Software Design
The Raspberry Pi Pico contains a dual-core processor. The first core handles the user interface, driving the display, rotary encoder, push buttons, and a flash interface. The second core is dedicated to implementing the DSP functions. The cores communicate using control and status structures, these structures are protected by mutexes. Control and status data are passed between the two cores periodically.
The ADC interface is configured in round-robin mode. Two DMA channels are used to transfer blocks of 4000 samples from the ADC to memory. The choice of 4000 samples is fairly arbitrary, longer blocks give an extra margin when the worst-case execution time is significantly longer than the average (at the expense of extra memory). The DMA channels are configured in a ping-pong fashion using DMA chaining. When each DMA channel completes, the other DMA channel automatically starts. The DMA chaining allows the ADCs to be read autonomously, without placing any load on the CPU.
As each DMA transfer completes, the process_block function is called. The process_block function takes a block of I/Q samples and outputs a block of Audio samples. At a sample rate of 500kSamples/s that gives us a real-time deadline of 8ms to process each block. At a CPU frequency of 125MHz, that means that we have exactly 1 million clock cycles for each block. After the work is complete, a timer measures the idle time until the next block is complete. The CPU utilisation can be calculated as utilisation = (8ms - idle_time)/8ms, it is useful to monitor the CPU utilisation during development so that the impact of each change can be assessed. The process_block function is the only part of the software that is time critical, and this part of the software uses fixed-point arithmetic and is run from RAM to maximise performance. The other parts of the software aren't particularly critical so it is run from flash and floating-point operations are used freely.
The first task is to remove DC, this is achieved by averaging the samples in each block, the average value represents the DC level, and this value is then subtracted from the next block. This turns out to be slightly faster than using a DC blocking filter. At this point in the DSP chain, the DC removal process isn't that critical. The receiver uses a low IF so the wanted signal is always offset from DC by a few kHz. Once we have frequency shifted the signal, any remaining DC is outside the pass band and is removed by the decimating filters. At first, I subtracted 2048 from the raw (unsigned 0 to 4095) ADC sample to give a signed value (-2048 to 2047). It turned out that this process was redundant, if we leave out the subtraction the DC removal process sees this as an additional DC level of 2048 and removes it anyway.
Before the samples can be frequency shifted, we need to convert the samples into complex format. The round-robin ADC alternates between I and Q samples, so even-numbered samples will be I and odd-numbered samples will be Q. The "missing" samples, needed to form a complex sample, need to be replaced by zeros.
int16_t i = (idx&1^1)*raw_sample; //even samples contain i data
int16_t q = (idx&1)*raw_sample; //odd samples contain q data
Since the RP2040 can perform a multiply in one clock cycle, it ended up being faster to multiply the sample by 1 or 0 than to select a sample using the ternary idx&1?raw_sample:0 syntax. This might not be true on other platforms. Once the signal is in complex format we can frequency shift the wanted signal to the centre of the spectrum using a complex multiply by a fixed frequency tone.
There are two components to the frequency offset, the first is compensating for the limited frequency resolution of the quadrature oscillator (the difference between the frequency we wanted and the frequency we got). The other component is the low-IF offset we have deliberately introduced to move the wanted signal away from DC. There tends to be a lot of interference close to DC caused by LO leakage, mains hum, etc. Applying a frequency offset allows us to filter out this interference.
We need to create a complex tone to "wipe off" the frequency offset. We can't calculate sin and cos values fast enough for real-time operation, so we calculate a lookup table of 2048 values representing a full cycle. Some memory is saved by using the same lookup table for sin and cos values, cos is calculated from the sin table by applying a pi/2 phase shift to the index. The values are scaled to give 15 fraction bits, with a magnitude of just less than 1 to make full use of the available 16 bits without causing overflow.
//pre-generate sin/cos lookup tables
float scaling_factor = (1 << 15) - 1;
for(uint16_t idx=0; idx<2048; idx++)
{
sin_table[idx] = sin(2.0*M_PI*idx/2048.0) * scaling_factor;
}
For each sample, the 32-bit phase accumulates a sample's worth of phase change (frequency). The 32-bit phase and frequency values are scaled so that 0 to (2^32)-1 represent the range 0 to (almost)2*pi. The 11 most significant bits of the phase accumulator are used as an index for the lookup table. Although only 11 bits of the phase accumulator are used to index the lookup table, the phase is accumulated to a much higher resolution. The rounding error caused by truncating the 21 least significant bits causes a short-term phase jitter, but this will tend to be compensated for in later cycles giving us a very precise average frequency in the long term.
const uint16_t phase_msbs = (phase >> 21);
const int16_t rotation_i = sin_table[(phase_msbss+512u) & 0x7ff]; //32 - 21 = 11MSBs
const int16_t rotation_q = -sin_table[phase_msbs];
phase += frequency;
The tone can then be applied to the signal using a complex multiply resulting in the wanted signal being shifted to the centre of the spectrum. The result of the multiplication now has an extra 15 fraction bits that need to be removed. The truncation causes about 1/2 and LSB of negative bias. This can be problematic later in the signal processing (particularly for CW signals where we deliberately shift DC into the audible range). We could use a better rounding method here to eliminate the bias, but this would require significant extra CPU cycles in a critical part of the software. A much more efficient approach is to estimate the bias introduced in each stage of the processing, the total bias can then be compensated later in one place, removing the bias after decimation greatly reduces the number of cycles needed.
const int16_t i_shifted = (((int32_t)i * rotation_i) - ((int32_t)q * rotation_q)) >> 15;
const int16_t q_shifted = (((int32_t)q * rotation_i) + ((int32_t)i * rotation_q)) >> 15;
At this point, we are still working at a sampling rate of 500kSamples/s which is much more than we need. The highest bandwidth signal we are trying to handle is an FM signal with 9kHz of bandwidth. At this stage we can reduce the sample rate by a large factor, this will reduce the computational load in later stages by the same factor. In this design, the round-robin IQ sampling introduces images in the outer half of the spectrum. These images are also removed during the decimation process.
Decimation is achieved using a combination of CIC and half-band filters to perform decimation leaving us with a narrow spectrum.
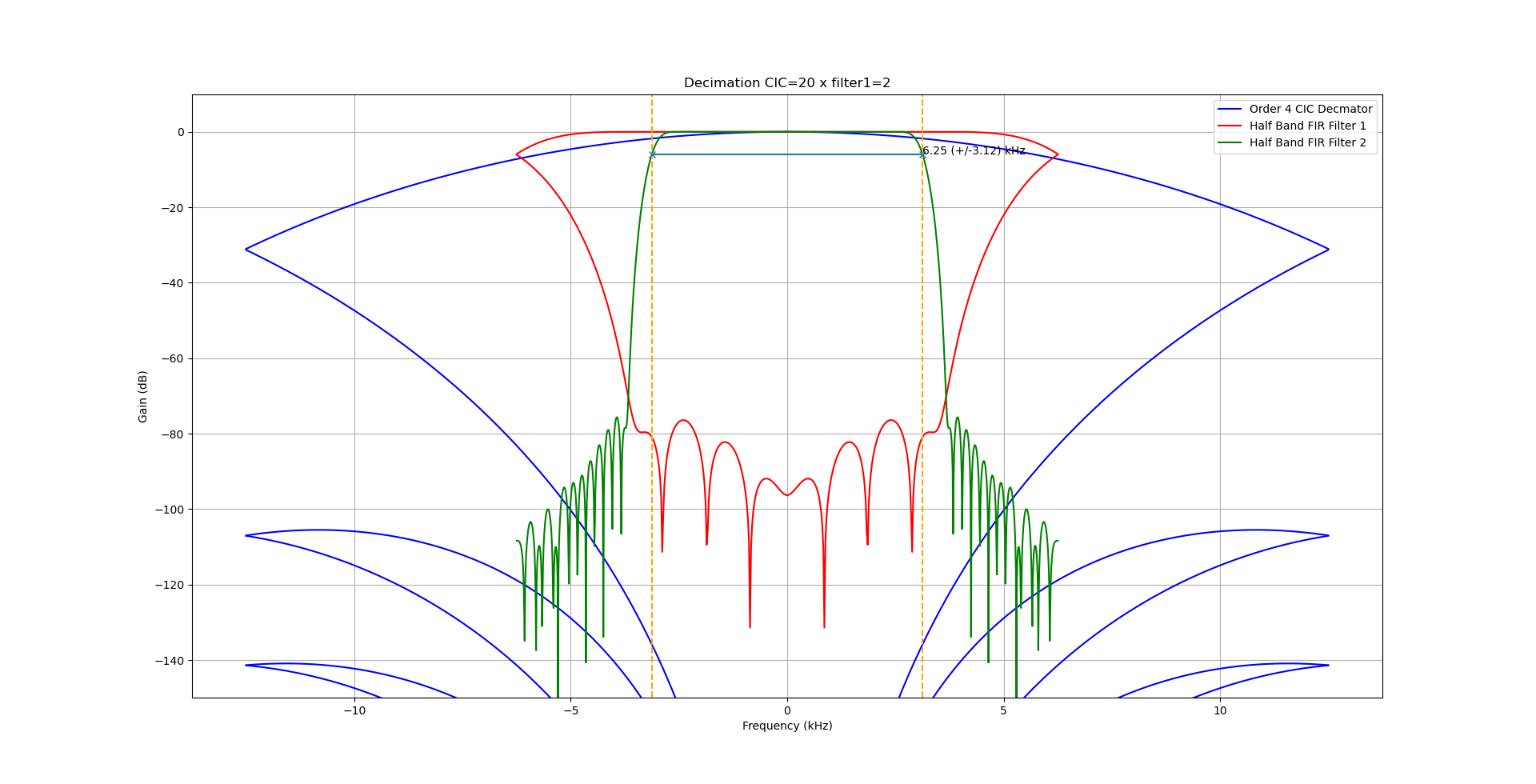
The CIC is a very efficient filter design, but it doesn't have very sharp edges which leads to aliasing at the edge of the spectrum. These aliases are removed using the first half-band filter before a further decimation by a factor of 2. A second and final half-band filter removes any aliases remaining at the band edge, the final half-band filter is a higher-order filter giving crisper edges. No decimation is performed in the final stage, so as not to introduce any further aliases.
In this design, the decimation factor is adjusted depending on the mode resulting in a different final sampling rate and bandwidth. This is an very simple and efficient way to vary the bandwidth of the final filter.
| Mode | Decimation CIC | Decimation HBF 1 | Post Decimation Sample Rate (Hz) | Post Decimation Bandwidth (Hz) |
|---|---|---|---|---|
| AM | 20 | 2 | 12500 | 6250 |
| CW | 20 | 2 | 12500 | 6250 (more filtering needed) |
| SSB | 25 | 2 | 10000 | 5000 (more filtering needed) |
| FM | 14 | 2 | 17857 | 8929 |
In this project, AM demodulation is achieved by taking the magnitude of the complex sample. To avoid the use of square roots, a more efficient approximation of the magnitude is calculated. This is calculated using the min/max approximation, based on a method I found here approximate magnitude.
uint16_t rectangular_2_magnitude(int16_t i, int16_t q)
{
//Measure magnitude
const int16_t absi = i>0?i:-i;
const int16_t absq = q>0?q:-q;
return absi > absq ? absi + absq / 4 : absq + absi / 4;
}
The AM carrier now looks like a large DC component which is removed using a DC-cancelling filter.
int16_t amplitude = rectangular_2_magnitude(i, q);
//measure DC using first-order IIR low-pass filter
audio_dc = amplitude+(audio_dc - (audio_dc >> 5));
//subtract DC component
return amplitude - (audio_dc >> 5);
This is one of the simplest methods of AM demodulation, implementing a synchronous AM detector should give improved performance.
