Data storage efficiency #1
Comments
|
Thank you for the feedback!
I knew that this section of the code was going to be hacky and inefficient, but it was "good enough" to make it usable for the experiment. Would you consider creating a pull request, or just simply providing some guidance on a better way to do it here?
I'd hesitate to remove this from the output since it's important to label the data. Is there another way to do it while maintaining properly formatted CSV?
That's good to know. Would you mind linking directly to where they are doing that for future reference?
Wow, that'd be a huge improvement! I'd love to get your help to pull that off -- I'm already a little outside my comfort zone in the Arduino world, so guidance would be greatly appreciated! Thanks again! |
|
No worries! First thing I would do is profile. Strip out everything extraneous and figure out how fast you can poll the sensor - can you achieve the datasheet 5kHz, for example? Something like: // Main Loop
void loop() {
unsigned long start = micros();
lis.read(); // get X Y and Z data at once
unsigned long stop = micros();
DEBUG_PRINTLN(stop-start);
DEBUG_PRINTLN(lis.x); // print, in case the compiler optimises lis away.
DEBUG_PRINTLN(lis.y);
DEBUG_PRINTLN(lis.z);
DEBUG_PRINTLN("-----");
}You can check the overhead of using // Main Loop
void loop() {
sensors_event_t event;
unsigned long start = micros();
lis.getEvent(&event);
unsigned long stop = micros();
DEBUG_PRINTLN(stop-start);
DEBUG_PRINTLN(event.acceleration.x);
DEBUG_PRINTLN(event.acceleration.y);
DEBUG_PRINTLN(event.acceleration.z);
DEBUG_PRINTLN("-----");
}The code for and here for reference. One thing, in your code you're calling Once you've done that, you can add other bits like the string conversion and writing to SD to see how much overhead you're adding. If you want to write as a CSV that's fine, but you don't need to print the units in every row. Just make the first row a header and put the units in there. |
That's a great idea! Your examples use the
Seems like something is missing here?
Great catch!
I see what you mean -- have a header row something like the following: That's a good solution, thanks! |
|
The print statements won't affect the timing, you only care about the stuff that happens between Yeah that's what I meant for the CSV, you can shove that in your setup. On your timestamp measurement: when you call |
|
I did a quick test based on your suggestion, here are some results (very promising)! Timing per-call:
Total samples per second:
Good point!
Also a great point. I didn't find having both to be very useful when doing the data analysis.
Possibly... The trouble is that the unix timestamp from the RTC isn't synced to when the board was initialized, and therefore it isn't synced to |
|
(Adding the following for myself) References: |
|
Great. The main takeaway from that is that What's interesting is that your read speed is really quite slow. I2C operates in fast mode at 400kHz. You want to transfer 6 bytes, plus probably another 4 bytes of overhead sending addresses and selecting the register to read. So that's about 72 bits per transaction. It should only take around 180 microseconds to do that. Your call is taking 1300, assuming the timing is accurate. There are a bunch of float divisions in Floating point division is always going to be slower than multiplying. I'm not familiar enough with the ARM M0 to say how many cycles floating point division takes, but you can test this by timing something like (pick some arbitrary numbers): unsigned long start = micros();
float a = 2000;
float x = 10;
float y = 15;
float z = 20;
x /= a;
y /= a;
z /= a;
unsigned long end = micros();
// print to avoid the compiler optimising the variables out
Serial.println(x);
Serial.println(y);
Serial.println(z);If you get an answer of around 1ms, then that's your bottleneck. Compare it to this, which should be lightning fast: unsigned long start = micros();
uint16_t = 2000;
uint16_t x = 100;
uint16_t y = 150;
uint16_t z = 200;
x /= a;
y /= a;
z /= a;
unsigned long end = micros();
Serial.println(x);
Serial.println(y);
Serial.println(z);You could call I saw you posted in the Adafruit repo, so I guess you realised that the default code sets up the IMU to operate at 400Hz by default. That shoudn't affect your read speed though, the library doesn't wait for the sensor to update, it just reads whatever the last value is. |
I looked into this a little bit and found some references that lead me to believe that it defaults to 100kHz.
