# SetFit - Efficient Few-shot Learning with Sentence Transformers
SetFit is an efficient and prompt-free framework for few-shot fine-tuning of [Sentence Transformers](https://sbert.net/). It achieves high accuracy with little labeled data - for instance, with only 8 labeled examples per class on the Customer Reviews sentiment dataset, SetFit is competitive with fine-tuning RoBERTa Large on the full training set of 3k examples 🤯!
-
Compared to other few-shot learning methods, SetFit has several unique features:
-* 🗣 **No prompts or verbalisers:** Current techniques for few-shot fine-tuning require handcrafted prompts or verbalisers to convert examples into a format that's suitable for the underlying language model. SetFit dispenses with prompts altogether by generating rich embeddings directly from text examples.
+* 🗣 **No prompts or verbalizers:** Current techniques for few-shot fine-tuning require handcrafted prompts or verbalizers to convert examples into a format suitable for the underlying language model. SetFit dispenses with prompts altogether by generating rich embeddings directly from text examples.
* 🏎 **Fast to train:** SetFit doesn't require large-scale models like T0 or GPT-3 to achieve high accuracy. As a result, it is typically an order of magnitude (or more) faster to train and run inference with.
* 🌎 **Multilingual support**: SetFit can be used with any [Sentence Transformer](https://huggingface.co/models?library=sentence-transformers&sort=downloads) on the Hub, which means you can classify text in multiple languages by simply fine-tuning a multilingual checkpoint.
+Check out the [SetFit Documentation](https://huggingface.co/docs/setfit) for more information!
+
## Installation
Download and install `setfit` by running:
```bash
-python -m pip install setfit
+pip install setfit
```
-If you want the bleeding-edge version, install from source by running:
+If you want the bleeding-edge version instead, install from source by running:
```bash
-python -m pip install git+https://github.com/huggingface/setfit.git
+pip install git+https://github.com/huggingface/setfit.git
```
## Usage
-The examples below provide a quick overview on the various features supported in `setfit`. For more examples, check out the [`notebooks`](https://github.com/huggingface/setfit/tree/main/notebooks) folder.
+The [quickstart](https://huggingface.co/docs/setfit/quickstart) is a good place to learn about training, saving, loading, and performing inference with SetFit models.
+
+For more examples, check out the [`notebooks`](https://github.com/huggingface/setfit/tree/main/notebooks) directory, the [tutorials](https://huggingface.co/docs/setfit/tutorials/overview), or the [how-to guides](https://huggingface.co/docs/setfit/how_to/overview).
### Training a SetFit model
`setfit` is integrated with the [Hugging Face Hub](https://huggingface.co/) and provides two main classes:
-* `SetFitModel`: a wrapper that combines a pretrained body from `sentence_transformers` and a classification head from either [`scikit-learn`](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html) or [`SetFitHead`](https://github.com/huggingface/setfit/blob/main/src/setfit/modeling.py) (a differentiable head built upon `PyTorch` with similar APIs to `sentence_transformers`).
-* `SetFitTrainer`: a helper class that wraps the fine-tuning process of SetFit.
+* [`SetFitModel`](https://huggingface.co/docs/setfit/reference/main#setfit.SetFitModel): a wrapper that combines a pretrained body from `sentence_transformers` and a classification head from either [`scikit-learn`](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html) or [`SetFitHead`](https://huggingface.co/docs/setfit/reference/main#setfit.SetFitHead) (a differentiable head built upon `PyTorch` with similar APIs to `sentence_transformers`).
+* [`Trainer`](https://huggingface.co/docs/setfit/reference/trainer#setfit.Trainer): a helper class that wraps the fine-tuning process of SetFit.
-Here is an end-to-end example using a classification head from `scikit-learn`:
+Here is a simple end-to-end training example using the default classification head from `scikit-learn`:
```python
from datasets import load_dataset
-from sentence_transformers.losses import CosineSimilarityLoss
-
-from setfit import SetFitModel, SetFitTrainer, sample_dataset
+from setfit import SetFitModel, Trainer, TrainingArguments, sample_dataset
# Load a dataset from the Hugging Face Hub
@@ -56,304 +57,50 @@ dataset = load_dataset("sst2")
# Simulate the few-shot regime by sampling 8 examples per class
train_dataset = sample_dataset(dataset["train"], label_column="label", num_samples=8)
-eval_dataset = dataset["validation"]
+eval_dataset = dataset["validation"].select(range(100))
+test_dataset = dataset["validation"].select(range(100, len(dataset["validation"])))
# Load a SetFit model from Hub
model = SetFitModel.from_pretrained("sentence-transformers/paraphrase-mpnet-base-v2")
-# Create trainer
-trainer = SetFitTrainer(
- model=model,
- train_dataset=train_dataset,
- eval_dataset=eval_dataset,
- loss_class=CosineSimilarityLoss,
- metric="accuracy",
+args = TrainingArguments(
batch_size=16,
- num_iterations=20, # The number of text pairs to generate for contrastive learning
- num_epochs=1, # The number of epochs to use for contrastive learning
- column_mapping={"sentence": "text", "label": "label"} # Map dataset columns to text/label expected by trainer
+ num_epochs=4,
+ evaluation_strategy="epoch",
+ save_strategy="epoch",
+ load_best_model_at_end=True,
)
-# Train and evaluate
-trainer.train()
-metrics = trainer.evaluate()
-
-# Push model to the Hub
-trainer.push_to_hub("my-awesome-setfit-model")
-
-# Download from Hub and run inference
-model = SetFitModel.from_pretrained("lewtun/my-awesome-setfit-model")
-# Run inference
-preds = model(["i loved the spiderman movie!", "pineapple on pizza is the worst 🤮"])
-```
-
-Here is an end-to-end example using `SetFitHead`:
-
-
-```python
-from datasets import load_dataset
-from sentence_transformers.losses import CosineSimilarityLoss
-
-from setfit import SetFitModel, SetFitTrainer, sample_dataset
-
-
-# Load a dataset from the Hugging Face Hub
-dataset = load_dataset("sst2")
-
-# Simulate the few-shot regime by sampling 8 examples per class
-train_dataset = sample_dataset(dataset["train"], label_column="label", num_samples=8)
-eval_dataset = dataset["validation"]
-
-# Load a SetFit model from Hub
-model = SetFitModel.from_pretrained(
- "sentence-transformers/paraphrase-mpnet-base-v2",
- use_differentiable_head=True,
- head_params={"out_features": num_classes},
-)
-
-# Create trainer
-trainer = SetFitTrainer(
+trainer = Trainer(
model=model,
+ args=args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
- loss_class=CosineSimilarityLoss,
metric="accuracy",
- batch_size=16,
- num_iterations=20, # The number of text pairs to generate for contrastive learning
- num_epochs=1, # The number of epochs to use for contrastive learning
- column_mapping={"sentence": "text", "label": "label"} # Map dataset columns to text/label expected by trainer
+ column_mapping={"sentence": "text", "label": "label"} # Map dataset columns to text/label expected by trainer
)
# Train and evaluate
-trainer.freeze() # Freeze the head
-trainer.train() # Train only the body
-
-# Unfreeze the head and freeze the body -> head-only training
-trainer.unfreeze(keep_body_frozen=True)
-# or
-# Unfreeze the head and unfreeze the body -> end-to-end training
-trainer.unfreeze(keep_body_frozen=False)
-
-trainer.train(
- num_epochs=25, # The number of epochs to train the head or the whole model (body and head)
- batch_size=16,
- body_learning_rate=1e-5, # The body's learning rate
- learning_rate=1e-2, # The head's learning rate
- l2_weight=0.0, # Weight decay on **both** the body and head. If `None`, will use 0.01.
-)
-metrics = trainer.evaluate()
+trainer.train()
+metrics = trainer.evaluate(test_dataset)
+print(metrics)
+# {'accuracy': 0.8691709844559585}
# Push model to the Hub
-trainer.push_to_hub("my-awesome-setfit-model")
+trainer.push_to_hub("tomaarsen/setfit-paraphrase-mpnet-base-v2-sst2")
-# Download from Hub and run inference
-model = SetFitModel.from_pretrained("lewtun/my-awesome-setfit-model")
+# Download from Hub
+model = SetFitModel.from_pretrained("tomaarsen/setfit-paraphrase-mpnet-base-v2-sst2")
# Run inference
-preds = model(["i loved the spiderman movie!", "pineapple on pizza is the worst 🤮"])
-```
-
-Based on our experiments, `SetFitHead` can achieve similar performance as using a `scikit-learn` head. We use `AdamW` as the optimizer and scale down learning rates by 0.5 every 5 epochs. For more details about the experiments, please check out [here](https://github.com/huggingface/setfit/pull/112#issuecomment-1295773537). We recommend using a large learning rate (e.g. `1e-2`) for `SetFitHead` and a small learning rate (e.g. `1e-5`) for the body in your first attempt.
-
-### Training on multilabel datasets
-
-To train SetFit models on multilabel datasets, specify the `multi_target_strategy` argument when loading the pretrained model:
-
-#### Example using a classification head from `scikit-learn`:
-
-```python
-from setfit import SetFitModel
-
-model = SetFitModel.from_pretrained(
- model_id,
- multi_target_strategy="one-vs-rest",
-)
-```
-
-This will initialise a multilabel classification head from `sklearn` - the following options are available for `multi_target_strategy`:
-
-* `one-vs-rest`: uses a `OneVsRestClassifier` head.
-* `multi-output`: uses a `MultiOutputClassifier` head.
-* `classifier-chain`: uses a `ClassifierChain` head.
-
-From here, you can instantiate a `SetFitTrainer` using the same example above, and train it as usual.
-
-#### Example using the differentiable `SetFitHead`:
-
-```python
-from setfit import SetFitModel
-
-model = SetFitModel.from_pretrained(
- model_id,
- multi_target_strategy="one-vs-rest"
- use_differentiable_head=True,
- head_params={"out_features": num_classes},
-)
-```
-**Note:** If you use the differentiable `SetFitHead` classifier head, it will automatically use `BCEWithLogitsLoss` for training. The prediction involves a `sigmoid` after which probabilities are rounded to 1 or 0. Furthermore, the `"one-vs-rest"` and `"multi-output"` multi-target strategies are equivalent for the differentiable `SetFitHead`.
-
-### Zero-shot text classification
-
-SetFit can also be applied to scenarios where no labels are available. To do so, create a synthetic dataset of training examples:
-
-```python
-from datasets import Dataset
-from setfit import get_templated_dataset
-
-candidate_labels = ["negative", "positive"]
-train_dataset = get_templated_dataset(candidate_labels=candidate_labels, sample_size=8)
-```
-
-This will create examples of the form `"This sentence is {}"`, where the `{}` is filled in with one of the candidate labels. From here you can train a SetFit model as usual:
-
-```python
-from setfit import SetFitModel, SetFitTrainer
-
-model = SetFitModel.from_pretrained("sentence-transformers/paraphrase-mpnet-base-v2")
-trainer = SetFitTrainer(
- model=model,
- train_dataset=train_dataset
-)
-trainer.train()
-```
-
-We find this approach typically outperforms the [zero-shot pipeline](https://huggingface.co/docs/transformers/v4.24.0/en/main_classes/pipelines#transformers.ZeroShotClassificationPipeline) in 🤗 Transformers (based on MNLI with Bart), while being 5x faster to generate predictions with.
-
-
-### Running hyperparameter search
-
-`SetFitTrainer` provides a `hyperparameter_search()` method that you can use to find good hyperparameters for your data. To use this feature, first install the `optuna` backend:
-
-```bash
-python -m pip install setfit[optuna]
-```
-
-To use this method, you need to define two functions:
-
-* `model_init()`: A function that instantiates the model to be used. If provided, each call to `train()` will start from a new instance of the model as given by this function.
-* `hp_space()`: A function that defines the hyperparameter search space.
-
-Here is an example of a `model_init()` function that we'll use to scan over the hyperparameters associated with the classification head in `SetFitModel`:
-
-```python
-from setfit import SetFitModel
-
-def model_init(params):
- params = params or {}
- max_iter = params.get("max_iter", 100)
- solver = params.get("solver", "liblinear")
- params = {
- "head_params": {
- "max_iter": max_iter,
- "solver": solver,
- }
- }
- return SetFitModel.from_pretrained("sentence-transformers/paraphrase-albert-small-v2", **params)
-```
-
-Similarly, to scan over hyperparameters associated with the SetFit training process, we can define a `hp_space()` function as follows:
-
-```python
-def hp_space(trial): # Training parameters
- return {
- "learning_rate": trial.suggest_float("learning_rate", 1e-6, 1e-4, log=True),
- "num_epochs": trial.suggest_int("num_epochs", 1, 5),
- "batch_size": trial.suggest_categorical("batch_size", [4, 8, 16, 32, 64]),
- "seed": trial.suggest_int("seed", 1, 40),
- "num_iterations": trial.suggest_categorical("num_iterations", [5, 10, 20]),
- "max_iter": trial.suggest_int("max_iter", 50, 300),
- "solver": trial.suggest_categorical("solver", ["newton-cg", "lbfgs", "liblinear"]),
- }
-```
-
-**Note:** In practice, we found `num_iterations` to be the most important hyperparameter for the contrastive learning process.
-
-The next step is to instantiate a `SetFitTrainer` and call `hyperparameter_search()`:
-
-```python
-from datasets import Dataset
-from setfit import SetFitTrainer
-
-dataset = Dataset.from_dict(
- {"text_new": ["a", "b", "c"], "label_new": [0, 1, 2], "extra_column": ["d", "e", "f"]}
- )
-
-trainer = SetFitTrainer(
- train_dataset=dataset,
- eval_dataset=dataset,
- model_init=model_init,
- column_mapping={"text_new": "text", "label_new": "label"},
-)
-best_run = trainer.hyperparameter_search(direction="maximize", hp_space=hp_space, n_trials=20)
-```
-
-Finally, you can apply the hyperparameters you found to the trainer, and lock in the optimal model, before training for
-a final time.
-
-```python
-trainer.apply_hyperparameters(best_run.hyperparameters, final_model=True)
-trainer.train()
-```
-
-## Compressing a SetFit model with knowledge distillation
-
-If you have access to unlabeled data, you can use knowledge distillation to compress a trained SetFit model into a smaller version. The result is a model that can run inference much faster, with little to no drop in accuracy. Here's an end-to-end example (see our paper for more details):
-
-```python
-from datasets import load_dataset
-from sentence_transformers.losses import CosineSimilarityLoss
-
-from setfit import SetFitModel, SetFitTrainer, DistillationSetFitTrainer, sample_dataset
-
-# Load a dataset from the Hugging Face Hub
-dataset = load_dataset("ag_news")
-
-# Create a sample few-shot dataset to train the teacher model
-train_dataset_teacher = sample_dataset(dataset["train"], label_column="label", num_samples=16)
-# Create a dataset of unlabeled examples to train the student
-train_dataset_student = dataset["train"].shuffle(seed=0).select(range(500))
-# Dataset for evaluation
-eval_dataset = dataset["test"]
-
-# Load teacher model
-teacher_model = SetFitModel.from_pretrained(
- "sentence-transformers/paraphrase-mpnet-base-v2"
-)
-
-# Create trainer for teacher model
-teacher_trainer = SetFitTrainer(
- model=teacher_model,
- train_dataset=train_dataset_teacher,
- eval_dataset=eval_dataset,
- loss_class=CosineSimilarityLoss,
-)
-
-# Train teacher model
-teacher_trainer.train()
-
-# Load small student model
-student_model = SetFitModel.from_pretrained("paraphrase-MiniLM-L3-v2")
-
-# Create trainer for knowledge distillation
-student_trainer = DistillationSetFitTrainer(
- teacher_model=teacher_model,
- train_dataset=train_dataset_student,
- student_model=student_model,
- eval_dataset=eval_dataset,
- loss_class=CosineSimilarityLoss,
- metric="accuracy",
- batch_size=16,
- num_iterations=20,
- num_epochs=1,
-)
-
-# Train student with knowledge distillation
-student_trainer.train()
+preds = model.predict(["i loved the spiderman movie!", "pineapple on pizza is the worst 🤮"])
+print(preds)
+# tensor([1, 0], dtype=torch.int32)
```
## Reproducing the results from the paper
-We provide scripts to reproduce the results for SetFit and various baselines presented in Table 2 of our paper. Check out the setup and training instructions in the `scripts/` directory.
+We provide scripts to reproduce the results for SetFit and various baselines presented in Table 2 of our paper. Check out the setup and training instructions in the [`scripts/`](scripts/) directory.
## Developer installation
@@ -366,10 +113,10 @@ conda create -n setfit python=3.9 && conda activate setfit
Then install the base requirements with:
```bash
-python -m pip install -e '.[dev]'
+pip install -e '.[dev]'
```
-This will install `datasets` and packages like `black` and `isort` that we use to ensure consistent code formatting.
+This will install mandatory packages for SetFit like `datasets` as well as development packages like `black` and `isort` that we use to ensure consistent code formatting.
### Formatting your code
@@ -379,14 +126,13 @@ We use `black` and `isort` to ensure consistent code formatting. After following
make style && make quality
```
-
-
## Project structure
```
├── LICENSE
├── Makefile <- Makefile with commands like `make style` or `make tests`
├── README.md <- The top-level README for developers using this project.
+├── docs <- Documentation source
├── notebooks <- Jupyter notebooks.
├── final_results <- Model predictions from the paper
├── scripts <- Scripts for training and inference
@@ -398,12 +144,14 @@ make style && make quality
## Related work
+* [https://github.com/pmbaumgartner/setfit](https://github.com/pmbaumgartner/setfit) - A scikit-learn API version of SetFit.
* [jxpress/setfit-pytorch-lightning](https://github.com/jxpress/setfit-pytorch-lightning) - A PyTorch Lightning implementation of SetFit.
* [davidberenstein1957/spacy-setfit](https://github.com/davidberenstein1957/spacy-setfit) - An easy and intuitive approach to use SetFit in combination with spaCy.
## Citation
-```@misc{https://doi.org/10.48550/arxiv.2209.11055,
+```bibtex
+@misc{https://doi.org/10.48550/arxiv.2209.11055,
doi = {10.48550/ARXIV.2209.11055},
url = {https://arxiv.org/abs/2209.11055},
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
@@ -411,5 +159,6 @@ make style && make quality
title = {Efficient Few-Shot Learning Without Prompts},
publisher = {arXiv},
year = {2022},
- copyright = {Creative Commons Attribution 4.0 International}}
+ copyright = {Creative Commons Attribution 4.0 International}
+}
```
diff --git a/docs/README.md b/docs/README.md
index befedf88..0178011d 100644
--- a/docs/README.md
+++ b/docs/README.md
@@ -5,7 +5,7 @@ Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
- http://www.apache.org/licenses/LICENSE-2.0
+ https://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
@@ -78,7 +78,7 @@ The `preview` command only works with existing doc files. When you add a complet
Accepted files are Markdown (.md or .mdx).
Create a file with its extension and put it in the source directory. You can then link it to the toc-tree by putting
-the filename without the extension in the [`_toctree.yml`](https://github.com/huggingface/setfit/blob/main/docs/source/_toctree.yml) file.
+the filename without the extension in the [`_toctree.yml`](https://github.com/huggingface/setfit/blob/main/docs/source/en/_toctree.yml) file.
## Renaming section headers and moving sections
@@ -103,7 +103,7 @@ Sections that were moved:
Use the relative style to link to the new file so that the versioned docs continue to work.
-For an example of a rich moved section set please see the very end of [the Trainer doc](https://github.com/huggingface/transformers/blob/main/docs/source/en/main_classes/trainer.mdx).
+For an example of a rich moved section set please see the very end of [the Trainer doc](https://github.com/huggingface/transformers/blob/main/docs/source/en/main_classes/trainer.md).
## Writing Documentation - Specification
@@ -123,34 +123,10 @@ Make sure to put your new file under the proper section. It's unlikely to go in
depending on the intended targets (beginners, more advanced users, or researchers) it should go in sections two, three, or
four.
-### Translating
-When translating, refer to the guide at [./TRANSLATING.md](https://github.com/huggingface/setfit/blob/main/docs/TRANSLATING.md).
+### Autodoc
-
-### Adding a new model
-
-When adding a new model:
-
-- Create a file `xxx.mdx` or under `./source/model_doc` (don't hesitate to copy an existing file as template).
-- Link that file in `./source/_toctree.yml`.
-- Write a short overview of the model:
- - Overview with paper & authors
- - Paper abstract
- - Tips and tricks and how to use it best
-- Add the classes that should be linked in the model. This generally includes the configuration, the tokenizer, and
- every model of that class (the base model, alongside models with additional heads), both in PyTorch and TensorFlow.
- The order is generally:
- - Configuration,
- - Tokenizer
- - PyTorch base model
- - PyTorch head models
- - TensorFlow base model
- - TensorFlow head models
- - Flax base model
- - Flax head models
-
-These classes should be added using our Markdown syntax. Usually as follows:
+The following are some examples of `[[autodoc]]` for documentation building.
```
## XXXConfig
diff --git a/docs/source/_config.py b/docs/source/_config.py
new file mode 100644
index 00000000..2f4f5c51
--- /dev/null
+++ b/docs/source/_config.py
@@ -0,0 +1,9 @@
+# docstyle-ignore
+INSTALL_CONTENT = """
+# SetFit installation
+! pip install setfit
+# To install from source instead of the last release, comment the command above and uncomment the following one.
+# ! pip install git+https://github.com/huggingface/setfit.git
+"""
+
+notebook_first_cells = [{"type": "code", "content": INSTALL_CONTENT}]
\ No newline at end of file
diff --git a/docs/source/en/_toctree.yml b/docs/source/en/_toctree.yml
index bea05d0b..24123729 100644
--- a/docs/source/en/_toctree.yml
+++ b/docs/source/en/_toctree.yml
@@ -6,21 +6,53 @@
- local: installation
title: Installation
title: Get started
+
- sections:
- - local: tutorials/placeholder
- title: Placeholder
+ - local: tutorials/overview
+ title: Overview
+ - local: tutorials/zero_shot
+ title: Zero-shot Text Classification
+ - local: tutorials/onnx
+ title: Efficiently run SetFit with ONNX
title: Tutorials
+
- sections:
- - local: how_to/placeholder
- title: Placeholder
+ - local: how_to/overview
+ title: Overview
+ - local: how_to/callbacks
+ title: Callbacks
+ - local: how_to/model_cards
+ title: Model Cards
+ - local: how_to/classification_heads
+ title: Classification Heads
+ - local: how_to/multilabel
+ title: Multilabel Text Classification
+ - local: how_to/zero_shot
+ title: Zero-shot Text Classification
+ - local: how_to/hyperparameter_optimization
+ title: Hyperparameter Optimization
+ - local: how_to/knowledge_distillation
+ title: Knowledge Distillation
+ - local: how_to/batch_sizes
+ title: Batch Sizes for Inference
+ - local: how_to/absa
+ title: Aspect Based Sentiment Analysis
+ - local: how_to/v1.0.0_migration_guide
+ title: v1.0.0 Migration Guide
title: How-to Guides
+
- sections:
- - local: conceptual_guides/placeholder
- title: Placeholder
+ - local: conceptual_guides/setfit
+ title: SetFit
+ - local: conceptual_guides/sampling_strategies
+ title: Sampling Strategies
title: Conceptual Guides
+
- sections:
- - local: api/main
+ - local: reference/main
title: Main classes
- - local: api/trainer
+ - local: reference/trainer
title: Trainer classes
- title: API
\ No newline at end of file
+ - local: reference/utility
+ title: Utility
+ title: Reference
\ No newline at end of file
diff --git a/docs/source/en/api/main.mdx b/docs/source/en/api/main.mdx
deleted file mode 100644
index ac2b77e4..00000000
--- a/docs/source/en/api/main.mdx
+++ /dev/null
@@ -1,8 +0,0 @@
-
-# SetFitModel
-
-[[autodoc]] SetFitModel
-
-# SetFitHead
-
-[[autodoc]] SetFitHead
diff --git a/docs/source/en/api/trainer.mdx b/docs/source/en/api/trainer.mdx
deleted file mode 100644
index a51df833..00000000
--- a/docs/source/en/api/trainer.mdx
+++ /dev/null
@@ -1,8 +0,0 @@
-
-# SetFitTrainer
-
-[[autodoc]] SetFitTrainer
-
-# DistillationSetFitTrainer
-
-[[autodoc]] DistillationSetFitTrainer
\ No newline at end of file
diff --git a/docs/source/en/conceptual_guides/placeholder.mdx b/docs/source/en/conceptual_guides/placeholder.mdx
deleted file mode 100644
index b79fc271..00000000
--- a/docs/source/en/conceptual_guides/placeholder.mdx
+++ /dev/null
@@ -1,3 +0,0 @@
-
-# Conceptual Guides
-Work in Progress!
\ No newline at end of file
diff --git a/docs/source/en/conceptual_guides/sampling_strategies.mdx b/docs/source/en/conceptual_guides/sampling_strategies.mdx
new file mode 100644
index 00000000..e076138f
--- /dev/null
+++ b/docs/source/en/conceptual_guides/sampling_strategies.mdx
@@ -0,0 +1,87 @@
+
+# SetFit Sampling Strategies
+
+SetFit supports various contrastive pair sampling strategies in [`TrainingArguments`]. In this conceptual guide, we will learn about the following four sampling strategies:
+
+1. `"oversampling"` (the default)
+2. `"undersampling"`
+3. `"unique"`
+4. `"num_iterations"`
+
+Consider first reading the [SetFit conceptual guide](../setfit) for a background on contrastive learning and positive & negative pairs.
+
+## Running example
+
+Throughout this conceptual guide, we will use to the following example scenario:
+
+* 3 classes: "happy", "content", and "sad".
+* 20 total samples: 8 "happy", 4 "content", and 8 "sad" samples.
+
+Considering that a sentence pair of `(X, Y)` and `(Y, X)` result in the same embedding distance/loss, we only want to consider one of those two cases. Furthermore, we don't want pairs where both sentences are the same, e.g. no `(X, X)`.
+
+The resulting positive and negative pairs can be visualized in a table like below. The `+` and `-` represent positive and negative pairs, respectively. Furthermore, `h-n` represents the n-th "happy" sentence, `c-n` the n-th "content" sentence, and `s-n` the n-th "sad" sentence. Note that the area below the diagonal is not used as `(X, Y)` and `(Y, X)` result in the same embedding distances, and that the diagonal is not used as we are not interested in pairs where both sentences are identical.
+
+| |h-1|h-2|h-3|h-4|h-5|h-6|h-7|h-8|c-1|c-2|c-3|c-4|s-1|s-2|s-3|s-4|s-5|s-6|s-7|s-8|
+|-------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
+|**h-1**| | + | + | + | + | + | + | + | - | - | - | - | - | - | - | - | - | - | - | - |
+|**h-2**| | | + | + | + | + | + | + | - | - | - | - | - | - | - | - | - | - | - | - |
+|**h-3**| | | | + | + | + | + | + | - | - | - | - | - | - | - | - | - | - | - | - |
+|**h-4**| | | | | + | + | + | + | - | - | - | - | - | - | - | - | - | - | - | - |
+|**h-5**| | | | | | + | + | + | - | - | - | - | - | - | - | - | - | - | - | - |
+|**h-6**| | | | | | | + | + | - | - | - | - | - | - | - | - | - | - | - | - |
+|**h-7**| | | | | | | | + | - | - | - | - | - | - | - | - | - | - | - | - |
+|**h-8**| | | | | | | | | - | - | - | - | - | - | - | - | - | - | - | - |
+|**c-1**| | | | | | | | | | + | + | + | - | - | - | - | - | - | - | - |
+|**c-2**| | | | | | | | | | | + | + | - | - | - | - | - | - | - | - |
+|**c-3**| | | | | | | | | | | | + | - | - | - | - | - | - | - | - |
+|**c-4**| | | | | | | | | | | | | - | - | - | - | - | - | - | - |
+|**s-1**| | | | | | | | | | | | | | + | + | + | + | + | + | + |
+|**s-2**| | | | | | | | | | | | | | | + | + | + | + | + | + |
+|**s-3**| | | | | | | | | | | | | | | | + | + | + | + | + |
+|**s-4**| | | | | | | | | | | | | | | | | + | + | + | + |
+|**s-5**| | | | | | | | | | | | | | | | | | + | + | + |
+|**s-6**| | | | | | | | | | | | | | | | | | | + | + |
+|**s-7**| | | | | | | | | | | | | | | | | | | | + |
+|**s-8**| | | | | | | | | | | | | | | | | | | | |
+
+As shown in the prior table, we have 28 positive pairs for "happy", 6 positive pairs for "content", and another 28 positive pairs for "sad". In total, this is 62 positive pairs. Also, we have 32 negative pairs between "happy" and "content", 64 negative pairs between "happy" and "sad", and 32 negative pairs between "content" and "sad". In total, this is 128 negative pairs.
+
+## Oversampling
+
+By default, SetFit applies the oversampling strategy for its contrastive pairs. This strategy samples an equal amount of positive and negative training pairs, oversampling the minority pair type to match that of the majority pair type. As the number of negative pairs is generally larger than the number of positive pairs, this usually involves oversampling the positive pairs.
+
+In our running example, this would involve oversampling the 62 positive pairs up to 128, resulting in one epoch of 128 + 128 = 256 pairs. In summary:
+
+* ✅ An equal amount of positive and negative pairs are sampled.
+* ✅ Every possible pair is used.
+* ❌ There is some data duplication.
+
+## Undersampling
+
+Like oversampling, this strategy samples an equal amount of positive and negative training pairs. However, it undersamples the majority pair type to match that of the minority pair type. This usually involves undersampling the negative pairs to match the positive pairs.
+
+In our running example, this would involve undersampling the 128 negative pairs down to 62, resulting in one epoch of 62 + 62 = 124 pairs. In summary:
+
+* ✅ An equal amount of positive and negative pairs are sampled.
+* ❌ **Not** every possible pair is used.
+* ✅ There is **no** data duplication.
+
+## Unique
+
+Thirdly, the unique strategy does not sample an equal amount of positive and negative training pairs. Instead, it simply samples all possible pairs exactly once. No form of oversampling or undersampling is used here.
+
+In our running example, this would involve sampling all negative and positive pairs, resulting in one epoch of 62 + 128 = 190 pairs. In summary:
+
+* ❌ **Not** an equal amount of positive and negative pairs are sampled.
+* ✅ Every possible pair is used.
+* ✅ There is **no** data duplication.
+
+## `num_iterations`
+
+Lastly, SetFit can still be used with a deprecated sampling strategy involving the `num_iterations` training argument. Unlike the other sampling strategies, this strategy does not involve the number of possible pairs. Instead, it samples `num_iterations` positive pairs and `num_iterations` negative pairs for each training sample.
+
+In our running example, if we assume `num_iterations=20`, then we would sample 20 positive pairs and 20 negative pairs per training sample. Because there's 20 samples, this involves (20 + 20) * 20 = 800 pairs. Because there are only 190 unique pairs, this certainly involves some data duplication. However, it does not guarantee that every possible pair is used. In summary:
+
+* ✅ **Not** an equal amount of positive and negative pairs are sampled.
+* ❌ Not necessarily every possible pair is used.
+* ❌ There is some data duplication.
\ No newline at end of file
diff --git a/docs/source/en/conceptual_guides/setfit.mdx b/docs/source/en/conceptual_guides/setfit.mdx
new file mode 100644
index 00000000..b4f158f7
--- /dev/null
+++ b/docs/source/en/conceptual_guides/setfit.mdx
@@ -0,0 +1,28 @@
+
+# Sentence Transformers Finetuning (SetFit)
+
+SetFit is a model framework to efficiently train text classification models with surprisingly little training data. For example, with only 8 labeled examples per class on the Customer Reviews (CR) sentiment dataset, SetFit is competitive with fine-tuning RoBERTa Large on the full training set of 3k examples. Furthermore, SetFit is fast to train and run inference with, and can easily support multilingual tasks.
+
+Every SetFit model consists of two parts: a **sentence transformer** embedding model (the body) and a **classifier** (the head). These two parts are trained in two separate phases: the **embedding finetuning phase** and the **classifier training phase**. This conceptual guide will elaborate on the intuition between these phases, and why SetFit works so well.
+
+## Embedding finetuning phase
+
+The first phase has one primary goal: finetune a sentence transformer embedding model to produce useful embeddings for *our* classification task. The [Hugging Face Hub](https://huggingface.co/models?library=sentence-transformers) already has thousands of sentence transformer available, many of which have been trained to very accurately group the embeddings of texts with similar semantic meaning.
+
+However, models that are good at Semantic Textual Similarity (STS) are not necessarily immediately good at *our* classification task. For example, according to an embedding model, the sentence of 1) `"He biked to work."` will be much more similar to 2) `"He drove his car to work."` than to 3) `"Peter decided to take the bicycle to the beach party!"`. But if our classification task involves classifying texts into transportation modes, then we want our embedding model to place sentences 1 and 3 closely together, and 2 further away.
+
+To do so, we can finetune the chosen sentence transformer embedding model. The goal here is to nudge the model to use its pretrained knowledge in a different way that better aligns with our classification task, rather than making the completely forget what it has learned.
+
+For finetuning, SetFit uses **contrastive learning**. This training approach involves creating **positive and negative pairs** of sentences. A sentence pair will be positive if both of the sentences are of the same class, and negative otherwise. For example, in the case of binary "positive"-"negative" sentiment analysis, `("The movie was awesome", "I loved it")` is a positive pair, and `("The movie was awesome", "It was quite disappointing")` is a negative pair.
+
+During training, the embedding model receives these pairs, and will convert the sentences to embeddings. If the pair is positive, then it will pull on the model weights such that the text embeddings will be more similar, and vice versa for a negative pair. Through this approach, sentences with the same label will be embedded more similarly, and sentences with different labels less similarly.
+
+Conveniently, this contrastive learning works with pairs rather than individual samples, and we can create plenty of unique pairs from just a few samples. For example, given 8 positive sentences and 8 negative sentences, we can create 28 positive pairs and 64 negative pairs for 92 unique training pairs. This grows exponentially to the number of sentences and classes, and that is why SetFit can train with just a few examples and still correctly finetune the sentence transformer embedding model. However, we should still be wary of overfitting.
+
+## Classifier training phase
+
+Once the sentence transformer embedding model has been finetuned for our task at hand, we can start training the classifier. This phase has one primary goal: create a good mapping from the sentence transformer embeddings to the classes.
+
+Unlike with the first phase, training the classifier is done from scratch and using the labeled samples directly, rather than using pairs. By default, the classifier is a simple **logistic regression** classifier from scikit-learn. First, all training sentences are fed through the now-finetuned sentence transformer embedding model, and then the sentence embeddings and labels are used to fit the logistic regression classifier. The result is a strong and efficient classifier.
+
+Using these two parts, SetFit models are efficient, performant and easy to train, even on CPU-only devices.
\ No newline at end of file
diff --git a/docs/source/en/how_to/absa.mdx b/docs/source/en/how_to/absa.mdx
new file mode 100644
index 00000000..68992827
--- /dev/null
+++ b/docs/source/en/how_to/absa.mdx
@@ -0,0 +1,230 @@
+
+# SetFit for Aspect Based Sentiment Analysis
+
+SetFitABSA is an efficient framework for few-shot Aspect Based Sentiment Analysis, achieving competitive performance with little training data. It consists of three phases:
+
+1. Using spaCy to find potential aspect candidates.
+2. Using a SetFit model for filtering these aspect candidates.
+3. Using a SetFit model for classifying the filtered aspect candidates.
+
+This guide will show you how to train, predict, save and load these models.
+
+## Getting Started
+
+First of all, SetFitABSA also requires spaCy to be installed, so we must install it:
+
+```
+!pip install "setfit[absa]"
+# or
+# !pip install spacy
+```
+
+Then, we must download the spaCy model that we intend on using. By default, SetFitABSA uses `en_core_web_lg`, but `en_core_web_sm` and `en_core_web_md` are also good options.
+
+```
+!spacy download en_core_web_lg
+!spacy download en_core_web_sm
+```
+
+## Training SetFitABSA
+
+First of all, we must instantiate a new [`AbsaModel`] via [`AbsaModel.from_pretrained`]. This can be done by providing configuration for each of the three phases for SetFitABSA:
+
+1. Provide the name or path of a Sentence Transformer model to be used for the **aspect filtering** SetFit model as the first argument.
+2. (Optional) Provide the name or path of a Sentence Transformer model to be used for the **polarity classification** SetFit model as the second argument. If not provided, the same Sentence Transformer model as the aspect filtering model is also used for the polarity classification model.
+3. (Optional) Provide the spaCy model to use via the `spacy_model` keyword argument.
+
+For example:
+
+```py
+from setfit import AbsaModel
+
+model = AbsaModel.from_pretrained(
+ "sentence-transformers/all-MiniLM-L6-v2",
+ "sentence-transformers/all-mpnet-base-v2",
+ spacy_model="en_core_web_sm",
+)
+```
+
+Or a minimal example:
+
+```py
+from setfit import AbsaModel
+
+model = AbsaModel.from_pretrained("BAAI/bge-small-en-v1.5")
+```
+
+Then we have to prepare a training/testing set. These datasets must have `"text"`, `"span"`, `"label"`, and `"ordinal"` columns:
+
+* `"text"`: The full sentence or text containing the aspects. For example: `"But the staff was so horrible to us."`.
+* `"span"`: An aspect from the full sentence. Can be multiple words. For example: `"staff"`.
+* `"label"`: The (polarity) label corresponding to the aspect span. For example: `"negative"`.
+* `"ordinal"`: If the aspect span occurs multiple times in the text, then this ordinal represents the index of those occurrences. Often this is just 0. For example: `0`.
+
+Two datasets that already match this format are these datasets of reviews from the SemEval-2014 Task 4:
+
+* [tomaarsen/setfit-absa-semeval-restaurants](https://huggingface.co/datasets/tomaarsen/setfit-absa-semeval-restaurants)
+* [tomaarsen/setfit-absa-semeval-laptops](https://huggingface.co/datasets/tomaarsen/setfit-absa-semeval-laptops)
+
+```py
+# The training/eval dataset must have `text`, `span`, `label`, and `ordinal` columns
+dataset = load_dataset("tomaarsen/setfit-absa-semeval-restaurants", split="train")
+train_dataset = dataset.select(range(128))
+eval_dataset = dataset.select(range(128, 256))
+```
+
+We can commence training like with normal SetFit, but now using [`AbsaTrainer`] instead.
+
+
+
+If you wish, you can specify separate training arguments for the aspect model as the polarity model by using both the `args` and `polarity_args` keyword arguments.
+
+
+
+```py
+args = TrainingArguments(
+ output_dir="models",
+ num_epochs=5,
+ use_amp=True,
+ batch_size=128,
+ evaluation_strategy="steps",
+ eval_steps=50,
+ save_steps=50,
+ load_best_model_at_end=True,
+)
+
+trainer = AbsaTrainer(
+ model,
+ args=args,
+ train_dataset=train_dataset,
+ eval_dataset=eval_dataset,
+ callbacks=[EarlyStoppingCallback(early_stopping_patience=5)],
+)
+trainer.train()
+```
+```
+***** Running training *****
+ Num examples = 249
+ Num epochs = 5
+ Total optimization steps = 1245
+ Total train batch size = 128
+{'aspect_embedding_loss': 0.2542, 'learning_rate': 1.6e-07, 'epoch': 0.0}
+{'aspect_embedding_loss': 0.2437, 'learning_rate': 8.000000000000001e-06, 'epoch': 0.2}
+{'eval_aspect_embedding_loss': 0.2511, 'learning_rate': 8.000000000000001e-06, 'epoch': 0.2}
+{'aspect_embedding_loss': 0.2209, 'learning_rate': 1.6000000000000003e-05, 'epoch': 0.4}
+{'eval_aspect_embedding_loss': 0.2385, 'learning_rate': 1.6000000000000003e-05, 'epoch': 0.4}
+{'aspect_embedding_loss': 0.0165, 'learning_rate': 1.955357142857143e-05, 'epoch': 0.6}
+{'eval_aspect_embedding_loss': 0.2776, 'learning_rate': 1.955357142857143e-05, 'epoch': 0.6}
+{'aspect_embedding_loss': 0.0158, 'learning_rate': 1.8660714285714287e-05, 'epoch': 0.8}
+{'eval_aspect_embedding_loss': 0.2848, 'learning_rate': 1.8660714285714287e-05, 'epoch': 0.8}
+{'aspect_embedding_loss': 0.0015, 'learning_rate': 1.7767857142857143e-05, 'epoch': 1.0}
+{'eval_aspect_embedding_loss': 0.3133, 'learning_rate': 1.7767857142857143e-05, 'epoch': 1.0}
+{'aspect_embedding_loss': 0.0012, 'learning_rate': 1.6875e-05, 'epoch': 1.2}
+{'eval_aspect_embedding_loss': 0.2966, 'learning_rate': 1.6875e-05, 'epoch': 1.2}
+{'aspect_embedding_loss': 0.0009, 'learning_rate': 1.598214285714286e-05, 'epoch': 1.41}
+{'eval_aspect_embedding_loss': 0.2996, 'learning_rate': 1.598214285714286e-05, 'epoch': 1.41}
+ 28%|██████████████████████████████████▎ | 350/1245 [03:40<09:24, 1.59it/s]
+Loading best SentenceTransformer model from step 100.
+{'train_runtime': 226.7429, 'train_samples_per_second': 702.822, 'train_steps_per_second': 5.491, 'epoch': 1.41}
+***** Running training *****
+ Num examples = 39
+ Num epochs = 5
+ Total optimization steps = 195
+ Total train batch size = 128
+{'polarity_embedding_loss': 0.2267, 'learning_rate': 1.0000000000000002e-06, 'epoch': 0.03}
+{'polarity_embedding_loss': 0.1038, 'learning_rate': 1.6571428571428574e-05, 'epoch': 1.28}
+{'eval_polarity_embedding_loss': 0.1946, 'learning_rate': 1.6571428571428574e-05, 'epoch': 1.28}
+{'polarity_embedding_loss': 0.0116, 'learning_rate': 1.0857142857142858e-05, 'epoch': 2.56}
+{'eval_polarity_embedding_loss': 0.2364, 'learning_rate': 1.0857142857142858e-05, 'epoch': 2.56}
+{'polarity_embedding_loss': 0.0059, 'learning_rate': 5.142857142857142e-06, 'epoch': 3.85}
+{'eval_polarity_embedding_loss': 0.2401, 'learning_rate': 5.142857142857142e-06, 'epoch': 3.85}
+100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 195/195 [00:54<00:00, 3.58it/s]
+Loading best SentenceTransformer model from step 50.
+{'train_runtime': 54.4104, 'train_samples_per_second': 458.736, 'train_steps_per_second': 3.584, 'epoch': 5.0}
+```
+
+Evaluation is also like normal, although you now get results from the aspect and polarity models separately:
+
+```py
+metrics = trainer.evaluate(eval_dataset)
+print(metrics)
+```
+```
+***** Running evaluation *****
+{'aspect': {'accuracy': 0.7130649876321116}, 'polarity': {'accuracy': 0.7102310231023102}}
+```
+
+
+
+Note that the aspect accuracy refers to the accuracy of classifying aspect candidate spans from the spaCy model as a true aspect or not, and the polarity accuracy refers to the accuracy of classifying only the filtered aspect candidate spans to the correct class.
+
+
+
+## Saving a SetFitABSA model
+
+Once trained, we can use familiar [`AbsaModel.save_pretrained`] and [`AbsaTrainer.push_to_hub`]/[`AbsaModel.push_to_hub`] methods to save the model. However, unlike normally, saving an [`AbsaModel`] involves saving two separate models: the **aspect** SetFit model and the **polarity** SetFit model. Consequently, we can provide two directories or `repo_id`'s:
+
+```py
+model.save_pretrained(
+ "models/setfit-absa-model-aspect",
+ "models/setfit-absa-model-polarity",
+)
+# or
+model.push_to_hub(
+ "tomaarsen/setfit-absa-bge-small-en-v1.5-restaurants-aspect",
+ "tomaarsen/setfit-absa-bge-small-en-v1.5-restaurants-polarity",
+)
+```
+However, you can also provide just one directory or `repo_id`, and `-aspect` and `-polarity` will be automatically added. So, the following code is equivalent to the previous snippet:
+
+```py
+model.save_pretrained("models/setfit-absa-model")
+# or
+model.push_to_hub("tomaarsen/setfit-absa-bge-small-en-v1.5-restaurants")
+```
+
+## Loading a SetFitABSA model
+
+Loading a trained [`AbsaModel`] involves calling [`AbsaModel.from_pretrained`] with details for each of the three phases for SetFitABSA:
+
+1. Provide the name or path of a trained SetFit ABSA model to be used for the **aspect filtering** model as the first argument.
+2. Provide the name or path of a trained SetFit ABSA model to be used for the **polarity classification** model as the second argument.
+3. (Optional) Provide the spaCy model to use via the `spacy_model` keyword argument. It is recommended to match this with the model used during training. The default is `"en_core_web_lg"`.
+
+For example:
+
+```py
+from setfit import AbsaModel
+
+model = AbsaModel.from_pretrained(
+ "tomaarsen/setfit-absa-bge-small-en-v1.5-restaurants-aspect",
+ "tomaarsen/setfit-absa-bge-small-en-v1.5-restaurants-polarity",
+ spacy_model="en_core_web_lg",
+)
+```
+
+We've now successfully loaded the SetFitABSA model from:
+* [tomaarsen/setfit-absa-bge-small-en-v1.5-restaurants-aspect](https://huggingface.co/tomaarsen/setfit-absa-bge-small-en-v1.5-restaurants-aspect)
+* [tomaarsen/setfit-absa-bge-small-en-v1.5-restaurants-polarity](https://huggingface.co/tomaarsen/setfit-absa-bge-small-en-v1.5-restaurants-polarity)
+
+## Inference with a SetFitABSA model
+
+To perform inference with a trained [`AbsaModel`], we can use [`AbsaModel.predict`]:
+
+```py
+preds = model.predict([
+ "Best pizza outside of Italy and really tasty.",
+ "The food variations are great and the prices are absolutely fair.",
+ "Unfortunately, you have to expect some waiting time and get a note with a waiting number if it should be very full."
+])
+print(preds)
+# [
+# [{'span': 'pizza', 'polarity': 'positive'}],
+# [{'span': 'food variations', 'polarity': 'positive'}, {'span': 'prices', 'polarity': 'positive'}],
+# [{'span': 'waiting number', 'polarity': 'negative'}]
+# ]
+```
+
+## Challenge
+
+If you're up for it, then I challenge you to train and upload a SetFitABSA model for [laptop reviews](https://huggingface.co/datasets/tomaarsen/setfit-absa-semeval-laptops) based on this documentation.
diff --git a/docs/source/en/how_to/batch_sizes.mdx b/docs/source/en/how_to/batch_sizes.mdx
new file mode 100644
index 00000000..5f4d71c0
--- /dev/null
+++ b/docs/source/en/how_to/batch_sizes.mdx
@@ -0,0 +1,21 @@
+
+# Batch sizes for Inference
+In this how-to guide we will explore the effects of increasing the batch sizes in [`SetFitModel.predict`].
+
+## What are they?
+When processing on GPUs, often times not all data fits on the GPU its VRAM at once. As a result, the data gets split up into **batches** of some often pre-determined batch size. This is done both during training and during inference. In both scenarios, increasing the batch size often has notable consequences to processing efficiency and VRAM memory usage, as transferring data to and from the GPU can be relatively slow.
+
+For inference, it is often recommended to set the batch size high to get notably quicker processing speeds.
+
+## In SetFit
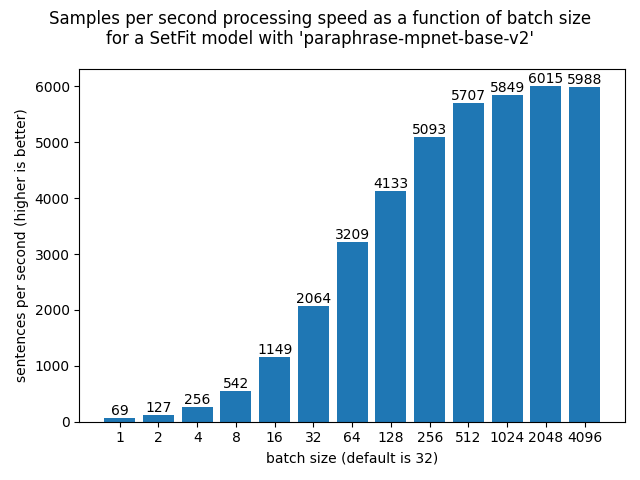
+The batch size for inference in SetFit is set to 32, but it can be affected by passing a `batch_size` argument to [`SetFitModel.predict`]. For example, on a RTX 3090 with a SetFit model based on the [paraphrase-mpnet-base-v2](https://huggingface.co/sentence-transformers/paraphrase-mpnet-base-v2) Sentence Transformer, the following throughputs are reached:
+
+
+
+
+
+Each sentence consists of 11 words in this experiment.
+
+
+
+The default batch size of 32 does not result in the highest possible throughput on this hardware. Consider experimenting with the batch size to reach your highest possible throughput.
\ No newline at end of file
diff --git a/docs/source/en/how_to/callbacks.mdx b/docs/source/en/how_to/callbacks.mdx
new file mode 100644
index 00000000..6ff557f5
--- /dev/null
+++ b/docs/source/en/how_to/callbacks.mdx
@@ -0,0 +1,104 @@
+
+# Callbacks
+SetFit models can be influenced by callbacks, for example for logging or early stopping.
+
+This guide will show you what they are and how they can be used.
+
+## Callbacks in SetFit
+
+Callbacks are objects that customize the behaviour of the training loop in the SetFit [`Trainer`] that can inspect the training loop state (for progress reporting, logging, inspecting embeddings during training) and take decisions (e.g. early stopping).
+
+In particular, the [`Trainer`] uses a [`TrainerControl`](https://huggingface.co/docs/transformers/main_classes/callback#transformers.TrainerControl) that can be influenced by callbacks to stop training, save models, evaluate, or log, and a [`TrainerState`](https://huggingface.co/docs/transformers/main_classes/callback#transformers.TrainerState) which tracks some training loop metrics during training, such as the number of training steps so far.
+
+SetFit relies on the Callbacks implemented in `transformers`, as described in the `transformers` documentation [here](https://huggingface.co/docs/transformers/main_classes/callback).
+
+## Default Callbacks
+
+SetFit uses the `TrainingArguments.report_to` argument to specify which of the built-in callbacks should be enabled. This argument defaults to `"all"`, meaning that all third-party callbacks from `transformers` that are also installed will be enabled. For example the [`TensorBoardCallback`](https://huggingface.co/docs/transformers/main_classes/callback#transformers.integrations.TensorBoardCallback) or the [`WandbCallback`](https://huggingface.co/docs/transformers/main_classes/callback#transformers.integrations.WandbCallback).
+
+Beyond that, the [`PrinterCallback`](https://huggingface.co/docs/transformers/main_classes/callback#transformers.PrinterCallback) or [`ProgressCallback`](https://huggingface.co/docs/transformers/main_classes/callback#transformers.ProgressCallback) is always enabled to show the training progress, and [`DefaultFlowCallback`](https://huggingface.co/docs/transformers/main_classes/callback#transformers.DefaultFlowCallback) is also always enabled to properly update the `TrainerControl`.
+
+## Using Callbacks
+
+As mentioned, you can use `TrainingArguments.report_to` to specify exactly which callbacks you would like to enable. For example:
+
+```py
+from setfit import TrainingArguments
+
+args = TrainingArguments(
+ ...,
+ report_to="wandb",
+ ...,
+)
+# or
+args = TrainingArguments(
+ ...,
+ report_to=["wandb", "tensorboard"],
+ ...,
+)
+```
+You can also use [`Trainer.add_callback`], [`Trainer.pop_callback`] and [`Trainer.remove_callback`] to influence the trainer callbacks, and you can specify callbacks via the [`Trainer`] init, e.g.:
+
+```py
+from setfit import Trainer
+
+...
+
+trainer = Trainer(
+ model,
+ args=args,
+ train_dataset=train_dataset,
+ eval_dataset=eval_dataset,
+ callbacks=[EarlyStoppingCallback(early_stopping_patience=5)],
+)
+trainer.train()
+```
+
+## Custom Callbacks
+
+SetFit supports custom callbacks in the same way that `transformers` does: by subclassing [`TrainerCallback`](https://huggingface.co/docs/transformers/main_classes/callback#transformers.TrainerCallback). This class implements a lot of `on_...` methods that can be overridden. For example, the following script shows a custom callback that saves plots of the tSNE of the training and evaluation embeddings during training.
+
+```py
+import matplotlib.pyplot as plt
+from sklearn.manifold import TSNE
+
+class EmbeddingPlotCallback(TrainerCallback):
+ """Simple embedding plotting callback that plots the tSNE of the training and evaluation datasets throughout training."""
+ def on_evaluate(self, args: TrainingArguments, state: TrainerState, control: TrainerControl, model: SetFitModel, **kwargs):
+ train_embeddings = model.encode(train_dataset["text"])
+ eval_embeddings = model.encode(eval_dataset["text"])
+
+ fig, (train_ax, eval_ax) = plt.subplots(ncols=2)
+
+ train_X = TSNE(n_components=2).fit_transform(train_embeddings)
+ train_ax.scatter(*train_X.T, c=train_dataset["label"], label=train_dataset["label"])
+ train_ax.set_title("Training embeddings")
+
+ eval_X = TSNE(n_components=2).fit_transform(eval_embeddings)
+ eval_ax.scatter(*eval_X.T, c=eval_dataset["label"], label=eval_dataset["label"])
+ eval_ax.set_title("Evaluation embeddings")
+
+ fig.suptitle(f"tSNE of training and evaluation embeddings at step {state.global_step} of {state.max_steps}.")
+ fig.savefig(f"logs/step_{state.global_step}.png")
+```
+
+with
+
+```py
+trainer = Trainer(
+ model=model,
+ args=args,
+ train_dataset=train_dataset,
+ eval_dataset=eval_dataset,
+ callbacks=[EmbeddingPlotCallback()]
+)
+trainer.train()
+```
+
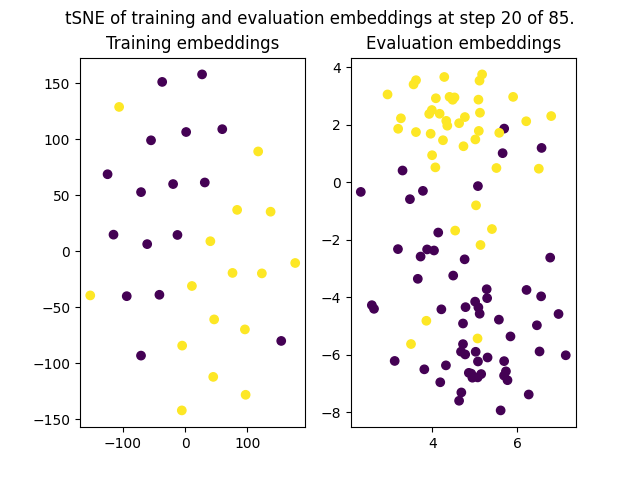
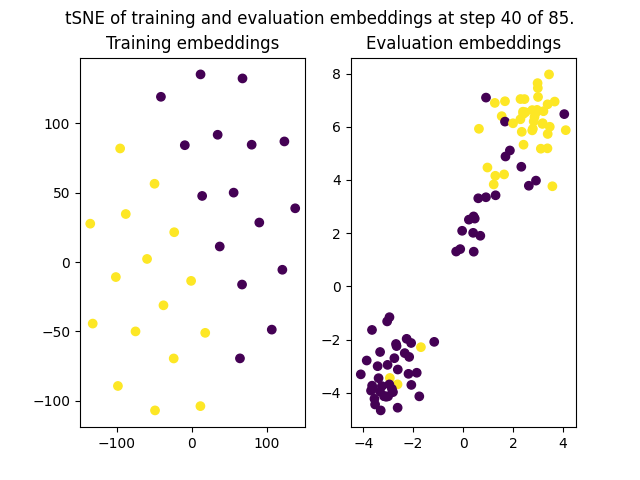
+The `on_evaluate` from `EmbeddingPlotCallback` will be triggered on every single evaluation call. In the case of this example, it resulted in the following figures being plotted:
+
+| Step 20 | Step 40 |
+|-------------|-------------|
+|  |  |
+| **Step 60** | **Step 80** |
+| 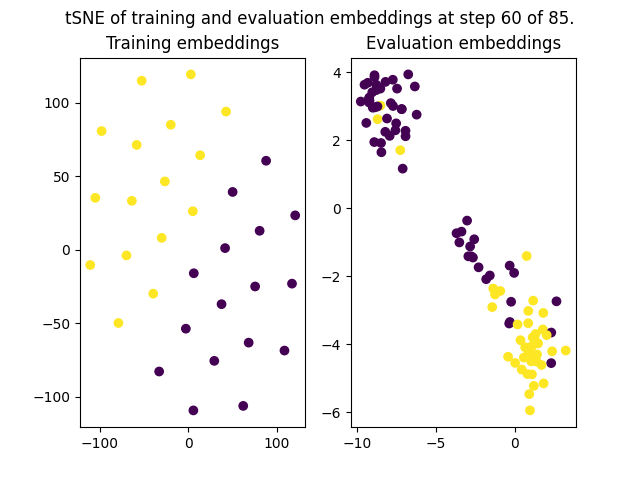 | 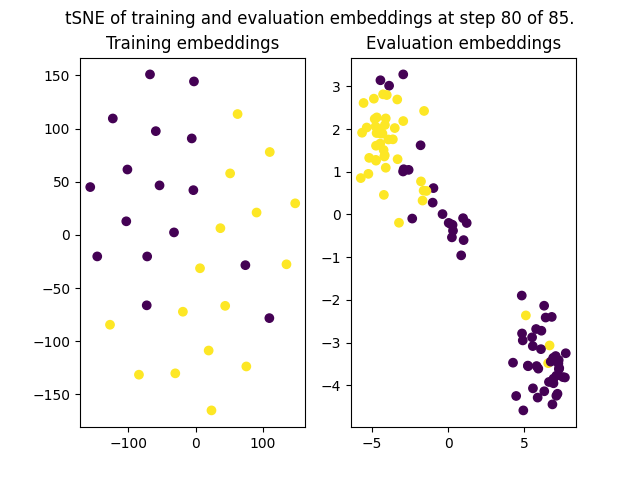 |
\ No newline at end of file
diff --git a/docs/source/en/how_to/classification_heads.mdx b/docs/source/en/how_to/classification_heads.mdx
new file mode 100644
index 00000000..cb1ef413
--- /dev/null
+++ b/docs/source/en/how_to/classification_heads.mdx
@@ -0,0 +1,208 @@
+
+# Classification heads
+
+[[open-in-colab]]
+
+Any 🤗 SetFit model consists of two parts: a [SentenceTransformer](https://sbert.net/) embedding body and a classification head.
+
+This guide will show you:
+* The built-in logistic regression classification head
+* The built-in differentiable classification head
+* The requirements for a custom classification head
+
+## Logistic Regression classification head
+
+When a new SetFit model is initialized, a [scikit-learn logistic regression](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html) head is chosen by default. This has been shown to be highly effective when applied on top of a finetuned sentence transformer body, and it remains the recommended classification head. Initializing a new SetFit model with a Logistic Regression head is simple:
+
+```py
+>>> from setfit import SetFitModel
+
+>>> model = SetFitModel.from_pretrained("BAAI/bge-small-en-v1.5")
+>>> model.model_head
+LogisticRegression()
+```
+
+To initialize the Logistic Regression head (or any other head) with additional parameters, then you can use the `head_params` argument on [`SetFitModel.from_pretrained`]:
+
+```py
+>>> from setfit import SetFitModel
+
+>>> model = SetFitModel.from_pretrained("BAAI/bge-small-en-v1.5", head_params={"solver": "liblinear", "max_iter": 300})
+>>> model.model_head
+LogisticRegression(max_iter=300, solver='liblinear')
+```
+
+## Differentiable classification head
+
+SetFit also provides [`SetFitHead`] as an exclusively `torch` classification head. It uses a linear layer to map the embeddings to the class. It can be used by setting the `use_differentiable_head` argument on [`SetFitModel.from_pretrained`] to `True`:
+
+```py
+>>> from setfit import SetFitModel
+
+>>> model = SetFitModel.from_pretrained("BAAI/bge-small-en-v1.5", use_differentiable_head=True)
+>>> model.model_head
+SetFitHead({'in_features': 384, 'out_features': 2, 'temperature': 1.0, 'bias': True, 'device': 'cuda'})
+```
+
+By default, this will assume binary classification. To change that, also set the `out_features` via `head_params` to the number of classes that you are using.
+
+```py
+>>> from setfit import SetFitModel
+
+>>> model = SetFitModel.from_pretrained("BAAI/bge-small-en-v1.5", use_differentiable_head=True, head_params={"out_features": 5})
+>>> model.model_head
+SetFitHead({'in_features': 384, 'out_features': 5, 'temperature': 1.0, 'bias': True, 'device': 'cuda'})
+```
+
+
+
+Unlike the default Logistic Regression head, the differentiable classification head only supports integer labels in the following range: `[0, num_classes)`.
+
+
+
+### Training with a differentiable classification head
+
+Using the [`SetFitHead`] unlocks some new [`TrainingArguments`] that are not used with a sklearn-based head. Note that training with SetFit consists of two phases behind the scenes: **finetuning embeddings** and **training a classification head**. As a result, some of the training arguments can be tuples, where the two values are used for each of the two phases, respectively. For a lot of these cases, the second value is only used if the classification head is differentiable. For example:
+
+* **batch_size**: (`Union[int, Tuple[int, int]]`, defaults to `(16, 2)`) - The second value in the tuple determines the batch size when training the differentiable SetFitHead.
+* **num_epochs**: (`Union[int, Tuple[int, int]]`, defaults to `(1, 16)`) - The second value in the tuple determines the number of epochs when training the differentiable SetFitHead. In practice, the `num_epochs` is usually larger for training the classification head. There are two reasons for this:
+
+ 1. This training phase does not train with contrastive pairs, so unlike when finetuning the embedding model, you only get one training sample per labeled training text.
+ 2. This training phase involves training a classifier from scratch, not finetuning an already capable model. We need more training steps for this.
+* **end_to_end**: (`bool`, defaults to `False`) - If `True`, train the entire model end-to-end during the classifier training phase. Otherwise, freeze the Sentence Transformer body and only train the head.
+* **body_learning_rate**: (`Union[float, Tuple[float, float]]`, defaults to `(2e-5, 1e-5)`) - The second value in the tuple determines the learning rate of the Sentence Transformer body during the classifier training phase. This is only relevant if `end_to_end` is `True`, as otherwise the Sentence Transformer body is frozen when training the classifier.
+* **head_learning_rate** (`float`, defaults to `1e-2`) - This value determines the learning rate of the differentiable head during the classifier training phase. It is only used if the differentiable head is used.
+* **l2_weight** (`float`, *optional*) - Optional l2 weight for both the model body and head, passed to the `AdamW` optimizer in the classifier training phase only if a differentiable head is used.
+
+For example, a full training script using a differentiable classification head may look something like this:
+
+```py
+from setfit import SetFitModel, Trainer, TrainingArguments, sample_dataset
+from datasets import load_dataset
+
+# Initializing a new SetFit model
+model = SetFitModel.from_pretrained("BAAI/bge-small-en-v1.5", use_differentiable_head=True, head_params={"out_features": 2})
+
+# Preparing the dataset
+dataset = load_dataset("SetFit/sst2")
+train_dataset = sample_dataset(dataset["train"], label_column="label", num_samples=32)
+test_dataset = dataset["test"]
+
+# Preparing the training arguments
+args = TrainingArguments(
+ batch_size=(32, 16),
+ num_epochs=(3, 8),
+ end_to_end=True,
+ body_learning_rate=(2e-5, 5e-6),
+ head_learning_rate=2e-3,
+ l2_weight=0.01,
+)
+
+# Preparing the trainer
+trainer = Trainer(
+ model=model,
+ args=args,
+ train_dataset=train_dataset,
+)
+trainer.train()
+# ***** Running training *****
+# Num examples = 66
+# Num epochs = 3
+# Total optimization steps = 198
+# Total train batch size = 3
+# {'embedding_loss': 0.2204, 'learning_rate': 1.0000000000000002e-06, 'epoch': 0.02}
+# {'embedding_loss': 0.0058, 'learning_rate': 1.662921348314607e-05, 'epoch': 0.76}
+# {'embedding_loss': 0.0026, 'learning_rate': 1.101123595505618e-05, 'epoch': 1.52}
+# {'embedding_loss': 0.0022, 'learning_rate': 5.393258426966292e-06, 'epoch': 2.27}
+# {'train_runtime': 36.6756, 'train_samples_per_second': 172.758, 'train_steps_per_second': 5.399, 'epoch': 3.0}
+# 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 198/198 [00:30<00:00, 6.45it/s]
+# The `max_length` is `None`. Using the maximum acceptable length according to the current model body: 512.
+# Epoch: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 8/8 [00:07<00:00, 1.03it/s]
+
+# Evaluating
+metrics = trainer.evaluate(test_dataset)
+print(metrics)
+# => {'accuracy': 0.8632619439868204}
+
+# Performing inference
+preds = model.predict([
+ "It's a charming and often affecting journey.",
+ "It's slow -- very, very slow.",
+ "A sometimes tedious film.",
+])
+print(preds)
+# => tensor([1, 0, 0], device='cuda:0')
+```
+
+## Custom classification head
+Alongside the two built-in options, SetFit allows you to specify a custom classification head. There are two forms of supported heads: a custom **differentiable** head or a custom **non-differentiable** head. Both heads must implement the following two methods:
+
+### Custom differentiable head
+A custom differentiable head must follow these requirements:
+
+* Must subclass `nn.Module`.
+* A `predict` method: `(self, torch.Tensor with shape [num_inputs, embedding_size]) -> torch.Tensor with shape [num_inputs]` - This method classifies the embeddings. The output must integers in the range of `[0, num_classes)`.
+* A `predict_proba` method: `(self, torch.Tensor with shape [num_inputs, embedding_size]) -> torch.Tensor with shape [num_inputs, num_classes]` - This method classifies the embeddings into probabilities for each class. For each input, the tensor of size `num_classes` must sum to 1. Applying `torch.argmax(output, dim=-1)` should result in the output for `predict`.
+* A `get_loss_fn` method: `(self) -> nn.Module` - Returns an initialized loss function, e.g. `torch.nn.CrossEntropyLoss()`.
+* A `forward` method: `(self, Dict[str, torch.Tensor]) -> Dict[str, torch.Tensor]` - Given the output from the Sentence Transformer body, i.e. a dictionary of `'input_ids'`, `'token_type_ids'`, `'attention_mask'`, `'token_embeddings'` and `'sentence_embedding'` keys, return a dictionary with a `'logits'` key and a `torch.Tensor` value with shape `[batch_size, num_classes]`.
+
+### Custom non-differentiable head
+A custom non-differentiable head must follow these requirements:
+
+* A `predict` method: `(self, np.array with shape [num_inputs, embedding_size]) -> np.array with shape [num_inputs]` - This method classifies the embeddings. The output must integers in the range of `[0, num_classes)`.
+* A `predict_proba` method: `(self, np.array with shape [num_inputs, embedding_size]) -> np.array with shape [num_inputs, num_classes]` - This method classifies the embeddings into probabilities for each class. For each input, the array of size `num_classes` must sum to 1. Applying `np.argmax(output, dim=-1)` should result in the output for `predict`.
+* A `fit` method: `(self, np.array with shape [num_inputs, embedding_size], List[Any]) -> None` - This method must take a `numpy` array of embeddings and a list of corresponding labels. The labels need not be integers per se.
+
+Many classifiers from sklearn already fit these requirements, such as [`RandomForestClassifier`](https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html#sklearn.ensemble.RandomForestClassifier), [`MLPClassifier`](https://scikit-learn.org/stable/modules/generated/sklearn.neural_network.MLPClassifier.html#sklearn.neural_network.MLPClassifier), [`KNeighborsClassifier`](https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html#sklearn.neighbors.KNeighborsClassifier), etc.
+
+When initializing a SetFit model using your custom (non-)differentiable classification head, it is recommended to use the regular `__init__` method:
+
+```py
+from setfit import SetFitModel
+from sklearn.svm import LinearSVC
+from sentence_transformers import SentenceTransformer
+
+# Initializing a new SetFit model
+model_body = SentenceTransformer("BAAI/bge-small-en-v1.5")
+model_head = LinearSVC()
+model = SetFitModel(model_body, model_head)
+```
+
+Then, training and inference can commence like normal, e.g.:
+```py
+from setfit import Trainer, TrainingArguments, sample_dataset
+from datasets import load_dataset
+
+# Preparing the dataset
+dataset = load_dataset("SetFit/sst2")
+train_dataset = sample_dataset(dataset["train"], label_column="label", num_samples=32)
+test_dataset = dataset["test"]
+
+# Preparing the training arguments
+args = TrainingArguments(
+ batch_size=32,
+ num_epochs=3,
+)
+
+# Preparing the trainer
+trainer = Trainer(
+ model=model,
+ args=args,
+ train_dataset=train_dataset,
+)
+trainer.train()
+
+# Evaluating
+metrics = trainer.evaluate(test_dataset)
+print(metrics)
+# => {'accuracy': 0.8638110928061504}
+
+# Performing inference
+preds = model.predict([
+ "It's a charming and often affecting journey.",
+ "It's slow -- very, very slow.",
+ "A sometimes tedious film.",
+])
+print(preds)
+# => tensor([1, 0, 0], dtype=torch.int32)
+```
diff --git a/docs/source/en/how_to/hyperparameter_optimization.mdx b/docs/source/en/how_to/hyperparameter_optimization.mdx
new file mode 100644
index 00000000..db687044
--- /dev/null
+++ b/docs/source/en/how_to/hyperparameter_optimization.mdx
@@ -0,0 +1,376 @@
+
+# Hyperparameter Optimization
+
+SetFit models are often very quick to train, making them very suitable for hyperparameter optimization (HPO) to select the best hyperparameters.
+
+This guide will show you how to apply HPO for SetFit.
+
+## Requirements
+
+To use HPO, first install the `optuna` backend:
+
+```bash
+pip install optuna
+```
+
+To use this method, you need to define two functions:
+
+* `model_init()`: A function that instantiates the model to be used. If provided, each call to `train()` will start from a new instance of the model as given by this function.
+* `hp_space()`: A function that defines the hyperparameter search space.
+
+Here is an example of a `model_init()` function that we'll use to scan over the hyperparameters associated with the classification head in `SetFitModel`:
+
+```python
+from setfit import SetFitModel
+from typing import Dict, Any
+
+def model_init(params: Dict[str, Any]) -> SetFitModel:
+ params = params or {}
+ max_iter = params.get("max_iter", 100)
+ solver = params.get("solver", "liblinear")
+ params = {
+ "head_params": {
+ "max_iter": max_iter,
+ "solver": solver,
+ }
+ }
+ return SetFitModel.from_pretrained("BAAI/bge-small-en-v1.5", **params)
+```
+
+Then, to scan over hyperparameters associated with the SetFit training process, we can define a `hp_space(trial)` function as follows:
+
+```python
+from optuna import Trial
+from typing import Dict, Union
+
+def hp_space(trial: Trial) -> Dict[str, Union[float, int, str]]:
+ return {
+ "body_learning_rate": trial.suggest_float("body_learning_rate", 1e-6, 1e-3, log=True),
+ "num_epochs": trial.suggest_int("num_epochs", 1, 3),
+ "batch_size": trial.suggest_categorical("batch_size", [16, 32, 64]),
+ "seed": trial.suggest_int("seed", 1, 40),
+ "max_iter": trial.suggest_int("max_iter", 50, 300),
+ "solver": trial.suggest_categorical("solver", ["newton-cg", "lbfgs", "liblinear"]),
+ }
+```
+
+
+
+In practice, we found `num_epochs`, `max_steps`, and `body_learning_rate` to be the most important hyperparameters for the contrastive learning process.
+
+
+
+The next step is to prepare a dataset.
+
+```py
+from datasets import load_dataset
+from setfit import Trainer, sample_dataset
+
+dataset = load_dataset("SetFit/emotion")
+train_dataset = sample_dataset(dataset["train"], label_column="label", num_samples=8)
+test_dataset = dataset["test"]
+```
+
+After which we can instantiate a [`Trainer`] and commence HPO via [`Trainer.hyperparameter_search`]. I've split up the logs from each trial into separate codeblocks for readability:
+
+```py
+trainer = Trainer(
+ train_dataset=train_dataset,
+ eval_dataset=test_dataset,
+ model_init=model_init,
+)
+best_run = trainer.hyperparameter_search(direction="maximize", hp_space=hp_space, n_trials=10)
+```
+```
+[I 2023-11-14 20:36:55,736] A new study created in memory with name: no-name-d9c6ec29-c5d8-48a2-8f09-299b1f3740f1
+Trial: {'body_learning_rate': 1.937397586885703e-06, 'num_epochs': 3, 'batch_size': 32, 'seed': 16, 'max_iter': 223, 'solver': 'newton-cg'}
+model_head.pkl not found on HuggingFace Hub, initialising classification head with random weights. You should TRAIN this model on a downstream task to use it for predictions and inference.
+***** Running training *****
+ Num examples = 60
+ Num epochs = 3
+ Total optimization steps = 180
+ Total train batch size = 32
+{'embedding_loss': 0.26, 'learning_rate': 1.0763319927142795e-07, 'epoch': 0.02}
+{'embedding_loss': 0.2069, 'learning_rate': 1.5547017672539594e-06, 'epoch': 0.83}
+{'embedding_loss': 0.2145, 'learning_rate': 9.567395490793595e-07, 'epoch': 1.67}
+{'embedding_loss': 0.2236, 'learning_rate': 3.587773309047598e-07, 'epoch': 2.5}
+{'train_runtime': 36.1299, 'train_samples_per_second': 159.425, 'train_steps_per_second': 4.982, 'epoch': 3.0}
+100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 180/180 [00:29<00:00, 6.02it/s]
+***** Running evaluation *****
+[I 2023-11-14 20:37:33,895] Trial 0 finished with value: 0.44 and parameters: {'body_learning_rate': 1.937397586885703e-06, 'num_epochs': 3, 'batch_size': 32, 'seed': 16, 'max_iter': 223, 'solver': 'newton-cg'}. Best is trial 0 with value: 0.44.
+```
+```
+Trial: {'body_learning_rate': 0.000946449838705604, 'num_epochs': 2, 'batch_size': 16, 'seed': 8, 'max_iter': 60, 'solver': 'liblinear'}
+model_head.pkl not found on HuggingFace Hub, initialising classification head with random weights. You should TRAIN this model on a downstream task to use it for predictions and inference.
+***** Running training *****
+ Num examples = 120
+ Num epochs = 2
+ Total optimization steps = 240
+ Total train batch size = 16
+{'embedding_loss': 0.2354, 'learning_rate': 3.943540994606683e-05, 'epoch': 0.01}
+{'embedding_loss': 0.2419, 'learning_rate': 0.0008325253210836332, 'epoch': 0.42}
+{'embedding_loss': 0.3601, 'learning_rate': 0.0006134397102721508, 'epoch': 0.83}
+{'embedding_loss': 0.2694, 'learning_rate': 0.00039435409946066835, 'epoch': 1.25}
+{'embedding_loss': 0.2496, 'learning_rate': 0.0001752684886491859, 'epoch': 1.67}
+{'train_runtime': 33.5015, 'train_samples_per_second': 114.622, 'train_steps_per_second': 7.164, 'epoch': 2.0}
+100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 240/240 [00:33<00:00, 7.16it/s]
+***** Running evaluation *****
+[I 2023-11-14 20:38:09,485] Trial 1 finished with value: 0.207 and parameters: {'body_learning_rate': 0.000946449838705604, 'num_epochs': 2, 'batch_size': 16, 'seed': 8, 'max_iter': 60, 'solver': 'liblinear'}. Best is trial 0 with value: 0.44.
+```
+```
+Trial: {'body_learning_rate': 8.050718146495058e-06, 'num_epochs': 1, 'batch_size': 32, 'seed': 20, 'max_iter': 260, 'solver': 'lbfgs'}
+model_head.pkl not found on HuggingFace Hub, initialising classification head with random weights. You should TRAIN this model on a downstream task to use it for predictions and inference.
+***** Running training *****
+ Num examples = 60
+ Num epochs = 1
+ Total optimization steps = 60
+ Total train batch size = 32
+{'embedding_loss': 0.2499, 'learning_rate': 1.3417863577491763e-06, 'epoch': 0.02}
+{'embedding_loss': 0.1714, 'learning_rate': 1.490873730832418e-06, 'epoch': 0.83}
+{'train_runtime': 9.5338, 'train_samples_per_second': 201.388, 'train_steps_per_second': 6.293, 'epoch': 1.0}
+100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 60/60 [00:09<00:00, 6.30it/s]
+***** Running evaluation *****
+[I 2023-11-14 20:38:21,069] Trial 2 finished with value: 0.436 and parameters: {'body_learning_rate': 8.050718146495058e-06, 'num_epochs': 1, 'batch_size': 32, 'seed': 20, 'max_iter': 260, 'solver': 'lbfgs'}. Best is trial 0 with value: 0.44.
+```
+```
+Trial: {'body_learning_rate': 0.000995585414046506, 'num_epochs': 1, 'batch_size': 32, 'seed': 29, 'max_iter': 105, 'solver': 'lbfgs'}
+model_head.pkl not found on HuggingFace Hub, initialising classification head with random weights. You should TRAIN this model on a downstream task to use it for predictions and inference.
+***** Running training *****
+ Num examples = 60
+ Num epochs = 1
+ Total optimization steps = 60
+ Total train batch size = 32
+{'embedding_loss': 0.2556, 'learning_rate': 0.00016593090234108434, 'epoch': 0.02}
+{'embedding_loss': 0.0625, 'learning_rate': 0.0001843676692678715, 'epoch': 0.83}
+{'train_runtime': 9.5629, 'train_samples_per_second': 200.776, 'train_steps_per_second': 6.274, 'epoch': 1.0}
+100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 60/60 [00:09<00:00, 6.28it/s]
+***** Running evaluation *****
+[I 2023-11-14 20:38:32,890] Trial 3 finished with value: 0.283 and parameters: {'body_learning_rate': 0.000995585414046506, 'num_epochs': 1, 'batch_size': 32, 'seed': 29, 'max_iter': 105, 'solver': 'lbfgs'}. Best is trial 0 with value: 0.44.
+```
+```
+Trial: {'body_learning_rate': 8.541092571911196e-06, 'num_epochs': 3, 'batch_size': 32, 'seed': 2, 'max_iter': 223, 'solver': 'newton-cg'}
+model_head.pkl not found on HuggingFace Hub, initialising classification head with random weights. You should TRAIN this model on a downstream task to use it for predictions and inference.
+***** Running training *****
+ Num examples = 60
+ Num epochs = 3
+ Total optimization steps = 180
+ Total train batch size = 32
+{'embedding_loss': 0.2578, 'learning_rate': 4.745051428839553e-07, 'epoch': 0.02}
+{'embedding_loss': 0.1725, 'learning_rate': 6.8539631749904665e-06, 'epoch': 0.83}
+{'embedding_loss': 0.1589, 'learning_rate': 4.217823492301825e-06, 'epoch': 1.67}
+{'embedding_loss': 0.1153, 'learning_rate': 1.5816838096131844e-06, 'epoch': 2.5}
+{'train_runtime': 28.3099, 'train_samples_per_second': 203.462, 'train_steps_per_second': 6.358, 'epoch': 3.0}
+100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 180/180 [00:28<00:00, 6.36it/s]
+***** Running evaluation *****
+[I 2023-11-14 20:39:03,196] Trial 4 finished with value: 0.4415 and parameters: {'body_learning_rate': 8.541092571911196e-06, 'num_epochs': 3, 'batch_size': 32, 'seed': 2, 'max_iter': 223, 'solver': 'newton-cg'}. Best is trial 4 with value: 0.4415.
+```
+```
+Trial: {'body_learning_rate': 2.3916782417792657e-05, 'num_epochs': 1, 'batch_size': 64, 'seed': 23, 'max_iter': 258, 'solver': 'liblinear'}
+model_head.pkl not found on HuggingFace Hub, initialising classification head with random weights. You should TRAIN this model on a downstream task to use it for predictions and inference.
+***** Running training *****
+ Num examples = 30
+ Num epochs = 1
+ Total optimization steps = 30
+ Total train batch size = 64
+{'embedding_loss': 0.2478, 'learning_rate': 7.972260805930886e-06, 'epoch': 0.03}
+{'train_runtime': 6.4905, 'train_samples_per_second': 295.818, 'train_steps_per_second': 4.622, 'epoch': 1.0}
+100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 30/30 [00:06<00:00, 4.62it/s]
+***** Running evaluation *****
+[I 2023-11-14 20:39:12,024] Trial 5 finished with value: 0.4345 and parameters: {'body_learning_rate': 2.3916782417792657e-05, 'num_epochs': 1, 'batch_size': 64, 'seed': 23, 'max_iter': 258, 'solver': 'liblinear'}. Best is trial 4 with value: 0.4415.
+```
+```
+Trial: {'body_learning_rate': 0.00012856431493122938, 'num_epochs': 1, 'batch_size': 32, 'seed': 29, 'max_iter': 97, 'solver': 'liblinear'}
+model_head.pkl not found on HuggingFace Hub, initialising classification head with random weights. You should TRAIN this model on a downstream task to use it for predictions and inference.
+***** Running training *****
+ Num examples = 60
+ Num epochs = 1
+ Total optimization steps = 60
+ Total train batch size = 32
+{'embedding_loss': 0.2556, 'learning_rate': 2.1427385821871562e-05, 'epoch': 0.02}
+{'embedding_loss': 0.023, 'learning_rate': 2.380820646874618e-05, 'epoch': 0.83}
+{'train_runtime': 9.2295, 'train_samples_per_second': 208.029, 'train_steps_per_second': 6.501, 'epoch': 1.0}
+100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 60/60 [00:09<00:00, 6.50it/s]
+***** Running evaluation *****
+[I 2023-11-14 20:39:23,302] Trial 6 finished with value: 0.4675 and parameters: {'body_learning_rate': 0.00012856431493122938, 'num_epochs': 1, 'batch_size': 32, 'seed': 29, 'max_iter': 97, 'solver': 'liblinear'}. Best is trial 6 with value: 0.4675.
+```
+```
+Trial: {'body_learning_rate': 3.839168294105717e-06, 'num_epochs': 3, 'batch_size': 16, 'seed': 16, 'max_iter': 297, 'solver': 'newton-cg'}
+***** Running training *****
+ Num examples = 120
+ Num epochs = 3
+ Total optimization steps = 360
+ Total train batch size = 16
+{'embedding_loss': 0.2357, 'learning_rate': 1.066435637251588e-07, 'epoch': 0.01}
+{'embedding_loss': 0.2268, 'learning_rate': 3.6732783060888037e-06, 'epoch': 0.42}
+{'embedding_loss': 0.1308, 'learning_rate': 3.0808140631712545e-06, 'epoch': 0.83}
+{'embedding_loss': 0.2032, 'learning_rate': 2.4883498202537057e-06, 'epoch': 1.25}
+{'embedding_loss': 0.1617, 'learning_rate': 1.8958855773361567e-06, 'epoch': 1.67}
+{'embedding_loss': 0.1363, 'learning_rate': 1.3034213344186077e-06, 'epoch': 2.08}
+{'embedding_loss': 0.1559, 'learning_rate': 7.109570915010587e-07, 'epoch': 2.5}
+{'embedding_loss': 0.1761, 'learning_rate': 1.1849284858350979e-07, 'epoch': 2.92}
+{'train_runtime': 49.8712, 'train_samples_per_second': 115.497, 'train_steps_per_second': 7.219, 'epoch': 3.0}
+100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 360/360 [00:49<00:00, 7.22it/s]
+***** Running evaluation *****
+[I 2023-11-14 20:40:15,350] Trial 7 finished with value: 0.442 and parameters: {'body_learning_rate': 3.839168294105717e-06, 'num_epochs': 3, 'batch_size': 16, 'seed': 16, 'max_iter': 297, 'solver': 'newton-cg'}. Best is trial 6 with value: 0.4675.
+```
+```
+Trial: {'body_learning_rate': 0.0005575631179396824, 'num_epochs': 1, 'batch_size': 32, 'seed': 31, 'max_iter': 264, 'solver': 'newton-cg'}
+***** Running training *****
+ Num examples = 60
+ Num epochs = 1
+ Total optimization steps = 60
+ Total train batch size = 32
+{'embedding_loss': 0.2588, 'learning_rate': 9.29271863232804e-05, 'epoch': 0.02}
+{'embedding_loss': 0.0025, 'learning_rate': 0.00010325242924808932, 'epoch': 0.83}
+{'train_runtime': 9.4608, 'train_samples_per_second': 202.942, 'train_steps_per_second': 6.342, 'epoch': 1.0}
+100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 60/60 [00:09<00:00, 6.34it/s]
+***** Running evaluation *****
+[I 2023-11-14 20:40:26,886] Trial 8 finished with value: 0.4785 and parameters: {'body_learning_rate': 0.0005575631179396824, 'num_epochs': 1, 'batch_size': 32, 'seed': 31, 'max_iter': 264, 'solver': 'newton-cg'}. Best is trial 8 with value: 0.4785.
+```
+```
+Trial: {'body_learning_rate': 0.00021830594983845785, 'num_epochs': 2, 'batch_size': 16, 'seed': 38, 'max_iter': 267, 'solver': 'lbfgs'}
+***** Running training *****
+ Num examples = 120
+ Num epochs = 2
+ Total optimization steps = 240
+ Total train batch size = 16
+{'embedding_loss': 0.2356, 'learning_rate': 9.096081243269076e-06, 'epoch': 0.01}
+{'embedding_loss': 0.071, 'learning_rate': 0.00019202838180234718, 'epoch': 0.42}
+{'embedding_loss': 0.0021, 'learning_rate': 0.000141494597117519, 'epoch': 0.83}
+{'embedding_loss': 0.0018, 'learning_rate': 9.096081243269078e-05, 'epoch': 1.25}
+{'embedding_loss': 0.0012, 'learning_rate': 4.0427027747862565e-05, 'epoch': 1.67}
+{'train_runtime': 32.7462, 'train_samples_per_second': 117.265, 'train_steps_per_second': 7.329, 'epoch': 2.0}
+100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 240/240 [00:32<00:00, 7.33it/s]
+***** Running evaluation *****
+[I 2023-11-14 20:41:01,722] Trial 9 finished with value: 0.4615 and parameters: {'body_learning_rate': 0.00021830594983845785, 'num_epochs': 2, 'batch_size': 16, 'seed': 38, 'max_iter': 267, 'solver': 'lbfgs'}. Best is trial 8 with value: 0.4785.
+```
+Let's observe the best found hyperparameters:
+
+```py
+print(best_run)
+```
+```
+BestRun(run_id='8', objective=0.4785, hyperparameters={'body_learning_rate': 0.0005575631179396824, 'num_epochs': 1, 'batch_size': 32, 'seed': 31, 'max_iter': 264, 'solver': 'newton-cg'}, backend=)
+```
+
+Finally, you can apply the hyperparameters you found to the trainer, and lock in the optimal model, before training for
+a final time.
+
+```py
+trainer.apply_hyperparameters(best_run.hyperparameters, final_model=True)
+trainer.train()
+```
+```
+***** Running training *****
+ Num examples = 60
+ Num epochs = 1
+ Total optimization steps = 60
+ Total train batch size = 32
+{'embedding_loss': 0.2588, 'learning_rate': 9.29271863232804e-05, 'epoch': 0.02}
+{'embedding_loss': 0.0025, 'learning_rate': 0.00010325242924808932, 'epoch': 0.83}
+{'train_runtime': 9.4331, 'train_samples_per_second': 203.54, 'train_steps_per_second': 6.361, 'epoch': 1.0}
+100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 60/60 [00:09<00:00, 6.36it/s]
+```
+For peace of mind, we can evaluate this model once more:
+
+```py
+metrics = trainer.evaluate()
+print(metrics)
+```
+```
+***** Running evaluation *****
+{'accuracy': 0.4785}
+```
+As expected, the accuracy matches that of the best run.
+
+## Baseline
+
+As a comparison, let's observe the same metrics for the same setup but with the default training arguments:
+
+```py
+from datasets import load_dataset
+from setfit import SetFitModel, Trainer, sample_dataset
+
+model = SetFitModel.from_pretrained("BAAI/bge-small-en-v1.5")
+
+dataset = load_dataset("SetFit/emotion")
+train_dataset = sample_dataset(dataset["train"], label_column="label", num_samples=8)
+test_dataset = dataset["test"]
+
+trainer = Trainer(
+ model=model,
+ train_dataset=train_dataset,
+ eval_dataset=test_dataset,
+)
+trainer.train()
+
+metrics = trainer.evaluate()
+print(metrics)
+```
+```
+***** Running training *****
+ Num examples = 120
+ Num epochs = 1
+ Total optimization steps = 120
+ Total train batch size = 16
+{'embedding_loss': 0.246, 'learning_rate': 1.6666666666666667e-06, 'epoch': 0.01}
+{'embedding_loss': 0.1734, 'learning_rate': 1.2962962962962964e-05, 'epoch': 0.42}
+{'embedding_loss': 0.0411, 'learning_rate': 3.7037037037037037e-06, 'epoch': 0.83}
+{'train_runtime': 23.8184, 'train_samples_per_second': 80.61, 'train_steps_per_second': 5.038, 'epoch': 1.0}
+100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 120/120 [00:17<00:00, 6.83it/s]
+***** Running evaluation *****
+{'accuracy': 0.4235}
+```
+42.35% versus 47.85%! Quite a big difference for just a few minutes of hyperparameter searching.
+
+## End-to-end
+
+This snippet shows the entire hyperparameter optimization strategy in an end-to-end example:
+
+```py
+from datasets import load_dataset
+from setfit import SetFitModel, Trainer, sample_dataset
+from optuna import Trial
+from typing import Dict, Union, Any
+
+def model_init(params: Dict[str, Any]) -> SetFitModel:
+ params = params or {}
+ max_iter = params.get("max_iter", 100)
+ solver = params.get("solver", "liblinear")
+ params = {
+ "head_params": {
+ "max_iter": max_iter,
+ "solver": solver,
+ }
+ }
+ return SetFitModel.from_pretrained("BAAI/bge-small-en-v1.5", **params)
+
+def hp_space(trial: Trial) -> Dict[str, Union[float, int, str]]:
+ return {
+ "body_learning_rate": trial.suggest_float("body_learning_rate", 1e-6, 1e-3, log=True),
+ "num_epochs": trial.suggest_int("num_epochs", 1, 3),
+ "batch_size": trial.suggest_categorical("batch_size", [16, 32, 64]),
+ "seed": trial.suggest_int("seed", 1, 40),
+ "max_iter": trial.suggest_int("max_iter", 50, 300),
+ "solver": trial.suggest_categorical("solver", ["newton-cg", "lbfgs", "liblinear"]),
+ }
+
+dataset = load_dataset("SetFit/emotion")
+train_dataset = sample_dataset(dataset["train"], label_column="label", num_samples=8)
+test_dataset = dataset["test"]
+
+trainer = Trainer(
+ train_dataset=train_dataset,
+ eval_dataset=test_dataset,
+ model_init=model_init,
+)
+best_run = trainer.hyperparameter_search(direction="maximize", hp_space=hp_space, n_trials=10)
+print(best_run)
+
+trainer.apply_hyperparameters(best_run.hyperparameters, final_model=True)
+trainer.train()
+
+metrics = trainer.evaluate()
+print(metrics)
+# => {'accuracy': 0.4785}
+```
\ No newline at end of file
diff --git a/docs/source/en/how_to/knowledge_distillation.mdx b/docs/source/en/how_to/knowledge_distillation.mdx
new file mode 100644
index 00000000..031969e0
--- /dev/null
+++ b/docs/source/en/how_to/knowledge_distillation.mdx
@@ -0,0 +1,293 @@
+
+# Knowledge Distillation
+
+If you have access to unlabeled data, then you can use knowledge distillation to improve the performance of your small SetFit model. The approach involves training a larger model and using unlabeled data to distil its performance into your smaller SetFit model. As a result, your SetFit model will become stronger.
+
+Additionally, you can also use knowledge distillation to replace your trained SetFit model with a more efficient model at less of a performance decrease.
+
+This guide will show you how to proceed with knowledge distillation.
+
+## Data preparation
+
+Let's consider a scenario with a little bit of labeled training data (e.g. 64 sentences). We will simulate this scenario using the [ag_news](https://huggingface.co/datasets/ag_news) dataset for this guide.
+
+```py
+from datasets import load_dataset
+from setfit import sample_dataset
+
+# Load a dataset from the Hugging Face Hub
+dataset = load_dataset("ag_news")
+
+# Create a sample few-shot dataset to train with
+train_dataset = sample_dataset(dataset["train"], label_column="label", num_samples=16)
+# Dataset({
+# features: ['text', 'label'],
+# num_rows: 64
+# })
+
+# Dataset for evaluation
+eval_dataset = dataset["test"]
+# Dataset({
+# features: ['text', 'label'],
+# num_rows: 7600
+# })
+```
+
+## Baseline model
+We can use standard SetFit training approach to prepare a model.
+
+```py
+from setfit import SetFitModel, TrainingArguments, Trainer
+
+model = SetFitModel.from_pretrained("sentence-transformers/paraphrase-MiniLM-L3-v2")
+
+args = TrainingArguments(
+ batch_size=64,
+ num_epochs=5,
+)
+
+trainer = Trainer(
+ model=model,
+ args=args,
+ train_dataset=train_dataset,
+ eval_dataset=eval_dataset,
+)
+trainer.train()
+
+metrics = trainer.evaluate()
+print(metrics)
+```
+```
+***** Running training *****
+ Num examples = 48
+ Num epochs = 5
+ Total optimization steps = 240
+ Total train batch size = 64
+{'embedding_loss': 0.4173, 'learning_rate': 8.333333333333333e-07, 'epoch': 0.02}
+{'embedding_loss': 0.1756, 'learning_rate': 1.7592592592592595e-05, 'epoch': 1.04}
+{'embedding_loss': 0.119, 'learning_rate': 1.2962962962962964e-05, 'epoch': 2.08}
+{'embedding_loss': 0.0872, 'learning_rate': 8.333333333333334e-06, 'epoch': 3.12}
+{'embedding_loss': 0.0542, 'learning_rate': 3.7037037037037037e-06, 'epoch': 4.17}
+{'train_runtime': 26.0837, 'train_samples_per_second': 588.873, 'train_steps_per_second': 9.201, 'epoch': 5.0}
+100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 240/240 [00:20<00:00, 11.97it/s]
+***** Running evaluation *****
+{'accuracy': 0.7818421052631579}
+```
+This model reaches 78.18% on our dataset. Certainly respectable given the tiny amount of training data, but we can use knowledge distillation to squeeze more performance out of our model.
+
+## Unlabeled Data Preparation
+
+Alongside our labeled training data, we may als have a lot of unlabeled training data (e.g. 500 sentences). Let's prepare it:
+
+```py
+# Create a dataset of unlabeled examples to perform knowledge distillation
+unlabeled_train_dataset = dataset["train"].shuffle(seed=0).select(range(500))
+unlabeled_train_dataset = unlabeled_train_dataset.remove_columns("label")
+# Dataset({
+# features: ['text'],
+# num_rows: 500
+# })
+```
+
+## Teacher model
+
+Then, we will prepare a larger trained SetFit model that will act as the teacher to our smaller student model. The strong [`sentence-transformers/paraphrase-mpnet-base-v2`](https://huggingface.co/sentence-transformers/paraphrase-mpnet-base-v2) Sentence Transformer model will be used to initialize the SetFit model.
+
+```py
+from setfit import SetFitModel
+
+teacher_model = SetFitModel.from_pretrained("sentence-transformers/paraphrase-mpnet-base-v2")
+```
+
+We need to train this model on the labeled dataset first:
+
+```py
+from setfit import TrainingArguments, Trainer
+
+teacher_args = TrainingArguments(
+ batch_size=16,
+ num_epochs=2,
+)
+
+teacher_trainer = Trainer(
+ model=teacher_model,
+ args=teacher_args,
+ train_dataset=train_dataset,
+ eval_dataset=eval_dataset,
+)
+
+# Train teacher model
+teacher_trainer.train()
+teacher_metrics = teacher_trainer.evaluate()
+print(teacher_metrics)
+```
+```
+***** Running training *****
+ Num examples = 192
+ Num epochs = 2
+ Total optimization steps = 384
+ Total train batch size = 16
+{'embedding_loss': 0.4093, 'learning_rate': 5.128205128205128e-07, 'epoch': 0.01}
+{'embedding_loss': 0.1087, 'learning_rate': 1.9362318840579713e-05, 'epoch': 0.26}
+{'embedding_loss': 0.001, 'learning_rate': 1.6463768115942028e-05, 'epoch': 0.52}
+{'embedding_loss': 0.0006, 'learning_rate': 1.3565217391304348e-05, 'epoch': 0.78}
+{'embedding_loss': 0.0003, 'learning_rate': 1.0666666666666667e-05, 'epoch': 1.04}
+{'embedding_loss': 0.0004, 'learning_rate': 7.768115942028987e-06, 'epoch': 1.3}
+{'embedding_loss': 0.0002, 'learning_rate': 4.869565217391305e-06, 'epoch': 1.56}
+{'embedding_loss': 0.0003, 'learning_rate': 1.9710144927536233e-06, 'epoch': 1.82}
+{'train_runtime': 84.3703, 'train_samples_per_second': 72.822, 'train_steps_per_second': 4.551, 'epoch': 2.0}
+100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 384/384 [01:24<00:00, 4.55it/s]
+***** Running evaluation *****
+{'accuracy': 0.8378947368421052}
+```
+This large teacher model reaches 83.79%, which is quite strong for this little data, and noticeably, stronger than the 78.18% from our smaller (but more efficient) model.
+
+## Knowledge Distillation
+
+The performance from the stronger teacher_model can be distilled into the smaller model using the [`DistillationTrainer`]. It accepts a teacher and a student model, as well as an unlabeled dataset.
+
+
+
+Note that this trainer uses pairs between sentences as the training samples, so the number of training steps grows exponentially to the number of unlabeled examples. To avoid overfitting, consider setting `max_steps` relatively low.
+
+
+
+```py
+from setfit import DistillationTrainer
+
+distillation_args = TrainingArguments(
+ batch_size=16,
+ max_steps=500,
+)
+
+distillation_trainer = DistillationTrainer(
+ teacher_model=teacher_model,
+ student_model=model,
+ args=distillation_args,
+ train_dataset=unlabeled_train_dataset,
+ eval_dataset=eval_dataset,
+)
+# Train student with knowledge distillation
+distillation_trainer.train()
+distillation_metrics = distillation_trainer.evaluate()
+print(distillation_metrics)
+```
+```py
+***** Running training *****
+ Num examples = 7829
+ Num epochs = 1
+ Total optimization steps = 7829
+ Total train batch size = 16
+{'embedding_loss': 0.5048, 'learning_rate': 2.554278416347382e-08, 'epoch': 0.0}
+{'embedding_loss': 0.4514, 'learning_rate': 1.277139208173691e-06, 'epoch': 0.01}
+{'embedding_loss': 0.33, 'learning_rate': 2.554278416347382e-06, 'epoch': 0.01}
+{'embedding_loss': 0.1218, 'learning_rate': 3.831417624521073e-06, 'epoch': 0.02}
+{'embedding_loss': 0.0213, 'learning_rate': 5.108556832694764e-06, 'epoch': 0.03}
+{'embedding_loss': 0.016, 'learning_rate': 6.385696040868455e-06, 'epoch': 0.03}
+{'embedding_loss': 0.0054, 'learning_rate': 7.662835249042147e-06, 'epoch': 0.04}
+{'embedding_loss': 0.0049, 'learning_rate': 8.939974457215838e-06, 'epoch': 0.04}
+{'embedding_loss': 0.002, 'learning_rate': 1.0217113665389528e-05, 'epoch': 0.05}
+{'embedding_loss': 0.0019, 'learning_rate': 1.1494252873563218e-05, 'epoch': 0.06}
+{'embedding_loss': 0.0012, 'learning_rate': 1.277139208173691e-05, 'epoch': 0.06}
+{'train_runtime': 22.2725, 'train_samples_per_second': 359.188, 'train_steps_per_second': 22.449, 'epoch': 0.06}
+100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 500/500 [00:22<00:00, 22.45it/s]
+***** Running evaluation *****
+{'accuracy': 0.8084210526315789}
+```
+Using knowledge distillation, we were able to improve our model from 78.18% to 80.84% in a few minutes of training.
+
+## End-to-end
+
+This snippet shows the entire knowledge distillation strategy in an end-to-end example:
+
+```py
+from datasets import load_dataset
+from setfit import sample_dataset
+
+# Load a dataset from the Hugging Face Hub
+dataset = load_dataset("ag_news")
+
+# Create a sample few-shot dataset to train with
+train_dataset = sample_dataset(dataset["train"], label_column="label", num_samples=16)
+# Dataset({
+# features: ['text', 'label'],
+# num_rows: 64
+# })
+
+# Dataset for evaluation
+eval_dataset = dataset["test"]
+# Dataset({
+# features: ['text', 'label'],
+# num_rows: 7600
+# })
+
+from setfit import SetFitModel, TrainingArguments, Trainer
+
+model = SetFitModel.from_pretrained("sentence-transformers/paraphrase-MiniLM-L3-v2")
+
+args = TrainingArguments(
+ batch_size=64,
+ num_epochs=5,
+)
+
+trainer = Trainer(
+ model=model,
+ args=args,
+ train_dataset=train_dataset,
+ eval_dataset=eval_dataset,
+)
+trainer.train()
+
+metrics = trainer.evaluate()
+print(metrics)
+
+# Create a dataset of unlabeled examples to perform knowledge distillation
+unlabeled_train_dataset = dataset["train"].shuffle(seed=0).select(range(500))
+unlabeled_train_dataset = unlabeled_train_dataset.remove_columns("label")
+# Dataset({
+# features: ['text'],
+# num_rows: 500
+# })
+
+from setfit import SetFitModel
+
+teacher_model = SetFitModel.from_pretrained("sentence-transformers/paraphrase-mpnet-base-v2")
+
+from setfit import TrainingArguments, Trainer
+
+teacher_args = TrainingArguments(
+ batch_size=16,
+ num_epochs=2,
+)
+
+teacher_trainer = Trainer(
+ model=teacher_model,
+ args=teacher_args,
+ train_dataset=train_dataset,
+ eval_dataset=eval_dataset,
+)
+
+# Train teacher model
+teacher_trainer.train()
+teacher_metrics = teacher_trainer.evaluate()
+print(teacher_metrics)
+
+from setfit import DistillationTrainer
+
+distillation_args = TrainingArguments(
+ batch_size=16,
+ max_steps=500,
+)
+
+distillation_trainer = DistillationTrainer(
+ teacher_model=teacher_model,
+ student_model=model,
+ args=distillation_args,
+ train_dataset=unlabeled_train_dataset,
+ eval_dataset=eval_dataset,
+)
+# Train student with knowledge distillation
+distillation_trainer.train()
+distillation_metrics = distillation_trainer.evaluate()
+print(distillation_metrics)
+```
\ No newline at end of file
diff --git a/docs/source/en/how_to/model_cards.mdx b/docs/source/en/how_to/model_cards.mdx
new file mode 100644
index 00000000..96b0bcff
--- /dev/null
+++ b/docs/source/en/how_to/model_cards.mdx
@@ -0,0 +1,100 @@
+
+# Model Cards
+
+SetFit comes with extensive automatically generated model cards/READMEs. In this how-to guide, we will explore how to make the most of this automatic generation.
+
+As an example, the [tomaarsen/setfit-all-MiniLM-L6-v2-sst2-32-shot](https://huggingface.co/tomaarsen/setfit-all-MiniLM-L6-v2-sst2-32-shot) model has followed all steps from this guide to produce the most extensive automatically generated model card.
+
+## Specifying Metadata
+
+Although SetFit can infer a lot of information about your model through its training and configuration, some metadata can often not be (trivially) inferred. For example:
+
+* **language**: The model language, e.g. "en" for English.
+* **license**: The model license, e.g. "mit" or "apache-2.0".
+* **dataset_name**: The pretty name of a dataset, e.g. "Amazon Counterfactual".
+* **dataset_id**: The dataset ID of the dataset, e.g. "dair-ai/emotion".
+
+It is recommended to specify this information to the [`SetFitModel`] upon calling [`SetFitModel.from_pretrained`], to allow this information to be included in the model card and its metadata. This can be done using an [`SetFitModelCardData`] instance and the `model_card_data` key-word argument, e.g. like so:
+
+```py
+from setfit import SetFitModel
+
+model = SetFitModel.from_pretrained(
+ "BAAI/bge-small-en-v1.5",
+ model_card_data=SetFitModelCardData(
+ language="en",
+ license="apache-2.0",
+ dataset_id="sst2",
+ dataset_name="SST2",
+ )
+)
+```
+
+See the [`SetFitModelCardData`] documentation for more information that you can specify to be used in the README.
+
+## Labels
+
+If the labels from your training dataset are all integers, then you are recommended to provide your [`SetFitModel`] with labels. These labels can then 1) be used in inference and 2) be used in your model card. For example, if your training labels are `0` and `1` for negative and positive, respectively, then you can load your model like so:
+
+```py
+model = SetFitModel.from_pretrained(
+ "BAAI/bge-small-en-v1.5",
+ labels=["negative", "positive"],
+ model_card_data=SetFitModelCardData(
+ language="en",
+ license="apache-2.0",
+ dataset_id="sst2",
+ dataset_name="SST2",
+ )
+)
+```
+
+When calling [`SetFitModel.predict`], the trained model will now output strings or lists of strings, rather than your integer labels:
+
+```py
+model.predict([
+ "It's a charming and often affecting journey.",
+ "It's slow -- very, very slow.",
+ "A sometimes tedious film.",
+])
+# => ['positive', 'negative', 'negative']
+```
+
+Additionally, the model card will include the labels, e.g. it will use the following table:
+
+| Label | Examples |
+|:---------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+| negative |
'a tough pill to swallow and '
'indignation '
'that the typical hollywood disregard for historical truth and realism is at work here '
|
+| positive |
"a moving experience for people who have n't read the book "
'in the best possible senses of both those words '
'to serve the work especially well '
|
+
+Rather than this one:
+
+| Label | Examples |
+|:---------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+| 0 |
'a tough pill to swallow and '
'indignation '
'that the typical hollywood disregard for historical truth and realism is at work here '
|
+| 1 |
"a moving experience for people who have n't read the book "
'in the best possible senses of both those words '
'to serve the work especially well '
|
+
+And the following table:
+
+| Label | Training Sample Count |
+|:---------|:----------------------|
+| negative | 32 |
+| positive | 32 |
+
+Rather than this one:
+
+| Label | Training Sample Count |
+|:------|:----------------------|
+| 0 | 32 |
+| 1 | 32 |
+
+## Emissions Tracking
+
+The [``codecarbon``](https://github.com/mlco2/codecarbon) Python package can be installed to automatically track carbon emissions during training. This information will be included in the model card, e.g. in a list [like so](https://huggingface.co/tomaarsen/setfit-all-MiniLM-L6-v2-sst2-32-shot#environmental-impact):
+
+
Environmental Impact
+
+Carbon emissions were measured using [CodeCarbon](https://github.com/mlco2/codecarbon).
+
+- **Carbon Emitted**: 0.003 kg of CO2
+- **Hours Used**: 0.072 hours
diff --git a/docs/source/en/how_to/multilabel.mdx b/docs/source/en/how_to/multilabel.mdx
new file mode 100644
index 00000000..da09fa66
--- /dev/null
+++ b/docs/source/en/how_to/multilabel.mdx
@@ -0,0 +1,48 @@
+
+# Multilabel Text Classification
+
+SetFit supports multilabel classification, allowing multiple labels to be assigned to each instance.
+
+
+
+Unless each instance must be assigned multiple outputs, you frequently do not need to specify a multi target strategy.
+
+
+
+This guide will show you how to train and use multilabel SetFit models.
+
+## Multilabel strategies
+
+SetFit will initialise a multilabel classification head from `sklearn` - the following options are available for `multi_target_strategy`:
+
+* `"one-vs-rest"`: uses a [`OneVsRestClassifier`](https://scikit-learn.org/stable/modules/generated/sklearn.multiclass.OneVsRestClassifier.html) head.
+* `"multi-output"`: uses a [`MultiOutputClassifier`](https://scikit-learn.org/stable/modules/generated/sklearn.multioutput.MultiOutputClassifier.html) head.
+* `"classifier-chain"`: uses a [`ClassifierChain`](https://scikit-learn.org/stable/modules/generated/sklearn.multioutput.ClassifierChain.html) head.
+
+See the [scikit-learn documentation for multiclass and multioutput classification](https://scikit-learn.org/stable/modules/multiclass.html#multiclass-classification) for more details.
+
+## Initializing SetFit models with multilabel strategies
+
+Using the default LogisticRegression head, we can apply multi target strategies like so:
+
+```py
+from setfit import SetFitModel
+
+model = SetFitModel.from_pretrained(
+ model_id, # e.g. "BAAI/bge-small-en-v1.5"
+ multi_target_strategy="multi-output",
+)
+```
+
+With a differentiable head it looks like so:
+
+```py
+from setfit import SetFitModel
+
+model = SetFitModel.from_pretrained(
+ model_id, # e.g. "BAAI/bge-small-en-v1.5"
+ multi_target_strategy="one-vs-rest"
+ use_differentiable_head=True,
+ head_params={"out_features": num_classes},
+)
+```
\ No newline at end of file
diff --git a/docs/source/en/how_to/overview.mdx b/docs/source/en/how_to/overview.mdx
new file mode 100644
index 00000000..6bf99847
--- /dev/null
+++ b/docs/source/en/how_to/overview.mdx
@@ -0,0 +1,9 @@
+
+# Overview
+
+Welcome to the SetFit How-to Guides! The how-to guides offer a more comprehensive overview of all the tools 🤗 SetFit offers and how to use them.
+These guides are designed to be concise and code-heavy, written in "show, don't tell" style. For example, using these guides you may learn how to perform hyperparameter optimization, knowledge distillation, apply callbacks, etc.
+
+Most how-to guides end with an "end to end" script showing all code from the guide for easy adaptation into your own code.
+
+For simpler documentation explaining SetFit functionality from start to finish, consider visiting the [Tutorials](../tutorials/overview) section or the [quickstart](../quickstart).
diff --git a/docs/source/en/how_to/placeholder.mdx b/docs/source/en/how_to/placeholder.mdx
deleted file mode 100644
index 219da7be..00000000
--- a/docs/source/en/how_to/placeholder.mdx
+++ /dev/null
@@ -1,3 +0,0 @@
-
-# How-to Guide
-Work in Progress!
\ No newline at end of file
diff --git a/docs/source/en/how_to/v1.0.0_migration_guide.mdx b/docs/source/en/how_to/v1.0.0_migration_guide.mdx
new file mode 100644
index 00000000..daa8a87f
--- /dev/null
+++ b/docs/source/en/how_to/v1.0.0_migration_guide.mdx
@@ -0,0 +1,93 @@
+
+# SetFit v1.0.0 Migration Guide
+
+To update your code to work with v1.0.0, the following changes must be made:
+
+## General Migration Guide
+
+1. `keep_body_frozen` from `SetFitModel.unfreeze` has been deprecated, simply either pass `"head"`, `"body"` or no arguments to unfreeze both.
+2. `SupConLoss` has been moved from `setfit.modeling` to `setfit.losses`. If you are importing it using `from setfit.modeling import SupConLoss`, then import it like `from setfit import SupConLoss` now instead.
+3. `use_auth_token` has been renamed to `token` in [`SetFitModel.from_pretrained`]. `use_auth_token` will keep working until the next major version, but with a warning.
+
+## Training Migration Guide
+
+1. Replace all uses of `SetFitTrainer` with [`Trainer`], and all uses of `DistillationSetFitTrainer` with [`DistillationTrainer`].
+2. Remove `num_iterations`, `num_epochs`, `learning_rate`, `batch_size`, `seed`, `use_amp`, `warmup_proportion`, `distance_metric`, `margin`, `samples_per_label` and `loss_class` from a `Trainer` initialization, and move them to a `TrainerArguments` initialization instead. This instance should then be passed to the trainer via the `args` argument.
+
+ * `num_iterations` has been deprecated, the number of training steps should now be controlled via `num_epochs`, `max_steps` or [`EarlyStoppingCallback`](https://huggingface.co/docs/transformers/main_classes/callback#transformers.EarlyStoppingCallback).
+ * `learning_rate` has been split up into `body_learning_rate` and `head_learning_rate`.
+ * `loss_class` has been renamed to `loss`.
+
+3. Stop providing training arguments like `num_epochs` directly to `Trainer.train`: pass a `TrainingArguments` instance via the `args` argument instead.
+4. Refactor multiple `trainer.train()`, `trainer.freeze()` and `trainer.unfreeze()` calls that were previously necessary to train the differentiable head into just one `trainer.train()` call by setting `batch_size` and `num_epochs` on the `TrainingArguments` dataclass with tuples. The first value in the tuple is for training the embeddings, and the second is for training the classifier.
+
+## Hard deprecations
+
+* `SetFitBaseModel`, `SKLearnWrapper` and `SetFitPipeline` have been removed. These can no longer be used starting from v1.0.0.
+
+## v1.0.0 Changelog
+
+This list contains new functionality that can be used starting from v1.0.0.
+
+* [`SetFitModel.from_pretrained`] now accepts new arguments:
+ * `device`: Specifies the device on which to load the SetFit model.
+ * `labels`: Specify labels corresponding to the training labels - useful if the training labels are integers ranging from `0` to `num_classes - 1`. These are automatically applied on calling [`SetFitModel.predict`].
+ * `model_card_data`: Provide a [`SetFitModelCardData`] instance storing data such as model language, license, dataset name, etc. to be used in the automatically generated model cards.
+* Certain SetFit configuration options, such as the new `labels` argument from [`SetFitModel.from_pretrained`], now get saved in `config_setfit.json` files when a model is saved. This allows `labels` to be automatically fetched when a model is loaded.
+* [`SetFitModel.predict`] now accepts new arguments:
+ * `batch_size` (defaults to `32`): The batch size to use in encoding the sentences to embeddings. Higher often means faster processing but higher memory usage.
+ * `use_labels` (defaults to `True`): Whether to use the `SetFitModel.labels` to convert integer labels to string labels. Not used if the training labels are already strings.
+* [`SetFitModel.encode`] has been introduce to convert input sentences to embeddings using the `SentenceTransformer` body.
+* [`SetFitModel.device`] has been introduced to determine the device of the model.
+* [`AbsaTrainer`] and [`AbsaModel`] have been introduced for applying [SetFit for Aspect Based Sentiment Analysis](absa).
+* [`Trainer`] now supports a `callbacks` argument for a list of [`transformers` `TrainerCallback` instances](https://huggingface.co/docs/transformers/main/en/main_classes/callback).
+ * By default, all installed callbacks integrated with `transformers` are supported, including [`TensorBoardCallback`](https://huggingface.co/docs/transformers/main/en/main_classes/callback#transformers.integrations.TensorBoardCallback), [`WandbCallback`](https://huggingface.co/docs/transformers/main/en/main_classes/callback#transformers.integrations.WandbCallback) to log training logs to [TensorBoard](https://www.tensorflow.org/tensorboard) and [W&B](https://wandb.ai), respectively.
+ * The [`Trainer`] will now print `embedding_loss` in the terminal, as well as `eval_embedding_loss` if `evaluation_strategy` is set to `"epoch"` or `"steps"` in [`TrainingArguments`].
+* [`Trainer.evaluate`] now works with string labels.
+* An updated contrastive pair sampler increases the variety of training pairs.
+* [`TrainingArguments`] supports various new arguments:
+ * `output_dir`: The output directory where the model predictions and checkpoints will be written.
+ * `max_steps`: If set to a positive number, the total number of training steps to perform. Overrides num_epochs. The training may stop before reaching the set number of steps when all data is exhausted.
+ * `sampling_strategy`: The sampling strategy of how to draw pairs in training. Possible values are:
+
+ * `"oversampling"`: Draws even number of positive/negative sentence pairs until every sentence pair has been drawn.
+ * `"undersampling"`: Draws the minimum number of positive/negative sentence pairs until every sentence pair in the minority class has been drawn.
+ * `"unique"`: Draws every sentence pair combination (likely resulting in unbalanced number of positive/negative sentence pairs).
+
+ The default is set to `"oversampling"`, ensuring all sentence pairs are drawn at least once. Alternatively, setting `num_iterations` will override this argument and determine the number of generated sentence pairs.
+ * `report_to`: The list of integrations to report the results and logs to. Supported platforms are `"azure_ml"`, `"comet_ml"`, `"mlflow"`, `"neptune"`, `"tensorboard"`,`"clearml"` and `"wandb"`. Use `"all"` to report to all integrations installed, `"none"` for no integrations.
+ * `run_name`: A descriptor for the run. Typically used for [wandb](https://wandb.ai/) and [mlflow](https://www.mlflow.org/) logging.
+ * `logging_strategy`: The logging strategy to adopt during training. Possible values are:
+
+ - `"no"`: No logging is done during training.
+ - `"epoch"`: Logging is done at the end of each epoch.
+ - `"steps"`: Logging is done every `logging_steps`.
+
+ * `logging_first_step`: Whether to log and evaluate the first `global_step` or not.
+ * `logging_steps`: Number of update steps between two logs if `logging_strategy="steps"`.
+ * `evaluation_strategy`: The evaluation strategy to adopt during training. Possible values are:
+
+ - `"no"`: No evaluation is done during training.
+ - `"steps"`: Evaluation is done (and logged) every `eval_steps`.
+ - `"epoch"`: Evaluation is done at the end of each epoch.
+
+ * `eval_steps`: Number of update steps between two evaluations if `evaluation_strategy="steps"`. Will default to the same as `logging_steps` if not set.
+ * `eval_delay`: Number of epochs or steps to wait for before the first evaluation can be performed, depending on the `evaluation_strategy`.
+ * `eval_max_steps`: If set to a positive number, the total number of evaluation steps to perform. The evaluation may stop before reaching the set number of steps when all data is exhausted.
+ * `save_strategy`: The checkpoint save strategy to adopt during training. Possible values are:
+
+ - `"no"`: No save is done during training.
+ - `"epoch"`: Save is done at the end of each epoch.
+ - `"steps"`: Save is done every `save_steps`.
+
+ * `save_steps`: Number of updates steps before two checkpoint saves if `save_strategy="steps"`.
+ * `save_total_limit`: If a value is passed, will limit the total amount of checkpoints. Deletes the older checkpoints in `output_dir`. Note, the best model is always preserved if the `evaluation_strategy` is not `"no"`.
+ * `load_best_model_at_end`: Whether or not to load the best model found during training at the end of training.
+
+
+
+ When set to `True`, the parameters `save_strategy` needs to be the same as `evaluation_strategy`, and in
+ the case it is "steps", `save_steps` must be a round multiple of `eval_steps`.
+
+
+* Pushing SetFit or SetFitABSA models to the Hub with [`SetFitModel.push_to_hub`] or [`AbsaModel.push_to_hub`] now results in a detailed model card. As an example, see [this SetFitModel](https://huggingface.co/tomaarsen/setfit-paraphrase-mpnet-base-v2-sst2-8-shot) or [this SetFitABSA polarity model](https://huggingface.co/tomaarsen/setfit-absa-bge-small-en-v1.5-restaurants-polarity).
\ No newline at end of file
diff --git a/docs/source/en/how_to/zero_shot.mdx b/docs/source/en/how_to/zero_shot.mdx
new file mode 100644
index 00000000..95b45b2d
--- /dev/null
+++ b/docs/source/en/how_to/zero_shot.mdx
@@ -0,0 +1,169 @@
+
+# Zero-shot Text Classification
+
+[[open-in-colab]]
+
+Your class names are likely already good descriptors of the text that you're looking to classify. With 🤗 SetFit, you can use these class names with strong pretrained Sentence Transformer models to get a strong baseline model without any training samples.
+
+This guide will show you how to perform zero-shot text classification.
+
+## Testing dataset
+
+We'll use the [dair-ai/emotion](https://huggingface.co/datasets/dair-ai/emotion) dataset to test the performance of our zero-shot model.
+
+```py
+from datasets import load_dataset
+
+test_dataset = load_dataset("dair-ai/emotion", "split", split="test")
+```
+
+This dataset stores the class names within the dataset `Features`, so we'll extract the classes like so:
+```py
+classes = test_dataset.features["label"].names
+# => ['sadness', 'joy', 'love', 'anger', 'fear', 'surprise']
+```
+Otherwise, we could manually set the list of classes.
+
+## Synthetic dataset
+
+Then, we can use [`get_templated_dataset`] to synthetically generate a dummy dataset given these class names.
+
+```py
+from setfit import get_templated_dataset
+
+train_dataset = get_templated_dataset()
+```
+```py
+print(train_dataset)
+# => Dataset({
+# features: ['text', 'label'],
+# num_rows: 48
+# })
+print(train_dataset[0])
+# {'text': 'This sentence is sadness', 'label': 0}
+```
+
+## Training
+
+We can use this dataset to train a SetFit model just like normal:
+
+```py
+from setfit import SetFitModel, Trainer, TrainingArguments
+
+model = SetFitModel.from_pretrained("BAAI/bge-small-en-v1.5")
+
+args = TrainingArguments(
+ batch_size=32,
+ num_epochs=1,
+)
+
+trainer = Trainer(
+ model=model,
+ args=args,
+ train_dataset=train_dataset,
+ eval_dataset=test_dataset,
+)
+trainer.train()
+```
+```
+***** Running training *****
+ Num examples = 60
+ Num epochs = 1
+ Total optimization steps = 60
+ Total train batch size = 32
+{'embedding_loss': 0.2628, 'learning_rate': 3.3333333333333333e-06, 'epoch': 0.02}
+{'embedding_loss': 0.0222, 'learning_rate': 3.7037037037037037e-06, 'epoch': 0.83}
+{'train_runtime': 15.4717, 'train_samples_per_second': 124.098, 'train_steps_per_second': 3.878, 'epoch': 1.0}
+100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 60/60 [00:09<00:00, 6.35it/s]
+```
+
+Once trained, we can evaluate the model:
+
+```py
+metrics = trainer.evaluate()
+print(metrics)
+```
+```
+***** Running evaluation *****
+{'accuracy': 0.591}
+```
+
+And run predictions:
+
+```py
+preds = model.predict([
+ "i am just feeling cranky and blue",
+ "i feel incredibly lucky just to be able to talk to her",
+ "you're pissing me off right now",
+ "i definitely have thalassophobia, don't get me near water like that",
+ "i did not see that coming at all",
+])
+print([classes[idx] for idx in preds])
+```
+```py
+['sadness', 'joy', 'anger', 'fear', 'surprise']
+```
+
+These predictions all look right!
+
+## Baseline
+
+To show that the zero-shot performance of SetFit works well, we'll compare it against a zero-shot classification model from `transformers`.
+
+```py
+from transformers import pipeline
+from datasets import load_dataset
+import evaluate
+
+# Prepare the testing dataset
+test_dataset = load_dataset("dair-ai/emotion", "split", split="test")
+classes = test_dataset.features["label"].names
+
+# Set up the zero-shot classification pipeline from transformers
+# Uses 'facebook/bart-large-mnli' by default
+pipe = pipeline("zero-shot-classification", device=0)
+zeroshot_preds = pipe(test_dataset["text"], batch_size=16, candidate_labels=classes)
+preds = [classes.index(pred["labels"][0]) for pred in zeroshot_preds]
+
+# Compute the accuracy
+metric = evaluate.load("accuracy")
+transformers_accuracy = metric.compute(predictions=preds, references=test_dataset["label"])
+print(transformers_accuracy)
+```
+```py
+{'accuracy': 0.3765}
+```
+
+With its 59.1% accuracy, the 0-shot SetFit heavily outperforms the recommended zero-shot model by `transformers`.
+
+## Prediction latency
+
+Beyond getting higher accuracies, SetFit is much faster too. Let's compute the latency of SetFit with `BAAI/bge-small-en-v1.5` versus the latency of `transformers` with `facebook/bart-large-mnli`. Both tests were performed on a GPU.
+
+```py
+import time
+
+start_t = time.time()
+pipe(test_dataset["text"], batch_size=32, candidate_labels=classes)
+delta_t = time.time() - start_t
+print(f"`transformers` with `facebook/bart-large-mnli` latency: {delta_t / len(test_dataset['text']) * 1000:.4f}ms per sentence")
+```
+```
+`transformers` with `facebook/bart-large-mnli` latency: 31.1765ms per sentence
+```
+
+```py
+import time
+
+start_t = time.time()
+model.predict(test_dataset["text"])
+delta_t = time.time() - start_t
+print(f"SetFit with `BAAI/bge-small-en-v1.5` latency: {delta_t / len(test_dataset['text']) * 1000:.4f}ms per sentence")
+```
+```
+SetFit with `BAAI/bge-small-en-v1.5` latency: 0.4600ms per sentence
+```
+
+So, SetFit with `BAAI/bge-small-en-v1.5` is 67x faster than `transformers` with `facebook/bart-large-mnli`, alongside being more accurate:
+
+
diff --git a/docs/source/en/index.mdx b/docs/source/en/index.mdx
index 35eb5ae3..35b87fa2 100644
--- a/docs/source/en/index.mdx
+++ b/docs/source/en/index.mdx
@@ -10,25 +10,25 @@
Compared to other few-shot learning methods, SetFit has several unique features:
-* 🗣 **No prompts or verbalisers:** Current techniques for few-shot fine-tuning require handcrafted prompts or verbalisers to convert examples into a format that's suitable for the underlying language model. SetFit dispenses with prompts altogether by generating rich embeddings directly from text examples.
-* 🏎 **Fast to train:** SetFit doesn't require large-scale models like T0 or GPT-3 to achieve high accuracy. As a result, it is typically an order of magnitude (or more) faster to train and run inference with.
+* 🗣 **No prompts or verbalizers:** Current techniques for few-shot fine-tuning require handcrafted prompts or verbalizers to convert examples into a format suitable for the underlying language model. SetFit dispenses with prompts altogether by generating rich embeddings directly from text examples.
+* 🏎 **Fast to train:** SetFit doesn't require large-scale models like T0, Llama or GPT-4 to achieve high accuracy. As a result, it is typically an order of magnitude (or more) faster to train and run inference with.
* 🌎 **Multilingual support**: SetFit can be used with any [Sentence Transformer](https://huggingface.co/models?library=sentence-transformers&sort=downloads) on the Hub, which means you can classify text in multiple languages by simply fine-tuning a multilingual checkpoint.
diff --git a/docs/source/en/installation.mdx b/docs/source/en/installation.mdx
index 140163fa..f792501c 100644
--- a/docs/source/en/installation.mdx
+++ b/docs/source/en/installation.mdx
@@ -1,14 +1,42 @@
# Installation
-Download and install `setfit` by running:
+Before you start, you'll need to setup your environment and install the appropriate packages. 🤗 SetFit is tested on **Python 3.7+**.
+
+## pip
+
+The most straightforward way to install 🤗 Datasets is with pip:
+
+```bash
+pip install setfit
+```
+
+If you have a CUDA-capable graphics card, then it is recommended to [install `torch` with CUDA support](https://pytorch.org/get-started/locally/) to train and performing inference much more quickly:
+
+```bash
+pip install torch --index-url https://download.pytorch.org/whl/cu118
+```
+
+## Installing from source
+
+Building 🤗 SetFit from source lets you make changes to the code base. To install from the source, clone the repository and install 🤗 SetFit in [editable mode](https://setuptools.pypa.io/en/latest/userguide/development_mode.html) with the following commands:
+
+```bash
+git clone https://github.com/huggingface/setfit.git
+cd setfit
+pip install -e .
+```
+
+If you just want the bleeding-edge version without making any changes of your own, then install from source by running:
```bash
-python -m pip install setfit
+pip install git+https://github.com/huggingface/setfit.git
```
-If you want the bleeding-edge version, install from source by running:
+## Conda
+
+If conda is your package management system of choice, then you can install 🤗 SetFit like so:
```bash
-python -m pip install git+https://github.com/huggingface/setfit.git
+conda install -c conda-forge setfit
```
\ No newline at end of file
diff --git a/docs/source/en/quickstart.mdx b/docs/source/en/quickstart.mdx
index cc10ba5b..4779f745 100644
--- a/docs/source/en/quickstart.mdx
+++ b/docs/source/en/quickstart.mdx
@@ -1,323 +1,233 @@
# Quickstart
-## Usage
+[[open-in-colab]]
-The examples below provide a quick overview on the various features supported in `setfit`. For more examples, check out the [`notebooks`](https://github.com/huggingface/setfit/tree/main/notebooks) folder.
+This quickstart is intended for developers who are ready to dive into the code and see an example of how to train and use 🤗 SetFit models. We recommend starting with this quickstart, and then proceeding to the [tutorials](./tutorials/overview) or [how-to guides](./how_to/overview) for additional material. Additionally, the [conceptual guides](./conceptual_guides/setfit) help explain exactly how SetFit works.
+Start by installing 🤗 SetFit:
-### Training a SetFit model
-
-`setfit` is integrated with the [Hugging Face Hub](https://huggingface.co/) and provides two main classes:
-
-* `SetFitModel`: a wrapper that combines a pretrained body from `sentence_transformers` and a classification head from either [`scikit-learn`](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html) or [`SetFitHead`](https://github.com/huggingface/setfit/blob/main/src/setfit/modeling.py) (a differentiable head built upon `PyTorch` with similar APIs to `sentence_transformers`).
-* `SetFitTrainer`: a helper class that wraps the fine-tuning process of SetFit.
-
-Here is an end-to-end example using a classification head from `scikit-learn`:
-
-
-```python
-from datasets import load_dataset
-from sentence_transformers.losses import CosineSimilarityLoss
-
-from setfit import SetFitModel, SetFitTrainer, sample_dataset
-
-
-# Load a dataset from the Hugging Face Hub
-dataset = load_dataset("sst2")
-
-# Simulate the few-shot regime by sampling 8 examples per class
-train_dataset = sample_dataset(dataset["train"], label_column="label", num_samples=8)
-eval_dataset = dataset["validation"]
-
-# Load a SetFit model from Hub
-model = SetFitModel.from_pretrained("sentence-transformers/paraphrase-mpnet-base-v2")
-
-# Create trainer
-trainer = SetFitTrainer(
- model=model,
- train_dataset=train_dataset,
- eval_dataset=eval_dataset,
- loss_class=CosineSimilarityLoss,
- metric="accuracy",
- batch_size=16,
- num_iterations=20, # The number of text pairs to generate for contrastive learning
- num_epochs=1, # The number of epochs to use for contrastive learning
- column_mapping={"sentence": "text", "label": "label"} # Map dataset columns to text/label expected by trainer
-)
-
-# Train and evaluate
-trainer.train()
-metrics = trainer.evaluate()
-
-# Push model to the Hub
-trainer.push_to_hub("my-awesome-setfit-model")
-
-# Download from Hub and run inference
-model = SetFitModel.from_pretrained("lewtun/my-awesome-setfit-model")
-# Run inference
-preds = model(["i loved the spiderman movie!", "pineapple on pizza is the worst 🤮"])
+```bash
+pip install setfit
```
-Here is an end-to-end example using `SetFitHead`:
-
-
-```python
-from datasets import load_dataset
-from sentence_transformers.losses import CosineSimilarityLoss
-
-from setfit import SetFitModel, SetFitTrainer, sample_dataset
+If you have a CUDA-capable graphics card, then it is recommended to [install `torch` with CUDA support](https://pytorch.org/get-started/locally/) to train and performing inference much more quickly:
+```bash
+pip install torch --index-url https://download.pytorch.org/whl/cu118
+```
-# Load a dataset from the Hugging Face Hub
-dataset = load_dataset("sst2")
-
-# Simulate the few-shot regime by sampling 8 examples per class
-train_dataset = sample_dataset(dataset["train"], label_column="label", num_samples=8)
-eval_dataset = dataset["validation"]
+## SetFit
-# Load a SetFit model from Hub
-model = SetFitModel.from_pretrained(
- "sentence-transformers/paraphrase-mpnet-base-v2",
- use_differentiable_head=True,
- head_params={"out_features": num_classes},
-)
+SetFit is an efficient framework to train low-latency text classification models using little training data. In this Quickstart, you'll learn how to train a SetFit model, how to perform inference with it, and how to save it to the Hugging Face Hub.
-# Create trainer
-trainer = SetFitTrainer(
- model=model,
- train_dataset=train_dataset,
- eval_dataset=eval_dataset,
- loss_class=CosineSimilarityLoss,
- metric="accuracy",
- batch_size=16,
- num_iterations=20, # The number of text pairs to generate for contrastive learning
- num_epochs=1, # The number of epochs to use for contrastive learning
- column_mapping={"sentence": "text", "label": "label"} # Map dataset columns to text/label expected by trainer
-)
+### Training
-# Train and evaluate
-trainer.freeze() # Freeze the head
-trainer.train() # Train only the body
+In this section, you'll load a [Sentence Transformer model](https://huggingface.co/models?library=sentence-transformers) and further finetune it for classifying movie reviews as positive or negative. To train a model, we will need to prepare the following three: 1) a **model**, 2) a **dataset**, and 3) **training arguments**.
-# Unfreeze the head and freeze the body -> head-only training
-trainer.unfreeze(keep_body_frozen=True)
-# or
-# Unfreeze the head and unfreeze the body -> end-to-end training
-trainer.unfreeze(keep_body_frozen=False)
-
-trainer.train(
- num_epochs=25, # The number of epochs to train the head or the whole model (body and head)
- batch_size=16,
- body_learning_rate=1e-5, # The body's learning rate
- learning_rate=1e-2, # The head's learning rate
- l2_weight=0.0, # Weight decay on **both** the body and head. If `None`, will use 0.01.
-)
-metrics = trainer.evaluate()
+**1**. Initialize a SetFit model using a Sentence Transformer model of our choice. Consider using the [MTEB Leaderboard](https://huggingface.co/spaces/mteb/leaderboard) to guide your decision on which Sentence Transformer model to choose. We will use [BAAI/bge-small-en-v1.5](https://huggingface.co/BAAI/bge-small-en-v1.5), a small but performant model.
-# Push model to the Hub
-trainer.push_to_hub("my-awesome-setfit-model")
+```py
+>>> from setfit import SetFitModel
-# Download from Hub and run inference
-model = SetFitModel.from_pretrained("lewtun/my-awesome-setfit-model")
-# Run inference
-preds = model(["i loved the spiderman movie!", "pineapple on pizza is the worst 🤮"])
+>>> model = SetFitModel.from_pretrained("BAAI/bge-small-en-v1.5")
```
-Based on our experiments, `SetFitHead` can achieve similar performance as using a `scikit-learn` head. We use `AdamW` as the optimizer and scale down learning rates by 0.5 every 5 epochs. For more details about the experiments, please check out [here](https://github.com/huggingface/setfit/pull/112#issuecomment-1295773537). We recommend using a large learning rate (e.g. `1e-2`) for `SetFitHead` and a small learning rate (e.g. `1e-5`) for the body in your first attempt.
-
-### Training on multilabel datasets
+**2a**. Next, load both the "train" and "test" splits of the [SetFit/sst2](https://huggingface.co/datasets/sst2) dataset. Note that the dataset has `"text"` and `"label"` columns: this is exactly the format that 🤗 SetFit expects. If your dataset has different columns, then you can use the column_mapping argument of the [`Trainer`] in step 4 to map the column names to `"text"` and `"label"`.
+
+```py
+>>> from datasets import load_dataset
+
+>>> dataset = load_dataset("SetFit/sst2")
+>>> dataset
+DatasetDict({
+ train: Dataset({
+ features: ['text', 'label', 'label_text'],
+ num_rows: 6920
+ })
+ test: Dataset({
+ features: ['text', 'label', 'label_text'],
+ num_rows: 1821
+ })
+ validation: Dataset({
+ features: ['text', 'label', 'label_text'],
+ num_rows: 872
+ })
+})
+```
-To train SetFit models on multilabel datasets, specify the `multi_target_strategy` argument when loading the pretrained model:
+**2b**. In real world scenarios it is very uncommon to have ~7.000 high quality labeled training samples, so we will heavily shrink the training dataset to give a better idea of how 🤗 SetFit would work in real settings. To be specific, the `sample_dataset` function will sample only 8 samples for each class. The testing set is left unaffected for better evaluation.
-#### Example using a classification head from `scikit-learn`:
+```py
+>>> from setfit import sample_dataset
-```python
-from setfit import SetFitModel
+>>> train_dataset = sample_dataset(dataset["train"], label_column="label", num_samples=8)
+>>> train_dataset
+Dataset({
+ features: ['text', 'label', 'label_text'],
+ num_rows: 16
+})
+```
-model = SetFitModel.from_pretrained(
- model_id,
- multi_target_strategy="one-vs-rest",
-)
+```py
+>>> test_dataset = dataset["test"]
+>>> test_dataset
+Dataset({
+ features: ['text', 'label', 'label_text'],
+ num_rows: 1821
+})
```
-This will initialise a multilabel classification head from `sklearn` - the following options are available for `multi_target_strategy`:
+**2c**. We can apply the labels from the dataset on the model, so the predictions output readable classes. You can also provide the labels directly to [`SetFitModel.from_pretrained`].
-* `one-vs-rest`: uses a `OneVsRestClassifier` head.
-* `multi-output`: uses a `MultiOutputClassifier` head.
-* `classifier-chain`: uses a `ClassifierChain` head.
+```py
+>>> model.labels = ["negative", "positive"]
+```
-From here, you can instantiate a `SetFitTrainer` using the same example above, and train it as usual.
+**3**. Prepare the [`TrainingArguments`] for training. Note that training with 🤗 SetFit consists of two phases behind the scenes: **finetuning embeddings** and **training a classification head**. As a result, some of the training arguments can be tuples, where the two values are used for each of the two phases, respectively.
-#### Example using the differentiable `SetFitHead`:
+The `num_epochs` and `max_steps` arguments are frequently used to increase and decrease the number of total training steps. Consider that with SetFit, better performance is reached with **more data, not more training**! Don't be afraid to train for less than 1 epoch if you have a lot of data.
-```python
-from setfit import SetFitModel
+```py
+>>> from setfit import TrainingArguments
-model = SetFitModel.from_pretrained(
- model_id,
- multi_target_strategy="one-vs-rest"
- use_differentiable_head=True,
- head_params={"out_features": num_classes},
-)
+>>> args = TrainingArguments(
+... batch_size=32,
+... num_epochs=10,
+... )
```
-**Note:** If you use the differentiable `SetFitHead` classifier head, it will automatically use `BCEWithLogitsLoss` for training. The prediction involves a `sigmoid` after which probabilities are rounded to 1 or 0. Furthermore, the `"one-vs-rest"` and `"multi-output"` multi-target strategies are equivalent for the differentiable `SetFitHead`.
-
-### Zero-shot text classification
-SetFit can also be applied to scenarios where no labels are available. To do so, create a synthetic dataset of training examples:
+**4**. Initialize the [`Trainer`] and perform training.
-```python
-from datasets import Dataset
-from setfit import get_templated_dataset
+```py
+>>> from setfit import Trainer
-candidate_labels = ["negative", "positive"]
-train_dataset = get_templated_dataset(candidate_labels=candidate_labels, sample_size=8)
+>>> trainer = Trainer(
+... model=model,
+... args=args,
+... train_dataset=train_dataset,
+... )
```
-This will create examples of the form `"This sentence is {}"`, where the `{}` is filled in with one of the candidate labels. From here you can train a SetFit model as usual:
+```py
+>>> trainer.train()
+***** Running training *****
+ Num examples = 5
+ Num epochs = 10
+ Total optimization steps = 50
+ Total train batch size = 32
+{'embedding_loss': 0.2077, 'learning_rate': 4.000000000000001e-06, 'epoch': 0.2}
+{'embedding_loss': 0.0097, 'learning_rate': 0.0, 'epoch': 10.0}
+{'train_runtime': 14.705, 'train_samples_per_second': 108.807, 'train_steps_per_second': 3.4, 'epoch': 10.0}
+100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 50/50 [00:08<00:00, 5.70it/s]
+```
-```python
-from setfit import SetFitModel, SetFitTrainer
+**5**. Perform evaluation using the provided testing dataset.
-model = SetFitModel.from_pretrained("sentence-transformers/paraphrase-mpnet-base-v2")
-trainer = SetFitTrainer(
- model=model,
- train_dataset=train_dataset
-)
-trainer.train()
+```py
+>>> trainer.evaluate(test_dataset)
+***** Running evaluation *****
+{'accuracy': 0.8511806699615596}
```
-We find this approach typically outperforms the [zero-shot pipeline](https://huggingface.co/docs/transformers/v4.24.0/en/main_classes/pipelines#transformers.ZeroShotClassificationPipeline) in 🤗 Transformers (based on MNLI with Bart), while being 5x faster to generate predictions with.
+Feel free to experiment with increasing the number of samples per class to observe the improvements in accuracy. As a challenge, you can play with the samples per class, learning rate, number of epochs, maximum number of steps, and the base Sentence Transformer model to try and improve the accuracy over 90% using very little data.
+### Saving a 🤗 SetFit model
-### Running hyperparameter search
+After training, you can save a 🤗 SetFit model to your local filesystem or to the Hugging Face Hub. Save a model to a local directory using [`SetFitModel.save_pretrained`] by providing a `save_directory`:
-`SetFitTrainer` provides a `hyperparameter_search()` method that you can use to find good hyperparameters for your data. To use this feature, first install the `optuna` backend:
-
-```bash
-python -m pip install setfit[optuna]
+```py
+>>> model.save_pretrained("setfit-bge-small-v1.5-sst2-8-shot")
```
-To use this method, you need to define two functions:
+Alternatively, push a model to the Hugging Face Hub using [`SetFitModel.push_to_hub`] by providing a `repo_id`:
-* `model_init()`: A function that instantiates the model to be used. If provided, each call to `train()` will start from a new instance of the model as given by this function.
-* `hp_space()`: A function that defines the hyperparameter search space.
+```py
+>>> model.push_to_hub("tomaarsen/setfit-bge-small-v1.5-sst2-8-shot")
+```
-Here is an example of a `model_init()` function that we'll use to scan over the hyperparameters associated with the classification head in `SetFitModel`:
+### Loading a 🤗 SetFit model
-```python
-from setfit import SetFitModel
+A 🤗 SetFit model can be loaded using [`SetFitModel.from_pretrained`] by providing 1) a `repo_id` from the Hugging Face Hub or 2) a path to a local directory:
-def model_init(params):
- params = params or {}
- max_iter = params.get("max_iter", 100)
- solver = params.get("solver", "liblinear")
- params = {
- "head_params": {
- "max_iter": max_iter,
- "solver": solver,
- }
- }
- return SetFitModel.from_pretrained("sentence-transformers/paraphrase-albert-small-v2", **params)
-```
+```py
+>>> model = SetFitModel.from_pretrained("tomaarsen/setfit-bge-small-v1.5-sst2-8-shot") # Load from the Hugging Face Hub
-Similarly, to scan over hyperparameters associated with the SetFit training process, we can define a `hp_space()` function as follows:
-
-```python
-def hp_space(trial): # Training parameters
- return {
- "learning_rate": trial.suggest_float("learning_rate", 1e-6, 1e-4, log=True),
- "num_epochs": trial.suggest_int("num_epochs", 1, 5),
- "batch_size": trial.suggest_categorical("batch_size", [4, 8, 16, 32, 64]),
- "seed": trial.suggest_int("seed", 1, 40),
- "num_iterations": trial.suggest_categorical("num_iterations", [5, 10, 20]),
- "max_iter": trial.suggest_int("max_iter", 50, 300),
- "solver": trial.suggest_categorical("solver", ["newton-cg", "lbfgs", "liblinear"]),
- }
+>>> model = SetFitModel.from_pretrained("setfit-bge-small-v1.5-sst2-8-shot") # Load from a local directory
```
-**Note:** In practice, we found `num_iterations` to be the most important hyperparameter for the contrastive learning process.
+### Inference
-The next step is to instantiate a `SetFitTrainer` and call `hyperparameter_search()`:
+Once a 🤗 SetFit model has been trained, then it can be used for inference to classify reviews using [`SetFitModel.predict`] or [`SetFitModel.__call__`]:
-```python
-from datasets import Dataset
-from setfit import SetFitTrainer
-
-dataset = Dataset.from_dict(
- {"text_new": ["a", "b", "c"], "label_new": [0, 1, 2], "extra_column": ["d", "e", "f"]}
- )
-
-trainer = SetFitTrainer(
- train_dataset=dataset,
- eval_dataset=dataset,
- model_init=model_init,
- column_mapping={"text_new": "text", "label_new": "label"},
-)
-best_run = trainer.hyperparameter_search(direction="maximize", hp_space=hp_space, n_trials=20)
+```py
+>>> preds = model.predict([
+... "It's a charming and often affecting journey.",
+... "It's slow -- very, very slow.",
+... "A sometimes tedious film.",
+... ])
+>>> preds
+['positive' 'negative' 'negative']
```
+These predictions rely on the `model.labels`. If not set, it will return predictions in the format that was used during training, e.g. `tensor([1, 0, 0])`.
-Finally, you can apply the hyperparameters you found to the trainer, and lock in the optimal model, before training for
-a final time.
+## What's next?
-```python
-trainer.apply_hyperparameters(best_run.hyperparameters, final_model=True)
-trainer.train()
-```
+You've completed the 🤗 SetFit quickstart! You can train, save, load and perform inference with 🤗 SetFit models!
-## Compressing a SetFit model with knowledge distillation
+For your next steps, take a look at our [How-to guides](./how_to/overview) and learn how to do more specific things like hyperparameter search, knowledge distillation, or zero-shot text classification. If you're interested in learning more about how 🤗 SetFit works, grab a cup of coffee and read our [Conceptual Guides](./conceptual_guides/setfit)!
-If you have access to unlabeled data, you can use knowledge distillation to compress a trained SetFit model into a smaller version. The result is a model that can run inference much faster, with little to no drop in accuracy. Here's an end-to-end example (see our paper for more details):
+## End-to-end
-```python
-from datasets import load_dataset
-from sentence_transformers.losses import CosineSimilarityLoss
+This snippet shows the entire quickstart in an end-to-end example:
-from setfit import SetFitModel, SetFitTrainer, DistillationSetFitTrainer, sample_dataset
+```py
+from setfit import SetFitModel, Trainer, TrainingArguments, sample_dataset
+from datasets import load_dataset
-# Load a dataset from the Hugging Face Hub
-dataset = load_dataset("ag_news")
+# Initializing a new SetFit model
+model = SetFitModel.from_pretrained("BAAI/bge-small-en-v1.5", labels=["negative", "positive"])
-# Create a sample few-shot dataset to train the teacher model
-train_dataset_teacher = sample_dataset(dataset["train"], label_column="label", num_samples=16)
-# Create a dataset of unlabeled examples to train the student
-train_dataset_student = dataset["train"].shuffle(seed=0).select(range(500))
-# Dataset for evaluation
-eval_dataset = dataset["test"]
+# Preparing the dataset
+dataset = load_dataset("SetFit/sst2")
+train_dataset = sample_dataset(dataset["train"], label_column="label", num_samples=8)
+test_dataset = dataset["test"]
-# Load teacher model
-teacher_model = SetFitModel.from_pretrained(
- "sentence-transformers/paraphrase-mpnet-base-v2"
+# Preparing the training arguments
+args = TrainingArguments(
+ batch_size=32,
+ num_epochs=10,
)
-# Create trainer for teacher model
-teacher_trainer = SetFitTrainer(
- model=teacher_model,
- train_dataset=train_dataset_teacher,
- eval_dataset=eval_dataset,
- loss_class=CosineSimilarityLoss,
+# Preparing the trainer
+trainer = Trainer(
+ model=model,
+ args=args,
+ train_dataset=train_dataset,
)
+trainer.train()
-# Train teacher model
-teacher_trainer.train()
-
-# Load small student model
-student_model = SetFitModel.from_pretrained("paraphrase-MiniLM-L3-v2")
-
-# Create trainer for knowledge distillation
-student_trainer = DistillationSetFitTrainer(
- teacher_model=teacher_model,
- train_dataset=train_dataset_student,
- student_model=student_model,
- eval_dataset=eval_dataset,
- loss_class=CosineSimilarityLoss,
- metric="accuracy",
- batch_size=16,
- num_iterations=20,
- num_epochs=1,
-)
+# Evaluating
+metrics = trainer.evaluate(test_dataset)
+print(metrics)
+# => {'accuracy': 0.8511806699615596}
-# Train student with knowledge distillation
-student_trainer.train()
-```
\ No newline at end of file
+# Saving the trained model
+model.save_pretrained("setfit-bge-small-v1.5-sst2-8-shot")
+# or
+model.push_to_hub("tomaarsen/setfit-bge-small-v1.5-sst2-8-shot")
+
+# Loading a trained model
+model = SetFitModel.from_pretrained("tomaarsen/setfit-bge-small-v1.5-sst2-8-shot") # Load from the Hugging Face Hub
+# or
+model = SetFitModel.from_pretrained("setfit-bge-small-v1.5-sst2-8-shot") # Load from a local directory
+
+# Performing inference
+preds = model.predict([
+ "It's a charming and often affecting journey.",
+ "It's slow -- very, very slow.",
+ "A sometimes tedious film.",
+])
+print(preds)
+# => ["positive", "negative", "negative"]
+```
diff --git a/docs/source/en/reference/main.mdx b/docs/source/en/reference/main.mdx
new file mode 100644
index 00000000..2138f9fe
--- /dev/null
+++ b/docs/source/en/reference/main.mdx
@@ -0,0 +1,56 @@
+
+# Main Classes
+
+## SetFitModel
+
+[[autodoc]] SetFitModel
+ - all
+ - from_pretrained
+ - save_pretrained
+ - push_to_hub
+ - __call__
+ - label2id
+ - id2label
+
+## SetFitHead
+
+[[autodoc]] SetFitHead
+
+## SetFitModelCardData
+
+[[autodoc]] SetFitModelCardData
+ - to_dict
+ - to_yaml
+
+## AbsaModel
+
+[[autodoc]] AbsaModel
+ - __call__
+ - device
+ - from_pretrained
+ - predict
+ - push_to_hub
+ - to
+ - save_pretrained
+
+### AspectModel
+
+[[autodoc]] AspectModel
+ - __call__
+ - device
+ - from_pretrained
+ - predict
+ - push_to_hub
+ - save_pretrained
+ - to
+
+### PolarityModel
+
+[[autodoc]] PolarityModel
+ - __call__
+ - device
+ - from_pretrained
+ - predict
+ - push_to_hub
+ - save_pretrained
+ - to
diff --git a/docs/source/en/reference/trainer.mdx b/docs/source/en/reference/trainer.mdx
new file mode 100644
index 00000000..ddc26da8
--- /dev/null
+++ b/docs/source/en/reference/trainer.mdx
@@ -0,0 +1,52 @@
+
+# Trainer Classes
+
+## TrainingArguments
+
+[[autodoc]] TrainingArguments
+ - to_dict
+ - from_dict
+ - copy
+ - update
+
+## Trainer
+
+[[autodoc]] Trainer
+ - add_callback
+ - apply_hyperparameters
+ - evaluate
+ - hyperparameter_search
+ - log
+ - pop_callback
+ - push_to_hub
+ - remove_callback
+ - train
+ - train_classifier
+ - train_embeddings
+
+## DistillationTrainer
+
+[[autodoc]] DistillationTrainer
+ - add_callback
+ - apply_hyperparameters
+ - evaluate
+ - hyperparameter_search
+ - log
+ - pop_callback
+ - push_to_hub
+ - remove_callback
+ - train
+ - train_classifier
+ - train_embeddings
+
+## AbsaTrainer
+
+[[autodoc]] AbsaTrainer
+ - add_callback
+ - evaluate
+ - pop_callback
+ - push_to_hub
+ - remove_callback
+ - train
+ - train_aspect
+ - train_polarity
diff --git a/docs/source/en/reference/utility.mdx b/docs/source/en/reference/utility.mdx
new file mode 100644
index 00000000..d4741acf
--- /dev/null
+++ b/docs/source/en/reference/utility.mdx
@@ -0,0 +1,6 @@
+
+# Utility Functions
+
+[[autodoc]] get_templated_dataset
+
+[[autodoc]] sample_dataset
\ No newline at end of file
diff --git a/docs/source/en/tutorials/onnx.mdx b/docs/source/en/tutorials/onnx.mdx
new file mode 100644
index 00000000..ad1f2e16
--- /dev/null
+++ b/docs/source/en/tutorials/onnx.mdx
@@ -0,0 +1,313 @@
+# Efficiently run SetFit Models with Optimum
+
+[SetFit](https://github.com/huggingface/setfit) is a technique for few-shot text classification that uses contrastive learning to fine-tune Sentence Transformers in domains where little to no labeled data is available. It achieves comparable performance to existing state-of-the-art methods based on large language models, yet requires no prompts and is efficient to train (typically a few seconds on a GPU to minutes on a CPU).
+
+In this notebook you'll learn how to further compress SetFit models for faster inference & deployment on GPU using Optimum Onnx.
+
+## 1. Setup development environment
+
+Our first step is to install SetFit. Running the following cell will install all the required packages for us.
+
+```
+!pip install setfit accelerate -qqq
+```
+
+## 2. Create a performance benchmark
+
+Before we train and optimize any models, let's define a performance benchmark that we can use to compare our models. In general, deploying ML models in production environments involves a tradeoff among several constraints:
+
+* Model performance: how well does the model perform on a well crafted test set?
+* Latency: how fast can our model deliver predictions?
+* Memory: on what cloud instance or device can we store and load our model?
+
+The class below defines a simple benchmark that measure each quantity for a given SetFit model and test dataset:
+
+```py
+from pathlib import Path
+from time import perf_counter
+
+import evaluate
+import numpy as np
+import torch
+from tqdm.auto import tqdm
+
+metric = evaluate.load("accuracy")
+
+
+class PerformanceBenchmark:
+ def __init__(self, model, dataset, optim_type):
+ self.model = model
+ self.dataset = dataset
+ self.optim_type = optim_type
+
+ def compute_accuracy(self):
+ preds = self.model.predict(self.dataset["text"])
+ labels = self.dataset["label"]
+ accuracy = metric.compute(predictions=preds, references=labels)
+ print(f"Accuracy on test set - {accuracy['accuracy']:.3f}")
+ return accuracy
+
+ def compute_size(self):
+ state_dict = self.model.model_body.state_dict()
+ tmp_path = Path("model.pt")
+ torch.save(state_dict, tmp_path)
+ # Calculate size in megabytes
+ size_mb = Path(tmp_path).stat().st_size / (1024 * 1024)
+ # Delete temporary file
+ tmp_path.unlink()
+ print(f"Model size (MB) - {size_mb:.2f}")
+ return {"size_mb": size_mb}
+
+ def time_model(self, query="that loves its characters and communicates something rather beautiful about human nature"):
+ latencies = []
+ # Warmup
+ for _ in range(10):
+ _ = self.model([query])
+ # Timed run
+ for _ in range(100):
+ start_time = perf_counter()
+ _ = self.model([query])
+ latency = perf_counter() - start_time
+ latencies.append(latency)
+ # Compute run statistics
+ time_avg_ms = 1000 * np.mean(latencies)
+ time_std_ms = 1000 * np.std(latencies)
+ print(rf"Average latency (ms) - {time_avg_ms:.2f} +\- {time_std_ms:.2f}")
+ return {"time_avg_ms": time_avg_ms, "time_std_ms": time_std_ms}
+
+ def run_benchmark(self):
+ metrics = {}
+ metrics[self.optim_type] = self.compute_size()
+ metrics[self.optim_type].update(self.compute_accuracy())
+ metrics[self.optim_type].update(self.time_model())
+ return metrics
+```
+
+Beyond that, we'll create a simple function to plot the performances reported by this benchmark.
+
+```py
+import matplotlib.pyplot as plt
+import pandas as pd
+
+
+def plot_metrics(perf_metrics):
+ df = pd.DataFrame.from_dict(perf_metrics, orient="index")
+
+ for idx in df.index:
+ df_opt = df.loc[idx]
+ plt.errorbar(
+ df_opt["time_avg_ms"],
+ df_opt["accuracy"] * 100,
+ xerr=df_opt["time_std_ms"],
+ fmt="o",
+ alpha=0.5,
+ ms=df_opt["size_mb"] / 15,
+ label=idx,
+ capsize=5,
+ capthick=1,
+ )
+
+ legend = plt.legend(loc="lower right")
+
+ plt.ylim(63, 95)
+ # Use the slowest model to define the x-axis range
+ xlim = max([metrics["time_avg_ms"] for metrics in perf_metrics.values()]) * 1.2
+ plt.xlim(0, xlim)
+ plt.ylabel("Accuracy (%)")
+ plt.xlabel("Average latency with batch_size=1 (ms)")
+ plt.show()
+```
+
+## 3. Train/evaluate bge-small SetFit models
+
+Before we optimize any models, let's train a few baselines as a point of reference. We'll use the [sst-2](https://huggingface.co/datasets/SetFit/sst2) dataset, which is a collection of sentiment text catagorized into 2 classes: positive, negative
+
+Let's start by loading the dataset from the Hub:
+
+```
+from datasets import load_dataset
+
+dataset = load_dataset("SetFit/sst2")
+dataset
+```
+```
+DatasetDict({
+ train: Dataset({
+ features: ['text', 'label', 'label_text'],
+ num_rows: 6920
+ })
+ validation: Dataset({
+ features: ['text', 'label', 'label_text'],
+ num_rows: 872
+ })
+ test: Dataset({
+ features: ['text', 'label', 'label_text'],
+ num_rows: 1821
+ })
+})
+```
+
+We train a SetFit model with the full dataset. Recall that SetFit excels with few-shot scenario, but this time we are interested to achieve maximum accuracy.
+
+```py
+train_dataset = dataset["train"]
+test_dataset = dataset["validation"]
+```
+
+Use the following line code to download the [already finetuned model](https://huggingface.co/moshew/bge-small-en-v1.5_setfit-sst2-english) and evaluate. Alternatively, uncomment the code below it to fine-tune the base model from scratch.
+
+Note that we perform the evaluations on Google Colab using the free T4 GPU.
+
+```py
+# Evaluate the uploaded model!
+from setfit import SetFitModel
+
+small_model = SetFitModel.from_pretrained("moshew/bge-small-en-v1.5_setfit-sst2-english")
+pb = PerformanceBenchmark(model=small_model, dataset=test_dataset, optim_type="bge-small (PyTorch)")
+perf_metrics = pb.run_benchmark()
+```
+```
+Model size (MB) - 127.33
+Accuracy on test set - 0.906
+Average latency (ms) - 17.42 +\- 4.47
+```
+
+```py
+# # Fine-tune the base model and Evaluate!
+# from setfit import SetFitModel, Trainer, TrainingArguments
+
+# # Load pretrained model from the Hub
+# small_model = SetFitModel.from_pretrained(
+# "BAAI/bge-small-en-v1.5"
+# )
+# args = TrainingArguments(num_iterations=20)
+
+# # Create trainer
+# small_trainer = Trainer(
+# model=small_model, args=args, train_dataset=train_dataset
+# )
+# # Train!
+# small_trainer.train()
+
+# # Evaluate!
+# pb = PerformanceBenchmark(
+# model=small_trainer.model, dataset=test_dataset, optim_type="bge-small (base)"
+# )
+# perf_metrics = pb.run_benchmark()
+```
+
+Let's plot the results to visualise the performance:
+
+```
+plot_metrics(perf_metrics)
+```
+
+
+
+## 4. Compressing with Optimum ONNX and CUDAExecutionProvider
+
+We'll be using Optimum's ONNX Runtime support with `CUDAExecutionProvider` [because it's fast while also supporting dynamic shapes](https://github.com/huggingface/optimum-benchmark/tree/main/examples/fast-mteb#notes).
+
+```
+!pip install optimum[onnxruntime-gpu] -qqq
+```
+
+[`optimum-cli`](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/optimization#optimizing-a-model-during-the-onnx-export) makes it extremely easy to export a model to ONNX and apply SOTA graph optimizations / kernel fusions.
+
+```py
+!optimum-cli export onnx \
+ --model moshew/bge-small-en-v1.5_setfit-sst2-english \
+ --task feature-extraction \
+ --optimize O4 \
+ --device cuda \
+ bge_auto_opt_O4
+```
+
+We may see some warnings, but these are not ones to be concerned about. We'll see later that it does not affect the model performance.
+
+First of all, we'll create a subclass of our performance benchmark to also allow benchmarking ONNX models.
+
+```py
+class OnnxPerformanceBenchmark(PerformanceBenchmark):
+ def __init__(self, *args, model_path, **kwargs):
+ super().__init__(*args, **kwargs)
+ self.model_path = model_path
+
+ def compute_size(self):
+ size_mb = Path(self.model_path).stat().st_size / (1024 * 1024)
+ print(f"Model size (MB) - {size_mb:.2f}")
+ return {"size_mb": size_mb}
+```
+
+Then, we can load the converted SentenceTransformer model with the `"CUDAExecutionProvider"` provider. Feel free to also experiment with other providers, such as `"TensorrtExecutionProvider"` and `"CPUExecutionProvider"`. The former may be even faster than `"CUDAExecutionProvider"`, but requires more installation.
+
+```py
+import torch
+from transformers import AutoTokenizer
+from optimum.onnxruntime import ORTModelForFeatureExtraction
+
+# Load model from HuggingFace Hub
+tokenizer = AutoTokenizer.from_pretrained('bge_auto_opt_O4', model_max_length=512)
+ort_model = ORTModelForFeatureExtraction.from_pretrained('bge_auto_opt_O4', provider="CUDAExecutionProvider")
+```
+
+And let's make a class that uses the tokenizer, ONNX Runtime (ORT) model and a SetFit model head.
+
+```py
+from setfit.exporters.utils import mean_pooling
+
+
+class OnnxSetFitModel:
+ def __init__(self, ort_model, tokenizer, model_head):
+ self.ort_model = ort_model
+ self.tokenizer = tokenizer
+ self.model_head = model_head
+
+ def predict(self, inputs):
+ encoded_inputs = self.tokenizer(
+ inputs, padding=True, truncation=True, return_tensors="pt"
+ ).to(self.ort_model.device)
+
+ outputs = self.ort_model(**encoded_inputs)
+ embeddings = mean_pooling(
+ outputs["last_hidden_state"], encoded_inputs["attention_mask"]
+ )
+ return self.model_head.predict(embeddings.cpu())
+
+ def __call__(self, inputs):
+ return self.predict(inputs)
+```
+
+We can initialize this model like so:
+
+```py
+model = SetFitModel.from_pretrained("moshew/bge-small-en-v1.5_setfit-sst2-english")
+onnx_setfit_model = OnnxSetFitModel(ort_model, tokenizer, model.model_head)
+
+# Perform inference
+onnx_setfit_model(test_dataset["text"][:2])
+```
+```
+array([0, 0])
+```
+
+Time to benchmark this ONNX model.
+
+```py
+pb = OnnxPerformanceBenchmark(
+ onnx_setfit_model,
+ test_dataset,
+ "bge-small (optimum ONNX)",
+ model_path="bge_auto_opt_O4/model.onnx",
+)
+perf_metrics.update(pb.run_benchmark())
+```
+```py
+plot_metrics(perf_metrics)
+```
+
+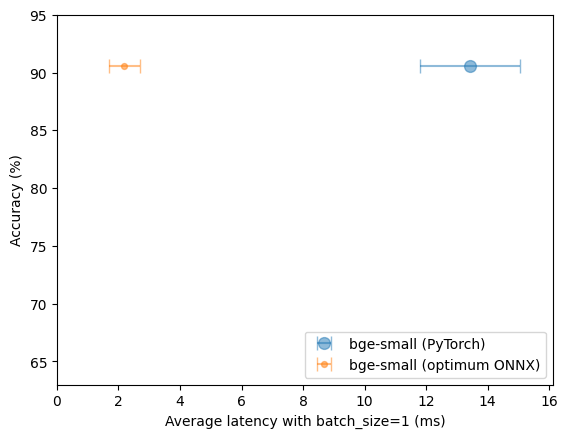
+
+By applying ONNX, we were able to improve the latency from 13.43ms per sample to 2.19ms per sample, for a speedup of 6.13x!
+
+For further improvements, we recommend increasing the inference batch size, as this may also heavily improve the throughput. For example, setting the batch size to 128 reduces the latency further down to 0.3ms, and down to 0.2ms at a batch size of 2048.
\ No newline at end of file
diff --git a/docs/source/en/tutorials/overview.mdx b/docs/source/en/tutorials/overview.mdx
new file mode 100644
index 00000000..52010122
--- /dev/null
+++ b/docs/source/en/tutorials/overview.mdx
@@ -0,0 +1,8 @@
+
+# Overview
+
+Welcome to the SetFit tutorials! These tutorials are designed to walk you through particular applications. For example, we'll delve into topics such as zero-shot text classification, where you'll learn how to use SetFit without any predefined labels or examples during training. See also the [SetFit Notebooks](https://github.com/huggingface/setfit/tree/main/notebooks) for more applications, such as hyperparameter searching and ONNX, though some might be outdated.
+
+For more concise guides on how to configure SetFit or use it for specific forms of text classification, see the [How-to Guides](../how_to/overview) section.
+
+If you have any questions about SetFit, feel free to open an [issue](https://github.com/huggingface/setfit/issues).
diff --git a/docs/source/en/tutorials/placeholder.mdx b/docs/source/en/tutorials/placeholder.mdx
deleted file mode 100644
index f68bd40a..00000000
--- a/docs/source/en/tutorials/placeholder.mdx
+++ /dev/null
@@ -1,3 +0,0 @@
-
-# Tutorial
-Work in Progress!
\ No newline at end of file
diff --git a/docs/source/en/tutorials/zero_shot.mdx b/docs/source/en/tutorials/zero_shot.mdx
new file mode 100644
index 00000000..28bb0fcd
--- /dev/null
+++ b/docs/source/en/tutorials/zero_shot.mdx
@@ -0,0 +1,327 @@
+# Zero-shot Text Classification
+
+[[open-in-colab]]
+
+Although SetFit was designed for few-shot learning, the method can also be applied in scenarios where no labeled data is available. The main trick is to create _synthetic examples_ that resemble the classification task, and then train a SetFit model on them.
+
+Remarkably, this simple technique typically outperforms the zero-shot pipeline in 🤗 Transformers, and can generate predictions by a factor of 5x (or more) faster!
+
+In this tutorial, we'll explore how:
+
+* SetFit can be applied for zero-shot classification
+* Adding synthetic examples can also provide a performance boost to few-shot classification.
+
+## Setup
+
+If you're running this Notebook on Colab or some other cloud platform, you will need to install the `setfit` library. Uncomment the following cell and run it:
+
+```py
+# %pip install setfit matplotlib
+```
+
+To benchmark the performance of the "zero-shot" method, we'll use the following dataset and pretrained model:
+
+```py
+dataset_id = "emotion"
+model_id = "sentence-transformers/paraphrase-mpnet-base-v2"
+```
+
+Next, we'll download the reference dataset from the Hugging Face Hub:
+
+```py
+from datasets import load_dataset
+
+reference_dataset = load_dataset(dataset_id)
+reference_dataset
+```
+```py
+DatasetDict({
+ train: Dataset({
+ features: ['text', 'label'],
+ num_rows: 16000
+ })
+ validation: Dataset({
+ features: ['text', 'label'],
+ num_rows: 2000
+ })
+ test: Dataset({
+ features: ['text', 'label'],
+ num_rows: 2000
+ })
+})
+```
+
+Now that we're set up, let's create some synthetic data to train on!
+
+## Creating a synthetic dataset
+
+The first thing we need to do is create a dataset of synthetic examples. In `setfit`, we can do this by applying the `get_templated_dataset()` function to a dummy dataset. This function expects a few main things:
+
+* A list of candidate labels to classify with. We'll use the labels from the reference dataset here, but this could be anything that's relevant to the task and dataset at hand.
+* A template to generate examples with. By default, it is `"This sentence is {}"`, where the `{}` will be filled by one of the candidate labels
+* A sample size $N$, which will create $N$ synthetic examples per class. We find $N=8$ usually works best.
+
+Armed with this information, let's first extract some candidate labels from the dataset:
+
+```py
+# Extract ClassLabel feature from "label" column
+label_features = reference_dataset["train"].features["label"]
+# Label names to classify with
+candidate_labels = label_features.names
+candidate_labels
+```
+```
+['sadness', 'joy', 'love', 'anger', 'fear', 'surprise']
+```
+
+
+
+Some datasets on the Hugging Face Hub don't have a `ClassLabel` feature for the label column. In these cases, you should compute the candidate labels manually by first computing the id2label mapping as follows:
+
+
+
+```py
+def get_id2label(dataset):
+ # The column with the label names
+ label_names = dataset.unique("label_text")
+ # The column with the label IDs
+ label_ids = dataset.unique("label")
+ id2label = dict(zip(label_ids, label_names))
+ # Sort by label ID
+ return {key: val for key, val in sorted(id2label.items(), key = lambda x: x[0])}
+
+id2label = get_id2label(reference_dataset["train"])
+candidate_labels = list(id2label.values())
+```
+
+Now that we have the labels, it's a simple matter to create synthetic examples:
+
+```py
+from datasets import Dataset
+from setfit import get_templated_dataset
+
+# A dummy dataset to fill with synthetic examples
+dummy_dataset = Dataset.from_dict({})
+train_dataset = get_templated_dataset(dummy_dataset, candidate_labels=candidate_labels, sample_size=8)
+train_dataset
+```
+```
+Dataset({
+ features: ['text', 'label'],
+ num_rows: 48
+})
+```
+
+
+
+You might find you can get better performance by tweaking the `template` argument from the default of `"The sentence is {}"` to variants like `"This sentence is {}"` or `"This example is {}"`.
+
+
+
+
+Since our dataset has 6 classes and we chose a sample size of 8, our synthetic dataset contains $6\times 8=48$ examples. If we take a look at a few of the examples:
+
+```py
+train_dataset.shuffle()[:3]
+```
+```
+{'text': ['This sentence is love',
+ 'This sentence is fear',
+ 'This sentence is joy'],
+ 'label': [2, 4, 1]}
+```
+
+We can see that each input takes the form of the template and has a corresponding label associated with it.
+
+Let's not train a SetFit model on these examples!
+
+## Fine-tuning the model
+
+To train a SetFit model, the first thing to do is download a pretrained checkpoint from the Hub. We can do so by using the [`SetFitModel.from_pretrained`] method:
+
+```py
+from setfit import SetFitModel
+
+model = SetFitModel.from_pretrained(model_id)
+```
+
+Here, we've downloaded a pretrained Sentence Transformer from the Hub and added a logistic classification head to the create the SetFit model. As indicated in the message, we need to train this model on some labeled examples. We can do so by using the [`Trainer`] class as follows:
+
+```py
+from setfit import Trainer
+
+trainer = Trainer(
+ model=model,
+ train_dataset=train_dataset,
+ eval_dataset=reference_dataset["test"]
+)
+```
+
+Now that we've created a trainer, we can train it! While we're at it, let's time how long it takes to train and evaluate the model:
+
+```py
+%%time
+trainer.train()
+zeroshot_metrics = trainer.evaluate()
+zeroshot_metrics
+```
+```py
+***** Running training *****
+ Num examples = 1920
+ Num epochs = 1
+ Total optimization steps = 120
+ Total train batch size = 16
+***** Running evaluation *****
+{'accuracy': 0.5345}
+```
+```
+CPU times: user 12.9 s, sys: 2.37 s, total: 15.2 s
+Wall time: 11 s
+```
+
+Great, now that we have a reference score let's compare against the zero-shot pipeline from 🤗 Transformers.
+
+## Comparing against the zero-shot pipeline from 🤗 Transformers
+🤗 Transformers provides a zero-shot pipeline that frames text classification as a natural language inference task. Let's load the pipeline and place it on the GPU for fast inference:
+
+```py
+from transformers import pipeline
+
+pipe = pipeline("zero-shot-classification", device=0)
+```
+
+Now that we have the model, let's generate some predictions. We'll use the same candidate labels as we did with SetFit and increase the batch size for to speed things up:
+
+```py
+%%time
+zeroshot_preds = pipe(reference_dataset["test"]["text"], batch_size=16, candidate_labels=candidate_labels)
+```
+```
+CPU times: user 1min 10s, sys: 166 ms, total: 1min 11s
+Wall time: 53.1 s
+```
+
+Note that this took almost 5x longer to generate predictions than SetFit! OK, so how well does it perform? Since each prediction is a dictionary of label names ranked by score:
+
+```py
+zeroshot_preds[0]
+```
+```py
+{'sequence': 'im feeling rather rotten so im not very ambitious right now',
+ 'labels': ['sadness', 'anger', 'surprise', 'fear', 'joy', 'love'],
+ 'scores': [0.7367985844612122,
+ 0.10041674226522446,
+ 0.09770156443119049,
+ 0.05880110710859299,
+ 0.004266355652362108,
+ 0.0020156768150627613]}
+```
+
+We can use the `str2int()` function from the `label` column to convert them to integers.
+
+```py
+preds = [label_features.str2int(pred["labels"][0]) for pred in zeroshot_preds]
+```
+
+**Note:** As noted earlier, if you're using a dataset that doesn't have a `ClassLabel` feature for the label column, you'll need to compute the label mapping manually with something like:
+
+```py
+id2label = get_id2label(reference_dataset["train"])
+label2id = {v:k for k,v in id2label.items()}
+preds = [label2id[pred["labels"][0]] for pred in zeroshot_preds]
+```
+
+The last step is to compute accuracy using 🤗 Evaluate:
+
+```py
+import evaluate
+
+metric = evaluate.load("accuracy")
+transformers_metrics = metric.compute(predictions=preds, references=reference_dataset["test"]["label"])
+transformers_metrics
+```
+```py
+{'accuracy': 0.3765}
+```
+
+Compared to SetFit, this approach performs significantly worse. Let's wrap up our analysis by combining synthetic examples with a few labeled ones.
+
+## Augmenting labeled data with synthetic examples
+
+If you have a few labeled examples, adding synthetic data can often boost performance. To simulate this, let's first sample 8 labeled examples from our reference dataset:
+
+```py
+from setfit import sample_dataset
+
+train_dataset = sample_dataset(reference_dataset["train"])
+train_dataset
+```
+```py
+Dataset({
+ features: ['text', 'label'],
+ num_rows: 48
+})
+```
+
+To warm up, we'll train a SetFit model on these true labels:
+```py
+model = SetFitModel.from_pretrained(model_id)
+
+trainer = Trainer(
+ model=model,
+ train_dataset=train_dataset,
+ eval_dataset=reference_dataset["test"]
+)
+trainer.train()
+fewshot_metrics = trainer.evaluate()
+fewshot_metrics
+```
+```py
+{'accuracy': 0.4705}
+```
+
+Note that for this particular dataset, the performance with true labels is _worse_ than training on synthetic examples! In our experiments, we found that the difference depends strongly on the dataset in question. Since SetFit models are fast to train, you can always try both approaches and pick the best one.
+
+In any case, let's now add some synthetic examples to our training set:
+
+```py
+augmented_dataset = get_templated_dataset(train_dataset, candidate_labels=candidate_labels, sample_size=8)
+augmented_dataset
+```
+```py
+Dataset({
+ features: ['text', 'label'],
+ num_rows: 96
+})
+```
+
+As before, we can train and evaluate SetFit with the augmented dataset:
+
+```py
+model = SetFitModel.from_pretrained(model_id)
+
+trainer = Trainer(
+ model=model,
+ train_dataset=augmented_dataset,
+ eval_dataset=reference_dataset["test"]
+)
+trainer.train()
+augmented_metrics = trainer.evaluate()
+augmented_metrics
+```
+```
+{'accuracy': 0.613}
+```
+
+Great, this has given us a significant boost in performance and given us a few percentage points over the purely synthetic example.
+
+Let's plot the final results for comparison:
+
+```py
+import pandas as pd
+
+df = pd.DataFrame.from_dict({"Method":["Transformers (zero-shot)", "SetFit (zero-shot)", "SetFit (augmented)"], "Accuracy": [transformers_metrics["accuracy"], zeroshot_metrics["accuracy"], augmented_metrics["accuracy"]]})
+df.plot(kind="barh", x="Method");
+```
+
+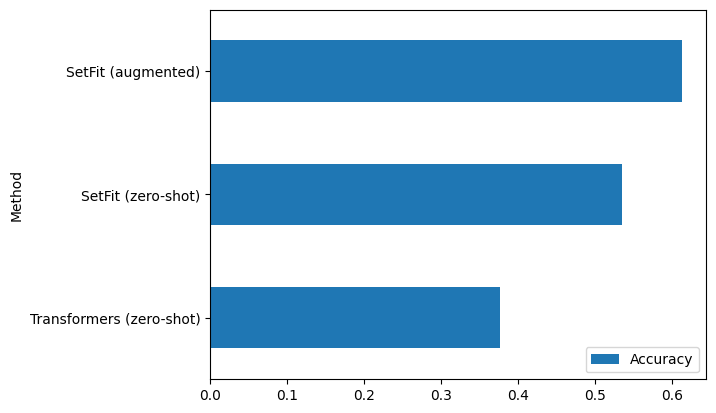
\ No newline at end of file
diff --git a/notebooks/setfit-onnx-optimum.ipynb b/notebooks/setfit-onnx-optimum.ipynb
new file mode 100644
index 00000000..a7634df1
--- /dev/null
+++ b/notebooks/setfit-onnx-optimum.ipynb
@@ -0,0 +1,774 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "76571396-8f54-40ed-9e81-6c7531e6eaee",
+ "metadata": {
+ "id": "76571396-8f54-40ed-9e81-6c7531e6eaee"
+ },
+ "source": [
+ "# Efficiently run SetFit Models with Optimum"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "24fd5853-812f-45a4-8a7b-0a0c9a60d0a2",
+ "metadata": {
+ "id": "24fd5853-812f-45a4-8a7b-0a0c9a60d0a2"
+ },
+ "source": [
+ "[SetFit](https://github.com/huggingface/setfit) is a technique for few-shot text classification that uses contrastive learning to fine-tune Sentence Transformers in domains where little to no labeled data is available. It achieves comparable performance to existing state-of-the-art methods based on large language models, yet requires no prompts and is efficient to train (typically a few seconds on a GPU to minutes on a CPU).\n",
+ "\n",
+ "In this notebook you'll learn how to further compress SetFit models for faster inference & deployment on GPU using Optimum Onnx."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a3b30b35-7875-498f-a771-068132f4084f",
+ "metadata": {
+ "id": "a3b30b35-7875-498f-a771-068132f4084f",
+ "tags": []
+ },
+ "source": [
+ "## 1. Setup development environment"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "dc40c7af-1f4f-4324-847c-dc9b7797b60c",
+ "metadata": {
+ "id": "dc40c7af-1f4f-4324-847c-dc9b7797b60c"
+ },
+ "source": [
+ "Our first step is to install SetFit. Running the following cell will install all the required packages for us."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 156,
+ "id": "Cu9et-iSaU0i",
+ "metadata": {
+ "id": "Cu9et-iSaU0i"
+ },
+ "outputs": [],
+ "source": [
+ "!pip install setfit accelerate -qqq"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ffbea843-2e86-4f14-961c-b8895f9de77d",
+ "metadata": {
+ "id": "ffbea843-2e86-4f14-961c-b8895f9de77d"
+ },
+ "source": [
+ "## 2. Create a performance benchmark\n",
+ "\n",
+ "Before we train and optimize any models, let's define a performance benchmark that we can use to compare our models. In general, deploying ML models in production environments involves a tradeoff among several constraints:\n",
+ "\n",
+ "* Model performance: how well does the model perform on a well crafted test set?\n",
+ "* Latency: how fast can our model deliver predictions?\n",
+ "* Memory: on what cloud instance or device can we store and load our model?\n",
+ "\n",
+ "The class below defines a simple benchmark that measure each quantity for a given SetFit model and test dataset:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 157,
+ "id": "55756fec-fc22-4590-84d7-2f3df37b9256",
+ "metadata": {
+ "id": "55756fec-fc22-4590-84d7-2f3df37b9256"
+ },
+ "outputs": [],
+ "source": [
+ "from pathlib import Path\n",
+ "from time import perf_counter\n",
+ "\n",
+ "import evaluate\n",
+ "import numpy as np\n",
+ "import torch\n",
+ "from tqdm.auto import tqdm\n",
+ "\n",
+ "metric = evaluate.load(\"accuracy\")\n",
+ "\n",
+ "\n",
+ "class PerformanceBenchmark:\n",
+ " def __init__(self, model, dataset, optim_type):\n",
+ " self.model = model\n",
+ " self.dataset = dataset\n",
+ " self.optim_type = optim_type\n",
+ "\n",
+ " def compute_accuracy(self):\n",
+ " preds = self.model.predict(self.dataset[\"text\"])\n",
+ " labels = self.dataset[\"label\"]\n",
+ " accuracy = metric.compute(predictions=preds, references=labels)\n",
+ " print(f\"Accuracy on test set - {accuracy['accuracy']:.3f}\")\n",
+ " return accuracy\n",
+ "\n",
+ " def compute_size(self):\n",
+ " state_dict = self.model.model_body.state_dict()\n",
+ " tmp_path = Path(\"model.pt\")\n",
+ " torch.save(state_dict, tmp_path)\n",
+ " # Calculate size in megabytes\n",
+ " size_mb = Path(tmp_path).stat().st_size / (1024 * 1024)\n",
+ " # Delete temporary file\n",
+ " tmp_path.unlink()\n",
+ " print(f\"Model size (MB) - {size_mb:.2f}\")\n",
+ " return {\"size_mb\": size_mb}\n",
+ "\n",
+ " def time_model(self, query=\"that loves its characters and communicates something rather beautiful about human nature\"):\n",
+ " latencies = []\n",
+ " # Warmup\n",
+ " for _ in range(10):\n",
+ " _ = self.model([query])\n",
+ " # Timed run\n",
+ " for _ in range(100):\n",
+ " start_time = perf_counter()\n",
+ " _ = self.model([query])\n",
+ " latency = perf_counter() - start_time\n",
+ " latencies.append(latency)\n",
+ " # Compute run statistics\n",
+ " time_avg_ms = 1000 * np.mean(latencies)\n",
+ " time_std_ms = 1000 * np.std(latencies)\n",
+ " print(rf\"Average latency (ms) - {time_avg_ms:.2f} +\\- {time_std_ms:.2f}\")\n",
+ " return {\"time_avg_ms\": time_avg_ms, \"time_std_ms\": time_std_ms}\n",
+ "\n",
+ " def run_benchmark(self):\n",
+ " metrics = {}\n",
+ " metrics[self.optim_type] = self.compute_size()\n",
+ " metrics[self.optim_type].update(self.compute_accuracy())\n",
+ " metrics[self.optim_type].update(self.time_model())\n",
+ " return metrics"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "4QkMcqR0qcBZ"
+ },
+ "source": [
+ "Beyond that, we'll create a simple function to plot the performances reported by this benchmark."
+ ],
+ "id": "4QkMcqR0qcBZ"
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 194,
+ "metadata": {
+ "id": "PurksLh3qcBa"
+ },
+ "outputs": [],
+ "source": [
+ "import matplotlib.pyplot as plt\n",
+ "import pandas as pd\n",
+ "\n",
+ "\n",
+ "def plot_metrics(perf_metrics):\n",
+ " df = pd.DataFrame.from_dict(perf_metrics, orient=\"index\")\n",
+ "\n",
+ " for idx in df.index:\n",
+ " df_opt = df.loc[idx]\n",
+ " plt.errorbar(\n",
+ " df_opt[\"time_avg_ms\"],\n",
+ " df_opt[\"accuracy\"] * 100,\n",
+ " xerr=df_opt[\"time_std_ms\"],\n",
+ " fmt=\"o\",\n",
+ " alpha=0.5,\n",
+ " ms=df_opt[\"size_mb\"] / 15,\n",
+ " label=idx,\n",
+ " capsize=5,\n",
+ " capthick=1,\n",
+ " )\n",
+ "\n",
+ " legend = plt.legend(loc=\"lower right\")\n",
+ "\n",
+ " plt.ylim(63, 95)\n",
+ " # Use the slowest model to define the x-axis range\n",
+ " xlim = max([metrics[\"time_avg_ms\"] for metrics in perf_metrics.values()]) * 1.2\n",
+ " plt.xlim(0, xlim)\n",
+ " plt.ylabel(\"Accuracy (%)\")\n",
+ " plt.xlabel(\"Average latency with batch_size=1 (ms)\")\n",
+ " plt.show()\n"
+ ],
+ "id": "PurksLh3qcBa"
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1402c1ba-aa7f-4b0b-9db5-1e6f0d301e70",
+ "metadata": {
+ "id": "1402c1ba-aa7f-4b0b-9db5-1e6f0d301e70"
+ },
+ "source": [
+ "## 3. Train/evaluate bge-small SetFit models"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5a850dfb-fffb-4e03-b468-b1f78d434705",
+ "metadata": {
+ "id": "5a850dfb-fffb-4e03-b468-b1f78d434705"
+ },
+ "source": [
+ "Before we optimize any models, let's train a few baselines as a point of reference. We'll use the [sst-2](https://huggingface.co/datasets/SetFit/sst2) dataset, which is a collection of sentiment text catagorized into 2 classes: positive, negative\n",
+ "\n",
+ "Let's start by loading the dataset from the Hub:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 159,
+ "id": "7850d846-07c8-48eb-9aa6-2ce1af276ff4",
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "7850d846-07c8-48eb-9aa6-2ce1af276ff4",
+ "outputId": "056eff7c-293f-4fd8-e76e-29d261abff1b"
+ },
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stderr",
+ "text": [
+ "/usr/local/lib/python3.10/dist-packages/huggingface_hub/repocard.py:105: UserWarning: Repo card metadata block was not found. Setting CardData to empty.\n",
+ " warnings.warn(\"Repo card metadata block was not found. Setting CardData to empty.\")\n"
+ ]
+ },
+ {
+ "output_type": "execute_result",
+ "data": {
+ "text/plain": [
+ "DatasetDict({\n",
+ " train: Dataset({\n",
+ " features: ['text', 'label', 'label_text'],\n",
+ " num_rows: 6920\n",
+ " })\n",
+ " validation: Dataset({\n",
+ " features: ['text', 'label', 'label_text'],\n",
+ " num_rows: 872\n",
+ " })\n",
+ " test: Dataset({\n",
+ " features: ['text', 'label', 'label_text'],\n",
+ " num_rows: 1821\n",
+ " })\n",
+ "})"
+ ]
+ },
+ "metadata": {},
+ "execution_count": 159
+ }
+ ],
+ "source": [
+ "from datasets import load_dataset\n",
+ "\n",
+ "dataset = load_dataset(\"SetFit/sst2\")\n",
+ "dataset"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a714cf95-a831-41b7-8f04-ffe0350d4659",
+ "metadata": {
+ "id": "a714cf95-a831-41b7-8f04-ffe0350d4659"
+ },
+ "source": [
+ "We train a SetFit model with the full dataset. Recall that SetFit excels with few-shot scenario, but this time we are interested to achieve maximum accuracy."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 160,
+ "id": "a628cbfa-cfcd-4e4f-ab48-b454e5695ac8",
+ "metadata": {
+ "id": "a628cbfa-cfcd-4e4f-ab48-b454e5695ac8"
+ },
+ "outputs": [],
+ "source": [
+ "train_dataset = dataset[\"train\"]\n",
+ "test_dataset = dataset[\"validation\"]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "P8yY_SBbWlv9",
+ "metadata": {
+ "id": "P8yY_SBbWlv9"
+ },
+ "source": [
+ "Use the following line code to download the [already finetuned model](https://huggingface.co/moshew/bge-small-en-v1.5_setfit-sst2-english) and evaluate. Alternatively, uncomment the code below it to fine-tune the base model from scratch.\n",
+ "\n",
+ "Note that we perform the evaluations on Google Colab using the free T4 GPU."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 197,
+ "id": "u-w99Y2qW4lU",
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "u-w99Y2qW4lU",
+ "outputId": "57f0b8f7-6dad-4e90-c779-658a7de6e960"
+ },
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "Model size (MB) - 127.33\n",
+ "Accuracy on test set - 0.906\n",
+ "Average latency (ms) - 13.43 +\\- 1.62\n"
+ ]
+ }
+ ],
+ "source": [
+ "# Evaluate the uploaded model!\n",
+ "from setfit import SetFitModel\n",
+ "\n",
+ "small_model = SetFitModel.from_pretrained(\"moshew/bge-small-en-v1.5_setfit-sst2-english\")\n",
+ "pb = PerformanceBenchmark(model=small_model, dataset=test_dataset, optim_type=\"bge-small (PyTorch)\")\n",
+ "perf_metrics = pb.run_benchmark()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 162,
+ "id": "52b3bc70-dc3e-4c23-a152-7a149b8b46fe",
+ "metadata": {
+ "id": "52b3bc70-dc3e-4c23-a152-7a149b8b46fe"
+ },
+ "outputs": [],
+ "source": [
+ "# # Fine-tune the base model and Evaluate!\n",
+ "# from setfit import SetFitModel, Trainer, TrainingArguments\n",
+ "\n",
+ "# # Load pretrained model from the Hub\n",
+ "# small_model = SetFitModel.from_pretrained(\n",
+ "# \"BAAI/bge-small-en-v1.5\"\n",
+ "# )\n",
+ "# args = TrainingArguments(num_iterations=20)\n",
+ "\n",
+ "# # Create trainer\n",
+ "# small_trainer = Trainer(\n",
+ "# model=small_model, args=args, train_dataset=train_dataset\n",
+ "# )\n",
+ "# # Train!\n",
+ "# small_trainer.train()\n",
+ "\n",
+ "# # Evaluate!\n",
+ "# pb = PerformanceBenchmark(\n",
+ "# model=small_trainer.model, dataset=test_dataset, optim_type=\"bge-small (base)\"\n",
+ "# )\n",
+ "# perf_metrics = pb.run_benchmark()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "82bf3e15-2804-4669-97d6-87e1bbef7223",
+ "metadata": {
+ "id": "82bf3e15-2804-4669-97d6-87e1bbef7223"
+ },
+ "source": [
+ "Let's plot the results to visualise the performance:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 198,
+ "id": "89d0a144-d463-4a61-b78a-861d0d8cd061",
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 455
+ },
+ "id": "89d0a144-d463-4a61-b78a-861d0d8cd061",
+ "outputId": "9ba81223-b2d2-4b10-f78d-2691846782a2"
+ },
+ "outputs": [
+ {
+ "output_type": "display_data",
+ "data": {
+ "text/plain": [
+ ""
+ ],
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAAjgAAAG2CAYAAAByJ/zDAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjcuMSwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy/bCgiHAAAACXBIWXMAAA9hAAAPYQGoP6dpAABMHUlEQVR4nO3deVhUZf8/8PcwwDCsIshWbAKCC+4b2qOWGJq5pLmXIppplGKlqWVZLqSl+Wh9NctwR1vU0jIVCpdyV1xCUZDABSQXGNYBZu7fH/6cxwlEloGBw/t1Xee6nLN+7jPjzJtz7nOOTAghQERERCQhJsYugIiIiMjQGHCIiIhIchhwiIiISHIYcIiIiEhyGHCIiIhIchhwiIiISHIYcIiIiEhyGHCIiIhIchhwiIiISHIYcIiIiEhyjBpwcnJyEBERAU9PTyiVSnTr1g0nTpzQTQ8NDYVMJtMb+vbta8SKiYiIqD4wNebGJ06ciAsXLmDjxo1wc3PDpk2bEBwcjISEBDzxxBMAgL59+yIqKkq3jEKhMFa5REREVE/IjPWwzYKCAtjY2ODHH39E//79deM7dOiAfv36YcGCBQgNDUVWVhZ27txpjBKJiIionjLaEZySkhJoNBpYWFjojVcqlTh8+LDudVxcHJycnGBvb49nnnkGCxYsgIODwyPXq1aroVarda+1Wi3u3r0LBwcHyGQywzeEiIiIDE4IgZycHLi5ucHEpAo9aoQRBQUFiZ49e4obN26IkpISsXHjRmFiYiKaNWsmhBAiOjpa/Pjjj+LcuXNix44donnz5qJTp06ipKTkkev84IMPBAAOHDhw4MCBgwSGa9euVSljGO0UFQAkJycjLCwMBw8ehFwuR/v27dGsWTOcOnUKFy9eLDX/1atX4ePjg5iYGPTu3bvMdf77CE52djY8PDxw7do12Nra1lhbiIiIyHBUKhXc3d2RlZUFOzu7Si9v1E7GPj4+OHDgAPLy8qBSqeDq6ooRI0agadOmZc7ftGlTODo6Iikp6ZEBR6FQlNkR2dbWlgGHiIionqlq95I6cR8cKysruLq64t69e9i7dy8GDRpU5nzXr1/HnTt34OrqWssVEhERUX1i1CM4e/fuhRAC/v7+SEpKwowZMxAQEIDx48cjNzcXH374IYYOHQoXFxckJydj5syZ8PX1RUhIiDHLJiIiojrOqEdwsrOzER4ejoCAAIwdOxZPPfUU9u7dCzMzM8jlcpw7dw4DBw5Es2bNMGHCBHTo0AGHDh3ivXCIiIioXEbtZFwbVCoV7OzskJ2dzT44RERE9UR1f7/rRB8cIiIiIkNiwCEiIiLJYcAhIiIiyWHAISIiIslhwCEiIiLJYcAhIiIiyWHAISIiIslhwCEiIiLJYcAhIiIiyWHAISIiIslhwCEiIiLJYcAhIiIiyWHAISIiIslhwCEiIiLJYcAhIiIiyWHAISIiIslhwCEiIiLJYcAhIiIiyWHAISIiIslhwCEiIiLJYcAhIiIiyWHAISIiIslhwCEiIiLJYcAhIiIiyWHAISIiIslhwCEiIiLJYcAhIiIiyWHAISIiIslhwCEiIiLJYcAhIiIiyWHAISIiIslhwCEiIiLJYcAhIiIiyWHAISIiIslhwCEiIiLJYcAhIiIiyWHAISIiIslhwCEiIqPLVZfgSPId5KpLjF1KtZRotCgo0qBEozV2KdUihffD1NgFEBER5atLcPTqHfg0sYK1on79NGm1Aldv5+FM2j2cu56NEq0WpiYmaP2kHdp52KOpoxVMTGTGLrNS6vP78UD9rJqIiKgOUJdo8FP8TfyRdBuFxVrYWZrBXG6CIo0WsRcz8UfSbXT3dcTAtm5QmMqNXW6DwoBDRERUBVqtwE/xNxF7MRPOtgp4OpjrTXextUBWfhFiL2YCAIa2f7LeHcmpz9gHh4iIqAqu3s7DH0m34WyrQCNL8zLnaWRpDmdbBf5Iuo2UO3m1XGHDxiM4RERUJ2i0AkUaLYpK6kcH3RN/30WeWoMn7S2h0YpHzmdjYYb07EKcSLkLd3vLWqyw6orqeSdpgAGHiIjqiBN/30VhsQZW9aBTq1YrcODyP9AIAVVh8WPnz1WXIPp4Gm7cK6gXp6ny1CX14n0oD09RERERVZJGCGiFgFxWsbAil8mg0QpoxKOP9JBh1e94RkREktHJqzFGdnaHk42FsUt5rBKNFtkFxSgq0cLZ9vH13lIVQmFqgtef9oWpvO4fW8jMKcR3J68bu4xqYcAhIqI6QW4ig7ncBOamdT8AmJuaoK17I8RcvAW3RsrHzp9TWIIuLZxgWU9O+5jXgxD2OEZtQU5ODiIiIuDp6QmlUolu3brhxIkTuulCCLz//vtwdXWFUqlEcHAwrly5YsSKiYiI7mvnYQ+lmRxZ+UXlzpeVXwQLMxO087CvpcoIMHLAmThxIvbv34+NGzfi/PnzePbZZxEcHIwbN24AAJYsWYIVK1Zg9erVOHbsGKysrBASEoLCwkJjlk1ERISmjlbo7uuIWyr1I0NOVn4RbqnU6O7rCG8Hq1qusGEzWsApKCjADz/8gCVLlqBHjx7w9fXFvHnz4Ovri1WrVkEIgeXLl+O9997DoEGD0Lp1a2zYsAE3b97Ezp07jVU2ERERAMDERIaBbd3Qu7kTsguKkZiRgwxVIe7mFSFDVYjEjBxkFxSjd3MnDGzrVi+unpISo50MLCkpgUajgYWFfucspVKJw4cPIyUlBRkZGQgODtZNs7OzQ5cuXXDkyBGMHDmyzPWq1Wqo1Wrda5VKVTMNICKiBk9hKsfQ9k+ivac9zqTdw/nr2SjWaGFhaoJOLZzQzsMe3g7171lUUmC0gGNjY4OgoCDMnz8fzZs3h7OzM6Kjo3HkyBH4+voiIyMDAODs7Ky3nLOzs25aWSIjI/Hhhx/WaO1ERGRYlgpTdG3qUG864T7MxEQGnybW8GlijcFtn0CxRsBMLqsXV0s9Sn1+Px4w6t7fuHEjhBB44oknoFAosGLFCowaNQomJlUva/bs2cjOztYN165dM2DFRERUE6wVpgjycai3T65+wFRuAqW5vF6HG0Aa74dR3wEfHx8cOHAAubm5uHbtGo4fP47i4mI0bdoULi4uAIBbt27pLXPr1i3dtLIoFArY2trqDURERNSw1ImIaWVlBVdXV9y7dw979+7FoEGD4O3tDRcXF8TGxurmU6lUOHbsGIKCgoxYLREREdV1Rj32tHfvXggh4O/vj6SkJMyYMQMBAQEYP348ZDIZIiIisGDBAvj5+cHb2xtz586Fm5sbBg8ebMyyiYiIqI4zasDJzs7G7Nmzcf36dTRu3BhDhw7FwoULYWZmBgCYOXMm8vLyMGnSJGRlZeGpp57Cr7/+WurKKyIiIqKHyYSQ9pO/VCoV7OzskJ2dzf44RERE9UR1f7/rRB8cIiIiIkNiwCEiIiLJYcAhIiIiyWHAISIiIslhwCEiIiLJYcAhIiIiyWHAISIiIslhwCEiIiLJYcAhIiIiyWHAISIiIslhwCEiIiLJYcAhIiIiyWHAISIiIslhwCEiIiLJYcAhIiIiyWHAISIiIslhwCEiIiLJYcAhIiIiyWHAISIiIslhwCEiIiLJYcAhIiIiyWHAISIiIslhwCEiIiLJYcAhIiIiyWHAISIiIslhwCEiIiLJYcAhIiIiyWHAISIiIslhwCEiIiLJYcAhIiIiyWHAISIiIslhwCEiIiLJYcAhIiIiyWHAISIiIslhwCEiIiLJYcAhIiIiyWHAISIiIslhwCEiIiLJYcAhIiIiyWHAISIiIslhwCEiIiLJYcAhIiIiyWHAISIiIslhwCEiIiLJYcAhIiIiyWHAISIiIskxasDRaDSYO3cuvL29oVQq4ePjg/nz50MIoZsnNDQUMplMb+jbt68RqyYiIqK6ztSYG1+8eDFWrVqF9evXo2XLljh58iTGjx8POzs7TJ06VTdf3759ERUVpXutUCiMUS4RERHVE0YNOH/++ScGDRqE/v37AwC8vLwQHR2N48eP682nUCjg4uJijBKJiIioHjLqKapu3bohNjYWly9fBgCcPXsWhw8fRr9+/fTmi4uLg5OTE/z9/TFlyhTcuXPnketUq9VQqVR6AxERETUsRj2CM2vWLKhUKgQEBEAul0Oj0WDhwoUYM2aMbp6+fftiyJAh8Pb2RnJyMubMmYN+/frhyJEjkMvlpdYZGRmJDz/8sDabQURERHWMTDzco7eWbd26FTNmzMAnn3yCli1bIj4+HhEREVi2bBnGjRtX5jJXr16Fj48PYmJi0Lt371LT1Wo11Gq17rVKpYK7uzuys7Nha2tbY20hIiIiw1GpVLCzs6vy77dRj+DMmDEDs2bNwsiRIwEAgYGBSE1NRWRk5CMDTtOmTeHo6IikpKQyA45CoWAnZCIiogbOqH1w8vPzYWKiX4JcLodWq33kMtevX8edO3fg6upa0+URERFRPWXUIzgDBgzAwoUL4eHhgZYtW+LMmTNYtmwZwsLCAAC5ubn48MMPMXToULi4uCA5ORkzZ86Er68vQkJCjFk6ERER1WFG7YOTk5ODuXPnYseOHcjMzISbmxtGjRqF999/H+bm5igoKMDgwYNx5swZZGVlwc3NDc8++yzmz58PZ2fnCm2juufwiIiIqPZV9/fbqAGnNjDgEBER1T/V/f3ms6iIiIhIchhwiIiISHIYcIiIiEhyGHCIiIhIchhwiIiISHIYcIiIiEhyGHCIiIhIchhwiIiISHIYcIiIiEhyGHCIiIhIchhwiIiISHIYcIiIiEhyGHCIiIhIchhwiIiISHIYcIiIiEhyGHCIiIhIchhwiIiISHIYcIiIiEhyGHCIiIhIckwrM7NWq8WBAwdw6NAhpKamIj8/H02aNEG7du0QHBwMd3f3mqqTiIiIqMIqdASnoKAACxYsgLu7O5577jns2bMHWVlZkMvlSEpKwgcffABvb28899xzOHr0aE3XTERERFSuCh3BadasGYKCgvDVV1+hT58+MDMzKzVPamoqtmzZgpEjR+Ldd9/FK6+8YvBiiYiIiCpCJoQQj5vp4sWLaN68eYVWWFxcjLS0NPj4+FS7OENQqVSws7NDdnY2bG1tjV0OERERVUB1f78rdIqqouEGAMzMzOpMuCEiIqKGqVKdjB9WUlKCL7/8EnFxcdBoNOjevTvCw8NhYWFhyPqIiIiIKq3KAWfq1Km4fPkyhgwZguLiYmzYsAEnT55EdHS0IesjIiIiqrQKB5wdO3bghRde0L3et28fEhMTIZfLAQAhISHo2rWr4SskIiIiqqQK3+jvm2++weDBg3Hz5k0AQPv27TF58mT8+uuv2LVrF2bOnIlOnTrVWKFEREREFVXhgLNr1y6MGjUKvXr1wsqVK7FmzRrY2tri3Xffxdy5c+Hu7o4tW7bUZK1EREREFVKhy8QflpWVhZkzZ+Ls2bNYvXo12rVrV1O1GQQvEyciIqp/auUy8Yc1atQIa9aswSeffIKxY8dixowZKCwsrPSGiYiIiGpKhQNOWloahg8fjsDAQIwZMwZ+fn44deoULC0t0aZNG+zZs6cm6yQiIiKqsAqfourVqxdcXFwQGhqKvXv3Ijk5GT/99BOA+3c6fvXVV+Hi4oJvv/22RguuLJ6iIiIiqn+q+/td4cvET548ibNnz8LHxwchISHw9vbWTWvevDkOHjyINWvWVLoAIiIiIkOrcMDp0KED3n//fYwbNw4xMTEIDAwsNc+kSZMMWhwRERFRVVS4D86GDRugVqsxffp03LhxA19++WVN1kVERERUZRU+guPp6Ynvv/++JmshIiIiMogKHcHJy8ur1EorOz8RERGRIVUo4Pj6+uLjjz9Genr6I+cRQmD//v3o168fVqxYYbACiYiIiCqrQqeo4uLiMGfOHMybNw9t2rRBx44d4ebmBgsLC9y7dw8JCQk4cuQITE1NMXv2bLz66qs1XTcRERHRI1XqUQ1paWn47rvvcOjQIaSmpqKgoACOjo5o164dQkJC0K9fP93TxesK3geHiIio/qnu73eln0VV3zDgEBER1T+1/iwqIiIiorqOAYeIiIgkhwGHiIiIJIcBh4iIiCSHAYeIiIgkp9IBx8vLCx999BHS0tKqvXGNRoO5c+fC29sbSqUSPj4+mD9/Ph6+sEsIgffffx+urq5QKpUIDg7GlStXqr1tIiIikq5KB5yIiAhs374dTZs2RZ8+fbB161ao1eoqbXzx4sVYtWoVPv/8c1y8eBGLFy/GkiVLsHLlSt08S5YswYoVK7B69WocO3YMVlZWCAkJQWFhYZW2SURERNJX5fvgnD59GuvWrUN0dDQ0Gg1Gjx6NsLAwtG/fvsLreP755+Hs7Iy1a9fqxg0dOhRKpRKbNm2CEAJubm5466238PbbbwMAsrOz4ezsjHXr1mHkyJGP3Qbvg0NERFT/GO0+OO3bt8eKFStw8+ZNfPDBB/j666/RqVMntG3bFt988w0qkpu6deuG2NhYXL58GQBw9uxZHD58GP369QMApKSkICMjA8HBwbpl7Ozs0KVLFxw5cqTMdarVaqhUKr2BiIiIGpYKPYuqLMXFxdixYweioqKwf/9+dO3aFRMmTMD169cxZ84cxMTEYMuWLeWuY9asWVCpVAgICIBcLodGo8HChQsxZswYAEBGRgYAwNnZWW85Z2dn3bR/i4yMxIcffljVZhEREZEEVDrgnD59GlFRUYiOjoaJiQnGjh2Lzz77DAEBAbp5XnjhBXTq1Omx6/r222+xefNmbNmyBS1btkR8fDwiIiLg5uaGcePGVbY0AMDs2bPx5ptv6l6rVCq4u7tXaV1ERERUP1U64HTq1Al9+vTBqlWrMHjwYJiZmZWax9vbu0L9Y2bMmIFZs2bp5g0MDERqaioiIyMxbtw4uLi4AABu3boFV1dX3XK3bt1C27Zty1ynQqGAQqGobLOIiIhIQiodcK5evQpPT89y57GyskJUVNRj15Wfnw8TE/1uQHK5HFqtFsD9oOTi4oLY2FhdoFGpVDh27BimTJlS2dKJiIiogah0wMnMzERGRga6dOmiN/7YsWOQy+Xo2LFjhdc1YMAALFy4EB4eHmjZsiXOnDmDZcuWISwsDAAgk8kQERGBBQsWwM/PD97e3pg7dy7c3NwwePDgypZOREREDUSlr6IKDw/HtWvXSo2/ceMGwsPDK7WulStX4sUXX8Rrr72G5s2b4+2338arr76K+fPn6+aZOXMm3njjDUyaNAmdOnVCbm4ufv31V1hYWFS2dCIiImogKn0fHGtra5w7dw5NmzbVG5+SkoLWrVsjJyfHoAVWF++DQ0REVP/U+n1wFAoFbt26VWp8eno6TE2rfNU5ERERkcFUOuA8++yzmD17NrKzs3XjsrKyMGfOHPTp08egxRERERFVRaUPuXz66afo0aMHPD090a5dOwBAfHw8nJ2dsXHjRoMXSERERFRZlQ44TzzxBM6dO4fNmzfj7NmzUCqVGD9+PEaNGlXmPXGIiIiIaluVOs1YWVlh0qRJhq6FiIiIyCCq3Cs4ISEBaWlpKCoq0hs/cODAahdFREREVB1VupPxCy+8gPPnz0Mmk+meGi6TyQAAGo3GsBUSERERVVKlr6KaNm0avL29kZmZCUtLS/z11184ePAgOnbsiLi4uBookYiIiKhyKn0E58iRI/jtt9/g6OgIExMTmJiY4KmnnkJkZCSmTp2KM2fO1ESdRERERBVW6SM4Go0GNjY2AABHR0fcvHkTAODp6YnExETDVkdERERUBZU+gtOqVSucPXsW3t7e6NKlC5YsWQJzc3OsWbOm1OMbiIiIiIyh0gHnvffeQ15eHgDgo48+wvPPP4///Oc/cHBwwLZt2wxeIBEREVFlVfphm2W5e/cu7O3tdVdS1SV82CYREVH9U6sP2ywuLoapqSkuXLigN75x48Z1MtwQERFRw1SpgGNmZgYPDw/e64aIiIjqtEpfRfXuu+9izpw5uHv3bk3UQ0RERFRtle5k/PnnnyMpKQlubm7w9PSElZWV3vTTp08brDgiIiKiqqh0wBk8eHANlEFERERkOAa5iqou41VURERE9U+tXkVFREREVB9U+hSViYlJuZeE8worIiIiMrZKB5wdO3bovS4uLsaZM2ewfv16fPjhhwYrjIiIiKiqDNYHZ8uWLdi2bRt+/PFHQ6zOYNgHh4iIqP6pM31wunbtitjYWEOtjoiIiKjKDBJwCgoKsGLFCjzxxBOGWB0RERFRtVS6D86/H6ophEBOTg4sLS2xadMmgxZHREREVBWVDjifffaZXsAxMTFBkyZN0KVLF9jb2xu0OCIiIqKqqHTACQ0NrYEyiIiIiAyn0n1woqKi8N1335Ua/91332H9+vUGKYqIiIioOiodcCIjI+Ho6FhqvJOTExYtWmSQooiIiIiqo9IBJy0tDd7e3qXGe3p6Ii0tzSBFEREREVVHpQOOk5MTzp07V2r82bNn4eDgYJCiiIiIiKqj0gFn1KhRmDp1Kn7//XdoNBpoNBr89ttvmDZtGkaOHFkTNRIRERFVSqWvopo/fz7+/vtv9O7dG6am9xfXarUYO3Ys++AQERFRnVDlZ1FduXIF8fHxUCqVCAwMhKenp6FrMwg+i4qIiKj+qe7vd6WP4Dzg5+cHPz+/qi5OREREVGMq3Qdn6NChWLx4canxS5YswbBhwwxSFBEREVF1VDrgHDx4EM8991yp8f369cPBgwcNUhQRERFRdVQ64OTm5sLc3LzUeDMzM6hUKoMURURERFQdlQ44gYGB2LZtW6nxW7duRYsWLQxSFBEREVF1VLqT8dy5czFkyBAkJyfjmWeeAQDExsYiOjq6zGdUEREREdW2SgecAQMGYOfOnVi0aBG+//57KJVKtG7dGjExMejZs2dN1EhERERUKVW+D05ZLly4gFatWhlqdQbB++AQERHVP9X9/a50H5x/y8nJwZo1a9C5c2e0adOmuqsjIiIiqrYqB5yDBw9i7NixcHV1xaeffopnnnkGR48eNWRtRERERFVSqT44GRkZWLduHdauXQuVSoXhw4dDrVZj586dvIKKiIiI6owKH8EZMGAA/P39ce7cOSxfvhw3b97EypUra7I2IiIioiqpcMDZs2cPJkyYgA8//BD9+/eHXC6v9sa9vLwgk8lKDeHh4QCAXr16lZo2efLkam+XiIiIpK3CAefw4cPIyclBhw4d0KVLF3z++ee4fft2tTZ+4sQJpKen64b9+/cDgN4zrV555RW9eZYsWVKtbRIREZH0VTjgdO3aFV999RXS09Px6quvYuvWrXBzc4NWq8X+/fuRk5NT6Y03adIELi4uumH37t3w8fHRu5+OpaWl3jy81JuIiIgep9JXUVlZWSEsLAyHDx/G+fPn8dZbb+Hjjz+Gk5MTBg4cWOVCioqKsGnTJoSFhUEmk+nGb968GY6OjmjVqhVmz56N/Pz8ctejVquhUqn0BiIiImpYqnUfHH9/fyxZsgTXr19HdHR0tQrZuXMnsrKyEBoaqhs3evRobNq0Cb///jtmz56NjRs34qWXXip3PZGRkbCzs9MN7u7u1aqLiIiI6h+D3sm4OkJCQmBubo5du3Y9cp7ffvsNvXv3RlJSEnx8fMqcR61WQ61W616rVCq4u7vzTsZERET1SHXvZFzpZ1HVhNTUVMTExGD79u3lztelSxcAKDfgKBQKKBQKg9dIRERE9Ue1H9VgCFFRUXByckL//v3LnS8+Ph4A4OrqWgtVERERUX1l9CM4Wq0WUVFRGDduHExN/1dOcnIytmzZgueeew4ODg44d+4cpk+fjh49eqB169ZGrJiIiIjqOqMHnJiYGKSlpSEsLExvvLm5OWJiYrB8+XLk5eXB3d0dQ4cOxXvvvWekSomIiKi+qDOdjGtKdTspERERUe2r7u93neiDQ0RERGRIDDhEREQkOQw4REREJDkMOERERCQ5DDhEREQkOQw4REREJDkMOERERCQ5DDhEREQkOQw4REREJDkMOERERCQ5DDhEREQkOQw4REREJDkMOERERCQ5DDhEREQkOQw4REREJDkMOERERCQ5DDhEREQkOQw4REREJDkMOERERCQ5DDhEREQkOQw4REREJDkMOERERCQ5DDhEREQkOQw4REREJDkMOERERCQ5DDhEREQkOQw4REREJDkMOERERCQ5DDhEREQkOQw4REREJDkMOERERCQ5DDhEREQkOQw4REREJDkMOERERCQ5DDhEREQkOQw4REREJDkMOERERCQ5DDhEREQkOQw4REREJDkMOERERCQ5DDhEREQkOQw4REREJDkMOERERCQ5DDhEREQkOQw4REREJDkMOERERCQ5DDhEREQkOUYNOF5eXpDJZKWG8PBwAEBhYSHCw8Ph4OAAa2trDB06FLdu3TJmyURERFQPGDXgnDhxAunp6bph//79AIBhw4YBAKZPn45du3bhu+++w4EDB3Dz5k0MGTLEmCUTERFRPSATQghjF/FAREQEdu/ejStXrkClUqFJkybYsmULXnzxRQDApUuX0Lx5cxw5cgRdu3at0DpVKhXs7OyQnZ0NW1vbmiyfiIiIDKS6v991pg9OUVERNm3ahLCwMMhkMpw6dQrFxcUIDg7WzRMQEAAPDw8cOXLkketRq9VQqVR6AxERETUsdSbg7Ny5E1lZWQgNDQUAZGRkwNzcHI0aNdKbz9nZGRkZGY9cT2RkJOzs7HSDu7t7DVZNREREdVGdCThr165Fv3794ObmVq31zJ49G9nZ2brh2rVrBqqQiIiI6gtTYxcAAKmpqYiJicH27dt141xcXFBUVISsrCy9ozi3bt2Ci4vLI9elUCigUChqslwiIiKq4+rEEZyoqCg4OTmhf//+unEdOnSAmZkZYmNjdeMSExORlpaGoKAgY5RJRERE9YTRj+BotVpERUVh3LhxMDX9Xzl2dnaYMGEC3nzzTTRu3Bi2trZ44403EBQUVOErqIiIiKhhMnrAiYmJQVpaGsLCwkpN++yzz2BiYoKhQ4dCrVYjJCQE//d//2eEKomIiKg+qVP3wakJvA8OERFR/SOZ++AQERERGQoDDhEREUkOAw4RERFJDgMOERERSQ4DDhEREUkOAw4RERFJDgMOERERSQ4DDhEREUkOAw4RERFJDgMOERERSQ4DDhEREUkOAw4RERFJDgMOERERSQ4DDhEREUkOAw4RERFJDgMOERERSQ4DDhEREUkOAw4RERFJDgMOERERSQ4DDhEREUkOAw4RERFJDgMOERERSQ4DDhEREUkOAw4RERFJDgMOERERSQ4DDhEREUkOAw4RERFJDgMOERERSQ4DDhEREUkOAw4RERFJDgMOERERSQ4DDhEREUkOAw4RERFJDgMOERERSQ4DDhEREUkOAw4RERFJDgMOERERSQ4DDhEREUkOAw4RERFJDgMOERERSQ4DDhEREUmOqbELICKisgkhUFJSAo1GY+xSiAxOLpfD1NQUMpmsRtbPgENEVAcVFRUhPT0d+fn5xi6FqMZYWlrC1dUV5ubmBl83Aw4RUR2j1WqRkpICuVwONzc3mJub19hfuUTGIIRAUVER/vnnH6SkpMDPzw8mJobtNcOAQ0RUxxQVFUGr1cLd3R2WlpbGLoeoRiiVSpiZmSE1NRVFRUWwsLAw6PrZyZiIqI4y9F+0RHVNTX7G+b+HiEgCctUlOJJ8B7nqklLTSjRaFBRpUKLRVmo5ovrM6AHnxo0beOmll+Dg4AClUonAwECcPHlSNz00NBQymUxv6Nu3rxErJiKqe/LVJTh69Q7y/39Q0WoFkjJz8d3Ja/hwVwI+2v0XPtyVgO9OXkNSZi60WlHmckRSYdSAc+/ePXTv3h1mZmbYs2cPEhISsHTpUtjb2+vN17dvX6Snp+uG6OhoI1VMRFT3qUs0+OH0dXz+2xXEXsxEkUYLUxMTFGm0iL2Yic9/u4IfTl+HusTwl5/36tULERERBl9vXbVu3To0atRI93revHlo27btY5ebO3cuJk2aVHOF1bB/t7sss2bNwhtvvFE7BZXBqJ2MFy9eDHd3d0RFRenGeXt7l5pPoVDAxcWlQutUq9VQq9W61yqVqvqFEhHVE1oh8FP8TcRezISzrQKeDvqX37rYWiArvwixFzMBAP/xczRGmQ1aRkYG/vvf/+L8+fO6caGhoVi/fj0AwMzMDB4eHhg7dizmzJkDU9Pyf6rXrVuH8ePHlztPSkoKvLy8ql17Zbz99tto2rQppk+fjqZNm9bqtgEjH8H56aef0LFjRwwbNgxOTk5o164dvvrqq1LzxcXFwcnJCf7+/pgyZQru3LnzyHVGRkbCzs5ON7i7u9dkE4iI6pS0O/n4I+k2nG0VaGRZ9r1FGlmaw9lWgT+SbuPaXd5np7Z9/fXX6NatGzw9PfXGPzhbceXKFbz11luYN28ePvnkk8eub8SIEXpnOYKCgvDKK6/ojavMb2FRUVGl21QWR0dHhISEYNWqVQZZX2UZNeBcvXoVq1atgp+fH/bu3YspU6Zg6tSpuhQL3H/DN2zYgNjYWCxevBgHDhxAv379Hnlnz9mzZyM7O1s3XLt2rbaaQ0RkVBqtQPy1LOSpNbCxMINGKx452FiYIb9IgzPXsgxeR0lJCV5//XXY2dnB0dERc+fOhRBCNz09PR39+/eHUqmEt7c3tmzZAi8vLyxfvlw3T1ZWFiZOnIgmTZrA1tYWzzzzDM6ePVvuduPi4tC5c2dYWVmhUaNG6N69O1JTUwH879TRN998Aw8PD1hbW+O1116DRqPBkiVL4OLiAicnJyxcuFBvncuWLUNgYCCsrKzg7u6O1157Dbm5udXaP1u3bsWAAQNKjX9wtsLT0xNTpkxBcHAwfvrpJ+Tl5cHW1hbff/+93vw7d+6ElZUVSkpK4OLiohvMzc1haWmpe11UVIQhQ4bA2toatra2GD58OG7duqVbz4N98/XXX8Pb21t3uXZWVhZeffVVODs7w8LCAq1atcLu3bv1ati7dy+aN28Oa2trXUB72IABA7B169Zq7a+qMuopKq1Wi44dO2LRokUAgHbt2uHChQtYvXo1xo0bBwAYOXKkbv7AwEC0bt0aPj4+iIuLQ+/evUutU6FQQKFQ1E4DiIjqkOMpd5BTWAITExlUhcWPnT9XXYLrZ/LRO8DZoHWsX78eEyZMwPHjx3Hy5ElMmjQJHh4eeOWVVwAAY8eOxe3btxEXFwczMzO8+eabyMzM1FvHsGHDoFQqsWfPHtjZ2eHLL79E7969cfnyZTRu3LjUNktKSjB48GC88soriI6ORlFREY4fP653g8Tk5GTs2bMHv/76K5KTk/Hiiy/i6tWraNasGQ4cOIA///wTYWFhCA4ORpcuXQDcv4x5xYoV8Pb2xtWrV/Haa69h5syZ+L//+78q7Zu7d+8iISEBHTt2fOy8SqUSd+7cgZWVFUaOHImoqCi8+OKLuukPXtvY2DxyHVqtFoMGDYK1tTUOHDiAkpIShIeHY8SIEYiLi9PNl5SUhB9++AHbt2+HXC6HVqtFv379kJOTg02bNsHHxwcJCQmQy+W6ZfLz8/Hpp59i48aNMDExwUsvvYS3334bmzdv1s3TuXNnXL9+HX///XetnyIzasBxdXVFixYt9MY1b94cP/zwwyOXadq0KRwdHZGUlFRmwCEiaqi04n4fHDNZxQ7Oy2UyFGm00Dx0dMUQ3N3d8dlnn0Emk8Hf3x/nz5/HZ599hldeeQWXLl1CTEwMTpw4ofuR//rrr+Hn56db/vDhwzh+/DgyMzN1f7B++umn2LlzJ77//vsyO+eqVCpkZ2fj+eefh4+PD4D7vycP02q1+Oabb2BjY4MWLVrg6aefRmJiIn755ReYmJjA398fixcvxu+//64LOA93mPby8sKCBQswefLkKgectLQ0CCHg5ub2yHmEEIiNjcXevXt1nXQnTpyIbt26IT09Ha6ursjMzMQvv/yCmJiYcrcXGxuL8+fPIyUlRXeaasOGDWjZsiVOnDiBTp06Abh/WmrDhg1o0qQJAGDfvn04fvw4Ll68iGbNmgFAqX40xcXFWL16tW5/v/766/joo4/05nnQztTU1IYVcLp3747ExES9cZcvXy51XvJh169fx507d+Dq6lrT5RER1SudvRojQ1UAuYkJnG0ff1fYW6pCaIWA3MCPgejatavekZOgoCAsXboUGo0GiYmJMDU1Rfv27XXTfX199a6ePXv2LHJzc+Hg4KC33oKCAiQnJyMtLU3vj+M5c+Zgzpw5CA0NRUhICPr06YPg4GAMHz5c77fCy8tL72iHs7Mz5HK53s3mnJ2d9Y4mxcTEIDIyEpcuXYJKpUJJSQkKCwuRn59fpbtMFxQUAECZd+3dvXs3rK2tUVxcDK1Wi9GjR2PevHkA7h8JadmyJdavX49Zs2Zh06ZN8PT0RI8ePcrd3sWLF+Hu7q7XB6dFixZo1KgRLl68qAs4np6eunADAPHx8XjyySd14aYslpaWunADQBe8HqZUKgHAKM9UM2ofnOnTp+Po0aNYtGgRkpKSsGXLFqxZswbh4eEAgNzcXMyYMQNHjx7F33//jdjYWAwaNAi+vr4ICQkxZulERHWOmakJWrrZQVVYDLmJ7LFDTmEJWrrZwsSkbj3nKjc3F66uroiPj9cbEhMTMWPGDLi5uemNnzx5MoD7p2yOHDmCbt26Ydu2bWjWrBmOHj2qW6+ZmZnedmQyWZnjtNr7N0T8+++/8fzzz6N169b44YcfcOrUKXzxxRcAqt4R19Hx/lVr9+7dKzXt6aefRnx8PK5cuYKCggKsX78eVlZWuukTJ07EunXrdG0dP368wZ5R9vB2gP8Fk/KUte/Ev44G3r17FwD0wlNtMWrA6dSpE3bs2IHo6Gi0atUK8+fPx/LlyzFmzBgA9x+lfu7cOQwcOBDNmjXDhAkT0KFDBxw6dIj9bIiIyhD4hB2UZnJk5Zf/A5yVXwQLMxMEPmFn8BqOHTum9/ro0aPw8/ODXC6Hv78/SkpKcObMGd30pKQkvR/89u3bIyMjA6ampvD19dUbHB0dS41/uE9Ou3btMHv2bPz5559o1aoVtmzZUuV2nDp1ClqtFkuXLkXXrl3RrFkz3Lx5s8rrAwAfHx/Y2toiISGh1DQrKyv4+vrCw8OjzEvDX3rpJaSmpmLFihVISEjQ9VUtT/PmzXHt2jW9C24SEhKQlZVVqovIw1q3bo3r16/j8uXLFWxZ2S5cuAAzMzO0bNmyWuupCqM/bPP555/H888/X+Y0pVKJvXv31nJFRET1l4eDJbr7Ouruc1PWpeJZ+UW4pVKjd3MnuDe2BPDoW29URVpaGt588028+uqrOH36NFauXImlS5cCAAICAhAcHIxJkyZh1apVMDMzw1tvvQWlUqk7GhEcHIygoCAMHjwYS5Ys0QWLn3/+GS+88EKZHXRTUlKwZs0aDBw4EG5ubkhMTMSVK1cwduzYKrfD19cXxcXFWLlyJQYMGIA//vgDq1evrvL6gPudloODg3H48GEMHjy4Usva29tjyJAhmDFjBp599lk8+eSTj10mODgYgYGBGDNmDJYvX46SkhK89tpr6NmzZ7kdnXv27IkePXpg6NChWLZsGXx9fXHp0qVKP03g0KFD+M9//lOhI0KGZvRHNRARkeGYyGQY2NYNvZs7IbugGIkZOchQFeJuXhEyVIVIzMhBdkExejd3wsC2bjAxcP8b4P5VUgUFBejcuTPCw8Mxbdo0vY7BGzZsgLOzM3r06IEXXngBr7zyCmxsbHT9UmQyGX755Rf06NED48ePR7NmzTBy5EikpqbC2bnsK74sLS1x6dIlDB06FM2aNcOkSZMQHh6OV199tcrtaNOmDZYtW4bFixejVatW2Lx5MyIjI6u8vgcmTpyIrVu36k6FVcaECRNQVFSEsLCwCs0vk8nw448/wt7eHj169EBwcDCaNm2Kbdu2PXbZH374AZ06dcKoUaPQokULzJw585G3aHmUrVu36q6eq20y8e8TZhKjUqlgZ2eH7Oxs2NraGrscIqLHKiwsREpKit49SR4nU1WIzcfSMKaLB5xsLaDVCqTcycOZtHs4fz0bxRotzOQmCHzSDu087OHtYAUTE1mp5Yzh+vXrcHd3R0xMTIO4OlYIgS5dumD69OkYNWpUpZbduHEjpk+fjps3b8LcvOwbOdYVe/bswVtvvYVz58498m7M5X3Wq/v7bfRTVEREVH2WClN0beoAS8X9r3UTExl8mljDp4k1Brd9AsUaATO5DKZyk3KXqw2//fYbcnNzERgYiPT0dMycORNeXl6PvSJIKmQyGdasWaP3qIbHyc/PR3p6Oj7++GO8+uqrdT7cAEBeXh6ioqIe+6iJmsKAQ0QkAdYKUwT5OJQ5zVRuAlN5mZPKXa6mFBcXY86cObh69SpsbGzQrVs3bN68udRVOVLWtm3bCj2U84ElS5Zg4cKF6NGjB2bPnl1zhRnQwzclNAaeoiIiqmOqcoqKqD6qyVNU7GRMREREksOAQ0RUR0n8ADtRjX7GGXCIiOqYB31RjHF7e6La9OAzXhP9r9jJmIiojpHL5WjUqJHuuT6WlpYGuyU/UV0ghEB+fj4yMzPRqFEjvaeUGwoDDhFRHeTi4gIApR5eSCQljRo10n3WDY0Bh4ioDpLJZHB1dYWTkxOKi4uNXQ6RwZmZmdXIkZsHGHCIiOowuVxeoz8CRFLFTsZEREQkOQw4REREJDkMOERERCQ5ku+D8+AmQiqVysiVEBERUUU9+N2u6s0AJR9w7ty5AwBwd3c3ciVERERUWTk5ObCzs6v0cpIPOI0bNwYApKWlVWkH1UcqlQru7u64du1ag3rAKNvdcNrdENsMNMx2N8Q2Aw2z3f9usxACOTk5cHNzq9L6JB9wTEzudzOys7NrMB+SB2xtbRtcmwG2uyFpiG0GGma7G2KbgYbZ7ofbXJ0DE+xkTERERJLDgENERESSI/mAo1Ao8MEHH0ChUBi7lFrTENsMsN0Nqd0Nsc1Aw2x3Q2wz0DDbbeg2y0RVr78iIiIiqqMkfwSHiIiIGh4GHCIiIpIcBhwiIiKSHAYcIiIikhxJB5wvvvgCXl5esLCwQJcuXXD8+HFjl1SjIiMj0alTJ9jY2MDJyQmDBw9GYmKiscuqVR9//DFkMhkiIiKMXUqNu3HjBl566SU4ODhAqVQiMDAQJ0+eNHZZNUqj0WDu3Lnw9vaGUqmEj48P5s+fX+Vn1dRFBw8exIABA+Dm5gaZTIadO3fqTRdC4P3334erqyuUSiWCg4Nx5coV4xRrQOW1u7i4GO+88w4CAwNhZWUFNzc3jB07Fjdv3jRewQbwuPf6YZMnT4ZMJsPy5ctrrb6aUpF2X7x4EQMHDoSdnR2srKzQqVMnpKWlVWo7kg0427Ztw5tvvokPPvgAp0+fRps2bRASEoLMzExjl1ZjDhw4gPDwcBw9ehT79+9HcXExnn32WeTl5Rm7tFpx4sQJfPnll2jdurWxS6lx9+7dQ/fu3WFmZoY9e/YgISEBS5cuhb29vbFLq1GLFy/GqlWr8Pnnn+PixYtYvHgxlixZgpUrVxq7NIPJy8tDmzZt8MUXX5Q5fcmSJVixYgVWr16NY8eOwcrKCiEhISgsLKzlSg2rvHbn5+fj9OnTmDt3Lk6fPo3t27cjMTERAwcONEKlhvO49/qBHTt24OjRo1V+ZEFd87h2Jycn46mnnkJAQADi4uJw7tw5zJ07FxYWFpXbkJCozp07i/DwcN1rjUYj3NzcRGRkpBGrql2ZmZkCgDhw4ICxS6lxOTk5ws/PT+zfv1/07NlTTJs2zdgl1ah33nlHPPXUU8Yuo9b1799fhIWF6Y0bMmSIGDNmjJEqqlkAxI4dO3SvtVqtcHFxEZ988oluXFZWllAoFCI6OtoIFdaMf7e7LMePHxcARGpqau0UVcMe1ebr16+LJ554Qly4cEF4enqKzz77rNZrq0lltXvEiBHipZdeqva6JXkEp6ioCKdOnUJwcLBunImJCYKDg3HkyBEjVla7srOzAfzvgaNSFh4ejv79++u951L2008/oWPHjhg2bBicnJzQrl07fPXVV8Yuq8Z169YNsbGxuHz5MgDg7NmzOHz4MPr162fkympHSkoKMjIy9D7ndnZ26NKlS4P6bgPuf7/JZDI0atTI2KXUGK1Wi5dffhkzZsxAy5YtjV1OrdBqtfj555/RrFkzhISEwMnJCV26dCn39N2jSDLg3L59GxqNBs7OznrjnZ2dkZGRYaSqapdWq0VERAS6d++OVq1aGbucGrV161acPn0akZGRxi6l1ly9ehWrVq2Cn58f9u7diylTpmDq1KlYv369sUurUbNmzcLIkSMREBAAMzMztGvXDhERERgzZoyxS6sVD76/GvJ3GwAUFhbinXfewahRoyT9IMrFixfD1NQUU6dONXYptSYzMxO5ubn4+OOP0bdvX+zbtw8vvPAChgwZggMHDlRqXZJ/mnhDFR4ejgsXLuDw4cPGLqVGXbt2DdOmTcP+/fsrf362HtNqtejYsSMWLVoEAGjXrh0uXLiA1atXY9y4cUauruZ8++232Lx5M7Zs2YKWLVsiPj4eERERcHNzk3S76X+Ki4sxfPhwCCGwatUqY5dTY06dOoX//ve/OH36NGQymbHLqTVarRYAMGjQIEyfPh0A0LZtW/z5559YvXo1evbsWeF1SfIIjqOjI+RyOW7duqU3/tatW3BxcTFSVbXn9ddfx+7du/H777/jySefNHY5NerUqVPIzMxE+/btYWpqClNTUxw4cAArVqyAqakpNBqNsUusEa6urmjRooXeuObNm1f6KoP6ZsaMGbqjOIGBgXj55Zcxffr0BnP07sH3V0P9bnsQblJTU7F//35JH705dOgQMjMz4eHhoftuS01NxVtvvQUvLy9jl1djHB0dYWpqapDvN0kGHHNzc3To0AGxsbG6cVqtFrGxsQgKCjJiZTVLCIHXX38dO3bswG+//QZvb29jl1TjevfujfPnzyM+Pl43dOzYEWPGjEF8fDzkcrmxS6wR3bt3L3ULgMuXL8PT09NIFdWO/Px8mJjof23J5XLdX31S5+3tDRcXF73vNpVKhWPHjkn6uw34X7i5cuUKYmJi4ODgYOySatTLL7+Mc+fO6X23ubm5YcaMGdi7d6+xy6sx5ubm6NSpk0G+3yR7iurNN9/EuHHj0LFjR3Tu3BnLly9HXl4exo8fb+zSakx4eDi2bNmCH3/8ETY2Nrpz8nZ2dlAqlUaurmbY2NiU6mNkZWUFBwcHSfc9mj59Orp164ZFixZh+PDhOH78ONasWYM1a9YYu7QaNWDAACxcuBAeHh5o2bIlzpw5g2XLliEsLMzYpRlMbm4ukpKSdK9TUlIQHx+Pxo0bw8PDAxEREViwYAH8/Pzg7e2NuXPnws3NDYMHDzZe0QZQXrtdXV3x4osv4vTp09i9ezc0Go3u+61x48YwNzc3VtnV8rj3+t8hzszMDC4uLvD396/tUg3qce2eMWMGRowYgR49euDpp5/Gr7/+il27diEuLq5yG6r2dVh12MqVK4WHh4cwNzcXnTt3FkePHjV2STUKQJlDVFSUsUurVQ3hMnEhhNi1a5do1aqVUCgUIiAgQKxZs8bYJdU4lUolpk2bJjw8PISFhYVo2rSpePfdd4VarTZ2aQbz+++/l/n/eNy4cUKI+5eKz507Vzg7OwuFQiF69+4tEhMTjVu0AZTX7pSUlEd+v/3+++/GLr3KHvde/5tULhOvSLvXrl0rfH19hYWFhWjTpo3YuXNnpbcjE0JCtwAlIiIigkT74BAREVHDxoBDREREksOAQ0RERJLDgENERESSw4BDREREksOAQ0RERJLDgENERESSw4BDREREksOAQ1RH/P3335DJZIiPjzd2KUYXFxcHmUyGrKyscufz8vLC8uXLK7XuXr16ISIiosq1VVVNvr8V3V91TVFREXx9ffHnn3/W2DZWr16NAQMG1Nj6qe5iwKE67ciRI5DL5ejfv7+xS6mTQkND6/0ziMrSrVs3pKenw87ODgCwbt06NGrUyLhFPaSuBYp/76/atn37djz77LNwcHCoVIhbvXo1vL290a1btxqrLSwsDKdPn8ahQ4dqbBtUNzHgUJ22du1avPHGGzh48CBu3rxZo9sSQqCkpKRGt0EVY25uDhcXF8hkMmOXUi8Ye3/l5eXhqaeewuLFiyu8jBACn3/+OSZMmFCDld3fN6NHj8aKFStqdDtU9zDgUJ2Vm5uLbdu2YcqUKejfvz/WrVunmzZ69GiMGDFCb/7i4mI4Ojpiw4YNAACtVovIyEh4e3tDqVSiTZs2+P7773XzP/grfM+ePejQoQMUCgUOHz6M5ORkDBo0CM7OzrC2tkanTp0QExOjt6309HT0798fSqUS3t7e2LJlS6nTJVlZWZg4cSKaNGkCW1tbPPPMMzh79myF26/RaDBhwgRd/f7+/vjvf/+rmz5v3jysX78eP/74I2QyGWQyme5pu9euXcPw4cPRqFEjNG7cGIMGDcLff/+tW/bBkZ9PP/0Urq6ucHBwQHh4OIqLi3XzqNVqvPPOO3B3d4dCoYCvry/Wrl0LIQR8fX3x6aef6tUbHx8PmUym95TgBy5cuAATExP8888/AIC7d+/CxMQEI0eO1M2zYMECPPXUU3rvTVZWFuLi4jB+/HhkZ2fr2jlv3jzdcvn5+QgLC4ONjQ08PDwq9ET1kpISvP7667Czs4OjoyPmzp2Lhx/Lt3HjRnTs2BE2NjZwcXHB6NGjkZmZCeD+qaann34aAGBvbw+ZTIbQ0FAA9z9zS5Ysga+vLxQKBTw8PLBw4UK9bV+9ehVPP/00LC0t0aZNGxw5cuSx9QJAamoqBgwYAHt7e1hZWaFly5b45ZdfSu0v4P5puAf76uHhwWegup/Nf3v55Zfx/vvvIzg4uMLLnDp1CsnJyXpHZx+cxvv222/xn//8B0qlEp06dcLly5dx4sQJdOzYEdbW1ujXr5/us/Sg/Z07d4aVlRUaNWqE7t27IzU1VTd9wIAB+Omnn1BQUFDlNlI9ZJBHgxLVgLVr14qOHTsKIe4/OdvHx0dotVohhBC7d+8WSqVS5OTk6ObftWuXUCqVQqVSCSGEWLBggQgICBC//vqrSE5OFlFRUUKhUIi4uDghxP+eaNu6dWuxb98+kZSUJO7cuSPi4+PF6tWrxfnz58Xly5fFe++9JywsLERqaqpuW8HBwaJt27bi6NGj4tSpU6Jnz55CqVTqPek3ODhYDBgwQJw4cUJcvnxZvPXWW8LBwUHcuXOnzPY+eGLymTNnhBBCFBUViffff1+cOHFCXL16VWzatElYWlqKbdu2CSGEyMnJEcOHDxd9+/YV6enpIj09XajValFUVCSaN28uwsLCxLlz50RCQoIYPXq08Pf31z11e9y4ccLW1lZMnjxZXLx4UezatUtYWlrqPZF8+PDhwt3dXWzfvl0kJyeLmJgYsXXrViGEEAsXLhQtWrTQq3/q1KmiR48eZbZNq9UKR0dH8d133wkhhNi5c6dwdHQULi4uevvr3Xff1Xtv7t27J9RqtVi+fLmwtbXVtfPB++7p6SkaN24svvjiC3HlyhURGRkpTExMxKVLl8qsQ4j7T5u3trYW06ZNE5cuXdLt14fbvnbtWvHLL7+I5ORkceTIEREUFCT69esnhBCipKRE/PDDDwKASExMFOnp6SIrK0sIIcTMmTOFvb29WLdunUhKShKHDh0SX331ld77GxAQIHbv3i0SExPFiy++KDw9PUVxcfEj632gf//+ok+fPuLcuXMiOTlZ7Nq1Sxw4cKDU/hJCiDt37uj2VXp6uhgyZIjw9/cX+fn5un1d3mfz4MGDwsrKqtxh06ZNpWr892e4PMuWLRMBAQFlLv/g/21CQoLo2rWr6NChg+jVq5c4fPiwOH36tPD19RWTJ08WQghRXFws7OzsxNtvvy2SkpJEQkKCWLdund7/17y8PGFiYlKvnzxOlceAQ3VWt27dxPLly4UQ97/EHB0ddV9QD15v2LBBN/+oUaPEiBEjhBBCFBYWCktLS/Hnn3/qrXPChAli1KhRQoj//Sjs3LnzsbW0bNlSrFy5UgghxMWLFwUAceLECd30K1euCAC6gHPo0CFha2srCgsL9dbj4+MjvvzyyzK3UZEfh/DwcDF06FDd63HjxolBgwbpzbNx40bh7++vC4NCCKFWq4VSqRR79+7VLefp6SlKSkp08wwbNky3/xITEwUAsX///jLruHHjhpDL5eLYsWNCiPthzNHRUaxbt+6RtQ8ZMkSEh4cLIYSIiIgQM2bMEPb29uLixYuiqKhIWFpain379gkhSv9gR0VFCTs7u1Lr9PT0FC+99JLutVarFU5OTmLVqlWPrKNnz56iefPmevvnnXfeEc2bN3/kMidOnBAAdMHq3/UJIYRKpRIKhUIXaP7twfv79ddf68b99ddfAoC4ePHiI7f9QGBgoJg3b16Z08qq54Fly5aJRo0aicTERCFExT6b+fn54sqVK+UOD/6QKKuNFQk406ZNE88880yZyz+8j6KjowUAERsbqxsXGRkp/P39hRD3wxwA3R8uj/IgeFLDYVqLB4uIKiwxMRHHjx/Hjh07AACmpqYYMWIE1q5di169esHU1BTDhw/H5s2b8fLLLyMvLw8//vgjtm7dCgBISkpCfn4++vTpo7feoqIitGvXTm9cx44d9V7n5uZi3rx5+Pnnn5Geno6SkhIUFBQgLS1NV5upqSnat2+vW8bX1xf29va612fPnkVubi4cHBz01l1QUIDk5OQK74cvvvgC33zzDdLS0lBQUICioiK0bdu23GXOnj2LpKQk2NjY6I0vLCzU23bLli0hl8t1r11dXXH+/HkA9083yeVy9OzZs8xtuLm5oX///vjmm2/QuXNn7Nq1C2q1GsOGDXtkXT179tSdPjpw4AAWLVqEy5cvIy4uDnfv3kVxcTG6d+9ebtvK0rp1a92/ZTIZXFxcdKeTHqVr1656/VWCgoKwdOlSaDQayOVynDp1CvPmzcPZs2dx7949aLVaAEBaWhpatGhR5jovXrwItVqN3r17V7heV1dXAEBmZiYCAgLKXW7q1KmYMmUK9u3bh+DgYAwdOlRvXWXZs2cPZs2ahV27dqFZs2YAKvbZVCqV8PX1LXfd1VVQUAALC4sypz3cLmdnZwBAYGCg3rgH73Hjxo0RGhqKkJAQ9OnTB8HBwRg+fLhu3z6gVCqRn59v6GZQHcaAQ3XS2rVrUVJSAjc3N904IQQUCgU+//xz2NnZYcyYMejZsycyMzOxf/9+KJVK9O3bF8D9kAIAP//8M5544gm9dSsUCr3XVlZWeq/ffvtt7N+/H59++il8fX2hVCrx4osvoqioqML15+bmwtXVVdcn5mEVvRpo69atePvtt7F06VIEBQXBxsYGn3zyCY4dO/bYbXfo0AGbN28uNa1Jkya6f5uZmelNk8lkuh9ypVL52PomTpyIl19+GZ999hmioqIwYsQIWFpaPnL+B5dnX7lyBQkJCXjqqadw6dIlxMXF4d69e+jYsWO5yz9Kee2oiry8PISEhCAkJASbN29GkyZNkJaWhpCQkHI/AxXZZ/+u90HIqki9EydOREhICH7++Wfs27cPkZGRWLp0Kd54440y509ISMDIkSPx8ccf49lnn9WNr8hn89ChQ+jXr1+59Xz55ZcYM2bMY+t+FEdHR12g/rey9tG/xz28z6KiojB16lT8+uuv2LZtG9577z3s378fXbt21c1z9+5dvc8/SR8DDtU5JSUl2LBhA5YuXar3xQwAgwcPRnR0NCZPnoxu3brB3d0d27Ztw549ezBs2DDdl2CLFi2gUCiQlpb2yKMQj/LHH38gNDQUL7zwAoD7PwgPd9D19/dHSUkJzpw5gw4dOgC4f8To3r17unnat2+PjIwMmJqawsvLqwp74X4d3bp1w2uvvaYb9++jP+bm5tBoNHrj2rdvj23btsHJyQm2trZV2nZgYCC0Wi0OHDjwyI6jzz33HKysrLBq1Sr8+uuvOHjw4GPXaW9vjwULFqBt27awtrZGr169sHjxYty7dw+9evV65LJltbM6/h0Sjx49Cj8/P8jlcly6dAl37tzBxx9/DHd3dwDAyZMnS9UDQK8mPz8/KJVKxMbGYuLEiQar9WHu7u6YPHkyJk+ejNmzZ+Orr74qM+Dcvn0bAwYMwNChQzF9+nS9aRX5bHbs2PGxl3o/OLJSVe3atcOqVasghDDI1V/t2rVDu3btMHv2bAQFBWHLli26gJOcnIzCwsJSR29J2ngVFdU5u3fvxr179zBhwgS0atVKbxg6dCjWrl2rm3f06NFYvXo19u/fr/fXpI2NDd5++21Mnz4d69evR3JyMk6fPo2VK1di/fr15W7fz88P27dvR3x8PM6ePYvRo0fr/bUYEBCA4OBgTJo0CcePH8eZM2cwadIkKJVK3Rd1cHAwgoKCMHjwYOzbtw9///03/vzzT7z77rulfizLq+PkyZPYu3cvLl++jLlz5+LEiRN683h5eeHcuXNITEzE7du3UVxcjDFjxsDR0RGDBg3CoUOHkJKSgri4OEydOhXXr1+v0La9vLwwbtw4hIWFYefOnbp1fPvtt7p55HI5QkNDMXv2bPj5+SEoKKjcdcpkMvTo0QObN2/WhZnWrVtDrVYjNja23CDq5eWF3NxcxMbG4vbt29U+1ZCWloY333wTiYmJiI6OxsqVKzFt2jQAgIeHB8zNzbFy5UpcvXoVP/30E+bPn6+3vKenJ2QyGXbv3o1//vkHubm5sLCwwDvvvIOZM2diw4YNSE5OxtGjR/U+r9URERGBvXv3IiUlBadPn8bvv/+O5s2blznv0KFDYWlpiXnz5iEjI0M3aDSaCn02H5yiKm94+BTo3bt3ER8fj4SEBAD3T+PGx8cjIyPjke15+umnkZubi7/++qta+yUlJQWzZ8/GkSNHkJqain379uHKlSt6++bQoUNo2rQpfHx8qrUtqmeM3QmI6N+ef/558dxzz5U57dixYwKAOHv2rBBCiISEBAFAeHp66nUaFeJ+h9Ply5cLf39/YWZmJpo0aSJCQkIeeeXJAykpKeLpp58WSqVSuLu7i88//1z07NlTTJs2TTfPzZs3Rb9+/YRCoRCenp5iy5YtwsnJSaxevVo3j0qlEm+88YZwc3MTZmZmwt3dXYwZM0akpaWV2bZ/d9AsLCwUoaGhws7OTjRq1EhMmTJFzJo1S7Rp00a3TGZmpujTp4+wtrYWAHSdsNPT08XYsWOFo6OjUCgUomnTpuKVV14R2dnZQoiyOydPmzZN9OzZU/e6oKBATJ8+Xbi6ugpzc3Ph6+srvvnmG71lkpOTBQCxZMmSMtv0b5999pkAIPbs2aMbN2jQIGFqaqp3RVxZ783kyZOFg4ODACA++OADIcT9TsYPX7kmhBBt2rTRTS9Lz549xWuvvSYmT54sbG1thb29vZgzZ47e52fLli3Cy8tLKBQKERQUJH766adSnWc/+ugj4eLiImQymRg3bpwQQgiNRiMWLFggPD09hZmZmfDw8BCLFi0SQpTdAffevXt671t5Xn/9deHj4yMUCoVo0qSJePnll8Xt27fL3F8AyhxSUlKEEJX/bD5OVFRUmdsr730Q4v6VerNmzdK9LmsflfVZeLjTeUZGhhg8eLDuc+rp6Snef/99odFodPM/++yzIjIyskpto/pLJsRDN38goiq5fv063N3dERMT89hOplJy6NAh9O7dG9euXav2KQtqeM6dO4c+ffogOTkZ1tbWNbKNv/76C8888wwuX75stDs9k3Ew4BBVwW+//Ybc3FwEBgYiPT0dM2fOxI0bN3D58uVSnV6lSK1W459//sG4cePg4uJSZodmoopYt24dOnTooHeVlCHFxMRAo9EgJCSkRtZPdRf74BBVQXFxMebMmYOWLVvihRdeQJMmTRAXF9cgwg0AREdHw9PTE1lZWViyZImxy5GEfv36wdrausxh0aJFxi6vxoSGhtZYuAHu94djuGmYeASHiKgOuHHjxiMfJdC4cWM0bty4lisiqt8YcIiIiEhyeIqKiIiIJIcBh4iIiCSHAYeIiIgkhwGHiIiIJIcBh4iIiCSHAYeIiIgkhwGHiIiIJOf/AUuPmGmgH3wzAAAAAElFTkSuQmCC\n"
+ },
+ "metadata": {}
+ }
+ ],
+ "source": [
+ "plot_metrics(perf_metrics)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "AiPUhOCNWRny",
+ "metadata": {
+ "id": "AiPUhOCNWRny"
+ },
+ "source": [
+ "## 4. Compressing with Optimum ONNX and CUDAExecutionProvider\n",
+ "\n",
+ "We'll be using Optimum's ONNX Runtime support with `CUDAExecutionProvider` [because it's fast while also supporting dynamic shapes](https://github.com/huggingface/optimum-benchmark/tree/main/examples/fast-mteb#notes)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 164,
+ "id": "NEnwnsEQWRn8",
+ "metadata": {
+ "cellView": "form",
+ "id": "NEnwnsEQWRn8"
+ },
+ "outputs": [],
+ "source": [
+ "!pip install optimum[onnxruntime-gpu] -qqq"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "HjeZkCtSqcBe"
+ },
+ "source": [
+ "[`optimum-cli`](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/optimization#optimizing-a-model-during-the-onnx-export) makes it extremely easy to export a model to ONNX and apply SOTA graph optimizations / kernel fusions."
+ ],
+ "id": "HjeZkCtSqcBe"
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 165,
+ "id": "hPqEcDi8WRn8",
+ "metadata": {
+ "id": "hPqEcDi8WRn8",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "outputId": "0e1202d8-aa84-422c-f10f-6bb0b43d1ef8"
+ },
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "2023-11-27 12:23:25.781950: E tensorflow/compiler/xla/stream_executor/cuda/cuda_dnn.cc:9342] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered\n",
+ "2023-11-27 12:23:25.782000: E tensorflow/compiler/xla/stream_executor/cuda/cuda_fft.cc:609] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered\n",
+ "2023-11-27 12:23:25.782035: E tensorflow/compiler/xla/stream_executor/cuda/cuda_blas.cc:1518] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered\n",
+ "2023-11-27 12:23:26.931536: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT\n",
+ "Framework not specified. Using pt to export to ONNX.\n",
+ "Using the export variant default. Available variants are:\n",
+ " - default: The default ONNX variant.\n",
+ "Using framework PyTorch: 2.1.0+cu118\n",
+ "Overriding 1 configuration item(s)\n",
+ "\t- use_cache -> False\n",
+ "2023-11-27 12:23:34.728172634 [W:onnxruntime:, session_state.cc:1162 VerifyEachNodeIsAssignedToAnEp] Some nodes were not assigned to the preferred execution providers which may or may not have an negative impact on performance. e.g. ORT explicitly assigns shape related ops to CPU to improve perf.\n",
+ "2023-11-27 12:23:34.728200557 [W:onnxruntime:, session_state.cc:1164 VerifyEachNodeIsAssignedToAnEp] Rerunning with verbose output on a non-minimal build will show node assignments.\n",
+ "Overridding for_gpu=False to for_gpu=True as half precision is available only on GPU.\n",
+ "/usr/local/lib/python3.10/dist-packages/optimum/onnxruntime/configuration.py:770: FutureWarning: disable_embed_layer_norm will be deprecated soon, use disable_embed_layer_norm_fusion instead, disable_embed_layer_norm_fusion is set to True.\n",
+ " warnings.warn(\n",
+ "Optimizing model...\n",
+ "2023-11-27 12:23:36.378780811 [W:onnxruntime:, session_state.cc:1162 VerifyEachNodeIsAssignedToAnEp] Some nodes were not assigned to the preferred execution providers which may or may not have an negative impact on performance. e.g. ORT explicitly assigns shape related ops to CPU to improve perf.\n",
+ "2023-11-27 12:23:36.378811421 [W:onnxruntime:, session_state.cc:1164 VerifyEachNodeIsAssignedToAnEp] Rerunning with verbose output on a non-minimal build will show node assignments.\n",
+ "symbolic shape inference disabled or failed.\n",
+ "symbolic shape inference disabled or failed.\n",
+ "Configuration saved in bge_auto_opt_O4/ort_config.json\n",
+ "Optimized model saved at: bge_auto_opt_O4 (external data format: False; saved all tensor to one file: True)\n",
+ "Post-processing the exported models...\n",
+ "Deduplicating shared (tied) weights...\n",
+ "Validating models in subprocesses...\n",
+ "2023-11-27 12:23:48.005601: E tensorflow/compiler/xla/stream_executor/cuda/cuda_dnn.cc:9342] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered\n",
+ "2023-11-27 12:23:48.005666: E tensorflow/compiler/xla/stream_executor/cuda/cuda_fft.cc:609] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered\n",
+ "2023-11-27 12:23:48.005707: E tensorflow/compiler/xla/stream_executor/cuda/cuda_blas.cc:1518] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered\n",
+ "2023-11-27 12:23:50.980859: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT\n",
+ "Validating ONNX model bge_auto_opt_O4/model.onnx...\n",
+ "2023-11-27 12:23:54.208836299 [W:onnxruntime:, session_state.cc:1162 VerifyEachNodeIsAssignedToAnEp] Some nodes were not assigned to the preferred execution providers which may or may not have an negative impact on performance. e.g. ORT explicitly assigns shape related ops to CPU to improve perf.\n",
+ "2023-11-27 12:23:54.208860681 [W:onnxruntime:, session_state.cc:1164 VerifyEachNodeIsAssignedToAnEp] Rerunning with verbose output on a non-minimal build will show node assignments.\n",
+ "\t-[✓] ONNX model output names match reference model (last_hidden_state)\n",
+ "\t- Validating ONNX Model output \"last_hidden_state\":\n",
+ "\t\t-[✓] (2, 16, 384) matches (2, 16, 384)\n",
+ "\t\t-[x] values not close enough, max diff: 2.1155929565429688 (atol: 0.0001)\n",
+ "The ONNX export succeeded with the warning: The maximum absolute difference between the output of the reference model and the ONNX exported model is not within the set tolerance 0.0001:\n",
+ "- last_hidden_state: max diff = 2.1155929565429688.\n",
+ " The exported model was saved at: bge_auto_opt_O4\n"
+ ]
+ }
+ ],
+ "source": [
+ "!optimum-cli export onnx \\\n",
+ " --model moshew/bge-small-en-v1.5_setfit-sst2-english \\\n",
+ " --task feature-extraction \\\n",
+ " --optimize O4 \\\n",
+ " --device cuda \\\n",
+ " bge_auto_opt_O4"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "IYkxQOTRqcBe"
+ },
+ "source": [
+ "We may see some warnings, but these are not ones to be concerned about. We'll see later that it does not affect the model performance.\n",
+ "\n",
+ "First of all, we'll create a subclass of our performance benchmark to also allow benchmarking ONNX models."
+ ],
+ "id": "IYkxQOTRqcBe"
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 166,
+ "id": "8hvfl3xvlnEs",
+ "metadata": {
+ "id": "8hvfl3xvlnEs"
+ },
+ "outputs": [],
+ "source": [
+ "class OnnxPerformanceBenchmark(PerformanceBenchmark):\n",
+ " def __init__(self, *args, model_path, **kwargs):\n",
+ " super().__init__(*args, **kwargs)\n",
+ " self.model_path = model_path\n",
+ "\n",
+ " def compute_size(self):\n",
+ " size_mb = Path(self.model_path).stat().st_size / (1024 * 1024)\n",
+ " print(f\"Model size (MB) - {size_mb:.2f}\")\n",
+ " return {\"size_mb\": size_mb}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "4ht5U1qUqcBe"
+ },
+ "source": [
+ "Then, we can load the converted SentenceTransformer model with the `\"CUDAExecutionProvider\"` provider. Feel free to also experiment with other providers, such as `\"TensorrtExecutionProvider\"` and `\"CPUExecutionProvider\"`. The former may be even faster than `\"CUDAExecutionProvider\"`, but requires more installation."
+ ],
+ "id": "4ht5U1qUqcBe"
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 169,
+ "id": "IpoDwkPiWRn8",
+ "metadata": {
+ "id": "IpoDwkPiWRn8"
+ },
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "from transformers import AutoTokenizer\n",
+ "from optimum.onnxruntime import ORTModelForFeatureExtraction\n",
+ "\n",
+ "# Load model from HuggingFace Hub\n",
+ "tokenizer = AutoTokenizer.from_pretrained('bge_auto_opt_O4', model_max_length=512)\n",
+ "ort_model = ORTModelForFeatureExtraction.from_pretrained('bge_auto_opt_O4', provider=\"CUDAExecutionProvider\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Odn2lSPJqcBf"
+ },
+ "source": [
+ "And let's make a class that uses the tokenizer, ONNX Runtime (ORT) model and a model head."
+ ],
+ "id": "Odn2lSPJqcBf"
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 170,
+ "id": "enaQpBF9WRn9",
+ "metadata": {
+ "id": "enaQpBF9WRn9"
+ },
+ "outputs": [],
+ "source": [
+ "from setfit.exporters.utils import mean_pooling\n",
+ "\n",
+ "\n",
+ "class OnnxSetFitModel:\n",
+ " def __init__(self, ort_model, tokenizer, model_head):\n",
+ " self.ort_model = ort_model\n",
+ " self.tokenizer = tokenizer\n",
+ " self.model_head = model_head\n",
+ "\n",
+ " def predict(self, inputs):\n",
+ " encoded_inputs = self.tokenizer(\n",
+ " inputs, padding=True, truncation=True, return_tensors=\"pt\"\n",
+ " ).to(self.ort_model.device)\n",
+ "\n",
+ " outputs = self.ort_model(**encoded_inputs)\n",
+ " embeddings = mean_pooling(\n",
+ " outputs[\"last_hidden_state\"], encoded_inputs[\"attention_mask\"]\n",
+ " )\n",
+ " return self.model_head.predict(embeddings.cpu())\n",
+ "\n",
+ " def __call__(self, inputs):\n",
+ " return self.predict(inputs)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "N1TDdcOkqcBh"
+ },
+ "source": [
+ "We can initialize this model like so:"
+ ],
+ "id": "N1TDdcOkqcBh"
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 171,
+ "id": "qRviEk2WWRn9",
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "qRviEk2WWRn9",
+ "outputId": "33f010a8-376e-4f0c-b21b-97fe25bf1a81"
+ },
+ "outputs": [
+ {
+ "output_type": "execute_result",
+ "data": {
+ "text/plain": [
+ "array([0, 0])"
+ ]
+ },
+ "metadata": {},
+ "execution_count": 171
+ }
+ ],
+ "source": [
+ "model = SetFitModel.from_pretrained(\"moshew/bge-small-en-v1.5_setfit-sst2-english\")\n",
+ "onnx_setfit_model = OnnxSetFitModel(ort_model, tokenizer, model.model_head)\n",
+ "\n",
+ "# Perform inference\n",
+ "onnx_setfit_model(test_dataset[\"text\"][:2])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "3DPl1ZpYqcBh"
+ },
+ "source": [
+ "Time to benchmark this ONNX model."
