- Paper
https://doi.org/10.1086/688176
- Doc2vec
https://radimrehurek.com/gensim/index.html
- Read

we can define what type of report ( FILING_10K ) we want to request

- Parse (34GB -> 140MB)
with the help of re and bs4 packages.

- Tokenize (46MB, one file)
many steps... ( see in comment )

We will use doc.feather in .ipynb file.
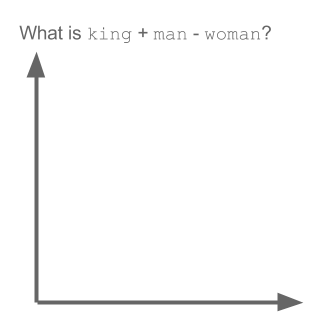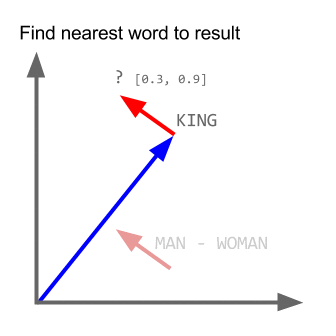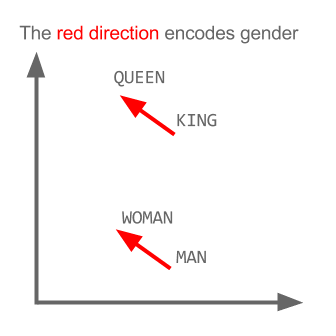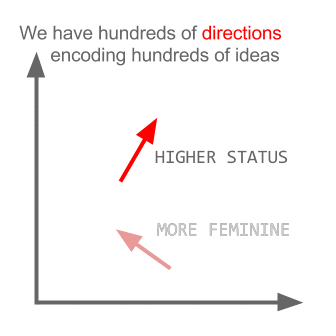
A Word is Worth a Thousand Vectors
- bag of words (what the original paper does)
John likes to watch movies. Mary likes movies too.
John also likes to watch football games. Mary hates football.
The model outputs the vectors:
[1, 2, 1, 1, 2, 1, 1, 0, 0, 0, 0]
[1, 1, 1, 1, 0, 1, 0, 1, 2, 1, 1]
Each vector has 10 elements, where each element counts the number of times a particular word occurred in the document. The order of elements is arbitrary. In the example above, the order of the elements corresponds to the words: ["John", "likes", "to", "watch", "movies", "Mary", "too", "also", "football", "games", "hates"].
disadvantage: pick the word by yourself!
- word2vec
Word2Vec is a more recent model that embeds words in a lower-dimensional vector space using a shallow neural network.
- doc2vec
https://cs.stanford.edu/~quocle/paragraph_vector.pdf
In word2vec, you train to find word vectors and then run similarity queries between words. In doc2vec, you tag your text and you also get tag vectors. For instance, you have different documents from different authors and use authors as tags on documents. Then, after doc2vec training you can use the same vector aritmetics to run similarity queries on author tags: i.e who are the most similar authors to
AUTHOR_X? If two authors generally use the same words then their vector will be closer.AUTHOR_Xis not a real word which is part of your corpus just something you determine. So you don't need to have it or manually insert it into your text. Gensim allows you to train doc2vec with or without word vectors (i.e. if you only care about tag similarities between each other).
jupyter notebook --NotebookApp.iopub_data_rate_limit=1.0e10