diff --git a/units/en/unit1/deep-rl.mdx b/units/en/unit1/deep-rl.mdx
index acbbac1b..8609937e 100644
--- a/units/en/unit1/deep-rl.mdx
+++ b/units/en/unit1/deep-rl.mdx
@@ -1,21 +1,20 @@
-# The “Deep” in Reinforcement Learning [[deep-rl]]
-
-
-What we've talked about so far is Reinforcement Learning. But where does the "Deep" come into play?
-
-
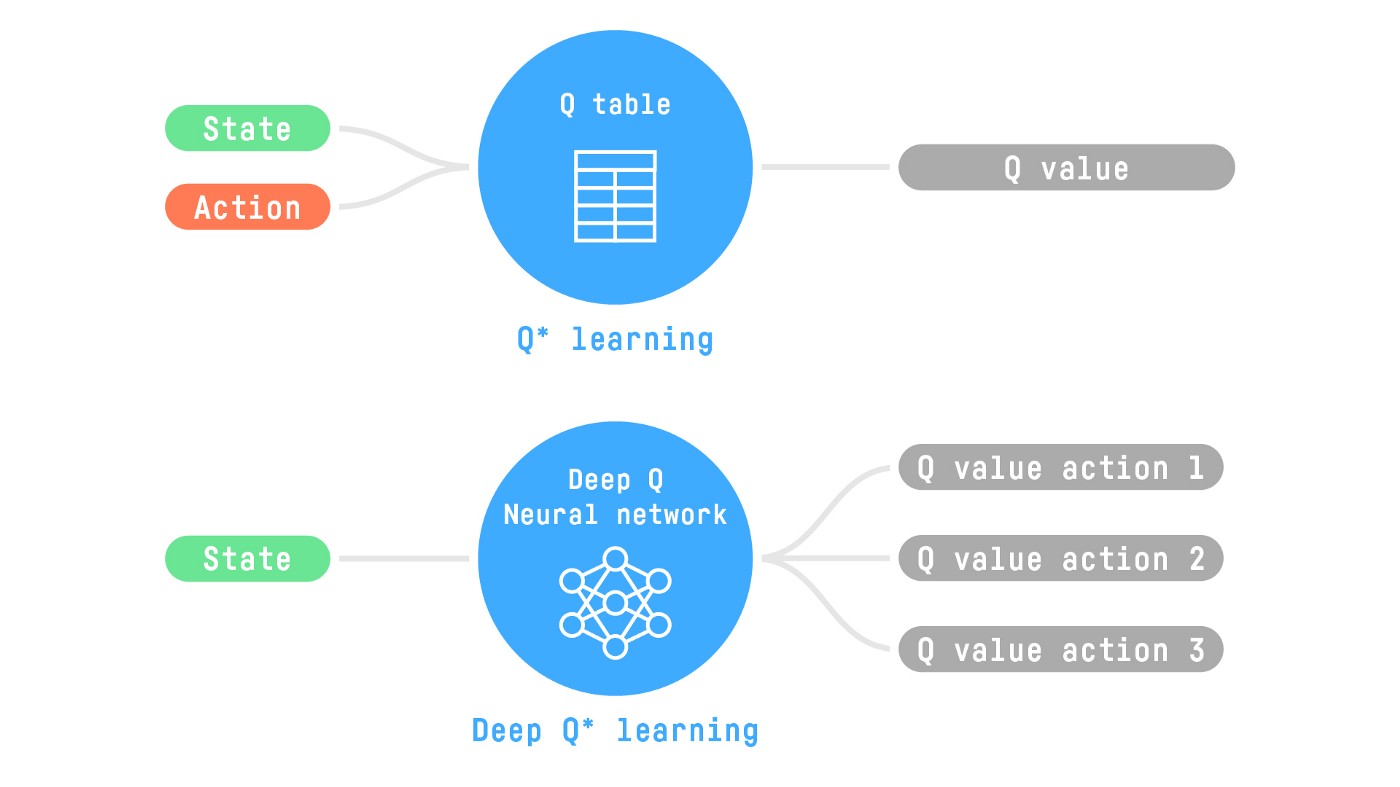
-Deep Reinforcement Learning introduces **deep neural networks to solve Reinforcement Learning problems** — hence the name “deep”.
-
-For instance, in the next unit, we’ll learn about two value-based algorithms: Q-Learning (classic Reinforcement Learning) and then Deep Q-Learning.
-
-You’ll see the difference is that, in the first approach, **we use a traditional algorithm** to create a Q table that helps us find what action to take for each state.
-
-In the second approach, **we will use a Neural Network** (to approximate the Q value).
-
-
-
-Schema inspired by the Q learning notebook by Udacity
-
-
-
-If you are not familiar with Deep Learning you should definitely watch [the FastAI Practical Deep Learning for Coders](https://course.fast.ai) (Free).
+# The “Deep” in Reinforcement Learning [[deep-rl]]
+
+> [!TIP]
+> What we've talked about so far is Reinforcement Learning. But where does the "Deep" come into play?
+
+Deep Reinforcement Learning introduces **deep neural networks to solve Reinforcement Learning problems** — hence the name “deep”.
+
+For instance, in the next unit, we’ll learn about two value-based algorithms: Q-Learning (classic Reinforcement Learning) and then Deep Q-Learning.
+
+You’ll see the difference is that, in the first approach, **we use a traditional algorithm** to create a Q table that helps us find what action to take for each state.
+
+In the second approach, **we will use a Neural Network** (to approximate the Q value).
+
+
+
+Schema inspired by the Q learning notebook by Udacity
+
+
+
+If you are not familiar with Deep Learning you should definitely watch [the FastAI Practical Deep Learning for Coders](https://course.fast.ai) (Free).
diff --git a/units/en/unit1/rl-framework.mdx b/units/en/unit1/rl-framework.mdx
index 97453575..ad96e513 100644
--- a/units/en/unit1/rl-framework.mdx
+++ b/units/en/unit1/rl-framework.mdx
@@ -1,144 +1,143 @@
-# The Reinforcement Learning Framework [[the-reinforcement-learning-framework]]
-
-## The RL Process [[the-rl-process]]
-
-
-
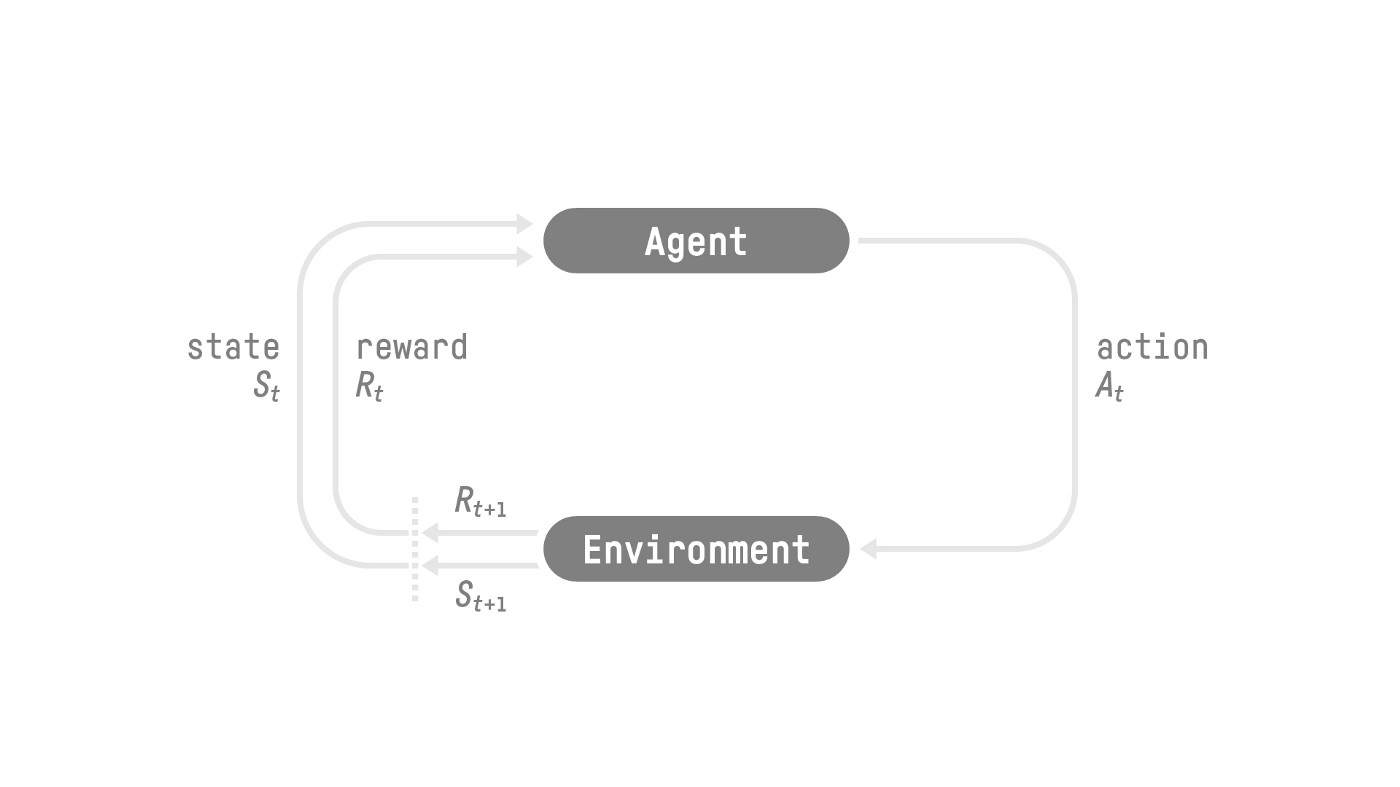
-The RL Process: a loop of state, action, reward and next state
-Source: Reinforcement Learning: An Introduction, Richard Sutton and Andrew G. Barto
-
-
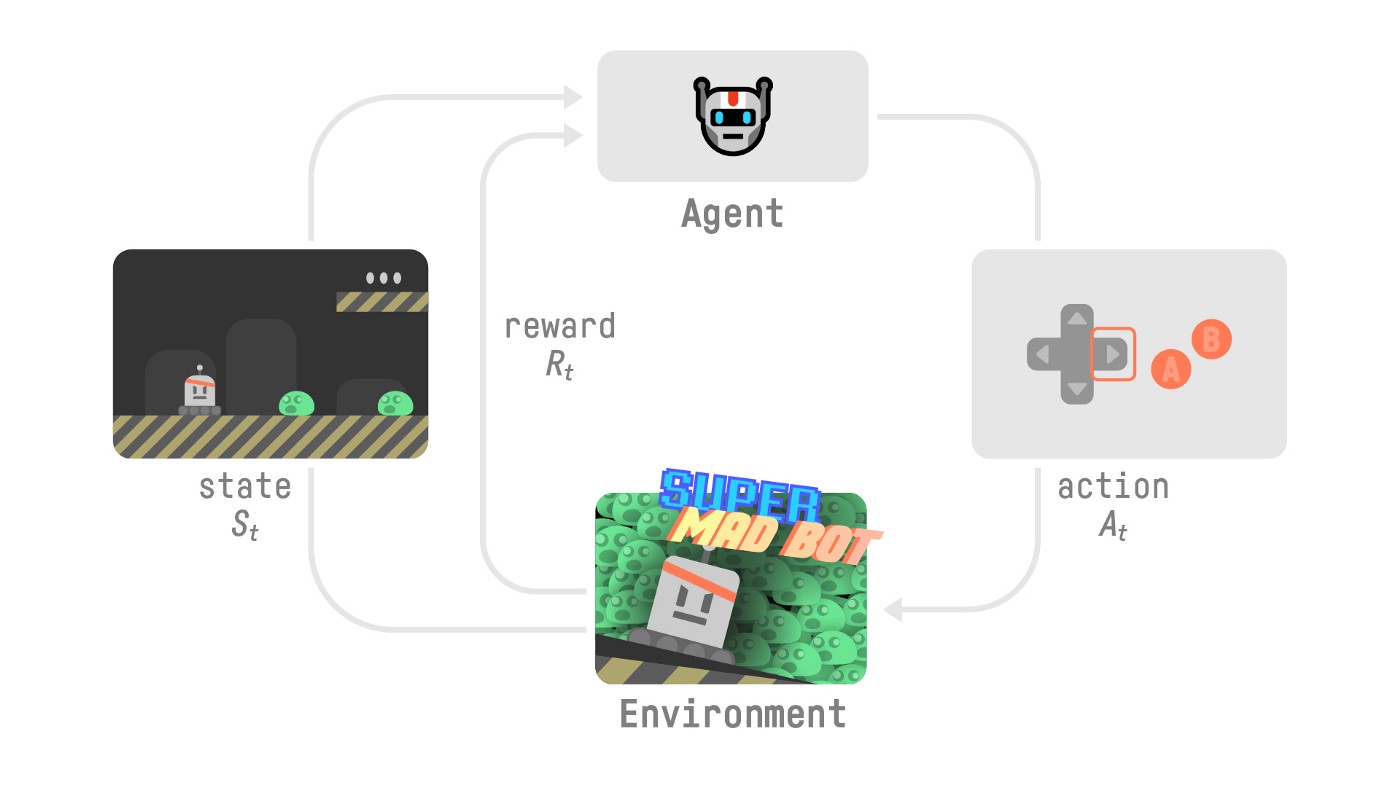
-To understand the RL process, let’s imagine an agent learning to play a platform game:
-
-
-
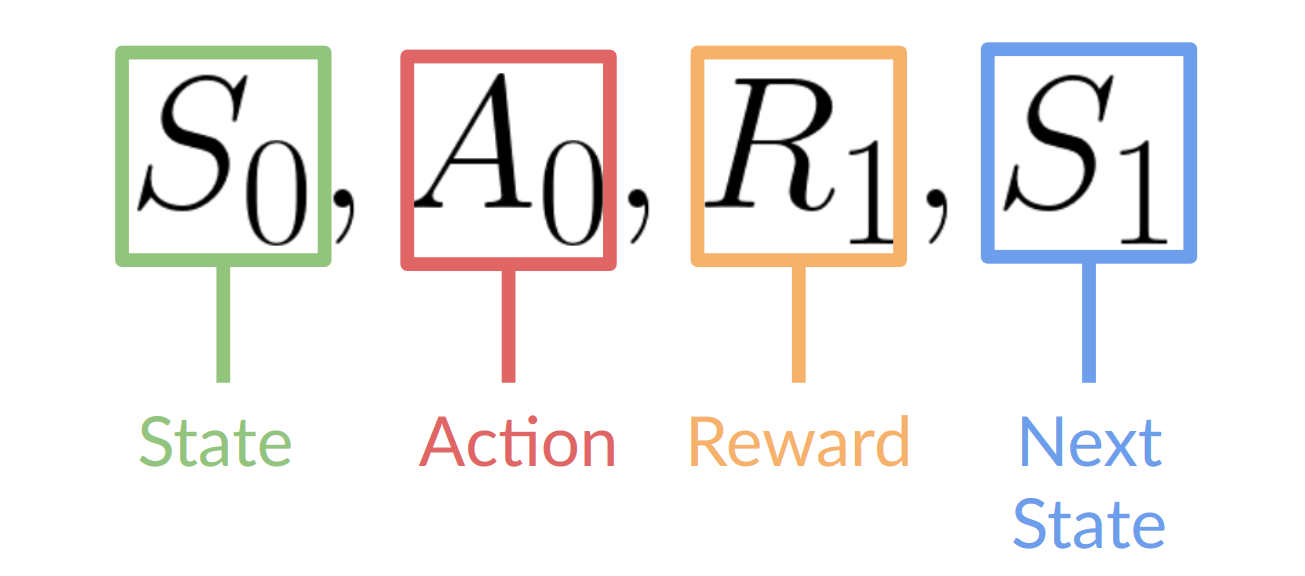
-- Our Agent receives **state \\(S_0\\)** from the **Environment** — we receive the first frame of our game (Environment).
-- Based on that **state \\(S_0\\),** the Agent takes **action \\(A_0\\)** — our Agent will move to the right.
-- The environment goes to a **new** **state \\(S_1\\)** — new frame.
-- The environment gives some **reward \\(R_1\\)** to the Agent — we’re not dead *(Positive Reward +1)*.
-
-This RL loop outputs a sequence of **state, action, reward and next state.**
-
-
-
-The agent's goal is to _maximize_ its cumulative reward, **called the expected return.**
-
-## The reward hypothesis: the central idea of Reinforcement Learning [[reward-hypothesis]]
-
-⇒ Why is the goal of the agent to maximize the expected return?
-
-Because RL is based on the **reward hypothesis**, which is that all goals can be described as the **maximization of the expected return** (expected cumulative reward).
-
-That’s why in Reinforcement Learning, **to have the best behavior,** we aim to learn to take actions that **maximize the expected cumulative reward.**
-
-
-## Markov Property [[markov-property]]
-
-In papers, you’ll see that the RL process is called a **Markov Decision Process** (MDP).
-
-We’ll talk again about the Markov Property in the following units. But if you need to remember something today about it, it's this: the Markov Property implies that our agent needs **only the current state to decide** what action to take and **not the history of all the states and actions** they took before.
