Home
Timely dataflow is a data-parallel dataflow abstraction intended for low-latency cyclic dataflow graphs. The main idea in timely dataflow is to augment the messages in a possibly cyclic dataflow graph with logical timestamps, allowing for a logically acyclic interpretation of the dataflow graph. You get all the good properties of acyclic graphs (scheduling, resource management, determinism) without compromising on the efficiency and expressive capabilities of cyclic graphs.
As an example, consider a streaming computation on graph-structured data: each second a new set of edges (source, target) arrive, and perhaps some old edges depart (perhaps they age-out). While we can produce simple statistics over this stream, for example the degree distribution of the vertices, things get a lot more complicated if we want to have an iterative subcomputation.
Imagine you would like your stream of edges to enter an iterative subcomputation. Determining the connected-component structure of the graph using label propagation is a commonly used example. In this case, we get a dataflow graph that looks roughly like this:
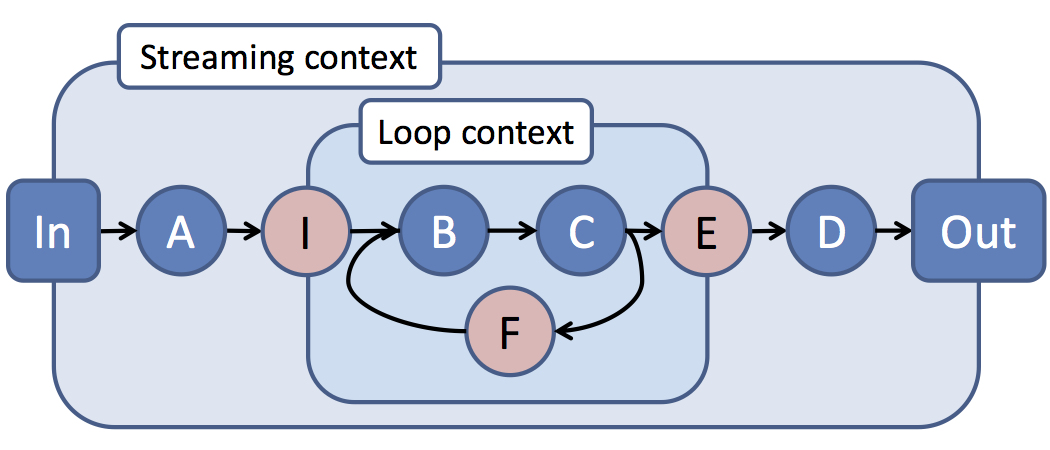
The typical challenge with this type of graph is that the existing progress tracking techniques (restricted to those we are aware of) will either:
- serialize the execution of the iterations, limiting inter-epoch parallelism,
- conflate epochs and iterations, producing semantically unclear outputs,
- unroll any loops, limiting the efficient implementation of vertices in the loop,
Timely dataflow deals with this type of graph by augmenting messages with (epoch, iteration) logical timestamps, allowing the dataflow vertex implementations to produce semantically clear outputs despite overlapped arrival of data.
This project is an attempt at a flexible and modular implementation of timely dataflow in Rust. The only previous implementation of timely dataflow was in the Naiad project, which was a first cut, and from which we learned a great deal about how to improve.
The main contribution of this implementation is a hierarchical organization of dataflow subgraphs. Rather than a large but flat and unstructured graph, regions of the graph are grouped logically and their implementation is hidden behind a narrow interface. This abstraction provides a number of benefits:
- Subgraphs may measure progress using [nearly] arbitrary types and logic. Previously the logical timestamps needed to be homogenous, which restricted them to counting loop iterations (as the most important feature for Naiad).
- The progress-tracking communication and data-exchange can be restricted to smaller sets of workers at a finer granularity. Although Naiad could restrict the exchange of data manually, the progress-tracking logic could not take advantage of this and coordinate among fewer workers.
- Subgraphs may be implemented in other languages and on other runtimes. Progress-tracking is implemented through a very simple asynchronous protocol, and relies on no shared state or synchronization.
- The data plane is wholly decoupled from the progress-tracking protocol, allowing workers to exchange data through traditional in-memory structures, pipes, and network sockets, but also other media like file systems, shared resilient queues, and whatever comes along next.