Working with the ForkOperator
The ForkOperator is a type of control operators that allow a task flow to branch into multiple streams (or forked branches) as represented by a Fork, each of which goes to a separately configured sink with its own data writer. The ForkOperator gives users more flexibility in terms of controlling where and how ingested data should be output. This is useful for situations, e.g., that data records need to be written into multiple different storages, or that data records need to be written out to the same storage (say, HDFS) but in different forms for different downstream consumers. The best practices of using the ForkOperator that we recommend, though, are discussed below. The diagram below illustrates how the ForkOperator in a Gobblin task flow allows an input stream to be forked into multiple output streams, each of which can have its own converters, quality checkers, and writers.
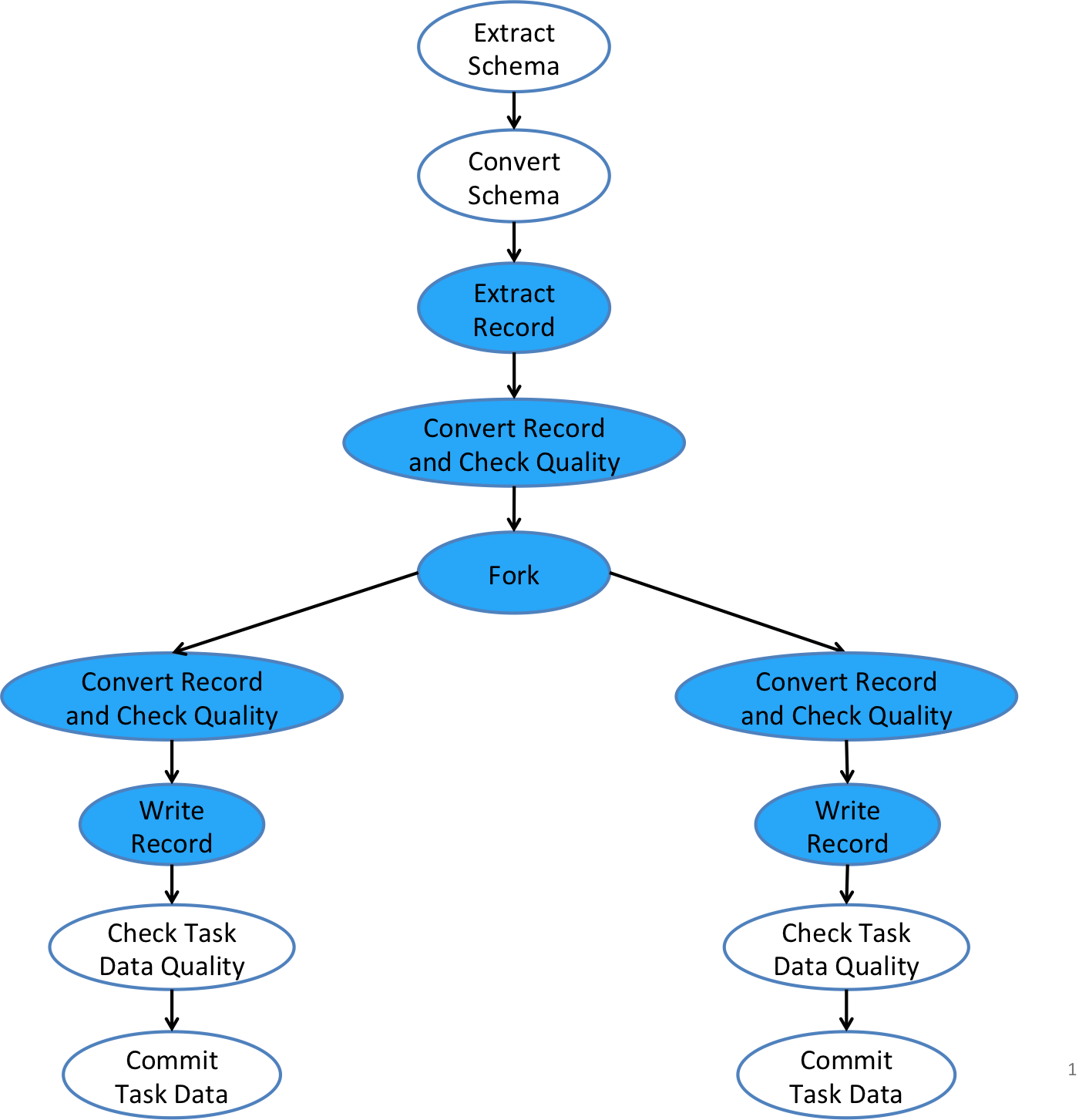
Gobblin task flow.
The ForkOperator, like most other operators in a Gobblin task flow, is pluggable through the configuration, or more specifically , the configuration property fork.operator.class that points to a class that implements the ForkOperator interface. By default, if no ForkOperator class is specified, internally Gobblin uses the default implementation IdentityForkOperator with a single forked branch (although it does supports multiple forked branches). The IdentityForkOperator simply connects the pre-fork branch and the given number of forked branches and passes schema and data records between them.
The expected number of forked branches is given by the method getBranches of the ForkOperator. If the number of forked branches for the input schema or data records does not match the expected number, a ForkBranchMismatchException will be thrown. Note that the ForkOperator itself is not making and returning a copy for the input schema and data records, but rather just providing a boolean for each forked branch telling if the schema or data records should be in each particular branch. Each forked branch has a branch index starting at 0. So if there are three forked branches, the branches will have indices 0, 1, and 2, respectively. Branch indices are useful to tell which branch the Gobblin task flow is in. Each branch also has a name associated with it that can be specified using the configuration property fork.branch.name.<branch index>. Note that the branch index is added as a suffix to the property name in this case. More on this later. If the user does not specify a name for the branches, the names in the form fork_<branch index> will be used.
The use of the ForkOperator with the possibility that the schema and/or data records may be in more than one forked branches has some special requirement on the input schema and data records to the ForkOperator. Specifically, because the same schema or data records will be used as input to each forked branch that may alter the schema or data records in place, it is necessary for the Gobblin task flow to make a copy of the input schema or data records for each forked branch so any modification within one branch won't affect any other branches. To guarantee that it is always able to make a copy in such a case, Gobblin requires the input schema and data records to be of type Copyable when there are more than one forked branch. Copyable is an interface that defines a method copy for making a copy of an instance of a given type. The Gobblin task flow will check if the input schema and data records are instances of Copyable and throw a CopyNotSupportedException if not. Gobblin ships with some built-in Copyable implementations, e.g., CopyableSchema and CopyableGenericRecord for Avro's Schema and GenericRecord.
Since each forked branch may have it's own converters, quality checkers, and writers, in addition to the ones in the pre-fork stream (which does not have a writer apparently), there must be a way to tell the converter, quality checker, and writer classes of one branch from another. Gobblin uses a pretty straightforward approach: if a configuration property is used to specify something for a branch in a multi-branch use case, the branch index should be appended as a suffix to the property name. The original configuration name is generally reserved for the pre-fork stream. For example, converter.classes.0 and converter.classes.1 are used to specify the list of converter classes for branch 0 and 1, respectively, whereas converter.classes is reserved for the pre-fork stream. If there's only a single branch (the default case), then the index suffix is applicable. Without being a comprehensive list, the following groups of built-in configuration properties may be used with branch indices as suffices to specify things for forked branches:
- Converter configuration properties: configuration properties whose names start with
converter. - Quality checker configuration properties: configuration properties whose names start with
qualitychecker. - Writer configuration properties: configuration properties whose names start with
writer.
Internally, each forked branch as represented by a Fork maintains a bounded record queue, which serves as a buffer between the pre-fork stream and the forked stream of the particular branch. The size if this bounded record queue can be configured through the property fork.record.queue.capacity. A larger queue allows for more data records to be buffered therefore giving the producer (the pre-fork stream) more head room to move forward. On the other hand, a larger queue requires more memory. The bounded record queue imposes a timeout time on all blocking operations such as putting a new record to the tail and polling a record off the head of the queue. Tuning the queue size and timeout time together offers a lot of flexibility and a tradeoff between queuing performance vs. memory consumption.
Since the built-in default implementation IdentityForkOperator simply blindly forks the input schema and data records to every branches, it's often necessary to have a custom implementation of the ForkOperator interface for more fine-grained control on the actual branching. Checkout the interface ForkOperator for the methods that need to be implemented.