There wasn't a measurable difference between either of the two methods. Each took around 1-2 microseconds.
I gave this a try and compared it against calling
Yeah, it would be nice to get that set faster so that it doesn't become a bottleneck. I don't get the sense that Adafruit spends a lot of resources maintaining these libraries long after release. Thank you again for all of the help. I'm already seeing a massive performance increase (almost 3x!) and hope that we can get it even faster! |
|
That does make sense, 1500 odd cycles for the divisions at 48Mhz shouldn't take long. So at 100kHz that might go some way to explain it (ie 800us just for the transfer). Without really looking at what the arduino i2c library is doing there might be other things going on in there that's slowing you down. If you have access to an oscilloscope or a logic analyser you can see what's happening on the bus. Or try wiring it up using the spi interface instead? Since you can just download the library, you could also try profiling within the read function to see what's going on.. But at this point a 3x speedup is good to get started! |
I've read some articles which state that calls like I have neither an oscilloscope or logic analyzer.
I know that I can chain multiple devices, but I'm not certain if that's true for SPI. The FeatherWing I'm using adds RTC + microSD -- the latter utilizes the SPI connections.
Yeah, that might be my next approach. Do you have any thoughts on buffering the data in memory and writing to the SD card only when acceleration events are detected? |
|
Yeah digital write is much slower than directly using the pin registers. Though the I2C interface ought to be reasonably quick. Saying that I had similar problems on other platforms where there were large delays between SPI transfers. SPI is mediated with the (well, a) chip select (CS) pin, so you connect all the sck/mosi/miso pins in parallel and each device has a separate CS. When you make the accelerometer object, the constructor takes CS as an input. Should be the same with the SD card. There's a default CS pin, but you don't need to use it, and if you have multiple devices obviously you need other pins. Buffering is definitely an option, but always a trade off between how much you can store and how often you need to dump it. |
|
I made a bit more progress without much effort by setting This moved me from ~400hz to ~650hz. It also reduced the call time for Edit: Using fast mode plus moved the needle to ~750hz and |
|
One more update for the day. Here's a small sample of the new data structure (formatted for readability):
I ran the unit with these improvements with Samples were taken approximately every 1-2ms, with a ~10ms delay for writing to the SD card (using SDfat) every 800 iterations. I have a 600yd match on Saturday, where I'll be firing ~50 rounds. I'll run this code on the unit during that match to collect data for a follow up. If all goes well, I'll create a PR with the changes. |
|
A sample from today's experiment (zoomed in on one round fired).
|
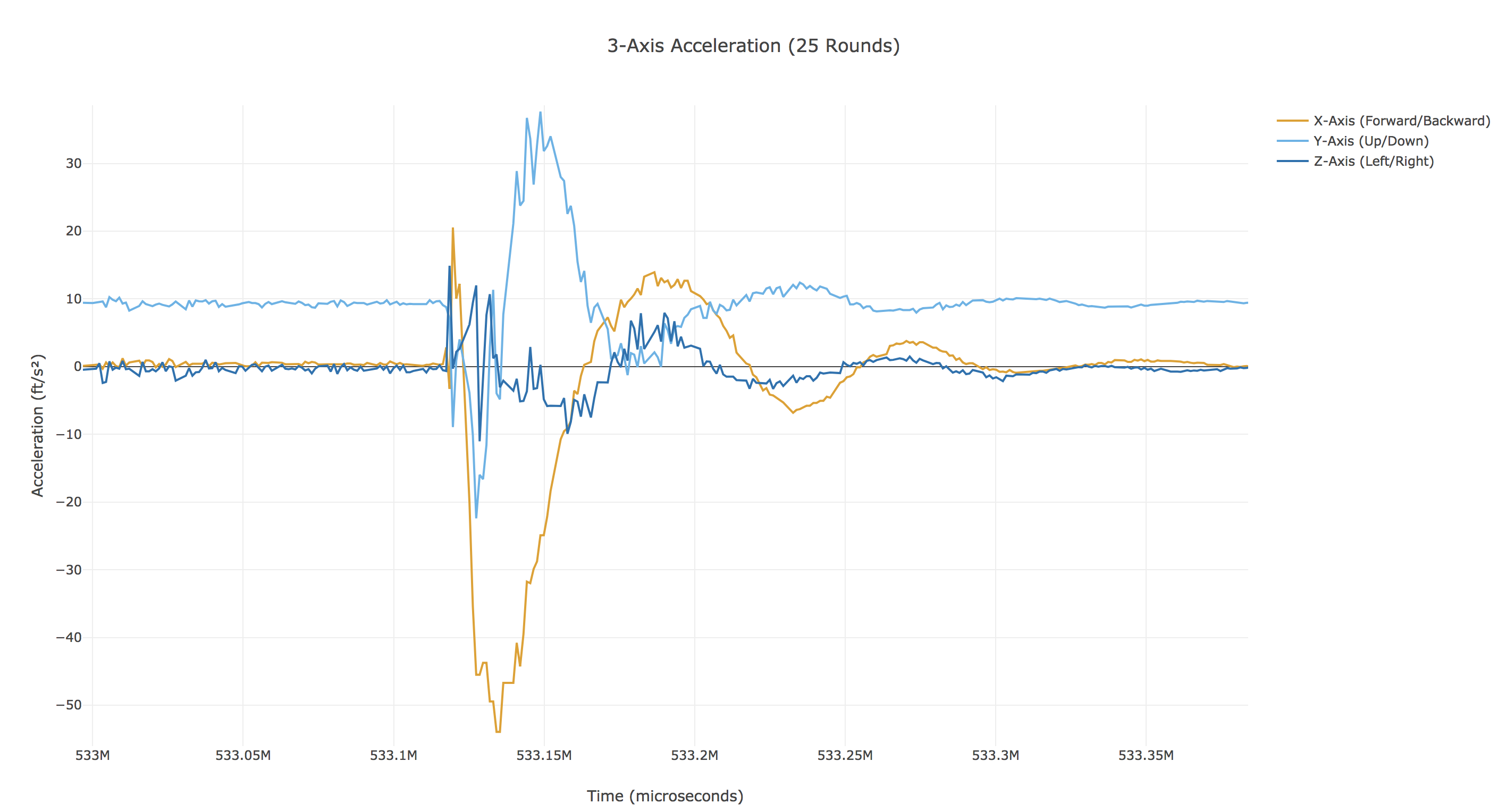
|
Greetings, Have enjoyed reading your comments above as I have also been working on improving my sketch's sampling speed of an accelerometer. I am using an Adafruit Feather Adalogger MO and the Sparkfun breakout board for the LIS331HH, which has a max reading rate of 1000 Hz. My first attempt produced 62 Hz. It turns out that I did most of the things suggested above and it reads much faster now. If I remove the code for waiting for the next valid reading (meaning it'll read the same data multiple times) it can make >3800 readings per second. Enough blathering, here is my suggestion for getting raw data: Early on I had problems with the LIS331 library so I figured out how to do without it. That made my code more bulky, but I like to think it is more efficient. The attached script shows how to write to the control registers to set operating parameters, and read the raw data. After a cursory look at the LIS3DH datasheet it appears it uses a similar process although the register addresses are different. LIS331_Read_Store_n_points_fast_MO.txt (That was probably the wrong way to share code - first timer on GetHub and just trying to help) The reading for each axis is stored in two registers. It takes bit of math to combine the two registers' contents into a single int reading. It is that single number that is recorded in this script. It can be converted to whatever units you like later on. I wonder if recording the 2 registers and combining them later on would be even faster. This may not be useful for your application, but putting the raw data in an array an then doing the format/print/store later really sped things up. I doubt there's enough memory to store as much data as you need. Perhaps pursuing your idea of saving data between shots could make this possible. My next challenge is to put the data on the SD card as it collected and see how much that slows it down. Anyway, I hope my approach to getting the raw data will help speed things up for you. Best of luck in all of your projects. |
|
Changed the script to write the data to the SD card. Writing the data to the buffer is keeping up with the 1000 Hz sample rate, but every so often there is a 4ms delay when the buffer is actually written to the card. A 1000 sample buffer was collected at 938 Hz. Then I took your suggestion and increased the I2C rate to 1000000 which increased the speed to 968 Hz. A 10,000 sample collection took 10,534 mS for a rate of 949 Hz. A 100,000 sample collection took 105046 ms for a rate of 952 Hz. |
|
@RipVW Thanks for sharing your results! I just merged the suggestions from @jveitchmichaelis into the master branch. I have not yet had a chance to go through all of your suggestions and add those (sorry). Would you be interested in creating a Pull Request so that I can review your changes and make them available to everyone? |
|
Hi Eric, We've both made a lot of progress since we started, but perhaps because I've had the luxury of spending a lot of time on this I think I've made a bit more progress. Every time I've discovered something helpful or implemented another improvement I've thought to myself, "I ought to tell that 'rifle guy' about this". Have reviewed all of the above, read through your .ino, and looked at the datasheet for your accelerometer. I don't mean to be condescending but I'm sure there is room for improvement not only in terms of readings/second, but also in continuing to collect data while the SD card is busy so that there are no gaps in your data. What I've been thinking about over the past couple of weeks is creating a set of pointers for you, like the very generous and helpful jveitchmichaelis did earlier. I'm not familiar with "pull requests" and feel more comfortable just adding my ideas to this thread. Topic 1: Compressing your data even more. Can probably spend 2-4 hours a week elaborating on the above topics if you think it will be helpful. The accelerometer I've been using, the LIS331HH only provides readings at 1 kHz. Have taken over 1,000,000 readings at 1 kHz without missing a single one. My script spends a lot of time waiting for the next reading to be ready, so I think we can easily get your script reading well over 1 kHz since it won't have to wait for the next reading. |
