The Augmentor.jl package is licensed under the MIT "Expat" License:
Copyright (c) 2017: Christof Stocker.
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
diff --git a/assets/ConvertEltype.png b/assets/ConvertEltype.png
deleted file mode 100644
index 8b7f43a3..00000000
Binary files a/assets/ConvertEltype.png and /dev/null differ
diff --git a/assets/Crop.png b/assets/Crop.png
deleted file mode 100644
index 16bef546..00000000
Binary files a/assets/Crop.png and /dev/null differ
diff --git a/assets/CropRatio.png b/assets/CropRatio.png
deleted file mode 100644
index 92d1d014..00000000
Binary files a/assets/CropRatio.png and /dev/null differ
diff --git a/assets/CropSize.png b/assets/CropSize.png
deleted file mode 100644
index 880dc245..00000000
Binary files a/assets/CropSize.png and /dev/null differ
diff --git a/assets/ElasticDistortion.gif b/assets/ElasticDistortion.gif
deleted file mode 100644
index b139bea1..00000000
Binary files a/assets/ElasticDistortion.gif and /dev/null differ
diff --git a/assets/ElasticDistortion2.gif b/assets/ElasticDistortion2.gif
deleted file mode 100644
index 064c6bb2..00000000
Binary files a/assets/ElasticDistortion2.gif and /dev/null differ
diff --git a/assets/FlipX.png b/assets/FlipX.png
deleted file mode 100644
index 0e64ac04..00000000
Binary files a/assets/FlipX.png and /dev/null differ
diff --git a/assets/FlipY.png b/assets/FlipY.png
deleted file mode 100644
index fb1da196..00000000
Binary files a/assets/FlipY.png and /dev/null differ
diff --git a/assets/RCropRatio.gif b/assets/RCropRatio.gif
deleted file mode 100644
index c1f8a790..00000000
Binary files a/assets/RCropRatio.gif and /dev/null differ
diff --git a/assets/Resize.png b/assets/Resize.png
deleted file mode 100644
index 1863f665..00000000
Binary files a/assets/Resize.png and /dev/null differ
diff --git a/assets/Rotate.gif b/assets/Rotate.gif
deleted file mode 100644
index d632a47c..00000000
Binary files a/assets/Rotate.gif and /dev/null differ
diff --git a/assets/Rotate.png b/assets/Rotate.png
deleted file mode 100644
index dfc4e322..00000000
Binary files a/assets/Rotate.png and /dev/null differ
diff --git a/assets/Rotate180.png b/assets/Rotate180.png
deleted file mode 100644
index 8d3bd5cc..00000000
Binary files a/assets/Rotate180.png and /dev/null differ
diff --git a/assets/Rotate270.png b/assets/Rotate270.png
deleted file mode 100644
index 1c86b8d7..00000000
Binary files a/assets/Rotate270.png and /dev/null differ
diff --git a/assets/Rotate90.png b/assets/Rotate90.png
deleted file mode 100644
index 9822c023..00000000
Binary files a/assets/Rotate90.png and /dev/null differ
diff --git a/assets/Scale.gif b/assets/Scale.gif
deleted file mode 100644
index 6fd59112..00000000
Binary files a/assets/Scale.gif and /dev/null differ
diff --git a/assets/Scale.png b/assets/Scale.png
deleted file mode 100644
index 41dea91b..00000000
Binary files a/assets/Scale.png and /dev/null differ
diff --git a/assets/Scale2.png b/assets/Scale2.png
deleted file mode 100644
index 31404f02..00000000
Binary files a/assets/Scale2.png and /dev/null differ
diff --git a/assets/ShearX.gif b/assets/ShearX.gif
deleted file mode 100644
index ae4e5d61..00000000
Binary files a/assets/ShearX.gif and /dev/null differ
diff --git a/assets/ShearX.png b/assets/ShearX.png
deleted file mode 100644
index 3e5f364d..00000000
Binary files a/assets/ShearX.png and /dev/null differ
diff --git a/assets/ShearY.gif b/assets/ShearY.gif
deleted file mode 100644
index e1cc2da3..00000000
Binary files a/assets/ShearY.gif and /dev/null differ
diff --git a/assets/ShearY.png b/assets/ShearY.png
deleted file mode 100644
index f862d247..00000000
Binary files a/assets/ShearY.png and /dev/null differ
diff --git a/assets/Zoom.gif b/assets/Zoom.gif
deleted file mode 100644
index bc7a1f1c..00000000
Binary files a/assets/Zoom.gif and /dev/null differ
diff --git a/assets/Zoom.png b/assets/Zoom.png
deleted file mode 100644
index ea3c11f3..00000000
Binary files a/assets/Zoom.png and /dev/null differ
diff --git a/assets/arrow.svg b/assets/arrow.svg
deleted file mode 100644
index ee2798d3..00000000
--- a/assets/arrow.svg
+++ /dev/null
@@ -1,63 +0,0 @@
-
-
-
-
diff --git a/assets/bg_isic_in.png b/assets/bg_isic_in.png
deleted file mode 100644
index 567fde0d..00000000
Binary files a/assets/bg_isic_in.png and /dev/null differ
diff --git a/assets/bg_isic_out.png b/assets/bg_isic_out.png
deleted file mode 100644
index b7cf6bde..00000000
Binary files a/assets/bg_isic_out.png and /dev/null differ
diff --git a/assets/bg_mnist_in.png b/assets/bg_mnist_in.png
deleted file mode 100644
index 82ad4c5a..00000000
Binary files a/assets/bg_mnist_in.png and /dev/null differ
diff --git a/assets/bg_mnist_out.png b/assets/bg_mnist_out.png
deleted file mode 100644
index 32638b2d..00000000
Binary files a/assets/bg_mnist_out.png and /dev/null differ
diff --git a/assets/big_pattern.png b/assets/big_pattern.png
deleted file mode 100644
index be8d255e..00000000
Binary files a/assets/big_pattern.png and /dev/null differ
diff --git a/assets/cropn1.png b/assets/cropn1.png
deleted file mode 100644
index 1a6954dc..00000000
Binary files a/assets/cropn1.png and /dev/null differ
diff --git a/assets/cropn2.png b/assets/cropn2.png
deleted file mode 100644
index a695991d..00000000
Binary files a/assets/cropn2.png and /dev/null differ
diff --git a/assets/documenter.css b/assets/documenter.css
deleted file mode 100644
index 26c8166f..00000000
--- a/assets/documenter.css
+++ /dev/null
@@ -1,573 +0,0 @@
-/*
- * The default CSS style for Documenter.jl generated sites
- *
- * Heavily inspired by the Julia Sphinx theme
- * https://github.com/JuliaLang/JuliaDoc
- * which extends the sphinx_rtd_theme
- * https://github.com/snide/sphinx_rtd_theme
- *
- * Part of Documenter.jl
- * https://github.com/JuliaDocs/Documenter.jl
- *
- * License: MIT
- */
-
-/* fonts */
-body, input {
- font-family: 'Lato', 'Helvetica Neue', Arial, sans-serif;
- font-size: 16px;
- color: #222;
- text-rendering: optimizeLegibility;
-}
-
-pre, code, kbd {
- font-family: 'Roboto Mono', Monaco, courier, monospace;
- font-size: 0.90em;
-}
-
-pre code {
- font-size: 1em;
-}
-
-a {
- color: #2980b9;
- text-decoration: none;
-}
-
-a:hover {
- color: #3091d1;
-}
-
-a:visited {
- color: #9b59b6;
-}
-
-body {
- line-height: 1.5;
-}
-
-h1 {
- font-size: 1.75em;
-}
-
-/* Unless the
The term data augmentation is commonly used to describe the process of repeatedly applying various transformations to some dataset, with the hope that the output (i.e. the newly generated observations) bias the model towards learning better features. Depending on the structure and semantics of the data, coming up with such transformations can be a challenge by itself.
Images are a special class of data that exhibit some interesting properties in respect to their structure. For example do the dimensions of an image (i.e. the pixel) exhibit a spatial relationship to each other. As such, a lot of commonly used augmentation strategies for image data revolve around affine transformations, such as translations or rotations. Because images are such a popular and special case of data, they deserve their own sub-category of data augmentation, which we will unsurprisingly refer to as image augmentation.
The general idea is the following: if we want our model to generalize well, then we should design the learning process in such a way as to bias the model into learning such transformation-equivariant properties. One way to do this is via the design of the model itself, which for example was idea behind convolutional neural networks. An orthogonal approach to bias the model to learn about this equivariance - and the focus of this package - is by using label-preserving transformations.
Before attempting to train a model using some augmentation pipeline, it's a good idea to invest some time in deciding on an appropriate set of transformations to choose from. Some of these transformations also have parameters to tune, and we should also make sure that we settle on a decent set of values for those.
What constitutes as "decent" depends on the dataset. In general we want the augmented images to be fairly dissimilar to the originals. However, we need to be careful that the augmented images still visually represent the same concept (and thus label). If a pipeline only produces output images that have this property we call this pipeline label-preserving.
Consider the following example from the MNIST database of handwritten digits [MNIST1998]. Our input image clearly represents its associated label "6". If we were to use the transformation Rotate180 in our augmentation pipeline for this type of images, we could end up with the situation depicted by the image on the right side.
using Augmentor, MLDatasets
-input_img = MNIST.convert2image(MNIST.traintensor(19))
-output_img = augment(input_img, Rotate180())
Input (input_img)
Output (output_img)
To a human, this newly transformed image clearly represents the label "9", and not "6" like the original image did. In image augmentation, however, the assumption is that the output of the pipeline has the same label as the input. That means that in this example we would tell our model that the correct answer for the image on the right side is "6", which is clearly undesirable for obvious reasons.
Thus, for the MNIST dataset, the transformation Rotate180 is not label-preserving and should not be used for augmentation.
On the other hand, the exact same transformation could very well be label-preserving for other types of images. Let us take a look at a different set of image data; this time from the medical domain.
The International Skin Imaging Collaboration [ISIC] hosts a large collection of publicly available and labeled skin lesion images. A subset of that data was used in 2016's ISBI challenge [ISBI2016] where a subtask was lesion classification.
Let's consider the following input image on the left side. It shows a photo of a skin lesion that was taken from above. By applying the Rotate180 operation to the input image, we end up with a transformed version shown on the right side.
After looking at both images, one could argue that the orientation of the camera is somewhat arbitrary as long as it points to the lesion at an approximately orthogonal angle. Thus, for the ISIC dataset, the transformation Rotate180 could be considered as label-preserving and very well be tried for augmentation. Of course this does not guarantee that it will improve training time or model accuracy, but the point is that it is unlikely to hurt.
Gutman, David; Codella, Noel C. F.; Celebi, Emre; Helba, Brian; Marchetti, Michael; Mishra, Nabin; Halpern, Allan. "Skin Lesion Analysis toward Melanoma Detection: A Challenge at the International Symposium on Biomedical Imaging (ISBI) 2016, hosted by the International Skin Imaging Collaboration (ISIC)". eprint arXiv:1605.01397. 2016.
diff --git a/generated/mnist_1.png b/generated/mnist_1.png
deleted file mode 100644
index 34ad3143..00000000
Binary files a/generated/mnist_1.png and /dev/null differ
diff --git a/generated/mnist_elastic.ipynb b/generated/mnist_elastic.ipynb
deleted file mode 100644
index bdd079c5..00000000
--- a/generated/mnist_elastic.ipynb
+++ /dev/null
@@ -1,585 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "# [MNIST: Elastic Distortions](@id elastic)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "In this example we are going to use Augmentor on the famous\n",
- "**MNIST database of handwritten digits** [MNIST1998] to\n",
- "reproduce the elastic distortions discussed in [SIMARD2003].\n",
- "It may be interesting to point out, that the way Augmentor\n",
- "implements distortions is a little different to how it is\n",
- "described by the authors of the paper.\n",
- "This is for a couple of reasons, most notably that we want the\n",
- "parameters for our deformations to be independent of the size\n",
- "of image it is applied on. As a consequence the\n",
- "parameter-numbers specified in the paper are not 1-to-1\n",
- "transferable to Augmentor."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "If the effects are sensible for the dataset, then applying\n",
- "elastic distortions can be a really effective way to improve\n",
- "the generalization ability of the network.\n",
- "That said, our implementation of [`ElasticDistortion`](@ref)\n",
- "has a lot of possible parameters to choose from. To that end,\n",
- "we will introduce a simple strategy for interactively\n",
- "exploring the parameter space on our dataset of interest."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Loading the MNIST Trainingset"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "In order to access and visualize the MNIST images we employ\n",
- "the help of two additional Julia packages. In the interest of\n",
- "time and space we will not go into great detail about their\n",
- "functionality. Feel free to click on their respective names to\n",
- "find out more information about the utility they can provide.\n",
- "\n",
- "- [Images.jl](https://github.com/JuliaImages/Images.jl) will\n",
- " provide us with the necessary tools for working with image\n",
- " data in Julia.\n",
- "\n",
- "- [MLDatasets.jl](https://github.com/JuliaML/MLDatasets.jl)\n",
- " has an MNIST submodule that offers a convenience interface\n",
- " to read the MNIST database."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "The function `MNIST.traintensor` returns the MNIST training\n",
- "images corresponding to the given indices as a\n",
- "multi-dimensional array. These images are stored in the native\n",
- "horizontal-major memory layout as a single floating point\n",
- "array, where all values are scaled to be between 0.0 and 1.0."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 2,
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "summary(train_tensor) = \"28×28×60000 Array{N0f8,3}\"\n"
- ]
- }
- ],
- "source": [
- "using Images, MLDatasets\n",
- "train_tensor = MNIST.traintensor()\n",
- "@show summary(train_tensor);"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "This horizontal-major format is the standard way of utilizing\n",
- "this dataset for training machine learning models.\n",
- "In this tutorial, however, we are more interested in working\n",
- "with the MNIST images as actual Julia images in vertical-major\n",
- "layout, and as black digits on white background."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "We can convert the \"tensor\" to a `Colorant` array using the\n",
- "provided function `MNIST.convert2image`.\n",
- "This way, Julia knows we are dealing with image data and can\n",
- "tell programming environments such as Juypter how to visualize\n",
- "it. If you are working in the terminal you may want to use the\n",
- "package [ImageInTerminal.jl](https://github.com/JuliaImages/ImageInTerminal.jl)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 2,
- "metadata": {},
- "outputs": [
- {
- "data": {
- "image/png": "iVBORw0KGgoAAAANSUhEUgAAAHAAAABwCAAAAADji6uXAAAABGdBTUEAALGPC/xhBQAAAAJiS0dEAP+Hj8y/AAAAB3RJTUUH4gcJBioDqp9ikwAAAZxJREFUaN7t2r0rRXEcx/Hb9ZASsioGmVhkUMqiKDaFwWSQQVZFpNgsJv4ByoiMBhmZFBkUi/K0SEomT+9POXW7nTqXuudBn9dyb93ueS/3d87vfM/NfcUs56CDDjrooIMOOpiC4DueCqxgDsO4wzhyqMEyHEw+eIMrbGIKY8iHaMEI9L4OvTiCg8kGT9GIfIRKbGHnxzEuEXZMB+MNamG3ISzSgyFogdcj6sfnYDJB2cMkNhDEuvAKfX4BnRAcTG9QXvAJHVjBbZQacDAdwcAsFOzDBxzMXlCLXTFFD+Bg9oJyDV1wtfGdwDp0UnAwO0HZRQOCC/Iq7uFgdoJyjgEE0WncwsHsBOUZuhGtgKL9cDBbwUA1FNRr2DDIwXQGz7CEQQSLvxNRG2QHkw9qaDeDJhQOiqqgQVHU9x1MLviANbSieNDXjX2UchwH4w8+4hDtCBvSalP8mwGDg/EFNWAfRdiQXQ+yNLh9Q6khB+MLnkAPHptRHKrFAoIB+184WP6g/gRQGOnAPBahm5e/hhyML1huDjrooIP/MPgNqMMZJ8UsgboAAAAASUVORK5CYII=",
- "text/plain": [
- "28×28 Array{Gray{N0f8},2}:\n",
- " Gray{N0f8}(1.0) Gray{N0f8}(1.0) … Gray{N0f8}(1.0) Gray{N0f8}(1.0)\n",
- " Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0)\n",
- " Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0)\n",
- " Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0)\n",
- " Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0)\n",
- " Gray{N0f8}(1.0) Gray{N0f8}(1.0) … Gray{N0f8}(1.0) Gray{N0f8}(1.0)\n",
- " Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0)\n",
- " Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0)\n",
- " Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0)\n",
- " Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0)\n",
- " Gray{N0f8}(1.0) Gray{N0f8}(1.0) … Gray{N0f8}(1.0) Gray{N0f8}(1.0)\n",
- " Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0)\n",
- " Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0)\n",
- " ⋮ ⋱ \n",
- " Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0)\n",
- " Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0)\n",
- " Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0)\n",
- " Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0)\n",
- " Gray{N0f8}(1.0) Gray{N0f8}(1.0) … Gray{N0f8}(1.0) Gray{N0f8}(1.0)\n",
- " Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0)\n",
- " Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0)\n",
- " Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0)\n",
- " Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0)\n",
- " Gray{N0f8}(1.0) Gray{N0f8}(1.0) … Gray{N0f8}(1.0) Gray{N0f8}(1.0)\n",
- " Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0)\n",
- " Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0) Gray{N0f8}(1.0)"
- ]
- },
- "execution_count": 2,
- "metadata": {},
- "output_type": "execute_result"
- }
- ],
- "source": [
- "train_images = MNIST.convert2image(train_tensor)\n",
- "img_1 = train_images[:,:,1] # show first image"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Visualizing the Effects"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "Before applying an operation (or pipeline of operations) on\n",
- "some dataset to train a network, we strongly recommend\n",
- "investing some time in selecting a decent set of hyper\n",
- "parameters for the operation(s). A useful tool for tasks like\n",
- "this is the package [Interact.jl](https://github.com/JuliaGizmos/Interact.jl).\n",
- "We will use this package to define a number of widgets for\n",
- "controlling the parameters to our operation."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "Note that while the code below only focuses on configuring\n",
- "the parameters of a single operation, specifically\n",
- "[`ElasticDistortion`](@ref), it could also be adapted to tweak\n",
- "a whole pipeline. Take a look at the corresponding section in\n",
- "[High-level Interface](@ref pipeline) for more information\n",
- "on how to define and use a pipeline."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 3,
- "metadata": {},
- "outputs": [
- {
- "data": {
- "text/html": [
- "
In this example we are going to use Augmentor on the famous MNIST database of handwritten digits[MNIST1998] to reproduce the elastic distortions discussed in [SIMARD2003]. It may be interesting to point out, that the way Augmentor implements distortions is a little different to how it is described by the authors of the paper. This is for a couple of reasons, most notably that we want the parameters for our deformations to be independent of the size of image it is applied on. As a consequence the parameter-numbers specified in the paper are not 1-to-1 transferable to Augmentor.
If the effects are sensible for the dataset, then applying elastic distortions can be a really effective way to improve the generalization ability of the network. That said, our implementation of ElasticDistortion has a lot of possible parameters to choose from. To that end, we will introduce a simple strategy for interactively exploring the parameter space on our dataset of interest.
Note
This tutorial was designed to be performed in a Juypter notebook. You can find a link to the Juypter version of this tutorial in the top right corner of this page.
In order to access and visualize the MNIST images we employ the help of two additional Julia packages. In the interest of time and space we will not go into great detail about their functionality. Feel free to click on their respective names to find out more information about the utility they can provide.
Images.jl will provide us with the necessary tools for working with image data in Julia.
MLDatasets.jl has an MNIST submodule that offers a convenience interface to read the MNIST database.
The function MNIST.traintensor returns the MNIST training images corresponding to the given indices as a multi-dimensional array. These images are stored in the native horizontal-major memory layout as a single floating point array, where all values are scaled to be between 0.0 and 1.0.
using Images, MLDatasets
-train_tensor = MNIST.traintensor()
-@show summary(train_tensor);
This horizontal-major format is the standard way of utilizing this dataset for training machine learning models. In this tutorial, however, we are more interested in working with the MNIST images as actual Julia images in vertical-major layout, and as black digits on white background.
We can convert the "tensor" to a Colorant array using the provided function MNIST.convert2image. This way, Julia knows we are dealing with image data and can tell programming environments such as Juypter how to visualize it. If you are working in the terminal you may want to use the package ImageInTerminal.jl
train_images = MNIST.convert2image(train_tensor)
-img_1 = train_images[:,:,1] # show first image
Before applying an operation (or pipeline of operations) on some dataset to train a network, we strongly recommend investing some time in selecting a decent set of hyper parameters for the operation(s). A useful tool for tasks like this is the package Interact.jl. We will use this package to define a number of widgets for controlling the parameters to our operation.
Note that while the code below only focuses on configuring the parameters of a single operation, specifically ElasticDistortion, it could also be adapted to tweak a whole pipeline. Take a look at the corresponding section in High-level Interface for more information on how to define and use a pipeline.
# These two package will provide us with the capabilities
-# to perform interactive visualisations in a jupyter notebook
-using Augmentor, Interact, Reactive
-
-# The manipulate macro will turn the parameters of the
-# loop into interactive widgets.
-@manipulate for
- unpaused = true,
- ticks = fpswhen(signal(unpaused), 5.),
- image_index = 1:100,
- grid_size = 3:20,
- scale = .1:.1:.5,
- sigma = 1:5,
- iterations = 1:6,
- free_border = true
- op = ElasticDistortion(grid_size, grid_size, # equal width & height
- sigma = sigma,
- scale = scale,
- iter = iterations,
- border = free_border)
- augment(train_images[:, :, image_index], op)
-end
-nothing # hide
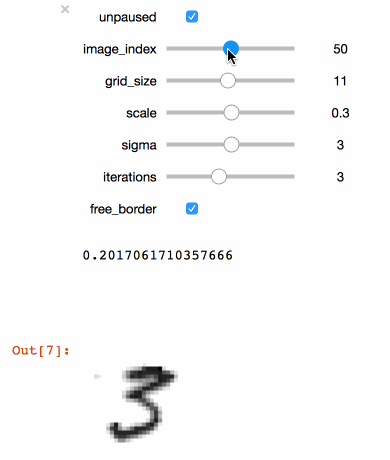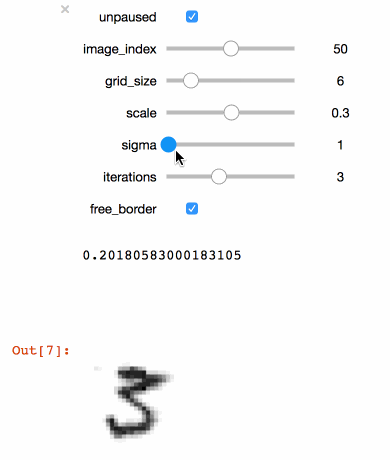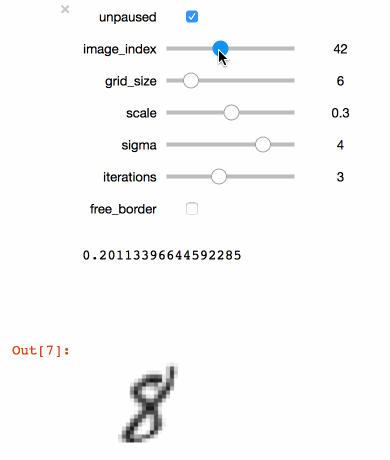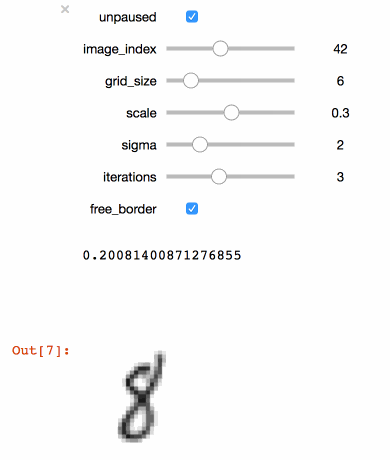
Executing the code above in a Juypter notebook will result in the following interactive visualisation. You can now use the sliders to investigate the effects that different parameters have on the MNIST training images.
Tip
You should always use your training set to do this kind of visualisation (not the test test!). Otherwise you are likely to achieve overly optimistic (i.e. biased) results during training.
Congratulations! With just a few simple lines of code, you created a simple interactive tool to visualize your image augmentation pipeline. Once you found a set of parameters that you think are appropriate for your dataset you can go ahead and train your model.
diff --git a/generated/mnist_knet.ipynb b/generated/mnist_knet.ipynb
deleted file mode 100644
index fa5fb9d4..00000000
--- a/generated/mnist_knet.ipynb
+++ /dev/null
@@ -1,1265 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "# MNIST: Knet.jl CNN"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "In this tutorial we will adapt the\n",
- "[MNIST example](http://denizyuret.github.io/Knet.jl/latest/tutorial.html#Convolutional-neural-network-1)\n",
- "from [Knet.jl](https://github.com/denizyuret/Knet.jl)\n",
- "to utilize a custom augmentation pipeline.\n",
- "In order to showcase the effect that image augmentation can\n",
- "have on a neural network's ability to generalize, we will\n",
- "limit the training set to just the first 500 images (of the\n",
- "available 60,000!). For more information on the dataset see\n",
- "[MNIST1998]."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Preparing the MNIST dataset"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "In order to access, prepare, and visualize the MNIST images we\n",
- "employ the help of three additional Julia packages. In the\n",
- "interest of time and space we will not go into great detail\n",
- "about their functionality. Feel free to click on their\n",
- "respective names to find out more information about the\n",
- "utility they can provide.\n",
- "\n",
- "- [MLDatasets.jl](https://github.com/JuliaML/MLDatasets.jl)\n",
- " has an MNIST submodule that offers a convenience interface\n",
- " to read the MNIST database.\n",
- "\n",
- "- [Images.jl](https://github.com/JuliaImages/Images.jl) will\n",
- " provide us with the necessary tools to process and display\n",
- " the image data in Julia / Juypter.\n",
- "\n",
- "- [MLDataUtils.jl](https://github.com/JuliaML/MLDataUtils.jl)\n",
- " implements a variety of functions to convert and partition\n",
- " Machine Learning datasets. This will help us prepare the\n",
- " MNIST data to be used with Knet.jl."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "using Images, MLDatasets, MLDataUtils\n",
- "srand(42);"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "As you may have seen previously in the\n",
- "[elastic distortions tutorial](@ref elastic), the function\n",
- "`MNIST.traintensor` returns the MNIST training images\n",
- "corresponding to the given indices as a multi-dimensional\n",
- "array. These images are stored in the native horizontal-major\n",
- "memory layout as a single array. Because we specify that\n",
- "the `eltype` of that array should be `Float32`, all the\n",
- "individual values are scaled to be between `0.0` and `1.0`.\n",
- "Also note, how the observations are laid out along the last\n",
- "array dimension"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 2,
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "summary(MNIST.traintensor(Float32, 1:500)) = \"28×28×500 Array{Float32,3}\"\n"
- ]
- }
- ],
- "source": [
- "@show summary(MNIST.traintensor(Float32, 1:500));"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "The corresponding label of each image is stored as an integer\n",
- "value between `0` and `9`. That means that if the label has\n",
- "the value `3`, then the corresponding image is known to be a\n",
- "handwritten \"3\". To show a more concrete example, the\n",
- "following code reveals that the first training image denotes a\n",
- "\"5\" and the second training image a \"0\" (etc)."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 3,
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "summary(MNIST.trainlabels(1:500)) = \"500-element Array{Int64,1}\"\n",
- "First eight labels: 5, 0, 4, 1, 9, 2, 1, 3\n"
- ]
- }
- ],
- "source": [
- "@show summary(MNIST.trainlabels(1:500))\n",
- "println(\"First eight labels: \", join(MNIST.trainlabels(1:8),\", \"))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "For Knet we will require a slightly format for the images\n",
- "and also the labels. More specifically, we add an additional\n",
- "singleton dimension of length 1 to our image array. Think of\n",
- "this as our single color channel (because MNIST images are gray).\n",
- "Additionally we will convert our labels to proper 1-based indices.\n",
- "This is because some functions provided by Knet expect the labels\n",
- "to be in this format. We will do all this by creating a little\n",
- "utility function that we will name `prepare_mnist`."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 4,
- "metadata": {},
- "outputs": [
- {
- "data": {
- "text/plain": [
- "prepare_mnist"
- ]
- },
- "execution_count": 4,
- "metadata": {},
- "output_type": "execute_result"
- }
- ],
- "source": [
- "\"\"\"\n",
- " prepare_mnist(images, labels) -> (X, Y)\n",
- "\n",
- "Change the dimension layout x1×x2×N of the given array\n",
- "`images` to x1×x2×1×N and return the result as `X`.\n",
- "The given integer vector `labels` is transformed into\n",
- "an integer vector denoting 1-based class indices.\n",
- "\"\"\"\n",
- "function prepare_mnist(images, labels)\n",
- " X = reshape(images, (28, 28, 1, :))\n",
- " Y = convertlabel(LabelEnc.Indices{Int8}, labels, 0:9)\n",
- " X, Y\n",
- "end"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "With `prepare_mnist` defined, we can now use it in conjunction\n",
- "with the functions in the `MLDatasets.MNIST` sub-module to load\n",
- "and prepare our training set. Recall that for this tutorial only\n",
- "the first 500 images of the training set will be used."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 5,
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "summary(train_x) = \"28×28×1×500 Array{Float32,4}\"\n",
- "summary(train_y) = \"500-element Array{Int8,1}\"\n"
- ]
- },
- {
- "data": {
- "text/html": [
- "
In this tutorial we will adapt the MNIST example from Knet.jl to utilize a custom augmentation pipeline. In order to showcase the effect that image augmentation can have on a neural network's ability to generalize, we will limit the training set to just the first 500 images (of the available 60,000!). For more information on the dataset see [MNIST1998].
Note
This tutorial is also available as a Juypter notebook. You can find a link to the Juypter version of this tutorial in the top right corner of this page.
In order to access, prepare, and visualize the MNIST images we employ the help of three additional Julia packages. In the interest of time and space we will not go into great detail about their functionality. Feel free to click on their respective names to find out more information about the utility they can provide.
MLDatasets.jl has an MNIST submodule that offers a convenience interface to read the MNIST database.
Images.jl will provide us with the necessary tools to process and display the image data in Julia / Juypter.
MLDataUtils.jl implements a variety of functions to convert and partition Machine Learning datasets. This will help us prepare the MNIST data to be used with Knet.jl.
using Images, MLDatasets, MLDataUtils
-srand(42);
As you may have seen previously in the elastic distortions tutorial, the function MNIST.traintensor returns the MNIST training images corresponding to the given indices as a multi-dimensional array. These images are stored in the native horizontal-major memory layout as a single array. Because we specify that the eltype of that array should be Float32, all the individual values are scaled to be between 0.0 and 1.0. Also note, how the observations are laid out along the last array dimension
The corresponding label of each image is stored as an integer value between 0 and 9. That means that if the label has the value 3, then the corresponding image is known to be a handwritten "3". To show a more concrete example, the following code reveals that the first training image denotes a "5" and the second training image a "0" (etc).
For Knet we will require a slightly format for the images and also the labels. More specifically, we add an additional singleton dimension of length 1 to our image array. Think of this as our single color channel (because MNIST images are gray). Additionally we will convert our labels to proper 1-based indices. This is because some functions provided by Knet expect the labels to be in this format. We will do all this by creating a little utility function that we will name prepare_mnist.
"""
- prepare_mnist(images, labels) -> (X, Y)
-
-Change the dimension layout x1×x2×N of the given array
-`images` to x1×x2×1×N and return the result as `X`.
-The given integer vector `labels` is transformed into
-an integer vector denoting 1-based class indices.
-"""
-function prepare_mnist(images, labels)
- X = reshape(images, (28, 28, 1, :))
- Y = convertlabel(LabelEnc.Indices{Int8}, labels, 0:9)
- X, Y
-end
With prepare_mnist defined, we can now use it in conjunction with the functions in the MLDatasets.MNIST sub-module to load and prepare our training set. Recall that for this tutorial only the first 500 images of the training set will be used.
train_x, train_y = prepare_mnist(MNIST.traintensor(Float32, 1:500), MNIST.trainlabels(1:500))
-@show summary(train_x) summary(train_y);
-[MNIST.convert2image(train_x[:,:,1,i]) for i in 1:8]
Similarly, we use MNIST.testtensor and MNIST.testlabels to load the full MNIST test set. We will utilize that data to measure how well the network is able to generalize with and without augmentation.
test_x, test_y = prepare_mnist(MNIST.testtensor(Float32), MNIST.testlabels())
-@show summary(test_x) summary(test_y);
-[MNIST.convert2image(test_x[:,:,1,i]) for i in 1:8]
With the dataset prepared, we can now define and instantiate our neural network. To keep things simple, we will use the same convolutional network as defined in the MNIST example of the Knet.jl package.
using Knet
The first thing we will do is define the forward pass through the network. This will effectively outline the computation graph of the network architecture. Note how this does not define some details, such as the number of neurons per layer. We will define those later when initializing our vector of weight arrays w.
"""
- forward(w, x) -> a
-
-Compute the forward pass for the given minibatch `x` by using the
-neural network parameters in `w`. The resulting (unnormalized)
-activations of the last layer are returned as `a`.
-"""
-function forward(w, x)
- # conv1 (2x2 maxpool)
- a1 = pool(relu.(conv4(w[1], x) .+ w[2]))
- # conv2 (2x2 maxpool)
- a2 = pool(relu.(conv4(w[3], a1) .+ w[4]))
- # dense1 (relu)
- a3 = relu.(w[5] * mat(a2) .+ w[6])
- # dense2 (identity)
- a4 = w[7] * a3 .+ w[8]
- return a4
-end
In order to be able to train our network we need to choose a cost function. Because this is a classification problem we will use the negative log-likelihood (provided by Knet.nll). With the cost function defined we can the simply use the higher-order function grad to create a new function costgrad that computes us the corresponding gradients.
"""
- cost(w, x, y) -> AbstractFloat
-
-Compute the per-instance negative log-likelihood for the data
-in the minibatch `(x, y)` given the network with the current
-parameters in `w`.
-"""
-cost(w, x, y) = nll(forward(w, x), y)
-costgrad = grad(cost)
Aside from the cost function that we need for training, we would also like a more interpretable performance measurement. In this tutorial we will use "accuracy" for its simplicity and because we know that the class distribution for MNIST is close to uniform.
"""
- acc(w, X, Y; [batchsize]) -> Float64
-
-Compute the accuracy for the data in `(X,Y)` given the network
-with the current parameters in `w`. The resulting value is
-computed by iterating over the data in minibatches of size
-`batchsize`.
-"""
-function acc(w, X, Y; batchsize = 100)
- sum = 0; count = 0
- for (x_cpu, y) in eachbatch((X, Y), maxsize = batchsize)
- x = KnetArray{Float32}(x_cpu)
- sum += Int(accuracy(forward(w,x), y, average = false))
- count += length(y)
- end
- return sum / count
-end
Before we can train or even just use our network, we need to define how we initialize w, which is our the vector of parameter arrays. The dimensions of these individual arrays specify the filter sizes and number of neurons. It can be helpful to compare the indices here with the indices used in our forward function to see which array corresponds to which computation node of our network.
In order to get an intuition for how useful augmentation can be, we need a sensible baseline to compare to. To that end, we will first train the network we just defined using only the (unaltered) 500 training examples.
The package ValueHistories.jl will help us record the accuracy during the training process. We will use those logs later to visualize the differences between having augmentation or no augmentation.
using ValueHistories
To keep things simple, we will not overly optimize our training function. Thus, we will be content with using a closure. Because both, the baseline and the augmented version, will share this "inefficiency", we should still get a decent enough picture of their performance differences.
function train_baseline(; epochs = 500, batchsize = 100, lr = .03)
- w = weights()
- log = MVHistory()
- for epoch in 1:epochs
- for (batch_x_cpu, batch_y) in eachbatch((train_x ,train_y), batchsize)
- batch_x = KnetArray{Float32}(batch_x_cpu)
- g = costgrad(w, batch_x, batch_y)
- Knet.update!(w, g, lr = lr)
- end
-
- if (epoch % 5) == 0
- train = acc(w, train_x, train_y)
- test = acc(w, test_x, test_y)
- @trace log epoch train test
- msg = "epoch " * lpad(epoch,4) * ": train accuracy " * rpad(round(train,3),5,"0") * ", test accuracy " * rpad(round(test,3),5,"0")
- println(msg)
- end
- end
- log
-end
Aside from the accuracy, we will also keep an eye on the training time. In particular we would like to see if and how the addition of augmentation causes our training time to increase.
epoch 5: train accuracy 0.550, test accuracy 0.460
-epoch 10: train accuracy 0.694, test accuracy 0.592
-epoch 15: train accuracy 0.820, test accuracy 0.749
-epoch 20: train accuracy 0.862, test accuracy 0.781
-epoch 25: train accuracy 0.890, test accuracy 0.815
-epoch 30: train accuracy 0.896, test accuracy 0.850
-epoch 35: train accuracy 0.920, test accuracy 0.866
-epoch 40: train accuracy 0.930, test accuracy 0.875
-epoch 45: train accuracy 0.940, test accuracy 0.882
-epoch 50: train accuracy 0.954, test accuracy 0.885
-epoch 55: train accuracy 0.964, test accuracy 0.889
-epoch 60: train accuracy 0.968, test accuracy 0.891
-epoch 65: train accuracy 0.972, test accuracy 0.893
-epoch 70: train accuracy 0.978, test accuracy 0.895
-epoch 75: train accuracy 0.982, test accuracy 0.896
-epoch 80: train accuracy 0.988, test accuracy 0.898
-epoch 85: train accuracy 0.994, test accuracy 0.899
-epoch 90: train accuracy 0.996, test accuracy 0.899
-epoch 95: train accuracy 0.998, test accuracy 0.901
-epoch 100: train accuracy 1.000, test accuracy 0.901
-epoch 105: train accuracy 1.000, test accuracy 0.902
-epoch 110: train accuracy 1.000, test accuracy 0.902
-epoch 115: train accuracy 1.000, test accuracy 0.902
-epoch 120: train accuracy 1.000, test accuracy 0.902
-epoch 125: train accuracy 1.000, test accuracy 0.903
-epoch 130: train accuracy 1.000, test accuracy 0.902
-epoch 135: train accuracy 1.000, test accuracy 0.904
-epoch 140: train accuracy 1.000, test accuracy 0.903
-epoch 145: train accuracy 1.000, test accuracy 0.903
-epoch 150: train accuracy 1.000, test accuracy 0.903
-epoch 155: train accuracy 1.000, test accuracy 0.903
-epoch 160: train accuracy 1.000, test accuracy 0.903
-epoch 165: train accuracy 1.000, test accuracy 0.903
-epoch 170: train accuracy 1.000, test accuracy 0.903
-epoch 175: train accuracy 1.000, test accuracy 0.903
-epoch 180: train accuracy 1.000, test accuracy 0.903
-epoch 185: train accuracy 1.000, test accuracy 0.903
-epoch 190: train accuracy 1.000, test accuracy 0.903
-epoch 195: train accuracy 1.000, test accuracy 0.903
-epoch 200: train accuracy 1.000, test accuracy 0.902
- 7.121126 seconds (3.18 M allocations: 274.946 MiB, 1.54% gc time)
As we can see, the accuracy on the training set is around a 100%, while the accuracy on the test set peaks around 90%. For a mere 500 training examples, this isn't actually that bad of a result.
Now that we have a network architecture with a baseline to compare to, let us finally see what it takes to add Augmentor to our experiment. First, we need to include the package to our experiment.
using Augmentor
The next step, and maybe the most human-hour consuming part of adding image augmentation to a prediction problem, is to design and select a sensible augmentation pipeline. Take a look at the elastic distortions tutorial for an example of how to do just that.
For this example, we already choose a quite complicated but promising augmentation pipeline for you. This pipeline was designed to yield a large variation of effects as well as to showcase how even deep pipelines are quite efficient in terms of performance.
10-step Augmentor.ImmutablePipeline:
- 1.) Reshape array to 28×28
- 2.) Permute dimension order to (2, 1)
- 3.) Either: (50%) ShearX by ϕ ∈ -5:5 degree. (50%) ShearY by ψ ∈ -5:5 degree.
- 4.) Rotate by θ ∈ -15:15 degree
- 5.) Crop a 28×28 window around the center
- 6.) Zoom by I ∈ {0.9×0.9, 1.0×1.0, 1.1×1.1, 1.2×1.2}
- 7.) Cache into temporary buffer
- 8.) Distort using a smoothed and normalized 10×10 grid with pinned border
- 9.) Permute dimension order to (2, 1)
- 10.) Reshape array to 28×28×1
Most of the used operations are quite self explanatory, but there are some details about this pipeline worth pointing out explicitly.
We use the operation PermuteDims to convert the horizontal-major MNIST image to a julia-native vertical-major image. The vertical-major image is then processed and converted back to a horizontal-major array. We mainly do this here to showcase the option, but it is also to keep consistent with how the data is usually used in the literature. Alternatively, one could just work with the MNIST data in a vertical-major format all the way through without any issue.
As counter-intuitive as it sounds, the operation CacheImage right before ElasticDistortion is actually used to improve performance. If we were to omit it, then the whole pipeline would be applied in one single pass. In this case, applying distortions on top of affine transformations lazily is in fact less efficient than using a temporary variable.
With the pipeline now defined, let us quickly peek at what kind of effects we can achieve with it. In particular, lets apply the pipeline multiple times to the first training image and look at what kind of results it produces.
[MNIST.convert2image(reshape(augment(train_x[:,:,:,1], pl), (28, 28))) for i in 1:8, j in 1:2]
As we can see, we can achieve a wide range of effects, from more subtle to more pronounced. The important part is that all examples are still clearly representative of the true label.
Next, we have to adapt the function train_baseline to make use of our augmentation pipeline. To integrate Augmentor efficiently, there are three necessary changes we have to make.
Preallocate a buffer with the same size and element type that each batch has.
Add a call to augmentbatch! in the inner loop of the batch iterator using our pipeline and buffer.
augmentbatch!(batch_x_aug, batch_x_org, pl)
Replace batch_x_org with batch_x_aug in the constructor of KnetArray.
batch_x = KnetArray{Float32}(batch_x_aug)
Applying these changes to our train_baseline function will give us something similar to the following function. Note how all the other parts of the function remain exactly the same as before.
function train_augmented(; epochs = 500, batchsize = 100, lr = .03)
- w = weights()
- log = MVHistory()
- batch_x_aug = zeros(Float32, size(train_x,1), size(train_x,2), 1, batchsize)
- for epoch in 1:epochs
- for (batch_x_cpu, batch_y) in eachbatch((train_x ,train_y), batchsize)
- augmentbatch!(CPUThreads(), batch_x_aug, batch_x_cpu, pl)
- batch_x = KnetArray{Float32}(batch_x_aug)
- g = costgrad(w, batch_x, batch_y)
- Knet.update!(w, g, lr = lr)
- end
-
- if (epoch % 5) == 0
- train = acc(w, train_x, train_y)
- test = acc(w, test_x, test_y)
- @trace log epoch train test
- msg = "epoch " * lpad(epoch,4) * ": train accuracy " * rpad(round(train,3),5,"0") * ", test accuracy " * rpad(round(test,3),5,"0")
- println(msg)
- end
- end
- log
-end
You may have noticed in the code above that we also pass a CPUThreads() as the first argument to augmentbatch!. This instructs Augmentor to process the images of the batch in parallel using multi-threading. For this to work properly you will need to set the environment variable JULIA_NUM_THREADS to the number of threads you wish to use. You can check how many threads are used with the function Threads.nthreads()
@show Threads.nthreads();
Threads.nthreads() = 10
Now that all pieces are in place, let us train our network once more. We will use the same parameters except that now instead of the original training images we will be using randomly augmented images. This will cause every epoch to be different.
epoch 5: train accuracy 0.526, test accuracy 0.464
-epoch 10: train accuracy 0.646, test accuracy 0.559
-epoch 15: train accuracy 0.742, test accuracy 0.684
-epoch 20: train accuracy 0.786, test accuracy 0.732
-epoch 25: train accuracy 0.846, test accuracy 0.798
-epoch 30: train accuracy 0.864, test accuracy 0.823
-epoch 35: train accuracy 0.872, test accuracy 0.833
-epoch 40: train accuracy 0.896, test accuracy 0.869
-epoch 45: train accuracy 0.908, test accuracy 0.881
-epoch 50: train accuracy 0.918, test accuracy 0.890
-epoch 55: train accuracy 0.922, test accuracy 0.891
-epoch 60: train accuracy 0.926, test accuracy 0.897
-epoch 65: train accuracy 0.936, test accuracy 0.911
-epoch 70: train accuracy 0.946, test accuracy 0.899
-epoch 75: train accuracy 0.936, test accuracy 0.898
-epoch 80: train accuracy 0.950, test accuracy 0.916
-epoch 85: train accuracy 0.924, test accuracy 0.881
-epoch 90: train accuracy 0.958, test accuracy 0.921
-epoch 95: train accuracy 0.968, test accuracy 0.933
-epoch 100: train accuracy 0.976, test accuracy 0.928
-epoch 105: train accuracy 0.982, test accuracy 0.932
-epoch 110: train accuracy 0.982, test accuracy 0.925
-epoch 115: train accuracy 0.986, test accuracy 0.934
-epoch 120: train accuracy 0.982, test accuracy 0.932
-epoch 125: train accuracy 0.992, test accuracy 0.946
-epoch 130: train accuracy 0.992, test accuracy 0.944
-epoch 135: train accuracy 0.992, test accuracy 0.940
-epoch 140: train accuracy 0.988, test accuracy 0.930
-epoch 145: train accuracy 0.990, test accuracy 0.943
-epoch 150: train accuracy 0.992, test accuracy 0.936
-epoch 155: train accuracy 0.992, test accuracy 0.949
-epoch 160: train accuracy 0.996, test accuracy 0.945
-epoch 165: train accuracy 0.992, test accuracy 0.948
-epoch 170: train accuracy 0.992, test accuracy 0.928
-epoch 175: train accuracy 0.998, test accuracy 0.948
-epoch 180: train accuracy 0.998, test accuracy 0.952
-epoch 185: train accuracy 0.998, test accuracy 0.942
-epoch 190: train accuracy 0.996, test accuracy 0.948
-epoch 195: train accuracy 0.998, test accuracy 0.949
-epoch 200: train accuracy 0.998, test accuracy 0.953
- 26.931174 seconds (38.83 M allocations: 21.677 GiB, 13.46% gc time)
As we can see, our network reaches far better results on our testset than our baseline network did. However, we can also see that the training took quite a bit longer than before. This difference generally decreases as the complexity of the utilized neural network increases. Yet another way to improve performance (aside from simplifying the augmentation pipeline) would be to increase the number of available threads.
One of the most effective ways to make the most out of the available resources is to augment the next (couple) mini-batch while the current minibatch is being processed on the GPU. We can do this via julia's build in parallel computing capabilities
First we need a worker process that will be responsible for augmenting our dataset each epoch. This worker also needs access to a couple of our packages
# addprocs(1)
-# @everywhere using Augmentor, MLDataUtils
Next, we replace the inner eachbatch loop with a more complicated version using a RemoteChannel to exchange and queue the augmented data.
function async_train_augmented(; epochs = 500, batchsize = 100, lr = .03)
- w = weights()
- log = MVHistory()
- for epoch in 1:epochs
- @sync begin
- local_ch = Channel{Tuple}(4) # prepare up to 4 minibatches in adavnce
- remote_ch = RemoteChannel(()->local_ch)
- @spawn begin
- # This block is executed on the worker process
- batch_x_aug = zeros(Float32, size(train_x,1), size(train_x,2), 1, batchsize)
- for (batch_x_cpu, batch_y) in eachbatch((train_x ,train_y), batchsize)
- # we are still using multithreading
- augmentbatch!(CPUThreads(), batch_x_aug, batch_x_cpu, pl)
- put!(remote_ch, (batch_x_aug, batch_y))
- end
- close(remote_ch)
- end
- @async begin
- # This block is executed on the main process
- for (batch_x_aug, batch_y) in local_ch
- batch_x = KnetArray{Float32}(batch_x_aug)
- g = costgrad(w, batch_x, batch_y)
- Knet.update!(w, g, lr = lr)
- end
- end
- end
-
- if (epoch % 5) == 0
- train = acc(w, train_x, train_y)
- test = acc(w, test_x, test_y)
- @trace log epoch train test
- msg = "epoch " * lpad(epoch,4) * ": train accuracy " * rpad(round(train,3),5,"0") * ", test accuracy " * rpad(round(test,3),5,"0")
- println(msg)
- end
- end
- log
-end
Note that for this toy example the overhead of this approach is greater than the benefit.
Before we end this tutorial, let us make use the Plots.jl package to visualize and discuss the recorded training curves. We will plot the accuracy curves of both networks side by side in order to get a good feeling about their differences.
Note how the accuracy on the (unaltered) training set increases faster for the baseline network than for the augmented one. This is to be expected, since our augmented network doesn't actually use the unaltered images for training, and thus has not actually seen them. Given this information, it is worth pointing out explicitly how the accuracy on training set is still greater than on the test set for the augmented network as well. This is also not a surprise, given that the augmented images are likely more similar to their original ones than to the test images.
