Classification & Regression
RF 是基于 DT 进行了ensemble
小姐姐选完了备胎有些拿不准,纠集了几个闺蜜探讨一番,再得出最终结论。🤦♀️🙅♀️💁♀️🤷♀️ 这就是集群的智慧,能够尽最大程度消除个人bias (individual errors)。
Bagging就是这种集成算法最初的学名。采用自助采样法(bootstrap sampling)采样数据(有放回抽取若干个样本)。
Procedure:
- 给定包含m个样本的数据集,我们先随机取出一个样本放入采样集中,再把该样本放回初始数据集,使得下次采样时,样本仍可能被选中, 这样,经过m次随机采样操作,我们得到包含m个样本的采样集;
- 我们可以采样出T个含m个训练样本的采样集,然后基于每个采样集训练出一个基本学习器;
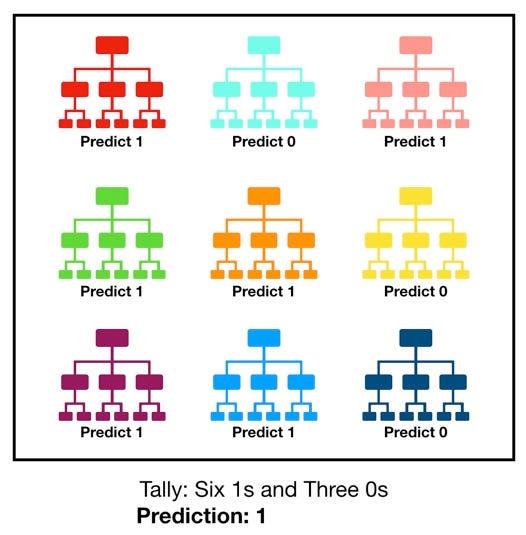
- 再将这些基本学习器进行结合。
- 结合使用简单投票法。(就是少数服从多数,票数一样就随机选)

Boosting也是一族集成算法,它引入了反馈控制的思想。
闺蜜A觉得男F不错,但是小姐姐觉得他有点矮,不符合自己175+的身高,那么闺蜜A下次挑选的时候就记住了姐妹的喜好。

Boosting族我们之后再详细介绍。
RF是Bagging的扩展变体,以决策树为基学习器。 Each individual tree in the random forest spits out a class prediction and the class with the most votes becomes our model’s prediction.
RF比Bagging更进一步在于随机属性选择:在随机森林中,对基决策树的每个节点,先从该节点的属性集合中随机选择一个包含k个属性的子集,然后再从这个子集中选择一个最优属性用于划分。 这里的参数k控制了随机性的引入程度。
闺蜜A负责找高、帅的,闺蜜B负责找有才、多金的......