`, ``, та `` від їх контенту.
+
+## 10.2. Використання
+
+Markdown може використовуватися для різних цілей: websites, документи, нотатки, книги, презентації, повідомлення на пошту, та технічної документації. Нижче коротко наведені ці варіанти використання.
+
+Markdown був розроблений для Інтернету, тому не дивно, що існує багато застосунків, спеціально розроблених для створення контенту веб-сайту на ньому. Якщо ви шукаєте найпростіший можливий спосіб створити веб-сайт із файлами Markdown, перегляньте [blot.im](https://blot.im) та [smallvictori.es](https://smallvictori.es). Після реєстрації в одній із цих служб вони створюють папку Dropbox на вашому комп’ютері. Для відображення змісту на ВебСайті необхідні файли Markdown просто копіюються у потрібну папку.
+
+Якщо ви знайомі з HTML, CSS та контролем версій, перегляньте [Jekyll](https://www.markdownguide.org/tools/jekyll/), популярний генератор статичних сайтів, який приймає файли Markdown та створює веб-сайт HTML. Однією з переваг цього підходу є те, що [GitHub Pages](https://www.markdownguide.org/tools/github-pages/) надають безкоштовний хостинг для веб-сайтів, створених [Jekyll](https://www.markdownguide.org/tools/jekyll/).
+
+Якщо ви хочете використовувати систему управління вмістом (CMS) для підтримки свого веб-сайту, подивіться на [Ghost](https://www.markdownguide.org/tools/ghost/). Це безкоштовна платформа для блогів із відкритим кодом із приємним редактором Markdown. Якщо ви користувач WordPress, ви будете раді дізнатися, що існує [підтримка Markdown](https://en.support.wordpress.com/markdown/) для веб-сайтів, розміщених на WordPress.com. Сайти WordPress, що розміщуються на власних веб-сайтах, можуть використовувати плагін [Jetpack](https://jetpack.com/support/markdown/).
+
+У Markdown немає всіх можливостей текстових процесорів, таких як Microsoft Word, але він досить добре підходить для створення основних документів, таких як завдання та листи. Ви можете використовувати застосунок для створення документів Markdown, експорту документів з формату Markdown у PDF або HTML. У свою чергу, маючи документ PDF, ви можете зробити з ним що завгодно - роздрукувати , надіслати електронною поштою або завантажити його на веб-сайт.
+
+Майже в усіх напрямках Markdown є ідеальним синтаксисом для нотаток. На жаль, [Evernote](https://evernote.com/) та [OneNote](https://www.onenote.com/), два найпопулярніші застосунки для нотаток, наразі не підтримують Markdown. Але є кілька інших застосунків для нотаток, які підтримують Markdown, зокрема [Simplenote](https://www.markdownguide.org/tools/simplenote/), [Notable](https://www.markdownguide.org/tools/notable/), [Bear](https://www.markdownguide.org/tools/bear/) , [Boostnote](https://www.markdownguide.org/tools/boostnote/) та інші.
+
+Для створення електронних книг можна використати спеціальні сервіси, наприклад [Leanpub](https://leanpub.com/), які приймають вихідні файли у форматі Markdown. Leanpub видає книгу у форматі файлів PDF, EPUB та MOBI. Для створення копії книги в паперовому вигляді, можна завантажити файл PDF в інший сервіс, наприклад [Kindle Direct Publishing](https://kdp.amazon.com). Щоб дізнатися більше про написання та самостійне видання книги за допомогою Markdown, прочитайте [цю публікацію в блозі](https://medium.com/techspiration-ideas-making-it-happen/how-i-wrote-and-publisher-my -novel-using-only-open-source-tools-5cdfbd7c00ca).
+
+Можна створювати презентації з файлів, відформатованих Markdown. Це може бути хорошою альтернативою використанню застосунків, таких як PowerPoint або Keynote. [Remark](https://remarkjs.com) ([проект GitHub](https://github.com/gnab/remark)) - популярний браузерний інструмент для слайд-шоу від Markdown, як і [Cleaver](https://jdan.github.io/cleaver/)([проект GitHub](https://github.com/jdan/cleaver)).
+
+Існує простий спосіб писати форматоване повідомлення електронної пошти за допомогою Markdown. [Markdown Here](https://www.markdownguide.org/tools/markdown-here/) - це вільне розширення для браузера з відкритим кодом, яке перетворює текст у форматі Markdown у HTML, готовий для надсилання.
+
+Markdown - може використовуватися для ведення технічної документації. Якщо ви пишете документацію для товару чи послуги, подивіться на ці зручні інструменти:
+
+- [Read the Docs](https://readthedocs.org) можна створити веб-сайт документації з ваших файлів Markdown з відкритим кодом. Просто підключіть свій сховище GitHub до їх служби та push - Прочитайте Документи робить все інше. Вони також мають [послугу для комерційних структур](https://readthedocs.com/).
+- [MkDocs](https://www.markdownguide.org/tools/mkdocs/) - це швидкий і простий генератор статичних сайтів, орієнтований на створення проектної документації. Джерельні файли документації записуються в Markdown і налаштовуються одним файлом конфігурації YAML. У MkDocs є кілька [вбудованих тем](https://www.mkdocs.org/user-guide/styling-your-docs/), включаючи порт [Read the Docs](https://readthedocs.org/ ) тема документації для використання з MkDocs. Однією з найновіших тем є [MkDocs Material](https://squidfunk.github.io/mkdocs-material/).
+- [Docusaurus](https://www.markdownguide.org/tools/docusaurus/) - статичний генератор сайтів, призначений виключно для створення веб-сайтів з документацією. Він підтримує переклади, пошук та версії.
+- [VuePress](https://vuepress.vuejs.org/) - статичний генератор сайту, що працює від [Vue](https://vuejs.org/) та оптимізований для написання технічної документації.
+- [Jekyll](https://www.markdownguide.org/tools/jekyll/) згадувався раніше у розділі на веб-сайтах, але це також хороший варіант для створення веб-сайту документації з файлів Markdown. Якщо ви йдете цим шляхом, обов’язково ознайомтеся з [темою документації на Jekyll](https://idratherbewriting.com/documentation-theme-jekyll/).
+
+## 10.3. Редактори
+
+Хоча Markdown є полегшеною мовою розмітки яку легко читати та редагувати звичайними текстовими редакторами, існують спеціально розроблені редактори, які дозволяють попередньо переглядати зі стилями. Є багато таких редакторів, які наявні для всіх основних платформ. Існує плаґін [підсвітки синтаксису](https://uk.wikipedia.org/wiki/Підсвітка_синтаксису) для Markdown, вбудований у [gedit](https://uk.wikipedia.org/wiki/Gedit) та [Vim](https://uk.wikipedia.org/wiki/Vim).
+
+Деякі з редакторів:
+
+- **Mac:** [MacDown](https://www.markdownguide.org/tools/macdown/), [iA Writer](https://www.markdownguide.org/tools/ia-writer/), або[Marked](https://marked2app.com/)
+- **iOS / Android:** [iA Writer](https://www.markdownguide.org/tools/ia-writer/)
+- **Windows:** [ghostwriter](https://wereturtle.github.io/ghostwriter/) або [Markdown Monster](https://markdownmonster.west-wind.com/), https://v2.docusaurus.io/
+- **Linux:** [ReText](https://github.com/retext-project/retext) або [ghostwriter](https://wereturtle.github.io/ghostwriter/)
+- **Web:** [Dillinger](https://www.markdownguide.org/tools/dillinger/) або [StackEdit](https://www.markdownguide.org/tools/stackedit/)
+
+Крім наведених вище є набагато більше платних та безкоштовних редакторів. Наприклад [Typora](https://typora.io/) - це редактор Markdown що працює за принципом *Live Preview*, тобто після введення редагування тексту, він одразу показує результат. Підтримує багато мов локалізації, у тому числі українську. Завантажується [за посиланням](https://typora.io/#download). Наразі знаходиться в режимі бета-тестування, тому є безкоштовним. Typora використовує аромат Markdown сумісний з GitHub.
+
+Visual Studio Code має кілька плагінів для роботи з MD, так само як і Notepad++. Таким чином кожен може вибрати собі редактор, який буде йому зручний.
+
+## 10.4. Розширений синтаксис
+
+Елементів базового синтаксису, що викладений в оригінальному проектному документі Джона Грубера, може бути недостатньо для деяких функцій. Декілька людей та організацій взяли на себе завдання розширити основний синтаксис, додавши додаткові елементи, такі як таблиці, кодові блоки, підсвічування синтаксису, автоматичне посилання URL-адрес та виноски. Ці елементи можна ввімкнути за допомогою легкої мови розмітки, що базується на базовому синтаксисі Markdown, або додавши розширення до сумісного процесора Markdown. Слід нагадати, що не всі програми Markdown підтримують розширені елементи синтаксису, а перелік цих елементів залежить від використовуваного Markdown-аромату.
+
+Існує кілька легких мов розмітки, які є *супер-наборами* у Markdown. Вони включають основний синтаксис Грубера та надбудовують його, додаючи додаткові елементи, такі як таблиці, кодові блоки, підсвічування синтаксису, автоматичне посилання URL-адрес та виноски. У багатьох найпопулярніших застосунках Markdown використовується одна з таких легких мов розмітки:
+
+- [CommonMark](https://commonmark.org)
+- [GitHub Flavored Markdown (GFM)](https://github.github.com/gfm/)
+- [Markdown Extra](https://michelf.ca/projects/php-markdown/extra/)
+- [MultiMarkdown](https://fletcherpenney.net/multimarkdown/)
+- [R Markdown](https://rmarkdown.rstudio.com/)
+
+### Таблиці
+
+Щоб додати таблицю, використовуйте три чи більше дефісів (`---`), щоб створити заголовок кожного стовпця, а для розділення кожного стовпця використовуйте труби (` | `). Ви можете додатково додати труби на будь-якому кінці таблиці.
+
+```markdown
+| Syntax | Description |
+| ----------- | ----------- |
+| Header | Title |
+| Paragraph | Text |
+```
+
+Результат матиме наступний вигляд:
+
+| Syntax | Description |
+| --------- | ----------- |
+| Header | Title |
+| Paragraph | Text |
+
+Ширина комірок може змінюватися, як показано нижче. Але результат матиме однаковий вигляд.
+
+```markdown
+| Syntax | Description |
+| --- | ----------- |
+| Header | Title |
+| Paragraph | Text |
+```
+
+Створення таблиць з дефісами та трубами може бути втомливим. Щоб прискорити процес, спробуйте скористатися [Генератором таблиць Markdown](https://www.tablesgenerator.com/markdown_tables). Створіть таблицю за допомогою графічного інтерфейсу, а потім скопіюйте створений текст у форматі Markdown у свій файл. Крім того редактори можуть мати вбудовані редактори таблиць, аналогічно як наприклад у MS Word.
+
+Ви можете вирівняти текст у стовпцях ліворуч, праворуч або по центру, додавши двокрапку (`:`) зліва, справа або з обох боків дефісів у рядку заголовка.
+
+```
+| Syntax | Description | Test Text |
+| :--- | :----: | ---: |
+| Header | Title | Here's this |
+| Paragraph | Text | And more |
+```
+
+Це матиме наступний вигляд:
+
+| Syntax | Description | Test Text |
+| :-------- | :---------: | ----------: |
+| Header | Title | Here’s this |
+| Paragraph | Text | And more |
+
+Ви можете відформатувати текст у таблицях. Наприклад, ви можете додати посилання, код, і форматування. Але ви не можете додавати заголовки, блоки цитат, списки, горизонтальні правила, зображення чи теги HTML.
+
+### Огороджені блоки коду
+
+Основний синтаксис Markdown дозволяє створити кодові блоки шляхом відступу рядків на чотири пробіли або одну вкладку. Якщо вам це незручно, спробуйте використовувати огороджені кодові блоки. Залежно від процесора або редактора Markdown, ви будете використовувати три зворотні одинарні лапки ```` `або три тилди (` ~~~ `) на рядках до і після кодового блоку. Не потрібно відступати жодних рядків!
+
+```
+```
+{
+ "firstName": "John",
+ "lastName": "Smith",
+ "age": 25
+}
+```
+```
+
+Зрештою, це матиме вигляд:
+
+```
+{
+ "firstName": "John",
+ "lastName": "Smith",
+ "age": 25
+}
+```
+
+Багато процесорів Markdown для огороджених блоків коду підтримують підсвічування синтаксису . Ця функція дозволяє додавати кольорове підсвічування для будь-якої мови, на якій був написаний ваш код. Щоб додати підсвічування синтаксису, вкажіть мову поруч із задніми позначками перед огородженим кодом блоку. Наступний шматок тексту
+
+```
+```json
+{
+ "firstName": "John",
+ "lastName": "Smith",
+ "age": 25
+}
+```
+```
+
+матиме такий вигляд:
+
+```json
+{
+ "firstName": "John",
+ "lastName": "Smith",
+ "age": 25
+}
+```
+
+### Виноски
+
+Виноски дозволяють додавати примітки та посилання, не захаращуючи тіло документа. Коли ви створюєте виноску, з'являється надрядковий номер з посиланням на виноску. Читачі можуть натиснути посилання, щоб перейти до вмісту виноски внизу сторінки.
+
+Щоб створити посилання на виноску, додайте каретку та ідентифікатор всередині дужок (`[^1]`). Ідентифікатори можуть бути числами або словами, але вони не можуть містити пробілів чи вкладок. Ідентифікатори лише співвідносять посилання виноски із самою виноскою - у висновку виноски нумеруються послідовно.
+
+Додайте виноску, використовуючи іншу каретку та цифру всередині дужок із двокрапкою та текстом (`[^1]: My footnote.`). Не потрібно ставити виноски в кінці документа. Ви можете розмістити їх куди завгодно, крім інших елементів, таких як списки, блокові лапки та таблиці.
+
+```
+Here's a simple footnote,[^1] and here's a longer one.[^bignote]
+[^1]: This is the first footnote.
+[^bignote]: Here's one with multiple paragraphs and code.
+ Indent paragraphs to include them in the footnote.
+ `{ my code }`
+ Add as many paragraphs as you like.
+```
+
+Це матиме вигляд:
+
+
+
+### Ідентифікатори заголовків (Heading ID)
+
+Багато процесорів Markdown підтримують власні ідентифікатори для [заголовків](https://www.markdownguide.org/basic-syntax/#headings) - деякі процесори Markdown автоматично додають їх. Додавання спеціальних ідентифікаторів дозволяє вам безпосередньо посилатися на заголовки та змінювати їх за допомогою CSS. Щоб додати спеціальний ідентифікатор заголовка, додайте його до фігурних фігурних дужок у тому ж рядку, що й заголовка.
+
+```
+#### My Great Heading {#custom-id}
+```
+
+HTML матиме наступний вигляд:
+
+```html
+
My Great Heading
+```
+
+Ви можете зв’язати заголовки зі спеціальними ідентифікаторами у файлі, створивши [стандартне посилання](https://www.markdownguide.org/basic-syntax/#links) зі знаком цифри (`#`), за яким слідує ідентифікатор заголовку.
+
+| Markdown | HTML | Вигляд |
+| ----------------------------- | ------------------------------ | ------------------------------------------------------------ |
+| `[Heading IDs](#heading-ids)` | ` [Heading IDs](#heading-ids)` | [Heading IDs](https://www.markdownguide.org/extended-syntax/#heading-ids) |
+
+Інші веб-сайти можуть посилатися на заголовок, додавши спеціальний ідентифікатор заголовка до повної URL-адреси веб-сторінки (наприклад,
+
+`[Heading IDs](https://www.markdownguide.org/extended-syntax#heading-ids)`.
+
+### Списки означень
+
+Деякі процесори Markdown дозволяють створювати *списки означень* термінів та їх відповідні означення. Щоб створити список означень, введіть термін у перший рядок. У наступному рядку введіть двокрапку, а потім пробіл та означення.
+
+```markdown
+First Term
+: This is the definition of the first term.
+
+Second Term
+: This is one definition of the second term.
+: This is another definition of the second term.
+```
+
+HTML матиме вигляд:
+
+```html
+
+ - First Term
+ - This is the definition of the first term.
+ - Second Term
+ - This is one definition of the second term.
+ - This is another definition of the second term.
+
+```
+
+У переглядачі це матиме вигляд:
+
+
+
+### Список завдань
+
+Списки завдань дозволяють створити список елементів за допомогою прапорців. У додатках Markdown, що підтримують списки завдань, поруч із вмістом відображатимуться прапорці. Щоб створити список завдань, перед пунктами списку завдань додайте тире (`-`) і дужки з пробілом (` [ ] `). Щоб встановити прапорець, додайте між дужками "x" (`[x]`).
+
+```
+- [x] Write the press release
+- [ ] Update the website
+- [ ] Contact the media
+```
+
+Це матиме вигляд:
+
+- [x] Write the press release
+- [ ] Update the website
+- [ ] Contact the media
+
+
+
+### Емоджі (смайли)
+
+Є два способи додати смайли до файлів Markdown: скопіювати та вставити смайли у текст, відформатований Markdown, або введення *короткого коду емоджи*. У більшості випадків ви можете просто скопіювати емоджи з такого джерела, як [Emojipedia](https://emojipedia.org/), і вставити його у свій документ. Багато застосунків Markdown автоматично відображатимуть емоджи у тексті, відформатованому Markdown. Файли HTML та PDF, які ви експортуєте зі своєї програми Markdown, ткож повинні відображати емоджи.
+
+Деякі програми Markdown дозволяють вставляти смайли, вводячи короткі коди смайлів. Вони починаються і закінчуються двокрапкою і включають назву емоджи.
+
+```markdown
+Gone camping! :tent: Be back soon.
+That is so funny! :joy:
+```
+
+Матиме вигляд:
+
+Gone camping! ⛺ Be back soon.
+
+That is so funny! 😂
+
+Ви можете використовувати цей [список коротких кодів емоджі](https://gist.github.com/rxaviers/7360908), але майте на увазі, що короткі коди емоджі відрізняються для різних застосунків.
+
+### Автоматичне зв'язування URL
+
+Багато процесорів Markdown автоматично перетворюють URL-адреси в посилання. Це означає, що якщо ви введете http://www.example.com, ваш процесор Markdown автоматично перетворить його на посилання, навіть якщо ви не [використали дужки](https://www.markdownguide.org/basic-syntax/ # посилання). Тобто введений текст
+
+```
+http://www.example.com
+```
+
+автоматично буде сприйматися як лінк:
+
+http://www.example.com
+
+Якщо ви не хочете, щоб URL-адресу було автоматично пов’язано, ви можете видалити посилання, [позначаючи URL-адресу як код](https://www.markdownguide.org/basic-syntax/#code) за допомогою зворотних лапок.
+
+```
+`http://www.example.com`
+```
+
+## Запитання для самоперевірки
+
+1. Яка основна ідея використання MarkDown? Чому текстові формати подібні до MsWORD можуть не підійти для цих задач?
+2. Прокоментуйте принципи роботи застосунків MarkDown.
+3. Поясніть що таке Flavors MD? У чому причина появи різних Flavors?
+4. Перерахуйте основні елементи синтаксису форматування MarkDown.
+5. Розкажіть про області використання MarkDown.
+6. Назвіть кілька редакторів для MarkDown.
+7. Назвіть ряд елементів розширеного синтаксису форматування MarkDown. Які обмеження їх використання?
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
+
diff --git "a/\320\233\320\265\320\272\321\206/11_db.md" "b/\320\233\320\265\320\272\321\206/11_db.md"
new file mode 100644
index 0000000..bda56be
--- /dev/null
+++ "b/\320\233\320\265\320\272\321\206/11_db.md"
@@ -0,0 +1,176 @@
+**Програмна інженерія в системах управління. Лекції.** Автор і лектор: Олександр Пупена
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
+
+# 11. Бази даних та систем керування базами даних
+
+## 11.1. Бази даних та системи керування базами даних
+
+**База даних** (*database*, надалі **БД**) – сукупність даних, організованих в єдину концептуальну сутність, що описує характеристику цих даних і взаємозв'язки між їх елементами. У загальному випадку база даних містить схеми, таблиці, подання, збережені процедури та інші об'єкти. Таким чином, сучасна база даних, крім саме даних, містить їх опис та може містити засоби для їх обробки.
+
+З базою даних можна працювати напряму з програмного застосунку. Для цього треба знати формат збереження даних та інших об'єктів, і проводити їх обробку. Враховуючи велику кількість рутини, яку треба для цього робити, як правило з БД напряму не працюють, а використовують спеціальні застосунки - СКБД. **Система керування базами даних** (Database Management Systems, СКБД, СУБД, DBMS) — це система, заснована на програмних та технічних засобах, яка забезпечує означення, створення, маніпулювання, контроль, керування та використання баз даних . Застосунки для роботи з базою даних можуть бути частиною СКБД або автономними. Найпопулярнішими [СКБД](https://uk.wikipedia.org/wiki/Система_керування_базами_даних) є [MySQL](https://uk.wikipedia.org/wiki/MySQL), [PostgreSQL](https://uk.wikipedia.org/wiki/PostgreSQL), [Microsoft SQL Server](https://uk.wikipedia.org/wiki/Microsoft_SQL_Server), [Oracle](https://uk.wikipedia.org/wiki/Oracle), [Sybase](https://uk.wikipedia.org/wiki/Sybase), [Interbase](https://uk.wikipedia.org/wiki/Interbase), [Firebird](https://uk.wikipedia.org/wiki/Firebird) та [IBM DB2](https://uk.wikipedia.org/wiki/IBM_DB2). СКБД дозволяють ефективно працювати з базами даних, обсяг яких робить неможливим їх ручне опрацювання.
+
+Через тісний зв'язок баз даних з СКБД під терміном «база даних» інколи необґрунтовано та неточно мають на увазі систему керування базами даних. Але варто розрізняти базу даних — сховище даних, та СКБД — засоби для роботи з базою даних. СКБД з інформаційної системи може бути видалена, але база даних продовжить існувати. І навпаки: СКБД може функціонувати без жодної бази даних.
+
+В загальному базу даних неможливо просто перемістити з однієї СКБД до іншої. Ти не менше СКБД використовують стандарти ([SQL](sql.md), [ODBC](https://uk.wikipedia.org/wiki/ODBC), [JDBC](https://uk.wikipedia.org/wiki/JDBC)), які уніфікують ряд операцій по роботі з даними і дозволяють різним застосункам працювати з базами даних різних СКБД. [СКБД](https://uk.wikipedia.org/wiki/Система_керування_базами_даних) часто класифікують за моделлю організації даних. Найвживаніші СКБД використовують реляційну модель, у якій дані подають у виді таблиць. Для кінцевого користувача (та прикладних програм) робота з базою даних напряму неможлива. Всі маніпуляції над даними здійснюють через спеціальні запити, які надсилають до СКБД. СКБД опрацьовує їх і повертає результат. Безпосередньо з базою даних працює виключно СКБД.
+
+Сучасні СКБД забезпечують функції щодо керування даними, які можна поділити на такі групи:
+
+- Оголошення даних — створення, зміна та видалення визначень, які описують організацію даних.
+- Модифікація даних — додавання даних, їх редагування та видалення.
+- Отримання даних — надання даних за запитом застосунку у формі, яка дозволяє їх безпосереднє використання. Дані можуть надаватись або у формі, в якій вони зберігаються у базі даних, або в іншій формі (наприклад, через поєднання різних даних).
+- Адміністрування даних — реєстрування та відслідковування дій користувачів, дотримання безпеки роботи з даними, забезпечення надійності та цілісності даних, моніторинг продуктивності, резервне копіювання та відновлення даних тощо.
+
+## 11.2. Дані та моделі даних
+
+Основоположними поняттями в концепції баз даних є узагальнені категорії «дані» і «модель даних».
+
+Поняття ***дані*** в концепції баз даних - це набір конкретних значень, параметрів, що характеризують об'єкт, умову, ситуацію або будь-які інші чинники, Приклади даних: `Іваненко Іван`, `$ 30` і т. д. Дані не мають властивість структурності, вони стають інформацією тоді , коли користувач задає їм певну структуру, тобто усвідомлює їх смисловий зміст. Тому центральним поняттям в області баз даних є поняття моделі. Не існує однозначного означення цього терміну, у різних авторів ця абстракція означується з деякими відмінностями але, тим не менш, можна виділити щось загальне в цих означеннях.
+
+***Модель даних*** - це деяка абстракція, яка, будучи застосовною до конкретних даних, дозволяє користувачам і розробникам трактувати їх уже як інформацію. Тобто це відомості, що містять не тільки дані, але і взаємозв'язок між ними.
+
+За допомогою моделі даних можуть бути представлені об'єкти предметної області та взаємозв'язку між ними. Залежно від виду організації даних розрізняють такі моделі БД:
+
+- ієрархічні
+
+- мережні
+
+- реляційні
+
+- Об'єктно-орієнтовані
+
+- [No-SQL](https://uk.wikipedia.org/wiki/NoSQL) бази даних, до яких відносять:
+
+ - [ключ-значення](https://uk.wikipedia.org/wiki/База_даних_"ключ—значення") (Key/Value)
+
+ - [граф ](https://uk.wikipedia.org/wiki/Графова_база_даних)[(graph](https://uk.wikipedia.org/wiki/Графова_база_даних)[)](https://uk.wikipedia.org/wiki/Графова_база_даних)
+
+ - [документо](https://uk.wikipedia.org/wiki/Документо-орієнтована_система_керування_базами_даних)[-орієнтовані ](https://uk.wikipedia.org/wiki/Документо-орієнтована_система_керування_базами_даних)(document)
+
+ - [стовпчик (](https://en.wikipedia.org/wiki/Column_(data_store))[Column](https://en.wikipedia.org/wiki/Column_(data_store))[)](https://en.wikipedia.org/wiki/Column_(data_store))
+
+ - [мультимодельні](https://en.wikipedia.org/wiki/Multi-model_database)[ (](https://en.wikipedia.org/wiki/Multi-model_database)[Multi-model](https://en.wikipedia.org/wiki/Multi-model_database)[)](https://en.wikipedia.org/wiki/Multi-model_database)
+
+На сьогоднішній день найпопулярнішими БД є ***реляційні*** , які отримали свою назву від англійського терміну relation (таблиця). Реляційна БД є сукупністю таблиць, пов'язаних відношеннями. Перевагами реляційної моделі даних є простота, гнучкість структури. Крім того її зручно реалізовувати на комп'ютері. Більшість сучасних БД для персональних комп'ютерів є реляційними.
+
+## 11.3. Архітектури СКБД
+
+Серед архітектур баз даних варто виділити «файл-сервер» та «клієнт-сервер».
+
+Архітектура «файл-сервер»передбачає виділення однієї з машин мережі як головної (сервер). На такій машині зберігається спільна централізована БД (рис.11.1 праворуч). Усі інші машини мережі виконують функції робочих станцій, за допомогою яких підтримується доступ користувацької системи до бази даних. Файли бази даних відповідно до призначених для користувача запитів передаються на робочі станції, де в основному і проводиться обробка даних. При великій інтенсивності доступу до одних і тих же даних продуктивність інформаційної системи різко падає. Користувачі також можуть створювати на робочих станціях локальні БД, які використовуються ними монопольно.
+
+У сучасних мережевих інформаційних системах для роботи із загальною базою даних використовують архітектуру «клієнт-сервер» (рис.11.1 ліворуч).. При цьому в мережі розміщують сервер баз даних. Ним виступає комп'ютер (або комп'ютери), який містить бази даних, СКБД та пов'язане з ними програмне забезпечення, і налаштований для надання користувачам інформаційної системи доступу до бази даних. Клієнти, які працюють із даними (вони можуть бути розташовані на різних комп'ютерах мережі), надсилають відповідні запити серверу. Сервер їх отримує, опрацьовує, та надсилає відповідь клієнту. Сучасні СКБД ([MySQL](https://uk.wikipedia.org/wiki/MySQL), [PostgreSQL](https://uk.wikipedia.org/wiki/PostgreSQL), [Microsoft SQL Server](https://uk.wikipedia.org/wiki/Microsoft_SQL_Server) та інші) працюють відповідно до цієї архітектури. Сервер баз даних, як правило, є достатньо потужною багатопроцесорною системою, яка використовує масиви дисків RAID для підвищення надійності зберігання даних. Використання дискових масивів RAID дозволяє відновити дані, навіть якщо один з дисків вийшов з ладу.
+
+
+
+рис.11.1. Клієнт-серверна та файл-серверна архітектура
+
+## 11.4. Реляційні бази даних
+
+### Структура
+
+Реляційна модель базується на представлені БД як пов'язаних ***таблиць***. Однак варто розуміти, що це логічне а не фізичне (у файлах) представлення. Рядками є записи (record), а стовпчиками поля (field) записів.
+
+
+
+рис.11.2. Принцип побудови таблиці в реляційних базах даних.
+
+У наступному прикладі 3 записи і 6 полів. Для першого запису поле `City` має значення `Київ`.
+
+| Bno | City | Postcode | Street | Tel_No | Fax_No |
+| ---- | ----- | -------- | -------- | ------- | ------- |
+| 23 | Київ | 111111 | Бандери | 1231112 | 1231113 |
+| 24 | Рівне | 3334546 | Франка | 1334456 | 1334455 |
+| 25 | Львів | 456009 | Українки | 1213345 | 1213346 |
+
+Таблиця має унікальне ім'я, поля в ній також мають унікальні імена.
+
+### Ключі
+
+**Первинний ключ (primary key)** – це поле, або набір полів, яке використовується для забезпечення унікальності даних в таблиці. Це означає, що значення (інформація) в полі первинного ключа в кожному рядку (запису) таблиці має бути унікальним.
+
+Унікальність необхідна для уникнення неоднозначності, коли невідомо до якого запису таблиці потрібно звернутися, якщо в таблиці є записи що повторюються (два записи мають однакові значення у всіх полях таблиці).
+
+Нерідко бувають декілька варіантів вибору первинного ключа. Наприклад, це може бути унікальний табельний номер співробітника, або унікальна комбінація прізвища імені та по-батькові. У таких випадках при виборі первинного ключа перевага надається найбільш простому. Інші кандидати на роль первинного ключа називаються альтернативними.
+
+Вимоги до первинного ключа: унікальність в таблиці; не може містити пустих значень.
+
+За полями, які часто використовуються при пошуку та сортування даних встановлюються ***вторинні ключі***: вони допоможуть системі значно швидше знайти потрібні дані. На відміну від первинних ключів поля для ***індексів*** (***index***, вторинні ключі) можуть містити неунікальні значення.
+
+Первинні ключі використовуються для встановлення зав'язків між таблицями в реляційній БД. В цьому випадку первинному ключу однієї таблиці (батьківської) відповідає зовнішній ключ іншої таблиці (дочірньої). Зовнішній ключ містить значення пов'язаного з ним поля, що є первинним ключем. Значення в зовнішньому ключі можуть бути не унікальні, але не повинні бути порожніми. Первинний і зовнішній ключі повинні бути однакового типу.
+
+### Відношення між таблицями
+
+Записи в таблиці можуть залежати від однієї або декількох записів іншої таблиці. Такі таблиці між таблицями називаються ***зв'язками*** Зв'язок означується наступним чином: поле або кілька полів однієї таблиці, зване ***зовнішнім ключем***(foreign key), посилається на первинний ключ іншої таблиці (рис.11.3).
+
+
+
+рис.11.3. Первинні ключі
+
+Розглянемо приклад, в якому є дві таблиці - "Працівник", якій є перелік усіх співробітників з їх унікальним табельним номером, та "Зарплата" (рис.11.4), у яку заносяться усі нарахування зарплатні конкретному працівникові за його табельним номером. Ці таблиці зв'язані ключем "табельний номер" причому для таблиці "Працівник" це буде первинним ключем, тоді як для "Зарплата" - зовнішнім .
+
+
+
+рис.11.4. Використання первинних ключів.
+
+Тепер, наприклад, якщо потрібно пошукати нараховану заробітну плату в таблиці “Зарплата” для працівника Баумана А.А., то потрібно виконати такі дії:
+
+- знайти табельний номер працівника Баумана А.А у таблиці “Працівник”. Значення табельного номеру рівне 2145;
+- у таблиці “Зарплата” знайти усі значення, що рівні 2145 (табельний номер);
+- вибрати з таблиці “Зарплата” усі значення поля “Нараховано”, що відповідають табельному номеру 2145.
+
+
+
+рис.11.5. Використання первинних ключів
+
+Виникає резонне питання, чому б в таблиці "Зарплата" не містити замість поля "Табельний номер" безпосередньо прізвище працівника? Слід розуміти, що з таблицею "Працівник" може бути пов'язано набагато більше таблиць. Крім того, в таблиці працівник може міститися вся інформація про співробітників, яка може змінюватися (у тому числі і прізвище), окрім табельного номера, який залишається незмінним і унікальним.
+
+Існує три типи зв'язків між таблицями: Один до одного, Один до багатьох та Багато до багатьох.
+
+***Один до одного*** --- кожен запис батьківської таблиці пов'язаний тільки з одним записом дочірньої. Такий зв'язок зустрічається на практиці набагато рідше, ніж зв'язок один до багатьох і реалізується шляхом означення унікального зовнішнього ключа. Зв'язок "один до одного" використовують, якщо не хочуть, щоб таблиця «розпухала» від великої кількості полів. У наведеному нижче прикладі дочірня таблиця водійських прав (Driving License Detail) містить зовнішній ключ ідентифікатора працівника "EmpID", який посилається на первинний ключ батьківської таблиці працівників ("Employee"). Враховуючи, що у працівника не може бути більше ніж одних водійських прав, кожен запис таблиці працівників буде відповідати не більше одного запису в таблиці водійських прав і навпаки.
+
+
+
+рис.11.6. Співвідношення один "до одного"
+
+***Один до багатьох*** --- кожен запис батьківської таблиці пов'язаний з одним або декількома записами дочірньої. Наприклад, один працівник може бути задіяний в кількох проектах. Зв'язок "один до багатьох" є найпоширенішою для реляційних баз даних.
+
+
+
+рис.11.7. Співвідношення один до багатьох.
+
+***Багато до багатьох*** --- декілька записів однієї таблиці пов'язані з декількома записами іншої. Наприклад, один працівник може мати кілька типів полісів (Policy Detail), і навпаки - кілька працівників можуть мати однаковий тип полісів. У разі такого зв'язку в загальному випадку неможливо визначити, яка запис однієї таблиці відповідає обраному запису іншої таблиці, що робить неможливою фізичну (на рівні індексів і тригерів) реалізацію такого зв'язку між відповідними таблицями. Тому перед переходом до фізичної моделі всі зв'язки "багато до багатьох" повинні бути переозначені (деякі CASE-засоби, якщо такі використовуються при проектуванні даних, роблять це автоматично). Подібний зв'язок між двома таблицями реалізується шляхом створення третьої мостової (bridge) таблиці і реалізації зв'язку типу «один до багатьох» кожної з наявних таблиць з проміжною таблицею. У даному прикладі третя таблиця містить два зовнішні ключі.
+
+
+
+ рис.11.8. Співвідношення багато до багатьох.
+
+### Індексація
+
+***Індекс*** --- це структура даних, яка допомагає СКБД швидше знаходити окремі записи в таблицях, і тому дозволяє скоротити час виконання запитів користувача. Таблиці можуть мати велику кількість рядків, а так як рядки не йдуть в заздалегідь визначеному порядку, на їх пошук за вказаним значенням може знадобитися час. Функціонування Індексу в базі даних схоже на використання предметного покажчика, наведеного в кінці книги. Це структура, пов'язана з таблицею і призначена для пошуку інформації за тим же принципом, що і предметний покажчик в книзі.
+
+Сутність індексів полягає в тому, що вони зберігають значення індексних полів (тобто полів, за якими побудований індекс) і покажчик на конкретний запис в таблиці.
+
+При ***послідовному методі доступу*** для виконання запиту до отримання записів з таблиці БД проглядаються усі записи цієї таблиці, від першої до останньої. При ***індексно-послідовному методі доступу*** для виконання запиту, пошук відбувається в індексі, після чого покажчик встановлюється на перший рядок, що задовольняє умові запиту.
+
+Визначення первинних і зовнішніх ключів таблиць БД призводять до створення індексів по полям, оголошеним в складі первинних або зовнішніх ключів.
+
+## Запитання для самоперевірки
+
+1. Що таке база даних?
+2. Що таке система керування базами даних?
+3. Які функції щодо керування даними забезпечують системи керування базами даних?
+4. Назвіть кілька моделей відповідно до організації даних в баз даних.
+5. Поясніть відмінності в архітектурах баз даних «файл-сервер» та «клієнт-сервер».
+6. Яка типова структура реляційних баз даних.
+7. Поясніть принципи використання первинних ключів та вторинних ключів.
+8. Поясніть, як формуються зв'язки між таблицями в реляційних базах даних.
+9. Поясніть принципи роботи індексації реляційних баз даних.
+
+
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
\ No newline at end of file
diff --git "a/\320\233\320\265\320\272\321\206/12_sql.md" "b/\320\233\320\265\320\272\321\206/12_sql.md"
new file mode 100644
index 0000000..0aefa19
--- /dev/null
+++ "b/\320\233\320\265\320\272\321\206/12_sql.md"
@@ -0,0 +1,369 @@
+**Програмна інженерія в системах управління. Лекції.** Автор і лектор: Олександр Пупена
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
+
+# 12. Мова SQL
+
+## 12.1. Загальні принципи
+
+***SQL*** (Structured Query Language – мова структурованих запитів) – це універсальна мова для створення, модифікації і керування даними в реляційних базах даних. Дана мова описана в ряді стандартів ANSI, ISO/IEC і на момент написання останньою версією є SQL:2019. На сьогоднішній день практично всі відомі СКБД підтримують даний стандарт, з деяким розширеннями до нього для адаптації під свої формати даних та функціональні можливості серверів. Такі мови називають діалектами SQL. Так, наприклад діалект СКБД MS SQL Server має назву «Transact-SQL», а MySQL – «SQL/PSM». Перед використанням SQL для конкретної СКБД варто ознайомитися з підтримуваними командами.
+
+
+
+рис.12.1. Принципи роботи SQL
+
+При необхідності використовувати мови SQL в ПЗ для доступу до даних, варто перевірити роботу SQL-запитів в тестових утилітах. Для здійсненні запиту використовується якийсь із інтерфейсів СКБД, який дозволяє обмінюватися текстовими повідомленнями. Тим не менше часто з СКБД постачаються консольні програми, які дозволяють взаємодіяти з СКБД командами в тому числі SQL.
+
+Наприклад, в СКБД mariadb можна запустити однойменну програму (рис.12.2), ввести ім'я користувача та пароль доступу до СКБД, та зайти у меню введення SQL команд. На ис.12.2 показаний приклад виведення списку баз даних та усіх записів з таблиці testdb.
+
+
+
+рис.12.2. Робота з консоллю
+
+Для того, щоб команди виконалися, необхідно завершити їх символом `;` .
+
+Є багато графічних клієнтських утиліт, які з’єднуються з базами даних через різні інтерфейси і надають можливість керувати ними. Наприклад, `Microsoft SQL Server Management Studio` дає можливість не лише виконувати запити SQL, але і надає інструменти для їх побудови (`Query Designer`).
+
+На рис.12.3 показаний приклад перевірки SQL-запиту в інший безкоштовній утиліті HeidiSQL, яка ставиться разом з MariaDB.
+
+
+
+рис.12.3. Тестова утиліта для робота з СКБД
+
+Мова SQL задає тільки формат повідомлень запитів та відповідей між застосунком-клієнтом та сервером. Однак яким чином цей запит передається, як формується з’єднання між застосунками, створюється та розриваються сеанси і т.п. вирішується на інших рівнях взаємодії. Усі сучасні стандартизовані технології доступу до даних (ODBC, JDBC, OLE DB, ADO, .NET) надають інтерфейс через SQL.
+
+Мова SQL розроблена для взаємодії з реляційними БД для інших типів вона не завжди застосовна. Тим не менше, багато NoSQL СКБД підтримують SQL-подібні мови.
+
+## 12.2. Загальний опис SQL команд
+
+SQL використовується для створення структури бази даних, маніпуляції з даними, тобто їх вибірки і модифікації, та для їх адміністрування. Будь яка операція по вибірці, модифікації, визначенню або адмініструванню виконується за допомогою ***оператору*** (***statement***) або ***команди*** (***command***) SQL.
+
+Use – використовується в усіх реляційних базах даних для вказівки бази даних за замовчуванням.
+
+```sql
+USE db1;
+SELECT COUNT(*) FROM mytable; # вибірка з db1.mytable
+USE db2;
+SELECT COUNT(*) FROM mytable; # вибірка з db2.mytable
+```
+
+**SHOW** **DATABASES** – показує перелік БД.
+
+**SHOW** **TABLES** – показує перелік таблиць. Наприклад:
+
+```sql
+SHOW DATABASES;
+SHOW TABLES FROM testdb;
+```
+
+Мова SQL надає широкі можливості для роботи з означенням схеми даних та самими даними, як прийнято відносити до однієї з груп:
+
+- **[DDL](https://uk.wikipedia.org/wiki/DDL)** ([Data Definition Language](https://uk.wikipedia.org/wiki/Data_Definition_Language)) — робота зі структурою бази
+- **[DML](https://uk.wikipedia.org/wiki/DML)** ([Data Manipulation Language](https://uk.wikipedia.org/wiki/Data_Manipulation_Language)) — робота з записами
+- **[DCL](https://uk.wikipedia.org/wiki/DCL)** ([Data Control Language](https://uk.wikipedia.org/wiki/Data_Control_Language)) — робота з правами
+- **TCL** ([Transaction Control Language](https://uk.wikipedia.org/w/index.php?title=Transaction_Control_Language&action=edit&redlink=1)) — робота з транзакціями
+
+Основні команди SQL відповідно до цих груп наведені на рис.12.4.
+
+
+
+рис.12.4. Класифікація команд за призначенням
+
+Однак найбільш вживаними серед цих груп є команди означення схеми даних та роботи з записами даних. Тому надалі зупинимося на них детальніше.
+
+## 12.3. Запити для означення схеми даних
+
+**CREATE** – створює базу даних або таблицю в базі даних. Наприклад:
+
+```sql
+CREATE TABLE Persons (
+ PersonID int,
+ LastName varchar(255),
+ FirstName varchar(255),
+ Address varchar(255),
+ City varchar(255)
+);
+```
+
+Колонка типу даних (datatype) означує які значення в полі : integer, character, money, date and time, binary і т.п. Для різних типів БД типи можуть відрізнятися. У таблицях 12.1-12.3 показані для прикладу типи даних для MySQL.
+
+Таблиця 12.1. Деякі текстові типи даних MySQL
+
+| Тип | Характеристики |
+| --------------- | ------------------------------------------------------------ |
+| CHAR(size) | Рядок із фіксованою довжиною (може містити літери, цифри та спеціальні символи). Параметр size означує довжину стовпця в символах - може бути від 0 до 255. За замовчуванням 1 |
+| VARCHAR(size) | Рядок із змінною довжиною (може містити літери, цифри та спеціальні символи). Параметр size означує максимальну довжину стовпця в символах - може становити від 0 до 65535 |
+| BINARY(size) | Аналогічний CHAR (), але зберігає двійкові байтові рядки. Параметр size означує довжину стовпця в байтах. За замовчуванням 1 |
+| VARBINARY(size) | Аналогічний VARCHAR (), але зберігає двійкові байтові рядки. Параметр size означує максимальну довжину стовпця в байтах. |
+| TINYBLOB | Для BLOBів (Binary Large OBjects). Макс довжина: 255 bytes |
+| TINYTEXT | Зберігає string з максимальною довжиною 255 символів |
+| TEXT(size) | Зберігає string з максимальною довжиною 65,535 байт |
+| BLOB(size) | Для BLOBs (Binary Large OBjects). Зберігає до 65,535 байтів даних |
+
+Таблиця 12.2. Деякі числові типи даних MySQL
+
+| Тип | Характеристики |
+| ---------------------------------- | ------------------------------------------------------------ |
+| BIT(size) | Тип бітового значення. Кількість бітів на значення вказано в розмірі. Параметр size може містити значення від 1 до 64. Значення за замовчуванням для size доівнює 1. |
+| TINYINT(size) | Дуже маленьке ціле число. Діапазон для знакового числа від -128 до 127, для беззнакового - від 0 до 255. Параметр розміру означує максимальну ширину відображення (яка становить 255) |
+| BOOL або BOOLEAN | Нуль вважається хибним, ненульові значення - істинними. |
+| SMALLINT(size) | Невелике ціле число. Діапазон для знакового числа від -32768 до 32767, для беззнакового - від 0 до 65535. Параметр розміру визначає максимальну ширину відображення (яка становить 255) |
+| INT(size) або INTEGER(size) | Ціле число. Діапазон для знакового числа від -2147483648 до 2147483647, для беззнакового - від 0 до 4294967295. Параметр розміру визначає максимальну ширину відображення (яка становить 255) |
+| FLOAT(p) | Число з плаваючою комою. MySQL використовує значення p, щоб визначити, чи використовувати FLOAT або DOUBLE для результуючого типу даних. Якщо p від 0 до 24, тип даних стає FLOAT (). Якщо p становить від 25 до 53, тип даних стає DOUBLE () |
+| DECIMAL(size, d) або DEC(size, d) | Точне число з фіксованою точкою. Загальна кількість цифр вказана в розмірі. Кількість цифр після десяткової коми визначається параметром d. Максимальне число для розміру - 65. Максимальне число для d - 30. Значення за замовчуванням для розміру - 10. Значення за замовчуванням для d - 0. |
+
+Таблиця 12.2. Типи даних дати та часу в MySQL
+
+| Тип | Характеристики |
+| -------------- | ------------------------------------------------------------ |
+| DATE | Дата. Формат: YYYY-MM-DD. Підтримуваний діапазон - від "1000-01-01" до "9999-12-31" |
+| DATETIME(fsp) | Поєднання дати та часу. Формат: YYYY-MM-DD hh:mm:ss. Підтримуваний діапазон - від "1000-01-01 00:00:00" до "9999-12-31 23:59:59". Додавання DEFAULT та ON UPDATE у визначення стовпця приведе до отримання автоматичної ініціалізації та оновлення поточною датою та часом |
+| TIMESTAMP(fsp) | Мітка часу. Значення TIMESTAMP зберігаються як кількість секунд з епохи Unix ('1970-01-01 00:00:00' UTC). Формат: YYYY-MM-DD hh:mm:ss. Підтримуваний діапазон - від '1970-01-01 00:00:01' UTC до '2038-01-09 03:14:07' UTC. Автоматичну ініціалізацію та оновлення поточною датою та часом можна вказати за допомогою DEFAULT CURRENT_TIMESTAMP та ON UPDATE CURRENT_TIMESTAMP у означенні стовпця |
+| TIME(fsp) | Час. Формат: hh: mm: ss. Підтримуваний діапазон: від -838: 59: 59 до 838: 59: 59. |
+| YEAR | Рік у чотирьох-символьному форматі. Значення, дозволені у чотиризначному форматі: від 1901 до 2155 та 0000. MySQL 8.0 не підтримує рік у двосимвольному форматі. |
+
+**DROP** – видаляє об'єкт з бази даних: database, table, index, view та інші. Наприклад у наступному прикладі видаляється таблиця.
+
+```sql
+DROP TABLE Persons;
+```
+
+А в цьому видаляється база даних.
+
+```sql
+DROP DATABASE testDB;
+```
+
+**Створення індексу** в MySQL відбувається через означення його в таблиці через ключове словосполучення **PRIMARY KEY**:
+
+```sql
+CREATE TABLE Persons (
+ ID int NOT NULL,
+ LastName varchar(255) NOT NULL,
+ FirstName varchar(255),
+ Age int,
+ PRIMARY KEY (ID)
+ );
+```
+
+Те саме для СКБД MS SQL Server/Oracle/MS Access матиме вигляд:
+
+```sql
+CREATE TABLE Persons (
+ ID int NOT NULL PRIMARY KEY,
+ LastName varchar(255) NOT NULL,
+ FirstName varchar(255),
+ Age int
+ );
+```
+
+**ALTER** - змінює структуру об'єктів бази даних. Модифікує існуючий об’єкт.
+
+У наступному прикладі добавляється колонка `nicname`:
+
+```sql
+ALTER TABLE Persons ADD nicname varchar(255);
+```
+
+У цьому прикладі видаляється колонка `nicname`
+
+```sql
+ALTER TABLE Persons DROP COLUMN nicname ;
+```
+
+У цьому прикладі модифікується тип колонки `Age`
+
+```sql
+ALTER TABLE persons MODIFY COLUMN Age SMALLINT;
+SHOW CREATE TABLE persons;
+```
+
+**TRUNCATE** – очищає весь зміст таблиці (видаляє всі дані в таблиці). Він працює швидше за *DELETE*.
+
+```sql
+TRUNCATE testdb.persons;
+```
+
+## 12.4. Запити для створення та модифікації даних
+
+Є дві можливості операцій по маніпуляції з даними – ***вибірка даних*** (data retrieval) і ***модифікація даних*** (data modification). Вибірка – це пошук необхідних даних, а модифікація означає добавлення, знищення або заміна даних. Операції по вибірці називають ***SQL запитами*** (***SQL queries***). Вони проводять пошук в базі даних, найбільш ефективно вибирають необхідну інформацію і відображають її. У всіх запитах SQL використовується ключове слово `SELECT`. Операції по модифікації виконуються відповідно з використанням ключових слів `INSERT`, `DELETE` та `UPDATE`.
+
+**INSERT INTO** – вставлення даних в таблицю (створення запису в таблиці).
+
+У наступному прикладі в таблицю Persons вставляються записи з вказаними значеннями. Якщо поля перераховуються в дужках після назви таблиці, то можна не вказувати їх всі а послідовність записуваних значень змінювати. Якщо за назвою таблиці одразу йде ключове слово VALUES, то значення вказуються в тій кількості і послідовності, як вони задаються при означенні таблиці.
+
+```sql
+DROP TABLE persons; /*видалимо стару таблицю*/
+CREATE TABLE Persons (
+ PersonID INT NOT NULL AUTO_INCREMENT, /*тип лічильник*/
+ LastName varchar(255) COLLATE 'utf8_unicode_ci', /*кодування utf8*/
+ FirstName varchar(255) COLLATE 'utf8_unicode_ci',
+ Address varchar(255) COLLATE 'utf8_unicode_ci',
+ City varchar(255) COLLATE 'utf8_unicode_ci',
+ PRIMARY KEY (PersonID) /*первинний ключ*/
+);
+
+INSERT INTO Persons (LastName, FirstName, Address, City)
+VALUES ('Озерний', 'Олександр', 'Володимирська 68', 'Київ');
+
+INSERT INTO Persons VALUES (0, 'Іваненко', 'Іван', 'Стрийська 1', 'Львів');
+INSERT INTO Persons VALUES (0, 'Романенко', 'Роман', 'Виноградна 1', 'Одеса');
+INSERT INTO Persons VALUES (0, 'Петренко', 'Петро', 'Тениста', 'Одеса');
+```
+
+**UPDATE** – оновлення (модифікація) існуючих даних в таблиці. У цьому прикладі для усіх записів, я яких значення поля `PersonID`<3, будуть замінені значення полів `LastName` та `FirstName`
+
+```sql
+UPDATE testdb.persons
+SET LastName = 'Супер', FirstName = 'Стар'
+WHERE PersonID<3;
+```
+
+У цьому прикладі для всіх записів таблиці `persons` значення поля `LastName` буде дорівнювати об'єднанню полів `LastName` та `FirstName`
+
+```sql
+UPDATE persons
+SET LastName = CONCAT (LastName, " " , FirstName);
+```
+
+**SELECT** – отримання даних з БД.
+
+Спрощена його конструкція має вигляд:
+
+```sql
+SELECT список_стовпчиків
+FROM список_таблиць
+[WHERE умови]
+```
+
+де слова в квадратних дужках `[]` – не обов’язкові.
+
+У списку стовпчиків (полів записів) вказуються ті поля таблиці, які повертаються після обробки запиту. Список таблиць означує з яких таблиць необхідно проводити вибірку, а в умовах вказують умови для вибірки рядків.
+
+У даному прикладі повертаються усі записи з таблиці `Persons`
+
+```sql
+SELECT * FROM Persons
+```
+
+А у цьому повертаються тільки поля `LastName` та `FirstName`
+
+```sql
+SELECT LastName, FirstName
+FROM Persons
+```
+
+У цьому прикладі задається умова, при якій будуть повертатися тільки ті запити, в яких поле `City`='Одеса'
+
+```sql
+SELECT LastName, FirstName, Address
+FROM Persons
+WHERE City='Одеса'
+```
+
+Ключове слово **WHERE** - використовується для команд SELECT, UPDATE, DELETE і інших для вказівки умови, що має задовольняти запис. Ці умови задаються операторами: порівняння, логічними, визначення діапазону:
+
+- порівняння (=,<,>, >=, <=, <> або != )
+- логічними (AND, OR, NOT)
+- визначення діапазону ([BETWEEN ](https://www.w3schools.com/sql/sql_between.asp)і NOT BETWEEN)
+- символьному порівнянню за шаблоном ([LIKE](https://www.w3schools.com/sql/sql_like.asp))
+- входження в перелік IN
+
+У наступному прикладі будуть повертатися усі записи, в яких поле `LastName` буде містити текст `%енко`
+
+```sql
+SELECT LastName, FirstName
+FROM Persons
+WHERE LastName LIKE '%енко'
+```
+
+Повний синтаксис оператора `SELECT` має наступний вигляд:
+
+```sql
+SELECT [ALL|DISTINCT] список_стовпчиків
+[INTO нова_таблиця]
+FROM {таблиця | курсор}[,{таблиця | курсор}…]
+[WHERE умови]
+[GROUP BY стовпчик [, стовпчик…]]
+[HEAVING умови]
+[ORDER BY {ім’я_стовпчика | список_вибору}[ASC|DESC] ... ]
+```
+
+У списку `SELECT` вказуються ті поля (стовпчики), які необхідно повернути запитом. Є можливість зробити деякі операції над полями перед відображенням: +,-,*, /.
+
+Ключове слово `INTO` вказує на необхідність створення нової таблиці з вказаним іменем.
+
+Умови в `WHERE` задаються операторами порівняння (`=`,`<`,`>`, `>=`, `<=`, `!=` або `<>`), логічними (`AND`, `OR`, `NOT`), визначення діапазону (`BETWEEN` і `NOT BETWEEN`), символьному порівнянню за шаблоном (`LIKE`) та ін.
+
+Ключове слово `ORDER BY` дозволяє упорядковувати знайдені записи по вказаному стовпчику по зростанню `ASC`, або по спаданню `DESC`.
+
+У наступному прикладі буде виведено перелік записів упорядкованих за полем `LastName` по зростанню
+
+```sql
+SELECT * FROM Persons
+ORDER BY LastName ASC
+```
+
+Додатково про ORDER BY можна почитати [за посиланням](https://www.w3schools.com/sql/sql_orderby.asp)
+
+**GROUP BY** – може групувати записи за певними полями. У цьому прикладі, виводиться значення кількості записів, що мають однакові поля `City`
+
+```sql
+SELECT COUNT(city), city
+FROM persons
+GROUP BY City
+ORDER BY COUNT(city) DESC;
+```
+
+
+
+рис.12.5. Приклад групування
+
+У наведеному вище прикладі використовується функція `COUNT`. СКБД як правило підтримують велику кількість [функцій](https://www.w3schools.com/sql/sql_ref_mysql.asp). Серед них є функції агрегації, наприклад:
+
+- **COUNT** (column_name) – кількість колонок, що відповідають критеріям
+- **SUM** (column_name) - сума
+- **MAX (**column_name**)** - максимальне
+- **MIN (**column_name**)** **-** мінімальне
+- **AVG (**column_name**)** **-** середнє
+
+Для визначення доступних функцій необхідно звертатися до довідкової системи.
+
+Команда **DELETE** призначена для видалення усіх записів з таблиці, залишається місце для записів(команда що видаляє таблиці які задовільняють умову)
+
+Для користувача частіше всього зручно дивитися назви колонок (полів) у читабельному вигляді, а не так як вони називаються в таблицях. Для цього використовуються **ALIAS (псевдоніми)**, які дає можливість виводити поля під певним текстом. Наприклад, запис виду:
+
+```sql
+SELECT COUNT(City) AS 'кількість', city AS 'місто'
+FROM persons
+GROUP BY city
+ORDER BY 'кількість' DESC;
+```
+
+виведе записи у вигляді, як на рис.12.6. Зверніть увагу, на назви колонок.
+
+
+
+рис.12.6. Виведення назви колонок через псевдоніми.
+
+## Запитання для самоперевірки
+
+1. Яке призначення мови SQL?
+2. Яким чином можна скористатися мовою при роботі з СКБД?
+3. Які групи команд мови роботи з БД підтримує SQL?
+4. Розкажіть про команду CREATE.
+5. Розкажіть про типи даних на прикладі MySQL.
+6. Розкажіть про команду DROP.
+7. Розкажіть про команду ALTER.
+8. Розкажіть про команду INSERT INTO.
+9. Розкажіть про команду UPDATE
+10. Розкажіть про команду SELECT.
+11. Розкажіть про використання ключового слова WHERE.
+12. Розкажіть про призначення функцій SQL. Наведіть приклад.
+13. Розкажіть про призначення псевдонімів у запитах SQL.
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
\ No newline at end of file
diff --git "a/\320\233\320\265\320\272\321\206/13_js.md" "b/\320\233\320\265\320\272\321\206/13_js.md"
new file mode 100644
index 0000000..5d2b330
--- /dev/null
+++ "b/\320\233\320\265\320\272\321\206/13_js.md"
@@ -0,0 +1,1082 @@
+**Програмна інженерія в системах управління. Лекції.** Автор і лектор: Олександр Пупена
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
+
+# 13. Основи JavaScript
+
+## 13.1. Основні поняття
+
+**JavaScript (скорочено JS )** — мова програмування, яка використовується для сценаріїв (скриптів). Рушій JavaScript підключається до об'єктів свого середовища виконання (наприклад, веб-браузера) та надає можливість керування ними.
+
+JS це реалізація стандарту [ECMAScript](http://xn--80adth0aefm3i.xn--j1amh/ECMAScript). **ES** - це скорочення від **E**CMA**S**cript. Кожне видання специфікації отримує назву з абревіатурою ES та номеру версії. Починаючи з ES6 офіційна назва специфікації позначається роком виходу. Тобто ES2015...ES2019...
+
+Не дивлячись на схожість назв і елементів синтаксису, JavaScript та Java - це різні мови, які навіть відрізняються парадигмами програмування. Серед відмінностей окремо виділимо середовища виконання.
+
+Java компілюється в проміжний байт-код, який на необхідному для виконання середовищі перетворюється на машинний код та виконується за допомогою **Java-машини**. Таким чином, реалізовуючи Java-машину (**JVM**) на різному залізі т ОС реалізовується крос-платформність.
+
+
+
+рис.13.1. Принципи роботи Java для порівняння з Java Script
+
+На відміну від системи з проміжною компіляцією, мова JavaScript - інтерпретована. Тобто аналізується та виконується вихідний код програми **JavaScript-рушієм**. Цей рушій може бути вбудований наприклад в браузер.
+
+Таким чином, JavaScript найчастіше використовується як частина браузера, що надає можливість виконання коду на стороні клієнта (на пристрої кінцевого користувача), взаємодіяти з ним, керувати браузером, обмінюватися даними з сервером, змінювати структуру та зовнішній вигляд веб-сторінки. Однак рушій може бути частиною іншого застосунку або бути окремим застосунком, наприклад серверним.
+
+
+
+рис.13.2. Принципи роботи Java Script
+
+Таким чином, JavaScript використовується для:
+
+- написання сценаріїв веб-сторінок для надання їм інтерактивності;
+- створення односторінкових веб-застосунків ([React](https://uk.wikipedia.org/wiki/React), [AngularJS](https://uk.wikipedia.org/wiki/AngularJS), [Vue.js](https://uk.wikipedia.org/wiki/Vue.js));
+- програмування на стороні сервера ([Node.js](https://uk.wikipedia.org/wiki/Node.js));
+- стаціонарних застосунків ([Electron](https://electron.atom.io/), [NW.js](https://nwjs.io/));
+- мобільних застосунків ([React Native](https://facebook.github.io/react-native/), [Cordova](https://cordova.apache.org/));
+- сценаріїв в прикладному ПЗ (наприклад, в програмах зі складу [Adobe Creative Suite](https://uk.wikipedia.org/wiki/Adobe_Creative_Suite) чи [Apache JMeter](https://uk.wikipedia.org/wiki/Apache_JMeter));
+- всередині PDF-документів тощо.
+
+Серед рушіїв можна виділити:
+
+- [V8](https://uk.wikipedia.org/wiki/V8_(%D1%80%D1%83%D1%88%D1%96%D0%B9_JavaScript)) – використовується в Chrome, Opera, Node.js.
+- [SpiderMonkey](https://uk.wikipedia.org/wiki/SpiderMonkey) – використовується Firefox.
+
+Якщо спрощено, рушії працюють за таким алгоритмом: читають та розбирають (парсять) текст скрипта; перетворюють скрипт в машинний код; запускають машинний код. При цьому можуть використовуватися алгоритми оптимізації.
+
+У даному курсі будуть використовуватися приклади в основному для серверних застосунків, що виконуються на Node.js
+
+Для створення скриптів та застосунків можна використовувати різні редактори, IDE (інтегровані середовища розробки, Integrated Development Environment) або/та утиліти розробки. При розробці скриптів для Веб-сторінок можна скористатися інтегрованими у Веб-бразуери утилітами. Наприклад для FireFox є Веб-консоль, яка може працювати у мультирядковому режимі. Можна вводити туди JS код і дивитися результат, запустивши його на виконання.
+
+
+
+рис.13.3. Налагоджувач JS в консолі WEB-браузера FireFox
+
+У останніх версіях, при намаганні скопіювати в консоль текст, FireFox попросить один раз явно написати дозвіл на виконання копіпасту. Слід також розуміти, що код в консолі буде запускатися в контексті відкритої сторінки.
+
+У Google Chrome можливість перевірки коду доступна в Інструментах розробника. Введені у консолі інструкції одразу виконуються після натискання `Enter`. Якщо необхідно ввести кілька рядків інструкцій, після кожної треба вводити `Shift+Enter`.
+
+
+
+рис.13.4. Налагоджувач JS в консолі WEB-браузера Google Chrome
+
+У даному курсі усі приклади для лабораторних робіт наводяться для безкоштовного IDE середовища [Visual Studio Code](https://code.visualstudio.com/). Код пишеться в файлах `*.js`, які можна об'єднати в один проект, наприклад для серверу `Node.js`.
+
+
+
+рис.13.5. Інструментальне середовище Visual Studo Code
+
+Таким чином, усі приклади, що наведені нижче, можете тестувати у [Visual Studio Code](https://code.visualstudio.com/): створити файл, зберегти його як `test.js`, копіювати туди код і запускати на виконання `F5`.
+
+## 13.2. Основні конструкції JavaScript
+
+### Побудова коду програми
+
+Код складається з набору інструкцій, які розділені символом `;`. У наступному фрагменті дві інструкції введені через крапку з комою в одному рядку.
+
+```javascript
+console.log("Привіт світ!"); console.log("Друга інструкція.");
+```
+
+У наведених вище інструкціях викликається метод `log` вбудованого системного об'єкту `console`. Це дає можливість виводити на налагоджувальну консоль текстові повідомлення.
+
+Мова JavaScript чутлива до регістру. Наприклад код `console.Log()` видасть помилку, так як у системному об'єкті `console` методу `Log` не існує, натомість є метод `log`.
+
+Синтаксис коментарів такий самий, як в `C` та багатьох інших мовах програмування:
+
+```js
+console.log("Привіт світ!"); // коментар для одного рядка
+/* довгий коментар
+ на кілька рядків
+*/
+/* Однак, не можна /* змішувати коментарі */ тут буде SyntaxError */
+```
+
+При необхідності виконувати кілька інструкцій при керуванні потоком виконання (наприклад, `if`, `for`, `while`), використовують блокові інструкції `{` та `}`. Все що знаходиться в межах фігурних дужок об'єднується в одну інструкцію.
+
+```javascript
+let a=3; let b=2;
+if (a>b) //якщо треба виконати кілька інструкцій коли a>b
+{ //початок блоку
+ console.log("Це перша інструкція блоку.");
+ console.log("Це друга інструкція блоку.");
+} //кінець блоку
+```
+
+### Змінні та константи
+
+Для створення змінної в JavaScript використовуються ключові слова `let` та `var`. Оператор **`let`** оголошує локальну змінну, яка видима в межах блоку, де вона оголошена (`{}`). Оператор **`var`** має область видимості у межах усіє функції. Є ще ряд відмінностей між `let` та `var`, але тут вони не розглядаються. У нових скриптах рекомендується використовувати `let` .
+
+Наведений нижче приклад створює (іншими словами: *об'являє* або *означує*) змінну з іменем `message`, і поміщає в неї дані, використовуючи оператор присвоювання `=` . Рядок збережеться в області пам'яті, зв'язаною зі змінною. Ми можемо отримати до неї доступ, використовуючи ім'я змінної.
+
+```javascript
+let message1;
+message1 = 'Hello'; // записати рядок в змінну
+console.log(message1); // пише в консоль значення змінної
+let message2 = 'Hello';//Можна суміщати об'явлення змінної і запис даних в один рядок.
+let user = 'John', age = 25, message3 = 'Hello';//можна кілька змінних об'являти в одному рядку
+//або навіть так
+let user1 = 'John',
+ age1 = 25,
+ message4 = 'Hello';
+```
+
+Оголошення **`const`** створює посилання на значення, доступне лише для читання. Що **не** гарантує незмінність значення, на котре вказує посилання, а лише той факт, що не можна повторно присвоїти будь-яке значення змінній з відповідним ім'ям.
+
+Коли ви оголошуєте змінну за межами будь-якої функції, вона називається **глобальною змінною**, оскільки вона доступна для будь-якого іншого коду в поточному документі. Коли ви оголошуєте змінну в межах функції, вона називається **локальною змінною**, оскільки доступна лише в межах цієї функції.
+
+### Типи даних
+
+Змінна в JavaScript може містити будь-які дані. У один момент там може бути текст, а в інший – число. Тобто під час виконання програми тип може змінюватися кілька раз (так звана "динамічна типізація"). У наведеному нижче коді, одній змінній присвоюють різні за типом значення. Оператор `typeof` повертає значення типу.
+
+```javascript
+//в JS тип може змінюватися під час виконання програми
+let message = "hello"; //це текст, і message тепер типу string
+console.log (typeof(message));//string
+message = 123456; //це число, і message тепер типу number
+console.log (typeof(message));//number
+```
+
+У JavaScript існує сім типів даних: `number`, `string`, `boolean`, `null`, `undefined`, `object`, `symbol`. Спочатку розглянемо базові (примітивні) типи, усі інші типи будуть розглянуті пізніше. Детальніший розгляд типів можна подивитися у [розділі "Типи даних та літерали" з довідника](../Довідники/js/js.md#types).
+
+У JavaScript примітивні типи даних `number`, `string`, `boolean`, подібно об'єктам мають методи і властивості, до яких можна звертатися через крапку. Для цього JavaScript при такому доступі створює спеціальний об'єкт-обгортку, який надає потрібну функційність, після чого видаляється. Ці об'єкти мають відповідні назви `String`, `Number`, `Boolean` і `Symbol`, і мають різний набір методів. Наприклад, у наведеному нижче фрагменті, метод `toUpperCase` з об'єкту типу`String` виводить рядок зі зміненим регістром літер на усі великі.
+
+```javascript
+let message = "привіт";
+console.log (message);//привіт
+console.log (message.toUpperCase());//ПРИВІТ
+```
+
+Особливими типами є `null` та `undefined`. Тип і значення `null` значить буквально `нічого`. Значення `undefined` значить, що змінна є, але їй не було присвоєне значення.
+
+```javascript
+let x;
+console.log(x); // виведе "undefined"
+```
+
+### Булеві змінні та оператори
+
+Булевий тип (`boolean`) може приймати значення: `true` (істина) і `false` (хибність). Можна записати у таку змінну результат операції порівняння або логічної операції.
+
+```javascript
+let isGreater = 4 > 1;
+console.log(isGreater); // буде true
+let a = true; // використання булевого літералу "true"
+```
+
+До булевих значень можна застосовувати логічні оператори "І" (`&&`), "АБО"(`||`), "НЕ"(`!`). Однак, оператори `&&` та `||` насправді повертають значення одного з заданих операндів. Тому, якщо ці оператори використовуються зі значеннями не булевого типу, вони повернуть значення того самого типу. Оскільки логічні вирази обчислюються зліва направо, вони перевіряються на можливе "коротке замикання", тобто обчислення проходить за наступними правилами:
+
+- `false` `&&` *`будь-що`* дає результат `false`.
+- `true` `||` *`будь-що`* дає результат `true`.
+
+Правила логіки гарантують, що ці обчислення завжди будуть правильними. Зауважте, що частина виразу *`будь-що`* не обчислюється, тому будь-які побічні ефекти від цих обчислень не відбудуться.
+
+```js
+let a1 = true && true; // t && t вертає true
+let a2 = true && false; // t && f вертає false
+let a3 = false && true; // f && t вертає false
+let a4 = false && (3 == 4); // f && f вертає false
+let a5 = 'Кіт' && 'Пес'; // t && t вертає Пес
+let a6 = false && 'Кіт'; // f && t вертає false
+let a7 = 'Кіт' && false; // t && f вертає false
+let o1 = true || true; // t || t вертає true
+let o2 = false || true; // f || t вертає true
+let o3 = true || false; // t || f вертає true
+let o4 = false || (3 == 4); // f || f вертає false
+let o5 = 'Кіт' || 'Пес'; // t || t вертає Кіт
+let o6 = false || 'Кіт'; // f || t вертає Кіт
+let o7 = 'Кіт' || false; // t || f вертає Кіт
+let n1 = !true; // !t вертає false
+let n2 = !false; // !f вертає true
+let n3 = !'Кіт'; // !t вертає false
+```
+
+### Числові змінні
+
+У JavaScript усі числові дані, як цілочисельні значення, так і числа з плаваючою комою представлені через тип даних (`number`). Для дуже великих цілих чисел (більше за модулем, ніж два в степені 53), застосовується спеціальний об'єкт - `BigInt`, у цій лекції не будемо його розглядати.
+
+У якості літералів, крім звичайних чисел (`15` чи `36.6`) існують спеціальні числові значення: `Infinity` (нескінченність), `-Infinity` (мінус нескінченність) і `NaN` (не число).
+
+```js
+console.log(1+2);//видасть 3
+console.log(1.1+2.1);//видасть 3.2
+console.log("2"+3);//видасть "23"
+console.log("два"+3);//видасть "два3"
+console.log(2/"0.5");//видасть 4
+console.log("два"/3);//видасть NaN
+console.log(1/0);//видасть Infinity
+```
+
+Цілочисельні літерали типу `number` можна виразити у різних формах. Це задається першою літерою літералу:
+
+- без літери - для 10-кової,
+- `0o` - вісімкової ,
+- `0x` - 16-кової,
+- `0b` - для 2-кової.
+
+```js
+console.log(-345); //-345
+console.log(-0o77); //-63
+console.log(-0xF1A7); //-61863
+console.log(-0b11); //-3
+```
+
+Літерали з плаваючою комою можуть задаватися у різному форматі:
+
+```js
+console.log(3.1415926); //3.1415926
+console.log(-.123456789);//-0.123456789
+console.log(-3.1E+12); //-3100000000000
+console.log(.1e-3); //0.0001
+```
+
+Як наводилося вище, примітивні типи можуть використовуватися як об'єкти. Об'єкт-обгортка `Number` має багато корисних властивостей та методів. Наприклад метод `toString` виводить значення типу `String` у вказаній у дужках системі числення.
+
+```js
+let a=0xF; //16-ковий формат
+console.log (a.toString(2)); // 1111 - двійковий формат
+```
+
+Про об'єктні властивості та методи `Number` можна прочитати у [наступній лекції](jsobjects.md).
+
+### Змінні `string`
+
+Рядок (`string`) в JavaScript повинна бути взята в лапки.
+
+```javascript
+let str = "Рядок в подвійних лапках";
+let str2 = 'Можна використовувати одинарні лапки';
+let phrase = `Зворотні лапки (зліва від '1') дозволяють вставляти значення змінних ${str}, інші лапки таке не дозвоялють робити`;
+```
+
+Крім звичайних символів до рядків можна також включати спеціальні, як це показано в наступному прикладі. Весь перелік символів доступний [у розділі string з довідника](../Довідники/js/js.md#string).
+
+```js
+console.log ("один рядок \n інший рядок"); //виведеться в два рядки
+```
+
+Об'єкт-обгортка `String` мають багато корисних методів і властивостей. Повний перелік наведений у [довіднику](https://wiki.developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/String). У прикладі нижче, деякі з них:
+
+```javascript
+let a='Текст';
+console.log (a.length); //5 - довжина, тобто кільксть літер
+console.log (a.toLowerCase());//текст - усі літери маленькі
+console.log (a[2]); //к - доступ до літери по номеру
+for (let char of a='Текст') {//перебір усіх символів
+ console.log(char); // Т,е,к,с,т
+}
+console.log(a.substring(0,3)); //Тек - підрядок з 0-го по 3-й не включно
+console.log(a.substr(1,2)); //ек - підрядок з 1-го, 2 шт
+```
+
+Додатково про роботу зі змінними `string` та виразами можна почитати за [цим посиланням](https://wiki.developer.mozilla.org/uk/docs/Web/JavaScript/Guide/Text_formatting) або [за цим](https://learn.javascript.ru/string).
+
+### Оператор typeof
+
+Оператор `typeof` повертає тип аргумента. Він працює однаково з довма синтаксисами
+
+```js
+typeof операнд
+typeof (операнд)
+```
+
+```javascript
+console.log (typeof undefined);// "undefined"
+console.log (typeof 0) ;// "number"
+console.log (typeof true); // "boolean"
+console.log (typeof "foo"); // "string"
+console.log (typeof Symbol("id")); // "symbol"
+conso;e.log (typeof (['Я','М']));//"object", бо масиви це об'єкти
+console.log (typeof Math); // "object" - так як Math вбудований в JS обєкт для роботи з мат.операціями
+console.log (typeof null); // "object" - хоч це не так
+console.log (typeof console.log); // "function" - хоч формально такого типу немає, для методів і функцій повертається "function"
+```
+
+### Перетворення типів
+
+Найчастіше оператори і функції автоматично перетворюють передані їм значення (примітивного типу) до потрібного типу. Наприклад, `console.log` автоматично перетворює будь-яке значення до типу `string`. Математичні оператори перетворюють значення до чисел. Але є випадки, коли потрібно явно перетворити значення в очікуваний тип.
+
+Можна використовувати функцію `String (value)`, щоб явно перетворити значення до рядка:
+
+```javascript
+let value = true;
+console.log (typeof value); // boolean
+value = String(value); // тепер це рядок, що дорівнює "true"
+console.log (typeof value); // string
+```
+
+Можна використати функцію `Number(value)`, щоб явно перетворити `value` в число. Якщо рядок не може бути перетворений в число, результатом буде `NaN`.
+
+```javascript
+let str = "123"; console.log(typeof str); // string
+let num = Number(str); console.log(typeof num); // стає числом 123, тому number
+let age = Number("Будь який рядок без числа"); console.log(age); // NaN, перетворення не вдалося
+console.log(Number(" 123 ") ); // 123
+console.log(Number("123z") ); // NaN (помилка читання числа в "z")
+console.log(Number(true) ); // 1
+console.log(Number(false) ); // 0
+```
+
+Майже усі математичні оператори виконують чисельне перетворення, за виключенням `+`. Якщо один із доданків є рядком, тоді всі інші приводяться до строчок і робиться конкатенація (з'єднання).
+
+```js
+console.log("1.1" + "1.1"); //"1.11.1"
+console.log((+"1.1") + (+"1.1"));//2.2
+```
+
+У випадку, коли значення, що представляє число, знаходиться в пам'яті як рядок, існують методи для перетворення [`parseInt()`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/parseInt) та [`parseFloat()`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/parseFloat).
+
+```javascript
+console.log(Boolean(1)); // true
+console.log(Boolean(0)); // false
+console.log(Boolean("Привіт!")); // true
+console.log(Boolean("")); // false
+console.log(Boolean("0")); // true
+console.log(Boolean(" ")); // пробіл це також true (любий непустий рядок це true)
+```
+
+### Оператор присвоєння (=)
+
+Лівосторонньому операнду `=` дається значення правостороннього виразу.
+
+```javascript
+let x = 2 * 2 + 1;
+console.log(x); // 5
+let a, b, c;
+a = b = c = 2 + 2; //присвоєння ланцюжком, усім змінним буде присвоєно 4
+let a1 = 1; //1
+let b1 = 2; //2
+let c1 = 3 - (a1 = b1 + 1);//0
+```
+
+### Оператори порівняння
+
+Оператор порівняння порівнює операнди та повертає логічне значення істинності порівняння. Операнди можуть бути числовими, рядками, логічними значеннями або об'єктами. Рядки порівнюються згідно стандартного лексикографічного порядку, з використанням значень Unicode.
+
+У більшості випадків, якщо два операнди не належать до одного типу, JavaScript намагається привести їх до належного для порівняння типу. Зазвичай це призводить до числового порівняння операндів. Єдиними винятками у конвертації типів під час порівняння є оператори `===` та `!==`, які виконують перевірку на строгу рівність та строгу нерівність. Ці оператори не намагаються перед перевіркою на рівність привести операнди до спільного типу.
+
+Наступний приклад показує як працюють оператори. Усі виведення в консоль будуть давати результат TRUE.
+
+```js
+let var1 = 3; let var2 = 4;
+//усі наведені нижче приклади виведуть значення TRUE;
+console.log (3 == var1); //рівність
+console.log ("3" == var1); //рівність
+console.log ("3" == 3); //рівність
+console.log (var1 != 4); //нерівність
+console.log (var2 != "3"); //нерівність
+console.log (3 === var1); //строга рівність, оператори рівні і одного типу
+console.log (var1 !== "3"); //строга нерівність, оператори одного типу, але нерівні
+console.log (3 !== '3'); //строга нерівність, оператори різного типу
+console.log (var2 > var1); //більше ніж
+console.log ("12" > 2); //більше ніж
+console.log (var2 >= var1); //більше абл дорівнює
+console.log (var1 < var2); //менше ніж
+console.log (var1 <= var2); //менше або дорівнює
+```
+
+### Арифметичні оператори
+
+Арифметичний оператор приймає числові значення (літерали чи змінні) в якості операндів та повертає єдине числове значення. Стандартними арифметичними операторами є додавання (`+`), віднімання (`-`), множення (`*`) та ділення (`/`). Ці оператори працюють так само, як і в більшості інших мов програмування, при використанні з числами з рухомою комою (зокрема, зауважте, що ділення на нуль повертає [`Infinity`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/Infinity)). Робота з іншими арифметичними операторами показана у прикладі нижче:
+
+```javascript
+let x=3;
+console.log (12 % 5); //2, остача від ділення
+console.log (++x); console.log (x); //4(інкрменет, потім вивід), потім 4
+console.log (x++); console.log (x); //4(вивід потім інкремент), потім 5
+console.log (--x); console.log (x); //4(декрменет, потім вивід), потім 4
+console.log (x--); console.log (x); //4(вивід потім декремент), потім 3
+console.log (-x); //-3, унарний мінус робить знак протилежним
+console.log (+"3"); //-3, унарний плюс перетворює операнд на число
+console.log (2**3); //8, підносить до степеня
+```
+
+### Бітові оператори
+
+Бітовий оператор опрацьовує свої операнди, як послідовність 32-х бітів (нулів та одиниць). Бітові оператори виконують операції над цими бітовими представленнями і повертають стандартні числові значення JavaScript. Кожен біт першого операнду ставиться у пару до відповідного біту другого операнду: перший до першого, другий до другого, і так далі. Наступний приклад показує результати таких операцій.
+
+```javascript
+let a;
+a = 0b1101 & 0b1000; console.log (a.toString(2));//1000, побітове І
+a = 0b1101 | 0b1010; console.log (a.toString(2));//1111, побітове АБО
+a = 0b1101 ^ 0b0001; console.log (a.toString(2));//1100, побітове виключне АБО, повертає 0 там де біти однакові
+a = ~ 0xFFFF_FFF0; console.log (a.toString(2));//1111, інвертує біти
+//при зсуві усі біти на краю куди зсовують "випадають", а звідки - заповнюються нулями
+a = 0b0011 << 3; console.log (a.toString(2));//11000, зсуває на три біти ліворуч
+a = 0b11100 >> 4; console.log (a.toString(2));//1, зсуває на 4 біти праворуч,
+a = 0x8000_0000 >> 16; console.log (a.toString(16));//-8000, зсуває на 16 біт праворуч, але знак залишає
+a = 0x8000_0000 >>> 16; console.log (a.toString(16));//8000, зсуває на 16 біт праворуч, знак приймає як біт
+```
+
+### Оператори з рядками
+
+На додачу до операторів порівняння, які можуть застосовуватись до рядкових значень, оператор конкатенації (+) об'єднує значення двох рядків, повертаючи єдиний рядок. Наприклад,
+
+```js
+console.log('мій ' + 'рядок'); // консоль виводить рядок "мій рядок".
+```
+
+Для конкатенації рядків може також застосовуватись скорочений оператор присвоєння += . Наприклад,
+
+```js
+let mystring = 'алфа';
+console.log (mystring += 'віт'); // повертає "алфавіт" та присвоює це значення mystring.
+```
+
+### Умовний оператор
+
+Умовний оператор - єдиний оператор у JavaScript, який приймає три операнди. У оператора може бути одне чи два значення, в залежності від умови. Використовує наступний синтаксис:
+
+```javascript
+умова ? значення1 : значення2
+```
+
+Якщо `умова` дорівнює `true`, оператор повертає `значення1`. В іншому випадку - `значення2`. Умовний оператор можна використовувати будь-де, де використовується звичайний оператор. Наприклад:
+
+```js
+let age = 19;
+let status = (age >= 18) ? 'дорослий' : 'неповнолітній';
+console.log (status); //дорослий
+```
+
+Ця інструкція присвоює значення "дорослий" змінній `status`, якщо значення `age` (вік) більше чи дорівнює 18. Інакше, вона присвоює змінній `status` значення "неповнолітній".
+
+### Оператор кома
+
+Оператор кома (`,`) обчислює обидва свої операнди та повертає значення останнього операнду. Цей оператор найчастіше використовується всередині циклу `for`, що дозволяє оновлювати більше однієї змінної на кожному проході циклу. Наприклад, якщо `a` є двовимірним масивом з 10 елементами по кожній стороні, наступний код використовує оператор кому, щоб оновити дві змінні одночасно. Код виводить значення діагональних елементів масиву:
+
+```js
+for (var i = 0, j = 9; i <= j; i++, j--)
+ console.log('a[' + i + '][' + j + ']= ' + a[i][j]);
+```
+
+### Умовні інструкції
+
+Як і в інших мовах **if**, дозволяє робити галуження.
+
+```javascript
+let a=3; let b=2;
+if (a>b) {
+ console.log ("a>b");
+} else {
+ console.log ("a<=b");
+}
+//використання else if
+if (a>b) {
+ console.log ("a>b");
+} else if (a`
+
+На минулій лекції розглянуто два синтаксиса створення функцій - шляхом оголошення та за допомогою функціонального виразу. Ще одним синтаксисом створення функцій подібно до функціонального виразу є «функції-стрілки» або «стрілочні функції» (arrow functions).
+
+```javascript
+let sum1 = (a, b) => a + b; //стрілочна функція
+let sum2 = function(a, b) {return a + b};//аналогічна форма через функціональний вираз
+console.log(sum1(1, 2) ); // 3
+console.log(sum2(1, 2) ); // 3
+```
+
+При використанні одного аргументу, запис буде ще коротше:
+
+```javascript
+let double1 = function(n) { return n * 2 }
+let double2 = n => n * 2; //анаогічний попередньому
+```
+
+Якщо немає аргументів, це матиме вигляд:
+
+```javascript
+let sayHi = () => console.log("Hello!");
+```
+
+Такі функції зручні для простих однорядкових дій. Однак вони мають додаткові можливості, які наразі розглядати не будемо.
+
+### Залишкові параметри та `arguments`
+
+Якщо кількість аргументів може варіюватися, тобто якісь з аргументів не є обов'язковими, можна скористатися залишковими параметрами. ***Залишкові параметри*** (rest parameters) - це представлення усіх фактичних параметрів при виклику функції у вигляді одного масиву. При означенні функції, ці параметри вказуються після `...` і якщо використовуються, повинні бути в кінці списку параметрів. Після залишкових параметрів не можна вказувати інші.
+
+```javascript
+function showName(firstName, lastName, ...titles) { //titles - масив залишкових параметрів
+ console.log( firstName + ' ' + lastName ); // Юлій Цезарь
+ // Інші параметри підуть в масив
+ // titles = ["Консул", "Імператор"]
+ console.log( titles[0] ); // Консул
+ console.log( titles[1] ); // Імператор
+ console.log( titles.length ); // 2
+}
+showName("Юлій", "Цезарь", "Консул", "Імператор");
+```
+
+Усі аргументи функції знаходяться в псевдо-масиві `arguments` під своїми порядковими номерами. Зрештою, при оголошенні функції, аргументи можна взагалі не вказувати і перебирати їх через `arguments`.
+
+```javascript
+function showName() { //формальні параметри не вказуються
+ console.log (arguments.length); //4
+ for (let arg of arguments)
+ {
+ console.log(arg); // послідовно буде виводити усі аргументи
+ }
+}
+showName("Юлій", "Цезарь", "Консул", "Імператор");
+```
+
+### Функції зворотного виклику та асинхронність
+
+Багато функцій JavaScript та його середовищ виконання одразу повертають результат, ще до того як вона виконала цільову дію. Це корисно тоді, коли завершення обробки функції займає багато часу, яке при очікуванні буде гальмувати виконання програми.
+
+Наприклад, функція `setTimeout` повинна виконати якусь дію через вказаний інтервал часу. Для того щоб вказати цю дію, вона записується як інструкції в функції, яка буде викликатися через цей інтервал. Наприклад:
+
+```javascript
+let fn = function () {console.log ("пройшло 2 секунди")};
+console.log ("Запускаємо таймер");
+setTimeout(fn, 2000);
+console.log ("Таймер запущено, чекаємо...");
+```
+
+У даному прикладі, функція `fn` містить інструкцію, яку необхідно виконати через 2 секунди. При виклику `setTimeout` ця функція передається в якості аргументу разом з інтервалом (задається в мілісекундах). Замість того, щоб чекати 2 секунди, функція `setTimeout` одразу обробляється і передає керування наступній інструкції, що йде за нею. У цей час десь на рівні ОС запускається окремий програмний потік, задача якого відслідкувати спрацювання таймеру. Однак цей потік не зупиняє виконання програми JavaScript, вона виконується далі. Коли системний потік з таймером виявить, що час пройшов, він викличе функцію `fn`.
+
+Таким чином наведена вище програма спочатку виведе повідомлення "Запускаємо таймер", потім "Таймер запущено, чекаємо..." і через 2 секунди "пройшло 2 секунди". Така функція, яка запускається на виконання, одразу віддає керування потоку, що її визвав, ще до завершення результату називається ***асинхронною***. Функція, яка передається в якості аргументу для її виклику називається ***функцією зворотного виклику*** (колбек, callback). У наведеному вище прикладі функція `setTimeout` є асинхронною, а `fn` - функцією зворотного виклику.
+
+Наведений вище код з використанням функцій стрілок може виглядіти наступним чином:
+
+```javascript
+console.log ("Запускаємо таймер");
+setTimeout(() => console.log ("пройшло 2 секунди"), 2000);
+console.log ("Таймер запущено, чекаємо...");
+```
+
+Асинхронно також працює функція `setInterval`, яка запускає функцію, з вказаною періодичністю:
+
+```javascript
+let fn = function () {console.log ("пройшло 2 секунди")};
+console.log ("Запускаємо таймер");
+setInterval(fn, 2000);
+console.log ("Таймер запущено, чекаємо...");
+```
+
+Асинхронність є дуже корисною характеристикою тих функцій, які працюють з зовнішніми засобами. Якщо дані необхідно кудись записати, скільки це займе часу. Нижче наведений приклад, де показані в тактах ЦПУ час, що потребується для цього (числа умовні, але порядок буде такий самий).
+
+Таблиця 14.1. Порівняльна таблиця часу, який необхідний для виконання різних операцій.
+
+| **Операція запису в** | **Кількість тактів CPU (приблизно)** |
+| --------------------- | ------------------------------------ |
+| CPU Registers | 3 такти |
+| L1 Cache | 8 тактів |
+| L2 Cache | 12 тактів |
+| RAM | 150 тактів |
+| Диск | 30,000,000 тактів |
+| Мережа | 250,000,000 тактів |
+
+Якщо б операції доступу (читання/запису) по мережі до даних реалізовувалися через синхронні функції, програмний потік JavaScript просто б постійно зависав. Замість цього асинхронна функція запускається з передачею функції зворотного виклику і програма далі працює. У цей час ОС виконує необхідну операцію. Як тільки вона буде оброблена, буде викликана функція зворотного виклику.
+
+### Створення тіла функції через New
+
+Конструктор `Function` створює новий об'єкт `Function`. Прямий виклик конструктора може створювати функції динамічно, але має проблеми з безпекою та схожі з [`eval`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/eval) (але менш значні) проблеми з продуктивністю. Однак, на відміну від `eval`, конструктор `Function` створює функції, які виконуються тільки у глобальній області видимості.
+
+```javascript
+new Function (arg1, arg2, ...argN,functionBody)
+```
+
+- `arg1, arg2, ... argN`- імена, які будуть використані функцією в якості імен формальних аргументів. Кожне ім'я має бути рядком, який представляє ідентифікатор JavaScript, або списком таких рядків, розділених комою; наприклад, "`x`", "`theValue`" або "`a,b`".
+- `functionBody`- рядок, що містить інструкції JavaScript, які складають означення цієї функції.
+
+```javascript
+//у змінній strfn знаходиться код функції
+let strfn = "let y = a+b+c; console.log ('Значення суми = ' + y + '!')";
+let fno = new Function ("a","b","c", strfn);
+fno (100,10,1); //Значення суми = 111!
+```
+
+Додатково про це можна прочитати [за цим](https://learn.javascript.ru/new-function) або [за цим](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/Function) посиланням.
+
+Додатково про властивості і методи функцій як об'єктів наведено нижче.
+
+## 14.2. Об'єкти
+
+На минулій лекції були коротко розглянуті призначення об'єктів, їх створення через літерал та робота з властивостями та методами. Тут продовжимо розглядати об'єкти та їх призначення.
+
+### Методи об'єктів
+
+Окрім властивостей об'єктів, які надають можливість доступитися до певного його параметру, можна користуватися певними діями, які може робити об'єкт. Такі дії в JavaScript представлені властивостями-функціями об'єкта.
+
+```javascript
+let user = {
+ name: "Джон",
+ age: 30
+};
+user.sayHi = function() {
+ console.log("Привіт!");
+};
+user.sayHi(); // Привіт!
+```
+
+У наведеному вище прикладі властивості `user.sayHi` об'єкта був присвоєний функціональний вираз (Function Expression). Тепер цю властивість можна використовувати для виклику функції. Властивості-функції об'єкту називають ***методом*** цього об'єкту.
+
+Альтернативний спосіб через оголошення функції матиме вигляд:
+
+```javascript
+let user = {
+ name: "Джон",
+ age: 30
+};
+// спочатку оголошуємо
+function sayHi() {
+ console.log("Привіт!");
+};
+// потім добалвяємо в якості метода
+user.sayHi = sayHi;
+user.sayHi(); // Привіт!
+```
+
+Існують також короткі синтаксиси для методів при створенні об'єктів через літерал:
+
+```javascript
+let user1 = {
+ sayHi: function() { //метод створюється при створенні об'єкту
+ console.log("Привіт!");
+ }
+};
+let user2 = {
+ sayHi() { // те саме, що і "sayHi: function()"
+ console.log("Привіт!");
+ }
+};
+user1.sayHi();user2.sayHi();
+```
+
+До методів об'єктів також можна доступатися не тільки через крапку, але і через прямокутні дужки, адже це також властивості. Це дає можливість вказувати метод через змінну, наприклад:
+
+```javascript
+let user = {
+ sayHi() {console.log("Привіт!")}
+};
+let method = "sayHi";
+user[method]();
+```
+
+Слід звернути увагу, що звернення до методу без дужок, значить звернення до самої функції, а не її виклик, наприклад.
+
+```javascript
+let user = {
+ sayHi() {console.log("Привіт!")}
+};
+let method = user.sayHi; //назначаємо змінній функцію
+method(); //викликаємо функцію - Привіт!
+console.log (user.sayHi);//sayHi() { … }
+console.log (method); //sayHi() { … }
+```
+
+### Ключове слово `this`
+
+Як правило, методу об'єкта необхідний доступ до інформації, яка зберігається в об'єкті, щоб виконати з нею які-небудь дії (у відповідності з призначенням методу). Наприклад, коду в об'єкті необхідний доступ до інформації, яка зберігається в тому ж об'єкті, щоб виконати з нею які-небудь дії (у відповідності з призначенням методу). Наприклад, коду всередині `user.sayHi()` може знадобитися ім'я користувача, яке також зберігається в цьому об'єкті.
+
+Для того щоб звернутися до свого ж об'єкту, використовується ключове слово **`this`**. Наприклад,
+
+```javascript
+let user = {
+ name: "Джон",
+ age: 30,
+ sayHi() {
+ // this - це "плинний об'єкт"
+ console.log("Привіт, мене звати " + this.name + " !");
+ }
+};
+user.sayHi(); // Привіт, мене звати Джон !
+```
+
+Тут під час виконання `user.sayHi()` значенням`this` буде `user` (посилання на об'єкт `user`). Можна також звертатися безпосередньо до об'єкту `user`, але назва об'єкту може бути різною, а нас цікавить саме цей об'єкт, в якому викликається метод.
+
+Значення `this` розраховується під час виконання і залежить від контексту.
+
+### Конструктори об'єктів
+
+Літеральний синтаксис `{...}` дозволяє створювати один унікальний об'єкт. Але часто необхідно створити багато однотипних об'єктів. Це можна робити з використанням функції-конструктора і ключового слова `new`.
+
+***Функції-конструктори*** призначені для побудови об'єктів. До них є певні вимоги:
+
+- ім'я функції-конструктора повинно починатися з великої букви (не обов'язково, але є гарним тоном);
+- вона повинна викликатися за допомогою оператора `new`
+
+ Коли функція викликається як `new User(...)`, відбувається наступне:
+
+1. Створюється новий порожній об'єкт, який присвоюється `this`
+2. Виконується код функції. Зазвичай він модифікує `this`, добавляє туди нові властивості
+3. Повертається значення `this`
+
+Іншими словами, виклик `new User(...)` робить приблизно наступне:
+
+```javascript
+function User(name) {
+ // this = {}; (неявно)
+ // добавлення властивостей, методів і додаткові дії інціалізації і т.п.
+ this.name = name;
+ this.isAdmin = false;
+ // return this; (неявно)
+}
+let user = new User("Вася");
+console.log(user.name); // Вася
+console.log(user.isAdmin); // false
+```
+
+Таким чином, результат виклику `new User("Вася")` буде той самий об'єкт, що і
+
+```javascript
+let user = {
+ name: "Вася",
+ isAdmin: false
+};
+```
+
+Однак, на відміну від літерального способу, створення об'єктів з такими самими властивостями тепер зводиться до виклику функції-конструктора, а не до повторення літералів.
+
+```javascript
+// літеральний
+let user1 = {name: "Вася",isAdmin: false};// для кожного користувача повний перелік властивостей
+let user2 = {name: "Міша", isAdmin: false};
+
+//через конструктор
+function User(name) { this.name = name; this.isAdmin = false} // один конструктор
+let user3 = new User("Вася");//створення властивостей для кожного користувача через виклик конструктору
+let user4 = new User("Міша");
+```
+
+Не важко помітити, що коли кількість властивостей та об'єктів зростає, використання конструктору значно спрощує створення однотипних об'єктів. Функція-конструктор призначена і використовується саме для створення об'єктів.
+
+Якщо в функції-конструкторі повертається значення через `return` це повинно бути об'єктною змінною, інакше буде повернено `this`.
+
+У конструкторі можна також створювати методи.
+
+```javascript
+function User(name) {
+ this.name = name;
+ this.sayHi = function() {console.log( "Мене звати " + this.name )};
+}
+let user1 = new User("Вася");
+user1.sayHi(); // Мене звати: Вася
+```
+
+Для складних об'єктів є ще один синтаксис - класи, які у даному курсі не будуть розглядатися.
+
+## 14.3. Вбудовані об'єкти JavaScript
+
+У JavaScript є багато вбудованих об'єктів. У цьому розділі розглянемо кілька з них.
+
+### Об'єкт Number
+
+Вбудований об'єкт [`Number`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Number) представляє об'єкт-обгортку для змінних та констант однойменного типу. Будь які змінні та літерали можна використовувати як об'єкт `Number`. Наприклад, можна звернутися до методу `toString` літералу:
+
+```javascript
+console.log ((255).toString(16)); // ff - 16-ковий формат
+console.log ((0xFF).toString()); // 255 - 10-ковий формат
+```
+
+Об'єкт вміщує ряд властивостей, такі як масимальне числове значення, не-число(NaN) та безкінечність (infinity) та інші. У таблиці нижче деякі з них:
+
+Таблиця 14.2. Властивості об'єкту Number
+
+| Властивість | Опис |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| [`Number.NaN`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/Number/NaN) | Спеціальне значення "не-число" |
+| [`Number.NEGATIVE_INFINITY`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/Number/NEGATIVE_INFINITY) | Спеціальне від'ємне безкінечне число; повертається при переповненні |
+| [`Number.POSITIVE_INFINITY`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/Number/POSITIVE_INFINITY) | Спеціальне додатне безкінечне число; повертається при переповненні |
+
+Ви не можете змінювати значення цих властивостей, але можете використовувати їх для читання.
+
+Об'єкт Number також надає множину методів для роботи з числами, зокрема:
+
+Таблиця 14.3. Методи об'єкту Number
+
+| Метод | Опис |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| [`Number.parseFloat()`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/Number/parseFloat) | Приймає рядок в якості аргументу та повертає число з плаваючою комою, яке вдалося розпізнати. Аналог глобальній функції [`parseFloat()`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/parseFloat). |
+| [`Number.parseInt()`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/Number/parseInt) | Приймає рядок в якості аргументу та поверає ціле число в заданій системі числення, якщо аргумент вдалося розпізнати. Аналог глобальній функції [`parseInt()`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/parseInt). |
+| [`Number.isFinite()`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/Number/isFinite) | Визначає, чи передане значення є кінцевим числом. |
+| [`Number.isInteger()`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/Number/isInteger) | Визначає, чи передане число є цілим. |
+| [`Number.isNaN()`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/Number/isNaN) | Визначає, чи передане число є [`NaN`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/NaN). Більш надійніша версія оригінальної глобальної функції [`isNaN()`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/isNaN). |
+| [`Number.isSafeInteger()`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/Number/isSafeInteger) | Визначає, чи передане значення є числом, що є безпечним цілим. |
+| [Nuber.toString(radix)](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Number/toString) | Вертає рядкове предствлення числа у вказаній у дужках (`radix`) системі числення |
+
+```javascript
+let a=0xF; //16-ковий формат
+console.log (a.toString()); // 15 - 10-ковий формат
+console.log (a.toString(2)); // 1111 - двійковий формат
+console.log (a.toString(16)); // f - 16-ковий формат
+```
+
+Прототип `Number` надає методи для отримання інформації з об'єкту `Number` в різноманітних форматах. Наступній таблиці представлені методи з `Number.prototype`.
+
+Таблиця 14.4. Методи об'єкту Number.prototype.
+
+| Методи | Опис |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| [`toExponential(fractionDigits)`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/Number/toExponential) | Повертає рядок, що представляє число в експоненціальній нотації з `fractionDigits` цифр після коми |
+| [`toFixed(digits)`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/Number/toFixed) | Повертає рядок, що представляє число з плаваючою комою з `digits` цифр після коми |
+| [`toPrecision(precision)`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/Number/toPrecision) | Повертає рядок, що представляє число із заданою точністю у позначені плаваючої коми з `precision` кількістю цифр. |
+
+```javascript
+let numObj = 77.1234;
+console.log(numObj.toExponential()); //'7.71234e+1'
+console.log(numObj.toExponential(2)); //'7.71e+1'
+console.log(numObj.toFixed()); // '77'
+console.log(numObj.toFixed(1)); // '77.1'
+console.log(numObj.toPrecision()) // '77.1234'
+console.log(numObj.toPrecision(5)) // '77.123'
+console.log(numObj.toPrecision(2)) // '77'
+console.log(numObj.toPrecision(1)) // '8e+1'
+```
+
+### Об'єкт Math
+
+Вбудований об'єкт [`Math`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/Math) має властивості та методи для математичних констант та функцій.
+
+На відміну від інших глобальних об'єктів, `Math()` не є конструктором. Тобто необхідно використовувати безпосередньо методи об'єкту `Math`.
+
+```javascript
+let a = new Number();//так можна робити
+console.log (a.toString());//0
+let b = new Math(); // помилка Math is not a constructor
+```
+
+Всі поля і методи `Math` статичні. Тобто до сталої Пі потрібно звертатись `Math.PI`, а функцію синуса викликати через `Math.sin(x)`, де `x` є аргументом статичного методу. Всі константи задані із максимальною для дійсних чисел у JavaScript точністю.
+
+Нижче наведені кілька властивостей та методів, усі інші можна подивитися у [довіднику](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/Math) Через властивості доступні деякі константи, зокрема, які наведені в таб.14.5.
+
+Таблиця 14.5. Константи Math.
+
+| Властивість | Опис |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| [`Math.E`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/Math/E) | Стала Ейлера, основа натуральних логарифмів. Приблизно дорівнює 2.718. |
+| [`Math.PI`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/Math/PI) | Значення відношення довжини кола до його діаметру, наближено дорівнює 3.14159. |
+| [`Math.SQRT2`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/Math/SQRT2) | Значення квадратного кореня від 2, наближено 1.414. |
+
+```javascript
+let a = Math.E;
+console.log (a); //2.718281828459045
+```
+
+Математичні функції представлені через методи, які наведені у таблиці 14.6:
+
+Таблиця 14.6. Методи об'єкту Math.
+
+| Метод | Опис |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| [`Math.asin(x)`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/Math/asin) | Повертає арксинус числа. |
+| [`Math.sin(x)`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/Math/sin) | Повертає значення синуса аргументу. Через аналогічні методи доступні усі тригонометричні функції |
+| [`Math.abs(x)`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/Math/abs) | Повертає абсолютне значення (модуль) числа. |
+| [`Math.sqrt(x)`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/Math/sqrt) | Повертає додатне значення квадратного кореня від аргументу. |
+| [`Math.cbrt(x)`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/Math/cbrt) | Повертає кубічний корінь числа. |
+| [`Math.pow(x, y)`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/Math/pow) | Повертає результат піднесення `x` до степеня `y`. |
+| [`Math.ceil(x)`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/Math/ceil) | Повертає число, округлене "до більшого". |
+| [`Math.floor(x)`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/Math/floor) | Повертає результат округлення "до меншого", тобто відкидує дробову частину. |
+| [`Math.round(x)`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/Math/round) | Повертає значення аргументу, округлене до найближчого цілого. |
+| [`Math.trunc(x)`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/Math/trunc) | Повертає цілу частину аргументу, відкидаючи всю дробову частину. |
+| [`Math.log10(x)`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/Math/log10) | Повертає логарифм за основою 10 від аргументу. |
+| [`Math.random()`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/Math/random) | Повертає псевдовипадкове число з-поміж 0.0 і 1.0. |
+| [`Math.sign(x)`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/Math/sign) | Повертає знак поданого числа. Визначає, чи являється аргумент додатним числом (вертає 1), від'ємним (вертає -1), чи дорівнює 0 (вертає 0). |
+
+Варто зазначити, що тригонометричні функції (sin(), asin() ..) очікують або повертають значення у радіанах. Для конвертації достатньо пам'ятати, що 1 кутовий градус - це (Math.PI / 180) радіан.
+
+```javascript
+console.log (Math.random()); //випадкове число від 0 до 1
+console.log (Math.sin(Math.PI/10));//0.3090169943749474
+console.log (Math.sign(-15.34)); //-1
+```
+
+### Об'єкт Date
+
+JavaScript не має окремого типу даних для збереження дат. Тим не менше, для роботи з датою та часом можна використовувати об'єкт [`Date`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/Date) та його методи . Він має велику кількість методів для встановлення, отримання та маніпулювання датами, але не має жодних властивостей.
+
+JavaScript зберігають дату, як кількість мілісекунд, що минули з 00:00:00 1 січня 1970 року. Значення в часу в мілісекундах також називається ***TimeStamp***.
+
+Об'єкт `Date` має окремі методи для підтримки UTC (всесвітній час) та місцевого часу. UTC (узгоджений всесвітній час) означає час встановлений світовим стандартом. Натомість місцевий час — це час того комп'ютера, на якому виконується код JavaScript.
+
+Для того, щоб створити власний екземпляр об'єкту `Date` можна викликати однойменний конструктор:
+
+```javascript
+let dateObjectName = new Date([parameters]);
+```
+
+де `dateObjectName` ім'я змінної в яку присвоюється створене значення з типом `Date`; це може бути як новий об'єкт, або як властивість існуючого об'єкту.
+
+`parameters` (в наведеному вище синтаксисі) може бути представлений одним з наступних значень:
+
+```javascript
+new Date();//Пусто: створюється сьогоднішня дата та час.
+new Date(value);//кількість мілісекунд з 1970 - TimeStamp
+new Date(dateString);//Набір цілих значень для року, місяця і дня
+new Date(year, month[, day[, hours[, minutes[, seconds[, milliseconds]]]]]); //Набір цілих значень для року, місяця, дня, години, хвилини та секунди.
+```
+
+`value` --- ціле число, що вказує кількість мілісекунд з 1 січня 1970 року 00:00:00 за UTC без врахування високосних секунд. Це те саме, що *час Unix*, але зважайте на те, що більшість функцій часу й дати Unix рахують у секундах.
+
+`dateString` --- Рядок, що вказує дату й час. Має бути у форматі, що розпізнається методом [`Date.parse()`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/Date/parse) ([IETF-compliant RFC 2822 timestamps](http://tools.ietf.org/html/rfc2822#page-14), і також [різновид ISO8601](http://www.ecma-international.org/ecma-262/5.1/#sec-15.9.1.15)).
+
+Зверніть увагу, що `month` задається від `0` (січень) до `11` (грудень)
+
+Приклад:
+
+```javascript
+let DT1 = new Date(); //теперішня дата
+let DT2 = new Date(1587227373000);//TimeStamp
+console.log (DT2); //Sat Apr 18 2020 19:29:33 GMT+0300 (GMT+03:00)
+let DT3 = new Date("2020, 4, 18 19:29:33");
+console.log (DT3); //Sat Apr 18 2020 19:29:33 GMT+0300 (GMT+03:00)
+let DT4 = new Date(2020, 3, 18, 19, 29, 33); // 3 - Квітень, бо 0 - січень
+console.log (DT4); //Sat Apr 18 2020 19:29:33 GMT+0300 (GMT+03:00)
+```
+
+Виклик `Date` як функції, тобто без оператора `new`, повертає теперішню дату та час як рядок (string).
+
+```javascript
+console.log (Date()); //виведе плинну дату та час
+```
+
+Наступні методи працюють для глобального об'єкту `Date`, але не для об'єктів створених за допомогою конструктора `Date`.
+
+Таблиця 14.7. Методи об'єкту `Date`.
+
+| Метод | Опис |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| [`Date.now()`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/Date/now) | Вертає ціле число, що позначає поточний час — кількість мілісекунд від 00:00:00 за UTC 1 січня 1970 року без врахування високосних секунд. |
+| [`Date.parse()`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/Date/parse) | Розбирає текстовий запис (рядок) із датою (часом) та повертає кількість мілісекунд між 00:00:00 за UTC 1 січня 1970 та зазначеною миттю у часі. Високосні секунди не враховуються. |
+| [`Date.UTC()`](https://developer.mozilla.org/uk/docs/Web/JavaScript/Reference/Global_Objects/Date/UTC) | Приймає ті самі параметри, що й найдовша форма конструктора (від 2 до 7), та вертає кількість мілісекунд між 00:00:00 1 січня 1970 року за UTC та зазначеною миттю у часі без врахування високосних секунд. |
+
+```javascript
+tsDT1 = Date.now();
+console.log (tsDT1); //1587225137339
+tsDT2 = Date.parse("2020, 4, 18 19:29:33");
+console.log(tsDT2); //1587227373000
+tsDT3 = Date.UTC(2020, 3, 18, 19, 29, 33);
+console.log (tsDT3); //1587238173000
+console.log ((tsDT3-tsDT2)/(60*60*1000));//3 - години різниці
+```
+
+Методи об'єкта `Date` для роботи з датами та часом діляться на наступні категорії::
+
+- `set` методи, для встановлення дати та часу в об'єкт `Date`.
+- `get` методи, для отримання дати та часу з об'єкту `Date`.
+- `to` методи, для отримання значення об'єкта `Date` в рядковому вигляді.
+
+За допомогою методів групи `get` та `set` можна встановлювати секунди, хвилини, години, дні місяця, дні тижнів, місяці та роки окремо. Слід звернути увагу на метод `getDay`, який повертає день тижня, але не існує відповідного методу `setDay`, оскільки день тижня встановлюється(вираховується) автоматично. Всі ці методи використовують цілі числа для представлення відповідних даних, як показано нижче:
+
+- Мілісекунди: `0` до `9999`
+- Секунди та хвилини: `0` до `59`
+- Години: `0` до `23`
+- День: `0` (Неділя) до `6` (Субота)
+- Дата: від `1` до `31` (день місяця)
+- Місяці: від `0` (Січень) до `11` (Грудень)
+- Роки: з `1900`
+
+Методи `get` наведені в наступній таблиці:
+
+Таблиця 14.8. Методи get об'єкту Date.
+
+| Метод | Опис |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| [`getFullYear()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Date/getFullYear), [`getMonth()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Date/getMonth), [`getDate()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Date/getDate), [`getDay()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Date/getDay), [`getHours()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Date/getHours), [`getMinutes()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Date/getMinutes), [`getSeconds()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Date/getSeconds), [`getMilliseconds()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Date/getMilliseconds) | отримання відповідно року, місяця, дати, дня тижня, години, хвилини, секунди, мілісекунди |
+| [`getTime()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Date/getTime) | отримання TimeStamp |
+| getUTC | те саме що і `get` тільки для часу UTC |
+| [`getTimezoneOffset()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Date/getTimezoneOffset) | зміщення в хвилинах місцевої часової зони, що налаштована в пристрої (ПК) відносно UTC |
+
+```javascript
+let DT1 = new Date("2020, 4, 18 19:29:33");
+console.log (DT1.getFullYear());//2020
+console.log (DT1.getMonth()); //3 - квітень, бо 0 -січень
+console.log (DT1.getDate()); //18
+console.log (DT1.getDay()); //6 - субота (0 - неділя)
+console.log (DT1.getTime()); //1587227373000 - TimeStamp
+console.log (DT1.getHours()); //19
+console.log (DT1.getMinutes()); //29
+console.log (DT1.getSeconds()); //33
+console.log (DT1.getTimezoneOffset());//-180 - 3 години до UTC
+```
+
+Методи `set` наведені в наступній таблиці
+
+Таблиця 14.9. Методи set об'єкту Date.
+
+| Метод | Опис |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| [`setFullYear()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Date/setFullYear), [`setMonth()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Date/setMonth), [`setDate()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Date/setDate) , [`setHours()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Date/setHours), [`setMinutes()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Date/setMinutes), [`setSeconds()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Date/setSeconds), [`setMilliseconds()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Date/setMilliseconds) | встановлення відповідно року, місяця, дати, години, хвилини, секунди, мілісекунди |
+| [`setTime()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Date/setTime) | встановлення часу через мілісекунди (TimeStamp) |
+| Date.prototype.setUTC | те саме що і `set` але для часу UTC |
+
+```javascript
+let DT1 = new Date(0); console.log (DT1); //Jan 01 1970 03:00:00
+DT1.setFullYear (2020);//можна DT1.setFullYear (2020, 3, 18) щоб задати повністю дату
+DT1.setMonth(3);//3 - квітень, бо 0-січень;можна DT1.setMonth(3, 18), щоб задати ще і дату
+DT1.setDate(18);
+DT1.setHours(19);//години, можна DT1.setHours(19,29,33) щоб задати повінстю час
+DT1.setMinutes(29);//хвилини, можна DT1.setMinutes(29,33) щоб задати ще хвилини
+DT1.setSeconds(33);//секунди, можна DT1.setSeconds(33,500), щоб задати мс
+console.log (DT1); //Apr 18 2020 19:29:33
+DT1.setTime(1000); //1587227373000 - TimeStamp
+console.log (DT1); //Jan 01 1970 03:00:01
+```
+
+Наступні методи перетворюють дату в один з форматів:
+
+Таблиця 14.10. Методи to об'єкту Date.
+
+| Метод | Опис |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| [`toString()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Date/toString) | перетворює в строкове представлення дати та часу в форматі ECMA-262 |
+| [`toDateString()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Date/toDateString), [`toTimeString()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Date/toTimeString) | перетворює в строкове представлення відповідно дати та часу в форматі перетворює в строкове представлення дати та часу в форматі ECMA-262 |
+| [`toISOString()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Date/toISOString) | перетворює в строкове представлення дати та часу в форматі [ISO 8601](http://en.wikipedia.org/wiki/ISO_8601) |
+| [`toJSON()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Date/toJSON) | перетворює в строкове представлення дати та часу аналогічно попередньому |
+| [`toLocaleString()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Date/toLocaleString) | перетворює в строкове представлення дати та часу відповідно до національних налаштувань (задаються в аргументах) |
+| [`toLocaleTimeString()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Date/toLocaleTimeString), [`toLocaleDateString()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Date/toLocaleDateString) | перетворює в строкове представлення відповідно дату та час до національних налаштувань (задаються в аргументах) |
+| [`toUTCString()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Date/toUTCString) | перетворює в строкове представлення UTC |
+| [`valueOf()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Date/valueOf) | перетворення в примітивний тип, тобто в TimeStamp |
+
+```javascript
+let DT1 = new Date("2020, 4, 18 19:29:33");
+console.log (DT1.toString()); //Sat Apr 18 2020 19:29:33 GMT+0300 (GMT+03:00)
+console.log (DT1.toDateString()); //Sat Apr 18 2020
+console.log (DT1.toTimeString()); //19:29:33 GMT+0300 (GMT+03:00)
+console.log (DT1.toLocaleString("en-US")); //4/18/2020, 7:29:33 PM
+console.log (DT1.toLocaleString()); //2020-4-18 19:29:33
+console.log (DT1.toLocaleDateString());//2020-4-18
+console.log (DT1.toLocaleTimeString());//19:29:33
+console.log (DT1.toISOString()); //2020-04-18T16:29:33.000Z
+console.log (DT1.toUTCString()); //Sat, 18 Apr 2020 16:29:33 GMT
+console.log (DT1.toJSON()); //2020-04-18T16:29:33.000Z
+console.log (DT1.valueOf()); //1587227373000
+```
+
+Враховуючи, що дата по суті представлена в числовому форматі, з ними можна проводити операції, як з числами.
+
+```javascript
+let DT1 = new Date("2020, 4, 18 19:29:33");
+let DT2 = new Date("2019, 4, 18 19:29:33");
+console.log (DT2>DT1); //false
+console.log (DT2' +
+ toNY.days.toString() + ' днів
'+
+ toNY.days.toString() + ' днів
' +
+ toNY.hours.toString() + ' годин
' +
+ toNY.mins.toString() + ' хвилин
' +
+ toNY.secs.toString() + ' секунд')
+};
+```
+
+Таким чином для виводу часу у форматі html необхідно буде підключити `timetohtml.js`, який у свою чергу підключає `toNY.js` . У цьому випадку, до проекту треба підключати не один файл, а кілька об'єднаних файлів, які зручно тримати в одній папці. Крім того, у застосунку можуть знадобитися обидві експортовані функції, тому можна зробити модуль, який би експортував обидві функції.
+
+У даному прикладі ці два файли необхідно перенести в окрему папку, наприклад `toNYhtml`. І підключати в якості модуля всю директорію, у даному випадку це матиме наступний вигляд:
+
+```javascript
+let toNYhtml = require('./toNYhtml');
+```
+
+При такому записі шукатимуться спочатку файли `toNYhtml.js` та `toNYhtml.json`, потім файл `index.js` у папці `toNYhtml`. Таким чином при підключені папки усі експортовані функції та об'єкти модуля треба прописувати в `index.js`. У наведеному прикладі можна перейменувати `timetohtml.js` в `index.js`, а можна створити новий файл для експорту потрібних функцій. У нашому прикладі зробимо файл, що просто експортує усі потрібні функції з усіх інших файлів:
+
+```javascript
+exports.toNY = require('./toNY.js').toNY;
+exports.gettimehtml = require('./timetohtml.js').gettimehtml;
+```
+
+Тепер, застосунок, що виводить дату та час на ВЕБ-сторінку, буде включати головний файл `serer.js` який підключає модуль-папку і матиме вигляд:
+
+```javascript
+let toNYhtml = require('./toNYhtml');//підключення модуля-папки
+let http = require('http');
+let fn = function (req, res) {
+ res.writeHead (200, {'Content-Type': 'text/html; charset=utf-8'});
+ console.log (toNYhtml.toNY());//виводити в консоль як об'єкт
+ res.write (toNYhtml.gettimehtml());//вивести в форматі html
+ res.end ();
+}
+let httpserver = http.createServer (fn);
+httpserver.listen(8080);
+```
+
+Усі файли організовують наступну структуру:
+
+
+
+рис.16.3. Приклад структури модулів.
+
+## 16.3. Менеджер пакунків NPM
+
+### Вступ до NPM
+
+**npm** (Node Package Manager) - це [менеджер пакунків](https://uk.wikipedia.org/wiki/Система_керування_пакунками) для мови програмування JavaScript. Для середовища виконання Node.js це менеджер пакунків за замовчуванням. Включає в себе:
+
+- клієнт командного рядка, який називається також `npm`,
+- онлайн-базу даних публічних та приватних пакунків, яка називається **реєстром npm** або репозиторієм npm;
+
+Реєстр доступний через клієнт, а доступні пакунки можна переглядати та шукати через веб-сайт npm. Це дозволяє користувачам користуватися модулями JavaScript та розповсюджувати їх.
+
+Головна сторінка реєстру знаходиться за посиланням [https://registry.npmjs.com/](https://registry.npmjs.com/) . Реєстр NPM - це база даних `Couch DB`. Кожен пакунок в реєстрі доступний за іменем за адресою:
+
+```http
+https://registry.npmjs.com/<назва пакунку>
+```
+
+наприклад
+
+```http
+https://registry.npmjs.com/node-iplocate
+```
+
+Пакунки в реєстрі знаходяться у форматі [CommonJS](https://uk.wikipedia.org/wiki/CommonJS) і включають в себе файли метаданих у форматі JSON. Там також знходяться посилання на архіви пакунків та на залежності.
+
+Реєстр не має процедури перевірки, а це означає, що знайдені там пакунки можуть бути низькоякісними або небезпечними. Натомість npm спирається на звіти користувачів, щоб видаляти пакунки, якщо вони порушують політику безпеки (є незахищеними, зловмисними або низькоякісними). npm показує статистику, включаючи кількість завантажень та кількість пакунків, щоб допомогти розробникам оцінювати якість пакунків. Ось, наприклад, на рис.16.4 показано як виглядає опис пакунку для Node-RED.
+
+Все, що знаходиться в реєстрі NPM - відкрито для всіх. Тим не менше можна створити власний реєстр і налатувати взаємодію клієнта з ним.
+
+
+
+рис.16.4. Опис пакунку Node-RED в репозиторії.
+
+### Клієнт командного рядка `npm`
+
+Клієнт командного рядка має багато команд для роботи з пакунками. Перелік доступних команд, та як з ними працювати можна подивитися через вбудовану довідникову систему
+
+```bash
+npm help
+Usage: npm
+where is one of:
+ access, adduser, audit, bin, bugs, c, cache, ci, cit,
+ clean-install, clean-install-test, completion, config,
+ create, ddp, dedupe, deprecate, dist-tag, docs, doctor,
+ edit, explore, fund, get, help, help-search, hook, i, init,
+ install, install-ci-test, install-test, it, link, list, ln,
+ login, logout, ls, org, outdated, owner, pack, ping, prefix,
+ profile, prune, publish, rb, rebuild, repo, restart, root,
+ run, run-script, s, se, search, set, shrinkwrap, star,
+ stars, start, stop, t, team, test, token, tst, un,
+ uninstall, unpublish, unstar, up, update, v, version, view,
+ whoami
+
+npm -h коротка допомога по
+npm -l відображає повну інформацію по командам
+npm help шукає допомогу по в довідниковій системі
+npm help npm викликає довідникову систему
+```
+
+### Опис пакунку `package.json`
+
+Для того, щоб npm міг керувати пакунками, які включають в себе взаємозалежні модулі, необхідно ці залежності прописати в спеціальному файлі, який називається `package.json`. У файлі package.json кожна залежність може означити діапазон дійсних версій, використовуючи схему семантичної версії, що дозволяє розробникам автоматично оновлювати свої пакети, одночасно уникаючи небажаних змін.
+
+Файл `package.json` має знаходитися в папці модуля, і включати в себе наступну мінімально необхідну інформацію:
+
+- `name` - ім'я модуля
+- `version` - версія
+
+Наприклад, для наведеного вище прикладу, для означення пакунку для модуля `toNYhtml` необхідно в цій папці створити створити`package.json`, у який написати наступне:
+
+```json
+{
+ "name": "tonyhtml",
+ "version": "0.0.1"
+}
+```
+
+Можна також з командного рядку (знаходячись у папці модуля) викликати клієнтський застосунок `npm` з командою `init`, який заповнить цей файл введеною у діалоговому режимі інформацією. Після заповнення через
+
+```bash
+npm init
+```
+
+означення пакунка може мати наступний вигляд:
+
+```json
+{
+ "name": "tonyhtml",
+ "version": "0.0.1",
+ "description": "Визначення часу до нового року",
+ "main": "index.js",
+ "scripts": {
+ "test": "echo \"Error: no test specified\" && exit 1"
+ },
+ "author": "",
+ "license": "ISC"
+}
+```
+
+Поле `main` задає файл входження пакунку, тобто той, який буде підключатися для формування об'єктів експорту. За замовченням це `index.js`.
+
+Версійність пакетів означується парою з трьох цифр `МАЖОРНА.МІНОРНА.ПАТЧ`. Більш детально про семантичне версіювання читайте за посиланням [https://semver.org/lang/uk/](https://semver.org/lang/uk/)
+
+У реальних пакунках полів набагато більше, але розгляд їх виходить за рамки цієї лекції.
+
+### Пошук пакунків
+
+Для пошуку пакунків використовується команда `npm search` (або `s`). Ось, наприклад, пошуковий запит на пакунок за ключовими словами `location from ip`
+
+```bash
+npm search location from ip
+```
+
+Серед знайдених пакунків можна вибрати один і відкрити опис за посиланням
+
+```http
+https://www.npmjs.com/package/<назва пакунку>
+```
+
+наприклад
+
+```http
+https://www.npmjs.com/package/node-iplocate
+```
+
+### Встановлення та оновлення пакунків та `package-lock.json`
+
+Встановлення необхідного пакунку проводиться за допомогою команди `npm insttall`. Встановлення модулів проводиться в папку `node_modules` тієї папки, в якій запускається команда. Так, наприклад, якщо для наведеного вище прикладу перейти в папку `tonyhtml`, і там запустити наступну команду
+
+```bash
+npm install node-iplocate
+```
+
+то в папці модуля з'явиться папка `node_modules` а також файл `package-lock.json` . Файл `package-lock.json` автоматично генерується для будь яких операцій, де npm модифікує дерево `node_modules`, або ` package.json`. Він описує точне дерево, яке було сформовано таким чином, що наступні установки можуть генерувати однакові дерева, незалежно від проміжних оновлень залежності.
+
+Використання цього модулю тепер доступне в файлах папки `tonyhtml`.
+
+```bash
+const iplocate = require("node-iplocate");
+iplocate("193.28.200.2", null, function(err, results) {
+ console.log(JSON.stringify(results, null, 2));
+});
+```
+
+Слід звернути увагу, що при інсталяції пакунку, `npm` спочатку шукає папку `node_modules` або ` package.json` в локальній директорії, потім на рівень вище і т.д, поки не знайде корінь проекту. І тільки якщо такої директорії і ` package.json` не знайдено, створює цю папку.
+
+Команда `npm install` без додаткових уточнень в назві пакунку встановить останню стабільну версію. Для встановлення конкретної версії, треба використовувати додаткові параметри, наприклад
+
+```bash
+npm install node-iplocate@1.0.1
+```
+
+встановить версію 1.0.1.
+
+Перегляд пакунків проводиться командою `npm list`
+
+```bash
+npm list
+npm list node-iplocate
+```
+
+Видалення пакунку проводиться командою `npm uninstall`, наприклад
+
+```bash
+npm uninstall node-iplocate
+```
+
+Для перевірки та оновлення модулів використовується команда `npm update` .
+
+### Видалення пакунків
+
+Видалення пакунка без оновлення package.json
+
+```bash
+npm uninstall
+```
+
+Видалення пакунка та оновлення зав'язків в package.json
+
+```bash
+npm uninstall --save
+```
+
+Видалення пакунка та оновлення зав'язків в `devDependencies` в `package.json`
+
+```bash
+npm uninstall --save-dev
+```
+
+### Глобальні модулі
+
+Пакунки можна інсталювати та керувати ними (наприклад, видаляти, оновлювати) глобально для всієї системи. Для цього використовується опція `-g`. Так, наприклад для інсталювання пакету глобально необхідно викликати наступну команду:
+
+```bash
+npm -g install node-iplocate
+```
+
+Таким чином є два способи встановлення пакунків - на рівні проекту, та на рівні всієї системи. Так, наприклад `NodeRed` встановлює для себе свої версії пакунків директорію `.node-red`.
+
+### Публікація пакунку
+
+Для публікації пакунку в публічному реєстрі використовується відповідна команда
+
+```bash
+npm publish
+```
+
+Для можливості публікації необхідно зареєструватися, а до цього добавити себе як користувача в глобальний реєстр:
+
+```bash
+npm adduser
+```
+
+## 16.4. Основні модулі Node.js
+
+### Змінні модуля та глобальні об'єкти
+
+**Змінні модуля** доступні в межах кожного модуля (область видимості модуля):
+
+- __dirname – ім'я директорії плинного модуля, те саме що і path.dirname()
+- __filename - ім'я файлу плинного модуля. Це абсолютний шлях поточного файлу модуля з розв’язаними символічними посиланнями
+- exports – коротка форма module.exports
+- module – змінна-посилання на модуль
+- require() – для імпорту
+
+**Глобальні об'єкти** – це об'єкти, що вбудовані в JS або в середовище. У Node.js є об'єкт **global**, але можна звертатися напряму до його властивостей та методу. Крім того в global можна писати свої змінні. Ці об'єкти доступні напряму і не потребують об'явлення Require.
+
+Нижче наведені деякі глобальні об'єкти:
+
+- Class: Buffer – робота з бінарними даними
+- setInterval, setTimeout , clearImmediate, clearInterval, clearTimeout – робота з таймерами
+- console – робота з консоллю
+- global – для роботи з глобальною областю
+- performance – для роботи з метриками (показниками продуктивності)
+- process – доступ до властивостей Node.js process
+- TextDecoder, TextEncoder – робота з текстовим кодуванням
+- URL, URLSearchParams – робота з URL посиланнями
+
+### os
+
+Модуль `os` призначений для отримання системної інформації.
+
+```js
+const os = require('os'); //підключення модуля роботи з os
+console.log(os.platform()); //платформа
+console.log(os.arch()); //архітектура
+console.log(os.cpus()); //інформація про ЦПУ
+console.log(os.freemem()); //вільна пам'ять
+console.log(os.totalmem()); //скільки пам'яті
+console.log(os.homedir()); //коренева директорія
+console.log(os.uptime()); //час роботи системи
+```
+
+### path
+
+Модуль `path` представляє утиліти для роботи з шляхами до файлів і директорій.
+
+За замовченням операції модулю залежать від ОС, де виконується Node.js. Наприклад для Windows розділювачем шляхів є символ `\` а для систем POSIX (наприклад Linux) – `/`. Якщо необхідно вказати конкретний формат використовується `path.win32` або `path.posix`.
+
+На рис.16.5 показані різні представлення шляхів у залежності від ОС.
+
+
+
+рис.16.5. Різне представлення шляхів для різних ОС.
+
+```js
+const os = require('os');
+const path = require('path');
+
+console.log(path.sep); // виведе \
+let homedir = os.homedir();
+console.log(homedir);
+// для Windows виведе C:\Users\username
+console.log (path.parse(homedir));
+```
+
+```js
+//path.basename повертає останню частину шляху з розширенням чи без нього
+console.log (path.basename('/foo/bar/baz/asdf/quux.html'));// 'quux.html'
+console.log (path.basename('/foo/bar/baz/asdf/quux.html','.html')); // 'quux'
+//delimiter - повертає розділювач шляхів (';' - Windows, ':' - POSIX)
+console.log (path.delimiter); //виведе ; у Windows
+//dirname - повертає шлях до кінцевого обєкту в шляху (файлу чи папки)
+console.log (path.dirname('/foo/bar/baz/asdf/quux')); // /foo/bar/baz/asdf
+console.log (path.extname('index.html')); //повертає розширення .html
+//format ({dir, root, base, name, ext}) - поверає рядок шляху
+console.log (path.format({root:'C:\\tmp\\', base:'file.txt'}));// C:\tmp\file.txt
+console.log (path.format({dir:'C:\\tmp', name:'file', ext:'.txt'}));// C:\tmp\file.txt
+
+//join - обєднує усі сегменти шляху разом з використанням платформового розділювача
+console.log (path.join(homedir,'f1','sf1','file.txt'));// C:\Users\username\f1\sf1\file.txt
+console.log (path.normalize('C:/temp\\\\foo\\bar\\../1.txt'));// нормалізує до C:\temp\foo\1.txt
+
+//resolve - перетворення шляху в абсолютний шлях
+console.log(path.resolve());//без параметрів - плинна директорія
+console.log(path.resolve(homedir, '..', 'newuser'));// C:\Users\newuser
+console.log(homedir.split(path.sep)); //[ 'C:', 'Users', 'username' ]
+```
+
+### fs
+
+Модуль `fs` призначений для роботи з файлами (читання, запис, зміна). Він має як синхронні так і асинхронні методи. Він може працювати як через Buffer для бінарних файлів так і через string для текстових файлів. У свою чергу зміст можна зчитувати цілком, або через потік.
+
+```js
+const fs = require('fs');
+try {
+ //вказане кодування тому повертає string
+ const content = fs.readFileSync('file1.txt', 'utf8');
+ console.log(content); //виводить: 'Це зміст текстового файлу.'
+} catch (e) { console.log(e)}
+try {
+ //не вказане кодування тому повертає Buffer
+ const content = fs.readFileSync('file1.txt');
+ console.log(content); //виводить: 'd0 a6 d0 b5 20 d0 b7 d0 bc d1 96..'
+} catch (e) { console.log(e)}
+//асинхронний варіант читання
+fs.readFile('file1.txt', 'utf8', (err, data) => {
+ if (err) throw err
+ console.log(data);
+})
+//усі синхронні операції варто добавляти в try..catch
+fs.writeFileSync('file1.txt', 'Цей текст запишеться у файл\n', 'utf8');
+fs.appendFileSync('file1.txt', 'Цей текст добавиться у файл\n', 'utf8');
+console.log (fs.readdirSync('./', 'utf8'));//список файлів та директорій у плинній директорії
+fs.copyFileSync('file1.txt', 'destination.txt');
+```
+
+### events
+
+Асинхронність в JS досягається через виклик функцій-обробників, які викликаються за виконанням певної події. У простому випадку в асинхронну функцію передають функцію зворотного виклику. Але є і інші способи, наприклад з використанням принципів подіє-орієнтованого програмування, при якому об’єктом генеруються події які обробляються спеціальними обробниками цих подій.
+
+У модулі events є клас Emitter. Екземпляри цього класу (об'єкти-**емітери**) генерують різноманітні події, на які можна підписатися і вказати функції, які будуть викликатися при виникненні цих подій. Таким чином всередині об'єкту йде генерація подій, а ззовні їх обробка.
+
+Багато класів в інших модулях наслідують емітери для формування подіє-орієнтованого підходу.
+
+```js
+const Emitter = require('events');//імпортувати клас емітер
+let emitter = new Emitter(); //створити новий емітер
+let eventName = 'greet';
+//спочатку зв'язати подію eventName з функцією зворотного виклику
+emitter.on( //on - метод для зв'язуання, "слухати"
+ eventName, //подія
+ function(){console.log('Hello all!')} //функція обробки
+);
+emitter.on(eventName, function(){
+ console.log("Привіт усі!")
+});
+//emit - метод для генерування події
+emitter.emit(eventName);//перший параметр - назва події
+//передача параметрів еміттеру
+let emitter1 = new Emitter();
+emitter1.on(eventName, function(data){
+ console.log(data);
+});
+//другий параметр методу emit - параметри функції обробника
+emitter1.emit(eventName, "Привіт світ!");
+
+```
+
+### http
+
+Модуль `http` використовується для роботи з клієнтськими та серверними http-запитами. Нижче наведений фрагмент коду для роботи з клієнтським http.
+
+```js
+const http = require('http');
+//опції запиту
+const options = {
+ hostname: 'www.example.org',
+ port: 80, path: '/',
+ method: 'GET', headers: {}
+};
+//створення обробки запиту
+const req = http.request(options, (res) => {
+ console.log(`STATUS: ${res.statusCode}`);
+ console.log(`HEADERS: ${JSON.stringify(res.headers)}`);
+ res.setEncoding('utf8');
+ //у res є події:'end', 'data'
+ res.on('data', (chunk) => { //обробник події 'data' -
+ console.log(`BODY: ${chunk}`);
+ });
+});
+// у req є події: 'response', 'socket', 'error'
+req.on('error', (e) => {
+ console.error(`problem with request: ${e.message}`);
+});
+req.end();
+```
+
+Нижче наведений фрагмент запиту з серверним http.
+
+```js
+const http = require('http');
+const host = '127.0.0.1';
+const port = 7001;
+//створення серверу
+const server = http.createServer((req, res) => {
+ if (req.method === 'GET') {
+ switch (req.url) {
+ case '/':
+ case '/home': {
+ res.statusCode = 200;
+ res.setHeader('Content-Type', 'text/plain;charset=utf-8');
+ res.end('Домашня сторінка\n');//завершити з'єднання
+ break}
+ default: {
+ res.statusCode = 404;
+ res.setHeader('Content-Type', 'text/plain;charset=utf-8');
+ res.end('Не знайдено\n');
+ break}}}})
+//запуск прослуховуваня
+server.listen(port, host, () => {
+ console.log(`Server listens http://${host}:${port}`)
+})
+```
+
+Для спрощення розробки серверних застосунків можна використовувати фреймворки, наприклад **Express**
+
+
+
+Корисні посилання за темою:
+
+https://learn.javascript.ru/screencast/nodejs
+
+https://nodejs.org/api/
+
+https://www.youtube.com/watch?v=3aGSqasVPsI
+
+https://nodejs.org/uk/docs/
+
+https://www.w3schools.com/nodejs/nodejs_intro.asp
+
+https://medium.com/devschacht/node-hero-6a07ef8d822d
+
+https://metanit.com/web/nodejs/
+
+## Запитання для самоперевірки
+
+1. Розкажіть про основні принципи функціонування виконавчої системи Node.js.
+2. Що таке модулі? Як вони підключаються?
+3. Як створювати власні модулі?
+4. Які можливості надає менеджер пакунків?
+5. Яке призначення package.json?
+6. Назвіть основні команди клієнту командного рядку npm.
+7. Розкажіть про змінні модуля та глобальні обєкти.
+8. Розкажіть про модуль `os`.
+9. Розкажіть про модуль `path`.
+10. Розкажіть про модуль `fs`.
+11. Розкажіть про модуль `events`.
+12. Розкажіть про модуль `http`.
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
+
diff --git "a/\320\233\320\265\320\272\321\206/17_lyfecycle.md" "b/\320\233\320\265\320\272\321\206/17_lyfecycle.md"
new file mode 100644
index 0000000..20f39ce
--- /dev/null
+++ "b/\320\233\320\265\320\272\321\206/17_lyfecycle.md"
@@ -0,0 +1,248 @@
+**Програмна інженерія в системах управління. Лекції.** Автор і лектор: Олександр Пупена
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
+
+# 17. Моделі життєвого циклу
+
+## 17.1. Життєвий цикл систем
+
+Для кращого розуміння керування життєвими циклами систем та ПЗ коротко зупинимося на основах системної інженерії. Розглянемо систему з точки зору стандарту ДСТУ ISO/IEC 15288 "Інформаційні технології. Системна інженерія. Процеси життєвого циклу системи".
+
+***Система*** (system) - це комбінація взаємодіючих елементів, організованих для досягнення однієї або декількох поставлених цілей. Сприйняття та означення конкретної системи, її архітектури та системних елементів залежить від інтересів і обов'язків спостерігача. Умовна особа (людина або організація) яка має певний інтерес до системи називається ***зацікавленою особою*** (***stakeholder***). Виділена при цьому система називається ***цільовою системою*** (***system-of-interest***). Роль інших систем в зовнішньому світі відносно цільової системи можуть бути також уточнені: забезпечуючи система, система в середовищі функціонування (які взаємодіють з цільовою).
+
+ ***Забезпечуючими системами (еnabling system***) називають системи, які забезпечують створення, розвиток, функціонування і утилізацію цільової системи протягом її життєвого циклу. Такими системами можуть бути, наприклад, системи проектування, для виробництва складових цільової системи, з навчання, з обслуговування цільової системи і т.д. Поняття забезпечуючої системи тісно зв’язано з життєвим циклом цільової системи. До забезпечуючих систем можна також віднести організації, які приймають участь в життєвому циклі забезпечуючої системи.
+
+Таким чином, серед усієї купи систем (або ПЗ), та, яку ви розглядаєте в даний момент називається цільовою, а усі ніші які з нею взаємодіють - системи в навколишньому середовищі. При цьому ту організацію, яка розробляє цю систему, або супроводжує, або налагоджує називають забезпечуючою.
+
+Відповідно до ISO/IEC/IEEE 15288:2015, ***життєвий цикл*** (***ЖЦ***, life cycle) – це розвиток системи, продукції, послуги, проекту або іншої, створюваної людиною ***сутності*** від задумки до списання. Життєвий цикл (ЖЦ) систем, у тому числі програмних, включає в себе усі стадії від виникнення потреби в системі певного цільового призначення до повного завершення її використання, у зв’язку з моральним старінням або за втрати необхідності.
+
+Як вже було сказано вище, у життєвому циклі будь якої системи приймають участь багато інших систем. Деякі організації, як забзепечуючі системи, приймають участь тільки на певних відрізках часу життєвого циклу цільової системи. Тому для них роботи по просуванню цільової системи по життєвому циклу можуть початися пізніше і закінчитися раніше, ніж це відбувається в життєвому циклі цієї системи. Вони розглядають цю частину робіт і часу, як ***проект***, для якого виділяються ресурси, та час відповідно до вимог. Цей проект також описується в термінах життєвого циклу. Тому слід розуміти що життєвий цикл проекту та цільової системи - це різні життєві цикли, але взаємопов'язані між собою. Так, наприклад, розробка програмного забезпечення може цілком бути проектом, якщо там не передбачаються роботи по супроводженню та виведення з експлуатації.
+
+Життєвий цикл традиційно ділять на ***стадії***, кожна з яких розглядається як роботи над системою (наприклад ПЗ) , що приводять до зміни її стану. За результатами цих робіт з’являються якісь артефакти (документи, програми, системні компоненти тощо) і приймають якісь важливі рішення щодо інших стадій. Стадії відрізняються за характером робіт. Наприклад, стадія "проектування" зосереджена на розробці певного типу документації, за яким проводять реалізацію, а "введення в дію" - на самій реалізації. Поділ життєвого циклу системи на стадії залежить від її типу та прийнятих правилах в тих організаціях, що її розроблюють. У якості прикладу, життєвий цикл будь-якої системи можна розглядати як наступні стадії:
+
+- задум: формування основних вимог до системи; вигляд системи - технічні вимоги, технічне завдання, опис прототипу;
+- проектування: розробка необхідної для реалізації системи документації; вигляд системи - проектна документація;
+- розроблення і тестування: створення системи в її кінцевому вигляді з тестуванням;
+- введення в дію: впровадження реалізованої системи у її робочому середовищі, перевірка на відповідність до замовлення;
+- експлуатація (включаючи підтримку): супроводження, внесення змін в систему;
+- утилізація (виведення з експлуатації): роботи по знищенню системи.
+
+Наприклад, якщо необхідно написати якийсь програмний застосунок, спочатку обдумують яким він повинен бути і формують певний набір функціональних та інших вимог. Потім за цими вимогами роблять якісь схеми та описи, розділяють роботу на невеликі частини (модулі, функції) для яких прописують правила та інтерфейси і т.п, тобто роблять проектування. Потім пишуть код і тестують його у певних тестових середовищах. Звісно тестування проходить не відразу в середовищі, яким користується замовник. Після завершення усіх робіт, ПЗ розгортається (вводиться в дію) в його робочу середовищі, наприклад у замовника, де воно буде працювати. Під час функціонування, в ПЗ треба буде вносити зміни, робити оновлення, тощо - це стадія експлуатації. Коли замовнику вже не потрібно ПЗ, він його видаляє (утилізує).
+
+Слід відмітити, що часто розробники систем останню стадію не враховують, вважаючи що після введення в дію та гарантійного терміну експлуатації інше лежить на плечах кінцевого замовника.
+
+Стадії як правило йдуть послідовно в часі, хоч можуть перекриватися. У сучасних методологіях розробки ПЗ поділ на стадії є досить умовним, і відноситься більше не до часу проведення робіт, а характеру діяльностей, які там виконуються. Послідовність стадій та процесів залежить від обраної моделі життєвого циклу.
+
+## 17.2. Процеси життєвого циклу
+
+***Модель життєвого циклу*** – структурна основа процесів і діяльностей, яка відноситься до життєвого циклу, що слугує в якості загального посилання для встановлення зв’язків та взаєморозуміння сторін. Процеси життєвого циклу для розробки систем описані в стандарті ДСТУ ISO/IEC/IEEE 15288:2016 а для програмного забезпечення в ISO/IEC12207.
+
+Стандарт ISO/IEC 15288 означує множину процесів, названих процесами життєвого циклу, за допомогою яких може бути змодельований життєвий цикл системи. Термін ***процес*** (process) взятий із ISO 9000 і значить сукупність взаємозв'язаних ресурсів і діяльностей, яка перетворює вхідні елементи у вихідні, задля досягнення певної цілі. Результатами процесу згідно [12] та [13] може бути ***продукт*** (product), послуга (service), інформація, ***артефакт*** (наприклад документи, схеми).
+
+Таким чином, **життєвий цикл системи є складною організацією процесів, які можуть виконуватися паралельно в часі, бути ітеративними (повторюються), рекурсивними (ініціюють запуск таких саме процесів на нижньому рівні) і мають залежні від часу характеристики**.
+
+Спосіб керування цими процесами означується прийнятою в організаціях методологією розробки. Під методологією розробки ПЗ (Software development methodology) розуміють сукупність методів, які використовуються для розробки програмного продукту. Методології часто включають загальний філософський підхід, означення життєвого циклу, передбачають набір практик, які будуть використовуватися та організацію робіт. Під практиками розуміються процеси, способи та технології для їх виконання.
+
+Основою методології є прийнята модель життєвого циклу проекту, яким займається організація. Нагадаємо, що проект може охоплювати певні стадії життєвого циклу системи. Серед великої кількості моделей життєвого циклу можна умовно виділити три фундаментальних: водоспадна (каскадна), інкрементна та еволюційна. Кожна з цих моделей може використовуватися самостійно або в комбінації з іншими. Варто відмітити, що це не єдина класифікація моделей життєвого циклу.
+
+Надалі розглянемо деякі з моделей, але не в контексті життєвих циклів систем а – програмних проектів, враховуючи, що стадії експлуатації та виведення з обслуговування не використовується.
+
+## 17.3. Водоспадна модель (Waterfall Model)
+
+***Водоспадна*** (каскадна) модель життєвого циклу передбачає, що всі процеси виконуються в межах певних стадій, виконання яких означено в часі. Весь цикл передбачає одноразове поступове проходження стадій від означення вимог до експлуатації. Для розробки ПЗ цю модель можна представити як на рис.17.1. Після кожної стадії приймаються важливі рішення (так звані gate) про перехід до іншої, після чого повернення назад не передбачається. Можливе паралельне виконання робіт (етапів) але в рамках однієї стадії.
+
+
+
+
+Рис.17.1. Приклад каскадної моделі.
+
+Типовим ЖЦ подібного плану є описаний в ГОСТ 34.601-90, який до недавнього часу діяв і в Україні. Водоспадна модель дуже зручна для розрахунку ресурсів, але в чистому вигляді мало коли здійснена. Вона має ряд недоліків:
+
+- передбачається, що усі стадії виконуються ідеально, помилки на ранніх стадіях однозначно приводять до важких наслідків на наступних, які не можливо усунути не повернувшись назад;
+- неможливо внести зміни у вимоги, які з'являються після стадії "Формування вимог", бо це суперечить послідовності стадійності;
+- продукт (систему, ПЗ) можна використовувати тільки в кінці життєвого циклу проекту;
+- потребують залучення певного виду ресурсу у великих кількостях тільки на певних етапах стадій.
+
+Водоспадну модель як правило використовують тоді, коли є великий досвід розробки подібних систем і напрацьовані практики. Вона популярна при розробці фізичних систем, в яких практично важко вносити зміни "в залізі", якщо вони не були передбачені на ранніх стадіях. Сьогодні цю модель використовують з певними модифікаціями, зокрема V-model.
+
+## 17.4. V-model
+
+Класична каскадна модель погано справляється з проблемами, що виникають на заключних стадіях життєвого циклу. Наслідком даних проблем стає зниження якості поставленого товару, причому часто не стільки з позицій якості виготовлення (наприклад, стабільності і безвідмовності роботи), а в частині відповідності очікувань замовника щодо вирішення його задач. Саме ця особливість підштовхувала практиків до модифікації каскадної моделі, з метою уникнення відриву рішень, виконаних на початкових стадіях аналізу і проектування від заключних стадій випробувань, впровадження та супроводу програмного продукту. Однією з таких модифікацій стала V-подібна модель життєвого циклу - ***V-model***.
+
+Назва моделі пішла від форми латинської букви V, яка показує форму лінії часу, що перегнута навпіл в точці, де стадії означення систем переходять в стадії реалізації та впровадження. Для програмних систем цю модель можна представити як на рис.17.2. У даному випадку час вважається логічним, тобто не по ходу виконання робіт, а по ходу проходження процесів, які використовуються. Перелом потрібен для того, щоб показати суть верифікації і валідації: виготовлення частин та системи проводить перевірку через механізм верифікації (перевірки відповідності формальних вимог), а впровадження - через валідацію (задоволення вимог замовника).
+
+
+ Рис.17.2.Приклад V-моделі
+
+Враховуючи, що перевірка (тестування) передбачає більш чітку формалізацію вимог, які потрібно використовувати при верифікації та валідації, вияв та виправлення помилок проводиться на ранніх стадіях реалізації системи. Крім того, у результаті більш чіткого постановлення вимог, зменшується ступінь невизначеності на стадіях означення системи.
+
+## 17.5. Інкрементні моделі (Incremental Model)
+
+***Інкрементні*** моделі життєвого циклу передбачають заплановане нарощування продукту (конструкції). Життєвий цикл проекту починається з видачі повного набору вимог, після чого йде розробка першої конструкції по всім стадіям, яка реалізовує тільки частину з вимог (див.рис.17.3). Далі виконують роботи над іншою конструкцією, в якій реалізовують іншу частину вимог і т.д., поки буде не завершено створення задуманої системи, яка б задовольняла усім вимогам. Кожна конструкція включає реалізацію вимог попередньої і нових, таким чином нарощуючи свій функціонал.
+
+
+
+
+Рис.17.3. Інкрементна модель
+
+Для кожної конструкції виконують необхідні процеси, роботи і завдання. Наприклад, аналіз вимог і створення архітектури можуть бути виконані відразу для всіх конструкцій, тоді як розробку технічного проекту програмного засобу, його програмування і тестування, введення в дію (розгортання) і кваліфікаційні випробування (валідацію) виконують при створенні кожної з наступних конструкцій.
+
+У даній моделі при розробленні кожної конструкції, роботи і задачі процесів виконують послідовно, або частково паралельно з перекриттям. Тобто, роботи над різними конструкціями можуть виконуватися паралельно, при цьому вихідна інформація якихось процесів розроблення для однієї конструкції може виконуватися як вхідна для іншої (на рис.17.3 показано пунктирними лініями).
+
+Процеси супроводу та експлуатації можуть бути реалізовані паралельно з процесом розроблення. Процеси замовлення і постачання, а також допоміжні і організаційні процеси зазвичай виконують паралельно з процесом розроблення.
+
+Серед переваг інкрементної моделі можна виділити:
+
+- чітке розуміння усіх вимог на усіх ітераціях, оскільки вони не змінюються;
+- придатність для використання проміжного продукту (конструкції) за короткий час;
+- природний поділ системи на нарощувані компоненти (інкремент);
+- можливості виділення ресурсів на кожній ітерації за необхідності;
+- простіше навчання персоналу;
+- можливість внесення невеликих змін та виправлення помилок в уже працюючу систему на наступних ітераціях.
+
+З іншого боку, чітке означення усіх вимог та можливостей, які передбачає модель, не дає можливості вносити в них зміни.
+
+Одним із видів інкрементальних моделей можна виділити RAD, в якій вимоги реалізовуються паралельно кількома командами розробників після чого відбувається їх інтеграція.
+
+
+## 17.6. Еволюційні моделі (Iterative Model)
+
+У ***еволюційних*** (ітеративних, Iterative) моделях систему також розробляють у вигляді окремих конструкцій, але на відміну від інкрементних, вимоги означуються на кожній ітерації. Тобто на початковій ітерації формують тільки частину вимог, які відомі на той час. Після розробки конструкції, яка задовольняє цим вимогам, повертаються знову до етапу означення вимог для нової конструкції, і т.д. Графічно ця модель для ПЗ представлена на рис.17.4.
+
+
+
+
+Рис.17.4 Еволюційна модель.
+
+При такому методі для кожної інструкції роботи і задачі процесу розробки виконують послідовно або паралельно з частковим перекриванням.
+
+Серед переваг використання даної моделі модна навести наступні:
+
+- придатність для використання проміжного продукту за короткий час;
+- можливості виділення ресурсів на кожній ітерації за необхідності;
+- простіше навчання персоналу;
+- задіяння замовника у формування вимог перед кожною ітерацією;
+- можливість внесення змін при зміні в технологіях;
+- можливість внесення невеликих змін та виправлення помилок в уже працюючу систему на наступних ітераціях.
+
+Серед можливих недоліків можна назвати підвищені вимоги до замовника, що передбачає постійне задіяння його в процесах. Крім того, не маючи повний перелік вимог практично не можливо розрахувати необхідний часу розробки всього проекту та необхідних для цього ресурсів (час, бюджету).
+
+Один із видів еволюційної моделі є ***спіральна***. У ній після кожної ітерації (витка спіралі) проводиться аналіз ризиків для створення нової конструкції. Тобто на кожній ітерації проводиться аналіз і приймається рішення, чи варто взагалі робити наступний виток (ітерацію). Для аналізу ризиків може використовуватися модель (прототип).
+
+## 17.7. Методології розробки Agile
+
+На сьогоднішній день для більшості невеликих ІТ-компаній характерне використання неформальних методологій розробки ІТ-продуктів, що відомі під загальною назвою ***Agile development*** або «гнучкі методи розробки». Вони базуються на так званому «Маніфесту Agile», який звучить так:
+
+- люди і взаємодія важливіше процесів та інструментів;
+
+- працюючий продукт важливіше за вичерпну документацію;
+
+- співпраця з замовником важливіше узгодження умов контракту;
+
+- готовність до змін важливіше проходження за попереднім планом;
+
+
+Даний маніфест розкривається в наступних принципах:
+
+1. Найвищим пріоритетом є задоволення потреб замовника, завдяки регулярному і ранньому постачанню готового програмного забезпечення.
+
+2. Зміна вимог вітається, навіть на пізніх стадіях розробки.
+3. Agile-процеси дозволяють використовувати зміни для забезпечення замовнику конкурентної переваги.
+
+4. Працюючий продукт слід випускати якомога частіше (з періодичністю від кількох тижнів до кількох місяців).
+
+5. Працюючий продукт - основний показник прогресу.
+
+6. Протягом всього проекту розробники і представники бізнесу повинні щодня працювати разом.
+
+7. Над проектом повинні працювати мотивовані професіонали.
+
+8. Щоб робота була зроблена, необхідно створити для професіоналів умови, забезпечити підтримку і повністю довіритися їм.
+
+9. Безпосереднє спілкування є найбільш практичним і ефективним способом обміну інформацією як з самою командою, так і всередині команди.
+
+10. Інвестори, розробники і користувачі повинні мати можливість підтримувати постійний ритм нескінченно. Agile допомагає налагодити такий стійкий процес розробки.
+
+11. Постійна увага до технічної досконалості і якості проектування підвищує гнучкість проекту.
+
+12. Простота - мистецтво мінімізації зайвого клопоту - вкрай необхідна.
+
+13. Найкращі вимоги, архітектурні та технічні рішення народжуються у самоорганізованих командах.
+
+14. Команда повинна систематично аналізувати можливі способи поліпшення ефективності і відповідно коригувати стиль своєї роботи.
+
+
+У випадку Agile складно говорити про проходженні компанією будь-якої певної моделі ЖЦ розробки ПЗ. Хоча, по суті, така розробка потрапляє в клас еволюційних моделей, що характеризуються розробкою продукту в ході декількох ітерацій, де безперервно і паралельно йдуть процеси аналізу і коригування результатів роботи.
+
+Серед ризиків може бути створений у результаті постійної взаємодії всіх учасників хаос, що впливає на всі сфери розробки. Тому використовуючи Agile потрібно розуміти обмеження: команди повинні бути невеликі, учасники повинні бути компетентні та мотивовані, ітерації короткі з максимально зрозумілими цілями, встановлені чіткі обмеження за часом і кінцевий результат повинен бути очевидним.
+
+Боротьба з невизначеністю проходить шляхом планування на короткі періоди. Правило таке: чим вища невизначеність - тим коротша ітерація. На початку кожної ітерації неминуче виконується контроль, ретроспектива, оцінка та аналіз результатів, планування наступної ітерації.
+
+До Agile відносять ряд практик, підходів і методологій, у тому числі Scrum - каркас для керування проектами та Kanban - метод керування розробкою .
+
+Останнім часом найбільш відомим і популярним методом такої "швидкої" розробки є методологія ***Scrum***. Творці методології відзначають, що ключовим принципом Scrum є прийняття розробником факту можливості змін вимог замовника в ході роботи, зміни його розуміння цілей проекту в ході його виконання. Тому в даній методології, замість занурення в розуміння проблеми замовника на початкових стадіях, що виконує проект команда фокусується на можливостях надати продукт або, як мінімум його частини, як можна швидше, а потім терміново відреагувати на знову з'явилися (уточнені) вимоги.
+
+На відміну від основних моделей життєвого циклу розробки ПЗ, методологія Scrum не наказує певну послідовність розробки продукту і не означує склад робіт. Замість цього дана методологія жорстко фіксує час ітерації («спринту»), за яке повинні бути отримані конкретні результати, так званий «інкремент продукту» (Potentially shippable increments, PSIs). При цьому склад необхідних компонентів і функціональності «інкремент продукту» означується командою безпосередньо перед початком «спринту», за допомогою інструменту, званого «беглог проекту» - переліку вимог, що підтримує їх пріоритизації за важливістю для стейкхолдерів проекту. Самі вимоги до продукту записуються у вигляді «користувацьких історій» (User stories) - спеціального шаблону, який застосовується і в інших методологіях Agile:
+
+```
+Як <роль> я хочу <мета/дія>, щоб отримати <цінність>
+```
+
+Методологія Scrum має на увазі повторення «спринтів» до того, поки всі вимоги, описані в «беглозі проекту», не будуть реалізовані в продукт що поставляється.
+
+В Методології Scrum існують три ключових ролі:
+
+1. Власник продукту (Product owner) - це людина, яка представляє в проекті зацікавлених осіб (Stakeholders). Він висловлює команді вимоги і побажання замовника і саме він здійснює документування вимог до майбутнього продукту.
+
+2. Команда розробників (Scrum Team) - це система, що самоорганізується з групи осіб, відповідальних за розробку і постачання інкрементів продукту до кінця кожного завершення ітерації розробки - спринту.
+
+3. Скрам майстер (Scrum master) - це людина, відповідальна за усунення перешкод для можливостей команди виконати завдання в строк. При цьому Скрам майстер не є керівником команди/проекту, в традиційному розумінні функції керівництва, але в той же час є буфером між командою і її зовнішнім оточенням.
+
+
+Графічно методологія Scrum представлена на рис.17.5.
+
+
+
+
+ Рис.17.5 Методологія Scrum
+
+Метод ***Kanban*** передбачає керування роботами за допомогою віртуальної дошки, яка розбита на колонки, що вказує на стан виконання певного завдання. При необхідності виконання завдання, воно виставляється у ліву колонку. Потім виконавець, або відповідальна особа по мірі виконання завдання переносить його з колонки в колонку, поки воно не досягне правої крайньої колонки, що буде вказувати на завершення виконання завдання.
+
+
+
+рис.17.6. Керування роботами з використанням методу Kanban
+
+Для успішної реалізації Kanban рекомендується користуватися практиками:
+
+1. Візуалізуйте. Візуалізація процесів роботи допомагає в правильному розумінні змін, що плануються і допомагає впроваджувати їх згідно з планом. Типовим способом візуалізувати процес роботи є використання дошки з колонками і картками. Колонки на дошці позначають різні кроки процесу роботи.
+
+2. Обмежуйте задачі в процесі виконання. Використовується система «витягування» на частинах, або всьому процесі роботи. Враховується, що робота, котра перебуває в стані виконання на кожному кроці робочого процесу (колонці), є обмеженою, і що нова робота «витягується» на крок, коли з'являється місце в колонці кроку.
+
+3. Керуйте потоком. Кожен перехід між станами в потоці моніториться, вимірюється і звітується. Активне керування потоком дозволяє оцінити позитивні та негативні ефекти змін у системі.
+
+4. Зробіть політики явними. Поки механізм чи процес не стане явним, часто важко чи неможливо здійснювати обговорення щодо його вдосконалення. Без явного розуміння, як все працює, будь-які обговорення проблем стають емоційними та суб'єктивними. З явним розумінням можливо перейти до більш раціональних, емпіричних та об'єктивних обговорень проблем.
+
+5. Створіть цикли зворотного зв'язку. Організації що не створили другий рівень зворотнього зв'язку — перегляд операцій, — зазвичай не бачать вдосконалення процесу поза локалізованим рівнем команди.
+
+6. Вдосконалюйте співпрацюючи, розвивайтесь експериментально (використовуючи моделі та науковий метод. Метод Канбан пропагує малі поступові, постійні та еволюційні зміни які приживаються. Коли команди мають спільне розуміння теорій про роботу, процес, ризики, вони більш ймовірно будуть здатними виробити спільне розуміння проблем та запропонувати вдосконалення які будуть результатом консенсусу.
+
+Kanban може використовуватися для керування будь-якими роботами, а не тільки розробкою систем чи ПЗ. Є багато безкоштовних, або частково-безкоштовних застосунків, з інтуїтивно зрозумілим інтерфейсом, наприклад Trello (https://trello.com).
+
+## Запитання для самоперевірки
+
+1. Що таке життєвий цикл?
+2. Чим ЖЦ проекта відрізняється від ЖЦ системи?
+3. Що таке процеси ЖЦ?
+4. Опишіть водоспадну модель ЖЦ, назвіть її переваги та недоліки.
+5. Опишіть V-модель ЖЦ, назвіть її переваги порівняно з водоспадною.
+6. Опишіть інкрементні моделі ЖЦ, назвіть їх переваги та недоліки.
+7. Опишіть еволюційні моделі ЖЦ, назвіть її переваги та недоліки.
+8. Опишіть методології розробки Agile.
+9. Опишіть методологію Scrum.
+10. Розкажіть про керування роботами з використанням методу Kanban.
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
\ No newline at end of file
diff --git "a/\320\233\320\265\320\272\321\206/18_githubadd.md" "b/\320\233\320\265\320\272\321\206/18_githubadd.md"
new file mode 100644
index 0000000..844d982
--- /dev/null
+++ "b/\320\233\320\265\320\272\321\206/18_githubadd.md"
@@ -0,0 +1,107 @@
+**Програмна інженерія в системах управління. Лекції.** Автор і лектор: Олександр Пупена
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
+
+# 18. Організація роботи в GitHub
+
+## 18.1. Організація роботи з використанням обговорення питань (issues)
+
+Для відстеження ідей, удосконалень, завдань або помилок при роботі в GitHub можна використовувати **Питання для обговорення ([issues](https://help.github.com/en/github/managing-your-work-on-github/about-issues)**). Це має форму своєрідного форуму репозиторію. У якості мови форматування використовується MarkDown.
+
+Можна збирати відгуки користувачів, повідомляти про помилки в програмному забезпеченні та впорядковувати завдання, які необхідно виконати відповідно до обговорюваного питання у сховищі. Питання для обговорень можуть виступати більше ніж просто в якості місця для повідомлення про помилки в програмному забезпеченні. Можна пов’язати запит на пул із питанням, щоб показати, що виправлення триває, і автоматично закрити питання, коли хтось підтверджує або закриває запит на пул.
+
+Щоб бути в курсі останніх коментарів щодо обговорюваного питання, можна підписатися для отримування сповіщення про останні коментарі. Щоб швидко знайти посилання на нещодавно оновлені питання, на які ви підписалися, відвідайте інформаційну панель (dashboard).
+
+Використовуючи обговорення питань можна:
+
+- відстежити та розставляти пріоритети своєї роботи, використовуючи дошки проектів (`project boards`).
+- створювати нові питання для обговорення для відстеження зворотного зв'язку з коментарями до питання або розгляду запиту на пул.
+- створювати шаблони питань, щоб допомогти авторам ставити змістовні питання для обговорень.
+- передавати відкриті питання до інших сховищ.
+- закріплювати важливі питання, щоб полегшити їх пошук, запобігаючи повторним створенням питань та зменшуючи рівень шуму.
+- відстежувати дублікати питань, використовуючи збережені відповіді.
+- повідомляти про коментарі, що порушують [Керівні принципи спільноти GitHub](https://help.github.com/en/articles/github-community-guidelines).
+
+Питання також можуть бути [присвоєні іншим користувачам](https://help.github.com/en/articles/assigning-isissue-and-pull-requests-to-other-github-users), [позначені мітками](https://help.github.com/en/articles/applying-labels-to-isissue-and-pull-requests) для швидшого пошуку.
+
+У публічному сховищі будь який користувач може створити питання для обговорення, якщо це не заборонено налаштуваннями. Можна створити питання із існуючого запиту на пул, або безпосередньо з коментарю в обговоренні іншого питання або запиту на пул. При використанні для відстеження та пріоритизації робіт проектних дошок, питання для обговорення можна перетворювати з нотаток на дошках.
+
+
+
+рис.18.1. Вигляд вікна issues
+
+Використовуючи формат MarkDown можна створювати списки завдань як набір опцій в коментарях до обговорень питань та запитів на пул. Користувачі будуть вибирати опції простим вибором мишою. У списку питань для обговорень та запитів на пул відображатимуться прогрес виконання завдань (помічених опцією).
+
+Можна також змінювати послідовність опцій звичайним перетягуванням.
+
+
+
+Про використання проектів можна прочитати за [цим посиланням](https://docs.github.com/en/issues).
+
+## 18.2. Робота з сайтами GitHub Pages
+
+ З репозиторію GitHub можна безпосередньо створювати [вебсайти](https://help.github.com/en/github/working-with-github-pages) як для нових, так і для існуючих сховищ. Це дає наступні можливості:
+
+- Сайти підтримують теми для кастомізації виглядів сторінок.
+- Якщо для свого сайту ви використовуєте джерело публікації GitHub Pages за замовчуванням, ваш сайт публікується автоматично. Ви також можете опублікувати сайт свого проекту з іншої гілки чи папки.
+- Можна використовувати налаштовувані сторінки помилки 404 (сторінка не знайдена).
+- Можна змусити використовувати на Ваших сторінках тільки HTTPS-запити.
+- Можна використовувати підмодулі з GitHub Pages для включення інших проектів у свій код сайту.
+- Можна скасувати публікацію свого сайту GitHub Pages, щоб сайт більше не був публічно доступний.
+
+GitHub Pages - статична служба розміщення веб-сайтів, яка приймає файли HTML, CSS та JavaScript прямо зі сховища на GitHub, за бажанням запускає файли через процес збирання та публікує веб-сайт. Ви можете побачити приклади сайтів GitHub Pages у колекції [приклади сторінок GitHub](https://github.com/collections/github-pages-examples).
+
+Ви можете розмістити свій сайт на домені GitHub `github.io` або на власному власному домені. Для отримання додаткової інформації див. "[Використання користувацького домену зі сторінками GitHub](https://help.github.com/en/articles/using-a-custom-domain-with-github-pages)."
+
+Існує три типи сайтів GitHub Pages: проектний, користувацький та організації. Сайти проекту підключені до конкретного проекту, розміщеного на GitHub, наприклад, бібліотеки JavaScript або колекції рецептів. Веб-сайти користувачів та організацій підключені до конкретного облікового запису GitHub.
+
+Щоб опублікувати сайт користувача (тільки один сайт на користувача), ви повинні створити сховище (що належить вашому обліковому запису користувача) з назвою `.github.io`. Щоб опублікувати сайт організації (тільки один сайт на організацію), ви повинні створити сховище (що належить організації) з назвою `.github.io`. Якщо ви не використовуєте користувацький домен, веб-сайти користувачів та організацій доступні на веб-сторінці `http(s)://.github.io` або ` http(s)://.github.io`.
+
+Вихідні файли для сайту проекту зберігаються в тому ж сховищі, що і їх проект. Якщо ви не використовуєте користувальницький домен, сайти проектів доступні за адресою `http(s)://.github.io/` або `http(s)://.github.io/`.
+
+Ресурсними даними публікації для вашого сайту GitHub Pages є гілка або папка, де зберігаються вихідні файли для вашого сайту. Усі сайти мають ресурсні дані публікації за замовчуванням, а сайти проектів мають додаткові ресурси публікації.
+
+Сайти GitHub Pages доступні для всіх в Інтернеті, навіть якщо їх сховища є приватними або внутрішніми. Якщо у вас є конфіденційні дані у сховищі вашого сайту, ви можете видалити їх перед публікацією. Для отримання додаткової інформації див. "[Про видимість сховища](https://help.github.com/en/github/creating-cloning-and-archiving-repositories/about-repository-visibility)."
+
+Джерелом публікації за замовчуванням для сайтів користувачів та організацій є гілка `master`. Якщо у сховищі для вашого користувача або на сайті організації є гілка `master`, ваш сайт автоматично публікується з цієї гілки. Ви не можете вибрати інше джерело публікації для сайтів користувачів або організації.
+
+Джерелом публікації за замовчуванням для сайту проекту є гілки `gh-pages`. Якщо у сховищі для вашого проекту веб-сайту є гілка `gh-pages`, ваш сайт автоматично публікується з цієї гілки. Сайти проекту також можуть бути опубліковані з гілки `master` або з папки ` /docs` на гілці `master`. Щоб опублікувати свій сайт з одного з цих джерел, потрібно налаштувати інше джерело публікації. Для отримання додаткової інформації див. "[Налаштування джерела публікації для вашого веб-сайту GitHub](https://help.github.com/en/articles/configuring-a-publishing-source-for-your-github-pages-site# вибір-публікація-джерело)."
+
+
+
+рис.18.2. Налаштування публікації.
+
+Якщо ви вибрали папку `/docs` гілки `master` як джерело публікації, GitHub Pages прочитає все, щоб опублікувати ваш сайт, включаючи файл *CNAME*, із папки `/docs`. Наприклад, коли ви редагуєте власний домен через налаштування GitHub Pages, користувацький домен буде записаний в `/docs/CNAME`. Щоб отримати додаткові відомості про файли *CNAME*, див. "[Managing a custom domain for your GitHub Pages site](https://help.github.com/en/articles/managing-a-custom-domain-for-your-github-pages-site). "
+
+Ви не можете публікувати свій сайт проекту у будь-якій іншій гілці, навіть якщо гілка за замовчуванням не є `master` або `gh-pages`.
+
+GitHub Pages публікує будь-які статичні файли, які Ви завантажуєте до Вашого сховища. Ви можете створювати власні статичні файли або використовувати генератор статичних сайтів для їх створення. Ви також можете налаштувати свій власний процес збирання (build) локально або на іншому сервері. Ми рекомендуємо статичний генератор сайту **Jekyll** із вбудованою підтримкою GitHub Pages і спрощеним процесом збирання. Для отримання додаткової інформації див. [About GitHub Pages and Jekyll](https://help.github.com/en/articles/about-github-pages-and-jekyll).
+
+GitHub Pages використовуватимуть **Jekyll** для створення вашого сайту за замовчуванням. Якщо ви хочете використовувати генератор статичного сайту, відмінний від Jekyll, відключіть процес збирання Jekyll, створивши порожній файл під назвою `.nojekyll` у корені вашого джерела публікації, а потім дотримуйтесь інструкцій генератора статичних веб-сайтів щодо створення свого сайту локально.
+
+GitHub Pages не підтримує серверні мови типу PHP, Ruby, або Python.
+
+Є наступні обмеження за обємом:
+
+- GitHub Pages ресурси репозиторію рекомендується обмежувати до 1GB.
+- Публіковані сайти GitHub Pages можуть бути не більше ніж 1 GB.
+- Сайти GitHub Pages мають межу пропускної здатності до 100 Гб на місяць
+- Сайти GitHub Pages мають обмеження 10 збирань (builds) на годину.
+
+Якщо ваш сайт перевищує ці квоти використання, GitHub не буде обслуговувати ваш сайт. Або ви можете отримати ввічливий електронний лист від GitHub Support, що пропонує стратегії зменшення впливу вашого сайту на сервери GitHub , включаючи розміщення сторонньої мережі розповсюдження контенту (CDN) перед вашим сайтом, використання інших функцій GitHub, таких як релізи, або перехід до іншої послуги хостингу, яка може краще відповідати вашим потребам.
+
+Про додаткові правила та обмеження читайте на [Prohibited uses](https://help.github.com/en/github/working-with-github-pages/about-github-pages#prohibited-uses).
+
+## Запитання для самоперевірки
+
+1. Розкажіть про основні можливості issues.
+2. Як відбувається інтеграція з pull requets і проектами?
+3. Які можливості надає GitHub Pages?
+4. Як опублікувати сайт на основі репозиторію з використанням GitHub Pages?
+5. Як створити власну сторінку з використанням GitHub Pages?
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
\ No newline at end of file
diff --git "a/\320\233\320\265\320\272\321\206/19_devops.md" "b/\320\233\320\265\320\272\321\206/19_devops.md"
new file mode 100644
index 0000000..a7d766c
--- /dev/null
+++ "b/\320\233\320\265\320\272\321\206/19_devops.md"
@@ -0,0 +1,332 @@
+**Програмна інженерія в системах управління. Лекції.** Автор і лектор: Олександр Пупена
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
+
+# 19.Вступ до Devops
+
+## 19.1. Ідеологія та практики DevOps
+
+**DevOps** – сукупність практик, що поєднують процеси розробки (Dev) та експлуатації (Ops), що спрямовані на скорочення часу між фіксацією змін в системі та впровадженням цих змін у виробництво, забезпечуючи високу якість продукту, в нашому випадку систем IoT в цілому або програмної частини. Тобто, мета DevOps - скоротити етапи розробки в життєвому циклі та забезпечити гнучку співпрацю між різними командами. Методологія DevOps добре зарекомендувала себе в ІТ галузі. Процес розробки системи зі застосуванням практик DevOps може виглядати таким чином: формування вимог - ТЗ - розробка - введення в дію - отримання метрик роботи - формування вимог - і знову цикл повторюється. Таким чином нові вимоги добре простежуються, а метрики інтегруються до суміжних рівнів.
+
+Створення міцного фундаменту, необхідного для впровадження ефективних devops-методів, потребує розуміння його ключових термінів і поняття. Протягом всієї історії обчислювальної техніки був описаний ряд методологій, що застосовуються для поліпшення і полегшення розробки або експлуатації програмного забезпечення. У кожній методології передбачається розбиття роботи на етапи, кожна з яких являє собою окремий набір дій. Для багатьох методологій типовим є розділення процесу розробки від експлуатації, що призводить до конфлікту цілей у різних команд. Крім цього, якщо змушувати членів інших команд слідувати тим чи іншим методологіям, які не відповідають використовуваним в цих командах процесам і ідеям, це може привести до невдоволення і розчарування. Знання особливостей і переваг різних методологій допоможе поліпшити розуміння суті проблем що виникають і зменшить непорозуміння між членами команди.
+
+Моделі життєвих циклів а також методології розробки розглядалися у попередній лекції.
+
+Практики DevOps відображають ідею постійного вдосконалення та автоматизації. Більшість практик фокусуються на одній або декількох етапах циклу розвитку.
+
+
+
+Рис. 19.1. Етапи життєвого циклу DevOps
+
+**Безперервна розробка**
+ Ця практика охоплює фази планування та кодування життєвого циклу DevOps. Для реалізації можуть бути задіяні механізми керування версіями, наприклад Git.
+
+**Безперервне тестування**
+Ця практика включає автоматизовані, заздалегідь заплановані, постійні тести коду під час його написання або оновлення коду програми. Такі тести можуть пришвидшити доставку коду до виробництва.
+
+**Безперервна інтеграція**
+Ця практика поєднує інструменти управління конфігурацією разом з іншими інструментами тестування та розробки для відстеження того, наскільки розроблений код готовий до виробництва. Це передбачає швидкий зворотній зв'язок між тестуванням та розробкою для своєчасного виявлення та вирішення проблем із кодом.
+
+Безперервна інтеграція (Continuous Integration; CI) - це процес інтегрування нового коду, написаного розробниками, в основний код або гілку «майстер», який здійснюється протягом робочого дня. Цей підхід відрізняється від методики, відповідно до якої розробники працюють з незалежними гілками тижнями або місяцями, виконуючи злиття коду в основну гілку тільки після повного завершення роботи над проектом. Тривалі періоди часу між злиттями призводять до того, що в код вноситься дуже багато змін, що підвищує ймовірність появи помилок. При роботі з великими пакетами змін набагато важче ізолювати і ідентифікувати фрагмент коду, який викликав збій. Якщо ж використовуються невеликі набори змін, для яких часто виконується злиття, пошук помилок значно спрощується. Ідея полягає в тому щоб прагнути уникнути проблем, пов'язаних з інтеграцією, які неминуче з'являться при злитті великих наборів змін.
+
+У системах безперервної інтеграції після завершення злиття нових змін зазвичай автоматично виконується набір тестів. Ці тести виконуються після фіксації змін і завершення злиття. Це дозволяє уникнути накладних витрат, пов'язаних з використанням ручної праці тестерів. Чим більше додаткових витрат вимагає виконувана дія, тим менша ймовірність, що вона буде виконана, особливо в разі нестачі часу. Результати виконання цих тестів часто візуалізують. Якщо результати виділені зеленим кольором, значить, тест завершився успішно, а тільки що інтегрований програмний реліз не містить помилок. Провальні або «червоні» тести означають, що реліз містить помилки і повинен бути виправлений. Завдяки використанню цього робочого потоку ідентифікація і усунення проблем здійснюються набагато швидше.
+
+**Безперервна доставка**
+Методологія безперервної доставки (Continuous Delivery) ця практика являє собою набір загальних принципів з розробки програмного забезпечення, які дозволяють часто створювати нові релізи програмного забезпечення із залученням автоматизованого тестування і безперервної інтеграції, автоматизує доставку змін коду після тестування до передвиробничого або проміжного середовища. Співробітник може прийняти рішення дозволити ці зміни або відхилити. Це дозволяє переконатися в тому, що нові зміни можуть бути інтегровані без звернення до автоматичних тестів. У разі безперервної доставки забезпечується розгортання змін.
+
+**Безперервне розгортання**
+Безперервне розгортання (Continuous deployment; CD) подібно до постійної доставки, ця практика автоматизує випуск нового або зміненого коду у виробництво. Компанія, яка здійснює постійне розгортання, може випускати зміни коду або функції кілька разів на день. Використання контейнерних технологій, таких як Docker та Kubernetes може забезпечити постійне розгортання, допомагаючи підтримувати узгодженість коду на різних платформах та середовищах розгортання. У той час як безперервна доставка дозволяє гарантувати розгортання нових змін, безперервне розгортання означає, що виконується розгортання змін у виробничому циклі.
+
+Чим швидше зміни програмного забезпечення впроваджуються у виробництво, тим швидше співробітники побачать результати своєї роботи. Завдяки «прозорості» зростає ступінь задоволеності роботою, з'являються позитивні емоції, що, в свою чергу, сприяє зростанню продуктивності. Також з'являються можливості для швидкого навчання. Якщо в коді функції або в дизайні програми допущена серйозна помилка, її легше виявити і виправити шляхом перегляду недавно зміненого робочого контенту.
+
+**Безперервний моніторинг**
+Ця практика передбачає постійний моніторинг як діючого коду, так і базової інфраструктури, яка його підтримує. Цикл зворотного зв'язку, який повідомляє про помилки або проблеми повертається до розробки.
+
+**Інфраструктура як код**
+Цю практику можна використовувати на різних етапах DevOps для автоматизації створення інфраструктури, необхідної для випуску програмного забезпечення шляхом написання коду. Цей спосіб виключає необхідність ручного конфігурування і оновлення для окремих компонентів обладнання, інфраструктура стає більш "гнучкою" в налаштуванні та масштабуванні. Ця практика також дозволяє операційним групам контролювати конфігурації середовища, відстежувати зміни та спрощувати повернення до попередніх конфігурацій. Прикладами таких практик є інструменти Ansible та Terraform.
+
+## 19.2. Методи devops
+
+Методи devops визначені не настільки жорстко, як методології, засновані на заборонах. Спочатку ідеї devops з'явилися серед практиків, які були прихильниками гнучкого системного адміністрування і кооперації між командами розробників і експлуатації. Особливості застосовуваної при цьому практики залежали від середовища.
+
+Процес розбиття діяльності по розробці ПЗ на окремі етапи називається методологією розробки програмного забезпечення. Зазвичай виділяються наступні етапи:
+
+- специфікація кінцевих результатів роботи або артефактів;
+- розробка та верифікація коду відповідно до специфікації;
+- розгортання коду у фінальному споживацькому або виробничому середовищі.
+
+Впровадження ефективних devops-методик ґрунтується на наступних чотирьох стовпах:
+
+- співпраця;
+- близькість;
+- інструменти;
+- масштабування.
+
+Співпраця - це процес досягнення поставленої мети з допомогою взаємодії між декількома людьми. Керівним принципом руху devops стала кооперація між командами по розробці та експлуатації програмного забезпечення. Перш ніж організувати успішну взаємодію між командами, що мають різні цілі, потрібно налагодити групову роботу в одній команді. Якщо в командах не налагоджена робота на індивідуальному і груповому рівні, взаємодія між командами не буде успішною.
+
+Крім розвитку і підтримки відносин співробітництва між окремими людьми, групами і відділами всередині організації, важливі міцні взаємини в галузі. Близькість - це процес формування взаємовідносин між командами, що сприяє свободі вибору різних цілей або показників при збереженні загальних цілей організації. При цьому полегшується розвиток емпатії і навчання в різних групах. Близькість може проявлятися на рівні взаємин між організаціями, дозволяючи їм ділитися історіями і вчитися один у друга. В результаті створюється колективна база культурних і технічних знань.
+
+Інструменти - це стимулятор змін, реалізованих на основі поточної культури і цілей.
+Необхідно правильно вибрати інструменти, так як вони впливають на існуючі структури, щоб запобігти появі проблем в командах і організаціях, пов'язаних з цінностями, нормами і організаційної структурою. Якщо обрані інструменти (або їх відсутність) заважають працювати окремим співробітникам, ініціатива по впровадженню devops буде приречена на провал. І якщо ціна налагодження співробітництва і так висока, то відсутність інвестицій в інструменти (або інвестиції в погані інструменти) призведе до подальшого зростання ціни на продукт.
+
+Масштабування концентрується на процесах і рушійній силі, які повинні використовувати організації протягом усього життєвого циклу. Це також дозволяє керувати іншими стовпами ефективних devops-методик на рівні організацій. Управління здійснюється в міру зростання, досягнення зрілості і навіть скорочення організацій.
+
+DevOps на відміну від водоспадної моделі застосовується в більш широких аспектах і зосереджений навколо: організаційних змін, зокрема при підтримці тісної співпраці між різними типами працівників що займаються поставками програмного забезпечення, а ці працівники є частиною циклу технічного процесу; розробників; операцій; гарантії якості; управління; системного адміністрування, обслуговування систем; адміністрування баз даних; координаторів; автоматизації процесів в поставці програмного забезпечення.
+
+## 19.3. Інструменти DevOps
+
+Оскільки DevOps має на меті функціональний режим роботи, для його провадження на практиці використовують різні набори інструментів, які відповідають одній або декільком наступним категоріям:
+
+- інструменти розробки і збірки (building)
+
+- інструменти для автоматизації тестування
+
+- інструменти для організації розгортання
+
+- Runtime-інструменти
+
+- інструменти для спільної роботи
+
+Успішне і сплановане впровадження Devops-практик містить інструменти із всіх 5 груп.
+
+
+
+Рис. 19.2. Інструменти DevOps
+
+**Інструменти розробки і збірки (building)** - це основа стеку CI/CD-пайплайну, тому що тут починаються всі процеси. Кращі інструменти в цій категорії можуть керувати кількома потоками подій і легко інтегруватися з іншими продуктами.
+
+На цьому етапі життєвого циклу розробки виділяють три групи інструментів:
+
+- система управління версіями (SCM)
+- безперервна інтеграція (CI)
+- керування даними (Data management)
+
+У 2020 р GIT зарекомендував себе з позитивного боку, тому SCM-інструмент повинен мати бездоганну підтримку для GIT. Для CI обов'язкова умова - здатність виконувати і запускати збірки в ізольованому контейнерному середовищі. Що стосується управління даними, тут потрібна можливість вносити зміни в схему бази даних і підтримувати бази даних відповідно до версії програми. GitHub та GitLab одні з популярніших інструментів розробки і збірки.
+
+Інструменти для керування даними дозволяють створювати версії баз даних, відслідковувати міграції баз даних, легко переносити або повертати зміни схеми без використання додаткових інструментів. М
+
+Піраміда тестування (тестів) має 4 рівня:
+
+- Юніт-тести - Це основа всього процесу автоматизованого тестування. Юніт-тестів має бути більше в порівнянні з іншими видами тестів. Розробники пишуть і запускають юніт-тести, щоб переконатися, що частина програми (відома як «юніт») відповідає своїй конструкції і поводиться як належить.
+
+- Компонентні тести - Основна мета тестування компонента - перевірити поведінку введення/виведення об'єкта тестування. Допомагає переконатися, що функціональність тестового об'єкта реалізована правильно згідно специфікації.
+
+- Інтеграційні тести - Вид тестування, при якому окремі програмні модулі об'єднуються і тестуються як група.
+
+- Наскрізні тести - допомагає спостерігати за роботою всієї програми і зробити так, щоб все функціонувало, як було заплановано.
+
+Серед прикладів інструментів для автоматизації тестування ПЗ можна виділити наступні.
+
+- Cucumber. Підходить для інтеграційного тестування. Об'єднує специфікації і тестову документацію в єдиний документ. Специфікації завжди актуальні, так як вони автоматично тестуються Cucumber. При потребі зібрати фреймворк для автоматизованого тестування з нуля і моделювати поведінку користувача в веб-застосунку, то Selenium WebDriver з Java і Cucumber BDD - відмінний спосіб вивчити і впровадити Cucumber в проекті.
+- SoapUI Pro. Інструмент для наскрізного тестування. Функціональне тестування.
+- LoadRunner. Інструмент для наскрізного тестування. Дозволяє бути впевненим що новий код буде працювати в умовах екстремального навантаження. Підтримує велику кількість протоколів.
+
+Інструменти для організації розгортання можна поділити на три підкатегорії:
+
+- керування артефактами
+
+- керування конфігураціями
+
+- розгортання
+
+Серед прикладів інструментів для організації розгортання ПЗ можна виділити наступні.
+
+- Nexus. Репозиторій артефактів Nexus підтримує практично всі основні технології: від Java до NPM і Docker. Можливість використовувати цей інструмент для зберігання всіх використовуваних артефактів. Проксінг віддалених менеджерів пакунків також значно прискорює процес збірок CI, роблячи пакети доступніше для збірки. Інша перевага - можливість отримати повне уявлення про всі пакетах, які використовуються в декількох програмних проектах, блокуючи небезпечні open source пакети (що можуть виступати вектором атаки).
+- Ansible. Інструмент для керування конфігураціями. При запуску, такий інструмент, отримавши бажану конфігурацію, буде намагатися виправити поточну конфігурацію програми. А при новому підході присутні тільки компоненти з відсутністю стану. Нові версії коду є артефактами, які розгортають для заміни існуючих. Це можна вважати певним ефемерним, короткостроковим оточенням.
+- Terraform. Інструмент для розгортання. Terraform вирішує проблему опису вашої інфраструктури як коду: починаючи з мережевих компонентів і закінчуючи повноцінними образами сервера. Цей продукт пройшов довгий шлях з моменту першого випуску: створено величезну кількість плагінів і створено спільному, що точно буде в нагоді при будь-якому сценарії розгортання. Здатність підтримувати будь-який тип оточення (локально, в хмарі або десь ще) не має рівних.
+
+Кінцевою метою будь-якого проекту розробки є запуск програми на кінцевому пристрої (ях). У світі DevOps ми хочемо отримувати повну інформацію про всі можливі проблеми з середовищем, а також хочемо звести до мінімуму втручання вручну. Вибір правильного набору Runtime-інструментів вкрай важливий, щоб досягти перемоги при розробці програми.
+
+Підкатегорії Runtime-інструментів:
+
+- X-як сервіс (XaaS)
+
+- оркестрація
+
+- моніторинг
+
+- логування
+
+Серед прикладів Runtime-інструментів для ПЗ можна виділити наступні.
+
+- Amazon Web Services.
+- OpenShift.
+- New Reliс.
+- Splunk.
+
+Інструменти для спільної роботи можна поділити на підкатегорії:
+
+- відслідковування задач
+
+- ChatOps
+
+- документування
+
+Серед прикладів Інструментів для спільної роботи можна виділити наступні.
+
+- Jira. Інструмент відслідковування проблем та задач. Дозволяє командам розробки і супроводу управляти проектною роботою і завданнями спринту. Вбудовані стандарти, які використовують Agile-термінологію, спрощують перехід від традиційних методів роботи до більш ефективних процесів.
+- Trello. Інструмент відслідковування проблем та задач. Сервіс користується методом Kanban.
+- MatterMost. ChatOps інструмент. Для загального спілкування всередині компанії.
+- Confluence. Інструмент для збереження технічної документації. Дозволяє створити внутрішній інтернет-портал і дати до нього доступ потрібним користувачам.
+
+Також постачальники хмарних технологій використовують готові набори інструментів, так звані фреймворки.
+
+## 19.4. Основи YAML
+
+[YAML](https://uk.wikipedia.org/wiki/YAML) — зручний для читання людиною формат серіалізаціі даних, концептуально близький до мов розмітки, але орієнтований на зручність введення-виведення типових структур даних багатьох мов програмування. YAML в основному використовується як формат для файлів конфігурації.
+
+- файли YAML мають розширення `.yaml` або `.yml`
+- YAML є чутливим до регістру.
+- YAML не дозволяє використовувати табуляцію, натомість використовуються пробіли.
+
+Коментарі починаються з октоторпа (його також називають "хеш", "гострий", "фунт" або "знак числа" - `#`).
+
+Означення початку та кінця документа необов'язково. Початок документа позначається '`---`' , що розміщується з самого зверху, а кінець - '`...`'.
+
+YAML має базові типи **відображення (mappings)** (хеші/словники), **послідовності (sequences)** (масиви / списки) та **скаляри** (рядки/числа). Хоча його можна використовувати з більшістю мов програмування, він найкраще працює з мовами, побудованими навколо цих типів структури даних. Сюди входять: PHP, Python, Perl, JavaScript та Ruby.
+
+Скаляри часто називають змінними в програмуванні. Скаляри представляють собою рядки та числа, які складають дані на сторінці. Скаляр може бути:
+
+- булевою властивістю, наприклад `Так`,
+- цілим (числом), наприклад `5`,
+- або рядком тексту, наприклад речення чи назва веб-сайту.
+
+Більшість скалярів не беруться в лапки, але якщо ви вводите рядок, який використовує пунктуацію та інші елементи, які можна переплутати з синтаксисом YAML (тире, колонки тощо), ви можете процитувати ці дані за допомогою одинарних (`''` )або подвійних (`""` ) лапок. Подвійні лапки дозволяють використовувати escapings для представлення символів ASCII та Unicode.
+
+```yaml
+integer: 25
+string: "25"
+float: 25.0
+boolean: Yes
+```
+
+Послідовності (Sequences) - це базовий список з кожним елементом у списку, розміщеним у його власному рядку. Це аналог масиву в інших мовах. Блок послідовностей позначають кожен запис з тире та пробілом (`- `).
+
+```yaml
+- Cat
+- Dog
+- Goldfish
+```
+
+Ця послідовність розміщує кожен елемент у списку на одному рівні. Якщо ви хочете створити вкладену послідовність з елементами та підпунктами, це можна зробити, розмістивши перед кожним тире в підпунктах один пробіл. YAML використовує для відступу пробіли, **НЕ** табуляцію. Приклад цього ви можете побачити нижче.
+
+```yaml
+-
+ - Cat
+ - Dog
+ - Goldfish
+-
+ - Python
+ - Lion
+ - Tiger
+```
+
+Це аналогічно 2-мірному масиву в інших мовах. Якщо ви хочете вкласти свої послідовності ще глибше, вам просто потрібно додати більше рівнів.
+
+```yaml
+-
+ -
+ - Cat
+ - Dog
+ - Goldfish
+```
+
+Послідовності можуть бути додані до інших типів структури даних, таких як відображення чи скаляри.
+
+Відображення (Mappings) дає можливість перелічити ключі з їх значеннями. Це аналог асоційованого масиву. Для відображення використовується двокрапка та пробіл (`: ` ) для позначення кожної пари ключ : значення.
+
+```yaml
+animal: pets
+```
+
+Цей приклад відображає значення `pets` до ключа `animal` .
+
+Використовуючи спільно з послідовністю, ви можете побачити, що ви починаєте складати список `pets`. У наступному прикладі тире, яке використовується для позначення кожного елемента, починається з відступу (пробілу), що робить лінію елементів дочірніми, в відображаючи лінію `pets` - батьківською.
+
+```yaml
+pets:
+ - Cat
+ - Dog
+ - Goldfish
+```
+
+YAML також має стилі потоку, використовуючи явні показники, а не відступи для позначення області. Послідовність потоку записується як розділений комою список у квадратних дужках. Аналогічним чином у потоці відображень (flow mapping) використовуються фігурні дужки.
+
+```yaml
+# Sequence of Sequences
+- [name , hr, avg ]
+- [Mark McGwire, 65, 0.278]
+- [Sammy Sosa , 63, 0.288]
+# Mapping of Mappings
+Mark McGwire: {hr: 65, avg: 0.278}
+Sammy Sosa: {
+ hr: 63,
+ avg: 0.288
+ }
+```
+
+Будь-який вузол YAML може бути закріплений і посилатися в іншому місці як псевдонім. Щоб закріпити певне значення або набір значень, використовуйте `&name of anchor`. Для посилання на нього використовується `*name of anchor`
+
+```yaml
+item:
+ - method: UPDATE
+ where: &FREE_ITEMS
+ - Portable Hole
+ - Light Feather
+ SellPrice: 0
+ BuyPrice: 0
+
+npc:
+ - method: MERGE
+ merge-from: {name: General Goods Vendor}
+ items: *FREE_ITEMS
+```
+
+Блокові колекції (Collections) AML використовують відступи для сфери застосування та починають кожен запис у своєму власному рядку.
+
+```yaml
+# Sequence of Scalars
+- Mark McGwire
+- Sammy Sosa
+- Ken Griffey
+# Mapping Scalars to Scalars
+hr: 65 # Home runs
+avg: 0.278 # Batting average
+rbi: 147 # Runs Batted In
+# Mapping Scalars to Sequences
+american:
+ - Boston Red Sox
+ - Detroit Tigers
+ - New York Yankees
+national:
+ - New York Mets
+ - Chicago Cubs
+ - Atlanta Braves
+# Sequence of Mappings
+-
+ name: Mark McGwire
+ hr: 65
+ avg: 0.278
+-
+ name: Sammy Sosa
+ hr: 63
+ avg: 0.288
+```
+
+Додаткові посилання
+
+## Запитання для самоперевірки
+
+1. Поясніть що таке DevOps.
+2. Назвіть практики DevOps та коротко опишіть їх.
+3. Назвіть методи devops та коротко опишіть їх.
+4. Назвіть типи інструментів DevOps та коротко опишіть їх можливості.
+5. Яке призначення файлів YAML?
+6. Назвіть основні конструкції YAML.
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
+
diff --git "a/\320\233\320\265\320\272\321\206/1_intro.md" "b/\320\233\320\265\320\272\321\206/1_intro.md"
new file mode 100644
index 0000000..991d575
--- /dev/null
+++ "b/\320\233\320\265\320\272\321\206/1_intro.md"
@@ -0,0 +1,284 @@
+**Програмна інженерія в системах управління. Лекції.** Автор і лектор: Олександр Пупена
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
+
+# Вступ
+
+Мета дисципліни «Програмна інженерія в системах управління» -- формування знань з розробки програмного забезпечення, орієнтованого на автоматизовані системи керування (управління), що відносяться до технологічного та виробничого рівня (АСУТП, IIoT, MES та інші). Дисципліна направлена на вивчення методів та засобів програмної інженерії, розуміння основ побудов систем керування побудованих на основі архітектури Інтернету речей (IoT), поглиблення знання в програмуванні мови JavaScript, робота в середовищі Node.js, мережних технологіях Інтернету та використання СКБД. У якості основного інструментального середовища для лабораторних робіт використовується Node-RED.
+
+У даній дисципліні розглядається два аспекти:
+
+- технології, засоби та практики розробки програмного забезпечення для автоматизованих систем керування (АСК) на прикладі систем IoT
+- основи програмної інженерії для АСК
+
+# 1. Вступ до програмної інженерії в системах автоматизованого керування
+
+## 1.1. Автоматизовані системи керування та їх ПЗ
+
+**Керування** (також використовують слово **управління**) — сукупність цілеспрямованих дій, що включає оцінку ситуації та стану об'єкта керування, вибір керівних дій та їх реалізацію
+
+**Автоматичне керування** – це керування, яке відбувається різноманітними апаратними та програмними засобами без участі людини.
+
+**Автоматизоване керування** – це керування, яке відбувається за участі людини
+
+**Автоматизована система керування (АСК)** - автоматизована система, що ґрунтується на комплексному використанні технічних, математичних, інформаційних та організаційних засобів для керування складними технічними й економічними об'єктами.
+
+АСК — це сукупність керованого об'єкта й автоматичних вимірювальних та керуючих пристроїв, у якій частину функцій виконує людина. На рис.1.1 показана типова структура автоматизованої системи керування. Об'єкт керування керується автоматичними засобами, які представлені апаратними та програмними засобами керування. Людина взаємодіє з цими засобами через людино-машинний інтерфейс і таким чином впливає на процес керування. Людина в даному випадку є частиною системи керування. Люди можуть також взаємодіяти з об'єктом безпосередньо, без використання автоматичних засобів керування.
+
+
+
+рис.1.1. Структура автоматизованої системи керування
+
+У даній дисципліні увага приділяється програмному забезпеченню, що використовується в автоматизованих ***системах керування (управління) технологічними процесами*** (***АСКТП або АСУТП***). Розгляд компонентів таких систем, а також алгоритмічного забезпечення, процесів керування та проектування є предметом багатьох дисциплін, які будуть читатися на старших курсах. Тут їх розглянемо тільки поверхово для розуміння загальних процесів керування та роль ПЗ в них.
+
+Спрощена структура таких систем показана на рис.1.2.
+
+
+
+рис.1.2. Типова структура АСКТП
+
+АСУТП потрібна для автоматизації керування різнорідними процесами. Для взаємодії системи з тим, що автоматизують (технологічний процес, часто називають ***об'єкт управління***) існують датчики (сенсори) та виконавчі механізми (актуатори).
+
+***Датчики*** (давачі) системі потрібні як людині зір, слух, нюх, різні рецептори, сенсорика і т.п. За допомогою датчиків система може дізнатися про значення температури (термометри) або про прохід людини через турнікет в метро (оптичні датчики). Типів датчиків та способів вимірювання настільки багато, що існують книги на кілька томів, які присвячені тільки цим засобам.
+
+***Виконавчі механізми*** (ВМ) приводять в дію регулюючі органи (РО). Регулюючі органи безпосередньо впливають на об'єкт управління. Наприклад водопровідний кран -- це типовий регулюючий орган, який може закривати/відкривати людина своїм руками. Руки людини -- це її виконавчий орган, який можна замінити на виконавчий механізм системи -- двигун.
+
+Датчики та виконавчі механізми підключаються до регуляторів, в яких закладена логіка управління об'єктом. Маючи інформацію з датчиків а також бажане значення він може діяти через виконавчий механізм на об'єкт забезпечуючи бажаний стан. Для алгоритмічно складних об'єктів використовують програмовані контролери (***ПЛК***). Це спеціалізовані комп'ютери з операційними системами реального часу, які програмуються на спеціалізованих мовах програмування, в тому числі текстових схожих на C чи JavaScript. Розробка такого ПЗ -- це також компетенції спеціаліста з автоматизації і буде розглядатися в старших курсах.
+
+Більшість систем є ***автоматизованими***, тобто такими, де людина приймає участь в деяких рішеннях. У повністю ***автоматичних*** системах, машина бере на себе усі функції управління. Для автоматизованих систем необхідний ***людино-машинний інтерфейс*** (ЛМІ) -- комплекс засобів у тому числі програмних, які дають можливість взаємодіяти людині з регуляторами або ПЛК. Розробка ЛМІ також входить в компетенції спеціалістів з автоматизації і буде розглядатися в інших дисциплінах. Крім локальних засобів ЛМІ, великі АСКТП потребують диспетчерського управління, де в спеціальних пунктах спостерігають за всім виробництвом та координують дії.
+
+Таким чином, у системах АСКТП програмні засоби займають велику роль, а їх розробка та супроводження є частиною життєвого циклу всієї системи.
+
+Сучасні системи управління можуть бути розроблені різним способом. Для автоматизації різного рівня задач можуть використовуватися системи типу «Інтернет речей» (Internet of Things, IoT) або його промислове виконання «Промисловий Інтернет речей» (Industrial Internet of Things, IIoT). Саме програми та технології IoT будуть предметом даної дисципліни, життєвими циклами якої (у більшості програмною його частиною) необхідно буде управляти.
+
+## 1.2. Інтернет речей
+
+Інтернет речей (**Internet of Things**, **IoT**) — концепція мережі, що складається із взаємозв'язаних фізичних пристроїв, які мають вбудовані датчики, а також програмне забезпечення, що дозволяє здійснювати передачу і обмін даними між фізичним світом і комп'ютерними системами, за допомогою використання стандартних протоколів зв'язку. Окрім датчиків, мережа може мати виконавчі пристрої, вбудовані у фізичні об'єкти і пов'язані між собою через дротові чи бездротові мережі. Ці взаємопов'язані пристрої мають можливість зчитування та приведення в дію, функцію програмування та ідентифікації, а також дозволяють виключити необхідність участі людини, за рахунок використання інтелектуальних інтерфейсів.
+
+Термін «інтернет речей», зобов'язаний своєю появою Кевіну Ештону, який в 1997 р, працюючи на компанію Proctor and Gamble, застосував технологію **радіочастотної ідентифікації** (**RFID**) для керування системою поставок. Завдяки цій роботі в 1999 році його запросили в Масачусетський технологічний інститут, де він з групою однодумців організував дослідний консорціум Auto-ID Center (більш детальну інформацію можна знайти на [сайті]([www.smithsonianmag.com/innovation/kevin- ashton- describes-the-internet-of-things-180953749](http://www.smithsonianmag.com/innovation/kevin- ashton- describes-the-internet-of-things-180953749))). З тих пір Інтернет речей звершив перехід від простих радіочастотних міток до екосистеми і індустрії. Аж до 2012 р ідея підключення речей до Інтернету переважно відносилася до смартфонів, планшетів, ПК і ноутбуків. По суті, до тих пристроїв, які в усіх відношеннях виступають в якості комп'ютера. До цього, з моменту появи перших боязких зачатків Інтернету (таких як створена в 1969 р мережу ARPANET), більшості технологій, на яких будується Інтернет речей, просто не існувало.
+
+Зараз до Інтернету речей можна підключати будь-які речі. Область застосування Інтернету речей можна подивитися на рис.1.3.
+
+
+
+рис.1.3. Застосування Інтернету речей
+
+**Промисловий Інтернет речей** (**Industrial IoT**, **IIoT**) - це один з найбільш великих сегментів Інтернету речей з точки зору кількості підключених пристроїв і ступеня корисності цих сервісів для виробництва і автоматизації підприємств. Цей сегмент традиційно служить операційно-технологічною базою. Сюди входять апаратні і програмні засоби моніторингу фізичних пристроїв.
+
+Приклади застосування Промислового Інтернету Речей.
+
+- профілактичне обслуговування промислового обладнання;
+- зростання продуктивності завдяки попиту в реальному часі;
+- енергозбереження;
+- системи безпеки, такі як вимірювання температури, вимірювання тиску і контроль над витоком газу;
+- експертна система для виробничого цеху.
+
+До екосистеми Інтернету речей відносяться усі засоби, сервіси і технології, які використовуються в Інтернеті речей (рис.1.4).
+
+
+
+рис.1.4 Екосистема Інтернету речей
+
+До таких засобів можна віднести:
+
+- **sensors (розумні датчики/виконавчі механізми)**: вбудовані системи, операційні системи реального часу, джерела безперебійного живлення, мікро-електромеханічні системи (МЕМС);
+- **системи зв'язку з датчиками**: зона охоплення бездротових персональних мереж становить від 0 см до 100 м. Для обміну даними між датчиками застосовуються низькошвидкісні малопотужні інформаційні канали, які часто побудовані не на протоколі IP;
+- **локальні обчислювальні мережі (LAN)**: зазвичай це системи обміну даними на основі протоколу IP, наприклад, 802.11 Wi-Fi-мережу для швидкої радіозв'язку, часто це пирингові або зіркоподібні мережі;
+
+- **агрегатори, маршрутизатори** **(routers), шлюзи** (gateways), пограничні пристрої (Edge Device) : постачальники вбудованих систем, самі бюджетні складові (процесори, динамічна оперативна пам'ять і система зберігання даних), виробники модулів, виробники пасивних компонентів, виробники тонких клієнтів, виробники стільникових і бездротових радіосистем, постачальники міжплатформового програмного забезпечення, розробники інфраструктури туманних обчислень, інструментарій для граничної аналітики, безпеку граничних пристроїв, системи управління сертифікатами;
+
+- **глобальна обчислювальна мережа**: оператори стільникового зв'язку, оператори супутникового зв'язку, оператори малопотужних глобальних мереж (Low- Power Wide-Area Network, LPWAN). Зазвичай застосовуються транспортні протоколи Інтернету для IoT і мережевих пристроїв (MQTT, CoAP і навіть HTTP);
+
+
+- **хмара**: інфраструктура в якості постачальника послуг, платформа в якості постачальника послуг, розробники баз даних, постачальники послуг потокової і пакетної обробки даних, інструменти для аналізу даних, програмне забезпечення в якості постачальника послуг, постачальники озер даних, оператори програмно-визначених мереж / програмно-визначених периметрів, сервіси машинного навчання;
+- **сервіси аналізу даних**: величезні масиви інформації передаються в хмару. Робота з великими обсягами даних і отримання з них користі - це завдання, що вимагає комплексної обробки подій, аналітики і прийомів машинного навчання;
+- **засоби кібербезпеки (security)**: при зведенні всіх елементів архітектури воєдино постають питання кібербезпеки. Безпека стосується кожного компонента: від датчиків фізичних величин до ЦПУ і цифрового апаратного забезпечення, систем радіозв'язку і самих протоколів передачі даних. На кожному рівні необхідно забезпечити безпеку, достовірність і цілісність. У цьому ланцюзі не повинно бути слабких ланок, оскільки Інтернет речей стане головною мішенню для атак хакерів в світі.
+
+Архітектура Інтернету речей відрізняється в залежності від реалізації. Один із прикладів архітектури показаний на рис.1.5.
+
+
+
+рис.1.5. Архітектура Інтернету речей
+
+Взаємодія з «речами» відбувається через датчики (sensors) та виконавчі механізми (Actuators). Ці датчики разом з усією інфраструктурою для інтеграції з рівнем обробки подій через мережу Internet формують так звану граничну область (**Edge**). Події (дані) що поступають з граничної області зберігаються і обробляються відповідно до задачі (рівень обробки подій і аналітики). На цьому рівні події(дані) зберігаються в сховищі, обробляються, перенаправляються потрібним застосункам. Додатково на цьому рівні відбувається адміністрування та керування пристроями з граничної області. Події (дані) обробляються з використанням аналітичних сервісів на основі них проводиться машинне навчання, що дозволяє зробити певні висновки про об’єкт. Цей рівень як правило реалізований з використанням хмарних (Cloud) або туманних (Fog) обчислень. Отримання результатів, контроль, віддалене керування та адміністрування системи проводиться через кінцеві застосунки з використанням Internet.
+
+На відміну від багатьох існуючих ІТ-пристроїв, Інтернет речей здебільшого пов'язаний з фізичною дією або подією. Він формує реакцію на якийсь фактор реального світу. Іноді при цьому один-єдиний датчик може згенерувати величезний обсяг даних, наприклад, акустичний датчик для профілактичного огляду обладнання. В інших випадках всього одного біта даних достатньо, щоб передати життєво важливі відомості про стан здоров'я пацієнта. Системи датчиків еволюціонували і зменшилися до субнанометрових розмірів і стали істотно дешевше, тому до Інтернету речей все більше будуть підключатися різноманітні пристрої.
+
+Розглядаючи Інтернет Речей, необхідно розглядати мікроелектромеханічні системи, датчики і інші типи недорогих граничних пристроїв і їх електрофізичних властивостей. Також це стосується силових і енергетичних систем, необхідних для живлення цих граничних пристроїв. Не можна вважати, що граничні пристрої забезпечуються енергією за замовчуванням. Мільярди маленьких датчиків все одно потребують великої кількості енергії. З питанням живлення також пов’язані питання організації хмарних сервісів IoT.
+
+Велика увага при розробці IoT приділяється встановленню з'єднання і роботі мереж. Інтернету речей не існувало б без надійних технологій передачі даних з найвіддаленіших і несприятливих областей в найбільші центри збору даних компаній Google, Amazon, Microsoft і IBM. Словосполучення «Інтернет речей» містить слово «Інтернет», тому необхідно вивчати питання, що стосуються мережних технологій та обміну даними. Базова опора Інтернету речей - це не датчики і не програми, а можливість встановити з'єднання.
+
+Передача даних і встановлення мережевого з'єднання базуються на базі систем зв'язку ближньої дії - персональних мереж (PAN), зазвичай побудованих без дотримання правил IP-протоколу. Це може бути як дротові так і бездротові мережі. До бездротових IoT-мереж/протоколів як правило відносяться протоколи Bluetooth, mesh-мережі, Zigbee, Z-Wave. Для IIoT це також Wireless Hart та ISA100. Це яскравий приклад різноманіття бездротових систем зв'язку IoT. Перелік дротових мереж ще більший, так як сюди входять усі можливі промислові мережі та протоколи. Крім PAN використовуються бездротові локальні мережі та системи зв'язку на основі IP-протоколу, включаючи широкий діапазон Wi-Fi-мереж на основі стандартів IEEE 802.11, 6LoWPAN і технології Thread. Нерідко використовуються телекомунікації на основі стільникових стандартів (3G, 4G LTE) і нові стандарти, що забезпечують роботу Інтернету речей і міжмашинної взаємодії, такими як Cat-1 і Cat-NB, а також протоколи LoRaWAN і Sigfox, що використовуються саме для IoT.
+
+Для передачі даних від датчиків в Інтернет-простір необхідні дві технології: маршрутизатор-шлюз і опорні інтернет-протоколи, що забезпечують ефективність обміну даними. Маршрутизатор особливо важливий в таких аспектах, як безпека, управління і напрям даних. Граничні маршрутизатори (Edge routers) керують і стежать за станом відповідних mesh-мереж, а також вирівнюють і підтримують якість даних. Також велике значення належить конфіденційності та безпеки даних. Маршрутизатор відіграє важливу роль в створенні віртуальних приватних мереж, віртуальних локальних мереж і програмно-визначених глобальних мереж. Вони в буквальному сенсі можуть містити тисячі вузлів, що обслуговуються єдиним граничним маршрутизатором, і в якійсь мірі маршрутизатор служить розширенням для хмари (edge device).
+
+На цьому рівні використовується ряд протоколів, необхідних для обміну даними між вузлами, маршрутизаторами і хмарними сервісами в межах IoT-системи. Інтернет речей відкрив дорогу новим IoT-протоколам, які виходять на один рівень з традиційними протоколами HTTP і SNMP, які застосовуються вже кілька десятків років. Для передачі IoT-даних потрібні ефективні, енергозберігаючі протоколи з малою затримкою, здатні легко і безпечно відправляти дані в хмару і з нього. Зокрема тут використовуються такі протоколи, як всюдисущий MQTT, AMPQ і CoAP.
+
+При проектуванні необхідно вирішити, що робити з потоком даних, що надходять в хмарний сервіс з граничного вузла (Edge Device). Щоб навчитися правильно оцінювати, як система буде розвиватися і рости, необхідно розібратися у всіх тонкощах і складнощах архітектури хмарних систем, який вплив на IoT-систему робить запізнювання. Крім того, не все треба відправляти в хмару. Пересилання всіх IoT-даних обходиться значно дорожче, ніж їх обробка на кордоні мережі (граничні обчислення, Edge Computing) або включення граничного маршрутизатора в зону, яку обслуговує хмарний сервіс (туманні обчислення, Fog computing). Туманні обчислення також стандартизуються, зокрема є стандарт туманних обчислень, наприклад архітектура OpenFog.
+
+Багато IoT-систем не будуть обмежені безпечним простором будинку або офісу. Вони будуть розташовуватися в громадських місцях, в дуже віддалених областях, в рухомих транспортних засобах або навіть всередині людини. Інтернет речей - це величезна єдина мішень для будь-яких видів хакерських атак. Вже було виявлено нескінченна кількість направлених на IoT-пристрої навчальних атак, добре організованих зломів і навіть уразливостей в системі безпеки національного масштабу. Розробник ІоТ рішень повинен знати особливості таких вразливостей і способи їх усунення, стандартні заходи, спрямовані на захист Інтернету речей або будь-якого компонента мережі.
+
+## 1.3. Вступ до програмної інженерії
+
+У курсі «Основи програмування» Ви познайомилися з основними підходами та мовами програмування. Очевидним є, що в загальному програма (*program, routine*) -- це впорядкована послідовність команд (інструкцій) або операторів для вирішення конкретної задачі. Сукупність програм, а також необхідних для їх експлуатації документів для виконання певного переліку функцій, як єдиної системи прийнято називати ***програмним забезпеченням*** (**ПЗ**, *software*). По суті один виконавчий файл можна називати програмою, але взаємопов'язану систему таких файлів та документації на них -- ПЗ.
+
+Все програмне забезпечення можна умовно поділити на такі типи:
+
+- системне ПЗ
+
+- прикладне ПЗ (включаючи інструментальне ПЗ)
+
+***Системне ПЗ*** (***System Software***) -- сукупність програм і програмних комплексів для забезпечення роботи комп'ютера та обчислювальних мереж. Це операційна система та додаткові системні служби. По суті, кінцевий користувач напряму не використовує це ПЗ, його використовують інші програми. А от ***прикладне ПЗ*** слугує вирішенню певних задач і розраховане на кінцевого користувача. Прикладне ПЗ виконуються з використанням системного, тому його прийнято називати також ***застосунком*** (***application***).
+
+
+
+рис.1.6. Типи програмного забезпечення.
+
+Можна окремо виділити також такий тип застосунку, як ***інструментальне ПЗ*** -- програмне забезпечення, призначене для проектування, розробки і супроводження програм. За допомогою цього типу ПЗ розробляються інші програми. Комплекс інструментального ПЗ який призначений для виконання різних етапів розробки програм називається ***інтегрованим середовищем розробки*** (*Integrated development environment*, *IDE*). Туди як правило входить:
+
+- редактор (текстовий, або графічний)
+
+- компілятор/інтерпретатор
+
+- засоби автоматизації зборки, розгортання
+
+- відлагоджувач
+
+- довідникова система
+
+- систему підтримки життєвого циклу продукту
+
+- інше
+
+Інтегрованим середовищем набагато зручніше користуватися, ніж розрізненим набором.
+
+Створення невеликих програм може зайняти кілька годин. Це характерно для утилітарних програм (розроблених для власного користування) і вони, як правило, мають сервісне призначення та не призначені для широкого розповсюдження, або поширюються безкоштовно.
+
+Програмний продукт комерційного характеру -- це комплекс взаємопов'язаних програм для вирішення певної проблеми (задачі) часто масового попиту, підготовлений до реалізації аналогічно будь-якому іншому виду промислової продукції. Програмний продукт повинен бути відповідним чином підготовлений до експлуатації (відлагоджений), мати необхідну технічну документацію, надавати сервіс і гарантію надійної роботи. Великі програмні продукти є системою взаємопов'язаних виконавчих програм, бібліотек та баз даних. Як правило розробкою таких програмних систем займається кілька людей, або навіть десятків чи сотень і при цьому необхідна чітка організація та інженерна діяльність, чим займається програмна інженерія.
+
+***Програмна інженерія*** --- це застосування системного, вимірюваного підходу до розробки, використання та супроводу програмного забезпечення, а також дослідження цих підходів, тобто застосування принципів інженерії до програмного забезпечення.
+
+Програмна інженерія може бути розділена на такі дисципліни:
+
+- [Вимоги](https://uk.wikipedia.org/wiki/Вимоги_до_програмного_забезпечення): виявлення, аналіз, специфікація, перевірка вимог.
+- [Проектування](https://uk.wikipedia.org/wiki/Проектування_програмного_забезпечення): процес визначення архітектури, складу компонентів, інтерфейсів та інших характеристик до системи.
+- [Конструювання](https://uk.wikipedia.org/wiki/Життєвий_цикл_програмного_забезпечення#Конструюван): кодування, модульне та інтеграційне тестування, відлагодження.
+- [Тестування](https://uk.wikipedia.org/wiki/Тестування_програмного_забезпечення): перевірка поведінки системи на відповідність до специфікації, пошук дефектів.
+- [Супровід програмного забезпечення](https://uk.wikipedia.org/wiki/Супровід_програмного_забезпечення): поліпшення, оптимізація системи та процесів роботи з нею після вводу до експлуатації.
+- [Конфігураційне керування](https://uk.wikipedia.org/wiki/Керування_конфігурацією): систематизує зміни до системи, що роблять розробники в процесі розробки та супроводу. Попереджують небажані та непередбачені ефекти.
+- [Менеджмент](https://uk.wikipedia.org/wiki/Менеджмент): застосування методів та практик менеджменту для керування учасниками процесу розробки [ПЗ](https://uk.wikipedia.org/wiki/Програмне_забезпечення).
+- [Цикл розробки ПЗ](https://uk.wikipedia.org/wiki/Життєвий_цикл_програмного_забезпечення): визначення, реалізація, оцінювання, вимірювання, керування та покращення [циклу розробки ПЗ](https://uk.wikipedia.org/w/index.php?title=Цикл_розробки_ПЗ&action=edit&redlink=1) як такого.
+- Інструменти [комп'ютерних наук](https://uk.wikipedia.org/wiki/Комп'ютерні_науки): різні комп'ютерні системи що допомагають та дозволяють проводити процес розробки.
+- [Якість програмного забезпечення](https://uk.wikipedia.org/wiki/Якість_програмного_забезпечення): відповідність [програмного продукту](https://uk.wikipedia.org/wiki/Програмний_продукт) вимогам.
+
+Будь яка фізична сутність, у тому числі програмна, колись задумується, з'являється на світ і зникає. Кажуть, що вона проходить свій життєвий цикл. Весь комплекс процесів програмної (і системної) інженерії пов\'язаний з упорядкування робіт навколо життєвого циклу. Тобто планування робіт, використання інструментів та інших засобів для створення, зміни, чи обслуговування, перевірку виконання робіт та інші дії розглядають в контексті знаходження програмного продукту на певній стадії життєвого циклу.
+
+***Життєвий цикл*** програмних систем включає в себе усі стадії від виникнення потреби в програмі певного цільового призначення до повного завершення використання цієї системи, у зв'язку з моральним старінням або втрати необхідності.
+
+Стадії життєвого циклу виділяють по різному. Найпростіше життєвий цикл будь-якої системи можна розглядати як наступні стадії: задум, розробка, введення в дію, експлуатація, утилізація. Часто розробники систем останню стадію не враховують, вважаючи що після введення в дію та гарантійного терміну експлуатації, інше лежить на плечах покупця. Для програмного забезпечення вона також втрачає сенс, особливо для продуктів масового вжитку.
+
+З точки зору розробника ПЗ основними стадіями життєвого циклу умовно можна виділити наступні стадії (рис.1.7):
+
+- постановка задачі
+- аналіз вимого і означення специфікацій
+- проектування
+- реалізація
+- впровадження та тестування
+- супровід
+
+
+
+рис.1.7. Стадійність життєвого циклу
+
+На стадії **постановка задачі** чітко формулюють призначення програмного забезпечення і означують основні вимоги до нього. Кожна вимога представляє собою опис необхідної або бажаної властивості ПЗ. Розрізняють функціональні та експлуатаційні вимоги. ***Функціональні вимоги*** означують функції, які повинно виконувати розроблювальне програмне забезпечення. ***Експлуатаційні вимоги*** вказують на особливості його функціонування. При формуванні вимог до нового ПЗ, що не має аналогів інколи необхідно провести спеціальні передпроектні дослідження. Стадія завершується розробкою ***Технічного Завдання*** (***ТЗ***), яке фіксує принципові вимоги та основні проектні рішення.
+
+Після аналізу вимог означують специфікації. **Специфікаціями** називають точний формалізований опис функцій і обмежень розроблювального ПЗ. Розрізняють функціональні та експлуатаційні специфікації, а також специфікацію якості майбутнього ПЗ. Сукупність специфікацій представляє собою загальну логічну модель проектованого ПЗ. Спочатку виконують аналіз вимог ТЗ, формують змістовну постановку задачі, вибирають математичний апарат формалізації, будують модель предметної області, визначають підзадачі і вибирають або розробляють методи їх вирішення. Частина специфікацій може бути означена в процесі передпроектних досліджень і відповідно зафіксована в технічному завданні. На цій стадії доцільно сформувати тести для пошуку помилок в проектованому ПЗ, вказавши очікувані результати.
+
+Основною задачею стадії **проектування** є означення докладних специфікацій розроблюваного програмного забезпечення. Процес проектування складного програмного забезпечення зазвичай включає:
+
+- проектування загальної структури - визначення основних компонентів і їх взаємозв\'язків;
+
+- декомпозицію компонентів і побудова структурних ієрархій відповідно до рекомендацій блочно-ієрархічного підходу;
+
+- проектування компонентів.
+
+Результатом проектування є детальна модель розроблюваного програмного забезпечення разом зі специфікаціями його компонентів всіх рівнів. Тип моделі залежить від обраного підходу (структурний, об\'єктний або компонентний) і конкретної технології проектування. Однак в будь-якому випадку процес проектування охоплює як проектування програм (підпрограм) і визначення взаємозв\'язків між ними, так і проектування даних, з якими взаємодіють ці програми або підпрограми.
+
+Прийнято розрізняти також два аспекти проектування:
+
+- логічне проектування, яке включає ті проектні операції, які безпосередньо не залежать від наявних технічних і програмних засобів, що складають середовище функціонування майбутнього програмного продукту;
+
+- фізичне проектування - прив\'язка до конкретних технічних і програмних засобів середовища функціонування, тобто. врахування обмежень, означених у специфікаціях.
+
+**Реалізація** -- це процес поетапного написання кодів програми з обраною мовою програмування (кодування), їх тестування і налагодження. По суті ця стадія включає ітераційні етапи:
+
+- написання коду,
+- тестування програми (верифікація),
+- налагодження.
+
+**Впровадження ПЗ** це введення його в дію безпосередньо на місці використання та перевірка ПЗ відповідно до вимог. Ця стадія передбачає розгортання вже протестованого ПЗ на місці призначення та проходження кінцевого тестування.
+
+**Супровід** - це процес створення і впровадження нових версій програмного продукту. Причинами випуску нових версій можуть служити:
+
+- необхідність виправлення помилок, виявлених в процесі експлуатації попередніх версій;
+
+- необхідність вдосконалення попередніх версій, наприклад, поліпшення інтерфейсу або підвищення його продуктивності, розширення складу виконуваних функцій;
+
+- зміна середовища функціонування, наприклад, поява нових технічних засобів та/або програмних продуктів, з якими взаємодіє супроводжуване програмне забезпечення.
+
+На цій стадії в програмний продукт вносять необхідні зміни, які так само, як в інших випадках, можуть вимагати перегляду проектних рішень, прийнятих на будь-якій попередній стадії.
+
+Слід зазначити, що стадії в різних представленнях життєвого циклу можуть бути відмінні від перерахованих вище. Наприклад етап тестування (верифікації) програми відповідно до проектних вимог може бути виділено в окрему стадію.
+
+Для керування процесами життєвого циклу використовують різні методології, які відображаються в **моделях життєвих циклів**. Нижче наведена для прикладу одна модель.
+
+***Водоспадна*** або ***каскадна модель*** (waterfall model) - послідовний метод розробки програмного забезпечення, названий так через діаграму, схожу на водоспад (як на ілюстрації).
+
+
+
+рис.1.8. Каскадна модель
+
+Ця модель використовувалася і використовується для фізичних систем, де фізична реалізація вимагає чіткого продумування і виконання без помилок кожної попередньої стадії. Наприклад, якщо архітектор зробив помилки на стадії проектування, побудована будівля під час експлуатації може не витримати сильного вітру, або під час будівництва (реалізація) може не вистачити матеріалів. Якщо на стадії реалізації зробити неправильні дії, на стадії експлуатації можуть бути також проблеми. Тому на практиці часто використовують інші моделі, які будуть розглядатися в одній із лекцій.
+
+## Питання для самоконтролю
+
+1. Чим автоматичне керування відрізняється від автоматизованого?
+
+2. Які складові входять до структури автоматизованої системи керування?
+
+3. Яке призначення датчиків?
+
+4. Яке призначення виконавчих механізмів?
+
+5. Яку роль в системі керування відіграють програмовані контролери?
+
+6. Яке призначення засобів людино-машинного інтерфейсу?
+
+7. Поясніть що таке Інтернет речей (IoT) і Промисловий Інтернет речей (IIoT).
+
+8. Які складові як правило входять в екосистему Інтернету речей?
+
+9. Поясніть призначення IoT-шлюзів (IoT-gateways, Edge-gateways).
+
+10. Чому кібербезпека в питання Інтернету речей займає дуже важливе місце?
+
+11. Які типи ПЗ можете виділити?
+
+12. Для чого призначене інструментальне програмне забезпечення?
+
+13. Які складові входять до складу інтегрованого середовища розробки?
+
+14. Які дисципліни входять до програмної інженерії?
+
+15. Поясніть що таке життєвий цикл.
+
+16. Які стадії можете виділити з життєвого циклу ПЗ? Поясніть призначення цих стадій.
+
+
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
+
diff --git "a/\320\233\320\265\320\272\321\206/20_githubwrkflw.md" "b/\320\233\320\265\320\272\321\206/20_githubwrkflw.md"
new file mode 100644
index 0000000..21b38d0
--- /dev/null
+++ "b/\320\233\320\265\320\272\321\206/20_githubwrkflw.md"
@@ -0,0 +1,715 @@
+**Програмна інженерія в системах управління. Лекції.** Автор і лектор: Олександр Пупена
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
+
+# 20. Git Hub actions
+
+## 20.1. Основи роботи з Git Hub actions
+
+Дії GitHub допоможуть вам автоматизувати робочі процеси з розробки програмного забезпечення в тому самому місці, де ви зберігаєте код та співпрацюєте над запитами на пул. Ви можете писати окремі завдання, що називаються діями ([actions](https://help.github.com/en/actions/getting-started-with-github-actions/about-github-actions)), і комбінувати їх для створення користувальницького робочого процесу (workflow).
+
+**Робочі процеси** (**workflow**) - це спеціалізовані автоматизовані процеси, які ви можете налаштувати у своєму сховищі для побудови, тестування, пакування, випуску чи розгортання будь-якого кодового проекту на GitHub.
+
+За допомогою GitHub Actions ви можете будувати безперервну інтеграцію (CI) та можливості неперервного розгортання (CD) безпосередньо у вашому сховищі. Дії GitHub (GitHub Actions) надають повноцінну послугу безперервної інтеграції GitHub.
+
+Робочі процеси працюють у Linux, macOS, Windows та контейнерах на машинах, розміщених на GitHub, названі **виконувачами** ('**runners**'). Крім того, ви також можете розмістити власних виконувачів для запуску робочих процесів на машинах, якими ви володієте або керуєте.
+
+Ви можете створювати робочі процеси, використовуючи дії, означені у вашому сховищі, дії з відкритим кодом у загальнодоступному сховищі на GitHub або опублікованим образом контейнера Docker. Робочі процеси у сховищах форк не працюють за замовчуванням.
+
+Ви можете виявити дії, які потрібно використовувати у своєму робочому процесі на GitHub, та створити дії, які потрібно ділитися спільнотою з GitHub.
+
+Наведений нижче приклад файлу YAML для означення workflow, який запускається при прикріпленні будь якої теми і виводить в консоль віртуальної машини фразу "Hello World"!
+
+```yaml
+# самий прстий workflow, простіше я не придумав
+# створює віртуалку і запускає там команду в bash
+name: Hello world 1 # назва workflow
+on: # це подія, яка вказує коли буде запускатися workflow
+ issues: # назва події - коли щось відбувається з issues
+ types: pinned # тип активності - прикрпілення
+# https://help.github.com/en/actions/reference/events-that-trigger-workflows#issues-event-issues
+jobs: # перелік завдань
+ job1: # назва першого завдання
+ runs-on: ubuntu-latest # тип машини, на якій виконувати завдання
+ steps: # кроки
+ - name: step1 # назва кроку
+ run: echo Hello world! # виконує команди командного рядка
+```
+
+Після запуску на GitHub можна побачити результат запуску для кожного завдання та кроку.
+
+
+
+рис.20.1. Приклад виконання Git Hub actions
+
+## 20.2. Основні принципи конфігурування та керування робочими процесами
+
+У цьому розділі розглядаються тільки основні положення, деталі читайте [за посиланням](https://help.github.com/en/actions/configuring-and-managing-workflows).
+
+Практика розробки програмного забезпечення часто здійснює невеликі зміни коду до спільного сховища. За допомогою GitHub Actions ви можете створювати власні робочі процеси неперервної інтеграції (**CI**), які автоматизують створення та тестування вашого коду. З вашого сховища ви можете переглянути стан змін вашого коду та докладні журнали для кожної дії у вашому робочому процесі. CI економить час розробників, надаючи негайний зворотній зв'язок щодо змін коду для швидшого виявлення та усунення помилок.
+
+Неперервне розгортання (**CD**) ґрунтується на неперервній інтеграції (CI). Коли новий код введено і проходить ваші тести на CI, код автоматично розгортається у місце виконання. За допомогою GitHub Actions ви можете створювати власні робочі процеси CD, щоб автоматично розгортати ваш код у будь-яку хмару, сервіс, що розміщений на власній основі, або платформу зі свого сховища. CD економить час розробників за рахунок автоматизації процесу розгортання та розгортає перевірений, стабільний код швидше змінюється для ваших клієнтів.
+
+### Конфігурування робочих процесів
+
+Можна створити більше одного робочого процесу в сховищі. Вони зберігаються в каталозі `.github/workflows` у корені сховища як файли ` .yml` або `.yaml` на мові YAML яка розглядалася на попередній лекції. Після запуску робочого процесу можна побачити журнали збірки, результати тестів, артефакти та статуси для кожного кроку робочого процесу. Також можна отримувати сповіщення про оновлення стану робочого процесу (див. "[Configuring notifications](https://help.github.com/en/github/managing-subscriptions-and-notifications-on-github/configuring-notifications#github-actions-notification-options).")
+
+
+
+рис.20.2. Налагодження робочих процесів
+
+Робочі процеси повинні мати принаймні одне завдання (**job**), а завдання містити набір кроків (**steps**), які виконують окремі задачі (task). Кроки можуть запускати команди або використовувати дію (**action**). Ви можете створювати власні дії або використовувати дії, якими ділиться спільнота GitHub, та налаштовувати їх за потребою.
+
+### Змінні середовища
+
+GitHub встановлює змінні середовища за замовчуванням для кожного запущеного робочого процесу GitHub Actions. Ви також можете встановити власні змінні середовища у файлі робочого процесу. До змінних середовища можна звертатися за іменем, використовуючи знак `$`. Назва змінних середовища чутлива до регістру.
+
+Команди, що виконуються в діях або кроках, можуть створювати, читати та змінювати змінні середовища. Щоб встановити власні змінні середовища, потрібно вказати змінні у файлі робочого процесу для кроку, завдання або всього робочого процесу за допомогою ключових слів [`jobs..steps.env`](https://help.github.com/en/github/automating-your-workflow-with-github-actions/workflow-syntax-for-github-actions#jobsjob_idstepsenv), [`jobs..env`](https://help.github.com/en/github/automating-your-workflow-with-github-actions/workflow-syntax-for-github-actions#jobsjob_idenv), та [`env`](https://help.github.com/en/github/automating-your-workflow-with-github-actions/workflow-syntax-for-github-actions#env) , які описані нижче.
+
+```yaml
+steps:
+ - name: Hello world
+ run: echo Hello world $FIRST_NAME $middle_name $Last_Name!
+ env:
+ FIRST_NAME: Mona
+ Last_Name: Octocat
+```
+
+Ви також можете скористатися командою `set-env` робочого процесу для встановлення змінної середовища, яку можуть використовувати наступні кроки в робочому процесі. Команда `set-env` може використовуватися безпосередньо дією або як команда shell у файлі робочого процесу за допомогою ключового слова `run` .
+
+Ми настійно рекомендуємо діям використовувати змінні середовища для доступу до файлової системи, а не використовувати прямі шляхи до файлів. GitHub встановлює змінні середовища для дій, які потрібно використовувати у всіх середовищах виконувача.
+
+Таблиця 20.2. Змінні середовища GitHub
+
+| Змінна середовища | Опис |
+| ------------------- | ------------------------------------------------------------ |
+| `CI` | Завжди встановлено в `true`. |
+| `HOME` | Шлях до домашньої директорії GitHub використовується для збереження користувацьких даних. Наприклад, `/github/home`. |
+| `GITHUB_WORKFLOW` | Ім'я workflow. |
+| `GITHUB_RUN_ID` | Унікальний номер для кожного запуску в сховищі. Це число не змінюється, якщо ви повторно запустите робочий процес. |
+| `GITHUB_RUN_NUMBER` | Унікальний номер для кожного запуску певного робочого процесу в сховищі. Це число починається з 1 для першого запуску робочого процесу та збільшується з кожним новим виконанням. Це число не змінюється, якщо ви повторно запустите робочий процес. |
+| `GITHUB_ACTION` | Унікальний ідентифікатор дії (`id`). |
+| `GITHUB_ACTIONS` | Завжди встановлене в значення `true`, коли GitHub Actions виконує робочий процес. Ви можете використовувати цю змінну для розмежування, коли тести виконуються локально або за допомогою GitHub Actions. |
+| `GITHUB_ACTOR` | Ім’я особи чи програми, яка ініціювала робочий процес. Наприклад, `octocat`. |
+| `GITHUB_REPOSITORY` | Назва власника та сховища. Наприклад, `octocat/Hello-World`. |
+| `GITHUB_EVENT_NAME` | Назва події webhook, яка спровокувала робочий процес. |
+| `GITHUB_EVENT_PATH` | Шлях до файлу з повним навантаженням події в webhook. Наприклад, `/github/workflow/event.json`. |
+| `GITHUB_WORKSPACE` | Шлях до каталогу робочого середовища GitHub. Каталог робочого середовища містить підкаталог із копією вашого сховища, якщо ваш робочий процес використовує дію [actions/checkout](https://github.com/actions/checkout). Якщо ви не використовуєте дію `actions/checkout`, каталог буде порожнім. Наприклад, `/home/runner/work/my-repo-name/my-repo-name`. |
+| `GITHUB_SHA` | SHA коміта, який ініціює workflow. Наприклад, `ffac537e6cbbf934b08745a378932722df287a53`. |
+| `GITHUB_REF` | Посилання на гілку чи тег, що ініціював робочий процес. Наприклад, `refs/heads/feature-branch-1`. Якщо для типу події не доступна ні гілка, ні тег, змінна не буде існувати. |
+| `GITHUB_HEAD_REF` | Встановлюється лише для сховищ-форків. Відділення базового сховища. |
+| `GITHUB_BASE_REF` | Встановлюється лише для сховищ-форків. Гілка базового схоивща. |
+
+### Artifact (Артефакт)
+
+Артефакти дозволяють зберігати дані після завершення завдання та ділитися цими даними з іншим завданням у тому ж робочому процесі. **Артефакт** - це файл або колекція файлів, що утворюються під час виконання робочого процесу. Наприклад, ви можете використовувати артефакти, щоб зберегти свої збірки та випробування після закінчення запуску робочого процесу. GitHub для артефактів зберігає артефакти протягом 90 днів. Період збереження для запиту на пул перезапускається кожного разу, коли хтось робить новий запит на пул.
+
+Ось деякі поширені артефакти, які ви можете завантажити:
+
+- Журнали файлів та основні дампів
+- Результати тестів, збої та скріншоти
+- Двійкові або стислі файли
+- Вихід результатів тестів випробувань та результати покриття коду
+
+Артефакти завантажуються під час виконання робочого процесу, і ви можете переглянути ім'я та розмір артефакту в інтерфейсі користувача. Коли артефакт завантажується за допомогою інтерфейсу GitHub, всі файли, які були окремо завантажені як частина артефакту, стискаються в один файл.
+
+GitHub надає дві дії, які можна використовувати для завантаження та вивантаження артефактів. Для отримання додаткової інформації, див. [actions/upload-artifact](https://github.com/actions/upload-artifact) та [download-artifact](https://github.com/actions/download-artifact) actions. Робота з цими діями показана нижче.
+
+## 20.3. Основні розділи описового файлу.
+
+На початку вказується назва робочого процесу. Якщо опустити `name` GitHub встановлює його до шляху файлу робочого процесу відносно кореня сховища.
+
+**Event** (**Подія**) - конкретна діяльність, яка запускає робочий процес. Вона означується через параметр `on` . Наприклад, активність може походити з GitHub, коли хтось натискає на коміт до сховища або коли створюється запит на пул чи issue. Ви також можете налаштувати робочий процес для запуску, коли відбувається зовнішня подія, використовуючи repository dispatch webhook.
+
+На наведеному вище прикладі тип події був означений як `pinned` (прикріплення) в `issues`. Тобто, коли будь яка issue буде прикірплена.
+
+```yaml
+on: # це подія, яка вказує коли буде запускатися workflow
+ issues: # назва події - коли щось відбувається з issues
+ types: pinned # тип активності - прикрпілення
+```
+
+Можна налаштувати робочий процес для запуску як за певною подією GitHub (webhook events), так і за календарним графіком (Scheduled events) або із зовнішньої події (External events).
+
+Щоб запустити робочий процес за подією на GitHub, додайте `on:` та значення події після імені робочого процесу. Наприклад, цей робочий процес спрацьовує, коли пушаться зміни до будь-якої гілки сховища.
+
+```yaml
+on: push
+```
+
+Для планування робочого процесу можна використовувати синтаксис POSIX cron у вашому файлі робочого процесу. Найкоротший інтервал, з якого можна виконувати заплановані робочі процеси, - один раз на 5 хвилин. Наприклад, цей робочий процес спрацьовує щогодини.
+
+```yaml
+on:
+ schedule:
+ - cron: '0 * * * *'
+```
+
+Щоб запустити робочий процес після того, як відбувається зовнішня подія, ви можете викликати подію webhook `repository_dispatch`, викликавши кінцеву точку REST API "Create a repository dispatch event". Для отримання додаткової інформації див. "[Create a repository dispatch event](https://developer.github.com/v3/repos/#create-a-repository-dispatch-event)" в документації GitHub Developer.
+
+Можна надати одну подію `string`, масив (`array` ) подій, "масив" типів подій ( `array` of event `types`), або відображення конфігурації події (event configuration `map` ), яка планує робочий процес або обмежує виконання робочого процесу певними файлами, тегами або змінами гілки. Список доступних подій див "[Events that trigger workflows](https://help.github.com/en/articles/events-that-trigger-workflows)."
+
+```yaml
+# Приклад масиву подій: заупскати при push або pull_request
+on: [push, pull_request]
+```
+
+Якщо вам потрібно вказати типи дій або конфігурацію події, потрібно налаштувати кожну подію окремо. Ви повинні додати двокрапку (`:`) до всіх подій, включаючи події без конфігурації.
+
+```yaml
+on:
+ # спрацьовує при push або pull request,
+ # аде тільки для гілки master
+ push:
+ branches:
+ - master
+ pull_request:
+ branches:
+ - master
+ # спрацьовує при page_build, а також при події release created
+ page_build:
+ release:
+ types: # This configuration does not affect the page_build event above
+ - created
+```
+
+Наприклад, цей робочий процес запускається, коли пуш, що включає файли в каталозі `test`, робиться на гілці ` master`, або пушиться в тег `v1`.
+
+```yaml
+on:
+ push:
+ branches:
+ - master
+ tags:
+ - v1
+ # шляхи до файлу, які слід врахувати у події. Необов’язково; за замовчуванням для всіх.
+ paths:
+ - 'test/*'
+```
+
+Для отримання додаткової інформації про синтаксис фільтрів гілок, тегів та шляхів див "[`on..`](https://help.github.com/en/articles/workflow-syntax-for-github-actions#onpushpull_requestbranchestags)" та "[`on..paths`](https://help.github.com/en/articles/workflow-syntax-for-github-actions#onpushpull_requestpaths).". Повний перелік подій можна подивитися [тут](https://help.github.com/en/actions/reference/events-that-trigger-workflows#webhook-events).
+
+Для отримання додаткової інформації та прикладів, див "[Events that trigger workflows](https://help.github.com/en/articles/events-that-trigger-workflows#webhook-events)."
+
+Розділ `env` відповідає за змінні середовища, тут йде відображення `map` змінних середовищ, які доступні для всіх завдань і кроків робочого процесу. Ви також можете встановити змінні середовища, які доступні лише для завдання чи кроку. Коли більше однієї змінної середовища визначено з тим самим іменем, GitHub використовує найбільш конкретну змінну середовища. Наприклад, коли виконується крок, змінна середовища, означена на кроці, буде заміняти змінні завдання та робочого процесу з тим самим іменем, .
+
+```yaml
+env:
+ SERVER: production # змінна SERVER має значення production
+```
+
+Розділ завдання `jobs` розглянемо більш детально.
+
+## 20.4. Завдання `jobs`
+
+**Завдання** (**job**) - набір кроків, які виконуються на одному виконувачі. Ви можете визначити правила залежності того, як виконуються завдання у файлі робочого процесу. Завдання можуть працювати паралельно або послідовно виконуватись залежно від стану попереднього завдання.
+
+Кожне завдання повинно мати ідентифікатор, який асоціюється з роботою. Ключ **`job_id`** - це рядок, його значення - відображення даних конфігурації завдання. Ви повинні замінити `` на рядок, унікальний для об'єкта `jobs.` .
+
+```yaml
+jobs:
+ my_first_job: #індентифікатор завдання
+ name: My first job #імя завдання
+ my_second_job:
+ name: My second job
+```
+
+За замовчуванням завдання виконуються паралельно. Щоб послідовно виконувати завдання, ви можете визначити залежності від інших завдань за допомогою ключового слова **`needs`**. Це слово означує завдання, після успішного виконання яких запускається це завдання. Це може бути рядок або масив рядків. Якщо завдання помилково завершується, усі завдання, які його потребують, пропускаються, якщо тільки завдання не використовують умовний вислів, який призводить до продовження роботи. Завдання в наведеному нижче прикладі виконують послідовно: `job1`, `job2` а потім `job3`
+
+```yaml
+jobs:
+ job1:
+ job2: #почне виконуватися тільки після успішного завершення job1
+ needs: job1
+ job3: #почне виконуватися тільки після успішного завершення job1 та job2
+ needs: [job1, job2]
+```
+
+Кожне завдання виконується в середовищі (типі машини), означеному **`runs-on`**. Цей параметр є обов'язковим. Машина може бути або виконувачем, розміщеним у GitHub, або виконувачем, що влаштовується власноруч.
+
+### Віртуальна машина для виконання (`runs-on`)
+
+**Runner** (**виконувач**) - це будь-яка машина із встановленим застосунком виконувача GitHub Actions.
+
+Віртуальне середовище виконувача, розміщеного у GitHub, включає конфігурацію апаратного забезпечення віртуальної машини, операційну систему та встановлене програмне забезпечення.
+
+Ви можете запускати робочі процеси на виконувачах, розміщених на серверах GitHub або виконувачах, що розміщуються самостійно. Завдання можуть працювати безпосередньо на машині або в контейнері Docker. Ви можете вказати виконувач для кожного завдання в робочому процесі, використовуючи `runs-on`. Для отримання додаткової інформації про `runs-on`, див "[Workflow syntax for GitHub Actions](https://help.github.com/en/articles/workflow-syntax-for-github-actions#jobsjob_idruns-on)."
+
+Якщо ви використовуєте виконувач, розміщений у GitHub, кожне завдання виконується у новому екземплярі віртуального середовища, означеного `runs-on`. Доступними типами виконувачів, розміщених у GitHub, є:
+
+Таблиця 20.1. Типи виконувачів GitHub ("[Virtual environments for GitHub-hosted runners](https://help.github.com/en/github/automating-your-workflow-with-github-actions/virtual-environments-for-github-hosted-runners).")
+
+| Віртуальне середовище | мітка workflow YAML |
+| --------------------- | ---------------------------------- |
+| Windows Server 2019 | `windows-latest` або`windows-2019` |
+| Ubuntu 20.04 | `ubuntu-20.04` |
+| Ubuntu 18.04 | `ubuntu-latest` або `ubuntu-18.04` |
+| Ubuntu 16.04 | `ubuntu-16.04` |
+| macOS Catalina 10.15 | `macos-latest` or `macos-10.15` |
+
+```yaml
+runs-on: ubuntu-latest
+```
+
+Щоб вказати власний (**self-hosted**) виконувач для свого завдання, конфігуруйте `runs-on` у вашому файлі робочого процесу за допомогою власників міток виконувача. Усі self-hosted виконувачі, мають мітку `self-hosted`. Див "[About self-hosted runners](https://help.github.com/en/github/automating-your-workflow-with-github-actions/about-self-hosted-runners)" та"[Using self-hosted runners in a workflow](https://help.github.com/en/github/automating-your-workflow-with-github-actions/using-self-hosted-runners-in-a-workflow).
+
+```yaml
+runs-on: [self-hosted, linux]
+```
+
+### Виходи завдання (`outputs`)
+
+Виходи завдання - це рядки, які містять вирази, які розраховуються на виконувачі в кінці кожного завдання. Виходи, що містять паролі, редагуються на виконувачі і не надсилаються в GitHub Actions.
+
+```yaml
+jobs:
+ job1:
+ runs-on: ubuntu-latest
+ # Відображення виходів кроків на виходи завдань
+ outputs:
+ output1: ${{ steps.step1.outputs.test }}
+ output2: ${{ steps.step2.outputs.test }}
+ steps:
+ - id: step1
+ run: echo "::set-output name=test::hello"
+ - id: step2
+ run: echo "::set-output name=test::world"
+ job2:
+ runs-on: ubuntu-latest
+ needs: job1
+ steps:
+ - run: echo ${{needs.job1.outputs.output1}} ${{needs.job1.outputs.output2}}
+```
+
+### Змінні середовища для завдання `env`
+
+Відображення змінних середовища, які доступні для всіх кроків завдання.
+
+```yaml
+jobs:
+ job1:
+ env:
+ FIRST_NAME: Mona
+```
+
+### Налаштування за замовченням (`defaults`)
+
+Відображення налаштувань за замовчуванням, яка застосовуватиметься до всіх кроків завдання.
+
+```yaml
+jobs:
+ job1:
+ runs-on: ubuntu-latest
+ defaults: #налаштуванн для всіх кроків за замовченням
+ run:
+ shell: bash
+ working-directory: scripts
+```
+
+### Умовне виконання (`if` )
+
+Ви можете використовувати умовний елемент `if` , щоб запобігти виконанню роботи, якщо умова не виконується.
+
+### Кроки (`steps`)
+
+Завдання містить послідовність задач (task), що називається `steps`. Кроки можуть:
+
+- запускати команди,
+- виконувати завдання налаштування
+- виконувати дії у вашому сховищі, загальнодоступному сховищі або дії, опублікованих у реєстрі Docker.
+
+Не всі кроки виконують дії, але всі дії виконуються як крок. Кожен крок працює у своєму процесі в тому ж середовищі виконувача і має доступ до робочої області та файлової системи. Оскільки дії виконуються в їх власному процесі, зміни змінних оточуючих середовищ не зберігаються між кроками. GitHub пропонує вбудовані кроки для налаштування та завершення завдання.
+
+Аналогічно завданням кроки мають:
+
+- `id` та `name`
+- `if` умовне виконання
+- `env` змінні середовища кроку
+
+```yaml
+name: Greeting from Mona
+on: push
+jobs:
+ my-job:
+ name: My Job
+ runs-on: ubuntu-latest
+ steps:
+ - name: Print a greeting
+ env:
+ MY_VAR: Hi there! My name is
+ FIRST_NAME: Mona
+ MIDDLE_NAME: The
+ LAST_NAME: Octocat
+ run: |
+ echo $MY_VAR $FIRST_NAME $MIDDLE_NAME $LAST_NAME.
+```
+
+Цей крок виконується лише тоді, коли тип події є `pull_request` і дія події `unassigned`.
+
+```yaml
+steps:
+ - name: My first step
+ if: ${{ github.event_name == 'pull_request' && github.event.action == 'unassigned' }}
+ run: echo This event is a pull request that had an assignee removed.
+```
+
+Крок `my backup step` запускається лише тоді, коли попередній крок завдання закінчується. Для отримання додаткової інформації див "[Context and expression syntax for GitHub Actions](https://help.github.com/en/actions/reference/context-and-expression-syntax-for-github-actions#job-status-check-functions)."
+
+```yaml
+steps:
+ - name: My first step
+ uses: monacorp/action-name@master
+ - name: My backup step
+ if: ${{ failure() }}
+ uses: actions/heroku@master
+```
+
+`steps.continue-on-error` Запобігає відмови від роботи, коли крок не вдається. Установіть значення `true` , щоб дозволити роботу пройти, коли цей крок не вдався.
+
+`steps.timeout-minutes` - максимальна кількість хвилин, щоб виконати крок перед тим, як вбити процес.
+
+Для вибору дії для кроку завдання вказується `steps.uses`. **Дія** (**`action`** ) - це одиниця коду для багаторазового використання. Ви можете використовувати дію, означену в тому ж сховищі, що і робочий процес, в загальнодоступному сховищі або [published Docker container image](https://hub.docker.com/).
+
+Дії (actions) - це або файли JavaScript, або контейнери Docker. Якщо дія, яку ви використовуєте, є контейнером Docker, ви повинні запустити завдання в середовищі Linux. Докладніше див. У розділі [`runs-on`](https://help.github.com/en/actions/reference/workflow-syntax-for-github-actions#jobsjob_idruns-on).
+
+Ви можете переглядати та використовувати дії, створені GitHub в організації [github.com/actions](https://github.com/actions). Щоб відвідати Docker Hub, див. "[Docker Hub](https://www.docker.com/products/docker-hub)" на сайті Docker. Щоб посилатися на дії у вашому файлі робочого процесу з правильним синтаксисом, ви повинні врахувати, де означено дію.
+
+Для використання дії, означеної в приватному сховищі, і файл робочого процесу, і дія повинні бути в одному сховищі. Ваш робочий процес не може використовувати дії, означені в інших приватних сховищах, навіть якщо інше приватне сховище знаходиться в одній організації.
+
+Щоб зберегти робочий процес стабільним, навіть коли проводиться оновлення дії, ви можете посилатися на версію дії, яку ви використовуєте, вказавши номер файлу Git ref чи Docker у файлі робочого процесу.
+
+```yaml
+steps:
+ # посилання на вказаний commit
+ - uses: actions/setup-node@74bc508
+ # посилання на версію випуску
+ - uses: actions/setup-node@v1.2
+ # посилання на гілку
+ - uses: actions/setup-node@master
+```
+
+Для використання публічних дій використовується синтаксиси
+
+```
+{owner}/{repo}@{ref}
+{owner}/{repo}/{path}@{ref}
+```
+
+Наприклад
+
+```yaml
+jobs:
+ my_first_job:
+ steps:
+ - name: My first step
+ # Uses the master branch of a public repository
+ uses: actions/heroku@master
+ - name: My second step
+ # Uses a specific version tag of a public repository
+ uses: actions/aws@v2.0.1
+```
+
+Для використання дій в тому самому репозиторії як workflow використовується синтаксис
+
+```
+./path/to/dir
+```
+
+Шлях до каталогу, який містить дії у сховищі вашого робочого процесу. Ви повинні перевірити сховище, перш ніж використовувати дію.
+
+```yaml
+jobs:
+ my_first_job:
+ steps:
+ #спочатку
+ - name: Check out repository
+ uses: actions/checkout@v2
+ - name: Use local my-action
+ uses: ./.github/actions/my-action
+```
+
+Синтаксис використання дій Docker Hub
+
+```
+docker://{image}:{tag}
+```
+
+Образ Docker опублікований на [Docker Hub](https://hub.docker.com/).
+
+```yaml
+jobs:
+ my_first_job:
+ steps:
+ - name: My first step
+ uses: docker://alpine:3.8
+```
+
+Приклад використання дій Docker public registry
+
+```
+docker://{host}/{image}:{tag}
+```
+
+Образ Docker у публічному репозитрію.
+
+```yaml
+jobs:
+ my_first_job:
+ steps:
+ - name: My first step
+ uses: docker://gcr.io/cloud-builders/gradle
+```
+
+Деякі дії вимагають введення даних, які потрібно встановити за допомогою ключового слова [`with`](https://help.github.com/en/actions/reference/workflow-syntax-for-github-actions#jobsjob_idstepswith) .
+
+Параметр `steps.run` запускає програми командного рядка, використовуючи оболонку операційної системи. Якщо ви не вкажете `name`, ім'я кроку за замовчуванням буде текстом, визначеним у команді `run` . Команди виконуються за допомогою стандартних оболонок, які входять у систему. Ви можете вибрати іншу оболонку та налаштувати оболонку, яка використовується для виконання команд. Для отримання додаткової інформації, "[Using a specific shell](https://help.github.com/en/actions/reference/workflow-syntax-for-github-actions#using-a-specific-shell)". Кожне ключове слово `run` представляє собою новий процес і оболонку в середовищі runner. Коли ви надаєте багаторядкові команди, кожен рядок працює в одній оболонці. Наприклад:
+
+- Однорядкова команда:
+
+ ```yaml
+ - name: Install Dependencies
+ run: npm install
+ ```
+
+- Багаторядкова команда:
+
+ ```yaml
+ - name: Clean install dependencies and build
+ run: |
+ npm ci
+ npm run build
+ ```
+
+Використовуючи ключове слово `working-directory` , ви можете вказати робочий каталог, де запустити команду.
+
+```yaml
+- name: Clean temp directory
+ run: rm -rf *
+ working-directory: ./temp
+```
+
+Ви можете змінити параметри оболонки за замовчуванням в операційній системі виконувача за допомогою ключового слова `shell`.
+
+```yaml
+steps:
+ - name: Display the path
+ run: echo $PATH
+ shell: bash
+```
+
+Кожен вхідний параметр означується в `steps.with` як пара ключ/значення, який встановлюється як змінна середовища. Змінна отримує префікс `INPUT_` і перетворюється у верхній регістр. Наступний приклад означує два вхідні параметри (`first_name`, та `last_name`), означені дією `hello_world` . Ці вхідні змінні будуть доступні для дії `hello_world` як змінні середовища `INPUT_FIRST_NAME` і `INPUT_LAST_NAME` .
+
+```yaml
+jobs:
+ my_first_job:
+ steps:
+ - name: My first step
+ uses: actions/hello_world@master
+ with:
+ first_name: Mona
+ last_name: Octocat
+```
+
+Для контейнерів докер в steps.with означуються також `args` та `entrypoint`.
+
+`Args` - це рядок, який означує входи для контейнера Docker. GitHub передає `args` в контейнер 'ENTRYPOINT', коли контейнер запускається. Цей параметр не підтримує `array of strings`.
+
+```yaml
+steps:
+ - name: Explain why this job ran
+ uses: monacorp/action-name@master
+ with:
+ entrypoint: /bin/echo
+ args: The ${{ github.event_name }} event triggered this step.
+```
+
+`entrypoint` переміщує Докер `ENTRYPOINT` у `Dockerfile` або встановлює його, якщо його ще не було вказано. На відміну від інструкції Docker `ENTRYPOINT`, яка має форму оболонки та виконується, ключове слово ` entrypoint` приймає лише один рядок, що означує виконуваний файл, який слід запустити.
+
+```yaml
+steps:
+ - name: Run a custom command
+ uses: monacorp/action-name@master
+ with:
+ entrypoint: /a/different/executable
+```
+
+Ключове слово `entrypoint` призначене для використання з контейнерними діями Docker, але ви також можете використовувати його з діями JavaScript, які не означують жодних входів.
+
+### Стандартні дії в кроках
+
+Перелік публічних дій в кроках доступний за [посиланням](https://github.com/sdras/awesome-actions). Серед них є так звані [офіційні дії](https://github.com/sdras/awesome-actions#official-actions), які розглянуті в цьому розділі.
+
+- [actions/checkout](https://github.com/actions/checkout) - налаштовує своє сховище для доступу з робочого процесу (workflow)
+- [actions/upload-artifact](https://github.com/actions/upload-artifact) - вивантажує артефакти з вашого workflow
+- [actions/download-artifact](https://github.com/actions/download-artifact) - завантажує артефакт з вашого build
+- [actions/cache](https://github.com/actions/cache) - кешує залежності та виходи білдів в GitHub Actions
+- [actions/github-script](https://github.com/actions/github-script) - записує скрипт для GitHub API і конекстів workflow
+
+Дія checkout - це стандартна дія, яку потрібно включити у свій робочий процес перед іншими діями, якщо:
+
+- Для вашого робочого процесу потрібна копія коду вашого сховища, наприклад, коли ви створюєте і тестуєте своє сховище або використовуєте постійну інтеграцію.
+- у вашому робочому процесі є хоча б одна дія, визначена в одному сховищі. Для отримання додаткової інформації, див "[Referencing actions in your workflow](https://help.github.com/en/actions/configuring-and-managing-workflows/configuring-a-workflow#referencing-actions-in-your-workflow)."
+
+Щоб використовувати стандартну дію цей крок має наступну форму використання:
+
+```yaml
+- uses: actions/checkout@v2
+```
+
+Використання `v2` у цьому прикладі гарантує, що ви використовуєте стабільну версію дії з оформлення замовлення.
+
+За такого підходу усі необхідні файли репозиторію будуть доступні через кореневу папку. Наприклад доступ до `log.txt` в папці `.github/workflows` на виконувачі буде за наступною адресою
+
+```bash
+./.github/workflows/log.txt
+```
+
+Для отримання додаткової інформації див [the checkout action](https://github.com/actions/checkout).
+
+Для виконувачів, що розміщуються в GitHub, кожне завдання в робочому процесі виконується в новому екземплярі віртуального середовища. Коли завдання завершено, виконувач припиняє і видаляє екземпляр віртуальної середовища.
+
+Для обміну даними з завданнями можна використовувати стандартні дії з артефактами [actions/upload-artifact](https://github.com/actions/upload-artifact) та [download-artifact](https://github.com/actions/download-artifact):
+
+- **Вивантаження (Uploading) файлів**: Дайте ім'я вивантажуваному файлу та вивантажте дані до завершення завдання.
+- **Завантаження (Downloading) файлів**: Ви можете завантажувати лише артефакти, які були вивантажені під час того ж робочого процесу. Завантажуючи файл, ви можете посилатися на нього по імені.
+
+## 20.5. Приклади з використанням кроків
+
+Змінимо наведений на початку приклад, щоб він брав існуючий файл в репозиторію і добавляв туди запис
+
+```yaml
+jobs: # перелік завдань
+ job1: # назва першого завдання
+ runs-on: ubuntu-latest # тип машини, на якій виконувати завдання
+ steps: # кроки
+ - name: uses my repository
+ uses: actions/checkout@v2
+ - name: step1 # назва кроку
+ run: echo Hello world! >> ./.github/workflows/log.txt # добавляє в файл текстовий рядок
+ - name: upload file from vm # вивантажує артефакт в файл текстовий рядок
+ uses: actions/upload-artifact@v2
+ with:
+ name: log
+ path: ./.github/workflows/log.txt
+```
+
+Зверніть увагу, що файл `log.txt` у сховищі не зміниться.
+
+Кроки завдання поділяють одне і те ж середовище на машині виконувача, але виконуються у власних індивідуальних процесах. Для передачі даних між кроками в завданні можна використовувати входи та виходи.
+
+Наступний приклад робочого процесу ілюструє, як передавати дані між завданнями в одному і тому ж робочому процесі.
+
+```yaml
+name: Share data between jobs
+
+on: [push]
+
+jobs:
+ job_1:
+ name: Add 3 and 7
+ runs-on: ubuntu-latest
+ steps:
+ - shell: bash
+ run: |
+ expr 3 + 7 > math-homework.txt # в файл записується 10
+ - name: Upload math result for job 1
+ uses: actions/upload-artifact@v1 #виклик upload-artifact
+ with: # вхідні аргументи
+ name: homework # імя артефакту
+ path: math-homework.txt # вивантажити файл
+ # дія розміщує файл у каталозі під назвою `homework`
+
+ job_2:
+ name: Multiply by 9
+ needs: job_1
+ runs-on: windows-latest
+ steps:
+ - name: Download math result for job 1
+ uses: actions/download-artifact@v1 # завнтажити файл
+ with: # вхідні аргументи
+ name: homework # імя артефакту
+ - shell: bash
+ run: |
+ value=`cat homework/math-homework.txt`
+ expr $value \* 9 > homework/math-homework.txt
+ - name: Upload math result for job 2
+ uses: actions/upload-artifact@v1
+ with:
+ name: homework
+ path: homework/math-homework.txt
+
+ job_3:
+ name: Display results
+ needs: job_2
+ runs-on: macOS-latest
+ steps:
+ - name: Download math result for job 2
+ uses: actions/download-artifact@v1
+ with:
+ name: homework
+ - name: Print the final result
+ shell: bash
+ run: |
+ value=`cat homework/math-homework.txt`
+ echo The result is $value
+```
+
+Завдання, які залежать від артефактів попереднього завдання, повинні чекати успішного виконання залежного завдання. Цей робочий процес використовує ключове слово `needs`, щоб забезпечити послідовне виконання `job_1`, `job_2`, та `job_3` . Наприклад, для `job_2` потрібує ` job_1`, використовуючи синтаксис `needs: job_1`.
+
+Job 1 виконує наступні дії:
+
+- Виконує математичний обчислення та зберігає результат у текстовому файлі під назвою `math-homework.txt`.
+- Використовує дію `upload-artifact` для вивантаження файлу `math-homework.txt` з назвою `homework`. Дія розміщує файл у каталозі під назвою`homework`
+
+Job 2 використовує результат у попередній роботі:
+
+- Завантажує артефакт `homework` , вивантажений у попередньому завданні. За замовчуванням дія `download-artifact` завантажує артефакти в каталог робочої області, в якому виконується крок. Ви можете використовувати вхідний параметр ` path`, щоб вказати інший каталог завантажень.
+- читає значення з файлу `homework/math-homework.txt`, виконує математичний обчислення та зберігає результат у ` math-homework.txt`.
+- Вивантажує файл `math-homework.txt`. Це вивантаження перезаписує попереднє вивантаження, оскільки обидва вивантаження мають одне ім’я.
+
+Job 3 відображає результат, вивантажений у попередньому завданні:
+
+- Завантажує артефакт `homework`.
+- Друкує результат журналу математичного рівняння.
+
+Повна математична операція, виконана в цьому прикладі робочого процесу, є `(3 + 7) x 9 = 90`.
+
+Після завершення робочого процесу ви можете завантажити стислий файл вивантажених артефактів на GitHub, знайшовши робочий процес на вкладці **Actions** . Також ви можете використовувати API GITHub REST для завантаження артефактів. Для отримання додаткової інформації див. "[Artifacts](https://developer.github.com/v3/actions/artifacts/)" в документації на GitHub Developer.
+
+Якщо вам потрібно отримати доступ до артефактів із попереднього запуску робочого процесу, вам потрібно буде десь зберігати артефакти. Наприклад, ви можете запустити сценарій в кінці робочого процесу для зберігання збірок артефактів на Amazon S3 або Artifactory, а потім скористатися API служби зберігання для отримання цих артефактів у майбутньому робочому процесі.
+
+Ви можете завантажити артефакти, які були вивантажені під час робочого процесу. Артефакти автоматично закінчуються через 90 днів, однак ви завжди можете повернути використані сховища в GitHub Actions, видаливши артефакти, перш ніж вони закінчуються на GitHub.
+
+Для завантаження артефактів виконується наступна послідовність. Вибирається дії (рис.20.4), потім на лівій бічній панелі натисніть робочий процес, який ви хочете бачити (рис.20.5). У розділі "Запуск робочого процесу" натисніть назву процесу, який ви хочете побачити.
+
+
+
+
+рис.20.4. Вибір Actions
+
+
+
+рис.20.5. Вибір робочого процесу
+
+Для завантаження артефактів використовуйте спадне меню **Artifacts**, і виберіть артефакт, який ви хочете завантажити (рис.20.6).
+
+
+
+рис.20.6. Завантаження артефактів
+
+## Запитання для самоперевірки
+
+1. Розкажіть про призначення GitHub workflow.
+2. Що таке виконувачі runners?
+3. Наведіть основні кроки конфігурування робочих процесів.
+4. Як використовуються змінні середовища в GitHub workflow?
+5. Що таке артефакти? Як відбувається їх передача між кроками і завданнями?
+6. Розкажіть про означення завдань.
+7. Розкажіть про організацію кроків в завданнях.
+8. Прокоментуйте приклад з використанням кроків.
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
\ No newline at end of file
diff --git "a/\320\233\320\265\320\272\321\206/2_nodered.md" "b/\320\233\320\265\320\272\321\206/2_nodered.md"
new file mode 100644
index 0000000..5968492
--- /dev/null
+++ "b/\320\233\320\265\320\272\321\206/2_nodered.md"
@@ -0,0 +1,390 @@
+**Програмна інженерія в системах управління. Лекції.** Автор і лектор: Олександр Пупена
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
+
+# 2. Основи Node-RED
+
+## 2.1. Про NODE-RED
+
+**Node-RED** - це інструмент для візуального програмування потоків даних, розроблений працівниками компанії IBM для поєднання різноманітних пристроїв, API та онлайн-сервісів як складових частин Інтернету речей. Node-RED дає можливість програмувати об’єднані апаратні пристрої, API та сервіси онлайн новими способами, інколи навіть не використовуючи текстові мови програмування.
+
+Редактор Node-RED базується на браузері, який дозволяє легко об’єднувати в потоки вузли з широкого набору палітри, які можуть бути розгорнуті для виконання лише одним клацанням миші.
+
+Node-RED дає змогу працювати з браузерним редактором потоків даних як окремими вузлами з різним функціоналом, що уможливлюють створення JavaScript-функцій. Причому можна використовувати як базові вузли, якими одразу забезпечений Node-RED, так і встановлювати вузли з додатковим функціоналом з репозиторію NPM або ж навіть створити свій власний вузол з унікальним функціоналом.
+
+Програми або ж їхні частини, розроблені за допомогою Node-RED, можуть бути збережені та поширені для вільного використання. Саме середовище побудовано на основі **Node.js**, яке буде вивчатися в одній з наступних лекцій. За ініціативою IBM у 2016 році Node-RED став відкритим програмним забезпеченням (open-source) як частина проекту JS Foundation.
+
+Легке середовище виконання (runtime) побудоване на Node.js, в повній мірі використовуючи перевагу його подіє-орієнтованої не блокуючої моделі. Це робить його ідеальним для роботи на краю (Edge) мережі на недорогих апаратних засобах, таких як Raspberry Pi, а також у хмарі.
+
+Діапазон вузлів палітри легко розширити додаванням великої кількості модулів (сотні тисяч) зі сховища Node щоб отримати нові можливості.
+
+Потоки, створені в Node-RED, зберігаються за допомогою JSON, що дозволяє легко імпортувати та експортувати їх для спільного використання з іншими.
+
+## 2.2. Редактор
+
+Детальний опис редактору доступний [за посиланням](https://pupenasan.github.io/NodeREDGuidUKR/base/1_2.html)
+
+Редактор складається з таких 4 компонентів:
+
+- у верхній частині міститься заголовок, що містить кнопку розгортання, головне меню, і якщо користувач пройшов автентифікацію, меню користувача.
+- ліворуч знаходиться **палітра (palette),** яка містить вузли доступні для використання
+- посередині знаходиться основна **робоча область(workspace)**, в якій створюються потоки
+- праворуч знаходиться бічна панель (**sidebar**)
+
+
+
+рис.2.1. Вигляд редактору Node-RED.
+
+Уся програма складається з об’єднання вузлів – **потоків** (**flow**). Потоки розробляються в межах вкладок браузера з певною назвою. Вкладки також називаються потоками, хоч на них може бути кілька наборів об’єднаних вузлів.
+
+Термін “потік” також використовується для неофіційного опису одного набору підключених вузлів. Таким чином, потік (вкладка) може містити кілька потоків (набори з’єднаних вузлів).
+
+Потоки можна добавляти, видаляти, деактивувати (вони не розгортаються). До потоків можна добавляти опис у форматі MarkDown.
+
+**Вузли** (**Nodes**) можуть бути додані до робочої області з палітри або безпосередньо по імені.
+
+Вузли з’єднуються один з одним за допомогою з’єднань через їхні входи та виходи, які називаються **портами**. Вузол може мати:
+
+- не більше одного вхідного порту
+- багато вихідних портів.
+
+Порт може мати мітку (label), що буде показуватися при наведенні курсору. Деякі вузли відображають статусне повідомлення або піктограми поряд з ними. Це використовується для позначення стану вузла в режимі виконання. Якщо вузол має які-небудь зміни, що не були розгорнуті в режимі виконання, це буде відображено синім кружком над ним. Якщо є помилки у конфігурації, то буде відображатися червоний трикутник. Вузли `Inject` і `Debug` є єдиними вузлами, які мають кнопки керування: вприскування (`Inject` ) та відображення повідомлення (`Debug` ).
+
+Діалогове вікно редагування вузла має три окремих розділи: властивості (properties), опис (Description) та зовнішній вигляд (Appearance) .
+
+**Конфігураційні вузли** (**config Node**) - це спеціальний тип вузла, що містить конфігурацію багаторазової доступності, що може бути розподілена між звичайними вузлами потоку. Доступ до них відбувається через бічну панель.
+
+Вузли можуть бути об’єднані разом, щоб утворити **групу** (**Group**). Потім вони можуть бути переміщені або скопійовані як єдиний об’єкт у редакторі.
+
+**Під-потоки** (**subflow**) - це сукупність вузлів, які згортаються в єдиний вузол у робочій області. Вони можуть бути використані для зменшення певної візуальної складності потоку або для об’єднання групи вузлів, що використовується в різних місцях. Після створення, під-потік додається до палітри доступних вузлів. Потім окремі екземпляри під-потоку можна додати до робочої області, як і будь-який інший вузол. Під-потік не може існувати сам собою без жодних вузлів, він повинен містити їх прямо або опосередковано. Як і в звичайних потоках у вузлах підпотоків, може бути не більше одного вводу та багато виходів, за необхідності. Кожен запис у таблиці властивостей можна розширити, щоб налаштувати його відображення під час редагування екземпляру підпотоку.
+
+Потоки можна імпортувати та експортувати з редактора, використовуючи формат JSON, що дозволяє дуже легко обмінюватися потоками з іншими редакторами.
+
+Діалогове вікно Імпорту можна використовувати для імпорту потоку за допомогою таких методів:
+
+- вставлення в потік JSON потоку безпосередньо,
+- завантаження файлу потоку з JSON,
+- вибір локальної бібліотеки потоків,
+- вибір потоків прикладів, передбачених встановленими вузлами.
+
+Палітра містить всі вузли, які встановлені та доступні для використання. Вони організовані в декілька категорій починаючи зверху з inputs, outputs та functions. Якщо є під-потоки, вони з'являються у категорії у верхній частині палітри.
+
+Для встановлення нових вузлів до палітри може використовуватися **менеджер палітри** (Palette Manager). Доступ до нього можна отримати за вкладкою Palette tab в User Settings dialog.
+
+**Бічна панель** надає наступні можливості:
+
+- Information -- переглянути інформацію про вузли та отримати довідкову інформацію про них
+- Debug -- перегляд повідомлень, переданих вузлам Debug
+- Configuration Nodes -- керування конфігураційними вузлами
+- Context data -- перегляд вмісту контекстів
+
+Деякі вузли додають власні панелі бічної панелі, наприклад **node-red-dashboard**
+
+## 2.3. Робота з повідомленнями
+
+Потік Node-RED працює, передаючи повідомлення між вузлами. Повідомлення є простими об'єктами JavaScript, які можуть мати будь-який набір властивостей. Повідомлення, як правило, мають властивість `payload`, це властивість за умовчанням, з якою працюватиме більшість вузлів. Node-RED також додає властивість, що називається `_msgid` - це ідентифікатор для повідомлення, яке може використовуватися для відстеження його проходження потоком
+
+```json
+{
+"_msgid": "12345",
+ "payload": "..."
+}
+```
+
+Значенням властивості може бути будь-який дійсний тип JavaScript, наприклад
+
+- `Boolean` – true, false
+- `Number` – наприклад 0, 123.4
+- `String` – "hello"
+- `Array` - [1,2,3,4]
+- `Object` - { "a": 1, "b": 2}
+- `Null`
+
+Докладніше про типи JavaScript буде в наступних лекціях.
+
+Найпростіший спосіб зрозуміти структуру повідомлення - передати його в вузол `Debug` і переглянути його на бічній панелі Debug. За замовчуванням на вузлі Debug відображатиметься властивість `msg.payload` , але може бути налаштована для відображення будь-яка інша властивість або все повідомлення цілком. При відображенні масиву, або об'єкта, бічна панель забезпечує структурований вигляд, який може використовуватися для вивчення повідомлення.
+
+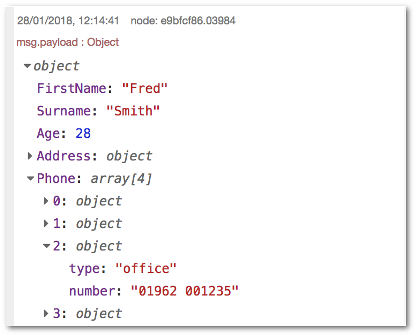
+
+рис.2.2. Перегляд структури повідомлення на бічній панелі Debug
+
+- в самому верху він показує ім'я властивості, яке було передано. Тут за замовчуванням використано `msg.payload`
+- поруч із назвою є назва типу властивості - Object, String, Array ін..
+- потім він показує вміст властивості. Для масивів і об'єктів властивість розкладається на рядки. Клацаючи по ньому, властивість розгорнеться, щоб показати більш детальну інформацію.
+
+## 2.4. Огляд основних вузлів
+
+До вузлів, що входять до стандартної комплектації Node-RED v.1.1 відносяться:
+
+- Загальні (common) -- найбільш загальні вузли для роботи з потоками.
+- Функціональні (function) -- функції перетворення повідомлень та керування потоком
+- Послідовності (sequence) -- розбивка на послідовності та збирання послідовностей повідомлень
+- Сховища (storage) -- робота з читанням/записом файлів
+- Мережні (network) -- робота з WEB та IoT протколами
+- Парсери (parser) -- функції перетворенння форматів
+
+Мережні вузли, парсери та storage будуть розглянуті в інших лекціях.
+
+Довідник по всім основним вузлам доступний [за посиланням](https://pupenasan.github.io/NodeREDGuidUKR/#стандартна-комплектація).
+
+
+
+рис.2.3. Основні вузли Node-RED
+
+## 2.5. Загальні вузли (Common)
+
+Таблиця 2.1. Перелік загальних вузлів
+
+| Вузол | Призначення |
+| :----------------------------------------------------------: | ------------------------------------------------------------ |
+|  | [Inject](https://pupenasan.github.io/NodeREDGuidUKR/base/1_4_1.html#inject-ініціювання-повідомлення) для ініціювання потоку (відправки повідомлення) користувачем, автоматично при запуску, періодично або за розкладом. |
+|  | [Debug](https://pupenasan.github.io/NodeREDGuidUKR/base/1_4_1.html#debug-вивести-на-відлагодження) використовується для відображення повідомлень на бічній панелі Debug у редакторі. |
+|  | [Complete](https://pupenasan.github.io/NodeREDGuidUKR/base/1_4_1.html#complete) запускає потік, коли інший вузол завершує оброблення повідомлення. |
+|  | [Catch](https://pupenasan.github.io/NodeREDGuidUKR/base/1_4_1.html#catch-обробник-помилок) ловить помилки виконання інших вузлів у тому самому потоці (вкладці) і формує повідомлення з інформацією про них. |
+|  | [Status](https://pupenasan.github.io/NodeREDGuidUKR/base/1_4_1.html#status-стан-вузлу) показує стан (status message) вказаних або усіх вузлів в потоці. |
+|  | [Link in](https://pupenasan.github.io/NodeREDGuidUKR/base/1_4_1.html#link-in-та-link-out-посилання) вхідне з’єднання з іншого потоку |
+|  | [Link out](https://pupenasan.github.io/NodeREDGuidUKR/base/1_4_1.html#link-in-та-link-out-посилання) вихідне з’єднання до іншого потоку |
+|  | [Comment](https://pupenasan.github.io/NodeREDGuidUKR/base/1_4_1.html#comment) для добавлення коментарів в потік. |
+|  | [Unknown](https://pupenasan.github.io/NodeREDGuidUKR/base/1_4_1.html#unknown-невідомий) вузол невідомого типу для встановленого Node-RED |
+
+Вузол **[Inject](https://pupenasan.github.io/NodeREDGuidUKR/base/1_4_1.html#inject-ініціювання-повідомлення)** потрібен для ініціювання потоку (відправки повідомлення) користувачем, автоматично при запуску, періодично або за розкладом. У налаштуваннях вузла можна вказати тему повідомлення (`Topic`) та значення `Payload` . У новіших версіях можливості вузла `Inject` значно розширилися. Тепер в ньому можна задавати будь яку властивість повідомлення а також вказувати налаштування запуску в певні дні тижня по календарю. Для payload можна встановити різні типи: відмітку часу (Timestamp), константу, значення [контекстів](https://pupenasan.github.io/NodeREDGuidUKR/base/1_7.html) потоку (`flow context`) або глобального контексту (`global context`), `$env variable` – змінну середовища Node.js, `J:expression` – [JSONata](https://pupenasan.github.io/NodeREDGuidUKR/jsonata/) перетворення.
+
+Вузол **[Debug](https://pupenasan.github.io/NodeREDGuidUKR/base/1_4_1.html#debug-вивести-на-відлагодження)** використовуватися для відображення повідомлень на бічній панелі Debug у редакторі, середовища виконання або зображення статусу вузла. Бічна панель забезпечує структурований перегляд повідомлень, що надсилаються, що полегшує вивчення цього повідомлення. Поряд з кожним повідомленням бічна панель налагодження включає в себе інформацію про час надходження повідомлення та місце з якого вузлу воно надіслане. Натискання на ідентифікатор вихідного вузла покаже цей вузол у робочій області. Кнопку на вузлі можна використовувати для ввімкнення або вимкнення його виходів.
+
+Потоки різних вкладок можна з'єднувати між собою інформаційними дротами. Це робиться за допомогою вузлів **[Link in](https://pupenasan.github.io/NodeREDGuidUKR/base/1_4_1.html#link-in-та-link-out-посилання)** (вхідне з’єднання з іншого потоку) та **[Link out](https://pupenasan.github.io/NodeREDGuidUKR/base/1_4_1.html#link-in-та-link-out-посилання)** (вихідне з’єднання до іншого потоку). Таким чином потік на одній вкладці передає повідомлення до потоку іншої вкладки.
+
+Вузол [Catch](https://pupenasan.github.io/NodeREDGuidUKR/base/1_4_1.html#catch-обробник-помилок) буде розглянуто в іншій темі.
+
+## 2.6. Ознайомлення з JSON
+
+**JSON** ([JavaScript Object Notation](http://json.org/)) - це стандартний спосіб подання об'єкта JavaScript у вигляді рядку (string). Він часто використовується у веб-API для відправки та повернення даних.
+
+Усі об'єкти беруться у фігурні дужки. Це приклад порожнього об'єкту.
+
+```json
+{}
+```
+
+Властивості об'єкту типу ключ-значення записуються наступним чином:
+
+```json
+{"key1" : 23 , "key2" : "24", "key5" : {"key5_1": 37, "key5_2": [123, 124]} }
+```
+
+Ключі обовязково беруться в подвійні лапки.
+
+Масиви записуються з використанням квадратних дужок, в яких перераховуються елементи масиву:
+
+```json
+[10, "20", 30]
+```
+
+У якості елементів можна використовувати різні типи даних: Number, String (“”), Object, Array, true/false, null. Таким чином масиви та об'єкти можуть включати у свою чергу масиви та об'єкти.
+
+Структура msg та змінні контексту в Node-RED є об'єктами. Усі їх поля можна представити у вигляді JSON. Якщо властивість повідомлення містить рядок JSON, то перед тим, як отримувати доступ до його властивостей, його слід перетворити до еквівалентного об'єкта JavaScript. Щоб визначити, чи властивість вміщує String чи Object, може бути використаний вузол Debug. Для здійснення цього перетворення Node-RED забезпечує вузол JSON з розділу "парсери".
+
+## 2.7. Поняття контекстів
+
+Node-RED забезпечує спосіб зберігання інформації, яка може бути розподілена між різними вузлами, без використання повідомлень, що проходять через потоки. Це називається **контекстом** (**context**). Контекст можна сприймати як внутрішні змінні, для зберігання проміжних значень, які мають різні області видимості. Існує три рівні контексту:
+
+- **Node** - видимий тільки для вузла, який встановлює значення
+- **Flow** - видимий для всіх вузлів на одному потоці (або вкладки у редакторі)
+- **Global** - видимий для всіх вузлів
+
+Вибір області видимості для будь-якого конкретного значення залежить від того, як воно використовується. Наприклад кожен екземпляр вузлу типу Function, може зберігати всередині значення змінних між викликами. Потоки можуть зберігати значення змінних для доступу з усіх вузлів цього потоку. Глобальний контекст зручний у тому випадку, коли треба розподіляти змінні для всіх вузлів проекту.
+
+За замовчуванням контекст зберігається лише в пам\'яті. Це означає, що його вміст очищується, коли Node-RED перезавантажується. З випуском версії 0.19 можна налаштувати Node-RED для збереження контекстних даних, щоб він став доступним і після перезавантаження.
+
+Найпростішим способом встановити значення контексту є використання вузла Change. Наприклад, наступне правило вузлу Change зберігатиме значення `msg.payload` в контексті потоку (flow) під ключем (назвою) `myData`
+
+
+
+рис.2.4. Використання Change для збереження в контекст.
+
+Різні вузли можуть безпосередньо отримати доступ до контексту. Наприклад, вузол Inject може бути налаштований для введення значення в контекст, а вузол Switch може маршрутизувати повідомлення на основі значення, збереженого в контексті. Використання контексту у вузлі Function буде розглянуто в одній з наступних лекцій.
+
+Контекст можна остаточно видалити, використовуючи вузол `Change` та правило `delete`.
+
+
+
+рис.2.5. Приклад видалення властивості потоку з використанням вузла Change
+
+Для перегляду та видалення контексту вручну можна скористатися бічною панеллю редактора. Детальніше читайте [за посиланням](https://pupenasan.github.io/NodeREDGuidUKR/base/1_2.html#%D0%B1%D1%96%D1%87%D0%BD%D0%B0-%D0%BF%D0%B0%D0%BD%D0%B5%D0%BB%D1%8C-%D0%BA%D0%BE%D0%BD%D1%82%D0%B5%D0%BA%D1%81%D1%82%D0%BD%D1%96-%D0%B4%D0%B0%D0%BD%D1%96-context-data). Детально про роботу з контекстом можна прочитати з [довідника](https://pupenasan.github.io/NodeREDGuidUKR/base/1_7.html).
+
+## 2.8. Функціональні вузли (function)
+
+Вузли цієї групи призначені для перетворення повідомлень та керування потоком.
+
+Таблиця 2.2. Функціональні вузли
+
+| Вузол | Призначення |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+|  | [Function](https://pupenasan.github.io/NodeREDGuidUKR/base/1_5.html) дозволяє виконувати код JavaScript для обробки повідомлень, що передаються через нього. |
+|  | [Switch](https://pupenasan.github.io/NodeREDGuidUKR/base/1_4_1.html#switch-перемикач-повідомлення) дозволяє передавати повідомлення до різних гілок потоку, оцінюючи набір правил для кожного повідомлення |
+|  | [Change](https://pupenasan.github.io/NodeREDGuidUKR/base/1_4_1.html#change-зміна-повідомлення-в-потоці) для зміни властивостей повідомлення та контекстів (потоку і глобального) без необхідності вдаватися до вузла Function |
+|  | [Range](https://pupenasan.github.io/NodeREDGuidUKR/base/1_4_1.html#range-масштабування) масштабує числові значення відповідно до вказаних вхідних та вихідних діапазонів |
+|  | [Template](https://pupenasan.github.io/NodeREDGuidUKR/base/1_4_1.html#template-шаблон) використовується для створення тексту з властивостей повідомлення з використанням означеного шаблону Mustache |
+|  | [Delay](https://pupenasan.github.io/NodeREDGuidUKR/base/1_4_1.html#delay-затримка) робить затримку для кожного повідомлення, що проходить через вузол, або обмежує швидкість, з якою вони можуть пройти. |
+|  | [Trigger](https://pupenasan.github.io/NodeREDGuidUKR/base/1_4_1.html#trigger) відправляє повідомлення з вказаним інтервалом |
+|  | [Exec](https://pupenasan.github.io/NodeREDGuidUKR/base/1_4_1.html#exec-запуск-команди) запускає системну команду. |
+|  | [Rbe](https://pupenasan.github.io/NodeREDGuidUKR/base/1_4_1.html#rbe-гістерезис-нечутливість) пропускає повідомлення лише у випадку зміни корисного навантаження |
+
+Вузол **[Change](https://pupenasan.github.io/NodeREDGuidUKR/base/1_4_1.html#change-зміна-повідомлення-в-потоці)** використовується для зміни властивостей повідомлення та контекстів (потоку і глобального) без необхідності вдаватися до вузла Function. Кожен вузол може бути налаштований з декількома операціями, які застосовуються у вказаному порядку. Доступні операції:
+
+- **Set** - встановити властивість. Значення може бути з різними типами або може бути взяте з існуючого повідомлення або властивості контексту.
+- **Change** - пошук і заміна частин властивості повідомлення.
+- **Move** - перемістити або перейменувати властивість.
+- **Delete** – видалити властивість.
+
+Для кожного правила вказується що саме треба змінити: властивість змінної `msg. ` , контекст потоку (`flow.`) або глобальний контекст (`global.`). Для `set` вказується яке саме значення необхідно присвоїти властивості. Це може бути константа, відмітка часу, значення властивості змінної `msg`, контексту чи змінної середовища, значення також може бути результатом виразу JSONata (буде розглянуто в одній із наступних лекцій).
+
+Вузол **[Switch](https://pupenasan.github.io/NodeREDGuidUKR/base/1_4_1.html#switch-перемикач-повідомлення)** дозволяє передавати повідомлення до різних гілок потоку, оцінюючи набір правил для кожного повідомлення і направивши його на конкретний порт. Цей вузол налаштовано за допомогою властивості для перевірки - це може бути або властивість повідомлення (message property), або властивість контексту (context property). Також в якості першого аргументу для порівняння може використовуватися вираз JSONata або змінна середовища. Існує чотири типи правил:
+
+- **Value** - правила оцінюються для зконфігурованої властивості
+- **Sequence** - правила можуть бути використані для послідовності повідомлень, наприклад, ті, які створені вузлом `Split`
+- може бути надана JSONata **Expression**, який буде використаний для перевірки всього повідомлення і буде відповідати, якщо вираз повертає значення true .
+- **Otherwise** - правило може бути використане для відповідності, якщо жодне з попередніх правил не співпало.
+
+Вузол **[Delay](https://pupenasan.github.io/NodeREDGuidUKR/base/1_4_1.html#delay-затримка)** робить затримку для кожного повідомлення, що проходить через вузол, або обмежує швидкість, з якою вони можуть пройти. Якщо налаштовано на затримку повідомлень (delay messages), інтервал затримки може бути фіксованим значенням, випадковим значенням у межах діапазону або динамічно заданим для кожного повідомлення. Кожне повідомлення затримується незалежно від будь-якого іншого повідомлення, але залежно від часу його надходження.
+
+Вузол **[Range](https://pupenasan.github.io/NodeREDGuidUKR/base/1_4_1.html#range-масштабування)** масштабує числові значення відповідно до вказаних вхідних та вихідних діапазонів. Масштабування відбувається відповідно до налаштованого вхідного діапазону (input range) та цільового діапазону (target range). Вхідне та вихідне значення мусять бути числового формату, інакше вузол намагатиметься перетворити їх в такий.
+
+Вузли [Function](https://pupenasan.github.io/NodeREDGuidUKR/base/1_5.html) та [Template](https://pupenasan.github.io/NodeREDGuidUKR/base/1_4_1.html#template-шаблон) будуть розглянуті в одній з наступних лекцій. З іншими вузлами ознайомтеся самостійно.
+
+## 2.9. Ознайомлення з JSONata
+
+[JSONata](http://docs.jsonata.org/overview) - це мова запитів і перетворень даних JSON. Іншими словами це мова яка вказує як з вхідного JSON зробити вихідний JSON. JSONata використовується в багатьох вузлах Node-RED. У якості вхідних даних для JSONata є змінна повідомлення `msg`, яка розглядається як вхідний документ JSON. Тому до властивостей об'єкта `msg` доступаються безпосередньо через імена, наприклад `msg.payload` доступний просто як `payload`.
+
+JSONata проводить послідовні розрахунки відповідно до вказаного виразу. Після кожного розрахунку результат знаходиться в певній контекстній змінній (називатимемо розрахунковий контекст), який можна використовувати в наступних розрахунках. Звернутися до контексту можна через знак `$`. Перед початком розрахунків в контексті знаходиться вхідний документ, тобто `msg`, тому звертатись до нього можна через `$`. Тобто, якщо потрібно отримати доступ до всього об'єкту `msg` на верхньому рівні виразу, можна використовувати змінну `$` . Наприклад `$._msgid` поверне унікальний ідентифікатор повідомлення. Якщо звертання йде всередині розрахунку, то розрахунковий контекст буде містити проміжні результати, тому при необхідності оцінювання вхідного документу до нього звертаються через подвійний "долар" `$$`
+
+З символу `$` починаються також усі функції JSONata та змінні користувача. Останні використовуються тоді, коли є необхідність писати не просто вирази а підпрограми на мові JSONata.
+
+У розрахунках можна також використовувати літеральні константи у форматі JavaScript, значення глобального контексту та контексту потоку, значення змінної середовища та комбінацію всього перерахованого.
+
+Аналогічно як Java Script через крапку можна доступатися до полів властивостей будь якого рівня вкладеності, а через `[]` до індексу масиву. Однак в JSONata квадратні дужки використовуються також для позначення умови пошуку (предикату). Якщо результат треба перетворити в інший вигляд, використовуються конструктори масивів (`[]`) та об'єктів (`{}`). Так наступне повідомлення сформує обєкт з двома полями, в одне запише `payload` вхідного повідомлення, а в інше - `topic`.
+
+Доступ до контекстів потоку та глобального контексту можна робити через відповідні функції. Доступ до глобального контексту відбувається через вбудовану у Node-RED JSONata функцію `$globalContext()` в якій вказується назва змінної та за необхідності сховище (другим аргументом). Аналогічно попередній, функція `$flowContext()` доступається до контексту потоку.
+
+Для рядків у JSONata можна використовувати оператор конкатенації `&`. Числові літетерали та вирази можуть бути використані в розрахунках результатів з використанням звичайних математичних операторів. Можна використовувати оператори порівняння двох значень, які повертають логічні значення `true` або `false` (типу `>`, `<` і т.д).
+
+Детальніше про JSONata в [довіднику](https://pupenasan.github.io/NodeREDGuidUKR/jsonata/).
+
+## 2.10. Регулярні вирази
+
+**Регулярні вирази** це шаблони, що використовуються для пошуку збігу, співпадіння в тексті чи рядках. Ці шаблони використовуються для пошуку збігу у тексті. Тобто текст у регулярному виразі вказує на правила пошуку.
+
+Якщо в регулярному виразі просто вказати текст, наприклад `ABC`, то буде пошук співпадіння саме цієї комбінації, причому з урахуванням регістру. Для завдання спеціальних правил, необхідно використовувати спеціальні (службові) символи, типу:
+
+```
+. ^ $ * + ? { } [ ] | ( )
+```
+
+Використання регулярних виразів відрізняться в різних реалізаціях. Тут розглянуті тільки пояснення щодо принципів їх використання, застосовно до вузлів, наприклад `Change`. Нижче наведений приклад для пошуку та заміни усіх комбінацій `ABC`. Кожна комбінація змінюється на символ заміни.
+
+
+
+рис.2.6. Приклад використання регулярного виразу.
+
+Квадратні дужки `[]` використовуються для вказівки будь якого символу з наведених. Якщо в наведеному вище прикладі регулярний вираз замінити на `[ABC]` то в результаті буде `--- abc 123 --- abc 123 `.
+
+Якщо в послідовності треба шукати спеціальні символи, то їх необхідно екранувати `\` , щоб вони не сприймалися як службові. Наприклад, якщо в тексті `[ABC][abc]` треба замінити усі квадратні дужки пробілами, то пошуковий текст треба написати так `[\[\]]`, де перша і остання квадратна дужка вказує на те, що шукаються будь які з наведених символів, а зворотня коса вказує на те, що символи `[` та`]` не є службовими.
+
+Зірочка `*` показує що символ, після якого він іде може зустрічатися один або нуль разів. Наприклад у тексті `baobaboooo` пошуковий запит `bo*` з зміною на `-` поверне результат `-ao-a-`, бо змінюються комбінація `bo` з будь якою кількістю `o`, навіть з 0-ю.
+
+Плюс `+`, на відміну від зірочки шукає результати як мінімум з одним символом. Наприклад у тексті `baobaboooo` пошуковий запит `bo+` з зміною на `-` поверне результат `baoba-`, бо змінюються комбінація `bo` з будь якою кількістю `o` більшою або рівною 1.
+
+Використання регулярних виразів у вузлах дещо обмежене. Так, наприклад, наразі не підтримуються у вузлах типу `change` прапорці. Детальніше про регулярні вирази можна прочитати за [посиланням](https://developer.mozilla.org/uk/docs/Web/JavaScript/Guide/Regular_Expressions)
+
+## 2.11. Змінні середовища
+
+**Змінні середовища** (environment variables) -- це конфігураційні змінні, які задаються у файлі `settings.js` безпосередньо, або через "Project Settings" (планується у майбутніх версіях Node-RED) чи налаштування підпотоку. Ці змінні можна використовувати (зчитувати) в середовищі виконання для різноманітних функцій.
+
+Змінні середовища можуть бути доступні через добавлення в розділ `functionGlobalContext:` файлу `settings.js` наступної властивості (перераховуються через кому):
+
+```
+env: process.env
+```
+
+Після введення ви можете отримати доступ до них у будь-якому вузлі, який має текстове поле (a/z), або у функціональному вузлі. Щоб оголосити власну змінну навколишнього середовища (наприклад `ENV_VAR`), потрібно її назву внести у файл `settings.js`. Додайте такі рядки безпосередньо перед рядком `module.exports = {`:
+
+```
+process.env.ENV_VAR = ‘just another bar’;
+```
+
+Після внесення змін у файл `settings.js` зупиніть/перезапустіть node-red, щоб зробити їх доступними для використання.
+
+
+
+рис.2.7. Добавлення змінних середовища.
+
+Будь-яку властивість вузла можна встановити змінною середовища, встановивши його значення на рядок форми `${ENV_VAR}`. Коли Node-RED виконує завантаження потоків, він замінить значення цієї змінної середовища перед передачею її у вузол.
+
+До змінних середовища можна також отримати доступ у виразах JSONata, таких як у вузлі Change, використовуючи функцію `$env`:
+
+```
+$env('ENV_VAR')
+```
+
+У вузлі Function доступ до змінних середовища можна отримати за допомогою функції `env.get`:
+
+```
+let foo = env.get("FOO");
+```
+
+Починаючи з 0,20, підпотоки можна налаштувати з властивостями екземпляра. Вони відображаються як змінні середовища в підпотоці і можуть бути налаштовані для окремих екземплярів підпотоку.
+
+## 2.1.2. Послідовності (sequence)
+
+**Послідовність повідомлень** - це впорядкована серія повідомлень, які певним чином пов'язані між собою. Деякі вузли призначені для обробки таких послідовностей. Наприклад, вузол `Split` може перетворювати одне повідомлення, яке є масивом `payload` , у послідовність повідомлень, де кожне повідомлення містить payload що відповідає одному з елементів масиву. До групи `sequnece` входять вузли, які можуть працювати з послідовностями повідомлень.
+
+Таблиця 2.3. Вузли для роботи з послідовностями повідомлень
+
+| Вузол | Призначення |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+|  | [Split](https://pupenasan.github.io/NodeREDGuidUKR/base/1_6.html#split) розділює одне повідомлення в послідовність повідомлень. |
+|  | [Join](https://pupenasan.github.io/NodeREDGuidUKR/base/1_6.html#join) об’єднує послідовність повідомлень у єдине повідомлення |
+|  | [Sort](https://pupenasan.github.io/NodeREDGuidUKR/base/1_6.html#sort) сортує масив або послідовність повідомлень на основі значення властивості або результату виразу JSONata |
+|  | [Batch](https://pupenasan.github.io/NodeREDGuidUKR/base/1_6.html#batch) створює нові послідовності згрупованих повідомлень з отриманих. |
+
+Кожне повідомлення в послідовності має властивість `msg.parts`. Це об'єкт, який містить інформацію про те, як повідомлення входить у послідовність. Він має такі властивості:
+
+- `id` - ідентифікатор послідовності (групи повідомлень)
+- `index` - позиція в середині послідовності (групи)
+- `count` - якщо відома загальна кількість повідомлень в групі. Див `streaming mode` нижче
+- `type` - тип повідомлення - string/array/object/buffer
+- `ch` - для string або buffer, дані (наприклад рядок), що використовуються для розділення повідомлення як рядка або масиву байтів
+- `key` - для розділення об'єкту, ключ або властивість, з якого було створено це повідомлення. Вузол може бути налаштований також для копіювання цього значення в інші властивості повідомлення, такі як `msg.topic`.
+- `len` -- довжина кожного повідомлення при розділенні з використанням фіксованого значення довжини
+
+Вузол **[Split](https://pupenasan.github.io/NodeREDGuidUKR/base/1_6.html#split)** розділює одне повідомлення в послідовність повідомлень. Конкретна поведінка вузла залежить від типу `msg.payload`: `String/Buffer` , `Array` або `Object`. Вихідне повідомлення містить властивості, які вказують скільки повідомлень було створено, індекс повідомлення, тип, який символ використовувався для розділення та параметри розділення для об'єкта. Вузол `Split` дозволяє легко створити потік, який виконує загальні дії по всій послідовності повідомлень перед тим, як використати вузол **join** , рекомбінуючи послідовність знову в одне повідомлення. Він використовує властивість `msg.parts` для відстеження окремих частин послідовності.
+
+Вузол **[Join](https://pupenasan.github.io/NodeREDGuidUKR/base/1_6.html#join)** об’єднує послідовність повідомлень у єдине повідомлення. Вузол забезпечує три режими роботи: автоматичний (по властивостям, що сформував Split), ручний - кофігурується, за правилами JSONata.
+
+**[Sort](https://pupenasan.github.io/NodeREDGuidUKR/base/1_6.html#sort)** сортує масив або послідовність повідомлень на основі значення властивості або результату вираження JSONata. Якщо вузол налаштований для сортування властивості повідомлення (`Sort = msg`), вузол сортує дані масиву, на які вказує задана властивість повідомлення. Якщо налаштовано для сортування послідовності повідомлень (`Sort = messge seqence`), вузол буде змінювати їх порядок. Під час сортування послідовності повідомлень вузол сортування покладається на отримані повідомлення, щоб встановити `msg.parts`. м імен в невідсортованому порядку.
+
+## Питання до самоперевірки
+
+1. Яке програмне середовище використовується для виконання Node-RED?
+2. На яких платформах може виконуватися середовище Node-RED?
+3. Коли виконуються (обробляються) вузли Node-RED?
+4. Скільки вхідних та вихідних портів може мати вузол?
+5. Що таке конфігураційний вузол?
+6. Розкажіть про призначення та функції вузла `Inject`.
+7. Розкажіть про призначення та функції вузла `Debug` .
+8. Яке призначення бічної панелі Debug?
+9. Що таке JSON?
+10. Що таке контексти? Які вони бувають і для чого використовуються?
+11. Розкажіть про призначення та функції вузла `Change`.
+12. Розкажіть про призначення та функції вузла `Switch`
+13. Розкажіть про призначення та функції вузла `Range`
+14. Розкажіть про призначення вузла `Fucntion`
+15. Що таке JSONata? Яка функціональність надається в JSONata?
+16. Розкажіть про призначення та функції вузла `Split`
+17. Розкажіть про призначення та функції вузла `Join`. Які вимоги до повідомлень ставляться в автоматичному режимі роботи?
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
+
diff --git "a/\320\233\320\265\320\272\321\206/3_tcpudp.md" "b/\320\233\320\265\320\272\321\206/3_tcpudp.md"
new file mode 100644
index 0000000..0e1906c
--- /dev/null
+++ "b/\320\233\320\265\320\272\321\206/3_tcpudp.md"
@@ -0,0 +1,228 @@
+**Програмна інженерія в системах управління. Лекції.** Автор і лектор: Олександр Пупена
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
+
+# 3. Робота з TCP/UDP
+
+## 3.1. Загальний принцип функціонування обміну між застосунками в мережах
+
+Прикладні програми (застосунки) спілкуються між собою з використанням мереж. Для того щоб потрібна інформація дісталася від одного застосунку до іншого необхідно вирішити ряд завдань. Не достатньо просто передати побітово дані через провідники чи через ефір (бездротова передача), треба забезпечити їх доставку конкретному пристрою (вузлу), та конкретному застосунку на цьому пристрої. Якщо ж пристрої знаходяться в різних мережах, які об'єднані між собою маршрутизаторами, необхідно також забезпечити маршрутизацію пакетів. Для спрощення цих задач їх вирішують різні протоколи які взаємодіють між собою. Розглянемо це на прикладі функціонування стеку протоколів TCP, IP та Ethernet, взаємодія яких показана на рис.3.1.
+
+
+
+рис.3.1.Функціонування стеку протоколів.
+
+Коли один застосунок відправляє іншому якісь дані він послуговується протоколом транспортного рівня, звертаючись до відповідного драйверу з запитом на відправку даних. У даному випадку показаний протокол TCP, який функціонує умовно на 4-му рівні. Цей протокол не забезпечує доставку даних в мережі, його задача доставити дані від одного застосунку до іншого, у тому числі, якщо вони знаходяться на одному і тому ж пристрою. Для того щоб це зробити, до корисних даних, які треба передати (Upper Layer SDU (Data)) добавляється службова інформація, зокрема адреси застосунку-отримувача та відправника (tcp-порти). Ця інформація передається перед корисними даними разом з ними і називається **пакетом**. Кажуть що пакет TCP включає в себе (**інкапсулює**) дані протоколу верхнього рівня як **корисне навантаження** і має **заголовок** (**header**), в якому передається додаткова службова інформація. Пакет аналізується драйвером пристрою отримувача і за відповідним портом отримувача у заголовку шукає той застосунок, кому призначений даний пакет і віддає йому корисні дані. За необхідності корисне навантаження передається кількома частинами, які називаються сегментами. Тоді драйвер пристрою-отримувача повинен зібрати ці дані разом.
+
+Для того щоб tcp-пакет досяг потрібного пристрою, необхідно вирішити ще кілька задач. По-перше, дані можуть передаватися між пристроями в різних мережах, які об'єднані між собою. Наприклад пристрої можуть спілкуватися через мережу Інтернет. Для цього драйвер TCP, просить передати драйвер IP (3-й рівень) його tcp-пакет конкретному вузлу в об'єднаній мережі. Для драйвера IP цей tcp-пакет інкапсулюється як корисне навантаження, а для його передачі в об'єднаній мережі використовується IP-адреси відправника та отримувача, яка поміщається в заголовок. Про функціонування пакету IP наведено нижче, тут зауважимо, що для передачі IP-пакету по мережі, драйвер IP послуговується послугами драйверу мережного інтерфейсу, наприклад Ethernet чи WiFi.
+
+Задача Ethernet (2-й рівень), забезпечити доставку даних від одного пристрою до іншого (інших), які знаходяться в тій самій мережі. Для цього він інкапсулює IP-пакет в **кадр** (**frame**), який містить заголовок з інформацією про апаратну адресу картки (**MAC-адресу**) відправника та отримувача. Крім того в кінцевику (footer), кадр містить контрольну суму, за допомогою якої контролюється достовірність отримання вмісту кадру.
+
+Сформований кадр відправляється побітово по мережі (1-й рівень). Всі пристрої прослуховують мережу, і отримавши кадр призначений їм, починають зворотній процес перетворення. За допомогою контрольної суми перевіряють чи кадр прийшов без спотворень. Якщо все гаразд, вилучають корисне навантаження і передають його драйверу IP. За адресою отримувача визначають, чи пакет дійсно призначений їм, якщо ні - очевидно пристрій повинен його відправити на інший порт (див. нижче). Якщо отримувач дійсно цей пристрій, корисне навантаження переправляється драйверу TCP. За адресою tcp-порта той визначає якому застосунку призначене дане корисне навантаження, за необхідністю робить складання сегментів разом і віддає корисне навантаження застосунку.
+
+У наведеному вище прикладу показаний тільки прямий шлях передач даних між застосунками. Враховуючи, що на кожному етапі перетворення (рівні мережі) в заголовках передається також адреса відправника, застосунок може переслати повідомлення-відповідь до адресату, який ініціював передачу.
+
+Розглянемо принципи маршрутизації, яка вирішується протоколом IP та засобами рівня 3. Сьогодні є дві версії протоколів IP - `IP v4` (4-байтна адресація) та `IP v6`(16-байтна адресація). У будь якому випадку, адресація передбачає виділення адреси мережі та вузла. У `IP v4` адреса мережі визначається за маскою, яка задається послідовністю бітів, що виділяє адресу мережі з вказаної адреси. Наприклад в адресі `192.168.1.1` з маскою `255.255.255.0`, перші три байти вказують на адресу мережі. Тобто при такому завданні адреса мережі буде `192.168.1.0` а пристрій буде мати адресу `1`.
+
+
+
+ рис.3.2. Визначення адреси мережі та вузла (пристрою) за маскою
+
+Для маршрутизації пакетів в об'єднаній мережі використовуються **маршутизатори** (**router**). Вони знаходяться в місцях підключень кількох мереж, і забезпечують передачу пакетів з однієї мережі в іншу. Для цього маршрутизатори містять маршрутні таблиці, які містять записи з адресами та портами, куди треба відправляти пакети, якщо їх адреса задовільняє правило маршрутизації. На рис.3.3 показаний приклад маршрутизації. Розглянемо його детальніше.
+
+
+
+ рис.3.3. Функціонування маршрутизаторів
+
+На пристроях в налаштуваннях драйвера IP вказуються також маршрутні таблиці. Як мінімум, там повинен бути вказана (або видана автоматично) IP адреса маршрутизатора за замовченням (може називатися "шлюз за замовченням"). Коли драйвер IP повинен відправити пакет за певним призначенням, він спочатку визначає (наприклад за маскою), чи знаходиться цей пакет в цій же мережі. Далі:
+
+- Якщо так, він відправляє цей пакет за відповідно до цієї IP-адреси МАС-адресою
+- Якщо ні, він відправляє цей пакет за відповідно до IP-адреси маршрутизатора МАС-адресою
+
+Для того щоб дізнатися відповідну МАС-адресу до IP-адреси використовуються ARP-таблиці. Ви можете переглянути такі таблиці на вашому пристрої через командний рядок, викликавши команду:
+
+```bash
+arp -a
+```
+
+ Ці таблиці як правило формуються автоматично за допомогою протоколу ARP. Це працює наступним чином:
+
+- драйвер IP шукає в ARP-таблиці відповідну до адреси отримувача MAC-адресу
+ - якщо запис існує, драйвер IP просить драйвер Ethernet відправити пакет за вказаною MAC-адресою
+ - якщо запису немає:
+ - драйвер IP просить драйвер Ethernet відправити ARP-пакет з широкомовним (усім в мережі) запитом-питанням (у кого такий IP)
+ - пристрій з вказаним IP відповідає
+ - адреса заноситься в таблицю ARP
+ - драйвер IP просить драйвер Ethernet відправити пакет за вказаною MAC-адресою
+
+Слід також зазначити, що є особливі адреси, для яких діють особливі правила адресації. Наприклад `127.0.0.1` - це адреса того самого пристрою, так званий `loopback`.
+
+Вище описаний дуже короткий принцип функціонування стеку з кількох протоколів.
+
+## 3.2. Протоколи TCP та UDP
+
+Як зазначалося вище, протоколи транспортного рівня слугують для забезпечення передачі даних між застосунками. На сьогодні найбільш популярними є протоколи **TCP** (Transmission Control Protocol) та **UDP** - (User Datagram Protocol).
+
+Протокол UDP дуже простий і призначений для доставки пакету до застосунку за вказаним портом udp (рис.4). Він не передбачає контролю доставки, контроль цілісності повідомлення та фрагментацію. За рахунок цього він швидкий, бо не потребує додаткових полів заголовку (які треба обробляти) а найголовніше - додаткового обміну службовою інформацією. Крім того він може використовуватися для широкомовлення (broacast, тобто всім) та мультиадерсної доставки (multicast). Його використовують у тому випадку коли дані повинні надійти швидко, навіть за умови втрати пакетів.
+
+
+
+рис.3.4. Порівняння протоколів TCP та UDP
+
+На противагу до UDP протокол TCP призначений для гарантованої доставки даних. Для цього перед обміном даних для застосунків встановлюється сеанс зв'язку, в межах якого буде проводитися обмін. Для встановлення сеансу проводиться домовленість, що передбачає передачу службових повідомлень (потрійне рукостискання), після чого йде обмін пакетами з контролем правильності доставки та підтвердженням отримання. Ці службові пакети роблять передачу надійною, але набагато повільнішою ніж UDP.
+
+Обидва протоколи використовують для доставки даних до конкретного застосунку адресацію з використанням номерів портів. Для TCP ініціатор зв'язку називається клієнтом (Client) а застосунок, який очікує з'єднання - сервером (Server). Таким чином, щоб сервер отримав повідомлення від клієнта, клієнту треба вказати в заголовку відправленого пакету, а саме в порті отримувача, той порт, який прослуховує сервер. У свою чергу, сервер зможе відповісти клієнту, використавши з заголовку отриманого пакету адресу порта відправника. Тобто клієнт заздалегідь повинен знати порт, який прослуховує сервер. А серверу інформація про партнера стає відомою після отриманого повідомлення.
+
+Слід зазначити, що самі по собі протоколи TCP та UDP кінцевими застосунками рідко використовуються, так як не містять інформацію, що тлумачить що значить дані, що передаються. Цими протоколами послуговуються різноманітні протоколи прикладного рівня. Зокрема, дуже відомий протокол HTTP, яким користуються браузери для доступу до WEB-серверів, використовує для доставки запитів та відповідей протокол TCP. Враховуючи популярність протоколів прикладного рівня, для них визначені типові адреси портів, які також називаються **добре відомі** порти (**Well-Known**). Наприклад, за HTTP-сервером закріплений порт `80`. Якщо в браузері не вказати адресу порта (через двокрапку), буде вважатися використання порта 80. Тобто http://example.com та http://example.com:80 будуть доступатися до того ж порту.
+
+
+
+рис.3.5. Номери портів
+
+Клієнтським застосункам при підключенні, як правило виділяються вільні порти, тобто ті, які на даний момент на даному пристрої не використовуються драйвером TCP. Нижче наведений розподіл портів:
+
+- 0-1023 – добре відомі, системні порти (Well-Known, System)
+- 1024-49151 – користувацькі (User)
+- 49152-65535 – динамічні або приватні порти (Dynamic, Private)
+
+При побудові власних застосунків з використанням TCP та UDP, як правило користуються бібліотеками, які спрощують обмін з використанням так званих **сокетів** (**Socket**). Сокет - це такий програмний об'єкт, який слугує початковою або кінцевою точкою з'єднання, через який можна передати або отримати дані. Перед обміном даними сокет налаштовується на конкретний мережний інтерфейс та порт (рис.3.6). Таким чином адреса сокету є комбінацією з адреси IP та порту. Клієнтські сокети з'єднуються з серверними з використанням ідентифікатору підключення, який містить протокол, IP адреси та номери портів відправника (src) та отримувача (dst):
+
+**Protocol** **+** **IPdst** **+** **PORTdst** **+** **IPsrc** **+** **PORTsrc** (5 tuple)
+
+
+
+рис.3.6. Принципи роботи сокетів
+
+На рис.3.7. показані етапи роботи сокетів для протоколу TCP. Спочатку в застосунку створюються сокети (примітив `socket`). Далі відбувається зв'язок локальної адреси (IP та порт) з сокетом (примітив `bind`). Серверний сокет вказує на очікування з'єднання від клієнта (примітив `listen`). Клієнтський сокет викликає примітив `connect` для підключення до серверного сокету. В примітиві він вказує адресу серверного сокету. Серверний сокет підтверджує підключення примітивом `accept`, після чого будь який з партнерів може відправляти (`send`) та отримувати (`recv`) дані. Примітив `close` розриває з'єднання.
+
+
+
+рис.3.7. Етапи роботи сокета
+
+Таблиця 3.1. Примітиви роботи з сокетом.
+
+| **Примітив** | **Призначення** |
+| ------------ | ---------------------------------- |
+| SOCKET | створити сокет |
+| BIND | зв'язати локальну адресу з сокетом |
+| LISTEN | очікувати з'єднання від клієнта |
+| ACCEPT | підтвердити з'єднання |
+| CONNECT | підключатися до серверу |
+| SEND | відправити по каналу |
+| RECEIVE | отримати з каналу |
+| CLOSE | розірвати з'єднання |
+
+## 3.3. Робота з TCP та UDP в Node-RED
+
+У Node-RED для роботи з TCP та UDP є відповідні вузли з палітри `Network`, які встановлюються разом з Node-RED. У цьому розділі розглянемо їх.
+
+### UDP out
+
+Цей вузол відправляє `msg.payload` на призначений хост і порт UDP. Підтримується багатоадресна передача.
+
+На рис.3.8 показано налаштування `UDP out`. При відправлені можна задати як конкретний порт так і випадковий (`bind to random local port`).
+
+
+
+рис.3.8.Налаштування UDP out
+
+Можна також використовувати `msg.ip` і `msg.port` для встановлення значень IP-адреси та порта призначення, але слід зауважити, що у цьому випадку статично налаштовані значення повинні бути порожніми.
+
+Якщо вибрати широкомовлення (`broadcast`), тоді необхідно встановити адресу на ip адресу локального широкомовлення, або, `255.255.255.255`, яка є глобальною адресою широкомовної передачі. **Примітка**: У деяких системах вам може знадобитися мати root, щоб використовувати порти нижче 1024 та/або широкомовлення.
+
+### UDP in
+
+Вузол введення UDP, який виробляє `msg.payload`, що містить буфер, рядок або base64-кодований рядок. Підтримується багатоадресне отримування.
+
+
+
+рис.3.9. Налаштування `UDP in`
+
+Він також забезпечує передачу `msg.ip` та ` msg.port`, встановлені на ip-адресу та порт, з якого було отримано повідомлення. У деяких системах може знадобитися root або адміністраторський доступ для використання портів нижче 1024 та/або широкомовлення.
+
+На рис.3.10 вказаний приклад використання UDP, де Node-RED відсилає повідомлення до самого себе.
+
+
+
+рис.3.10. Приклад роботи UDP
+
+### TCP in
+
+ Забезпечує отримання вхідних даних з порта TCP.
+
+Можна або підключитися до віддаленого порту TCP (`Type = Connect To`), або прийняти вхідні з'єднання (`Type = Liasten On`).
+
+
+
+рис.3.11. Налаштування `TCP in`
+
+У деяких системах вам може знадобитися root або адміністратор для доступу до портів нижче 1024.
+
+При підключенні до віддаленого порту вузол для цього підключення буде тільки приймати вхідні повідомлення. При необхідності підключення в режимі запит/відповідь варто використовувати вузол TCP request.
+
+### TCP out
+
+Забезпечує відправлення вихідного повідомлення на TCP-порт.
+
+Можна або підключитися до віддаленого порту TCP (`Type=Connect to`), приймати вхідні з'єднання (`Type=Listen on`) або відповідати на повідомлення, отримані від вузла TCP In (`Type=Reply to TCP`).
+
+
+
+рис.3.12. Налаштування `TCP out`
+
+Надсилається лише `msg.payload`. Якщо `msg.payload` - рядок, що містить кодування бінарних даних Base64, опція `decode Base64` призведе до того, що вона буде перетворена назад у двійкові дані перед відправкою.
+
+Якщо `msg._session` немає, корисне навантаження надсилається **всім** підключеним клієнтам. У деяких системах вам може знадобитися root або адміністратор для доступу до портів нижче 1024.
+
+При підключенні до віддаленого порту вузол для цього підключення буде тільки відправляти вихідні повідомлення. При необхідності підключення в режимі запит/відповідь варто використовувати вузол TCP request.
+
+### TCP Request
+
+Простий вузол для відправки клієнтського запиту TCP та очікування відповіді. Запит відправляється через msg.payload на порт TCP-сервера, після чого очікується відповідь. Конфігурування вузла показано на рис.3.13.
+
+
+
+рис.3.13. Налаштування `TCP Request`
+
+Вузол підключається по TCP, надсилає запит і чекає відповідь, яку формує на виході вузла `msg.payload`. За допомогою параметра Return налаштовується різні режими очікування відповіді для видачі отриманих даних в `msg.payload` та закриття з'єднання:
+
+- за фіксованою кількістю символів у буфері (`fixed number of charts`),
+- за вказаним символом, який сигналізує про завершення передачі (`when character received`)
+- за фіксованим часом очікування (`after a fixed timeout`),
+- передавати дані за надходженням і ніколи не закривати з'єднання (`never`)
+- відправляти запит, а потім негайно закрити з'єднання, не чекаючи відповідь (`immediately`).
+
+Відповідь буде виводитися у `msg.payload` як буфер. Для текстового перетворення можна скористатися методом `.toString()`.
+
+Якщо в налаштуваннях залишити хост або порт tcp порожнім, їх потрібно встановити, використовуючи властивості `msg.host` та `msg.port` у кожному повідомленні, надісланому до вузла.
+
+На рис.3.14 показаний приклад роботи вузлів TCP. У даному прикладі в Node-RED реалізоване як серверне так і клієнтське підключення для з'єднання самого з собою. Сервер відправляє клієнту те саме повідомлення, яке отримав (ехо-відповідь).
+
+
+
+рис.3.14. Приклад роботи вузлів TCP
+
+## Питання для самоперевірки.
+
+1. Яке призначення протоколів IP?
+2. Як у IPv4 з використанням масок з адреси вузла виділяється адреса мережі?
+3. Куди відправляється пакет за замовченням, якщо адреса IPv4 не в даній підмережі?
+4. Поясніть що таке протокол ARP та таблиця ARP?
+5. Яке призначення у транспортних протоколів TCP та UDP?
+6. Поверх якого протоколу працюють TCP та UDP?
+7. Виділіть основні відмінності в принципах роботи TCP та UDP.
+8. Поясніть що таке порти TCP та UDP.
+9. Поясніть на прикладі що таке добре відомі (Well-Known) порти TCP та UDP.
+10. Які, як правило номери портів виділяються TCP та UDP клієнтам?
+11. Поясніть принципи функціонування сокетів.
+12. Яка принципова відмінність в роботі клієнтських та серверних сокетів TCP та UDP?
+13. Яке призначення вузлів UDP-in та UDP-out в Node-RED?
+14. Яке призначення вузлів TCP-in та TCP-out в Node-RED?
+15. Яке призначення вузла TCP-request в Node-RED?
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
+
diff --git "a/\320\233\320\265\320\272\321\206/4_http.md" "b/\320\233\320\265\320\272\321\206/4_http.md"
new file mode 100644
index 0000000..decd072
--- /dev/null
+++ "b/\320\233\320\265\320\272\321\206/4_http.md"
@@ -0,0 +1,407 @@
+**Програмна інженерія в системах управління. Лекції.** Автор і лектор: Олександр Пупена
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
+
+# 4. Основи HTTP
+
+## 4.1. Протокол HTTP
+
+**HTTP** (HyperText Transfer Protocol — «протокол передачі гіпертексту») — протокол прикладного рівня передачі даних, який є повінстю текстовим, тобто використовуються тільки літери та цифри. Початково проткол використовувався для передачі гіпертекстових документів HTML, зараз використовується для передачі чого завгодно.
+
+У обміні приймають участь два застосунки (рис.4.1):
+
+- HTTP Клієнт (наприклад Web Browser) - ініціатор, той застосунок, якому потрібні ресурси серверу. Він формує запит (Request Message) на сервер на виконання операціъ з ресурсом.
+- HTTP Сервер (Web Server) - той застосунок, у якого є ресурси. Він обробляє запит клієнта і відправляє відповідь (Response Message), у якому повертає результат обробки ресурсу, або сам ресурс.
+
+
+
+рис.4.1. Клієнт-серверний обмін в HTTP.
+
+На сьогодні інсує кілька версій: HTTP/1.1, впроваджується HTTP/2 (з 2015) та HTTP/3 (з 2019).
+
+HTTP так само і багато споріднених протоколів використовує стандартний стек TCP, UDP, IP та інші (рис.4.2)
+
+
+
+рис.4.2. Стек протоколів HTTP
+
+Розглянемо приниципи функціонування HTTP на прикладі (рис.4.3).
+
+1) Коли користувач заходить за посиланням на WEB-ресурс він вказує *URL* того ресурсу (наприклад сторінки), який необхідно завантажити.
+
+2) Браузер запитує цей ресурс за допомогою повідомлення в текстовому форматі, що починається з назви методу `GET` в якому передається адреса ресурсу та додаткові параметри запиту. Це повідомлення передається по TCP до серверу по вказаному порту. Якщо користувач не вказав порт він буде рівним 80 (див. попередню лекцію).
+
+
+
+рис.4.3. Приклад фунуціонування протоколу HTTP.
+
+3) Сервер, отримавши повідомлення на отримання ресурсу, шукає його за URL.
+
+4) У випадку знаходження ресурсу сервер відправляє відповідь, в заголовку якої вказує позитивний результат виконання запиту `200 Ok`. Також в корисному навантаженні він передає запрошуваний ресурс.
+
+5) Браузер виводить ресурс, якщо це буде HTML-сторінка показує її у відповідному вигляді.
+
+### Ідентифікація ресурсу
+
+**Ресурси** на сервері - це документи у різному форматі, які можна отримати, записати, змінити і т.п. Для доступу до потрібного ресурсу вказується його унікальний для серверу ідентифікатор розміщення - **URL (**Uniform Resource Locator). Він задається у вигялді рядку і має наступний формат:
+
+```http
+<схема>://<логін>:<пароль>@<хост>:<порт>/<шлях>?<параметри>#<якір>
+```
+
+- схема – це означення того, який проткол використовується для доступу ресурсу, наприклад `http` або `https`
+- логін та пароль – це ім'я і пароль користувача, якщо доступ до ресурсу обмежений; як видно вони розділені двокрапкою; якщо дсотуп до ресурсу не обмежується, логін та пароль не вказуються
+- хост - доменне ім'я хоста (DNS) або IP-адреса
+- порт – TCP порт хоста, якщо не вказується,
+- шлях – інформація що уточнює місцезнаходження ресурсу
+- параметри – рядок запиту з параметрами, що передаються на сервер (методом GET)
+ - використовується разділювач параметрів — знак &.
+- #<якір> - якір, тобто заголовок всередині документа, або атрибут id
+
+Приклади:
+
+`https://uk.wikipedia.org/wiki/Уніфікований_локатор_ресурсів#Cтруктура` `http://asu.in.ua/viewtopic.php?p=6135#p6135`
+
+### Структура повідомлення
+
+Як зазначалося в протоколі HTTP повідомлення-запит та повідомлення-відповідь мають повністю текстовий формат. Повідомлення складається з (рис.5):
+
+- стартового рядку, який завершується символом кінця рядку і включає в себе
+ - для запиту вказується рядок запиту (`request line`): у ньому вказується метод (на рисунку `GET`), ресурс (на рисунку `/doc/test.html`) та версія протоколу (на рисунку `HTTP/1.1`)
+ - для відповіді вказується статусний рядок (`status line`): у ньому вказується версія протоколу (на рисунку `HTTP/1.1`), код статусу (на рисунку `200`) та текстове представлення статусу (на рисунку `OK`)
+- headers (заголовки), які уточнюють повідомлення; кожен заголовок закінчується символом кінця рядку; є тільки один обовязковий заголовок для клієнта - `Host`, в якому треба вказати імя хоста, до якого відбувається звернення; усі інші заголовки добалвяються за необхідності;
+- body (тіло повідомлення), яке включає зміст ресурсу; може бути порожнім, наприклад у повідомленні-запиті на отримання ресурсу
+- розділювач - пустий рядок, який розділяє заголовки і тіло повідомлення
+
+
+
+рис.4.4. Структура повідомлення HTTP
+
+Перевірити роботу http можна за допомогою програми-терміналу, наприклад для систем Windows це PuTTY (рис.4.5). Для цього треба підключитися до потрібного порта потрібного `host` в режимі передачі тексту (`raw`). Далі у консольному вікні набрати текстове повідомлення, після подвійного `Enter` з'явиться відповідь від серверу.
+
+
+
+рис.4.5. Приклад перевірки роботи HTTP за допомогою PuTTY.
+
+### Методи запитів
+
+Метод запиту (HTTP Method) - це означення дії, яку необхідно провести над ресурсом. За великим рахунком це може бути довільний символьний набір, але цей метод повинен підтримуватися і Client і Server. Тим не менше є стандартні методи, зокрема:
+
+- **GET** – запит на зміст ресурсу
+- **POST** – передача даних для існуючого ресурсу
+- **HEAD** – запит інформації про ресурс але без змісту
+- **PUT** – розміщення нового ресурсу на Web-сервері
+- PATCH – часткова зміна ресурсу
+- DELETE – видалення ресурсу з Web-серверу
+- TRACE – трасировка (ехо-запит) перевірки зміни запиту по шляху
+- OPTIONS – запит підтримуваних методів HTTP та розширень
+- CONNECT – підключення до Web-серверу через проксі
+
+### Статуси відповідей
+
+Статус відповіді вказує на результат виконання сервером запиту. Він включає числове представлення у вигялді коду та текстову рошифровку. Перша цифра тризначного коду (сотні) вказують на тип відповіді:
+
+- **1XX** – інформаційна; наприклад `101 switching protocols` вказує на те, що відбулося переключення на інший протокол (наприклад з HTTP на WebSocket)
+- **2XX** – успішне виконання; наприклад `200 ОК`
+- **3ХХ** – перенаправлення на інше розміщення ресурсу; наприклад `301` – перенаправлення на постійне розміщення, `307` – перенаправлення на тимчасове переміщення
+- **4ХХ** – помилка з причини клієнта; наприклад `403` –доступ заборонений за неправильної вказівки користувача та пароля, `404` – ресурс не знайдено за вказаним посиланням
+- **5ХХ** – помилка на сервері; наприклад `500` – відбулася внутрішня помилка серверу
+
+### Заголовки
+
+Заголовки HTTP (HTTP Headers) уточнюють повідомлення. Описуються парою `ім'я: значення` (див. рис.4.6). Наприклад
+
+```http
+Content-Type: text/html;charset=utf-8
+```
+
+задає формат і спосіб представлення тіла повідомлення типу `text/html` з кодуванням `charset=utf-8`.
+
+Існують стандартні заголовки, які описані в документах RFC. Нестандартні заголовки повинні починатися з `X-`. Для протоколу HTTP > v1.1 заголовок «Host» в повідомленні-запиті повинен бути обов'язковим, так як на одному IP/домені може бути декілька Веб-серверів. Список заголовків можна подивитися на [Вікіпедії](https://uk.wikipedia.org/wiki/Список_заголовків_HTTP).
+
+Розглянемо вплив заголовку `Connection` на функціонування обміну. Заголовок вказує на властивість підключення, зокрема `Connection: Keep-Alive` вказує на необхідність утримання (`persistent`) з'єднання після відповіді на запит. У протоколі `HTTP/1.0` передбачалося, що після обробки кожного запиту – з'єднання розривається. Однак для багатьох випадків це може спричинити до значних часових затрат. Розглянемо це на прикладі (рис.7). Якщо при завантаженні сторінки необхідно додатково зробити запит, наприклад, на завантаження рисунків для неї, то в звичайному варіанті після кожного запиту GET TCP-з'єднання в `HTTP/1.0` буде розриватися, хоча логічний сеанс обміну при цьому триває. Як відомо з попередньої лекції це приведе до додаткових часових затрат, тому для утримання з'єднання в HTTP/1.0 потрібен заголовок `Connection: Keep-Alive`, який після відповіді серверу тримає TCP-з'єднання активним протягом 5-15 секунд (залежить від реалізації серверу). У версії `HTTP/1.1` за замовченням вважається даний параметр `persistent` а у 2-й версії заголовок взагалі заборонений.
+
+
+
+рис.4.6. Функціонування постійного з'єднання `Persisten Connection`
+
+Інший прикладом є використання заголовку `Cache-Control`. Для прискорення обміну завантажувані ресурси можуть кешуватися, тобто зберігатися на локальних (приватних) або проміжних загальнодоступних (shared) кешах (рис.8). Тобто якщо запит проходить через сервера, які передбачають кешування, може повернутися старе значення ресурсу. Це з одного боку зменшує трафік, так як надає багатьом клієнтам швидше доступ до одного і того ж ресурсу. З іншого боку, якщо ресурс (наприклад сторінка) змінився, усі клієнти отримають старе значення. Для вказівки параметрів роботи з кешем передбачений заголовок: `Cashe Control`, наприклад:
+
+- `Cache-Control: no-cache, no-store` - не кешувати, не зберігати,
+- `Cache-Control: max-age=31536000` - максимальний час збереження в кеші в секундах
+
+## 4.2. Робота з HTTP в Node-RED
+
+У Node-RED є вузли для роботи як з клієнтськими запитами так і для реалізації серверної обробки.
+
+### HTTP requests (робота з клієнтськими запитами)
+
+Відправляє запити HTTP і повертає відповідь на нього (рис.9). В якості вхідного значення приймає наступні властивості повідомлень:
+
+- `url` (string) – якщо не сконфігуроване у вузлі, ця опціональна властивість виставляє url для запиту.
+- `method` (string) - якщо не сконфігуроване у вузлі, ця опціональна властивість виставляє метод HTTP для запиту. Повинно бути GET, PUT, POST, PATCH бо DELETE.
+- `headers` (object) – виставляє HTTP заголовки в запиті
+- `cookies` (object) – якщо вказані, можуть бути використані для відправки куків з запитом
+- `payload` – виставляє тіло для запиту
+- `rejectUnauthorized` – якщо виставлено в false дозволяє робити запити на сайти https, які використовують сертифікати, які підписуються самостійно
+- `followRedirects` – якщо виставлено в false запобігає наступним перенаправленням (`HTTP 301`). true за замовчуванням
+
+
+
+рис.4.7. Налаштування вузлу HTTP requests
+
+На виході формує:
+
+- `payload` (string | object | buffer) – тіло відповіді. Вузол може бути налаштований так, щоб повернути тіло у вигляді string, спробувати розпарсити його як рядок JSON або залишити його у вигляді двійкового буфера.
+- `statusCode` (number) - код стану відповіді або код помилки, якщо запит не може бути завершений.
+- `headers` (object) – об’єкт, що містить заголовки відповідей
+- `responseUrl` (string) - у випадку, якщо під час обробки запиту відбулися будь-які перенаправлення, це властивість є останньою адресою, що переадресовується. В іншому випадку це URL оригінального запиту.
+- `responseCookies` (object) - якщо відповідь включає файли cookie, ця властивість є об'єктом пар імені/значення для кожного cookie.
+
+Якщо сконфігуровано у вузлі, властивість URL може містити теги [mustache-style](http://mustache.github.io/mustache.5.html). Вони дозволяють створювати URL, використовуючи значення вхідного повідомлення. Наприклад, якщо URL-адресу встановлено `example.com/{{{topic}}}` в це місце буде автоматично додано` `msg.topic. Використання потрійних фігурних дужок `{{{...}}}` запобігає вилученню `mustache` із символів на зразок `/&` і т.д.
+
+Примітка: Якщо запускається за проксі-сервері, необхідно встановити стандартну змінну середовища `http_proxy=...` і перезапустити Node-RED, або використовувати вузол Proxy Configuration. Якщо було встановлено вузол Proxy Configuration, конфігурація цього вузлу має перевагу перед змінною середовища.
+
+Для того щоб використовувати більше одного з таких вузлів в тому самому потоці, необхідно дотримуватися властивості `msg.headers`. Перший вузол встановить цю властивість з заголовками відповіді. Тоді наступний вузол буде використовувати ці заголовки для свого запиту - це звичайно не правильно. Якщо властивість `msg.headers` залишається незмінною між вузлами, вона буде ігноруватися другим вузлом. Щоб встановити користувальницькі заголовки, `msg.headers` слід спочатку видалити або скинути порожнім об'єктом: `{}`.
+
+Властивість cookies, передана вузлу, повинна бути об'єктом з парою ім'я : значення. Значення для встановлення значення cookie може бути string, або об'єктом з єдиною властивістю value. Будь-які файли cookie, повернені запитом, передаються назад у властивості responseCookies.
+
+Для виконання запиту завантаження файлу, `msg.headers["content-type"]` слід встановити на `multipart/form-data` , а `msg.payload` , переданий у вузол, повинен бути об'єктом із такою структурою:
+
+```json
+{
+ "KEY": {
+ "value": FILE_CONTENTS,
+ "options": {
+ "filename": "FILENAME"
+ }
+ }
+}
+```
+
+Значення KEY, FILE_CONTENTS та FILENAME слід встановити у відповідні значення.
+
+Якщо `msg.payload` є Object, вузол буде автоматично встановлювати тип контенту запиту в `application/json` і кодувати тіло відповідним чином.
+
+Для кодування запиту як форми даних `msg.headers["content-type"]` буде встановлюватися як `application/x-www-form-urlencoded`.
+
+На рис.4.8 показаний приклад з вузлом HTTP requests
+
+
+
+рис.4.8. Приклад використання HTTP requests
+
+### Http in (вхідне повідомлення HTTP-серверу)
+
+ Створює точку для з`єднання HTTP для створення веб-служб (рис.4.9).
+
+
+
+
+
+рис.4.9. Налаштування `Http in`
+
+На виході формує:
+
+- `Payload (object)` - Для запиту `GET` містить об'єкт з параметрами рядка запиту. В іншому випадку, містить тіло запиту HTTP.
+- `req (object)` - Об'єкт запиту HTTP. Цей об'єкт містить кілька властивостей, які надають інформацію про запит.
+
+Вузол прослуховує конфігурований шлях для запитів певного типу. Шлях може бути повністю означений, наприклад `/user`, або включати іменовані параметри, які приймають будь-яке значення, наприклад `/user/:name`. Коли використовуються іменовані параметри, їх фактичне значення в запиті може бути доступне за посиланнями `msg.req.params`.
+ Для запитів, які включають тіло, наприклад `POST` або `PUT`, вміст запиту доступний як msg.payload.
+
+Якщо тип вмісту запиту може бути визначений, тіло буде проаналізовано до будь-якого відповідного типу. Наприклад, `application/json` буде парсений до його представлення в об'єкти JavaScript.
+
+Примітка: цей вузол не надсилає відповіді на запит. Потік повинен містити вузол HTTP Response для завершення запиту.
+
+### Http response (вихідне повідомлення HTTP-серверу)
+
+ Надсилає відповіді на запити, отримані від вузла HTTP In (рис.4.10).
+
+
+
+рис.4.10. Налаштування `Http response`
+
+В якості вхідного значення приймає наступні властивості повідомлень:
+
+- `payload (string)` – тіло відповіді
+- `statusCode (number)` – якщо встановлений, використовується в якості статусного коду відповіді. За замовченням `200`
+- `headers (object)` – заголовки, якщо встановлений забезпечує HTTP заголовки, які включаються у відповідь
+- `cookies (object)` – якщо встановлений, може бути використаний для встановлення або видалення куків (cookies)
+
+statusCode і headers також можуть бути встановлені в налаштуваннях самого вузла. У цьому випадку їх не можна перевизначити відповідними властивостями повідомлення.
+
+Властивість cookies повинна бути об'єктом пар імен/значень. Значення може бути або рядком для встановлення значення куки з параметрами за замовчуванням, або це може бути об'єктом опцій.
+
+Наступний приклад встановлює два файли cookies - один з них називається name зі значенням nick, інший називається session зі значенням 1234 з терміном дії 15 хвилин.
+
+```json
+msg.cookies = {
+ name: 'nick',
+ session: {
+ value: '1234',
+ maxAge: 900000
+ }
+}
+```
+
+Допустимі опції:
+
+- `domain` - (String) ім’я домену для куки
+- `expires` - (Date) термін дії в GMT. Якщо не вказано або встановлено на 0, створює сеансовий cookie
+- `maxAge` - (String) термін дії відносно поточного часу в мілісекундах
+- `path` - (String) шлях куки, за замовченням `/`
+- `value` - (String) значення для куки
+
+Для видалення, куки встановлюється в `null`
+
+На рис.4.11 показаний приклад використання вузлів http in/out в парі. Коли відбувається запит на сторінку hello видається текстовий зміст.
+
+
+
+рис.4.11. Приклад використання `http in/out`
+
+## 4.3. Робота зі змістом HTML повідомлень
+
+### Тип змісту тіла повідомлення (Content-Type)
+
+Хоч протокол HTTP повністю текстовий, за допомогою тексту можна кодувати будь-який зміст тіла, навіть бінарні файли. Однак для їх правильної інтерпретації необхідно вказати тип змісту за допомогою заголовка `Content-Type`. Заголовок може включати декілька директив, розділені крапкою з комою:
+
+- `media-type`, тип змісту, наприклад `text/html`, або `multipart` - для вказівки багато-частинних повідомлень
+- `charset` – стандарт кодування, наприклад `utf-8`
+- `boundary` – для багато-частинних (`multipart`) повідомлень розділювач
+
+Наприклад:
+
+```text
+Content-Type: text/html; charset=utf-8
+Content-Type: multipart/form-data; boundary=something
+```
+
+Тип змісту, визначається типом **MIME**(Multipurpose Internet Mail Extensions) – стандарт на характер і формат документу, файлу або даних. Він описується парою тип/підтип, тобто:
+
+```
+type/subtype
+```
+
+Ці типи можуть бути дискретними, тобто які описують весь формат, або у випадку змішаного формату (наприклад текст та рисунки) включати кілька частин. Популярні дискретні формати
+
+```
+application/octet-stream (бінарний)
+text/plain (текстовий)
+text/css, text/html, text/javascript, text/xml (текстовий з ромзіткою)
+image/gif, image/jpeg, image/png (зображення)
+application/json (JSON)
+```
+
+Інші дискретні формати:
+
+```
+text/css, audio/mpeg, audio/ogg, audio/*, video/mp4, application/*, pplication/ecmascript
+application/octet-stream ...
+```
+
+Для змісту що включає кілька розділів (зміст) виділяється тип **MIME Multipart**. На рис.4.12 показаний приклад використання змісту, який включає кілька розділів. Це тіло повідомлення відправлення HTML-форми. Для цього використовується директива `multipart/form-data` заголовку `Content Type` . Директива`boundary` вказує на роздільник, який використовується для ідентифікації початку частин. Далі кожен розділ тіла повідомлення починається з вказаного роздільника, після чого вказується тип формату через `Content-type` .
+
+
+
+рис.4.12. Приклад використання MIME Multipart
+
+### Вузол HTML
+
+ Витягує елементи з HTML-документа, що міститься в msg.payload за допомогою селекторів CSS (рис.4.13).
+
+В якості вхідного значення приймає наступні властивості повідомлень:
+
+- `payload (string)` – html- рядок з якого вилучаються елементи.
+- `select (string)` - селектор, може бути використане це значення властивості msg, якщо воно не налаштовано на панелі редагування.
+
+
+
+рис.4.13. Налаштування вузлу HTML
+
+На виході формує:
+
+- `payload` (array | string) - результатом може бути одне повідомлення з корисним навантаженням, що містить масив відповідних елементів, або кілька повідомлень, кожен з яких містить відповідний елемент.
+- Якщо надсилаються декілька повідомлень, вони також мають набір parts.
+
+Цей вузол підтримує комбінацію селекторів CSS і jQuery. Докладніше про підтримуваний синтаксис див. [за цим посиланням](https://developer.mozilla.org/uk/docs/Web/CSS/CSS_Selectors) або [Документацію css-select](https://github.com/fb55/CSSselect#user-content-supported-selectors).
+
+На рис.4.14 наведений приклад використання HTML-парсера. Вузол `http request` робить запит на сторінку з сайту `example.org` використовуючи метод `get`. Сторінка завантажується в Payload як текстове повідомлення. Далі повідомлення проходить через вузол парсера body, який витягує html-зміст усіх html-тегів body та відправляє їх окремими повідомленнями в payload. Враховуючи, щ вузол body в html-документі тільки один, його зміст виводиться один раз на панелі налагодження. Корисне навантаження цього повідомлення переходить через інший html-парсер з іменем p де вилучаються усі абзаци (тег p) і відправляються як масив повідомлень в форматі html.
+
+
+
+рис.4.14. Приклад використання HTML-парсера
+
+### Вузол Template
+
+Вузол Template може використовуватися для створення текстового значення за допомогою означеного шаблону та властивостей повідомлення, які вказуються в конкретних полях. Для формування результату він використовує шаблонну мову [Mustache](https://mustache.github.io/mustache.5.html), у якій поля-замінники в шаблоні виділяються подвійними фігурними дужками. Наприклад, шаблон:
+
+`This is the payload: {{payload}} !`
+
+замінить `{{payload}}` з значенням властивості повідомлення payload.
+
+На рис.4.15 показано приклад налаштування вузла `Template`. Налаштування `Property` вказує на те, яка саме властивість буде змінюватися даним вузлом на виході. У якості шаблону можна задавати статичний шаблон, який записаний у полі Template, або передати його через властивість `msg.template`. У останньому випадку необхідно щоб поле `Template` в конфігурації вузла було порожнім. Можна вибирати різний синтаксис підсвічування в залежності від призначення виходу.
+
+
+
+рис.4.15. Налаштування вузла Template
+
+На рис.4.16 показаний простий приклад використання вузла Template.
+
+
+
+рис.4.16. Простий приклад використання вузла Template
+
+Для формування замінників в шаблоні окрім властивостей повідомлення можна використовувати значення контекстів. Це може бути як контекст за замовченням `{{flow.name}}` або `{{global.name}}`, так і іменоване сховище для контексту `{{flow[store].name}}` або `{{global[store].name}}`.
+
+За замовчуванням, Mustache замінить певні символи своїми HTML-кодами. Щоб зупинити це, треба скористатися потрійними фігурними дужками: `{{{payload}}}`. На рис.4.17 показаний приклад, у якому для формування змісту у форматі html використовуються обидва варіанти – з подвійним і з потрійними дужками. Шаблони для обидвох вузлів зроблені у форматі html, який включає тег тіла, що у свою чергу включає замінник msg.payload. На їх вхід подається значення у форматі html. У першому варіанті (верхній вузол) символи що використовуються у форматуванні html замінені на їх кодові представлення (спецсимволи). Це робиться тому, що подвійні дужки вказують на те, що зміст має бути представлений як текст, а не як html. Тому відбувається перетворення, щоб зберегти відображення спецсимволів на кшталт "<" , "/", ">" у тому ж вигляді. При потрійних дужках ніякого попереднього перетворення не робиться, тому увесь зміст зрештою буде інтерпретуватися як html.
+
+
+
+рис.4.17. Приклад використання потрійних фігурних дужок.
+
+Mustache за допомогою секцій підтримують прості цикли у списках. Наприклад, якщо `msg.payload` містить масив імен, таких як: `["Nick", "Dave", "Claire"]`, то шаблон типу:
+
+```
+
+{{#payload}}
+ - {{.}}
+{{/payload}}
+
+```
+
+створить список HTML імен:
+
+```
+
+```
+
+Додатково про форматування Mustache можна ознайомитися за [посиланням](https://pupenasan.github.io/NodeREDGuidUKR/base/mustach.html). Якщо шаблон генерує валідний вміст JSON або YAML, його можна налаштувати для аналізу результату на відповідний об'єкт JavaScript.
+
+## Питання для самоперевірки.
+
+1. Розкажіть про загальні принципи функціонування протоколу HTTP.
+2. На якому протоколі транспортного рівня базується HTTP?
+3. Поясніть що таке ресурс HTTP? Як він ідентифікується на сервері?
+4. Розкажіть про структуру повідомлення HTTP.
+5. Розкажіть про призначення методів запитів HTTP.
+6. Розкажіть про призначення статусів відповіді HTTP.
+7. Розкажіть про призначення заголовків HTTP.
+8. Розкажіть про призначення кешування в HTTP. Як можна керувати кешем в протоколі HTTP?
+9. Як реалізована робота клієнта HTTP в Node-RED?
+10. Як реалізована робота HTTP-сервера в Node-RED?
+11. Як вказується формат повідомлення в HTTP?
+12. Що таке Multipart повідомлення?
+13. Рокзажіть про роботу вузла HTML-парсера в Node-RED.
+14. Рокзажіть про роботу вузла `Template` в Node-RED.
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
+
diff --git "a/\320\233\320\265\320\272\321\206/5_mqtt.md" "b/\320\233\320\265\320\272\321\206/5_mqtt.md"
new file mode 100644
index 0000000..faf3fa1
--- /dev/null
+++ "b/\320\233\320\265\320\272\321\206/5_mqtt.md"
@@ -0,0 +1,237 @@
+**Програмна інженерія в системах управління. Лекції.** Автор і лектор: Олександр Пупена
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
+
+# 5. Передача даних в архітектурі IoT: MQTT
+
+## 5.1. Загальні принципи функціонування MQTT
+
+У структурі Інтернету речей засоби взаємодіють між собою через мережу Інтернет безпосередньо, або через комунікаційні шлюзи. При такому обміні може і не бути явно виділеного серверу, куди треба передавати дані, адже IoT передбачає зв\'язок «речей» між собою а не з централізованим «концентратором» даних. Тому поряд з використанням HTTP API та WebSocket, в IoT є спеціальні протоколи Інтернету речей, такі як AMQP, MQTT, STOMP та інші, які не передбачають зв\'язок типу клієнт-сервер. У цих протоколах одні засоби розміщують повідомлення в буфері або стеці, інші -- зчитують їх. MQTT є одним з таких.
+
+MQTT свого часу був внутрішнім і пропрієтарним протоколом для IBM протягом багатьох років. У 2010 р він був випущений у версії 3.1 в якості безкоштовного продукту, у 2013 р. -- стандартизований і прийнятий в консорціум OASIS, у 2014 р. -- OASIS опублікував його публічно як версію MQTT 3.1.1. MQTT також є стандартом ISO (ISO / IECPRF 20922).
+
+Протокол MQTT базується на стеці TCP/IP. У ньому використовується модель публікації-підписки (publish-subscribe, або pub/sub). Клієнт, що передає повідомлення, називається ***видавцем*** (***publisher***); клієнт, який отримує повідомлення - ***абонентом*** (***subscriber***). У центрі знаходиться ***MQTT-брокер*** (***MQTT broker***), який несе відповідальність за обмін повідомленнями між клієнтами і фільтрацію даних (див.рис.5.1). Таким способом йде відокремлення клієнта, що відправляє повідомлення, від іншого клієнта, який отримує повідомлення. На відміну від традиційної моделі клієнт-сервер, клієнти що публікують і підписуються на повідомлення не обізнані про будь-які фізичні ідентифікатори інтерфейсів пристроїв або застосунків (на зразок IP-адреси, або TCP/UDP порту). Вони знають тільки про розміщення в мережі брокера, через який відбувається обмін. У MQTT може бути багато видавців і багато абонентів.
+
+
+
+рис.5.1. Принцип обміну MQTT повідомленнями через брокер
+
+Абонент, підписуючись під отримування повідомлень від видавців використовує різноманітні фільтри, які забезпечують:
+
+- **фільтрацію за темами** (**Topic Filters**) - за задумом, клієнти підписуються на ***теми*** (***topic***) і певні гілки тем, тому не отримують не потрібні їм дані. Кожне опубліковане повідомлення повинно містити тему (topic), і брокер несе відповідальність за повторну передачу цього повідомлення абонентам або ігнорування його;
+
+- **фільтрація по вмісту** - брокери мають можливість перевіряти і фільтрувати опубліковані дані. Таким чином, будь-які дані, які не зашифровані, можуть керуватися брокером до того, як зберегти їх або передати іншим клієнтам;
+
+- **фільтрація за типом** - клієнт, що прослуховує потік даних, на які він підписаний, може також застосовувати свої власні фільтри. Вхідні дані можуть аналізуватися, і в залежності від цього потік даних обробляється далі або ігнорується.
+
+Підписник може підписатися на кілька тем. Одна із особливостей моделі видавець/Підписник полягає в тому, що перед початком передачі клієнти повинні знати тему гілки і формат даних, але не взаємне розміщення один одного. Це дуже корисно при розгортанні IoT, оскільки IP-адреса клієнтів може бути динамічною або/та приватною.
+
+MQTT є часово-незалежним протоколом. Це значить, що повідомлення, опубліковане одним клієнтом-видавцем, може бути прочитане абонентом в будь-який час. Підписник може перебувати в місці з низьким енергоспоживанням або обмеженою пропускною здатністю і відповісти на повідомлення через кілька хвилин або годин.
+
+Брокери можуть бути розгорнуті на будь якому загально-доступному усім клієнтам ресурсі, і мати виділену і відому їм адресу. При реалізації IoT з використанням хмарних платформ, функцію брокера бере на себе відповідний сервіс. Керовані хмарою брокери MQTT зазвичай можуть поглинати мільйони повідомлень на годину і підтримувати десятки тисяч видавців.
+
+MQTT не залежить від формату даних. Корисне навантаження (payload) може містити будь-який тип даних, тому і видавці, і абоненти повинні розуміти і погоджувати формат даних. У корисному навантаженні можна передавати текстові повідомлення, дані зображення, звукові дані, зашифровані дані, двійкові дані, об\'єкти JSON або практично будь-яку іншу структуру. Тим не менше, текстові і двійкові дані JSON є найбільш поширеними типами даних корисного навантаження.
+
+Максимально допустимий розмір пакета в MQTT становить 256 Мб, що дозволяє отримати надзвичайно велике корисне навантаження. Зверніть увагу, однак, що це також залежить від обмеження клієнтів, хмарних сервісів (якщо використовуються) і брокера. Наприклад, хмарний сервіс IBM Watson дозволяє обробляти дані розміром до 128 Кб, а Google підтримує 256 Кб. З іншого боку, опубліковане повідомлення може включати корисне навантаження нульової довжини, тобто поле корисного навантаження не є обов\'язковим. Доцільно звірити відповідність розмірів корисного навантаження з хмарним провайдером або конкретною реалізацією брокеру.
+
+У Інтернеті є безкоштовні MQTT брокери, використовуючи які можна обмінюватися між пристроями IoT не маючи власного серверу або виділеного хмарного сервісу для MQTT. Серед найбільш відомих MQTT брокерів є:
+
+- [http://test.mosquitto.org](http://test.mosquitto.org/gauge/)
+
+-
+
+Тут слід наголосити, що використання публічних брокерів в Інтернет може стати в нагоді для навчання або тестів, однак з точки зору промислового використання є небезпечним і ненадійним. Для побудови проектів диспетчеризації необхідно розгортати власний брокер (є безкоштовні версії) або користуватися відповідними хмарними сервісами IoT.
+
+Також для перевірки обміну по MQTT можна скористатися тестовими MQTT-клієнтами, наприклад онлайн-клієнт **[HiveMQ](http://www.hivemq.com/demos/websocket-client)** або офлайновий [**MQTT-explorer**](http://mqtt-explorer.com/). На рис.5.2 показаний зовнішній вигляд вікна клієнта HiveMQ для перевірки відправки (publish) та отримування повідомлень (subscription), у даному випадку той же клієнт може бути як видавцем так і абонентом. У полі «hosts» вказується DNS-ім'я або IP-адреса брокера, також вказується порт та власний ідентифікатор. Для відправки вказується тема (Topic) та корисне навантаження (Message), для отримування тема підписки.
+
+
+
+рис.5.2. Вікно тестового MQTT-клієнта.
+
+## 5.2. Деталі архітектури MQTT
+
+MQTT може зберігати повідомлення в брокері необмежено довго. Цей режим роботи керується відповідним прапорцем. Збережене на брокері повідомлення відправляється будь-якому клієнту, який підписується на цю тематичну гілку MQTT. При підписці, повідомлення негайно відправляється новому абоненту, що дозволяє йому отримати статус або сигнал з теми без очікування. Може виникнути ситуація, що Підписник може очікувати годину або навіть дні, перш ніж видавець опублікує нові дані.
+
+MQTT означує додатковий об\'єкт під назвою ***Остання воля і заповіт*** (***LWT***). LWT - це повідомлення, яке вказує клієнт брокеру на етапі підключення. LWT містить назву теми «Останньої волі» (Last-Will Topic), QoS (Last-Will QoS) і фактичне повідомлення (Last-Will Message, див.рис.5.2). Якщо клієнт неправильно відключається від брокерського з\'єднання (наприклад, тайм-аут keep-alive, помилка введення-виведення, або клієнт закриває сеанс без відключення), тоді брокер зобов\'язаний транслювати повідомлення LWT всім іншим підписаним на цю тему клієнтам.
+
+Незважаючи на те, що MQTT заснований на TCP, з\'єднання можуть обриватися, особливо в разі бездротових датчиків. Пристрій може втратити живлення, зв\'язок, або може відбутися поломка, і сеанс перейде в напіввідкритий стан (тобто з одного боку вважається що з'єднання є, а з іншого воно відсутнє). У цьому випадку TCP-сервер брокера буде вважати, що з\'єднання як і раніше є надійним і очікувати дані. Щоб вийти з цього напіввідкритого стану, MQTT використовує систему ***keep-alive* (**утримування**)**. Використовуючи цю систему, як брокер MQTT, так і клієнт мають гарантію того, що з\'єднання залишається працездатним, навіть якщо протягом деякого часу не було передачі. Значення часу утримування задається клієнтом при підключенні (див.рис.5.2). Після отримання чергового будь-якого пакету, таймери keep-alive скидаються на клієнті і сервері і починають відлік. Якщо протягом часу keep-alive клієнти не мають даних для відправки, вони повинні відправити пакет PINGREQ брокеру, який, в свою чергу, підтверджує повідомлення за допомогою PINGRESP. Якщо протягом півтора часу keep-alive пакет не буде отримано, брокер закриє з'єднання і відправить LWT-пакет всім клієнтам. Максимальний час keep-alive -- 18 годин 12 хвилин 15 секунд.
+
+MQTT дозволяє також підтримувати постійні сеанси (persistent session). Постійний сеанс зберігає на стороні брокера наступне:
+
+- всі підписки клієнта;
+
+- всі повідомлення з QoS рівним 1 або 2, які не були підтверджені клієнтом;
+
+- всі нові повідомлення з QoS рівним 1 або 2, пропущені клієнтом;
+
+- всі повідомлення з QoS рівним 2, але не підтверджені клієнтом внаслідок втрати зв'язку.
+
+Для цього клієнт при підключенні вказує свій client\_id (див.рис.5.2). Клієнт може запитувати постійний сеанс, проте брокер може відхилити запит і примусово перезапустити новий сеанс. При з\'єднанні з брокером клієнт використовує прапорець cleanSession (див.рис.5.2) для вказівки відсутності необхідності постійного сеансу. Клієнт може визначити, чи зберігся попередній сеанс за допомогою повідомлення-відповіді CONNACK.
+
+Постійні сеанси повинні використовуватися для клієнтів, які повинні отримувати всі повідомлення, навіть коли немає зв\'язку. Вони не повинні використовуватися в ситуаціях, коли клієнт тільки публікує (записує) дані в теми.
+
+Більше інформації про MQTT можна прочитати [за посиланням](https://www.hivemq.com/mqtt-essentials/).
+
+## 5.3 Рівні якості обслуговування MQTT
+
+У MQTT є три рівня якості обслуговування передачі повідомлень (див.рис.5.3):
+
+- **QoS-0 (незавірена передача)** -- це мінімальний рівень QoS, який можна назвати «відправити і забути». Це найефективніший процес доставки без підтвердження одержувачем повідомлення і без повторної передачі повідомлення відправником при втраті даних;
+
+- **QoS-1 (гарантована передача)** - цей режим гарантує доставку повідомлення хоча б один раз одержувачу. Повідомлення може бути доставлено кілька разів, і одержувач на кожне з них відправить назад підтвердження з відповіддю PUBACK;
+
+- **QoS-2 (гарантований сервіс)** - це найвищий рівень QoS, який забезпечує переконання в доставці і інформування відправника і одержувача, що повідомлення було передано правильно. Цей режим генерує більше трафіку через багатокрокове рукостискання між відправником і отримувачем.
+
+ 
+
+рис.5.3. Рівні обслуговування MQTT
+
+QoS в MQTT визначається і контролюється відправником, і у кожного відправника може бути своя політика. Типові випадки використання:
+
+- QoS-0 слід використовувати, коли повідомлення не потрібно зберігати в черзі. QoS-0 найкраще підходить для дротового підключення, або коли система сильно обмежена в пропускної здатності;
+
+- Qos-1 слід використовувати за замовчуванням; QoS1 набагато швидше, ніж QoS2, і значно знижує вартість передачі;
+
+- QoS-2 - для критично важливих застосунків; крім того, для випадків, коли повторна передача дубльованого повідомлення може привести до помилок.
+
+## 5.4 Встановлення з'єднання та обмін повідомленнями в MQTT
+
+MQTT базується на з'єднаннях клієнтів з сервером-брокером. Кожен клієнт ідентифікує себе з використанням унікального імені, за яким брокер може регулювати правила підключення. Для безпечності з'єднання може також використовуватися ідентифікація користувача та пароль. Також можна використовувати шифровану передачу поверх TLS/SSL
+
+З\'єднання з використанням MQTT починається з того, що клієнт відправляє повідомлення CONNECT брокеру. Тільки клієнт може ініціювати сеанс, і жоден клієнт не може безпосередньо зв\'язатися з іншим клієнтом. У відповідь на повідомлення CONNECT брокер завжди буде відсилати CONNACK і код статусу. Після встановлення з\'єднання, воно починає працювати.
+
+
+
+рис.5.4. Послідовність встановлення обміну по MQTT для передачі
+
+У табл.5.1 наведені дані для з'єднання п процедурі CONNECT MQTT.
+
+Таблиця 5.1.Значення полів при з'єднанні клієнта з брокером.
+
+| **Поле** | **Обов’язкове поле** | **Опис** |
+| --------------- | --------------------- | ------------------------------------------------------------ |
+| clientID | Так | Ідентифікує клієнта не сервері. Кожний клієнт має унікальний ідентифікатор, від 1 до 23 байт UTF-8. |
+| cleanSession | Ні | 0: сервер повинен відновити сеанс з клієнтом; клієнт і сервер повинні зберегти стан сеансу після відключення; 1: клієнт і сервер повинні відмінити попередній сеанс і почати новий |
+| username | Ні | Ім’я, що використовується сервером для автентифікації |
+| password | Ні | пароль |
+| lastWillTopic | Ні | тема (topic) гілки для публікації повідомлення «останньої волі» |
+| lastWillQos | Ні | рівень QoS (0…2) повідомлення «останньої волі» |
+| lastWillMessage | Ні | Корисне навантаження (payload) повідомлення «останньої волі» |
+| lastWillRetain | Ні | Чи зберігається повідомлення «останньої волі» після публікації |
+| keepAlive | Ні | Інтервал часу в секундах keep-alive (утримування) |
+
+При відповіді CONNACK, сервер (брокер) буде повертати код відповіді, які наведені в таблиці 2.
+
+Таблиця 5.2. Коди відповідей клієнта.
+
+| **Код відповіді** | **Опис** |
+| ----------------- | ------------------------------------------------------------ |
+| 0 | Успішне з’єднання |
+| 1 | У з’єднанні відмовлено : неприйнятна версія протоколу MQTT |
+| 2 | У з’єднанні відмовлено : ідентифікатор клієнта – це правильний UTF-8, однак не дозволений сервером |
+| 3 | У з’єднанні відмовлено : сервер не досяжний |
+| 4 | У з’єднанні відмовлено : невірне ім’я користувача чи пароль |
+| 5 | У з’єднанні відмовлено : клієнт не авторизований для з’єднання |
+
+Клієнт MQTT може публікувати повідомлення, як тільки він підключається до брокера. MQTT використовує фільтрування повідомлень на брокері на основі тем. Кожне повідомлення має містити тему, яку брокер може використовувати для пересилання повідомлення зацікавленим клієнтам. Як правило, кожне повідомлення має корисну інформацію, яка містить дані для передачі у форматі байтів MQTT.
+
+Клієнт, що публікує дані (видавець) вирішує, які дані він хоче відправити: двійкові, текстові, XML або JSON. Повідомлення публікації (PUBLISH**)** у MQTT має кілька атрибутів, які вказані в таблиці 5.3:
+
+Таблиця 5.3. Атрибути повідомлення PUBLISH
+
+| **Поле** | **Обов’язкове поле** | **Опис** |
+| ---------- | --------------------- | ------------------------------------------------------------ |
+| packetID | Так | Унікально ідентифікує пакет у змінному заголовку. Для QoS-0 завжди 0. |
+| topicName | Так | Тема гілки для публікації (наприклад, Drive/Speed) |
+| qos | Так | рівень QoS (0..2) |
+| retainFlag | Так | прапорець, який вказує чи буде дане повідомлення зберігатися як останнє хороше; якщо новий клієнт підпишеться під дану гілку він автоматично отримає це повідомлення |
+| payload | Ні | корисне навантаження |
+| dupFlag | Так | прапорець, що вказує на те, що повідомлення є дублікатом і відправлено повторно |
+
+Коли клієнт надсилає повідомлення до MQTT брокера для публікації, брокер читає повідомлення, підтверджує його (відповідно до рівня QoS) і обробляє. Обробка брокером включає в себе визначення того, які клієнти підписалися на тему та надсилання їм повідомлення.
+
+Клієнт, який спочатку публікує повідомлення, турбується тільки про доставку повідомлення PUBLISH брокеру. Як тільки брокер отримує повідомлення PUBLISH, він зобов\'язаний доставити його всім абонентам. Видавець не отримує жодних відгуків щодо того, хто цікавиться опублікованим повідомленням, чи скільки клієнтів отримали повідомлення від брокера.
+
+Щоб отримувати повідомлення на потрібні теми, клієнт надсилає до брокера MQTT повідомлення SUBSCRIBE (див.рис.5.5). Це повідомлення містить унікальний ідентифікатор пакета та список підписок на теми (перелік topicID). Кожна підписка складається з теми та рівня QoS. Тема в повідомленні підписки може містити підстановки, які дозволяють підписатися на теми за вказаним шаблоном, а не на одну конкретну тему. Якщо для одного клієнта існує паралельне підключення, брокер доставляє повідомлення, яке має найвищий рівень QoS для цієї теми.
+
+Таблиця 5.4. Атрибути повідомлення SUBSCRIBE
+
+| **Поле** | **Обов’язкове поле** | **Опис** |
+| -------- | -------------------- | --------------------------------------- |
+| packetID | Так | унікальний ідентифікатор пакету |
+| topic_1 | Так | перша гілка, на яку підписується клієнт |
+| qos_1 | Так | рівень QoS (0..2) для першої гілки |
+| topic_2 | Ні | друга гілка, на яку підписується клієнт |
+| qos_2 | Ні | рівень QoS (0..2) для другої гілки |
+| … | | |
+
+
+
+рис.5.5. Підписка на повідомлення по MQTT
+
+Для підписки на декілька тем в одному повідомленні можуть використовуватися знаки підстановки. Детальніше про це читайте в наступному параграфі. Щоб підтвердити кожну підписку, брокер надсилає Клієнту повідомлення про підтвердження SUBAK. Це повідомлення містить ідентифікатор пакета оригінального повідомлення SUBSCRIBE (щоб чітко ідентифікувати повідомлення) та список кодів повернення.
+
+0 - Успішно, Maximum QoS 0
+
+1 - Успішно, Maximum QoS 1
+
+2 - Успішно, Maximum QoS 2
+
+128 - Відмова
+
+Для відписки від теми використовується пакет Unsubscribe
+
+## 5.5. Теми повідомлень та використання шаблонів MQTT
+
+У MQTT слово «тема» («topic») відноситься до рядка UTF-8, який брокер використовує для фільтрування повідомлень для кожного зв\'язаного клієнта. Тема складається з одного або декількох рівнів. Кожен рівень теми розділений косою рискою («/» - роздільник рівня теми).
+
+
+
+Клієнтові не потрібно створювати потрібну тему, перш ніж її публікувати або підписатися на неї. Брокер приймає кожну дійсну тему без попередньої ініціалізації. Кожна тема повинна містити щонайменше 1 символ, рядок теми може мати пробіли. Теми є чутливими до регістру.
+
+Коли клієнт підписується на тему, він може підписатися на конкретну тему опублікованого повідомлення, або використовувати шаблони для підписки на кілька тем одночасно. ***Шаблони*** (***Wildcards***) можуть використовуватися лише для підписки на теми, а не для публікації повідомлення. Існує два різних типи шаблонів: single-level (однорівневий) та multi-level (багаторівневий).
+
+Як випливає з назви, однорівневий шаблон замінює один рівень теми. Символ «+» є однорівневим символом у темі.
+
+
+
+Будь-яка тема відповідає вказаній в однорівневому шаблоні, якщо вона містить довільний рядок замість символу підстановки («+») в шаблоні. Наприклад, підписка на
+
+*myhome/groundfloor/+/temperature*
+
+може дати наступні результати (зелена галочка -- відповідність фільтру):
+
+
+
+Багаторівневий шаблон охоплює багато рівнів тем і позначається символом «\#». Для того, щоб брокер визначив, які теми співпадають, багаторівневий підзаголовок слід розміщувати як останній символ у темі, перед яким передує коса риска.
+
+
+
+
+
+Коли клієнт підписується на тему з багаторівневим шаблоном, він отримує всі повідомлення тем, які починаються з шаблону перед символом підстановки, незалежно від того, яка довга назва цієї теми. Якщо ви вказали лише багаторівневий шаблон як тему (\#), ви отримуєте всі повідомлення, які надсилаються брокеру MQTT.
+
+Як правило, клієнти можуть публікувати теми MQTT з будь якими назвами, за виключенням тих, що починаються з символу «\$». Такі теми зарезервовані для внутрішньої статистики брокера MQTT, тому клієнти не можуть публікувати повідомлення з такими назвами тем. Наразі немає офіційної стандартизації на використання тем з «\$». Зазвичай, використовується теми з «\$SYS», але реалізація брокерів змінюється. Для прикладу, нижче за тему вибрано повний шлях до деяких системних тем, доступних для брокеру mosquito:
+
+
+
+Більше інформації про MQTT можна прочитати [за посиланням](https://www.hivemq.com/mqtt-essentials/).
+
+## Питання для самоперевірки.
+
+1. Розкажіть про загальні принципи функціонування протоколу MQTT.
+2. Розкажіть про призначення брокера.
+3. Як отримувач даних ідентифікує необхідні дані в MQTT?
+4. Які вимоги до наявності доступу по адресі (IP або DNS) до брокерів, видавців та підписників?
+5. Що включає в себе повідомлення MQTT?
+6. Розкажіть про призначення QoS.
+7. Розкажіть про повідомлення LWT.
+8. Навіщо може використовуватися clientID?
+9. На що впливає retainFlag?
+10. Розкажіть про призначення та принципи використання шаблонів тем повідомлень MQTT.
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
\ No newline at end of file
diff --git "a/\320\233\320\265\320\272\321\206/6_httpapi.md" "b/\320\233\320\265\320\272\321\206/6_httpapi.md"
new file mode 100644
index 0000000..d76f192
--- /dev/null
+++ "b/\320\233\320\265\320\272\321\206/6_httpapi.md"
@@ -0,0 +1,189 @@
+**Програмна інженерія в системах управління. Лекції.** Автор і лектор: Олександр Пупена
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
+
+# 6. Використання HTPP для обміну даними та керування доступом.
+
+## 6.1. WEB API
+
+**Прикладний програмний інтерфейс (інтерфейс програмування застосунків, інтерфейс прикладного програмування)** (*Application Programming Interface*, *API*) — набір означень підпрограм, протоколів взаємодії та засобів для створення програмного забезпечення. Спрощено - це набір чітко означених методів (функцій) для взаємодії різних компонентів. API надає розробнику засоби для швидкої розробки програмного забезпечення оскільки можна скористуватися готовими об’єктами (функціями) іншого програмного забезпечення через означені в останньому правила взаємодії. API може бути для веб-базованих систем, операційних систем, баз даних, апаратного забезпечення, програмних бібліотек.
+
+При використанні прикладного програмного інтерфейсу в контексті веб-розробки, як правило, API означується набором повідомлень-запитів HTTP та структурою повідомлень-відповідей. Повідомлення можуть мати різний формат, як правило це XML або JSON. Доступ відбувається до з однієї або декількох загальнодоступних кінцевих точок (endpoints).
+
+**Кінцеві точки** є важливими аспектами взаємодії з веб-інтерфейсами на стороні сервера, оскільки вони вказують, де знаходяться ресурси, доступ до яких може отримати стороння програма. Зазвичай доступ здійснюється через URI, до якого надсилаються HTTP-запити, і звідки очікується відповідь. Кінцеві точки повинні бути статичними, інакше правильне функціонування програмного забезпечення, яке взаємодіє з нею, не може бути гарантоване. Якщо місце розташування ресурсу змінюється (і разом з ним кінцева точка), то раніше написане програмне забезпечення буде перервано, оскільки потрібний ресурс більше не може бути знайдено в одному місці. Оскільки постачальники API все ще хочуть оновлювати свої веб-API, багато хто з них запровадили систему версій в URI, яка вказує на кінцеву точку.
+
+Наприклад, Clarifai API: кінцева точка для функцій позначення в Web API має такий URI: `https://api.google.com/v1/tag/`
+
+де `/V1/` частина URI визначає доступ до першої версії веб-API. Якщо Clarifai вирішить оновити до другої версії, вони можуть це зробити, зберігаючи при цьому підтримку стороннього програмного забезпечення, яке використовує першу версію.
+
+
+
+рис.6.1.Принципи роботи WEB-API.
+
+Веб-інтерфейси Web 2.0 часто використовують взаємодії на основі таких технологій як REST та SOAP. У той час як прикладний програмний інтерфейс у Web історично був практично синонімом для веб-служби, останнім часом тенденція змінилась (так званий Web 2.0) на відхід від Simple Object Access Protocol (SOAP) на основі веб-сервісів і сервіс-орієнтованої архітектури (SOA) до більш прямих передач репрезентативного стану (REST) стилів веб-ресурсів та ресурсно-орієнтованої архітектури (ROA). RESTful Веб-інтерфейси зазвичай базуються на основі методів HTTP для доступу до ресурсів за допомогою URL-кодуваних параметрів та використання JSON або XML для передачі даних. На відміну від цього, протоколи SOAP стандартизуються W3C і мандату на використання XML як формату корисного завантаження, як правило, над HTTP. Крім того, веб-API на базі SOAP використовує перевірку XML для забезпечення структурної цілісності повідомлень, використовуючи XML-схеми, забезпечені документами WSDL. Документ WSDL точно визначає повідомлення XML та транспортні прив'язки веб-служби.
+
+При використанні деяких Web API, що мають певні обмеження для використання або потребують ідентифікації програмного забезпечення, що викликається, необхідно вказувати API key. **Application programming interface key** (**API key**) - це код, який передається комп'ютерними програмами, викликаючи прикладний програмний інтерфейс (API) на веб-сайті, для ідентифікації викликаючої програми, її розробника чи її користувача. API key використовуються для відстеження та керування використанням API, наприклад, для запобігання зловмисному використанню або зловживання API (як це визначено, можливо, умовами надання послуг). API key часто виступає і як унікальний ідентифікатор, так і секретний маркер (токен) для автентифікації, і, як правило, має набір прав доступу до пов'язаного з ним API. API key можуть базуватися на універсально унікальному ідентифікаторі (UUID) щоб забезпечити унікальність кожного користувача.
+
+## 6.2. Основи REST
+
+**REST** (Representational State Transfer, «передача репрезентативного стану») означує ряд архітектурних принципів проектування Web-сервісів, орієнтованих на ресурси. Ці принципи включають способи обробки і передачі станів ресурсів по HTTP різноманітними клієнтськими застосунками, написаними різними мовами програмування.
+
+За останні кілька років REST стала переважаючою моделлю проектування Web-сервісів. Фактично REST зробила настільки великий вплив на Web, що практично витіснила розробку інтерфейсу, заснованого на SOAP і WSDL, через значно більш простий стиль проектування.
+
+Передбачається, що конкретна реалізація Web-сервісів REST слідує чотирьом базовим принципам проектування:
+
+– Явне використання HTTP-методів.
+
+– Незбереження стану.
+
+– Надання URI, аналогічних структурі каталогів.
+
+– Передача даних в XML, JavaScript Object Notation (JSON) або в обох форматах.
+
+Нижче розглядаються ці чотири принципи.
+
+---
+
+## 6.3. Явне використання HTTP-методів
+
+Однією з ключових характеристик Web-сервісу RESTful є явне використання HTTP-методів згідно з протоколом, означеним в RFC 2616. Адже цей HTTP передбачає наявність всіх методів для доступу до ресурсів як для читання та запису так і для зміни. Наприклад, HTTP GET означений як метод генерування даних, використовуваний клієнтським застосунком для вилучення ресурсу, отримання даних з Web-сервера або виконання запиту в надії на те, що Web-сервер знайде і поверне набір відповідних ресурсів.
+
+
+
+рис.6.2.Принципи роботи REST-API.
+
+REST пропонує розробникам використовувати HTTP-методи явно відповідно до означення протоколу. Цей основний принцип проектування REST встановлює однозначну відповідність між операціями create, read, update і delete (CRUD) і HTTP-методами. Згідно з цим необхідно використовувати методи:
+
+– POST - для створення ресурсу на сервері;
+
+– GET - для отримання ресурсу з серверу;
+
+– PUT – для зміни стану ресурсу або його поновлення;
+
+– DELETE - для видалення ресурсу.
+
+Недоліком проектування багатьох Web API є використання HTTP-методів не за прямим призначенням. Наприклад, URI запиту в HTTP GET мало б означувати один конкретний ресурс. Або рядок запиту в URI містить ряд параметрів, що означують критерії пошуку сервером набору відповідних ресурсів. Принаймні саме так описаний метод GET в HTTP/1.1 RFC. Однак часто зустрічаються непривабливі Web API, що використовують HTTP GET для виконання різного роду транзакцій на сервері (наприклад, для додавання записів в базу даних). У таких випадках URI запиту GET використовується некоректно або, принаймні, не використовується в REST-стилі (RESTfully). Якщо Web API використовує GET для запуску віддалених процедур, запит для непривабливого API може виглядати приблизно так:
+
+```http
+GET /adduser?name=Robert HTTP/1.1
+```
+
+Це невдалий проект, оскільки вищезгаданий Web-метод за допомогою HTTP-запиту GET підтримує операцію, що змінює стан. Інакше кажучи, HTTP-запит GET має побічні ефекти. У разі успішного виконання запиту в сховище даних буде додано нового користувача (в нашому прикладі - Robert). Проблема тут в основному семантична. Web-сервери призначені для відповідей на HTTP-запити GET шляхом вилучення ресурсів відповідно до URI запиту (або критерію запиту) і повернення їх або їхні уявлення у відповіді, а не для додавання запису в базу даних. З точки зору передбачуваного використання і з точки зору HTTP/1.1-сумісних Web-серверів таке використання GET є неналежним.
+
+Крім семантики ще однією проблемою є те, що для видалення, зміни або додавання запису в базу даних або для зміни будь-яким чином стану на стороні сервера GET привертає різні засоби Web-кешування (роботи) і пошукові механізми, які можуть виконувати ненавмисні зміни на сервері шляхом простого обходу посилання. Найпростішим способом вирішення цієї загальної проблеми є вставлення імен та значень параметрів URI запиту в XML-теги. Ці теги (XML-представлення створюваного об'єкта) можна відправити в тілі HTTP-запиту POST, URI якого є батьком об'єкта. Тобто наведений вище запит мав би виглядати так:
+
+```http
+POST /users HTTP/1.1
+Host: myserver
+Content-Type: application/xml
+
+
+ Robert
+
+```
+
+Це зразок RESTful-запиту: HTTP-запит POST використовується коректно, а тіло запиту містить корисне навантаження. На приймаючій стороні в запит може бути доданий ресурс, що міститься в тілі, підлеглий ресурсові, визначеному в URI запиті; в даному випадку новий ресурс повинен додаватися як нащадок /users. Таке ставлення включення (containment) між новим логічним об'єктом і його батьком, вказане в запиті POST, аналогічно відношенню підпорядкування між файлом і батьківським каталогом. Клієнтська програма встановлює відношення між логічним об'єктом і його батьком і означує URI нового об'єкта в запиті POST. Потім клієнтська програма може отримати уявлення ресурсу, використовуючи новий URI, який вказує, що принаймні логічно ресурс розташований в /users
+
+```http
+GET /users/Robert HTTP/1.1
+Host: myserver
+Accept: application/xml
+```
+
+Це правильне застосування запиту GET, оскільки він служить тільки для отримання даних. GET - це операція, яка повинна бути вільною від побічних ефектів.
+
+Загальноприйнятим підходом, відповідних рекомендацій REST по явному застосуванню HTTP-методів, є використання в URI іменників замість дієслів. У Web-сервісі RESTful дієслова POST, GET, PUT і DELETE вже означені протоколом. В ідеалі для реалізації узагальненого інтерфейсу і явного виклику операцій клієнтськими додатками Web-сервіс не повинен означувати додаткові команди або віддалені процедури, наприклад /adduser або /updateuser. Цей загальний принцип можна застосувати також до тіла HTTP-запиту, який призначений для передачі стану ресурсу, а не імені віддаленого методу або віддаленої процедури, що викликається.
+
+## 6.4. Незбереження стану
+
+Серверні застосунки при RESTful не повинні орієнтуватися на стан пов'язаний з сеансом зв'язку з клієнтом. З одного боку, наявність такого стану значно ускладнює роботу ВЕБ-застосунку та його налагодження. Крім того це вимагає наявність додаткових ресурсів для кожного підключеного клієнта. Крім того для задоволення постійно зростаючих вимог до продуктивності Web-сервіси REST повинні бути масштабованими. Для формування топології сервісів, що дозволяє при необхідності перенаправляти запити з одного сервера на інший з метою зменшення загального часу реакції на виклик Web-сервісу, зазвичай застосовують кластери серверів з можливістю розподілу навантаження і аварійного перемикання на резерв, проксі-сервери і шлюзи. Використання проміжних серверів для поліпшення масштабованості вимагає, щоб клієнти Web-сервісів REST відправляли повні самодостатні запити, що містять всі необхідні для їх виконання дані, щоб компоненти на проміжних серверах могли перенаправляти, маршрутизувати і розподіляти навантаження без локального збереження стану між запитами.
+
+При обробці повного самодостатнього запиту серверу не потрібно витягувати стан або контекст програми. Застосунок (або клієнт) Web-сервісу REST включає в HTTP-заголовки і в тіло запиту всі параметри, контекст і дані, необхідні серверному компоненту для генерування відповіді. У цьому сенсі незбереження стану (statelessness) покращує продуктивність Web-сервісу і спрощує проектування і реалізацію серверних компонентів, оскільки відсутність стану на сервері усуває необхідність синхронізації сеансових даних із зовнішнім застосунком.
+
+## 6.5. Відображення URI, аналогічних структурі каталогів
+
+З точки зору звернення до ресурсів з клієнтського за стосунку URI, що надаються, означують наскільки інтуїтивним буде Web-сервіс REST і чи буде він використовуватися так, як припускав розробник. Третя характеристика Web-сервісу RESTful повністю присвячена URI.
+
+URI-адреси Web-сервісу REST повинні бути інтуїтивно зрозумілими. Розглядайте URI як якийсь самодокументований інтерфейс, що майже не вимагає пояснень або звернення до розробника для його розуміння і для отримання відповідних ресурсів. Тому структура URI повинна бути простою, передбачуваною і зрозумілою.
+
+Один із способів досягти такого рівня зручності використання - побудова URI за аналогією зі структурою каталогів. Такого роду URI є ієрархічними, що походить із одного кореневого шляху, розгалуження якого відображають основні функції сервісу. Згідно з цим означенням, URI - це не просто рядок з косими як роздільниками, а скоріше дерево з встановленими вище і нижче лежачими гілками, з'єднаними в вузлах. Наприклад, в сервісі обговорень різних тем можна означити структурований набір URI такого вигляду:
+
+```http
+http://www.myservice.org/discussion/topics/{topic}
+```
+
+Корінь /discussion має нижчий вузол /topics. Нижче розташовуються назви тем (наприклад, gossip (чутки), technology (технологія) і т.д.), кожна з яких вказує на свою гілку обговорення. В рамках цієї структури можна легко викликати гілки обговорення простим введенням чогось після /topics/.
+
+У деяких випадках каталого-подібна структура особливо добре підходить для шляхів до ресурсів. Як приклад можна назвати ресурси, впорядковані за датою. Для них дуже добре підходить ієрархічний синтаксис.
+
+Наступний приклад інтуїтивно зрозумілий, оскільки заснований на правилах:
+
+```http
+ http://www.myservice.org/discussion/2008/12/10/{topic}
+```
+
+Перший фрагмент шляху - чотири цифри року, другий - дві цифри дня і третій - дві цифри місяця. Подібне пояснення може здатися дещо спрощеним, але це саме той рівень простоти, який нам потрібен. Люди і комп'ютери можуть легко генерувати подібні структуровані URI, оскільки вони засновані на правилах. Вказівка фрагментів шляху у відповідних позиціях згідно синтаксису робить URI уніфікованими, оскільки існує закономірність їх створення:
+
+```http
+ http://www.myservice.org/discussion/{year}/{day}/{month}/{topic}
+```
+
+## 6. 6. Передача XML, JSON або обох
+
+Представлення ресурсу, як правило, відображає поточний стан ресурсу (і його атрибутів) на момент його запиту клієнтським додатком. Представлення ресурсів в цьому сенсі є просто знімками в конкретні моменти часу. Ці представлення повинні бути такими ж простими, як представлення запису в базі даних, що складається з відображення між іменами стовпців і XML-тегами, де значення елементів в XML містять значення рядків. Якщо система має модель даних, то згідно з цим визначенням представлення ресурсу є знімком стану атрибутів одного з об'єктів моделі даних системи. Це ті об'єкти, які буде обслуговувати Web-сервіс REST.
+
+Останній набір обмежень, тісно пов'язаний з розробкою Web-сервісів RESTful, відноситься до формату даних, якими обмінюються застосунок і сервіс при роботі в режимі запит/відповідь або в тілі HTTP-запиту. Тут особливо важливі простота, читабельність і зв'язаність.
+
+Об'єкти моделі даних зазвичай якось пов'язані, і ці відносини між об'єктами (ресурсами) моделі даних повинні відображатися в способі їх подання для передачі клієнтського додатку. У сервісі обговорень приклад представлень пов'язаних ресурсів може включати в себе кореневу тему обговорення і її атрибути, а також вбудовані посилання на відповіді, надіслані в цю тему.
+
+```xml
+
+
+ {comment}
+
+
+
+
+
+```
+
+Нарешті, щоб надати клієнтським застосункам можливість запитувати конкретний найбільш підходящий їм тип вмісту, проектують сервіс так, щоб він використовував вбудований HTTP-заголовок Accept, значення якого є MIME-типом. Деякі загальновживані MIME-типи, які використовуються RESTful-сервісами, перераховані в таблиці 6.1.
+
+Таблиця 6.1. Загально-вживані MIME-типи, що використовують RESTful-сервіси
+
+| MIME-тип | Тип змісту |
+| -------- | --------------------- |
+| JSON | application/json |
+| XML | application/xml |
+| XHTML | application/xhtml+xml |
+
+Це дозволить використовувати сервіс клієнтським застосунком, написаним на різних мовах і працюючим на різних платформах і пристроях. Використання MIME-типів і HTTP-заголовку Accept є механізм узгодження вмісту (content negotiation), що дозволяє клієнтським застосункам вибирати відповідний для них формат даних і мінімізувати зв'язність даних між сервісом і застосунком, що його використовує.
+
+## Запитання для самоперевірки
+
+1. Поясніть що таке API.
+
+2. Поясніть що таке кінцева точка у WEB API. Чому вона не повинна змінюватися?
+
+3. Поясніть своїми словами як функціонує WEB API.
+
+4. Яка роль API-key у WEB API?
+
+5. Що таке REST?
+
+6. Розкажіть про вимогу явного використання методів HTTP в технології REST.
+
+7. Які методи HTTP і для чого пропонується використовувати в REST.
+
+8. Розкажіть і поясніть приклад неправильного (не RESTful) використання методу GET.
+
+9. Що значить вимога "незбереження стану" в REST?
+
+10. Які вимоги до структури URI в REST?
+11. Яким чином кодуються дані, які передаються по REST API?
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
\ No newline at end of file
diff --git "a/\320\233\320\265\320\272\321\206/7_git.md" "b/\320\233\320\265\320\272\321\206/7_git.md"
new file mode 100644
index 0000000..2d8b995
--- /dev/null
+++ "b/\320\233\320\265\320\272\321\206/7_git.md"
@@ -0,0 +1,457 @@
+**Програмна інженерія в системах управління. Лекції.** Автор і лектор: Олександр Пупена
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
+
+# 7. Системи керування версіями: Git, GitHub
+
+## 7.1. Системи керування версіями
+
+Система керування версіями (***СКВ,*** source code management, SCM) - це система, що записує зміни у файл або набір файлів протягом деякого часу таким чином, що можна повернутися до певної версії пізніше. Це може бути як програмний код так і будь-які інші файли.
+
+Системи керування версіями зазвичай використовуються при розробці програмного забезпечення для відстеження, документування та контролю над поступовими змінами в електронних документах: у сирцевому коді застосунків, кресленнях, електронних моделях та інших документах, над змінами яких одночасно працюють декілька людей. Кожна версія позначається унікальною цифрою чи літерою, зміни документу занотовуються. Зазвичай також зберігаються дані про автора зробленої зміни та її час. Інструменти для керування версіями входять до складу багатьох інтегрованих середовищ розробки.
+
+СКВ дозволяє повернути вибрані файли до попереднього стану, повернути весь проект до попереднього стану, побачити зміни, побачити, хто останній змінював щось і спровокував проблему, хто вказав на проблему і коли, та багато іншого.
+
+Існують три основні типи систем керування версіями: локальні, з централізованим сховищем та розподіленим (деценралізованим).
+
+Багато людей в якості одного з методів керування версіями застосовують копіювання файлів в окрему директорію (можливо навіть директорію з відміткою за часом). Даний підхід є дуже поширеним завдяки його простоті, проте він, схильний до появи помилок. Можна легко забути в якій директорії ви знаходитеся і випадково змінити не той файл або скопіювати не ті файли, які ви хотіли. Щоб справитися з цією проблемою, програмісти розробили локальні СКВ, що мають просту базу даних, яка зберігає всі зміни в файлах під керуванням версіями (рис.7.1). Сховище (база даних) з набором файлів та змін, які відбувалися над ними, що керуються СКВ називається ***репозиторієм***. По суті репозиторій як правило є одним проектом, над яким проводяться операції як з єдиним набором файлів.
+
+
+
+Рис.7.1. Принципи роботи локальних систем керування версіями.
+
+СКВ дає можливість:
+
+- зберігати код;
+
+- запам'ятовувати історію змін до коду, та дозволяти у будь-який момент побачити хто саме зробив зміни, коли зробив зміни;
+
+- відкотитися до будь-якої версії коду у будь-який момент;
+
+- об'єднувати зміни різних версій, станів та розробників;
+
+Наступним важливим питанням, з яким стикаються люди, є необхідність співпрацювати з іншими розробниками. Щоб справитися з цією проблемою, були розроблені централізовані системи керування версіями (**ЦСКВ**). Такі системи як CVS, Subversion і Perforce, мають єдиний сервер, який містить всі версії файлів, та деяке число клієнтів, які отримують файли з центрального місця.
+
+
+
+Рис. 7.2. Централізовані системи керування версіями.
+
+Такий підхід має безліч переваг, особливо над локальними СКВ. Наприклад, кожному учаснику проекту відомо, певною мірою, чим займаються інші. Адміністратори мають повний контроль над тим, хто і що може робити. Набагато легше адмініструвати ЦСКВ, ніж мати справу з локальними базами даних для кожного клієнта. Але цей підхід також має деякі серйозні недоліки. Найбільш очевидним є єдина точка відмови, яким є централізований сервер. Якщо сервер виходить з ладу протягом години, то протягом цієї години ніхто не може співпрацювати або зберігати зміни над якими вони працюють. Якщо жорсткий диск центральної бази даних на сервері пошкоджено, і своєчасні резервні копії не були зроблені, то втрачається абсолютно все --- вся історія проекту, крім одиночних знімків проекту, що збереглися на локальних машинах людей. Локальні СКВ страждають тією ж проблемою --- щоразу, коли вся історія проекту зберігається в одному місці, ви ризикуєте втратити все.
+
+У розподілених системах керування версіями (**РСКВ**, Distributed Version Control System) клієнти не просто отримують останній знімок файлів репозиторія: натомість вони є повною копією сховища разом з усією його історією. Таким чином, якщо ламається який-небудь сервер, через який співпрацюють розробники, будь-який з клієнтських репозиторіїв може бути скопійований назад до серверу, щоб відновити його. Кожна копія дійсно є повною резервною копією всіх даних. Крім того, багато з цих систем дуже добре взаємодіють з декількома віддаленими репозиторіями, так що можна співпрацювати з різними групами людей, застосовуючи різні підходи в межах одного проекту одночасно. Це дозволяє налаштувати декілька типів робочих процесів, таких як ієрархічні моделі, які неможливі в централізованих системах.
+
+
+
+Рис 7.3. Розподілені системи керування версіями.
+
+## 7.2. Система керування версіями GIT
+
+***Git*** --- розподілена система керування версіями файлів та спільної роботи. Проект створив Лінус Торвальдс для керування розробкою ядра Linux, а сьогодні підтримується Джуніо Хамано (англ. Junio C. Hamano). Git є однією з найефективніших, надійних і високопродуктивних систем керування версіями, що надає гнучкі засоби нелінійної розробки, що базуються на відгалуженні і злитті гілок. Програма є вільною і випущена під ліцензією GNU GPL версії 2.
+
+Система спроектована як набір програм, спеціально розроблених з врахуванням їхнього використання у скриптах. Це дозволяє зручно створювати спеціалізовані системи керування версіями на базі Git або користувацькі інтерфейси. Система має ряд користувацьких інтерфейсів: наприклад, **gitk** та **git-gui** розповсюджуються з самим Git. Віддалений доступ до репозиторіїв Git забезпечується git-демоном (службою), SSH або HTTP сервером.
+
+Для керування Git можна використовувати різні варіанти клієнтів, зокрема Git-SCM . Крім оригінальних клієнтів командного рядка, є безліч клієнтів з графічним інтерфейсом користувача з різними можливостями. Командний рядок --- єдине місце, де можна виконувати всі команди Git, оскільки більшість графічних інтерфейсів для простоти реалізують тільки деяку підмножину функціональності Git. Для інсталяції Git під Windows достатньо перейти за посиланнями і завантаження почнеться автоматично.
+
+Після інсталяції Git необхідно провести початкові налаштування. До Git входить утиліта що має назву git config, яка дозволяє отримати чи встановити параметри, що контролюють усіма аспектами того, як Git виглядає чи працює. Ці параметри можуть бути збережені в різних місцях. У системах Windows, Git шукає файл .gitconfig в каталозі \$HOME (C:\\Users\\\$USER для більшості користувачів). Він також все одно шукає файл /etc/gitconfig, хоча відносно кореня MSys, котрий знаходиться там, де ви вирішили встановити Git у вашій Windows системі, коли ви запускали інсталяцію. Є також системний конфігураційний файл C:\\ProgramData\\Git\\config. Цей файл може бути зміненим лише за допомогою git config -f \<файл\> адміністратором.
+
+Перше, що необхідно зробити після інсталяції Git - встановити ім'я користувача та адресу електронної пошти. Це важливо, тому що кожен коміт в Git використовує цю інформацію, і вона незмінно включена у комміти, які ви робите:
+
+```bash
+git config --global user.name "John Doe"
+git config --global user.email johndoe@example.com
+```
+
+Якщо ви передаєте опцію \--global, ці налаштування потрібно зробити тільки один раз, тоді Git завжди буде використовувати цю інформацію для всього, що ви робите у цій системі. Якщо ви хочете, перевизначити ім'я або адресу електронної пошти для конкретних проектів, ви можете виконати цю ж команду без опції \--global в каталозі необхідного проекту. Багато з графічних інструментів допомагають зробити це при першому запуску.
+
+Якщо ви хочете подивитися на свої налаштування, можете скористатися командою
+
+```bash
+git config –-list
+```
+
+, щоб переглянути всі налаштування, які Git може знайти.
+
+Для отримання допомоги по конкретній команді, можна викликати:
+
+```bash
+git help
+```
+
+або
+
+```bash
+git -h
+```
+
+## 7.3. Основи роботи з Git для локального репозиторію
+
+Більшість дій можна виконувати на локальній файловій системі без використання інтернет підключення. Вся історія змін зберігається локально і при необхідності вивантажується у віддалений репозиторій. Будь-який знімок в Git спочатку робиться локально, а потім вивантажується у віддалений репозиторій.
+
+Git зберігає дані набором знімків. Кожного разу при фіксації поточної версії проекту Git зберігає зліпок того, як виглядають всі файли проекту. Але якщо файл не змінювався, то дається посилання на раніше збережений файл (див. рис. 7.4). Git схожий на своєрідну файлову систему з інструментами, які працюють поверх неї.
+
+
+
+Рис. 7.4. Дані як зліпки стану проекту в часі
+
+Усі зміни користувачем проводяться у файлах ***робочої директорії*** (Working Directory). По суті, робоча директорія -- це місце розміщення плинної редагованої версії усіх файлів проекту (див.рис.7.5). У робочій директорії знаходиться папка «.git», яка вміщує ***репозиторій проекту***, тобто базу даних всієї необхідної інформації для контролю версій: зліпки файлів, розмір, час створення і останньої зміни. За необхідності фіксації файлів робочої папки вони передаються і зберігаються в репозиторію, при необхідності редагування конкретної версії -- витягуються з репозиторію.
+
+У своїй базі Git зберігає все по контрольним сумам (хешам) файлів. Перед кожним збереженням файлів Git, використовуючи спеціальний алгоритм (SHA-1) за змістом файлу обчислює хеш (контрольну суму). Отриманий хеш стає унікальним індексом файлу в Git. Використовуючи хеш Git легко відслідковує зміни в файлах.
+
+
+
+Рис. 7.5. Приклад робочої директорії
+
+При редагуванні файлів в робочій директорії вони змінюються, тобто не відповідають їх версії в репозиторію. Коли змінювані (***modified***) файли є сенс зафіксувати в репозиторії, спочатку їх індексують (***stage***). Під час індексації, у файл індекса, який також називають областю додавання (***staging area***), що зазвичай знаходиться в директорії Git, розміщується інформація про те, що саме буде зафіксовано у наступному знімку (див.рис.7.6). Після індексації усіх необхідних файлів, фіксація проводиться командою ***commit***, а файли вважаються зафіксованими або «збереженими в коміті» (***commited***).
+
+Таким чином, у випадку, якщо окрема версія файлу вже є в директорії Git, цей файл вважається збереженим у коміті. Якщо він зазнав змін і перебуває в індексі, то він індексований. Якщо ж його стан відрізняється від того, який був у коміті, і файл не знаходиться в індексі, то він називається зміненим.
+
+
+
+Рис. 7.6. Області збереження в Git.
+
+Для роботи з проектом, що наразі не перебуває під СКВ, спочатку треба перейти до теки цього проекту. У командному рядку Windows для цього можна використати команду cd:
+
+```bash
+cd /c/user/my_project
+```
+
+та виконати:
+
+```bash
+git init
+```
+
+Це створить новий підкаталог .git, який містить всі необхідні файли репозиторія --- скелет Git-репозиторія. На цей момент, у даному проекті ще нічого не відстежується. Якщо необхідно додати існуючі файли під керування версіями (на відміну від порожнього каталогу), слід проіндексувати ці файли і зробити перший коміт. Це можна зробити за допомогою декількох команд git add, що означують файли, за якими необхідно слідкувати, після яких треба виконати git commit:
+
+```bash
+git add *.c
+git add LICENSE.txt
+git commit -m 'Перша версія проекту'
+```
+
+У цьому прикладі було проіндексовано усі файли з розширенням \*.c та файл LICENSE.txt, після чого вони були зафіксованими в коміті.
+
+Після цих команд на машині буде локальний Git репозиторій та робоча директорія з усіма файлами цього проекту. При кожній зміні файлів в робочій не обов'язково їх відправляти в репозиторій. Зазвичай, це робиться коли треба зафіксувати певну версію проекту для можливості повернення до неї.
+
+Кожен файл робочої директорії може бути в одному з двох станів (рис.7): ***контрольований*** (***tracked***) чи ***неконтрольований*** (***untracked***). Контрольовані файли --- це файли, що були в останньому знімку. Вони можуть бути не зміненими (***unmodified***), зміненими (***modified***) або індексованими (staged). Якщо стисло, контрольовані файли --- це файли, про які Git щось знає. Неконтрольовані файли --- це все інше, будь-які файли у вашій робочій директорії, що не були у вашому останньому знімку та не існують у вашому індексі. Якщо ви щойно зробили клон репозиторія, усі ваші файли контрольовані та не змінені, адже Git щойно їх отримав, а ви нічого не редагували.
+
+По мірі редагування файлів, Git бачить, що вони змінені, адже їх змінили після останнього коміту. Впродовж роботи розробник вибірково індексує ці змінені фали та потім зберігає всі індексовані зміни, та цей цикл повторюється.
+
+
+
+Рис.7.7. Стан файлів Git в робочій директорії
+
+Перевірку стану можна зробити через команду `git status` , або через `git status -s` для короткої версії статусу.
+
+Добавлення нових або змінених файлів до індексу робиться з використанням команди
+
+```bash
+git add <файли>
+```
+
+Команда `git add` приймає шлях файлу або директорії. Якщо це директорія, команда додає усі файли в цій директорії включно з піддерикторіями. `git add` -- багатоцільова команда, її слід використовувати щоб почати контролювати нові файли, щоб додавати файли та для інших речей, наприклад позначання конфліктних файлів як розв'язаних.
+
+Команда `git diff` показує які саме зміни були внесені у змінені файли відносно останнього коміту.
+
+Для внесення індексованих файлів в коміт, використовується команда
+
+```bash
+git commit
+```
+
+Додавання опції `-a` до команди `git commit`, змушує Git автоматично додати кожен файл, що вже контролюється, до коміту, що дозволяє вам пропустити команди `git add`.
+
+Щоб видалити файл з Git, вам треба прибрати його з контрольованих файлів (вірніше, видалити його з вашого індексу) та створити коміт. Це робить команда `git rm`, а також видаляє файл з вашої робочої директорії, щоб наступного разу він не відображався неконтрольованим. Якщо ви просто видалите файл з вашої робочої директорії, при виводі команди `git status` він з'явиться під заголовком `Changes not staged for commit` (тобто, *неіндексованим*) Потім, якщо ви виконаєте `git rm`, файл буде індексованим на видалення.
+
+Для перейменування файлу у Git, можна виконати наступну команду:
+
+```bash
+git mv стара_назва нова_назва
+```
+
+Для перегляду історії комітів використовується команда `git log` , яка має багато опцій для налаштувань.
+
+Для того, щоб Git не звертав уваги на деякі файли в робочій директорії, можна створити файл `.gitignore`, що містить шаблони, за яким файли ігноруються. Налаштування у файлі **[.gitignore](https://git-scm.com/docs/gitignore)** означують які ще не контрольовані файли потрібно ігнорувати при наступній індексації. Ці налаштування ніяк не впливають на індексацію файлів, які вже контрольовані (tracked) Gitом.
+
+## 7.4. Основи роботи з галуженнями
+
+Як вже зазначалося, Git зберігає дані не як послідовність змін, а як послідовність знімків. Коли фіксуються зміни (рис.7.8), Git зберігає об'єкт фіксації, що містить вказівник на знімок файлу, ім'я та поштову адресу автора, набране при коміті повідомлення та вказівники на попередні фіксації (parent). При першій фіксації (98ca9 на рис.7.8), посилання на попередню буде нульовим. Кожна інша фіксація буде містити посилання на попередню (стрілками вказується саме посилання на попередній коміт а не послідовність). Таким чином формується одна гілка з усією історією фіксацій.
+
+
+
+Рис.7.8. Фіксації та їх батьки.
+
+Гілка в Git це просто легкий вказівник, що може пересуватись, на одну з цих фіксацій шляхом поступового переходу між ними. Загальноприйнятим ім'ям першої гілки в Git колись була ***master***, а з 2020 року ***main*** . При ініціалізації (створенні) репозиторія, за замовчуванням, Git створює тільки цю гілку. Коли ви почнете робити фіксації, вам надається гілка master(main), що вказує на останню зроблену фіксацію. Таким чином, щоразу, коли відбувається фіксація, вказівник «переміщується» вперед на останню фіксацію автоматично.
+
+Галуження (***branches***) --- це відмежування від основної лінії розробки для продовження своєї частини роботи та уникнення конфліктів з основною лінією. Git дозволяє створити декілька гілок і перемикатися між ними. Це корисно, оскільки дозволяє працювати декільком розробникам над своїм функціоналом не заважаючи іншим і не псуючи основну гілку. Гілки у Git дуже просто використовувати. Приклад використання галужень в проекті показаний на рис.7.9.
+
+
+
+рис.7.9.Використання галужень в проекті
+
+З певного моменту код розгалужується, над кожною гілкою можна працювати окремо, наприклад кільком розробникам, а тоді гілки об'єднуються назад у головну гілку, де всі можуть бачити і використовувати зроблені зміни.
+
+Гілка в Git просто є вказівником на одну із фіксацій. При кожній новій фіксації гілка в Git рухається автоматично (тобто перемикається на конкретну фіксацію). Гілка є простим файлом, який містить 40 символів контрольної суми SHA-1 фіксації. Тобто коли створюється нова гілка, створюється новий файл-вказівник, який вказує на конкретну фіксацію.
+
+Cтворення нової гілки робиться за допомогою команди `git branch`:
+
+```bash
+git branch testing
+```
+
+У результаті цього створюється новий вказівник на фіксацію, в якій ви зараз знаходитесь.
+
+
+
+рис.7.10. Дві гілки вказують на одну послідовність фіксацій
+
+У певний момент часу Git знаходиться на одній із гілок. Для цього він зберігає особливий вказівник під назвою ***HEAD*** - це просто вказівник на активну локальну гілку. Команда git branch тільки створює нову гілку --- вона не переключає на неї, а залишається на активній.
+
+Щоб переключитися на існуючу гілку, треба виконати команду `git checkout`. Наприклад для переключення на нову гілку testing:
+
+```bash
+git checkout testing
+```
+
+Це пересуває HEAD, щоб він вказував на гілку testing.
+
+
+
+рис.7.11. HEAD вказує на поточну гілку
+
+Після чергової фіксації, гілка testing пересунулась уперед, а гілка master досі вказує на фіксацію, що був у момент виконання `git checkout` для переключення гілок.
+
+
+
+рис.7.12. Гілка testing пересувається уперед при фіксації
+
+Після переключення назад до гілки master:
+
+```bash
+git checkout master
+```
+
+вказівник HEAD пересувається назад на гілку master, та повертаються файли у робочій папці до стану знімку, на який вказує master. Це також означає, що якщо зараз робляться нові зміни, вони будуть походити від ранішої версії проекту (рис.7.13).
+
+
+
+рис.7.13. HEAD пересувається, коли ви отримуєте (checkout)
+
+Важливо зауважити, що коли переключаються гілки в Git, файли у робочій директорії змінюються. Якщо переключитися до старшої гілки, робоча папка буде повернута до того стану, який був на момент останнього фіксування у тій гілці. Якщо Git не може зробити це без проблем, він не дасть переключитися взагалі.
+
+Якщо зробити декілька змін та зафіксувати:
+
+```bash
+git commit -a -m 'Зробив інші зміни'
+```
+
+то історія проекту розійшлася (diverged) по двом різним гілкам. Ви створили гілку, дещо в ній зробили, переключились на головну гілку та зробили там щось інше. Обидві зміни ізольовані в окремих гілках. Ви можете переключатись між цими гілками та злити їх разом, коли вони будуть готові. І все це робиться за допомогою простих команд `branch`, `checkout` та `commit`.
+
+
+
+рис.7.14. Розходження історій
+
+Зливання (об'єднання, ***merge***, мердж) гілок покажемо на прикладі. Припустимо є три гілки mster, iss53 і hotfix (рис.7.15).
+
+
+
+рис.7.15. Приклад з 3-ма гілками
+
+Для злиття (merge) гілки hotfix до master використовується команда `git merge`. Перед цим за допомогою checkout йде переключення на гілку master
+
+```bash
+git checkout master
+git merge hotfix
+Updating f42c576..3a0874c
+Fast-forward
+ index.html | 2 ++
+ 1 file changed, 2 insertions(+)
+```
+
+Зверніть увагу на фразу "fast-forward" у цьому злитті. Через те, що коміт C4, який зливався, належав гілці hotfix, що була безпосередньо попереду поточного коміту C2, Git просто переміщує вказівник вперед. Іншими словами, коли ви зливаєте один коміт з іншим, і це можна досягнути слідуючи історії першого коміту, Git просто переставляє вказівник, оскільки немає змін-відмінностей, які потрібно зливати разом - це називається "перемоткою" ("fast-forward"). Тепер це має вигляд як на рис.7.16
+
+
+
+рис.7.16. master перекинутий на hotfix
+
+Для видалення гілки hotfix використовується команда `git branch` з опцією -d:
+
+```bash
+git branch -d hotfix
+Deleted branch hotfix (3a0874c).
+```
+
+Зауважте, що тепер зміни з гілки hotfix відсутні в гілці iss53. Якщо вам потрібні ці зміни підчас роботи над iss53, ви можете злити master з iss53 командою git merge master, або просто почекати до того моменту коли ви будете інтегровувати iss53 в master.
+
+Припустимо, що необхідно злити iss53 з гілкою master. Все що потрібно це перемкнутися на робочу гілку і виконати команду git merge:
+
+```bash
+git checkout master
+Switched to branch 'master'
+git merge iss53
+Merge made by the 'recursive' strategy.
+index.html | 1 +
+1 file changed, 1 insertion(+)
+```
+
+Виглядає трошки інакше, ніж те, що було з гілкою hotfix. У цьому випадку історія змін двох гілок почала відрізнятися в якийсь момент. Оскільки коміт поточної гілки не є прямим нащадком гілки, в яку зливаються зміни, Git мусить робити триточкове злиття, користуючись двома знімками, що вказують на гілки та третім знімком - їх спільним нащадком.
+
+
+
+рис.7.17. Три відбитки типового злиття
+
+Замість того, щоб просто пересунути вказівник гілки вперед, Git створює новий знімок, що є результатом 3-точкового злиття, і автоматично створює новий коміт, що вказує на нього. Його називають комітом злиття (merge commit) та його особливістю є те, що він має більше одного батьківського коміту.
+
+
+
+рис.7.18. Коміт злиття
+
+Варто зауважити, що Git сам визначає найбільш підходящого спільного нащадка, якого брати за основу зливання.
+
+Перегляд усіх гілок доступний через команду
+
+```bash
+git branch
+ iss53
+* master
+ testing
+```
+
+Зверніть увагу на символ \* перед master: це вказівник на вашу поточно вибрану гілку (тобто ту, на котру вказує HEAD). Це означає, що якщо ви зараз захочете зробити коміт, master оновиться вашими новими змінами. Щоб побачити ваші останні коміти - запустіть git branch -v:
+
+```bash
+git branch -v
+ iss53 93b412c fix javascript issue
+* master 7a98805 Merge branch 'iss53'
+ testing 782fd34 add scott to the author list in the readmes
+```
+
+Опції `--merged` та `--no-merged` корисні для фільтрування списку гілок залежно від того чи вони були злиті з поточною гілкою.
+
+## 7.5. Вирішення конфліктів злиття
+
+Трапляється, що процес злиття не проходить гладко. Якщо ви маєте зміни в одному й тому самому місці в двох різних гілках, Git не зможе їх просто злити. Якщо підчас роботи над `iss53` ви поміняли ту саму частину файлу, що й у гілці `hotfix`, ви отримаєте конфлікт, що виглядає приблизно так:
+
+```bash
+git merge iss53
+Auto-merging index.html
+CONFLICT (content): Merge conflict in index.html
+Automatic merge failed; fix conflicts and then commit the result.
+```
+
+У цьому випадку Git не створив автоматичний коміт зливання. Він призупинив процес допоки ви не вирішите конфлікт. Для того, щоб переглянути знову які саме файли спричинили конфлікт, спочатку треба переглянути `git status`:
+
+```bash
+git status
+On branch master
+You have unmerged paths.
+ (fix conflicts and run "git commit")
+
+Unmerged paths:
+ (use "git add ..." to mark resolution)
+
+ both modified: index.html
+
+no changes added to commit (use "git add" and/or "git commit -a")
+```
+
+Все, що має конфлікти, які не були вирішені є в списку ***незлитих*** (***unmerged***) файлів. У кожен такий файл Git додає стандартні позначки-вирішенння для конфліктів, отже ви можете відкрити ці файли і вирішити конфлікти самостійно. Якщо ви хочете використовувати графічний інструмент для розв'язання конфліктів, виконайте команду `git mergetool`, яка запустить графічний редактор та проведе вас по всьому процесу.
+
+У вашому файлі з конфліктом появиться блок, схожий на таке:
+
+```html
+<<<<<<< HEAD:index.html
+
+=======
+
+>>>>>>> iss53:index.html
+```
+
+Розглянемо, як це розуміти. Версія файлу в `HEAD` (з вашої `master` гілки, оскільки ви запустили зливання, будучи на ній) у верхній частині блоку (все вище `=======`), а версія з `iss53` - все, що нижче. Щоб розв’язати цю несумісність, вам потрібно вибрати одну із версій, або самостійно (вручну) поредагувати вміст файлу. Наприклад, ви можете вирішити цей конфілікт, замінивши блок повністю:
+
+```html
+
+```
+
+В цьому випадку ми взяли потрохи з кожної секції, а стрічки `<<<<<<<`, `=======` та `>>>>>>>` видалили повністю. Після того, як ви розв’язали подібні несумісності в кожному блоці конфліктних файлів, виконайте для них `git add`, щоб індексувати та позначити, як ті, що розв’язані. Індексуючи файл, ви позначаєте його для Git таким, що більше не має конфлікту. Якщо ви хочете використовувати графічний інструмент для розв’язання конфліктів, виконайте команду `git mergetool`, яка запустить графічний редактор та проведе вас по всьому процесу:
+
+```bash
+git mergetool
+
+This message is displayed because 'merge.tool' is not configured.
+See 'git mergetool --tool-help' or 'git help config' for more details.
+'git mergetool' will now attempt to use one of the following tools:
+opendiff kdiff3 tkdiff xxdiff meld tortoisemerge gvimdiff diffuse diffmerge ecmerge p4merge araxis bc3 codecompare vimdiff emerge
+Merging:
+index.html
+
+Normal merge conflict for 'index.html':
+ {local}: modified file
+ {remote}: modified file
+Hit return to start merge resolution tool (opendiff):
+```
+
+Для того, щоб використовувати інструмент-програму іншу, ніж по-замовчуванню (Git обрав `opendiff`, оскільки команду було запущено з Mac), подивіться на список сумісних зверху одразу після “one of the following tools.” Просто введіть ім’я потрібного інструменту.
+
+Після того, як ви вийшли з програми для зливання, Git спитає вас чи було зливання успішним. Якщо ви відповісте, що так, Git проіндексує файл для того, щоб позначити файл як безконфліктний. Можете виконати `git status` знову, щоб перевірити чи всі конфлікти розв’язані:
+
+```bash
+$ git status
+On branch master
+All conflicts fixed but you are still merging.
+ (use "git commit" to conclude merge)
+
+Changes to be committed:
+
+ modified: index.html
+```
+
+Якщо ви задоволені результатом та перевірили, що всі файли, котрі містили несумісності, проіндексовані, можете виконувати `git commit` і, таким чином, завершувати злиття. Повідомлення після коміту виглядає приблизно так:
+
+```bash
+Merge branch 'iss53'
+
+Conflicts:
+ index.html
+#
+# It looks like you may be committing a merge.
+# If this is not correct, please remove the file
+# .git/MERGE_HEAD
+# and try again.
+
+
+# Please enter the commit message for your changes. Lines starting
+# with '#' will be ignored, and an empty message aborts the commit.
+# On branch master
+# All conflicts fixed but you are still merging.
+#
+# Changes to be committed:
+# modified: index.html
+#
+```
+
+Якщо ви вважаєте, що це допоможе іншим зрозуміти коміт злиття у майбутньому, можете змінити його повідомлення — докладно розказати, як ви розвʼязали конфлікт, чому ви зробили саме такі зміни, якщо це й без того не є очевидним.
+
+Детальніше про роботу з Git читайте в українському варіанті онлайн книги [Pro Git](https://git-scm.com/book/uk/v2)
+
+## Запитання для самоперевірки
+
+1. Поясніть призначення систем керування версіями.
+2. Які принципи функціонування централізованих та розподілених системи керування версіями?
+3. Які принципи функціонування Git?
+4. Що таке stage, commit?
+5. Що таке tracked файли в Git? Як можна задати які файли будуть tracked?
+6. Розкажіть про основні принципи роботи з галуженнями.
+7. Що робить команда checkout в Git?
+8. Розкажіть про принципи об'єднання (merge) гілок.
+9. Розкажіть про причину виникнення конфліктів зливання та спосіб їх вирішення.
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
\ No newline at end of file
diff --git "a/\320\233\320\265\320\272\321\206/8_github.md" "b/\320\233\320\265\320\272\321\206/8_github.md"
new file mode 100644
index 0000000..9e59c71
--- /dev/null
+++ "b/\320\233\320\265\320\272\321\206/8_github.md"
@@ -0,0 +1,219 @@
+**Програмна інженерія в системах управління. Лекції.** Автор і лектор: Олександр Пупена
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
+
+# 8. Робота з віддаленими сховищами в Git/GitHub
+
+## 8.1. Загальні основи використання GitHub
+
+**GitHub** - це найбільший хостинг для сховищ (репозиторіїв) Git, та є центром співпраці між мільйонами розробників та проектів. Великий відсоток усіх сховищ Git мають в якості віддаленого сховища GitHub. Багато проектів з відкритим кодом використовують його задля Git хостингу, керування завданнями, перегляду коду та для багато чого іншого.
+
+Для користування GitHub треба створити безкоштовний обліковий запис: зайти до https://github.com, обрати ім’я користувача, якого ще ні в кого немає, надати адресу електронної пошти та пароль, натиснути на кнопку “Sign up for Github” (Зареєструватись на Github). Після цього можна авторизовуватися щойно створеними ім’ям та паролем та зв’язуватися з Git сховищами за допомогою протоколу `https://` або `SSH`. Тим не менше, щоб просто клонувати публічні проекти, не треба навіть реєструватися. Облікові записи необхідні тоді, коли необхідно створювати власні сховища та викладати до них зміни.
+
+Після реєстрації, перейшовши на основну сторінку GitHub (можна у будь який момент натиснути на зображення "котика"), на лівій бічній панелі можна подивитися список усіх доступних репозиторіїв та створити новий репозиторій. У правій частині екрану відображається репозиторії, які можуть Вас зацікавити. У центральній частині відображаються останні активності пов'язані з Вашим обліковим записом.
+
+
+
+рис.8.1. Зовнішній вигляд WEB-інтерфейсу GitHub
+
+Вибравши відповідний пункту меню в верху екрану можна перейти на активні (не закриті) по всім репозиторіям запити на пул (pull requests), питань для обговорень (issues), застосунки для використання (Marketplace), оглянути цікавинки в репозиторіях інших собі чи організацій (Explore). Деякі з цих діяльностей будуть розглядатися в наступних лекціях.
+
+Кнопки в правому верхньому кутку дозволяють:
+
+- (дзвіночок) - передивитися нові повідомлення;
+- (+) - доступитися до команд створення/імпорту репозиторію, проекту;
+- (зображення користувача) - доступитися до сторінок стану та налаштувань свого користувача;
+
+GitHub виділяє кілька типів репозиторіїв в залежності від необхідного доступу: приватні (***private***), публічні (***public***) та внутрішні (***internal***). GitHub надає увесь свій функціонал безкоштовно, з тим обмеженням, що всі сховища повністю публічні (усі мають доступ на читання). Оплачувані послуги також пропонують можливість створювати приватні сховища, які доступні безкоштовно в лімітованому варіанті. Надалі приватні сховища не обговорюються.
+
+Для сховища доступні різноманітні сервіси, які пов'язані не тільки з функціями керування версіями. На рис. 8.2 показаний зовнішній вигляд вікна керування сховищем для дисципліни "Програмна інженерія в системах управління".
+
+
+
+рис.8.2. Закладки вікна репозиторію
+
+GitHub пропонує наступні основні функції роботи з репозиторієм (див.рис.8.2):
+
+- `Code` - перегляд змісту сховища, файлів будь-якого коміту з будь-якої гілки; змістом може бути не тільки код, а будь які інші файли;
+- `Issues` - постановка і обговорення питань, що мають відношення до сховища;
+- `Pull requests` - запити на пул (наприклад для об'єднання гілок);
+- `Actions` - автоматизація дій з кодом сховища(workflow): побудова (компілювання), тестування, розгортання на цільовій або тестових середовищах виконання;
+- `Projects` - робота з проектами по методології "Канбан";
+- `Wiki` - створення Вікісторінок для проекту;
+- `Security` - налаштування політик безпеки для сховища;
+- `Insights` - перегляд аналітики по сховищу;
+- `Settings` - налаштування сховища.
+
+Поступово в цій та інших лекціях, більшість з цих функцій будуть розглядатися.
+
+Прийнято щоб в кореневій папці (та і у включених папках репозиторію) вміщувався файл README в форматі MD. У цьому випадку вміст файлу автоматично показується в нижній частині екрану. У цьому файлі як правило розміщують інформацію про ліцензію використання репозиторію, налаштування-рекомендації для учасників, кодекс поведінки та інше, що повідомляти про проект та очікування щодо участі в ньому.
+
+## 8.2. Загальні основи командної роботи
+
+До репозиторіїв можна добавляти користувачів як ***співавторів*** сховища (***collaborate***), які матимуть права на запис. Для приватних репозиторіїв добавлені користувачі також матимуть доступ до читання (для публічних будь хто має право читати), а кількість співавторів команди в безкоштовному користуванні є обмеженою. Якщо не налаштовані обмеження на гілки (див. налаштування захисту гілок), будь хто зі співавторів може робити в них зміни (push). Тому, в загальному, при роботі в команді з одним репозиторієм прийняті наступні рекомендації:
+
+1. Створюється нова гілка в локальному репозиторії.
+2. Редагуються файли та робиться коміт. Надсилаються зміни у віддалений репозиторій на GitHub (push).
+3. Робиться (відкривається) запит на Пул з редагованої гілки з пропозиціями змін (на об'єднання гілок) та/або для початку дискусії. Цей запит не обов'язково проводиться в час необхідності об'єднання (мерджа), він може ініціюватися для обговорення, або прохання допомоги, тощо.
+4. У результаті обговорення, при необхідності, робляться певні зміни в гілці. Робиться коміт і пуш. Запит на пул оновлюється автоматично.
+5. За готовності гілки до об'єднання, проводиться зливання (мердж) відповідно до запиту на Пул .
+6. Прибирається гілка методом видалення на сторінці запита на пул або самої гілки.
+
+Цей процес графічно показаний [за посиланням](https://guides.github.com/introduction/flow/). Додатково можна почитати [англомовну документацію](https://help.github.com/en/github/collaborating-with-issues-and-pull-requests/overview) щодо командної роботи.
+
+Є ще варіант сумісної роботи через форк (умовно створення копії) репозиторію, в якій ведуться всі зміни, після чого можна робити їх синхронізацію. Про це - нижче.
+
+**Запит на пул (Pull request)** - це пропозиція користувача на внесення зміни до певної гілки сховища GitHub, як правило способом об'єднання (мерджа) з іншою гілкою. Вони можуть бути прийняті або відхилені співавторами сховища, які мають на це право. Як тільки створено запит на пул, може проводитися дискусія щодо змін, неодноразове внесення наступних змін в гілці запиту, після чого гілка може бути об'єднана (змерджена) з базовою гілкою, або запит може бути скасовано (закрито) без внесення змін. Подібно до завдання (issues), запити на пул мають свій окремий форум для обговорення. Запити на пул можуть зв'язуватися також з завданнями.
+
+Спосіб використання запитів на Пул залежить від типу моделі розробки, яка використовується у проекті. Є дві основні типи моделей командної розробки, з якими можна використовувати запити на Пул:
+
+1. ***Shared repository model*** (***модель загально-доступного репозиторію***): співавторам надається простий доступ до одного спільного сховища, а коли потрібно внести зміни - тоді створюються тематичні гілки, які об'єднуються у результаті підтвердження запитів на пул. Запит на пул у цій моделі ініціює перегляд коду та загальну дискусію про необхідні зміни перед об'єднанням у основну розроблювальну гілку. Ця модель є більш поширеною для роботи в невеликих командах та організаціях над приватними проектами. У такій моделі варто налаштувати захист основних гілок від несанкціонованих змін, у цьому випадку в захищені гілки можуть вноситися зміни тільки за певних умов (див. налаштування захисту гілок).
+2. ***Fork and pull model*** (***модель форку та пулу***): кожен може зробити форк (копію) наявного сховища та надіслати (push) зміни на свій особистий форк, не потребуючи доступу до вихідного сховища, після чого репозиторії синхронізуються шляхом запитів на пул. Запити на пул відкриваютья для пропозиції зміни з гілки форку на гілку в сховищі джерела (upstream). Можна дозволити, щоб будь-хто, хто має push-доступ до upstream-сховища, міг вносити зміни у цей запит на пул. Ця модель користується популярністю у проектах з відкритим кодом, оскільки вона не створює додаткового опору для нових учасників та дозволяє людям працювати самостійно без попередньої координації.
+
+## 8.3. Робота з форками
+
+Якщо є бажання зробити внесок до існуючого публічного сховища, проте у користувача немає права на це, він можете створити для себе ***форк*** (***`fork`***) цього репозиторію. У цьому випадку GitHub створює копію цього сховища, що є існує в просторі імен користувача, який може викладати до неї зміни. Форк дозволяє вносити зміни в репозиторій, не впливаючи на оригінальне (вихідне) сховище. Користувач може отримувати оновлення з оригінального сховища або надсилати зміни з нього з допомогою ***запитів на пул*** (pull requests).
+
+Хоч створення форку оригінального сховища подібне до створення його копії, між ними залишається зв'язок, який дає можливість:
+
+- використовувати запит на пул, щоб запропонувати зміни від форку до ***оригінального*** сховища, також відомого як ***upstream***-сховище;
+- вносити зміни з upstream-сховища до локального форку шляхом синхронізації;
+
+Видалення форку не видаляє оригінальне upstream сховище. Можна вносити будь-які зміни у форк - додавати співавторів, перейменувати файли, генерувати сторінки GitHub - не впливаючи на upstream-сховище. Однак не можна відновити сховище форк після його видалення.
+
+У проектах з відкритим кодом форки часто використовуються для повторення ідей або змін до того, як вони будуть запропоновані назад у upstream-сховище. Після внесення змін у форк, можна відкрити запит на пул для порівняння сховища форку з upstream-сховищем. Це може надати можливість надсилати запити на зміни до гілки форку будь-кому, хто має доступ на зміни до upstream-сховища. Це прискорює співпрацю, дозволяючи підтримуючим репозиторіям можливість локально робити коміти або запускати тести, перед тим як зробити запит на пул для об'єднання (мерджа).
+
+При необхідності створення копії наявного сховища без необхідності в майбутньому синхронізації та об'єднання гілок з upstream-сховищем, використовується дублювання (duplicate ) репозиторію. Можна також використовувати сховище як шаблон. Для отримання додаткової інформації див. [Дублювання сховища](https://help.github.com/en/articles/duplicating-a-repository) та [Створення репозиторію з шаблону](https://help.github.com/en/github/creating-cloning-and-archiving-repositories/creating-a-template-repository)
+
+Ви повинні сконфігурувати в Git підключення локального репозиторію до віддаленого оригінального (upstream) сховища для синхронізації змін, що Ви робите у вашому форку для зміни їх в оригінальному репозиторію. Це також дозволить синхронізувати зміни у форку при зміні їх у оригінальному репозиторію.
+
+Для Windows через Git Bash:
+
+1. Відкрийте Git Bash.
+
+2. Виведіть список сконфігурованих на даний момент відділених репозиторіїв для форка.
+
+ ```shell
+ git remote -v
+ > origin https://github.com/YOUR_USERNAME/YOUR_FORK.git (fetch)
+ > origin https://github.com/YOUR_USERNAME/YOUR_FORK.git (push)
+ ```
+
+3. Вкажіть новий віддалений оригніальний (*upstream* ) репозиторій щоб можна було синхронізувати Ваш форк зі змінами в ньому.
+
+ ```shell
+ git remote add upstream https://github.com/ORIGINAL_OWNER/ORIGINAL_REPOSITORY.git
+ ```
+
+4. Перевірте нове сховище, яке ви вказали для свого форку.
+
+ ```shell
+ git remote -v
+ > origin https://github.com/YOUR_USERNAME/YOUR_FORK.git (fetch)
+ > origin https://github.com/YOUR_USERNAME/YOUR_FORK.git (push)
+ > upstream https://github.com/ORIGINAL_OWNER/ORIGINAL_REPOSITORY.git (fetch)
+ > upstream https://github.com/ORIGINAL_OWNER/ORIGINAL_REPOSITORY.git (push)
+ ```
+
+Для Windows через Git Gui:
+
+1. Відкрийте Git Gui.
+2. Вкажіть новий віддалений оригніальний (*upstream* ) репозиторій щоб можна було синхронізувати Ваш форк зі змінами в ньому, наприклад.
+
+
+
+рис.8.3. Добавлення репозиорію.
+
+Після добавлення в конфігурації посилання на віддаленний репозиторій, можна синхронізувати з ним локальний репозиторй. У Git Bash це робиться наступним чином
+
+1. Відкрийте Git Bash.
+
+2. Перейдіть на необхідну робочу директорію.
+
+3. Отримайте нові дані (комміти) з віддаленого `upstream` сховища через команду `fetch` . У результаті комміти з `master` оригінального `upstream` будуть збережені в локальній папці `upstream/master`.
+
+ ```shell
+ git fetch upstream
+ > remote: Counting objects: 75, done.
+ > remote: Compressing objects: 100% (53/53), done.
+ > remote: Total 62 (delta 27), reused 44 (delta 9)
+ > Unpacking objects: 100% (62/62), done.
+ > From https://github.com/ORIGINAL_OWNER/ORIGINAL_REPOSITORY
+ > * [new branch] master -> upstream/master
+ ```
+
+4. Перейдіть (Check out) на вашу локальну гілку форка `master` .
+
+ ```shell
+ git checkout master
+ > Switched to branch 'master'
+ ```
+
+5. Злийте (Merge) зміни з `upstream/master` у локальну гілку `master`. Це приводить гілку `master` вашого форка синхронізованою до оригінального сховища, не втрачаючи локальних змін.
+
+ ```shell
+ git merge upstream/master
+ > Updating a422352..5fdff0f
+ > Fast-forward
+ > README | 9 -------
+ > README.md | 7 ++++++
+ > 2 files changed, 7 insertions(+), 9 deletions(-)
+ > delete mode 100644 README
+ > create mode 100644 README.md
+ ```
+
+ If your local branch didn't have any unique commits, Git will instead perform a "fast-forward":
+
+ Якщо у вашої локальної гілки не було жодних унікальних комітів, Git замість цього здійснить "швидку перемотку" ("fast-forward"):
+
+ ```shell
+ git merge upstream/master
+ > Updating 34e91da..16c56ad
+ > Fast-forward
+ > README.md | 5 +++--
+ > 1 file changed, 3 insertions(+), 2 deletions(-)
+ ```
+
+Зверніться до [довідникової системи GitHub](https://help.github.com/en/github/collaborating-with-issues-and-pull-requests/about-forks) для детального вивчення матеріалу.
+
+## 8.4. Налаштування доступу та захисту
+
+***Захищені гілки*** (***Protected branches***) гарантують, що співавтори сховища не можуть внести безпосередньо зміни до гілок. Також це дозволяє ввімкнути інші необов'язкові перевірки та вимоги, наприклад, потреба в перевірці стану та необхідні огляди.
+
+За замовчуванням будь-який запит на Пул можна об’єднати (змерджити) в будь-який час, якщо тільки гілка не суперечить базовій гілці. Можна застосувати обмеження щодо об'єднання через запит на Пул зі сховищем. Власники репозиторію та люди, які мають права адміністратора для сховища, можуть забезпечити виконання певних робочих процесів або вимог, створивши правила захищеної гілки. Адміністратор може створити у сховищі правило для певної гілки, усіх гілок чи будь-якої гілки, яка відповідає ***шаблону іменування*** (***Branch name pattern***), визначеному синтаксисом fnmatch. Наприклад, можна вимагати щоб у будь-якої гілки, що містить слово `release`, перед об'єднанням було щонайменше два огляди запиту на пул. у цьому випадку ви можете створити правило для гілки ` *release* `. Якщо у сховищі є кілька правил захищених гілок, які впливають на одні і ті ж гілки, правила, які містять конкретну назву гілки, мають найвищий пріоритет. Коли адміністратор створює правило захисту гілки в сховищі, співавтори не можуть змусити надіслати зміни (пуш) на захищену гілку або видалити гілку за замовчуванням.
+
+Правила створюються та редагуються у налаштуваннях репозиторію Settings -> Branches.
+
+
+
+рис.8.4. Вікно налаштування захисту репозиторію
+
+Вимога переглядів гарантує, що перш ніж співавтори можуть вносити зміни до захищеної гілки, запити на пул матимуть певну кількість схвальних відгуків. Адміністратори репозиторію можуть вимагати, щоб усі запити на пул перш ніж вони об’єднаються у захищену гілку отримували певну кількість схвальних відгуків від людей, які мають у сховищі дозволи *write* або *admin*, або від призначеного власника коду. Якщо особа з дозволами *admin* у перегляді обирає опцію **Request changes**, тоді ця особа повинна схвалити запит на пул, перш ніж його можна буде об'єднати. Якщо рецензент, який вимагає зміни на запит на пул недоступний, кожен, хто має дозволи *admin* або *write* для сховища, може відхилити blocking review.
+
+Якщо ви застосували захист гілок у вашому сховищі, ви можете встановити необхідні перевірки статусу. Після ввімкнення повинні пройти всі необхідні перевірки стану, перш ніж гілки можуть бути об'єднані в захищену гілку.
+
+Ви можете застосувати обмеження для гілок, щоб лише певні користувачі, команди чи застосунки могли переходити до захищеної гілки у сховищах, що належать вашій організації. У ліцензії GitHub Free захист гілок доступний тільки для публічних сховищ.
+
+Ви можете надати доступ до надсилання змін (push) захищеної гілки лише користувачам, командам або встановленим застосункам GitHub Apps із доступом `write` до сховища. Люди та застосунки, що мають права адміністратора до сховища, завжди можуть перейти до захищеної гілки, за винятком, якщо в обмеженнях буде стояти "Include administrators".
+
+Детально українською про GitHub Ви можете прочитати [за посиланням](https://git-scm.com/book/uk/v2/GitHub-%D0%A1%D1%82%D0%B2%D0%BE%D1%80%D0%B5%D0%BD%D0%BD%D1%8F-%D1%82%D0%B0-%D0%BD%D0%B0%D0%BB%D0%B0%D1%88%D1%82%D1%83%D0%B2%D0%B0%D0%BD%D0%BD%D1%8F-%D0%BE%D0%B1%D0%BB%D1%96%D0%BA%D0%BE%D0%B2%D0%BE%D0%B3%D0%BE-%D0%B7%D0%B0%D0%BF%D0%B8%D1%81%D1%83), довідникова система англійською - за [цим](https://help.github.com/en/github) посиланням.
+
+## Запитання для самоперевірки
+
+1. Яке призначення GitHub?
+2. Які типи репозиторіїв доступні в GitHub?
+3. Які функції роботи з репозиторієм пропонує GitHub?
+4. Розкажіть про основні принципи командної роботи з одним репозиторієм в GitHub.
+5. Поясніть що таке `Pull request`? Як відбувається робота зі змінами в межах одного `Pull request`?
+6. Які типи моделей розробки можна використовувати для сумісної роботи в межах одного репозиторію в GitHub?
+7. Поясніть що таке форк репозиторію?
+8. Як відбувається робота в межах форку та синхронізація з основним репозиторієм?
+9. Як відбувається оновлення форку даними з основного репозиторію?
+10. Розкажіть про механізм налаштування доступу до внесення змін в гілки.
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
+
diff --git "a/\320\233\320\265\320\272\321\206/9_rpi.md" "b/\320\233\320\265\320\272\321\206/9_rpi.md"
new file mode 100644
index 0000000..d7e72e8
--- /dev/null
+++ "b/\320\233\320\265\320\272\321\206/9_rpi.md"
@@ -0,0 +1,198 @@
+**Програмна інженерія в системах управління. Лекції.** Автор і лектор: Олександр Пупена
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
+
+# 9. Апаратне забезпечення Raspberry PI 3
+
+## 9.1. Загальні характеристики та призначення
+
+[https://www.raspberrypi.org](https://www.raspberrypi.org/)
+
+Raspberry Pi (читається як Ра́збері па́й; буквально: укр. малиновий пиріг, надалі **RPI**) — одноплатний комп'ютер, розроблений британським фондом Raspberry Pi Foundation. Головне призначення — сприяти вивченню базових комп'ютерних навичок школярами. Модельний ряд цих комп'ютерів постійно оновлюється, але їх вартість варіюється в районі 50$, що дозволяє їх використовувати у різноманітних застосуваннях у тому числі IoT.
+
+На рис.9.1 показаний зовнішній вигляд плати Raspberry PI версії 3 без корпусу.
+
+
+
+
+
+рис.9.1. Загальний вигляд Raspberry PI без корпусу.
+
+На момент написання остання версія **Raspberry Pi 4 Model B** - четверте покоління основної лінійки міні-комп'ютерів від Raspberry Pi Foundation. На цей час існує три варіанти комплектації, що розрізняються між собою обсягом оперативної пам'яті: **2G**, **4G** і **8G** **LPDDR4-3200 SDRAM**. Серцем даних платформ є 4х ядерний Х64-bit Cortex-A72 Broadcom (BCM2711B0) ARM-v8 SoC 1.5GHz процесор. На борту з'явилися два USB порти 3.0, тепер в розпорядженні користувача два USB 2.0 і два USB 3.0 проти чотирьох USB 2.0 встановлених на Rpi 3 B/B+. Зміні піддався і HDMI роз'єм, його змінили два micro-HDMI з підтримкою роздільної здатності 4Kp60. Так само модуль бездротового зв'язку отримав підтримку дводіапазонного Wi-Fi (стандарт IEEE 802.11ac) з підтримкою Bluetooth 5.0. І на завершення, роз'єм живлення USB-Type-C змінив свого попередника micro-USB.
+
+Не варто забувати, що з новим процесором і його тактовою частотою, зросла і робоча температура. З цієї причини настійно рекомендується встановлювати хороше пасивне або активне охолодження. В іншому випадку, комп'ютер буде грітися, що своєю чергою буде приводити до не бажаних наслідків.
+
+Важливим фактором є і джерело живлення. В якості джерела живлення варто використовувати тільки якісні блоки живлення, з характеристиками 5В - 3А. Використання неякісних блоків живлення або зарядних пристроїв мобільних телефонів призводить до виходу з ладу внутрішнього джерела живлення і не є гарантійним випадком! Максимальне значення вхідної напруги живлення становить 5.5В. При вхідній напрузі 6В (навіть імпульсному) мікросхема перетворювача напруги гарантовано вийде з ладу. До подібного результату призведе замикання будь-якого виходу внутрішнього перетворювача напруги на землю.
+
+В якості операційної системи, користувач може використовувати, як Raspberry Pi OS (Raspbian) або інші збірки операційних систем засновані на базі Linux систем.
+
+Оскільки вхідні схеми живлення виконана в спрощеному варіанті інтерфейсу USB-C не всі блоки живлення коректно працюють з Raspberry Pi 4. У останніх редакціях міні-комп'ютера даний недолік виправлений.
+
+На рис. 9.2 показані основні компоненти Raspberry PI 4 включаючи інтерфейси. Основні характеристики даної моделі:
+
+- Процесор: 1.5 ГГц 64-бітний чотирьохядерний процесор ARM Cortex-A72
+- Об'єм оперативної пам'яті: 2, 4 або 8ГБ LPDDR4 SDRAM
+- Мережеві інтерфейси:
+ - Гігабітний Ethernet з повною пропускною спроможністю інтерфейсу
+ - Двохдіапазонна бездротова мережа 802.11ac
+ - Bluetooth 5.0
+- USB порти:
+ - Два порти USB 3.0
+ - Два порти USB 2.0
+- Відеовихід: два micro-HDMI з підтримкою двох моніторів з роздільною здатністю до 4K
+- Графічний інтерфейс: VideoCore VI, що підтримує OpenGL ES 3.x
+- Апаратне декодування 4Kp60 відео HEVC
+- Сумісність: Повна сумісність з більш ранніми продуктами Raspberry Pi
+- Роз'єм живлення: USB-C
+- Напруга живлення: 5В
+- Додаткове живлення: Ethernet PoE Hat
+- Максимальний споживаний струм: 3А
+- Розширений 40-контактний роз'єм GPIO
+
+
+
+рис.9.2. Компоненти Raspberry PI 4.
+
+До базової комплектації можна віднести плату комп'ютера, блок живлення та карта MicroSD. Усе інше підбирається в залежності від задачі.
+
+
+
+рис.9.3. Базова комплектація Raspberry PI
+
+Підключення периферії можна проводити як через наявні інтерфейси так і через контакти роз'єму [GPIO - General-purpose input/output](https://uk.wikipedia.org/wiki/GPIO) . Призначення контактів GPIO для Raspberry PI показано на рис.9.4 а також доступне [за посиланням](https://www.raspberrypi.org/documentation/usage/gpio/)
+
+
+
+
+
+рис.9.4. Призначення контактів GPIO на Raspberry PI
+
+
+
+рис.9.5. Принципова схема GPIO на Raspberry PI
+
+## 9.2. Типи сигналів
+
+У залежності від характеру інформації, яку необхідно отримати або видати, вона кодується в різних формах.
+
+**Аналогові сигнали** – характеризуються тільки діапазоном значень і є неперервними в часі. Так, наприклад, у резистивних датчиках температури при зміні температури змінюєтья значення опору. Ця зміна неперервна в часі і в значенні.
+
+**Дискретні сигнали** - характеризуються кінцевою множиною (набором) значень. Тобто сигнал може приймати конкретне значення з цього набору. Надалі вважатимемо що **дискретні сигнали** можуть приймати тільки два значення: «ТАК»/«НІ», 1/0, “TRUE”/”FALSE”, «ВКЛ»/«ВИКЛ»і т.д. Так наприклад, якщо треба дізнатися чи відкрити двері можна скористатися герконовим реле, в якому магніт замикає контакт. Якщо до контакту підвести живлення, то коли він буде замкнутий по ланцюгу піде струм, якщо ні - не піде. Ці два стани (є струм і немає струму) і використовуються як дискретні сигнали.
+
+Якщо інформацію необхідно отримати з датчика, то для RPI це буде вхідним сигналом. Якщо навпаки, необхідно керувати чимось, наприклад включити якесь реле, то це буде вихідним сигналом. Таким чином, у на GPIO RPI можуть бути використані:
+
+- Дискретні (цифрові) входи – Digital Inputs
+- Дискретні (цифрові виходи) – Digital Outputs
+- Аналогові входи – Analog Inputs (у RPI3 відсутні)
+- Аналогові виходи – Analog Outputs (у RPI3 відсутні)
+
+Цифрова техніка працює з цифровим сигналом, в якому все кодується як комбінація "0" та "1". Так, наприклад значення 254 у десятковому кодується як "11111110" у двійковому. Для того щоб аналоговий сигнал, який є неперервним як за часом (continuous time) так і за значенням (continuous value) мав цифрову форму його перетворюють на спеціалізованих платах - АЦП (аналогово-цифрових перетворювачах). Це робиться в кілька тактів (рис.9.6): значення модулюється за рівнем, тобто приводиться до певних дискретних значень в діапазоні розмірностей, яка визначається розрядністю АЦП.
+
+Так, наприклад, якщо розрядність АЦП дорівнює 8 біт, то кількість значень буде 256 (0..255). Тобто, якщо з датчика отримується значення в діапазоні від 0 до 10 Вольт, то АЦП може його оцифрувати з точністю до 10/256= 0,04 Вольта. При цьому рівень в приблизно 5 вольт буде відповідати або значенню 127 або 128, але ніяк не 127,5 . Зрозуміло, що точність такого представлення залежить від розрядності АЦП, тому чим розрядність вище - тим точніше йде перетворення. Перетворення з аналогової форми в цифрову відбувається з певною частотою а не неперервно за часом. Перетворенням з аналогової форми в цифрову займається цифроаналогові перетворювачі (ЦАП).
+
+
+
+рис.9.6. Аналогово-цифрове перетворення.
+
+З дискретними сигналами перетворення як правило зводиться до підсилення або послаблення сигналу та їх розділення по ланцюгам живлення. Таке розділення називається гальванічною розв'язкою і може проводитися різними способами. На рис.9.7 показана розв'язка дискретного входу через оптопару (optocoupler), яка є комбінацією фотодіода та світлодіода. Коли через контур зі світлодіодом проходить струм він замикає контур з фотодіодом. Така схема є дуже популярною і використовується в промислових контролерах (PLC), які будуть даватися на старших курсах.
+
+
+
+рис.9.7. Приклад реалізації дискретних входів з гальванічною розв'язкою через оптопару.
+
+На рис.9.8 показана реалізація дискретних виходів через оптопару, а на рис.9.9 через проміжне реле.
+
+
+
+рис.9.8. Приклад реалізації дискретних виходів з гальванічною розв'язкою через оптопару та .
+
+
+
+рис.9.9. Приклад реалізації дискретних виходів з гальванічною розв'язкою через реле.
+
+Додатково до аналогових і дискретних способів представлення інформації, сигнал може кодуватися часом активності (шириною імпульсу) дискретного сигналу. Так, наприклад, якщо спіраль в електричних нагрівачах буде під напругою, вона поступово буде нагріватися до певної температури. Якщо напругу зняти - вона буде охолоджуватися. Якщо напругу подавати на короткі моменти, то спіраль не буде встигати нагріватися до максимуму. Таким чином змінюючи час на який буде включатися подача напруги на спіраль можна керувати ступеню нагрівання. Перетворення аналогового сигналу в імпульсний з певною шириною імпульсу називається широтно-імпульсною модуляцією (**ШІМ**, **PWM** (pulse-wide modulation) (рис.9.10)
+
+
+
+
+
+рис.9.10. Приклад широтноімпульсної модуляції.
+
+Контакти GPIO в RPI не призначені для підключення зовнішніх датчиків безпосередньо, так як знаходяться близько один до одного і до плати. Для можливості фізичного підключення сигналів до контактів в прототипах можна використовувати макетну плату, яка через спеціальні провідні перемички підключається до GPIO (9.11).
+
+
+
+рис.9.11. Приклад підключення макетної плати до GPIO
+
+## 9.3. Приклади роботи з цифровими та аналоговими сигналами
+
+На рис.9.12 показаний простий приклад підключення світлодіоду до GPIO. Окрім світлодіода, монтажної плати та перемичок використовується резистор для зменшення струму в колі.
+
+
+
+рис.9.12. Монтажна схема підключення світлодіода до GPIO
+
+Приклад програми керування світлодіодом показано на рис.9.13. З бібліотеки GPIO вибирається вузол PIN у якому вибирається номер піну та його тип. Світлодіод керується дискретним виходом, тому вибирається Type "Digital output". Можна вказати значення ініціалізації виходу при старті Node-RED.
+
+
+
+рис.9.13. Реалізація простої програми керування світлодіодом в Node-RED
+
+## 9.4. Комунікаційні інтерфейси
+
+Окрім дискретних та аналогових сигналів GPIO, деякі контакти використовуються для підключення цифрових інтерфейсів шин. Тут коротко ознайомимося з деякими з них.
+
+**Інтерфейс I²C (розробник Philips)**
+
+Кожний підключений до лінії I²C пристрій (Ведений, Slave) має власну адресу, до якої до неї підключається Raspberry Pi (Ведучий, Master). Швидкість 400 кбіт/с, 100 кбіт/с, 10 кбіт/с (є і до 3,4 Мбіт/с), кількість пристроїв (до 127 – стара версія, 1024 – нова версія), кілька метрів (рис.9.14) .
+
+
+
+рис.9.14. Шина I2C
+
+**One-wire**
+
+1-Wire подібна за концепцією на I²C, але із меншою швидкістю передачі даних (9600 біт/с) на більшу відстань (100-500 м). Вона зазвичай використовується для зв'язку із малими недорогими пристроями, такими як цифрові термометри і погодні пристрої. Однією відмінною особливістю цієї шини є можливість використання лише двох проводів: для даних і землі (рис.9.15-9.16). Детальніше можна прочитати [за посиланням](http://mikrotik.kpi.ua/index.php/courses-list/category-python/117-connecting-sensors-with-1-wire-to-raspberry-pi-lesson-20)[Wire ](http://mikrotik.kpi.ua/index.php/courses-list/category-python/117-connecting-sensors-with-1-wire-to-raspberry-pi-lesson-20)[до ](http://mikrotik.kpi.ua/index.php/courses-list/category-python/117-connecting-sensors-with-1-wire-to-raspberry-pi-lesson-20)[Raspberry Pi | ](http://mikrotik.kpi.ua/index.php/courses-list/category-python/117-connecting-sensors-with-1-wire-to-raspberry-pi-lesson-20)[Заняття 20 ](http://mikrotik.kpi.ua/index.php/courses-list/category-python/117-connecting-sensors-with-1-wire-to-raspberry-pi-lesson-20)
+
+
+
+рис.9.15. Структура шини One-wire
+
+
+
+рис.9.16. Приклад використання One-wire з датчиками температури
+
+**Інтерфейс SPI**
+
+SPI (англ. Serial Peripheral Interface, SPI bus — послідовний периферійний інтерфейс, шина SPI) — фактичний послідовний синхронний повнодуплексний стандарт передачі даних, розроблений фірмою Motorola для забезпечення простого сполучення мікроконтролерів та периферії. SPI також називають чотирьох-провідним (англ. four-wire) інтерфейсом (рис.9.17). Основні характеристики: повнодуплексний, швидший за I²C, менше споживання, не потрібна адресація, немає стандарту, до кількох метрів.
+
+
+
+рис.9.17. Приклад використання SPI bus
+
+**UART**
+
+UART (англ. universal asynchronous receiver/transmitter — універсальний асинхронний приймач/передавач) — тип асинхронного приймача-передавача, компонентів комп'ютерів та периферійних пристроїв, що передає дані між паралельною та послідовною формами. UART звичайно використовується спільно з іншими комунікаційними стандартами, такими як EIA RS-232. UART це зазвичай окрема мікросхема чи частина мікросхеми, що використовується для з'єднання через комп'ютерний чи периферійний послідовний порт. UART нині загалом включені в мікроконтролери (рис.9.18).
+
+
+
+рис.9.18. Використання UART
+
+## Запитання для самоперевірки
+
+1. Які основні характеристики Raspberry PI?
+2. Що можна віднести до базової комплектації Raspberry PI?
+3. Поясніть що таке аналогові та дискретні сигнали.
+4. Поясніть принцип роботи аналогово-цифрового перетворення.
+5. Розкажіть як розрядність АЦП впливає на точність оцифрування і поясніть чому.
+6. Що таке гальванічна розв'язка? Як вона може бути реалізована?
+7. Що для Raspberry PI можна вважати входами а що виходами?
+8. Який принцип роботи ШІМ? Розкажіть на прикладі.
+9. Які вузли використовуються в Node-RED для роботи з GPIO?
+10. Перерахуйте наявні цифрові інтерфейси в Raspberry PI.
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
\ No newline at end of file
diff --git "a/\320\233\320\265\320\272\321\206/GitHubMedia/1.png" "b/\320\233\320\265\320\272\321\206/GitHubMedia/1.png"
new file mode 100644
index 0000000..4ccb7aa
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/GitHubMedia/1.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/GitHubMedia/10.png" "b/\320\233\320\265\320\272\321\206/GitHubMedia/10.png"
new file mode 100644
index 0000000..4fabda6
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/GitHubMedia/10.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/GitHubMedia/10_1.png" "b/\320\233\320\265\320\272\321\206/GitHubMedia/10_1.png"
new file mode 100644
index 0000000..83b3697
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/GitHubMedia/10_1.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/GitHubMedia/12.png" "b/\320\233\320\265\320\272\321\206/GitHubMedia/12.png"
new file mode 100644
index 0000000..82dc9f7
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/GitHubMedia/12.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/GitHubMedia/13.png" "b/\320\233\320\265\320\272\321\206/GitHubMedia/13.png"
new file mode 100644
index 0000000..3b99581
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/GitHubMedia/13.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/GitHubMedia/2.png" "b/\320\233\320\265\320\272\321\206/GitHubMedia/2.png"
new file mode 100644
index 0000000..9e65ac6
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/GitHubMedia/2.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/GitHubMedia/3.png" "b/\320\233\320\265\320\272\321\206/GitHubMedia/3.png"
new file mode 100644
index 0000000..713311a
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/GitHubMedia/3.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/GitHubMedia/6.png" "b/\320\233\320\265\320\272\321\206/GitHubMedia/6.png"
new file mode 100644
index 0000000..ab51e3d
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/GitHubMedia/6.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/GitHubMedia/7.png" "b/\320\233\320\265\320\272\321\206/GitHubMedia/7.png"
new file mode 100644
index 0000000..83a1533
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/GitHubMedia/7.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/GitHubMedia/8.png" "b/\320\233\320\265\320\272\321\206/GitHubMedia/8.png"
new file mode 100644
index 0000000..be79a3e
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/GitHubMedia/8.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/GitHubMedia/9.png" "b/\320\233\320\265\320\272\321\206/GitHubMedia/9.png"
new file mode 100644
index 0000000..577ada8
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/GitHubMedia/9.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/GitHubMedia/github.png" "b/\320\233\320\265\320\272\321\206/GitHubMedia/github.png"
new file mode 100644
index 0000000..e2b633f
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/GitHubMedia/github.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/GitHubMedia/githubui.png" "b/\320\233\320\265\320\272\321\206/GitHubMedia/githubui.png"
new file mode 100644
index 0000000..49a1e88
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/GitHubMedia/githubui.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/GitHubMedia/task-list-reordered.gif" "b/\320\233\320\265\320\272\321\206/GitHubMedia/task-list-reordered.gif"
new file mode 100644
index 0000000..0967303
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/GitHubMedia/task-list-reordered.gif" differ
diff --git "a/\320\233\320\265\320\272\321\206/GitHubWrkflw.md" "b/\320\233\320\265\320\272\321\206/GitHubWrkflw.md"
new file mode 100644
index 0000000..abea925
--- /dev/null
+++ "b/\320\233\320\265\320\272\321\206/GitHubWrkflw.md"
@@ -0,0 +1,808 @@
+**Програмна інженерія в системах управління. Лекції.** Автор і лектор: Олександр Пупена
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
+
+# Git Hub actions
+
+## [Про Git Hub actions](https://help.github.com/en/actions/getting-started-with-github-actions/about-github-actions)
+
+Дії GitHub допоможуть вам автоматизувати робочі процеси з розробки програмного забезпечення в тому самому місці, де ви зберігаєте код та співпрацюєте над запитами на пул. Ви можете писати окремі завдання, що називаються діями (actions), і комбінувати їх для створення користувальницького робочого процесу (workflow). **Робочі процеси** (**workflow**) - це спеціалізовані автоматизовані процеси, які ви можете налаштувати у своєму сховищі для побудови, тестування, пакування, випуску чи розгортання будь-якого кодового проекту на GitHub.
+
+За допомогою GitHub Actions ви можете будувати безперервну інтеграцію (CI) та можливості неперервного розгортання (CD) безпосередньо у вашому сховищі. Дії GitHub (GitHub Actions) надають повноцінну послугу безперервної інтеграції GitHub. Для отримання додаткової інформації див. "[About continuous integration](https://help.github.com/en/articles/about-continuous-integration)."
+
+Робочі процеси працюють у Linux, macOS, Windows та контейнерах на машинах, розміщених на GitHub, названі **виконувачами** ('**runners**'). Крім того, ви також можете розмістити власних виконувачів для запуску робочих процесів на машинах, якими ви володієте або керуєте. Для отримання додаткової інформації див. "[About self-hosted runners](https://help.github.com/en/actions/automating-your-workflow-with-github-actions/about-self-hosted-runners)."
+
+Ви можете створювати робочі процеси, використовуючи дії, означені у вашому сховищі, дії з відкритим кодом у загальнодоступному сховищі на GitHub або опублікованим образом контейнера Docker. Робочі процеси у сховищах форк не працюють за замовчуванням.
+
+Ви можете виявити дії, які потрібно використовувати у своєму робочому процесі на GitHub, та створити дії, які потрібно ділитися спільнотою з GitHub. Для отримання додаткової інформації про створення власної дії див "[Creating actions](https://help.github.com/en/actions/creating-actions)."
+
+## Простий приклад
+
+Наведений нижче приклад файлу YAML для означення workflow, який запускається при прикріпленні будь якої теми і виводить в консоль віртуальної машини фразу "Hello World"!
+
+```yaml
+# самий прстий workflow, простіше я не придумав
+# створює віртуалку і запускає там команду в bash
+name: Hello world 1 # назва workflow
+on: # це подія, яка вказує коли буде запускатися workflow
+ issues: # назва події - коли щось відбувається з issues
+ types: pinned # тип активності - прикрпілення
+# https://help.github.com/en/actions/reference/events-that-trigger-workflows#issues-event-issues
+jobs: # перелік завдань
+ job1: # назва першого завдання
+ runs-on: ubuntu-latest # тип машини, на якій виконувати завдання
+ steps: # кроки
+ - name: step1 # назва кроку
+ run: echo Hello world! # виконує команди командного рядка
+```
+
+Після запуску на GitHub можна побачити результат запуску для кожного завдання та кроку.
+
+
+
+
+
+
+
+## [Конфігурування та керування робочими процесами](https://help.github.com/en/actions/configuring-and-managing-workflows)
+
+### Continuous integration (CI)
+
+Практика розробки програмного забезпечення часто здійснює невеликі зміни коду до спільного сховища. За допомогою GitHub Actions ви можете створювати власні робочі процеси CI, які автоматизують створення та тестування вашого коду. З вашого сховища ви можете переглянути стан змін вашого коду та докладні журнали для кожної дії у вашому робочому процесі. CI економить час розробників, надаючи негайний зворотній зв'язок щодо змін коду для швидшого виявлення та усунення помилок.
+
+### Continuous deployment (CD)
+
+Неперервне розгортання ґрунтується на неперервній інтеграції (CI). Коли новий код введено і проходить ваші тести на CI, код автоматично розгортається на виробництво. За допомогою GitHub Actions ви можете створювати власні робочі процеси CD, щоб автоматично розгортати ваш код у будь-яку хмару, сервіс, що розміщений на власній основі, або платформу зі свого сховища. CD економить час розробників за рахунок автоматизації процесу розгортання та розгортає перевірений, стабільний код швидше змінюється для ваших клієнтів.
+
+### Конфігурування робочих процесів
+
+Можна створити більше одного робочого процесу в сховищі. Вони зберігаються в каталозі `.github/workflows` у корені сховища як файли файл ` .yml` або `.yaml` на мові YAML, з описом якого ви можете ознайомитися в [цій лекції](yaml.md). Опис вибору подій, запуску дії, додавання дій та налаштування робочого процесу дано в "[Workflow syntax for GitHub Actions](https://help.github.com/en/articles/workflow-syntax-for-github-actions)" . Після запуску робочого процесу можна побачити журнали збірки, результати тестів, артефакти та статуси для кожного кроку робочого процесу. Також можна отримувати сповіщення про оновлення стану робочого процесу (див. "[Configuring notifications](https://help.github.com/en/github/managing-subscriptions-and-notifications-on-github/configuring-notifications#github-actions-notification-options).")
+
+
+
+
+
+Робочі процеси повинні мати принаймні одне завдання (**job**), а завдання містити набір кроків (**steps**), які виконують окремі задачі (task). Кроки можуть запускати команди або використовувати дію (**action**). Ви можете створювати власні дії або використовувати дії, якими ділиться спільнота GitHub, та налаштовувати їх за потребою.
+
+### Змінні середовища
+
+GitHub встановлює змінні середовища за замовчуванням для кожного запущеного робочого процесу GitHub Actions. Ви також можете встановити власні змінні середовища у файлі робочого процесу. До змінних середовища можна звертатися за іменем, використовуючи знак `$`. Назва змінних середовища чутлива до регістру.
+
+Команди, що виконуються в діях або кроках, можуть створювати, читати та змінювати змінні середовища. Щоб встановити власні змінні середовища, потрібно вказати змінні у файлі робочого процесу для кроку, завдання або всього робочого процесу за допомогою ключових слів [`jobs..steps.env`](https://help.github.com/en/github/automating-your-workflow-with-github-actions/workflow-syntax-for-github-actions#jobsjob_idstepsenv), [`jobs..env`](https://help.github.com/en/github/automating-your-workflow-with-github-actions/workflow-syntax-for-github-actions#jobsjob_idenv), та [`env`](https://help.github.com/en/github/automating-your-workflow-with-github-actions/workflow-syntax-for-github-actions#env) , які описані нижче.
+
+```yaml
+steps:
+ - name: Hello world
+ run: echo Hello world $FIRST_NAME $middle_name $Last_Name!
+ env:
+ FIRST_NAME: Mona
+ Last_Name: Octocat
+```
+
+Ви також можете скористатися командою `set-env` робочого процесу для встановлення змінної середовища, яку можуть використовувати наступні кроки в робочому процесі. Команда `set-env` може використовуватися безпосередньо дією або як команда shell у файлі робочого процесу за допомогою ключового слова `run` .
+
+Ми настійно рекомендуємо діям використовувати змінні середовища для доступу до файлової системи, а не використовувати прямі шляхи до файлів. GitHub встановлює змінні середовища для дій, які потрібно використовувати у всіх середовищах виконувача.
+
+| Змінна середовища | Опис |
+| ------------------- | ------------------------------------------------------------ |
+| `CI` | Завжди встановлено в `true`. |
+| `HOME` | Шлях до домашньої директорії GitHub використовується для збереження користувацьких даних. Наприклад, `/github/home`. |
+| `GITHUB_WORKFLOW` | Ім'я workflow. |
+| `GITHUB_RUN_ID` | Унікальний номер для кожного запуску в сховищі. Це число не змінюється, якщо ви повторно запустите робочий процес. |
+| `GITHUB_RUN_NUMBER` | Унікальний номер для кожного запуску певного робочого процесу в сховищі. Це число починається з 1 для першого запуску робочого процесу та збільшується з кожним новим виконанням. Це число не змінюється, якщо ви повторно запустите робочий процес. |
+| `GITHUB_ACTION` | Унікальний ідентифікатор дії (`id`). |
+| `GITHUB_ACTIONS` | Завжди встановлене в значення `true`, коли GitHub Actions виконує робочий процес. Ви можете використовувати цю змінну для розмежування, коли тести виконуються локально або за допомогою GitHub Actions. |
+| `GITHUB_ACTOR` | Ім’я особи чи програми, яка ініціювала робочий процес. Наприклад, `octocat`. |
+| `GITHUB_REPOSITORY` | Назва власника та сховища. Наприклад, `octocat/Hello-World`. |
+| `GITHUB_EVENT_NAME` | Назва події webhook, яка спровокувала робочий процес. |
+| `GITHUB_EVENT_PATH` | Шлях до файлу з повним навантаженням події в webhook. Наприклад, `/github/workflow/event.json`. |
+| `GITHUB_WORKSPACE` | Шлях до каталогу робочого середовища GitHub. Каталог робочого середовища містить підкаталог із копією вашого сховища, якщо ваш робочий процес використовує дію [actions/checkout](https://github.com/actions/checkout). Якщо ви не використовуєте дію `actions/checkout`, каталог буде порожнім. Наприклад, `/home/runner/work/my-repo-name/my-repo-name`. |
+| `GITHUB_SHA` | SHA коміта, який ініціює workflow. Наприклад, `ffac537e6cbbf934b08745a378932722df287a53`. |
+| `GITHUB_REF` | Посилання на гілку чи тег, що ініціював робочий процес. Наприклад, `refs/heads/feature-branch-1`. Якщо для типу події не доступна ні гілка, ні тег, змінна не буде існувати. |
+| `GITHUB_HEAD_REF` | Встановлюється лише для сховищ-форків. Відділення базового сховища. |
+| `GITHUB_BASE_REF` | Встановлюється лише для сховищ-форків. Гілка базового схоивща. |
+
+### Artifact (Артефакт)
+
+Артефакти дозволяють зберігати дані після завершення завдання та ділитися цими даними з іншим завданням у тому ж робочому процесі. Артефакт - це файл або колекція файлів, що утворюються під час виконання робочого процесу. Наприклад, ви можете використовувати артефакти, щоб зберегти свої збірки та випробування після закінчення запуску робочого процесу. GitHub для артефактів зберігає артефакти протягом 90 днів. Період збереження для запиту на пул перезапускається кожного разу, коли хтось робить новий запит на пул.
+
+Ось деякі поширені артефакти, які ви можете завантажити:
+
+- Журнали файлів та основні дампів
+- Результати тестів, збої та скріншоти
+- Двійкові або стислі файли
+- Вихід результатів тестів випробувань та результати покриття коду
+
+Артефакти завантажуються під час виконання робочого процесу, і ви можете переглянути ім'я та розмір артефакту в інтерфейсі користувача. Коли артефакт завантажується за допомогою інтерфейсу GitHub, всі файли, які були окремо завантажені як частина артефакту, стискаються в один файл.
+
+GitHub надає дві дії, які можна використовувати для завантаження та вивантаження артефактів. Для отримання додаткової інформації, див. [actions/upload-artifact](https://github.com/actions/upload-artifact) та [download-artifact](https://github.com/actions/download-artifact) actions. Робота з цими діями показана нижче.
+
+
+
+
+
+Далі розглянемо основні розділи описового файлу.
+
+### Ім'я (`name`)
+
+Напочатку вказується назва робочого процесу. Якщо опустити `name` GitHub встановлює його до шляху файлу робочого процесу відносно кореня сховища.
+
+### Події (`on`)
+
+**Event** (**Подія**) - конкретна діяльність, яка запускає робочий процес. Наприклад, активність може походити з GitHub, коли хтось натискає на коміт до сховища або коли створюється запит на пул чи issue. Ви також можете налаштувати робочий процес для запуску, коли відбувається зовнішня подія, використовуючи repository dispatch webhook. На наведеному вище прикладі тип події був означений як `pinned` - прикрпілення.
+
+```yaml
+on: # це подія, яка вказує коли буде запускатися workflow
+ issues: # назва події - коли щось відбувається з issues
+ types: pinned # тип активності - прикрпілення
+```
+
+Можна налаштувати робочий процес для запуску за певною подією GitHub (webhook events), за календарним графіком (Scheduled events) або із зовнішньої події (External events).
+
+Щоб запустити робочий процес за подією на GitHub, додайте `on:` та значення події після імені робочого процесу. Наприклад, цей робочий процес спрацьовує, коли пушаться зміни до будь-якої гілки сховища.
+
+```yaml
+on: push
+```
+
+Для планування робочого процесу можна використовувати синтаксис POSIX cron у вашому файлі робочого процесу. Найкоротший інтервал, з якого можна виконувати заплановані робочі процеси, - один раз на 5 хвилин. Наприклад, цей робочий процес спрацьовує щогодини.
+
+```yaml
+on:
+ schedule:
+ - cron: '0 * * * *'
+```
+
+Щоб запустити робочий процес після того, як відбувається зовнішня подія, ви можете викликати подію webhook `repository_dispatch`, викликавши кінцеву точку REST API "Create a repository dispatch event". Для отримання додаткової інформації див. "[Create a repository dispatch event](https://developer.github.com/v3/repos/#create-a-repository-dispatch-event)" в документації GitHub Developer.
+
+Можна надати одну подію `string`, масив (`array` ) подій, "масив" типів подій ( `array` of event `types`), або відображення конфігурації події (event configuration `map` ), яка планує робочий процес або обмежує виконання робочого процесу певними файлами, тегами або змінами гілки. Список доступних подій див "[Events that trigger workflows](https://help.github.com/en/articles/events-that-trigger-workflows)."
+
+```yaml
+# Приклад масиву подій: заупскати при push або pull_request
+on: [push, pull_request]
+```
+
+Якщо вам потрібно вказати типи дій або конфігурацію події, потрібно налаштувати кожну подію окремо. Ви повинні додати двокрапку (`:`) до всіх подій, включаючи події без конфігурації.
+
+```yaml
+on:
+ # спрацьовує при push або pull request,
+ # аде тільки для гілки master
+ push:
+ branches:
+ - master
+ pull_request:
+ branches:
+ - master
+ # спрацьовує при page_build, а також при події release created
+ page_build:
+ release:
+ types: # This configuration does not affect the page_build event above
+ - created
+```
+
+Наприклад, цей робочий процес запускається, коли пуш, що включає файли в каталозі `test`, робиться на гілці ` master`, або пушиться в тег `v1`.
+
+```yaml
+on:
+ push:
+ branches:
+ - master
+ tags:
+ - v1
+ # шляхи до файлу, які слід врахувати у події. Необов’язково; за замовчуванням для всіх.
+ paths:
+ - 'test/*'
+```
+
+Для отримання додаткової інформації про синтаксис фільтрів гілок, тегів та шляхів див "[`on..`](https://help.github.com/en/articles/workflow-syntax-for-github-actions#onpushpull_requestbranchestags)" та "[`on..paths`](https://help.github.com/en/articles/workflow-syntax-for-github-actions#onpushpull_requestpaths).". Повний перелік подій можна подивитися [тут](https://help.github.com/en/actions/reference/events-that-trigger-workflows#webhook-events).
+
+Для отримання додаткової інформації та прикладів, див "[Events that trigger workflows](https://help.github.com/en/articles/events-that-trigger-workflows#webhook-events)."
+
+Приклад наведений спочатку використовує тип [`issues`](https://help.github.com/en/actions/reference/events-that-trigger-workflows#issues-event-issues), в якому тип активності `pinned`
+
+```yaml
+on: # це подія, яка вказує коли буде запускатися workflow
+ issues: # назва події - коли щось відбувається з issues
+ types: pinned # тип активності - прикрпілення
+```
+
+### Змінні середовища `env`
+
+Відображення `map` змінних середовищ, які доступні для всіх завдань і кроків робочого процесу. Ви також можете встановити змінні середовища, які доступні лише для завдання чи кроку. Коли більше однієї змінної середовища визначено з тим самим іменем, GitHub використовує найбільш специфічну змінну середовища. Наприклад, змінна середовища, означена на кроці, буде заміняти змінні завдання та робочого процесу з тим самим іменем, коли виконується крок.
+
+```yaml
+env:
+ SERVER: production # змінна SERVER має значення production
+```
+
+### Завдання `jobs`
+
+**Завдання** (**job**) - набір кроків, які виконуються на одному виконувачі. Ви можете визначити правила залежності того, як виконуються завдання у файлі робочого процесу. Завдання можуть працювати паралельно або послідовно виконуватись залежно від стану попереднього завдання.
+
+#### Ідентифікатор та ім'я (`job_id`)
+
+Кожне завдання повинно мати ідентифікатор, який асоціюється з роботою. Ключ **`job_id`** - це рядок, його значення - відображення даних конфігурації завдання. Ви повинні замінити `` на рядок, унікальний для об'єкта `jobs.` .
+
+```yaml
+jobs:
+ my_first_job: #індентифікатор завдання
+ name: My first job #імя завдання
+ my_second_job:
+ name: My second job
+```
+
+#### Послідовність виконання кількох завдань (`needs`)
+
+Завдання виконуються паралельно за замовчуванням. Щоб послідовно виконувати завдання, ви можете визначити залежності від інших завдань за допомогою ключового слова **`needs`**, який означує завдання, після успішного виконання яких запускається це завдання. Це може бути рядок або масив рядків. Якщо завдання помилково завершується, усі завдання, які його потребують, пропускаються, якщо тільки завдання не використовують умовний вислів, який призводить до продовження роботи. Завдання в наведеному нижче прикладі виконують послідовно: `job1`, `job2` а потім `job3`
+
+```yaml
+jobs:
+ job1:
+ job2: #почне виконуватися тільки після успішного завершення job1
+ needs: job1
+ job3: #почне виконуватися тільки після успішного завершення job1 та job2
+ needs: [job1, job2]
+```
+
+Кожне завдання виконується в середовищі (типі машини), означеному **`runs-on`**. Цей параметр є обов'язковим. Машина може бути або виконувачем, розміщеним у GitHub, або виконувачем, що влаштовується власноруч.
+
+#### Віртуальна машина для виконання (`runs-on`)
+
+**Runner** (**виконувач**) - це будь-яка машина із встановленим застосунком виконувача GitHub Actions.
+
+Віртуальне середовище виконувача, розміщеного у GitHub, включає конфігурацію апаратного забезпечення віртуальної машини, операційну систему та встановлене програмне забезпечення.
+
+Ви можете запускати робочі процеси на виконувачах, розміщених на GitHub або виконувачах, що розміщуються самостійно. Завдання можуть працювати безпосередньо на машині або в контейнері Docker. Ви можете вказати виконувач для кожного завдання в робочому процесі, використовуючи `runs-on`. Для отримання додаткової інформації про `runs-on`, див "[Workflow syntax for GitHub Actions](https://help.github.com/en/articles/workflow-syntax-for-github-actions#jobsjob_idruns-on)."
+
+Якщо ви використовуєте виконувач, розміщений у GitHub, кожне завдання виконується у новому екземплярі віртуального середовища, означеного `runs-on`. Доступними типами виконувачів, розміщених у GitHub, є:
+
+| Віртуальне середовище | мітка workflow YAML |
+| --------------------- | ---------------------------------- |
+| Windows Server 2019 | `windows-latest` або`windows-2019` |
+| Ubuntu 20.04 | `ubuntu-20.04` |
+| Ubuntu 18.04 | `ubuntu-latest` або `ubuntu-18.04` |
+| Ubuntu 16.04 | `ubuntu-16.04` |
+| macOS Catalina 10.15 | `macos-latest` or `macos-10.15` |
+
+```yaml
+runs-on: ubuntu-latest
+```
+
+Див "[Virtual environments for GitHub-hosted runners](https://help.github.com/en/github/automating-your-workflow-with-github-actions/virtual-environments-for-github-hosted-runners)."
+
+Щоб вказати власний (**self-hosted**) виконувач для свого завдання, конфігуруйте `runs-on` у вашому файлі робочого процесу за допомогою власників міток виконувача. Усі self-hosted виконувачі, мають мітку `self-hosted`. Див "[About self-hosted runners](https://help.github.com/en/github/automating-your-workflow-with-github-actions/about-self-hosted-runners)" та"[Using self-hosted runners in a workflow](https://help.github.com/en/github/automating-your-workflow-with-github-actions/using-self-hosted-runners-in-a-workflow).
+
+```yaml
+runs-on: [self-hosted, linux]
+```
+
+#### Виходи завдання (`outputs`)
+
+Виходи завдання - це рядки, які містять вирази, які розраховуються на виконувачі в кінці кожного завдання. Виходи, що містять паролі, редагуються на виконувачі і не надсилаються в GitHub Actions.
+
+```yaml
+jobs:
+ job1:
+ runs-on: ubuntu-latest
+ # Выдображення виходыв крокыв на виходи завдань
+ outputs:
+ output1: ${{ steps.step1.outputs.test }}
+ output2: ${{ steps.step2.outputs.test }}
+ steps:
+ - id: step1
+ run: echo "::set-output name=test::hello"
+ - id: step2
+ run: echo "::set-output name=test::world"
+ job2:
+ runs-on: ubuntu-latest
+ needs: job1
+ steps:
+ - run: echo ${{needs.job1.outputs.output1}} ${{needs.job1.outputs.output2}}
+```
+
+#### Змінні середовища для завдання `env`
+
+Відображення змінних середовища, які доступні для всіх кроків завдання.
+
+```yaml
+jobs:
+ job1:
+ env:
+ FIRST_NAME: Mona
+```
+
+#### Налаштування за замовченням (`defaults`)
+
+Відображення налаштувань за замовчуванням, яка застосовуватиметься до всіх кроків завдання.
+
+```yaml
+jobs:
+ job1:
+ runs-on: ubuntu-latest
+ defaults: #налаштуванн для всіх кроків за замовченням
+ run:
+ shell: bash
+ working-directory: scripts
+```
+
+#### Умовне виконання (`if` )
+
+Ви можете використовувати умовний елемент `if` , щоб запобігти виконанню роботи, якщо умова не виконується.
+
+#### Кроки (`steps`)
+
+Завдання містить послідовність задач (task), що називається `steps`. Кроки можуть:
+
+- запускати команди,
+- виконувати завдання налаштування
+- виконувати дії у вашому сховищі, загальнодоступному сховищі або дії, опублікованих у реєстрі Docker.
+
+Не всі кроки виконують дії, але всі дії виконуються як крок. Кожен крок працює у своєму процесі в тому ж середовищі виконувача і має доступ до робочої області та файлової системи. Оскільки дії виконуються в їх власному процесі, зміни змінних оточуючих середовищ не зберігаються між кроками. GitHub пропонує вбудовані кроки для налаштування та завершення завдання.
+
+Аналогічно завданням кроки мають:
+
+- `id` та `name`
+- `if` умовне виконання
+- `env` змінні середовища кроку
+
+```yaml
+name: Greeting from Mona
+on: push
+jobs:
+ my-job:
+ name: My Job
+ runs-on: ubuntu-latest
+ steps:
+ - name: Print a greeting
+ env:
+ MY_VAR: Hi there! My name is
+ FIRST_NAME: Mona
+ MIDDLE_NAME: The
+ LAST_NAME: Octocat
+ run: |
+ echo $MY_VAR $FIRST_NAME $MIDDLE_NAME $LAST_NAME.
+```
+
+Цей крок виконується лише тоді, коли тип події є `pull_request` і дія події `unassigned`.
+
+```yaml
+steps:
+ - name: My first step
+ if: ${{ github.event_name == 'pull_request' && github.event.action == 'unassigned' }}
+ run: echo This event is a pull request that had an assignee removed.
+```
+
+Крок `my backup step` запускається лише тоді, коли попередній крок завдання закінчується. Для отримання додаткової інформації див "[Context and expression syntax for GitHub Actions](https://help.github.com/en/actions/reference/context-and-expression-syntax-for-github-actions#job-status-check-functions)."
+
+```yaml
+steps:
+ - name: My first step
+ uses: monacorp/action-name@master
+ - name: My backup step
+ if: ${{ failure() }}
+ uses: actions/heroku@master
+```
+
+`steps.continue-on-error` Запобігає відмови від роботи, коли крок не вдається. Установіть значення `true` , щоб дозволити роботу пройти, коли цей крок не вдався.
+
+`steps.timeout-minutes` - максимальна кількість хвилин, щоб виконати крок перед тим, як вбити процес.
+
+#### Запуск дій: файлів або контейнерів в кроці (`steps.uses`)
+
+Для вибору дії для кроку завдання вказується `steps.uses`. **Дія** (**`action`** ) - це одиниця коду для багаторазового використання. Ви можете використовувати дію, означену в тому ж сховищі, що і робочий процес, в загальнодоступному сховищі або [published Docker container image](https://hub.docker.com/).
+
+Дії (actions) - це або файли JavaScript, або контейнери Docker. Якщо дія, яку ви використовуєте, є контейнером Docker, ви повинні запустити завдання в середовищі Linux. Докладніше див. У розділі [`runs-on`](https://help.github.com/en/actions/reference/workflow-syntax-for-github-actions#jobsjob_idruns-on).
+
+Ви можете переглядати та використовувати дії, створені GitHub в організації [github.com/actions](https://github.com/actions). Щоб відвідати Docker Hub, див. "[Docker Hub](https://www.docker.com/products/docker-hub)" на сайті Docker. Щоб посилатися на дії у вашому файлі робочого процесу з правильним синтаксисом, ви повинні врахувати, де означено дію.
+
+Для використання дії, означеної в приватному сховищі, і файл робочого процесу, і дія повинні бути в одному сховищі. Ваш робочий процес не може використовувати дії, означені в інших приватних сховищах, навіть якщо інше приватне сховище знаходиться в одній організації.
+
+Щоб зберегти робочий процес стабільним, навіть коли проводиться оновлення дії, ви можете посилатися на версію дії, яку ви використовуєте, вказавши номер файлу Git ref чи Docker у файлі робочого процесу.
+
+```yaml
+steps:
+ # посилання на вказаний commit
+ - uses: actions/setup-node@74bc508
+ # посилання на версію випуску
+ - uses: actions/setup-node@v1.2
+ # посилання на гілку
+ - uses: actions/setup-node@master
+```
+
+Для використання публічних дій використовується синтаксиси
+
+```
+{owner}/{repo}@{ref}
+{owner}/{repo}/{path}@{ref}
+```
+
+Наприклад
+
+```yaml
+jobs:
+ my_first_job:
+ steps:
+ - name: My first step
+ # Uses the master branch of a public repository
+ uses: actions/heroku@master
+ - name: My second step
+ # Uses a specific version tag of a public repository
+ uses: actions/aws@v2.0.1
+```
+
+Для використання дій в тому самому репозиторії як workflow використовується синтаксис
+
+```
+./path/to/dir
+```
+
+Шлях до каталогу, який містить дії у сховищі вашого робочого процесу. Ви повинні перевірити сховище, перш ніж використовувати дію.
+
+```yaml
+jobs:
+ my_first_job:
+ steps:
+ #спочатку
+ - name: Check out repository
+ uses: actions/checkout@v2
+ - name: Use local my-action
+ uses: ./.github/actions/my-action
+```
+
+Синтаксис використання дій Docker Hub
+
+```
+docker://{image}:{tag}
+```
+
+Образ Docker опублікований на [Docker Hub](https://hub.docker.com/).
+
+```yaml
+jobs:
+ my_first_job:
+ steps:
+ - name: My first step
+ uses: docker://alpine:3.8
+```
+
+Приклад використання дій Docker public registry
+
+```
+docker://{host}/{image}:{tag}
+```
+
+Образ Docker у публічному репозитрію.
+
+```yaml
+jobs:
+ my_first_job:
+ steps:
+ - name: My first step
+ uses: docker://gcr.io/cloud-builders/gradle
+```
+
+Деякі дії вимагають введення даних, які потрібно встановити за допомогою ключового слова [`with`](https://help.github.com/en/actions/reference/workflow-syntax-for-github-actions#jobsjob_idstepswith) .
+
+#### Запуск команд в командному рядку (`steps.run`)
+
+Запускає програми командного рядка, використовуючи оболонку операційної системи. Якщо ви не вкажете `name`, ім'я кроку за замовчуванням буде текстом, визначеним у команді `run` . Команди виконуються за допомогою стандартних оболонок, які входять у систему. Ви можете вибрати іншу оболонку та налаштувати оболонку, яка використовується для виконання команд. Для отримання додаткової інформації, "[Using a specific shell](https://help.github.com/en/actions/reference/workflow-syntax-for-github-actions#using-a-specific-shell)". Кожне ключове слово `run` представляє собою новий процес і оболонку в середовищі runner. Коли ви надаєте багаторядкові команди, кожен рядок працює в одній оболонці. Наприклад:
+
+- Однорядкова команда:
+
+ ```yaml
+ - name: Install Dependencies
+ run: npm install
+ ```
+
+- Багаторядкова команда:
+
+ ```yaml
+ - name: Clean install dependencies and build
+ run: |
+ npm ci
+ npm run build
+ ```
+
+Використовуючи ключове слово `working-directory` , ви можете вказати робочий каталог, де запустити команду.
+
+```yaml
+- name: Clean temp directory
+ run: rm -rf *
+ working-directory: ./temp
+```
+
+Ви можете змінити параметри оболонки за замовчуванням в операційній системі виконувача за допомогою ключового слова `shell`.
+
+```yaml
+steps:
+ - name: Display the path
+ run: echo $PATH
+ shell: bash
+```
+
+#### Передача параметрів в крок (`steps.with`)
+
+Кожен вхідний параметр означується в `steps.with` як пара ключ/значення, який встановлюється як змінна середовища. Змінна отримує префікс `INPUT_` і перетворюється у верхній регістр. Наступний приклад означує два вхідні параметри (`first_name`, та `last_name`), означені дією `hello_world` . Ці вхідні змінні будуть доступні для дії `hello_world` як змінні середовища `INPUT_FIRST_NAME` і `INPUT_LAST_NAME` .
+
+```yaml
+jobs:
+ my_first_job:
+ steps:
+ - name: My first step
+ uses: actions/hello_world@master
+ with:
+ first_name: Mona
+ last_name: Octocat
+```
+
+Для контейнерів докер в steps.with означуються також `args` та `entrypoint`.
+
+`Args` - це рядок, який означує входи для контейнера Docker. GitHub передає `args` в контейнер 'ENTRYPOINT', коли контейнер запускається. Цей параметр не підтримує `array of strings`.
+
+```yaml
+steps:
+ - name: Explain why this job ran
+ uses: monacorp/action-name@master
+ with:
+ entrypoint: /bin/echo
+ args: The ${{ github.event_name }} event triggered this step.
+```
+
+`entrypoint` переміщує Докер `ENTRYPOINT` у `Dockerfile` або встановлює його, якщо його ще не було вказано. На відміну від інструкції Docker `ENTRYPOINT`, яка має форму оболонки та виконується, ключове слово ` entrypoint` приймає лише один рядок, що означує виконуваний файл, який слід запустити.
+
+```yaml
+steps:
+ - name: Run a custom command
+ uses: monacorp/action-name@master
+ with:
+ entrypoint: /a/different/executable
+```
+
+Ключове слово `entrypoint` призначене для використання з контейнерними діями Docker, але ви також можете використовувати його з діями JavaScript, які не означують жодних входів.
+
+### Стандартні дії в кроках
+
+Перелік публічних дій в кроках доступний за [посиланням](https://github.com/sdras/awesome-actions). Серед них є так звані [офіційні дії](https://github.com/sdras/awesome-actions#official-actions), які розглянуті в цьому розділі.
+
+- [actions/checkout](https://github.com/actions/checkout) - налаштовує своє сховище для доступу з робочого процесу (workflow)
+- [actions/upload-artifact](https://github.com/actions/upload-artifact) - вивантажує артефакти з вашого workflow
+- [actions/download-artifact](https://github.com/actions/download-artifact) - завантажує артефакт з вашого build
+- [actions/cache](https://github.com/actions/cache) - кешує залежності та виходи білдів в GitHub Actions
+- [actions/github-script](https://github.com/actions/github-script) - записує скрипт для GitHub API і конекстів workflow
+
+#### Використання checkout дій
+
+Дія checkout - це стандартна дія, яку потрібно включити у свій робочий процес перед іншими діями, якщо:
+
+- Для вашого робочого процесу потрібна копія коду вашого сховища, наприклад, коли ви створюєте і тестуєте своє сховище або використовуєте постійну інтеграцію.
+- у вашому робочому процесі є хоча б одна дія, визначена в одному сховищі. Для отримання додаткової інформації, див "[Referencing actions in your workflow](https://help.github.com/en/actions/configuring-and-managing-workflows/configuring-a-workflow#referencing-actions-in-your-workflow)."
+
+Щоб використовувати стандартну дію цей крок має наступну форму використання:
+
+```yaml
+- uses: actions/checkout@v2
+```
+
+Використання `v2` у цьому прикладі гарантує, що ви використовуєте стабільну версію дії з оформлення замовлення.
+
+За такого підходу усі необхідні файли репозиторію будуть доступні через кореневу папку. Наприклад доступ до `log.txt` в папці `.github/workflows` на виконувачі буде за наступною адресою
+
+```bash
+./.github/workflows/log.txt
+```
+
+Для отримання додаткової інформації див [the checkout action](https://github.com/actions/checkout).
+
+#### Дії з артефактами (artifact)
+
+Для виконувачів, що розміщуються в GitHub, кожне завдання в робочому процесі виконується в новому екземплярі віртуального середовища. Коли завдання завершено, виконувач припиняє і видаляє екземпляр віртуальної середовища.
+
+Для обміну даними з завданнями можна використовувати стандартні дії з артефактами [actions/upload-artifact](https://github.com/actions/upload-artifact) та [download-artifact](https://github.com/actions/download-artifact):
+
+- **Вивантаження (Uploading) файлів**: Дайте ім'я вивантажуваному файлу та вивантажте дані до завершення завдання.
+- **Завантаження (Downloading) файлів**: Ви можете завантажувати лише артефакти, які були вивантажені під час того ж робочого процесу. Завантажуючи файл, ви можете посилатися на нього по імені.
+
+Кроки завдання поділяють одне і те ж середовище на машині виконувача, але виконуються у власних індивідуальних процесах. Для передачі даних між кроками в завданні можна використовувати входи та виходи. Цей приклад робочого процесу ілюструє, як передавати дані між завданнями в одному і тому ж робочому процесі.
+
+```yaml
+name: Share data between jobs
+
+on: [push]
+
+jobs:
+ job_1:
+ name: Add 3 and 7
+ runs-on: ubuntu-latest
+ steps:
+ - shell: bash
+ run: |
+ expr 3 + 7 > math-homework.txt # в файл записується 10
+ - name: Upload math result for job 1
+ uses: actions/upload-artifact@v1 #виклик upload-artifact
+ with: # вхідні аргументи
+ name: homework # імя артефакту
+ path: math-homework.txt # вивантажити файл
+ # дія розміщує файл у каталозі під назвою `homework`
+
+ job_2:
+ name: Multiply by 9
+ needs: job_1
+ runs-on: windows-latest
+ steps:
+ - name: Download math result for job 1
+ uses: actions/download-artifact@v1 # завнтажити файл
+ with: # вхідні аргументи
+ name: homework # імя артефакту
+ - shell: bash
+ run: |
+ value=`cat homework/math-homework.txt`
+ expr $value \* 9 > homework/math-homework.txt
+ - name: Upload math result for job 2
+ uses: actions/upload-artifact@v1
+ with:
+ name: homework
+ path: homework/math-homework.txt
+
+ job_3:
+ name: Display results
+ needs: job_2
+ runs-on: macOS-latest
+ steps:
+ - name: Download math result for job 2
+ uses: actions/download-artifact@v1
+ with:
+ name: homework
+ - name: Print the final result
+ shell: bash
+ run: |
+ value=`cat homework/math-homework.txt`
+ echo The result is $value
+```
+
+Завдання, які залежать від артефактів попереднього завдання, повинні чекати успішного виконання залежного завдання. Цей робочий процес використовує ключове слово `needs`, щоб забезпечити послідовне виконання `job_1`, `job_2`, та `job_3` . Наприклад, для `job_2` потрібує ` job_1`, використовуючи синтаксис `needs: job_1`.
+
+Job 1 виконує наступні дії:
+
+- Виконує математичний обчислення та зберігає результат у текстовому файлі під назвою `math-homework.txt`.
+- Використовує дію `upload-artifact` для вивантаження файлу `math-homework.txt` з назвою `homework`. Дія розміщує файл у каталозі під назвою`homework`
+
+Job 2 використовує результат у попередній роботі:
+
+- Завантажує артефакт `homework` , вивантажений у попередньому завданні. За замовчуванням дія `download-artifact` завантажує артефакти в каталог робочої області, в якому виконується крок. Ви можете використовувати вхідний параметр ` path`, щоб вказати інший каталог завантажень.
+- читає значення з файлу `homework/math-homework.txt`, виконує математичний обчислення та зберігає результат у ` math-homework.txt`.
+- Вивантажує файл `math-homework.txt`. Це вивантаження перезаписує попереднє вивантаження, оскільки обидва вивантаження мають одне ім’я.
+
+Job 3 відображає результат, вивантажений у попередньому завданні:
+
+- Завантажує артефакт `homework`.
+- Друкує результат журналу математичного рівняння.
+
+Повна математична операція, виконана в цьому прикладі робочого процесу, є `(3 + 7) x 9 = 90`.
+
+Після завершення робочого процесу ви можете завантажити стислий файл вивантажених артефактів на GitHub, знайшовши робочий процес на вкладці **Actions** . Також ви можете використовувати API GITHub REST для завантаження артефактів. Для отримання додаткової інформації див. "[Artifacts](https://developer.github.com/v3/actions/artifacts/)" в документації на GitHub Developer.
+
+Якщо вам потрібно отримати доступ до артефактів із попереднього запуску робочого процесу, вам потрібно буде десь зберігати артефакти. Наприклад, ви можете запустити сценарій в кінці робочого процесу для зберігання збірок артефактів на Amazon S3 або Artifactory, а потім скористатися API служби зберігання для отримання цих артефактів у майбутньому робочому процесі.
+
+Ви можете завантажити артефакти, які були вивантажені під час робочого процесу. Артефакти автоматично закінчуються через 90 днів, однак ви завжди можете повернути використані сховища в GitHub Actions, видаливши артефакти, перш ніж вони закінчуються на GitHub.
+
+
+
+
+3. На лівій бічній панелі натисніть робочий процес, який ви хочете бачити.
+
+
+
+4. У розділі "Запуск робочого процесу" натисніть назву запуску, який ви хочете побачити.
+
+
+
+5. Для завантаження артефактів використовуйте спадне меню **Artifacts**, і виберіть артефакт, який ви хочете завантажити.
+
+
+
+6. Для видалення артефактів, використовуйте спадне меню **Artifacts** та натисніть на корзинку
+
+
+
+### Простий приклад 2
+
+Змінимо наведений вище приклад, щоб він брав існуючий файл в репозиторію і добавляв туди запис
+
+```yaml
+jobs: # перелік завдань
+ job1: # назва першого завдання
+ runs-on: ubuntu-latest # тип машини, на якій виконувати завдання
+ steps: # кроки
+ - name: uses my repository
+ uses: actions/checkout@v2
+ - name: step1 # назва кроку
+ run: echo Hello world! >> ./.github/workflows/log.txt # добавляє в файл текстовий рядок
+ - name: upload file from vm # вивантажує артефакт в файл текстовий рядок
+ uses: actions/upload-artifact@v2
+ with:
+ name: log
+ path: ./.github/workflows/log.txt
+```
+
+Зверніть увагу, що файл `log.txt` у сховищі не зміниться.
+
+
+
+### Додавання знаку статусу workflow до вашого репозиторію
+
+Значки стану показують, чи поточний процес в даний час не працює або проходить. Загальне місце для додавання значка статусу - у файлі README.md вашого сховища, але ви можете додати його на будь-яку веб-сторінку, яку ви хочете. За замовчуванням значки відображають статус вашої гілки за замовчуванням (як правило, `master`). Ви також можете відобразити стан запуску робочого процесу для певної гілки чи події, використовуючи параметри запиту `branch` та `event` в URL-адресі.
+
+
+
+Якщо у вашому робочому процесі використовується ключове слово `name` , вам слід посилатися на робочий процес за назвою. Якщо назва вашого робочого процесу містить пробіл, вам потрібно буде замінити пробіл кодованою URL-адресою рядка `% 20`. Більше інформації про ключове слово `name` див "[Workflow syntax for GitHub Actions](https://help.github.com/en/articles/workflow-syntax-for-github-actions#name)."
+
+```vim
+https://github.com///workflows//badge.svg
+```
+
+Крім того, якщо у вашому робочому процесі немає `name`, Ви повинні посилатися на файл робочого процесу за допомогою шляху файлу щодо кореневого каталогу сховища.
+
+**Примітка.** Посилання на файл робочого процесу за допомогою шляху файлу не працює, якщо робочий процес має `name`
+
+```vim
+https://github.com///workflows//badge.svg
+```
+
+#### Приклад використання workflow name
+
+This Markdown example adds a status badge for a workflow with the name "Greet Everyone." The `OWNER` of the repository is the `actions` organization and the `REPOSITORY` name is `hello-world`.
+
+Цей приклад Markdown додає значок статусу для робочого процесу з назвою "Greet Everyone". `OWNER` сховища - це організація `actions` , а назва `REPOSITORY` - `hello-world`..
+
+```crystal
+
+```
+
+#### Приклад використання шляху workflow file
+
+Цей приклад розміщення додає значок статусу для робочого процесу за допомогою файлу `.github/workflows/main.yml`. `OWNER` сховища - це організація `actions` , а назва `REPOSITORY` - `hello-world`.
+
+```crystal
+
+```
+
+#### Приклад використання параметру `branch`
+
+Цей приклад розміщення додає значок статусу для гілки з назвою `feature-1`.
+
+```crystal
+
+```
+
+#### Приклад використання параметру `event`
+
+Цей приклад розміщення додає значок, який відображає стан запуску робочого процесу, ініційований подією `pull_request`.
+
+```crystal
+
+```
+
+## Створення власних Actions (дії)
+
+**Actions** (**дії**) - це індивідуальні завдання, які можна комбінувати для створення робіт та налаштування робочого процесу (workflow). Ви можете створювати власні дії, а також використовувати та налаштовувати дії, якими ділиться спільнота GitHub. Щоб використовувати дію в робочому процесі, потрібно включити її як крок.
+
+Ви можете створювати дії, записуючи власний код, який взаємодіє з вашим сховищем будь-яким способом, включаючи інтеграцію з GitHub API та будь-яким стороннім доступним стороннім API. Наприклад, дія може публікувати npm-модулі, надсилати SMS-сповіщення, коли створюються нагальні питання (issues), або розгортати готовий до виробництва код.
+
+Дії можуть виконуватися безпосередньо на машині або в контейнері Docker. Ви можете визначити вхідні, вихідні змінні та змінні середовища для дії.
+
+Ви можете створити контейнер Docker та дії JavaScript. Для дій потрібен файл метаданих для означення входів, виходів та основної точки входу для вашої дії. Ім'я файлу метаданих має бути або `action.yml` , або `action.yaml`. Для отримання додаткової інформації див. "[Синтаксис метаданих для дій GitHub](https://help.github.com/en/articles/metadata-syntax-for-github-actions)."
+
+Якщо ви будуєте дію, яку ви не плануєте надавати загальнодоступній, ви можете зберігати файли дії в будь-якому місці вашого сховища. Якщо ви плануєте поєднувати дії, робочий процес та код програми в одному сховищі, радимо зберігати дії в каталозі `.github`. Наприклад, `.github/actions/action-a` та `.github/actions/action-b`.
+
+[Creating a Docker container action](https://docs.github.com/en/actions/creating-actions/creating-a-docker-container-action)
+
+[Створення та збереження шифрованих паролів](https://help.github.com/en/actions/configuring-and-managing-workflows/creating-and-storing-encrypted-secrets)
+
+[Автентифікація з GITHUB_TOKEN](https://help.github.com/en/actions/configuring-and-managing-workflows/authenticating-with-the-github_token)
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
\ No newline at end of file
diff --git "a/\320\233\320\265\320\272\321\206/GitMedia/1.png" "b/\320\233\320\265\320\272\321\206/GitMedia/1.png"
new file mode 100644
index 0000000..cb694c6
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/GitMedia/1.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/GitMedia/10.png" "b/\320\233\320\265\320\272\321\206/GitMedia/10.png"
new file mode 100644
index 0000000..6c84f84
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/GitMedia/10.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/GitMedia/11.png" "b/\320\233\320\265\320\272\321\206/GitMedia/11.png"
new file mode 100644
index 0000000..0c6b307
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/GitMedia/11.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/GitMedia/12.png" "b/\320\233\320\265\320\272\321\206/GitMedia/12.png"
new file mode 100644
index 0000000..a614a19
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/GitMedia/12.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/GitMedia/13.png" "b/\320\233\320\265\320\272\321\206/GitMedia/13.png"
new file mode 100644
index 0000000..ea498bd
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/GitMedia/13.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/GitMedia/14.png" "b/\320\233\320\265\320\272\321\206/GitMedia/14.png"
new file mode 100644
index 0000000..496f6f1
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/GitMedia/14.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/GitMedia/15.png" "b/\320\233\320\265\320\272\321\206/GitMedia/15.png"
new file mode 100644
index 0000000..328bb89
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/GitMedia/15.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/GitMedia/16.png" "b/\320\233\320\265\320\272\321\206/GitMedia/16.png"
new file mode 100644
index 0000000..48e9c7f
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/GitMedia/16.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/GitMedia/17.png" "b/\320\233\320\265\320\272\321\206/GitMedia/17.png"
new file mode 100644
index 0000000..8add818
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/GitMedia/17.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/GitMedia/18.png" "b/\320\233\320\265\320\272\321\206/GitMedia/18.png"
new file mode 100644
index 0000000..d25a1c1
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/GitMedia/18.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/GitMedia/2.png" "b/\320\233\320\265\320\272\321\206/GitMedia/2.png"
new file mode 100644
index 0000000..c12b5aa
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/GitMedia/2.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/GitMedia/3.png" "b/\320\233\320\265\320\272\321\206/GitMedia/3.png"
new file mode 100644
index 0000000..6a5de87
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/GitMedia/3.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/GitMedia/4.png" "b/\320\233\320\265\320\272\321\206/GitMedia/4.png"
new file mode 100644
index 0000000..5a35b6c
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/GitMedia/4.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/GitMedia/5.png" "b/\320\233\320\265\320\272\321\206/GitMedia/5.png"
new file mode 100644
index 0000000..91a1803
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/GitMedia/5.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/GitMedia/6.png" "b/\320\233\320\265\320\272\321\206/GitMedia/6.png"
new file mode 100644
index 0000000..aec566b
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/GitMedia/6.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/GitMedia/7.png" "b/\320\233\320\265\320\272\321\206/GitMedia/7.png"
new file mode 100644
index 0000000..61f0d02
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/GitMedia/7.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/GitMedia/7_1.png" "b/\320\233\320\265\320\272\321\206/GitMedia/7_1.png"
new file mode 100644
index 0000000..61d4052
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/GitMedia/7_1.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/GitMedia/8.png" "b/\320\233\320\265\320\272\321\206/GitMedia/8.png"
new file mode 100644
index 0000000..9efc90b
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/GitMedia/8.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/GitMedia/9.png" "b/\320\233\320\265\320\272\321\206/GitMedia/9.png"
new file mode 100644
index 0000000..84f51b7
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/GitMedia/9.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/GitMedia/branch-rule-settings.png" "b/\320\233\320\265\320\272\321\206/GitMedia/branch-rule-settings.png"
new file mode 100644
index 0000000..a0b44c6
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/GitMedia/branch-rule-settings.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/GitMedia/remote-branches-1.png" "b/\320\233\320\265\320\272\321\206/GitMedia/remote-branches-1.png"
new file mode 100644
index 0000000..187c279
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/GitMedia/remote-branches-1.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/GitMedia/remote-branches-2.png" "b/\320\233\320\265\320\272\321\206/GitMedia/remote-branches-2.png"
new file mode 100644
index 0000000..fbd661d
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/GitMedia/remote-branches-2.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/GitMedia/remote-branches-3.png" "b/\320\233\320\265\320\272\321\206/GitMedia/remote-branches-3.png"
new file mode 100644
index 0000000..8742ab6
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/GitMedia/remote-branches-3.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/GitMedia/remote-branches-4.png" "b/\320\233\320\265\320\272\321\206/GitMedia/remote-branches-4.png"
new file mode 100644
index 0000000..28106d1
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/GitMedia/remote-branches-4.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/GitMedia/remote-branches-5.png" "b/\320\233\320\265\320\272\321\206/GitMedia/remote-branches-5.png"
new file mode 100644
index 0000000..6c5237d
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/GitMedia/remote-branches-5.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/IntroMedia/1.png" "b/\320\233\320\265\320\272\321\206/IntroMedia/1.png"
new file mode 100644
index 0000000..cd7c8dc
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/IntroMedia/1.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/IntroMedia/10.png" "b/\320\233\320\265\320\272\321\206/IntroMedia/10.png"
new file mode 100644
index 0000000..3049356
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/IntroMedia/10.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/IntroMedia/11.png" "b/\320\233\320\265\320\272\321\206/IntroMedia/11.png"
new file mode 100644
index 0000000..9462b5c
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/IntroMedia/11.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/IntroMedia/12.png" "b/\320\233\320\265\320\272\321\206/IntroMedia/12.png"
new file mode 100644
index 0000000..fcdb716
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/IntroMedia/12.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/IntroMedia/13.jpg" "b/\320\233\320\265\320\272\321\206/IntroMedia/13.jpg"
new file mode 100644
index 0000000..ddb7a9d
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/IntroMedia/13.jpg" differ
diff --git "a/\320\233\320\265\320\272\321\206/IntroMedia/14.png" "b/\320\233\320\265\320\272\321\206/IntroMedia/14.png"
new file mode 100644
index 0000000..8806060
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/IntroMedia/14.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/IntroMedia/15.png" "b/\320\233\320\265\320\272\321\206/IntroMedia/15.png"
new file mode 100644
index 0000000..e6eb0fc
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/IntroMedia/15.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/IntroMedia/1_1.png" "b/\320\233\320\265\320\272\321\206/IntroMedia/1_1.png"
new file mode 100644
index 0000000..c2d651c
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/IntroMedia/1_1.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/IntroMedia/1_2.png" "b/\320\233\320\265\320\272\321\206/IntroMedia/1_2.png"
new file mode 100644
index 0000000..e49b859
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/IntroMedia/1_2.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/IntroMedia/2.gif" "b/\320\233\320\265\320\272\321\206/IntroMedia/2.gif"
new file mode 100644
index 0000000..39b8e47
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/IntroMedia/2.gif" differ
diff --git "a/\320\233\320\265\320\272\321\206/IntroMedia/2.jpg" "b/\320\233\320\265\320\272\321\206/IntroMedia/2.jpg"
new file mode 100644
index 0000000..a9a58c4
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/IntroMedia/2.jpg" differ
diff --git "a/\320\233\320\265\320\272\321\206/IntroMedia/3.jpg" "b/\320\233\320\265\320\272\321\206/IntroMedia/3.jpg"
new file mode 100644
index 0000000..b32a0f3
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/IntroMedia/3.jpg" differ
diff --git "a/\320\233\320\265\320\272\321\206/IntroMedia/3.png" "b/\320\233\320\265\320\272\321\206/IntroMedia/3.png"
new file mode 100644
index 0000000..8518b3a
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/IntroMedia/3.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/IntroMedia/4.png" "b/\320\233\320\265\320\272\321\206/IntroMedia/4.png"
new file mode 100644
index 0000000..9e0b8d3
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/IntroMedia/4.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/IntroMedia/4_1.png" "b/\320\233\320\265\320\272\321\206/IntroMedia/4_1.png"
new file mode 100644
index 0000000..dbf3e13
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/IntroMedia/4_1.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/IntroMedia/5.png" "b/\320\233\320\265\320\272\321\206/IntroMedia/5.png"
new file mode 100644
index 0000000..11b1be6
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/IntroMedia/5.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/IntroMedia/5_1.png" "b/\320\233\320\265\320\272\321\206/IntroMedia/5_1.png"
new file mode 100644
index 0000000..6e2691a
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/IntroMedia/5_1.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/IntroMedia/6.png" "b/\320\233\320\265\320\272\321\206/IntroMedia/6.png"
new file mode 100644
index 0000000..23845c4
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/IntroMedia/6.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/IntroMedia/7.png" "b/\320\233\320\265\320\272\321\206/IntroMedia/7.png"
new file mode 100644
index 0000000..1f745fe
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/IntroMedia/7.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/IntroMedia/8.png" "b/\320\233\320\265\320\272\321\206/IntroMedia/8.png"
new file mode 100644
index 0000000..1480f78
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/IntroMedia/8.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/IntroMedia/9.png" "b/\320\233\320\265\320\272\321\206/IntroMedia/9.png"
new file mode 100644
index 0000000..0da6f45
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/IntroMedia/9.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/IntroMedia/as.png" "b/\320\233\320\265\320\272\321\206/IntroMedia/as.png"
new file mode 100644
index 0000000..43bb7ae
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/IntroMedia/as.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/MQTTMedia/1.png" "b/\320\233\320\265\320\272\321\206/MQTTMedia/1.png"
new file mode 100644
index 0000000..4b0d562
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/MQTTMedia/1.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/MQTTMedia/2.png" "b/\320\233\320\265\320\272\321\206/MQTTMedia/2.png"
new file mode 100644
index 0000000..431c4e2
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/MQTTMedia/2.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/MQTTMedia/3.png" "b/\320\233\320\265\320\272\321\206/MQTTMedia/3.png"
new file mode 100644
index 0000000..c6d5164
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/MQTTMedia/3.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/MQTTMedia/4.png" "b/\320\233\320\265\320\272\321\206/MQTTMedia/4.png"
new file mode 100644
index 0000000..fe639f1
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/MQTTMedia/4.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/MQTTMedia/5.png" "b/\320\233\320\265\320\272\321\206/MQTTMedia/5.png"
new file mode 100644
index 0000000..fd3a9d9
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/MQTTMedia/5.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/MQTTMedia/5_1.png" "b/\320\233\320\265\320\272\321\206/MQTTMedia/5_1.png"
new file mode 100644
index 0000000..26fbb73
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/MQTTMedia/5_1.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/MQTTMedia/5_2.png" "b/\320\233\320\265\320\272\321\206/MQTTMedia/5_2.png"
new file mode 100644
index 0000000..984dd5c
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/MQTTMedia/5_2.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/MQTTMedia/5_3.png" "b/\320\233\320\265\320\272\321\206/MQTTMedia/5_3.png"
new file mode 100644
index 0000000..e9d3d19
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/MQTTMedia/5_3.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/MQTTMedia/5_4.png" "b/\320\233\320\265\320\272\321\206/MQTTMedia/5_4.png"
new file mode 100644
index 0000000..416d0db
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/MQTTMedia/5_4.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/MQTTMedia/5_5.png" "b/\320\233\320\265\320\272\321\206/MQTTMedia/5_5.png"
new file mode 100644
index 0000000..96d9452
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/MQTTMedia/5_5.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/MQTTMedia/5_6.png" "b/\320\233\320\265\320\272\321\206/MQTTMedia/5_6.png"
new file mode 100644
index 0000000..099dd5b
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/MQTTMedia/5_6.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/MarkDownHTML.html" "b/\320\233\320\265\320\272\321\206/MarkDownHTML.html"
new file mode 100644
index 0000000..0c5d0d3
--- /dev/null
+++ "b/\320\233\320\265\320\272\321\206/MarkDownHTML.html"
@@ -0,0 +1,568 @@
+
+
+
+ Title
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git "a/\320\233\320\265\320\272\321\206/MdMedia/process.png" "b/\320\233\320\265\320\272\321\206/MdMedia/process.png"
new file mode 100644
index 0000000..8587eb7
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/MdMedia/process.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/MdMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2721.png" "b/\320\233\320\265\320\272\321\206/MdMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2721.png"
new file mode 100644
index 0000000..2713556
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/MdMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2721.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/MdMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2722.png" "b/\320\233\320\265\320\272\321\206/MdMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2722.png"
new file mode 100644
index 0000000..38c0c31
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/MdMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2722.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/MdMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2723.png" "b/\320\233\320\265\320\272\321\206/MdMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2723.png"
new file mode 100644
index 0000000..fca249a
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/MdMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2723.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/MdMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2724.png" "b/\320\233\320\265\320\272\321\206/MdMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2724.png"
new file mode 100644
index 0000000..c0fcbdd
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/MdMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2724.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/MdMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2725.png" "b/\320\233\320\265\320\272\321\206/MdMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2725.png"
new file mode 100644
index 0000000..e39d5cb
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/MdMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2725.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/README.md" "b/\320\233\320\265\320\272\321\206/README.md"
new file mode 100644
index 0000000..68f4682
--- /dev/null
+++ "b/\320\233\320\265\320\272\321\206/README.md"
@@ -0,0 +1,57 @@
+[<- На головну](../)
+
+Автор і лектор: Олександр Пупена
+
+# Програмна інженерія в системах управління: лекції
+
+Мета дисципліни «Програмна інженерія в системах управління» -- формування знань з розробки програмного забезпечення, орієнтованого на автоматизовані системи керування (управління), що відносяться до технологічного та виробничого рівня (АСУТП, IIoT, MES та інші). Дисципліна направлена на вивчення методів та засобів програмної інженерії, розуміння основ побудов систем керування побудованих на основі архітектури Інтернету речей (IoT), поглиблення знання в програмуванні мови JavaScript, робота в середовищі Node.js, мережних технологіях Інтернету та використання СКБД. У якості основного інструментального середовища для лабораторних робіт використовується Node-RED.
+
+У даній дисципліні розглядається два аспекти:
+
+- технології, засоби та практики розробки програмного забезпечення для автоматизованих систем керування (АСК) на прикладі систем IoT
+- основи програмної інженерії для АСК
+
+## Основні теми курсу
+
+- Лек 1. [Вступ до програмної інженерії в системах автоматизованого керування](1_intro.md)
+
+- Лек 2. [Основи Node-RED](2_nodered.md).
+
+- Лек 3. [Робота з TCP/UDP](3_tcpudp.md).
+
+- Лек 4. [Основи HTTP](4_http.md).
+
+- Лек 5. [Передача даних в архітектурі IoT: MQTT](5_mqtt.md)
+
+- Лек 6. [Використання HTPP для обміну даними та керування доступом](6_httpapi.md)
+
+- Лек 7. [Основи роботи з Git та GitHub](7_git.md)
+
+- Лек 8. [Робота з віддаленими сховищами в Git/GitHub](8_github.md)
+
+- Лек 9. [Апаратне забезпечення Raspberry PI 3](9_rpi.md)
+
+- Лек 10. [Створення документації на основі MarkDown](10_markdown.md)
+
+- Лек 11. [Бази даних та систем керування базами даних](11_db.md)
+
+- Лек 12. [Мова SQL](12_sql.md).
+
+- Лек 13. [Основи Java Script](13_js.md).
+
+- Лек 14. [Функції та об'єкти Java Script та Node-RED](14_jsobjects.md)
+
+- Лек 15. [Використання хмарних сервісів для IoT](15_cloud.md)
+
+- Лек 16. [Вступ до Node.js](16_nodejs.md)
+
+- Лек 17. [Моделі життєвого циклу](17_lyfecycle.md)
+
+- Лек 18. [Додаткові можливості GitHub](18_githubadd.md)
+
+- Лек 19. [Вступ до DevOPS](19_devops.md)
+
+- Лек 20. [Діяльності по керуванню ЖЦ в GitHub](20_githubwrkflw.md)
+
+
+
diff --git "a/\320\233\320\265\320\272\321\206/RPIMedia/rpi4.jpg" "b/\320\233\320\265\320\272\321\206/RPIMedia/rpi4.jpg"
new file mode 100644
index 0000000..12bc3d0
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/RPIMedia/rpi4.jpg" differ
diff --git "a/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2721.jpg" "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2721.jpg"
new file mode 100644
index 0000000..7c3ffdd
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2721.jpg" differ
diff --git "a/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27210.png" "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27210.png"
new file mode 100644
index 0000000..42bfbdb
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27210.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27211.png" "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27211.png"
new file mode 100644
index 0000000..a538656
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27211.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27212.png" "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27212.png"
new file mode 100644
index 0000000..98156c9
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27212.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27213.png" "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27213.png"
new file mode 100644
index 0000000..2df4bfa
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27213.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27214.png" "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27214.png"
new file mode 100644
index 0000000..b2fdbd4
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27214.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27215.png" "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27215.png"
new file mode 100644
index 0000000..6a2f357
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27215.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27216.png" "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27216.png"
new file mode 100644
index 0000000..ccf4935
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27216.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27217.png" "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27217.png"
new file mode 100644
index 0000000..c549511
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27217.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27218.png" "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27218.png"
new file mode 100644
index 0000000..4e3e1a6
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27218.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27219.png" "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27219.png"
new file mode 100644
index 0000000..bca3c4c
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27219.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2722.png" "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2722.png"
new file mode 100644
index 0000000..315fed6
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2722.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27220.png" "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27220.png"
new file mode 100644
index 0000000..56a7ad1
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27220.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27221.png" "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27221.png"
new file mode 100644
index 0000000..8662f73
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27221.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27222.png" "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27222.png"
new file mode 100644
index 0000000..118b002
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27222.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27223.png" "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27223.png"
new file mode 100644
index 0000000..bd2a926
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27223.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27224.png" "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27224.png"
new file mode 100644
index 0000000..6969dbc
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27224.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27225.png" "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27225.png"
new file mode 100644
index 0000000..5dcbff4
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\27225.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2723.png" "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2723.png"
new file mode 100644
index 0000000..f71f607
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2723.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2724.jpg" "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2724.jpg"
new file mode 100644
index 0000000..1fcb83f
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2724.jpg" differ
diff --git "a/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2725.png" "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2725.png"
new file mode 100644
index 0000000..77e1787
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2725.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2726.png" "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2726.png"
new file mode 100644
index 0000000..17f36da
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2726.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2727.png" "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2727.png"
new file mode 100644
index 0000000..bf64b08
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2727.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2728.png" "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2728.png"
new file mode 100644
index 0000000..3201647
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2728.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2729.png" "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2729.png"
new file mode 100644
index 0000000..24fa1da
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/RPIMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2729.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/cloudmedia/1.png" "b/\320\233\320\265\320\272\321\206/cloudmedia/1.png"
new file mode 100644
index 0000000..b10748b
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/cloudmedia/1.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/cloudmedia/10.png" "b/\320\233\320\265\320\272\321\206/cloudmedia/10.png"
new file mode 100644
index 0000000..6e8a787
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/cloudmedia/10.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/cloudmedia/11.jpg" "b/\320\233\320\265\320\272\321\206/cloudmedia/11.jpg"
new file mode 100644
index 0000000..2fa9c6a
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/cloudmedia/11.jpg" differ
diff --git "a/\320\233\320\265\320\272\321\206/cloudmedia/12.png" "b/\320\233\320\265\320\272\321\206/cloudmedia/12.png"
new file mode 100644
index 0000000..4917bea
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/cloudmedia/12.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/cloudmedia/13.png" "b/\320\233\320\265\320\272\321\206/cloudmedia/13.png"
new file mode 100644
index 0000000..a457d52
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/cloudmedia/13.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/cloudmedia/2.png" "b/\320\233\320\265\320\272\321\206/cloudmedia/2.png"
new file mode 100644
index 0000000..ca53b18
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/cloudmedia/2.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/cloudmedia/3.png" "b/\320\233\320\265\320\272\321\206/cloudmedia/3.png"
new file mode 100644
index 0000000..074b60c
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/cloudmedia/3.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/cloudmedia/4.png" "b/\320\233\320\265\320\272\321\206/cloudmedia/4.png"
new file mode 100644
index 0000000..394662a
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/cloudmedia/4.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/cloudmedia/5.png" "b/\320\233\320\265\320\272\321\206/cloudmedia/5.png"
new file mode 100644
index 0000000..76c99d3
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/cloudmedia/5.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/cloudmedia/6.png" "b/\320\233\320\265\320\272\321\206/cloudmedia/6.png"
new file mode 100644
index 0000000..c66309d
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/cloudmedia/6.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/cloudmedia/7.png" "b/\320\233\320\265\320\272\321\206/cloudmedia/7.png"
new file mode 100644
index 0000000..ffaf29b
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/cloudmedia/7.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/cloudmedia/8.png" "b/\320\233\320\265\320\272\321\206/cloudmedia/8.png"
new file mode 100644
index 0000000..3ec1250
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/cloudmedia/8.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/cloudmedia/9.png" "b/\320\233\320\265\320\272\321\206/cloudmedia/9.png"
new file mode 100644
index 0000000..89d174a
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/cloudmedia/9.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/cloudmedia/9_35.png" "b/\320\233\320\265\320\272\321\206/cloudmedia/9_35.png"
new file mode 100644
index 0000000..a1f82b4
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/cloudmedia/9_35.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/cloudmedia/9_36.png" "b/\320\233\320\265\320\272\321\206/cloudmedia/9_36.png"
new file mode 100644
index 0000000..073352f
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/cloudmedia/9_36.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/cloudmedia/9_37.png" "b/\320\233\320\265\320\272\321\206/cloudmedia/9_37.png"
new file mode 100644
index 0000000..280a33c
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/cloudmedia/9_37.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/cloudmedia/9_38.png" "b/\320\233\320\265\320\272\321\206/cloudmedia/9_38.png"
new file mode 100644
index 0000000..1a4a00e
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/cloudmedia/9_38.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/cloudmedia/Cloud.png" "b/\320\233\320\265\320\272\321\206/cloudmedia/Cloud.png"
new file mode 100644
index 0000000..2d77f4e
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/cloudmedia/Cloud.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/cloudmedia/IoT Protocols.png" "b/\320\233\320\265\320\272\321\206/cloudmedia/IoT Protocols.png"
new file mode 100644
index 0000000..e2f18a6
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/cloudmedia/IoT Protocols.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/cloudmedia/Key players.png" "b/\320\233\320\265\320\272\321\206/cloudmedia/Key players.png"
new file mode 100644
index 0000000..7bd5a42
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/cloudmedia/Key players.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/cloudmedia/KeyParts.png" "b/\320\233\320\265\320\272\321\206/cloudmedia/KeyParts.png"
new file mode 100644
index 0000000..93e17ad
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/cloudmedia/KeyParts.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/cloudmedia/KeyPartsClouds.png" "b/\320\233\320\265\320\272\321\206/cloudmedia/KeyPartsClouds.png"
new file mode 100644
index 0000000..2aff3e0
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/cloudmedia/KeyPartsClouds.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/cloudmedia/archi.png" "b/\320\233\320\265\320\272\321\206/cloudmedia/archi.png"
new file mode 100644
index 0000000..cfb5140
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/cloudmedia/archi.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/cloudmedia/clouds.png" "b/\320\233\320\265\320\272\321\206/cloudmedia/clouds.png"
new file mode 100644
index 0000000..1d374ce
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/cloudmedia/clouds.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/cloudmedia/conteiner.png" "b/\320\233\320\265\320\272\321\206/cloudmedia/conteiner.png"
new file mode 100644
index 0000000..aea3e0f
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/cloudmedia/conteiner.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/cloudmedia/redhat.png" "b/\320\233\320\265\320\272\321\206/cloudmedia/redhat.png"
new file mode 100644
index 0000000..6efe278
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/cloudmedia/redhat.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/cloudmedia/vm.png" "b/\320\233\320\265\320\272\321\206/cloudmedia/vm.png"
new file mode 100644
index 0000000..c1a2e44
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/cloudmedia/vm.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/cloudmedia/vsphere.png" "b/\320\233\320\265\320\272\321\206/cloudmedia/vsphere.png"
new file mode 100644
index 0000000..27210a2
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/cloudmedia/vsphere.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/cloudmedia/xen.jpg" "b/\320\233\320\265\320\272\321\206/cloudmedia/xen.jpg"
new file mode 100644
index 0000000..822c757
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/cloudmedia/xen.jpg" differ
diff --git "a/\320\233\320\265\320\272\321\206/dbmedia/1.png" "b/\320\233\320\265\320\272\321\206/dbmedia/1.png"
new file mode 100644
index 0000000..eef797c
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/dbmedia/1.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/dbmedia/2.jpg" "b/\320\233\320\265\320\272\321\206/dbmedia/2.jpg"
new file mode 100644
index 0000000..17a5974
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/dbmedia/2.jpg" differ
diff --git "a/\320\233\320\265\320\272\321\206/dbmedia/2_1.png" "b/\320\233\320\265\320\272\321\206/dbmedia/2_1.png"
new file mode 100644
index 0000000..d728dc4
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/dbmedia/2_1.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/dbmedia/2_2.png" "b/\320\233\320\265\320\272\321\206/dbmedia/2_2.png"
new file mode 100644
index 0000000..1d1d4e7
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/dbmedia/2_2.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/dbmedia/2_3.png" "b/\320\233\320\265\320\272\321\206/dbmedia/2_3.png"
new file mode 100644
index 0000000..d635530
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/dbmedia/2_3.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/dbmedia/3.jpg" "b/\320\233\320\265\320\272\321\206/dbmedia/3.jpg"
new file mode 100644
index 0000000..5469319
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/dbmedia/3.jpg" differ
diff --git "a/\320\233\320\265\320\272\321\206/dbmedia/4.png" "b/\320\233\320\265\320\272\321\206/dbmedia/4.png"
new file mode 100644
index 0000000..04ed58e
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/dbmedia/4.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/dbmedia/5.png" "b/\320\233\320\265\320\272\321\206/dbmedia/5.png"
new file mode 100644
index 0000000..fecd2fa
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/dbmedia/5.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/dbmedia/6.png" "b/\320\233\320\265\320\272\321\206/dbmedia/6.png"
new file mode 100644
index 0000000..1181263
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/dbmedia/6.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/dbmedia/7.png" "b/\320\233\320\265\320\272\321\206/dbmedia/7.png"
new file mode 100644
index 0000000..9fcc4c2
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/dbmedia/7.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/dbmedia/relational-model.svg" "b/\320\233\320\265\320\272\321\206/dbmedia/relational-model.svg"
new file mode 100644
index 0000000..84be41c
--- /dev/null
+++ "b/\320\233\320\265\320\272\321\206/dbmedia/relational-model.svg"
@@ -0,0 +1 @@
+
\ No newline at end of file
diff --git "a/\320\233\320\265\320\272\321\206/devopsmeida/1.png" "b/\320\233\320\265\320\272\321\206/devopsmeida/1.png"
new file mode 100644
index 0000000..eea609b
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/devopsmeida/1.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/devopsmeida/10.png" "b/\320\233\320\265\320\272\321\206/devopsmeida/10.png"
new file mode 100644
index 0000000..91d8ed3
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/devopsmeida/10.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/devopsmeida/11.png" "b/\320\233\320\265\320\272\321\206/devopsmeida/11.png"
new file mode 100644
index 0000000..4a9f7b5
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/devopsmeida/11.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/devopsmeida/12.jpg" "b/\320\233\320\265\320\272\321\206/devopsmeida/12.jpg"
new file mode 100644
index 0000000..5d4d344
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/devopsmeida/12.jpg" differ
diff --git "a/\320\233\320\265\320\272\321\206/devopsmeida/13.png" "b/\320\233\320\265\320\272\321\206/devopsmeida/13.png"
new file mode 100644
index 0000000..79fc322
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/devopsmeida/13.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/devopsmeida/2.png" "b/\320\233\320\265\320\272\321\206/devopsmeida/2.png"
new file mode 100644
index 0000000..1207d7c
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/devopsmeida/2.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/devopsmeida/3.jpg" "b/\320\233\320\265\320\272\321\206/devopsmeida/3.jpg"
new file mode 100644
index 0000000..584a3b8
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/devopsmeida/3.jpg" differ
diff --git "a/\320\233\320\265\320\272\321\206/devopsmeida/4.png" "b/\320\233\320\265\320\272\321\206/devopsmeida/4.png"
new file mode 100644
index 0000000..7baeae3
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/devopsmeida/4.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/devopsmeida/5.png" "b/\320\233\320\265\320\272\321\206/devopsmeida/5.png"
new file mode 100644
index 0000000..1c37f2d
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/devopsmeida/5.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/devopsmeida/6.png" "b/\320\233\320\265\320\272\321\206/devopsmeida/6.png"
new file mode 100644
index 0000000..f08d92c
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/devopsmeida/6.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/devopsmeida/7.png" "b/\320\233\320\265\320\272\321\206/devopsmeida/7.png"
new file mode 100644
index 0000000..eb86c18
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/devopsmeida/7.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/devopsmeida/8.png" "b/\320\233\320\265\320\272\321\206/devopsmeida/8.png"
new file mode 100644
index 0000000..54c01bb
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/devopsmeida/8.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/devopsmeida/9.jpg" "b/\320\233\320\265\320\272\321\206/devopsmeida/9.jpg"
new file mode 100644
index 0000000..f45b2f8
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/devopsmeida/9.jpg" differ
diff --git "a/\320\233\320\265\320\272\321\206/devopsmeida/clip_image002.png" "b/\320\233\320\265\320\272\321\206/devopsmeida/clip_image002.png"
new file mode 100644
index 0000000..96302d2
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/devopsmeida/clip_image002.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/generate.cmd" "b/\320\233\320\265\320\272\321\206/generate.cmd"
new file mode 100644
index 0000000..bba0c45
--- /dev/null
+++ "b/\320\233\320\265\320\272\321\206/generate.cmd"
@@ -0,0 +1 @@
+ python C:\xampp\htdocs\convertor_md\read.py "C:\xampp\htdocs\convertor_md\Лекц\README.md"
\ No newline at end of file
diff --git "a/\320\233\320\265\320\272\321\206/gitfull.md" "b/\320\233\320\265\320\272\321\206/gitfull.md"
new file mode 100644
index 0000000..af56e3f
--- /dev/null
+++ "b/\320\233\320\265\320\272\321\206/gitfull.md"
@@ -0,0 +1,676 @@
+**Програмна інженерія в системах управління. Лекції.** Автор і лектор: Олександр Пупена
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
+
+# Системи керування версіями: Git, GitHub
+
+Про системи керування версіями. Вступ до Git. Вступ до GitHub. Робота з Git.
+
+## Системи керування версіями.
+
+Система керування версіями (***СКВ,*** source code management, SCM) - це система, що записує зміни у файл або набір файлів протягом деякого часу таким чином, що можна повернутися до певної версії пізніше. Це може бути як програмний код так і будь-які інші файли.
+
+Системи керування версіями зазвичай використовуються при розробці програмного забезпечення для відстеження, документування та контролю над поступовими змінами в електронних документах: у сирцевому коді застосунків, кресленнях, електронних моделях та інших документах, над змінами яких одночасно працюють декілька людей. Кожна версія позначається унікальною цифрою чи літерою, зміни документу занотовуються. Зазвичай також зберігаються дані про автора зробленої зміни та її час. Інструменти для керування версіями входять до складу багатьох інтегрованих середовищ розробки.
+
+СКВ дозволяє повернути вибрані файли до попереднього стану, повернути весь проект до попереднього стану, побачити зміни, побачити, хто останній змінював щось і спровокував проблему, хто вказав на проблему і коли, та багато іншого.
+
+Існують три основні типи систем керування версіями: локальні, з централізованим сховищем та розподіленим (деценралізованим).
+
+Багато людей в якості одного з методів контролю версій застосовують копіювання файлів в окрему директорію (можливо навіть директорію з відміткою за часом, якщо вони достатньо розумні). Даний підхід є дуже поширеним завдяки його простоті, проте він, схильний до появи помилок. Можна легко забути в якій директорії ви знаходитеся і випадково змінити не той файл або скопіювати не ті файли, які ви хотіли. Щоб справитися з цією проблемою, програмісти розробили локальні СКВ, що мають просту базу даних, яка зберігає всі зміни в файлах під керуванням версіями (рис.1). Сховище (база даних) з набором файлів та змін, які відбувалися над ними, що керуються СКВ називається ***репозиторієм***. По суті репозиторій як правило є одним проектом, над яким проводяться операції як з єдиним набором файлів.
+
+Одним з найбільш поширених інструментів СКВ була система під назвою RCS, яка досі поширюється з багатьма комп'ютерами сьогодні.
+
+
+
+Рис.1. Локальні системи керування версіями.
+
+СКВ дає можливість:
+
+- зберігати код;
+
+- запам'ятовувати історію змін до коду, та дозволяти у будь-який момент побачити хто саме зробив зміни, коли зробив зміни;
+
+- відкотитися до будь-якої версії коду у будь-який момент;
+
+- об'єднувати зміни різних версій, станів та розробників;
+
+Наступним важливим питанням, з яким стикаються люди, є необхідність співпрацювати з іншими розробниками. Щоб справитися з цією проблемою, були розроблені централізовані системи керування версіями (ЦСКВ). Такі системи як CVS, Subversion і Perforce, мають єдиний сервер, який містить всі версії файлів, та деяке число клієнтів, які отримують файли з центрального місця.
+
+
+
+Рис. 2. Централізовані системи керування версіями.
+
+Такий підхід має безліч переваг, особливо над локальними СКВ. Наприклад, кожному учаснику проекту відомо, певною мірою, чим займаються інші. Адміністратори мають повний контроль над тим, хто і що може робити. Набагато легше адмініструвати ЦСКВ, ніж мати справу з локальними базами даних для кожного клієнта. Але цей підхід також має деякі серйозні недоліки. Найбільш очевидним є єдина точка відмови, яким є централізований сервер. Якщо сервер виходить з ладу протягом години, то протягом цієї години ніхто не може співпрацювати або зберігати зміни над якими вони працюють. Якщо жорсткий диск центральної бази даних на сервері пошкоджено, і своєчасні резервні копії не були зроблені, то втрачається абсолютно все --- вся історія проекту, крім одиночних знімків проекту, що збереглися на локальних машинах людей. Локальні СКВ страждають тією ж проблемою --- щоразу, коли вся історія проекту зберігається в одному місці, ви ризикуєте втратити все.
+
+У розподілених системах керування версіями (РСКВ, Distributed Version Control System) клієнти не просто отримують останній знімок файлів репозиторія: натомість вони є повною копією сховища разом з усією його історією. Таким чином, якщо ламається який-небудь сервер, через який співпрацюють розробники, будь-який з клієнтських репозиторіїв може бути скопійований назад до серверу, щоб відновити його. Кожна копія дійсно є повною резервною копією всіх даних. Крім того, багато з цих систем дуже добре взаємодіють з декількома віддаленими репозиторіями, так що можна співпрацювати з різними групами людей, застосовуючи різні підходи в межах одного проекту одночасно. Це дозволяє налаштувати декілька типів робочих процесів, таких як ієрархічні моделі, які неможливі в централізованих системах.
+
+
+
+Рис 3. Розподілені системи керування версіями.
+
+## Система керування версіями GIT.
+
+***Git*** --- розподілена система керування версіями файлів та спільної роботи. Проект створив Лінус Торвальдс для керування розробкою ядра Linux, а сьогодні підтримується Джуніо Хамано (англ. Junio C. Hamano). Git є однією з найефективніших, надійних і високопродуктивних систем керування версіями, що надає гнучкі засоби нелінійної розробки, що базуються на відгалуженні і злитті гілок. Програма є вільною і випущена під ліцензією GNU GPL версії 2.
+
+Система спроектована як набір програм, спеціально розроблених з врахуванням їхнього використання у скриптах. Це дозволяє зручно створювати спеціалізовані системи керування версіями на базі Git або користувацькі інтерфейси. Система має ряд користувацьких інтерфейсів: наприклад, **gitk** та **git-gui** розповсюджуються з самим Git. Віддалений доступ до репозиторіїв Git забезпечується git-демоном (службою), SSH або HTTP сервером.
+
+### Встановлення та початкове конфігурування Git
+
+Для керування Git можна використовувати різні варіанти клієнтів, зокрема Git-SCM . Крім оригінальних клієнтів командного рядка, є безліч клієнтів з графічним інтерфейсом користувача з різними можливостями. Командний рядок --- єдине місце, де можна виконувати всі команди Git, оскільки більшість графічних інтерфейсів для простоти реалізують тільки деяку підмножину функціональності Git. Для інсталяції Git під Windows достатньо перейти за посиланнями і завантаження почнеться автоматично.
+
+#### Конфігурування (config)
+
+Після інсталяції Git необхідно провести початкові налаштування. До Git входить утиліта що має назву git config, яка дозволяє отримати чи встановити параметри, що контролюють усіма аспектами того, як Git виглядає чи працює. Ці параметри можуть бути збережені в різних місцях. У системах Windows, Git шукає файл .gitconfig в каталозі \$HOME (C:\\Users\\\$USER для більшості користувачів). Він також все одно шукає файл /etc/gitconfig, хоча відносно кореня MSys, котрий знаходиться там, де ви вирішили встановити Git у вашій Windows системі, коли ви запускали інсталяцію. Є також системний конфігураційний файл C:\\ProgramData\\Git\\config. Цей файл може бути зміненим лише за допомогою git config -f \<файл\> адміністратором.
+
+Перше, що необхідно зробити після інсталяції Git - встановити ім'я користувача та адресу електронної пошти. Це важливо, тому що кожен коміт в Git використовує цю інформацію, і вона незмінно включена у комміти, які ви робите:
+
+```bash
+$ git config --global user.name "John Doe"
+$ git config --global user.email johndoe@example.com
+```
+
+Знову ж таки, якщо ви передаєте опцію \--global, ці налаштування потрібно зробити тільки один раз, тоді Git завжди буде використовувати цю інформацію для всього, що ви робите у цій системі. Якщо ви хочете, перевизначити ім'я або адресу електронної пошти для конкретних проектів, ви можете виконати цю ж команду без опції \--global в каталозі необхідного проекту. Багато з графічних інструментів допомагають зробити це при першому запуску.
+
+Якщо ви хочете подивитися на свої налаштування, можете скористатися командою
+
+```bash
+$ git config –-list
+```
+
+, щоб переглянути всі налаштування, які Git може знайти.
+
+#### Виклик допомоги (help)
+
+Для отримання допомоги по конкретній команді, можна викликати:
+
+```bash
+$ git help
+```
+
+або
+
+```bash
+$ git -h
+```
+
+### Основи роботи з Git для локального репозиторію
+
+Більшість дій можна виконувати на локальній файловій системі без використання інтернет підключення. Вся історія змін зберігається локально і при необхідності вивантажується у віддалений репозиторій. На відміну від Subversion, де без підключення до інтернету можна лише редагувати файли, але зберегти зміни в вашу базу даних неможливо (оскільки вона відключена від репозиторія), будь-який знімок спочатку робиться локально, а потім вивантажується у віддалений репозиторій.
+
+Git, на відміну від Subversion і подібних до неї систем, не зберігає інформацію як список змін (патчів) для файлів. Замість цього Git зберігає дані набором знімків. Кожного разу при фіксації поточної версії проекту Git зберігає зліпок того, як виглядають всі файли проекту. Але якщо файл не змінювався, то дається посилання на раніше збережений файл (див. рис. 4). Git схожий на своєрідну файлову систему з інструментами, які працюють поверх неї.
+
+
+
+Рис. 4. Дані як зліпки стану проекту в часі
+
+Усі зміни користувачем проводяться у файлах ***робочої директорії*** (Working Directory). По суті, робоча директорія -- це місце розміщення плинної редагованої версії усіх файлів проекту (див.рис.5). У робочій директорії знаходиться папка «.git», яка вміщує ***репозиторій проекту***, тобто базу даних всієї необхідної інформації для контролю версій: зліпки файлів, розмір, час створення і останньої зміни. За необхідності фіксації файлів робочої папки вони передаються і зберігаються в репозиторію, при необхідності редагування конкретної версії -- витягуються з репозиторію.
+
+У своїй базі Git зберігає все по контрольним сумам (хешам) файлів. Перед кожним збереженням файлів Git, використовуючи спеціальний алгоритм (SHA-1) за змістом файлу обчислює хеш (контрольну суму). Отриманий хеш стає унікальним індексом файлу в Git. Використовуючи хеш Git легко відслідковує зміни в файлах.
+
+
+
+Рис. 5. Робоча директорія
+
+При редагуванні файлів в робочій директорії вони змінюються, тобто не відповідають їх версії в репозиторію. Коли змінювані (***modified***) файли є сенс зафіксувати в репозиторії, спочатку їх індексують (***stage***). Під час індексації, у файл індекса, який також називають областю додавання (***staging area***), що зазвичай знаходиться в директорії Git, розміщується інформація про те, що саме буде зафіксовано у наступному знімку (див.рис.6). Після індексації усіх необхідних файлів, фіксація проводиться командою ***commit***, а файли вважаються зафіксованими або «збереженими в коміті» (***commited***).
+
+Таким чином, у випадку, якщо окрема версія файлу вже є в директорії Git, цей файл вважається збереженим у коміті. Якщо він зазнав змін і перебуває в індексі, то він індексований. Якщо ж його стан відрізняється від того, який був у коміті, і файл не знаходиться в індексі, то він називається зміненим. У [Основи Git](https://git-scm.com/book/uk/v2/ch00/ch02-git-basics-chapter) ви дізнаєтесь більше про ці стани, а також про те, як використовувати їхні переваги або взагалі пропускати етап індексу.
+
+> 
+>
+> Рис. 6. Області збереження в Git.
+
+#### Створення порожнього локального репозиторію (init)
+
+Для роботи з проектом, що наразі не перебуває під СКВ, спочатку треба перейти до теки цього проекту. У командному рядку Windows для цього можна використати команду cd:
+
+```bash
+$ cd /c/user/my_project
+```
+
+та виконати:
+
+```bash
+$ git init
+```
+
+Це створить новий підкаталог .git, який містить всі необхідні файли репозиторія --- скелет Git-репозиторія. На цей момент, у даному проекті ще нічого не відстежується. Якщо необхідно додати існуючі файли під керування версіями (на відміну від порожнього каталогу), слід проіндексувати ці файли і зробити перший коміт. Це можна зробити за допомогою декількох команд git add, що означують файли, за якими необхідно слідкувати, після яких треба виконати git commit:
+
+```bash
+$ git add *.c
+$ git add LICENSE.txt
+$ git commit -m 'Перша версія проекту'
+```
+
+У цьому прикладі було проіндексовано усі файли з розширенням \*.c та файл LICENSE.txt, після чого вони були зафіксованими в коміті.
+
+Після цих команд на машині буде локальний Git репозиторій та робоча директорія з усіма файлами цього проекту. При кожній зміні файлів в робочій не обов'язково їх відправляти в репозиторій. Зазвичай, це робиться коли треба зафіксувати певну версію проекту для можливості повернення до неї.
+
+Кожен файл робочої директорії може бути в одному з двох станів (рис.7): ***контрольований*** (***tracked***) чи ***неконтрольований*** (***untracked***). Контрольовані файли --- це файли, що були в останньому знімку. Вони можуть бути не зміненими (***unmodified***), зміненими (***modified***) або індексованими (staged). Якщо стисло, контрольовані файли --- це файли, про які Git щось знає. Неконтрольовані файли --- це все інше, будь-які файли у вашій робочій директорії, що не були у вашому останньому знімку та не існують у вашому індексі. Якщо ви щойно зробили клон репозиторія, усі ваші файли контрольовані та не змінені, адже Git щойно їх отримав, а ви нічого не редагували.
+
+По мірі редагування файлів, Git бачить, що вони змінені, адже їх змінили після останнього коміту. Впродовж роботи розробник вибірково індексує ці змінені фали та потім зберігає всі індексовані зміни, та цей цикл повторюється.
+
+
+
+Рис. 7. Стан файлів Git в робочій директорії
+
+#### Перевірка стану репозиторію (status)
+
+Перевірку стану можна зробити через команду git status , або через git status -s для короткої версії статусу
+
+Для того, щоб Git не звертав уваги на деякі файли в робочій директорії, можна створити файл .gitignore, що містить шаблони, за яким файли ігноруються.
+
+#### Добавлення до індексу (add)
+
+Добавлення нових або змінених файлів до індексу робиться з використанням команди
+
+```bash
+$ git add <файли>
+```
+
+Команда git add приймає шлях файлу або директорії. Якщо це директорія, команда додає усі файли в цій директорії включно з піддерикторіями. git add багатоцільова команда --- її слід використовувати щоб почати контролювати нові файли, щоб додавати файли, та для інших речей, наприклад позначання конфліктних файлів як розв'язаних.
+
+#### Перегляд змін (diff)
+
+Команда git diff показує які саме зміни були внесені у змінені файли відносно останнього коміту.
+
+#### Створення відбитку (commit)
+
+Для внесення індексованих файлів в коміт, використовується команда
+
+```bash
+$ git commit
+```
+
+Додавання опції -a до команди git commit, змушує Git автоматично додати кожен файл, що вже контролюється, до коміту, що дозволяє вам пропустити команди git add.
+
+Щоб видалити файл з Git, вам треба прибрати його з контрольованих файлів (вірніше, видалити його з вашого індексу) та створити коміт. Це робить команда git rm, а також видаляє файл з вашої робочої директорії, щоб наступного разу він не відображався неконтрольованим. Якщо ви просто видалите файл з вашої робочої директорії, він з'явиться під заголовком "Changes not staged for commit" (тобто, *неіндексованим*) виводу команди git status. Потім, якщо ви виконаєте git rm, файл буде індексованим на видалення.
+
+#### Перейменування (mv)
+
+Для перейменування файлу у Git, можна виконати наступну команду:
+
+```bash
+$ git mv стара_назва нова_назва
+```
+
+Для перегляду історії комітів використовується команда git log , яка має багато опцій для налаштувань.
+
+#### Файл .gitignore
+
+[Оригінальна стаття](https://git-scm.com/docs/gitignore)
+
+Налаштування у файлі **.gitignore** означують які ще не контрольовані файли потрібно ігнорувати при наступній індексації. Ці налаштування ніяк не впливають на індексацію файлів, які вже контрольовані (tracked) Gitом.
+
+Кожен рядок у файлі `gitignore` означує шаблон. Вирішуючи, чи ігнорувати шлях, Git зазвичай перевіряє шаблони `gitignore` з кількох джерел із наступним порядком пріоритету, від найвищого до найнижчого (в межах одного рівня переваги, останній відповідний шаблон вирішує результат):
+
+- Шаблони, прочитані з командного рядка для тих команд, які їх підтримують.
+
+- Шаблони, прочитані з файлу `.gitignore` в тому ж каталозі, що і шлях, або в будь-якому батьківському каталозі, причому шаблони у файлах вищого рівня (до верхнього рівня робочого дерева) замінюються тими, що знаходяться у файлах нижчого рівня до каталогу, що містить файл. Ці шаблони відповідають розташуванню файлу `.gitignore`. Проект зазвичай містить такі файли .gitignore у своєму сховищі, що містять шаблони для файлів, створених як частини побудови проекту.
+- Шаблони, прочитані з `$GIT_DIR/info/exclude`.
+- Шаблони, зчитувані з файлу, зазначеного конфігураційною змінною `core.excludesFile`.
+
+У якому файлі розмістити шаблон, залежить від того, як шаблон призначений для використання.
+
+- Шаблони, які слід контролювати за версією та розповсюджувати в інших сховищах через клон (тобто файли, які всі розробники хочуть ігнорувати), повинні переходити у файл `.gitignore` .
+- Шаблони, які є специфічними для конкретного сховища, але яких не потрібно надавати спільно з іншими схожими сховищами (наприклад, допоміжні файли, що знаходяться всередині сховища, але специфічні для робочого циклу одного користувача), повинні переходити в `$GIT_DIR/info/exclude `файл.
+- Шаблони, які користувач хоче, щоб Git ігнорував у будь-яких ситуаціях (наприклад, резервні копії або тимчасові файли, створені вибраним редактором користувача), як правило, потрапляють у файл, вказаний `core.excludesFile` в користувацькому` ~/.gitconfig`. Його значення за замовчуванням `$XDG_CONFIG_HOME/git/ignore`. Якщо `$XDG_CONFIG_HOME` або не встановлений, або порожній, замість нього використовується `$HOME/.config/git/ignore`.
+
+Основні інструменти Git, такі як *git ls-files* і *git read-tree*, читають шаблони `gitignore`, визначені параметрами командного рядка, або з файлів, зазначених параметрами командного рядка. Інструменти Git вищого рівня, такі як *git status* та *git add*, використовують шаблони із зазначених вище джерел.
+
+- Порожній рядок не відповідає жодним файлам, тому він може служити роздільником для читабельності.
+
+- Рядок, що починається з #, служить коментарем. Поставте зворотну скісну риску ("`\`") перед першим хешем для шаблонів, які починаються з хешу.
+
+- Кінцеві пробіли ігноруються, якщо вони не вказані у зворотній косою рискою ("` \ `").
+
+- Необов’язковий префікс "`!` " - заперечує шаблон; будь-який відповідний файл, виключений попереднім шаблоном, буде знову включений. Неможливо повторно включити файл, якщо виключено батьківський каталог цього файлу. Git не перелічує виключені каталоги з міркувань продуктивності, тому будь-які шаблони у файлах, що містяться, не впливають незалежно від того, де вони визначені. Поставте зворотну скісну риску ("`\`") перед першим "`! `" для шаблонів, які починаються з літери "`!`", наприклад,"`\!important!.txt`".
+
+- Коса риса */* використовується як роздільник каталогів. Розділювачі можуть виникати на початку, в середині або в кінці шаблону пошуку `.gitignore`.
+
+- Якщо на початку або в середині (або обох) шаблону є роздільник, то шаблон є відносно рівня каталогу конкретного файлу `.gitignore`.. В іншому випадку шаблон може також збігатися на будь-якому рівні нижче рівня `.gitignore`.
+
+- Якщо в кінці шаблону є роздільник, то шаблон буде відповідати лише каталогам, інакше шаблон може відповідати як файлам, так і каталогам.
+
+ Наприклад, шаблон `doc/frotz/` відповідає каталогу `doc/frotz`, але не каталогу ` a/doc/frotz`; однак `frotz/` відповідає `frotz` та ` a/frotz`, що є каталогом (усі шляхи відносні до файлу `.gitignore`).
+
+- Зірочка "`*`" відповідає будь-чому, крім скісної риски. Символ "`?`" відповідає будь-якому одному символу, крім "`/`". Позначення діапазону, напр. `[a-zA-Z]`, може використовуватися для зіставлення одного з символів у діапазоні.
+
+Дві послідовні зірочки ("`**`") у шаблонах, що відповідають повній імені шляху, можуть мати особливе значення.:
+
+Щоб зупинити контролювання файлу, який вже контролюється на даний момент, використовуйте *git rm --cached*.
+
+### Основи роботи з галуженнями
+
+Як вже зазначалося, Git зберігає дані не як послідовність змін, а як послідовність знімків. Коли фіксуються зміни (див.рис.7), Git зберігає об'єкт фіксації, що містить вказівник на знімок файлу, ім'я та поштову адресу автора, набране при коміті повідомлення та вказівники на попередні фіксації (parent). При першій фіксації (98ca9 на рис.7), посилання на попередню буде нульовим. Кожна інша фіксація буде містити посилання на попередню (стрілками вказується саме посиалння на попередній коміт а не послідовність). Таким чином формується одна гілка з усією історією фіксацій.
+
+
+
+Рис.7. Фіксації та їх батьки.
+
+Гілка в Git це просто легкий вказівник, що може пересуватись, на одну з цих фіксацій шляхом поступового переходу між ними. Загальноприйнятим ім'ям першої гілки в Git є ***master***. При ініціалізації (створенні) репозиторія, за замовчуванням, Git створює тільки цю гілку. Коли ви почнете робити фіксації, вам надається гілка master, що вказує на останню зроблену фіксацію. Таким чином, щоразу, коли відбувається фіксація, вказівник «переміщується» вперед на останню фіксацію автоматично.
+
+Галуження (***branches***) --- це відмежування від основної лінії розробки для продовження своєї частини роботи та уникнення конфліктів з основною лінією. Git дозволяє створити декілька гілок і перемикатися між ними. Це корисно, оскільки дозволяє працювати декільком розробникам над своїм функціоналом не заважаючи іншим і не псуючи основну гілку. Гілки у Git дуже просто використовувати. Приклад використання галужень в проекті показаний на рис.8.
+
+
+
+рис.8.Використання галужень в проекті
+
+З певного моменту код розгалуджуєтья, над кожною гілкою можна працювати окремо, наприклад кільком розробникам, а тоді гілки об'єднуються назад у головну гілку, де всі можуть бачити і використовувати зроблені зміни.
+
+Гілка в Git просто є вказівником на одну із фіксацій. При кожній новій фіксації гілка в Git рухається автоматично (тобто перемикається на конкретну фіксацію). Гілка є простим файлом, який містить 40 символів контрольної суми SHA-1 фіксації. Тобто коли створюється нова гілка, створюється новий файл-вказівник, який вказує на конкретну фіксацію.
+
+#### Створення нової гілки (branch \)
+
+Наприклад, створюється нова гілку під назвою testing. Це робиться за допомогою команди git branch:
+
+```bash
+$ git branch testing
+```
+
+У результаті цього створюється новий вказівник на фіксацію, в якій ви зараз знаходитесь.
+
+
+
+рис.9. Дві гілки вказують на одну послідовність фіксацій
+
+У певний момент часу Git знаходиться на одній із гілок. Для цього він зберігає особливий вказівник під назвою ***HEAD*** - це просто вказівник на активну локальну гілку. Команда git branch тільки створює нову гілку --- вона не переключає на неї, а залишається на активній.
+
+#### Переключення на гілку (checkout)
+
+Щоб переключитися на існуючу гілку, треба виконати команду git checkout. Наприклад для переключення на нову гілку testing:
+
+```bash
+$ git checkout testing
+```
+
+Це пересуває HEAD, щоб він вказував на гілку testing.
+
+
+
+рис.10. HEAD вказує на поточну гілку
+
+Після чергової фіксації, гілка testing пересунулась уперед, а гілка master досі вказує на фіксацію, що був у момент виконання git checkout для переключення гілок.
+
+
+
+рис.11. Гілка testing пересувається уперед при фіксації
+
+Після переключення назад до гілки master:
+
+```bash
+$ git checkout master
+```
+
+вказівник HEAD пересувається назад на гілку master, та повертаються файли у робочій папці до стану знімку, на який вказує master. Це також означає, що якщо зараз робляться нові зміни, вони будуть походити від ранішої версії проекту (рис.12).
+
+
+
+рис.12. HEAD пересувається, коли ви отримуєте (checkout)
+
+Важливо зауважити, що коли переключаються гілки в Git, файли у робочій директорії змінюються. Якщо переключитися до старшої гілки, робоча папка буде повернута до того стану, який був на момент останнього фіксування у тій гілці. Якщо Git не може зробити це без проблем, він не дасть переключитися взагалі.
+
+Якщо зробити декілька змін та зафіксувати:
+
+```bash
+$ git commit -a -m 'Зробив інші зміни'
+```
+
+то історія проекту розійшлася (diverged) по двом різним гілкам. Ви створили гілку, дещо в ній зробили, переключились на головну гілку та зробили там щось інше. Обидві зміни ізольовані в окремих гілках. Ви можете переключатись між цими гілками та злити їх разом, коли вони будуть готові. І все це робиться за допомогою простих команд branch, checkout та commit.
+
+
+
+рис.13. Розходження історій
+
+#### Зливання(об'єднання) гілок (merge)
+
+Зливання (об'єднання, ***merge***, мердж) гілок покажемо на прикладі. Припустимо є три гілки mster, iss53 і hotfix (рис.14).
+
+
+
+рис.14. Приклад з 3-ма гілками
+
+Для злиття (merge) гілки hotfix до master використовується команда git merge. Перед цим за допомогою checkout йде переключення на гілку master
+
+```bash
+$ git checkout master
+$ git merge hotfix
+Updating f42c576..3a0874c
+Fast-forward
+ index.html | 2 ++
+ 1 file changed, 2 insertions(+)
+```
+
+Зверніть увагу на фразу "fast-forward" у цьому злитті. Через те, що коміт C4, який зливався, належав гілці hotfix, що була безпосередньо попереду поточного коміту C2, Git просто переміщує вказівник вперед. Іншими словами, коли ви зливаєте один коміт з іншим, і це можна досягнути слідуючи історії першого коміту, Git просто переставляє вказівник, оскільки немає змін-відмінностей, які потрібно зливати разом - це називається "перемоткою" ("fast-forward"). Тепер це має вигляд як на рис.15
+
+
+
+рис.15. master перемотаний на hotfix
+
+#### Видалення гілок (branch -d)
+
+Для видалення гілки hotfix використовується команда git branch з опцією -d:
+
+```bash
+$ git branch -d hotfix
+Deleted branch hotfix (3a0874c).
+```
+
+Deleted branch hotfix (3a0874c).
+
+Зауважте, що тепер зміни з гілки hotfix відсутні в гілці iss53. Якщо вам потрібні ці зміни підчас роботи над iss53, ви можете злити master з iss53 командою git merge master, або просто почекати до того моменту коли ви будете інтегровувати iss53 в master.
+
+Припустимо, що необхідно злити iss53 з гілкою master. Все що потрібно це перемкнутися на робочу гілку і виконати команду git merge:
+
+```bash
+$ git checkout master
+Switched to branch 'master'
+$ git merge iss53
+Merge made by the 'recursive' strategy.
+index.html | 1 +
+1 file changed, 1 insertion(+)
+```
+
+Виглядає трошки інакше, ніж те, що було з гілкою hotfix. У цьому випадку історія змін двох гілок почала відрізнятися в якийсь момент. Оскільки коміт поточної гілки не є прямим нащадком гілки, в яку зливаються зміни, Git мусить робити триточкове злиття, користуючись двома знімками, що вказують на гілки та третім знімком - їх спільним нащадком.
+
+
+
+рис.16. Три відбитки типового злиття
+
+Замість того, щоб просто пересунути вказівник гілки вперед, Git створює новий знімок, що є результатом 3-точкового злиття, і автоматично створює новий коміт, що вказує на нього. Його називають комітом злиття (merge commit) та його особливістю є те, що він має більше одного батьківського коміту.
+
+
+
+рис.17. Коміт злиття
+
+Варто зауважити, що Git сам визначає найбільш підходящого спільного нащадка, якого брати за основу зливання.
+
+Трапляється, що цей процес не проходить гладко. Якщо ви маєте зміни в одному й тому самому місці в двох різних гілках, Git не зможе їх просто злити. Якщо підчас роботи над iss53 ви поміняли ту саму частину файлу, що й у гілці hotfix, ви отримаєте конфлікт, що виглядає приблизно так:
+
+```bash
+$ git merge iss53
+Auto-merging index.html
+CONFLICT (content): Merge conflict in index.html
+Automatic merge failed; fix conflicts and then commit the result.
+```
+
+У цьому випадку Git не створив автоматичний коміт зливання. Він призупинив процес допоки ви не вирішите конфлікт. Для того, щоб переглянути знову які саме файли спричинили конфлікт, спочатку треба переглянути git status:
+
+Все, що має конфлікти, які не були вирішені є в списку ***незлитих*** (***unmerged***) файлів. У кожен такий файл Git додає стандартні позначки-вирішенння для конфліктів, отже ви можете відкрити ці файли і вирішити конфлікти самостійно. Якщо ви хочете використовувати графічний інструмент для розв'язання конфліктів, виконайте команду git mergetool, яка запустить графічний редактор та проведе вас по всьому процесу.
+
+#### Перегляд гілок (branch)
+
+Перегляд усіх гілок доступний через команду
+
+```bash
+$ git branch
+ iss53
+* master
+ testing
+```
+
+Зверніть увагу на символ \* перед master: це вказівник на вашу поточно вибрану гілку (тобто ту, на котру вказує HEAD). Це означає, що якщо ви зараз захочете зробити коміт, master оновиться вашими новими змінами. Щоб побачити ваші останні коміти - запустіть git branch -v:
+
+```bash
+$ git branch -v
+ iss53 93b412c fix javascript issue
+* master 7a98805 Merge branch 'iss53'
+ testing 782fd34 add scott to the author list in the readmes
+```
+
+Опції \--merged та \--no-merged корисні для фільтрування списку гілок залежно від того чи вони були злиті з поточною гілкою.
+
+#### Тегування (tag)
+
+Команда git tag використовується, щоб створити сталу закладку на окремий момент в історії коду. Зазвичай, це використовується для речей, на кшталт видань (release). Отримати список доступних теґів у Git можна через команду git tag (з опціональним -l чи \--list), наприклад:
+
+```bash
+$ git tag
+v0.1
+v1.3
+```
+
+Детальніше інформацію про тегування можна отримати [за посиланням](https://git-scm.com/book/uk/v2/%D0%9E%D1%81%D0%BD%D0%BE%D0%B2%D0%B8-Git-%D0%A2%D0%B5%D2%91%D1%83%D0%B2%D0%B0%D0%BD%D0%BD%D1%8F).
+
+#### Скидання (reset)
+
+Деталі [за посиланням](https://git-scm.com/book/uk/v2/%D0%86%D0%BD%D1%81%D1%82%D1%80%D1%83%D0%BC%D0%B5%D0%BD%D1%82%D0%B8-Git-%D0%A3%D1%81%D0%B2%D1%96%D0%B4%D0%BE%D0%BC%D0%BB%D0%B5%D0%BD%D0%BD%D1%8F-%D1%81%D0%BA%D0%B8%D0%B4%D0%B0%D0%BD%D0%BD%D1%8F-reset).
+
+### Робота з віддаленим репозиторієм
+
+Задля співпраці з будь-яким проектом Git, необхідно знати, як керувати віддаленими сховищами. ***Віддалені сховища*** (***Remote repositories***) --- це версії вашого проекту, що розташовані в Інтернеті, або десь у мережі. Їх може бути декілька, кожне зазвичай або тільки для читання, або для читання та змін. Співпраця з іншими вимагає керування цими віддаленими сховищами, надсилання (pushing) та отримання (pulling) даних до та з них, коли ви хочете зробити внесок. Керування віддаленими сховищами потребує знань про додавання віддалених сховищ, видалення сховищ, що більше не потрібні, керування різноманітними віддаленими гілками та визначення слідкування за ними, і багато іншого. У цій секції, ми пройдемо ці вміння керування віддаленими сховищами.
+
+Цілком можливо, що ви працюватимете з "віддаленим" сховищем, що, насправді, міститься на тій саме машині, що ви за нею працюєте. Слово "віддалений" не обов'язково означає, що сховище зберігається десь в мережі чи Інтернеті --- лише що воно деінде. Взаємодія з таким віддаленим сховищем все одно включатиме звичні операції push, pull і fetch --- як і з будь-яким іншим віддаленим сховищем.
+
+#### Додавання нового віддаленого сховища (remote add).
+
+Щоб додати нове віддалене Git сховище під заданим ім'ям, на яке ви можете легко посилатись, виконайте git remote add \<ім'я\> \<посилання\>:
+
+```bash
+$ git remote add pb https://github.com/paulboone/ticgit
+$ git remote -v
+```
+
+Тепер ви можете використати рядок pb в командному рядку замість повного посилання. Наприклад гілка master в ньому буде доступна локально як pb/master.
+
+#### Отримання нових даних з віддаленого сховища (fetch).
+
+Щоб отримати дані з ваших віддалених проектів, ви можете виконати:
+
+```bash
+$ git fetch
+```
+
+Команда `git fetch`, під час виконання, отримує всі оновлення, яких ви ще не маєте, але, зовсім не змінює вашу робочу директорію. Вона просто отримує дані для того, щоб ви могли самотужки злити зміни. Існує команда `git pull`, яка, по своїй суті та в більшості випадків, є послідовним виконанням команд `git fetch` та `git merge`. Якщо у вас є відслідковувана гілка (див [відслідковувані гілки](#tracking_branch) ), — створена та самостійно налаштована, чи як результат `clone` чи `checkout`, команда `git pull` буде звертатися до відслідковуваних сервера та віддаленої гілки, отримувати оновлення і тоді робити спробу зливання. Переважно простіше користуватися `fetch` та `merge` явно, оскільки магічний `git pull` часом може збивати з пантелику.
+
+#### Отримання нових даних з віддаленого сховища зі зливанням (pull).
+
+Команда `git pull` є загалом комбінацією `git fetch` та `git merge`, тобто Git отримає зміни зі заданого віддаленого сховища, а потім одразу спробує злити їх до поточної гілки.
+
+#### Клонування віддаленого сховища (clone).
+
+Для отримання копії існуючого Git репозиторія --- наприклад, проекту, в якому ви хочете прийняти участь --- вам потрібна команда git clone. Замість отримання просто робочої копії, Git отримує повну копію майже всіх даних, що є у сервера. Коли виконується git clone кожна версія кожного файлу в історії проекту витягується автоматично. Насправді, якщо щось станеться з диском вашого серверу, ви зазвичай можете використати майже будь-який з клонів на будь-якому клієнті щоб повернути сервер до стану на момент клонування.
+
+Щоб клонувати репозиторій через протокол HTTP треба використати команду git clone \. Наприклад, якщо ви бажаєте зробити клон бібліотеки Git libgit2, ви можете це зробити так:
+
+```bash
+$ git clone https://github.com/libgit2/libgit2
+```
+
+Це створить директорію під назвою libgit2, проведе ініціалізацію директорії .git, забере всі дані для репозиторія, та приведе директорію до стану останньої версії. Якщо ви зайдете до щойно створеної директорії libgit2, ви побачите, що всі файли проекту на місці, готові для використання.
+
+Якщо ви бажаєте зробити клон репозиторія в директорію з іншою назвою, ви можете передати її як другий параметр команди:
+
+```bash
+$ git clone https://github.com/libgit2/libgit2 mylibgit
+```
+
+Ця команда робить те саме, що й попередня, тільки цільова директорія називається mylibgit.
+
+При необхідності використання протоколу SSH, команда клонування буде мати такий синтаксис:
+
+```bash
+$ git clone user@server:шлях_до_репозиторія.git.
+```
+
+Команда git clone насправді є чимось на кшталт обгортки над декількома іншими командами. Вона створює нову директорію, переходить до неї та виконує git init, щоб зробити порожнє сховище Git, додає віддалене сховище (git remote add) з URL, яке ви надали їй (типово називає його origin), виконує git fetch з нього, а потім отримує останній коміт до вашої робочої директорії за допомогою git checkout.
+
+Якщо ви зробили клон сховища, команда автоматично додає це віддалене сховище під ім'ям "origin". Отже, git fetch origin отримує будь-яку нову працю, що її виклали на той сервер після того, як ви зробили його клон (або востаннє отримували зміни з нього). Важливо зауважити, що команда git fetch лише завантажує дані до вашого локального сховища ---вона автоматично не зливає їх з вашою роботою, та не змінює вашу поточну працю. Вам буде потрібно вручну її злити, коли ви будете готові.
+
+Якщо ваша поточна гілка налаштована слідкувати за віддаленою гілкою, ви можете виконати команду git pull щоб автоматично отримати зміни та злити віддалену гілку до вашої поточної гілки. Це може бути легшим та зручнішим методом для вас. Та команда git clone автоматично налаштовує вашу локальну гілку master слідкувати за віддаленою гілкою master (хоча вона може називатись і по іншому) на віддаленому сервері, з якого ви зробили клон. Виконання git pull зазвичай дістає дані з серверу, з якого ви зробили клон, та намагається злити її з кодом, над яким ви зараз працюєте.
+
+#### Перегляд налаштованих віддалених серверів (remote).
+
+Щоб побачити, які віддалені сервера налаштовувані в Git, ви можете виконати команду git remote. Вона виводить список коротких імен кожного віддаленого сховища, яке ви задали. Якщо ви отримали своє сховище клонуванням, ви маєте побачити хоча б origin ---таке ім'я Git дає серверу, з якого ви зробили клон. Ви також можете дати опцію -v, яка покаже вам посилання, які Git зберігає та використовує при читанні та записі до цього сховища.
+
+#### Надсилання змін до віддалених сховищ (push)
+
+Коли ви довели свій проект до стану, коли хочете ним поділитись, вам треба надіслати (push) ваші зміни нагору (upstream). Це робиться простою командою:
+
+```bash
+git push <назва сховища> <назва гілки>
+```
+
+Якщо ви бажаєте викласти свою гілку master до вашого серверу origin (клонування зазвичай налаштовує обидва імені для вас автоматично), ви можете виконати наступне для надсилання всіх зроблених комітів до сервера:
+
+```bash
+$ git push origin master
+```
+
+Ця команда спрацює тільки в разі, якщо ви зробили клон з серверу, до якого у вас є доступ на запис, та ніхто не оновлював його після цього. Якщо хтось інший зробив клон та надіслав щось назад перед вами, вашій спробі буде слушно відмовлено. Вам доведеться спершу отримати їхню працю й вбудувати її до вашої до того, як вам дозволять надіслати свої зміни.
+
+#### Оглядання віддаленого сховища (remote show)
+
+Якщо ви бажаєте більше дізнатись про окреме віддалене сховище, ви можете використати команду
+
+```bash
+git remote show <назва сховища>
+```
+
+Ця команда показує, до яких гілок автоматично надсилаються ваші зміни, коли ви виконуєте git push, доки перебуваєте на певної гілці. Вона також показує, яких віддалених гілок з серверу у вас нема, які віддалені гілки, що у вас є, були видалені з серверу, і декілька локальних гілок, що можуть автоматично зливатися з віддаленими гілками, за якими стежать, коли ви виконуєте git pull.
+
+Якщо ви виконаєте цю команду з окремим ім'ям, наприклад origin, ви отримаєте щось на кшталт:
+
+```bash
+$ git remote show origin
+* remote origin
+ Fetch URL: https://github.com/schacon/ticgit
+ Push URL: https://github.com/schacon/ticgit
+ HEAD branch: master
+ Remote branches:
+ master tracked
+ dev-branch tracked
+ Local branch configured for 'git pull':
+ master merges with remote master
+ Local ref configured for 'git push':
+ master pushes to master (up to date)
+```
+
+Вона виводить посилання для віддаленого сховища, а також інформацію про слідкування за гілками. Команда ґречно розповідає вам, що якщо ви на гілці master та виконаєте команду git pull, вона автоматично зіллє гілку master з віддаленою після того, як отримає всі дані з віддаленого сховища. Також видано список усіх віддалених посилань, які були забрані.
+
+#### Перейменування віддалених сховищ (remote rename)
+
+Ви можете виконати git remote rename, щоб перейменувати віддалене сховище. Наприклад, щоб перейменувати pb на paul, ви можете зробити це за допомогою git remote rename:
+
+```bash
+$ git remote rename pb paul
+$ git remote
+origin
+paul
+```
+
+Варто зазначити, що це змінює і всі назви ваших віддалених гілок. Що раніше мало назву pb/master, тепер називається paul/master.
+
+#### Видалення віддалених сховищ (remote remove)
+
+Якщо ви з якоїсь причини бажаєте видалити віддалене сховище --- ви перемістили сервер або більше не використовуєте якесь дзеркало, або можливо хтось припинив співпрацю --- ви можете використати git remote remove або git remote rm:
+
+```bash
+$ git remote remove paul
+$ git remote
+origin
+```
+
+На рис.18 показаний приклад з основними командами для роботи з віддаленим репозиторієм. Спочатку усі зміни проводяться з локальним репозиторієм. Потім за необхідності внести зміни в проект у віддаленому репозиторії виконується команда «push».
+
+
+
+рис.18. Коміт злиття
+
+#### Віддалені гілки
+
+Віддалені посилання — це посилання (вказівники) у ваших віддалених сховищах: гілки, теґи тощо. Для повного списку віддалених посилань виконайте `git ls-remote [remote]`, або `git remote show [remote]` для детальної інформації про віддалені гілки. Проте, найпоширеніше застосування — це віддалено-відслідковувані гілки.
+
+Віддалено-відслідковувані гілки — це вказівники на стан віддалених гілок. Локально ці вказівники неможливо змінити, але їх змінює Git, коли ви виконуєте мережеві операції, щоб вони точно відповідали стану віддаленого сховища. Вважайте їх закладками, що нагадують вам про стан віддалених репозиторіїв на момент вашого останнього зв’язку з ними.
+
+Віддалені гілки мають такий запис: `<віддалене сховище>/<гілка>`. Наприклад, якщо ви хочете побачити як виглядала гілка `master` з віддаленого сховища `origin`, коли ви востаннє зв’язувалися з ним, перейдіть на гілку `origin/master`. Припустимо, ви працювали з колегами над одним завданням і вони вже виклали свої зміни. У вас може бути своя локальна гілка `iss53`, але гілці на сервері відповідатиме віддалена гілка `origin/iss53`.
+
+Розгляньмо приклад. Скажімо, ви працюєте з Git сервером, що доступний у вашій мережі за адресою `git.ourcompany.com`. Коли ви склонуєте з нього, команда `clone` автоматично іменує його `origin`, стягує всі дані, створює вказівник на те місце, де зараз знаходиться `master` і локально іменує це посилання `origin/master`, щоб ви могли з чогось почати працювати.
+
+
+
+Якщо ви виконали якусь роботу на локальній гілці `master`, і водночас, хтось виклав зміни на `git.ourcompany.com` в `master`, тоді ваші історії прогресують по-різному. Доки ви не синхронізуєтесь з сервером, вказівник `origin/master` не буде рухатись.
+
+
+
+Щоб відновити синхронність, виконайте команду `git fetch origin`. Ця команда шукає який сервер відповідає імені “origin” (у нашому випадку `git.ourcompany.com`), отримує дані, яких ви ще не маєте і оновлює вашу локальну базу даних, переміщаючи вказівник `origin/master` на нову, більш актуальну, позицію.
+
+
+
+Щоб продемонструвати роботу з кількома віддаленими серверами і як виглядають віддалені гілки для віддалених проектів, уявімо, що ви маєте ще один внутрішній Git сервер, котрий використовує лиш одна з ваших спринт команд. Cервер розташований за адресою `git.team1.ourcompany.com`. Ви можете додати його як нове віддалене посилання до вашого поточного проекту за допомогою команди `git remote add`, як розповідалося в [Основи Git](https://git-scm.com/book/uk/v2/ch00/ch02-git-basics-chapter). Дайте йому ім’я `teamone`, і це буде вашим скороченням для повного URL.
+
+
+
+Тепер виконайте `git fetch teamone` щоб витягнути з `teamone` всі оновлення. Оскільки `teamone` на даний момент є підмножиною `origin`, то Git не отримує нових даних і нічого не оновлює, а просто ставить віддалено-відслідковувану гілку `teamone/master` вказувати на коміт, на котрому зараз знаходиться гілка `master` для сервера `origin`.
+
+
+
+#### Відслідковувані гілки {#tracking_branch}
+
+Перемикання на локальну гілку з віддалено-відслідковуваної автоматично створює так звану відслідковувану гілку “tracking branch” (а гілка, за якою вона стежить називається “upstream branch”). Відслідковувані гілки — це локальні гілки, що мають безпосередній зв’язок з віддаленою гілкою. Якщо ви знаходитеся на відслідковуваній гілці і потягнете зміни, виконуючи `git pull`, Git відразу знатиме з якого сервера брати та з якої гілки зливати зміни.
+
+```bash
+$ git branch master --track origin/master
+```
+
+Коли ви клонуєте репозиторій, Git автоматично створює гілку `master`, яка слідкує за `origin/master` Проте, ви можете налаштувати й інші відслідковувані гілки — такі, що слідкують за іншими віддаленими посиланнями, або за гілкою, відмінною від `master`. Як у випадку, що ви бачили в прикладі, виконуючи `git checkout -b <гілка> <назва віддаленого сховища>/<гілка>`. Це досить поширена дія, Git має опцію `--track` для скороченого запису:
+
+```bash
+$ git checkout --track origin/serverfix
+Branch serverfix set up to track remote branch serverfix from origin.
+Switched to a new branch 'serverfix'
+```
+
+Насправді, це настільки поширено, що навіть для цього скорочення є скорочення. Якщо назва гілки, яку ви намагаєтеся отримати (а) не існує і (б) має таку саму назву, як і гілка тільки з одного віддаленого сховища, то Git створить стежачу гілку:
+
+```bash
+$ git checkout serverfix
+Branch serverfix set up to track remote branch serverfix from origin.
+Switched to a new branch 'serverfix'
+```
+
+Щоб дати локальній гілці назву, що відрізняється від серверної, виконайте попередню повну команду, вказуючи бажане ім’я гілки:
+
+```bash
+$ git checkout -b sf origin/serverfix
+Branch sf set up to track remote branch serverfix from origin.
+Switched to a new branch 'sf'
+```
+
+Тепер локальна гілка `sf` буде автоматично витягувати зміни з `origin/serverfix`.
+
+Якщо ж у вас вже є локальна гілка і ви хочете прив’язати її до віддаленої, чи змінити віддалену (upstream) гілку, можете використовувати опції `-u` чи `--set-upstream-to` до команди `git branch`.
+
+```bash
+$ git branch -u origin/serverfix
+Branch serverfix set up to track remote branch serverfix from origin.
+```
+
+Скорочене звертання до upstream Коли відслідковувана гілка налаштована, ви можете використовувати скорочений запис `@{upstream}` чи `@{u}`. Тобто, при бажанні, знаходячись на `master`, що слідкує за `origin/master`, користуйтеся чимось на зразок `git merge @{u}` замість повного `git merge origin/master`.
+
+Опція `-vv` до `git branch` дозволяє дізнатися, які у вас налаштовані відслідковувані гілки. Результатом буде список локальних гілок та інформація про них, включаючи, які гілки відслідковуються та деталі про те, чи вони випереджають чи відстають від локальних (чи те й інше).
+
+```bash
+$ git branch -vv
+ iss53 7e424c3 [origin/iss53: ahead 2] forgot the brackets
+ master 1ae2a45 [origin/master] deploying index fix
+* serverfix f8674d9 [teamone/server-fix-good: ahead 3, behind 1] this should do it
+ testing 5ea463a trying something new
+```
+
+Тут ми бачимо, що гілка `iss53` слідкує за `origin/iss53` та випереджає її (“ahead”) на два, тобто ми маємо локально два коміти, які ще не надіслані на сервер. Також ми бачимо, що `master` слідкує за `origin/master` та її стан є актуальним. Далі бачимо, що `serverfix` слідкує за гілкою `server-fix-good` з сервера `teamone` та випереджає його на три й відстає на один, тобто існує один коміт на сервері, який ми ще не злили та три коміти локально, які ми ще не надіслали. Насамкінець бачимо, що локальна гілка `testing` не слідкує за жодною віддаленою.
+
+Варто зауважити, що ці числа відображають стан віддалених гілок на час останнього оновлення з кожного сервера. Сама по собі команда не сягає серверів, вона просто відображає те, що збережено про ці сервери локально. Якщо ж ви хочете отримати найостаннішу інформацію про випередження чи відставання гілок, оновіть спочатку всі віддалені посилання. Можете це зробити ось як:
+
+```bash
+$ git fetch --all; git branch -vv
+```
+
+Книжка українською по Git [https://git-scm.com/book/uk/v2](https://git-scm.com/book/uk/v2?fbclid=IwAR0GVMcHP89ApW4WLZL0Idu8VNWFN7B93fH2GQFG3Res_H6-kShIM64K-2M)
+
+Детально про GitHub Ви можете прочитати [за посиланням](https://git-scm.com/book/uk/v2/GitHub-%D0%A1%D1%82%D0%B2%D0%BE%D1%80%D0%B5%D0%BD%D0%BD%D1%8F-%D1%82%D0%B0-%D0%BD%D0%B0%D0%BB%D0%B0%D1%88%D1%82%D1%83%D0%B2%D0%B0%D0%BD%D0%BD%D1%8F-%D0%BE%D0%B1%D0%BB%D1%96%D0%BA%D0%BE%D0%B2%D0%BE%D0%B3%D0%BE-%D0%B7%D0%B0%D0%BF%D0%B8%D1%81%D1%83).
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
\ No newline at end of file
diff --git "a/\320\233\320\265\320\272\321\206/go.md" "b/\320\233\320\265\320\272\321\206/go.md"
new file mode 100644
index 0000000..4de9ac6
--- /dev/null
+++ "b/\320\233\320\265\320\272\321\206/go.md"
@@ -0,0 +1,13 @@
+# Мова Go
+
+https://echo.lviv.ua/dev/6247
+
+https://go.dev/
+
+https://habr.com/ru/post/219459/
+
+https://habr.com/ru/post/326798/
+
+https://youtu.be/pfmxPtLIW34
+
+https://metanit.com/go/tutorial/1.3.php
\ No newline at end of file
diff --git "a/\320\233\320\265\320\272\321\206/gs.md" "b/\320\233\320\265\320\272\321\206/gs.md"
new file mode 100644
index 0000000..c23fde6
--- /dev/null
+++ "b/\320\233\320\265\320\272\321\206/gs.md"
@@ -0,0 +1,118 @@
+
+
+**Програмна інженерія в системах управління. Лекції.** Автор і лектор: Олександр Пупена
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
+
+# Google Apps Script
+
+
+
+## Загальний огляд
+
+**Google Apps Script** - це платформа для розробки застосунків, що дозволяє швидко та легко створювати бізнес-застосунки, які інтегруються з [G Suite](https://uk.wikipedia.org/wiki/G_Suite). Код пишеться на сучасній версії JavaScript, при цьому з надається доступ до вбудованих бібліотек для програм `G Suite`, таких як `Gmail`, `Календар`, `Диск` тощо. Для використання не потрібно встановлювати нічого - редактор надається безпосередньо в браузері, а сценарії працюють на серверах Google.
+
+У Apps Script як і для багатьох інших реалізацій JavaScript *середовище виконання* містить рушій JavaScript, який аналізує та виконує код сценарію (див. [лекцію по JS](javascript.md)). Під час виконання програми передбачені правила доступу до пам'яті, як програма може взаємодіяти з операційною системою комп'ютера та який синтаксис програми є законним. Кожен веб-браузер має середовище виконання JavaScript.
+
+Історично склалося, що програми Apps Script використовувався [**Інтерпретатор JavaScript від Rhino**](https://developer.mozilla.org/en-US/docs/Mozilla/Projects/Rhino). Хоча Rhino надав зручні можливості для виконання сценаріїв Apps Script, він також прив’язав Apps Script до певної версії JavaScript ([ES5](https://www.w3schools.com/whatis/whatis_es5.asp)). Тому розробники Apps Script не могли використовувати більш сучасні синтаксиси та функції JavaScript у сценаріях, що використовують середовище виконання Rhino. Щоб вирішити цю проблему, Apps Script тепер підтримує [**рушій V8**](https://v8.dev/), який використовують наприклад `Google Chrome` та `Node.js`. Тепер можна [конвертувати існуючі сценарії Rhino у версію V8](https://developers.google.com/apps-script/guides/v8-runtime/migration), щоб скористатися сучасним синтаксисом та функціями JavaScript.
+
+## Можливості Apps Script
+
+Apps Script є універсальним. Зокрема він дозволяє:
+
+- Додати [користувацькі меню](https://developers.google.com/apps-script/guides/menus), [діалоги та бічні панелі](https://developers.google.com/apps-script/guides/dialogs ) до Документів, Таблиць(Sheets) та Форм Google.
+- Писати [користувацькі функції](https://developers.google.com/apps-script/execution_custom_functions) та [макроси](https://developers.google.com/apps-script/guides/sheets/macros) для Google Sheets.
+- Публікувати [веб-застосунки](https://developers.google.com/apps-script/execution_web_apps) - самостійно або вбудовані в Google Sites.
+- Взаємодіяти з іншими [сервісами Google](https://developers.google.com/apps-script/guides/services), включаючи AdSense, Analytics, Календар, Диск, Gmail та Картами.
+- Створювати [add-ons](https://developers.google.com/gsuite/add-ons/overview) для розширення Документів, Таблиць, Слайдів та форм Google і публікувати їх у магазині застосунків.
+- Конвертувати Android App в [Android add-on](https://developers.google.com/gsuite/add-ons/mobile), щоб він міг обмінюватися даними з Google Doc або Листом користувача на мобільному пристрої.
+- Упорядкуйте робочі процеси чату Hangouts, створивши [чат-бот](https://developers.google.com/hangouts/chat/quickstart/apps-script-bot).
+
+## Використання Apps Script як Веб-застосунків.
+
+Скрипти створюються на сторінці [Google Apps Script https://script.google.com](https://script.google.com). Для роботи з цим сервісом, так само як і з більшістю інших необхідно мати обліковий запис Google.
+
+### Швидкий старт
+
+- Перейдіть [Google Apps Script](https://script.google.com) , натисніть "Новий проект".
+- Напишіть простий код для виводу тексту в консоль.
+
+
+
+- Збережіть проект.
+- Запустіть проект на виконання (позначено трикутником, або меню "Запустити - Запустити функцію - myFunction").
+
+- Повідомлення консолі можна передивитися через меню Вигляд -> Журнали.
+
+
+
+### Надання веб-контенту за запитом
+
+Коли сценарій публікується як веб-застосунок, кожного разу коли відбувається запит до URL-адреси сценарію - викликаються спеціальні функції зворотного виклику `doGet()` і `doPost()` . Замість повернення об’єкта інтерфейсу користувача, створеного за допомогою [HTML service](https://developers.google.com/apps-script/guides/html), можна використовувати [Content service](https://developers.google.com/apps-script/reference/content) для повернення необробленого текстового вмісту. Це дозволяє писати сценарії, які діють як "служби", відповідаючи на запити `GET` та `POST` та обслуговуючи дані різних типів MIME. Таким чином можна організувати HTTP-API інтерфейс наприклад для роботи з сервісами в Інтернеті, що доступні 24/7.
+
+Простий приклад для сервісу Content, який просто повертає текст при запиті сторінки, матиме наступний вигляд.
+
+```javascript
+function doGet() {
+ return ContentService.createTextOutput('Привіт світ!');
+}
+```
+
+Після написання коду скрипт необхідно зберегти і опублікувати.
+
+
+
+Для перевірки роботи скрипту треба вписати в поле адреси браузера вказаний URL. Повинен з'явитися відповідний текст.
+
+Слід зауважити, що кожного разу при публікації сервісу після зміни коду необхідно вибирати нову версію.
+
+
+
+Використовуючи ці ж об'єкти можна відповідати на запити в форматі ATOM, CSV, iCal, JavaScript, JSON, RSS, vCard, та XML.
+
+## Надання дозволів скриптам
+
+При запуску скриптів, що доступаються до застосунків Google, необхідно надавати дозволи. Якщо при запуску скрипта з'являється повідомлення про необхідність авторизації необхідно надати дозволи.
+
+
+
+Найпростіший спосіб - надати дозволи самостійно.
+
+
+
+## Використання Apps Script в Google Sheets
+
+Скрипти Apps Script можуть використовуватися разом з Google Таблицями. Це має те саме призначення, що і мова VBA в `MS Excel` .
+
+### Швидкий старт
+
+- Перейдіть на [Гугл Таблиці](https://docs.google.com/spreadsheets/)
+- Створіть нову або відкрийте існуючу таблицю.
+- Зайдіть в меню "Інструменти - Редактор сценаріїв"
+- Змініть код, як наведено нижче
+
+```javascript
+function myFunction() {
+ let sheet = SpreadsheetApp.getActiveSpreadsheet().getActiveSheet(); //отримати активну сторінку
+ sheet.getRange(1,1).setValue("Приві світ"); // на активній сторінці у комірці 1,1 виведе повідомлення
+}
+```
+
+- збережіть код і запустіть на виконання
+- спосіб надання дозволів описаний вище
+
+
+
+**Посилання**.
+
+[створення коду](https://netpeak.net/ru/blog/google-apps-script-poleznyye-funktsii-i-fishki-dlya-seo-chast-pervaya/)
+
+https://xakep.ru/2015/01/08/google-apps-script/
+
+https://developers.google.com/apps-script/guides/content
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
\ No newline at end of file
diff --git "a/\320\233\320\265\320\272\321\206/gsmedia/1.png" "b/\320\233\320\265\320\272\321\206/gsmedia/1.png"
new file mode 100644
index 0000000..c333826
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/gsmedia/1.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/gsmedia/2.png" "b/\320\233\320\265\320\272\321\206/gsmedia/2.png"
new file mode 100644
index 0000000..dce398c
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/gsmedia/2.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/gsmedia/3.png" "b/\320\233\320\265\320\272\321\206/gsmedia/3.png"
new file mode 100644
index 0000000..e1e0385
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/gsmedia/3.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/gsmedia/4.png" "b/\320\233\320\265\320\272\321\206/gsmedia/4.png"
new file mode 100644
index 0000000..b2e5f5e
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/gsmedia/4.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/gsmedia/5.png" "b/\320\233\320\265\320\272\321\206/gsmedia/5.png"
new file mode 100644
index 0000000..de57312
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/gsmedia/5.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/gsmedia/6.png" "b/\320\233\320\265\320\272\321\206/gsmedia/6.png"
new file mode 100644
index 0000000..95f3760
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/gsmedia/6.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/gsmedia/7.png" "b/\320\233\320\265\320\272\321\206/gsmedia/7.png"
new file mode 100644
index 0000000..1244880
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/gsmedia/7.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/gsmedia/logo.png" "b/\320\233\320\265\320\272\321\206/gsmedia/logo.png"
new file mode 100644
index 0000000..a0c0779
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/gsmedia/logo.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/1.png" "b/\320\233\320\265\320\272\321\206/httpMedia/1.png"
new file mode 100644
index 0000000..c594c0d
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/1.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/10_1.png" "b/\320\233\320\265\320\272\321\206/httpMedia/10_1.png"
new file mode 100644
index 0000000..6732f9f
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/10_1.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/10_2.png" "b/\320\233\320\265\320\272\321\206/httpMedia/10_2.png"
new file mode 100644
index 0000000..c473fb5
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/10_2.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/10_3.png" "b/\320\233\320\265\320\272\321\206/httpMedia/10_3.png"
new file mode 100644
index 0000000..7e7510d
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/10_3.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/10_4.png" "b/\320\233\320\265\320\272\321\206/httpMedia/10_4.png"
new file mode 100644
index 0000000..2e47fa3
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/10_4.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/10_5.png" "b/\320\233\320\265\320\272\321\206/httpMedia/10_5.png"
new file mode 100644
index 0000000..20abb5b
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/10_5.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/10_6.png" "b/\320\233\320\265\320\272\321\206/httpMedia/10_6.png"
new file mode 100644
index 0000000..efda474
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/10_6.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/10_7.png" "b/\320\233\320\265\320\272\321\206/httpMedia/10_7.png"
new file mode 100644
index 0000000..fae5137
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/10_7.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/10_8.png" "b/\320\233\320\265\320\272\321\206/httpMedia/10_8.png"
new file mode 100644
index 0000000..3b64175
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/10_8.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/12.png" "b/\320\233\320\265\320\272\321\206/httpMedia/12.png"
new file mode 100644
index 0000000..e062110
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/12.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/16.png" "b/\320\233\320\265\320\272\321\206/httpMedia/16.png"
new file mode 100644
index 0000000..301133b
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/16.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/17.png" "b/\320\233\320\265\320\272\321\206/httpMedia/17.png"
new file mode 100644
index 0000000..f94ed31
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/17.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/18.png" "b/\320\233\320\265\320\272\321\206/httpMedia/18.png"
new file mode 100644
index 0000000..95b9cb0
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/18.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/19.png" "b/\320\233\320\265\320\272\321\206/httpMedia/19.png"
new file mode 100644
index 0000000..4bd28e3
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/19.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/1_74.png" "b/\320\233\320\265\320\272\321\206/httpMedia/1_74.png"
new file mode 100644
index 0000000..f1005ea
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/1_74.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/1_75.png" "b/\320\233\320\265\320\272\321\206/httpMedia/1_75.png"
new file mode 100644
index 0000000..e8d1ec8
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/1_75.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/1_76.png" "b/\320\233\320\265\320\272\321\206/httpMedia/1_76.png"
new file mode 100644
index 0000000..8cae306
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/1_76.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/2.png" "b/\320\233\320\265\320\272\321\206/httpMedia/2.png"
new file mode 100644
index 0000000..092b010
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/2.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/20.png" "b/\320\233\320\265\320\272\321\206/httpMedia/20.png"
new file mode 100644
index 0000000..8cde834
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/20.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/23.png" "b/\320\233\320\265\320\272\321\206/httpMedia/23.png"
new file mode 100644
index 0000000..389afe0
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/23.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/24_1.png" "b/\320\233\320\265\320\272\321\206/httpMedia/24_1.png"
new file mode 100644
index 0000000..1fc28f4
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/24_1.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/24_2.png" "b/\320\233\320\265\320\272\321\206/httpMedia/24_2.png"
new file mode 100644
index 0000000..34c8f6b
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/24_2.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/25.png" "b/\320\233\320\265\320\272\321\206/httpMedia/25.png"
new file mode 100644
index 0000000..c800a4d
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/25.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/26.png" "b/\320\233\320\265\320\272\321\206/httpMedia/26.png"
new file mode 100644
index 0000000..dbed11e
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/26.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/27.png" "b/\320\233\320\265\320\272\321\206/httpMedia/27.png"
new file mode 100644
index 0000000..bb14ce9
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/27.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/28.png" "b/\320\233\320\265\320\272\321\206/httpMedia/28.png"
new file mode 100644
index 0000000..b74f2cd
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/28.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/29_1.png" "b/\320\233\320\265\320\272\321\206/httpMedia/29_1.png"
new file mode 100644
index 0000000..94ad50b
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/29_1.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/29_2.png" "b/\320\233\320\265\320\272\321\206/httpMedia/29_2.png"
new file mode 100644
index 0000000..61fabdb
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/29_2.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/3.png" "b/\320\233\320\265\320\272\321\206/httpMedia/3.png"
new file mode 100644
index 0000000..d48d2b8
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/3.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/30.png" "b/\320\233\320\265\320\272\321\206/httpMedia/30.png"
new file mode 100644
index 0000000..5e3a9b9
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/30.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/31.png" "b/\320\233\320\265\320\272\321\206/httpMedia/31.png"
new file mode 100644
index 0000000..5c2098a
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/31.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/32.png" "b/\320\233\320\265\320\272\321\206/httpMedia/32.png"
new file mode 100644
index 0000000..07e12ec
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/32.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/34.png" "b/\320\233\320\265\320\272\321\206/httpMedia/34.png"
new file mode 100644
index 0000000..f8fe647
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/34.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/36_1.png" "b/\320\233\320\265\320\272\321\206/httpMedia/36_1.png"
new file mode 100644
index 0000000..9df7b9c
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/36_1.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/36_2.png" "b/\320\233\320\265\320\272\321\206/httpMedia/36_2.png"
new file mode 100644
index 0000000..fe33771
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/36_2.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/37.png" "b/\320\233\320\265\320\272\321\206/httpMedia/37.png"
new file mode 100644
index 0000000..886e2c6
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/37.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/38.png" "b/\320\233\320\265\320\272\321\206/httpMedia/38.png"
new file mode 100644
index 0000000..f05c44f
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/38.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/39.png" "b/\320\233\320\265\320\272\321\206/httpMedia/39.png"
new file mode 100644
index 0000000..1dfa0be
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/39.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/4.png" "b/\320\233\320\265\320\272\321\206/httpMedia/4.png"
new file mode 100644
index 0000000..964538a
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/4.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/40.png" "b/\320\233\320\265\320\272\321\206/httpMedia/40.png"
new file mode 100644
index 0000000..15108f3
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/40.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/43_1.png" "b/\320\233\320\265\320\272\321\206/httpMedia/43_1.png"
new file mode 100644
index 0000000..7c68cdf
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/43_1.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/43_2.png" "b/\320\233\320\265\320\272\321\206/httpMedia/43_2.png"
new file mode 100644
index 0000000..86c328a
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/43_2.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/43_3.png" "b/\320\233\320\265\320\272\321\206/httpMedia/43_3.png"
new file mode 100644
index 0000000..e466c6b
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/43_3.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/44_1.png" "b/\320\233\320\265\320\272\321\206/httpMedia/44_1.png"
new file mode 100644
index 0000000..0c5521e
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/44_1.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/44_2.png" "b/\320\233\320\265\320\272\321\206/httpMedia/44_2.png"
new file mode 100644
index 0000000..731e4b1
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/44_2.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/45_5.png" "b/\320\233\320\265\320\272\321\206/httpMedia/45_5.png"
new file mode 100644
index 0000000..dcc668a
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/45_5.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/5.png" "b/\320\233\320\265\320\272\321\206/httpMedia/5.png"
new file mode 100644
index 0000000..5969157
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/5.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/9_1.png" "b/\320\233\320\265\320\272\321\206/httpMedia/9_1.png"
new file mode 100644
index 0000000..77fc59c
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/9_1.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/9_2.png" "b/\320\233\320\265\320\272\321\206/httpMedia/9_2.png"
new file mode 100644
index 0000000..f79fc6d
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/9_2.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/9_3.png" "b/\320\233\320\265\320\272\321\206/httpMedia/9_3.png"
new file mode 100644
index 0000000..5db810c
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/9_3.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/9_4.png" "b/\320\233\320\265\320\272\321\206/httpMedia/9_4.png"
new file mode 100644
index 0000000..fe28703
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/9_4.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/REST1.png" "b/\320\233\320\265\320\272\321\206/httpMedia/REST1.png"
new file mode 100644
index 0000000..0326a30
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/REST1.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/REST2.png" "b/\320\233\320\265\320\272\321\206/httpMedia/REST2.png"
new file mode 100644
index 0000000..028ca11
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/REST2.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/REST3.png" "b/\320\233\320\265\320\272\321\206/httpMedia/REST3.png"
new file mode 100644
index 0000000..17303be
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/REST3.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/WebAPI.png" "b/\320\233\320\265\320\272\321\206/httpMedia/WebAPI.png"
new file mode 100644
index 0000000..364ac89
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/WebAPI.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/cashe.png" "b/\320\233\320\265\320\272\321\206/httpMedia/cashe.png"
new file mode 100644
index 0000000..7d8d142
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/cashe.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/clientserver.png" "b/\320\233\320\265\320\272\321\206/httpMedia/clientserver.png"
new file mode 100644
index 0000000..0b17972
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/clientserver.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/csv.png" "b/\320\233\320\265\320\272\321\206/httpMedia/csv.png"
new file mode 100644
index 0000000..690e3b1
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/csv.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/html.png" "b/\320\233\320\265\320\272\321\206/httpMedia/html.png"
new file mode 100644
index 0000000..ff6ee73
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/html.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/htmlin.png" "b/\320\233\320\265\320\272\321\206/httpMedia/htmlin.png"
new file mode 100644
index 0000000..ff6ee73
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/htmlin.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/http.png" "b/\320\233\320\265\320\272\321\206/httpMedia/http.png"
new file mode 100644
index 0000000..88781ca
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/http.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/httpexample.png" "b/\320\233\320\265\320\272\321\206/httpMedia/httpexample.png"
new file mode 100644
index 0000000..0979f71
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/httpexample.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/httprequest.png" "b/\320\233\320\265\320\272\321\206/httpMedia/httprequest.png"
new file mode 100644
index 0000000..8876160
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/httprequest.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/httprequestexmpl.png" "b/\320\233\320\265\320\272\321\206/httpMedia/httprequestexmpl.png"
new file mode 100644
index 0000000..f5cfe80
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/httprequestexmpl.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/httpresponse.png" "b/\320\233\320\265\320\272\321\206/httpMedia/httpresponse.png"
new file mode 100644
index 0000000..e813276
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/httpresponse.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/json.png" "b/\320\233\320\265\320\272\321\206/httpMedia/json.png"
new file mode 100644
index 0000000..38ab76d
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/json.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/keepalive.png" "b/\320\233\320\265\320\272\321\206/httpMedia/keepalive.png"
new file mode 100644
index 0000000..8c47ab5
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/keepalive.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/multipart.png" "b/\320\233\320\265\320\272\321\206/httpMedia/multipart.png"
new file mode 100644
index 0000000..4bdd6e2
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/multipart.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/stack.png" "b/\320\233\320\265\320\272\321\206/httpMedia/stack.png"
new file mode 100644
index 0000000..285088d
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/stack.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/structmsg.png" "b/\320\233\320\265\320\272\321\206/httpMedia/structmsg.png"
new file mode 100644
index 0000000..d318f75
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/structmsg.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/template.png" "b/\320\233\320\265\320\272\321\206/httpMedia/template.png"
new file mode 100644
index 0000000..4257760
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/template.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/websocket.png" "b/\320\233\320\265\320\272\321\206/httpMedia/websocket.png"
new file mode 100644
index 0000000..7b1c447
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/websocket.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/websocketin.png" "b/\320\233\320\265\320\272\321\206/httpMedia/websocketin.png"
new file mode 100644
index 0000000..7b1c447
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/websocketin.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/websocketout.png" "b/\320\233\320\265\320\272\321\206/httpMedia/websocketout.png"
new file mode 100644
index 0000000..9f2c21f
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/websocketout.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/xml.png" "b/\320\233\320\265\320\272\321\206/httpMedia/xml.png"
new file mode 100644
index 0000000..56ddc47
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/xml.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2721.gif" "b/\320\233\320\265\320\272\321\206/httpMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2721.gif"
new file mode 100644
index 0000000..dda6e20
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2721.gif" differ
diff --git "a/\320\233\320\265\320\272\321\206/httpMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2722.gif" "b/\320\233\320\265\320\272\321\206/httpMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2722.gif"
new file mode 100644
index 0000000..fc10518
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/httpMedia/\320\240\320\270\321\201\321\203\320\275\320\276\320\2722.gif" differ
diff --git "a/\320\233\320\265\320\272\321\206/jsclass.md" "b/\320\233\320\265\320\272\321\206/jsclass.md"
new file mode 100644
index 0000000..cbc82a3
--- /dev/null
+++ "b/\320\233\320\265\320\272\321\206/jsclass.md"
@@ -0,0 +1,41 @@
+**Програмна інженерія в системах управління. Лекції.** Автор і лектор: Олександр Пупена
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| --------------------------------- | ----------------------------------------- |
+| [<-до попередньої](javascript.md) | |
+
+# Об'єктно-орієнтоване програмування в JavaScript
+
+
+
+
+
+У цій лекції розглядається об'єктно-орієнтоване програмування в JavaScript.
+
+# Властивості об'єктів та їх конфігурація
+
+## Прапорці та дескриптори властивостей
+
+https://learn.javascript.ru/property-descriptors
+
+## Доступ до властивостей через `get` та`set`
+
+https://learn.javascript.ru/property-accessors
+
+# Прототипи та наслідування
+
+1. [Прототипное наследование](https://learn.javascript.ru/prototype-inheritance)
+2. [F.prototype](https://learn.javascript.ru/function-prototype)
+3. [Встроенные прототипы](https://learn.javascript.ru/native-prototypes)
+4. [Методы прототипов, объекты без свойства __proto__](https://learn.javascript.ru/prototype-methods)
+
+
+
+## Джерела:
+
+- [Современный учебник JavaScript](https://learn.javascript.ru/)
+- [Посібник JavaScript MDN](https://developer.mozilla.org/uk/docs/Web/JavaScript/Guide)
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| --------------------------------- | ----------------------------------------- |
+| [<-до попередньої](javascript.md) | |
\ No newline at end of file
diff --git "a/\320\233\320\265\320\272\321\206/jsmedia/1.png" "b/\320\233\320\265\320\272\321\206/jsmedia/1.png"
new file mode 100644
index 0000000..fec60f8
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/jsmedia/1.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/jsmedia/JVM.png" "b/\320\233\320\265\320\272\321\206/jsmedia/JVM.png"
new file mode 100644
index 0000000..0d3459b
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/jsmedia/JVM.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/jsmedia/google.png" "b/\320\233\320\265\320\272\321\206/jsmedia/google.png"
new file mode 100644
index 0000000..acc82bb
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/jsmedia/google.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/jsmedia/js_name.png" "b/\320\233\320\265\320\272\321\206/jsmedia/js_name.png"
new file mode 100644
index 0000000..c3acdf6
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/jsmedia/js_name.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/jsmedia/js_ob.png" "b/\320\233\320\265\320\272\321\206/jsmedia/js_ob.png"
new file mode 100644
index 0000000..c47dd12
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/jsmedia/js_ob.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/jsmedia/jsengines.png" "b/\320\233\320\265\320\272\321\206/jsmedia/jsengines.png"
new file mode 100644
index 0000000..6f0c50f
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/jsmedia/jsengines.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/jsmedia/mozilla.png" "b/\320\233\320\265\320\272\321\206/jsmedia/mozilla.png"
new file mode 100644
index 0000000..814d6fc
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/jsmedia/mozilla.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/jsmedia/node.png" "b/\320\233\320\265\320\272\321\206/jsmedia/node.png"
new file mode 100644
index 0000000..7f65bbf
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/jsmedia/node.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/jsmedia/pop.png" "b/\320\233\320\265\320\272\321\206/jsmedia/pop.png"
new file mode 100644
index 0000000..1cc46d8
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/jsmedia/pop.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/jsmedia/vsc.png" "b/\320\233\320\265\320\272\321\206/jsmedia/vsc.png"
new file mode 100644
index 0000000..a4a84e1
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/jsmedia/vsc.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/lifecyclemedia/evolution.dia" "b/\320\233\320\265\320\272\321\206/lifecyclemedia/evolution.dia"
new file mode 100644
index 0000000..9bcc352
--- /dev/null
+++ "b/\320\233\320\265\320\272\321\206/lifecyclemedia/evolution.dia"
@@ -0,0 +1,1432 @@
+
+
+
+
+
+
+
+
+
+
+
+
+ #A4#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Вимоги 1#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Проекту
+вання#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Програм.
+Тестув.#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Ввдеення
+в дію#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Роботи над конструкцією 1#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Роботи над конструкцією 2#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Роботи над конструкцією 3#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Проекту
+вання#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Програм.
+Тестув.#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Ввдеення
+в дію#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Проекту
+вання#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Програм.
+Тестув.#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Ввдеення
+в дію#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Вимоги 2#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Вимоги 3#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git "a/\320\233\320\265\320\272\321\206/lifecyclemedia/evolution.dia~" "b/\320\233\320\265\320\272\321\206/lifecyclemedia/evolution.dia~"
new file mode 100644
index 0000000..9bcc352
--- /dev/null
+++ "b/\320\233\320\265\320\272\321\206/lifecyclemedia/evolution.dia~"
@@ -0,0 +1,1432 @@
+
+
+
+
+
+
+
+
+
+
+
+
+ #A4#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Вимоги 1#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Проекту
+вання#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Програм.
+Тестув.#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Ввдеення
+в дію#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Роботи над конструкцією 1#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Роботи над конструкцією 2#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Роботи над конструкцією 3#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Проекту
+вання#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Програм.
+Тестув.#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Ввдеення
+в дію#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Проекту
+вання#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Програм.
+Тестув.#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Ввдеення
+в дію#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Вимоги 2#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Вимоги 3#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git "a/\320\233\320\265\320\272\321\206/lifecyclemedia/evolution.png" "b/\320\233\320\265\320\272\321\206/lifecyclemedia/evolution.png"
new file mode 100644
index 0000000..73b274d
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/lifecyclemedia/evolution.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/lifecyclemedia/incrmodel.dia" "b/\320\233\320\265\320\272\321\206/lifecyclemedia/incrmodel.dia"
new file mode 100644
index 0000000..413f8c5
--- /dev/null
+++ "b/\320\233\320\265\320\272\321\206/lifecyclemedia/incrmodel.dia"
@@ -0,0 +1,1535 @@
+
+
+
+
+
+
+
+
+
+
+
+
+ #A4#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Вимоги#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Вимоги 1#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Вимоги 2#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Вимоги 3#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Проекту
+вання#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Програм.
+Тестув.#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Ввдеення
+в дію#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Роботи над конструкцією 1#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Роботи над конструкцією 2#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Роботи над конструкцією 3#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Проекту
+вання#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Програм.
+Тестув.#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Ввдеення
+в дію#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Проекту
+вання#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Програм.
+Тестув.#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Ввдеення
+в дію#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git "a/\320\233\320\265\320\272\321\206/lifecyclemedia/incrmodel.dia~" "b/\320\233\320\265\320\272\321\206/lifecyclemedia/incrmodel.dia~"
new file mode 100644
index 0000000..11ef675
--- /dev/null
+++ "b/\320\233\320\265\320\272\321\206/lifecyclemedia/incrmodel.dia~"
@@ -0,0 +1,1535 @@
+
+
+
+
+
+
+
+
+
+
+
+
+ #A4#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Вимоги#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Вимоги 1#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Вимоги 2#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Вимоги 3#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Проекту
+вання#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Програм.
+Тестув.#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Ввдеення
+в дію#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Роботи над конструкцією 1#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Роботи над конструкцією 2#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Роботи над конструкцією 3#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Проекту
+вання#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Програм.
+Тестув.#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Ввдеення
+в дію#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Проекту
+вання#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Програм.
+Тестув.#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Ввдеення
+в дію#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git "a/\320\233\320\265\320\272\321\206/lifecyclemedia/incrmodel.png" "b/\320\233\320\265\320\272\321\206/lifecyclemedia/incrmodel.png"
new file mode 100644
index 0000000..79bff3d
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/lifecyclemedia/incrmodel.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/lifecyclemedia/incrmodel~" "b/\320\233\320\265\320\272\321\206/lifecyclemedia/incrmodel~"
new file mode 100644
index 0000000..86277a2
--- /dev/null
+++ "b/\320\233\320\265\320\272\321\206/lifecyclemedia/incrmodel~"
@@ -0,0 +1,1509 @@
+
+
+
+
+
+
+
+
+
+
+
+
+ #A4#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Вимоги#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Вимоги 1#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Вимоги 2#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Вимоги 3#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Проекту
+вання#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Програм.
+Тестув.#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Ввдеення
+в дію#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Роботи над конструкцією 1#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Роботи над конструкцією 2#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Роботи над конструкцією 3#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Проекту
+вання#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Програм.
+Тестув.#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Ввдеення
+в дію#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Проекту
+вання#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Програм.
+Тестув.#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Ввдеення
+в дію#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git "a/\320\233\320\265\320\272\321\206/lifecyclemedia/kanban.jpg" "b/\320\233\320\265\320\272\321\206/lifecyclemedia/kanban.jpg"
new file mode 100644
index 0000000..2472044
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/lifecyclemedia/kanban.jpg" differ
diff --git "a/\320\233\320\265\320\272\321\206/lifecyclemedia/srum.gif" "b/\320\233\320\265\320\272\321\206/lifecyclemedia/srum.gif"
new file mode 100644
index 0000000..fff9d31
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/lifecyclemedia/srum.gif" differ
diff --git "a/\320\233\320\265\320\272\321\206/lifecyclemedia/vmodel.dia" "b/\320\233\320\265\320\272\321\206/lifecyclemedia/vmodel.dia"
new file mode 100644
index 0000000..4aef036
--- /dev/null
+++ "b/\320\233\320\265\320\272\321\206/lifecyclemedia/vmodel.dia"
@@ -0,0 +1,1205 @@
+
+
+
+
+
+
+
+
+
+
+
+
+ #A4#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Тестування
+компонентів#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Проектування
+системи#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Програмування#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Введення
+в дію#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Проектування
+компонентів#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Комплексні
+випробування#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Вимоги #
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #верифікація#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #верифікація#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #валідація#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #означення
+системи#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #реалізація
+системи#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #панування випробувань на об'єкті#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #панування комплексних
+випробувань на макеті#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #панування випробувань
+для компоненту#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git "a/\320\233\320\265\320\272\321\206/lifecyclemedia/vmodel.dia~" "b/\320\233\320\265\320\272\321\206/lifecyclemedia/vmodel.dia~"
new file mode 100644
index 0000000..3a9d956
--- /dev/null
+++ "b/\320\233\320\265\320\272\321\206/lifecyclemedia/vmodel.dia~"
@@ -0,0 +1,1101 @@
+
+
+
+
+
+
+
+
+
+
+
+
+ #A4#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Тестування
+компонентів#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Проектування
+системи#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Програмування#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Введення
+в дію#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Проектування
+компонентів#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Комплексні
+випробування#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Вимоги #
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #верифікація#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #верифікація#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #валідація#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #означення
+системи#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #реалізація
+системи#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git "a/\320\233\320\265\320\272\321\206/lifecyclemedia/vmodel.png" "b/\320\233\320\265\320\272\321\206/lifecyclemedia/vmodel.png"
new file mode 100644
index 0000000..e0c96bc
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/lifecyclemedia/vmodel.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/lifecyclemedia/waterfall.dia" "b/\320\233\320\265\320\272\321\206/lifecyclemedia/waterfall.dia"
new file mode 100644
index 0000000..c5477e6
--- /dev/null
+++ "b/\320\233\320\265\320\272\321\206/lifecyclemedia/waterfall.dia"
@@ -0,0 +1,458 @@
+
+
+
+
+
+
+
+
+
+
+
+
+ #A4#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Проекту
+вання#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Вимоги#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Програм.
+Тестув.#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Ввдеення
+в дію#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git "a/\320\233\320\265\320\272\321\206/lifecyclemedia/waterfall.dia~" "b/\320\233\320\265\320\272\321\206/lifecyclemedia/waterfall.dia~"
new file mode 100644
index 0000000..3027324
--- /dev/null
+++ "b/\320\233\320\265\320\272\321\206/lifecyclemedia/waterfall.dia~"
@@ -0,0 +1,432 @@
+
+
+
+
+
+
+
+
+
+
+
+
+ #A4#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Проекту
+вання#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Вимоги#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Програм.
+Тестув.#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ #Ввдеення
+в дію#
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git "a/\320\233\320\265\320\272\321\206/lifecyclemedia/waterfall.png" "b/\320\233\320\265\320\272\321\206/lifecyclemedia/waterfall.png"
new file mode 100644
index 0000000..d30fbaf
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/lifecyclemedia/waterfall.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/lua.md" "b/\320\233\320\265\320\272\321\206/lua.md"
new file mode 100644
index 0000000..8975962
--- /dev/null
+++ "b/\320\233\320\265\320\272\321\206/lua.md"
@@ -0,0 +1,818 @@
+# Мова Lua
+
+Робоча чернетка.
+
+[Learn Lua in 15 Minutes](http://tylerneylon.com/a/learn-lua/ )
+
+[wiki](https://uk.wikipedia.org/wiki/Lua)
+
+[Lua 5.0 Reference Manual](https://www.lua.org/manual/5.0/)
+
+[Programming in Lua (first edition)](https://www.lua.org/pil/contents.html)
+
+[CronosPRO — Lua](https://www.cronos.ru/kb-cronospro-lua.html)
+
+## Вступ
+
+Lua ([лу́а], порт. місяць) — швидка і компактна скриптова мова програмування, розроблена підрозділом Tecgraf Католицького університету Ріо-де-Жанейро (Computer Graphics Technology Group of Pontifical Catholic University of Rio de Janeiro in Brazil). Є вільно-поширюваною, з відкритим сирцевим кодом на мові Сі.
+
+За можливостями, ідеологією і реалізацією, мова найближча до JavaScript, проте Lua відрізняється могутнішими і набагато гнучкішими конструкціями, спроектованими з метою «не плодити сутності понад необхідне». Хоча Lua не містить поняття класу і об'єкта в явному вигляді, механізми об'єктно-орієнтованого програмування з підтримкою прототипів (включаючи множинне успадкування) легко реалізуються з використанням метатаблиць, які також дозволяють перевантаження операцій, тощо. Реалізована модель ООП (як і в JavaScript) — прототипна.
+
+Lua отримала велике поширення в ролі вбудованої в інші проекти мови сценаріїв (наприклад, для визначення конфігурації або для написання розширень). Lua комбінує простий процедурний синтаксис з потужними можливостями опису даних через використання асоціативних масивів і розширюваної семантики мови. У Lua використовується динамічна типізація, мовні конструкції перетворюються на байт-код, який виконується поверх регістрової віртуальної машини з автоматичним збирачем сміття. Сам інтерпретатор оформлений у вигляді бібліотеки, легко інтегрованої в проекти на мовах Сі та Сі++. Код інтерпретатора Lua написаний на мові Сі і розповсюджується під ліцензією MIT.
+
+Як і багато інтерпретованих мов програмування, реалізація Lua має окремо компілятор з сирцевого коду у виконуваний байт-код і віртуальну машину для виконання згенерованого байт-коду. Особливістю є те, що байт-код — це команди не стекової машини, команди віртуального регістрового процесора, який більше відповідає реальним ЦПУ. Таке архітектурне рішення майже прямо транслюється на команди сучасних CPU. Це суттєво зменшує операції з перетворення. За рахунок зменшення технологічних операцій перетворення, зростає ефективність виконання Lua-скриптів. Стандартна віртуальна машина Lua використовує розподіл пам'яті із прибиранням сміття (аналогічно Java або .NET).
+
+```lua
+print("Вітаю, світе!") -- дві риски для однолінійного коментаря
+--[[
+ Добавляючи дві квадратні дужки [ і ] з рисками
+ створюються мультирядкові коментарі
+--]]
+```
+
+## Типи даних, літерали та функція `type`
+
+Lua is a *dynamically typed language*. That means that variables do not have types; only values do. There are no type definitions in the language. All values carry their own type.
+
+Lua - це *динамічно типізована мова*.
+
+Тут є вісім базових типів: *nil*, *boolean*, *number*, *string*, *function*, *userdata*, *thread*, та *table*. *Nil* це тип значення **nil**, головна властивість якого відрізнятися від будь-якого іншого значення; зазвичай це представляє собою відсутність корисного значення. *Boolean* це тип значень **false** та **true**. В Lua, обивда значення **nil** та **false** повертають при порівнянні false; будь які інші значення повертають true. *Number* пердставляє чсила real (двойної точності floating-point). Легко побудувати інтерпретаторів Lua, які використовують інші внутрішні представлення для чисел, наприклад, числа з плаваючою комою одинарної точності або повдійні цілі числа. 64-бітні double мають 52 біти зберігання точних значень int; точність машини є не проблема для ints, яким потрібно <52 біт. *String* представлений масивом символів. Lua базується на 8-бітному представленні симовлів у тому числі з 0-м значенням (`'\0'`) (див [2.1](https://www.lua.org/manual/5.0/manual.html#lexical)).
+
+Функції - це *першокласні значення* в Lua. Це означає, що функції можуть зберігатися у змінних, передаватися як аргументи іншим функціям та повертатися як результати. Lua може викликати (і маніпулювати) функціями, написаними в Lua, і функціями, написаними на C (див [2.5.7](https://www.lua.org/manual/5.0/manual.html#functioncall)).
+
+Тип *userdata* надається, щоб дозволити збереження довільних даних C у змінних Lua. Цей тип відповідає блоку необмеженої пам'яті і не має заздалегідь означених операцій у Lua, за винятком assignment (присвоєння) та тестування ідентичності (identity test). Однак, використовуючи *metatables*, програміст може означити операції для значень даних користувачів (див. [2.8](https://www.lua.org/manual/5.0/manual.html#metatable)). Значення Userdata не можна створювати або змінювати в Lua, лише через C API. Це гарантує цілісність даних, що належать хост-програмі.
+
+Тип *thread* представляє собою незалежні потоки виконання, і він використовується для реалізації співпрограми (coroutines).
+
+Тип *table* (таблиця) реалізує асоціативні масиви, тобто масиви, які можна індексувати не тільки цифрами, але і будь-яким значенням (крім **nil**). Більше того, таблиці можуть бути *heterogeneous* (неоднорідними), тобто вони можуть містити значення всіх типів (крім **nil**). Таблиці - єдиний механізм структурування даних в Lua; їх можна використовувати для представлення звичайних масивів, таблиць символів, наборів, записів, графіків, дерев тощо. Для подання записів Lua використовує назву поля як індекс. Мова підтримує це подання, надаючи `a.name` як синтаксичний цукор для ` a ["name"] `. У Луа є кілька зручних способів створення таблиць (див. [2.5.6](https://www.lua.org/manual/5.0/manual.html#tableconstructor)).
+
+Як і індекси, значення таблиці таблиці може бути будь-якого типу (крім **nil**). Зокрема, оскільки функції - це значення першого класу, поля таблиці можуть містити функції. Таким чином, таблиці також можуть містити *методи* (див. [2.5.8](https://www.lua.org/manual/5.0/manual.html#func-def)).
+
+Таблиці, функції та значення userdata - це *об’єкти*: змінні насправді не містять цих значень, лише *посилання* на них. Призначення, передача параметрів і повернення функції завжди маніпулюють посиланнями на такі значення; ці операції не передбачають жодного копіювання.
+
+Бібліотечна функція `type` повертає рядок з описом типу вказаного значення (див [5.1](https://www.lua.org/manual/5.0/manual.html#pdf-type)).
+
+```lua
+print (type (nil)) --> nil
+print (type (true)) --> boolean
+print (type ("рядок")) --> string
+print (type (4.5)) --> number
+print (type ({"це таблиця"})) --> table
+print (type(io.stdin)) --> userdata
+print (type(print)) --> function
+```
+
+## Змінні
+
+У Lua є три види змінних: глобальні змінні, локальні змінні та поля таблиці. Змінні вважаються глобальними, якщо не оголошені локальними (`local`). Локальні змінні охоплені лексичним колом: до локальних змінних можна вільно дістатися за допомогою функцій, означених всередині їхньої області.
+
+Перед першим назначенням змінної її значення дорівнює **nil**.
+
+```lua
+num = 42
+local f = 23.4
+s = 'walternate' -- для strings одинарні лапки
+t = "подвійні лапки теж норм"
+u = [[ Подвійні квадратні дужки
+ починають і завершують
+ мультирядковий string]]
+t = nil -- неозначений t; Lua має збірщика сміття.
+```
+
+## Кусок (Chunk) та блоки
+
+Частина програми, що компілюється як єдиний блок називається куском `Chunk`.
+
+У одному рядку інстуркції можуть розділятися `; `
+
+```lua
+a =10; b=12 -- кілька інструкцій через ;
+```
+
+Явне виділення куска з коду проводиться блоком, який обмежується операторами`do` `end`. Локальні змінні мають область видимості в межах блоків.
+
+```lua
+a = 1
+do
+ local a = 2
+ print(a) -- 2
+end
+print(a) -- 1
+```
+
+## Вирази
+
+Lua підтримує звичайні арифметичні оператори: `+` (додавання),` -` (віднімання), `*` (множення),` /` (ділення) та унарне `-` (заперечення). Усі вони працюють з реальними числами.
+
+Lua також пропонує часткову підтримку `^` (експоненція). Однією з дизайнерських цілей Lua є створення крихітного стрижня. Операція експоненціації (реалізована через функцію pow у C) означала б, що нам завжди потрібно зв’язувати Lua з математичною бібліотекою C. Щоб уникнути цієї потреби, ядро Lua пропонує лише синтаксис бінарного оператора `^`, який має більшу перевагу серед усіх операцій. Математична бібліотека (яка є стандартною, але не є частиною ядра Луа) надає цьому оператору очікуване значення.
+
+Порівняння:
+
+```
+ < > <= >= == ~=
+```
+
+
+
+## If
+
+```lua
+-- If clauses:
+if num > 40 then
+ print('over 40')
+elseif s ~= 'walternate' then -- ~= не дорівнює
+ -- перевірка на рівність == подібно JS; ok for strs.
+ io.write('not over 40\n') -- за замовченням виводить в stdout
+else
+ -- змінні глобальні за замовченням
+ thisIsGlobal = 5 -- поишрений Верблюжий регістр (кілька слів в одному без пробілів з Великої літери)
+
+ -- як створити змінну локальною:
+ local line = io.read() -- зчитує наступний рядок з stdin
+
+ -- конкатенація рядків робиться через оператор .. :
+ print('Winter is coming, ' .. line)
+end
+```
+```lua
+-- неозначені змінні повертають nil
+-- це не є помилкою:
+foo = anUnknownVariable -- тепер foo = nil
+```
+```lua
+aBoolValue = false
+```
+```lua
+-- тільки nil та false є хибними; 0 та '' є істинне!
+if not aBoolValue then print('twas false') end
+```
+```lua
+-- 'or' та 'and' є коротко-замкненими
+-- Це подібно до оператору a?b:c в C/js:
+ans = aBoolValue and 'так' or 'ні' --> 'ні'
+```
+## Цикли
+
+```lua
+t = {t1 = 23.4, t2 = "45"}
+for key, val in pairs(t) do
+ print ("Значення " .. key .. " = " .. val)
+end
+--[[ виведе:
+Значення t2 = 45
+Значення t1 = 234
+--]]
+```
+
+```lua
+karlSum = 0
+for i = 1, 100 do -- діапазон включає обидва кінця
+ karlSum = karlSum + i
+end
+```
+```lua
+-- використовуйте "100, 1, -1" як діапазон для підрахунку вниз:
+fredSum = 0
+for j = 100, 1, -1 do fredSum = fredSum + j end
+```
+```lua
+-- в загальному, діапазон задається begin, end[, step]
+```
+```lua
+-- інша конструкція циклу:
+repeat
+ print('the way of the future')
+ num = num - 1
+until num == 0
+```
+
+## Функції
+
+Функції в Lua є значеннями першого класу, що означає, що функції можна передавати до інших функцій, повертати з них та використовувати замикання. Функції можуть повертати будь-яку кількість значень. Також функцію можна викликати з будь-якою кількістю параметрів: зайві будуть ігноруватись, а тим, яких не вистачає, буде присвоєно значення nil.
+
+```lua
+function fib(n)
+ if n < 2 then return 1 end
+ return fib(n - 2) + fib(n - 1)
+end
+
+-- Closures and anonymous functions are ok:
+function adder(x)
+ -- The returned function is created when adder is
+ -- called, and remembers the value of x:
+ return function (y) return x + y end
+end
+a1 = adder(9)
+a2 = adder(36)
+print(a1(16)) --> 25
+print(a2(64)) --> 100
+
+-- Повернення, виклики функцій та назнчення виконуються у всіх списках
+-- які можуть відповідати довжині
+-- невідповідні приймачі нульові;
+-- несумісні відправники відкидаються.
+
+x, y, z = 1, 2, 3, 4
+-- тепер x = 1, y = 2, z = 3, а 4 викдиається
+
+function bar(a, b, c)
+ print(a, b, c)
+ return 4, 8, 15, 16, 23, 42
+end
+
+x, y = bar('zaphod') --> друкує "zaphod nil nil"
+-- Now x = 4, y = 8, values 15..42 are discarded.
+
+-- Functions are first-class, may be local/global.
+-- These are the same:
+function f(x) return x * x end
+f = function (x) return x * x end
+
+-- And so are these:
+local function g(x) return math.sin(x) end
+local g; g = function (x) return math.sin(x) end
+-- the 'local g' decl makes g-self-references ok.
+
+-- Trig funcs work in radians, by the way.
+
+-- Calls with one string param don't need parens:
+print 'hello' -- Works fine.
+```
+
+### Базові функції
+
+[5.1 – Basic Functions](https://www.lua.org/manual/5.0/manual.html#5.1)
+
+###### `tonumber (e [, base])`
+
+An optional argument specifies the base to interpret the numeral. The base may be any integer between 2 and 36, inclusive. In bases above 10, the letter ``A`´ (in either upper or lower case) represents 10, ``B`´ represents 11, and so forth, with ``Z`´ representing 35. In base 10 (the default), the number may have a decimal part, as well as an optional exponent part (see [2.2.1](https://www.lua.org/manual/5.0/manual.html#coercion)). In other bases, only unsigned integers are accepted.
+
+Намагається перетворити його аргумент в число. Якщо аргументом є вже число або рядок, конвертований у число, то `tonumber` повертає це число; в іншому випадку він повертає **nil**.
+
+Необов’язковий аргумент вказує основу для інтерпретації числа. Основою може бути будь-яке ціле число між 2 і 36 включно. У прикладі вище 10 буква "A" (у верхньому або нижньому регістрі) являє собою 10, `B` являє собою 11 і так далі, а` `Z`` представляє 35. У базі 10 (за замовчуванням ), число може містити десяткову частину, а також необов'язкову частину експонента (див. [2.2.1](https://www.lua.org/manual/5.0/manual.html#coercion)). В інших базах приймаються лише непідписані цілі числа.
+
+### Математині функції
+
+[5.5 – Mathematical Functions](https://www.lua.org/manual/5.0/manual.html#5.5)
+
+### Функції для роботи зі string
+
+[5.3 – String Manipulation](https://www.lua.org/manual/5.0/manual.html#5.3)
+
+###### `string.sub (s, i [, j])`
+
+Returns the substring of `s` that starts at `i` and continues until `j`; `i` and `j` may be negative. If `j` is absent, then it is assumed to be equal to *-1* (which is the same as the string length). In particular, the call `string.sub(s,1,j)` returns a prefix of `s` with length `j`, and `string.sub(s, -i)` returns a suffix of `s` with length `i`.
+
+###### `string.find (s, pattern [, init [, plain]])`
+
+Looks for the first *match* of `pattern` in the string `s`. If it finds one, then `find` returns the indices of `s` where this occurrence starts and ends; otherwise, it returns **nil**. If the pattern specifies captures (see `string.gsub` below), the captured strings are returned as extra results. A third, optional numerical argument `init` specifies where to start the search; it may be negative and its default value is 1. A value of **true** as a fourth, optional argument `plain` turns off the pattern matching facilities, so the function does a plain "find substring" operation, with no characters in `pattern` being considered "magic". Note that if `plain` is given, then `init` must be given too.
+
+###### Patterns
+
+A *character class* is used to represent a set of characters. The following combinations are allowed in describing a character class:
+
+- ***x\*** (where *x* is not one of the magic characters `^$()%.[]*+-?`) --- represents the character *x* itself.
+
+- **`.`** --- (a dot) represents all characters.
+
+- **`%a`** --- represents all letters.
+
+- **`%c`** --- represents all control characters.
+
+- **`%d`** --- represents all digits.
+
+- **`%l`** --- represents all lowercase letters.
+
+- **`%p`** --- represents all punctuation characters.
+
+- **`%s`** --- represents all space characters.
+
+- **`%u`** --- represents all uppercase letters.
+
+- **`%w`** --- represents all alphanumeric characters.
+
+- **`%x`** --- represents all hexadecimal digits.
+
+- **`%z`** --- represents the character with representation 0.
+
+- `%*x*`
+
+ (where
+
+ x
+
+ is any non-alphanumeric character) --- represents the character
+
+ x
+
+ . This is the standard way to escape the magic characters. Any punctuation character (even the non magic) can be preceded by a `
+
+ ```
+ %
+ ```
+
+ ´ when used to represent itself in a pattern.
+
+
+
+- `[*set*]`
+
+ --- represents the class which is the union of all characters in
+
+ set
+
+ . A range of characters may be specified by separating the end characters of the range with a `
+
+ ```
+ -
+ ```
+
+ ´. All classes
+
+ ```
+ %
+ ```
+
+ x
+
+ described above may also be used as components in
+
+ set
+
+ . All other characters in
+
+ set
+
+ represent themselves. For example,
+
+ ```
+ [%w_]
+ ```
+
+ (or
+
+ ```
+ [_%w]
+ ```
+
+ ) represents all alphanumeric characters plus the underscore,
+
+ ```
+ [0-7]
+ ```
+
+ represents the octal digits, and
+
+ ```
+ [0-7%l%-]
+ ```
+
+ represents the octal digits plus the lowercase letters plus the `
+
+ ```
+ -
+ ```
+
+ ´ character.
+
+ The interaction between ranges and classes is not defined. Therefore, patterns like `[%a-z]` or `[a-%%]` have no meaning.
+
+
+
+- **`[^\*set\*]`** --- represents the complement of *set*, where *set* is interpreted as above.
+
+For all classes represented by single letters (`%a`, `%c`, etc.), the corresponding uppercase letter represents the complement of the class. For instance, `%S` represents all non-space characters.
+
+The definitions of letter, space, and other character groups depend on the current locale. In particular, the class `[a-z]` may not be equivalent to `%l`. The second form should be preferred for portability.
+
+A *pattern item* may be
+
+- a single character class, which matches any single character in the class;
+- a single character class followed by ``*`´, which matches 0 or more repetitions of characters in the class. These repetition items will always match the longest possible sequence;
+- a single character class followed by ``+`´, which matches 1 or more repetitions of characters in the class. These repetition items will always match the longest possible sequence;
+- a single character class followed by ``-`´, which also matches 0 or more repetitions of characters in the class. Unlike ``*`´, these repetition items will always match the *shortest* possible sequence;
+- a single character class followed by ``?`´, which matches 0 or 1 occurrence of a character in the class;
+- `%*n*`, for *n* between 1 and 9; such item matches a substring equal to the *n*-th captured string (see below);
+- `%b*xy*`, where *x* and *y* are two distinct characters; such item matches strings that start with *x*, end with *y*, and where the *x* and *y* are *balanced*. This means that, if one reads the string from left to right, counting *+1* for an *x* and *-1* for a *y*, the ending *y* is the first *y* where the count reaches 0. For instance, the item `%b()` matches expressions with balanced parentheses.
+
+
+
+A *pattern* is a sequence of pattern items. A ``^`´ at the beginning of a pattern anchors the match at the beginning of the subject string. A ``$`´ at the end of a pattern anchors the match at the end of the subject string. At other positions, ``^`´ and ``$`´ have no special meaning and represent themselves.
+
+
+
+A pattern may contain sub-patterns enclosed in parentheses; they describe *captures*. When a match succeeds, the substrings of the subject string that match captures are stored (*captured*) for future use. Captures are numbered according to their left parentheses. For instance, in the pattern `"(a*(.)%w(%s*))"`, the part of the string matching `"a*(.)%w(%s*)"` is stored as the first capture (and therefore has number 1); the character matching `.` is captured with number 2, and the part matching `%s*` has number 3.
+
+As a special case, the empty capture `()` captures the current string position (a number). For instance, if we apply the pattern `"()aa()"` on the string `"flaaap"`, there will be two captures: 3 and 5.
+
+A pattern cannot contain embedded zeros. Use `%z` instead.
+
+### Функції IO
+
+https://www.lua.org/manual/5.0/manual.html#5.6
+
+###### `io.input ([file])`
+
+При виклику з ім'ям файлу він відкриває вказаний файл (у текстовому режимі) та встановлює його обробку як вхідний файл за замовчуванням. При виклику з файловим дескриптором він просто встановлює цей дескриптор як файл вводу за замовчуванням. При виклику без параметрів він повертає поточний файл вводу за замовчуванням.
+
+У разі помилок ця функція викликає помилку замість повернення коду помилки.
+
+###### `io.open (filename [, mode])`
+
+Ця функція відкриває файл у режимі, означеному у рядку `mode`. Він повертає новий дескриптор файлу, або, у випадку помилок, **nil** плюс повідомлення про помилку.
+
+Режими `mode` може бути одним із наступних:
+
+- **"r"** read mode (the default);
+- **"w"** write mode;
+- **"a"** append mode;
+- **"r+"** update mode, all previous data is preserved;
+- **"w+"** update mode, all previous data is erased;
+- **"a+"** append update mode, previous data is preserved, writing is only allowed at the end of file.
+
+Рядок `mode` може також мати в кінці `b`, який потрібен в деяких системах для відкриття файлу в бінарному режимі. Цей рядок є таким саме, що використовується у стандартній функції C `fopen` .
+
+###### `file:read (format1, ...)`
+
+Читає файл з дескриптором `file`, відповідно до заданих форматів, які вказують, що читати. Для кожного формату функція повертає рядок (або число) з прочитаними символами, або **nil**, якщо вона не може прочитати дані у визначеному форматі. Коли викликається без форматів, він використовує формат за замовчуванням, який читає весь наступний рядок (див. Нижче).
+
+Доступні настпуні формати:
+
+- **"\*n"** reads a number; this is the only format that returns a number instead of a string.
+- **"\*a"** читає весь файл, починаючи з поточного положення. Після закінчення файлу він повертає порожній рядок.
+- **"\*l"** reads the next line (skipping the end of line), returning **nil** on end of file. This is the default format.
+- ***number\*** reads a string with up to that number of characters, returning **nil** on end of file. If number is zero, it reads nothing and returns an empty string, or **nil** on end of file.
+
+## Таблиці
+
+Таблиці є найважливішим типом даних в Lua і є основою для типів даних користувача, таких як структури, масиви, списки, множини. Таблиця в Lua являє собою набір пар -- (Ключ, Значення). Ключем може бути будь-яке значення окрім nil.
+
+Таблиці не мають фіксованого розміру. Тому можна додавати скільки завгодно елементів в таблицю динамічно.
+
+```lua
+t = { } -- пуста таблиця
+t['k'] = 10 -- Ключ k, значення 10
+t[20] = " super " -- Ключ 20, значення " super "
+t.IP = '192.168.0.1' -- Ключ IP, значення 192.168.0.1
+```
+
+Розмірність списку (одномірного масиву) можна перевірити за допомогою #
+
+```lua
+t = {"A", 1}
+print (#t) -- виведе 2
+```
+
+Таблиці можна використовувати і як звичайні масиви. Для цього варто скористатись записом `t = {'a', 'b', 'c', 'd', 'e'}`, після чого до елементів можна звертатись за індексом: `print(t[2]) --виведе b`. Зверніть увагу, що створені таким чином масиви, починаються з одиниці, а не з нуля, як в більшості інших мов.
+
+```lua
+t = {key1 = 'value1', key2 = false}
+print(t.key1) -- Prints 'value1'.
+t.newKey = {} -- добавляє нову пару key/value
+t.key2 = nil -- видалити key2 з таблиці
+-- Literal notation for any (non-nil) value as key:
+u = {['@!#'] = 'qbert', [{}] = 1729, [6.28] = 'tau'}
+print(u[6.28]) -- prints "tau"
+a = u['@!#'] -- тепер a = 'qbert'.
+b = u[{}] -- Ми можемо очікувати 1729, але тут буде nil:
+[[ b = nil since the lookup fails. It fails
+because the key we used is not the same object
+as the one used to store the original value. So
+strings & numbers are more portable keys.]]
+
+-- Виклик функції однієї таблиці-парам не потребує паронів
+function h(x) print(x.key1) end
+h{key1 = 'Sonmi~451'} -- Prints 'Sonmi~451'.
+```
+Для виводу пар -- (Ключ, Значення) з таблиці на екран скористайтесь циклом `for`, базовою функцією `pairs()` та функцією `print()`:
+
+```lua
+for key, val in pairs(t) do
+ print(key, val)
+end
+```
+
+В результаті отримаємо пари:
+
+```lua
+20 super
+k 10
+IP 192.168.0.1
+```
+
+Таблиці можна використовувати і як звичайні масиви. Для цього варто скористатись записом `t = {'a', 'b', 'c', 'd', 'e'}`, після чого до елементів можна звертатись за індексом:
+
+```lua
+t = {'a', 'b', 'c', 'd', 'e'}
+print(t[2]) --виведе b`
+```
+
+Зверніть увагу, що створені таким чином масиви, починаються з одиниці, а не з нуля, як в більшості інших мов.
+
+```lua
+for key, val in pairs(u) do -- Table iteration.
+ print(key, val)
+end
+```
+```lua
+-- _G is a special table of all globals.
+print(_G['_G'] == _G) -- Prints 'true'.
+```
+```lua
+-- Використання таблиць як списків / масивів:
+-- Список літералів неявно налаштованих ключів int:
+v = {'value1', 'value2', 1.21, 'gigawatts'}
+for i = 1, #v do -- #v is the size of v for lists.
+ print(v[i]) -- починаючи з 1
+end
+-- "Список" не є реальним типом. v - просто таблиця
+-- із послідовними цілими ключами, які трактуються як список.
+```
+
+### Функції для роботи з таблицями
+
+[Table Manipulation](https://www.lua.org/manual/5.3/manual.html#6.6)
+
+This library provides generic functions for table manipulation. It provides all its functions inside the table `table`.
+
+Remember that, whenever an operation needs the length of a table, all caveats about the length operator apply (see [§3.4.7](https://www.lua.org/manual/5.3/manual.html#3.4.7)). All functions ignore non-numeric keys in the tables given as arguments.
+
+###### `table.concat (list [, sep [, i [, j]]])`
+
+Given a list where all elements are strings or numbers, returns the string `list[i]..sep..list[i+1] ··· sep..list[j]`. The default value for `sep` is the empty string, the default for `i` is 1, and the default for `j` is `#list`. If `i` is greater than `j`, returns the empty string.
+
+###### `table.insert (list, [pos,] value)`
+
+Inserts element `value` at position `pos` in `list`, shifting up the elements `list[pos], list[pos+1], ···, list[#list]`. The default value for `pos` is `#list+1`, so that a call `table.insert(t,x)` inserts `x` at the end of list `t`.
+
+###### `table.move (a1, f, e, t [,a2])`
+
+Moves elements from table `a1` to table `a2`, performing the equivalent to the following multiple assignment: `a2[t],··· = a1[f],···,a1[e]`. The default for `a2` is `a1`. The destination range can overlap with the source range. The number of elements to be moved must fit in a Lua integer.
+
+Returns the destination table `a2`.
+
+###### `table.pack (···)`
+
+Returns a new table with all arguments stored into keys 1, 2, etc. and with a field "`n`" with the total number of arguments. Note that the resulting table may not be a sequence.
+
+###### `table.remove (list [, pos])`
+
+Removes from `list` the element at position `pos`, returning the value of the removed element. When `pos` is an integer between 1 and `#list`, it shifts down the elements `list[pos+1], list[pos+2], ···, list[#list]` and erases element `list[#list]`; The index `pos` can also be 0 when `#list` is 0, or `#list + 1`; in those cases, the function erases the element `list[pos]`.
+
+The default value for `pos` is `#list`, so that a call `table.remove(l)` removes the last element of list `l`.
+
+###### `table.sort (list [, comp])`
+
+Sorts list elements in a given order, *in-place*, from `list[1]` to `list[#list]`. If `comp` is given, then it must be a function that receives two list elements and returns true when the first element must come before the second in the final order (so that, after the sort, `i < j` implies `not comp(list[j],list[i])`). If `comp` is not given, then the standard Lua operator `<` is used instead.
+
+Note that the `comp` function must define a strict partial order over the elements in the list; that is, it must be asymmetric and transitive. Otherwise, no valid sort may be possible.
+
+The sort algorithm is not stable: elements considered equal by the given order may have their relative positions changed by the sort.
+
+###### `table.unpack (list [, i [, j]])`
+
+Returns the elements from the given list. This function is equivalent to
+
+```
+return list[i], list[i+1], ···, list[j]
+```
+
+By default, `i` is 1 and `j` is `#list`.
+
+
+
+### Metatables and metamethods.
+
+```lua
+-- Таблиця може мати метатаблицю, яка дає таблицю
+-- поведінка з перевантаженням оператора. Пізніше ми побачимо
+-- як метатаблиці підтримують поведінку прототипів js.
+
+f1 = {a = 1, b = 2} -- Represents the fraction a/b.
+f2 = {a = 2, b = 3}
+
+-- This would fail:
+-- s = f1 + f2
+
+metafraction = {}
+function metafraction.__add(f1, f2)
+ sum = {}
+ sum.b = f1.b * f2.b
+ sum.a = f1.a * f2.b + f2.a * f1.b
+ return sum
+end
+
+setmetatable(f1, metafraction)
+setmetatable(f2, metafraction)
+
+s = f1 + f2 -- call __add(f1, f2) on f1's metatable
+
+-- f1, f2 have no key for their metatable, unlike
+-- prototypes in js, so you must retrieve it as in
+-- getmetatable(f1). The metatable is a normal table
+-- with keys that Lua knows about, like __add.
+
+-- But the next line fails since s has no metatable:
+-- t = s + s
+-- Class-like patterns given below would fix this.
+
+-- An __index on a metatable overloads dot lookups:
+defaultFavs = {animal = 'gru', food = 'donuts'}
+myFavs = {food = 'pizza'}
+setmetatable(myFavs, {__index = defaultFavs})
+eatenBy = myFavs.animal -- works! thanks, metatable
+
+-- Direct table lookups that fail will retry using
+-- the metatable's __index value, and this recurses.
+
+-- An __index value can also be a function(tbl, key)
+-- for more customized lookups.
+
+-- Values of __index,add, .. are called metamethods.
+-- Full list. Here a is a table with the metamethod.
+
+-- __add(a, b) for a + b
+-- __sub(a, b) for a - b
+-- __mul(a, b) for a * b
+-- __div(a, b) for a / b
+-- __mod(a, b) for a % b
+-- __pow(a, b) for a ^ b
+-- __unm(a) for -a
+-- __concat(a, b) for a .. b
+-- __len(a) for #a
+-- __eq(a, b) for a == b
+-- __lt(a, b) for a < b
+-- __le(a, b) for a <= b
+-- __index(a, b) for a.b
+-- __newindex(a, b, c) for a.b = c
+-- __call(a, ...) for a(...)
+```
+
+### Class-like tables and inheritance.
+
+```lua
+-- Classes aren't built in; there are different ways
+-- to make them using tables and metatables.
+
+-- Explanation for this example is below it.
+
+Dog = {} -- 1.
+
+function Dog:new() -- 2.
+ newObj = {sound = 'woof'} -- 3.
+ self.__index = self -- 4.
+ return setmetatable(newObj, self) -- 5.
+end
+
+function Dog:makeSound() -- 6.
+ print('I say ' .. self.sound)
+end
+
+mrDog = Dog:new() -- 7.
+mrDog:makeSound() -- 'I say woof' -- 8.
+
+-- 1. Dog acts like a class; it's really a table.
+-- 2. function tablename:fn(...) is the same as
+-- function tablename.fn(self, ...)
+-- The : just adds a first arg called self.
+-- Read 7 & 8 below for how self gets its value.
+-- 3. newObj will be an instance of class Dog.
+-- 4. self = the class being instantiated. Often
+-- self = Dog, but inheritance can change it.
+-- newObj gets self's functions when we set both
+-- newObj's metatable and self's __index to self.
+-- 5. Reminder: setmetatable returns its first arg.
+-- 6. The : works as in 2, but this time we expect
+-- self to be an instance instead of a class.
+-- 7. Same as Dog.new(Dog), so self = Dog in new().
+-- 8. Same as mrDog.makeSound(mrDog); self = mrDog.
+
+----------------------------------------------------
+
+-- Inheritance example:
+
+LoudDog = Dog:new() -- 1.
+
+function LoudDog:makeSound()
+ s = self.sound .. ' ' -- 2.
+ print(s .. s .. s)
+end
+
+seymour = LoudDog:new() -- 3.
+seymour:makeSound() -- 'woof woof woof' -- 4.
+
+-- 1. LoudDog gets Dog's methods and variables.
+-- 2. self has a 'sound' key from new(), see 3.
+-- 3. Same as LoudDog.new(LoudDog), and converted to
+-- Dog.new(LoudDog) as LoudDog has no 'new' key,
+-- but does have __index = Dog on its metatable.
+-- Result: seymour's metatable is LoudDog, and
+-- LoudDog.__index = LoudDog. So seymour.key will
+-- = seymour.key, LoudDog.key, Dog.key, whichever
+-- table is the first with the given key.
+-- 4. The 'makeSound' key is found in LoudDog; this
+-- is the same as LoudDog.makeSound(seymour).
+
+-- If needed, a subclass's new() is like the base's:
+function LoudDog:new()
+ newObj = {}
+ -- set up newObj
+ self.__index = self
+ return setmetatable(newObj, self)
+end
+```
+
+## 4. Modules.
+
+```lua
+--[[ I'm commenting out this section so the rest of
+-- this script remains runnable.
+
+-- Suppose the file mod.lua looks like this:
+local M = {}
+
+local function sayMyName()
+ print('Hrunkner')
+end
+
+function M.sayHello()
+ print('Why hello there')
+ sayMyName()
+end
+
+return M
+
+-- Another file can use mod.lua's functionality:
+local mod = require('mod') -- Run the file mod.lua.
+
+-- require is the standard way to include modules.
+-- require acts like: (if not cached; see below)
+local mod = (function ()
+
+end)()
+-- It's like mod.lua is a function body, so that
+-- locals inside mod.lua are invisible outside it.
+
+-- This works because mod here = M in mod.lua:
+mod.sayHello() -- Says hello to Hrunkner.
+
+-- This is wrong; sayMyName only exists in mod.lua:
+mod.sayMyName() -- error
+
+-- require's return values are cached so a file is
+-- run at most once, even when require'd many times.
+
+-- Suppose mod2.lua contains "print('Hi!')".
+local a = require('mod2') -- Prints Hi!
+local b = require('mod2') -- Doesn't print; a=b.
+
+-- dofile is like require without caching:
+dofile('mod2.lua') --> Hi!
+dofile('mod2.lua') --> Hi! (runs it again)
+
+-- loadfile loads a lua file but doesn't run it yet.
+f = loadfile('mod2.lua') -- Call f() to run it.
+
+-- loadstring is loadfile for strings.
+g = loadstring('print(343)') -- Returns a function.
+g() -- Prints out 343; nothing printed before now.
+
+--]]
+```
+
+## 5.References
+
+```lua
+--[[
+
+I was excited to learn Lua so I could make games
+with the Löve 2D game engine. That's the why.
+
+I started with BlackBulletIV's Lua for programmers.
+Next I read the official Programming in Lua book.
+That's the how.
+
+It might be helpful to check out the Lua short
+reference on lua-users.org.
+
+The main topics not covered are standard libraries:
+ * string library
+ * table library
+ * math library
+ * io library
+ * os library
+
+By the way, this entire file is valid Lua; save it
+as learn.lua and run it with "lua learn.lua" !
+
+This was first written for tylerneylon.com. It's
+also available as a github gist. Tutorials for other
+languages, in the same style as this one, are here:
+
+http://learnxinyminutes.com/
+
+Have fun with Lua!
+
+--]]
+```
+
diff --git "a/\320\233\320\265\320\272\321\206/media1/common_nodes.png" "b/\320\233\320\265\320\272\321\206/media1/common_nodes.png"
new file mode 100644
index 0000000..0d9588e
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/media1/common_nodes.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/media1/editor.png" "b/\320\233\320\265\320\272\321\206/media1/editor.png"
new file mode 100644
index 0000000..8c352ec
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/media1/editor.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/media1/envvarcfg.png" "b/\320\233\320\265\320\272\321\206/media1/envvarcfg.png"
new file mode 100644
index 0000000..6265e32
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/media1/envvarcfg.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/media1/jsoneditor.png" "b/\320\233\320\265\320\272\321\206/media1/jsoneditor.png"
new file mode 100644
index 0000000..842f31d
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/media1/jsoneditor.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/media1/regexp1.png" "b/\320\233\320\265\320\272\321\206/media1/regexp1.png"
new file mode 100644
index 0000000..44be3b8
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/media1/regexp1.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/nodemedia/1.png" "b/\320\233\320\265\320\272\321\206/nodemedia/1.png"
new file mode 100644
index 0000000..c4bf494
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/nodemedia/1.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/nodemedia/2.png" "b/\320\233\320\265\320\272\321\206/nodemedia/2.png"
new file mode 100644
index 0000000..a175591
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/nodemedia/2.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/nodemedia/3.png" "b/\320\233\320\265\320\272\321\206/nodemedia/3.png"
new file mode 100644
index 0000000..16365cb
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/nodemedia/3.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/nodemedia/4.png" "b/\320\233\320\265\320\272\321\206/nodemedia/4.png"
new file mode 100644
index 0000000..7b42093
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/nodemedia/4.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/nodemedia/5.png" "b/\320\233\320\265\320\272\321\206/nodemedia/5.png"
new file mode 100644
index 0000000..819010e
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/nodemedia/5.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/nodemedia/6.png" "b/\320\233\320\265\320\272\321\206/nodemedia/6.png"
new file mode 100644
index 0000000..17a599e
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/nodemedia/6.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/nodeob.md" "b/\320\233\320\265\320\272\321\206/nodeob.md"
new file mode 100644
index 0000000..21decec
--- /dev/null
+++ "b/\320\233\320\265\320\272\321\206/nodeob.md"
@@ -0,0 +1,55 @@
+**Програмна інженерія в системах управління. Лекції.** Автор і лектор: Олександр Пупена
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
+
+
+
+# Веб-програмування в node.js
+
+## Деякі вбудовані об'єкти та модулі node.js
+
+### [console](https://nodejs.org/api/console.html)
+
+```javascript
+console.log ("Звичайне повідомлення");
+console.warn ("Пвідомлення про попередження");
+console.error ("Повідомлення про помилку");
+```
+
+### webserver
+
+https://learn.javascript.ru/screencast/nodejs#nodejs-server-intro
+
+
+
+## Інструменти налагодження
+
+https://learn.javascript.ru/screencast/nodejs#nodejs-dev-debug
+
+## Основи асинхронного програмування
+
+https://learn.javascript.ru/screencast/nodejs#nodejs-event-loop-async
+
+https://www.youtube.com/watch?time_continue=33&v=8cV4ZvHXQL4&feature=emb_logo
+
+https://habr.com/ru/post/337528/
+
+https://proglib.io/p/asynchrony/
+
+## Посилання
+
+https://www.w3schools.com/nodejs/nodejs_intro.asp
+
+https://nodejs.org/uk/docs/
+
+https://habr.com/ru/post/460661/
+
+https://medium.com/devschacht/node-hero-6a07ef8d822d
+
+
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
\ No newline at end of file
diff --git "a/\320\233\320\265\320\272\321\206/reporting.md" "b/\320\233\320\265\320\272\321\206/reporting.md"
new file mode 100644
index 0000000..3c47598
--- /dev/null
+++ "b/\320\233\320\265\320\272\321\206/reporting.md"
@@ -0,0 +1,5 @@
+**Програмна інженерія в системах управління. Лекції.** Автор і лектор: Олександр Пупена
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
\ No newline at end of file
diff --git "a/\320\233\320\265\320\272\321\206/secur.md" "b/\320\233\320\265\320\272\321\206/secur.md"
new file mode 100644
index 0000000..be677f1
--- /dev/null
+++ "b/\320\233\320\265\320\272\321\206/secur.md"
@@ -0,0 +1,337 @@
+**Програмна інженерія в системах управління. Лекції.** Автор і лектор: Олександр Пупена
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
+
+# Керування ідентифікацією і доступом
+
+### Процедури керування ідентифікацією доступу
+
+Керування ідентифікацією та доступом(**Identity** **and** **Access** **Management**), **IAM**
+
+- IAM – політики і технології для забезпечення доступу людей та/або застосунків до певних ресурсів
+
+- процедури
+ - **Ідентифікація** – розпізнавання користувача (назвися!)
+ - за іменем (username ),
+ - за адресою email,
+ - номер облікового запису і т.п.
+ - **Автентифікація** – визначення того, що це дійсно він, а не хтось інший, наприклад за паролем (доведи що це ти!)
+ - **Авторизація** – що можна йому робити, а що ні, наприклад за роллю (тобі можна тільки це!)
+ - керування усіма процедурами
+
+#### Шари захисту
+
+**вирішується на різних рівнях мережних протоколів**
+
+- фізичний: захист середовища від прослуховування і підключення (напр. в трубах с газом, падіння тиску - тривога)
+- канальний, мережний, транспортний: шифрування (конфіденційність), контрольні суми/хеші (цілісність), екрани (аналіз трафіку на підозрілі пакети)
+- прикладний: автентифікація, електронний підпис
+
+
+
+
+
+#### Учасники обміну
+
+•служби(сервіси)/застосунки: наприклад Node-RED, хмарні застосунки
+
+•користувачі(люди)
+
+як правило використовуються різні способи для застосунків та користувачів
+
+#### Типи автентифікації
+
+•користувач/пароль (для людей):
+
+•вбудовані в Http, basic та інші -> норм при шифруванні
+
+•через форму (POST, PUT, PATCH) -> найбільш безпечний
+
+•через параметри запиту -> не рекомендуються
+
+•двофакторна автентифікація (для людей)
+
+•сертифікати (для застосунків)
+
+•API key (для застосунків)
+
+•маркери (для застосунків): OAuth и OpenID …
+
+### Автентифікація: користувач + пароль
+
+#### HTTP-автентифікація
+
+- ім'я користувача/пошта + пароль
+- зберігається на сервері
+- послідовність для Basic HTTP:
+ - перше підключення - сервер повертає "401 Unauthorized» + заголовок "WWW-Authenticate"
+ - браузер реагує формою вводу ім'я/пароль
+ - браузер відправляє усі запити с заголовком "[Authorization](https://developer.mozilla.org/ru/docs/Web/HTTP/Заголовки/Authorization)”, в якому передається ім'я користувача і пароль:
+ - в кодуванні base64 (Basic), не рекомендується без HTTPS
+ - шифрування (Digest), не рекомендується без HTTPS
+ - авторизація вирішується на стороні серверу (ролі або інших дани)
+
+
+
+#### HTTP-Basic у вузлі HTTP Request
+
+
+
+#### HTTP-Basic у серверній частині Node-RED
+
+Використовується для:
+
+- Admin console – доступ до редактору
+- Nodes
+- Static Pages
+
+
+
+#### HTTP-Basic в HTTP-in, Dashboard
+
+•httpNodeRoot (HTTP-in, Dashboard) – тільки один користувач
+
+•httpStatic (статические страницы, usr/lib/node-modules/public )– тільки один користувач
+
+•налаштовується в “Settings.js “
+
+```json
+httpNodeAuth: {user:"user",pass:"$2a$08$zZWtXTja0fB1pzD4sHCMyOCMYz2Z6dNbM6tl8sJogENOMcxWV9DN."},
+
+```
+
+```json
+httpStaticAuth: {user:"fred",pass:"$2a$04$3gkGX/Q4VZ//F37kWvSU9eE9EM1WO2rdWk1oj/kfXIbeBON5eA56S"},
+```
+
+•http-in відобразить тільки коли користувач успішно зайшов
+
+
+
+#### Автентифікація через форму
+
+- немає певного стандарту -> реалізації специфічні
+
+- послідовність:
+ - запускається HTML-форма,
+ - користувач вводить ім'я, пароль
+ - відправляється на сервер через HTTP POST
+ - якщо Ок, створюється маркер сесії (session token),
+ - як правило маркер розміщується в куки (cookies), при наступних запитах автоматично передається на сервер для авторизації
+
+- не рекомендується без HTTPS
+
+
+
+#### Користувач + пароль: проблеми
+
+- логіни і паролі в різних системах користувачі вибирають однаковими
+- записують і розповідають іншим
+- коли система скомпрометована, ніхто навіть не дізнається про це
+- прості паролі легко перебираються
+- схильні до злому при невдалій реалізації серверу
+
+### Автентифікація по сертифікатам, TLS/SSL, HTTPs
+
+#### TLS/SSL
+
+- Протоколи безпечної передачі даних в Інтернет:
+ - TLS –Transport Layer Security, протокол защиты транспортного уровня, TLS1.2/**TLS 1.3** (2018), RFC 8446
+ - SSL –Secure Sockets Layer, рівень захищених сокетів (**застарів в 2015**)
+ - «SSL» використовується як назва сімейства протоколів захисту і бібліотек, наприклад OpenSSL, LibreSSL
+- для забезпечення безпечної передачі даних в загальнодоступній мережі
+- використовується в:
+ - **HTTPS** -Hypertext Transfer Protocol Secure, **порт 443**
+ - SMTPS, POP3S, IMAPS – захищені протоколи електронної пошти
+
+
+
+#### Безпека передачі даних
+
+- **приватність** (privacy, захист від несанкціонованого доступу) – шляхом шифрування
+- **цілісність** (integrity, захист від підробки даних) - хеш-функції
+- **автентифікація** (authentication, захист від видачі за іншого) – цифровий підпис, інфраструктура відкритих ключів
+
+
+
+
+
+#### Шифрування
+
+повідомлення -> **шифрування** –> незрозуміле повідомлення –> **дешифрування** –> повідомлення
+
+- симетричне (однаковий ключ) – швидка робота, важкість збереженості ключів
+- асиметричне (різні):
+- повільніше, але закритий (приватний) ключ тільки у володаря
+- відкритий (публічний) ключ генерується на базі закритого
+- комбінують: асиметричним передають ключ для симетричного
+
+
+
+#### Цілісність і хеш-функції
+
+- цілісність – наприклад через контрольну суму CRC, механізм хеш-функцій такий саме, але з більшими вимогами
+
+**Хеш-функції** (hash function):
+
+- перетворення масиву даних в рядок фіксованої довжини – хеш
+- за хешем не можна визначити, на основі яких даних він був створений
+- колізія – одне і те ж значення хешу для різних вхідних даних
+- різні криптографічні хеш функції (MD5 , SHA …) ті ж функції що і для шифрування
+- зловмисник може замінити як дані так і хеш, якщо ключ йому відомий
+
+
+
+MAC - Message Authentication Code
+
+#### Автентифікація і електронний (цифровий) підпис
+
+- як визначити, що застосунок/людина дійсно той, за кого себе видає? при підключенні обмін повідомленнями може бути зі зловмисником
+- електронний цифровий підпис:
+ - засвідчує відправника
+ - використовується для перевірки цілісності даних
+- закритий ключ - > для шифрування, відкритий –> для розшифровування: якщо відкритим розшифровується, значить повідомлення прийшло від потрібного вузлу/застосунку
+- хто підтвердить, що відкритий ключ дійсно від того застосунку?
+
+
+
+#### Сертифікати
+
+- вузли в мережі не довіряють один одному, але довіряють центру сертифікації
+- центр видає сертифікати – файли з різноманітною інформацією, в тому числі відкритим ключом серверу
+- справжність сертифіката центр завіряє своїм підписом (одержувач має відкритий ключ центру і довіряє йому апріорі)
+- коли вузол видає іншому вузлу сертифікат, той перевіряє його валідність
+- сертифікати мать термін дії
+- іноді сертифікати потрібно відправляти від клієнта до сервера
+
+
+
+#### Інфраструктура відкритих ключів (KPI)
+
+- ланцюжок центрів
+- кореневі – видають сертифікати центру сертифікації
+
+
+
+
+
+#### Само-підписаний сертифікат
+
+- якщо вузли довіряють сертифікатам його можна включити в дозволені
+
+- кореневі - само-підписані сертифікати, вони за замовченням вже знаходяться в сховищах на ОС
+
+
+
+#### Установка з'єднання TLS1.2
+
+
+
+#### З'єднання TLS1.2
+
+
+
+#### Файли сертифікату
+
+.pem, .crt, .cer - готовий, підписаний центром сертифікації сертифікат.key - закритий або відкритий ключ;
+
+.csr - запит на підпис сертифікату, в цьому файлі зберігається відкритий ключ плюс інформація про компанію і домен, який вказали
+
+#### Створення серифікату: OpenSSL
+
+- завантажити і встановити [OpenSSL](https://slproweb.com/products/Win32OpenSSL.html) (мін.версію)
+- запустити
+- ввести команду для створення і само-підписання сертифікату
+
+```bash
+req -newkey rsa:2048 -nodes -keyout c:/temp/domain.key -x509 -days 365 -out c:/temp/domain.crt
+```
+
+
+
+### HTTPs в Node-RED
+
+#### Активація HTTPS в Node-RED
+
+**settings.js**
+
+
+
+
+
+#### Https/wss-клієнти в Node-RED
+
+
+
+#### Http-request в Node-RED : підключення до серверу з самопідписаним сертифікатом
+
+
+
+- виставити властивість «rejectUnauthorized=false» - дозволяє
+- або в налаштуваннях конфігурації TLS прибрати Veriy server sertificate
+
+#### Web-socket клієнт в Node-RED: підключення до серверу з само-підписаним сертифікатом
+
+
+
+#### Додаткове налаштування Web-socket
+
+**settings.js**
+
+
+
+### Інші види автентифікації
+
+#### Двофакторна автентифікація
+
+- одноразові паролі
+- генеруються на основі двофакторної авторизації:
+ - що користувач знає: ім'я і пароль
+ - чим володіє: телефон, генератор паролів
+
+#### API-key
+
+- API-key: довгі символьні послідовності
+- використовуються для обміну між додатками
+- генеруються автоматично, важко підібрати
+- користувач не показує своє ім'я та пароль застосунку
+- користувач може анулювати ключ
+
+
+
+
+
+- реалізується через тіло або заголовки
+
+
+
+
+
+#### Token
+
+- провайдер сервісів дає доступ до своїх сервісів через API
+- провайдер сервісів (**service provider**) делегує функцію аутентифікації провайдеру аутентифікації (**authentication service**)
+- прикладом провайдеру аутентифікації є соц.мережі, наприклад Facebook. Linkedin
+- послідовність:
+ - клієнтська програма автентіфікується на провайдері аутентифікації (наприклад по паролю)
+ - отримує від нього маркер (**token**) для конкретного провайдера сервісів: містить інформацію про генератора, одержувача, термін дії ...
+ - використовує цей маркер для зв'язку з провайдером сервісів
+- стандарти: OAuth, OpenID Connect, SAML, і WS-Federation.
+
+
+
+
+
+#### API-key (Google)
+
+
+
+
+
+- [Обзор способов и протоколов аутентификации в веб-приложениях](https://habr.com/ru/company/dataart/blog/262817/)
+
+| [<- до лекцій](README.md) | [на основну сторінку курсу](../README.md) |
+| ------------------------- | ----------------------------------------- |
+| | |
\ No newline at end of file
diff --git "a/\320\233\320\265\320\272\321\206/sqlmedia/1.png" "b/\320\233\320\265\320\272\321\206/sqlmedia/1.png"
new file mode 100644
index 0000000..2ecb5e2
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/sqlmedia/1.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/sqlmedia/2.png" "b/\320\233\320\265\320\272\321\206/sqlmedia/2.png"
new file mode 100644
index 0000000..aa2dcbc
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/sqlmedia/2.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/sqlmedia/3.png" "b/\320\233\320\265\320\272\321\206/sqlmedia/3.png"
new file mode 100644
index 0000000..6682b16
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/sqlmedia/3.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/sqlmedia/4.png" "b/\320\233\320\265\320\272\321\206/sqlmedia/4.png"
new file mode 100644
index 0000000..8be6171
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/sqlmedia/4.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/sqlmedia/5.png" "b/\320\233\320\265\320\272\321\206/sqlmedia/5.png"
new file mode 100644
index 0000000..0d7ee22
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/sqlmedia/5.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/sqlmedia/6.png" "b/\320\233\320\265\320\272\321\206/sqlmedia/6.png"
new file mode 100644
index 0000000..2d9b61d
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/sqlmedia/6.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/tcpudpmedia/ipadr.png" "b/\320\233\320\265\320\272\321\206/tcpudpmedia/ipadr.png"
new file mode 100644
index 0000000..7d2df14
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/tcpudpmedia/ipadr.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/tcpudpmedia/nets.png" "b/\320\233\320\265\320\272\321\206/tcpudpmedia/nets.png"
new file mode 100644
index 0000000..bdcdba9
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/tcpudpmedia/nets.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/tcpudpmedia/ports.png" "b/\320\233\320\265\320\272\321\206/tcpudpmedia/ports.png"
new file mode 100644
index 0000000..1fd2ec4
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/tcpudpmedia/ports.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/tcpudpmedia/router.png" "b/\320\233\320\265\320\272\321\206/tcpudpmedia/router.png"
new file mode 100644
index 0000000..6407122
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/tcpudpmedia/router.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/tcpudpmedia/router1.png" "b/\320\233\320\265\320\272\321\206/tcpudpmedia/router1.png"
new file mode 100644
index 0000000..2b97354
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/tcpudpmedia/router1.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/tcpudpmedia/sockets.png" "b/\320\233\320\265\320\272\321\206/tcpudpmedia/sockets.png"
new file mode 100644
index 0000000..f5df08f
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/tcpudpmedia/sockets.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/tcpudpmedia/sockets1.png" "b/\320\233\320\265\320\272\321\206/tcpudpmedia/sockets1.png"
new file mode 100644
index 0000000..44d7bed
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/tcpudpmedia/sockets1.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/tcpudpmedia/sockstages.png" "b/\320\233\320\265\320\272\321\206/tcpudpmedia/sockstages.png"
new file mode 100644
index 0000000..215c61b
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/tcpudpmedia/sockstages.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/tcpudpmedia/tcp-in.png" "b/\320\233\320\265\320\272\321\206/tcpudpmedia/tcp-in.png"
new file mode 100644
index 0000000..daadc77
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/tcpudpmedia/tcp-in.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/tcpudpmedia/tcp-out.png" "b/\320\233\320\265\320\272\321\206/tcpudpmedia/tcp-out.png"
new file mode 100644
index 0000000..1cffee8
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/tcpudpmedia/tcp-out.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/tcpudpmedia/tcp-request.png" "b/\320\233\320\265\320\272\321\206/tcpudpmedia/tcp-request.png"
new file mode 100644
index 0000000..a095c55
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/tcpudpmedia/tcp-request.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/tcpudpmedia/tcpexmpl.png" "b/\320\233\320\265\320\272\321\206/tcpudpmedia/tcpexmpl.png"
new file mode 100644
index 0000000..fe91b2a
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/tcpudpmedia/tcpexmpl.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/tcpudpmedia/tcpin_cfg.png" "b/\320\233\320\265\320\272\321\206/tcpudpmedia/tcpin_cfg.png"
new file mode 100644
index 0000000..473e833
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/tcpudpmedia/tcpin_cfg.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/tcpudpmedia/tcpout_cfg.png" "b/\320\233\320\265\320\272\321\206/tcpudpmedia/tcpout_cfg.png"
new file mode 100644
index 0000000..947a0fa
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/tcpudpmedia/tcpout_cfg.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/tcpudpmedia/tcprequest_cfg.png" "b/\320\233\320\265\320\272\321\206/tcpudpmedia/tcprequest_cfg.png"
new file mode 100644
index 0000000..dc7507c
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/tcpudpmedia/tcprequest_cfg.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/tcpudpmedia/tcpvsudp.png" "b/\320\233\320\265\320\272\321\206/tcpudpmedia/tcpvsudp.png"
new file mode 100644
index 0000000..827fea0
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/tcpudpmedia/tcpvsudp.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/tcpudpmedia/udp-in.png" "b/\320\233\320\265\320\272\321\206/tcpudpmedia/udp-in.png"
new file mode 100644
index 0000000..dc7ce6d
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/tcpudpmedia/udp-in.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/tcpudpmedia/udp-out.png" "b/\320\233\320\265\320\272\321\206/tcpudpmedia/udp-out.png"
new file mode 100644
index 0000000..ff931e6
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/tcpudpmedia/udp-out.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/tcpudpmedia/udpexmpl.png" "b/\320\233\320\265\320\272\321\206/tcpudpmedia/udpexmpl.png"
new file mode 100644
index 0000000..f8c964e
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/tcpudpmedia/udpexmpl.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/tcpudpmedia/udpin_cfg.png" "b/\320\233\320\265\320\272\321\206/tcpudpmedia/udpin_cfg.png"
new file mode 100644
index 0000000..cd1b9cd
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/tcpudpmedia/udpin_cfg.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/tcpudpmedia/udpout_cfg.png" "b/\320\233\320\265\320\272\321\206/tcpudpmedia/udpout_cfg.png"
new file mode 100644
index 0000000..f3623ed
Binary files /dev/null and "b/\320\233\320\265\320\272\321\206/tcpudpmedia/udpout_cfg.png" differ
diff --git "a/\320\233\320\265\320\272\321\206/yaml.md" "b/\320\233\320\265\320\272\321\206/yaml.md"
new file mode 100644
index 0000000..792f5b9
--- /dev/null
+++ "b/\320\233\320\265\320\272\321\206/yaml.md"
@@ -0,0 +1,172 @@
+# YAML
+
+[Learn YAML in five minutes!](https://www.codeproject.com/Articles/1214409/Learn-YAML-in-five-minutes)
+
+[YAML™ Specification Index](https://yaml.org/spec/)
+
+[YAML Syntax](https://learn.getgrav.org/16/advanced/yaml)
+
+[YAML](https://uk.wikipedia.org/wiki/YAML) — зручний для читання людиною формат серіалізаціі даних, концептуально близький до мов розмітки, але орієнтований на зручність введення-виведення типових структур даних багатьох мов програмування. YAML в основному використовується як формат для файлів конфігурації.
+
+- файли YAML мають розширення `.yaml` або `.yml`
+- YAML є чутливим до регістру.
+- YAML не дозволяє використовувати табуляцію, натомість використовуються пробіли.
+
+Коментарі починаються з октоторпа (його також називають "хеш", "гострий", "фунт" або "знак числа" - `#`).
+
+Означення початку та кінця документа необов'язково. Початок документа позначається '`---`' , що розміщується з самого зверху, а кінець - '`...`'.
+
+## Базові типи даних
+
+YAML має базові типи **відображення (mappings)** (хеші/словники), **послідовності (sequences)** (масиви / списки) та **скаляри** (рядки/числа). Хоча його можна використовувати з більшістю мов програмування, він найкраще працює з мовами, побудованими навколо цих типів структури даних. Сюди входять: PHP, Python, Perl, JavaScript та Ruby.
+
+### Скаляри (Scalars)
+
+Скаляри часто називають змінними в програмуванні. Скаляри представляють собою рядки та числа, які складають дані на сторінці. Скаляр може бути:
+
+- булевою властивістю, наприклад `Так`,
+- цілим (числом), наприклад `5`,
+- або рядком тексту, наприклад речення чи назва веб-сайту.
+
+Більшість скалярів не беруться в лапки, але якщо ви вводите рядок, який використовує пунктуацію та інші елементи, які можна переплутати з синтаксисом YAML (тире, колонки тощо), ви можете процитувати ці дані за допомогою одинарних (`''` )або подвійних (`""` ) лапок. Подвійні лапки дозволяють використовувати escapings для представлення символів ASCII та Unicode.
+
+```yaml
+integer: 25
+string: "25"
+float: 25.0
+boolean: Yes
+```
+
+## [Block Scalars](https://yaml-multiline.info/)
+
+A block scalar header has three parts:
+
+**Block Style Indicator**: The *[block style](https://yaml.org/spec/1.2/spec.html#id2795688)* indicates how newlines inside the block should behave. If you would like them to be kept as newlines, use the **literal** style, indicated by a pipe (`|`). If instead you want them to be replaced by spaces, use the **folded** style, indicated by a right angle bracket (`>`). (To get a newline using the folded style, leave a blank line by putting *two* newlines in. Lines with extra indentation are also not folded.)
+
+**Block Chomping Indicator**: The *[chomping indicator](https://yaml.org/spec/1.2/spec.html#id2794534)* controls what should happen with newlines at the *end* of the string. The default, **clip**, puts a single newline at the end of the string. To remove all newlines, **strip** them by putting a minus sign (`-`) after the style indicator. Both clip and strip ignore how many newlines are actually at the end of the block; to **keep** them all put a plus sign (`+`) after the style indicator.
+
+**Indentation Indicator**: Ordinarily, the number of spaces you're using to indent a block will be automatically guessed from its first line. You may need a *[block indentation indicator](https://yaml.org/spec/1.2/spec.html#id2793979)* if the first line of the block starts with extra spaces. In this case, simply put the number of spaces used for indentation (between 1 and 9) at the end of the header.
+
+
+
+### Послідовності (Sequences)
+
+Це базовий список з кожним елементом у списку, розміщеним у його власному рядку. Це аналог масиву в інших мовах. Блок послідовностей позначають кожен запис з тире та пробілом (`- `).
+
+```yaml
+- Cat
+- Dog
+- Goldfish
+```
+
+Ця послідовність розміщує кожен елемент у списку на одному рівні. Якщо ви хочете створити вкладену послідовність з елементами та підпунктами, це можна зробити, розмістивши перед кожним тире в підпунктах один пробіл. YAML використовує для відступу пробіли, **НЕ** табуляцію. Приклад цього ви можете побачити нижче.
+
+```yaml
+-
+ - Cat
+ - Dog
+ - Goldfish
+-
+ - Python
+ - Lion
+ - Tiger
+```
+
+Це аналогічно 2-мірному масиву в інших мовах. Якщо ви хочете вкласти свої послідовності ще глибше, вам просто потрібно додати більше рівнів.
+
+```yaml
+-
+ -
+ - Cat
+ - Dog
+ - Goldfish
+```
+
+Послідовності можуть бути додані до інших типів структури даних, таких як відображення чи скаляри.
+
+### Відображення (Mappings)
+
+Відображення дає можливість перелічити ключі з їх значеннями. Це аналог асоційованого масиву. Для відображення використовується двокрапка та пробіл (`: ` ) для позначення кожної пари ключ : значення.
+
+```yaml
+animal: pets
+```
+
+Цей приклад відображає значення `pets` до ключа `animal` .
+
+Використовуючи спільно з послідовністю, ви можете побачити, що ви починаєте складати список `pets`. У наступному прикладі тире, яке використовується для позначення кожного елемента, починається з відступу (пробілу), що робить лінію елементів дочірніми, в відображаючи лінію `pets` - батьківською.
+
+```yaml
+pets:
+ - Cat
+ - Dog
+ - Goldfish
+```
+
+YAML також має стилі потоку, використовуючи явні показники, а не відступи для позначення області. Послідовність потоку записується як розділений комою список у квадратних дужках. Аналогічним чином у потоці відображень (flow mapping) використовуються фігурні дужки.
+
+```yaml
+# Sequence of Sequences
+- [name , hr, avg ]
+- [Mark McGwire, 65, 0.278]
+- [Sammy Sosa , 63, 0.288]
+# Mapping of Mappings
+Mark McGwire: {hr: 65, avg: 0.278}
+Sammy Sosa: {
+ hr: 63,
+ avg: 0.288
+ }
+```
+
+## Використання якорів (Anchors)
+
+Будь-який вузол YAML може бути закріплений і посилатися в іншому місці як псевдонім. Щоб закріпити певне значення або набір значень, використовуйте `&name of anchor`. Для посилання на нього використовується `*name of anchor`
+
+```yaml
+item:
+ - method: UPDATE
+ where: &FREE_ITEMS
+ - Portable Hole
+ - Light Feather
+ SellPrice: 0
+ BuyPrice: 0
+
+npc:
+ - method: MERGE
+ merge-from: {name: General Goods Vendor}
+ items: *FREE_ITEMS
+```
+
+## Колекції (Collections)
+
+Блокові колекції AML використовують відступи для сфери застосування та починають кожен запис у своєму власному рядку.
+
+```yaml
+# Sequence of Scalars
+- Mark McGwire
+- Sammy Sosa
+- Ken Griffey
+# Mapping Scalars to Scalars
+hr: 65 # Home runs
+avg: 0.278 # Batting average
+rbi: 147 # Runs Batted In
+# Mapping Scalars to Sequences
+american:
+ - Boston Red Sox
+ - Detroit Tigers
+ - New York Yankees
+national:
+ - New York Mets
+ - Chicago Cubs
+ - Atlanta Braves
+# Sequence of Mappings
+-
+ name: Mark McGwire
+ hr: 65
+ avg: 0.278
+-
+ name: Sammy Sosa
+ hr: 63
+ avg: 0.288
+```
+