diff --git a/docs/source/_toctree.yml b/docs/source/_toctree.yml
index aa79f0df2e..4ba37d472f 100644
--- a/docs/source/_toctree.yml
+++ b/docs/source/_toctree.yml
@@ -1,6 +1,6 @@
- sections:
- local: index
- title: 🤗 Optimum Habana
+ title: 🤗 Optimum for Intel Gaudi
- local: installation
title: Installation
- local: quickstart
@@ -16,12 +16,14 @@
title: Run Inference
- local: tutorials/stable_diffusion
title: Stable Diffusion
- - local: tutorials/stable_diffusion_ldm3d
- title: LDM3D
+ - local: tutorials/tgi
+ title: TGI on Gaudi
title: Tutorials
- sections:
- local: usage_guides/overview
title: Overview
+ - local: usage_guides/script_adaptation
+ title: Script Adaptation
- local: usage_guides/pretraining
title: Pretraining Transformers
- local: usage_guides/accelerate_training
@@ -32,20 +34,16 @@
title: How to use DeepSpeed
- local: usage_guides/multi_node_training
title: Multi-node Training
+ - local: usage_guides/quantization
+ title: Quantization
title: How-To Guides
- - sections:
- - local: concept_guides/hpu
- title: What are Habana's Gaudi and HPUs?
- title: Conceptual Guides
- sections:
- local: package_reference/trainer
title: Gaudi Trainer
- local: package_reference/gaudi_config
title: Gaudi Configuration
- - local: package_reference/stable_diffusion_pipeline
- title: Gaudi Stable Diffusion Pipeline
- local: package_reference/distributed_runner
title: Distributed Runner
title: Reference
- title: Optimum Habana
- isExpanded: false
+ title: Optimum for Intel Gaudi
+ isExpanded: false
\ No newline at end of file
diff --git a/docs/source/concept_guides/hpu.mdx b/docs/source/concept_guides/hpu.mdx
deleted file mode 100644
index 111f8be903..0000000000
--- a/docs/source/concept_guides/hpu.mdx
+++ /dev/null
@@ -1,49 +0,0 @@
-
-
-# What are Intel® Gaudi® 1, Intel® Gaudi® 2 and HPUs?
-
-[Intel Gaudi 1](https://habana.ai/training/gaudi/) and [Intel Gaudi 2](https://habana.ai/training/gaudi2/) are the first- and second-generation AI hardware accelerators designed by Habana Labs and Intel.
-A single server contains 8 devices called Habana Processing Units (HPUs) with 96GB of memory each on Gaudi2 and 32GB on first-gen Gaudi.
-Check out [here](https://docs.habana.ai/en/latest/Gaudi_Overview/Gaudi_Architecture.html) for more information about the underlying hardware architecture.
-
-The Habana SDK is called [SynapseAI](https://docs.habana.ai/en/latest/index.html) and is common to both first-gen Gaudi and Gaudi2.
-As a consequence, 🤗 Optimum Habana is fully compatible with both generations of accelerators.
-
-
-## Execution modes
-
-Two execution modes are supported on HPUs for PyTorch, which is the main deep learning framework the 🤗 Transformers and 🤗 Diffusers libraries rely on:
-
-- *Eager mode* execution, where the framework executes one operation at a time as defined in [standard PyTorch eager mode](https://pytorch.org/tutorials/beginner/hybrid_frontend/learning_hybrid_frontend_through_example_tutorial.html).
-- *Lazy mode* execution, where operations are internally accumulated in a graph. The execution of the operations in the accumulated graph is triggered in a lazy manner, only when a tensor value is required by the user or when it is explicitly required in the script. The [SynapseAI graph compiler](https://docs.habana.ai/en/latest/Gaudi_Overview/SynapseAI_Software_Suite.html#graph-compiler-and-runtime) will optimize the execution of the operations accumulated in the graph (e.g. operator fusion, data layout management, parallelization, pipelining and memory management, graph-level optimizations).
-
-See [here](../usage_guides/accelerate_training#lazy-mode) how to use these execution modes in Optimum for Intel Gaudi.
-
-
-## Distributed training
-
-First-gen Gaudi and Gaudi2 are well-equipped for distributed training:
-
-- *Scale-up* to 8 devices on one server. See [here](../tutorials/distributed) how to perform distributed training on a single node.
-- *Scale-out* to 1000s of devices on several servers. See [here](../usage_guides/multi_node_training) how to do multi-node training.
-
-
-## Inference
-
-HPUs can also be used to perform inference:
-- Through HPU graphs that are well-suited for latency-sensitive applications. Check out [here](../usage_guides/accelerate_inference) how to use them.
-- In lazy mode, which can be used the same way as for training.
diff --git a/docs/source/index.mdx b/docs/source/index.mdx
index 2b0606364e..f7de4312dd 100644
--- a/docs/source/index.mdx
+++ b/docs/source/index.mdx
@@ -15,15 +15,36 @@ limitations under the License.
-->
-# Optimum for Intel Gaudi
+# Optimum for Intel® Gaudi® AI Accelerator
-Optimum for Intel Gaudi is the interface between the Transformers and Diffusers libraries and [Intel® Gaudi® AI Accelerators (HPUs)](https://docs.habana.ai/en/latest/index.html).
+Optimum for Intel Gaudi AI accelerator is the interface between Hugging Face libraries (Transformers, Diffusers, Accelerate,...) and [Intel Gaudi AI Accelerators (HPUs)](https://docs.habana.ai/en/latest/index.html).
It provides a set of tools that enable easy model loading, training and inference on single- and multi-HPU settings for various downstream tasks as shown in the table below.
-HPUs offer fast model training and inference as well as a great price-performance ratio.
-Check out [this blog post about BERT pre-training](https://huggingface.co/blog/pretraining-bert) and [this post benchmarking Intel Gaudi 2 with NVIDIA A100 GPUs](https://huggingface.co/blog/habana-gaudi-2-benchmark) for concrete examples.
-If you are not familiar with HPUs, we recommend you take a look at [our conceptual guide](./concept_guides/hpu).
+
+
+The Intel Gaudi AI accelerator family currently includes three product generations:
+[Intel Gaudi 1](https://habana.ai/products/gaudi/),
+[Intel Gaudi 2](https://habana.ai/products/gaudi2/), and
+[Intel Gaudi 3](https://habana.ai/products/gaudi3/).
+Each server is equipped with 8 devices, known as Habana Processing Units (HPUs), providing 128GB of memory on Gaudi 3,
+96GB on Gaudi 2, and 32GB on the first-gen Gaudi. For more details on the underlying hardware architecture, check out the
+[Gaudi Architecture Overview](https://docs.habana.ai/en/latest/Gaudi_Overview/Gaudi_Architecture.html).
+Optimum for Intel Gaudi library is fully compatible with all three generations of Gaudi accelerators.
+For in-depth examples of running workloads on Gaudi, explore the following blog posts:
+- [Benchmarking Intel Gaudi 2 with NVIDIA A100 GPUs](https://huggingface.co/blog/habana-gaudi-2-benchmark)
+- [Accelerating Vision-Language Models: BridgeTower on Habana Gaudi2](https://huggingface.co/blog/bridgetower)
The following model architectures, tasks and device distributions have been validated for Optimum for Intel Gaudi:
@@ -91,7 +112,7 @@ In the tables below, ✅ means single-card, multi-card and DeepSpeed have all be
| Stable Diffusion XL | [fine-tuning](https://github.com/huggingface/optimum-habana/tree/main/examples/stable-diffusion/training#fine-tuning-for-stable-diffusion-xl) | Single card | [text-to-image generation](https://github.com/huggingface/optimum-habana/tree/main/examples/stable-diffusion) |
| Stable Diffusion Depth2img | | Single card | [depth-to-image generation](https://github.com/huggingface/optimum-habana/tree/main/examples/stable-diffusion) |
| LDM3D | | Single card | [text-to-image generation](https://github.com/huggingface/optimum-habana/tree/main/examples/stable-diffusion) |
-| Text to Video | | Single card | [text-to-video generation](https://github.com/huggingface/optimum-habana/tree/main/examples/text-to-video) |
+| Text to Video | | Single card | [text-to-video generation](https://github.com/huggingface/optimum-habana/tree/main/examples/text-to-video) |
- PyTorch Image Models/TIMM:
@@ -109,27 +130,5 @@ In the tables below, ✅ means single-card, multi-card and DeepSpeed have all be
Other models and tasks supported by the 🤗 Transformers and 🤗 Diffusers library may also work.
-You can refer to this [section](https://github.com/huggingface/optimum-habana#how-to-use-it) for using them with 🤗 Optimum Habana.
-Besides, [this page](https://github.com/huggingface/optimum-habana/tree/main/examples) explains how to modify any [example](https://github.com/huggingface/transformers/tree/main/examples/pytorch) from the 🤗 Transformers library to make it work with 🤗 Optimum Habana.
-
-
-
+You can refer to this [section](https://github.com/huggingface/optimum-habana#how-to-use-it) for using them with 🤗 Optimum for Intel Gaudi.
+In addition, [this page](https://github.com/huggingface/optimum-habana/tree/main/examples) explains how to modify any [example](https://github.com/huggingface/transformers/tree/main/examples/pytorch) from the 🤗 Transformers library to make it work with 🤗 Optimum for Intel Gaudi.
diff --git a/docs/source/installation.mdx b/docs/source/installation.mdx
index 44fff7c10c..2b6e8a0a5c 100644
--- a/docs/source/installation.mdx
+++ b/docs/source/installation.mdx
@@ -12,7 +12,8 @@ specific language governing permissions and limitations under the License.
# Installation
-To install Optimum for Intel Gaudi, you first need to install SynapseAI and the Intel® Gaudi® drivers by following the official [installation guide](https://docs.habana.ai/en/latest/Installation_Guide/index.html).
+To install Optimum for Intel® Gaudi® AI accelerator, you first need to install Intel Gaudi Software and the Intel Gaudi
+AI accelerator drivers by following the official [installation guide](https://docs.habana.ai/en/latest/Installation_Guide/index.html).
Then, Optimum for Intel Gaudi can be installed using `pip` as follows:
```bash
@@ -20,9 +21,13 @@ python -m pip install --upgrade-strategy eager optimum[habana]
```
-To use DeepSpeed on HPUs, you also need to run the following command:
+To use Microsoft® DeepSpeed with Intel Gaudi devices, you also need to run the following command:
```bash
python -m pip install git+https://github.com/HabanaAI/DeepSpeed.git@1.18.0
```
+To ensure that you are installing the correct Intel Gaudi Software, please run the `hl-smi` command to confirm the software version
+being used in the system and apply the same version when running the DeepSpeed installation; please review the Intel Gaudi
+[Support Matrix](https://docs.habana.ai/en/latest/Support_Matrix/Support_Matrix.html) and ensure that you are using an appropriate
+version of DeepSpeed.
diff --git a/docs/source/package_reference/gaudi_config.mdx b/docs/source/package_reference/gaudi_config.mdx
index a7b9f077b5..90dc16edcb 100644
--- a/docs/source/package_reference/gaudi_config.mdx
+++ b/docs/source/package_reference/gaudi_config.mdx
@@ -16,20 +16,109 @@ limitations under the License.
# GaudiConfig
+To define a configuration for a specific workload you can use `GaudiConfig` class.
+
Here is a description of each configuration parameter:
-- `use_fused_adam` enables to decide whether to use the [custom fused implementation of the ADAM optimizer provided by Intel® Gaudi® AI Accelerator](https://docs.habana.ai/en/latest/PyTorch/Model_Optimization_PyTorch/Custom_Ops_PyTorch.html#custom-optimizers).
-- `use_fused_clip_norm` enables to decide whether to use the [custom fused implementation of gradient norm clipping provided by Intel® Gaudi® AI Accelerator](https://docs.habana.ai/en/latest/PyTorch/Model_Optimization_PyTorch/Custom_Ops_PyTorch.html#other-custom-ops).
-- `use_torch_autocast` enables PyTorch autocast; used to define good pre-defined config; users should favor `--bf16` training argument
-- `autocast_bf16_ops` list of operations that should be run with bf16 precision under autocast context; using environment flag PT_HPU_AUTOCAST_LOWER_PRECISION_OPS_LIST is a preffered way for operator autocast list override
-- `autocast_fp32_ops` list of operations that should be run with fp32 precision under autocast context; using environment flag PT_HPU_AUTOCAST_FP32_OPS_LIST is a preffered way for operator autocast list override
+- `use_fused_adam` controls whether to use the [custom fused implementation of the ADAM optimizer provided by Intel® Gaudi® AI Accelerator](https://docs.habana.ai/en/latest/PyTorch/Model_Optimization_PyTorch/Custom_Ops_PyTorch.html#custom-optimizers).
+- `use_fused_clip_norm` controls whether to use the [custom fused implementation of gradient norm clipping provided by Intel® Gaudi® AI Accelerator](https://docs.habana.ai/en/latest/PyTorch/Model_Optimization_PyTorch/Custom_Ops_PyTorch.html#other-custom-ops).
+- `use_torch_autocast` controls whether to enable PyTorch autocast; used to define good pre-defined config; users should favor `--bf16` training argument
+- `use_dynamic_shapes` controls whether to enable dynamic shapes suppport when processing input dataset
+- `autocast_bf16_ops` list of operations that should be run with bf16 precision under autocast context; using environment flag LOWER_LIST is a preffered way for operator autocast list override
+- `autocast_fp32_ops` list of operations that should be run with fp32 precision under autocast context; using environment flag FP32_LIST is a preffered way for operator autocast list override
+Parameter values of this class can be set from an external JSON file.
-You can find examples of Gaudi configurations in the [Habana model repository on the Hugging Face Hub](https://huggingface.co/habana). For instance, [for BERT Large we have](https://huggingface.co/Habana/bert-large-uncased-whole-word-masking/blob/main/gaudi_config.json):
+You can find examples of Gaudi configurations in the [Intel Gaudi model repository on the Hugging Face Hub](https://huggingface.co/habana).
+For instance, [for BERT Large we have](https://huggingface.co/Habana/bert-large-uncased-whole-word-masking/blob/main/gaudi_config.json):
+```JSON
+{
+ "use_fused_adam": true,
+ "use_fused_clip_norm": true,
+ "use_torch_autocast": true
+}
+```
+More advanced configuration file [for Stable Diffusion 2](https://huggingface.co/Habana/stable-diffusion-2/blob/main/gaudi_config.json):
```JSON
{
+ "use_torch_autocast": true,
"use_fused_adam": true,
"use_fused_clip_norm": true,
+ "autocast_bf16_ops": [
+ "_convolution.deprecated",
+ "_convolution",
+ "conv1d",
+ "conv2d",
+ "conv3d",
+ "conv_tbc",
+ "conv_transpose1d",
+ "conv_transpose2d.input",
+ "conv_transpose3d.input",
+ "convolution",
+ "prelu",
+ "addmm",
+ "addmv",
+ "addr",
+ "matmul",
+ "einsum",
+ "mm",
+ "mv",
+ "silu",
+ "linear",
+ "addbmm",
+ "baddbmm",
+ "bmm",
+ "chain_matmul",
+ "linalg_multi_dot",
+ "layer_norm",
+ "group_norm"
+ ],
+ "autocast_fp32_ops": [
+ "acos",
+ "asin",
+ "cosh",
+ "erfinv",
+ "exp",
+ "expm1",
+ "log",
+ "log10",
+ "log2",
+ "log1p",
+ "reciprocal",
+ "rsqrt",
+ "sinh",
+ "tan",
+ "pow.Tensor_Scalar",
+ "pow.Tensor_Tensor",
+ "pow.Scalar",
+ "softplus",
+ "frobenius_norm",
+ "frobenius_norm.dim",
+ "nuclear_norm",
+ "nuclear_norm.dim",
+ "cosine_similarity",
+ "poisson_nll_loss",
+ "cosine_embedding_loss",
+ "nll_loss",
+ "nll_loss2d",
+ "hinge_embedding_loss",
+ "kl_div",
+ "l1_loss",
+ "smooth_l1_loss",
+ "huber_loss",
+ "mse_loss",
+ "margin_ranking_loss",
+ "multilabel_margin_loss",
+ "soft_margin_loss",
+ "triplet_margin_loss",
+ "multi_margin_loss",
+ "binary_cross_entropy_with_logits",
+ "dist",
+ "pdist",
+ "cdist",
+ "renorm",
+ "logsumexp"
+ ]
}
```
diff --git a/docs/source/package_reference/stable_diffusion_pipeline.mdx b/docs/source/package_reference/stable_diffusion_pipeline.mdx
deleted file mode 100644
index 5eb09a817c..0000000000
--- a/docs/source/package_reference/stable_diffusion_pipeline.mdx
+++ /dev/null
@@ -1,85 +0,0 @@
-
-
-# GaudiStableDiffusionPipeline
-
-The `GaudiStableDiffusionPipeline` class enables to perform text-to-image generation on HPUs.
-It inherits from the `GaudiDiffusionPipeline` class that is the parent to any kind of diffuser pipeline.
-
-To get the most out of it, it should be associated with a scheduler that is optimized for HPUs like `GaudiDDIMScheduler`.
-
-
-## GaudiStableDiffusionPipeline
-
-[[autodoc]] diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.GaudiStableDiffusionPipeline
- - __call__
-
-
-## GaudiDiffusionPipeline
-
-[[autodoc]] diffusers.pipelines.pipeline_utils.GaudiDiffusionPipeline
- - all
-
-
-## GaudiDDIMScheduler
-
-[[autodoc]] diffusers.schedulers.scheduling_ddim.GaudiDDIMScheduler
- - all
-
-
-# GaudiStableDiffusionXLPipeline
-
-The `GaudiStableDiffusionXLPipeline` class enables to perform text-to-image generation on HPUs using SDXL models.
-It inherits from the `GaudiDiffusionPipeline` class that is the parent to any kind of diffuser pipeline.
-
-To get the most out of it, it should be associated with a scheduler that is optimized for HPUs like `GaudiDDIMScheduler`.
-Recommended schedulers are `GaudiEulerDiscreteScheduler` for SDXL base and `GaudiEulerAncestralDiscreteScheduler` for SDXL turbo.
-
-
-## GaudiStableDiffusionXLPipeline
-
-[[autodoc]] diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.GaudiStableDiffusionXLPipeline
- - __call__
-
-
-## GaudiEulerDiscreteScheduler
-
-[[autodoc]] diffusers.schedulers.scheduling_euler_discrete.GaudiEulerDiscreteScheduler
- - all
-
-
-## GaudiEulerAncestralDiscreteScheduler
-
-[[autodoc]] diffusers.schedulers.scheduling_euler_ancestral_discrete.GaudiEulerAncestralDiscreteScheduler
- - all
-
-
-# GaudiStableDiffusionUpscalePipeline
-
-The `GaudiStableDiffusionUpscalePipeline` is used to enhance the resolution of input images by a factor of 4 on HPUs.
-It inherits from the `GaudiDiffusionPipeline` class that is the parent to any kind of diffuser pipeline.
-
-
-[[autodoc]] diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_upscale.GaudiStableDiffusionUpscalePipeline
- - __call__
-
-
-# GaudiDDPMPipeline
-
-The `GaudiDDPMPipeline` is to enable unconditional image generations on HPUs. It has similar APIs as the regular `DiffusionPipeline`.
-It shares a common parent class, `GaudiDiffusionPipeline`, with other existing Gaudi pipelines. It now supports both DDPM and DDIM scheduler.
-It is recommended to use the optimized scheduler, `GaudiDDIMScheduler`, to obtain the best performance and image outputs.
-
diff --git a/docs/source/package_reference/trainer.mdx b/docs/source/package_reference/trainer.mdx
index e584294fc5..740038cee8 100644
--- a/docs/source/package_reference/trainer.mdx
+++ b/docs/source/package_reference/trainer.mdx
@@ -22,7 +22,7 @@ Before instantiating your [`GaudiTrainer`](https://huggingface.co/docs/optimum/h
-The [`GaudiTrainer`](https://huggingface.co/docs/optimum/habana/package_reference/trainer#optimum.habana.GaudiTrainer) class is optimized for 🤗 Transformers models running on Habana Gaudi.
+The [`GaudiTrainer`](https://huggingface.co/docs/optimum/habana/package_reference/trainer#optimum.habana.GaudiTrainer) class is optimized for 🤗 Transformers models running on Intel Gaudi.
diff --git a/docs/source/quickstart.mdx b/docs/source/quickstart.mdx
index 178eef7336..ec79ac05f9 100644
--- a/docs/source/quickstart.mdx
+++ b/docs/source/quickstart.mdx
@@ -17,51 +17,207 @@ limitations under the License.
# Quickstart
-🤗 Optimum Habana was designed with one goal in mind: **making training and evaluation straightforward for any 🤗 Transformers user while leveraging the complete power of Gaudi processors**.
-There are two main classes one needs to know:
-- [`GaudiTrainer`](https://huggingface.co/docs/optimum/habana/package_reference/trainer): the trainer class that takes care of compiling (lazy or eager mode) and distributing the model to run on HPUs, and of performing training and evaluation.
-- [`GaudiConfig`](https://huggingface.co/docs/optimum/habana/package_reference/gaudi_config): the class that enables to configure Habana Mixed Precision and to decide whether optimized operators and optimizers should be used or not.
+Running your AI workloads on Intel® Gaudi® accelerators can be accomplished in just a few simple steps.
+In this quick guide, we show how to run inference with GPT-2 model on Intel Gaudi 2 accelerators using the 🤗 Optimum for Intel Gaudi library.
-The [`GaudiTrainer`](https://huggingface.co/docs/optimum/habana/package_reference/trainer) is very similar to the [🤗 Transformers Trainer](https://huggingface.co/docs/transformers/main_classes/trainer), and adapting a script using the Trainer to make it work with Gaudi will mostly consist in simply swapping the `Trainer` class for the `GaudiTrainer` one.
-That is how most of the [example scripts](https://github.com/huggingface/optimum-habana/tree/main/examples) were adapted from their [original counterparts](https://github.com/huggingface/transformers/tree/main/examples/pytorch).
+Optimum for Intel Gaudi library is optimized for running various AI workloads on Intel Gaudi accelerators and it contains fully documented
+inference, training and fine-tuning examples. Please refer to the [Optimum for Intel Gaudi GitHub](https://github.com/huggingface/optimum-habana)
+page for more information.
-```diff
-- from transformers import Trainer, TrainingArguments
-+ from optimum.habana import GaudiTrainer, GaudiTrainingArguments
+## Accessing Intel Gaudi AI Accelerator
+To access an Intel Gaudi AI accelerator node in the Intel® Tiber™ AI Cloud, you will go to
+[Intel Tiber AI Cloud](https://console.cloud.intel.com/hardware) and access the hardware instances to select the Intel Gaudi AI accelerator
+platform for deep learning and follow the steps to start and connect to the node.
