We propose HQ-SAM2 to upgrade SAM2 to higher quality by extending our training strategy in HQ-SAM.
2024/11/17 -- HQ-SAM 2 is released
- A new suite of improved model checkpoints (denoted as HQ-SAM 2, beta-version) are released. See Model Description for details.
HQ-SAM 2 needs to be installed first before use. The code requires python>=3.10, as well as torch>=2.3.1 and torchvision>=0.18.1. Please follow the instructions here to install both PyTorch and TorchVision dependencies. You can install SAM 2 on a GPU machine using:
git clone https://github.com/SysCV/sam-hq.git
conda create -n sam_hq2 python=3.10 -y
conda activate sam_hq2
cd sam-hq/sam-hq2
pip install -e .If you are installing on Windows, it's strongly recommended to use Windows Subsystem for Linux (WSL) with Ubuntu.
To use the HQ-SAM 2 predictor and run the example notebooks, jupyter and matplotlib are required and can be installed by:
pip install -e ".[notebooks]"Note:
- It's recommended to create a new Python environment via Anaconda for this installation and install PyTorch 2.3.1 (or higher) via
pipfollowing https://pytorch.org/. If you have a PyTorch version lower than 2.3.1 in your current environment, the installation command above will try to upgrade it to the latest PyTorch version usingpip. - The step above requires compiling a custom CUDA kernel with the
nvcccompiler. If it isn't already available on your machine, please install the CUDA toolkits with a version that matches your PyTorch CUDA version. - If you see a message like
Failed to build the SAM 2 CUDA extensionduring installation, you can ignore it and still use SAM 2 (some post-processing functionality may be limited, but it doesn't affect the results in most cases).
Please see INSTALL.md for FAQs on potential issues and solutions.
First, we need to download a model checkpoint. All the model checkpoints can be downloaded by running:
cd checkpoints && \
./download_ckpts.sh && \
cd ..or individually from:
(note that these are the improved checkpoints denoted as SAM 2.1; see Model Description for details.)
Then HQ-SAM 2 can be used in a few lines as follows for image and video prediction.
HQ-SAM 2 has all the capabilities of HQ-SAM on static images, and we provide image prediction APIs that closely resemble SAM for image use cases. The SAM2ImagePredictor class has an easy interface for image prompting.
import torch
from sam2.build_sam import build_sam2
from sam2.sam2_image_predictor import SAM2ImagePredictor
# Baseline SAM2.1
# checkpoint = "./checkpoints/sam2.1_hiera_large.pt"
# model_cfg = "configs/sam2.1/sam2.1_hiera_l.yaml"
# Ours HQ-SAM 2
checkpoint = "./checkpoints/sam2.1_hq_hiera_large.pt"
model_cfg = "configs/sam2.1/sam2.1_hq_hiera_l.yaml"
predictor = SAM2ImagePredictor(build_sam2(model_cfg, checkpoint))
with torch.inference_mode(), torch.autocast("cuda", dtype=torch.bfloat16):
predictor.set_image(<your_image>)
masks, _, _ = predictor.predict(<input_prompts>, multimask_output=False)Please refer to the examples in python demo/demo_hqsam2.py for details on how to add click or box prompts.
Please refer to the examples in image_predictor_example.ipynb for static image use cases.
For promptable segmentation and tracking in videos, we provide a video predictor with APIs for example to add prompts and propagate masklets throughout a video. SAM 2 supports video inference on multiple objects and uses an inference state to keep track of the interactions in each video.
import torch
from sam2.build_sam import build_sam2_video_predictor
from sam2.build_sam import build_sam2_hq_video_predictor
# Baseline SAM2.1
# checkpoint = "./checkpoints/sam2.1_hiera_large.pt"
# model_cfg = "configs/sam2.1/sam2.1_hiera_l.yaml"
# predictor = build_sam2_video_predictor(model_cfg, checkpoint)
# Ours HQ-SAM 2
checkpoint = "./checkpoints/sam2.1_hq_hiera_large.pt"
model_cfg = "configs/sam2.1/sam2.1_hq_hiera_l.yaml"
predictor = build_sam2_hq_video_predictor(model_cfg, checkpoint)
with torch.inference_mode(), torch.autocast("cuda", dtype=torch.bfloat16):
state = predictor.init_state(<your_video>)
# add new prompts and instantly get the output on the same frame
frame_idx, object_ids, masks = predictor.add_new_points_or_box(state, <your_prompts>):
# propagate the prompts to get masklets throughout the video
for frame_idx, object_ids, masks in predictor.propagate_in_video(state):
...Please refer to the examples in video_predictor_example.ipynb for static image use cases.
