[RFC] Dynamic Shape Support - Graph Dispatching #4118
Comments
|
Thanks a lot for working on this, this is going to be really impactful, especially toward supporting NLP models. I have a couple of questions:
|
|
Thanks for the proposal. One high level comment: ideally we want to keep the module API minimum, and move transformation-like operations to the transform namespace :) |
|
|
@soiferj For |
|
@tqchen Sure. Dispatch function doesn't need to couple with relay::Module. |
|
any progress update about this feature? Thanks |
|
I'm still curious what will happen if we have conv2d(5, 3, 224, 224)? We'll use conv2d(8, 3, 224, 224)? Do we need to do some padding to use the kernel conv2d(8, 3, 224, 224)? Thanks @kevinthesun for the clarification. |
|
@zhanghaohit This feature is one part of dynamic codegen. We are working some significant backend features and will update this later. |
|
@kevinthesun Any timeframe? Off topic, I want to mention TensorRT supports dynamic shape from 7.0. To provide better performance, it supports multiple optimization profiles for different shape range. Say your input is 1d ranged from 1 to 1024. You can create profiles whatever shape you specified, overlap or non-overlap, e.g. Users can manually select profile to use. In terms of https://sampl.cs.washington.edu/tvmconf/slides/2019/Jared-Roesch-Haichen-Shen-RelayVM.pdf I have some questions, |
|
@cloudhan Thanks for your info. @icemelon9 Do we have any work related to dynamic axis range? In terms of codegen, indeed efficiency(and also how to limit the number of buckets but loss less performance) is one of the difficult part. We are working on improving some fundamental infra to see how we can achieve a practical workflow in tvm. Currently it is still in researching stage. |
Hi @kevinthesun . For this question, do we plan to do padding or resize? Thanks |
|
@zhanghaohit It's still under investigation for different options, but it's more likely a static shape will fall into a bucket and call corresponding kernel. |
|
How is this RFC going ? Are there any following pull requests? |
|
May I ask whether there are some working code examples for graph dispatch available? Thank you! |
|
@tiandiao123 this feature is still WIP. |
|
Dose any progress in dynamic input shape inference? I am expecting it |
|
I assume this is no longer active. |
Overview
There are more and more deployment requirements regarding dynamic input graphs, such as dynamic batching CV models and dynamic BERT. While dynamic input graph is supported in eager mode(Pytorch, Tensorflow Eager, MXNet Gluon) for model developing, TVM still just support static shape input models. In this thread I'll discuss about possible solution for dynamic shape AOT compilation.
Let's start by considering supporting a single operator with dynamic shape. TVM has already supported tensor expression with symbolic variable well, which means we have no difficulty in expressing a dynamic shape kernel with existing compute and schedule system. However, a single schedule cannot achieve desired performance for all possible values for a symbolic axis. For example, a dynamic batch conv2d on cuda can require quite different values of block_z and thread_z for different batch sizes. A possible method to solve this problem is to split symbolic axes into several buckets:

For each bucket, we select a representative kernel which performs well in the corresponding range for symbolic axis.
In this thread, I won't focus on this topic and @icemelon9 @comaniac @sxjscience will dive deep into this issue in other threads.
In this thread, we will discuss graph dispatching for dynamic shape. Bucketing method for kernel works well in runtime for operators which doesn’t require layout transformation, such as dense and batch_matmul(as for today's tvm implementation). However, in computer vision models, conv2d usually requires layout transformation to achieve better performance. Two issues raise to use kernel dispatch function in runtime:
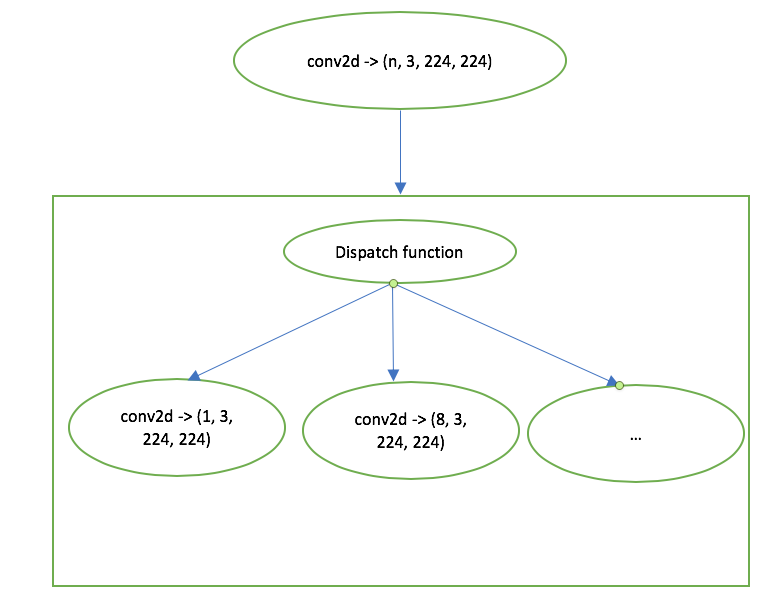
To resolve these issues, instead of kernel dispatch function, we use graph dispatch function which splits input shape of the whole graph into buckets and clone a graph for each bucket:
Graph dispatch function is a nested IfThenElse statement block which selects copy of graph depending on actual input shape. Thanks to the functional nature of relay, we can easily create global function in relay module to represent different clone of graph, and share parameters through function call. These are advantages for graph dispatch function:
API
We will add a new member function Dispatch to Relay Module:
This function update a global function inside module to be a dispatching block followed by copied functions. dispatch_func decides how to generate buckets.
Dispatch Function
Dispatch function is a function from an input shape dictionary to a map from input name to a map from symbolic axis index to list of intervals. For example, for input shape dictionary which represents a CV model allowing arbitrary image sizes:
{"data": (1, 3, tvm.relay.Any(), tvm.relay.Any())}A logarithmical dispatch function returns a dictionary:
{ "data": { 2: [(1, 2), (2, 4), (4, 8), (8, 16), (16, 32), (32, 64), (64, 128), (128, 256), (256, None)], 3: [(1, 2), (2, 4), (4, 8), (8, 16), (16, 32), (32, 64), (64, 128), (128, 256), (256, None)], } }As a result, in the final main function there will be 9 * 9 = 81 copies of original graph. Here introduces a tradeoff between overall performance and number of function kernels.
We will provide two pre-defined dispatching functions splitting uniformly and logarithmically. User can define their own customized dispatching function.
Prune buckets though boundary for symbolic axis.
In most practical cases, we don't really need a complete range [1, +inf) for symbolic axis. Boundary for tvm.var can greatly reduce the number of buckets and thus the number of kernel functions. In this design we don't consider any boundary pruning yet. We might want to leverage the idea in this topic: https://discuss.tvm.ai/t/discuss-embed-more-bound-information-into-var-or-expr/4079.
A working example:
TODO
@tqchen @jroesch @icemelon9 @comaniac @sxjscience @yzhliu @wweic @zhiics @yongwww @antinucleon @junrushao1994
The text was updated successfully, but these errors were encountered: