|
| 1 | +(indexing-and-storage)= |
| 2 | +(storage-internals)= |
| 3 | + |
| 4 | +# Indexing and storage in CrateDB |
| 5 | + |
| 6 | +:::{article-info} |
| 7 | +--- |
| 8 | +avatar: https://avatars.githubusercontent.com/u/7926726?v=4 |
| 9 | +avatar-link: https://github.com/marijaselakovic |
| 10 | +avatar-outline: muted |
| 11 | +author: Marija Selakovic |
| 12 | +date: November 12, 2021 |
| 13 | +read-time: 8 min read |
| 14 | +class-container: sd-p-2 sd-outline-muted sd-rounded-1 |
| 15 | +--- |
| 16 | +::: |
| 17 | + |
| 18 | +## Introduction |
| 19 | + |
| 20 | +In this article series, we look at CrateDB from different perspectives. We start |
| 21 | +from the bottom of CrateDB architecture and gradually move up to higher layers, |
| 22 | +presenting the most important aspects of CrateDB internals. The motivation is to |
| 23 | +better understand CrateDB, as well as to aid users in maximizing the |
| 24 | +effectiveness of CrateDB features. |
| 25 | + |
| 26 | +In the first part, we explore the internal workings of the storage layer in |
| 27 | +CrateDB. The storage layer ensures that data is stored in a safe and accurate |
| 28 | +way and returned completely and efficiently. The CrateDB storage layer is based |
| 29 | +on Lucene indexes. Lucene offers scalable and high-performance indexing which |
| 30 | +enables efficient search and aggregations over documents and rapid updates to |
| 31 | +the existing documents. We will look at the three main Lucene structures that |
| 32 | +are used within CrateDB: Inverted Indexes for text values, BKD-Trees for numeric |
| 33 | +values, and Doc Values. |
| 34 | + |
| 35 | +## What's inside |
| 36 | + |
| 37 | +This article explores the internal workings of the storage layer in CrateDB, |
| 38 | +with a focus on Lucene's indexing strategies. |
| 39 | + |
| 40 | +The CrateDB storage layer is based on Lucene indexes. Lucene offers scalable and |
| 41 | +high-performance indexing which enables efficient search and aggregations over |
| 42 | +documents and rapid updates to the existing documents. We will look at the three |
| 43 | +main Lucene structures that are used within CrateDB: Inverted Indexes for text |
| 44 | +values, BKD-Trees for numeric values, and Doc Values. |
| 45 | + |
| 46 | +:Inverted Index: You will learn how inverted indexes are implemented in Lucene |
| 47 | +and CrateDB, and how they are used for indexing text values. |
| 48 | + |
| 49 | +:BKD Tree: Better understand the BKD tree, starting from KD trees, and how this |
| 50 | +data structure supports range queries on numeric values in CrateDB. |
| 51 | + |
| 52 | +:Doc Values: This data structure supports more efficient querying document |
| 53 | +fields by id, performs column-oriented retrieval of data, and improves the |
| 54 | +performance of aggregation and sorting operations. |
| 55 | + |
| 56 | +## Indexing text values |
| 57 | + |
| 58 | +The Lucene indexing strategy relies on a data structure called *inverted index*. |
| 59 | +An inverted index is defined as a “data structure storing a mapping from |
| 60 | +content, such as words and numbers, to its location in the database file, |
| 61 | +document or set of documents“ [Wikipedia]. In Lucene, an index can store an |
| 62 | +arbitrary size of documents, with an arbitrary number of different fields. |
| 63 | + |
| 64 | +To better explain how inverted indexes are implemented in Lucene, we first |
| 65 | +introduce *Lucene Documents*. A Lucene Document is a unit of information for |
| 66 | +search and indexing that contains a set of fields, where each field has a name |
| 67 | +and value. Furthermore, each field can be tokenized to create *terms*. We refer |
| 68 | +to terms as the smallest units of search and index and they are represented as a |
| 69 | +combination of a field name with a token. Depending on the analysis, generated |
| 70 | +terms dictate what type of search we can do efficiently and which not. |
| 71 | + |
| 72 | +Finally, the Lucene index is implemented as a mapping from terms to documents |
| 73 | +and it is called inverted because it reverses the usual mapping of a document to |
| 74 | +the terms it contains. The inverted index provides an effective mechanism for |
| 75 | +scoring search results: if several search terms map to the same document, then |
| 76 | +that document is likely to be relevant. |
| 77 | + |
| 78 | +Indexing is done before retrieval, and access is done on indexed documents. The |
| 79 | +major steps in the creation of the Lucene index are illustrated in the following |
| 80 | +example: |
| 81 | + |
| 82 | +1. Imagine that we collected two documents to be indexed: “My favorite sweet |
| 83 | + dish is strawberry cake.“ and “Strawberries are bright red and sweet.“ |
| 84 | +1. The next step is the tokenization of text into words: “My“, “favorite“, |
| 85 | + “sweet“, “dish“, etc. |
| 86 | +1. To produce indexing terms, we use linguistic processing for token |
| 87 | + normalization. For example, the term “Strawberries“ is normalized to |
| 88 | + “strawberry“ and the result is used as an indexing term. |
| 89 | +1. Each indexing term is then mapped to document id and the resulting sequence |
| 90 | + of terms is sorted alphabetically. The instances of the same term are then |
| 91 | + grouped by word and by document id. The final index contains indexing terms |
| 92 | + and pointers to the posting lists, i.e., the list of document ids that hold |
| 93 | + the term. |
| 94 | + |
| 95 | +The diagram below shows the indexing terms from two documents, the sorted |
| 96 | +sequence, and finally the index. |
| 97 | + |
| 98 | +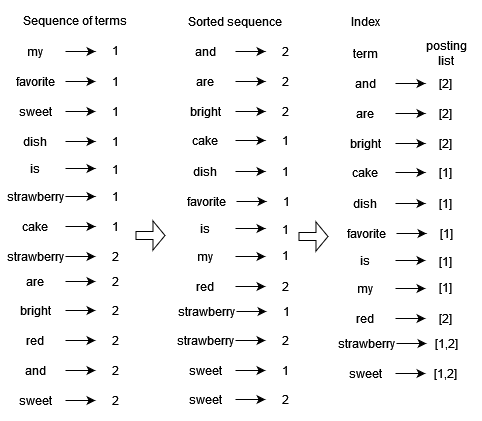 |
| 99 | + |
| 100 | +### Lucene segments |
| 101 | + |
| 102 | +A Lucene index is composed of one or more sub-indexes. A sub-index is called a |
| 103 | +segment, it is immutable and built from a set of documents. When new documents |
| 104 | +are added to the existing index, they are added to the next segment. Previous |
| 105 | +segments are never modified. If the number of segments becomes too large, the |
| 106 | +system may decide to merge some segments and discard the corresponding |
| 107 | +documents. This way, adding a new document does not require rebuilding the index |
| 108 | +structure. |
| 109 | + |
| 110 | +### Inverted indexes |
| 111 | + |
| 112 | +CrateDB splits tables into shards and replicas, meaning that tables are divided |
| 113 | +and distributed across the nodes of a cluster. Each shard in CrateDB is a Lucene |
| 114 | +index broken into segments and stored on the filesystem. Depending on the |
| 115 | +configuration of a column the index can be plain (default) or full-text. An |
| 116 | +index of type plain indexes content of one or more fields without analyzing and |
| 117 | +tokenizing their values into terms. To create a full-text index, the field value |
| 118 | +is first analyzed and based on the used analyzer, split into smaller units, such |
| 119 | +as individual words. A full-text index is then created for each text unit |
| 120 | +separately. |
| 121 | + |
| 122 | +To illustrate both indexing methods, let’s consider a simple table called |
| 123 | +*Product*: |
| 124 | + |
| 125 | +| | | | |
| 126 | +| ------------- | ------------ | ------------ | |
| 127 | +| **productID** | **name** | **quantity** | |
| 128 | +| 1 | Almond Milk | 100 | |
| 129 | +| 2 | Almond Flour | 200 | |
| 130 | +| 3 | Milk | 300 | |
| 131 | + |
| 132 | +The inverted index enables a very efficient search over textual data. For our |
| 133 | +case, it makes sense to index the column “name”. The next two tables illustrate |
| 134 | +the resulting plain and full-text indexes: |
| 135 | + |
| 136 | +Plain index |
| 137 | + |
| 138 | +| **name** | **docID** | |
| 139 | +| ------------ | --------- | |
| 140 | +| Almond Milk | 1 | |
| 141 | +| Almond Flour | 2 | |
| 142 | +| Milk | 3 | |
| 143 | + |
| 144 | +Fulltext index |
| 145 | + |
| 146 | +| **name** | **docID** | |
| 147 | +| -------- | --------- | |
| 148 | +| Almond | 1,2 | |
| 149 | +| Milk | 1,3 | |
| 150 | +| Flour | 2 | |
| 151 | + |
| 152 | +There are in total three names in the plain index mapped to different document |
| 153 | +ids. On the other side, there are three values in the full-text index as a |
| 154 | +result of column tokenization: in this case, the terms Almond and Milk point to |
| 155 | +more documents. |
| 156 | + |
| 157 | +## Indexing numeric values |
| 158 | + |
| 159 | +Until Lucene 6.0 there was no exclusive field type for numeric values, so all |
| 160 | +value types were simply stored as strings and an inverted index was stored in |
| 161 | +the Trie-Tree data structure. This type of data structure was very efficient for |
| 162 | +queries based on terms. However, the problem was that even numeric types were |
| 163 | +represented as a simple text token. For queries that filter on the numeric |
| 164 | +range, the efficiency was relatively low. To optimize numeric range queries, |
| 165 | +Lucene 6.0 adds an implementation of Block KD (BKD) tree data structure. |
| 166 | + |
| 167 | +### BKD tree |
| 168 | + |
| 169 | +To better understand the BKD tree data structure, let’s start with a short |
| 170 | +introduction to KD trees. A KD tree is a binary tree for multidimensional |
| 171 | +queries. KD tree shares the same properties as binary search trees (BST), but |
| 172 | +the dimensions alternate for each level of the tree. For instance, starting from |
| 173 | +the root node, the x value of the left nodes is always less than the x value of |
| 174 | +the root node. The same applies to the right node and all intermediate nodes up |
| 175 | +to leaf nodes. KDB tree is a special kind of KD tree with properties found in |
| 176 | +the B+ trees. This means: |
| 177 | + |
| 178 | +- KDB tree is a self-balanced tree and can contain more than one dimension |
| 179 | +- In KDB tree data is stored only in leaf nodes, while the intermediate nodes |
| 180 | + are used as pointers |
| 181 | + |
| 182 | +Finally, BKD trees are composed of several KDB trees. BKD trees provide very |
| 183 | +efficient space utilization and query performance, regardless of the number of |
| 184 | +queries. |
| 185 | + |
| 186 | +To construct the KDB tree, we need to choose a dimension as a segmentation |
| 187 | +criterion. This can be done by calculating the difference range of each |
| 188 | +dimension and selecting the dimension with the largest difference. Another |
| 189 | +common selection method is the variance method, where the dimension is chosen |
| 190 | +based on how large the variance of each dimension is. In the following example, |
| 191 | +we illustrate the construction of the KDB tree based on the “dimension |
| 192 | +difference” method. |
| 193 | + |
| 194 | +We start with a total of 8 point data where each point has two dimensions we |
| 195 | +refer to as x-dimension and y-dimension. The set of points is: {1,2}, {2,8}, |
| 196 | +{3,4}, {4,3}, {4,6}, {6,7}, {7,11} and {8,9}. Furthermore, we assume that |
| 197 | +intermediate nodes in the KDB tree can have a maximum of two children. The |
| 198 | +construction process is as follows: |
| 199 | + |
| 200 | +- The first segmentation is done on y dimension as (max_x - min_x) < (max_y - |
| 201 | + min_y) or: 7 < 9. To divide data points we first sort them according to the |
| 202 | + value of the y dimension. The result after sorting is the following list: |
| 203 | + {1,2} → {4,3} → {3,4} → {4,6} → {6,7} → {2,8} → {8,9} → {7,11}. |
| 204 | +- Then, we choose the first half of the sorted list as left subtree data and the |
| 205 | + second half of the list as right subtree data. |
| 206 | +- We continue to segment further the left subtree: now the segmentation criteria |
| 207 | + is dimension y (4 > 3). However, the segmentation criteria for the right |
| 208 | + subtree is dimension x (6 > 4). The next splitting is done in the same |
| 209 | + fashion: the data are sorted and split into left subtree and right subtree |
| 210 | + data. After this step, each intermediate node has exactly two children and the |
| 211 | + construction process stops. Finally, the KDB tree is constructed as |
| 212 | + illustrated in the figure below: |
| 213 | + |
| 214 | +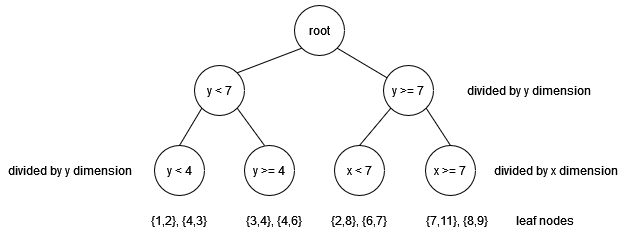 |
| 215 | + |
| 216 | +The index file with the resulting data structure is then created as a series of |
| 217 | +blocks that contain data from leaf nodes, intermediate nodes, and the metadata |
| 218 | +of the BKD tree. The internal representation of index files is beyond the scope |
| 219 | +of this article. |
| 220 | + |
| 221 | +### Range queries |
| 222 | + |
| 223 | +Numerical indexing relies on BKD-Tree to accelerate the performance of range |
| 224 | +queries. Considering our KDB tree, to query all points in the range x in [1,8] |
| 225 | +and y in [9,11], the engine does the following: |
| 226 | + |
| 227 | +- Starting from the root node we know from the segmentation dimension that all |
| 228 | + points where y is in [9,11] range are in the right subtree, so the next step |
| 229 | + is to traverse the right subtree. |
| 230 | +- The next segmentation dimension is the x value and from the segmentation |
| 231 | + condition, we know that points, where x is in [1,8] range, are in both left |
| 232 | + and right subtrees. So, we need to traverse both subtrees. |
| 233 | +- All child nodes of the right subtree satisfy our query range and zero child |
| 234 | + nodes from the left subtree. Finally, the query output is: {7,11} and {8,9}. |
| 235 | + |
| 236 | +## Doc Values |
| 237 | + |
| 238 | +Until Lucene 4.0 columns were indexed using an inverted index data structure |
| 239 | +that maps terms to document ids. For searching documents by terms, this is a |
| 240 | +very good solution. However, if we have to find field values given document id, |
| 241 | +this solution was not equally effective. Furthermore, to perform column-oriented |
| 242 | +retrieval of data, it was necessary to traverse and extract all fields that |
| 243 | +appear in the collection of documents. This can cause memory and performance |
| 244 | +issues if we need to extract a large amount of data. |
| 245 | + |
| 246 | +To improve the performance of aggregations and sorting, a new data structure was |
| 247 | +introduced, namely Doc Values. Doc Values is a column-based data storage built |
| 248 | +at document index time. They store all field values that are not analyzed as |
| 249 | +strings in a compact column making it more effective for sorting and |
| 250 | +aggregations. |
| 251 | + |
| 252 | +CrateDB implements Column Store based on Doc Values in Lucene. The Column Store |
| 253 | +is created for each field in a document and generated as the following |
| 254 | +structures for fields in the Product table: |
| 255 | + |
| 256 | +| | **Document 1** | **Document 2** | **Document 3** | |
| 257 | +| --------- | -------------- | -------------- | -------------- | |
| 258 | +| productID | 1 | 2 | 3 | |
| 259 | +| name | Almond Milk | Almond Flour | Milk | |
| 260 | +| quantity | 100 | 200 | 300 | |
| 261 | + |
| 262 | +For example, for the first document, CrateDB creates the following mappings as |
| 263 | +Column Store: {productID → 1, name → “Almond Milk“, quantity → 100}. |
| 264 | + |
| 265 | +Column Store significantly improves aggregations and grouping as the data for |
| 266 | +one column is packed in one place. Instead of traversing each document and |
| 267 | +fetching values of the field that can also be very scattered, we extract all |
| 268 | +field data from the existing Column Store. This approach significantly improves |
| 269 | +the performance of sorting, grouping, and aggregation operations. In CrateDB, |
| 270 | +Column Store is enabled by default and can be disabled only for text fields, not |
| 271 | +for other primitive types. Furthermore, CrateDB does not support storing values |
| 272 | +for {ref}`container <container>` and {ref}`geographic <geospatial>` data types |
| 273 | +in Column Store. |
| 274 | + |
| 275 | +Besides fields, CrateDB also supports Column Store for the JSON representation |
| 276 | +of each row in a table. For our example, row-based Column Store is generated as |
| 277 | +the following: |
| 278 | + |
| 279 | +| **Document** | **Row** | |
| 280 | +| ------------ | ----------------------------------------------- | |
| 281 | +| 1 | {“id“:1, “name“:”Almond Milk”, “quantity“:100} | |
| 282 | +| 2 | {“id“:2, “name“:”Almond Flour”, “quantity“:200} | |
| 283 | +| 3 | {“id“:3, “name“:”Milk”, “quantity“:300} | |
| 284 | + |
| 285 | +The use of Column Store results in a small disk footprint, thanks to specialized |
| 286 | +compression algorithms such as delta encoding, bit packing, and GCD. |
| 287 | + |
| 288 | +## Summary |
| 289 | + |
| 290 | +This article describes the core design principles of the storage layer in |
| 291 | +CrateDB. Being based on the Lucene index, it enables effective and efficient |
| 292 | +search over the arbitrary size of documents with an arbitrary number of fields. |
| 293 | + |
| 294 | +Besides inverted indexes, the Lucene indexing strategy also relies on BKD trees |
| 295 | +and Doc Values that are successfully adopted by CrateDB as well as many popular |
| 296 | +search engines. With a better understanding of the storage layer, we move to |
| 297 | +another interesting topic: [Handling Dynamic Objects in CrateDB]. |
| 298 | + |
| 299 | +[Handling Dynamic Objects in CrateDB]: https://cratedb.com/blog/handling-dynamic-objects-in-cratedb |
0 commit comments