本文将使用ssd_mobilenet_v1_voc算法,以一个例子说明,如何利用paddleDetection完成一个项目----从准备数据集到完成树莓派部署,项目用到的工具是百度的AI Studio在线AI开发平台和树莓派4B
本项目是用的数据集格式是VOC格式,标注工具为labelimg,图像数据是手动拍摄获取。

-
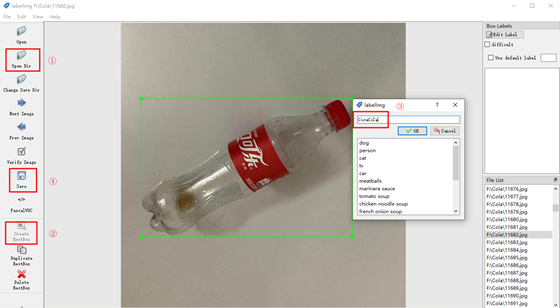
点击Open Dir,打开文件夹,载入图片
-
点击Create RectBox,即可在图像上画框标注
-
输入标签,点击OK
-
点击Save保存,保存下来的是XML文件
XML文件内容如下:

整理成VOC格式的数据集: 创建三个文件夹:Annotations、ImageSets、JPEGImages

将标注生成的XML文件存入Annotations,图片存入JPEGImages,训练集、测试集、验证集的划分情况存入ImageSets。 在ImageSets下创建一个Main文件夹,并且在Mian文件夹下建立label_list.txt,里面存入标注的标签。 此label_list.txt文件复制一份与Annotations、ImageSets、JPEGImages同级位置放置。 其内容如下:

运行该代码将会生成trainval.txt、train.txt、val.txt、test.txt,将我们标注的600张图像按照训练集、验证集、测试集的形式做一个划分。
import os
import random
trainval_percent = 0.95 #训练集验证集总占比
train_percent = 0.9 #训练集在trainval_percent里的train占比
xmlfilepath = 'F:/Cola/Annotations'
txtsavepath = 'F:/Cola/ImageSets/Main'
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
ftrainval = open('F:/Cola/ImageSets/Main/trainval.txt', 'w')
ftest = open('F:/Cola/ImageSets/Main/test.txt', 'w')
ftrain = open('F:/Cola/ImageSets/Main/train.txt', 'w')
fval = open('F:/Cola/ImageSets/Main/val.txt', 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest .close()以下代码可根据在Main文件夹中划分好的数据集进行位置索引,生成含有图像及对应的XML文件的地址信息的文件。
import os
import re
import random
devkit_dir = './'
output_dir = './'
def get_dir(devkit_dir, type):
return os.path.join(devkit_dir, type)
def walk_dir(devkit_dir):
filelist_dir = get_dir(devkit_dir, 'ImageSets/Main')
annotation_dir = get_dir(devkit_dir, 'Annotations')
img_dir = get_dir(devkit_dir, 'JPEGImages')
trainval_list = []
train_list = []
val_list = []
test_list = []
added = set()
for _, _, files in os.walk(filelist_dir):
for fname in files:
print(fname)
img_ann_list = []
if re.match('trainval.txt', fname):
img_ann_list = trainval_list
elif re.match('train.txt', fname):
img_ann_list = train_list
elif re.match('val.txt', fname):
img_ann_list = val_list
elif re.match('test.txt', fname):
img_ann_list = test_list
else:
continue
fpath = os.path.join(filelist_dir, fname)
for line in open(fpath):
name_prefix = line.strip().split()[0]
print(name_prefix)
added.add(name_prefix)
#ann_path = os.path.join(annotation_dir, name_prefix + '.xml')
ann_path = annotation_dir + '/' + name_prefix + '.xml'
print(ann_path)
#img_path = os.path.join(img_dir, name_prefix + '.jpg')
img_path = img_dir + '/' + name_prefix + '.jpg'
assert os.path.isfile(ann_path), 'file %s not found.' % ann_path
assert os.path.isfile(img_path), 'file %s not found.' % img_path
img_ann_list.append((img_path, ann_path))
print(img_ann_list)
return trainval_list, train_list, val_list, test_list
def prepare_filelist(devkit_dir, output_dir):
trainval_list = []
train_list = []
val_list = []
test_list = []
trainval, train, val, test = walk_dir(devkit_dir)
trainval_list.extend(trainval)
train_list.extend(train)
val_list.extend(val)
test_list.extend(test)
#print(trainval)
with open(os.path.join(output_dir, 'trainval.txt'), 'w') as ftrainval:
for item in trainval_list:
ftrainval.write(item[0] + ' ' + item[1] + '\n')
with open(os.path.join(output_dir, 'train.txt'), 'w') as ftrain:
for item in train_list:
ftrain.write(item[0] + ' ' + item[1] + '\n')
with open(os.path.join(output_dir, 'val.txt'), 'w') as fval:
for item in val_list:
fval.write(item[0] + ' ' + item[1] + '\n')
with open(os.path.join(output_dir, 'test.txt'), 'w') as ftest:
for item in test_list:
ftest.write(item[0] + ' ' + item[1] + '\n')
if __name__ == '__main__':
prepare_filelist(devkit_dir, output_dir)最终创建完成的VOC数据集如下:

将整个文件拷贝至 ./PaddleDetection/dataset/voc 下 以上全部完成后,还需要修改两个地方,ssd_mobilenet_v1_voc源码中是以20类目标为准设计的,本项目的目标仅为两类
- 找到 ./PaddleDetection/configs/ssd/ssd_mobilenet_v1_voc.yml文件,修改第12行的num_classes,3代表2个标签加一个背景
# 2(label_class) + 1(background)
num_classes: 3- 找到 ./PaddleDetection/ppdet/data/source/voc.py文件,修改167行的pascalvoc_label()函数,按照前面设定的label_list.txt文件里的标签顺序依次修改,并将多余的内容删掉
def pascalvoc_label(with_background=True):
labels_map = {
'PepsiCola': 1,
'CocaCola': 2
}
if not with_background:
labels_map = {k: v - 1 for k, v in labels_map.items()}
return labels_map至此,整个数据集制作及配置完成。
数据集制作完成后,上传至AI Studio,准备开始训练模型
#解压数据集
!unzip data/data25497/Cola.zip#进入PaddleDetection目录
%cd /home/aistudio/PaddleDetection/home/aistudio/PaddleDetection
#安装Python依赖库
!pip install -r requirements.txt#配置python环境变量
%env PYTHONPATH=/home/aistudio/PaddleDetectionenv: PYTHONPATH=/home/aistudio/PaddleDetection
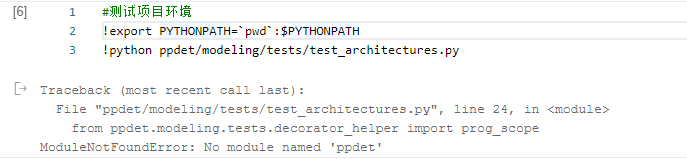
出现 No module named 'ppdet' 是环境配置的问题,有两种解决办法:
- 设置环境变量
%env PYTHONPATH=/home/aistudio/PaddleDetection- 找到报错的文件添加以下代码
import sys
DIR = '/home/aistudio/PaddleDetection'
sys.path.append(DIR)#测试项目环境
!export PYTHONPATH=`pwd`:$PYTHONPATH
!python ppdet/modeling/tests/test_architectures.py/home/aistudio/PaddleDetection/ppdet/core/workspace.py:117: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
isinstance(merge_dct[k], collections.Mapping)):
............
----------------------------------------------------------------------
Ran 12 tests in 3.681s
OK
测试环境通过后,就可以开始训练了
训练命令如下:
#开始训练
%cd home/aistudio/PaddleDetection/
!python -u tools/train.py -c configs/ssd/ssd_mobilenet_v1_voc.yml --use_tb=True --eval训练完成后输出的模型保存在 ./PaddleDetection/output/ssd_mobilenet_v1_voc 文件夹下,本次训练总轮数默认为28000轮,每隔2000轮保存一次模型,以轮次命名的均为阶段性模型,model_final为训练结束时保存的模型,best_model是每次评估后的最佳mAP模型
#测试,查看模型效果
%cd /home/aistudio/PaddleDetection/
!python tools/infer.py -c configs/ssd/ssd_mobilenet_v1_voc.yml --infer_img=/home/aistudio/2001.jpg
#infer_img输入需要预测图片的路径,看一下效果/home/aistudio/PaddleDetection
W0321 15:33:09.230892 1188 device_context.cc:237] Please NOTE: device: 0, CUDA Capability: 70, Driver API Version: 10.1, Runtime API Version: 9.0
W0321 15:33:09.234310 1188 device_context.cc:245] device: 0, cuDNN Version: 7.3.
2020-03-21 15:33:10,850-INFO: Loading parameters from output/ssd_mobilenet_v1_voc/model_final...
2020-03-21 15:33:11,110-INFO: Not found annotation file test.txt, load voc2012 categories.
2020-03-21 15:33:11,301-INFO: Infer iter 0
2020-03-21 15:33:11,320-INFO: Detection bbox results save in output/2001.jpg
接下来,需要将原生模型转化为预测模型
#转化为预测模型
!python -u tools/export_model.py -c configs/ssd/ssd_mobilenet_v1_voc.yml --output_dir=./inference_model_final2020-03-21 15:38:20,453-INFO: Loading parameters from output/ssd_mobilenet_v1_voc/model_final...
2020-03-21 15:38:20,762-INFO: save_inference_model pruned unused feed variables im_id
2020-03-21 15:38:20,762-INFO: save_inference_model pruned unused feed variables im_shape
2020-03-21 15:38:20,762-INFO: Export inference model to ./inference_model_final/ssd_mobilenet_v1_voc, input: ['image'], output: ['detection_output_0.tmp_0']...
生成的预测模型保存在 ./PaddleDetection/inference_model_final/ssd_mobilenet_v1_voc 文件夹下,会生成两个文件,模型文件名和参数文件名分别为__model__和__params__
由于部署到树莓派4B上需要使用Paddle-Lite,而PaddlePaddle的原生模型需要经过opt工具转化为Paddle-Lite可以支持的naive_buffer格式
%cd /home/aistudio/
#复制opt文件到相应目录下
!cp opt /home/aistudio/PaddleDetection/inference_model_final/ssd_mobilenet_v1_voc
#进入预测模型文件夹
%cd /home/aistudio/PaddleDetection/inference_model_final/ssd_mobilenet_v1_voc
#下载opt文件
#!wget https://github.com/PaddlePaddle/Paddle-Lite/releases/download/v2.3.0/opt
#给opt加上可执行权限
!chmod +x opt
#使用opt进行模型转化,将__model__和__params__转化为model.nb
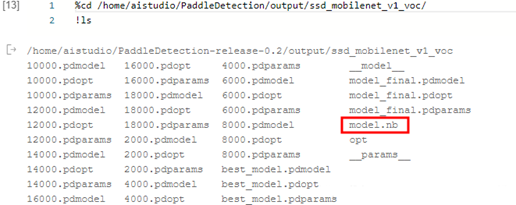
!./opt --model_file=__model__ --param_file=__params__ --optimize_out_type=naive_buffer --optimize_out=./model
!ls这个opt自己下载实在是太慢了,因此我在网盘里已经准备好了opt文件,可以直接上传至AI Studio操作,最终结果如下图所示:
到目前为止,在AI Studio上的所有内容已经完成,文章(一)(二)的目的就是为了生成这个model.nb文件,将其部署在树莓派4B上使用。
Paddle-Lite目前支持三种编译的环境:
- Docker 容器环境
- Linux(推荐 Ubuntu 16.04)环境
- Mac OS 环境
本次项目仅涉及到树莓派的ARMLinux环境编译,其他编译环境请参考Paddle-Lite官方文档
编译环境要求 gcc、g++、git、make、wget、python cmake(建议使用3.10或以上版本) 官方安装流程如下:
# 1. Install basic software
apt update
apt-get install -y --no-install-recomends \
gcc g++ make wget python unzip
# 2. install cmake 3.10 or above
wget https://www.cmake.org/files/v3.10/cmake-3.10.3.tar.gz
tar -zxvf cmake-3.10.3.tar.gz
cd cmake-3.10.3
./configure
make
sudo make install此环境树莓派应该是会有的,可以自行检查,没有的包安装上即可。 至此完成所有的编译环境配置。 将 Paddle-Lite 和 Paddle-Lite-Demo 移动至树莓派中,放在自己方便的目录下即可,在这里我的 Paddle-Lite 放在了 /home/pi/ 下,将 Paddle-Lite-Demo 放在了 /home/pi/Desktop/ 下,并且将 /home/pi/Paddle/Paddle-Lite/lite/tools/build.sh 加上执行权限
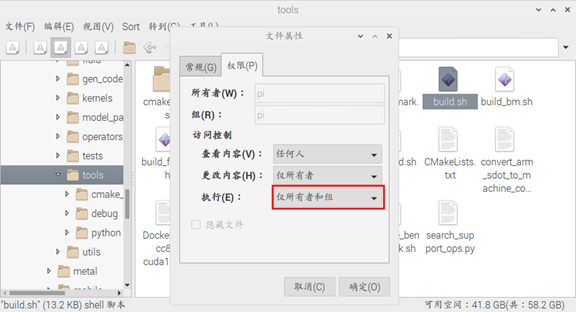
所有工作完成后,即可开始编译Paddle-Lite
cd /home/pi/Paddle/Paddle-Lite
sudo ./lite/tools/build.sh \
--build_extra=OFF \
--arm_os=armlinux \
--arm_abi=armv7hf \
--arm_lang=gcc \
tiny_publish虽然树莓派4B已经是 ARMv8 的CPU架构,但官方系统为32位,还是需要使用ARMv7架构的编译方式
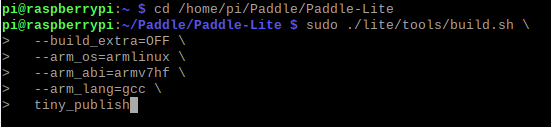
编译结束,结果如下:
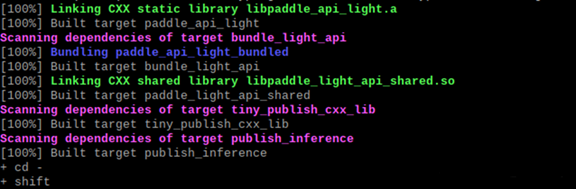
整体文件结构如下:
object_detection_demo
Paddle-Lite:
include (编译好的Paddle—Lite的头文件)
libs(存放armv7hf)
armv7hf(编译好的Paddle—Lite的库文件)
code:
models(模型文件:model.nb)
images(测试图片)
CMakeLists.txt
mask_detection.cc
run.sh
- 打开 /home/pi/Desktop/Paddle-Lite-Demo/PaddleLite-armlinux-demo/object_detection_demo 文件夹,在此目录下新建 Paddle-Lite、code 文件夹
- Paddle-Lite文件夹下新建 include、libs 文件夹
- libs文件夹下新建 armv7hf 文件夹
- 将 images、labels、CMakeLists.txt、run.sh、object_detection_demo.cc 文件移入 code 文件夹下
对于 Paddle-Lite 的编译结果,我们需要使用的东西在 /home/pi/Paddle/Paddle-Lite/build.lite.armlinux.armv7hf.gcc/inference_lite_lib.armlinux.armv7hf/cxx 文件夹下
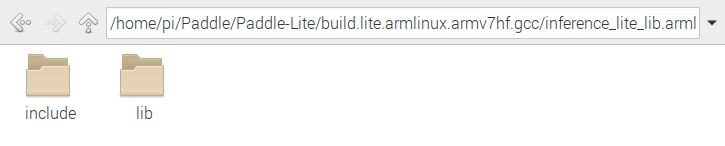
将 include 和 lib 中的头文件和库文件提取出来,分别放入 include 和 armv7hf 文件夹中 至此已做好文件结构的搭建
接下来就是最后一步了,将模型放进文件中,稍作修改就大功告成了!
- 进入 code 文件夹
- 修改 labels 文件夹下的 pascalvoc_label_list ,内容必须与训练时的 label_list.txt 文件内容一致 (注意 pascalvoc_label_list 是纯文本文档,不是 .txt 文本文档,弄错了预测出来的框选标签会打 unknow 的!)
- 将在PaddlePaddle学习之使用PaddleDetection在树莓派4B进行模型部署(二)----- 深度学习模型训练得到的 model.nb 放进 models 文件夹
- 打开 run.sh 文件,注释掉第四行的 TARGET_ARCH_ABI=armv8 ,打开第五行的,取消第5行 TARGET_ARCH_ABI=armv7hf 的注释
- 修改第六行的 PADDLE_LITE_DIR 索引到文件中Paddle-Lite目录
- 修改第十九行的model文件的模型索引目录和预测图片的索引目录
#!/bin/bash
# configure
#TARGET_ARCH_ABI=armv8 # for RK3399, set to default arch abi
TARGET_ARCH_ABI=armv7hf # for Raspberry Pi 3B
PADDLE_LITE_DIR=/home/pi/Desktop/Paddle-Lite-Demo/PaddleLite-armlinux-demo/object_detection_demo/Paddle-Lite
if [ "x$1" != "x" ]; then
TARGET_ARCH_ABI=$1
fi
# build
rm -rf build
mkdir build
cd build
cmake -DPADDLE_LITE_DIR=${PADDLE_LITE_DIR} -DTARGET_ARCH_ABI=${TARGET_ARCH_ABI} ..
make
#run
LD_LIBRARY_PATH=$LD_LIBRARY_PATH:${PADDLE_LITE_DIR}/libs/${TARGET_ARCH_ABI} ./object_detection_demo ../models/model.nb ../labels/pascalvoc_label_list ../images/2001.jpg ./result.jpg修改完run.sh文件后,就算是完成了所有的配置内容,可以开始放心的 RUN 了!!
/home/pi/Desktop/Paddle-Lite-Demo/PaddleLite-armlinux-demo/object_detection_demo/code
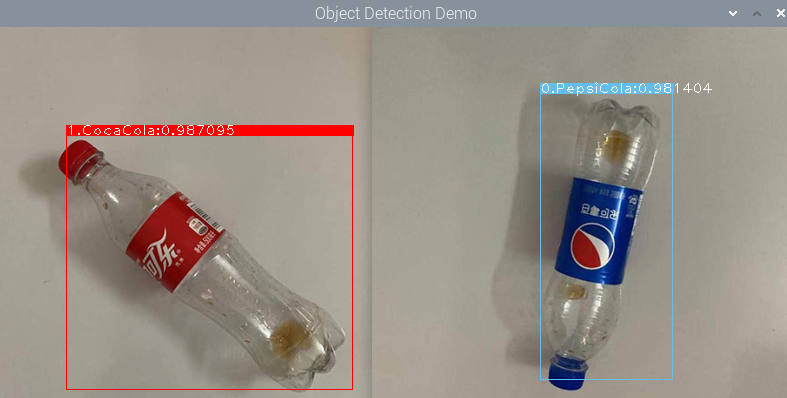
sudo ./run.sh最后的输出结果如下:
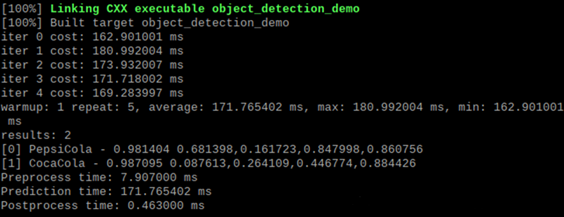
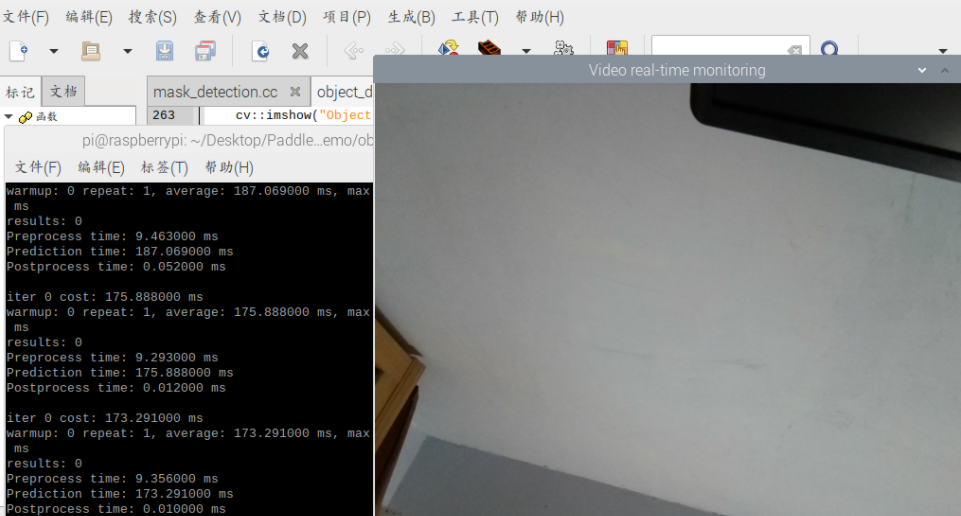
关于视频流的实时监测,在源代码的主函数中可以看到
if (argc > 3) {
WARMUP_COUNT = 1;
REPEAT_COUNT = 5;
std::string input_image_path = argv[3];
std::string output_image_path = argv[4];
cv::Mat input_image = cv::imread(input_image_path);
cv::Mat output_image = process(input_image, word_labels, predictor);
cv::imwrite(output_image_path, output_image);
cv::imshow("Object Detection Demo", output_image);
cv::waitKey(0);
} else {
cv::VideoCapture cap(-1);
cap.set(cv::CAP_PROP_FRAME_WIDTH, 640);
cap.set(cv::CAP_PROP_FRAME_HEIGHT, 480);
if (!cap.isOpened()) {
return -1;
}
while (1) {
cv::Mat input_image;
cap >> input_image;
cv::Mat output_image = process(input_image, word_labels, predictor);
cv::imshow("Object Detection Demo", output_image);
if (cv::waitKey(1) == char('q')) {
break;
}
}
cap.release();
cv::destroyAllWindows();
}当我们在 run.sh 文件中设置小于三个参数时,即可使用视频流实时监测
#run
LD_LIBRARY_PATH=$LD_LIBRARY_PATH:${PADDLE_LITE_DIR}/libs/${TARGET_ARCH_ABI} ./object_detection_demo ../models/ssd_mobilenet_v1_pascalvoc_for_cpu/best.nb ../labels/pascalvoc_label_list
#../images/2.jpg ./result.jpg在这里注释掉图片路径和输出路径即可
注:如果有用 Opencv-4.1.0 版本的,可能在编译 object_detection_demo.cc 时在 267、268 行会报错 源代码如下:
cap.set(CV_CAP_PROP_FRAME_WIDTH, 640);
cap.set(CV_CAP_PROP_FRAME_HEIGHT, 480); cap.set(CV_CAP_PROP_FRAME_WIDTH, 640); cap.set(CV_CAP_PROP_FRAME_HEIGHT, 480);
由于新版本的API发生了变化。需要修改为如下代码:
cap.set(cv::CAP_PROP_FRAME_WIDTH, 640);
cap.set(cv::CAP_PROP_FRAME_HEIGHT, 480);图片:
视频流: