'); + + results.forEach(function(result) { + var item = loaded_data[result.ref]; + var appendString = ''+item.title+'
'+prod_url+base_url+item.url.trim()+'
'+item.excerpt+'
'; + + $search_results.append(appendString); + }); + } else { + $search_results.html('
Your search did not match any documents.
Make sure that all words are spelled correctly or try more general keywords.
 +
+### 2. Using
+
+Spell works like an interpreter. Use the `MAGIC` value to execute spell in a note. (you might need to refresh after enabling)
+For example, Use `%echo` for the Echo Spell.
+
+
+
+### 2. Using
+
+Spell works like an interpreter. Use the `MAGIC` value to execute spell in a note. (you might need to refresh after enabling)
+For example, Use `%echo` for the Echo Spell.
+
+ +
+
+## Write a new Spell
+
+Making a new spell is similar to [Helium Visualization#write-new-visualization](./writingzeppelinvisualization.html#write-new-visualization).
+
+- Add framework dependency called zeppelin-spell into `package.json`
+- Write code using framework
+- Publish your spell to [npm]("https://www.npmjs.com/")
+
+### 1. Create a npm package
+
+Create a [package.json](https://docs.npmjs.com/files/package.json) in new directory for spell.
+
+- You have to add a framework called `zeppelin-spell` as a dependency to create spell ([zeppelin-spell](https://github.com/apache/zeppelin/tree/master/zeppelin-web/src/app/spell))
+- Also, you can add any dependencies you want to utilise.
+
+Here's an example
+
+```json
+{
+ "name": "zeppelin-echo-spell",
+ "description": "Zeppelin Echo Spell (example)",
+ "version": "1.0.0",
+ "main": "index",
+ "author": "",
+ "license": "Apache-2.0",
+ "dependencies": {
+ "zeppelin-spell": "*"
+ },
+ "helium": {
+ "icon" : "",
+ "spell": {
+ "magic": "%echo",
+ "usage": "%echo
+
+
+## Write a new Spell
+
+Making a new spell is similar to [Helium Visualization#write-new-visualization](./writingzeppelinvisualization.html#write-new-visualization).
+
+- Add framework dependency called zeppelin-spell into `package.json`
+- Write code using framework
+- Publish your spell to [npm]("https://www.npmjs.com/")
+
+### 1. Create a npm package
+
+Create a [package.json](https://docs.npmjs.com/files/package.json) in new directory for spell.
+
+- You have to add a framework called `zeppelin-spell` as a dependency to create spell ([zeppelin-spell](https://github.com/apache/zeppelin/tree/master/zeppelin-web/src/app/spell))
+- Also, you can add any dependencies you want to utilise.
+
+Here's an example
+
+```json
+{
+ "name": "zeppelin-echo-spell",
+ "description": "Zeppelin Echo Spell (example)",
+ "version": "1.0.0",
+ "main": "index",
+ "author": "",
+ "license": "Apache-2.0",
+ "dependencies": {
+ "zeppelin-spell": "*"
+ },
+ "helium": {
+ "icon" : "",
+ "spell": {
+ "magic": "%echo",
+ "usage": "%echo  +
+
+#### 3. Create and load visualization bundle on the fly
+
+Once a Visualization package is enabled, [HeliumBundleFactory](https://github.com/apache/zeppelin/blob/master/zeppelin-zengine/src/main/java/org/apache/zeppelin/helium/HeliumBundleFactory.java) creates a js bundle. The js bundle is served by `helium/bundle/load` rest api endpoint.
+
+#### 4. Run visualization
+
+Zeppelin shows additional button for loaded Visualizations.
+User can use just like any other built-in visualizations.
+
+
+
+
+#### 3. Create and load visualization bundle on the fly
+
+Once a Visualization package is enabled, [HeliumBundleFactory](https://github.com/apache/zeppelin/blob/master/zeppelin-zengine/src/main/java/org/apache/zeppelin/helium/HeliumBundleFactory.java) creates a js bundle. The js bundle is served by `helium/bundle/load` rest api endpoint.
+
+#### 4. Run visualization
+
+Zeppelin shows additional button for loaded Visualizations.
+User can use just like any other built-in visualizations.
+
+ +
+
+
+## Write new Visualization
+
+#### 1. Create a npm package
+
+Create a [package.json](https://docs.npmjs.com/files/package.json) in your new Visualization directory. You can add any dependencies in package.json, but you **must include two dependencies: [zeppelin-vis](https://github.com/apache/zeppelin/tree/master/zeppelin-web/src/app/visualization) and [zeppelin-tabledata](https://github.com/apache/zeppelin/tree/master/zeppelin-web/src/app/tabledata).**
+
+Here's an example
+
+```json
+{
+ "name": "zeppelin_horizontalbar",
+ "description" : "Horizontal Bar chart",
+ "version": "1.0.0",
+ "main": "horizontalbar",
+ "author": "",
+ "license": "Apache-2.0",
+ "dependencies": {
+ "zeppelin-tabledata": "*",
+ "zeppelin-vis": "*"
+ }
+}
+```
+
+#### 2. Create your own visualization
+
+To create your own visualization, you need to create a js file and import [Visualization](https://github.com/apache/zeppelin/blob/master/zeppelin-web/src/app/visualization/visualization.js) class from [zeppelin-vis](https://github.com/apache/zeppelin/tree/master/zeppelin-web/src/app/visualization) package and extend the class. [zeppelin-tabledata](https://github.com/apache/zeppelin/tree/master/zeppelin-web/src/app/tabledata) package provides some useful transformations, like pivot, you can use in your visualization. (you can create your own transformation, too).
+
+[Visualization](https://github.com/apache/zeppelin/blob/master/zeppelin-web/src/app/visualization/visualization.js) class, there're several methods that you need to override and implement. Here's simple visualization that just prints `Hello world`.
+
+```js
+import Visualization from 'zeppelin-vis'
+import PassthroughTransformation from 'zeppelin-tabledata/passthrough'
+
+export default class helloworld extends Visualization {
+ constructor(targetEl, config) {
+ super(targetEl, config)
+ this.passthrough = new PassthroughTransformation(config);
+ }
+
+ render(tableData) {
+ this.targetEl.html('Hello world!')
+ }
+
+ getTransformation() {
+ return this.passthrough
+ }
+}
+```
+
+To learn more about `Visualization` class, check [visualization.js](https://github.com/apache/zeppelin/blob/master/zeppelin-web/src/app/visualization/visualization.js).
+
+You can check complete visualization package example [here](https://github.com/apache/zeppelin/tree/master/zeppelin-examples/zeppelin-example-horizontalbar).
+
+Zeppelin's built-in visualization uses the same API, so you can check [built-in visualizations](https://github.com/apache/zeppelin/tree/master/zeppelin-web/src/app/visualization/builtins) as additional examples.
+
+
+#### 3. Create __Helium package file__ and locally deploy
+
+__Helium Package file__ is a json file that provides information about the application.
+Json file contains the following information
+
+```json
+{
+ "type" : "VISUALIZATION",
+ "name" : "zeppelin_horizontalbar",
+ "description" : "Horizontal Bar chart (example)",
+ "license" : "Apache-2.0",
+ "artifact" : "./zeppelin-examples/zeppelin-example-horizontalbar",
+ "icon" : ""
+}
+```
+
+Place this file in your local registry directory (default `./helium`).
+
+
+##### type
+
+When you're creating a visualization, 'type' should be 'VISUALIZATION'.
+Check [application](./writingzeppelinapplication.html) type if you're interested in the other types of package.
+
+##### name
+
+Name of visualization. Should be unique. Allows `[A-Za-z90-9_]`.
+
+
+##### description
+
+A short description about visualization.
+
+##### artifact
+
+Location of the visualization npm package. Support npm package with version or local filesystem path.
+
+e.g.
+
+When artifact exists in npm repository
+
+```json
+"artifact": "my-visualiztion@1.0.0"
+```
+
+
+When artifact exists in local file system
+
+```json
+"artifact": "/path/to/my/visualization"
+```
+
+##### license
+
+License information.
+
+e.g.
+
+```json
+"license": "Apache-2.0"
+```
+
+##### icon
+
+Icon to be used in visualization select button. String in this field will be rendered as a HTML tag.
+
+e.g.
+
+```json
+"icon": ""
+```
+
+
+#### 4. Run in dev mode
+
+Place your __Helium package file__ in local registry (ZEPPELIN_HOME/helium).
+Run Zeppelin. And then run zeppelin-web in visualization dev mode.
+
+```bash
+cd zeppelin-web
+yarn run dev:helium
+```
+
+You can browse localhost:9000. Everytime refresh your browser, Zeppelin will rebuild your visualization and reload changes.
+
+
+#### 5. Publish your visualization
+
+Once it's done, publish your visualization package using `npm publish`.
+That's it. With in an hour, your visualization will be available in Zeppelin's helium menu.
diff --git a/docs/development/writingzeppelinvisualization_transformation.md b/docs/development/writingzeppelinvisualization_transformation.md
new file mode 100644
index 00000000000..22bf130b124
--- /dev/null
+++ b/docs/development/writingzeppelinvisualization_transformation.md
@@ -0,0 +1,281 @@
+---
+layout: page
+title: "Transformations for Zeppelin Visualization"
+description: "Description for Transformations"
+group: development
+---
+
+{% include JB/setup %}
+
+# Transformations for Zeppelin Visualization
+
+
+
+## Overview
+
+Transformations
+
+- **renders** setting which allows users to set columns and
+- **transforms** table rows according to the configured columns.
+
+Zeppelin provides 4 types of transformations.
+
+## 1. PassthroughTransformation
+
+`PassthroughTransformation` is the simple transformation which does not convert original tabledata at all.
+
+See [passthrough.js](https://github.com/apache/zeppelin/blob/master/zeppelin-web/src/app/tabledata/passthrough.js)
+
+## 2. ColumnselectorTransformation
+
+`ColumnselectorTransformation` is uses when you need `N` axes but do not need aggregation.
+
+See [columnselector.js](https://github.com/apache/zeppelin/blob/master/zeppelin-web/src/app/tabledata/columnselector.js)
+
+## 3. PivotTransformation
+
+`PivotTransformation` provides group by and aggregation. Every chart using `PivotTransformation` has 3 axes. `Keys`, `Groups` and `Values`.
+
+See [pivot.js](https://github.com/apache/zeppelin/blob/master/zeppelin-web/src/app/tabledata/pivot.js)
+
+## 4. AdvancedTransformation
+
+`AdvancedTransformation` has more detailed options while providing existing features of `PivotTransformation` and `ColumnselectorTransformation`
+
+- multiple sub charts
+- configurable chart axes
+- parameter widgets: `input`, `checkbox`, `option`, `textarea`
+- parsing parameters automatically based on their types
+- expand / fold axis and parameter panels
+- multiple transformation methods while supporting lazy converting
+- re-initialize the whole configuration based on spec hash.
+
+### Spec
+
+`AdvancedTransformation` requires `spec` which includes axis and parameter details for charts.
+
+Let's create 2 sub-charts called `line` and `no-group`. Each sub chart can have different axis and parameter depending on their requirements.
+
+
+
+
+
+## Write new Visualization
+
+#### 1. Create a npm package
+
+Create a [package.json](https://docs.npmjs.com/files/package.json) in your new Visualization directory. You can add any dependencies in package.json, but you **must include two dependencies: [zeppelin-vis](https://github.com/apache/zeppelin/tree/master/zeppelin-web/src/app/visualization) and [zeppelin-tabledata](https://github.com/apache/zeppelin/tree/master/zeppelin-web/src/app/tabledata).**
+
+Here's an example
+
+```json
+{
+ "name": "zeppelin_horizontalbar",
+ "description" : "Horizontal Bar chart",
+ "version": "1.0.0",
+ "main": "horizontalbar",
+ "author": "",
+ "license": "Apache-2.0",
+ "dependencies": {
+ "zeppelin-tabledata": "*",
+ "zeppelin-vis": "*"
+ }
+}
+```
+
+#### 2. Create your own visualization
+
+To create your own visualization, you need to create a js file and import [Visualization](https://github.com/apache/zeppelin/blob/master/zeppelin-web/src/app/visualization/visualization.js) class from [zeppelin-vis](https://github.com/apache/zeppelin/tree/master/zeppelin-web/src/app/visualization) package and extend the class. [zeppelin-tabledata](https://github.com/apache/zeppelin/tree/master/zeppelin-web/src/app/tabledata) package provides some useful transformations, like pivot, you can use in your visualization. (you can create your own transformation, too).
+
+[Visualization](https://github.com/apache/zeppelin/blob/master/zeppelin-web/src/app/visualization/visualization.js) class, there're several methods that you need to override and implement. Here's simple visualization that just prints `Hello world`.
+
+```js
+import Visualization from 'zeppelin-vis'
+import PassthroughTransformation from 'zeppelin-tabledata/passthrough'
+
+export default class helloworld extends Visualization {
+ constructor(targetEl, config) {
+ super(targetEl, config)
+ this.passthrough = new PassthroughTransformation(config);
+ }
+
+ render(tableData) {
+ this.targetEl.html('Hello world!')
+ }
+
+ getTransformation() {
+ return this.passthrough
+ }
+}
+```
+
+To learn more about `Visualization` class, check [visualization.js](https://github.com/apache/zeppelin/blob/master/zeppelin-web/src/app/visualization/visualization.js).
+
+You can check complete visualization package example [here](https://github.com/apache/zeppelin/tree/master/zeppelin-examples/zeppelin-example-horizontalbar).
+
+Zeppelin's built-in visualization uses the same API, so you can check [built-in visualizations](https://github.com/apache/zeppelin/tree/master/zeppelin-web/src/app/visualization/builtins) as additional examples.
+
+
+#### 3. Create __Helium package file__ and locally deploy
+
+__Helium Package file__ is a json file that provides information about the application.
+Json file contains the following information
+
+```json
+{
+ "type" : "VISUALIZATION",
+ "name" : "zeppelin_horizontalbar",
+ "description" : "Horizontal Bar chart (example)",
+ "license" : "Apache-2.0",
+ "artifact" : "./zeppelin-examples/zeppelin-example-horizontalbar",
+ "icon" : ""
+}
+```
+
+Place this file in your local registry directory (default `./helium`).
+
+
+##### type
+
+When you're creating a visualization, 'type' should be 'VISUALIZATION'.
+Check [application](./writingzeppelinapplication.html) type if you're interested in the other types of package.
+
+##### name
+
+Name of visualization. Should be unique. Allows `[A-Za-z90-9_]`.
+
+
+##### description
+
+A short description about visualization.
+
+##### artifact
+
+Location of the visualization npm package. Support npm package with version or local filesystem path.
+
+e.g.
+
+When artifact exists in npm repository
+
+```json
+"artifact": "my-visualiztion@1.0.0"
+```
+
+
+When artifact exists in local file system
+
+```json
+"artifact": "/path/to/my/visualization"
+```
+
+##### license
+
+License information.
+
+e.g.
+
+```json
+"license": "Apache-2.0"
+```
+
+##### icon
+
+Icon to be used in visualization select button. String in this field will be rendered as a HTML tag.
+
+e.g.
+
+```json
+"icon": ""
+```
+
+
+#### 4. Run in dev mode
+
+Place your __Helium package file__ in local registry (ZEPPELIN_HOME/helium).
+Run Zeppelin. And then run zeppelin-web in visualization dev mode.
+
+```bash
+cd zeppelin-web
+yarn run dev:helium
+```
+
+You can browse localhost:9000. Everytime refresh your browser, Zeppelin will rebuild your visualization and reload changes.
+
+
+#### 5. Publish your visualization
+
+Once it's done, publish your visualization package using `npm publish`.
+That's it. With in an hour, your visualization will be available in Zeppelin's helium menu.
diff --git a/docs/development/writingzeppelinvisualization_transformation.md b/docs/development/writingzeppelinvisualization_transformation.md
new file mode 100644
index 00000000000..22bf130b124
--- /dev/null
+++ b/docs/development/writingzeppelinvisualization_transformation.md
@@ -0,0 +1,281 @@
+---
+layout: page
+title: "Transformations for Zeppelin Visualization"
+description: "Description for Transformations"
+group: development
+---
+
+{% include JB/setup %}
+
+# Transformations for Zeppelin Visualization
+
+
+
+## Overview
+
+Transformations
+
+- **renders** setting which allows users to set columns and
+- **transforms** table rows according to the configured columns.
+
+Zeppelin provides 4 types of transformations.
+
+## 1. PassthroughTransformation
+
+`PassthroughTransformation` is the simple transformation which does not convert original tabledata at all.
+
+See [passthrough.js](https://github.com/apache/zeppelin/blob/master/zeppelin-web/src/app/tabledata/passthrough.js)
+
+## 2. ColumnselectorTransformation
+
+`ColumnselectorTransformation` is uses when you need `N` axes but do not need aggregation.
+
+See [columnselector.js](https://github.com/apache/zeppelin/blob/master/zeppelin-web/src/app/tabledata/columnselector.js)
+
+## 3. PivotTransformation
+
+`PivotTransformation` provides group by and aggregation. Every chart using `PivotTransformation` has 3 axes. `Keys`, `Groups` and `Values`.
+
+See [pivot.js](https://github.com/apache/zeppelin/blob/master/zeppelin-web/src/app/tabledata/pivot.js)
+
+## 4. AdvancedTransformation
+
+`AdvancedTransformation` has more detailed options while providing existing features of `PivotTransformation` and `ColumnselectorTransformation`
+
+- multiple sub charts
+- configurable chart axes
+- parameter widgets: `input`, `checkbox`, `option`, `textarea`
+- parsing parameters automatically based on their types
+- expand / fold axis and parameter panels
+- multiple transformation methods while supporting lazy converting
+- re-initialize the whole configuration based on spec hash.
+
+### Spec
+
+`AdvancedTransformation` requires `spec` which includes axis and parameter details for charts.
+
+Let's create 2 sub-charts called `line` and `no-group`. Each sub chart can have different axis and parameter depending on their requirements.
+
++ +```js +class AwesomeVisualization extends Visualization { + constructor(targetEl, config) { + super(targetEl, config) + + const spec = { + charts: { + 'line': { + transform: { method: 'object', }, + sharedAxis: false, /** set if you want to share axes between sub charts, default is `false` */ + axis: { + 'xAxis': { dimension: 'multiple', axisType: 'key', description: 'serial', }, + 'yAxis': { dimension: 'multiple', axisType: 'aggregator', description: 'serial', }, + 'category': { dimension: 'multiple', axisType: 'group', description: 'categorical', }, + }, + parameter: { + 'xAxisUnit': { valueType: 'string', defaultValue: '', description: 'unit of xAxis', }, + 'yAxisUnit': { valueType: 'string', defaultValue: '', description: 'unit of yAxis', }, + 'lineWidth': { valueType: 'int', defaultValue: 0, description: 'width of line', }, + }, + }, + + 'no-group': { + transform: { method: 'object', }, + sharedAxis: false, + axis: { + 'xAxis': { dimension: 'single', axisType: 'key', }, + 'yAxis': { dimension: 'multiple', axisType: 'value', }, + }, + parameter: { + 'xAxisUnit': { valueType: 'string', defaultValue: '', description: 'unit of xAxis', }, + 'yAxisUnit': { valueType: 'string', defaultValue: '', description: 'unit of yAxis', }, + }, + }, + } + + this.transformation = new AdvancedTransformation(config, spec) + } + + ... + + // `render` will be called whenever `axis` or `parameter` is changed + render(data) { + const { chart, parameter, column, transformer, } = data + + if (chart === 'line') { + const transformed = transformer() + // draw line chart + } else if (chart === 'no-group') { + const transformed = transformer() + // draw no-group chart + } + } +} +``` + +
+ +### Spec: `axis` + +| Field Name | Available Values (type) | Description | +| --- | --- | --- | +|`dimension` | `single` | Axis can contains only 1 column | +|`dimension` | `multiple` | Axis can contains multiple columns | +|`axisType` | `key` | Column(s) in this axis will be used as `key` like in `PivotTransformation`. These columns will be served in `column.key` | +|`axisType` | `aggregator` | Column(s) in this axis will be used as `value` like in `PivotTransformation`. These columns will be served in `column.aggregator` | +|`axisType` | `group` | Column(s) in this axis will be used as `group` like in `PivotTransformation`. These columns will be served in `column.group` | +|`axisType` | (string) | Any string value can be used here. These columns will be served in `column.custom` | +|`maxAxisCount` (optional) | (int) | The max number of columns that this axis can contain. (unlimited if `undefined`) | +|`minAxisCount` (optional) | (int) | The min number of columns that this axis should contain to draw chart. (`1` in case of single dimension) | +|`description` (optional) | (string) | Description for the axis. | + +
+ +Here is an example. + +```js +axis: { + 'xAxis': { dimension: 'multiple', axisType: 'key', }, + 'yAxis': { dimension: 'multiple', axisType: 'aggregator'}, + 'category': { dimension: 'multiple', axisType: 'group', maxAxisCount: 2, valueType: 'string', }, +}, +``` + +
+ +### Spec: `sharedAxis` + +If you set `sharedAxis: false` for sub charts, then their axes are persisted in global space (shared). It's useful for when you creating multiple sub charts sharing their axes but have different parameters. For example, + +- `basic-column`, `stacked-column`, `percent-column` +- `pie` and `donut` + +
+ +Here is an example. + +```js + const spec = { + charts: { + 'column': { + transform: { method: 'array', }, + sharedAxis: true, + axis: { ... }, + parameter: { ... }, + }, + + 'stacked': { + transform: { method: 'array', }, + sharedAxis: true, + axis: { ... } + parameter: { ... }, + }, +``` + +
+ +### Spec: `parameter` + +| Field Name | Available Values (type) | Description | +| --- | --- | --- | +|`valueType` | `string` | Parameter which has string value | +|`valueType` | `int` | Parameter which has int value | +|`valueType` | `float` | Parameter which has float value | +|`valueType` | `boolean` | Parameter which has boolean value used with `checkbox` widget usually | +|`valueType` | `JSON` | Parameter which has JSON value used with `textarea` widget usually. `defaultValue` should be `""` (empty string). This ||`defaultValue` | (any) | Default value of this parameter. `JSON` type should have `""` (empty string) | +|`description` | (string) | Description of this parameter. This value will be parsed as HTML for pretty output | +|`widget` | `input` | Use [input](https://developer.mozilla.org/en/docs/Web/HTML/Element/input) widget. This is the default widget (if `widget` is undefined)| +|`widget` | `checkbox` | Use [checkbox](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/input/checkbox) widget. | +|`widget` | `textarea` | Use [textarea](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/textarea) widget. | +|`widget` | `option` | Use [select + option](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/select) widget. This parameter should have `optionValues` field as well. | +|`optionValues` | (Array
+ +Here is an example. + +```js +parameter: { + // string type, input widget + 'xAxisUnit': { valueType: 'string', defaultValue: '', description: 'unit of xAxis', }, + + // boolean type, checkbox widget + 'inverted': { widget: 'checkbox', valueType: 'boolean', defaultValue: false, description: 'invert x and y axes', }, + + // string type, option widget with `optionValues` + 'graphType': { widget: 'option', valueType: 'string', defaultValue: 'line', description: 'graph type', optionValues: [ 'line', 'smoothedLine', 'step', ], }, + + // HTML in `description` + 'dateFormat': { valueType: 'string', defaultValue: '', description: 'format of date (doc) (e.g YYYY-MM-DD)', }, + + // JSON type, textarea widget + 'yAxisGuides': { widget: 'textarea', valueType: 'JSON', defaultValue: '', description: 'guides of yAxis ', }, +``` + +
+ +### Spec: `transform` + +| Field Name | Available Values (type) | Description | +| --- | --- | --- | +|`method` | `object` | designed for rows requiring object manipulation | +|`method` | `array` | designed for rows requiring array manipulation | +|`method` | `array:2-key` | designed for xyz charts (e.g bubble chart) | +|`method` | `drill-down` | designed for drill-down charts | +|`method` | `raw` | will return the original `tableData.rows` | + +
+ +Whatever you specified as `transform.method`, the `transformer` value will be always function for lazy computation. + +```js +// advanced-transformation.util#getTransformer + +if (transformSpec.method === 'raw') { + transformer = () => { return rows; } +} else if (transformSpec.method === 'array') { + transformer = () => { + ... + return { ... } + } +} +``` + +Here is actual usage. + +```js +class AwesomeVisualization extends Visualization { + constructor(...) { /** setup your spec */ } + + ... + + // `render` will be called whenever `axis` or `parameter` are changed + render(data) { + const { chart, parameter, column, transformer, } = data + + if (chart === 'line') { + const transformed = transformer() + // draw line chart + } else if (chart === 'no-group') { + const transformed = transformer() + // draw no-group chart + } + } + + ... +} +``` + diff --git a/docs/displaysystem/back-end-angular.md b/docs/displaysystem/back-end-angular.md index d84a033d6fd..fb43ea41a6b 100644 --- a/docs/displaysystem/back-end-angular.md +++ b/docs/displaysystem/back-end-angular.md @@ -1,7 +1,7 @@ --- layout: page -title: "Angular (backend API)" -description: "Angular (backend API)" +title: "Back-end Angular API in Apache Zeppelin" +description: "Apache Zeppelin provides a gateway between your interpreter and your compiled AngularJS view templates. You can not only update scope variables from your interpreter but also watch them in the interpreter, which is JVM process." group: display --- +{% include JB/setup %} + +## Building from Source + + + +If you want to build from source, you must first install the following dependencies: + +
| Name | +Value | +
|---|---|
| Git | +(Any Version) | +
| Maven | +3.1.x or higher | +
| JDK | +1.7 | +
 +
+### 5. Run Zeppelin with Spark interpreter
+After running a single paragraph with Spark interpreter in Zeppelin,
+
+
+
+### 5. Run Zeppelin with Spark interpreter
+After running a single paragraph with Spark interpreter in Zeppelin,
+
+ +
+
+
++ +browse `http://
 +
diff --git a/docs/install/configuration.md b/docs/install/configuration.md
new file mode 100644
index 00000000000..a35eb91594c
--- /dev/null
+++ b/docs/install/configuration.md
@@ -0,0 +1,433 @@
+---
+layout: page
+title: "Apache Zeppelin Configuration"
+description: "This page will guide you to configure Apache Zeppelin using either environment variables or Java properties. Also, you can configure SSL for Zeppelin."
+group: install
+---
+
+{% include JB/setup %}
+
+# Apache Zeppelin Configuration
+
+
+
+## Zeppelin Properties
+There are two locations you can configure Apache Zeppelin.
+
+* **Environment variables** can be defined `conf/zeppelin-env.sh`(`conf\zeppelin-env.cmd` for Windows).
+* **Java properties** can ba defined in `conf/zeppelin-site.xml`.
+
+If both are defined, then the **environment variables** will take priority.
+> Mouse hover on each property and click then you can get a link for that.
+
+
+
diff --git a/docs/install/configuration.md b/docs/install/configuration.md
new file mode 100644
index 00000000000..a35eb91594c
--- /dev/null
+++ b/docs/install/configuration.md
@@ -0,0 +1,433 @@
+---
+layout: page
+title: "Apache Zeppelin Configuration"
+description: "This page will guide you to configure Apache Zeppelin using either environment variables or Java properties. Also, you can configure SSL for Zeppelin."
+group: install
+---
+
+{% include JB/setup %}
+
+# Apache Zeppelin Configuration
+
+
+
+## Zeppelin Properties
+There are two locations you can configure Apache Zeppelin.
+
+* **Environment variables** can be defined `conf/zeppelin-env.sh`(`conf\zeppelin-env.cmd` for Windows).
+* **Java properties** can ba defined in `conf/zeppelin-site.xml`.
+
+If both are defined, then the **environment variables** will take priority.
+> Mouse hover on each property and click then you can get a link for that.
+
+| zeppelin-env.sh | +zeppelin-site.xml | +Default value | +Description | +
|---|---|---|---|
ZEPPELIN_PORT |
+ zeppelin.server.port |
+ 8080 | +Zeppelin server port + Note: Please make sure you're not using the same port with + Zeppelin web application development port (default: 9000). | +
ZEPPELIN_SSL_PORT |
+ zeppelin.server.ssl.port |
+ 8443 | +Zeppelin Server ssl port (used when ssl environment/property is set to true) | +
ZEPPELIN_MEM |
+ N/A | +-Xmx1024m -XX:MaxPermSize=512m | +JVM mem options | +
ZEPPELIN_INTP_MEM |
+ N/A | +ZEPPELIN_MEM | +JVM mem options for interpreter process | +
ZEPPELIN_JAVA_OPTS |
+ N/A | ++ | JVM options | +
ZEPPELIN_ALLOWED_ORIGINS |
+ zeppelin.server.allowed.origins |
+ * | +Enables a way to specify a ',' separated list of allowed origins for REST and websockets. e.g. http://localhost:8080 |
+
| N/A | +zeppelin.anonymous.allowed |
+ true | +The anonymous user is allowed by default. | +
ZEPPELIN_SERVER_CONTEXT_PATH |
+ zeppelin.server.context.path |
+ / | +Context path of the web application | +
ZEPPELIN_SSL |
+ zeppelin.ssl |
+ false | ++ |
ZEPPELIN_SSL_CLIENT_AUTH |
+ zeppelin.ssl.client.auth |
+ false | ++ |
ZEPPELIN_SSL_KEYSTORE_PATH |
+ zeppelin.ssl.keystore.path |
+ keystore | ++ |
ZEPPELIN_SSL_KEYSTORE_TYPE |
+ zeppelin.ssl.keystore.type |
+ JKS | ++ |
ZEPPELIN_SSL_KEYSTORE_PASSWORD |
+ zeppelin.ssl.keystore.password |
+ + | + |
ZEPPELIN_SSL_KEY_MANAGER_PASSWORD |
+ zeppelin.ssl.key.manager.password |
+ + | + |
ZEPPELIN_SSL_TRUSTSTORE_PATH |
+ zeppelin.ssl.truststore.path |
+ + | + |
ZEPPELIN_SSL_TRUSTSTORE_TYPE |
+ zeppelin.ssl.truststore.type |
+ + | + |
ZEPPELIN_SSL_TRUSTSTORE_PASSWORD |
+ zeppelin.ssl.truststore.password |
+ + | + |
ZEPPELIN_NOTEBOOK_HOMESCREEN |
+ zeppelin.notebook.homescreen |
+ + | Display note IDs on the Apache Zeppelin homescreen e.g. 2A94M5J1Z |
+
ZEPPELIN_NOTEBOOK_HOMESCREEN_HIDE |
+ zeppelin.notebook.homescreen.hide |
+ false | +Hide the note ID set by ZEPPELIN_NOTEBOOK_HOMESCREEN on the Apache Zeppelin homescreen. For the further information, please read Customize your Zeppelin homepage. |
+
ZEPPELIN_WAR_TEMPDIR |
+ zeppelin.war.tempdir |
+ webapps | +Location of the jetty temporary directory | +
ZEPPELIN_NOTEBOOK_DIR |
+ zeppelin.notebook.dir |
+ notebook | +The root directory where notebook directories are saved | +
ZEPPELIN_NOTEBOOK_S3_BUCKET |
+ zeppelin.notebook.s3.bucket |
+ zeppelin | +S3 Bucket where notebook files will be saved | +
ZEPPELIN_NOTEBOOK_S3_USER |
+ zeppelin.notebook.s3.user |
+ user | +User name of an S3 bucket e.g. bucket/user/notebook/2A94M5J1Z/note.json |
+
ZEPPELIN_NOTEBOOK_S3_ENDPOINT |
+ zeppelin.notebook.s3.endpoint |
+ s3.amazonaws.com | +Endpoint for the bucket | +
ZEPPELIN_NOTEBOOK_S3_KMS_KEY_ID |
+ zeppelin.notebook.s3.kmsKeyID |
+ + | AWS KMS Key ID to use for encrypting data in S3 (optional) | +
ZEPPELIN_NOTEBOOK_S3_EMP |
+ zeppelin.notebook.s3.encryptionMaterialsProvider |
+ + | Class name of a custom S3 encryption materials provider implementation to use for encrypting data in S3 (optional) | +
ZEPPELIN_NOTEBOOK_S3_SSE |
+ zeppelin.notebook.s3.sse |
+ false | +Save notebooks to S3 with server-side encryption enabled | +
ZEPPELIN_NOTEBOOK_AZURE_CONNECTION_STRING |
+ zeppelin.notebook.azure.connectionString |
+ + | The Azure storage account connection string e.g. DefaultEndpointsProtocol=https; |
+
ZEPPELIN_NOTEBOOK_AZURE_SHARE |
+ zeppelin.notebook.azure.share |
+ zeppelin | +Azure Share where the notebook files will be saved | +
ZEPPELIN_NOTEBOOK_AZURE_USER |
+ zeppelin.notebook.azure.user |
+ user | +Optional user name of an Azure file share e.g. share/user/notebook/2A94M5J1Z/note.json |
+
ZEPPELIN_NOTEBOOK_STORAGE |
+ zeppelin.notebook.storage |
+ org.apache.zeppelin.notebook.repo.GitNotebookRepo | +Comma separated list of notebook storage locations | +
ZEPPELIN_NOTEBOOK_ONE_WAY_SYNC |
+ zeppelin.notebook.one.way.sync |
+ false | +If there are multiple notebook storage locations, should we treat the first one as the only source of truth? | +
ZEPPELIN_NOTEBOOK_PUBLIC |
+ zeppelin.notebook.public |
+ true | +Make notebook public (set only owners) by default when created/imported. If set to false will add user to readers and writers as well, making it private and invisible to other users unless permissions are granted. |
+
ZEPPELIN_INTERPRETERS |
+ zeppelin.interpreters |
+ org.apache.zeppelin.spark.SparkInterpreter, org.apache.zeppelin.spark.PySparkInterpreter, org.apache.zeppelin.spark.SparkSqlInterpreter, org.apache.zeppelin.spark.DepInterpreter, org.apache.zeppelin.markdown.Markdown, org.apache.zeppelin.shell.ShellInterpreter, + ... + |
+
+ Comma separated interpreter configurations [Class] + NOTE: This property is deprecated since Zeppelin-0.6.0 and will not be supported from Zeppelin-0.7.0. + |
+
ZEPPELIN_INTERPRETER_DIR |
+ zeppelin.interpreter.dir |
+ interpreter | +Interpreter directory | +
ZEPPELIN_INTERPRETER_DEP_MVNREPO |
+ zeppelin.interpreter.dep.mvnRepo |
+ http://repo1.maven.org/maven2/ | +Remote principal repository for interpreter's additional dependency loading | +
ZEPPELIN_INTERPRETER_OUTPUT_LIMIT |
+ zeppelin.interpreter.output.limit |
+ 102400 | +Output message from interpreter exceeding the limit will be truncated | +
ZEPPELIN_INTERPRETER_CONNECT_TIMEOUT |
+ zeppelin.interpreter.connect.timeout |
+ 30000 | +Output message from interpreter exceeding the limit will be truncated | +
ZEPPELIN_DEP_LOCALREPO |
+ zeppelin.dep.localrepo |
+ local-repo | +Local repository for dependency loader. ex)visualiztion modules of npm. |
+
ZEPPELIN_HELIUM_NPM_REGISTRY |
+ zeppelin.helium.npm.registry |
+ http://registry.npmjs.org/ | +Remote Npm registry for Helium dependency loader | +
ZEPPELIN_WEBSOCKET_MAX_TEXT_MESSAGE_SIZE |
+ zeppelin.websocket.max.text.message.size |
+ 1024000 | +Size(in characters) of the maximum text message that can be received by websocket. | +
ZEPPELIN_SERVER_DEFAULT_DIR_ALLOWED |
+ zeppelin.server.default.dir.allowed |
+ false | +Enable directory listings on server. | +
 +
+### 4. Run Zeppelin with Spark interpreter
+After running single paragraph with Spark interpreter in Zeppelin, browse `https://
+
+### 4. Run Zeppelin with Spark interpreter
+After running single paragraph with Spark interpreter in Zeppelin, browse `https:// +
+You can also simply verify that Spark is running well in Docker with below command.
+
+```
+ps -ef | grep spark
+```
+
+
+## Spark on YARN mode
+You can simply set up [Spark on YARN](http://spark.apache.org/docs/latest/running-on-yarn.html) docker environment with below steps.
+
+> **Note :** Since Apache Zeppelin and Spark use same `8080` port for their web UI, you might need to change `zeppelin.server.port` in `conf/zeppelin-site.xml`.
+
+### 1. Build Docker file
+You can find docker script files under `scripts/docker/spark-cluster-managers`.
+
+```
+cd $ZEPPELIN_HOME/scripts/docker/spark-cluster-managers/spark_yarn_cluster
+docker build -t "spark_yarn" .
+```
+
+### 2. Run docker
+
+```
+docker run -it \
+ -p 5000:5000 \
+ -p 9000:9000 \
+ -p 9001:9001 \
+ -p 8088:8088 \
+ -p 8042:8042 \
+ -p 8030:8030 \
+ -p 8031:8031 \
+ -p 8032:8032 \
+ -p 8033:8033 \
+ -p 8080:8080 \
+ -p 7077:7077 \
+ -p 8888:8888 \
+ -p 8081:8081 \
+ -p 50010:50010 \
+ -p 50075:50075 \
+ -p 50020:50020 \
+ -p 50070:50070 \
+ --name spark_yarn \
+ -h sparkmaster \
+ spark_yarn bash;
+```
+
+Note that `sparkmaster` hostname used here to run docker container should be defined in your `/etc/hosts`.
+
+### 3. Verify running Spark on YARN.
+
+You can simply verify the processes of Spark and YARN are running well in Docker with below command.
+
+```
+ps -ef
+```
+
+You can also check each application web UI for HDFS on `http://
+
+### 5. Run Zeppelin with Spark interpreter
+After running a single paragraph with Spark interpreter in Zeppelin, browse `http://
+
+You can also simply verify that Spark is running well in Docker with below command.
+
+```
+ps -ef | grep spark
+```
+
+
+## Spark on YARN mode
+You can simply set up [Spark on YARN](http://spark.apache.org/docs/latest/running-on-yarn.html) docker environment with below steps.
+
+> **Note :** Since Apache Zeppelin and Spark use same `8080` port for their web UI, you might need to change `zeppelin.server.port` in `conf/zeppelin-site.xml`.
+
+### 1. Build Docker file
+You can find docker script files under `scripts/docker/spark-cluster-managers`.
+
+```
+cd $ZEPPELIN_HOME/scripts/docker/spark-cluster-managers/spark_yarn_cluster
+docker build -t "spark_yarn" .
+```
+
+### 2. Run docker
+
+```
+docker run -it \
+ -p 5000:5000 \
+ -p 9000:9000 \
+ -p 9001:9001 \
+ -p 8088:8088 \
+ -p 8042:8042 \
+ -p 8030:8030 \
+ -p 8031:8031 \
+ -p 8032:8032 \
+ -p 8033:8033 \
+ -p 8080:8080 \
+ -p 7077:7077 \
+ -p 8888:8888 \
+ -p 8081:8081 \
+ -p 50010:50010 \
+ -p 50075:50075 \
+ -p 50020:50020 \
+ -p 50070:50070 \
+ --name spark_yarn \
+ -h sparkmaster \
+ spark_yarn bash;
+```
+
+Note that `sparkmaster` hostname used here to run docker container should be defined in your `/etc/hosts`.
+
+### 3. Verify running Spark on YARN.
+
+You can simply verify the processes of Spark and YARN are running well in Docker with below command.
+
+```
+ps -ef
+```
+
+You can also check each application web UI for HDFS on `http://
+
+### 5. Run Zeppelin with Spark interpreter
+After running a single paragraph with Spark interpreter in Zeppelin, browse `http:// +
+
+
+## Spark on Mesos mode
+You can simply set up [Spark on Mesos](http://spark.apache.org/docs/latest/running-on-mesos.html) docker environment with below steps.
+
+
+### 1. Build Docker file
+
+```
+cd $ZEPPELIN_HOME/scripts/docker/spark-cluster-managers/spark_mesos
+docker build -t "spark_mesos" .
+```
+
+
+### 2. Run docker
+
+```
+docker run --net=host -it \
+-p 8080:8080 \
+-p 7077:7077 \
+-p 8888:8888 \
+-p 8081:8081 \
+-p 8082:8082 \
+-p 5050:5050 \
+-p 5051:5051 \
+-p 4040:4040 \
+-h sparkmaster \
+--name spark_mesos \
+spark_mesos bash;
+```
+
+Note that `sparkmaster` hostname used here to run docker container should be defined in your `/etc/hosts`.
+
+### 3. Verify running Spark on Mesos.
+
+You can simply verify the processes of Spark and Mesos are running well in Docker with below command.
+
+```
+ps -ef
+```
+
+You can also check each application web UI for Mesos on `http://
+
+
+
+## Spark on Mesos mode
+You can simply set up [Spark on Mesos](http://spark.apache.org/docs/latest/running-on-mesos.html) docker environment with below steps.
+
+
+### 1. Build Docker file
+
+```
+cd $ZEPPELIN_HOME/scripts/docker/spark-cluster-managers/spark_mesos
+docker build -t "spark_mesos" .
+```
+
+
+### 2. Run docker
+
+```
+docker run --net=host -it \
+-p 8080:8080 \
+-p 7077:7077 \
+-p 8888:8888 \
+-p 8081:8081 \
+-p 8082:8082 \
+-p 5050:5050 \
+-p 5051:5051 \
+-p 4040:4040 \
+-h sparkmaster \
+--name spark_mesos \
+spark_mesos bash;
+```
+
+Note that `sparkmaster` hostname used here to run docker container should be defined in your `/etc/hosts`.
+
+### 3. Verify running Spark on Mesos.
+
+You can simply verify the processes of Spark and Mesos are running well in Docker with below command.
+
+```
+ps -ef
+```
+
+You can also check each application web UI for Mesos on `http:// +
+
+### 5. Run Zeppelin with Spark interpreter
+After running a single paragraph with Spark interpreter in Zeppelin, browse `http://
+
+
+### 5. Run Zeppelin with Spark interpreter
+After running a single paragraph with Spark interpreter in Zeppelin, browse `http:// +
+### Troubleshooting for Spark on Mesos
+
+- If you have problem with hostname, use `--add-host` option when executing `dockerrun`
+
+```
+## use `--add-host=moby:127.0.0.1` option to resolve
+## since docker container couldn't resolve `moby`
+
+: java.net.UnknownHostException: moby: moby: Name or service not known
+ at java.net.InetAddress.getLocalHost(InetAddress.java:1496)
+ at org.apache.spark.util.Utils$.findLocalInetAddress(Utils.scala:789)
+ at org.apache.spark.util.Utils$.org$apache$spark$util$Utils$$localIpAddress$lzycompute(Utils.scala:782)
+ at org.apache.spark.util.Utils$.org$apache$spark$util$Utils$$localIpAddress(Utils.scala:782)
+```
+
+- If you have problem with mesos master, try `mesos://127.0.0.1` instead of `mesos://127.0.1.1`
+
+```
+I0103 20:17:22.329269 340 sched.cpp:330] New master detected at master@127.0.1.1:5050
+I0103 20:17:22.330749 340 sched.cpp:341] No credentials provided. Attempting to register without authentication
+W0103 20:17:22.333531 340 sched.cpp:736] Ignoring framework registered message because it was sentfrom 'master@127.0.0.1:5050' instead of the leading master 'master@127.0.1.1:5050'
+W0103 20:17:24.040252 339 sched.cpp:736] Ignoring framework registered message because it was sentfrom 'master@127.0.0.1:5050' instead of the leading master 'master@127.0.1.1:5050'
+W0103 20:17:26.150250 339 sched.cpp:736] Ignoring framework registered message because it was sentfrom 'master@127.0.0.1:5050' instead of the leading master 'master@127.0.1.1:5050'
+W0103 20:17:26.737604 339 sched.cpp:736] Ignoring framework registered message because it was sentfrom 'master@127.0.0.1:5050' instead of the leading master 'master@127.0.1.1:5050'
+W0103 20:17:35.241714 336 sched.cpp:736] Ignoring framework registered message because it was sentfrom 'master@127.0.0.1:5050' instead of the leading master 'master@127.0.1.1:5050'
+```
\ No newline at end of file
diff --git a/docs/install/upgrade.md b/docs/install/upgrade.md
index d5642869126..61d2d68792d 100644
--- a/docs/install/upgrade.md
+++ b/docs/install/upgrade.md
@@ -1,7 +1,7 @@
---
layout: page
-title: "Manual upgrade procedure for Zeppelin"
-description: ""
+title: "Manual Zeppelin version upgrade procedure"
+description: "This document will guide you through a procedure of manual upgrade your Apache Zeppelin instance to a newer version. Apache Zeppelin keeps backward compatibility for the notebook file format."
group: install
---
{% include JB/setup %}
-# Vagrant Virtual Machine for Apache Zeppelin
+# Apache Zeppelin on Vagrant Virtual Machine
## Overview
-Apache Zeppelin distribution includes a scripts directory
+Apache Zeppelin distribution includes a script directory
`scripts/vagrant/zeppelin-dev`
-This script creates a virtual machine that launches a repeatable, known set of core dependencies required for developing Zeppelin. It can also be used to run an existing Zeppelin build if you don't plan to build from source.
+This script creates a virtual machine that launches a repeatable, known set of core dependencies required for developing Zeppelin. It can also be used to run an existing Zeppelin build if you don't plan to build from source.
For PySpark users, this script includes several helpful [Python Libraries](#python-extras).
For SparkR users, this script includes several helpful [R Libraries](#r-extras).
@@ -75,7 +75,7 @@ into a directory on your host machine, or directly in your virtual machine.
Cloning Zeppelin into the `/scripts/vagrant/zeppelin-dev` directory from the host, will allow the directory to be shared between your host and the guest machine.
-Cloning the project again may seem counter intuitive, since this script likley originated from the project repository. Consider copying just the vagrant/zeppelin-dev script from the Zeppelin project as a stand alone directory, then once again clone the specific branch you wish to build.
+Cloning the project again may seem counter intuitive, since this script likely originated from the project repository. Consider copying just the vagrant/zeppelin-dev script from the Zeppelin project as a stand alone directory, then once again clone the specific branch you wish to build.
Synced folders enable Vagrant to sync a folder on the host machine to the guest machine, allowing you to continue working on your project's files on your host machine, but use the resources in the guest machine to compile or run your project. _[(1) Synced Folder Description from Vagrant Up](https://docs.vagrantup.com/v2/synced-folders/index.html)_
@@ -88,7 +88,7 @@ By default, Vagrant will share your project directory (the directory with the Va
Running the following commands in the guest machine should display these expected versions:
`node --version` should report *v0.12.7*
-`mvn --version` should report *Apache Maven 3.3.3* and *Java version: 1.7.0_85*
+`mvn --version` should report *Apache Maven 3.3.9* and *Java version: 1.7.0_85*
The virtual machine consists of:
@@ -96,7 +96,7 @@ The virtual machine consists of:
- Node.js 0.12.7
- npm 2.11.3
- ruby 1.9.3 + rake, make and bundler (only required if building jekyll documentation)
- - Maven 3.3.3
+ - Maven 3.3.9
- Git
- Unzip
- libfontconfig to avoid phatomJs missing dependency issues
@@ -110,7 +110,7 @@ This assumes you've already cloned the project either on the host machine in the
```
cd /zeppelin
-mvn clean package -Pspark-1.6 -Ppyspark -Phadoop-2.4 -Psparkr -DskipTests
+mvn clean package -Pspark-1.6 -Phadoop-2.4 -DskipTests
./bin/zeppelin-daemon.sh start
```
@@ -163,7 +163,7 @@ import matplotlib.pyplot as plt
import numpy as np
import StringIO
-# clear out any previous plots on this notebook
+# clear out any previous plots on this note
plt.clf()
def show(p):
diff --git a/docs/install/yarn_install.md b/docs/install/yarn_install.md
index 466007d2daa..e2427546a66 100644
--- a/docs/install/yarn_install.md
+++ b/docs/install/yarn_install.md
@@ -1,7 +1,7 @@
---
layout: page
title: "Install Zeppelin to connect with existing YARN cluster"
-description: ""
+description: "This page describes how to pre-configure a bare metal node, configure Apache Zeppelin and connect it to existing YARN cluster running Hortonworks flavour of Hadoop."
group: install
---
{% include JB/setup %}
# Alluxio Interpreter for Apache Zeppelin
diff --git a/docs/interpreter/beam.md b/docs/interpreter/beam.md
new file mode 100644
index 00000000000..cbcd5e37d51
--- /dev/null
+++ b/docs/interpreter/beam.md
@@ -0,0 +1,124 @@
+---
+layout: page
+title: Beam interpreter in Apache Zeppelin
+description: Apache Beam is an open source, unified programming model that you can use to create a data processing pipeline.
+group: interpreter
+---
+
+
+{% include JB/setup %}
+
+# Beam interpreter for Apache Zeppelin
+
+
+
+## Overview
+[Apache Beam](http://beam.incubator.apache.org) is an open source unified platform for data processing pipelines. A pipeline can be build using one of the Beam SDKs.
+The execution of the pipeline is done by different Runners. Currently, Beam supports Apache Flink Runner, Apache Spark Runner, and Google Dataflow Runner.
+
+## How to use
+Basically, you can write normal Beam java code where you can determine the Runner. You should write the main method inside a class becuase the interpreter invoke this main to execute the pipeline. Unlike Zeppelin normal pattern, each paragraph is considered as a separate job, there isn't any relation to any other paragraph.
+
+The following is a demonstration of a word count example with data represented in array of strings
+But it can read data from files by replacing `Create.of(SENTENCES).withCoder(StringUtf8Coder.of())` with `TextIO.Read.from("path/to/filename.txt")`
+
+```java
+%beam
+
+// most used imports
+import org.apache.beam.sdk.coders.StringUtf8Coder;
+import org.apache.beam.sdk.transforms.Create;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.List;
+import java.util.ArrayList;
+import org.apache.spark.api.java.*;
+import org.apache.spark.api.java.function.Function;
+import org.apache.spark.SparkConf;
+import org.apache.spark.streaming.*;
+import org.apache.spark.SparkContext;
+import org.apache.beam.runners.direct.*;
+import org.apache.beam.sdk.runners.*;
+import org.apache.beam.sdk.options.*;
+import org.apache.beam.runners.spark.*;
+import org.apache.beam.runners.spark.io.ConsoleIO;
+import org.apache.beam.runners.flink.*;
+import org.apache.beam.runners.flink.examples.WordCount.Options;
+import org.apache.beam.sdk.Pipeline;
+import org.apache.beam.sdk.io.TextIO;
+import org.apache.beam.sdk.options.PipelineOptionsFactory;
+import org.apache.beam.sdk.transforms.Count;
+import org.apache.beam.sdk.transforms.DoFn;
+import org.apache.beam.sdk.transforms.MapElements;
+import org.apache.beam.sdk.transforms.ParDo;
+import org.apache.beam.sdk.transforms.SimpleFunction;
+import org.apache.beam.sdk.values.KV;
+import org.apache.beam.sdk.options.PipelineOptions;
+
+public class MinimalWordCount {
+ static List
+
+### Troubleshooting for Spark on Mesos
+
+- If you have problem with hostname, use `--add-host` option when executing `dockerrun`
+
+```
+## use `--add-host=moby:127.0.0.1` option to resolve
+## since docker container couldn't resolve `moby`
+
+: java.net.UnknownHostException: moby: moby: Name or service not known
+ at java.net.InetAddress.getLocalHost(InetAddress.java:1496)
+ at org.apache.spark.util.Utils$.findLocalInetAddress(Utils.scala:789)
+ at org.apache.spark.util.Utils$.org$apache$spark$util$Utils$$localIpAddress$lzycompute(Utils.scala:782)
+ at org.apache.spark.util.Utils$.org$apache$spark$util$Utils$$localIpAddress(Utils.scala:782)
+```
+
+- If you have problem with mesos master, try `mesos://127.0.0.1` instead of `mesos://127.0.1.1`
+
+```
+I0103 20:17:22.329269 340 sched.cpp:330] New master detected at master@127.0.1.1:5050
+I0103 20:17:22.330749 340 sched.cpp:341] No credentials provided. Attempting to register without authentication
+W0103 20:17:22.333531 340 sched.cpp:736] Ignoring framework registered message because it was sentfrom 'master@127.0.0.1:5050' instead of the leading master 'master@127.0.1.1:5050'
+W0103 20:17:24.040252 339 sched.cpp:736] Ignoring framework registered message because it was sentfrom 'master@127.0.0.1:5050' instead of the leading master 'master@127.0.1.1:5050'
+W0103 20:17:26.150250 339 sched.cpp:736] Ignoring framework registered message because it was sentfrom 'master@127.0.0.1:5050' instead of the leading master 'master@127.0.1.1:5050'
+W0103 20:17:26.737604 339 sched.cpp:736] Ignoring framework registered message because it was sentfrom 'master@127.0.0.1:5050' instead of the leading master 'master@127.0.1.1:5050'
+W0103 20:17:35.241714 336 sched.cpp:736] Ignoring framework registered message because it was sentfrom 'master@127.0.0.1:5050' instead of the leading master 'master@127.0.1.1:5050'
+```
\ No newline at end of file
diff --git a/docs/install/upgrade.md b/docs/install/upgrade.md
index d5642869126..61d2d68792d 100644
--- a/docs/install/upgrade.md
+++ b/docs/install/upgrade.md
@@ -1,7 +1,7 @@
---
layout: page
-title: "Manual upgrade procedure for Zeppelin"
-description: ""
+title: "Manual Zeppelin version upgrade procedure"
+description: "This document will guide you through a procedure of manual upgrade your Apache Zeppelin instance to a newer version. Apache Zeppelin keeps backward compatibility for the notebook file format."
group: install
---
{% include JB/setup %}
-# Vagrant Virtual Machine for Apache Zeppelin
+# Apache Zeppelin on Vagrant Virtual Machine
## Overview
-Apache Zeppelin distribution includes a scripts directory
+Apache Zeppelin distribution includes a script directory
`scripts/vagrant/zeppelin-dev`
-This script creates a virtual machine that launches a repeatable, known set of core dependencies required for developing Zeppelin. It can also be used to run an existing Zeppelin build if you don't plan to build from source.
+This script creates a virtual machine that launches a repeatable, known set of core dependencies required for developing Zeppelin. It can also be used to run an existing Zeppelin build if you don't plan to build from source.
For PySpark users, this script includes several helpful [Python Libraries](#python-extras).
For SparkR users, this script includes several helpful [R Libraries](#r-extras).
@@ -75,7 +75,7 @@ into a directory on your host machine, or directly in your virtual machine.
Cloning Zeppelin into the `/scripts/vagrant/zeppelin-dev` directory from the host, will allow the directory to be shared between your host and the guest machine.
-Cloning the project again may seem counter intuitive, since this script likley originated from the project repository. Consider copying just the vagrant/zeppelin-dev script from the Zeppelin project as a stand alone directory, then once again clone the specific branch you wish to build.
+Cloning the project again may seem counter intuitive, since this script likely originated from the project repository. Consider copying just the vagrant/zeppelin-dev script from the Zeppelin project as a stand alone directory, then once again clone the specific branch you wish to build.
Synced folders enable Vagrant to sync a folder on the host machine to the guest machine, allowing you to continue working on your project's files on your host machine, but use the resources in the guest machine to compile or run your project. _[(1) Synced Folder Description from Vagrant Up](https://docs.vagrantup.com/v2/synced-folders/index.html)_
@@ -88,7 +88,7 @@ By default, Vagrant will share your project directory (the directory with the Va
Running the following commands in the guest machine should display these expected versions:
`node --version` should report *v0.12.7*
-`mvn --version` should report *Apache Maven 3.3.3* and *Java version: 1.7.0_85*
+`mvn --version` should report *Apache Maven 3.3.9* and *Java version: 1.7.0_85*
The virtual machine consists of:
@@ -96,7 +96,7 @@ The virtual machine consists of:
- Node.js 0.12.7
- npm 2.11.3
- ruby 1.9.3 + rake, make and bundler (only required if building jekyll documentation)
- - Maven 3.3.3
+ - Maven 3.3.9
- Git
- Unzip
- libfontconfig to avoid phatomJs missing dependency issues
@@ -110,7 +110,7 @@ This assumes you've already cloned the project either on the host machine in the
```
cd /zeppelin
-mvn clean package -Pspark-1.6 -Ppyspark -Phadoop-2.4 -Psparkr -DskipTests
+mvn clean package -Pspark-1.6 -Phadoop-2.4 -DskipTests
./bin/zeppelin-daemon.sh start
```
@@ -163,7 +163,7 @@ import matplotlib.pyplot as plt
import numpy as np
import StringIO
-# clear out any previous plots on this notebook
+# clear out any previous plots on this note
plt.clf()
def show(p):
diff --git a/docs/install/yarn_install.md b/docs/install/yarn_install.md
index 466007d2daa..e2427546a66 100644
--- a/docs/install/yarn_install.md
+++ b/docs/install/yarn_install.md
@@ -1,7 +1,7 @@
---
layout: page
title: "Install Zeppelin to connect with existing YARN cluster"
-description: ""
+description: "This page describes how to pre-configure a bare metal node, configure Apache Zeppelin and connect it to existing YARN cluster running Hortonworks flavour of Hadoop."
group: install
---
{% include JB/setup %}
# Alluxio Interpreter for Apache Zeppelin
diff --git a/docs/interpreter/beam.md b/docs/interpreter/beam.md
new file mode 100644
index 00000000000..cbcd5e37d51
--- /dev/null
+++ b/docs/interpreter/beam.md
@@ -0,0 +1,124 @@
+---
+layout: page
+title: Beam interpreter in Apache Zeppelin
+description: Apache Beam is an open source, unified programming model that you can use to create a data processing pipeline.
+group: interpreter
+---
+
+
+{% include JB/setup %}
+
+# Beam interpreter for Apache Zeppelin
+
+
+
+## Overview
+[Apache Beam](http://beam.incubator.apache.org) is an open source unified platform for data processing pipelines. A pipeline can be build using one of the Beam SDKs.
+The execution of the pipeline is done by different Runners. Currently, Beam supports Apache Flink Runner, Apache Spark Runner, and Google Dataflow Runner.
+
+## How to use
+Basically, you can write normal Beam java code where you can determine the Runner. You should write the main method inside a class becuase the interpreter invoke this main to execute the pipeline. Unlike Zeppelin normal pattern, each paragraph is considered as a separate job, there isn't any relation to any other paragraph.
+
+The following is a demonstration of a word count example with data represented in array of strings
+But it can read data from files by replacing `Create.of(SENTENCES).withCoder(StringUtf8Coder.of())` with `TextIO.Read.from("path/to/filename.txt")`
+
+```java
+%beam
+
+// most used imports
+import org.apache.beam.sdk.coders.StringUtf8Coder;
+import org.apache.beam.sdk.transforms.Create;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.List;
+import java.util.ArrayList;
+import org.apache.spark.api.java.*;
+import org.apache.spark.api.java.function.Function;
+import org.apache.spark.SparkConf;
+import org.apache.spark.streaming.*;
+import org.apache.spark.SparkContext;
+import org.apache.beam.runners.direct.*;
+import org.apache.beam.sdk.runners.*;
+import org.apache.beam.sdk.options.*;
+import org.apache.beam.runners.spark.*;
+import org.apache.beam.runners.spark.io.ConsoleIO;
+import org.apache.beam.runners.flink.*;
+import org.apache.beam.runners.flink.examples.WordCount.Options;
+import org.apache.beam.sdk.Pipeline;
+import org.apache.beam.sdk.io.TextIO;
+import org.apache.beam.sdk.options.PipelineOptionsFactory;
+import org.apache.beam.sdk.transforms.Count;
+import org.apache.beam.sdk.transforms.DoFn;
+import org.apache.beam.sdk.transforms.MapElements;
+import org.apache.beam.sdk.transforms.ParDo;
+import org.apache.beam.sdk.transforms.SimpleFunction;
+import org.apache.beam.sdk.values.KV;
+import org.apache.beam.sdk.options.PipelineOptions;
+
+public class MinimalWordCount {
+ static ListCurrently, Zeppelin provides ignite only in Zeppelin source release. So, if you download Zeppelin binary release( `zeppelin-0.5.0-incubating-bin-spark-xxx-hadoop-xx` ), you can not use ignite interpreter on Zeppelin. We are planning to include ignite in a future binary release. -2. Examples are shipped as a separate Maven project, so to start running you simply need to import provided
diff --git a/docs/interpreter/jdbc.md b/docs/interpreter/jdbc.md index f977dd1bcbb..b7ac45ae442 100644 --- a/docs/interpreter/jdbc.md +++ b/docs/interpreter/jdbc.md @@ -1,75 +1,190 @@ --- layout: page -title: "Generic JDBC Interpreter" -description: "JDBC user guide" -group: manual +title: "Generic JDBC Interpreter for Apache Zeppelin" +description: "Generic JDBC Interpreter lets you create a JDBC connection to any data source. You can use Postgres, MySql, MariaDB, Redshift, Apache Hive, Apache Phoenix, Apache Drill and Apache Tajo using JDBC interpreter." +group: interpreter --- + {% include JB/setup %} - -# Generic JDBC Interpreter for Apache Zeppelin +# Generic JDBC Interpreter for Apache Zeppelin ## Overview -This interpreter lets you create a JDBC connection to any data source, by now it has been tested with: +JDBC interpreter lets you create a JDBC connection to any data sources seamlessly. + +Inserts, Updates, and Upserts are applied immediately after running each statement. + +By now, it has been tested with: -* Postgres -* MySql -* MariaDB -* Redshift -* Apache Hive -* Apache Phoenix -* Apache Drill (Details on using [Drill JDBC Driver](https://drill.apache.org/docs/using-the-jdbc-driver)) -* Apache Tajo +
+
-If someone else used another database please report how it works to improve functionality.
+If you are using other databases not in the above list, please feel free to share your use case. It would be helpful to improve the functionality of JDBC interpreter.
-## Create Interpreter
+## Create a new JDBC Interpreter
-When you create a interpreter by default use PostgreSQL with the next properties:
+First, click `+ Create` button at the top-right corner in the interpreter setting page.
+
+
+  +
+
+
+
+
+ Postgresql -
+ JDBC Driver
+
+
+ Mysql -
+ JDBC Driver
+
+
+ MariaDB -
+ JDBC Driver
+
+
+ Redshift -
+ JDBC Driver
+
+
+ Apache Hive -
+ JDBC Driver
+
+
+ Apache Phoenix itself is a JDBC driver
+
+
+ Apache Drill -
+ JDBC Driver
+
+
+ Apache Tajo -
+ JDBC Driver
+
+
+ +
+Fill `Interpreter name` field with whatever you want to use as the alias(e.g. mysql, mysql2, hive, redshift, and etc..). Please note that this alias will be used as `%interpreter_name` to call the interpreter in the paragraph.
+Then select `jdbc` as an `Interpreter group`.
+
+
+
+Fill `Interpreter name` field with whatever you want to use as the alias(e.g. mysql, mysql2, hive, redshift, and etc..). Please note that this alias will be used as `%interpreter_name` to call the interpreter in the paragraph.
+Then select `jdbc` as an `Interpreter group`.
+
+ +
+The default driver of JDBC interpreter is set as `PostgreSQL`. It means Zeppelin includes `PostgreSQL` driver jar in itself.
+So you don't need to add any dependencies(e.g. the artifact name or path for `PostgreSQL` driver jar) for `PostgreSQL` connection.
+The JDBC interpreter properties are defined by default like below.
+
+The default driver of JDBC interpreter is set as `PostgreSQL`. It means Zeppelin includes `PostgreSQL` driver jar in itself.
+So you don't need to add any dependencies(e.g. the artifact name or path for `PostgreSQL` driver jar) for `PostgreSQL` connection.
+The JDBC interpreter properties are defined by default like below.
| name | -value | +Name | +Default Value | +Description |
|---|---|---|---|---|
| common.max_count | 1000 | +The maximun number of SQL result to display | ||
| default.driver | org.postgresql.Driver | +JDBC Driver Name | ||
| default.password | -******** | ++ | The JDBC user password | |
| default.url | jdbc:postgresql://localhost:5432/ | +The URL for JDBC | ||
| default.user | gpadmin | -The JDBC user name | + +||
| default.precode | ++ | Some SQL which executes every time after initialization of the interpreter (see [Binding mode](../manual/interpreters.md#interpreter-binding-mode)) | +||
| default.completer.schemaFilters | ++ | Сomma separated schema (schema = catalog = database) filters to get metadata for completions. Supports '%' symbol is equivalent to any set of characters. (ex. prod_v_%,public%,info) | +
 -
-
-
+The last step is **Dependency Setting**. Since Zeppelin only includes `PostgreSQL` driver jar by default, you need to add each driver's maven coordinates or JDBC driver's jar file path for the other databases.
+
+
-  -
-
-
-  +
+That's it. You can find more JDBC connection setting examples([Mysql](#mysql), [MariaDB](#mariadb), [Redshift](#redshift), [Apache Hive](#apache-hive), [Apache Phoenix](#apache-phoenix), and [Apache Tajo](#apache-tajo)) in [this section](#examples).
+
+## More properties
+There are more JDBC interpreter properties you can specify like below.
+
+
+
+That's it. You can find more JDBC connection setting examples([Mysql](#mysql), [MariaDB](#mariadb), [Redshift](#redshift), [Apache Hive](#apache-hive), [Apache Phoenix](#apache-phoenix), and [Apache Tajo](#apache-tajo)) in [this section](#examples).
+
+## More properties
+There are more JDBC interpreter properties you can specify like below.
+
+| Property Name | +Description | +
|---|---|
| common.max_result | +Max number of SQL result to display to prevent the browser overload. This is common properties for all connections | +
| zeppelin.jdbc.auth.type | +Types of authentications' methods supported are SIMPLE, and KERBEROS |
+
| zeppelin.jdbc.principal | +The principal name to load from the keytab | +
| zeppelin.jdbc.keytab.location | +The path to the keytab file | +
| zeppelin.jdbc.auth.kerberos.proxy.enable | +When auth type is Kerberos, enable/disable Kerberos proxy with the login user to get the connection. Default value is true. | +
| default.jceks.file | +jceks store path (e.g: jceks://file/tmp/zeppelin.jceks) | +
| default.jceks.credentialKey | +jceks credential key | +
| value | |||
|---|---|---|---|
| common.max_count | -1000 | +default.schema | +schema_name | +
 +
+Select(blue) or deselect(white) the interpreter buttons depending on your use cases.
+If you need to use more than one interpreter in the notebook, activate several buttons.
+Don't forget to click `Save` button, or you will face `Interpreter *** is not found` error.
+
+
+
+Select(blue) or deselect(white) the interpreter buttons depending on your use cases.
+If you need to use more than one interpreter in the notebook, activate several buttons.
+Don't forget to click `Save` button, or you will face `Interpreter *** is not found` error.
+
+ +
+## How to use
+### Run the paragraph with JDBC interpreter
+To test whether your databases and Zeppelin are successfully connected or not, type `%jdbc_interpreter_name`(e.g. `%mysql`) at the top of the paragraph and run `show databases`.
+
+```sql
+%jdbc_interpreter_name
+show databases
+```
+If the paragraph is `FINISHED` without any errors, a new paragraph will be automatically added after the previous one with `%jdbc_interpreter_name`.
+So you don't need to type this prefix in every paragraphs' header.
+
+
+
+## How to use
+### Run the paragraph with JDBC interpreter
+To test whether your databases and Zeppelin are successfully connected or not, type `%jdbc_interpreter_name`(e.g. `%mysql`) at the top of the paragraph and run `show databases`.
+
+```sql
+%jdbc_interpreter_name
+show databases
+```
+If the paragraph is `FINISHED` without any errors, a new paragraph will be automatically added after the previous one with `%jdbc_interpreter_name`.
+So you don't need to type this prefix in every paragraphs' header.
+
+ +
+### Apply Zeppelin Dynamic Forms
+
+You can leverage [Zeppelin Dynamic Form](../manual/dynamicform.html) inside your queries. You can use both the `text input` and `select form` parametrization features.
+
+```sql
+%jdbc_interpreter_name
+SELECT name, country, performer
+FROM demo.performers
+WHERE name='{{"{{performer=Sheryl Crow|Doof|Fanfarlo|Los Paranoia"}}}}'
+```
+### Usage *precode*
+You can set *precode* for each data source. Code runs once while opening the connection.
+
+##### Properties
+An example settings of interpreter for the two data sources, each of which has its *precode* parameter.
+
+
+
+### Apply Zeppelin Dynamic Forms
+
+You can leverage [Zeppelin Dynamic Form](../manual/dynamicform.html) inside your queries. You can use both the `text input` and `select form` parametrization features.
+
+```sql
+%jdbc_interpreter_name
+SELECT name, country, performer
+FROM demo.performers
+WHERE name='{{"{{performer=Sheryl Crow|Doof|Fanfarlo|Los Paranoia"}}}}'
+```
+### Usage *precode*
+You can set *precode* for each data source. Code runs once while opening the connection.
+
+##### Properties
+An example settings of interpreter for the two data sources, each of which has its *precode* parameter.
+
+| Property Name | +Value | |
|---|---|---|
| default.driver | -driver name | +org.postgresql.Driver |
| default.password | -******** | +1 |
| default.url | -jdbc url | +jdbc:postgresql://localhost:5432/ |
| default.user | -user name | -postgres | + +
| default.precode | +set search_path='test_path' | +|
| mysql.driver | +com.mysql.jdbc.Driver | +|
| mysql.password | +1 | +|
| mysql.url | +jdbc:mysql://localhost:3306/ | +|
| mysql.user | +root | +|
| mysql.precode | +set @v=12 | +
-
+```sql
+%jdbc(mysql)
+select @v
+```
+Returns value of `v` which is set in the *mysql.precode*.
+
+
+## Examples
+Here are some examples you can refer to. Including the below connectors, you can connect every databases as long as it can be configured with it's JDBC driver.
-You can add all the jars you need to make multiple connections into the same JDBC interpreter. To create the interpreter you must specify the parameters. For example we will create two connections to MySQL and Redshift, the respective prefixes are `default` and `redshift`:
+### Postgres
+
-  -
-
-
-  +
+##### Properties
+
+##### Properties
| name | -value | +Name | +Value |
|---|---|---|---|
| common.max_count | -1000 | +default.driver | +org.postgresql.Driver | +
| default.url | +jdbc:postgresql://localhost:5432/ | +||
| default.user | +mysql_user | +||
| default.password | +mysql_password | +
| Artifact | +Excludes | +
|---|---|
| org.postgresql:postgresql:9.4.1211 | ++ |
 +
+##### Properties
+
+
+##### Properties
+| Name | +Value | |
|---|---|---|
| default.driver | com.mysql.jdbc.Driver | |
| default.url | +jdbc:mysql://localhost:3306/ | +|
| default.user | +mysql_user | +|
| default.password | -******** | +mysql_password | +
| Artifact | +Excludes | +
|---|---|
| mysql:mysql-connector-java:5.1.38 | ++ |
 +
+##### Properties
+
+
+##### Properties
+| Name | +Value | +|
|---|---|---|
| default.driver | +org.mariadb.jdbc.Driver | |
| default.url | -jdbc:mysql://localhost:3306/ | +jdbc:mariadb://localhost:3306 | +
| default.user | +mariadb_user | +|
| default.password | +mariadb_password | +
| Artifact | +Excludes | +
|---|---|
| org.mariadb.jdbc:mariadb-java-client:1.5.4 | ++ |
 +
+##### Properties
+
+
+##### Properties
+| Name | +Value | +|
|---|---|---|
| default.driver | +com.amazon.redshift.jdbc42.Driver | +|
| default.url | +jdbc:redshift://your-redshift-instance-address.redshift.amazonaws.com:5439/your-database | |
| default.user | -mysql-user | +redshift_user | +
| default.password | +redshift_password | +
| Artifact | +Excludes | ||
|---|---|---|---|
| redshift.driver | -com.amazon.redshift.jdbc4.Driver | +com.amazonaws:aws-java-sdk-redshift:1.11.51 | +
 +
+##### Properties
+
+
+##### Properties
+| redshift.password | -******** | +Name | +Value |
|---|---|---|---|
| redshift.url | -jdbc:redshift://examplecluster.abc123xyz789.us-west-2.redshift.amazonaws.com:5439 | +default.driver | +org.apache.hive.jdbc.HiveDriver |
| redshift.user | -redshift-user | -default.url | +jdbc:hive2://localhost:10000 | + +
| default.user | +hive_user | +||
| default.password | +hive_password | +||
| default.proxy.user.property | +Example value: hive.server2.proxy.user | +
| Artifact | +Excludes | +
|---|---|
| org.apache.hive:hive-jdbc:0.14.0 | ++ |
| org.apache.hadoop:hadoop-common:2.6.0 | ++ |
| Property Name | -Description | -
|---|---|
| {prefix}.url | -JDBC URL to connect, the URL must include the name of the database | -
| {prefix}.user | -JDBC user name | -
| {prefix}.password | -JDBC password | -
| {prefix}.driver | -JDBC driver name. | -
| common.max_result | -Max number of SQL result to display to prevent the browser overload. This is common properties for all connections | -
| name | -value | +Name | +Value |
|---|---|---|---|
| {prefix}.schema | -schema_name | +hive.driver | +org.apache.hive.jdbc.HiveDriver | +
| hive.password | ++ | ||
| hive.url | +jdbc:hive2://hive-server-host:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2 | +||
| hive.proxy.user.property | +hive.server2.proxy.user | +||
| zeppelin.jdbc.auth.type | +SIMPLE |
| Name | -Value | -
|---|---|
| hive.driver | -org.apache.hive.jdbc.HiveDriver | -
| hive.url | -jdbc:hive2://localhost:10000 | -
| hive.user | -hive_user | -
| hive.password | -hive_password | -
| Artifact | -Excludes | -
|---|---|
| org.apache.hive:hive-jdbc:0.14.0 | -- |
| org.apache.hadoop:hadoop-common:2.6.0 | -- |
| Name | -Value | -Description | -
|---|---|---|
| phoenix.driver | -org.apache.phoenix.jdbc.PhoenixDriver | -'Thick Client', connects directly to Phoenix | -
| phoenix.driver | -org.apache.phoenix.queryserver.client.Driver | -'Thin Client', connects via Phoenix Query Server | -
| phoenix.url | -jdbc:phoenix:localhost:2181:/hbase-unsecure | -'Thick Client', connects directly to Phoenix | -
| phoenix.url | -jdbc:phoenix:thin:url=http://localhost:8765;serialization=PROTOBUF | -'Thin Client', connects via Phoenix Query Server | -
| phoenix.user | -phoenix_user | -- |
| phoenix.password | -phoenix_password | -- |
| Artifact | -Excludes | -Description | -
|---|---|---|
| org.apache.phoenix:phoenix-core:4.4.0-HBase-1.0 | -- | 'Thick Client', connects directly to Phoenix | -
| org.apache.phoenix:phoenix-server-client:4.7.0-HBase-1.1 | -- | 'Thin Client' for Phoenix 4.7, connects via Phoenix Query Server | -
| org.apache.phoenix:phoenix-queryserver-client:4.8.0-HBase-1.2 | -- | 'Thin Client' for Phoenix 4.8+, connects via Phoenix Query Server | -
| Name | -Value | -
|---|---|
| tajo.driver | -org.apache.tajo.jdbc.TajoDriver | -
| tajo.url | -jdbc:tajo://localhost:26002/default | -
| Artifact | -Excludes | -
|---|---|
| org.apache.tajo:tajo-jdbc:0.11.0 | -- |
 -```sql
-%jdbc(prefix)
-SELECT * FROM db_name;
+##### Properties
+
-```sql
-%jdbc(prefix)
-SELECT * FROM db_name;
+##### Properties
+| Name | +Value | +
|---|---|
| default.driver | +org.apache.phoenix.jdbc.PhoenixDriver | +
| default.url | +jdbc:phoenix:localhost:2181:/hbase-unsecure | +
| default.user | +phoenix_user | +
| default.password | +phoenix_password | +
| Artifact | +Excludes | +
|---|---|
| org.apache.phoenix:phoenix-core:4.4.0-HBase-1.0 | ++ |
 +
+##### Properties
+
+
+##### Properties
+| Name | +Value | +
|---|---|
| default.driver | +org.apache.phoenix.queryserver.client.Driver | +
| default.url | +jdbc:phoenix:thin:url=http://localhost:8765;serialization=PROTOBUF | +
| default.user | +phoenix_user | +
| default.password | +phoenix_password | +
| Artifact | +Excludes | +Description | +
|---|---|---|
| org.apache.phoenix:phoenix-server-client:4.7.0-HBase-1.1 | ++ | For Phoenix 4.7 |
+
| org.apache.phoenix:phoenix-queryserver-client:4.8.0-HBase-1.2 | ++ | For Phoenix 4.8+ |
+
 +
+##### Properties
+
+
+##### Properties
+| Name | +Value | +
|---|---|
| default.driver | +org.apache.tajo.jdbc.TajoDriver | +
| default.url | +jdbc:tajo://localhost:26002/default | +
| Artifact | +Excludes | +
|---|---|
| org.apache.tajo:tajo-jdbc:0.11.0 | ++ |
| Name | +Default | +Description | +
|---|---|---|
| kylin.api.url | +http://localhost:7070/kylin/api/query | +kylin query POST API The format can be like http://<host>:<port>/kylin/api/query |
+
| kylin.api.user | +ADMIN | +kylin user | +
| kylin.api.password | +KYLIN | +kylin password | +
| kylin.query.project | +learn_kylin | +String, Project to perform query. Could update at notebook level | +
| kylin.query.ispartial | +true | +true|false (@Deprecated since Apache Kylin V1.5) Whether accept a partial result or not, default be “false”. Set to “false” for production use. |
+
| kylin.query.limit | +5000 | +int, Query limit If limit is set in sql, perPage will be ignored. |
+
| kylin.query.offset | +0 | +int, Query offset If offset is set in sql, curIndex will be ignored. |
+
| Property | Default | Description | ||
|---|---|---|---|---|
| livy.spark.master | -local[*] | -Spark master uri. ex) spark://masterhost:7077 | -||
| zeppelin.livy.url | http://localhost:8998 | URL where livy server is running | ||
| zeppelin.livy.spark.maxResult | +zeppelin.livy.spark.sql.maxResult | 1000 | -Max number of SparkSQL result to display. | +Max number of Spark SQL result to display. |
| zeppelin.livy.spark.sql.field.truncate | +true | +Whether to truncate field values longer than 20 characters or not | +||
| zeppelin.livy.session.create_timeout | +120 | +Timeout in seconds for session creation | +||
| zeppelin.livy.displayAppInfo | +false | +Whether to display app info | +||
| zeppelin.livy.pull_status.interval.millis | +1000 | +The interval for checking paragraph execution status | +||
| livy.spark.driver.cores | Driver cores. ex) 1, 2. | @@ -102,8 +130,43 @@ Example: `spark.master` to `livy.spark.master`Upper bound for the number of executors. | ||
| livy.spark.jars.packages | ++ | Adding extra libraries to livy interpreter | +||
| zeppelin.livy.ssl.trustStore | ++ | client trustStore file. Used when livy ssl is enabled | +||
| zeppelin.livy.ssl.trustStorePassword | ++ | password for trustStore file. Used when livy ssl is enabled | +
| Property | +Example | +Description | +
|---|---|---|
| livy.spark.jars.packages | +io.spray:spray-json_2.10:1.3.1 | +Adding extra libraries to livy interpreter | +
| Argument | +Description | +Example | +
|---|---|---|
| --zeppelin_home | +This is the path to the Zeppelin installation. This flag is not needed if the script is run from the top-level installation directory or from the `zeppelin/scripts/mahout` directory. | +/path/to/zeppelin | +
| --mahout_home | +If the user has already installed Mahout, this flag can set the path to `MAHOUT_HOME`. If this is set, downloading Mahout will be skipped. | +/path/to/mahout_home | +
| --restart_later | +Restarting is necessary for updates to take effect. By default the script will restart Zeppelin for you- restart will be skipped if this flag is set. | +NA | +
| --force_download | +This flag will force the script to re-download the binary even if it already exists. This is useful for previously failed downloads. | +NA | +
| --overwrite_existing | +This flag will force the script to overwrite existing `%sparkMahout` and `%flinkMahout` interpreters. Useful when you want to just start over. | +NA | +
 +
+ ## Example
+
The following example demonstrates the basic usage of Markdown in a Zeppelin notebook.
-
## Example
+
The following example demonstrates the basic usage of Markdown in a Zeppelin notebook.
- +
+ +
+## Mathematical expression
+
+Markdown interpreter leverages %html display system internally. That means you can mix mathematical expressions with markdown syntax. For more information, please see [Mathematical Expression](../displaysystem/basicdisplaysystem.html#mathematical-expressions) section.
+
+## Configuration
+
+
+## Mathematical expression
+
+Markdown interpreter leverages %html display system internally. That means you can mix mathematical expressions with markdown syntax. For more information, please see [Mathematical Expression](../displaysystem/basicdisplaysystem.html#mathematical-expressions) section.
+
+## Configuration
+| Name | +Default Value | +Description | +
|---|---|---|
| markdown.parser.type | +pegdown | +Markdown Parser Type. Available values: pegdown, markdown4j. |
+
 +
+`pegdown` parser provides [YUML](http://yuml.me/) and [Websequence](https://www.websequencediagrams.com/) plugins also.
+
+
+
+`pegdown` parser provides [YUML](http://yuml.me/) and [Websequence](https://www.websequencediagrams.com/) plugins also.
+
+ +
+### Markdown4j Parser
+
+Since pegdown parser is more accurate and provides much more markdown syntax
+`markdown4j` option might be removed later. But keep this parser for the backward compatibility.
+
+
diff --git a/docs/interpreter/pig.md b/docs/interpreter/pig.md
new file mode 100644
index 00000000000..d1f18fa8cb1
--- /dev/null
+++ b/docs/interpreter/pig.md
@@ -0,0 +1,148 @@
+---
+layout: page
+title: "Pig Interpreter for Apache Zeppelin"
+description: "Apache Pig is a platform for analyzing large data sets that consists of a high-level language for expressing data analysis programs, coupled with infrastructure for evaluating these programs."
+group: manual
+---
+{% include JB/setup %}
+
+
+# Pig Interpreter for Apache Zeppelin
+
+
+
+## Overview
+[Apache Pig](https://pig.apache.org/) is a platform for analyzing large data sets that consists of a high-level language for expressing data analysis programs, coupled with infrastructure for evaluating these programs. The salient property of Pig programs is that their structure is amenable to substantial parallelization, which in turns enables them to handle very large data sets.
+
+## Supported interpreter type
+ - `%pig.script` (default Pig interpreter, so you can use `%pig`)
+
+ `%pig.script` is like the Pig grunt shell. Anything you can run in Pig grunt shell can be run in `%pig.script` interpreter, it is used for running Pig script where you don’t need to visualize the data, it is suitable for data munging.
+
+ - `%pig.query`
+
+ `%pig.query` is a little different compared with `%pig.script`. It is used for exploratory data analysis via Pig latin where you can leverage Zeppelin’s visualization ability. There're 2 minor differences in the last statement between `%pig.script` and `%pig.query`
+ - No pig alias in the last statement in `%pig.query` (read the examples below).
+ - The last statement must be in single line in `%pig.query`
+
+## Supported runtime mode
+ - Local
+ - MapReduce
+ - Tez_Local (Only Tez 0.7 is supported)
+ - Tez (Only Tez 0.7 is supported)
+
+## How to use
+
+### How to setup Pig
+
+- Local Mode
+
+ Nothing needs to be done for local mode
+
+- MapReduce Mode
+
+ HADOOP\_CONF\_DIR needs to be specified in `ZEPPELIN_HOME/conf/zeppelin-env.sh`.
+
+- Tez Local Mode
+
+ Nothing needs to be done for tez local mode
+
+- Tez Mode
+
+ HADOOP\_CONF\_DIR and TEZ\_CONF\_DIR needs to be specified in `ZEPPELIN_HOME/conf/zeppelin-env.sh`.
+
+### How to configure interpreter
+
+At the Interpreters menu, you have to create a new Pig interpreter. Pig interpreter has below properties by default.
+And you can set any Pig properties here which will be passed to Pig engine. (like tez.queue.name & mapred.job.queue.name).
+Besides, we use paragraph title as job name if it exists, else use the last line of Pig script. So you can use that to find app running in YARN RM UI.
+
+
+
+### Markdown4j Parser
+
+Since pegdown parser is more accurate and provides much more markdown syntax
+`markdown4j` option might be removed later. But keep this parser for the backward compatibility.
+
+
diff --git a/docs/interpreter/pig.md b/docs/interpreter/pig.md
new file mode 100644
index 00000000000..d1f18fa8cb1
--- /dev/null
+++ b/docs/interpreter/pig.md
@@ -0,0 +1,148 @@
+---
+layout: page
+title: "Pig Interpreter for Apache Zeppelin"
+description: "Apache Pig is a platform for analyzing large data sets that consists of a high-level language for expressing data analysis programs, coupled with infrastructure for evaluating these programs."
+group: manual
+---
+{% include JB/setup %}
+
+
+# Pig Interpreter for Apache Zeppelin
+
+
+
+## Overview
+[Apache Pig](https://pig.apache.org/) is a platform for analyzing large data sets that consists of a high-level language for expressing data analysis programs, coupled with infrastructure for evaluating these programs. The salient property of Pig programs is that their structure is amenable to substantial parallelization, which in turns enables them to handle very large data sets.
+
+## Supported interpreter type
+ - `%pig.script` (default Pig interpreter, so you can use `%pig`)
+
+ `%pig.script` is like the Pig grunt shell. Anything you can run in Pig grunt shell can be run in `%pig.script` interpreter, it is used for running Pig script where you don’t need to visualize the data, it is suitable for data munging.
+
+ - `%pig.query`
+
+ `%pig.query` is a little different compared with `%pig.script`. It is used for exploratory data analysis via Pig latin where you can leverage Zeppelin’s visualization ability. There're 2 minor differences in the last statement between `%pig.script` and `%pig.query`
+ - No pig alias in the last statement in `%pig.query` (read the examples below).
+ - The last statement must be in single line in `%pig.query`
+
+## Supported runtime mode
+ - Local
+ - MapReduce
+ - Tez_Local (Only Tez 0.7 is supported)
+ - Tez (Only Tez 0.7 is supported)
+
+## How to use
+
+### How to setup Pig
+
+- Local Mode
+
+ Nothing needs to be done for local mode
+
+- MapReduce Mode
+
+ HADOOP\_CONF\_DIR needs to be specified in `ZEPPELIN_HOME/conf/zeppelin-env.sh`.
+
+- Tez Local Mode
+
+ Nothing needs to be done for tez local mode
+
+- Tez Mode
+
+ HADOOP\_CONF\_DIR and TEZ\_CONF\_DIR needs to be specified in `ZEPPELIN_HOME/conf/zeppelin-env.sh`.
+
+### How to configure interpreter
+
+At the Interpreters menu, you have to create a new Pig interpreter. Pig interpreter has below properties by default.
+And you can set any Pig properties here which will be passed to Pig engine. (like tez.queue.name & mapred.job.queue.name).
+Besides, we use paragraph title as job name if it exists, else use the last line of Pig script. So you can use that to find app running in YARN RM UI.
+
+| Property | +Default | +Description | +
|---|---|---|
| zeppelin.pig.execType | +mapreduce | +Execution mode for pig runtime. local | mapreduce | tez_local | tez | +
| zeppelin.pig.includeJobStats | +false | +whether display jobStats info in %pig.script |
+
| zeppelin.pig.maxResult | +1000 | +max row number displayed in %pig.query |
+
| tez.queue.name | +default | +queue name for tez engine | +
| mapred.job.queue.name | +default | +queue name for mapreduce engine | +
 +
+
+Data is shared between `%pig` and `%pig.query`, so that you can do some common work in `%pig`, and do different kinds of query based on the data of `%pig`.
+Besides, we recommend you to specify alias explicitly so that the visualization can display the column name correctly. In the above example 2 and 3 of `%pig.query`, we name `COUNT($1)` as `count`. If you don't do this,
+then we will name it using position. E.g. in the above first example of `%pig.query`, we will use `col_1` in chart to represent `COUNT($1)`.
+
+
diff --git a/docs/interpreter/postgresql.md b/docs/interpreter/postgresql.md
index 107fda1d809..52dac169c6f 100644
--- a/docs/interpreter/postgresql.md
+++ b/docs/interpreter/postgresql.md
@@ -1,217 +1,29 @@
----
-layout: page
-title: "PostgreSQL and HAWQ Interpreter"
-description: ""
-group: manual
----
-{% include JB/setup %}
-
-# PostgreSQL, Apache HAWQ (incubating) Interpreter for Apache Zeppelin
-
-
-
-## Important Notice
-
-Postgresql Interpreter will be deprecated and merged into JDBC Interpreter. You can use Postgresql by using JDBC Interpreter with same functionality. See the example below of settings and dependencies.
-
-### Properties
-
+
+
+Data is shared between `%pig` and `%pig.query`, so that you can do some common work in `%pig`, and do different kinds of query based on the data of `%pig`.
+Besides, we recommend you to specify alias explicitly so that the visualization can display the column name correctly. In the above example 2 and 3 of `%pig.query`, we name `COUNT($1)` as `count`. If you don't do this,
+then we will name it using position. E.g. in the above first example of `%pig.query`, we will use `col_1` in chart to represent `COUNT($1)`.
+
+
diff --git a/docs/interpreter/postgresql.md b/docs/interpreter/postgresql.md
index 107fda1d809..52dac169c6f 100644
--- a/docs/interpreter/postgresql.md
+++ b/docs/interpreter/postgresql.md
@@ -1,217 +1,29 @@
----
-layout: page
-title: "PostgreSQL and HAWQ Interpreter"
-description: ""
-group: manual
----
-{% include JB/setup %}
-
-# PostgreSQL, Apache HAWQ (incubating) Interpreter for Apache Zeppelin
-
-
-
-## Important Notice
-
-Postgresql Interpreter will be deprecated and merged into JDBC Interpreter. You can use Postgresql by using JDBC Interpreter with same functionality. See the example below of settings and dependencies.
-
-### Properties
-| Property | -Value | -
|---|---|
| psql.driver | -org.postgresql.Driver | -
| psql.url | -jdbc:postgresql://localhost:5432/ | -
| psql.user | -psqlUser | -
| psql.password | -psqlPassword | -
| Artifact | -Exclude | -
|---|---|
| org.postgresql:postgresql:9.4-1201-jdbc41 | -- |
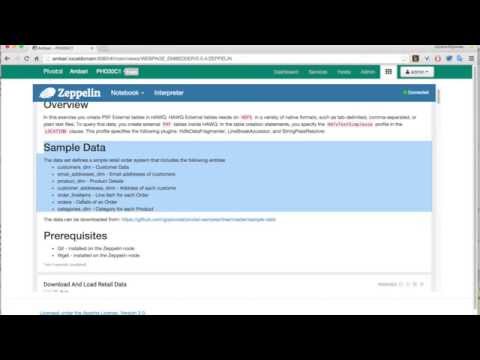 ](https://www.youtube.com/watch?v=wqXXQhJ5Uk8)
-
-This interpreter seamlessly supports the following SQL data processing engines:
-
-* [PostgreSQL](http://www.postgresql.org/) - OSS, Object-relational database management system (ORDBMS)
-* [pache HAWQ (incubating)](http://hawq.incubator.apache.org/) - Powerful open source SQL-On-Hadoop engine.
-* [Greenplum](http://pivotal.io/big-data/pivotal-greenplum-database) - MPP database built on open source PostgreSQL.
-
-This [Video Tutorial](https://www.youtube.com/watch?v=wqXXQhJ5Uk8) illustrates some of the features provided by the `Postgresql Interpreter`.
-
-
](https://www.youtube.com/watch?v=wqXXQhJ5Uk8)
-
-This interpreter seamlessly supports the following SQL data processing engines:
-
-* [PostgreSQL](http://www.postgresql.org/) - OSS, Object-relational database management system (ORDBMS)
-* [pache HAWQ (incubating)](http://hawq.incubator.apache.org/) - Powerful open source SQL-On-Hadoop engine.
-* [Greenplum](http://pivotal.io/big-data/pivotal-greenplum-database) - MPP database built on open source PostgreSQL.
-
-This [Video Tutorial](https://www.youtube.com/watch?v=wqXXQhJ5Uk8) illustrates some of the features provided by the `Postgresql Interpreter`.
-
-| Name | -Class | -Description | -
|---|---|---|
| %psql.sql | -PostgreSqlInterpreter | -Provides SQL environment for PostgreSQL, HAWQ and Greenplum | -
| Property Name | -Description | -Default Value | -
|---|---|---|
| postgresql.url | -JDBC URL to connect to | -jdbc:postgresql://localhost:5432 | -
| postgresql.user | -JDBC user name | -gpadmin | -
| postgresql.password | -JDBC password | -- |
| postgresql.driver.name | -JDBC driver name. In this version the driver name is fixed and should not be changed | -org.postgresql.Driver | -
| postgresql.max.result | -Max number of SQL result to display to prevent the browser overload | -1000 | -
 ## Pandas integration
-[Zeppelin Display System]({{BASE_PATH}}/displaysystem/basicdisplaysystem.html#table) provides simple API to visualize data in Pandas DataFrames, same as in Matplotlib.
+Apache Zeppelin [Table Display System](../displaysystem/basicdisplaysystem.html#table) provides built-in data visualization capabilities. Python interpreter leverages it to visualize Pandas DataFrames though similar `z.show()` API, same as with [Matplotlib integration](#matplotlib-integration).
Example:
@@ -99,6 +182,42 @@ rates = pd.read_csv("bank.csv", sep=";")
z.show(rates)
```
+## SQL over Pandas DataFrames
+
+There is a convenience `%python.sql` interpreter that matches Apache Spark experience in Zeppelin and enables usage of SQL language to query [Pandas DataFrames](http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.html) and visualization of results though built-in [Table Display System](../displaysystem/basicdisplaysystem.html#table).
+
+ **Pre-requests**
+
+ - Pandas `pip install pandas`
+ - PandaSQL `pip install -U pandasql`
+
+In case default binded interpreter is Python (first in the interpreter list, under the _Gear Icon_), you can just use it as `%sql` i.e
+
+ - first paragraph
+
+ ```python
+import pandas as pd
+rates = pd.read_csv("bank.csv", sep=";")
+ ```
+
+ - next paragraph
+
+ ```sql
+%sql
+SELECT * FROM rates WHERE age < 40
+ ```
+
+Otherwise it can be referred to as `%python.sql`
+
+
## Technical description
-For in-depth technical details on current implementation plese reffer [python/README.md](https://github.com/apache/zeppelin/blob/master/python/README.md).
+For in-depth technical details on current implementation please refer to [python/README.md](https://github.com/apache/zeppelin/blob/master/python/README.md).
+
+
+### Some features not yet implemented in the Python Interpreter
+
+* Interrupt a paragraph execution (`cancel()` method) is currently only supported in Linux and MacOs. If interpreter runs in another operating system (for instance MS Windows) , interrupt a paragraph will close the whole interpreter. A JIRA ticket ([ZEPPELIN-893](https://issues.apache.org/jira/browse/ZEPPELIN-893)) is opened to implement this feature in a next release of the interpreter.
+* Progression bar in webUI (`getProgress()` method) is currently not implemented.
+* Code-completion is currently not implemented.
+
diff --git a/docs/interpreter/r.md b/docs/interpreter/r.md
index c03e548cabf..2b224917ceb 100644
--- a/docs/interpreter/r.md
+++ b/docs/interpreter/r.md
@@ -1,9 +1,22 @@
---
layout: page
-title: "R Interpreter"
-description: ""
-group: manual
+title: "R Interpreter for Apache Zeppelin"
+description: "R is a free software environment for statistical computing and graphics."
+group: interpreter
---
+
{% include JB/setup %}
# R Interpreter for Apache Zeppelin
diff --git a/docs/interpreter/scalding.md b/docs/interpreter/scalding.md
index e8774df67fa..22027f22dee 100644
--- a/docs/interpreter/scalding.md
+++ b/docs/interpreter/scalding.md
@@ -1,9 +1,22 @@
---
layout: page
-title: "Scalding Interpreter"
-description: ""
-group: manual
+title: "Scalding Interpreter for Apache Zeppelin"
+description: "Scalding is an open source Scala library for writing MapReduce jobs."
+group: interpreter
---
+
{% include JB/setup %}
# Scalding Interpreter for Apache Zeppelin
diff --git a/docs/interpreter/scio.md b/docs/interpreter/scio.md
new file mode 100644
index 00000000000..cb8d1278ec0
--- /dev/null
+++ b/docs/interpreter/scio.md
@@ -0,0 +1,169 @@
+---
+layout: page
+title: "Scio Interpreter for Apache Zeppelin"
+description: "Scio is a Scala DSL for Apache Beam/Google Dataflow model."
+group: interpreter
+---
+
+{% include JB/setup %}
+
+# Scio Interpreter for Apache Zeppelin
+
+
+
+## Overview
+Scio is a Scala DSL for [Google Cloud Dataflow](https://github.com/GoogleCloudPlatform/DataflowJavaSDK) and [Apache Beam](http://beam.incubator.apache.org/) inspired by [Spark](http://spark.apache.org/) and [Scalding](https://github.com/twitter/scalding). See the current [wiki](https://github.com/spotify/scio/wiki) and [API documentation](http://spotify.github.io/scio/) for more information.
+
+## Configuration
+
## Pandas integration
-[Zeppelin Display System]({{BASE_PATH}}/displaysystem/basicdisplaysystem.html#table) provides simple API to visualize data in Pandas DataFrames, same as in Matplotlib.
+Apache Zeppelin [Table Display System](../displaysystem/basicdisplaysystem.html#table) provides built-in data visualization capabilities. Python interpreter leverages it to visualize Pandas DataFrames though similar `z.show()` API, same as with [Matplotlib integration](#matplotlib-integration).
Example:
@@ -99,6 +182,42 @@ rates = pd.read_csv("bank.csv", sep=";")
z.show(rates)
```
+## SQL over Pandas DataFrames
+
+There is a convenience `%python.sql` interpreter that matches Apache Spark experience in Zeppelin and enables usage of SQL language to query [Pandas DataFrames](http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.html) and visualization of results though built-in [Table Display System](../displaysystem/basicdisplaysystem.html#table).
+
+ **Pre-requests**
+
+ - Pandas `pip install pandas`
+ - PandaSQL `pip install -U pandasql`
+
+In case default binded interpreter is Python (first in the interpreter list, under the _Gear Icon_), you can just use it as `%sql` i.e
+
+ - first paragraph
+
+ ```python
+import pandas as pd
+rates = pd.read_csv("bank.csv", sep=";")
+ ```
+
+ - next paragraph
+
+ ```sql
+%sql
+SELECT * FROM rates WHERE age < 40
+ ```
+
+Otherwise it can be referred to as `%python.sql`
+
+
## Technical description
-For in-depth technical details on current implementation plese reffer [python/README.md](https://github.com/apache/zeppelin/blob/master/python/README.md).
+For in-depth technical details on current implementation please refer to [python/README.md](https://github.com/apache/zeppelin/blob/master/python/README.md).
+
+
+### Some features not yet implemented in the Python Interpreter
+
+* Interrupt a paragraph execution (`cancel()` method) is currently only supported in Linux and MacOs. If interpreter runs in another operating system (for instance MS Windows) , interrupt a paragraph will close the whole interpreter. A JIRA ticket ([ZEPPELIN-893](https://issues.apache.org/jira/browse/ZEPPELIN-893)) is opened to implement this feature in a next release of the interpreter.
+* Progression bar in webUI (`getProgress()` method) is currently not implemented.
+* Code-completion is currently not implemented.
+
diff --git a/docs/interpreter/r.md b/docs/interpreter/r.md
index c03e548cabf..2b224917ceb 100644
--- a/docs/interpreter/r.md
+++ b/docs/interpreter/r.md
@@ -1,9 +1,22 @@
---
layout: page
-title: "R Interpreter"
-description: ""
-group: manual
+title: "R Interpreter for Apache Zeppelin"
+description: "R is a free software environment for statistical computing and graphics."
+group: interpreter
---
+
{% include JB/setup %}
# R Interpreter for Apache Zeppelin
diff --git a/docs/interpreter/scalding.md b/docs/interpreter/scalding.md
index e8774df67fa..22027f22dee 100644
--- a/docs/interpreter/scalding.md
+++ b/docs/interpreter/scalding.md
@@ -1,9 +1,22 @@
---
layout: page
-title: "Scalding Interpreter"
-description: ""
-group: manual
+title: "Scalding Interpreter for Apache Zeppelin"
+description: "Scalding is an open source Scala library for writing MapReduce jobs."
+group: interpreter
---
+
{% include JB/setup %}
# Scalding Interpreter for Apache Zeppelin
diff --git a/docs/interpreter/scio.md b/docs/interpreter/scio.md
new file mode 100644
index 00000000000..cb8d1278ec0
--- /dev/null
+++ b/docs/interpreter/scio.md
@@ -0,0 +1,169 @@
+---
+layout: page
+title: "Scio Interpreter for Apache Zeppelin"
+description: "Scio is a Scala DSL for Apache Beam/Google Dataflow model."
+group: interpreter
+---
+
+{% include JB/setup %}
+
+# Scio Interpreter for Apache Zeppelin
+
+
+
+## Overview
+Scio is a Scala DSL for [Google Cloud Dataflow](https://github.com/GoogleCloudPlatform/DataflowJavaSDK) and [Apache Beam](http://beam.incubator.apache.org/) inspired by [Spark](http://spark.apache.org/) and [Scalding](https://github.com/twitter/scalding). See the current [wiki](https://github.com/spotify/scio/wiki) and [API documentation](http://spotify.github.io/scio/) for more information.
+
+## Configuration
+| Name | +Default Value | +Description | +
|---|---|---|
| zeppelin.scio.argz | +--runner=InProcessPipelineRunner | +Scio interpreter wide arguments. Documentation: https://github.com/spotify/scio/wiki#options and https://cloud.google.com/dataflow/pipelines/specifying-exec-params | +
| zeppelin.scio.maxResult | +1000 | +Max number of SCollection results to display | +
| Name | +Value | +Description | +
|---|---|---|
| shell.command.timeout.millisecs | +60000 | +Shell command time out in millisecs | +
| zeppelin.shell.auth.type | ++ | Types of authentications' methods supported are SIMPLE, and KERBEROS | +
| zeppelin.shell.principal | ++ | The principal name to load from the keytab | +
| zeppelin.shell.keytab.location | ++ | The path to the keytab file | +
 +
+If you need further information about **Zeppelin Interpreter Setting** for using Shell interpreter, please read [What is interpreter setting?](../manual/interpreters.html#what-is-interpreter-setting) section first.
\ No newline at end of file
diff --git a/docs/interpreter/spark.md b/docs/interpreter/spark.md
index a183033bf7c..59b3430584d 100644
--- a/docs/interpreter/spark.md
+++ b/docs/interpreter/spark.md
@@ -1,21 +1,32 @@
---
layout: page
-title: "Spark Interpreter Group"
-description: ""
-group: manual
+title: "Apache Spark Interpreter for Apache Zeppelin"
+description: "Apache Spark is a fast and general-purpose cluster computing system. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution engine."
+group: interpreter
---
+
{% include JB/setup %}
-
# Spark Interpreter for Apache Zeppelin
## Overview
[Apache Spark](http://spark.apache.org) is a fast and general-purpose cluster computing system.
-It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs
-Apache Spark is supported in Zeppelin with
-Spark Interpreter group, which consists of five interpreters.
+It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs.
+Apache Spark is supported in Zeppelin with Spark interpreter group which consists of below five interpreters.
+
+If you need further information about **Zeppelin Interpreter Setting** for using Shell interpreter, please read [What is interpreter setting?](../manual/interpreters.html#what-is-interpreter-setting) section first.
\ No newline at end of file
diff --git a/docs/interpreter/spark.md b/docs/interpreter/spark.md
index a183033bf7c..59b3430584d 100644
--- a/docs/interpreter/spark.md
+++ b/docs/interpreter/spark.md
@@ -1,21 +1,32 @@
---
layout: page
-title: "Spark Interpreter Group"
-description: ""
-group: manual
+title: "Apache Spark Interpreter for Apache Zeppelin"
+description: "Apache Spark is a fast and general-purpose cluster computing system. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution engine."
+group: interpreter
---
+
{% include JB/setup %}
-
# Spark Interpreter for Apache Zeppelin
## Overview
[Apache Spark](http://spark.apache.org) is a fast and general-purpose cluster computing system.
-It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs
-Apache Spark is supported in Zeppelin with
-Spark Interpreter group, which consists of five interpreters.
+It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs.
+Apache Spark is supported in Zeppelin with Spark interpreter group which consists of below five interpreters.
| %spark | SparkInterpreter | -Creates a SparkContext and provides a scala environment | +Creates a SparkContext and provides a Scala environment | |
| %pyspark | +%spark.pyspark | PySparkInterpreter | -Provides a python environment | +Provides a Python environment |
| %r | +%spark.r | SparkRInterpreter | Provides an R environment with SparkR support | |
| %sql | +%spark.sql | SparkSQLInterpreter | Provides a SQL environment | |
| %dep | +%spark.dep | DepInterpreter | Dependency loader | |
| spark.executor.memory | -512m | +1g | Executor memory per worker instance. ex) 512m, 32g |
|
| Local repository for dependency loader | ||||
| zeppelin.pyspark.python | +PYSPARK_PYTHON | python | -Python command to run pyspark with | +Python binary executable to use for PySpark in both driver and workers (default is python).
+ Property spark.pyspark.python take precedence if it is set |
+
| PYSPARK_DRIVER_PYTHON | +python | +Python binary executable to use for PySpark in driver only (default is PYSPARK_PYTHON).
+ Property spark.pyspark.driver.python take precedence if it is set |
||
| zeppelin.spark.concurrentSQL | @@ -105,7 +123,7 @@ You can also set other Spark properties which are not listed in the table. For a||||
| zeppelin.spark.maxResult | 1000 | -Max number of SparkSQL result to display. | +Max number of Spark SQL result to display. | |
| zeppelin.spark.printREPLOutput | @@ -122,116 +140,128 @@ You can also set other Spark properties which are not listed in the table. For atrue | Import implicits, UDF collection, and sql if set true. | ||
| zeppelin.spark.enableSupportedVersionCheck | +true | +Do not change - developer only setting, not for production use | +
| spark-defaults.conf | SPARK_SUBMIT_OPTIONS | -Applicable Interpreter | Description | |
|---|---|---|---|---|
| spark.jars | --jars | -%spark | Comma-separated list of local jars to include on the driver and executor classpaths. | |
| spark.jars.packages | --packages | -%spark | -Comma-separated list of maven coordinates of jars to include on the driver and executor classpaths. Will search the local maven repo, then maven central and any additional remote repositories given by --repositories. The format for the coordinates should be groupId:artifactId:version. | +Comma-separated list of maven coordinates of jars to include on the driver and executor classpaths. Will search the local maven repo, then maven central and any additional remote repositories given by --repositories. The format for the coordinates should be groupId:artifactId:version. |
| spark.files | --files | -%pyspark | Comma-separated list of files to be placed in the working directory of each executor. |
@@ -279,6 +309,12 @@ So you can put some object from scala and read it from python, vise versa.
%spark
val myObject = ...
z.put("objName", myObject)
+
+// Exchanging data frames
+myScalaDataFrame = ...
+z.put("myScalaDataFrame", myScalaDataFrame)
+
+val myPythonDataFrame = z.get("myPythonDataFrame").asInstanceOf[DataFrame]
{% endhighlight %}
@@ -286,8 +322,14 @@ z.put("objName", myObject)
{% highlight python %}
# Get object from python
-%pyspark
+%spark.pyspark
myObject = z.get("objName")
+
+# Exchanging data frames
+myPythonDataFrame = ...
+z.put("myPythonDataFrame", postsDf._jdf)
+
+myScalaDataFrame = DataFrame(z.get("myScalaDataFrame"), sqlContext)
{% endhighlight %}
@@ -321,7 +363,7 @@ z.select("formName", "option1", Seq(("option1", "option1DisplayName"),
{% highlight python %}
-%pyspark
+%spark.pyspark
# Create text input form
z.input("formName")
@@ -342,17 +384,22 @@ z.select("formName", [("option1", "option1DisplayName"),
In sql environment, you can create form in simple template.
-```
-%sql
+```sql
+%spark.sql
select * from ${table=defaultTableName} where text like '%${search}%'
```
To learn more about dynamic form, checkout [Dynamic Form](../manual/dynamicform.html).
+## Matplotlib Integration (pyspark)
+Both the `python` and `pyspark` interpreters have built-in support for inline visualization using `matplotlib`, a popular plotting library for python. More details can be found in the [python interpreter documentation](../interpreter/python.html), since matplotlib support is identical. More advanced interactive plotting can be done with pyspark through utilizing Zeppelin's built-in [Angular Display System](../displaysystem/back-end-angular.html), as shown below:
+
+ +
## Interpreter setting option
-Interpreter setting can choose one of 'shared', 'scoped', 'isolated' option. Spark interpreter creates separate scala compiler per each notebook but share a single SparkContext in 'scoped' mode (experimental). It creates separate SparkContext per each notebook in 'isolated' mode.
+You can choose one of `shared`, `scoped` and `isolated` options wheh you configure Spark interpreter. Spark interpreter creates separated Scala compiler per each notebook but share a single SparkContext in `scoped` mode (experimental). It creates separated SparkContext per each notebook in `isolated` mode.
## Setting up Zeppelin with Kerberos
@@ -365,14 +412,14 @@ Logical setup with Zeppelin, Kerberos Key Distribution Center (KDC), and Spark o
1. On the server that Zeppelin is installed, install Kerberos client modules and configuration, krb5.conf.
This is to make the server communicate with KDC.
-2. Set SPARK\_HOME in `[ZEPPELIN\_HOME]/conf/zeppelin-env.sh` to use spark-submit
-(Additionally, you might have to set `export HADOOP\_CONF\_DIR=/etc/hadoop/conf`)
+2. Set `SPARK_HOME` in `[ZEPPELIN_HOME]/conf/zeppelin-env.sh` to use spark-submit
+(Additionally, you might have to set `export HADOOP_CONF_DIR=/etc/hadoop/conf`)
-3. Add the two properties below to spark configuration (`[SPARK_HOME]/conf/spark-defaults.conf`):
+3. Add the two properties below to Spark configuration (`[SPARK_HOME]/conf/spark-defaults.conf`):
spark.yarn.principal
spark.yarn.keytab
- > **NOTE:** If you do not have access to the above spark-defaults.conf file, optionally, you may add the lines to the Spark Interpreter through the Interpreter tab in the Zeppelin UI.
+ > **NOTE:** If you do not have permission to access for the above spark-defaults.conf file, optionally, you can add the above lines to the Spark Interpreter setting through the Interpreter tab in the Zeppelin UI.
4. That's it. Play with Zeppelin!
diff --git a/docs/manual/dependencymanagement.md b/docs/manual/dependencymanagement.md
index acf6002e8f2..44068dae1fd 100644
--- a/docs/manual/dependencymanagement.md
+++ b/docs/manual/dependencymanagement.md
@@ -1,7 +1,7 @@
---
layout: page
-title: "Dependency Management"
-description: ""
+title: "Dependency Management for Apache Spark Interpreter"
+description: "Include external libraries to Apache Spark Interpreter by setting dependencies in interpreter menu."
group: manual
---
+{% include JB/setup %}
+
+# Interpreter Execution Hooks (Experimental)
+
+
+
+## Overview
+
+Apache Zeppelin allows for users to specify additional code to be executed by an interpreter at pre and post-paragraph code execution.
+This is primarily useful if you need to run the same set of code for all of the paragraphs within your notebook at specific times.
+Currently, this feature is only available for the spark and pyspark interpreters.
+To specify your hook code, you may use `z.registerHook()`.
+For example, enter the following into one paragraph:
+
+```python
+%pyspark
+z.registerHook("post_exec", "print 'This code should be executed before the parapgraph code!'")
+z.registerHook("pre_exec", "print 'This code should be executed after the paragraph code!'")
+```
+
+These calls will not take into effect until the next time you run a paragraph.
+
+
+In another paragraph, enter
+
+```python
+%pyspark
+print "This code should be entered into the paragraph by the user!"
+```
+
+The output should be:
+
+```
+This code should be executed before the paragraph code!
+This code should be entered into the paragraph by the user!
+This code should be executed after the paragraph code!
+```
+
+If you ever need to know the hook code, use `z.getHook()`:
+
+```python
+%pyspark
+print z.getHook("post_exec")
+
+print 'This code should be executed after the paragraph code!'
+```
+Any call to `z.registerHook()` will automatically overwrite what was previously registered.
+To completely unregister a hook event, use `z.unregisterHook(eventCode)`.
+Currently only `"post_exec"` and `"pre_exec"` are valid event codes for the Zeppelin Hook Registry system.
+
+Finally, the hook registry is internally shared by other interpreters in the same group.
+This would allow for hook code for one interpreter REPL to be set by another as follows:
+
+```scala
+%spark
+z.unregisterHook("post_exec", "pyspark")
+```
+
+The API is identical for both the spark (scala) and pyspark (python) implementations.
+
+### Caveats
+Calls to `z.registerHook("pre_exec", ...)` should be made with care. If there are errors in your specified hook code, this will cause the interpreter REPL to become unable to execute any code pass the pre-execute stage making it impossible for direct calls to `z.unregisterHook()` to take into effect. Current workarounds include calling `z.unregisterHook()` from a different interpreter REPL in the same interpreter group (see above) or manually restarting the interpreter group in the UI.
diff --git a/docs/manual/interpreterinstallation.md b/docs/manual/interpreterinstallation.md
index cfd58105a94..5825d1d6297 100644
--- a/docs/manual/interpreterinstallation.md
+++ b/docs/manual/interpreterinstallation.md
@@ -1,7 +1,7 @@
---
layout: page
-title: "Interpreter Installation"
-description: ""
+title: "Interpreter Installation in Netinst Binary Package"
+description: "Apache Zeppelin provides Interpreter Installation mechanism for whom downloaded Zeppelin netinst binary package, or just want to install another 3rd party interpreters."
group: manual
---
+{% include JB/setup %}
+
+## Run zeppelin interpreter process as web front end user
+
+ * Enable shiro auth in shiro.ini
+
+```
+[users]
+user1 = password1, role1
+user2 = password2, role2
+```
+
+ * Enable password-less ssh for the user you want to impersonate (say user1).
+
+```
+adduser user1
+#ssh-keygen (optional if you don't already have generated ssh-key.
+ssh user1@localhost mkdir -p .ssh
+cat ~/.ssh/id_rsa.pub | ssh user1@localhost 'cat >> .ssh/authorized_keys'
+```
+
+* Alternatively instead of password-less, user can override ZEPPELIN_IMPERSONATE_CMD in zeppelin-env.sh
+
+```
+export ZEPPELIN_IMPERSONATE_CMD='sudo -H -u ${ZEPPELIN_IMPERSONATE_USER} bash -c '
+```
+
+
+ * Start zeppelin server.
+
+
+
## Interpreter setting option
-Interpreter setting can choose one of 'shared', 'scoped', 'isolated' option. Spark interpreter creates separate scala compiler per each notebook but share a single SparkContext in 'scoped' mode (experimental). It creates separate SparkContext per each notebook in 'isolated' mode.
+You can choose one of `shared`, `scoped` and `isolated` options wheh you configure Spark interpreter. Spark interpreter creates separated Scala compiler per each notebook but share a single SparkContext in `scoped` mode (experimental). It creates separated SparkContext per each notebook in `isolated` mode.
## Setting up Zeppelin with Kerberos
@@ -365,14 +412,14 @@ Logical setup with Zeppelin, Kerberos Key Distribution Center (KDC), and Spark o
1. On the server that Zeppelin is installed, install Kerberos client modules and configuration, krb5.conf.
This is to make the server communicate with KDC.
-2. Set SPARK\_HOME in `[ZEPPELIN\_HOME]/conf/zeppelin-env.sh` to use spark-submit
-(Additionally, you might have to set `export HADOOP\_CONF\_DIR=/etc/hadoop/conf`)
+2. Set `SPARK_HOME` in `[ZEPPELIN_HOME]/conf/zeppelin-env.sh` to use spark-submit
+(Additionally, you might have to set `export HADOOP_CONF_DIR=/etc/hadoop/conf`)
-3. Add the two properties below to spark configuration (`[SPARK_HOME]/conf/spark-defaults.conf`):
+3. Add the two properties below to Spark configuration (`[SPARK_HOME]/conf/spark-defaults.conf`):
spark.yarn.principal
spark.yarn.keytab
- > **NOTE:** If you do not have access to the above spark-defaults.conf file, optionally, you may add the lines to the Spark Interpreter through the Interpreter tab in the Zeppelin UI.
+ > **NOTE:** If you do not have permission to access for the above spark-defaults.conf file, optionally, you can add the above lines to the Spark Interpreter setting through the Interpreter tab in the Zeppelin UI.
4. That's it. Play with Zeppelin!
diff --git a/docs/manual/dependencymanagement.md b/docs/manual/dependencymanagement.md
index acf6002e8f2..44068dae1fd 100644
--- a/docs/manual/dependencymanagement.md
+++ b/docs/manual/dependencymanagement.md
@@ -1,7 +1,7 @@
---
layout: page
-title: "Dependency Management"
-description: ""
+title: "Dependency Management for Apache Spark Interpreter"
+description: "Include external libraries to Apache Spark Interpreter by setting dependencies in interpreter menu."
group: manual
---
+{% include JB/setup %}
+
+# Interpreter Execution Hooks (Experimental)
+
+
+
+## Overview
+
+Apache Zeppelin allows for users to specify additional code to be executed by an interpreter at pre and post-paragraph code execution.
+This is primarily useful if you need to run the same set of code for all of the paragraphs within your notebook at specific times.
+Currently, this feature is only available for the spark and pyspark interpreters.
+To specify your hook code, you may use `z.registerHook()`.
+For example, enter the following into one paragraph:
+
+```python
+%pyspark
+z.registerHook("post_exec", "print 'This code should be executed before the parapgraph code!'")
+z.registerHook("pre_exec", "print 'This code should be executed after the paragraph code!'")
+```
+
+These calls will not take into effect until the next time you run a paragraph.
+
+
+In another paragraph, enter
+
+```python
+%pyspark
+print "This code should be entered into the paragraph by the user!"
+```
+
+The output should be:
+
+```
+This code should be executed before the paragraph code!
+This code should be entered into the paragraph by the user!
+This code should be executed after the paragraph code!
+```
+
+If you ever need to know the hook code, use `z.getHook()`:
+
+```python
+%pyspark
+print z.getHook("post_exec")
+
+print 'This code should be executed after the paragraph code!'
+```
+Any call to `z.registerHook()` will automatically overwrite what was previously registered.
+To completely unregister a hook event, use `z.unregisterHook(eventCode)`.
+Currently only `"post_exec"` and `"pre_exec"` are valid event codes for the Zeppelin Hook Registry system.
+
+Finally, the hook registry is internally shared by other interpreters in the same group.
+This would allow for hook code for one interpreter REPL to be set by another as follows:
+
+```scala
+%spark
+z.unregisterHook("post_exec", "pyspark")
+```
+
+The API is identical for both the spark (scala) and pyspark (python) implementations.
+
+### Caveats
+Calls to `z.registerHook("pre_exec", ...)` should be made with care. If there are errors in your specified hook code, this will cause the interpreter REPL to become unable to execute any code pass the pre-execute stage making it impossible for direct calls to `z.unregisterHook()` to take into effect. Current workarounds include calling `z.unregisterHook()` from a different interpreter REPL in the same interpreter group (see above) or manually restarting the interpreter group in the UI.
diff --git a/docs/manual/interpreterinstallation.md b/docs/manual/interpreterinstallation.md
index cfd58105a94..5825d1d6297 100644
--- a/docs/manual/interpreterinstallation.md
+++ b/docs/manual/interpreterinstallation.md
@@ -1,7 +1,7 @@
---
layout: page
-title: "Interpreter Installation"
-description: ""
+title: "Interpreter Installation in Netinst Binary Package"
+description: "Apache Zeppelin provides Interpreter Installation mechanism for whom downloaded Zeppelin netinst binary package, or just want to install another 3rd party interpreters."
group: manual
---
+{% include JB/setup %}
+
+## Run zeppelin interpreter process as web front end user
+
+ * Enable shiro auth in shiro.ini
+
+```
+[users]
+user1 = password1, role1
+user2 = password2, role2
+```
+
+ * Enable password-less ssh for the user you want to impersonate (say user1).
+
+```
+adduser user1
+#ssh-keygen (optional if you don't already have generated ssh-key.
+ssh user1@localhost mkdir -p .ssh
+cat ~/.ssh/id_rsa.pub | ssh user1@localhost 'cat >> .ssh/authorized_keys'
+```
+
+* Alternatively instead of password-less, user can override ZEPPELIN_IMPERSONATE_CMD in zeppelin-env.sh
+
+```
+export ZEPPELIN_IMPERSONATE_CMD='sudo -H -u ${ZEPPELIN_IMPERSONATE_USER} bash -c '
+```
+
+
+ * Start zeppelin server.
+
+
+
+ + * Go to interpreter setting page, and enable "User Impersonate" in any of the interpreter (in my example its shell interpreter) + + * Test with a simple paragraph + +``` +%sh +whoami +``` + + +Note that usage of "User Impersonate" option will enable Spark interpreter to use `--proxy-user` option with current user by default. If you want to disable `--proxy-user` option, then refer to `ZEPPELIN_IMPERSONATE_SPARK_PROXY_USER` variable in `conf/zeppelin-env.sh` diff --git a/docs/pleasecontribute.md b/docs/pleasecontribute.md index 063b48f2bee..746b39dc87c 100644 --- a/docs/pleasecontribute.md +++ b/docs/pleasecontribute.md @@ -1,8 +1,8 @@ --- layout: page -title: "Please contribute" -description: "" -group: development +title: +description: +group: --- +{% include JB/setup %} + # Explore Apache Zeppelin UI ## Main home -The first time you connect to Zeppelin, you'll land at the main page similar to the below screen capture. +The first time you connect to Zeppelin ([default installations start on http://localhost:8080](http://localhost:8080/)), you'll land at the main page similar to the below screen capture. diff --git a/docs/quickstart/install_with_flink_and_spark_cluster.md b/docs/quickstart/install_with_flink_and_spark_cluster.md
new file mode 100644
index 00000000000..89d6d6edc64
--- /dev/null
+++ b/docs/quickstart/install_with_flink_and_spark_cluster.md
@@ -0,0 +1,421 @@
+---
+layout: page
+title: "Install Zeppelin with Flink and Spark in cluster mode"
+description: "Tutorial is valid for Spark 1.6.x and Flink 1.1.2"
+group: tutorial
+---
+
+
+{% include JB/setup %}
+
+# Install with flink and spark cluster
+
+
+
+This tutorial is extremely entry-level. It assumes no prior knowledge of Linux, git, or other tools. If you carefully type what I tell you when I tell you, you should be able to get Zeppelin running.
+
+## Installing Zeppelin with Flink and Spark in cluster mode
+
+This tutorial assumes the user has a machine (real or [virtual](https://www.virtualbox.org/wiki/Downloads) with a fresh, minimal installation of [Ubuntu 14.04.3 Server](http://www.ubuntu.com/download/server).
+
+**Note:** On the size requirements of the Virtual Machine, some users reported trouble when using the default virtual machine sizes, specifically that the hard drive needed to be at least 16GB- other users did not have this issue.
+
+There are many good tutorials on how to install Ubuntu Server on a virtual box, [here is one of them](http://ilearnstack.com/2013/04/13/setting-ubuntu-vm-in-virtualbox/)
+
+### Required Programs
+
+Assuming the minimal install, there are several programs that we will need to install before Zeppelin, Flink, and Spark.
+
+- git
+- openssh-server
+- OpenJDK 7
+- Maven 3.1+
+
+For git, openssh-server, and OpenJDK 7 we will be using the apt package manager.
+
+##### git
+From the command prompt:
+
+```
+sudo apt-get install git
+```
+
+##### openssh-server
+
+```
+sudo apt-get install openssh-server
+```
+
+##### OpenJDK 7
+
+```
+sudo apt-get install openjdk-7-jdk openjdk-7-jre-lib
+```
+*A note for those using Ubuntu 16.04*: To install `openjdk-7` on Ubuntu 16.04, one must add a repository. [Source](http://askubuntu.com/questions/761127/ubuntu-16-04-and-openjdk-7)
+
+``` bash
+sudo add-apt-repository ppa:openjdk-r/ppa
+sudo apt-get update
+sudo apt-get install openjdk-7-jdk openjdk-7-jre-lib
+```
+
+##### Maven 3.1+
+Zeppelin requires maven version 3.x. The version available in the repositories at the time of writing is 2.x, so maven must be installed manually.
+
+Purge any existing versions of maven.
+
+```
+sudo apt-get purge maven maven2
+```
+
+Download the maven 3.3.9 binary.
+
+```
+wget "http://www.us.apache.org/dist/maven/maven-3/3.3.9/binaries/apache-maven-3.3.9-bin.tar.gz"
+```
+
+Unarchive the binary and move to the `/usr/local` directory.
+
+```
+tar -zxvf apache-maven-3.3.9-bin.tar.gz
+sudo mv ./apache-maven-3.3.9 /usr/local
+```
+
+Create symbolic links in `/usr/bin`.
+
+```
+sudo ln -s /usr/local/apache-maven-3.3.9/bin/mvn /usr/bin/mvn
+```
+
+### Installing Zeppelin
+This provides a quick overview of Zeppelin installation from source, however the reader is encouraged to review the [Zeppelin Installation Guide](../install/install.html)
+
+From the command prompt:
+Clone Zeppelin.
+
+```
+git clone https://github.com/apache/zeppelin.git
+```
+
+Enter the Zeppelin root directory.
+
+```
+cd zeppelin
+```
+
+Package Zeppelin.
+
+```
+mvn clean package -DskipTests -Pspark-1.6 -Dflink.version=1.1.3 -Pscala-2.10
+```
+
+`-DskipTests` skips build tests- you're not developing (yet), so you don't need to do tests, the clone version *should* build.
+
+`-Pspark-1.6` tells maven to build a Zeppelin with Spark 1.6. This is important because Zeppelin has its own Spark interpreter and the versions must be the same.
+
+`-Dflink.version=1.1.3` tells maven specifically to build Zeppelin with Flink version 1.1.3.
+
+-`-Pscala-2.10` tells maven to build with Scala v2.10.
+
+
+**Note:** You can build against any version of Spark that has a Zeppelin build profile available. The key is to make sure you check out the matching version of Spark to build. At the time of this writing, Spark 1.6 was the most recent Spark version available.
+
+**Note:** On build failures. Having installed Zeppelin close to 30 times now, I will tell you that sometimes the build fails for seemingly no reason.
+As long as you didn't edit any code, it is unlikely the build is failing because of something you did. What does tend to happen, is some dependency that maven is trying to download is unreachable. If your build fails on this step here are some tips:
+
+- Don't get discouraged.
+- Scroll up and read through the logs. There will be clues there.
+- Retry (that is, run the `mvn clean package -DskipTests -Pspark-1.6` again)
+- If there were clues that a dependency couldn't be downloaded wait a few hours or even days and retry again. Open source software when compiling is trying to download all of the dependencies it needs, if a server is off-line there is nothing you can do but wait for it to come back.
+- Make sure you followed all of the steps carefully.
+- Ask the community to help you. Go [here](http://zeppelin.apache.org/community.html) and join the user mailing list. People are there to help you. Make sure to copy and paste the build output (everything that happened in the console) and include that in your message.
+
+
+Start the Zeppelin daemon.
+
+```
+bin/zeppelin-daemon.sh start
+```
+
+Use `ifconfig` to determine the host machine's IP address. If you are not familiar with how to do this, a fairly comprehensive post can be found [here](http://www.cyberciti.biz/faq/how-to-find-out-the-ip-address-assigned-to-eth0-and-display-ip-only/).
+
+Open a web-browser on a machine connected to the same network as the host (or in the host operating system if using a virtual machine). Navigate to http://`yourip`:8080, where yourip is the IP address you found in `ifconfig`.
+
+See the [Zeppelin tutorial](../tutorial/tutorial.html) for basic Zeppelin usage. It is also advised that you take a moment to check out the tutorial notebook that is included with each Zeppelin install, and to familiarize yourself with basic notebook functionality.
+
+##### Flink Test
+Create a new notebook named "Flink Test" and copy and paste the following code.
+
+
+```scala
+
+%flink // let Zeppelin know what interpreter to use.
+
+val text = benv.fromElements("In the time of chimpanzees, I was a monkey", // some lines of text to analyze
+"Butane in my veins and I'm out to cut the junkie",
+"With the plastic eyeballs, spray paint the vegetables",
+"Dog food stalls with the beefcake pantyhose",
+"Kill the headlights and put it in neutral",
+"Stock car flamin' with a loser in the cruise control",
+"Baby's in Reno with the Vitamin D",
+"Got a couple of couches, sleep on the love seat",
+"Someone came in sayin' I'm insane to complain",
+"About a shotgun wedding and a stain on my shirt",
+"Don't believe everything that you breathe",
+"You get a parking violation and a maggot on your sleeve",
+"So shave your face with some mace in the dark",
+"Savin' all your food stamps and burnin' down the trailer park",
+"Yo, cut it")
+
+/* The meat and potatoes:
+ this tells Flink to iterate through the elements, in this case strings,
+ transform the string to lower case and split the string at white space into individual words
+ then finally aggregate the occurrence of each word.
+
+ This creates the count variable which is a list of tuples of the form (word, occurances)
+
+counts.collect().foreach(println(_)) // execute the script and print each element in the counts list
+
+*/
+val counts = text.flatMap{ _.toLowerCase.split("\\W+") }.map { (_,1) }.groupBy(0).sum(1)
+
+counts.collect().foreach(println(_)) // execute the script and print each element in the counts list
+
+```
+
+Run the code to make sure the built-in Zeppelin Flink interpreter is working properly.
+
+##### Spark Test
+Create a new notebook named "Spark Test" and copy and paste the following code.
+
+```scala
+%spark // let Zeppelin know what interpreter to use.
+
+val text = sc.parallelize(List("In the time of chimpanzees, I was a monkey", // some lines of text to analyze
+"Butane in my veins and I'm out to cut the junkie",
+"With the plastic eyeballs, spray paint the vegetables",
+"Dog food stalls with the beefcake pantyhose",
+"Kill the headlights and put it in neutral",
+"Stock car flamin' with a loser in the cruise control",
+"Baby's in Reno with the Vitamin D",
+"Got a couple of couches, sleep on the love seat",
+"Someone came in sayin' I'm insane to complain",
+"About a shotgun wedding and a stain on my shirt",
+"Don't believe everything that you breathe",
+"You get a parking violation and a maggot on your sleeve",
+"So shave your face with some mace in the dark",
+"Savin' all your food stamps and burnin' down the trailer park",
+"Yo, cut it"))
+
+
+/* The meat and potatoes:
+ this tells spark to iterate through the elements, in this case strings,
+ transform the string to lower case and split the string at white space into individual words
+ then finally aggregate the occurrence of each word.
+
+ This creates the count variable which is a list of tuples of the form (word, occurances)
+*/
+val counts = text.flatMap { _.toLowerCase.split("\\W+") }
+ .map { (_,1) }
+ .reduceByKey(_ + _)
+
+counts.collect().foreach(println(_)) // execute the script and print each element in the counts list
+```
+
+Run the code to make sure the built-in Zeppelin Flink interpreter is working properly.
+
+Finally, stop the Zeppelin daemon. From the command prompt run:
+
+```
+bin/zeppelin-daemon.sh stop
+```
+
+### Installing Clusters
+
+##### Flink Cluster
+
+###### Download Binaries
+
+Building from source is recommended where possible, for simplicity in this tutorial we will download Flink and Spark Binaries.
+
+To download the Flink Binary use `wget`
+
+```bash
+wget "http://mirror.cogentco.com/pub/apache/flink/flink-1.1.3/flink-1.1.3-bin-hadoop24-scala_2.10.tgz"
+tar -xzvf flink-1.1.3-bin-hadoop24-scala_2.10.tgz
+```
+
+This will download Flink 1.1.3, compatible with Hadoop 2.4. You do not have to install Hadoop for this binary to work, but if you are using Hadoop, please change `24` to your appropriate version.
+
+Start the Flink Cluster.
+
+```bash
+flink-1.1.3/bin/start-cluster.sh
+```
+
+###### Building From source
+
+If you wish to build Flink from source, the following will be instructive. Note that if you have downloaded and used the binary version this should be skipped. The changing nature of build tools and versions across platforms makes this section somewhat precarious. For example, Java8 and Maven 3.0.3 are recommended for building Flink, which are not recommended for Zeppelin at the time of writing. If the user wishes to attempt to build from source, this section will provide some reference. If errors are encountered, please contact the Apache Flink community.
+
+See the [Flink Installation guide](https://github.com/apache/flink/blob/master/README.md) for more detailed instructions.
+
+Return to the directory where you have been downloading, this tutorial assumes that is `$HOME`. Clone Flink, check out release-1.1.3-rc2, and build.
+
+```
+cd $HOME
+git clone https://github.com/apache/flink.git
+cd flink
+git checkout release-1.1.3-rc2
+mvn clean install -DskipTests
+```
+
+Start the Flink Cluster in stand-alone mode
+
+```
+build-target/bin/start-cluster.sh
+```
+
+###### Ensure the cluster is up
+
+In a browser, navigate to http://`yourip`:8082 to see the Flink Web-UI. Click on 'Task Managers' in the left navigation bar. Ensure there is at least one Task Manager present.
+
+
diff --git a/docs/quickstart/install_with_flink_and_spark_cluster.md b/docs/quickstart/install_with_flink_and_spark_cluster.md
new file mode 100644
index 00000000000..89d6d6edc64
--- /dev/null
+++ b/docs/quickstart/install_with_flink_and_spark_cluster.md
@@ -0,0 +1,421 @@
+---
+layout: page
+title: "Install Zeppelin with Flink and Spark in cluster mode"
+description: "Tutorial is valid for Spark 1.6.x and Flink 1.1.2"
+group: tutorial
+---
+
+
+{% include JB/setup %}
+
+# Install with flink and spark cluster
+
+
+
+This tutorial is extremely entry-level. It assumes no prior knowledge of Linux, git, or other tools. If you carefully type what I tell you when I tell you, you should be able to get Zeppelin running.
+
+## Installing Zeppelin with Flink and Spark in cluster mode
+
+This tutorial assumes the user has a machine (real or [virtual](https://www.virtualbox.org/wiki/Downloads) with a fresh, minimal installation of [Ubuntu 14.04.3 Server](http://www.ubuntu.com/download/server).
+
+**Note:** On the size requirements of the Virtual Machine, some users reported trouble when using the default virtual machine sizes, specifically that the hard drive needed to be at least 16GB- other users did not have this issue.
+
+There are many good tutorials on how to install Ubuntu Server on a virtual box, [here is one of them](http://ilearnstack.com/2013/04/13/setting-ubuntu-vm-in-virtualbox/)
+
+### Required Programs
+
+Assuming the minimal install, there are several programs that we will need to install before Zeppelin, Flink, and Spark.
+
+- git
+- openssh-server
+- OpenJDK 7
+- Maven 3.1+
+
+For git, openssh-server, and OpenJDK 7 we will be using the apt package manager.
+
+##### git
+From the command prompt:
+
+```
+sudo apt-get install git
+```
+
+##### openssh-server
+
+```
+sudo apt-get install openssh-server
+```
+
+##### OpenJDK 7
+
+```
+sudo apt-get install openjdk-7-jdk openjdk-7-jre-lib
+```
+*A note for those using Ubuntu 16.04*: To install `openjdk-7` on Ubuntu 16.04, one must add a repository. [Source](http://askubuntu.com/questions/761127/ubuntu-16-04-and-openjdk-7)
+
+``` bash
+sudo add-apt-repository ppa:openjdk-r/ppa
+sudo apt-get update
+sudo apt-get install openjdk-7-jdk openjdk-7-jre-lib
+```
+
+##### Maven 3.1+
+Zeppelin requires maven version 3.x. The version available in the repositories at the time of writing is 2.x, so maven must be installed manually.
+
+Purge any existing versions of maven.
+
+```
+sudo apt-get purge maven maven2
+```
+
+Download the maven 3.3.9 binary.
+
+```
+wget "http://www.us.apache.org/dist/maven/maven-3/3.3.9/binaries/apache-maven-3.3.9-bin.tar.gz"
+```
+
+Unarchive the binary and move to the `/usr/local` directory.
+
+```
+tar -zxvf apache-maven-3.3.9-bin.tar.gz
+sudo mv ./apache-maven-3.3.9 /usr/local
+```
+
+Create symbolic links in `/usr/bin`.
+
+```
+sudo ln -s /usr/local/apache-maven-3.3.9/bin/mvn /usr/bin/mvn
+```
+
+### Installing Zeppelin
+This provides a quick overview of Zeppelin installation from source, however the reader is encouraged to review the [Zeppelin Installation Guide](../install/install.html)
+
+From the command prompt:
+Clone Zeppelin.
+
+```
+git clone https://github.com/apache/zeppelin.git
+```
+
+Enter the Zeppelin root directory.
+
+```
+cd zeppelin
+```
+
+Package Zeppelin.
+
+```
+mvn clean package -DskipTests -Pspark-1.6 -Dflink.version=1.1.3 -Pscala-2.10
+```
+
+`-DskipTests` skips build tests- you're not developing (yet), so you don't need to do tests, the clone version *should* build.
+
+`-Pspark-1.6` tells maven to build a Zeppelin with Spark 1.6. This is important because Zeppelin has its own Spark interpreter and the versions must be the same.
+
+`-Dflink.version=1.1.3` tells maven specifically to build Zeppelin with Flink version 1.1.3.
+
+-`-Pscala-2.10` tells maven to build with Scala v2.10.
+
+
+**Note:** You can build against any version of Spark that has a Zeppelin build profile available. The key is to make sure you check out the matching version of Spark to build. At the time of this writing, Spark 1.6 was the most recent Spark version available.
+
+**Note:** On build failures. Having installed Zeppelin close to 30 times now, I will tell you that sometimes the build fails for seemingly no reason.
+As long as you didn't edit any code, it is unlikely the build is failing because of something you did. What does tend to happen, is some dependency that maven is trying to download is unreachable. If your build fails on this step here are some tips:
+
+- Don't get discouraged.
+- Scroll up and read through the logs. There will be clues there.
+- Retry (that is, run the `mvn clean package -DskipTests -Pspark-1.6` again)
+- If there were clues that a dependency couldn't be downloaded wait a few hours or even days and retry again. Open source software when compiling is trying to download all of the dependencies it needs, if a server is off-line there is nothing you can do but wait for it to come back.
+- Make sure you followed all of the steps carefully.
+- Ask the community to help you. Go [here](http://zeppelin.apache.org/community.html) and join the user mailing list. People are there to help you. Make sure to copy and paste the build output (everything that happened in the console) and include that in your message.
+
+
+Start the Zeppelin daemon.
+
+```
+bin/zeppelin-daemon.sh start
+```
+
+Use `ifconfig` to determine the host machine's IP address. If you are not familiar with how to do this, a fairly comprehensive post can be found [here](http://www.cyberciti.biz/faq/how-to-find-out-the-ip-address-assigned-to-eth0-and-display-ip-only/).
+
+Open a web-browser on a machine connected to the same network as the host (or in the host operating system if using a virtual machine). Navigate to http://`yourip`:8080, where yourip is the IP address you found in `ifconfig`.
+
+See the [Zeppelin tutorial](../tutorial/tutorial.html) for basic Zeppelin usage. It is also advised that you take a moment to check out the tutorial notebook that is included with each Zeppelin install, and to familiarize yourself with basic notebook functionality.
+
+##### Flink Test
+Create a new notebook named "Flink Test" and copy and paste the following code.
+
+
+```scala
+
+%flink // let Zeppelin know what interpreter to use.
+
+val text = benv.fromElements("In the time of chimpanzees, I was a monkey", // some lines of text to analyze
+"Butane in my veins and I'm out to cut the junkie",
+"With the plastic eyeballs, spray paint the vegetables",
+"Dog food stalls with the beefcake pantyhose",
+"Kill the headlights and put it in neutral",
+"Stock car flamin' with a loser in the cruise control",
+"Baby's in Reno with the Vitamin D",
+"Got a couple of couches, sleep on the love seat",
+"Someone came in sayin' I'm insane to complain",
+"About a shotgun wedding and a stain on my shirt",
+"Don't believe everything that you breathe",
+"You get a parking violation and a maggot on your sleeve",
+"So shave your face with some mace in the dark",
+"Savin' all your food stamps and burnin' down the trailer park",
+"Yo, cut it")
+
+/* The meat and potatoes:
+ this tells Flink to iterate through the elements, in this case strings,
+ transform the string to lower case and split the string at white space into individual words
+ then finally aggregate the occurrence of each word.
+
+ This creates the count variable which is a list of tuples of the form (word, occurances)
+
+counts.collect().foreach(println(_)) // execute the script and print each element in the counts list
+
+*/
+val counts = text.flatMap{ _.toLowerCase.split("\\W+") }.map { (_,1) }.groupBy(0).sum(1)
+
+counts.collect().foreach(println(_)) // execute the script and print each element in the counts list
+
+```
+
+Run the code to make sure the built-in Zeppelin Flink interpreter is working properly.
+
+##### Spark Test
+Create a new notebook named "Spark Test" and copy and paste the following code.
+
+```scala
+%spark // let Zeppelin know what interpreter to use.
+
+val text = sc.parallelize(List("In the time of chimpanzees, I was a monkey", // some lines of text to analyze
+"Butane in my veins and I'm out to cut the junkie",
+"With the plastic eyeballs, spray paint the vegetables",
+"Dog food stalls with the beefcake pantyhose",
+"Kill the headlights and put it in neutral",
+"Stock car flamin' with a loser in the cruise control",
+"Baby's in Reno with the Vitamin D",
+"Got a couple of couches, sleep on the love seat",
+"Someone came in sayin' I'm insane to complain",
+"About a shotgun wedding and a stain on my shirt",
+"Don't believe everything that you breathe",
+"You get a parking violation and a maggot on your sleeve",
+"So shave your face with some mace in the dark",
+"Savin' all your food stamps and burnin' down the trailer park",
+"Yo, cut it"))
+
+
+/* The meat and potatoes:
+ this tells spark to iterate through the elements, in this case strings,
+ transform the string to lower case and split the string at white space into individual words
+ then finally aggregate the occurrence of each word.
+
+ This creates the count variable which is a list of tuples of the form (word, occurances)
+*/
+val counts = text.flatMap { _.toLowerCase.split("\\W+") }
+ .map { (_,1) }
+ .reduceByKey(_ + _)
+
+counts.collect().foreach(println(_)) // execute the script and print each element in the counts list
+```
+
+Run the code to make sure the built-in Zeppelin Flink interpreter is working properly.
+
+Finally, stop the Zeppelin daemon. From the command prompt run:
+
+```
+bin/zeppelin-daemon.sh stop
+```
+
+### Installing Clusters
+
+##### Flink Cluster
+
+###### Download Binaries
+
+Building from source is recommended where possible, for simplicity in this tutorial we will download Flink and Spark Binaries.
+
+To download the Flink Binary use `wget`
+
+```bash
+wget "http://mirror.cogentco.com/pub/apache/flink/flink-1.1.3/flink-1.1.3-bin-hadoop24-scala_2.10.tgz"
+tar -xzvf flink-1.1.3-bin-hadoop24-scala_2.10.tgz
+```
+
+This will download Flink 1.1.3, compatible with Hadoop 2.4. You do not have to install Hadoop for this binary to work, but if you are using Hadoop, please change `24` to your appropriate version.
+
+Start the Flink Cluster.
+
+```bash
+flink-1.1.3/bin/start-cluster.sh
+```
+
+###### Building From source
+
+If you wish to build Flink from source, the following will be instructive. Note that if you have downloaded and used the binary version this should be skipped. The changing nature of build tools and versions across platforms makes this section somewhat precarious. For example, Java8 and Maven 3.0.3 are recommended for building Flink, which are not recommended for Zeppelin at the time of writing. If the user wishes to attempt to build from source, this section will provide some reference. If errors are encountered, please contact the Apache Flink community.
+
+See the [Flink Installation guide](https://github.com/apache/flink/blob/master/README.md) for more detailed instructions.
+
+Return to the directory where you have been downloading, this tutorial assumes that is `$HOME`. Clone Flink, check out release-1.1.3-rc2, and build.
+
+```
+cd $HOME
+git clone https://github.com/apache/flink.git
+cd flink
+git checkout release-1.1.3-rc2
+mvn clean install -DskipTests
+```
+
+Start the Flink Cluster in stand-alone mode
+
+```
+build-target/bin/start-cluster.sh
+```
+
+###### Ensure the cluster is up
+
+In a browser, navigate to http://`yourip`:8082 to see the Flink Web-UI. Click on 'Task Managers' in the left navigation bar. Ensure there is at least one Task Manager present.
+
+
+
+
+If no task managers are present, restart the Flink cluster with the following commands:
+
+(if binaries)
+```
+flink-1.1.3/bin/stop-cluster.sh
+flink-1.1.3/bin/start-cluster.sh
+```
+
+
+(if built from source)
+```
+build-target/bin/stop-cluster.sh
+build-target/bin/start-cluster.sh
+```
+
+
+##### Spark 1.6 Cluster
+
+###### Download Binaries
+
+Building from source is recommended where possible, for simplicity in this tutorial we will download Flink and Spark Binaries.
+
+Using binaries is also
+
+To download the Spark Binary use `wget`
+
+```bash
+wget "http://d3kbcqa49mib13.cloudfront.net/spark-1.6.3-bin-hadoop2.6.tgz"
+tar -xzvf spark-1.6.3-bin-hadoop2.6.tgz
+mv spark-1.6.3-bin-hadoop2.6 spark
+```
+
+This will download Spark 1.6.3, compatible with Hadoop 2.6. You do not have to install Hadoop for this binary to work, but if you are using Hadoop, please change `2.6` to your appropriate version.
+
+###### Building From source
+
+Spark is an extraordinarily large project, which takes considerable time to download and build. It is also prone to build failures for similar reasons listed in the Flink section. If the user wishes to attempt to build from source, this section will provide some reference. If errors are encountered, please contact the Apache Spark community.
+
+See the [Spark Installation](https://github.com/apache/spark/blob/master/README.md) guide for more detailed instructions.
+
+Return to the directory where you have been downloading, this tutorial assumes that is $HOME. Clone Spark, check out branch-1.6, and build.
+**Note:** Recall, we're only checking out 1.6 because it is the most recent Spark for which a Zeppelin profile exists at
+ the time of writing. You are free to check out other version, just make sure you build Zeppelin against the correct version of Spark. However if you use Spark 2.0, the word count example will need to be changed as Spark 2.0 is not compatible with the following examples.
+
+
+```
+cd $HOME
+```
+
+Clone, check out, and build Spark version 1.6.x.
+
+```
+git clone https://github.com/apache/spark.git
+cd spark
+git checkout branch-1.6
+mvn clean package -DskipTests
+```
+
+###### Start the Spark cluster
+
+Return to the `$HOME` directory.
+
+```bash
+cd $HOME
+```
+
+Start the Spark cluster in stand alone mode, specifying the webui-port as some port other than 8080 (the webui-port of Zeppelin).
+
+```
+spark/sbin/start-master.sh --webui-port 8082
+```
+**Note:** Why `--webui-port 8082`? There is a digression toward the end of this document that explains this.
+
+Open a browser and navigate to http://`yourip`:8082 to ensure the Spark master is running.
+
+
+
+Toward the top of the page there will be a *URL*: spark://`yourhost`:7077. Note this URL, the Spark Master URI, it will be needed in subsequent steps.
+
+Start the slave using the URI from the Spark master WebUI:
+
+```
+spark/sbin/start-slave.sh spark://yourhostname:7077
+```
+
+Return to the root directory and start the Zeppelin daemon.
+
+```
+cd $HOME
+
+zeppelin/bin/zeppelin-daemon.sh start
+```
+
+##### Configure Interpreters
+
+Open a web browser and go to the Zeppelin web-ui at http://yourip:8080.
+
+Now go back to the Zeppelin web-ui at http://`yourip`:8080 and this time click on *anonymous* at the top right, which will open a drop-down menu, select *Interpreters* to enter interpreter configuration.
+
+In the Spark section, click the edit button in the top right corner to make the property values editable (looks like a pencil).
+The only field that needs to be edited in the Spark interpreter is the master field. Change this value from `local[*]` to the URL you used to start the slave, mine was `spark://ubuntu:7077`.
+
+Click *Save* to update the parameters, and click *OK* when it asks you about restarting the interpreter.
+
+Now scroll down to the Flink section. Click the edit button and change the value of *host* from `local` to `localhost`. Click *Save* again.
+
+Reopen the examples and execute them again (I.e. you need to click the play button at the top of the screen, or the button on the paragraph .
+
+You should be able check the Flink and Spark webuis (at something like http://`yourip`:8081, http://`yourip`:8082, http://`yourip`:8083) and see that jobs have been run against the clusters.
+
+**Digression** Sorry to be vague and use terms such as 'something like', but exactly what web-ui is at what port is going to depend on what order you started things.
+ What is really going on here is you are pointing your browser at specific ports, namely 8081, 8082, and 8083. Flink and Spark all want to put their web-ui on port 8080, but are
+ well behaved and will take the next port available. Since Zeppelin started first, it will get port 8080. When Flink starts (assuming you started Flink first), it will try to bind to
+ port 8080, see that it is already taken, and go to the next one available, hopefully 8081. Spark has a webui for the master and the slave, so when they start they will try to bind to 8080
+ already taken by Zeppelin), then 8081 (already taken by Flink's webui), then 8082. If everything goes smoothy and you followed the directions precisely, the webuis should be 8081 and 8082.
+ It *is* possible to specify the port you want the webui to bind to (at the command line by passing the `--webui-port ` flag when you start the Flink and Spark, where `` is the port
+ you want to see that webui on. You can also set the default webui port of Spark and Flink (and Zeppelin) in the configuration files, but this is a tutorial for novices and slightly out of scope.
+
+
+
+### Next Steps
+
+Check out the [tutorial](./tutorial.html) for more cool things you can do with your new toy!
+
+[Join the community](http://zeppelin.apache.org/community.html), ask questions and contribute! Every little bit helps.
diff --git a/docs/quickstart/tutorial.md b/docs/quickstart/tutorial.md
index 9333d1437c7..4947f3ce8a0 100644
--- a/docs/quickstart/tutorial.md
+++ b/docs/quickstart/tutorial.md
@@ -1,7 +1,7 @@
---
layout: page
-title: "Tutorial"
-description: "Tutorial is valid for Spark 1.3 and higher"
+title: "Apache Zeppelin Tutorial"
+description: "This tutorial page contains a short walk-through tutorial that uses Apache Spark backend. Please note that this tutorial is valid for Spark 1.3 and higher."
group: quickstart
---
+{% include JB/setup %}
+
# Zeppelin Tutorial
diff --git a/docs/rest-api/rest-configuration.md b/docs/rest-api/rest-configuration.md
index 4323b6d0040..47c65f11d16 100644
--- a/docs/rest-api/rest-configuration.md
+++ b/docs/rest-api/rest-configuration.md
@@ -1,7 +1,7 @@
---
layout: page
-title: "Configuration REST API"
-description: ""
+title: "Apache Zeppelin Configuration REST API"
+description: "This page contains Apache Zeppelin Configuration REST API information."
group: rest-api
---
+{% include JB/setup %}
+
+# Apache Zeppelin Credential REST API
+
+
+
+## Overview
+Apache Zeppelin provides several REST APIs for interaction and remote activation of zeppelin functionality.
+All REST APIs are available starting with the following endpoint `http://[zeppelin-server]:[zeppelin-port]/api`.
+Note that Apache Zeppelin REST APIs receive or return JSON objects, it is recommended for you to install some JSON viewers such as [JSONView](https://chrome.google.com/webstore/detail/jsonview/chklaanhfefbnpoihckbnefhakgolnmc).
+
+If you work with Apache Zeppelin and find a need for an additional REST API, please [file an issue or send us an email](http://zeppelin.apache.org/community.html).
+
+
+## Credential REST API List + +### List Credential information +
+
+
+
+### Create an Credential Information +
+
+
+
+
+### Delete all Credential Information + +
+
+
+
+
+### Delete an Credential entity + +
+
+
+
+
+ diff --git a/docs/rest-api/rest-helium.md b/docs/rest-api/rest-helium.md new file mode 100644 index 00000000000..b78b5766879 --- /dev/null +++ b/docs/rest-api/rest-helium.md @@ -0,0 +1,378 @@ +--- +layout: page +title: "Apache Zeppelin Helium REST API" +description: "This page contains Apache Zeppelin Helium REST API information." +group: rest-api +--- + +{% include JB/setup %} + +# Apache Zeppelin Helium REST API + + + +## Overview +Apache Zeppelin provides several REST APIs for interaction and remote activation of zeppelin functionality. +All REST APIs are available starting with the following endpoint `http://[zeppelin-server]:[zeppelin-port]/api`. +Note that Apache Zeppelin REST APIs receive or return JSON objects, it is recommended for you to install some JSON viewers such as [JSONView](https://chrome.google.com/webstore/detail/jsonview/chklaanhfefbnpoihckbnefhakgolnmc). + +If you work with Apache Zeppelin and find a need for an additional REST API, please [file an issue or send us an email](http://zeppelin.apache.org/community.html). + +## Helium REST API List + +### List of all available helium packages + +
+
+
+
+### Suggest Helium application + +
+
+
+
+### Load helium Application on a paragraph + +
+
+
+
+### Load bundled visualization script + +
+
+
+
+### Enable package +
+
+
+
+### Disable package + +
+
+
+ +### Get visualization display order + +
+
+
+
+
+ +### Set visualization display order + +
+
\ No newline at end of file
diff --git a/docs/rest-api/rest-interpreter.md b/docs/rest-api/rest-interpreter.md
index bba7c9bd23c..d7dc6dd14a1 100644
--- a/docs/rest-api/rest-interpreter.md
+++ b/docs/rest-api/rest-interpreter.md
@@ -1,7 +1,7 @@
---
layout: page
-title: "Interpreter REST API"
-description: ""
+title: "Apache Zeppelin Interpreter REST API"
+description: "This page contains Apache Zeppelin Interpreter REST API information."
group: rest-api
---
+{% include JB/setup %}
+
+# Apache Zeppelin Notebook Repository API
+
+
+
+## Overview
+Apache Zeppelin provides several REST APIs for interaction and remote activation of zeppelin functionality.
+All REST APIs are available starting with the following endpoint `http://[zeppelin-server]:[zeppelin-port]/api`.
+Note that Apache Zeppelin REST APIs receive or return JSON objects, it is recommended for you to install some JSON viewers such as [JSONView](https://chrome.google.com/webstore/detail/jsonview/chklaanhfefbnpoihckbnefhakgolnmc).
+
+If you work with Apache Zeppelin and find a need for an additional REST API, please [file an issue or send us an email](http://zeppelin.apache.org/community.html).
+
+## Notebook Repository REST API List
+
+### List all available notebook repositories
+
+
+
+
+
+ +### Reload a notebook repository + +
+
+
+
+ +### Update a specific notebook repository + +
+
diff --git a/docs/rss.xml b/docs/rss.xml
index 106b649c273..8c2a9dd9a8c 100644
--- a/docs/rss.xml
+++ b/docs/rss.xml
@@ -1,6 +1,6 @@
---
layout: nil
-title : RSS Feed
+title :
---
diff --git a/docs/screenshots.md b/docs/screenshots.md
index 7a389b74c71..e7af542942e 100644
--- a/docs/screenshots.md
+++ b/docs/screenshots.md
@@ -1,7 +1,7 @@
---
layout: page
-title: "Screenshots"
-description: ""
+title:
+description:
---
+{% include JB/setup %}
+
+ +
+**Entity** can be the key that distinguishes each credential sets.(We suggest that the convention of the **Entity** is `[Interpreter Group].[Interpreter Name]`.)
+Please see [what is interpreter group](../manual/interpreters.html#what-is-interpreter-group) for the detailed information.
+
+Type **Username & Password** for your own credentials. ex) Mysql user & password of the JDBC Interpreter.
+
+
+
+**Entity** can be the key that distinguishes each credential sets.(We suggest that the convention of the **Entity** is `[Interpreter Group].[Interpreter Name]`.)
+Please see [what is interpreter group](../manual/interpreters.html#what-is-interpreter-group) for the detailed information.
+
+Type **Username & Password** for your own credentials. ex) Mysql user & password of the JDBC Interpreter.
+
+ +
+The credentials saved as per users defined in `conf/shiro.ini`.
+If you didn't activate [shiro authentication in Apache Zeppelin](./shiroauthentication.html), your credential information will be saved as `anonymous`.
+All credential information also can be found in `conf/credentials.json`.
+
+#### JDBC interpreter
+You need to maintain per-user connection pools.
+The interpret method takes the user string as a parameter and executes the jdbc call using a connection in the user's connection pool.
+
+#### Presto
+You don't need a password if the Presto DB server runs backend code using HDFS authorization for the user.
+
+#### Vertica and Mysql
+You have to store the password information for users.
+
+## Please note
+As a first step of data source authentication feature, [ZEPPELIN-828](https://issues.apache.org/jira/browse/ZEPPELIN-828) was proposed and implemented in Pull Request [#860](https://github.com/apache/zeppelin/pull/860).
+Currently, only customized 3rd party interpreters can use this feature. We are planning to apply this mechanism to [the community managed interpreters](../manual/interpreterinstallation.html#available-community-managed-interpreters) in the near future.
+Please keep track [ZEPPELIN-1070](https://issues.apache.org/jira/browse/ZEPPELIN-1070).
diff --git a/docs/security/interpreter_authorization.md b/docs/security/interpreter_authorization.md
deleted file mode 100644
index 6e59e0718a9..00000000000
--- a/docs/security/interpreter_authorization.md
+++ /dev/null
@@ -1,38 +0,0 @@
----
-layout: page
-title: "Notebook Authorization"
-description: "Notebook Authorization"
-group: security
----
-
-# Interpreter and Data Source Authorization
-
-
-
-## Interpreter Authorization
-
-Interpreter authorization involves permissions like creating an interpreter and execution queries using it.
-
-## Data Source Authorization
-
-Data source authorization involves authenticating to the data source like a Mysql database and letting it determine user permissions.
-
-For the JDBC interpreter, we need to maintain per-user connection pools.
-The interpret method takes the user string as parameter and executes the jdbc call using a connection in the user's connection pool.
-
-In case of Presto, we don't need password if the Presto DB server runs backend code using HDFS authorization for the user.
-For databases like Vertica and Mysql we have to store password information for users.
-
-The Credentials tab in the navbar allows users to save credentials for data sources which are passed to interpreters.
diff --git a/docs/security/notebook_authorization.md b/docs/security/notebook_authorization.md
index 87885676ef3..a22785441eb 100644
--- a/docs/security/notebook_authorization.md
+++ b/docs/security/notebook_authorization.md
@@ -1,7 +1,7 @@
---
layout: page
-title: "Notebook Authorization"
-description: "Notebook Authorization"
+title: "Notebook Authorization in Apache Zeppelin"
+description: "This page will guide you how you can set the permission for Zeppelin notebooks. This document assumes that Apache Shiro authentication was set up."
group: security
---
+{% include JB/setup %}
+
# Zeppelin Notebook Authorization
## Overview
-We assume that there is an **Shiro Authentication** component that associates a user string and a set of group strings with every NotebookSocket.
+We assume that there is an **Shiro Authentication** component that associates a user string and a set of group strings with every NotebookSocket.
If you don't set the authentication components yet, please check [Shiro authentication for Apache Zeppelin](./shiroauthentication.html) first.
## Authorization Setting
-You can set Zeppelin notebook permissions in each notebooks. Of course only **notebook owners** can change this configuration.
+You can set Zeppelin notebook permissions in each notebooks. Of course only **notebook owners** can change this configuration.
Just click **Lock icon** and open the permission setting page in your notebook.
-As you can see, each Zeppelin notebooks has 3 entities :
+As you can see, each Zeppelin notebooks has 3 entities :
* Owners ( users or groups )
* Readers ( users or groups )
@@ -40,16 +42,35 @@ As you can see, each Zeppelin notebooks has 3 entities :
Fill out the each forms with comma seperated **users** and **groups** configured in `conf/shiro.ini` file.
If the form is empty (*), it means that any users can perform that operation.
-If someone who doesn't have **read** permission is trying to access the notebook or someone who doesn't have **write** permission is trying to edit the notebook, Zeppelin will ask to login or block the user.
+If someone who doesn't have **read** permission is trying to access the notebook or someone who doesn't have **write** permission is trying to edit the notebook, Zeppelin will ask to login or block the user.
+
+The credentials saved as per users defined in `conf/shiro.ini`.
+If you didn't activate [shiro authentication in Apache Zeppelin](./shiroauthentication.html), your credential information will be saved as `anonymous`.
+All credential information also can be found in `conf/credentials.json`.
+
+#### JDBC interpreter
+You need to maintain per-user connection pools.
+The interpret method takes the user string as a parameter and executes the jdbc call using a connection in the user's connection pool.
+
+#### Presto
+You don't need a password if the Presto DB server runs backend code using HDFS authorization for the user.
+
+#### Vertica and Mysql
+You have to store the password information for users.
+
+## Please note
+As a first step of data source authentication feature, [ZEPPELIN-828](https://issues.apache.org/jira/browse/ZEPPELIN-828) was proposed and implemented in Pull Request [#860](https://github.com/apache/zeppelin/pull/860).
+Currently, only customized 3rd party interpreters can use this feature. We are planning to apply this mechanism to [the community managed interpreters](../manual/interpreterinstallation.html#available-community-managed-interpreters) in the near future.
+Please keep track [ZEPPELIN-1070](https://issues.apache.org/jira/browse/ZEPPELIN-1070).
diff --git a/docs/security/interpreter_authorization.md b/docs/security/interpreter_authorization.md
deleted file mode 100644
index 6e59e0718a9..00000000000
--- a/docs/security/interpreter_authorization.md
+++ /dev/null
@@ -1,38 +0,0 @@
----
-layout: page
-title: "Notebook Authorization"
-description: "Notebook Authorization"
-group: security
----
-
-# Interpreter and Data Source Authorization
-
-
-
-## Interpreter Authorization
-
-Interpreter authorization involves permissions like creating an interpreter and execution queries using it.
-
-## Data Source Authorization
-
-Data source authorization involves authenticating to the data source like a Mysql database and letting it determine user permissions.
-
-For the JDBC interpreter, we need to maintain per-user connection pools.
-The interpret method takes the user string as parameter and executes the jdbc call using a connection in the user's connection pool.
-
-In case of Presto, we don't need password if the Presto DB server runs backend code using HDFS authorization for the user.
-For databases like Vertica and Mysql we have to store password information for users.
-
-The Credentials tab in the navbar allows users to save credentials for data sources which are passed to interpreters.
diff --git a/docs/security/notebook_authorization.md b/docs/security/notebook_authorization.md
index 87885676ef3..a22785441eb 100644
--- a/docs/security/notebook_authorization.md
+++ b/docs/security/notebook_authorization.md
@@ -1,7 +1,7 @@
---
layout: page
-title: "Notebook Authorization"
-description: "Notebook Authorization"
+title: "Notebook Authorization in Apache Zeppelin"
+description: "This page will guide you how you can set the permission for Zeppelin notebooks. This document assumes that Apache Shiro authentication was set up."
group: security
---
+{% include JB/setup %}
+
# Zeppelin Notebook Authorization
## Overview
-We assume that there is an **Shiro Authentication** component that associates a user string and a set of group strings with every NotebookSocket.
+We assume that there is an **Shiro Authentication** component that associates a user string and a set of group strings with every NotebookSocket.
If you don't set the authentication components yet, please check [Shiro authentication for Apache Zeppelin](./shiroauthentication.html) first.
## Authorization Setting
-You can set Zeppelin notebook permissions in each notebooks. Of course only **notebook owners** can change this configuration.
+You can set Zeppelin notebook permissions in each notebooks. Of course only **notebook owners** can change this configuration.
Just click **Lock icon** and open the permission setting page in your notebook.
-As you can see, each Zeppelin notebooks has 3 entities :
+As you can see, each Zeppelin notebooks has 3 entities :
* Owners ( users or groups )
* Readers ( users or groups )
@@ -40,16 +42,35 @@ As you can see, each Zeppelin notebooks has 3 entities :
Fill out the each forms with comma seperated **users** and **groups** configured in `conf/shiro.ini` file.
If the form is empty (*), it means that any users can perform that operation.
-If someone who doesn't have **read** permission is trying to access the notebook or someone who doesn't have **write** permission is trying to edit the notebook, Zeppelin will ask to login or block the user.
+If someone who doesn't have **read** permission is trying to access the notebook or someone who doesn't have **write** permission is trying to edit the notebook, Zeppelin will ask to login or block the user.

+ zeppelin.notebook.public
+ false
+ Make notebook public by default when created, private otherwise
+
+```
+
+Behind the scenes, when you create a new note only the `owners` field is filled with current user, leaving `readers` and `writers` fields empty. All the notes with at least one empty authorization field are considered to be in `public` workspace. Thus when setting `zeppelin.notebook.public` (or corresponding `ZEPPELIN_NOTEBOOK_PUBLIC`) to false, newly created notes have `readers` and `writers` fields filled with current user, making note appear as in `private` workspace.
+
## How it works
In this section, we will explain the detail about how the notebook authorization works in backend side.
### NotebookServer
The [NotebookServer](https://github.com/apache/zeppelin/blob/master/zeppelin-server/src/main/java/org/apache/zeppelin/socket/NotebookServer.java) classifies every notebook operations into three categories: **Read**, **Write**, **Manage**.
-Before executing a notebook operation, it checks if the user and the groups associated with the `NotebookSocket` have permissions.
+Before executing a notebook operation, it checks if the user and the groups associated with the `NotebookSocket` have permissions.
For example, before executing a **Read** operation, it checks if the user and the groups have at least one entity that belongs to the **Reader** entities.
### Notebook REST API call
diff --git a/docs/security/shiroauthentication.md b/docs/security/shiroauthentication.md
index a7ddadd0c11..452600d3eb6 100644
--- a/docs/security/shiroauthentication.md
+++ b/docs/security/shiroauthentication.md
@@ -1,7 +1,7 @@
---
layout: page
-title: "Shiro Security for Apache Zeppelin"
-description: ""
+title: "Apache Shiro Authentication for Apache Zeppelin"
+description: "Apache Shiro is a powerful and easy-to-use Java security framework that performs authentication, authorization, cryptography, and session management. This document explains step by step how Shiro can be used for Zeppelin notebook authentication."
group: security
---
{% include JB/setup %}
-# Shiro authentication for Apache Zeppelin
+# Apache Shiro authentication for Apache Zeppelin
@@ -31,20 +31,12 @@ When you connect to Apache Zeppelin, you will be asked to enter your credentials
## Security Setup
You can setup **Zeppelin notebook authentication** in some simple steps.
-### 1. Secure the HTTP channel
-To secure the HTTP channel, you have to change both **anon** and **authc** settings in `conf/shiro.ini`. In here, **anon** means "the access is anonymous" and **authc** means "formed auth security".
-
-The default status of them is
-
-```
-/** = anon
-#/** = authc
-```
-Deactivate the line "/** = anon" and activate the line "/** = authc" in `conf/shiro.ini` file.
+### 1. Enable Shiro
+By default in `conf`, you will find `shiro.ini.template`, this file is used as an example and it is strongly recommended
+to create a `shiro.ini` file by doing the following command line
-```
-#/** = anon
-/** = authc
+```bash
+cp conf/shiro.ini.template conf/shiro.ini
```
For the further information about `shiro.ini` file format, please refer to [Shiro Configuration](http://shiro.apache.org/configuration.html#Configuration-INISections).
@@ -66,22 +58,27 @@ Finally, you can login using one of the below **username/password** combinations

-> **NOTE :** All of the above configurations are defined in the `conf/shiro.ini` file. This documentation is originally from [SECURITY-README.md](https://github.com/apache/zeppelin/blob/master/SECURITY-README.md). +> **NOTE :** All of the above configurations are defined in the `conf/shiro.ini` file. + + +## Other authentication methods + +- [HTTP Basic Authentication using NGINX](./authentication.html) diff --git a/docs/sitemap.txt b/docs/sitemap.txt index 360fa221c90..bda4c1b4b94 100644 --- a/docs/sitemap.txt +++ b/docs/sitemap.txt @@ -1,6 +1,6 @@ --- # Remember to set production_url in your _config.yml file! -title : Sitemap +title : --- {% for page in site.pages %} {{site.production_url}}{{ page.url }}{% endfor %} diff --git a/docs/storage/storage.md b/docs/storage/storage.md index 19ddd95af82..c99b135f9fb 100644 --- a/docs/storage/storage.md +++ b/docs/storage/storage.md @@ -1,7 +1,7 @@ --- layout: page -title: "Storage" -description: "Notebook Storage option for Zeppelin" +title: "Notebook Storage for Apache Zeppelin" +description: Apache Zeppelin has a pluggable notebook storage mechanism controlled by zeppelin.notebook.storage configuration option with multiple implementations." group: storage --- +{% include JB/setup %} + # Notebook storage options for Apache Zeppelin @@ -26,10 +28,12 @@ limitations under the License. Apache Zeppelin has a pluggable notebook storage mechanism controlled by `zeppelin.notebook.storage` configuration option with multiple implementations. There are few notebook storage systems available for a use out of the box: - * (default) all notes are saved in the notebook folder in your local File System - `VFSNotebookRepo` - * use local file system and version it using local Git repository - `GitNotebookRepo` + * (default) use local file system and version it using local Git repository - `GitNotebookRepo` + * all notes are saved in the notebook folder in your local File System - `VFSNotebookRepo` * storage using Amazon S3 service - `S3NotebookRepo` * storage using Azure service - `AzureNotebookRepo` + * storage using MongoDB - `MongoNotebookRepo` + * storage using HDFS - `HdfsNotebookRepo` Multiple storage systems can be used at the same time by providing a comma-separated list of the class-names in the configuration. By default, only first two of them will be automatically kept in sync by Zeppelin. @@ -98,13 +102,13 @@ Uncomment the next property for use S3NotebookRepo class: ``` -Comment out the next property to disable local notebook storage (the default): +Comment out the next property to disable local git notebook storage (the default): ```
zeppelin.notebook.storage
- org.apache.zeppelin.notebook.repo.VFSNotebookRepo
- notebook persistence layer implementation
+ org.apache.zeppelin.notebook.repo.GitNotebookRepo
+ versioned notebook persistence layer implementation
```
@@ -128,6 +132,23 @@ Or using the following setting in **zeppelin-site.xml**:
```
+In order to set custom KMS key region, set the following environment variable in the file **zeppelin-env.sh**:
+
+```
+export ZEPPELIN_NOTEBOOK_S3_KMS_KEY_REGION = kms-key-region
+```
+
+Or using the following setting in **zeppelin-site.xml**:
+
+```
+
+ zeppelin.notebook.s3.kmsKeyRegion
+ target-region
+ AWS KMS key region in your AWS account
+
+```
+Format of `target-region` is described in more details [here](http://docs.aws.amazon.com/general/latest/gr/rande.html#kms_region) in second `Region` column (e.g. `us-east-1`).
+
#### Custom Encryption Materials Provider class
You may use a custom [``EncryptionMaterialsProvider``](https://docs.aws.amazon.com/AWSJavaSDK/latest/javadoc/com/amazonaws/services/s3/model/EncryptionMaterialsProvider.html) class as long as it is available in the classpath and able to initialize itself from system properties or another mechanism. To use this, set the following environment variable in the file **zeppelin-env.sh**:
@@ -146,8 +167,26 @@ Or using the following setting in **zeppelin-site.xml**:
Custom encryption materials provider used to encrypt notebook data in S3
```
+#### Enable server-side encryption
+
+To request server-side encryption of notebooks, set the following environment variable in the file **zeppelin-env.sh**:
+
+```
+export ZEPPELIN_NOTEBOOK_S3_SSE = true
+```
+
+Or using the following setting in **zeppelin-site.xml**:
+
+```
+
+ zeppelin.notebook.s3.sse
+ true
+ Server-side encryption enabled for notebooks
+
+```
+
-## Notebook Storage in Azure
+## Notebook Storage in Azure
Using `AzureNotebookRepo` you can connect your Zeppelin with your Azure account for notebook storage.
@@ -172,8 +211,8 @@ Secondly, you can initialize `AzureNotebookRepo` class in the file **zeppelin-si
```
zeppelin.notebook.storage
- org.apache.zeppelin.notebook.repo.VFSNotebookRepo
- notebook persistence layer implementation
+ org.apache.zeppelin.notebook.repo.GitNotebookRepo
+ versioned notebook persistence layer implementation
```
@@ -187,12 +226,12 @@ and commenting out:
```
-In case you want to use simultaneously your local storage with Azure storage use the following property instead:
+In case you want to use simultaneously your local git storage with Azure storage use the following property instead:
```
zeppelin.notebook.storage
- org.apache.zeppelin.notebook.repo.VFSNotebookRepo, apache.zeppelin.notebook.repo.AzureNotebookRepo
+ org.apache.zeppelin.notebook.repo.GitNotebookRepo, apache.zeppelin.notebook.repo.AzureNotebookRepo
notebook persistence layer implementation
```
@@ -208,6 +247,31 @@ Optionally, you can specify Azure folder structure name in the file **zeppelin-s
```
+
+## Notebook Storage in Hdfs
+
+ To enable your notebooks to be stored on HDFS - uncomment the next property in `zeppelin-site.xml` in order to use HdfsNotebookRepo class:
+
+ ```
+
+ zeppelin.notebook.storage
+ org.apache.zeppelin.notebook.repo.HdfsNotebookRepo
+ notebook persistence layer implementation
+
+ ```
+
+ and replace the notebook directory property below by an absolute HDFS location as follows :
+ ```
+
+ zeppelin.notebook.dir
+ hdfs://localhost:9000/tmp/notebook
+ path or URI for notebook persist
+
+```
+
+
+
+
## Storage in ZeppelinHub
ZeppelinHub storage layer allows out of the box connection of Zeppelin instance with your ZeppelinHub account. First of all, you need to either comment out the following property in **zeppelin-site.xml**:
@@ -217,7 +281,7 @@ ZeppelinHub storage layer allows out of the box connection of Zeppelin instance
@@ -226,7 +290,7 @@ ZeppelinHub storage layer allows out of the box connection of Zeppelin instance
or set the environment variable in the file **zeppelin-env.sh**:
```
-export ZEPPELIN_NOTEBOOK_STORAGE="org.apache.zeppelin.notebook.repo.VFSNotebookRepo, org.apache.zeppelin.notebook.repo.zeppelinhub.ZeppelinHubRepo"
+export ZEPPELIN_NOTEBOOK_STORAGE="org.apache.zeppelin.notebook.repo.GitNotebookRepo, org.apache.zeppelin.notebook.repo.zeppelinhub.ZeppelinHubRepo"
```
Secondly, you need to set the environment variables in the file **zeppelin-env.sh**:
@@ -236,4 +300,73 @@ export ZEPPELINHUB_API_TOKEN = ZeppelinHub token
export ZEPPELINHUB_API_ADDRESS = address of ZeppelinHub service (e.g. https://www.zeppelinhub.com)
```
-You can get more information on generating `token` and using authentication on the corresponding [help page](http://help.zeppelinhub.com/zeppelin_integration/#add-a-new-zeppelin-instance-and-generate-a-token).
\ No newline at end of file
+You can get more information on generating `token` and using authentication on the corresponding [help page](http://help.zeppelinhub.com/zeppelin_integration/#add-a-new-zeppelin-instance-and-generate-a-token).
+
+
+## Notebook Storage in MongoDB
+Using `MongoNotebookRepo`, you can store your notebook in [MongoDB](https://www.mongodb.com/).
+
+### Why MongoDB?
+* **[High Availability (HA)](https://en.wikipedia.org/wiki/High_availability)** by a [replica set](https://docs.mongodb.com/manual/reference/glossary/#term-replica-set)
+* Seperation of storage from server
+
+### How to use
+You can use MongoDB as notebook storage by editting `zeppelin-env.sh` or `zeppelin-site.xml`.
+
+#### (Method 1) by editting `zeppelin-env.sh`
+Add a line below to `$ZEPPELIN_HOME/conf/zeppelin-env.sh`:
+
+```sh
+export ZEPPELIN_NOTEBOOK_STORAGE=org.apache.zeppelin.notebook.repo.MongoNotebookRepo
+```
+
+> *NOTE:* The default MongoDB connection URI is `mongodb://localhost`
+
+#### (Method 2) by editting `zeppelin-site.xml`
+Or, **uncomment** lines below at `$ZEPPELIN_HOME/conf/zeppelin-site.xml`:
+
+```xml
+
+ zeppelin.notebook.storage
+ org.apache.zeppelin.notebook.repo.MongoNotebookRepo
+ notebook persistence layer implementation
+
+```
+
+And **comment** lines below:
+
+```xml
+
+ zeppelin.notebook.storage
+ org.apache.zeppelin.notebook.repo.GitNotebookRepo
+ versioned notebook persistence layer implementation
+
+```
+
+### Configurable Options
+
+You can configure options below in `zeppelin-env.sh`.
+
+* `ZEPPELIN_NOTEBOOK_MONGO_URI` [MongoDB connection URI](https://docs.mongodb.com/manual/reference/connection-string/) used to connect to a MongoDB database server
+* `ZEPPELIN_NOTEBOOK_MONGO_DATABASE` Database name
+* `ZEPPELIN_NOTEBOOK_MONGO_COLLECTION` Collection name
+* `ZEPPELIN_NOTEBOOK_MONGO_AUTOIMPORT` If `true`, import local notes (refer to description below for details)
+
+Or, you can configure them in `zeppelin-site.xml`. Corresponding option names as follows:
+
+* `zeppelin.notebook.mongo.uri`
+* `zeppelin.notebook.mongo.database`
+* `zeppelin.notebook.mongo.collection`
+* `zeppelin.notebook.mongo.autoimport`
+
+#### Example configurations in `zeppelin-env.sh`
+
+```sh
+export ZEPPELIN_NOTEBOOK_MONGO_URI=mongodb://db1.example.com:27017
+export ZEPPELIN_NOTEBOOK_MONGO_DATABASE=myfancy
+export ZEPPELIN_NOTEBOOK_MONGO_COLLECTION=notebook
+export ZEPPELIN_NOTEBOOK_MONGO_AUTOIMPORT=true
+```
+
+#### Import your local notes automatically
+By setting `ZEPPELIN_NOTEBOOK_MONGO_AUTOIMPORT` as `true` (default `false`), you can import your local notes automatically when Zeppelin daemon starts up. This feature is for easy migration from local file system storage to MongoDB storage. A note with ID already existing in the collection will not be imported.
diff --git a/elasticsearch/pom.xml b/elasticsearch/pom.xml
index e5eefb9a911..6042a14eaee 100644
--- a/elasticsearch/pom.xml
+++ b/elasticsearch/pom.xml
@@ -22,20 +22,21 @@
zeppelin
org.apache.zeppelin
- 0.6.2-SNAPSHOT
+ 0.8.0-SNAPSHOT
..
- org.apache.zeppelin
zeppelin-elasticsearch
jar
- 0.6.2-SNAPSHOT
+ 0.8.0-SNAPSHOT
Zeppelin: Elasticsearch interpreter
- 2.3.3
+ 2.4.3
+ 4.0.2
18.0
0.1.6
+ 1.4.9
@@ -51,6 +52,12 @@
elasticsearch
${elasticsearch.version}
+
+
+ org.apache.httpcomponents
+ httpasyncclient
+ ${httpasyncclient.version}
+
com.google.guava
@@ -64,6 +71,12 @@
${json-flattener.version}
+
+ com.mashape.unirest
+ unirest-java
+ ${unirest.version}
+
+
org.slf4j
slf4j-api
@@ -80,8 +93,7 @@
maven-enforcer-plugin
- 1.3.1
-
+
enforce
none
@@ -91,7 +103,6 @@
maven-dependency-plugin
- 2.8
copy-dependencies
diff --git a/elasticsearch/src/main/java/org/apache/zeppelin/elasticsearch/ElasticsearchInterpreter.java b/elasticsearch/src/main/java/org/apache/zeppelin/elasticsearch/ElasticsearchInterpreter.java
index dfd27e59bca..33448df3db4 100644
--- a/elasticsearch/src/main/java/org/apache/zeppelin/elasticsearch/ElasticsearchInterpreter.java
+++ b/elasticsearch/src/main/java/org/apache/zeppelin/elasticsearch/ElasticsearchInterpreter.java
@@ -18,10 +18,10 @@
package org.apache.zeppelin.elasticsearch;
import java.io.IOException;
-import java.net.InetAddress;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
+import java.util.HashSet;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.List;
@@ -32,26 +32,21 @@
import java.util.regex.Matcher;
import java.util.regex.Pattern;
-import org.apache.commons.lang.StringUtils;
+import org.apache.commons.lang3.StringUtils;
+import org.apache.zeppelin.completer.CompletionType;
+import org.apache.zeppelin.elasticsearch.action.ActionResponse;
+import org.apache.zeppelin.elasticsearch.action.AggWrapper;
+import org.apache.zeppelin.elasticsearch.action.HitWrapper;
+import org.apache.zeppelin.elasticsearch.client.ElasticsearchClient;
+import org.apache.zeppelin.elasticsearch.client.HttpBasedClient;
+import org.apache.zeppelin.elasticsearch.client.TransportBasedClient;
import org.apache.zeppelin.interpreter.Interpreter;
import org.apache.zeppelin.interpreter.InterpreterContext;
-import org.apache.zeppelin.interpreter.InterpreterPropertyBuilder;
import org.apache.zeppelin.interpreter.InterpreterResult;
import org.apache.zeppelin.interpreter.thrift.InterpreterCompletion;
-import org.elasticsearch.action.delete.DeleteResponse;
-import org.elasticsearch.action.get.GetResponse;
-import org.elasticsearch.action.index.IndexResponse;
-import org.elasticsearch.action.search.SearchAction;
-import org.elasticsearch.action.search.SearchRequestBuilder;
-import org.elasticsearch.action.search.SearchResponse;
-import org.elasticsearch.client.Client;
-import org.elasticsearch.client.transport.TransportClient;
-import org.elasticsearch.common.settings.Settings;
-import org.elasticsearch.common.transport.InetSocketTransportAddress;
+import org.elasticsearch.common.xcontent.XContentBuilder;
+import org.elasticsearch.common.xcontent.XContentFactory;
import org.elasticsearch.common.xcontent.XContentHelper;
-import org.elasticsearch.index.query.QueryBuilders;
-import org.elasticsearch.search.SearchHit;
-import org.elasticsearch.search.SearchHitField;
import org.elasticsearch.search.aggregations.Aggregation;
import org.elasticsearch.search.aggregations.Aggregations;
import org.elasticsearch.search.aggregations.InternalMultiBucketAggregation;
@@ -64,7 +59,7 @@
import com.github.wnameless.json.flattener.JsonFlattener;
import com.google.gson.Gson;
import com.google.gson.GsonBuilder;
-import com.google.gson.JsonParseException;
+import com.google.gson.JsonObject;
/**
@@ -75,82 +70,82 @@ public class ElasticsearchInterpreter extends Interpreter {
private static Logger logger = LoggerFactory.getLogger(ElasticsearchInterpreter.class);
private static final String HELP = "Elasticsearch interpreter:\n"
- + "General format: ///
+
## Interpreter setting option
-Interpreter setting can choose one of 'shared', 'scoped', 'isolated' option. Spark interpreter creates separate scala compiler per each notebook but share a single SparkContext in 'scoped' mode (experimental). It creates separate SparkContext per each notebook in 'isolated' mode.
+You can choose one of `shared`, `scoped` and `isolated` options wheh you configure Spark interpreter. Spark interpreter creates separated Scala compiler per each notebook but share a single SparkContext in `scoped` mode (experimental). It creates separated SparkContext per each notebook in `isolated` mode.
## Setting up Zeppelin with Kerberos
@@ -365,14 +412,14 @@ Logical setup with Zeppelin, Kerberos Key Distribution Center (KDC), and Spark o
1. On the server that Zeppelin is installed, install Kerberos client modules and configuration, krb5.conf.
This is to make the server communicate with KDC.
-2. Set SPARK\_HOME in `[ZEPPELIN\_HOME]/conf/zeppelin-env.sh` to use spark-submit
-(Additionally, you might have to set `export HADOOP\_CONF\_DIR=/etc/hadoop/conf`)
+2. Set `SPARK_HOME` in `[ZEPPELIN_HOME]/conf/zeppelin-env.sh` to use spark-submit
+(Additionally, you might have to set `export HADOOP_CONF_DIR=/etc/hadoop/conf`)
-3. Add the two properties below to spark configuration (`[SPARK_HOME]/conf/spark-defaults.conf`):
+3. Add the two properties below to Spark configuration (`[SPARK_HOME]/conf/spark-defaults.conf`):
spark.yarn.principal
spark.yarn.keytab
- > **NOTE:** If you do not have access to the above spark-defaults.conf file, optionally, you may add the lines to the Spark Interpreter through the Interpreter tab in the Zeppelin UI.
+ > **NOTE:** If you do not have permission to access for the above spark-defaults.conf file, optionally, you can add the above lines to the Spark Interpreter setting through the Interpreter tab in the Zeppelin UI.
4. That's it. Play with Zeppelin!
diff --git a/docs/manual/dependencymanagement.md b/docs/manual/dependencymanagement.md
index acf6002e8f2..44068dae1fd 100644
--- a/docs/manual/dependencymanagement.md
+++ b/docs/manual/dependencymanagement.md
@@ -1,7 +1,7 @@
---
layout: page
-title: "Dependency Management"
-description: ""
+title: "Dependency Management for Apache Spark Interpreter"
+description: "Include external libraries to Apache Spark Interpreter by setting dependencies in interpreter menu."
group: manual
---
+{% include JB/setup %}
+
+# Interpreter Execution Hooks (Experimental)
+
+
+
+## Overview
+
+Apache Zeppelin allows for users to specify additional code to be executed by an interpreter at pre and post-paragraph code execution.
+This is primarily useful if you need to run the same set of code for all of the paragraphs within your notebook at specific times.
+Currently, this feature is only available for the spark and pyspark interpreters.
+To specify your hook code, you may use `z.registerHook()`.
+For example, enter the following into one paragraph:
+
+```python
+%pyspark
+z.registerHook("post_exec", "print 'This code should be executed before the parapgraph code!'")
+z.registerHook("pre_exec", "print 'This code should be executed after the paragraph code!'")
+```
+
+These calls will not take into effect until the next time you run a paragraph.
+
+
+In another paragraph, enter
+
+```python
+%pyspark
+print "This code should be entered into the paragraph by the user!"
+```
+
+The output should be:
+
+```
+This code should be executed before the paragraph code!
+This code should be entered into the paragraph by the user!
+This code should be executed after the paragraph code!
+```
+
+If you ever need to know the hook code, use `z.getHook()`:
+
+```python
+%pyspark
+print z.getHook("post_exec")
+
+print 'This code should be executed after the paragraph code!'
+```
+Any call to `z.registerHook()` will automatically overwrite what was previously registered.
+To completely unregister a hook event, use `z.unregisterHook(eventCode)`.
+Currently only `"post_exec"` and `"pre_exec"` are valid event codes for the Zeppelin Hook Registry system.
+
+Finally, the hook registry is internally shared by other interpreters in the same group.
+This would allow for hook code for one interpreter REPL to be set by another as follows:
+
+```scala
+%spark
+z.unregisterHook("post_exec", "pyspark")
+```
+
+The API is identical for both the spark (scala) and pyspark (python) implementations.
+
+### Caveats
+Calls to `z.registerHook("pre_exec", ...)` should be made with care. If there are errors in your specified hook code, this will cause the interpreter REPL to become unable to execute any code pass the pre-execute stage making it impossible for direct calls to `z.unregisterHook()` to take into effect. Current workarounds include calling `z.unregisterHook()` from a different interpreter REPL in the same interpreter group (see above) or manually restarting the interpreter group in the UI.
diff --git a/docs/manual/interpreterinstallation.md b/docs/manual/interpreterinstallation.md
index cfd58105a94..5825d1d6297 100644
--- a/docs/manual/interpreterinstallation.md
+++ b/docs/manual/interpreterinstallation.md
@@ -1,7 +1,7 @@
---
layout: page
-title: "Interpreter Installation"
-description: ""
+title: "Interpreter Installation in Netinst Binary Package"
+description: "Apache Zeppelin provides Interpreter Installation mechanism for whom downloaded Zeppelin netinst binary package, or just want to install another 3rd party interpreters."
group: manual
---
+{% include JB/setup %}
+
+## Run zeppelin interpreter process as web front end user
+
+ * Enable shiro auth in shiro.ini
+
+```
+[users]
+user1 = password1, role1
+user2 = password2, role2
+```
+
+ * Enable password-less ssh for the user you want to impersonate (say user1).
+
+```
+adduser user1
+#ssh-keygen (optional if you don't already have generated ssh-key.
+ssh user1@localhost mkdir -p .ssh
+cat ~/.ssh/id_rsa.pub | ssh user1@localhost 'cat >> .ssh/authorized_keys'
+```
+
+* Alternatively instead of password-less, user can override ZEPPELIN_IMPERSONATE_CMD in zeppelin-env.sh
+
+```
+export ZEPPELIN_IMPERSONATE_CMD='sudo -H -u ${ZEPPELIN_IMPERSONATE_USER} bash -c '
+```
+
+
+ * Start zeppelin server.
+
++
+
+
+ Screenshot
+
+
+ +
+
+  +
+
+
+
+
+
+
+
+
+ + + * Go to interpreter setting page, and enable "User Impersonate" in any of the interpreter (in my example its shell interpreter) + + * Test with a simple paragraph + +``` +%sh +whoami +``` + + +Note that usage of "User Impersonate" option will enable Spark interpreter to use `--proxy-user` option with current user by default. If you want to disable `--proxy-user` option, then refer to `ZEPPELIN_IMPERSONATE_SPARK_PROXY_USER` variable in `conf/zeppelin-env.sh` diff --git a/docs/pleasecontribute.md b/docs/pleasecontribute.md index 063b48f2bee..746b39dc87c 100644 --- a/docs/pleasecontribute.md +++ b/docs/pleasecontribute.md @@ -1,8 +1,8 @@ --- layout: page -title: "Please contribute" -description: "" -group: development +title: +description: +group: --- +{% include JB/setup %} + # Explore Apache Zeppelin UI ## Main home -The first time you connect to Zeppelin, you'll land at the main page similar to the below screen capture. +The first time you connect to Zeppelin ([default installations start on http://localhost:8080](http://localhost:8080/)), you'll land at the main page similar to the below screen capture.
diff --git a/docs/quickstart/install_with_flink_and_spark_cluster.md b/docs/quickstart/install_with_flink_and_spark_cluster.md
new file mode 100644
index 00000000000..89d6d6edc64
--- /dev/null
+++ b/docs/quickstart/install_with_flink_and_spark_cluster.md
@@ -0,0 +1,421 @@
+---
+layout: page
+title: "Install Zeppelin with Flink and Spark in cluster mode"
+description: "Tutorial is valid for Spark 1.6.x and Flink 1.1.2"
+group: tutorial
+---
+
+
+{% include JB/setup %}
+
+# Install with flink and spark cluster
+
+
+
+This tutorial is extremely entry-level. It assumes no prior knowledge of Linux, git, or other tools. If you carefully type what I tell you when I tell you, you should be able to get Zeppelin running.
+
+## Installing Zeppelin with Flink and Spark in cluster mode
+
+This tutorial assumes the user has a machine (real or [virtual](https://www.virtualbox.org/wiki/Downloads) with a fresh, minimal installation of [Ubuntu 14.04.3 Server](http://www.ubuntu.com/download/server).
+
+**Note:** On the size requirements of the Virtual Machine, some users reported trouble when using the default virtual machine sizes, specifically that the hard drive needed to be at least 16GB- other users did not have this issue.
+
+There are many good tutorials on how to install Ubuntu Server on a virtual box, [here is one of them](http://ilearnstack.com/2013/04/13/setting-ubuntu-vm-in-virtualbox/)
+
+### Required Programs
+
+Assuming the minimal install, there are several programs that we will need to install before Zeppelin, Flink, and Spark.
+
+- git
+- openssh-server
+- OpenJDK 7
+- Maven 3.1+
+
+For git, openssh-server, and OpenJDK 7 we will be using the apt package manager.
+
+##### git
+From the command prompt:
+
+```
+sudo apt-get install git
+```
+
+##### openssh-server
+
+```
+sudo apt-get install openssh-server
+```
+
+##### OpenJDK 7
+
+```
+sudo apt-get install openjdk-7-jdk openjdk-7-jre-lib
+```
+*A note for those using Ubuntu 16.04*: To install `openjdk-7` on Ubuntu 16.04, one must add a repository. [Source](http://askubuntu.com/questions/761127/ubuntu-16-04-and-openjdk-7)
+
+``` bash
+sudo add-apt-repository ppa:openjdk-r/ppa
+sudo apt-get update
+sudo apt-get install openjdk-7-jdk openjdk-7-jre-lib
+```
+
+##### Maven 3.1+
+Zeppelin requires maven version 3.x. The version available in the repositories at the time of writing is 2.x, so maven must be installed manually.
+
+Purge any existing versions of maven.
+
+```
+sudo apt-get purge maven maven2
+```
+
+Download the maven 3.3.9 binary.
+
+```
+wget "http://www.us.apache.org/dist/maven/maven-3/3.3.9/binaries/apache-maven-3.3.9-bin.tar.gz"
+```
+
+Unarchive the binary and move to the `/usr/local` directory.
+
+```
+tar -zxvf apache-maven-3.3.9-bin.tar.gz
+sudo mv ./apache-maven-3.3.9 /usr/local
+```
+
+Create symbolic links in `/usr/bin`.
+
+```
+sudo ln -s /usr/local/apache-maven-3.3.9/bin/mvn /usr/bin/mvn
+```
+
+### Installing Zeppelin
+This provides a quick overview of Zeppelin installation from source, however the reader is encouraged to review the [Zeppelin Installation Guide](../install/install.html)
+
+From the command prompt:
+Clone Zeppelin.
+
+```
+git clone https://github.com/apache/zeppelin.git
+```
+
+Enter the Zeppelin root directory.
+
+```
+cd zeppelin
+```
+
+Package Zeppelin.
+
+```
+mvn clean package -DskipTests -Pspark-1.6 -Dflink.version=1.1.3 -Pscala-2.10
+```
+
+`-DskipTests` skips build tests- you're not developing (yet), so you don't need to do tests, the clone version *should* build.
+
+`-Pspark-1.6` tells maven to build a Zeppelin with Spark 1.6. This is important because Zeppelin has its own Spark interpreter and the versions must be the same.
+
+`-Dflink.version=1.1.3` tells maven specifically to build Zeppelin with Flink version 1.1.3.
+
+-`-Pscala-2.10` tells maven to build with Scala v2.10.
+
+
+**Note:** You can build against any version of Spark that has a Zeppelin build profile available. The key is to make sure you check out the matching version of Spark to build. At the time of this writing, Spark 1.6 was the most recent Spark version available.
+
+**Note:** On build failures. Having installed Zeppelin close to 30 times now, I will tell you that sometimes the build fails for seemingly no reason.
+As long as you didn't edit any code, it is unlikely the build is failing because of something you did. What does tend to happen, is some dependency that maven is trying to download is unreachable. If your build fails on this step here are some tips:
+
+- Don't get discouraged.
+- Scroll up and read through the logs. There will be clues there.
+- Retry (that is, run the `mvn clean package -DskipTests -Pspark-1.6` again)
+- If there were clues that a dependency couldn't be downloaded wait a few hours or even days and retry again. Open source software when compiling is trying to download all of the dependencies it needs, if a server is off-line there is nothing you can do but wait for it to come back.
+- Make sure you followed all of the steps carefully.
+- Ask the community to help you. Go [here](http://zeppelin.apache.org/community.html) and join the user mailing list. People are there to help you. Make sure to copy and paste the build output (everything that happened in the console) and include that in your message.
+
+
+Start the Zeppelin daemon.
+
+```
+bin/zeppelin-daemon.sh start
+```
+
+Use `ifconfig` to determine the host machine's IP address. If you are not familiar with how to do this, a fairly comprehensive post can be found [here](http://www.cyberciti.biz/faq/how-to-find-out-the-ip-address-assigned-to-eth0-and-display-ip-only/).
+
+Open a web-browser on a machine connected to the same network as the host (or in the host operating system if using a virtual machine). Navigate to http://`yourip`:8080, where yourip is the IP address you found in `ifconfig`.
+
+See the [Zeppelin tutorial](../tutorial/tutorial.html) for basic Zeppelin usage. It is also advised that you take a moment to check out the tutorial notebook that is included with each Zeppelin install, and to familiarize yourself with basic notebook functionality.
+
+##### Flink Test
+Create a new notebook named "Flink Test" and copy and paste the following code.
+
+
+```scala
+
+%flink // let Zeppelin know what interpreter to use.
+
+val text = benv.fromElements("In the time of chimpanzees, I was a monkey", // some lines of text to analyze
+"Butane in my veins and I'm out to cut the junkie",
+"With the plastic eyeballs, spray paint the vegetables",
+"Dog food stalls with the beefcake pantyhose",
+"Kill the headlights and put it in neutral",
+"Stock car flamin' with a loser in the cruise control",
+"Baby's in Reno with the Vitamin D",
+"Got a couple of couches, sleep on the love seat",
+"Someone came in sayin' I'm insane to complain",
+"About a shotgun wedding and a stain on my shirt",
+"Don't believe everything that you breathe",
+"You get a parking violation and a maggot on your sleeve",
+"So shave your face with some mace in the dark",
+"Savin' all your food stamps and burnin' down the trailer park",
+"Yo, cut it")
+
+/* The meat and potatoes:
+ this tells Flink to iterate through the elements, in this case strings,
+ transform the string to lower case and split the string at white space into individual words
+ then finally aggregate the occurrence of each word.
+
+ This creates the count variable which is a list of tuples of the form (word, occurances)
+
+counts.collect().foreach(println(_)) // execute the script and print each element in the counts list
+
+*/
+val counts = text.flatMap{ _.toLowerCase.split("\\W+") }.map { (_,1) }.groupBy(0).sum(1)
+
+counts.collect().foreach(println(_)) // execute the script and print each element in the counts list
+
+```
+
+Run the code to make sure the built-in Zeppelin Flink interpreter is working properly.
+
+##### Spark Test
+Create a new notebook named "Spark Test" and copy and paste the following code.
+
+```scala
+%spark // let Zeppelin know what interpreter to use.
+
+val text = sc.parallelize(List("In the time of chimpanzees, I was a monkey", // some lines of text to analyze
+"Butane in my veins and I'm out to cut the junkie",
+"With the plastic eyeballs, spray paint the vegetables",
+"Dog food stalls with the beefcake pantyhose",
+"Kill the headlights and put it in neutral",
+"Stock car flamin' with a loser in the cruise control",
+"Baby's in Reno with the Vitamin D",
+"Got a couple of couches, sleep on the love seat",
+"Someone came in sayin' I'm insane to complain",
+"About a shotgun wedding and a stain on my shirt",
+"Don't believe everything that you breathe",
+"You get a parking violation and a maggot on your sleeve",
+"So shave your face with some mace in the dark",
+"Savin' all your food stamps and burnin' down the trailer park",
+"Yo, cut it"))
+
+
+/* The meat and potatoes:
+ this tells spark to iterate through the elements, in this case strings,
+ transform the string to lower case and split the string at white space into individual words
+ then finally aggregate the occurrence of each word.
+
+ This creates the count variable which is a list of tuples of the form (word, occurances)
+*/
+val counts = text.flatMap { _.toLowerCase.split("\\W+") }
+ .map { (_,1) }
+ .reduceByKey(_ + _)
+
+counts.collect().foreach(println(_)) // execute the script and print each element in the counts list
+```
+
+Run the code to make sure the built-in Zeppelin Flink interpreter is working properly.
+
+Finally, stop the Zeppelin daemon. From the command prompt run:
+
+```
+bin/zeppelin-daemon.sh stop
+```
+
+### Installing Clusters
+
+##### Flink Cluster
+
+###### Download Binaries
+
+Building from source is recommended where possible, for simplicity in this tutorial we will download Flink and Spark Binaries.
+
+To download the Flink Binary use `wget`
+
+```bash
+wget "http://mirror.cogentco.com/pub/apache/flink/flink-1.1.3/flink-1.1.3-bin-hadoop24-scala_2.10.tgz"
+tar -xzvf flink-1.1.3-bin-hadoop24-scala_2.10.tgz
+```
+
+This will download Flink 1.1.3, compatible with Hadoop 2.4. You do not have to install Hadoop for this binary to work, but if you are using Hadoop, please change `24` to your appropriate version.
+
+Start the Flink Cluster.
+
+```bash
+flink-1.1.3/bin/start-cluster.sh
+```
+
+###### Building From source
+
+If you wish to build Flink from source, the following will be instructive. Note that if you have downloaded and used the binary version this should be skipped. The changing nature of build tools and versions across platforms makes this section somewhat precarious. For example, Java8 and Maven 3.0.3 are recommended for building Flink, which are not recommended for Zeppelin at the time of writing. If the user wishes to attempt to build from source, this section will provide some reference. If errors are encountered, please contact the Apache Flink community.
+
+See the [Flink Installation guide](https://github.com/apache/flink/blob/master/README.md) for more detailed instructions.
+
+Return to the directory where you have been downloading, this tutorial assumes that is `$HOME`. Clone Flink, check out release-1.1.3-rc2, and build.
+
+```
+cd $HOME
+git clone https://github.com/apache/flink.git
+cd flink
+git checkout release-1.1.3-rc2
+mvn clean install -DskipTests
+```
+
+Start the Flink Cluster in stand-alone mode
+
+```
+build-target/bin/start-cluster.sh
+```
+
+###### Ensure the cluster is up
+
+In a browser, navigate to http://`yourip`:8082 to see the Flink Web-UI. Click on 'Task Managers' in the left navigation bar. Ensure there is at least one Task Manager present.
+
++## Credential REST API List + +### List Credential information +
| Description | +This ```GET``` method returns all key/value pairs of the credential information on the server. | +
| URL | +```http://[zeppelin-server]:[zeppelin-port]/api/credential``` | +
| Success code | +200 | +
| Fail code | +500 | +
| sample JSON response + | +
+
+{
+ "status": "OK",
+ "message": "",
+ "body": {
+ "userCredentials":{
+ "entity1":{
+ "username":"user1",
+ "password":"password1"
+ },
+ "entity2":{
+ "username":"user2",
+ "password":"password2"
+ }
+ }
+ }
+} |
+
+### Create an Credential Information +
| Description | +This ```PUT``` method creates the credential information with new properties. | +
| URL | +```http://[zeppelin-server]:[zeppelin-port]/api/credential/``` | +
| Success code | +200 | +
| Fail code | +500 | +
| Sample JSON input | +
+
+{
+ "entity": "e1",
+ "username": "user",
+ "password": "password"
+}
+
+ |
+
| Sample JSON response | +
+
+{
+ "status": "OK"
+}
+
+ |
+
+### Delete all Credential Information + +
| Description | +This ```DELETE``` method deletes the credential information. | +
| URL | +```http://[zeppelin-server]:[zeppelin-port]/api/credential``` | +
| Success code | +200 | +
| Fail code | +500 | +
| Sample JSON response | +
+ {"status":"OK"}
+ |
+
+### Delete an Credential entity + +
| Description | +This ```DELETE``` method deletes a given credential entity. | +
| URL | +```http://[zeppelin-server]:[zeppelin-port]/api/credential/[entity]``` | +
| Success code | +200 | +
| Fail code | +500 | +
| Sample JSON response | +
+ {"status":"OK"}
+ |
+
+ diff --git a/docs/rest-api/rest-helium.md b/docs/rest-api/rest-helium.md new file mode 100644 index 00000000000..b78b5766879 --- /dev/null +++ b/docs/rest-api/rest-helium.md @@ -0,0 +1,378 @@ +--- +layout: page +title: "Apache Zeppelin Helium REST API" +description: "This page contains Apache Zeppelin Helium REST API information." +group: rest-api +--- + +{% include JB/setup %} + +# Apache Zeppelin Helium REST API + + + +## Overview +Apache Zeppelin provides several REST APIs for interaction and remote activation of zeppelin functionality. +All REST APIs are available starting with the following endpoint `http://[zeppelin-server]:[zeppelin-port]/api`. +Note that Apache Zeppelin REST APIs receive or return JSON objects, it is recommended for you to install some JSON viewers such as [JSONView](https://chrome.google.com/webstore/detail/jsonview/chklaanhfefbnpoihckbnefhakgolnmc). + +If you work with Apache Zeppelin and find a need for an additional REST API, please [file an issue or send us an email](http://zeppelin.apache.org/community.html). + +## Helium REST API List + +### List of all available helium packages + +
| Description | +This ```GET``` method returns all the available helium packages in configured registries. | +
| URL | +```http://[zeppelin-server]:[zeppelin-port]/api/helium/all``` | +
| Success code | +200 | +
| Fail code | +500 | +
| Sample JSON response | +
+
+{
+ "status": "OK",
+ "message": "",
+ "body": {
+ "zeppelin.clock": [
+ {
+ "registry": "local",
+ "pkg": {
+ "type": "APPLICATION",
+ "name": "zeppelin.clock",
+ "description": "Clock (example)",
+ "artifact": "zeppelin-examples\/zeppelin-example-clock\/target\/zeppelin-example-clock-0.7.0-SNAPSHOT.jar",
+ "className": "org.apache.zeppelin.example.app.clock.Clock",
+ "resources": [
+ [
+ ":java.util.Date"
+ ]
+ ],
+ "icon": "icon"
+ },
+ "enabled": false
+ }
+ ],
+ "zeppelin-bubblechart": [
+ {
+ "registry": "local",
+ "pkg": {
+ "type": "VISUALIZATION",
+ "name": "zeppelin-bubblechart",
+ "description": "Animated bubble chart",
+ "artifact": ".\/..\/helium\/zeppelin-bubble",
+ "icon": "icon"
+ },
+ "enabled": true
+ },
+ {
+ "registry": "local",
+ "pkg": {
+ "type": "VISUALIZATION",
+ "name": "zeppelin-bubblechart",
+ "description": "Animated bubble chart",
+ "artifact": "zeppelin-bubblechart@0.0.2",
+ "icon": "icon"
+ },
+ "enabled": false
+ }
+ ],
+ "zeppelin\_horizontalbar": [
+ {
+ "registry": "local",
+ "pkg": {
+ "type": "VISUALIZATION",
+ "name": "zeppelin_horizontalbar",
+ "description": "Horizontal Bar chart (example)",
+ "artifact": ".\/zeppelin-examples\/zeppelin-example-horizontalbar",
+ "icon": "icon"
+ },
+ "enabled": true
+ }
+ ]
+ }
+}
+
+ |
+
+### Suggest Helium application + +
| Description | +This ```GET``` method returns suggested helium application for the paragraph. | +
| URL | +```http://[zeppelin-server]:[zeppelin-port]/api/helium/suggest/[Note ID]/[Paragraph ID]``` | +
| Success code | +200 | +
| Fail code | +
+ 404 on note or paragraph not exists + 500 + |
+
| Sample JSON response | +
+
+{
+ "status": "OK",
+ "message": "",
+ "body": {
+ "available": [
+ {
+ "registry": "local",
+ "pkg": {
+ "type": "APPLICATION",
+ "name": "zeppelin.clock",
+ "description": "Clock (example)",
+ "artifact": "zeppelin-examples\/zeppelin-example-clock\/target\/zeppelin-example-clock-0.7.0-SNAPSHOT.jar",
+ "className": "org.apache.zeppelin.example.app.clock.Clock",
+ "resources": [
+ [
+ ":java.util.Date"
+ ]
+ ],
+ "icon": "icon"
+ },
+ "enabled": true
+ }
+ ]
+ }
+}
+
+ |
+
+### Load helium Application on a paragraph + +
| Description | +This ```GET``` method returns a helium Application id on success. | +
| URL | +```http://[zeppelin-server]:[zeppelin-port]/api/helium/load/[Note ID]/[Paragraph ID]``` | +
| Success code | +200 | +
| Fail code | +
+ 404 on note or paragraph not exists + 500 for any other errors + |
+
| Sample JSON response | +
+
+{
+ "status": "OK",
+ "message": "",
+ "body": "app_2C5FYRZ1E-20170108-040449_2068241472zeppelin_clock"
+}
+
+ |
+
+### Load bundled visualization script + +
| Description | +This ```GET``` method returns bundled helium visualization javascript. When refresh=true (optional) is provided, Zeppelin rebuild bundle. otherwise, provided from cache | +
| URL | +```http://[zeppelin-server]:[zeppelin-port]/api/helium/visualizations/load[?refresh=true]``` | +
| Success code | +200 reponse body is executable javascript | +
| Fail code | +
+ 200 reponse body is error message string starts with ERROR: + |
+
+### Enable package +
| Description | +This ```POST``` method enables a helium package. Needs artifact name in input payload | +
| URL | +```http://[zeppelin-server]:[zeppelin-port]/api/helium/enable/[Package Name]``` | +
| Success code | +200 | +
| Fail code | +500 | +
| Sample input | +
+ +zeppelin-examples/zeppelin-example-clock/target/zeppelin-example-clock-0.7.0-SNAPSHOT.jar ++ |
+
| Sample JSON response | +
+
+{"status":"OK"}
+
+ |
+
+### Disable package + +
| Description | +This ```POST``` method disables a helium package. | +
| URL | +```http://[zeppelin-server]:[zeppelin-port]/api/helium/disable/[Package Name]``` | +
| Success code | +200 | +
| Fail code | +500 | +
| Sample JSON response | +
+ {"status":"OK"}
+ |
+
+ +### Get visualization display order + +
| Description | +This ```GET``` method returns display order of enabled visualization packages. | +
| URL | +```http://[zeppelin-server]:[zeppelin-port]/api/helium/visualizationOrder``` | +
| Success code | +200 | +
| Fail code | +500 | +
| Sample JSON response | +
+ {"status":"OK","body":["zeppelin_horizontalbar","zeppelin-bubblechart"]}
+ |
+
+ +### Set visualization display order + +
| Description | +This ```POST``` method sets visualization packages display order. | +
| URL | +```http://[zeppelin-server]:[zeppelin-port]/api/helium/visualizationOrder``` | +
| Success code | +200 | +
| Fail code | +500 | +
| Sample JSON input | +
+ ["zeppelin-bubblechart", "zeppelin_horizontalbar"]
+ |
+
| Sample JSON response | +
+ {"status":"OK"}
+ |
+
| Description | +This ```GET``` method returns all the available notebook repositories. | +
| URL | +```http://[zeppelin-server]:[zeppelin-port]/api/notebook-repositories``` | +
| Success code | +200 | +
| Fail code | +500 | +
| Sample JSON response | +
+
+{
+ "status": "OK",
+ "message": "",
+ "body": [
+ {
+ "name": "GitNotebookRepo",
+ "className": "org.apache.zeppelin.notebook.repo.GitNotebookRepo",
+ "settings": [
+ {
+ "type": "INPUT",
+ "value": [],
+ "selected": "ZEPPELIN_HOME/zeppelin/notebook/",
+ "name": "Notebook Path"
+ }
+ ]
+ }
+ ]
+}
+
+ |
+
+ +### Reload a notebook repository + +
| Description | +This ```GET``` method triggers reloading and broadcasting of the note list. | +
| URL | +```http://[zeppelin-server]:[zeppelin-port]/api/notebook-repositories/reload``` | +
| Success code | +200 | +
| Fail code | +500 | +
| Sample JSON response | +
+
+{
+ "status": "OK",
+ "message": ""
+}
+
+ |
+
+ +### Update a specific notebook repository + +
| Description | +This ```PUT``` method updates a specific notebook repository. | +
| URL | +```http://[zeppelin-server]:[zeppelin-port]/api/notebook-repositories``` | +
| Success code | +200 | +
| Fail code | +
+ 404 when the specified notebook repository doesn't exist + 406 for invalid payload + 500 for any other errors + |
+
| Sample JSON input | +
+
+{
+ "name":"org.apache.zeppelin.notebook.repo.GitNotebookRepo",
+ "settings":{
+ "Notebook Path":"/tmp/notebook/"
+ }
+}
+
+ |
+
| Sample JSON response | +
+
+{
+ "status": "OK",
+ "message": "",
+ "body": {
+ "name": "GitNotebookRepo",
+ "className": "org.apache.zeppelin.notebook.repo.GitNotebookRepo",
+ "settings": [
+ {
+ "type": "INPUT",
+ "value": [],
+ "selected": "/tmp/notebook/",
+ "name": "Notebook Path"
+ }
+ ]
+ }
+}
+
+ |
+
+
+
+
+ + + +
+ + +
diff --git a/docs/search_data.json b/docs/search_data.json
new file mode 100644
index 00000000000..3df19e958d6
--- /dev/null
+++ b/docs/search_data.json
@@ -0,0 +1,17 @@
+---
+layout: null
+---
+{
+ {% for page in site.pages %}{% if page.title != nil %}
+
+ "{{ page.url | slugify }}": {
+ "title": "{{ page.title | xml_escape }}",
+ "content" : "{{page.content | strip_html | strip_newlines | escape | remove: "\"}}",
+ "url": " {{ page.url | xml_escape }}",
+ "group": "{{ page.group }}",
+ "excerpt": {{ page.description | strip_html | truncatewords: 40 | jsonify }}
+ }
+ {% unless forloop.last %},{% endunless %}
+ {% endif %}
+ {% endfor %}
+}
diff --git a/docs/security/authentication.md b/docs/security/authentication.md
index 7ce160aa2b5..2723c56d307 100644
--- a/docs/security/authentication.md
+++ b/docs/security/authentication.md
@@ -1,7 +1,7 @@
---
layout: page
title: "Authentication for NGINX"
-description: "Authentication for NGINX"
+description: "There are multiple ways to enable authentication in Apache Zeppelin. This page describes HTTP basic auth using NGINX."
group: security
---
+{% include JB/setup %}
+
# Authentication for NGINX
-Authentication is company-specific.
-One option is to use [Basic Access Authentication](https://en.wikipedia.org/wiki/Basic_access_authentication).
+[Build in authentication mechanism](./shiroauthentication.html) is recommended way for authentication. In case of you want authenticate using NGINX and [HTTP basic auth](https://en.wikipedia.org/wiki/Basic_access_authentication), please read this document.
## HTTP Basic Authentication using NGINX
@@ -83,7 +84,7 @@ This instruction based on Ubuntu 14.04 LTS but may work with other OS with few c
}
location /ws { # For websocket support
- proxy_pass http://zeppelin;
+ proxy_pass http://zeppelin/ws;
proxy_http_version 1.1;
proxy_set_header Upgrade websocket;
proxy_set_header Connection upgrade;
@@ -128,4 +129,4 @@ This instruction based on Ubuntu 14.04 LTS but may work with other OS with few c
Another option is to have an authentication server that can verify user credentials in an LDAP server.
If an incoming request to the Zeppelin server does not have a cookie with user information encrypted with the authentication server public key, the user
is redirected to the authentication server. Once the user is verified, the authentication server redirects the browser to a specific URL in the Zeppelin server which sets the authentication cookie in the browser.
-The end result is that all requests to the Zeppelin web server have the authentication cookie which contains user and groups information.
\ No newline at end of file
+The end result is that all requests to the Zeppelin web server have the authentication cookie which contains user and groups information.
diff --git a/docs/security/datasource_authorization.md b/docs/security/datasource_authorization.md
new file mode 100644
index 00000000000..03165c8ac27
--- /dev/null
+++ b/docs/security/datasource_authorization.md
@@ -0,0 +1,64 @@
+---
+layout: page
+title: "Data Source Authorization in Apache Zeppelin"
+description: "Apache Zeppelin supports protected data sources. In case of a MySql database, every users can set up their own credentials to access it."
+group: security
+---
+
+{% include JB/setup %}
+
+# Data Source Authorization in Apache Zeppelin
+
+
+
+## Overview
+
+Data source authorization involves authenticating to the data source like a Mysql database and letting it determine user permissions.
+Apache Zeppelin allows users to use their own credentials to authenticate with **Data Sources**.
+
+For example, let's assume you have an account in the Vertica databases with credentials.
+You might want to use this account to create a JDBC connection instead of a shared account with all users who are defined in `conf/shiro.ini`.
+In this case, you can add your credential information to Apache Zeppelin and use them with below simple steps.
+
+## How to save the credential information?
+You can add new credentials in the dropdown menu for your data source which can be passed to interpreters.
+
+Search Docs
+ ++ + + +
+ + +
+
+**Entity** can be the key that distinguishes each credential sets.(We suggest that the convention of the **Entity** is `[Interpreter Group].[Interpreter Name]`.)
+Please see [what is interpreter group](../manual/interpreters.html#what-is-interpreter-group) for the detailed information.
+
+Type **Username & Password** for your own credentials. ex) Mysql user & password of the JDBC Interpreter.
+
+
+
+The credentials saved as per users defined in `conf/shiro.ini`.
+If you didn't activate [shiro authentication in Apache Zeppelin](./shiroauthentication.html), your credential information will be saved as `anonymous`.
+All credential information also can be found in `conf/credentials.json`.
+
+#### JDBC interpreter
+You need to maintain per-user connection pools.
+The interpret method takes the user string as a parameter and executes the jdbc call using a connection in the user's connection pool.
+
+#### Presto
+You don't need a password if the Presto DB server runs backend code using HDFS authorization for the user.
+
+#### Vertica and Mysql
+You have to store the password information for users.
+
+## Please note
+As a first step of data source authentication feature, [ZEPPELIN-828](https://issues.apache.org/jira/browse/ZEPPELIN-828) was proposed and implemented in Pull Request [#860](https://github.com/apache/zeppelin/pull/860).
+Currently, only customized 3rd party interpreters can use this feature. We are planning to apply this mechanism to [the community managed interpreters](../manual/interpreterinstallation.html#available-community-managed-interpreters) in the near future.
+Please keep track [ZEPPELIN-1070](https://issues.apache.org/jira/browse/ZEPPELIN-1070).
diff --git a/docs/security/interpreter_authorization.md b/docs/security/interpreter_authorization.md
deleted file mode 100644
index 6e59e0718a9..00000000000
--- a/docs/security/interpreter_authorization.md
+++ /dev/null
@@ -1,38 +0,0 @@
----
-layout: page
-title: "Notebook Authorization"
-description: "Notebook Authorization"
-group: security
----
-
-# Interpreter and Data Source Authorization
-
-
-
-## Interpreter Authorization
-
-Interpreter authorization involves permissions like creating an interpreter and execution queries using it.
-
-## Data Source Authorization
-
-Data source authorization involves authenticating to the data source like a Mysql database and letting it determine user permissions.
-
-For the JDBC interpreter, we need to maintain per-user connection pools.
-The interpret method takes the user string as parameter and executes the jdbc call using a connection in the user's connection pool.
-
-In case of Presto, we don't need password if the Presto DB server runs backend code using HDFS authorization for the user.
-For databases like Vertica and Mysql we have to store password information for users.
-
-The Credentials tab in the navbar allows users to save credentials for data sources which are passed to interpreters.
diff --git a/docs/security/notebook_authorization.md b/docs/security/notebook_authorization.md
index 87885676ef3..a22785441eb 100644
--- a/docs/security/notebook_authorization.md
+++ b/docs/security/notebook_authorization.md
@@ -1,7 +1,7 @@
---
layout: page
-title: "Notebook Authorization"
-description: "Notebook Authorization"
+title: "Notebook Authorization in Apache Zeppelin"
+description: "This page will guide you how you can set the permission for Zeppelin notebooks. This document assumes that Apache Shiro authentication was set up."
group: security
---
+{% include JB/setup %}
+
# Zeppelin Notebook Authorization
## Overview
-We assume that there is an **Shiro Authentication** component that associates a user string and a set of group strings with every NotebookSocket.
+We assume that there is an **Shiro Authentication** component that associates a user string and a set of group strings with every NotebookSocket.
If you don't set the authentication components yet, please check [Shiro authentication for Apache Zeppelin](./shiroauthentication.html) first.
## Authorization Setting
-You can set Zeppelin notebook permissions in each notebooks. Of course only **notebook owners** can change this configuration.
+You can set Zeppelin notebook permissions in each notebooks. Of course only **notebook owners** can change this configuration.
Just click **Lock icon** and open the permission setting page in your notebook.
-As you can see, each Zeppelin notebooks has 3 entities :
+As you can see, each Zeppelin notebooks has 3 entities :
* Owners ( users or groups )
* Readers ( users or groups )
@@ -40,16 +42,35 @@ As you can see, each Zeppelin notebooks has 3 entities :
Fill out the each forms with comma seperated **users** and **groups** configured in `conf/shiro.ini` file.
If the form is empty (*), it means that any users can perform that operation.
-If someone who doesn't have **read** permission is trying to access the notebook or someone who doesn't have **write** permission is trying to edit the notebook, Zeppelin will ask to login or block the user.
+If someone who doesn't have **read** permission is trying to access the notebook or someone who doesn't have **write** permission is trying to edit the notebook, Zeppelin will ask to login or block the user.
-> **NOTE :** All of the above configurations are defined in the `conf/shiro.ini` file. This documentation is originally from [SECURITY-README.md](https://github.com/apache/zeppelin/blob/master/SECURITY-README.md). +> **NOTE :** All of the above configurations are defined in the `conf/shiro.ini` file. + + +## Other authentication methods + +- [HTTP Basic Authentication using NGINX](./authentication.html) diff --git a/docs/sitemap.txt b/docs/sitemap.txt index 360fa221c90..bda4c1b4b94 100644 --- a/docs/sitemap.txt +++ b/docs/sitemap.txt @@ -1,6 +1,6 @@ --- # Remember to set production_url in your _config.yml file! -title : Sitemap +title : --- {% for page in site.pages %} {{site.production_url}}{{ page.url }}{% endfor %} diff --git a/docs/storage/storage.md b/docs/storage/storage.md index 19ddd95af82..c99b135f9fb 100644 --- a/docs/storage/storage.md +++ b/docs/storage/storage.md @@ -1,7 +1,7 @@ --- layout: page -title: "Storage" -description: "Notebook Storage option for Zeppelin" +title: "Notebook Storage for Apache Zeppelin" +description: Apache Zeppelin has a pluggable notebook storage mechanism controlled by zeppelin.notebook.storage configuration option with multiple implementations." group: storage --- +{% include JB/setup %} + # Notebook storage options for Apache Zeppelin @@ -26,10 +28,12 @@ limitations under the License. Apache Zeppelin has a pluggable notebook storage mechanism controlled by `zeppelin.notebook.storage` configuration option with multiple implementations. There are few notebook storage systems available for a use out of the box: - * (default) all notes are saved in the notebook folder in your local File System - `VFSNotebookRepo` - * use local file system and version it using local Git repository - `GitNotebookRepo` + * (default) use local file system and version it using local Git repository - `GitNotebookRepo` + * all notes are saved in the notebook folder in your local File System - `VFSNotebookRepo` * storage using Amazon S3 service - `S3NotebookRepo` * storage using Azure service - `AzureNotebookRepo` + * storage using MongoDB - `MongoNotebookRepo` + * storage using HDFS - `HdfsNotebookRepo` Multiple storage systems can be used at the same time by providing a comma-separated list of the class-names in the configuration. By default, only first two of them will be automatically kept in sync by Zeppelin. @@ -98,13 +102,13 @@ Uncomment the next property for use S3NotebookRepo class: ``` -Comment out the next property to disable local notebook storage (the default): +Comment out the next property to disable local git notebook storage (the default): ```