|
Topic 1: Compressing your data even more. Part 1 - Eliminate storing data you don't really need. The more you store, the more often the SD card is going to be busy moving your data from its buffer into permanent storage. Before I question why you're storing so much information I have to admit that over 1/2 the stuff I store is just for troubleshooting and has nothing to do with accelerometer data. Looking at your script and data table above, I don't understand why you store a timestamp with each and every sample. Do you really care if you took that shot at 10:31:58 or 10:31:59? Micros() only rolls over every ~70 minutes so you don't need the "seconds" to make sure all of your data points are in order. I see a counter in your loop, storing the value of that counter might be useful and take up a lot less space. I can understand your curiosity about delta (uS), but now that you know it's about 250 us do you really need to store that every time? Right now your data table shows 28 digits for each reading stored. Getting rid of the timestamp and delta would reduce that to 15 digits (plus all the commas and decimal points). Of course you may have great reasons for storing the timestamp and the delta and I just don't know enough about your application to appreciate your reasons for doing so. Part 2 - Some neat software things Eventually the data will be put into a buffer while the SD card is busy, then the data will be moved from 'your' buffer to the SD card's buffer. That means you'll be moving the data twice instead of just once which makes it doubly important to cut down on the amount of data. The first thing I found was sizeof(variable_name), a function that returns the length of whatever variable you put in the (). Try this in a script:
I am assuming you are not graphing in real time, and make your graphs later on after transferring the data to a laptop. Based on that, there is no need to put commas in your data when you store it. Eventually we'll talk about getting rid of the decimal points, but for now, lets get rid of the commas. Before going farther, please read this tutorial on STRUCT, this made a huge difference for my script: https://hackingmajenkoblog.wordpress.com/2016/03/25/fast-efficient-data-storage-on-an-arduino/ I think you can see how using a struct would get rid of the 5 commas, or 5 million commas if your script runs for 15-20 minutes at 1kHz. Looking ahead to putting your data into a buffer while the SD card is busy, it would be easier to put all of it into one array instead of having separate arrays for timestamp, delta, ....... Once you define a struct it can be used like a datatype to define variables and arrays. `// This is my struct with a lot of stuff in it I don't really need // This variable named accelRow has the datatype accelData, so it contains all the elements in the struct // This array looks one dimensional, but each row in the array has all of the elements in the struct I think if you trim your data and use structs you'll see some improvement in sampling speed. Doing these things lays the ground work for more improvements in the future. Btw, about the time you wrote today I received an email from Adafruit saying my order including a LIS3DH had been shipped. Looking at the preview I see I didn't get the code tags to work, oh well. |
|
@RipVW Thank you for sharing all of your thoughts in such great detail! I'll do my best to provide some background information here. First, some GitHub pro-tips that you might find useful.
No offense taken! Working on this specific project has not been my primary or even secondary concern. When I get helpful, actionable feedback, I try to incorporate it in a timely fashion so that everyone will benefit! I don't make any claims about my personal Arduino capabilities. 😄
Any advice would be helpful, and I thank you for it!
Nice work!!
Actually, yes. The timestamp information is incredibly useful for several reasons, but here are just a few:
I admit that the delta timer is more for debugging purposes and can easily be removed. Because this is a DIY project and not something I plan to sell/market, that could be a useful indicator for others experiencing slower speeds. I don't have a strong position on it though.
That's a good tip, thanks!
You assume correctly.
That's a helpful reference, thank you! I am familiar with STRUCTs in the context of C/C++. I can see how this is useful from the example code in this article. They are using a STRUCT as the data structure for writing to disk directly, rather than converting it to strings, saving some operations. A few things come to mine here that I think are worth discussing. While performance of this unit is important, I'm not entirely convinced that it's more important than usability, which gets sacrificed if the data cannot be read by common tools (e.g. spreadsheet software). Essentially, a performance obstacle is removed, but you gain another problem in post-processing -- an additional piece of software needs to be provided that folks can use to translate the data. The question is: is that the right tradeoff to make in this case? I'd personally prefer to take on all other performance options before this one. Maybe other use-cases can justify it, so I can see it as an option for those (like, the ultra-fast version, with documented caveats).
Makes sense. I'm curious if the other enhancements you're suggesting strictly require this to happen first?
Nice! Again, thank you so much for taking the time to write all of this out. I really do appreciate your contributions! 💯 🎉 👍 |
|
@erichiggins Thanks for the timely reply and Github pointers. Will try to implement those going forward. But first, I'd like to pick on you some more about all those digits you're storing. The timestamp "1547749706", which I think has units of seconds converts to 429930+ hours. I understand your reasons for storing the timestamp, but perhaps you could store the entire timestamp just once at the beginning and then store just the last 4 or 5 digits with each reading. Still trying to talk you into using struct...If you shorten the timestamp by 5 digits and use struct to ditch the 5 commas, the data file for 1 minute of data @ 1kHz will be 600,000 characters shorter. Actually quite a bit shorter than that since struct does more compaction than just ditching the commas. For example, one of my data files has 24,000 readings packaged in structs. The file size is 576120, after that is converted to a .csv file the file size is 903216. Although it may not seem like a big deal to shave micro seconds off of writing each set of data to the SD, avoiding a boatload of the ~10 mS delays while the SD is busy really adds up. You raise a valid point concerning performance vs usability. I'll try doing a pull request and include the code I use to convert the data file packed with structs to a .csv file. To answer your question, using struct is not strictly required to implement the other ideas, but it sure makes the code less clunky. It won't hurt my feelings if you decide to look at other options first. |
Yep. This format is known as a Unix time or Unix timestamp. Essentially, it gives you the date/time with an integer which represents the number of seconds since 00:00:00 Thursday, 1 January 1970.
This is a fair point. Having it in each row certainly improves some aspects of data analysis. For example, because the output of
Understood. I'll create a new branch to play around with this a bit to get some first-hand experience about the performance gains and usability tradeoffs. Maybe others will chime in to show/oppose support for that approach so as to make an informed decision.
Very much appreciated! From an earlier comment, here are a few things that I'm very interested to learn more about.
|
|
@erichiggins Tried to do a pull request and was unsuccessful. Either I'm missing something or it's because I don't have write privileges to your repository. Perhaps you could open a pull request titled something like "Using struct to compress data" and then I think I'll be able to add comments and the code I promised. |
|
@RipVW Sure thing. You should have permission to create branches and PRs, but I'll get you started. I've created a new branch for you named https://github.com/ammolytics/projects/tree/ripvw If you run Hope this helps! |
|
@erichiggins Thanks, will try that later on today. But first... Before going farther I should say that a lot of the progress I've made and inspiration I've had are due to this script written by Bill Greiman, the author of the SD Fat library. When I read the description of his program I thought I'd just open it up and see how to write the program for my accelerometer. It was a humbling experience to realize that for the most part I had no idea what he was doing. So, I set about trying to understand little pieces of it like using struct, using interrupts, and buffering the data while the SD card is busy. There are still parts I don't understand, although I think I've found some helpful information for when I'm ready to digest the remaining parts. It occurred to me that your experience with C/C++ might enable you to leapfrog over all the steps I've taken and just adapt Bill's program for your application. If so, I have some questions for you. |
|
Hello, Concerning speed and efficiency for raw data storage. I made the above functions public in Adafruit_LIS3DH.h uint8_t readRegister8(uint8_t reg); and used them for setting up the sensor and reading values. In my project I use a microcontroller and I sent data via WiFi and translate the raw data into accelerations of m/s2 on the backend on a pc and store them. I use 1344 Hz sampling rate for resolution purposes and I monitor the sampling time with an internal timer and I constantly get 1344 samples in a second. In my project I send the samplings every approximately 1.2 seconds (i need 1 second for sampling and 0.2 seconds to send data over wifi, but this depends on connection quality). I guess running on a multicore microprocessor you can parallel data transmission and sampling so you can achieve non stop measurements (I tried that but my 2 core mcu and libraries need wifi running in parallel with mqtt so I abandoned it) I don't think you can get faster and more efficient than this unless someone implements the above functions more efficiently, which contain only the SPI transaction in my case. So my advice is to read the datasheet carefully and use the above functions to program on register level. I also recommend running on SPI close to 10MHz. Also unlike strings working on the byte level you can have packets of data with a fixed measurement length so by writing filtering code carefully you can chop the data however u want without needing commas and extra overhead. In my case I just add a timestamp (per sampling as the sampling rate is known) and a byte for labeling x,y,z in each packet. |
|
@nalexopo Great work. I wish I had the skills to send the data over wifi. The functions you made public look very useful. I haven't been using the library because I prefer to read/write from the registers manually, which involves several lines of code. Using your functions would make things easier to read. Perhaps you can help me understand libraries. Most of the libraries I've tried to use don't have a user guide that explains each function. Do user guides exist and I just haven't found them? It seems that I have to read through all the code examples to figure out which functions are available and what function parameters are supported. I find it much easier to read the register mapping in the datasheet than to search though other people's code. Is there something I'm missing that makes using libraries seem so difficult? It sounds like you have a .2 second gap in your data during the wifi data transfer. Is that correct? I think your last paragraph describes the benefits of using "struct", in which case you don't need the byte for labeling the x, y, and z data. Do you have a github or other location that shares more details about your wifi setup? |
WiFi is surprisingly easy nowadays. Have a look at the ESP8266/ESP32 boards. They make it very easy to send data using TCP/UDP or using protocols like MQTT. There's also the Particle Photon which I like a lot. The downside of the ESP boards is that they can be a bit finnicky to set up and program.