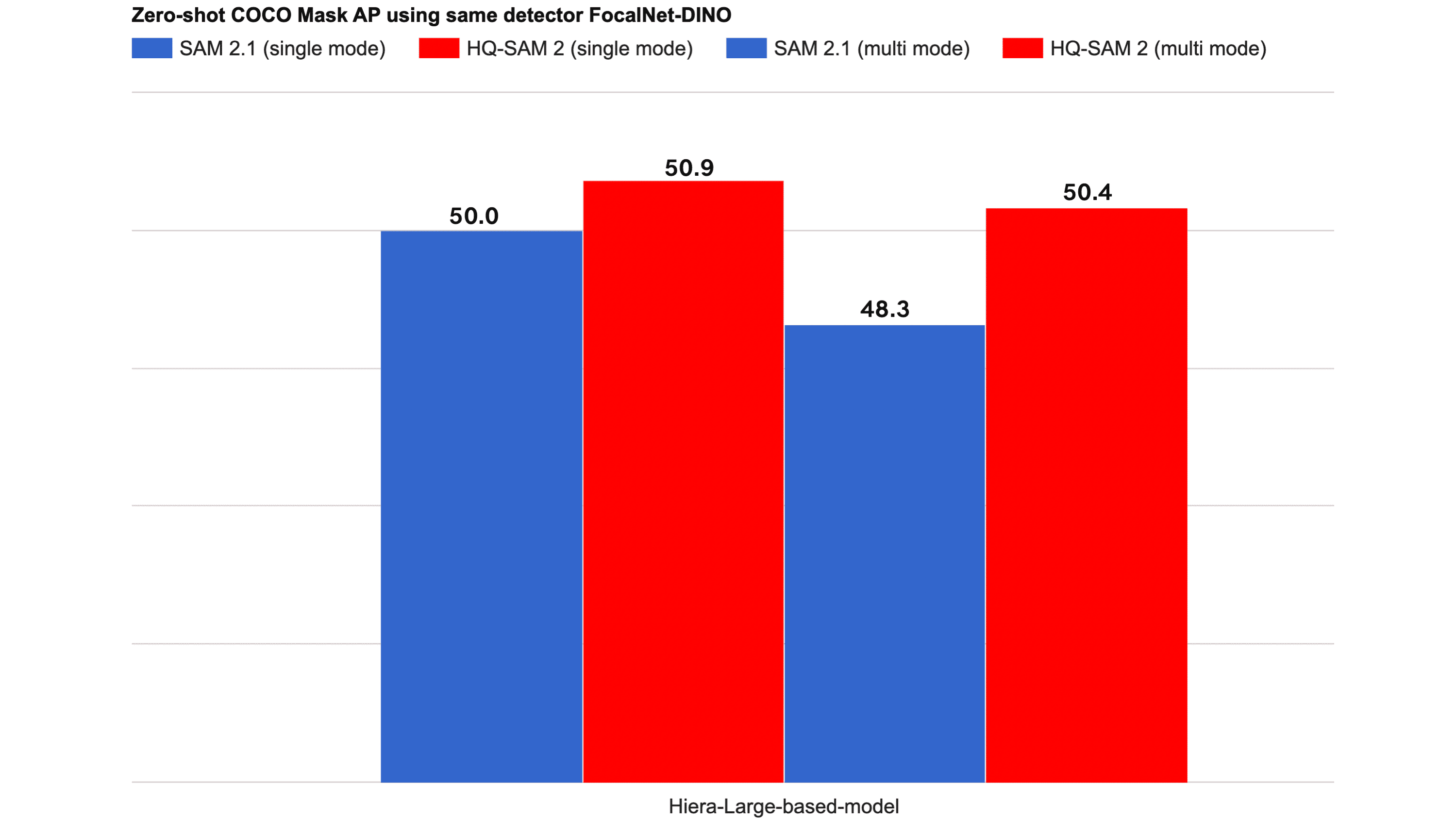
The table below shows the zero-shot image segmentation performance of SAM2.1 and HQ-SAM 2 on COCO (AP) using same bounding box detector from Focal-net DINO. The FPS speed of SAM2.1 and HQ-SAM 2 is on par.
| Model | Size (M) | Single Mode (AP) | Multi-Mode (AP) |
|---|---|---|---|
| sam2.1_hiera_large (config, checkpoint) |
224.4 | 50.0 | 48.3 |
| sam2.1_hq_hiera_large (config, checkpoint) |
224.7 | 50.9 | 50.4 |
The table below shows the zero-shot video object segmentation performance of SAM2.1 and HQ-SAM 2.
| Model | Size (M) | DAVIS val (J&F) | MOSE(J&F) |
|---|---|---|---|
| sam2.1_hiera_large (config, checkpoint) |
224.4 | 89.8 | 74.6 |
| sam2.1_hq_hiera_large (config, checkpoint) |
224.7 | 91.0 | 74.7 |
The HQ-SAM 2, SAM 2 model checkpoints, SAM 2 demo code (front-end and back-end), and SAM 2 training code are licensed under Apache 2.0, however the Inter Font and Noto Color Emoji used in the SAM 2 demo code are made available under the SIL Open Font License, version 1.1.
If you find HQ-SAM2 useful in your research or refer to the provided baseline results, please star ⭐ this repository and consider citing 📝:
@inproceedings{sam_hq,
title={Segment Anything in High Quality},
author={Ke, Lei and Ye, Mingqiao and Danelljan, Martin and Liu, Yifan and Tai, Yu-Wing and Tang, Chi-Keung and Yu, Fisher},
booktitle={NeurIPS},
year={2023}
}