Inefficient Storage after Moving or Renaming Files? #334
Comments
|
The new files like If you suspect this is the case, then reducing the chunk size is the first option. A chunk size of 1M (instead of the default 4M) has been shown to be able to significantly improve the deduplication efficiency: https://duplicacy.com/issue?id=5740615169998848 and https://duplicacy.com/issue?id=5747610597982208. Unfortunately, you can't change the chunk size after you initialize the storage. You will need to start a new one. The technique mentioned in #248 (which @fracai actually implemented on his branch) is another possibility. By introducing artificial chunk boundaries at large files, it can be guaranteed that moving larges files to a new location won't lead to any new chunks. However, this technique could potentially create many chunks that are too small and I'm unsure it would be better than just reducing the average chunk size. It is possible to retrospectively check the effect of different chunk sizes on the deduplication efficiency. First, create a duplicate of your original repository in a disposable directory, pointing to the same storage: Add two storages (ideally local disks for speed) with different chunk sizes: Then check out each revision and back up to both local storages: Finally check the storage efficiency using the |
Ah, I hadn't realized that. I see why that wouldn't help the matter now.
I tried a Chunk size of 1M Chunk size, and it did help but unfortunately it slowed down uploads to cloud destinations. I'm guessing I'll have to choose between space or speed as a priority. As a side note, when using 4M chunks I saw an increase of about I tested this across 5 different Photo projects/folders and and the results were surprisingly similar. I did notice a weird situation where the size would grow even if I was just moving the Folder from one parent to another. Initially I wasn't able to replicate it with a simple folder with dummy files, but eventually I was able to isolate the behavior in three steps, I'm not entirely sure why it happens though: Scenario The steps I take are as follows:
What happens: This is the resulting I have the entire log if it helps, but figured I'd start with this. I'm just kind of curious why in this circumstance the size would increase when moving between two folders. |
This information is very helpful. What is the average size of your photo files? I think the technique implemented by @fracai in his branch will definitely reduce the overhead further. Which cloud storage are you using? I ran a test to upload a 1GB random file to Wasabi with 16 threads and the differences between 4M and 1M are minimal. This is the result for the 4M test: This is the result from the 1M test:
This is actually normal. You can think of the pack-and-split approach as arranging files in order, and then packing them into a big tar ball, and finally splitting the tar ball into chunks. Reorganizing files changes the positions of many files in the tar ball, so a lot of new chunks will be created. Moving files from the "Backlog" folder to the "Catalogued" folder basically moves a sequence of files as whole, so new chunks will be created at the both ends of the sequence (as well as at the gap it left behind), but not inside the sequence (the variable-size chunks algorithm is able to split chunks at previous boundaries as much as it can). |
|
I suppose I should clear the dust off my branch and make a pull request. |
In this example
I'm using B2 at the moment and I noted it was about 50% slower with 1M instead of 4M. I'll retest on Monday when I'm back on my fast line, but I suspect its something that could be combated with more threads given my latency to the b2 storage servers is about 200ms (despite upload being 200-300Mbit). The other worry I had with using 1M chunks in the cloud was the cost of API hits in the future. I'm already a little worried about it given I hope to backup arround 10TB, so going from 4M to 1M is likely to make this worse. Wasabi may end up making more sense for me if this is the case (no API charge).
I think I follow. The main reason it seemed odd to me, was because there were no other files in the whole repository in this example, so I didn't think moving from "Backlog" would actually make a difference. Infact if I start the process at Step 4, the move doesn't result in any growth. This got me thinking about whether the same problem would exist if the order of the files was instead dictated by the modified date within the whole snapshot? As opposed to the Filename within a subfolder. I guess this would be problematic for a number of reasons; the first that springs to mind is needing to scan for all files in the whole repository before doing anything, and keep that in memory. But probably introducing more complexity for when files actually change or deduping across devices too.