There are a few factors involved. EDIT: So I realised you were talking about the accelerometer, not the micro. But below applies. The datasheet is supposed to be a self-contained description of how a component works. Different developers will have different views on how to translate that into code and sometimes that makes it very difficult to grok. Some libraries, like Adafruit's, are designed to have lots of generic components so they can make products which work well with each other and have a consistent interface. This does sometimes make the code more abstract though. Atmel (now Microchip) wrote exceptionally good documentation for the AVR series of microcontrollers. This is coupled with a very simple C library on top (avr-libc). As a result, if you know how to write one register, you can write any register because the naming conventions are consistent with the datasheet. If you download the full datasheet for e.g an Atmega328, that's basically all you need to understand the entire chip. It's amazingly well contained. Libraries offer convenience at the expense of performance. Adafruit's libraries, like Arduino in general, are designed to give you a working solution fast. They're not meant for absolute speed. There is, as you've found, a big difference between a well-documented library and a poorly-documented library. Documentation can be produced automatically using tools like Sphinx (for Python) or Doxygen (for C++) but it still relies on the developer commenting their code. And beyond that, that's no substitute for a good user guide.
Yes, there's no point wasting bytes labeling. If you have a blob of data that you've saved, you can cast it as an array of a struct of the same type when you read it back. I'm going to order a LIS3DH to have a play with. They're cheap! |
|
@jveitchmichaelis Glad to see you here again. Thank you for taking the time to write a detailed and very helpful reply. As a regular reader of the blogs on Hackaday et al I'm constantly reminded of the ESP boards, and their finicky reputation. Have heard of the Photon but never checked it out. Based on your recommendation I'll take a serious look at the Photon. Your comments about libraries were especially reassuring. Have been feeling stupid since I don't immediately and intuitively know how to use every function of each new library, the way the library authors seem to think I should. I actually enjoy reading datasheets working with registers, so it was great news that was as fast or faster than using libraries. USPS tracking says there's a LIS3DH in the mailbox - let the fun begin! |
@RipVW I put in my order on Mouser yesterday morning, so it should arrive this week :) |
|
@jveitchmichaelis Got the LIS3DH hooked up tonight. Luckily the similarities to the LIS331 meant not many changes to the script were required. The script kept up at 1.6 kHz and rapidly emptied out the buffer once the SD card got done with each busy spell. At 5 kHz it collected 2073 readings before the 600 row buffer overflowed, which is a lot better than I expected. Having recently reduced the isr from 20 to 13 uSec I think the first place to look for progress is to whittle down the 20 bytes stored with each reading. Getting to 5 kHz may require using the on-board fifo buffer and/or learning direct memory access. Am hoping you'll have some additional insights. |
|
@RipVW Had a quick look at the datasheet, I believe 5kHz is only available in 8 bit mode? |
|
@jveitchmichaelis You are correct. Am embarrassed to say that I was so focused on looking at the timing I didn't notice half of the data bytes were 0x00. I remember reading that low power modes were reduced precision, but had guessed that meant 12 bit rather than 16 bit. Looked through the datasheet again and couldn't find where it specified the reduced resolution was 8 bits. |
|
@RipVW yeah it's in Table 12. Good going though. I'm not getting any toys until Thursday apparently, so I'll have a look over the weekend. |
|
@jveitchmichaelis Thanks for pointing out Table 12, but either I'm being dense or we're looking at different documents. |
|
@RipVW I'm looking at the datasheet here: https://www.st.com/en/mems-and-sensors/lis3dh.html Looks like yours is an older revision (2010 vs 2016) |
|
Thank you for taking time to straighten that out. I wonder how many other old datasheets I've been using. |
|
There's no use sending all of those 0x00's to the SD card so that shortened each data set by 3 bytes. Original application required two accelerometers so a byte was stored with each data set to identify its source. So with each data set shortened from 20 bytes to 16 bytes the script kept up a bit longer at 5 kHz before the buffer was overrun at 12,447 samples. |
|
Realized that although I was only saving three bytes from the accelerometer instead of six, I was still reading all six bytes from the accelerometer. There are two options for reading less bytes from the accelerometer, the first of which is to read 5 sequential registers and ignore the low bytes. Or read 3 registers individually which would require adding two more data requests. I chose to read 5 sequential registers and found that made a significant improvement. |
|
@jveitchmichaelis Hope your 3dh showed up. Wondering if you have any insights to share. |
|
RipVW what mcu do you use? jveitchmichaelis guessed right I use esp32 and is fairly easy to send measurements via WiFi + mqtt, you can google one of the numerous tutorials. Esp32 is dual core at 80MHz and can easily sample at 5kHz rate even without reading sequential registers. In my project I chose 1344 Hz in order to have 10bit resolution. The labeling is done for the packets since I send raw measurement bytes via WiFi. You have to make your own protocol and data types when you send outside mcu. |
|
@RipVW Arrived, and then I realised that I hadn't thought about what I'd connect it to.. I think I have some knock-off Arduinos somewhere. :D |
|
@nalexopo Thank you for your comment and tips. Have been using an Adafruit Adalogger w/ Cortex M0, as the Arduino IDE is my comfort zone. It may be time to learn a new environment for the ESP32 or Particle Photon. Would like to change one of the registers on the M0 but not sure if the Arduino IDE can do that. So much to learn... Is the ESP development environment very different from the Arduino? |
|
@nalexopo Realized I had asked you a question that I could Google. Turns out the ESP can be used with the Arduino IDE. Is that what you use, or is there other software you'd suggest? |
|
@jveitchmichaelis Hopefully an Arduino will float to the top of your parts box. Have read about Particle Photons et al for 4-5 hours. To bad the mesh radio is 2.4 GHz. The mesh would be perfect for the farm if it had the same range as LORA. |
|
There are two ways to program an ESP. One is using arduino libraries and arduino IDE. I don't like arduino IDE much personally, so I use Microsoft visual studio + vMicro addon for arduino compatibility. The downsides of using arduino libraries is that you suffer a penalty on performance(i think someone measured it around -60% compared to freertos) and you cant exploit parallelism between the two cores(unless using freertos on top of arduino). The other is using freeRTOS and its API on eclipse environment. That is fairly simple if you have some parallelism background and your C is strong. However the way WiFi and BLE works in ESP32 can limit your parallelism. Since arduino is C++ you can use FreeRTOS on top of arduino enviroment, because freertos is in C. Using arduino libraries from freeRTOS enviroment is not possible. There are many people using ESP it is fairly easy to master the arduino portion in a few weeks. |
|
@nalexopo Thank you for the insights and encouragement. It's nice to know some of the options. Found a closeout sale on an ESP with LoRa board so have a couple on order. |
|
Great effort here, nice to see compact, neat arduino code. Did anyone get this ported across to ESP32? I can do that if anyone is interested in downloading the data to a mobile device/pc, the ESP32 basically creates a web page that you can view and download the data without needing to uplug the SD card. If unplugging the SD card is not too much of a hassle then there is not much to be gained from using the ESP32. The ESP32 it could probably store the data from one or 2 shots in its own memory without the need for an SD card. Not sure how many shots you want to store? |
I would switch to storing raw data, rather than strings.
There is probably a significant overhead in doing a string conversion, because you're implicitly calling itoa a bunch of times. You'd be better off having three 16-bit arrays to store the accelerations and just putting the raw measurements in there each loop.
projects/accelerometer/sensor_logger.ino
Lines 162 to 172 in a298bcd
It will also save a lot of space. This string
"m/s^2, "alone contains as much data as a single 3 axis measurement!The Adafruit library also does a bunch of float calculations which is also going to be a lot of extra cycles, but worry about that when you've optimised as far as you can with their library.
So in principle your max data rate is 3 x 5000 x 16 bits or around 240kbaud. From your writeup it looks like you're capturing at a much lower rate (around 140Hz). I'd be curious to see how much faster you can write to disk just making the changes above.
The text was updated successfully, but these errors were encountered: