Different implements about suporting S3 backend for tiered storage #6176
TheR1sing3un
started this conversation in
Ideas
Replies: 1 comment
-
|
We should not add the pre-fetching mechanism in the backend service provider. Similar to the file system in OS, the underlying interface reads files according to the specified position and length, and the OS maintains the page cache, which is a read-ahead cache in tiered storage (see TieredMessageFetcher for more details). If you want to batch upload, a shared upload buffer is okay. But when the messages are uploaded to s3, the data in the buffer should be cleaned immediately because we do not expect to access hot data from tiered storage. |
Beta Was this translation helpful? Give feedback.
0 replies
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
-
Support S3 backend for TiredStorage
Target
Implement
Elimated implement
One
Segmentmaps to an object on s3.Trouble
When we need to call
commit0to write the stream into the Segment's[position, position+length-1], since S3 uploaded objects don't support modification, nor do they support append writing like Alibaba Cloud OSS, we can only upload a new object to cover the old one if we want to update an object. Therefore, we need to get the data from[0, position-1], concatenate it with the incoming stream, and then upload the entire object. This not only occupies bandwidth, but also occupies memory. Especially when the Segment is approaching the default value of 1G, committing the data will require downloading nearly 1G of data, concatenating it in memory, and then uploading 1G of data. Therefore, this approach has been eliminated.Implement-1
new configuration
4 *1024* 1024chunknum in oneS3Segmentchunknum in eachread0callingtieredStoreGroupCommitSize/s3ChunkSizeA segment is treated as a logical file and is divided into multiple physical files, or multiple physical objects, in the S3 view. We assume that each physical object has a default size of 4 MB, which is named
chunk.For ease of process representation, we assume that readaheadChunkNum is 2 in the following.
Process
This is done in the
S3Segment#S3Segmentconstructor. The path of the logical segment file is constructed by concatenating the following components according to a set of rules:clusterName/brokerName/topic/queue/type-baseOffset. The path below this point is referred to asbaseDir.That is, the
S3Segment#createFile()method is called. Since no data has been written yet, we need to create the firstchunkobject and allocate 4MB of memory to cache the data for this chunk. We request the creation of an object from S3 in the formatbaseDir/chunk-startOffset, which means creating abaseDir/chunk-0object in S3 now.The
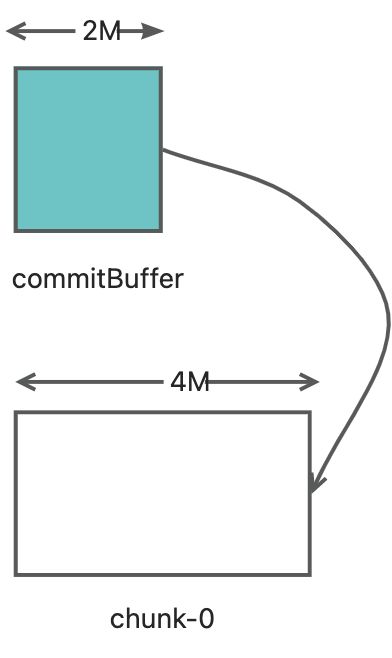
Segment#commit0()method is called.We assume that wrting 2MB data this time.
The data is directlly writed into
chunk-0, and uploaded to S3.That is, the
S3Segment#read0()method is called. Suppose we are currently reading 1MB of data withposition = 0 and length = 1024. Then it directly hits in the localchunk-0buffer and returns.Suppose this time we write
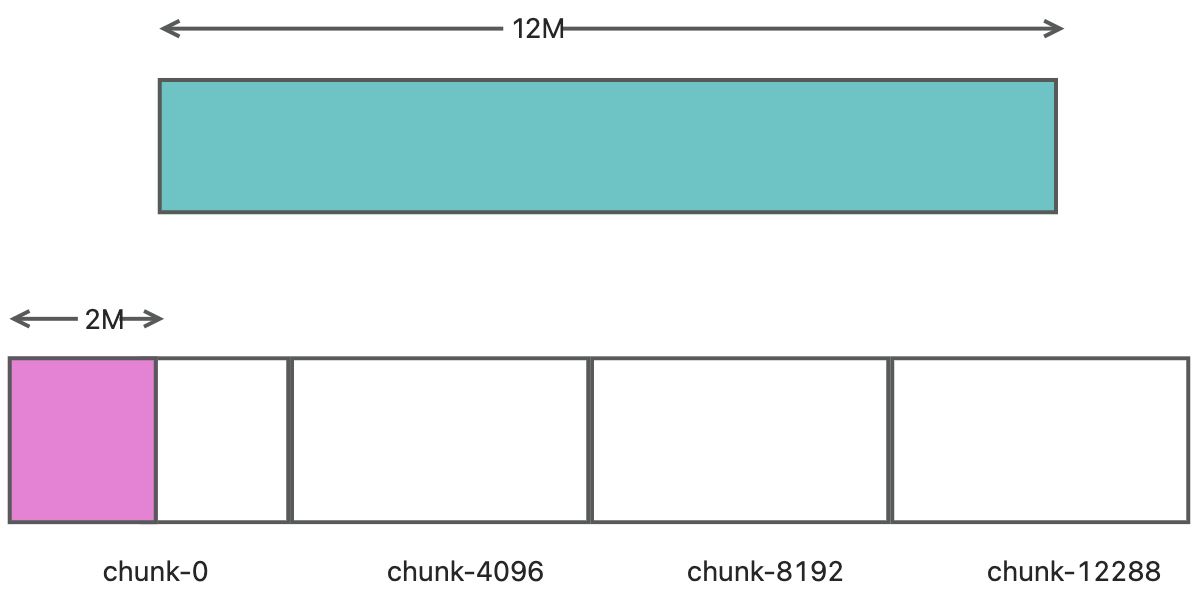
position= 2048, length= 12 * 1024data, that is, submit 12MB of data from 2MB position.At this point, the first 2MB of chunk-0 is cached locally, so we can directly concatenate the first 2MB of
chunk-0with the first 2MB of the stream to form a completechunk-0. Next, we correctly locate the first 2MB ofchunk-4096,chunk-8192, andchunk-12288, and then upload them to S3. For the case of multiple chunks uploading at the same time, we use asynchronous/thread pool to upload them. If some chunks fail to upload, they are cached and then retried in the background asynchronously. If they fail multiple times, appropriate logical processing is performed.After the above commit, only the first 2MB of
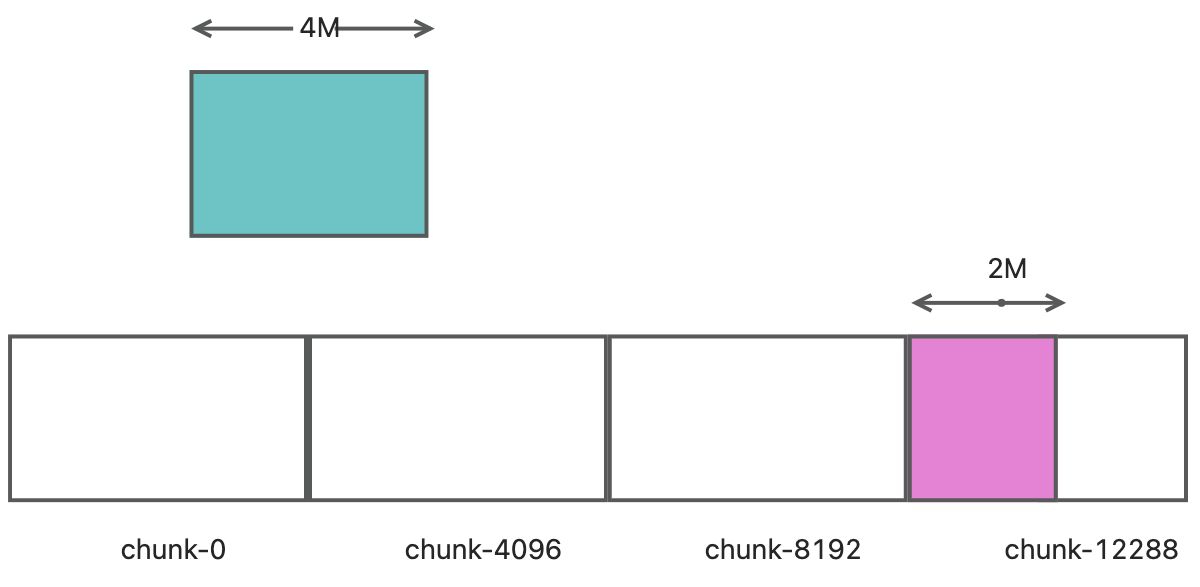
chunk-12288is cached locally. Now, we read 4096 bytes of data starting fromposition = 2048, which means reading the second half ofchunk-0and the first half ofchunk-4096. Since we have enabled the pre-reading mechanism and the parameter is 2, we need to read two more chunks. Considering that we only read half ofchunk-4096, we only need to read one more chunk, which ischunk-8192.Then we read
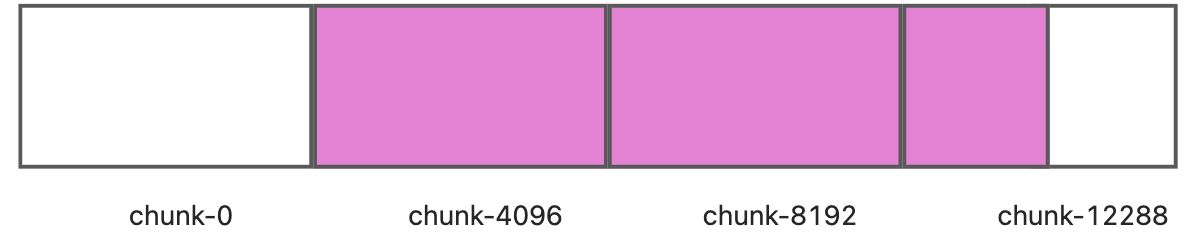
chunk-0,chunk-4096, andchunk-8192from S3. According to the pre-reading mechanism, we do not savechunk-0and only savechunk-4096andchunk-8192in memory.Now, we read 4096 bytes of data starting from
position = 6144, which means reading the second half ofchunk-4096and the first half ofchunk-8192. Since we have pre-loadedchunk-4096andchunk-8192into memory, we can directly return the data without reading from S3.At this point, we can asynchronously trigger an
uploadPartCopyoperation to consolidate all thechunksinto a single largesegmentobject, and record the basic information of thesegmentin the object metadata. The object path isclusterName/brokerName/topic/queue/type-baseOffset-seg. After the copy operation is successful, we can asynchronously delete the parent path of the chunks.Now we concatenate the path
clusterName/brokerName/topic/queue/type-baseOffset-segand check whether the object exists. If it exists, it means it is the already organized largeSegmentobject, then we record the corresponding metadata locally, andread0()can directly read the object based on the offset. Next, we check if there is an object under.../type-baseOffset. If it exists, it means the asynchronous deletion has not been successful, so we can re-attempt asynchronous deletion.If the path
.../type-baseOffset-segdoes not exist, it may be due to failed consolidation or the currentsegmenthas not been written to capacity. In this case, we can list all the chunk files under the path and then determine if the segment has been fully written (this can be checked by adding an interface that is called during recovery). If thesegmenthas been fully written, we can consolidate thechunksasynchronously and then delete them. If thesegmenthas not been fully written, we can simply recover the latestchunkby caching it.Advantages and disadvantages
chunkcaches can lead to excessive memory usage. Suppose that 1000 queues, even if only onechunkis cached for one queue, can reach 4GB of memory usage.Implment-2
To solve memory buffer ocupying problem, we can use a singleton
bufferPoolwith limited buffer size to cachechunk.Advantages and disadvantages
chunks, which fails to achieve the desired effect of pre-reading.Implment-3
Instead of using the aforementioned chunking method, we can directly use S3's
multiPartUploadto upload files in parts. In S3, a physical object corresponds to aSegment. When creating aSegment, start a multipart upload task and persist the upload task ID in S3 also. Every timecommit0()is called, apartis created for uploading, and apartIDis generated for represent this uploadpartand need to be persist to S3. When the entireSegmentis full, the multipart upload is completed.Fault recovery:
At this point, we can retrieve the current maximum upload number based on the persistent upload ID. The next time
commit0()is called, uploading can start from the number immediately following the maximum upload number.Advantages and disadvantages
Segmentcannot be read while the Segment is being uploaded.Plan
S3Segmentand corresponding methods to complete the basic storage requirements.S3SegmentBeta Was this translation helpful? Give feedback.
All reactions