静态语言:使用前就需要确认变量数据类型 动态语言:运行过程中需要检查数据类型
弱类型:支持隐式类型替换 强类型:不支持隐式类型替换
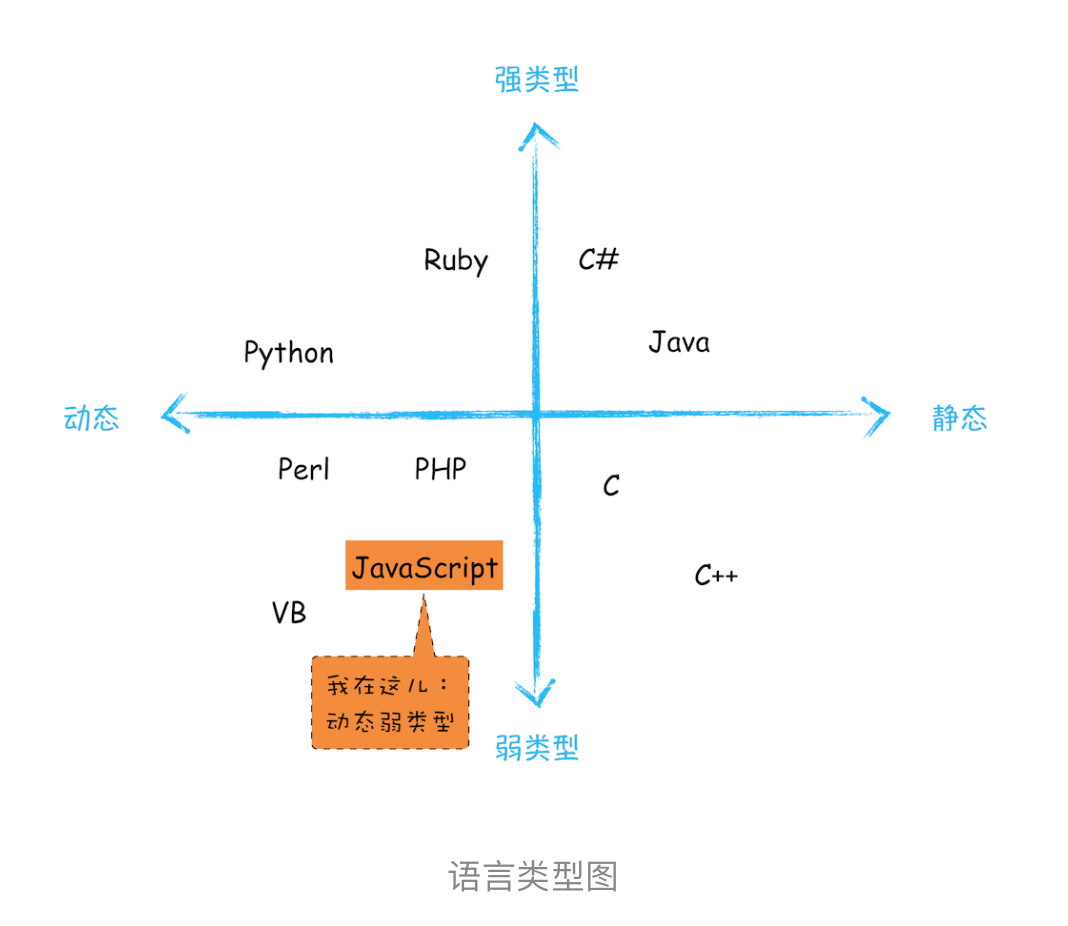
Javascript是动态、弱类型语言
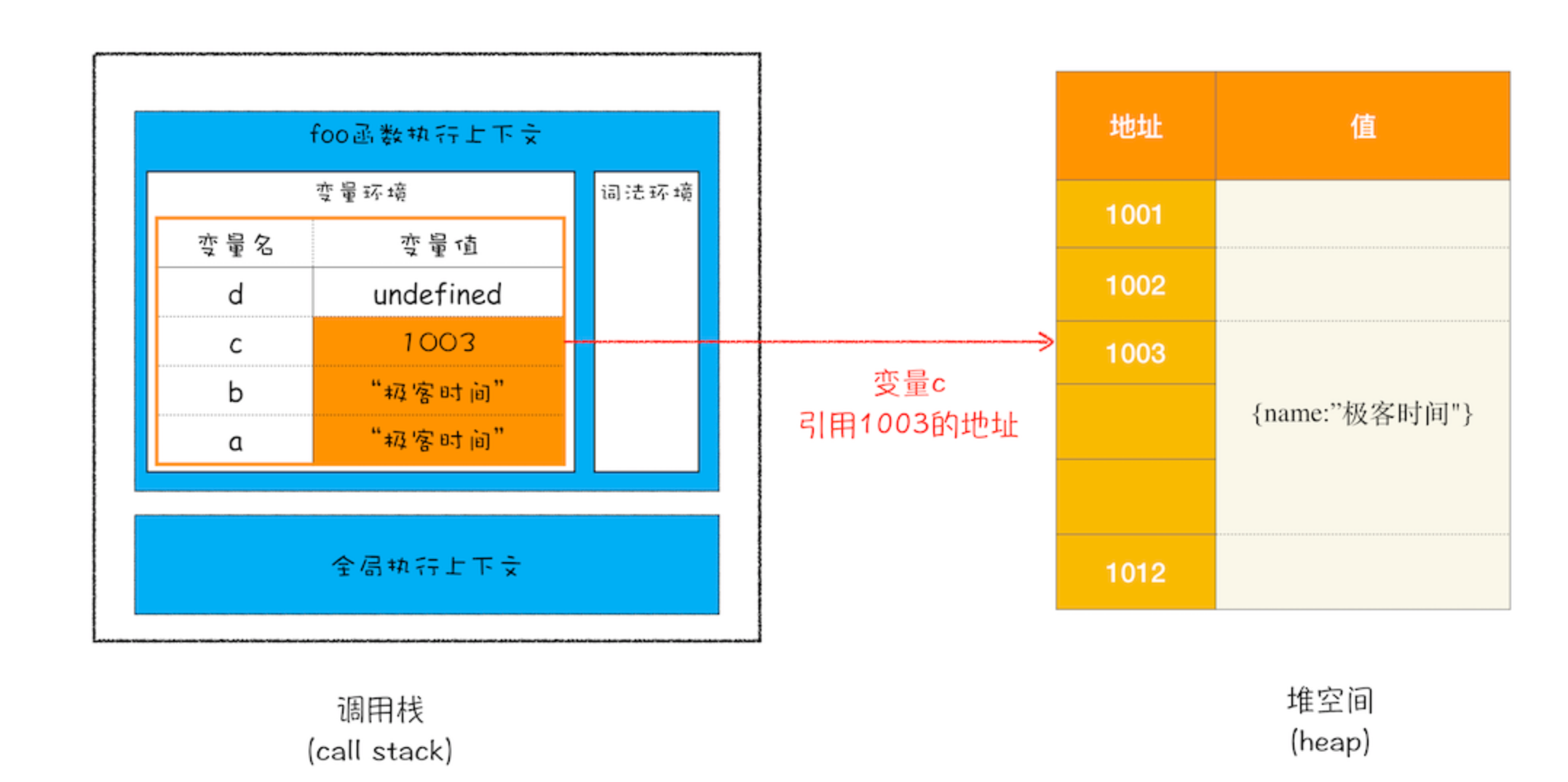
JS执行过程中,主要有3种类型的内存空间
- 代码空间
- 栈空间(一般不大)
- 调用栈,存储执行上下文
- 原始类型数据
- 堆空间(很大)
- 引用类型
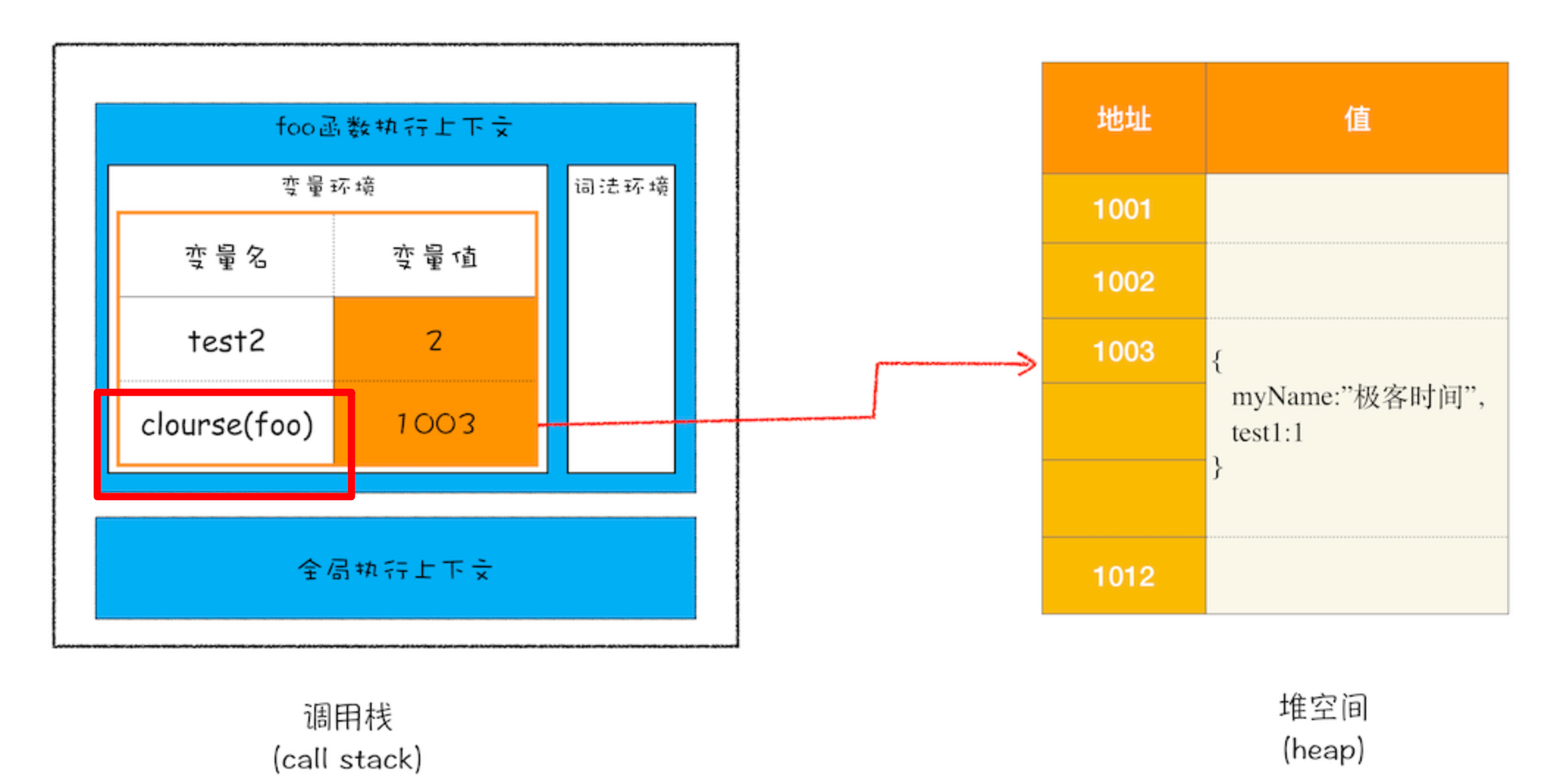
闭包的产生
JS引擎预扫描内部函数,判断为闭包后,在堆空间创建一个closure对象,用来保存外部变量,栈空间中保存着对闭包的引用
垃圾回收分为手动回收和自动回收两种策略
对于JS,分别看栈和堆中的垃圾回收
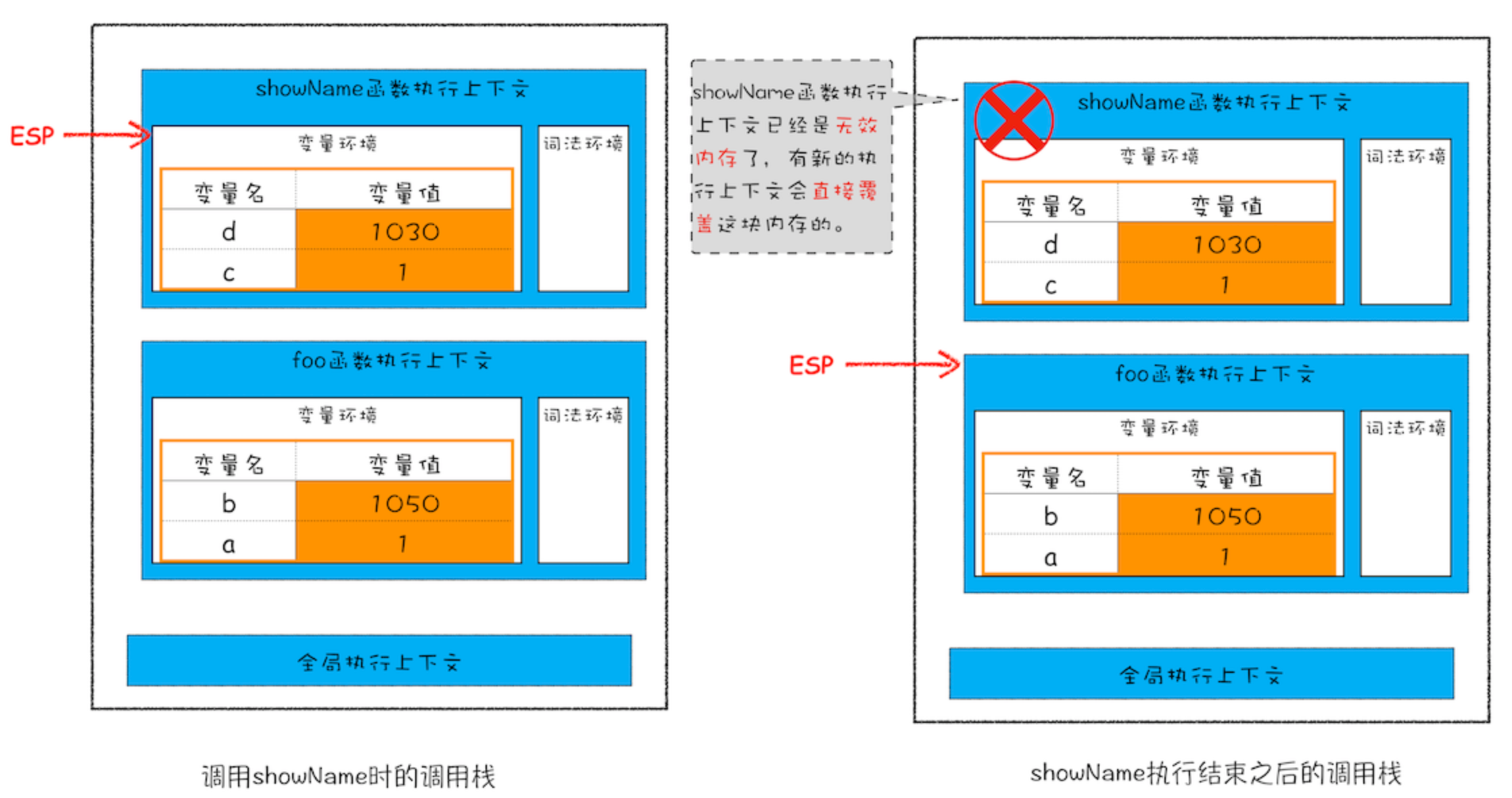
- 栈:当一个函数执行结束之后,JavaScript 引擎会通过向下移动 ESP(记录当前执行状态的指针) 来销毁该函数保存在栈中的执行上下文
- 堆:主要通过副垃圾回收器(新生代)和主垃圾回收器(老生代),副垃圾回收器采用scavenge算法将区域分为对象区域和空闲区域,通过两个区域的反转让新生代区域无限使用下去。主垃圾回收器采用Mark-Sweep(Mark-Compact Incremental Marking解决不同场景下问题的算法改进)算法进行空间回收的。无论是主副垃圾回收器的策略都是标记-清除-整理三个大的步骤。另外还有新生代的晋升策略(两次未清除的),大对象直接分配在老生代。
前置概念和原理
-
编译器(Compiler)
-
解释器(Interpreter)
-
抽象语法树(AST)
-
字节码(Bytecode)
-
即时编译器(JIT)
-
编译型语言:程序执行之前,需要经过编译器的编译过程,并且编译之后会直接保留机器能读懂的二进制文件,这样每次运行程序时,都可以直接运行该二进制文件,而不需要再次重新编译了。比如 C/C++、GO 等都是编译型语言。
-
解释型语言:每次运行时都需要通过解释器对程序进行动态解释和执行。比如 Python、JavaScript 等都属于解释型语言
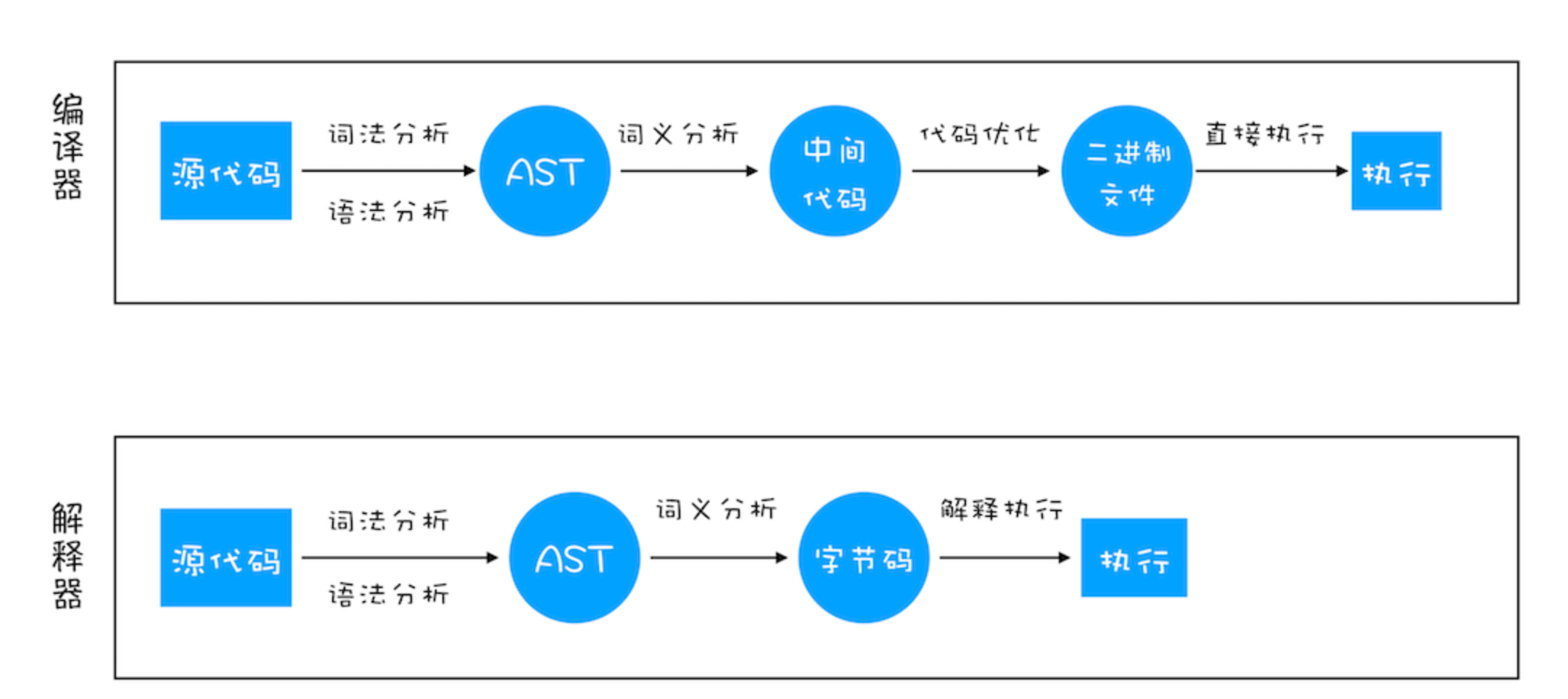
- 生成抽象语法树(AST)和执行上下文
- 分词(tokenize),词法分析
- 解析(parse),语法分析
- 生成字节码
- 字节码、机器码