Like most people, I have a real mixed collection of data I want to backup. For me, the vast majority in terms of raw MB is Photos (3MB-50MB) and Videos (100MB-4GB each), but I also have VMs (avg 20GB each), Docker Containers (avg 300MB each) and on the other end of the spectrum Node projects (thousands of small files < 50KB). If I have to run different chunk sizes (to different storages) I will, but would deffinately be good to know what's optimal for my needs. Your point about different profiles for different filesets is interesting, I can see that being really useful, even at a snapshot level. |
|
I think inserting chunk boundaries at file boundaries would be very beneficial regarding deduplication. Consider a folder where some randomly chosen files are edited or added every day. File boundaries are very natural break points for changed data and should thus be utilized. Of course storage performance is dependent on large enough chunks and this has to be weighed against file boundary chunking. In my opinion, any file boundary appearing after the minimum chunk size has been gathered should terminate the chunk, because then the minimum chunk size can be set by the user according to taste and storage requirements. For a random distribution of file sizes the real average chunk size should be approximately 2.1 times the configured average chunk size (sum of 1..n file sizes modulo [0.25 .. 4.0] x storage avg chunk size). Furthermore I think the rolling hash function should use a significantly smaller window size. The rolling hash is calculated over the minimum chunk size (call it M), which means any change in data within the last M bytes of the chunk (which is on average half of the chunk) would cause the chunk boundary in the stream to move to a new position, and that in turn could lead to a domino-effect spilling over several chunks if subsequent potential chunk boundaries are not within the min/max size limits. Calculating the rolling hash over a fairly short range of bytes (say 256 bytes) would provide much more stable chunk boundaries because small data changes would be very unlikely to affect the chunk boundary. |
I agree this is a good idea.
Duplicacy uses the minimum chunk size as the rolling hash window not only because it has one fewer parameter to configure, but also to avoid the worse scenario where you have too many boundaries (with a 256 byte window for instance). I think a much larger window will make the rolling hash tends more random (although I don't have data to support this claim). |
Too much randomness is not necessarily your friend. If the data stream has some reoccurring patterns, it could be beneficial to be able to find them using a smaller hashing window. The minimum chunk size will still limit the maximum number of chunks you can get. I would have thought that a 256 byte window would provide enough entropy to avoid degenerate cases of too many chunks, and I tried to run some test data using different windows sizes. The results were not really what I expected, leading me to believe I perhaps messed up the hashing code somehow. My test repository is a windows share with lots of rather small files (office documents, some executables) and storage initialized with 1M average chunk sizes: It strikes me as very odd that smaller window sizes that are even powers of two give significantly more chunks, while other window sizes perform almost identical to the original window size. The modified chunkmaker code can be seen in my hash_window branch. |
+1! |
That is interesting. What was your File Chunk Count for the Original Window Size. |
|
@jonreeves: The original window size is the minimum chunk size, i.e. 256 kB in my test. That gave 5943 chunks. |
@gilbertchen: My branch file_boundaries implements this. I had to increase the bufferCapacity to maximumChunkSize on order to detect file boundaries occurring in the whole range between minimumChunkSize and maximumChunkSize. For repositories with very small files (average file size well below the average chunk size) this chunking can give a slight increase in number of chunks (in my extreme testing I got ~20% more chunks), but for file sizes averaging at or above the average chunk size there should not be any measurable difference in number of chunks. I have not tested how effective this file boundary chunking is when editing or reordering files. |
|
@kairisku definitely. I'll be back with my data set on Saturday and can perform the same renames/moves as before and report back. |
|
@kairisku I tested out your branch. I have a source Folder that contains Images and have made duplicates of it in 8 different states to indicate 8 potential changes over time to the Location and Contents of the Folder. Directory Structure Stages / Snapshot Revisions None of the files change in this example, only new files are added and existing ones renamed or moved. Because of this I ensured the
Results Conclusions Thoughts I guess the intended way would be to make |
|
@jonreeves , @kairisku , maybe you're interested in some tests I'm doing: link They can give you some ideas... |
|
@jonreeves You could check how the file and chunk boundaries are aligned by extracting the file information of the snapshot with something like this:
and then look at the second number in the content -tag which should be zero if the file starts at the beginning of a chunk, i.e.
is an example of a file that starts at offset zero of chunk 1830. Since the number of files in your test is quite small, you could also show us all the content rows with
I would recommend using smaller chunks, e.g. average 1M chunks as that would decrease the probability of different files being bundled in the same chunk after reorganizing. |
Yes, I have looked at your tests regarding the optimization of the Evernote database causing massive data uploads. I cannot really say how much of the database is actually modified during the optimization. If there are many changes everywhere, then nothing much can be done about it. But I think the variable chunking algorithm in duplicacy has room for improvement (as I said in an earlier comment in this issue). By default duplicacy uses a hashing window equal to the minimum chunk size, so for your 1M average chunk size that means it hashes 256 kB at a time. If a single byte of that 256 kB has changed, the hash changes and the variable boundary gets moved to a new location which can give a cascade effect of many new chunks. Could you try my hash_window branch which uses a smaller window size of 255 bytes for the hash? It should keep the chunk boundaries more stable leading to less changed data in your case (provided the Evernote optimization actually leaves portions of the data unchanged). |
Ok! I could run a test with "official" Duplicacy vs. yours, both of them with 1M fix chunks. Is it a good setup? |
Not fixed, use variable size chunks with 1M average size.. :) |
|
I asked because the performance of Duplicacy with fixed chunks was better than with the variable for this case (basically a large SQLite file), and this is the setup recommended by Gilbert for the case. Then the setup would be: "official" Duplicacy with 1M fix x your branch with 1M var? Or both 1M var? |
|
I am hoping that my branch improves the variable chunking to be at least as efficient as using fixed chunks, leading to variable chunking being the best configuration for all cases. So your primary comparison should be official Duplicacy with 1M fixed chunks vs my branch with 1M variable chunks. Feel free to do any other comparison you find interesting (the mailbox -editing scenarios could also be interesting). |
|
Please, give me a little help, since I have no experience compiling programs in Go: I downloaded and installed Go, I cloned your main repository to But it complained of a number of dependencies (Google, Minio, etc). Do I have to download them all or is there any way to compile by accessing them on line? |
|
@TowerBR if I remember correctly the project uses You can then enter the |
@kairisku I re-ran the tests again, but with a
I think you're right. Each JPG is What seems odd to me, is that these JPG and ARW files don't change, so the File Hash should always be the same. You'd expect that if a new/moved file is discovered on a subsequent backup run, and it has the 'exact' same File Hash, that you could effectively just relink it to the existing Chunks and boundaries. I realize this likely isn't possible because of the current chunking approach and obviously you can't know the File Hash until you read it completely, by which time the "new" file is partially part of a new set of chunks unnecessarily. I semi-hoped the |
|
@jonreeves , thanks for the help! I moved a few steps ahead... The I already tried to run with my user and as admin. The first error seems to be no problem, but I didn't understand the last one (access denied, logged in as admin?). |
|
@TowerBR: I do not know the intricacies of go and its dependences. I just initially followed the installation instructions in the Duplicacy wiki, i.e. which fetched (took a long while) all the needed sources for me (and it took me a while to realize the three dots at the end of the command should actually be there!). After that I created my fork and could use the already fetched dependencies. Note: after checking out my branch you need to edit the import in @jonreeves: the above note applies to you too, since it seems you are not getting any file boundary chunks. Otherwise your conclusions seem correct. Duplicacy does not use file hashes at all to identify previously seen files that may have changed names or locations, but rather concatenates the contents of all files into a long data stream that is cut into chunks according to artificial boundaries based on a hash function. My file_boundaries branch also considers file boundaries as potential chunk separators (within the specified chunk size limits), which should result in two large enough files not being bundled into the same chunk. Of course in the case when the file boundary is found before the minimum chunk size has been collected it has to be bundled with one or more following files to achieve an large enough chunk. With the default chunk size limits I think there is a 1/16 chance of bundling still happening. My hash_window branch on the other hand uses a significantly smaller hash window which should result in the hash-based chunk boundaries being more stable when data within a file is changed (i.e. SQLite databases or virtual machine images). The hash-based chunk boundaries are created when the hash of the last n bytes give a specific pattern, which means any changes within the last n bytes of a chunk will cause the hash to change and the chunk boundary to move to a different location which in turn causes one or several subsequent chunks to also change. My branch changes n from the large value of minchunksize (1M if using the default 4M chunks) to 255, which means a data change within a chunk has a very low probability of affecting the chunk boundary. Both of my branches could be applied simultaneously (because each addresses different problems with the current chunking approach). I am also trying to test the changes myself, but do not actually have the very distinct issues @jonreeves and @TowerBR have been investigating, so I appreciate the testing assistance. |
|
@kairisku thanks for the guidance, I didn't think to check the I followed your suggestions and re-built the binary and re-ran the tests. A big improvement for sure this time: This time, every file has I'll try out the hash_window branch a bit later, and see what happens with that approach. Updated |
|
@jonreeves could you please also update the table with the number of chunks in each revision? that would also be useful since i am interested in the |
|
@TheBestPessimist good point, I'm also keeping an eye on this. Updated. |
|
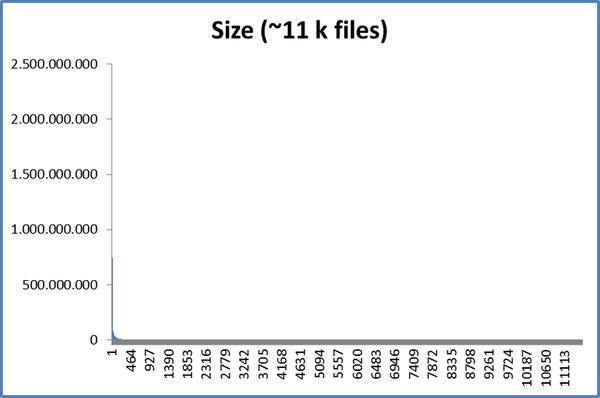
Interesting, I had not thought of that: ratio ... Perhaps, the issue is not the use of fixed or variable chunks, as in the tests I reported, but rather the relationship between minimum and maximum chunks sizes and their application in the repository. For example, when checking file sizes (~ 11,000 files) in my Thunderbird repository, we have this:
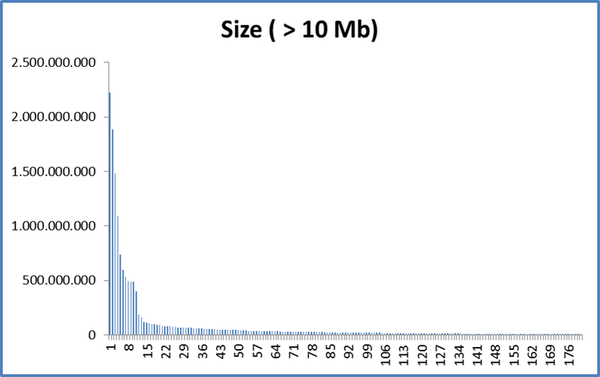
If we take only files with more than 10 Mb (183 files) we have:
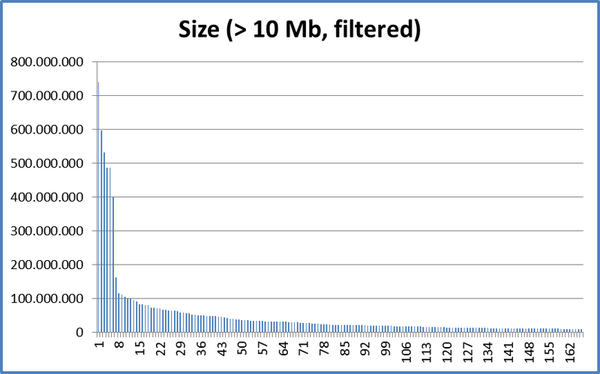
That is, there are more than 10,000 files with less than 10 Mb ... If we also filter the files with the same patterns from the
So it might be worth trying an |
|
Lots of data, and many good ideas here. @jonreeves You are correct in that the tiny .xmp-files cause problems after reorganization, because it indeed causes each .xml -file to be bundled with the following large file and that introduces lots of new chunks. As you proved, tweaking the chunk size limits can work around the difficulties, but it feels very unfeasible to require that level of insight to do that successfully. I think renaming/reorganizing otherwise unmodified files is a very specific special case that would require a dedicated solution. I am thinking Duplicacy should use the full file hashes collected from previous snapshots and when finding identical files in subsequent runs could just shortcut to the previous chunk segments. For files smaller than the buffer size, this should be quite simple to implement, but to support larger files the processing should be done in two phases. First collect hashes for all files to see if they are identical to files from previous snapshots, and then a new run to actually do chunking for new/updated files. Could be a lot of work, and possibly slow down the whole backup run significantly. I do not know if it is worth the effort.. Any attempt to sort the files before processing can also be catastrophic, because you never know how the files are manipulated in a way that drastically affects how they are sorted. The current Duplicacy algorithm can be described as bundle-AND-chunk, because it tries to bundle the files regardless of size and then cut them into chunks partly to be convenient to send to cloud storage and partly to perform deduplication. @thrnz and @fracai (and others as well?) have been thinking in a direction that I would call bundle-OR-chunk. Small files are bundled to meet the minium chunk size requirements, while large files are chunked to get deduplicable pieces. This could be implemented with two parallell processing pipelines, simply tossing the smaller files into one pipeline and the larger files into another, each pipeline spitting out chunks. I am still trying to wrap my head around all the data that @TowerBR produced. A few initial conclusions can be drawn. I think the Evernote database optimization simply changes so much of the database that there simply is not much of the old data that can be reused (deduped). The total number of chunks do not radically differ between branches (the graphs exaggerates by being relative). Certain types of files, such as databases and thick disk images, are probably always best handled with fixed size chunks (because data do not shift up or down with random edits), alternatively a more optimal hash window size needs to be found. Any other significant takeaways that should be considered? |
I think the same, as everything is new, everything has to be sent again, there is nothing different that can be done. But I think about the impact of this on really big databases. I'm very curious about how Vertical Backup works.
I agree, in fact it is not because they are relative, but because the graph scale is small (2610-2710, a "100" range).
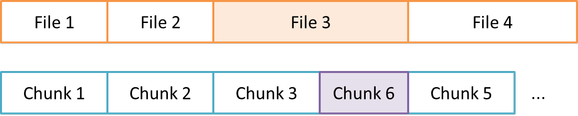
Exact. We must think of the "cause" of the problem, and I do not think the order is the main cause. I think that would be more the "not knowing" of the "coming forward" in the file queue. I have not yet studied the Duplicacy code like you do, so I do not know if what I'm going to say is correct and / or has already been implemented, but think of the file queue:
If file 3 has a small modification, I think what Duplicacy does today is to change the subsequent chunks until it finds an old chunk where the boundary fits, generating a new chunk 6, 7 and so on:
But if it could "see" that chunks 5 could be used, it would only generate chunk 6, to replace 4:
Is the current operation like this? |


|
I think you have the current operation correct; at least when using "-hash". Without "-hash", File4 wouldn't be chunked at all unless it has changed. bundle-OR-chunk and incrementally building up those small-file-bundles actually sounds like a really good combination though. |
|
Really interesting discussion. Thanks to everyone contributing to it, Trying to put all this into perspective, may I ask to what extent changes in how chunks are produced in some future or alternative version of duplicacy will require a newly initialized storage (i.e. starting an entirely new backup)? I understand that the chunksize parameters cannot be changed once the storage is initialized, but if those parameters remain the same ( My hunch is that it should be possible but chances are that it will lead to an very large upload, because so many chunks will have changed. But it would still be my preferred path because it would allow a gradual transition to a more efficient chunking algorithm as the old chunks gradually get pruned out. The only cost would be a temporary - though relatively long, depending on the prune settings - increase in storage use). Is it possible? Or can I expect that I will soon be re-uploading all my stuff once again? @kairisku re
Isn't it rather surprising that the file_boundary branch didn't perform any better than the official version? My tentative interpretation is that that this is due to the fact that @TowerBR 's tests were not about moving files around but mostly changing existing files (right?). Also, I believe the tests were run with a version before your most recent tweaks/bugfixes. But even so, It looks like honouring file boundaries only helps under specific conditions (or doesn't help under specific conditions). |
There is no lookahead. The files are simply processed in order (with
Any significant change to the chunking algorithm will change how the chunks are formed and thus will require a significant upload. The file boundary change will probably have a very large impact for repositories consisting of files that are smaller than the chunksize, but for repositories with very large files there are fewer file boundaries affecting the chunking. In the best case only the chunks around the file boundaries are affected, while the hash-based boundaries within the files should be stable. You can always test the branch with a dry-run to see what would happen.
The file boundary branch was intended for improving file rename/reorganize scenarios, so no big surprise there. |
I was starting to suspect this but thought I must be misunderstanding something. @gilbertchen I think this is quite serious (or is it only serious in theory?) Doesn't this mean that duplicacy's cross-source deduplication is only a matter of chance? If so, I suppose you will eventually accept a pull request from @kairisku at least for that branch? (Though it looks like the smaller hash window branch also has its benefits.)
Okay, I understand the that the aim was to improve those scenarios, but isn't it reasonable to expect it to also perform better in "ordinary use" without moving/renaming? What is the reason for the file-boundaries version consistently using more storage space than both other versions? (okay, except for the data base scenario where it was better than the original) |
You might think so, but hopefully not. The theory behind splitting chunks using a hash function, is to consistently find boundaries where the preceding data looks a certain way. If you have similar or identical files being backed up from different sources, the chunk boundaries should fall at the same positions resulting in identical chunks that can be deduplicated. Since the boundaries are selected within certain size limits, there is a chance of misalignment happening. Backups should be sufficiently fast, and therefore the algorithm cannot try a lot of different boundaries to perhaps find something that aligns with previous data, as that would require way too much resources. The current implementation does a reasonable good job, but then there are extreme situations where it falls short.
It should perform better or at least as good, but that is just my opinion. Chunks that are formed from the beginning of files should in theory have a slightly better chance of being deduplicated compared to chunks that are cut from random positions within a file. Consider editing some large file in a way that only changes the data at the end of the file. The beginning is then unchanged, as so is probably the following file whose beginning should not be bundled together with the end of previous file. I see no scenario where pasting together the end of one file and the beginning of another into the same chunk would be better than having the files in different chunks, except for the fact that many smaller chunks are not optimal for cloud storages.
I suspect @TowerBR tested with a slightly buggy version of the branch that did some extra splitting of the last chunk of a file. A bugfix was committed just after he started his long and detailed test. |
Though I'm not sure whether this is a matter of opinion, I agree. Your reasoning makes complete sense, which is basically why I thought the results were surprising. But if those were due to the little bug which is now fixed, what is keeping you from submitting a PR? Or do you first want to test a version that combines the smaller hash window with respecting file boundaries? I would love to see these features in the official version! |
|
I played a little with chunks settings and did a new test, but I'm really not sure what conclusions to take (lol): link |
|
My file_boundaries branch just got a commit for handling large and small files in two separate passes. I concluded this was the simplest change to implement a bundle-OR-chunk algorithm. All files larger than the minimum chunk size are processed first (with file boundary chunking), and in the second pass all the smaller files are bundled and chunked. I hope this will keep catastrophic cascades to a minimum. I have performed almost no tests at all, so there is a chance this commit breaks something in a spectacular way (e.g. if some internal logic goes totally haywire because files are now processed in a slightly different order). I will in time submit a pull request, but I would like the patch to have a significant positive benefit. The biggest problem is compatibility with chunks in existing storages. Because incremental backups only process new and modified files, the file boundary and processing order changes should actually not cause any problems. But if anyone is doing backups with the |
|
Interesting! Which would be a good setup (repository file type, chunks, etc) to do a test? ;-) |
What happens if I move files which have been backed up with the old (i.e. current official) algorithm? That will most likely trigger a larger upload, right? But with the benefit that subsequent moves or renames will not have any effects, i.e. no new uploads, right? |
@jonreeves had a good setup, i.e. first adding small files beside larger ones, doing a backup which uploaded only the small files, and then moving all files to another folder and backing up again (which will back up both the large and the small files). With the latest commit there should be improvements in that scenario.
You are almost correct! The old files will have a different chunk layout around the file boundaries, so by moving them you will (with my branch) get new chunks around the boundaries (and if unlucky, some further spillover). After that, subsequent moves/renames should have no impact for files larger than the minimum chunk size. There is still the case of small files that have been bundled into the same chunk, and if you move only some of those files, they will get bundled differently and that will result in new chunks. |
|
I updated my "test 09" with another job, after Gilbert's explanations here, setting the average chunks to the size of most files, and the result was exactly as expected, according to his explanation:
What led me to think: for repositories where most files have a similar size, setting the average chunks size close to this size of most files would have an effect similar to the "bundle-OR-chunk" approach described above? |

|
As Gilbert says: for the official duplicacy implementation, the size of the files have no effect on the chunk sizes, because all the files are bundled into one consecutive stream of data that is chunked using the hash function. With my file boundaries branch this indeed changes. If you have repositories where most files have a similar size, if that size falls within the min/max chunk size limits every file will be in its own chunk. The only deduplication that can happen in such a scenario, is if there are identical files to begin with. If files are larger than the maximum allowed chunk size, there is a possibility for identical chunks to be found from within otherwise non-identical files. With smaller chunks the probability increases (but probably not by much). There is no magic here, for any significant deduplication to take place where has to be some redundancy in the data to begin with. Such as copies of the same files, or only slightly edited files that have common parts with other files, virtual machine images containing common OS files, etc. |
Sure, but setting the size of the chunks to close to the size - of most - of the files, the number and size of the chunks is changed, and there are better chances that a change in a small file will not change many chunks. |
|
I've read up a bit on rolling hashes and content based slicing because I wanted to understand the principle by which chunks are created when it is not by file boundary and what I've learned is that you basically wait until the the first X digits of the hash of your rolling window are all zero. Once that happens, you apply a cut and then move on to the next chunk. X is a constant that you chose depending on how big you want the average chunk size to be. The more zeros you want, the more unlikely it is that you will actually get them (i.e. it will take longer until you get them) and hence the bigger your chunks will turn out on average. So this means that when we're setting the average chunk size, we're actually not actually telling duplicacy to make the chunks a particular size but we're telling it what the cut off criterion should be, i.e. how many zeros to watch out for, and that then leads to a distribution of chunk sizes that "happens" to have an about the average of what we requested in the setting (as @TowerBR's chart above nicely illustrates). I'm not sure if anyone else finds this interesting or non-trivial, but for me, this helped me understand why the average chunk size is not necessarily met exactly (but only on average), or - if I remember the term correctly from Maths class some decades ago - it's the "expected value". I also conclude from this that the file name of each chunk is the hash value of the entire chunk and therefore has nothing to do with the rolling hash (unless the chunk happened to be the same size as the rolling hash window, which is currently possible in duplicacy because the rolling hash window is set to min-chunk size, but which is impossible in the Kai's hash window branch, right?). And this, in turn, explains why we cannot quite foresee how well deduplication will work (i.e. what the chances are that a particular chunk will be used multiple times): the creation of the chunks has nothing to do with their "deduplicability". Chunking is one thing (based on rolling hashes) and deduplication is another (based on file hashes), right? Anyway, sorry for thinking out aloud. What I actually wanted to ask is this: am I correct in assuming that what the file boundary branch basically does is add a second cut criterion, making duplicacy not just watch out for those zeros but also checks each new byte in the rolling hash window whether it's and end-of-file character (or is it a string?) and if it is: snip! - no matter what the rolling hash is. Right? |