-# Define the training arguments
-- training_args = TrainingArguments(
-+ training_args = GaudiTrainingArguments(
-+ use_habana=True,
-+ use_lazy_mode=True,
-+ gaudi_config_name=gaudi_config_name,
- ...
-)
+## Docker Setup
-# Initialize our Trainer
-- trainer = Trainer(
-+ trainer = GaudiTrainer(
- model=model,
- args=training_args,
- train_dataset=train_dataset
- ... # other arguments
-)
+Now that you have access to the node, you will use the latest Intel Gaudi AI Accelerator docker image by executing the docker run command which will
+automatically download and run the docker. At the time of writing this guide, latest Gaudi docker version was 1.18.0:
+
+```bash
+release=1.18.0
+os=ubuntu22.04
+torch=2.4.0
+docker_image=vault.habana.ai/gaudi-docker/$release/$os/habanalabs/pytorch-installer-$torch:latest
+```
+
+
+Visit Intel Gaudi AI Accelerator Release Notes
+page to get the latest Intel Gaudi AI accelerator software release version. Alternatively, check
+https://vault.habana.ai/ui/native/gaudi-docker
+for the list of all released Intel® Gaudi® AI accelerator docker images.
+
+
+
+Execute docker run command:
+```bash
+docker run -itd \
+ --name Gaudi_Docker \
+ --runtime=habana \
+ -e HABANA_VISIBLE_DEVICES=all \
+ -e OMPI_MCA_btl_vader_single_copy_mechanism=none \
+ --cap-add=sys_nice \
+ --net=host \
+ --ipc=host \
+ ${docker_image}
+```
+
+## Optimum for Intel Gaudi Setup
+
+Check latest release of Optimum for Intel Gaudi [here](https://github.com/huggingface/optimum-habana/releases).
+At the time of writing this guide, latest Optimum for Intel Gaudi release version was v1.14.0, which is paired with Intel Gaudi Software release
+version 1.18.0. Install Optimum for Intel Gaudi as follows:
+
+```bash
+git clone -b v1.14.0 https://github.com/huggingface/optimum-habana
+pip install ./optimum-habana
```
-where `gaudi_config_name` is the name of a model from the [Hub](https://huggingface.co/Habana) (Gaudi configurations are stored in model repositories) or a path to a local Gaudi configuration file (you can see [here](./package_reference/gaudi_config) how to write your own).
+All available examples are under [optimum-habana/examples](https://github.com/huggingface/optimum-habana/tree/main/examples).
+Here is [text-generation](https://github.com/huggingface/optimum-habana/tree/main/examples/text-generation) example,
+to run Llama-2 7B text generation example on Gaudi, complete the prerequisite setup:
+```bash
+cd ~/optimum-habana/examples/text-generation
+pip install -r requirements.txt
+```
+
+To be able to run gated models like [Llama-2 7B](https://huggingface.co/meta-llama/Llama-2-7b-hf), you should:
+- Have a 🤗 account
+- Agree to the terms of use of the model in its [model card](https://huggingface.co/meta-llama/Llama-2-7b-hf)
+- Set your token as explained [here](https://huggingface.co/docs/hub/security-tokens)
+- Login to your account using the HF CLI: run `huggingface-cli login` before launching your script
+
+## Single Device Inference
+
+Run single Gaudi device (HPU) inference with Llama-2 7B model:
+```bash
+python run_generation.py \
+ --model_name_or_path meta-llama/Llama-2-7b-hf \
+ --use_hpu_graphs \
+ --use_kv_cache \
+ --max_new_tokens 100 \
+ --do_sample \
+ --prompt "Here is my prompt"
+```
+
+
+
+The list of all possible arguments can be obtained running the script with --help
-## Stable Diffusion
+
+
+## Multi-Device Inference
+
+With a multi-device Gaudi system, such as one with 8 HPUs, you can perform distributed inference using libraries like
+Microsoft® DeepSpeed. Gaudi-specific fork of the library is maintained by Intel at
+[https://github.com/HabanaAI/DeepSpeed](https://github.com/HabanaAI/DeepSpeed).
+
+To install the library compatible with the same Gaudi software release stack, use:
+```bash
+pip install git+https://github.com/HabanaAI/DeepSpeed.git@1.18.0
+```
+
+With DeepSpeed successfully installed we can now run a distributed GPT-2 inference on an 8 HPU system as follows:
+```bash
+number_of_devices=8 \
+python ../gaudi_spawn.py --use_deepspeed --world_size ${number_of_devices} \
+run_generation.py \
+ --model_name_or_path meta-llama/Llama-2-7b-hf \
+ --use_hpu_graphs \
+ --use_kv_cache \
+ --max_new_tokens=100 \
+ --do_sample \
+ --prompt="Here is my prompt"
+```
-🤗 Optimum Habana also features HPU-optimized support for the 🤗 Diffusers library.
-Thus, you can easily deploy Stable Diffusion on Gaudi for performing text-to-image generation.
+## Training on Gaudi
-Here is how to use it and the differences with the 🤗 Diffusers library:
+🤗 Optimum for Intel Gaudi contains a number of examples demonstrating single and multi Gaudi device training/fine-tuning.
+
+For example, a number of language models can be trained with the scripts provided
+[language modeling examples section](https://github.com/huggingface/optimum-habana/tree/main/examples/language-modeling).
+
+As an illustration, let us run GPT-2 single and multi card training examples on Gaudi.
+
+Install prerequisites with:
+```bash
+cd ~/optimum-habana/examples/language-modeling
+pip install -r requirements.txt
+```
+
+To train GPT-2 model on a single card, use:
+```bash
+python run_clm.py \
+ --model_name_or_path gpt2 \
+ --dataset_name wikitext \
+ --dataset_config_name wikitext-2-raw-v1 \
+ --per_device_train_batch_size 4 \
+ --per_device_eval_batch_size 4 \
+ --do_train \
+ --do_eval \
+ --output_dir /tmp/test-clm \
+ --gaudi_config_name Habana/gpt2 \
+ --use_habana \
+ --use_lazy_mode \
+ --use_hpu_graphs_for_inference \
+ --throughput_warmup_steps 3
+```
+
+To train GPT-2 model using multi-card Gaudi system:
+```bash
+number_of_devices=8 \
+python ../gaudi_spawn.py --use_deepspeed --world_size ${number_of_devices} \
+run_clm.py \
+ --model_name_or_path gpt2 \
+ --dataset_name wikitext \
+ --dataset_config_name wikitext-2-raw-v1 \
+ --per_device_train_batch_size 4 \
+ --per_device_eval_batch_size 4 \
+ --do_train \
+ --do_eval \
+ --output_dir /tmp/test-clm \
+ --gaudi_config_name Habana/gpt2 \
+ --use_habana \
+ --use_lazy_mode \
+ --use_hpu_graphs_for_inference \
+ --gradient_checkpointing \
+ --use_cache False \
+ --throughput_warmup_steps 3
+```
+
+## Diffusion Workloads
+
+🤗 Optimum for Intel Gaudi also features HPU-optimized support for the 🤗 Diffusers library.
+Thus, you can deploy Stable Diffusion and similar diffusion models on Gaudi and enable
+text-to-image generation and other diffusion-based workloads.
+
+Before running Stable Diffusion inference example on Gaudi, complete the prerequisite setup:
+```bash
+cd ~/optimum-habana/examples/stable-diffusion
+pip install -r requirements.txt
+```
+
+Here is an example of running Stable Diffusion text to image inference on Gaudi:
+```bash
+python text_to_image_generation.py \
+ --model_name_or_path CompVis/stable-diffusion-v1-4 \
+ --prompts "An image of a squirrel in Picasso style" \
+ --num_images_per_prompt 10 \
+ --batch_size 1 \
+ --image_save_dir /tmp/stable_diffusion_images \
+ --use_habana \
+ --use_hpu_graphs \
+ --gaudi_config Habana/stable-diffusion \
+ --bf16
+```
+
+Also, here is an example of modifying a basic 🤗 Diffusers Stable Diffusion pipeline call to work with Gaudi
+using the Optimum for Intel Gaudi library:
```diff
- from diffusers import DDIMScheduler, StableDiffusionPipeline
+ from optimum.habana.diffusers import GaudiDDIMScheduler, GaudiStableDiffusionPipeline
-
model_name = "CompVis/stable-diffusion-v1-4"
- scheduler = DDIMScheduler.from_pretrained(model_name, subfolder="scheduler")
@@ -83,23 +239,51 @@ outputs = pipeline(
)
```
+In addition, sample scripts for fine-tuning diffusion models are given in
+[Stable Diffusion training section](https://github.com/huggingface/optimum-habana/tree/main/examples/stable-diffusion/training).
+
+A more comprehensive list of examples in Optimum for Intel Gaudi is given next.
## Ready-to-Use Examples
+Now that you have run a full inference case, you can go back to the
+[Optimum for Intel Gaudi validated models](https://github.com/huggingface/optimum-habana?tab=readme-ov-file#validated-models)
+to see more options for running inference.
+
Here are examples for various modalities and tasks that can be used out of the box:
-- Text
- - [text classification](https://github.com/huggingface/optimum-habana/tree/main/examples/text-classification),
- - [question answering](https://github.com/huggingface/optimum-habana/tree/main/examples/question-answering),
- - [language modeling](https://github.com/huggingface/optimum-habana/tree/main/examples/language-modeling),
- - [text generation](https://github.com/huggingface/optimum-habana/tree/main/examples/text-generation),
- - [summarization](https://github.com/huggingface/optimum-habana/tree/main/examples/summarization),
- - [translation](https://github.com/huggingface/optimum-habana/tree/main/examples/translation),
+
+- **Text**
+ - [language modeling](https://github.com/huggingface/optimum-habana/tree/main/examples/language-modeling)
+ - [multi node training](https://github.com/huggingface/optimum-habana/tree/main/examples/multi-node-training)
- [protein folding](https://github.com/huggingface/optimum-habana/tree/main/examples/protein-folding)
-- Images
- - [image classification](https://github.com/huggingface/optimum-habana/tree/main/examples/image-classification)
-- Audio
- - [audio classification](https://github.com/huggingface/optimum-habana/tree/main/examples/audio-classification),
+ - [question answering](https://github.com/huggingface/optimum-habana/tree/main/examples/question-answering)
+ - [sentence transformers training](https://github.com/huggingface/optimum-habana/tree/main/examples/sentence-transformers-training)
+ - [summarization](https://github.com/huggingface/optimum-habana/tree/main/examples/summarization)
+ - [table detection](https://github.com/huggingface/optimum-habana/tree/main/examples/table-detection)
+ - [text classification](https://github.com/huggingface/optimum-habana/tree/main/examples/text-classification)
+ - [text feature extraction](https://github.com/huggingface/optimum-habana/tree/main/examples/text-feature-extraction)
+ - [text generation](https://github.com/huggingface/optimum-habana/tree/main/examples/text-generation)
+ - [translation](https://github.com/huggingface/optimum-habana/tree/main/examples/translation)
+ - [trl](https://github.com/huggingface/optimum-habana/tree/main/examples/trl)
+
+- **Audio**
+ - [audio classification](https://github.com/huggingface/optimum-habana/tree/main/examples/audio-classification)
- [speech recognition](https://github.com/huggingface/optimum-habana/tree/main/examples/speech-recognition)
-- Text and images
- - [text-to-image generation](https://github.com/huggingface/optimum-habana/tree/main/examples/stable-diffusion),
- - [contrastive image-text training](https://github.com/huggingface/optimum-habana/tree/main/examples/contrastive-image-text).