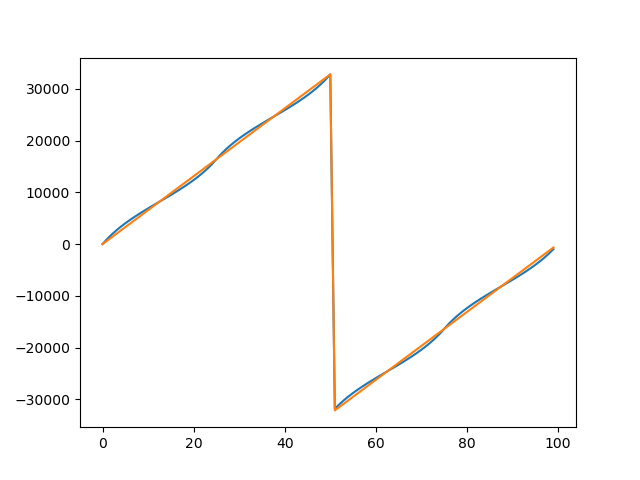
FM demodulation uses a similar approach to the AM demodulator. This time, we take the change in phase from one sample to the next. I found a phase approximation in the same place as I found the magnitude approximation and modified it for this application. I scaled the output to use the full range of a 16-bit integer. That way, I get the best possible resolution from the 16-bit number, and phase wrapping comes for free when the integer overflows.
int16_t rectangular_2_phase(int16_t i, int16_t q)
{
//handle condition where the phase is unknown
if(i==0 && q==0) return 0;
const int16_t absi=i>0?i:-i;
int16_t angle=0;
if (q>=0)
{
//scale r so that it lies in the range -8192 to 8192
const int16_t r = ((int32_t)(q - absi) << 13) / (q + absi);
angle = 8192 - r;
}
else
{
//scale r so that it lies in the range -8192 to 8192
const int16_t r = ((int32_t)(q + absi) << 13) / (absi - q);
angle = (3 * 8192) - r;
}
//angle lies in the range -32768 to 32767
if (i < 0) return(-angle); // negate if in quad III or IV
else return(angle);
}
The approximate method agrees quite closely with the ideal output.
It is now quite simple to demodulate an FM signal by comparing the phase of each sample with the phase of the previous sample.
int16_t phase = rectangular_2_phase(i, q);
int16_t frequency = phase - last_phase;
last_phase = phase;
return frequency;
;
This is one of the simplest methods of FM demodulation.

At the output of the decimator, we have a complex signal with 5kHz of bandwidth covering the frequency range from -2.5kHz to +2.5kHz. The positive frequencies represent the upper sideband and the negative frequencies contain the lower sideband. We only want one of the sidebands. The opposite sideband might contain another signal or interference so we would like to filter it out.
An efficient method of filtering an SSB signal is to up-shift the frequency by Fs/4 using a complex multiplier and filter the signal using a symmetrical half-band filter retaining only the negative frequency components. The frequency is then down-shifted by Fs/4 leaving only the lower sideband.
Fs/4 is chosen because it can be implemented efficiently. A complex sine wave with a frequency of Fs/4 consists of only 0,1 and -1. Multiplication by 0, 1, or -1 can be implemented using trivial arithmetic operations, no multiplications or trigonometry are needed.
Choosing a half-band filter -Fs/4 to Fs/4 allows further efficiency improvements. The kernel of a half-band filter is symmetrical, potentially this can approximately halve the number of multiplication operations, or halve the number of kernel values that need to be stored. In addition to this about half of the kernel values are 0, again approximately halving the number of multiplications. Overall, this filtering operation reduces the number of multiplications needed by an approximate factor of 4.
The structure as shown leaves the lower side-band part of the signal. An upper side-band signal could be generated by first down-shifting the frequency, and then up-shifting.
if(mode == USB)
{
ssb_phase = (ssb_phase + 1) & 3u;
}
else
{
ssb_phase = (ssb_phase - 1) & 3u;
}
const int16_t sample_i[4] = {i, q, -i, -q};
const int16_t sample_q[4] = {q, -i, -q, i};
int16_t ii = sample_i[ssb_phase];
int16_t qq = sample_q[ssb_phase];
ssb_filter.filter(ii, qq);
const int16_t audio[4] = {-qq, -ii, qq, ii};
return audio[ssb_phase];
Once we have filtered out the opposite side-band we are left with only 2.5kHz of bandwidth. We can now discard the imaginary component leaving us with a real audio signal.
CW signals use much less bandwidth than speech, many CW signals can be accommodated within the bandwidth of a speech signal. To pick out an individual signal we need a much narrower filter. To achieve this we use a second decimation filter of the same design. This time the CIC has a decimation rate of 10, followed by two half-band filters giving a final bandwidth of 150Hz. The resulting signal sits at or around DC, so it isn't audible. To convert the signal into an audible tone we need to apply a frequency shift by mixing with a CW side-tone. This uses the same frequency-shifting technique described above. The same sin lookup table is used, with a new phase accumulator tuned to the side-tone frequency. Since we are planning to throw away the imaginary (Q) part of the signal, we don't bother to calculate it in the first place.
if(cw_decimate(ii, qq)){
cw_i = ii;
cw_q = qq;
}
cw_sidetone_phase += cw_sidetone_frequency_Hz * 2048 * decimation_rate * 2 / adc_sample_rate;
const int16_t rotation_i = sin_table[(cw_sidetone_phase + 512u) & 0x7ffu];
const int16_t rotation_q = -sin_table[cw_sidetone_phase & 0x7ffu];
return ((cw_i * rotation_i) - (cw_q * rotation_q)) >> 15;
The loudness of an AM or SSB signal is dependent on the strength of the received signal. Very weak signals are tiny compared to strong signals. The amplitude of FM signals is dependent not on the strength of the signal, but the frequency deviation. Thus wideband FM signals will sound louder than narrow-band FM signals. In all cases, the AGC scales the output to give a similar loudness regardless of the signal strength or bandwidth.
This can be a little tricky, in speech, there are gaps between words. If the AGC were to react too quickly, then the gain would be adjusted to amplify the noise during the gaps. Conversely, if the AGC reacts too slowly, then sudden volume increases will cause the output to saturate. The UHSDR project has a good description, and the OpenXCVR design is based on similar principles.
The first stage of the AGC is to estimate the average magnitude of the signal. This is achieved using a leaky max hold circuit. When the input signal is larger than the magnitude estimate, the circuit reacts by quickly increasing the magnitude estimate (attack). When the input is smaller than the magnitude estimate waits for a period (the hang period) before responding. After the hang period has expired, the circuit responds by slowly reducing the magnitude estimate (decay). The attack period is always quite fast, but the hang and delay periods are programmable and are controlled by the AGC rate setting. The diagram shows, how the magnitude estimate responds to a changing input magnitude.

Having estimated the magnitude, the gain is calculated by dividing the desired magnitude by the estimated magnitude. Having calculated the gain, we simply multiply the signal by the gain to give an appropriately scaled output. on those occasions where the magnitude of the signal increases rapidly and the AGC does not have time to react, we need to prevent the signal from overflowing. This is achieved using a combination of soft and hard clipping. Signals above the soft clipping threshold are gradually reduced in size, and signals above the hard clipping limit are clamped to the limit value.
static const uint8_t extra_bits = 16;
int32_t audio = audio_in;
const int32_t audio_scaled = audio << extra_bits;
if(audio_scaled > max_hold)
{
//attack
max_hold += (audio_scaled - max_hold) >> attack_factor;
hang_timer = hang_time;
}
else if(hang_timer)
{
//hang
hang_timer--;
}
else if(max_hold > 0)
{
//decay
max_hold -= max_hold>>decay_factor;
}
//calculate gain needed to amplify to full scale
const int16_t magnitude = max_hold >> extra_bits;
const int16_t limit = INT16_MAX; //hard limit
const int16_t setpoint = limit/2; //about half full scale
//apply gain
if(magnitude > 0)
{
int16_t gain = setpoint/magnitude;
if(gain < 1) gain = 1;
audio *= gain;
}
//soft clip (compress)
if (audio > setpoint) audio = setpoint + ((audio-setpoint)>>1);
if (audio < -setpoint) audio = -setpoint - ((audio+setpoint)>>1);
//hard clamp
if (audio > limit) audio = limit;
if (audio < -limit) audio = -limit;
return audio;
Audio output is achieved using a PWM output. The output is filtered using a very simple low-pass RC filter. The PWM choice of PWM frequency results in a trade-off. A higher frequency results in a lower ripple, and a lower frequency results in a higher resolution. I found that a PWM frequency of 500kHz resulted in a good compromise. This gives about 8 bits worth of audio resolution while reducing the ripple to an acceptable level and moving it out of the audible band. Since we only need a few kHz of bandwidth, it should be possible to achieve a much greater resolution by using a higher-order low-pass filter on the output. However, the selected PWM frequency gives better audio quality than I had expected, using very simple and cost-effective hardware and doesn't noticeably degrade at lower volume settings.