By my understanding, yes, but let's wait for Kai, "father of the child"... |
|
Yes, @tophee describes the use of the rolling hash absolutely right. Although the name of a chunk is based on a totally different (more secure) hash from the rolling hash, and the chunk hash includes all data from the whole chunk, which the rolling hash typically is from a much shorter stretch of bytes. And the file boundary branch indeed adds a second cut criteron that can cut the chunk regardless of the rolling hash, but only if it would result in a chunk with allowable size. I am not totally clear what @TowerBR tried to show with his histograms of chunk sizes. If the testing was made with the file boundary branch, then yes the distribution of source file sizes will affect the sizes of the resulting chunks because the chunks are cut at the file boundaries. If testing with the original duplicacy implementation, then the chunk size should on average be just the average chunk size as specified when initializing the storage. For a random distribution of file sizes, I actually expect the file boundary branch to produce larger chunks on the average, because the min/max limits of the chunk sizes are 1/4 and 4x the average desired chunk size, and a random distribution from 0.25 to 4 should average 2.125. But in reality file sizes are not randomly distributed, but follow some funny long-tailed distribution I no longer remember the name of (Zipf?) and therefore the average will be lower. Specific data sets have their own size distributions (photos, office-documents, databases, etc.). |
The test was done with the original implementation. I did the test to see how the size distribution of the chunks would be "around" the average size, and whether that distribution would be affected by the minimum and maximum sizes with a ratio greater than 0.25 to 4. What I'm thinking is that if most chunks have sizes close to most files (setting the average chunk size close to the average size of most files), then we'll have a better chance of having minor chunks changes with unique file changes . |
|
My file_boundaries branch now identifies identical small files based on their content hash which avoids problems with new chunks being formed because small files might get packed differently within a chunk. With these latest changes all rename/reorganization operations should result in zero uploaded file chunks (only updated metadata). Adding the same file multiple times (e.g. in different directories or with different names) should also be properly detected and only one copy will be uploaded (something which the original implementation did not explicitly check for, and due to bundling could cause all copies to end up in different chunks). The latest changes have only been lightly tested, so do not use for critical production data! I am a bit uncertain about how e.g. pruning might possibly be affected, because it is now possible to have a snapshot where different files point to the same parts of a chunk when the content is identical. It might at least affect size statistics. |
|
Wow, this is fantastic. Can't wait for this to become part of the official version (though I somewhat fear having to re-upload more than a TB of data again). Though I'm not sure I quite understand the latest changes and what they mean with regard to your bundle-OR-chunk approach.
So, by small files you mean those smaller than the min chunk size, right? (because those are the ones that will be bundled.) If so, are you saying that you are no longer doing any bundling? Or maybe I should just ask: what do you mean by "identifies identical small files". Where else would files be identified by their content hash but in their file name? Which, implies that they are saved under that name rather than bundled. (??)
I believe this is already possible now in the official branch. Edit: Took a look at the code and see that you are still packaging the small files (as I thought you would), but I don't understand where you are keeping the index of the packaged small file hashes. Edit2: Oh, now I see that you are talking about "different files point to the same parts of a chunk". I missed the parts part before. So, yes, that may indeed be new. In fact, this now appears to me as quite a substantial change in the way how duplicacy works... Or maybe not (because what (I suppose) counts for pruning is that the chunk is referenced. Prune doesn't care which part of the chunk, right? |
|
By small files I mean files smaller than the minimum chunksize. Files larger than that are always aligned to begin at the beginning of a new chunk, so the chunking takes care of deduplication for identical files there. But since the small files are bundled several files into a chunk, there are always some files that starts somewhere in the middle of a chunk. If any such file is renamed or moved, it will most likely be bundled differently which means it would end up in a chunk that looks different from all old chunks. E.g. say you have files A, B and C that gets bundled into chunk X. Rename B to B2 and run a new backup, original duplicacy will only process B2 and put that at the beginning of a new chunk Y (because it is different from X) There are actually at least three different hashes in duplicacy: the rolling hash used to break large files into chunks, the hash of a whole chunk (which also determines the name of the chunk), and then there is a hash for each source file (a confident fingerprint of the content of the