diff --git a/contrib/SegmentAnything/README.md b/contrib/SegmentAnything/README.md
index 7513f937b4..786d05ed3a 100644
--- a/contrib/SegmentAnything/README.md
+++ b/contrib/SegmentAnything/README.md
@@ -1,25 +1,24 @@
# Segment Anything with PaddleSeg
-## Reference
-
-> Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollár, Ross Girshick. [Segment Anything](https://ai.facebook.com/research/publications/segment-anything/).
-
## Contents
1. Overview
2. Performance
3. Try it by yourself with one line of code
+4. Reference
+
##  Overview
-We implemente the segment anything with the PaddlePaddle framework. **Segment Anything Model (SAM)** is a new task, model, and dataset for image segmentation. It can produce high quality object masks from different types of prompts including points, boxes, masks and text. Further, SAM can generate masks for all objects in whole image. It built a largest segmentation [dataset](https://segment-anything.com/dataset/index.html) to date (by far), with over 1 billion masks on 11M licensed and privacy respecting images. SAM has impressive zero-shot performance on a variety of tasks, even often competitive with or even superior to prior fully supervised results.
+We implemente the segment anything with the PaddlePaddle framework. **Segment Anything Model (SAM)** is a new task, model, and dataset for image segmentation. It built a largest segmentation [dataset](https://segment-anything.com/dataset/index.html) to date (by far), with over 1 billion masks on 11M licensed and privacy respecting images. Further, SAM can produce high quality object masks from different types of prompts including points, boxes, masks and text. SAM has impressive zero-shot performance on a variety of tasks, even often competitive with or even superior to prior fully supervised results. However, the SAM model based on text prompt is not released at the moment. Therefore, we use a combination of **SAM** and **CLIP** to calculate the similarity between the output masks and text prompt. In this way, you can use **text prompt** to segment anything. In addition, we also implement SAM that can generate masks for all objects in whole image.
+
-We provide the pretrained model parameters of PaddlePaddle format, including [vit_b](https://bj.bcebos.com/paddleseg/dygraph/paddlesegAnything/vit_b/model.pdparams), [vit_l](https://bj.bcebos.com/paddleseg/dygraph/paddlesegAnything/vit_l/model.pdparams) and [vit_h](https://bj.bcebos.com/paddleseg/dygraph/paddlesegAnything/vit_h/model.pdparams).
+We provide the pretrained model parameters of PaddlePaddle format, including [vit_b](https://bj.bcebos.com/paddleseg/dygraph/paddlesegAnything/vit_b/model.pdparams), [vit_l](https://bj.bcebos.com/paddleseg/dygraph/paddlesegAnything/vit_l/model.pdparams) and [vit_h](https://bj.bcebos.com/paddleseg/dygraph/paddlesegAnything/vit_h/model.pdparams). For text prompt, we also provide the [CLIP_ViT_B](https://bj.bcebos.com/paddleseg/dygraph/clip/vit_b_32_pretrain/clip_vit_b_32.pdparams) model parameters of PaddlePaddle format.
##
Overview
-We implemente the segment anything with the PaddlePaddle framework. **Segment Anything Model (SAM)** is a new task, model, and dataset for image segmentation. It can produce high quality object masks from different types of prompts including points, boxes, masks and text. Further, SAM can generate masks for all objects in whole image. It built a largest segmentation [dataset](https://segment-anything.com/dataset/index.html) to date (by far), with over 1 billion masks on 11M licensed and privacy respecting images. SAM has impressive zero-shot performance on a variety of tasks, even often competitive with or even superior to prior fully supervised results.
+We implemente the segment anything with the PaddlePaddle framework. **Segment Anything Model (SAM)** is a new task, model, and dataset for image segmentation. It built a largest segmentation [dataset](https://segment-anything.com/dataset/index.html) to date (by far), with over 1 billion masks on 11M licensed and privacy respecting images. Further, SAM can produce high quality object masks from different types of prompts including points, boxes, masks and text. SAM has impressive zero-shot performance on a variety of tasks, even often competitive with or even superior to prior fully supervised results. However, the SAM model based on text prompt is not released at the moment. Therefore, we use a combination of **SAM** and **CLIP** to calculate the similarity between the output masks and text prompt. In this way, you can use **text prompt** to segment anything. In addition, we also implement SAM that can generate masks for all objects in whole image.