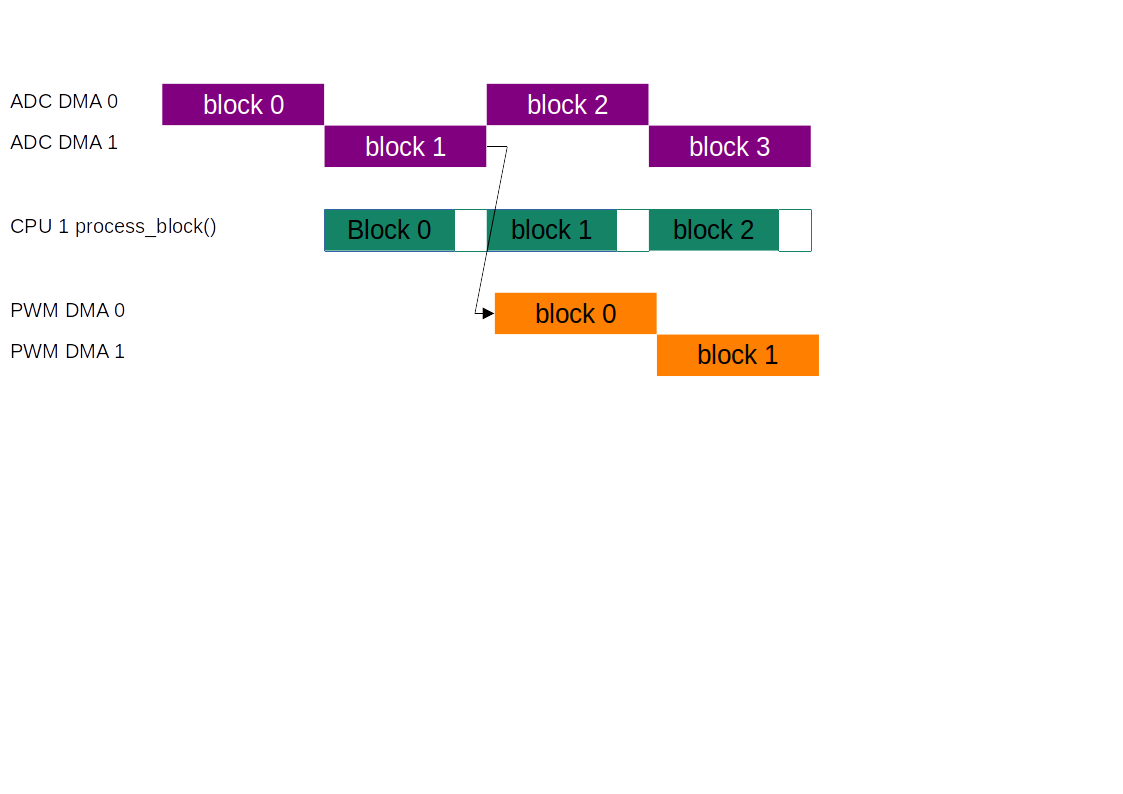
The PWM audio uses 2 DMA channels in a ping-pong arrangement similar to the ADC DMA. The ADC DMA, the process_block() function running on core 1 and the PWM DMA form a pipeline. At any one time, these three processes are each handling a block concurrently.