+ ],
+ "id": "3DPl1ZpYqcBh"
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 201,
+ "id": "O8jpZ3gdWRn9",
+ "metadata": {
+ "id": "O8jpZ3gdWRn9",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "outputId": "8d31c81a-67e4-4074-cf35-9f56d6dcdd20"
+ },
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "Model size (MB) - 63.39\n",
+ "Accuracy on test set - 0.906\n",
+ "Average latency (ms) - 2.19 +\\- 0.50\n"
+ ]
+ }
+ ],
+ "source": [
+ "pb = OnnxPerformanceBenchmark(\n",
+ " onnx_setfit_model,\n",
+ " test_dataset,\n",
+ " \"bge-small (optimum ONNX)\",\n",
+ " model_path=\"bge_auto_opt_O4/model.onnx\",\n",
+ ")\n",
+ "perf_metrics.update(pb.run_benchmark())"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 202,
+ "id": "tpjtxQQlZQPa",
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 455
+ },
+ "id": "tpjtxQQlZQPa",
+ "outputId": "01efad97-4780-4c47-f10f-3afa7e819d15"
+ },
+ "outputs": [
+ {
+ "output_type": "display_data",
+ "data": {
+ "text/plain": [
+ ""
+ ],
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAAjgAAAG2CAYAAAByJ/zDAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjcuMSwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy/bCgiHAAAACXBIWXMAAA9hAAAPYQGoP6dpAABbEklEQVR4nO3deVwV9f4/8NfhAIcDAio7xSYgouK+gV5XFM1My9yy3DWNUjQ1MTVLDbVc0vpqluK+tGlpuUHhcsVdXEJREEETJBc4IPs5n98f/DzXI4jsB4bX8/GYB56Zz8y8Z86R82LmMzMyIYQAERERkYQY6LsAIiIioorGgENERESSw4BDREREksOAQ0RERJLDgENERESSw4BDREREksOAQ0RERJLDgENERESSw4BDREREksOAQ0RERJKj14CTnp6OoKAguLi4QKlUws/PD2fOnNFOHzVqFGQymc7Qu3dvPVZMRERENYGhPlc+btw4XLlyBVu2bIGjoyO2bt0Kf39/REdH46WXXgIA9O7dG6Ghodp5FAqFvsolIiKiGkKmr4dtZmVlwdzcHL/++iv69u2rHd+6dWv06dMHCxcuxKhRo5Camoo9e/boo0QiIiKqofR2BCc/Px9qtRomJiY645VKJY4fP659HRERAVtbW9SrVw/du3fHwoULYWVl9dzl5uTkICcnR/tao9Hg4cOHsLKygkwmq/gNISIiogonhEB6ejocHR1hYFCGHjVCj3x9fUWXLl3EP//8I/Lz88WWLVuEgYGBaNiwoRBCiB07dohff/1VXLp0SezevVt4e3uLtm3bivz8/Ocu85NPPhEAOHDgwIEDBw4SGG7fvl2mjKG3U1QAEBcXhzFjxuDo0aOQy+Vo1aoVGjZsiHPnzuHq1auF2t+8eRPu7u4ICwtDjx49ilzms0dw0tLS4OzsjNu3b8PCwqLStoWIiIgqjkqlgpOTE1JTU2FpaVnq+fXaydjd3R1HjhzB48ePoVKp4ODggCFDhqBBgwZFtm/QoAGsra0RGxv73ICjUCiK7IhsYWHBgENERFTDlLV7SbW4D46ZmRkcHBzw6NEjHDx4EP379y+y3Z07d/DgwQM4ODhUcYVERERUk+j1CM7BgwchhICXlxdiY2MxY8YMNGrUCKNHj0ZGRgY+/fRTDBw4EPb29oiLi8PMmTPh4eGBgIAAfZZNRERE1Zxej+CkpaUhMDAQjRo1wogRI9CpUyccPHgQRkZGkMvluHTpEl577TU0bNgQY8eORevWrXHs2DHeC4eIiIiKpddOxlVBpVLB0tISaWlp7INDRERUQ5T3+7ta9MEhIiIiqkgMOERERCQ5DDhEREQkOQw4REREJDkMOERERCQ5DDhEREQkOQw4REREJDkMOERERCQ5DDhEREQkOQw4REREJDkMOERERCQ5DDhEREQkOQw4REREJDkMOERERCQ5DDhEREQkOQw4REREJDkMOERERCQ5DDhEREQkOQw4REREJDkMOERERCQ5DDhEREQkOQw4REREJDkMOERERCQ5DDhEREQkOQw4REREJDkMOERERCQ5DDhEREQkOQw4REREJDkMOERERCQ5DDhEREQkOQw4REREJDkMOERERCQ5DDhEREQkOQw4REREJDkMOERERCQ5DDhEREQkOQw4REREJDkMODVNTjoQf6zgZ21aNxFJWkZOPiLjHiAjJ1/fpZRLvlqDrFw18tUafZdSLlJ4Pwz1XQCVUu5j4NZxwNoTUJjXnnUTkaRl5uTj5M0HcLcxQx1Fzfpq0mgEbt5/jAuJj3DpThryNRoYGhig2cuWaOlcDw2szWBgINN3maVSk9+PJ2pm1URERNVATr4av0XdxX9j7yM7TwNLUyMYyw2Qq9Yg/GoK/ht7Hx09rPFaC0coDOX6LrdWYcCpTdT5QN5jwMgMkPOtJyIqD41G4Leouwi/mgI7CwVcrIx1pttbmCA1MxfhV1MAAANbvVzjjuTUZPyWqw00GiDhOBD7J5D5ADC1Ajy6Ay6dAAN2wyIiKoub9x/jv7H3YWehQF1T4yLbPBn/39j7aOVSD+42daqyxFqNAacm0qiB/NyCoSRuHQcubAZkcsCkLpB2Gzi7AVCrAdeOJV9vSddHRFQGao1ArlqD3Pya0UH3zK2HeJyjxsv1TKHWiOe2MzcxQlJaNs7EP4RTPdMqrLDscmt4J2mAAadmSjwB5GUBihL8JSA0QPxRIEcFKOsB6UkF47MeAUcWA4mdAVkJj+LkZJRsnUREZXDm1kNk56lhVgM6tWo0Akeu/wu1EFBl572wfUZOPnacTsQ/j7JqxGmqxzn5NeJ9KA7PT0idOhfIywQMTXTHG5oUhCQ1j8oQEZWWWghohIBcVrKwIpfJoNYIqMXzj/RQxarZ8ay2cvYDWo0AzO1f3FaTX3AUR3UXqOf2v/GP4gELR6DLR4BBCT8G6clA1Lay1UxE9AJtXetjaDsn2JqbvLixnuWrNUjLykNuvgZ2Fi+u954qGwpDA7zfzQOG8up/bCElPRs/nr2j7zLKhQGnJjKQA4bGBcMLGQOePYFzG4HURMDEEshOAyAAz16AcSnOB5dofUREZSM3kMFYbgBjw+ofAIwNDdDCqS7Crt6DY13lC9unZ+ejfWNbmNaQ0z7GNSCEvYhetyA9PR1BQUFwcXGBUqmEn58fzpw5o50uhMC8efPg4OAApVIJf39/3LhxQ48V11AunYDWowuO2KizC362Hg24lKKDMRER6WjpXA9KIzlSM4s/1Z+amQsTIwO0dK5XRZURoOcjOOPGjcOVK1ewZcsWODo6YuvWrfD390d0dDReeuklLF26FKtWrcKmTZvg5uaGuXPnIiAgANHR0TAxqf6HMKsNAwPA7T+Asy/vg0NEVEEaWJuho4e19j43RV0qnpqZi3uqHPTwtoWblVlVl1ir6e0ITlZWFn7++WcsXboUnTt3hoeHB+bPnw8PDw+sWbMGQgisXLkSc+bMQf/+/dGsWTNs3rwZd+/exZ49e/RVds0mNyw4RcVwQ0RUbgYGMrzWwhE9vG2RlpWHmOR0JKuy8fBxLpJV2YhJTkdaVh56eNvitRaONeLqKSnR2zddfn4+1Gp1oSMxSqUSx48fR3x8PJKTk+Hv76+dZmlpifbt2yMyMhJDhw4tcrk5OTnIycnRvlapVJWzAUREVOspDOUY2OpltHKphwuJj3D5Thry1BqYGBqgbWNbtHSuBzermvcsKinQW8AxNzeHr68vFixYAG9vb9jZ2WHHjh2IjIyEh4cHkpOTAQB2dnY689nZ2WmnFSUkJASffvpppdauV8ZmgGungp+1ad1EJGmmCkN0aGBVYzrhPs3AQAZ3mzpwt6mDAS1eQp5awEguqxFXSz1PTX4/ntDr3t+yZQuEEHjppZegUCiwatUqDBs2DAbleHxAcHAw0tLStMPt27crsOJqQGFe0J9GH0/z1ue6iUjS6igM4etuVWOfXP2EodwASmN5jQ43gDTeD72+A+7u7jhy5AgyMjJw+/ZtnD59Gnl5eWjQoAHs7Qvu8XLv3j2dee7du6edVhSFQgELCwudgYiIiGqXahExzczM4ODggEePHuHgwYPo378/3NzcYG9vj/DwcG07lUqFU6dOwdfXV4/VEhERUXWn12NPBw8ehBACXl5eiI2NxYwZM9CoUSOMHj0aMpkMQUFBWLhwITw9PbWXiTs6OmLAgAH6LJuIiIiqOb0GnLS0NAQHB+POnTuoX78+Bg4ciEWLFsHIyAgAMHPmTDx+/BgTJkxAamoqOnXqhAMHDvAeOERERFQsmRDSfvKXSqWCpaUl0tLS2B+HiIiohijv93e16INDREREVJEYcIiIiEhyGHCIiIhIchhwiIiISHIYcIiIiEhyGHCIiIhIchhwiIiISHIYcIiIiEhyGHCIiIhIchhwiIiISHIYcIiIiEhyGHCIiIhIchhwiIiISHIYcIiIiEhyGHCIiIhIchhwiIiISHIYcIiIiEhyGHCIiIhIchhwiIiISHIYcIiIiEhyGHCIiIhIchhwiIiISHIYcIiIiEhyGHCIiIhIchhwiIiISHIYcIiIiEhyGHCIiIhIchhwiIiISHIYcIiIiEhyGHCIiIhIchhwiIiISHIYcIiIiEhyGHCIiIhIchhwiIiISHIYcIiIiEhyGHCIiIhIchhwiIiISHIYcIiIiEhyGHCIiIhIchhwiIiISHIYcIiIiEhyGHCIiIhIchhwiIiISHIYcIiIiEhyGHCIiIhIchhwiIiISHL0GnDUajXmzp0LNzc3KJVKuLu7Y8GCBRBCaNuMGjUKMplMZ+jdu7ceqyYiIqLqzlCfK1+yZAnWrFmDTZs2oUmTJjh79ixGjx4NS0tLTJ48Wduud+/eCA0N1b5WKBT6KJeIiIhqCL0GnBMnTqB///7o27cvAMDV1RU7duzA6dOnddopFArY29vro0QiIiKqgfR6isrPzw/h4eG4fv06AODixYs4fvw4+vTpo9MuIiICtra28PLywqRJk/DgwYPnLjMnJwcqlUpnICIiotpFr0dwZs2aBZVKhUaNGkEul0OtVmPRokUYPny4tk3v3r3xxhtvwM3NDXFxcZg9ezb69OmDyMhIyOXyQssMCQnBp59+WpWbQURERNWMTDzdo7eK7dy5EzNmzMAXX3yBJk2aICoqCkFBQVi+fDlGjhxZ5Dw3b96Eu7s7wsLC0KNHj0LTc3JykJOTo32tUqng5OSEtLQ0WFhYVNq2EBERUcVRqVSwtLQs8/e3Xo/gzJgxA7NmzcLQoUMBAD4+PkhISEBISMhzA06DBg1gbW2N2NjYIgOOQqFgJ2QiIqJaTq99cDIzM2FgoFuCXC6HRqN57jx37tzBgwcP4ODgUNnlERERUQ2l1yM4/fr1w6JFi+Ds7IwmTZrgwoULWL58OcaMGQMAyMjIwKeffoqBAwfC3t4ecXFxmDlzJjw8PBAQEKDP0omIiKga02sfnPT0dMydOxe7d+9GSkoKHB0dMWzYMMybNw/GxsbIysrCgAEDcOHCBaSmpsLR0RG9evXCggULYGdnV6J1lPccHhEREVW98n5/6zXgVAUGHCIiopqnvN/ffBYVERERSQ4DDhEREUkOAw4RERFJDgMOERERSQ4DDhEREUkOAw4RERFJDgMOERERSQ4DDhEREUkOAw4RERFJDgMOERERSQ4DDhEREUkOAw4RERFJDgMOERERSQ4DDhEREUkOAw4RERFJDgMOERERSQ4DDhEREUkOAw4RERFJDgMOERERSY5haRprNBocOXIEx44dQ0JCAjIzM2FjY4OWLVvC398fTk5OlVUnERERUYmV6AhOVlYWFi5cCCcnJ7zyyivYv38/UlNTIZfLERsbi08++QRubm545ZVXcPLkycqumYiIiKhYJTqC07BhQ/j6+uK7775Dz549YWRkVKhNQkICtm/fjqFDh+Ljjz/G+PHjK7xYIiIiopKQCSHEixpdvXoV3t7eJVpgXl4eEhMT4e7uXu7iKoJKpYKlpSXS0tJgYWGh73KIiIioBMr7/V2iU1QlDTcAYGRkVG3CDREREdVOpepk/LT8/Hx8++23iIiIgFqtRseOHREYGAgTE5OKrI+IiIio1MoccCZPnozr16/jjTfeQF5eHjZv3oyzZ89ix44dFVkfERERUamVOODs3r0br7/+uvb1oUOHEBMTA7lcDgAICAhAhw4dKr5CIiIiolIq8Y3+NmzYgAEDBuDu3bsAgFatWmHixIk4cOAA9u7di5kzZ6Jt27aVVigRERFRSZU44OzduxfDhg1D165dsXr1aqxbtw4WFhb4+OOPMXfuXDg5OWH79u2VWSsRERFRiZToMvGnpaamYubMmbh48SLWrl2Lli1bVlZtFYKXiRMREdU8VXKZ+NPq1q2LdevW4YsvvsCIESMwY8YMZGdnl3rFRERERJWlxAEnMTERgwcPho+PD4YPHw5PT0+cO3cOpqamaN68Ofbv31+ZdRIRERGVWIlPUXXt2hX29vYYNWoUDh48iLi4OPz2228ACu50/O6778Le3h4//PBDpRZcWjxFRUREVPOU9/u7xJeJnz17FhcvXoS7uzsCAgLg5uamnebt7Y2jR49i3bp1pS6AiIiIqKKVOOC0bt0a8+bNw8iRIxEWFgYfH59CbSZMmFChxRERERGVRYn74GzevBk5OTmYOnUq/vnnH3z77beVWRcRERFRmZX4CI6Liwt++umnyqyFiIiIqEKU6AjO48ePS7XQ0rYnIiIiqkglCjgeHh5YvHgxkpKSnttGCIHDhw+jT58+WLVqVYUVSERERFRaJTpFFRERgdmzZ2P+/Plo3rw52rRpA0dHR5iYmODRo0eIjo5GZGQkDA0NERwcjHfffbey6yYiIiJ6rlI9qiExMRE//vgjjh07hoSEBGRlZcHa2hotW7ZEQEAA+vTpo326eHXB++AQERHVPOX9/i71s6hqGgYcIiKimqfKn0VFREREVN0x4BAREZHkMOAQERGR5DDgEBERkeQw4BAREZHklDrguLq64rPPPkNiYmK5V65WqzF37ly4ublBqVTC3d0dCxYswNMXdgkhMG/ePDg4OECpVMLf3x83btwo97qJiIhIukodcIKCgvDLL7+gQYMG6NmzJ3bu3ImcnJwyrXzJkiVYs2YNvv76a1y9ehVLlizB0qVLsXr1am2bpUuXYtWqVVi7di1OnToFMzMzBAQEIDs7u0zrJCIiIukr831wzp8/j40bN2LHjh1Qq9V46623MGbMGLRq1arEy3j11VdhZ2eH9evXa8cNHDgQSqUSW7duhRACjo6O+PDDDzF9+nQAQFpaGuzs7LBx40YMHTr0hevgfXCIiIhqHr3dB6dVq1ZYtWoV7t69i08++QTff/892rZtixYtWmDDhg0oSW7y8/NDeHg4rl+/DgC4ePEijh8/jj59+gAA4uPjkZycDH9/f+08lpaWaN++PSIjI4tcZk5ODlQqlc5AREREtUuJnkVVlLy8POzevRuhoaE4fPgwOnTogLFjx+LOnTuYPXs2wsLCsH379mKXMWvWLKhUKjRq1AhyuRxqtRqLFi3C8OHDAQDJyckAADs7O5357OzstNOeFRISgk8//bSsm0VEREQSUOqAc/78eYSGhmLHjh0wMDDAiBEjsGLFCjRq1Ejb5vXXX0fbtm1fuKwffvgB27Ztw/bt29GkSRNERUUhKCgIjo6OGDlyZGlLAwAEBwdj2rRp2tcqlQpOTk5lWhYRERHVTKUOOG3btkXPnj2xZs0aDBgwAEZGRoXauLm5lah/zIwZMzBr1ixtWx8fHyQkJCAkJAQjR46Evb09AODevXtwcHDQznfv3j20aNGiyGUqFAooFIrSbhYRERFJSKkDzs2bN+Hi4lJsGzMzM4SGhr5wWZmZmTAw0O0GJJfLodFoABQEJXt7e4SHh2sDjUqlwqlTpzBp0qTSlk5ERES1RKkDTkpKCpKTk9G+fXud8adOnYJcLkebNm1KvKx+/fph0aJFcHZ2RpMmTXDhwgUsX74cY8aMAQDIZDIEBQVh4cKF8PT0hJubG+bOnQtHR0cMGDCgtKUTERFRLVHqq6gCAwNx+/btQuP/+ecfBAYGlmpZq1evxptvvon33nsP3t7emD59Ot59910sWLBA22bmzJn44IMPMGHCBLRt2xYZGRk4cOAATExMSls6ERER1RKlvg9OnTp1cOnSJTRo0EBnfHx8PJo1a4b09PQKLbC8eB8cIiKimqfK74OjUChw7969QuOTkpJgaFjmq86JiIiIKkypA06vXr0QHByMtLQ07bjU1FTMnj0bPXv2rNDiiIiIiMqi1IdcvvzyS3Tu3BkuLi5o2bIlACAqKgp2dnbYsmVLhRdIREREVFqlDjgvvfQSLl26hG3btuHixYtQKpUYPXo0hg0bVuQ9cYiIiIiqWpk6zZiZmWHChAkVXQsRERFRhShzr+Do6GgkJiYiNzdXZ/xrr71W7qKIiIiIyqNMdzJ+/fXXcfnyZchkMu1Tw2UyGQBArVZXbIVEREREpVTqq6imTJkCNzc3pKSkwNTUFH///TeOHj2KNm3aICIiohJKJCIiIiqdUh/BiYyMxJ9//glra2sYGBjAwMAAnTp1QkhICCZPnowLFy5URp1EREREJVbqIzhqtRrm5uYAAGtra9y9excA4OLigpiYmIqtjoiIiKgMSn0Ep2nTprh48SLc3NzQvn17LF26FMbGxli3bl2hxzcQERER6UOpA86cOXPw+PFjAMBnn32GV199Ff/5z39gZWWFXbt2VXiBRERERKVV6odtFuXhw4eoV6+e9kqq6oQP2yQiIqp5qvRhm3l5eTA0NMSVK1d0xtevX79ahhsiIiKqnUoVcIyMjODs7Mx73RAREVG1VuqrqD7++GPMnj0bDx8+rIx6iIiIiMqt1J2Mv/76a8TGxsLR0REuLi4wMzPTmX7+/PkKK46IiIioLEodcAYMGFAJZRARERFVnAq5iqo641VURERENU+VXkVFREREVBOU+hSVgYFBsZeE8worIiIi0rdSB5zdu3frvM7Ly8OFCxewadMmfPrppxVWGBEREVFZVVgfnO3bt2PXrl349ddfK2JxFYZ9cIiIiGqeatMHp0OHDggPD6+oxRERERGVWYUEnKysLKxatQovvfRSRSyOiIiIqFxK3Qfn2YdqCiGQnp4OU1NTbN26tUKLIyIiIiqLUgecFStW6AQcAwMD2NjYoH379qhXr16FFkdERERUFqUOOKNGjaqEMoiIiIgqTqn74ISGhuLHH38sNP7HH3/Epk2bKqQoIiIiovIodcAJCQmBtbV1ofG2trb4/PPPK6QoIiIiovIodcBJTEyEm5tbofEuLi5ITEyskKKIiIiIyqPUAcfW1haXLl0qNP7ixYuwsrKqkKKIiIiIyqPUAWfYsGGYPHky/vrrL6jVaqjVavz555+YMmUKhg4dWhk1EhEREZVKqa+iWrBgAW7duoUePXrA0LBgdo1GgxEjRrAPDhEREVULZX4W1Y0bNxAVFQWlUgkfHx+4uLhUdG0Vgs+iIiIiqnnK+/1d6iM4T3h6esLT07OssxMRERFVmlL3wRk4cCCWLFlSaPzSpUsxaNCgCimKiIiIqDxKHXCOHj2KV155pdD4Pn364OjRoxVSFBEREVF5lDrgZGRkwNjYuNB4IyMjqFSqCimKiIiIqDxKHXB8fHywa9euQuN37tyJxo0bV0hRREREROVR6k7Gc+fOxRtvvIG4uDh0794dABAeHo4dO3YU+YwqIiIioqpW6oDTr18/7NmzB59//jl++uknKJVKNGvWDGFhYejSpUtl1EhERERUKmW+D05Rrly5gqZNm1bU4ioE74NDRERU85T3+7vUfXCelZ6ejnXr1qFdu3Zo3rx5eRdHREREVG5lDjhHjx7FiBEj4ODggC+//BLdu3fHyZMnK7I2IiIiojIpVR+c5ORkbNy4EevXr4dKpcLgwYORk5ODPXv28AoqIiIiqjZKfASnX79+8PLywqVLl7By5UrcvXsXq1evrszaiIiIiMqkxAFn//79GDt2LD799FP07dsXcrm83Ct3dXWFTCYrNAQGBgIAunbtWmjaxIkTy71eIiIikrYSB5zjx48jPT0drVu3Rvv27fH111/j/v375Vr5mTNnkJSUpB0OHz4MADrPtBo/frxOm6VLl5ZrnURERCR9JQ44HTp0wHfffYekpCS8++672LlzJxwdHaHRaHD48GGkp6eXeuU2Njawt7fXDvv27YO7u7vO/XRMTU112vBSbyIiInqRUl9FZWZmhjFjxuD48eO4fPkyPvzwQyxevBi2trZ47bXXylxIbm4utm7dijFjxkAmk2nHb9u2DdbW1mjatCmCg4ORmZlZ7HJycnKgUql0BiIiIqpdynUfHC8vLyxduhR37tzBjh07ylXInj17kJqailGjRmnHvfXWW9i6dSv++usvBAcHY8uWLXj77beLXU5ISAgsLS21g5OTU7nqIiIiopqnQu9kXB4BAQEwNjbG3r17n9vmzz//RI8ePRAbGwt3d/ci2+Tk5CAnJ0f7WqVSwcnJiXcyJiIiqkHKeyfjUj+LqjIkJCQgLCwMv/zyS7Ht2rdvDwDFBhyFQgGFQlHhNRIREVHNUe5HNVSE0NBQ2Nraom/fvsW2i4qKAgA4ODhUQVVERERUU+n9CI5Go0FoaChGjhwJQ8P/lRMXF4ft27fjlVdegZWVFS5duoSpU6eic+fOaNasmR4rJiIioupO7wEnLCwMiYmJGDNmjM54Y2NjhIWFYeXKlXj8+DGcnJwwcOBAzJkzR0+VEhERUU1RbToZV5bydlIiIiKiqlfe7+9q0QeHiIiIqCIx4BAREZHkMOAQERGR5DDgEBERkeQw4BAREZHkMOAQERGR5DDgEBERkeQw4BAREZHkMOAQERGR5DDgEBERkeQw4BAREZHkMOAQERGR5DDgEBERkeQw4BAREZHkMOAQERGR5DDgEBERkeQw4BAREZHkMOAQERGR5DDgEBERkeQw4BAREZHkMOAQERGR5DDgEBERkeQw4BAREZHkMOAQERGR5DDgEBERkeQw4BAREZHkMOAQERGR5DDgEBERkeQw4BAREZHkMOAQERGR5DDgEBERkeQw4BAREZHkMOAQERGR5DDgEBERkeQw4BAREZHkMOAQERGR5DDgEBERkeQw4BAREZHkMOAQERGR5DDgEBERkeQw4BAREZHkMOAQERGR5DDgEBERkeQw4BAREZHkMOAQERGR5DDgEBERkeQw4BAREZHk6DXguLq6QiaTFRoCAwMBANnZ2QgMDISVlRXq1KmDgQMH4t69e/osmYiIiGoAvQacM2fOICkpSTscPnwYADBo0CAAwNSpU7F37178+OOPOHLkCO7evYs33nhDnyUTERFRDSATQgh9F/FEUFAQ9u3bhxs3bkClUsHGxgbbt2/Hm2++CQC4du0avL29ERkZiQ4dOpRomSqVCpaWlkhLS4OFhUVllk9EREQVpLzf39WmD05ubi62bt2KMWPGQCaT4dy5c8jLy4O/v7+2TaNGjeDs7IzIyMjnLicnJwcqlUpnICIiotql2gScPXv2IDU1FaNGjQIAJCcnw9jYGHXr1tVpZ2dnh+Tk5OcuJyQkBJaWltrBycmpEqsmIiKi6qjaBJz169ejT58+cHR0LNdygoODkZaWph1u375dQRUSERFRTWGo7wIAICEhAWFhYfjll1+04+zt7ZGbm4vU1FSdozj37t2Dvb39c5elUCigUCgqs1wiIiKq5qrFEZzQ0FDY2tqib9++2nGtW7eGkZERwsPDteNiYmKQmJgIX19ffZRJRERENYTej+BoNBqEhoZi5MiRMDT8XzmWlpYYO3Yspk2bhvr168PCwgIffPABfH19S3wFFREREdVOeg84YWFhSExMxJgxYwpNW7FiBQwMDDBw4EDk5OQgICAA//d//6eHKomIiKgmqVb3wakMvA8OERFRzSOZ++AQERERVRQGHCIiIpIcBhwiIiKSHAYcIiIikhwGHCIiIpIcBhwiIiKSHAYcIiIikhwGHCIiIpIcBhwiIiKSHAYcIiIikhwGHCIiIpIcBhwiIiKSHAYcIiIikhwGHCIiIpIcBhwiIiKSHAYcIiIikhwGHCIiIpIcBhwiIiKSHAYcIiIikhwGHCIiIpIcQ30XQERUXmq1Gnl5efoug4hKQS6Xw9DQEDKZrFKWz4BDRDVaRkYG7ty5AyGEvksholIyNTWFg4MDjI2NK3zZDDhEVGOp1WrcuXMHpqamsLGxqbS/BImoYgkhkJubi3///Rfx8fHw9PSEgUHF9pphwCGiGisvLw9CCNjY2ECpVOq7HCIqBaVSCSMjIyQkJCA3NxcmJiYVunx2MiaiGo9Hbohqpoo+aqOz7EpbMhFRNZORk4/IuAfIyMkvNC1frUFWrhr5ak2p5iOi6omnqIio1sjMycfJmw/gbmOGOgpDaDQCN+8/xoXER7h0Jw35Gg0MDQzQ7GVLtHSuhwbWZjAwkBWaj4iqPx7BIaJaKSdfjZ/P38HXf95A+NUU5KoLwk2uWoPwqyn4+s8b+Pn8HeTkqyt83V27dkVQUFCFL7e62rhxI+rWrat9PX/+fLRo0eKF882dOxcTJkyovMIq2bPbXZRZs2bhgw8+qJqCahkGHCKqdTRC4Leouwi/mgJLpRG87M1hb2GC+mbGsLcwgZe9OSyVRgi/moLfou5Cw0vQq1xycjK++uorfPzxx9pxo0aNgkwmg0wmg7GxMTw8PPDZZ58hP//Fpw43btyonfd5w61btypxi4o2ffp0bNq0CTdv3qzydUsdAw4R1TqJDzLx39j7sLNQoK5p0fffqGtqDDsLBf4bex+3H2ZWcYX0/fffw8/PDy4uLjrje/fujaSkJNy4cQMffvgh5s+fjy+++OKFyxsyZAiSkpK0g6+vL8aPH68zzsnJqcT15ebmlnqbimJtbY2AgACsWbOmQpZH/8OAQ0S1ilojEHU7FY9z1DA3MYJaI547mJsYITNXjQu3Uyu8jvz8fLz//vuwtLSEtbU15s6dq3OzwqSkJPTt2xdKpRJubm7Yvn07XF1dsXLlSm2b1NRUjBs3DjY2NrCwsED37t1x8eLFYtcbERGBdu3awczMDHXr1kXHjh2RkJAA4H+njjZs2ABnZ2fUqVMH7733HtRqNZYuXQp7e3vY2tpi0aJFOstcvnw5fHx8YGZmBicnJ7z33nvIyMgo1/7ZuXMn+vXrV2i8QqGAvb09XFxcMGnSJPj7++O3337D48ePYWFhgZ9++kmn/Z49e2BmZob8/HzY29trB2NjY5iammpf5+bm4o033kCdOnVgYWGBwYMH4969e9rlPNk333//Pdzc3LSXNKempuLdd9+FnZ0dTExM0LRpU+zbt0+nhoMHD8Lb2xt16tTRBrSn9evXDzt37izX/qLC2FuOiGqV0/EPkJ6dDwMDGVTZL368Q0ZOPu5cyESPRnYVWsemTZswduxYnD59GmfPnsWECRPg7OyM8ePHAwBGjBiB+/fvIyIiAkZGRpg2bRpSUlJ0ljFo0CAolUrs378flpaW+Pbbb9GjRw9cv34d9evXL7TO/Px8DBgwAOPHj8eOHTuQm5uL06dP61xmHxcXh/379+PAgQOIi4vDm2++iZs3b6Jhw4Y4cuQITpw4gTFjxsDf3x/t27cHUHCp76pVq+Dm5oabN2/ivffew8yZM/F///d/Zdo3Dx8+RHR0NNq0afPCtkqlEg8ePICZmRmGDh2K0NBQvPnmm9rpT16bm5s/dxkajQb9+/dHnTp1cOTIEeTn5yMwMBBDhgxBRESEtl1sbCx+/vln/PLLL5DL5dBoNOjTpw/S09OxdetWuLu7Izo6GnK5XDtPZmYmvvzyS2zZsgUGBgZ4++23MX36dGzbtk3bpl27drhz5w5u3boFV1fX0u0sei4GHCKqVTSioA+OkaxkB7DlMhly1RqoK7gfjpOTE1asWAGZTAYvLy9cvnwZK1aswPjx43Ht2jWEhYXhzJkz2i/577//Hp6entr5jx8/jtOnTyMlJQUKhQIA8OWXX2LPnj346aefiuycq1KpkJaWhldffRXu7u4AAG9vb502Go0GGzZsgLm5ORo3boxu3bohJiYGf/zxBwwMDODl5YUlS5bgr7/+0gacpztMu7q6YuHChZg4cWKZA05iYiKEEHB0dHxuGyEEwsPDcfDgQW0n3XHjxsHPzw9JSUlwcHBASkoK/vjjD4SFhRW7vvDwcFy+fBnx8fHa01SbN29GkyZNcObMGbRt2xZAwWmpzZs3w8bGBgBw6NAhnD59GlevXkXDhg0BAA0aNNBZdl5eHtauXavd3++//z4+++wznTZPtjMhIYEBpwIx4BBRrdLOtT6SVVmQGxjAzuLFd069p8qGRgjIK/hmgh06dNA5cuLr64tly5ZBrVYjJiYGhoaGaNWqlXa6h4cH6tWrp3198eJFZGRkwMrKSme5WVlZiIuLQ2JiIho3bqwdP3v2bMyePRujRo1CQEAAevbsCX9/fwwePBgODg7adq6urjpHO+zs7CCXy3VuyGZnZ6dzNCksLAwhISG4du0aVCoV8vPzkZ2djczMTJiampZ632RlZQFAkXe23bdvH+rUqYO8vDxoNBq89dZbmD9/PoCCIyFNmjTBpk2bMGvWLGzduhUuLi7o3Llzseu7evUqnJycdPrgNG7cGHXr1sXVq1e1AcfFxUUbbgAgKioKL7/8sjbcFMXU1FQbbgBog9fTntyFOzOTfb0qEvvgEFGtYmRogCaOllBl50FuIHvhkJ6djyaOFjAwqF53S87IyICDgwOioqJ0hpiYGMyYMQOOjo464ydOnAig4JRNZGQk/Pz8sGvXLjRs2BAnT57ULtfIyEhnPTKZrMhxGk3BDRFv3bqFV199Fc2aNcPPP/+Mc+fO4ZtvvgFQ9o641tbWAIBHjx4VmtatWzdERUXhxo0byMrKwqZNm2BmZqadPm7cOGzcuFG7raNHj66wO10/vR4AJXo8SFH77tkHwz58+BAAdMITlR8DDhHVOj4vWUJpJEdqZvFfwKmZuTAxMoDPS5YVXsOpU6d0Xp88eRKenp6Qy+Xw8vJCfn4+Lly4oJ0eGxur84XfqlUrJCcnw9DQEB4eHjqDtbV1ofFP98lp2bIlgoODceLECTRt2hTbt28v83acO3cOGo0Gy5YtQ4cOHdCwYUPcvXu3zMsDAHd3d1hYWCA6OrrQNDMzM3h4eMDZ2RmGhoVPQrz99ttISEjAqlWrEB0djZEjR75wfd7e3rh9+zZu376tHRcdHY3U1FSdo2DPatasGe7cuYPr16+XcMuKduXKFRgZGaFJkyblWg7pYsAholrH2coUHT2scU+V89yQk5qZi3uqHHT0sIZT/dKfZnmRxMRETJs2DTExMdixYwdWr16NKVOmAAAaNWoEf39/TJgwAadPn8aFCxcwYcIEKJVK7dEIf39/+Pr6YsCAATh06BBu3bqFEydO4OOPP8bZs2eLXGd8fDyCg4MRGRmJhIQEHDp0CDdu3CjUD6c0PDw8kJeXh9WrV+PmzZvYsmUL1q5dW+blAQWdlv39/XH8+PFSz1uvXj288cYbmDFjBnr16oWXX375hfP4+/vDx8cHw4cPx/nz53H69GmMGDECXbp0Kbajc5cuXdC5c2cMHDgQhw8fRnx8vLaDdmkcO3YM//nPf/jA2ArGgENEtY6BTIbXWjiih7ct0rLyEJOcjmRVNh4+zkWyKhsxyelIy8pDD29bvNbCEQaV8DDPESNGICsrC+3atUNgYCCmTJmi0zF48+bNsLOzQ+fOnfH6669j/PjxMDc31/ZLkclk+OOPP9C5c2eMHj0aDRs2xNChQ5GQkAA7u6Kv+DI1NcW1a9cwcOBANGzYEBMmTEBgYCDefffdMm9H8+bNsXz5cixZsgRNmzbFtm3bEBISUublPTFu3Djs3LlTeyqsNMaOHYvc3FyMGTOmRO1lMhl+/fVX1KtXD507d4a/vz8aNGiAXbt2vXDen3/+GW3btsWwYcPQuHFjzJw5E2p16e5+vXPnTu3Vc1RxZOLZk4ESo1KpYGlpibS0NFhYWOi7HCKqQNnZ2YiPj9e5L0lxUlTZ2HYqEcPbO8PWwgQajUD8g4JnUV2+k4Y8tQZGcgP4/P9nUblZFTyL6tn59OHOnTtwcnJCWFgYevTooZcaqpIQAu3bt8fUqVMxbNiwUs27ZcsWTJ06FXfv3oWxcdE3cqwu9u/fjw8//BCXLl0q8pSb1BX3f7i839+1b28SUa1lqjBEhwZWMP3/D8w0MJDB3aYO3G3qYECLl5CnFjCSy2AoNyh2vqrw559/IiMjAz4+PkhKSsLMmTPh6ur6wiuCpEImk2HdunW4fPlyiefJzMxEUlISFi9ejHfffbfahxsAePz4MUJDQ2tluKls3KNEVGvUURjC192qyGmGcgMYyoucVOx8lSUvLw+zZ8/GzZs3YW5uDj8/P2zbtq3QVTlS1qJFixI9lPOJpUuXYtGiRejcuTOCg4Mrr7AK9PRNCali8RQVEdVYpT1FRUTVS2WeomInYyIiIpIcBhwiIiKSHAYcIiIikhwGHCIiIpIcBhwiqj1y0oH4YwU/q2I+ItIbvQecf/75B2+//TasrKygVCrh4+Ojc5vxUaNGQSaT6Qy9e/fWY8VEVGPlPgZuHS/4WRXzEZHe6DXgPHr0CB07doSRkRH279+P6OhoLFu2DPXq1dNp17t3byQlJWmHHTt26KliIqLy69q1K4KCgvRdRpXZuHEj6tatq309f/78Et3fZu7cuTqPr6hMrq6uWLlyZZWsq7YYOnQoli1bprf16zXgLFmyBE5OTggNDUW7du3g5uaGXr16wd3dXaedQqGAvb29dng2AD0tJycHKpVKZyAieiF1PpCdVvCT9C45ORlfffUVPv744wpd7rNh64kzZ85UWZiqKH///TcGDx4MGxsbKBQKNGzYEPPmzUNmZqZOO1dXV8hkMpw8eVJnfFBQELp27ap9PX/+fMhkMkycOFGnXVRUFGQyGW7dugUA+OOPP2BsbIzz58/rtFu2bBmsra2RnJwMAJgzZw4WLVqEtLS0Ctri0tFrwPntt9/Qpk0bDBo0CLa2tmjZsiW+++67Qu0iIiJga2sLLy8vTJo0CQ8ePHjuMkNCQmBpaakdnJycKnMTiKim02iA+KPAnwuBg3MKfsYfLRhPevP999/Dz88PLi4uVbI+GxsbmJpW/FPjK8vJkyfRvn175Obm4vfff8f169exaNEibNy4ET179kRubq5OexMTE3z00UcvXK6JiQnWr1+PGzduPLfNK6+8ghEjRmDEiBHIyckBAERHR2POnDn45ptvYG9vDwBo2rQp3N3dsXXr1nJsadnpNeDcvHkTa9asgaenJw4ePIhJkyZh8uTJ2LRpk7ZN7969sXnzZoSHh2PJkiU4cuQI+vTp89yntQYHByMtLU073L59u6o2h4hqAo0ayM/933AzAji7AUi7DciNC36e3QDcPKLbroLl5+fj/fffh6WlJaytrTF37lw8fWP5pKQk9O3bF0qlEm5ubti+fXuh0yipqakYN24cbGxsYGFhge7du+PixYvFrjciIgLt2rWDmZkZ6tati44dOyIhIQHA/04dbdiwAc7OzqhTpw7ee+89qNVqLF26FPb29rC1tcWiRYt0lrl8+XL4+PjAzMwMTk5OeO+995CRkVGu/bNz507069dPZ1xOTg4mT54MW1tbmJiYoFOnTjhz5ozOtslkMvz+++9o1qwZTExM0KFDB1y5ckU7ffTo0UhLS9P26Zw/fz6AwqeoZDIZvv32W7z66qswNTWFt7c3IiMjERsbi65du8LMzAx+fn6Ii4vTzjNq1CgMGDBAp+Znj5J07doVH3zwAYKCglCvXj3Y2dnhu+++w+PHjzF69GiYm5vDw8MD+/fvf+6+EUJg7Nix8Pb2xi+//IJ27drBxcUFgwYNwt69exEZGYkVK1bozDNhwgScPHkSf/zxR7H73cvLC926dXvhkbMVK1YgIyMDn3zyCfLz8zFy5Ej069cPQ4YM0WnXr18/7Ny5s9hlVRa9BhyNRoNWrVrh888/R8uWLTFhwgSMHz8ea9eu1bYZOnQoXnvtNfj4+GDAgAHYt28fzpw5g4iIiCKXqVAoYGFhoTMQEWklngBOfQscWwYc/QI4sgT4NwZITwL+vfr/f8YARxYXTD+2rKB9Bdu0aRMMDQ1x+vRpfPXVV1i+fDm+//577fQRI0bg7t27iIiIwM8//4x169YhJSVFZxmDBg1CSkoK9u/fj3PnzqFVq1bo0aMHHj58WOQ68/PzMWDAAHTp0gWXLl1CZGQkJkyYAJlMpm0TFxeH/fv348CBA9ixYwfWr1+Pvn374s6dOzhy5AiWLFmCOXPm4NSpU9p5DAwMsGrVKvz999/YtGkT/vzzT8ycObPM++bhw4eIjo5GmzZtdMbPnDkTP//8MzZt2oTz58/Dw8MDAQEBhbZ3xowZWLZsGc6cOQMbGxv069cPeXl58PPzw8qVK2FhYaHt0zl9+vTn1rFgwQKMGDECUVFRaNSoEd566y28++67CA4OxtmzZyGEwPvvv1/q7du0aROsra1x+vRpfPDBB5g0aRIGDRoEPz8/nD9/Hr169cI777xT6FTTE1FRUYiOjsa0adNgYKD7Nd68eXP4+/sX6qvq5uaGiRMnIjg4GJoXHJ1cvHgxfv75Z50Lfp5lbm6ODRs2YNmyZRg+fDhu376NNWvWFGrXrl07nD59WnukpyrpNeA4ODigcePGOuO8vb2RmJj43HkaNGgAa2trxMbGVnZ5RCR16lwgLxMwfOY5VoYmQF5WwfRK4uTkhBUrVsDLywvDhw/HBx98oP2r+9q1awgLC8N3332H9u3bo1WrVvj++++RlZWlnf/48eM4ffo0fvzxR7Rp0waenp748ssvUbduXfz0009FrlOlUiEtLQ2vvvoq3N3d4e3tjZEjR8LZ2VnbRqPRYMOGDWjcuDH69euHbt26ISYmBitXroSXlxdGjx4NLy8v/PXXX9p5goKC0K1bN7i6uqJ79+5YuHAhfvjhhzLvm8TERAgh4OjoqB33+PFjrFmzBl988QX69OmDxo0b47vvvoNSqcT69et15v/kk0/Qs2dP+Pj4YNOmTbh37x52794NY2NjWFpaQiaTaft01qlT57l1jB49GoMHD0bDhg3x0Ucf4datWxg+fDgCAgLg7e2NKVOmPPeP7eI0b94cc+bMgaenJ4KDg2FiYgJra2uMHz8enp6emDdvHh48eIBLly4VOf/169cBFHxfFsXb21vb5mlz5sxBfHw8tm3bVmx9rVq1wuDBg194Sqt79+5488038cMPP2DVqlWwsir8QFpHR0fk5uZq++VUJb0+Tbxjx46IiYnRGXf9+vViz7neuXMHDx48gIODQ2WXR0RS5OwHtBoBmNsDmnxAaADVXaCe2//aPIoHLByBLh8BBoZAejIQVfyXQml16NBB58iJr68vli1bBrVajZiYGBgaGqJVq1ba6R4eHjoXWFy8eBEZGRmFvlSysrIQFxeHxMREnT8gZ8+ejdmzZ2PUqFEICAhAz5494e/vj8GDB+v8PnV1dYW5ubn2tZ2dHeRyuc6RAjs7O52jSWFhYQgJCcG1a9egUqmQn5+P7OxsZGZmlqlfy5Mg9/TDF+Pi4pCXl4eOHTtqxxkZGaFdu3a4evWqzvy+vr7af9evXx9eXl6F2pREs2bNtP+2s7MDAPj4+OiMy87OhkqlKtXZgqeXK5fLYWVlVWi5AAodsXtWaZ+VbWNjg+nTp2PevHmFTiU9a+HChfD29sahQ4dga2tbZJt//vkHBw4cgKmpKY4dO4bBgwcXaqNUKgHguUejKpNej+BMnToVJ0+exOeff47Y2Fhs374d69atQ2BgIAAgIyMDM2bMwMmTJ3Hr1i2Eh4ejf//+2sOSRESlZiAHDI0LBmNTwLMnAAGkJhZcRZWaWPDas1fB9Cdtq5mMjAw4ODggKipKZ4iJicGMGTPg6OioM/7JlTGhoaGIjIyEn58fdu3ahYYNG+pcXWNkZKSzHplMVuS4J6c5bt26hVdffRXNmjXDzz//jHPnzuGbb74BgEIdXUvK2toaQMGtRPTp6e1+EkaLGvdkXxgYGBQKHXl5ecUu98lyilvusxo2bAgAzw1tV69e1bZ51rRp05CVlYX/+7//K3L6E+7u7hg/fjxmzZr13CA1fvx4tG7dGvv27cOaNWtw5MiRQm2enD60sbEpdn2VQa8Bp23btti9ezd27NiBpk2bYsGCBVi5ciWGDx8OoCDZXrp0Ca+99hoaNmyIsWPHonXr1jh27BgUCoU+SyciqXDpBLQeXXDERp1d8LP1aMCl44vnLYen+7AABVfFeHp6Qi6Xw8vLC/n5+bhw4YJ2emxsrM4XfqtWrZCcnAxDQ0N4eHjoDNbW1oXG169fXztvy5YtERwcjBMnTqBp06bYvn17mbfj3Llz0Gg0WLZsGTp06ICGDRvi7t27ZV4eUPDlamFhgejoaJ1xxsbG+O9//6sdl5eXhzNnzhTq6vB0YHv06BGuX7+uPZ1jbGz83ItUysvGxgZJSUk646Kioip8PS1atECjRo2wYsWKQiHo4sWLCAsLw7Bhw4qct06dOpg7dy4WLVqE9PTi78w9b948XL9+vchOwt9//z2OHz+O9evXo1u3bpg0aRLGjBmDx491b4Z55coVvPzyy9rQWpX0fifjV199FZcvX0Z2djauXr2K8ePHa6cplUocPHgQKSkpyM3Nxa1bt7Bu3Trt4TsionIzMADc/gN0nwP0Wljw0+0/BeMrUWJiIqZNm4aYmBjs2LEDq1evxpQpUwAAjRo1gr+/PyZMmIDTp0/jwoULmDBhApRKpfave39/f/j6+mLAgAE4dOgQbt26hRMnTuDjjz9+bufQ+Ph4BAcHIzIyEgkJCTh06BBu3Ljx3L4cJeHh4YG8vDysXr0aN2/exJYtW3QuFCkLAwMD+Pv74/jx49pxZmZmmDRpEmbMmIEDBw4gOjoa48ePR2ZmJsaOHasz/2effYbw8HBcuXIFo0aNgrW1tfbqJldXV2RkZCA8PBz379+v0FMn3bt3x9mzZ7F582bcuHEDn3zyifYKrookk8mwfv16REdHY+DAgTh9+jQSExPx448/ol+/fvD19S32RpITJkyApaXlC4OtnZ0dpk2bhlWrVumMT0hIwLRp0/Dll19qu5QsWbIEMpkMs2bN0ml77Ngx9OrVq2wbWk56DzhERNWC3BAwsSz4WQVGjBiBrKwstGvXDoGBgZgyZYrOjeY2b94MOzs7dO7cGa+//jrGjx8Pc3Nzbb8UmUyGP/74A507d8bo0aPRsGFDDB06FAkJCc/9I9DU1BTXrl3DwIED0bBhQ0yYMAGBgYF49913y7wdzZs3x/Lly7FkyRI0bdoU27ZtQ0hISJmX98S4ceOwc+dOnSMUixcvxsCBA/HOO++gVatWiI2NxcGDBwvd/HXx4sWYMmUKWrdujeTkZOzduxfGxgWnGf38/DBx4kQMGTIENjY2WLp0ablrfSIgIABz587FzJkz0bZtW6Snp2PEiBEVtvyn+fn54eTJk5DL5ejTpw88PDwQHByMkSNH4vDhw8We5TAyMsKCBQuQnZ39wvVMnz5dpyP2k0vUfX19dT6vpqam2Lhxo86pquzsbOzZs0fnwEVVkonS9lKqYVQqFSwtLZGWlsZLxokkJjs7G/Hx8XBzc9PpkPpc6cnA2VCgzeiCTsYlVdb5KtCdO3fg5OSEsLAw9OjRQy81VCUhBNq3b4+pU6c+93TLsyIiItCtWzc8evSoyLsVU9Vas2YNdu/ejUOHDj23TXH/h8v7/a3Xq6iIiKqUsRng2qngZ1XMVw5//vknMjIy4OPjg6SkJMycOROurq7o3LlzldWgTzKZDOvWrcPly5f1XQqVkZGREVavXq239TPgEFHtoTAv6F9TVfOVQ15eHmbPno2bN2/C3Nwcfn5+2LZtW6ErcKSsRYsWJXooJ1VP48aN0+v6GXCIiKqhgIAA3g6jlLp27Vrqe8OQdLGTMREREUkOAw4R1Xj8q52oZqrM/7sMOERUY8nlcgBlv2MuEenXk/sQVUbfMvbBIaIay9DQEKampvj3339hZGRU6MnKRFQ9CSGQmZmJlJQU1K1bV/vHSkViwCGiGksmk8HBwQHx8fFISEjQdzlEVEp169aFvX3l3FuKAYeIajRjY2N4enryNBVRDWNkZFQpR26eYMAhohrPwMCgZHcyJqJagyesiYiISHIYcIiIiEhyGHCIiIhIciTfB+fJTYRUKpWeKyEiIqKSevK9XdabAUo+4Dx48AAA4OTkpOdKiIiIqLTS09NhaWlZ6vkkH3Dq168PAEhMTCzTDqqJVCoVnJyccPv2bVhYWOi7nCrD7a49210btxmondtdG7cZqJ3b/ew2CyGQnp4OR0fHMi1P8gHnyZ1NLS0ta82H5AkLC4tat80At7s2qY3bDNTO7a6N2wzUzu1+epvLc2CCnYyJiIhIchhwiIiISHIkH3AUCgU++eQTKBQKfZdSZWrjNgPc7tq03bVxm4Haud21cZuB2rndFb3NMlHW66+IiIiIqinJH8EhIiKi2ocBh4iIiCSHAYeIiIgkhwGHiIiIJEfSAeebb76Bq6srTExM0L59e5w+fVrfJVWqkJAQtG3bFubm5rC1tcWAAQMQExOj77Kq1OLFiyGTyRAUFKTvUirdP//8g7fffhtWVlZQKpXw8fHB2bNn9V1WpVKr1Zg7dy7c3NygVCrh7u6OBQsWlPlZNdXR0aNH0a9fPzg6OkImk2HPnj0604UQmDdvHhwcHKBUKuHv748bN27op9gKVNx25+Xl4aOPPoKPjw/MzMzg6OiIESNG4O7du/oruAK86L1+2sSJEyGTybBy5coqq6+ylGS7r169itdeew2WlpYwMzND27ZtkZiYWKr1SDbg7Nq1C9OmTcMnn3yC8+fPo3nz5ggICEBKSoq+S6s0R44cQWBgIE6ePInDhw8jLy8PvXr1wuPHj/VdWpU4c+YMvv32WzRr1kzfpVS6R48eoWPHjjAyMsL+/fsRHR2NZcuWoV69evourVItWbIEa9aswddff42rV69iyZIlWLp0KVavXq3v0irM48eP0bx5c3zzzTdFTl+6dClWrVqFtWvX4tSpUzAzM0NAQACys7OruNKKVdx2Z2Zm4vz585g7dy7Onz+PX375BTExMXjttdf0UGnFedF7/cTu3btx8uTJMj+yoLp50XbHxcWhU6dOaNSoESIiInDp0iXMnTsXJiYmpVuRkKh27dqJwMBA7Wu1Wi0cHR1FSEiIHquqWikpKQKAOHLkiL5LqXTp6enC09NTHD58WHTp0kVMmTJF3yVVqo8++kh06tRJ32VUub59+4oxY8bojHvjjTfE8OHD9VRR5QIgdu/erX2t0WiEvb29+OKLL7TjUlNThUKhEDt27NBDhZXj2e0uyunTpwUAkZCQUDVFVbLnbfOdO3fESy+9JK5cuSJcXFzEihUrqry2ylTUdg8ZMkS8/fbb5V62JI/g5Obm4ty5c/D399eOMzAwgL+/PyIjI/VYWdVKS0sD8L8HjkpZYGAg+vbtq/OeS9lvv/2GNm3aYNCgQbC1tUXLli3x3Xff6busSufn54fw8HBcv34dAHDx4kUcP34cffr00XNlVSM+Ph7Jyck6n3NLS0u0b9++Vv1uAwp+v8lkMtStW1ffpVQajUaDd955BzNmzECTJk30XU6V0Gg0+P3339GwYUMEBATA1tYW7du3L/b03fNIMuDcv38farUadnZ2OuPt7OyQnJysp6qqlkajQVBQEDp27IimTZvqu5xKtXPnTpw/fx4hISH6LqXK3Lx5E2vWrIGnpycOHjyISZMmYfLkydi0aZO+S6tUs2bNwtChQ9GoUSMYGRmhZcuWCAoKwvDhw/VdWpV48vurNv9uA4Ds7Gx89NFHGDZsmKQfRLlkyRIYGhpi8uTJ+i6lyqSkpCAjIwOLFy9G7969cejQIbz++ut44403cOTIkVItS/JPE6+tAgMDceXKFRw/flzfpVSq27dvY8qUKTh8+HDpz8/WYBqNBm3atMHnn38OAGjZsiWuXLmCtWvXYuTIkXqurvL88MMP2LZtG7Zv344mTZogKioKQUFBcHR0lPR20//k5eVh8ODBEEJgzZo1+i6n0pw7dw5fffUVzp8/D5lMpu9yqoxGowEA9O/fH1OnTgUAtGjRAidOnMDatWvRpUuXEi9LkkdwrK2tIZfLce/ePZ3x9+7dg729vZ6qqjrvv/8+9u3bh7/++gsvv/yyvsupVOfOnUNKSgpatWoFQ0NDGBoa4siRI1i1ahUMDQ2hVqv1XWKlcHBwQOPGjXXGeXt7l/oqg5pmxowZ2qM4Pj4+eOeddzB16tRac/Tuye+v2vq77Um4SUhIwOHDhyV99ObYsWNISUmBs7Oz9ndbQkICPvzwQ7i6uuq7vEpjbW0NQ0PDCvn9JsmAY2xsjNatWyM8PFw7TqPRIDw8HL6+vnqsrHIJIfD+++9j9+7d+PPPP+Hm5qbvkipdjx49cPnyZURFRWmHNm3aYPjw4YiKioJcLtd3iZWiY8eOhW4BcP36dbi4uOipoqqRmZkJAwPdX1tyuVz7V5/Uubm5wd7eXud3m0qlwqlTpyT9uw34X7i5ceMGwsLCYGVlpe+SKtU777yDS5cu6fxuc3R0xIwZM3Dw4EF9l1dpjI2N0bZt2wr5/SbZU1TTpk3DyJEj0aZNG7Rr1w4rV67E48ePMXr0aH2XVmkCAwOxfft2/PrrrzA3N9eek7e0tIRSqdRzdZXD3Ny8UB8jMzMzWFlZSbrv0dSpU+Hn54fPP/8cgwcPxunTp7Fu3TqsW7dO36VVqn79+mHRokVwdnZGkyZNcOHCBSxfvhxjxozRd2kVJiMjA7GxsdrX8fHxiIqKQv369eHs7IygoCAsXLgQnp6ecHNzw9y5c+Ho6IgBAwbor+gKUNx2Ozg44M0338T58+exb98+qNVq7e+3+vXrw9jYWF9ll8uL3utnQ5yRkRHs7e3h5eVV1aVWqBdt94wZMzBkyBB07twZ3bp1w4EDB7B3715ERESUbkXlvg6rGlu9erVwdnYWxsbGol27duLkyZP6LqlSAShyCA0N1XdpVao2XCYuhBB79+4VTZs2FQqFQjRq1EisW7dO3yVVOpVKJaZMmSKcnZ2FiYmJaNCggfj4449FTk6OvkurMH/99VeR/49HjhwphCi4VHzu3LnCzs5OKBQK0aNHDxETE6PfoitAcdsdHx//3N9vf/31l75LL7MXvdfPkspl4iXZ7vXr1wsPDw9hYmIimjdvLvbs2VPq9ciEkNAtQImIiIgg0T44REREVLsx4BAREZHkMOAQERGR5DDgEBERkeQw4BAREZHkMOAQERGR5DDgEBERkeQw4BAREZHkMOAQVRO3bt2CTCZDVFSUvkvRu4iICMhkMqSmphbbztXVFStXrizVsrt27YqgoKAy11ZWlfn+lnR/VTe5ubnw8PDAiRMnKm0da9euRb9+/Spt+VR9MeBQtRYZGQm5XI6+ffvqu5RqadSoUTX+GURF8fPzQ1JSEiwtLQEAGzduRN26dfVb1FOqW6B4dn9VtV9++QW9evWClZVVqULc2rVr4ebmBj8/v0qrbcyYMTh//jyOHTtWaeug6okBh6q19evX44MPPsDRo0dx9+7dSl2XEAL5+fmVug4qGWNjY9jb20Mmk+m7lBpB3/vr8ePH6NSpE5YsWVLieYQQ+PrrrzF27NhKrKxg37z11ltYtWpVpa6Hqh8GHKq2MjIysGvXLkyaNAl9+/bFxo0btdPeeustDBkyRKd9Xl4erK2tsXnzZgCARqNBSEgI3NzcoFQq0bx5c/z000/a9k/+Ct+/fz9at24NhUKB48ePIy4uDv3794ednR3q1KmDtm3bIiwsTGddSUlJ6Nu3L5RKJdzc3LB9+/ZCp0tSU1Mxbtw42NjYwMLCAt27d8fFixdLvP1qtRpjx47V1u/l5YWvvvpKO33+/PnYtGkTfv31V8hkMshkMu3Tdm/fvo3Bgwejbt26qF+/Pvr3749bt25p531y5OfLL7+Eg4MDrKysEBgYiLy8PG2bnJwcfPTRR3BycoJCoYCHhwfWr18PIQQ8PDzw5Zdf6tQbFRUFmUym85TgJ65cuQIDAwP8+++/AICHDx/CwMAAQ4cO1bZZuHAhOnXqpPPepKamIiIiAqNHj0ZaWpp2O+fPn6+dLzMzE2PGjIG5uTmcnZ1L9ET1/Px8vP/++7C0tIS1tTXmzp2Lpx/Lt2XLFrRp0wbm5uawt7fHW2+9hZSUFAAFp5q6desGAKhXrx5kMhlGjRoFoOAzt3TpUnh4eEChUMDZ2RmLFi3SWffNmzfRrVs3mJqaonnz5oiMjHxhvQCQkJCAfv36oV69ejAzM0OTJk3wxx9/FNpfQMFpuCf76unhyWegvJ/NZ73zzjuYN28e/P39SzzPuXPnEBcXp3N09slpvB9++AH/+c9/oFQq0bZtW1y/fh1nzpxBmzZtUKdOHfTp00f7WXqy/e3atYOZmRnq1q2Ljh07IiEhQTu9X79++O2335CVlVXmbaQaqEIeDUpUCdavXy/atGkjhCh4cra7u7vQaDRCCCH27dsnlEqlSE9P17bfu3evUCqVQqVSCSGEWLhwoWjUqJE4cOCAiIuLE6GhoUKhUIiIiAghxP+eaNusWTNx6NAhERsbKx48eCCioqLE2rVrxeXLl8X169fFnDlzhImJiUhISNCuy9/fX7Ro0UKcPHlSnDt3TnTp0kUolUqdJ/36+/uLfv36iTNnzojr16+LDz/8UFhZWYkHDx4Uub1Pnph84cIFIYQQubm5Yt68eeLMmTPi5s2bYuvWrcLU1FTs2rVLCCFEenq6GDx4sOjdu7dISkoSSUlJIicnR+Tm5gpvb28xZswYcenSJREdHS3eeust4eXlpX3q9siRI4WFhYWYOHGiuHr1qti7d68wNTXVeSL54MGDhZOTk/jll19EXFycCAsLEzt37hRCCLFo0SLRuHFjnfonT54sOnfuXOS2aTQaYW1tLX788UchhBB79uwR1tbWwt7eXmd/ffzxxzrvzaNHj0ROTo5YuXKlsLCw0G7nk/fdxcVF1K9fX3zzzTfixo0bIiQkRBgYGIhr164VWYcQBU+br1OnjpgyZYq4du2adr8+ve3r168Xf/zxh4iLixORkZHC19dX9OnTRwghRH5+vvj5558FABETEyOSkpJEamqqEEKImTNninr16omNGzeK2NhYcezYMfHdd9/pvL+NGjUS+/btEzExMeLNN98ULi4uIi8v77n1PtG3b1/Rs2dPcenSJREXFyf27t0rjhw5Umh/CSHEgwcPtPsqKSlJvPHGG8LLy0tkZmZq93Vxn82jR48KMzOzYoetW7cWqvHZz3Bxli9fLho1alTk/E/+30ZHR4sOHTqI1q1bi65du4rjx4+L8+fPCw8PDzFx4kQhhBB5eXnC0tJSTJ8+XcTGxoro6GixceNGnf+vjx8/FgYGBjX6yeNUegw4VG35+fmJlStXCiEKfolZW1trf0E9eb1582Zt+2HDhokhQ4YIIYTIzs4Wpqam4sSJEzrLHDt2rBg2bJgQ4n9fCnv27HlhLU2aNBGrV68WQghx9epVAUCcOXNGO/3GjRsCgDbgHDt2TFhYWIjs7Gyd5bi7u4tvv/22yHWU5MshMDBQDBw4UPt65MiRon///jpttmzZIry8vLRhUAghcnJyhFKpFAcPHtTO5+LiIvLz87VtBg0apN1/MTExAoA4fPhwkXX8888/Qi6Xi1OnTgkhCsKYtbW12Lhx43Nrf+ONN0RgYKAQQoigoCAxY8YMUa9ePXH16lWRm5srTE1NxaFDh4QQhb+wQ0NDhaWlZaFluri4iLffflv7WqPRCFtbW7FmzZrn1tGlSxfh7e2ts38++ugj4e3t/dx5zpw5IwBog9Wz9QkhhEqlEgqFQhtonvXk/f3++++14/7++28BQFy9evW5637Cx8dHzJ8/v8hpRdXzxPLly0XdunVFTEyMEKJkn83MzExx48aNYocnf0gUtY0lCThTpkwR3bt3L3L+p/fRjh07BAARHh6uHRcSEiK8vLyEEAVhDoD2D5fneRI8qfYwrMKDRUQlFhMTg9OnT2P37t0AAENDQwwZMgTr169H165dYWhoiMGDB2Pbtm1455138PjxY/z666/YuXMnACA2NhaZmZno2bOnznJzc3PRsmVLnXFt2rTReZ2RkYH58+fj999/R1JSEvLz85GVlYXExERtbYaGhmjVqpV2Hg8PD9SrV0/7+uLFi8jIyICVlZXOsrOyshAXF1fi/fDNN99gw4YNSExMRFZWFnJzc9GiRYti57l48SJiY2Nhbm6uMz47O1tn3U2aNIFcLte+dnBwwOXLlwEUnG6Sy+Xo0qVLketwdHRE3759sWHDBrRr1w579+5FTk4OBg0a9Ny6unTpoj19dOTIEXz++ee4fv06IiIi8PDhQ+Tl5aFjx47FbltRmjVrpv23TCaDvb299nTS83To0EGnv4qvry+WLVsGtVoNuVyOc+fOYf78+bh48SIePXoEjUYDAEhMTETjxo2LXObVq1eRk5ODHj16lLheBwcHAEBKSgoaNWpU7HyTJ0/GpEmTcOjQIfj7+2PgwIE6yyrK/v37MWvWLOzduxcNGzYEULLPplKphIeHR7HLLq+srCyYmJgUOe3p7bKzswMA+Pj46Ix78h7Xr18fo0aNQkBAAHr27Al/f38MHjxYu2+fUCqVyMzMrOjNoGqMAYeqpfXr1yM/Px+Ojo7acUIIKBQKfP3117C0tMTw4cPRpUsXpKSk4PDhw1AqlejduzeAgpACAL///jteeuklnWUrFAqd12ZmZjqvp0+fjsOHD+PLL7+Eh4cHlEol3nzzTeTm5pa4/oyMDDg4OGj7xDytpFcD7dy5E9OnT8eyZcvg6+sLc3NzfPHFFzh16tQL1926dWts27at0DQbGxvtv42MjHSmyWQy7Re5Uql8YX3jxo3DO++8gxUrViA0NBRDhgyBqanpc9s/uTz7xo0biI6ORqdOnXDt2jVERETg0aNHaNOmTbHzP09x21EWjx8/RkBAAAICArBt2zbY2NggMTERAQEBxX4GSrLPnq33ScgqSb3jxo1DQEAAfv/9dxw6dAghISFYtmwZPvjggyLbR0dHY+jQoVi8eDF69eqlHV+Sz+axY8fQp0+fYuv59ttvMXz48BfW/TzW1tbaQP2sovbRs+Oe3mehoaGYPHkyDhw4gF27dmHOnDk4fPgwOnTooG3z8OFDnc8/SR8DDlU7+fn52Lx5M5YtW6bzixkABgwYgB07dmDixInw8/ODk5MTdu3ahf3792PQoEHaX4KNGzeGQqFAYmLic49CPM9///tfjBo1Cq+//jqAgi+Epzvoenl5IT8/HxcuXEDr1q0BFBwxevTokbZNq1atkJycDENDQ7i6upZhLxTU4efnh/fee0877tmjP8bGxlCr1TrjWrVqhV27dsHW1hYWFhZlWrePjw80Gg2OHDny3I6jr7zyCszMzLBmzRocOHAAR48efeEy69Wrh4ULF6JFixaoU6cOunbtiiVLluDRo0fo2rXrc+ctajvL49mQePLkSXh6ekIul+PatWt48OABFi9eDCcnJwDA2bNnC9UDQKcmT09PKJVKhIeHY9y4cRVW69OcnJwwceJETJw4EcHBwfjuu++KDDj3799Hv379MHDgQEydOlVnWkk+m23atHnhpd5PjqyUVcuWLbFmzRoIISrk6q+WLVuiZcuWCA4Ohq+vL7Zv364NOHFxccjOzi509JakjVdRUbWzb98+PHr0CGPHjkXTpk11hoEDB2L9+vXatm+99RbWrl2Lw4cP6/w1aW5ujunTp2Pq1KnYtGkT4uLicP78eaxevRqbNm0qdv2enp745ZdfEBUVhYsXL+Ktt97S+WuxUaNG8Pf3x4QJE3D69GlcuHABEyZMgFKp1P6i9vf3h6+vLwYMGIBDhw7h1q1bOHHiBD7++ONCX5bF1XH27FkcPHgQ169fx9y5c3HmzBmdNq6urrh06RJiYmJw//595OXlYfjw4bC2tkb//v1x7NgxxMfHIyIiApMnT8adO3dKtG5XV1eMHDkSY8aMwZ49e7TL+OGHH7Rt5HI5Ro0aheDgYHh6esLX17fYZcpkMnTu3Bnbtm3ThplmzZohJycH4eHhxQZRV1dXZGRkIDw8HPfv3y/3qYbExERMmzYNMTEx2LFjB1avXo0pU6YAAJydnWFsbIzVq1fj5s2b+O2337BgwQKd+V1cXCCTybBv3z78+++/yMjIgImJCT766CPMnDkTmzdvRlxcHE6ePKnzeS2PoKAgHDx4EPHx8Th//jz++usveHt7F9l24MCBMDU1xfz585GcnKwd1Gp1iT6bT05RFTc8fQr04cOHiIqKQnR0NICC07hRUVFITk5+7vZ069YNGRkZ+Pvvv8u1X+Lj4xEcHIzIyEgkJCTg0KFDuHHjhs6+OXbsGBo0aAB3d/dyrYtqGH13AiJ61quvvipeeeWVIqedOnVKABAXL14UQggRHR0tAAgXFxedTqNCFHQ4XblypfDy8hJGRkbCxsZGBAQEPPfKkyfi4+NFt27dhFKpFE5OTuLrr78WXbp0EVOmTNG2uXv3rujTp49QKBTCxcVFbN++Xdja2oq1a9dq26hUKvHBBx8IR0dHYWRkJJycnMTw4cNFYmJikdv2bAfN7OxsMWrUKGFpaSnq1q0rJk2aJGbNmiWaN2+unSclJUX07NlT1KlTRwDQdsJOSkoSI0aMENbW1kKhUIgGDRqI8ePHi7S0NCFE0Z2Tp0yZIrp06aJ9nZWVJaZOnSocHByEsbGx8PDwEBs2bNCZJy4uTgAQS5cuLXKbnrVixQoBQOzfv187rn///sLQ0FDnirii3puJEycKKysrAUB88sknQoiCTsZPX7kmhBDNmzfXTi9Kly5dxHvvvScmTpwoLCwsRL169cTs2bN1Pj/bt28Xrq6uQqFQCF9fX/Hbb78V6jz72WefCXt7eyGTycTIkSOFEEKo1WqxcOFC4eLiIoyMjISzs7P4/PPPhRBFd8B99OiRzvtWnPfff1+4u7sLhUIhbGxsxDvvvCPu379f5P4CUOQQHx8vhCj9Z/NFQkNDi1xfce+DEAVX6s2aNUv7uqh9VNRn4elO58nJyWLAgAHaz6mLi4uYN2+eUKvV2va9evUSISEhZdo2qrlkQjx18wciKpM7d+7AyckJYWFhL+xkKiXHjh1Djx49cPv27XKfsqDa59KlS+jZsyfi4uJQp06dSlnH33//je7du+P69et6u9Mz6QcDDlEZ/Pnnn8jIyICPjw+SkpIwc+ZM/PPPP7h+/XqhTq9SlJOTg3///RcjR46Evb19kR2aiUpi48aNaN26tc5VUhUpLCwMarUaAQEBlbJ8qr7YB4eoDPLy8jB79mw0adIEr7/+OmxsbBAREVErwg0A7NixAy4uLkhNTcXSpUv1XY4k9OnTB3Xq1Cly+Pzzz/VdXqUZNWpUpYUboKA/HMNN7cQjOERE1cA///zz3EcJ1K9fH/Xr16/iiohqNgYcIiIikhyeoiIiIiLJYcAhIiIiyWHAISIiIslhwCEiIiLJYcAhIiIiyWHAISIiIslhwCEiIiLJ+X9oulqb3DKLoAAAAABJRU5ErkJggg==\n"
+ },
+ "metadata": {}
+ }
+ ],
+ "source": [
+ "plot_metrics(perf_metrics)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "By applying ONNX, we were able to improve the latency from 13.43ms per sample to 2.19ms per sample, for a speedup of 6.13x!\n",
+ "\n",
+ "For further improvements, we recommend increasing the inference batch size, as this may also heavily improve the throughput. For example, setting the batch size to 128 reduces the latency further down to 0.3ms, and down to 0.2ms at a batch size of 2048."
+ ],
+ "metadata": {
+ "id": "gvdggvIbvowO"
+ },
+ "id": "gvdggvIbvowO"
+ },
+ {
+ "cell_type": "code",
+ "source": [],
+ "metadata": {
+ "id": "h5ExEou96k3Z"
+ },
+ "id": "h5ExEou96k3Z",
+ "execution_count": null,
+ "outputs": []
+ }
+ ],
+ "metadata": {
+ "accelerator": "GPU",
+ "colab": {
+ "gpuType": "T4",
+ "provenance": []
+ },
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.9.16"
+ },
+ "vscode": {
+ "interpreter": {
+ "hash": "31f2aee4e71d21fbe5cf8b01ff0e069b9275f58929596ceb00d14d90e3e16cd6"
+ }
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
\ No newline at end of file
diff --git a/notebooks/zero-shot-classification.ipynb b/notebooks/zero-shot-classification.ipynb
index 8a0f0737..509eeb03 100644
--- a/notebooks/zero-shot-classification.ipynb
+++ b/notebooks/zero-shot-classification.ipynb
@@ -297,7 +297,7 @@
"id": "85a0d010-389a-4bc1-aaef-4814c0c96e45",
"metadata": {},
"source": [
- "we can see that each input takes the form of the template and has a corresponding label associated with it. \n",
+ "We can see that each input takes the form of the template and has a corresponding label associated with it. \n",
"\n",
"Let's not train a SetFit model on these examples!"
]
@@ -562,7 +562,7 @@
"id": "01c7c784-3896-483f-bc60-43373a38b4ed",
"metadata": {},
"source": [
- "we can use the `str2int()` function from the `label` column to convert them to integers. "
+ "We can use the `str2int()` function from the `label` column to convert them to integers. "
]
},
{
@@ -988,7 +988,7 @@
"outputs": [
{
"data": {
- "image/png": "iVBORw0KGgoAAAANSUhEUgAAAswAAAGdCAYAAAAG6yXVAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjYuMiwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy8o6BhiAAAACXBIWXMAAA9hAAAPYQGoP6dpAAA8mklEQVR4nO3deVxV1f7/8fcBZFAGJxQoBIdwNkHTtJwxp0zNcriVoWldrWzStK+SUzmlpmWDM3brSpZm3lJTuel1SlPBVMiBK2KFQ06Imijs3x9e988juOUgehBfz8djPx6cfdZe+7MXlG8Wa+9jMwzDEAAAAIBcuTi7AAAAAKAwIzADAAAAFgjMAAAAgAUCMwAAAGCBwAwAAABYIDADAAAAFgjMAAAAgAUCMwAAAGDBzdkFAHe67Oxs/fHHH/Lx8ZHNZnN2OQAAIA8Mw9CZM2cUFBQkFxfrOWQCM3CT/vjjDwUHBzu7DAAAkA+HDh3Svffea9mGwAzcJB8fH0mX/4Pz9fV1cjUAACAv0tPTFRwcbP47boXADNykK8swfH19CcwAANxh8rKckpv+AAAAAAsEZgAAAMACgRkAAACwQGAGAAAALBCYAQAAAAsEZgAAAMACgRkAAACwQGAGAAAALBCYAQAAAAsEZgAAAMACgRkAAACwQGAGAAAALBCYAQAAAAsEZgAAAMACgRkAAACwQGAGAAAALBCYAQAAAAsEZgAAAMACgRkAAACwQGAGAAAALBCYAQAAAAsEZgAAAMACgRkAAACwQGAGAAAALBCYAQAAAAsEZgAAAMACgRkAAACw4ObsAoCiotaIH+TiUdzZZQAAUGSkjO/g7BIkMcMMAAAAWCIwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwFwI2m01LlizJ17HR0dF6/vnnC7agu0jz5s316quvmq8ffPBBLVq0yHkFAQCAQofAfJVjx46pf//+qlChgjw8PBQQEKA2bdpow4YNee5j5MiRqlu3bo79oaGhstlsdtu9994rSUpLS1O7du0kSSkpKbLZbEpISLjhuQ4fPqxp06Zp2LBhea6vKLg25Bak4cOHa+jQocrOzr4l/QMAgDsPgfkqXbt2VXx8vObPn6+9e/dq6dKlat68uY4fP14g/Y8ePVppaWnmFh8fL0kKCAiQh4eHw/3Nnj1bjRs3VkhISIHUB6ldu3Y6c+aMli9f7uxSAABAIUFg/p9Tp05p3bp1mjBhglq0aKGQkBA1aNBAb731lh577DG7dn379pW/v798fX3VsmVL7dixQ5IUExOjUaNGaceOHeYsckxMjHmsj4+PAgICzM3f31+S/ZKMihUrSpLCw8Nls9nUvHnz69YcGxurjh072u1bsWKFHn74YZUsWVJlypTRo48+quTkZPP9NWvWyGaz6dSpU+a+hIQE2Ww2paSkmPtmzZql4OBgFS9eXF26dNGUKVNUsmRJ8/0rM+lz585VhQoV5O3trQEDBigrK0sTJ05UQECAypUrp3fffTfHOF9v/K7u9x//+IdCQ0Pl5+enHj166MyZM5KkqKgorV27VtOmTTPH+Erdu3btUrt27eTt7a3y5cvrmWee0Z9//mn2ffbsWfXq1Uve3t4KDAzU5MmTc4ypq6ur2rdvr9jY2OuOOwAAuLsQmP/H29tb3t7eWrJkiS5cuHDddk8++aSOHj2q5cuXa9u2bYqIiFCrVq104sQJde/eXW+88YZq1qxpziJ3797doTq2bNkiSVq9erXS0tK0ePHiXNudOHFCiYmJql+/vt3+s2fP6vXXX9fWrVsVFxcnFxcXdenSxaElBhs2bNDf//53vfLKK0pISFDr1q1zBF9JSk5O1vLly7VixQotWLBAc+bMUYcOHfTbb79p7dq1mjBhgoYPH67Nmzebx1iN39X9LlmyRN99952+++47rV27VuPHj5ckTZs2TY0aNVK/fv3MMQ4ODtapU6fUsmVLhYeHa+vWrVqxYoWOHDmibt26mf0OHjxYa9eu1bfffquVK1dqzZo12r59e47ratCggdatW3fd8blw4YLS09PtNgAAUHS5ObuAwsLNzU0xMTHq16+fPv30U0VERKhZs2bq0aOH6tSpI0lav369tmzZoqNHj5pLKCZNmqQlS5bo66+/1vPPPy9vb2+5ubkpICAgxzmGDBmi4cOHm6/Hjh2rgQMH2rW5MutcpkyZXPu4IjU1VYZhKCgoyG5/165d7V7PnTtX/v7+SkxMVK1atfI0Fh9++KHatWunQYMGSZLCwsK0ceNGfffdd3btsrOzNXfuXPn4+KhGjRpq0aKF9uzZo2XLlsnFxUVVq1bVhAkT9OOPP6phw4Z5Gr8r/cbExMjHx0eS9MwzzyguLk7vvvuu/Pz85O7uruLFi9uNz/Tp0xUeHq6xY8faXXtwcLD27t2roKAgzZkzR59//rlatWolSZo/f765jvxqQUFBOnTokLKzs+XikvN3ynHjxmnUqFF5GksAAHDnY4b5Kl27dtUff/yhpUuXqm3btlqzZo0iIiLMZRU7duxQRkaGypQpY85Ie3t768CBA3bLHq5n8ODBSkhIMLdevXrlu9bz589Lkjw9Pe3279u3Tz179lSlSpXk6+ur0NBQSZcDdl7t2bNHDRo0sNt37Wvp8o2MV0KtJJUvX141atSwC5nly5fX0aNHJeV9/K7tNzAw0Ozjenbs2KEff/zRrt9q1apJujxjnZycrMzMTDVs2NA8pnTp0qpatWqOvry8vJSdnX3dvzS89dZbOn36tLkdOnTIsjYAAHBnY4b5Gp6enmrdurVat26t6Oho9e3bVyNGjFBUVJQyMjIUGBioNWvW5Dju6vW911O2bFlVqVKlQOosW7asJOnkyZPmrLQkdezYUSEhIZo1a5aCgoKUnZ2tWrVqKTMzU5LMMGsYhnnMxYsX81VDsWLF7F7bbLZc911ZDpLX8bPq43oyMjLUsWNHTZgwIcd7gYGB2r9/v+XxVztx4oRKlCghLy+vXN/38PDI102aAADgzkRgvoEaNWqYN+RFRETo8OHDcnNzM2dur+Xu7q6srKx8n8/d3V2SbthH5cqV5evrq8TERIWFhUmSjh8/rj179mjWrFlq0qSJpMvLSK52JVynpaWpVKlSkpTjEXZVq1bVzz//bLfv2tf5kZfxy4vcxjgiIkKLFi1SaGio3Nxy/lhXrlxZxYoV0+bNm1WhQgVJl3/Z2Lt3r5o1a2bXdteuXQoPD893fQAAoGhhScb/HD9+XC1bttTnn3+uX375RQcOHNBXX32liRMnqlOnTpKkyMhINWrUSJ07d9bKlSuVkpKijRs3atiwYdq6dauky8sJDhw4oISEBP3555+WNxDmply5cvLy8jJvWjt9+nSu7VxcXBQZGWkXiEuVKqUyZcpo5syZ2r9/v/7973/r9ddftzuuSpUqCg4O1siRI7Vv3z59//33OZ4W8fLLL2vZsmWaMmWK9u3bpxkzZmj58uWy2WwOXcu18jJ+eREaGqrNmzcrJSVFf/75p7Kzs/Xiiy/qxIkT6tmzp37++WclJyfrhx9+UO/evZWVlSVvb28999xzGjx4sP79739r165dioqKynWN8rp16/TII4/c1LUCAICig8D8P97e3mrYsKHef/99NW3aVLVq1VJ0dLT69eun6dOnS7q8NGDZsmVq2rSpevfurbCwMPXo0UMHDx5U+fLlJV1eB922bVu1aNFC/v7+WrBggUN1uLm56YMPPtCMGTMUFBRkhvXc9O3bV7GxseZyBRcXF8XGxmrbtm2qVauWXnvtNb333nt2xxQrVkwLFizQr7/+qjp16mjChAl655137No89NBD+vTTTzVlyhTdf//9WrFihV577bUc66UdlZfxy4tBgwbJ1dVVNWrUkL+/v1JTUxUUFKQNGzYoKytLjzzyiGrXrq1XX31VJUuWNEPxe++9pyZNmqhjx46KjIzUww8/rHr16tn1/fvvv2vjxo3q3bv3TV0rAAAoOmzG1YtZcUcxDEMNGzbUa6+9pp49e97Sc/Xr10+//vqr5ePWioIhQ4bo5MmTmjlzZp6PSU9Pl5+fn4JfXSgXj+K3sDoAAO4uKeM73LK+r/z7ffr0afn6+lq2ZYb5Dmaz2TRz5kxdunSpwPueNGmSduzYof379+vDDz/U/Pnz9eyzzxb4eQqbcuXKacyYMc4uAwAAFCLc9HeHq1u3rurWrVvg/W7ZskUTJ07UmTNnVKlSJX3wwQfq27dvgZ+nsHnjjTecXQIAAChkCMzI1cKFC51dAgAAQKHAkgwAAADAAoEZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAAoEZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAAoEZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAAoEZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAAoEZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAgpuzCwCKil2j2sjX19fZZQAAgALGDDMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABgwc3ZBQBFRa0RP8jFo7izywAAFGEp4zs4u4S7EjPMAAAAgAUCMwAAAGCBwAwAAABYIDADAAAAFgjMAAAAgAUCMwAAAGCBwAwAAABYIDADAAAAFvL8wSXh4eGy2Wx5art9+/Z8FwQAAAAUJnkOzJ07dza//uuvv/Txxx+rRo0aatSokSTpp59+0u7duzVgwIACLxIAAABwljwH5hEjRphf9+3bVwMHDtSYMWNytDl06FDBVQcAAAA4Wb7WMH/11Vfq1atXjv1PP/20Fi1adNNFAQAAAIVFvgKzl5eXNmzYkGP/hg0b5OnpedNFAQAAAIVFnpdkXO3VV19V//79tX37djVo0ECStHnzZs2dO1fR0dEFWiAAAADgTPkKzEOHDlWlSpU0bdo0ff7555Kk6tWra968eerWrVuBFggAAAA4U74CsyR169aNcAwAAIAiL9+BWZK2bdumpKQkSVLNmjUVHh5eIEUBAAAAhUW+AvPRo0fVo0cPrVmzRiVLlpQknTp1Si1atFBsbKz8/f0LskYAAADAafL1lIyXX35ZZ86c0e7du3XixAmdOHFCu3btUnp6ugYOHFjQNQIAAABOk68Z5hUrVmj16tWqXr26ua9GjRr66KOP9MgjjxRYcQAAAICz5WuGOTs7W8WKFcuxv1ixYsrOzr7pogAAAIDCIl+BuWXLlnrllVf0xx9/mPt+//13vfbaa2rVqlWBFQcAAAA4W74C8/Tp05Wenq7Q0FBVrlxZlStXVsWKFZWenq4PP/ywoGsEAAAAnCZfa5iDg4O1fft2rV69Wr/++qukyx9cEhkZWaDFAQAAAM6W7+cw22w2tW7dWq1bty7IegAAAIBCJd+BOS4uTnFxcTp69GiOG/3mzp1704Uhb2w2m7755ht17tzZ4WOjo6N15MgRzZw5s+ALu4WioqJ06tQpLVmypMD7fvDBBzV48GB17dq1wPsGAAB3pnytYR41apQeeeQRxcXF6c8//9TJkyfttrvRsWPH1L9/f1WoUEEeHh4KCAhQmzZttGHDhjz3MXLkSNWtWzfH/tDQUNlsNrvt3nvvlSSlpaWpXbt2kqSUlBTZbDYlJCTc8FyHDx/WtGnTNGzYsDzXV5TExMSYH7pzteHDh2vo0KE87QUAAJjyNcP86aefKiYmRs8880xB13PH6tq1qzIzMzV//nxVqlRJR44cUVxcnI4fP14g/Y8ePVr9+vUzX7u6ukqSAgIC8tXf7Nmz1bhxY4WEhBRIfbnJzMyUu7v7Lev/VmjXrp369u2r5cuXq0OHDs4uBwAAFAL5mmHOzMxU48aNC7qWO9apU6e0bt06TZgwQS1atFBISIgaNGigt956S4899phdu759+8rf31++vr5q2bKlduzYIenyjOeoUaO0Y8cOcxY5JibGPNbHx0cBAQHmduXjx202m7k0oWLFipKk8PBw2Ww2NW/e/Lo1x8bGqmPHjubrK7PT125X97F+/Xo1adJEXl5eCg4O1sCBA3X27Fnz/dDQUI0ZM0a9evWSr6+vnn/+eUnSokWLVLNmTXl4eCg0NFSTJ0++4Zh+/fXXql27try8vFSmTBlFRkbanUuSJk2apMDAQJUpU0YvvviiLl68aL538uRJ9erVS6VKlVLx4sXVrl077du3T5K0Zs0a9e7dW6dPnzavc+TIkZIu/yLSvn17xcbGXre2CxcuKD093W4DAABFV74Cc9++ffXPf/6zoGu5Y3l7e8vb21tLlizRhQsXrtvuySef1NGjR7V8+XJt27ZNERERatWqlU6cOKHu3bvrjTfeUM2aNZWWlqa0tDR1797doTq2bNkiSVq9erXS0tK0ePHiXNudOHFCiYmJql+/vrkvODjYPG9aWpri4+NVpkwZNW3aVJKUnJystm3bqmvXrvrll1/05Zdfav369XrppZfs+p40aZLuv/9+xcfHKzo6Wtu2bVO3bt3Uo0cP7dy5UyNHjlR0dLTdLwPXSktLU8+ePdWnTx8lJSVpzZo1evzxx2UYhtnmxx9/VHJysn788UfNnz9fMTExdn1GRUVp69atWrp0qTZt2iTDMNS+fXtdvHhRjRs31tSpU+Xr62te76BBg8xjGzRooHXr1l23vnHjxsnPz8/cgoODr9sWAADc+WzG1SnEwuuvv25+nZ2drfnz56tOnTqqU6dOjk/9mzJlSsFWeQdYtGiR+vXrp/PnzysiIkLNmjVTjx49VKdOHUmXZ2c7dOigo0ePysPDwzyuSpUqevPNN/X8889r5MiRWrJkSY41yKGhoUpLS7Mb57Fjx2rgwIF2N/2lpKSoYsWKio+Pz3Ut9BUJCQkKDw9XampqrmHvr7/+UvPmzeXv769vv/1WLi4u6tu3r1xdXTVjxgyz3fr169WsWTOdPXtWnp6eCg0NVXh4uL755huzzVNPPaVjx45p5cqV5r4333xT33//vXbv3p1rfdu3b1e9evWUkpKS65KRqKgorVmzRsnJyebSlG7dusnFxUWxsbHat2+fwsLCtGHDBvMvIcePH1dwcLDmz5+vJ598UjExMXr11Vd16tSpHP0vXbpUXbp00cWLF+XikvN3ygsXLtj9YpSenq7g4GAFv7pQLh7Fc70mAAAKQsp4lgsWlPT0dPn5+en06dPy9fW1bJvnNczx8fF2r68Esl27djleYRHUtWtXdejQQevWrdNPP/2k5cuXa+LEiZo9e7aioqK0Y8cOZWRkqEyZMnbHnT9/XsnJyTfsf/DgwYqKijJfly1bNt+1nj9/XpLk6emZ6/t9+vTRmTNntGrVKjMw7tixQ7/88ou++OILs51hGMrOztaBAwdUvXp1SbKbtZakpKQkderUyW7fQw89pKlTpyorK0sbN240b1qUpBkzZqhHjx5q1aqVateurTZt2uiRRx7RE088oVKlSpntatasaYZlSQoMDNTOnTvNc7q5ualhw4bm+2XKlFHVqlWVlJR0w/Hx8vJSdna2Lly4IC8vrxzve3h42P3SAwAAirY8B+Yff/zxVtZRJHh6eprPpo6Ojlbfvn01YsQIRUVFKSMjQ4GBgVqzZk2O43J7WsO1ypYtqypVqhRInVfC9smTJ8210Fe88847+uGHH7Rlyxb5+PiY+zMyMvTCCy9o4MCBOfqrUKGC+XWJEiUcqqV+/fp2M+rly5eXq6urVq1apY0bN2rlypX68MMPNWzYMG3evNlcp33tXzVsNluBPdnixIkTKlGiRK5hGQAA3H3ytYb5ygzktc6ePas+ffrcdFFFRY0aNcwb1SIiInT48GG5ubmpSpUqdtuVAOvu7q6srKx8n+/KEylu1EflypXl6+urxMREu/2LFi3S6NGjtXDhQlWuXNnuvYiICCUmJuaovUqVKpZPwqhevXqOR+tt2LBBYWFhcnV1lZeXl11fV0K6zWbTQw89pFGjRik+Pl7u7u52Sz2sVK9eXZcuXdLmzZvNfcePH9eePXtUo0YNSdZjvWvXLoWHh+fpXAAAoOjLV2CeP3+++Wf9q50/f16fffbZTRd1pzl+/Lhatmypzz//XL/88osOHDigr776ShMnTjSXI0RGRqpRo0bq3LmzVq5cqZSUFG3cuFHDhg3T1q1bJV1eq3zgwAElJCTozz//tLyBMDflypWTl5eXVqxYoSNHjuj06dO5tnNxcVFkZKTWr19v7tu1a5d69eqlIUOGqGbNmjp8+LAOHz6sEydOSJKGDBmijRs36qWXXlJCQoL27dunb7/9NsdNf9d64403FBcXpzFjxmjv3r2aP3++pk+fbneT3bU2b96ssWPHauvWrUpNTdXixYt17Ngxc9nHjdx3333q1KmT+vXrp/Xr12vHjh16+umndc8995jfj9DQUGVkZJjPEj937px5/Lp16/TII4/k6VwAAKDocygwp6en6/Tp0zIMQ2fOnLF7rNbJkye1bNkylStX7lbVWmh5e3urYcOGev/999W0aVPVqlVL0dHR6tevn6ZPny7p8ozpsmXL1LRpU/Xu3VthYWHq0aOHDh48qPLly0u6vA66bdu2atGihfz9/bVgwQKH6nBzc9MHH3ygGTNmKCgoKMfa4av17dtXsbGx5jKGrVu36ty5c3rnnXcUGBhobo8//rgkqU6dOlq7dq327t2rJk2aKDw8XG+//baCgoIsa4qIiNDChQsVGxurWrVq6e2339bo0aPt1mNfy9fXV//5z3/Uvn17hYWFafjw4Zo8ebLdWucbmTdvnurVq6dHH31UjRo1kmEYWrZsmbmUo3Hjxvr73/+u7t27y9/fXxMnTpQk/f7779q4caN69+6d53MBAICiLc9PyZAuz0zabLbrd2azadSoUXftp8fdSQzDUMOGDfXaa6+pZ8+ezi6n0BgyZIhOnjzp0MeFX7nLlqdkAABuNZ6SUXBuyVMypMs3/hmGoZYtW2rRokUqXbq0+Z67u7tCQkJuOOOIwsFms2nmzJnmkyVwWbly5eweoQgAAODQDPMVBw8eVIUKFSxnm4G7BTPMAIDbhRnmguPIDHO+bvoLCQnR+vXr9fTTT6tx48b6/fffJUn/+Mc/7G4kAwAAAO50+QrMixYtUps2beTl5aXt27ebT3M4ffq0xo4dW6AFAgAAAM6Ur8D8zjvv6NNPP9WsWbPsPkDioYce0vbt2wusOAAAAMDZ8hWY9+zZo6ZNm+bY7+fnp1OnTt1sTQAAAEChka/AHBAQoP379+fYv379elWqVOmmiwIAAAAKi3wF5n79+umVV17R5s2bZbPZ9Mcff+iLL77QoEGD1L9//4KuEQAAAHAah57DfMXQoUOVnZ2tVq1a6dy5c2ratKk8PDw0aNAgvfzyywVdIwAAAOA0+QrMNptNw4YN0+DBg7V//35lZGSoRo0a8vb2Luj6AAAAAKdyKDD36dMnT+3mzp2br2IAAACAwsahwBwTE6OQkBCFh4crHx8QCAAAANxxHArM/fv314IFC3TgwAH17t1bTz/9tEqXLn2ragMAAACczqGnZHz00UdKS0vTm2++qX/9618KDg5Wt27d9MMPPzDjDAAAgCLJ4cfKeXh4qGfPnlq1apUSExNVs2ZNDRgwQKGhocrIyLgVNQIAAABOk6/nMJsHu7jIZrPJMAxlZWUVVE0AAABAoeFwYL5w4YIWLFig1q1bKywsTDt37tT06dOVmprKY+UAAABQ5Dh009+AAQMUGxur4OBg9enTRwsWLFDZsmVvVW0AAACA0zkUmD/99FNVqFBBlSpV0tq1a7V27dpc2y1evLhAigMAAACczaHA3KtXL9lstltVCwAAAFDoOPzBJQAAAMDd5KaekgEAAAAUdQRmAAAAwIJDSzIAXN+uUW3k6+vr7DIAAEABY4YZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAAoEZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAAoEZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAAoEZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAAoEZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAAoEZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAAoEZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAAoEZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAAoEZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAAoEZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAAoEZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAAoEZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAAoEZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAAoEZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAAoEZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAAoEZAAAAsODm7AKAoqLWiB/k4lHc2WUAuEuljO/g7BKAIosZZgAAAMACgRkAAACwQGAGAAAALBCYAQAAAAsEZgAAAMACgRkAAACwQGAGAAAALBCYAQAAAAsEZgAAAMACgRkAAACwQGAGAAAALBCYAQAAAAsEZgAAAMACgRkAAACwQGAGAAAALBCYAQAAAAsEZgAAAMACgRkAAACwQGAGAAAALBCYAQAAAAsEZgAAAMACgRkAAACwQGAGAAAALBCYAQAAAAsEZgAAAMACgfkahw8fVuvWrVWiRAmVLFnS2eXcUsePH1e5cuWUkpLi7FIckpKSIpvNpoSEhALve8WKFapbt66ys7MLvG8AAHBnclpgttlsltvIkSOdUtf777+vtLQ0JSQkaO/evU6p4XZ599131alTJ4WGhjq7FKcIDQ3V1KlT7fa1bdtWxYoV0xdffOGcogAAQKHj5qwTp6WlmV9/+eWXevvtt7Vnzx5zn7e3t/m1YRjKysqSm9utLzc5OVn16tXTfffdl+8+MjMz5e7uXoBVWbt48aKKFSvm0DHnzp3TnDlz9MMPP9yiqqSsrCzZbDa5uNxZf8iIiorSBx98oGeeecbZpQAAgELAaUkmICDA3Pz8/GSz2czXv/76q3x8fLR8+XLVq1dPHh4eWr9+vZKTk9WpUyeVL19e3t7eeuCBB7R69Wq7fkNDQzV27Fj16dNHPj4+qlChgmbOnGm+n5mZqZdeekmBgYHy9PRUSEiIxo0bZx67aNEiffbZZ7LZbIqKipIkpaamqlOnTvL29pavr6+6deumI0eOmH2OHDlSdevW1ezZs1WxYkV5enpKujyLPmPGDD366KMqXry4qlevrk2bNmn//v1q3ry5SpQoocaNGys5OdnuGr799ltFRETI09NTlSpV0qhRo3Tp0iXzfZvNpk8++USPPfaYSpQooXfffVcnT57UU089JX9/f3l5eem+++7TvHnzrjv+y5Ytk4eHhx588EFzX1RUVK6z/WvWrJEkXbhwQYMGDdI999yjEiVKqGHDhuZ7khQTE6OSJUtq6dKlqlGjhjw8PJSamqqTJ0+qV69eKlWqlIoXL6527dpp3759lj8febme//73v2rRooWKFy+u+++/X5s2bbJ7f9GiRapZs6Y8PDwUGhqqyZMnm+81b95cBw8e1GuvvWZe5xUdO3bU1q1bc3xfAADA3alQT/0NHTpU48ePV1JSkurUqaOMjAy1b99ecXFxio+PV9u2bdWxY0elpqbaHTd58mTVr19f8fHxGjBggPr372/OXn/wwQdaunSpFi5cqD179uiLL74wlyT8/PPPatu2rbp166a0tDRNmzZN2dnZ6tSpk06cOKG1a9dq1apV+u9//6vu3bvbnXP//v1atGiRFi9ebLe2dsyYMerVq5cSEhJUrVo1/e1vf9MLL7ygt956S1u3bpVhGHrppZfM9uvWrVOvXr30yiuvKDExUTNmzFBMTIzeffddu/ONHDlSXbp00c6dO9WnTx9FR0crMTFRy5cvV1JSkj755BOVLVv2umO7bt061atXz27ftGnTlJaWZm6vvPKKypUrp2rVqkmSXnrpJW3atEmxsbH65Zdf9OSTT6pt27Z24ffcuXOaMGGCZs+erd27d6tcuXKKiorS1q1btXTpUm3atEmGYah9+/a6ePHidevLy/UMGzZMgwYNUkJCgsLCwtSzZ0/zF4tt27apW7du6tGjh3bu3KmRI0cqOjpaMTExkqTFixfr3nvv1ejRo83rvaJChQoqX7681q1bl2ttFy5cUHp6ut0GAACKLqctyciL0aNHq3Xr1ubr0qVL6/777zdfjxkzRt98842WLl1qFzrbt2+vAQMGSJKGDBmi999/Xz/++KOqVq2q1NRU3XfffXr44Ydls9kUEhJiHufv7y8PDw95eXkpICBAkrRq1Srt3LlTBw4cUHBwsCTps88+U82aNfXzzz/rgQcekHR55vqzzz6Tv7+/3TX07t1b3bp1M2tp1KiRoqOj1aZNG0nSK6+8ot69e5vtR40apaFDh+rZZ5+VJFWqVEljxozRm2++qREjRpjt/va3v9kdl5qaqvDwcNWvX1+Sbrgu+eDBgwoKCrLb5+fnJz8/P0mXA+WMGTO0evVqBQQEKDU1VfPmzVNqaqp53KBBg7RixQrNmzdPY8eOlXR5ecjHH39sfp/27dunpUuXasOGDWrcuLEk6YsvvlBwcLCWLFmiJ598Mtf68nI9gwYNUocOHcxxq1mzpvbv369q1appypQpatWqlaKjoyVJYWFhSkxM1HvvvaeoqCiVLl1arq6u8vHxMb/XVwsKCtLBgwdzrW3cuHEaNWrU9QcXAAAUKYV6hvlKWLoiIyNDgwYNUvXq1VWyZEl5e3srKSkpxwxznTp1zK+vLPU4evSopMvLDhISElS1alUNHDhQK1eutKwhKSlJwcHBZliWpBo1aqhkyZJKSkoy94WEhOQIy9fWUr58eUlS7dq17fb99ddf5izljh07NHr0aHl7e5tbv379lJaWpnPnzl13bPr376/Y2FjVrVtXb775pjZu3Gh5XefPnzeXjlwrPj5ezzzzjKZPn66HHnpIkrRz505lZWUpLCzMrra1a9faLV1wd3e3u+akpCS5ubmpYcOG5r4yZcqoatWq5vi1a9fO7K9mzZp5vp6rzxMYGChJ5vc5KSnJrP2Khx56SPv27VNWVpbl2EiSl5eX3Xhf7a233tLp06fN7dChQzfsDwAA3LkK9QxziRIl7F4PGjRIq1at0qRJk1SlShV5eXnpiSeeUGZmpl27a2+As9ls5mPCIiIidODAAS1fvlyrV69Wt27dFBkZqa+//rpAa82tlivrZHPbd6W+jIwMjRo1So8//niOvq4OuNeer127djp48KCWLVumVatWqVWrVnrxxRc1adKkXOsqW7asTp48mWP/4cOH9dhjj6lv37567rnnzP0ZGRlydXXVtm3b5OrqanfM1Tdoenl52a0HzovZs2fr/Pnzkv7/2OTleqzG8WadOHEi11+AJMnDw0MeHh4Fch4AAFD4FerAfK0NGzYoKipKXbp0kXQ5xOXnGcK+vr7q3r27unfvrieeeEJt27bViRMnVLp06Rxtq1evrkOHDunQoUPmLHNiYqJOnTqlGjVq3NT15CYiIkJ79uxRlSpVHD7W399fzz77rJ599lk1adJEgwcPvm5gDg8P1+eff26376+//lKnTp3MJQ3Xts/KytLRo0fVpEmTPNdUvXp1Xbp0SZs3bzaXZBw/flx79uwxx++ee+656evJ7bwbNmyw27dhwwaFhYWZgd/d3T3X2ea//vpLycnJCg8Pz/N1AgCAouuOCsz33XefFi9erI4dO8pmsyk6OtrhGcUpU6YoMDBQ4eHhcnFx0VdffaWAgIDrfkhJZGSkateuraeeekpTp07VpUuXNGDAADVr1izHsoiC8Pbbb+vRRx9VhQoV9MQTT8jFxUU7duzQrl279M4771geV69ePdWsWVMXLlzQd999p+rVq1+3fZs2bfTWW2/p5MmTKlWqlCTphRde0KFDhxQXF6djx46ZbUuXLq2wsDA99dRT6tWrlyZPnqzw8HAdO3ZMcXFxqlOnjrmW+Fr33XefOnXqpH79+mnGjBny8fHR0KFDdc8996hTp04Fdj3XeuONN/TAAw9ozJgx6t69uzZt2qTp06fr448/NtuEhobqP//5j3r06CEPDw/zpsKffvpJHh4eatSoUZ7PBwAAiq5CvYb5WlOmTFGpUqXUuHFjdezYUW3atFFERIRDffj4+GjixImqX7++HnjgAaWkpGjZsmXXfVawzWbTt99+q1KlSqlp06aKjIxUpUqV9OWXXxbEJeXQpk0bfffdd1q5cqUeeOABPfjgg3r//fftbk7Mjbu7u9566y3VqVNHTZs2laurq2JjY6/bvnbt2oqIiNDChQvNfWvXrlVaWppq1KihwMBAc7uyfnjevHnq1auX3njjDVWtWlWdO3fWzz//rAoVKljWNm/ePNWrV0+PPvqoGjVqJMMwtGzZMstnRzt6Pde6cm2xsbGqVauW3n77bY0ePdp8VKB0+abSlJQUVa5c2W75xYIFC/TUU0+pePHieT4fAAAoumyGYRjOLgLO8f3332vw4MHatWvXHffhIrfKn3/+qapVq2rr1q2qWLFino5JT0+Xn5+fgl9dKBcPQjYA50gZn/tf+gDk7sq/36dPn5avr69l2ztqSQYKVocOHbRv3z79/vvvdk8BuZulpKTo448/znNYBgAARR+B+S736quvOruEQqV+/fq3ZG06AAC4c/F3eAAAAMACgRkAAACwQGAGAAAALBCYAQAAAAsEZgAAAMACgRkAAACwQGAGAAAALBCYAQAAAAsEZgAAAMACgRkAAACwQGAGAAAALBCYAQAAAAsEZgAAAMACgRkAAACwQGAGAAAALBCYAQAAAAsEZgAAAMACgRkAAACwQGAGAAAALLg5uwAAAIDCLDs7W5mZmc4uAw4qVqyYXF1dC6QvAjMAAMB1ZGZm6sCBA8rOznZ2KciHkiVLKiAgQDab7ab6ITADBWTXqDby9fV1dhkAgAJiGIbS0tLk6uqq4OBgubiwkvVOYRiGzp07p6NHj0qSAgMDb6o/AjMAAEAuLl26pHPnzikoKEjFixd3djlwkJeXlyTp6NGjKleu3E0tz+BXJQAAgFxkZWVJktzd3Z1cCfLryi86Fy9evKl+CMwAAAAWbnb9K5ynoL53BGYAAADAAoEZAAAAsMBNfwAAAA4IHfr9bT1fyvgO+Tpu06ZNevjhh9W2bVt9//3trbmoYYYZAACgCJozZ45efvll/ec//9Eff/zhtDqKwoe+EJgBAACKmIyMDH355Zfq37+/OnTooJiYGLv3//Wvf+mBBx6Qp6enypYtqy5dupjvXbhwQUOGDFFwcLA8PDxUpUoVzZkzR5IUExOjkiVL2vW1ZMkSu5vrRo4cqbp162r27NmqWLGiPD09JUkrVqzQww8/rJIlS6pMmTJ69NFHlZycbNfXb7/9pp49e6p06dIqUaKE6tevr82bNyslJUUuLi7aunWrXfupU6cqJCTkln+wDIEZAACgiFm4cKGqVaumqlWr6umnn9bcuXNlGIYk6fvvv1eXLl3Uvn17xcfHKy4uTg0aNDCP7dWrlxYsWKAPPvhASUlJmjFjhry9vR06//79+7Vo0SItXrxYCQkJkqSzZ8/q9ddf19atWxUXFycXFxd16dLFDLsZGRlq1qyZfv/9dy1dulQ7duzQm2++qezsbIWGhioyMlLz5s2zO8+8efMUFRV1yz9UhjXMAAAARcycOXP09NNPS5Latm2r06dPa+3atWrevLneffdd9ejRQ6NGjTLb33///ZKkvXv3auHChVq1apUiIyMlSZUqVXL4/JmZmfrss8/k7+9v7uvatatdm7lz58rf31+JiYmqVauW/vnPf+rYsWP6+eefVbp0aUlSlSpVzPZ9+/bV3//+d02ZMkUeHh7avn27du7cqW+//dbh+hzFDDMAAEARsmfPHm3ZskU9e/aUJLm5ual79+7msoqEhAS1atUq12MTEhLk6uqqZs2a3VQNISEhdmFZkvbt26eePXuqUqVK8vX1VWhoqCQpNTXVPHd4eLgZlq/VuXNnubq66ptvvpF0eXlIixYtzH5uJWaYAQAAipA5c+bo0qVLCgoKMvcZhiEPDw9Nnz7d/Mjo3Fi9J0kuLi7m0o4rcvsUvRIlSuTY17FjR4WEhGjWrFkKCgpSdna2atWqZd4UeKNzu7u7q1evXpo3b54ef/xx/fOf/9S0adMsjykozDADAAAUEZcuXdJnn32myZMnKyEhwdx27NihoKAgLViwQHXq1FFcXFyux9euXVvZ2dlau3Ztru/7+/vrzJkzOnv2rLnvyhplK8ePH9eePXs0fPhwtWrVStWrV9fJkyft2tSpU0cJCQk6ceLEdfvp27evVq9erY8//liXLl3S448/fsNzFwRmmAEAAIqI7777TidPntRzzz0nPz8/u/e6du2qOXPm6L333lOrVq1UuXJl9ejRQ5cuXdKyZcs0ZMgQhYaG6tlnn1WfPn30wQcf6P7779fBgwd19OhRdevWTQ0bNlTx4sX1f//3fxo4cKA2b96c4wkcuSlVqpTKlCmjmTNnKjAwUKmpqRo6dKhdm549e2rs2LHq3Lmzxo0bp8DAQMXHxysoKEiNGjWSJFWvXl0PPvighgwZoj59+txwVrqgMMMMAABQRMyZM0eRkZE5wrJ0OTBv3bpVpUuX1ldffaWlS5eqbt26atmypbZs2WK2++STT/TEE09owIABqlatmvr162fOKJcuXVqff/65li1bptq1a2vBggUaOXLkDetycXFRbGystm3bplq1aum1117Te++9Z9fG3d1dK1euVLly5dS+fXvVrl1b48ePl6urq1275557TpmZmerTp08+Rih/bMa1C1EAOCQ9PV1+fn46ffq0fH19nV0OAKCA/PXXXzpw4IDds4ThfGPGjNFXX32lX3755YZtrb6Hjvz7zQwzAAAACr2MjAzt2rVL06dP18svv3xbz01gBgAAQKH30ksvqV69emrevPltXY4hcdMfAAAA7gAxMTF5usHwVmCGGQAAALBAYAYAAAAsEJgBAAAs8ECxO1d2dnaB9MMaZgAAgFwUK1ZMNptNx44dk7+/v2w2m7NLQh4ZhqHMzEwdO3ZMLi4ucnd3v6n+CMwAAAC5cHV11b333qvffvtNKSkpzi4H+VC8eHFVqFBBLi43t6iCwAwAAHAd3t7euu+++3Tx4kVnlwIHubq6ys3NrUD+MkBgBgAAsODq6prj45lxd+GmPwAAAMACgRkAAACwQGAGAAAALLCGGbhJV57PmZ6e7uRKAABAXl35dzsvz9kmMAM36fjx45Kk4OBgJ1cCAAAcdebMGfn5+Vm2ITADN6l06dKSpNTU1Bv+B4fL0tPTFRwcrEOHDsnX19fZ5dwRGDPHMWaOY8wcx5g5rrCMmWEYOnPmjIKCgm7YlsAM3KQrD0P38/Pjf5YO8vX1ZcwcxJg5jjFzHGPmOMbMcYVhzPI60cVNfwAAAIAFAjMAAABggcAM3CQPDw+NGDFCHh4ezi7ljsGYOY4xcxxj5jjGzHGMmePuxDGzGXl5lgYAAABwl2KGGQAAALBAYAYAAAAsEJgBAAAACwRmAAAAwAKBGciDjz76SKGhofL09FTDhg21ZcsWy/ZfffWVqlWrJk9PT9WuXVvLli27TZUWHo6M2e7du9W1a1eFhobKZrNp6tSpt6/QQsSRMZs1a5aaNGmiUqVKqVSpUoqMjLzhz2VR5MiYLV68WPXr11fJkiVVokQJ1a1bV//4xz9uY7WFg6P/P7siNjZWNptNnTt3vrUFFkKOjFlMTIxsNpvd5unpeRurLRwc/Tk7deqUXnzxRQUGBsrDw0NhYWGF699OA4Cl2NhYw93d3Zg7d66xe/duo1+/fkbJkiWNI0eO5Np+w4YNhqurqzFx4kQjMTHRGD58uFGsWDFj586dt7ly53F0zLZs2WIMGjTIWLBggREQEGC8//77t7fgQsDRMfvb3/5mfPTRR0Z8fLyRlJRkREVFGX5+fsZvv/12myt3HkfH7McffzQWL15sJCYmGvv37zemTp1quLq6GitWrLjNlTuPo2N2xYEDB4x77rnHaNKkidGpU6fbU2wh4eiYzZs3z/D19TXS0tLM7fDhw7e5audydMwuXLhg1K9f32jfvr2xfv1648CBA8aaNWuMhISE21z59RGYgRto0KCB8eKLL5qvs7KyjKCgIGPcuHG5tu/WrZvRoUMHu30NGzY0XnjhhVtaZ2Hi6JhdLSQk5K4MzDczZoZhGJcuXTJ8fHyM+fPn36oSC52bHTPDMIzw8HBj+PDht6K8Qik/Y3bp0iWjcePGxuzZs41nn332rgvMjo7ZvHnzDD8/v9tUXeHk6Jh98sknRqVKlYzMzMzbVaLDWJIBWMjMzNS2bdsUGRlp7nNxcVFkZKQ2bdqU6zGbNm2yay9Jbdq0uW77oiY/Y3a3K4gxO3funC5evKjSpUvfqjILlZsdM8MwFBcXpz179qhp06a3stRCI79jNnr0aJUrV07PPffc7SizUMnvmGVkZCgkJETBwcHq1KmTdu/efTvKLRTyM2ZLly5Vo0aN9OKLL6p8+fKqVauWxo4dq6ysrNtV9g0RmAELf/75p7KyslS+fHm7/eXLl9fhw4dzPebw4cMOtS9q8jNmd7uCGLMhQ4YoKCgoxy9rRVV+x+z06dPy9vaWu7u7OnTooA8//FCtW7e+1eUWCvkZs/Xr12vOnDmaNWvW7Six0MnPmFWtWlVz587Vt99+q88//1zZ2dlq3Lixfvvtt9tRstPlZ8z++9//6uuvv1ZWVpaWLVum6OhoTZ48We+8887tKDlP3JxdAADg5owfP16xsbFas2bNXXlzkSN8fHyUkJCgjIwMxcXF6fXXX1elSpXUvHlzZ5dW6Jw5c0bPPPOMZs2apbJlyzq7nDtGo0aN1KhRI/N148aNVb16dc2YMUNjxoxxYmWFV3Z2tsqVK6eZM2fK1dVV9erV0++//6733ntPI0aMcHZ5kgjMgKWyZcvK1dVVR44csdt/5MgRBQQE5HpMQECAQ+2LmvyM2d3uZsZs0qRJGj9+vFavXq06dercyjILlfyOmYuLi6pUqSJJqlu3rpKSkjRu3Li7IjA7OmbJyclKSUlRx44dzX3Z2dmSJDc3N+3Zs0eVK1e+tUU7WUH8/6xYsWIKDw/X/v37b0WJhU5+xiwwMFDFihWTq6urua969eo6fPiwMjMz5e7ufktrzguWZAAW3N3dVa9ePcXFxZn7srOzFRcXZzeDcLVGjRrZtZekVatWXbd9UZOfMbvb5XfMJk6cqDFjxmjFihWqX7/+7Si10Cion7Ps7GxduHDhVpRY6Dg6ZtWqVdPOnTuVkJBgbo899phatGihhIQEBQcH387ynaIgfs6ysrK0c+dOBQYG3qoyC5X8jNlDDz2k/fv3m7+QSdLevXsVGBhYKMKyJB4rB9xIbGys4eHhYcTExBiJiYnG888/b5QsWdJ8TNAzzzxjDB061Gy/YcMGw83NzZg0aZKRlJRkjBgx4q58rJwjY3bhwgUjPj7eiI+PNwIDA41BgwYZ8fHxxr59+5x1Cbedo2M2fvx4w93d3fj666/tHl915swZZ13CbefomI0dO9ZYuXKlkZycbCQmJhqTJk0y3NzcjFmzZjnrEm47R8fsWnfjUzIcHbNRo0YZP/zwg5GcnGxs27bN6NGjh+Hp6Wns3r3bWZdw2zk6ZqmpqYaPj4/x0ksvGXv27DG+++47o1y5csY777zjrEvIgcAM5MGHH35oVKhQwXB3dzcaNGhg/PTTT+Z7zZo1M5599lm79gsXLjTCwsIMd3d3o2bNmsb3339/myt2PkfG7MCBA4akHFuzZs1uf+FO5MiYhYSE5DpmI0aMuP2FO5EjYzZs2DCjSpUqhqenp1GqVCmjUaNGRmxsrBOqdi5H/392tbsxMBuGY2P26quvmm3Lly9vtG/f3ti+fbsTqnYuR3/ONm7caDRs2NDw8PAwKlWqZLz77rvGpUuXbnPV12czDMNw1uw2AAAAUNixhhkAAACwQGAGAAAALBCYAQAAAAsEZgAAAMACgRkAAACwQGAGAAAALBCYAQAAAAsEZgAAAMACgRkAAACwQGAGAAAALBCYAQAAAAsEZgAAAMDC/wP65VIMye3TlgAAAABJRU5ErkJggg==\n",
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAAswAAAGdCAYAAAAG6yXVAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjYuMiwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy8o6BhiAAAACXBIWXMAAA9hAAAPYQGoP6dpAAA8mklEQVR4nO3deVxV1f7/8fcBZFAGJxQoBIdwNkHTtJwxp0zNcriVoWldrWzStK+SUzmlpmWDM3brSpZm3lJTuel1SlPBVMiBK2KFQ06Imijs3x9e988juOUgehBfz8djPx6cfdZe+7MXlG8Wa+9jMwzDEAAAAIBcuTi7AAAAAKAwIzADAAAAFgjMAAAAgAUCMwAAAGCBwAwAAABYIDADAAAAFgjMAAAAgAUCMwAAAGDBzdkFAHe67Oxs/fHHH/Lx8ZHNZnN2OQAAIA8Mw9CZM2cUFBQkFxfrOWQCM3CT/vjjDwUHBzu7DAAAkA+HDh3Svffea9mGwAzcJB8fH0mX/4Pz9fV1cjUAACAv0tPTFRwcbP47boXADNykK8swfH19CcwAANxh8rKckpv+AAAAAAsEZgAAAMACgRkAAACwQGAGAAAALBCYAQAAAAsEZgAAAMACgRkAAACwQGAGAAAALBCYAQAAAAsEZgAAAMACgRkAAACwQGAGAAAALBCYAQAAAAsEZgAAAMACgRkAAACwQGAGAAAALBCYAQAAAAsEZgAAAMACgRkAAACwQGAGAAAALBCYAQAAAAsEZgAAAMACgRkAAACwQGAGAAAALBCYAQAAAAsEZgAAAMACgRkAAACw4ObsAoCiotaIH+TiUdzZZQAAUGSkjO/g7BIkMcMMAAAAWCIwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwFwI2m01LlizJ17HR0dF6/vnnC7agu0jz5s316quvmq8ffPBBLVq0yHkFAQCAQofAfJVjx46pf//+qlChgjw8PBQQEKA2bdpow4YNee5j5MiRqlu3bo79oaGhstlsdtu9994rSUpLS1O7du0kSSkpKbLZbEpISLjhuQ4fPqxp06Zp2LBhea6vKLg25Bak4cOHa+jQocrOzr4l/QMAgDsPgfkqXbt2VXx8vObPn6+9e/dq6dKlat68uY4fP14g/Y8ePVppaWnmFh8fL0kKCAiQh4eHw/3Nnj1bjRs3VkhISIHUB6ldu3Y6c+aMli9f7uxSAABAIUFg/p9Tp05p3bp1mjBhglq0aKGQkBA1aNBAb731lh577DG7dn379pW/v798fX3VsmVL7dixQ5IUExOjUaNGaceOHeYsckxMjHmsj4+PAgICzM3f31+S/ZKMihUrSpLCw8Nls9nUvHnz69YcGxurjh072u1bsWKFHn74YZUsWVJlypTRo48+quTkZPP9NWvWyGaz6dSpU+a+hIQE2Ww2paSkmPtmzZql4OBgFS9eXF26dNGUKVNUsmRJ8/0rM+lz585VhQoV5O3trQEDBigrK0sTJ05UQECAypUrp3fffTfHOF9v/K7u9x//+IdCQ0Pl5+enHj166MyZM5KkqKgorV27VtOmTTPH+Erdu3btUrt27eTt7a3y5cvrmWee0Z9//mn2ffbsWfXq1Uve3t4KDAzU5MmTc4ypq6ur2rdvr9jY2OuOOwAAuLsQmP/H29tb3t7eWrJkiS5cuHDddk8++aSOHj2q5cuXa9u2bYqIiFCrVq104sQJde/eXW+88YZq1qxpziJ3797doTq2bNkiSVq9erXS0tK0ePHiXNudOHFCiYmJql+/vt3+s2fP6vXXX9fWrVsVFxcnFxcXdenSxaElBhs2bNDf//53vfLKK0pISFDr1q1zBF9JSk5O1vLly7VixQotWLBAc+bMUYcOHfTbb79p7dq1mjBhgoYPH67Nmzebx1iN39X9LlmyRN99952+++47rV27VuPHj5ckTZs2TY0aNVK/fv3MMQ4ODtapU6fUsmVLhYeHa+vWrVqxYoWOHDmibt26mf0OHjxYa9eu1bfffquVK1dqzZo12r59e47ratCggdatW3fd8blw4YLS09PtNgAAUHS5ObuAwsLNzU0xMTHq16+fPv30U0VERKhZs2bq0aOH6tSpI0lav369tmzZoqNHj5pLKCZNmqQlS5bo66+/1vPPPy9vb2+5ubkpICAgxzmGDBmi4cOHm6/Hjh2rgQMH2rW5MutcpkyZXPu4IjU1VYZhKCgoyG5/165d7V7PnTtX/v7+SkxMVK1atfI0Fh9++KHatWunQYMGSZLCwsK0ceNGfffdd3btsrOzNXfuXPn4+KhGjRpq0aKF9uzZo2XLlsnFxUVVq1bVhAkT9OOPP6phw4Z5Gr8r/cbExMjHx0eS9MwzzyguLk7vvvuu/Pz85O7uruLFi9uNz/Tp0xUeHq6xY8faXXtwcLD27t2roKAgzZkzR59//rlatWolSZo/f765jvxqQUFBOnTokLKzs+XikvN3ynHjxmnUqFF5GksAAHDnY4b5Kl27dtUff/yhpUuXqm3btlqzZo0iIiLMZRU7duxQRkaGypQpY85Ie3t768CBA3bLHq5n8ODBSkhIMLdevXrlu9bz589Lkjw9Pe3279u3Tz179lSlSpXk6+ur0NBQSZcDdl7t2bNHDRo0sNt37Wvp8o2MV0KtJJUvX141atSwC5nly5fX0aNHJeV9/K7tNzAw0Ozjenbs2KEff/zRrt9q1apJujxjnZycrMzMTDVs2NA8pnTp0qpatWqOvry8vJSdnX3dvzS89dZbOn36tLkdOnTIsjYAAHBnY4b5Gp6enmrdurVat26t6Oho9e3bVyNGjFBUVJQyMjIUGBioNWvW5Dju6vW911O2bFlVqVKlQOosW7asJOnkyZPmrLQkdezYUSEhIZo1a5aCgoKUnZ2tWrVqKTMzU5LMMGsYhnnMxYsX81VDsWLF7F7bbLZc911ZDpLX8bPq43oyMjLUsWNHTZgwIcd7gYGB2r9/v+XxVztx4oRKlCghLy+vXN/38PDI102aAADgzkRgvoEaNWqYN+RFRETo8OHDcnNzM2dur+Xu7q6srKx8n8/d3V2SbthH5cqV5evrq8TERIWFhUmSjh8/rj179mjWrFlq0qSJpMvLSK52JVynpaWpVKlSkpTjEXZVq1bVzz//bLfv2tf5kZfxy4vcxjgiIkKLFi1SaGio3Nxy/lhXrlxZxYoV0+bNm1WhQgVJl3/Z2Lt3r5o1a2bXdteuXQoPD893fQAAoGhhScb/HD9+XC1bttTnn3+uX375RQcOHNBXX32liRMnqlOnTpKkyMhINWrUSJ07d9bKlSuVkpKijRs3atiwYdq6dauky8sJDhw4oISEBP3555+WNxDmply5cvLy8jJvWjt9+nSu7VxcXBQZGWkXiEuVKqUyZcpo5syZ2r9/v/7973/r9ddftzuuSpUqCg4O1siRI7Vv3z59//33OZ4W8fLLL2vZsmWaMmWK9u3bpxkzZmj58uWy2WwOXcu18jJ+eREaGqrNmzcrJSVFf/75p7Kzs/Xiiy/qxIkT6tmzp37++WclJyfrhx9+UO/evZWVlSVvb28999xzGjx4sP79739r165dioqKynWN8rp16/TII4/c1LUCAICig8D8P97e3mrYsKHef/99NW3aVLVq1VJ0dLT69eun6dOnS7q8NGDZsmVq2rSpevfurbCwMPXo0UMHDx5U+fLlJV1eB922bVu1aNFC/v7+WrBggUN1uLm56YMPPtCMGTMUFBRkhvXc9O3bV7GxseZyBRcXF8XGxmrbtm2qVauWXnvtNb333nt2xxQrVkwLFizQr7/+qjp16mjChAl655137No89NBD+vTTTzVlyhTdf//9WrFihV577bUc66UdlZfxy4tBgwbJ1dVVNWrUkL+/v1JTUxUUFKQNGzYoKytLjzzyiGrXrq1XX31VJUuWNEPxe++9pyZNmqhjx46KjIzUww8/rHr16tn1/fvvv2vjxo3q3bv3TV0rAAAoOmzG1YtZcUcxDEMNGzbUa6+9pp49e97Sc/Xr10+//vqr5ePWioIhQ4bo5MmTmjlzZp6PSU9Pl5+fn4JfXSgXj+K3sDoAAO4uKeM73LK+r/z7ffr0afn6+lq2ZYb5Dmaz2TRz5kxdunSpwPueNGmSduzYof379+vDDz/U/Pnz9eyzzxb4eQqbcuXKacyYMc4uAwAAFCLc9HeHq1u3rurWrVvg/W7ZskUTJ07UmTNnVKlSJX3wwQfq27dvgZ+nsHnjjTecXQIAAChkCMzI1cKFC51dAgAAQKHAkgwAAADAAoEZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAAoEZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAAoEZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAAoEZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAAoEZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAgpuzCwCKil2j2sjX19fZZQAAgALGDDMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABggcAMAAAAWCAwAwAAABYIzAAAAIAFAjMAAABgwc3ZBQBFRa0RP8jFo7izywAAFGEp4zs4u4S7EjPMAAAAgAUCMwAAAGCBwAwAAABYIDADAAAAFgjMAAAAgAUCMwAAAGCBwAwAAABYIDADAAAAFvL8wSXh4eGy2Wx5art9+/Z8FwQAAAAUJnkOzJ07dza//uuvv/Txxx+rRo0aatSokSTpp59+0u7duzVgwIACLxIAAABwljwH5hEjRphf9+3bVwMHDtSYMWNytDl06FDBVQcAAAA4Wb7WMH/11Vfq1atXjv1PP/20Fi1adNNFAQAAAIVFvgKzl5eXNmzYkGP/hg0b5OnpedNFAQAAAIVFnpdkXO3VV19V//79tX37djVo0ECStHnzZs2dO1fR0dEFWiAAAADgTPkKzEOHDlWlSpU0bdo0ff7555Kk6tWra968eerWrVuBFggAAAA4U74CsyR169aNcAwAAIAiL9+BWZK2bdumpKQkSVLNmjUVHh5eIEUBAAAAhUW+AvPRo0fVo0cPrVmzRiVLlpQknTp1Si1atFBsbKz8/f0LskYAAADAafL1lIyXX35ZZ86c0e7du3XixAmdOHFCu3btUnp6ugYOHFjQNQIAAABOk68Z5hUrVmj16tWqXr26ua9GjRr66KOP9MgjjxRYcQAAAICz5WuGOTs7W8WKFcuxv1ixYsrOzr7pogAAAIDCIl+BuWXLlnrllVf0xx9/mPt+//13vfbaa2rVqlWBFQcAAAA4W74C8/Tp05Wenq7Q0FBVrlxZlStXVsWKFZWenq4PP/ywoGsEAAAAnCZfa5iDg4O1fft2rV69Wr/++qukyx9cEhkZWaDFAQAAAM6W7+cw22w2tW7dWq1bty7IegAAAIBCJd+BOS4uTnFxcTp69GiOG/3mzp1704Uhb2w2m7755ht17tzZ4WOjo6N15MgRzZw5s+ALu4WioqJ06tQpLVmypMD7fvDBBzV48GB17dq1wPsGAAB3pnytYR41apQeeeQRxcXF6c8//9TJkyfttrvRsWPH1L9/f1WoUEEeHh4KCAhQmzZttGHDhjz3MXLkSNWtWzfH/tDQUNlsNrvt3nvvlSSlpaWpXbt2kqSUlBTZbDYlJCTc8FyHDx/WtGnTNGzYsDzXV5TExMSYH7pzteHDh2vo0KE87QUAAJjyNcP86aefKiYmRs8880xB13PH6tq1qzIzMzV//nxVqlRJR44cUVxcnI4fP14g/Y8ePVr9+vUzX7u6ukqSAgIC8tXf7Nmz1bhxY4WEhBRIfbnJzMyUu7v7Lev/VmjXrp369u2r5cuXq0OHDs4uBwAAFAL5mmHOzMxU48aNC7qWO9apU6e0bt06TZgwQS1atFBISIgaNGigt956S4899phdu759+8rf31++vr5q2bKlduzYIenyjOeoUaO0Y8cOcxY5JibGPNbHx0cBAQHmduXjx202m7k0oWLFipKk8PBw2Ww2NW/e/Lo1x8bGqmPHjubrK7PT125X97F+/Xo1adJEXl5eCg4O1sCBA3X27Fnz/dDQUI0ZM0a9evWSr6+vnn/+eUnSokWLVLNmTXl4eCg0NFSTJ0++4Zh+/fXXql27try8vFSmTBlFRkbanUuSJk2apMDAQJUpU0YvvviiLl68aL538uRJ9erVS6VKlVLx4sXVrl077du3T5K0Zs0a9e7dW6dPnzavc+TIkZIu/yLSvn17xcbGXre2CxcuKD093W4DAABFV74Cc9++ffXPf/6zoGu5Y3l7e8vb21tLlizRhQsXrtvuySef1NGjR7V8+XJt27ZNERERatWqlU6cOKHu3bvrjTfeUM2aNZWWlqa0tDR1797doTq2bNkiSVq9erXS0tK0ePHiXNudOHFCiYmJql+/vrkvODjYPG9aWpri4+NVpkwZNW3aVJKUnJystm3bqmvXrvrll1/05Zdfav369XrppZfs+p40aZLuv/9+xcfHKzo6Wtu2bVO3bt3Uo0cP7dy5UyNHjlR0dLTdLwPXSktLU8+ePdWnTx8lJSVpzZo1evzxx2UYhtnmxx9/VHJysn788UfNnz9fMTExdn1GRUVp69atWrp0qTZt2iTDMNS+fXtdvHhRjRs31tSpU+Xr62te76BBg8xjGzRooHXr1l23vnHjxsnPz8/cgoODr9sWAADc+WzG1SnEwuuvv25+nZ2drfnz56tOnTqqU6dOjk/9mzJlSsFWeQdYtGiR+vXrp/PnzysiIkLNmjVTjx49VKdOHUmXZ2c7dOigo0ePysPDwzyuSpUqevPNN/X8889r5MiRWrJkSY41yKGhoUpLS7Mb57Fjx2rgwIF2N/2lpKSoYsWKio+Pz3Ut9BUJCQkKDw9XampqrmHvr7/+UvPmzeXv769vv/1WLi4u6tu3r1xdXTVjxgyz3fr169WsWTOdPXtWnp6eCg0NVXh4uL755huzzVNPPaVjx45p5cqV5r4333xT33//vXbv3p1rfdu3b1e9evWUkpKS65KRqKgorVmzRsnJyebSlG7dusnFxUWxsbHat2+fwsLCtGHDBvMvIcePH1dwcLDmz5+vJ598UjExMXr11Vd16tSpHP0vXbpUXbp00cWLF+XikvN3ygsXLtj9YpSenq7g4GAFv7pQLh7Fc70mAAAKQsp4lgsWlPT0dPn5+en06dPy9fW1bJvnNczx8fF2r68Esl27djleYRHUtWtXdejQQevWrdNPP/2k5cuXa+LEiZo9e7aioqK0Y8cOZWRkqEyZMnbHnT9/XsnJyTfsf/DgwYqKijJfly1bNt+1nj9/XpLk6emZ6/t9+vTRmTNntGrVKjMw7tixQ7/88ou++OILs51hGMrOztaBAwdUvXp1SbKbtZakpKQkderUyW7fQw89pKlTpyorK0sbN240b1qUpBkzZqhHjx5q1aqVateurTZt2uiRRx7RE088oVKlSpntatasaYZlSQoMDNTOnTvNc7q5ualhw4bm+2XKlFHVqlWVlJR0w/Hx8vJSdna2Lly4IC8vrxzve3h42P3SAwAAirY8B+Yff/zxVtZRJHh6eprPpo6Ojlbfvn01YsQIRUVFKSMjQ4GBgVqzZk2O43J7WsO1ypYtqypVqhRInVfC9smTJ8210Fe88847+uGHH7Rlyxb5+PiY+zMyMvTCCy9o4MCBOfqrUKGC+XWJEiUcqqV+/fp2M+rly5eXq6urVq1apY0bN2rlypX68MMPNWzYMG3evNlcp33tXzVsNluBPdnixIkTKlGiRK5hGQAA3H3ytYb5ygzktc6ePas+ffrcdFFFRY0aNcwb1SIiInT48GG5ubmpSpUqdtuVAOvu7q6srKx8n+/KEylu1EflypXl6+urxMREu/2LFi3S6NGjtXDhQlWuXNnuvYiICCUmJuaovUqVKpZPwqhevXqOR+tt2LBBYWFhcnV1lZeXl11fV0K6zWbTQw89pFGjRik+Pl7u7u52Sz2sVK9eXZcuXdLmzZvNfcePH9eePXtUo0YNSdZjvWvXLoWHh+fpXAAAoOjLV2CeP3+++Wf9q50/f16fffbZTRd1pzl+/Lhatmypzz//XL/88osOHDigr776ShMnTjSXI0RGRqpRo0bq3LmzVq5cqZSUFG3cuFHDhg3T1q1bJV1eq3zgwAElJCTozz//tLyBMDflypWTl5eXVqxYoSNHjuj06dO5tnNxcVFkZKTWr19v7tu1a5d69eqlIUOGqGbNmjp8+LAOHz6sEydOSJKGDBmijRs36qWXXlJCQoL27dunb7/9NsdNf9d64403FBcXpzFjxmjv3r2aP3++pk+fbneT3bU2b96ssWPHauvWrUpNTdXixYt17Ngxc9nHjdx3333q1KmT+vXrp/Xr12vHjh16+umndc8995jfj9DQUGVkZJjPEj937px5/Lp16/TII4/k6VwAAKDocygwp6en6/Tp0zIMQ2fOnLF7rNbJkye1bNkylStX7lbVWmh5e3urYcOGev/999W0aVPVqlVL0dHR6tevn6ZPny7p8ozpsmXL1LRpU/Xu3VthYWHq0aOHDh48qPLly0u6vA66bdu2atGihfz9/bVgwQKH6nBzc9MHH3ygGTNmKCgoKMfa4av17dtXsbGx5jKGrVu36ty5c3rnnXcUGBhobo8//rgkqU6dOlq7dq327t2rJk2aKDw8XG+//baCgoIsa4qIiNDChQsVGxurWrVq6e2339bo0aPt1mNfy9fXV//5z3/Uvn17hYWFafjw4Zo8ebLdWucbmTdvnurVq6dHH31UjRo1kmEYWrZsmbmUo3Hjxvr73/+u7t27y9/fXxMnTpQk/f7779q4caN69+6d53MBAICiLc9PyZAuz0zabLbrd2azadSoUXftp8fdSQzDUMOGDfXaa6+pZ8+ezi6n0BgyZIhOnjzp0MeFX7nLlqdkAABuNZ6SUXBuyVMypMs3/hmGoZYtW2rRokUqXbq0+Z67u7tCQkJuOOOIwsFms2nmzJnmkyVwWbly5eweoQgAAODQDPMVBw8eVIUKFSxnm4G7BTPMAIDbhRnmguPIDHO+bvoLCQnR+vXr9fTTT6tx48b6/fffJUn/+Mc/7G4kAwAAAO50+QrMixYtUps2beTl5aXt27ebT3M4ffq0xo4dW6AFAgAAAM6Ur8D8zjvv6NNPP9WsWbPsPkDioYce0vbt2wusOAAAAMDZ8hWY9+zZo6ZNm+bY7+fnp1OnTt1sTQAAAEChka/AHBAQoP379+fYv379elWqVOmmiwIAAAAKi3wF5n79+umVV17R5s2bZbPZ9Mcff+iLL77QoEGD1L9//4KuEQAAAHAah57DfMXQoUOVnZ2tVq1a6dy5c2ratKk8PDw0aNAgvfzyywVdIwAAAOA0+QrMNptNw4YN0+DBg7V//35lZGSoRo0a8vb2Luj6AAAAAKdyKDD36dMnT+3mzp2br2IAAACAwsahwBwTE6OQkBCFh4crHx8QCAAAANxxHArM/fv314IFC3TgwAH17t1bTz/9tEqXLn2ragMAAACczqGnZHz00UdKS0vTm2++qX/9618KDg5Wt27d9MMPPzDjDAAAgCLJ4cfKeXh4qGfPnlq1apUSExNVs2ZNDRgwQKGhocrIyLgVNQIAAABOk6/nMJsHu7jIZrPJMAxlZWUVVE0AAABAoeFwYL5w4YIWLFig1q1bKywsTDt37tT06dOVmprKY+UAAABQ5Dh009+AAQMUGxur4OBg9enTRwsWLFDZsmVvVW0AAACA0zkUmD/99FNVqFBBlSpV0tq1a7V27dpc2y1evLhAigMAAACczaHA3KtXL9lstltVCwAAAFDoOPzBJQAAAMDd5KaekgEAAAAUdQRmAAAAwIJDSzIAXN+uUW3k6+vr7DIAAEABY4YZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAAoEZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAAoEZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAAoEZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAAoEZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAAoEZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAAoEZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAAoEZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAAoEZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAAoEZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAAoEZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAAoEZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAAoEZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAAoEZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAAoEZAAAAsEBgBgAAACwQmAEAAAALBGYAAADAAoEZAAAAsODm7AKAoqLWiB/k4lHc2WUAuEuljO/g7BKAIosZZgAAAMACgRkAAACwQGAGAAAALBCYAQAAAAsEZgAAAMACgRkAAACwQGAGAAAALBCYAQAAAAsEZgAAAMACgRkAAACwQGAGAAAALBCYAQAAAAsEZgAAAMACgRkAAACwQGAGAAAALBCYAQAAAAsEZgAAAMACgRkAAACwQGAGAAAALBCYAQAAAAsEZgAAAMACgRkAAACwQGAGAAAALBCYAQAAAAsEZgAAAMACgfkahw8fVuvWrVWiRAmVLFnS2eXcUsePH1e5cuWUkpLi7FIckpKSIpvNpoSEhALve8WKFapbt66ys7MLvG8AAHBnclpgttlsltvIkSOdUtf777+vtLQ0JSQkaO/evU6p4XZ599131alTJ4WGhjq7FKcIDQ3V1KlT7fa1bdtWxYoV0xdffOGcogAAQKHj5qwTp6WlmV9/+eWXevvtt7Vnzx5zn7e3t/m1YRjKysqSm9utLzc5OVn16tXTfffdl+8+MjMz5e7uXoBVWbt48aKKFSvm0DHnzp3TnDlz9MMPP9yiqqSsrCzZbDa5uNxZf8iIiorSBx98oGeeecbZpQAAgELAaUkmICDA3Pz8/GSz2czXv/76q3x8fLR8+XLVq1dPHh4eWr9+vZKTk9WpUyeVL19e3t7eeuCBB7R69Wq7fkNDQzV27Fj16dNHPj4+qlChgmbOnGm+n5mZqZdeekmBgYHy9PRUSEiIxo0bZx67aNEiffbZZ7LZbIqKipIkpaamqlOnTvL29pavr6+6deumI0eOmH2OHDlSdevW1ezZs1WxYkV5enpKujyLPmPGDD366KMqXry4qlevrk2bNmn//v1q3ry5SpQoocaNGys5OdnuGr799ltFRETI09NTlSpV0qhRo3Tp0iXzfZvNpk8++USPPfaYSpQooXfffVcnT57UU089JX9/f3l5eem+++7TvHnzrjv+y5Ytk4eHhx588EFzX1RUVK6z/WvWrJEkXbhwQYMGDdI999yjEiVKqGHDhuZ7khQTE6OSJUtq6dKlqlGjhjw8PJSamqqTJ0+qV69eKlWqlIoXL6527dpp3759lj8febme//73v2rRooWKFy+u+++/X5s2bbJ7f9GiRapZs6Y8PDwUGhqqyZMnm+81b95cBw8e1GuvvWZe5xUdO3bU1q1bc3xfAADA3alQT/0NHTpU48ePV1JSkurUqaOMjAy1b99ecXFxio+PV9u2bdWxY0elpqbaHTd58mTVr19f8fHxGjBggPr372/OXn/wwQdaunSpFi5cqD179uiLL74wlyT8/PPPatu2rbp166a0tDRNmzZN2dnZ6tSpk06cOKG1a9dq1apV+u9//6vu3bvbnXP//v1atGiRFi9ebLe2dsyYMerVq5cSEhJUrVo1/e1vf9MLL7ygt956S1u3bpVhGHrppZfM9uvWrVOvXr30yiuvKDExUTNmzFBMTIzeffddu/ONHDlSXbp00c6dO9WnTx9FR0crMTFRy5cvV1JSkj755BOVLVv2umO7bt061atXz27ftGnTlJaWZm6vvPKKypUrp2rVqkmSXnrpJW3atEmxsbH65Zdf9OSTT6pt27Z24ffcuXOaMGGCZs+erd27d6tcuXKKiorS1q1btXTpUm3atEmGYah9+/a6ePHidevLy/UMGzZMgwYNUkJCgsLCwtSzZ0/zF4tt27apW7du6tGjh3bu3KmRI0cqOjpaMTExkqTFixfr3nvv1ejRo83rvaJChQoqX7681q1bl2ttFy5cUHp6ut0GAACKLqctyciL0aNHq3Xr1ubr0qVL6/777zdfjxkzRt98842WLl1qFzrbt2+vAQMGSJKGDBmi999/Xz/++KOqVq2q1NRU3XfffXr44Ydls9kUEhJiHufv7y8PDw95eXkpICBAkrRq1Srt3LlTBw4cUHBwsCTps88+U82aNfXzzz/rgQcekHR55vqzzz6Tv7+/3TX07t1b3bp1M2tp1KiRoqOj1aZNG0nSK6+8ot69e5vtR40apaFDh+rZZ5+VJFWqVEljxozRm2++qREjRpjt/va3v9kdl5qaqvDwcNWvX1+Sbrgu+eDBgwoKCrLb5+fnJz8/P0mXA+WMGTO0evVqBQQEKDU1VfPmzVNqaqp53KBBg7RixQrNmzdPY8eOlXR5ecjHH39sfp/27dunpUuXasOGDWrcuLEk6YsvvlBwcLCWLFmiJ598Mtf68nI9gwYNUocOHcxxq1mzpvbv369q1appypQpatWqlaKjoyVJYWFhSkxM1HvvvaeoqCiVLl1arq6u8vHxMb/XVwsKCtLBgwdzrW3cuHEaNWrU9QcXAAAUKYV6hvlKWLoiIyNDgwYNUvXq1VWyZEl5e3srKSkpxwxznTp1zK+vLPU4evSopMvLDhISElS1alUNHDhQK1eutKwhKSlJwcHBZliWpBo1aqhkyZJKSkoy94WEhOQIy9fWUr58eUlS7dq17fb99ddf5izljh07NHr0aHl7e5tbv379lJaWpnPnzl13bPr376/Y2FjVrVtXb775pjZu3Gh5XefPnzeXjlwrPj5ezzzzjKZPn66HHnpIkrRz505lZWUpLCzMrra1a9faLV1wd3e3u+akpCS5ubmpYcOG5r4yZcqoatWq5vi1a9fO7K9mzZp5vp6rzxMYGChJ5vc5KSnJrP2Khx56SPv27VNWVpbl2EiSl5eX3Xhf7a233tLp06fN7dChQzfsDwAA3LkK9QxziRIl7F4PGjRIq1at0qRJk1SlShV5eXnpiSeeUGZmpl27a2+As9ls5mPCIiIidODAAS1fvlyrV69Wt27dFBkZqa+//rpAa82tlivrZHPbd6W+jIwMjRo1So8//niOvq4OuNeer127djp48KCWLVumVatWqVWrVnrxxRc1adKkXOsqW7asTp48mWP/4cOH9dhjj6lv37567rnnzP0ZGRlydXXVtm3b5OrqanfM1Tdoenl52a0HzovZs2fr/Pnzkv7/2OTleqzG8WadOHEi11+AJMnDw0MeHh4Fch4AAFD4FerAfK0NGzYoKipKXbp0kXQ5xOXnGcK+vr7q3r27unfvrieeeEJt27bViRMnVLp06Rxtq1evrkOHDunQoUPmLHNiYqJOnTqlGjVq3NT15CYiIkJ79uxRlSpVHD7W399fzz77rJ599lk1adJEgwcPvm5gDg8P1+eff26376+//lKnTp3MJQ3Xts/KytLRo0fVpEmTPNdUvXp1Xbp0SZs3bzaXZBw/flx79uwxx++ee+656evJ7bwbNmyw27dhwwaFhYWZgd/d3T3X2ea//vpLycnJCg8Pz/N1AgCAouuOCsz33XefFi9erI4dO8pmsyk6OtrhGcUpU6YoMDBQ4eHhcnFx0VdffaWAgIDrfkhJZGSkateuraeeekpTp07VpUuXNGDAADVr1izHsoiC8Pbbb+vRRx9VhQoV9MQTT8jFxUU7duzQrl279M4771geV69ePdWsWVMXLlzQd999p+rVq1+3fZs2bfTWW2/p5MmTKlWqlCTphRde0KFDhxQXF6djx46ZbUuXLq2wsDA99dRT6tWrlyZPnqzw8HAdO3ZMcXFxqlOnjrmW+Fr33XefOnXqpH79+mnGjBny8fHR0KFDdc8996hTp04Fdj3XeuONN/TAAw9ozJgx6t69uzZt2qTp06fr448/NtuEhobqP//5j3r06CEPDw/zpsKffvpJHh4eatSoUZ7PBwAAiq5CvYb5WlOmTFGpUqXUuHFjdezYUW3atFFERIRDffj4+GjixImqX7++HnjgAaWkpGjZsmXXfVawzWbTt99+q1KlSqlp06aKjIxUpUqV9OWXXxbEJeXQpk0bfffdd1q5cqUeeOABPfjgg3r//fftbk7Mjbu7u9566y3VqVNHTZs2laurq2JjY6/bvnbt2oqIiNDChQvNfWvXrlVaWppq1KihwMBAc7uyfnjevHnq1auX3njjDVWtWlWdO3fWzz//rAoVKljWNm/ePNWrV0+PPvqoGjVqJMMwtGzZMstnRzt6Pde6cm2xsbGqVauW3n77bY0ePdp8VKB0+abSlJQUVa5c2W75xYIFC/TUU0+pePHieT4fAAAoumyGYRjOLgLO8f3332vw4MHatWvXHffhIrfKn3/+qapVq2rr1q2qWLFino5JT0+Xn5+fgl9dKBcPQjYA50gZn/tf+gDk7sq/36dPn5avr69l2ztqSQYKVocOHbRv3z79/vvvdk8BuZulpKTo448/znNYBgAARR+B+S736quvOruEQqV+/fq3ZG06AAC4c/F3eAAAAMACgRkAAACwQGAGAAAALBCYAQAAAAsEZgAAAMACgRkAAACwQGAGAAAALBCYAQAAAAsEZgAAAMACgRkAAACwQGAGAAAALBCYAQAAAAsEZgAAAMACgRkAAACwQGAGAAAALBCYAQAAAAsEZgAAAMACgRkAAACwQGAGAAAALLg5uwAAAIDCLDs7W5mZmc4uAw4qVqyYXF1dC6QvAjMAAMB1ZGZm6sCBA8rOznZ2KciHkiVLKiAgQDab7ab6ITADBWTXqDby9fV1dhkAgAJiGIbS0tLk6uqq4OBgubiwkvVOYRiGzp07p6NHj0qSAgMDb6o/AjMAAEAuLl26pHPnzikoKEjFixd3djlwkJeXlyTp6NGjKleu3E0tz+BXJQAAgFxkZWVJktzd3Z1cCfLryi86Fy9evKl+CMwAAAAWbnb9K5ynoL53BGYAAADAAoEZAAAAsMBNfwAAAA4IHfr9bT1fyvgO+Tpu06ZNevjhh9W2bVt9//3trbmoYYYZAACgCJozZ45efvll/ec//9Eff/zhtDqKwoe+EJgBAACKmIyMDH355Zfq37+/OnTooJiYGLv3//Wvf+mBBx6Qp6enypYtqy5dupjvXbhwQUOGDFFwcLA8PDxUpUoVzZkzR5IUExOjkiVL2vW1ZMkSu5vrRo4cqbp162r27NmqWLGiPD09JUkrVqzQww8/rJIlS6pMmTJ69NFHlZycbNfXb7/9pp49e6p06dIqUaKE6tevr82bNyslJUUuLi7aunWrXfupU6cqJCTkln+wDIEZAACgiFm4cKGqVaumqlWr6umnn9bcuXNlGIYk6fvvv1eXLl3Uvn17xcfHKy4uTg0aNDCP7dWrlxYsWKAPPvhASUlJmjFjhry9vR06//79+7Vo0SItXrxYCQkJkqSzZ8/q9ddf19atWxUXFycXFxd16dLFDLsZGRlq1qyZfv/9dy1dulQ7duzQm2++qezsbIWGhioyMlLz5s2zO8+8efMUFRV1yz9UhjXMAAAARcycOXP09NNPS5Latm2r06dPa+3atWrevLneffdd9ejRQ6NGjTLb33///ZKkvXv3auHChVq1apUiIyMlSZUqVXL4/JmZmfrss8/k7+9v7uvatatdm7lz58rf31+JiYmqVauW/vnPf+rYsWP6+eefVbp0aUlSlSpVzPZ9+/bV3//+d02ZMkUeHh7avn27du7cqW+//dbh+hzFDDMAAEARsmfPHm3ZskU9e/aUJLm5ual79+7msoqEhAS1atUq12MTEhLk6uqqZs2a3VQNISEhdmFZkvbt26eePXuqUqVK8vX1VWhoqCQpNTXVPHd4eLgZlq/VuXNnubq66ptvvpF0eXlIixYtzH5uJWaYAQAAipA5c+bo0qVLCgoKMvcZhiEPDw9Nnz7d/Mjo3Fi9J0kuLi7m0o4rcvsUvRIlSuTY17FjR4WEhGjWrFkKCgpSdna2atWqZd4UeKNzu7u7q1evXpo3b54ef/xx/fOf/9S0adMsjykozDADAAAUEZcuXdJnn32myZMnKyEhwdx27NihoKAgLViwQHXq1FFcXFyux9euXVvZ2dlau3Ztru/7+/vrzJkzOnv2rLnvyhplK8ePH9eePXs0fPhwtWrVStWrV9fJkyft2tSpU0cJCQk6ceLEdfvp27evVq9erY8//liXLl3S448/fsNzFwRmmAEAAIqI7777TidPntRzzz0nPz8/u/e6du2qOXPm6L333lOrVq1UuXJl9ejRQ5cuXdKyZcs0ZMgQhYaG6tlnn1WfPn30wQcf6P7779fBgwd19OhRdevWTQ0bNlTx4sX1f//3fxo4cKA2b96c4wkcuSlVqpTKlCmjmTNnKjAwUKmpqRo6dKhdm549e2rs2LHq3Lmzxo0bp8DAQMXHxysoKEiNGjWSJFWvXl0PPvighgwZoj59+txwVrqgMMMMAABQRMyZM0eRkZE5wrJ0OTBv3bpVpUuX1ldffaWlS5eqbt26atmypbZs2WK2++STT/TEE09owIABqlatmvr162fOKJcuXVqff/65li1bptq1a2vBggUaOXLkDetycXFRbGystm3bplq1aum1117Te++9Z9fG3d1dK1euVLly5dS+fXvVrl1b48ePl6urq1275557TpmZmerTp08+Rih/bMa1C1EAOCQ9PV1+fn46ffq0fH19nV0OAKCA/PXXXzpw4IDds4ThfGPGjNFXX32lX3755YZtrb6Hjvz7zQwzAAAACr2MjAzt2rVL06dP18svv3xbz01gBgAAQKH30ksvqV69emrevPltXY4hcdMfAAAA7gAxMTF5usHwVmCGGQAAALBAYAYAAAAsEJgBAAAs8ECxO1d2dnaB9MMaZgAAgFwUK1ZMNptNx44dk7+/v2w2m7NLQh4ZhqHMzEwdO3ZMLi4ucnd3v6n+CMwAAAC5cHV11b333qvffvtNKSkpzi4H+VC8eHFVqFBBLi43t6iCwAwAAHAd3t7euu+++3Tx4kVnlwIHubq6ys3NrUD+MkBgBgAAsODq6prj45lxd+GmPwAAAMACgRkAAACwQGAGAAAALLCGGbhJV57PmZ6e7uRKAABAXl35dzsvz9kmMAM36fjx45Kk4OBgJ1cCAAAcdebMGfn5+Vm2ITADN6l06dKSpNTU1Bv+B4fL0tPTFRwcrEOHDsnX19fZ5dwRGDPHMWaOY8wcx5g5rrCMmWEYOnPmjIKCgm7YlsAM3KQrD0P38/Pjf5YO8vX1ZcwcxJg5jjFzHGPmOMbMcYVhzPI60cVNfwAAAIAFAjMAAABggcAM3CQPDw+NGDFCHh4ezi7ljsGYOY4xcxxj5jjGzHGMmePuxDGzGXl5lgYAAABwl2KGGQAAALBAYAYAAAAsEJgBAAAACwRmAAAAwAKBGciDjz76SKGhofL09FTDhg21ZcsWy/ZfffWVqlWrJk9PT9WuXVvLli27TZUWHo6M2e7du9W1a1eFhobKZrNp6tSpt6/QQsSRMZs1a5aaNGmiUqVKqVSpUoqMjLzhz2VR5MiYLV68WPXr11fJkiVVokQJ1a1bV//4xz9uY7WFg6P/P7siNjZWNptNnTt3vrUFFkKOjFlMTIxsNpvd5unpeRurLRwc/Tk7deqUXnzxRQUGBsrDw0NhYWGF699OA4Cl2NhYw93d3Zg7d66xe/duo1+/fkbJkiWNI0eO5Np+w4YNhqurqzFx4kQjMTHRGD58uFGsWDFj586dt7ly53F0zLZs2WIMGjTIWLBggREQEGC8//77t7fgQsDRMfvb3/5mfPTRR0Z8fLyRlJRkREVFGX5+fsZvv/12myt3HkfH7McffzQWL15sJCYmGvv37zemTp1quLq6GitWrLjNlTuPo2N2xYEDB4x77rnHaNKkidGpU6fbU2wh4eiYzZs3z/D19TXS0tLM7fDhw7e5audydMwuXLhg1K9f32jfvr2xfv1648CBA8aaNWuMhISE21z59RGYgRto0KCB8eKLL5qvs7KyjKCgIGPcuHG5tu/WrZvRoUMHu30NGzY0XnjhhVtaZ2Hi6JhdLSQk5K4MzDczZoZhGJcuXTJ8fHyM+fPn36oSC52bHTPDMIzw8HBj+PDht6K8Qik/Y3bp0iWjcePGxuzZs41nn332rgvMjo7ZvHnzDD8/v9tUXeHk6Jh98sknRqVKlYzMzMzbVaLDWJIBWMjMzNS2bdsUGRlp7nNxcVFkZKQ2bdqU6zGbNm2yay9Jbdq0uW77oiY/Y3a3K4gxO3funC5evKjSpUvfqjILlZsdM8MwFBcXpz179qhp06a3stRCI79jNnr0aJUrV07PPffc7SizUMnvmGVkZCgkJETBwcHq1KmTdu/efTvKLRTyM2ZLly5Vo0aN9OKLL6p8+fKqVauWxo4dq6ysrNtV9g0RmAELf/75p7KyslS+fHm7/eXLl9fhw4dzPebw4cMOtS9q8jNmd7uCGLMhQ4YoKCgoxy9rRVV+x+z06dPy9vaWu7u7OnTooA8//FCtW7e+1eUWCvkZs/Xr12vOnDmaNWvW7Six0MnPmFWtWlVz587Vt99+q88//1zZ2dlq3Lixfvvtt9tRstPlZ8z++9//6uuvv1ZWVpaWLVum6OhoTZ48We+8887tKDlP3JxdAADg5owfP16xsbFas2bNXXlzkSN8fHyUkJCgjIwMxcXF6fXXX1elSpXUvHlzZ5dW6Jw5c0bPPPOMZs2apbJlyzq7nDtGo0aN1KhRI/N148aNVb16dc2YMUNjxoxxYmWFV3Z2tsqVK6eZM2fK1dVV9erV0++//6733ntPI0aMcHZ5kgjMgKWyZcvK1dVVR44csdt/5MgRBQQE5HpMQECAQ+2LmvyM2d3uZsZs0qRJGj9+vFavXq06dercyjILlfyOmYuLi6pUqSJJqlu3rpKSkjRu3Li7IjA7OmbJyclKSUlRx44dzX3Z2dmSJDc3N+3Zs0eVK1e+tUU7WUH8/6xYsWIKDw/X/v37b0WJhU5+xiwwMFDFihWTq6urua969eo6fPiwMjMz5e7ufktrzguWZAAW3N3dVa9ePcXFxZn7srOzFRcXZzeDcLVGjRrZtZekVatWXbd9UZOfMbvb5XfMJk6cqDFjxmjFihWqX7/+7Si10Cion7Ps7GxduHDhVpRY6Dg6ZtWqVdPOnTuVkJBgbo899phatGihhIQEBQcH387ynaIgfs6ysrK0c+dOBQYG3qoyC5X8jNlDDz2k/fv3m7+QSdLevXsVGBhYKMKyJB4rB9xIbGys4eHhYcTExBiJiYnG888/b5QsWdJ8TNAzzzxjDB061Gy/YcMGw83NzZg0aZKRlJRkjBgx4q58rJwjY3bhwgUjPj7eiI+PNwIDA41BgwYZ8fHxxr59+5x1Cbedo2M2fvx4w93d3fj666/tHl915swZZ13CbefomI0dO9ZYuXKlkZycbCQmJhqTJk0y3NzcjFmzZjnrEm47R8fsWnfjUzIcHbNRo0YZP/zwg5GcnGxs27bN6NGjh+Hp6Wns3r3bWZdw2zk6ZqmpqYaPj4/x0ksvGXv27DG+++47o1y5csY777zjrEvIgcAM5MGHH35oVKhQwXB3dzcaNGhg/PTTT+Z7zZo1M5599lm79gsXLjTCwsIMd3d3o2bNmsb3339/myt2PkfG7MCBA4akHFuzZs1uf+FO5MiYhYSE5DpmI0aMuP2FO5EjYzZs2DCjSpUqhqenp1GqVCmjUaNGRmxsrBOqdi5H/392tbsxMBuGY2P26quvmm3Lly9vtG/f3ti+fbsTqnYuR3/ONm7caDRs2NDw8PAwKlWqZLz77rvGpUuXbnPV12czDMNw1uw2AAAAUNixhhkAAACwQGAGAAAALBCYAQAAAAsEZgAAAMACgRkAAACwQGAGAAAALBCYAQAAAAsEZgAAAMACgRkAAACwQGAGAAAALBCYAQAAAAsEZgAAAMDC/wP65VIMye3TlgAAAABJRU5ErkJggg==",
"text/plain": [
""
]
diff --git a/scripts/setfit/run_fewshot.py b/scripts/setfit/run_fewshot.py
index 1248fddc..08f7023e 100644
--- a/scripts/setfit/run_fewshot.py
+++ b/scripts/setfit/run_fewshot.py
@@ -59,6 +59,7 @@ def parse_args():
parser.add_argument("--override_results", default=False, action="store_true")
parser.add_argument("--keep_body_frozen", default=False, action="store_true")
parser.add_argument("--add_data_augmentation", default=False)
+ parser.add_argument("--evaluation_strategy", default=False)
args = parser.parse_args()
@@ -148,6 +149,8 @@ def main():
num_epochs=args.num_epochs,
num_iterations=args.num_iterations,
)
+ if not args.evaluation_strategy:
+ trainer.args.evaluation_strategy = "no"
if args.classifier == "pytorch":
trainer.freeze()
trainer.train()
diff --git a/setup.py b/setup.py
index dcd5a8ea..4aed657c 100644
--- a/setup.py
+++ b/setup.py
@@ -10,12 +10,20 @@
MAINTAINER_EMAIL = "lewis@huggingface.co"
INTEGRATIONS_REQUIRE = ["optuna"]
-REQUIRED_PKGS = ["datasets>=2.3.0", "sentence-transformers>=2.2.1", "evaluate>=0.3.0"]
+REQUIRED_PKGS = [
+ "datasets>=2.3.0",
+ "sentence-transformers>=2.2.1",
+ "evaluate>=0.3.0",
+ "huggingface_hub>=0.13.0",
+ "scikit-learn",
+]
+ABSA_REQUIRE = ["spacy"]
QUALITY_REQUIRE = ["black", "flake8", "isort", "tabulate"]
ONNX_REQUIRE = ["onnxruntime", "onnx", "skl2onnx"]
OPENVINO_REQUIRE = ["hummingbird-ml<0.4.9", "openvino==2022.3.0"]
-TESTS_REQUIRE = ["pytest", "pytest-cov"] + ONNX_REQUIRE + OPENVINO_REQUIRE
+TESTS_REQUIRE = ["pytest", "pytest-cov"] + ONNX_REQUIRE + OPENVINO_REQUIRE + ABSA_REQUIRE
DOCS_REQUIRE = ["hf-doc-builder>=0.3.0"]
+CODECARBON_REQUIRE = ["codecarbon"]
EXTRAS_REQUIRE = {
"optuna": INTEGRATIONS_REQUIRE,
"quality": QUALITY_REQUIRE,
@@ -23,6 +31,8 @@
"onnx": ONNX_REQUIRE,
"openvino": ONNX_REQUIRE + OPENVINO_REQUIRE,
"docs": DOCS_REQUIRE,
+ "absa": ABSA_REQUIRE,
+ "codecarbon": CODECARBON_REQUIRE,
}
@@ -34,23 +44,27 @@ def combine_requirements(base_keys):
# For the combatibility tests we add pandas<2, as pandas 2.0.0 onwards is incompatible with old datasets versions,
# and we assume few to no users would use old datasets versions with new pandas versions.
# The only alternative is incrementing the minimum version for datasets, which seems unnecessary.
+# Beyond that, fsspec is set to <2023.12.0 as that version is incompatible with datasets<=2.15.0
EXTRAS_REQUIRE["compat_tests"] = (
- [requirement.replace(">=", "==") for requirement in REQUIRED_PKGS] + TESTS_REQUIRE + ["pandas<2"]
+ [requirement.replace(">=", "==") for requirement in REQUIRED_PKGS]
+ + TESTS_REQUIRE
+ + ["pandas<2", "fsspec<2023.12.0"]
)
setup(
name="setfit",
- version="0.8.0.dev0",
+ version="1.0.0.dev0",
description="Efficient few-shot learning with Sentence Transformers",
long_description=README_TEXT,
long_description_content_type="text/markdown",
maintainer=MAINTAINER,
maintainer_email=MAINTAINER_EMAIL,
- url="https://github.com/SetFit/setfit",
- download_url="https://github.com/SetFit/setfit/tags",
+ url="https://github.com/huggingface/setfit",
+ download_url="https://github.com/huggingface/setfit/tags",
license="Apache 2.0",
package_dir={"": "src"},
packages=find_packages("src"),
+ include_package_data=True,
install_requires=REQUIRED_PKGS,
extras_require=EXTRAS_REQUIRE,
classifiers=[
diff --git a/src/setfit/__init__.py b/src/setfit/__init__.py
index 287d89c5..3c0ead98 100644
--- a/src/setfit/__init__.py
+++ b/src/setfit/__init__.py
@@ -1,6 +1,23 @@
-__version__ = "0.8.0.dev0"
+__version__ = "1.0.0.dev0"
-from .data import add_templated_examples, get_templated_dataset, sample_dataset
+import importlib
+import os
+import warnings
+
+from .data import get_templated_dataset, sample_dataset
+from .model_card import SetFitModelCardData
from .modeling import SetFitHead, SetFitModel
-from .trainer import SetFitTrainer
-from .trainer_distillation import DistillationSetFitTrainer
+from .span import AbsaModel, AbsaTrainer, AspectExtractor, AspectModel, PolarityModel
+from .trainer import SetFitTrainer, Trainer
+from .trainer_distillation import DistillationSetFitTrainer, DistillationTrainer
+from .training_args import TrainingArguments
+
+
+# Ensure that DeprecationWarnings are shown by default, as recommended by
+# https://docs.python.org/3/library/warnings.html#overriding-the-default-filter
+warnings.filterwarnings("default", category=DeprecationWarning)
+
+# If codecarbon is installed and the log level is not defined,
+# automatically overwrite the default to "error"
+if importlib.util.find_spec("codecarbon") and "CODECARBON_LOG_LEVEL" not in os.environ:
+ os.environ["CODECARBON_LOG_LEVEL"] = "error"
diff --git a/src/setfit/data.py b/src/setfit/data.py
index 8e6149d6..1441d2fa 100644
--- a/src/setfit/data.py
+++ b/src/setfit/data.py
@@ -1,4 +1,3 @@
-import warnings
from typing import TYPE_CHECKING, Dict, List, Optional, Tuple, Union
import pandas as pd
@@ -21,15 +20,6 @@
SAMPLE_SIZES = [2, 4, 8, 16, 32, 64]
-def get_augmented_samples(*args, **kwargs) -> None:
- warnings.warn(
- "`get_augmented_samples` has been deprecated and will be removed in v1.0.0 of SetFit. "
- "Please use `get_templated_dataset` instead.",
- DeprecationWarning,
- stacklevel=2,
- )
-
-
def get_templated_dataset(
dataset: Optional[Dataset] = None,
candidate_labels: Optional[List[str]] = None,
@@ -54,9 +44,9 @@ def get_templated_dataset(
Args:
dataset (`Dataset`, *optional*): A Dataset to add templated examples to.
candidate_labels (`List[str]`, *optional*): The list of candidate
- labels to be fed into the template to construct examples.
+ labels to be fed into the template to construct examples.
reference_dataset (`str`, *optional*): A dataset to take labels
- from, if `candidate_labels` is not supplied.
+ from, if `candidate_labels` is not supplied.
template (`str`, *optional*, defaults to `"This sentence is {}"`): The template
used to turn each label into a synthetic training example. This template
must include a {} for the candidate label to be inserted into the template.
@@ -64,16 +54,16 @@ def get_templated_dataset(
candidate label "sports", this would produce an example
"This sentence is sports".
sample_size (`int`, *optional*, defaults to 2): The number of examples to make for
- each candidate label.
+ each candidate label.
text_column (`str`, *optional*, defaults to `"text"`): The name of the column
- containing the text of the examples.
+ containing the text of the examples.
label_column (`str`, *optional*, defaults to `"label"`): The name of the column
- in `dataset` containing the labels of the examples.
+ in `dataset` containing the labels of the examples.
multi_label (`bool`, *optional*, defaults to `False`): Whether or not multiple
- candidate labels can be true.
+ candidate labels can be true.
label_names_column (`str`, *optional*, defaults to "label_text"): The name of the
- label column in the `reference_dataset`, to be used in case there is no ClassLabel
- feature for the label column.
+ label column in the `reference_dataset`, to be used in case there is no ClassLabel
+ feature for the label column.
Returns:
`Dataset`: A copy of the input Dataset with templated examples added.
@@ -115,15 +105,6 @@ def get_templated_dataset(
return dataset
-def add_templated_examples(*args, **kwargs) -> None:
- warnings.warn(
- "`add_templated_examples` has been deprecated and will be removed in v1.0.0 of SetFit. "
- "Please use `get_templated_dataset` instead.",
- DeprecationWarning,
- stacklevel=2,
- )
-
-
def get_candidate_labels(dataset_name: str, label_names_column: str = "label_text") -> List[str]:
dataset = load_dataset(dataset_name, split="train")
diff --git a/src/setfit/integrations.py b/src/setfit/integrations.py
index 94d7161e..a847d753 100644
--- a/src/setfit/integrations.py
+++ b/src/setfit/integrations.py
@@ -5,10 +5,10 @@
if TYPE_CHECKING:
- from .trainer import SetFitTrainer
+ from .trainer import Trainer
-def is_optuna_available():
+def is_optuna_available() -> bool:
return importlib.util.find_spec("optuna") is not None
@@ -17,7 +17,7 @@ def default_hp_search_backend():
return "optuna"
-def run_hp_search_optuna(trainer: "SetFitTrainer", n_trials: int, direction: str, **kwargs) -> BestRun:
+def run_hp_search_optuna(trainer: "Trainer", n_trials: int, direction: str, **kwargs) -> BestRun:
import optuna
# Heavily inspired by transformers.integrations.run_hp_search_optuna
diff --git a/src/setfit/losses.py b/src/setfit/losses.py
new file mode 100644
index 00000000..369c8451
--- /dev/null
+++ b/src/setfit/losses.py
@@ -0,0 +1,100 @@
+import torch
+from torch import nn
+
+
+class SupConLoss(nn.Module):
+ """Supervised Contrastive Learning: https://arxiv.org/pdf/2004.11362.pdf.
+
+ It also supports the unsupervised contrastive loss in SimCLR.
+ """
+
+ def __init__(self, model, temperature=0.07, contrast_mode="all", base_temperature=0.07):
+ super(SupConLoss, self).__init__()
+ self.model = model
+ self.temperature = temperature
+ self.contrast_mode = contrast_mode
+ self.base_temperature = base_temperature
+
+ def forward(self, sentence_features, labels=None, mask=None):
+ """Computes loss for model.
+
+ If both `labels` and `mask` are None, it degenerates to SimCLR unsupervised loss:
+ https://arxiv.org/pdf/2002.05709.pdf
+
+ Args:
+ features: hidden vector of shape [bsz, n_views, ...].
+ labels: ground truth of shape [bsz].
+ mask: contrastive mask of shape [bsz, bsz], mask_{i,j}=1 if sample j
+ has the same class as sample i. Can be asymmetric.
+
+ Returns:
+ A loss scalar.
+ """
+ features = self.model(sentence_features[0])["sentence_embedding"]
+
+ # Normalize embeddings
+ features = torch.nn.functional.normalize(features, p=2, dim=1)
+
+ # Add n_views dimension
+ features = torch.unsqueeze(features, 1)
+
+ device = features.device
+
+ if len(features.shape) < 3:
+ raise ValueError("`features` needs to be [bsz, n_views, ...]," "at least 3 dimensions are required")
+ if len(features.shape) > 3:
+ features = features.view(features.shape[0], features.shape[1], -1)
+
+ batch_size = features.shape[0]
+ if labels is not None and mask is not None:
+ raise ValueError("Cannot define both `labels` and `mask`")
+ elif labels is None and mask is None:
+ mask = torch.eye(batch_size, dtype=torch.float32).to(device)
+ elif labels is not None:
+ labels = labels.contiguous().view(-1, 1)
+ if labels.shape[0] != batch_size:
+ raise ValueError("Num of labels does not match num of features")
+ mask = torch.eq(labels, labels.T).float().to(device)
+ else:
+ mask = mask.float().to(device)
+
+ contrast_count = features.shape[1]
+ contrast_feature = torch.cat(torch.unbind(features, dim=1), dim=0)
+ if self.contrast_mode == "one":
+ anchor_feature = features[:, 0]
+ anchor_count = 1
+ elif self.contrast_mode == "all":
+ anchor_feature = contrast_feature
+ anchor_count = contrast_count
+ else:
+ raise ValueError("Unknown mode: {}".format(self.contrast_mode))
+
+ # Compute logits
+ anchor_dot_contrast = torch.div(torch.matmul(anchor_feature, contrast_feature.T), self.temperature)
+ # For numerical stability
+ logits_max, _ = torch.max(anchor_dot_contrast, dim=1, keepdim=True)
+ logits = anchor_dot_contrast - logits_max.detach()
+
+ # Tile mask
+ mask = mask.repeat(anchor_count, contrast_count)
+ # Mask-out self-contrast cases
+ logits_mask = torch.scatter(
+ torch.ones_like(mask),
+ 1,
+ torch.arange(batch_size * anchor_count).view(-1, 1).to(device),
+ 0,
+ )
+ mask = mask * logits_mask
+
+ # Compute log_prob
+ exp_logits = torch.exp(logits) * logits_mask
+ log_prob = logits - torch.log(exp_logits.sum(1, keepdim=True))
+
+ # Compute mean of log-likelihood over positive
+ mean_log_prob_pos = (mask * log_prob).sum(1) / mask.sum(1)
+
+ # Loss
+ loss = -(self.temperature / self.base_temperature) * mean_log_prob_pos
+ loss = loss.view(anchor_count, batch_size).mean()
+
+ return loss
diff --git a/src/setfit/model_card.py b/src/setfit/model_card.py
new file mode 100644
index 00000000..1960791c
--- /dev/null
+++ b/src/setfit/model_card.py
@@ -0,0 +1,566 @@
+import collections
+import random
+from collections import Counter, defaultdict
+from dataclasses import dataclass, field, fields
+from pathlib import Path
+from platform import python_version
+from typing import TYPE_CHECKING, Any, Dict, List, Optional, Tuple, Union
+
+import datasets
+import tokenizers
+import torch
+import transformers
+from datasets import Dataset
+from huggingface_hub import CardData, DatasetFilter, ModelCard, dataset_info, list_datasets, model_info
+from huggingface_hub.repocard_data import EvalResult, eval_results_to_model_index
+from huggingface_hub.utils import yaml_dump
+from sentence_transformers import __version__ as sentence_transformers_version
+from transformers import PretrainedConfig, TrainerCallback
+from transformers.integrations import CodeCarbonCallback
+from transformers.modelcard import make_markdown_table
+from transformers.trainer_callback import TrainerControl, TrainerState
+from transformers.training_args import TrainingArguments
+
+from setfit import __version__ as setfit_version
+
+from . import logging
+
+
+logger = logging.get_logger(__name__)
+
+if TYPE_CHECKING:
+ from setfit.modeling import SetFitModel
+ from setfit.trainer import Trainer
+
+
+class ModelCardCallback(TrainerCallback):
+ def __init__(self, trainer: "Trainer") -> None:
+ super().__init__()
+ self.trainer = trainer
+
+ callbacks = [
+ callback
+ for callback in self.trainer.callback_handler.callbacks
+ if isinstance(callback, CodeCarbonCallback)
+ ]
+ if callbacks:
+ trainer.model.model_card_data.code_carbon_callback = callbacks[0]
+
+ def on_init_end(
+ self, args: TrainingArguments, state: TrainerState, control: TrainerControl, model: "SetFitModel", **kwargs
+ ):
+ if not model.model_card_data.dataset_id:
+ # Inferring is hacky - it may break in the future, so let's be safe
+ try:
+ model.model_card_data.infer_dataset_id(self.trainer.train_dataset)
+ except Exception:
+ pass
+
+ dataset = self.trainer.eval_dataset or self.trainer.train_dataset
+ if dataset is not None:
+ if not model.model_card_data.widget:
+ model.model_card_data.set_widget_examples(dataset)
+
+ if self.trainer.train_dataset:
+ model.model_card_data.set_train_set_metrics(self.trainer.train_dataset)
+ # Does not work for multilabel
+ try:
+ model.model_card_data.num_classes = len(set(self.trainer.train_dataset["label"]))
+ model.model_card_data.set_label_examples(self.trainer.train_dataset)
+ except Exception:
+ pass
+
+ def on_train_begin(
+ self, args: TrainingArguments, state: TrainerState, control: TrainerControl, model: "SetFitModel", **kwargs
+ ) -> None:
+ # model.model_card_data.hyperparameters = extract_hyperparameters_from_trainer(self.trainer)
+ ignore_keys = {
+ "output_dir",
+ "logging_dir",
+ "logging_strategy",
+ "logging_first_step",
+ "logging_steps",
+ "evaluation_strategy",
+ "eval_steps",
+ "eval_delay",
+ "save_strategy",
+ "save_steps",
+ "save_total_limit",
+ "metric_for_best_model",
+ "greater_is_better",
+ "report_to",
+ "samples_per_label",
+ "show_progress_bar",
+ }
+ get_name_keys = {"loss", "distance_metric"}
+ args_dict = args.to_dict()
+ model.model_card_data.hyperparameters = {
+ key: value.__name__ if key in get_name_keys else value
+ for key, value in args_dict.items()
+ if key not in ignore_keys and value is not None
+ }
+
+ def on_evaluate(
+ self,
+ args: TrainingArguments,
+ state: TrainerState,
+ control: TrainerControl,
+ model: "SetFitModel",
+ metrics: Dict[str, float],
+ **kwargs,
+ ) -> None:
+ if (
+ model.model_card_data.eval_lines_list
+ and model.model_card_data.eval_lines_list[-1]["Step"] == state.global_step
+ ):
+ model.model_card_data.eval_lines_list[-1]["Validation Loss"] = metrics["eval_embedding_loss"]
+ else:
+ model.model_card_data.eval_lines_list.append(
+ {
+ # "Training Loss": self.state.log_history[-1]["loss"] if "loss" in self.state.log_history[-1] else "-",
+ "Epoch": state.epoch,
+ "Step": state.global_step,
+ "Training Loss": "-",
+ "Validation Loss": metrics["eval_embedding_loss"],
+ }
+ )
+
+ def on_log(
+ self,
+ args: TrainingArguments,
+ state: TrainerState,
+ control: TrainerControl,
+ model: "SetFitModel",
+ logs: Dict[str, float],
+ **kwargs,
+ ):
+ keys = {"embedding_loss", "polarity_embedding_loss", "aspect_embedding_loss"} & set(logs)
+ if keys:
+ if (
+ model.model_card_data.eval_lines_list
+ and model.model_card_data.eval_lines_list[-1]["Step"] == state.global_step
+ ):
+ model.model_card_data.eval_lines_list[-1]["Training Loss"] = logs[keys.pop()]
+ else:
+ model.model_card_data.eval_lines_list.append(
+ {
+ "Epoch": state.epoch,
+ "Step": state.global_step,
+ "Training Loss": logs[keys.pop()],
+ "Validation Loss": "-",
+ }
+ )
+
+
+YAML_FIELDS = [
+ "language",
+ "license",
+ "library_name",
+ "tags",
+ "datasets",
+ "metrics",
+ "pipeline_tag",
+ "widget",
+ "model-index",
+ "co2_eq_emissions",
+ "base_model",
+ "inference",
+]
+IGNORED_FIELDS = ["model"]
+
+
+@dataclass
+class SetFitModelCardData(CardData):
+ """A dataclass storing data used in the model card.
+
+ Args:
+ language (`Optional[Union[str, List[str]]]`): The model language, either a string or a list,
+ e.g. "en" or ["en", "de", "nl"]
+ license (`Optional[str]`): The license of the model, e.g. "apache-2.0", "mit",
+ or "cc-by-nc-sa-4.0"
+ model_name (`Optional[str]`): The pretty name of the model, e.g. "SetFit with mBERT-base on SST2".
+ If not defined, uses encoder_name/encoder_id and dataset_name/dataset_id to generate a model name.
+ model_id (`Optional[str]`): The model ID when pushing the model to the Hub,
+ e.g. "tomaarsen/span-marker-mbert-base-multinerd".
+ dataset_name (`Optional[str]`): The pretty name of the dataset, e.g. "SST2".
+ dataset_id (`Optional[str]`): The dataset ID of the dataset, e.g. "dair-ai/emotion".
+ dataset_revision (`Optional[str]`): The dataset revision/commit that was for training/evaluation.
+ st_id (`Optional[str]`): The Sentence Transformers model ID.
+
+
+
+ Install [``codecarbon``](https://github.com/mlco2/codecarbon) to automatically track carbon emission usage and
+ include it in your model cards.
+
+
+
+ Example::
+
+ >>> model = SetFitModel.from_pretrained(
+ ... "sentence-transformers/paraphrase-mpnet-base-v2",
+ ... labels=["negative", "positive"],
+ ... # Model card variables
+ ... model_card_data=SetFitModelCardData(
+ ... model_id="tomaarsen/setfit-paraphrase-mpnet-base-v2-sst2",
+ ... dataset_name="SST2,
+ ... dataset_id="sst2",
+ ... license="apache-2.0",
+ ... language="en",
+ ... ),
+ ... )
+ """
+
+ # Potentially provided by the user
+ language: Optional[Union[str, List[str]]] = None
+ license: Optional[str] = None
+ tags: Optional[List[str]] = field(
+ default_factory=lambda: [
+ "setfit",
+ "sentence-transformers",
+ "text-classification",
+ "generated_from_setfit_trainer",
+ ]
+ )
+ model_name: Optional[str] = None
+ model_id: Optional[str] = None
+ dataset_name: Optional[str] = None
+ dataset_id: Optional[str] = None
+ dataset_revision: Optional[str] = None
+ task_name: Optional[str] = None
+ st_id: Optional[str] = None
+
+ # Automatically filled by `ModelCardCallback` and the Trainer directly
+ hyperparameters: Dict[str, Any] = field(default_factory=dict, init=False)
+ eval_results_dict: Optional[Dict[str, Any]] = field(default_factory=dict, init=False)
+ eval_lines_list: List[Dict[str, float]] = field(default_factory=list, init=False)
+ metric_lines: List[Dict[str, float]] = field(default_factory=list, init=False)
+ widget: List[Dict[str, str]] = field(default_factory=list, init=False)
+ predict_example: Optional[str] = field(default=None, init=False)
+ label_example_list: List[Dict[str, str]] = field(default_factory=list, init=False)
+ tokenizer_warning: bool = field(default=False, init=False)
+ train_set_metrics_list: List[Dict[str, str]] = field(default_factory=list, init=False)
+ train_set_sentences_per_label_list: List[Dict[str, str]] = field(default_factory=list, init=False)
+ code_carbon_callback: Optional[CodeCarbonCallback] = field(default=None, init=False)
+ num_classes: Optional[int] = field(default=None, init=False)
+ best_model_step: Optional[int] = field(default=None, init=False)
+ metrics: List[str] = field(default_factory=lambda: ["accuracy"], init=False)
+
+ # Computed once, always unchanged
+ pipeline_tag: str = field(default="text-classification", init=False)
+ library_name: str = field(default="setfit", init=False)
+ version: Dict[str, str] = field(
+ default_factory=lambda: {
+ "python": python_version(),
+ "setfit": setfit_version,
+ "sentence_transformers": sentence_transformers_version,
+ "transformers": transformers.__version__,
+ "torch": torch.__version__,
+ "datasets": datasets.__version__,
+ "tokenizers": tokenizers.__version__,
+ },
+ init=False,
+ )
+
+ # ABSA-related arguments
+ absa: Dict[str, Any] = field(default=None, init=False, repr=False)
+
+ # Passed via `register_model` only
+ model: Optional["SetFitModel"] = field(default=None, init=False, repr=False)
+ head_class: Optional[str] = field(default=None, init=False, repr=False)
+ inference: Optional[bool] = field(default=True, init=False, repr=False)
+
+ def __post_init__(self):
+ # We don't want to save "ignore_metadata_errors" in our Model Card
+ if self.dataset_id:
+ if is_on_huggingface(self.dataset_id, is_model=False):
+ if self.language is None:
+ # if languages are not set, try to determine the language from the dataset on the Hub
+ try:
+ info = dataset_info(self.dataset_id)
+ except Exception:
+ pass
+ else:
+ if info.cardData:
+ self.language = info.cardData.get("language", self.language)
+ else:
+ logger.warning(
+ f"The provided {self.dataset_id!r} dataset could not be found on the Hugging Face Hub."
+ " Setting `dataset_id` to None."
+ )
+ self.dataset_id = None
+
+ if self.model_id and self.model_id.count("/") != 1:
+ logger.warning(
+ f"The provided {self.model_id!r} model ID should include the organization or user,"
+ ' such as "tomaarsen/setfit-bge-small-v1.5-sst2-8-shot". Setting `model_id` to None.'
+ )
+ self.model_id = None
+
+ def set_best_model_step(self, step: int) -> None:
+ self.best_model_step = step
+
+ def set_widget_examples(self, dataset: Dataset) -> None:
+ samples = dataset.select(random.sample(range(len(dataset)), k=min(len(dataset), 5)))["text"]
+ self.widget = [{"text": sample} for sample in samples]
+
+ samples.sort(key=len)
+ if samples:
+ self.predict_example = samples[0]
+
+ def set_train_set_metrics(self, dataset: Dataset) -> None:
+ def add_naive_word_count(sample: Dict[str, Any]) -> Dict[str, Any]:
+ sample["word_count"] = len(sample["text"].split(" "))
+ return sample
+
+ dataset = dataset.map(add_naive_word_count)
+ self.train_set_metrics_list = [
+ {
+ "Training set": "Word count",
+ "Min": min(dataset["word_count"]),
+ "Median": sum(dataset["word_count"]) / len(dataset),
+ "Max": max(dataset["word_count"]),
+ },
+ ]
+ # E.g. if unlabeled via DistillationTrainer
+ if "label" not in dataset.column_names:
+ return
+
+ sample_label = dataset[0]["label"]
+ if isinstance(sample_label, collections.abc.Sequence) and not isinstance(sample_label, str):
+ return
+ try:
+ counter = Counter(dataset["label"])
+ if self.model.labels:
+ self.train_set_sentences_per_label_list = [
+ {
+ "Label": str_label,
+ "Training Sample Count": counter[
+ str_label if isinstance(sample_label, str) else self.model.label2id[str_label]
+ ],
+ }
+ for str_label in self.model.labels
+ ]
+ else:
+ self.train_set_sentences_per_label_list = [
+ {
+ "Label": self.model.labels[label]
+ if self.model.labels and isinstance(label, int)
+ else str(label),
+ "Training Sample Count": count,
+ }
+ for label, count in sorted(counter.items())
+ ]
+ except Exception:
+ # There are some tricky edge cases possible, e.g. if the user provided integer labels that do not fall
+ # between 0 to num_classes-1, so we make sure we never cause errors.
+ pass
+
+ def set_label_examples(self, dataset: Dataset) -> None:
+ num_examples_per_label = 3
+ examples = defaultdict(list)
+ finished_labels = set()
+ for sample in dataset:
+ text = sample["text"]
+ label = sample["label"]
+ if label not in finished_labels:
+ examples[label].append(f"
{repr(text)}
")
+ if len(examples[label]) >= num_examples_per_label:
+ finished_labels.add(label)
+ if len(finished_labels) == self.num_classes:
+ break
+ self.label_example_list = [
+ {
+ "Label": self.model.labels[label] if self.model.labels and isinstance(label, int) else label,
+ "Examples": "
" + "".join(example_set) + "
",
+ }
+ for label, example_set in examples.items()
+ ]
+
+ def infer_dataset_id(self, dataset: Dataset) -> None:
+ def subtuple_finder(tuple: Tuple[str], subtuple: Tuple[str]) -> int:
+ for i, element in enumerate(tuple):
+ if element == subtuple[0] and tuple[i : i + len(subtuple)] == subtuple:
+ return i
+ return -1
+
+ def normalize(dataset_id: str) -> str:
+ for token in "/\\_-":
+ dataset_id = dataset_id.replace(token, "")
+ return dataset_id.lower()
+
+ cache_files = dataset.cache_files
+ if cache_files and "filename" in cache_files[0]:
+ cache_path_parts = Path(cache_files[0]["filename"]).parts
+ # Check if the cachefile is under "huggingface/datasets"
+ subtuple = ("huggingface", "datasets")
+ index = subtuple_finder(cache_path_parts, subtuple)
+ if index == -1:
+ return
+
+ # Get the folder after "huggingface/datasets"
+ cache_dataset_name = cache_path_parts[index + len(subtuple)]
+ # If the dataset has an author:
+ if "___" in cache_dataset_name:
+ author, dataset_name = cache_dataset_name.split("___")
+ else:
+ author = None
+ dataset_name = cache_dataset_name
+
+ # Make sure the normalized dataset IDs match
+ dataset_list = [
+ dataset
+ for dataset in list_datasets(filter=DatasetFilter(author=author, dataset_name=dataset_name))
+ if normalize(dataset.id) == normalize(cache_dataset_name)
+ ]
+ # If there's only one match, get the ID from it
+ if len(dataset_list) == 1:
+ self.dataset_id = dataset_list[0].id
+
+ def register_model(self, model: "SetFitModel") -> None:
+ self.model = model
+ head_class = model.model_head.__class__.__name__
+ self.head_class = {
+ "LogisticRegression": "[LogisticRegression](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html)",
+ "SetFitHead": "[SetFitHead](huggingface.co/docs/setfit/reference/main#setfit.SetFitHead)",
+ }.get(head_class, head_class)
+
+ if not self.model_name:
+ if self.st_id:
+ self.model_name = f"SetFit with {self.st_id}"
+ if self.dataset_name or self.dataset_id:
+ self.model_name += f" on {self.dataset_name or self.dataset_id}"
+ else:
+ self.model_name = "SetFit"
+
+ self.inference = self.model.multi_target_strategy is None
+
+ def infer_st_id(self, setfit_model_id: str) -> None:
+ config_dict, _ = PretrainedConfig.get_config_dict(setfit_model_id)
+ st_id = config_dict.get("_name_or_path")
+ st_id_path = Path(st_id)
+ # Sometimes the name_or_path ends exactly with the model_id, e.g.
+ # "C:\\Users\\tom/.cache\\torch\\sentence_transformers\\BAAI_bge-small-en-v1.5\\"
+ candidate_model_ids = ["/".join(st_id_path.parts[-2:])]
+ # Sometimes the name_or_path its final part contains the full model_id, with "/" replaced with a "_", e.g.
+ # "/root/.cache/torch/sentence_transformers/sentence-transformers_all-mpnet-base-v2/"
+ # In that case, we take the last part, split on _, and try all combinations
+ # e.g. "a_b_c_d" -> ['a/b_c_d', 'a_b/c_d', 'a_b_c/d']
+ splits = st_id_path.name.split("_")
+ candidate_model_ids += ["_".join(splits[:idx]) + "/" + "_".join(splits[idx:]) for idx in range(1, len(splits))]
+ for model_id in candidate_model_ids:
+ if is_on_huggingface(model_id):
+ self.st_id = model_id
+ break
+
+ def set_st_id(self, model_id: str) -> None:
+ if is_on_huggingface(model_id):
+ self.st_id = model_id
+
+ def post_training_eval_results(self, results: Dict[str, float]) -> None:
+ self.eval_results_dict = results
+
+ results_without_split = {key.split("_", maxsplit=1)[1].title(): value for key, value in results.items()}
+ self.metric_lines = [{"Label": "**all**", **results_without_split}]
+
+ def _maybe_round(self, v, decimals=4):
+ if isinstance(v, float) and len(str(v).split(".")) > 1 and len(str(v).split(".")[1]) > decimals:
+ return f"{v:.{decimals}f}"
+ return str(v)
+
+ def to_dict(self) -> Dict[str, Any]:
+ super_dict = {field.name: getattr(self, field.name) for field in fields(self)}
+
+ # Compute required formats from the raw data
+ if self.eval_results_dict:
+ dataset_split = list(self.eval_results_dict.keys())[0].split("_")[0]
+ dataset_id = self.dataset_id or "unknown"
+ dataset_name = self.dataset_name or self.dataset_id or "Unknown"
+ eval_results = [
+ EvalResult(
+ task_type="text-classification",
+ dataset_type=dataset_id,
+ dataset_name=dataset_name,
+ dataset_split=dataset_split,
+ dataset_revision=self.dataset_revision,
+ metric_type=metric_key.split("_", maxsplit=1)[1],
+ metric_value=metric_value,
+ task_name="Text Classification",
+ metric_name=metric_key.split("_", maxsplit=1)[1].title(),
+ )
+ for metric_key, metric_value in self.eval_results_dict.items()
+ ]
+ super_dict["metrics"] = [metric_key.split("_", maxsplit=1)[1] for metric_key in self.eval_results_dict]
+ super_dict["model-index"] = eval_results_to_model_index(self.model_name, eval_results)
+ eval_lines_list = [
+ {
+ key: f"**{self._maybe_round(value)}**" if line["Step"] == self.best_model_step else value
+ for key, value in line.items()
+ }
+ for line in self.eval_lines_list
+ ]
+ super_dict["eval_lines"] = make_markdown_table(eval_lines_list)
+ super_dict["explain_bold_in_eval"] = "**" in super_dict["eval_lines"]
+ # Replace |:---:| with |:---| for left alignment
+ super_dict["label_examples"] = make_markdown_table(self.label_example_list).replace("-:|", "--|")
+ super_dict["train_set_metrics"] = make_markdown_table(self.train_set_metrics_list).replace("-:|", "--|")
+ super_dict["train_set_sentences_per_label_list"] = make_markdown_table(
+ self.train_set_sentences_per_label_list
+ ).replace("-:|", "--|")
+ super_dict["metrics_table"] = make_markdown_table(self.metric_lines).replace("-:|", "--|")
+ if self.code_carbon_callback and self.code_carbon_callback.tracker:
+ emissions_data = self.code_carbon_callback.tracker._prepare_emissions_data()
+ super_dict["co2_eq_emissions"] = {
+ # * 1000 to convert kg to g
+ "emissions": float(emissions_data.emissions) * 1000,
+ "source": "codecarbon",
+ "training_type": "fine-tuning",
+ "on_cloud": emissions_data.on_cloud == "Y",
+ "cpu_model": emissions_data.cpu_model,
+ "ram_total_size": emissions_data.ram_total_size,
+ "hours_used": round(emissions_data.duration / 3600, 3),
+ }
+ if emissions_data.gpu_model:
+ super_dict["co2_eq_emissions"]["hardware_used"] = emissions_data.gpu_model
+ if self.dataset_id:
+ super_dict["datasets"] = [self.dataset_id]
+ if self.st_id:
+ super_dict["base_model"] = self.st_id
+ super_dict["model_max_length"] = self.model.model_body.get_max_seq_length()
+ if super_dict["num_classes"] is None:
+ if self.model.labels:
+ super_dict["num_classes"] = len(self.model.labels)
+ if super_dict["absa"]:
+ super_dict.update(super_dict.pop("absa"))
+
+ for key in IGNORED_FIELDS:
+ super_dict.pop(key, None)
+ return super_dict
+
+ def to_yaml(self, line_break=None) -> str:
+ return yaml_dump(
+ {key: value for key, value in self.to_dict().items() if key in YAML_FIELDS and value is not None},
+ sort_keys=False,
+ line_break=line_break,
+ ).strip()
+
+
+def is_on_huggingface(repo_id: str, is_model: bool = True) -> bool:
+ # Models with more than two 'sections' certainly are not public models
+ if len(repo_id.split("/")) > 2:
+ return False
+
+ try:
+ if is_model:
+ model_info(repo_id)
+ else:
+ dataset_info(repo_id)
+ return True
+ except Exception:
+ # Fetching models can fail for many reasons: Repository not existing, no internet access, HF down, etc.
+ return False
+
+
+def generate_model_card(model: "SetFitModel") -> str:
+ template_path = Path(__file__).parent / "model_card_template.md"
+ model_card = ModelCard.from_template(card_data=model.model_card_data, template_path=template_path, hf_emoji="🤗")
+ return model_card.content
diff --git a/src/setfit/model_card_template.md b/src/setfit/model_card_template.md
new file mode 100644
index 00000000..41c73cba
--- /dev/null
+++ b/src/setfit/model_card_template.md
@@ -0,0 +1,209 @@
+---
+# For reference on model card metadata, see the spec: https://github.com/huggingface/hub-docs/blob/main/modelcard.md?plain=1
+# Doc / guide: https://huggingface.co/docs/hub/model-cards
+{{ card_data }}
+---
+
+# {{ model_name if model_name else ( "SetFit Aspect Model for Aspect Based Sentiment Analysis" if is_aspect else ( "SetFit Polarity Model for Aspect Based Sentiment Analysis" if is_aspect is False else "SetFit Model for Text Classification"))}}
+
+This is a [SetFit](https://github.com/huggingface/setfit) model{% if dataset_id %} trained on the [{{ dataset_name if dataset_name else dataset_id }}](https://huggingface.co/datasets/{{ dataset_id }}) dataset{% endif %} that can be used for {{ task_name | default("Text Classification", true) }}.{% if st_id %} This SetFit model uses [{{ st_id }}](https://huggingface.co/{{ st_id }}) as the Sentence Transformer embedding model.{% endif %} A {{ head_class }} instance is used for classification.{% if is_absa %} In particular, this model is in charge of {{ "filtering aspect span candidates" if is_aspect else "classifying aspect polarities"}}.{% endif %}
+
+The model has been trained using an efficient few-shot learning technique that involves:
+
+1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
+2. Training a classification head with features from the fine-tuned Sentence Transformer.
+{% if is_absa %}
+This model was trained within the context of a larger system for ABSA, which looks like so:
+
+1. Use a spaCy model to select possible aspect span candidates.
+2. {{ "**" if is_aspect else "" }}Use {{ "this" if is_aspect else "a" }} SetFit model to filter these possible aspect span candidates.{{ "**" if is_aspect else "" }}
+3. {{ "**" if not is_aspect else "" }}Use {{ "this" if not is_aspect else "a" }} SetFit model to classify the filtered aspect span candidates.{{ "**" if not is_aspect else "" }}
+{% endif %}
+## Model Details
+
+### Model Description
+- **Model Type:** SetFit
+{% if st_id -%}
+ - **Sentence Transformer body:** [{{ st_id }}](https://huggingface.co/{{ st_id }})
+{%- else -%}
+
+{%- endif %}
+{% if head_class -%}
+ - **Classification head:** a {{ head_class }} instance
+{%- else -%}
+
+{%- endif %}
+{%- if spacy_model %}
+- **spaCy Model:** {{ spacy_model }}
+{%- endif %}
+{%- if aspect_model %}
+- **SetFitABSA Aspect Model:** [{{ aspect_model }}](https://huggingface.co/{{ aspect_model }})
+{%- endif %}
+{%- if polarity_model %}
+- **SetFitABSA Polarity Model:** [{{ polarity_model }}](https://huggingface.co/{{ polarity_model }})
+{%- endif %}
+- **Maximum Sequence Length:** {{ model_max_length }} tokens
+{% if num_classes -%}
+ - **Number of Classes:** {{ num_classes }} classes
+{%- else -%}
+
+{%- endif %}
+{% if dataset_id -%}
+ - **Training Dataset:** [{{ dataset_name if dataset_name else dataset_id }}](https://huggingface.co/datasets/{{ dataset_id }})
+{%- else -%}
+
+{%- endif %}
+{% if language -%}
+ - **Language{{"s" if language is not string and language | length > 1 else ""}}:**
+ {%- if language is string %} {{ language }}
+ {%- else %} {% for lang in language -%}
+ {{ lang }}{{ ", " if not loop.last else "" }}
+ {%- endfor %}
+ {%- endif %}
+{%- else -%}
+
+{%- endif %}
+{% if license -%}
+ - **License:** {{ license }}
+{%- else -%}
+
+{%- endif %}
+
+### Model Sources
+
+- **Repository:** [SetFit on GitHub](https://github.com/huggingface/setfit)
+- **Paper:** [Efficient Few-Shot Learning Without Prompts](https://arxiv.org/abs/2209.11055)
+- **Blogpost:** [SetFit: Efficient Few-Shot Learning Without Prompts](https://huggingface.co/blog/setfit)
+{% if label_examples %}
+### Model Labels
+{{ label_examples }}{% endif -%}
+{% if metrics_table %}
+## Evaluation
+
+### Metrics
+{{ metrics_table }}{% endif %}
+## Uses
+
+### Direct Use for Inference
+
+First install the SetFit library:
+
+```bash
+pip install setfit
+```
+
+Then you can load this model and run inference.
+{% if is_absa %}
+```python
+from setfit import AbsaModel
+
+# Download from the {{ hf_emoji }} Hub
+model = AbsaModel.from_pretrained(
+ "{{ aspect_model }}",
+ "{{ polarity_model }}",
+)
+# Run inference
+preds = model("The food was great, but the venue is just way too busy.")
+```
+{%- else %}
+```python
+from setfit import SetFitModel
+
+# Download from the {{ hf_emoji }} Hub
+model = SetFitModel.from_pretrained("{{ model_id | default('setfit_model_id', true) }}")
+# Run inference
+preds = model("{{ predict_example | default("I loved the spiderman movie!", true) | replace('"', '\\"') }}")
+```
+{%- endif %}
+
+
+
+
+
+
+
+
+
+## Training Details
+{% if train_set_metrics %}
+### Training Set Metrics
+{{ train_set_metrics }}{% if train_set_sentences_per_label_list %}
+{{ train_set_sentences_per_label_list }}{% endif %}{% endif %}{% if hyperparameters %}
+### Training Hyperparameters
+{% for name, value in hyperparameters.items() %}- {{ name }}: {{ value }}
+{% endfor %}{% endif %}{% if eval_lines %}
+### Training Results
+{{ eval_lines }}{% if explain_bold_in_eval %}
+* The bold row denotes the saved checkpoint.{% endif %}{% endif %}{% if co2_eq_emissions %}
+### Environmental Impact
+Carbon emissions were measured using [CodeCarbon](https://github.com/mlco2/codecarbon).
+- **Carbon Emitted**: {{ "%.3f"|format(co2_eq_emissions["emissions"] / 1000) }} kg of CO2
+- **Hours Used**: {{ co2_eq_emissions["hours_used"] }} hours
+
+### Training Hardware
+- **On Cloud**: {{ "Yes" if co2_eq_emissions["on_cloud"] else "No" }}
+- **GPU Model**: {{ co2_eq_emissions["hardware_used"] or "No GPU used" }}
+- **CPU Model**: {{ co2_eq_emissions["cpu_model"] }}
+- **RAM Size**: {{ "%.2f"|format(co2_eq_emissions["ram_total_size"]) }} GB
+{% endif %}
+### Framework Versions
+- Python: {{ version["python"] }}
+- SetFit: {{ version["setfit"] }}
+- Sentence Transformers: {{ version["sentence_transformers"] }}
+{%- if "spacy" in version %}
+- spaCy: {{ version["spacy"] }}
+{%- endif %}
+- Transformers: {{ version["transformers"] }}
+- PyTorch: {{ version["torch"] }}
+- Datasets: {{ version["datasets"] }}
+- Tokenizers: {{ version["tokenizers"] }}
+
+## Citation
+
+### BibTeX
+```bibtex
+@article{https://doi.org/10.48550/arxiv.2209.11055,
+ doi = {10.48550/ARXIV.2209.11055},
+ url = {https://arxiv.org/abs/2209.11055},
+ author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
+ keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
+ title = {Efficient Few-Shot Learning Without Prompts},
+ publisher = {arXiv},
+ year = {2022},
+ copyright = {Creative Commons Attribution 4.0 International}
+}
+```
+
+
+
+
+
+
\ No newline at end of file
diff --git a/src/setfit/modeling.py b/src/setfit/modeling.py
index f971d952..263c3021 100644
--- a/src/setfit/modeling.py
+++ b/src/setfit/modeling.py
@@ -1,11 +1,13 @@
+import json
import os
import tempfile
-from dataclasses import dataclass
+import warnings
+from dataclasses import dataclass, field
from pathlib import Path
-from typing import TYPE_CHECKING, Dict, List, Optional, Tuple, Union
+from typing import Dict, List, Optional, Set, Tuple, Union
-# Google Colab runs on Python 3.7, so we need this to be compatible
+# For Python 3.7 compatibility
try:
from typing import Literal
except ImportError:
@@ -15,88 +17,28 @@
import numpy as np
import requests
import torch
-import torch.nn as nn
from huggingface_hub import PyTorchModelHubMixin, hf_hub_download
-from sentence_transformers import InputExample, SentenceTransformer, models
+from huggingface_hub.utils import validate_hf_hub_args
+from sentence_transformers import SentenceTransformer, models
from sklearn.linear_model import LogisticRegression
from sklearn.multiclass import OneVsRestClassifier
from sklearn.multioutput import ClassifierChain, MultiOutputClassifier
+from torch import nn
from torch.utils.data import DataLoader
-from tqdm.auto import trange
+from tqdm.auto import tqdm, trange
+from transformers.utils import copy_func
from . import logging
from .data import SetFitDataset
-
-
-if TYPE_CHECKING:
- from numpy import ndarray
+from .model_card import SetFitModelCardData, generate_model_card
+from .utils import set_docstring
logging.set_verbosity_info()
logger = logging.get_logger(__name__)
MODEL_HEAD_NAME = "model_head.pkl"
-
-MODEL_CARD_TEMPLATE = """---
-license: apache-2.0
-tags:
-- setfit
-- sentence-transformers
-- text-classification
-pipeline_tag: text-classification
----
-
-# {model_name}
-
-This is a [SetFit model](https://github.com/huggingface/setfit) that can be used for text classification. \
-The model has been trained using an efficient few-shot learning technique that involves:
-
-1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
-2. Training a classification head with features from the fine-tuned Sentence Transformer.
-
-## Usage
-
-To use this model for inference, first install the SetFit library:
-
-```bash
-python -m pip install setfit
-```
-
-You can then run inference as follows:
-
-```python
-from setfit import SetFitModel
-
-# Download from Hub and run inference
-model = SetFitModel.from_pretrained("{model_name}")
-# Run inference
-preds = model(["i loved the spiderman movie!", "pineapple on pizza is the worst 🤮"])
-```
-
-## BibTeX entry and citation info
-
-```bibtex
-@article{{https://doi.org/10.48550/arxiv.2209.11055,
-doi = {{10.48550/ARXIV.2209.11055}},
-url = {{https://arxiv.org/abs/2209.11055}},
-author = {{Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren}},
-keywords = {{Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences}},
-title = {{Efficient Few-Shot Learning Without Prompts}},
-publisher = {{arXiv}},
-year = {{2022}},
-copyright = {{Creative Commons Attribution 4.0 International}}
-}}
-```
-"""
-
-
-class SetFitBaseModel:
- def __init__(self, model, max_seq_length: int, add_normalization_layer: bool) -> None:
- self.model = SentenceTransformer(model)
- self.model.max_seq_length = max_seq_length
-
- if add_normalization_layer:
- self.model._modules["2"] = models.Normalize()
+CONFIG_NAME = "config_setfit.json"
class SetFitHead(models.Dense):
@@ -217,7 +159,7 @@ def predict(self, x_test: torch.Tensor) -> torch.Tensor:
return torch.where(probs >= 0.5, 1, 0)
return torch.argmax(probs, dim=-1)
- def get_loss_fn(self):
+ def get_loss_fn(self) -> nn.Module:
if self.multitarget: # if sigmoid output
return torch.nn.BCEWithLogitsLoss()
return torch.nn.CrossEntropyLoss()
@@ -241,83 +183,133 @@ def get_config_dict(self) -> Dict[str, Optional[Union[int, float, bool]]]:
}
@staticmethod
- def _init_weight(module):
+ def _init_weight(module) -> None:
if isinstance(module, nn.Linear):
- torch.nn.init.xavier_uniform_(module.weight)
+ nn.init.xavier_uniform_(module.weight)
if module.bias is not None:
- torch.nn.init.constant_(module.bias, 1e-2)
+ nn.init.constant_(module.bias, 1e-2)
- def __repr__(self):
+ def __repr__(self) -> str:
return "SetFitHead({})".format(self.get_config_dict())
@dataclass
class SetFitModel(PyTorchModelHubMixin):
- """A SetFit model with integration to the Hugging Face Hub."""
+ """A SetFit model with integration to the [Hugging Face Hub](https://huggingface.co).
+
+ Example::
+
+ >>> from setfit import SetFitModel
+ >>> model = SetFitModel.from_pretrained("tomaarsen/setfit-bge-small-v1.5-sst2-8-shot")
+ >>> model.predict([
+ ... "It's a charming and often affecting journey.",
+ ... "It's slow -- very, very slow.",
+ ... "A sometimes tedious film.",
+ ... ])
+ ['positive', 'negative', 'negative']
+ """
- def __init__(
- self,
- model_body: Optional[SentenceTransformer] = None,
- model_head: Optional[Union[SetFitHead, LogisticRegression]] = None,
- multi_target_strategy: Optional[str] = None,
- l2_weight: float = 1e-2,
- normalize_embeddings: bool = False,
- ) -> None:
- super(SetFitModel, self).__init__()
- self.model_body = model_body
- self.model_head = model_head
+ model_body: Optional[SentenceTransformer] = None
+ model_head: Optional[Union[SetFitHead, LogisticRegression]] = None
+ multi_target_strategy: Optional[str] = None
+ normalize_embeddings: bool = False
+ labels: Optional[List[str]] = None
+ model_card_data: Optional[SetFitModelCardData] = field(default_factory=SetFitModelCardData)
- self.multi_target_strategy = multi_target_strategy
- self.l2_weight = l2_weight
+ attributes_to_save: Set[str] = field(
+ init=False, repr=False, default_factory=lambda: {"normalize_embeddings", "labels"}
+ )
- self.normalize_embeddings = normalize_embeddings
+ def __post_init__(self):
+ self.model_card_data.register_model(self)
@property
def has_differentiable_head(self) -> bool:
# if False, sklearn is assumed to be used instead
return isinstance(self.model_head, nn.Module)
+ @property
+ def id2label(self) -> Dict[int, str]:
+ """Return a mapping from integer IDs to string labels."""
+ if self.labels is None:
+ return {}
+ return dict(enumerate(self.labels))
+
+ @property
+ def label2id(self) -> Dict[str, int]:
+ """Return a mapping from string labels to integer IDs."""
+ if self.labels is None:
+ return {}
+ return {label: idx for idx, label in enumerate(self.labels)}
+
def fit(
self,
x_train: List[str],
y_train: Union[List[int], List[List[int]]],
num_epochs: int,
batch_size: Optional[int] = None,
- learning_rate: Optional[float] = None,
body_learning_rate: Optional[float] = None,
+ head_learning_rate: Optional[float] = None,
+ end_to_end: bool = False,
l2_weight: Optional[float] = None,
max_length: Optional[int] = None,
- show_progress_bar: Optional[bool] = None,
+ show_progress_bar: bool = True,
) -> None:
+ """Train the classifier head, only used if a differentiable PyTorch head is used.
+
+ Args:
+ x_train (`List[str]`): A list of training sentences.
+ y_train (`Union[List[int], List[List[int]]]`): A list of labels corresponding to the training sentences.
+ num_epochs (`int`): The number of epochs to train for.
+ batch_size (`int`, *optional*): The batch size to use.
+ body_learning_rate (`float`, *optional*): The learning rate for the `SentenceTransformer` body
+ in the `AdamW` optimizer. Disregarded if `end_to_end=False`.
+ head_learning_rate (`float`, *optional*): The learning rate for the differentiable torch head
+ in the `AdamW` optimizer.
+ end_to_end (`bool`, defaults to `False`): If True, train the entire model end-to-end.
+ Otherwise, freeze the `SentenceTransformer` body and only train the head.
+ l2_weight (`float`, *optional*): The l2 weight for both the model body and head
+ in the `AdamW` optimizer.
+ max_length (`int`, *optional*): The maximum token length a tokenizer can generate. If not provided,
+ the maximum length for the `SentenceTransformer` body is used.
+ show_progress_bar (`bool`, defaults to `True`): Whether to display a progress bar for the training
+ epochs and iterations.
+ """
if self.has_differentiable_head: # train with pyTorch
- device = self.model_body.device
self.model_body.train()
self.model_head.train()
+ if not end_to_end:
+ self.freeze("body")
dataloader = self._prepare_dataloader(x_train, y_train, batch_size, max_length)
criterion = self.model_head.get_loss_fn()
- optimizer = self._prepare_optimizer(learning_rate, body_learning_rate, l2_weight)
+ optimizer = self._prepare_optimizer(head_learning_rate, body_learning_rate, l2_weight)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.5)
for epoch_idx in trange(num_epochs, desc="Epoch", disable=not show_progress_bar):
- for batch in dataloader:
+ for batch in tqdm(dataloader, desc="Iteration", disable=not show_progress_bar, leave=False):
features, labels = batch
optimizer.zero_grad()
# to model's device
- features = {k: v.to(device) for k, v in features.items()}
- labels = labels.to(device)
+ features = {k: v.to(self.device) for k, v in features.items()}
+ labels = labels.to(self.device)
outputs = self.model_body(features)
if self.normalize_embeddings:
- outputs = torch.nn.functional.normalize(outputs, p=2, dim=1)
+ outputs["sentence_embedding"] = nn.functional.normalize(
+ outputs["sentence_embedding"], p=2, dim=1
+ )
outputs = self.model_head(outputs)
logits = outputs["logits"]
- loss = criterion(logits, labels)
+ loss: torch.Tensor = criterion(logits, labels)
loss.backward()
optimizer.step()
scheduler.step()
+
+ if not end_to_end:
+ self.unfreeze("body")
else: # train with sklearn
embeddings = self.model_body.encode(x_train, normalize_embeddings=self.normalize_embeddings)
self.model_head.fit(embeddings, y_train)
@@ -364,12 +356,12 @@ def _prepare_dataloader(
def _prepare_optimizer(
self,
- learning_rate: float,
+ head_learning_rate: float,
body_learning_rate: Optional[float],
l2_weight: float,
) -> torch.optim.Optimizer:
- body_learning_rate = body_learning_rate or learning_rate
- l2_weight = l2_weight or self.l2_weight
+ body_learning_rate = body_learning_rate or head_learning_rate
+ l2_weight = l2_weight or 1e-2
optimizer = torch.optim.AdamW(
[
{
@@ -377,37 +369,84 @@ def _prepare_optimizer(
"lr": body_learning_rate,
"weight_decay": l2_weight,
},
- {
- "params": self.model_head.parameters(),
- "lr": learning_rate,
- "weight_decay": l2_weight,
- },
+ {"params": self.model_head.parameters(), "lr": head_learning_rate, "weight_decay": l2_weight},
],
)
return optimizer
def freeze(self, component: Optional[Literal["body", "head"]] = None) -> None:
+ """Freeze the model body and/or the head, preventing further training on that component until unfrozen.
+
+ Args:
+ component (`Literal["body", "head"]`, *optional*): Either "body" or "head" to freeze that component.
+ If no component is provided, freeze both. Defaults to None.
+ """
if component is None or component == "body":
self._freeze_or_not(self.model_body, to_freeze=True)
- if component is None or component == "head":
+ if (component is None or component == "head") and self.has_differentiable_head:
self._freeze_or_not(self.model_head, to_freeze=True)
- def unfreeze(self, component: Optional[Literal["body", "head"]] = None) -> None:
+ def unfreeze(
+ self, component: Optional[Literal["body", "head"]] = None, keep_body_frozen: Optional[bool] = None
+ ) -> None:
+ """Unfreeze the model body and/or the head, allowing further training on that component.
+
+ Args:
+ component (`Literal["body", "head"]`, *optional*): Either "body" or "head" to unfreeze that component.
+ If no component is provided, unfreeze both. Defaults to None.
+ keep_body_frozen (`bool`, *optional*): Deprecated argument, use `component` instead.
+ """
+ if keep_body_frozen is not None:
+ warnings.warn(
+ "`keep_body_frozen` is deprecated and will be removed in v2.0.0 of SetFit. "
+ 'Please either pass "head", "body" or no arguments to unfreeze both.',
+ DeprecationWarning,
+ stacklevel=2,
+ )
+ # If the body must stay frozen, only unfreeze the head. Eventually, this entire if-branch
+ # can be removed.
+ if keep_body_frozen and not component:
+ component = "head"
+
if component is None or component == "body":
self._freeze_or_not(self.model_body, to_freeze=False)
- if component is None or component == "head":
+ if (component is None or component == "head") and self.has_differentiable_head:
self._freeze_or_not(self.model_head, to_freeze=False)
- def _freeze_or_not(self, model: torch.nn.Module, to_freeze: bool) -> None:
+ def _freeze_or_not(self, model: nn.Module, to_freeze: bool) -> None:
+ """Set `requires_grad=not to_freeze` for all parameters in `model`"""
for param in model.parameters():
param.requires_grad = not to_freeze
+ def encode(
+ self, inputs: List[str], batch_size: int = 32, show_progress_bar: Optional[bool] = None
+ ) -> Union[torch.Tensor, np.ndarray]:
+ """Convert input sentences to embeddings using the `SentenceTransformer` body.
+
+ Args:
+ inputs (`List[str]`): The input sentences to embed.
+ batch_size (`int`, defaults to `32`): The batch size to use in encoding the sentences to embeddings.
+ Higher often means faster processing but higher memory usage.
+ show_progress_bar (`Optional[bool]`, defaults to `None`): Whether to show a progress bar while encoding.
+
+ Returns:
+ Union[torch.Tensor, np.ndarray]: A matrix with shape [INPUT_LENGTH, EMBEDDING_SIZE], as a
+ torch Tensor if this model has a differentiable Torch head, or otherwise as a numpy array.
+ """
+ return self.model_body.encode(
+ inputs,
+ batch_size=batch_size,
+ normalize_embeddings=self.normalize_embeddings,
+ convert_to_tensor=self.has_differentiable_head,
+ show_progress_bar=show_progress_bar,
+ )
+
def _output_type_conversion(
- self, outputs: Union[torch.Tensor, "ndarray"], as_numpy: bool = False
- ) -> Union[torch.Tensor, "ndarray"]:
+ self, outputs: Union[torch.Tensor, np.ndarray], as_numpy: bool = False
+ ) -> Union[torch.Tensor, np.ndarray]:
"""Return `outputs` in the desired type:
* Numpy array if no differentiable head is used.
* Torch tensor if a differentiable head is used.
@@ -426,31 +465,142 @@ def _output_type_conversion(
outputs = torch.from_numpy(outputs)
return outputs
+ def predict_proba(
+ self,
+ inputs: Union[str, List[str]],
+ batch_size: int = 32,
+ as_numpy: bool = False,
+ show_progress_bar: Optional[bool] = None,
+ ) -> Union[torch.Tensor, np.ndarray]:
+ """Predict the probabilities of the various classes.
+
+ Args:
+ inputs (`Union[str, List[str]]`): The input sentences to predict class probabilities for.
+ batch_size (`int`, defaults to `32`): The batch size to use in encoding the sentences to embeddings.
+ Higher often means faster processing but higher memory usage.
+ as_numpy (`bool`, defaults to `False`): Whether to output as numpy array instead.
+ show_progress_bar (`Optional[bool]`, defaults to `None`): Whether to show a progress bar while encoding.
+
+ Example::
+
+ >>> model = SetFitModel.from_pretrained(...)
+ >>> model.predict_proba(["What a boring display", "Exhilarating through and through", "I'm wowed!"])
+ tensor([[0.9367, 0.0633],
+ [0.0627, 0.9373],
+ [0.0890, 0.9110]], dtype=torch.float64)
+ >>> model.predict_proba("That was cool!")
+ tensor([0.8421, 0.1579], dtype=torch.float64)
+
+ Returns:
+ `Union[torch.Tensor, np.ndarray]`: A matrix with shape [INPUT_LENGTH, NUM_CLASSES] denoting
+ probabilities of predicting an input as a class. If the input is a string, then the output
+ is a vector with shape [NUM_CLASSES,].
+ """
+ is_singular = isinstance(inputs, str)
+ if is_singular:
+ inputs = [inputs]
+ embeddings = self.encode(inputs, batch_size=batch_size, show_progress_bar=show_progress_bar)
+ probs = self.model_head.predict_proba(embeddings)
+ outputs = self._output_type_conversion(probs, as_numpy=as_numpy)
+ return outputs[0] if is_singular else outputs
+
def predict(
- self, x_test: List[str], as_numpy: bool = False, show_progress_bar: Optional[bool] = None
- ) -> Union[torch.Tensor, "ndarray"]:
- embeddings = self.model_body.encode(
- x_test,
- normalize_embeddings=self.normalize_embeddings,
- convert_to_tensor=self.has_differentiable_head,
- show_progress_bar=show_progress_bar,
- )
+ self,
+ inputs: Union[str, List[str]],
+ batch_size: int = 32,
+ as_numpy: bool = False,
+ use_labels: bool = True,
+ show_progress_bar: Optional[bool] = None,
+ ) -> Union[torch.Tensor, np.ndarray, List[str], int, str]:
+ """Predict the various classes.
- outputs = self.model_head.predict(embeddings)
- return self._output_type_conversion(outputs, as_numpy=as_numpy)
+ Args:
+ inputs (`Union[str, List[str]]`): The input sentence or sentences to predict classes for.
+ batch_size (`int`, defaults to `32`): The batch size to use in encoding the sentences to embeddings.
+ Higher often means faster processing but higher memory usage.
+ as_numpy (`bool`, defaults to `False`): Whether to output as numpy array instead.
+ use_labels (`bool`, defaults to `True`): Whether to try and return elements of `SetFitModel.labels`.
+ show_progress_bar (`Optional[bool]`, defaults to `None`): Whether to show a progress bar while encoding.
- def predict_proba(
- self, x_test: List[str], as_numpy: bool = False, show_progress_bar: Optional[bool] = None
- ) -> Union[torch.Tensor, "ndarray"]:
- embeddings = self.model_body.encode(
- x_test,
- normalize_embeddings=self.normalize_embeddings,
- convert_to_tensor=self.has_differentiable_head,
+ Example::
+
+ >>> model = SetFitModel.from_pretrained(...)
+ >>> model.predict(["What a boring display", "Exhilarating through and through", "I'm wowed!"])
+ ["negative", "positive", "positive"]
+ >>> model.predict("That was cool!")
+ "positive"
+
+ Returns:
+ `Union[torch.Tensor, np.ndarray, List[str], int, str]`: A list of string labels with equal length to the
+ inputs if `use_labels` is `True` and `SetFitModel.labels` has been defined. Otherwise a vector with
+ equal length to the inputs, denoting to which class each input is predicted to belong. If the inputs
+ is a single string, then the output is a single label as well.
+ """
+ is_singular = isinstance(inputs, str)
+ if is_singular:
+ inputs = [inputs]
+ embeddings = self.encode(inputs, batch_size=batch_size, show_progress_bar=show_progress_bar)
+ preds = self.model_head.predict(embeddings)
+ # If labels are defined, we don't have multilabels & the output is not already strings, then we convert to string labels
+ if (
+ use_labels
+ and self.labels
+ and preds.ndim == 1
+ and (self.has_differentiable_head or preds.dtype.char != "U")
+ ):
+ outputs = [self.labels[int(pred)] for pred in preds]
+ else:
+ outputs = self._output_type_conversion(preds, as_numpy=as_numpy)
+ return outputs[0] if is_singular else outputs
+
+ def __call__(
+ self,
+ inputs: Union[str, List[str]],
+ batch_size: int = 32,
+ as_numpy: bool = False,
+ use_labels: bool = True,
+ show_progress_bar: Optional[bool] = None,
+ ) -> Union[torch.Tensor, np.ndarray, List[str], int, str]:
+ """Predict the various classes.
+
+ Args:
+ inputs (`Union[str, List[str]]`): The input sentence or sentences to predict classes for.
+ batch_size (`int`, defaults to `32`): The batch size to use in encoding the sentences to embeddings.
+ Higher often means faster processing but higher memory usage.
+ as_numpy (`bool`, defaults to `False`): Whether to output as numpy array instead.
+ use_labels (`bool`, defaults to `True`): Whether to try and return elements of `SetFitModel.labels`.
+ show_progress_bar (`Optional[bool]`, defaults to `None`): Whether to show a progress bar while encoding.
+
+ Example::
+
+ >>> model = SetFitModel.from_pretrained(...)
+ >>> model(["What a boring display", "Exhilarating through and through", "I'm wowed!"])
+ ["negative", "positive", "positive"]
+ >>> model("That was cool!")
+ "positive"
+
+ Returns:
+ `Union[torch.Tensor, np.ndarray, List[str], int, str]`: A list of string labels with equal length to the
+ inputs if `use_labels` is `True` and `SetFitModel.labels` has been defined. Otherwise a vector with
+ equal length to the inputs, denoting to which class each input is predicted to belong. If the inputs
+ is a single string, then the output is a single label as well.
+ """
+ return self.predict(
+ inputs,
+ batch_size=batch_size,
+ as_numpy=as_numpy,
+ use_labels=use_labels,
show_progress_bar=show_progress_bar,
)
- outputs = self.model_head.predict_proba(embeddings)
- return self._output_type_conversion(outputs, as_numpy=as_numpy)
+ @property
+ def device(self) -> torch.device:
+ """Get the Torch device that this model is on.
+
+ Returns:
+ torch.device: The device that the model is on.
+ """
+ return self.model_body._target_device
def to(self, device: Union[str, torch.device]) -> "SetFitModel":
"""Move this SetFitModel to `device`, and then return `self`. This method does not copy.
@@ -458,6 +608,12 @@ def to(self, device: Union[str, torch.device]) -> "SetFitModel":
Args:
device (Union[str, torch.device]): The identifier of the device to move the model to.
+ Example::
+
+ >>> model = SetFitModel.from_pretrained(...)
+ >>> model.to("cpu")
+ >>> model(["cats are cute", "dogs are loyal"])
+
Returns:
SetFitModel: Returns the original model, but now on the desired device.
"""
@@ -486,22 +642,47 @@ def create_model_card(self, path: str, model_name: Optional[str] = "SetFit Model
# directories
model_path = Path(model_name)
if model_path.exists() and Path(tempfile.gettempdir()) in model_path.resolve().parents:
- model_name = "/".join(model_path.parts[-2:])
+ self.model_card_data.model_id = "/".join(model_path.parts[-2:])
- model_card_content = MODEL_CARD_TEMPLATE.format(model_name=model_name)
with open(os.path.join(path, "README.md"), "w", encoding="utf-8") as f:
- f.write(model_card_content)
+ f.write(self.generate_model_card())
+
+ def generate_model_card(self) -> str:
+ """Generate and return a model card string based on the model card data.
- def __call__(self, inputs):
- return self.predict(inputs)
+ Returns:
+ str: The model card string.
+ """
+ return generate_model_card(self)
def _save_pretrained(self, save_directory: Union[Path, str]) -> None:
save_directory = str(save_directory)
+ # Save the config
+ config_path = os.path.join(save_directory, CONFIG_NAME)
+ with open(config_path, "w") as f:
+ json.dump(
+ {
+ attr_name: getattr(self, attr_name)
+ for attr_name in self.attributes_to_save
+ if hasattr(self, attr_name)
+ },
+ f,
+ indent=2,
+ )
+ # Save the body
self.model_body.save(path=save_directory, create_model_card=False)
+ # Save the README
self.create_model_card(path=save_directory, model_name=save_directory)
+ # Move the head to the CPU before saving
+ if self.has_differentiable_head:
+ self.model_head.to("cpu")
+ # Save the classification head
joblib.dump(self.model_head, str(Path(save_directory) / MODEL_HEAD_NAME))
+ if self.has_differentiable_head:
+ self.model_head.to(self.device)
@classmethod
+ @validate_hf_hub_args
def _from_pretrained(
cls,
model_id: str,
@@ -511,16 +692,53 @@ def _from_pretrained(
proxies: Optional[Dict] = None,
resume_download: Optional[bool] = None,
local_files_only: Optional[bool] = None,
- use_auth_token: Optional[Union[bool, str]] = None,
+ token: Optional[Union[bool, str]] = None,
multi_target_strategy: Optional[str] = None,
use_differentiable_head: bool = False,
- normalize_embeddings: bool = False,
+ device: Optional[Union[torch.device, str]] = None,
**model_kwargs,
) -> "SetFitModel":
- model_body = SentenceTransformer(model_id, cache_folder=cache_dir, use_auth_token=use_auth_token)
- target_device = model_body._target_device
- model_body.to(target_device) # put `model_body` on the target device
+ model_body = SentenceTransformer(model_id, cache_folder=cache_dir, use_auth_token=token, device=device)
+ device = model_body._target_device
+ model_body.to(device) # put `model_body` on the target device
+ # Try to load a SetFit config file
+ config_file: Optional[str] = None
+ if os.path.isdir(model_id):
+ if CONFIG_NAME in os.listdir(model_id):
+ config_file = os.path.join(model_id, CONFIG_NAME)
+ else:
+ try:
+ config_file = hf_hub_download(
+ repo_id=model_id,
+ filename=CONFIG_NAME,
+ revision=revision,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ proxies=proxies,
+ resume_download=resume_download,
+ token=token,
+ local_files_only=local_files_only,
+ )
+ except requests.exceptions.RequestException:
+ pass
+
+ model_kwargs = {key: value for key, value in model_kwargs.items() if value is not None}
+
+ if config_file is not None:
+ with open(config_file, "r", encoding="utf-8") as f:
+ config = json.load(f)
+ # Update model_kwargs + warnings
+ for setting, value in config.items():
+ if setting in model_kwargs:
+ if model_kwargs[setting] != value:
+ logger.warning(
+ f"Overriding {setting} in model configuration from {value} to {model_kwargs[setting]}."
+ )
+ else:
+ model_kwargs[setting] = value
+
+ # Try to load a model head file
if os.path.isdir(model_id):
if MODEL_HEAD_NAME in os.listdir(model_id):
model_head_file = os.path.join(model_id, MODEL_HEAD_NAME)
@@ -541,7 +759,7 @@ def _from_pretrained(
force_download=force_download,
proxies=proxies,
resume_download=resume_download,
- use_auth_token=use_auth_token,
+ token=token,
local_files_only=local_files_only,
)
except requests.exceptions.RequestException:
@@ -551,10 +769,15 @@ def _from_pretrained(
)
model_head_file = None
+ model_card_data: SetFitModelCardData = model_kwargs.pop("model_card_data", SetFitModelCardData())
+
if model_head_file is not None:
model_head = joblib.load(model_head_file)
+ if isinstance(model_head, torch.nn.Module):
+ model_head.to(device)
+ model_card_data.infer_st_id(model_id)
else:
- head_params = model_kwargs.get("head_params", {})
+ head_params = model_kwargs.pop("head_params", {})
if use_differentiable_head:
if multi_target_strategy is None:
use_multitarget = False
@@ -570,7 +793,7 @@ def _from_pretrained(
# - follow the `model_body`, put `model_head` on the target device
base_head_params = {
"in_features": model_body.get_sentence_embedding_dimension(),
- "device": target_device,
+ "device": device,
"multitarget": use_multitarget,
}
model_head = SetFitHead(**{**head_params, **base_head_params})
@@ -590,207 +813,52 @@ def _from_pretrained(
else:
model_head = clf
+ model_card_data.set_st_id(model_id if "/" in model_id else f"sentence-transformers/{model_id}")
+
+ # Remove the `transformers` config
+ model_kwargs.pop("config", None)
return cls(
model_body=model_body,
model_head=model_head,
multi_target_strategy=multi_target_strategy,
- normalize_embeddings=normalize_embeddings,
+ model_card_data=model_card_data,
+ **model_kwargs,
)
-class SupConLoss(nn.Module):
- """Supervised Contrastive Learning: https://arxiv.org/pdf/2004.11362.pdf.
-
- It also supports the unsupervised contrastive loss in SimCLR.
- """
-
- def __init__(self, model, temperature=0.07, contrast_mode="all", base_temperature=0.07):
- super(SupConLoss, self).__init__()
- self.model = model
- self.temperature = temperature
- self.contrast_mode = contrast_mode
- self.base_temperature = base_temperature
-
- def forward(self, sentence_features, labels=None, mask=None):
- """Computes loss for model.
-
- If both `labels` and `mask` are None, it degenerates to SimCLR unsupervised loss:
- https://arxiv.org/pdf/2002.05709.pdf
-
- Args:
- features: hidden vector of shape [bsz, n_views, ...].
- labels: ground truth of shape [bsz].
- mask: contrastive mask of shape [bsz, bsz], mask_{i,j}=1 if sample j
- has the same class as sample i. Can be asymmetric.
-
- Returns:
- A loss scalar.
+docstring = SetFitModel.from_pretrained.__doc__
+cut_index = docstring.find("model_kwargs")
+if cut_index != -1:
+ docstring = (
+ docstring[:cut_index]
+ + """labels (`List[str]`, *optional*):
+ If the labels are integers ranging from `0` to `num_classes-1`, then these labels indicate
+ the corresponding labels.
+ model_card_data (`SetFitModelCardData`, *optional*):
+ A `SetFitModelCardData` instance storing data such as model language, license, dataset name,
+ etc. to be used in the automatically generated model cards.
+ multi_target_strategy (`str`, *optional*):
+ The strategy to use with multi-label classification. One of "one-vs-rest", "multi-output",
+ or "classifier-chain".
+ use_differentiable_head (`bool`, *optional*):
+ Whether to load SetFit using a differentiable (i.e., Torch) head instead of Logistic Regression.
+ normalize_embeddings (`bool`, *optional*):
+ Whether to apply normalization on the embeddings produced by the Sentence Transformer body.
+ device (`Union[torch.device, str]`, *optional*):
+ The device on which to load the SetFit model, e.g. `"cuda:0"`, `"mps"` or `torch.device("cuda")`.
+
+ Example::
+
+ >>> from setfit import SetFitModel
+ >>> model = SetFitModel.from_pretrained(
+ ... "sentence-transformers/paraphrase-mpnet-base-v2",
+ ... labels=["positive", "negative"],
+ ... )
"""
- features = self.model(sentence_features[0])["sentence_embedding"]
-
- # Normalize embeddings
- features = torch.nn.functional.normalize(features, p=2, dim=1)
-
- # Add n_views dimension
- features = torch.unsqueeze(features, 1)
-
- device = features.device
-
- if len(features.shape) < 3:
- raise ValueError("`features` needs to be [bsz, n_views, ...]," "at least 3 dimensions are required")
- if len(features.shape) > 3:
- features = features.view(features.shape[0], features.shape[1], -1)
-
- batch_size = features.shape[0]
- if labels is not None and mask is not None:
- raise ValueError("Cannot define both `labels` and `mask`")
- elif labels is None and mask is None:
- mask = torch.eye(batch_size, dtype=torch.float32).to(device)
- elif labels is not None:
- labels = labels.contiguous().view(-1, 1)
- if labels.shape[0] != batch_size:
- raise ValueError("Num of labels does not match num of features")
- mask = torch.eq(labels, labels.T).float().to(device)
- else:
- mask = mask.float().to(device)
-
- contrast_count = features.shape[1]
- contrast_feature = torch.cat(torch.unbind(features, dim=1), dim=0)
- if self.contrast_mode == "one":
- anchor_feature = features[:, 0]
- anchor_count = 1
- elif self.contrast_mode == "all":
- anchor_feature = contrast_feature
- anchor_count = contrast_count
- else:
- raise ValueError("Unknown mode: {}".format(self.contrast_mode))
-
- # Compute logits
- anchor_dot_contrast = torch.div(torch.matmul(anchor_feature, contrast_feature.T), self.temperature)
- # For numerical stability
- logits_max, _ = torch.max(anchor_dot_contrast, dim=1, keepdim=True)
- logits = anchor_dot_contrast - logits_max.detach()
-
- # Tile mask
- mask = mask.repeat(anchor_count, contrast_count)
- # Mask-out self-contrast cases
- logits_mask = torch.scatter(
- torch.ones_like(mask),
- 1,
- torch.arange(batch_size * anchor_count).view(-1, 1).to(device),
- 0,
- )
- mask = mask * logits_mask
-
- # Compute log_prob
- exp_logits = torch.exp(logits) * logits_mask
- log_prob = logits - torch.log(exp_logits.sum(1, keepdim=True))
-
- # Compute mean of log-likelihood over positive
- mean_log_prob_pos = (mask * log_prob).sum(1) / mask.sum(1)
-
- # Loss
- loss = -(self.temperature / self.base_temperature) * mean_log_prob_pos
- loss = loss.view(anchor_count, batch_size).mean()
-
- return loss
-
-
-def sentence_pairs_generation(sentences, labels, pairs):
- # Initialize two empty lists to hold the (sentence, sentence) pairs and
- # labels to indicate if a pair is positive or negative
-
- num_classes = np.unique(labels)
- label_to_idx = {x: i for i, x in enumerate(num_classes)}
- positive_idxs = [np.where(labels == i)[0] for i in num_classes]
- negative_idxs = [np.where(labels != i)[0] for i in num_classes]
-
- for first_idx in range(len(sentences)):
- current_sentence = sentences[first_idx]
- label = labels[first_idx]
- second_idx = np.random.choice(positive_idxs[label_to_idx[label]])
- positive_sentence = sentences[second_idx]
- # Prepare a positive pair and update the sentences and labels
- # lists, respectively
- pairs.append(InputExample(texts=[current_sentence, positive_sentence], label=1.0))
-
- third_idx = np.random.choice(negative_idxs[label_to_idx[label]])
- negative_sentence = sentences[third_idx]
- # Prepare a negative pair of sentences and update our lists
- pairs.append(InputExample(texts=[current_sentence, negative_sentence], label=0.0))
- # Return a 2-tuple of our sentence pairs and labels
- return pairs
-
-
-def sentence_pairs_generation_multilabel(sentences, labels, pairs):
- # Initialize two empty lists to hold the (sentence, sentence) pairs and
- # labels to indicate if a pair is positive or negative
- for first_idx in range(len(sentences)):
- current_sentence = sentences[first_idx]
- sample_labels = np.where(labels[first_idx, :] == 1)[0]
- if len(np.where(labels.dot(labels[first_idx, :].T) == 0)[0]) == 0:
- continue
- else:
- for _label in sample_labels:
- second_idx = np.random.choice(np.where(labels[:, _label] == 1)[0])
- positive_sentence = sentences[second_idx]
- # Prepare a positive pair and update the sentences and labels
- # lists, respectively
- pairs.append(InputExample(texts=[current_sentence, positive_sentence], label=1.0))
-
- # Search for sample that don't have a label in common with current
- # sentence
- negative_idx = np.where(labels.dot(labels[first_idx, :].T) == 0)[0]
- negative_sentence = sentences[np.random.choice(negative_idx)]
- # Prepare a negative pair of sentences and update our lists
- pairs.append(InputExample(texts=[current_sentence, negative_sentence], label=0.0))
- # Return a 2-tuple of our sentence pairs and labels
- return pairs
-
-
-def sentence_pairs_generation_cos_sim(sentences, pairs, cos_sim_matrix):
- # initialize two empty lists to hold the (sentence, sentence) pairs and
- # labels to indicate if a pair is positive or negative
-
- idx = list(range(len(sentences)))
-
- for first_idx in range(len(sentences)):
- current_sentence = sentences[first_idx]
- second_idx = int(np.random.choice([x for x in idx if x != first_idx]))
-
- cos_sim = float(cos_sim_matrix[first_idx][second_idx])
- paired_sentence = sentences[second_idx]
- pairs.append(InputExample(texts=[current_sentence, paired_sentence], label=cos_sim))
-
- third_idx = np.random.choice([x for x in idx if x != first_idx])
- cos_sim = float(cos_sim_matrix[first_idx][third_idx])
- paired_sentence = sentences[third_idx]
- pairs.append(InputExample(texts=[current_sentence, paired_sentence], label=cos_sim))
-
- return pairs
-
-
-class SKLearnWrapper:
- def __init__(self, st_model=None, clf=None):
- self.st_model = st_model
- self.clf = clf
-
- def fit(self, x_train, y_train):
- embeddings = self.st_model.encode(x_train)
- self.clf.fit(embeddings, y_train)
-
- def predict(self, x_test):
- embeddings = self.st_model.encode(x_test)
- return self.clf.predict(embeddings)
-
- def predict_proba(self, x_test):
- embeddings = self.st_model.encode(x_test)
- return self.clf.predict_proba(embeddings)
-
- def save(self, path):
- self.st_model.save(path=path)
- joblib.dump(self.clf, f"{path}/setfit_head.pkl")
+ )
+ SetFitModel.from_pretrained = set_docstring(SetFitModel.from_pretrained, docstring)
- def load(self, path):
- self.st_model = SentenceTransformer(model_name_or_path=path)
- self.clf = joblib.load(f"{path}/setfit_head.pkl")
+SetFitModel.save_pretrained = copy_func(SetFitModel.save_pretrained)
+SetFitModel.save_pretrained.__doc__ = SetFitModel.save_pretrained.__doc__.replace(
+ "~ModelHubMixin._from_pretrained", "SetFitModel.push_to_hub"
+)
diff --git a/src/setfit/pipeline.py b/src/setfit/pipeline.py
deleted file mode 100644
index 51e551ff..00000000
--- a/src/setfit/pipeline.py
+++ /dev/null
@@ -1,12 +0,0 @@
-from .modeling import SKLearnWrapper
-
-
-class SetFitPipeline:
- def __init__(self, model_name_or_path) -> None:
- base_model = SKLearnWrapper()
- base_model.load(model_name_or_path)
- self.model = base_model
-
- def __call__(self, inputs, *args, **kwargs):
- model_outputs = self.model.predict(inputs)
- return model_outputs
diff --git a/src/setfit/sampler.py b/src/setfit/sampler.py
new file mode 100644
index 00000000..d9045ed5
--- /dev/null
+++ b/src/setfit/sampler.py
@@ -0,0 +1,168 @@
+from itertools import zip_longest
+from typing import Generator, Iterable, List, Optional
+
+import numpy as np
+import torch
+from sentence_transformers import InputExample
+from torch.utils.data import IterableDataset
+
+from . import logging
+
+
+logging.set_verbosity_info()
+logger = logging.get_logger(__name__)
+
+
+def shuffle_combinations(iterable: Iterable, replacement: bool = True) -> Generator:
+ """Generates shuffled pair combinations for any iterable data provided.
+
+ Args:
+ iterable: data to generate pair combinations from
+ replacement: enable to include combinations of same samples,
+ equivalent to itertools.combinations_with_replacement
+
+ Returns:
+ Generator of shuffled pairs as a tuple
+ """
+ n = len(iterable)
+ k = 1 if not replacement else 0
+ idxs = np.stack(np.triu_indices(n, k), axis=-1)
+ for i in np.random.RandomState(seed=42).permutation(len(idxs)):
+ _idx, idx = idxs[i, :]
+ yield iterable[_idx], iterable[idx]
+
+
+class ContrastiveDataset(IterableDataset):
+ def __init__(
+ self,
+ examples: List[InputExample],
+ multilabel: bool,
+ num_iterations: Optional[None] = None,
+ sampling_strategy: str = "oversampling",
+ max_pairs: int = -1,
+ ) -> None:
+ """Generates positive and negative text pairs for contrastive learning.
+
+ Args:
+ examples (InputExample): text and labels in a text transformer dataclass
+ multilabel: set to process "multilabel" labels array
+ sampling_strategy: "unique", "oversampling", or "undersampling"
+ num_iterations: if provided explicitly sets the number of pairs to be generated
+ where n_pairs = n_iterations * n_sentences * 2 (for pos & neg pairs)
+ max_pairs: If not -1, then we only sample pairs until we have certainly reached
+ max_pairs pairs.
+ """
+ super().__init__()
+ self.pos_index = 0
+ self.neg_index = 0
+ self.pos_pairs = []
+ self.neg_pairs = []
+ self.sentences = np.array([s.texts[0] for s in examples])
+ self.labels = np.array([s.label for s in examples])
+ self.sentence_labels = list(zip(self.sentences, self.labels))
+ self.max_pairs = max_pairs
+
+ if multilabel:
+ self.generate_multilabel_pairs()
+ else:
+ self.generate_pairs()
+
+ if num_iterations is not None and num_iterations > 0:
+ self.len_pos_pairs = num_iterations * len(self.sentences)
+ self.len_neg_pairs = num_iterations * len(self.sentences)
+
+ elif sampling_strategy == "unique":
+ self.len_pos_pairs = len(self.pos_pairs)
+ self.len_neg_pairs = len(self.neg_pairs)
+
+ elif sampling_strategy == "undersampling":
+ self.len_pos_pairs = min(len(self.pos_pairs), len(self.neg_pairs))
+ self.len_neg_pairs = min(len(self.pos_pairs), len(self.neg_pairs))
+
+ elif sampling_strategy == "oversampling":
+ self.len_pos_pairs = max(len(self.pos_pairs), len(self.neg_pairs))
+ self.len_neg_pairs = max(len(self.pos_pairs), len(self.neg_pairs))
+
+ else:
+ raise ValueError("Invalid sampling strategy. Must be one of 'unique', 'oversampling', or 'undersampling'.")
+
+ def generate_pairs(self) -> None:
+ for (_text, _label), (text, label) in shuffle_combinations(self.sentence_labels):
+ if _label == label:
+ self.pos_pairs.append(InputExample(texts=[_text, text], label=1.0))
+ else:
+ self.neg_pairs.append(InputExample(texts=[_text, text], label=0.0))
+ if self.max_pairs != -1 and len(self.pos_pairs) > self.max_pairs and len(self.neg_pairs) > self.max_pairs:
+ break
+
+ def generate_multilabel_pairs(self) -> None:
+ for (_text, _label), (text, label) in shuffle_combinations(self.sentence_labels):
+ if any(np.logical_and(_label, label)):
+ # logical_and checks if labels are both set for each class
+ self.pos_pairs.append(InputExample(texts=[_text, text], label=1.0))
+ else:
+ self.neg_pairs.append(InputExample(texts=[_text, text], label=0.0))
+ if self.max_pairs != -1 and len(self.pos_pairs) > self.max_pairs and len(self.neg_pairs) > self.max_pairs:
+ break
+
+ def get_positive_pairs(self) -> List[InputExample]:
+ pairs = []
+ for _ in range(self.len_pos_pairs):
+ if self.pos_index >= len(self.pos_pairs):
+ self.pos_index = 0
+ pairs.append(self.pos_pairs[self.pos_index])
+ self.pos_index += 1
+ return pairs
+
+ def get_negative_pairs(self) -> List[InputExample]:
+ pairs = []
+ for _ in range(self.len_neg_pairs):
+ if self.neg_index >= len(self.neg_pairs):
+ self.neg_index = 0
+ pairs.append(self.neg_pairs[self.neg_index])
+ self.neg_index += 1
+ return pairs
+
+ def __iter__(self):
+ for pos_pair, neg_pair in zip_longest(self.get_positive_pairs(), self.get_negative_pairs()):
+ if pos_pair is not None:
+ yield pos_pair
+ if neg_pair is not None:
+ yield neg_pair
+
+ def __len__(self) -> int:
+ return self.len_pos_pairs + self.len_neg_pairs
+
+
+class ContrastiveDistillationDataset(ContrastiveDataset):
+ def __init__(
+ self,
+ examples: List[InputExample],
+ cos_sim_matrix: torch.Tensor,
+ num_iterations: Optional[None] = None,
+ sampling_strategy: str = "oversampling",
+ max_pairs: int = -1,
+ ) -> None:
+ self.cos_sim_matrix = cos_sim_matrix
+ super().__init__(
+ examples,
+ multilabel=False,
+ num_iterations=num_iterations,
+ sampling_strategy=sampling_strategy,
+ max_pairs=max_pairs,
+ )
+ # Internally we store all pairs in pos_pairs, regardless of sampling strategy.
+ # After all, without labels, there isn't much of a strategy.
+ self.sentence_labels = list(enumerate(self.sentences))
+
+ self.len_neg_pairs = 0
+ if num_iterations is not None and num_iterations > 0:
+ self.len_pos_pairs = num_iterations * len(self.sentences)
+ else:
+ self.len_pos_pairs = len(self.pos_pairs)
+
+ def generate_pairs(self) -> None:
+ for (text_one, id_one), (text_two, id_two) in shuffle_combinations(self.sentence_labels):
+ self.pos_pairs.append(InputExample(texts=[text_one, text_two], label=self.cos_sim_matrix[id_one][id_two]))
+ if self.max_pairs != -1 and len(self.pos_pairs) > self.max_pairs:
+ break
diff --git a/src/setfit/span/__init__.py b/src/setfit/span/__init__.py
new file mode 100644
index 00000000..7fc6f9db
--- /dev/null
+++ b/src/setfit/span/__init__.py
@@ -0,0 +1,3 @@
+from .aspect_extractor import AspectExtractor
+from .modeling import AbsaModel, AspectModel, PolarityModel
+from .trainer import AbsaTrainer
diff --git a/src/setfit/span/aspect_extractor.py b/src/setfit/span/aspect_extractor.py
new file mode 100644
index 00000000..aea39426
--- /dev/null
+++ b/src/setfit/span/aspect_extractor.py
@@ -0,0 +1,34 @@
+from typing import TYPE_CHECKING, List, Tuple
+
+
+if TYPE_CHECKING:
+ from spacy.tokens import Doc
+
+
+class AspectExtractor:
+ def __init__(self, spacy_model: str) -> None:
+ super().__init__()
+ import spacy
+
+ self.nlp = spacy.load(spacy_model)
+
+ def find_groups(self, aspect_mask: List[bool]):
+ start = None
+ for idx, flag in enumerate(aspect_mask):
+ if flag:
+ if start is None:
+ start = idx
+ else:
+ if start is not None:
+ yield slice(start, idx)
+ start = None
+ if start is not None:
+ yield slice(start, idx + 1)
+
+ def __call__(self, texts: List[str]) -> Tuple[List["Doc"], List[slice]]:
+ aspects_list = []
+ docs = list(self.nlp.pipe(texts))
+ for doc in docs:
+ aspect_mask = [token.pos_ in ("NOUN", "PROPN") for token in doc]
+ aspects_list.append(list(self.find_groups(aspect_mask)))
+ return docs, aspects_list
diff --git a/src/setfit/span/modeling.py b/src/setfit/span/modeling.py
new file mode 100644
index 00000000..efa95a64
--- /dev/null
+++ b/src/setfit/span/modeling.py
@@ -0,0 +1,292 @@
+import copy
+import os
+import tempfile
+import types
+from dataclasses import dataclass, field
+from pathlib import Path
+from typing import TYPE_CHECKING, Any, Dict, List, Optional, Set, Tuple, Union
+
+import torch
+from huggingface_hub.utils import SoftTemporaryDirectory
+
+from setfit.utils import set_docstring
+
+from .. import logging
+from ..modeling import SetFitModel
+from .aspect_extractor import AspectExtractor
+
+
+if TYPE_CHECKING:
+ from spacy.tokens import Doc
+
+logger = logging.get_logger(__name__)
+
+
+@dataclass
+class SpanSetFitModel(SetFitModel):
+ spacy_model: str = "en_core_web_lg"
+ span_context: int = 0
+
+ attributes_to_save: Set[str] = field(
+ init=False,
+ repr=False,
+ default_factory=lambda: {"normalize_embeddings", "labels", "span_context", "spacy_model"},
+ )
+
+ def prepend_aspects(self, docs: List["Doc"], aspects_list: List[List[slice]]) -> List[str]:
+ for doc, aspects in zip(docs, aspects_list):
+ for aspect_slice in aspects:
+ aspect = doc[max(aspect_slice.start - self.span_context, 0) : aspect_slice.stop + self.span_context]
+ # TODO: Investigate performance difference of different formats
+ yield aspect.text + ":" + doc.text
+
+ def __call__(self, docs: List["Doc"], aspects_list: List[List[slice]]) -> List[bool]:
+ inputs_list = list(self.prepend_aspects(docs, aspects_list))
+ preds = self.predict(inputs_list, as_numpy=True)
+ iter_preds = iter(preds)
+ return [[next(iter_preds) for _ in aspects] for aspects in aspects_list]
+
+ def create_model_card(self, path: str, model_name: Optional[str] = None) -> None:
+ """Creates and saves a model card for a SetFit model.
+
+ Args:
+ path (str): The path to save the model card to.
+ model_name (str, *optional*): The name of the model. Defaults to `SetFit Model`.
+ """
+ if not os.path.exists(path):
+ os.makedirs(path)
+
+ # If the model_path is a folder that exists locally, i.e. when create_model_card is called
+ # via push_to_hub, and the path is in a temporary folder, then we only take the last two
+ # directories
+ model_path = Path(model_name)
+ if model_path.exists() and Path(tempfile.gettempdir()) in model_path.resolve().parents:
+ model_name = "/".join(model_path.parts[-2:])
+
+ is_aspect = isinstance(self, AspectModel)
+ aspect_model = "setfit-absa-aspect"
+ polarity_model = "setfit-absa-polarity"
+ if model_name is not None:
+ if is_aspect:
+ aspect_model = model_name
+ if model_name.endswith("-aspect"):
+ polarity_model = model_name[: -len("-aspect")] + "-polarity"
+ else:
+ polarity_model = model_name
+ if model_name.endswith("-polarity"):
+ aspect_model = model_name[: -len("-polarity")] + "-aspect"
+
+ # Only once:
+ if self.model_card_data.absa is None and self.model_card_data.model_name:
+ from spacy import __version__ as spacy_version
+
+ self.model_card_data.model_name = self.model_card_data.model_name.replace(
+ "SetFit", "SetFit Aspect Model" if is_aspect else "SetFit Polarity Model", 1
+ )
+ self.model_card_data.tags.insert(1, "absa")
+ self.model_card_data.version["spacy"] = spacy_version
+ self.model_card_data.absa = {
+ "is_absa": True,
+ "is_aspect": is_aspect,
+ "spacy_model": self.spacy_model,
+ "aspect_model": aspect_model,
+ "polarity_model": polarity_model,
+ }
+ if self.model_card_data.task_name is None:
+ self.model_card_data.task_name = "Aspect Based Sentiment Analysis (ABSA)"
+ self.model_card_data.inference = False
+ with open(os.path.join(path, "README.md"), "w", encoding="utf-8") as f:
+ f.write(self.generate_model_card())
+
+
+docstring = SpanSetFitModel.from_pretrained.__doc__
+cut_index = docstring.find("multi_target_strategy")
+if cut_index != -1:
+ docstring = (
+ docstring[:cut_index]
+ + """model_card_data (`SetFitModelCardData`, *optional*):
+ A `SetFitModelCardData` instance storing data such as model language, license, dataset name,
+ etc. to be used in the automatically generated model cards.
+ use_differentiable_head (`bool`, *optional*):
+ Whether to load SetFit using a differentiable (i.e., Torch) head instead of Logistic Regression.
+ normalize_embeddings (`bool`, *optional*):
+ Whether to apply normalization on the embeddings produced by the Sentence Transformer body.
+ span_context (`int`, defaults to `0`):
+ The number of words before and after the span candidate that should be prepended to the full sentence.
+ By default, 0 for Aspect models and 3 for Polarity models.
+ device (`Union[torch.device, str]`, *optional*):
+ The device on which to load the SetFit model, e.g. `"cuda:0"`, `"mps"` or `torch.device("cuda")`."""
+ )
+ SpanSetFitModel.from_pretrained = set_docstring(SpanSetFitModel.from_pretrained, docstring, cls=SpanSetFitModel)
+
+
+class AspectModel(SpanSetFitModel):
+ def __call__(self, docs: List["Doc"], aspects_list: List[List[slice]]) -> List[bool]:
+ sentence_preds = super().__call__(docs, aspects_list)
+ return [
+ [aspect for aspect, pred in zip(aspects, preds) if pred == "aspect"]
+ for aspects, preds in zip(aspects_list, sentence_preds)
+ ]
+
+
+# The set_docstring magic has as a consequences that subclasses need to update the cls in the from_pretrained
+# classmethod, otherwise the wrong instance will be instantiated.
+AspectModel.from_pretrained = types.MethodType(AspectModel.from_pretrained.__func__, AspectModel)
+
+
+@dataclass
+class PolarityModel(SpanSetFitModel):
+ span_context: int = 3
+
+
+PolarityModel.from_pretrained = types.MethodType(PolarityModel.from_pretrained.__func__, PolarityModel)
+
+
+@dataclass
+class AbsaModel:
+ aspect_extractor: AspectExtractor
+ aspect_model: AspectModel
+ polarity_model: PolarityModel
+
+ def predict(self, inputs: Union[str, List[str]]) -> List[Dict[str, Any]]:
+ is_str = isinstance(inputs, str)
+ inputs_list = [inputs] if is_str else inputs
+ docs, aspects_list = self.aspect_extractor(inputs_list)
+ if sum(aspects_list, []) == []:
+ return aspects_list
+
+ aspects_list = self.aspect_model(docs, aspects_list)
+ if sum(aspects_list, []) == []:
+ return aspects_list
+
+ polarity_list = self.polarity_model(docs, aspects_list)
+ outputs = []
+ for docs, aspects, polarities in zip(docs, aspects_list, polarity_list):
+ outputs.append(
+ [
+ {"span": docs[aspect_slice].text, "polarity": polarity}
+ for aspect_slice, polarity in zip(aspects, polarities)
+ ]
+ )
+ return outputs if not is_str else outputs[0]
+
+ @property
+ def device(self) -> torch.device:
+ return self.aspect_model.device
+
+ def to(self, device: Union[str, torch.device]) -> "AbsaModel":
+ self.aspect_model.to(device)
+ self.polarity_model.to(device)
+
+ def __call__(self, inputs: Union[str, List[str]]) -> List[Dict[str, Any]]:
+ return self.predict(inputs)
+
+ def save_pretrained(
+ self,
+ save_directory: Union[str, Path],
+ polarity_save_directory: Optional[Union[str, Path]] = None,
+ push_to_hub: bool = False,
+ **kwargs,
+ ) -> None:
+ if polarity_save_directory is None:
+ base_save_directory = Path(save_directory)
+ save_directory = base_save_directory.parent / (base_save_directory.name + "-aspect")
+ polarity_save_directory = base_save_directory.parent / (base_save_directory.name + "-polarity")
+ self.aspect_model.save_pretrained(save_directory=save_directory, push_to_hub=push_to_hub, **kwargs)
+ self.polarity_model.save_pretrained(save_directory=polarity_save_directory, push_to_hub=push_to_hub, **kwargs)
+
+ @classmethod
+ def from_pretrained(
+ cls,
+ model_id: str,
+ polarity_model_id: Optional[str] = None,
+ spacy_model: Optional[str] = None,
+ span_contexts: Tuple[Optional[int], Optional[int]] = (None, None),
+ force_download: bool = None,
+ resume_download: bool = None,
+ proxies: Optional[Dict] = None,
+ token: Optional[Union[str, bool]] = None,
+ cache_dir: Optional[str] = None,
+ local_files_only: bool = None,
+ use_differentiable_head: bool = None,
+ normalize_embeddings: bool = None,
+ **model_kwargs,
+ ) -> "AbsaModel":
+ revision = None
+ if len(model_id.split("@")) == 2:
+ model_id, revision = model_id.split("@")
+ if spacy_model:
+ model_kwargs["spacy_model"] = spacy_model
+ aspect_model = AspectModel.from_pretrained(
+ model_id,
+ span_context=span_contexts[0],
+ revision=revision,
+ force_download=force_download,
+ resume_download=resume_download,
+ proxies=proxies,
+ token=token,
+ cache_dir=cache_dir,
+ local_files_only=local_files_only,
+ use_differentiable_head=use_differentiable_head,
+ normalize_embeddings=normalize_embeddings,
+ labels=["no aspect", "aspect"],
+ **model_kwargs,
+ )
+ if polarity_model_id:
+ model_id = polarity_model_id
+ revision = None
+ if len(model_id.split("@")) == 2:
+ model_id, revision = model_id.split("@")
+ # If model_card_data was provided, "separate" the instance between the Aspect
+ # and Polarity models.
+ model_card_data = model_kwargs.pop("model_card_data", None)
+ if model_card_data:
+ model_kwargs["model_card_data"] = copy.deepcopy(model_card_data)
+ polarity_model = PolarityModel.from_pretrained(
+ model_id,
+ span_context=span_contexts[1],
+ revision=revision,
+ force_download=force_download,
+ resume_download=resume_download,
+ proxies=proxies,
+ token=token,
+ cache_dir=cache_dir,
+ local_files_only=local_files_only,
+ use_differentiable_head=use_differentiable_head,
+ normalize_embeddings=normalize_embeddings,
+ **model_kwargs,
+ )
+ if aspect_model.spacy_model != polarity_model.spacy_model:
+ logger.warning(
+ "The Aspect and Polarity models are configured to use different spaCy models:\n"
+ f"* {repr(aspect_model.spacy_model)} for the aspect model, and\n"
+ f"* {repr(polarity_model.spacy_model)} for the polarity model.\n"
+ f"This model will use {repr(aspect_model.spacy_model)}."
+ )
+
+ aspect_extractor = AspectExtractor(spacy_model=aspect_model.spacy_model)
+
+ return cls(aspect_extractor, aspect_model, polarity_model)
+
+ def push_to_hub(self, repo_id: str, polarity_repo_id: Optional[str] = None, **kwargs) -> None:
+ if "/" not in repo_id:
+ raise ValueError(
+ '`repo_id` must be a full repository ID, including organisation, e.g. "tomaarsen/setfit-absa-restaurant".'
+ )
+ if polarity_repo_id is not None and "/" not in polarity_repo_id:
+ raise ValueError(
+ '`polarity_repo_id` must be a full repository ID, including organisation, e.g. "tomaarsen/setfit-absa-restaurant".'
+ )
+ commit_message = kwargs.pop("commit_message", "Add SetFit ABSA model")
+
+ # Push the files to the repo in a single commit
+ with SoftTemporaryDirectory() as tmp_dir:
+ save_directory = Path(tmp_dir) / repo_id
+ polarity_save_directory = None if polarity_repo_id is None else Path(tmp_dir) / polarity_repo_id
+ self.save_pretrained(
+ save_directory=save_directory,
+ polarity_save_directory=polarity_save_directory,
+ push_to_hub=True,
+ commit_message=commit_message,
+ **kwargs,
+ )
diff --git a/src/setfit/span/trainer.py b/src/setfit/span/trainer.py
new file mode 100644
index 00000000..846a945a
--- /dev/null
+++ b/src/setfit/span/trainer.py
@@ -0,0 +1,337 @@
+from collections import defaultdict
+from typing import TYPE_CHECKING, Any, Callable, Dict, List, Optional, Tuple, Union
+
+from datasets import Dataset
+from transformers.trainer_callback import TrainerCallback
+
+from setfit.span.modeling import AbsaModel, AspectModel, PolarityModel
+from setfit.training_args import TrainingArguments
+
+from .. import logging
+from ..trainer import ColumnMappingMixin, Trainer
+
+
+if TYPE_CHECKING:
+ import optuna
+
+logger = logging.get_logger(__name__)
+
+
+class AbsaTrainer(ColumnMappingMixin):
+ """Trainer to train a SetFit ABSA model.
+
+ Args:
+ model (`AbsaModel`):
+ The AbsaModel model to train.
+ args (`TrainingArguments`, *optional*):
+ The training arguments to use. If `polarity_args` is not defined, then `args` is used for both
+ the aspect and the polarity model.
+ polarity_args (`TrainingArguments`, *optional*):
+ The training arguments to use for the polarity model. If not defined, `args` is used for both
+ the aspect and the polarity model.
+ train_dataset (`Dataset`):
+ The training dataset. The dataset must have "text", "span", "label" and "ordinal" columns.
+ eval_dataset (`Dataset`, *optional*):
+ The evaluation dataset. The dataset must have "text", "span", "label" and "ordinal" columns.
+ metric (`str` or `Callable`, *optional*, defaults to `"accuracy"`):
+ The metric to use for evaluation. If a string is provided, we treat it as the metric
+ name and load it with default settings.
+ If a callable is provided, it must take two arguments (`y_pred`, `y_test`).
+ metric_kwargs (`Dict[str, Any]`, *optional*):
+ Keyword arguments passed to the evaluation function if `metric` is an evaluation string like "f1".
+ For example useful for providing an averaging strategy for computing f1 in a multi-label setting.
+ callbacks (`List[`[`~transformers.TrainerCallback`]`]`, *optional*):
+ A list of callbacks to customize the training loop. Will add those to the list of default callbacks
+ detailed in [here](https://huggingface.co/docs/transformers/main/en/main_classes/callback).
+ If you want to remove one of the default callbacks used, use the [`Trainer.remove_callback`] method.
+ column_mapping (`Dict[str, str]`, *optional*):
+ A mapping from the column names in the dataset to the column names expected by the model.
+ The expected format is a dictionary with the following format:
+ `{"text_column_name": "text", "span_column_name": "span", "label_column_name: "label", "ordinal_column_name": "ordinal"}`.
+ """
+
+ _REQUIRED_COLUMNS = {"text", "span", "label", "ordinal"}
+
+ def __init__(
+ self,
+ model: AbsaModel,
+ args: Optional[TrainingArguments] = None,
+ polarity_args: Optional[TrainingArguments] = None,
+ train_dataset: Optional["Dataset"] = None,
+ eval_dataset: Optional["Dataset"] = None,
+ metric: Union[str, Callable[["Dataset", "Dataset"], Dict[str, float]]] = "accuracy",
+ metric_kwargs: Optional[Dict[str, Any]] = None,
+ callbacks: Optional[List[TrainerCallback]] = None,
+ column_mapping: Optional[Dict[str, str]] = None,
+ ) -> None:
+ self.model = model
+ self.aspect_extractor = model.aspect_extractor
+
+ if train_dataset is not None and column_mapping:
+ train_dataset = self._apply_column_mapping(train_dataset, column_mapping)
+ aspect_train_dataset, polarity_train_dataset = self.preprocess_dataset(
+ model.aspect_model, model.polarity_model, train_dataset
+ )
+ if eval_dataset is not None and column_mapping:
+ eval_dataset = self._apply_column_mapping(eval_dataset, column_mapping)
+ aspect_eval_dataset, polarity_eval_dataset = self.preprocess_dataset(
+ model.aspect_model, model.polarity_model, eval_dataset
+ )
+
+ self.aspect_trainer = Trainer(
+ model.aspect_model,
+ args=args,
+ train_dataset=aspect_train_dataset,
+ eval_dataset=aspect_eval_dataset,
+ metric=metric,
+ metric_kwargs=metric_kwargs,
+ callbacks=callbacks,
+ )
+ self.aspect_trainer._set_logs_mapper(
+ {
+ "eval_embedding_loss": "eval_aspect_embedding_loss",
+ "embedding_loss": "aspect_embedding_loss",
+ }
+ )
+ self.polarity_trainer = Trainer(
+ model.polarity_model,
+ args=polarity_args or args,
+ train_dataset=polarity_train_dataset,
+ eval_dataset=polarity_eval_dataset,
+ metric=metric,
+ metric_kwargs=metric_kwargs,
+ callbacks=callbacks,
+ )
+ self.polarity_trainer._set_logs_mapper(
+ {
+ "eval_embedding_loss": "eval_polarity_embedding_loss",
+ "embedding_loss": "polarity_embedding_loss",
+ }
+ )
+
+ def preprocess_dataset(
+ self, aspect_model: AspectModel, polarity_model: PolarityModel, dataset: Dataset
+ ) -> Dataset:
+ if dataset is None:
+ return dataset, dataset
+
+ # Group by "text"
+ grouped_data = defaultdict(list)
+ for sample in dataset:
+ text = sample.pop("text")
+ grouped_data[text].append(sample)
+
+ def index_ordinal(text: str, target: str, ordinal: int) -> Tuple[int, int]:
+ find_from = 0
+ for _ in range(ordinal + 1):
+ start_idx = text.index(target, find_from)
+ find_from = start_idx + 1
+ return start_idx, start_idx + len(target)
+
+ def overlaps(aspect: slice, aspects: List[slice]) -> bool:
+ for test_aspect in aspects:
+ overlapping_indices = set(range(aspect.start, aspect.stop + 1)) & set(
+ range(test_aspect.start, test_aspect.stop + 1)
+ )
+ if overlapping_indices:
+ return True
+ return False
+
+ docs, aspects_list = self.aspect_extractor(grouped_data.keys())
+ aspect_aspect_list = []
+ aspect_labels = []
+ polarity_aspect_list = []
+ polarity_labels = []
+ for doc, aspects, text in zip(docs, aspects_list, grouped_data):
+ # Collect all of the gold aspects
+ gold_aspects = []
+ gold_polarity_labels = []
+ for annotation in grouped_data[text]:
+ try:
+ start, end = index_ordinal(text, annotation["span"], annotation["ordinal"])
+ except ValueError:
+ logger.info(
+ f"The ordinal of {annotation['ordinal']} for span {annotation['span']!r} in {text!r} is too high. "
+ "Skipping this sample."
+ )
+ continue
+
+ gold_aspect_span = doc.char_span(start, end)
+ if gold_aspect_span is None:
+ continue
+ gold_aspects.append(slice(gold_aspect_span.start, gold_aspect_span.end))
+ gold_polarity_labels.append(annotation["label"])
+
+ # The Aspect model uses all gold aspects as "True", and all non-overlapping predicted
+ # aspects as "False"
+ aspect_labels.extend([True] * len(gold_aspects))
+ aspect_aspect_list.append(gold_aspects[:])
+ for aspect in aspects:
+ if not overlaps(aspect, gold_aspects):
+ aspect_labels.append(False)
+ aspect_aspect_list[-1].append(aspect)
+
+ # The Polarity model uses only the gold aspects and labels
+ polarity_labels.extend(gold_polarity_labels)
+ polarity_aspect_list.append(gold_aspects)
+
+ aspect_texts = list(aspect_model.prepend_aspects(docs, aspect_aspect_list))
+ polarity_texts = list(polarity_model.prepend_aspects(docs, polarity_aspect_list))
+ return Dataset.from_dict({"text": aspect_texts, "label": aspect_labels}), Dataset.from_dict(
+ {"text": polarity_texts, "label": polarity_labels}
+ )
+
+ def train(
+ self,
+ args: Optional[TrainingArguments] = None,
+ polarity_args: Optional[TrainingArguments] = None,
+ trial: Optional[Union["optuna.Trial", Dict[str, Any]]] = None,
+ **kwargs,
+ ) -> None:
+ """
+ Main training entry point.
+
+ Args:
+ args (`TrainingArguments`, *optional*):
+ Temporarily change the aspect training arguments for this training call.
+ polarity_args (`TrainingArguments`, *optional*):
+ Temporarily change the polarity training arguments for this training call.
+ trial (`optuna.Trial` or `Dict[str, Any]`, *optional*):
+ The trial run or the hyperparameter dictionary for hyperparameter search.
+ """
+ self.train_aspect(args=args, trial=trial, **kwargs)
+ self.train_polarity(args=polarity_args, trial=trial, **kwargs)
+
+ def train_aspect(
+ self,
+ args: Optional[TrainingArguments] = None,
+ trial: Optional[Union["optuna.Trial", Dict[str, Any]]] = None,
+ **kwargs,
+ ) -> None:
+ """
+ Train the aspect model only.
+
+ Args:
+ args (`TrainingArguments`, *optional*):
+ Temporarily change the aspect training arguments for this training call.
+ trial (`optuna.Trial` or `Dict[str, Any]`, *optional*):
+ The trial run or the hyperparameter dictionary for hyperparameter search.
+ """
+ self.aspect_trainer.train(args=args, trial=trial, **kwargs)
+
+ def train_polarity(
+ self,
+ args: Optional[TrainingArguments] = None,
+ trial: Optional[Union["optuna.Trial", Dict[str, Any]]] = None,
+ **kwargs,
+ ) -> None:
+ """
+ Train the polarity model only.
+
+ Args:
+ args (`TrainingArguments`, *optional*):
+ Temporarily change the aspect training arguments for this training call.
+ trial (`optuna.Trial` or `Dict[str, Any]`, *optional*):
+ The trial run or the hyperparameter dictionary for hyperparameter search.
+ """
+ self.polarity_trainer.train(args=args, trial=trial, **kwargs)
+
+ def add_callback(self, callback: Union[type, TrainerCallback]) -> None:
+ """
+ Add a callback to the current list of [`~transformers.TrainerCallback`].
+
+ Args:
+ callback (`type` or [`~transformers.TrainerCallback`]):
+ A [`~transformers.TrainerCallback`] class or an instance of a [`~transformers.TrainerCallback`]. In the
+ first case, will instantiate a member of that class.
+ """
+ self.aspect_trainer.add_callback(callback)
+ self.polarity_trainer.add_callback(callback)
+
+ def pop_callback(self, callback: Union[type, TrainerCallback]) -> Tuple[TrainerCallback, TrainerCallback]:
+ """
+ Remove a callback from the current list of [`~transformers.TrainerCallback`] and returns it.
+
+ If the callback is not found, returns `None` (and no error is raised).
+
+ Args:
+ callback (`type` or [`~transformers.TrainerCallback`]):
+ A [`~transformers.TrainerCallback`] class or an instance of a [`~transformers.TrainerCallback`]. In the
+ first case, will pop the first member of that class found in the list of callbacks.
+
+ Returns:
+ `Tuple[`[`~transformers.TrainerCallback`], [`~transformers.TrainerCallback`]`]`: The callbacks removed from the
+ aspect and polarity trainers, if found.
+ """
+ return self.aspect_trainer.pop_callback(callback), self.polarity_trainer.pop_callback(callback)
+
+ def remove_callback(self, callback: Union[type, TrainerCallback]) -> None:
+ """
+ Remove a callback from the current list of [`~transformers.TrainerCallback`].
+
+ Args:
+ callback (`type` or [`~transformers.TrainerCallback`]):
+ A [`~transformers.TrainerCallback`] class or an instance of a [`~transformers.TrainerCallback`]. In the
+ first case, will remove the first member of that class found in the list of callbacks.
+ """
+ self.aspect_trainer.remove_callback(callback)
+ self.polarity_trainer.remove_callback(callback)
+
+ def push_to_hub(self, repo_id: str, polarity_repo_id: Optional[str] = None, **kwargs) -> None:
+ """Upload model checkpoint to the Hub using `huggingface_hub`.
+
+ See the full list of parameters for your `huggingface_hub` version in the\
+ [huggingface_hub documentation](https://huggingface.co/docs/huggingface_hub/package_reference/mixins#huggingface_hub.ModelHubMixin.push_to_hub).
+
+ Args:
+ repo_id (`str`):
+ The full repository ID to push to, e.g. `"tomaarsen/setfit-aspect"`.
+ repo_id (`str`):
+ The full repository ID to push to, e.g. `"tomaarsen/setfit-sst2"`.
+ config (`dict`, *optional*):
+ Configuration object to be saved alongside the model weights.
+ commit_message (`str`, *optional*):
+ Message to commit while pushing.
+ private (`bool`, *optional*, defaults to `False`):
+ Whether the repository created should be private.
+ api_endpoint (`str`, *optional*):
+ The API endpoint to use when pushing the model to the hub.
+ token (`str`, *optional*):
+ The token to use as HTTP bearer authorization for remote files.
+ If not set, will use the token set when logging in with
+ `transformers-cli login` (stored in `~/.huggingface`).
+ branch (`str`, *optional*):
+ The git branch on which to push the model. This defaults to
+ the default branch as specified in your repository, which
+ defaults to `"main"`.
+ create_pr (`boolean`, *optional*):
+ Whether or not to create a Pull Request from `branch` with that commit.
+ Defaults to `False`.
+ allow_patterns (`List[str]` or `str`, *optional*):
+ If provided, only files matching at least one pattern are pushed.
+ ignore_patterns (`List[str]` or `str`, *optional*):
+ If provided, files matching any of the patterns are not pushed.
+ """
+ return self.model.push_to_hub(repo_id=repo_id, polarity_repo_id=polarity_repo_id, **kwargs)
+
+ def evaluate(self, dataset: Optional[Dataset] = None) -> Dict[str, Dict[str, float]]:
+ """
+ Computes the metrics for a given classifier.
+
+ Args:
+ dataset (`Dataset`, *optional*):
+ The dataset to compute the metrics on. If not provided, will use the evaluation dataset passed via
+ the `eval_dataset` argument at `Trainer` initialization.
+
+ Returns:
+ `Dict[str, Dict[str, float]]`: The evaluation metrics.
+ """
+ aspect_eval_dataset = polarity_eval_dataset = None
+ if dataset:
+ aspect_eval_dataset, polarity_eval_dataset = self.preprocess_dataset(
+ self.model.aspect_model, self.model.polarity_model, dataset
+ )
+ return {
+ "aspect": self.aspect_trainer.evaluate(aspect_eval_dataset),
+ "polarity": self.polarity_trainer.evaluate(polarity_eval_dataset),
+ }
diff --git a/src/setfit/trainer.py b/src/setfit/trainer.py
index 6304ce5b..29fb2962 100644
--- a/src/setfit/trainer.py
+++ b/src/setfit/trainer.py
@@ -1,23 +1,60 @@
import math
-from typing import TYPE_CHECKING, Any, Callable, Dict, Optional, Union
+import os
+import shutil
+import time
+import warnings
+from pathlib import Path
+from typing import TYPE_CHECKING, Any, Callable, Dict, Iterable, List, Optional, Tuple, Union
import evaluate
-import numpy as np
import torch
from datasets import Dataset, DatasetDict
-from sentence_transformers import InputExample, losses
+from sentence_transformers import InputExample, SentenceTransformer, losses
from sentence_transformers.datasets import SentenceLabelDataset
from sentence_transformers.losses.BatchHardTripletLoss import BatchHardTripletLossDistanceFunction
+from sentence_transformers.util import batch_to_device
+from sklearn.preprocessing import LabelEncoder
+from torch import nn
+from torch.cuda.amp import autocast
from torch.utils.data import DataLoader
-from tqdm.auto import trange
-from transformers.trainer_utils import HPSearchBackend, default_compute_objective, number_of_arguments, set_seed
+from tqdm.autonotebook import tqdm
+from transformers.integrations import WandbCallback, get_reporting_integration_callbacks
+from transformers.trainer_callback import (
+ CallbackHandler,
+ DefaultFlowCallback,
+ IntervalStrategy,
+ PrinterCallback,
+ ProgressCallback,
+ TrainerCallback,
+ TrainerControl,
+ TrainerState,
+)
+from transformers.trainer_utils import (
+ HPSearchBackend,
+ default_compute_objective,
+ number_of_arguments,
+ set_seed,
+ speed_metrics,
+)
+from transformers.utils.import_utils import is_in_notebook
+
+from setfit.model_card import ModelCardCallback
from . import logging
from .integrations import default_hp_search_backend, is_optuna_available, run_hp_search_optuna
-from .modeling import SupConLoss, sentence_pairs_generation, sentence_pairs_generation_multilabel
+from .losses import SupConLoss
+from .sampler import ContrastiveDataset
+from .training_args import TrainingArguments
from .utils import BestRun, default_hp_space_optuna
+# For Python 3.7 compatibility
+try:
+ from typing import Literal
+except ImportError:
+ from typing_extensions import Literal
+
+
if TYPE_CHECKING:
import optuna
@@ -27,123 +64,24 @@
logger = logging.get_logger(__name__)
-class SetFitTrainer:
- """Trainer to train a SetFit model.
+DEFAULT_CALLBACKS = [DefaultFlowCallback]
+DEFAULT_PROGRESS_CALLBACK = ProgressCallback
- Args:
- model (`SetFitModel`, *optional*):
- The model to train. If not provided, a `model_init` must be passed.
- train_dataset (`Dataset`):
- The training dataset.
- eval_dataset (`Dataset`, *optional*):
- The evaluation dataset.
- model_init (`Callable[[], SetFitModel]`, *optional*):
- A function that instantiates the model to be used. If provided, each call to [`~SetFitTrainer.train`] will start
- from a new instance of the model as given by this function when a `trial` is passed.
- metric (`str` or `Callable`, *optional*, defaults to `"accuracy"`):
- The metric to use for evaluation. If a string is provided, we treat it as the metric name and load it with default settings.
- If a callable is provided, it must take two arguments (`y_pred`, `y_test`).
- metric_kwargs (`Dict[str, Any]`, *optional*):
- Keyword arguments passed to the evaluation function if `metric` is an evaluation string like "f1".
- For example useful for providing an averaging strategy for computing f1 in a multi-label setting.
- loss_class (`nn.Module`, *optional*, defaults to `CosineSimilarityLoss`):
- The loss function to use for contrastive training.
- num_iterations (`int`, *optional*, defaults to `20`):
- The number of iterations to generate sentence pairs for.
- This argument is ignored if triplet loss is used.
- It is only used in conjunction with `CosineSimilarityLoss`.
- num_epochs (`int`, *optional*, defaults to `1`):
- The number of epochs to train the Sentence Transformer body for.
- learning_rate (`float`, *optional*, defaults to `2e-5`):
- The learning rate to use for contrastive training.
- batch_size (`int`, *optional*, defaults to `16`):
- The batch size to use for contrastive training.
- seed (`int`, *optional*, defaults to 42):
- Random seed that will be set at the beginning of training. To ensure reproducibility across runs, use the
- [`~SetTrainer.model_init`] function to instantiate the model if it has some randomly initialized parameters.
- column_mapping (`Dict[str, str]`, *optional*):
- A mapping from the column names in the dataset to the column names expected by the model. The expected format is a dictionary with the following format: {"text_column_name": "text", "label_column_name: "label"}.
- use_amp (`bool`, *optional*, defaults to `False`):
- Use Automatic Mixed Precision (AMP). Only for Pytorch >= 1.6.0
- warmup_proportion (`float`, *optional*, defaults to `0.1`):
- Proportion of the warmup in the total training steps.
- Must be greater than or equal to 0.0 and less than or equal to 1.0.
- distance_metric (`Callable`, defaults to `BatchHardTripletLossDistanceFunction.cosine_distance`):
- Function that returns a distance between two embeddings.
- It is set for the triplet loss and
- is ignored for `CosineSimilarityLoss` and `SupConLoss`.
- margin (`float`, defaults to `0.25`): Margin for the triplet loss.
- Negative samples should be at least margin further apart from the anchor than the positive.
- This is ignored for `CosineSimilarityLoss`, `BatchHardSoftMarginTripletLoss` and `SupConLoss`.
- samples_per_label (`int`, defaults to `2`): Number of consecutive, random and unique samples drawn per label.
- This is only relevant for triplet loss and ignored for `CosineSimilarityLoss`.
- Batch size should be a multiple of samples_per_label.
- """
-
- def __init__(
- self,
- model: Optional["SetFitModel"] = None,
- train_dataset: Optional["Dataset"] = None,
- eval_dataset: Optional["Dataset"] = None,
- model_init: Optional[Callable[[], "SetFitModel"]] = None,
- metric: Union[str, Callable[["Dataset", "Dataset"], Dict[str, float]]] = "accuracy",
- metric_kwargs: Optional[Dict[str, Any]] = None,
- loss_class=losses.CosineSimilarityLoss,
- num_iterations: int = 20,
- num_epochs: int = 1,
- learning_rate: float = 2e-5,
- batch_size: int = 16,
- seed: int = 42,
- column_mapping: Optional[Dict[str, str]] = None,
- use_amp: bool = False,
- warmup_proportion: float = 0.1,
- distance_metric: Callable = BatchHardTripletLossDistanceFunction.cosine_distance,
- margin: float = 0.25,
- samples_per_label: int = 2,
- ) -> None:
- if (warmup_proportion < 0.0) or (warmup_proportion > 1.0):
- raise ValueError(
- f"warmup_proportion must be greater than or equal to 0.0 and less than or equal to 1.0! But it was: {warmup_proportion}"
- )
+if is_in_notebook():
+ from transformers.utils.notebook import NotebookProgressCallback
- self.train_dataset = train_dataset
- self.eval_dataset = eval_dataset
- self.model_init = model_init
- self.metric = metric
- self.metric_kwargs = metric_kwargs
- self.loss_class = loss_class
- self.num_iterations = num_iterations
- self.num_epochs = num_epochs
- self.learning_rate = learning_rate
- self.batch_size = batch_size
- self.seed = seed
- self.column_mapping = column_mapping
- self.use_amp = use_amp
- self.warmup_proportion = warmup_proportion
- self.distance_metric = distance_metric
- self.margin = margin
- self.samples_per_label = samples_per_label
+ DEFAULT_PROGRESS_CALLBACK = NotebookProgressCallback
- if model is None:
- if model_init is not None:
- model = self.call_model_init()
- else:
- raise RuntimeError("`SetFitTrainer` requires either a `model` or `model_init` argument")
- else:
- if model_init is not None:
- raise RuntimeError("`SetFitTrainer` requires either a `model` or `model_init` argument, but not both")
- self.model = model
- self.hp_search_backend = None
- self._freeze = True # If True, will train the body only; otherwise, train the body and head
+class ColumnMappingMixin:
+ _REQUIRED_COLUMNS = {"text", "label"}
def _validate_column_mapping(self, dataset: "Dataset") -> None:
"""
Validates the provided column mapping against the dataset.
"""
- required_columns = {"text", "label"}
column_names = set(dataset.column_names)
- if self.column_mapping is None and not required_columns.issubset(column_names):
+ if self.column_mapping is None and not self._REQUIRED_COLUMNS.issubset(column_names):
# Issue #226: load_dataset will automatically assign points to "train" if no split is specified
if column_names == {"train"} and isinstance(dataset, DatasetDict):
raise ValueError(
@@ -157,15 +95,20 @@ def _validate_column_mapping(self, dataset: "Dataset") -> None:
)
else:
raise ValueError(
- f"SetFit expected the dataset to have the columns {sorted(required_columns)}, "
+ f"SetFit expected the dataset to have the columns {sorted(self._REQUIRED_COLUMNS)}, "
f"but only the columns {sorted(column_names)} were found. "
- "Either make sure these columns are present, or specify which columns to use with column_mapping in SetFitTrainer."
+ "Either make sure these columns are present, or specify which columns to use with column_mapping in Trainer."
)
if self.column_mapping is not None:
- missing_columns = required_columns.difference(self.column_mapping.values())
+ missing_columns = set(self._REQUIRED_COLUMNS)
+ # Remove columns that will be provided via the column mapping
+ missing_columns -= set(self.column_mapping.values())
+ # Remove columns that will be provided because they are in the dataset & not mapped away
+ missing_columns -= set(dataset.column_names) - set(self.column_mapping.keys())
if missing_columns:
raise ValueError(
- f"The following columns are missing from the column mapping: {missing_columns}. Please provide a mapping for all required columns."
+ f"The following columns are missing from the column mapping: {missing_columns}. "
+ "Please provide a mapping for all required columns."
)
if not set(self.column_mapping.keys()).issubset(column_names):
raise ValueError(
@@ -181,7 +124,11 @@ def _apply_column_mapping(self, dataset: "Dataset", column_mapping: Dict[str, st
dataset = dataset.rename_columns(
{
**column_mapping,
- **{col: f"feat_{col}" for col in dataset.column_names if col not in column_mapping},
+ **{
+ col: f"feat_{col}"
+ for col in dataset.column_names
+ if col not in column_mapping and col not in self._REQUIRED_COLUMNS
+ },
}
)
dset_format = dataset.format
@@ -193,6 +140,147 @@ def _apply_column_mapping(self, dataset: "Dataset", column_mapping: Dict[str, st
)
return dataset
+
+class Trainer(ColumnMappingMixin):
+ """Trainer to train a SetFit model.
+
+ Args:
+ model (`SetFitModel`, *optional*):
+ The model to train. If not provided, a `model_init` must be passed.
+ args (`TrainingArguments`, *optional*):
+ The training arguments to use.
+ train_dataset (`Dataset`):
+ The training dataset.
+ eval_dataset (`Dataset`, *optional*):
+ The evaluation dataset.
+ model_init (`Callable[[], SetFitModel]`, *optional*):
+ A function that instantiates the model to be used. If provided, each call to
+ [`Trainer.train`] will start from a new instance of the model as given by this
+ function when a `trial` is passed.
+ metric (`str` or `Callable`, *optional*, defaults to `"accuracy"`):
+ The metric to use for evaluation. If a string is provided, we treat it as the metric
+ name and load it with default settings. If a callable is provided, it must take two arguments
+ (`y_pred`, `y_test`) and return a dictionary with metric keys to values.
+ metric_kwargs (`Dict[str, Any]`, *optional*):
+ Keyword arguments passed to the evaluation function if `metric` is an evaluation string like "f1".
+ For example useful for providing an averaging strategy for computing f1 in a multi-label setting.
+ callbacks (`List[`[`~transformers.TrainerCallback`]`]`, *optional*):
+ A list of callbacks to customize the training loop. Will add those to the list of default callbacks
+ detailed in [here](https://huggingface.co/docs/transformers/main/en/main_classes/callback).
+ If you want to remove one of the default callbacks used, use the [`Trainer.remove_callback`] method.
+ column_mapping (`Dict[str, str]`, *optional*):
+ A mapping from the column names in the dataset to the column names expected by the model.
+ The expected format is a dictionary with the following format:
+ `{"text_column_name": "text", "label_column_name: "label"}`.