-
-## Observations/States Space [[obs-space]]
-
-Observations/States are the **information our agent gets from the environment.** In the case of a video game, it can be a frame (a screenshot). In the case of the trading agent, it can be the value of a certain stock, etc.
-
-There is a differentiation to make between *observation* and *state*, however:
-
-- *State s*: is **a complete description of the state of the world** (there is no hidden information). In a fully observed environment.
-
-
-
-
-In chess game, we receive a state from the environment since we have access to the whole check board information.
-
-
-In a chess game, we have access to the whole board information, so we receive a state from the environment. In other words, the environment is fully observed.
-
-- *Observation o*: is a **partial description of the state.** In a partially observed environment.
-
-
-
-In Super Mario Bros, we only see the part of the level close to the player, so we receive an observation.
-
-
-In Super Mario Bros, we only see the part of the level close to the player, so we receive an observation.
-
-In Super Mario Bros, we are in a partially observed environment. We receive an observation **since we only see a part of the level.**
-
-
-In this course, we use the term "state" to denote both state and observation, but we will make the distinction in implementations.
-
-
-To recap:
-
-
-
-## Action Space [[action-space]]
-
-The Action space is the set of **all possible actions in an environment.**
-
-The actions can come from a *discrete* or *continuous space*:
-
-- *Discrete space*: the number of possible actions is **finite**.
-
-
-
-In Super Mario Bros, we have only 4 possible actions: left, right, up (jumping) and down (crouching).
-
-
-
-Again, in Super Mario Bros, we have a finite set of actions since we have only 4 directions.
-
-- *Continuous space*: the number of possible actions is **infinite**.
-
-
-
-A Self Driving Car agent has an infinite number of possible actions since it can turn left 20°, 21,1°, 21,2°, honk, turn right 20°…
-
-
-
-To recap:
-
-
-Taking this information into consideration is crucial because it will **have importance when choosing the RL algorithm in the future.**
-
-## Rewards and the discounting [[rewards]]
-
-The reward is fundamental in RL because it’s **the only feedback** for the agent. Thanks to it, our agent knows **if the action taken was good or not.**
-
-The cumulative reward at each time step **t** can be written as:
-
-
-
-The cumulative reward equals the sum of all rewards in the sequence.
-
-
-
-Which is equivalent to:
-
-
-
-The cumulative reward = rt+1 (rt+k+1 = rt+0+1 = rt+1)+ rt+2 (rt+k+1 = rt+1+1 = rt+2) + ...
-
-
-
-However, in reality, **we can’t just add them like that.** The rewards that come sooner (at the beginning of the game) **are more likely to happen** since they are more predictable than the long-term future reward.
-
-Let’s say your agent is this tiny mouse that can move one tile each time step, and your opponent is the cat (that can move too). The mouse's goal is **to eat the maximum amount of cheese before being eaten by the cat.**
-
-
-
-As we can see in the diagram, **it’s more probable to eat the cheese near us than the cheese close to the cat** (the closer we are to the cat, the more dangerous it is).
-
-Consequently, **the reward near the cat, even if it is bigger (more cheese), will be more discounted** since we’re not really sure we’ll be able to eat it.
-
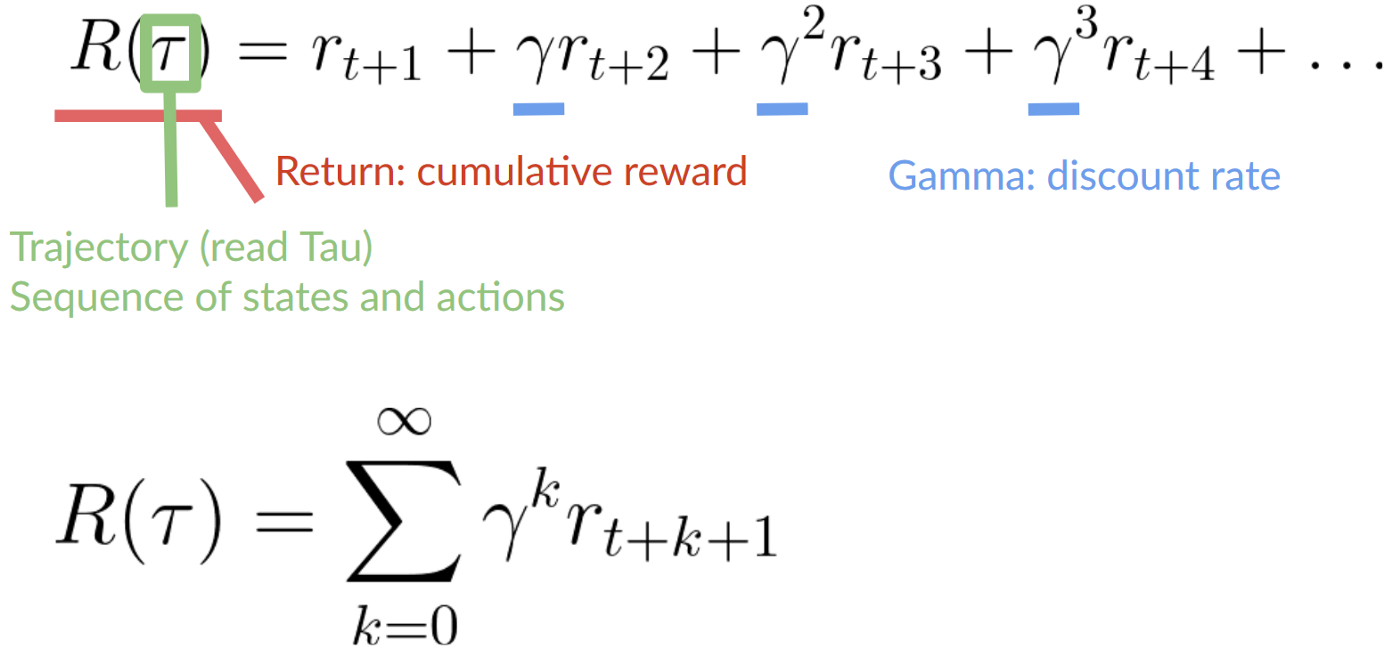
-To discount the rewards, we proceed like this:
-
-1. We define a discount rate called gamma. **It must be between 0 and 1.** Most of the time between **0.95 and 0.99**.
-- The larger the gamma, the smaller the discount. This means our agent **cares more about the long-term reward.**
-- On the other hand, the smaller the gamma, the bigger the discount. This means our **agent cares more about the short term reward (the nearest cheese).**
-
-2. Then, each reward will be discounted by gamma to the exponent of the time step. As the time step increases, the cat gets closer to us, **so the future reward is less and less likely to happen.**
-
-Our discounted expected cumulative reward is:
-
+# The Reinforcement Learning Framework [[the-reinforcement-learning-framework]]
+
+## The RL Process [[the-rl-process]]
+
+
+
+The RL Process: a loop of state, action, reward and next state
+Source: Reinforcement Learning: An Introduction, Richard Sutton and Andrew G. Barto
+
+
+To understand the RL process, let’s imagine an agent learning to play a platform game:
+
+
+
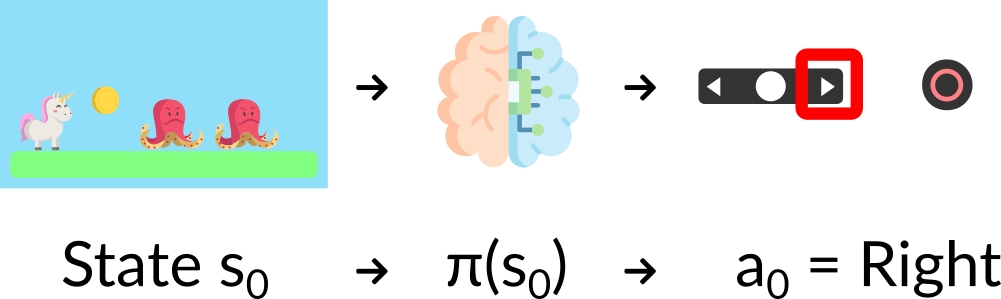
+- Our Agent receives **state \\(S_0\\)** from the **Environment** — we receive the first frame of our game (Environment).
+- Based on that **state \\(S_0\\),** the Agent takes **action \\(A_0\\)** — our Agent will move to the right.
+- The environment goes to a **new** **state \\(S_1\\)** — new frame.
+- The environment gives some **reward \\(R_1\\)** to the Agent — we’re not dead *(Positive Reward +1)*.
+
+This RL loop outputs a sequence of **state, action, reward and next state.**
+
+
+
+The agent's goal is to _maximize_ its cumulative reward, **called the expected return.**
+
+## The reward hypothesis: the central idea of Reinforcement Learning [[reward-hypothesis]]
+
+⇒ Why is the goal of the agent to maximize the expected return?
+
+Because RL is based on the **reward hypothesis**, which is that all goals can be described as the **maximization of the expected return** (expected cumulative reward).
+
+That’s why in Reinforcement Learning, **to have the best behavior,** we aim to learn to take actions that **maximize the expected cumulative reward.**
+
+
+## Markov Property [[markov-property]]
+
+In papers, you’ll see that the RL process is called a **Markov Decision Process** (MDP).
+
+We’ll talk again about the Markov Property in the following units. But if you need to remember something today about it, it's this: the Markov Property implies that our agent needs **only the current state to decide** what action to take and **not the history of all the states and actions** they took before.
+
+## Observations/States Space [[obs-space]]
+
+Observations/States are the **information our agent gets from the environment.** In the case of a video game, it can be a frame (a screenshot). In the case of the trading agent, it can be the value of a certain stock, etc.
+
+There is a differentiation to make between *observation* and *state*, however:
+
+- *State s*: is **a complete description of the state of the world** (there is no hidden information). In a fully observed environment.
+
+
+
+
+In chess game, we receive a state from the environment since we have access to the whole check board information.
+
+
+In a chess game, we have access to the whole board information, so we receive a state from the environment. In other words, the environment is fully observed.
+
+- *Observation o*: is a **partial description of the state.** In a partially observed environment.
+
+
+
+In Super Mario Bros, we only see the part of the level close to the player, so we receive an observation.
+
+
+In Super Mario Bros, we only see the part of the level close to the player, so we receive an observation.
+
+In Super Mario Bros, we are in a partially observed environment. We receive an observation **since we only see a part of the level.**
+
+> [!TIP]
+> In this course, we use the term "state" to denote both state and observation, but we will make the distinction in implementations.
+
+To recap:
+
+
+
+## Action Space [[action-space]]
+
+The Action space is the set of **all possible actions in an environment.**
+
+The actions can come from a *discrete* or *continuous space*:
+
+- *Discrete space*: the number of possible actions is **finite**.
+
+
+
+In Super Mario Bros, we have only 4 possible actions: left, right, up (jumping) and down (crouching).
+
+
+
+Again, in Super Mario Bros, we have a finite set of actions since we have only 4 directions.
+
+- *Continuous space*: the number of possible actions is **infinite**.
+
+
+
+A Self Driving Car agent has an infinite number of possible actions since it can turn left 20°, 21,1°, 21,2°, honk, turn right 20°…
+
+
+
+To recap:
+
+
+Taking this information into consideration is crucial because it will **have importance when choosing the RL algorithm in the future.**
+
+## Rewards and the discounting [[rewards]]
+
+The reward is fundamental in RL because it’s **the only feedback** for the agent. Thanks to it, our agent knows **if the action taken was good or not.**
+
+The cumulative reward at each time step **t** can be written as:
+
+
+
+The cumulative reward equals the sum of all rewards in the sequence.
+
+
+
+Which is equivalent to:
+
+
+
+The cumulative reward = rt+1 (rt+k+1 = rt+0+1 = rt+1)+ rt+2 (rt+k+1 = rt+1+1 = rt+2) + ...
+
+
+
+However, in reality, **we can’t just add them like that.** The rewards that come sooner (at the beginning of the game) **are more likely to happen** since they are more predictable than the long-term future reward.
+
+Let’s say your agent is this tiny mouse that can move one tile each time step, and your opponent is the cat (that can move too). The mouse's goal is **to eat the maximum amount of cheese before being eaten by the cat.**
+
+
+
+As we can see in the diagram, **it’s more probable to eat the cheese near us than the cheese close to the cat** (the closer we are to the cat, the more dangerous it is).
+
+Consequently, **the reward near the cat, even if it is bigger (more cheese), will be more discounted** since we’re not really sure we’ll be able to eat it.
+
+To discount the rewards, we proceed like this:
+
+1. We define a discount rate called gamma. **It must be between 0 and 1.** Most of the time between **0.95 and 0.99**.
+- The larger the gamma, the smaller the discount. This means our agent **cares more about the long-term reward.**
+- On the other hand, the smaller the gamma, the bigger the discount. This means our **agent cares more about the short term reward (the nearest cheese).**
+
+2. Then, each reward will be discounted by gamma to the exponent of the time step. As the time step increases, the cat gets closer to us, **so the future reward is less and less likely to happen.**
+
+Our discounted expected cumulative reward is:
+
diff --git a/units/en/unit1/two-methods.mdx b/units/en/unit1/two-methods.mdx
index fcfc04ad..113c3393 100644
--- a/units/en/unit1/two-methods.mdx
+++ b/units/en/unit1/two-methods.mdx
@@ -1,90 +1,89 @@
-# Two main approaches for solving RL problems [[two-methods]]
-
-
-Now that we learned the RL framework, how do we solve the RL problem?
-
-
-In other words, how do we build an RL agent that can **select the actions that maximize its expected cumulative reward?**
-
-## The Policy π: the agent’s brain [[policy]]
-
-The Policy **π** is the **brain of our Agent**, it’s the function that tells us what **action to take given the state we are in.** So it **defines the agent’s behavior** at a given time.
-
-
-
-Think of policy as the brain of our agent, the function that will tell us the action to take given a state
-
-
-This Policy **is the function we want to learn**, our goal is to find the optimal policy π\*, the policy that **maximizes expected return** when the agent acts according to it. We find this π\* **through training.**
-
-There are two approaches to train our agent to find this optimal policy π\*:
-
-- **Directly,** by teaching the agent to learn which **action to take,** given the current state: **Policy-Based Methods.**
-- Indirectly, **teach the agent to learn which state is more valuable** and then take the action that **leads to the more valuable states**: Value-Based Methods.
-
-## Policy-Based Methods [[policy-based]]
-
-In Policy-Based methods, **we learn a policy function directly.**
-
-This function will define a mapping from each state to the best corresponding action. Alternatively, it could define **a probability distribution over the set of possible actions at that state.**
-
-
-
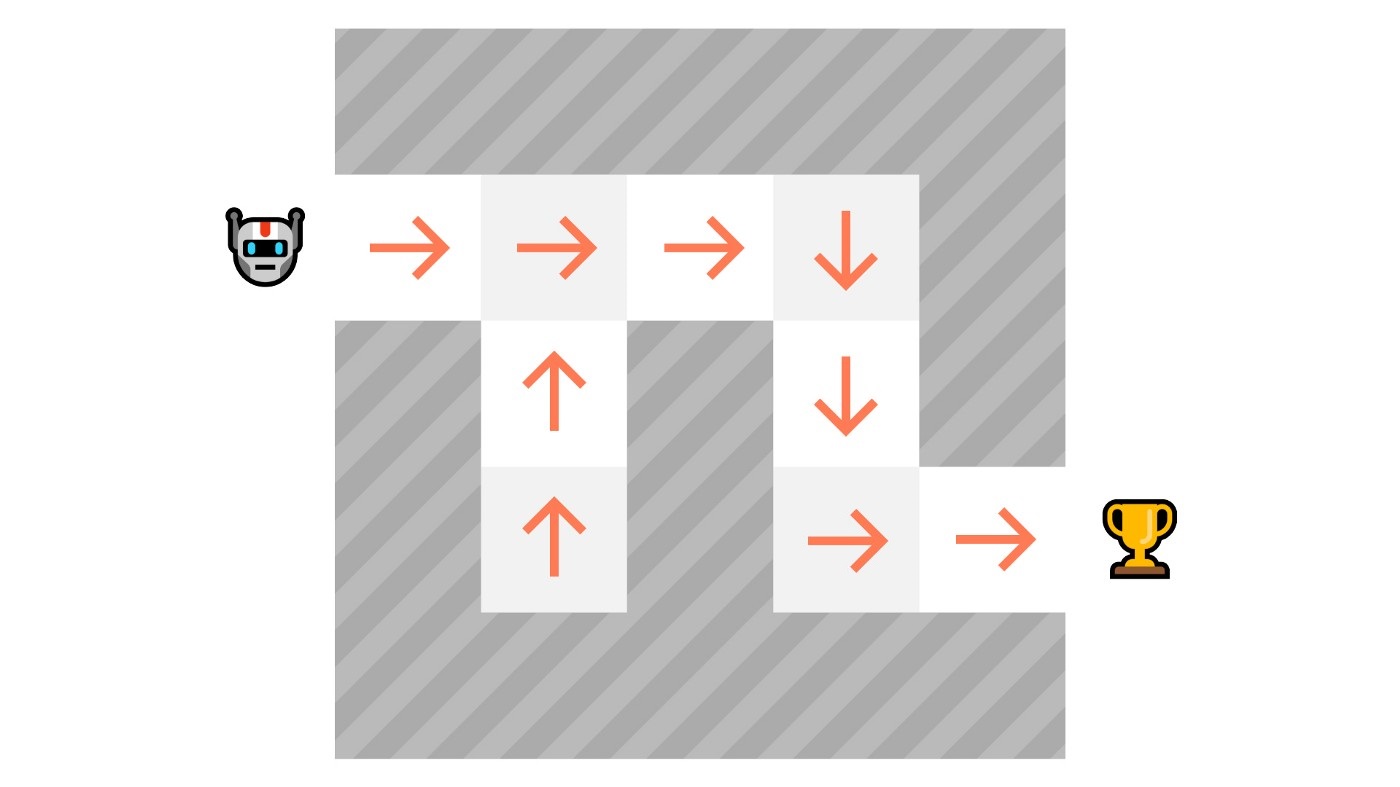
-As we can see here, the policy (deterministic) directly indicates the action to take for each step.
-
-
-
-We have two types of policies:
-
-
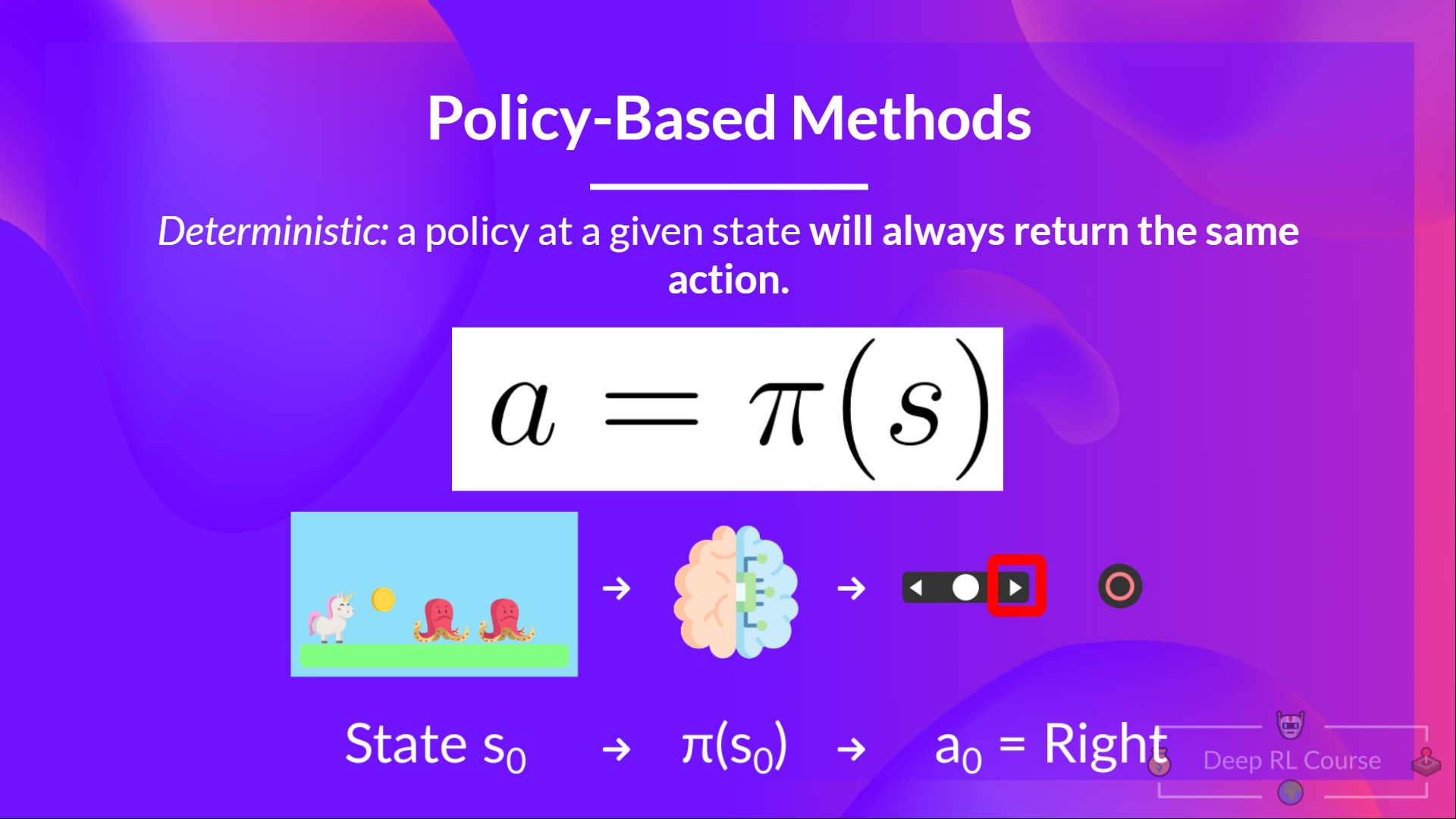
-- *Deterministic*: a policy at a given state **will always return the same action.**
-
-
-
-action = policy(state)
-
-
-
-
-- *Stochastic*: outputs **a probability distribution over actions.**
-
-
-
-policy(actions | state) = probability distribution over the set of actions given the current state
-
-
-
-
-Given an initial state, our stochastic policy will output probability distributions over the possible actions at that state.
-
-
-
-If we recap:
-
-
-
-
-
-## Value-based methods [[value-based]]
-
-In value-based methods, instead of learning a policy function, we **learn a value function** that maps a state to the expected value **of being at that state.**
-
-The value of a state is the **expected discounted return** the agent can get if it **starts in that state, and then acts according to our policy.**
-
-“Act according to our policy” just means that our policy is **“going to the state with the highest value”.**
-
-
-
-Here we see that our value function **defined values for each possible state.**
-
-
-
-Thanks to our value function, at each step our policy will select the state with the biggest value defined by the value function: -7, then -6, then -5 (and so on) to attain the goal.
-
-
-Thanks to our value function, at each step our policy will select the state with the biggest value defined by the value function: -7, then -6, then -5 (and so on) to attain the goal.
-
-If we recap:
-
-
-
+# Two main approaches for solving RL problems [[two-methods]]
+
+> [!TIP]
+> Now that we learned the RL framework, how do we solve the RL problem?
+
+In other words, how do we build an RL agent that can **select the actions that maximize its expected cumulative reward?**
+
+## The Policy π: the agent’s brain [[policy]]
+
+The Policy **π** is the **brain of our Agent**, it’s the function that tells us what **action to take given the state we are in.** So it **defines the agent’s behavior** at a given time.
+
+
+
+Think of policy as the brain of our agent, the function that will tell us the action to take given a state
+
+
+This Policy **is the function we want to learn**, our goal is to find the optimal policy π\*, the policy that **maximizes expected return** when the agent acts according to it. We find this π\* **through training.**
+
+There are two approaches to train our agent to find this optimal policy π\*:
+
+- **Directly,** by teaching the agent to learn which **action to take,** given the current state: **Policy-Based Methods.**
+- Indirectly, **teach the agent to learn which state is more valuable** and then take the action that **leads to the more valuable states**: Value-Based Methods.
+
+## Policy-Based Methods [[policy-based]]
+
+In Policy-Based methods, **we learn a policy function directly.**
+
+This function will define a mapping from each state to the best corresponding action. Alternatively, it could define **a probability distribution over the set of possible actions at that state.**
+
+
+
+As we can see here, the policy (deterministic) directly indicates the action to take for each step.
+
+
+
+We have two types of policies:
+
+
+- *Deterministic*: a policy at a given state **will always return the same action.**
+
+
+
+action = policy(state)
+
+
+
+
+- *Stochastic*: outputs **a probability distribution over actions.**
+
+
+
+policy(actions | state) = probability distribution over the set of actions given the current state
+
+
+
+
+Given an initial state, our stochastic policy will output probability distributions over the possible actions at that state.
+
+
+
+If we recap:
+
+
+
+
+
+## Value-based methods [[value-based]]
+
+In value-based methods, instead of learning a policy function, we **learn a value function** that maps a state to the expected value **of being at that state.**
+
+The value of a state is the **expected discounted return** the agent can get if it **starts in that state, and then acts according to our policy.**
+
+“Act according to our policy” just means that our policy is **“going to the state with the highest value”.**
+
+
+
+Here we see that our value function **defined values for each possible state.**
+
+
+
+Thanks to our value function, at each step our policy will select the state with the biggest value defined by the value function: -7, then -6, then -5 (and so on) to attain the goal.
+
+
+Thanks to our value function, at each step our policy will select the state with the biggest value defined by the value function: -7, then -6, then -5 (and so on) to attain the goal.
+
+If we recap:
+
+
+
diff --git a/units/en/unit1/what-is-rl.mdx b/units/en/unit1/what-is-rl.mdx
index ba63f92c..33afa5e2 100644
--- a/units/en/unit1/what-is-rl.mdx
+++ b/units/en/unit1/what-is-rl.mdx
@@ -1,40 +1,39 @@
-# What is Reinforcement Learning? [[what-is-reinforcement-learning]]
-
-To understand Reinforcement Learning, let’s start with the big picture.
-
-## The big picture [[the-big-picture]]
-
-The idea behind Reinforcement Learning is that an agent (an AI) will learn from the environment by **interacting with it** (through trial and error) and **receiving rewards** (negative or positive) as feedback for performing actions.
-
-Learning from interactions with the environment **comes from our natural experiences.**
-
-For instance, imagine putting your little brother in front of a video game he never played, giving him a controller, and leaving him alone.
-
-
-
-
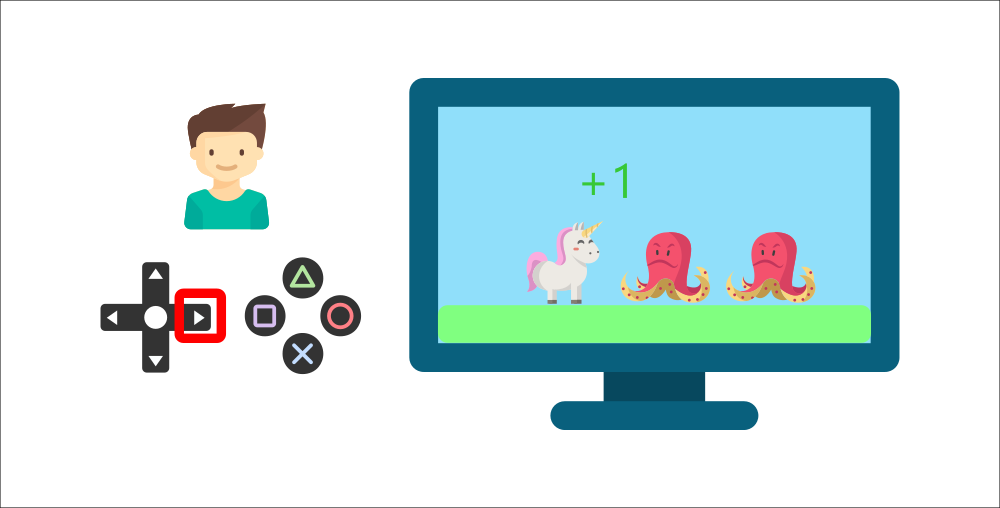
-Your brother will interact with the environment (the video game) by pressing the right button (action). He got a coin, that’s a +1 reward. It’s positive, he just understood that in this game **he must get the coins.**
-
-
-
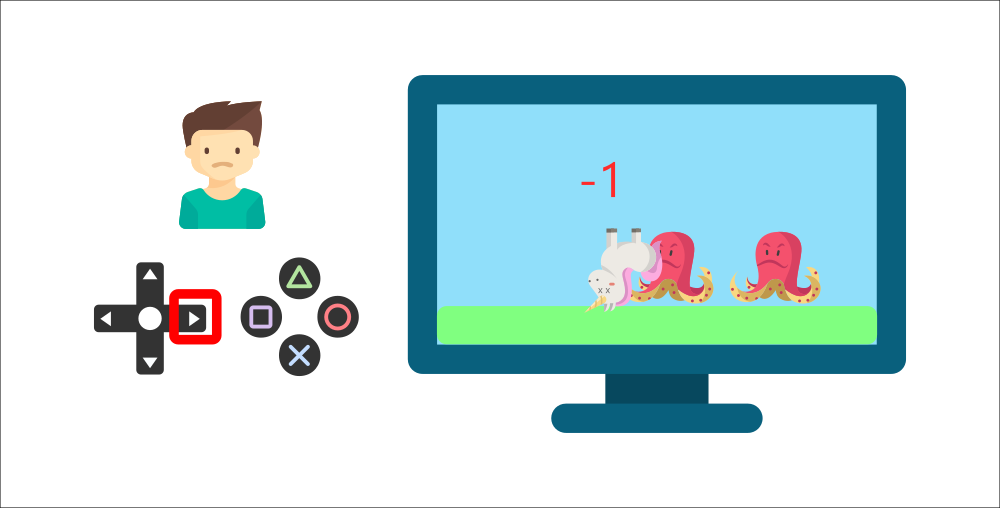
-But then, **he presses the right button again** and he touches an enemy. He just died, so that's a -1 reward.
-
-
-
-
-By interacting with his environment through trial and error, your little brother understands that **he needs to get coins in this environment but avoid the enemies.**
-
-**Without any supervision**, the child will get better and better at playing the game.
-
-That’s how humans and animals learn, **through interaction.** Reinforcement Learning is just a **computational approach of learning from actions.**
-
-
-### A formal definition [[a-formal-definition]]
-
-We can now make a formal definition:
-
-
-Reinforcement learning is a framework for solving control tasks (also called decision problems) by building agents that learn from the environment by interacting with it through trial and error and receiving rewards (positive or negative) as unique feedback.
-
-
-But how does Reinforcement Learning work?
+# What is Reinforcement Learning? [[what-is-reinforcement-learning]]
+
+To understand Reinforcement Learning, let’s start with the big picture.
+
+## The big picture [[the-big-picture]]
+
+The idea behind Reinforcement Learning is that an agent (an AI) will learn from the environment by **interacting with it** (through trial and error) and **receiving rewards** (negative or positive) as feedback for performing actions.
+
+Learning from interactions with the environment **comes from our natural experiences.**
+
+For instance, imagine putting your little brother in front of a video game he never played, giving him a controller, and leaving him alone.
+
+
+
+
+Your brother will interact with the environment (the video game) by pressing the right button (action). He got a coin, that’s a +1 reward. It’s positive, he just understood that in this game **he must get the coins.**
+
+
+
+But then, **he presses the right button again** and he touches an enemy. He just died, so that's a -1 reward.
+
+
+
+
+By interacting with his environment through trial and error, your little brother understands that **he needs to get coins in this environment but avoid the enemies.**
+
+**Without any supervision**, the child will get better and better at playing the game.
+
+That’s how humans and animals learn, **through interaction.** Reinforcement Learning is just a **computational approach of learning from actions.**
+
+
+### A formal definition [[a-formal-definition]]
+
+We can now make a formal definition:
+
+> [!TIP]
+> Reinforcement learning is a framework for solving control tasks (also called decision problems) by building agents that learn from the environment by interacting with it through trial and error and receiving rewards (positive or negative) as unique feedback.
+
+But how does Reinforcement Learning work?
diff --git a/units/en/unit2/two-types-value-based-methods.mdx b/units/en/unit2/two-types-value-based-methods.mdx
index 28f8b0b7..db4c0cf7 100644
--- a/units/en/unit2/two-types-value-based-methods.mdx
+++ b/units/en/unit2/two-types-value-based-methods.mdx
@@ -6,9 +6,8 @@ In value-based methods, **we learn a value function** that **maps a state to
The value of a state is the **expected discounted return** the agent can get if it **starts at that state and then acts according to our policy.**
-
-But what does it mean to act according to our policy? After all, we don't have a policy in value-based methods since we train a value function and not a policy.
-
+> [!TIP]
+> But what does it mean to act according to our policy? After all, we don't have a policy in value-based methods since we train a value function and not a policy.
Remember that the goal of an **RL agent is to have an optimal policy π\*.**
diff --git a/units/en/unitbonus5/getting-started.mdx b/units/en/unitbonus5/getting-started.mdx
index b8496e22..d55fe8db 100644
--- a/units/en/unitbonus5/getting-started.mdx
+++ b/units/en/unitbonus5/getting-started.mdx
@@ -14,9 +14,8 @@ Extract the zip file, open Godot, click “Import” and navigate to the `Starte
### Open the robot scene
-
-You can search for “robot” in the FileSystem search.
-
+> [!TIP]
+> You can search for “robot” in the FileSystem search.
This scene contains a couple of different nodes, including the `robot` node, which contains the visual shape of the robot, `CameraXRotation` node which is used to rotate the camera “up-down” using the mouse in human control modes. The AI agent does not control this node since it is not necessary for learning the task. `RaycastSensors` node contains two Raycast sensors that help the agent to “sense” parts of the game world, including walls, floors, etc.
@@ -24,9 +23,8 @@ This scene contains a couple of different nodes, including the `robot` node, whi
### Click on the scroll next to AIController3D to open the script for editing
-
-You might have to collapse the “robot” branch to find it more easily, or you can type `aicontroller` in the Filter box above the `Robot` node.
-
+> [!TIP]
+> You might have to collapse the “robot” branch to find it more easily, or you can type `aicontroller` in the Filter box above the `Robot` node.
