diff --git a/README.md b/README.md
index b11f5bc48dc8..9b0909f6cf84 100644
--- a/README.md
+++ b/README.md
@@ -399,6 +399,7 @@ Current number of checkpoints: ** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
1. **[Informer](https://huggingface.co/docs/transformers/model_doc/informer)** (from Beihang University, UC Berkeley, Rutgers University, SEDD Company) released with the paper [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
1. **[InstructBLIP](https://huggingface.co/docs/transformers/model_doc/instructblip)** (from Salesforce) released with the paper [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
+1. **[Jamba](https://huggingface.co/docs/transformers/main/model_doc/jamba)** (from AI21 Labs Ltd.) released with the paper [Jamba: A Hybrid Transformer-Mamba Language Model](https://arxiv.org/abs/2403.19887) by Opher Lieber, Barak Lenz, Hofit Bata, Gal Cohen, Jhonathan Osin, Itay Dalmedigos, Erez Safahi, Shaked Meirom, Yonatan Belinkov, Shai Shalev-Shwartz, Omri Abend, Raz Alon, Tomer Asida, Amir Bergman, Roman Glozman, Michael Gokhman, Avshalom Manevich, Nir Ratner, Noam Rozen, Erez Shwartz, Mor Zusman, Yoav Shoham.
1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (from OpenAI) released with the paper [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
1. **[KOSMOS-2](https://huggingface.co/docs/transformers/model_doc/kosmos-2)** (from Microsoft Research Asia) released with the paper [Kosmos-2: Grounding Multimodal Large Language Models to the World](https://arxiv.org/abs/2306.14824) by Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
diff --git a/README_de.md b/README_de.md
index a78fd6b11b2e..a3f50c382a3c 100644
--- a/README_de.md
+++ b/README_de.md
@@ -395,6 +395,7 @@ Aktuelle Anzahl der Checkpoints: ** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
1. **[Informer](https://huggingface.co/docs/transformers/model_doc/informer)** (from Beihang University, UC Berkeley, Rutgers University, SEDD Company) released with the paper [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
1. **[InstructBLIP](https://huggingface.co/docs/transformers/model_doc/instructblip)** (from Salesforce) released with the paper [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
+1. **[Jamba](https://huggingface.co/docs/transformers/main/model_doc/jamba)** (from AI21 Labs Ltd.) released with the paper [Jamba: A Hybrid Transformer-Mamba Language Model](https://arxiv.org/abs/2403.19887) by Opher Lieber, Barak Lenz, Hofit Bata, Gal Cohen, Jhonathan Osin, Itay Dalmedigos, Erez Safahi, Shaked Meirom, Yonatan Belinkov, Shai Shalev-Shwartz, Omri Abend, Raz Alon, Tomer Asida, Amir Bergman, Roman Glozman, Michael Gokhman, Avshalom Manevich, Nir Ratner, Noam Rozen, Erez Shwartz, Mor Zusman, Yoav Shoham.
1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (from OpenAI) released with the paper [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
1. **[KOSMOS-2](https://huggingface.co/docs/transformers/model_doc/kosmos-2)** (from Microsoft Research Asia) released with the paper [Kosmos-2: Grounding Multimodal Large Language Models to the World](https://arxiv.org/abs/2306.14824) by Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
diff --git a/README_es.md b/README_es.md
index bcfbaa4e81e6..19523cc7b371 100644
--- a/README_es.md
+++ b/README_es.md
@@ -372,6 +372,7 @@ Número actual de puntos de control: ** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
1. **[Informer](https://huggingface.co/docs/transformers/model_doc/informer)** (from Beihang University, UC Berkeley, Rutgers University, SEDD Company) released with the paper [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
1. **[InstructBLIP](https://huggingface.co/docs/transformers/model_doc/instructblip)** (from Salesforce) released with the paper [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
+1. **[Jamba](https://huggingface.co/docs/transformers/main/model_doc/jamba)** (from AI21 Labs Ltd.) released with the paper [Jamba: A Hybrid Transformer-Mamba Language Model](https://arxiv.org/abs/2403.19887) by Opher Lieber, Barak Lenz, Hofit Bata, Gal Cohen, Jhonathan Osin, Itay Dalmedigos, Erez Safahi, Shaked Meirom, Yonatan Belinkov, Shai Shalev-Shwartz, Omri Abend, Raz Alon, Tomer Asida, Amir Bergman, Roman Glozman, Michael Gokhman, Avshalom Manevich, Nir Ratner, Noam Rozen, Erez Shwartz, Mor Zusman, Yoav Shoham.
1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (from OpenAI) released with the paper [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
1. **[KOSMOS-2](https://huggingface.co/docs/transformers/model_doc/kosmos-2)** (from Microsoft Research Asia) released with the paper [Kosmos-2: Grounding Multimodal Large Language Models to the World](https://arxiv.org/abs/2306.14824) by Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
diff --git a/README_fr.md b/README_fr.md
index 788d5344c212..2aaaf243570c 100644
--- a/README_fr.md
+++ b/README_fr.md
@@ -393,6 +393,7 @@ Nombre actuel de points de contrôle : ** (d'OpenAI) a été publié dans l'article [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) par Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
1. **[Informer](https://huggingface.co/docs/transformers/model_doc/informer)** (de l'Université de Beihang, UC Berkeley, Rutgers University, SEDD Company) a été publié dans l'article [Informer : Au-delà du Transformer efficace pour la prévision de séries temporel
1. **[InstructBLIP](https://huggingface.co/docs/transformers/model_doc/instructblip)** (de Salesforce) a été publié dans l'article [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) de Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
+1. **[Jamba](https://huggingface.co/docs/transformers/main/model_doc/jamba)** (from AI21 Labs Ltd.) released with the paper [Jamba: A Hybrid Transformer-Mamba Language Model](https://arxiv.org/abs/2403.19887) by Opher Lieber, Barak Lenz, Hofit Bata, Gal Cohen, Jhonathan Osin, Itay Dalmedigos, Erez Safahi, Shaked Meirom, Yonatan Belinkov, Shai Shalev-Shwartz, Omri Abend, Raz Alon, Tomer Asida, Amir Bergman, Roman Glozman, Michael Gokhman, Avshalom Manevich, Nir Ratner, Noam Rozen, Erez Shwartz, Mor Zusman, Yoav Shoham.
1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (d'OpenAI) a été publié dans l'article [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) de Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
1. **[KOSMOS-2](https://huggingface.co/docs/transformers/model_doc/kosmos-2)** (de Microsoft Research Asia) a été publié dans l'article [Kosmos-2: Grounding Multimodal Large Language Models to the World](https://arxiv.org/abs/2306.14824) de Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (de Microsoft Research Asia) a été publié dans l'article [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) de Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
diff --git a/README_hd.md b/README_hd.md
index d4500d685002..b859c2931e78 100644
--- a/README_hd.md
+++ b/README_hd.md
@@ -346,6 +346,7 @@ conda install conda-forge::transformers
1. **[ImageGPT](https://huggingface.co/docs/transformers/model_doc/imagegpt)** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
1. **[Informer](https://huggingface.co/docs/transformers/model_doc/informer)** (from Beihang University, UC Berkeley, Rutgers University, SEDD Company) released with the paper [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
1. **[InstructBLIP](https://huggingface.co/docs/transformers/model_doc/instructblip)** (Salesforce से) Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi. द्वाराअनुसंधान पत्र [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) के साथ जारी किया गया
+1. **[Jamba](https://huggingface.co/docs/transformers/main/model_doc/jamba)** (from AI21 Labs Ltd.) released with the paper [Jamba: A Hybrid Transformer-Mamba Language Model](https://arxiv.org/abs/2403.19887) by Opher Lieber, Barak Lenz, Hofit Bata, Gal Cohen, Jhonathan Osin, Itay Dalmedigos, Erez Safahi, Shaked Meirom, Yonatan Belinkov, Shai Shalev-Shwartz, Omri Abend, Raz Alon, Tomer Asida, Amir Bergman, Roman Glozman, Michael Gokhman, Avshalom Manevich, Nir Ratner, Noam Rozen, Erez Shwartz, Mor Zusman, Yoav Shoham.