+ """
+
+ def __init__(
+ self,
+ model: Optional["SetFitModel"] = None,
+ args: Optional[TrainingArguments] = None,
+ train_dataset: Optional["Dataset"] = None,
+ eval_dataset: Optional["Dataset"] = None,
+ model_init: Optional[Callable[[], "SetFitModel"]] = None,
+ metric: Union[str, Callable[["Dataset", "Dataset"], Dict[str, float]]] = "accuracy",
+ metric_kwargs: Optional[Dict[str, Any]] = None,
+ callbacks: Optional[List[TrainerCallback]] = None,
+ column_mapping: Optional[Dict[str, str]] = None,
+ ) -> None:
+ if args is not None and not isinstance(args, TrainingArguments):
+ raise ValueError("`args` must be a `TrainingArguments` instance imported from `setfit`.")
+ self.args = args or TrainingArguments()
+ self.column_mapping = column_mapping
+ if train_dataset:
+ self._validate_column_mapping(train_dataset)
+ if self.column_mapping is not None:
+ logger.info("Applying column mapping to the training dataset")
+ train_dataset = self._apply_column_mapping(train_dataset, self.column_mapping)
+ self.train_dataset = train_dataset
+
+ if eval_dataset:
+ self._validate_column_mapping(eval_dataset)
+ if self.column_mapping is not None:
+ logger.info("Applying column mapping to the evaluation dataset")
+ eval_dataset = self._apply_column_mapping(eval_dataset, self.column_mapping)
+ self.eval_dataset = eval_dataset
+
+ self.model_init = model_init
+ self.metric = metric
+ self.metric_kwargs = metric_kwargs
+ self.logs_mapper = {}
+
+ # Seed must be set before instantiating the model when using model_init.
+ set_seed(12)
+
+ if model is None:
+ if model_init is not None:
+ model = self.call_model_init()
+ else:
+ raise RuntimeError("`Trainer` requires either a `model` or `model_init` argument.")
+ else:
+ if model_init is not None:
+ raise RuntimeError("`Trainer` requires either a `model` or `model_init` argument, but not both.")
+
+ self.model = model
+ self.hp_search_backend = None
+
+ # Setup the callbacks
+ default_callbacks = DEFAULT_CALLBACKS + get_reporting_integration_callbacks(self.args.report_to)
+ callbacks = default_callbacks if callbacks is None else default_callbacks + callbacks
+ if WandbCallback in callbacks:
+ # Set the W&B project via environment variables if it's not already set
+ os.environ.setdefault("WANDB_PROJECT", "setfit")
+ # TODO: Observe optimizer and scheduler by wrapping SentenceTransformer._get_scheduler
+ self.callback_handler = CallbackHandler(callbacks, self.model, self.model.model_body.tokenizer, None, None)
+ self.state = TrainerState()
+ self.control = TrainerControl()
+ self.add_callback(DEFAULT_PROGRESS_CALLBACK if self.args.show_progress_bar else PrinterCallback)
+ self.control = self.callback_handler.on_init_end(self.args, self.state, self.control)
+
+ # Add the callback for filling the model card data with hyperparameters
+ # and evaluation results
+ self.add_callback(ModelCardCallback(self))
+
+ self.callback_handler.on_init_end(args, self.state, self.control)
+
+ def add_callback(self, callback: Union[type, TrainerCallback]) -> None:
+ """
+ Add a callback to the current list of [`~transformers.TrainerCallback`].
+
+ Args:
+ callback (`type` or [`~transformers.TrainerCallback`]):
+ A [`~transformers.TrainerCallback`] class or an instance of a [`~transformers.TrainerCallback`]. In the
+ first case, will instantiate a member of that class.
+ """
+ self.callback_handler.add_callback(callback)
+
+ def pop_callback(self, callback: Union[type, TrainerCallback]) -> TrainerCallback:
+ """
+ Remove a callback from the current list of [`~transformers.TrainerCallback`] and returns it.
+
+ If the callback is not found, returns `None` (and no error is raised).
+
+ Args:
+ callback (`type` or [`~transformers.TrainerCallback`]):
+ A [`~transformers.TrainerCallback`] class or an instance of a [`~transformers.TrainerCallback`]. In the
+ first case, will pop the first member of that class found in the list of callbacks.
+
+ Returns:
+ [`~transformers.TrainerCallback`]: The callback removed, if found.
+ """
+ return self.callback_handler.pop_callback(callback)
+
+ def remove_callback(self, callback: Union[type, TrainerCallback]) -> None:
+ """
+ Remove a callback from the current list of [`~transformers.TrainerCallback`].
+
+ Args:
+ callback (`type` or [`~transformers.TrainerCallback`]):
+ A [`~transformers.TrainerCallback`] class or an instance of a [`~transformers.TrainerCallback`]. In the
+ first case, will remove the first member of that class found in the list of callbacks.
+ """
+ self.callback_handler.remove_callback(callback)
+
def apply_hyperparameters(self, params: Dict[str, Any], final_model: bool = False) -> None:
"""Applies a dictionary of hyperparameters to both the trainer and the model
@@ -200,19 +288,14 @@ def apply_hyperparameters(self, params: Dict[str, Any], final_model: bool = Fals
params (`Dict[str, Any]`): The parameters, usually from `BestRun.hyperparameters`
final_model (`bool`, *optional*, defaults to `False`): If `True`, replace the `model_init()` function with a fixed model based on the parameters.
"""
- for key, value in params.items():
- if hasattr(self, key):
- old_attr = getattr(self, key, None)
- # Casting value to the proper type
- if old_attr is not None:
- value = type(old_attr)(value)
- setattr(self, key, value)
- elif number_of_arguments(self.model_init) == 0: # we do not warn if model_init could be using it
- logger.warning(
- f"Trying to set {key!r} in the hyperparameter search but there is no corresponding field in "
- "`SetFitTrainer`, and `model_init` does not take any arguments."
- )
+ if self.args is not None:
+ self.args = self.args.update(params, ignore_extra=True)
+ else:
+ self.args = TrainingArguments.from_dict(params, ignore_extra=True)
+
+ # Seed must be set before instantiating the model when using model_init.
+ set_seed(self.args.seed)
self.model = self.model_init(params)
if final_model:
self.model_init = None
@@ -248,213 +331,534 @@ def call_model_init(self, params: Optional[Dict[str, Any]] = None) -> "SetFitMod
return model
- def freeze(self) -> None:
- """
- Freeze SetFitModel's differentiable head.
- Note: call this function only when using the differentiable head.
- """
- if not self.model.has_differentiable_head:
- raise ValueError("Please use the differentiable head in `SetFitModel` when calling this function.")
+ def freeze(self, component: Optional[Literal["body", "head"]] = None) -> None:
+ """Freeze the model body and/or the head, preventing further training on that component until unfrozen.
- self._freeze = True # Currently use self._freeze as a switch
- self.model.freeze("head")
+ This method is deprecated, use `SetFitModel.freeze` instead.
- def unfreeze(self, keep_body_frozen: bool = False) -> None:
+ Args:
+ component (`Literal["body", "head"]`, *optional*): Either "body" or "head" to freeze that component.
+ If no component is provided, freeze both. Defaults to None.
"""
- Unfreeze SetFitModel's differentiable head.
- Note: call this function only when using the differentiable head.
+ warnings.warn(
+ f"`{self.__class__.__name__}.freeze` is deprecated and will be removed in v2.0.0 of SetFit. "
+ "Please use `SetFitModel.freeze` directly instead.",
+ DeprecationWarning,
+ stacklevel=2,
+ )
+ return self.model.freeze(component)
+
+ def unfreeze(
+ self, component: Optional[Literal["body", "head"]] = None, keep_body_frozen: Optional[bool] = None
+ ) -> None:
+ """Unfreeze the model body and/or the head, allowing further training on that component.
+
+ This method is deprecated, use `SetFitModel.unfreeze` instead.
Args:
- keep_body_frozen (`bool`, *optional*, defaults to `False`):
- Whether to freeze the body when unfreeze the head.
+ component (`Literal["body", "head"]`, *optional*): Either "body" or "head" to unfreeze that component.
+ If no component is provided, unfreeze both. Defaults to None.
+ keep_body_frozen (`bool`, *optional*): Deprecated argument, use `component` instead.
"""
- if not self.model.has_differentiable_head:
- raise ValueError("Please use the differentiable head in `SetFitModel` when calling this function.")
-
- self._freeze = False # Currently use self._freeze as a switch
- self.model.unfreeze("head")
- if keep_body_frozen:
- self.model.freeze("body")
- else: # ensure to unfreeze the body
- self.model.unfreeze("body")
+ warnings.warn(
+ f"`{self.__class__.__name__}.unfreeze` is deprecated and will be removed in v2.0.0 of SetFit. "
+ "Please use `SetFitModel.unfreeze` directly instead.",
+ DeprecationWarning,
+ stacklevel=2,
+ )
+ return self.model.unfreeze(component, keep_body_frozen=keep_body_frozen)
def train(
self,
- num_epochs: Optional[int] = None,
- batch_size: Optional[int] = None,
- learning_rate: Optional[float] = None,
- body_learning_rate: Optional[float] = None,
- l2_weight: Optional[float] = None,
- max_length: Optional[int] = None,
+ args: Optional[TrainingArguments] = None,
trial: Optional[Union["optuna.Trial", Dict[str, Any]]] = None,
- show_progress_bar: bool = True,
+ **kwargs,
) -> None:
"""
Main training entry point.
Args:
- num_epochs (`int`, *optional*):
- Temporary change the number of epochs to train the Sentence Transformer body/head for.
- If ignore, will use the value given in initialization.
- batch_size (`int`, *optional*):
- Temporary change the batch size to use for contrastive training or logistic regression.
- If ignore, will use the value given in initialization.
- learning_rate (`float`, *optional*):
- Temporary change the learning rate to use for contrastive training or SetFitModel's head in logistic regression.
- If ignore, will use the value given in initialization.
- body_learning_rate (`float`, *optional*):
- Temporary change the learning rate to use for SetFitModel's body in logistic regression only.
- If ignore, will be the same as `learning_rate`.
- l2_weight (`float`, *optional*):
- Temporary change the weight of L2 regularization for SetFitModel's differentiable head in logistic regression.
- max_length (int, *optional*, defaults to `None`):
- The maximum number of tokens for one data sample. Currently only for training the differentiable head.
- If `None`, will use the maximum number of tokens the model body can accept.
- If `max_length` is greater than the maximum number of acceptable tokens the model body can accept, it will be set to the maximum number of acceptable tokens.
+ args (`TrainingArguments`, *optional*):
+ Temporarily change the training arguments for this training call.
trial (`optuna.Trial` or `Dict[str, Any]`, *optional*):
The trial run or the hyperparameter dictionary for hyperparameter search.
- show_progress_bar (`bool`, *optional*, defaults to `True`):
- Whether to show a bar that indicates training progress.
"""
- set_seed(self.seed) # Seed must be set before instantiating the model when using model_init.
+ if len(kwargs):
+ warnings.warn(
+ f"`{self.__class__.__name__}.train` does not accept keyword arguments anymore. "
+ f"Please provide training arguments via a `TrainingArguments` instance to the `{self.__class__.__name__}` "
+ f"initialisation or the `{self.__class__.__name__}.train` method.",
+ DeprecationWarning,
+ stacklevel=2,
+ )
if trial: # Trial and model initialization
self._hp_search_setup(trial) # sets trainer parameters and initializes model
+ args = args or self.args or TrainingArguments()
+
if self.train_dataset is None:
- raise ValueError("Training requires a `train_dataset` given to the `SetFitTrainer` initialization.")
+ raise ValueError(
+ f"Training requires a `train_dataset` given to the `{self.__class__.__name__}` initialization."
+ )
- self._validate_column_mapping(self.train_dataset)
- train_dataset = self.train_dataset
- if self.column_mapping is not None:
- logger.info("Applying column mapping to training dataset")
- train_dataset = self._apply_column_mapping(self.train_dataset, self.column_mapping)
-
- x_train = train_dataset["text"]
- y_train = train_dataset["label"]
- if self.loss_class is None:
- logger.warning("No `loss_class` detected! Using `CosineSimilarityLoss` as the default.")
- self.loss_class = losses.CosineSimilarityLoss
-
- num_epochs = num_epochs or self.num_epochs
- batch_size = batch_size or self.batch_size
- learning_rate = learning_rate or self.learning_rate
-
- if not self.model.has_differentiable_head or self._freeze:
- # sentence-transformers adaptation
- if self.loss_class in [
- losses.BatchAllTripletLoss,
- losses.BatchHardTripletLoss,
- losses.BatchSemiHardTripletLoss,
- losses.BatchHardSoftMarginTripletLoss,
- SupConLoss,
- ]:
- train_examples = [InputExample(texts=[text], label=label) for text, label in zip(x_train, y_train)]
- train_data_sampler = SentenceLabelDataset(train_examples, samples_per_label=self.samples_per_label)
-
- batch_size = min(batch_size, len(train_data_sampler))
- train_dataloader = DataLoader(train_data_sampler, batch_size=batch_size, drop_last=True)
-
- if self.loss_class is losses.BatchHardSoftMarginTripletLoss:
- train_loss = self.loss_class(
- model=self.model.model_body,
- distance_metric=self.distance_metric,
- )
- elif self.loss_class is SupConLoss:
- train_loss = self.loss_class(model=self.model.model_body)
- else:
- train_loss = self.loss_class(
- model=self.model.model_body,
- distance_metric=self.distance_metric,
- margin=self.margin,
- )
+ train_parameters = self.dataset_to_parameters(self.train_dataset)
+ full_parameters = (
+ train_parameters + self.dataset_to_parameters(self.eval_dataset) if self.eval_dataset else train_parameters
+ )
+
+ self.train_embeddings(*full_parameters, args=args)
+ self.train_classifier(*train_parameters, args=args)
+
+ def dataset_to_parameters(self, dataset: Dataset) -> List[Iterable]:
+ return [dataset["text"], dataset["label"]]
+
+ def train_embeddings(
+ self,
+ x_train: List[str],
+ y_train: Optional[Union[List[int], List[List[int]]]] = None,
+ x_eval: Optional[List[str]] = None,
+ y_eval: Optional[Union[List[int], List[List[int]]]] = None,
+ args: Optional[TrainingArguments] = None,
+ ) -> None:
+ """
+ Method to perform the embedding phase: finetuning the `SentenceTransformer` body.
+
+ Args:
+ x_train (`List[str]`): A list of training sentences.
+ y_train (`Union[List[int], List[List[int]]]`): A list of labels corresponding to the training sentences.
+ args (`TrainingArguments`, *optional*):
+ Temporarily change the training arguments for this training call.
+ """
+ args = args or self.args or TrainingArguments()
+ # Since transformers v4.32.0, the log/eval/save steps should be saved on the state instead
+ self.state.logging_steps = args.logging_steps
+ self.state.eval_steps = args.eval_steps
+ self.state.save_steps = args.save_steps
+ # Reset the state
+ self.state.global_step = 0
+ self.state.total_flos = 0
+
+ train_max_pairs = -1 if args.max_steps == -1 else args.max_steps * args.embedding_batch_size
+ train_dataloader, loss_func, batch_size = self.get_dataloader(
+ x_train, y_train, args=args, max_pairs=train_max_pairs
+ )
+ if x_eval is not None and args.evaluation_strategy != IntervalStrategy.NO:
+ eval_max_pairs = -1 if args.eval_max_steps == -1 else args.eval_max_steps * args.embedding_batch_size
+ eval_dataloader, _, _ = self.get_dataloader(x_eval, y_eval, args=args, max_pairs=eval_max_pairs)
+ else:
+ eval_dataloader = None
+
+ if args.max_steps > 0:
+ total_train_steps = args.max_steps
+ else:
+ total_train_steps = len(train_dataloader) * args.embedding_num_epochs
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataloader)}")
+ logger.info(f" Num epochs = {args.embedding_num_epochs}")
+ logger.info(f" Total optimization steps = {total_train_steps}")
+ logger.info(f" Total train batch size = {batch_size}")
+
+ warmup_steps = math.ceil(total_train_steps * args.warmup_proportion)
+ self._train_sentence_transformer(
+ self.model.model_body,
+ train_dataloader=train_dataloader,
+ eval_dataloader=eval_dataloader,
+ args=args,
+ loss_func=loss_func,
+ warmup_steps=warmup_steps,
+ )
+
+ def get_dataloader(
+ self, x: List[str], y: Union[List[int], List[List[int]]], args: TrainingArguments, max_pairs: int = -1
+ ) -> Tuple[DataLoader, nn.Module, int]:
+ # sentence-transformers adaptation
+ input_data = [InputExample(texts=[text], label=label) for text, label in zip(x, y)]
+
+ if args.loss in [
+ losses.BatchAllTripletLoss,
+ losses.BatchHardTripletLoss,
+ losses.BatchSemiHardTripletLoss,
+ losses.BatchHardSoftMarginTripletLoss,
+ SupConLoss,
+ ]:
+ data_sampler = SentenceLabelDataset(input_data, samples_per_label=args.samples_per_label)
+ batch_size = min(args.embedding_batch_size, len(data_sampler))
+ dataloader = DataLoader(data_sampler, batch_size=batch_size, drop_last=True)
+
+ if args.loss is losses.BatchHardSoftMarginTripletLoss:
+ loss = args.loss(
+ model=self.model.model_body,
+ distance_metric=args.distance_metric,
+ )
+ elif args.loss is SupConLoss:
+ loss = args.loss(model=self.model.model_body)
else:
- train_examples = []
-
- for _ in trange(self.num_iterations, desc="Generating Training Pairs", disable=not show_progress_bar):
- if self.model.multi_target_strategy is not None:
- train_examples = sentence_pairs_generation_multilabel(
- np.array(x_train), np.array(y_train), train_examples
- )
- else:
- train_examples = sentence_pairs_generation(
- np.array(x_train), np.array(y_train), train_examples
- )
-
- train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=batch_size)
- train_loss = self.loss_class(self.model.model_body)
-
- total_train_steps = len(train_dataloader) * num_epochs
- logger.info("***** Running training *****")
- logger.info(f" Num examples = {len(train_examples)}")
- logger.info(f" Num epochs = {num_epochs}")
- logger.info(f" Total optimization steps = {total_train_steps}")
- logger.info(f" Total train batch size = {batch_size}")
-
- warmup_steps = math.ceil(total_train_steps * self.warmup_proportion)
- self.model.model_body.fit(
- train_objectives=[(train_dataloader, train_loss)],
- epochs=num_epochs,
- optimizer_params={"lr": learning_rate},
- warmup_steps=warmup_steps,
- show_progress_bar=show_progress_bar,
- use_amp=self.use_amp,
+ loss = args.loss(
+ model=self.model.model_body,
+ distance_metric=args.distance_metric,
+ margin=args.margin,
+ )
+ else:
+ data_sampler = ContrastiveDataset(
+ input_data,
+ self.model.multi_target_strategy,
+ args.num_iterations,
+ args.sampling_strategy,
+ max_pairs=max_pairs,
)
+ # shuffle_sampler = True can be dropped in for further 'randomising'
+ shuffle_sampler = True if args.sampling_strategy == "unique" else False
+ batch_size = min(args.embedding_batch_size, len(data_sampler))
+ dataloader = DataLoader(data_sampler, batch_size=batch_size, shuffle=shuffle_sampler, drop_last=False)
+ loss = args.loss(self.model.model_body)
+
+ return dataloader, loss, batch_size
+
+ def log(self, args: TrainingArguments, logs: Dict[str, float]) -> None:
+ """
+ Log `logs` on the various objects watching training.
+
+ Subclass and override this method to inject custom behavior.
+
+ Args:
+ logs (`Dict[str, float]`):
+ The values to log.
+ """
+ logs = {self.logs_mapper.get(key, key): value for key, value in logs.items()}
+ if self.state.epoch is not None:
+ logs["epoch"] = round(self.state.epoch, 2)
+
+ output = {**logs, **{"step": self.state.global_step}}
+ self.state.log_history.append(output)
+ return self.callback_handler.on_log(args, self.state, self.control, logs)
+
+ def _set_logs_mapper(self, logs_mapper: Dict[str, str]) -> None:
+ """Set the logging mapper.
+
+ Args:
+ logs_mapper (str): The logging mapper, e.g. {"eval_embedding_loss": "eval_aspect_embedding_loss"}.
+ """
+ self.logs_mapper = logs_mapper
+
+ def _train_sentence_transformer(
+ self,
+ model_body: SentenceTransformer,
+ train_dataloader: DataLoader,
+ eval_dataloader: Optional[DataLoader],
+ args: TrainingArguments,
+ loss_func: nn.Module,
+ warmup_steps: int = 10000,
+ ) -> None:
+ """
+ Train the model with the given training objective
+ Each training objective is sampled in turn for one batch.
+ We sample only as many batches from each objective as there are in the smallest one
+ to make sure of equal training with each dataset.
+ """
+ # TODO: args.gradient_accumulation_steps
+ # TODO: fp16/bf16, etc.
+ # TODO: Safetensors
+
+ # Hardcoded training arguments
+ max_grad_norm = 1
+ weight_decay = 0.01
+
+ self.state.epoch = 0
+ start_time = time.time()
+ if args.max_steps > 0:
+ self.state.max_steps = args.max_steps
+ else:
+ self.state.max_steps = len(train_dataloader) * args.embedding_num_epochs
+ self.control = self.callback_handler.on_train_begin(args, self.state, self.control)
+ steps_per_epoch = len(train_dataloader)
+
+ if args.use_amp:
+ scaler = torch.cuda.amp.GradScaler()
+
+ model_body.to(model_body._target_device)
+ loss_func.to(model_body._target_device)
+
+ # Use smart batching
+ train_dataloader.collate_fn = model_body.smart_batching_collate
+ if eval_dataloader:
+ eval_dataloader.collate_fn = model_body.smart_batching_collate
+
+ # Prepare optimizers
+ param_optimizer = list(loss_func.named_parameters())
+
+ no_decay = ["bias", "LayerNorm.bias", "LayerNorm.weight"]
+ optimizer_grouped_parameters = [
+ {
+ "params": [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)],
+ "weight_decay": weight_decay,
+ },
+ {"params": [p for n, p in param_optimizer if any(nd in n for nd in no_decay)], "weight_decay": 0.0},
+ ]
+
+ optimizer = torch.optim.AdamW(optimizer_grouped_parameters, **{"lr": args.body_embedding_learning_rate})
+ scheduler_obj = model_body._get_scheduler(
+ optimizer, scheduler="WarmupLinear", warmup_steps=warmup_steps, t_total=self.state.max_steps
+ )
+ self.callback_handler.optimizer = optimizer
+ self.callback_handler.lr_scheduler = scheduler_obj
+ self.callback_handler.train_dataloader = train_dataloader
+ self.callback_handler.eval_dataloader = eval_dataloader
+
+ self.callback_handler.on_train_begin(args, self.state, self.control)
+
+ data_iterator = iter(train_dataloader)
+ skip_scheduler = False
+ for epoch in range(args.embedding_num_epochs):
+ self.control = self.callback_handler.on_epoch_begin(args, self.state, self.control)
+
+ loss_func.zero_grad()
+ loss_func.train()
+
+ for step in range(steps_per_epoch):
+ self.control = self.callback_handler.on_step_begin(args, self.state, self.control)
+
+ try:
+ data = next(data_iterator)
+ except StopIteration:
+ data_iterator = iter(train_dataloader)
+ data = next(data_iterator)
+
+ features, labels = data
+ labels = labels.to(model_body._target_device)
+ features = list(map(lambda batch: batch_to_device(batch, model_body._target_device), features))
+
+ if args.use_amp:
+ with autocast():
+ loss_value = loss_func(features, labels)
+
+ scale_before_step = scaler.get_scale()
+ scaler.scale(loss_value).backward()
+ scaler.unscale_(optimizer)
+ torch.nn.utils.clip_grad_norm_(loss_func.parameters(), max_grad_norm)
+ scaler.step(optimizer)
+ scaler.update()
+
+ skip_scheduler = scaler.get_scale() != scale_before_step
+ else:
+ loss_value = loss_func(features, labels)
+ loss_value.backward()
+ torch.nn.utils.clip_grad_norm_(loss_func.parameters(), max_grad_norm)
+ optimizer.step()
+
+ optimizer.zero_grad()
- if not self.model.has_differentiable_head or not self._freeze:
- # Train the final classifier
- self.model.fit(
- x_train,
- y_train,
- num_epochs=num_epochs,
- batch_size=batch_size,
- learning_rate=learning_rate,
- body_learning_rate=body_learning_rate,
- l2_weight=l2_weight,
- max_length=max_length,
- show_progress_bar=True,
+ if not skip_scheduler:
+ scheduler_obj.step()
+
+ self.state.global_step += 1
+ self.state.epoch = epoch + (step + 1) / steps_per_epoch
+ self.control = self.callback_handler.on_step_end(args, self.state, self.control)
+
+ self.maybe_log_eval_save(model_body, eval_dataloader, args, scheduler_obj, loss_func, loss_value)
+
+ if self.control.should_epoch_stop or self.control.should_training_stop:
+ break
+
+ self.control = self.callback_handler.on_epoch_end(args, self.state, self.control)
+
+ self.maybe_log_eval_save(model_body, eval_dataloader, args, scheduler_obj, loss_func, loss_value)
+
+ if self.control.should_training_stop:
+ break
+
+ if self.args.load_best_model_at_end and self.state.best_model_checkpoint:
+ dir_name = Path(self.state.best_model_checkpoint).name
+ if dir_name.startswith("step_"):
+ step_to_load = dir_name[5:]
+ logger.info(f"Loading best SentenceTransformer model from step {step_to_load}.")
+ self.model.model_card_data.set_best_model_step(int(step_to_load))
+ self.model.model_body = SentenceTransformer(
+ self.state.best_model_checkpoint, device=model_body._target_device
)
+ self.model.model_body.to(model_body._target_device)
+
+ # Ensure logging the speed metrics
+ num_train_samples = self.state.max_steps * args.embedding_batch_size # * args.gradient_accumulation_steps
+ metrics = speed_metrics("train", start_time, num_samples=num_train_samples, num_steps=self.state.max_steps)
+ self.control.should_log = True
+ self.log(args, metrics)
+
+ self.control = self.callback_handler.on_train_end(args, self.state, self.control)
+
+ def maybe_log_eval_save(
+ self,
+ model_body: SentenceTransformer,
+ eval_dataloader: Optional[DataLoader],
+ args: TrainingArguments,
+ scheduler_obj,
+ loss_func,
+ loss_value: torch.Tensor,
+ ) -> None:
+ if self.control.should_log:
+ learning_rate = scheduler_obj.get_last_lr()[0]
+ metrics = {"embedding_loss": round(loss_value.item(), 4), "learning_rate": learning_rate}
+ self.control = self.log(args, metrics)
+
+ eval_loss = None
+ if self.control.should_evaluate and eval_dataloader is not None:
+ eval_loss = self._evaluate_with_loss(model_body, eval_dataloader, args, loss_func)
+ learning_rate = scheduler_obj.get_last_lr()[0]
+ metrics = {"eval_embedding_loss": round(eval_loss, 4), "learning_rate": learning_rate}
+ self.control = self.log(args, metrics)
+
+ self.control = self.callback_handler.on_evaluate(args, self.state, self.control, metrics)
+
+ loss_func.zero_grad()
+ loss_func.train()
+
+ if self.control.should_save:
+ checkpoint_dir = self._checkpoint(self.args.output_dir, args.save_total_limit, self.state.global_step)
+ self.control = self.callback_handler.on_save(self.args, self.state, self.control)
- def evaluate(self, dataset: Optional[Dataset] = None) -> Dict[str, float]:
+ if eval_loss is not None and (self.state.best_metric is None or eval_loss < self.state.best_metric):
+ self.state.best_metric = eval_loss
+ self.state.best_model_checkpoint = checkpoint_dir
+
+ def _evaluate_with_loss(
+ self,
+ model_body: SentenceTransformer,
+ eval_dataloader: DataLoader,
+ args: TrainingArguments,
+ loss_func: nn.Module,
+ ) -> float:
+ model_body.eval()
+ losses = []
+ eval_steps = (
+ min(len(eval_dataloader), args.eval_max_steps) if args.eval_max_steps != -1 else len(eval_dataloader)
+ )
+ for step, data in enumerate(
+ tqdm(iter(eval_dataloader), total=eval_steps, leave=False, disable=not args.show_progress_bar), start=1
+ ):
+ features, labels = data
+ labels = labels.to(model_body._target_device)
+ features = list(map(lambda batch: batch_to_device(batch, model_body._target_device), features))
+
+ if args.use_amp:
+ with autocast():
+ loss_value = loss_func(features, labels)
+
+ losses.append(loss_value.item())
+ else:
+ losses.append(loss_func(features, labels).item())
+
+ if step >= eval_steps:
+ break
+
+ model_body.train()
+ return sum(losses) / len(losses)
+
+ def _checkpoint(self, checkpoint_path: str, checkpoint_save_total_limit: int, step: int) -> None:
+ # Delete old checkpoints
+ if checkpoint_save_total_limit is not None and checkpoint_save_total_limit > 0:
+ old_checkpoints = []
+ for subdir in Path(checkpoint_path).glob("step_*"):
+ if subdir.name[5:].isdigit() and (
+ self.state.best_model_checkpoint is None or subdir != Path(self.state.best_model_checkpoint)
+ ):
+ old_checkpoints.append({"step": int(subdir.name[5:]), "path": str(subdir)})
+
+ if len(old_checkpoints) > checkpoint_save_total_limit - 1:
+ old_checkpoints = sorted(old_checkpoints, key=lambda x: x["step"])
+ shutil.rmtree(old_checkpoints[0]["path"])
+
+ checkpoint_file_path = str(Path(checkpoint_path) / f"step_{step}")
+ self.model.save_pretrained(checkpoint_file_path)
+ return checkpoint_file_path
+
+ def train_classifier(
+ self, x_train: List[str], y_train: Union[List[int], List[List[int]]], args: Optional[TrainingArguments] = None
+ ) -> None:
+ """
+ Method to perform the classifier phase: fitting a classifier head.
+
+ Args:
+ x_train (`List[str]`): A list of training sentences.
+ y_train (`Union[List[int], List[List[int]]]`): A list of labels corresponding to the training sentences.
+ args (`TrainingArguments`, *optional*):
+ Temporarily change the training arguments for this training call.
+ """
+ args = args or self.args or TrainingArguments()
+
+ self.model.fit(
+ x_train,
+ y_train,
+ num_epochs=args.classifier_num_epochs,
+ batch_size=args.classifier_batch_size,
+ body_learning_rate=args.body_classifier_learning_rate,
+ head_learning_rate=args.head_learning_rate,
+ l2_weight=args.l2_weight,
+ max_length=args.max_length,
+ show_progress_bar=args.show_progress_bar,
+ end_to_end=args.end_to_end,
+ )
+
+ def evaluate(self, dataset: Optional[Dataset] = None, metric_key_prefix: str = "test") -> Dict[str, float]:
"""
Computes the metrics for a given classifier.
Args:
dataset (`Dataset`, *optional*):
- The dataset to compute the metrics on. If not provided, will use the evaluation dataset passed in the eval_dataset argument at `SetFitTrainer` initialization.
+ The dataset to compute the metrics on. If not provided, will use the evaluation dataset passed via
+ the `eval_dataset` argument at `Trainer` initialization.
Returns:
`Dict[str, float]`: The evaluation metrics.
"""
- eval_dataset = dataset or self.eval_dataset
- self._validate_column_mapping(eval_dataset)
+ if dataset is not None:
+ self._validate_column_mapping(dataset)
+ if self.column_mapping is not None:
+ logger.info("Applying column mapping to the evaluation dataset")
+ eval_dataset = self._apply_column_mapping(dataset, self.column_mapping)
+ else:
+ eval_dataset = dataset
+ else:
+ eval_dataset = self.eval_dataset
- if self.column_mapping is not None:
- logger.info("Applying column mapping to evaluation dataset")
- eval_dataset = self._apply_column_mapping(eval_dataset, self.column_mapping)
+ if eval_dataset is None:
+ raise ValueError("No evaluation dataset provided to `Trainer.evaluate` nor the `Trainer` initialzation.")
x_test = eval_dataset["text"]
y_test = eval_dataset["label"]
logger.info("***** Running evaluation *****")
- y_pred = self.model.predict(x_test)
+ y_pred = self.model.predict(x_test, use_labels=False)
if isinstance(y_pred, torch.Tensor):
y_pred = y_pred.cpu()
+ # Normalize string outputs
+ if y_test and isinstance(y_test[0], str):
+ encoder = LabelEncoder()
+ encoder.fit(list(y_test) + list(y_pred))
+ y_test = encoder.transform(y_test)
+ y_pred = encoder.transform(y_pred)
+
+ metric_kwargs = self.metric_kwargs or {}
if isinstance(self.metric, str):
metric_config = "multilabel" if self.model.multi_target_strategy is not None else None
metric_fn = evaluate.load(self.metric, config_name=metric_config)
- metric_kwargs = self.metric_kwargs or {}
- return metric_fn.compute(predictions=y_pred, references=y_test, **metric_kwargs)
+ results = metric_fn.compute(predictions=y_pred, references=y_test, **metric_kwargs)
elif callable(self.metric):
- return self.metric(y_pred, y_test)
+ results = self.metric(y_pred, y_test, **metric_kwargs)
else:
raise ValueError("metric must be a string or a callable")
+ if not isinstance(results, dict):
+ results = {"metric": results}
+ self.model.model_card_data.post_training_eval_results(
+ {f"{metric_key_prefix}_{key}": value for key, value in results.items()}
+ )
+ return results
+
def hyperparameter_search(
self,
hp_space: Optional[Callable[["optuna.Trial"], Dict[str, float]]] = None,
@@ -472,7 +876,7 @@ def hyperparameter_search(
- To use this method, you need to have provided a `model_init` when initializing your [`SetFitTrainer`]: we need to
+ To use this method, you need to have provided a `model_init` when initializing your [`Trainer`]: we need to
reinitialize the model at each new run.
@@ -480,16 +884,16 @@ def hyperparameter_search(
Args:
hp_space (`Callable[["optuna.Trial"], Dict[str, float]]`, *optional*):
A function that defines the hyperparameter search space. Will default to
- [`~trainer_utils.default_hp_space_optuna`].
+ [`~transformers.trainer_utils.default_hp_space_optuna`].
compute_objective (`Callable[[Dict[str, float]], float]`, *optional*):
A function computing the objective to minimize or maximize from the metrics returned by the `evaluate`
- method. Will default to [`~trainer_utils.default_compute_objective`] which uses the sum of metrics.
+ method. Will default to [`~transformers.trainer_utils.default_compute_objective`] which uses the sum of metrics.
n_trials (`int`, *optional*, defaults to 100):
The number of trial runs to test.
direction (`str`, *optional*, defaults to `"maximize"`):
Whether to optimize greater or lower objects. Can be `"minimize"` or `"maximize"`, you should pick
`"minimize"` when optimizing the validation loss, `"maximize"` when optimizing one or several metrics.
- backend (`str` or [`~training_utils.HPSearchBackend`], *optional*):
+ backend (`str` or [`~transformers.training_utils.HPSearchBackend`], *optional*):
The backend to use for hyperparameter search. Only optuna is supported for now.
TODO: add support for ray and sigopt.
hp_name (`Callable[["optuna.Trial"], str]]`, *optional*):
@@ -507,7 +911,7 @@ def hyperparameter_search(
if backend is None:
backend = default_hp_search_backend()
if backend is None:
- raise RuntimeError("optuna should be installed. " "To install optuna run `pip install optuna`. ")
+ raise RuntimeError("optuna should be installed. To install optuna run `pip install optuna`.")
backend = HPSearchBackend(backend)
if backend == HPSearchBackend.OPTUNA and not is_optuna_available():
raise RuntimeError("You picked the optuna backend, but it is not installed. Use `pip install optuna`.")
@@ -539,7 +943,7 @@ def push_to_hub(self, repo_id: str, **kwargs) -> str:
Args:
repo_id (`str`):
- The full repository ID to push to, e.g. `"tomaarsen/setfit_sst2"`.
+ The full repository ID to push to, e.g. `"tomaarsen/setfit-sst2"`.
config (`dict`, *optional*):
Configuration object to be saved alongside the model weights.
commit_message (`str`, *optional*):
@@ -569,7 +973,66 @@ def push_to_hub(self, repo_id: str, **kwargs) -> str:
"""
if "/" not in repo_id:
raise ValueError(
- '`repo_id` must be a full repository ID, including organisation, e.g. "tomaarsen/setfit_sst2".'
+ '`repo_id` must be a full repository ID, including organisation, e.g. "tomaarsen/setfit-sst2".'
)
commit_message = kwargs.pop("commit_message", "Add SetFit model")
return self.model.push_to_hub(repo_id, commit_message=commit_message, **kwargs)
+
+
+class SetFitTrainer(Trainer):
+ """
+ `SetFitTrainer` has been deprecated and will be removed in v2.0.0 of SetFit.
+ Please use `Trainer` instead.
+ """
+
+ def __init__(
+ self,
+ model: Optional["SetFitModel"] = None,
+ train_dataset: Optional["Dataset"] = None,
+ eval_dataset: Optional["Dataset"] = None,
+ model_init: Optional[Callable[[], "SetFitModel"]] = None,
+ metric: Union[str, Callable[["Dataset", "Dataset"], Dict[str, float]]] = "accuracy",
+ metric_kwargs: Optional[Dict[str, Any]] = None,
+ loss_class=losses.CosineSimilarityLoss,
+ num_iterations: int = 20,
+ num_epochs: int = 1,
+ learning_rate: float = 2e-5,
+ batch_size: int = 16,
+ seed: int = 42,
+ column_mapping: Optional[Dict[str, str]] = None,
+ use_amp: bool = False,
+ warmup_proportion: float = 0.1,
+ distance_metric: Callable = BatchHardTripletLossDistanceFunction.cosine_distance,
+ margin: float = 0.25,
+ samples_per_label: int = 2,
+ ):
+ warnings.warn(
+ "`SetFitTrainer` has been deprecated and will be removed in v2.0.0 of SetFit. "
+ "Please use `Trainer` instead.",
+ DeprecationWarning,
+ stacklevel=2,
+ )
+ args = TrainingArguments(
+ num_iterations=num_iterations,
+ num_epochs=num_epochs,
+ body_learning_rate=learning_rate,
+ head_learning_rate=learning_rate,
+ batch_size=batch_size,
+ seed=seed,
+ use_amp=use_amp,
+ warmup_proportion=warmup_proportion,
+ distance_metric=distance_metric,
+ margin=margin,
+ samples_per_label=samples_per_label,
+ loss=loss_class,
+ )
+ super().__init__(
+ model=model,
+ args=args,
+ train_dataset=train_dataset,
+ eval_dataset=eval_dataset,
+ model_init=model_init,
+ metric=metric,
+ metric_kwargs=metric_kwargs,
+ column_mapping=column_mapping,
+ )
diff --git a/src/setfit/trainer_distillation.py b/src/setfit/trainer_distillation.py
index ca194066..d3675051 100644
--- a/src/setfit/trainer_distillation.py
+++ b/src/setfit/trainer_distillation.py
@@ -1,245 +1,166 @@
-import math
-from typing import TYPE_CHECKING, Any, Callable, Dict, Optional, Union
+import warnings
+from typing import TYPE_CHECKING, Callable, Dict, Iterable, List, Optional, Tuple, Union
-import numpy as np
import torch
+from datasets import Dataset
from sentence_transformers import InputExample, losses, util
-from sentence_transformers.datasets import SentenceLabelDataset
-from sentence_transformers.losses.BatchHardTripletLoss import BatchHardTripletLossDistanceFunction
+from torch import nn
from torch.utils.data import DataLoader
-from transformers.trainer_utils import set_seed
-from . import SetFitTrainer, logging
-from .modeling import SupConLoss, sentence_pairs_generation_cos_sim
+from . import logging
+from .sampler import ContrastiveDistillationDataset
+from .trainer import Trainer
+from .training_args import TrainingArguments
if TYPE_CHECKING:
- import optuna
- from datasets import Dataset
-
from .modeling import SetFitModel
logging.set_verbosity_info()
logger = logging.get_logger(__name__)
-class DistillationSetFitTrainer(SetFitTrainer):
+class DistillationTrainer(Trainer):
"""Trainer to compress a SetFit model with knowledge distillation.
Args:
teacher_model (`SetFitModel`):
The teacher model to mimic.
+ student_model (`SetFitModel`, *optional*):
+ The model to train. If not provided, a `model_init` must be passed.
+ args (`TrainingArguments`, *optional*):
+ The training arguments to use.
train_dataset (`Dataset`):
The training dataset.
- student_model (`SetFitModel`):
- The student model to train. If not provided, a `model_init` must be passed.
eval_dataset (`Dataset`, *optional*):
The evaluation dataset.
model_init (`Callable[[], SetFitModel]`, *optional*):
- A function that instantiates the model to be used. If provided, each call to [`~DistillationSetFitTrainer.train`] will start
- from a new instance of the model as given by this function when a `trial` is passed.
+ A function that instantiates the model to be used. If provided, each call to
+ [`~DistillationTrainer.train`] will start from a new instance of the model as given by this
+ function when a `trial` is passed.
metric (`str` or `Callable`, *optional*, defaults to `"accuracy"`):
- The metric to use for evaluation. If a string is provided, we treat it as the metric name and load it with default settings.
+ The metric to use for evaluation. If a string is provided, we treat it as the metric
+ name and load it with default settings.
If a callable is provided, it must take two arguments (`y_pred`, `y_test`).
- loss_class (`nn.Module`, *optional*, defaults to `CosineSimilarityLoss`):
- The loss function to use for contrastive training.
- num_iterations (`int`, *optional*, defaults to `20`):
- The number of iterations to generate sentence pairs for.
- num_epochs (`int`, *optional*, defaults to `1`):
- The number of epochs to train the Sentence Transformer body for.
- learning_rate (`float`, *optional*, defaults to `2e-5`):
- The learning rate to use for contrastive training.
- batch_size (`int`, *optional*, defaults to `16`):
- The batch size to use for contrastive training.
- seed (`int`, *optional*, defaults to 42):
- Random seed that will be set at the beginning of training. To ensure reproducibility across runs, use the
- [`~SetTrainer.model_init`] function to instantiate the model if it has some randomly initialized parameters.
column_mapping (`Dict[str, str]`, *optional*):
- A mapping from the column names in the dataset to the column names expected by the model. The expected format is a dictionary with the following format: {"text_column_name": "text", "label_column_name: "label"}.
- use_amp (`bool`, *optional*, defaults to `False`):
- Use Automatic Mixed Precision (AMP). Only for Pytorch >= 1.6.0
- warmup_proportion (`float`, *optional*, defaults to `0.1`):
- Proportion of the warmup in the total training steps.
- Must be greater than or equal to 0.0 and less than or equal to 1.0.
+ A mapping from the column names in the dataset to the column names expected by the model.
+ The expected format is a dictionary with the following format:
+ `{"text_column_name": "text", "label_column_name: "label"}`.
"""
+ _REQUIRED_COLUMNS = {"text"}
+
def __init__(
self,
teacher_model: "SetFitModel",
student_model: Optional["SetFitModel"] = None,
+ args: TrainingArguments = None,
train_dataset: Optional["Dataset"] = None,
eval_dataset: Optional["Dataset"] = None,
model_init: Optional[Callable[[], "SetFitModel"]] = None,
metric: Union[str, Callable[["Dataset", "Dataset"], Dict[str, float]]] = "accuracy",
- loss_class: torch.nn.Module = losses.CosineSimilarityLoss,
- num_iterations: int = 20,
- num_epochs: int = 1,
- learning_rate: float = 2e-5,
- batch_size: int = 16,
- seed: int = 42,
column_mapping: Optional[Dict[str, str]] = None,
- use_amp: bool = False,
- warmup_proportion: float = 0.1,
) -> None:
- super(DistillationSetFitTrainer, self).__init__(
+ super().__init__(
model=student_model,
+ args=args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
model_init=model_init,
metric=metric,
- loss_class=loss_class,
- num_iterations=num_iterations,
- num_epochs=num_epochs,
- learning_rate=learning_rate,
- batch_size=batch_size,
- seed=seed,
column_mapping=column_mapping,
- use_amp=use_amp,
- warmup_proportion=warmup_proportion,
)
self.teacher_model = teacher_model
self.student_model = self.model
- def train(
+ def dataset_to_parameters(self, dataset: Dataset) -> List[Iterable]:
+ return [dataset["text"]]
+
+ def get_dataloader(
self,
- num_epochs: Optional[int] = None,
- batch_size: Optional[int] = None,
- learning_rate: Optional[float] = None,
- body_learning_rate: Optional[float] = None,
- l2_weight: Optional[float] = None,
- trial: Optional[Union["optuna.Trial", Dict[str, Any]]] = None,
- show_progress_bar: bool = True,
- ):
+ x: List[str],
+ y: Optional[Union[List[int], List[List[int]]]],
+ args: TrainingArguments,
+ max_pairs: int = -1,
+ ) -> Tuple[DataLoader, nn.Module, int]:
+ x_embd_student = self.teacher_model.model_body.encode(
+ x, convert_to_tensor=self.teacher_model.has_differentiable_head
+ )
+ cos_sim_matrix = util.cos_sim(x_embd_student, x_embd_student)
+
+ input_data = [InputExample(texts=[text]) for text in x]
+ data_sampler = ContrastiveDistillationDataset(
+ input_data, cos_sim_matrix, args.num_iterations, args.sampling_strategy, max_pairs=max_pairs
+ )
+ # shuffle_sampler = True can be dropped in for further 'randomising'
+ shuffle_sampler = True if args.sampling_strategy == "unique" else False
+ batch_size = min(args.embedding_batch_size, len(data_sampler))
+ dataloader = DataLoader(data_sampler, batch_size=batch_size, shuffle=shuffle_sampler, drop_last=False)
+ loss = args.loss(self.model.model_body)
+ return dataloader, loss, batch_size
+
+ def train_classifier(self, x_train: List[str], args: Optional[TrainingArguments] = None) -> None:
"""
- Main training entry point.
+ Method to perform the classifier phase: fitting the student classifier head.
Args:
- num_epochs (`int`, *optional*):
- Temporary change the number of epochs to train the Sentence Transformer body/head for.
- If ignore, will use the value given in initialization.
- batch_size (`int`, *optional*):
- Temporary change the batch size to use for contrastive training or logistic regression.
- If ignore, will use the value given in initialization.
- learning_rate (`float`, *optional*):
- Temporary change the learning rate to use for contrastive training or SetFitModel's head in logistic regression.
- If ignore, will use the value given in initialization.
- body_learning_rate (`float`, *optional*):
- Temporary change the learning rate to use for SetFitModel's body in logistic regression only.
- If ignore, will be the same as `learning_rate`.
- l2_weight (`float`, *optional*):
- Temporary change the weight of L2 regularization for SetFitModel's differentiable head in logistic regression.
- trial (`optuna.Trial` or `Dict[str, Any]`, *optional*):
- The trial run or the hyperparameter dictionary for hyperparameter search.
- show_progress_bar (`bool`, *optional*, defaults to `True`):
- Whether to show a bar that indicates training progress.
+ x_train (`List[str]`): A list of training sentences.
+ args (`TrainingArguments`, *optional*):
+ Temporarily change the training arguments for this training call.
"""
- set_seed(self.seed) # Seed must be set before instantiating the model when using model_init.
-
- if trial: # Trial and model initialization
- self._hp_search_setup(trial) # sets trainer parameters and initializes model
-
- if self.train_dataset is None:
- raise ValueError(
- "Training requires a `train_dataset` given to the `DistillationSetFitTrainer` initialization."
- )
-
- self._validate_column_mapping(self.train_dataset)
- train_dataset = self.train_dataset
- if self.column_mapping is not None:
- logger.info("Applying column mapping to training dataset")
- train_dataset = self._apply_column_mapping(self.train_dataset, self.column_mapping)
-
- x_train = train_dataset["text"]
- y_train = train_dataset["label"]
- if self.loss_class is None:
- logger.warning("No `loss_class` detected! Using `CosineSimilarityLoss` as the default.")
- self.loss_class = losses.CosineSimilarityLoss
-
- num_epochs = num_epochs or self.num_epochs
- batch_size = batch_size or self.batch_size
- learning_rate = learning_rate or self.learning_rate
-
- if not self.student_model.has_differentiable_head or self._freeze:
- # sentence-transformers adaptation
- if self.loss_class in [
- losses.BatchAllTripletLoss,
- losses.BatchHardTripletLoss,
- losses.BatchSemiHardTripletLoss,
- losses.BatchHardSoftMarginTripletLoss,
- SupConLoss,
- ]:
- train_examples = [InputExample(texts=[text], label=label) for text, label in zip(x_train, y_train)]
- train_data_sampler = SentenceLabelDataset(train_examples)
-
- batch_size = min(batch_size, len(train_data_sampler))
- train_dataloader = DataLoader(train_data_sampler, batch_size=batch_size, drop_last=True)
-
- if self.loss_class is losses.BatchHardSoftMarginTripletLoss:
- train_loss = self.loss_class(
- model=self.student_model,
- distance_metric=BatchHardTripletLossDistanceFunction.cosine_distance,
- )
- elif self.loss_class is SupConLoss:
- train_loss = self.loss_class(model=self.student_model)
- else:
- train_loss = self.loss_class(
- model=self.student_model,
- distance_metric=BatchHardTripletLossDistanceFunction.cosine_distance,
- margin=0.25,
- )
- else:
- train_examples = []
-
- # **************** student training ****************
- x_train_embd_student = self.teacher_model.model_body.encode(
- x_train, convert_to_tensor=self.teacher_model.has_differentiable_head
- )
- y_train = self.teacher_model.model_head.predict(x_train_embd_student)
- if not self.teacher_model.has_differentiable_head and self.student_model.has_differentiable_head:
- y_train = torch.from_numpy(y_train)
- elif self.teacher_model.has_differentiable_head and not self.student_model.has_differentiable_head:
- y_train = y_train.detach().cpu().numpy()
-
- cos_sim_matrix = util.cos_sim(x_train_embd_student, x_train_embd_student)
-
- train_examples = []
- for _ in range(self.num_iterations):
- train_examples = sentence_pairs_generation_cos_sim(
- np.array(x_train), train_examples, cos_sim_matrix
- )
-
- # **************** student training END ****************
-
- train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=batch_size)
- train_loss = self.loss_class(self.student_model.model_body)
-
- total_train_steps = len(train_dataloader) * num_epochs
- logger.info("***** Running training *****")
- logger.info(f" Num examples = {len(train_examples)}")
- logger.info(f" Num epochs = {num_epochs}")
- logger.info(f" Total optimization steps = {total_train_steps}")
- logger.info(f" Total train batch size = {batch_size}")
-
- warmup_steps = math.ceil(total_train_steps * self.warmup_proportion)
- self.student_model.model_body.fit(
- train_objectives=[(train_dataloader, train_loss)],
- epochs=num_epochs,
- optimizer_params={"lr": learning_rate},
- warmup_steps=warmup_steps,
- show_progress_bar=show_progress_bar,
- use_amp=self.use_amp,
- )
-
- if not self.student_model.has_differentiable_head or not self._freeze:
- # Train the final classifier
- self.student_model.fit(
- x_train,
- y_train,
- num_epochs=num_epochs,
- batch_size=batch_size,
- learning_rate=learning_rate,
- body_learning_rate=body_learning_rate,
- l2_weight=l2_weight,
- show_progress_bar=show_progress_bar,
- )
+ y_train = self.teacher_model.predict(x_train, as_numpy=not self.student_model.has_differentiable_head)
+ return super().train_classifier(x_train, y_train, args)
+
+
+class DistillationSetFitTrainer(DistillationTrainer):
+ """
+ `DistillationSetFitTrainer` has been deprecated and will be removed in v2.0.0 of SetFit.
+ Please use `DistillationTrainer` instead.
+ """
+
+ def __init__(
+ self,
+ teacher_model: "SetFitModel",
+ student_model: Optional["SetFitModel"] = None,
+ train_dataset: Optional["Dataset"] = None,
+ eval_dataset: Optional["Dataset"] = None,
+ model_init: Optional[Callable[[], "SetFitModel"]] = None,
+ metric: Union[str, Callable[["Dataset", "Dataset"], Dict[str, float]]] = "accuracy",
+ loss_class: torch.nn.Module = losses.CosineSimilarityLoss,
+ num_iterations: int = 20,
+ num_epochs: int = 1,
+ learning_rate: float = 2e-5,
+ batch_size: int = 16,
+ seed: int = 42,
+ column_mapping: Optional[Dict[str, str]] = None,
+ use_amp: bool = False,
+ warmup_proportion: float = 0.1,
+ ) -> None:
+ warnings.warn(
+ "`DistillationSetFitTrainer` has been deprecated and will be removed in v2.0.0 of SetFit. "
+ "Please use `DistillationTrainer` instead.",
+ DeprecationWarning,
+ stacklevel=2,
+ )
+ args = TrainingArguments(
+ num_iterations=num_iterations,
+ num_epochs=num_epochs,
+ body_learning_rate=learning_rate,
+ head_learning_rate=learning_rate,
+ batch_size=batch_size,
+ seed=seed,
+ use_amp=use_amp,
+ warmup_proportion=warmup_proportion,
+ loss=loss_class,
+ )
+ super().__init__(
+ teacher_model=teacher_model,
+ student_model=student_model,
+ args=args,
+ train_dataset=train_dataset,
+ eval_dataset=eval_dataset,
+ model_init=model_init,
+ metric=metric,
+ column_mapping=column_mapping,
+ )
diff --git a/src/setfit/training_args.py b/src/setfit/training_args.py
new file mode 100644
index 00000000..9669c460
--- /dev/null
+++ b/src/setfit/training_args.py
@@ -0,0 +1,355 @@
+from __future__ import annotations
+
+import inspect
+import json
+from copy import copy
+from dataclasses import dataclass, field, fields
+from typing import Any, Callable, Dict, Optional, Tuple, Union
+
+import torch
+from sentence_transformers import losses
+from transformers import IntervalStrategy
+from transformers.integrations import get_available_reporting_integrations
+from transformers.training_args import default_logdir
+from transformers.utils import is_torch_available
+
+from . import logging
+
+
+logger = logging.get_logger(__name__)
+
+
+@dataclass
+class TrainingArguments:
+ """
+ TrainingArguments is the subset of the arguments which relate to the training loop itself.
+ Note that training with SetFit consists of two phases behind the scenes: **finetuning embeddings** and
+ **training a classification head**. As a result, some of the training arguments can be tuples,
+ where the two values are used for each of the two phases, respectively. The second value is often only
+ used when training the model was loaded using `use_differentiable_head=True`.
+
+ Parameters:
+ output_dir (`str`, defaults to `"checkpoints"`):
+ The output directory where the model predictions and checkpoints will be written.
+ batch_size (`Union[int, Tuple[int, int]]`, defaults to `(16, 2)`):
+ Set the batch sizes for the embedding and classifier training phases respectively,
+ or set both if an integer is provided.
+ Note that the batch size for the classifier is only used with a differentiable PyTorch head.
+ num_epochs (`Union[int, Tuple[int, int]]`, defaults to `(1, 16)`):
+ Set the number of epochs the embedding and classifier training phases respectively,
+ or set both if an integer is provided.
+ Note that the number of epochs for the classifier is only used with a differentiable PyTorch head.
+ max_steps (`int`, defaults to `-1`):
+ If set to a positive number, the total number of training steps to perform. Overrides `num_epochs`.
+ The training may stop before reaching the set number of steps when all data is exhausted.
+ sampling_strategy (`str`, defaults to `"oversampling"`):
+ The sampling strategy of how to draw pairs in training. Possible values are:
+
+ - `"oversampling"`: Draws even number of positive/ negative sentence pairs until every
+ sentence pair has been drawn.
+ - `"undersampling"`: Draws the minimum number of positive/ negative sentence pairs until
+ every sentence pair in the minority class has been drawn.
+ - `"unique"`: Draws every sentence pair combination (likely resulting in unbalanced
+ number of positive/ negative sentence pairs).
+
+ The default is set to `"oversampling"`, ensuring all sentence pairs are drawn at least once.
+ Alternatively, setting `num_iterations` will override this argument and determine the number
+ of generated sentence pairs.
+ num_iterations (`int`, *optional*):
+ If not set the `sampling_strategy` will determine the number of sentence pairs to generate.
+ This argument sets the number of iterations to generate sentence pairs for
+ and provides compatability with Setfit = 1.6.0
+ warmup_proportion (`float`, defaults to `0.1`):
+ Proportion of the warmup in the total training steps.
+ Must be greater than or equal to 0.0 and less than or equal to 1.0.
+ l2_weight (`float`, *optional*):
+ Optional l2 weight for both the model body and head, passed to the `AdamW` optimizer in the
+ classifier training phase if a differentiable PyTorch head is used.
+ max_length (`int`, *optional*):
+ The maximum token length a tokenizer can generate. If not provided, the maximum length for
+ the `SentenceTransformer` body is used.
+ samples_per_label (`int`, defaults to `2`): Number of consecutive, random and unique samples drawn per label.
+ This is only relevant for triplet loss and ignored for `CosineSimilarityLoss`.
+ Batch size should be a multiple of samples_per_label.
+ show_progress_bar (`bool`, defaults to `True`):
+ Whether to display a progress bar for the training epochs and iterations.
+ seed (`int`, defaults to `42`):
+ Random seed that will be set at the beginning of training. To ensure reproducibility across
+ runs, use the `model_init` argument to [`Trainer`] to instantiate the model if it has some
+ randomly initialized parameters.
+ report_to (`str` or `List[str]`, *optional*, defaults to `"all"`):
+ The list of integrations to report the results and logs to. Supported platforms are `"azure_ml"`,
+ `"comet_ml"`, `"mlflow"`, `"neptune"`, `"tensorboard"`,`"clearml"` and `"wandb"`. Use `"all"` to report to
+ all integrations installed, `"none"` for no integrations.
+ run_name (`str`, *optional*):
+ A descriptor for the run. Typically used for [wandb](https://www.wandb.com/) and
+ [mlflow](https://www.mlflow.org/) logging.
+ logging_dir (`str`, *optional*):
+ [TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to
+ *runs/**CURRENT_DATETIME_HOSTNAME***.
+ logging_strategy (`str` or [`~transformers.trainer_utils.IntervalStrategy`], *optional*, defaults to `"steps"`):
+ The logging strategy to adopt during training. Possible values are:
+
+ - `"no"`: No logging is done during training.
+ - `"epoch"`: Logging is done at the end of each epoch.
+ - `"steps"`: Logging is done every `logging_steps`.
+
+ logging_first_step (`bool`, *optional*, defaults to `False`):
+ Whether to log and evaluate the first `global_step` or not.
+ logging_steps (`int`, defaults to 50):
+ Number of update steps between two logs if `logging_strategy="steps"`.
+ evaluation_strategy (`str` or [`~transformers.trainer_utils.IntervalStrategy`], *optional*, defaults to `"no"`):
+ The evaluation strategy to adopt during training. Possible values are:
+
+ - `"no"`: No evaluation is done during training.
+ - `"steps"`: Evaluation is done (and logged) every `eval_steps`.
+ - `"epoch"`: Evaluation is done at the end of each epoch.
+
+ eval_steps (`int`, *optional*):
+ Number of update steps between two evaluations if `evaluation_strategy="steps"`. Will default to the same
+ value as `logging_steps` if not set.
+ eval_delay (`float`, *optional*):
+ Number of epochs or steps to wait for before the first evaluation can be performed, depending on the
+ evaluation_strategy.
+ eval_max_steps (`int`, defaults to `-1`):
+ If set to a positive number, the total number of evaluation steps to perform. The evaluation may stop
+ before reaching the set number of steps when all data is exhausted.
+
+ save_strategy (`str` or [`~transformers.trainer_utils.IntervalStrategy`], *optional*, defaults to `"steps"`):
+ The checkpoint save strategy to adopt during training. Possible values are:
+
+ - `"no"`: No save is done during training.
+ - `"epoch"`: Save is done at the end of each epoch.
+ - `"steps"`: Save is done every `save_steps`.
+ save_steps (`int`, *optional*, defaults to 500):
+ Number of updates steps before two checkpoint saves if `save_strategy="steps"`.
+ save_total_limit (`int`, *optional*, defaults to `1`):
+ If a value is passed, will limit the total amount of checkpoints. Deletes the older checkpoints in
+ `output_dir`. Note, the best model is always preserved if the `evaluation_strategy` is not `"no"`.
+ load_best_model_at_end (`bool`, *optional*, defaults to `False`):
+ Whether or not to load the best model found during training at the end of training.
+
+
+
+ When set to `True`, the parameters `save_strategy` needs to be the same as `evaluation_strategy`, and in
+ the case it is "steps", `save_steps` must be a round multiple of `eval_steps`.
+
+
+ """
+
+ output_dir: str = "checkpoints"
+
+ # batch_size is only used to conveniently set `embedding_batch_size` and `classifier_batch_size`
+ # which are used in practice
+ batch_size: Union[int, Tuple[int, int]] = field(default=(16, 2), repr=False)
+
+ # num_epochs is only used to conveniently set `embedding_num_epochs` and `classifier_num_epochs`
+ # which are used in practice
+ num_epochs: Union[int, Tuple[int, int]] = field(default=(1, 16), repr=False)
+
+ max_steps: int = -1
+
+ sampling_strategy: str = "oversampling"
+ num_iterations: Optional[int] = None
+
+ # As with batch_size and num_epochs, the first value in the tuple is the learning rate
+ # for the embeddings step, while the second value is the learning rate for the classifier step.
+ body_learning_rate: Union[float, Tuple[float, float]] = field(default=(2e-5, 1e-5), repr=False)
+ head_learning_rate: float = 1e-2
+
+ # Loss-related arguments
+ loss: Callable = losses.CosineSimilarityLoss
+ distance_metric: Callable = losses.BatchHardTripletLossDistanceFunction.cosine_distance
+ margin: float = 0.25
+
+ end_to_end: bool = field(default=False)
+
+ use_amp: bool = False
+ warmup_proportion: float = 0.1
+ l2_weight: Optional[float] = None
+ max_length: Optional[int] = None
+ samples_per_label: int = 2
+
+ # Arguments that do not affect performance
+ show_progress_bar: bool = True
+ seed: int = 42
+
+ # Logging & callbacks
+ report_to: str = "all"
+ run_name: Optional[str] = None
+ logging_dir: Optional[str] = None
+ logging_strategy: str = "steps"
+ logging_first_step: bool = True
+ logging_steps: int = 50
+
+ evaluation_strategy: str = "no"
+ eval_steps: Optional[int] = None
+ eval_delay: int = 0
+ eval_max_steps: int = -1
+
+ save_strategy: str = "steps"
+ save_steps: int = 500
+ save_total_limit: Optional[int] = 1
+
+ load_best_model_at_end: bool = False
+ metric_for_best_model: str = field(default="embedding_loss", repr=False)
+ greater_is_better: bool = field(default=False, repr=False)
+
+ def __post_init__(self) -> None:
+ # Set `self.embedding_batch_size` and `self.classifier_batch_size` using values from `self.batch_size`
+ if isinstance(self.batch_size, int):
+ self.batch_size = (self.batch_size, self.batch_size)
+
+ # Set `self.embedding_num_epochs` and `self.classifier_num_epochs` using values from `self.num_epochs`
+ if isinstance(self.num_epochs, int):
+ self.num_epochs = (self.num_epochs, self.num_epochs)
+
+ # Set `self.body_embedding_learning_rate` and `self.body_classifier_learning_rate` using
+ # values from `self.body_learning_rate`
+ if isinstance(self.body_learning_rate, float):
+ self.body_learning_rate = (self.body_learning_rate, self.body_learning_rate)
+
+ if self.warmup_proportion < 0.0 or self.warmup_proportion > 1.0:
+ raise ValueError(
+ f"warmup_proportion must be greater than or equal to 0.0 and less than or equal to 1.0! But it was: {self.warmup_proportion}"
+ )
+
+ if self.report_to in (None, "all", ["all"]):
+ self.report_to = get_available_reporting_integrations()
+ elif self.report_to in ("none", ["none"]):
+ self.report_to = []
+ elif not isinstance(self.report_to, list):
+ self.report_to = [self.report_to]
+
+ if self.logging_dir is None:
+ self.logging_dir = default_logdir()
+
+ self.logging_strategy = IntervalStrategy(self.logging_strategy)
+ self.evaluation_strategy = IntervalStrategy(self.evaluation_strategy)
+
+ if self.eval_steps is not None and self.evaluation_strategy == IntervalStrategy.NO:
+ logger.info('Using `evaluation_strategy="steps"` as `eval_steps` is defined.')
+ self.evaluation_strategy = IntervalStrategy.STEPS
+
+ # eval_steps has to be defined and non-zero, fallbacks to logging_steps if the latter is non-zero
+ if self.evaluation_strategy == IntervalStrategy.STEPS and (self.eval_steps is None or self.eval_steps == 0):
+ if self.logging_steps > 0:
+ self.eval_steps = self.logging_steps
+ else:
+ raise ValueError(
+ f"evaluation strategy {self.evaluation_strategy} requires either non-zero `eval_steps` or"
+ " `logging_steps`"
+ )
+
+ # Sanity checks for load_best_model_at_end: we require save and eval strategies to be compatible.
+ if self.load_best_model_at_end:
+ if self.evaluation_strategy != self.save_strategy:
+ raise ValueError(
+ "`load_best_model_at_end` requires the save and eval strategy to match, but found\n- Evaluation "
+ f"strategy: {self.evaluation_strategy}\n- Save strategy: {self.save_strategy}"
+ )
+ if self.evaluation_strategy == IntervalStrategy.STEPS and self.save_steps % self.eval_steps != 0:
+ raise ValueError(
+ "`load_best_model_at_end` requires the saving steps to be a round multiple of the evaluation "
+ f"steps, but found {self.save_steps}, which is not a round multiple of {self.eval_steps}."
+ )
+
+ # logging_steps must be non-zero for logging_strategy that is other than 'no'
+ if self.logging_strategy == IntervalStrategy.STEPS and self.logging_steps == 0:
+ raise ValueError(f"Logging strategy {self.logging_strategy} requires non-zero `logging_steps`")
+
+ @property
+ def embedding_batch_size(self) -> int:
+ return self.batch_size[0]
+
+ @property
+ def classifier_batch_size(self) -> int:
+ return self.batch_size[1]
+
+ @property
+ def embedding_num_epochs(self) -> int:
+ return self.num_epochs[0]
+
+ @property
+ def classifier_num_epochs(self) -> int:
+ return self.num_epochs[1]
+
+ @property
+ def body_embedding_learning_rate(self) -> float:
+ return self.body_learning_rate[0]
+
+ @property
+ def body_classifier_learning_rate(self) -> float:
+ return self.body_learning_rate[1]
+
+ def to_dict(self) -> Dict[str, Any]:
+ """Convert this instance to a dictionary.
+
+ Returns:
+ `Dict[str, Any]`: The dictionary variant of this dataclass.
+ """
+ return {field.name: getattr(self, field.name) for field in fields(self) if field.init}
+
+ @classmethod
+ def from_dict(cls, arguments: Dict[str, Any], ignore_extra: bool = False) -> TrainingArguments:
+ """Initialize a TrainingArguments instance from a dictionary.
+
+ Args:
+ arguments (`Dict[str, Any]`): A dictionary of arguments.
+ ignore_extra (`bool`, *optional*): Whether to ignore arguments that do not occur in the
+ TrainingArguments __init__ signature. Defaults to False.
+
+ Returns:
+ `TrainingArguments`: The instantiated TrainingArguments instance.
+ """
+ if ignore_extra:
+ return cls(**{key: value for key, value in arguments.items() if key in inspect.signature(cls).parameters})
+ return cls(**arguments)
+
+ def copy(self) -> TrainingArguments:
+ """Create a shallow copy of this TrainingArguments instance."""
+ return copy(self)
+
+ def update(self, arguments: Dict[str, Any], ignore_extra: bool = False) -> TrainingArguments:
+ return TrainingArguments.from_dict({**self.to_dict(), **arguments}, ignore_extra=ignore_extra)
+
+ def to_json_string(self):
+ # Serializes this instance to a JSON string.
+ return json.dumps({key: str(value) for key, value in self.to_dict().items()}, indent=2)
+
+ def to_sanitized_dict(self) -> Dict[str, Any]:
+ # Sanitized serialization to use with TensorBoard’s hparams
+ d = self.to_dict()
+ d = {**d, **{"train_batch_size": self.embedding_batch_size, "eval_batch_size": self.embedding_batch_size}}
+
+ valid_types = [bool, int, float, str]
+ if is_torch_available():
+ valid_types.append(torch.Tensor)
+
+ return {k: v if type(v) in valid_types else str(v) for k, v in d.items()}
diff --git a/src/setfit/utils.py b/src/setfit/utils.py
index 57fb31d4..b10bb71d 100644
--- a/src/setfit/utils.py
+++ b/src/setfit/utils.py
@@ -1,3 +1,4 @@
+import types
from contextlib import contextmanager
from dataclasses import dataclass, field
from time import monotonic_ns
@@ -5,9 +6,10 @@
from datasets import Dataset, DatasetDict, load_dataset
from sentence_transformers import losses
+from transformers.utils import copy_func
from .data import create_fewshot_splits, create_fewshot_splits_multilabel
-from .modeling import SupConLoss
+from .losses import SupConLoss
SEC_TO_NS_SCALE = 1000000000
@@ -135,7 +137,7 @@ def summary(self) -> None:
class BestRun(NamedTuple):
"""
- The best run found by a hyperparameter search (see [`~SetFitTrainer.hyperparameter_search`]).
+ The best run found by a hyperparameter search (see [`~Trainer.hyperparameter_search`]).
Parameters:
run_id (`str`):
@@ -152,3 +154,9 @@ class BestRun(NamedTuple):
objective: float
hyperparameters: Dict[str, Any]
backend: Any = None
+
+
+def set_docstring(method, docstring, cls=None):
+ copied_function = copy_func(method)
+ copied_function.__doc__ = docstring
+ return types.MethodType(copied_function, cls or method.__self__)
diff --git a/tests/conftest.py b/tests/conftest.py
new file mode 100644
index 00000000..f92a81d8
--- /dev/null
+++ b/tests/conftest.py
@@ -0,0 +1,29 @@
+import pytest
+from datasets import Dataset
+
+from setfit import AbsaModel, SetFitModel
+
+
+@pytest.fixture()
+def model() -> SetFitModel:
+ return SetFitModel.from_pretrained("sentence-transformers/paraphrase-albert-small-v2")
+
+
+@pytest.fixture()
+def absa_model() -> AbsaModel:
+ return AbsaModel.from_pretrained("sentence-transformers/paraphrase-albert-small-v2", spacy_model="en_core_web_sm")
+
+
+@pytest.fixture()
+def absa_dataset() -> Dataset:
+ texts = [
+ "It is about food and ambiance, and imagine how dreadful it will be it we only had to listen to an idle engine.",
+ "It is about food and ambiance, and imagine how dreadful it will be it we only had to listen to an idle engine.",
+ "Food is great and inexpensive.",
+ "Good bagels and good cream cheese.",
+ "Good bagels and good cream cheese.",
+ ]
+ spans = ["food", "ambiance", "Food", "bagels", "cream cheese"]
+ labels = ["negative", "negative", "positive", "positive", "positive"]
+ ordinals = [0, 0, 0, 0, 0]
+ return Dataset.from_dict({"text": texts, "span": spans, "label": labels, "ordinal": ordinals})
diff --git a/tests/exporters/test_onnx.py b/tests/exporters/test_onnx.py
index 6c132d43..6e515d74 100644
--- a/tests/exporters/test_onnx.py
+++ b/tests/exporters/test_onnx.py
@@ -8,7 +8,8 @@
from setfit import SetFitModel
from setfit.data import get_templated_dataset
from setfit.exporters.onnx import export_onnx
-from setfit.trainer import SetFitTrainer
+from setfit.trainer import Trainer
+from setfit.training_args import TrainingArguments
@pytest.mark.parametrize(
@@ -71,25 +72,23 @@ def test_export_onnx_torch_head(out_features):
model_path, use_differentiable_head=True, head_params={"out_features": out_features}
)
- trainer = SetFitTrainer(
+ args = TrainingArguments(
+ num_iterations=15,
+ num_epochs=(1, 15),
+ batch_size=16,
+ body_learning_rate=(2e-5, 1e-5),
+ head_learning_rate=1e-2,
+ l2_weight=0.0,
+ end_to_end=True,
+ )
+ trainer = Trainer(
model=model,
+ args=args,
train_dataset=dataset,
eval_dataset=dataset,
- num_iterations=15,
column_mapping={"text": "text", "label": "label"},
)
- # Train and evaluate
- trainer.freeze() # Freeze the head
- trainer.train() # Train only the body
- # Unfreeze the head and unfreeze the body -> end-to-end training
- trainer.unfreeze(keep_body_frozen=False)
- trainer.train(
- num_epochs=15,
- batch_size=16,
- body_learning_rate=1e-5,
- learning_rate=1e-2,
- l2_weight=0.0,
- )
+ trainer.train()
# Export the sklearn based model
output_path = "model.onnx"
diff --git a/tests/model_card_pattern.py b/tests/model_card_pattern.py
new file mode 100644
index 00000000..8a058238
--- /dev/null
+++ b/tests/model_card_pattern.py
@@ -0,0 +1,224 @@
+# flake8: noqa
+
+import re
+
+
+MODEL_CARD_PATTERN = re.compile(
+ """\
+---
+language:
+- en
+license: apache-2\.0
+library_name: setfit
+tags:
+- setfit
+- sentence-transformers
+- text-classification
+- generated_from_setfit_trainer
+datasets:
+- sst2
+metrics:
+- accuracy
+widget:
+- text: .*
+pipeline_tag: text-classification
+inference: true
+co2_eq_emissions:
+ emissions: [\d\.\-e]+
+ source: codecarbon
+ training_type: fine-tuning
+ on_cloud: (false|true)
+ cpu_model: .+
+ ram_total_size: [\d\.]+
+ hours_used: [\d\.]+
+( hardware_used: .+
+)?base_model: sentence-transformers/paraphrase-albert-small-v2
+model-index:
+- name: SetFit with sentence-transformers\/paraphrase-albert-small-v2 on SST2
+ results:
+ - task:
+ type: text-classification
+ name: Text Classification
+ dataset:
+ name: SST2
+ type: sst2
+ split: test
+ metrics:
+ - type: accuracy
+ value: [\d\.]+
+ name: Accuracy
+---
+
+\# SetFit with sentence\-transformers/paraphrase\-albert\-small\-v2 on SST2
+
+This is a \[SetFit\]\(https://github\.com/huggingface/setfit\) model trained on the \[SST2\]\(https://huggingface\.co/datasets/sst2\) dataset that can be used for Text Classification\. This SetFit model uses \[sentence\-transformers/paraphrase\-albert\-small\-v2\]\(https://huggingface\.co/sentence\-transformers/paraphrase\-albert\-small\-v2\) as the Sentence Transformer embedding model\. A \[LogisticRegression\]\(https://scikit\-learn\.org/stable/modules/generated/sklearn\.linear_model\.LogisticRegression\.html\) instance is used for classification\.
+
+The model has been trained using an efficient few\-shot learning technique that involves:
+
+1\. Fine\-tuning a \[Sentence Transformer\]\(https://www\.sbert\.net\) with contrastive learning\.
+2\. Training a classification head with features from the fine\-tuned Sentence Transformer\.
+
+## Model Details
+
+### Model Description
+- \*\*Model Type:\*\* SetFit
+- \*\*Sentence Transformer body:\*\* \[sentence-transformers/paraphrase-albert-small-v2\]\(https://huggingface.co/sentence-transformers/paraphrase-albert-small-v2\)
+- \*\*Classification head:\*\* a \[LogisticRegression\]\(https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html\) instance
+- \*\*Maximum Sequence Length:\*\* 100 tokens
+- \*\*Number of Classes:\*\* 2 classes
+- \*\*Training Dataset:\*\* \[SST2\]\(https://huggingface.co/datasets/sst2\)
+- \*\*Language:\*\* en
+- \*\*License:\*\* apache-2.0
+
+### Model Sources
+
+- \*\*Repository:\*\* \[SetFit on GitHub\]\(https://github.com/huggingface/setfit\)
+- \*\*Paper:\*\* \[Efficient Few-Shot Learning Without Prompts\]\(https://arxiv.org/abs/2209.11055\)
+- \*\*Blogpost:\*\* \[SetFit: Efficient Few-Shot Learning Without Prompts\]\(https://huggingface.co/blog/setfit\)
+
+### Model Labels
+\| Label\s+\| Examples\s+\|
+\|:-+\|:-+\|
+\| negative\s+\| [^\|]+ \|
+\| positive\s+\| [^\|]+ \|
+
+## Evaluation
+
+### Metrics
+\| Label \| Accuracy \|
+\|:--------\|:---------\|
+\| \*\*all\*\* \| [\d\.]+\s+\|
+
+## Uses
+
+### Direct Use for Inference
+
+First install the SetFit library:
+
+```bash
+pip install setfit
+```
+
+Then you can load this model and run inference.
+
+```python
+from setfit import SetFitModel
+
+# Download from the [^H]+ Hub
+model = SetFitModel.from_pretrained\("tomaarsen/setfit-paraphrase-albert-small-v2-sst2"\)
+# Run inference
+preds = model\(".+"\)
+```
+
+
+
+
+
+
+
+
+
+## Training Details
+
+### Training Set Metrics
+\| Training set \| Min \| Median \| Max \|
+\|:-------------\|:----\|:--------\|:----\|
+\| Word count \| 2 \| 11.4375 \| 33 \|
+
+\| Label \| Training Sample Count \|
+\|:---------\|:----------------------\|
+\| negative \| 8 \|
+\| positive \| 8 \|
+
+### Training Hyperparameters
+- batch_size: \(1, 1\)
+- num_epochs: \(1, 16\)
+- max_steps: 2
+- sampling_strategy: oversampling
+- body_learning_rate: \(2e-05, 1e-05\)
+- head_learning_rate: 0.01
+- loss: CosineSimilarityLoss
+- distance_metric: cosine_distance
+- margin: 0.25
+- end_to_end: False
+- use_amp: False
+- warmup_proportion: 0.1
+- seed: 42
+- eval_max_steps: -1
+- load_best_model_at_end: False
+
+### Training Results
+\| Epoch \| Step \| Training Loss \| Validation Loss \|
+\|:------:\|:----:\|:-------------:\|:---------------:\|
+(\| [\d\.]+ +\| [\d\.]+ +\| [\d\.]+ +\| [\d\.]+ +\|\n)+
+### Environmental Impact
+Carbon emissions were measured using \[CodeCarbon\]\(https://github.com/mlco2/codecarbon\)\.
+- \*\*Carbon Emitted\*\*: [\d\.]+ kg of CO2
+- \*\*Hours Used\*\*: [\d\.]+ hours
+
+### Training Hardware
+- \*\*On Cloud\*\*: (Yes|No)
+- \*\*GPU Model\*\*: [^\n]+
+- \*\*CPU Model\*\*: [^\n]+
+- \*\*RAM Size\*\*: [\d\.]+ GB
+
+### Framework Versions
+- Python: [^\n]+
+- SetFit: [^\n]+
+- Sentence Transformers: [^\n]+
+- Transformers: [^\n]+
+- PyTorch: [^\n]+
+- Datasets: [^\n]+
+- Tokenizers: [^\n]+
+
+## Citation
+
+### BibTeX
+```bibtex
+@article{https://doi.org/10.48550/arxiv.2209.11055,
+ doi = {10.48550/ARXIV.2209.11055},
+ url = {https://arxiv.org/abs/2209.11055},
+ author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
+ keywords = {Computation and Language \(cs.CL\), FOS: Computer and information sciences, FOS: Computer and information sciences},
+ title = {Efficient Few-Shot Learning Without Prompts},
+ publisher = {arXiv},
+ year = \{2022\},
+ copyright = {Creative Commons Attribution 4.0 International}
+}
+```
+
+
+
+
+
+""",
+ flags=re.DOTALL,
+)
diff --git a/tests/span/__init__.py b/tests/span/__init__.py
new file mode 100644
index 00000000..e69de29b
diff --git a/tests/span/aspect_model_card_pattern.py b/tests/span/aspect_model_card_pattern.py
new file mode 100644
index 00000000..8295a25a
--- /dev/null
+++ b/tests/span/aspect_model_card_pattern.py
@@ -0,0 +1,237 @@
+# flake8: noqa
+
+import re
+
+
+ASPECT_MODEL_CARD_PATTERN = re.compile(
+ """\
+---
+language:
+- en
+license: apache-2\.0
+library_name: setfit
+tags:
+- setfit
+- absa
+- sentence-transformers
+- text-classification
+- generated_from_setfit_trainer
+metrics:
+- accuracy
+widget:
+- text: .*
+pipeline_tag: text-classification
+inference: false
+co2_eq_emissions:
+ emissions: [\d\.\-e]+
+ source: codecarbon
+ training_type: fine-tuning
+ on_cloud: (false|true)
+ cpu_model: .+
+ ram_total_size: [\d\.]+
+ hours_used: [\d\.]+
+( hardware_used: .+
+)?base_model: sentence-transformers/paraphrase-albert-small-v2
+model-index:
+- name: SetFit Aspect Model with sentence-transformers\/paraphrase-albert-small-v2
+ results:
+ - task:
+ type: text-classification
+ name: Text Classification
+ dataset:
+ name: Unknown
+ type: unknown
+ split: test
+ metrics:
+ - type: accuracy
+ value: [\d\.]+
+ name: Accuracy
+---
+
+\# SetFit Aspect Model with sentence\-transformers/paraphrase\-albert\-small\-v2
+
+This is a \[SetFit\]\(https://github\.com/huggingface/setfit\) model that can be used for Aspect Based Sentiment Analysis \(ABSA\)\. This SetFit model uses \[sentence\-transformers/paraphrase\-albert\-small\-v2\]\(https://huggingface\.co/sentence\-transformers/paraphrase\-albert\-small\-v2\) as the Sentence Transformer embedding model\. A \[LogisticRegression\]\(https://scikit\-learn\.org/stable/modules/generated/sklearn\.linear_model\.LogisticRegression\.html\) instance is used for classification\. In particular, this model is in charge of (filtering aspect span candidates|classifying aspect polarities)\.
+
+The model has been trained using an efficient few\-shot learning technique that involves:
+
+1\. Fine\-tuning a \[Sentence Transformer\]\(https://www\.sbert\.net\) with contrastive learning\.
+2\. Training a classification head with features from the fine\-tuned Sentence Transformer\.
+
+This model was trained within the context of a larger system for ABSA, which looks like so\:
+
+1\. Use a spaCy model to select possible aspect span candidates\.
+2\. \*\*Use this SetFit model to filter these possible aspect span candidates\.\*\*
+3\. Use a SetFit model to classify the filtered aspect span candidates\.
+
+## Model Details
+
+### Model Description
+- \*\*Model Type:\*\* SetFit
+- \*\*Sentence Transformer body:\*\* \[sentence-transformers/paraphrase-albert-small-v2\]\(https://huggingface.co/sentence-transformers/paraphrase-albert-small-v2\)
+- \*\*Classification head:\*\* a \[LogisticRegression\]\(https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html\) instance
+- \*\*spaCy Model:\*\* en_core_web_lg
+- \*\*SetFitABSA Aspect Model:\*\* \[\S+\]\(https:\/\/huggingface\.co/\S+\)
+- \*\*SetFitABSA Polarity Model:\*\* \[\S+\]\(https:\/\/huggingface\.co/\S+\)
+- \*\*Maximum Sequence Length:\*\* 100 tokens
+- \*\*Number of Classes:\*\* 2 classes
+
+- \*\*Language:\*\* en
+- \*\*License:\*\* apache-2.0
+
+### Model Sources
+
+- \*\*Repository:\*\* \[SetFit on GitHub\]\(https://github.com/huggingface/setfit\)
+- \*\*Paper:\*\* \[Efficient Few-Shot Learning Without Prompts\]\(https://arxiv.org/abs/2209.11055\)
+- \*\*Blogpost:\*\* \[SetFit: Efficient Few-Shot Learning Without Prompts\]\(https://huggingface.co/blog/setfit\)
+
+### Model Labels
+\| Label\s+\| Examples\s+\|
+\|:-+\|:-+\|
+\| aspect\s+\| [^\|]+ \|
+\| no aspect\s+\| [^\|]+ \|
+
+## Evaluation
+
+### Metrics
+\| Label \| Accuracy \|
+\|:--------\|:---------\|
+\| \*\*all\*\* \| [\d\.]+\s+\|
+
+## Uses
+
+### Direct Use for Inference
+
+First install the SetFit library:
+
+```bash
+pip install setfit
+```
+
+Then you can load this model and run inference.
+
+```python
+from setfit import AbsaModel
+
+# Download from the [^H]+ Hub
+model = AbsaModel.from_pretrained\(
+ "[^\"]+",
+ "[^\"]+",
+\)
+# Run inference
+preds = model\(".+"\)
+```
+
+
+
+
+
+
+
+
+
+## Training Details
+
+### Training Set Metrics
+\| Training set \| Min \| Median \| Max \|
+\|:-------------\|:----\|:-------\|:----\|
+\| Word count \| 5 \| 14.5 \| 23 \|
+
+\| Label \| Training Sample Count \|
+\|:----------\|:----------------------\|
+\| no aspect \| 1 \|
+\| aspect \| 5 \|
+
+### Training Hyperparameters
+- batch_size: \(1, 1\)
+- num_epochs: \(1, 16\)
+- max_steps: 2
+- sampling_strategy: oversampling
+- body_learning_rate: \(2e-05, 1e-05\)
+- head_learning_rate: 0.01
+- loss: CosineSimilarityLoss
+- distance_metric: cosine_distance
+- margin: 0.25
+- end_to_end: False
+- use_amp: False
+- warmup_proportion: 0.1
+- seed: 42
+- eval_max_steps: -1
+- load_best_model_at_end: False
+
+### Training Results
+\| Epoch \| Step \| Training Loss \| Validation Loss \|
+\|:------:\|:----:\|:-------------:\|:---------------:\|
+(\| [\d\.]+ +\| [\d\.]+ +\| [\d\.]+ +\| [\d\.]+ +\|\n)+
+### Environmental Impact
+Carbon emissions were measured using \[CodeCarbon\]\(https://github.com/mlco2/codecarbon\)\.
+- \*\*Carbon Emitted\*\*: [\d\.]+ kg of CO2
+- \*\*Hours Used\*\*: [\d\.]+ hours
+
+### Training Hardware
+- \*\*On Cloud\*\*: (Yes|No)
+- \*\*GPU Model\*\*: [^\n]+
+- \*\*CPU Model\*\*: [^\n]+
+- \*\*RAM Size\*\*: [\d\.]+ GB
+
+### Framework Versions
+- Python: [^\n]+
+- SetFit: [^\n]+
+- Sentence Transformers: [^\n]+
+- spaCy: [^\n]+
+- Transformers: [^\n]+
+- PyTorch: [^\n]+
+- Datasets: [^\n]+
+- Tokenizers: [^\n]+
+
+## Citation
+
+### BibTeX
+```bibtex
+@article{https://doi.org/10.48550/arxiv.2209.11055,
+ doi = {10.48550/ARXIV.2209.11055},
+ url = {https://arxiv.org/abs/2209.11055},
+ author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
+ keywords = {Computation and Language \(cs.CL\), FOS: Computer and information sciences, FOS: Computer and information sciences},
+ title = {Efficient Few-Shot Learning Without Prompts},
+ publisher = {arXiv},
+ year = \{2022\},
+ copyright = {Creative Commons Attribution 4.0 International}
+}
+```
+
+
+
+
+
+\
+""",
+ flags=re.DOTALL,
+)
diff --git a/tests/span/polarity_model_card_pattern.py b/tests/span/polarity_model_card_pattern.py
new file mode 100644
index 00000000..921ad2bb
--- /dev/null
+++ b/tests/span/polarity_model_card_pattern.py
@@ -0,0 +1,237 @@
+# flake8: noqa
+
+import re
+
+
+POLARITY_MODEL_CARD_PATTERN = re.compile(
+ """\
+---
+language:
+- en
+license: apache-2\.0
+library_name: setfit
+tags:
+- setfit
+- absa
+- sentence-transformers
+- text-classification
+- generated_from_setfit_trainer
+metrics:
+- accuracy
+widget:
+- text: .*
+pipeline_tag: text-classification
+inference: false
+co2_eq_emissions:
+ emissions: [\d\.\-e]+
+ source: codecarbon
+ training_type: fine-tuning
+ on_cloud: (false|true)
+ cpu_model: .+
+ ram_total_size: [\d\.]+
+ hours_used: [\d\.]+
+( hardware_used: .+
+)?base_model: sentence-transformers/paraphrase-albert-small-v2
+model-index:
+- name: SetFit Polarity Model with sentence-transformers\/paraphrase-albert-small-v2
+ results:
+ - task:
+ type: text-classification
+ name: Text Classification
+ dataset:
+ name: Unknown
+ type: unknown
+ split: test
+ metrics:
+ - type: accuracy
+ value: [\d\.]+
+ name: Accuracy
+---
+
+\# SetFit Polarity Model with sentence\-transformers/paraphrase\-albert\-small\-v2
+
+This is a \[SetFit\]\(https://github\.com/huggingface/setfit\) model that can be used for Aspect Based Sentiment Analysis \(ABSA\)\. This SetFit model uses \[sentence\-transformers/paraphrase\-albert\-small\-v2\]\(https://huggingface\.co/sentence\-transformers/paraphrase\-albert\-small\-v2\) as the Sentence Transformer embedding model\. A \[LogisticRegression\]\(https://scikit\-learn\.org/stable/modules/generated/sklearn\.linear_model\.LogisticRegression\.html\) instance is used for classification\. In particular, this model is in charge of (filtering aspect span candidates|classifying aspect polarities)\.
+
+The model has been trained using an efficient few\-shot learning technique that involves:
+
+1\. Fine\-tuning a \[Sentence Transformer\]\(https://www\.sbert\.net\) with contrastive learning\.
+2\. Training a classification head with features from the fine\-tuned Sentence Transformer\.
+
+This model was trained within the context of a larger system for ABSA, which looks like so\:
+
+1\. Use a spaCy model to select possible aspect span candidates\.
+2\. Use a SetFit model to filter these possible aspect span candidates\.
+3\. \*\*Use this SetFit model to classify the filtered aspect span candidates\.\*\*
+
+## Model Details
+
+### Model Description
+- \*\*Model Type:\*\* SetFit
+- \*\*Sentence Transformer body:\*\* \[sentence-transformers/paraphrase-albert-small-v2\]\(https://huggingface.co/sentence-transformers/paraphrase-albert-small-v2\)
+- \*\*Classification head:\*\* a \[LogisticRegression\]\(https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html\) instance
+- \*\*spaCy Model:\*\* en_core_web_lg
+- \*\*SetFitABSA Aspect Model:\*\* \[\S+\]\(https:\/\/huggingface\.co/\S+\)
+- \*\*SetFitABSA Polarity Model:\*\* \[\S+\]\(https:\/\/huggingface\.co/\S+\)
+- \*\*Maximum Sequence Length:\*\* 100 tokens
+- \*\*Number of Classes:\*\* 2 classes
+
+- \*\*Language:\*\* en
+- \*\*License:\*\* apache-2.0
+
+### Model Sources
+
+- \*\*Repository:\*\* \[SetFit on GitHub\]\(https://github.com/huggingface/setfit\)
+- \*\*Paper:\*\* \[Efficient Few-Shot Learning Without Prompts\]\(https://arxiv.org/abs/2209.11055\)
+- \*\*Blogpost:\*\* \[SetFit: Efficient Few-Shot Learning Without Prompts\]\(https://huggingface.co/blog/setfit\)
+
+### Model Labels
+\| Label\s+\| Examples\s+\|
+\|:-+\|:-+\|
+\| negative\s+\| [^\|]+ \|
+\| positive\s+\| [^\|]+ \|
+
+## Evaluation
+
+### Metrics
+\| Label \| Accuracy \|
+\|:--------\|:---------\|
+\| \*\*all\*\* \| [\d\.]+\s+\|
+
+## Uses
+
+### Direct Use for Inference
+
+First install the SetFit library:
+
+```bash
+pip install setfit
+```
+
+Then you can load this model and run inference.
+
+```python
+from setfit import AbsaModel
+
+# Download from the [^H]+ Hub
+model = AbsaModel.from_pretrained\(
+ "[^\"]+",
+ "[^\"]+",
+\)
+# Run inference
+preds = model\(".+"\)
+```
+
+
+
+
+
+
+
+
+
+## Training Details
+
+### Training Set Metrics
+\| Training set \| Min \| Median \| Max \|
+\|:-------------\|:----\|:-------\|:----\|
+\| Word count \| 8 \| 16.8 \| 28 \|
+
+\| Label \| Training Sample Count \|
+\|:---------\|:----------------------\|
+\| negative \| 2 \|
+\| positive \| 3 \|
+
+### Training Hyperparameters
+- batch_size: \(1, 1\)
+- num_epochs: \(1, 16\)
+- max_steps: 2
+- sampling_strategy: oversampling
+- body_learning_rate: \(2e-05, 1e-05\)
+- head_learning_rate: 0.01
+- loss: CosineSimilarityLoss
+- distance_metric: cosine_distance
+- margin: 0.25
+- end_to_end: False
+- use_amp: False
+- warmup_proportion: 0.1
+- seed: 42
+- eval_max_steps: -1
+- load_best_model_at_end: False
+
+### Training Results
+\| Epoch \| Step \| Training Loss \| Validation Loss \|
+\|:------:\|:----:\|:-------------:\|:---------------:\|
+(\| [\d\.]+ +\| [\d\.]+ +\| [\d\.]+ +\| [\d\.]+ +\|\n)+
+### Environmental Impact
+Carbon emissions were measured using \[CodeCarbon\]\(https://github.com/mlco2/codecarbon\)\.
+- \*\*Carbon Emitted\*\*: [\d\.]+ kg of CO2
+- \*\*Hours Used\*\*: [\d\.]+ hours
+
+### Training Hardware
+- \*\*On Cloud\*\*: (Yes|No)
+- \*\*GPU Model\*\*: [^\n]+
+- \*\*CPU Model\*\*: [^\n]+
+- \*\*RAM Size\*\*: [\d\.]+ GB
+
+### Framework Versions
+- Python: [^\n]+
+- SetFit: [^\n]+
+- Sentence Transformers: [^\n]+
+- spaCy: [^\n]+
+- Transformers: [^\n]+
+- PyTorch: [^\n]+
+- Datasets: [^\n]+
+- Tokenizers: [^\n]+
+
+## Citation
+
+### BibTeX
+```bibtex
+@article{https://doi.org/10.48550/arxiv.2209.11055,
+ doi = {10.48550/ARXIV.2209.11055},
+ url = {https://arxiv.org/abs/2209.11055},
+ author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
+ keywords = {Computation and Language \(cs.CL\), FOS: Computer and information sciences, FOS: Computer and information sciences},
+ title = {Efficient Few-Shot Learning Without Prompts},
+ publisher = {arXiv},
+ year = \{2022\},
+ copyright = {Creative Commons Attribution 4.0 International}
+}
+```
+
+
+
+
+
+\
+""",
+ flags=re.DOTALL,
+)
diff --git a/tests/span/test_model_card.py b/tests/span/test_model_card.py
new file mode 100644
index 00000000..4b636006
--- /dev/null
+++ b/tests/span/test_model_card.py
@@ -0,0 +1,49 @@
+from pathlib import Path
+
+from datasets import Dataset
+
+from setfit import AbsaModel, AbsaTrainer, SetFitModelCardData, TrainingArguments
+
+from .aspect_model_card_pattern import ASPECT_MODEL_CARD_PATTERN
+from .polarity_model_card_pattern import POLARITY_MODEL_CARD_PATTERN
+
+
+def test_model_card(absa_dataset: Dataset, tmp_path: Path) -> None:
+ model = AbsaModel.from_pretrained(
+ "sentence-transformers/paraphrase-albert-small-v2",
+ model_card_data=SetFitModelCardData(
+ model_id="tomaarsen/setfit-absa-paraphrase-albert-small-v2-laptops",
+ language=["en"],
+ license="apache-2.0",
+ ),
+ )
+
+ args = TrainingArguments(
+ str(tmp_path),
+ report_to="codecarbon",
+ batch_size=1,
+ eval_steps=1,
+ logging_steps=1,
+ max_steps=2,
+ evaluation_strategy="steps",
+ )
+ trainer = AbsaTrainer(
+ model=model,
+ args=args,
+ train_dataset=absa_dataset,
+ eval_dataset=absa_dataset,
+ )
+ trainer.train()
+ trainer.evaluate()
+
+ path = tmp_path / "aspect"
+ model.aspect_model.create_model_card(path, model_name=str(path))
+ with open(path / "README.md", "r", encoding="utf8") as f:
+ model_card = f.read()
+ assert ASPECT_MODEL_CARD_PATTERN.fullmatch(model_card)
+
+ path = tmp_path / "polarity"
+ model.polarity_model.create_model_card(path, model_name=str(path))
+ with open(path / "README.md", "r", encoding="utf8") as f:
+ model_card = f.read()
+ assert POLARITY_MODEL_CARD_PATTERN.fullmatch(model_card)
diff --git a/tests/span/test_modeling.py b/tests/span/test_modeling.py
new file mode 100644
index 00000000..c92b3def
--- /dev/null
+++ b/tests/span/test_modeling.py
@@ -0,0 +1,146 @@
+import json
+from pathlib import Path
+from tempfile import TemporaryDirectory
+
+import pytest
+import torch
+from pytest import LogCaptureFixture
+
+from setfit import AbsaModel
+from setfit.logging import get_logger
+from setfit.span.aspect_extractor import AspectExtractor
+from setfit.span.modeling import AspectModel, PolarityModel
+from tests.test_modeling import torch_cuda_available
+
+
+def test_loading():
+ model = AbsaModel.from_pretrained("sentence-transformers/paraphrase-albert-small-v2", spacy_model="en_core_web_sm")
+ assert isinstance(model, AbsaModel)
+ assert isinstance(model.aspect_extractor, AspectExtractor)
+ assert isinstance(model.aspect_model, AspectModel)
+ assert isinstance(model.polarity_model, PolarityModel)
+
+ model = AbsaModel.from_pretrained(
+ "sentence-transformers/paraphrase-albert-small-v2@6c91e73a51599e35bd1145dfdcd3289215225009",
+ "sentence-transformers/paraphrase-albert-small-v2",
+ spacy_model="en_core_web_sm",
+ )
+ assert isinstance(model, AbsaModel)
+
+ model = AbsaModel.from_pretrained(
+ "sentence-transformers/paraphrase-albert-small-v2",
+ "sentence-transformers/paraphrase-albert-small-v2@6c91e73a51599e35bd1145dfdcd3289215225009",
+ spacy_model="en_core_web_sm",
+ )
+ assert isinstance(model, AbsaModel)
+
+ with pytest.raises(OSError):
+ model = AbsaModel.from_pretrained(
+ "sentence-transformers/paraphrase-albert-small-v2", spacy_model="not_a_spacy_model"
+ )
+
+ model = AbsaModel.from_pretrained(
+ "sentence-transformers/paraphrase-albert-small-v2", spacy_model="en_core_web_sm", normalize_embeddings=True
+ )
+ assert model.aspect_model.normalize_embeddings
+ assert model.polarity_model.normalize_embeddings
+
+ aspect_model = AspectModel.from_pretrained("sentence-transformers/paraphrase-albert-small-v2", span_context=12)
+ assert aspect_model.span_context == 12
+ polarity_model = PolarityModel.from_pretrained("sentence-transformers/paraphrase-albert-small-v2", span_context=12)
+ assert polarity_model.span_context == 12
+
+ model = AbsaModel.from_pretrained(
+ "sentence-transformers/paraphrase-albert-small-v2", spacy_model="en_core_web_sm", span_contexts=(12, 4)
+ )
+ assert model.aspect_model.span_context == 12
+ assert model.polarity_model.span_context == 4
+
+
+def test_save_load(absa_model: AbsaModel, caplog: LogCaptureFixture) -> None:
+ logger = get_logger("setfit")
+ logger.propagate = True
+
+ absa_model.polarity_model.span_context = 5
+
+ with TemporaryDirectory() as tmp_dir:
+ tmp_dir = str(Path(tmp_dir) / "model")
+ absa_model.save_pretrained(tmp_dir)
+ assert (Path(tmp_dir + "-aspect") / "config_setfit.json").exists()
+ assert (Path(tmp_dir + "-polarity") / "config_setfit.json").exists()
+
+ fresh_model = AbsaModel.from_pretrained(
+ tmp_dir + "-aspect", tmp_dir + "-polarity", spacy_model="en_core_web_sm"
+ )
+ assert fresh_model.polarity_model.span_context == 5
+
+ # We expect a warning if we override the configured data:
+ AbsaModel.from_pretrained(tmp_dir + "-aspect", tmp_dir + "-polarity", span_contexts=[4, 4])
+ log_texts = [record[2] for record in caplog.record_tuples]
+ assert "Overriding span_context in model configuration from 0 to 4." in log_texts
+ assert "Overriding span_context in model configuration from 5 to 4." in log_texts
+ assert len(caplog.record_tuples) == 2
+ caplog.clear()
+
+ # Error because en_core_web_bla doesn't exist
+ with pytest.raises(OSError):
+ AbsaModel.from_pretrained(tmp_dir + "-aspect", tmp_dir + "-polarity", spacy_model="en_core_web_bla")
+ log_texts = [record[2] for record in caplog.record_tuples]
+ assert "Overriding spacy_model in model configuration from en_core_web_sm to en_core_web_bla." in log_texts
+ assert "Overriding spacy_model in model configuration from en_core_web_sm to en_core_web_bla." in log_texts
+ assert len(caplog.record_tuples) == 2
+ caplog.clear()
+
+ with TemporaryDirectory() as aspect_tmp_dir:
+ with TemporaryDirectory() as polarity_tmp_dir:
+ absa_model.save_pretrained(aspect_tmp_dir, polarity_tmp_dir)
+ assert (Path(aspect_tmp_dir) / "config_setfit.json").exists()
+ assert (Path(polarity_tmp_dir) / "config_setfit.json").exists()
+
+ fresh_model = AbsaModel.from_pretrained(aspect_tmp_dir, polarity_tmp_dir)
+ assert fresh_model.polarity_model.span_context == 5
+ assert fresh_model.aspect_model.spacy_model == "en_core_web_sm"
+ assert fresh_model.polarity_model.spacy_model == "en_core_web_sm"
+
+ # Loading a model with different spacy_model settings
+ polarity_config_path = str(Path(polarity_tmp_dir) / "config_setfit.json")
+ with open(polarity_config_path, "r") as f:
+ config = json.load(f)
+ assert config == {
+ "span_context": 5,
+ "normalize_embeddings": False,
+ "spacy_model": "en_core_web_sm",
+ "labels": None,
+ }
+ config["spacy_model"] = "en_core_web_bla"
+ with open(polarity_config_path, "w") as f:
+ json.dump(config, f)
+ # Load a model with the updated config, there should be a warning
+ fresh_model = AbsaModel.from_pretrained(aspect_tmp_dir, polarity_tmp_dir)
+ assert len(caplog.record_tuples) == 1
+ assert caplog.record_tuples[0][2] == (
+ "The Aspect and Polarity models are configured to use different spaCy models:\n"
+ "* 'en_core_web_sm' for the aspect model, and\n"
+ "* 'en_core_web_bla' for the polarity model.\n"
+ "This model will use 'en_core_web_sm'."
+ )
+
+ logger.propagate = False
+
+
+@pytest.mark.skipif(not torch.cuda.is_available(), reason="CUDA must be available to move a model between devices")
+def test_to(absa_model: AbsaModel) -> None:
+ assert absa_model.device.type == "cuda"
+ absa_model.to("cpu")
+ assert absa_model.device.type == "cpu"
+ assert absa_model.aspect_model.device.type == "cpu"
+ assert absa_model.polarity_model.device.type == "cpu"
+
+
+@torch_cuda_available
+@pytest.mark.parametrize("device", ["cpu", "cuda"])
+def test_load_model_on_device(device):
+ model = AbsaModel.from_pretrained("sentence-transformers/paraphrase-albert-small-v2", device=device)
+ assert model.device.type == device
+ assert model.polarity_model.device.type == device
+ assert model.aspect_model.device.type == device
diff --git a/tests/span/test_trainer.py b/tests/span/test_trainer.py
new file mode 100644
index 00000000..86610928
--- /dev/null
+++ b/tests/span/test_trainer.py
@@ -0,0 +1,93 @@
+import logging
+
+from datasets import Dataset
+from pytest import LogCaptureFixture
+from transformers import TrainerCallback
+
+from setfit import AbsaTrainer
+from setfit.logging import get_logger
+from setfit.span.modeling import AbsaModel
+
+
+def test_trainer(absa_model: AbsaModel, absa_dataset: Dataset) -> None:
+ trainer = AbsaTrainer(absa_model, train_dataset=absa_dataset, eval_dataset=absa_dataset)
+ trainer.train()
+
+ metrics = trainer.evaluate()
+ assert "aspect" in metrics
+ assert "polarity" in metrics
+ assert "accuracy" in metrics["aspect"]
+ assert "accuracy" in metrics["polarity"]
+ assert metrics["aspect"]["accuracy"] > 0.0
+ assert metrics["polarity"]["accuracy"] > 0.0
+ new_metrics = trainer.evaluate(absa_dataset)
+ assert metrics == new_metrics
+
+ predict = absa_model.predict("Best pizza outside of Italy and really tasty.")
+ assert {"span": "pizza", "polarity": "positive"} in predict
+ predict = absa_model.predict(["Best pizza outside of Italy and really tasty.", "This is another sentence"])
+ assert isinstance(predict, list) and len(predict) == 2 and isinstance(predict[0], list)
+ predict = absa_model(["Best pizza outside of Italy and really tasty.", "This is another sentence"])
+ assert isinstance(predict, list) and len(predict) == 2 and isinstance(predict[0], list)
+
+
+def test_trainer_callbacks(absa_model: AbsaModel) -> None:
+ trainer = AbsaTrainer(absa_model)
+ assert len(trainer.aspect_trainer.callback_handler.callbacks) >= 2
+ callback_names = {callback.__class__.__name__ for callback in trainer.aspect_trainer.callback_handler.callbacks}
+ assert {"DefaultFlowCallback", "ProgressCallback"} <= callback_names
+
+ class TestCallback(TrainerCallback):
+ pass
+
+ callback = TestCallback()
+ trainer.add_callback(callback)
+ assert len(trainer.aspect_trainer.callback_handler.callbacks) == len(callback_names) + 1
+ assert len(trainer.polarity_trainer.callback_handler.callbacks) == len(callback_names) + 1
+ assert trainer.aspect_trainer.callback_handler.callbacks[-1] == callback
+ assert trainer.polarity_trainer.callback_handler.callbacks[-1] == callback
+
+ assert trainer.pop_callback(callback) == (callback, callback)
+ trainer.add_callback(callback)
+ assert trainer.aspect_trainer.callback_handler.callbacks[-1] == callback
+ assert trainer.polarity_trainer.callback_handler.callbacks[-1] == callback
+ trainer.remove_callback(callback)
+ assert callback not in trainer.aspect_trainer.callback_handler.callbacks
+ assert callback not in trainer.polarity_trainer.callback_handler.callbacks
+
+
+def test_train_ordinal_too_high(absa_model: AbsaModel, caplog: LogCaptureFixture) -> None:
+ logger = get_logger("setfit")
+ logger.propagate = True
+
+ absa_dataset = Dataset.from_dict(
+ {
+ "text": [
+ "It is about food and ambiance, and imagine how dreadful it will be it we only had to listen to an idle engine."
+ ],
+ "span": ["food"],
+ "label": ["negative"],
+ "ordinal": [1],
+ }
+ )
+ with caplog.at_level(logging.INFO):
+ trainer = AbsaTrainer(absa_model, train_dataset=absa_dataset)
+ assert len(trainer.aspect_trainer.train_dataset) == 3
+ assert len(trainer.polarity_trainer.train_dataset) == 0
+ # These tests are ignored as the caplog is inconsistent:
+ # assert len(caplog.record_tuples) == 1
+ # assert caplog.record_tuples[0][2] == (
+ # "The ordinal of 1 for span 'food' in 'It is about food and ambiance, and imagine how dreadful it will be "
+ # "it we only had to listen to an idle engine.' is too high. Skipping this sample."
+ # )
+ # assert caplog.record_tuples[0][1] == logging.INFO
+
+ logger.propagate = False
+
+
+def test_train_column_mapping(absa_model: AbsaModel, absa_dataset: Dataset) -> None:
+ absa_dataset = absa_dataset.rename_columns({"text": "sentence", "span": "aspect"})
+ trainer = AbsaTrainer(
+ absa_model, train_dataset=absa_dataset, column_mapping={"sentence": "text", "aspect": "span"}
+ )
+ trainer.train()
diff --git a/tests/test_deprecated_trainer.py b/tests/test_deprecated_trainer.py
new file mode 100644
index 00000000..771838d5
--- /dev/null
+++ b/tests/test_deprecated_trainer.py
@@ -0,0 +1,526 @@
+import pathlib
+import re
+import tempfile
+from unittest import TestCase
+
+import evaluate
+import pytest
+import torch
+from datasets import Dataset, load_dataset
+from sentence_transformers import losses
+from transformers.testing_utils import require_optuna
+from transformers.utils.hp_naming import TrialShortNamer
+
+from setfit import logging
+from setfit.losses import SupConLoss
+from setfit.modeling import SetFitModel
+from setfit.trainer import SetFitTrainer
+from setfit.utils import BestRun
+
+
+logging.set_verbosity_warning()
+logging.enable_propagation()
+
+
+class SetFitTrainerTest(TestCase):
+ def setUp(self):
+ self.model = SetFitModel.from_pretrained("sentence-transformers/paraphrase-albert-small-v2")
+ self.num_iterations = 1
+
+ def test_trainer_works_with_model_init(self):
+ def get_model():
+ model_name = "sentence-transformers/paraphrase-albert-small-v2"
+ return SetFitModel.from_pretrained(model_name)
+
+ dataset = Dataset.from_dict(
+ {"text_new": ["a", "b", "c"], "label_new": [0, 1, 2], "extra_column": ["d", "e", "f"]}
+ )
+ trainer = SetFitTrainer(
+ model_init=get_model,
+ train_dataset=dataset,
+ eval_dataset=dataset,
+ num_iterations=self.num_iterations,
+ column_mapping={"text_new": "text", "label_new": "label"},
+ )
+ trainer.train()
+ metrics = trainer.evaluate()
+ self.assertEqual(metrics["accuracy"], 1.0)
+
+ def test_trainer_works_with_column_mapping(self):
+ dataset = Dataset.from_dict(
+ {"text_new": ["a", "b", "c"], "label_new": [0, 1, 2], "extra_column": ["d", "e", "f"]}
+ )
+ trainer = SetFitTrainer(
+ model=self.model,
+ train_dataset=dataset,
+ eval_dataset=dataset,
+ num_iterations=self.num_iterations,
+ column_mapping={"text_new": "text", "label_new": "label"},
+ )
+ trainer.train()
+ metrics = trainer.evaluate()
+ self.assertEqual(metrics["accuracy"], 1.0)
+
+ def test_trainer_works_with_default_columns(self):
+ dataset = Dataset.from_dict({"text": ["a", "b", "c"], "label": [0, 1, 2], "extra_column": ["d", "e", "f"]})
+ trainer = SetFitTrainer(
+ model=self.model, train_dataset=dataset, eval_dataset=dataset, num_iterations=self.num_iterations
+ )
+ trainer.train()
+ metrics = trainer.evaluate()
+ self.assertEqual(metrics["accuracy"], 1.0)
+
+ def test_trainer_works_with_alternate_dataset_for_evaluate(self):
+ dataset = Dataset.from_dict({"text": ["a", "b", "c"], "label": [0, 1, 2], "extra_column": ["d", "e", "f"]})
+ alternate_dataset = Dataset.from_dict(
+ {"text": ["x", "y", "z"], "label": [0, 1, 2], "extra_column": ["d", "e", "f"]}
+ )
+ trainer = SetFitTrainer(
+ model=self.model, train_dataset=dataset, eval_dataset=dataset, num_iterations=self.num_iterations
+ )
+ trainer.train()
+ metrics = trainer.evaluate(alternate_dataset)
+ self.assertNotEqual(metrics["accuracy"], 1.0)
+
+ def test_trainer_raises_error_with_missing_label(self):
+ dataset = Dataset.from_dict({"text": ["a", "b", "c"], "extra_column": ["d", "e", "f"]})
+ with pytest.raises(ValueError):
+ SetFitTrainer(
+ model=self.model, train_dataset=dataset, eval_dataset=dataset, num_iterations=self.num_iterations
+ )
+
+ def test_trainer_raises_error_with_missing_text(self):
+ """If the required columns are missing from the dataset, the library should throw an error and list the columns found."""
+ dataset = Dataset.from_dict({"label": [0, 1, 2], "extra_column": ["d", "e", "f"]})
+ expected_message = re.escape(
+ "SetFit expected the dataset to have the columns ['label', 'text'], "
+ "but only the columns ['extra_column', 'label'] were found. "
+ "Either make sure these columns are present, or specify which columns to use with column_mapping in Trainer."
+ )
+ with pytest.raises(ValueError, match=expected_message):
+ SetFitTrainer(
+ model=self.model, train_dataset=dataset, eval_dataset=dataset, num_iterations=self.num_iterations
+ )
+
+ def test_column_mapping_raises_error_when_mapped_columns_missing(self):
+ """If the columns specified in the column mapping are missing from the dataset, the library should throw an error and list the columns found."""
+ dataset = Dataset.from_dict({"text": ["a", "b", "c"], "extra_column": ["d", "e", "f"]})
+ expected_message = re.escape(
+ "The column mapping expected the columns ['label_new', 'text_new'] in the dataset, "
+ "but the dataset had the columns ['extra_column', 'text'].",
+ )
+ with pytest.raises(ValueError, match=expected_message):
+ SetFitTrainer(
+ model=self.model,
+ train_dataset=dataset,
+ eval_dataset=dataset,
+ num_iterations=self.num_iterations,
+ column_mapping={"text_new": "text", "label_new": "label"},
+ )
+
+ def test_trainer_raises_error_when_dataset_not_split(self):
+ """Verify that an error is raised if we pass an unsplit dataset to the trainer."""
+ dataset = Dataset.from_dict({"text": ["a", "b", "c", "d"], "label": [0, 0, 1, 1]}).train_test_split(
+ test_size=0.5
+ )
+ expected_message = re.escape(
+ "SetFit expected a Dataset, but it got a DatasetDict with the splits ['test', 'train']. "
+ "Did you mean to select one of these splits from the dataset?",
+ )
+ with pytest.raises(ValueError, match=expected_message):
+ SetFitTrainer(
+ model=self.model, train_dataset=dataset, eval_dataset=dataset, num_iterations=self.num_iterations
+ )
+
+ def test_trainer_raises_error_when_dataset_is_dataset_dict_with_train(self):
+ """Verify that a useful error is raised if we pass an unsplit dataset with only a `train` split to the trainer."""
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ path = pathlib.Path(tmpdirname) / "test_dataset_dict_with_train.csv"
+ path.write_text("label,text\n1,good\n0,terrible\n")
+ dataset = load_dataset("csv", data_files=str(path))
+ expected_message = re.escape(
+ "SetFit expected a Dataset, but it got a DatasetDict with the split ['train']. "
+ "Did you mean to select the training split with dataset['train']?",
+ )
+ with pytest.raises(ValueError, match=expected_message):
+ SetFitTrainer(
+ model=self.model, train_dataset=dataset, eval_dataset=dataset, num_iterations=self.num_iterations
+ )
+
+ def test_column_mapping_multilabel(self):
+ dataset = Dataset.from_dict({"text_new": ["a", "b", "c"], "label_new": [[0, 1], [1, 2], [2, 0]]})
+
+ trainer = SetFitTrainer(
+ model=self.model,
+ train_dataset=dataset,
+ eval_dataset=dataset,
+ num_iterations=self.num_iterations,
+ column_mapping={"text_new": "text", "label_new": "label"},
+ )
+
+ trainer._validate_column_mapping(dataset)
+ formatted_dataset = trainer._apply_column_mapping(dataset, trainer.column_mapping)
+
+ assert formatted_dataset.column_names == ["text", "label"]
+
+ assert formatted_dataset[0]["text"] == "a"
+ assert formatted_dataset[0]["label"] == [0, 1]
+
+ assert formatted_dataset[1]["text"] == "b"
+
+ def test_trainer_support_callable_as_metric(self):
+ dataset = Dataset.from_dict(
+ {"text_new": ["a", "b", "c"], "label_new": [0, 1, 2], "extra_column": ["d", "e", "f"]}
+ )
+
+ f1_metric = evaluate.load("f1")
+ accuracy_metric = evaluate.load("accuracy")
+
+ def compute_metrics(y_pred, y_test):
+ return {
+ "f1": f1_metric.compute(predictions=y_pred, references=y_test, average="micro")["f1"],
+ "accuracy": accuracy_metric.compute(predictions=y_pred, references=y_test)["accuracy"],
+ }
+
+ trainer = SetFitTrainer(
+ model=self.model,
+ train_dataset=dataset,
+ eval_dataset=dataset,
+ metric=compute_metrics,
+ num_iterations=self.num_iterations,
+ column_mapping={"text_new": "text", "label_new": "label"},
+ )
+
+ trainer.train()
+ metrics = trainer.evaluate()
+
+ self.assertEqual(
+ {
+ "f1": 1.0,
+ "accuracy": 1.0,
+ },
+ metrics,
+ )
+
+ def test_raise_when_metric_value_is_invalid(self):
+ dataset = Dataset.from_dict(
+ {"text_new": ["a", "b", "c"], "label_new": [0, 1, 2], "extra_column": ["d", "e", "f"]}
+ )
+
+ trainer = SetFitTrainer(
+ model=self.model,
+ train_dataset=dataset,
+ eval_dataset=dataset,
+ metric="this-metric-does-not-exist", # invalid metric value
+ num_iterations=self.num_iterations,
+ column_mapping={"text_new": "text", "label_new": "label"},
+ )
+
+ trainer.train()
+
+ with self.assertRaises(FileNotFoundError):
+ trainer.evaluate()
+
+ def test_trainer_raises_error_with_wrong_warmup_proportion(self):
+ # warmup_proportion must not be > 1.0
+ with pytest.raises(ValueError):
+ SetFitTrainer(warmup_proportion=1.1)
+
+ # warmup_proportion must not be < 0.0
+ with pytest.raises(ValueError):
+ SetFitTrainer(warmup_proportion=-0.1)
+
+
+class SetFitTrainerDifferentiableHeadTest(TestCase):
+ def setUp(self):
+ self.dataset = Dataset.from_dict(
+ {"text_new": ["a", "b", "c"], "label_new": [0, 1, 2], "extra_column": ["d", "e", "f"]}
+ )
+ self.model = SetFitModel.from_pretrained(
+ "sentence-transformers/paraphrase-albert-small-v2",
+ use_differentiable_head=True,
+ head_params={"out_features": 3},
+ )
+ self.num_iterations = 1
+
+ @pytest.mark.skip(reason="The `trainer.train` arguments are now ignored, causing this test to fail.")
+ def test_trainer_max_length_exceeds_max_acceptable_length(self):
+ trainer = SetFitTrainer(
+ model=self.model,
+ train_dataset=self.dataset,
+ eval_dataset=self.dataset,
+ num_iterations=self.num_iterations,
+ column_mapping={"text_new": "text", "label_new": "label"},
+ )
+ trainer.unfreeze(keep_body_frozen=True)
+ with self.assertLogs(level=logging.WARNING) as cm:
+ max_length = 4096
+ max_acceptable_length = self.model.model_body.get_max_seq_length()
+ trainer.train(
+ num_epochs=1,
+ batch_size=3,
+ learning_rate=1e-2,
+ l2_weight=0.0,
+ max_length=max_length,
+ )
+ self.assertEqual(
+ cm.output,
+ [
+ (
+ f"WARNING:setfit.modeling:The specified `max_length`: {max_length} is greater than the maximum length "
+ f"of the current model body: {max_acceptable_length}. Using {max_acceptable_length} instead."
+ )
+ ],
+ )
+
+ @pytest.mark.skip(reason="The `trainer.train` arguments are now ignored, causing this test to fail.")
+ def test_trainer_max_length_is_smaller_than_max_acceptable_length(self):
+ trainer = SetFitTrainer(
+ model=self.model,
+ train_dataset=self.dataset,
+ eval_dataset=self.dataset,
+ num_iterations=self.num_iterations,
+ column_mapping={"text_new": "text", "label_new": "label"},
+ )
+ trainer.unfreeze(keep_body_frozen=True)
+
+ # An alternative way of `assertNoLogs`, which is new in Python 3.10
+ try:
+ with self.assertLogs(level=logging.WARNING) as cm:
+ max_length = 32
+ trainer.train(
+ num_epochs=1,
+ batch_size=3,
+ learning_rate=1e-2,
+ l2_weight=0.0,
+ max_length=max_length,
+ )
+ self.assertEqual(cm.output, [])
+ except AssertionError as e:
+ if e.args[0] != "no logs of level WARNING or higher triggered on root":
+ raise AssertionError(e)
+
+
+class SetFitTrainerMultilabelTest(TestCase):
+ def setUp(self):
+ self.model = SetFitModel.from_pretrained(
+ "sentence-transformers/paraphrase-albert-small-v2", multi_target_strategy="one-vs-rest"
+ )
+ self.num_iterations = 1
+
+ def test_trainer_multilabel_support_callable_as_metric(self):
+ dataset = Dataset.from_dict({"text_new": ["a", "b", "c"], "label_new": [[1, 0, 0], [0, 1, 0], [0, 0, 1]]})
+
+ multilabel_f1_metric = evaluate.load("f1", "multilabel")
+ multilabel_accuracy_metric = evaluate.load("accuracy", "multilabel")
+
+ def compute_metrics(y_pred, y_test):
+ return {
+ "f1": multilabel_f1_metric.compute(predictions=y_pred, references=y_test, average="micro")["f1"],
+ "accuracy": multilabel_accuracy_metric.compute(predictions=y_pred, references=y_test)["accuracy"],
+ }
+
+ trainer = SetFitTrainer(
+ model=self.model,
+ train_dataset=dataset,
+ eval_dataset=dataset,
+ metric=compute_metrics,
+ num_iterations=self.num_iterations,
+ column_mapping={"text_new": "text", "label_new": "label"},
+ )
+
+ trainer.train()
+ metrics = trainer.evaluate()
+
+ self.assertEqual(
+ {
+ "f1": 1.0,
+ "accuracy": 1.0,
+ },
+ metrics,
+ )
+
+
+@pytest.mark.skip(
+ reason=(
+ "The `trainer.freeze()` before `trainer.train()` now freezes the body as well as the head, "
+ "which means the backwards call from `trainer.train()` will fail."
+ )
+)
+class SetFitTrainerMultilabelDifferentiableTest(TestCase):
+ def setUp(self):
+ self.model = SetFitModel.from_pretrained(
+ "sentence-transformers/paraphrase-albert-small-v2",
+ multi_target_strategy="one-vs-rest",
+ use_differentiable_head=True,
+ head_params={"out_features": 2},
+ )
+ self.num_iterations = 1
+
+ def test_trainer_multilabel_support_callable_as_metric(self):
+ dataset = Dataset.from_dict({"text_new": ["", "a", "b", "ab"], "label_new": [[0, 0], [1, 0], [0, 1], [1, 1]]})
+
+ multilabel_f1_metric = evaluate.load("f1", "multilabel")
+ multilabel_accuracy_metric = evaluate.load("accuracy", "multilabel")
+
+ def compute_metrics(y_pred, y_test):
+ return {
+ "f1": multilabel_f1_metric.compute(predictions=y_pred, references=y_test, average="micro")["f1"],
+ "accuracy": multilabel_accuracy_metric.compute(predictions=y_pred, references=y_test)["accuracy"],
+ }
+
+ trainer = SetFitTrainer(
+ model=self.model,
+ train_dataset=dataset,
+ eval_dataset=dataset,
+ metric=compute_metrics,
+ num_iterations=self.num_iterations,
+ column_mapping={"text_new": "text", "label_new": "label"},
+ )
+
+ trainer.freeze()
+ trainer.train()
+
+ trainer.unfreeze(keep_body_frozen=False)
+ trainer.train(5)
+ metrics = trainer.evaluate()
+
+ self.assertEqual(
+ {
+ "f1": 1.0,
+ "accuracy": 1.0,
+ },
+ metrics,
+ )
+
+
+@require_optuna
+class TrainerHyperParameterOptunaIntegrationTest(TestCase):
+ def setUp(self):
+ self.dataset = Dataset.from_dict(
+ {"text_new": ["a", "b", "c"], "label_new": [0, 1, 2], "extra_column": ["d", "e", "f"]}
+ )
+ self.num_iterations = 1
+
+ def test_hyperparameter_search(self):
+ class MyTrialShortNamer(TrialShortNamer):
+ DEFAULTS = {"max_iter": 100, "solver": "liblinear"}
+
+ def hp_space(trial):
+ return {
+ "learning_rate": trial.suggest_float("learning_rate", 1e-6, 1e-4, log=True),
+ "batch_size": trial.suggest_categorical("batch_size", [4, 8, 16, 32, 64]),
+ "max_iter": trial.suggest_int("max_iter", 50, 300),
+ "solver": trial.suggest_categorical("solver", ["newton-cg", "lbfgs", "liblinear"]),
+ }
+
+ def model_init(params):
+ params = params or {}
+ max_iter = params.get("max_iter", 100)
+ solver = params.get("solver", "liblinear")
+ params = {
+ "head_params": {
+ "max_iter": max_iter,
+ "solver": solver,
+ }
+ }
+ return SetFitModel.from_pretrained("sentence-transformers/paraphrase-albert-small-v2", **params)
+
+ def hp_name(trial):
+ return MyTrialShortNamer.shortname(trial.params)
+
+ trainer = SetFitTrainer(
+ train_dataset=self.dataset,
+ eval_dataset=self.dataset,
+ num_iterations=self.num_iterations,
+ model_init=model_init,
+ column_mapping={"text_new": "text", "label_new": "label"},
+ )
+ result = trainer.hyperparameter_search(direction="minimize", hp_space=hp_space, hp_name=hp_name, n_trials=4)
+ assert isinstance(result, BestRun)
+ assert result.hyperparameters.keys() == {"learning_rate", "batch_size", "max_iter", "solver"}
+
+
+# regression test for https://github.com/huggingface/setfit/issues/153
+@pytest.mark.parametrize(
+ "loss_class",
+ [
+ losses.BatchAllTripletLoss,
+ losses.BatchHardTripletLoss,
+ losses.BatchSemiHardTripletLoss,
+ losses.BatchHardSoftMarginTripletLoss,
+ SupConLoss,
+ ],
+)
+def test_trainer_works_with_non_default_loss_class(loss_class):
+ dataset = Dataset.from_dict({"text": ["a 1", "b 1", "c 1", "a 2", "b 2", "c 2"], "label": [0, 1, 2, 0, 1, 2]})
+ model = SetFitModel.from_pretrained("sentence-transformers/paraphrase-albert-small-v2")
+ trainer = SetFitTrainer(
+ model=model,
+ train_dataset=dataset,
+ eval_dataset=dataset,
+ num_iterations=1,
+ loss_class=loss_class,
+ )
+ trainer.train()
+ # no asserts here because this is a regression test - we only test if an exception is raised
+
+
+def test_trainer_evaluate_with_strings():
+ dataset = Dataset.from_dict(
+ {"text": ["positive sentence", "negative sentence"], "label": ["positive", "negative"]}
+ )
+ model = SetFitModel.from_pretrained("sentence-transformers/paraphrase-albert-small-v2")
+ trainer = SetFitTrainer(
+ model=model,
+ train_dataset=dataset,
+ eval_dataset=dataset,
+ num_iterations=1,
+ )
+ trainer.train()
+ # This used to fail due to "TypeError: can't convert np.ndarray of type numpy.str_.
+ # The only supported types are: float64, float32, float16, complex64, complex128, int64, int32, int16, int8, uint8, and bool."
+ model.predict(["another positive sentence"])
+
+
+def test_trainer_evaluate_multilabel_f1():
+ dataset = Dataset.from_dict({"text_new": ["", "a", "b", "ab"], "label_new": [[0, 0], [1, 0], [0, 1], [1, 1]]})
+ model = SetFitModel.from_pretrained(
+ "sentence-transformers/paraphrase-albert-small-v2", multi_target_strategy="one-vs-rest"
+ )
+
+ trainer = SetFitTrainer(
+ model=model,
+ train_dataset=dataset,
+ eval_dataset=dataset,
+ metric="f1",
+ metric_kwargs={"average": "micro"},
+ num_iterations=5,
+ column_mapping={"text_new": "text", "label_new": "label"},
+ )
+
+ trainer.train()
+ metrics = trainer.evaluate()
+ assert metrics == {"f1": 1.0}
+
+
+def test_trainer_evaluate_on_cpu() -> None:
+ # This test used to fail if CUDA was available
+ dataset = Dataset.from_dict({"text": ["positive sentence", "negative sentence"], "label": [1, 0]})
+ model = SetFitModel.from_pretrained(
+ "sentence-transformers/paraphrase-albert-small-v2", use_differentiable_head=True
+ )
+
+ def compute_metric(y_pred, y_test) -> None:
+ assert y_pred.device == torch.device("cpu")
+ return 1.0
+
+ trainer = SetFitTrainer(
+ model=model,
+ train_dataset=dataset,
+ eval_dataset=dataset,
+ metric=compute_metric,
+ num_iterations=5,
+ )
+ trainer.train()
+ trainer.evaluate()
diff --git a/tests/test_deprecated_trainer_distillation.py b/tests/test_deprecated_trainer_distillation.py
new file mode 100644
index 00000000..d476e73b
--- /dev/null
+++ b/tests/test_deprecated_trainer_distillation.py
@@ -0,0 +1,115 @@
+from unittest import TestCase
+
+import pytest
+from datasets import Dataset
+from sentence_transformers.losses import CosineSimilarityLoss
+
+from setfit import DistillationSetFitTrainer, SetFitTrainer
+from setfit.modeling import SetFitModel
+
+
+class DistillationSetFitTrainerTest(TestCase):
+ def setUp(self):
+ self.teacher_model = SetFitModel.from_pretrained("sentence-transformers/paraphrase-albert-small-v2")
+ self.student_model = SetFitModel.from_pretrained("sentence-transformers/paraphrase-MiniLM-L3-v2")
+ self.num_iterations = 1
+
+ def test_trainer_works_with_default_columns(self):
+ dataset = Dataset.from_dict({"text": ["a", "b", "c"], "label": [0, 1, 2], "extra_column": ["d", "e", "f"]})
+ # train a teacher model
+ teacher_trainer = SetFitTrainer(
+ model=self.teacher_model,
+ train_dataset=dataset,
+ eval_dataset=dataset,
+ loss_class=CosineSimilarityLoss,
+ metric="accuracy",
+ )
+ # Teacher Train and evaluate
+ teacher_trainer.train()
+ teacher_model = teacher_trainer.model
+
+ student_trainer = DistillationSetFitTrainer(
+ teacher_model=teacher_model,
+ train_dataset=dataset,
+ student_model=self.student_model,
+ eval_dataset=dataset,
+ loss_class=CosineSimilarityLoss,
+ metric="accuracy",
+ )
+
+ # Student Train and evaluate
+ student_trainer.train()
+ metrics = student_trainer.evaluate()
+ print("Student results: ", metrics)
+ self.assertEqual(metrics["accuracy"], 1.0)
+
+ def test_trainer_raises_error_with_missing_label(self):
+ labeled_dataset = Dataset.from_dict(
+ {"text": ["a", "b", "c"], "label": [0, 1, 2], "extra_column": ["d", "e", "f"]}
+ )
+ # train a teacher model
+ teacher_trainer = SetFitTrainer(
+ model=self.teacher_model,
+ train_dataset=labeled_dataset,
+ eval_dataset=labeled_dataset,
+ metric="accuracy",
+ num_iterations=self.num_iterations,
+ )
+ # Teacher Train and evaluate
+ teacher_trainer.train()
+
+ unlabeled_dataset = Dataset.from_dict({"text": ["a", "b", "c"], "extra_column": ["d", "e", "f"]})
+ student_trainer = DistillationSetFitTrainer(
+ teacher_model=self.teacher_model,
+ student_model=self.student_model,
+ train_dataset=unlabeled_dataset,
+ eval_dataset=labeled_dataset,
+ num_iterations=self.num_iterations,
+ )
+ student_trainer.train()
+ metrics = student_trainer.evaluate()
+ print("Student results: ", metrics)
+ self.assertEqual(metrics["accuracy"], 1.0)
+
+ def test_trainer_raises_error_with_missing_text(self):
+ dataset = Dataset.from_dict({"label": [0, 1, 2], "extra_column": ["d", "e", "f"]})
+ with pytest.raises(ValueError):
+ DistillationSetFitTrainer(
+ teacher_model=self.teacher_model,
+ train_dataset=dataset,
+ student_model=self.student_model,
+ eval_dataset=dataset,
+ num_iterations=self.num_iterations,
+ )
+
+ def test_column_mapping_with_missing_text(self):
+ dataset = Dataset.from_dict({"text": ["a", "b", "c"], "extra_column": ["d", "e", "f"]})
+ with pytest.raises(ValueError):
+ DistillationSetFitTrainer(
+ teacher_model=self.teacher_model,
+ train_dataset=dataset,
+ student_model=self.student_model,
+ eval_dataset=dataset,
+ num_iterations=self.num_iterations,
+ column_mapping={"label_new": "label"},
+ )
+
+ def test_column_mapping_multilabel(self):
+ dataset = Dataset.from_dict({"text_new": ["a", "b", "c"], "label_new": [[0, 1], [1, 2], [2, 0]]})
+
+ trainer = DistillationSetFitTrainer(
+ teacher_model=self.teacher_model,
+ train_dataset=dataset,
+ student_model=self.student_model,
+ eval_dataset=dataset,
+ num_iterations=self.num_iterations,
+ column_mapping={"text_new": "text", "label_new": "label"},
+ )
+
+ trainer._validate_column_mapping(dataset)
+ formatted_dataset = trainer._apply_column_mapping(dataset, trainer.column_mapping)
+
+ assert formatted_dataset.column_names == ["text", "label"]
+ assert formatted_dataset[0]["text"] == "a"
+ assert formatted_dataset[0]["label"] == [0, 1]
+ assert formatted_dataset[1]["text"] == "b"
diff --git a/tests/test_model_card.py b/tests/test_model_card.py
new file mode 100644
index 00000000..73cdc92d
--- /dev/null
+++ b/tests/test_model_card.py
@@ -0,0 +1,88 @@
+from pathlib import Path
+
+import datasets
+import pytest
+from datasets import Dataset, load_dataset
+from packaging.version import Version, parse
+
+from setfit import SetFitModel, SetFitModelCardData, Trainer, TrainingArguments
+from setfit.data import sample_dataset
+from setfit.model_card import generate_model_card, is_on_huggingface
+
+from .model_card_pattern import MODEL_CARD_PATTERN
+
+
+def test_model_card(tmp_path: Path) -> None:
+ dataset = load_dataset("sst2")
+ train_dataset = sample_dataset(dataset["train"], label_column="label", num_samples=8)
+ eval_dataset = dataset["validation"].select(range(10))
+ model = SetFitModel.from_pretrained(
+ "sentence-transformers/paraphrase-albert-small-v2",
+ labels=["negative", "positive"],
+ model_card_data=SetFitModelCardData(
+ model_id="tomaarsen/setfit-paraphrase-albert-small-v2-sst2",
+ dataset_id="sst2",
+ dataset_name="SST2",
+ language=["en"],
+ license="apache-2.0",
+ ),
+ )
+
+ args = TrainingArguments(
+ str(tmp_path),
+ report_to="codecarbon",
+ batch_size=1,
+ eval_steps=1,
+ logging_steps=1,
+ max_steps=2,
+ evaluation_strategy="steps",
+ )
+ trainer = Trainer(
+ model=model,
+ args=args,
+ train_dataset=train_dataset,
+ eval_dataset=eval_dataset,
+ column_mapping={"sentence": "text"},
+ )
+ trainer.train()
+ trainer.evaluate()
+ model_card = generate_model_card(trainer.model)
+ assert MODEL_CARD_PATTERN.fullmatch(model_card)
+
+
+def test_model_card_languages() -> None:
+ model = SetFitModel.from_pretrained(
+ "sentence-transformers/paraphrase-albert-small-v2",
+ model_card_data=SetFitModelCardData(
+ language=["en", "nl", "de"],
+ ),
+ )
+ model_card = model.generate_model_card()
+ assert "**Languages:** en, nl, de" in model_card
+
+
+def test_is_on_huggingface_edge_case() -> None:
+ assert not is_on_huggingface("test_value")
+ assert not is_on_huggingface("a/test/value")
+
+
+@pytest.mark.skipif(
+ parse(datasets.__version__) < Version("2.14.0"), reason="Inferring dataset_id only works from datasets >= 2.14.0"
+)
+@pytest.mark.parametrize("dataset_id", ("SetFit/emotion", "SetFit/sst2"))
+def test_infer_dataset_id(dataset_id: str) -> None:
+ model = SetFitModel.from_pretrained("sentence-transformers/paraphrase-albert-small-v2")
+ train_dataset = load_dataset(dataset_id, split="train")
+
+ # This triggers inferring the dataset_id from train_dataset
+ Trainer(model=model, train_dataset=train_dataset)
+ assert model.model_card_data.dataset_id == dataset_id
+
+
+def test_cant_infer_dataset_id():
+ model = SetFitModel.from_pretrained("sentence-transformers/paraphrase-albert-small-v2")
+ train_dataset = Dataset.from_dict({"text": ["a", "b", "c", "d"], "label": [0, 1, 1, 0]})
+
+ # This triggers inferring the dataset_id from train_dataset
+ Trainer(model=model, train_dataset=train_dataset)
+ assert model.model_card_data.dataset_id is None
diff --git a/tests/test_modeling.py b/tests/test_modeling.py
index c31417d2..5e75e9d9 100644
--- a/tests/test_modeling.py
+++ b/tests/test_modeling.py
@@ -1,3 +1,6 @@
+import json
+from pathlib import Path
+from tempfile import TemporaryDirectory
from unittest import TestCase
import numpy as np
@@ -10,42 +13,12 @@
from sklearn.multioutput import ClassifierChain, MultiOutputClassifier
from setfit import SetFitHead, SetFitModel
-from setfit.modeling import MODEL_HEAD_NAME, sentence_pairs_generation, sentence_pairs_generation_multilabel
+from setfit.modeling import MODEL_HEAD_NAME
torch_cuda_available = pytest.mark.skipif(not torch.cuda.is_available(), reason="PyTorch must be compiled with CUDA")
-def test_sentence_pairs_generation():
- sentences = np.array(["sent 1", "sent 2", "sent 3"])
- labels = np.array(["label 1", "label 2", "label 3"])
-
- pairs = []
- n_iterations = 2
-
- for _ in range(n_iterations):
- pairs = sentence_pairs_generation(sentences, labels, pairs)
-
- assert len(pairs) == 12
- assert pairs[0].texts == ["sent 1", "sent 1"]
- assert pairs[0].label == 1.0
-
-
-def test_sentence_pairs_generation_multilabel():
- sentences = np.array(["sent 1", "sent 2", "sent 3"])
- labels = np.array([[1, 0, 0, 0], [0, 1, 0, 0], [0, 0, 1, 0]])
-
- pairs = []
- n_iterations = 2
-
- for _ in range(n_iterations):
- pairs = sentence_pairs_generation_multilabel(sentences, labels, pairs)
-
- assert len(pairs) == 12
- assert pairs[0].texts == ["sent 1", "sent 1"]
- assert pairs[0].label == 1.0
-
-
def test_setfit_model_body():
model = SetFitModel.from_pretrained("sentence-transformers/paraphrase-albert-small-v2")
@@ -276,3 +249,78 @@ def test_to_sentence_transformer_device_reset(use_differentiable_head):
model.model_body.encode("This is a test sample to encode")
assert model.model_body.device == torch.device("cpu")
+
+
+@torch_cuda_available
+@pytest.mark.parametrize("device", ["cpu", "cuda"])
+def test_load_model_on_device(device):
+ model = SetFitModel.from_pretrained("sentence-transformers/paraphrase-albert-small-v2", device=device)
+ assert model.device.type == device
+ assert model.model_body.device.type == device
+
+ model.model_body.encode("This is a test sample to encode")
+
+
+def test_save_load_config(model: SetFitModel) -> None:
+ with TemporaryDirectory() as tmp_dir:
+ tmp_dir = str(Path(tmp_dir) / "model")
+ model.save_pretrained(tmp_dir)
+ config_path = Path(tmp_dir) / "config_setfit.json"
+ assert config_path.exists()
+ with open(config_path, "r") as f:
+ config = json.load(f)
+ assert config == {"normalize_embeddings": False, "labels": None}
+
+ with TemporaryDirectory() as tmp_dir:
+ tmp_dir = str(Path(tmp_dir) / "model")
+ model.normalize_embeddings = True
+ model.labels = ["negative", "positive"]
+ model.save_pretrained(tmp_dir)
+ config_path = Path(tmp_dir) / "config_setfit.json"
+ assert config_path.exists()
+ with open(config_path, "r") as f:
+ config = json.load(f)
+ assert config == {"normalize_embeddings": True, "labels": ["negative", "positive"]}
+
+ fresh_model = model.from_pretrained(tmp_dir)
+ assert fresh_model.normalize_embeddings is True
+ assert fresh_model.labels == ["negative", "positive"]
+
+
+def test_load_model() -> None:
+ model = SetFitModel.from_pretrained(
+ "sentence-transformers/paraphrase-albert-small-v2", labels=["foo", "bar", "baz"]
+ )
+ assert model.labels == ["foo", "bar", "baz"]
+ assert model.label2id == {"foo": 0, "bar": 1, "baz": 2}
+ assert model.id2label == {0: "foo", 1: "bar", 2: "baz"}
+
+
+def test_inference_with_labels() -> None:
+ model = SetFitModel.from_pretrained("SetFit/test-setfit-sst2")
+ assert model.labels is None
+ assert model.predict(["Very good"]) == torch.tensor([1], dtype=torch.int32)
+ model.labels = ["negative", "positive"]
+ assert model.predict(["Very good"]) == ["positive"]
+
+ model = SetFitModel.from_pretrained("SetFit/test-setfit-sst2-string-labels")
+ assert model.labels is None
+ assert model.predict(["Very good"]) == np.array(["positive"], dtype=" None:
+ model = SetFitModel.from_pretrained("SetFit/test-setfit-sst2")
+ assert model.predict("That was cool!") == torch.tensor(1, dtype=torch.int32)
+ probs = model.predict_proba("That was cool!")
+ assert probs.shape == (2,)
+ assert probs.argmax() == 1
+ model.labels = ["negative", "positive"]
+ assert model("That was cool!") == "positive"
diff --git a/tests/test_sampler.py b/tests/test_sampler.py
new file mode 100644
index 00000000..d8d37712
--- /dev/null
+++ b/tests/test_sampler.py
@@ -0,0 +1,49 @@
+import numpy as np
+import pytest
+from sentence_transformers import InputExample
+
+from setfit.sampler import ContrastiveDataset
+
+
+@pytest.mark.parametrize(
+ "sampling_strategy, expected_pos_pairs, expected_neg_pairs",
+ [("unique", 4, 2), ("undersampling", 2, 2), ("oversampling", 4, 4)],
+)
+def test_sentence_pairs_generation(sampling_strategy: str, expected_pos_pairs: int, expected_neg_pairs: int):
+ sentences = np.array(["sent 1", "sent 2", "sent 3"])
+ labels = np.array(["label 1", "label 1", "label 2"])
+
+ data = [InputExample(texts=[text], label=label) for text, label in zip(sentences, labels)]
+ multilabel = False
+
+ data_sampler = ContrastiveDataset(data, multilabel, sampling_strategy=sampling_strategy)
+
+ assert data_sampler.len_pos_pairs == expected_pos_pairs
+ assert data_sampler.len_neg_pairs == expected_neg_pairs
+
+ pairs = [i for i in data_sampler]
+
+ assert len(pairs) == expected_pos_pairs + expected_neg_pairs
+ assert pairs[0].texts == ["sent 1", "sent 1"]
+ assert pairs[0].label == 1.0
+
+
+@pytest.mark.parametrize(
+ "sampling_strategy, expected_pos_pairs, expected_neg_pairs",
+ [("unique", 6, 4), ("undersampling", 4, 4), ("oversampling", 6, 6)],
+)
+def test_sentence_pairs_generation_multilabel(
+ sampling_strategy: str, expected_pos_pairs: int, expected_neg_pairs: int
+):
+ sentences = np.array(["sent 1", "sent 2", "sent 3", "sent 4"])
+ labels = np.array([[1, 0, 0, 1], [0, 1, 1, 0], [0, 0, 1, 0], [0, 0, 0, 1]])
+
+ data = [InputExample(texts=[text], label=label) for text, label in zip(sentences, labels)]
+ multilabel = True
+
+ data_sampler = ContrastiveDataset(data, multilabel, sampling_strategy=sampling_strategy)
+ assert data_sampler.len_pos_pairs == expected_pos_pairs
+ assert data_sampler.len_neg_pairs == expected_neg_pairs
+
+ pairs = [i for i in data_sampler]
+ assert len(pairs) == expected_pos_pairs + expected_neg_pairs
diff --git a/tests/test_trainer.py b/tests/test_trainer.py
index af2c9a82..0814c758 100644
--- a/tests/test_trainer.py
+++ b/tests/test_trainer.py
@@ -1,19 +1,24 @@
-import pathlib
+import os
import re
import tempfile
+from pathlib import Path
from unittest import TestCase
import evaluate
import pytest
import torch
from datasets import Dataset, load_dataset
+from pytest import LogCaptureFixture
from sentence_transformers import losses
+from transformers import TrainerCallback
from transformers.testing_utils import require_optuna
from transformers.utils.hp_naming import TrialShortNamer
from setfit import logging
-from setfit.modeling import SetFitModel, SupConLoss
-from setfit.trainer import SetFitTrainer
+from setfit.losses import SupConLoss
+from setfit.modeling import SetFitModel
+from setfit.trainer import Trainer
+from setfit.training_args import TrainingArguments
from setfit.utils import BestRun
@@ -21,10 +26,10 @@
logging.enable_propagation()
-class SetFitTrainerTest(TestCase):
+class TrainerTest(TestCase):
def setUp(self):
self.model = SetFitModel.from_pretrained("sentence-transformers/paraphrase-albert-small-v2")
- self.num_iterations = 1
+ self.args = TrainingArguments(num_iterations=1)
def test_trainer_works_with_model_init(self):
def get_model():
@@ -34,11 +39,11 @@ def get_model():
dataset = Dataset.from_dict(
{"text_new": ["a", "b", "c"], "label_new": [0, 1, 2], "extra_column": ["d", "e", "f"]}
)
- trainer = SetFitTrainer(
+ trainer = Trainer(
model_init=get_model,
+ args=self.args,
train_dataset=dataset,
eval_dataset=dataset,
- num_iterations=self.num_iterations,
column_mapping={"text_new": "text", "label_new": "label"},
)
trainer.train()
@@ -49,22 +54,33 @@ def test_trainer_works_with_column_mapping(self):
dataset = Dataset.from_dict(
{"text_new": ["a", "b", "c"], "label_new": [0, 1, 2], "extra_column": ["d", "e", "f"]}
)
- trainer = SetFitTrainer(
+ trainer = Trainer(
model=self.model,
+ args=self.args,
train_dataset=dataset,
eval_dataset=dataset,
- num_iterations=self.num_iterations,
column_mapping={"text_new": "text", "label_new": "label"},
)
trainer.train()
metrics = trainer.evaluate()
self.assertEqual(metrics["accuracy"], 1.0)
+ def test_trainer_works_with_partial_column_mapping(self):
+ dataset = Dataset.from_dict({"text_new": ["a", "b", "c"], "label": [0, 1, 2], "extra_column": ["d", "e", "f"]})
+ trainer = Trainer(
+ model=self.model,
+ args=self.args,
+ train_dataset=dataset,
+ eval_dataset=dataset,
+ column_mapping={"text_new": "text"},
+ )
+ trainer.train()
+ metrics = trainer.evaluate()
+ self.assertEqual(metrics["accuracy"], 1.0)
+
def test_trainer_works_with_default_columns(self):
dataset = Dataset.from_dict({"text": ["a", "b", "c"], "label": [0, 1, 2], "extra_column": ["d", "e", "f"]})
- trainer = SetFitTrainer(
- model=self.model, train_dataset=dataset, eval_dataset=dataset, num_iterations=self.num_iterations
- )
+ trainer = Trainer(model=self.model, args=self.args, train_dataset=dataset, eval_dataset=dataset)
trainer.train()
metrics = trainer.evaluate()
self.assertEqual(metrics["accuracy"], 1.0)
@@ -74,96 +90,81 @@ def test_trainer_works_with_alternate_dataset_for_evaluate(self):
alternate_dataset = Dataset.from_dict(
{"text": ["x", "y", "z"], "label": [0, 1, 2], "extra_column": ["d", "e", "f"]}
)
- trainer = SetFitTrainer(
- model=self.model, train_dataset=dataset, eval_dataset=dataset, num_iterations=self.num_iterations
- )
+ trainer = Trainer(model=self.model, args=self.args, train_dataset=dataset, eval_dataset=dataset)
trainer.train()
metrics = trainer.evaluate(alternate_dataset)
self.assertNotEqual(metrics["accuracy"], 1.0)
def test_trainer_raises_error_with_missing_label(self):
dataset = Dataset.from_dict({"text": ["a", "b", "c"], "extra_column": ["d", "e", "f"]})
- trainer = SetFitTrainer(
- model=self.model, train_dataset=dataset, eval_dataset=dataset, num_iterations=self.num_iterations
- )
with pytest.raises(ValueError):
- trainer.train()
+ Trainer(model=self.model, args=self.args, train_dataset=dataset, eval_dataset=dataset)
def test_trainer_raises_error_with_missing_text(self):
"""If the required columns are missing from the dataset, the library should throw an error and list the columns found."""
dataset = Dataset.from_dict({"label": [0, 1, 2], "extra_column": ["d", "e", "f"]})
- trainer = SetFitTrainer(
- model=self.model, train_dataset=dataset, eval_dataset=dataset, num_iterations=self.num_iterations
- )
expected_message = re.escape(
"SetFit expected the dataset to have the columns ['label', 'text'], "
"but only the columns ['extra_column', 'label'] were found. "
- "Either make sure these columns are present, or specify which columns to use with column_mapping in SetFitTrainer."
+ "Either make sure these columns are present, or specify which columns to use with column_mapping in Trainer."
)
with pytest.raises(ValueError, match=expected_message):
- trainer._validate_column_mapping(trainer.train_dataset)
+ Trainer(model=self.model, args=self.args, train_dataset=dataset, eval_dataset=dataset)
def test_column_mapping_raises_error_when_mapped_columns_missing(self):
"""If the columns specified in the column mapping are missing from the dataset, the library should throw an error and list the columns found."""
dataset = Dataset.from_dict({"text": ["a", "b", "c"], "extra_column": ["d", "e", "f"]})
- trainer = SetFitTrainer(
- model=self.model,
- train_dataset=dataset,
- eval_dataset=dataset,
- num_iterations=self.num_iterations,
- column_mapping={"text_new": "text", "label_new": "label"},
- )
expected_message = re.escape(
"The column mapping expected the columns ['label_new', 'text_new'] in the dataset, "
"but the dataset had the columns ['extra_column', 'text'].",
)
with pytest.raises(ValueError, match=expected_message):
- trainer._validate_column_mapping(trainer.train_dataset)
+ Trainer(
+ model=self.model,
+ args=self.args,
+ train_dataset=dataset,
+ eval_dataset=dataset,
+ column_mapping={"text_new": "text", "label_new": "label"},
+ )
def test_trainer_raises_error_when_dataset_not_split(self):
"""Verify that an error is raised if we pass an unsplit dataset to the trainer."""
dataset = Dataset.from_dict({"text": ["a", "b", "c", "d"], "label": [0, 0, 1, 1]}).train_test_split(
test_size=0.5
)
- trainer = SetFitTrainer(
- model=self.model, train_dataset=dataset, eval_dataset=dataset, num_iterations=self.num_iterations
- )
expected_message = re.escape(
"SetFit expected a Dataset, but it got a DatasetDict with the splits ['test', 'train']. "
"Did you mean to select one of these splits from the dataset?",
)
with pytest.raises(ValueError, match=expected_message):
- trainer._validate_column_mapping(trainer.train_dataset)
+ Trainer(model=self.model, args=self.args, train_dataset=dataset, eval_dataset=dataset)
def test_trainer_raises_error_when_dataset_is_dataset_dict_with_train(self):
"""Verify that a useful error is raised if we pass an unsplit dataset with only a `train` split to the trainer."""
with tempfile.TemporaryDirectory() as tmpdirname:
- path = pathlib.Path(tmpdirname) / "test_dataset_dict_with_train.csv"
+ path = Path(tmpdirname) / "test_dataset_dict_with_train.csv"
path.write_text("label,text\n1,good\n0,terrible\n")
dataset = load_dataset("csv", data_files=str(path))
- trainer = SetFitTrainer(
- model=self.model, train_dataset=dataset, eval_dataset=dataset, num_iterations=self.num_iterations
- )
expected_message = re.escape(
"SetFit expected a Dataset, but it got a DatasetDict with the split ['train']. "
"Did you mean to select the training split with dataset['train']?",
)
with pytest.raises(ValueError, match=expected_message):
- trainer._validate_column_mapping(trainer.train_dataset)
+ Trainer(model=self.model, args=self.args, train_dataset=dataset, eval_dataset=dataset)
def test_column_mapping_multilabel(self):
dataset = Dataset.from_dict({"text_new": ["a", "b", "c"], "label_new": [[0, 1], [1, 2], [2, 0]]})
- trainer = SetFitTrainer(
+ trainer = Trainer(
model=self.model,
+ args=self.args,
train_dataset=dataset,
eval_dataset=dataset,
- num_iterations=self.num_iterations,
column_mapping={"text_new": "text", "label_new": "label"},
)
- trainer._validate_column_mapping(trainer.train_dataset)
- formatted_dataset = trainer._apply_column_mapping(trainer.train_dataset, trainer.column_mapping)
+ trainer._validate_column_mapping(dataset)
+ formatted_dataset = trainer._apply_column_mapping(dataset, trainer.column_mapping)
assert formatted_dataset.column_names == ["text", "label"]
@@ -186,12 +187,12 @@ def compute_metrics(y_pred, y_test):
"accuracy": accuracy_metric.compute(predictions=y_pred, references=y_test)["accuracy"],
}
- trainer = SetFitTrainer(
+ trainer = Trainer(
model=self.model,
+ args=self.args,
train_dataset=dataset,
eval_dataset=dataset,
metric=compute_metrics,
- num_iterations=self.num_iterations,
column_mapping={"text_new": "text", "label_new": "label"},
)
@@ -211,12 +212,12 @@ def test_raise_when_metric_value_is_invalid(self):
{"text_new": ["a", "b", "c"], "label_new": [0, 1, 2], "extra_column": ["d", "e", "f"]}
)
- trainer = SetFitTrainer(
+ trainer = Trainer(
model=self.model,
+ args=self.args,
train_dataset=dataset,
eval_dataset=dataset,
metric="this-metric-does-not-exist", # invalid metric value
- num_iterations=self.num_iterations,
column_mapping={"text_new": "text", "label_new": "label"},
)
@@ -225,17 +226,8 @@ def test_raise_when_metric_value_is_invalid(self):
with self.assertRaises(FileNotFoundError):
trainer.evaluate()
- def test_trainer_raises_error_with_wrong_warmup_proportion(self):
- # warmup_proportion must not be > 1.0
- with pytest.raises(ValueError):
- SetFitTrainer(warmup_proportion=1.1)
-
- # warmup_proportion must not be < 0.0
- with pytest.raises(ValueError):
- SetFitTrainer(warmup_proportion=-0.1)
-
-class SetFitTrainerDifferentiableHeadTest(TestCase):
+class TrainerDifferentiableHeadTest(TestCase):
def setUp(self):
self.dataset = Dataset.from_dict(
{"text_new": ["a", "b", "c"], "label_new": [0, 1, 2], "extra_column": ["d", "e", "f"]}
@@ -245,27 +237,40 @@ def setUp(self):
use_differentiable_head=True,
head_params={"out_features": 3},
)
- self.num_iterations = 1
+ self.args = TrainingArguments(num_iterations=1)
+
+ def test_trainer_normalize(self):
+ self.model = SetFitModel.from_pretrained(
+ "sentence-transformers/paraphrase-albert-small-v2",
+ use_differentiable_head=True,
+ head_params={"out_features": 3},
+ normalize_embeddings=True,
+ )
+ trainer = Trainer(
+ model=self.model,
+ args=self.args,
+ train_dataset=self.dataset,
+ eval_dataset=self.dataset,
+ column_mapping={"text_new": "text", "label_new": "label"},
+ )
+ trainer.train()
+ metrics = trainer.evaluate()
+ self.assertEqual(metrics, {"accuracy": 1.0})
def test_trainer_max_length_exceeds_max_acceptable_length(self):
- trainer = SetFitTrainer(
+ trainer = Trainer(
model=self.model,
+ args=self.args,
train_dataset=self.dataset,
eval_dataset=self.dataset,
- num_iterations=self.num_iterations,
column_mapping={"text_new": "text", "label_new": "label"},
)
trainer.unfreeze(keep_body_frozen=True)
with self.assertLogs(level=logging.WARNING) as cm:
max_length = 4096
max_acceptable_length = self.model.model_body.get_max_seq_length()
- trainer.train(
- num_epochs=1,
- batch_size=3,
- learning_rate=1e-2,
- l2_weight=0.0,
- max_length=max_length,
- )
+ args = TrainingArguments(num_iterations=1, max_length=max_length)
+ trainer.train(args)
self.assertEqual(
cm.output,
[
@@ -277,38 +282,32 @@ def test_trainer_max_length_exceeds_max_acceptable_length(self):
)
def test_trainer_max_length_is_smaller_than_max_acceptable_length(self):
- trainer = SetFitTrainer(
+ trainer = Trainer(
model=self.model,
+ args=self.args,
train_dataset=self.dataset,
eval_dataset=self.dataset,
- num_iterations=self.num_iterations,
column_mapping={"text_new": "text", "label_new": "label"},
)
- trainer.unfreeze(keep_body_frozen=True)
# An alternative way of `assertNoLogs`, which is new in Python 3.10
try:
with self.assertLogs(level=logging.WARNING) as cm:
max_length = 32
- trainer.train(
- num_epochs=1,
- batch_size=3,
- learning_rate=1e-2,
- l2_weight=0.0,
- max_length=max_length,
- )
+ args = TrainingArguments(num_iterations=1, max_length=max_length)
+ trainer.train(args)
self.assertEqual(cm.output, [])
except AssertionError as e:
if e.args[0] != "no logs of level WARNING or higher triggered on root":
raise AssertionError(e)
-class SetFitTrainerMultilabelTest(TestCase):
+class TrainerMultilabelTest(TestCase):
def setUp(self):
self.model = SetFitModel.from_pretrained(
"sentence-transformers/paraphrase-albert-small-v2", multi_target_strategy="one-vs-rest"
)
- self.num_iterations = 1
+ self.args = TrainingArguments(num_iterations=1)
def test_trainer_multilabel_support_callable_as_metric(self):
dataset = Dataset.from_dict({"text_new": ["a", "b", "c"], "label_new": [[1, 0, 0], [0, 1, 0], [0, 0, 1]]})
@@ -322,12 +321,12 @@ def compute_metrics(y_pred, y_test):
"accuracy": multilabel_accuracy_metric.compute(predictions=y_pred, references=y_test)["accuracy"],
}
- trainer = SetFitTrainer(
+ trainer = Trainer(
model=self.model,
+ args=self.args,
train_dataset=dataset,
eval_dataset=dataset,
metric=compute_metrics,
- num_iterations=self.num_iterations,
column_mapping={"text_new": "text", "label_new": "label"},
)
@@ -343,7 +342,7 @@ def compute_metrics(y_pred, y_test):
)
-class SetFitTrainerMultilabelDifferentiableTest(TestCase):
+class TrainerMultilabelDifferentiableTest(TestCase):
def setUp(self):
self.model = SetFitModel.from_pretrained(
"sentence-transformers/paraphrase-albert-small-v2",
@@ -351,7 +350,7 @@ def setUp(self):
use_differentiable_head=True,
head_params={"out_features": 2},
)
- self.num_iterations = 1
+ self.args = TrainingArguments(num_iterations=1)
def test_trainer_multilabel_support_callable_as_metric(self):
dataset = Dataset.from_dict({"text_new": ["", "a", "b", "ab"], "label_new": [[0, 0], [1, 0], [0, 1], [1, 1]]})
@@ -365,20 +364,16 @@ def compute_metrics(y_pred, y_test):
"accuracy": multilabel_accuracy_metric.compute(predictions=y_pred, references=y_test)["accuracy"],
}
- trainer = SetFitTrainer(
+ trainer = Trainer(
model=self.model,
+ args=self.args,
train_dataset=dataset,
eval_dataset=dataset,
metric=compute_metrics,
- num_iterations=self.num_iterations,
column_mapping={"text_new": "text", "label_new": "label"},
)
- trainer.freeze()
trainer.train()
-
- trainer.unfreeze(keep_body_frozen=False)
- trainer.train(5)
metrics = trainer.evaluate()
self.assertEqual(
@@ -396,7 +391,7 @@ def setUp(self):
self.dataset = Dataset.from_dict(
{"text_new": ["a", "b", "c"], "label_new": [0, 1, 2], "extra_column": ["d", "e", "f"]}
)
- self.num_iterations = 1
+ self.args = TrainingArguments(num_iterations=1)
def test_hyperparameter_search(self):
class MyTrialShortNamer(TrialShortNamer):
@@ -425,10 +420,10 @@ def model_init(params):
def hp_name(trial):
return MyTrialShortNamer.shortname(trial.params)
- trainer = SetFitTrainer(
+ trainer = Trainer(
+ args=self.args,
train_dataset=self.dataset,
eval_dataset=self.dataset,
- num_iterations=self.num_iterations,
model_init=model_init,
column_mapping={"text_new": "text", "label_new": "label"},
)
@@ -451,27 +446,26 @@ def hp_name(trial):
def test_trainer_works_with_non_default_loss_class(loss_class):
dataset = Dataset.from_dict({"text": ["a 1", "b 1", "c 1", "a 2", "b 2", "c 2"], "label": [0, 1, 2, 0, 1, 2]})
model = SetFitModel.from_pretrained("sentence-transformers/paraphrase-albert-small-v2")
- trainer = SetFitTrainer(
+ args = TrainingArguments(num_iterations=1, loss=loss_class)
+ trainer = Trainer(
model=model,
+ args=args,
train_dataset=dataset,
eval_dataset=dataset,
- num_iterations=1,
- loss_class=loss_class,
)
trainer.train()
# no asserts here because this is a regression test - we only test if an exception is raised
-def test_trainer_evaluate_with_strings():
+def test_trainer_evaluate_with_strings(model: SetFitModel):
dataset = Dataset.from_dict(
{"text": ["positive sentence", "negative sentence"], "label": ["positive", "negative"]}
)
- model = SetFitModel.from_pretrained("sentence-transformers/paraphrase-albert-small-v2")
- trainer = SetFitTrainer(
+ trainer = Trainer(
model=model,
+ args=TrainingArguments(num_iterations=1),
train_dataset=dataset,
eval_dataset=dataset,
- num_iterations=1,
)
trainer.train()
# This used to fail due to "TypeError: can't convert np.ndarray of type numpy.str_.
@@ -485,13 +479,13 @@ def test_trainer_evaluate_multilabel_f1():
"sentence-transformers/paraphrase-albert-small-v2", multi_target_strategy="one-vs-rest"
)
- trainer = SetFitTrainer(
+ trainer = Trainer(
model=model,
+ args=TrainingArguments(num_iterations=5),
train_dataset=dataset,
eval_dataset=dataset,
metric="f1",
metric_kwargs={"average": "micro"},
- num_iterations=5,
column_mapping={"text_new": "text", "label_new": "label"},
)
@@ -502,9 +496,7 @@ def test_trainer_evaluate_multilabel_f1():
def test_trainer_evaluate_on_cpu() -> None:
# This test used to fail if CUDA was available
- dataset = Dataset.from_dict(
- {"text": ["positive sentence", "negative sentence"], "label": ["positive", "negative"]}
- )
+ dataset = Dataset.from_dict({"text": ["positive sentence", "negative sentence"], "label": [1, 0]})
model = SetFitModel.from_pretrained(
"sentence-transformers/paraphrase-albert-small-v2", use_differentiable_head=True
)
@@ -513,12 +505,111 @@ def compute_metric(y_pred, y_test) -> None:
assert y_pred.device == torch.device("cpu")
return 1.0
- trainer = SetFitTrainer(
+ args = TrainingArguments(num_iterations=5)
+ trainer = Trainer(
model=model,
+ args=args,
train_dataset=dataset,
eval_dataset=dataset,
metric=compute_metric,
- num_iterations=5,
)
trainer.train()
trainer.evaluate()
+
+
+def test_no_model_no_model_init():
+ with pytest.raises(RuntimeError, match="`Trainer` requires either a `model` or `model_init` argument."):
+ Trainer()
+
+
+def test_model_and_model_init(model: SetFitModel):
+ def model_init() -> SetFitModel:
+ return model
+
+ with pytest.raises(RuntimeError, match="`Trainer` requires either a `model` or `model_init` argument."):
+ Trainer(model=model, model_init=model_init)
+
+
+def test_trainer_callbacks(model: SetFitModel):
+ trainer = Trainer(model=model)
+ assert len(trainer.callback_handler.callbacks) >= 2
+ callback_names = {callback.__class__.__name__ for callback in trainer.callback_handler.callbacks}
+ assert {"DefaultFlowCallback", "ProgressCallback"} <= callback_names
+
+ class TestCallback(TrainerCallback):
+ pass
+
+ callback = TestCallback()
+ trainer.add_callback(callback)
+ assert len(trainer.callback_handler.callbacks) == len(callback_names) + 1
+ assert trainer.callback_handler.callbacks[-1] == callback
+
+ assert trainer.pop_callback(callback) == callback
+ trainer.add_callback(callback)
+ assert trainer.callback_handler.callbacks[-1] == callback
+ trainer.remove_callback(callback)
+ assert callback not in trainer.callback_handler.callbacks
+
+
+def test_trainer_warn_freeze(model: SetFitModel):
+ trainer = Trainer(model)
+ with pytest.warns(
+ DeprecationWarning,
+ match="Trainer.freeze` is deprecated and will be removed in v2.0.0 of SetFit. "
+ "Please use `SetFitModel.freeze` directly instead.",
+ ):
+ trainer.freeze()
+
+
+def test_train_with_kwargs(model: SetFitModel) -> None:
+ train_dataset = Dataset.from_dict({"text": ["positive sentence", "negative sentence"], "label": [1, 0]})
+ trainer = Trainer(model, train_dataset=train_dataset)
+ with pytest.warns(DeprecationWarning, match="`Trainer.train` does not accept keyword arguments anymore."):
+ trainer.train(num_epochs=5)
+
+
+def test_train_no_dataset(model: SetFitModel) -> None:
+ trainer = Trainer(model)
+ with pytest.raises(ValueError, match="Training requires a `train_dataset` given to the `Trainer` initialization."):
+ trainer.train()
+
+
+def test_train_amp_save(model: SetFitModel, tmp_path: Path) -> None:
+ args = TrainingArguments(output_dir=tmp_path, use_amp=True, save_steps=5, num_epochs=5)
+ dataset = Dataset.from_dict({"text": ["a", "b", "c"], "label": [0, 1, 2]})
+ trainer = Trainer(model, args=args, train_dataset=dataset, eval_dataset=dataset)
+ trainer.train()
+ assert trainer.evaluate() == {"accuracy": 1.0}
+ assert "step_5" in os.listdir(tmp_path)
+
+
+def test_train_load_best(model: SetFitModel, tmp_path: Path, caplog: LogCaptureFixture) -> None:
+ args = TrainingArguments(
+ output_dir=tmp_path,
+ save_steps=5,
+ eval_steps=5,
+ evaluation_strategy="steps",
+ load_best_model_at_end=True,
+ num_epochs=5,
+ )
+ dataset = Dataset.from_dict({"text": ["a", "b", "c"], "label": [0, 1, 2]})
+ trainer = Trainer(model, args=args, train_dataset=dataset, eval_dataset=dataset)
+ with caplog.at_level(logging.INFO):
+ trainer.train()
+
+ assert any("Load pretrained SentenceTransformer" in text for _, _, text in caplog.record_tuples)
+
+
+def test_evaluate_with_strings(model: SetFitModel) -> None:
+ dataset = Dataset.from_dict({"text": ["a", "b", "c"], "label": ["positive", "positive", "negative"]})
+ trainer = Trainer(model, train_dataset=dataset, eval_dataset=dataset)
+ trainer.train()
+ metrics = trainer.evaluate()
+ assert "accuracy" in metrics
+
+
+def test_trainer_wrong_args(model: SetFitModel, tmp_path: Path) -> None:
+ dataset = Dataset.from_dict({"text": ["a", "b", "c"], "label": [0, 1, 2]})
+ expected = "`args` must be a `TrainingArguments` instance imported from `setfit`."
+ with pytest.raises(ValueError, match=expected):
+ Trainer(model, dataset)
diff --git a/tests/test_trainer_distillation.py b/tests/test_trainer_distillation.py
index 82dd0b05..866c37ad 100644
--- a/tests/test_trainer_distillation.py
+++ b/tests/test_trainer_distillation.py
@@ -2,39 +2,36 @@
import pytest
from datasets import Dataset
-from sentence_transformers.losses import CosineSimilarityLoss
-from setfit import DistillationSetFitTrainer, SetFitTrainer
+from setfit import DistillationTrainer, Trainer
from setfit.modeling import SetFitModel
+from setfit.training_args import TrainingArguments
-class DistillationSetFitTrainerTest(TestCase):
+class DistillationTrainerTest(TestCase):
def setUp(self):
self.teacher_model = SetFitModel.from_pretrained("sentence-transformers/paraphrase-albert-small-v2")
self.student_model = SetFitModel.from_pretrained("sentence-transformers/paraphrase-MiniLM-L3-v2")
- self.num_iterations = 1
+ self.args = TrainingArguments(num_iterations=1)
def test_trainer_works_with_default_columns(self):
dataset = Dataset.from_dict({"text": ["a", "b", "c"], "label": [0, 1, 2], "extra_column": ["d", "e", "f"]})
# train a teacher model
- teacher_trainer = SetFitTrainer(
+ teacher_trainer = Trainer(
model=self.teacher_model,
train_dataset=dataset,
eval_dataset=dataset,
- loss_class=CosineSimilarityLoss,
metric="accuracy",
)
# Teacher Train and evaluate
teacher_trainer.train()
- metrics = teacher_trainer.evaluate()
teacher_model = teacher_trainer.model
- student_trainer = DistillationSetFitTrainer(
+ student_trainer = DistillationTrainer(
teacher_model=teacher_model,
train_dataset=dataset,
student_model=self.student_model,
eval_dataset=dataset,
- loss_class=CosineSimilarityLoss,
metric="accuracy",
)
@@ -45,56 +42,70 @@ def test_trainer_works_with_default_columns(self):
self.assertEqual(metrics["accuracy"], 1.0)
def test_trainer_raises_error_with_missing_label(self):
- dataset = Dataset.from_dict({"text": ["a", "b", "c"], "extra_column": ["d", "e", "f"]})
- trainer = DistillationSetFitTrainer(
+ labeled_dataset = Dataset.from_dict(
+ {"text": ["a", "b", "c"], "label": [0, 1, 2], "extra_column": ["d", "e", "f"]}
+ )
+ # train a teacher model
+ teacher_trainer = Trainer(
+ model=self.teacher_model,
+ train_dataset=labeled_dataset,
+ eval_dataset=labeled_dataset,
+ metric="accuracy",
+ args=self.args,
+ )
+ # Teacher Train and evaluate
+ teacher_trainer.train()
+
+ unlabeled_dataset = Dataset.from_dict({"text": ["a", "b", "c"], "extra_column": ["d", "e", "f"]})
+ student_trainer = DistillationTrainer(
teacher_model=self.teacher_model,
- train_dataset=dataset,
student_model=self.student_model,
- eval_dataset=dataset,
- num_iterations=self.num_iterations,
+ train_dataset=unlabeled_dataset,
+ eval_dataset=labeled_dataset,
+ args=self.args,
)
- with pytest.raises(ValueError):
- trainer.train()
+ student_trainer.train()
+ metrics = student_trainer.evaluate()
+ print("Student results: ", metrics)
+ self.assertEqual(metrics["accuracy"], 1.0)
def test_trainer_raises_error_with_missing_text(self):
dataset = Dataset.from_dict({"label": [0, 1, 2], "extra_column": ["d", "e", "f"]})
- trainer = DistillationSetFitTrainer(
- teacher_model=self.teacher_model,
- train_dataset=dataset,
- student_model=self.student_model,
- eval_dataset=dataset,
- num_iterations=self.num_iterations,
- )
with pytest.raises(ValueError):
- trainer.train()
+ DistillationTrainer(
+ teacher_model=self.teacher_model,
+ train_dataset=dataset,
+ student_model=self.student_model,
+ eval_dataset=dataset,
+ args=self.args,
+ )
def test_column_mapping_with_missing_text(self):
dataset = Dataset.from_dict({"text": ["a", "b", "c"], "extra_column": ["d", "e", "f"]})
- trainer = DistillationSetFitTrainer(
- teacher_model=self.teacher_model,
- train_dataset=dataset,
- student_model=self.student_model,
- eval_dataset=dataset,
- num_iterations=self.num_iterations,
- column_mapping={"label_new": "label"},
- )
with pytest.raises(ValueError):
- trainer._validate_column_mapping(trainer.train_dataset)
+ DistillationTrainer(
+ teacher_model=self.teacher_model,
+ train_dataset=dataset,
+ student_model=self.student_model,
+ eval_dataset=dataset,
+ args=self.args,
+ column_mapping={"label_new": "label"},
+ )
def test_column_mapping_multilabel(self):
dataset = Dataset.from_dict({"text_new": ["a", "b", "c"], "label_new": [[0, 1], [1, 2], [2, 0]]})
- trainer = DistillationSetFitTrainer(
+ trainer = DistillationTrainer(
teacher_model=self.teacher_model,
train_dataset=dataset,
student_model=self.student_model,
eval_dataset=dataset,
- num_iterations=self.num_iterations,
+ args=self.args,
column_mapping={"text_new": "text", "label_new": "label"},
)
- trainer._validate_column_mapping(trainer.train_dataset)
- formatted_dataset = trainer._apply_column_mapping(trainer.train_dataset, trainer.column_mapping)
+ trainer._validate_column_mapping(dataset)
+ formatted_dataset = trainer._apply_column_mapping(dataset, trainer.column_mapping)
assert formatted_dataset.column_names == ["text", "label"]
assert formatted_dataset[0]["text"] == "a"
@@ -102,22 +113,8 @@ def test_column_mapping_multilabel(self):
assert formatted_dataset[1]["text"] == "b"
-def train_diff(trainer: SetFitTrainer):
- # Teacher Train and evaluate
- trainer.freeze() # Freeze the head
- trainer.train() # Train only the body
-
- # Unfreeze the head and unfreeze the body -> end-to-end training
- trainer.unfreeze(keep_body_frozen=False)
-
- trainer.train(num_epochs=5)
-
-
-def train_lr(trainer: SetFitTrainer):
- trainer.train()
-
-
-@pytest.mark.parametrize(("teacher_diff", "student_diff"), [[True, False], [True, False]])
+@pytest.mark.parametrize("teacher_diff", [True, False])
+@pytest.mark.parametrize("student_diff", [True, False])
def test_differentiable_models(teacher_diff: bool, student_diff: bool) -> None:
if teacher_diff:
teacher_model = SetFitModel.from_pretrained(
@@ -125,34 +122,32 @@ def test_differentiable_models(teacher_diff: bool, student_diff: bool) -> None:
use_differentiable_head=True,
head_params={"out_features": 3},
)
- teacher_train_func = train_diff
else:
teacher_model = SetFitModel.from_pretrained("sentence-transformers/paraphrase-albert-small-v2")
- teacher_train_func = train_lr
if student_diff:
student_model = SetFitModel.from_pretrained(
"sentence-transformers/paraphrase-MiniLM-L3-v2",
use_differentiable_head=True,
head_params={"out_features": 3},
)
- student_train_func = train_diff
else:
student_model = SetFitModel.from_pretrained("sentence-transformers/paraphrase-MiniLM-L3-v2")
- student_train_func = train_lr
dataset = Dataset.from_dict({"text": ["a", "b", "c"], "label": [0, 1, 2], "extra_column": ["d", "e", "f"]})
# train a teacher model
- teacher_trainer = SetFitTrainer(
+ teacher_trainer = Trainer(
model=teacher_model,
train_dataset=dataset,
eval_dataset=dataset,
metric="accuracy",
)
- teacher_train_func(teacher_trainer)
+ teacher_trainer.train()
metrics = teacher_trainer.evaluate()
+ print("Teacher results: ", metrics)
+ assert metrics["accuracy"] == 1.0
teacher_model = teacher_trainer.model
- student_trainer = DistillationSetFitTrainer(
+ student_trainer = DistillationTrainer(
teacher_model=teacher_model,
train_dataset=dataset,
student_model=student_model,
@@ -161,7 +156,7 @@ def test_differentiable_models(teacher_diff: bool, student_diff: bool) -> None:
)
# Student Train and evaluate
- student_train_func(student_trainer)
+ student_trainer.train()
metrics = student_trainer.evaluate()
print("Student results: ", metrics)
assert metrics["accuracy"] == 1.0
diff --git a/tests/test_training_args.py b/tests/test_training_args.py
new file mode 100644
index 00000000..ee7b4f88
--- /dev/null
+++ b/tests/test_training_args.py
@@ -0,0 +1,105 @@
+from unittest import TestCase
+
+import pytest
+from transformers import IntervalStrategy
+
+from setfit.training_args import TrainingArguments
+
+
+class TestTrainingArguments(TestCase):
+ def test_raises_error_with_wrong_warmup_proportion(self):
+ # warmup_proportion must not be > 1.0
+ with pytest.raises(ValueError):
+ TrainingArguments(warmup_proportion=1.1)
+
+ # warmup_proportion must not be < 0.0
+ with pytest.raises(ValueError):
+ TrainingArguments(warmup_proportion=-0.1)
+
+ def test_batch_sizes(self):
+ batch_size_A = 12
+ batch_size_B = 4
+
+ args = TrainingArguments(batch_size=batch_size_A)
+ self.assertEqual(args.batch_size, (batch_size_A, batch_size_A))
+ self.assertEqual(args.embedding_batch_size, batch_size_A)
+ self.assertEqual(args.classifier_batch_size, batch_size_A)
+
+ args = TrainingArguments(batch_size=(batch_size_A, batch_size_B))
+ self.assertEqual(args.batch_size, (batch_size_A, batch_size_B))
+ self.assertEqual(args.embedding_batch_size, batch_size_A)
+ self.assertEqual(args.classifier_batch_size, batch_size_B)
+
+ def test_num_epochs(self):
+ num_epochs_A = 12
+ num_epochs_B = 4
+
+ args = TrainingArguments(num_epochs=num_epochs_A)
+ self.assertEqual(args.num_epochs, (num_epochs_A, num_epochs_A))
+ self.assertEqual(args.embedding_num_epochs, num_epochs_A)
+ self.assertEqual(args.classifier_num_epochs, num_epochs_A)
+
+ args = TrainingArguments(num_epochs=(num_epochs_A, num_epochs_B))
+ self.assertEqual(args.num_epochs, (num_epochs_A, num_epochs_B))
+ self.assertEqual(args.embedding_num_epochs, num_epochs_A)
+ self.assertEqual(args.classifier_num_epochs, num_epochs_B)
+
+ def test_learning_rates(self):
+ learning_rate_A = 1e-2
+ learning_rate_B = 1e-3
+
+ base = TrainingArguments()
+
+ args = TrainingArguments(body_learning_rate=learning_rate_A)
+ self.assertEqual(args.body_learning_rate, (learning_rate_A, learning_rate_A))
+ self.assertEqual(args.body_embedding_learning_rate, learning_rate_A)
+ self.assertEqual(args.body_classifier_learning_rate, learning_rate_A)
+ self.assertEqual(args.head_learning_rate, base.head_learning_rate)
+
+ args = TrainingArguments(body_learning_rate=(learning_rate_A, learning_rate_B))
+ self.assertEqual(args.body_learning_rate, (learning_rate_A, learning_rate_B))
+ self.assertEqual(args.body_embedding_learning_rate, learning_rate_A)
+ self.assertEqual(args.body_classifier_learning_rate, learning_rate_B)
+ self.assertEqual(args.head_learning_rate, base.head_learning_rate)
+
+ def test_report_to(self):
+ args = TrainingArguments(report_to="none")
+ self.assertEqual(args.report_to, [])
+ args = TrainingArguments(report_to=["none"])
+ self.assertEqual(args.report_to, [])
+ args = TrainingArguments(report_to="hello")
+ self.assertEqual(args.report_to, ["hello"])
+
+ def test_eval_steps_without_eval_strat(self):
+ args = TrainingArguments(eval_steps=5)
+ self.assertEqual(args.evaluation_strategy, IntervalStrategy.STEPS)
+
+ def test_eval_strat_steps_without_eval_steps(self):
+ args = TrainingArguments(evaluation_strategy="steps")
+ self.assertEqual(args.eval_steps, args.logging_steps)
+ with self.assertRaises(ValueError):
+ TrainingArguments(evaluation_strategy="steps", logging_steps=0, logging_strategy="no")
+
+ def test_load_best_model(self):
+ with self.assertRaises(ValueError):
+ TrainingArguments(load_best_model_at_end=True, evaluation_strategy="steps", save_strategy="epoch")
+ with self.assertRaises(ValueError):
+ TrainingArguments(
+ load_best_model_at_end=True,
+ evaluation_strategy="steps",
+ save_strategy="steps",
+ eval_steps=100,
+ save_steps=50,
+ )
+ # No error: save_steps is a round multiple of eval_steps
+ TrainingArguments(
+ load_best_model_at_end=True,
+ evaluation_strategy="steps",
+ save_strategy="steps",
+ eval_steps=50,
+ save_steps=100,
+ )
+
+ def test_logging_steps_zero(self):
+ with self.assertRaises(ValueError):
+ TrainingArguments(logging_strategy="steps", logging_steps=0)