#develop/Front-End/浏览器原理
本系列文章,是学习浏览器工作原理与实践_浏览器_V8原理-极客时间的总结和扩展,部分内容和图片都来自于这门课程,先做个说明,算是部分转载
01 | Chrome架构:仅仅打开了1个页面,为什么有4个进程?-极客时间
先从一个问题开始,开一个chrome页面,会启动多少个进程?
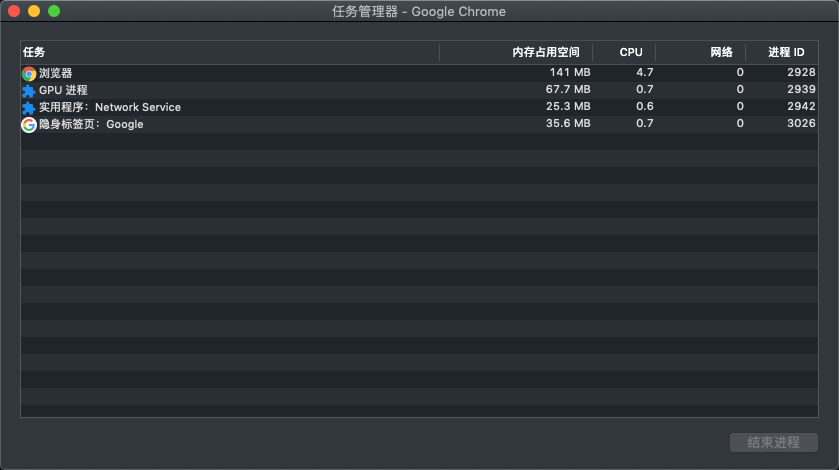
打开一个最简单的无痕浏览器,关闭所有插件,只开一个tab访问google首页,然后从【右上角选项 -> 更多工具 -> 任务管理器】,打开chrome的任务管理器窗口,可以看到有有4个进程
在聊4个进程之前,先来了解一下进程和线程的概念
一个进程就是一个程序的运行实例。详细解释就是,启动一个程序的时候,操作系统会为该程序创建一块内存,用来存放代码、运行中的数据和一个执行任务的主线程,我们把这样的一个运行环境叫进程。
线程是依附于进程的,并不能单独存在,由进程来启动和管理
进程分为单线程和多线程,如下图理解,进程中使用多线程并行处理能提升运算效率
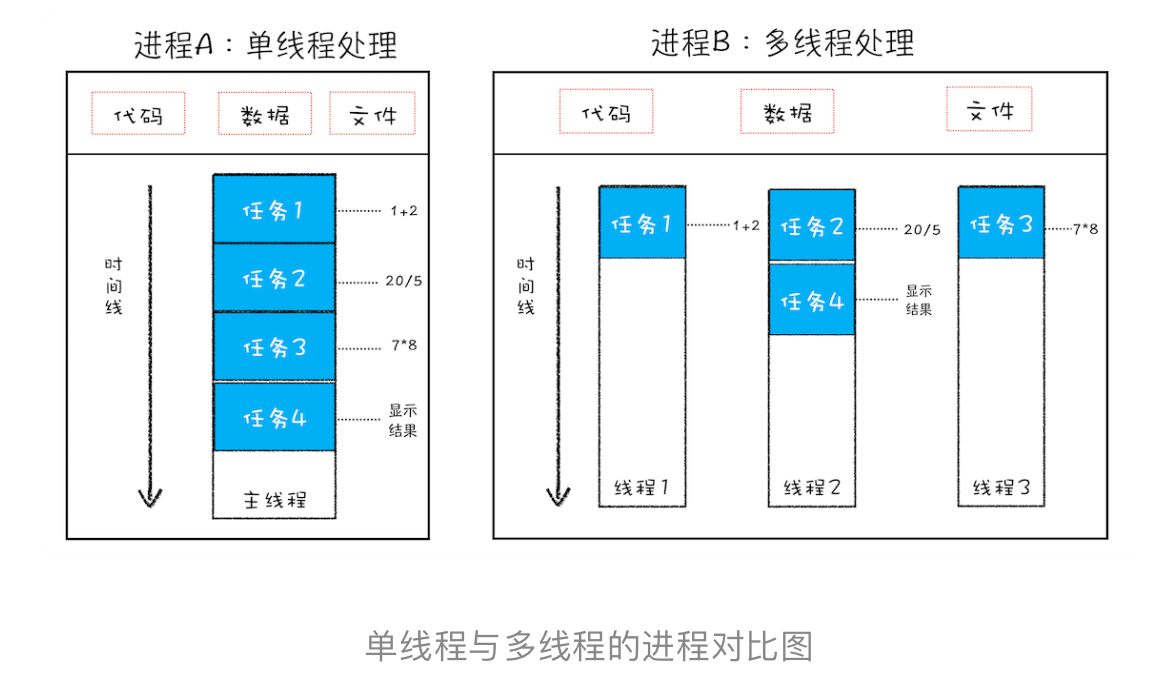
线程和进程之间的关系有4个特点
- 1、进程中的任意一线程执行出错,都会导致整个进程的崩溃
- 2、线程之间共享进程中的数据
- 3、当一个进程关闭之后,操作系统会回收进程所占用的内存
- 4、进程之间的内容相互隔离
单进程浏览器是指浏览器的所有功能模块都是运行在同一个进程里,这些模块包含了网络、插件、JavaScript 运行环境、渲染引擎和页面等。
2008年chrome浏览器面世之前,市面上的浏览器都是单进程的,单进程浏览器有几个缺点
- 1、不稳定,插件或者渲染引擎(这两货极其不稳定)只要有一个崩溃,整个浏览器就崩溃了
- 2、不流畅,如果某个插件或者脚本执行非常慢,或者内存泄露,那么整个浏览器都会卡顿
- 3、不安全,还是插件和脚本,无论是C/C++插件获取操作系统资源还是JS脚本通过浏览器漏洞获取系统权限,都能引发安全问题
08年 chrome带来了多进程浏览器架构
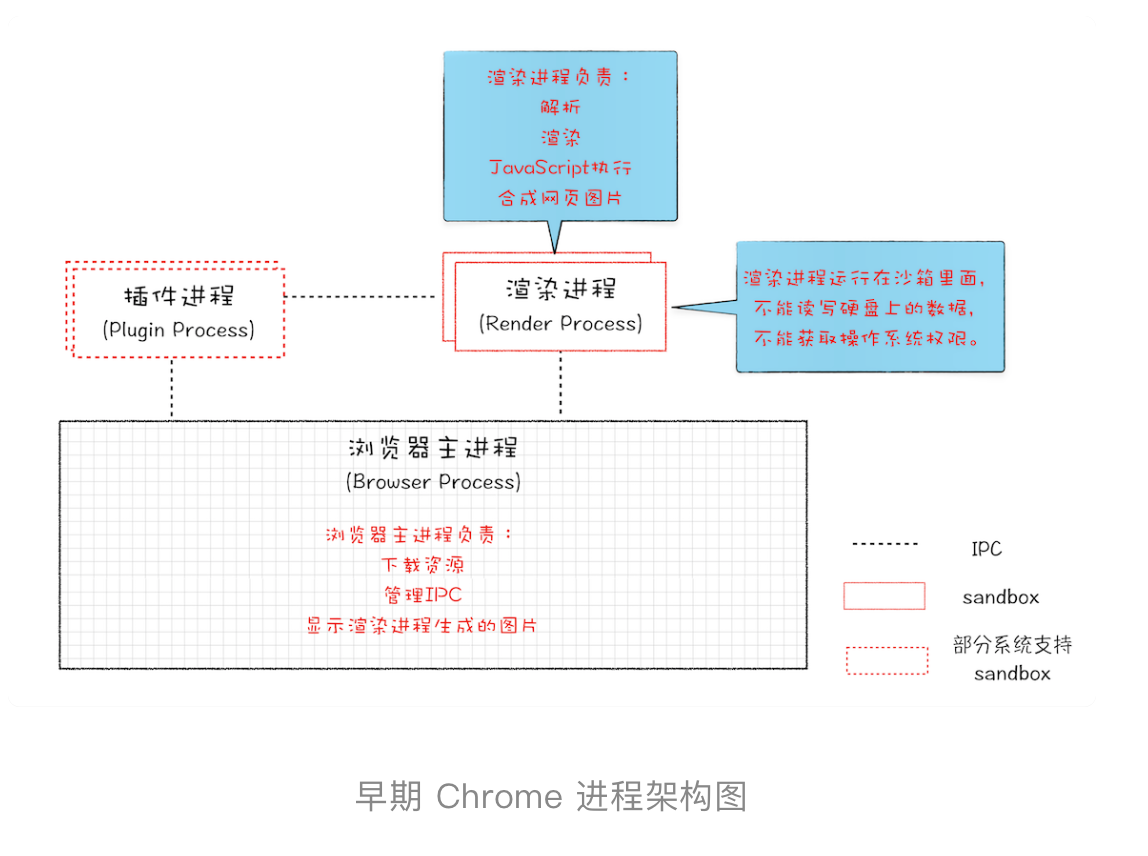
插件和渲染使用独立的进程,进程之间是互相隔离的安全沙箱环境,上面提到的3个问题都迎刃而解
现代浏览器基于以上多进程架构有了一定的扩展和变化
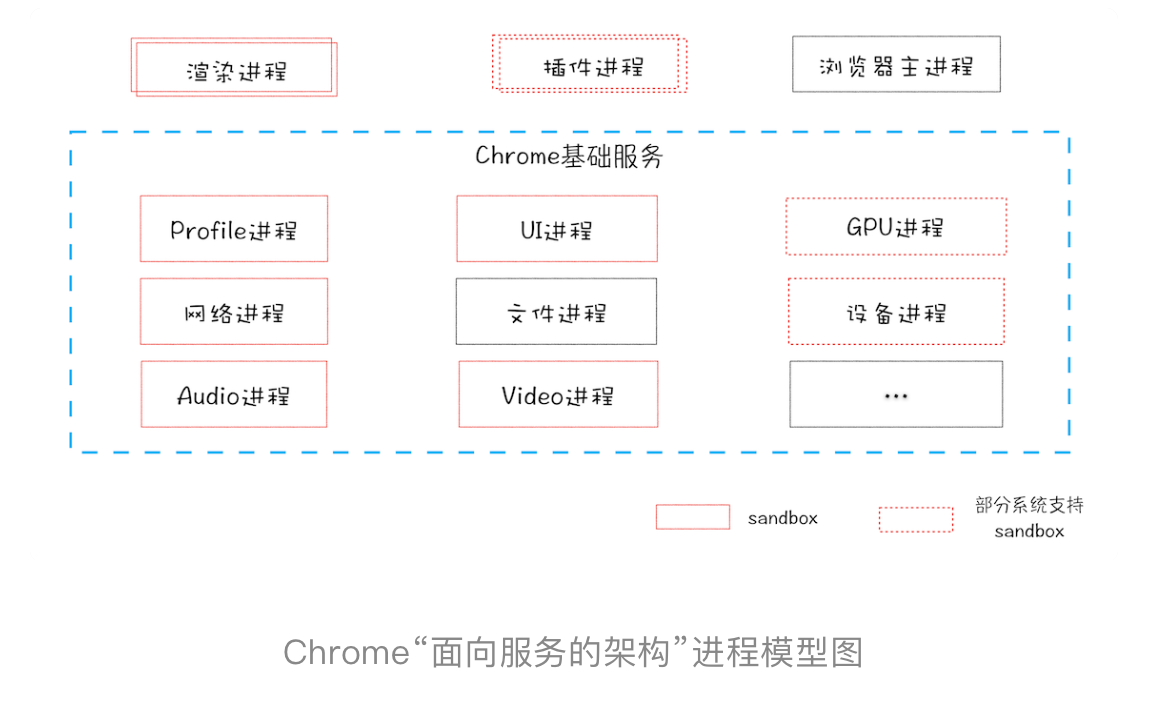
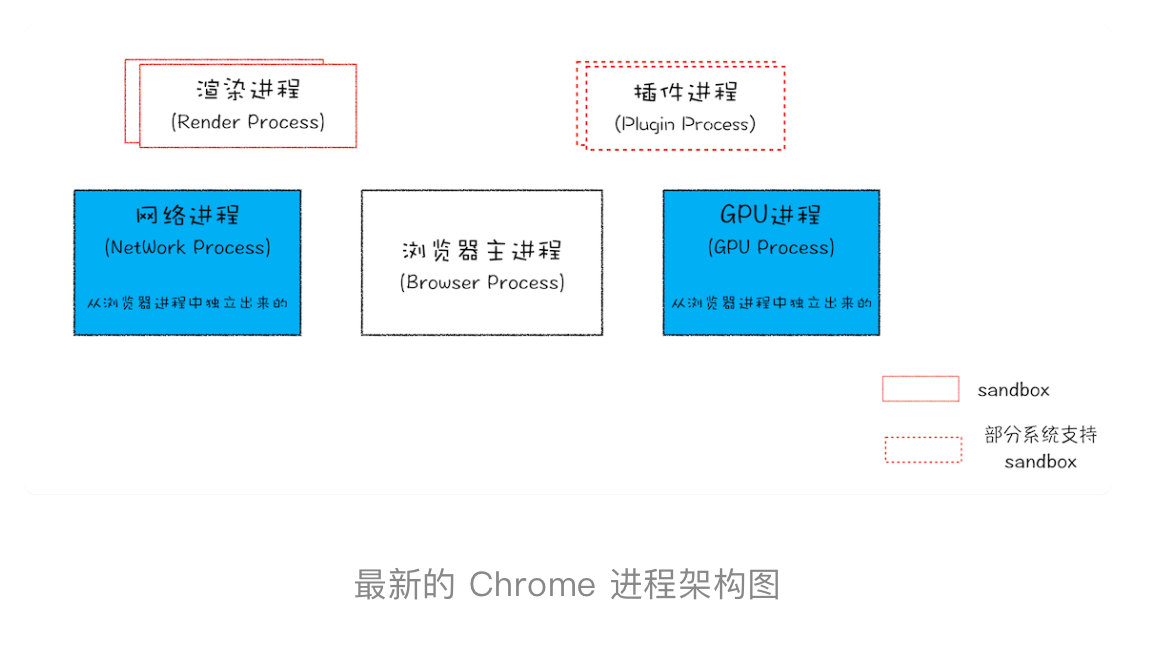 核心的进程有
核心的进程有
- 浏览器进程,主要负责界面显示、用户交互、子进程管理,同时提供存储等功能
- 渲染进程(多个,暂时理解为一个tab页面一个渲染进程),排版引擎 Blink 和 JavaScript 引擎 V8 都是运行在该进程中
- GPU进程,网页、Chrome 的 UI 界面都选择采用 GPU 来绘制
- 网络进程,主要负责页面的网络资源加载
- 插件进程(多个),插件容易崩溃,最是需要独立隔离
Chrome 整体架构会朝向现代操作系统所采用的“面向服务的架构” 方向发展,原来的各种模块会被重构成独立的服务(Service),每个服务(Service)都可以在独立的进程中运行,访问服务(Service)必须使用定义好的接口,通过 IPC 来通信,从而构建一个更内聚、松耦合、易于维护和扩展的系统,更好实现 Chrome 简单、稳定、高速、安全的目标
02 | TCP协议:如何保证页面文件能被完整送达浏览器?-极客时间
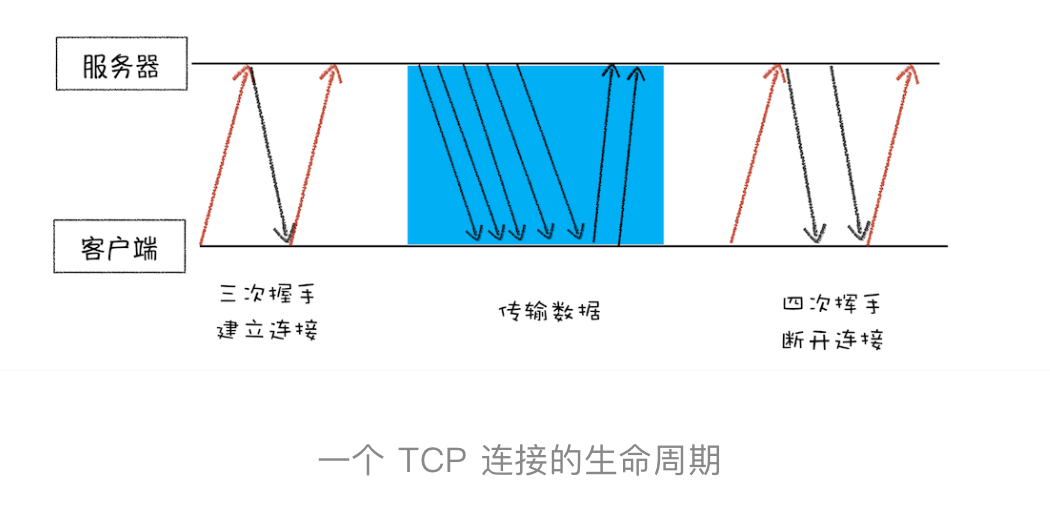
TCP(Transmission Control Protocol,传输控制协议)是一种面向连接的、可靠的、基于字节流的传输层通信协议
- 互联网中的数据是通过数据包来传输的,数据包在传输过程中容易丢失或出错。
- IP用来寻址,寻找到对应计算机的地址,负责把数据包送达目的主机
- UDP通过端口号来寻找对应的处理程序,负责把数据包送达具体应用(通过端口号),但会丢包
- TCP 引入了重传机制和数据排序机制来保证数据完整地传输,TCP连接分为三个阶段:建立连接(三次握手)、传输数据和断开连接(四次挥手),但为了保证数据传输的可靠性,牺牲了数据包的传输速度
几个小问题
- HTTP和TCP的区别
- HTTP协议和TCP协议都是TCP/IP协议簇的子集。
- HTTP协议属于应用层,TCP协议属于传输层,HTTP协议位于TCP协议的上层
- http 和 websocket的区别
- 都是应用层协议,而且websocket名字取的比较有迷惑性,其实和socket完全不一样,可以把websocket看出是http的改造版本,增加了服务器向客户端主动发送消息的能力
03 | HTTP请求流程:为什么很多站点第二次打开速度会很快?-极客时间
HTTP 的内容是通过 TCP 的传输数据阶段来实现的
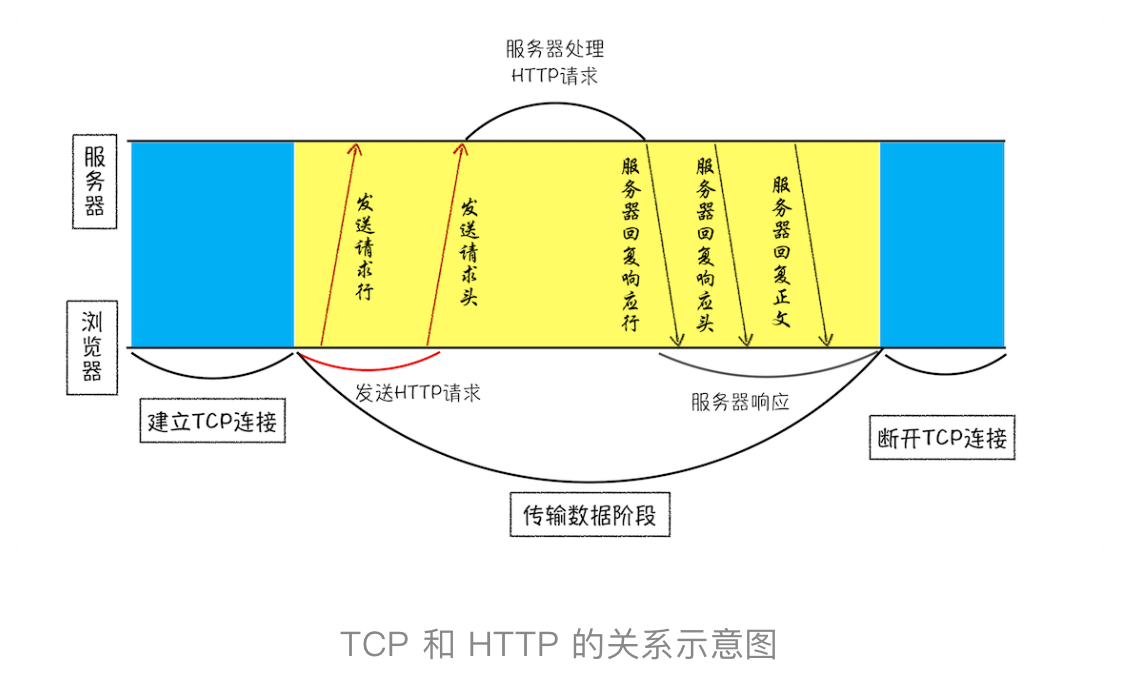
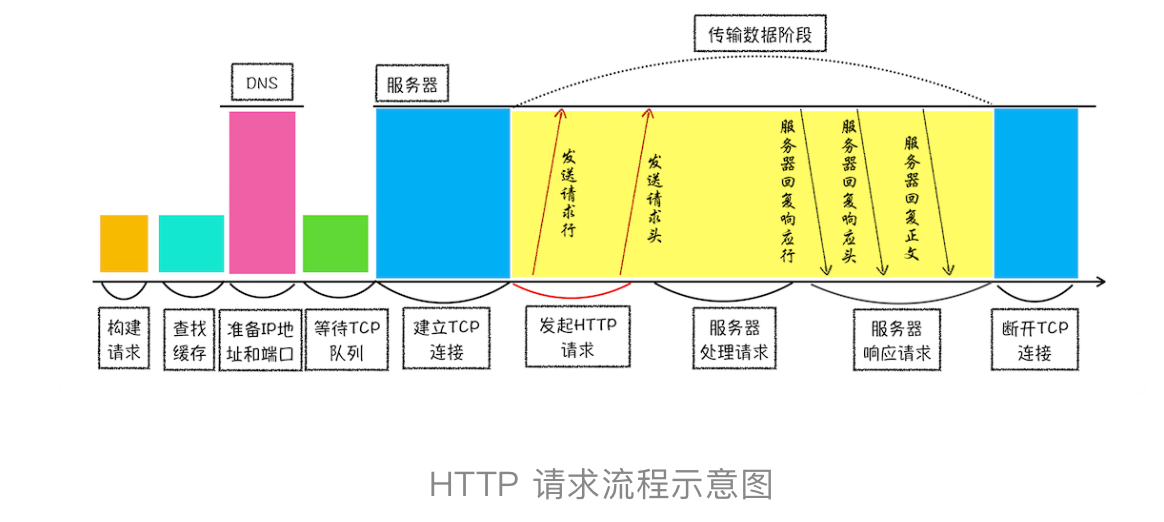
同一个域名同时最多只能建立 6 个 TCP 连接,不光是指Ajax,还包括页面中的资源加载,只要是一个域名下的资源,浏览器同一时刻最多只支持6个并行请求
但如果换成http2,可以并行请求资源,但浏览器只会为每个域名维护一个TCP连接
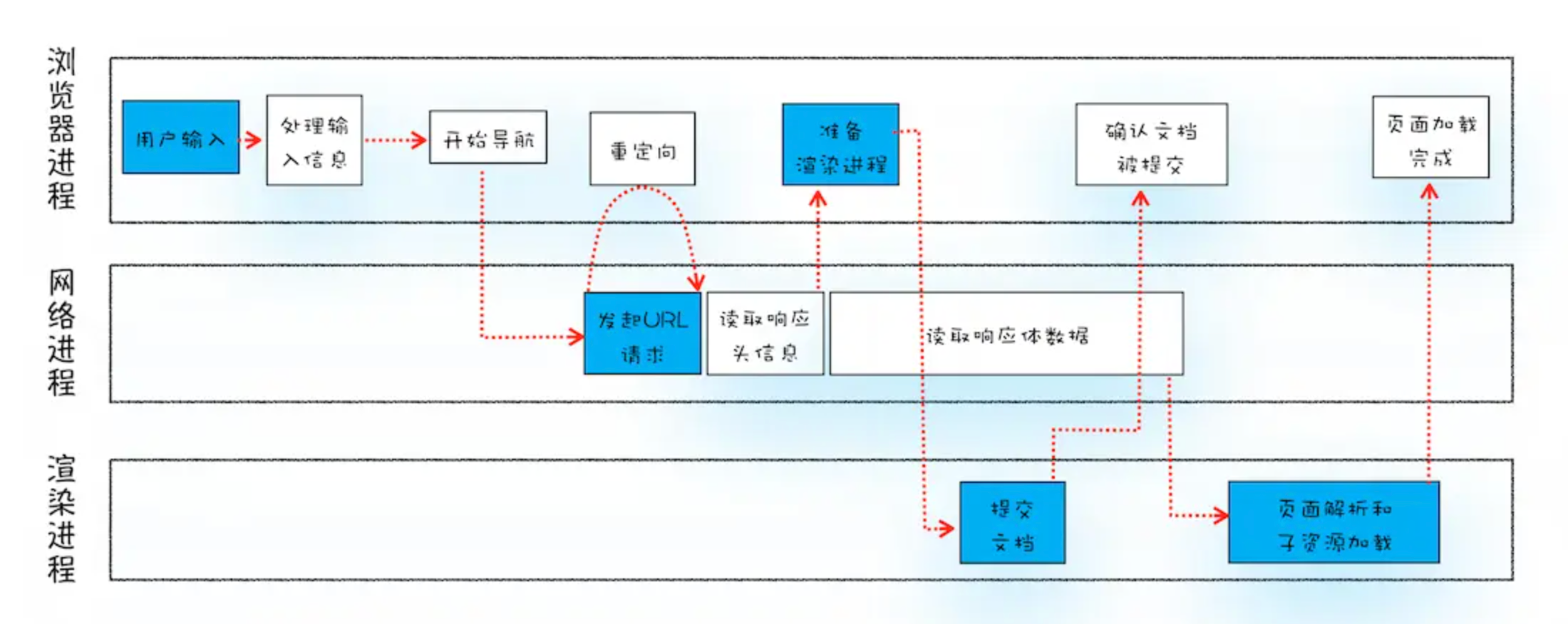
用户输入URL并回车,地址栏判断是搜索内容还是请求URL
- 搜索内容,使用默认搜索引擎,拼接成URL再往下走
- 请求URL合法,(如果没有监听beforeUnload事件或者同意往下走),加上协议头,浏览器主进程通过 IPC (进程间通信) 将 URL 请求传输给网络进程,如
GET /index.html HTTP1.1
这时候,标签页上的图标以及进入了加载状态,但当前页面显示的依然是之前打开的页面,当前属于等待提交文档的阶段
在浏览器中输入地址后页面没有马上消失,这一步是触发当前页的卸载事件和收集需要释放的内存,占用一些时间,大头是请求新的url的返回
-
网络进程检查本地缓存,如果有缓存资源,直接 200 返回资源(from menory 或者 from disk)给浏览器进程;如果没有缓存资源,进入网络请求流程
-
进行DNS解析(本地hosts -> DNS域名解析服务器),获取 IP 地址,如果是 HTTPS 请求,先建立 TLS 连接
-
根据 IP 地址与服务器建立 TCP 连接,浏览器端构建请求行、请求头、附加 Cookie 信息,向服务器发送构建的请求信息
-
服务器收到请求信息后,根据请求信息生成响应数据,发给网络进程;网络进程接收到响应行和响应头后,开始解析响应头的内容
-
网络进程解析响应头,如果是301(永久)/302(临时),网络进程从 Location 字段读取重定向地址,重新发起 HTTP(S) 请求,一切重头开始
-
分析下载类型
Content-Type,判断响应体的数据类型,如果碰到application/octet-stream这种字节流类型,则按照下载类型来处理,将请求提交给浏览器的下载管理器,当前URL的导航流程结束;text/html则是 HTML格式,继续往下走,准备渲染流程
这里补充 Chrome 的一个机制,同一个域名同时最多只能建立 6 个TCP 连接(如果只有一个TCP连接 那就串行了 100张图片会炸,但TCP连接太多,服务器又吃不消),如果在同一个域名下同时有 10 个请求发生,那么其中 4 个请求会进入排队等待状态,直至进行中的请求完成。如果当前请求数量少于6个,会直接建立TCP连接。
- 默认情况下,Chrome会为每个页面分配一个新的渲染进程,但也有例外,如果打开的新页面和当前页面属于同一站点,那么新页面会复用父页面的渲染进程,官方策略叫
process-per-site-instance
- 当浏览器进程收到网络进程的响应头数据后,向渲染进程发起CommitNavigation 【提交文档】的消息,会携带响应头等消息
- 渲染进程收到消息后,开始准备接收HTML数据,和网络进程建立传输数据的管道
- 文档数据(响应体数据,第一批html数据,无须等里面的JS和CSS)传输完成后,渲染进程会返回【确认提交】的消息给浏览器进程 Inside look at modern web browser (part 2) | Google Developers
- 浏览器进程收到确认的消息后,更新浏览器界面状态,包括安全状态、地址栏URL、前进后退历史,更新当前页面,此时页面是空白的
- 文档提交后,渲染进程开始页面解析和子资源加载(下一节),一旦页面生成完成,渲染进程发送消息给浏览器进程,停止标签页上的loading加载动画
浏览器渲染详细过程:重绘、重排和 composite 只是冰山一角 - 前端 - 掘金 辅助理解 浏览器重绘(repaint)重排(reflow)与优化浏览器机制 - 掘金
- 1、构建DOM树:渲染引擎将HTML解析为浏览器可以理解的DOM
- 2、样式计算(Recalculate Style):根据 CSS 样式表,计算出 DOM 树所有节点的样式
- 3、构建布局树 (Render Tree):计算每个元素的几何坐标位置,并将信息保存在布局树中
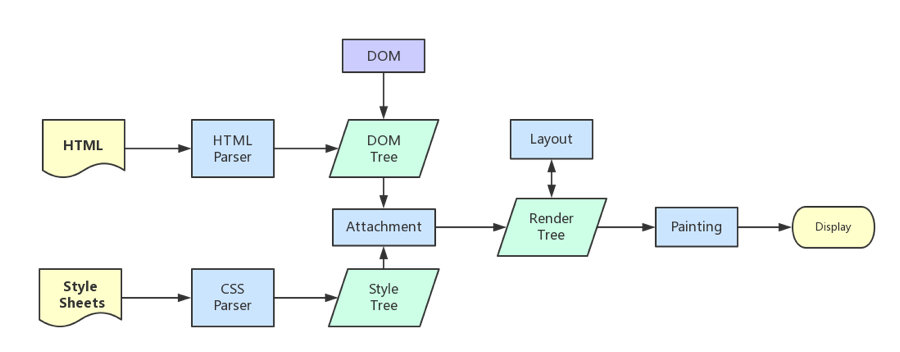
一个小问题,加深理解 1、如果下载 CSS 文件阻塞了,会阻塞 DOM 树的合成吗?会阻塞页面的显示吗? 个人理解:外链CSS文件加载(单独的网络进程下载)不会阻塞DOM树解析,但会阻塞Render树渲染,但现代浏览器会有超时限制,可以直接用user-agent的默认样式,因为HTML本身也是有语义化的
接下来是真正的渲染过程
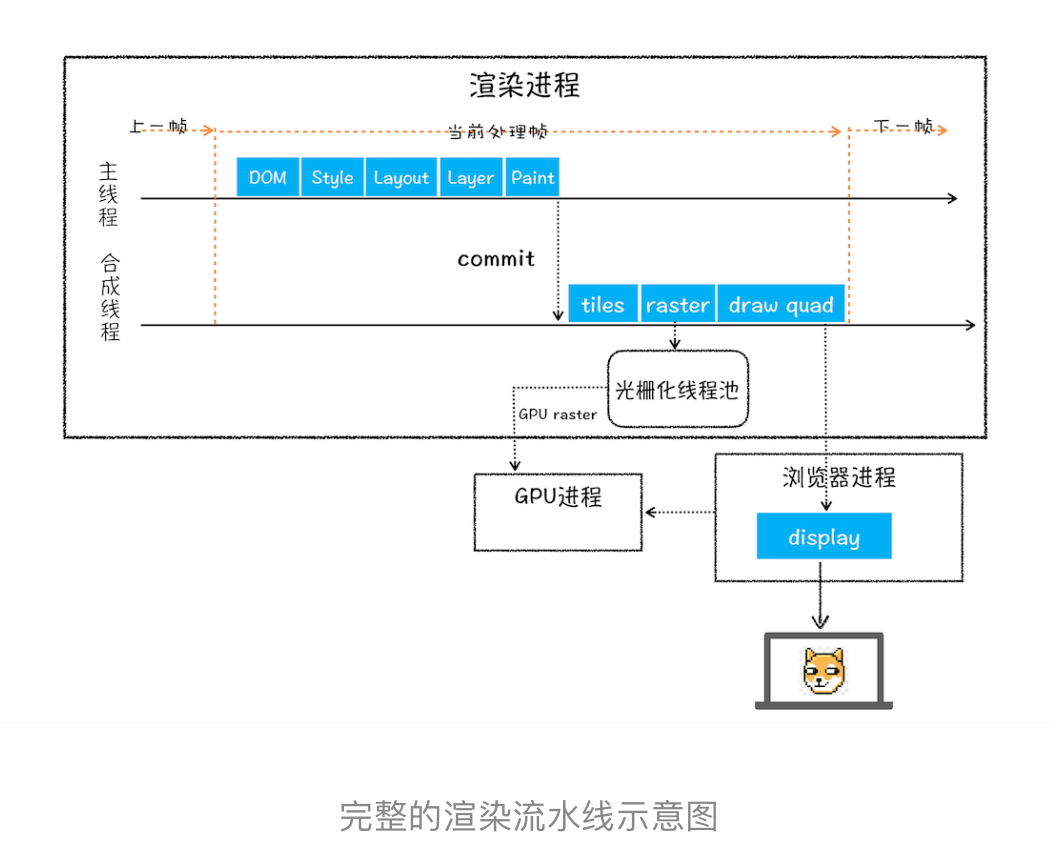
- 4、分层:对布局树进行分层生成分层树
- 5、图层绘制:为每个图层生成绘制列表,并提交到合成线程
- 6、栅格化(raster):绘制列表只是用来记录绘制顺序和绘制指令的列表,而实际上绘制操作是由渲染引擎中的合成线程来完成的,这一步由合成线程将图层分成图块,在光栅化线程池中转为位图
- 7、合成与显示:合成线程发送绘制图块命令 DrawQuad 给浏览器进程,合成和显示,浏览器进程根据 DrawQuad 消息生成页面,并显示到显示器上
浏览器Layers标签中可以看到详细的绘制过程
- 重绘跳过了布局和分层阶段,执行效率会比重排稍高一些
- 直接合成效率最高,直接跳过布局和绘制,只执行后续的合成操作,比如CSS的transform动画不占用主线程上资源
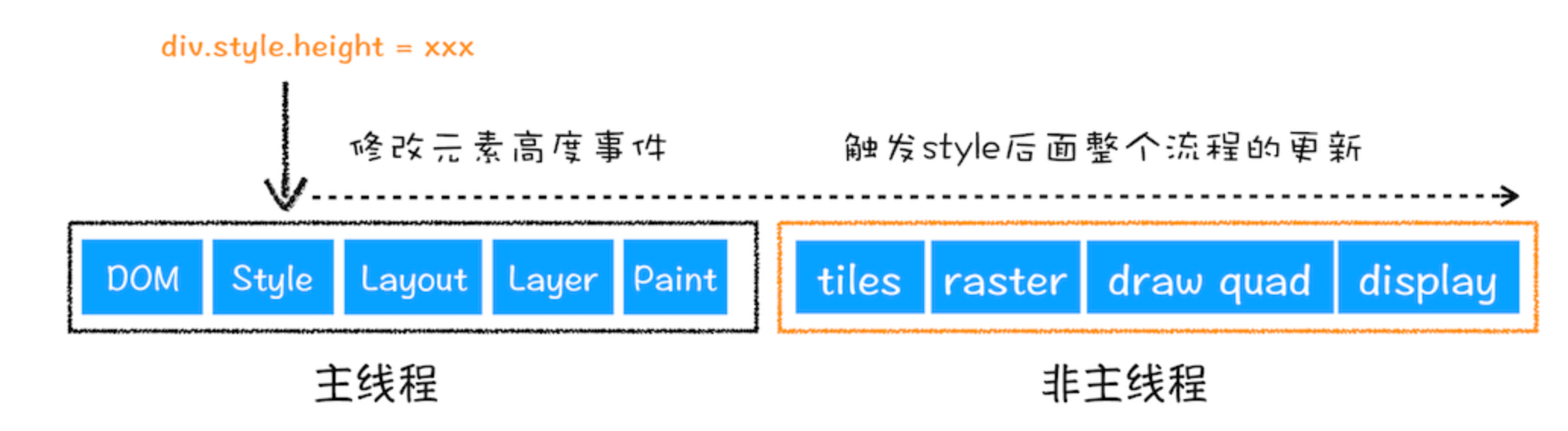
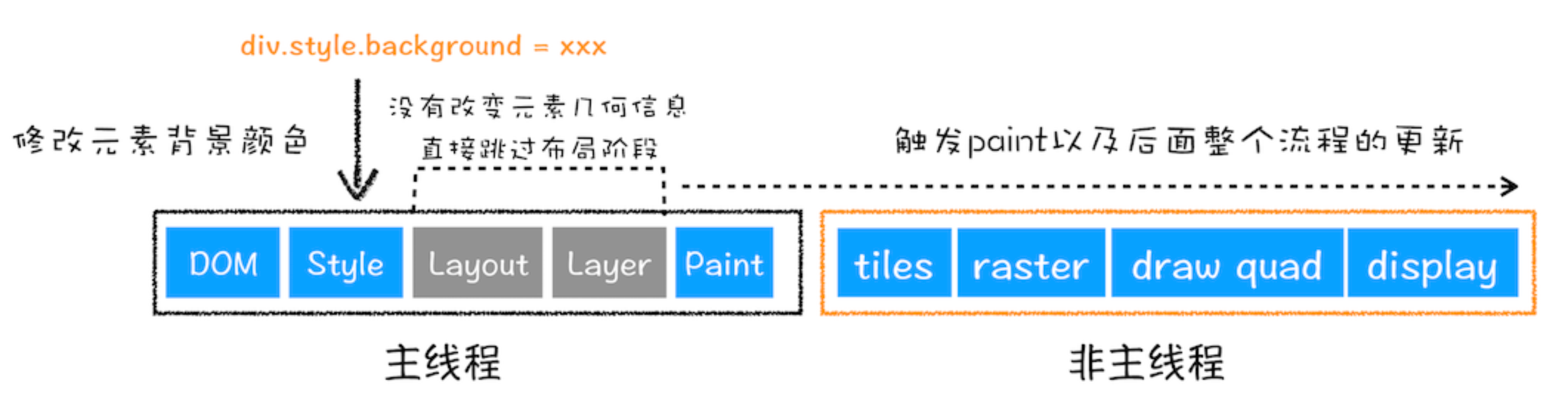
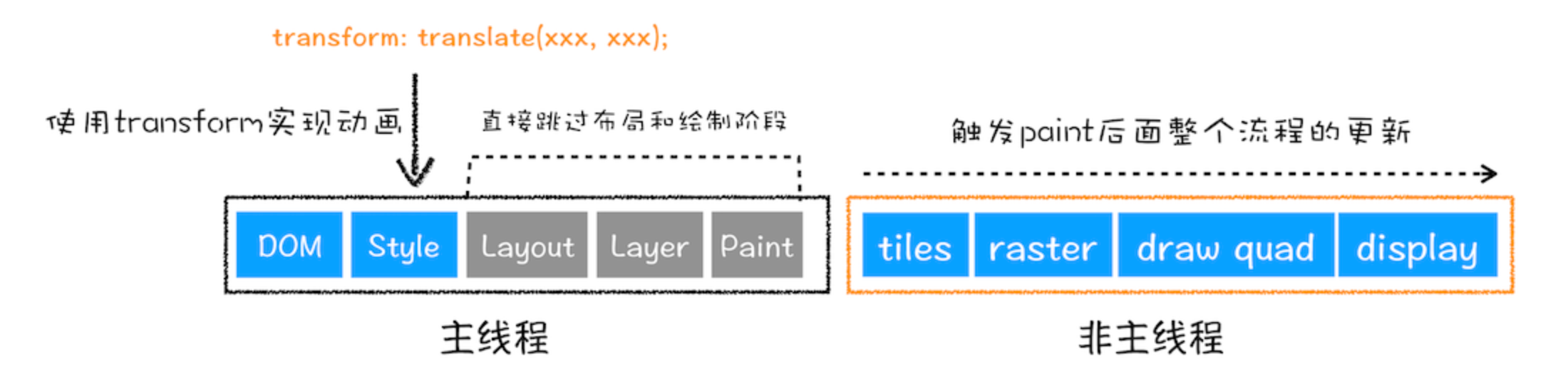
一些优化手段
- DOM样式读写分离
// 这样会触发2次重排+重绘
div.style.left = '10px';
div.style.top = '10px';
console.log(div.offsetLeft);
console.log(div.offsetTop);
// 前面两个写操作的渲染队列已被清空,console操作不会触发重排
div.style.left = '10px';
console.log(div.offsetLeft);
div.style.top = '10px';
console.log(div.offsetTop);- 样式集中改变,用class集中一次改变样式
- 避免使用table布局
- 缓存布局信息
- 离线改变dom -> 进阶版使用虚拟dom -> vue/react
- 先通过
display: none隐藏元素,修改完后再恢复 - 使用DocumentFragment - Web API 接口参考 | MDN先创建文档水平,操作完后再添加到文档,只会触发一次重排
- 复制节点,在副本上操作,再替换
- 先通过
- 固定或者绝对定位,
position: fixed/absolute - Debounce window resize事件
- 动画,启用GPU加速
- Canvas2D、CSS3转换
transition、3D变换transform、WebGL、视频
- Canvas2D、CSS3转换
- will-change 提前告诉浏览器需要做优化的元素