diff --git a/doc/developer-guide/multi_node.md b/doc/developer-guide/multi_node.md
new file mode 100644
index 000000000000..3f43636b41dd
--- /dev/null
+++ b/doc/developer-guide/multi_node.md
@@ -0,0 +1,94 @@
+# Multi-devices and multi-machines
+
+## Introduction
+
+MXNet uses a two-level *parameter server* for data synchronization.
+
+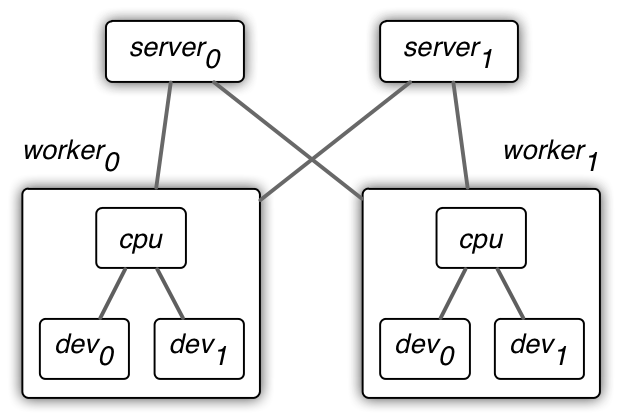 +
+- On the first layer, data are synchronized over multiple devices within a
+ single worker machine. A device could be a GPU card, CPU, or other computational
+ units. We often use sequential consistency model, also known as BSP, on this
+ level.
+
+- On the second layer, data are synchronize over multiple workers via server
+ machines. We can either use a sequential consistency model for guaranteed
+ convergence or an (partial)-asynchronous model for better system performance.
+
+## KVStore
+
+MXNet implemented the two-level parameter server in class *KVStore*. We
+currently provide the following three types. Given the batch size *b*:
+
+| kvstore type | #devices | #workers | #ex per device | #ex per update | max delay |
+| :--- | --- | --- | --- | --- | --- |
+| `local` | *k* | 1 | *b / k* | *b* | *0* |
+| `dist_sync` | *k* | *n* | *b / k* | *b × n* | *0* |
+| `dist_async` | *k* | *n* | *b / k* | *b* | inf |
+
+where the number of devices *k* used on a worker could vary for different
+workers. And
+
+- **number examples per update** : for each update, the number of examples used to
+ calculate the averaged gradients. Often the larger, the slower the convergence.
+- **number examples per device** : the number of examples batched to one device
+ each time. Often the larger, the better the performance.
+- **max delay** : The maximal delay of the weight a worker can get. Given a worker,
+ a delay *d* for weight *w* means when this worker uses *w* (to calculate the
+ gradient), *w* have been already updated by *d* times on some other places. A
+ larger delay often improves the performance, but may slows down the
+ convergence.
+
+## Multiple devices on a single machine
+
+KV store `local` synchronizes data over multiple devices on a single machine.
+It gives the same results (e.g. model accuracy) as the single device case. But
+comparing to the latter, assume there are *k* devices, then each device only
+processes *1 / k* examples each time (also consumes *1 / k* device memory). We
+often increase the batch size *b* for better system performance.
+
+When using `local`, the system will automatically chooses one of the following
+three types. Their differences are on where to average
+the gradients over all devices, and where to update the weight.
+
+| kvstore type | average gradient | perform update |
+| :--- | :--- | --- |
+| `local_update_cpu` | CPU | CPU |
+| `local_allreduce_cpu` | CPU | all devices |
+| `local_allreduce_device` | a device | all devices |
+
+They produce (almost) the same results, but may vary on speed.
+
+- `local_update_cpu`, gradients are first copied to main memory, next averaged on CPU,
+ and then update the weight on CPU. It is suitable when the average size of
+ weights are not large and there are a large number of weight. For example the
+ google Inception network.
+
+- `local_allreduce_cpu` is similar to `local_update_cpu` except that the
+ averaged gradients are copied back to the devices, and then weights are
+ updated on devices. It is faster than 1 when the weight size is large so we
+ can use the device to accelerate the computation (but we increase the workload
+ by *k* times). Examples are AlexNet on imagenet.
+
+- `local_allreduce_device` is similar to `local_allreduce_cpu` except that the
+ gradient are averaged on a chosen device. It may take advantage of the
+ possible device-to-device communication, and may accelerate the averaging
+ step. It is faster than 2 when the gradients are huge. But it requires more
+ device memory.
+
+## Multiple machines
+
+Both `dist_async` and `dist_sync` can handle the multiple machines
+situation. But they are different on both semantic and performance.
+
+- `dist_sync`: the gradients are first averaged on the servers, and then send to
+ back to workers for updating the weight. It is similar to `local` and
+ `update_on_kvstore=false` if we treat a machine as a device. It guarantees
+ almost identical convergence with the single machine single device situation
+ if reduces the batch size to *b / n*. However, it requires synchronization
+ between all workers, and therefore may harm the system performance.
+
+- `dist_async`: the gradient is sent to the servers, and the weight is updated
+ there. The weights a worker has may be stale. This loose data consistency
+ model reduces the machine synchronization cost and therefore could improve the
+ system performance. But it may harm the convergence speed.
diff --git a/include/mxnet/c_api.h b/include/mxnet/c_api.h
index b7c22ee9fb65..76a6d80eee47 100644
--- a/include/mxnet/c_api.h
+++ b/include/mxnet/c_api.h
@@ -787,6 +787,14 @@ MXNET_DLL int MXKVStoreSetUpdater(KVStoreHandle handle,
MXKVStoreUpdater updater);
+/*!
+ * \brief get the type of the kvstore
+ * \param handle handle to the KVStore
+ * \param type a string type
+ * \return 0 when success, -1 when failure happens
+ */
+MXNET_DLL int MXKVStoreGetType(KVStoreHandle handle,
+ const char** type);
//--------------------------------------------
// Part 6: advanced KVStore for multi-machines
//--------------------------------------------
diff --git a/include/mxnet/kvstore.h b/include/mxnet/kvstore.h
index da7d94a75cfd..59d3c2390c7d 100644
--- a/include/mxnet/kvstore.h
+++ b/include/mxnet/kvstore.h
@@ -25,13 +25,22 @@ class KVStore {
/*!
* \brief Factory function to create a new KVStore.
- * \param type The type of the kvstore, can be "local" or "dist"
- * - local works for multiple devices on a single machine (single process)
- * - dist works for multi-machines (multiple processes)
+ * \param type The type of the kvstore,
+ * 'local' : multi-devices on a single machine. can be also
+ * 'local_update_cpu', 'local_allreduce_cpu'
+ * 'device' or 'local_allreduce_device' : same to local but use gpus for kv
+ * allreduce
+ * 'dist_sync' : multi-machines with BSP
+ * 'dist_async' : multi-machines with partical asynchronous
* \return a new created KVStore.
*/
static KVStore *Create(const char *type = "local");
+ /**
+ * \brief return the type
+ */
+ inline const std::string& type() { return type_; }
+
/*!
* \brief Initialize a list of key-value pair to the store.
*
@@ -269,6 +278,11 @@ class KVStore {
* \brief the user-defined updater
*/
Updater updater_;
+
+ /**
+ * \brief the kvstore type
+ */
+ std::string type_;
};
} // namespace mxnet
diff --git a/python/mxnet/context.py b/python/mxnet/context.py
index 1ed3dae5fb23..b35d910407a8 100644
--- a/python/mxnet/context.py
+++ b/python/mxnet/context.py
@@ -29,8 +29,8 @@ class Context(object):
"""
# static class variable
default_ctx = None
- devtype2str = {1: 'cpu', 2: 'gpu'}
- devstr2type = {'cpu': 1, 'gpu': 2}
+ devtype2str = {1: 'cpu', 2: 'gpu', 3: 'cpu_pinned'}
+ devstr2type = {'cpu': 1, 'gpu': 2, 'cpu_pinned': 3}
def __init__(self, device_type, device_id=0):
if isinstance(device_type, Context):
self.device_typeid = device_type.device_typeid
diff --git a/python/mxnet/kvstore.py b/python/mxnet/kvstore.py
index ffd7433281ae..4e2ab83d0a8d 100644
--- a/python/mxnet/kvstore.py
+++ b/python/mxnet/kvstore.py
@@ -6,7 +6,7 @@
import pickle
from .ndarray import NDArray
from .base import _LIB
-from .base import check_call, c_array, c_str, string_types, mx_uint
+from .base import check_call, c_array, c_str, string_types, mx_uint, py_str
from .base import NDArrayHandle, KVStoreHandle
from . import optimizer as opt
@@ -68,7 +68,7 @@ def init(self, key, value):
For each key, one must init it before push and pull.
- Only worker 0's (get_rank() == 0) data are used.
+ Only worker 0's (rank == 0) data are used.