1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (from OpenAI) released with the paper [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
1. **[KOSMOS-2](https://huggingface.co/docs/transformers/model_doc/kosmos-2)** (from Microsoft Research Asia) released with the paper [Kosmos-2: Grounding Multimodal Large Language Models to the World](https://arxiv.org/abs/2306.14824) by Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
diff --git a/README_ja.md b/README_ja.md
index dd0ca695a890..af10255ac418 100644
--- a/README_ja.md
+++ b/README_ja.md
@@ -406,6 +406,7 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
1. **[ImageGPT](https://huggingface.co/docs/transformers/model_doc/imagegpt)** (OpenAI から) Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever から公開された研究論文: [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/)
1. **[Informer](https://huggingface.co/docs/transformers/model_doc/informer)** (from Beihang University, UC Berkeley, Rutgers University, SEDD Company) released with the paper [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
1. **[InstructBLIP](https://huggingface.co/docs/transformers/model_doc/instructblip)** (Salesforce から) Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi. から公開された研究論文 [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500)
+1. **[Jamba](https://huggingface.co/docs/transformers/main/model_doc/jamba)** (from AI21 Labs Ltd.) released with the paper [Jamba: A Hybrid Transformer-Mamba Language Model](https://arxiv.org/abs/2403.19887) by Opher Lieber, Barak Lenz, Hofit Bata, Gal Cohen, Jhonathan Osin, Itay Dalmedigos, Erez Safahi, Shaked Meirom, Yonatan Belinkov, Shai Shalev-Shwartz, Omri Abend, Raz Alon, Tomer Asida, Amir Bergman, Roman Glozman, Michael Gokhman, Avshalom Manevich, Nir Ratner, Noam Rozen, Erez Shwartz, Mor Zusman, Yoav Shoham.
1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (OpenAI から) Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever から公開された研究論文: [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf)
1. **[KOSMOS-2](https://huggingface.co/docs/transformers/model_doc/kosmos-2)** (from Microsoft Research Asia) released with the paper [Kosmos-2: Grounding Multimodal Large Language Models to the World](https://arxiv.org/abs/2306.14824) by Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (Microsoft Research Asia から) Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou から公開された研究論文: [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318)
diff --git a/README_ko.md b/README_ko.md
index 8e90082e7603..f471611a6fce 100644
--- a/README_ko.md
+++ b/README_ko.md
@@ -321,6 +321,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
1. **[ImageGPT](https://huggingface.co/docs/transformers/model_doc/imagegpt)** (OpenAI 에서) Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever 의 [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) 논문과 함께 발표했습니다.
1. **[Informer](https://huggingface.co/docs/transformers/model_doc/informer)** (from Beihang University, UC Berkeley, Rutgers University, SEDD Company) released with the paper [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
1. **[InstructBLIP](https://huggingface.co/docs/transformers/model_doc/instructblip)** (Salesforce 에서 제공)은 Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.의 [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500)논문과 함께 발표했습니다.
+1. **[Jamba](https://huggingface.co/docs/transformers/main/model_doc/jamba)** (from AI21 Labs Ltd.) released with the paper [Jamba: A Hybrid Transformer-Mamba Language Model](https://arxiv.org/abs/2403.19887) by Opher Lieber, Barak Lenz, Hofit Bata, Gal Cohen, Jhonathan Osin, Itay Dalmedigos, Erez Safahi, Shaked Meirom, Yonatan Belinkov, Shai Shalev-Shwartz, Omri Abend, Raz Alon, Tomer Asida, Amir Bergman, Roman Glozman, Michael Gokhman, Avshalom Manevich, Nir Ratner, Noam Rozen, Erez Shwartz, Mor Zusman, Yoav Shoham.
1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (OpenAI 에서) Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever 의 [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) 논문과 함께 발표했습니다.
1. **[KOSMOS-2](https://huggingface.co/docs/transformers/model_doc/kosmos-2)** (from Microsoft Research Asia) released with the paper [Kosmos-2: Grounding Multimodal Large Language Models to the World](https://arxiv.org/abs/2306.14824) by Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (Microsoft Research Asia 에서) Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou 의 [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) 논문과 함께 발표했습니다.
diff --git a/README_pt-br.md b/README_pt-br.md
index 76f5e8ca08d2..379176fa42ee 100644
--- a/README_pt-br.md
+++ b/README_pt-br.md
@@ -404,6 +404,7 @@ Número atual de pontos de verificação: ** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
1. **[Informer](https://huggingface.co/docs/transformers/model_doc/informer)** (from Beihang University, UC Berkeley, Rutgers University, SEDD Company) released with the paper [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
1. **[InstructBLIP](https://huggingface.co/docs/transformers/model_doc/instructblip)** (from Salesforce) released with the paper [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
+1. **[Jamba](https://huggingface.co/docs/transformers/main/model_doc/jamba)** (from AI21 Labs Ltd.) released with the paper [Jamba: A Hybrid Transformer-Mamba Language Model](https://arxiv.org/abs/2403.19887) by Opher Lieber, Barak Lenz, Hofit Bata, Gal Cohen, Jhonathan Osin, Itay Dalmedigos, Erez Safahi, Shaked Meirom, Yonatan Belinkov, Shai Shalev-Shwartz, Omri Abend, Raz Alon, Tomer Asida, Amir Bergman, Roman Glozman, Michael Gokhman, Avshalom Manevich, Nir Ratner, Noam Rozen, Erez Shwartz, Mor Zusman, Yoav Shoham.
1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (from OpenAI) released with the paper [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
1. **[KOSMOS-2](https://huggingface.co/docs/transformers/model_doc/kosmos-2)** (from Microsoft Research Asia) released with the paper [Kosmos-2: Grounding Multimodal Large Language Models to the World](https://arxiv.org/abs/2306.14824) by Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
diff --git a/README_ru.md b/README_ru.md
index 0f75eac533d2..ca8d27b4e880 100644
--- a/README_ru.md
+++ b/README_ru.md
@@ -394,6 +394,7 @@ conda install conda-forge::transformers
1. **[ImageGPT](https://huggingface.co/docs/transformers/model_doc/imagegpt)** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
1. **[Informer](https://huggingface.co/docs/transformers/model_doc/informer)** (from Beihang University, UC Berkeley, Rutgers University, SEDD Company) released with the paper [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
1. **[InstructBLIP](https://huggingface.co/docs/transformers/model_doc/instructblip)** (from Salesforce) released with the paper [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
+1. **[Jamba](https://huggingface.co/docs/transformers/main/model_doc/jamba)** (from AI21 Labs Ltd.) released with the paper [Jamba: A Hybrid Transformer-Mamba Language Model](https://arxiv.org/abs/2403.19887) by Opher Lieber, Barak Lenz, Hofit Bata, Gal Cohen, Jhonathan Osin, Itay Dalmedigos, Erez Safahi, Shaked Meirom, Yonatan Belinkov, Shai Shalev-Shwartz, Omri Abend, Raz Alon, Tomer Asida, Amir Bergman, Roman Glozman, Michael Gokhman, Avshalom Manevich, Nir Ratner, Noam Rozen, Erez Shwartz, Mor Zusman, Yoav Shoham.
1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (from OpenAI) released with the paper [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
1. **[KOSMOS-2](https://huggingface.co/docs/transformers/model_doc/kosmos-2)** (from Microsoft Research Asia) released with the paper [Kosmos-2: Grounding Multimodal Large Language Models to the World](https://arxiv.org/abs/2306.14824) by Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
diff --git a/README_te.md b/README_te.md
index a629d02f4718..4651bb7f6389 100644
--- a/README_te.md
+++ b/README_te.md
@@ -396,6 +396,7 @@ Flax, PyTorch లేదా TensorFlow యొక్క ఇన్స్టా
1. **[ImageGPT](https://huggingface.co/docs/transformers/model_doc/imagegpt)** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
1. **[Informer](https://huggingface.co/docs/transformers/model_doc/informer)** (from Beihang University, UC Berkeley, Rutgers University, SEDD Company) released with the paper [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
1. **[InstructBLIP](https://huggingface.co/docs/transformers/model_doc/instructblip)** (from Salesforce) released with the paper [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
+1. **[Jamba](https://huggingface.co/docs/transformers/main/model_doc/jamba)** (from AI21 Labs Ltd.) released with the paper [Jamba: A Hybrid Transformer-Mamba Language Model](https://arxiv.org/abs/2403.19887) by Opher Lieber, Barak Lenz, Hofit Bata, Gal Cohen, Jhonathan Osin, Itay Dalmedigos, Erez Safahi, Shaked Meirom, Yonatan Belinkov, Shai Shalev-Shwartz, Omri Abend, Raz Alon, Tomer Asida, Amir Bergman, Roman Glozman, Michael Gokhman, Avshalom Manevich, Nir Ratner, Noam Rozen, Erez Shwartz, Mor Zusman, Yoav Shoham.
1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (from OpenAI) released with the paper [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
1. **[KOSMOS-2](https://huggingface.co/docs/transformers/model_doc/kosmos-2)** (from Microsoft Research Asia) released with the paper [Kosmos-2: Grounding Multimodal Large Language Models to the World](https://arxiv.org/abs/2306.14824) by Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
diff --git a/README_vi.md b/README_vi.md
index 0f3129d8c029..67981890770a 100644
--- a/README_vi.md
+++ b/README_vi.md
@@ -395,6 +395,7 @@ Số lượng điểm kiểm tra hiện tại: ** (từ OpenAI) được phát hành với bài báo [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
1. **[Informer](https://huggingface.co/docs/transformers/model_doc/informer)** (từ Beihang University, UC Berkeley, Rutgers University, SEDD Company) được phát hành với bài báo [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
1. **[InstructBLIP](https://huggingface.co/docs/transformers/model_doc/instructblip)** (từ Salesforce) được phát hành với bài báo [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
+1. **[Jamba](https://huggingface.co/docs/transformers/main/model_doc/jamba)** (from AI21 Labs Ltd.) released with the paper [Jamba: A Hybrid Transformer-Mamba Language Model](https://arxiv.org/abs/2403.19887) by Opher Lieber, Barak Lenz, Hofit Bata, Gal Cohen, Jhonathan Osin, Itay Dalmedigos, Erez Safahi, Shaked Meirom, Yonatan Belinkov, Shai Shalev-Shwartz, Omri Abend, Raz Alon, Tomer Asida, Amir Bergman, Roman Glozman, Michael Gokhman, Avshalom Manevich, Nir Ratner, Noam Rozen, Erez Shwartz, Mor Zusman, Yoav Shoham.
1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (từ OpenAI) được phát hành với bài báo [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
1. **[KOSMOS-2](https://huggingface.co/docs/transformers/model_doc/kosmos-2)** (từ Microsoft Research Asia) được phát hành với bài báo [Kosmos-2: Grounding Multimodal Large Language Models to the World](https://arxiv.org/abs/2306.14824) by Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (từ Microsoft Research Asia) được phát hành với bài báo [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
diff --git a/README_zh-hans.md b/README_zh-hans.md
index e5a5eb7c0b16..04d9c22d51b9 100644
--- a/README_zh-hans.md
+++ b/README_zh-hans.md
@@ -345,6 +345,7 @@ conda install conda-forge::transformers
1. **[ImageGPT](https://huggingface.co/docs/transformers/model_doc/imagegpt)** (来自 OpenAI) 伴随论文 [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) 由 Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever 发布。
1. **[Informer](https://huggingface.co/docs/transformers/model_doc/informer)** (from Beihang University, UC Berkeley, Rutgers University, SEDD Company) released with the paper [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
1. **[InstructBLIP](https://huggingface.co/docs/transformers/model_doc/instructblip)** (来自 Salesforce) 伴随论文 [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) 由 Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi 发布。
+1. **[Jamba](https://huggingface.co/docs/transformers/main/model_doc/jamba)** (from AI21 Labs Ltd.) released with the paper [Jamba: A Hybrid Transformer-Mamba Language Model](https://arxiv.org/abs/2403.19887) by Opher Lieber, Barak Lenz, Hofit Bata, Gal Cohen, Jhonathan Osin, Itay Dalmedigos, Erez Safahi, Shaked Meirom, Yonatan Belinkov, Shai Shalev-Shwartz, Omri Abend, Raz Alon, Tomer Asida, Amir Bergman, Roman Glozman, Michael Gokhman, Avshalom Manevich, Nir Ratner, Noam Rozen, Erez Shwartz, Mor Zusman, Yoav Shoham.
1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (from OpenAI) released with the paper [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
1. **[KOSMOS-2](https://huggingface.co/docs/transformers/model_doc/kosmos-2)** (from Microsoft Research Asia) released with the paper [Kosmos-2: Grounding Multimodal Large Language Models to the World](https://arxiv.org/abs/2306.14824) by Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (来自 Microsoft Research Asia) 伴随论文 [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) 由 Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou 发布。
diff --git a/README_zh-hant.md b/README_zh-hant.md
index ea934e1cb874..36f51ba5c12e 100644
--- a/README_zh-hant.md
+++ b/README_zh-hant.md
@@ -357,6 +357,7 @@ conda install conda-forge::transformers
1. **[ImageGPT](https://huggingface.co/docs/transformers/model_doc/imagegpt)** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
1. **[Informer](https://huggingface.co/docs/transformers/model_doc/informer)** (from Beihang University, UC Berkeley, Rutgers University, SEDD Company) released with the paper [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
1. **[InstructBLIP](https://huggingface.co/docs/transformers/model_doc/instructblip)** (from Salesforce) released with the paper [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
+1. **[Jamba](https://huggingface.co/docs/transformers/main/model_doc/jamba)** (from AI21 Labs Ltd.) released with the paper [Jamba: A Hybrid Transformer-Mamba Language Model](https://arxiv.org/abs/2403.19887) by Opher Lieber, Barak Lenz, Hofit Bata, Gal Cohen, Jhonathan Osin, Itay Dalmedigos, Erez Safahi, Shaked Meirom, Yonatan Belinkov, Shai Shalev-Shwartz, Omri Abend, Raz Alon, Tomer Asida, Amir Bergman, Roman Glozman, Michael Gokhman, Avshalom Manevich, Nir Ratner, Noam Rozen, Erez Shwartz, Mor Zusman, Yoav Shoham.
1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (from OpenAI) released with the paper [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
1. **[KOSMOS-2](https://huggingface.co/docs/transformers/model_doc/kosmos-2)** (from Microsoft Research Asia) released with the paper [Kosmos-2: Grounding Multimodal Large Language Models to the World](https://arxiv.org/abs/2306.14824) by Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
diff --git a/docs/source/en/_toctree.yml b/docs/source/en/_toctree.yml
index 2591ebea1c91..52e7587fae7f 100644
--- a/docs/source/en/_toctree.yml
+++ b/docs/source/en/_toctree.yml
@@ -382,6 +382,8 @@
title: HerBERT
- local: model_doc/ibert
title: I-BERT
+ - local: model_doc/jamba
+ title: Jamba
- local: model_doc/jukebox
title: Jukebox
- local: model_doc/led
diff --git a/docs/source/en/index.md b/docs/source/en/index.md
index 90cea85e077a..ea4eb92a38d7 100644
--- a/docs/source/en/index.md
+++ b/docs/source/en/index.md
@@ -164,6 +164,7 @@ Flax), PyTorch, and/or TensorFlow.
| [ImageGPT](model_doc/imagegpt) | ✅ | ❌ | ❌ |
| [Informer](model_doc/informer) | ✅ | ❌ | ❌ |
| [InstructBLIP](model_doc/instructblip) | ✅ | ❌ | ❌ |
+| [Jamba](model_doc/jamba) | ✅ | ❌ | ❌ |
| [Jukebox](model_doc/jukebox) | ✅ | ❌ | ❌ |
| [KOSMOS-2](model_doc/kosmos-2) | ✅ | ❌ | ❌ |
| [LayoutLM](model_doc/layoutlm) | ✅ | ✅ | ❌ |
diff --git a/docs/source/en/model_doc/jamba.md b/docs/source/en/model_doc/jamba.md
new file mode 100644
index 000000000000..d8de36771da2
--- /dev/null
+++ b/docs/source/en/model_doc/jamba.md
@@ -0,0 +1,122 @@
+
+
+# Jamba
+
+## Overview
+
+Jamba is a state-of-the-art, hybrid SSM-Transformer LLM. It is the first production-scale Mamba implementation, which opens up interesting research and application opportunities. While this initial experimentation shows encouraging gains, we expect these to be further enhanced with future optimizations and explorations.
+
+For full details of this model please read the [release blog post](https://www.ai21.com/blog/announcing-jamba).
+
+### Model Details
+
+Jamba is a pretrained, mixture-of-experts (MoE) generative text model, with 12B active parameters and an overall of 52B parameters across all experts. It supports a 256K context length, and can fit up to 140K tokens on a single 80GB GPU.
+
+As depicted in the diagram below, Jamba's architecture features a blocks-and-layers approach that allows Jamba to successfully integrate Transformer and Mamba architectures altogether. Each Jamba block contains either an attention or a Mamba layer, followed by a multi-layer perceptron (MLP), producing an overall ratio of one Transformer layer out of every eight total layers.
+
+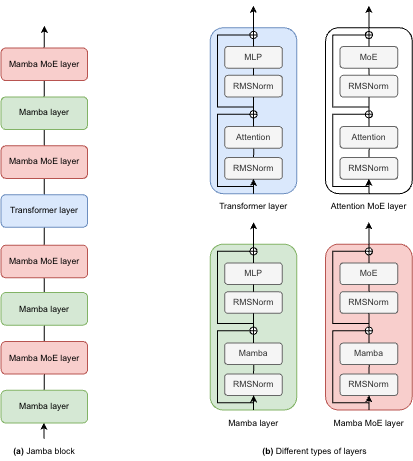 +
+## Usage
+
+### Presequities
+
+Jamba requires you use `transformers` version 4.39.0 or higher:
+```bash
+pip install transformers>=4.39.0
+```
+
+In order to run optimized Mamba implementations, you first need to install `mamba-ssm` and `causal-conv1d`:
+```bash
+pip install mamba-ssm causal-conv1d>=1.2.0
+```
+You also have to have the model on a CUDA device.
+
+You can run the model not using the optimized Mamba kernels, but it is **not** recommended as it will result in significantly lower latencies. In order to do that, you'll need to specify `use_mamba_kernels=False` when loading the model.
+
+### Run the model
+```python
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+model = AutoModelForCausalLM.from_pretrained("ai21labs/Jamba-v0.1")
+tokenizer = AutoTokenizer.from_pretrained("ai21labs/Jamba-v0.1")
+
+input_ids = tokenizer("In the recent Super Bowl LVIII,", return_tensors='pt').to(model.device)["input_ids"]
+
+outputs = model.generate(input_ids, max_new_tokens=216)
+
+print(tokenizer.batch_decode(outputs))
+# ["<|startoftext|>In the recent Super Bowl LVIII, the Kansas City Chiefs emerged victorious, defeating the San Francisco 49ers in a thrilling overtime showdown. The game was a nail-biter, with both teams showcasing their skills and determination.\n\nThe Chiefs, led by their star quarterback Patrick Mahomes, displayed their offensive prowess, while the 49ers, led by their strong defense, put up a tough fight. The game went into overtime, with the Chiefs ultimately securing the win with a touchdown.\n\nThe victory marked the Chiefs' second Super Bowl win in four years, solidifying their status as one of the top teams in the NFL. The game was a testament to the skill and talent of both teams, and a thrilling end to the NFL season.\n\nThe Super Bowl is not just about the game itself, but also about the halftime show and the commercials. This year's halftime show featured a star-studded lineup, including Usher, Alicia Keys, and Lil Jon. The show was a spectacle of music and dance, with the performers delivering an energetic and entertaining performance.\n"]
+```
+
+
+
+## Usage
+
+### Presequities
+
+Jamba requires you use `transformers` version 4.39.0 or higher:
+```bash
+pip install transformers>=4.39.0
+```
+
+In order to run optimized Mamba implementations, you first need to install `mamba-ssm` and `causal-conv1d`:
+```bash
+pip install mamba-ssm causal-conv1d>=1.2.0
+```
+You also have to have the model on a CUDA device.
+
+You can run the model not using the optimized Mamba kernels, but it is **not** recommended as it will result in significantly lower latencies. In order to do that, you'll need to specify `use_mamba_kernels=False` when loading the model.
+
+### Run the model
+```python
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+model = AutoModelForCausalLM.from_pretrained("ai21labs/Jamba-v0.1")
+tokenizer = AutoTokenizer.from_pretrained("ai21labs/Jamba-v0.1")
+
+input_ids = tokenizer("In the recent Super Bowl LVIII,", return_tensors='pt').to(model.device)["input_ids"]
+
+outputs = model.generate(input_ids, max_new_tokens=216)
+
+print(tokenizer.batch_decode(outputs))
+# ["<|startoftext|>In the recent Super Bowl LVIII, the Kansas City Chiefs emerged victorious, defeating the San Francisco 49ers in a thrilling overtime showdown. The game was a nail-biter, with both teams showcasing their skills and determination.\n\nThe Chiefs, led by their star quarterback Patrick Mahomes, displayed their offensive prowess, while the 49ers, led by their strong defense, put up a tough fight. The game went into overtime, with the Chiefs ultimately securing the win with a touchdown.\n\nThe victory marked the Chiefs' second Super Bowl win in four years, solidifying their status as one of the top teams in the NFL. The game was a testament to the skill and talent of both teams, and a thrilling end to the NFL season.\n\nThe Super Bowl is not just about the game itself, but also about the halftime show and the commercials. This year's halftime show featured a star-studded lineup, including Usher, Alicia Keys, and Lil Jon. The show was a spectacle of music and dance, with the performers delivering an energetic and entertaining performance.\n"]
+```
+
+
+Loading the model in half precision
+
+The published checkpoint is saved in BF16. In order to load it into RAM in BF16/FP16, you need to specify `torch_dtype`:
+
+```python
+from transformers import AutoModelForCausalLM
+import torch
+model = AutoModelForCausalLM.from_pretrained("ai21labs/Jamba-v0.1", torch_dtype=torch.bfloat16)
+# you can also use torch_dtype=torch.float16
+```
+
+When using half precision, you can enable the [FlashAttention2](https://github.com/Dao-AILab/flash-attention) implementation of the Attention blocks. In order to use it, you also need the model on a CUDA device. Since in this precision the model is to big to fit on a single 80GB GPU, you'll also need to parallelize it using [accelerate](https://huggingface.co/docs/accelerate/index):
+```python
+from transformers import AutoModelForCausalLM
+import torch
+model = AutoModelForCausalLM.from_pretrained("ai21labs/Jamba-v0.1",
+ torch_dtype=torch.bfloat16,
+ attn_implementation="flash_attention_2",
+ device_map="auto")
+```
+
+
+Load the model in 8-bit
+
+**Using 8-bit precision, it is possible to fit up to 140K sequence lengths on a single 80GB GPU.** You can easily quantize the model to 8-bit using [bitsandbytes](https://huggingface.co/docs/bitsandbytes/index). In order to not degrade model quality, we recommend to exclude the Mamba blocks from the quantization:
+
+```python
+from transformers import AutoModelForCausalLM, BitsAndBytesConfig
+quantization_config = BitsAndBytesConfig(load_in_8bit=True, llm_int8_skip_modules=["mamba"])
+model = AutoModelForCausalLM.from_pretrained(
+ "ai21labs/Jamba-v0.1", torch_dtype=torch.bfloat16, attn_implementation="flash_attention_2", quantization_config=quantization_config
+)
+```
+