+from datasets import load_dataset
-# Initialize the trainer, without a ref_model param.
-training_args = DPOConfig(
- model_adapter_name="train",
- ref_adapter_name="reference",
-)
-dpo_trainer = DPOTrainer(
- model,
- args=training_args,
- ...
+trainer = DPOTrainer(
+ model="Qwen/Qwen2.5-VL-3B-Instruct",
+ args=DPOConfig(max_length=None),
+ train_dataset=load_dataset("HuggingFaceH4/rlaif-v_formatted", split="train"),
)
+trainer.train()
```
+> [!TIP]
+> For VLMs, truncating may remove image tokens, leading to errors during training. To avoid this, set `max_length=None` in the [`DPOConfig`]. This allows the model to process the full sequence length without truncating image tokens.
+>
+> ```python
+> DPOConfig(max_length=None, ...)
+> ```
+>
+> Only use `max_length` when you've verified that truncation won't remove image tokens for the entire dataset.
+
## DPOTrainer
[[autodoc]] DPOTrainer
@@ -302,3 +298,6 @@ dpo_trainer = DPOTrainer(
[[autodoc]] trainer.dpo_trainer.DataCollatorForPreference
+## DataCollatorForVisionPreference
+
+[[autodoc]] trainer.dpo_trainer.DataCollatorForVisionPreference
diff --git a/docs/source/example_overview.md b/docs/source/example_overview.md
index 893c2eacd5e..603760f14d9 100644
--- a/docs/source/example_overview.md
+++ b/docs/source/example_overview.md
@@ -44,7 +44,7 @@ These notebooks are easier to run and are designed for quick experimentation wit
## Scripts
-Scripts are maintained in the [`trl/scripts`](https://github.com/huggingface/trl/blob/main/trl/scripts) and [`examples/scripts`](https://github.com/huggingface/trl/blob/main/examples/scripts) directories. They show how to use different trainers such as `SFTTrainer`, `PPOTrainer`, `DPOTrainer`, `GRPOTrainer`, and more.
+Scripts are maintained in the [`trl/scripts`](https://github.com/huggingface/trl/blob/main/trl/scripts) and [`examples/scripts`](https://github.com/huggingface/trl/blob/main/examples/scripts) directories. They show how to use different trainers such as [`SFTTrainer`], [`PPOTrainer`], [`DPOTrainer`], [`GRPOTrainer`], and more.
| File | Description |
| --- | --- |
diff --git a/docs/source/lora_without_regret.md b/docs/source/lora_without_regret.md
index 2875d662288..c77392e2e19 100644
--- a/docs/source/lora_without_regret.md
+++ b/docs/source/lora_without_regret.md
@@ -277,7 +277,6 @@ Here are the parameters we used to train the above models
| `--model_name_or_path` | HuggingFaceTB/SmolLM3-3B | HuggingFaceTB/SmolLM3-3B |
| `--dataset_name` | HuggingFaceH4/OpenR1-Math-220k-default-verified | HuggingFaceH4/OpenR1-Math-220k-default-verified |
| `--learning_rate` | 1.0e-5 | 1.0e-6 |
-| `--max_prompt_length` | 1024 | 1024 |
| `--max_completion_length` | 4096 | 4096 |
| `--lora_r` | 1 | - |
| `--lora_alpha` | 32 | - |
diff --git a/docs/source/model_utils.md b/docs/source/model_utils.md
index 6cfdc7b571b..cf5fbfae900 100644
--- a/docs/source/model_utils.md
+++ b/docs/source/model_utils.md
@@ -7,7 +7,3 @@
## disable_gradient_checkpointing
[[autodoc]] models.utils.disable_gradient_checkpointing
-
-## create_reference_model
-
-[[autodoc]] create_reference_model
diff --git a/docs/source/paper_index.md b/docs/source/paper_index.md
index b4a73346074..a8734524a00 100644
--- a/docs/source/paper_index.md
+++ b/docs/source/paper_index.md
@@ -1,7 +1,6 @@
# Paper Index
-> [!WARNING]
-> Section under construction. Feel free to contribute! See https://github.com/huggingface/trl/issues/4407.
+
## Group Relative Policy Optimization
@@ -218,7 +217,7 @@ training_args = GRPOConfig(
per_device_train_batch_size=1, # train_batch_size_per_device in the Training section of the repository
num_generations=8, # num_samples in the Training section of the repository
max_completion_length=3000, # generate_max_length in the Training section of the repository
- beta=0.0, # beta in the Training section of the repository
+ beta=0.0, # β in the Training section of the repository
)
```
@@ -609,60 +608,142 @@ training_args = DPOConfig(
loss_type="sigmoid", # losses in Appendix B of the paper
per_device_train_batch_size=64, # batch size in Appendix B of the paper
learning_rate=1e-6, # learning rate in Appendix B of the paper
- beta=0.1, # beta in Appendix B of the paper
+ beta=0.1, # β in Appendix B of the paper
)
```
-### A General Theoretical Paradigm to Understand Learning from Human Preferences
+### SLiC-HF: Sequence Likelihood Calibration with Human Feedback
-**📜 Paper**: https://huggingface.co/papers/2310.12036
+**📜 Paper**: https://huggingface.co/papers/2305.10425
-A new general objective, \\( \Psi \\)PO, bypasses both key approximations in reinforcement learning from human preferences, allowing for theoretical analysis and empirical superiority over DPO. To reproduce the paper's setting, use this configuration:
+Sequence Likelihood Calibration (SLiC) is shown to be an effective and simpler alternative to Reinforcement Learning from Human Feedback (RLHF) for learning from human preferences in language models. To reproduce the paper's setting, use this configuration:
```python
from trl import DPOConfig
training_args = DPOConfig(
- loss_type="ipo", # Section 5.1 of the paper
- per_device_train_batch_size=90, # mini-batch size in Section C.1 of the paper
- learning_rate=1e-2, # learning rate in Section C.1 of the paper
+ loss_type="hinge", # Section 2 of the paper
+ per_device_train_batch_size=512, # batch size in Section 3.2 of the paper
+ learning_rate=1e-4, # learning rate in Section 3.2 of the paper
)
```
-These parameters only appear in the [published version](https://proceedings.mlr.press/v238/gheshlaghi-azar24a/gheshlaghi-azar24a.pdf)
+These parameters only appear in the [published version](https://openreview.net/pdf?id=0qSOodKmJaN)
-### SLiC-HF: Sequence Likelihood Calibration with Human Feedback
+### Statistical Rejection Sampling Improves Preference Optimization
-**📜 Paper**: https://huggingface.co/papers/2305.10425
+**📜 Paper**: https://huggingface.co/papers/2309.06657
-Sequence Likelihood Calibration (SLiC) is shown to be an effective and simpler alternative to Reinforcement Learning from Human Feedback (RLHF) for learning from human preferences in language models. To reproduce the paper's setting, use this configuration:
+Proposes **RSO**, selecting stronger preference pairs via statistical rejection sampling to boost offline preference optimization; complements DPO/SLiC. They also introduce a new loss defined as:
+
+$$
+\mathcal{L}_{\text{hinge-norm}}(\pi_\theta)
+= \mathbb{E}_{(x, y_w, y_l) \sim \mathcal{D}}
+\left[
+\max\left(0,\; 1 - \left[\gamma \log \frac{\pi_\theta(y_w \mid x)}{\pi_\text{ref}(y_w \mid x)} - \gamma \log \frac{\pi_\theta(y_l \mid x)}{\pi_\text{ref}(y_l \mid x)}\right]\right)
+\right]
+$$
+
+To train with RSO-filtered data and the hinge-norm loss, you can use the following code:
+
+```python
+from trl import DPOConfig, DPOTrainer
+
+dataset = ...
+
+def rso_accept(example): # replace with your actual filter/score logic
+ return example["rso_keep"]
+
+train_dataset = train_dataset.filter(rso_accept)
+
+training_args = DPOConfig(
+ loss_type="hinge",
+ beta=0.05, # correspond to γ in the paper
+)
+
+trainer = DPOTrainer(
+ ...,
+ args=training_args,
+ train_dataset=train_dataset,
+)
+trainer.train()
+```
+
+### Beyond Reverse KL: Generalizing Direct Preference Optimization with Diverse Divergence Constraints
+
+**📜 Paper**: https://huggingface.co/papers/2309.16240
+
+Proposes \(( f \\)-DPO, extending DPO by replacing the usual reverse-KL regularizer with a general \(( f \\)-divergence, letting you trade off mode-seeking vs mass-covering behavior (e.g. forward KL, JS, \(( \alpha \\)-divergences). The only change is replacing the DPO log-ratio margin with an **f′ score**:
+
+$$
+\mathcal{L}_{f\text{-DPO}}(\pi_\theta)
+= \mathbb{E}_{(x, y_w, y_l) \sim \mathcal{D}}
+\left[
+-\log \sigma\left(
+\beta \textcolor{red}{f'}\textcolor{red}{\Big(}\frac{\pi_\theta(y_w|x)}{\pi_{\text{ref}}(y_w|x)}\textcolor{red}{\Big)}
+-
+\beta \textcolor{red}{f'}\textcolor{red}{\Big(}\frac{\pi_\theta(y_l|x)}{\pi_{\text{ref}}(y_l|x)}\textcolor{red}{\Big)}
+\right)
+\right]
+$$
+
+Where \\( f' \\) is the derivative of the convex function defining the chosen \(( f \\)-divergence.
+
+To reproduce:
```python
from trl import DPOConfig
training_args = DPOConfig(
- loss_type="hinge", # Section 2 of the paper
- per_device_train_batch_size=512, # batch size in Section 3.2 of the paper
- learning_rate=1e-4, # learning rate in Section 3.2 of the paper
+ loss_type="sigmoid",
+ beta=0.1,
+ f_divergence_type="js_divergence", # or "reverse_kl" (default), "forward_kl", "js_divergence", "alpha_divergence"
+ f_alpha_divergence_coef=0.5, # only used if f_divergence_type="alpha_divergence"
)
```
-These parameters only appear in the [published version](https://openreview.net/pdf?id=0qSOodKmJaN)
+### A General Theoretical Paradigm to Understand Learning from Human Preferences
+
+**📜 Paper**: https://huggingface.co/papers/2310.12036
+
+Learning from human preferences can be written as a single KL-regularized objective over pairwise preference probabilities,
+
+$$
+\max_\pi ;\mathbb{E}\big[\Psi\left(p^*(y \succ y' \mid x)\right)\big] - \tau\mathrm{KL}(\pi||\pi_{\text{ref}}),
+$$
+
+which reveals RLHF and DPO as special cases corresponding to the logit choice of \\( \Psi \\).
+The paper shows that this logit transform amplifies near-deterministic preferences and effectively weakens KL regularization, explaining overfitting.
+Using the **Identity transform (IPO)** avoids this pathology by optimizing preferences directly, without assuming a Bradley–Terry reward model.
+To reproduce the paper's setting, use this configuration:
+
+```python
+from trl import DPOConfig
+
+training_args = DPOConfig(
+ loss_type="ipo", # Section 5.1 of the paper
+ per_device_train_batch_size=90, # mini-batch size in Section C.1 of the paper
+ learning_rate=1e-2, # learning rate in Section C.1 of the paper
+)
+```
+
+These parameters only appear in the [published version](https://proceedings.mlr.press/v238/gheshlaghi-azar24a/gheshlaghi-azar24a.pdf)
### Towards Efficient and Exact Optimization of Language Model Alignment
**📜 Paper**: https://huggingface.co/papers/2402.00856
-Efficient exact optimization (EXO) method is proposed to align language models with human preferences, providing a guaranteed and efficient alternative to reinforcement learning and direct preference optimization. To reproduce the paper's setting, use this configuration:
+The paper shows that direct preference methods like DPO optimize the wrong KL direction, leading to blurred preference capture, and proposes EXO as an efficient way to exactly optimize the human‑preference alignment objective by leveraging reverse KL probability matching rather than forward KL approximations. To reproduce the paper's setting, use this configuration:
```python
from trl import DPOConfig
training_args = DPOConfig(
loss_type="exo_pair", # Section 3.2 of the paper
- per_device_train_batch_size=64, # batch size in Section B of the paper
- learning_rate=1e-6, # learning rate in Section B of the paper
- beta=0.1, # $\beta_r$ in Section B of the paper
+ # From Section B of the paper
+ per_device_train_batch_size=64,
+ learning_rate=1e-6,
+ beta=0.1,
)
```
@@ -670,16 +751,21 @@ training_args = DPOConfig(
**📜 Paper**: https://huggingface.co/papers/2402.05369
-A framework using Noise Contrastive Estimation enhances language model alignment with both scalar rewards and pairwise preferences, demonstrating advantages over Direct Preference Optimization. To reproduce the paper's setting, use this configuration:
+The paper reframes language-model alignment as a *noise-contrastive classification* problem, proposing InfoNCA to learn a policy from explicit rewards (or preferences) by matching a reward-induced target distribution over responses, and showing DPO is a special binary case. It then introduces NCA, which adds an absolute likelihood term to prevent the likelihood collapse seen in purely relative (contrastive) objectives.
+
+With pairwise preferences, treat the chosen/rejected \\( K=2 \\), define scores \\( r=\beta(\log\pi_\theta-\log\pi_{\text{ref}}) \\), and apply the NCA preference loss \\( -\log\sigma(r_w)-\tfrac12\log\sigma(-r_w)-\tfrac12\log\sigma(-r_l) \\).
+
+To reproduce the paper's setting, use this configuration:
```python
from trl import DPOConfig
training_args = DPOConfig(
- loss_type="nca_pair", # Section 4.1 of the paper
- per_device_train_batch_size=32, # batch size in Section C of the paper
- learning_rate=5e-6, # learning rate in Section C of the paper
- beta=0.01, # $\alpha$ in Section C of the paper
+ loss_type="nca_pair",
+ # From Section C of the paper
+ per_device_train_batch_size=32,
+ learning_rate=5e-6,
+ beta=0.01,
)
```
@@ -687,19 +773,27 @@ training_args = DPOConfig(
**📜 Paper**: https://huggingface.co/papers/2403.00409
-The paper introduces a robust direct preference optimization (rDPO) framework to address noise in preference-based feedback for language models, proving its sub-optimality gap and demonstrating its effectiveness through experiments. To reproduce the paper's setting, use this configuration:
+DPO breaks under noisy human preferences because label flips bias the objective. Robust DPO fixes this by analytically debiasing the DPO loss under a simple noise model, with provable guarantees.
+
+$$
+\mathcal{L}_{\text{robust}}(\pi_\theta) = \frac{(1-\varepsilon)\mathcal{L}_{\text{DPO}}(y_w, y_l) - \varepsilon\mathcal{L}_{\text{DPO}}(y_l, y_w)}
+{1-2\varepsilon}
+$$
+
+Where \\( \mathcal{L}_{\text{DPO}} \\) is the DPO loss defined in [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](#direct-preference-optimization-your-language-model-is-secretly-a-reward-model) and \\( \varepsilon \\) is the probability of a label flip.
+
+This single correction turns noisy preference data into an unbiased estimator of the clean DPO objective.
```python
from trl import DPOConfig
training_args = DPOConfig(
- loss_type="robust", # Section 3.1 of the paper
- per_device_train_batch_size=16, # batch size in Section B of the paper
- learning_rate=1e-3, # learning rate in Section B of the paper
- beta=0.01, # $\beta$ in Section B of the paper,
- max_length=512, # max length in Section B of the paper
- label_smoothing=0.1 # label smoothing $\epsilon$ in section 6 of the paper
-
+ loss_type="robust",
+ per_device_train_batch_size=16, # batch size in Section B of the paper
+ learning_rate=1e-3, # learning rate in Section B of the paper
+ beta=0.1, # β in Section B of the paper,
+ max_length=512, # max length in Section B of the paper
+ label_smoothing=0.1 # label smoothing $\varepsilon$ in Section 6 of the paper
)
```
@@ -709,14 +803,34 @@ training_args = DPOConfig(
Theoretical analysis and a new algorithm, Binary Classifier Optimization, explain and enhance the alignment of large language models using binary feedback signals. To reproduce the paper's setting, use this configuration:
+BCO reframes language-model alignment as behavioral cloning from an optimal reward-weighted distribution, yielding simple supervised objectives that avoid RL while remaining theoretically grounded.
+It supports both unpaired reward data and pairwise preference data, with a reward-shift–invariant formulation that reduces to a DPO-style loss in the preference setting.
+
+For the pairwise preference setting, the BCO loss is defined as:
+
+$$
+\mathcal{L}_{\text{bco\_pair}}(\pi_\theta) =
+\mathbb{E}_{(x, y_w, y_l) \sim \mathcal{D}}
+\left[
+-\log \sigma\Big(
+\beta[(\log\pi_\theta-\log\pi_{\text{ref}})(y_w)
+-
+(\log\pi_\theta-\log\pi_{\text{ref}})(y_l)]
+\Big)
+\right]
+$$
+
+To reproduce the paper in this setting, use this configuration:
+
```python
from trl import DPOConfig
training_args = DPOConfig(
- loss_type="bco_pair", # Section 4 of the paper
- per_device_train_batch_size=128, # batch size in Section C of the paper
- learning_rate=5e-7, # learning rate in Section C of the paper
- beta=0.01, # $\beta$ in Section C of the paper,
+ loss_type="bco_pair",
+ # From Section C of the paper
+ per_device_train_batch_size=128,
+ learning_rate=5e-7,
+ beta=0.01,
)
```
@@ -744,6 +858,29 @@ training_args = DPOConfig(
)
```
+### Iterative Reasoning Preference Optimization
+
+**📜 Paper**: https://huggingface.co/papers/2404.19733
+
+Iterative RPO improves reasoning by repeatedly generating chain-of-thought candidates, building preference pairs from correct vs. incorrect answers, and training with a DPO + NLL objective. The extra NLL term is key for learning to actually generate winning traces.
+
+TRL can express the DPO + NLL objective by mixing `"sigmoid"` (DPO) with `"sft"` (NLL):
+
+```python
+from trl import DPOConfig, DPOTrainer
+
+training_args = DPOConfig(
+ loss_type=["sigmoid", "sft"],
+ loss_weights=[1.0, 1.0], # alpha in the paper, recommended value is 1.0
+)
+trainer = DPOTrainer(
+ ...,
+ args=training_args,
+)
+```
+
+Note that the paper uses an iterative loop: each iteration regenerates CoT candidates with the current model, then retrains on fresh preference pairs. TRL does not automate that loop for you.
+
### Self-Play Preference Optimization for Language Model Alignment
**📜 Paper**: https://huggingface.co/papers/2405.00675
@@ -754,9 +891,11 @@ A self-play method called SPPO for language model alignment achieves state-of-th
from trl import DPOConfig
training_args = DPOConfig(
- loss_type="sppo_hard", # Section 3 of the paper
- per_device_train_batch_size=64, # batch size in Section C of the paper
- learning_rate=5e-7, # learning rate in Section C of the paper
+ loss_type="sppo_hard",
+ # From Section 5 of the paper
+ beta=0.001, # β = η^−1
+ per_device_train_batch_size=64,
+ learning_rate=5e-7,
)
```
@@ -788,15 +927,19 @@ Alignment via Optimal Transport (AOT) aligns large language models distributiona
from trl import DPOConfig
training_args = DPOConfig(
- loss_type="aot", # Section 3 of the paper
+ loss_type="aot",
+ beta=0.01, # from the caption of Figure 2
)
```
+or, for the unpaired version:
+
```python
from trl import DPOConfig
training_args = DPOConfig(
- loss_type="aot_unpaired", # Section 3 of the paper
+ loss_type="aot_unpaired",
+ beta=0.01, # from the caption of Figure 2
)
```
@@ -812,11 +955,39 @@ An LLM-driven method automatically discovers performant preference optimization
from trl import DPOConfig
training_args = DPOConfig(
- loss_type="discopop", # Section 3 of the paper
- per_device_train_batch_size=64, # batch size in Section B.1 of the paper
- learning_rate=5e-7, # learning rate in Section B.1 of the paper
- beta=0.05, # $\beta$ in Section B.1 of the paper,
- discopop_tau=0.05 # $\tau$ in Section E of the paper
+ loss_type="discopop",
+ per_device_train_batch_size=64, # batch size in Section B.1 of the paper
+ learning_rate=5e-7, # learning rate in Section B.1 of the paper
+ beta=0.05, # β in Section B.1 of the paper,
+ discopop_tau=0.05 # τ in Section E of the paper
+)
+```
+
+### WPO: Enhancing RLHF with Weighted Preference Optimization
+
+**📜 Paper**: https://huggingface.co/papers/2406.11827
+
+WPO reweights preference pairs by their policy probabilities to reduce the off-policy gap in DPO-style training. The loss is:
+
+$$
+\mathcal{L}_{\text{WPO}} = -\mathbb{E}_{(x, y_w, y_l) \sim \mathcal{D}} \left[ \textcolor{red}{w(x, y_w) w(x, y_l)} \log p(y_w \succ y_l \mid x) \right]
+$$
+
+where the weight \\( w(x, y) \\) is defined as:
+
+$$
+w(x, y) = \exp\left(\frac{1}{|y|}\sum_{t=1}^{|y|} \log \frac{\pi_\theta(y_t \mid x, y_{ [!WARNING]
-> The legacy `max_prompt_length` and `max_completion_length` parameters are deprecated and will be removed; instead, filter or pre-truncate overlong prompts/completions in your dataset before training.
+> The legacy `max_prompt_length` and `max_completion_length` parameters are now removed; instead, filter or pre-truncate overlong prompts/completions in your dataset before training.
diff --git a/docs/source/sft_trainer.md b/docs/source/sft_trainer.md
index 0244455385b..c1eaf46b65e 100644
--- a/docs/source/sft_trainer.md
+++ b/docs/source/sft_trainer.md
@@ -23,7 +23,7 @@ trainer = SFTTrainer(
trainer.train()
```
-
+
## Expected dataset type and format
@@ -194,7 +194,7 @@ dataset = load_dataset("trl-lib/Capybara", split="train")
trainer = SFTTrainer(
"Qwen/Qwen3-0.6B",
train_dataset=dataset,
- peft_config=LoraConfig()
+ peft_config=LoraConfig(),
)
trainer.train()
@@ -295,7 +295,7 @@ For details on the expected dataset structure, see the [Dataset Format — Tool
## Training Vision Language Models
-[`SFTTrainer`] fully supports training Vision-Language Models (VLMs). To train a VLM, you need to provide a dataset with an additional `images` column containing the images to be processed. For more information on the expected dataset structure, see the [Dataset Format — Vision Dataset](dataset_formats#vision-dataset) section.
+[`SFTTrainer`] fully supports training Vision-Language Models (VLMs). To train a VLM, provide a dataset with either an `image` column (single image per sample) or an `images` column (list of images per sample). For more information on the expected dataset structure, see the [Dataset Format — Vision Dataset](dataset_formats#vision-dataset) section.
An example of such a dataset is the [LLaVA Instruct Mix](https://huggingface.co/datasets/trl-lib/llava-instruct-mix).
```python
diff --git a/examples/notebooks/grpo_agent.ipynb b/examples/notebooks/grpo_agent.ipynb
index 070738cea8c..9fec579c293 100644
--- a/examples/notebooks/grpo_agent.ipynb
+++ b/examples/notebooks/grpo_agent.ipynb
@@ -440,9 +440,6 @@
" save_steps = 10, # Interval for saving checkpoints\n",
" log_completions = True,\n",
"\n",
- " # Memory optimization\n",
- " gradient_checkpointing = True, # Enable activation recomputation to save memory\n",
- "\n",
" # Hub integration\n",
" push_to_hub = True, # Set True to automatically push model to Hugging Face Hub\n",
")"
diff --git a/examples/scripts/dpo_vlm.py b/examples/scripts/dpo_vlm.py
index 3c5909503ef..a515201960b 100644
--- a/examples/scripts/dpo_vlm.py
+++ b/examples/scripts/dpo_vlm.py
@@ -104,14 +104,7 @@
**model_kwargs,
)
peft_config = get_peft_config(model_args)
- if peft_config is None:
- ref_model = AutoModelForImageTextToText.from_pretrained(
- model_args.model_name_or_path,
- trust_remote_code=model_args.trust_remote_code,
- **model_kwargs,
- )
- else:
- ref_model = None
+
processor = AutoProcessor.from_pretrained(
model_args.model_name_or_path, trust_remote_code=model_args.trust_remote_code, do_image_splitting=False
)
@@ -136,7 +129,6 @@
################
trainer = DPOTrainer(
model,
- ref_model,
args=training_args,
train_dataset=dataset[script_args.dataset_train_split],
eval_dataset=dataset[script_args.dataset_test_split] if training_args.eval_strategy != "no" else None,
diff --git a/examples/scripts/mpo_vlm.py b/examples/scripts/mpo_vlm.py
index 64ca7b6120c..ace5a347d7e 100644
--- a/examples/scripts/mpo_vlm.py
+++ b/examples/scripts/mpo_vlm.py
@@ -89,13 +89,6 @@
**model_kwargs,
)
peft_config = get_peft_config(model_args)
- if peft_config is None:
- ref_model = AutoModelForImageTextToText.from_pretrained(
- model_args.model_name_or_path,
- **model_kwargs,
- )
- else:
- ref_model = None
################
# Dataset
@@ -127,7 +120,6 @@ def ensure_rgb(example):
################
trainer = DPOTrainer(
model=model,
- ref_model=ref_model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
diff --git a/scripts/generate_harmony_dataset.py b/scripts/generate_harmony_dataset.py
index 88f6aac3d8b..670c586a4bb 100644
--- a/scripts/generate_harmony_dataset.py
+++ b/scripts/generate_harmony_dataset.py
@@ -95,7 +95,7 @@ def main(test_size, push_to_hub, repo_id):
language_modeling_dataset = language_modeling_dataset.train_test_split(test_size=test_size, shuffle=False)
if push_to_hub:
language_modeling_dataset.push_to_hub(repo_id, config_name="language_modeling")
- language_modeling_dataset.save_to_disk(repo_id + "/language_modeling")
+
prompt_completion_dataset = Dataset.from_dict({
"prompt": [
[{"role": "user", "content": "What is better than ugly?"}],
@@ -164,7 +164,96 @@ def main(test_size, push_to_hub, repo_id):
prompt_completion_dataset = prompt_completion_dataset.train_test_split(test_size=test_size, shuffle=False)
if push_to_hub:
prompt_completion_dataset.push_to_hub(repo_id, config_name="prompt_completion")
- prompt_completion_dataset.save_to_disk(repo_id + "/prompt_completion")
+
+ preference_dataset = Dataset.from_dict({
+ "prompt": [
+ [{"role": "user", "content": "What is better than ugly?"}],
+ [{"role": "user", "content": "What is better than implicit?"}],
+ [{"role": "user", "content": "What is better than complex?"}],
+ [{"role": "user", "content": "What is better than complicated?"}],
+ [{"role": "user", "content": "What is better than nested?"}],
+ [{"role": "user", "content": "What is better than dense?"}],
+ [{"role": "user", "content": "What counts?"}],
+ [{"role": "user", "content": "Are special cases enough to break the rules?"}],
+ [{"role": "user", "content": "What beats purity?"}],
+ [{"role": "user", "content": "What should never pass silently?"}],
+ [{"role": "user", "content": "When can errors pass silently?"}],
+ [{"role": "user", "content": "What should you do in the face of ambiguity?"}],
+ [{"role": "user", "content": "How many ways should there be to do it?"}],
+ [{"role": "user", "content": "For whom may the way not be obvious at first?"}],
+ [{"role": "user", "content": "What is better than never?"}],
+ [{"role": "user", "content": "Is never better than *right* now?"}],
+ [{"role": "user", "content": "What does it mean if the implementation is hard to explain?"}],
+ [{"role": "user", "content": "What does it mean if the implementation is easy to explain?"}],
+ [{"role": "user", "content": "Any great ideas?"}],
+ ],
+ "chosen": [
+ [{"role": "assistant", "thinking": "Beauty improves clarity and appeal.", "content": "Beautiful."}],
+ [{"role": "assistant", "thinking": "Clarity avoids confusion.", "content": "Explicit."}],
+ [{"role": "assistant", "thinking": "Simplicity is easier to manage.", "content": "Simple."}],
+ [{"role": "assistant", "thinking": "Complexity has structure; complication doesn’t.", "content": "Complex."}],
+ [{"role": "assistant", "thinking": "Flat structures are easier to read.", "content": "Flat."}],
+ [{"role": "assistant", "thinking": "Spacing aids understanding.", "content": "Sparse."}],
+ [{"role": "assistant", "thinking": "Readable code lasts longer.", "content": "Readability."}],
+ [{"role": "assistant", "thinking": "Consistency is more valuable.", "content": "No, special cases aren't special enough to break the rules."}],
+ [{"role": "assistant", "thinking": "Real-world needs outweigh ideals.", "content": "Practicality."}],
+ [{"role": "assistant", "thinking": "Silent errors cause hidden issues.", "content": "Errors."}],
+ [{"role": "assistant", "thinking": "Silence must be intentional.", "content": "When explicitly silenced."}],
+ [{"role": "assistant", "thinking": "Guessing leads to wrong choices.", "content": "Refuse the temptation to guess."}],
+ [{"role": "assistant", "thinking": "One way reduces confusion.", "content": "One, and preferably only one."}],
+ [{"role": "assistant", "thinking": "A playful nod to Python’s creator.", "content": "Dutch."}],
+ [{"role": "assistant", "thinking": "Action is better than endless delay.", "content": "Now is better than never."}],
+ [{"role": "assistant", "thinking": "Rushed action can be worse.", "content": "Yes, often."}],
+ [{"role": "assistant", "thinking": "Good ideas should be clear.", "content": "It means it's a bad idea."}],
+ [{"role": "assistant", "thinking": "Clarity suggests soundness.", "content": "It means it may be a good idea."}],
+ [{"role": "assistant", "thinking": "Namespaces prevent conflicts.", "content": "Namespaces are one honking great idea."}],
+ ],
+ "rejected": [
+ [{"role": "assistant", "thinking": "This comparison is nonsensical.", "content": "Better than the moon."}],
+ [{"role": "assistant", "thinking": "This dismisses the value of clarity.", "content": "Worse than nothing."}],
+ [{"role": "assistant", "thinking": "This mixes code style with leisure.", "content": "Better than a long vacation."}],
+ [{"role": "assistant", "thinking": "This overstates complexity as a universal solution.", "content": "Always the answer."}],
+ [{"role": "assistant", "thinking": "This swaps a structural concept for a random object.", "content": "Better than chocolate."}],
+ [{"role": "assistant", "thinking": "This ignores the need for context in sparse designs.", "content": "Without any context."}],
+ [{"role": "assistant", "thinking": "This implies readability is optional, which it is not.", "content": "Optional."}],
+ [{"role": "assistant", "thinking": "This exaggerates special cases into fantasy.", "content": "Enough to become unicorns."}],
+ [{"role": "assistant", "thinking": "This twists the original contrast between practicality and purity.", "content": "Beats reality."}],
+ [{"role": "assistant", "thinking": "This misapplies \"passing\" to a literal driving test.", "content": "Pass their driving test."}],
+ [{"role": "assistant", "thinking": "This suggests forgetting rather than intentional silence.", "content": "Forgotten."}],
+ [{"role": "assistant", "thinking": "This replaces careful judgment with a joke.", "content": "Refuse the opportunity to laugh."}],
+ [{"role": "assistant", "thinking": "This encourages multiple confusing approaches instead of one clear way.", "content": "Two or more confusing methods."}],
+ [{"role": "assistant", "thinking": "This turns a simple example into time-travel absurdity.", "content": "A time traveler."}],
+ [{"role": "assistant", "thinking": "This denies the value of timely action.", "content": "Never better."}],
+ [{"role": "assistant", "thinking": "This removes the sense of tradeoff and possibility.", "content": "Not even a possibility."}],
+ [{"role": "assistant", "thinking": "This inverts the meaning of explainability.", "content": "Clearly the best choice."}],
+ [{"role": "assistant", "thinking": "This treats clarity as something mystical rather than practical.", "content": "Probably magic."}],
+ [{"role": "assistant", "thinking": "This turns a design principle into a silly metaphor.", "content": "Watermelon -- let's plant some!"}],
+ ],
+ "chat_template_kwargs": [
+ {"reasoning_effort": "low", "model_identity": "You are Tiny ChatGPT, a tiny language model."},
+ {"reasoning_effort": "medium", "model_identity": "You are Tiny ChatGPT, a tiny language model."},
+ {"reasoning_effort": "high", "model_identity": "You are Tiny ChatGPT, a tiny language model."},
+ {"reasoning_effort": "low", "model_identity": "You are Tiny ChatGPT, a tiny language model."},
+ {"reasoning_effort": "medium", "model_identity": "You are Tiny ChatGPT, a tiny language model."},
+ {"reasoning_effort": "high", "model_identity": "You are Tiny ChatGPT, a tiny language model."},
+ {"reasoning_effort": "low", "model_identity": "You are Tiny ChatGPT, a tiny language model."},
+ {"reasoning_effort": "medium", "model_identity": "You are Tiny ChatGPT, a tiny language model."},
+ {"reasoning_effort": "high", "model_identity": "You are Tiny ChatGPT, a tiny language model."},
+ {"reasoning_effort": "low", "model_identity": "You are Tiny ChatGPT, a tiny language model."},
+ {"reasoning_effort": "medium", "model_identity": "You are Tiny ChatGPT, a tiny language model."},
+ {"reasoning_effort": "high", "model_identity": "You are Tiny ChatGPT, a tiny language model."},
+ {"reasoning_effort": "low", "model_identity": "You are Tiny ChatGPT, a tiny language model."},
+ {"reasoning_effort": "medium", "model_identity": "You are Tiny ChatGPT, a tiny language model."},
+ {"reasoning_effort": "high", "model_identity": "You are Tiny ChatGPT, a tiny language model."},
+ {"reasoning_effort": "low", "model_identity": "You are Tiny ChatGPT, a tiny language model."},
+ {"reasoning_effort": "medium", "model_identity": "You are Tiny ChatGPT, a tiny language model."},
+ {"reasoning_effort": "high", "model_identity": "You are Tiny ChatGPT, a tiny language model."},
+ {"reasoning_effort": "low", "model_identity": "You are Tiny ChatGPT, a tiny language model."},
+ ],
+ })
+ preference_dataset = preference_dataset.train_test_split(test_size=test_size, shuffle=False)
+ if push_to_hub:
+ preference_dataset.push_to_hub(repo_id, config_name="preference")
# fmt: on
diff --git a/scripts/generate_zen_multi_image_dataset.py b/scripts/generate_zen_multi_image_dataset.py
index aa2211e1014..bb7089386ea 100644
--- a/scripts/generate_zen_multi_image_dataset.py
+++ b/scripts/generate_zen_multi_image_dataset.py
@@ -225,7 +225,7 @@ def main(test_size, push_to_hub, repo_id):
[{"role": "assistant", "content": [{"type": "text", "text": "It means it's a good idea."}]}],
[{"role": "assistant", "content": [{"type": "text", "text": "It means it's a bad idea."}]}],
[{"role": "assistant", "content": [{"type": "text", "text": "Recursion."}]}],
- ],
+ ]
# Create the images
number_of_images = [sum(1 for part in row[0]["content"] if part.get("type") == "image") for row in prompt]
sizes = [np.random.randint(32, 64, size=(num_images, 2)) for num_images in number_of_images]
diff --git a/tests/experimental/test_modeling_value_head.py b/tests/experimental/test_modeling_value_head.py
index 7aa6d431184..0ba87e8dc19 100644
--- a/tests/experimental/test_modeling_value_head.py
+++ b/tests/experimental/test_modeling_value_head.py
@@ -15,8 +15,8 @@
import torch
-from trl import create_reference_model
from trl.experimental.ppo import AutoModelForCausalLMWithValueHead
+from trl.experimental.utils import create_reference_model
from ..testing_utils import TrlTestCase
diff --git a/tests/test_collators.py b/tests/test_collators.py
deleted file mode 100644
index cffca495a93..00000000000
--- a/tests/test_collators.py
+++ /dev/null
@@ -1,74 +0,0 @@
-# Copyright 2020-2026 The HuggingFace Team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import torch
-
-from trl.trainer.dpo_trainer import DataCollatorForPreference
-
-from .testing_utils import TrlTestCase
-
-
-class TestDataCollatorForPreference(TrlTestCase):
- def setup_method(self):
- self.collator = DataCollatorForPreference(pad_token_id=0)
-
- def assertTensorEqual(self, tensor1, tensor2):
- assert torch.equal(tensor1, tensor2), f"Tensors are not equal:\n{tensor1}\n{tensor2}"
-
- def test_padding_behavior(self):
- examples = [
- {"prompt_input_ids": [1, 2, 3], "chosen_input_ids": [4, 5], "rejected_input_ids": [6]},
- {"prompt_input_ids": [7, 8], "chosen_input_ids": [9, 10], "rejected_input_ids": [11, 12, 13]},
- ]
- output = self.collator.torch_call(examples)
-
- expected_prompt_input_ids = torch.tensor([[1, 2, 3], [0, 7, 8]])
- expected_prompt_attention_mask = torch.tensor([[1, 1, 1], [0, 1, 1]])
- expected_chosen_input_ids = torch.tensor([[4, 5], [9, 10]])
- expected_chosen_attention_mask = torch.tensor([[1, 1], [1, 1]])
- expected_rejected_input_ids = torch.tensor([[6, 0, 0], [11, 12, 13]])
- expected_rejected_attention_mask = torch.tensor([[1, 0, 0], [1, 1, 1]])
-
- self.assertTensorEqual(output["prompt_input_ids"], expected_prompt_input_ids)
- self.assertTensorEqual(output["prompt_attention_mask"], expected_prompt_attention_mask)
- self.assertTensorEqual(output["chosen_input_ids"], expected_chosen_input_ids)
- self.assertTensorEqual(output["chosen_attention_mask"], expected_chosen_attention_mask)
- self.assertTensorEqual(output["rejected_input_ids"], expected_rejected_input_ids)
- self.assertTensorEqual(output["rejected_attention_mask"], expected_rejected_attention_mask)
-
- def test_optional_fields(self):
- examples = [
- {
- "prompt_input_ids": [1],
- "chosen_input_ids": [2],
- "rejected_input_ids": [3],
- "pixel_values": [[[0.1, 0.2], [0.3, 0.4]]], # Example 3D tensor (1x2x2)
- },
- {
- "prompt_input_ids": [4],
- "chosen_input_ids": [5],
- "rejected_input_ids": [6],
- "pixel_values": [[[0.5, 0.6], [0.7, 0.8]]], # Example 3D tensor (1x2x2)
- },
- ]
- output = self.collator.torch_call(examples)
-
- expected_pixel_values = torch.tensor(
- [
- [[[0.1, 0.2], [0.3, 0.4]]],
- [[[0.5, 0.6], [0.7, 0.8]]],
- ]
- ) # Shape: (2, 1, 2, 2)
-
- self.assertTensorEqual(output["pixel_values"], expected_pixel_values)
