Udacity Data Science Nanodegree Term 2
This projects consists of the model that classifies disaster messages and a Wep App. Web App includes 3 Graphs of the data analysis and a text classifier.
-
Run the following commands in the project's root directory to set up your database and model.
- To run ETL pipeline that cleans data and stores in database
python data/process_data.py data/disaster_messages.csv data/disaster_categories.csv data/DisasterResponse.db - To run ML pipeline that trains classifier and saves
python models/train_classifier.py data/DisasterResponse.db models/classifier.pkl
- To run ETL pipeline that cleans data and stores in database
-
In the terminal, use this command to get the link for vieweing the app: env | grep WORK
The link wil be: http://WORKSPACESPACEID-3001.WORKSPACEDOMAIN replacing WORKSPACEID and WORKSPACEDOMAIN with your values.
- Run the following command in the app's directory to run your web app.
python run.py
process_data.py is used as the pipeline for processing the data and preparing in for the further usage.
train_classifier.py is used to create a model needed for the given classification problem.
run.py, go.html, master.html are used to run the Web App.
Markdown cells were used to assist in walking through the thought process for individual steps.
3 Graphs and a text classifier can be observed in the constructed Web App. Example:
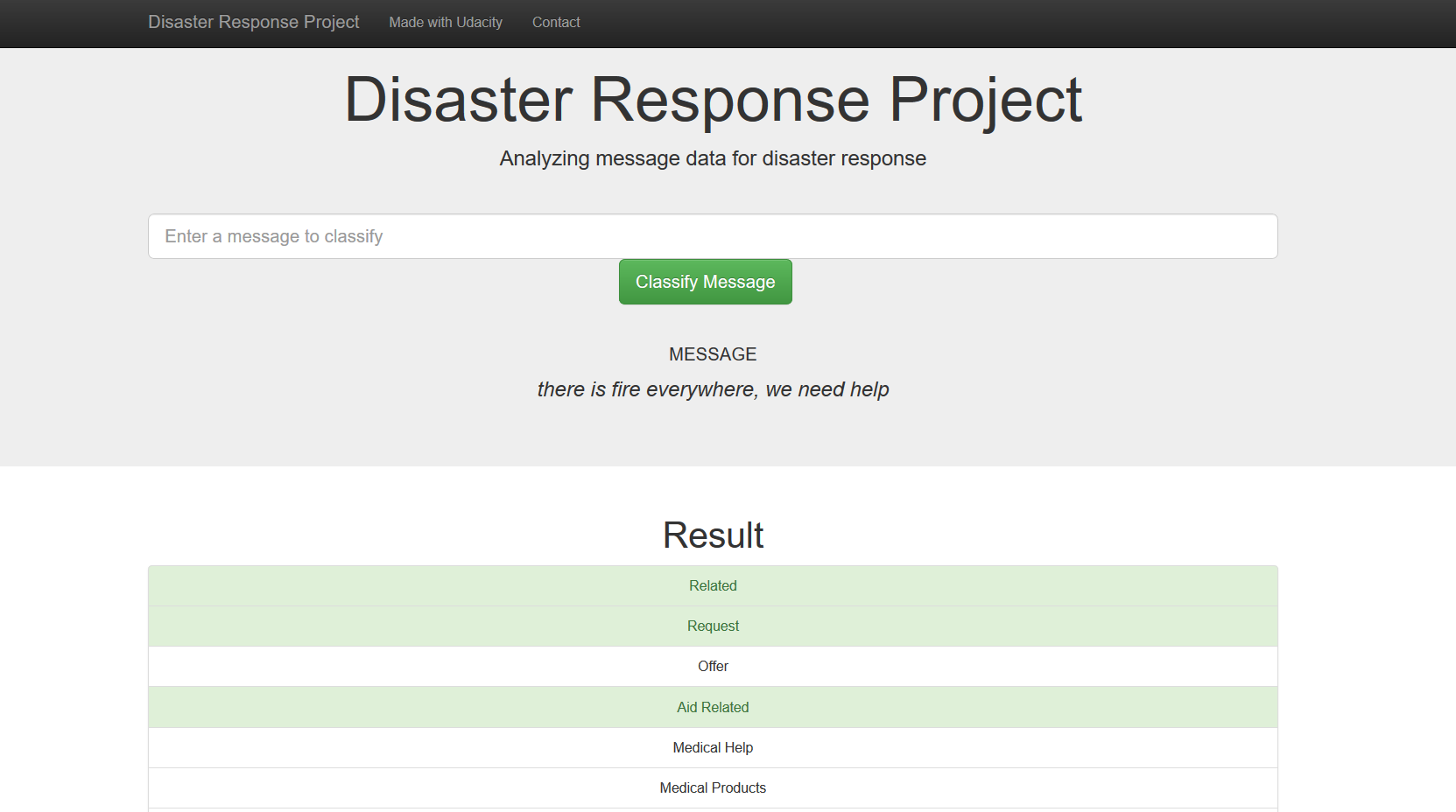
Must give credit to Udacity for the data. Feel free to use the code here as you would like!