![]()



Docs | Discord | Twitter | LinkedIn
Albumentations is a Python library for image augmentation. Image augmentation is used in deep learning and computer vision tasks to increase the quality of trained models. The purpose of image augmentation is to create new training samples from the existing data.
Here is an example of how you can apply some pixel-level augmentations from Albumentations to create new images from the original one:

- Complete Computer Vision Support: Works with all major CV tasks including classification, segmentation (semantic & instance), object detection, and pose estimation.
- Simple, Unified API: One consistent interface for all data types - RGB/grayscale/multispectral images, masks, bounding boxes, and keypoints.
- Rich Augmentation Library: 70+ high-quality augmentations to enhance your training data.
- Fast: Consistently benchmarked as the fastest augmentation library, with optimizations for production use.
- Deep Learning Integration: Works with PyTorch, TensorFlow, and other frameworks. Part of the PyTorch ecosystem.
- Created by Experts: Built by developers with deep experience in computer vision and machine learning competitions.
Albumentations thrives on developer contributions. We appreciate our sponsors who help sustain the project's infrastructure.
| 🏆 Gold Sponsors |
|---|
| Your company could be here |
| 🥈 Silver Sponsors |
|---|
 |
| 🥉 Bronze Sponsors |
|---|
 |
Your sponsorship is a way to say "thank you" to the maintainers and contributors who spend their free time building and maintaining Albumentations. Sponsors are featured on our website and README. View sponsorship tiers on GitHub Sponsors
- Albumentations
- Why Albumentations
- Community-Driven Project, Supported By
- Table of contents
- Authors
- Installation
- Documentation
- A simple example
- Getting started
- Who is using Albumentations
- List of augmentations
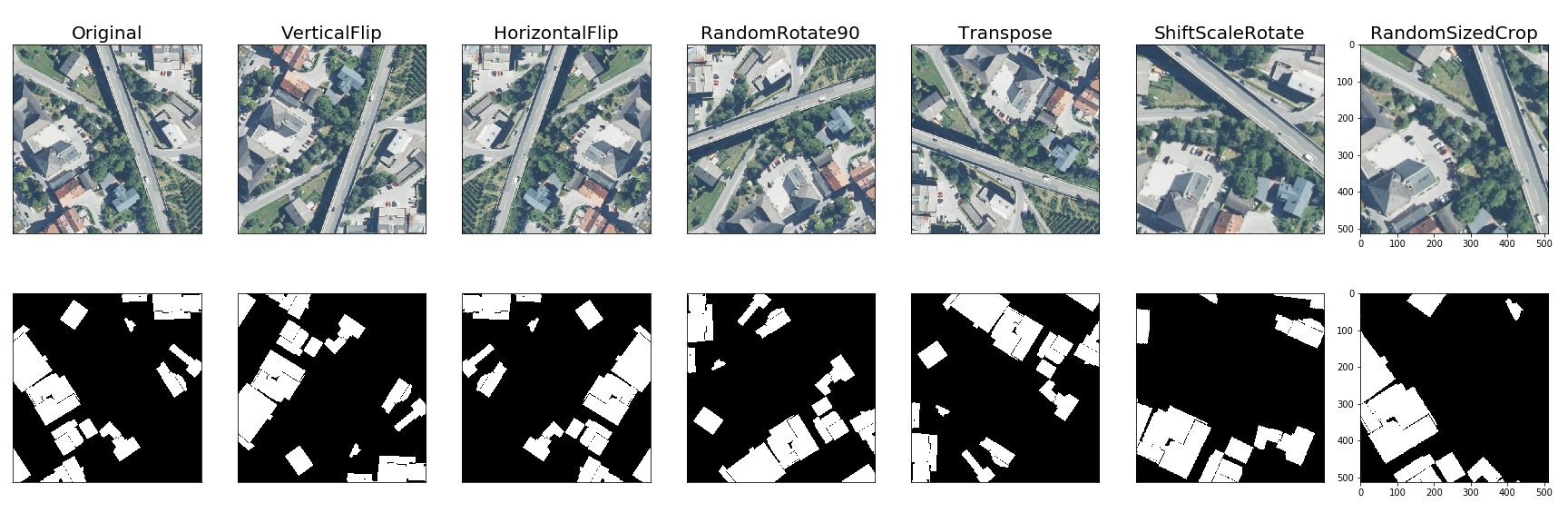
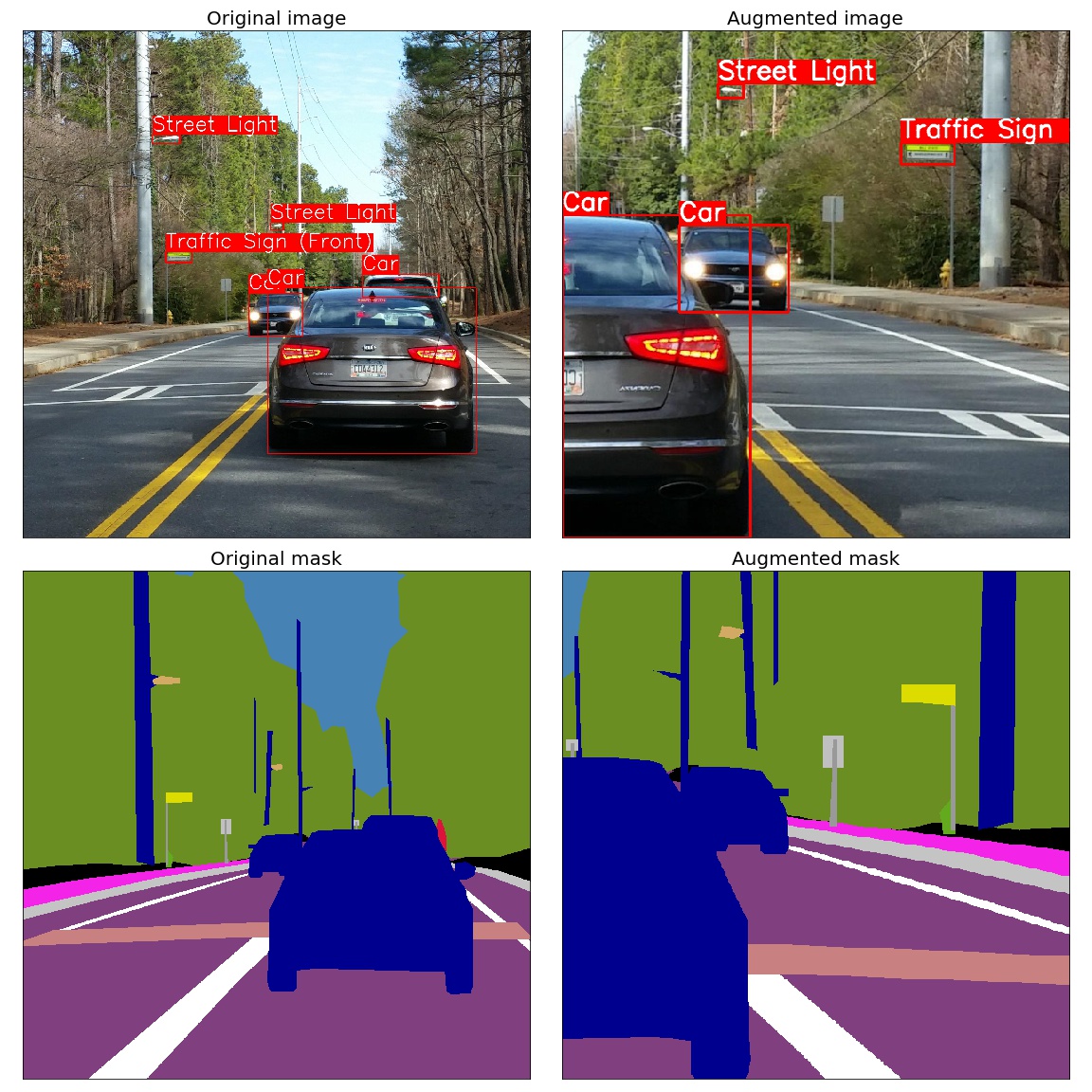
- A few more examples of augmentations
- Benchmarking results
- Performance Comparison
- Contributing
- Community
- Citing
Vladimir I. Iglovikov | Kaggle Grandmaster
Mikhail Druzhinin | Kaggle Expert
Alexander Buslaev | Kaggle Master
Eugene Khvedchenya | Kaggle Grandmaster
Albumentations requires Python 3.9 or higher. To install the latest version from PyPI:
pip install -U albumentationsOther installation options are described in the documentation.
