分类算法
支持某项属性的事件发生得愈多,则该属性成立的可能性就愈大。
通俗来讲,Louis总做好事,你就会觉得他是个好人。
转换到数学语言就是:
在B事件发生的条件下A事件发生的条件概率,等于A事件发生条件下B事件发生的条件概率乘以A事件的概率,再除以B事件发生的概率。公式中,P(A)也叫做先验概率,P(A|B)叫做后验概率。严格地讲,贝叶斯公式至少应被称为“贝叶斯-拉普拉斯公式”。
我们解读一下,A 事件是Louis是好人, B是做好事
- 首先,在我们对这个人不了解的情况下,是不是好人还有待商榷,故先验概率
$P(A: Louis是好人)=0.5$ ; - 接下来,这个人做了好事,那么我们就可以藉此重新评估一下他的品质
$P(A: Louis是好人|B:做好事)$ ,也即是他做了好事的条件下,我们会不会认为他这个人有一点好呢? - 我们知道世界上所有人做好事和坏事的概率差不多是一定的,就定做
$P(B: 做好事)=0.5$ 吧。Louis总做好事,很少做坏事,$P(B: 做好事|A: Louis是好人)=0.8>0.5$ $$ \dfrac{P(B: 做好事|A: Louis是好人)}{P(B: 做好事)}=1.6>1 $$ - 上一步是在A: Louis是好人的条件下进行的,那么把我们对Louis的第一印象乘进去,即: $$ \dfrac{P(B: 做好事|A: Louis是好人)}{P(B: 做好事|A+\bar{A}: 好人加坏人)}\times P(A: Louis是好人)=0.8>0.5 $$ 可见,我们对Louis的印象有了明显的改观,并且通过不断地做好事,可以提高$P(B: 做好事|A: Louis是好人)$,进而提高我们认为Louis是好人的概率。
- 这意味着什么?意味着只要你持续帮助自己暗恋的小姐姐,那么你就可以得到好人卡啦!制胜之道呀,isn't it?
上面是一个single feature的例子,这样对一个人的认识过于片面,不足以让小姐姐动心,需要从多角度审视
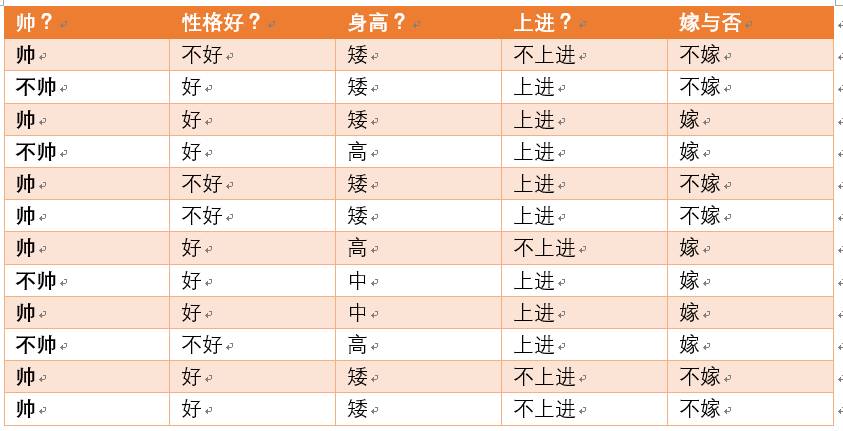
Problem occurs: 之前求一个$P(B: 做好事)$还好估计,现在特征这么多。帅包括{帅,不帅},性格包括{不好,好,爆好},身高包括{高,矮,中},上进包括{不上进,上进}四个特征排列一下就是2x3x3x2=36种,去哪里找那么多数据,即使阅人无数的妹子也不会都能遇到。这就引出了朴素的概念:
朴素贝叶斯算法假设各个特征之间相互独立
我们不需要知道$P(features)$,只需要知道

剩下的就和上一节一样了,具体的计算过程详见:带你理解朴素贝叶斯分类算法
def fit(self, X_train, Y_train):
self.X = X_train
self.y = Y_train
self.classes = np.unique(Y_train) # 从label中找出不同的类别
self.parameters = {}
for i, c in enumerate(self.classes):
# 计算每个种类的平均值,方差,先验概率
X_Index_c = self.X[np.where(Y_train == c)]
X_index_c_mean = np.mean(X_Index_c, axis=0, keepdims=True)
X_index_c_var = np.var(X_Index_c, axis=0, keepdims=True)
parameters = {"mean": X_index_c_mean, "var": X_index_c_var, "prior": X_Index_c.shape[0] / self.X.shape[0]}
self.parameters["class" + str(c)] = parameters