Working with the ForkOperator
The ForkOperator is a type of control operators that allow a task flow to branch into multiple streams, each of which goes to a separately configured sink with its own data writer. The ForkOperator gives users more flexibility in terms of controlling where and how ingested data should be output. This is useful for situations, e.g., that data records need to be written into multiple different storages, or that data records need to be written out to the same storage (say, HDFS) but in different forms for different downstream consumers. The best practices of using the ForkOperator that we recommend, though, are discussed below. The diagram below illustrates how the ForkOperator in a Gobblin task flow allows an input stream to be forked into multiple output streams, each of which can have its own converters, quality checkers, and writers.
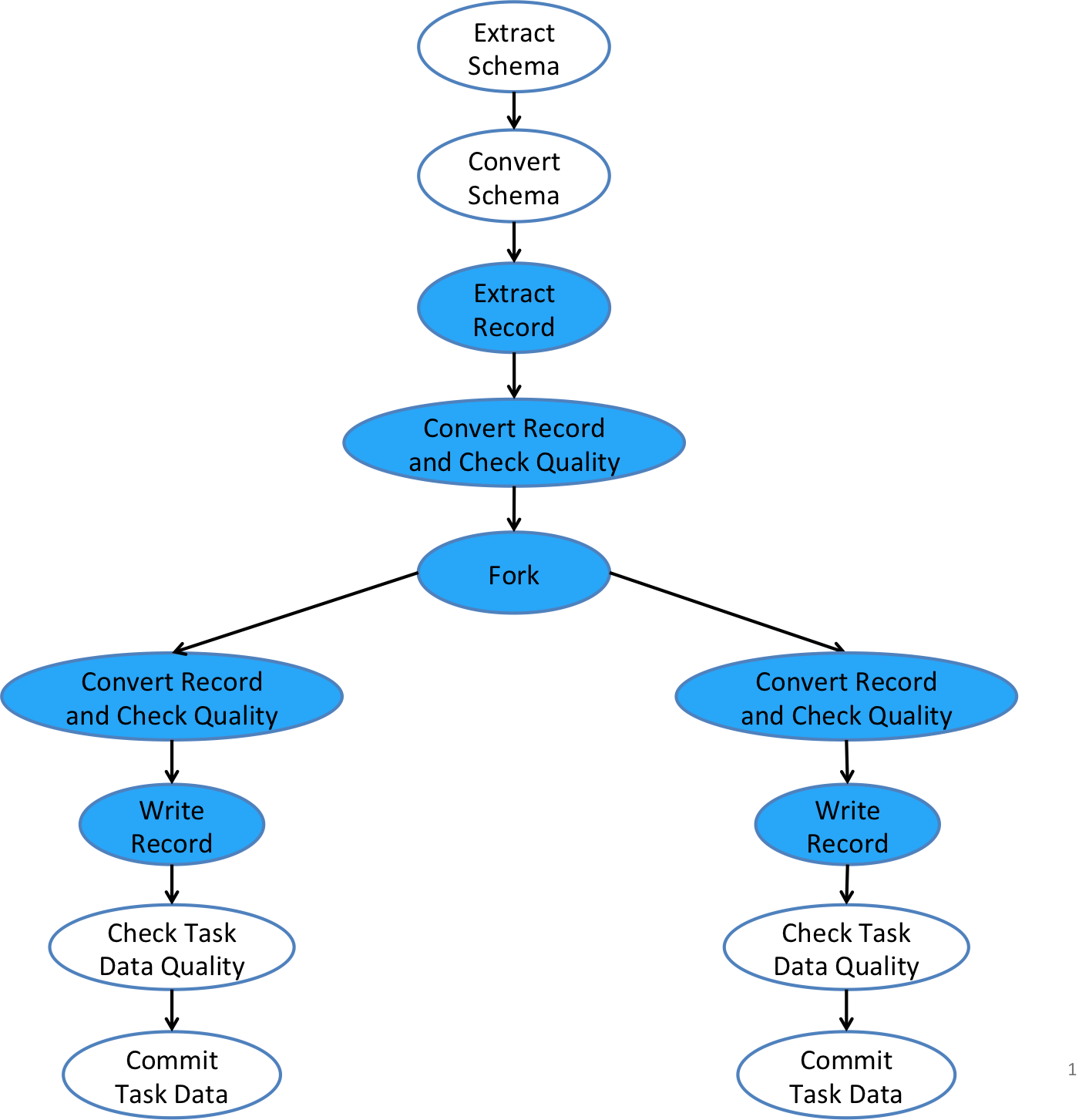
Gobblin task flow.
The ForkOperator, like most other operators in a Gobblin task flow, is pluggable through the configuration, or more specifically , the configuration property fork.operator.class that points to a class that implements the ForkOperator interface. By default, if no ForkOperator class is specified, internally Gobblin uses the default implementation IdentityForkOperator with a single forked branch (although it does supports multiple forked branches). The IdentityForkOperator simply connects the pre-fork branch and the given number of forked branches and passes schema and data records between them.
The use of the ForkOperator with more than one forked branch has some special requirement on the input schema and data records to the ForkOperator. Specifically, because the same schema or data record will be used as input to each forked branch that may alter the schema or data record in place, it is necessary for the Gobblin task flow to make a copy of the input schema or data record for each forked branch so any modification within one branch won't affect any other branches. To guarantee that it is always able to make a copy in such a case, Gobblin requires the input schema and data records to be of type Copyable when there are more than one forked branch. Copyable is an interface that defines a method copy for making a copy of an instance of a given type.