| title | layout | filename |
|---|---|---|
Workers and threads |
template |
workers_and_threads.md |
Not strictly FastAPI performance tuning, but performance improvement on runner environment naturally helps for the system. Gunicorn is one straightforward option to run FastAPI in production environment For high performance low latency, cheap, robust and reliable services it is important to get the maximum out of a single computing unit. In this example we will focus on a container with only 2 CPU cores allocated. This is typically used and GitHub Action container has two CPU cores allocated where these measurements were executed.
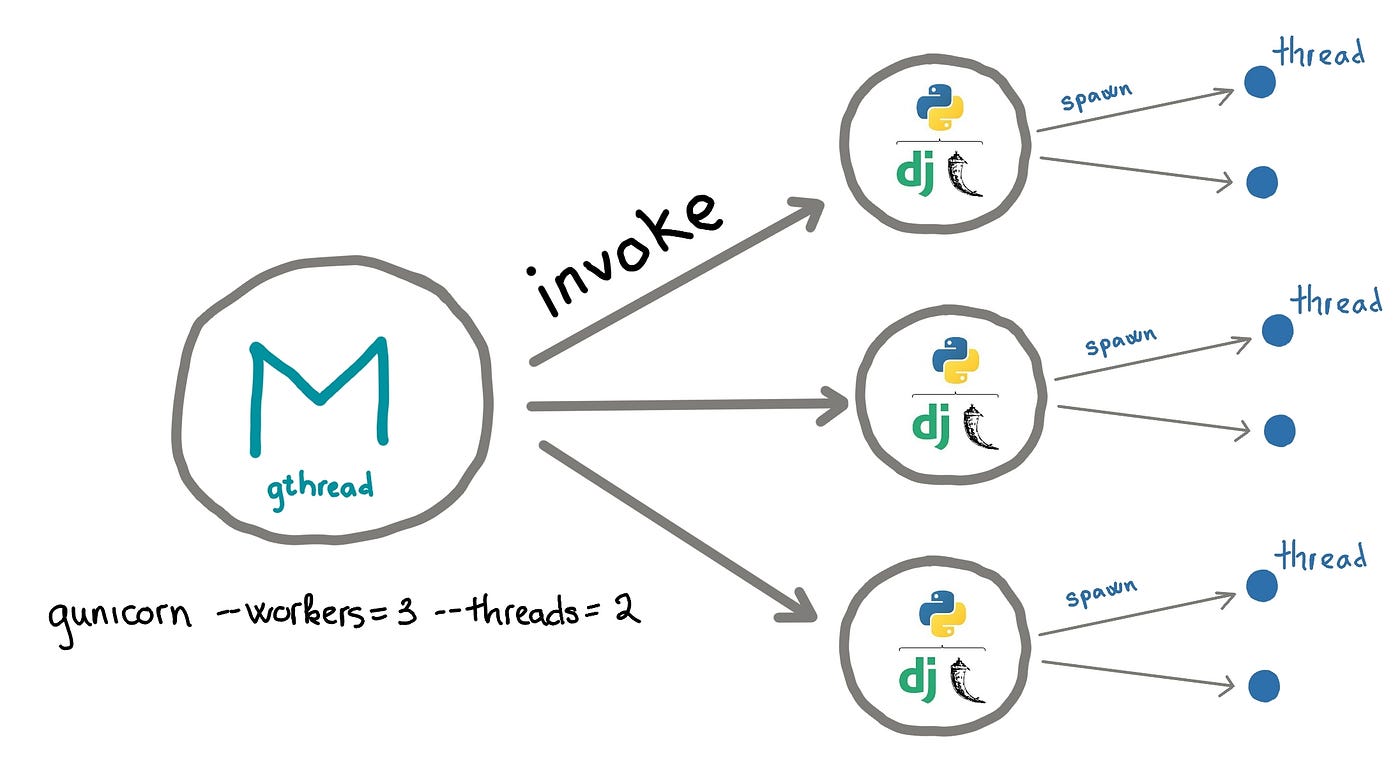
Gunicorn is a mature, fully featured server and process manager. Gunicorn can manage the processes and threads for us and run UvicornWorker which can carry FastAPI application
Uvicorn can run FastAPI application even with multiple workers, convenient during development thanks to the reload capability but even their documentation suggests to run with Gunicorn in production
Workers are pre-forked processes spawn by Gunicorn. Number of workers had to be pre-defined, there is no process pool like e.g: php-fpm
Gunicorn documentation suggests using (2 x $num_cores) + 1 as the number of workers, but also reminds: Always remember, there is such a thing as too many workers. After a point your worker processes will start thrashing system resources decreasing the throughput of the entire system.
We will see it in our measurements
Gunicorn can also fork processes for each worker. We know the story around GIL, but don't judge, measure This is how it looks like in action:
1-5 Workers and 1-5 threads were measured, this together is 25 measurements in the usual way. There would be place for further measurements E.g measuring with 0 threads or raising the counts to even higher and so on. Also note that some values are not fitting due to intermittent performance issue during measurement. Request is the same in allcases the difference is the size of the response (few bytes vs 1MB)

2 worker configuration outperforms all others, thread number seems no significant impact

Result is not as clear as for synchronous endpoint, 3 workers and 1 thread seems the winner

Similar to small responses 2 workers performing the best

- For some strange reason 2 and 5 threads working the best at each worker count, but best results are at 2 and 3 workers
- FastAPI latency was lowest at 3 workers and 2 threads
No clear winner, but suggestion of Gunicorn documentation was right, there is such a thing as too many workers.
It is highly recommended making a measurement like this and select the best combination for the given usecase. Feel free to reuse the test code
You may ask why use Gunicorn instead of Uvicorn for application where latency is not that critical and high load is not expected? Let's see:
1 worker, 0 thread
| Test attribute | Test run 1 | Test run 2 | Test run 3 | Average |
|---|---|---|---|---|
| Requests per second | 1182.34 | 1202.61 | 1181.1 | 1188.68 |
| Time per request [ms] | 84.578 | 83.153 | 84.667 | 84.1327 |
| Test attribute | Test run 1 | Test run 2 | Test run 3 | Average | Difference to baseline |
|---|---|---|---|---|---|
| Requests per second | 1116.09 | 1139.08 | 1151.8 | 1135.66 | -4.46 % |
| Time per request [ms] | 89.598 | 87.79 | 86.821 | 88.0697 | -3.94 ms |
2 workers, 0 threads
| Test attribute | Test run 1 | Test run 2 | Test run 3 | Average |
|---|---|---|---|---|
| Requests per second | 1658.62 | 1518.47 | 1697.9 | 1625 |
| Time per request [ms] | 60.291 | 65.856 | 58.896 | 61.681 |
| Test attribute | Test run 1 | Test run 2 | Test run 3 | Average | Difference to baseline |
|---|---|---|---|---|---|
| Requests per second | 1518.02 | 1554.76 | 1564.23 | 1545.67 | -4.88 % |
| Time per request [ms] | 65.875 | 64.318 | 63.929 | 64.7073 | -3.03 ms |
Not a big difference, but Gunicorn performs a bit better however requires extra package installed, a bit more configuration, etc.