相似性搜索就是给定一个查询,目标是在所有的数据库文档中找出最相似的文档。
在数据科学领域,相似性搜索通常出现在NLP、搜索引擎或推荐系统等领域,其中需要检索最相关的文档或者数据项来进行查询。通常文档或者数据项以文本或图像的形式表示。然而,机器学习算法不能直接处理原始文本或图像,这就是为什么文档或者数据项被预处理并存储为数字向量的原因。
有时,向量的每个组成部分都可以存储一个语义,我们也称这些向量为嵌入。这些嵌入可以有成百上千的维度,他们的数量可以达到数百万。由于数量巨大,任何信息检索系统都必须能够快速检索到相关文件。
为了提高搜索性能,在数据集嵌入的基础上构建了一个特殊的数据结构,这样的数据结构称为索引。目前索引技术已有大量的研究,并发展出许多类型的索引。在选择一个索引来执行某种任务之前,有必要了解它是如何运作的,因为每个索引都有不用的用途和优缺点。
在这篇文章中,我们将看到最朴素的算法:KNN,基于KNN,然后介绍倒排文件索引这是一个用于可扩展性更强的搜索的索引,可以以几倍的速度加速搜索过程。
kNN是用于相似性搜索的最简单、最朴素的算法。考虑一个向量数据集和一个新的查询向量Q。我们想找到与Q最相似的前k个数据集向量。首先要考虑的是如何测量两个向量之间的相似性(距离)。事实上,有几个相似性指标可以做到这一点。其中一些指标如下图所示。
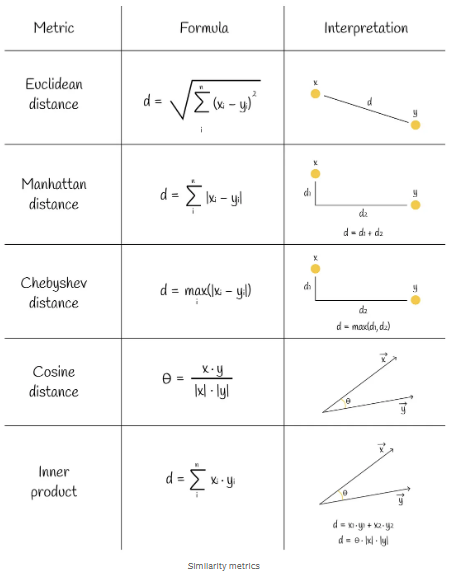
kNN是机器学习中为数不多的不需要训练阶段的算法之一。在选择了一个合适的度量之后,我们可以直接进行预测。
对于一个新对象,该算法会依次计算到所有其他对象的距离。之后,它会找到距离最小的k个对象,并将它们作为结果返回。
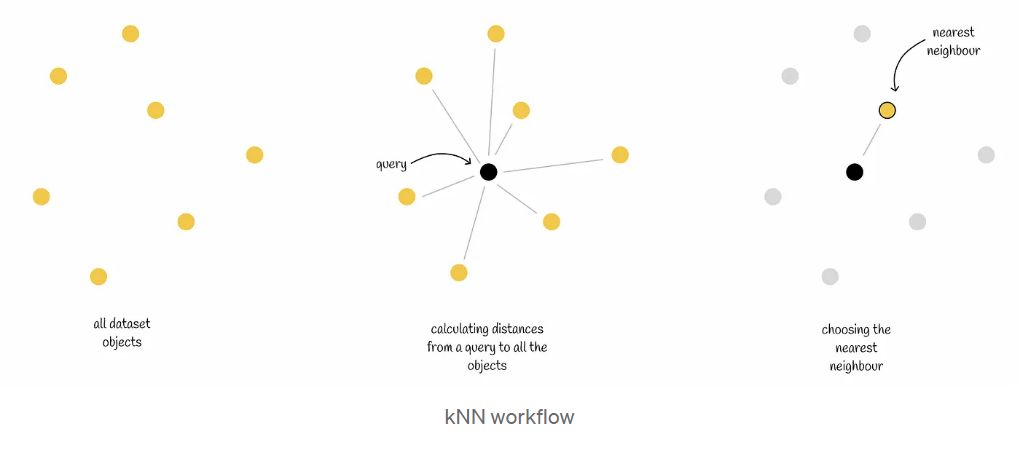
显然,通过检查到所有数据集向量的距离,kNN可以保证100%准确的结果。然而,就时间性能而言,这种暴力方法是非常低效的。如果数据集由具有m个维度的n个向量组成,则对于n个向量中的每一个,需要$O(m)$时间来计算从查询Q到它的距离,这导致$O(mn)$总时间复杂度。正如我们稍后将看到的,存在更有效的方法。
此外,对于原始向量没有压缩机制。想象一下,一个包含数十亿个对象的数据集。将它们全部存储在RAM中可能是不可能的!
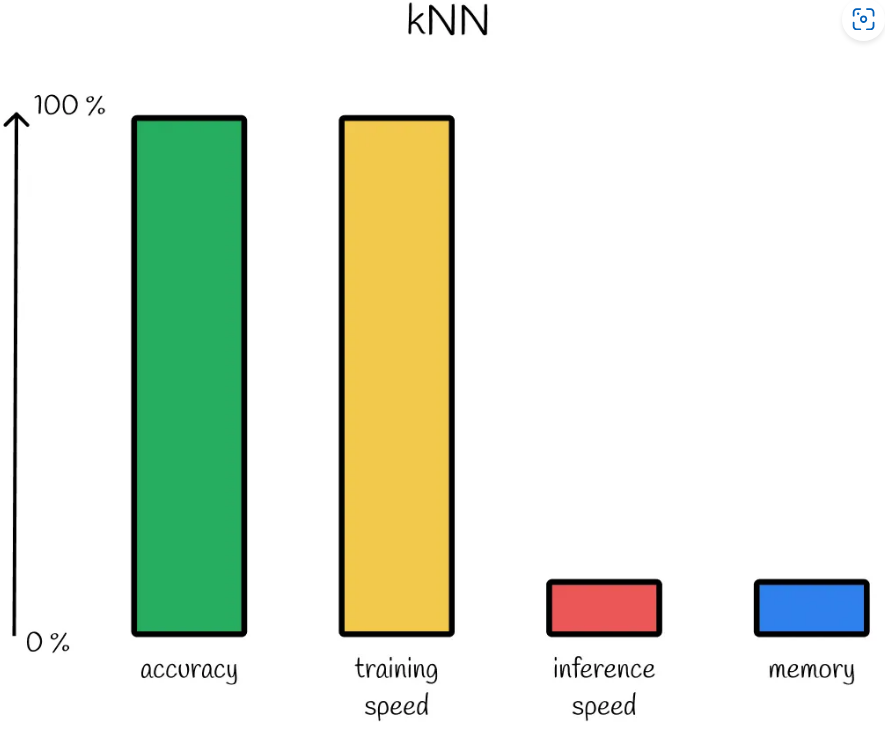
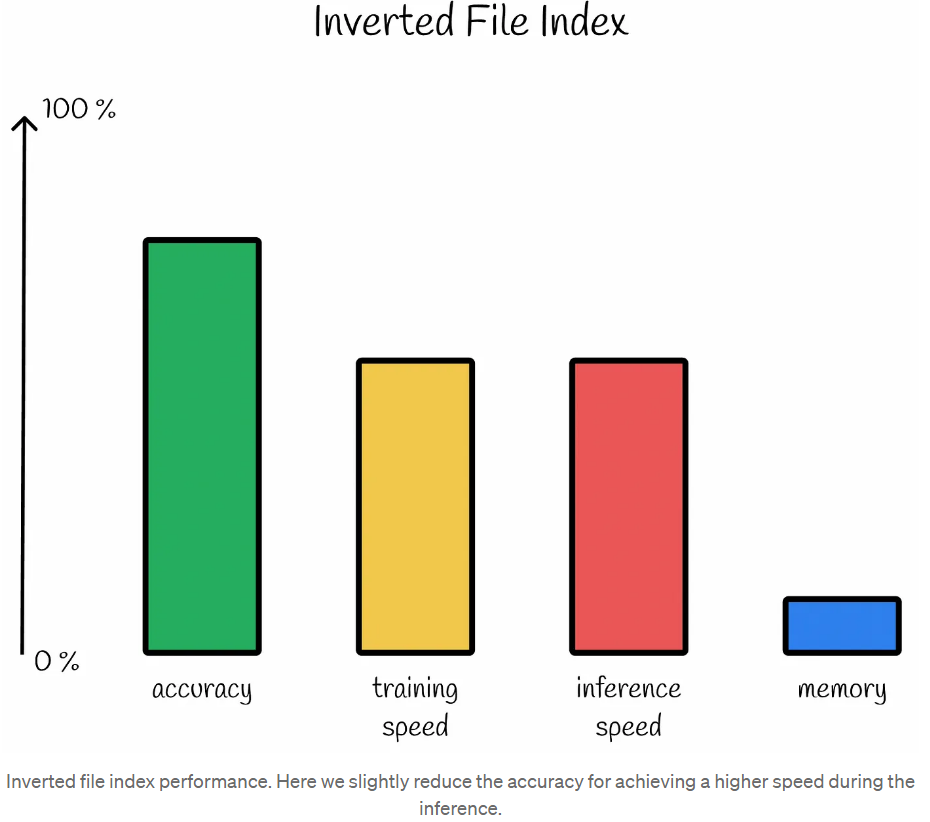
kNN性能。具有100%的准确性并且没有训练阶段导致在推理期间的穷举搜索并且没有向量的内存压缩。注:这种类型的图表显示了不同算法的相对比较。根据情况和选择的超参数,性能可能会有所不同。
kNN的应用范围有限,只能在以下情况之一中使用:
- 数据集大小或嵌入维度相对较小。这个方面确保了算法仍然执行得很快。
- 算法的要求精度必须为100%。就准确性而言,没有其他最近邻算法可以优于kNN。
基本上,有两种主要的方法来改进kNN(我们稍后将讨论):
- 减少搜索范围。
- 降低向量的维度。
当使用这两种方法中的一种时,我们将不会再次进行完全的搜索。这种算法被称为近似最近邻居(ANN),因为它们不能保证100%的准确结果。
执行查询时,将计算查询输入的哈希函数,并从哈希表中获取映射值。这些映射的值中的每一个都包含其自己的一组潜在候选,然后根据成为查询的最近邻居的条件对其进行完全检查。通过这样做,减少了所有数据库矢量的搜索范围。
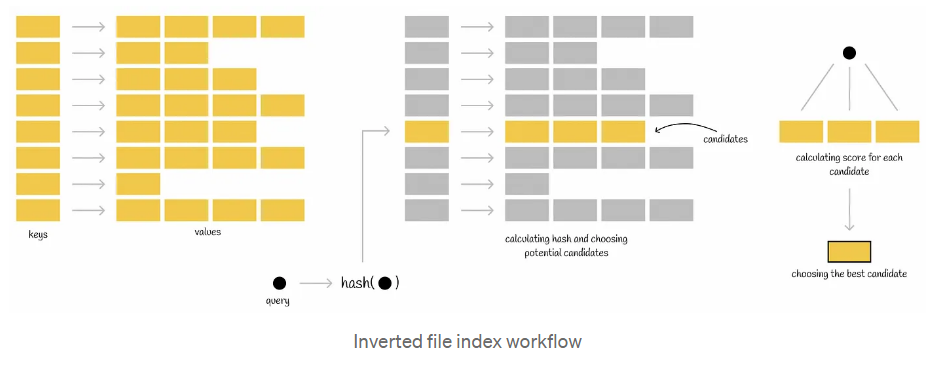
根据散列函数的计算方式,该索引有不同的实现方式。我们要看的实现是使用Voronoi图(或Dirichlet镶嵌)的实现。
该算法的思想是创建几个不相交的区域,每个数据集点将属于这些区域。每个区域都有自己的质心,该质心指向该区域的中心。

Voronoi图示例。白点是包含一组候选者的各个分区的中心。
Voronoi图的主要性质是,从一个质心到其区域中任何一点的距离小于从该点到另一个质心的距离。
当给定一个新对象时,将计算到Voronoi分区的所有质心的距离。然后选择距离最小的质心,然后将包含在该分区中的向量作为候选。
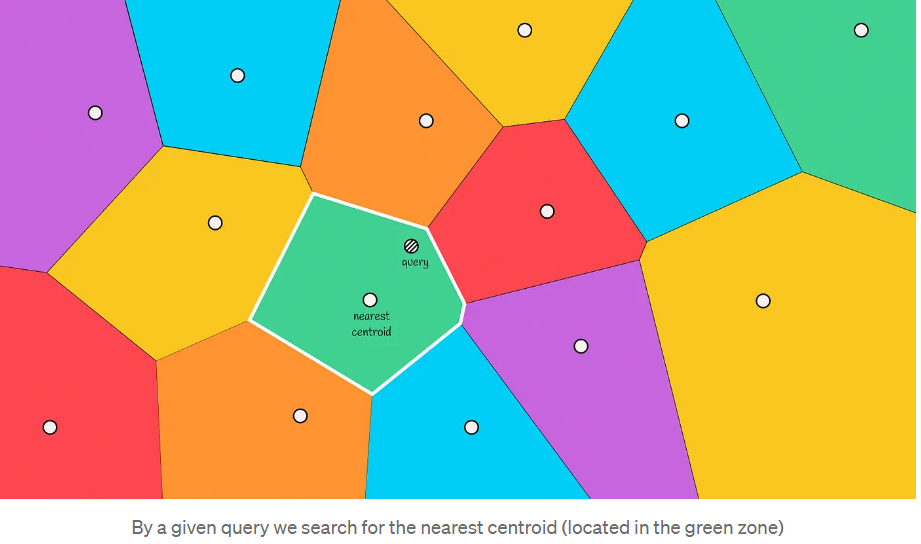
最终,通过计算到候选者的距离并选择最接近的前k个,返回最终答案。
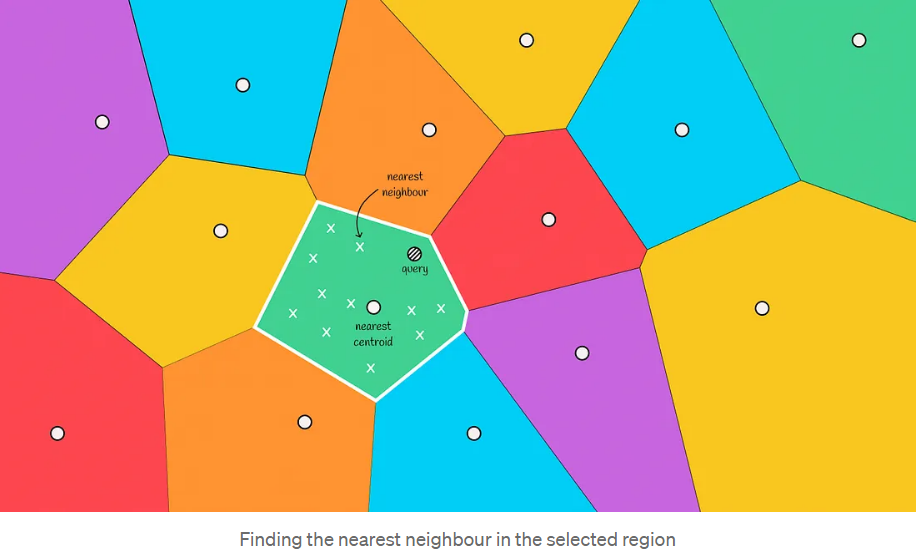
正如你所看到的,这种方法比以前的方法快得多,因为我们不必查看所有的数据集向量。
随着搜索速度的提高,倒排文件索引也有一个缺点:它不能保证找到的对象总是最近的。
在下图中,我们可以看到这样一种情况:实际最近的邻居位于红色区域,但我们只从绿色区域中选择候选人。这种情况被称为边缘问题。
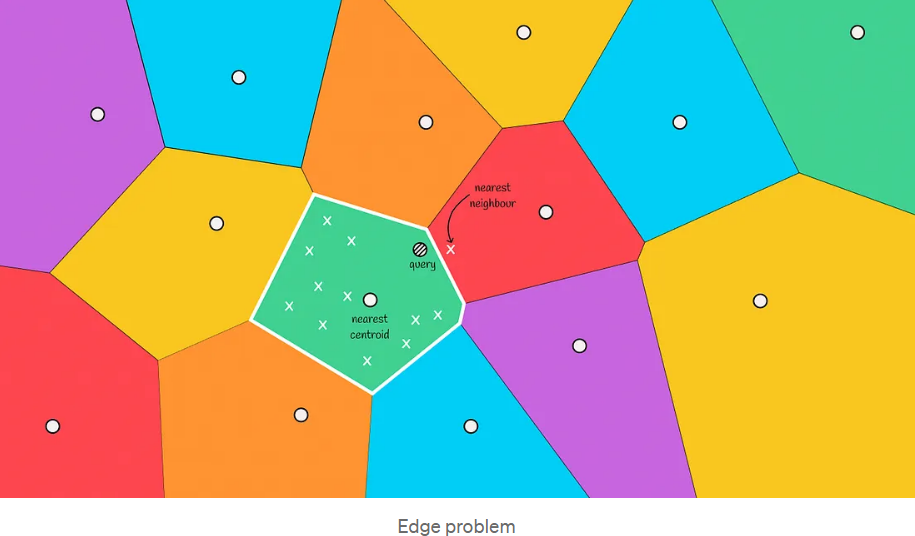
这种情况通常发生在查询对象位于与另一个区域的边界附近时。为了减少这种情况下的错误数量,我们可以增加搜索范围,并根据距离对象最近的前m个质心选择几个区域来搜索候选者。
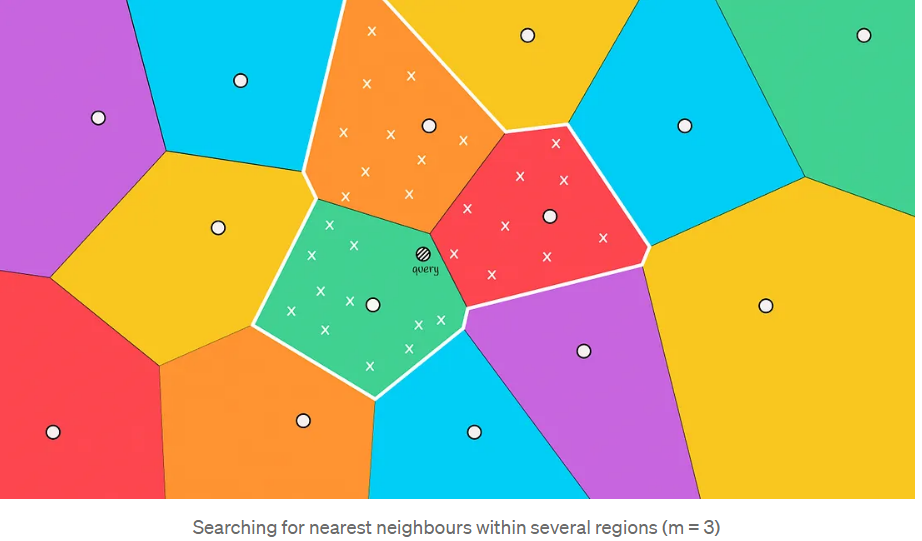
搜索的区域越多,结果就越准确,计算它们所需的时间也就越多。
尽管存在边缘问题,但倒排文件索引在实践中显示出了不错的效果。在我们想要在精度上稍微降低一点以实现几倍的速度增长的情况下,使用它是完美的。
其中一个用例示例是基于内容的推荐系统。想象一下,它根据用户过去看过的其他电影向用户推荐一部电影。该数据库包含一百万部电影可供选择。
-
通过使用kNN,系统确实为用户选择了最相关的电影并进行推荐。然而,执行查询所需的时间非常长。
-
让我们假设,在倒排文件索引的情况下,系统会推荐第5部最相关的电影,这可能是现实生活中的情况。搜索时间比kNN快20倍。
从用户体验来看,很难区分这两个推荐的质量结果:第1个和第5个最相关的结果都是来自一百万部可能的电影的好推荐。用户可能会对这些推荐中的任何一个感到满意。从时间的角度来看,倒排显然是赢家。这就是为什么在这种情况下,最好使用后一种方法。
Faiss(Facebook AI搜索相似性)是一个用C++编写的Python库,用于优化相似性搜索。该库提供不同类型的索引,这些索引是用于有效存储数据和执行查询的数据结构。
根据Faiss文档中的信息,我们将了解索引是如何创建和设置参数的。
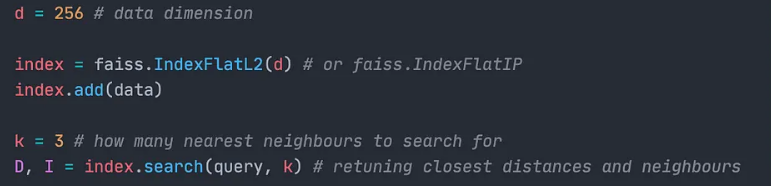
实现kNN方法的索引在Faiss中被称为Flat索引,因为它们不压缩任何信息。它们是保证正确搜索结果的唯一索引。事实上,Faiss中存在两种类型的Flat索引:
- IndexFlatL2:使用欧几里得距离计算相似度。
- IndexFlatIP:使用内积计算相似度。
这两个索引的构造函数中都需要一个参数d:数据维度。这些索引没有任何可调参数。
需要4个字节来存储矢量的单个分量。因此,为了存储维度为d的单个向量,需要4*d个字节。
对于所描述的反转文件,Faiss实现了IndexIVFFlat类。与kNN的情况一样,单词“Flat”表示没有对原始向量进行解压缩,并且它们被完全存储。
要创建这个索引,我们首先需要传递一个量化器——一个确定如何存储和比较数据库向量的对象。
IndexIVFFlat有两个重要参数:
- nlist:定义在训练期间要创建的多个区域(Voronoi单元)。
- nprobe:确定搜索候选对象的区域数量。更改nprobe参数不需要重新训练。

与前面的情况一样,我们需要4*d个字节来存储单个向量。但现在我们还必须存储数据集向量所属的Voronoi区域的信息。在Faiss实现中,每个向量需要8个字节的信息。因此,存储单个矢量所需的内存为: $$ bytes=4 * d+8 $$
我们已经研究了相似性搜索中的两种基本算法。实际上,kNN几乎不应该用于机器学习应用程序,因为除了特定情况外,它的可扩展性很差。另一方面,倒排文件为加速搜索提供了良好的启发式方法,其质量可以通过调整其超参数来提高。搜索性能仍然可以从不同的角度得到提高。在本系列文章的下一部分中,我们将了解其中一种用于压缩数据集向量的方法。
Similarity Search, Part 1: kNN & Inverted File Index | by Vyacheslav Efimov | Towards Data Science