diff --git a/docs/source/_toctree.yml b/docs/source/_toctree.yml
index e69a418f305..37ca392e4e1 100644
--- a/docs/source/_toctree.yml
+++ b/docs/source/_toctree.yml
@@ -37,6 +37,8 @@
title: CPO Trainer
- local: ddpo_trainer
title: Denoising Diffusion Policy Optimization
+ - local: alignprop_trainer
+ title: AlignProp Trainer
- local: orpo_trainer
title: ORPO Trainer
- local: iterative_sft_trainer
diff --git a/docs/source/alignprop_trainer.mdx b/docs/source/alignprop_trainer.mdx
new file mode 100644
index 00000000000..f1c508f529e
--- /dev/null
+++ b/docs/source/alignprop_trainer.mdx
@@ -0,0 +1,91 @@
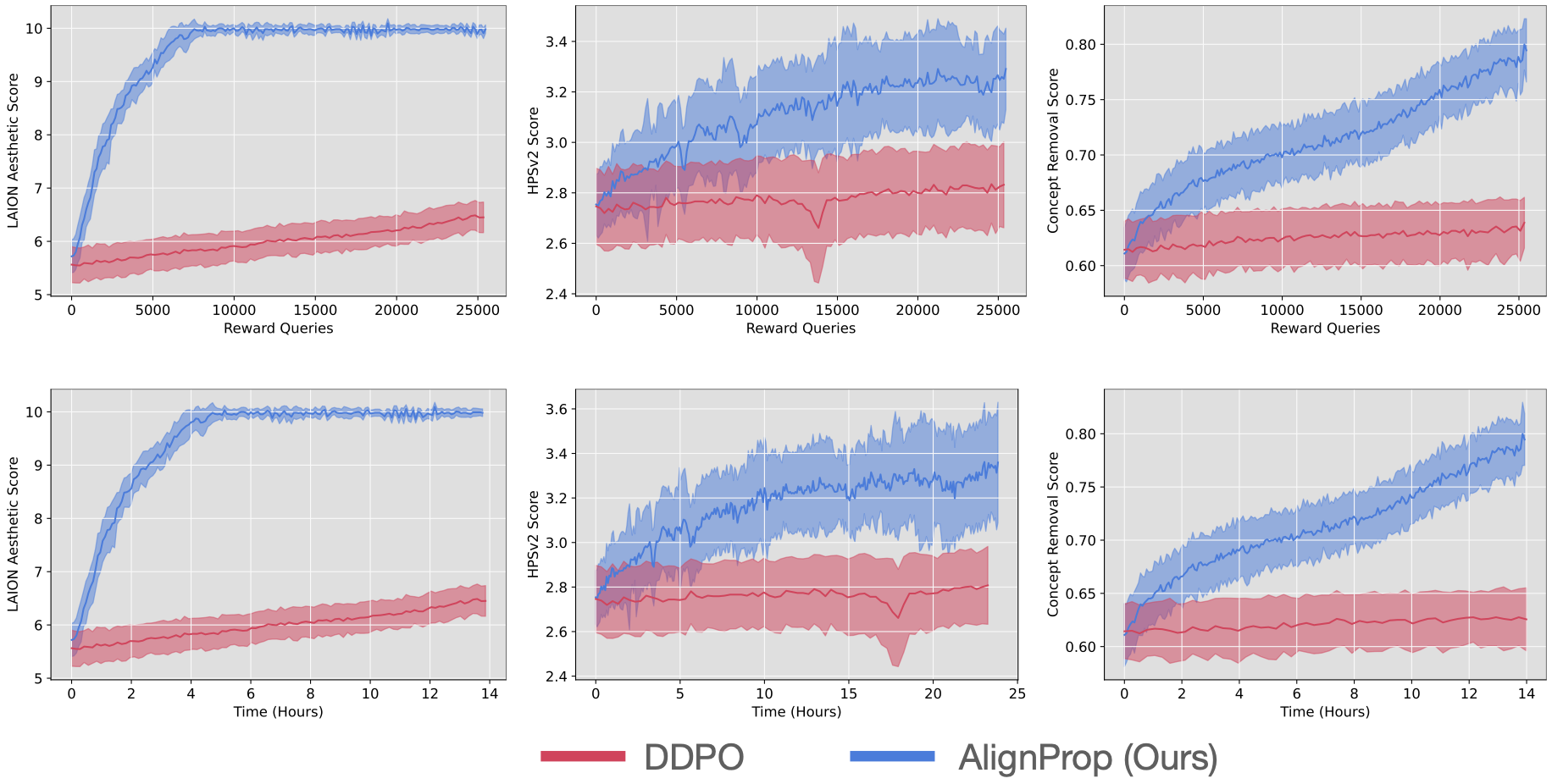
+# Aligning Text-to-Image Diffusion Models with Reward Backpropagation
+
+## The why
+
+If your reward function is differentiable, directly backpropagating gradients from the reward models to the diffusion model is significantly more sample and compute efficient (25x) than doing policy gradient algorithm like DDPO.
+AlignProp does full backpropagation through time, which allows updating the earlier steps of denoising via reward backpropagation.
+
+