在前面的JS破解方案中,提到了一种Node还原的方案,该方案的实现的指导思想就是「将对方的JS代码或文件拷贝到Node环境中执行」。
Node环境和浏览器环境最大的区别在于DOM操作渲染和浏览器提供的API上,可以理解为NodeJS只是在JS执行引擎上做了简单封装,浏览器则基于JS执行引擎上做了全套的界面渲染。因此,若我们移植的代码中引用了浏览器中独有的API,我们的执行过程将会报错。
所以我们在迁移的过程中主要做的就是JS执行环境模拟和还原即浏览器环境补齐,之所以叫补齐而不是补全就是因为只需要满足对方JS代码执行所需即可,补全也是不太现实,主要流程为:
- 真实浏览器环境 -> 本地浏览器
- 本地浏览器 -> Node环境(核心)
- Node环境 -> JVM环境
第一步中真实浏览器环境到本地浏览器的意思为,直接尝试将对方的JS代码直接本地新开一个浏览器中打开,这一步的意义在于确定除了浏览器相关环境,JS代码中是否包含一些上下文对象,保证还原至Node环境的可能性。
第二步则是我们的核心操作,这一步会遇到许多问题,但都可以通过执行时抛出的异常和调试来定位所需要的浏览器对象,这一步中还有一些用于通过JS Hook或者Proxy的方式来批量获取调用的浏览器对象。
第三步则是用于我们线上的生产操作,原理就是NodeJS基于V8引擎,因此理论上Node中可以执行的,在Java中也可以调用V8引擎或其他的JS执行引擎例如JDK8后自带的Nashorn引擎来达到同样的效果,在JVM中的JS执行引擎可以这两者的使用方法和区别以及注意事项。
Ctrip eleven参数的生成算法采用了Ctrip 自研的混淆算法,基本不可能被还原,只能通过调试来观察其中的状态机和摸清执行流程,下面会给出Ctrip eleven生成算法还原时用到的浏览器环境对象。(也可以使用rpc的方式直接调用,非常简单)
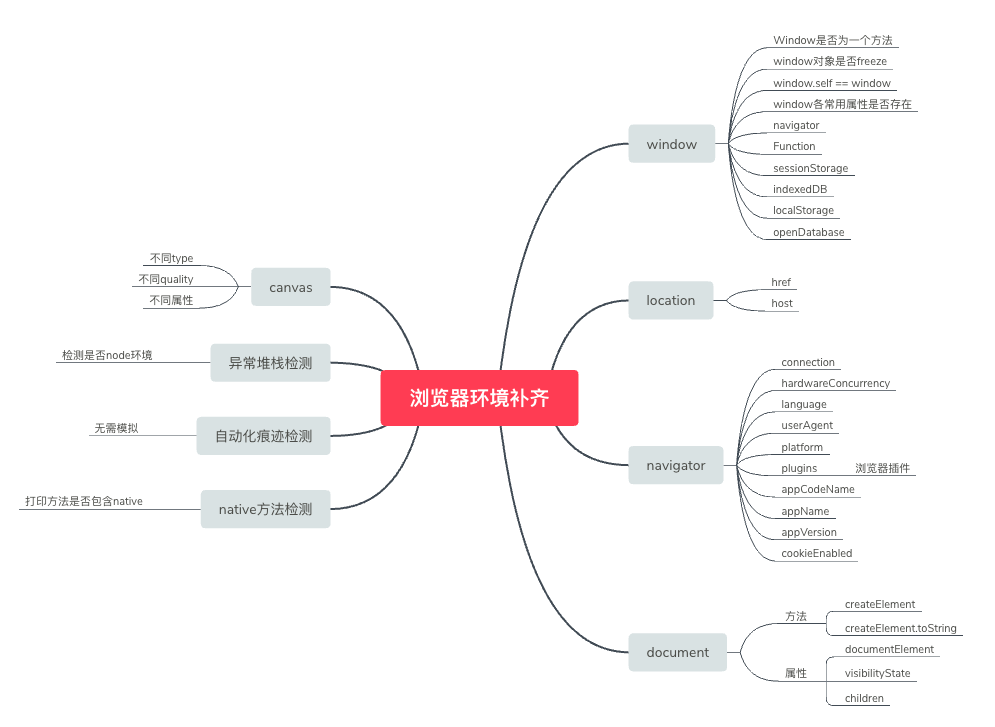
上面的脑图中是在还原Ctrip eleven参数时所需要补齐的浏览器环境,其中有几项是较为偏僻的反爬措施。
下面就列举了需要额外注意的几个地方:
网上有开源的jsdom模块专门用于在node环境中模拟dom操作,可以参考。
https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/Object/freeze
在正常的JS环境中,window和navigator等属于不可变对象,而在模拟浏览器环境时由于是自定义的对象,所以很容易被检测出来是在模拟,因此模拟完毕后,记得Object.freeze()一下
异常堆栈检测在安卓中也是常用的反hook检测手段,在JS中,可以通过检测堆栈来判断所处的执行环境,例如Node环境的特征为「/modules/cjs/loader」,绕过方式也特别简单:
// 直接重写String的查找方法
var _indexOf = String.prototype.indexOf;
String.prototype.indexOf = function (searchValue, fromIndex) {
if (searchValue == '/modules/cjs/loader') {
return -1;
}
return _indexOf.apply(this, [searchValue, fromIndex]);
}
在JS中存在许多native方法,其中某些方法也是node环境中所不存在需要模拟的,针对这类方法,Ctrip 可以通过打印该方法判断该方法是否被重写,因此绕过方式也是重写Function的toString方法:
var originString = Function.prototype.toString;
// native方法检测
Function.prototype.toString = function () {
if (this == Window || this == Location || this == Function.prototype.toString) {
return "function Window() { [native code] }";
}
return originString.apply(this);
};
canvas指纹是浏览器指纹中绕不开的存在,通过不同设备绘制图片时的细微差异来标识不同的浏览器。
一般的JS在获取该信息时,通常是直接绘制一次图片来获取指纹,但实际上在模拟时有很多需要注意的地方,比如:
- 不同类型图片的canvas指纹应当不一样,如.jpg .png
- 不同质量quality的canvas指纹应该不一样
- 不同属性的canvas指纹应该不一样
- 同一个条件的canvas多次绘制时应该保持一致
自动化痕迹虽然不是node环境补齐浏览器环境需要考虑的东西,但在Ctrip 的反爬JS中也是可以看到二十多项检测自动化属性的地方,因此自动化痕迹也是前端所需要知悉的一个对抗点。
目前已知的较为完美绕过自动化框架检测的一个办法是使用无头chrome浏览器或jvppeteer:
https://intoli.com/blog/not-possible-to-block-chrome-headless/
https://github.com/fanyong920/jvppeteer
通过Ctrip 的反爬JS也可以看出来Ctrip 在JS中搜集的浏览器指纹,虽然在浏览器中获取指纹其实并不可靠,获取的信息也并不权威。
常见的浏览器指纹信息:
- window.screen 屏幕分辨率/宽高
- navigator.useragent
- location.href/host
- navigator.platform 平台、语言等信息
- canvas 2D图像指纹
- navigator.plugin 浏览器插件信息
- webgl 3D图像指纹