- 执行代码
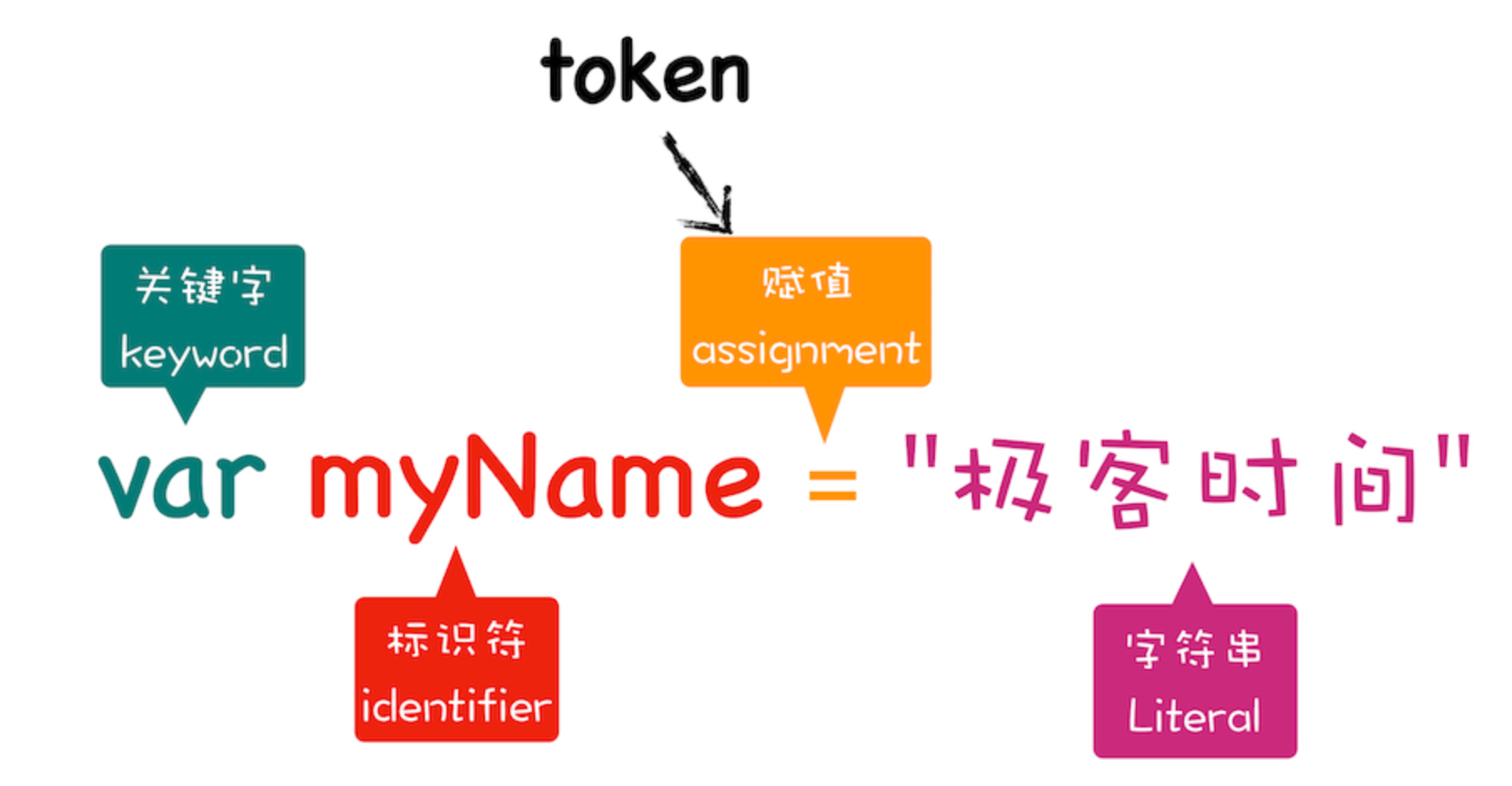
分词(tokenize),词法分析:将一行行的源码拆解成一个个 token,即语法上不可能再分的、最小的单个字符或字符串
解析(parse),语法分析:将上一步生成的 token 数据,根据语法规则转为 AST
AST的应用非常广泛,比如Babel,工作原理就是先将 ES6 源码转换为 AST,然后再将 ES6 语法的 AST 转换为 ES5 语法的 AST,最后利用 ES5 的 AST 生成 JavaScript 源代码。比如Eslint也是利用了AST来检查JS语法
生成字节码:V8的解释器 Ignition会根据 AST 生成字节码,并解释执行字节码
其实一开始 V8 并没有字节码,而是直接将 AST 转换为机器码,由于执行机器码的效率是非常高效的,但机器码的问题在于占用内存比较大,V8团队就引入了字节码
字节码就是介于 AST 和机器码之间的一种代码。但是与特定类型的机器码无关,字节码需要通过解释器将其转换为机器码后才能执行

- 第一次碰到字节码,解释器Ignition会逐条解释执行
- 如果发现了热点代码(多次使用),交给编译器TurboFan 编译为机器码并保存下来,下次执行就会更加高效
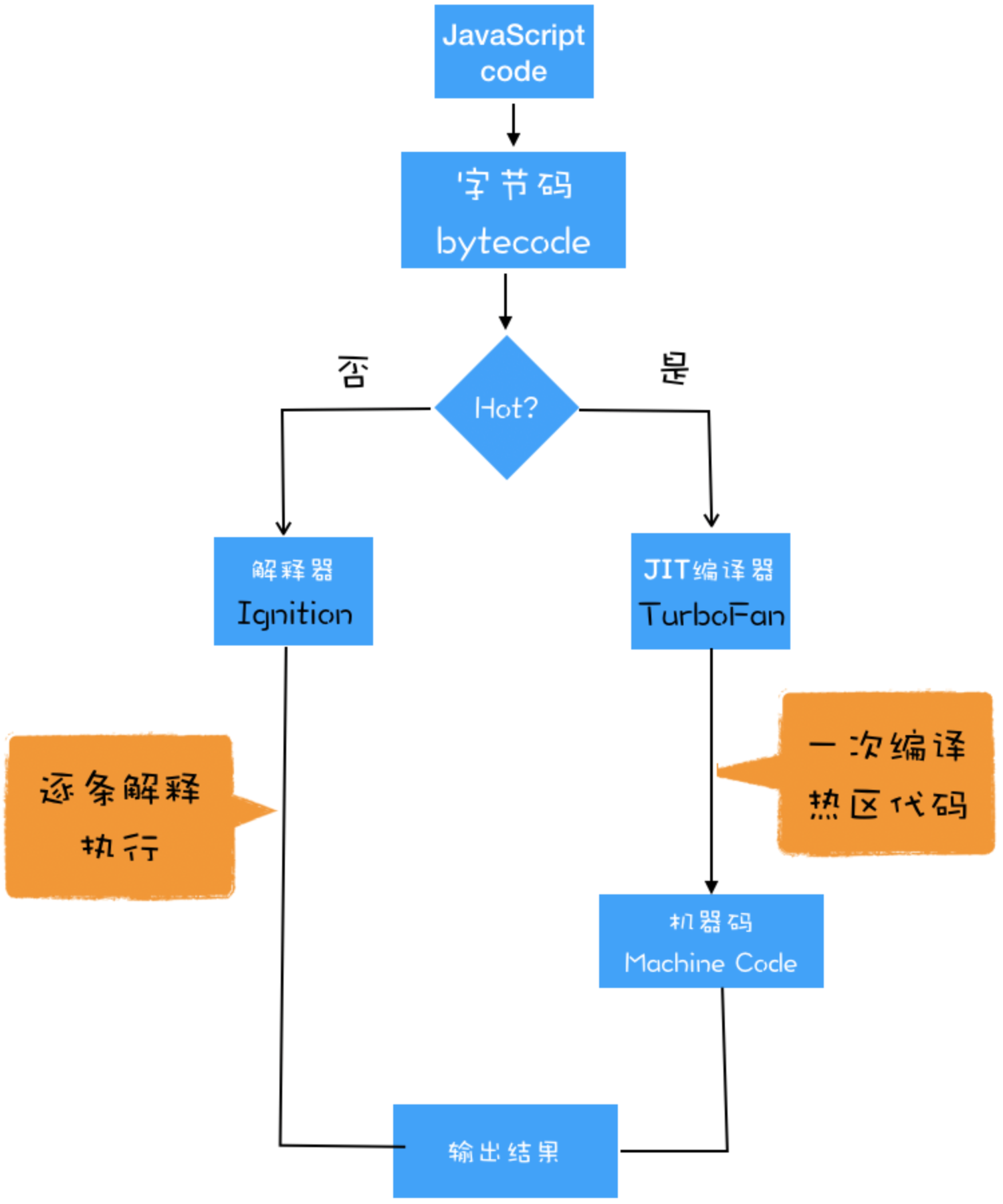
字节码配合解释器和编译器的技术被称之为即时编译JIT,Java 和 Python 的虚拟机也都是基于这种技术实现的
V8执行越久,被编译成机器码的热点代码就越多,所以整体执行效率就越高 由于引入了字节码,有了弹性空间,也可以在内存和执行速度之间做调节了 相比之前的V8,将JS代码全部编译成字节码,这种模式就没有协商的空间了
其实上面的策略,V8已经做得很牛逼了,对于开发者来说,基本不太需要关注底层的实现,而是将更多的精力花在单次脚本执行时间和网络下载资源上