@@ -47,13 +47,13 @@ PaddleSeg is an end-to-end high-efficent development toolkit for image segmentat
##
Features
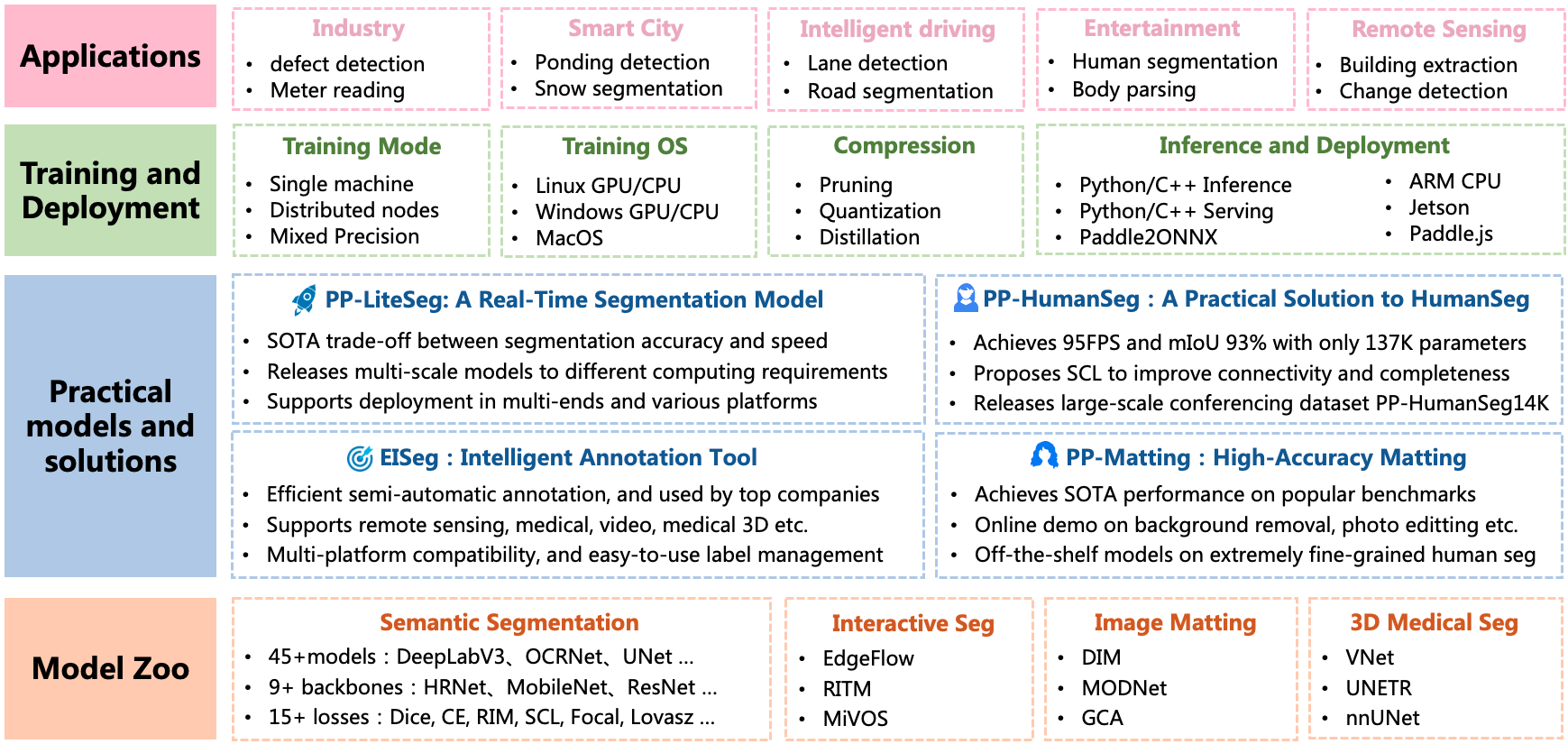
-* **High-Performance Model**: Following the state of the art segmentation methods and use the high-performance backbone, we provide 40+ models and 140+ high-quality pre-training models, which are better than other open-source implementations.
+* **High-Performance Model**: Following the state of the art segmentation methods and using high-performance backbone networks, we provide 40+ models and 140+ high-quality pre-training models, which are better than other open-source implementations.
-* **High Efficiency**: PaddleSeg provides multi-process asynchronous I/O, multi-card parallel training, evaluation, and other acceleration strategies, combined with the memory optimization function of the PaddlePaddle, which can greatly reduce the training overhead of the segmentation model, all this allowing developers to lower cost and more efficiently train image segmentation model.
+* **High Efficiency**: PaddleSeg provides multi-process asynchronous I/O, multi-card parallel training, evaluation, and other acceleration strategies, combined with the memory optimization function of the PaddlePaddle, which can greatly reduce the training overhead of the segmentation model, all these allowing developers to train image segmentation models more efficiently and at a lower cost.
-* **Modular Design**: We desigin PaddleSeg with the modular design philosophy. Therefore, based on actual application scenarios, developers can assemble diversified training configurations with *data enhancement strategies*, *segmentation models*, *backbone networks*, *loss functions* and other different components to meet different performance and accuracy requirements.
+* **Modular Design**: We build PaddleSeg with the modular design philosophy. Therefore, based on actual application scenarios, developers can assemble diversified training configurations with *data augmentation strategies*, *segmentation models*, *backbone networks*, *loss functions*, and other different components to meet different performance and accuracy requirements.
-* **Complete Flow**: PaddleSeg support image labeling, model designing, model training, model compression and model deployment. With the help of PaddleSeg, developers can easily finish all taskes.
+* **Complete Flow**: PaddleSeg supports image labeling, model designing, model training, model compression, and model deployment. With the help of PaddleSeg, developers can easily finish all tasks in the entire workflow.
@@ -61,8 +61,8 @@ PaddleSeg is an end-to-end high-efficent development toolkit for image segmentat
##

Community
-* If you have any questions, suggestions and feature requests, please create an issues in [GitHub Issues](https://github.com/PaddlePaddle/PaddleSeg/issues).
-* Welcome to scan the following QR code and join paddleseg wechat group to communicate with us.
+* If you have any questions, suggestions or feature requests, please do not hesitate to create an issue in [GitHub Issues](https://github.com/PaddlePaddle/PaddleSeg/issues).
+* Please scan the following QR code to join PaddleSeg WeChat group to communicate with us:

@@ -321,7 +321,7 @@ PaddleSeg is an end-to-end high-efficent development toolkit for image segmentat
| CCNet | ResNet101_OS8 | 80.95 | 3.24 | [yml](./configs/ccnet/) |
Note that:
-* Test the inference speed on Nvidia GPU V100: use PaddleInference Python API, enable TensorRT, the data type is FP32, the dimension of input is 1x3x1024x2048.
+* We test the inference speed on Nvidia GPU V100. We use PaddleInference Python API with TensorRT enabled. The data type is FP32, and the shape of input tensor is 1x3x1024x2048.
@@ -344,8 +344,8 @@ Note that:
| SFNet | ResNet18_OS8 | 78.72 | *10.72* | - | [yml](./configs/sfnet/) |
Note that:
-* Test the inference speed on Nvidia GPU V100: use PaddleInference Python API, enable TensorRT, the data type is FP32, the dimension of input is 1x3x1024x2048.
-* Test the inference speed on Snapdragon 855: use PaddleLite CPP API, 1 thread, the dimension of input is 1x3x256x256.
+* We test the inference speed on Nvidia GPU V100. We use PaddleInference Python API with TensorRT enabled. The data type is FP32, and the shape of input tensor is 1x3x1024x2048.
+* We test the inference speed on Snapdragon 855. We use PaddleLite CPP API with 1 thread, and the shape of input tensor is 1x3x256x256.
@@ -364,8 +364,8 @@ Note that:
| MobileSeg | GhostNet_x1_0 | 71.88 | *35.58* | 38.74 | [yml](./configs/mobileseg/) |
Note that:
-* Test the inference speed on Nvidia GPU V100: use PaddleInference Python API, enable TensorRT, the data type is FP32, the dimension of input is 1x3x1024x2048.
-* Test the inference speed on Snapdragon 855: use PaddleLite CPP API, 1 thread, the dimension of input is 1x3x256x256.
+* We test the inference speed on Nvidia GPU V100. We use PaddleInference Python API with TensorRT enabled. The data type is FP32, and the shape of input tensor is 1x3x1024x2048.
+* We test the inference speed on Snapdragon 855. We use PaddleLite CPP API with 1 thread, and the shape of input tensor is 1x3x256x256.
@@ -394,7 +394,7 @@ Note that:
* [Export Inference Model](./docs/model_export.md)
* [Export ONNX Model](./docs/model_export_onnx.md)
-* Model Deploy
+* Model Deployment
* [Paddle Inference (Python)](./docs/deployment/inference/python_inference.md)
* [Paddle Inference (C++)](./docs/deployment/inference/cpp_inference.md)
* [Paddle Lite](./docs/deployment/lite/lite.md)
@@ -409,7 +409,7 @@ Note that:
* Model Compression
* [Quantization](./docs/deployment/slim/quant/quant.md)
* [Distillation](./docs/deployment/slim/distill/distill.md)
- * [Prune](./docs/deployment/slim/prune/prune.md)
+ * [Pruning](./docs/deployment/slim/prune/prune.md)
* [FAQ](./docs/faq/faq/faq.md)
diff --git a/deploy/python/collect_dynamic_shape.py b/deploy/python/collect_dynamic_shape.py
index 8b4725935a..276e7c1844 100644
--- a/deploy/python/collect_dynamic_shape.py
+++ b/deploy/python/collect_dynamic_shape.py
@@ -13,20 +13,14 @@
# limitations under the License.
import argparse
-import codecs
import os
-import sys
-import yaml
import numpy as np
-from paddle.inference import create_predictor, PrecisionType
+from paddle.inference import create_predictor
from paddle.inference import Config as PredictConfig
-LOCAL_PATH = os.path.dirname(os.path.abspath(__file__))
-sys.path.append(os.path.join(LOCAL_PATH, '..', '..'))
-
from paddleseg.utils import logger, get_image_list, progbar
-from infer import DeployConfig
+from paddleseg.deploy.infer import DeployConfig
"""
Load images and run the model, it collects and saves dynamic shapes,
which are used in deployment with TRT.
diff --git a/deploy/python/infer.py b/deploy/python/infer.py
index d5fe6940a9..5bdbd1182d 100644
--- a/deploy/python/infer.py
+++ b/deploy/python/infer.py
@@ -13,129 +13,17 @@
# limitations under the License.
import argparse
-import codecs
import os
-import sys
-LOCAL_PATH = os.path.dirname(os.path.abspath(__file__))
-sys.path.append(os.path.join(LOCAL_PATH, '..', '..'))
-
-import yaml
import numpy as np
from paddle.inference import create_predictor, PrecisionType
from paddle.inference import Config as PredictConfig
-import paddleseg.transforms as T
-from paddleseg.cvlibs import manager
-from paddleseg.utils import get_sys_env, logger, get_image_list
+from paddleseg.deploy.infer import DeployConfig
+from paddleseg.utils import get_image_list, logger
from paddleseg.utils.visualize import get_pseudo_color_map
-def parse_args():
- parser = argparse.ArgumentParser(description='Test')
- parser.add_argument(
- "--config",
- dest="cfg",
- help="The config file.",
- default=None,
- type=str,
- required=True)
- parser.add_argument(
- '--image_path',
- dest='image_path',
- help='The directory or path or file list of the images to be predicted.',
- type=str,
- default=None,
- required=True)
- parser.add_argument(
- '--batch_size',
- dest='batch_size',
- help='Mini batch size of one gpu or cpu.',
- type=int,
- default=1)
- parser.add_argument(
- '--save_dir',
- dest='save_dir',
- help='The directory for saving the predict result.',
- type=str,
- default='./output')
- parser.add_argument(
- '--device',
- choices=['cpu', 'gpu', 'xpu', 'npu'],
- default="gpu",
- help="Select which device to inference, defaults to gpu.")
-
- parser.add_argument(
- '--use_trt',
- default=False,
- type=eval,
- choices=[True, False],
- help='Whether to use Nvidia TensorRT to accelerate prediction.')
- parser.add_argument(
- "--precision",
- default="fp32",
- type=str,
- choices=["fp32", "fp16", "int8"],
- help='The tensorrt precision.')
- parser.add_argument(
- '--min_subgraph_size',
- default=3,
- type=int,
- help='The min subgraph size in tensorrt prediction.')
- parser.add_argument(
- '--enable_auto_tune',
- default=False,
- type=eval,
- choices=[True, False],
- help='Whether to enable tuned dynamic shape. We uses some images to collect '
- 'the dynamic shape for trt sub graph, which avoids setting dynamic shape manually.'
- )
- parser.add_argument(
- '--auto_tuned_shape_file',
- type=str,
- default="auto_tune_tmp.pbtxt",
- help='The temp file to save tuned dynamic shape.')
-
- parser.add_argument(
- '--cpu_threads',
- default=10,
- type=int,
- help='Number of threads to predict when using cpu.')
- parser.add_argument(
- '--enable_mkldnn',
- default=False,
- type=eval,
- choices=[True, False],
- help='Enable to use mkldnn to speed up when using cpu.')
-
- parser.add_argument(
- "--benchmark",
- type=eval,
- default=False,
- help="Whether to log some information about environment, model, configuration and performance."
- )
- parser.add_argument(
- "--model_name",
- default="",
- type=str,
- help='When `--benchmark` is True, the specified model name is displayed.'
- )
-
- parser.add_argument(
- '--with_argmax',
- dest='with_argmax',
- help='Perform argmax operation on the predict result.',
- action='store_true')
- parser.add_argument(
- '--print_detail',
- default=True,
- type=eval,
- choices=[True, False],
- help='Print GLOG information of Paddle Inference.')
-
- return parser.parse_args()
-
-
def use_auto_tune(args):
return hasattr(PredictConfig, "collect_shape_range_info") \
and hasattr(PredictConfig, "enable_tuned_tensorrt_dynamic_shape") \
@@ -197,38 +85,6 @@ def auto_tune(args, imgs, img_nums):
logger.info("Auto tune success.\n")
-class DeployConfig:
- def __init__(self, path):
- with codecs.open(path, 'r', 'utf-8') as file:
- self.dic = yaml.load(file, Loader=yaml.FullLoader)
-
- self._transforms = self.load_transforms(self.dic['Deploy'][
- 'transforms'])
- self._dir = os.path.dirname(path)
-
- @property
- def transforms(self):
- return self._transforms
-
- @property
- def model(self):
- return os.path.join(self._dir, self.dic['Deploy']['model'])
-
- @property
- def params(self):
- return os.path.join(self._dir, self.dic['Deploy']['params'])
-
- @staticmethod
- def load_transforms(t_list):
- com = manager.TRANSFORMS
- transforms = []
- for t in t_list:
- ctype = t.pop('type')
- transforms.append(com[ctype](**t))
-
- return T.Compose(transforms)
-
-
class Predictor:
def __init__(self, args):
"""
@@ -410,6 +266,111 @@ def _save_imgs(self, results, imgs_path):
result.save(os.path.join(self.args.save_dir, basename))
+def parse_args():
+ parser = argparse.ArgumentParser(description='Test')
+ parser.add_argument(
+ "--config",
+ dest="cfg",
+ help="The config file.",
+ default=None,
+ type=str,
+ required=True)
+ parser.add_argument(
+ '--image_path',
+ dest='image_path',
+ help='The directory or path or file list of the images to be predicted.',
+ type=str,
+ default=None,
+ required=True)
+ parser.add_argument(
+ '--batch_size',
+ dest='batch_size',
+ help='Mini batch size of one gpu or cpu.',
+ type=int,
+ default=1)
+ parser.add_argument(
+ '--save_dir',
+ dest='save_dir',
+ help='The directory for saving the predict result.',
+ type=str,
+ default='./output')
+ parser.add_argument(
+ '--device',
+ choices=['cpu', 'gpu', 'xpu', 'npu'],
+ default="gpu",
+ help="Select which device to inference, defaults to gpu.")
+
+ parser.add_argument(
+ '--use_trt',
+ default=False,
+ type=eval,
+ choices=[True, False],
+ help='Whether to use Nvidia TensorRT to accelerate prediction.')
+ parser.add_argument(
+ "--precision",
+ default="fp32",
+ type=str,
+ choices=["fp32", "fp16", "int8"],
+ help='The tensorrt precision.')
+ parser.add_argument(
+ '--min_subgraph_size',
+ default=3,
+ type=int,
+ help='The min subgraph size in tensorrt prediction.')
+ parser.add_argument(
+ '--enable_auto_tune',
+ default=False,
+ type=eval,
+ choices=[True, False],
+ help='Whether to enable tuned dynamic shape. We uses some images to collect '
+ 'the dynamic shape for trt sub graph, which avoids setting dynamic shape manually.'
+ )
+ parser.add_argument(
+ '--auto_tuned_shape_file',
+ type=str,
+ default="auto_tune_tmp.pbtxt",
+ help='The temp file to save tuned dynamic shape.')
+
+ parser.add_argument(
+ '--cpu_threads',
+ default=10,
+ type=int,
+ help='Number of threads to predict when using cpu.')
+ parser.add_argument(
+ '--enable_mkldnn',
+ default=False,
+ type=eval,
+ choices=[True, False],
+ help='Enable to use mkldnn to speed up when using cpu.')
+
+ parser.add_argument(
+ "--benchmark",
+ type=eval,
+ default=False,
+ help="Whether to log some information about environment, model, configuration and performance."
+ )
+ parser.add_argument(
+ "--model_name",
+ default="",
+ type=str,
+ help='When `--benchmark` is True, the specified model name is displayed.'
+ )
+
+ parser.add_argument(
+ '--with_argmax',
+ dest='with_argmax',
+ help='Perform argmax operation on the predict result.',
+ action='store_true')
+ parser.add_argument(
+ '--print_detail',
+ default=True,
+ type=eval,
+ choices=[True, False],
+ help='Print GLOG information of Paddle Inference.')
+
+ return parser.parse_args()
+
+
def main(args):
imgs_list, _ = get_image_list(args.image_path)
diff --git a/deploy/python/infer_benchmark.py b/deploy/python/infer_benchmark.py
index faba6e3b84..deecfdcb2c 100644
--- a/deploy/python/infer_benchmark.py
+++ b/deploy/python/infer_benchmark.py
@@ -15,23 +15,15 @@
import argparse
import codecs
import os
-import sys
import time
-LOCAL_PATH = os.path.dirname(os.path.abspath(__file__))
-sys.path.append(os.path.join(LOCAL_PATH, '..', '..'))
-
import yaml
import numpy as np
-from paddle.inference import create_predictor, PrecisionType
-from paddle.inference import Config as PredictConfig
-import paddleseg.transforms as T
-from paddleseg.cvlibs import manager
-from paddleseg.utils import get_sys_env, logger, get_image_list
+from paddleseg.deploy.infer import DeployConfig
+from paddleseg.utils import logger
from paddleseg.utils.visualize import get_pseudo_color_map
-
-from infer import use_auto_tune, auto_tune, DeployConfig, Predictor
+from infer import auto_tune, use_auto_tune, Predictor
def parse_args():
diff --git a/deploy/python/infer_dataset.py b/deploy/python/infer_dataset.py
index 4dab60d695..0faddd2809 100644
--- a/deploy/python/infer_dataset.py
+++ b/deploy/python/infer_dataset.py
@@ -15,25 +15,19 @@
import argparse
import codecs
import os
-import sys
import time
import yaml
import numpy as np
import paddle
import paddle.nn.functional as F
-
-from paddle.inference import create_predictor, PrecisionType
+from paddle.inference import create_predictor
from paddle.inference import Config as PredictConfig
-LOCAL_PATH = os.path.dirname(os.path.abspath(__file__))
-sys.path.append(os.path.join(LOCAL_PATH, '..', '..'))
-
-import paddleseg
+from paddleseg.deploy.infer import DeployConfig
from paddleseg.cvlibs import manager
from paddleseg.utils import logger, metrics, progbar
-
-from infer import Predictor, DeployConfig, use_auto_tune
+from infer import auto_tune, use_auto_tune, Predictor
def parse_args():
diff --git a/deploy/python/infer_onnx_trt.py b/deploy/python/infer_onnx_trt.py
index 75bb7c3b53..a379c12ef7 100644
--- a/deploy/python/infer_onnx_trt.py
+++ b/deploy/python/infer_onnx_trt.py
@@ -13,29 +13,19 @@
# limitations under the License.
import argparse
-import codecs
import os
-import sys
import time
import numpy as np
-from tqdm import tqdm
import paddle
-
import tensorrt as trt
import pycuda.driver as cuda
import pycuda.autoinit
import onnx
import onnxruntime
-LOCAL_PATH = os.path.dirname(os.path.abspath(__file__))
-sys.path.append(os.path.join(LOCAL_PATH, '..', '..'))
-
-import paddleseg.transforms as T
from paddleseg.cvlibs import Config
-from paddleseg.utils import logger, get_image_list, utils
-from paddleseg.utils.visualize import get_pseudo_color_map
-from export import SavedSegmentationNet
+from paddleseg.utils import logger, utils
"""
Export the Paddle model to ONNX, infer the ONNX model by TRT.
Or, load the ONNX model and infer it by TRT.
@@ -410,7 +400,6 @@ def export_load_infer(args, model=None):
utils.load_entire_model(model, args.model_path)
logger.info('Loaded trained params of model successfully')
- #model = SavedSegmentationNet(model) # add argmax to the last layer
model.eval()
if args.print_model:
print(model)
diff --git a/deploy/serving/test_serving.py b/deploy/serving/test_serving.py
index 1645ea6f19..535514e7eb 100644
--- a/deploy/serving/test_serving.py
+++ b/deploy/serving/test_serving.py
@@ -1,11 +1,6 @@
-import sys
import os
-import numpy as np
import argparse
-__dir__ = os.path.dirname(os.path.abspath(__file__))
-sys.path.append(os.path.abspath(os.path.join(__dir__, '../../')))
-
from paddle_serving_client import Client
from paddle_serving_app.reader import Sequential, File2Image, Resize, CenterCrop
from paddle_serving_app.reader import RGB2BGR, Transpose, Div, Normalize
diff --git a/deploy/slim/distill/distill_train.py b/deploy/slim/distill/distill_train.py
index a420f937dd..3b5d764ba3 100644
--- a/deploy/slim/distill/distill_train.py
+++ b/deploy/slim/distill/distill_train.py
@@ -14,23 +14,16 @@
import argparse
import random
-import os
-import sys
import paddle
import numpy as np
-
-__dir__ = os.path.dirname(os.path.abspath(__file__))
-sys.path.append(os.path.abspath(os.path.join(__dir__, '../../../')))
+from paddleslim.dygraph.dist import Distill
from paddleseg.cvlibs import manager, Config
from paddleseg.utils import get_sys_env, logger, utils
-
from distill_utils import distill_train
from distill_config import prepare_distill_adaptor, prepare_distill_config
-from paddleslim.dygraph.dist import Distill
-
def parse_args():
parser = argparse.ArgumentParser(description='Model training')
diff --git a/deploy/slim/quant/qat_export.py b/deploy/slim/quant/qat_export.py
index bc42afb88c..8ccbfbab4c 100644
--- a/deploy/slim/quant/qat_export.py
+++ b/deploy/slim/quant/qat_export.py
@@ -14,21 +14,16 @@
import argparse
import os
-import sys
import paddle
import yaml
-
-__dir__ = os.path.dirname(os.path.abspath(__file__))
-sys.path.append(os.path.abspath(os.path.join(__dir__, '../../../')))
+from paddleslim import QAT
from paddleseg.cvlibs import Config
from paddleseg.utils import logger, utils
+from paddleseg.deploy.export import WrappedModel
from qat_config import quant_config
from qat_train import skip_quant
-from export import SavedSegmentationNet
-
-from paddleslim import QAT
def parse_args():
@@ -85,8 +80,7 @@ def main(args):
'`--with_softmax` will be deprecated. Please use `--output_op`.')
output_op = 'softmax'
- new_net = net if output_op == 'none' else SavedSegmentationNet(net,
- output_op)
+ new_net = net if output_op == 'none' else WrappedModel(net, output_op)
new_net.eval()
save_path = os.path.join(args.save_dir, 'model')
diff --git a/deploy/slim/quant/qat_train.py b/deploy/slim/quant/qat_train.py
index 373c342264..5ca863a0e4 100644
--- a/deploy/slim/quant/qat_train.py
+++ b/deploy/slim/quant/qat_train.py
@@ -14,21 +14,15 @@
import argparse
import random
-import os
-import sys
import paddle
import numpy as np
-
-__dir__ = os.path.dirname(os.path.abspath(__file__))
-sys.path.append(os.path.abspath(os.path.join(__dir__, '../../../')))
+from paddleslim import QAT
from paddleseg.cvlibs import manager, Config
from paddleseg.utils import get_sys_env, logger, utils
from paddleseg.core import train
from qat_config import quant_config
-
-from paddleslim import QAT
"""
Apply quantization to segmentation model.
NOTE: Only conv2d and linear in backbone are quantized.
diff --git a/deploy/slim/quant/qat_val.py b/deploy/slim/quant/qat_val.py
index c32c4732a0..5ede978ba3 100644
--- a/deploy/slim/quant/qat_val.py
+++ b/deploy/slim/quant/qat_val.py
@@ -17,9 +17,7 @@
import sys
import paddle
-
-__dir__ = os.path.dirname(os.path.abspath(__file__))
-sys.path.append(os.path.abspath(os.path.join(__dir__, '../../../')))
+from paddleslim import QAT
from paddleseg.cvlibs import manager, Config
from paddleseg.core import evaluate
@@ -27,8 +25,6 @@
from qat_config import quant_config
from qat_train import skip_quant
-from paddleslim import QAT
-
def get_test_config(cfg, args):
diff --git a/paddleseg/cvlibs/config_checker.py b/paddleseg/cvlibs/config_checker.py
index 415bceec18..98e366cb3b 100644
--- a/paddleseg/cvlibs/config_checker.py
+++ b/paddleseg/cvlibs/config_checker.py
@@ -46,6 +46,9 @@ def apply_all_rules(self, cfg):
for i in range(len(self.rule_list)):
self.apply_rule(i, cfg)
+ def add_rule(self, rule):
+ self.rule_list.append(rule)
+
class Rule(object):
def check_and_correct(self, cfg):
diff --git a/paddleseg/deploy/__init__.py b/paddleseg/deploy/__init__.py
new file mode 100644
index 0000000000..571a1e85cb
--- /dev/null
+++ b/paddleseg/deploy/__init__.py
@@ -0,0 +1,12 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
diff --git a/paddleseg/deploy/export.py b/paddleseg/deploy/export.py
new file mode 100644
index 0000000000..ff4f6cc438
--- /dev/null
+++ b/paddleseg/deploy/export.py
@@ -0,0 +1,34 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+
+import paddle
+
+
+class WrappedModel(paddle.nn.Layer):
+ def __init__(self, model, output_op):
+ super().__init__()
+ self.model = model
+ self.output_op = output_op
+ assert output_op in ['argmax', 'softmax'], \
+ "output_op should in ['argmax', 'softmax']"
+
+ def forward(self, x):
+ outs = self.model(x)
+ new_outs = []
+ for out in outs:
+ if self.output_op == 'argmax':
+ out = paddle.argmax(out, axis=1, dtype='int32')
+ elif self.output_op == 'softmax':
+ out = paddle.nn.functional.softmax(out, axis=1)
+ new_outs.append(out)
+ return new_outs
diff --git a/paddleseg/deploy/infer.py b/paddleseg/deploy/infer.py
new file mode 100644
index 0000000000..40038e1445
--- /dev/null
+++ b/paddleseg/deploy/infer.py
@@ -0,0 +1,52 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+
+import codecs
+import os
+
+import yaml
+
+import paddleseg.transforms as T
+from paddleseg.cvlibs import manager
+
+
+class DeployConfig:
+ def __init__(self, path):
+ with codecs.open(path, 'r', 'utf-8') as file:
+ self.dic = yaml.load(file, Loader=yaml.FullLoader)
+
+ self._transforms = self.load_transforms(self.dic['Deploy'][
+ 'transforms'])
+ self._dir = os.path.dirname(path)
+
+ @property
+ def transforms(self):
+ return self._transforms
+
+ @property
+ def model(self):
+ return os.path.join(self._dir, self.dic['Deploy']['model'])
+
+ @property
+ def params(self):
+ return os.path.join(self._dir, self.dic['Deploy']['params'])
+
+ @staticmethod
+ def load_transforms(t_list):
+ com = manager.TRANSFORMS
+ transforms = []
+ for t in t_list:
+ ctype = t.pop('type')
+ transforms.append(com[ctype](**t))
+
+ return T.Compose(transforms)
diff --git a/test_tipc/configs/fcn_uhrnetw18_small/train_infer_python.txt b/test_tipc/configs/fcn_uhrnetw18_small/train_infer_python.txt
index 00784c2314..6833f40286 100644
--- a/test_tipc/configs/fcn_uhrnetw18_small/train_infer_python.txt
+++ b/test_tipc/configs/fcn_uhrnetw18_small/train_infer_python.txt
@@ -13,7 +13,7 @@ train_infer_img_dir:test_tipc/data/cityscapes/cityscapes_val_5.list
null:null
##
trainer:norm_train
-norm_train:train.py --config test_tipc/configs/fcn_uhrnetw18_small/fcn_uhrnetw18_small_cityscapes_1024x512_80k.yml --device gpu --do_eval --save_interval 500 --seed 100
+norm_train:tools/train.py --config test_tipc/configs/fcn_uhrnetw18_small/fcn_uhrnetw18_small_cityscapes_1024x512_80k.yml --device gpu --do_eval --save_interval 500 --seed 100
pact_train:null
fpgm_train:null
distill_train:null
diff --git a/test_tipc/configs/rtformer/train_infer_python.txt b/test_tipc/configs/rtformer/train_infer_python.txt
index e7b2eeb28d..8c4e98449b 100644
--- a/test_tipc/configs/rtformer/train_infer_python.txt
+++ b/test_tipc/configs/rtformer/train_infer_python.txt
@@ -13,7 +13,7 @@ train_infer_img_dir:test_tipc/data/cityscapes/cityscapes_val_5.list
null:null
##
trainer:norm_train
-norm_train:train.py --config test_tipc/configs/rtformer/rtformer_base_cityscapes_1024x512_120k.yml --device gpu --do_eval --save_interval 500 --seed 100
+norm_train:tools/train.py --config test_tipc/configs/rtformer/rtformer_base_cityscapes_1024x512_120k.yml --device gpu --do_eval --save_interval 500 --seed 100
pact_train:null
fpgm_train:null
distill_train:null
diff --git a/tools/data/cityscapes_trainid2labelid.py b/tools/data/cityscapes_trainid2labelid.py
index 5a95aab8de..49f36d37bf 100644
--- a/tools/data/cityscapes_trainid2labelid.py
+++ b/tools/data/cityscapes_trainid2labelid.py
@@ -20,15 +20,12 @@
import argparse
import os
-import sys
from collections import namedtuple
import numpy as np
from PIL import Image
from tqdm import tqdm
-LOCAL_PATH = os.path.dirname(os.path.abspath(__file__))
-sys.path.append(os.path.join(LOCAL_PATH, '..'))
from paddleseg.utils import get_image_list
diff --git a/tools/data/visualize_annotation.py b/tools/data/visualize_annotation.py
index 1fc973b0c2..40f9e7d492 100644
--- a/tools/data/visualize_annotation.py
+++ b/tools/data/visualize_annotation.py
@@ -19,18 +19,14 @@
import argparse
import os
-import sys
import shutil
import cv2
import numpy as np
from PIL import Image
-__dir__ = os.path.dirname(os.path.abspath(__file__))
-sys.path.append(os.path.abspath(os.path.join(__dir__, '../')))
-
from paddleseg import utils
-from paddleseg.utils import logger, progbar, visualize
+from paddleseg.utils import progbar, visualize
def parse_args():
diff --git a/tools/export.py b/tools/export.py
index 99417dd96d..a576b67576 100644
--- a/tools/export.py
+++ b/tools/export.py
@@ -20,6 +20,7 @@
from paddleseg.cvlibs import Config
from paddleseg.utils import logger, utils
+from paddleseg.deploy.export import WrappedModel
def parse_args():
@@ -53,26 +54,6 @@ def parse_args():
return parser.parse_args()
-class WrappedModel(paddle.nn.Layer):
- def __init__(self, model, output_op):
- super().__init__()
- self.model = model
- self.output_op = output_op
- assert output_op in ['argmax', 'softmax'], \
- "output_op should in ['argmax', 'softmax']"
-
- def forward(self, x):
- outs = self.model(x)
- new_outs = []
- for out in outs:
- if self.output_op == 'argmax':
- out = paddle.argmax(out, axis=1, dtype='int32')
- elif self.output_op == 'softmax':
- out = paddle.nn.functional.softmax(out, axis=1)
- new_outs.append(out)
- return new_outs
-
-
def main(args):
assert args.config is not None, \
'No configuration file specified, please set --config'
 @@ -47,13 +47,13 @@ PaddleSeg is an end-to-end high-efficent development toolkit for image segmentat
##
@@ -47,13 +47,13 @@ PaddleSeg is an end-to-end high-efficent development toolkit for image segmentat
##