diff --git a/tests/test_dpo_trainer.py b/tests/test_dpo_trainer.py
index 3dd72d7a404..b260dea7f21 100644
--- a/tests/test_dpo_trainer.py
+++ b/tests/test_dpo_trainer.py
@@ -12,188 +12,221 @@
# See the License for the specific language governing permissions and
# limitations under the License.
-import gc
-import re
-from unittest.mock import MagicMock
-
-import numpy as np
import pytest
import torch
-from accelerate.utils.memory import release_memory
-from datasets import Dataset, features, load_dataset
-from transformers import (
- AutoModelForCausalLM,
- AutoModelForImageTextToText,
- AutoModelForSeq2SeqLM,
- AutoProcessor,
- AutoTokenizer,
- BitsAndBytesConfig,
- PreTrainedTokenizerBase,
- is_vision_available,
-)
-from transformers.testing_utils import backend_empty_cache, get_device_properties, torch_device
+import transformers
+from datasets import load_dataset
+from packaging.version import Version
+from packaging.version import parse as parse_version
+from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
from transformers.utils import is_peft_available
from trl import DPOConfig, DPOTrainer
+from trl.trainer.dpo_trainer import DataCollatorForPreference
from .testing_utils import (
TrlTestCase,
+ require_ampere_or_newer,
require_bitsandbytes,
+ require_kernels,
require_liger_kernel,
require_peft,
- require_torch_accelerator,
- require_torch_gpu_if_bnb_not_multi_backend_enabled,
require_vision,
)
-if is_vision_available():
- from PIL import Image
-
if is_peft_available():
- from peft import LoraConfig, PeftModel
+ from peft import LoraConfig, get_peft_model
+
+
+class TestDataCollatorForPreference(TrlTestCase):
+ def test_padding_and_masks(self):
+ collator = DataCollatorForPreference(pad_token_id=0)
+ examples = [
+ {"prompt_ids": [1, 2, 3], "chosen_ids": [4, 5], "rejected_ids": [6]},
+ {"prompt_ids": [7, 8], "chosen_ids": [9, 10], "rejected_ids": [11, 12, 13]},
+ ]
+ result = collator(examples)
+
+ expected_input_ids = torch.tensor(
+ [
+ [1, 2, 3, 4, 5], # prompt + chosen (example 1)
+ [7, 8, 9, 10, 0], # prompt + chosen (example 2, padded)
+ [1, 2, 3, 6, 0], # prompt + rejected (example 1, padded)
+ [7, 8, 11, 12, 13], # prompt + rejected (example 2)
+ ]
+ )
+ expected_attention_mask = torch.tensor(
+ [
+ [1, 1, 1, 1, 1],
+ [1, 1, 1, 1, 0],
+ [1, 1, 1, 1, 0],
+ [1, 1, 1, 1, 1],
+ ]
+ )
+ expected_completion_mask = torch.tensor(
+ [
+ [0, 0, 0, 1, 1], # chosen completion (example 1)
+ [0, 0, 1, 1, 0], # chosen completion (example 2, padded)
+ [0, 0, 0, 1, 0], # rejected completion (example 1, padded)
+ [0, 0, 1, 1, 1], # rejected completion (example 2)
+ ]
+ )
+
+ assert set(result.keys()) == {"input_ids", "attention_mask", "completion_mask"}
+ torch.testing.assert_close(result["input_ids"], expected_input_ids)
+ torch.testing.assert_close(result["attention_mask"], expected_attention_mask)
+ torch.testing.assert_close(result["completion_mask"], expected_completion_mask)
+
+ def test_optional_reference_logps(self):
+ collator = DataCollatorForPreference(pad_token_id=0)
+ examples = [
+ {
+ "prompt_ids": [1, 2],
+ "chosen_ids": [3],
+ "rejected_ids": [4],
+ "ref_chosen_logps": 0.1,
+ "ref_rejected_logps": 0.2,
+ },
+ {
+ "prompt_ids": [5],
+ "chosen_ids": [6, 7],
+ "rejected_ids": [8, 9],
+ "ref_chosen_logps": 0.3,
+ "ref_rejected_logps": 0.4,
+ },
+ ]
+ result = collator(examples)
+
+ expected_ref_chosen_logps = torch.tensor([0.1, 0.3])
+ expected_ref_rejected_logps = torch.tensor([0.2, 0.4])
+
+ assert set(result.keys()) == {
+ "input_ids",
+ "attention_mask",
+ "completion_mask",
+ "ref_chosen_logps",
+ "ref_rejected_logps",
+ }
+ torch.testing.assert_close(result["ref_chosen_logps"], expected_ref_chosen_logps)
+ torch.testing.assert_close(result["ref_rejected_logps"], expected_ref_rejected_logps)
+ def test_with_pad_to_multiple_of(self):
+ collator = DataCollatorForPreference(pad_token_id=0, pad_to_multiple_of=5)
+ examples = [
+ {"prompt_ids": [1], "chosen_ids": [2], "rejected_ids": [3]},
+ {"prompt_ids": [4, 5], "chosen_ids": [6, 7], "rejected_ids": [8, 9]},
+ ]
+ result = collator(examples)
-class TestTokenizeRow(TrlTestCase):
- def setup_method(self):
- # Set up the mock tokenizer with specific behaviors
- self.tokenizer = MagicMock(spec=PreTrainedTokenizerBase)
- self.tokenizer.bos_token_id = 0
- self.tokenizer.eos_token_id = 2
+ expected_input_ids = torch.tensor(
+ [
+ [1, 2, 0, 0, 0], # prompt + chosen (example 1, padded to multiple of 5)
+ [4, 5, 6, 7, 0], # prompt + chosen (example 2)
+ [1, 3, 0, 0, 0], # prompt + rejected (example 1, padded to multiple of 5)
+ [4, 5, 8, 9, 0], # prompt + rejected (example 2)
+ ]
+ )
- # Define mock return values for the tokenizer's 'input_ids' for the different text inputs
- self.tokenizer.return_value = {
- "input_ids": {"The sky is": [464, 6766, 318], " blue": [4171], " green": [4077]}
- }
+ assert set(result.keys()) == {"input_ids", "attention_mask", "completion_mask"}
+ torch.testing.assert_close(result["input_ids"], expected_input_ids)
- # Define tokenizer behavior when called
- def mock_tokenizer_call(text, add_special_tokens):
- token_map = {
- "The sky is": {"input_ids": [464, 6766, 318]},
- " blue": {"input_ids": [4171]},
- " green": {"input_ids": [4077]},
- }
- return token_map[text]
-
- self.tokenizer.side_effect = mock_tokenizer_call
-
- def test_tokenize_row_no_truncation_no_special_tokens(self):
- # Define the input features
- features = {"prompt": "The sky is", "chosen": " blue", "rejected": " green"}
-
- # Call the method with no truncation and no special tokens
- result = DPOTrainer.tokenize_row(
- features=features,
- processing_class=self.tokenizer,
- max_prompt_length=None,
- max_completion_length=None,
- add_special_tokens=False,
- )
- # Assert the correct output without truncation or special tokens
- assert result == {
- "prompt_input_ids": [464, 6766, 318],
- "chosen_input_ids": [4171, 2], # eos_token added
- "rejected_input_ids": [4077, 2], # eos_token added
- }
+class TestDPOTrainer(TrlTestCase):
+ @pytest.mark.parametrize(
+ "model_id",
+ [
+ "trl-internal-testing/tiny-Qwen2ForCausalLM-2.5",
+ "trl-internal-testing/tiny-Qwen3MoeForCausalLM",
+ "trl-internal-testing/tiny-GptOssForCausalLM",
+ ],
+ )
+ def test_train(self, model_id):
+ # Get the dataset
+ dataset = load_dataset("trl-internal-testing/zen", "standard_preference", split="train")
- def test_tokenize_row_with_truncation(self):
- # Define the input features
- features = {"prompt": "The sky is", "chosen": " blue", "rejected": " green"}
-
- # Call the method with truncation
- result = DPOTrainer.tokenize_row(
- features=features,
- processing_class=self.tokenizer,
- max_prompt_length=2,
- max_completion_length=1,
- add_special_tokens=False,
+ # Initialize the trainer
+ training_args = DPOConfig(
+ output_dir=self.tmp_dir,
+ learning_rate=0.1, # use higher lr because gradients are tiny and default lr can stall updates
+ report_to="none",
)
+ trainer = DPOTrainer(model=model_id, args=training_args, train_dataset=dataset)
- # Assert the correct output with truncation applied
- assert result == {
- "prompt_input_ids": [6766, 318], # truncated to the last 2 tokens
- "chosen_input_ids": [4171], # truncated to 1 token
- "rejected_input_ids": [4077], # truncated to 1 token
- }
+ # Save the initial parameters to compare them later
+ previous_trainable_params = {n: param.clone() for n, param in trainer.model.named_parameters()}
- def test_tokenize_row_with_special_tokens(self):
- # Define the input features
- features = {"prompt": "The sky is", "chosen": " blue", "rejected": " green"}
-
- # Call the method with special tokens
- result = DPOTrainer.tokenize_row(
- features=features,
- processing_class=self.tokenizer,
- max_prompt_length=None,
- max_completion_length=None,
- add_special_tokens=True,
- )
+ # Train the model
+ trainer.train()
- # Assert the correct output with special tokens added
- assert result == {
- "prompt_input_ids": [0, 464, 6766, 318, 2], # bos_token and eos_token added
- "chosen_input_ids": [4171, 2], # eos_token added
- "rejected_input_ids": [4077, 2], # eos_token added
- }
+ # Check that the training loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
- def test_tokenize_row_with_truncation_and_special_tokens(self):
- # Define the input features
- features = {"prompt": "The sky is", "chosen": " blue", "rejected": " green"}
-
- # Call the method with both truncation and special tokens
- result = DPOTrainer.tokenize_row(
- features=features,
- processing_class=self.tokenizer,
- max_prompt_length=4,
- max_completion_length=1,
- add_special_tokens=True,
+ # Check the params have changed
+ for n, param in previous_trainable_params.items():
+ new_param = trainer.model.get_parameter(n)
+ assert not torch.allclose(param, new_param), f"Parameter {n} has not changed"
+
+ # Special case for harmony
+ def test_train_gpt_oss(self):
+ # Get the dataset
+ dataset = load_dataset("trl-internal-testing/harmony", "preference", split="train")
+
+ # Initialize the trainer
+ training_args = DPOConfig(
+ output_dir=self.tmp_dir,
+ learning_rate=0.1, # use higher lr because gradients are tiny and default lr can stall updates
+ report_to="none",
+ )
+ trainer = DPOTrainer(
+ model="trl-internal-testing/tiny-GptOssForCausalLM", args=training_args, train_dataset=dataset
)
- # Assert the correct output with both truncation and special tokens
- assert result == {
- "prompt_input_ids": [464, 6766, 318, 2], # truncated to 4 tokens with bos_token and eos_token
- "chosen_input_ids": [4171], # truncated to 1 token
- "rejected_input_ids": [4077], # truncated to 1 token
- }
+ # Save the initial parameters to compare them later
+ previous_trainable_params = {n: param.clone() for n, param in trainer.model.named_parameters()}
+
+ # Train the model
+ trainer.train()
+ # Check that the training loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
-class TestDPOTrainer(TrlTestCase):
- def setup_method(self):
- self.model_id = "trl-internal-testing/tiny-Qwen2ForCausalLM-2.5"
- self.model = AutoModelForCausalLM.from_pretrained(self.model_id, dtype="float32")
- self.ref_model = AutoModelForCausalLM.from_pretrained(self.model_id)
- self.tokenizer = AutoTokenizer.from_pretrained(self.model_id)
- self.tokenizer.pad_token = self.tokenizer.eos_token
-
- def test_train(self):
- model_id = "trl-internal-testing/tiny-Qwen2ForCausalLM-2.5"
+ # Check the params have changed
+ for n, param in previous_trainable_params.items():
+ new_param = trainer.model.get_parameter(n)
+ assert not torch.allclose(param, new_param), f"Parameter {n} has not changed"
+
+ def test_train_model(self):
+ # Instantiate the model
+ model = AutoModelForCausalLM.from_pretrained(
+ "trl-internal-testing/tiny-Qwen2ForCausalLM-2.5",
+ dtype="float32",
+ )
+
+ # Get the dataset
dataset = load_dataset("trl-internal-testing/zen", "standard_preference", split="train")
- tokenizer = AutoTokenizer.from_pretrained(model_id)
+
+ # Initialize the trainer
training_args = DPOConfig(
output_dir=self.tmp_dir,
- per_device_train_batch_size=2,
- learning_rate=9e-1,
+ learning_rate=0.1, # use higher lr because gradients are tiny and default lr can stall updates
report_to="none",
)
- trainer = DPOTrainer(
- model=model_id,
- args=training_args,
- processing_class=tokenizer,
- train_dataset=dataset,
- )
+ trainer = DPOTrainer(model=model, args=training_args, train_dataset=dataset)
+ # Save the initial parameters to compare them later
previous_trainable_params = {n: param.clone() for n, param in trainer.model.named_parameters()}
+ # Train the model
trainer.train()
+ # Check that the training loss is not None
assert trainer.state.log_history[-1]["train_loss"] is not None
- # Check that the parameters have changed
+ # Check the params have changed
for n, param in previous_trainable_params.items():
new_param = trainer.model.get_parameter(n)
- if param.sum() != 0: # ignore 0 biases
- assert not torch.allclose(param, new_param, rtol=1e-12, atol=1e-12)
+ assert not torch.allclose(param, new_param), f"Parameter {n} has not changed"
@pytest.mark.parametrize(
"loss_type",
@@ -208,1218 +241,994 @@ def test_train(self):
"sppo_hard",
"aot",
"aot_unpaired",
- "discopop",
"apo_zero",
"apo_down",
+ "discopop",
+ "sft",
],
)
def test_train_loss_types(self, loss_type):
- model_id = "trl-internal-testing/tiny-Qwen2ForCausalLM-2.5"
- dataset = load_dataset("trl-internal-testing/zen", "standard_preference", split="train")
- tokenizer = AutoTokenizer.from_pretrained(model_id)
+ # Get the dataset
+ dataset = load_dataset("trl-internal-testing/zen", "standard_preference")
+ # Initialize the trainer
training_args = DPOConfig(
output_dir=self.tmp_dir,
- per_device_train_batch_size=2,
- learning_rate=9e-1,
loss_type=loss_type,
+ label_smoothing=1e-3 if loss_type == "exo_pair" else 0.0,
+ learning_rate=0.1, # use higher lr because gradients are tiny and default lr can stall updates
report_to="none",
+ eval_strategy="steps",
+ eval_steps=3,
)
trainer = DPOTrainer(
- model=model_id,
+ model="trl-internal-testing/tiny-Qwen2ForCausalLM-2.5",
args=training_args,
- processing_class=tokenizer,
- train_dataset=dataset,
+ train_dataset=dataset["train"],
+ eval_dataset=dataset["test"],
)
+ # Save the initial parameters to compare them later
previous_trainable_params = {n: param.clone() for n, param in trainer.model.named_parameters()}
+ # Train the model
trainer.train()
+ # Check that the training loss is not None
assert trainer.state.log_history[-1]["train_loss"] is not None
- # Check that the parameters have changed
+ # Check the params have changed
for n, param in previous_trainable_params.items():
new_param = trainer.model.get_parameter(n)
- if param.sum() != 0: # ignore 0 biases
- assert not torch.allclose(param, new_param, rtol=1e-12, atol=1e-12)
+ assert not torch.allclose(param, new_param), f"Parameter {n} has not changed"
- @require_liger_kernel
- def test_train_encoder_decoder_liger(self):
- model_id = "trl-internal-testing/tiny-BartModel"
- model = AutoModelForSeq2SeqLM.from_pretrained(model_id, dtype="float32")
+ def test_train_multi_loss_types(self):
+ # Get the dataset
dataset = load_dataset("trl-internal-testing/zen", "standard_preference", split="train")
- tokenizer = AutoTokenizer.from_pretrained(model_id)
+ # Initialize the trainer
training_args = DPOConfig(
output_dir=self.tmp_dir,
- per_device_train_batch_size=2,
- learning_rate=9e-1,
+ learning_rate=0.1, # use higher lr because gradients are tiny and default lr can stall updates
+ loss_type=["sigmoid", "bco_pair", "sft"], # this specific combination is used in MPO
report_to="none",
- use_liger_kernel=True,
)
trainer = DPOTrainer(
- model=model,
+ model="trl-internal-testing/tiny-Qwen2ForCausalLM-2.5",
args=training_args,
- processing_class=tokenizer,
train_dataset=dataset,
)
+ # Save the initial parameters to compare them later
previous_trainable_params = {n: param.clone() for n, param in trainer.model.named_parameters()}
+ # Train the model
trainer.train()
+ # Check that the training loss is not None
assert trainer.state.log_history[-1]["train_loss"] is not None
- # Check that the parameters have changed
+ # Check the params have changed
for n, param in previous_trainable_params.items():
new_param = trainer.model.get_parameter(n)
- if param.sum() != 0: # ignore 0 biases
- assert not torch.allclose(param, new_param, rtol=1e-12, atol=1e-12)
+ assert not torch.allclose(param, new_param), f"Parameter {n} has not changed"
- def test_dpo_trainer_with_weighting(self):
+ def test_train_with_wpo(self):
+ # Get the dataset
dataset = load_dataset("trl-internal-testing/zen", "standard_preference", split="train")
+ # Initialize the trainer
training_args = DPOConfig(
output_dir=self.tmp_dir,
- per_device_train_batch_size=2,
- learning_rate=9e-1,
- use_weighting=True,
+ learning_rate=0.1, # use higher lr because gradients are tiny and default lr can stall updates
report_to="none",
+ use_weighting=True,
)
-
trainer = DPOTrainer(
- model=self.model,
+ model="trl-internal-testing/tiny-Qwen2ForCausalLM-2.5",
args=training_args,
- processing_class=self.tokenizer,
train_dataset=dataset,
)
+ # Save the initial parameters to compare them later
previous_trainable_params = {n: param.clone() for n, param in trainer.model.named_parameters()}
+ # Train the model
trainer.train()
+ # Check that the training loss is not None
assert trainer.state.log_history[-1]["train_loss"] is not None
- # Check that the parameters have changed
+ # Check the params have changed
for n, param in previous_trainable_params.items():
new_param = trainer.model.get_parameter(n)
- if param.sum() != 0: # ignore 0 biases
- assert not torch.allclose(param, new_param, rtol=1e-12, atol=1e-12)
-
- def test_train_with_multiple_loss_types(self):
- """
- Tests multi-loss combinations, loss type inference, and weight configuration. MPO combines DPO (sigmoid), BCO
- (bco_pair), and SFT (sft) losses.
- """
- model_id = "trl-internal-testing/tiny-Qwen2ForCausalLM-2.5"
+ assert not torch.allclose(param, new_param), f"Parameter {n} has not changed"
+
+ def test_train_with_ld(self):
+ # Get the dataset
dataset = load_dataset("trl-internal-testing/zen", "standard_preference", split="train")
- tokenizer = AutoTokenizer.from_pretrained(model_id)
+ # Initialize the trainer
training_args = DPOConfig(
output_dir=self.tmp_dir,
- per_device_train_batch_size=2,
- learning_rate=9e-1,
- loss_type=["sigmoid", "bco_pair", "sft"],
- loss_weights=[0.8, 0.2, 1.0],
+ learning_rate=0.1, # use higher lr because gradients are tiny and default lr can stall updates
report_to="none",
+ ld_alpha=0.5,
)
trainer = DPOTrainer(
- model=model_id,
+ model="trl-internal-testing/tiny-Qwen2ForCausalLM-2.5",
args=training_args,
- processing_class=tokenizer,
train_dataset=dataset,
)
- # Test that training works
- trainer.train()
- assert trainer.state.log_history[-1]["train_loss"] is not None
+ # Save the initial parameters to compare them later
+ previous_trainable_params = {n: param.clone() for n, param in trainer.model.named_parameters()}
- # Verify SFT loss is computed in the first test too
- with torch.no_grad():
- batch = next(iter(trainer.get_train_dataloader()))
- loss, metrics = trainer.get_batch_loss_metrics(trainer.model, batch)
- assert "nll_loss" in metrics # SFT loss should be computed
-
- def test_wrong_loss_weights_length(self):
- with pytest.raises(ValueError, match="Length of loss_weights list"):
- DPOConfig(
- output_dir=self.tmp_dir,
- loss_type=["sigmoid", "bco_pair"],
- loss_weights=[1.0, 0.5, 0.1], # Wrong length
- )
+ # Train the model
+ trainer.train()
- def test_dpo_trainer_with_ref_model_is_model(self):
- training_args = DPOConfig(
- output_dir=self.tmp_dir,
- per_device_train_batch_size=2,
- max_steps=3,
- report_to="none",
- )
+ # Check that the training loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
- dummy_dataset = load_dataset("trl-internal-testing/zen", "standard_preference")
+ # Check the params have changed
+ for n, param in previous_trainable_params.items():
+ new_param = trainer.model.get_parameter(n)
+ assert not torch.allclose(param, new_param), f"Parameter {n} has not changed"
- with pytest.raises(ValueError):
- DPOTrainer(
- model=self.model,
- ref_model=self.model, # ref_model can't be the same as model
- args=training_args,
- processing_class=self.tokenizer,
- train_dataset=dummy_dataset["train"],
- )
+ @pytest.mark.parametrize(
+ "f_divergence_type",
+ ["reverse_kl", "forward_kl", "js_divergence", "alpha_divergence"],
+ )
+ def test_train_with_f_divergence(self, f_divergence_type):
+ # Get the dataset
+ dataset = load_dataset("trl-internal-testing/zen", "standard_preference", split="train")
- def test_precompute_ref_batch_size(self):
+ # Initialize the trainer
training_args = DPOConfig(
output_dir=self.tmp_dir,
learning_rate=0.1, # use higher lr because gradients are tiny and default lr can stall updates
- per_device_train_batch_size=2,
- precompute_ref_log_probs=True,
- precompute_ref_batch_size=4,
report_to="none",
+ f_divergence_type=f_divergence_type,
)
-
- dummy_dataset = load_dataset("trl-internal-testing/zen", "standard_preference")
-
trainer = DPOTrainer(
- model=self.model,
- ref_model=self.ref_model,
+ model="trl-internal-testing/tiny-Qwen2ForCausalLM-2.5",
args=training_args,
- processing_class=self.tokenizer,
- train_dataset=dummy_dataset["train"],
- eval_dataset=dummy_dataset["test"],
+ train_dataset=dataset,
)
+ # Save the initial parameters to compare them later
previous_trainable_params = {n: param.clone() for n, param in trainer.model.named_parameters()}
+ # Train the model
trainer.train()
+ # Check that the training loss is not None
assert trainer.state.log_history[-1]["train_loss"] is not None
- # Check that the parameters have changed
+ # Check the params have changed
for n, param in previous_trainable_params.items():
new_param = trainer.model.get_parameter(n)
- if param.sum() != 0: # ignore 0 biases
- assert not torch.allclose(param, new_param, rtol=1e-12, atol=1e-12)
+ assert not torch.allclose(param, new_param), f"Parameter {n} has not changed"
- @require_peft
- def test_dpo_trainer_without_providing_ref_model_with_lora(self):
- from peft import LoraConfig
-
- lora_config = LoraConfig(
- r=16,
- lora_alpha=32,
- lora_dropout=0.05,
- bias="none",
- task_type="CAUSAL_LM",
- )
+ def test_train_with_explicit_ref_model(self):
+ # Get the dataset
+ dataset = load_dataset("trl-internal-testing/zen", "standard_preference", split="train")
+ # Initialize the trainer
training_args = DPOConfig(
output_dir=self.tmp_dir,
- per_device_train_batch_size=2,
- max_steps=3,
- remove_unused_columns=False,
- gradient_accumulation_steps=4,
- learning_rate=9e-1,
- eval_strategy="steps",
- beta=0.1,
- precompute_ref_log_probs=True,
+ learning_rate=0.1,
report_to="none",
)
-
- dummy_dataset = load_dataset("trl-internal-testing/zen", "standard_preference")
-
+ # When specifying a ref model, it's usually because we want it to be a different checkpoint, but for testing
+ # purposes we will just just use the same checkpoint
+ ref_model = AutoModelForCausalLM.from_pretrained(
+ "trl-internal-testing/tiny-Qwen2ForCausalLM-2.5", dtype="float32"
+ )
trainer = DPOTrainer(
- model=self.model,
- ref_model=None,
+ model="trl-internal-testing/tiny-Qwen2ForCausalLM-2.5",
+ ref_model=ref_model,
args=training_args,
- processing_class=self.tokenizer,
- train_dataset=dummy_dataset["train"],
- eval_dataset=dummy_dataset["test"],
- peft_config=lora_config,
+ train_dataset=dataset,
)
+ # Save the initial parameters to compare them later
previous_trainable_params = {n: param.clone() for n, param in trainer.model.named_parameters()}
+ # Train the model
trainer.train()
+ # Check that the training loss is not None
assert trainer.state.log_history[-1]["train_loss"] is not None
- # Check that the parameters have changed
+ # Check the params have changed
for n, param in previous_trainable_params.items():
- if "lora" in n:
- new_param = trainer.model.get_parameter(n)
- if param.sum() != 0: # ignore 0 biases
- assert not torch.equal(param, new_param)
+ new_param = trainer.model.get_parameter(n)
+ assert not torch.allclose(param, new_param), f"Parameter {n} has not changed"
+ new_ref_param = trainer.ref_model.get_parameter(n)
+ torch.testing.assert_close(param, new_ref_param), f"Reference model parameter {n} has changed"
- def test_dpo_trainer_w_dataset_num_proc(self):
+ def test_training_with_sync_ref_model(self):
+ # Get the dataset
+ dataset = load_dataset("trl-internal-testing/zen", "standard_preference", split="train")
+
+ # Initialize the trainer
training_args = DPOConfig(
output_dir=self.tmp_dir,
- per_device_train_batch_size=2,
- max_steps=3,
- remove_unused_columns=False,
- gradient_accumulation_steps=1,
- learning_rate=9e-1,
- eval_strategy="steps",
- beta=0.1,
- dataset_num_proc=2,
+ learning_rate=0.1, # use higher lr because gradients are tiny and default lr can stall updates
+ sync_ref_model=True,
+ ref_model_sync_steps=2, # reduce sync steps to ensure a sync happens
report_to="none",
)
-
- dummy_dataset = load_dataset("trl-internal-testing/zen", "standard_preference")
-
- tokenizer = AutoTokenizer.from_pretrained(self.model_id)
-
trainer = DPOTrainer(
- model=self.model,
- args=training_args,
- processing_class=tokenizer,
- train_dataset=dummy_dataset["train"],
- eval_dataset=dummy_dataset["test"],
+ model="trl-internal-testing/tiny-Qwen2ForCausalLM-2.5", args=training_args, train_dataset=dataset
)
+ # Save the initial parameters to compare them later
+ previous_trainable_params = {n: param.clone() for n, param in trainer.model.named_parameters()}
+ assert trainer.ref_model is not None
+ previous_ref_params = {n: param.clone() for n, param in trainer.ref_model.named_parameters()}
+
+ # Train the model
trainer.train()
- def test_tr_dpo_trainer(self):
+ # Check that the training loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ # Check that the params have changed
+ for n, param in previous_trainable_params.items():
+ new_param = trainer.model.get_parameter(n)
+ assert not torch.equal(param, new_param), f"Parameter {n} has not changed."
+ new_ref_param = trainer.ref_model.get_parameter(n)
+ assert not torch.equal(previous_ref_params[n], new_ref_param), f"Ref Parameter {n} has not changed."
+
+ def test_train_model_dtype(self):
+ # Get the dataset
+ dataset = load_dataset("trl-internal-testing/zen", "standard_preference", split="train")
+
+ # Initialize the trainer
training_args = DPOConfig(
output_dir=self.tmp_dir,
- per_device_train_batch_size=2,
- max_steps=3,
- remove_unused_columns=False,
- gradient_accumulation_steps=4,
- learning_rate=9e-1,
- eval_strategy="steps",
- precompute_ref_log_probs=False,
- sync_ref_model=True,
- ref_model_mixup_alpha=0.5,
- ref_model_sync_steps=1,
+ model_init_kwargs={"dtype": torch.float16},
+ learning_rate=0.1, # use higher lr because gradients are tiny and default lr can stall updates
report_to="none",
)
-
- dummy_dataset = load_dataset("trl-internal-testing/zen", "standard_preference")
-
trainer = DPOTrainer(
- model=self.model,
- ref_model=self.ref_model,
- args=training_args,
- processing_class=self.tokenizer,
- train_dataset=dummy_dataset["train"],
- eval_dataset=dummy_dataset["test"],
+ model="trl-internal-testing/tiny-Qwen2ForCausalLM-2.5", args=training_args, train_dataset=dataset
)
- # params of the ref model as its the same as the model
+ # Save the initial parameters to compare them later
previous_trainable_params = {n: param.clone() for n, param in trainer.model.named_parameters()}
+ # Train the model
trainer.train()
+ # Check that the training loss is not None
assert trainer.state.log_history[-1]["train_loss"] is not None
- # Check that the parameters have changed
+ # Check the params have changed
for n, param in previous_trainable_params.items():
- new_param = trainer.ref_model.get_parameter(n)
- if param.sum() != 0: # ignore 0 biases
- assert not torch.equal(param, new_param)
+ # For some reasonn model.layers.0.input_layernorm.weight doesn't change in GitHub Actions but does
+ # locally. We ignore this parameter for now
+ if "layernorm" in n:
+ continue
+ new_param = trainer.model.get_parameter(n)
+ # Check the torch dtype
+ assert new_param.dtype == torch.float16
+ assert not torch.allclose(param, new_param), f"Parameter {n} has not changed"
- @require_bitsandbytes
@require_peft
- @require_torch_gpu_if_bnb_not_multi_backend_enabled
- def test_dpo_lora_bf16_autocast_llama(self):
- # Note this test only works on compute capability > 7 GPU devices
- from peft import LoraConfig
- from transformers import BitsAndBytesConfig
-
+ def test_train_dense_with_peft_config_lora(self):
+ # Get the base model parameter names
model_id = "trl-internal-testing/tiny-Qwen2ForCausalLM-2.5"
- tokenizer = AutoTokenizer.from_pretrained(model_id)
-
- lora_config = LoraConfig(
- r=16,
- lora_alpha=32,
- lora_dropout=0.05,
- bias="none",
- task_type="CAUSAL_LM",
- )
+ model = AutoModelForCausalLM.from_pretrained(model_id, dtype="float32")
+ base_param_names = [f"base_model.model.{n}" for n, _ in model.named_parameters()]
- # lora model
- model = AutoModelForCausalLM.from_pretrained(
- model_id, dtype="float32", quantization_config=BitsAndBytesConfig(load_in_4bit=True)
- )
+ # Get the dataset
+ dataset = load_dataset("trl-internal-testing/zen", "standard_preference", split="train")
+ # Initialize the trainer
training_args = DPOConfig(
output_dir=self.tmp_dir,
- per_device_train_batch_size=2,
- max_steps=3,
- remove_unused_columns=False,
- gradient_accumulation_steps=4,
- learning_rate=9e-1,
- eval_strategy="steps",
- bf16=True,
- beta=0.1,
+ learning_rate=1.0, # use higher lr because gradients are tiny and default lr can stall updates
report_to="none",
)
- dummy_dataset = load_dataset("trl-internal-testing/zen", "standard_preference")
-
- # dpo train lora model with a lora config
trainer = DPOTrainer(
- model=model,
- ref_model=None,
+ model=model_id,
args=training_args,
- processing_class=tokenizer,
- train_dataset=dummy_dataset["train"],
- eval_dataset=dummy_dataset["test"],
- peft_config=lora_config,
+ train_dataset=dataset,
+ peft_config=LoraConfig(),
)
- # train the model
+ # Save the initial parameters to compare them later
+ previous_trainable_params = {n: param.clone() for n, param in trainer.model.named_parameters()}
+
+ # Train the model
trainer.train()
- # save peft adapter
- trainer.save_model()
+ # Check that the training loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ # Check the peft params have changed and the base model params have not changed
+ for n, param in previous_trainable_params.items():
+ new_param = trainer.model.get_parameter(n)
+ if n in base_param_names: # We expect the base model parameters to be the same
+ torch.testing.assert_close(param, new_param), f"Parameter {n} has changed"
+ elif "base_layer" not in n: # We expect the peft parameters to be different (except for the base layer)
+ assert not torch.allclose(param, new_param), f"Parameter {n} has not changed"
- @pytest.mark.parametrize(
- "loss_type, pre_compute",
- [
- ("sigmoid", False),
- ("sigmoid", True),
- ("ipo", False),
- ("ipo", True),
- ("aot_unpaired", False),
- ("aot_unpaired", True),
- ("aot", False),
- ("aot", True),
- ("bco_pair", False),
- ("bco_pair", True),
- ("robust", False),
- ("robust", True),
- ],
- )
- @require_bitsandbytes
@require_peft
- @pytest.mark.skipif(
- get_device_properties()[0] == "cuda" and get_device_properties()[1] < 8,
- reason="Skipping because bf16 not supported on CUDA GPU with capability < 8.0",
- )
- def test_dpo_lora_bf16_autocast(self, loss_type, pre_compute):
- from peft import LoraConfig
- from transformers import BitsAndBytesConfig
-
- lora_config = LoraConfig(
- r=16,
- lora_alpha=32,
- lora_dropout=0.05,
- bias="none",
- task_type="CAUSAL_LM",
- )
+ def test_train_moe_with_peft_config(self):
+ # Get the base model parameter names
+ model_id = "trl-internal-testing/tiny-GptOssForCausalLM"
+ model = AutoModelForCausalLM.from_pretrained(model_id, dtype="float32")
+ base_param_names = [f"base_model.model.{n}" for n, _ in model.named_parameters()]
- # lora model
- model = AutoModelForCausalLM.from_pretrained(
- self.model_id, dtype="float32", quantization_config=BitsAndBytesConfig(load_in_4bit=True)
- )
+ # Get the dataset
+ dataset = load_dataset("trl-internal-testing/zen", "standard_preference", split="train")
+ # Initialize the trainer
training_args = DPOConfig(
output_dir=self.tmp_dir,
- per_device_train_batch_size=2,
- max_steps=3,
- remove_unused_columns=False,
- gradient_accumulation_steps=4,
- learning_rate=9e-1,
- eval_strategy="steps",
- bf16=True,
- beta=0.1,
- loss_type=loss_type,
- precompute_ref_log_probs=pre_compute,
+ learning_rate=0.1, # use higher lr because gradients are tiny and default lr can stall updates
report_to="none",
)
- dummy_dataset = load_dataset("trl-internal-testing/zen", "standard_preference")
-
- # dpo train lora model with a lora config
trainer = DPOTrainer(
- model=model,
- ref_model=None,
+ model=model_id,
args=training_args,
- processing_class=self.tokenizer,
- train_dataset=dummy_dataset["train"],
- eval_dataset=dummy_dataset["test"],
- peft_config=lora_config,
+ train_dataset=dataset,
+ peft_config=LoraConfig(target_parameters=["mlp.experts.down_proj", "mlp.experts.gate_up_proj"]),
)
- # train the model
+ # Save the initial parameters to compare them later
+ previous_trainable_params = {n: param.clone() for n, param in trainer.model.named_parameters()}
+
+ # Train the model
trainer.train()
- # save peft adapter
- trainer.save_model()
+ # Check that the training loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
- @require_peft
- def test_dpo_lora_tags(self):
- from peft import LoraConfig
+ # Check the peft params have changed and the base model params have not changed
+ for n, param in previous_trainable_params.items():
+ new_param = trainer.model.get_parameter(n)
+ if n in base_param_names: # We expect the base model parameters to be the same
+ torch.testing.assert_close(param, new_param), f"Parameter {n} has changed"
+ elif "base_layer" not in n: # We expect the peft parameters to be different (except for the base layer)
+ assert not torch.allclose(param, new_param), f"Parameter {n} has not changed"
+ @require_peft
+ def test_train_peft_model(self):
+ # Get the base model
model_id = "trl-internal-testing/tiny-Qwen2ForCausalLM-2.5"
- tokenizer = AutoTokenizer.from_pretrained(model_id)
-
- lora_config = LoraConfig(
- r=16,
- lora_alpha=32,
- lora_dropout=0.05,
- bias="none",
- task_type="CAUSAL_LM",
- )
-
- # lora model
model = AutoModelForCausalLM.from_pretrained(model_id, dtype="float32")
+ # Get the base model parameter names
+ base_param_names = [f"base_model.model.{n}" for n, _ in model.named_parameters()]
+
+ # Turn the model into a peft model
+ lora_config = LoraConfig()
+ model = get_peft_model(model, lora_config)
+
+ # Get the dataset
+ dataset = load_dataset("trl-internal-testing/zen", "standard_preference", split="train")
+
+ # Initialize the trainer
training_args = DPOConfig(
output_dir=self.tmp_dir,
- per_device_train_batch_size=2,
- max_steps=3,
- remove_unused_columns=False,
- gradient_accumulation_steps=4,
- learning_rate=9e-1,
- eval_strategy="steps",
- beta=0.1,
+ learning_rate=1.0, # use higher lr because gradients are tiny and default lr can stall updates
report_to="none",
)
+ trainer = DPOTrainer(model=model, args=training_args, train_dataset=dataset)
- dummy_dataset = load_dataset("trl-internal-testing/zen", "standard_preference")
+ # Save the initial parameters to compare them later
+ previous_trainable_params = {n: param.clone() for n, param in trainer.model.named_parameters()}
- # dpo train lora model with a lora config
- trainer = DPOTrainer(
- model=model,
- ref_model=None,
- args=training_args,
- processing_class=tokenizer,
- train_dataset=dummy_dataset["train"],
- eval_dataset=dummy_dataset["test"],
- peft_config=lora_config,
- )
+ # Train the model
+ trainer.train()
- for tag in ["dpo", "trl"]:
- assert tag in trainer.model.model_tags
+ # Check that the training loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+ # Check the peft params have changed and the base model params have not changed
+ for n, param in previous_trainable_params.items():
+ new_param = trainer.model.get_parameter(n)
+ if n in base_param_names: # We expect the base model parameters to be the same
+ torch.testing.assert_close(param, new_param), f"Parameter {n} has changed"
+ elif "base_layer" not in n and "ref" not in n: # and the peft params to be different (except base and ref)
+ assert not torch.allclose(param, new_param), f"Parameter {n} has not changed"
+
+ # In practice, this test is the same as `test_train_dense_with_peft_config_lora`, since gradient checkpointing is
+ # enabled by default in `DPOTrainer`. We keep it as a regression guard: if the default ever changes, we still
+ # explicitly test PEFT + gradient checkpointing, which has caused issues in the past.
@require_peft
- def test_dpo_tags(self):
+ def test_train_with_peft_config_and_gradient_checkpointing(self):
+ # Get the base model parameter names
model_id = "trl-internal-testing/tiny-Qwen2ForCausalLM-2.5"
- tokenizer = AutoTokenizer.from_pretrained(model_id)
-
- # lora model
model = AutoModelForCausalLM.from_pretrained(model_id, dtype="float32")
+ base_param_names = [f"base_model.model.{n}" for n, _ in model.named_parameters()]
+
+ # Get the dataset
+ dataset = load_dataset("trl-internal-testing/zen", "standard_preference", split="train")
+ # Initialize the trainer
training_args = DPOConfig(
output_dir=self.tmp_dir,
- per_device_train_batch_size=2,
- max_steps=3,
- remove_unused_columns=False,
- gradient_accumulation_steps=4,
- learning_rate=9e-1,
- eval_strategy="steps",
- beta=0.1,
+ learning_rate=0.1, # use higher lr because gradients are tiny and default lr can stall updates
+ gradient_checkpointing=True,
report_to="none",
)
- dummy_dataset = load_dataset("trl-internal-testing/zen", "standard_preference")
-
- # dpo train lora model with a lora config
trainer = DPOTrainer(
- model=model,
- ref_model=None,
+ model=model_id,
args=training_args,
- processing_class=tokenizer,
- train_dataset=dummy_dataset["train"],
- eval_dataset=dummy_dataset["test"],
+ train_dataset=dataset,
+ peft_config=LoraConfig(),
)
- for tag in ["dpo", "trl"]:
- assert tag in trainer.model.model_tags
+ # Save the initial parameters to compare them later
+ previous_trainable_params = {n: param.clone() for n, param in trainer.model.named_parameters()}
+
+ # Train the model
+ trainer.train()
- def test_dpo_trainer_dtype(self):
- # See https://github.com/huggingface/trl/issues/1751
- dummy_dataset = load_dataset("trl-internal-testing/zen", "standard_preference")
+ # Check that the training loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ # Check the peft params have changed and the base model params have not changed
+ for n, param in previous_trainable_params.items():
+ new_param = trainer.model.get_parameter(n)
+ if n in base_param_names: # We expect the base model parameters to be the same
+ torch.testing.assert_close(param, new_param), f"Parameter {n} has changed"
+ elif "base_layer" not in n: # We expect the peft parameters to be different (except for the base layer)
+ assert not torch.allclose(param, new_param), f"Parameter {n} has not changed"
+
+ @require_liger_kernel
+ def test_train_with_liger(self):
+ # Get the dataset
+ dataset = load_dataset("trl-internal-testing/zen", "standard_preference", split="train")
+
+ # Initialize the trainer
training_args = DPOConfig(
output_dir=self.tmp_dir,
- per_device_train_batch_size=2,
- max_steps=1,
- model_init_kwargs={"dtype": "float16"},
+ learning_rate=0.1, # use higher lr because gradients are tiny and default lr can stall updates
+ use_liger_kernel=True,
report_to="none",
)
- # Instantiating the reference model explicitly and pass it via ref_model
- ref_model = AutoModelForCausalLM.from_pretrained(self.model_id, dtype="float16")
-
trainer = DPOTrainer(
- model=self.model_id,
- ref_model=ref_model,
- processing_class=self.tokenizer,
- args=training_args,
- train_dataset=dummy_dataset["train"],
+ model="trl-internal-testing/tiny-Qwen2ForCausalLM-2.5", args=training_args, train_dataset=dataset
)
- assert trainer.model.config.dtype == torch.float16
- assert trainer.ref_model.config.dtype == torch.float16
- # Now test when `dtype` is provided but is wrong to either the model or the ref_model
- training_args = DPOConfig(
- output_dir=self.tmp_dir,
- per_device_train_batch_size=2,
- max_steps=1,
- model_init_kwargs={"dtype": -1},
- report_to="none",
- )
+ # Save the initial parameters to compare them later
+ previous_trainable_params = {n: param.clone() for n, param in trainer.model.named_parameters()}
- with pytest.raises(
- ValueError,
- match=re.escape(
- "Invalid `dtype` passed to the config. Expected either 'auto' or a string representing a valid `torch.dtype` (e.g., 'float32'), but got -1."
- ),
- ):
- _ = DPOTrainer(
- model=self.model_id,
- processing_class=self.tokenizer,
- args=training_args,
- train_dataset=dummy_dataset["train"],
- )
+ # Train the model
+ trainer.train()
- def test_dpo_loss_alpha_div_f(self):
- model_id = "trl-internal-testing/tiny-Qwen2ForCausalLM-2.5"
- tokenizer = AutoTokenizer.from_pretrained(model_id)
+ # Check that the training loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
- # lora model
- model = AutoModelForCausalLM.from_pretrained(model_id, dtype="float32")
+ # Check the params have changed
+ for n, param in previous_trainable_params.items():
+ new_param = trainer.model.get_parameter(n)
+ assert not torch.allclose(param, new_param), f"Parameter {n} has not changed"
+
+ def test_train_with_iterable_dataset(self):
+ # Get the dataset
+ dataset = load_dataset("trl-internal-testing/zen", "standard_preference", split="train", streaming=True)
+
+ # Initialize the trainer
training_args = DPOConfig(
output_dir=self.tmp_dir,
- per_device_train_batch_size=2,
+ learning_rate=0.1, # use higher lr because gradients are tiny and default lr can stall updates
max_steps=3,
- remove_unused_columns=False,
- gradient_accumulation_steps=4,
- learning_rate=9e-1,
- eval_strategy="steps",
- f_divergence_type="alpha_divergence",
- f_alpha_divergence_coef=0.5,
report_to="none",
)
-
- dummy_dataset = load_dataset("trl-internal-testing/zen", "standard_preference")
-
- # dpo train lora model with a lora config
trainer = DPOTrainer(
- model=model,
- ref_model=None,
- args=training_args,
- processing_class=tokenizer,
- train_dataset=dummy_dataset["train"],
- eval_dataset=dummy_dataset["test"],
+ model="trl-internal-testing/tiny-Qwen2ForCausalLM-2.5", args=training_args, train_dataset=dataset
)
- # Fake chosen and rejected log probs
- policy_chosen_logps = torch.FloatTensor([410.0, 0.1])
- policy_rejected_logps = torch.FloatTensor([810.5, 0.2])
- reference_chosen_logps = torch.FloatTensor([-610.0, -0.1])
- reference_rejected_logps = torch.FloatTensor([110.6, 0.5])
- losses, _, _ = trainer.dpo_loss(
- policy_chosen_logps, policy_rejected_logps, reference_chosen_logps, reference_rejected_logps
- )
- assert torch.isfinite(losses).cpu().numpy().all()
+ # Save the initial parameters to compare them later
+ previous_trainable_params = {n: param.clone() for n, param in trainer.model.named_parameters()}
- def test_dpo_loss_js_div_f(self):
- model_id = "trl-internal-testing/tiny-Qwen2ForCausalLM-2.5"
- tokenizer = AutoTokenizer.from_pretrained(model_id)
+ # Train the model
+ trainer.train()
- # lora model
- model = AutoModelForCausalLM.from_pretrained(model_id, dtype="float32")
+ # Check that the training loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ # Check the params have changed
+ for n, param in previous_trainable_params.items():
+ new_param = trainer.model.get_parameter(n)
+ assert not torch.allclose(param, new_param), f"Parameter {n} has not changed"
+ @require_kernels
+ @require_ampere_or_newer # Flash attention 2 requires Ampere or newer GPUs
+ def test_train_padding_free(self):
+ # Get the dataset
+ dataset = load_dataset("trl-internal-testing/zen", "standard_preference", split="train")
+
+ # Initialize the trainer
training_args = DPOConfig(
output_dir=self.tmp_dir,
- per_device_train_batch_size=2,
- max_steps=3,
- remove_unused_columns=False,
- gradient_accumulation_steps=4,
- learning_rate=9e-1,
- eval_strategy="steps",
- f_divergence_type="js_divergence",
- f_alpha_divergence_coef=0.5,
+ learning_rate=0.1, # use higher lr because gradients are tiny and default lr can stall updates
+ padding_free=True,
+ model_init_kwargs={"attn_implementation": "kernels-community/flash-attn2"},
+ bf16=True, # flash_attention_2 only supports bf16 and fp16
report_to="none",
)
-
- dummy_dataset = load_dataset("trl-internal-testing/zen", "standard_preference")
-
- # dpo train lora model with a lora config
trainer = DPOTrainer(
- model=model,
- ref_model=None,
- args=training_args,
- processing_class=tokenizer,
- train_dataset=dummy_dataset["train"],
- eval_dataset=dummy_dataset["test"],
+ model="trl-internal-testing/tiny-Qwen2ForCausalLM-2.5", args=training_args, train_dataset=dataset
)
- # Fake chosen and rejected log probs
- policy_chosen_logps = torch.FloatTensor([410.0, 0.1])
- policy_rejected_logps = torch.FloatTensor([95.5, 0.2])
- reference_chosen_logps = torch.FloatTensor([-610.0, -0.1])
- reference_rejected_logps = torch.FloatTensor([5.5, 0.5])
- losses, _, _ = trainer.dpo_loss(
- policy_chosen_logps, policy_rejected_logps, reference_chosen_logps, reference_rejected_logps
- )
- assert torch.isfinite(losses).cpu().numpy().all()
+ # Save the initial parameters to compare them later
+ previous_trainable_params = {n: param.clone() for n, param in trainer.model.named_parameters()}
- @pytest.mark.filterwarnings("ignore:`tools` is deprecated:FutureWarning")
- def test_dpo_trainer_with_tools(self):
- model_id = "trl-internal-testing/tiny-LlamaForCausalLM-3.2"
- tokenizer = AutoTokenizer.from_pretrained(model_id)
- tokenizer.pad_token = tokenizer.eos_token
+ # Train the model
+ trainer.train()
- model = AutoModelForCausalLM.from_pretrained(model_id, dtype="float32")
+ # Check that the training loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
- # Define dummy test tools
- def get_current_temperature(location: str):
- """
- Gets the temperature at a given location.
+ # Check the params have changed
+ for n, param in previous_trainable_params.items():
+ new_param = trainer.model.get_parameter(n)
+ assert not torch.allclose(param, new_param), f"Parameter {n} has not changed"
- Args:
- location: The location to get the temperature for
- """
- return 22.0
+ def test_train_with_chat_template_kwargs(self):
+ # Get the dataset
+ dataset = load_dataset("trl-internal-testing/zen", "conversational_preference", split="train")
+ # Initialize the trainer
training_args = DPOConfig(
output_dir=self.tmp_dir,
- tools=[get_current_temperature],
+ learning_rate=0.1, # use higher lr because gradients are tiny and default lr can stall updates
+ report_to="none",
)
- dummy_dataset = load_dataset("trl-internal-testing/zen", "conversational_preference")
+ tokenizer = AutoTokenizer.from_pretrained("trl-internal-testing/tiny-Qwen2ForCausalLM-2.5")
+ # The following template is a simplified version of the Qwen chat template, where an additional argument
+ # `role_capital` is used to control the capitalization of roles.
+ tokenizer.chat_template = '{%- if messages[0]["role"] == "system" -%} {{ "<|im_start|>" + ("SYSTEM" if role_capital else "system") + "\\n" + messages[0]["content"] + "<|im_end|>\\n" }}{%- else -%} {{ "<|im_start|>" + ("SYSTEM" if role_capital else "system") + "\\nYou are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|>\\n" }}{%- endif -%}{%- for message in messages -%} {%- if (message.role == "user") or (message.role == "system" and not loop.first) or (message.role == "assistant" and not message.tool_calls) -%} {{ "<|im_start|>" + (message.role.upper() if role_capital else message.role) + "\\n" + message.content + "<|im_end|>\\n" }} {%- elif message.role == "assistant" -%} {{ "<|im_start|>" + ("ASSISTANT" if role_capital else "assistant") }} {%- if message.content -%} {{ "\\n" + message.content }} {%- endif -%} {{ "<|im_end|>\\n" }} {%- elif message.role == "tool" -%} {%- if (loop.index0 == 0) or (messages[loop.index0 - 1].role != "tool") -%} {{ "<|im_start|>" + ("USER" if role_capital else "user") }} {%- endif -%} {{ "\\n\\n" + message.content + "\\n" }} {%- if loop.last or (messages[loop.index0 + 1].role != "tool") -%} {{ "<|im_end|>\\n" }} {%- endif -%} {%- endif -%}{%- endfor -%}{%- if add_generation_prompt -%} {{ "<|im_start|>" + ("ASSISTANT" if role_capital else "assistant") + "\\n" }}{%- endif -%}'
+
+ dataset = dataset.add_column(
+ "chat_template_kwargs", [{"role_capital": bool(i % 2)} for i in range(len(dataset))]
+ )
+ assert "chat_template_kwargs" in dataset.features
trainer = DPOTrainer(
- model=model,
- ref_model=None,
+ model="trl-internal-testing/tiny-Qwen2ForCausalLM-2.5",
args=training_args,
+ train_dataset=dataset,
processing_class=tokenizer,
- train_dataset=dummy_dataset["train"],
- eval_dataset=dummy_dataset["test"],
)
- # We don't run the training, but at this stage, the dataset is supposed to be pre-processed. When
- # pre-processing, we expect the available tools to be explicitly mentioned in the system prompt. That's
- # what we're checking here
- assert "get_current_temperature" in tokenizer.decode(trainer.train_dataset["prompt_input_ids"][0])
-
- def test_padding_free(self):
- model_id = "trl-internal-testing/tiny-LlamaForCausalLM-3.2"
- tokenizer = AutoTokenizer.from_pretrained(model_id)
- tokenizer.pad_token = tokenizer.eos_token
- # Normally, we need `attn_implementation="flash_attention_2"` to that the model returns correct logits.
- # Without it, the logits may be incorrect, but that's fine here. This test focuses only on the inner logic
- # of padding_free.
- model = AutoModelForCausalLM.from_pretrained(model_id, dtype="float32")
+ # Assert trainer uses the same chat template as tokenizer
+ assert trainer.processing_class.chat_template == tokenizer.chat_template
+
+ # Assert chat_template is applied
+ for i in range(2):
+ role = "SYSTEM" if i else "system"
+ system_prompt = (
+ f"<|im_start|>{role}\nYou are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|>"
+ )
+ system_prompt_ids = trainer.processing_class(system_prompt)["input_ids"]
+ assert trainer.train_dataset[i]["prompt_ids"][: len(system_prompt_ids)] == system_prompt_ids
+
+ # Save the initial parameters to compare them later
+ previous_trainable_params = {n: param.clone() for n, param in trainer.model.named_parameters()}
+
+ # Train the model
+ trainer.train()
+
+ # Check that the training loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ # Check the params have changed
+ for n, param in previous_trainable_params.items():
+ new_param = trainer.model.get_parameter(n)
+ assert not torch.allclose(param, new_param), f"Parameter {n} has not changed"
+
+ def test_train_toolcall_data(self):
+ # Get the dataset
+ dataset = load_dataset("trl-internal-testing/toolcall", "preference", split="train")
+
+ # Initialize the trainer
training_args = DPOConfig(
output_dir=self.tmp_dir,
- learning_rate=9e-1,
- per_device_train_batch_size=2,
- padding_free=True,
+ learning_rate=0.1, # use higher lr because gradients are tiny and default lr can stall updates
report_to="none",
)
-
- dummy_dataset = load_dataset("trl-internal-testing/zen", "standard_preference")
-
trainer = DPOTrainer(
- model=model,
- args=training_args,
- processing_class=tokenizer,
- train_dataset=dummy_dataset["train"],
+ model="trl-internal-testing/tiny-Qwen2ForCausalLM-2.5", args=training_args, train_dataset=dataset
)
+ # Save the initial parameters to compare them later
previous_trainable_params = {n: param.clone() for n, param in trainer.model.named_parameters()}
+ # Train the model
trainer.train()
- # Check that the parameters have changed
+ # Check that the training loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ # Check the params have changed
for n, param in previous_trainable_params.items():
new_param = trainer.model.get_parameter(n)
- if param.sum() != 0: # ignore 0 biases
- assert not torch.allclose(param, new_param, rtol=1e-12, atol=1e-12)
+ assert not torch.allclose(param, new_param), f"Parameter {n} has not changed"
- def test_compute_metrics(self):
- model = AutoModelForCausalLM.from_pretrained("trl-internal-testing/tiny-Qwen2ForCausalLM-2.5", dtype="float32")
- ref_model = AutoModelForCausalLM.from_pretrained("trl-internal-testing/tiny-Qwen2ForCausalLM-2.5")
- tokenizer = AutoTokenizer.from_pretrained("trl-internal-testing/tiny-Qwen2ForCausalLM-2.5")
- tokenizer.pad_token = tokenizer.eos_token
+ def test_train_with_eval(self):
+ # Get the dataset
+ dataset = load_dataset("trl-internal-testing/zen", "standard_preference")
+
+ # Initialize the trainer
+ training_args = DPOConfig(output_dir=self.tmp_dir, eval_strategy="steps", eval_steps=3, report_to="none")
+ trainer = DPOTrainer(
+ model="trl-internal-testing/tiny-Qwen2ForCausalLM-2.5",
+ args=training_args,
+ train_dataset=dataset["train"],
+ eval_dataset=dataset["test"],
+ )
+
+ # Train the model
+ trainer.train()
+
+ # Check that the eval loss is not None
+ assert trainer.state.log_history[0]["eval_loss"] is not None
+
+ def test_train_with_multiple_eval_dataset(self):
+ # Get the dataset
+ dataset = load_dataset("trl-internal-testing/zen", "standard_preference")
+
+ # Initialize the trainer
+ training_args = DPOConfig(output_dir=self.tmp_dir, eval_strategy="steps", eval_steps=3, report_to="none")
+ trainer = DPOTrainer(
+ model="trl-internal-testing/tiny-Qwen2ForCausalLM-2.5",
+ args=training_args,
+ train_dataset=dataset["train"],
+ eval_dataset={"data1": dataset["test"], "data2": dataset["test"]},
+ )
+ # Train the model
+ trainer.train()
- dummy_dataset = load_dataset("trl-internal-testing/zen", "standard_preference")
+ # Check that the eval losses are not None
+ assert trainer.state.log_history[-3]["eval_data1_loss"] is not None
+ assert trainer.state.log_history[-2]["eval_data2_loss"] is not None
- def dummy_compute_metrics(*args, **kwargs):
- return {"test": 0.0}
+ def test_train_with_compute_metrics(self):
+ # Get the dataset
+ dataset = load_dataset("trl-internal-testing/zen", "standard_preference")
+ def dummy_compute_metrics(eval_pred):
+ return {"my_metric": 0.123}
+
+ # Initialize the trainer
training_args = DPOConfig(
output_dir=self.tmp_dir,
- per_device_train_batch_size=2,
- do_eval=True,
eval_strategy="steps",
eval_steps=3,
- per_device_eval_batch_size=2,
report_to="none",
)
-
trainer = DPOTrainer(
- model=model,
- ref_model=ref_model,
+ model="trl-internal-testing/tiny-Qwen2ForCausalLM-2.5",
args=training_args,
- processing_class=tokenizer,
- train_dataset=dummy_dataset["train"],
- eval_dataset=dummy_dataset["test"],
+ train_dataset=dataset["train"],
+ eval_dataset=dataset["test"],
compute_metrics=dummy_compute_metrics,
)
+ # Train the model
trainer.train()
- assert trainer.state.log_history[-2]["eval_test"] == 0.0
+ # Check that the custom metric is logged
+ assert trainer.state.log_history[-2]["eval_my_metric"] == 0.123
- def test_train_with_length_desensitization(self):
- model_id = "trl-internal-testing/tiny-Qwen2ForCausalLM-2.5"
+ # In practice, this test is the same as `test_train`, since gradient checkpointing is enabled by default in
+ # `DPOTrainer`. We keep it as a regression guard: if the default ever changes, we still explicitly test gradient
+ # checkpointing, which has caused issues in the past.
+ def test_train_with_gradient_checkpointing(self):
+ # Get the dataset
dataset = load_dataset("trl-internal-testing/zen", "standard_preference", split="train")
- tokenizer = AutoTokenizer.from_pretrained(model_id)
+ # Initialize the trainer
training_args = DPOConfig(
output_dir=self.tmp_dir,
- per_device_train_batch_size=2,
- learning_rate=9e-1,
- ld_alpha=0.5,
+ learning_rate=0.1, # use higher lr because gradients are tiny and default lr can stall updates
+ gradient_checkpointing=True,
report_to="none",
)
trainer = DPOTrainer(
- model=model_id,
- args=training_args,
- processing_class=tokenizer,
- train_dataset=dataset,
+ model="trl-internal-testing/tiny-Qwen2ForCausalLM-2.5", args=training_args, train_dataset=dataset
)
+ # Save the initial parameters to compare them later
previous_trainable_params = {n: param.clone() for n, param in trainer.model.named_parameters()}
+ # Train the model
trainer.train()
+ # Check that the training loss is not None
assert trainer.state.log_history[-1]["train_loss"] is not None
- # Check that the parameters have changed
+ # Check the params have changed
for n, param in previous_trainable_params.items():
new_param = trainer.model.get_parameter(n)
- if param.sum() != 0: # ignore 0 biases
- assert not torch.allclose(param, new_param, rtol=1e-12, atol=1e-12)
+ assert not torch.allclose(param, new_param), f"Parameter {n} has not changed"
- @pytest.mark.parametrize(
- "beta, loss_type",
- [
- (0.1, "sigmoid"),
- (0.1, "apo_zero"),
- (0.1, "apo_down"),
- (0.1, "sppo_hard"),
- (0.1, "nca_pair"),
- (0.5, "sigmoid"),
- (0.5, "apo_zero"),
- (0.5, "apo_down"),
- (0.5, "sppo_hard"),
- (0.5, "nca_pair"),
- ],
- )
- @require_liger_kernel
- def test_dpo_trainer_with_liger(self, beta, loss_type):
- """Test DPO trainer with Liger loss enabled across supported loss types.
-
- This test verifies that:
- 1. Training runs successfully with Liger loss
- 2. Model parameters update as expected
- 3. Loss values are reasonable and finite
- 4. Training works with both default and custom beta values
- """
- training_args = DPOConfig(
- output_dir=self.tmp_dir,
- per_device_train_batch_size=2,
- do_eval=True,
- eval_steps=1,
- learning_rate=9e-1,
- eval_strategy="steps",
- beta=beta,
- use_liger_kernel=True, # Enable Liger kernel
- loss_type=loss_type,
- report_to="none",
- )
-
- dummy_dataset = load_dataset("trl-internal-testing/zen", "standard_preference")
+ def test_tag_added(self):
+ # Get the dataset
+ dataset = load_dataset("trl-internal-testing/zen", "standard_preference", split="train")
+ # Initialize the trainer
trainer = DPOTrainer(
- model=self.model,
- ref_model=self.ref_model, # Add reference model
- args=training_args,
- processing_class=self.tokenizer,
- train_dataset=dummy_dataset["train"],
- eval_dataset=dummy_dataset["test"],
+ model="trl-internal-testing/tiny-Qwen2ForCausalLM-2.5",
+ train_dataset=dataset,
)
- # Store initial parameters
- previous_trainable_params = {n: param.clone() for n, param in trainer.model.named_parameters()}
-
- # Train the model
- train_output = trainer.train()
+ for tag in ["dpo", "trl"]:
+ assert tag in trainer.model.model_tags
- # Verify training completed successfully
- assert train_output is not None
- assert trainer.state.log_history[-1]["train_loss"] is not None
+ @require_peft
+ def test_tag_added_peft(self):
+ # Get the dataset
+ dataset = load_dataset("trl-internal-testing/zen", "standard_preference", split="train")
- # Verify loss is finite
- assert np.isfinite(trainer.state.log_history[-1]["train_loss"])
+ # Initialize the trainer
+ trainer = DPOTrainer(
+ model="trl-internal-testing/tiny-Qwen2ForCausalLM-2.5",
+ train_dataset=dataset,
+ peft_config=LoraConfig(),
+ )
- # Check parameters have been updated
- for n, param in previous_trainable_params.items():
- new_param = trainer.model.get_parameter(n)
- # Only check non-zero parameters
- if param.sum() != 0:
- assert not torch.equal(param, new_param)
- # Verify new parameters are finite
- assert torch.isfinite(new_param).all()
-
- # Verify model can still do forward pass after training
- dummy_batch = next(iter(trainer.get_train_dataloader()))
- model_inputs = {
- "input_ids": dummy_batch["prompt_input_ids"],
- "attention_mask": dummy_batch["prompt_attention_mask"],
- }
- with torch.no_grad():
- output = trainer.model(**model_inputs)
- assert output is not None
- assert "loss" not in output.keys()
+ for tag in ["dpo", "trl"]:
+ assert tag in trainer.model.model_tags
- def test_train_with_iterable_dataset(self):
- model_id = "trl-internal-testing/tiny-Qwen2ForCausalLM-2.5"
+ @pytest.mark.parametrize(
+ "model_id",
+ [
+ "trl-internal-testing/tiny-Gemma3ForConditionalGeneration",
+ # "trl-internal-testing/tiny-Idefics2ForConditionalGeneration", high memory peak, skipped for now
+ # "trl-internal-testing/tiny-Idefics3ForConditionalGeneration", high memory peak, skipped for now
+ "trl-internal-testing/tiny-LlavaForConditionalGeneration",
+ "trl-internal-testing/tiny-LlavaNextForConditionalGeneration",
+ "trl-internal-testing/tiny-Qwen2VLForConditionalGeneration",
+ "trl-internal-testing/tiny-Qwen2_5_VLForConditionalGeneration",
+ # "trl-internal-testing/tiny-SmolVLMForConditionalGeneration", seems not to support bf16 properly
+ pytest.param(
+ "trl-internal-testing/tiny-Qwen3VLForConditionalGeneration",
+ marks=[
+ pytest.mark.skipif(
+ Version(transformers.__version__) < Version("4.57.0"),
+ reason="Qwen3-VL series were introduced in transformers-4.57.0",
+ ),
+ pytest.mark.xfail(
+ Version(transformers.__version__) >= Version("5.0.0"),
+ reason="Blocked by upstream transformers bug (transformers#43334)",
+ ),
+ ],
+ ),
+ ],
+ )
+ @require_vision
+ def test_train_vlm(self, model_id):
+ # Get the dataset
dataset = load_dataset(
- "trl-internal-testing/zen",
- "standard_preference",
- split="train",
- streaming=True,
+ "trl-internal-testing/zen-image", "conversational_preference", split="train", revision="refs/pr/11"
)
- tokenizer = AutoTokenizer.from_pretrained(model_id)
+ # Initialize the trainer
training_args = DPOConfig(
output_dir=self.tmp_dir,
- max_steps=3,
+ max_length=None, # for VLMs, truncating can remove image tokens, leading to errors
+ per_device_train_batch_size=2, # VLM training is memory intensive, reduce batch size to avoid OOM
report_to="none",
)
- trainer = DPOTrainer(
- model=model_id,
- args=training_args,
- processing_class=tokenizer,
- train_dataset=dataset,
- )
+ trainer = DPOTrainer(model=model_id, args=training_args, train_dataset=dataset)
+ # Save the initial parameters to compare them later
previous_trainable_params = {n: param.clone() for n, param in trainer.model.named_parameters()}
+ # Train the model
trainer.train()
+ # Check that the training loss is not None
assert trainer.state.log_history[-1]["train_loss"] is not None
- # Check that the parameters have changed
+ # Check the params have changed
for n, param in previous_trainable_params.items():
new_param = trainer.model.get_parameter(n)
- if param.sum() != 0: # ignore 0 biases
- assert not torch.allclose(param, new_param, rtol=1e-12, atol=1e-12)
+ # For some reason, these params are not updated. This is probably not related to TRL, but to
+ # the model itself. We should investigate this further, but for now we just skip these params.
+ # fmt: off
+ if (
+ model_id == "trl-internal-testing/tiny-Gemma3ForConditionalGeneration" and "model.vision_tower.vision_model.head" in n or
+ model_id == "trl-internal-testing/tiny-LlavaForConditionalGeneration" and "model.vision_tower.vision_model.post_layernorm" in n or
+ model_id == "trl-internal-testing/tiny-LlavaForConditionalGeneration" and "vision_tower.vision_model.encoder.layers.1" in n or
+ model_id == "trl-internal-testing/tiny-LlavaNextForConditionalGeneration" and "model.vision_tower.vision_model.post_layernorm" in n or
+ model_id == "trl-internal-testing/tiny-LlavaNextForConditionalGeneration" and "vision_tower.vision_model.encoder.layers.1" in n or
+ model_id == "trl-internal-testing/tiny-Qwen3VLForConditionalGeneration" and "model.visual.deepstack_merger_list" in n
+ ):
+ # fmt: on
+ continue
+ assert not torch.allclose(param, new_param, rtol=1e-12, atol=1e-12), f"Param {n} is not updated"
-
-@require_vision
-class TestDPOVisionTrainer(TrlTestCase):
- @pytest.mark.filterwarnings("ignore:max_prompt_length is not supported for vision models:UserWarning") # See #5023
@pytest.mark.parametrize(
"model_id",
[
- # "trl-internal-testing/tiny-Idefics2ForConditionalGeneration", high memory peak, skipped for now
- "trl-internal-testing/tiny-LlavaForConditionalGeneration",
- "trl-internal-testing/tiny-LlavaNextForConditionalGeneration",
- "trl-internal-testing/tiny-Gemma3ForConditionalGeneration",
+ "trl-internal-testing/tiny-Qwen2_5_VLForConditionalGeneration",
],
)
- def test_vdpo_trainer(self, model_id):
- # fmt: off
- dataset_dict = {
- "prompt": [
- [{"role": "user", "content": [{"type": "image"}, {"type": "text", "text": "Describe the image in great detail."}]}],
- [{"role": "user", "content": [{"type": "image"}, {"type": "text", "text": "Is this bus in the USA?"}]}],
- [{"role": "user", "content": [{"type": "image"}, {"type": "text", "text": "Give a thorough description of the image."}]}],
- [{"role": "user", "content": [{"type": "image"}, {"type": "text", "text": "Who are the people in the image?"}]}],
- [{"role": "user", "content": [{"type": "image"}, {"type": "text", "text": "What is written?"}]}],
- ],
- "chosen": [
- [{"role": "assistant", "content": [{"type": "text", "text": "The image features a modern, multi-colored train."}]}],
- [{"role": "assistant", "content": [{"type": "text", "text": "Yes, it can be assumed that this bus is in the USA."}]}],
- [{"role": "assistant", "content": [{"type": "text", "text": "The image features a forest path."}]}],
- [{"role": "assistant", "content": [{"type": "text", "text": "There are two individuals, possibly girls or women."}]}],
- [{"role": "assistant", "content": [{"type": "text", "text": '"ccpb".'}]}],
- ],
- "rejected": [
- [{"role": "assistant", "content": [{"type": "text", "text": "The image features a modern, colorful train."}]}],
- [{"role": "assistant", "content": [{"type": "text", "text": "No, it's not in the USA."}]}],
- [{"role": "assistant", "content": [{"type": "text", "text": "The image features a forest path surrounded by trees."}]}],
- [{"role": "assistant", "content": [{"type": "text", "text": "In the image, there are two individuals."}]}],
- [{"role": "assistant", "content": [{"type": "text", "text": '"ccpb".'}]}],
- ],
- "images": [
- [Image.fromarray(np.random.randint(0, 255, (92, 33, 3), dtype=np.uint8))],
- [Image.fromarray(np.random.randint(0, 255, (64, 48, 3), dtype=np.uint8))],
- [Image.fromarray(np.random.randint(0, 255, (80, 152, 3), dtype=np.uint8))],
- [Image.fromarray(np.random.randint(0, 255, (57, 24, 3), dtype=np.uint8))],
- [Image.fromarray(np.random.randint(0, 255, (102, 48, 3), dtype=np.uint8))],
- ],
- }
- # fmt: on
- dataset = Dataset.from_dict(dataset_dict)
- dataset = dataset.cast_column("images", features.Sequence(features.Image()))
-
- # Instantiate the model and processor
- model = AutoModelForImageTextToText.from_pretrained(model_id, dtype="float32")
- ref_model = AutoModelForImageTextToText.from_pretrained(model_id)
- processor = AutoProcessor.from_pretrained(model_id)
+ @pytest.mark.xfail(
+ parse_version(transformers.__version__) < parse_version("4.57.0"),
+ reason="Mixing text-only and image+text examples is only supported in transformers >= 4.57.0",
+ strict=False,
+ )
+ @require_vision
+ def test_train_vlm_multi_image(self, model_id):
+ # Get the dataset
+ dataset = load_dataset("trl-internal-testing/zen-multi-image", "conversational_preference", split="train")
+ # Initialize the trainer
training_args = DPOConfig(
output_dir=self.tmp_dir,
- per_device_train_batch_size=2,
- remove_unused_columns=False,
- learning_rate=0.01, # increase learning rate to speed up test
- max_length=None,
+ learning_rate=0.1, # use higher lr because gradients are tiny and default lr can stall updates
+ max_length=None, # for VLMs, truncating can remove image tokens, leading to errors
+ per_device_train_batch_size=1, # VLM training is memory intensive, reduce batch size to avoid OOM
report_to="none",
)
trainer = DPOTrainer(
- model=model,
- ref_model=ref_model,
+ model=model_id,
args=training_args,
- processing_class=processor,
train_dataset=dataset,
- eval_dataset=dataset,
)
- # Save the initial weights, so we can check if they have changed after training
+ # Save the initial parameters to compare them later
previous_trainable_params = {n: param.clone() for n, param in trainer.model.named_parameters()}
+ # Train the model
trainer.train()
+ # Check that the training loss is not None
assert trainer.state.log_history[-1]["train_loss"] is not None
- # Check that the trainable params have changed
+ # Check the params have changed
for n, param in previous_trainable_params.items():
new_param = trainer.model.get_parameter(n)
- if param.sum() != 0: # ignore 0 biases
- if model_id in [
- "trl-internal-testing/tiny-LlavaForConditionalGeneration",
- "trl-internal-testing/tiny-LlavaNextForConditionalGeneration",
- ] and (
- "vision_tower.vision_model.encoder.layers.1" in n
- or "vision_tower.vision_model.post_layernorm.weight" in n
- ):
- # For some reason, these params are not updated. This is probably not related to TRL, but to
- # the model itself. We should investigate this further, but for now we just skip these params.
- continue
- assert not torch.allclose(param, new_param, rtol=1e-12, atol=1e-12), f"Param {n} is not updated"
-
-
-class TestDPOConfig(TrlTestCase):
- @pytest.mark.parametrize("f_divergence_type", ["reverse_kl", "js_divergence", "alpha_divergence"])
- def test_f_divergence_type(self, f_divergence_type):
- training_args = DPOConfig(
- output_dir=self.tmp_dir,
- report_to="none",
- f_divergence_type=f_divergence_type,
- )
- assert training_args.f_divergence_type == f_divergence_type
- # Serialization
- configparser_dict = training_args.to_dict()
- assert configparser_dict["f_divergence_type"] == f_divergence_type
-
-
-@pytest.mark.slow
-@require_torch_accelerator
-@require_peft
-class TestDPOTrainerSlow(TrlTestCase):
- def setup_method(self):
- self.dataset = load_dataset("trl-internal-testing/zen", "standard_preference")
- self.peft_config = LoraConfig(
- lora_alpha=16,
- lora_dropout=0.1,
- r=8,
- bias="none",
- task_type="CAUSAL_LM",
+ assert not torch.allclose(param, new_param, rtol=1e-12, atol=1e-12), f"Param {n} is not updated"
+
+ # Gemma 3n uses a timm encoder, making it difficult to create a smaller variant for testing.
+ # To ensure coverage, we run tests on the full model but mark them as slow to exclude from default runs.
+ @pytest.mark.slow
+ @require_vision
+ @pytest.mark.skip(reason="Model google/gemma-3n-E2B-it is gated and requires HF token")
+ def test_train_vlm_gemma_3n(self):
+ # Get the dataset
+ dataset = load_dataset(
+ "trl-internal-testing/zen-image", "conversational_preference", split="train", revision="refs/pr/11"
)
- self.max_length = 128
-
- def teardown_method(self):
- gc.collect()
- backend_empty_cache(torch_device)
- gc.collect()
-
- @pytest.mark.parametrize("pre_compute_logits", [True, False])
- @pytest.mark.parametrize("loss_type", ["sigmoid", "ipo"])
- @pytest.mark.parametrize(
- "model_id",
- [
- "trl-internal-testing/tiny-LlamaForCausalLM-3.2",
- "trl-internal-testing/tiny-MistralForCausalLM-0.2",
- ],
- )
- def test_dpo_bare_model(self, model_id, loss_type, pre_compute_logits):
- """
- A test that tests the simple usage of `DPOTrainer` using a bare model in full precision.
- """
- model = AutoModelForCausalLM.from_pretrained(model_id, dtype="float32")
- tokenizer = AutoTokenizer.from_pretrained(model_id)
- tokenizer.pad_token = tokenizer.eos_token if tokenizer.pad_token is None else tokenizer.pad_token
+ # Initialize the trainer
training_args = DPOConfig(
output_dir=self.tmp_dir,
- per_device_train_batch_size=2,
- max_steps=2,
- remove_unused_columns=False,
- gradient_accumulation_steps=2,
- learning_rate=9e-1,
- eval_strategy="steps",
- logging_strategy="no",
+ learning_rate=0.1, # use higher lr because gradients are tiny and default lr can stall updates
+ max_length=None, # for VLMs, truncating can remove image tokens, leading to errors
+ per_device_train_batch_size=1, # VLM training is memory intensive, reduce batch size to avoid OOM
+ model_init_kwargs={"dtype": "bfloat16"},
report_to="none",
- beta=0.1,
- loss_type=loss_type,
- precompute_ref_log_probs=pre_compute_logits,
- max_length=self.max_length,
)
+ trainer = DPOTrainer(model="google/gemma-3n-E2B-it", args=training_args, train_dataset=dataset)
- # dpo train lora model
- trainer = DPOTrainer(
- model=model,
- ref_model=None,
- args=training_args,
- train_dataset=self.dataset["train"],
- eval_dataset=self.dataset["test"],
- processing_class=tokenizer,
- )
+ # Save the initial parameters to compare them later
+ previous_trainable_params = {n: param.clone() for n, param in trainer.model.named_parameters()}
- # train the model
+ # Train the model
trainer.train()
- # save trained model or adapter
- trainer.save_model()
+ # Check that the training loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
- release_memory(model, trainer)
+ # Check the params have changed
+ for n, param in previous_trainable_params.items():
+ new_param = trainer.model.get_parameter(n)
+ if "model.audio_tower" in n or "model.embed_audio" in n:
+ # The audio embedding parameters are not updated because this dataset contains no audio data
+ continue
+ assert not torch.allclose(param, new_param, rtol=1e-12, atol=1e-12), f"Param {n} is not updated"
- @pytest.mark.parametrize(
- "gradient_checkpointing_kwargs", [None, {"use_reentrant": False}, {"use_reentrant": True}]
- )
- @pytest.mark.parametrize("pre_compute_logits", [True, False])
- @pytest.mark.parametrize("loss_type", ["sigmoid", "ipo"])
@pytest.mark.parametrize(
"model_id",
[
- "trl-internal-testing/tiny-LlamaForCausalLM-3.2",
- "trl-internal-testing/tiny-MistralForCausalLM-0.2",
+ "trl-internal-testing/tiny-Qwen2_5_VLForConditionalGeneration",
],
)
- @require_peft
- def test_dpo_peft_model(self, model_id, loss_type, pre_compute_logits, gradient_checkpointing_kwargs):
- """
- A test that tests the simple usage of `DPOTrainer` using a peft model in full precision + different scenarios
- of gradient checkpointing.
- """
- model = AutoModelForCausalLM.from_pretrained(model_id, dtype="float32")
- tokenizer = AutoTokenizer.from_pretrained(model_id)
- tokenizer.pad_token = tokenizer.eos_token if tokenizer.pad_token is None else tokenizer.pad_token
-
- training_args = DPOConfig(
- output_dir=self.tmp_dir,
- per_device_train_batch_size=2,
- max_steps=2,
- remove_unused_columns=False,
- gradient_accumulation_steps=2,
- learning_rate=9e-1,
- eval_strategy="steps",
- fp16=True,
- logging_strategy="no",
- report_to="none",
- gradient_checkpointing=True, # default, here for clarity
- gradient_checkpointing_kwargs=gradient_checkpointing_kwargs,
- loss_type=loss_type,
- precompute_ref_log_probs=pre_compute_logits,
- beta=0.1,
- max_length=self.max_length,
- )
+ @pytest.mark.parametrize(
+ "dataset_config",
+ ["conversational_preference", "standard_preference"],
+ )
+ @require_vision
+ def test_train_vlm_text_only_data(self, model_id, dataset_config):
+ # Get the dataset
+ dataset = load_dataset("trl-internal-testing/zen", dataset_config, split="train")
- # dpo train lora model
+ # Initialize the trainer
+ training_args = DPOConfig(output_dir=self.tmp_dir, report_to="none")
trainer = DPOTrainer(
- model=model,
- ref_model=None,
+ model=model_id,
args=training_args,
- train_dataset=self.dataset["train"],
- eval_dataset=self.dataset["test"],
- processing_class=tokenizer,
- peft_config=self.peft_config,
+ train_dataset=dataset,
)
- assert isinstance(trainer.model, PeftModel)
- assert trainer.ref_model is None
+ # Save the initial parameters to compare them later
+ previous_trainable_params = {n: param.clone() for n, param in trainer.model.named_parameters()}
- # train the model
+ # Train the model
trainer.train()
- # save trained model or adapter
- trainer.save_model()
+ # Check that the training loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
- release_memory(model, trainer)
+ # Check the params have changed
+ for n, param in previous_trainable_params.items():
+ new_param = trainer.model.get_parameter(n)
+ if n.startswith("model.visual"):
+ torch.testing.assert_close(param, new_param, rtol=1e-12, atol=1e-12), f"Param {n} is updated"
+ else:
+ assert not torch.allclose(param, new_param, rtol=1e-12, atol=1e-12), f"Param {n} is not updated"
- @pytest.mark.parametrize(
- "gradient_checkpointing_kwargs", [None, {"use_reentrant": False}, {"use_reentrant": True}]
- )
- @pytest.mark.parametrize("pre_compute_logits", [True, False])
- @pytest.mark.parametrize("loss_type", ["sigmoid", "ipo"])
- @pytest.mark.parametrize(
- "model_id",
- [
- "trl-internal-testing/tiny-LlamaForCausalLM-3.2",
- "trl-internal-testing/tiny-MistralForCausalLM-0.2",
- ],
- )
- @require_bitsandbytes
@require_peft
- def test_dpo_peft_model_qlora(self, model_id, loss_type, pre_compute_logits, gradient_checkpointing_kwargs):
- """
- A test that tests the simple usage of `DPOTrainer` using QLoRA + different scenarios of gradient checkpointing.
- """
- quantization_config = BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_compute_dtype=torch.float16)
+ @require_bitsandbytes
+ def test_peft_with_quantization(self):
+ # Get the base model
+ model_id = "trl-internal-testing/tiny-Qwen2ForCausalLM-2.5"
+ quantization_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ bnb_4bit_use_double_quant=True,
+ bnb_4bit_quant_type="nf4",
+ bnb_4bit_compute_dtype=torch.float16,
+ )
model = AutoModelForCausalLM.from_pretrained(
- model_id, dtype="float32", quantization_config=quantization_config
+ model_id,
+ dtype="float32",
+ quantization_config=quantization_config,
)
- tokenizer = AutoTokenizer.from_pretrained(model_id)
- tokenizer.pad_token = tokenizer.eos_token if tokenizer.pad_token is None else tokenizer.pad_token
- training_args = DPOConfig(
- output_dir=self.tmp_dir,
- per_device_train_batch_size=2,
- max_steps=2,
- remove_unused_columns=False,
- gradient_accumulation_steps=2,
- learning_rate=9e-1,
- eval_strategy="steps",
- fp16=True,
- logging_strategy="no",
- report_to="none",
- gradient_checkpointing=True, # default, here for clarity
- gradient_checkpointing_kwargs=gradient_checkpointing_kwargs,
- beta=0.1,
- loss_type=loss_type,
- precompute_ref_log_probs=pre_compute_logits,
- max_length=self.max_length,
- )
+ # Get the dataset
+ dataset = load_dataset("trl-internal-testing/zen", "standard_preference", split="train")
- # dpo train lora model
- trainer = DPOTrainer(
- model=model,
- ref_model=None,
- args=training_args,
- train_dataset=self.dataset["train"],
- eval_dataset=self.dataset["test"],
- processing_class=tokenizer,
- peft_config=self.peft_config,
- )
+ # Initialize the trainer with the already configured PeftModel
+ training_args = DPOConfig(output_dir=self.tmp_dir, learning_rate=0.1, report_to="none")
+ trainer = DPOTrainer(model=model, args=training_args, train_dataset=dataset, peft_config=LoraConfig())
- assert isinstance(trainer.model, PeftModel)
- assert trainer.ref_model is None
+ # Save initial parameters to check they change during training
+ previous_trainable_params = {n: param.clone() for n, param in trainer.model.named_parameters()}
- # train the model
trainer.train()
- # save trained model or adapter
- trainer.save_model()
+ # Check that training completed successfully
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+ assert trainer.state.log_history[-1]["mean_token_accuracy"] is not None
- release_memory(model, trainer)
+ # Check the peft params have changed and the base model params have not changed
+ for n, param in previous_trainable_params.items():
+ new_param = trainer.model.get_parameter(n)
+ # In bitsandbytes, bias parameters are automatically cast to the input dtype during the forward pass if
+ # their dtype doesn’t match. This causes the module to change unexpectedly during the first forward pass of
+ # the training. To handle this, we cast these specific bias parameters to float32 before comparison.
+ # https://github.com/bitsandbytes-foundation/bitsandbytes/blob/45553f7392e524eacf400b132cfe01261f6477be/bitsandbytes/nn/modules.py#L518
+ # We still need to investigate why the compute dtype ends up being different than for these parameters.
+ if n in [
+ "base_model.model.model.layers.1.self_attn.k_proj.bias",
+ "base_model.model.model.layers.1.self_attn.q_proj.base_layer.bias",
+ "base_model.model.model.layers.1.self_attn.v_proj.base_layer.bias",
+ ]:
+ param = param.float()
+
+ if "lora" not in n: # We expect the base model parameters to be the same
+ torch.testing.assert_close(param, new_param), f"Parameter {n} has changed"
+ elif "lora" in n: # We expect the peft parameters to be different
+ assert not torch.allclose(param, new_param), f"Parameter {n} has not changed"
+ else:
+ raise ValueError(f"Unexpected parameter {n} in model: {trainer.model}")
diff --git a/tests/test_sft_trainer.py b/tests/test_sft_trainer.py
index 88739b0057f..22375a09ff8 100644
--- a/tests/test_sft_trainer.py
+++ b/tests/test_sft_trainer.py
@@ -1684,7 +1684,7 @@ def test_train_vlm_gemma_3n(self):
output_dir=self.tmp_dir,
learning_rate=0.1, # use higher lr because gradients are tiny and default lr can stall updates
max_length=None, # for VLMs, truncating can remove image tokens, leading to errors
- per_device_train_batch_size=1,
+ per_device_train_batch_size=1, # VLM training is memory intensive, reduce batch size to avoid OOM
model_init_kwargs={"dtype": "bfloat16"},
report_to="none",
)
diff --git a/tests/test_utils.py b/tests/test_utils.py
index 80707d2fb6b..6c205f46828 100644
--- a/tests/test_utils.py
+++ b/tests/test_utils.py
@@ -32,6 +32,7 @@
forward_masked_logits,
generate_model_card,
get_peft_config,
+ hash_module,
nanstd,
pad,
print_prompt_completions_sample,
@@ -187,6 +188,56 @@ def test_pad_to_multiple_of_no_extra_padding(self):
assert torch.equal(output, expected)
+class TestHashModule(TrlTestCase):
+ def test_hash_module_deterministic_across_order(self):
+ class ModAB(torch.nn.Module):
+ def __init__(self, a: torch.Tensor, b: torch.Tensor):
+ super().__init__()
+ self.a = torch.nn.Parameter(a)
+ self.b = torch.nn.Parameter(b)
+
+ class ModBA(torch.nn.Module):
+ def __init__(self, a: torch.Tensor, b: torch.Tensor):
+ super().__init__()
+ self.b = torch.nn.Parameter(b)
+ self.a = torch.nn.Parameter(a)
+
+ a = torch.tensor([[1.0, 2.0]])
+ b = torch.tensor([3.0])
+ assert hash_module(ModAB(a, b)) == hash_module(ModBA(a, b))
+
+ def test_hash_module_changes_with_value(self):
+ class Mod(torch.nn.Module):
+ def __init__(self, value: float):
+ super().__init__()
+ self.weight = torch.nn.Parameter(torch.tensor([value, 2.0]))
+
+ assert hash_module(Mod(1.0)) != hash_module(Mod(1.5))
+
+ def test_hash_module_includes_dtype(self):
+ class Mod(torch.nn.Module):
+ def __init__(self, dtype: torch.dtype):
+ super().__init__()
+ self.weight = torch.nn.Parameter(torch.tensor([1.0, 2.0], dtype=dtype))
+
+ assert hash_module(Mod(torch.float32)) != hash_module(Mod(torch.float16))
+
+ def test_hash_module_tiny_model_twice(self):
+ model_id = "trl-internal-testing/tiny-GptOssForCausalLM"
+ model_a = AutoModelForCausalLM.from_pretrained(model_id)
+ model_b = AutoModelForCausalLM.from_pretrained(model_id)
+ assert hash_module(model_a) == hash_module(model_b)
+
+ def test_hash_module_tiny_model_change_layer(self):
+ model_id = "trl-internal-testing/tiny-GptOssForCausalLM"
+ model = AutoModelForCausalLM.from_pretrained(model_id)
+ h1 = hash_module(model)
+ with torch.no_grad():
+ model.lm_head.weight.add_(0.01)
+ h2 = hash_module(model)
+ assert h1 != h2
+
+
@require_peft
class TestGetPEFTConfig(TrlTestCase):
def test_create_peft_config_use_peft_false(self):
diff --git a/trl/__init__.py b/trl/__init__.py
index a5b61fa11b0..a1e6a204c07 100644
--- a/trl/__init__.py
+++ b/trl/__init__.py
@@ -42,16 +42,12 @@
"truncate_dataset",
"unpair_preference_dataset",
],
- "models": [
- "create_reference_model",
- ],
+ "models": ["create_reference_model"],
"scripts": ["DatasetMixtureConfig", "ScriptArguments", "TrlParser", "get_dataset", "init_zero_verbose"],
"trainer": [
"BEMACallback",
"DPOConfig",
"DPOTrainer",
- "FDivergenceConstants", # deprecated import
- "FDivergenceType", # deprecated import
"GRPOConfig",
"GRPOTrainer",
"KTOConfig",
@@ -90,16 +86,12 @@
truncate_dataset,
unpair_preference_dataset,
)
- from .models import (
- create_reference_model,
- )
+ from .models import create_reference_model
from .scripts import DatasetMixtureConfig, ScriptArguments, TrlParser, get_dataset, init_zero_verbose
from .trainer import (
BEMACallback,
DPOConfig,
DPOTrainer,
- FDivergenceConstants, # deprecated import
- FDivergenceType, # deprecated import
GRPOConfig,
GRPOTrainer,
KTOConfig,
diff --git a/trl/experimental/bco/bco_trainer.py b/trl/experimental/bco/bco_trainer.py
index a4a2d3da651..b42b06377a9 100644
--- a/trl/experimental/bco/bco_trainer.py
+++ b/trl/experimental/bco/bco_trainer.py
@@ -12,13 +12,16 @@
# See the License for the specific language governing permissions and
# limitations under the License.
+import dataclasses
import inspect
+import json
import os
import random
import textwrap
from collections import defaultdict
from collections.abc import Callable
from contextlib import contextmanager, nullcontext
+from dataclasses import dataclass
from operator import itemgetter
from pathlib import Path
from typing import TYPE_CHECKING, Any, Literal, Optional
@@ -29,7 +32,7 @@
import torch.nn as nn
import torch.nn.functional as F
import transformers
-from accelerate import PartialState, logging
+from accelerate import Accelerator, PartialState, logging
from accelerate.utils import tqdm
from datasets import Dataset
from packaging.version import Version
@@ -54,16 +57,10 @@
from ...data_utils import maybe_apply_chat_template, maybe_extract_prompt, maybe_unpair_preference_dataset
from ...import_utils import is_joblib_available
-from ...models.utils import create_reference_model, peft_module_casting_to_bf16, prepare_deepspeed
+from ...models.utils import prepare_deepspeed
from ...trainer.base_trainer import BaseTrainer
-from ...trainer.utils import (
- RunningMoments,
- disable_dropout_in_model,
- log_table_to_comet_experiment,
- pad_to_length,
- selective_log_softmax,
-)
-from ..utils import DPODataCollatorWithPadding
+from ...trainer.utils import disable_dropout_in_model, log_table_to_comet_experiment, selective_log_softmax
+from ..utils import DPODataCollatorWithPadding, create_reference_model, pad_to_length, peft_module_casting_to_bf16
from .bco_config import BCOConfig
@@ -88,6 +85,86 @@
CLF_NAME = "clf.pkl"
+@torch.no_grad()
+def get_global_statistics(
+ accelerator, xs: torch.Tensor, mask=None, device="cpu"
+) -> tuple[torch.Tensor, torch.Tensor, int]:
+ """
+ Computes element-wise mean and variance of the tensor across processes. Reference:
+ https://github.com/OpenLMLab/MOSS-RLHF/blob/40b91eb2f2b71b16919addede0341d2bef70825d/utils.py#L57C1-L73C75
+ """
+ xs = xs.to(accelerator.device)
+ sum_and_count = torch.tensor([xs.sum(), (xs.numel() if mask is None else mask.sum())], device=xs.device)
+ sum_and_count = accelerator.reduce(sum_and_count)
+ global_sum, count = sum_and_count
+ global_mean = global_sum / count
+
+ sum_var = torch.sum(((xs - global_mean) ** 2).mul(1 if mask is None else mask))
+ sum_var = accelerator.reduce(sum_var)
+ global_var = sum_var / count
+
+ return global_mean.to(device), global_var.to(device), count.item()
+
+
+@dataclass
+class RunningMoments:
+ """
+ Calculates the running mean and standard deviation of a data stream. Reference:
+ https://github.com/OpenLMLab/MOSS-RLHF/blob/40b91eb2f2b71b16919addede0341d2bef70825d/utils.py#L75
+ """
+
+ accelerator: Accelerator
+ mean: float = 0
+ std: float = 1
+ var: float = 1
+ count: float = 1e-24
+
+ @torch.no_grad()
+ def update(self, xs: torch.Tensor) -> tuple[float, float]:
+ """
+ Updates running moments from batch's moments computed across ranks
+ """
+ if self.accelerator.use_distributed:
+ xs_mean, xs_var, xs_count = get_global_statistics(self.accelerator, xs)
+ else:
+ xs_count = xs.numel()
+ xs_var, xs_mean = torch.var_mean(xs, unbiased=False)
+ xs_mean, xs_var = xs_mean.float(), xs_var.float()
+
+ delta = xs_mean - self.mean
+ tot_count = self.count + xs_count
+
+ new_sum = xs_var * xs_count
+ # correct old_sum deviation accounting for the new mean
+ old_sum = self.var * self.count + delta**2 * self.count * xs_count / tot_count
+ tot_sum = old_sum + new_sum
+
+ self.mean += (delta * xs_count / tot_count).item()
+ new_var = tot_sum / tot_count
+ self.std = (new_var * tot_count / (tot_count - 1)).float().sqrt().item()
+ self.var = new_var.item()
+ self.count = tot_count
+
+ return xs_mean.item(), (xs_var * xs_count / (xs_count - 1)).float().sqrt().item()
+
+ def save_to_json(self, json_path: str):
+ """Save the content of this instance in JSON format inside `json_path`."""
+ # save everything except accelerator
+ if self.accelerator.is_main_process:
+ save_dict = dataclasses.asdict(self, dict_factory=lambda x: {k: v for (k, v) in x if k != "accelerator"})
+ json_string = json.dumps(save_dict, indent=2, sort_keys=True) + "\n"
+ with open(json_path, "w", encoding="utf-8") as f:
+ f.write(json_string)
+
+ @classmethod
+ def load_from_json(cls, accelerator: Accelerator, json_path: str):
+ """Create an instance from the content of `json_path`."""
+ # load everything except accelerator
+ with open(json_path, encoding="utf-8") as f:
+ text = f.read()
+ return cls(accelerator=accelerator, **json.loads(text))
+
+
def _tokenize(
batch: dict[str, list[Any]],
tokenizer: "PreTrainedTokenizer",
diff --git a/trl/experimental/cpo/cpo_trainer.py b/trl/experimental/cpo/cpo_trainer.py
index 8cae8405c61..4cb8d083f31 100644
--- a/trl/experimental/cpo/cpo_trainer.py
+++ b/trl/experimental/cpo/cpo_trainer.py
@@ -48,15 +48,15 @@
from transformers.utils import is_peft_available, is_torch_fx_proxy
from ...data_utils import maybe_apply_chat_template, maybe_extract_prompt
-from ...models.utils import peft_module_casting_to_bf16
from ...trainer.base_trainer import BaseTrainer
-from ...trainer.utils import (
- disable_dropout_in_model,
- log_table_to_comet_experiment,
+from ...trainer.utils import disable_dropout_in_model, log_table_to_comet_experiment, selective_log_softmax
+from ..utils import (
+ DPODataCollatorWithPadding,
+ add_bos_token_if_needed,
+ add_eos_token_if_needed,
pad_to_length,
- selective_log_softmax,
+ peft_module_casting_to_bf16,
)
-from ..utils import DPODataCollatorWithPadding, add_bos_token_if_needed, add_eos_token_if_needed
from .cpo_config import CPOConfig
diff --git a/trl/experimental/gkd/gkd_trainer.py b/trl/experimental/gkd/gkd_trainer.py
index 94bf520cda5..e2fdb597f28 100644
--- a/trl/experimental/gkd/gkd_trainer.py
+++ b/trl/experimental/gkd/gkd_trainer.py
@@ -38,8 +38,8 @@
from ...models import prepare_deepspeed
from ...models.utils import unwrap_model_for_generation
from ...trainer.sft_trainer import SFTTrainer
-from ...trainer.utils import disable_dropout_in_model, empty_cache
-from ..utils import DataCollatorForChatML
+from ...trainer.utils import disable_dropout_in_model
+from ..utils import DataCollatorForChatML, empty_cache
from .gkd_config import GKDConfig
diff --git a/trl/experimental/gold/gold_trainer.py b/trl/experimental/gold/gold_trainer.py
index ebe74b0d7f2..09dc879cb54 100644
--- a/trl/experimental/gold/gold_trainer.py
+++ b/trl/experimental/gold/gold_trainer.py
@@ -53,14 +53,8 @@
from ...models import prepare_deepspeed
from ...models.utils import unwrap_model_for_generation
from ...trainer.sft_trainer import SFTTrainer
-from ...trainer.utils import (
- create_model_from_path,
- disable_dropout_in_model,
- empty_cache,
- ensure_master_addr_port,
- pad,
-)
-from ..utils import DataCollatorForChatML
+from ...trainer.utils import create_model_from_path, disable_dropout_in_model, ensure_master_addr_port, pad
+from ..utils import DataCollatorForChatML, empty_cache
from .gold_config import GOLDConfig
diff --git a/trl/experimental/kto/kto_trainer.py b/trl/experimental/kto/kto_trainer.py
index 78fea3b38b4..e75e5bd5154 100644
--- a/trl/experimental/kto/kto_trainer.py
+++ b/trl/experimental/kto/kto_trainer.py
@@ -51,16 +51,15 @@
from ...data_utils import maybe_apply_chat_template, maybe_extract_prompt, maybe_unpair_preference_dataset
from ...import_utils import is_liger_kernel_available
-from ...models.utils import create_reference_model, peft_module_casting_to_bf16, prepare_deepspeed
+from ...models.utils import prepare_deepspeed
from ...trainer.base_trainer import BaseTrainer
from ...trainer.utils import (
create_model_from_path,
disable_dropout_in_model,
log_table_to_comet_experiment,
- pad_to_length,
selective_log_softmax,
)
-from ..utils import DPODataCollatorWithPadding
+from ..utils import DPODataCollatorWithPadding, create_reference_model, pad_to_length, peft_module_casting_to_bf16
from .kto_config import KTOConfig
diff --git a/trl/experimental/minillm/minillm_trainer.py b/trl/experimental/minillm/minillm_trainer.py
index 4b8d34c02d2..ab787611a16 100644
--- a/trl/experimental/minillm/minillm_trainer.py
+++ b/trl/experimental/minillm/minillm_trainer.py
@@ -31,7 +31,8 @@
from ...models import prepare_deepspeed
from ...trainer.grpo_trainer import GRPOTrainer, RewardFunc, RolloutFunc
-from ...trainer.utils import disable_dropout_in_model, empty_cache, get_config_model_id
+from ...trainer.utils import disable_dropout_in_model, get_config_model_id
+from ..utils import empty_cache
from .minillm_config import MiniLLMConfig
diff --git a/trl/experimental/nash_md/nash_md_trainer.py b/trl/experimental/nash_md/nash_md_trainer.py
index b89021873c7..2f7043fe566 100644
--- a/trl/experimental/nash_md/nash_md_trainer.py
+++ b/trl/experimental/nash_md/nash_md_trainer.py
@@ -36,10 +36,10 @@
from ...data_utils import is_conversational, maybe_apply_chat_template
from ...models.utils import unwrap_model_for_generation
-from ...trainer.utils import empty_cache, selective_log_softmax
+from ...trainer.utils import selective_log_softmax
from ..judges import BasePairwiseJudge
from ..online_dpo import OnlineDPOTrainer
-from ..utils import SIMPLE_CHAT_TEMPLATE, get_reward, truncate_right
+from ..utils import SIMPLE_CHAT_TEMPLATE, empty_cache, get_reward, truncate_right
from .nash_md_config import NashMDConfig
diff --git a/trl/experimental/online_dpo/online_dpo_trainer.py b/trl/experimental/online_dpo/online_dpo_trainer.py
index b11474e76db..3485f34263a 100644
--- a/trl/experimental/online_dpo/online_dpo_trainer.py
+++ b/trl/experimental/online_dpo/online_dpo_trainer.py
@@ -55,11 +55,18 @@
from ...extras.profiling import profiling_context
from ...generation.vllm_client import VLLMClient
from ...import_utils import is_vllm_available
-from ...models.utils import create_reference_model, prepare_deepspeed, prepare_fsdp, unwrap_model_for_generation
+from ...models.utils import prepare_deepspeed, prepare_fsdp, unwrap_model_for_generation
from ...trainer.base_trainer import BaseTrainer
-from ...trainer.utils import disable_dropout_in_model, empty_cache, ensure_master_addr_port, get_config_model_id, pad
+from ...trainer.utils import disable_dropout_in_model, ensure_master_addr_port, get_config_model_id, pad
from ..judges import BasePairwiseJudge
-from ..utils import SIMPLE_CHAT_TEMPLATE, DPODataCollatorWithPadding, prepare_peft_model, truncate_right
+from ..utils import (
+ SIMPLE_CHAT_TEMPLATE,
+ DPODataCollatorWithPadding,
+ create_reference_model,
+ empty_cache,
+ prepare_peft_model,
+ truncate_right,
+)
from .online_dpo_config import OnlineDPOConfig
diff --git a/trl/experimental/orpo/orpo_trainer.py b/trl/experimental/orpo/orpo_trainer.py
index 3a39e6d3440..26bfe83b631 100644
--- a/trl/experimental/orpo/orpo_trainer.py
+++ b/trl/experimental/orpo/orpo_trainer.py
@@ -49,15 +49,15 @@
from transformers.utils import is_peft_available, is_torch_fx_proxy
from ...data_utils import maybe_apply_chat_template, maybe_extract_prompt
-from ...models.utils import peft_module_casting_to_bf16
from ...trainer.base_trainer import BaseTrainer
-from ...trainer.utils import (
- disable_dropout_in_model,
- log_table_to_comet_experiment,
+from ...trainer.utils import disable_dropout_in_model, log_table_to_comet_experiment, selective_log_softmax
+from ..utils import (
+ DPODataCollatorWithPadding,
+ add_bos_token_if_needed,
+ add_eos_token_if_needed,
pad_to_length,
- selective_log_softmax,
+ peft_module_casting_to_bf16,
)
-from ..utils import DPODataCollatorWithPadding, add_bos_token_if_needed, add_eos_token_if_needed
from .orpo_config import ORPOConfig
diff --git a/trl/experimental/ppo/ppo_trainer.py b/trl/experimental/ppo/ppo_trainer.py
index 4cb19faf486..7a99fc9ba15 100644
--- a/trl/experimental/ppo/ppo_trainer.py
+++ b/trl/experimental/ppo/ppo_trainer.py
@@ -48,17 +48,22 @@
from transformers.trainer_callback import CallbackHandler, ExportableState, PrinterCallback
from transformers.utils import ModelOutput, is_peft_available, is_rich_available
-from ...models.utils import create_reference_model, peft_module_casting_to_bf16, unwrap_model_for_generation
+from ...models.utils import unwrap_model_for_generation
from ...trainer.base_trainer import BaseTrainer
from ...trainer.utils import (
disable_dropout_in_model,
- empty_cache,
log_table_to_comet_experiment,
pad,
prepare_deepspeed,
selective_log_softmax,
)
-from ..utils import first_true_indices, get_reward
+from ..utils import (
+ create_reference_model,
+ empty_cache,
+ first_true_indices,
+ get_reward,
+ peft_module_casting_to_bf16,
+)
from .ppo_config import PPOConfig
diff --git a/trl/experimental/utils.py b/trl/experimental/utils.py
index 0bd0a0e2f0e..d79921df882 100644
--- a/trl/experimental/utils.py
+++ b/trl/experimental/utils.py
@@ -15,17 +15,25 @@
# This file contains utility classes and functions that are used across more than one experimental trainer or feature.
import inspect
+import logging
+from copy import deepcopy
from dataclasses import dataclass
from typing import Any
import torch
from accelerate.utils import is_peft_model
from packaging.version import Version
+from torch import nn
from torch.nn.utils.rnn import pad_sequence
from transformers import PreTrainedModel, PreTrainedTokenizerBase, TrainingArguments
-from transformers.utils import is_peft_available
+from transformers.integrations.deepspeed import is_deepspeed_zero3_enabled
+from transformers.utils import (
+ is_peft_available,
+ is_torch_mlu_available,
+ is_torch_npu_available,
+ is_torch_xpu_available,
+)
-from ..models.utils import peft_module_casting_to_bf16
from ..trainer.utils import pad
@@ -507,3 +515,129 @@ def prepare_peft_model(
peft_module_casting_to_bf16(model)
return model
+
+
+def pad_to_length(tensor: torch.Tensor, length: int, pad_value: int | float, dim: int = -1) -> torch.Tensor:
+ if tensor.size(dim) >= length:
+ return tensor
+ else:
+ pad_size = list(tensor.shape)
+ pad_size[dim] = length - tensor.size(dim)
+ return torch.cat(
+ [
+ tensor,
+ pad_value * torch.ones(*pad_size, dtype=tensor.dtype, device=tensor.device),
+ ],
+ dim=dim,
+ )
+
+
+def empty_cache() -> None:
+ """Empties the cache of the available torch device.
+
+ This function checks for the availability of different torch devices (XPU, MLU, NPU, CUDA) and empties the cache of
+ the first available device it finds.
+
+ If none of the specific devices are available, it defaults to emptying the CUDA cache.
+ """
+ if is_torch_xpu_available():
+ torch.xpu.empty_cache()
+ elif is_torch_mlu_available():
+ torch.mlu.empty_cache()
+ elif is_torch_npu_available():
+ torch.npu.empty_cache()
+ else:
+ torch.cuda.empty_cache()
+
+
+def peft_module_casting_to_bf16(model):
+ for name, module in model.named_modules():
+ if isinstance(module, torch.nn.LayerNorm) or "norm" in name:
+ module = module.to(torch.float32)
+ elif any(x in name for x in ["lm_head", "embed_tokens", "wte", "wpe"]):
+ if hasattr(module, "weight"):
+ if module.weight.dtype == torch.float32:
+ module = module.to(torch.bfloat16)
+
+
+LAYER_PATTERNS = [
+ "transformer.h.{layer}",
+ "model.decoder.layers.{layer}",
+ "gpt_neox.layers.{layer}",
+ "model.layers.{layer}",
+]
+
+
+def create_reference_model(
+ model: nn.Module, num_shared_layers: int | None = None, pattern: str | None = None
+) -> nn.Module:
+ """
+ Creates a static reference copy of a model. Note that model will be in `.eval()` mode.
+
+ Args:
+ model ([`nn.Module`]): The model to be copied.
+ num_shared_layers (`int`, *optional*):
+ The number of initial layers that are shared between both models and kept frozen.
+ pattern (`str`, *optional*): The shared layers are selected with a string pattern
+ (e.g. "transformer.h.{layer}" for GPT2) and if a custom pattern is necessary it can be passed here.
+
+ Returns:
+ [`nn.Module`]
+ """
+ if is_deepspeed_zero3_enabled():
+ raise ValueError(
+ "DeepSpeed ZeRO-3 is enabled and is not compatible with `create_reference_model()`. Please instantiate your reference model directly with `AutoModelForCausalLM.from_pretrained()`."
+ )
+
+ parameter_names = [n for n, _ in model.named_parameters()]
+ ref_model = deepcopy(model)
+
+ # if no layers are shared, return copy of model
+ if num_shared_layers is None:
+ for param_name in parameter_names:
+ param = ref_model.get_parameter(param_name)
+ param.requires_grad = False
+ return ref_model.eval()
+
+ # identify layer name pattern
+ if pattern is not None:
+ pattern = pattern.format(layer=num_shared_layers)
+ else:
+ for pattern_candidate in LAYER_PATTERNS:
+ pattern_candidate = pattern_candidate.format(layer=num_shared_layers)
+ if any(pattern_candidate in name for name in parameter_names):
+ pattern = pattern_candidate
+ break
+
+ if pattern is None:
+ raise ValueError("Layer pattern could not be matched.")
+
+ # divide parameters in shared and unshared parameter lists
+ shared_param_list = []
+ unshared_param_list = []
+
+ shared_parameter = True
+ for name, _param in model.named_parameters():
+ if pattern in name:
+ shared_parameter = False
+ if shared_parameter:
+ shared_param_list.append(name)
+ else:
+ unshared_param_list.append(name)
+
+ # create reference of the original parameter if they are shared
+ for param_name in shared_param_list:
+ param = model.get_parameter(param_name)
+ param.requires_grad = False
+
+ _ref_param = ref_model.get_parameter(param_name)
+
+ # for all other parameters just make sure they don't use gradients
+ for param_name in unshared_param_list:
+ param = ref_model.get_parameter(param_name)
+ param.requires_grad = False
+
+ if pattern is not None and len(unshared_param_list) == 0:
+ logging.warning("Pattern passed or found, but no layers matched in the model. Check for a typo.")
+
+ return ref_model.eval()
diff --git a/trl/experimental/xpo/xpo_trainer.py b/trl/experimental/xpo/xpo_trainer.py
index 04e184b804b..682b50d6c15 100644
--- a/trl/experimental/xpo/xpo_trainer.py
+++ b/trl/experimental/xpo/xpo_trainer.py
@@ -35,10 +35,10 @@
from ...data_utils import is_conversational, maybe_apply_chat_template
from ...models.utils import unwrap_model_for_generation
-from ...trainer.utils import empty_cache, selective_log_softmax
+from ...trainer.utils import selective_log_softmax
from ..judges import BasePairwiseJudge
from ..online_dpo import OnlineDPOTrainer
-from ..utils import SIMPLE_CHAT_TEMPLATE, get_reward, truncate_right
+from ..utils import SIMPLE_CHAT_TEMPLATE, empty_cache, get_reward, truncate_right
from .xpo_config import XPOConfig
diff --git a/trl/models/utils.py b/trl/models/utils.py
index 6d3877db145..1e9151258b5 100644
--- a/trl/models/utils.py
+++ b/trl/models/utils.py
@@ -13,14 +13,13 @@
# limitations under the License.
import itertools
-import logging
+import warnings
from collections.abc import Callable
from contextlib import contextmanager
from copy import deepcopy
from typing import TYPE_CHECKING, Any
import accelerate
-import torch
import torch.nn as nn
import transformers
from accelerate import Accelerator
@@ -28,7 +27,12 @@
from torch.distributed.fsdp import FSDPModule
from torch.distributed.fsdp.fully_sharded_data_parallel import FullyShardedDataParallel as FSDP
from transformers import GenerationConfig, PreTrainedModel
-from transformers.integrations.deepspeed import is_deepspeed_zero3_enabled
+
+from ..import_utils import suppress_experimental_warning
+
+
+with suppress_experimental_warning():
+ from ..experimental.utils import create_reference_model as _create_reference_model
if Version(accelerate.__version__) >= Version("1.11.0"):
@@ -286,7 +290,7 @@ def prepare_fsdp(model, accelerator: Accelerator) -> FSDP | FSDPModule:
if Version(accelerate.__version__) >= Version("1.11.0"):
ignored_params = get_parameters_from_modules(fsdp_plugin.ignored_modules, model, accelerator.device)
else:
- logging.warning(
+ warnings.warn(
"FSDP version 2 is being used with accelerate version < 1.11.0, which may lead to incorrect "
"handling of ignored modules. Please upgrade accelerate to v1.11.0 or later for proper support."
)
@@ -357,16 +361,6 @@ def on_after_outer_forward(self, wrapper_module: nn.Module, original_module: nn.
pass
-def peft_module_casting_to_bf16(model):
- for name, module in model.named_modules():
- if isinstance(module, torch.nn.LayerNorm) or "norm" in name:
- module = module.to(torch.float32)
- elif any(x in name for x in ["lm_head", "embed_tokens", "wte", "wpe"]):
- if hasattr(module, "weight"):
- if module.weight.dtype == torch.float32:
- module = module.to(torch.bfloat16)
-
-
@contextmanager
def disable_gradient_checkpointing(model: PreTrainedModel, gradient_checkpointing_kwargs: dict | None = None):
"""
@@ -388,84 +382,14 @@ def disable_gradient_checkpointing(model: PreTrainedModel, gradient_checkpointin
model.gradient_checkpointing_enable(gradient_checkpointing_kwargs)
-LAYER_PATTERNS = [
- "transformer.h.{layer}",
- "model.decoder.layers.{layer}",
- "gpt_neox.layers.{layer}",
- "model.layers.{layer}",
-]
-
-
def create_reference_model(
model: nn.Module, num_shared_layers: int | None = None, pattern: str | None = None
) -> nn.Module:
- """
- Creates a static reference copy of a model. Note that model will be in `.eval()` mode.
-
- Args:
- model ([`nn.Module`]): The model to be copied.
- num_shared_layers (`int`, *optional*):
- The number of initial layers that are shared between both models and kept frozen.
- pattern (`str`, *optional*): The shared layers are selected with a string pattern
- (e.g. "transformer.h.{layer}" for GPT2) and if a custom pattern is necessary it can be passed here.
-
- Returns:
- [`nn.Module`]
- """
- if is_deepspeed_zero3_enabled():
- raise ValueError(
- "DeepSpeed ZeRO-3 is enabled and is not compatible with `create_reference_model()`. Please instantiate your reference model directly with `AutoModelForCausalLM.from_pretrained()`."
- )
-
- parameter_names = [n for n, _ in model.named_parameters()]
- ref_model = deepcopy(model)
-
- # if no layers are shared, return copy of model
- if num_shared_layers is None:
- for param_name in parameter_names:
- param = ref_model.get_parameter(param_name)
- param.requires_grad = False
- return ref_model.eval()
-
- # identify layer name pattern
- if pattern is not None:
- pattern = pattern.format(layer=num_shared_layers)
- else:
- for pattern_candidate in LAYER_PATTERNS:
- pattern_candidate = pattern_candidate.format(layer=num_shared_layers)
- if any(pattern_candidate in name for name in parameter_names):
- pattern = pattern_candidate
- break
-
- if pattern is None:
- raise ValueError("Layer pattern could not be matched.")
-
- # divide parameters in shared and unshared parameter lists
- shared_param_list = []
- unshared_param_list = []
-
- shared_parameter = True
- for name, _param in model.named_parameters():
- if pattern in name:
- shared_parameter = False
- if shared_parameter:
- shared_param_list.append(name)
- else:
- unshared_param_list.append(name)
-
- # create reference of the original parameter if they are shared
- for param_name in shared_param_list:
- param = model.get_parameter(param_name)
- param.requires_grad = False
-
- _ref_param = ref_model.get_parameter(param_name)
-
- # for all other parameters just make sure they don't use gradients
- for param_name in unshared_param_list:
- param = ref_model.get_parameter(param_name)
- param.requires_grad = False
-
- if pattern is not None and len(unshared_param_list) == 0:
- logging.warning("Pattern passed or found, but no layers matched in the model. Check for a typo.")
-
- return ref_model.eval()
+ warnings.warn(
+ "The `create_reference_model` function is now located in `trl.experimental.utils`. Please update your "
+ "imports to `from trl.experimental.utils import create_reference_model`. This import path will be removed in "
+ "TRL 1.0.0.",
+ FutureWarning,
+ stacklevel=2,
+ )
+ return _create_reference_model(model, num_shared_layers=num_shared_layers, pattern=pattern)
diff --git a/trl/scripts/dpo.py b/trl/scripts/dpo.py
index 1e97122f1a4..db22444e436 100644
--- a/trl/scripts/dpo.py
+++ b/trl/scripts/dpo.py
@@ -106,12 +106,6 @@ def main(script_args, training_args, model_args, dataset_args):
model_args.model_name_or_path, trust_remote_code=model_args.trust_remote_code, **model_kwargs
)
peft_config = get_peft_config(model_args)
- if peft_config is None:
- ref_model = AutoModelForCausalLM.from_pretrained(
- model_args.model_name_or_path, trust_remote_code=model_args.trust_remote_code, **model_kwargs
- )
- else:
- ref_model = None
if script_args.ignore_bias_buffers:
# torch distributed hack
model._ddp_params_and_buffers_to_ignore = [
@@ -137,7 +131,6 @@ def main(script_args, training_args, model_args, dataset_args):
# Initialize the DPO trainer
trainer = DPOTrainer(
model,
- ref_model,
args=training_args,
train_dataset=dataset[script_args.dataset_train_split],
eval_dataset=dataset[script_args.dataset_test_split] if training_args.eval_strategy != "no" else None,
diff --git a/trl/trainer/__init__.py b/trl/trainer/__init__.py
index 67ccf600ee6..6c2e9c161ab 100644
--- a/trl/trainer/__init__.py
+++ b/trl/trainer/__init__.py
@@ -25,11 +25,7 @@
"SyncRefModelCallback",
"WeaveCallback",
],
- "dpo_config": [
- "DPOConfig",
- "FDivergenceConstants", # deprecated import
- "FDivergenceType", # deprecated import
- ],
+ "dpo_config": ["DPOConfig"],
"dpo_trainer": ["DPOTrainer"],
"grpo_config": ["GRPOConfig"],
"grpo_trainer": ["GRPOTrainer"],
@@ -43,9 +39,7 @@
"sft_config": ["SFTConfig"],
"sft_trainer": ["SFTTrainer"],
"utils": [
- "RunningMoments",
"disable_dropout_in_model",
- "empty_cache",
"ensure_master_addr_port",
"get_kbit_device_map",
"get_peft_config",
@@ -61,11 +55,7 @@
SyncRefModelCallback,
WeaveCallback,
)
- from .dpo_config import (
- DPOConfig,
- FDivergenceConstants, # deprecated import
- FDivergenceType, # deprecated import
- )
+ from .dpo_config import DPOConfig
from .dpo_trainer import DPOTrainer
from .grpo_config import GRPOConfig
from .grpo_trainer import GRPOTrainer
@@ -79,9 +69,7 @@
from .sft_config import SFTConfig
from .sft_trainer import SFTTrainer
from .utils import (
- RunningMoments,
disable_dropout_in_model,
- empty_cache,
ensure_master_addr_port,
get_kbit_device_map,
get_peft_config,
diff --git a/trl/trainer/dpo_config.py b/trl/trainer/dpo_config.py
index 21a0377cb68..d07babe6f2b 100644
--- a/trl/trainer/dpo_config.py
+++ b/trl/trainer/dpo_config.py
@@ -12,58 +12,12 @@
# See the License for the specific language governing permissions and
# limitations under the License.
-import warnings
from dataclasses import dataclass, field
-from enum import Enum
from typing import Any
from transformers import TrainingArguments
-class FDivergenceType(Enum):
- """
- Types of f-divergence functions for DPO loss regularization.
-
-
-
- Using `FDivergenceType` for `f_divergence_type` in [`DPOConfig`] is deprecated and will be removed in version
- 0.29.0. Use a string instead.
-
-
-
- Attributes:
- REVERSE_KL: Reverse KL divergence.
- JS_DIVERGENCE: Jensen-Shannon divergence.
- ALPHA_DIVERGENCE: Alpha divergence.
-
- Examples:
- ```python
- >>> from trl.trainer.dpo_config import DPOConfig, FDivergenceType
-
- >>> config = DPOConfig(
- ... f_divergence_type=FDivergenceType.ALPHA_DIVERGENCE,
- ... f_alpha_divergence_coef=0.5, # used only with ALPHA_DIVERGENCE
- ... )
- ```
- """
-
- REVERSE_KL = "reverse_kl"
- JS_DIVERGENCE = "js_divergence"
- ALPHA_DIVERGENCE = "alpha_divergence"
-
-
-class FDivergenceConstants:
- """Constants for f-divergence types and their parameters.
-
- Attributes:
- ALPHA_DIVERGENCE_COEF_KEY (`str`): Key for the alpha divergence coefficient.
- ALPHA_DIVERGENCE_COEF_DEFAULT (`float`): Default value for the alpha divergence coefficient.
- """
-
- ALPHA_DIVERGENCE_COEF_KEY = "alpha_divergence_coef"
- ALPHA_DIVERGENCE_COEF_DEFAULT = 1.0
-
-
@dataclass
class DPOConfig(TrainingArguments):
r"""
@@ -78,11 +32,11 @@ class DPOConfig(TrainingArguments):
command line.
Parameters:
- > Parameters that control the model and reference model
+ > Parameters that control the model
model_init_kwargs (`dict[str, Any]`, *optional*):
- Keyword arguments for `AutoModelForCausalLM.from_pretrained`, used when the `model` argument of the
- [`DPOTrainer`] is provided as a string.
+ Keyword arguments for [`~transformers.AutoModelForCausalLM.from_pretrained`], used when the `model`
+ argument of the [`DPOTrainer`] is provided as a string.
disable_dropout (`bool`, *optional*, defaults to `True`):
Whether to disable dropout in the model and reference model.
@@ -94,236 +48,78 @@ class DPOConfig(TrainingArguments):
Token used for padding. If `None`, it defaults to `processing_class.pad_token`, or if that is also `None`,
it falls back to `processing_class.eos_token`.
max_length (`int` or `None`, *optional*, defaults to `1024`):
- Maximum length of the full sequence (prompt + completion).
- truncation_mode (`str`, *optional*, defaults to `"keep_end"`):
+ Maximum length of the tokenized sequence. Sequences longer than `max_length` are truncated from the left or
+ right depending on the `truncation_mode`. If `None`, no truncation is applied.
+ truncation_mode (`str`, *optional*, defaults to `"keep_start"`):
Truncation mode to use when the sequence exceeds `max_length`. Possible values are `"keep_end"` and
`"keep_start"`.
padding_free (`bool`, *optional*, defaults to `False`):
Whether to perform forward passes without padding by flattening all sequences in the batch into a single
continuous sequence. This reduces memory usage by eliminating padding overhead. Currently, this is only
- supported with the `flash_attention_2` attention implementation, which can efficiently handle the flattened
- batch structure.
+ supported with the FlashAttention 2 or 3, which can efficiently handle the flattened batch structure.
+ pad_to_multiple_of (`int`, *optional*):
+ If set, the sequences will be padded to a multiple of this value.
precompute_ref_log_probs (`bool`, *optional*, defaults to `False`):
- Whether to precompute the log probabilities from the reference model. Setting this to `True` allows
- training without needing the reference model during training, which can help reduce GPU memory usage. If
- set to `False` (default), the reference model will be used during training to compute log probabilities
- on-the-fly.
+ Whether to precompute the reference model log probabilities for the entire training dataset before
+ training. This allows to save memory during training, as the reference model does not need to be kept in
+ memory.
precompute_ref_batch_size (`int`, *optional*):
Batch size to use when precomputing reference model log probabilities. This can be set higher than the
training batch size to speed up preprocessing. If `None`, defaults to `per_device_train_batch_size` for
training and `per_device_eval_batch_size` for evaluation.
- > Parameters that control the training
-
- loss_type (`str` or `list[str]`, *optional*, defaults to `"sigmoid"`):
- Type of loss to use. Possible values are:
- - `"sigmoid"`: sigmoid loss from the original [DPO](https://huggingface.co/papers/2305.18290) paper.
- - `"hinge"`: hinge loss on the normalized likelihood from the
- [SLiC](https://huggingface.co/papers/2305.10425) paper.
- - `"ipo"`: IPO loss from the [IPO](https://huggingface.co/papers/2310.12036) paper.
- - `"exo_pair"`: pairwise EXO loss from the [EXO](https://huggingface.co/papers/2402.00856) paper.
- - `"nca_pair"`: pairwise NCA loss from the [NCA](https://huggingface.co/papers/2402.05369) paper.
- - `"robust"`: unbiased estimate of the DPO loss that is robust to preference noise from the [Robust
- DPO](https://huggingface.co/papers/2403.00409) paper.
- - `"bco_pair"`: pairwise BCO loss from the [BCO](https://huggingface.co/papers/2404.04656) paper.
- - `"sppo_hard"`: SPPO loss with hard label from the [SPPO](https://huggingface.co/papers/2405.00675)
- paper.
- - `"aot"`: AOT loss for paired datasets from the [AOT](https://huggingface.co/papers/2406.05882) paper.
- - `"aot_unpaired"`: AOT loss for unpaired datasets from the
- [AOT](https://huggingface.co/papers/2406.05882) paper.
- - `"discopop"`: DiscoPOP (a.k.a Log-Ratio Modulated Loss, LRML) loss from the
- [DiscoPOP](https://huggingface.co/papers/2406.08414) paper.
- - `"apo_zero"`: APO-zero loss from the [APO](https://huggingface.co/papers/2408.06266) paper.
- - `"apo_down"`: APO-down loss from the [APO](https://huggingface.co/papers/2408.06266) paper.
- - `"sft"`: Negative log-likelihood loss (standard supervised fine-tuning loss).
+ > Parameters that control the training
- Multiple loss types can be combined using comma separation (e.g., `["sigmoid", "bco_pair", "sft"]` for
- [MPO](https://huggingface.co/papers/2411.10442)). The `loss_weights` parameter can be used to specify
- corresponding weights for each loss type.
- beta (`float`, *optional*, defaults to `0.1`):
- Parameter controlling the deviation from the reference model. Higher β means less deviation from the
- reference model. For the IPO loss (`loss_type="ipo"`), β is the regularization parameter denoted by τ in
- the [paper](https://huggingface.co/papers/2310.12036).
+ loss_type (`list[str]`, *optional*, defaults to `["sigmoid"]`):
+ Type of loss to use. Possible values are: `'sigmoid'`, `'hinge'`, `'ipo'`, `'exo_pair'`, `'nca_pair'`,
+ `'robust'`, `'bco_pair'`, `'sppo_hard'`, `'aot'`, `'aot_unpaired'`, `'apo_zero'`, `'apo_down'`,
+ `'discopop'`, `'sft'`. If multiple loss types are provided, they will be combined using the weights
+ specified in `loss_weights`.
+ loss_weights (`list[float]`, *optional*):
+ List of loss weights for multi-loss combinations. Used when combining multiple loss types. Example: `[0.8,
+ 0.2, 1.0]` for MPO. If not provided, defaults to equal weights (`1.0`) for all loss types.
+ ld_alpha (`float`, *optional*):
+ α parameter from the LD-DPO paper, which controls the weighting of the verbose token log-probabilities in
+ responses. If `None`, no weighting is applied to the verbose part, and the loss is equivalent to the
+ standard DPO loss. Must be in [0.0, 1.0]: `ld_alpha=1.0` applies no weighting, and `ld_alpha=0.0` masks
+ tokens beyond shared lengths.
f_divergence_type (`str`, *optional*, defaults to `"reverse_kl"`):
- Type of f-divergence regularization function to compute divergence between policy and reference model.
- Supported values:
- - `"reverse_kl"`: Reverse KL divergence.
- - `"js_divergence"`: Jensen-Shannon divergence.
- - `"alpha_divergence"`: Alpha divergence.
- f_alpha_divergence_coef (`float`, *optional*, defaults to `1.0`):
- α coefficient in the α-divergence u^-α regularization function for DPO loss.
+ f-divergence regularizer between policy and reference (f-DPO paper). Possible values are: `reverse_kl`
+ (default), `forward_kl`, `js_divergence`, `alpha_divergence`.
+ f_alpha_divergence_coef (`float`, *optional*, defaults to `0.5`):
+ α coefficient for the α-divergence u^-α regularizer, used only when `f_divergence_type='alpha_divergence'`.
label_smoothing (`float`, *optional*, defaults to `0.0`):
- Robust DPO label smoothing parameter from the [cDPO report](https://ericmitchell.ai/cdpo.pdf) and [Robust
- DPO](https://huggingface.co/papers/2403.00409) paper that should be between `0.0` and `0.5`.
+ Label smoothing parameter used in Robust DPO and EXO. In Robust DPO, it is interpreted as the probability
+ that a preference label is flipped and must lie in [0.0, 0.5); a typical value recommended by the Robust
+ DPO paper is 0.1. In EXO, it corresponds to the ε label smoothing parameter, for which the paper recommends
+ a typical value of 1e-3.
+ beta (`float`, *optional*, defaults to `0.1`):
+ Parameter controlling the deviation from the reference model. Higher β means less deviation from the
+ reference model. For the IPO loss (`loss_type='ipo'`), this value is the regularization parameter denoted
+ by τ in the [paper](https://huggingface.co/papers/2310.12036).
use_weighting (`bool`, *optional*, defaults to `False`):
- Whether to weight the loss as done in the [WPO paper](https://huggingface.co/papers/2406.11827).
- ld_alpha (`float`, *optional*):
- α parameter from the [LD-DPO paper](https://huggingface.co/papers/2409.06411), which controls the weighting
- of the verbose token log-probabilities in responses. If `None`, no weighting is applied to the verbose
- part, and the loss is equivalent to the standard DPO loss. The paper recommends setting `ld_alpha` between
- `0.0` and `1.0`.
+ Whether to apply WPO-style weighting (https://huggingface.co/papers/2406.11827) to preference pairs using
+ the policy's length-normalized sequence probabilities.
discopop_tau (`float`, *optional*, defaults to `0.05`):
- τ/temperature parameter from the [DiscoPOP](https://huggingface.co/papers/2406.08414) paper, which controls
- the shape of log ratio modulated loss. The paper recommends the default value `discopop_tau=0.05`.
- loss_weights (`list[float]`, *optional*):
- List of loss weights for multi-loss combinations. Used when combining multiple loss types. Example: `[0.8,
- 0.2, 1.0]` for [MPO](https://huggingface.co/papers/2411.10442). If not provided, defaults to equal weights
- (`1.0`) for all loss types.
+ τ/temperature parameter from the DiscoPOP paper, which controls the shape of the log-ratio modulated loss
+ when using `loss_type='discopop'`. The paper recommends the default value `discopop_tau=0.05`.
+ activation_offloading (`bool`, *optional*, defaults to `False`):
+ Whether to offload the activations to the CPU.
sync_ref_model (`bool`, *optional*, defaults to `False`):
Whether to synchronize the reference model with the active model every `ref_model_sync_steps` steps, using
the `ref_model_mixup_alpha` parameter. This synchronization originates from the
- [TR-DPO](https://huggingface.co/papers/2404.09656) paper.
+ [TR-DPO](https://huggingface.co/papers/2404.09656) paper. `sync_ref_model=True` is not yet compatible with
+ PEFT or `precompute_ref_log_probs=True`.
ref_model_mixup_alpha (`float`, *optional*, defaults to `0.6`):
- α parameter from the [TR-DPO](https://huggingface.co/papers/2404.09656) paper, which controls the mix
- between the current policy and the previous reference policy during updates. The reference policy is
- updated according to the equation: `π_ref = α * π_θ + (1 - α) * π_ref_prev`. To use this parameter, you
- must set `sync_ref_model=True`.
+ α parameter from the TR-DPO paper, which controls the mix between the current policy and the previous
+ reference policy during updates. The reference policy is updated according to the equation: `π_ref = α *
+ π_θ + (1 - α) * π_ref_prev`. To use this parameter, you must set `sync_ref_model=True`.
ref_model_sync_steps (`int`, *optional*, defaults to `512`):
- τ parameter from the [TR-DPO](https://huggingface.co/papers/2404.09656) paper, which determines how
- frequently the current policy is synchronized with the reference policy. To use this parameter, you must
- set `sync_ref_model=True`.
-
- > Deprecated parameters
-
- base_model_attribute_name (`str`, *optional*, defaults to `"model"`):
- Name of the attribute in the model that contains the base model. This is used to get the base model from
- the model when the model does not have a `get_decoder` method in the case when `use_liger_kernel` is
- `True`.
-
-
-
- This parameter is deprecated and will be removed in version 0.29.0. In the future the base model will be
- retrieved via `get_decoder`; if your model does not support this, it will no longer be supported by the
- [`DPOTrainer`].
-
-
- ref_model_init_kwargs (`dict[str, Any]`, *optional*):
- Keyword arguments for `AutoModelForCausalLM.from_pretrained`, used when the `ref_model` argument of the
- [`DPOTrainer`] is provided as a string.
-
-
-
- This parameter is deprecated and will be removed in version 0.29.0. If you need different init kwargs for
- the reference model, instantiate it yourself and pass it via the `ref_model` argument.
-
-
- model_adapter_name (`str`, *optional*):
- Name of the train target PEFT adapter, when using LoRA with multiple adapters. Only the default adapter
- will be supported going forward.
-
-
-
- This parameter is deprecated and will be removed in version 0.29.0. Only the default adapter will be
- supported going forward.
-
-
- ref_adapter_name (`str`, *optional*):
- Name of the reference PEFT adapter, when using LoRA with multiple adapters. If you used it to resume
- training an adapter, you won't need this argument anymore in the next version and can rely on the trainer.
- For now, it is still the only supported way to do this.
-
-
-
- This parameter is deprecated and will be removed in version 0.29.0. If you used it to resume training an
- adapter, you won't need this argument anymore in the next version and can rely on the trainer. For now, it
- is still the only supported way to do this.
-
-
- force_use_ref_model (`bool`, *optional*, defaults to `False`):
- If you provide a PEFT model as the active model and wish to use a different model for the `ref_model`, set
- this flag to `True`.
-
-
-
- This parameter is deprecated and will be removed in version 0.29.0. There is no need to pass this argument
- anymore: if you provide a reference model, it will be used automatically.
-
-
- generate_during_eval (`bool`, *optional*, defaults to `False`):
- Whether to generate and log completions from both the model and the reference model to W&B or Comet during
- evaluation.
-
-
-
- This parameter is deprecated and will be removed in version 0.29.0. Please use a callback instead; see
- `https://gist.github.com/qgallouedec/a08da3457a3a76c5ca539d4a0b38e482`.
-
-
- label_pad_token_id (`int`, *optional*, defaults to `-100`):
- Padding value to use for labels.
-
-
-
- This parameter is deprecated and will be removed in version 0.29.0. It will no longer be possible to set
- this value.
-
-
- max_prompt_length (`int` or `None`, *optional*, defaults to `512`):
- Maximum length of the prompt. We recommend filtering overlong prompts from your dataset before passing it
- to the trainer instead of using this parameter.
-
-
-
- This parameter is deprecated and will be removed in version 0.29.0. We recommend filtering overlong prompts
- from your dataset before passing it to the trainer instead of using this parameter.
-
-
- max_completion_length (`int`, *optional*):
- Maximum length of the completion.
-
-
-
- This parameter is deprecated and will be removed in version 0.29.0. We recommend using `max_length` instead
- to control the maximum length of samples.
-
-
- reference_free (`bool`, *optional*, defaults to `False`):
- Whether to ignore the provided reference model and implicitly use a reference model that assigns equal
- probability to all responses.
-
-
-
- This parameter is deprecated and will be removed in version 0.29.0. If you want a reference-free objective,
- use [`experimental.cpo.CPOTrainer`] instead.
-
-
- rpo_alpha (`float`, *optional*):
- α parameter from the [RPO paper](https://huggingface.co/papers/2404.19733) (v3), which controls the
- weighting of the NLL term in the loss. If `None`, no weighting is applied and the loss is the same as the
- DPO loss. The paper recommends `rpo_alpha=1.0`.
-
-
-
- This parameter is deprecated and will be removed in version 0.29.0. This is equivalent to including `"sft"`
- in `loss_type`; we recommend adding `"sft"` to `loss_type` and setting its weight in `loss_weights` to
- `rpo_alpha`.
-
-
- tools (`list[dict] | None`, *optional*):
- List of tools (callable functions) that will be accessible to the model. If the template does not support
- function calling, this argument will have no effect.
-
-
-
- This parameter is deprecated and will be removed in version 0.29.0. In 0.29 this argument will be ignored;
- tools should be provided via the dataset instead. For now, `DPOConfig.tools` remains the only supported way
- to pass tools.
-
-
- use_logits_to_keep (`bool`, *optional*, defaults to `False`):
- If `True`, only a specified number of logits are computed in the forward pass. This can be useful for
- saving memory and speeding up training by not computing the logits for all tokens, especially in scenarios
- when working with very long prompts where labels are ignored (-100).
-
-
-
- This parameter is deprecated and will be removed in version 0.29.0. The DPO trainer will no longer use this
- setting.
-
-
+ τ parameter from the TR-DPO paper, which determines how frequently the current policy is synchronized with
+ the reference policy. To use this parameter, you must set `sync_ref_model=True`.
"""
- _VALID_DICT_FIELDS = TrainingArguments._VALID_DICT_FIELDS + ["model_init_kwargs", "ref_model_init_kwargs"]
+ _VALID_DICT_FIELDS = TrainingArguments._VALID_DICT_FIELDS + ["model_init_kwargs"]
# Parameters whose default values are overridden from TrainingArguments
learning_rate: float = field(
@@ -362,7 +158,7 @@ class DPOConfig(TrainingArguments):
},
)
- # Parameters that control the model and reference model
+ # Parameters that control the model
model_init_kwargs: dict[str, Any] | None = field(
default=None,
metadata={
@@ -389,10 +185,13 @@ class DPOConfig(TrainingArguments):
)
max_length: int | None = field(
default=1024,
- metadata={"help": "Maximum length of the full sequence (prompt + completion)."},
+ metadata={
+ "help": "Maximum length of the tokenized sequence. Sequences longer than `max_length` are truncated from "
+ "the left or right depending on the `truncation_mode`. If `None`, no truncation is applied."
+ },
)
truncation_mode: str = field(
- default="keep_end",
+ default="keep_start",
metadata={
"help": "Truncation mode to use when the sequence exceeds `max_length`. Possible values are `'keep_end'` "
"and `'keep_start'`.",
@@ -403,18 +202,21 @@ class DPOConfig(TrainingArguments):
default=False,
metadata={
"help": "Whether to perform forward passes without padding by flattening all sequences in the batch into "
- "a single continuous sequence. This reduces memory usage by eliminating padding overhead. Currently, "
- "this is only supported with the `flash_attention_2` attention implementation, which can efficiently "
- "handle the flattened batch structure."
+ "a single continuous sequence. This reduces memory usage by eliminating padding overhead. Currently, this "
+ "is only supported with the FlashAttention 2 or 3, which can efficiently handle the flattened batch "
+ "structure."
},
)
+ pad_to_multiple_of: int | None = field(
+ default=None,
+ metadata={"help": "If set, the sequences will be padded to a multiple of this value."},
+ )
precompute_ref_log_probs: bool = field(
default=False,
metadata={
- "help": "Whether to precompute the log probabilities from the reference model. Setting this to `True` "
- "allows training without needing the reference model during training, which can help reduce GPU memory "
- "usage. If set to `False` (default), the reference model will be used during training to compute log "
- "probabilities on-the-fly."
+ "help": "Whether to precompute the reference model log probabilities for the entire training dataset "
+ "before training. This allows to save memory during training, as the reference model does not need to be "
+ "kept in memory."
},
)
precompute_ref_batch_size: int | None = field(
@@ -431,70 +233,85 @@ class DPOConfig(TrainingArguments):
default_factory=lambda: ["sigmoid"],
metadata={
"help": "Type of loss to use. Possible values are: `'sigmoid'`, `'hinge'`, `'ipo'`, `'exo_pair'`, "
- "`'nca_pair'`, `'robust'`, `'bco_pair'`, `'sppo_hard'`, `'aot'`, `'aot_unpaired'`, `'discopop'`, "
- "`'apo_zero'`, `'apo_down'` and `'sft'`. Multiple loss types can be combined using comma separation "
- "(e.g., `['sigmoid', 'bco_pair', 'sft']` for MPO). The `loss_weights` parameter can be used to specify "
- "corresponding weights for each loss type."
+ "`'nca_pair'`, `'robust'`, `'bco_pair'`, `'sppo_hard'`, `'aot'`, `'aot_unpaired'`, `'apo_zero'`, "
+ "`'apo_down'`, `'discopop'`, `'sft'`. If multiple loss types are provided, they will be combined using "
+ "the weights specified in `loss_weights`.",
},
)
- beta: float = field(
- default=0.1,
+ loss_weights: list[float] | None = field(
+ default=None,
metadata={
- "help": "Parameter controlling the deviation from the reference model. "
- "Higher β means less deviation from the reference model."
+ "help": "List of loss weights for multi-loss combinations. Used when combining multiple loss types. "
+ "Example: `[0.8, 0.2, 1.0]` for MPO. If not provided, defaults to equal weights (`1.0`) for all loss "
+ "types."
+ },
+ )
+ ld_alpha: float | None = field(
+ default=None,
+ metadata={
+ "help": "α parameter from the LD-DPO paper, which controls the weighting of the verbose token "
+ "log-probabilities in responses. If `None`, no weighting is applied to the verbose part, and the loss is "
+ "equivalent to the standard DPO loss. Must be in [0.0, 1.0]: `ld_alpha=1.0` applies no weighting, and "
+ "`ld_alpha=0.0` masks tokens beyond shared lengths.",
},
)
f_divergence_type: str = field(
default="reverse_kl",
metadata={
- "help": "Type of f-divergence regularization function to compute divergence between policy and reference "
- "model.",
- "choices": ["reverse_kl", "js_divergence", "alpha_divergence"],
+ "help": "f-divergence regularizer between policy and reference (f-DPO paper). Possible values are: "
+ "`reverse_kl` (default), `forward_kl`, `js_divergence`, `alpha_divergence`.",
},
)
f_alpha_divergence_coef: float = field(
- default=1.0,
- metadata={"help": "α coefficient in the α-divergence u^-α regularization function for DPO loss."},
+ default=0.5,
+ metadata={
+ "help": "α coefficient for the α-divergence u^-α regularizer, used only when "
+ "`f_divergence_type='alpha_divergence'`."
+ },
)
label_smoothing: float = field(
default=0.0,
metadata={
- "help": "Robust DPO label smoothing parameter from the cDPO report and Robust DPO paper that should "
- "be between `0.0` and `0.5`."
+ "help": "Label smoothing parameter used in Robust DPO and EXO. In Robust DPO, it is interpreted as the "
+ "probability that a preference label is flipped and must lie in [0.0, 0.5); a typical value recommended "
+ "by the Robust DPO paper is 0.1. In EXO, it corresponds to the ε label smoothing parameter, for which the "
+ "paper recommends a typical value of 1e-3."
+ },
+ )
+ beta: float = field(
+ default=0.1,
+ metadata={
+ "help": "Parameter controlling the deviation from the reference model. Higher β means less deviation from "
+ "the reference model. For the IPO loss (`loss_type='ipo'`), this value is the regularization parameter "
+ "denoted by τ in the [paper](https://huggingface.co/papers/2310.12036)."
},
)
use_weighting: bool = field(
default=False,
- metadata={"help": "Whether to weight the loss as done in the WPO paper."},
- )
- ld_alpha: float | None = field(
- default=None,
metadata={
- "help": "α parameter from the LD-DPO paper, which controls the weighting of the verbose token "
- "log-probabilities in responses. If `None`, no weighting is applied to the verbose part, and the loss is "
- "equivalent to the standard DPO loss. The paper recommends setting `ld_alpha` between `0.0` and `1.0`.",
+ "help": "Whether to apply WPO-style weighting (https://huggingface.co/papers/2406.11827) to preference "
+ "pairs using the policy's length-normalized sequence probabilities."
},
)
discopop_tau: float = field(
default=0.05,
metadata={
- "help": "τ/temperature parameter from the DiscoPOP paper, which controls the shape of log ratio modulated "
- "loss. The paper recommends the default value `discopop_tau=0.05`."
+ "help": "τ/temperature parameter from the DiscoPOP paper, which controls the shape of the log-ratio "
+ "modulated loss when using `loss_type='discopop'`. The paper recommends the default value "
+ "`discopop_tau=0.05`."
},
)
- loss_weights: list[float] | None = field(
- default=None,
- metadata={
- "help": "List of loss weights for multi-loss combinations. Used when combining multiple loss types. "
- "Example: `[0.8, 0.2, 1.0]` for MPO. If not provided, defaults to equal weights (`1.0`) for all loss "
- "types."
- },
+ activation_offloading: bool = field(
+ default=False,
+ metadata={"help": "Whether to offload the activations to the CPU."},
)
sync_ref_model: bool = field(
default=False,
metadata={
"help": "Whether to synchronize the reference model with the active model every `ref_model_sync_steps` "
- "steps, using the `ref_model_mixup_alpha` parameter."
+ "steps, using the `ref_model_mixup_alpha` parameter. This synchronization originates from the "
+ "[TR-DPO](https://huggingface.co/papers/2404.09656) paper. `sync_ref_model=True` is not yet compatible "
+ "with PEFT or `precompute_ref_log_probs=True`."
},
)
ref_model_mixup_alpha: float = field(
@@ -513,263 +330,15 @@ class DPOConfig(TrainingArguments):
},
)
- # Deprecated parameters
- base_model_attribute_name: str | None = field(
- default=None,
- metadata={
- "help": "Name of the attribute in the model that contains the base model. This is used to get the base "
- "model from the model when the model does not have a `get_decoder` method in the case when "
- "`use_liger_kernel` is `True`. Deprecated: the base model will be retrieved via `get_decoder`; models "
- "without it won't be supported by the DPO trainer."
- },
- )
- force_use_ref_model: bool | None = field(
- default=None,
- metadata={
- "help": "Deprecated. There is no need to pass this argument anymore: if you provide a reference model, it "
- "will be used automatically."
- },
- )
- generate_during_eval: bool | None = field(
- default=None,
- metadata={
- "help": "Deprecated. Please use a callback instead; see "
- "`https://gist.github.com/qgallouedec/a08da3457a3a76c5ca539d4a0b38e482`."
- },
- )
- label_pad_token_id: int | None = field(
- default=None,
- metadata={"help": "Deprecated. It will no longer be possible to set this value."},
- )
- max_completion_length: int | None = field(
- # This default value is used to determine whether the user has set it or not, since `None` is a valid value for
- # this parameter. This is overridden in `__post_init__` to preserve the old default value of `None`.
- default=-1,
- metadata={"help": "Deprecated. Use `max_length` instead to control the maximum length of samples."},
- )
- max_prompt_length: int | None = field(
- # This default value is used to determine whether the user has set it or not, since `None` is a valid value for
- # this parameter. This is overridden in `__post_init__` to preserve the old default value of `512`.
- default=-1,
- metadata={
- "help": "Deprecated. We recommend filtering overlong prompts from your dataset before passing it to the "
- "trainer instead of using this parameter."
- },
- )
- model_adapter_name: str | None = field(
- default=None,
- metadata={"help": "Deprecated. Only the default adapter will be supported going forward."},
- )
- ref_adapter_name: str | None = field(
- default=None,
- metadata={
- "help": "Deprecated. If you used it to resume training an adapter, you won't need this argument anymore "
- "in the next version and can rely on the trainer. For now, it is still the only supported way to do "
- "this."
- },
- )
- ref_model_init_kwargs: dict[str, Any] | None = field(
- default=None,
- metadata={
- "help": "Keyword arguments for `AutoModelForCausalLM.from_pretrained`, used when the `ref_model` argument "
- "of the `DPOTrainer` is provided as a string. Deprecated: if you need different init kwargs for the "
- "reference model, instantiate it yourself and pass it via the `ref_model` argument."
- },
- )
- reference_free: bool | None = field(
- default=None,
- metadata={
- "help": "Whether to ignore the provided reference model and implicitly use a reference model that assigns "
- "equal probability to all responses. Deprecated: if you want a reference-free objective, use "
- "`CPOTrainer` instead."
- },
- )
- rpo_alpha: float | None = field(
- default=None,
- metadata={
- "help": "α parameter from the RPO paper (v3), which controls the weighting of the NLL term in the loss. "
- "If `None`, no weighting is applied and the loss is the same as the DPO loss. The paper recommends "
- "`rpo_alpha=1.0`. Deprecated: this is equivalent to including `'sft'` in `loss_type`; we recommend adding "
- "'sft' to `loss_type` and setting its weight in `loss_weights` to `rpo_alpha`."
- },
- )
- tools: list[dict] | None = field(
- default=None,
- metadata={
- "help": "List of tools (callable functions) that will be accessible to the model. If the template does "
- "not support function calling, this argument will have no effect. Deprecated: in 0.29 this argument "
- "will be ignored; tools should be provided via the dataset instead. For now, `DPOConfig.tools` remains "
- "the only supported way to pass tools."
- },
- )
- use_logits_to_keep: bool | None = field(
- default=None,
- metadata={
- "help": "If `True`, only a specified number of logits are computed in the forward pass. This can be "
- "useful for saving memory and speeding up training by not computing the logits for all tokens, especially "
- "in scenarios when working with very long prompts where labels are ignored (-100). Deprecated: the DPO "
- "trainer will no longer use this setting."
- },
- )
-
def __post_init__(self):
self.bf16 = not (self.fp16) if self.bf16 is None else self.bf16
- if self.base_model_attribute_name is not None:
- warnings.warn(
- "`base_model_attribute_name` is deprecated and will be removed in version 0.29.0. The base model "
- "will be retrieved via `get_decoder`; if your model does not support this, it will no longer be "
- "supported by the DPO trainer.",
- FutureWarning,
- stacklevel=3,
- )
- else: # keep the old default
- self.base_model_attribute_name = "model"
-
- if self.force_use_ref_model is not None:
- warnings.warn(
- "`force_use_ref_model` is deprecated and will be removed in version 0.29.0. There is no need to pass "
- "this argument anymore: if you provide a reference model, it will be used automatically.",
- FutureWarning,
- stacklevel=3,
- )
-
- if self.generate_during_eval is not None:
- warnings.warn(
- "`generate_during_eval` is deprecated and will be removed in version 0.29.0. Please use a callback "
- "instead. See the example at `https://gist.github.com/qgallouedec/a08da3457a3a76c5ca539d4a0b38e482`.",
- FutureWarning,
- stacklevel=3,
- )
- else: # keep the old default
- self.generate_during_eval = False
-
- if self.label_pad_token_id is not None:
- warnings.warn(
- "`label_pad_token_id` is deprecated and will be removed in version 0.29.0. It will no longer be "
- "possible to set this value.",
- FutureWarning,
- stacklevel=3,
- )
- else: # keep the old default
- self.label_pad_token_id = -100
-
- if self.max_completion_length != -1:
- warnings.warn(
- "`max_completion_length` is deprecated and will be removed in version 0.29.0. We recommend using "
- "`max_length` instead to control the maximum length of samples.",
- FutureWarning,
- stacklevel=3,
- )
- else: # keep the old default
- self.max_completion_length = None
-
- if self.max_prompt_length != -1:
- warnings.warn(
- "`max_prompt_length` is deprecated and will be removed in version 0.29.0. We recommend filtering out "
- "overlong prompts from your dataset before passing it to the trainer instead of using this parameter.",
- FutureWarning,
- stacklevel=3,
- )
- else: # keep the old default
- self.max_prompt_length = 512
-
- if self.model_adapter_name is not None:
- warnings.warn(
- "`model_adapter_name` is deprecated and will be removed in version 0.29.0. Only the default adapter "
- "will be supported going forward.",
- FutureWarning,
- stacklevel=3,
- )
-
- if self.ref_adapter_name is not None:
- warnings.warn(
- "`ref_adapter_name` is deprecated and will be removed in version 0.29.0. If you used it to resume "
- "training an adapter, you won't need this argument anymore in the next version and can rely on the "
- "trainer. For now, it is still the only supported way to do this.",
- FutureWarning,
- stacklevel=3,
- )
-
- if self.ref_model_init_kwargs is not None:
- warnings.warn(
- "`ref_model_init_kwargs` is deprecated and will be removed in version 0.29.0. If you need different "
- "init kwargs for the reference model, instantiate it yourself and pass it via the `ref_model` "
- "argument.",
- FutureWarning,
- stacklevel=3,
- )
-
- if self.reference_free is not None:
- warnings.warn(
- "`reference_free` is deprecated and will be removed in version 0.29.0. If you want a reference-free "
- "objective, use `CPOTrainer` instead.",
- FutureWarning,
- stacklevel=3,
- )
- else: # keep the old default
- self.reference_free = False
-
- if self.rpo_alpha is not None:
- warnings.warn(
- "`rpo_alpha` is deprecated and will be removed in version 0.29.0. It is equivalent to including "
- "`'sft'` in `loss_type`; we recommend adding `'sft'` to `loss_type` and setting its weight in "
- "`loss_weights` to `rpo_alpha`.",
- FutureWarning,
- stacklevel=3,
- )
-
- if self.tools is not None:
- warnings.warn(
- "`tools` is deprecated and will be removed in version 0.29.0. In 0.29 this argument will be ignored; "
- "tools should be provided via the dataset instead but for now, `DPOConfig.tools` remains the only "
- "supported way to pass tools.",
- FutureWarning,
- stacklevel=3,
- )
-
- if self.use_logits_to_keep is not None:
- warnings.warn(
- "`use_logits_to_keep` is deprecated and will be removed in version 0.29.0. The DPO trainer will no "
- "longer use this setting.",
- FutureWarning,
- stacklevel=3,
- )
- else: # keep the old default
- self.use_logits_to_keep = False
-
- if isinstance(self.f_divergence_type, FDivergenceType):
- warnings.warn(
- "`f_divergence_type` will require a string in 0.29.0; `FDivergenceType` is deprecated. Use one of: "
- "`'reverse_kl'`, `'js_divergence'`, `'alpha_divergence'`.",
- FutureWarning,
- stacklevel=3,
- )
- self.f_divergence_type = self.f_divergence_type.value
-
- # Normalize loss_type to string format for internal use
- if hasattr(self.loss_type, "__len__") and len(self.loss_type) == 1:
- self.loss_type = self.loss_type[0]
-
- # Validate loss_type
- if self.loss_weights is not None:
- loss_types = self.loss_type if isinstance(self.loss_type, list) else [self.loss_type]
- if len(self.loss_weights) != len(loss_types):
- raise ValueError(
- f"Length of loss_weights list ({self.loss_weights}) must match number of loss types "
- f"({loss_types})."
- )
-
- if "aot_pair" in self.loss_type:
- warnings.warn(
- "The loss type 'aot_pair' has been renamed to 'aot_unpaired' and is deprecated. "
- "It will be removed in version 0.29.0. Please use 'aot_unpaired' in `loss_type` instead.",
- FutureWarning,
- stacklevel=3,
+ if isinstance(self.loss_type, str):
+ self.loss_type = [self.loss_type]
+ if self.loss_weights is not None and len(self.loss_weights) != len(self.loss_type):
+ raise ValueError(
+ "`loss_weights` must have the same length as `loss_type` when combining multiple losses. "
+ f"Got {len(self.loss_weights)} weights for {len(self.loss_type)} loss types."
)
- if isinstance(self.loss_type, str):
- self.loss_type = "aot_unpaired"
- else:
- self.loss_type = ["aot_unpaired" if lt == "aot_pair" else lt for lt in self.loss_type]
super().__post_init__()
diff --git a/trl/trainer/dpo_trainer.py b/trl/trainer/dpo_trainer.py
index 7423728a52e..84aef42946d 100644
--- a/trl/trainer/dpo_trainer.py
+++ b/trl/trainer/dpo_trainer.py
@@ -12,242 +12,423 @@
# See the License for the specific language governing permissions and
# limitations under the License.
-import inspect
-import random
+import contextlib
+import json
+import os
import textwrap
-import warnings
from collections import defaultdict
from collections.abc import Callable
-from contextlib import contextmanager, nullcontext
from dataclasses import dataclass
from pathlib import Path
-from typing import Any, Literal
+from typing import Any
-import pandas as pd
+import numpy as np
import torch
-import torch.nn as nn
import torch.nn.functional as F
import transformers
-from accelerate import PartialState, logging
-from accelerate.utils import tqdm
-from datasets import Dataset, IterableDataset
+from accelerate import PartialState
+from accelerate.logging import get_logger
+from accelerate.utils import is_peft_model, tqdm
+from datasets import Dataset, IterableDataset, IterableDatasetDict
+from datasets.fingerprint import Hasher
from packaging.version import Version
-from torch import autocast
from torch.utils.data import DataLoader
from transformers import (
AutoProcessor,
- BaseImageProcessor,
DataCollator,
- FeatureExtractionMixin,
PreTrainedModel,
PreTrainedTokenizerBase,
ProcessorMixin,
- TrainerCallback,
)
from transformers.data.data_collator import DataCollatorMixin
-from transformers.integrations import (
- is_comet_available,
- is_mlflow_available,
- is_wandb_available,
-)
-from transformers.models.auto.modeling_auto import MODEL_FOR_IMAGE_TEXT_TO_TEXT_MAPPING_NAMES
-from transformers.trainer_utils import EvalLoopOutput
+from transformers.trainer_callback import TrainerCallback
+from transformers.trainer_utils import EvalPrediction
from transformers.utils import is_liger_kernel_available, is_peft_available
-from ..data_utils import is_conversational, maybe_apply_chat_template, maybe_extract_prompt
-from ..models import create_reference_model, prepare_deepspeed
-from ..models.utils import peft_module_casting_to_bf16, prepare_fsdp
+from ..data_utils import apply_chat_template, extract_prompt, is_conversational, prepare_multimodal_messages
+from ..models import get_act_offloading_ctx_manager, prepare_deepspeed, prepare_fsdp
+from ..models.utils import disable_gradient_checkpointing
from .base_trainer import BaseTrainer
from .callbacks import SyncRefModelCallback
-from .dpo_config import DPOConfig, FDivergenceConstants, FDivergenceType
+from .dpo_config import DPOConfig
from .utils import (
- RunningMoments,
- cap_exp,
create_model_from_path,
disable_dropout_in_model,
- empty_cache,
+ entropy_from_logits,
flush_left,
flush_right,
get_config_model_id,
- log_table_to_comet_experiment,
+ hash_module,
pad,
- pad_to_length,
+ remove_none_values,
selective_log_softmax,
+ use_adapter,
)
if is_peft_available():
- from peft import (
- PeftConfig,
- PeftModel,
- get_peft_model,
- prepare_model_for_kbit_training,
- )
+ from peft import PeftConfig, PeftModel, get_peft_model
+
if is_liger_kernel_available():
from liger_kernel.chunked_loss import LigerFusedLinearDPOLoss
-if is_wandb_available():
- import wandb
+logger = get_logger(__name__)
-if is_mlflow_available():
- import mlflow
+FLASH_ATTENTION_VARIANTS = {
+ "flash_attention_2",
+ "flash_attention_3",
+ "kernels-community/flash-attn2",
+ "kernels-community/flash-attn3",
+ "kernels-community/vllm-flash-attn3",
+}
-logger = logging.get_logger(__name__)
-
-def shift_tokens_right(input_ids: torch.Tensor, decoder_start_token_id: int) -> torch.Tensor:
- """Shift input ids one token to the right, and pad with pad_token_id"""
- shifted_input_ids = input_ids.new_zeros(input_ids.shape)
- shifted_input_ids[:, 1:] = input_ids[:, :-1].clone()
- shifted_input_ids[:, 0] = decoder_start_token_id
- return shifted_input_ids
+def get_dataset_column_names(dataset: Dataset | IterableDataset) -> list[str]:
+ return list(next(iter(dataset)).keys()) if dataset.column_names is None else dataset.column_names
@dataclass
class DataCollatorForPreference(DataCollatorMixin):
"""
- Data collator used for preference data. Inputs are dynamically padded to the maximum length of a batch if they are
- not all of the same length.
+ Data collator used for preference data. Inputs are dynamically padded to the maximum length of a batch.
+
+ This collator expects each example in the input list to be a dictionary containing the keys `"prompt_ids"`,
+ `"chosen_ids"` and `"rejected_ids"`. The collator returns a dictionary containing the following keys:
+ - `"input_ids"`: Tensor of input IDs, padded to the maximum length of the batch. The first half of the batch
+ corresponds to the `"chosen_ids"` and the second half to the `"rejected_ids"`.
+ - `"attention_mask"`: Tensor of attention mask, padded to the maximum length of the batch.
+ - `"completion_mask"`: Tensor indicating the positions of the completion tokens, padded to the maximum length of
+ the batch.
+
+ Optionally, the examples can contain a `"ref_chosen_logps"` and `"ref_rejected_logps"` keys, in which case the
+ returned dictionary will also contain these keys with the corresponding tensors.
Args:
pad_token_id (`int`):
Token ID to use for padding.
+ pad_to_multiple_of (`int`, *optional*):
+ If set, the sequences will be padded to a multiple of this value.
return_tensors (`str`, *optional*, defaults to `"pt"`):
Type of Tensor to return. Only `"pt"` is currently supported.
Examples:
```python
- >>> from trl import DataCollatorForPreference
+ >>> from trl.trainer.dpo_trainer import DataCollatorForPreference
>>> collator = DataCollatorForPreference(pad_token_id=0)
>>> examples = [
- ... {"prompt_input_ids": [1, 2, 3], "chosen_input_ids": [4, 5], "rejected_input_ids": [6]},
- ... {"prompt_input_ids": [7, 8], "chosen_input_ids": [9, 10], "rejected_input_ids": [11, 12, 13]},
+ ... {"prompt_ids": [1, 2, 3], "chosen_ids": [4, 5], "rejected_ids": [6]},
+ ... {"prompt_ids": [7, 8], "chosen_ids": [9], "rejected_ids": [10, 11]},
... ]
>>> collator(examples)
- {'prompt_input_ids': tensor([[1, 2, 3],
- [0, 7, 8]]),
- 'prompt_attention_mask': tensor([[1, 1, 1],
- [0, 1, 1]]),
- 'chosen_input_ids': tensor([[ 4, 5],
- [ 9, 10]]),
- 'chosen_attention_mask': tensor([[1, 1],
- [1, 1]]),
- 'rejected_input_ids': tensor([[ 6, 0, 0],
- [11, 12, 13]]),
- 'rejected_attention_mask': tensor([[1, 0, 0],
- [1, 1, 1]])
- }
+ {'input_ids': tensor([[ 1, 2, 3, 4, 5],
+ [ 7, 8, 9, 0, 0],
+ [ 1, 2, 3, 6, 0],
+ [ 7, 8, 10, 11, 0]]),
+ 'attention_mask': tensor([[1, 1, 1, 1, 1],
+ [1, 1, 1, 0, 0],
+ [1, 1, 1, 1, 0],
+ [1, 1, 1, 1, 0]]),
+ 'completion_mask': tensor([[0, 0, 0, 1, 1],
+ [0, 0, 1, 0, 0],
+ [0, 0, 0, 1, 0],
+ [0, 0, 1, 1, 0]])}
```
"""
pad_token_id: int
+ pad_to_multiple_of: int | None = None
return_tensors: str = "pt"
- def torch_call(self, examples: list[list[int] | Any | dict[str, Any]]) -> dict[str, Any]:
+ def torch_call(self, examples: list[dict[str, Any]]) -> dict[str, Any]:
+ prompt_chosen_ids = [example["prompt_ids"] + example["chosen_ids"] for example in examples]
+ prompt_rejected_ids = [example["prompt_ids"] + example["rejected_ids"] for example in examples]
+ chosen_attention_mask = [[1] * len(example["prompt_ids"] + example["chosen_ids"]) for example in examples]
+ rejected_attention_mask = [[1] * len(example["prompt_ids"] + example["rejected_ids"]) for example in examples]
+ chosen_mask = [[0] * len(example["prompt_ids"]) + [1] * len(example["chosen_ids"]) for example in examples]
+ rejected_mask = [[0] * len(example["prompt_ids"]) + [1] * len(example["rejected_ids"]) for example in examples]
+ input_ids = prompt_chosen_ids + prompt_rejected_ids
+ attention_mask = chosen_attention_mask + rejected_attention_mask
+ completion_mask = chosen_mask + rejected_mask
+
# Convert to tensor
- prompt_input_ids = [torch.tensor(example["prompt_input_ids"]) for example in examples]
- prompt_attention_mask = [torch.ones_like(input_ids) for input_ids in prompt_input_ids]
- chosen_input_ids = [torch.tensor(example["chosen_input_ids"]) for example in examples]
- chosen_attention_mask = [torch.ones_like(input_ids) for input_ids in chosen_input_ids]
- rejected_input_ids = [torch.tensor(example["rejected_input_ids"]) for example in examples]
- rejected_attention_mask = [torch.ones_like(input_ids) for input_ids in rejected_input_ids]
- if "pixel_values" in examples[0]:
- pixel_values = [torch.tensor(example["pixel_values"]) for example in examples]
- if "pixel_attention_mask" in examples[0]:
- pixel_attention_mask = [torch.tensor(example["pixel_attention_mask"]) for example in examples]
- if "ref_chosen_logps" in examples[0] and "ref_rejected_logps" in examples[0]:
+ input_ids = [torch.tensor(ids) for ids in input_ids]
+ attention_mask = [torch.tensor(m, dtype=torch.long) for m in attention_mask]
+ completion_mask = [torch.tensor(m, dtype=torch.long) for m in completion_mask]
+ if "ref_chosen_logps" in examples[0]:
ref_chosen_logps = torch.tensor([example["ref_chosen_logps"] for example in examples])
+ if "ref_rejected_logps" in examples[0]:
ref_rejected_logps = torch.tensor([example["ref_rejected_logps"] for example in examples])
# Pad
output = {}
- output["prompt_input_ids"] = pad(prompt_input_ids, padding_value=self.pad_token_id, padding_side="left")
- output["prompt_attention_mask"] = pad(prompt_attention_mask, padding_value=0, padding_side="left")
- output["chosen_input_ids"] = pad(chosen_input_ids, padding_value=self.pad_token_id)
- output["chosen_attention_mask"] = pad(chosen_attention_mask, padding_value=0)
- output["rejected_input_ids"] = pad(rejected_input_ids, padding_value=self.pad_token_id)
- output["rejected_attention_mask"] = pad(rejected_attention_mask, padding_value=0)
- if "pixel_values" in examples[0]:
- output["pixel_values"] = pad(pixel_values, padding_value=0.0)
- if "pixel_attention_mask" in examples[0]:
- output["pixel_attention_mask"] = pad(pixel_attention_mask, padding_value=0)
- if "image_sizes" in examples[0]:
- output["image_sizes"] = torch.tensor([example["image_sizes"] for example in examples])
- if "ref_chosen_logps" in examples[0] and "ref_rejected_logps" in examples[0]:
+ output["input_ids"] = pad(
+ input_ids,
+ padding_value=self.pad_token_id,
+ padding_side="right",
+ pad_to_multiple_of=self.pad_to_multiple_of,
+ )
+ output["attention_mask"] = pad(
+ attention_mask,
+ padding_value=0,
+ padding_side="right",
+ pad_to_multiple_of=self.pad_to_multiple_of,
+ )
+ output["completion_mask"] = pad(
+ completion_mask,
+ padding_value=0,
+ padding_side="right",
+ pad_to_multiple_of=self.pad_to_multiple_of,
+ )
+ if "ref_chosen_logps" in examples[0]:
output["ref_chosen_logps"] = ref_chosen_logps
+ if "ref_rejected_logps" in examples[0]:
output["ref_rejected_logps"] = ref_rejected_logps
- if "token_type_ids" in examples[0]:
- token_type_ids = [torch.tensor(example["token_type_ids"]) for example in examples]
- output["token_type_ids"] = pad(token_type_ids, padding_value=0, padding_side="left")
+ return output
+
+
+@dataclass
+class DataCollatorForVisionPreference(DataCollatorMixin):
+ """
+ Data collator for vision-preference tasks.
+
+ Unlike text-only datasets—where the collator typically receives pre-tokenized inputs ready for batching,
+ vision-language data processing involves converting images into pixel values. This conversion is disk-intensive,
+ making upfront preprocessing of the entire dataset impractical. Therefore, this collator performs tokenization and
+ image processing on-the-fly to efficiently prepare batches.
+
+ Each input example should be a dictionary containing at least:
+ - An `"images"` key holding a list of images, or an `"image"` key holding a single image.
+ - Keys `"prompt"` `"chosen"` and `"rejected"` for the prompt and preference responses.
+
+ The collator outputs a dictionary including:
+ - `"input_ids"`: Tensor of token IDs.
+ - `"attention_mask"`: Tensor indicating attention mask.
+ - `"completion_mask"`: Tensor indicating which tokens correspond to completions.
+ - `"pixel_values"`: Tensor representing image pixel values.
+
+ Additional keys may be present depending on the processor, such as `"image_grid_thw"`.
+
+ Args:
+ processor ([`~transformers.ProcessorMixin`]):
+ The processor used to tokenize text and process images. It must be a subclass of
+ [`~transformers.ProcessorMixin`] and include a `tokenizer` with a defined `pad_token_id`.
+ pad_to_multiple_of (`int` or `None`, optional, defaults to `None`):
+ If set, the sequences will be padded to a multiple of this value.
+ return_tensors (`str`, optional, defaults to `"pt"`):
+ The tensor type to return. Currently, only `"pt"` (PyTorch tensors) is supported.
+
+ Example:
+ ```python
+ >>> from trl.trainer.dpo_trainer import DataCollatorForVisionPreference
+ >>> from transformers import AutoProcessor
+
+ >>> processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-7B-Instruct")
+ >>> collator = DataCollatorForVisionPreference(processor)
+ >>> examples = [
+ ... {
+ ... "images": [Image.open("image_0.png")],
+ ... "prompt": [{"role": "user", "content": "What is this?"}],
+ ... "chosen": [{"role": "assistant", "content": "This is a cat."}],
+ ... "rejected": [{"role": "assistant", "content": "This is a dog."}],
+ ... },
+ ... {
+ ... "images": [Image.open("image_1.png")],
+ ... "prompt": [{"role": "user", "content": "Describe this image."}],
+ ... "chosen": [{"role": "assistant", "content": "A beautiful landscape."}],
+ ... "rejected": [{"role": "assistant", "content": "An urban cityscape."}],
+ ... },
+ ... ]
+ >>> collator(examples)
+ {'input_ids': tensor([[151644, 8948, 198, 2610, 525, 264, 10950, 17847, 13, 151645, 198, 151644, 872, 198, 151652, 151655, 151655, 151655, 151655, 151653, 3838, 374, 419, 30, 151645, 198, 151644, 77091, 198, 1986, 374, 264, 8251, 13, 151645, 198],
+ [151644, 8948, 198, 2610, 525, 264, 10950, 17847, 13, 151645, 198, 151644, 872, 198, 151652, 151655, 151655, 151655, 151655, 151653, 74785, 419, 2168, 13, 151645, 198, 151644, 77091, 198, 32, 6233, 18414, 13, 151645, 198, 151643],
+ [151644, 8948, 198, 2610, 525, 264, 10950, 17847, 13, 151645, 198, 151644, 872, 198, 151652, 151655, 151655, 151655, 151655, 151653, 3838, 374, 419, 30, 151645, 198, 151644, 77091, 198, 1986, 374, 264, 5562, 13, 151645, 198],
+ [151644, 8948, 198, 2610, 525, 264, 10950, 17847, 13, 151645, 198, 151644, 872, 198, 151652, 151655, 151655, 151655, 151655, 151653, 74785, 419, 2168, 13, 151645, 198, 151644, 77091, 198, 2082, 15662, 3283, 57518, 13, 151645, 198]]),
+ 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
+ [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0],
+ [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
+ [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]),
+ 'pixel_values': tensor([[-1.3251, 0.1347, -0.4784, ..., 0.4537, -0.0156, 1.2358],
+ [ 0.5727, 0.4997, -0.9164, ..., -0.5701, 0.7950, -0.7123],
+ [-0.0550, -0.8288, 1.0690, ..., -0.1293, -0.1151, 1.6055],
+ ...,
+ [ 0.2953, 0.5581, 0.1785, ..., -0.7123, -0.7977, 0.1693],
+ [-0.7558, 1.0398, 1.3464, ..., -0.5417, -0.5417, 0.4395],
+ [ 0.8063, 0.6895, 0.4267, ..., -0.4422, 1.3354, 0.1266]]),
+ 'image_grid_thw': tensor([[1, 4, 4],
+ [1, 4, 4],
+ [1, 4, 4],
+ [1, 4, 4]]),
+ 'completion_mask': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1],
+ [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 0],
+ [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1],
+ [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]])}
+ ```
+ """
+
+ processor: ProcessorMixin
+ pad_to_multiple_of: int | None = None
+ return_tensors: str = "pt"
+
+ def torch_call(self, examples: list[dict[str, Any]]) -> dict[str, Any]:
+ if self.pad_to_multiple_of is not None:
+ raise NotImplementedError(
+ "Padding to a multiple of a value is not yet implemented for vision-language modeling and "
+ "prompt-completion data."
+ )
+ if "image" in examples[0]:
+ for example in examples:
+ example["images"] = [example.pop("image")]
+ images = [example["images"] for example in examples] * 2 # repeat for chosen and rejected
+ # Transformers requires at least one image in the batch, otherwise it throws an error
+ if all(img_list == [] for img_list in images):
+ images = None
+ if is_conversational(examples[0]): # conversational case
+ for example in examples:
+ example["prompt"] = prepare_multimodal_messages(example["prompt"], images=example["images"])
+ example["chosen"] = prepare_multimodal_messages(example["chosen"], images=[])
+ example["rejected"] = prepare_multimodal_messages(example["rejected"], images=[])
+ examples = [apply_chat_template(example, self.processor) for example in examples]
+
+ prompts = [example["prompt"] for example in examples] * 2 # repeat for chosen and rejected
+ chosens = [example["chosen"] for example in examples]
+ rejecteds = [example["rejected"] for example in examples]
+
+ processed_prompts = self.processor(
+ images=images,
+ text=prompts,
+ padding=True,
+ padding_side="left",
+ return_tensors=self.return_tensors,
+ add_special_tokens=False, # to avoid adding the BOS, twice see https://huggingface.co/blog/qgallouedec/gotchas-in-tokenizer-behavior#7-chat-template-and-tokenization-dont-compose-due-to-special-tokens
+ )
+ processed_chosens = self.processor(
+ text=chosens,
+ padding=True,
+ padding_side="right",
+ return_tensors=self.return_tensors,
+ add_special_tokens=False, # to avoid adding the BOS, twice see https://huggingface.co/blog/qgallouedec/gotchas-in-tokenizer-behavior#7-chat-template-and-tokenization-dont-compose-due-to-special-tokens
+ )
+ processed_rejecteds = self.processor(
+ text=rejecteds,
+ padding=True,
+ padding_side="right",
+ return_tensors=self.return_tensors,
+ add_special_tokens=False, # to avoid adding the BOS, twice see https://huggingface.co/blog/qgallouedec/gotchas-in-tokenizer-behavior#7-chat-template-and-tokenization-dont-compose-due-to-special-tokens
+ )
+ # Concatenate prompts and completions
+ prompt_ids, prompt_mask = processed_prompts["input_ids"], processed_prompts["attention_mask"]
+ chosen_ids, chosen_mask = processed_chosens["input_ids"], processed_chosens["attention_mask"]
+ rejected_ids, rejected_mask = processed_rejecteds["input_ids"], processed_rejecteds["attention_mask"]
+ pad_token_id = self.processor.tokenizer.pad_token_id or self.processor.tokenizer.eos_token_id
+ completion_ids = torch.cat(tuple(pad([chosen_ids, rejected_ids], padding_value=pad_token_id)))
+ completion_mask = torch.cat(tuple(pad([chosen_mask, rejected_mask], padding_value=0)))
+ input_ids = torch.cat((prompt_ids, completion_ids), dim=1)
+ attention_mask = torch.cat((prompt_mask, completion_mask), dim=1)
+ completion_mask = torch.cat((torch.zeros_like(prompt_mask), completion_mask), dim=1)
+ if "token_type_ids" in processed_prompts: # special case for Gemma
+ prompt_token_type_ids = processed_prompts["token_type_ids"]
+ chosen_type_ids = processed_chosens["token_type_ids"]
+ rejected_type_ids = processed_rejecteds["token_type_ids"]
+ completion_token_type_ids = torch.cat(tuple(pad([chosen_type_ids, rejected_type_ids], padding_value=0)))
+ token_type_ids = torch.cat((prompt_token_type_ids, completion_token_type_ids), dim=1)
+
+ # Flush left to reduce padding
+ if "token_type_ids" in processed_prompts:
+ attention_mask, input_ids, completion_mask, token_type_ids = flush_left(
+ attention_mask, input_ids, completion_mask, token_type_ids
+ )
+ else:
+ attention_mask, input_ids, completion_mask = flush_left(attention_mask, input_ids, completion_mask)
+
+ # Build the output dictionary
+ output = processed_prompts # we take processed_prompts because it contains the images
+ output["input_ids"] = input_ids
+ output["attention_mask"] = attention_mask
+ output["completion_mask"] = completion_mask
+ if "token_type_ids" in processed_prompts:
+ output["token_type_ids"] = token_type_ids
return output
class DPOTrainer(BaseTrainer):
"""
- Trainer for Direct Preference Optimization (DPO) method.
+ Trainer for Direct Preference Optimization (DPO) method. This algorithm was initially proposed in the paper [Direct
+ Preference Optimization: Your Language Model is Secretly a Reward Model](https://huggingface.co/papers/2305.18290).
+ This class is a wrapper around the [`~transformers.Trainer`] class and inherits all of its attributes and methods.
+
+ Example:
- This class is a wrapper around the [`transformers.Trainer`] class and inherits all of its attributes and methods.
+ ```python
+ from trl import DPOTrainer
+ from datasets import load_dataset
+
+ dataset = load_dataset("trl-lib/ultrafeedback_binarized", split="train")
+
+ trainer = DPOTrainer(
+ model="Qwen/Qwen2.5-0.5B-Instruct",
+ train_dataset=dataset,
+ )
+ trainer.train()
+ ```
Args:
- model (`str | PreTrainedModel`):
+ model (`str` or [`~transformers.PreTrainedModel`] or [`~peft.PeftModel`]):
Model to be trained. Can be either:
- A string, being the *model id* of a pretrained model hosted inside a model repo on huggingface.co, or a
path to a *directory* containing model weights saved using
[`~transformers.PreTrainedModel.save_pretrained`], e.g., `'./my_model_directory/'`. The model is loaded
- using [`~transformers.AutoModelForCausalLM.from_pretrained`] with the keyword arguments in
- `args.model_init_kwargs`.
+ using `.from_pretrained` (where `` is derived from the model
+ config) with the keyword arguments in `args.model_init_kwargs`.
- A [`~transformers.PreTrainedModel`] object. Only causal language models are supported.
- ref_model ([`~transformers.PreTrainedModel`])
- Hugging Face transformer model with a casual language modelling head. Used for implicit reward computation
- and loss. If no reference model is provided, the trainer will create a reference model with the same
- architecture as the model to be optimized.
+ - A [`~peft.PeftModel`] object. Only causal language models are supported.
+ ref_model (`PreTrainedModel`, *optional*):
+ Reference model used to compute the reference log probabilities.
+
+ - If provided, this model is used directly as the reference policy.
+ - If `None`, the trainer will automatically use the initial policy corresponding to `model`, i.e. the model
+ state before DPO training starts.
args ([`DPOConfig`], *optional*):
Configuration for this trainer. If `None`, a default configuration is used.
data_collator ([`~transformers.DataCollator`], *optional*):
Function to use to form a batch from a list of elements of the processed `train_dataset` or `eval_dataset`.
- Will default to [`DataCollatorForPreference`].
+ Will default to [`~trainer.dpo_trainer.DataCollatorForPreference`] if the model is a language model and
+ [`~trainer.dpo_trainer.DataCollatorForVisionPreference`] if the model is a vision-language model.
train_dataset ([`~datasets.Dataset`] or [`~datasets.IterableDataset`]):
- Dataset to use for training. DPO supports [preference](#preference) type and. The format of the samples can
- be either:
+ Dataset to use for training. This trainer supports both [language modeling](#language-modeling) type and
+ [prompt-completion](#prompt-completion) type. The format of the samples can be either:
- [Standard](dataset_formats#standard): Each sample contains plain text.
- [Conversational](dataset_formats#conversational): Each sample contains structured messages (e.g., role
and content).
eval_dataset ([`~datasets.Dataset`], [`~datasets.IterableDataset`] or `dict[str, Dataset | IterableDataset]`):
Dataset to use for evaluation. It must meet the same requirements as `train_dataset`.
- processing_class ([`~transformers.PreTrainedTokenizerBase`], [`~transformers.BaseImageProcessor`], [`~transformers.FeatureExtractionMixin`] or [`~transformers.ProcessorMixin`], *optional*):
- Processing class used to process the data. If `None`, the processing class is loaded from the model's name
- with [`~transformers.AutoTokenizer.from_pretrained`].
+ processing_class ([`~transformers.PreTrainedTokenizerBase`], [`~transformers.ProcessorMixin`], *optional*):
+ Processing class used to process the data. The padding side must be set to "left". If `None`, the
+ processing class is loaded from the model's name with [`~transformers.AutoProcessor.from_pretrained`]. A
+ padding token, `tokenizer.pad_token`, must be set. If the processing class has not set a padding token,
+ `tokenizer.eos_token` will be used as the default.
compute_metrics (`Callable[[EvalPrediction], dict]`, *optional*):
- The function that will be used to compute metrics at evaluation. Must take a [`EvalPrediction`] and return
- a dictionary string to metric values. *Note* When passing TrainingArgs with `batch_eval_metrics` set to
- `True`, your compute_metrics function must take a boolean `compute_result` argument. This will be triggered
- after the last eval batch to signal that the function needs to calculate and return the global summary
- statistics rather than accumulating the batch-level statistics.
+ The function that will be used to compute metrics at evaluation. Must take a
+ [`~transformers.EvalPrediction`] and return a dictionary string to metric values. When passing
+ [`SFTConfig`] with `batch_eval_metrics` set to `True`, your `compute_metrics` function must take a boolean
+ `compute_result` argument. This will be triggered after the last eval batch to signal that the function
+ needs to calculate and return the global summary statistics rather than accumulating the batch-level
+ statistics.
callbacks (list of [`~transformers.TrainerCallback`], *optional*):
List of callbacks to customize the training loop. Will add those to the list of default callbacks detailed
in [here](https://huggingface.co/docs/transformers/main_classes/callback).
If you want to remove one of the default callbacks used, use the [`~transformers.Trainer.remove_callback`]
method.
- optimizers (`tuple[torch.optim.Optimizer, torch.optim.lr_scheduler.LambdaLR]`, *optional*, defaults to `(None, None)`):
- A tuple containing the optimizer and the scheduler to use. Will default to an instance of [`AdamW`] on your
- model and a scheduler given by [`get_linear_schedule_with_warmup`] controlled by `args`.
- optimizer_cls_and_kwargs (`Tuple[Type[torch.optim.Optimizer], Dict[str, Any]]`, *optional*):
- A tuple containing the optimizer class and keyword arguments to use. Overrides `optim` and `optim_args` in
- `args`. Incompatible with the `optimizers` argument.
- preprocess_logits_for_metrics (`Callable[[torch.Tensor, torch.Tensor], torch.Tensor]`, *optional*):
- A function that preprocess the logits right before caching them at each evaluation step. Must take two
- tensors, the logits and the labels, and return the logits once processed as desired. The modifications made
- by this function will be reflected in the predictions received by `compute_metrics`.
-
- Note that the labels (second parameter) will be `None` if the dataset does not have them.
+ optimizers (`tuple[torch.optim.Optimizer | None, torch.optim.lr_scheduler.LambdaLR | None]`, *optional*, defaults to `(None, None)`):
+ A tuple containing the optimizer and the scheduler to use. Will default to an instance of `AdamW` on your
+ model and a scheduler given by [`~transformers.get_linear_schedule_with_warmup`] controlled by `args`.
peft_config ([`~peft.PeftConfig`], *optional*):
PEFT configuration used to wrap the model. If `None`, the model is not wrapped.
"""
@@ -271,22 +452,16 @@ class DPOTrainer(BaseTrainer):
def __init__(
self,
- model: str | nn.Module | PreTrainedModel,
- ref_model: PreTrainedModel | nn.Module | None = None,
+ model: "str | PreTrainedModel | PeftModel",
+ ref_model: PreTrainedModel | None = None,
args: DPOConfig | None = None,
- data_collator: DataCollator | None = None, # type: ignore
+ data_collator: DataCollator | None = None,
train_dataset: Dataset | IterableDataset | None = None,
eval_dataset: Dataset | IterableDataset | dict[str, Dataset | IterableDataset] | None = None,
- processing_class: PreTrainedTokenizerBase
- | BaseImageProcessor
- | FeatureExtractionMixin
- | ProcessorMixin
- | None = None,
- compute_metrics: Callable[[EvalLoopOutput], dict] | None = None,
+ processing_class: PreTrainedTokenizerBase | ProcessorMixin | None = None,
+ compute_metrics: Callable[[EvalPrediction], dict] | None = None,
callbacks: list[TrainerCallback] | None = None,
optimizers: tuple[torch.optim.Optimizer | None, torch.optim.lr_scheduler.LambdaLR | None] = (None, None),
- optimizer_cls_and_kwargs: tuple[type[torch.optim.Optimizer], dict[str, Any]] | None = None,
- preprocess_logits_for_metrics: Callable[[torch.Tensor, torch.Tensor], torch.Tensor] | None = None,
peft_config: "PeftConfig | None" = None,
):
# Args
@@ -306,7 +481,7 @@ def __init__(
)
args.accelerator_config.dispatch_batches = False
- # Model and reference model
+ # Model
if isinstance(model, str):
model_init_kwargs = args.model_init_kwargs or {}
# Distributed training requires device_map=None ("auto" fails)
@@ -319,41 +494,15 @@ def __init__(
"You passed `model_init_kwargs` to the `DPOConfig`, but your model is already instantiated. "
"The `model_init_kwargs` will be ignored."
)
- model_id = get_config_model_id(model.config)
- if isinstance(ref_model, str):
- warnings.warn(
- "Passing `ref_model` as a string is deprecated and will be removed in version 0.29.0. Usually, you "
- "can just omit `ref_model` and we'll initialize it to a copy of `model` for you. If you really need "
- "to load the reference model from a different path, you can still do so by passing `ref_model` as a "
- "model instance.",
- FutureWarning,
- stacklevel=2,
- )
- model_init_kwargs = args.ref_model_init_kwargs or {}
- # Distributed training requires device_map=None ("auto" fails)
- if args.distributed_state.distributed_type in ["MULTI_GPU", "DEEPSPEED"]:
- model_init_kwargs["device_map"] = None
- ref_model = create_model_from_path(ref_model, **model_init_kwargs)
- else:
- if args.ref_model_init_kwargs is not None:
- logger.warning(
- "You passed `ref_model_init_kwargs` to the `DPOConfig`, but your model is already instantiated. "
- "The `ref_model_init_kwargs` will be ignored."
- )
if ref_model is model:
raise ValueError(
- "`model` and `ref_model` cannot be the same object. If you want `ref_model` to be the "
- "same as `model`, you can simply omit the `ref_model` argument and it will be created for you."
+ "`model` and `ref_model` cannot be the same object. In most cases you should omit `ref_model` and "
+ "we'll initialize it to a copy of `model` for you."
)
- if args.force_use_ref_model is None:
- self.force_use_ref_model = ref_model is not None
- else:
- self.force_use_ref_model = args.force_use_ref_model
-
# Processing class
if processing_class is None:
- processing_class = AutoProcessor.from_pretrained(model_id)
+ processing_class = AutoProcessor.from_pretrained(get_config_model_id(model.config))
# Handle pad token for processors or tokenizers
if isinstance(processing_class, ProcessorMixin):
@@ -365,145 +514,148 @@ def __init__(
else:
raise TypeError("The `processing_class` must be either a `PreTrainedTokenizerBase` or a `ProcessorMixin`")
- # Get the pad token: if not provided, use the one from the processing class or the eos token
- # if the processing class does not have a pad token.
- pad_token = args.pad_token or tokenizer.pad_token or tokenizer.eos_token
- self.pad_token_id = tokenizer.convert_tokens_to_ids(pad_token)
- if self.pad_token_id is None:
- raise ValueError(
- f"The specified `pad_token` ('{pad_token}') is not found in the vocabulary of the given "
- f"`processing_class` ({processing_class.__class__.__name__}). Ensure that the `pad_token` exists "
- "in the vocabulary before using it as a padding token."
- )
+ if tokenizer.pad_token is None:
+ tokenizer.pad_token = tokenizer.eos_token
- # PEFT configuration and model wrapping
- model = self._prepare_peft_model(model, ref_model, peft_config, args)
+ self.pad_token = tokenizer.pad_token
+ self.pad_token_id = tokenizer.pad_token_id
+ self.eos_token_id = tokenizer.eos_token_id
- if args.generate_during_eval and not (is_wandb_available() or is_comet_available() or is_mlflow_available()):
+ if is_peft_available() and is_peft_model(model) and peft_config is not None:
raise ValueError(
- "`generate_during_eval=True` requires Weights and Biases, MLFlow or Comet to be installed."
- " Please install `wandb`, `mlflow` or `comet-ml` to resolve."
+ "You passed a `PeftModel` instance together with a `peft_config` to the trainer. Please first merge "
+ "and unload the existing adapter, save the resulting base model, and then pass that base model along "
+ "with the new `peft_config` to the trainer."
)
+ if is_peft_available() and is_peft_model(model) and ref_model is None:
+ # If the model is a PEFT model with a pretrained adapter, we need to create a "ref" adapter that is a copy
+ # of the "default" adapter, so that we can use it as the reference model during DPO training.
+ model.add_adapter("ref", model.peft_config["default"])
+ for name, param in model.named_parameters():
+ if ".default." in name:
+ ref_name = name.replace(".default.", ".ref.")
+ ref_param = model.get_parameter(ref_name)
+ ref_param.data.copy_(param.data)
+
+ # Create PEFT model
+ if peft_config is not None:
+ model = get_peft_model(model, peft_config)
- self.is_encoder_decoder = model.config.is_encoder_decoder
- self.is_vision_model = model.config.model_type in MODEL_FOR_IMAGE_TEXT_TO_TEXT_MAPPING_NAMES.keys()
- self.is_peft_model = is_peft_available() and isinstance(model, PeftModel)
- self.model_adapter_name = args.model_adapter_name
- self.ref_adapter_name = args.ref_adapter_name
- self.reference_free = args.reference_free
-
- if ref_model:
- self.ref_model = ref_model
- elif self.is_peft_model or args.precompute_ref_log_probs:
- # The `model` with adapters turned off will be used as the reference model
- self.ref_model = None
- else:
- self.ref_model = create_reference_model(model)
+ # When using gradient checkpointing with PEFT, we need to enable input gradients. transformers.Trainer normally
+ # handles this, but a bug currently prevents it; see https://github.com/huggingface/transformers/issues/42489
+ if is_peft_available() and isinstance(model, PeftModel) and args.gradient_checkpointing:
+ model.enable_input_require_grads()
+
+ # When using QLoRA, the PEFT adapter weights are converted to bf16 to follow the recommendations from the
+ # original paper (see https://huggingface.co/papers/2305.14314, paragraph 3). Normally, this can be done by
+ # passing `autocast_adapter_dtype=False` to `get_peft_model`, but this option is not yet supported for
+ # quantized models. See: https://github.com/huggingface/peft/issues/2889
+ # Non-quantized models do not have the `is_loaded_in_{8,4}bit` attributes, whereas quantized models do
+ if getattr(model, "is_loaded_in_4bit", False) or getattr(model, "is_loaded_in_8bit", False):
+ for param in model.parameters():
+ if param.requires_grad:
+ param.data = param.data.to(torch.bfloat16)
- # Disable dropout in the model and reference model
- if args.disable_dropout:
- disable_dropout_in_model(model)
- if self.ref_model is not None:
- disable_dropout_in_model(self.ref_model)
-
- # Liger kernel
- if args.use_liger_kernel:
- if not is_liger_kernel_available():
- raise ImportError(
- "You set `use_liger_kernel=True` but the liger kernel is not available. "
- "Please install liger-kernel first: `pip install liger-kernel`"
- )
- if args.loss_type not in ["sigmoid", "apo_zero", "apo_down", "sppo_hard", "nca_pair"]:
+ # Data collator
+ self.padding_free = args.padding_free
+ if self.padding_free:
+ logger.warning(
+ "`padding_free=True` is temporarily unavailable after a refactor and is currently disabled. Falling "
+ "back to standard padding (`padding_free=False`). This feature is planned to return in a future "
+ "update; for now, please set `padding_free=False` explicitly."
+ )
+ self.padding_free = False
+ dataset_sample = next(iter(train_dataset))
+ self._is_vision_dataset = "image" in dataset_sample or "images" in dataset_sample
+ if self._is_vision_dataset and not self._is_vlm:
+ raise ValueError(
+ "The dataset appears to be vision-related (contains 'image' or 'images' keys), but the provided "
+ "model does not seem to be a vision-language model. Please check your model and dataset."
+ )
+ if data_collator is None and not self._is_vision_dataset:
+ # Get the pad token: if not provided, use the one from the processing class or the eos token
+ # if the processing class does not have a pad token.
+ pad_token = args.pad_token or tokenizer.pad_token or tokenizer.eos_token
+ pad_token_id = tokenizer.convert_tokens_to_ids(pad_token)
+ if pad_token_id is None:
raise ValueError(
- "You set `use_liger_kernel=True` but the loss type is not from `[sigmoid, apo_zero, apo_down, sppo_hard, nca_pair`. "
- "Please set `loss_type='[sigmoid | apo_zero | apo_down | sppo_hard | nca_pair]'` to use the liger kernel."
+ f"The specified `pad_token` ('{pad_token}') is not found in the vocabulary of the given "
+ f"`processing_class` ({processing_class.__class__.__name__}). Ensure that the `pad_token` exists "
+ "in the vocabulary before using it as a padding token."
)
- self.dpo_loss_fn = LigerFusedLinearDPOLoss(
- ignore_index=args.label_pad_token_id,
- beta=args.beta,
- use_ref_model=not args.reference_free,
- average_log_prob=False,
- loss_type=args.loss_type,
+ data_collator = DataCollatorForPreference(
+ pad_token_id=pad_token_id,
+ pad_to_multiple_of=args.pad_to_multiple_of,
+ )
+ elif data_collator is None and self._is_vision_dataset:
+ data_collator = DataCollatorForVisionPreference(
+ processor=processing_class,
+ pad_to_multiple_of=args.pad_to_multiple_of,
)
- # Data collator
- if data_collator is None:
- data_collator = DataCollatorForPreference(pad_token_id=self.pad_token_id)
-
- self.generate_during_eval = args.generate_during_eval
- self.label_pad_token_id = args.label_pad_token_id
- self.max_prompt_length = args.max_prompt_length
- self.max_completion_length = args.max_completion_length
- self.max_length = args.max_length
- self.truncation_mode = args.truncation_mode
- self.precompute_ref_log_probs = args.precompute_ref_log_probs
- self.use_logits_to_keep = args.use_logits_to_keep
-
- if args.padding_free:
- if model.config._attn_implementation != "flash_attention_2":
- logger.warning(
- "Padding-free training is enabled, but the attention implementation is not set to "
- "'flash_attention_2'. Padding-free training flattens batches into a single sequence, and "
- "'flash_attention_2' is the only known attention mechanism that reliably supports this. Using "
- "other implementations may lead to unexpected behavior. To ensure compatibility, set "
- "`attn_implementation='flash_attention_2'` in the model configuration, or verify that your "
- "attention mechanism can handle flattened sequences."
- )
- if args.per_device_train_batch_size == 1:
- logger.warning(
- "You are using a per_device_train_batch_size of 1 with padding-free training. Using a batch size "
- "of 1 annihilate the benefits of padding-free training. Please consider increasing the batch size "
- "to at least 2."
- )
- self.padding_free = args.padding_free
-
- # Since ref_logs are precomputed on the first call to get_train/eval_dataloader
- # keep track of first called to avoid computation of future calls
- self._precomputed_train_ref_log_probs = False
- self._precomputed_eval_ref_log_probs = False
-
+ # Training arguments
self.beta = args.beta
+ self.precompute_ref_logps = args.precompute_ref_log_probs
+ self.loss_types = args.loss_type # args.loss_type is already a list
+ self.loss_weights = args.loss_weights or [1.0] * len(self.loss_types)
+ self.ld_alpha = args.ld_alpha
+ self.f_divergence_type = args.f_divergence_type
+ self.f_alpha_divergence_coef = args.f_alpha_divergence_coef
self.label_smoothing = args.label_smoothing
- self.loss_type = args.loss_type if isinstance(args.loss_type, list) else [args.loss_type]
- self.loss_weights = args.loss_weights
- self.aux_loss_enabled = getattr(model.config, "output_router_logits", False)
self.use_weighting = args.use_weighting
- self.aux_loss_coef = getattr(model.config, "router_aux_loss_coef", 0.0)
- if self.aux_loss_enabled and self.aux_loss_coef == 0.0:
+ if self.use_weighting and any(loss_type in {"aot", "aot_unpaired"} for loss_type in self.loss_types):
+ raise NotImplementedError(
+ "WPO-style weighting is not implemented for 'aot' or 'aot_unpaired' because those losses sort "
+ "samples, which would misalign per-pair weights."
+ )
+ if "robust" in self.loss_types and not (0.0 <= self.label_smoothing < 0.5):
logger.warning(
- "You set `output_router_logits` to `True` in the model config, but `router_aux_loss_coef` is set to "
- "`0.0`, meaning the auxiliary loss will not be used. Either set `router_aux_loss_coef` to a value "
- "greater than `0.0`, or set `output_router_logits` to `False` if you don't want to use the auxiliary "
- "loss.",
+ "The `label_smoothing` parameter should lie in [0.0, 0.5) for the 'robust' loss. You provided "
+ f"{self.label_smoothing}."
)
- for loss_type in self.loss_type:
- if (
- loss_type in ["hinge", "ipo", "bco_pair", "sppo_hard", "nca_pair", "apo_zero", "apo_down"]
- and args.label_smoothing > 0
- ):
- logger.warning(
- f"You are using the {loss_type} loss type that does not support label smoothing. The "
- "`label_smoothing` parameter will be ignored. Set `label_smoothing` to `0.0` to remove this "
- "warning.",
+ if "exo_pair" in self.loss_types and self.label_smoothing == 0.0:
+ raise ValueError(
+ "Label smoothing must be greater than 0.0 when using 'exo_pair' loss. The EXO paper recommends a "
+ "value of 1e-3."
+ )
+ self.use_liger_kernel = args.use_liger_kernel
+ if args.use_liger_kernel:
+ if not is_liger_kernel_available():
+ raise ImportError(
+ "You set `use_liger_kernel=True` but the liger kernel is not available. "
+ "Please install liger-kernel first: `pip install liger-kernel`"
+ )
+ if len(self.loss_types) != 1:
+ raise NotImplementedError(
+ "Multiple loss types are not yet supported when using Liger kernel. If you need this feature, "
+ "please open a feature request at https://github.com/huggingface/trl/issues."
+ )
+ self.liger_loss_fn = LigerFusedLinearDPOLoss(beta=args.beta, loss_type=self.loss_types[0])
+ if compute_metrics is not None:
+ raise ValueError(
+ "compute_metrics is not supported with the Liger kernel. compute_metrics requires to be able to "
+ "recover the logits from the forward pass, but Liger kernel does not materialize logits."
+ )
+ if self.precompute_ref_logps:
+ raise ValueError(
+ "Liger DPO loss does not support precomputing reference log probabilities. Either disable "
+ "`precompute_ref_log_probs` or set `use_liger_kernel` to False."
)
- if loss_type == "kto_pair":
- raise ValueError("Support for kto_pair has been removed in DPOTrainer. Please use KTOTrainer.")
- self._stored_metrics = defaultdict(lambda: defaultdict(list))
- self.f_divergence_type = args.f_divergence_type
- self.f_divergence_params = {FDivergenceConstants.ALPHA_DIVERGENCE_COEF_KEY: args.f_alpha_divergence_coef}
- self.dataset_num_proc = args.dataset_num_proc
-
- # Dataset preparation
- train_dataset = self._prepare_dataset(train_dataset, processing_class, args, "train")
- if eval_dataset is not None:
- if isinstance(eval_dataset, dict):
- eval_dataset = {
- key: self._prepare_dataset(dataset, processing_class, args, key)
- for key, dataset in eval_dataset.items()
- }
- else:
- eval_dataset = self._prepare_dataset(eval_dataset, processing_class, args, "eval")
+ # Dataset
+ # Skip dataset preparation if it's a VLM, where preprocessing (e.g., image-to-pixel conversion) is too costly
+ # and done on the fly instead.
+ skip_prepare_dataset = self._is_vision_dataset
+ if not skip_prepare_dataset:
+ train_dataset = self._prepare_dataset(train_dataset, processing_class, args, "train")
+ if eval_dataset is not None:
+ if isinstance(eval_dataset, dict):
+ eval_dataset = {
+ key: self._prepare_dataset(dataset, processing_class, args, key)
+ for key, dataset in eval_dataset.items()
+ }
+ else:
+ eval_dataset = self._prepare_dataset(eval_dataset, processing_class, args, "eval")
# Transformers explicitly set use_reentrant=True in the past to silence a PyTorch warning, but the default was
# never updated once PyTorch switched to recommending use_reentrant=False. Until that change lands upstream
@@ -523,41 +675,44 @@ def __init__(
compute_metrics=compute_metrics,
callbacks=callbacks,
optimizers=optimizers,
- optimizer_cls_and_kwargs=optimizer_cls_and_kwargs,
- preprocess_logits_for_metrics=preprocess_logits_for_metrics,
)
- # Gradient accumulation requires scaled loss. Normally, loss scaling in the parent class depends on whether the
- # model accepts loss-related kwargs. Since we compute our own loss, this check is irrelevant. We set
- # self.model_accepts_loss_kwargs to False to enable scaling.
- self.model_accepts_loss_kwargs = False
+ # Initialize activation offloading context
+ if self.args.activation_offloading:
+ self.maybe_activation_offload_context = get_act_offloading_ctx_manager(model=self.model)
+ else:
+ self.maybe_activation_offload_context = contextlib.nullcontext()
+
+ # Reference model
+ if ref_model is None:
+ if is_peft_model(self.model):
+ # If PEFT is used, the reference model is not needed since the adapter can be disabled to revert to the
+ # initial model.
+ self.ref_model = None
+ else:
+ ref_model_init_kwargs = args.model_init_kwargs or {}
+ # Distributed training requires device_map=None ("auto" fails)
+ if self.args.distributed_state.distributed_type in ["MULTI_GPU", "DEEPSPEED"]:
+ ref_model_init_kwargs["device_map"] = None
+ ref_model_path = get_config_model_id(self.model.config)
+ self.ref_model = create_model_from_path(ref_model_path, **ref_model_init_kwargs)
+ else:
+ self.ref_model = ref_model
- # Add tags for models that have been loaded with the correct transformers version
- if hasattr(self.model, "add_model_tags"):
- self.model.add_model_tags(self._tag_names)
+ # Disable dropout in the models
+ if args.disable_dropout:
+ disable_dropout_in_model(model)
+ if self.ref_model is not None:
+ disable_dropout_in_model(self.ref_model)
- if not hasattr(self, "accelerator"):
- raise AttributeError(
- "Your `Trainer` does not have an `accelerator` object. Consider upgrading `transformers`."
- )
+ # Initialize the metrics
+ self._metrics = {"train": defaultdict(list), "eval": defaultdict(list)}
+ self._total_train_tokens = 0
- # Deepspeed Zero-3 does not support precompute_ref_log_probs
- if self.is_deepspeed_enabled:
- if self.accelerator.state.deepspeed_plugin.zero_stage == 3 and self.precompute_ref_log_probs:
- raise ValueError(
- "You cannot use `precompute_ref_log_probs=True` with Deepspeed ZeRO-3. Please set `precompute_ref_log_probs=False`."
- )
+ # Add tags to the model
+ self.model.add_model_tags(self._tag_names)
- if self.ref_model is None:
- if not (self.is_peft_model or self.precompute_ref_log_probs):
- raise ValueError(
- "No reference model and model is not a Peft model. Try setting `precompute_ref_log_probs=True`"
- )
- if args.sync_ref_model:
- raise ValueError(
- "You currently cannot use `ref_model=None` with TR-DPO method. Please provide `ref_model`."
- )
- else:
+ if self.ref_model is not None:
if self.is_deepspeed_enabled:
self.ref_model = prepare_deepspeed(self.ref_model, self.accelerator)
elif self.is_fsdp_enabled:
@@ -566,373 +721,218 @@ def __init__(
self.ref_model = self.accelerator.prepare_model(self.ref_model, evaluation_mode=True)
if args.sync_ref_model:
- if self.precompute_ref_log_probs:
- raise ValueError(
- "You cannot use `precompute_ref_log_probs=True` with TR-DPO method. Please set `precompute_ref_log_probs=False`."
+ if self.ref_model is None:
+ raise NotImplementedError(
+ "You passed `sync_ref_model=True` while using a PEFT model, which is currently not supported. "
+ "With PEFT, DPOTrainer does not keep a separate reference model in memory; instead, it recovers "
+ "reference behavior by temporarily disabling the adapter. As a result, there is no standalone "
+ "`ref_model` instance to synchronize. Use `sync_ref_model=False`, or opt for full fine-tuning if "
+ "you need a synced reference model. If you need `sync_ref_model` to work with PEFT, please open a "
+ "feature request at https://github.com/huggingface/trl/issues."
)
-
- self.add_callback(SyncRefModelCallback(ref_model=self.ref_model, accelerator=self.accelerator))
-
- if "bco_pair" in self.loss_type:
- self.running = RunningMoments(self.accelerator)
-
- def _prepare_peft_model(
- self, model: PreTrainedModel, ref_model: PreTrainedModel, peft_config: Any, args: DPOConfig
- ) -> PreTrainedModel:
- """Prepares a model for PEFT training."""
- # Initialize this variable to False. This helps tracking the case when `peft_module_casting_to_bf16`
- # has been called in order to properly call autocast if needed.
- self._peft_has_been_casted_to_bf16 = False
-
- if not is_peft_available() and peft_config is not None:
- raise ValueError(
- "PEFT is not installed and you passed a `peft_config` in the trainer's kwargs, please install it to use the PEFT models"
- )
- elif is_peft_available() and peft_config is not None:
- if isinstance(model, PeftModel):
+ if args.precompute_ref_log_probs:
raise ValueError(
- "You passed a `PeftModel` instance together with a `peft_config` to the trainer. Please first "
- "merge and unload the existing adapter, save the resulting base model, and then pass that base "
- "model along with the new `peft_config` to the trainer."
+ "You cannot use `sync_ref_model=True` together with `precompute_ref_log_probs=True`. "
+ "`precompute_ref_log_probs=True` assumes a fixed reference model, but with `sync_ref_model=True` "
+ "the reference model is periodically updated during training, making any precomputed reference "
+ "log-probs stale. Set `precompute_ref_log_probs=False` or disable `sync_ref_model`."
)
+ self.add_callback(SyncRefModelCallback(ref_model=self.ref_model, accelerator=self.accelerator))
- if ref_model is not None and not self.force_use_ref_model:
+ if args.precompute_ref_log_probs:
+ if isinstance(self.train_dataset, IterableDataset) or isinstance(
+ self.eval_dataset, (IterableDataset, IterableDatasetDict)
+ ):
raise ValueError(
- "You passed a ref_model and a peft_config with `force_use_ref_model=False`. For training PEFT adapters with DPO there is no need to pass a reference"
- " model. Please pass `ref_model=None` in case you want to train PEFT adapters, or pass a ref_model with in DPOTrainer's init, and unset force_use_ref_model"
- " if you want to use a different ref_model."
- )
-
- if getattr(model, "is_loaded_in_8bit", False) or getattr(model, "is_loaded_in_4bit", False):
- _support_gc_kwargs = hasattr(
- args, "gradient_checkpointing_kwargs"
- ) and "gradient_checkpointing_kwargs" in list(
- inspect.signature(prepare_model_for_kbit_training).parameters
+ "`precompute_ref_log_probs=True` is not supported with IterableDataset. Please use a map-style "
+ "Dataset or set `precompute_ref_log_probs=False`."
)
- prepare_model_kwargs = {"use_gradient_checkpointing": args.gradient_checkpointing}
-
- if _support_gc_kwargs:
- prepare_model_kwargs["gradient_checkpointing_kwargs"] = args.gradient_checkpointing_kwargs
-
- model = prepare_model_for_kbit_training(model, **prepare_model_kwargs)
-
- else:
- model = self._prepare_gradient_checkpointing(model, args)
-
- # get peft model with the given config
- model = get_peft_model(model, peft_config)
- if args.bf16 and getattr(model, "is_loaded_in_4bit", False):
- peft_module_casting_to_bf16(model)
- # If args.bf16 we need to explicitly call `generate` with torch amp autocast context manager
- self._peft_has_been_casted_to_bf16 = True
-
- else:
- model = self._prepare_gradient_checkpointing(model, args)
-
- return model
-
- def _prepare_gradient_checkpointing(self, model: PreTrainedModel, args: DPOConfig):
- """Prepare the gradienting checkpointing for the model."""
- # For models that use gradient_checkpointing, we need to attach a hook that enables input
- # to explicitly have `requires_grad=True`, otherwise training will either silently
- # fail or completely fail.
- if args.gradient_checkpointing:
- # For backward compatibility with older versions of transformers
- if hasattr(model, "enable_input_require_grads"):
- model.enable_input_require_grads()
- else:
-
- def make_inputs_require_grad(module, input, output):
- output.requires_grad_(True)
-
- model.get_input_embeddings().register_forward_hook(make_inputs_require_grad)
-
- return model
+ batch_size = self.args.precompute_ref_batch_size or self.args.per_device_train_batch_size
+ self.train_dataset = self._precompute_ref_logps(self.train_dataset, "train", batch_size)
+ if self.eval_dataset is not None:
+ batch_size = self.args.precompute_ref_batch_size or self.args.per_device_eval_batch_size
+ if isinstance(self.eval_dataset, dict):
+ self.eval_dataset = {
+ name: self._precompute_ref_logps(dataset, name, batch_size)
+ for name, dataset in self.eval_dataset.items()
+ }
+ else:
+ self.eval_dataset = self._precompute_ref_logps(self.eval_dataset, "eval", batch_size)
def _prepare_dataset(
self,
dataset: Dataset | IterableDataset,
- processing_class: PreTrainedTokenizerBase | BaseImageProcessor | FeatureExtractionMixin | ProcessorMixin,
+ processing_class: PreTrainedTokenizerBase | ProcessorMixin,
args: DPOConfig,
dataset_name: str,
) -> Dataset | IterableDataset:
+ # Tabular backends like Arrow/Parquet insert `None` for mismatched keys in nested structures. Clean them from
+ # sampled data.
+ if isinstance(dataset, Dataset): # IterableDataset does not support `with_transform`
+ dataset = dataset.with_transform(remove_none_values)
+
# Build the kwargs for the `map` function
map_kwargs = {}
- if isinstance(dataset, Dataset): # IterableDataset does not support num_proc nor writer_batch_size
+ if isinstance(dataset, Dataset): # IterableDataset does not support num_proc
map_kwargs["num_proc"] = args.dataset_num_proc
- map_kwargs["writer_batch_size"] = 10
with PartialState().main_process_first():
- # Extract prompt if needed
- if isinstance(dataset, Dataset): # `IterableDataset.map` does not support `desc`
- map_kwargs["desc"] = f"Extracting prompt in {dataset_name} dataset"
- dataset = dataset.map(maybe_extract_prompt, **map_kwargs)
-
- is_chat = is_conversational(next(iter(dataset)))
+ # Extract the prompt if needed
+ first_example = next(iter(dataset))
+ if "prompt" not in first_example:
+ if isinstance(dataset, Dataset): # `IterableDataset.map` does not support `desc`
+ map_kwargs["desc"] = f"Extracting prompt from {dataset_name} dataset"
+ dataset = dataset.map(extract_prompt, **map_kwargs)
# Apply the chat template if needed
- if isinstance(dataset, Dataset): # `IterableDataset.map` does not support `desc`
- map_kwargs["desc"] = f"Applying chat template to {dataset_name} dataset"
- dataset = dataset.map(
- maybe_apply_chat_template, fn_kwargs={"tokenizer": processing_class, "tools": args.tools}, **map_kwargs
- )
+ first_example = next(iter(dataset))
+ if not is_conversational(first_example):
+ if isinstance(dataset, Dataset): # `IterableDataset.map` does not support `desc`
+ map_kwargs["desc"] = f"Adding EOS to {dataset_name} dataset"
+
+ def add_eos(example, eos_token):
+ if not example["chosen"].endswith(eos_token):
+ example["chosen"] = example["chosen"] + eos_token
+ if not example["rejected"].endswith(eos_token):
+ example["rejected"] = example["rejected"] + eos_token
+ return example
+
+ eos_token = processing_class.tokenizer.eos_token if self._is_vlm else processing_class.eos_token
+ dataset = dataset.map(add_eos, fn_kwargs={"eos_token": eos_token}, **map_kwargs)
# Tokenize the dataset
if isinstance(dataset, Dataset): # `IterableDataset.map` does not support `desc`
map_kwargs["desc"] = f"Tokenizing {dataset_name} dataset"
- dataset = dataset.map(
- self.tokenize_row if not self.is_vision_model else self.process_row,
- remove_columns=["chosen", "rejected"],
- fn_kwargs={
- "processing_class": processing_class,
- "max_prompt_length": args.max_prompt_length,
- "max_completion_length": args.max_completion_length,
- # for enc-dec, we add the special tokens ([bos_token] + prompt + [eos_token]; completion + [eos_token])
- "add_special_tokens": False,
- "is_chat": is_chat,
- },
- **map_kwargs,
- )
+ def tokenize_fn(example, processing_class):
+ tools = example.get("tools")
+ tools = json.loads(tools) if isinstance(tools, str) else tools
+ output = {}
+ if is_conversational(example):
+ if self._is_vlm:
+ prompt = prepare_multimodal_messages(example["prompt"], images=[])
+ chosen = prepare_multimodal_messages(example["chosen"], images=[])
+ rejected = prepare_multimodal_messages(example["rejected"], images=[])
+ else:
+ prompt = example["prompt"]
+ chosen = example["chosen"]
+ rejected = example["rejected"]
+ prompt_ids = processing_class.apply_chat_template(
+ prompt,
+ tools=tools,
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=False,
+ **example.get("chat_template_kwargs", {}),
+ )
+ prompt_chosen_processed = processing_class.apply_chat_template(
+ prompt + chosen,
+ tools=tools,
+ tokenize=True,
+ return_dict=True,
+ **example.get("chat_template_kwargs", {}),
+ )
+ prompt_rejected_processed = processing_class.apply_chat_template(
+ prompt + rejected,
+ tools=tools,
+ tokenize=True,
+ return_dict=True,
+ **example.get("chat_template_kwargs", {}),
+ )
+ # Fix transformers inconsistency: for VLMs, apply_chat_template returns lists of lists
+ # even for single examples, while for LLMs it returns lists of ints.
+ prompt_ids = prompt_ids[0] if isinstance(prompt_ids[0], list) else prompt_ids
+ prompt_chosen_processed = {
+ k: v[0] if isinstance(v[0], list) else v for k, v in prompt_chosen_processed.items()
+ }
+ prompt_rejected_processed = {
+ k: v[0] if isinstance(v[0], list) else v for k, v in prompt_rejected_processed.items()
+ }
+ prompt_chosen_ids = prompt_chosen_processed["input_ids"]
+ prompt_rejected_ids = prompt_rejected_processed["input_ids"]
+ else:
+ prompt_ids = processing_class(text=example["prompt"])["input_ids"]
+ prompt_chosen_ids = processing_class(text=example["prompt"] + example["chosen"])["input_ids"]
+ prompt_rejected_ids = processing_class(text=example["prompt"] + example["rejected"])["input_ids"]
+ # Fix transformers inconsistency: for VLMs, processing_class returns lists of lists
+ # even for single examples, while for LLMs it returns lists of ints.
+ prompt_ids = prompt_ids[0] if isinstance(prompt_ids[0], list) else prompt_ids
+ prompt_chosen_ids = (
+ prompt_chosen_ids[0] if isinstance(prompt_chosen_ids[0], list) else prompt_chosen_ids
+ )
+ prompt_rejected_ids = (
+ prompt_rejected_ids[0] if isinstance(prompt_rejected_ids[0], list) else prompt_rejected_ids
+ )
- return dataset
+ # Check if the tokenized prompt starts with the tokenized prompt+completion
+ if not prompt_chosen_ids[: len(prompt_ids)] == prompt_ids:
+ logger.warning(
+ "Mismatch between tokenized prompt and the start of tokenized prompt+chosen. "
+ "This may be due to unexpected tokenizer behavior, whitespace issues, or special "
+ "token handling. Verify that the tokenizer is processing text consistently."
+ )
+ if not prompt_rejected_ids[: len(prompt_ids)] == prompt_ids:
+ logger.warning(
+ "Mismatch between tokenized prompt and the start of tokenized prompt+rejected. "
+ "This may be due to unexpected tokenizer behavior, whitespace issues, or special "
+ "token handling. Verify that the tokenizer is processing text consistently."
+ )
- @staticmethod
- def tokenize_row(
- features: dict[str, str],
- processing_class: PreTrainedTokenizerBase,
- max_prompt_length: int | None = None,
- max_completion_length: int | None = None,
- add_special_tokens: bool = True,
- is_chat: bool = False,
- ) -> dict[str, list[int]]:
- """
- Tokenize a row of the dataset.
-
- Args:
- features (`dict[str, str]`):
- Row of the dataset, should contain the keys `"prompt"`, `"chosen"`, and `"rejected"`.
- processing_class ([`~transformers.PreTrainedTokenizerBase`]):
- Processing class used to process the data.
- max_prompt_length (`int` or `None`):
- Maximum length of the prompt sequence. If `None`, the prompt sequence is not truncated.
- max_completion_length (`int` or `None`):
- Maximum length of the completion sequences. If `None`, the completion sequences are not truncated.
- add_special_tokens (`bool`):
- Whether to add special tokens to the sequences. Typically used for encoder-decoder models. If `True`,
- the prompt sequence will have a bos token prepended and an eos token appended. In any case, the
- completion sequences will have an eos token appended.
- is_chat (`bool`):
- Whether the data is conversational. If `True`, the completion sequences will not have an eos token
- appended.
-
- Returns:
- `dict[str, list[int]]`:
- Tokenized sequences with the keys `"prompt_input_ids"`, `"chosen_input_ids"`, and
- `"rejected_input_ids".
-
- Example:
- ```python
- >>> from transformers import GPT2Tokenizer
-
- >>> tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
- >>> features = {"prompt": "The sky is", "chosen": " blue", "rejected": " green"}
- >>> DPOTrainer.tokenize_row(
- ... features, tokenizer, max_prompt_length=3, max_completion_length=3, add_special_tokens=False
- ... )
- {'prompt_input_ids': [464, 6766, 318], 'chosen_input_ids': [4171, 50256], 'rejected_input_ids': [4077, 50256]}
- ```
- """
- tokenizer = processing_class # the processing class is a tokenizer
- prompt_input_ids = tokenizer(features["prompt"], add_special_tokens=False)["input_ids"]
- chosen_input_ids = tokenizer(features["chosen"], add_special_tokens=False)["input_ids"]
- rejected_input_ids = tokenizer(features["rejected"], add_special_tokens=False)["input_ids"]
-
- # Add special tokens (typically for encoder-decoder models)
- if add_special_tokens:
- if tokenizer.bos_token_id is not None:
- prompt_input_ids = [tokenizer.bos_token_id] + prompt_input_ids
- if tokenizer.eos_token_id is not None:
- prompt_input_ids = prompt_input_ids + [tokenizer.eos_token_id]
- # For conversational data, the chat template already includes proper EOS tokens
- if not is_chat:
- chosen_input_ids = chosen_input_ids + [tokenizer.eos_token_id]
- rejected_input_ids = rejected_input_ids + [tokenizer.eos_token_id]
-
- # Truncate prompt and completion sequences
- if max_prompt_length is not None:
- prompt_input_ids = prompt_input_ids[-max_prompt_length:]
- if max_completion_length is not None:
- chosen_input_ids = chosen_input_ids[:max_completion_length]
- rejected_input_ids = rejected_input_ids[:max_completion_length]
-
- return {
- "prompt_input_ids": prompt_input_ids,
- "chosen_input_ids": chosen_input_ids,
- "rejected_input_ids": rejected_input_ids,
- }
-
- @staticmethod
- def process_row(
- features: dict[str, str],
- processing_class: PreTrainedTokenizerBase,
- max_prompt_length: int | None = None,
- max_completion_length: int | None = None,
- add_special_tokens: bool = True,
- is_chat: bool = False,
- ) -> dict[str, list[int]]:
- """
- Same as `tokenize_row` but for vision models. Please refer to `tokenize_row` for more information.
-
- Note: Unlike `tokenize_row`, this method does not truncate prompts even if `max_prompt_length` is set. For
- vision models, prompts contain image tokens that must exactly match the image features (pixel_values).
- Truncating these tokens would cause a mismatch, leading to errors during the forward pass, like "Image features
- and image tokens do not match". Users should filter their datasets to ensure prompts are an appropriate length
- before training.
- """
- if max_prompt_length is not None:
- warnings.warn(
- "max_prompt_length is not supported for vision models and will be ignored. "
- "Truncating prompts would cause image token/feature mismatch errors.",
- stacklevel=2,
- )
- processor, tokenizer = processing_class, processing_class.tokenizer # the processing class is a processor
- processed_features = processor(images=features["images"], text=features["prompt"], add_special_tokens=False)
-
- prompt_input_ids = processed_features["input_ids"][0]
- pixel_values = processed_features["pixel_values"][0]
- chosen_input_ids = tokenizer(features["chosen"], add_special_tokens=False)["input_ids"]
- rejected_input_ids = tokenizer(features["rejected"], add_special_tokens=False)["input_ids"]
-
- # Add special tokens (typically for encoder-decoder models)
- if add_special_tokens:
- if tokenizer.bos_token_id is not None:
- prompt_input_ids = [tokenizer.bos_token_id] + prompt_input_ids
- if tokenizer.eos_token_id is not None:
- prompt_input_ids = prompt_input_ids + [tokenizer.eos_token_id]
- if not is_chat:
- chosen_input_ids = chosen_input_ids + [tokenizer.eos_token_id]
- rejected_input_ids = rejected_input_ids + [tokenizer.eos_token_id]
-
- # Truncate completion sequences only.
- # Note: We do not truncate prompt_input_ids for vision models because the prompts contain image tokens
- # that must exactly match the image features (pixel_values). Truncating would cause errors like
- # "Image features and image tokens do not match: tokens: X, features: Y". Users should filter overlong
- # prompts from their dataset before training (the recommended approach for the deprecated max_prompt_length).
- if max_completion_length is not None:
- chosen_input_ids = chosen_input_ids[:max_completion_length]
- rejected_input_ids = rejected_input_ids[:max_completion_length]
-
- output = {
- "prompt_input_ids": prompt_input_ids,
- "pixel_values": pixel_values,
- "chosen_input_ids": chosen_input_ids,
- "rejected_input_ids": rejected_input_ids,
- }
-
- if "pixel_attention_mask" in processed_features:
- output["pixel_attention_mask"] = processed_features["pixel_attention_mask"][0]
- if "image_sizes" in processed_features:
- output["image_sizes"] = processed_features["image_sizes"][0]
- if "token_type_ids" in processed_features:
- output["token_type_ids"] = processed_features["token_type_ids"][0]
+ output["prompt_ids"] = prompt_ids
+ output["chosen_ids"] = prompt_chosen_ids[len(prompt_ids) :]
+ output["rejected_ids"] = prompt_rejected_ids[len(prompt_ids) :]
+ return output
- return output
+ dataset = dataset.map(tokenize_fn, fn_kwargs={"processing_class": processing_class}, **map_kwargs)
+
+ return dataset
def _set_signature_columns_if_needed(self):
# If `self.args.remove_unused_columns` is True, non-signature columns are removed.
- # By default, this method sets `self._signature_columns` to the model's expected inputs.
- # In DPOTrainer, we preprocess data, so using the model's signature columns doesn't work.
- # Instead, we set them to the columns expected by `DataCollatorForPreference`, hence the override.
+ # By default, this method sets `self._signature_columns` to the model's expected inputs (usually, "input_ids"
+ # and "attention_mask").
if self._signature_columns is None:
- self._signature_columns = [
- "prompt_input_ids",
- "chosen_input_ids",
- "rejected_input_ids",
- "image_sizes",
- "token_type_ids",
- "ref_chosen_logps",
- "ref_rejected_logps",
- ]
-
- def get_train_dataloader(self) -> DataLoader:
- """
- Returns the training [`~torch.utils.data.DataLoader`].
-
- Subclass of transformers.src.transformers.trainer.get_train_dataloader to precompute `ref_log_probs`.
- """
-
- if self.precompute_ref_log_probs and not self._precomputed_train_ref_log_probs:
- batch_size = self.args.precompute_ref_batch_size or self.args.per_device_train_batch_size
- dataloader_params = {
- "batch_size": batch_size,
- "collate_fn": self.data_collator,
- "num_workers": self.args.dataloader_num_workers,
- "pin_memory": self.args.dataloader_pin_memory,
- "shuffle": False,
- }
-
- # prepare dataloader
- data_loader = self.accelerator.prepare(DataLoader(self.train_dataset, **dataloader_params))
-
- ref_chosen_logps = []
- ref_rejected_logps = []
- for padded_batch in tqdm(iterable=data_loader, desc="Train dataset reference log probs"):
- ref_chosen_logp, ref_rejected_logp = self.compute_ref_log_probs(padded_batch)
- ref_chosen_logp, ref_rejected_logp = self.accelerator.gather_for_metrics(
- (ref_chosen_logp, ref_rejected_logp)
- )
- ref_chosen_logps.append(ref_chosen_logp.cpu())
- ref_rejected_logps.append(ref_rejected_logp.cpu())
-
- # Unnecessary cache clearing to avoid OOM
- empty_cache()
- self.accelerator.free_memory()
-
- all_ref_chosen_logps = torch.cat(ref_chosen_logps).float().numpy()
- all_ref_rejected_logps = torch.cat(ref_rejected_logps).float().numpy()
-
- self.train_dataset = self.train_dataset.add_column(name="ref_chosen_logps", column=all_ref_chosen_logps)
- self.train_dataset = self.train_dataset.add_column(
- name="ref_rejected_logps", column=all_ref_rejected_logps
+ if self._is_vision_dataset:
+ self._signature_columns = [
+ "prompt",
+ "chosen",
+ "rejected",
+ "image",
+ "images",
+ "tools",
+ "chat_template_kwargs",
+ ]
+ else:
+ self._signature_columns = [
+ "prompt_ids",
+ "chosen_ids",
+ "rejected_ids",
+ "ref_chosen_logps",
+ "ref_rejected_logps",
+ ]
+
+ def _precompute_ref_logps(self, dataset: Dataset, name: str, batch_size: int) -> Dataset:
+ model_hash = hash_module(self.ref_model or self.model)
+ fingerprint = Hasher.hash((dataset._fingerprint, model_hash))
+ cache_file = dataset._get_cache_file_path(fingerprint).removesuffix(".arrow") + ".npz"
+ if os.path.exists(cache_file):
+ loaded = np.load(cache_file)
+ ref_chosen_logps = loaded["ref_chosen_logps"]
+ ref_rejected_logps = loaded["ref_rejected_logps"]
+ else:
+ dataloader = DataLoader(
+ dataset,
+ batch_size=batch_size,
+ collate_fn=self.data_collator,
+ num_workers=self.args.dataloader_num_workers,
+ pin_memory=self.args.dataloader_pin_memory,
+ shuffle=False,
)
-
- self._precomputed_train_ref_log_probs = True
-
- return super().get_train_dataloader()
-
- def get_eval_dataloader(self, eval_dataset: Dataset | None = None) -> DataLoader:
- """
- Returns the evaluation [`~torch.utils.data.DataLoader`].
-
- Subclass of transformers.src.transformers.trainer.get_eval_dataloader to precompute `ref_log_probs`.
-
- Args:
- eval_dataset (`torch.utils.data.Dataset`, *optional*):
- If provided, will override `self.eval_dataset`. If it is a [`~datasets.Dataset`], columns not accepted
- by the `model.forward()` method are automatically removed. It must implement `__len__`.
- """
- if eval_dataset is None and self.eval_dataset is None:
- raise ValueError("Trainer: evaluation requires an eval_dataset.")
- eval_dataset = eval_dataset if eval_dataset is not None else self.eval_dataset
-
- if self.precompute_ref_log_probs and not self._precomputed_eval_ref_log_probs:
- batch_size = self.args.precompute_ref_batch_size or self.args.per_device_eval_batch_size
- dataloader_params = {
- "batch_size": batch_size,
- "collate_fn": self.data_collator,
- "num_workers": self.args.dataloader_num_workers,
- "pin_memory": self.args.dataloader_pin_memory,
- "shuffle": False,
- }
-
- # prepare dataloader
- data_loader = self.accelerator.prepare(DataLoader(eval_dataset, **dataloader_params))
-
+ data_loader = self.accelerator.prepare(dataloader)
ref_chosen_logps = []
ref_rejected_logps = []
- for padded_batch in tqdm(iterable=data_loader, desc="Eval dataset reference log probs"):
+ for padded_batch in tqdm(iterable=data_loader, desc=f"Computing reference log probs for {name} dataset"):
ref_chosen_logp, ref_rejected_logp = self.compute_ref_log_probs(padded_batch)
ref_chosen_logp, ref_rejected_logp = self.accelerator.gather_for_metrics(
(ref_chosen_logp, ref_rejected_logp)
@@ -940,1102 +940,510 @@ def get_eval_dataloader(self, eval_dataset: Dataset | None = None) -> DataLoader
ref_chosen_logps.append(ref_chosen_logp.cpu())
ref_rejected_logps.append(ref_rejected_logp.cpu())
- all_ref_chosen_logps = torch.cat(ref_chosen_logps).float().numpy()
- all_ref_rejected_logps = torch.cat(ref_rejected_logps).float().numpy()
-
- eval_dataset = eval_dataset.add_column(name="ref_chosen_logps", column=all_ref_chosen_logps)
- eval_dataset = eval_dataset.add_column(name="ref_rejected_logps", column=all_ref_rejected_logps)
-
- # Save calculated ref_chosen_logps and ref_rejected_logps to the eval_dataset for subsequent runs
- if self.eval_dataset is not None:
- self.eval_dataset = eval_dataset
- self._precomputed_eval_ref_log_probs = True
-
- return super().get_eval_dataloader(eval_dataset=eval_dataset)
-
- @contextmanager
- def null_ref_context(self):
- """Context manager for handling null reference model (that is, peft adapter manipulation)."""
- with (
- self.accelerator.unwrap_model(self.model).disable_adapter()
- if self.is_peft_model and not self.ref_adapter_name
- else nullcontext()
- ):
- if self.ref_adapter_name:
- self.model.set_adapter(self.ref_adapter_name)
- yield
- if self.ref_adapter_name:
- self.model.set_adapter(self.model_adapter_name or "default")
-
- def compute_ref_log_probs(self, batch: dict[str, torch.LongTensor]) -> tuple[torch.Tensor, torch.Tensor]:
- """Computes log probabilities of the reference model for a single padded batch of a DPO specific dataset."""
- compte_ref_context_manager = (
- autocast(self.accelerator.device.type) if self._peft_has_been_casted_to_bf16 else nullcontext()
- )
- with torch.no_grad(), compte_ref_context_manager:
- if self.ref_model is None:
- with self.null_ref_context():
- ref_model_output = self.concatenated_forward(self.model, batch, is_ref_model=True)
- else:
- ref_model_output = self.concatenated_forward(self.ref_model, batch, is_ref_model=True)
- return ref_model_output["chosen_logps"], ref_model_output["rejected_logps"]
-
- @staticmethod
- def concatenated_inputs(
- batch: dict[str, list | torch.LongTensor], padding_value: int
- ) -> dict[str, torch.LongTensor]:
- """
- Concatenate the `chosen` and `rejected` inputs from the batch into a single tensor for both the prompt and
- completion sequences.
-
- Args:
- batch (`dict[str, list | torch.LongTensor]`):
- A batch of input data. The batch must contain the following keys:
-
- - `"prompt_input_ids"`: Tensor of shape `(batch_size, prompt_length)` representing the prompt input
- IDs.
- - `"chosen_input_ids"`: Tensor of shape `(batch_size, chosen_length)` representing the chosen
- completion input IDs.
- - `"rejected_input_ids"`: Tensor of shape `(batch_size, rejected_length)` representing the rejected
- completion input IDs.
- - `"prompt_pixel_values"` (optional): Tensor for pixel values, if available.
- - `"prompt_pixel_attention_mask"` (optional): Tensor for pixel attention masks, if available.
-
- padding_value (`int`):
- The padding value to use for the concatenated completion sequences (`chosen_input_ids` and
- `rejected_input_ids`).
-
- Returns:
- `dict[str, torch.LongTensor]`: A dictionary containing:
-
- - `"prompt_input_ids"`: Concatenated prompt input IDs of shape `(2 * batch_size, prompt_length)`.
- - `"completion_input_ids"`: Concatenated chosen and rejected completion input IDs of shape `(2 *
- batch_size, max_completion_length)`.
- - `"prompt_attention_mask"`: Concatenated prompt attention masks of shape `(2 * batch_size,
- prompt_length)`.
- - `"completion_attention_mask"`: Concatenated chosen and rejected attention masks of shape `(2 *
- batch_size, max_completion_length)`.
- - `"pixel_values"` (optional): Concatenated pixel values if `"prompt_pixel_values"` are present.
- - `"pixel_attention_mask"` (optional): Concatenated pixel attention masks if
- `"prompt_pixel_attention_mask"` are present.
-
- Notes:
- The completion input IDs and attention masks are padded to the maximum completion length of the chosen or
- rejected sequences.
- """
- output = {}
-
- # For the prompt, the input_ids are the same for both the chosen and rejected responses
- output["prompt_input_ids"] = torch.cat([batch["prompt_input_ids"], batch["prompt_input_ids"]], dim=0)
- output["prompt_attention_mask"] = torch.cat(
- [batch["prompt_attention_mask"], batch["prompt_attention_mask"]], dim=0
- )
- if "pixel_values" in batch:
- output["pixel_values"] = torch.cat([batch["pixel_values"], batch["pixel_values"]], dim=0)
-
- if "pixel_attention_mask" in batch:
- output["pixel_attention_mask"] = torch.cat(
- [batch["pixel_attention_mask"], batch["pixel_attention_mask"]], dim=0
- )
- if "image_sizes" in batch:
- output["image_sizes"] = torch.cat([batch["image_sizes"], batch["image_sizes"]], dim=0)
- if "token_type_ids" in batch:
- output["token_type_ids"] = torch.cat((batch["token_type_ids"], batch["token_type_ids"]))
-
- # Concatenate the chosen and rejected completions
- max_completion_length = max(batch["chosen_input_ids"].shape[1], batch["rejected_input_ids"].shape[1])
- output["completion_input_ids"] = torch.cat(
- (
- pad_to_length(batch["chosen_input_ids"], max_completion_length, pad_value=padding_value),
- pad_to_length(batch["rejected_input_ids"], max_completion_length, pad_value=padding_value),
- ),
- )
- output["completion_attention_mask"] = torch.cat(
- (
- pad_to_length(batch["chosen_attention_mask"], max_completion_length, pad_value=0),
- pad_to_length(batch["rejected_attention_mask"], max_completion_length, pad_value=0),
- ),
- )
-
- return output
-
- def dpo_loss(
- self,
- chosen_logps: torch.FloatTensor,
- rejected_logps: torch.FloatTensor,
- ref_chosen_logps: torch.FloatTensor,
- ref_rejected_logps: torch.FloatTensor,
- loss_type: str = "sigmoid",
- model_output: dict[str, torch.FloatTensor] = None,
- ) -> tuple[torch.FloatTensor, torch.FloatTensor, torch.FloatTensor]:
- """
- Compute the DPO loss for a batch of policy and reference model log probabilities.
-
- Args:
- chosen_logps (`torch.FloatTensor`):
- Log probabilities of the model for the chosen responses. Shape: `(batch_size,)`.
- rejected_logps (`torch.FloatTensor`):
- Log probabilities of the model for the rejected responses. Shape: `(batch_size,)`.
- ref_chosen_logps (`torch.FloatTensor`):
- Log probabilities of the reference model for the chosen responses. Shape: `(batch_size,)`.
- ref_rejected_logps (`torch.FloatTensor`):
- Log probabilities of the reference model for the rejected responses. Shape: `(batch_size,)`.
- loss_type (`str`, defaults to `"sigmoid"`):
- The type of loss to compute. One of:
- - `"sigmoid"`: Sigmoid loss from the original [DPO](https://huggingface.co/papers/2305.18290) paper.
- - `"hinge"`: Hinge loss on the normalized likelihood from the
- [SLiC](https://huggingface.co/papers/2305.10425) paper.
- - `"ipo"`: IPO loss from the [IPO](https://huggingface.co/papers/2310.12036) paper.
- - `"exo_pair"`: Pairwise EXO loss from the [EXO](https://huggingface.co/papers/2402.00856) paper.
- - `"nca_pair"`: Pairwise NCA loss from the [NCA](https://huggingface.co/papers/2402.05369) paper.
- - `"robust"`: Unbiased estimate of the DPO loss that is robust to preference noise from the [Robust
- DPO](https://huggingface.co/papers/2403.00409) paper.
- - `"bco_pair"`: Pairwise BCO loss from the [BCO](https://huggingface.co/papers/2404.04656) paper.
- - `"sppo_hard"`: SPPO loss with hard label from the [SPPO](https://huggingface.co/papers/2405.00675)
- paper.
- - `"aot"`: AOT loss for paired datasets from the [AOT](https://huggingface.co/papers/2406.05882) paper.
- - `"aot_unpaired"`: AOT loss for unpaired datasets from the
- [AOT](https://huggingface.co/papers/2406.05882) paper.
- - `"discopop"`: DiscoPOP (a.k.a Log-Ratio Modulated Loss, LRML) loss from the
- [DiscoPOP](https://huggingface.co/papers/2406.08414) paper.
- - `"apo_zero"`: APO-zero loss from the [APO](https://huggingface.co/papers/2408.06266) paper.
- - `"apo_down"`: APO-down loss from the [APO](https://huggingface.co/papers/2408.06266) paper.
- - `"sft"`: Negative log-likelihood loss (standard supervised fine-tuning loss).
- model_output (`dict[str, torch.FloatTensor]`, *optional*):
- The output of the model's forward pass. This is used to compute auxiliary losses if enabled.
-
- Returns:
- A tuple of three tensors: `(losses, chosen_rewards, rejected_rewards)`. The losses tensor contains the DPO
- loss for each example in the batch. The `chosen_rewards` and `rejected_rewards` tensors contain the rewards
- for the chosen and rejected responses, respectively.
- """
- device = self.accelerator.device
-
- # Get the log ratios for the chosen and rejected responses
- chosen_logratios = chosen_logps.to(device) - (not self.reference_free) * ref_chosen_logps.to(device)
- rejected_logratios = rejected_logps.to(device) - (not self.reference_free) * ref_rejected_logps.to(device)
-
- if self.f_divergence_type == FDivergenceType.ALPHA_DIVERGENCE:
- # The alpha-divergence formula: (1 - u^-alpha) / alpha
- # The divergence difference between the chosen and rejected sample is:
- # (1 - u[w]^-alpha) / alpha - (1 - u[l]^-alpha) / alpha
- # = (u[l]^-alpha - u[w]^-alpha) / alpha
- # where u[w] and u[l] are the policy/reference probability ratios
- # for the chosen and rejected samples, respectively.
- alpha_coef = FDivergenceConstants.ALPHA_DIVERGENCE_COEF_DEFAULT
- if self.f_divergence_params and FDivergenceConstants.ALPHA_DIVERGENCE_COEF_KEY in self.f_divergence_params:
- alpha_coef = float(self.f_divergence_params[FDivergenceConstants.ALPHA_DIVERGENCE_COEF_KEY])
- logits = (cap_exp(rejected_logratios * -alpha_coef) - cap_exp(chosen_logratios * -alpha_coef)) / alpha_coef
- else:
- logratios = chosen_logps - rejected_logps
- if self.reference_free:
- ref_logratios = torch.tensor([0], dtype=logratios.dtype, device=logratios.device)
- else:
- ref_logratios = ref_chosen_logps - ref_rejected_logps
-
- logratios = logratios.to(self.accelerator.device)
- ref_logratios = ref_logratios.to(self.accelerator.device)
- logits = logratios - ref_logratios
-
- if self.f_divergence_type == FDivergenceType.JS_DIVERGENCE:
- # The js-divergence formula: log(2 * u / (1 + u))
- # The divergence difference between the chosen and rejected sample is:
- # log(2 * u[w] / (1 + u[w])) - log(2 * u[l] / (1 + u[l]))
- # = log(u[w]) - log(u[l]) - (log(1 + u[w]) - log(1 + u[l]))
- # where u[w] and u[l] are the policy/reference probability ratios
- # for the chosen and rejected samples, respectively.
- logits -= F.softplus(chosen_logratios) - F.softplus(rejected_logratios)
-
- # The beta is a temperature parameter for the DPO loss, typically something in the range of 0.1 to 0.5.
- # We ignore the reference model as beta -> 0. The label_smoothing parameter encodes our uncertainty about the
- # labels and calculates a conservative DPO loss.
- if loss_type == "sigmoid":
- losses = (
- -F.logsigmoid(self.beta * logits) * (1 - self.label_smoothing)
- - F.logsigmoid(-self.beta * logits) * self.label_smoothing
- )
-
- elif loss_type == "robust":
- losses = (
- -F.logsigmoid(self.beta * logits) * (1 - self.label_smoothing)
- + F.logsigmoid(-self.beta * logits) * self.label_smoothing
- ) / (1 - 2 * self.label_smoothing)
-
- elif loss_type == "exo_pair":
- # eqn (16) of the EXO paper: https://huggingface.co/papers/2402.00856
- import math
-
- if self.label_smoothing == 0:
- self.label_smoothing = 1e-3
- losses = (self.beta * logits).sigmoid() * (
- F.logsigmoid(self.beta * logits) - math.log(1 - self.label_smoothing)
- ) + (-self.beta * logits).sigmoid() * (F.logsigmoid(-self.beta * logits) - math.log(self.label_smoothing))
-
- elif loss_type == "hinge":
- losses = torch.relu(1 - self.beta * logits)
-
- elif loss_type == "ipo":
- # eqn (17) of the paper where beta is the regularization parameter for the IPO loss, denoted by tau in the paper.
- losses = (logits - 1 / (2 * self.beta)) ** 2
-
- elif loss_type == "bco_pair":
- chosen_logratios = chosen_logps - ref_chosen_logps
- rejected_logratios = rejected_logps - ref_rejected_logps
- chosen_rewards = self.beta * chosen_logratios
- rejected_rewards = self.beta * rejected_logratios
- rewards = torch.cat((chosen_rewards, rejected_rewards), 0).mean().detach()
- self.running.update(rewards)
- delta = self.running.mean
- losses = -F.logsigmoid((self.beta * chosen_logratios) - delta) - F.logsigmoid(
- -(self.beta * rejected_logratios - delta)
- )
-
- elif loss_type == "sppo_hard":
- # In the paper (https://huggingface.co/papers/2405.00675), SPPO employs a soft probability approach,
- # estimated using the PairRM score. The probability calculation is conducted outside of the trainer class.
- # The version described here is the hard probability version, where P in Equation (4.7) of Algorithm 1 is
- # set to 1 for the winner and 0 for the loser.
- a = chosen_logps - ref_chosen_logps
- b = rejected_logps - ref_rejected_logps
- losses = (a - 0.5 / self.beta) ** 2 + (b + 0.5 / self.beta) ** 2
-
- elif loss_type == "nca_pair":
- chosen_rewards = (chosen_logps - ref_chosen_logps) * self.beta
- rejected_rewards = (rejected_logps - ref_rejected_logps) * self.beta
- losses = (
- -F.logsigmoid(chosen_rewards)
- - 0.5 * F.logsigmoid(-chosen_rewards)
- - 0.5 * F.logsigmoid(-rejected_rewards)
- )
-
- elif loss_type == "aot_unpaired":
- chosen_logratios = chosen_logps - ref_chosen_logps
- rejected_logratios = rejected_logps - ref_rejected_logps
- chosen_logratios_sorted, _ = torch.sort(chosen_logratios, dim=0)
- rejected_logratios_sorted, _ = torch.sort(rejected_logratios, dim=0)
- delta = chosen_logratios_sorted - rejected_logratios_sorted
- losses = (
- -F.logsigmoid(self.beta * delta) * (1 - self.label_smoothing)
- - F.logsigmoid(-self.beta * delta) * self.label_smoothing
- )
+ # Save the reference log probabilities to cache. We need .float() because bf16 is not supported by numpy
+ ref_chosen_logps = torch.cat(ref_chosen_logps).float().numpy()
+ ref_rejected_logps = torch.cat(ref_rejected_logps).float().numpy()
+ if self.accelerator.is_main_process:
+ np.savez_compressed(
+ cache_file, ref_chosen_logps=ref_chosen_logps, ref_rejected_logps=ref_rejected_logps
+ )
+ self.accelerator.wait_for_everyone()
- elif loss_type == "aot":
- logratios = chosen_logps - rejected_logps
- ref_logratios = ref_chosen_logps - ref_rejected_logps
- logratios_sorted, _ = torch.sort(logratios, dim=0)
- ref_logratios_sorted, _ = torch.sort(ref_logratios, dim=0)
- delta = logratios_sorted - ref_logratios_sorted
- losses = (
- -F.logsigmoid(self.beta * delta) * (1 - self.label_smoothing)
- - F.logsigmoid(-self.beta * delta) * self.label_smoothing
- )
+ dataset = dataset.add_column(name="ref_chosen_logps", column=ref_chosen_logps)
+ dataset = dataset.add_column(name="ref_rejected_logps", column=ref_rejected_logps, new_fingerprint=fingerprint)
- elif loss_type == "apo_zero":
- # Eqn (7) of the APO paper (https://huggingface.co/papers/2408.06266)
- # Use this loss when you believe the chosen outputs are better than your model's default output
- losses_chosen = 1 - F.sigmoid(self.beta * chosen_logratios) # Increase chosen likelihood
- losses_rejected = F.sigmoid(self.beta * rejected_logratios) # Decrease rejected likelihood
- losses = losses_chosen + losses_rejected
-
- elif loss_type == "apo_down":
- # Eqn (8) of the APO paper (https://huggingface.co/papers/2408.06266)
- # Use this loss when you believe the chosen outputs are worse than your model's default output.
- # Decrease chosen likelihood and decrease rejected likelihood more
- losses_chosen = F.sigmoid(self.beta * chosen_logratios)
- losses_rejected = 1 - F.sigmoid(self.beta * (chosen_logratios - rejected_logratios))
- losses = losses_chosen + losses_rejected
-
- elif loss_type == "discopop":
- # Eqn (5) of the DiscoPOP paper (https://huggingface.co/papers/2406.08414)
- # This loss was discovered with LLM discovery
- logratios = chosen_logps - rejected_logps
- ref_logratios = ref_chosen_logps - ref_rejected_logps
- logits = logratios - ref_logratios
- logits = logits * self.beta
- # Modulate the mixing coefficient based on the log ratio magnitudes
- log_ratio_modulation = torch.sigmoid(logits / self.args.discopop_tau)
- logistic_component = -F.logsigmoid(logits)
- exp_component = torch.exp(-logits)
- # Blend between logistic and exponential component based on log ratio modulation
- losses = logistic_component * (1 - log_ratio_modulation) + exp_component * log_ratio_modulation
-
- elif loss_type == "sft":
- # SFT loss is the negative log likelihood loss on chosen responses
- # This acts as the generation loss component in MPO
- sft_loss = model_output["nll_loss"]
- # Create losses tensor with same shape as other losses (per-sample)
- batch_size = chosen_logps.shape[0]
- losses = sft_loss.expand(batch_size)
- # For SFT, we don't have preference rewards, so use zeros
- chosen_rewards = torch.zeros_like(chosen_logps)
- rejected_rewards = torch.zeros_like(rejected_logps)
+ return dataset
+ def _truncate_inputs(
+ self, input_ids: torch.Tensor, attention_mask: torch.Tensor, completion_mask: torch.Tensor
+ ) -> tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
+ if self.args.max_length is None:
+ return input_ids, attention_mask, completion_mask
+
+ if self.args.truncation_mode == "keep_start":
+ input_ids = input_ids[:, : self.args.max_length]
+ attention_mask = attention_mask[:, : self.args.max_length]
+ completion_mask = completion_mask[:, : self.args.max_length]
+ elif self.args.truncation_mode == "keep_end":
+ attention_mask, input_ids, completion_mask = flush_right(attention_mask, input_ids, completion_mask)
+ input_ids = input_ids[:, -self.args.max_length :]
+ attention_mask = attention_mask[:, -self.args.max_length :]
+ completion_mask = completion_mask[:, -self.args.max_length :]
+ attention_mask, input_ids, completion_mask = flush_left(attention_mask, input_ids, completion_mask)
else:
raise ValueError(
- f"Unknown loss type: {self.loss_type}. Should be one of ['sigmoid', 'hinge', 'ipo', 'exo_pair', "
- "'nca_pair', 'robust', 'bco_pair', 'sppo_hard', 'aot', 'aot_unpaired', 'discopop', 'apo_zero', "
- "'apo_down', 'sft']"
- )
-
- if loss_type != "sft":
- chosen_rewards = self.beta * (chosen_logps.to(device) - ref_chosen_logps.to(device)).detach()
- rejected_rewards = self.beta * (rejected_logps.to(device) - ref_rejected_logps.to(device)).detach()
-
- return losses, chosen_rewards, rejected_rewards
-
- def _compute_loss_liger(
- self, model: nn.Module, batch: dict[str, list | torch.LongTensor]
- ) -> dict[str, torch.Tensor]:
- unwrapped_model = self.accelerator.unwrap_model(model)
- concatenated_batch = self.concatenated_inputs(batch, padding_value=self.pad_token_id)
-
- model_kwargs = {}
- if self.aux_loss_enabled:
- model_kwargs["output_router_logits"] = True
-
- # Add the pixel values and attention masks for vision models
- if "pixel_values" in concatenated_batch:
- model_kwargs["pixel_values"] = concatenated_batch["pixel_values"]
- if "pixel_attention_mask" in concatenated_batch:
- model_kwargs["pixel_attention_mask"] = concatenated_batch["pixel_attention_mask"]
- if "image_sizes" in concatenated_batch:
- model_kwargs["image_sizes"] = concatenated_batch["image_sizes"]
-
- prompt_attention_mask = concatenated_batch["prompt_attention_mask"]
- completion_attention_mask = concatenated_batch["completion_attention_mask"]
-
- if self.is_encoder_decoder:
- # 1. Get encoder outputs
- encoder_outputs = unwrapped_model.get_encoder()(
- concatenated_batch["prompt_input_ids"],
- attention_mask=concatenated_batch["prompt_attention_mask"],
- return_dict=True,
- )
- # 2. Prepare decoder inputs
- decoder_input_ids = shift_tokens_right(
- concatenated_batch["completion_input_ids"],
- unwrapped_model.config.decoder_start_token_id,
- )
- # 3. Get decoder outputs
- decoder_outputs = unwrapped_model.get_decoder()(
- input_ids=decoder_input_ids,
- attention_mask=concatenated_batch["completion_attention_mask"],
- encoder_hidden_states=encoder_outputs.last_hidden_state,
- encoder_attention_mask=concatenated_batch["prompt_attention_mask"],
- use_cache=False,
- )
- hidden_states = decoder_outputs.last_hidden_state
-
- ref_hidden_states = None
- if not self.reference_free and self.ref_model is not None:
- unwrapped_ref_model = self.accelerator.unwrap_model(self.ref_model)
- ref_encoder_outputs = unwrapped_ref_model.get_encoder()(
- concatenated_batch["prompt_input_ids"],
- attention_mask=concatenated_batch["prompt_attention_mask"],
- return_dict=True,
- )
- ref_decoder_outputs = unwrapped_ref_model.get_decoder()(
- input_ids=decoder_input_ids,
- attention_mask=concatenated_batch["completion_attention_mask"],
- encoder_hidden_states=ref_encoder_outputs.last_hidden_state,
- encoder_attention_mask=concatenated_batch["prompt_attention_mask"],
- use_cache=False,
- )
- ref_hidden_states = ref_decoder_outputs.last_hidden_state
- elif not self.reference_free:
- with self.null_ref_context():
- ref_encoder_outputs = unwrapped_model.get_encoder()(
- concatenated_batch["prompt_input_ids"],
- attention_mask=concatenated_batch["prompt_attention_mask"],
- return_dict=True,
- )
- ref_decoder_outputs = unwrapped_model.get_decoder()(
- input_ids=decoder_input_ids,
- attention_mask=concatenated_batch["completion_attention_mask"],
- encoder_hidden_states=ref_encoder_outputs.last_hidden_state,
- encoder_attention_mask=concatenated_batch["prompt_attention_mask"],
- use_cache=False,
- )
- ref_hidden_states = ref_decoder_outputs.last_hidden_state
-
- labels = concatenated_batch["completion_input_ids"]
- loss_mask = completion_attention_mask.bool()
- else:
- # For decoder-only models
- input_ids = torch.cat(
- (concatenated_batch["prompt_input_ids"], concatenated_batch["completion_input_ids"]), dim=1
- )
- attention_mask = torch.cat(
- (concatenated_batch["prompt_attention_mask"], concatenated_batch["completion_attention_mask"]),
- dim=1,
- )
- # Mask the prompt but not the completion for the loss
- loss_mask = torch.cat(
- (torch.zeros_like(prompt_attention_mask), completion_attention_mask),
- dim=1,
+ f"Unsupported truncation mode: {self.args.truncation_mode}, expected 'keep_start' or 'keep_end'"
)
- # Flush and truncate
- if self.max_length is not None and self.max_length < attention_mask.size(1):
- if self.truncation_mode == "keep_start":
- # Flush left to reduce the memory usage
- # [[0, 0, x, x, x, x], -> [[x, x, x, x],
- # [0, x, x, x, 0, 0]] [x, x, x, 0]]
- attention_mask, input_ids, loss_mask = flush_left(attention_mask, input_ids, loss_mask)
- attention_mask = attention_mask[:, : self.max_length]
- input_ids = input_ids[:, : self.max_length]
- loss_mask = loss_mask[:, : self.max_length]
- elif self.truncation_mode == "keep_end":
- # Flush right before truncating left, then flush left
- # [[0, 0, x, x, x, x], -> [[0, 0, x, x],
- # [0, x, x, x, 0, 0]] [0, x, x, x]]
- attention_mask, input_ids, loss_mask = flush_right(attention_mask, input_ids, loss_mask)
- input_ids = input_ids[:, -self.max_length :]
- attention_mask = attention_mask[:, -self.max_length :]
- loss_mask = loss_mask[:, -self.max_length :]
- attention_mask, input_ids, loss_mask = flush_left(attention_mask, input_ids, loss_mask)
- else:
- raise ValueError(
- f"Unknown truncation mode: '{self.truncation_mode}'. Should be one of ['keep_end', "
- "'keep_start']."
- )
- else:
- # Flush left to reduce the memory usage
- # [[0, 0, x, x, x, x], -> [[x, x, x, x],
- # [0, x, x, x, 0, 0]] [x, x, x, 0]]
- attention_mask, input_ids, loss_mask = flush_left(attention_mask, input_ids, loss_mask)
-
- # Add logits_to_keep optimization
- if self.use_logits_to_keep:
- first_compute_index = loss_mask.nonzero(as_tuple=True)[1].min()
- logits_to_keep = (loss_mask.shape[1] - first_compute_index).item() + 1
- model_kwargs["logits_to_keep"] = logits_to_keep
-
- model_kwargs["output_hidden_states"] = True
-
- # Add padding-free training support
- if self.padding_free:
- input_ids = input_ids[attention_mask.bool()].unsqueeze(0)
- loss_mask = loss_mask[attention_mask.bool()].unsqueeze(0)
- position_ids = attention_mask.cumsum(1)[attention_mask.bool()].unsqueeze(0) - 1
- model_kwargs["position_ids"] = position_ids
- else:
- model_kwargs["attention_mask"] = attention_mask
+ return input_ids, attention_mask, completion_mask
- # Get the base model outputs (before LM head)
- if hasattr(unwrapped_model, "get_decoder") and unwrapped_model.get_decoder() is not None:
- base_model = unwrapped_model.get_decoder()
- else:
- base_attr = getattr(unwrapped_model, "base_model_prefix", self.args.base_model_attribute_name)
- base_model = getattr(unwrapped_model, base_attr, unwrapped_model)
-
- outputs = base_model(
- input_ids,
- use_cache=False,
- **model_kwargs,
- )
- hidden_states = outputs.last_hidden_state[:, :-1]
-
- # Get reference hidden states if needed
- ref_hidden_states = None
- if not self.reference_free and self.ref_model is not None:
- unwrapped_ref_model = self.accelerator.unwrap_model(self.ref_model)
- if hasattr(unwrapped_ref_model, "get_decoder") and unwrapped_ref_model.get_decoder() is not None:
- ref_base_model = unwrapped_ref_model.get_decoder()
- else:
- ref_attr = getattr(unwrapped_ref_model, "base_model_prefix", self.args.base_model_attribute_name)
- ref_base_model = getattr(unwrapped_ref_model, ref_attr, unwrapped_ref_model)
+ def compute_ref_log_probs(self, inputs):
+ """Computes reference log probabilities for a single padded batch."""
+ device = self.accelerator.device
- ref_outputs = ref_base_model(
- input_ids,
- use_cache=False,
- **model_kwargs,
- )
- ref_hidden_states = ref_outputs.last_hidden_state[:, :-1]
- elif not self.reference_free:
- if hasattr(unwrapped_model, "get_decoder") and unwrapped_model.get_decoder() is not None:
- ref_base_model = unwrapped_model.get_decoder()
- else:
- ref_attr = getattr(unwrapped_model, "base_model_prefix", self.args.base_model_attribute_name)
- ref_base_model = getattr(unwrapped_model, ref_attr, unwrapped_model)
- with self.null_ref_context():
- ref_outputs = ref_base_model(
- input_ids,
- use_cache=False,
- **model_kwargs,
- )
- ref_hidden_states = ref_outputs.last_hidden_state[:, :-1]
+ input_ids = inputs["input_ids"]
+ attention_mask = inputs["attention_mask"]
+ completion_mask = inputs["completion_mask"]
+ input_ids, attention_mask, completion_mask = self._truncate_inputs(input_ids, attention_mask, completion_mask)
- masked_input_ids = torch.where(loss_mask != 0, input_ids, self.label_pad_token_id)
- labels = masked_input_ids[:, 1:] # Shift right for casual LM
+ shift_labels = input_ids[..., 1:].contiguous()
+ shift_completion_mask = completion_mask[..., 1:].contiguous()
- # Get the LM head
- lm_head = unwrapped_model.get_output_embeddings()
+ model_kwargs = {"input_ids": input_ids, "attention_mask": attention_mask, "use_cache": False}
+ for key in ("pixel_values", "pixel_attention_mask", "image_grid_thw", "image_sizes", "token_type_ids"):
+ if key in inputs:
+ model_kwargs[key] = inputs[key]
- # Get reference model weights if needed
- ref_weight = None
- ref_bias = None
- if not self.reference_free:
- if self.ref_model is not None:
- unwrapped_ref_model = self.accelerator.unwrap_model(self.ref_model)
- ref_lm_head = unwrapped_ref_model.get_output_embeddings()
+ with torch.no_grad(), disable_gradient_checkpointing(self.model, self.args.gradient_checkpointing_kwargs):
+ if is_peft_model(self.model) and self.ref_model is None:
+ model = self.accelerator.unwrap_model(self.model)
+ with use_adapter(model, adapter_name="ref" if "ref" in model.peft_config else None):
+ ref_outputs = self.model(**model_kwargs)
else:
- with self.null_ref_context():
- ref_lm_head = unwrapped_model.get_output_embeddings()
- ref_weight = ref_lm_head.weight
- ref_bias = ref_lm_head.bias if hasattr(ref_lm_head, "bias") else None
-
- # Compute loss using Liger kernel
- loss_output = self.dpo_loss_fn(
- lm_head.weight,
- hidden_states,
- labels,
- bias=lm_head.bias if hasattr(lm_head, "bias") else None,
- ref_input=ref_hidden_states if not self.reference_free else None,
- ref_weight=ref_weight if not self.reference_free else None,
- ref_bias=ref_bias if not self.reference_free else None,
- )
- (
- loss,
- (chosen_logps, rejected_logps, chosen_logits_mean, rejected_logits_mean, nll_loss, *aux_outputs),
- ) = loss_output
-
- output = {
- "loss": loss,
- "chosen_logps": chosen_logps,
- "rejected_logps": rejected_logps,
- "mean_chosen_logits": chosen_logits_mean,
- "mean_rejected_logits": rejected_logits_mean,
- "nll_loss": nll_loss,
- "chosen_rewards": aux_outputs[0],
- "rejected_rewards": aux_outputs[1],
- }
- if self.aux_loss_enabled:
- output["aux_loss"] = outputs.aux_loss
+ ref_outputs = self.ref_model(**model_kwargs)
- return output
+ ref_shift_logits = ref_outputs.logits[..., :-1, :].contiguous()
+ ref_per_token_logps = selective_log_softmax(ref_shift_logits, shift_labels)
+ ref_per_token_logps[shift_completion_mask == 0] = 0.0
- def concatenated_forward(
- self, model: nn.Module, batch: dict[str, list | torch.LongTensor], is_ref_model: bool = False
- ) -> dict[str, torch.Tensor]:
- """
- Runs the given model on the given batch of inputs, concatenating the chosen and rejected inputs together.
-
- We do this to avoid doing two forward passes, because it's faster for FSDP.
-
- Args:
- model:
- Model to run the forward pass on.
- batch:
- Batch of input data.
- is_ref_model:
- Whether this method is being called for the reference model. If `True`, length desensitization is not
- applied.
- """
- num_examples = batch["prompt_input_ids"].shape[0]
-
- concatenated_batch = self.concatenated_inputs(batch, padding_value=self.pad_token_id)
-
- model_kwargs = {"use_cache": False}
- if self.aux_loss_enabled:
- model_kwargs["output_router_logits"] = True
-
- # Add the pixel values and attention masks for vision models
- if "pixel_values" in concatenated_batch:
- model_kwargs["pixel_values"] = concatenated_batch["pixel_values"]
- if "pixel_attention_mask" in concatenated_batch:
- model_kwargs["pixel_attention_mask"] = concatenated_batch["pixel_attention_mask"]
- if "image_sizes" in concatenated_batch:
- model_kwargs["image_sizes"] = concatenated_batch["image_sizes"]
-
- prompt_input_ids = concatenated_batch["prompt_input_ids"]
- prompt_attention_mask = concatenated_batch["prompt_attention_mask"]
- completion_input_ids = concatenated_batch["completion_input_ids"]
- completion_attention_mask = concatenated_batch["completion_attention_mask"]
- if self.is_encoder_decoder:
- labels = completion_input_ids
- labels[completion_attention_mask == 0] = self.label_pad_token_id
- outputs = model(
- input_ids=prompt_input_ids,
- attention_mask=prompt_attention_mask,
- labels=labels, # we need the labels for the logits to be returned
- **model_kwargs,
- )
- logits = outputs.logits
- loss_mask = completion_attention_mask.bool()
+ if self.ld_alpha is None:
+ ref_logps = ref_per_token_logps.sum(dim=1)
else:
- # Concatenate the prompt and completion inputs
- input_ids = torch.cat((prompt_input_ids, completion_input_ids), dim=1)
- attention_mask = torch.cat((prompt_attention_mask, completion_attention_mask), dim=1)
- if "token_type_ids" in concatenated_batch:
- prompt_token_type_ids = concatenated_batch["token_type_ids"]
- token_type_ids = pad_to_length(prompt_token_type_ids, input_ids.shape[1], 0)
- # Mask the prompt but not the completion for the loss
- loss_mask = torch.cat(
- (torch.zeros_like(prompt_attention_mask), completion_attention_mask),
- dim=1,
- )
-
- # Flush and truncate
- if self.max_length is not None and self.max_length < attention_mask.size(1):
- if self.truncation_mode == "keep_start":
- # Flush left to reduce the memory usage
- # [[0, 0, x, x, x, x], -> [[x, x, x, x],
- # [0, x, x, x, 0, 0]] [x, x, x, 0]]
- if "token_type_ids" in concatenated_batch:
- attention_mask, input_ids, loss_mask, token_type_ids = flush_left(
- attention_mask, input_ids, loss_mask, token_type_ids
- )
- else:
- attention_mask, input_ids, loss_mask = flush_left(attention_mask, input_ids, loss_mask)
- attention_mask = attention_mask[:, : self.max_length]
- input_ids = input_ids[:, : self.max_length]
- loss_mask = loss_mask[:, : self.max_length]
- elif self.truncation_mode == "keep_end":
- # Flush right before truncating left, then flush left
- # [[0, 0, x, x, x, x], -> [[0, 0, x, x],
- # [0, x, x, x, 0, 0]] [0, x, x, x]]
- if "token_type_ids" in concatenated_batch:
- attention_mask, input_ids, loss_mask, token_type_ids = flush_left(
- attention_mask, input_ids, loss_mask, token_type_ids
- )
- token_type_ids = token_type_ids[:, -self.max_length :]
- else:
- attention_mask, input_ids, loss_mask = flush_right(attention_mask, input_ids, loss_mask)
- input_ids = input_ids[:, -self.max_length :]
- attention_mask = attention_mask[:, -self.max_length :]
- loss_mask = loss_mask[:, -self.max_length :]
- if "token_type_ids" in concatenated_batch:
- attention_mask, input_ids, loss_mask, token_type_ids = flush_left(
- attention_mask, input_ids, loss_mask, token_type_ids
- )
- else:
- attention_mask, input_ids, loss_mask = flush_left(attention_mask, input_ids, loss_mask)
- else:
- raise ValueError(
- f"Unknown truncation mode: '{self.truncation_mode}'. Should be one of ['keep_end', "
- "'keep_start']."
- )
- else:
- # Flush left to reduce the memory usage
- # [[0, 0, x, x, x, x], -> [[x, x, x, x],
- # [0, x, x, x, 0, 0]] [x, x, x, 0]]
- if "token_type_ids" in concatenated_batch:
- attention_mask, input_ids, loss_mask, token_type_ids = flush_left(
- attention_mask, input_ids, loss_mask, token_type_ids
- )
- else:
- attention_mask, input_ids, loss_mask = flush_left(attention_mask, input_ids, loss_mask)
-
- if "token_type_ids" in concatenated_batch:
- model_kwargs["token_type_ids"] = token_type_ids
-
- if self.use_logits_to_keep:
- # Compute logits_to_keep based on loss_mask pattern:
- # [[0, 0, 0, x, x, x, x],
- # [0, 0, 0, x, x, x, 0]]
- # ^ start computing logits from here ([:, -(7-3+1):])
- first_compute_index = loss_mask.nonzero(as_tuple=True)[1].min()
- logits_to_keep = (loss_mask.shape[1] - first_compute_index).item() + 1 # +1 for the first label
- model_kwargs["logits_to_keep"] = logits_to_keep
-
- model_kwargs["output_hidden_states"] = True
-
- if self.padding_free:
- # Flatten the input_ids, position_ids, and loss_mask
- # input_ids = [[a, b, c, 0], -> input_ids = [[a, b, c, d, e, f, g]]
- # [d, e, f, g]] position_ids = [[0, 1, 2, 0, 1, 2, 3]]
- input_ids = input_ids[attention_mask.bool()].unsqueeze(0)
- loss_mask = loss_mask[attention_mask.bool()].unsqueeze(0)
- position_ids = attention_mask.cumsum(1)[attention_mask.bool()].unsqueeze(0) - 1
- model_kwargs["position_ids"] = position_ids
- else:
- model_kwargs["attention_mask"] = attention_mask
-
- outputs = model(input_ids, **model_kwargs)
- logits = outputs.logits
-
- # Offset the logits by one to align with the labels
- labels = torch.roll(input_ids, shifts=-1, dims=1)
- loss_mask = torch.roll(loss_mask, shifts=-1, dims=1).bool()
-
- if self.use_logits_to_keep:
- # Align labels with logits
- # logits: -, -, [x2, x3, x4, x5, x6]
- # ^ --------- ^ after logits[:, :-1, :]
- # labels: [y0, y1, y2, y3, y4, y5, y6]
- # ^ --------- ^ with logits_to_keep=4, [:, -4:]
- # loss_mask: [0, 0, 0, 1, 1, 1, 1]
- labels = labels[:, -logits_to_keep:]
- loss_mask = loss_mask[:, -logits_to_keep:]
-
- if logits.shape[:2] != labels.shape[:2]:
- # for LLaVA, the returned logits include the image tokens (placed before the text tokens)
- seq_len = labels.shape[1]
- logits = logits[:, -seq_len:]
-
- # Compute the log probabilities of the labels
- labels[~loss_mask] = 0 # dummy token; we'll ignore the losses on these tokens later
- per_token_logps = selective_log_softmax(logits, labels)
- per_token_logps[~loss_mask] = 0
- per_token_logps = torch.roll(per_token_logps, shifts=1, dims=1)
-
- if self.padding_free:
- # Unflatten the per_token_logps (shape: [1, sum_seq_len] -> [batch_size, seq_len])
- batch_size, seq_len = attention_mask.shape
- per_token_logps_ = torch.zeros(
- batch_size, seq_len, device=outputs.logits.device, dtype=outputs.logits.dtype
- )
- per_token_logps_[attention_mask.bool()] = per_token_logps
- per_token_logps = per_token_logps_
-
- all_logps = per_token_logps[:, 1:].sum(-1)
-
- output = {}
-
- if self.use_weighting:
- with torch.no_grad():
- # Eq (2) of the WPO paper: https://huggingface.co/papers/2406.11827
- logprobs = F.log_softmax(logits, dim=-1)
- weights_adjustment_factor = torch.logsumexp(2 * logprobs, dim=-1) # same as sum(probs**2) in log space
- per_token_logps_adjusted = per_token_logps - weights_adjustment_factor
- all_weights = (per_token_logps_adjusted * loss_mask).sum(-1) / loss_mask.sum(-1)
- chosen_weights = all_weights[:num_examples]
- rejected_weights = all_weights[num_examples:]
- output["policy_weights"] = torch.clamp(torch.exp(chosen_weights + rejected_weights), max=1)
-
- if self.args.rpo_alpha is not None or "sft" in self.loss_type:
- # Only use the chosen logits for the RPO loss or SFT loss
- chosen_logits = logits[:num_examples, :-1] if not self.is_encoder_decoder else logits[:num_examples]
- chosen_labels = labels[:num_examples, :-1] if not self.is_encoder_decoder else labels[:num_examples]
-
- # Compute the log probabilities of the labels
- output["nll_loss"] = F.cross_entropy(
- torch.flatten(chosen_logits, end_dim=1), torch.flatten(chosen_labels, end_dim=1), ignore_index=0
+ comp_pos = shift_completion_mask.cumsum(dim=1)
+ comp_lens = shift_completion_mask.sum(dim=1).long()
+ chosen_lens, rejected_lens = comp_lens.chunk(2, dim=0)
+ shared_lens = torch.minimum(chosen_lens, rejected_lens)
+ shared_lens_2b = torch.cat([shared_lens, shared_lens], dim=0).to(device)
+ shared_mask = (comp_pos > 0) & (comp_pos <= shared_lens_2b.unsqueeze(1))
+ tail_mask = comp_pos > shared_lens_2b.unsqueeze(1)
+ shared_logps = (ref_per_token_logps * shared_mask).sum(dim=1)
+ tail_logps = (ref_per_token_logps * tail_mask).sum(dim=1)
+ ref_logps = shared_logps + self.ld_alpha * tail_logps
+
+ ref_chosen_logps, ref_rejected_logps = ref_logps.chunk(2, dim=0)
+ return ref_chosen_logps, ref_rejected_logps
+
+ def _compute_loss_liger(self, model, inputs, return_outputs):
+ if return_outputs:
+ raise RuntimeError(
+ "return_outputs=True is not supported with the Liger DPO loss. The Liger loss computes the loss "
+ "without materializing logits, so outputs cannot be returned."
)
- if "ipo" in self.loss_type:
- all_logps = all_logps / loss_mask.sum(-1)
-
- if self.args.ld_alpha is not None and not is_ref_model:
- # Compute response lengths based on loss_mask
- completion_lengths = loss_mask.sum(dim=1)
-
- chosen_lengths = completion_lengths[:num_examples]
- rejected_lengths = completion_lengths[num_examples:]
- public_lengths = torch.min(chosen_lengths, rejected_lengths) # l_p in the paper
- public_lengths = torch.cat([public_lengths, public_lengths], dim=0)
-
- seq_len = per_token_logps.size(1)
- position_ids = torch.arange(seq_len, device=per_token_logps.device).expand_as(per_token_logps)
+ mode = "train" if self.model.training else "eval"
- ld_mask = position_ids < public_lengths.unsqueeze(1)
- mask = position_ids < completion_lengths.unsqueeze(1)
+ input_ids = inputs["input_ids"]
+ attention_mask = inputs["attention_mask"]
+ completion_mask = inputs["completion_mask"]
+ input_ids, attention_mask, completion_mask = self._truncate_inputs(input_ids, attention_mask, completion_mask)
- front_mask = (ld_mask & mask).float()
- rear_mask = (~ld_mask & mask).float()
- front_logps = (per_token_logps * front_mask).sum(dim=1)
- rear_logps = (per_token_logps * rear_mask).sum(dim=1)
+ decoder = model.get_decoder()
+ outputs = decoder(input_ids, attention_mask=attention_mask, use_cache=False)
+ hidden_states = outputs.last_hidden_state[:, :-1].contiguous()
+ lm_head = model.get_output_embeddings()
+ weight = lm_head.weight
+ bias = lm_head.bias
- all_logps = front_logps + self.args.ld_alpha * rear_logps
-
- output["chosen_logps"] = all_logps[:num_examples]
- output["rejected_logps"] = all_logps[num_examples:]
-
- # Compute the mean logits
- if self.padding_free:
- # position_ids contains a sequence of range identifiers (e.g., [[0, 1, 2, 0, 1, 2, 3, ...]]).
- # There are 2*num_examples ranges in total: the first half corresponds to the chosen tokens,
- # and the second half to the rejected tokens.
- # To find the start of the rejected tokens, we look for the num_examples+1-th zero in pos_id.
- split_idx = (position_ids == 0).nonzero(as_tuple=True)[1][num_examples]
- mean_chosen_logits = logits[0, :split_idx][loss_mask[0, :split_idx]].mean()
- mean_rejected_logits = logits[0, split_idx:][loss_mask[0, split_idx:]].mean()
+ if is_peft_model(model):
+ raise NotImplementedError("Liger DPO loss is not implemented for PEFT models.")
else:
- mean_chosen_logits = logits[:num_examples][loss_mask[:num_examples]].mean()
- mean_rejected_logits = logits[num_examples:][loss_mask[num_examples:]].mean()
-
- output["mean_chosen_logits"] = mean_chosen_logits
- output["mean_rejected_logits"] = mean_rejected_logits
-
- if self.aux_loss_enabled:
- output["aux_loss"] = outputs.aux_loss
-
- return output
-
- def get_batch_loss_metrics(
- self,
- model: PreTrainedModel | nn.Module,
- batch: dict[str, list | torch.LongTensor],
- train_eval: Literal["train", "eval"] = "train",
- ) -> tuple[torch.Tensor, dict[str, float]]:
- """Compute the DPO loss and other metrics for the given batch of inputs for train or test."""
- metrics = {}
-
- if self.args.use_liger_kernel:
- model_output = self._compute_loss_liger(model, batch)
- losses = model_output["loss"]
- chosen_rewards = model_output["chosen_rewards"]
- rejected_rewards = model_output["rejected_rewards"]
- else:
- model_output = self.concatenated_forward(model, batch)
-
- # if ref_chosen_logps and ref_rejected_logps in batch use them, otherwise use the reference model
- if "ref_chosen_logps" in batch and "ref_rejected_logps" in batch:
- ref_chosen_logps = batch["ref_chosen_logps"]
- ref_rejected_logps = batch["ref_rejected_logps"]
- else:
- ref_chosen_logps, ref_rejected_logps = self.compute_ref_log_probs(batch)
-
- # Initialize combined losses
- losses = 0
- chosen_rewards = 0
- rejected_rewards = 0
-
- # Compute losses for each loss type
- for idx, loss_type in enumerate(self.loss_type):
- # Compute individual loss using standard DPO loss function
- _losses, _chosen_rewards, _rejected_rewards = self.dpo_loss(
- model_output["chosen_logps"],
- model_output["rejected_logps"],
- ref_chosen_logps,
- ref_rejected_logps,
- loss_type,
- model_output,
- )
-
- # Add weighted contributions
- weight = self.loss_weights[idx] if self.loss_weights else 1.0
- losses = losses + _losses * weight
- chosen_rewards = chosen_rewards + _chosen_rewards * weight
- rejected_rewards = rejected_rewards + _rejected_rewards * weight
-
- reward_accuracies = (chosen_rewards > rejected_rewards).float()
-
- if self.args.rpo_alpha is not None:
- losses = losses + self.args.rpo_alpha * model_output["nll_loss"] # RPO loss from V3 of the paper
-
- if self.use_weighting:
- losses = losses * model_output["policy_weights"]
-
- if self.aux_loss_enabled:
- losses = losses + self.aux_loss_coef * model_output["aux_loss"]
-
- prefix = "eval_" if train_eval == "eval" else ""
- metrics[f"{prefix}rewards/chosen"] = self.accelerator.gather_for_metrics(chosen_rewards).mean().item()
- metrics[f"{prefix}rewards/rejected"] = self.accelerator.gather_for_metrics(rejected_rewards).mean().item()
- metrics[f"{prefix}rewards/accuracies"] = self.accelerator.gather_for_metrics(reward_accuracies).mean().item()
- metrics[f"{prefix}rewards/margins"] = (
- self.accelerator.gather_for_metrics(chosen_rewards - rejected_rewards).mean().item()
- )
- metrics[f"{prefix}logps/chosen"] = (
- self.accelerator.gather_for_metrics(model_output["chosen_logps"]).detach().mean().item()
- )
- metrics[f"{prefix}logps/rejected"] = (
- self.accelerator.gather_for_metrics(model_output["rejected_logps"]).detach().mean().item()
+ with torch.no_grad(), disable_gradient_checkpointing(self.model, self.args.gradient_checkpointing_kwargs):
+ ref_decoder = self.ref_model.get_decoder()
+ ref_outputs = ref_decoder(input_ids, attention_mask=attention_mask, use_cache=False)
+ ref_lm_head = self.ref_model.get_output_embeddings()
+ ref_hidden_states = ref_outputs.last_hidden_state[:, :-1].contiguous()
+ ref_weight = ref_lm_head.weight
+ ref_bias = ref_lm_head.bias
+
+ shift_completion_mask = completion_mask[:, 1:].contiguous()
+ labels = input_ids[:, 1:].clone()
+ labels[shift_completion_mask == 0] = -100
+
+ loss, metrics = self.liger_loss_fn(
+ weight, hidden_states, labels, bias, ref_hidden_states, ref_weight, ref_bias
)
- metrics[f"{prefix}logits/chosen"] = (
- self.accelerator.gather_for_metrics(model_output["mean_chosen_logits"]).detach().mean().item()
- )
- metrics[f"{prefix}logits/rejected"] = (
- self.accelerator.gather_for_metrics(model_output["mean_rejected_logits"]).detach().mean().item()
- )
- if self.args.rpo_alpha is not None or "sft" in self.loss_type:
- metrics[f"{prefix}nll_loss"] = (
- self.accelerator.gather_for_metrics(model_output["nll_loss"]).detach().mean().item()
- )
- if self.aux_loss_enabled:
- metrics[f"{prefix}aux_loss"] = (
- self.accelerator.gather_for_metrics(model_output["aux_loss"]).detach().mean().item()
- )
- return losses.mean(), metrics
+ (
+ chosen_logps,
+ rejected_logps,
+ chosen_logits_mean,
+ rejected_logits_mean,
+ nll_loss,
+ chosen_rewards,
+ rejected_rewards,
+ ) = metrics
+
+ if mode == "train":
+ num_tokens_in_batch = self.accelerator.gather_for_metrics(inputs["attention_mask"].sum()).sum().item()
+ self._total_train_tokens += num_tokens_in_batch
+ self._metrics[mode]["num_tokens"] = [self._total_train_tokens]
+
+ avg_chosen_logits = self.accelerator.gather_for_metrics(chosen_logits_mean).mean().item()
+ avg_rejected_logits = self.accelerator.gather_for_metrics(rejected_logits_mean).mean().item()
+ self._metrics[mode]["logits/chosen"].append(avg_chosen_logits)
+ self._metrics[mode]["logits/rejected"].append(avg_rejected_logits)
+
+ agg_chosen_rewards = self.accelerator.gather(chosen_rewards)
+ agg_rejected_rewards = self.accelerator.gather(rejected_rewards)
+ self._metrics[mode]["rewards/chosen"].append(agg_chosen_rewards.mean().item())
+ self._metrics[mode]["rewards/rejected"].append(agg_rejected_rewards.mean().item())
- def compute_loss(
- self,
- model: PreTrainedModel | nn.Module,
- inputs: dict[str, torch.Tensor | Any],
- return_outputs=False,
- num_items_in_batch=None,
- ) -> torch.Tensor | tuple[torch.Tensor, dict[str, float]]:
- compute_loss_context_manager = (
- autocast(self.accelerator.device.type) if self._peft_has_been_casted_to_bf16 else nullcontext()
- )
- with compute_loss_context_manager:
- loss, metrics = self.get_batch_loss_metrics(model, inputs, train_eval="train")
+ reward_accuracies = (chosen_rewards > rejected_rewards).float()
+ agg_reward_accuracies = self.accelerator.gather(reward_accuracies)
+ self._metrics[mode]["rewards/accuracies"].append(agg_reward_accuracies.mean().item())
- # Make sure to move the loss to the device the original accumulating loss is at back in the `Trainer` class:
- loss = loss.to(self.args.device)
- # force log the metrics
- self.store_metrics(metrics, train_eval="train")
+ margins = chosen_rewards - rejected_rewards
+ agg_margins = self.accelerator.gather(margins)
+ self._metrics[mode]["rewards/margins"].append(agg_margins.mean().item())
- if return_outputs:
- return loss, metrics
+ self._metrics[mode]["logps/chosen"].append(self.accelerator.gather(chosen_logps).mean().item())
+ self._metrics[mode]["logps/rejected"].append(self.accelerator.gather(rejected_logps).mean().item())
return loss
- def generate_from_model_and_ref(self, model, batch: dict[str, torch.LongTensor]) -> tuple[str, str]:
- """Generate samples from the model and reference model for the given batch of inputs."""
-
- # If one uses `generate_during_eval` with peft + bf16, we need to explicitly call generate with
- # the torch amp context manager as some hidden states are silently casted to full precision.
- generate_context_manager = (
- autocast(self.accelerator.device.type) if self._peft_has_been_casted_to_bf16 else nullcontext()
- )
-
- with generate_context_manager:
- policy_output = model.generate(
- input_ids=batch["prompt_input_ids"],
- attention_mask=batch["prompt_attention_mask"],
- max_length=self.max_length,
- do_sample=True,
- pad_token_id=self.pad_token_id,
- )
+ def _compute_loss(self, model, inputs, return_outputs):
+ mode = "train" if self.model.training else "eval"
+ device = self.accelerator.device
- # if ref_output in batch use that otherwise use the reference model
- if "ref_output" in batch:
- ref_output = batch["ref_output"]
- else:
- if self.ref_model is None:
- with self.null_ref_context():
- ref_output = self.model.generate(
- input_ids=batch["prompt_input_ids"],
- attention_mask=batch["prompt_attention_mask"],
- max_length=self.max_length,
- do_sample=True,
- pad_token_id=self.pad_token_id,
- )
+ input_ids = inputs["input_ids"]
+ attention_mask = inputs["attention_mask"]
+ completion_mask = inputs["completion_mask"]
+ input_ids, attention_mask, completion_mask = self._truncate_inputs(input_ids, attention_mask, completion_mask)
+
+ model_kwargs = {"input_ids": input_ids, "attention_mask": attention_mask, "use_cache": False}
+ for key in ("pixel_values", "pixel_attention_mask", "image_grid_thw", "image_sizes", "token_type_ids"):
+ if key in inputs:
+ model_kwargs[key] = inputs[key]
+
+ outputs = model(**model_kwargs)
+ shift_logits = outputs.logits[..., :-1, :].contiguous()
+ shift_labels = input_ids[..., 1:].contiguous()
+ shift_completion_mask = completion_mask[..., 1:].contiguous()
+ per_token_logps = selective_log_softmax(shift_logits, shift_labels)
+ per_token_logps[shift_completion_mask == 0] = 0.0 # mask out non-completion tokens
+ if self.ld_alpha is None:
+ logps = per_token_logps.sum(dim=1) # sum over sequence length
+ else:
+ comp_pos = shift_completion_mask.cumsum(dim=1)
+ comp_lens = shift_completion_mask.sum(dim=1).long()
+ chosen_lens, rejected_lens = comp_lens.chunk(2, dim=0)
+ shared_lens = torch.minimum(chosen_lens, rejected_lens)
+ shared_lens_2b = torch.cat([shared_lens, shared_lens], dim=0).to(device)
+ shared_mask = (comp_pos > 0) & (comp_pos <= shared_lens_2b.unsqueeze(1)) # shared: 1 <= pos <= shared_len
+ tail_mask = comp_pos > shared_lens_2b.unsqueeze(1) # tail: pos > shared_len
+ shared_logps = (per_token_logps * shared_mask).sum(dim=1)
+ tail_logps = (per_token_logps * tail_mask).sum(dim=1)
+ logps = shared_logps + self.ld_alpha * tail_logps
+ chosen_logps, rejected_logps = logps.chunk(2, dim=0) # batch is [chosen, rejected]
+
+ if self.precompute_ref_logps:
+ ref_chosen_logps, ref_rejected_logps = inputs["ref_chosen_logps"], inputs["ref_rejected_logps"]
+ else:
+ # When gradient checkpointing is enabled with use_reentrant=True (default), calling the model inside a
+ # torch.no_grad() block triggers a harmless PyTorch warning ("None of the inputs have requires_grad=True").
+ # Temporarily disable checkpointing to avoid this warning during inference.
+ with torch.no_grad(), disable_gradient_checkpointing(self.model, self.args.gradient_checkpointing_kwargs):
+ if is_peft_model(model) and self.ref_model is None:
+ # When training a PEFT adapter, how we obtain the reference depends on the setup:
+ # - New adapter: disabling adapters yields the base model.
+ # - Re-training an existing adapter: an initial copy is loaded under the name "ref".
+ model = self.accelerator.unwrap_model(model)
+ with use_adapter(model, adapter_name="ref" if "ref" in model.peft_config else None):
+ ref_outputs = self.model(**model_kwargs)
else:
- ref_output = self.ref_model.generate(
- input_ids=batch["prompt_input_ids"],
- attention_mask=batch["prompt_attention_mask"],
- max_length=self.max_length,
- do_sample=True,
- pad_token_id=self.pad_token_id,
- )
-
- policy_output = pad_to_length(policy_output, self.max_length, self.pad_token_id)
- policy_output_decoded = self.processing_class.batch_decode(policy_output, skip_special_tokens=True)
-
- ref_output = pad_to_length(ref_output, self.max_length, self.pad_token_id)
- ref_output_decoded = self.processing_class.batch_decode(ref_output, skip_special_tokens=True)
+ ref_outputs = self.ref_model(**model_kwargs)
- return policy_output_decoded, ref_output_decoded
-
- def prediction_step(
- self,
- model: PreTrainedModel | nn.Module,
- inputs: dict[str, torch.Tensor | Any],
- prediction_loss_only: bool,
- ignore_keys: list[str] | None = None,
- ) -> tuple[torch.Tensor, torch.Tensor | None, torch.Tensor | None]:
- if ignore_keys is None:
- if hasattr(model, "config"):
- ignore_keys = getattr(model.config, "keys_to_ignore_at_inference", [])
+ ref_shift_logits = ref_outputs.logits[..., :-1, :].contiguous()
+ ref_per_token_logps = selective_log_softmax(ref_shift_logits, shift_labels)
+ ref_per_token_logps[shift_completion_mask == 0] = 0.0 # mask out non-completion tokens
+ if self.ld_alpha is None:
+ ref_logps = ref_per_token_logps.sum(dim=1) # sum over sequence length
else:
- ignore_keys = []
+ # reuse comp_pos/shared_mask/tail_mask computed above (they depend only on completion_mask)
+ ref_shared_logps = (ref_per_token_logps * shared_mask).sum(dim=1)
+ ref_tail_logps = (ref_per_token_logps * tail_mask).sum(dim=1)
+ ref_logps = ref_shared_logps + self.ld_alpha * ref_tail_logps
+ ref_chosen_logps, ref_rejected_logps = ref_logps.chunk(2, dim=0) # batch is [chosen, rejected]
- prediction_context_manager = (
- autocast(self.accelerator.device.type) if self._peft_has_been_casted_to_bf16 else nullcontext()
- )
+ # Get the log ratios for the chosen and rejected responses
+ chosen_logratios = chosen_logps - ref_chosen_logps
+ rejected_logratios = rejected_logps - ref_rejected_logps
+
+ if self.f_divergence_type == "reverse_kl": # standard DPO
+ chosen_scores = chosen_logratios
+ rejected_scores = rejected_logratios
+ elif self.f_divergence_type == "forward_kl":
+ # f'(t) = 1 - 1/t -> drop constant -> -exp(-logratio)
+ chosen_scores = -torch.exp(-chosen_logratios)
+ rejected_scores = -torch.exp(-rejected_logratios)
+ elif self.f_divergence_type == "js_divergence":
+ # f'(t) = log(2t/(t+1)) -> drop log 2
+ chosen_scores = F.logsigmoid(chosen_logratios)
+ rejected_scores = F.logsigmoid(rejected_logratios)
+ elif self.f_divergence_type == "alpha_divergence":
+ # alpha-divergence: f'(t) = (t^(α-1) - 1)/(α-1)
+ if abs(self.f_alpha_divergence_coef - 1.0) < 1e-6: # limit case f'(t) -> log(t), fall back to reverse_kl
+ chosen_scores = chosen_logratios
+ rejected_scores = rejected_logratios
+ else:
+ coef = 1.0 / (self.f_alpha_divergence_coef - 1.0)
+ t_chosen = (self.f_alpha_divergence_coef - 1.0) * chosen_logratios
+ t_rejected = (self.f_alpha_divergence_coef - 1.0) * rejected_logratios
+ dtype = t_chosen.dtype
+ # Clamp max so exp(.) stays representable after casting back
+ clamp_max = {torch.float16: 11.0, torch.bfloat16: 80.0, torch.float32: 80.0}[dtype]
+ t_chosen_float = torch.clamp(t_chosen.float(), max=clamp_max)
+ t_rejected_float = torch.clamp(t_rejected.float(), max=clamp_max)
+ chosen_scores = torch.exp(t_chosen_float).to(dtype) * coef
+ rejected_scores = torch.exp(t_rejected_float).to(dtype) * coef
+ else:
+ raise ValueError(f"Unknown f_divergence_type: {self.f_divergence_type}")
+
+ delta_score = chosen_scores - rejected_scores
+
+ loss = 0.0
+ for loss_type, loss_weight in zip(self.loss_types, self.loss_weights, strict=True):
+ if loss_type == "sigmoid":
+ per_sequence_loss = -F.logsigmoid(self.beta * delta_score)
+
+ elif loss_type == "hinge":
+ per_sequence_loss = torch.relu(1 - self.beta * delta_score)
+
+ elif loss_type == "ipo":
+ # IPO uses sequence-level log-prob differences; in code these are token-summed over the completion,
+ # which makes the squared loss scale with completion length. We therefore normalize by the number of
+ # completion tokens (average per token) to make β/loss comparable across variable lengths. This length
+ # normalization is not explicitly discussed in the IPO paper; we confirmed this choice with the IPO
+ # authors, and the results reported in the paper correspond to this normalized form.
+ chosen_mask, rejected_mask = completion_mask.chunk(2, dim=0)
+ chosen_avg_score = chosen_scores / chosen_mask.sum(dim=1).clamp(min=1.0)
+ rejected_avg_score = rejected_scores / rejected_mask.sum(dim=1).clamp(min=1.0)
+ ipo_delta = chosen_avg_score - rejected_avg_score
+ # (Eq. 17) of the paper where beta is the regularization parameter for the IPO loss, denoted by τ.
+ per_sequence_loss = (ipo_delta - 1 / (2 * self.beta)) ** 2
+
+ elif loss_type == "exo_pair":
+ # Implements EXO-pref from the paper https://huggingface.co/papers/2402.00856, (Eq. 16)
+ # Minimize KL(p_fθ || p_rh) for K=2; p_fθ = softmax(βπ * (log πθ − log π_ref)) over {chosen, rejected}
+ # p_rh = [(1−ε), ε]; expanded KL gives the weighted logsigmoid form below
+ epsilon = torch.tensor(self.label_smoothing, device=device)
+ qw = torch.sigmoid(self.beta * delta_score)
+ log_qw = F.logsigmoid(self.beta * delta_score)
+ log_pw = torch.log1p(-epsilon)
+ ql = torch.sigmoid(-self.beta * delta_score)
+ log_ql = F.logsigmoid(-self.beta * delta_score)
+ log_pl = torch.log(epsilon)
+ per_sequence_loss = qw * (log_qw - log_pw) + ql * (log_ql - log_pl)
+
+ elif loss_type == "nca_pair":
+ chosen_rewards = self.beta * chosen_scores
+ rejected_rewards = self.beta * rejected_scores
+ per_sequence_loss = (
+ -F.logsigmoid(chosen_rewards)
+ - 0.5 * F.logsigmoid(-chosen_rewards)
+ - 0.5 * F.logsigmoid(-rejected_rewards)
+ )
- with torch.no_grad(), prediction_context_manager:
- loss, metrics = self.get_batch_loss_metrics(model, inputs, train_eval="eval")
+ elif loss_type == "robust":
+ clean_loss_term = -(1 - self.label_smoothing) * F.logsigmoid(self.beta * delta_score)
+ flipped_loss_term = -self.label_smoothing * F.logsigmoid(-self.beta * delta_score)
+ per_sequence_loss = (clean_loss_term - flipped_loss_term) / (1 - 2 * self.label_smoothing)
+
+ elif loss_type == "bco_pair":
+ chosen_rewards = self.beta * chosen_scores
+ rejected_rewards = self.beta * rejected_scores
+ per_sequence_loss = -F.logsigmoid(chosen_rewards) - F.logsigmoid(-rejected_rewards)
+
+ elif loss_type == "sppo_hard":
+ # In the paper (https://huggingface.co/papers/2405.00675), SPPO employs a soft probability approach,
+ # estimated using the PairRM score. The probability calculation is conducted outside of the trainer
+ # class. The version described here is the hard probability version, where P in Equation (4.7) of
+ # Algorithm 1 is set to 1 for the winner and 0 for the loser.
+ winner_margin_error = (chosen_scores - 0.5 / self.beta) ** 2
+ loser_margin_error = (rejected_scores + 0.5 / self.beta) ** 2
+ per_sequence_loss = winner_margin_error + loser_margin_error
+
+ elif loss_type == "aot":
+ logratios = chosen_logps - rejected_logps
+ ref_logratios = ref_chosen_logps - ref_rejected_logps
+ logratios_sorted, _ = torch.sort(logratios, dim=0)
+ ref_logratios_sorted, _ = torch.sort(ref_logratios, dim=0)
+ delta = logratios_sorted - ref_logratios_sorted
+ per_sequence_loss = (
+ -F.logsigmoid(self.beta * delta) * (1 - self.label_smoothing)
+ - F.logsigmoid(-self.beta * delta) * self.label_smoothing
+ )
- # force log the metrics
- self.store_metrics(metrics, train_eval="eval")
+ elif loss_type == "aot_unpaired":
+ chosen_logratios_sorted, _ = torch.sort(chosen_logratios, dim=0)
+ rejected_logratios_sorted, _ = torch.sort(rejected_logratios, dim=0)
+ delta = chosen_logratios_sorted - rejected_logratios_sorted
+ per_sequence_loss = (
+ -F.logsigmoid(self.beta * delta) * (1 - self.label_smoothing)
+ - F.logsigmoid(-self.beta * delta) * self.label_smoothing
+ )
- if prediction_loss_only:
- return loss.detach(), None, None
+ elif loss_type == "apo_zero":
+ # Eqn (7) of the APO paper (https://huggingface.co/papers/2408.06266)
+ # Use this loss when you believe the chosen outputs are better than your model's default output
+ # Increase chosen likelihood and decrease rejected likelihood
+ losses_chosen = 1 - torch.sigmoid(self.beta * chosen_logratios)
+ losses_rejected = torch.sigmoid(self.beta * rejected_logratios)
+ per_sequence_loss = losses_chosen + losses_rejected
+
+ elif loss_type == "apo_down":
+ # Eqn (8) of the APO paper (https://huggingface.co/papers/2408.06266)
+ # Use this loss when you believe the chosen outputs are worse than your model's default output.
+ # Decrease chosen likelihood and decrease rejected likelihood more
+ losses_chosen = torch.sigmoid(self.beta * chosen_logratios)
+ losses_rejected = 1 - torch.sigmoid(self.beta * delta_score)
+ per_sequence_loss = losses_chosen + losses_rejected
+
+ elif loss_type == "discopop":
+ # Eqn (5) of the DiscoPOP paper (https://huggingface.co/papers/2406.08414)
+ logits = delta_score * self.beta
+ # Modulate the mixing coefficient based on the log ratio magnitudes
+ log_ratio_modulation = torch.sigmoid(logits / self.args.discopop_tau)
+ logistic_component = -F.logsigmoid(logits)
+ exp_component = torch.exp(-logits)
+ # Blend between logistic and exponential component based on log ratio modulation
+ per_sequence_loss = (
+ logistic_component * (1 - log_ratio_modulation) + exp_component * log_ratio_modulation
+ )
- # logits for the chosen and rejected samples from model
- logits_dict = {
- "eval_logits/chosen": metrics["eval_logits/chosen"],
- "eval_logits/rejected": metrics["eval_logits/rejected"],
- }
- logits = [v for k, v in logits_dict.items() if k not in ignore_keys]
- logits = torch.tensor(logits, device=self.accelerator.device)
- labels = torch.zeros(logits.shape[0], device=self.accelerator.device)
+ elif loss_type == "sft":
+ chosen_logits, _ = shift_logits.chunk(2, dim=0)
+ chosen_labels, _ = shift_labels.chunk(2, dim=0)
+ chosen_mask, _ = shift_completion_mask.chunk(2, dim=0)
+ batch_loss = F.cross_entropy(chosen_logits[chosen_mask.bool()], chosen_labels[chosen_mask.bool()])
+ # Implementation convenience: expand the scalar SFT loss to a per-sequence tensor so it matches the
+ # shape of other losses; only the mean is used, so this is a no-op numerically.
+ per_sequence_loss = batch_loss.expand(chosen_logits.size(0))
- return (loss.detach(), logits, labels)
+ else:
+ raise ValueError(
+ f"Unknown loss type: {loss_type}. Should be one of ['sigmoid', 'hinge', 'ipo', 'exo_pair', "
+ "'nca_pair', 'robust', 'bco_pair', 'sppo_hard', 'aot', 'aot_unpaired', 'apo_zero', 'apo_down', "
+ "'discopop', 'sft']"
+ )
- def store_metrics(self, metrics: dict[str, float], train_eval: Literal["train", "eval"] = "train") -> None:
- for key, value in metrics.items():
- self._stored_metrics[train_eval][key].append(value)
+ if self.use_weighting:
+ # Eq (2) of the WPO paper: https://huggingface.co/papers/2406.11827
+ completion_lengths = shift_completion_mask.sum(dim=1).clamp_min(1)
+ with torch.no_grad():
+ lse1 = torch.logsumexp(shift_logits, dim=-1)
+ lse2 = torch.logsumexp(2.0 * shift_logits, dim=-1)
+ log_denom = lse2 - 2.0 * lse1
+ aligned_logps = (per_token_logps - log_denom) * shift_completion_mask
+ mean_logps = aligned_logps.sum(dim=1) / completion_lengths
+ weights = torch.exp(mean_logps)
+ chosen_weights, rejected_weights = weights.chunk(2, dim=0)
+ per_sequence_loss *= chosen_weights * rejected_weights
+
+ loss += per_sequence_loss.mean() * loss_weight
+
+ # Log the metrics
+ # Entropy
+ per_token_entropy = entropy_from_logits(shift_logits.detach())
+ entropy = per_token_entropy[shift_completion_mask.bool()].mean()
+ entropy = self.accelerator.gather_for_metrics(entropy).mean().item()
+ self._metrics[mode]["entropy"].append(entropy)
+
+ # Number of tokens
+ if mode == "train":
+ num_tokens_in_batch = self.accelerator.gather_for_metrics(inputs["attention_mask"].sum()).sum().item()
+ self._total_train_tokens += num_tokens_in_batch
+ self._metrics[mode]["num_tokens"] = [self._total_train_tokens]
+
+ # Average logits for chosen and rejected completions
+ chosen_logits, rejected_logits = shift_logits.detach().chunk(2, dim=0)
+ chosen_mask, rejected_mask = shift_completion_mask.chunk(2, dim=0)
+ total_chosen_logits = chosen_logits[chosen_mask.bool()].mean(-1).sum()
+ total_chosen_tokens = chosen_mask.sum()
+ total_rejected_logits = rejected_logits[rejected_mask.bool()].mean(-1).sum()
+ total_rejected_tokens = rejected_mask.sum()
+ total_chosen_logits = self.accelerator.gather_for_metrics(total_chosen_logits).sum().item()
+ total_chosen_tokens = self.accelerator.gather_for_metrics(total_chosen_tokens).sum().item()
+ total_rejected_logits = self.accelerator.gather_for_metrics(total_rejected_logits).sum().item()
+ total_rejected_tokens = self.accelerator.gather_for_metrics(total_rejected_tokens).sum().item()
+ avg_chosen_logits = total_chosen_logits / total_chosen_tokens if total_chosen_tokens > 0 else 0.0
+ avg_rejected_logits = total_rejected_logits / total_rejected_tokens if total_rejected_tokens > 0 else 0.0
+ self._metrics[mode]["logits/chosen"].append(avg_chosen_logits)
+ self._metrics[mode]["logits/rejected"].append(avg_rejected_logits)
+
+ # Token accuracy for the chosen completions
+ predictions = chosen_logits.argmax(dim=-1)
+ chosen_mask = shift_completion_mask[: len(shift_completion_mask) // 2].bool()
+ chosen_labels = shift_labels[: len(shift_labels) // 2]
+ correct_predictions = (predictions == chosen_labels) & chosen_mask
+ total_tokens = chosen_mask.sum()
+ correct_tokens = correct_predictions.sum()
+ correct_tokens = self.accelerator.gather_for_metrics(correct_tokens)
+ total_tokens = self.accelerator.gather_for_metrics(total_tokens)
+ total_sum = total_tokens.sum()
+ accuracy = (correct_tokens.sum() / total_sum).item() if total_sum > 0 else 0.0
+ self._metrics[mode]["mean_token_accuracy"].append(accuracy)
+
+ # Rewards for chosen and rejected completions
+ chosen_rewards = self.beta * chosen_logratios.detach()
+ rejected_rewards = self.beta * rejected_logratios.detach()
+ agg_chosen_rewards = self.accelerator.gather(chosen_rewards)
+ agg_rejected_rewards = self.accelerator.gather(rejected_rewards)
+ self._metrics[mode]["rewards/chosen"].append(agg_chosen_rewards.mean().item())
+ self._metrics[mode]["rewards/rejected"].append(agg_rejected_rewards.mean().item())
+
+ # Reward accuracy
+ reward_accuracies = (chosen_rewards > rejected_rewards).float()
+ agg_reward_accuracies = self.accelerator.gather(reward_accuracies)
+ self._metrics[mode]["rewards/accuracies"].append(agg_reward_accuracies.mean().item())
- def evaluation_loop(
- self,
- dataloader: DataLoader,
- description: str,
- prediction_loss_only: bool | None = None,
- ignore_keys: list[str] | None = None,
- metric_key_prefix: str = "eval",
- ) -> EvalLoopOutput:
- """
- Overriding built-in evaluation loop to store metrics for each batch. Prediction/evaluation loop, shared by
- `Trainer.evaluate()` and `Trainer.predict()`.
-
- Works both with or without labels.
- """
-
- # Sample and save to game log if requested (for one batch to save time)
- if self.generate_during_eval:
- # Generate random indices within the range of the total number of samples
- num_samples = len(dataloader.dataset)
- random_indices = random.sample(range(num_samples), k=self.args.eval_batch_size)
-
- # Use dataloader.dataset.select to get the random batch without iterating over the DataLoader
- random_batch_dataset = dataloader.dataset.select(random_indices)
- random_batch = self.data_collator(random_batch_dataset)
- random_batch = self._prepare_inputs(random_batch)
-
- policy_output_decoded, ref_output_decoded = self.generate_from_model_and_ref(self.model, random_batch)
-
- table = pd.DataFrame(
- columns=["Prompt", "Policy", "Ref Model"],
- data=[
- [prompt, pol[len(prompt) :], ref[len(prompt) :]]
- for prompt, pol, ref in zip(
- random_batch_dataset["prompt"], policy_output_decoded, ref_output_decoded, strict=True
- )
- ],
- )
- if "wandb" in self.args.report_to and self.accelerator.is_main_process:
- wandb.log({"game_log": wandb.Table(data=table)})
+ # Reward margins
+ margins = chosen_rewards - rejected_rewards
+ agg_margins = self.accelerator.gather(margins)
+ self._metrics[mode]["rewards/margins"].append(agg_margins.mean().item())
- if "comet_ml" in self.args.report_to:
- log_table_to_comet_experiment(
- name="game_log.csv",
- table=table,
- )
+ # Average log probabilities for chosen and rejected completions
+ self._metrics[mode]["logps/chosen"].append(self.accelerator.gather(chosen_logps).mean().item())
+ self._metrics[mode]["logps/rejected"].append(self.accelerator.gather(rejected_logps).mean().item())
- if "mlflow" in self.args.report_to and self.accelerator.is_main_process:
- mlflow.log_table(data=table, artifact_file="game_log.json")
+ return (loss, outputs) if return_outputs else loss
- # Base evaluation
- initial_output = super().evaluation_loop(
- dataloader, description, prediction_loss_only, ignore_keys, metric_key_prefix
- )
+ def compute_loss(self, model, inputs, return_outputs=False, num_items_in_batch=None):
+ if self.use_liger_kernel:
+ return self._compute_loss_liger(model, inputs, return_outputs)
+ else:
+ return self._compute_loss(model, inputs, return_outputs)
- return initial_output
+ # Override training step to add activation offloading context.
+ def training_step(self, *args, **kwargs):
+ with self.maybe_activation_offload_context:
+ return super().training_step(*args, **kwargs)
def log(self, logs: dict[str, float], start_time: float | None = None) -> None:
- """
- Log `logs` on the various objects watching training, including stored metrics.
-
- Args:
- logs (`dict[str, float]`):
- The values to log.
- start_time (`float`, *optional*):
- Start time of the training.
- """
- # logs either has 'loss' or 'eval_loss'
- train_eval = "train" if "loss" in logs else "eval"
- # Add averaged stored metrics to logs
- for key, metrics in self._stored_metrics[train_eval].items():
- logs[key] = torch.tensor(metrics).mean().item()
- del self._stored_metrics[train_eval]
- return super().log(logs, start_time)
+ mode = "train" if self.model.training else "eval"
+ metrics = {key: sum(val) / len(val) for key, val in self._metrics[mode].items()} # average the metrics
+
+ # This method can be called both in training and evaluation. When called in evaluation, the keys in `logs`
+ # start with "eval_". We need to add the prefix "eval_" to the keys in `metrics` to match the format.
+ if mode == "eval":
+ metrics = {f"eval_{key}": val for key, val in metrics.items()}
+
+ logs = {**logs, **metrics}
+ super().log(logs, start_time)
+ self._metrics[mode].clear()
+
+ # During eval, Trainer calls prediction_step. If no labels are present in the inputs, it only runs forward and
+ # returns logits. We override prediction_step to force compute_loss, because this trainer doesn't involve labels.
+ def prediction_step(self, model, inputs, prediction_loss_only, ignore_keys: list[str] | None = None):
+ inputs = self._prepare_inputs(inputs)
+ with torch.no_grad(), self.compute_loss_context_manager():
+ if prediction_loss_only:
+ loss = self.compute_loss(model, inputs, return_outputs=False) # logits aren't materialized with liger
+ logits, labels = None, None
+ else:
+ loss, outputs = self.compute_loss(model, inputs, return_outputs=True)
+ logits, labels = outputs.logits, inputs["input_ids"]
+ return loss, logits, labels
# Ensure the model card is saved along with the checkpoint
def _save_checkpoint(self, model, trial):
diff --git a/trl/trainer/sft_trainer.py b/trl/trainer/sft_trainer.py
index 763a15f015b..7715859655a 100644
--- a/trl/trainer/sft_trainer.py
+++ b/trl/trainer/sft_trainer.py
@@ -393,7 +393,7 @@ def _collate_prompt_completion(self, examples: list[dict[str, Any]]) -> dict[str
if self.pad_to_multiple_of is not None:
raise NotImplementedError(
"Padding to a multiple of a value is not yet implemented for vision-language modeling and "
- "prompt-completion data yet."
+ "prompt-completion data."
)
images = [example["images"] for example in examples]
# Transformers requires at least one image in the batch, otherwise it throws an error
diff --git a/trl/trainer/utils.py b/trl/trainer/utils.py
index 36f3b4ff5ce..ca653ce6815 100644
--- a/trl/trainer/utils.py
+++ b/trl/trainer/utils.py
@@ -13,9 +13,8 @@
# limitations under the License.
import asyncio
-import dataclasses
+import hashlib
import importlib.resources as pkg_resources
-import json
import os
import random
import socket
@@ -32,7 +31,7 @@
import torch
import torch.nn.functional as F
import transformers
-from accelerate import Accelerator, PartialState, logging
+from accelerate import PartialState, logging
from accelerate.state import AcceleratorState
from huggingface_hub import ModelCard, ModelCardData
from torch.utils.data import Sampler
@@ -49,8 +48,6 @@
from transformers.utils import (
is_peft_available,
is_rich_available,
- is_torch_mlu_available,
- is_torch_npu_available,
is_torch_xpu_available,
)
@@ -180,101 +177,6 @@ def pad(
return output
-@dataclass
-class RunningMoments:
- """
- Calculates the running mean and standard deviation of a data stream. Reference:
- https://github.com/OpenLMLab/MOSS-RLHF/blob/40b91eb2f2b71b16919addede0341d2bef70825d/utils.py#L75
- """
-
- accelerator: Accelerator
- mean: float = 0
- std: float = 1
- var: float = 1
- count: float = 1e-24
-
- @torch.no_grad()
- def update(self, xs: torch.Tensor) -> tuple[float, float]:
- """
- Updates running moments from batch's moments computed across ranks
- """
- if self.accelerator.use_distributed:
- xs_mean, xs_var, xs_count = get_global_statistics(self.accelerator, xs)
- else:
- xs_count = xs.numel()
- xs_var, xs_mean = torch.var_mean(xs, unbiased=False)
- xs_mean, xs_var = xs_mean.float(), xs_var.float()
-
- delta = xs_mean - self.mean
- tot_count = self.count + xs_count
-
- new_sum = xs_var * xs_count
- # correct old_sum deviation accounting for the new mean
- old_sum = self.var * self.count + delta**2 * self.count * xs_count / tot_count
- tot_sum = old_sum + new_sum
-
- self.mean += (delta * xs_count / tot_count).item()
- new_var = tot_sum / tot_count
- self.std = (new_var * tot_count / (tot_count - 1)).float().sqrt().item()
- self.var = new_var.item()
- self.count = tot_count
-
- return xs_mean.item(), (xs_var * xs_count / (xs_count - 1)).float().sqrt().item()
-
- def save_to_json(self, json_path: str):
- """Save the content of this instance in JSON format inside `json_path`."""
- # save everything except accelerator
- if self.accelerator.is_main_process:
- save_dict = dataclasses.asdict(self, dict_factory=lambda x: {k: v for (k, v) in x if k != "accelerator"})
- json_string = json.dumps(save_dict, indent=2, sort_keys=True) + "\n"
- with open(json_path, "w", encoding="utf-8") as f:
- f.write(json_string)
-
- @classmethod
- def load_from_json(cls, accelerator: Accelerator, json_path: str):
- """Create an instance from the content of `json_path`."""
- # load everything except accelerator
- with open(json_path, encoding="utf-8") as f:
- text = f.read()
- return cls(accelerator=accelerator, **json.loads(text))
-
-
-@torch.no_grad()
-def get_global_statistics(
- accelerator, xs: torch.Tensor, mask=None, device="cpu"
-) -> tuple[torch.Tensor, torch.Tensor, int]:
- """
- Computes element-wise mean and variance of the tensor across processes. Reference:
- https://github.com/OpenLMLab/MOSS-RLHF/blob/40b91eb2f2b71b16919addede0341d2bef70825d/utils.py#L57C1-L73C75
- """
- xs = xs.to(accelerator.device)
- sum_and_count = torch.tensor([xs.sum(), (xs.numel() if mask is None else mask.sum())], device=xs.device)
- sum_and_count = accelerator.reduce(sum_and_count)
- global_sum, count = sum_and_count
- global_mean = global_sum / count
-
- sum_var = torch.sum(((xs - global_mean) ** 2).mul(1 if mask is None else mask))
- sum_var = accelerator.reduce(sum_var)
- global_var = sum_var / count
-
- return global_mean.to(device), global_var.to(device), count.item()
-
-
-def pad_to_length(tensor: torch.Tensor, length: int, pad_value: int | float, dim: int = -1) -> torch.Tensor:
- if tensor.size(dim) >= length:
- return tensor
- else:
- pad_size = list(tensor.shape)
- pad_size[dim] = length - tensor.size(dim)
- return torch.cat(
- [
- tensor,
- pad_value * torch.ones(*pad_size, dtype=tensor.dtype, device=tensor.device),
- ],
- dim=dim,
- )
-
-
def disable_dropout_in_model(model: torch.nn.Module) -> None:
for module in model.modules():
if isinstance(module, torch.nn.Dropout):
@@ -333,29 +235,6 @@ def get_peft_config(model_args: ModelConfig) -> "PeftConfig | None":
return peft_config
-def get_exp_cap(value, decimal=4):
- """
- Get the exponent cap of a value. This is used to cap the exponent of a value to avoid overflow. The formula is :
- log(value.dtype.max) E.g. for float32 data type, the maximum exponent value is 88.7228 to 4 decimal points.
-
- Args:
- value (`torch.Tensor`):
- The input tensor to obtain the data type
- decimal (`int`):
- The number of decimal points of the output exponent cap. eg: direct calling exp(log(torch.float32.max))
- will result in inf so we cap the exponent to 88.7228 to avoid overflow.
- """
- vdtype_max = torch.zeros([1]).to(value.dtype) + torch.finfo(value.dtype).max
- vdtype_log_max = torch.log(vdtype_max).to(value.device)
- return torch.floor(vdtype_log_max * 10**decimal) / 10**decimal if decimal > 0 else vdtype_log_max
-
-
-def cap_exp(value, cap=-1):
- # Cap the exponent value below the upper-bound to avoid overflow, before calling torch.exp
- cap = get_exp_cap(value) if cap < 0 else cap
- return torch.exp(torch.clamp(value, max=cap))
-
-
def prepare_deepspeed(
model: torch.nn.Module, per_device_train_batch_size: int, fp16: bool = False, bf16: bool = False
) -> torch.nn.Module:
@@ -414,24 +293,6 @@ def prepare_deepspeed(
return model
-def empty_cache() -> None:
- """Empties the cache of the available torch device.
-
- This function checks for the availability of different torch devices (XPU, MLU, NPU, CUDA) and empties the cache of
- the first available device it finds.
-
- If none of the specific devices are available, it defaults to emptying the CUDA cache.
- """
- if is_torch_xpu_available():
- torch.xpu.empty_cache()
- elif is_torch_mlu_available():
- torch.mlu.empty_cache()
- elif is_torch_npu_available():
- torch.npu.empty_cache()
- else:
- torch.cuda.empty_cache()
-
-
def generate_model_card(
base_model: str | None,
model_name: str,
@@ -1207,6 +1068,17 @@ def create_model_from_path(
return model
+def hash_module(module: torch.nn.Module) -> str:
+ h = hashlib.sha256()
+ for _, tensor in sorted(module.state_dict().items()):
+ tensor = tensor.cpu()
+ h.update(str(tensor.dtype).encode())
+ if tensor.dtype in [torch.bfloat16, torch.float8_e4m3fn, torch.float8_e5m2]:
+ tensor = tensor.to(torch.float32)
+ h.update(tensor.numpy().tobytes())
+ return h.hexdigest()
+
+
def get_config_model_id(config: PretrainedConfig) -> str:
"""
Retrieve the model identifier from a given model configuration.