### Replace the `get_obs()` and `get_reward()` methods with the implementation below:
@@ -218,9 +216,8 @@ This code part records mouse movement in case of human control and demo record m
### Open the demo record scene, and click on AIController3D node
-
-You can search for “demo” in the FileSystem search, and you can search for “aicontroller” in the scene's filter box.
-
+> [!TIP]
+> You can search for “demo” in the FileSystem search, and you can search for “aicontroller” in the scene's filter box.
@@ -238,9 +235,8 @@ Another way to make episode recording easier in challenging environments is to s
### Let’s record some demos:
-
-Note that the demos will only be saved if we have recorded at least one complete episode and closed the game window by clicking on "X" or pressing ALT+F4. Using the stop button in Godot editor will not save the demos. It’s best to try recording just one episode first, then check if you see "expert_demos.json" in the filesystem or in the Godot project folder.
-
+> [!TIP]
+> Note that the demos will only be saved if we have recorded at least one complete episode and closed the game window by clicking on "X" or pressing ALT+F4. Using the stop button in Godot editor will not save the demos. It’s best to try recording just one episode first, then check if you see "expert_demos.json" in the filesystem or in the Godot project folder.
Make sure that you are still in the `demo_record_scene`, `press F6` and the demo recording will start.
diff --git a/units/en/unitbonus5/train-our-robot.mdx b/units/en/unitbonus5/train-our-robot.mdx
index 3492a0f3..97d83cc3 100644
--- a/units/en/unitbonus5/train-our-robot.mdx
+++ b/units/en/unitbonus5/train-our-robot.mdx
@@ -1,8 +1,7 @@
# Train our robot
-
-In order to start training, we’ll first need to install the imitation library in the same venv / conda env where you installed Godot RL Agents by using: pip install imitation
-
+> [!TIP]
+> In order to start training, we’ll first need to install the imitation library in the same venv / conda env where you installed Godot RL Agents by using: pip install imitation
### Download a copy of the [imitation learning](https://github.com/edbeeching/godot_rl_agents/blob/main/examples/sb3_imitation.py) script from the Godot RL Repository.
@@ -24,9 +23,8 @@ Here are the `ep_rew_mean` and `ep_rew_wrapped_mean` stats from the logs display
en/unit13/training_results.png" alt="training results"/>
-
-You can find the logs in `logs/ILTutorial` relative to the path you started training from. If making multiple runs, change the `--experiment_name` argument between each.
-
+> [!TIP]
+> You can find the logs in `logs/ILTutorial` relative to the path you started training from. If making multiple runs, change the `--experiment_name` argument between each.
Even though setting the env rewards is not necessary and not used for the training here, a simple sparse reward was implemented to track success. Falling outside the map, in water, or traps sets `reward += -1`, while activating the lever, collecting the key, and opening the chest each set `reward += 1`. If the `ep_rew_mean` approaches 3, we are getting a good result. `ep_rew_wrapped_mean` is the reward from the GAIL discriminator, which does not directly tell us how successful the agent is at solving the environment.
 -
- -
- -
-- Our Agent receives **state \\(S_0\\)** from the **Environment** — we receive the first frame of our game (Environment).
-- Based on that **state \\(S_0\\),** the Agent takes **action \\(A_0\\)** — our Agent will move to the right.
-- The environment goes to a **new** **state \\(S_1\\)** — new frame.
-- The environment gives some **reward \\(R_1\\)** to the Agent — we’re not dead *(Positive Reward +1)*.
-
-This RL loop outputs a sequence of **state, action, reward and next state.**
-
-
-
-- Our Agent receives **state \\(S_0\\)** from the **Environment** — we receive the first frame of our game (Environment).
-- Based on that **state \\(S_0\\),** the Agent takes **action \\(A_0\\)** — our Agent will move to the right.
-- The environment goes to a **new** **state \\(S_1\\)** — new frame.
-- The environment gives some **reward \\(R_1\\)** to the Agent — we’re not dead *(Positive Reward +1)*.
-
-This RL loop outputs a sequence of **state, action, reward and next state.**
-
- -
-The agent's goal is to _maximize_ its cumulative reward, **called the expected return.**
-
-## The reward hypothesis: the central idea of Reinforcement Learning [[reward-hypothesis]]
-
-⇒ Why is the goal of the agent to maximize the expected return?
-
-Because RL is based on the **reward hypothesis**, which is that all goals can be described as the **maximization of the expected return** (expected cumulative reward).
-
-That’s why in Reinforcement Learning, **to have the best behavior,** we aim to learn to take actions that **maximize the expected cumulative reward.**
-
-
-## Markov Property [[markov-property]]
-
-In papers, you’ll see that the RL process is called a **Markov Decision Process** (MDP).
-
-We’ll talk again about the Markov Property in the following units. But if you need to remember something today about it, it's this: the Markov Property implies that our agent needs **only the current state to decide** what action to take and **not the history of all the states and actions** they took before.
-
-## Observations/States Space [[obs-space]]
-
-Observations/States are the **information our agent gets from the environment.** In the case of a video game, it can be a frame (a screenshot). In the case of the trading agent, it can be the value of a certain stock, etc.
-
-There is a differentiation to make between *observation* and *state*, however:
-
-- *State s*: is **a complete description of the state of the world** (there is no hidden information). In a fully observed environment.
-
-
-
-
-The agent's goal is to _maximize_ its cumulative reward, **called the expected return.**
-
-## The reward hypothesis: the central idea of Reinforcement Learning [[reward-hypothesis]]
-
-⇒ Why is the goal of the agent to maximize the expected return?
-
-Because RL is based on the **reward hypothesis**, which is that all goals can be described as the **maximization of the expected return** (expected cumulative reward).
-
-That’s why in Reinforcement Learning, **to have the best behavior,** we aim to learn to take actions that **maximize the expected cumulative reward.**
-
-
-## Markov Property [[markov-property]]
-
-In papers, you’ll see that the RL process is called a **Markov Decision Process** (MDP).
-
-We’ll talk again about the Markov Property in the following units. But if you need to remember something today about it, it's this: the Markov Property implies that our agent needs **only the current state to decide** what action to take and **not the history of all the states and actions** they took before.
-
-## Observations/States Space [[obs-space]]
-
-Observations/States are the **information our agent gets from the environment.** In the case of a video game, it can be a frame (a screenshot). In the case of the trading agent, it can be the value of a certain stock, etc.
-
-There is a differentiation to make between *observation* and *state*, however:
-
-- *State s*: is **a complete description of the state of the world** (there is no hidden information). In a fully observed environment.
-
-
- -
- -
- -
-
-## Action Space [[action-space]]
-
-The Action space is the set of **all possible actions in an environment.**
-
-The actions can come from a *discrete* or *continuous space*:
-
-- *Discrete space*: the number of possible actions is **finite**.
-
-
-
-
-## Action Space [[action-space]]
-
-The Action space is the set of **all possible actions in an environment.**
-
-The actions can come from a *discrete* or *continuous space*:
-
-- *Discrete space*: the number of possible actions is **finite**.
-
- -
- -
-Taking this information into consideration is crucial because it will **have importance when choosing the RL algorithm in the future.**
-
-## Rewards and the discounting [[rewards]]
-
-The reward is fundamental in RL because it’s **the only feedback** for the agent. Thanks to it, our agent knows **if the action taken was good or not.**
-
-The cumulative reward at each time step **t** can be written as:
-
-
-
-Taking this information into consideration is crucial because it will **have importance when choosing the RL algorithm in the future.**
-
-## Rewards and the discounting [[rewards]]
-
-The reward is fundamental in RL because it’s **the only feedback** for the agent. Thanks to it, our agent knows **if the action taken was good or not.**
-
-The cumulative reward at each time step **t** can be written as:
-
-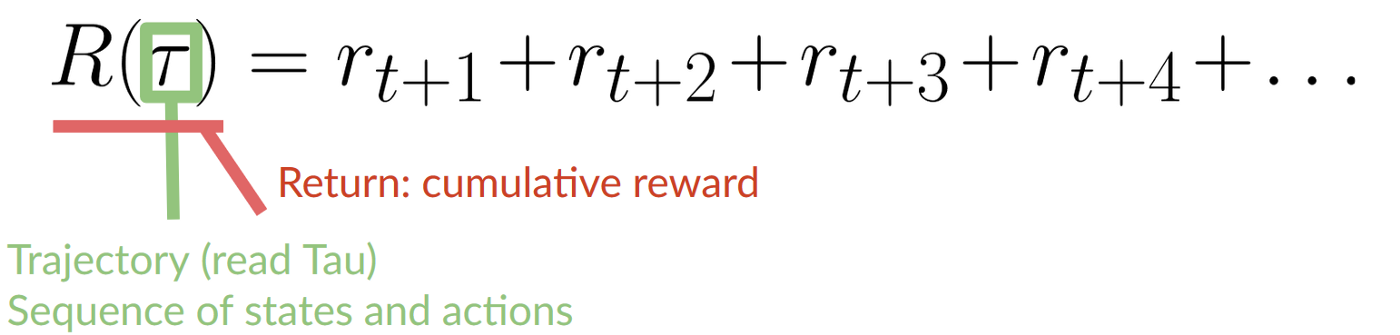 -
-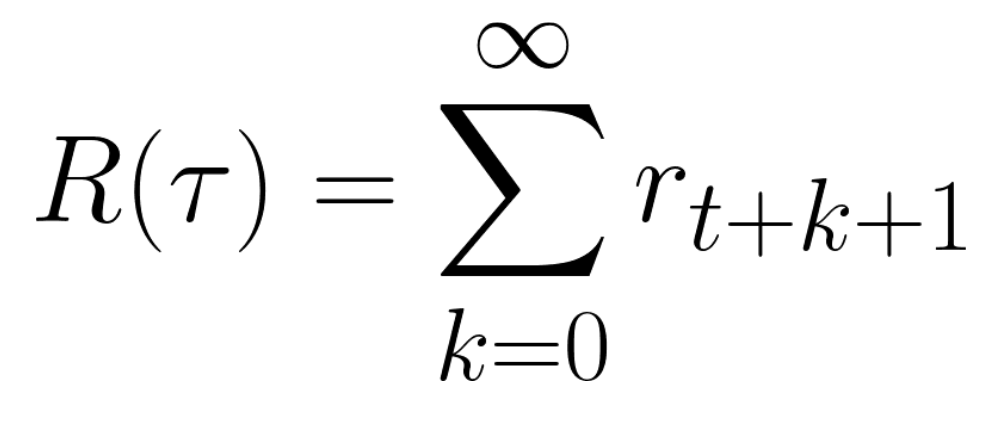 -
- -
-As we can see in the diagram, **it’s more probable to eat the cheese near us than the cheese close to the cat** (the closer we are to the cat, the more dangerous it is).
-
-Consequently, **the reward near the cat, even if it is bigger (more cheese), will be more discounted** since we’re not really sure we’ll be able to eat it.
-
-To discount the rewards, we proceed like this:
-
-1. We define a discount rate called gamma. **It must be between 0 and 1.** Most of the time between **0.95 and 0.99**.
-- The larger the gamma, the smaller the discount. This means our agent **cares more about the long-term reward.**
-- On the other hand, the smaller the gamma, the bigger the discount. This means our **agent cares more about the short term reward (the nearest cheese).**
-
-2. Then, each reward will be discounted by gamma to the exponent of the time step. As the time step increases, the cat gets closer to us, **so the future reward is less and less likely to happen.**
-
-Our discounted expected cumulative reward is:
-
-
-As we can see in the diagram, **it’s more probable to eat the cheese near us than the cheese close to the cat** (the closer we are to the cat, the more dangerous it is).
-
-Consequently, **the reward near the cat, even if it is bigger (more cheese), will be more discounted** since we’re not really sure we’ll be able to eat it.
-
-To discount the rewards, we proceed like this:
-
-1. We define a discount rate called gamma. **It must be between 0 and 1.** Most of the time between **0.95 and 0.99**.
-- The larger the gamma, the smaller the discount. This means our agent **cares more about the long-term reward.**
-- On the other hand, the smaller the gamma, the bigger the discount. This means our **agent cares more about the short term reward (the nearest cheese).**
-
-2. Then, each reward will be discounted by gamma to the exponent of the time step. As the time step increases, the cat gets closer to us, **so the future reward is less and less likely to happen.**
-
-Our discounted expected cumulative reward is:
- +# The Reinforcement Learning Framework [[the-reinforcement-learning-framework]]
+
+## The RL Process [[the-rl-process]]
+
+
+# The Reinforcement Learning Framework [[the-reinforcement-learning-framework]]
+
+## The RL Process [[the-rl-process]]
+
+ -
- -
-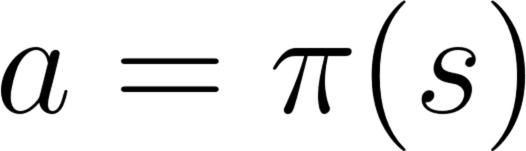 -
- -
-- *Stochastic*: outputs **a probability distribution over actions.**
-
-
-
-- *Stochastic*: outputs **a probability distribution over actions.**
-
- -
- -
- -
- -
-
-## Value-based methods [[value-based]]
-
-In value-based methods, instead of learning a policy function, we **learn a value function** that maps a state to the expected value **of being at that state.**
-
-The value of a state is the **expected discounted return** the agent can get if it **starts in that state, and then acts according to our policy.**
-
-“Act according to our policy” just means that our policy is **“going to the state with the highest value”.**
-
-
-
-
-## Value-based methods [[value-based]]
-
-In value-based methods, instead of learning a policy function, we **learn a value function** that maps a state to the expected value **of being at that state.**
-
-The value of a state is the **expected discounted return** the agent can get if it **starts in that state, and then acts according to our policy.**
-
-“Act according to our policy” just means that our policy is **“going to the state with the highest value”.**
-
-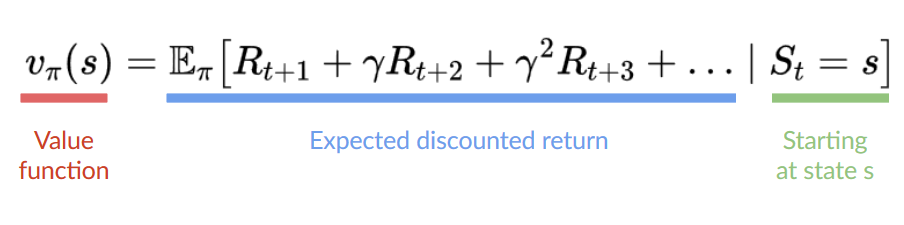 -
-Here we see that our value function **defined values for each possible state.**
-
-
-
-Here we see that our value function **defined values for each possible state.**
-
- -
- -
- +# Two main approaches for solving RL problems [[two-methods]]
+
+> [!TIP]
+> Now that we learned the RL framework, how do we solve the RL problem?
+
+In other words, how do we build an RL agent that can **select the actions that maximize its expected cumulative reward?**
+
+## The Policy π: the agent’s brain [[policy]]
+
+The Policy **π** is the **brain of our Agent**, it’s the function that tells us what **action to take given the state we are in.** So it **defines the agent’s behavior** at a given time.
+
+
+# Two main approaches for solving RL problems [[two-methods]]
+
+> [!TIP]
+> Now that we learned the RL framework, how do we solve the RL problem?
+
+In other words, how do we build an RL agent that can **select the actions that maximize its expected cumulative reward?**
+
+## The Policy π: the agent’s brain [[policy]]
+
+The Policy **π** is the **brain of our Agent**, it’s the function that tells us what **action to take given the state we are in.** So it **defines the agent’s behavior** at a given time.
+
+ -
-Your brother will interact with the environment (the video game) by pressing the right button (action). He got a coin, that’s a +1 reward. It’s positive, he just understood that in this game **he must get the coins.**
-
-
-
-Your brother will interact with the environment (the video game) by pressing the right button (action). He got a coin, that’s a +1 reward. It’s positive, he just understood that in this game **he must get the coins.**
-
- -
-But then, **he presses the right button again** and he touches an enemy. He just died, so that's a -1 reward.
-
-
-
-
-But then, **he presses the right button again** and he touches an enemy. He just died, so that's a -1 reward.
-
-
- -
-By interacting with his environment through trial and error, your little brother understands that **he needs to get coins in this environment but avoid the enemies.**
-
-**Without any supervision**, the child will get better and better at playing the game.
-
-That’s how humans and animals learn, **through interaction.** Reinforcement Learning is just a **computational approach of learning from actions.**
-
-
-### A formal definition [[a-formal-definition]]
-
-We can now make a formal definition:
-
-
-
-By interacting with his environment through trial and error, your little brother understands that **he needs to get coins in this environment but avoid the enemies.**
-
-**Without any supervision**, the child will get better and better at playing the game.
-
-That’s how humans and animals learn, **through interaction.** Reinforcement Learning is just a **computational approach of learning from actions.**
-
-
-### A formal definition [[a-formal-definition]]
-
-We can now make a formal definition:
-
- @@ -238,9 +235,8 @@ Another way to make episode recording easier in challenging environments is to s
### Let’s record some demos:
-
@@ -238,9 +235,8 @@ Another way to make episode recording easier in challenging environments is to s
### Let’s record some demos:
-