The user interface provides a simple spectrum scope. Although the bulk of the processing for the spectrum scope is performed in the user interface on core 0, the data needs to be captured during the processing of each block. The data is captured after the frequency shift into a capture buffer. It is not necessary to capture data during every block, it is only necessary to update at the refresh rate of the display. The capture buffer is protected by a mutex, but it is important that gaining access to the mutex never delays the signal processing. For this reason, data is only ever captured when the mutex is already available. Once a buffer worth of data has been captured, the mutex is released.
Although not strictly essential, the ability to monitor the battery voltage and CPU temperature are nice features to have, and the Raspberry Pi Pico makes provision to monitor these using the ADC. Unfortunately, the ADC is maxed out capturing the IQ data. A workaround is to interrupt the IQ capture for a few samples to capture the temperature and voltage channels. Although missing these samples every minute or so has little effect on the audio quality, we must pick up the IQ sampling at exactly the right time. Achieving this reliably involves completely halting the receiver process. The DMA channels are all halted and flushed. The ADC can then capture the voltage and temperature in single-shot mode before being reconfigured into round-robin mode and restarting the receiver.
The user interface is very simple consisting of a rotary encoder, push buttons and a small OLED display. The receiver is configured using a menu. The PIO feature greatly simplifies the implementation of the rotary encoder. The PIO can keep track of steps independently of the software, removing the need to frequently check for changes in position.
The OLED display has enough space to implement a very crude spectrum scope. This is achieved by windowing the capture buffer and performing an FFT. Due to the round-robin sampling method, the outer half of the spectrum doesn't contain any useful information, so only the central 128 points of the 256 points are captured. To reduce the noise level, the results from several FFTs are combined incoherently. The spectrum is scaled to occupy 128 pixels wide by 64 high. The magnitudes are auto-scaled into 64 steps. The display doesn't allow the brightness of pixels to be changed individually, so it isn't possible to implement a waterfall display. However, it should be relatively straightforward to implement a waterfall plot if another type of display was used.
The receiver includes a 512-channel memory, where each memory can hold a single frequency or a band of interest. The channels are pre-programmed to useful preset values at compile time, but the memories can be overwritten by the user through the menu. Although this functionality would have been fairly straightforward to implement using an external i2c EEPROM device, it is possible to emulate this functionality by accessing an unused area of flash. While a suitable EEPROM would admittedly be quite cheap, reducing the hardware complexity (and cost) is one of the main objectives of this project.
Reading from the flash is fairly straightforward, the compiler can be instructed to place a constant array in flash by using the __in_flash() attribute. Writing to the flash is a different matter, the flash data can only be erased and programmed on a sector-by-sector basis. It is also important that the flash is not being used by the software while it is arranged. The process to write a single channel to flash is:
- Copy the whole sector to RAM
- Within the RAM copy, update the part of the sector that holds the memory channel
- Suspend the receiver, terminating all DMA transfers
- Halt core 1
- Disable all interrupts
- Erase flash sector
- Write RAM copy of sector back to flash
- Re-enable interrupts
- Resume core 1
- Resume receiver restarting DMA transfers
The process was quite complicated to implement, but worth the effort. It all happens in the blink of an eye to the user. It is also useful for the receiver to remember settings like volume, squelch etc across power cycles. Volume is particularly important for users wearing headphones. The flash memory is expected to have an endurance of about 100,000 erase cycles. If the settings were stored to flash each time the settings changed, this might limit the life of the device particularly if frequency changes were stored each time the rotary encoder changed position. To extend the life of the flash, the settings are stored in a bank of 512 channels. Each time a setting is saved, the next free channel is used. Once all the channels are exhausted, the channels are all erased and the first channel is overwritten. Each time the receiver powers up, the settings are restored from the last channel to be written. This effectively increases the life of the flash by a factor of 512 giving an endurance of 51,200,000 stores. This would allow the settings to be stored once per second for more than a year of continuous use. This is likely to last well beyond the lifetime of the receiver given a more realistic level of usage.