This function returns after data have been initialized successfully
@@ -95,7 +95,7 @@ def init(self, key, value):
>>> keys = [5, 7, 9]
>>> kv.init(keys, [mx.nd.ones(shape)]*len(keys))
"""
- if (self.get_rank() == 0):
+ if (self.rank == 0):
ckeys, cvals = _ctype_key_value(key, value)
check_call(_LIB.MXKVStoreInit(
self.handle, mx_uint(len(ckeys)), ckeys, cvals))
@@ -169,6 +169,9 @@ def push(self, key, value, priority=0):
self.handle, mx_uint(len(ckeys)), ckeys, cvals,
ctypes.c_int(priority)))
+ # self._wait(key)
+ # self._barrier()
+
def pull(self, key, out=None, priority=0):
""" Pull a single value or a sequence of values from the store.
@@ -261,9 +264,23 @@ def set_optimizer(self, optimizer):
raise
self._send_command_to_servers(0, optim_str)
else:
- self._set_updater(opt.optimizer_clossure(optimizer))
+ self._set_updater(opt.get_updater(optimizer))
+
+ @property
+ def type(self):
+ """Get the type of this kvstore
+
+ Returns
+ -------
+ type : str
+ the string type
+ """
+ kv_type = ctypes.c_char_p()
+ check_call(_LIB.MXKVStoreGetType(self.handle, ctypes.byref(kv_type)))
+ return py_str(kv_type.value)
- def get_rank(self):
+ @property
+ def rank(self):
"""Get the rank of this worker node
Returns
@@ -275,7 +292,8 @@ def get_rank(self):
check_call(_LIB.MXKVStoreGetRank(self.handle, ctypes.byref(rank)))
return rank.value
- def get_num_workers(self):
+ @property
+ def num_workers(self):
"""Get the number of worker ndoes
Returns
@@ -329,17 +347,17 @@ def _barrier(self):
pulling, we can place a barrier to guarantee that the initialization is
finished.
- The following codes run on n machines in parallel
-
- >>> if kv.get_rank() == 0:
- ... kv.init(keys, values);
- ... kv.barrier()
- ... kv.pull(keys, out = values);
-
But note that, this functions only blocks the main thread of workers
until all of them are reached this point. It doesn't guarantee that all
operations issued before are actually finished, such as \ref Push and
\ref Pull. In that case, we need to call \ref Wait or \ref WaitAll
+
+ The following codes implement a BSP model
+
+ >>> kv.push(keys, values)
+ ... kv._wait(keys)
+ ... kv._barrier()
+ ... kv.pull(keys, out = values);
"""
check_call(_LIB.MXKVStoreBarrier(self.handle))
diff --git a/python/mxnet/kvstore_server.py b/python/mxnet/kvstore_server.py
index 85f9c26ef5ae..dc4356925b40 100644
--- a/python/mxnet/kvstore_server.py
+++ b/python/mxnet/kvstore_server.py
@@ -31,7 +31,7 @@ def server_controller(cmd_id, cmd_body):
self.kvstore.set_optimizer(optimizer)
else:
print ("server %d, unknown command (%d, %s)" % (
- self.kvstore.get_rank(), cmd_id, cmd_body))
+ self.kvstore.rank, cmd_id, cmd_body))
return server_controller
def run(self):
diff --git a/python/mxnet/model.py b/python/mxnet/model.py
index 719f5385ebe7..a8430e55c6eb 100644
--- a/python/mxnet/model.py
+++ b/python/mxnet/model.py
@@ -11,10 +11,11 @@
from . import symbol as sym
from . import optimizer as opt
from . import metric
-from . import kvstore
+from . import kvstore as kvs
from .context import Context, cpu
from .initializer import Uniform
from collections import namedtuple
+from .optimizer import get_updater
BASE_ESTIMATOR = object
@@ -122,14 +123,57 @@ def _split_input_slice(input_shape, num_split):
shapes.append(tuple(s))
return (slices, shapes)
+def _create_kvstore(kvstore, num_device, arg_params):
+ """Create kvstore
+
+ This function select and create a proper kvstore if given the kvstore type
+
+ Parameters
+ ----------
+
+ kvstore : KVStore or str
+ The kvstore
+
+ num_device : int
+ The number of devices
+
+ arg_params : dict of str to NDArray
+ Model parameter, dict of name to NDArray of net's weights.
+ """
+
+ if isinstance(kvstore, kvs.KVStore):
+ kv = kvstore
+ elif isinstance(kvstore, str):
+ # create kvstore using the string type
+ if num_device is 1 and 'dist' not in kvstore:
+ # no need to use kv for single device and single machine
+ kv = None
+ else:
+ if kvstore is 'local':
+ # automatically select a proper local
+ max_size = max(np.prod(param.shape) for param in arg_params.values())
+ if max_size < 1024 * 1024 * 16:
+ kvstore = 'local_update_cpu'
+ else:
+ kvstore = 'local_allreduce_cpu'
+ logging.info('Auto-select kvstore type = %s', kvstore)
+ kv = kvs.create(kvstore)
+ else:
+ raise TypeError('kvstore must be either KVStore or str')
+
+ # detect whether or not update weight on kvstore
+ update_on_kvstore = True
+ if not kv or 'local_allreduce' in kv.type:
+ update_on_kvstore = False
+
+ return (kv, update_on_kvstore)
def _train_multi_device(symbol, ctx, input_shape,
arg_params, aux_params,
begin_round, end_round, optimizer,
train_data, eval_data=None, eval_metric=None,
iter_end_callback=None, epoch_end_callback=None,
- update_on_kvstore=None, kvstore_type='local',
- logger=None):
+ kvstore='local', logger=None):
"""Internal training function on multiple devices.
This function will also work for single device as well.
@@ -177,11 +221,15 @@ def _train_multi_device(symbol, ctx, input_shape,
A callback that is invoked at end of each batch.
This can be used to measure speed, get result from evaluation metric. etc.
- update_on_kvstore : boolean, optional
- Whether to perform parameter update on kvstore instead of training device.
+ kvstore: KVStore or str, optional
+ The KVStore or a string kvstore type:
+ 'local' : multi-devices on a single machine, will automatically
+ choose one from 'local_update_cpu', 'local_allreduce_cpu', and
+ 'local_allreduce_device'
+ 'dist_sync' : multi-machines with BSP
+ 'dist_async' : multi-machines with partical asynchronous
- kvstore_type : {'local', 'device'}, optional
- Type of kvstore used for synchronization.
+ In default uses 'local', often no need to change for single machiine.
logger : logging logger
When not specified, default logger will be used.
@@ -189,10 +237,6 @@ def _train_multi_device(symbol, ctx, input_shape,
Notes
-----
- This function will inplace update the NDArrays in arg_parans and aux_states.
- - Turning update_on_kvstore on and off can affect speed of multi-gpu training.
- - It is auto selected by default.
- - update_on_kvstore=True works well for inception type nets that contains many small weights.
- - update_on_kvstore=False works better for Alexnet style net with bulk weights.
"""
if logger is None:
logger = logging
@@ -219,40 +263,29 @@ def _train_multi_device(symbol, ctx, input_shape,
for texec in train_execs:
texec.copy_params_from(arg_params, aux_params)
- # ky value store
- kv = kvstore.create(kvstore_type) if num_device != 1 else None
- if kv is None or kvstore_type == 'device':
- update_on_kvstore = False
- else:
- # auto decide update_on_kvstore
- if update_on_kvstore is None:
- max_size = max(np.prod(param.shape) for param in arg_params.values())
- update_on_kvstore = max_size < 1024 * 1024 * 16
- logging.info('Auto-select update_on_kvstore=%s', str(update_on_kvstore))
-
- opt_state_blocks = []
- # If there are multiple devices, initialize the weights.
- for index, pair in enumerate(zip(arg_blocks, grad_blocks)):
- arg_list, grad_list = pair
- if grad_list[0] is not None:
- if kv:
- kv.init(index, arg_list[0])
- # attach state direct to weight
- if update_on_kvstore:
- opt_state_blocks.append(nd.zeros(arg_list[0].shape, cpu()))
- else:
- opt_list = [optimizer.create_state(index, w) for w in arg_list]
- opt_state_blocks.append(opt_list)
- else:
- opt_state_blocks.append(None)
+ # create kvstore
+ (kv, update_on_kvstore) = _create_kvstore(kvstore, num_device, arg_params)
+
+ # init optimizer before give it to kv or get_updater
+ optimizer.begin_round(begin_round)
- def kv_updater(index, grad, weight):
- """Internal updater on KVstore, used when update_on_kvstore=True."""
- optimizer.update(index, weight, grad, opt_state_blocks[index])
+ if not update_on_kvstore:
+ updater = get_updater(optimizer)
- # pylint: disable=protected-access
- if update_on_kvstore:
- kv._set_updater(kv_updater)
+ if kv:
+ # init optimizer
+ if update_on_kvstore:
+ kv.set_optimizer(optimizer)
+
+ # init kv
+ for index, pair in enumerate(zip(arg_blocks, grad_blocks)):
+ arg_list, grad_list = pair
+ if grad_list[0] is not None:
+ kv.init(index, arg_list[0])
+
+ # pull the weight back
+ if update_on_kvstore:
+ kv.pull(index, arg_list, priority=-index)
# Input and output data structure
data_index, label_index = _check_arguments(symbol)
@@ -265,7 +298,6 @@ def kv_updater(index, grad, weight):
for iteration in range(begin_round, end_round):
# Training phase
tic = time.time()
- optimizer.begin_round(iteration)
eval_metric.reset()
nbatch = 0
# Iterate over training data.
@@ -297,10 +329,13 @@ def kv_updater(index, grad, weight):
# pull back the sum gradients, to the same locations.
kv.pull(index, grad_list, priority=-index)
if not update_on_kvstore:
- opt_list = opt_state_blocks[index]
- # optimizea
- for w, g, state in zip(arg_list, grad_list, opt_list):
- optimizer.update(index, w, g, state)
+ for k, p in enumerate(zip(arg_list, grad_list)):
+ # faked an index here, to make optimizer create diff
+ # state for the same index but on diff devs, TODO(mli)
+ # use a better solution latter
+ w, g = p
+ updater(index*num_device+k, g, w)
+
nbatch += 1
# epoch callback (for print purpose)
if epoch_end_callback != None:
@@ -607,8 +642,7 @@ def predict(self, X):
def fit(self, X, y=None, eval_data=None, eval_metric='acc',
iter_end_callback=None, epoch_end_callback=None,
- update_on_kvstore=None, kvstore_type='local',
- logger=None):
+ kvstore='local', logger=None):
"""Fit the model.
Parameters
@@ -635,15 +669,19 @@ def fit(self, X, y=None, eval_data=None, eval_metric='acc',
A callback that is invoked at end of each batch
For print purpose
- update_on_kvstore: boolean, optional
- Whether to perform parameter update on kvstore instead of training device.
- By default, the trainer will automatically decide the policy.
+ kvstore: KVStore or str, optional
+ The KVStore or a string kvstore type:
+ 'local' : multi-devices on a single machine, will automatically
+ choose one from 'local_update_cpu', 'local_allreduce_cpu', and
+ 'local_allreduce_device'
+ 'dist_sync' : multi-machines with BSP
+ 'dist_async' : multi-machines with partical asynchronous
- kvstore_type : {'local', 'device'}, optional
- Type of kvstore used for synchronization, usually no need to set.
+ In default uses 'local', often no need to change for single machiine.
logger : logging logger, optional
When not specified, default logger will be used.
+
"""
X = self._init_iter(X, y, is_train=True)
# Simply ignore the first example to get input_shape
@@ -672,8 +710,7 @@ def fit(self, X, y=None, eval_data=None, eval_metric='acc',
eval_metric=eval_metric,
iter_end_callback=iter_end_callback,
epoch_end_callback=epoch_end_callback,
- update_on_kvstore=update_on_kvstore,
- kvstore_type=kvstore_type,
+ kvstore=kvstore,
logger=logger)
def save(self, prefix, iteration=None):
@@ -739,8 +776,7 @@ def load(prefix, iteration, ctx=None, **kwargs):
def create(symbol, X, y=None, ctx=None,
num_round=None, optimizer='sgd', initializer=Uniform(0.01),
eval_data=None, eval_metric='acc', iter_end_callback=None,
- update_on_kvstore=None, kvstore_type='local',
- logger=None, **kwargs):
+ kvstore='local', logger=None, **kwargs):
"""Functional style to create a model.
This function will be more consistent with functional
@@ -782,20 +818,20 @@ def create(symbol, X, y=None, ctx=None,
A callback that is invoked at end of each iteration.
This can be used to checkpoint model each iteration.
- update_on_kvstore: boolean, optional
- Whether to perform parameter update on kvstore instead of training device.
- By default, the trainer will automatically decide the policy.
-
- kvstore_type : {'local', 'device'}, optional
- Type of kvstore used for synchronization, usually no need to set.
+ kvstore: KVStore or str, optional
+ The KVStore or a string kvstore type:
+ 'local' : multi-devices on a single machine, will automatically
+ choose one from 'local_update_cpu', 'local_allreduce_cpu', and
+ 'local_allreduce_device'
+ 'dist_sync' : multi-machines with BSP
+ 'dist_async' : multi-machines with partical asynchronous
- logger : logging logger, optional
+ In default uses 'local', often no need to change for single machiine.
"""
model = FeedForward(symbol, ctx=ctx, num_round=num_round,
optimizer=optimizer, initializer=initializer, **kwargs)
model.fit(X, y, eval_data=eval_data, eval_metric=eval_metric,
iter_end_callback=iter_end_callback,
- update_on_kvstore=update_on_kvstore,
- kvstore_type=kvstore_type,
+ kvstore=kvstore,
logger=logger)
return model
diff --git a/python/mxnet/optimizer.py b/python/mxnet/optimizer.py
index da336aff29e4..ad2b1fbdd6e6 100644
--- a/python/mxnet/optimizer.py
+++ b/python/mxnet/optimizer.py
@@ -148,8 +148,7 @@ def create(name, rescale_grad=1, **kwargs):
else:
raise ValueError('Cannot find optimizer %s' % name)
-
-def optimizer_clossure(optimizer):
+def get_updater(optimizer):
"""Return a clossure of the updater needed for kvstore
Parameters
diff --git a/src/c_api.cc b/src/c_api.cc
index 1a12fe65ea3d..d50189d66a11 100644
--- a/src/c_api.cc
+++ b/src/c_api.cc
@@ -1088,3 +1088,10 @@ int MXKVStoreSendCommmandToServers(KVStoreHandle handle,
cmd_id, std::string(cmd_body));
API_END();
}
+
+int MXKVStoreGetType(KVStoreHandle handle,
+ const char** type) {
+ API_BEGIN();
+ *CHECK_NOTNULL(type) = static_cast(handle)->type().c_str();
+ API_END();
+}
diff --git a/src/io/iter_image_recordio.cc b/src/io/iter_image_recordio.cc
index 37bfe0020b6d..6ca610e8a410 100644
--- a/src/io/iter_image_recordio.cc
+++ b/src/io/iter_image_recordio.cc
@@ -101,6 +101,11 @@ struct ImageRecParserParam : public dmlc::Parameter {
int preprocess_threads;
/*! \brief whether to remain silent */
bool verbose;
+ /*! \brief partition the data into multiple parts */
+ int num_parts;
+ /*! \brief the index of the part will read*/
+ int part_index;
+
// declare parameters
DMLC_DECLARE_PARAMETER(ImageRecParserParam) {
DMLC_DECLARE_FIELD(path_imglist).set_default("")
@@ -116,6 +121,10 @@ struct ImageRecParserParam : public dmlc::Parameter {
.describe("Backend Param: Number of thread to do preprocessing.");
DMLC_DECLARE_FIELD(verbose).set_default(true)
.describe("Auxiliary Param: Whether to output parser information.");
+ DMLC_DECLARE_FIELD(num_parts).set_default(1)
+ .describe("partition the data into multiple parts");
+ DMLC_DECLARE_FIELD(part_index).set_default(0)
+ .describe("the index of the part will read");
}
};
@@ -203,12 +212,9 @@ inline void ImageRecordIOParser::Init(
LOG(INFO) << "ImageRecordIOParser: " << param_.path_imgrec
<< ", use " << threadget << " threads for decoding..";
}
- // TODO(mu, tianjun) add DMLC env variable to detect parition
- const int part_index = 0;
- const int num_parts = 1;
source_ = dmlc::InputSplit::Create(
- param_.path_imgrec.c_str(), part_index,
- num_parts, "recordio");
+ param_.path_imgrec.c_str(), param_.part_index,
+ param_.num_parts, "recordio");
// use 64 MB chunk when possible
source_->HintChunkSize(8 << 20UL);
#else
diff --git a/src/io/iter_mnist.cc b/src/io/iter_mnist.cc
index a1f03dbd8e83..cb2e2a853e0d 100644
--- a/src/io/iter_mnist.cc
+++ b/src/io/iter_mnist.cc
@@ -31,6 +31,10 @@ struct MNISTParam : public dmlc::Parameter {
bool flat;
/*! \brief random seed */
int seed;
+ /*! \brief partition the data into multiple parts */
+ int num_parts;
+ /*! \brief the index of the part will read*/
+ int part_index;
// declare parameters
DMLC_DECLARE_PARAMETER(MNISTParam) {
DMLC_DECLARE_FIELD(image).set_default("./train-images-idx3-ubyte")
@@ -47,6 +51,10 @@ struct MNISTParam : public dmlc::Parameter {
.describe("Augmentation Param: Random Seed.");
DMLC_DECLARE_FIELD(silent).set_default(false)
.describe("Auxiliary Param: Whether to print out data info.");
+ DMLC_DECLARE_FIELD(num_parts).set_default(1)
+ .describe("partition the data into multiple parts");
+ DMLC_DECLARE_FIELD(part_index).set_default(0)
+ .describe("the index of the part will read");
}
};
@@ -113,13 +121,32 @@ class MNISTIter: public IIterator {
}
private:
+ inline void GetPart(int count, int* start, int *end) {
+ CHECK_GE(param_.part_index, 0);
+ CHECK_GT(param_.num_parts, 0);
+ CHECK_GT(param_.num_parts, param_.part_index);
+
+ *start = static_cast(
+ static_cast(count) / param_.num_parts * param_.part_index);
+ *end = static_cast(
+ static_cast(count) / param_.num_parts * (param_.part_index+1));
+ }
+
inline void LoadImage(void) {
- dmlc::Stream *stdimg = dmlc::Stream::Create(param_.image.c_str(), "r");
+ dmlc::SeekStream* stdimg
+ = dmlc::SeekStream::CreateForRead(param_.image.c_str());
ReadInt(stdimg);
int image_count = ReadInt(stdimg);
int image_rows = ReadInt(stdimg);
int image_cols = ReadInt(stdimg);
+ int start, end;
+ GetPart(image_count, &start, &end);
+ image_count = end - start;
+ if (start > 0) {
+ stdimg->Seek(stdimg->Tell() + start * image_rows * image_cols);
+ }
+
img_.shape_ = mshadow::Shape3(image_count, image_rows, image_cols);
img_.stride_ = img_.size(2);
@@ -139,9 +166,18 @@ class MNISTIter: public IIterator {
delete stdimg;
}
inline void LoadLabel(void) {
- dmlc::Stream *stdlabel = dmlc::Stream::Create(param_.label.c_str(), "r");
+ dmlc::SeekStream* stdlabel
+ = dmlc::SeekStream::CreateForRead(param_.label.c_str());
ReadInt(stdlabel);
int labels_count = ReadInt(stdlabel);
+
+ int start, end;
+ GetPart(labels_count, &start, &end);
+ labels_count = end - start;
+ if (start > 0) {
+ stdlabel->Seek(stdlabel->Tell() + start);
+ }
+
labels_.resize(labels_count);
for (int i = 0; i < labels_count; ++i) {
unsigned char ch;
diff --git a/src/kvstore/kvstore.cc b/src/kvstore/kvstore.cc
index c11cb98461dc..edd78e617b75 100644
--- a/src/kvstore/kvstore.cc
+++ b/src/kvstore/kvstore.cc
@@ -17,20 +17,35 @@ namespace mxnet {
KVStore* KVStore::Create(const char *type_name) {
std::string tname = type_name;
- if (tname == "local") {
- return new kvstore::KVStoreLocal();
- } else if (tname == "device") {
- return new kvstore::KVStoreDevice();
- } else if (tname == "dist") {
+ std::transform(tname.begin(), tname.end(), tname.begin(), ::tolower);
+ KVStore* kv = nullptr;
+ if (tname == "local" ||
+ tname == "local_update_cpu" ||
+ tname == "local_allreduce_cpu") {
+ kv = new kvstore::KVStoreLocal();
+ } else if (tname == "device" ||
+ tname == "local_allreduce_device") {
+ tname = "local_allreduce_device";
+ kv = new kvstore::KVStoreDevice();
+ } else if (tname == "dist_async") {
#if MXNET_USE_DIST_KVSTORE
- return new kvstore::KVStoreDist();
+ kv = new kvstore::KVStoreDist();
#else
- LOG(FATAL) << "compile with USE_DIST_KVSTORE=1";
+ LOG(FATAL) << "compile with USE_DIST_KVSTORE=1 to use " << tname;
return nullptr;
#endif // MXNET_USE_DIST_KVSTORE
+ } else if (tname == "dist_sync") {
+#if MXNET_USE_DIST_KVSTORE
+ kv = new kvstore::KVStoreDist();
+#else
+ LOG(FATAL) << "compile with USE_DIST_KVSTORE=1 to use " << tname;
+ return nullptr;
+#endif // MXNET_USE_DIST_KVSTORE
+ } else {
+ LOG(FATAL) << "Unknown KVStore type \"" << tname << "\"";
}
- LOG(FATAL) << "Unknown KVStore type \"" << type_name << "\"";
- return nullptr;
+ kv->type_ = tname;
+ return kv;
}
} // namespace mxnet
diff --git a/src/kvstore/kvstore_dist.h b/src/kvstore/kvstore_dist.h
index 2721accd5c04..6bfcbe19a9ba 100644
--- a/src/kvstore/kvstore_dist.h
+++ b/src/kvstore/kvstore_dist.h
@@ -10,6 +10,7 @@
#include "./kvstore_local.h"
#include "./mxnet_ps_node.h"
#include "mxnet/engine.h"
+// #include "dmlc/parameter.h"
#include "ps.h"
#include "base/range.h"
@@ -43,6 +44,7 @@ class KVStoreDist : public KVStoreLocal {
// stop the executor at servers
SendCommandToServers(CommandID::kStop, "");
}
+ Barrier();
ps::StopSystem();
}
}
diff --git a/tests/python/distributed/test_mlp.py b/tests/python/distributed/test_mlp.py
new file mode 100755
index 000000000000..7b5c55588644
--- /dev/null
+++ b/tests/python/distributed/test_mlp.py
@@ -0,0 +1,73 @@
+#!/usr/bin/env python
+# pylint: skip-file
+
+import mxnet as mx
+import numpy as np
+import os, sys
+import pickle as pickle
+import logging
+curr_path = os.path.dirname(os.path.abspath(os.path.expanduser(__file__)))
+sys.path.append(os.path.join(curr_path, '../common/'))
+import models
+import get_data
+
+# symbol net
+batch_size = 100
+data = mx.symbol.Variable('data')
+fc1 = mx.symbol.FullyConnected(data, name='fc1', num_hidden=128)
+act1 = mx.symbol.Activation(fc1, name='relu1', act_type="relu")
+fc2 = mx.symbol.FullyConnected(act1, name = 'fc2', num_hidden = 64)
+act2 = mx.symbol.Activation(fc2, name='relu2', act_type="relu")
+fc3 = mx.symbol.FullyConnected(act2, name='fc3', num_hidden=10)
+softmax = mx.symbol.Softmax(fc3, name = 'sm')
+
+def accuracy(label, pred):
+ py = np.argmax(pred, axis=1)
+ return np.sum(py == label) / float(label.size)
+
+num_round = 4
+prefix = './mlp'
+
+kv = mx.kvstore.create('dist')
+batch_size /= kv.get_num_workers()
+
+#check data
+get_data.GetMNIST_ubyte()
+
+train_dataiter = mx.io.MNISTIter(
+ image="data/train-images-idx3-ubyte",
+ label="data/train-labels-idx1-ubyte",
+ data_shape=(784,), num_parts=kv.get_num_workers(), part_index=kv.get_rank(),
+ batch_size=batch_size, shuffle=True, flat=True, silent=False, seed=10)
+val_dataiter = mx.io.MNISTIter(
+ image="data/t10k-images-idx3-ubyte",
+ label="data/t10k-labels-idx1-ubyte",
+ data_shape=(784,),
+ batch_size=batch_size, shuffle=True, flat=True, silent=False)
+
+def test_mlp():
+ logging.basicConfig(level=logging.DEBUG)
+
+ model = mx.model.FeedForward.create(
+ softmax,
+ X=train_dataiter,
+ eval_data=val_dataiter,
+ eval_metric=mx.metric.np(accuracy),
+ ctx=[mx.cpu(i) for i in range(1)],
+ num_round=num_round,
+ learning_rate=0.05, wd=0.0004,
+ momentum=0.9,
+ kvstore=kv,
+ )
+ logging.info('Finish traning...')
+ prob = model.predict(val_dataiter)
+ logging.info('Finish predict...')
+ val_dataiter.reset()
+ y = np.concatenate([label.asnumpy() for _, label in val_dataiter]).astype('int')
+ py = np.argmax(prob, axis=1)
+ acc = float(np.sum(py == y)) / len(y)
+ logging.info('final accuracy = %f', acc)
+ assert(acc > 0.93)
+
+if __name__ == "__main__":
+ test_mlp()
diff --git a/tests/python/train/test_mlp.py b/tests/python/train/test_mlp.py
index 65f3d90d9e3d..85266e12df52 100644
--- a/tests/python/train/test_mlp.py
+++ b/tests/python/train/test_mlp.py
@@ -40,9 +40,6 @@ def accuracy(label, pred):
def test_mlp():
# print logging by default
logging.basicConfig(level=logging.DEBUG)
- console = logging.StreamHandler()
- console.setLevel(logging.DEBUG)
- logging.getLogger('').addHandler(console)
model = mx.model.FeedForward.create(
softmax,
@@ -53,8 +50,7 @@ def test_mlp():
ctx=[mx.cpu(i) for i in range(2)],
num_round=num_round,
learning_rate=0.1, wd=0.0004,
- momentum=0.9,
- update_on_kvstore=True)
+ momentum=0.9)
logging.info('Finish traning...')
prob = model.predict(val_dataiter)
diff --git a/tests/python/unittest/test_kvstore.py b/tests/python/unittest/test_kvstore.py
index ada94490ce86..77439677320f 100644
--- a/tests/python/unittest/test_kvstore.py
+++ b/tests/python/unittest/test_kvstore.py
@@ -104,8 +104,13 @@ def test_updater(dev = 'cpu'):
for v in vv:
check_diff_to_scalar(v, num_devs * num_push)
+def test_get_type():
+ kvtype = 'local_allreduce_cpu'
+ kv = mx.kv.create(kvtype)
+ assert kv.type == kvtype
if __name__ == '__main__':
+ test_get_type()
test_single_kv_pair()
test_list_kv_pair()
test_aggregator()
+
+- On the first layer, data are synchronized over multiple devices within a
+ single worker machine. A device could be a GPU card, CPU, or other computational
+ units. We often use sequential consistency model, also known as BSP, on this
+ level.
+
+- On the second layer, data are synchronize over multiple workers via server
+ machines. We can either use a sequential consistency model for guaranteed
+ convergence or an (partial)-asynchronous model for better system performance.
+
+## KVStore
+
+MXNet implemented the two-level parameter server in class *KVStore*. We
+currently provide the following three types. Given the batch size *b*:
+
+| kvstore type | #devices | #workers | #ex per device | #ex per update | max delay |
+| :--- | --- | --- | --- | --- | --- |
+| `local` | *k* | 1 | *b / k* | *b* | *0* |
+| `dist_sync` | *k* | *n* | *b / k* | *b × n* | *0* |
+| `dist_async` | *k* | *n* | *b / k* | *b* | inf |
+
+where the number of devices *k* used on a worker could vary for different
+workers. And
+
+- **number examples per update** : for each update, the number of examples used to
+ calculate the averaged gradients. Often the larger, the slower the convergence.
+- **number examples per device** : the number of examples batched to one device
+ each time. Often the larger, the better the performance.
+- **max delay** : The maximal delay of the weight a worker can get. Given a worker,
+ a delay *d* for weight *w* means when this worker uses *w* (to calculate the
+ gradient), *w* have been already updated by *d* times on some other places. A
+ larger delay often improves the performance, but may slows down the
+ convergence.
+
+## Multiple devices on a single machine
+
+KV store `local` synchronizes data over multiple devices on a single machine.
+It gives the same results (e.g. model accuracy) as the single device case. But
+comparing to the latter, assume there are *k* devices, then each device only
+processes *1 / k* examples each time (also consumes *1 / k* device memory). We
+often increase the batch size *b* for better system performance.
+
+When using `local`, the system will automatically chooses one of the following
+three types. Their differences are on where to average
+the gradients over all devices, and where to update the weight.
+
+| kvstore type | average gradient | perform update |
+| :--- | :--- | --- |
+| `local_update_cpu` | CPU | CPU |
+| `local_allreduce_cpu` | CPU | all devices |
+| `local_allreduce_device` | a device | all devices |
+
+They produce (almost) the same results, but may vary on speed.
+
+- `local_update_cpu`, gradients are first copied to main memory, next averaged on CPU,
+ and then update the weight on CPU. It is suitable when the average size of
+ weights are not large and there are a large number of weight. For example the
+ google Inception network.
+
+- `local_allreduce_cpu` is similar to `local_update_cpu` except that the
+ averaged gradients are copied back to the devices, and then weights are
+ updated on devices. It is faster than 1 when the weight size is large so we
+ can use the device to accelerate the computation (but we increase the workload
+ by *k* times). Examples are AlexNet on imagenet.
+
+- `local_allreduce_device` is similar to `local_allreduce_cpu` except that the
+ gradient are averaged on a chosen device. It may take advantage of the
+ possible device-to-device communication, and may accelerate the averaging
+ step. It is faster than 2 when the gradients are huge. But it requires more
+ device memory.
+
+## Multiple machines
+
+Both `dist_async` and `dist_sync` can handle the multiple machines
+situation. But they are different on both semantic and performance.
+
+- `dist_sync`: the gradients are first averaged on the servers, and then send to
+ back to workers for updating the weight. It is similar to `local` and
+ `update_on_kvstore=false` if we treat a machine as a device. It guarantees
+ almost identical convergence with the single machine single device situation
+ if reduces the batch size to *b / n*. However, it requires synchronization
+ between all workers, and therefore may harm the system performance.
+
+- `dist_async`: the gradient is sent to the servers, and the weight is updated
+ there. The weights a worker has may be stale. This loose data consistency
+ model reduces the machine synchronization cost and therefore could improve the
+ system performance. But it may harm the convergence speed.
diff --git a/include/mxnet/c_api.h b/include/mxnet/c_api.h
index b7c22ee9fb65..76a6d80eee47 100644
--- a/include/mxnet/c_api.h
+++ b/include/mxnet/c_api.h
@@ -787,6 +787,14 @@ MXNET_DLL int MXKVStoreSetUpdater(KVStoreHandle handle,
MXKVStoreUpdater updater);
+/*!
+ * \brief get the type of the kvstore
+ * \param handle handle to the KVStore
+ * \param type a string type
+ * \return 0 when success, -1 when failure happens
+ */
+MXNET_DLL int MXKVStoreGetType(KVStoreHandle handle,
+ const char** type);
//--------------------------------------------
// Part 6: advanced KVStore for multi-machines
//--------------------------------------------
diff --git a/include/mxnet/kvstore.h b/include/mxnet/kvstore.h
index da7d94a75cfd..59d3c2390c7d 100644
--- a/include/mxnet/kvstore.h
+++ b/include/mxnet/kvstore.h
@@ -25,13 +25,22 @@ class KVStore {
/*!
* \brief Factory function to create a new KVStore.
- * \param type The type of the kvstore, can be "local" or "dist"
- * - local works for multiple devices on a single machine (single process)
- * - dist works for multi-machines (multiple processes)
+ * \param type The type of the kvstore,
+ * 'local' : multi-devices on a single machine. can be also
+ * 'local_update_cpu', 'local_allreduce_cpu'
+ * 'device' or 'local_allreduce_device' : same to local but use gpus for kv
+ * allreduce
+ * 'dist_sync' : multi-machines with BSP
+ * 'dist_async' : multi-machines with partical asynchronous
* \return a new created KVStore.
*/
static KVStore *Create(const char *type = "local");
+ /**
+ * \brief return the type
+ */
+ inline const std::string& type() { return type_; }
+
/*!
* \brief Initialize a list of key-value pair to the store.
*
@@ -269,6 +278,11 @@ class KVStore {
* \brief the user-defined updater
*/
Updater updater_;
+
+ /**
+ * \brief the kvstore type
+ */
+ std::string type_;
};
} // namespace mxnet
diff --git a/python/mxnet/context.py b/python/mxnet/context.py
index 1ed3dae5fb23..b35d910407a8 100644
--- a/python/mxnet/context.py
+++ b/python/mxnet/context.py
@@ -29,8 +29,8 @@ class Context(object):
"""
# static class variable
default_ctx = None
- devtype2str = {1: 'cpu', 2: 'gpu'}
- devstr2type = {'cpu': 1, 'gpu': 2}
+ devtype2str = {1: 'cpu', 2: 'gpu', 3: 'cpu_pinned'}
+ devstr2type = {'cpu': 1, 'gpu': 2, 'cpu_pinned': 3}
def __init__(self, device_type, device_id=0):
if isinstance(device_type, Context):
self.device_typeid = device_type.device_typeid
diff --git a/python/mxnet/kvstore.py b/python/mxnet/kvstore.py
index ffd7433281ae..4e2ab83d0a8d 100644
--- a/python/mxnet/kvstore.py
+++ b/python/mxnet/kvstore.py
@@ -6,7 +6,7 @@
import pickle
from .ndarray import NDArray
from .base import _LIB
-from .base import check_call, c_array, c_str, string_types, mx_uint
+from .base import check_call, c_array, c_str, string_types, mx_uint, py_str
from .base import NDArrayHandle, KVStoreHandle
from . import optimizer as opt
@@ -68,7 +68,7 @@ def init(self, key, value):
For each key, one must init it before push and pull.
- Only worker 0's (get_rank() == 0) data are used.
+ Only worker 0's (rank == 0) data are used.
This function returns after data have been initialized successfully
@@ -95,7 +95,7 @@ def init(self, key, value):
>>> keys = [5, 7, 9]
>>> kv.init(keys, [mx.nd.ones(shape)]*len(keys))
"""
- if (self.get_rank() == 0):
+ if (self.rank == 0):
ckeys, cvals = _ctype_key_value(key, value)
check_call(_LIB.MXKVStoreInit(
self.handle, mx_uint(len(ckeys)), ckeys, cvals))
@@ -169,6 +169,9 @@ def push(self, key, value, priority=0):
self.handle, mx_uint(len(ckeys)), ckeys, cvals,
ctypes.c_int(priority)))
+ # self._wait(key)
+ # self._barrier()
+
def pull(self, key, out=None, priority=0):
""" Pull a single value or a sequence of values from the store.
@@ -261,9 +264,23 @@ def set_optimizer(self, optimizer):
raise
self._send_command_to_servers(0, optim_str)
else:
- self._set_updater(opt.optimizer_clossure(optimizer))
+ self._set_updater(opt.get_updater(optimizer))
+
+ @property
+ def type(self):
+ """Get the type of this kvstore
+
+ Returns
+ -------
+ type : str
+ the string type
+ """
+ kv_type = ctypes.c_char_p()
+ check_call(_LIB.MXKVStoreGetType(self.handle, ctypes.byref(kv_type)))
+ return py_str(kv_type.value)
- def get_rank(self):
+ @property
+ def rank(self):
"""Get the rank of this worker node
Returns
@@ -275,7 +292,8 @@ def get_rank(self):
check_call(_LIB.MXKVStoreGetRank(self.handle, ctypes.byref(rank)))
return rank.value
- def get_num_workers(self):
+ @property
+ def num_workers(self):
"""Get the number of worker ndoes
Returns
@@ -329,17 +347,17 @@ def _barrier(self):
pulling, we can place a barrier to guarantee that the initialization is
finished.
- The following codes run on n machines in parallel
-
- >>> if kv.get_rank() == 0:
- ... kv.init(keys, values);
- ... kv.barrier()
- ... kv.pull(keys, out = values);
-
But note that, this functions only blocks the main thread of workers
until all of them are reached this point. It doesn't guarantee that all
operations issued before are actually finished, such as \ref Push and
\ref Pull. In that case, we need to call \ref Wait or \ref WaitAll
+
+ The following codes implement a BSP model
+
+ >>> kv.push(keys, values)
+ ... kv._wait(keys)
+ ... kv._barrier()
+ ... kv.pull(keys, out = values);
"""
check_call(_LIB.MXKVStoreBarrier(self.handle))
diff --git a/python/mxnet/kvstore_server.py b/python/mxnet/kvstore_server.py
index 85f9c26ef5ae..dc4356925b40 100644
--- a/python/mxnet/kvstore_server.py
+++ b/python/mxnet/kvstore_server.py
@@ -31,7 +31,7 @@ def server_controller(cmd_id, cmd_body):
self.kvstore.set_optimizer(optimizer)
else:
print ("server %d, unknown command (%d, %s)" % (
- self.kvstore.get_rank(), cmd_id, cmd_body))
+ self.kvstore.rank, cmd_id, cmd_body))
return server_controller
def run(self):
diff --git a/python/mxnet/model.py b/python/mxnet/model.py
index 719f5385ebe7..a8430e55c6eb 100644
--- a/python/mxnet/model.py
+++ b/python/mxnet/model.py
@@ -11,10 +11,11 @@
from . import symbol as sym
from . import optimizer as opt
from . import metric
-from . import kvstore
+from . import kvstore as kvs
from .context import Context, cpu
from .initializer import Uniform
from collections import namedtuple
+from .optimizer import get_updater
BASE_ESTIMATOR = object
@@ -122,14 +123,57 @@ def _split_input_slice(input_shape, num_split):
shapes.append(tuple(s))
return (slices, shapes)
+def _create_kvstore(kvstore, num_device, arg_params):
+ """Create kvstore
+
+ This function select and create a proper kvstore if given the kvstore type
+
+ Parameters
+ ----------
+
+ kvstore : KVStore or str
+ The kvstore
+
+ num_device : int
+ The number of devices
+
+ arg_params : dict of str to NDArray
+ Model parameter, dict of name to NDArray of net's weights.
+ """
+
+ if isinstance(kvstore, kvs.KVStore):
+ kv = kvstore
+ elif isinstance(kvstore, str):
+ # create kvstore using the string type
+ if num_device is 1 and 'dist' not in kvstore:
+ # no need to use kv for single device and single machine
+ kv = None
+ else:
+ if kvstore is 'local':
+ # automatically select a proper local
+ max_size = max(np.prod(param.shape) for param in arg_params.values())
+ if max_size < 1024 * 1024 * 16:
+ kvstore = 'local_update_cpu'
+ else:
+ kvstore = 'local_allreduce_cpu'
+ logging.info('Auto-select kvstore type = %s', kvstore)
+ kv = kvs.create(kvstore)
+ else:
+ raise TypeError('kvstore must be either KVStore or str')
+
+ # detect whether or not update weight on kvstore
+ update_on_kvstore = True
+ if not kv or 'local_allreduce' in kv.type:
+ update_on_kvstore = False
+
+ return (kv, update_on_kvstore)
def _train_multi_device(symbol, ctx, input_shape,
arg_params, aux_params,
begin_round, end_round, optimizer,
train_data, eval_data=None, eval_metric=None,
iter_end_callback=None, epoch_end_callback=None,
- update_on_kvstore=None, kvstore_type='local',
- logger=None):
+ kvstore='local', logger=None):
"""Internal training function on multiple devices.
This function will also work for single device as well.
@@ -177,11 +221,15 @@ def _train_multi_device(symbol, ctx, input_shape,
A callback that is invoked at end of each batch.
This can be used to measure speed, get result from evaluation metric. etc.
- update_on_kvstore : boolean, optional
- Whether to perform parameter update on kvstore instead of training device.
+ kvstore: KVStore or str, optional
+ The KVStore or a string kvstore type:
+ 'local' : multi-devices on a single machine, will automatically
+ choose one from 'local_update_cpu', 'local_allreduce_cpu', and
+ 'local_allreduce_device'
+ 'dist_sync' : multi-machines with BSP
+ 'dist_async' : multi-machines with partical asynchronous
- kvstore_type : {'local', 'device'}, optional
- Type of kvstore used for synchronization.
+ In default uses 'local', often no need to change for single machiine.
logger : logging logger
When not specified, default logger will be used.
@@ -189,10 +237,6 @@ def _train_multi_device(symbol, ctx, input_shape,
Notes
-----
- This function will inplace update the NDArrays in arg_parans and aux_states.
- - Turning update_on_kvstore on and off can affect speed of multi-gpu training.
- - It is auto selected by default.
- - update_on_kvstore=True works well for inception type nets that contains many small weights.
- - update_on_kvstore=False works better for Alexnet style net with bulk weights.
"""
if logger is None:
logger = logging
@@ -219,40 +263,29 @@ def _train_multi_device(symbol, ctx, input_shape,
for texec in train_execs:
texec.copy_params_from(arg_params, aux_params)
- # ky value store
- kv = kvstore.create(kvstore_type) if num_device != 1 else None
- if kv is None or kvstore_type == 'device':
- update_on_kvstore = False
- else:
- # auto decide update_on_kvstore
- if update_on_kvstore is None:
- max_size = max(np.prod(param.shape) for param in arg_params.values())
- update_on_kvstore = max_size < 1024 * 1024 * 16
- logging.info('Auto-select update_on_kvstore=%s', str(update_on_kvstore))
-
- opt_state_blocks = []
- # If there are multiple devices, initialize the weights.
- for index, pair in enumerate(zip(arg_blocks, grad_blocks)):
- arg_list, grad_list = pair
- if grad_list[0] is not None:
- if kv:
- kv.init(index, arg_list[0])
- # attach state direct to weight
- if update_on_kvstore:
- opt_state_blocks.append(nd.zeros(arg_list[0].shape, cpu()))
- else:
- opt_list = [optimizer.create_state(index, w) for w in arg_list]
- opt_state_blocks.append(opt_list)
- else:
- opt_state_blocks.append(None)
+ # create kvstore
+ (kv, update_on_kvstore) = _create_kvstore(kvstore, num_device, arg_params)
+
+ # init optimizer before give it to kv or get_updater
+ optimizer.begin_round(begin_round)
- def kv_updater(index, grad, weight):
- """Internal updater on KVstore, used when update_on_kvstore=True."""
- optimizer.update(index, weight, grad, opt_state_blocks[index])
+ if not update_on_kvstore:
+ updater = get_updater(optimizer)
- # pylint: disable=protected-access
- if update_on_kvstore:
- kv._set_updater(kv_updater)
+ if kv:
+ # init optimizer
+ if update_on_kvstore:
+ kv.set_optimizer(optimizer)
+
+ # init kv
+ for index, pair in enumerate(zip(arg_blocks, grad_blocks)):
+ arg_list, grad_list = pair
+ if grad_list[0] is not None:
+ kv.init(index, arg_list[0])
+
+ # pull the weight back
+ if update_on_kvstore:
+ kv.pull(index, arg_list, priority=-index)
# Input and output data structure
data_index, label_index = _check_arguments(symbol)
@@ -265,7 +298,6 @@ def kv_updater(index, grad, weight):
for iteration in range(begin_round, end_round):
# Training phase
tic = time.time()
- optimizer.begin_round(iteration)
eval_metric.reset()
nbatch = 0
# Iterate over training data.
@@ -297,10 +329,13 @@ def kv_updater(index, grad, weight):
# pull back the sum gradients, to the same locations.
kv.pull(index, grad_list, priority=-index)
if not update_on_kvstore:
- opt_list = opt_state_blocks[index]
- # optimizea
- for w, g, state in zip(arg_list, grad_list, opt_list):
- optimizer.update(index, w, g, state)
+ for k, p in enumerate(zip(arg_list, grad_list)):
+ # faked an index here, to make optimizer create diff
+ # state for the same index but on diff devs, TODO(mli)
+ # use a better solution latter
+ w, g = p
+ updater(index*num_device+k, g, w)
+
nbatch += 1
# epoch callback (for print purpose)
if epoch_end_callback != None:
@@ -607,8 +642,7 @@ def predict(self, X):
def fit(self, X, y=None, eval_data=None, eval_metric='acc',
iter_end_callback=None, epoch_end_callback=None,
- update_on_kvstore=None, kvstore_type='local',
- logger=None):
+ kvstore='local', logger=None):
"""Fit the model.
Parameters
@@ -635,15 +669,19 @@ def fit(self, X, y=None, eval_data=None, eval_metric='acc',
A callback that is invoked at end of each batch
For print purpose
- update_on_kvstore: boolean, optional
- Whether to perform parameter update on kvstore instead of training device.
- By default, the trainer will automatically decide the policy.
+ kvstore: KVStore or str, optional
+ The KVStore or a string kvstore type:
+ 'local' : multi-devices on a single machine, will automatically
+ choose one from 'local_update_cpu', 'local_allreduce_cpu', and
+ 'local_allreduce_device'
+ 'dist_sync' : multi-machines with BSP
+ 'dist_async' : multi-machines with partical asynchronous
- kvstore_type : {'local', 'device'}, optional
- Type of kvstore used for synchronization, usually no need to set.
+ In default uses 'local', often no need to change for single machiine.
logger : logging logger, optional
When not specified, default logger will be used.
+
"""
X = self._init_iter(X, y, is_train=True)
# Simply ignore the first example to get input_shape
@@ -672,8 +710,7 @@ def fit(self, X, y=None, eval_data=None, eval_metric='acc',
eval_metric=eval_metric,
iter_end_callback=iter_end_callback,
epoch_end_callback=epoch_end_callback,
- update_on_kvstore=update_on_kvstore,
- kvstore_type=kvstore_type,
+ kvstore=kvstore,
logger=logger)
def save(self, prefix, iteration=None):
@@ -739,8 +776,7 @@ def load(prefix, iteration, ctx=None, **kwargs):
def create(symbol, X, y=None, ctx=None,
num_round=None, optimizer='sgd', initializer=Uniform(0.01),
eval_data=None, eval_metric='acc', iter_end_callback=None,
- update_on_kvstore=None, kvstore_type='local',
- logger=None, **kwargs):
+ kvstore='local', logger=None, **kwargs):
"""Functional style to create a model.
This function will be more consistent with functional
@@ -782,20 +818,20 @@ def create(symbol, X, y=None, ctx=None,
A callback that is invoked at end of each iteration.
This can be used to checkpoint model each iteration.
- update_on_kvstore: boolean, optional
- Whether to perform parameter update on kvstore instead of training device.
- By default, the trainer will automatically decide the policy.
-
- kvstore_type : {'local', 'device'}, optional
- Type of kvstore used for synchronization, usually no need to set.
+ kvstore: KVStore or str, optional
+ The KVStore or a string kvstore type:
+ 'local' : multi-devices on a single machine, will automatically
+ choose one from 'local_update_cpu', 'local_allreduce_cpu', and
+ 'local_allreduce_device'
+ 'dist_sync' : multi-machines with BSP
+ 'dist_async' : multi-machines with partical asynchronous
- logger : logging logger, optional
+ In default uses 'local', often no need to change for single machiine.
"""
model = FeedForward(symbol, ctx=ctx, num_round=num_round,
optimizer=optimizer, initializer=initializer, **kwargs)
model.fit(X, y, eval_data=eval_data, eval_metric=eval_metric,
iter_end_callback=iter_end_callback,
- update_on_kvstore=update_on_kvstore,
- kvstore_type=kvstore_type,
+ kvstore=kvstore,
logger=logger)
return model
diff --git a/python/mxnet/optimizer.py b/python/mxnet/optimizer.py
index da336aff29e4..ad2b1fbdd6e6 100644
--- a/python/mxnet/optimizer.py
+++ b/python/mxnet/optimizer.py
@@ -148,8 +148,7 @@ def create(name, rescale_grad=1, **kwargs):
else:
raise ValueError('Cannot find optimizer %s' % name)
-
-def optimizer_clossure(optimizer):
+def get_updater(optimizer):
"""Return a clossure of the updater needed for kvstore
Parameters
diff --git a/src/c_api.cc b/src/c_api.cc
index 1a12fe65ea3d..d50189d66a11 100644
--- a/src/c_api.cc
+++ b/src/c_api.cc
@@ -1088,3 +1088,10 @@ int MXKVStoreSendCommmandToServers(KVStoreHandle handle,
cmd_id, std::string(cmd_body));
API_END();
}
+
+int MXKVStoreGetType(KVStoreHandle handle,
+ const char** type) {
+ API_BEGIN();
+ *CHECK_NOTNULL(type) = static_cast(handle)->type().c_str();
+ API_END();
+}
diff --git a/src/io/iter_image_recordio.cc b/src/io/iter_image_recordio.cc
index 37bfe0020b6d..6ca610e8a410 100644
--- a/src/io/iter_image_recordio.cc
+++ b/src/io/iter_image_recordio.cc
@@ -101,6 +101,11 @@ struct ImageRecParserParam : public dmlc::Parameter {
int preprocess_threads;
/*! \brief whether to remain silent */
bool verbose;
+ /*! \brief partition the data into multiple parts */
+ int num_parts;
+ /*! \brief the index of the part will read*/
+ int part_index;
+
// declare parameters
DMLC_DECLARE_PARAMETER(ImageRecParserParam) {
DMLC_DECLARE_FIELD(path_imglist).set_default("")
@@ -116,6 +121,10 @@ struct ImageRecParserParam : public dmlc::Parameter {
.describe("Backend Param: Number of thread to do preprocessing.");
DMLC_DECLARE_FIELD(verbose).set_default(true)
.describe("Auxiliary Param: Whether to output parser information.");
+ DMLC_DECLARE_FIELD(num_parts).set_default(1)
+ .describe("partition the data into multiple parts");
+ DMLC_DECLARE_FIELD(part_index).set_default(0)
+ .describe("the index of the part will read");
}
};
@@ -203,12 +212,9 @@ inline void ImageRecordIOParser::Init(
LOG(INFO) << "ImageRecordIOParser: " << param_.path_imgrec
<< ", use " << threadget << " threads for decoding..";
}
- // TODO(mu, tianjun) add DMLC env variable to detect parition
- const int part_index = 0;
- const int num_parts = 1;
source_ = dmlc::InputSplit::Create(
- param_.path_imgrec.c_str(), part_index,
- num_parts, "recordio");
+ param_.path_imgrec.c_str(), param_.part_index,
+ param_.num_parts, "recordio");
// use 64 MB chunk when possible
source_->HintChunkSize(8 << 20UL);
#else
diff --git a/src/io/iter_mnist.cc b/src/io/iter_mnist.cc
index a1f03dbd8e83..cb2e2a853e0d 100644
--- a/src/io/iter_mnist.cc
+++ b/src/io/iter_mnist.cc
@@ -31,6 +31,10 @@ struct MNISTParam : public dmlc::Parameter {
bool flat;
/*! \brief random seed */
int seed;
+ /*! \brief partition the data into multiple parts */
+ int num_parts;
+ /*! \brief the index of the part will read*/
+ int part_index;
// declare parameters
DMLC_DECLARE_PARAMETER(MNISTParam) {
DMLC_DECLARE_FIELD(image).set_default("./train-images-idx3-ubyte")
@@ -47,6 +51,10 @@ struct MNISTParam : public dmlc::Parameter {
.describe("Augmentation Param: Random Seed.");
DMLC_DECLARE_FIELD(silent).set_default(false)
.describe("Auxiliary Param: Whether to print out data info.");
+ DMLC_DECLARE_FIELD(num_parts).set_default(1)
+ .describe("partition the data into multiple parts");
+ DMLC_DECLARE_FIELD(part_index).set_default(0)
+ .describe("the index of the part will read");
}
};
@@ -113,13 +121,32 @@ class MNISTIter: public IIterator {
}
private:
+ inline void GetPart(int count, int* start, int *end) {
+ CHECK_GE(param_.part_index, 0);
+ CHECK_GT(param_.num_parts, 0);
+ CHECK_GT(param_.num_parts, param_.part_index);
+
+ *start = static_cast(
+ static_cast(count) / param_.num_parts * param_.part_index);
+ *end = static_cast(
+ static_cast(count) / param_.num_parts * (param_.part_index+1));
+ }
+
inline void LoadImage(void) {
- dmlc::Stream *stdimg = dmlc::Stream::Create(param_.image.c_str(), "r");
+ dmlc::SeekStream* stdimg
+ = dmlc::SeekStream::CreateForRead(param_.image.c_str());
ReadInt(stdimg);
int image_count = ReadInt(stdimg);
int image_rows = ReadInt(stdimg);
int image_cols = ReadInt(stdimg);
+ int start, end;
+ GetPart(image_count, &start, &end);
+ image_count = end - start;
+ if (start > 0) {
+ stdimg->Seek(stdimg->Tell() + start * image_rows * image_cols);
+ }
+
img_.shape_ = mshadow::Shape3(image_count, image_rows, image_cols);
img_.stride_ = img_.size(2);
@@ -139,9 +166,18 @@ class MNISTIter: public IIterator {
delete stdimg;
}
inline void LoadLabel(void) {
- dmlc::Stream *stdlabel = dmlc::Stream::Create(param_.label.c_str(), "r");
+ dmlc::SeekStream* stdlabel
+ = dmlc::SeekStream::CreateForRead(param_.label.c_str());
ReadInt(stdlabel);
int labels_count = ReadInt(stdlabel);
+
+ int start, end;
+ GetPart(labels_count, &start, &end);
+ labels_count = end - start;
+ if (start > 0) {
+ stdlabel->Seek(stdlabel->Tell() + start);
+ }
+
labels_.resize(labels_count);
for (int i = 0; i < labels_count; ++i) {
unsigned char ch;
diff --git a/src/kvstore/kvstore.cc b/src/kvstore/kvstore.cc
index c11cb98461dc..edd78e617b75 100644
--- a/src/kvstore/kvstore.cc
+++ b/src/kvstore/kvstore.cc
@@ -17,20 +17,35 @@ namespace mxnet {
KVStore* KVStore::Create(const char *type_name) {
std::string tname = type_name;
- if (tname == "local") {
- return new kvstore::KVStoreLocal();
- } else if (tname == "device") {
- return new kvstore::KVStoreDevice();
- } else if (tname == "dist") {
+ std::transform(tname.begin(), tname.end(), tname.begin(), ::tolower);
+ KVStore* kv = nullptr;
+ if (tname == "local" ||
+ tname == "local_update_cpu" ||
+ tname == "local_allreduce_cpu") {
+ kv = new kvstore::KVStoreLocal();
+ } else if (tname == "device" ||
+ tname == "local_allreduce_device") {
+ tname = "local_allreduce_device";
+ kv = new kvstore::KVStoreDevice();
+ } else if (tname == "dist_async") {
#if MXNET_USE_DIST_KVSTORE
- return new kvstore::KVStoreDist();
+ kv = new kvstore::KVStoreDist();
#else
- LOG(FATAL) << "compile with USE_DIST_KVSTORE=1";
+ LOG(FATAL) << "compile with USE_DIST_KVSTORE=1 to use " << tname;
return nullptr;
#endif // MXNET_USE_DIST_KVSTORE
+ } else if (tname == "dist_sync") {
+#if MXNET_USE_DIST_KVSTORE
+ kv = new kvstore::KVStoreDist();
+#else
+ LOG(FATAL) << "compile with USE_DIST_KVSTORE=1 to use " << tname;
+ return nullptr;
+#endif // MXNET_USE_DIST_KVSTORE
+ } else {
+ LOG(FATAL) << "Unknown KVStore type \"" << tname << "\"";
}
- LOG(FATAL) << "Unknown KVStore type \"" << type_name << "\"";
- return nullptr;
+ kv->type_ = tname;
+ return kv;
}
} // namespace mxnet
diff --git a/src/kvstore/kvstore_dist.h b/src/kvstore/kvstore_dist.h
index 2721accd5c04..6bfcbe19a9ba 100644
--- a/src/kvstore/kvstore_dist.h
+++ b/src/kvstore/kvstore_dist.h
@@ -10,6 +10,7 @@
#include "./kvstore_local.h"
#include "./mxnet_ps_node.h"
#include "mxnet/engine.h"
+// #include "dmlc/parameter.h"
#include "ps.h"
#include "base/range.h"
@@ -43,6 +44,7 @@ class KVStoreDist : public KVStoreLocal {
// stop the executor at servers
SendCommandToServers(CommandID::kStop, "");
}
+ Barrier();
ps::StopSystem();
}
}
diff --git a/tests/python/distributed/test_mlp.py b/tests/python/distributed/test_mlp.py
new file mode 100755
index 000000000000..7b5c55588644
--- /dev/null
+++ b/tests/python/distributed/test_mlp.py
@@ -0,0 +1,73 @@
+#!/usr/bin/env python
+# pylint: skip-file
+
+import mxnet as mx
+import numpy as np
+import os, sys
+import pickle as pickle
+import logging
+curr_path = os.path.dirname(os.path.abspath(os.path.expanduser(__file__)))
+sys.path.append(os.path.join(curr_path, '../common/'))
+import models
+import get_data
+
+# symbol net
+batch_size = 100
+data = mx.symbol.Variable('data')
+fc1 = mx.symbol.FullyConnected(data, name='fc1', num_hidden=128)
+act1 = mx.symbol.Activation(fc1, name='relu1', act_type="relu")
+fc2 = mx.symbol.FullyConnected(act1, name = 'fc2', num_hidden = 64)
+act2 = mx.symbol.Activation(fc2, name='relu2', act_type="relu")
+fc3 = mx.symbol.FullyConnected(act2, name='fc3', num_hidden=10)
+softmax = mx.symbol.Softmax(fc3, name = 'sm')
+
+def accuracy(label, pred):
+ py = np.argmax(pred, axis=1)
+ return np.sum(py == label) / float(label.size)
+
+num_round = 4
+prefix = './mlp'
+
+kv = mx.kvstore.create('dist')
+batch_size /= kv.get_num_workers()
+
+#check data
+get_data.GetMNIST_ubyte()
+
+train_dataiter = mx.io.MNISTIter(
+ image="data/train-images-idx3-ubyte",
+ label="data/train-labels-idx1-ubyte",
+ data_shape=(784,), num_parts=kv.get_num_workers(), part_index=kv.get_rank(),
+ batch_size=batch_size, shuffle=True, flat=True, silent=False, seed=10)
+val_dataiter = mx.io.MNISTIter(
+ image="data/t10k-images-idx3-ubyte",
+ label="data/t10k-labels-idx1-ubyte",
+ data_shape=(784,),
+ batch_size=batch_size, shuffle=True, flat=True, silent=False)
+
+def test_mlp():
+ logging.basicConfig(level=logging.DEBUG)
+
+ model = mx.model.FeedForward.create(
+ softmax,
+ X=train_dataiter,
+ eval_data=val_dataiter,
+ eval_metric=mx.metric.np(accuracy),
+ ctx=[mx.cpu(i) for i in range(1)],
+ num_round=num_round,
+ learning_rate=0.05, wd=0.0004,
+ momentum=0.9,
+ kvstore=kv,
+ )
+ logging.info('Finish traning...')
+ prob = model.predict(val_dataiter)
+ logging.info('Finish predict...')
+ val_dataiter.reset()
+ y = np.concatenate([label.asnumpy() for _, label in val_dataiter]).astype('int')
+ py = np.argmax(prob, axis=1)
+ acc = float(np.sum(py == y)) / len(y)
+ logging.info('final accuracy = %f', acc)
+ assert(acc > 0.93)
+
+if __name__ == "__main__":
+ test_mlp()
diff --git a/tests/python/train/test_mlp.py b/tests/python/train/test_mlp.py
index 65f3d90d9e3d..85266e12df52 100644
--- a/tests/python/train/test_mlp.py
+++ b/tests/python/train/test_mlp.py
@@ -40,9 +40,6 @@ def accuracy(label, pred):
def test_mlp():
# print logging by default
logging.basicConfig(level=logging.DEBUG)
- console = logging.StreamHandler()
- console.setLevel(logging.DEBUG)
- logging.getLogger('').addHandler(console)
model = mx.model.FeedForward.create(
softmax,
@@ -53,8 +50,7 @@ def test_mlp():
ctx=[mx.cpu(i) for i in range(2)],
num_round=num_round,
learning_rate=0.1, wd=0.0004,
- momentum=0.9,
- update_on_kvstore=True)
+ momentum=0.9)
logging.info('Finish traning...')
prob = model.predict(val_dataiter)
diff --git a/tests/python/unittest/test_kvstore.py b/tests/python/unittest/test_kvstore.py
index ada94490ce86..77439677320f 100644
--- a/tests/python/unittest/test_kvstore.py
+++ b/tests/python/unittest/test_kvstore.py
@@ -104,8 +104,13 @@ def test_updater(dev = 'cpu'):
for v in vv:
check_diff_to_scalar(v, num_devs * num_push)
+def test_get_type():
+ kvtype = 'local_allreduce_cpu'
+ kv = mx.kv.create(kvtype)
+ assert kv.type == kvtype
if __name__ == '__main__':
+ test_get_type()
test_single_kv_pair()
test_list_kv_pair()
test_aggregator()