+
-We provide the pretrained model parameters of PaddlePaddle format, including [vit_b](https://bj.bcebos.com/paddleseg/dygraph/paddlesegAnything/vit_b/model.pdparams), [vit_l](https://bj.bcebos.com/paddleseg/dygraph/paddlesegAnything/vit_l/model.pdparams) and [vit_h](https://bj.bcebos.com/paddleseg/dygraph/paddlesegAnything/vit_h/model.pdparams).
+We provide the pretrained model parameters of PaddlePaddle format, including [vit_b](https://bj.bcebos.com/paddleseg/dygraph/paddlesegAnything/vit_b/model.pdparams), [vit_l](https://bj.bcebos.com/paddleseg/dygraph/paddlesegAnything/vit_l/model.pdparams) and [vit_h](https://bj.bcebos.com/paddleseg/dygraph/paddlesegAnything/vit_h/model.pdparams). For text prompt, we also provide the [CLIP_ViT_B](https://bj.bcebos.com/paddleseg/dygraph/clip/vit_b_32_pretrain/clip_vit_b_32.pdparams) model parameters of PaddlePaddle format.
##  Performance
Performance
-

+

-
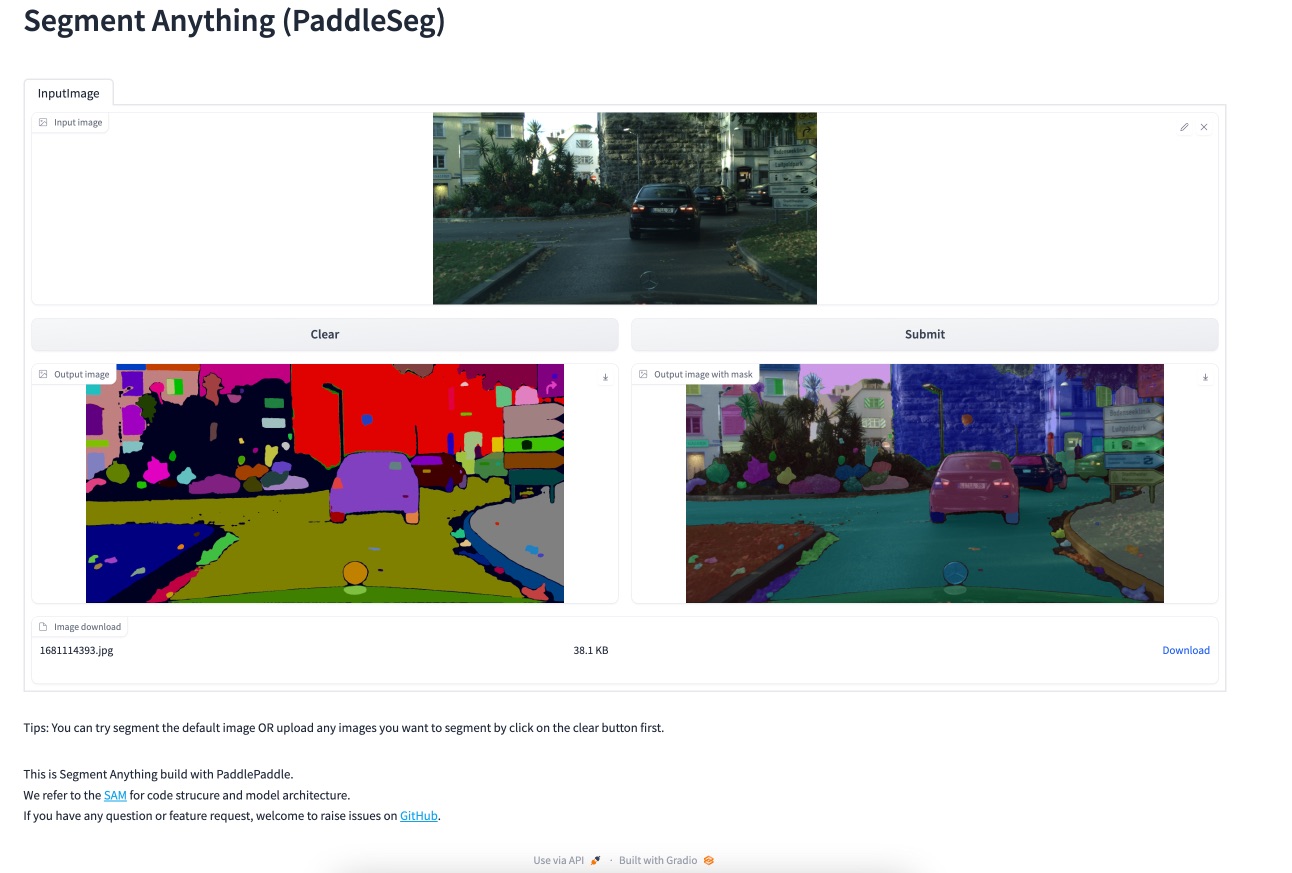
+

\
+ SAM+CLIP: Text prompt for segmentation.
\
+ Choose an example below; Or, upload by yourself:
\
+ 1. Upload images to be tested to 'input image'. 2. Input a text prompt to 'input text prompt' and click 'submit'.
\
+
",
+ cache_examples=False,
+ allow_flagging="never", )
+
+ demo = gr.TabbedInterface(
+ [demo_mask_sam, ], ['SAM+CLIP(Text to Segment)'],
+ title=" 🔥 Text to Segment Anything with PaddleSeg 🔥")
+ demo.launch(
+ server_name="0.0.0.0", enable_queue=False, server_port=8078, share=True)
+
+
+args = parser.parse_args()
+print("Loading model...")
+
+if paddle.is_compiled_with_cuda():
+ paddle.set_device("gpu")
+else:
+ paddle.set_device("cpu")
+
+sam = sam_model_registry[args.model_type](
+ checkpoint=model_link[args.model_type])
+mask_generator = SamAutomaticMaskGenerator(sam)
+
+model, transform = build_clip_model(model_link["clip_b_32"])
+gradio_display()
diff --git a/contrib/SegmentAnything/segment_anything/build_sam.py b/contrib/SegmentAnything/segment_anything/build_sam.py
index f19d033eb8..039c61e6dd 100644
--- a/contrib/SegmentAnything/segment_anything/build_sam.py
+++ b/contrib/SegmentAnything/segment_anything/build_sam.py
@@ -17,7 +17,7 @@
from functools import partial
-from paddleseg import utils
+from paddleseg.utils import load_entire_model
from .modeling import ImageEncoderViT, MaskDecoder, PromptEncoder, Sam, TwoWayTransformer
@@ -104,5 +104,5 @@ def _build_sam(
pixel_std=[58.395, 57.12, 57.375], )
sam.eval()
if checkpoint is not None:
- utils.load_entire_model(sam, checkpoint)
+ load_entire_model(sam, checkpoint)
return sam
diff --git a/contrib/SegmentAnything/segment_anything/modeling/__init__.py b/contrib/SegmentAnything/segment_anything/modeling/__init__.py
index fe9172c737..f68b25daab 100644
--- a/contrib/SegmentAnything/segment_anything/modeling/__init__.py
+++ b/contrib/SegmentAnything/segment_anything/modeling/__init__.py
@@ -15,6 +15,7 @@
# This implementation refers to: https://github.com/facebookresearch/segment-anything
from .sam import Sam
+from .clip_paddle import *
from .image_encoder import ImageEncoderViT
from .mask_decoder import MaskDecoder
from .prompt_encoder import PromptEncoder
diff --git a/contrib/SegmentAnything/segment_anything/modeling/clip_paddle.py b/contrib/SegmentAnything/segment_anything/modeling/clip_paddle.py
new file mode 100644
index 0000000000..2984ce6ac6
--- /dev/null
+++ b/contrib/SegmentAnything/segment_anything/modeling/clip_paddle.py
@@ -0,0 +1,318 @@
+# Copyright (c) 2023 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# This implementation refers to: https://github.com/openai/CLIP
+
+from collections import OrderedDict
+from typing import Tuple, Union
+
+import numpy as np
+import paddle
+from paddle.nn.initializer import Constant
+from paddle.vision.transforms import Compose, Resize, CenterCrop, ToTensor, Normalize
+
+zeros_ = Constant(value=0.)
+
+
+class QuickGELU(paddle.nn.Layer):
+ def forward(self, x: paddle.Tensor):
+ return x * paddle.nn.functional.sigmoid(x=1.702 * x)
+
+
+class ResidualAttentionBlock(paddle.nn.Layer):
+ def __init__(self, d_model: int, n_head: int,
+ attn_mask: paddle.Tensor=None):
+ super().__init__()
+ self.attn = paddle.nn.MultiHeadAttention(
+ d_model,
+ n_head,
+ need_weights=False, )
+ self.ln_1 = paddle.nn.LayerNorm(d_model)
+ self.mlp = paddle.nn.Sequential(*[('c_fc', paddle.nn.Linear(
+ in_features=d_model, out_features=d_model *
+ 4)), ('gelu', QuickGELU()), ('c_proj', paddle.nn.Linear(
+ in_features=d_model * 4, out_features=d_model))])
+ self.ln_2 = paddle.nn.LayerNorm(d_model)
+ self.attn_mask = attn_mask
+
+ def attention(self, x: paddle.Tensor):
+ """Class Method: *.to, not convert, please check whether it is torch.Tensor.*/Optimizer.*/nn.Module.*, and convert manually"""
+ self.attn_mask = self.attn_mask.astype(
+ x.dtype) if self.attn_mask is not None else None
+ x = x.transpose([1, 0, 2])
+ x = self.attn(x, x, x, attn_mask=self.attn_mask)
+ return x.transpose([1, 0, 2])
+
+ def forward(self, x: paddle.Tensor):
+ x = x + self.attention(self.ln_1(x))
+ x = x + self.mlp(self.ln_2(x))
+ return x
+
+
+class Transformer(paddle.nn.Layer):
+ def __init__(self,
+ width: int,
+ layers: int,
+ heads: int,
+ attn_mask: paddle.Tensor=None):
+ super().__init__()
+ self.width = width
+ self.layers = layers
+ self.resblocks = paddle.nn.Sequential(*[
+ ResidualAttentionBlock(width, heads, attn_mask)
+ for _ in range(layers)
+ ])
+
+ def forward(self, x: paddle.Tensor):
+ return self.resblocks(x)
+
+
+class VisionTransformer(paddle.nn.Layer):
+ def __init__(self,
+ input_resolution: int,
+ patch_size: int,
+ width: int,
+ layers: int,
+ heads: int,
+ output_dim: int):
+ super().__init__()
+ self.input_resolution = input_resolution
+ self.output_dim = output_dim
+ self.conv1 = paddle.nn.Conv2D(
+ in_channels=3,
+ out_channels=width,
+ kernel_size=patch_size,
+ stride=patch_size,
+ bias_attr=False)
+ scale = width**-0.5
+ self.class_embedding = self.create_parameter(
+ shape=(width, ), default_initializer=zeros_)
+ self.add_parameter("class_embedding", self.class_embedding)
+
+ self.positional_embedding = self.create_parameter(
+ shape=((input_resolution // patch_size)**2 + 1, width),
+ default_initializer=zeros_)
+ self.add_parameter("positional_embedding", self.positional_embedding)
+ self.ln_pre = paddle.nn.LayerNorm(width)
+ self.transformer = Transformer(width, layers, heads)
+ self.ln_post = paddle.nn.LayerNorm(width)
+ self.proj = self.create_parameter(
+ shape=(width, output_dim), default_initializer=zeros_)
+ self.add_parameter("proj", self.proj)
+
+ def forward(self, x: paddle.Tensor):
+
+ x = self.conv1(x)
+ x = x.flatten(2).transpose((0, 2, 1))
+
+ x = paddle.concat(
+ [
+ self.class_embedding.astype(x.dtype) + paddle.zeros(
+ shape=[x.shape[0], 1, x.shape[-1]], dtype=x.dtype), x
+ ],
+ axis=1)
+
+ x = x + self.positional_embedding.astype(x.dtype)
+ x = self.ln_pre(x)
+ x = x.transpose(perm=[1, 0, 2])
+ x = self.transformer(x)
+ x = x.transpose(perm=[1, 0, 2])
+ x = self.ln_post(x[:, 0, :])
+
+ if self.proj is not None:
+ x = x @self.proj
+ return x
+
+
+class CLIP(paddle.nn.Layer):
+ def __init__(self,
+ embed_dim: int,
+ image_resolution: int,
+ vision_layers: Union[Tuple[int, int, int, int], int],
+ vision_width: int,
+ vision_patch_size: int,
+ context_length: int,
+ vocab_size: int,
+ transformer_width: int,
+ transformer_heads: int,
+ transformer_layers: int):
+ super().__init__()
+ self.context_length = context_length
+
+ vision_heads = vision_width // 64
+ self.visual = VisionTransformer(
+ input_resolution=image_resolution,
+ patch_size=vision_patch_size,
+ width=vision_width,
+ layers=vision_layers,
+ heads=vision_heads,
+ output_dim=embed_dim)
+ self.transformer = Transformer(
+ width=transformer_width,
+ layers=transformer_layers,
+ heads=transformer_heads,
+ attn_mask=self.build_attention_mask())
+ self.vocab_size = vocab_size
+ self.token_embedding = paddle.nn.Embedding(vocab_size,
+ transformer_width)
+
+ self.positional_embedding = self.create_parameter(
+ shape=(self.context_length, transformer_width),
+ default_initializer=zeros_)
+ self.add_parameter("positional_embedding", self.positional_embedding)
+
+ self.ln_final = paddle.nn.LayerNorm(transformer_width)
+
+ self.text_projection = self.create_parameter(
+ shape=(transformer_width, embed_dim), default_initializer=zeros_)
+ self.add_parameter("text_projection", self.text_projection)
+
+ def build_attention_mask(self):
+ mask = paddle.empty(shape=[self.context_length, self.context_length])
+ mask.fill_(value=float('-inf'))
+ mask = paddle.tensor.triu(mask, diagonal=1)
+ return mask
+
+ @property
+ def dtype(self):
+ return self.visual.conv1.weight.dtype
+
+ def encode_image(self, image):
+ return self.visual(image.astype(self.dtype))
+
+ def encode_text(self, text):
+ x = self.token_embedding(text).astype(self.dtype)
+ x = x + self.positional_embedding.astype(self.dtype)
+ x = x.transpose(perm=[1, 0, 2])
+ x = self.transformer(x)
+ x = x.transpose(perm=[1, 0, 2])
+ x = self.ln_final(x).astype(self.dtype)
+ x = x[paddle.arange(start=x.shape[0]), text.argmax(
+ axis=-1)] @self.text_projection
+ return x[None, :]
+
+ def forward(self, image, text):
+ text_features = self.encode_text(text)[None, :]
+ image_features = self.encode_image(image)
+
+ image_features = image_features / image_features.norm(
+ axis=1, keepdim=True)
+ text_features = text_features / text_features.norm(axis=1, keepdim=True)
+ # cosine similarity as logits
+ logits_per_image = image_features @text_features.t()
+ logits_per_text = logits_per_image.t()
+ return logits_per_image, logits_per_text
+
+
+def convert_weights(model: paddle.nn.Layer):
+ """Convert applicable model parameters to fp16"""
+
+ def _convert_weights_to_fp16(param):
+ if isinstance(param,
+ (paddle.nn.Conv1D, paddle.nn.Conv2D, paddle.nn.Linear)):
+ param.weight.data = param.weight.astype('float16')
+ if param.bias is not None:
+ param.bias.data = param.bias.astype('float16')
+ if isinstance(param, paddle.nn.MultiHeadAttention):
+ for attr in [
+ * [f'{s}_proj_weight' for s in ['in', 'q', 'k', 'v']],
+ 'in_proj_bias', 'bias_k', 'bias_v'
+ ]:
+ tensor_l = getattr(param, attr)
+ if tensor_l is not None:
+ tensor_l.data = tensor_l.astype('float16')
+ for name in ['text_projection', 'proj']:
+ if hasattr(param, name):
+ attr = getattr(param, name)
+ if attr is not None:
+ attr.data = attr.astype('float16')
+
+ model.apply(fn=_convert_weights_to_fp16)
+
+
+def load_pretrain_clip(pretrained_model):
+ from urllib.parse import urlparse
+ from paddleseg.utils import download_pretrained_model
+ if urlparse(pretrained_model).netloc:
+ pretrained_model = download_pretrained_model(pretrained_model)
+ state = paddle.load(pretrained_model)
+ return state
+
+
+def build_clip_model(pretrained_model):
+ state_dict = load_pretrain_clip(pretrained_model)
+ vit = 'visual.proj' in state_dict
+ if vit:
+ vision_width = state_dict['visual.conv1.weight'].shape[0]
+ vision_layers = len([
+ k for k in state_dict.keys()
+ if k.startswith('visual.') and k.endswith('.attn.q_proj.weight')
+ ])
+ vision_patch_size = state_dict['visual.conv1.weight'].shape[-1]
+ grid_size = round((state_dict['visual.positional_embedding'].shape[0] -
+ 1)**0.5)
+ image_resolution = vision_patch_size * grid_size
+ else:
+ """Class Method: *.split, not convert, please check whether it is torch.Tensor.*/Optimizer.*/nn.Module.*, and convert manually"""
+ counts: list = [
+ len(
+ set(
+ k.split('.')[2] for k in state_dict
+ if k.startswith(f'visual.layer{b}')))
+ for b in [1, 2, 3, 4]
+ ]
+ vision_layers = tuple(counts)
+ vision_width = state_dict['visual.layer1.0.conv1.weight'].shape[0]
+ output_width = round((state_dict['visual.attnpool.positional_embedding']
+ .shape[0] - 1)**0.5)
+ vision_patch_size = None
+ assert output_width**2 + 1 == state_dict[
+ 'visual.attnpool.positional_embedding'].shape[0]
+ image_resolution = output_width * 32
+ embed_dim = state_dict['text_projection'].shape[1]
+ context_length = state_dict['positional_embedding'].shape[0]
+ vocab_size = state_dict['token_embedding.weight'].shape[0]
+ transformer_width = state_dict['ln_final.weight'].shape[0]
+ transformer_heads = transformer_width // 64
+ """Class Method: *.split, not convert, please check whether it is torch.Tensor.*/Optimizer.*/nn.Module.*, and convert manually"""
+ transformer_layers = len(
+ set(
+ k.split('.')[2] for k in state_dict
+ if k.startswith('transformer.resblocks')))
+ model = CLIP(embed_dim, image_resolution, vision_layers, vision_width,
+ vision_patch_size, context_length, vocab_size,
+ transformer_width, transformer_heads, transformer_layers)
+ for key in ['input_resolution', 'context_length', 'vocab_size']:
+ if key in state_dict:
+ del state_dict[key]
+ #convert_weights(model)
+ model.eval()
+ model.set_state_dict(state_dict=state_dict)
+ return model, _transform(model.visual.input_resolution)
+
+
+def _convert_image_to_rgb(image):
+ return image.convert("RGB")
+
+
+def _transform(n_px):
+
+ return Compose([
+ Resize(n_px),
+ CenterCrop(n_px),
+ _convert_image_to_rgb,
+ ToTensor(),
+ Normalize((0.48145466, 0.4578275, 0.40821073),
+ (0.26862954, 0.26130258, 0.27577711)),
+ ])
diff --git a/contrib/SegmentAnything/segment_anything/utils/__init__.py b/contrib/SegmentAnything/segment_anything/utils/__init__.py
index e69de29bb2..98f12e9b35 100644
--- a/contrib/SegmentAnything/segment_anything/utils/__init__.py
+++ b/contrib/SegmentAnything/segment_anything/utils/__init__.py
@@ -0,0 +1 @@
+from .sample_tokenizer import tokenize
diff --git a/contrib/SegmentAnything/segment_anything/utils/sample_tokenizer.py b/contrib/SegmentAnything/segment_anything/utils/sample_tokenizer.py
new file mode 100644
index 0000000000..2dbcacc93c
--- /dev/null
+++ b/contrib/SegmentAnything/segment_anything/utils/sample_tokenizer.py
@@ -0,0 +1,205 @@
+# Copyright (c) 2023 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# This implementation refers to: https://github.com/openai/CLIP
+
+import gzip
+import html
+import os
+from functools import lru_cache
+
+import ftfy
+import regex as re
+import paddle
+
+
+@lru_cache()
+def default_bpe():
+ return os.path.join(
+ os.path.dirname(os.path.abspath(__file__)), *(['..'] * 2),
+ "bpe_simple_vocab_16e6.txt.gz")
+
+
+@lru_cache()
+def bytes_to_unicode():
+ """
+ Returns list of utf-8 byte and a corresponding list of unicode strings.
+ The reversible bpe codes work on unicode strings.
+ This means you need a large # of unicode characters in your vocab if you want to avoid UNKs.
+ When you're at something like a 10B token dataset you end up needing around 5K for decent coverage.
+ This is a signficant percentage of your normal, say, 32K bpe vocab.
+ To avoid that, we want lookup tables between utf-8 bytes and unicode strings.
+ And avoids mapping to whitespace/control characters the bpe code barfs on.
+ """
+ bs = list(range(ord("!"), ord("~") + 1)) + list(
+ range(ord("¡"), ord("¬") + 1)) + list(range(ord("®"), ord("ÿ") + 1))
+ cs = bs[:]
+ n = 0
+ for b in range(2**8):
+ if b not in bs:
+ bs.append(b)
+ cs.append(2**8 + n)
+ n += 1
+ cs = [chr(n) for n in cs]
+ return dict(zip(bs, cs))
+
+
+def get_pairs(word):
+ """Return set of symbol pairs in a word.
+ Word is represented as tuple of symbols (symbols being variable-length strings).
+ """
+ pairs = set()
+ prev_char = word[0]
+ for char in word[1:]:
+ pairs.add((prev_char, char))
+ prev_char = char
+ return pairs
+
+
+def basic_clean(text):
+ text = ftfy.fix_text(text)
+ text = html.unescape(html.unescape(text))
+ return text.strip()
+
+
+def whitespace_clean(text):
+ text = re.sub(r'\s+', ' ', text)
+ text = text.strip()
+ return text
+
+
+class SimpleTokenizer(object):
+ def __init__(self, bpe_path: str=default_bpe()):
+ self.byte_encoder = bytes_to_unicode()
+ self.byte_decoder = {v: k for k, v in self.byte_encoder.items()}
+ merges = gzip.open(bpe_path).read().decode("utf-8").split('\n')
+ merges = merges[1:49152 - 256 - 2 + 1]
+ merges = [tuple(merge.split()) for merge in merges]
+ vocab = list(bytes_to_unicode().values())
+ vocab = vocab + [v + '' for v in vocab]
+ for merge in merges:
+ vocab.append(''.join(merge))
+ vocab.extend(['<|startoftext|>', '<|endoftext|>'])
+ self.encoder = dict(zip(vocab, range(len(vocab))))
+ self.decoder = {v: k for k, v in self.encoder.items()}
+ self.bpe_ranks = dict(zip(merges, range(len(merges))))
+ self.cache = {
+ '<|startoftext|>': '<|startoftext|>',
+ '<|endoftext|>': '<|endoftext|>'
+ }
+ self.pat = re.compile(
+ r"""<\|startoftext\|>|<\|endoftext\|>|'s|'t|'re|'ve|'m|'ll|'d|[\p{L}]+|[\p{N}]|[^\s\p{L}\p{N}]+""",
+ re.IGNORECASE)
+
+ def bpe(self, token):
+ if token in self.cache:
+ return self.cache[token]
+ word = tuple(token[:-1]) + (token[-1] + '', )
+ pairs = get_pairs(word)
+
+ if not pairs:
+ return token + ''
+
+ while True:
+ bigram = min(
+ pairs, key=lambda pair: self.bpe_ranks.get(pair, float('inf')))
+ if bigram not in self.bpe_ranks:
+ break
+ first, second = bigram
+ new_word = []
+ i = 0
+ while i < len(word):
+ try:
+ j = word.index(first, i)
+ new_word.extend(word[i:j])
+ i = j
+ except:
+ new_word.extend(word[i:])
+ break
+
+ if word[i] == first and i < len(word) - 1 and word[i +
+ 1] == second:
+ new_word.append(first + second)
+ i += 2
+ else:
+ new_word.append(word[i])
+ i += 1
+ new_word = tuple(new_word)
+ word = new_word
+ if len(word) == 1:
+ break
+ else:
+ pairs = get_pairs(word)
+ word = ' '.join(word)
+ self.cache[token] = word
+ return word
+
+ def encode(self, text):
+ bpe_tokens = []
+ text = whitespace_clean(basic_clean(text)).lower()
+ for token in re.findall(self.pat, text):
+ token = ''.join(self.byte_encoder[b] for b in token.encode('utf-8'))
+ bpe_tokens.extend(self.encoder[bpe_token]
+ for bpe_token in self.bpe(token).split(' '))
+ return bpe_tokens
+
+ def decode(self, tokens):
+ text = ''.join([self.decoder[token] for token in tokens])
+ text = bytearray([self.byte_decoder[c] for c in text]).decode(
+ 'utf-8', errors="replace").replace('', ' ')
+ return text
+
+
+def tokenize(texts, context_length=77, truncate=False):
+ """
+ Returns the tokenized representation of given input string(s)
+
+ Parameters
+ ----------
+ texts : Union[str, List[str]]
+ An input string or a list of input strings to tokenize
+
+ context_length : int
+ The context length to use; all CLIP models use 77 as the context length
+
+ truncate: bool
+ Whether to truncate the text in case its encoding is longer than the context length
+
+ Returns
+ -------
+ A two-dimensional tensor containing the resulting tokens, shape = [number of input strings, context_length].
+ We return LongTensor when torch version is <1.8.0, since older index_select requires indices to be long.
+ """
+ if isinstance(texts, str):
+ texts = [texts]
+ _tokenizer = SimpleTokenizer()
+ sot_token = _tokenizer.encoder["<|startoftext|>"]
+ eot_token = _tokenizer.encoder["<|endoftext|>"]
+ all_tokens = [[sot_token] + _tokenizer.encode(text) + [eot_token]
+ for text in texts]
+
+ result = paddle.zeros((len(all_tokens), context_length), dtype='int64')
+
+ for i, tokens in enumerate(all_tokens):
+ if len(tokens) > context_length:
+ if truncate:
+ tokens = tokens[:context_length]
+ tokens[-1] = eot_token
+ else:
+ raise RuntimeError(
+ f"Input {texts[i]} is too long for context length {context_length}"
+ )
+ result[i, :len(tokens)] = paddle.to_tensor(tokens)
+
+ return result