+ - [text to speech](https://github.com/huggingface/optimum-habana/tree/main/examples/text-to-speech)
+
+- **Images**
+ - [object detection](https://github.com/huggingface/optimum-habana/tree/main/examples/object-detection)
+ - [object segementation](https://github.com/huggingface/optimum-habana/tree/main/examples/object-segementation)
+ - [image classification](https://github.com/huggingface/optimum-habana/tree/main/examples/image-classification)
+ - [image to text](https://github.com/huggingface/optimum-habana/tree/main/examples/image-to-text)
+ - [contrastive image text](https://github.com/huggingface/optimum-habana/tree/main/examples/contrastive-image-text)
+ - [stable diffusion](https://github.com/huggingface/optimum-habana/tree/main/examples/stable-diffusion)
+ - [visual question answering](https://github.com/huggingface/optimum-habana/tree/main/examples/visual-question-answering)
+ - [zero-shot object detection](https://github.com/huggingface/optimum-habana/tree/main/examples/zero-shot-object-detection)
+
+- **Video**
+ - [stable-video-diffusion](https://github.com/huggingface/optimum-habana/tree/main/examples/stable-diffusion)
+ - [video-classification](https://github.com/huggingface/optimum-habana/tree/main/examples/video-classification)
+
+To learn more about how to adapt 🤗 Transformers or Diffusers scripts for Intel Gaudi, check out
+[Script Adaptation](https://huggingface.co/docs/optimum/habana/usage_guides/script_adaptation) guide.
diff --git a/docs/source/tutorials/distributed.mdx b/docs/source/tutorials/distributed.mdx
index dd81e8da52..f664ab4e14 100644
--- a/docs/source/tutorials/distributed.mdx
+++ b/docs/source/tutorials/distributed.mdx
@@ -14,41 +14,55 @@ See the License for the specific language governing permissions and
limitations under the License.
-->
-# Distributed training with Optimum Habana
+# Distributed training with Optimum for Intel Gaudi
As models get bigger, parallelism has emerged as a strategy for training larger models on limited hardware and accelerating training speed by several orders of magnitude.
-All the [PyTorch examples](https://github.com/huggingface/optimum-habana/tree/main/examples) and the [`GaudiTrainer`](https://huggingface.co/docs/optimum/habana/package_reference/trainer) script work out of the box with distributed training.
+All the [PyTorch examples](https://github.com/huggingface/optimum-habana/tree/main/examples) and the `GaudiTrainer` script work out of the box with distributed training.
There are two ways of launching them:
1. Using the [gaudi_spawn.py](https://github.com/huggingface/optimum-habana/blob/main/examples/gaudi_spawn.py) script:
-```bash
-python gaudi_spawn.py \
- --world_size number_of_hpu_you_have --use_mpi \
- path_to_script.py --args1 --args2 ... --argsN
-```
-where `--argX` is an argument of the script to run in a distributed way.
-Examples are given for question answering [here](https://github.com/huggingface/optimum-habana/blob/main/examples/question-answering/README.md#multi-card-training) and text classification [here](https://github.com/huggingface/optimum-habana/tree/main/examples/text-classification#multi-card-training).
+ - Use MPI for distributed training:
-2. Using the [`DistributedRunner`](https://huggingface.co/docs/optimum/habana/package_reference/distributed_runner) directly in code:
+ ```bash
+ python gaudi_spawn.py \
+ --world_size number_of_hpu_you_have --use_mpi \
+ path_to_script.py --args1 --args2 ... --argsN
+ ```
-```python
-from optimum.habana.distributed import DistributedRunner
-from optimum.utils import logging
+ where `--argX` is an argument of the script to run in a distributed way.
+ Examples are given for question answering [here](https://github.com/huggingface/optimum-habana/blob/main/examples/question-answering/README.md#multi-card-training) and text classification [here](https://github.com/huggingface/optimum-habana/tree/main/examples/text-classification#multi-card-training).
-world_size=8 # Number of HPUs to use (1 or 8)
+ - Use DeepSpeed for distributed training:
-# define distributed runner
-distributed_runner = DistributedRunner(
- command_list=["scripts/train.py --args1 --args2 ... --argsN"],
- world_size=world_size,
- use_mpi=True,
-)
+ ```bash
+ python gaudi_spawn.py \
+ --world_size number_of_hpu_you_have --use_deepspeed \
+ path_to_script.py --args1 --args2 ... --argsN
+ ```
-# start job
-ret_code = distributed_runner.run()
-```
+ where `--argX` is an argument of the script to run in a distributed way.
+ Examples are given for question answering [here](https://github.com/huggingface/optimum-habana/blob/main/examples/question-answering/README.md#using-deepspeed) and text classification [here](https://github.com/huggingface/optimum-habana/tree/main/examples/text-classification#using-deepspeed).
+
+2. Using the `DistributedRunner` directly in code:
+
+ ```python
+ from optimum.habana.distributed import DistributedRunner
+ from optimum.utils import logging
+
+ world_size=8 # Number of HPUs to use (1 or 8)
+
+ # define distributed runner
+ distributed_runner = DistributedRunner(
+ command_list=["scripts/train.py --args1 --args2 ... --argsN"],
+ world_size=world_size,
+ use_mpi=True,
+ )
+
+ # start job
+ ret_code = distributed_runner.run()
+ ```
diff --git a/docs/source/tutorials/inference.mdx b/docs/source/tutorials/inference.mdx
index a7cb9b5f25..b69cc2b81d 100644
--- a/docs/source/tutorials/inference.mdx
+++ b/docs/source/tutorials/inference.mdx
@@ -16,7 +16,16 @@ limitations under the License.
# Run Inference
-This section shows how to run inference-only workloads on Gaudi.
+This section shows how to run inference-only workloads on Intel Gaudi accelerator.
+
+An effective quick start would be to review the inference examples provided in the Optimum for Intel Gaudi
+[here].
+
+You can also explore the
+[examples in the Optimum for Intel Gaudi repository]((https://github.com/huggingface/optimum-habana/tree/main/examples)).
+While the examples folder includes both training and inference, the inference-specific content
+provides valuable guidance for optimizing and running workloads on Intel Gaudi accelerators.
+
For more advanced information about how to speed up inference, check out [this guide](../usage_guides/accelerate_inference).
diff --git a/docs/source/tutorials/overview.mdx b/docs/source/tutorials/overview.mdx
index 7e8b306d1d..26cc31320f 100644
--- a/docs/source/tutorials/overview.mdx
+++ b/docs/source/tutorials/overview.mdx
@@ -16,9 +16,10 @@ limitations under the License.
# Overview
-Welcome to the 🤗 Optimum Habana tutorials!
+Welcome to the 🤗 Optimum for Intel Gaudi tutorials!
They will help you to get started quickly on the following topics:
- How to [train a model on a single device](./single_hpu)
- How to [train a model on several devices](./distributed)
- How to [run inference with your model](./inference)
- How to [generate images from text with Stable Diffusion](./stable_diffusion)
+- How to [run TGI service on Gaudi](./tgi)
diff --git a/docs/source/tutorials/stable_diffusion.mdx b/docs/source/tutorials/stable_diffusion.mdx
index 6354533394..da786891e6 100644
--- a/docs/source/tutorials/stable_diffusion.mdx
+++ b/docs/source/tutorials/stable_diffusion.mdx
@@ -23,12 +23,12 @@ Check out this [blog post](https://huggingface.co/blog/stable_diffusion) for mor
## How to generate images?
To generate images with Stable Diffusion on Gaudi, you need to instantiate two instances:
-- A pipeline with [`GaudiStableDiffusionPipeline`](https://huggingface.co/docs/optimum/habana/package_reference/stable_diffusion_pipeline). This pipeline supports *text-to-image generation*.
-- A scheduler with [`GaudiDDIMScheduler`](https://huggingface.co/docs/optimum/habana/package_reference/stable_diffusion_pipeline#optimum.habana.diffusers.GaudiDDIMScheduler). This scheduler has been optimized for Gaudi.
+- A pipeline with `GaudiStableDiffusionPipeline`. This pipeline supports *text-to-image generation*.
+- A scheduler with `GaudiDDIMScheduler`. This scheduler has been optimized for Gaudi.
When initializing the pipeline, you have to specify `use_habana=True` to deploy it on HPUs.
Furthermore, to get the fastest possible generations you should enable **HPU graphs** with `use_hpu_graphs=True`.
-Finally, you will need to specify a [Gaudi configuration](https://huggingface.co/docs/optimum/habana/package_reference/gaudi_config) which can be downloaded from the Hugging Face Hub.
+Finally, you will need to specify a [Gaudi configuration](../package_reference/gaudi_config) which can be downloaded from the Hugging Face Hub.
```python
from optimum.habana.diffusers import GaudiDDIMScheduler, GaudiStableDiffusionPipeline
@@ -56,7 +56,7 @@ outputs = pipeline(
)
```
-Outputs can be PIL images or Numpy arrays. See [here](https://huggingface.co/docs/optimum/habana/package_reference/stable_diffusion_pipeline#optimum.habana.diffusers.StableDiffusionPipeline.__call__) all the parameters you can set to tailor generations to your taste.
+Generated images can be returned as either PIL images or NumPy arrays, depending on the `output_type` option.
@@ -67,13 +67,12 @@ Check out the [example](https://github.com/huggingface/optimum-habana/tree/main/
## Stable Diffusion 2
-[Stable Diffusion 2](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion_2) can be used with the exact same classes.
+[Stable Diffusion 2](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_2) can be used with the exact same classes.
Here is an example:
```python
from optimum.habana.diffusers import GaudiDDIMScheduler, GaudiStableDiffusionPipeline
-
model_name = "stabilityai/stable-diffusion-2-1"
scheduler = GaudiDDIMScheduler.from_pretrained(model_name, subfolder="scheduler")
@@ -114,8 +113,8 @@ See [here](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/
### How to upscale low resolution images?
To generate RGB and depth images with Stable Diffusion Upscale on Gaudi, you need to instantiate two instances:
-- A pipeline with [`GaudiStableDiffusionUpscalePipeline`](../package_reference/stable_diffusion_pipeline#optimum.habana.diffusers.GaudiStableDiffusionUpscalePipeline).
-- A scheduler with [`GaudiDDIMScheduler`](../package_reference/stable_diffusion_pipeline#optimum.habana.diffusers.GaudiDDIMScheduler). This scheduler has been optimized for Gaudi.
+- A pipeline with `GaudiStableDiffusionUpscalePipeline`.
+- A scheduler with `GaudiDDIMScheduler`. This scheduler has been optimized for Gaudi.
When initializing the pipeline, you have to specify `use_habana=True` to deploy it on HPUs.
Furthermore, to get the fastest possible generations you should enable **HPU graphs** with `use_hpu_graphs=True`.
diff --git a/docs/source/tutorials/stable_diffusion_ldm3d.mdx b/docs/source/tutorials/stable_diffusion_ldm3d.mdx
deleted file mode 100644
index d7c975ceb6..0000000000
--- a/docs/source/tutorials/stable_diffusion_ldm3d.mdx
+++ /dev/null
@@ -1,67 +0,0 @@
-
-
-# Text-to-(RGB, depth)
-
-LDM3D was proposed in [LDM3D: Latent Diffusion Model for 3D](https://huggingface.co/papers/2305.10853) by Gabriela Ben Melech Stan, Diana Wofk, Scottie Fox, Alex Redden, Will Saxton, Jean Yu, Estelle Aflalo, Shao-Yen Tseng, Fabio Nonato, Matthias Muller, and Vasudev Lal. LDM3D generates an image and a depth map from a given text prompt unlike the existing text-to-image diffusion models such as [Stable Diffusion](./stable_diffusion) which only generates an image. With almost the same number of parameters, LDM3D achieves to create a latent space that can compress both the RGB images and the depth maps.
-
-The abstract from the paper is:
-
-*This research paper proposes a Latent Diffusion Model for 3D (LDM3D) that generates both image and depth map data from a given text prompt, allowing users to generate RGBD images from text prompts. The LDM3D model is fine-tuned on a dataset of tuples containing an RGB image, depth map and caption, and validated through extensive experiments. We also develop an application called DepthFusion, which uses the generated RGB images and depth maps to create immersive and interactive 360-degree-view experiences using TouchDesigner. This technology has the potential to transform a wide range of industries, from entertainment and gaming to architecture and design. Overall, this paper presents a significant contribution to the field of generative AI and computer vision, and showcases the potential of LDM3D and DepthFusion to revolutionize content creation and digital experiences. A short video summarizing the approach can be found at [this url](https://t.ly/tdi2).*
-
-
-## How to generate RGB and depth images?
-
-To generate RGB and depth images with Stable Diffusion LDM3D on Gaudi, you need to instantiate two instances:
-- A pipeline with [`GaudiStableDiffusionLDM3DPipeline`]. This pipeline supports *text-to-(rgb, depth) generation*.
-- A scheduler with [`GaudiDDIMScheduler`](https://huggingface.co/docs/optimum/habana/package_reference/stable_diffusion_pipeline#optimum.habana.diffusers.GaudiDDIMScheduler). This scheduler has been optimized for Gaudi.
-
-When initializing the pipeline, you have to specify `use_habana=True` to deploy it on HPUs.
-Furthermore, to get the fastest possible generations you should enable **HPU graphs** with `use_hpu_graphs=True`.
-Finally, you will need to specify a [Gaudi configuration](https://huggingface.co/docs/optimum/habana/package_reference/gaudi_config) which can be downloaded from the Hugging Face Hub.
-
-```python
-from optimum.habana.diffusers import GaudiDDIMScheduler, GaudiStableDiffusionLDM3DPipeline
-from optimum.habana.utils import set_seed
-
-model_name = "Intel/ldm3d-4c"
-
-scheduler = GaudiDDIMScheduler.from_pretrained(model_name, subfolder="scheduler")
-
-set_seed(42)
-
-pipeline = GaudiStableDiffusionLDM3DPipeline.from_pretrained(
- model_name,
- scheduler=scheduler,
- use_habana=True,
- use_hpu_graphs=True,
- gaudi_config="Habana/stable-diffusion",
-)
-outputs = pipeline(
- prompt=["High quality photo of an astronaut riding a horse in space"],
- num_images_per_prompt=1,
- batch_size=1,
- output_type="pil",
- num_inference_steps=40,
- guidance_scale=5.0,
- negative_prompt=None
-)
-
-
-rgb_image, depth_image = outputs.rgb, outputs.depth
-rgb_image[0].save("astronaut_ldm3d_rgb.png")
-depth_image[0].save("astronaut_ldm3d_depth.png")
-```
diff --git a/docs/source/tutorials/tgi.mdx b/docs/source/tutorials/tgi.mdx
new file mode 100644
index 0000000000..ab4887cbe2
--- /dev/null
+++ b/docs/source/tutorials/tgi.mdx
@@ -0,0 +1,48 @@
+
+
+# TGI on Gaudi
+
+Text Generation Inference (TGI) on Intel® Gaudi® AI Accelerator is supported via [Intel® Gaudi® TGI repository](https://github.com/huggingface/tgi-gaudi).
+Start TGI service on Gaudi system simply by [pulling a TGI Gaudi Docker image](https://github.com/huggingface/tgi-gaudi/pkgs/container/tgi-gaudi) and launching a local TGI service instance.
+
+For example, TGI service on Gaudi for *Llama 2 7B* model can be started with:
+```bash
+docker run \
+ -p 8080:80 \
+ -v $PWD/data:/data \
+ --runtime=habana \
+ -e HABANA_VISIBLE_DEVICES=all \
+ -e OMPI_MCA_btl_vader_single_copy_mechanism=none \
+ --cap-add=sys_nice \
+ --ipc=host ghcr.io/huggingface/tgi-gaudi:2.0.1 \
+ --model-id meta-llama/Llama-2-7b-hf \
+ --max-input-tokens 1024 \
+ --max-total-tokens 2048
+```
+
+You can then send a simple request:
+```bash
+curl 127.0.0.1:8080/generate \
+ -X POST \
+ -d '{"inputs":"What is Deep Learning?","parameters":{"max_new_tokens":32}}' \
+ -H 'Content-Type: application/json'
+```
+
+To run static benchmark test, please refer to
+[TGI's benchmark tool](https://github.com/huggingface/text-generation-inference/tree/main/benchmark).
+More examples of running the service instances on single or multi HPU device system are available
+[here](https://github.com/huggingface/tgi-gaudi?tab=readme-ov-file#running-tgi-on-gaudi).
diff --git a/docs/source/usage_guides/accelerate_inference.mdx b/docs/source/usage_guides/accelerate_inference.mdx
index 1858cf399d..3b2d4d5d83 100644
--- a/docs/source/usage_guides/accelerate_inference.mdx
+++ b/docs/source/usage_guides/accelerate_inference.mdx
@@ -16,16 +16,26 @@ limitations under the License.
# Accelerating Inference
-Gaudi offers several possibilities to make inference faster.
+Intel Gaudi offers several possibilities to make inference faster.
## Lazy Mode
-Two execution modes are proposed:
-- *Lazy mode*, where operations are accumulated in a graph whose execution is triggered in a lazy manner. This allows the graph compiler to optimize the device execution for these operations.
+The following execution modes are supported:
+- *Lazy mode*, where operations are accumulated in a graph whose execution is triggered in a lazy manner.
+ This allows the graph compiler to optimize the device execution for these operations.
- *Eager mode*, where one operation at a time is executed.
+- *Eager mode* with *torch.compile*, where a model (or part of a model) is enclosed into a graph.
-In lazy mode, the graph compiler generates optimized binary code that implements the given model topology on Gaudi. It performs operator fusion, data layout management, parallelization, pipelining and memory management, as well as graph-level optimizations.
+
+
+Not all models are yet supported with Eager mode and Eager mode with torch.compile (still in development).
+Lazy mode is the default mode.
+
+
+
+In lazy mode, the graph compiler generates optimized binary code that implements the given model topology on Gaudi.
+It performs operator fusion, data layout management, parallelization, pipelining and memory management, as well as graph-level optimizations.
To execute inference in lazy mode, you must provide the following arguments:
```python
@@ -50,7 +60,7 @@ Gaudi provides a way to run fast inference with HPU Graphs.
It consists in capturing a series of operations (i.e. graphs) in an HPU stream and then replaying them in an optimized way (more information [here](https://docs.habana.ai/en/latest/PyTorch/Inference_on_Gaudi/Inference_using_HPU_Graphs/Inference_using_HPU_Graphs.html)).
Thus, you can apply this to the `forward` method of your model to run it efficiently at inference.
-HPU Graphs are integrated into the [`GaudiTrainer`](../package_reference/trainer) and the [`GaudiStableDiffusionPipeline`](../package_reference/stable_diffusion_pipeline) so that one can use them very easily:
+HPU Graphs are integrated into the `GaudiTrainer` and the `GaudiStableDiffusionPipeline` so that one can use them very easily:
- `GaudiTrainer` needs the training argument `use_hpu_graphs_for_inference` to be set to `True` as follows:
```python
from optimum.habana import GaudiTrainer, GaudiTrainingArguments
@@ -100,3 +110,15 @@ outputs = generator(
With HPU Graphs and in lazy mode, the *first couple of iterations* may be slower due to graph compilations.
+
+
+## Custom Operators
+
+Intel Gaudi provides a few custom operators that achieve better performance than their PyTorch counterparts.
+You can also define your own custom operator for Gaudi as described [here](https://docs.habana.ai/en/latest/PyTorch/PyTorch_CustomOp_API/page_index.html).
+
+
+### Gaudi Optimized Flash Attention
+
+Flash attention algorithm with additional Intel Gaudi AI Accelerator optimizations is supported for both Lazy and Eager mode.
+See [Using Fused Scaled Dot Product Attention (FusedSDPA)](https://docs.habana.ai/en/latest/PyTorch/Model_Optimization_PyTorch/Optimization_in_PyTorch_Models.html#using-fused-scaled-dot-product-attention-fusedsdpa).
diff --git a/docs/source/usage_guides/accelerate_training.mdx b/docs/source/usage_guides/accelerate_training.mdx
index dd2f1530d4..ea2304fc72 100644
--- a/docs/source/usage_guides/accelerate_training.mdx
+++ b/docs/source/usage_guides/accelerate_training.mdx
@@ -20,11 +20,20 @@ Gaudi offers several possibilities to make training faster.
They are all compatible with each other and can be coupled with [distributed training](https://huggingface.co/docs/optimum/habana/usage_guides/distributed).
-## Lazy Mode
+## Execution Modes
-Two execution modes are proposed:
-- *Lazy mode*, where operations are accumulated in a graph whose execution is triggered in a lazy manner. This allows the graph compiler to optimize the device execution for these operations.
+The following execution modes are supported:
+- *Lazy mode*, where operations are accumulated in a graph whose execution is triggered in a lazy manner.
+ This allows the graph compiler to optimize the device execution for these operations.
- *Eager mode*, where one operation at a time is executed.
+- *Eager mode* with *torch.compile*, where a model (or part of a model) is enclosed into a graph.
+
+
+
+Not all models are yet supported with Eager mode and Eager mode with torch.compile (still in development).
+Lazy mode is the default mode.
+
+
In lazy mode, the graph compiler generates optimized binary code that implements the given model topology on Gaudi. It performs operator fusion, data layout management, parallelization, pipelining and memory management, as well as graph-level optimizations.
@@ -57,7 +66,7 @@ To not take them into account in the computation of the throughput at the end of
## Mixed-Precision Training
Mixed-precision training enables to compute some operations using lighter data types to accelerate training.
-Optimum Habana enables mixed precision training in a similar fashion as 🤗 Transformers:
+Optimum for Intel Gaudi enables mixed precision training in a similar fashion as 🤗 Transformers:
- argument `--bf16` enables usage of PyTorch autocast
- argument `--half_precision_backend [hpu_amp, cpu_amp]` is used to specify a device on which mixed precision operations should be performed
@@ -74,13 +83,13 @@ Please refer to the [advanced autocast usage on Gaudi](https://docs.habana.ai/en
## HPU Graphs
The flexibility of PyTorch comes at a price - usually the same pythonic logic is processed every training step over and over.
-This may lead to a situation where it takes longer for CPU to schedule the work on Habana accelerator than it is effectively computed by it.
+This may lead to a situation where it takes longer for CPU to schedule the work on Gaudi than it is effectively computed by it.
To cope with such host-bound workloads, you may want to try enabling the _HPU Graphs_ feature, which records the computational graph once, then only triggers it for execution much faster multiple times.
-To do so, specify [`--use_hpu_graphs_for_training True`](https://huggingface.co/docs/optimum/habana/package_reference/trainer#optimum.habana.GaudiTrainingArguments.use_hpu_graphs_for_training).
+To do so, specify `--use_hpu_graphs_for_training True`.
This option will wrap the model in [`habana_frameworks.torch.hpu.ModuleCacher`](https://docs.habana.ai/en/latest/PyTorch/Model_Optimization_PyTorch/HPU_Graphs_Training.html#training-loop-with-modulecacher), which automatically records _HPU Graphs_ on the model's usage.
-For multi-worker distributed training, you also need to specify [`--distribution_strategy fast_ddp`](https://huggingface.co/docs/optimum/habana/package_reference/trainer#optimum.habana.GaudiTrainingArguments.distribution_strategy).
+For multi-worker distributed training, you also need to specify `--distribution_strategy fast_ddp`.
This option replaces the usage of `torch.nn.parallel.DistributedDataParallel` with much simpler and usually faster `optimum.habana.distributed.all_reduce_gradients`.
@@ -93,13 +102,13 @@ However, the potential performance gain could be dramatic!
## Fast DDP
-For distributed training on several devices, you can also specify [`--distribution_strategy fast_ddp`](https://huggingface.co/docs/optimum/habana/package_reference/trainer#optimum.habana.GaudiTrainingArguments.distribution_strategy).
+For distributed training on several devices, you can also specify `--distribution_strategy fast_ddp`.
This option replaces the usage of `torch.nn.parallel.DistributedDataParallel` with much simpler and usually faster `optimum.habana.distributed.all_reduce_gradients`.
## Pipelining Forward and Backward Passes
-There are two stages when running models on Habana HPU: python code interpretation on CPU and HPU recipe computation.
+There are two stages when running models on Intel Gaudi HPU: python code interpretation on CPU and HPU recipe computation.
The HPU computation stage can be triggered manually or when a copy to the CPU is requested, and generally HPU computation is triggered after `loss.backward()` to make the CPU code interpretation and HPU recipe computation overlap as shown in the following illustration:
```
@@ -116,7 +125,7 @@ CPU:...forward ...backward ...optimizer ...forward ...backward ...optim
HPU:.............forward.......backward......optimizer......forward.....backward.......optimizer
```
-To enable this optimization, you can set the following training argument [`--pipelining_fwd_bwd True`](https://huggingface.co/docs/optimum/habana/package_reference/trainer#optimum.habana.GaudiTrainingArguments.pipelining_fwd_bwd).
+To enable this optimization, you can set the following training argument `--pipelining_fwd_bwd True`.
**We recommend using it on Gaudi2** as the host will often be the bottleneck.
You should be able to see a speedup on first-generation Gaudi too, but it will be less significant than on Gaudi2 because your run is more likely to be HPU-bound.
@@ -136,7 +145,7 @@ Besides, using `--dataloader_num_workers 1` should help in most cases as it enab
## Non-Blocking Data Copy
This optimization is well-suited for models with a high cost of copying data from the host to the device (e.g. vision models like ViT or Swin).
-You can enable it with the training argument [`--non_blocking_data_copy True`](https://huggingface.co/docs/optimum/habana/package_reference/trainer#optimum.habana.GaudiTrainingArguments.non_blocking_data_copy).
+You can enable it with the training argument `--non_blocking_data_copy True`.
**We recommend using it on Gaudi2** where the host can continue to execute other tasks (e.g. graph building) to get a better pipelining between the host and the device.
On first-generation Gaudi, the device executing time is longer so one should not expect to get any speedup.
@@ -144,27 +153,31 @@ On first-generation Gaudi, the device executing time is longer so one should not
## Custom Operators
-Habana provides a few custom operators that achieve better performance than their PyTorch counterparts on Gaudi.
+Intel Gaudi provides a few custom operators that achieve better performance than their PyTorch counterparts on Gaudi.
You can also define your own custom operator for Gaudi as described [here](https://docs.habana.ai/en/latest/PyTorch/PyTorch_CustomOp_API/page_index.html).
### Fused ADAM
-Habana provides a [custom fused ADAM implementation](https://docs.habana.ai/en/latest/PyTorch/Model_Optimization_PyTorch/Custom_Ops_PyTorch.html#custom-optimizers).
+Intel Gaudi offers a [custom fused ADAM implementation](https://docs.habana.ai/en/latest/PyTorch/Model_Optimization_PyTorch/Custom_Ops_PyTorch.html#custom-optimizers).
It can be used by specifying `"use_fused_adam": true` in the Gaudi configuration file.
-The default value of *epsilon* is `1e-6` for the Habana fused ADAM optimizer, while it is `1e-8` for `torch.optim.AdamW`.
+The default value of *epsilon* is `1e-6` for the Intel Gaudi fused ADAM optimizer, while it is `1e-8` for `torch.optim.AdamW`.
### Fused Gradient Norm Clipping
-Habana provides a [custom gradient norm clipping implementation](https://docs.habana.ai/en/latest/PyTorch/Model_Optimization_PyTorch/Custom_Ops_PyTorch.html#other-custom-ops).
+Intel Gaudi provides a [custom gradient norm clipping implementation](https://docs.habana.ai/en/latest/PyTorch/Model_Optimization_PyTorch/Custom_Ops_PyTorch.html#other-custom-ops).
It can be used by specifying `"use_fused_clip_norm": true` in the Gaudi configuration file.
+### Gaudi Optimized Flash Attention
+
+Flash attention algorithm with additional Intel® Gaudi® AI Accelerator optimizetions is supported for both Lazy and Eager mode.
+See [Using Fused Scaled Dot Product Attention (FusedSDPA)](https://docs.habana.ai/en/latest/PyTorch/Model_Optimization_PyTorch/Optimization_in_PyTorch_Models.html#using-fused-scaled-dot-product-attention-fusedsdpa).
## Tracking Memory Usage
@@ -181,4 +194,4 @@ In distributed mode, memory stats are communicated only by the main process.
-You can take a look at [Intel® Gaudi® AI Accelerator's official documentation](https://docs.habana.ai/en/latest/PyTorch/PyTorch_User_Guide/Python_Packages.html#memory-stats-apis) for more information about the memory stats API.
\ No newline at end of file
+You can take a look at [Intel Gaudi AI Accelerator's official documentation](https://docs.habana.ai/en/latest/PyTorch/PyTorch_User_Guide/Python_Packages.html#memory-stats-apis) for more information about the memory stats API.
diff --git a/docs/source/usage_guides/deepspeed.mdx b/docs/source/usage_guides/deepspeed.mdx
index 3117f8f468..833358d9c4 100644
--- a/docs/source/usage_guides/deepspeed.mdx
+++ b/docs/source/usage_guides/deepspeed.mdx
@@ -20,24 +20,25 @@ limitations under the License.
In particular, you can use the two following ZeRO configurations that have been validated to be fully functioning with Gaudi:
- **ZeRO-1**: partitions the optimizer states across processes.
- **ZeRO-2**: partitions the optimizer states + gradients across processes.
+- **ZeRO-3**: ZeRO-2 + full model state is partitioned across the processes.
-These configurations are fully compatible with Habana Mixed Precision and can thus be used to train your model in *bf16* precision.
+These configurations are fully compatible with Intel Gaudi Mixed Precision and can thus be used to train your model in *bf16* precision.
You can find more information about DeepSpeed Gaudi integration [here](https://docs.habana.ai/en/latest/PyTorch/DeepSpeed/DeepSpeed_User_Guide/DeepSpeed_User_Guide.html#deepspeed-user-guide).
## Setup
-To use DeepSpeed on Gaudi, you need to install Optimum Habana and [Habana's DeepSpeed fork](https://github.com/HabanaAI/DeepSpeed) with:
+To use DeepSpeed on Gaudi, you need to install Optimum for Intel Gaudi and [DeepSpeed fork for Intel Gaudi](https://github.com/HabanaAI/DeepSpeed) with:
```bash
pip install optimum[habana]
pip install git+https://github.com/HabanaAI/DeepSpeed.git@1.18.0
```
-## Using DeepSpeed with Optimum Habana
+## Using DeepSpeed with Optimum for Intel Gaudi
-The [`GaudiTrainer`](https://huggingface.co/docs/optimum/habana/package_reference/trainer) allows using DeepSpeed as easily as the [Transformers Trainer](https://huggingface.co/docs/transformers/main_classes/trainer).
+The `GaudiTrainer` allows using DeepSpeed as easily as the [Transformers Trainer](https://huggingface.co/docs/transformers/main_classes/trainer).
This can be done in 3 steps:
1. A DeepSpeed configuration has to be defined.
2. The `deepspeed` training argument enables to specify the path to the DeepSpeed configuration.
@@ -78,7 +79,7 @@ It is strongly advised to read [this section](https://huggingface.co/docs/transf
-Other examples of configurations for HPUs are proposed [here](https://github.com/HabanaAI/Model-References/tree/1.18.0/PyTorch/nlp/DeepSpeedExamples/deepspeed-bert/scripts) by Habana.
+Other examples of configurations for HPUs are proposed [here](https://github.com/HabanaAI/Model-References/tree/1.18.0/PyTorch/nlp/DeepSpeedExamples/deepspeed-bert/scripts) by Intel.
The [Transformers documentation](https://huggingface.co/docs/transformers/main_classes/deepspeed#configuration) explains how to write a configuration from scratch very well.
A more complete description of all configuration possibilities is available [here](https://www.deepspeed.ai/docs/config-json/).
@@ -114,7 +115,7 @@ python gaudi_spawn.py \
```
where `--argX` is an argument of the script to run with DeepSpeed.
-2. Using the [`DistributedRunner`](https://huggingface.co/docs/optimum/habana/package_reference/distributed_runner) directly in code:
+2. Using the `DistributedRunner` directly in code:
```python
from optimum.habana.distributed import DistributedRunner
diff --git a/docs/source/usage_guides/multi_node_training.mdx b/docs/source/usage_guides/multi_node_training.mdx
index 73239b8f7a..19bdb80e54 100644
--- a/docs/source/usage_guides/multi_node_training.mdx
+++ b/docs/source/usage_guides/multi_node_training.mdx
@@ -26,70 +26,23 @@ Using several Gaudi servers to perform multi-node training can be done easily. T
Two types of configurations are possible:
- scale-out using Gaudi NICs or Host NICs (on-premises)
-- scale-out using AWS DL1 instances
+- scale-out using Intel® Tiber™ AI Cloud instances
### On premises
-To set up your servers on premises, check out the [installation](https://docs.habana.ai/en/latest/Installation_Guide/Bare_Metal_Fresh_OS.html) and [distributed training](https://docs.habana.ai/en/latest/PyTorch/PyTorch_Scaling_Guide/index.html) pages of Habana Gaudi's documentation.
+To set up your servers on premises, check out the [installation](https://docs.habana.ai/en/latest/Installation_Guide/Bare_Metal_Fresh_OS.html) and [distributed training](https://docs.habana.ai/en/latest/PyTorch/PyTorch_Scaling_Guide/index.html) pages of Intel® Gaudi® AI Accelerator's documentation.
-### AWS DL1 instances
+### Intel Tiber AI Cloud instances
-Proceed with the following steps to correctly set up your DL1 instances.
-
-
-#### 1. Set up an EFA-enabled security group
-
-To allow all instances to communicate with each other, you need to set up a *security group* as described by AWS in step 1 of [this link](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/efa-start.html#efa-start-security).
-Once this is done, it should look as follows:
-
- 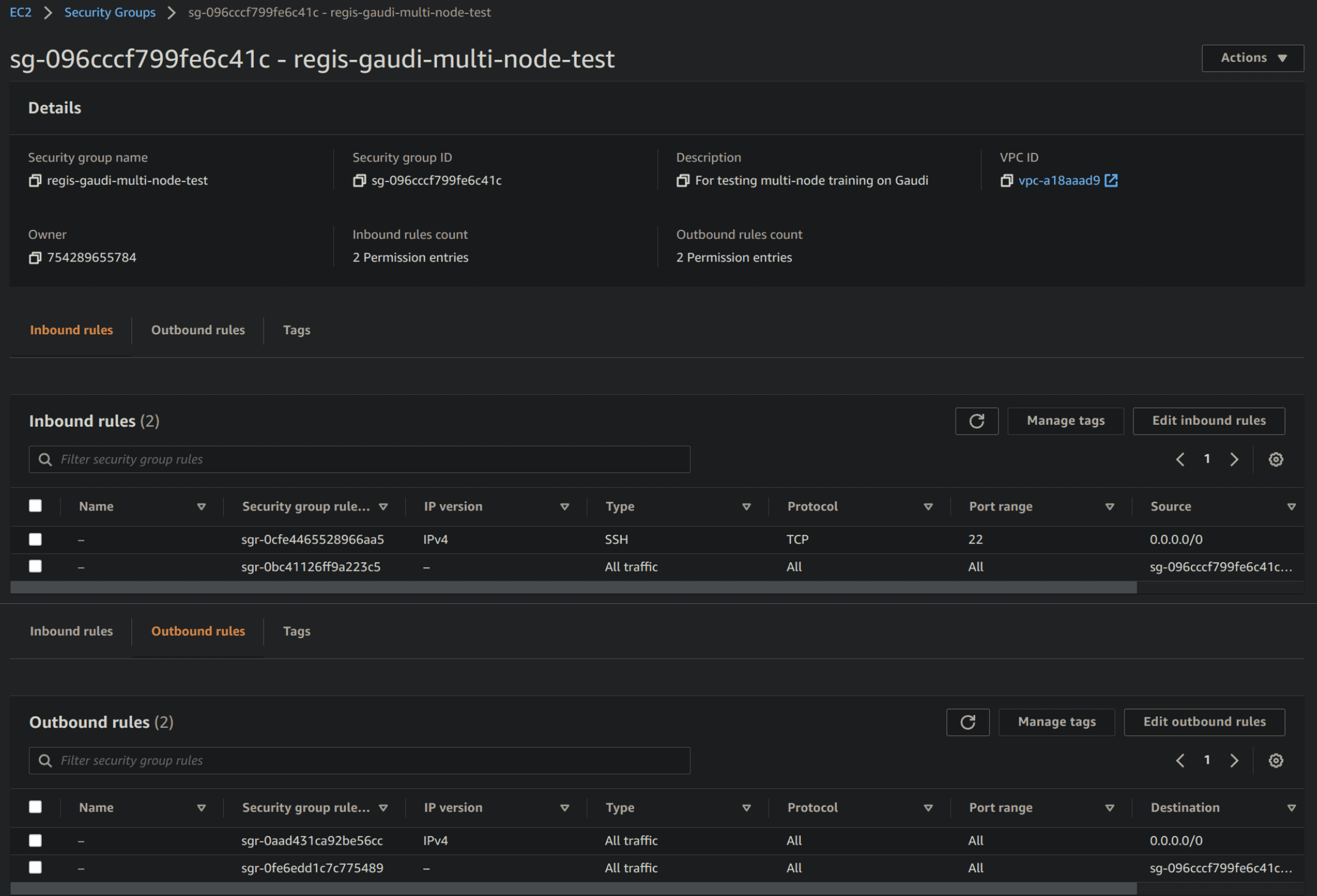 - Security group for multi-node training on AWS DL1 instances
-
- Security group for multi-node training on AWS DL1 instances
-
-
-
-#### 2. Launching instances
-
-When you launch instances from the AWS EC2 console, you can choose the number of nodes to set up.
-
-We recommend using the [Habana Deep Learning Base AMI](https://docs.habana.ai/en/latest/Installation_Guide/Habana_Deep_Learning_AMI.html) for your AWS DL1 instances.
-It is an EFA-enabled AMI so you do not need to install the EFA software (which may be necessary if you use a different AMI, installation instructions [here](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/efa-start.html)).
-
-Then, in the *Network settings*, select the *security group* you created in the previous step. You also have to select a specific *subnet* to unlock the *Advanced network configuration* in which you can enable the *Elastic Fabric Adapter*.
-
-The last parameter to set is the *Placement group* in the *Advanced details*. You can create one if you do not have any. The *placement strategy* should be set to *cluster*.
-
-Here is how it should look:
-
- 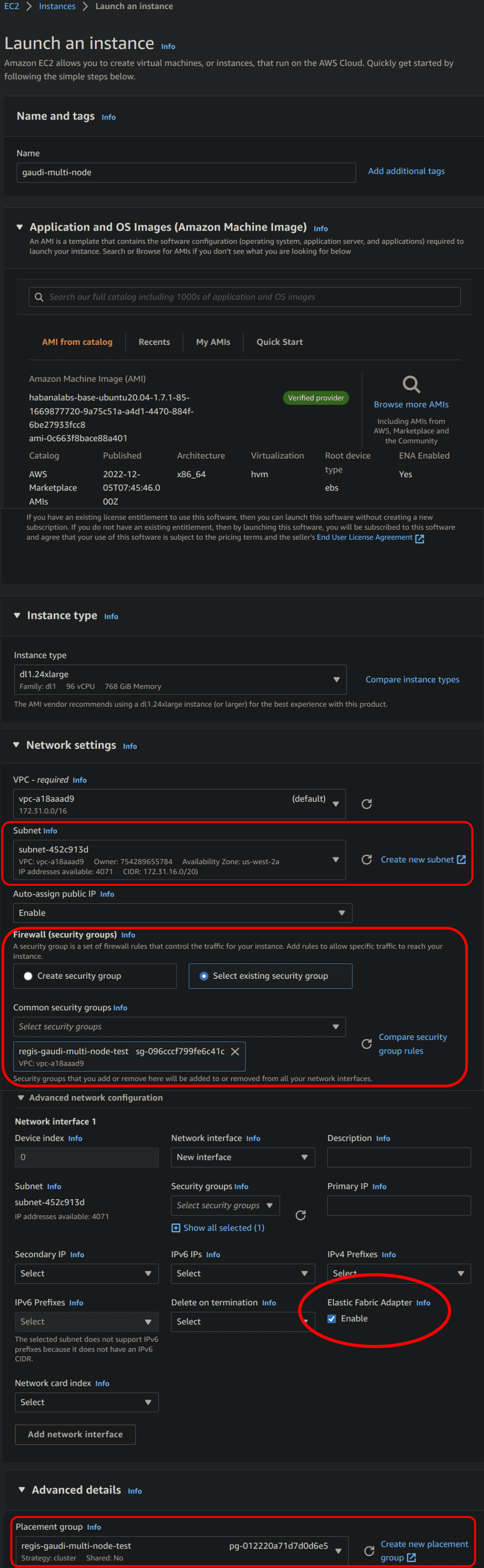 - Parameters for launching EFA-enabled AWS instances. The important parameters to set are circled in red. For the sake of clarity, not all parameters are represented.
-
- Parameters for launching EFA-enabled AWS instances. The important parameters to set are circled in red. For the sake of clarity, not all parameters are represented.
-
-
-More information [here](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/efa-start.html#efa-start-instances).
+Follow the steps on [creating an account and getting an instance](https://docs.habana.ai/en/latest/Intel_DevCloud_Quick_Start/Intel_DevCloud_Quick_Start.html#creating-an-account-and-getting-an-instance) pages of Intel® Gaudi® AI Accelerator's documentation.
## Launching a Multi-node Run
-Once your Gaudi instances are ready, you need to:
-
-1. Enable password-less SSH on your instances so that they can communicate with each other. [This explains how to do it](https://docs.habana.ai/en/latest/AWS_User_Guides/AWS_Distributed_Training_Multiple_DL1/AWS_Distributed_Training_Multiple_DL1.html#running-distributed-training-over-multiple-dl1-instances).
-2. On AWS, to train through EFA, `hccl_ofi_wrapper` should be installed. [Here is how to do it](https://docs.habana.ai/en/latest/AWS_User_Guides/AWS_Distributed_Training_Multiple_DL1/AWS_Distributed_Training_Multiple_DL1.html#build-and-store-custom-docker-image-for-training).
-3. On AWS, you need to set the following environment variables (the easiest way is to write a `.deepspeed_env` file as described [here](https://huggingface.co/docs/optimum/habana/usage_guides/multi_node_training#environment-variables)):
- - `HCCL_OVER_OFI=1`
- - `LD_LIBRARY_PATH=path_to_hccl_ofi_wrapper:/opt/amazon/openmpi/lib:/opt/amazon/efa/lib` where `path_to_hccl_ofi_wrapper` is the path to the `hccl_ofi_wrapper` folder which you installed in the previous step.
- - (optional) `HCCL_SOCKET_IFNAME=my_network_interface`. If not set, the first network interface with a name that does not start with `lo` or `docker` will be used. More information [here](https://docs.habana.ai/en/latest/API_Reference_Guides/HCCL_APIs/Using_HCCL.html?highlight=HCCL_SOCKET_IFNAME#hccl-socket-ifname).
-
-To make this easier, we provide a Dockerfile [here](https://github.com/huggingface/optimum-habana/tree/main/examples/multi-node-training).
-You will just have to copy the public key of the leader node in the `~/.ssh/authorized_keys` file of all other nodes to enable password-less SSH.
+Once your Intel Gaudi instances are ready, follow the steps for [setting up a multi-server environment](https://docs.habana.ai/en/latest/Intel_DevCloud_Quick_Start/Intel_DevCloud_Quick_Start.html#setting-up-a-multi-server-environment) pages of Intel® Gaudi® AI Accelerator's documentation.
-Then, you need to write a [hostfile](https://www.deepspeed.ai/getting-started/#resource-configuration-multi-node) with the addresses and the numbers of devices of your nodes as follows:
-```
-ip_1 slots=8
-ip_2 slots=8
-...
-ip_n slots=8
-```
Finally, there are two possible ways to run your training script on several nodes:
@@ -102,7 +55,7 @@ python gaudi_spawn.py \
```
where `--argX` is an argument of the script to run.
-2. With the [`DistributedRunner`](https://huggingface.co/docs/optimum/habana/package_reference/distributed_runner), you can add this code snippet to a script:
+2. With the `DistributedRunner`, you can add this code snippet to a script:
```python
from optimum.habana.distributed import DistributedRunner
@@ -123,15 +76,13 @@ env_variable_2_name=value
...
```
-You can find an example for AWS instances [here](https://github.com/huggingface/optimum-habana/tree/main/examples/multi-node-training/EFA/.deepspeed_env).
-
## Recommendations
- It is strongly recommended to use gradient checkpointing for multi-node runs to get the highest speedups. You can enable it with `--gradient_checkpointing` in [these examples](https://github.com/huggingface/optimum-habana/tree/main/examples) or with `gradient_checkpointing=True` in your `GaudiTrainingArguments`.
- Larger batch sizes should lead to higher speedups.
- Multi-node inference is not recommended and can provide inconsistent results.
-- On AWS DL1 instances, run your Docker containers with the `--privileged` flag so that EFA devices are visible.
+- On Intel Tiber AI Cloud instances, run your Docker containers with the `--privileged` flag so that EFA devices are visible.
## Example
diff --git a/docs/source/usage_guides/overview.mdx b/docs/source/usage_guides/overview.mdx
index 426f702645..b0c0db1eca 100644
--- a/docs/source/usage_guides/overview.mdx
+++ b/docs/source/usage_guides/overview.mdx
@@ -16,10 +16,15 @@ limitations under the License.
# Overview
-Welcome to the Optimum for Intel Gaudi how-to guides!
-These guides tackle more advanced topics and will show you how to easily get the best from HPUs:
-- [Pretraining models](./pretraining)
-- [Accelerating training](./accelerate_training)
-- [Accelerating inference](./accelerate_inference)
-- [Using DeepSpeed](./deepspeed) to train larger models
-- [Multi-node training](./multi_node_training) for faster runs
+Welcome to the Optimum for Intel® Gaudi® AI Accelerator how-to guides!
+
+These guides tackle more advanced topics and will show you how to easily get the best from HPUs.
+Here's what you'll find:
+
+- [Script adaptation](./script_adaptation): Learn how to adapt a Transformers/Diffusers script for Intel Gaudi
+- [Pretraining models](./pretraining): A guide to pretraining a model using Transformers
+- [Accelerating training](./accelerate_training): Discover techniques to speed up training
+- [Accelerating inference](./accelerate_inference) Learn how to optimize inference for faster execution
+- [Using DeepSpeed](./deepspeed): Scale your training to handle larger models
+- [Multi-node training](./multi_node_training): Speed up runs with multi-node setups
+- [Quantization](./quantization): Explore FP8 and UINT4 quantization for optimized inference
diff --git a/docs/source/usage_guides/pretraining.mdx b/docs/source/usage_guides/pretraining.mdx
index 39a94c504d..ae2fd87954 100644
--- a/docs/source/usage_guides/pretraining.mdx
+++ b/docs/source/usage_guides/pretraining.mdx
@@ -15,7 +15,7 @@ limitations under the License.
-->
-# Pretraining Transformers with Optimum Habana
+# Pretraining Transformers with Optimum for Intel Gaudi
Pretraining a model from Transformers, like BERT, is as easy as fine-tuning it.
The model should be instantiated from a configuration with `.from_config` and not from a pretrained checkpoint with `.from_pretrained`.
diff --git a/docs/source/usage_guides/quantization.mdx b/docs/source/usage_guides/quantization.mdx
new file mode 100644
index 0000000000..a22cc1a9c8
--- /dev/null
+++ b/docs/source/usage_guides/quantization.mdx
@@ -0,0 +1,42 @@
+
+
+# Quantization
+
+Intel® Gaudi® offers several possibilities to make inference faster. For examples of FP8 and UINT4 for Inference, see the
+[text-generation](https://github.com/huggingface/optimum-habana/tree/main/examples/text-generation) example.
+
+This guide provides the steps required to enable FP8 and UINT4 precision on your Intel® Gaudi® AI
+accelerator using the Intel® Neural Compressor (INC) package.
+
+## Run Inference Using FP8
+
+When running inference on large language models (LLMs), high memory usage is often the bottleneck. Therefore
+using FP8 data type for inference on large language models halves the required memory bandwidth. In addition,
+FP8 compute is twice as fast as BF16 compute, so even compute-bound workloads, such as offline inference on
+large batch sizes benefit.
+
+References to [Run Inference Using FP8](https://docs.habana.ai/en/latest/PyTorch/Inference_on_PyTorch/Inference_Using_FP8.html)
+section on [Intel® Gaudi® AI Accelerator Documentation](https://docs.habana.ai/en/latest/index.html).
+
+## Run Inference Using UINT4
+
+When running inference on large language models (LLMs), high memory usage is often the bottleneck. Therefore,
+using UINT4 data type for inference on large language models halves the required memory bandwidth compared to
+running inference in FP8.
+
+References to [Run Inference Using UINT4](https://docs.habana.ai/en/latest/PyTorch/Inference_on_PyTorch/Inference_Using_UINT4.html)
+section on [Intel® Gaudi® AI Accelerator Documentation](https://docs.habana.ai/en/latest/index.html).
diff --git a/docs/source/usage_guides/script_adaptation.mdx b/docs/source/usage_guides/script_adaptation.mdx
new file mode 100644
index 0000000000..387b07c069
--- /dev/null
+++ b/docs/source/usage_guides/script_adaptation.mdx
@@ -0,0 +1,83 @@
+
+
+
+# Adapt a Transformers/Diffusers script to Intel Gaudi
+
+🤗 Optimum for Intel Gaudi features HPU-optimized support for many of the latest 🤗 Transformers and Diffusers models.
+To convert a script to use model optimized for a Gaudi device, simple adaptation can be performed.
+
+## Transformers
+
+Here is how to do a transformers script adaptation for Intel Gaudi:
+```diff
+- from transformers import Trainer, TrainingArguments
++ from optimum.habana import GaudiTrainer, GaudiTrainingArguments
+
+# Define the training arguments
+- training_args = TrainingArguments(
++ training_args = GaudiTrainingArguments(
++ use_habana=True,
++ use_lazy_mode=True,
++ gaudi_config_name=gaudi_config_name,
+ ...
+)
+
+# Initialize our Trainer
+- trainer = Trainer(
++ trainer = GaudiTrainer(
+ model=model,
+ args=training_args,
+ train_dataset=train_dataset
+ ... # other arguments
+)
+```
+
+where `gaudi_config_name` is the name of a model from the [Hub](https://huggingface.co/Habana) a path to a local Gaudi configuration file.
+Gaudi configurations are stored as JSON files in model repositories but you can write your own.
+More information can be found [here](../package_reference/gaudi_config).
+
+## Diffusers
+
+🤗 Optimum for Intel Gaudi also features HPU-optimized support for the 🤗 Diffusers library.
+Thus, you can easily deploy Stable Diffusion on Gaudi for performing text-to-image generation.
+
+Here is how to use it and the differences with the 🤗 Diffusers library:
+```diff
+- from diffusers import DDIMScheduler, StableDiffusionPipeline
++ from optimum.habana.diffusers import GaudiDDIMScheduler, GaudiStableDiffusionPipeline
+
+
+model_name = "runwayml/stable-diffusion-v1-5"
+
+- scheduler = DDIMScheduler.from_pretrained(model_name, subfolder="scheduler")
++ scheduler = GaudiDDIMScheduler.from_pretrained(model_name, subfolder="scheduler")
+
+- pipeline = StableDiffusionPipeline.from_pretrained(
++ pipeline = GaudiStableDiffusionPipeline.from_pretrained(
+ model_name,
+ scheduler=scheduler,
++ use_habana=True,
++ use_hpu_graphs=True,
++ gaudi_config="Habana/stable-diffusion",
+)
+
+outputs = pipeline(
+ ["An image of a squirrel in Picasso style"],
+ num_images_per_prompt=16,
++ batch_size=4,
+)
+```
diff --git a/optimum/habana/transformers/gradient_checkpointing.py b/optimum/habana/transformers/gradient_checkpointing.py
index 1279de3f56..f2983bab2c 100644
--- a/optimum/habana/transformers/gradient_checkpointing.py
+++ b/optimum/habana/transformers/gradient_checkpointing.py
@@ -181,8 +181,10 @@ def backward(ctx, *args):
set_device_states(ctx.fwd_devices, ctx.fwd_device_states)
detached_inputs = detach_variable(tuple(inputs))
- with torch.enable_grad(), torch.autocast(**ctx.hpu_autocast_kwargs), torch.amp.autocast(
- "cpu", **ctx.cpu_autocast_kwargs
+ with (
+ torch.enable_grad(),
+ torch.autocast(**ctx.hpu_autocast_kwargs),
+ torch.amp.autocast("cpu", **ctx.cpu_autocast_kwargs),
):
outputs = ctx.run_function(*detached_inputs)
diff --git a/optimum/habana/transformers/models/falcon/modeling_falcon.py b/optimum/habana/transformers/models/falcon/modeling_falcon.py
index f4c9d454ab..84ccf01095 100644
--- a/optimum/habana/transformers/models/falcon/modeling_falcon.py
+++ b/optimum/habana/transformers/models/falcon/modeling_falcon.py
@@ -453,9 +453,11 @@ def pre_attn_forward(
)
else:
# TODO very similar to the fp8 case above, could be merged.
- with sdp_kernel(
- enable_recompute=flash_attention_recompute
- ) if SDPContext else contextlib.nullcontext():
+ with (
+ sdp_kernel(enable_recompute=flash_attention_recompute)
+ if SDPContext
+ else contextlib.nullcontext()
+ ):
attn_output = FusedSDPA.apply(
query_layer,
key_layer,
diff --git a/optimum/habana/transformers/models/mixtral/modeling_mixtral.py b/optimum/habana/transformers/models/mixtral/modeling_mixtral.py
index 5dfc29625a..edcaf2f631 100644
--- a/optimum/habana/transformers/models/mixtral/modeling_mixtral.py
+++ b/optimum/habana/transformers/models/mixtral/modeling_mixtral.py
@@ -362,9 +362,9 @@ def forward(
)
htcore.mark_step()
else:
- with sdp_kernel(
- enable_recompute=flash_attention_recompute
- ) if SDPContext else contextlib.nullcontext():
+ with (
+ sdp_kernel(enable_recompute=flash_attention_recompute) if SDPContext else contextlib.nullcontext()
+ ):
attn_output = FusedSDPA.apply(
query_states, key_states, value_states, attention_mask, 0.0, False, None
)
diff --git a/tests/test_pipeline.py b/tests/test_pipeline.py
index f94ebe6a4f..200f2a78a2 100644
--- a/tests/test_pipeline.py
+++ b/tests/test_pipeline.py
@@ -87,9 +87,11 @@ def test_text_to_speech(self, model, expected_sample_rate):
generate_kwargs = {"lazy_mode": True, "ignore_eos": False, "hpu_graphs": True}
generator.model = wrap_in_hpu_graph(generator.model)
- with torch.autocast(
- "hpu", torch.bfloat16, enabled=(model_dtype == torch.bfloat16)
- ), torch.no_grad(), torch.inference_mode():
+ with (
+ torch.autocast("hpu", torch.bfloat16, enabled=(model_dtype == torch.bfloat16)),
+ torch.no_grad(),
+ torch.inference_mode(),
+ ):
for i in range(3):
output = generator(text, forward_params=forward_params, generate_kwargs=generate_kwargs)
assert isinstance(output["audio"], np.ndarray)
diff --git a/tests/transformers/tests/models/wav2vec2/test_modeling_wav2vec2.py b/tests/transformers/tests/models/wav2vec2/test_modeling_wav2vec2.py
index cabd9e9785..4d37712e7b 100644
--- a/tests/transformers/tests/models/wav2vec2/test_modeling_wav2vec2.py
+++ b/tests/transformers/tests/models/wav2vec2/test_modeling_wav2vec2.py
@@ -1639,9 +1639,10 @@ def test_wav2vec2_with_lm_pool(self):
self.assertEqual(transcription[0], "habitan aguas poco profundas y rocosas")
# user-managed pool + num_processes should trigger a warning
- with CaptureLogger(processing_wav2vec2_with_lm.logger) as cl, multiprocessing.get_context("fork").Pool(
- 2
- ) as pool:
+ with (
+ CaptureLogger(processing_wav2vec2_with_lm.logger) as cl,
+ multiprocessing.get_context("fork").Pool(2) as pool,
+ ):
transcription = processor.batch_decode(logits.cpu().numpy(), pool, num_processes=2).text
self.assertIn("num_process", cl.out)