file). What my latest commit does is entirely based on this last hash, i.e. in the above scenario it will immediately see that B2 is actually identical to B and just record in the snapshot that B2 uses the same part of the same chunk that B previously used. As a slight drawback, should you delete files A and C and prune them from the storage, no chunks will be removed, because the chunk that B2 references must still be kept although parts of the chunk is no longer needed. Because the metadata for A and C have been lost, the unused parts of the chunk will essentially be junk and cannot easily be reused even if A or C should reappear. I do not think this is too much of a problem. Original duplicacy also has the problem if you make multiple copies of a file, like D1, D2 and D3 and then run a backup, it will pack D1+D2+D3 into a new chunk. With my branch, if D1 is already in the previous snapshot, nothing will be uploaded at all. If D1 is really a new file, that will be bundled into a chunk, but then D2 and D3 will just point to the same chunk fragment where D1 is located. Although this might sound fantastic, the latest fixes really only concern scenarios where you have small files being renamed or copied. Depending on your data, this might be very significant, or have no impact at all. Did these explanations clarify things, or does something still need a better explanation? |
|
Yes, this clarifies a lot. Thanks for the detailed explanation. However, what I still don't understand is where you are storing the information about those small files (i.e. their hashes)? Or is it already stored in the snaåshot files and you are just using it to compare it with apparently new files? BTW: By "fantastic" I meant that it is a great improvement because it makes duplicacy behave more reasonable and efficient. Even if it may not have any effect in some scenarios, it's still gives me a good feeling because it improves the code. |
|
Nice work. Depending on the data being backed up, these changes would have a significant positive benefit on deduplication. I'd be interested to see if there is any tradeoff performance/memory wise when there are a large number of files involved. Both with the 'second pass' for chunking smaller files, and with checking to see if a small file's hash already exists. I might have a go at setting up and running some tests later to compare. |
Every file hash is already present in the snapshot (it is e.g. used when validating a snapshot using
Yes, please do some tests! The two-pass chunking should not really have any performance impact, because duplicacy first builds a list of all files that need to be processed and then just goes through the list in order. With my change it just goes through the in-memory list twice, processing the large files in the first pass and the small files in the second pass. I/O might be slightly affected in the sense that the throughput during the second pass can be a bit lower when processing lots of small files (if the reading of the source files is the bottleneck). The extra hashing of all new small files before starting the whole chunking process can on the other hand have a measurable impact. I didn't have the guts to try any fancy multithreading (not that familiar with Go), so there will probably be an I/O bottleneck when duplicacy in a single thread reads and hashes all the new small files while trying to decide if they really need to be processed or not. Improvements are gladly welcome! |
|
No I have not tried that, nor do I understand how that would make any difference. Chunks are immutable, once a chunk is created it will not be changed or touched in any way. During an incremental backup, only new and modified files are processed while any old unmodified files are skipped (unless you use the -hash option), so all new and modified files will end up creating new chunks. I see no benefit from changing the order in which files are bundled. I am not familiar with the worst case behaviour regarding git repositories you are referring to. Moving and copying of small files are already handled in my branch which causes them to never be included in new chunks if the identical data is already present in an existing chunk. I really should get around to making a PR of my improvements.. :) |
I think this may be related to issue #248 .
I noticed that backups of my active folders were growing in size significantly where I expected them to change very little. The best example I can give is my "Photos" folder/snapshot...
I regularly download my sd cards to a temporary named project folder under a "Backlog" subfolder. It can be days or months before I work on these images, but usually this will involve Renaming ALL the files and separating them into subfolders by Scene/Location or Purpose (print, portfolio, etc...). The project folder gets renamed too and the whole thing is then moved from out of "Backlog" to "Catalogued". None of the content of any of the files have physically changed during all this, file hashes should be the same.
The renaming and moving alone appears to be enough to make the backup double in size. Any image edits in theory shouldn't have an impact as typically the original file is untouched... The good thing about modern photo processing is edits are non destructive to the original image file. Instead and XML sidecar file is saved along side the image file with meta about the edits applied.
I'm yet to test the impact of making image edits but I suspect it may make things worse because each file gets another file added after it, and it seemed like file order made a difference to how the rolling hash was calculated.
Becomes...
This should be perfect for an incremental backup system, but it seems like duplicacy struggles under these circumstances. I figured the
-hashoption might help, but it didn't seem to.Am I doing something wrong or missing an option?
Is this a bug, or just a design decision?
Is there any possible way to improve this?
Although the above example may sound unique I find this happens in almost all my everyday folders. Design projects, website coding projects, Files and Folders are just often reorganized.
I'm guessing the only way to reclaim this space would be to prune the older snapshots where the files were named differently?
The text was updated successfully, but these errors were encountered: