diff --git a/docs/tutorials/index.md b/docs/tutorials/index.md
index ae0851425be0..32c4a16a8e0d 100644
--- a/docs/tutorials/index.md
+++ b/docs/tutorials/index.md
@@ -40,6 +40,7 @@ Select API:
* Practitioner Guides
* [Multi-GPU training](http://gluon.mxnet.io/chapter07_distributed-learning/multiple-gpus-gluon.html)  * [Checkpointing and Model Serialization (a.k.a. saving and loading)](/tutorials/gluon/save_load_params.html) ([Alternative](http://gluon.mxnet.io/chapter03_deep-neural-networks/serialization.html))
+ * [Distributed Training](https://github.com/apache/incubator-mxnet/tree/master/example/distributed_training)
* [Inference using an ONNX model](/tutorials/onnx/inference_on_onnx_model.html)
* [Fine-tuning an ONNX model on Gluon](/tutorials/onnx/fine_tuning_gluon.html)
* [Visualizing Decisions of Convolutional Neural Networks](/tutorials/vision/cnn_visualization.html)
diff --git a/example/distributed_training/README.md b/example/distributed_training/README.md
new file mode 100644
index 000000000000..b0b0447725b5
--- /dev/null
+++ b/example/distributed_training/README.md
@@ -0,0 +1,255 @@
+# Distributed Training using Gluon
+
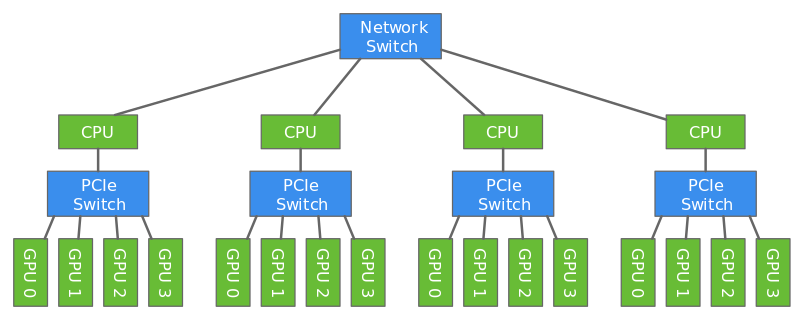
+Deep learning models are usually trained using GPUs because GPUs can do a lot more computations in parallel that CPUs. But even with the modern GPUs, it could take several days to train big models. Training can be done faster by using multiple GPUs like described in [this](https://gluon.mxnet.io/chapter07_distributed-learning/multiple-gpus-gluon.html) tutorial. However only a certain number of GPUs can be attached to one host (typically 8 or 16). To make the training even faster, we can use multiple GPUs attached to multiple hosts.
+
+In this tutorial, we will show how to train a model faster using multi-host distributed training.
+
+
+
+We will use data parallelism to distribute the training which involves splitting the training data across GPUs attached to multiple hosts. Since the hosts are working with different subset of the training data in parallel, the training completes a lot faster.
+
+In this tutorial, we will train a ResNet18 network using CIFAR-10 dataset using two hosts each having four GPUs.
+
+## Distributed Training Architecture:
+
+Multihost distributed training involves working with three different types of processes - worker, parameter server and scheduler.
+
+
+
+### Parameter Server:
+The parameters of the model needs to be shared with all hosts since multiple hosts are working together to train one model. To make this sharing efficient, the parameters are split across multiple hosts. A parameter server in each host stores a subset of parameters. In the figure above, parameters are split evenly between the two hosts. At the end of every iteration, each host communicates with every other host to update all parameters of the model.
+
+### Worker:
+Each host has a worker process which in each iteration fetches a batch of data, runs forward and backward pass on all GPUs in the host, computes the parameter updates and sends those updates to the parameter servers in each host. Since we have multiple workers to train the model, each worker only needs to process 1/N part of the training data where N is the number of workers.
+
+### Scheduler:
+Scheduler is responsible for scheduling the workers and parameter servers. There is only one scheduler in the entire cluster.
+
+## Moving to distributed training:
+
+[cifar10_dist.py](cifar10_dist.py) contains code that trains a ResNet18 network using distributed training. In this section we'll walk through parts of that file that are unique to distributed training.
+
+### Step 1: Use a distributed key-value store:
+
+Like mentioned above, in distributed training, parameters are split into N parts and distributed across N hosts. This is done automatically by the [distributed key-value store](https://mxnet.incubator.apache.org/tutorials/python/kvstore.html). User only needs to create the distributed kv store and ask the `Trainer` to use the created store.
+
+```python
+store = mxnet.kv.create('dist')
+```
+
+It is the job of the trainer to take the gradients computed in the backward pass and update the parameters of the model. We'll tell the trainer to store and update the parameters in the distributed kv store we just created instead of doing it in GPU of CPU memory. For example,
+
+```python
+trainer = gluon.Trainer(net.collect_params(),
+ 'adam', {'learning_rate': .001},
+ kvstore=store)
+```
+
+## Step 2: Split the training data:
+
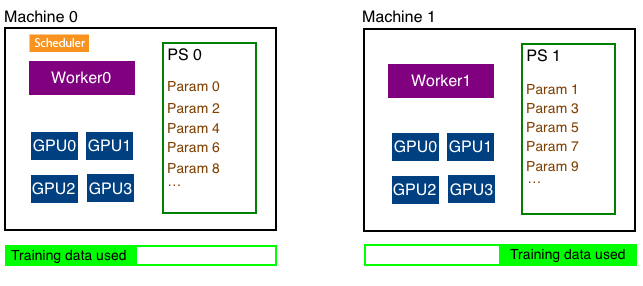
+In distributed training (using data parallelism), training data is split into equal parts across all workers and each worker uses its subset of the training data for training. For example, if we had two machines, each running a worker, each worker managing four GPUs we'll split the data like shown below. Note that we don't split the data depending on the number of GPUs but split it depending on the number of workers.
+
+
+
+Each worker can find out the total number of workers in the cluster and its own rank which is an integer between 0 and N-1 where N is the number of workers.
+
+```python
+store = kv.create('dist')
+print("Total number of workers: %d" % store.num_workers)
+print("This worker's rank: %d" % store.rank)
+```
+
+```
+Total number of workers: 2
+This worker's rank: 0
+```
+
+Knowing the number of workers and a particular worker's rank, it is easy to split the dataset into partitions and pick one partition to train depending on the rank of the worker. Here is a sampler that does exactly that.
+
+```python
+class SplitSampler(gluon.data.sampler.Sampler):
+ """ Split the dataset into `num_parts` parts and sample from the part with index `part_index`
+ Parameters
+ ----------
+ length: int
+ Number of examples in the dataset
+ num_parts: int
+ Partition the data into multiple parts
+ part_index: int
+ The index of the part to read from
+ """
+ def __init__(self, length, num_parts=1, part_index=0):
+ # Compute the length of each partition
+ self.part_len = length // num_parts
+ # Compute the start index for this partition
+ self.start = self.part_len * part_index
+ # Compute the end index for this partition
+ self.end = self.start + self.part_len
+
+ def __iter__(self):
+ # Extract examples between `start` and `end`, shuffle and return them.
+ indices = list(range(self.start, self.end))
+ random.shuffle(indices)
+ return iter(indices)
+
+ def __len__(self):
+ return self.part_len
+```
+
+We can then create a `DataLoader` using the `SplitSampler` like shown below:
+
+```python
+# Load the training data
+train_data = gluon.data.DataLoader(gluon.data.vision.CIFAR10(train=True, transform=transform),
+ batch_size,
+ sampler=SplitSampler(50000, store.num_workers, store.rank))
+```
+
+## Step 3: Training with multiple GPUs
+
+Note that we didn't split the dataset by the number of GPUs. We split it by the number of workers which usually translates to number of machines. It is the worker's responsibility to split the partition it has across multiple GPUs it might have and run the training in parallel across multiple GPUs.
+
+To train with multiple GPUs, we first need to specify the list of GPUs we want to use for training:
+
+```python
+ctx = [mx.gpu(i) for i in range(gpus_per_machine)]
+```
+
+We can then train a batch like shown below:
+
+```python
+# Train a batch using multiple GPUs
+def train_batch(batch, ctx, net, trainer):
+
+ # Split and load data into multiple GPUs
+ data = batch[0]
+ data = gluon.utils.split_and_load(data, ctx)
+
+ # Split and load label into multiple GPUs
+ label = batch[1]
+ label = gluon.utils.split_and_load(label, ctx)
+
+ # Run the forward and backward pass
+ forward_backward(net, data, label)
+
+ # Update the parameters
+ this_batch_size = batch[0].shape[0]
+ trainer.step(this_batch_size)
+```
+
+Here is the code that runs the forward (computing loss) and backward (computing gradients) pass on multiple GPUs:
+
+```python
+# We'll use cross entropy loss since we are doing multiclass classification
+loss = gluon.loss.SoftmaxCrossEntropyLoss()
+
+# Run one forward and backward pass on multiple GPUs
+def forward_backward(net, data, label):
+
+ # Ask autograd to remember the forward pass
+ with autograd.record():
+ # Compute the loss on all GPUs
+ losses = [loss(net(X), Y) for X, Y in zip(data, label)]
+
+ # Run the backward pass (calculate gradients) on all GPUs
+ for l in losses:
+ l.backward()
+```
+
+Given `train_batch`, training an epoch is simple:
+
+```python
+for batch in train_data:
+ # Train the batch using multiple GPUs
+ train_batch(batch, ctx, net, trainer)
+```
+
+## Final Step: Launching the distributed training
+
+Note that there are several processes that needs to be launched on multiple machines to do distributed training. One worker and one parameter server needs to be launched on each host. Scheduler needs to be launched on one of the hosts. While this can be done manually, MXNet provides the [`launch.py`](https://github.com/apache/incubator-mxnet/blob/master/tools/launch.py) tool to make this easy.
+
+For example, the following command launches distributed training on two machines:
+
+```
+python ~/mxnet/tools/launch.py -n 2 -s 2 -H hosts \
+ --sync-dst-dir /home/ubuntu/cifar10_dist \
+ --launcher ssh \
+ "python /home/ubuntu/cifar10_dist/cifar10_dist.py"
+```
+
+- `-n 2` specifies the number of workers that must be launched
+- `-s 2` specifies the number of parameter servers that must be launched.
+- `--sync-dst-dir` specifies a destination location where the contents of the current directory will be rsync'd
+- `--launcher ssh` tells `launch.py` to use ssh to login on each machine in the cluster and launch processes.
+- `"python /home/ubuntu/dist/dist.py"` is the command that will get executed in each of the launched processes.
+- Finally, `-H hosts` specifies the list of hosts in the cluster to be used for distributed training.
+
+Let's take a look at the `hosts` file.
+
+```
+~/dist$ cat hosts
+d1
+d2
+```
+
+'d1' and 'd2' are the hostnames of the hosts we want to run distributed training using. `launch.py` should be able to ssh into these hosts by providing just the hostname on the command line. For example:
+
+```
+~/dist$ ssh d1
+Welcome to Ubuntu 16.04.3 LTS (GNU/Linux 4.4.0-1049-aws x86_64)
+
+ * Documentation: https://help.ubuntu.com
+ * Management: https://landscape.canonical.com
+ * Support: https://ubuntu.com/advantage
+
+ Get cloud support with Ubuntu Advantage Cloud Guest:
+ http://www.ubuntu.com/business/services/cloud
+
+0 packages can be updated.
+0 updates are security updates.
+
+
+Last login: Wed Jan 31 18:06:45 2018 from 72.21.198.67
+```
+
+Note that no authentication information was provided to login to the host. This can be done using multiple methods. One easy way is to specify the ssh certificates in `~/.ssh/config`. Example:
+
+```
+~$ cat ~/.ssh/config
+Host d1
+ HostName ec2-34-201-108-233.compute-1.amazonaws.com
+ port 22
+ user ubuntu
+ IdentityFile /home/ubuntu/my_key.pem
+ IdentitiesOnly yes
+
+Host d2
+ HostName ec2-34-238-232-97.compute-1.amazonaws.com
+ port 22
+ user ubuntu
+ IdentityFile /home/ubuntu/my_key.pem
+ IdentitiesOnly yes
+```
+
+A better way is to use ssh agent forwarding. Check [this](https://aws.amazon.com/blogs/security/securely-connect-to-linux-instances-running-in-a-private-amazon-vpc/) article for more details.
+
+Here is a sample output from running distributed training:
+
+```
+$ python ~/mxnet/tools/launch.py -n 2 -s 2 -H hosts --sync-dst-dir /home/ubuntu/cifar10_dist --launcher ssh "python /home/ubuntu/cifar10_dist/cifar10_dist.py"
+2018-06-03 05:30:05,609 INFO rsync /home/ubuntu/cifar10_dist/ -> a1:/home/ubuntu/cifar10_dist
+2018-06-03 05:30:05,879 INFO rsync /home/ubuntu/cifar10_dist/ -> a2:/home/ubuntu/cifar10_dist
+Epoch 0: Test_acc 0.467400
+Epoch 0: Test_acc 0.466800
+Epoch 1: Test_acc 0.568500
+Epoch 1: Test_acc 0.571300
+Epoch 2: Test_acc 0.586300
+Epoch 2: Test_acc 0.594000
+Epoch 3: Test_acc 0.659200
+Epoch 3: Test_acc 0.653300
+Epoch 4: Test_acc 0.681200
+Epoch 4: Test_acc 0.687900
+```
+
+Note that the output from all hosts are merged and printed to the console.
+
diff --git a/example/distributed_training/cifar10_dist.py b/example/distributed_training/cifar10_dist.py
new file mode 100644
index 000000000000..506afbbe081a
--- /dev/null
+++ b/example/distributed_training/cifar10_dist.py
@@ -0,0 +1,176 @@
+#!/usr/bin/env python
+
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+from __future__ import print_function
+import random, sys
+
+import mxnet as mx
+from mxnet import autograd, gluon, kv, nd
+from mxnet.gluon.model_zoo import vision
+
+import numpy as np
+
+# Create a distributed key-value store
+store = kv.create('dist')
+
+# Clasify the images into one of the 10 digits
+num_outputs = 10
+
+# 64 images in a batch
+batch_size_per_gpu = 64
+# How many epochs to run the training
+epochs = 5
+
+# How many GPUs per machine
+gpus_per_machine = 4
+# Effective batch size across all GPUs
+batch_size = batch_size_per_gpu * gpus_per_machine
+
+# Create the context (a list of all GPUs to be used for training)
+ctx = [mx.gpu(i) for i in range(gpus_per_machine)]
+
+# Convert to float 32
+# Having channel as the first dimension makes computation more efficient. Hence the (2,0,1) transpose.
+# Dividing by 255 normalizes the input between 0 and 1
+def transform(data, label):
+ return nd.transpose(data.astype(np.float32), (2,0,1))/255, label.astype(np.float32)
+
+class SplitSampler(gluon.data.sampler.Sampler):
+ """ Split the dataset into `num_parts` parts and sample from the part with index `part_index`
+
+ Parameters
+ ----------
+ length: int
+ Number of examples in the dataset
+ num_parts: int
+ Partition the data into multiple parts
+ part_index: int
+ The index of the part to read from
+ """
+ def __init__(self, length, num_parts=1, part_index=0):
+ # Compute the length of each partition
+ self.part_len = length // num_parts
+ # Compute the start index for this partition
+ self.start = self.part_len * part_index
+ # Compute the end index for this partition
+ self.end = self.start + self.part_len
+
+ def __iter__(self):
+ # Extract examples between `start` and `end`, shuffle and return them.
+ indices = list(range(self.start, self.end))
+ random.shuffle(indices)
+ return iter(indices)
+
+ def __len__(self):
+ return self.part_len
+
+# Load the training data
+train_data = gluon.data.DataLoader(gluon.data.vision.CIFAR10(train=True, transform=transform),
+ batch_size,
+ sampler=SplitSampler(50000, store.num_workers, store.rank))
+
+# Load the test data
+test_data = gluon.data.DataLoader(gluon.data.vision.CIFAR10(train=False, transform=transform),
+ batch_size, shuffle=False)
+
+# Use ResNet from model zoo
+net = vision.resnet18_v1()
+
+# Initialize the parameters with Xavier initializer
+net.collect_params().initialize(mx.init.Xavier(), ctx=ctx)
+
+# SoftmaxCrossEntropy is the most common choice of loss function for multiclass classification
+softmax_cross_entropy = gluon.loss.SoftmaxCrossEntropyLoss()
+
+# Use Adam optimizer. Ask trainer to use the distributer kv store.
+trainer = gluon.Trainer(net.collect_params(), 'adam', {'learning_rate': .001}, kvstore=store)
+
+# Evaluate accuracy of the given network using the given data
+def evaluate_accuracy(data_iterator, net):
+
+ acc = mx.metric.Accuracy()
+
+ # Iterate through data and label
+ for i, (data, label) in enumerate(data_iterator):
+
+ # Get the data and label into the GPU
+ data = data.as_in_context(ctx[0])
+ label = label.as_in_context(ctx[0])
+
+ # Get network's output which is a probability distribution
+ # Apply argmax on the probability distribution to get network's classification.
+ output = net(data)
+ predictions = nd.argmax(output, axis=1)
+
+ # Give network's prediction and the correct label to update the metric
+ acc.update(preds=predictions, labels=label)
+
+ # Return the accuracy
+ return acc.get()[1]
+
+# We'll use cross entropy loss since we are doing multiclass classification
+loss = gluon.loss.SoftmaxCrossEntropyLoss()
+
+# Run one forward and backward pass on multiple GPUs
+def forward_backward(net, data, label):
+
+ # Ask autograd to remember the forward pass
+ with autograd.record():
+ # Compute the loss on all GPUs
+ losses = [loss(net(X), Y) for X, Y in zip(data, label)]
+
+ # Run the backward pass (calculate gradients) on all GPUs
+ for l in losses:
+ l.backward()
+
+# Train a batch using multiple GPUs
+def train_batch(batch, ctx, net, trainer):
+
+ # Split and load data into multiple GPUs
+ data = batch[0]
+ data = gluon.utils.split_and_load(data, ctx)
+
+ # Split and load label into multiple GPUs
+ label = batch[1]
+ label = gluon.utils.split_and_load(label, ctx)
+
+ # Run the forward and backward pass
+ forward_backward(net, data, label)
+
+ # Update the parameters
+ this_batch_size = batch[0].shape[0]
+ trainer.step(this_batch_size)
+
+# Run as many epochs as required
+for epoch in range(epochs):
+
+ # Iterate through batches and run training using multiple GPUs
+ batch_num = 1
+ for batch in train_data:
+
+ # Train the batch using multiple GPUs
+ train_batch(batch, ctx, net, trainer)
+
+ batch_num += 1
+
+ # Print test accuracy after every epoch
+ test_accuracy = evaluate_accuracy(test_data, net)
+ print("Epoch %d: Test_acc %f" % (epoch, test_accuracy))
+ sys.stdout.flush()
+
* [Checkpointing and Model Serialization (a.k.a. saving and loading)](/tutorials/gluon/save_load_params.html) ([Alternative](http://gluon.mxnet.io/chapter03_deep-neural-networks/serialization.html))
+ * [Distributed Training](https://github.com/apache/incubator-mxnet/tree/master/example/distributed_training)
* [Inference using an ONNX model](/tutorials/onnx/inference_on_onnx_model.html)
* [Fine-tuning an ONNX model on Gluon](/tutorials/onnx/fine_tuning_gluon.html)
* [Visualizing Decisions of Convolutional Neural Networks](/tutorials/vision/cnn_visualization.html)
diff --git a/example/distributed_training/README.md b/example/distributed_training/README.md
new file mode 100644
index 000000000000..b0b0447725b5
--- /dev/null
+++ b/example/distributed_training/README.md
@@ -0,0 +1,255 @@
+# Distributed Training using Gluon
+
+Deep learning models are usually trained using GPUs because GPUs can do a lot more computations in parallel that CPUs. But even with the modern GPUs, it could take several days to train big models. Training can be done faster by using multiple GPUs like described in [this](https://gluon.mxnet.io/chapter07_distributed-learning/multiple-gpus-gluon.html) tutorial. However only a certain number of GPUs can be attached to one host (typically 8 or 16). To make the training even faster, we can use multiple GPUs attached to multiple hosts.
+
+In this tutorial, we will show how to train a model faster using multi-host distributed training.
+
+
+
+We will use data parallelism to distribute the training which involves splitting the training data across GPUs attached to multiple hosts. Since the hosts are working with different subset of the training data in parallel, the training completes a lot faster.
+
+In this tutorial, we will train a ResNet18 network using CIFAR-10 dataset using two hosts each having four GPUs.
+
+## Distributed Training Architecture:
+
+Multihost distributed training involves working with three different types of processes - worker, parameter server and scheduler.
+
+
+
+### Parameter Server:
+The parameters of the model needs to be shared with all hosts since multiple hosts are working together to train one model. To make this sharing efficient, the parameters are split across multiple hosts. A parameter server in each host stores a subset of parameters. In the figure above, parameters are split evenly between the two hosts. At the end of every iteration, each host communicates with every other host to update all parameters of the model.
+
+### Worker:
+Each host has a worker process which in each iteration fetches a batch of data, runs forward and backward pass on all GPUs in the host, computes the parameter updates and sends those updates to the parameter servers in each host. Since we have multiple workers to train the model, each worker only needs to process 1/N part of the training data where N is the number of workers.
+
+### Scheduler:
+Scheduler is responsible for scheduling the workers and parameter servers. There is only one scheduler in the entire cluster.
+
+## Moving to distributed training:
+
+[cifar10_dist.py](cifar10_dist.py) contains code that trains a ResNet18 network using distributed training. In this section we'll walk through parts of that file that are unique to distributed training.
+
+### Step 1: Use a distributed key-value store:
+
+Like mentioned above, in distributed training, parameters are split into N parts and distributed across N hosts. This is done automatically by the [distributed key-value store](https://mxnet.incubator.apache.org/tutorials/python/kvstore.html). User only needs to create the distributed kv store and ask the `Trainer` to use the created store.
+
+```python
+store = mxnet.kv.create('dist')
+```
+
+It is the job of the trainer to take the gradients computed in the backward pass and update the parameters of the model. We'll tell the trainer to store and update the parameters in the distributed kv store we just created instead of doing it in GPU of CPU memory. For example,
+
+```python
+trainer = gluon.Trainer(net.collect_params(),
+ 'adam', {'learning_rate': .001},
+ kvstore=store)
+```
+
+## Step 2: Split the training data:
+
+In distributed training (using data parallelism), training data is split into equal parts across all workers and each worker uses its subset of the training data for training. For example, if we had two machines, each running a worker, each worker managing four GPUs we'll split the data like shown below. Note that we don't split the data depending on the number of GPUs but split it depending on the number of workers.
+
+
+
+Each worker can find out the total number of workers in the cluster and its own rank which is an integer between 0 and N-1 where N is the number of workers.
+
+```python
+store = kv.create('dist')
+print("Total number of workers: %d" % store.num_workers)
+print("This worker's rank: %d" % store.rank)
+```
+
+```
+Total number of workers: 2
+This worker's rank: 0
+```
+
+Knowing the number of workers and a particular worker's rank, it is easy to split the dataset into partitions and pick one partition to train depending on the rank of the worker. Here is a sampler that does exactly that.
+
+```python
+class SplitSampler(gluon.data.sampler.Sampler):
+ """ Split the dataset into `num_parts` parts and sample from the part with index `part_index`
+ Parameters
+ ----------
+ length: int
+ Number of examples in the dataset
+ num_parts: int
+ Partition the data into multiple parts
+ part_index: int
+ The index of the part to read from
+ """
+ def __init__(self, length, num_parts=1, part_index=0):
+ # Compute the length of each partition
+ self.part_len = length // num_parts
+ # Compute the start index for this partition
+ self.start = self.part_len * part_index
+ # Compute the end index for this partition
+ self.end = self.start + self.part_len
+
+ def __iter__(self):
+ # Extract examples between `start` and `end`, shuffle and return them.
+ indices = list(range(self.start, self.end))
+ random.shuffle(indices)
+ return iter(indices)
+
+ def __len__(self):
+ return self.part_len
+```
+
+We can then create a `DataLoader` using the `SplitSampler` like shown below:
+
+```python
+# Load the training data
+train_data = gluon.data.DataLoader(gluon.data.vision.CIFAR10(train=True, transform=transform),
+ batch_size,
+ sampler=SplitSampler(50000, store.num_workers, store.rank))
+```
+
+## Step 3: Training with multiple GPUs
+
+Note that we didn't split the dataset by the number of GPUs. We split it by the number of workers which usually translates to number of machines. It is the worker's responsibility to split the partition it has across multiple GPUs it might have and run the training in parallel across multiple GPUs.
+
+To train with multiple GPUs, we first need to specify the list of GPUs we want to use for training:
+
+```python
+ctx = [mx.gpu(i) for i in range(gpus_per_machine)]
+```
+
+We can then train a batch like shown below:
+
+```python
+# Train a batch using multiple GPUs
+def train_batch(batch, ctx, net, trainer):
+
+ # Split and load data into multiple GPUs
+ data = batch[0]
+ data = gluon.utils.split_and_load(data, ctx)
+
+ # Split and load label into multiple GPUs
+ label = batch[1]
+ label = gluon.utils.split_and_load(label, ctx)
+
+ # Run the forward and backward pass
+ forward_backward(net, data, label)
+
+ # Update the parameters
+ this_batch_size = batch[0].shape[0]
+ trainer.step(this_batch_size)
+```
+
+Here is the code that runs the forward (computing loss) and backward (computing gradients) pass on multiple GPUs:
+
+```python
+# We'll use cross entropy loss since we are doing multiclass classification
+loss = gluon.loss.SoftmaxCrossEntropyLoss()
+
+# Run one forward and backward pass on multiple GPUs
+def forward_backward(net, data, label):
+
+ # Ask autograd to remember the forward pass
+ with autograd.record():
+ # Compute the loss on all GPUs
+ losses = [loss(net(X), Y) for X, Y in zip(data, label)]
+
+ # Run the backward pass (calculate gradients) on all GPUs
+ for l in losses:
+ l.backward()
+```
+
+Given `train_batch`, training an epoch is simple:
+
+```python
+for batch in train_data:
+ # Train the batch using multiple GPUs
+ train_batch(batch, ctx, net, trainer)
+```
+
+## Final Step: Launching the distributed training
+
+Note that there are several processes that needs to be launched on multiple machines to do distributed training. One worker and one parameter server needs to be launched on each host. Scheduler needs to be launched on one of the hosts. While this can be done manually, MXNet provides the [`launch.py`](https://github.com/apache/incubator-mxnet/blob/master/tools/launch.py) tool to make this easy.
+
+For example, the following command launches distributed training on two machines:
+
+```
+python ~/mxnet/tools/launch.py -n 2 -s 2 -H hosts \
+ --sync-dst-dir /home/ubuntu/cifar10_dist \
+ --launcher ssh \
+ "python /home/ubuntu/cifar10_dist/cifar10_dist.py"
+```
+
+- `-n 2` specifies the number of workers that must be launched
+- `-s 2` specifies the number of parameter servers that must be launched.
+- `--sync-dst-dir` specifies a destination location where the contents of the current directory will be rsync'd
+- `--launcher ssh` tells `launch.py` to use ssh to login on each machine in the cluster and launch processes.
+- `"python /home/ubuntu/dist/dist.py"` is the command that will get executed in each of the launched processes.
+- Finally, `-H hosts` specifies the list of hosts in the cluster to be used for distributed training.
+
+Let's take a look at the `hosts` file.
+
+```
+~/dist$ cat hosts
+d1
+d2
+```
+
+'d1' and 'd2' are the hostnames of the hosts we want to run distributed training using. `launch.py` should be able to ssh into these hosts by providing just the hostname on the command line. For example:
+
+```
+~/dist$ ssh d1
+Welcome to Ubuntu 16.04.3 LTS (GNU/Linux 4.4.0-1049-aws x86_64)
+
+ * Documentation: https://help.ubuntu.com
+ * Management: https://landscape.canonical.com
+ * Support: https://ubuntu.com/advantage
+
+ Get cloud support with Ubuntu Advantage Cloud Guest:
+ http://www.ubuntu.com/business/services/cloud
+
+0 packages can be updated.
+0 updates are security updates.
+
+
+Last login: Wed Jan 31 18:06:45 2018 from 72.21.198.67
+```
+
+Note that no authentication information was provided to login to the host. This can be done using multiple methods. One easy way is to specify the ssh certificates in `~/.ssh/config`. Example:
+
+```
+~$ cat ~/.ssh/config
+Host d1
+ HostName ec2-34-201-108-233.compute-1.amazonaws.com
+ port 22
+ user ubuntu
+ IdentityFile /home/ubuntu/my_key.pem
+ IdentitiesOnly yes
+
+Host d2
+ HostName ec2-34-238-232-97.compute-1.amazonaws.com
+ port 22
+ user ubuntu
+ IdentityFile /home/ubuntu/my_key.pem
+ IdentitiesOnly yes
+```
+
+A better way is to use ssh agent forwarding. Check [this](https://aws.amazon.com/blogs/security/securely-connect-to-linux-instances-running-in-a-private-amazon-vpc/) article for more details.
+
+Here is a sample output from running distributed training:
+
+```
+$ python ~/mxnet/tools/launch.py -n 2 -s 2 -H hosts --sync-dst-dir /home/ubuntu/cifar10_dist --launcher ssh "python /home/ubuntu/cifar10_dist/cifar10_dist.py"
+2018-06-03 05:30:05,609 INFO rsync /home/ubuntu/cifar10_dist/ -> a1:/home/ubuntu/cifar10_dist
+2018-06-03 05:30:05,879 INFO rsync /home/ubuntu/cifar10_dist/ -> a2:/home/ubuntu/cifar10_dist
+Epoch 0: Test_acc 0.467400
+Epoch 0: Test_acc 0.466800
+Epoch 1: Test_acc 0.568500
+Epoch 1: Test_acc 0.571300
+Epoch 2: Test_acc 0.586300
+Epoch 2: Test_acc 0.594000
+Epoch 3: Test_acc 0.659200
+Epoch 3: Test_acc 0.653300
+Epoch 4: Test_acc 0.681200
+Epoch 4: Test_acc 0.687900
+```
+
+Note that the output from all hosts are merged and printed to the console.
+
diff --git a/example/distributed_training/cifar10_dist.py b/example/distributed_training/cifar10_dist.py
new file mode 100644
index 000000000000..506afbbe081a
--- /dev/null
+++ b/example/distributed_training/cifar10_dist.py
@@ -0,0 +1,176 @@
+#!/usr/bin/env python
+
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+from __future__ import print_function
+import random, sys
+
+import mxnet as mx
+from mxnet import autograd, gluon, kv, nd
+from mxnet.gluon.model_zoo import vision
+
+import numpy as np
+
+# Create a distributed key-value store
+store = kv.create('dist')
+
+# Clasify the images into one of the 10 digits
+num_outputs = 10
+
+# 64 images in a batch
+batch_size_per_gpu = 64
+# How many epochs to run the training
+epochs = 5
+
+# How many GPUs per machine
+gpus_per_machine = 4
+# Effective batch size across all GPUs
+batch_size = batch_size_per_gpu * gpus_per_machine
+
+# Create the context (a list of all GPUs to be used for training)
+ctx = [mx.gpu(i) for i in range(gpus_per_machine)]
+
+# Convert to float 32
+# Having channel as the first dimension makes computation more efficient. Hence the (2,0,1) transpose.
+# Dividing by 255 normalizes the input between 0 and 1
+def transform(data, label):
+ return nd.transpose(data.astype(np.float32), (2,0,1))/255, label.astype(np.float32)
+
+class SplitSampler(gluon.data.sampler.Sampler):
+ """ Split the dataset into `num_parts` parts and sample from the part with index `part_index`
+
+ Parameters
+ ----------
+ length: int
+ Number of examples in the dataset
+ num_parts: int
+ Partition the data into multiple parts
+ part_index: int
+ The index of the part to read from
+ """
+ def __init__(self, length, num_parts=1, part_index=0):
+ # Compute the length of each partition
+ self.part_len = length // num_parts
+ # Compute the start index for this partition
+ self.start = self.part_len * part_index
+ # Compute the end index for this partition
+ self.end = self.start + self.part_len
+
+ def __iter__(self):
+ # Extract examples between `start` and `end`, shuffle and return them.
+ indices = list(range(self.start, self.end))
+ random.shuffle(indices)
+ return iter(indices)
+
+ def __len__(self):
+ return self.part_len
+
+# Load the training data
+train_data = gluon.data.DataLoader(gluon.data.vision.CIFAR10(train=True, transform=transform),
+ batch_size,
+ sampler=SplitSampler(50000, store.num_workers, store.rank))
+
+# Load the test data
+test_data = gluon.data.DataLoader(gluon.data.vision.CIFAR10(train=False, transform=transform),
+ batch_size, shuffle=False)
+
+# Use ResNet from model zoo
+net = vision.resnet18_v1()
+
+# Initialize the parameters with Xavier initializer
+net.collect_params().initialize(mx.init.Xavier(), ctx=ctx)
+
+# SoftmaxCrossEntropy is the most common choice of loss function for multiclass classification
+softmax_cross_entropy = gluon.loss.SoftmaxCrossEntropyLoss()
+
+# Use Adam optimizer. Ask trainer to use the distributer kv store.
+trainer = gluon.Trainer(net.collect_params(), 'adam', {'learning_rate': .001}, kvstore=store)
+
+# Evaluate accuracy of the given network using the given data
+def evaluate_accuracy(data_iterator, net):
+
+ acc = mx.metric.Accuracy()
+
+ # Iterate through data and label
+ for i, (data, label) in enumerate(data_iterator):
+
+ # Get the data and label into the GPU
+ data = data.as_in_context(ctx[0])
+ label = label.as_in_context(ctx[0])
+
+ # Get network's output which is a probability distribution
+ # Apply argmax on the probability distribution to get network's classification.
+ output = net(data)
+ predictions = nd.argmax(output, axis=1)
+
+ # Give network's prediction and the correct label to update the metric
+ acc.update(preds=predictions, labels=label)
+
+ # Return the accuracy
+ return acc.get()[1]
+
+# We'll use cross entropy loss since we are doing multiclass classification
+loss = gluon.loss.SoftmaxCrossEntropyLoss()
+
+# Run one forward and backward pass on multiple GPUs
+def forward_backward(net, data, label):
+
+ # Ask autograd to remember the forward pass
+ with autograd.record():
+ # Compute the loss on all GPUs
+ losses = [loss(net(X), Y) for X, Y in zip(data, label)]
+
+ # Run the backward pass (calculate gradients) on all GPUs
+ for l in losses:
+ l.backward()
+
+# Train a batch using multiple GPUs
+def train_batch(batch, ctx, net, trainer):
+
+ # Split and load data into multiple GPUs
+ data = batch[0]
+ data = gluon.utils.split_and_load(data, ctx)
+
+ # Split and load label into multiple GPUs
+ label = batch[1]
+ label = gluon.utils.split_and_load(label, ctx)
+
+ # Run the forward and backward pass
+ forward_backward(net, data, label)
+
+ # Update the parameters
+ this_batch_size = batch[0].shape[0]
+ trainer.step(this_batch_size)
+
+# Run as many epochs as required
+for epoch in range(epochs):
+
+ # Iterate through batches and run training using multiple GPUs
+ batch_num = 1
+ for batch in train_data:
+
+ # Train the batch using multiple GPUs
+ train_batch(batch, ctx, net, trainer)
+
+ batch_num += 1
+
+ # Print test accuracy after every epoch
+ test_accuracy = evaluate_accuracy(test_data, net)
+ print("Epoch %d: Test_acc %f" % (epoch, test_accuracy))
+ sys.stdout.flush()
+