The full documentation is available at https://albumentations.ai/docs/.
import albumentations as A
import cv2
# Declare an augmentation pipeline
transform = A.Compose([
A.RandomCrop(width=256, height=256),
A.HorizontalFlip(p=0.5),
A.RandomBrightnessContrast(p=0.2),
])
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("image.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = transform(image=image)
transformed_image = transformed["image"]Please start with the introduction articles about why image augmentation is important and how it helps to build better models.
If you want to use Albumentations for a specific task such as classification, segmentation, or object detection, refer to the set of articles that has an in-depth description of this task. We also have a list of examples on applying Albumentations for different use cases.
We have examples of using Albumentations along with PyTorch and TensorFlow.
Check the online demo of the library. With it, you can apply augmentations to different images and see the result. Also, we have a list of all available augmentations and their targets.














Pixel-level transforms will change just an input image and will leave any additional targets such as masks, bounding boxes, and keypoints unchanged. For volumetric data (volumes and 3D masks), these transforms are applied independently to each slice along the Z-axis (depth dimension), maintaining consistency across the volume. The list of pixel-level transforms:
- AdditiveNoise
- AdvancedBlur
- AutoContrast
- Blur
- CLAHE
- ChannelDropout
- ChannelShuffle
- ChromaticAberration
- ColorJitter
- Defocus
- Downscale
- Emboss
- Equalize
- FDA
- FancyPCA
- FromFloat
- GaussNoise
- GaussianBlur
- GlassBlur
- HEStain
- HistogramMatching
- HueSaturationValue
- ISONoise
- Illumination
- ImageCompression
- InvertImg
- MedianBlur
- MotionBlur
- MultiplicativeNoise
- Normalize
- PixelDistributionAdaptation
- PlanckianJitter
- PlasmaBrightnessContrast
- PlasmaShadow
- Posterize
- RGBShift
- RandomBrightnessContrast
- RandomFog
- RandomGamma
- RandomGravel
- RandomRain
- RandomShadow
- RandomSnow
- RandomSunFlare
- RandomToneCurve
- RingingOvershoot
- SaltAndPepper
- Sharpen
- ShotNoise
- Solarize
- Spatter
- Superpixels
- TemplateTransform
- TextImage
- ToFloat
- ToGray
- ToRGB
- ToSepia
- UnsharpMask
- ZoomBlur
Spatial-level transforms will simultaneously change both an input image as well as additional targets such as masks, bounding boxes, and keypoints. For volumetric data (volumes and 3D masks), these transforms are applied independently to each slice along the Z-axis (depth dimension), maintaining consistency across the volume. The following table shows which additional targets are supported by each transform:
- Volume: 3D array of shape (D, H, W) or (D, H, W, C) where D is depth, H is height, W is width, and C is number of channels (optional)
- Mask3D: Binary or multi-class 3D mask of shape (D, H, W) where each slice represents segmentation for the corresponding volume slice
| Transform | Image | Mask | BBoxes | Keypoints | Volume | Mask3D |
|---|---|---|---|---|---|---|
| Affine | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| AtLeastOneBBoxRandomCrop | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| BBoxSafeRandomCrop | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| CenterCrop | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| CoarseDropout | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| ConstrainedCoarseDropout | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Crop | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| CropAndPad | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| CropNonEmptyMaskIfExists | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| D4 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| ElasticTransform | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Erasing | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| FrequencyMasking | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| GridDistortion | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| GridDropout | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| GridElasticDeform | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| HorizontalFlip | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Lambda | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| LongestMaxSize | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| MaskDropout | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Morphological | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| NoOp | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| OpticalDistortion | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| OverlayElements | ✓ | ✓ | ||||
| Pad | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| PadIfNeeded | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Perspective | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| PiecewiseAffine | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| PixelDropout | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| RandomCrop | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| RandomCropFromBorders | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| RandomCropNearBBox | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| RandomGridShuffle | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| RandomResizedCrop | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| RandomRotate90 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| RandomScale | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| RandomSizedBBoxSafeCrop | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| RandomSizedCrop | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Resize | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Rotate | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| SafeRotate | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| ShiftScaleRotate | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| SmallestMaxSize | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| ThinPlateSpline | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| TimeMasking | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| TimeReverse | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Transpose | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| VerticalFlip | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| XYMasking | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
3D transforms operate on volumetric data and can modify both the input volume and associated 3D mask.
