Tensorboard Epoch Weird Chart #510
Labels
bug
Something isn't working
Comments
|
Cool setup - we also do complicated model loading/weights transfering setups. The first thing that comes to mind is that you may be resetting the steps when loading the student, so when the student starts training it does that thing where it goes back in 'time'.
|
|
fwiw - try restarting tensorboard server. i have found that it frequently has a 'hangover' from the prior run that gives graph results that are reminiscent of yours. restarting and clearing log files always clears it up for me. |
|
@karanchahal if this is not indeed fixed, happy to reopen. |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Describe the bug
I am getting these weird graphs in my tensorboard, it worked fine when I was doing model.cuda() manually , but when I shifted to the automated stuff using gpus = 1 and distributed backend = None.
I have posted this graph below:
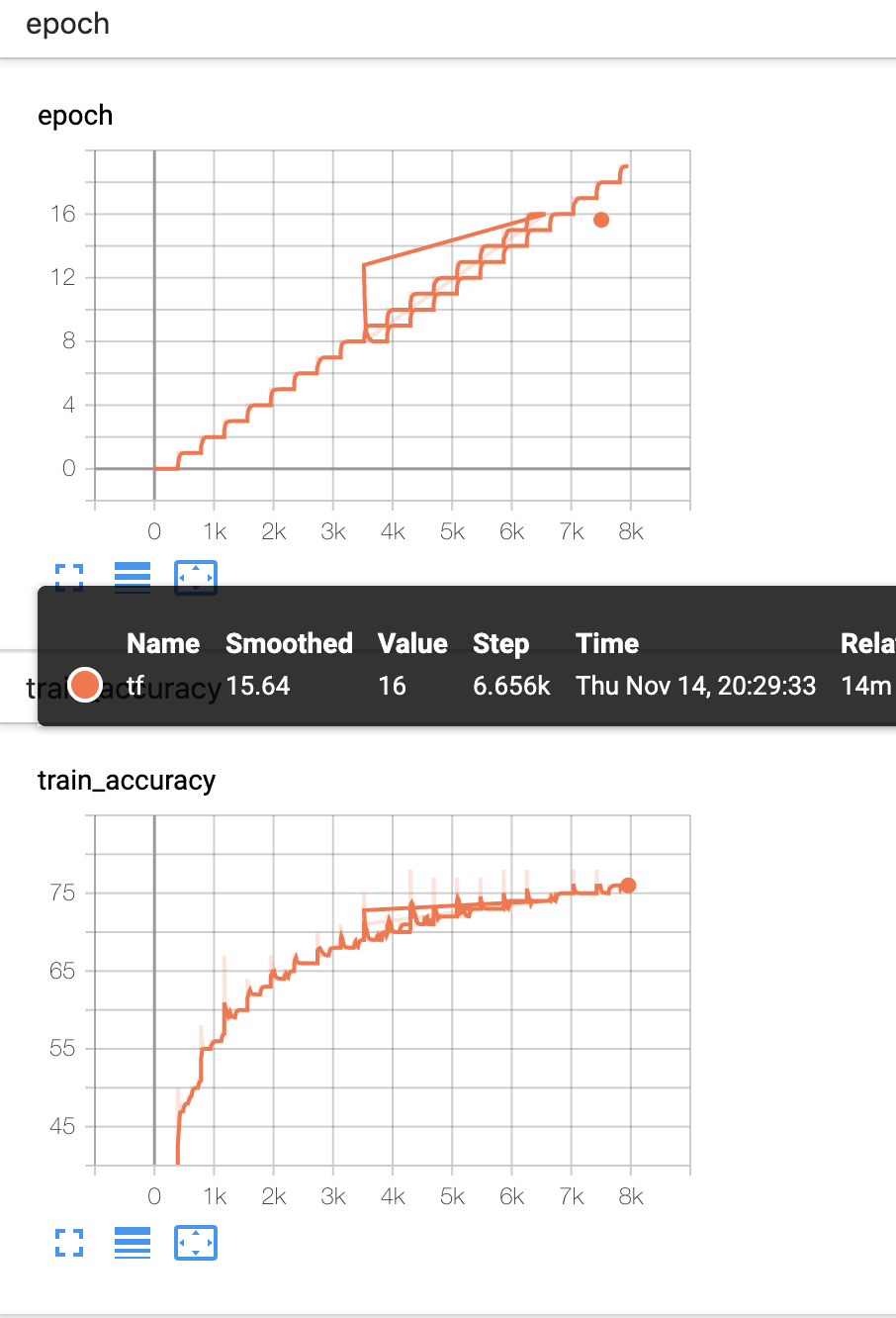
My code of trainer and lightning module is as follows:
Trainer:
Lightning Module
The text was updated successfully, but these errors were encountered: