This repository is the official implementation of VMC.
[CVPR 2024] VMC: Video Motion Customization using Temporal Attention Adaption for Text-to-Video Diffusion Models
Hyeonho Jeong*,
Geon Yeong Park*,
Jong Chul Ye,
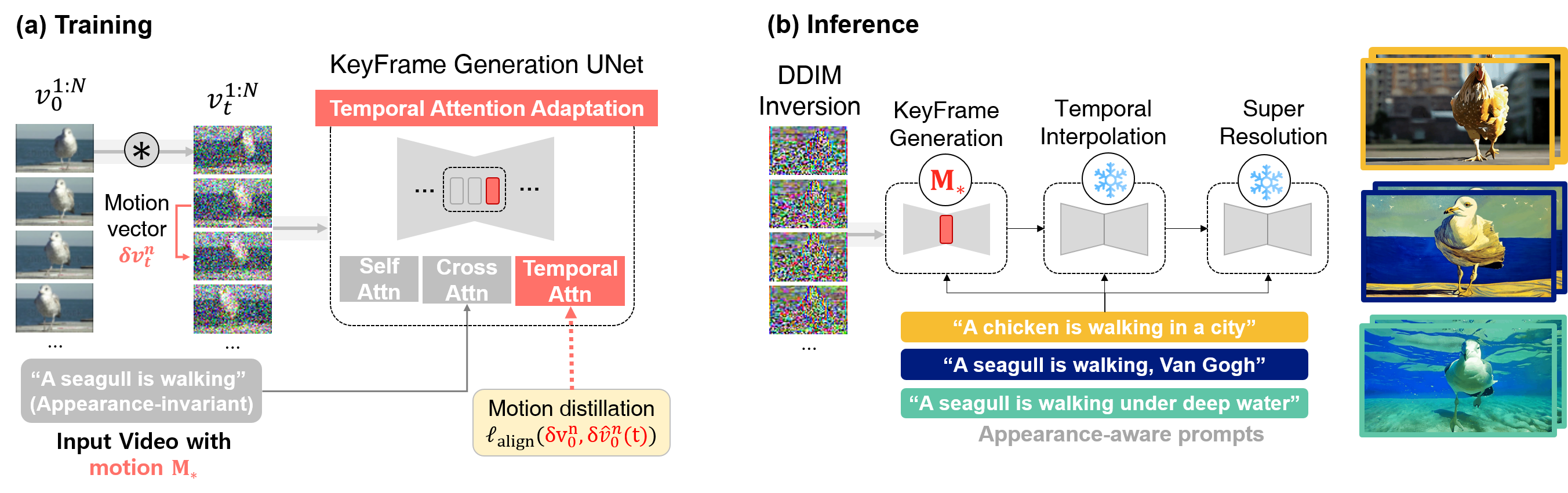
Given an input video with any type of motion patterns, our framework, VMC fine-tunes only the Keyframe Generation Module within hierarchical Video Diffusion Models for motion-customized video generation.
- [2023.11.30] Initial Code Release (Additional codes will be uploaded.)
pip install -r requirements.txtThe following command will run "train & inference" at the same time:
accelerate launch train_inference.py --config configs/car_forest.yml*Additional scripts of 'train_only' and 'inference_with_pretrained' will be uploaded too.
- PNG files: Google Drive Folder
- GIF files: Google Drive Folder
| Input Videos | Output Videos |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
|
 |
|
 |
 |
 |
 |
 |
| Reversed Videos | Output Videos |
 |
 |
 |
 |
 |
 |
 |
 |
If you find our work interesting, please cite our paper.
@article{jeong2023vmc,
title={VMC: Video Motion Customization using Temporal Attention Adaption for Text-to-Video Diffusion Models},
author={Jeong, Hyeonho and Park, Geon Yeong and Ye, Jong Chul},
journal={arXiv preprint arXiv:2312.00845},
year={2023}
}- VMC directly employs an open-source project on cascaded Video Diffusion Models, Show-1, along with DeepFloyd IF.
- This code builds upon Diffusers and we referenced the code logic of Tune-A-Video.
- We conducted evaluation against 4 great projects: VideoComposer, Gen-1, Tune-A-Video, Control-A-Video
Thanks all for open-sourcing!