- 服务模型的变化:同步 -> 复制进程 -> 多线程 -> 事件驱动
- Node多进程
- Nodejs进程创建 child_process | Node.js API 文档
- Nodejs多进程架构模型
- cluster应用与原理
- 如何多个进程监听一个端口的
- 多个进程之间如何通信 (IPC)
- 句柄传递
- 如何守护进程(PM2)
- 同步
- 假设每次响应服务耗时N秒,QPS为1/N
- 复制进程
- N 个连接启动N个进程来服务
- 缺点:复制进程内部状态带来浪费,并发过高时内存随着进程数增长会耗尽
- 如果进程上限为M个,QPS为 M/N
- 多线程
- 线程之间共享数据,内存浪费的问题得到一定解决,还可以利用线程池减少创建和销毁线程的开销
- CPU核心一个时刻只能做一件事,操作系统需要通过时间切片的方法来不断切换线程的上下文,线程数量过多时,时间耗在上下文切换
- 事件驱动
- 基于事件驱动的单线程,避免了不必要的内存开销和上下文切换开销,可伸缩性比较高,影响性能的点在于CPU的计算能力
- 核心:多核CPU利用率不足
// master.ts
const path = require('path');
const { fork } = require('child_process');
const numCPUs = require('os').cpus().length;
for (let i = 0; i < numCPUs; i++) {
fork(path.resolve(__dirname, './worker.ts'));
}// worker.ts
const http = require('http');
const PORT = Math.round(8001 + Math.random() * 1000);
http.createServer((req, res) => {
res.writeHead(200);
res.end(`hello world, I'm worker with pid: ${process.pid}, port: ${PORT} \n`);
}).listen(PORT);
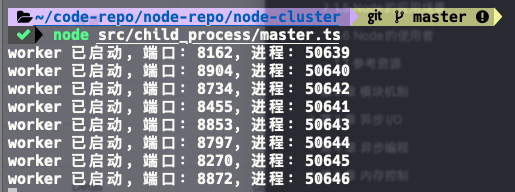
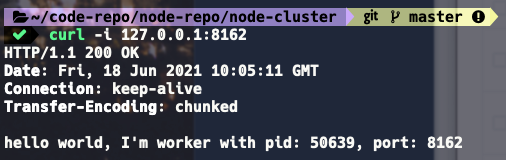
console.log(`worker 已启动, 端口:${PORT}, 进程:${process.pid}`);启动服务,然后访问其中一个子进程监听的端口
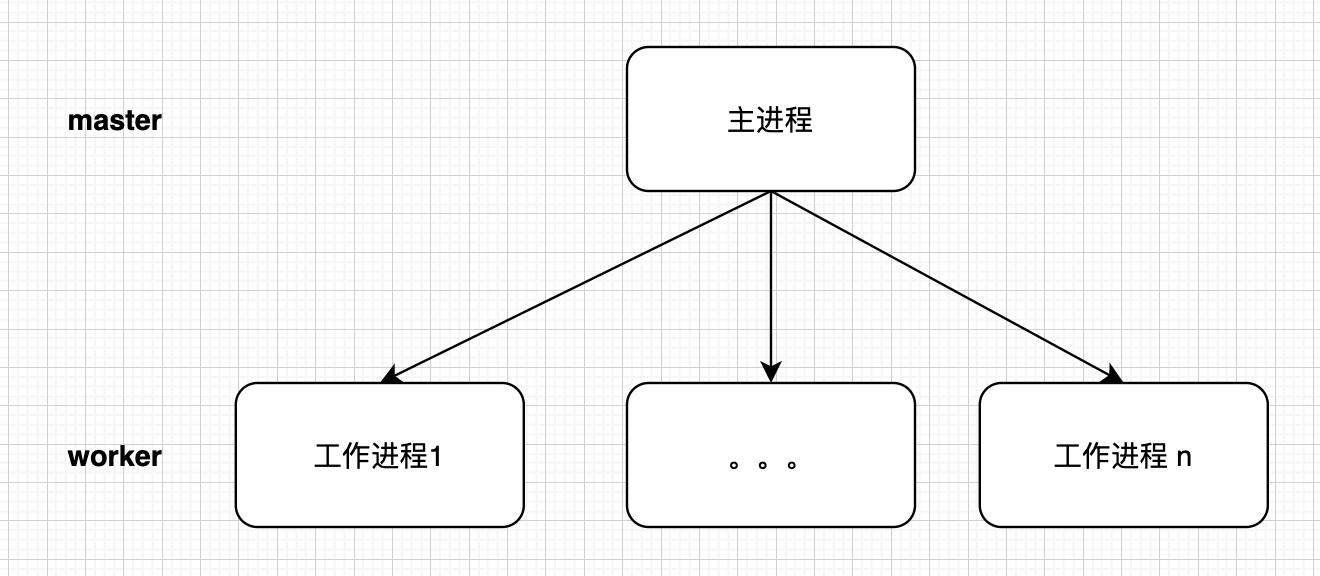
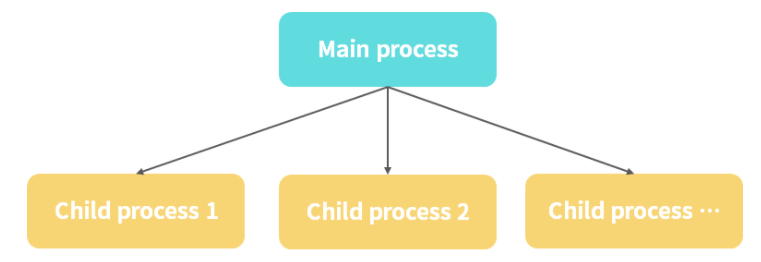
典型的 【Master-Worker】 模式,也叫主从模式
Child process | Node.js v16.3.0 Documentation child_process 子进程 | Node.js API 文档
master和worker之间可以利用IPC进行通信,通过process.on('message')和 process.send()
// master.ts
const path = require('path');
const { fork } = require('child_process');
const numCPUs = require('os').cpus().length;
for (let i = 0; i < numCPUs; i++) {
const worker = fork(path.resolve(__dirname, './worker.ts'));
worker.on('message', msg => {
console.log(`master get message from worker: ${msg}`);
});
worker.send('我是爸爸');
}// wrker.ts
const http = require('http');
const PORT = Math.round(8001 + Math.random() * 1000);
http.createServer((req, res) => {
res.writeHead(200);
res.end(`hello world, I'm worker with pid: ${process.pid}, port: ${PORT} \n`);
}).listen(PORT);
console.log(`worker 已启动, 端口:${PORT}, 进程:${process.pid}`);
process.on('message', msg => {
console.log(`worker get message from master: ${msg}`);
});
process.send(`${PORT} ready`);上面是主进程与子进程之间的通信,那么子进程与子进程之间呢? Node Cluster Workers IPC
cluster | Node.js API 文档
为了充分利用主机的多核CPU能力,Node 提供了cluster模式用于实现多进程分发策略
其实就是上面的官方封装版
有两种实现模式
- 主进程监听一个端口,子进程不监听端口,通过主进程分发请求到子进程 (cluster模式的实现)
主进程与子进程分别监听不同端口,通过主进程分发请求到子进程
const cluster = require('cluster');
const http = require('http');
const numCPUs = require('os').cpus().length;
if (cluster.isMaster) {
console.log(`主进程 ${process.pid} 正在运行`);
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on('exit', (worker, code, signal) => {
console.log(`工作进程 ${worker.process.pid} 已退出`);
});
} else {
http.createServer((req, res) => {
res.writeHead(200);
res.end(`hello world, start with cluster ${process.pid} \n`);
}).listen(8000);
console.log(`工作进程 ${process.pid} 已启动`);
}- 先判断是否主进程,是则创建具体的http服务
- 如果是子进程,则使用
cluster.fork()创建子进程
启动成功后,再通过curl -i http://127.0.0.1:8000多次访问,后面的进程ID比较有规律,都是我们fork出来的子进程的ID
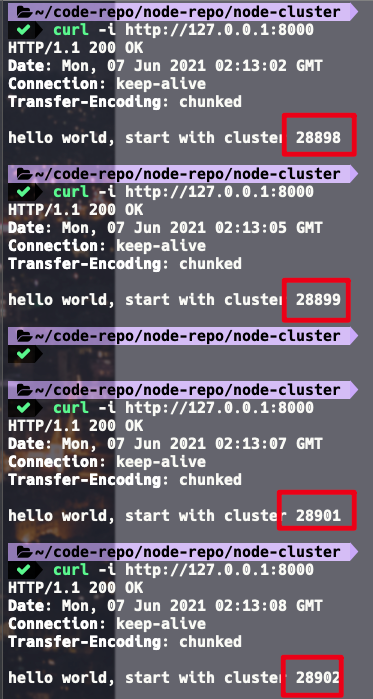
对比child_process和cluster的实现,有一个很大的区别
- child_process的实现,每个worker监听单独的接口
- cluster模式只由master监听一个端口,再转发给所有worker
那么,围绕下面3个问题出发,需要从源码找一下答案
- Node.js 的 cluster 是如何做到多个进程监听一个端口的
- 多个进程之间如何通信
- Node.js 是如何进行负载均衡请求分发的(RoundRobin)
看cluster的入口
// lib/cluster.js
'use strict';
const childOrPrimary = 'NODE_UNIQUE_ID' in process.env ? 'child' : 'primary';
module.exports = require(`internal/cluster/${childOrPrimary}`);- 如果没有设置过进程环境变量
NODE_UNIQUE_ID(cluster实现里的一个自增id),则为master进程(第一次调用) - 否则为子进程
分部require不同的文件
lib/internal/cluster/primary.jslib/internal/cluster/child.js
先看master的创建过程,调用cluster.fork时首先调用了cluster.setupPrimary方法,通过全局变量initialized来区分是否首次
cluster.setupPrimary = function(options) {
// ...
// 通过全局变量来区分是否首次创建
if (initialized === true)
return process.nextTick(setupSettingsNT, settings);
initialized = true;
//...看cluster.fork具体实现
cluster.fork = function(env) {
// 1、创建主进程,
cluster.setupPrimary();
const id = ++ids;
// 2、创建 worker 子进程,最终是通过 `child_process` 来创建子进程
const workerProcess = createWorkerProcess(id, env);
const worker = new Worker({
id: id,
process: workerProcess
});
worker.on('message', function(message, handle) {
cluster.emit('message', this, message, handle);
});
// ...
process.nextTick(emitForkNT, worker);
cluster.workers[worker.id] = worker;
return worker;
};- 在最初我们写的初始化代码中,调用了
numCPUs次cluster.fork方法,通过createWorkerProcess创建了numCPUs个子进程,本质上是调用child_process.fork child_process.fork()的时候会重新运行 node 的启动命令,这时候就会重新调用根目录下的lib/cluster.js来启动新实例- 由于
cluster.isMaster为false,因此调用lib/internal/cluster/child.js模块 - 由于是worker进程,最顶部的代码开始执行创建 http 服务的逻辑
- (这段看后面)
在http服务中虽然是启动了监听端口,由于监听端口的方法被重写了,因此只是向主进程发送了一个消息,告诉父进程可以向我发送消息了,因此可以一个端口多个进程来服务
if (cluster.isMaster) {
// ...
} else {
http.createServer((req, res) => {
res.writeHead(200);
res.end(`hello world, start with cluster ${process.pid} \n`);
}).listen(8000);
console.log(`工作进程 ${process.pid} 已启动`);
}在master的server监听了具体的端口,重点在于 server.listen方法,代码在lib/net.js
Server.prototype.listen 重点调用了 listenInCluster 方法
function listenInCluster(server, address, port, addressType,
backlog, fd, exclusive, flags) {
exclusive = !!exclusive;
if (cluster === undefined) cluster = require('cluster');
// 1、如果是主进程,开始真实监听端口启动服务
if (cluster.isPrimary || exclusive) {
// Will create a new handle
// _listen2 sets up the listened handle, it is still named like this
// to avoid breaking code that wraps this method
server._listen2(address, port, addressType, backlog, fd, flags);
return;
}
const serverQuery = {
address: address,
port: port,
addressType: addressType,
fd: fd,
flags,
};
// 2、非主进程,调用cluster._getServer
// Get the primary's server handle, and listen on it
cluster._getServer(server, serverQuery, listenOnPrimaryHandle);
function listenOnPrimaryHandle(err, handle) {
// ...
}
}重点看看子进程调用的cluster._getServer方法
// 定义在`lib/internal/cluster/child.js`模块
obj.once('listening', () => {
cluster.worker.state = 'listening';
const address = obj.address();
message.act = 'listening';
message.port = (address && address.port) || options.port;
send(message);
});cluster._getServer主要做了两件事来进行请求转发
- 向master进程注册该worker,若master进程是第一次接收到监听此端口/描述符下的worker,则起一个内部TCP服务器,来承担监听该端口/描述符的职责,随后在master中记录下该worker
- Hack掉worker进程中的net.Server实例的listen方法里监听端口/描述符的部分,使其不再承担该职责()
总结一下cluster的原理:
- cluster 模块应用
child_process来创建子进程,子进程通过复写掉cluster._getServer方法,从而在 server.listen 来保证只有主进程监听端口,主子进程通过 IPC 进行通信 - 其次主进程根据平台或者协议不同,应用两种不同模块
round_robin_handle和shared_handle进行请求分发给子进程处理
参考 《深入浅出 Node.js 》9.2.3 句柄传递
如果多个进程监听同一个端口,会抛出EADDRINUSE异常,说明端口被占用,新的进程不能继续监听同一个端口
通过master进程统一监听端口然后代理转发给子进程的方式,解决了端口不能重复监听的问题,甚至还可以做适当的负载均衡,但是新的问题来了
- 每个进程接收到一个连接,会用掉一个文件描述符
- 客户端连接到master进程,master进程连接到子进程,需要用掉2个文件描述符
- 操作系统的文件描述符是有限的,以上方案浪费了一倍数量,影响了系统的扩展能力
为了解决这个问题,Node引入了进程间发送句柄的能力,send方法除了能通过IPC发送数据,还能发送句柄(第二个参数)
child.send(message, [sendHandle])句柄是一种可以用来标识资源的引用,内部包含了指向对象的文件描述符,可以用来标识的类型有服务器端socket对象、客户端socket对象、 UDP套接字、管道等
发送句柄可以直接去掉代理方案,让主进程直接将socket发送给子进程,主进程发送完句柄后,可以关闭监听端口,由子进程自行监听端口
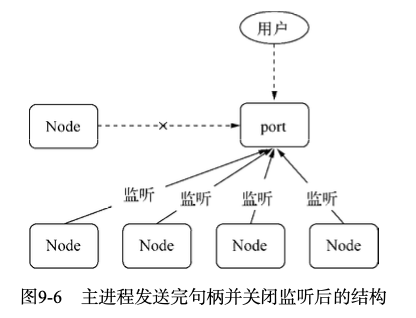
这种结构下,多个子进程同时监听同一个端口,再也没EADDRINUSE异常了
这个问题是怎么被解决的?句柄发送真的相当于将服务器对象发送给子进程了吗?
实际上Node进程之间只有消息传递,不会真正传递对象,句柄中的文件描述符实质上是一个整数值,子进程可以通过message.type+文件描述符还原出真正的对象
那端口是如何共同监听的?
在独立启动的进程中,TCP服务器端socket套接字的文件描述符并不相同,所以监听相同端口时会失败。但对于send()发送的句柄还原出来的服务而言,它们的文件描述符是相同的,所以监听相同端口不会引起异常
对于Node这种多个子进程监听相同端口的情况,文件描述符同一时间只能被某个进程所用,也就是说对于同一请求,只有一个幸运的子进程能够抢到连接,只有它能为请求提供服务,这是一种抢占式的进程服务
Node.js V0.12新特性之Cluster轮转法负载均衡-InfoQ Node负载均衡,Node 核心开发者的文章 nodejs负载均衡(一):服务负载均衡 - 知乎 服务器集群和Node本身集群的架构 nodejs负载均衡(二):RPC负载均衡 - 知乎
能读到这里,那么对守护进程应该有些感觉了
- 对于子进程:父进程监听子进程退出事件,适当fork新的子进程
那如果父进程崩了呢?谁来重启父进程
pm2、docker走起~
-
进程与线程的一个简单解释 - 阮一峰的网络日志 文章以工厂/车间/工人来类比进程/线程之间的关系,可作为入门理解,但真正精彩的内容在评论区
-
Node.js 进阶之进程与线程-五月君 五月君的
-
cluster是怎样开启多进程的,并且一个端口可以被多个 进程监听吗?_包磊磊的博客-CSDN博客 比较深入代码细节,有比较多实现demo
-
Node.js进阶:cluster模块深入剖析 端口转发那一节流程图画的好
-
深入浅出 Node.js Cluster 宏观层面解释,不读代码
-
淘系前端团队- 当我们谈论 cluster 时我们在谈论什么(下) 比较久的文章,但依然是精华
Node.js 多线程 —— worker_threads 初体验 | Sukka’s Blog
- 以下偏源码
- 【nodejs原理&源码赏析(4)】深度剖析cluster模块源码与node.js多进程(上) - 大史不说话 - 博客园
- 【nodejs原理&源码赏析(5)】net模块与通讯的实现 - 大史不说话 - 博客园
- Nodejs cluster模块深入探究 - SegmentFault 思否
- 源码分析Node的Cluster模块-阿里云开发者社区
- 通过Node.js的Cluster模块源码,深入PM2原理 - SegmentFault 思否
- 句柄是什么? - 知乎 读端口转发时辅助理解
- 子进程 | Node.js 中文文档 | Node.js 中文网
- 浅析 NodeJS 多进程和集群
- deep-into-node/chapter4-1.md at master · yjhjstz/deep-into-node · GitHub