Where:
- Volume: 3D array of shape (D, H, W) or (D, H, W, C) where D is depth, H is height, W is width, and C is number of channels (optional)
- Mask3D: Binary or multi-class 3D mask of shape (D, H, W) where each slice represents segmentation for the corresponding volume slice
| Transform | Volume | Mask3D | Keypoints |
|---|---|---|---|
| CenterCrop3D | ✓ | ✓ | ✓ |
| CoarseDropout3D | ✓ | ✓ | ✓ |
| CubicSymmetry | ✓ | ✓ | ✓ |
| Pad3D | ✓ | ✓ | ✓ |
| PadIfNeeded3D | ✓ | ✓ | ✓ |
| RandomCrop3D | ✓ | ✓ | ✓ |


- Platform: macOS-15.1-arm64-arm-64bit
- Processor: arm
- Python Version: 3.12.8
- Number of images: 2000
- Runs per transform: 5
- Max warmup iterations: 1000
- albumentations: 2.0.2
- augly: 1.0.0
- imgaug: 0.4.0
- kornia: 0.8.0
- torchvision: 0.20.1
Number shows how many uint8 images per second can be processed on one CPU thread. Larger is better.
| Transform | albumentations 2.0.2 |
augly 1.0.0 |
imgaug 0.4.0 |
kornia 0.8.0 |
torchvision 0.20.1 |
|---|---|---|---|---|---|
| Resize | 3662 ± 54 | 1083 ± 21 | 2995 ± 70 | 645 ± 13 | 260 ± 9 |
| RandomCrop128 | 116784 ± 2222 | 45395 ± 934 | 21408 ± 622 | 2946 ± 42 | 31450 ± 249 |
| HorizontalFlip | 12649 ± 238 | 8808 ± 1012 | 9599 ± 495 | 1297 ± 13 | 2486 ± 107 |
| VerticalFlip | 24989 ± 904 | 16830 ± 1653 | 19935 ± 1708 | 2872 ± 37 | 4696 ± 161 |
| Rotate | 3066 ± 83 | 1739 ± 105 | 2574 ± 10 | 256 ± 2 | 258 ± 4 |
| Affine | 1503 ± 29 | - | 1328 ± 16 | 248 ± 6 | 188 ± 2 |
| Perspective | 1222 ± 16 | - | 908 ± 8 | 154 ± 3 | 147 ± 5 |
| Elastic | 359 ± 7 | - | 395 ± 14 | 1 ± 0 | 3 ± 0 |
| ChannelShuffle | 8162 ± 180 | - | 1252 ± 26 | 1328 ± 44 | 4417 ± 234 |
| Grayscale | 37212 ± 1856 | 6088 ± 107 | 3100 ± 24 | 1201 ± 52 | 2600 ± 23 |
| GaussianBlur | 943 ± 11 | 387 ± 4 | 1460 ± 23 | 254 ± 5 | 127 ± 4 |
| GaussianNoise | 234 ± 7 | - | 263 ± 9 | 125 ± 1 | - |
| Invert | 35494 ± 17186 | - | 3682 ± 79 | 2881 ± 43 | 4244 ± 30 |
| Posterize | 14146 ± 1381 | - | 3111 ± 95 | 836 ± 30 | 4247 ± 26 |
| Solarize | 12920 ± 1097 | - | 3843 ± 80 | 263 ± 6 | 1032 ± 14 |
| Sharpen | 2375 ± 38 | - | 1101 ± 30 | 201 ± 2 | 220 ± 3 |
| Equalize | 1303 ± 64 | - | 814 ± 11 | 306 ± 1 | 795 ± 3 |
| JpegCompression | 1354 ± 23 | 1202 ± 19 | 687 ± 26 | 120 ± 1 | 889 ± 7 |
| RandomGamma | 12631 ± 1159 | - | 3504 ± 72 | 230 ± 3 | - |
| MedianBlur | 1259 ± 8 | - | 1152 ± 14 | 6 ± 0 | - |
| MotionBlur | 3608 ± 18 | - | 928 ± 37 | 159 ± 1 | - |
| CLAHE | 649 ± 13 | - | 555 ± 14 | 165 ± 3 | - |
| Brightness | 11254 ± 418 | 2108 ± 32 | 1076 ± 32 | 1127 ± 27 | 854 ± 13 |
| Contrast | 11255 ± 242 | 1379 ± 25 | 717 ± 5 | 1109 ± 41 | 602 ± 13 |
| CoarseDropout | 15760 ± 594 | - | 1190 ± 22 | - | - |
| Blur | 7403 ± 114 | 386 ± 4 | 5381 ± 125 | 265 ± 11 | - |
| Saturation | 1581 ± 127 | - | 495 ± 3 | 155 ± 2 | - |
| Shear | 1336 ± 18 | - | 1244 ± 14 | 261 ± 1 | - |
| ColorJitter | 968 ± 52 | 418 ± 5 | - | 104 ± 4 | 87 ± 1 |
| RandomResizedCrop | 4521 ± 17 | - | - | 661 ± 16 | 837 ± 37 |
| Pad | 31866 ± 530 | - | - | - | 4889 ± 183 |
| AutoContrast | 1534 ± 115 | - | - | 541 ± 8 | 344 ± 1 |
| Normalize | 1797 ± 190 | - | - | 1251 ± 14 | 1018 ± 7 |
| Erasing | 25411 ± 5727 | - | - | 1210 ± 27 | 3577 ± 49 |
| CenterCrop128 | 119630 ± 3484 | - | - | - | - |
| RGBShift | 3526 ± 128 | - | - | 896 ± 9 | - |
| PlankianJitter | 3351 ± 42 | - | - | 2150 ± 52 | - |
| HSV | 1277 ± 91 | - | - | - | - |
| ChannelDropout | 10988 ± 243 | - | - | 2283 ± 24 | - |
| LinearIllumination | 462 ± 52 | - | - | 708 ± 6 | - |
| CornerIllumination | 464 ± 45 | - | - | 452 ± 3 | - |
| GaussianIllumination | 670 ± 91 | - | - | 436 ± 13 | - |
| Hue | 1846 ± 193 | - | - | 150 ± 1 | - |
| PlasmaBrightness | 163 ± 1 | - | - | 85 ± 1 | - |
| PlasmaContrast | 138 ± 4 | - | - | 84 ± 0 | - |
| PlasmaShadow | 190 ± 3 | - | - | 216 ± 5 | - |
| Rain | 2121 ± 64 | - | - | 1493 ± 9 | - |
| SaltAndPepper | 2233 ± 35 | - | - | 480 ± 12 | - |
| Snow | 588 ± 32 | - | - | 143 ± 1 | - |
| OpticalDistortion | 687 ± 38 | - | - | 174 ± 0 | - |
| ThinPlateSpline | 75 ± 5 | - | - | 58 ± 0 | - |
To create a pull request to the repository, follow the documentation at CONTRIBUTING.md
If you find this library useful for your research, please consider citing Albumentations: Fast and Flexible Image Augmentations:
@Article{info11020125,
AUTHOR = {Buslaev, Alexander and Iglovikov, Vladimir I. and Khvedchenya, Eugene and Parinov, Alex and Druzhinin, Mikhail and Kalinin, Alexandr A.},
TITLE = {Albumentations: Fast and Flexible Image Augmentations},
JOURNAL = {Information},
VOLUME = {11},
YEAR = {2020},
NUMBER = {2},
ARTICLE-NUMBER = {125},
URL = {https://www.mdpi.com/2078-2489/11/2/125},
ISSN = {2078-2489},
DOI = {10.3390/info11020125}
}