For the baseline network, the accuracy on the test set plateaus quite quickly (around 90%). For the augmented network on the other hand, it the accuracy keeps increasing for quite a while longer.
diff --git a/generated/mnist_knet_aug.png b/generated/mnist_knet_aug.png
deleted file mode 100644
index 24e96f2a..00000000
Binary files a/generated/mnist_knet_aug.png and /dev/null differ
diff --git a/generated/mnist_knet_curves.png b/generated/mnist_knet_curves.png
deleted file mode 100644
index e6c20aa5..00000000
Binary files a/generated/mnist_knet_curves.png and /dev/null differ
diff --git a/generated/mnist_knet_test.png b/generated/mnist_knet_test.png
deleted file mode 100644
index 8639231b..00000000
Binary files a/generated/mnist_knet_test.png and /dev/null differ
diff --git a/generated/mnist_knet_train.png b/generated/mnist_knet_train.png
deleted file mode 100644
index 8f9536cc..00000000
Binary files a/generated/mnist_knet_train.png and /dev/null differ
diff --git a/generated/mnist_tensorflow.ipynb b/generated/mnist_tensorflow.ipynb
deleted file mode 100644
index e09c9c00..00000000
--- a/generated/mnist_tensorflow.ipynb
+++ /dev/null
@@ -1,942 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "# MNIST: TensorFlow CNN\n",
- "\n",
- "In this tutorial we will adapt the\n",
- "[MNIST example](https://github.com/malmaud/TensorFlow.jl/blob/master/examples/mnist_full.jl)\n",
- "from [TensorFlow.jl](https://github.com/malmaud/TensorFlow.jl)\n",
- "to utilize a custom augmentation pipeline.\n",
- "In order to showcase the effect that image augmentation can\n",
- "have on a neural network's ability to generalize, we will\n",
- "limit the training set to just the first 500 images (of the\n",
- "available 60,000!). For more information on the dataset see\n",
- "[MNIST1998].\n",
- "\n",
- "\n",
- "## Preparing the MNIST dataset\n",
- "\n",
- "In order to access, prepare, and visualize the MNIST images we\n",
- "employ the help of three additional Julia packages. In the\n",
- "interest of time and space we will not go into great detail\n",
- "about their functionality. Feel free to click on their\n",
- "respective names to find out more information about the\n",
- "utility they can provide.\n",
- "\n",
- "- [MLDatasets.jl](https://github.com/JuliaML/MLDatasets.jl)\n",
- " has an MNIST submodule that offers a convenience interface\n",
- " to read the MNIST database.\n",
- "\n",
- "- [Images.jl](https://github.com/JuliaImages/Images.jl) will\n",
- " provide us with the necessary tools to process and display\n",
- " the image data in Julia / Juypter.\n",
- "\n",
- "- [MLDataUtils.jl](https://github.com/JuliaML/MLDataUtils.jl)\n",
- " implements a variety of functions to convert and partition\n",
- " Machine Learning datasets. This will help us prepare the\n",
- " MNIST data to be used with TensorFlow."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 1,
- "metadata": {
- "collapsed": true
- },
- "outputs": [],
- "source": [
- "using Images, MLDatasets, MLDataUtils\n",
- "srand(42);"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "As you may have seen previously in the\n",
- "[elastic distortions tutorial](@ref elastic), the function\n",
- "`MNIST.traintensor` returns the MNIST training images\n",
- "corresponding to the given indices as a multi-dimensional\n",
- "array. These images are stored in the native horizontal-major\n",
- "memory layout as a single array of `Float64`. All the\n",
- "individual values are scaled to be between `0.0` and `1.0`.\n",
- "Also note, how the observations are laid out along the last\n",
- "array dimension"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 2,
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "summary(MNIST.traintensor(1:500)) = \"28×28×500 Array{Float64,3}\"\n"
- ]
- }
- ],
- "source": [
- "@show summary(MNIST.traintensor(1:500));"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "The corresponding label of each image is stored as an integer\n",
- "value between `0` and `9`. That means that if the label has\n",
- "the value `3`, then the corresponding image is known to be a\n",
- "handwritten \"3\". To show a more concrete example, the\n",
- "following code reveals that the first training image denotes a\n",
- "\"5\" and the second training image a \"0\" (etc)."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 3,
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "summary(MNIST.trainlabels(1:500)) = \"500-element Array{Int64,1}\"\n",
- "First eight labels: 5, 0, 4, 1, 9, 2, 1, 3\n"
- ]
- }
- ],
- "source": [
- "@show summary(MNIST.trainlabels(1:500))\n",
- "println(\"First eight labels: \", join(MNIST.trainlabels(1:8),\", \"))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "For TensorFlow we will require a slightly different dimension\n",
- "layout for the images. More specifically, we will move the\n",
- "observations into the first array dimension. The labels will\n",
- "be transformed into a one-of-k matrix. For performance reasons,\n",
- "we will further convert all the numerical values to be of type\n",
- "`Float32`. We will do all this by creating a little utility\n",
- "function that we will name `prepare_mnist`."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 4,
- "metadata": {},
- "outputs": [
- {
- "data": {
- "text/plain": [
- "prepare_mnist"
- ]
- },
- "execution_count": 4,
- "metadata": {},
- "output_type": "execute_result"
- }
- ],
- "source": [
- "\"\"\"\n",
- " prepare_mnist(tensor, labels) -> (X, Y)\n",
- "\n",
- "Change the dimension layout x1×x2×N of the given array\n",
- "`tensor` to N×x1×x2 and store the result in `X`.\n",
- "The given vector `labels` is transformed into a 10×N\n",
- "one-hot matrix `Y`. Both, `X` and `Y`, will have the\n",
- "element type `Float32`.\n",
- "\"\"\"\n",
- "function prepare_mnist(tensor, labels)\n",
- " features = convert(Array{Float32}, permutedims(tensor, (3,1,2)))\n",
- " targets = convertlabel(LabelEnc.OneOfK{Float32}, labels, 0:9, ObsDim.First())\n",
- " features, targets\n",
- "end"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "With `prepare_mnist` defined, we can now use it in conjunction\n",
- "with the functions in the `MLDatasets.MNIST` sub-module to load\n",
- "and prepare our training set. Recall that for this tutorial only\n",
- "use the first 500 images of the training set will be used."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 5,
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "summary(train_x) = \"500×28×28 Array{Float32,3}\"\n",
- "summary(train_y) = \"500×10 Array{Float32,2}\"\n"
- ]
- },
- {
- "data": {
- "text/html": [
- "
"
- ],
- "text/plain": [
- "8-element Array{Array{ColorTypes.Gray{Float32},2},1}:\n",
- " ColorTypes.Gray{Float32}[Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); … ; Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0)]\n",
- " ColorTypes.Gray{Float32}[Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); … ; Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0)]\n",
- " ColorTypes.Gray{Float32}[Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); … ; Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0)]\n",
- " ColorTypes.Gray{Float32}[Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); … ; Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0)]\n",
- " ColorTypes.Gray{Float32}[Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); … ; Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0)]\n",
- " ColorTypes.Gray{Float32}[Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); … ; Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0)]\n",
- " ColorTypes.Gray{Float32}[Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); … ; Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0)]\n",
- " ColorTypes.Gray{Float32}[Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); … ; Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0)]"
- ]
- },
- "execution_count": 6,
- "metadata": {},
- "output_type": "execute_result"
- }
- ],
- "source": [
- "test_x, test_y = prepare_mnist(MNIST.testtensor(), MNIST.testlabels())\n",
- "@show summary(test_x) summary(test_y);\n",
- "[MNIST.convert2image(test_x[i,:,:]) for i in 1:8]"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Defining the Network\n",
- "\n",
- "With the dataset prepared, we can now instantiate our neural\n",
- "network. To keep things simple, we will use the same\n",
- "convolutional network as defined in the\n",
- "[MNIST example](https://github.com/malmaud/TensorFlow.jl/blob/master/examples/mnist_full.jl)\n",
- "of Julia's TensorFlow package."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 7,
- "metadata": {},
- "outputs": [
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "2017-09-29 02:28:54.313988: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE4.1 instructions, but these are available on your machine and could speed up CPU computations.\n",
- "2017-09-29 02:28:54.314009: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE4.2 instructions, but these are available on your machine and could speed up CPU computations.\n",
- "2017-09-29 02:28:54.314013: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX instructions, but these are available on your machine and could speed up CPU computations.\n",
- "2017-09-29 02:28:54.314028: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX2 instructions, but these are available on your machine and could speed up CPU computations.\n",
- "2017-09-29 02:28:54.314031: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use FMA instructions, but these are available on your machine and could speed up CPU computations.\n",
- "2017-09-29 02:28:54.654851: I tensorflow/core/common_runtime/gpu/gpu_device.cc:955] Found device 0 with properties: \n",
- "name: Quadro M6000 24GB\n",
- "major: 5 minor: 2 memoryClockRate (GHz) 1.114\n",
- "pciBusID 0000:02:00.0\n",
- "Total memory: 23.86GiB\n",
- "Free memory: 23.48GiB\n",
- "2017-09-29 02:28:54.654870: I tensorflow/core/common_runtime/gpu/gpu_device.cc:976] DMA: 0 \n",
- "2017-09-29 02:28:54.654874: I tensorflow/core/common_runtime/gpu/gpu_device.cc:986] 0: Y \n",
- "2017-09-29 02:28:54.654882: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1045] Creating TensorFlow device (/gpu:0) -> (device: 0, name: Quadro M6000 24GB, pci bus id: 0000:02:00.0)\n"
- ]
- }
- ],
- "source": [
- "using TensorFlow, Distributions\n",
- "session = Session(Graph());"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 8,
- "metadata": {},
- "outputs": [
- {
- "data": {
- "text/plain": [
- "max_pool_2x2 (generic function with 1 method)"
- ]
- },
- "execution_count": 8,
- "metadata": {},
- "output_type": "execute_result"
- }
- ],
- "source": [
- "function weight_variable(shape...)\n",
- " initial = map(Float32, rand(Normal(0, .001), shape...))\n",
- " return Variable(initial)\n",
- "end\n",
- "\n",
- "function bias_variable(shape...)\n",
- " initial = fill(Float32(.1), shape...)\n",
- " return Variable(initial)\n",
- "end\n",
- "\n",
- "function conv2d(x, W)\n",
- " nn.conv2d(x, W, [1, 1, 1, 1], \"SAME\")\n",
- "end\n",
- "\n",
- "function max_pool_2x2(x)\n",
- " nn.max_pool(x, [1, 2, 2, 1], [1, 2, 2, 1], \"SAME\")\n",
- "end"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 9,
- "metadata": {},
- "outputs": [
- {
- "data": {
- "text/plain": [
- ""
- ]
- },
- "execution_count": 9,
- "metadata": {},
- "output_type": "execute_result"
- }
- ],
- "source": [
- "@tf begin\n",
- " x = placeholder(Float32)\n",
- " y = placeholder(Float32)\n",
- "\n",
- " W_conv1 = weight_variable(5, 5, 1, 32)\n",
- " b_conv1 = bias_variable(32)\n",
- "\n",
- " x_image = reshape(x, [-1, 28, 28, 1])\n",
- "\n",
- " h_conv1 = nn.relu(conv2d(x_image, W_conv1) + b_conv1)\n",
- " h_pool1 = max_pool_2x2(h_conv1)\n",
- "\n",
- " W_conv2 = weight_variable(5, 5, 32, 64)\n",
- " b_conv2 = bias_variable(64)\n",
- "\n",
- " h_conv2 = nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)\n",
- " h_pool2 = max_pool_2x2(h_conv2)\n",
- "\n",
- " W_fc1 = weight_variable(7*7*64, 1024)\n",
- " b_fc1 = bias_variable(1024)\n",
- "\n",
- " h_pool2_flat = reshape(h_pool2, [-1, 7*7*64])\n",
- " h_fc1 = nn.relu(h_pool2_flat * W_fc1 + b_fc1)\n",
- "\n",
- " keep_prob = placeholder(Float32)\n",
- " h_fc1_drop = nn.dropout(h_fc1, keep_prob)\n",
- "\n",
- " W_fc2 = weight_variable(1024, 10)\n",
- " b_fc2 = bias_variable(10)\n",
- "\n",
- " y_conv = nn.softmax(h_fc1_drop * W_fc2 + b_fc2)\n",
- "\n",
- " global cross_entropy = reduce_mean(-reduce_sum(y.*log(y_conv+1e-8), axis=[2]))\n",
- " global optimizer = train.minimize(train.AdamOptimizer(1e-4), cross_entropy)\n",
- "\n",
- " correct_prediction = broadcast(==, indmax(y_conv, 2), indmax(y, 2))\n",
- " global accuracy = reduce_mean(cast(correct_prediction, Float32))\n",
- "end"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Training without Augmentation\n",
- "\n",
- "In order to get an intuition for how useful augmentation can\n",
- "be, we need a sensible baseline to compare to. To that end, we\n",
- "will first train the network we just defined using only the\n",
- "(unaltered) 500 training examples.\n",
- "\n",
- "The package\n",
- "[ValueHistories.jl](https://github.com/JuliaML/ValueHistories.jl)\n",
- "will help us record the accuracy during the training process.\n",
- "We will use those logs later to visualize the differences\n",
- "between having augmentation or no augmentation."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 10,
- "metadata": {
- "collapsed": true
- },
- "outputs": [],
- "source": [
- "using ValueHistories"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "To keep things simple, we will not overly optimize our\n",
- "training function. Thus, we will be content with using a\n",
- "closure. Because both, the baseline and the augmented version,\n",
- "will share this \"inefficiency\", we should still get a decent\n",
- "enough picture of their performance differences."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 11,
- "metadata": {},
- "outputs": [
- {
- "data": {
- "text/plain": [
- "train_baseline (generic function with 1 method)"
- ]
- },
- "execution_count": 11,
- "metadata": {},
- "output_type": "execute_result"
- }
- ],
- "source": [
- "function train_baseline(; epochs=500, batchsize=100, reset=true)\n",
- " reset && run(session, global_variables_initializer())\n",
- " log = MVHistory()\n",
- " for epoch in 1:epochs\n",
- " for (batch_x, batch_y) in eachbatch(shuffleobs((train_x, train_y), obsdim=1), size=batchsize, obsdim=1)\n",
- " run(session, optimizer, Dict(x=>batch_x, y=>batch_y, keep_prob=>0.5))\n",
- " end\n",
- "\n",
- " if (epoch % 50) == 0\n",
- " train = run(session, accuracy, Dict(x=>train_x, y=>train_y, keep_prob=>1.0))\n",
- " test = run(session, accuracy, Dict(x=>test_x, y=>test_y, keep_prob=>1.0))\n",
- " @trace log epoch train test\n",
- " msg = \"epoch \" * lpad(epoch,4) * \": train accuracy \" * rpad(round(train,3),5,\"0\") * \", test accuracy \" * rpad(round(test,3),5,\"0\")\n",
- " println(msg)\n",
- " end\n",
- " end\n",
- " log\n",
- "end"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "Aside from the accuracy, we will also keep an eye on the\n",
- "training time. In particular we would like to see if and how\n",
- "the addition of augmentation causes our training time to\n",
- "increase."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 12,
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "epoch 50: train accuracy 0.658, test accuracy 0.570\n",
- "epoch 100: train accuracy 0.846, test accuracy 0.749\n",
- "epoch 150: train accuracy 0.878, test accuracy 0.781\n",
- "epoch 200: train accuracy 0.906, test accuracy 0.807\n",
- "epoch 250: train accuracy 0.930, test accuracy 0.819\n",
- "epoch 300: train accuracy 0.950, test accuracy 0.824\n",
- "epoch 350: train accuracy 0.962, test accuracy 0.829\n",
- "epoch 400: train accuracy 0.980, test accuracy 0.835\n",
- "epoch 450: train accuracy 0.992, test accuracy 0.834\n",
- "epoch 500: train accuracy 0.994, test accuracy 0.832\n",
- "epoch 550: train accuracy 0.998, test accuracy 0.835\n",
- "epoch 600: train accuracy 1.000, test accuracy 0.836\n",
- "epoch 650: train accuracy 1.000, test accuracy 0.836\n",
- "epoch 700: train accuracy 1.000, test accuracy 0.838\n",
- "epoch 750: train accuracy 1.000, test accuracy 0.836\n",
- "epoch 800: train accuracy 1.000, test accuracy 0.843\n",
- "epoch 850: train accuracy 1.000, test accuracy 0.834\n",
- "epoch 900: train accuracy 1.000, test accuracy 0.839\n",
- "epoch 950: train accuracy 1.000, test accuracy 0.839\n",
- "epoch 1000: train accuracy 1.000, test accuracy 0.840\n",
- " 59.346103 seconds (3.15 M allocations: 2.579 GiB, 0.95% gc time)\n"
- ]
- }
- ],
- "source": [
- "train_baseline(epochs=1) # warm-up\n",
- "baseline_log = @time train_baseline(epochs=1000);"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "As we can see, the accuracy on the training set is around a\n",
- "100%, while the accuracy on the test set peaks around 85%. For\n",
- "a mere 500 training examples, this isn't actually that bad of\n",
- "a result.\n",
- "\n",
- "## Integrating Augmentor\n",
- "\n",
- "Now that we have a network architecture with a baseline to\n",
- "compare to, let us finally see what it takes to add Augmentor\n",
- "to our experiment. First, we need to include the package to\n",
- "our experiment."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 13,
- "metadata": {
- "collapsed": true
- },
- "outputs": [],
- "source": [
- "using Augmentor"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "The next step, and maybe the most human-hour consuming part of\n",
- "adding image augmentation to a prediction problem, is to\n",
- "design and select a sensible augmentation pipeline. Take a\n",
- "look at the [elastic distortions tutorial](@ref elastic) for\n",
- "an example of how to do just that.\n",
- "\n",
- "For this example, we already choose a quite complicated but\n",
- "promising augmentation pipeline for you. This pipeline was\n",
- "designed to yield a large variation of effects as well as to\n",
- "showcase how even deep pipelines are quite efficient in terms\n",
- "of performance."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 14,
- "metadata": {},
- "outputs": [
- {
- "data": {
- "text/plain": [
- "8-step Augmentor.ImmutablePipeline:\n",
- " 1.) Permute dimension order to (2, 1)\n",
- " 2.) Either: (50%) ShearX by ϕ ∈ -5:5 degree. (50%) ShearY by ψ ∈ -5:5 degree.\n",
- " 3.) Rotate by θ ∈ -15:15 degree\n",
- " 4.) Crop a 28×28 window around the center\n",
- " 5.) Zoom by I ∈ {0.9×0.9, 1.0×1.0, 1.1×1.1, 1.2×1.2}\n",
- " 6.) Cache into temporary buffer\n",
- " 7.) Distort using a smoothed and normalized 10×10 grid with pinned border\n",
- " 8.) Permute dimension order to (2, 1)"
- ]
- },
- "execution_count": 14,
- "metadata": {},
- "output_type": "execute_result"
- }
- ],
- "source": [
- "pl = PermuteDims(2,1) |>\n",
- " ShearX(-5:5) * ShearY(-5:5) |>\n",
- " Rotate(-15:15) |>\n",
- " CropSize(28,28) |>\n",
- " Zoom(0.9:0.1:1.2) |>\n",
- " CacheImage() |>\n",
- " ElasticDistortion(10) |>\n",
- " PermuteDims(2,1)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "Most of the used operations are quite self explanatory, but\n",
- "there are some details about this pipeline worth pointing out\n",
- "explicitly.\n",
- "\n",
- "1. We use the operation [`PermuteDims`](@ref) to convert the\n",
- " horizontal-major MNIST image to a julia-native\n",
- " vertical-major image. The vertical-major image is then\n",
- " processed and converted back to a horizontal-major array.\n",
- " We mainly do this here to showcase the option, but it is\n",
- " also to keep consistent with how the data is usually used\n",
- " in the literature. Alternatively, one could just work with\n",
- " the MNIST data in a vertical-major format all the way\n",
- " through without any issue.\n",
- "\n",
- "2. As counter-intuitive as it sounds, the operation\n",
- " [`CacheImage`](@ref) right before\n",
- " [`ElasticDistortion`](@ref) is actually used to improve\n",
- " performance. If we were to omit it, then the whole pipeline\n",
- " would be applied in one single pass. In this case, applying\n",
- " distortions on top of affine transformations lazily is in\n",
- " fact less efficient than using a temporary variable.\n",
- "\n",
- "With the pipeline now defined, let us quickly peek at what\n",
- "kind of effects we can achieve with it. In particular, lets\n",
- "apply the pipeline multiple times to the first training image\n",
- "and look at what kind of results it produces."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 15,
- "metadata": {},
- "outputs": [
- {
- "data": {
- "text/html": [
- "
"
- ],
- "text/plain": [
- "8×2 Array{Array{ColorTypes.Gray{Float32},2},2}:\n",
- " ColorTypes.Gray{Float32}[Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); … ; Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0)] … ColorTypes.Gray{Float32}[Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); … ; Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0)] \n",
- " ColorTypes.Gray{Float32}[Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); … ; Gray{Float32}(1.0) Gray{Float32}(0.971794) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0)] ColorTypes.Gray{Float32}[Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); … ; Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0)] \n",
- " ColorTypes.Gray{Float32}[Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); … ; Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0)] ColorTypes.Gray{Float32}[Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); … ; Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0)] \n",
- " ColorTypes.Gray{Float32}[Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); … ; Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0)] ColorTypes.Gray{Float32}[Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); … ; Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0)] \n",
- " ColorTypes.Gray{Float32}[Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); … ; Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0)] ColorTypes.Gray{Float32}[Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); … ; Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0)] \n",
- " ColorTypes.Gray{Float32}[Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); … ; Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0)] … ColorTypes.Gray{Float32}[Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); … ; Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0)] \n",
- " ColorTypes.Gray{Float32}[Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); … ; Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0)] ColorTypes.Gray{Float32}[Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); … ; Gray{Float32}(0.969688) Gray{Float32}(0.87171) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0)]\n",
- " ColorTypes.Gray{Float32}[Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); … ; Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0)] ColorTypes.Gray{Float32}[Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); … ; Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0); Gray{Float32}(1.0) Gray{Float32}(1.0) … Gray{Float32}(1.0) Gray{Float32}(1.0)] "
- ]
- },
- "execution_count": 15,
- "metadata": {},
- "output_type": "execute_result"
- }
- ],
- "source": [
- "[MNIST.convert2image(augment(train_x[1,:,:], pl)) for i in 1:8, j in 1:2]"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "As we can see, we can achieve a wide range of effects, from\n",
- "more subtle to more pronounced. The important part is that all\n",
- "examples are still clearly representative of the true label.\n",
- "\n",
- "Next, we have to adapt the function `train_baseline` to make\n",
- "use of our augmentation pipeline. To integrate Augmentor\n",
- "efficiently, there are three necessary changes we have to\n",
- "make.\n",
- "\n",
- "1. Preallocate a buffer with the same size and element type\n",
- " that each batch has.\n",
- "\n",
- " ```\n",
- " augmented_x = zeros(Float32, batchsize, 28, 28)\n",
- " ```\n",
- "\n",
- "2. Add a call to [`augmentbatch!`](@ref) in the inner loop of\n",
- " the batch iterator using our pipeline and buffer.\n",
- "\n",
- " ```\n",
- " augmentbatch!(augmented_x, batch_x, pl, ObsDim.First())\n",
- " ```\n",
- "\n",
- "3. Replace `x=>batch_x` with `x=>augmented_x` in the call to\n",
- " TensorFlow's `run(session, ...)`.\n",
- "\n",
- "Applying these changes to our `train_baseline` function\n",
- "will give us something similar to the following function.\n",
- "Note how all the other parts of the function remain exactly\n",
- "the same as before."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 16,
- "metadata": {},
- "outputs": [
- {
- "data": {
- "text/plain": [
- "train_augmented (generic function with 1 method)"
- ]
- },
- "execution_count": 16,
- "metadata": {},
- "output_type": "execute_result"
- }
- ],
- "source": [
- "function train_augmented(; epochs=500, batchsize=100, reset=true)\n",
- " reset && run(session, global_variables_initializer())\n",
- " log = MVHistory()\n",
- " augm_x = zeros(Float32, batchsize, size(train_x,2), size(train_x,3))\n",
- " for epoch in 1:epochs\n",
- " for (batch_x, batch_y) in eachbatch(shuffleobs((train_x, train_y), obsdim=1), size=batchsize, obsdim=1)\n",
- " augmentbatch!(CPUThreads(), augm_x, batch_x, pl, ObsDim.First())\n",
- " run(session, optimizer, Dict(x=>augm_x, y=>batch_y, keep_prob=>0.5))\n",
- " end\n",
- "\n",
- " if (epoch % 50) == 0\n",
- " train = run(session, accuracy, Dict(x=>train_x, y=>train_y, keep_prob=>1.0))\n",
- " test = run(session, accuracy, Dict(x=>test_x, y=>test_y, keep_prob=>1.0))\n",
- " @trace log epoch train test\n",
- " msg = \"epoch \" * lpad(epoch,4) * \": train accuracy \" * rpad(round(train,3),5,\"0\") * \", test accuracy \" * rpad(round(test,3),5,\"0\")\n",
- " println(msg)\n",
- " end\n",
- " end\n",
- " log\n",
- "end"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "You may have noticed in the code above that we also pass a\n",
- "`CPUThreads()` as the first argument to [`augmentbatch!`](@ref).\n",
- "This instructs Augmentor to process the images of the batch in\n",
- "parallel using multi-threading. For this to work properly you\n",
- "will need to set the environment variable `JULIA_NUM_THREADS`\n",
- "to the number of threads you wish to use. You can check how\n",
- "many threads are used with the function `Threads.nthreads()`"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 17,
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Threads.nthreads() = 12\n"
- ]
- }
- ],
- "source": [
- "@show Threads.nthreads();"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "Now that all pieces are in place, let us train our network\n",
- "once more. We will use the same parameters except that now\n",
- "instead of the original training images we will be using\n",
- "randomly augmented images. This will cause every epoch to be\n",
- "different."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 18,
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "epoch 50: train accuracy 0.650, test accuracy 0.574\n",
- "epoch 100: train accuracy 0.812, test accuracy 0.729\n",
- "epoch 150: train accuracy 0.852, test accuracy 0.772\n",
- "epoch 200: train accuracy 0.868, test accuracy 0.794\n",
- "epoch 250: train accuracy 0.878, test accuracy 0.814\n",
- "epoch 300: train accuracy 0.898, test accuracy 0.828\n",
- "epoch 350: train accuracy 0.922, test accuracy 0.833\n",
- "epoch 400: train accuracy 0.932, test accuracy 0.844\n",
- "epoch 450: train accuracy 0.934, test accuracy 0.853\n",
- "epoch 500: train accuracy 0.940, test accuracy 0.852\n",
- "epoch 550: train accuracy 0.946, test accuracy 0.864\n",
- "epoch 600: train accuracy 0.954, test accuracy 0.874\n",
- "epoch 650: train accuracy 0.960, test accuracy 0.872\n",
- "epoch 700: train accuracy 0.962, test accuracy 0.872\n",
- "epoch 750: train accuracy 0.974, test accuracy 0.884\n",
- "epoch 800: train accuracy 0.978, test accuracy 0.894\n",
- "epoch 850: train accuracy 0.984, test accuracy 0.896\n",
- "epoch 900: train accuracy 0.978, test accuracy 0.902\n",
- "epoch 950: train accuracy 0.984, test accuracy 0.902\n",
- "epoch 1000: train accuracy 0.988, test accuracy 0.909\n",
- "124.314467 seconds (120.96 M allocations: 127.304 GiB, 8.08% gc time)\n"
- ]
- }
- ],
- "source": [
- "train_augmented(epochs=1) # warm-up\n",
- "augmented_log = @time train_augmented(epochs=1000);"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "As we can see, our network reaches far better results on our\n",
- "testset than our baseline network did. However, we can also\n",
- "see that the training took quite a bit longer than before.\n",
- "This difference generally decreases as the complexity of the\n",
- "utilized neural network increases. Yet another way to improve\n",
- "performance (aside from simplifying the augmentation pipeline)\n",
- "would be to increase the number of available threads.\n",
- "\n",
- "## Visualizing the Results\n",
- "\n",
- "Before we end this tutorial, let us make use the\n",
- "[Plots.jl](https://github.com/JuliaPlots/Plots.jl) package to\n",
- "visualize and discuss the recorded training curves.\n",
- "We will plot the accuracy curves of both networks side by side\n",
- "in order to get a good feeling about their differences."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 19,
- "metadata": {},
- "outputs": [
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "WARNING: No working GUI backend found for matplotlib\n"
- ]
- },
- {
- "data": {
- "text/plain": [
- "Plots.PyPlotBackend()"
- ]
- },
- "execution_count": 19,
- "metadata": {},
- "output_type": "execute_result"
- }
- ],
- "source": [
- "using Plots\n",
- "pyplot()"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 22,
- "metadata": {},
- "outputs": [
- {
- "data": {
- "text/html": [
- ""
- ]
- },
- "execution_count": 22,
- "metadata": {},
- "output_type": "execute_result"
- }
- ],
- "source": [
- "plt = plot(\n",
- " plot(baseline_log, title=\"Accuracy (baseline)\", ylim=(.5,1)),\n",
- " plot(augmented_log, title=\"Accuracy (augmented)\", ylim=(.5,1)),\n",
- " size = (900, 400),\n",
- " markersize = 1\n",
- ")\n",
- "plt"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "Note how the accuracy on the (unaltered) training set\n",
- "increases much faster for the baseline network than for the\n",
- "augmented one. This is to be expected, since our augmented\n",
- "network doesn't actually use the unaltered images for\n",
- "training, and thus has not actually seen them. Given this\n",
- "information, it is worth pointing out explicitly how the\n",
- "accuracy on training set is still greater than on the test set\n",
- "for the augmented network as well. This is also not a\n",
- "surprise, given that the augmented images are likely more\n",
- "similar to their original ones than to the test images.\n",
- "\n",
- "For the baseline network, the accuracy on the test set\n",
- "plateaus quite quickly (around 85%). For the augmented network\n",
- "on the other hand, it the accuracy keeps increasing for quite\n",
- "a while longer. If you let the network train long enough you\n",
- "can achieve around 97% even before it stops learning.\n",
- "\n",
- "## References\n",
- "\n",
- "**MNIST1998**: LeCun, Yan, Corinna Cortes, Christopher J.C. Burges. [\"The MNIST database of handwritten digits\"](http://yann.lecun.com/exdb/mnist/) Website. 1998."
- ]
- }
- ],
- "metadata": {
- "kernelspec": {
- "display_name": "Julia 0.6.1-pre",
- "language": "julia",
- "name": "julia-0.6"
- },
- "language_info": {
- "file_extension": ".jl",
- "mimetype": "application/julia",
- "name": "julia",
- "version": "0.6.1"
- }
- },
- "nbformat": 4,
- "nbformat_minor": 2
-}
diff --git a/generated/mnist_tensorflow.md.old b/generated/mnist_tensorflow.md.old
deleted file mode 100644
index b277556c..00000000
--- a/generated/mnist_tensorflow.md.old
+++ /dev/null
@@ -1,493 +0,0 @@
-# MNIST: TensorFlow CNN
-
-In this tutorial we will adapt the
-[MNIST example](https://github.com/malmaud/TensorFlow.jl/blob/master/examples/mnist_full.jl)
-from [TensorFlow.jl](https://github.com/malmaud/TensorFlow.jl)
-to utilize a custom augmentation pipeline.
-In order to showcase the effect that image augmentation can
-have on a neural network's ability to generalize, we will
-limit the training set to just the first 500 images (of the
-available 60,000!). For more information on the dataset see
-[^MNIST1998].
-
-!!! note
-
- This tutorial is also available as a
- [Juypter](https://jupyter.org/) notebook. You can
- find a link to the Juypter version of this tutorial
- in the top right corner of this page.
-
-## Preparing the MNIST dataset
-
-In order to access, prepare, and visualize the MNIST images we
-employ the help of three additional Julia packages. In the
-interest of time and space we will not go into great detail
-about their functionality. Feel free to click on their
-respective names to find out more information about the
-utility they can provide.
-
-- [MLDatasets.jl](https://github.com/JuliaML/MLDatasets.jl)
- has an MNIST submodule that offers a convenience interface
- to read the MNIST database.
-
-- [Images.jl](https://github.com/JuliaImages/Images.jl) will
- provide us with the necessary tools to process and display
- the image data in Julia / Juypter.
-
-- [MLDataUtils.jl](https://github.com/JuliaML/MLDataUtils.jl)
- implements a variety of functions to convert and partition
- Machine Learning datasets. This will help us prepare the
- MNIST data to be used with TensorFlow.
-
-
-```@example mnist_tensorflow
-using Images, MLDatasets, MLDataUtils
-srand(42);
-nothing # hide
-```
-
-As you may have seen previously in the
-[elastic distortions tutorial](@ref elastic), the function
-`MNIST.traintensor` returns the MNIST training images
-corresponding to the given indices as a multi-dimensional
-array. These images are stored in the native horizontal-major
-memory layout as a single array of `Float64`. All the
-individual values are scaled to be between `0.0` and `1.0`.
-Also note, how the observations are laid out along the last
-array dimension
-
-
-```@example mnist_tensorflow
-@show summary(MNIST.traintensor(1:500));
-nothing # hide
-```
-
-The corresponding label of each image is stored as an integer
-value between `0` and `9`. That means that if the label has
-the value `3`, then the corresponding image is known to be a
-handwritten "3". To show a more concrete example, the
-following code reveals that the first training image denotes a
-"5" and the second training image a "0" (etc).
-
-
-```@example mnist_tensorflow
-@show summary(MNIST.trainlabels(1:500))
-println("First eight labels: ", join(MNIST.trainlabels(1:8),", "))
-```
-
-For TensorFlow we will require a slightly different dimension
-layout for the images. More specifically, we will move the
-observations into the first array dimension. The labels will
-be transformed into a one-of-k matrix. For performance reasons,
-we will further convert all the numerical values to be of type
-`Float32`. We will do all this by creating a little utility
-function that we will name `prepare_mnist`.
-
-
-```@example mnist_tensorflow
-"""
- prepare_mnist(tensor, labels) -> (X, Y)
-
-Change the dimension layout x1×x2×N of the given array
-`tensor` to N×x1×x2 and store the result in `X`.
-The given vector `labels` is transformed into a 10×N
-one-hot matrix `Y`. Both, `X` and `Y`, will have the
-element type `Float32`.
-"""
-function prepare_mnist(tensor, labels)
- features = convert(Array{Float32}, permutedims(tensor, (3,1,2)))
- targets = convertlabel(LabelEnc.OneOfK{Float32}, labels, 0:9, ObsDim.First())
- features, targets
-end
-nothing # hide
-```
-
-With `prepare_mnist` defined, we can now use it in conjunction
-with the functions in the `MLDatasets.MNIST` sub-module to load
-and prepare our training set. Recall that for this tutorial only
-use the first 500 images of the training set will be used.
-
-
-```@example mnist_tensorflow
-train_x, train_y = prepare_mnist(MNIST.traintensor(1:500), MNIST.trainlabels(1:500))
-@show summary(train_x) summary(train_y);
-[MNIST.convert2image(train_x[i,:,:]) for i in 1:8]
-tmp = hcat(ans...) # hide
-save("mnist_tf_train.png",repeat(tmp, inner=(4,4))) # hide
-nothing # hide
-```
-
-
-
-Similarly, we use `MNIST.testtensor` and `MNIST.testlabels`
-to load the full MNIST test set. We will utilize that data to
-measure how well the network is able to generalize with and
-without augmentation.
-
-
-```@example mnist_tensorflow
-test_x, test_y = prepare_mnist(MNIST.testtensor(), MNIST.testlabels())
-@show summary(test_x) summary(test_y);
-[MNIST.convert2image(test_x[i,:,:]) for i in 1:8]
-tmp = hcat(ans...) # hide
-save("mnist_tf_test.png",repeat(tmp, inner=(4,4))) # hide
-nothing # hide
-```
-
-
-
-## Defining the Network
-
-With the dataset prepared, we can now instantiate our neural
-network. To keep things simple, we will use the same
-convolutional network as defined in the
-[MNIST example](https://github.com/malmaud/TensorFlow.jl/blob/master/examples/mnist_full.jl)
-of Julia's TensorFlow package.
-
-
-```@example mnist_tensorflow
-using TensorFlow, Distributions
-session = Session(Graph());
-nothing # hide
-```
-
-```@example mnist_tensorflow
-function weight_variable(shape...)
- initial = map(Float32, rand(Normal(0, .001), shape...))
- return Variable(initial)
-end
-
-function bias_variable(shape...)
- initial = fill(Float32(.1), shape...)
- return Variable(initial)
-end
-
-function conv2d(x, W)
- nn.conv2d(x, W, [1, 1, 1, 1], "SAME")
-end
-
-function max_pool_2x2(x)
- nn.max_pool(x, [1, 2, 2, 1], [1, 2, 2, 1], "SAME")
-end
-nothing # hide
-```
-
-```@example mnist_tensorflow
-@tf begin
- x = placeholder(Float32)
- y = placeholder(Float32)
-
- W_conv1 = weight_variable(5, 5, 1, 32)
- b_conv1 = bias_variable(32)
-
- x_image = reshape(x, [-1, 28, 28, 1])
-
- h_conv1 = nn.relu(conv2d(x_image, W_conv1) + b_conv1)
- h_pool1 = max_pool_2x2(h_conv1)
-
- W_conv2 = weight_variable(5, 5, 32, 64)
- b_conv2 = bias_variable(64)
-
- h_conv2 = nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
- h_pool2 = max_pool_2x2(h_conv2)
-
- W_fc1 = weight_variable(7*7*64, 1024)
- b_fc1 = bias_variable(1024)
-
- h_pool2_flat = reshape(h_pool2, [-1, 7*7*64])
- h_fc1 = nn.relu(h_pool2_flat * W_fc1 + b_fc1)
-
- keep_prob = placeholder(Float32)
- h_fc1_drop = nn.dropout(h_fc1, keep_prob)
-
- W_fc2 = weight_variable(1024, 10)
- b_fc2 = bias_variable(10)
-
- y_conv = nn.softmax(h_fc1_drop * W_fc2 + b_fc2)
-
- global cross_entropy = reduce_mean(-reduce_sum(y.*log(y_conv+1e-8), axis=[2]))
- global optimizer = train.minimize(train.AdamOptimizer(1e-4), cross_entropy)
-
- correct_prediction = broadcast(==, indmax(y_conv, 2), indmax(y, 2))
- global accuracy = reduce_mean(cast(correct_prediction, Float32))
-end
-nothing # hide
-```
-
-## Training without Augmentation
-
-In order to get an intuition for how useful augmentation can
-be, we need a sensible baseline to compare to. To that end, we
-will first train the network we just defined using only the
-(unaltered) 500 training examples.
-
-The package
-[ValueHistories.jl](https://github.com/JuliaML/ValueHistories.jl)
-will help us record the accuracy during the training process.
-We will use those logs later to visualize the differences
-between having augmentation or no augmentation.
-
-
-```@example mnist_tensorflow
-using ValueHistories
-```
-
-To keep things simple, we will not overly optimize our
-training function. Thus, we will be content with using a
-closure. Because both, the baseline and the augmented version,
-will share this "inefficiency", we should still get a decent
-enough picture of their performance differences.
-
-
-```@example mnist_tensorflow
-function train_baseline(; epochs=500, batchsize=100, reset=true)
- reset && run(session, global_variables_initializer())
- log = MVHistory()
- for epoch in 1:epochs
- for (batch_x, batch_y) in eachbatch(shuffleobs((train_x, train_y), obsdim=1), size=batchsize, obsdim=1)
- run(session, optimizer, Dict(x=>batch_x, y=>batch_y, keep_prob=>0.5))
- end
-
- if (epoch % 50) == 0
- train = run(session, accuracy, Dict(x=>train_x, y=>train_y, keep_prob=>1.0))
- test = run(session, accuracy, Dict(x=>test_x, y=>test_y, keep_prob=>1.0))
- @trace log epoch train test
- msg = "epoch " * lpad(epoch,4) * ": train accuracy " * rpad(round(train,3),5,"0") * ", test accuracy " * rpad(round(test,3),5,"0")
- println(msg)
- end
- end
- log
-end
-nothing # hide
-```
-
-Aside from the accuracy, we will also keep an eye on the
-training time. In particular we would like to see if and how
-the addition of augmentation causes our training time to
-increase.
-
-
-```@example mnist_tensorflow
-train_baseline(epochs=1) # warm-up
-baseline_log = @time train_baseline(epochs=1000);
-nothing # hide
-```
-
-As we can see, the accuracy on the training set is around a
-100%, while the accuracy on the test set peaks around 85%. For
-a mere 500 training examples, this isn't actually that bad of
-a result.
-
-## Integrating Augmentor
-
-Now that we have a network architecture with a baseline to
-compare to, let us finally see what it takes to add Augmentor
-to our experiment. First, we need to include the package to
-our experiment.
-
-
-```@example mnist_tensorflow
-using Augmentor
-```
-
-The next step, and maybe the most human-hour consuming part of
-adding image augmentation to a prediction problem, is to
-design and select a sensible augmentation pipeline. Take a
-look at the [elastic distortions tutorial](@ref elastic) for
-an example of how to do just that.
-
-For this example, we already choose a quite complicated but
-promising augmentation pipeline for you. This pipeline was
-designed to yield a large variation of effects as well as to
-showcase how even deep pipelines are quite efficient in terms
-of performance.
-
-
-```@example mnist_tensorflow
-pl = PermuteDims(2,1) |>
- ShearX(-5:5) * ShearY(-5:5) |>
- Rotate(-15:15) |>
- CropSize(28,28) |>
- Zoom(0.9:0.1:1.2) |>
- CacheImage() |>
- ElasticDistortion(10) |>
- PermuteDims(2,1)
-```
-
-Most of the used operations are quite self explanatory, but
-there are some details about this pipeline worth pointing out
-explicitly.
-
-1. We use the operation [`PermuteDims`](@ref) to convert the
- horizontal-major MNIST image to a julia-native
- vertical-major image. The vertical-major image is then
- processed and converted back to a horizontal-major array.
- We mainly do this here to showcase the option, but it is
- also to keep consistent with how the data is usually used
- in the literature. Alternatively, one could just work with
- the MNIST data in a vertical-major format all the way
- through without any issue.
-
-2. As counter-intuitive as it sounds, the operation
- [`CacheImage`](@ref) right before
- [`ElasticDistortion`](@ref) is actually used to improve
- performance. If we were to omit it, then the whole pipeline
- would be applied in one single pass. In this case, applying
- distortions on top of affine transformations lazily is in
- fact less efficient than using a temporary variable.
-
-With the pipeline now defined, let us quickly peek at what
-kind of effects we can achieve with it. In particular, lets
-apply the pipeline multiple times to the first training image
-and look at what kind of results it produces.
-
-
-```@example mnist_tensorflow
-[MNIST.convert2image(augment(train_x[1,:,:], pl)) for i in 1:8, j in 1:2]
-tmp = vcat(hcat(ans[:,1]...), hcat(ans[:,2]...)) # hide
-save("mnist_tf_aug.png",repeat(tmp, inner=(4,4))) # hide
-nothing # hide
-```
-
-
-
-As we can see, we can achieve a wide range of effects, from
-more subtle to more pronounced. The important part is that all
-examples are still clearly representative of the true label.
-
-Next, we have to adapt the function `train_baseline` to make
-use of our augmentation pipeline. To integrate Augmentor
-efficiently, there are three necessary changes we have to
-make.
-
-1. Preallocate a buffer with the same size and element type
- that each batch has.
-
- ```
- augmented_x = zeros(Float32, batchsize, 28, 28)
- ```
-
-2. Add a call to [`augmentbatch!`](@ref) in the inner loop of
- the batch iterator using our pipeline and buffer.
-
- ```
- augmentbatch!(augmented_x, batch_x, pl, ObsDim.First())
- ```
-
-3. Replace `x=>batch_x` with `x=>augmented_x` in the call to
- TensorFlow's `run(session, ...)`.
-
-Applying these changes to our `train_baseline` function
-will give us something similar to the following function.
-Note how all the other parts of the function remain exactly
-the same as before.
-
-
-```@example mnist_tensorflow
-function train_augmented(; epochs=500, batchsize=100, reset=true)
- reset && run(session, global_variables_initializer())
- log = MVHistory()
- augm_x = zeros(Float32, batchsize, size(train_x,2), size(train_x,3))
- for epoch in 1:epochs
- for (batch_x, batch_y) in eachbatch(shuffleobs((train_x, train_y), obsdim=1), size=batchsize, obsdim=1)
- augmentbatch!(CPUThreads(), augm_x, batch_x, pl, ObsDim.First())
- run(session, optimizer, Dict(x=>augm_x, y=>batch_y, keep_prob=>0.5))
- end
-
- if (epoch % 50) == 0
- train = run(session, accuracy, Dict(x=>train_x, y=>train_y, keep_prob=>1.0))
- test = run(session, accuracy, Dict(x=>test_x, y=>test_y, keep_prob=>1.0))
- @trace log epoch train test
- msg = "epoch " * lpad(epoch,4) * ": train accuracy " * rpad(round(train,3),5,"0") * ", test accuracy " * rpad(round(test,3),5,"0")
- println(msg)
- end
- end
- log
-end
-nothing # hide
-```
-
-You may have noticed in the code above that we also pass a
-`CPUThreads()` as the first argument to [`augmentbatch!`](@ref).
-This instructs Augmentor to process the images of the batch in
-parallel using multi-threading. For this to work properly you
-will need to set the environment variable `JULIA_NUM_THREADS`
-to the number of threads you wish to use. You can check how
-many threads are used with the function `Threads.nthreads()`
-
-
-```@example mnist_tensorflow
-@show Threads.nthreads();
-nothing # hide
-```
-
-Now that all pieces are in place, let us train our network
-once more. We will use the same parameters except that now
-instead of the original training images we will be using
-randomly augmented images. This will cause every epoch to be
-different.
-
-
-```@example mnist_tensorflow
-train_augmented(epochs=1) # warm-up
-augmented_log = @time train_augmented(epochs=1000);
-nothing # hide
-```
-
-As we can see, our network reaches far better results on our
-testset than our baseline network did. However, we can also
-see that the training took quite a bit longer than before.
-This difference generally decreases as the complexity of the
-utilized neural network increases. Yet another way to improve
-performance (aside from simplifying the augmentation pipeline)
-would be to increase the number of available threads.
-
-## Visualizing the Results
-
-Before we end this tutorial, let us make use the
-[Plots.jl](https://github.com/JuliaPlots/Plots.jl) package to
-visualize and discuss the recorded training curves.
-We will plot the accuracy curves of both networks side by side
-in order to get a good feeling about their differences.
-
-
-```@example mnist_tensorflow
-using Plots
-pyplot()
-nothing # hide
-```
-
-```@example mnist_tensorflow
-default(bg_outside=colorant"#FFFFFF") # hide
-plt = plot(
- plot(baseline_log, title="Accuracy (baseline)", ylim=(.5,1)),
- plot(augmented_log, title="Accuracy (augmented)", ylim=(.5,1)),
- size = (900, 400),
- markersize = 1
-)
-png(plt, "mnist_tf_curves.png") # hide
-nothing # hide
-```
-
-
-Note how the accuracy on the (unaltered) training set
-increases much faster for the baseline network than for the
-augmented one. This is to be expected, since our augmented
-network doesn't actually use the unaltered images for
-training, and thus has not actually seen them. Given this
-information, it is worth pointing out explicitly how the
-accuracy on training set is still greater than on the test set
-for the augmented network as well. This is also not a
-surprise, given that the augmented images are likely more
-similar to their original ones than to the test images.
-
-For the baseline network, the accuracy on the test set
-plateaus quite quickly (around 85%). For the augmented network
-on the other hand, it the accuracy keeps increasing for quite
-a while longer. If you let the network train long enough you
-can achieve around 97% even before it stops learning.
-
-## References
-
-[^MNIST1998]: LeCun, Yan, Corinna Cortes, Christopher J.C. Burges. ["The MNIST database of handwritten digits"](http://yann.lecun.com/exdb/mnist/) Website. 1998.
-
diff --git a/gettingstarted/index.html b/gettingstarted/index.html
deleted file mode 100644
index 09f150cc..00000000
--- a/gettingstarted/index.html
+++ /dev/null
@@ -1,24 +0,0 @@
-
-Getting Started · Augmentor.jl
In this section we will provide a condensed overview of the package. In order to keep this overview concise, we will not discuss any background information or theory on the losses here in detail.
To install Augmentor.jl, start up Julia and type the following code-snipped into the REPL. It makes use of the native Julia package manger.
Pkg.add("Augmentor")
Additionally, for example if you encounter any sudden issues, or in the case you would like to contribute to the package, you can manually choose to be on the latest (untagged) version.
The following code snippet shows how a stochastic augmentation pipeline can be specified using simple building blocks that we call "operations". In order to give the example some meaning, we will use a real medical image from the publicly available ISIC archive as input. The concrete image can be downloaded here using their Web API.
julia> using Augmentor, ISICArchive
-
-julia> img = get(ImageThumbnailRequest(id = "5592ac599fc3c13155a57a85"))
-169×256 Array{RGB{N0f8},2}:
-[...]
-
-julia> pl = Either(1=>FlipX(), 1=>FlipY(), 2=>NoOp()) |>
- Rotate(0:360) |>
- ShearX(-5:5) * ShearY(-5:5) |>
- CropSize(165, 165) |>
- Zoom(1:0.05:1.2) |>
- Resize(64, 64)
-6-step Augmentor.ImmutablePipeline:
- 1.) Either: (25%) Flip the X axis. (25%) Flip the Y axis. (50%) No operation.
- 2.) Rotate by θ ∈ 0:360 degree
- 3.) Either: (50%) ShearX by ϕ ∈ -5:5 degree. (50%) ShearY by ψ ∈ -5:5 degree.
- 4.) Crop a 165×165 window around the center
- 5.) Zoom by I ∈ {1.0×1.0, 1.05×1.05, 1.1×1.1, 1.15×1.15, 1.2×1.2}
- 6.) Resize to 64×64
-
-julia> img_new = augment(img, pl)
-64×64 Array{RGB{N0f8},2}:
-[...]
The function augment will generate a single augmented image from the given input image and pipeline. To visualize the effect we compiled a few resulting output images into a GIF using the plotting library Plots.jl with the PyPlot.jl back-end. You can inspect the full code by clicking on "Edit on Github" in the top right corner of this page.
To get help on specific functionality you can either look up the information here, or if you prefer you can make use of Julia's native doc-system. The following example shows how to get additional information on augment within Julia's REPL:
?augment
If you find yourself stuck or have other questions concerning the package you can find us at gitter or the Machine Learning domain on discourse.julialang.org
The Julia language provides a rich syntax as well as large set of highly-optimized functionality for working with (multi-dimensional) arrays of what is known as "bit types" or compositions of such. Because of this, the language lends itself particularly well to the fairly simple idea of treating images as just plain arrays. Even though this may sound as a rather tedious low-level approach, Julia makes it possible to still allow for powerful abstraction layers without the loss of generality that usually comes with that. This is accomplished with help of Julia's flexible type system and multiple dispatch (both of which are beyond the scope of this tutorial).
While the images-are-arrays-approach makes working with images in Julia very performant, it has also been source of confusion to new community members. This beginner's guide is an attempt to provide a step-by-step overview of how pixel data is handled in Julia. To get a more detailed explanation on some particular concept involved, please take a look at the documentation of the JuliaImages ecosystem.
To wrap our heads around Julia's array-based treatment of images, we first need to understand what Julia arrays are and how we can work with them.
Note
This section is only intended provide a simplified and thus partial overview of Julia's arrays capabilities in order to gain some intuition about pixel data. For a more detailed treatment of the topic please have a look at the official documentation
Whenever we work with an Array in which the elements are bit-types (e.g. Int64, Float32, UInt8, etc), we can think of the array as a continuous block of memory. This is useful for many different reasons, such as cache locality and interacting with external libraries.
The same block of memory can be interpreted in a number of ways. Consider the following example in which we allocate a vector (i.e. a one dimensional array) of UInt8 (i.e. bytes) with some ordered example values ranging from 1 to 6. We will think of this as our physical memory block, since it is a pretty close representation.
The same block of memory could also be interpreted differently. For example we could think of this as a matrix with 3 rows and 2 columns instead (or even the other way around). The function reinterpret allows us to do just that
Note how we specified the number of rows first. This is because the Julia language follows the column-major convention for multi dimensional arrays. What this means can be observed when we compare our new matrix A with the initial vector memory and look at the element layout. Both variables are using the same underlying memory (i.e the value 0x01 is physically stored right next to the value 0x02 in our example, while 0x01 and 0x04 are quite far apart even though the matrix interpretation makes it look like they are neighbors; which they are not).
Tip
A quick and dirty way to check if two variables are representing the same block of memory is by comparing the output of pointer(myvariable). Note, however, that technically this only tells you where a variable starts in memory and thus has its limitations.
This idea can also be generalized for higher dimensions. For example we can think of this as a 3D array as well.
If you take a closer look at the dimension sizes, you can see that all we did in that example was add a new dimension of size 1, while not changing the other numbers. In fact we can add any number of practically empty dimensions, otherwise known as singleton dimensions.
This is a useful property to have when we are confronted with greyscale datasets that do not have a color channel, yet we still want to work with a library that expects the images to have one.
There are a number of different conventions for how to store image data into a binary format. The first question one has to address is the order in which the image dimensions are transcribed.
We have seen before that Julia follows the column-major convention for its arrays, which for images would lead to the corresponding convention of being vertical-major. In the image domain, however, it is fairly common to store the pixels in a horizontal-major layout. In other words, horizontal-major means that images are stored in memory (or file) one pixel row after the other.
In most cases, when working within the JuliaImages ecosystem, the images should already be in the Julia-native column major layout. If for some reason that is not the case there are two possible ways to convert the image to that format.
The first way to alter the pixel order is by using the function Base.permutedims. In contrast to what we have seen before, this function will allocate a new array and copy the values in the appropriate manner.
The second way is using the function ImageCore.permuteddimsview which results in a lazy view that does not allocate a new array but instead only computes the correct values when queried.
julia> using ImageCore
-
-julia> C = permuteddimsview(At, (2,1))
-3×2 PermutedDimsArray(::Array{UInt8,2}, (2, 1)) with element type UInt8:
- 0x01 0x04
- 0x02 0x05
- 0x03 0x06
Either way, it is in general a good idea to make sure that the array one is working with ends up in a column-major layout.
Up to this point, all we talked about was how to reinterpreting or permuting the dimensional layout of some continuous memory block. If you look at the examples above you will see that all the arrays have elements of type UInt8, which just means that each element is represented by a single byte in memory.
Knowing all this, we can now take the idea a step further and think about reinterpreting the element types of the array. Let us consider our original vector memory again.
Note how each byte is thought of as an individual element. One thing we could do instead, is think of this memory block as a vector of 3 UInt16 elements.
Pay attention to where our original bytes ended up. In contrast to just rearranging elements as we did before, we ended up with significantly different element values. One may ask why it would ever be practical to reinterpret a memory block like this. The one word answer to this is Colors! As we will see in the remainder of this tutorial, it turns out to be a very useful thing to do when your arrays represent pixel data.
As we discussed before, there are a various number of conventions on how to store pixel data into a binary format. That is not only true for dimension priority, but also for color information.
One way color information can differ is in the color model in which they are described in. Two famous examples for color models are RGB and HSV. They essentially define how colors are conceptually made up in terms of some components. Additionally, one can decide on how many bits to use to describe each color component. By doing so one defines the available color depth.
Before we look into using the actual implementation of Julia's color models, let us prototype our own imperfect toy model in order to get a better understanding of what is happening under the hood.
# define our toy color model
-struct MyRGB
- r::UInt8
- b::UInt8
- g::UInt8
-end
Note how we defined our new toy color model as struct. Because of this and the fact that all its components are bit types (in this case UInt8), any instantiation of our new type will be represented as a continuous block of memory as well.
We can now apply our color model to our memory vector from above, and interpret the underlying memory as a vector of to MyRGB values instead.
Similar to the UInt16 example, we now group neighboring bytes into larger units (namely MyRGB). In contrast to the UInt16 example we are still able to access the individual components underneath. This simple toy color model already allows us to do a lot of useful things. We could define functions that work on MyRGB values in a color-space appropriate fashion. We could also define other color models and implement function to convert between them.
However, our little toy color model is not yet optimal. For example it hard-codes a predefined color depth of 24 bit. We may have use-cases where we need a richer color space. One thing we could do to achieve that would be to introduce a new type in similar fashion. Still, because they have a different range of available numbers per channel (because they have a different amount of bits per channel), we would have to write a lot of specialized code to be able to appropriately handle all color models and depth.
Luckily, the creators of ColorTypes.jl went a with a more generic strategy: Using parameterized types and fixed point numbers.
Tip
If you are interested in how various color models are actually designed and/or implemented in Julia, you can take a look at the ColorTypes.jl package.
The idea behind using fixed point numbers for each color component is fairly simple. No matter how many bits a component is made up of, we always want the largest possible value of the component to be equal to 1.0 and the smallest possible value to be equal to 0. Of course, the amount of possible intermediate numbers still depends on the number of underlying bits in the memory, but that is not much of an issue.
Not only does this allow for simple conversion between different color depths, it also allows us to implement generic algorithms, that are completely agnostic to the utilized color depth.
It is worth pointing out again, that we get all these goodies without actually changing or copying the original memory block. Remember how during this whole tutorial we have only changed the interpretation of some underlying memory, and have not had the need to copy any data so far.
Tip
For pixel data we are mainly interested in unsigned fixed point numbers, but there are others too. Check out the package FixedPointNumbers.jl for more information on fixed point numbers in general.
Let us now leave our toy model behind and use the actual implementation of RGB on our example vector memory. With the first command we will interpret our data as two pixels with 8 bit per color channel, and with the second command as a single pixel of 16 bit per color channel
Augmentor is a real-time image augmentation library designed to render the process of artificial dataset enlargement more convenient, less error prone, and easier to reproduce. It offers the user the ability to build a stochastic image-processing pipeline (or simply augmentation pipeline) using image operations as building blocks. In other words, an augmentation pipeline is little more but a sequence of operations for which the parameters can (but need not) be random variables, as the following code snippet demonstrates.
julia> using Augmentor
-
-julia> pl = ElasticDistortion(6, scale=0.3, border=true) |>
- Rotate([10, -5, -3, 0, 3, 5, 10]) |>
- ShearX(-10:10) * ShearY(-10:10) |>
- CropSize(28, 28) |>
- Zoom(0.9:0.1:1.2)
-5-step Augmentor.ImmutablePipeline:
- 1.) Distort using a smoothed and normalized 6×6 grid
- 2.) Rotate by θ ∈ [10, -5, -3, 0, 3, 5, 10] degree
- 3.) Either: (50%) ShearX by ϕ ∈ -10:10 degree. (50%) ShearY by ψ ∈ -10:10 degree.
- 4.) Crop a 28×28 window around the center
- 5.) Zoom by I ∈ {0.9×0.9, 1.0×1.0, 1.1×1.1, 1.2×1.2}
Such a pipeline can then be used for sampling. Here we use the first few examples of the MNIST database.
The Julia version of Augmentor is engineered specifically for high performance applications. It makes use of multiple heuristics to generate efficient tailor-made code for the concrete user-specified augmentation pipeline. In particular Augmentor tries to avoid the need for any intermediate images, but instead aims to compute the output image directly from the input in one single pass.
If this is the first time you consider using Augmentor.jl for your machine learning related experiments or packages, make sure to check out the "Getting Started" section. There we list the installation instructions and some simple hello world examples.
If you are new to image augmentation in general, or are simply interested in some background information, feel free to take a look at the following sections. There we discuss the concepts involved and outline the most important terms and definitions.
In case you have not worked with image data in Julia before, feel free to browse the following documents for a crash course on how image data is represented in the Julia language, as well as how to visualize it. For more information on image processing in Julia, take a look at the documentation for the vast JuliaImages ecosystem.
As the name suggests, Augmentor was designed with image augmentation for machine learning in mind. That said, the way the library is implemented allows it to also be used for efficient image processing outside the machine learning domain.
The following section describes the high-level user interface in detail. In particular it focuses on how a (stochastic) image-processing pipeline can be defined and then be applied to an image (or a set of images). It also discusses how batch processing of multiple images can be performed in parallel using multi-threading.
We mentioned before that an augmentation pipeline is just a sequence of image operations. Augmentor ships with a number of predefined operations, which should be sufficient to describe the most commonly utilized augmentation strategies. Each operation is represented as its own unique type. The following section provides a complete list of all the exported operations and their documentation.
Just like an image can say more than a thousand words, a simple hands-on tutorial showing actual code can say more than many pages of formal documentation.
The first step of devising a successful augmentation strategy is to identify an appropriate set of operations and parameters. What that means can vary widely, because the utility of each operation depends on the dataset at hand (see label-preserving transformations for an example). To that end, we will spend the first tutorial discussing a simple but useful approach to interactively explore and visualize the space of possible parameters.
In the next tutorials we will take a close look at how we can actually use Augmentor in combination with popular deep learning frameworks. The first framework we will discuss will be Knet. In particular we will focus on adapting an already existing example to make use of a (quite complicated) augmentation pipeline. Furthermore, this tutorial will also serve to showcase the various ways that augmentation can influence the performance of your network.
If you use Augmentor for academic research and wish to cite it, please use the following paper.
Marcus D. Bloice, Christof Stocker, and Andreas Holzinger, Augmentor: An Image Augmentation Library for Machine Learning, arXiv preprint arXiv:1708.04680, https://arxiv.org/abs/1708.04680, 2017.
Integrating Augmentor into an existing project should in general not require any major changes to your code. In most cases it should break down to the three basic steps outlined below. We will spend the rest of this document investigating these in more detail.
Import Augmentor into the namespace of your program.
using Augmentor
Define a (stochastic) image processing pipeline by chaining the desired operations using |> and *.
julia> pl = FlipX() * FlipY() |> Zoom(0.9:0.1:1.2) |> CropSize(64,64)
-3-step Augmentor.ImmutablePipeline:
- 1.) Either: (50%) Flip the X axis. (50%) Flip the Y axis.
- 2.) Zoom by I ∈ {0.9×0.9, 1.0×1.0, 1.1×1.1, 1.2×1.2}
- 3.) Crop a 64×64 window around the center
Apply the pipeline to the existing image or set of images.
img_processed = augment(img_original, pl)
Depending on the complexity of your problem, you may want to iterate between 2. and 3. to identify an appropriate pipeline. Take a look at the Elastic Distortions Tutorial for an example of how such an iterative process could look like.
In Augmentor, a (stochastic) image-processing pipeline can be understood as a sequence of operations, for which the parameters can (but need not) be random variables. What that essentially means is that the user explicitly specifies which image operation to perform in what order. A complete list of available operations can be found at Supported Operations.
To start off with a simple example, let us assume that we want to first rotate our image(s) counter-clockwise by 14°, then crop them down to the biggest possible square, and lastly resize the image(s) to a fixed size of 64 by 64 pixel. Such a pipeline would be defined as follows:
julia> pl = Rotate(14) |> CropRatio(1) |> Resize(64,64)
-3-step Augmentor.ImmutablePipeline:
- 1.) Rotate 14 degree
- 2.) Crop to 1:1 aspect ratio
- 3.) Resize to 64×64
Notice that in the example above there is no room for randomness. In other words, the same input image would always result in the same output image given that pipeline. If we wish for more variation we can do so by using a vector as our parameters, instead of a single number.
Note
In this subsection we will focus only on how to define a pipeline, without actually thinking too much about how to apply that pipeline to an actual image. The later will be the main topic of the rest of this document.
Say we wish to adapt our pipeline such that the rotation is a little more random. More specifically, lets say we want our image to be rotated by either -10°, -5°, 5°, 10°, or not at all. Other than that change we will leave the rest of the pipeline as is.
julia> pl = Rotate([-10,-5,0,5,10]) |> CropRatio(1) |> Resize(64,64)
-3-step Augmentor.ImmutablePipeline:
- 1.) Rotate by θ ∈ [-10, -5, 0, 5, 10] degree
- 2.) Crop to 1:1 aspect ratio
- 3.) Resize to 64×64
Variation in the parameters is only one of the two main ways to introduce randomness to our pipeline. Additionally, one can specify that an operation should be sampled randomly from a chosen set of operations . This can be accomplished using a utility operation called Either, which has its own convenience syntax.
As an example, let us assume we wish to first either mirror our image(s) horizontally, or vertically, or not at all, and then crop it down to a size of 100 by 100 pixel around the image's center. We can specify the "either" using the * operator.
julia> pl = FlipX() * FlipY() * NoOp() |> CropSize(100,100)
-2-step Augmentor.ImmutablePipeline:
- 1.) Either: (33%) Flip the X axis. (33%) Flip the Y axis. (33%) No operation.
- 2.) Crop a 100×100 window around the center
It is also possible to specify the odds of for such an "either". For example we may want the NoOp to be twice as likely as either of the mirroring options.
julia> pl = (1=>FlipX()) * (1=>FlipY()) * (2=>NoOp()) |> CropSize(100,100)
-2-step Augmentor.ImmutablePipeline:
- 1.) Either: (25%) Flip the X axis. (25%) Flip the Y axis. (50%) No operation.
- 2.) Crop a 100×100 window around the center
Now that we know how to define a pipeline, let us think about how to apply it to an image or a set of images.
Augmentor ships with a custom example image, which was specifically designed for visualizing augmentation effects. It can be accessed by calling the function testpattern(). That said, doing so explicitly should rarely be necessary in practice, because most high-level functions will default to using testpattern() if no other image is specified.
The returned image was specifically designed to be informative about the effects of the applied augmentation operations. It is thus well suited to prototype an augmentation pipeline, because it makes it easy to see what kind of effects one can achieve with it.
Once a pipeline is constructed it can be applied to an image (i.e. AbstractArray{<:ColorTypes.Colorant}), or even just to an array of numbers (i.e. AbstractArray{<:Number}), using the function augment.
The parameter img can either be a single image, or a tuple of multiple images. In case img is a tuple of images, its elements will be assumed to be conceptually connected. Consequently, all images in the tuple will take the exact same path through the pipeline; even when randomness is involved. This is useful for the purpose of image segmentation, for which the input and output are both images that need to be transformed exactly the same way.
We also provide a mutating version of augment that writes the output into preallocated memory. While this function avoids allocation, it does have the caveat that the size of the output image must be known beforehand (and thus must not be random).
Apply the operations of the given pipeline sequentially to the image img and write the resulting image into the preallocated parameter out. For convenience out is also the function's return-value.
The parameter img can either be a single image, or a tuple of multiple images. In case img is a tuple of images, the parameter out has to be a tuple of the same length and ordering. See augment for more information.
In most machine learning scenarios we will want to process a whole batch of images at once, instead of a single image at a time. For this reason we provide the function augmentbatch!, which also supports multi-threading.
Apply the operations of the given pipeline to the images in imgs and write the resulting images into outs.
Both outs and imgs have to contain the same number of images. Each of these two variables can either be in the form of a higher dimensional array, in the form of a vector of arrays for which each vector element denotes an image.
# create five example observations of size 3x3
-imgs = rand(3,3,5)
-# create output arrays of appropriate shape
-outs = similar(imgs)
-# transform the batch of images
-augmentbatch!(outs, imgs, FlipX() |> FlipY())
If one (or both) of the two parameters outs and imgs is a higher dimensional array, then the optional parameter obsdim can be used specify which dimension denotes the observations (defaults to ObsDim.Last()),
# create five example observations of size 3x3
-imgs = rand(5,3,3)
-# create output arrays of appropriate shape
-outs = similar(imgs)
-# transform the batch of images
-augmentbatch!(outs, imgs, FlipX() |> FlipY(), ObsDim.First())
Similar to augment!, it is also allowed for outs and imgs to both be tuples of the same length. If that is the case, then each tuple element can be in any of the forms listed above. This is useful for tasks such as image segmentation, where each observations is made up of more than one image.
# create five example observations where each observation is
-# made up of two conceptually linked 3x3 arrays
-imgs = (rand(3,3,5), rand(3,3,5))
-# create output arrays of appropriate shape
-outs = similar.(imgs)
-# transform the batch of images
-augmentbatch!(outs, imgs, FlipX() |> FlipY())
The parameter pipeline can be a Augmentor.Pipeline, a tuple of Augmentor.Operation, or a single Augmentor.Operation.
The optional first parameter resource can either be CPU1() (default) or CPUThreads(). In the later case the images will be augmented in parallel. For this to make sense make sure that the environment variable JULIA_NUM_THREADS is set to a reasonable number so that Threads.nthreads() is greater than 1.
# transform the batch of images in parallel using multithreading
-augmentbatch!(CPUThreads(), outs, imgs, FlipX() |> FlipY())
source
diff --git a/operations/aggmapfun/index.html b/operations/aggmapfun/index.html
deleted file mode 100644
index d3b9717a..00000000
--- a/operations/aggmapfun/index.html
+++ /dev/null
@@ -1,6 +0,0 @@
-
-AggregateThenMapFun: Aggregate and Map over Image · Augmentor.jl
Compute some aggregated value of the current image using the given function aggfun, and map that value over the current image using the given function mapfun.
This is particularly useful for achieving effects such as per-image normalization.
Usage
AggregateThenMapFun(aggfun, mapfun)
Arguments
aggfun : A function that takes the whole current image as input and which result will also be passed to mapfun. It should have a signature of img -> agg, where img will the the current image. What type and value agg should be is up to the user.
mapfun : The binary function that should be mapped over all individual array elements. It should have a signature of (px, agg) -> new_px where px is a single element of the current image, and agg is the output of aggfun.
using Augmentor
-img = testpattern()
-
-# subtract the average RGB value of the current image
-augment(img, AggregateThenMapFun(img -> mean(img), (px, agg) -> px - agg))
source
diff --git a/operations/cacheimage/index.html b/operations/cacheimage/index.html
deleted file mode 100644
index 060a85eb..00000000
--- a/operations/cacheimage/index.html
+++ /dev/null
@@ -1,15 +0,0 @@
-
-CacheImage: Buffer current state · Augmentor.jl
Write the current state of the image into the working memory. Optionally a user has the option to specify a preallocated buffer to write the image into. Note that if a buffer is provided, then it has to be of the correct size and eltype.
Even without a preallocated buffer it can be beneficial in some situations to cache the image. An example for such a scenario is when chaining a number of affine transformations after an elastic distortion, because performing that lazily requires nested interpolation.
Usage
CacheImage()
-
-CacheImage(buffer)
Arguments
buffer : Optional. A preallocated AbstractArray of the appropriate size and eltype.
using Augmentor
-
-# make pipeline that forces caching after elastic distortion
-pl = ElasticDistortion(3,3) |> CacheImage() |> Rotate(-10:10) |> ShearX(-5:5)
-
-# cache output of elastic distortion into the allocated
-# 20x20 Matrix{Float64}. Note that for this case this assumes that
-# the input image is also a 20x20 Matrix{Float64}
-pl = ElasticDistortion(3,3) |> CacheImage(zeros(20,20)) |> Rotate(-10:10)
-
-# convenience syntax with the same effect as above.
-pl = ElasticDistortion(3,3) |> zeros(20,20) |> Rotate(-10:10)
Combines the first dimension of a given array into a colorant of type colortype using the function ImageCore.colorview. The main difference is that a separate color channel is also expected for Gray images.
The shape of the input image has to be appropriate for the given colortype, which also means that the separated color channel has to be the first dimension of the array. See PermuteDims if that is not the case.
Usage
CombineChannels(colortype)
Arguments
colortype : The color type of the resulting image. Must be a subtype of ColorTypes.Colorant and match the color channel of the given image.
Convert the element type of the given array/image into the given eltype. This operation is especially useful for converting color images to grayscale (or the other way around). That said, the operation is not specific to color types and can also be used for numeric arrays (e.g. with separated channels).
Note that this is an element-wise convert function. Thus it can not be used to combine or separate color channels. Use SplitChannels or CombineChannels for those purposes.
Crops out the area denoted by the specified pixel ranges.
For example the operation Crop(5:100, 2:10) would denote a crop for the rectangle that starts at x=2 and y=5 in the top left corner and ends at x=10 and y=100 in the bottom right corner. As we can see the y-axis is specified first, because that is how the image is stored in an array. Thus the order of the provided indices ranges needs to reflect the order of the array dimensions.
Usage
Crop(indices)
-
-Crop(indices...)
Arguments
indices : NTuple or Vararg of UnitRange that denote the cropping range for each array dimension. This is very similar to how the indices for view are specified.
Crops out the area denoted by the specified pixel ranges.
For example the operation CropNative(5:100, 2:10) would denote a crop for the rectangle that starts at x=2 and y=5 in the top left corner of native space and ends at x=10 and y=100 in the bottom right corner of native space.
In contrast to Crop, the position x=1y=1 is not necessarily located at the top left of the current image, but instead depends on the cumulative effect of the previous transformations. The reason for this is because affine transformations are usually performed around the center of the image, which is reflected in "native space". This is useful for combining transformations such as Rotate or ShearX with a crop around the center area.
Usage
CropNative(indices)
-
-CropNative(indices...)
Arguments
indices : NTuple or Vararg of UnitRange that denote the cropping range for each array dimension. This is very similar to how the indices for view are specified.
using Augmentor
-img = testpattern()
-
-# cropped at top left corner
-augment(img, Rotate(45) |> Crop(1:300, 1:400))
-
-# cropped around center of rotated image
-augment(img, Rotate(45) |> CropNative(1:300, 1:400))
Crops out the biggest area around the center of the given image such that the output image satisfies the specified aspect ratio (i.e. width divided by height).
For example the operation CropRatio(1) would denote a crop for the biggest square around the center of the image.
For randomly placed crops take a look at RCropRatio.
Usage
CropRatio(ratio)
-
-CropRatio(; ratio = 1)
Arguments
ratio::Number : Optional. A number denoting the aspect ratio. For example specifying ratio=16/9 would denote a 16:9 aspect ratio. Defaults to 1, which describes a square crop.
Chooses between the given operations at random when applied. This is particularly useful if one for example wants to first either rotate the image 90 degree clockwise or anticlockwise (but never both), and then apply some other operation(s) afterwards.
When compiling a pipeline, Either will analyze the provided operations in order to identify the preferred formalism to use when applied. The chosen formalism is chosen such that it is supported by all given operations. This way the output of applying Either will be inferable and the whole pipeline will remain type-stable (even though randomness is involved).
By default each specified image operation has the same probability of occurrence. This default behaviour can be overwritten by specifying the chance manually.
operations : NTuple or Vararg of Augmentor.ImageOperation that denote the possible choices to sample from when applied.
chances : Optional. Denotes the relative chances for an operation to be sampled. Has to contain the same number of elements as operations. Either an NTuple of numbers if specified as positional argument, or alternatively a AbstractVector of numbers if specified as a keyword argument. If omitted every operation will have equal probability of occurring.
pairs : Vararg of Pair{<:Real,<:Augmentor.ImageOperation}. A compact way to specify an operation and its chance of occurring together.
Distorts the given image using a randomly (uniform) generated vector field of the given grid size. This field will be stretched over the given image when applied, which in turn will morph the original image into a new image using a linear interpolation of both the image and the vector field.
In contrast to [RandomDistortion], the resulting vector field is also smoothed using a Gaussian filter with of parameter sigma. This will result in a less chaotic vector field and thus resemble a more natural distortion.
gridheight : The grid height of the displacement vector field. This effectively specifies the number of vertices along the Y dimension used as landmarks, where all the positions between the grid points are interpolated.
gridwidth : The grid width of the displacement vector field. This effectively specifies the number of vertices along the Y dimension used as landmarks, where all the positions between the grid points are interpolated.
scale : Optional. The scaling factor applied to all displacement vectors in the field. This effectively defines the "strength" of the deformation. There is no theoretical upper limit to this factor, but a value somewhere between 0.01 and 1.0 seem to be the most reasonable choices. Default to 0.2.
sigma : Optional. Sigma parameter of the Gaussian filter. This parameter effectively controls the strength of the smoothing. Defaults to 2.
iter : Optional. The number of times the smoothing operation is applied to the displacement vector field. This is especially useful if border = false because the border will be reset to zero after each pass. Thus the displacement is a little less aggressive towards the borders of the image than it is towards its center. Defaults to 1.
border : Optional. Specifies if the borders should be distorted as well. If false, the borders of the image will be preserved. This effectively pins the outermost vertices on their original position and the operation thus only distorts the inner content of the image. Defaults to false.
norm : Optional. If true, the displacement vectors of the field will be normalized by the norm of the field. This will have the effect that the scale factor should be more or less independent of the grid size. Defaults to true.
Reverses the x-order of each pixel row. Another way of describing it would be that it mirrors the image on the y-axis, or that it mirrors the image horizontally.
If created using the parameter p, the operation will be lifted into Either(p=>FlipX(), 1-p=>NoOp()), where p denotes the probability of applying FlipX and 1-p the probability for applying NoOp. See the documentation of Either for more information.
Usage
FlipX()
-
-FlipX(p)
Arguments
p::Number : Optional. Probability of applying the operation. Must be in the interval [0,1].
Reverses the y-order of each pixel column. Another way of describing it would be that it mirrors the image on the x-axis, or that it mirrors the image vertically.
If created using the parameter p, the operation will be lifted into Either(p=>FlipY(), 1-p=>NoOp()), where p denotes the probability of applying FlipY and 1-p the probability for applying NoOp. See the documentation of Either for more information.
Usage
FlipY()
-
-FlipY(p)
Arguments
p::Number : Optional. Probability of applying the operation. Must be in the interval [0,1].
Augmentor provides a wide varitey of build-in image operations. This page provides an overview of all exported operations organized by their main category. These categories are chosen because they serve some practical purpose. For example Affine Operations allow for a special optimization under the hood when chained together.
A sizeable amount of the provided operations fall under the category of affine transformations. As such, they can be described using what is known as an affine map, which are inherently compose-able if chained together. However, utilizing such a affine formulation requires (costly) interpolation, which may not always be needed to achieve the desired effect. For that reason do some of the operations below also provide a special purpose implementation to produce their specified result. Those are usually preferred over the affine formulation if sensible considering the complete pipeline.
Aside from affine transformations, Augmentor also provides functionality for performing a variety of distortions. These types of operations usually provide a much larger distribution of possible output images.
The input images from a given dataset can be of various shapes and sizes. Yet, it is often required by the algorithm that the data must be of uniform structure. To that end Augmentor provides a number of ways to alter or subset given images.
The process of cropping is useful to discard parts of the input image. To provide this functionality lazily, applying a crop introduces a layer of representation called a "view" or SubArray. This is different yet compatible with how affine operations or other special purpose implementations work. This means that chaining a crop with some affine operation is perfectly fine if done sequentially. However, it is generally not advised to combine affine operations with crop operations within an Either block. Doing that would force the Either to trigger the eager computation of its branches in order to preserve type-stability.
It is not uncommon that machine learning frameworks require the data in a specific form and layout. For example many deep learning frameworks expect the colorchannel of the images to be encoded in the third dimension of a 4-dimensional array. Augmentor allows to convert from (and to) these different layouts using special operations that are mainly useful in the beginning or end of a augmentation pipeline.
Aside from "true" operations that specify some kind of transformation, there are also a couple of special utility operations used for functionality such as stochastic branching.
Maps the given function over all individual array elements.
This means that the given function is called with an individual elements and is expected to return a transformed element that should take the original's place. This further implies that the function is expected to be unary. It is encouraged that the function should be consistent with its return type and type-stable.
Usage
MapFun(fun)
Arguments
fun : The unary function that should be mapped over all individual array elements.
using Augmentor, ColorTypes
-img = testpattern()
-
-# subtract the constant RGBA value from each pixel
-augment(img, MapFun(px -> px - RGBA(0.5, 0.3, 0.7, 0.0)))
-
-# separate channels to scale each numeric element by a constant value
-pl = SplitChannels() |> MapFun(el -> el * 0.5) |> CombineChannels(RGBA)
-augment(img, pl)
Permute the dimensions of the given array with the predefined permutation perm. This operation is particularly useful if the order of the dimensions needs to be different than the default "julian" layout (described below).
Augmentor expects the given images to be in vertical-major layout for which the colors are encoded in the element type itself. Many deep learning frameworks however require their input in a different order. For example it is not untypical that separate color channels are expected to be encoded in the third dimension.
Usage
PermuteDims(perm)
-
-PermuteDims(perm...)
Arguments
perm : The concrete dimension permutation that should be used. Has to be specified as a Vararg{Int} or as a NTuple of Int. The length of perm has to match the number of dimensions of the expected input image to that operation.
Crops out the biggest possible area at some random position of the given image, such that the output image satisfies the specified aspect ratio (i.e. width divided by height).
For example the operation RCropRatio(1) would denote a crop for the biggest possible square. If there is more than one such square, then one will be selected at random.
Usage
RCropRatio(ratio)
-
-RCropRatio(; ratio = 1)
Arguments
ratio::Number : Optional. A number denoting the aspect ratio. For example specifying ratio=16/9 would denote a 16:9 aspect ratio. Defaults to 1, which describes a square crop.
Reinterpret the shape of the given array of numbers or colorants. This is useful for example to create singleton-dimensions that deep learning frameworks may need for colorless images, or for converting an image array to a feature vector (and vice versa).
Usage
Reshape(dims)
-
-Reshape(dims...)
Arguments
dims : The new sizes for each dimension of the output image. Has to be specified as a Vararg{Int} or as a NTuple of Int.
Rescales the image to a fixed pre-specified pixel size.
This operation does not take any measures to preserve aspect ratio of the source image. Instead, the original image will simply be resized to the given dimensions. This is useful when one needs a set of images to all be of the exact same size.
Rotate the image upwards for the given degree. This operation can only be performed as an affine transformation and will in general cause other operations of the pipeline to use their affine formulation as well (if they have one).
In contrast to the special case rotations (e.g. Rotate90, the type Rotate can describe any arbitrary number of degrees. It will always perform the rotation around the center of the image. This can be particularly useful when combining the operation with CropNative.
Usage
Rotate(degree)
Arguments
degree : Real or AbstractVector of Real that denote the rotation angle(s) in degree. If a vector is provided, then a random element will be sampled each time the operation is applied.
In contrast to the special case rotations outlined above, the type Rotate can describe any arbitrary number of degrees. It will always perform the rotation around the center of the image. This can be particularly useful when combining the operation with CropNative.
Input
Output for Rotate(15)
It is also possible to pass some abstract vector to the constructor, in which case Augmentor will randomly sample one of its elements every time the operation is applied.
Rotates the image 180 degrees. This is a special case rotation because it can be performed very efficiently by simply rearranging the existing pixels. Furthermore, the output image will have the same dimensions as the input image.
If created using the parameter p, the operation will be lifted into Either(p=>Rotate180(), 1-p=>NoOp()), where p denotes the probability of applying Rotate180 and 1-p the probability for applying NoOp. See the documentation of Either for more information.
Usage
Rotate180()
-
-Rotate180(p)
Arguments
p::Number : Optional. Probability of applying the operation. Must be in the interval [0,1].
Rotates the image upwards 270 degrees, which can also be described as rotating the image downwards 90 degrees. This is a special case rotation, because it can be performed very efficiently by simply rearranging the existing pixels. However, it is generally not the case that the output image will have the same size as the input image, which is something to be aware of.
If created using the parameter p, the operation will be lifted into Either(p=>Rotate270(), 1-p=>NoOp()), where p denotes the probability of applying Rotate270 and 1-p the probability for applying NoOp. See the documentation of Either for more information.
Usage
Rotate270()
-
-Rotate270(p)
Arguments
p::Number : Optional. Probability of applying the operation. Must be in the interval [0,1].
Rotates the image upwards 90 degrees. This is a special case rotation because it can be performed very efficiently by simply rearranging the existing pixels. However, it is generally not the case that the output image will have the same size as the input image, which is something to be aware of.
If created using the parameter p, the operation will be lifted into Either(p=>Rotate90(), 1-p=>NoOp()), where p denotes the probability of applying Rotate90 and 1-p the probability for applying NoOp. See the documentation of Either for more information.
Usage
Rotate90()
-
-Rotate90(p)
Arguments
p::Number : Optional. Probability of applying the operation. Must be in the interval [0,1].
Multiplies the image height and image width by the specified factors. This means that the size of the output image depends on the size of the input image.
The provided factors can either be numbers or vectors of numbers.
If numbers are provided, then the operation is deterministic and will always scale the input image with the same factors.
In the case vectors are provided, then each time the operation is applied a valid index is sampled and the elements corresponding to that index are used as scaling factors.
The scaling is performed relative to the image center, which can be useful when following the operation with CropNative.
Usage
Scale(factors)
-
-Scale(factors...)
Arguments
factors : NTuple or Vararg of Real or AbstractVector that denote the scale factor(s) for each array dimension. If only one variable is specified it is assumed that height and width should be scaled by the same factor(s).
using Augmentor
-img = testpattern()
-
-# half the image size
-augment(img, Scale(0.5))
-
-# uniformly scale by a random factor from 1.2, 1.3, or 1.4
-augment(img, Scale([1.2, 1.3, 1.4]))
-
-# scale by either 0.5x0.7 or by 0.6x0.8
-augment(img, Scale([0.5, 0.6], [0.7, 0.8]))
In the case that only a single scale factor is specified, the operation will assume that the intention is to scale all dimensions uniformly by that factor.
Input
Output for Scale(1.2)
It is also possible to pass some abstract vector(s) to the constructor, in which case Augmentor will randomly sample one of its elements every time the operation is applied.
Shear the image horizontally for the given degree. This operation can only be performed as an affine transformation and will in general cause other operations of the pipeline to use their affine formulation as well (if they have one).
It will always perform the transformation around the center of the image. This can be particularly useful when combining the operation with CropNative.
Usage
ShearX(degree)
Arguments
degree : Real or AbstractVector of Real that denote the shearing angle(s) in degree. If a vector is provided, then a random element will be sampled each time the operation is applied.
using Augmentor
-img = testpattern()
-
-# shear horizontally exactly 5 degree
-augment(img, ShearX(5))
-
-# shear horizontally between 10 and 20 degree to the right
-augment(img, ShearX(10:20))
-
-# shear horizontally one of the five specified degrees
-augment(img, ShearX([-10, -5, 0, 5, 10]))
It will always perform the transformation around the center of the image. This can be particularly useful when combining the operation with CropNative.
Input
Output for ShearX(10)
It is also possible to pass some abstract vector to the constructor, in which case Augmentor will randomly sample one of its elements every time the operation is applied.
Shear the image vertically for the given degree. This operation can only be performed as an affine transformation and will in general cause other operations of the pipeline to use their affine formulation as well (if they have one).
It will always perform the transformation around the center of the image. This can be particularly useful when combining the operation with CropNative.
Usage
ShearY(degree)
Arguments
degree : Real or AbstractVector of Real that denote the shearing angle(s) in degree. If a vector is provided, then a random element will be sampled each time the operation is applied.
It will always perform the transformation around the center of the image. This can be particularly useful when combining the operation with CropNative.
Input
Output for ShearY(10)
It is also possible to pass some abstract vector to the constructor, in which case Augmentor will randomly sample one of its elements every time the operation is applied.
Input
Samples for ShearY(-10:10)
diff --git a/operations/splitchannels/index.html b/operations/splitchannels/index.html
deleted file mode 100644
index db965f88..00000000
--- a/operations/splitchannels/index.html
+++ /dev/null
@@ -1,14 +0,0 @@
-
-SplitChannels: Separate color channels · Augmentor.jl
Splits out the color channels of the given image using the function ImageCore.channelview. This will effectively create a new array dimension for the colors in the front. In contrast to ImageCore.channelview it will also result in a new dimension for gray images.
This operation is mainly useful at the end of a pipeline in combination with PermuteDims in order to prepare the image for the training algorithm, which often requires the color channels to be separate.
Scales the image height and image width by the specified factors, but crops the image such that the original size is preserved.
The provided factors can either be numbers or vectors of numbers.
If numbers are provided, then the operation is deterministic and will always scale the input image with the same factors.
In the case vectors are provided, then each time the operation is applied a valid index is sampled and the elements corresponding to that index are used as scaling factors.
In contrast to Scale the size of the output image is the same as the size of the input image, while the content is scaled the same way. The same effect could be achieved by following a Scale with a CropSize, with the caveat that one would need to know the exact size of the input image before-hand.
Usage
Zoom(factors)
-
-Zoom(factors...)
Arguments
factors : NTuple or Vararg of Real or AbstractVector that denote the scale factor(s) for each array dimension. If only one variable is specified it is assumed that height and width should be scaled by the same factor(s).
using Augmentor
-img = testpattern()
-
-# half the image size
-augment(img, Zoom(0.5))
-
-# uniformly scale by a random factor from 1.2, 1.3, or 1.4
-augment(img, Zoom([1.2, 1.3, 1.4]))
-
-# scale by either 0.5x0.7 or by 0.6x0.8
-augment(img, Zoom([0.5, 0.6], [0.7, 0.8]))
It is also possible to pass some abstract vector to the constructor, in which case Augmentor will randomly sample one of its elements every time the operation is applied.
diff --git a/search_index.js b/search_index.js
deleted file mode 100644
index acdba0e8..00000000
--- a/search_index.js
+++ /dev/null
@@ -1,1147 +0,0 @@
-var documenterSearchIndex = {"docs": [
-
-{
- "location": "#",
- "page": "Home",
- "title": "Home",
- "category": "page",
- "text": "(Image: header)A fast library for increasing the number of training images by applying various transformations."
-},
-
-{
- "location": "#Augmentor.jl\'s-documentation-1",
- "page": "Home",
- "title": "Augmentor.jl\'s documentation",
- "category": "section",
- "text": "Augmentor is a real-time image augmentation library designed to render the process of artificial dataset enlargement more convenient, less error prone, and easier to reproduce. It offers the user the ability to build a stochastic image-processing pipeline (or simply augmentation pipeline) using image operations as building blocks. In other words, an augmentation pipeline is little more but a sequence of operations for which the parameters can (but need not) be random variables, as the following code snippet demonstrates.using Augmentor\npl = ElasticDistortion(6, scale=0.3, border=true) |>\n Rotate([10, -5, -3, 0, 3, 5, 10]) |>\n ShearX(-10:10) * ShearY(-10:10) |>\n CropSize(28, 28) |>\n Zoom(0.9:0.1:1.2)Such a pipeline can then be used for sampling. Here we use the first few examples of the MNIST database.# I can\'t use Reel.jl, because the way it stores the tmp pngs\n# causes the images to be upscaled too much.\nusing Augmentor, MLDatasets, Images, Colors\nusing PaddedViews, OffsetArrays\n\npl = ElasticDistortion(6, scale=0.3, border=true) |>\n Rotate([10, -5, -3, 0, 3, 5, 10]) |>\n ShearX(-10:10) * ShearY(-10:10) |>\n CropSize(28, 28) |>\n Zoom(0.9:0.1:1.2)\n\nmd_imgs = String[]\nfor i in 1:24\n srand(i) # somehow srand in the beginning isn\'t enough\n input = MNIST.convert2image(MNIST.traintensor(i))\n imgs = [augment(input, pl) for j in 1:20]\n insert!(imgs, 1, first(imgs)) # otherwise loop isn\'t smooth\n fnames = map(imgs) do img\n tpath = tempname() * \".png\"\n save(tpath, img)\n tpath\n end\n args = reduce(vcat, [[fname, \"-delay\", \"1x4\", \"-alpha\", \"deactivate\"] for fname in fnames])\n convert = strip(readstring(`which convert`))\n outname = joinpath(\"assets\", \"idx_mnist_$i.gif\")\n run(`$convert $args $outname`)\n push!(md_imgs, \"[](@ref mnist)\")\n foreach(fname -> rm(fname), fnames)\nend\nMarkdown.parse(join(md_imgs, \" \"))The Julia version of Augmentor is engineered specifically for high performance applications. It makes use of multiple heuristics to generate efficient tailor-made code for the concrete user-specified augmentation pipeline. In particular Augmentor tries to avoid the need for any intermediate images, but instead aims to compute the output image directly from the input in one single pass."
-},
-
-{
- "location": "#Where-to-begin?-1",
- "page": "Home",
- "title": "Where to begin?",
- "category": "section",
- "text": "If this is the first time you consider using Augmentor.jl for your machine learning related experiments or packages, make sure to check out the \"Getting Started\" section. There we list the installation instructions and some simple hello world examples.Pages = [\"gettingstarted.md\"]\nDepth = 2Augmentor.jl is the Julia package for Augmentor. You can find the Python version here."
-},
-
-{
- "location": "#Introduction-and-Motivation-1",
- "page": "Home",
- "title": "Introduction and Motivation",
- "category": "section",
- "text": "If you are new to image augmentation in general, or are simply interested in some background information, feel free to take a look at the following sections. There we discuss the concepts involved and outline the most important terms and definitions.Pages = [\"background.md\"]\nDepth = 2In case you have not worked with image data in Julia before, feel free to browse the following documents for a crash course on how image data is represented in the Julia language, as well as how to visualize it. For more information on image processing in Julia, take a look at the documentation for the vast JuliaImages ecosystem.Pages = [\"images.md\"]\nDepth = 2"
-},
-
-{
- "location": "#User\'s-Guide-1",
- "page": "Home",
- "title": "User\'s Guide",
- "category": "section",
- "text": "As the name suggests, Augmentor was designed with image augmentation for machine learning in mind. That said, the way the library is implemented allows it to also be used for efficient image processing outside the machine learning domain.The following section describes the high-level user interface in detail. In particular it focuses on how a (stochastic) image-processing pipeline can be defined and then be applied to an image (or a set of images). It also discusses how batch processing of multiple images can be performed in parallel using multi-threading.Pages = [\"interface.md\"]\nDepth = 2We mentioned before that an augmentation pipeline is just a sequence of image operations. Augmentor ships with a number of predefined operations, which should be sufficient to describe the most commonly utilized augmentation strategies. Each operation is represented as its own unique type. The following section provides a complete list of all the exported operations and their documentation.Pages = [\"operations.md\"]\nDepth = 2"
-},
-
-{
- "location": "#Tutorials-1",
- "page": "Home",
- "title": "Tutorials",
- "category": "section",
- "text": "Just like an image can say more than a thousand words, a simple hands-on tutorial showing actual code can say more than many pages of formal documentation.The first step of devising a successful augmentation strategy is to identify an appropriate set of operations and parameters. What that means can vary widely, because the utility of each operation depends on the dataset at hand (see label-preserving transformations for an example). To that end, we will spend the first tutorial discussing a simple but useful approach to interactively explore and visualize the space of possible parameters.Pages = [joinpath(\"generated\", \"mnist_elastic.md\")]\nDepth = 2In the next tutorials we will take a close look at how we can actually use Augmentor in combination with popular deep learning frameworks. The first framework we will discuss will be Knet. In particular we will focus on adapting an already existing example to make use of a (quite complicated) augmentation pipeline. Furthermore, this tutorial will also serve to showcase the various ways that augmentation can influence the performance of your network.Pages = [joinpath(\"generated\", \"mnist_knet.md\")]\nDepth = 2# Pages = [joinpath(\"generated\", fname) for fname in readdir(\"generated\") if splitext(fname)[2] == \".md\"]\n# Depth = 2"
-},
-
-{
- "location": "#Citing-Augmentor-1",
- "page": "Home",
- "title": "Citing Augmentor",
- "category": "section",
- "text": "If you use Augmentor for academic research and wish to cite it, please use the following paper.Marcus D. Bloice, Christof Stocker, and Andreas Holzinger, Augmentor: An Image Augmentation Library for Machine Learning, arXiv preprint arXiv:1708.04680, https://arxiv.org/abs/1708.04680, 2017."
-},
-
-{
- "location": "#Indices-1",
- "page": "Home",
- "title": "Indices",
- "category": "section",
- "text": "Pages = [\"indices.md\"]"
-},
-
-{
- "location": "gettingstarted/#",
- "page": "Getting Started",
- "title": "Getting Started",
- "category": "page",
- "text": ""
-},
-
-{
- "location": "gettingstarted/#Getting-Started-1",
- "page": "Getting Started",
- "title": "Getting Started",
- "category": "section",
- "text": "In this section we will provide a condensed overview of the package. In order to keep this overview concise, we will not discuss any background information or theory on the losses here in detail."
-},
-
-{
- "location": "gettingstarted/#Installation-1",
- "page": "Getting Started",
- "title": "Installation",
- "category": "section",
- "text": "To install Augmentor.jl, start up Julia and type the following code-snipped into the REPL. It makes use of the native Julia package manger.Pkg.add(\"Augmentor\")Additionally, for example if you encounter any sudden issues, or in the case you would like to contribute to the package, you can manually choose to be on the latest (untagged) version.Pkg.checkout(\"Augmentor\")"
-},
-
-{
- "location": "gettingstarted/#Example-1",
- "page": "Getting Started",
- "title": "Example",
- "category": "section",
- "text": "The following code snippet shows how a stochastic augmentation pipeline can be specified using simple building blocks that we call \"operations\". In order to give the example some meaning, we will use a real medical image from the publicly available ISIC archive as input. The concrete image can be downloaded here using their Web API.julia> using Augmentor, ISICArchive\n\njulia> img = get(ImageThumbnailRequest(id = \"5592ac599fc3c13155a57a85\"))\n169×256 Array{RGB{N0f8},2}:\n[...]\n\njulia> pl = Either(1=>FlipX(), 1=>FlipY(), 2=>NoOp()) |>\n Rotate(0:360) |>\n ShearX(-5:5) * ShearY(-5:5) |>\n CropSize(165, 165) |>\n Zoom(1:0.05:1.2) |>\n Resize(64, 64)\n6-step Augmentor.ImmutablePipeline:\n 1.) Either: (25%) Flip the X axis. (25%) Flip the Y axis. (50%) No operation.\n 2.) Rotate by θ ∈ 0:360 degree\n 3.) Either: (50%) ShearX by ϕ ∈ -5:5 degree. (50%) ShearY by ψ ∈ -5:5 degree.\n 4.) Crop a 165×165 window around the center\n 5.) Zoom by I ∈ {1.0×1.0, 1.05×1.05, 1.1×1.1, 1.15×1.15, 1.2×1.2}\n 6.) Resize to 64×64\n\njulia> img_new = augment(img, pl)\n64×64 Array{RGB{N0f8},2}:\n[...]using Augmentor, ISICArchive;\n\nimg = get(ImageThumbnailRequest(id = \"5592ac599fc3c13155a57a85\"))\n\npl = Either(1=>FlipX(), 1=>FlipY(), 2=>NoOp()) |>\n Rotate(0:360) |>\n ShearX(-5:5) * ShearY(-5:5) |>\n CropSize(165, 165) |>\n Zoom(1:0.05:1.2) |>\n Resize(64, 64)\n\nimg_new = augment(img, pl)\n\nusing Plots\npyplot(reuse = true)\ndefault(bg_outside=colorant\"#F3F6F6\")\nsrand(123)\n\n# Create image that shows the input\nplot(img, size=(256,169), xlim=(1,255), ylim=(1,168), grid=false, ticks=true)\nPlots.png(joinpath(\"assets\",\"isic_in.png\"))\n\n# create animate gif that shows 10 outputs\nanim = @animate for i=1:10\n plot(augment(img, pl), size=(169,169), xlim=(1,63), ylim=(1,63), grid=false, ticks=true)\nend\nPlots.gif(anim, joinpath(\"assets\",\"isic_out.gif\"), fps = 2)\n\nnothingThe function augment will generate a single augmented image from the given input image and pipeline. To visualize the effect we compiled a few resulting output images into a GIF using the plotting library Plots.jl with the PyPlot.jl back-end. You can inspect the full code by clicking on \"Edit on Github\" in the top right corner of this page.Input (img) Output (img_new)\n(Image: input) → (Image: output)"
-},
-
-{
- "location": "gettingstarted/#Getting-Help-1",
- "page": "Getting Started",
- "title": "Getting Help",
- "category": "section",
- "text": "To get help on specific functionality you can either look up the information here, or if you prefer you can make use of Julia\'s native doc-system. The following example shows how to get additional information on augment within Julia\'s REPL:?augmentIf you find yourself stuck or have other questions concerning the package you can find us at gitter or the Machine Learning domain on discourse.julialang.orgJulia ML on Gitter\nMachine Learning on JulialangIf you encounter a bug or would like to participate in the development of this package come find us on Github.Evizero/Augmentor.jl"
-},
-
-{
- "location": "background/#",
- "page": "Background and Motivation",
- "title": "Background and Motivation",
- "category": "page",
- "text": ""
-},
-
-{
- "location": "background/#Background-and-Motivation-1",
- "page": "Background and Motivation",
- "title": "Background and Motivation",
- "category": "section",
- "text": "In this section we will discuss the concept of image augmentation in general. In particular we will introduce some terminology and useful definitions."
-},
-
-{
- "location": "background/#What-is-Image-Augmentation?-1",
- "page": "Background and Motivation",
- "title": "What is Image Augmentation?",
- "category": "section",
- "text": "The term data augmentation is commonly used to describe the process of repeatedly applying various transformations to some dataset, with the hope that the output (i.e. the newly generated observations) bias the model towards learning better features. Depending on the structure and semantics of the data, coming up with such transformations can be a challenge by itself.Images are a special class of data that exhibit some interesting properties in respect to their structure. For example do the dimensions of an image (i.e. the pixel) exhibit a spatial relationship to each other. As such, a lot of commonly used augmentation strategies for image data revolve around affine transformations, such as translations or rotations. Because images are such a popular and special case of data, they deserve their own sub-category of data augmentation, which we will unsurprisingly refer to as image augmentation.The general idea is the following: if we want our model to generalize well, then we should design the learning process in such a way as to bias the model into learning such transformation-equivariant properties. One way to do this is via the design of the model itself, which for example was idea behind convolutional neural networks. An orthogonal approach to bias the model to learn about this equivariance - and the focus of this package - is by using label-preserving transformations."
-},
-
-{
- "location": "background/#labelpreserving-1",
- "page": "Background and Motivation",
- "title": "Label-preserving Transformations",
- "category": "section",
- "text": "Before attempting to train a model using some augmentation pipeline, it\'s a good idea to invest some time in deciding on an appropriate set of transformations to choose from. Some of these transformations also have parameters to tune, and we should also make sure that we settle on a decent set of values for those.What constitutes as \"decent\" depends on the dataset. In general we want the augmented images to be fairly dissimilar to the originals. However, we need to be careful that the augmented images still visually represent the same concept (and thus label). If a pipeline only produces output images that have this property we call this pipeline label-preserving."
-},
-
-{
- "location": "background/#mnist-1",
- "page": "Background and Motivation",
- "title": "Example: MNIST Handwritten Digits",
- "category": "section",
- "text": "Consider the following example from the MNIST database of handwritten digits [MNIST1998]. Our input image clearly represents its associated label \"6\". If we were to use the transformation Rotate180 in our augmentation pipeline for this type of images, we could end up with the situation depicted by the image on the right side.using Augmentor, MLDatasets\ninput_img = MNIST.convert2image(MNIST.traintensor(19))\noutput_img = augment(input_img, Rotate180())\nusing Images, FileIO; # hide\nupsize(A) = repeat(A, inner=(4,4)); # hide\nsave(joinpath(\"assets\",\"bg_mnist_in.png\"), upsize(input_img)); # hide\nsave(joinpath(\"assets\",\"bg_mnist_out.png\"), upsize(output_img)); # hide\nnothing # hideInput (input_img) Output (output_img)\n(Image: input) (Image: output)To a human, this newly transformed image clearly represents the label \"9\", and not \"6\" like the original image did. In image augmentation, however, the assumption is that the output of the pipeline has the same label as the input. That means that in this example we would tell our model that the correct answer for the image on the right side is \"6\", which is clearly undesirable for obvious reasons.Thus, for the MNIST dataset, the transformation Rotate180 is not label-preserving and should not be used for augmentation.[MNIST1998]: LeCun, Yan, Corinna Cortes, Christopher J.C. Burges. \"The MNIST database of handwritten digits\" Website. 1998."
-},
-
-{
- "location": "background/#Example:-ISIC-Skin-Lesions-1",
- "page": "Background and Motivation",
- "title": "Example: ISIC Skin Lesions",
- "category": "section",
- "text": "On the other hand, the exact same transformation could very well be label-preserving for other types of images. Let us take a look at a different set of image data; this time from the medical domain.The International Skin Imaging Collaboration [ISIC] hosts a large collection of publicly available and labeled skin lesion images. A subset of that data was used in 2016\'s ISBI challenge [ISBI2016] where a subtask was lesion classification.Let\'s consider the following input image on the left side. It shows a photo of a skin lesion that was taken from above. By applying the Rotate180 operation to the input image, we end up with a transformed version shown on the right side.using Augmentor, ISICArchive\ninput_img = get(ImageThumbnailRequest(id = \"5592ac599fc3c13155a57a85\"))\noutput_img = augment(input_img, Rotate180())\nusing FileIO; # hide\nsave(joinpath(\"assets\",\"bg_isic_in.png\"), input_img); # hide\nsave(joinpath(\"assets\",\"bg_isic_out.png\"), output_img); # hide\nnothing # hideInput (input_img) Output (output_img)\n(Image: input) (Image: output)After looking at both images, one could argue that the orientation of the camera is somewhat arbitrary as long as it points to the lesion at an approximately orthogonal angle. Thus, for the ISIC dataset, the transformation Rotate180 could be considered as label-preserving and very well be tried for augmentation. Of course this does not guarantee that it will improve training time or model accuracy, but the point is that it is unlikely to hurt.[ISIC]: https://isic-archive.com/[ISBI2016]: Gutman, David; Codella, Noel C. F.; Celebi, Emre; Helba, Brian; Marchetti, Michael; Mishra, Nabin; Halpern, Allan. \"Skin Lesion Analysis toward Melanoma Detection: A Challenge at the International Symposium on Biomedical Imaging (ISBI) 2016, hosted by the International Skin Imaging Collaboration (ISIC)\". eprint arXiv:1605.01397. 2016."
-},
-
-{
- "location": "images/#",
- "page": "Working with Images in Julia",
- "title": "Working with Images in Julia",
- "category": "page",
- "text": ""
-},
-
-{
- "location": "images/#Working-with-Images-in-Julia-1",
- "page": "Working with Images in Julia",
- "title": "Working with Images in Julia",
- "category": "section",
- "text": "The Julia language provides a rich syntax as well as large set of highly-optimized functionality for working with (multi-dimensional) arrays of what is known as \"bit types\" or compositions of such. Because of this, the language lends itself particularly well to the fairly simple idea of treating images as just plain arrays. Even though this may sound as a rather tedious low-level approach, Julia makes it possible to still allow for powerful abstraction layers without the loss of generality that usually comes with that. This is accomplished with help of Julia\'s flexible type system and multiple dispatch (both of which are beyond the scope of this tutorial).While the images-are-arrays-approach makes working with images in Julia very performant, it has also been source of confusion to new community members. This beginner\'s guide is an attempt to provide a step-by-step overview of how pixel data is handled in Julia. To get a more detailed explanation on some particular concept involved, please take a look at the documentation of the JuliaImages ecosystem."
-},
-
-{
- "location": "images/#Multi-dimensional-Arrays-1",
- "page": "Working with Images in Julia",
- "title": "Multi-dimensional Arrays",
- "category": "section",
- "text": "To wrap our heads around Julia\'s array-based treatment of images, we first need to understand what Julia arrays are and how we can work with them.note: Note\nThis section is only intended provide a simplified and thus partial overview of Julia\'s arrays capabilities in order to gain some intuition about pixel data. For a more detailed treatment of the topic please have a look at the official documentationWhenever we work with an Array in which the elements are bit-types (e.g. Int64, Float32, UInt8, etc), we can think of the array as a continuous block of memory. This is useful for many different reasons, such as cache locality and interacting with external libraries.The same block of memory can be interpreted in a number of ways. Consider the following example in which we allocate a vector (i.e. a one dimensional array) of UInt8 (i.e. bytes) with some ordered example values ranging from 1 to 6. We will think of this as our physical memory block, since it is a pretty close representation.julia> memory = [0x1, 0x2, 0x3, 0x4, 0x5, 0x6]\n6-element Array{UInt8,1}:\n 0x01\n 0x02\n 0x03\n 0x04\n 0x05\n 0x06The same block of memory could also be interpreted differently. For example we could think of this as a matrix with 3 rows and 2 columns instead (or even the other way around). The function reinterpret allows us to do just thatjulia> A = reinterpret(UInt8, memory, (3,2))\n3×2 Array{UInt8,2}:\n 0x01 0x04\n 0x02 0x05\n 0x03 0x06Note how we specified the number of rows first. This is because the Julia language follows the column-major convention for multi dimensional arrays. What this means can be observed when we compare our new matrix A with the initial vector memory and look at the element layout. Both variables are using the same underlying memory (i.e the value 0x01 is physically stored right next to the value 0x02 in our example, while 0x01 and 0x04 are quite far apart even though the matrix interpretation makes it look like they are neighbors; which they are not).tip: Tip\nA quick and dirty way to check if two variables are representing the same block of memory is by comparing the output of pointer(myvariable). Note, however, that technically this only tells you where a variable starts in memory and thus has its limitations.This idea can also be generalized for higher dimensions. For example we can think of this as a 3D array as well.julia> reinterpret(UInt8, memory, (3,1,2))\n3×1×2 Array{UInt8,3}:\n[:, :, 1] =\n 0x01\n 0x02\n 0x03\n\n[:, :, 2] =\n 0x04\n 0x05\n 0x06If you take a closer look at the dimension sizes, you can see that all we did in that example was add a new dimension of size 1, while not changing the other numbers. In fact we can add any number of practically empty dimensions, otherwise known as singleton dimensions.julia> reinterpret(UInt8, memory, (3,1,1,1,2))\n3×1×1×1×2 Array{UInt8,5}:\n[:, :, 1, 1, 1] =\n 0x01\n 0x02\n 0x03\n\n[:, :, 1, 1, 2] =\n 0x04\n 0x05\n 0x06This is a useful property to have when we are confronted with greyscale datasets that do not have a color channel, yet we still want to work with a library that expects the images to have one."
-},
-
-{
- "location": "images/#Vertical-Major-vs-Horizontal-Major-1",
- "page": "Working with Images in Julia",
- "title": "Vertical-Major vs Horizontal-Major",
- "category": "section",
- "text": "There are a number of different conventions for how to store image data into a binary format. The first question one has to address is the order in which the image dimensions are transcribed.We have seen before that Julia follows the column-major convention for its arrays, which for images would lead to the corresponding convention of being vertical-major. In the image domain, however, it is fairly common to store the pixels in a horizontal-major layout. In other words, horizontal-major means that images are stored in memory (or file) one pixel row after the other.In most cases, when working within the JuliaImages ecosystem, the images should already be in the Julia-native column major layout. If for some reason that is not the case there are two possible ways to convert the image to that format.julia> At = reinterpret(UInt8, memory, (3,2))\' # \"row-major\" layout\n2×3 Array{UInt8,2}:\n 0x01 0x02 0x03\n 0x04 0x05 0x06The first way to alter the pixel order is by using the function Base.permutedims. In contrast to what we have seen before, this function will allocate a new array and copy the values in the appropriate manner.\njulia> B = permutedims(At, (2,1))\n3×2 Array{UInt8,2}:\n 0x01 0x04\n 0x02 0x05\n 0x03 0x06\nThe second way is using the function ImageCore.permuteddimsview which results in a lazy view that does not allocate a new array but instead only computes the correct values when queried.\njulia> using ImageCore\n\njulia> C = permuteddimsview(At, (2,1))\n3×2 PermutedDimsArray(::Array{UInt8,2}, (2, 1)) with element type UInt8:\n 0x01 0x04\n 0x02 0x05\n 0x03 0x06Either way, it is in general a good idea to make sure that the array one is working with ends up in a column-major layout."
-},
-
-{
- "location": "images/#Reinterpreting-Elements-1",
- "page": "Working with Images in Julia",
- "title": "Reinterpreting Elements",
- "category": "section",
- "text": "Up to this point, all we talked about was how to reinterpreting or permuting the dimensional layout of some continuous memory block. If you look at the examples above you will see that all the arrays have elements of type UInt8, which just means that each element is represented by a single byte in memory.Knowing all this, we can now take the idea a step further and think about reinterpreting the element types of the array. Let us consider our original vector memory again.julia> memory = [0x1, 0x2, 0x3, 0x4, 0x5, 0x6]\n6-element Array{UInt8,1}:\n 0x01\n 0x02\n 0x03\n 0x04\n 0x05\n 0x06Note how each byte is thought of as an individual element. One thing we could do instead, is think of this memory block as a vector of 3 UInt16 elements.julia> reinterpret(UInt16, memory)\n3-element Array{UInt16,1}:\n 0x0201\n 0x0403\n 0x0605Pay attention to where our original bytes ended up. In contrast to just rearranging elements as we did before, we ended up with significantly different element values. One may ask why it would ever be practical to reinterpret a memory block like this. The one word answer to this is Colors! As we will see in the remainder of this tutorial, it turns out to be a very useful thing to do when your arrays represent pixel data."
-},
-
-{
- "location": "images/#Introduction-to-Color-Models-1",
- "page": "Working with Images in Julia",
- "title": "Introduction to Color Models",
- "category": "section",
- "text": "As we discussed before, there are a various number of conventions on how to store pixel data into a binary format. That is not only true for dimension priority, but also for color information.One way color information can differ is in the color model in which they are described in. Two famous examples for color models are RGB and HSV. They essentially define how colors are conceptually made up in terms of some components. Additionally, one can decide on how many bits to use to describe each color component. By doing so one defines the available color depth.Before we look into using the actual implementation of Julia\'s color models, let us prototype our own imperfect toy model in order to get a better understanding of what is happening under the hood.# define our toy color model\nstruct MyRGB\n r::UInt8\n b::UInt8\n g::UInt8\nendNote how we defined our new toy color model as struct. Because of this and the fact that all its components are bit types (in this case UInt8), any instantiation of our new type will be represented as a continuous block of memory as well.We can now apply our color model to our memory vector from above, and interpret the underlying memory as a vector of to MyRGB values instead.julia> reinterpret(MyRGB, memory)\n2-element Array{MyRGB,1}:\n MyRGB(0x01,0x02,0x03)\n MyRGB(0x04,0x05,0x06)Similar to the UInt16 example, we now group neighboring bytes into larger units (namely MyRGB). In contrast to the UInt16 example we are still able to access the individual components underneath. This simple toy color model already allows us to do a lot of useful things. We could define functions that work on MyRGB values in a color-space appropriate fashion. We could also define other color models and implement function to convert between them.However, our little toy color model is not yet optimal. For example it hard-codes a predefined color depth of 24 bit. We may have use-cases where we need a richer color space. One thing we could do to achieve that would be to introduce a new type in similar fashion. Still, because they have a different range of available numbers per channel (because they have a different amount of bits per channel), we would have to write a lot of specialized code to be able to appropriately handle all color models and depth.Luckily, the creators of ColorTypes.jl went a with a more generic strategy: Using parameterized types and fixed point numbers.tip: Tip\nIf you are interested in how various color models are actually designed and/or implemented in Julia, you can take a look at the ColorTypes.jl package."
-},
-
-{
- "location": "images/#Fixed-Point-Numbers-1",
- "page": "Working with Images in Julia",
- "title": "Fixed Point Numbers",
- "category": "section",
- "text": "The idea behind using fixed point numbers for each color component is fairly simple. No matter how many bits a component is made up of, we always want the largest possible value of the component to be equal to 1.0 and the smallest possible value to be equal to 0. Of course, the amount of possible intermediate numbers still depends on the number of underlying bits in the memory, but that is not much of an issue.julia> using FixedPointNumbers;\n\njulia> reinterpret(N0f8, 0xFF)\n1.0N0f8\n\njulia> reinterpret(N0f16, 0xFFFF)\n1.0N0f16Not only does this allow for simple conversion between different color depths, it also allows us to implement generic algorithms, that are completely agnostic to the utilized color depth.It is worth pointing out again, that we get all these goodies without actually changing or copying the original memory block. Remember how during this whole tutorial we have only changed the interpretation of some underlying memory, and have not had the need to copy any data so far.tip: Tip\nFor pixel data we are mainly interested in unsigned fixed point numbers, but there are others too. Check out the package FixedPointNumbers.jl for more information on fixed point numbers in general.Let us now leave our toy model behind and use the actual implementation of RGB on our example vector memory. With the first command we will interpret our data as two pixels with 8 bit per color channel, and with the second command as a single pixel of 16 bit per color channeljulia> using Colors, FixedPointNumbers;\n\njulia> reinterpret(RGB{N0f8}, memory)\n2-element Array{RGB{N0f8},1}:\n RGB{N0f8}(0.004,0.008,0.012)\n RGB{N0f8}(0.016,0.02,0.024)\n\njulia> reinterpret(RGB{N0f16}, memory)\n1-element Array{RGB{N0f16},1}:\n RGB{N0f16}(0.00783,0.01567,0.02351)Note how the values are now interpreted as floating point numbers."
-},
-
-{
- "location": "interface/#",
- "page": "High-level Interface",
- "title": "High-level Interface",
- "category": "page",
- "text": ""
-},
-
-{
- "location": "interface/#High-level-Interface-1",
- "page": "High-level Interface",
- "title": "High-level Interface",
- "category": "section",
- "text": "Integrating Augmentor into an existing project should in general not require any major changes to your code. In most cases it should break down to the three basic steps outlined below. We will spend the rest of this document investigating these in more detail.Import Augmentor into the namespace of your program.\nusing Augmentor\nDefine a (stochastic) image processing pipeline by chaining the desired operations using |> and *.\njulia> pl = FlipX() * FlipY() |> Zoom(0.9:0.1:1.2) |> CropSize(64,64)\n3-step Augmentor.ImmutablePipeline:\n 1.) Either: (50%) Flip the X axis. (50%) Flip the Y axis.\n 2.) Zoom by I ∈ {0.9×0.9, 1.0×1.0, 1.1×1.1, 1.2×1.2}\n 3.) Crop a 64×64 window around the center\nApply the pipeline to the existing image or set of images.\nimg_processed = augment(img_original, pl)Depending on the complexity of your problem, you may want to iterate between 2. and 3. to identify an appropriate pipeline. Take a look at the Elastic Distortions Tutorial for an example of how such an iterative process could look like."
-},
-
-{
- "location": "interface/#pipeline-1",
- "page": "High-level Interface",
- "title": "Defining a Pipeline",
- "category": "section",
- "text": "In Augmentor, a (stochastic) image-processing pipeline can be understood as a sequence of operations, for which the parameters can (but need not) be random variables. What that essentially means is that the user explicitly specifies which image operation to perform in what order. A complete list of available operations can be found at Supported Operations.To start off with a simple example, let us assume that we want to first rotate our image(s) counter-clockwise by 14°, then crop them down to the biggest possible square, and lastly resize the image(s) to a fixed size of 64 by 64 pixel. Such a pipeline would be defined as follows:julia> pl = Rotate(14) |> CropRatio(1) |> Resize(64,64)\n3-step Augmentor.ImmutablePipeline:\n 1.) Rotate 14 degree\n 2.) Crop to 1:1 aspect ratio\n 3.) Resize to 64×64Notice that in the example above there is no room for randomness. In other words, the same input image would always result in the same output image given that pipeline. If we wish for more variation we can do so by using a vector as our parameters, instead of a single number.note: Note\nIn this subsection we will focus only on how to define a pipeline, without actually thinking too much about how to apply that pipeline to an actual image. The later will be the main topic of the rest of this document.Say we wish to adapt our pipeline such that the rotation is a little more random. More specifically, lets say we want our image to be rotated by either -10°, -5°, 5°, 10°, or not at all. Other than that change we will leave the rest of the pipeline as is.julia> pl = Rotate([-10,-5,0,5,10]) |> CropRatio(1) |> Resize(64,64)\n3-step Augmentor.ImmutablePipeline:\n 1.) Rotate by θ ∈ [-10, -5, 0, 5, 10] degree\n 2.) Crop to 1:1 aspect ratio\n 3.) Resize to 64×64Variation in the parameters is only one of the two main ways to introduce randomness to our pipeline. Additionally, one can specify that an operation should be sampled randomly from a chosen set of operations . This can be accomplished using a utility operation called Either, which has its own convenience syntax.As an example, let us assume we wish to first either mirror our image(s) horizontally, or vertically, or not at all, and then crop it down to a size of 100 by 100 pixel around the image\'s center. We can specify the \"either\" using the * operator.julia> pl = FlipX() * FlipY() * NoOp() |> CropSize(100,100)\n2-step Augmentor.ImmutablePipeline:\n 1.) Either: (33%) Flip the X axis. (33%) Flip the Y axis. (33%) No operation.\n 2.) Crop a 100×100 window around the centerIt is also possible to specify the odds of for such an \"either\". For example we may want the NoOp to be twice as likely as either of the mirroring options.julia> pl = (1=>FlipX()) * (1=>FlipY()) * (2=>NoOp()) |> CropSize(100,100)\n2-step Augmentor.ImmutablePipeline:\n 1.) Either: (25%) Flip the X axis. (25%) Flip the Y axis. (50%) No operation.\n 2.) Crop a 100×100 window around the centerNow that we know how to define a pipeline, let us think about how to apply it to an image or a set of images."
-},
-
-{
- "location": "interface/#Augmentor.testpattern",
- "page": "High-level Interface",
- "title": "Augmentor.testpattern",
- "category": "function",
- "text": "testpattern() -> Matrix{RGBA{N0f8}}\n\nLoad and return the provided 300x400 test image.\n\nThe returned image was specifically designed to be informative about the effects of the applied augmentation operations. It is thus well suited to prototype an augmentation pipeline, because it makes it easy to see what kind of effects one can achieve with it.\n\n\n\n"
-},
-
-{
- "location": "interface/#Loading-the-Example-Image-1",
- "page": "High-level Interface",
- "title": "Loading the Example Image",
- "category": "section",
- "text": "Augmentor ships with a custom example image, which was specifically designed for visualizing augmentation effects. It can be accessed by calling the function testpattern(). That said, doing so explicitly should rarely be necessary in practice, because most high-level functions will default to using testpattern() if no other image is specified.testpatternusing Augmentor\nimg = testpattern()\nusing Images; # hide\nsave(joinpath(\"assets\",\"big_pattern.png\"), img); # hide\nnothing # hide(Image: testpattern)"
-},
-
-{
- "location": "interface/#Augmentor.augment",
- "page": "High-level Interface",
- "title": "Augmentor.augment",
- "category": "function",
- "text": "augment([img], pipeline) -> out\n\nApply the operations of the given pipeline sequentially to the given image img and return the resulting image out.\n\njulia> img = testpattern();\n\njulia> out = augment(img, FlipX() |> FlipY())\n3×2 Array{Gray{N0f8},2}:\n[...]\n\nThe parameter img can either be a single image, or a tuple of multiple images. In case img is a tuple of images, its elements will be assumed to be conceptually connected. Consequently, all images in the tuple will take the exact same path through the pipeline; even when randomness is involved. This is useful for the purpose of image segmentation, for which the input and output are both images that need to be transformed exactly the same way.\n\nimg1 = testpattern()\nimg2 = Gray.(testpattern())\nout1, out2 = augment((img1, img2), FlipX() |> FlipY())\n\nThe parameter pipeline can be a Augmentor.Pipeline, a tuple of Augmentor.Operation, or a single Augmentor.Operation.\n\nimg = testpattern()\naugment(img, FlipX() |> FlipY())\naugment(img, (FlipX(), FlipY()))\naugment(img, FlipX())\n\nIf img is omitted, Augmentor will use the augmentation test image provided by the function testpattern as the input image.\n\naugment(FlipX())\n\n\n\n"
-},
-
-{
- "location": "interface/#Augmentor.augment!",
- "page": "High-level Interface",
- "title": "Augmentor.augment!",
- "category": "function",
- "text": "augment!(out, img, pipeline) -> out\n\nApply the operations of the given pipeline sequentially to the image img and write the resulting image into the preallocated parameter out. For convenience out is also the function\'s return-value.\n\nimg = testpattern()\nout = similar(img)\naugment!(out, img, FlipX() |> FlipY())\n\nThe parameter img can either be a single image, or a tuple of multiple images. In case img is a tuple of images, the parameter out has to be a tuple of the same length and ordering. See augment for more information.\n\nimgs = (testpattern(), Gray.(testpattern()))\nouts = (similar(imgs[1]), similar(imgs[2]))\naugment!(outs, imgs, FlipX() |> FlipY())\n\nThe parameter pipeline can be a Augmentor.Pipeline, a tuple of Augmentor.Operation, or a single Augmentor.Operation.\n\nimg = testpattern()\nout = similar(img)\naugment!(out, img, FlipX() |> FlipY())\naugment!(out, img, (FlipX(), FlipY()))\naugment!(out, img, FlipX())\n\n\n\n"
-},
-
-{
- "location": "interface/#Augmenting-an-Image-1",
- "page": "High-level Interface",
- "title": "Augmenting an Image",
- "category": "section",
- "text": "Once a pipeline is constructed it can be applied to an image (i.e. AbstractArray{<:ColorTypes.Colorant}), or even just to an array of numbers (i.e. AbstractArray{<:Number}), using the function augment.augmentWe also provide a mutating version of augment that writes the output into preallocated memory. While this function avoids allocation, it does have the caveat that the size of the output image must be known beforehand (and thus must not be random).augment!"
-},
-
-{
- "location": "interface/#Augmentor.augmentbatch!",
- "page": "High-level Interface",
- "title": "Augmentor.augmentbatch!",
- "category": "function",
- "text": "augmentbatch!([resource], outs, imgs, pipeline, [obsdim]) -> outs\n\nApply the operations of the given pipeline to the images in imgs and write the resulting images into outs.\n\nBoth outs and imgs have to contain the same number of images. Each of these two variables can either be in the form of a higher dimensional array, in the form of a vector of arrays for which each vector element denotes an image.\n\n# create five example observations of size 3x3\nimgs = rand(3,3,5)\n# create output arrays of appropriate shape\nouts = similar(imgs)\n# transform the batch of images\naugmentbatch!(outs, imgs, FlipX() |> FlipY())\n\nIf one (or both) of the two parameters outs and imgs is a higher dimensional array, then the optional parameter obsdim can be used specify which dimension denotes the observations (defaults to ObsDim.Last()),\n\n# create five example observations of size 3x3\nimgs = rand(5,3,3)\n# create output arrays of appropriate shape\nouts = similar(imgs)\n# transform the batch of images\naugmentbatch!(outs, imgs, FlipX() |> FlipY(), ObsDim.First())\n\nSimilar to augment!, it is also allowed for outs and imgs to both be tuples of the same length. If that is the case, then each tuple element can be in any of the forms listed above. This is useful for tasks such as image segmentation, where each observations is made up of more than one image.\n\n# create five example observations where each observation is\n# made up of two conceptually linked 3x3 arrays\nimgs = (rand(3,3,5), rand(3,3,5))\n# create output arrays of appropriate shape\nouts = similar.(imgs)\n# transform the batch of images\naugmentbatch!(outs, imgs, FlipX() |> FlipY())\n\nThe parameter pipeline can be a Augmentor.Pipeline, a tuple of Augmentor.Operation, or a single Augmentor.Operation.\n\naugmentbatch!(outs, imgs, FlipX() |> FlipY())\naugmentbatch!(outs, imgs, (FlipX(), FlipY()))\naugmentbatch!(outs, imgs, FlipX())\n\nThe optional first parameter resource can either be CPU1() (default) or CPUThreads(). In the later case the images will be augmented in parallel. For this to make sense make sure that the environment variable JULIA_NUM_THREADS is set to a reasonable number so that Threads.nthreads() is greater than 1.\n\n# transform the batch of images in parallel using multithreading\naugmentbatch!(CPUThreads(), outs, imgs, FlipX() |> FlipY())\n\n\n\n"
-},
-
-{
- "location": "interface/#Augmenting-Image-Batches-1",
- "page": "High-level Interface",
- "title": "Augmenting Image Batches",
- "category": "section",
- "text": "In most machine learning scenarios we will want to process a whole batch of images at once, instead of a single image at a time. For this reason we provide the function augmentbatch!, which also supports multi-threading.augmentbatch!"
-},
-
-{
- "location": "operations/#",
- "page": "Supported Operations",
- "title": "Supported Operations",
- "category": "page",
- "text": "using Augmentor, Images, Colors\nsrand(1337)\npattern = imresize(restrict(restrict(testpattern())), (60, 80))\nsave(\"assets/tiny_pattern.png\", pattern)\n# Affine Transformations\nsave(\"assets/tiny_FlipX.png\", augment(pattern, FlipX()))\nsave(\"assets/tiny_FlipY.png\", augment(pattern, FlipY()))\nsave(\"assets/tiny_Rotate90.png\", augment(pattern, Rotate90()))\nsave(\"assets/tiny_Rotate270.png\", augment(pattern, Rotate270()))\nsave(\"assets/tiny_Rotate180.png\", augment(pattern, Rotate180()))\nsave(\"assets/tiny_Rotate.png\", augment(pattern, Rotate(15)))\nsave(\"assets/tiny_ShearX.png\", augment(pattern, ShearX(10)))\nsave(\"assets/tiny_ShearY.png\", augment(pattern, ShearY(10)))\nsave(\"assets/tiny_Scale.png\", augment(pattern, Scale(0.9,1.2)))\nsave(\"assets/tiny_Zoom.png\", augment(pattern, Zoom(0.9,1.2)))\n# Distortions\nsrand(1337)\nsave(\"assets/tiny_ED1.png\", augment(pattern, ElasticDistortion(15,15,0.1)))\nsave(\"assets/tiny_ED2.png\", augment(pattern, ElasticDistortion(10,10,0.2,4,3,true)))\n# Resizing and Subsetting\nsave(\"assets/tiny_Resize.png\", augment(pattern, Resize(60,60)))\nsave(\"assets/tiny_Crop.png\", augment(pattern, Rotate(45) |> Crop(1:50,1:80)))\nsave(\"assets/tiny_CropNative.png\", augment(pattern, Rotate(45) |> CropNative(1:50,1:80)))\nsave(\"assets/tiny_CropSize.png\", augment(pattern, CropSize(20,65)))\nsave(\"assets/tiny_CropRatio.png\", augment(pattern, CropRatio(1)))\nsrand(1337)\nsave(\"assets/tiny_RCropRatio.png\", augment(pattern, RCropRatio(1)))\n# Conversion\nsave(\"assets/tiny_ConvertEltype.png\", augment(pattern, ConvertEltype(GrayA{N0f8})))\nnothing;"
-},
-
-{
- "location": "operations/#operations-1",
- "page": "Supported Operations",
- "title": "Supported Operations",
- "category": "section",
- "text": "Augmentor provides a wide varitey of build-in image operations. This page provides an overview of all exported operations organized by their main category. These categories are chosen because they serve some practical purpose. For example Affine Operations allow for a special optimization under the hood when chained together.tip: Tip\nClick on an image operation for more details."
-},
-
-{
- "location": "operations/#Affine-Transformations-1",
- "page": "Supported Operations",
- "title": "Affine Transformations",
- "category": "section",
- "text": "A sizeable amount of the provided operations fall under the category of affine transformations. As such, they can be described using what is known as an affine map, which are inherently compose-able if chained together. However, utilizing such a affine formulation requires (costly) interpolation, which may not always be needed to achieve the desired effect. For that reason do some of the operations below also provide a special purpose implementation to produce their specified result. Those are usually preferred over the affine formulation if sensible considering the complete pipeline.Input FlipX FlipY Rotate90 Rotate270 Rotate180\n(Image: ) → (Image: ) (Image: ) (Image: ) (Image: ) (Image: )\nInput Rotate ShearX ShearY Scale Zoom\n(Image: ) → (Image: ) (Image: ) (Image: ) (Image: ) (Image: )"
-},
-
-{
- "location": "operations/#Distortions-1",
- "page": "Supported Operations",
- "title": "Distortions",
- "category": "section",
- "text": "Aside from affine transformations, Augmentor also provides functionality for performing a variety of distortions. These types of operations usually provide a much larger distribution of possible output images.Input ElasticDistortion\n(Image: ) → (Image: )"
-},
-
-{
- "location": "operations/#Resizing-and-Subsetting-1",
- "page": "Supported Operations",
- "title": "Resizing and Subsetting",
- "category": "section",
- "text": "The input images from a given dataset can be of various shapes and sizes. Yet, it is often required by the algorithm that the data must be of uniform structure. To that end Augmentor provides a number of ways to alter or subset given images.Input Resize\n(Image: ) → (Image: )The process of cropping is useful to discard parts of the input image. To provide this functionality lazily, applying a crop introduces a layer of representation called a \"view\" or SubArray. This is different yet compatible with how affine operations or other special purpose implementations work. This means that chaining a crop with some affine operation is perfectly fine if done sequentially. However, it is generally not advised to combine affine operations with crop operations within an Either block. Doing that would force the Either to trigger the eager computation of its branches in order to preserve type-stability.Input Crop CropNative CropSize CropRatio RCropRatio\n(Image: ) → (Image: ) (Image: ) (Image: ) (Image: ) (Image: )"
-},
-
-{
- "location": "operations/#Element-wise-Transformations-and-Layout-1",
- "page": "Supported Operations",
- "title": "Element-wise Transformations and Layout",
- "category": "section",
- "text": "It is not uncommon that machine learning frameworks require the data in a specific form and layout. For example many deep learning frameworks expect the colorchannel of the images to be encoded in the third dimension of a 4-dimensional array. Augmentor allows to convert from (and to) these different layouts using special operations that are mainly useful in the beginning or end of a augmentation pipeline.Category Available Operations\nConversion ConvertEltype (e.g. convert to grayscale)\nMapping MapFun, AggregateThenMapFun\nInformation Layout SplitChannels, CombineChannels, PermuteDims, Reshape"
-},
-
-{
- "location": "operations/#Utility-Operations-1",
- "page": "Supported Operations",
- "title": "Utility Operations",
- "category": "section",
- "text": "Aside from \"true\" operations that specify some kind of transformation, there are also a couple of special utility operations used for functionality such as stochastic branching.Category Available Operations\nUtility Operations NoOp, CacheImage, Either"
-},
-
-{
- "location": "operations/flipx/#",
- "page": "FlipX: Mirror horizontally",
- "title": "FlipX: Mirror horizontally",
- "category": "page",
- "text": ""
-},
-
-{
- "location": "operations/flipx/#Augmentor.FlipX",
- "page": "FlipX: Mirror horizontally",
- "title": "Augmentor.FlipX",
- "category": "type",
- "text": "FlipX <: Augmentor.AffineOperation\n\nDescription\n\nReverses the x-order of each pixel row. Another way of describing it would be that it mirrors the image on the y-axis, or that it mirrors the image horizontally.\n\nIf created using the parameter p, the operation will be lifted into Either(p=>FlipX(), 1-p=>NoOp()), where p denotes the probability of applying FlipX and 1-p the probability for applying NoOp. See the documentation of Either for more information.\n\nUsage\n\nFlipX()\n\nFlipX(p)\n\nArguments\n\np::Number : Optional. Probability of applying the operation. Must be in the interval [0,1].\n\nSee also\n\nFlipY, Either, augment\n\nExamples\n\njulia> using Augmentor\n\njulia> img = [200 150; 50 1]\n2×2 Array{Int64,2}:\n 200 150\n 50 1\n\njulia> img_new = augment(img, FlipX())\n2×2 Array{Int64,2}:\n 150 200\n 1 50\n\n\n\n"
-},
-
-{
- "location": "operations/flipx/#FlipX-1",
- "page": "FlipX: Mirror horizontally",
- "title": "FlipX: Mirror horizontally",
- "category": "section",
- "text": "FlipXinclude(\"optable.jl\")\n@optable FlipX()"
-},
-
-{
- "location": "operations/flipy/#",
- "page": "FlipY: Mirror vertically",
- "title": "FlipY: Mirror vertically",
- "category": "page",
- "text": ""
-},
-
-{
- "location": "operations/flipy/#Augmentor.FlipY",
- "page": "FlipY: Mirror vertically",
- "title": "Augmentor.FlipY",
- "category": "type",
- "text": "FlipY <: Augmentor.AffineOperation\n\nDescription\n\nReverses the y-order of each pixel column. Another way of describing it would be that it mirrors the image on the x-axis, or that it mirrors the image vertically.\n\nIf created using the parameter p, the operation will be lifted into Either(p=>FlipY(), 1-p=>NoOp()), where p denotes the probability of applying FlipY and 1-p the probability for applying NoOp. See the documentation of Either for more information.\n\nUsage\n\nFlipY()\n\nFlipY(p)\n\nArguments\n\np::Number : Optional. Probability of applying the operation. Must be in the interval [0,1].\n\nSee also\n\nFlipX, Either, augment\n\nExamples\n\njulia> using Augmentor\n\njulia> img = [200 150; 50 1]\n2×2 Array{Int64,2}:\n 200 150\n 50 1\n\njulia> img_new = augment(img, FlipY())\n2×2 Array{Int64,2}:\n 50 1\n 200 150\n\n\n\n"
-},
-
-{
- "location": "operations/flipy/#FlipY-1",
- "page": "FlipY: Mirror vertically",
- "title": "FlipY: Mirror vertically",
- "category": "section",
- "text": "FlipYinclude(\"optable.jl\")\n@optable FlipY()"
-},
-
-{
- "location": "operations/rotate90/#",
- "page": "Rotate90: Rotate upwards 90 degree",
- "title": "Rotate90: Rotate upwards 90 degree",
- "category": "page",
- "text": ""
-},
-
-{
- "location": "operations/rotate90/#Augmentor.Rotate90",
- "page": "Rotate90: Rotate upwards 90 degree",
- "title": "Augmentor.Rotate90",
- "category": "type",
- "text": "Rotate90 <: Augmentor.AffineOperation\n\nDescription\n\nRotates the image upwards 90 degrees. This is a special case rotation because it can be performed very efficiently by simply rearranging the existing pixels. However, it is generally not the case that the output image will have the same size as the input image, which is something to be aware of.\n\nIf created using the parameter p, the operation will be lifted into Either(p=>Rotate90(), 1-p=>NoOp()), where p denotes the probability of applying Rotate90 and 1-p the probability for applying NoOp. See the documentation of Either for more information.\n\nUsage\n\nRotate90()\n\nRotate90(p)\n\nArguments\n\np::Number : Optional. Probability of applying the operation. Must be in the interval [0,1].\n\nSee also\n\nRotate180, Rotate270, Rotate, Either, augment\n\nExamples\n\njulia> using Augmentor\n\njulia> img = [200 150; 50 1]\n2×2 Array{Int64,2}:\n 200 150\n 50 1\n\njulia> img_new = augment(img, Rotate90())\n2×2 Array{Int64,2}:\n 150 1\n 200 50\n\n\n\n"
-},
-
-{
- "location": "operations/rotate90/#Rotate90-1",
- "page": "Rotate90: Rotate upwards 90 degree",
- "title": "Rotate90: Rotate upwards 90 degree",
- "category": "section",
- "text": "Rotate90include(\"optable.jl\")\n@optable Rotate90()"
-},
-
-{
- "location": "operations/rotate270/#",
- "page": "Rotate270: Rotate downwards 90 degree",
- "title": "Rotate270: Rotate downwards 90 degree",
- "category": "page",
- "text": ""
-},
-
-{
- "location": "operations/rotate270/#Augmentor.Rotate270",
- "page": "Rotate270: Rotate downwards 90 degree",
- "title": "Augmentor.Rotate270",
- "category": "type",
- "text": "Rotate270 <: Augmentor.AffineOperation\n\nDescription\n\nRotates the image upwards 270 degrees, which can also be described as rotating the image downwards 90 degrees. This is a special case rotation, because it can be performed very efficiently by simply rearranging the existing pixels. However, it is generally not the case that the output image will have the same size as the input image, which is something to be aware of.\n\nIf created using the parameter p, the operation will be lifted into Either(p=>Rotate270(), 1-p=>NoOp()), where p denotes the probability of applying Rotate270 and 1-p the probability for applying NoOp. See the documentation of Either for more information.\n\nUsage\n\nRotate270()\n\nRotate270(p)\n\nArguments\n\np::Number : Optional. Probability of applying the operation. Must be in the interval [0,1].\n\nSee also\n\nRotate90, Rotate180, Rotate, Either, augment\n\nExamples\n\njulia> using Augmentor\n\njulia> img = [200 150; 50 1]\n2×2 Array{Int64,2}:\n 200 150\n 50 1\n\njulia> img_new = augment(img, Rotate270())\n2×2 Array{Int64,2}:\n 50 200\n 1 150\n\n\n\n"
-},
-
-{
- "location": "operations/rotate270/#Rotate270-1",
- "page": "Rotate270: Rotate downwards 90 degree",
- "title": "Rotate270: Rotate downwards 90 degree",
- "category": "section",
- "text": "Rotate270include(\"optable.jl\")\n@optable Rotate270()"
-},
-
-{
- "location": "operations/rotate180/#",
- "page": "Rotate180: Rotate by 180 degree",
- "title": "Rotate180: Rotate by 180 degree",
- "category": "page",
- "text": ""
-},
-
-{
- "location": "operations/rotate180/#Augmentor.Rotate180",
- "page": "Rotate180: Rotate by 180 degree",
- "title": "Augmentor.Rotate180",
- "category": "type",
- "text": "Rotate180 <: Augmentor.AffineOperation\n\nDescription\n\nRotates the image 180 degrees. This is a special case rotation because it can be performed very efficiently by simply rearranging the existing pixels. Furthermore, the output image will have the same dimensions as the input image.\n\nIf created using the parameter p, the operation will be lifted into Either(p=>Rotate180(), 1-p=>NoOp()), where p denotes the probability of applying Rotate180 and 1-p the probability for applying NoOp. See the documentation of Either for more information.\n\nUsage\n\nRotate180()\n\nRotate180(p)\n\nArguments\n\np::Number : Optional. Probability of applying the operation. Must be in the interval [0,1].\n\nSee also\n\nRotate90, Rotate270, Rotate, Either, augment\n\nExamples\n\njulia> using Augmentor\n\njulia> img = [200 150; 50 1]\n2×2 Array{Int64,2}:\n 200 150\n 50 1\n\njulia> img_new = augment(img, Rotate180())\n2×2 Array{Int64,2}:\n 1 50\n 150 200\n\n\n\n"
-},
-
-{
- "location": "operations/rotate180/#Rotate180-1",
- "page": "Rotate180: Rotate by 180 degree",
- "title": "Rotate180: Rotate by 180 degree",
- "category": "section",
- "text": "Rotate180include(\"optable.jl\")\n@optable Rotate180()"
-},
-
-{
- "location": "operations/rotate/#",
- "page": "Rotate: Arbitrary rotations",
- "title": "Rotate: Arbitrary rotations",
- "category": "page",
- "text": ""
-},
-
-{
- "location": "operations/rotate/#Augmentor.Rotate",
- "page": "Rotate: Arbitrary rotations",
- "title": "Augmentor.Rotate",
- "category": "type",
- "text": "Rotate <: Augmentor.AffineOperation\n\nDescription\n\nRotate the image upwards for the given degree. This operation can only be performed as an affine transformation and will in general cause other operations of the pipeline to use their affine formulation as well (if they have one).\n\nIn contrast to the special case rotations (e.g. Rotate90, the type Rotate can describe any arbitrary number of degrees. It will always perform the rotation around the center of the image. This can be particularly useful when combining the operation with CropNative.\n\nUsage\n\nRotate(degree)\n\nArguments\n\ndegree : Real or AbstractVector of Real that denote the rotation angle(s) in degree. If a vector is provided, then a random element will be sampled each time the operation is applied.\n\nSee also\n\nRotate90, Rotate180, Rotate270, CropNative, augment\n\nExamples\n\nusing Augmentor\nimg = testpattern()\n\n# rotate exactly 45 degree\naugment(img, Rotate(45))\n\n# rotate between 10 and 20 degree upwards\naugment(img, Rotate(10:20))\n\n# rotate one of the five specified degrees\naugment(img, Rotate([-10, -5, 0, 5, 10]))\n\n\n\n"
-},
-
-{
- "location": "operations/rotate/#Rotate-1",
- "page": "Rotate: Arbitrary rotations",
- "title": "Rotate: Arbitrary rotations",
- "category": "section",
- "text": "RotateIn contrast to the special case rotations outlined above, the type Rotate can describe any arbitrary number of degrees. It will always perform the rotation around the center of the image. This can be particularly useful when combining the operation with CropNative.include(\"optable.jl\")\n@optable Rotate(15)It is also possible to pass some abstract vector to the constructor, in which case Augmentor will randomly sample one of its elements every time the operation is applied.include(\"optable.jl\")\n@optable 10 => Rotate(-10:10)"
-},
-
-{
- "location": "operations/shearx/#",
- "page": "ShearX: Shear horizontally",
- "title": "ShearX: Shear horizontally",
- "category": "page",
- "text": ""
-},
-
-{
- "location": "operations/shearx/#Augmentor.ShearX",
- "page": "ShearX: Shear horizontally",
- "title": "Augmentor.ShearX",
- "category": "type",
- "text": "ShearX <: Augmentor.AffineOperation\n\nDescription\n\nShear the image horizontally for the given degree. This operation can only be performed as an affine transformation and will in general cause other operations of the pipeline to use their affine formulation as well (if they have one).\n\nIt will always perform the transformation around the center of the image. This can be particularly useful when combining the operation with CropNative.\n\nUsage\n\nShearX(degree)\n\nArguments\n\ndegree : Real or AbstractVector of Real that denote the shearing angle(s) in degree. If a vector is provided, then a random element will be sampled each time the operation is applied.\n\nSee also\n\nShearY, CropNative, augment\n\nExamples\n\nusing Augmentor\nimg = testpattern()\n\n# shear horizontally exactly 5 degree\naugment(img, ShearX(5))\n\n# shear horizontally between 10 and 20 degree to the right\naugment(img, ShearX(10:20))\n\n# shear horizontally one of the five specified degrees\naugment(img, ShearX([-10, -5, 0, 5, 10]))\n\n\n\n"
-},
-
-{
- "location": "operations/shearx/#ShearX-1",
- "page": "ShearX: Shear horizontally",
- "title": "ShearX: Shear horizontally",
- "category": "section",
- "text": "ShearXIt will always perform the transformation around the center of the image. This can be particularly useful when combining the operation with CropNative.include(\"optable.jl\")\n@optable ShearX(10)It is also possible to pass some abstract vector to the constructor, in which case Augmentor will randomly sample one of its elements every time the operation is applied.include(\"optable.jl\")\n@optable 10 => ShearX(-10:10)"
-},
-
-{
- "location": "operations/sheary/#",
- "page": "ShearY: Shear vertically",
- "title": "ShearY: Shear vertically",
- "category": "page",
- "text": ""
-},
-
-{
- "location": "operations/sheary/#Augmentor.ShearY",
- "page": "ShearY: Shear vertically",
- "title": "Augmentor.ShearY",
- "category": "type",
- "text": "ShearY <: Augmentor.AffineOperation\n\nDescription\n\nShear the image vertically for the given degree. This operation can only be performed as an affine transformation and will in general cause other operations of the pipeline to use their affine formulation as well (if they have one).\n\nIt will always perform the transformation around the center of the image. This can be particularly useful when combining the operation with CropNative.\n\nUsage\n\nShearY(degree)\n\nArguments\n\ndegree : Real or AbstractVector of Real that denote the shearing angle(s) in degree. If a vector is provided, then a random element will be sampled each time the operation is applied.\n\nSee also\n\nShearX, CropNative, augment\n\nExamples\n\nusing Augmentor\nimg = testpattern()\n\n# shear vertically exactly 5 degree\naugment(img, ShearY(5))\n\n# shear vertically between 10 and 20 degree upwards\naugment(img, ShearY(10:20))\n\n# shear vertically one of the five specified degrees\naugment(img, ShearY([-10, -5, 0, 5, 10]))\n\n\n\n"
-},
-
-{
- "location": "operations/sheary/#ShearY-1",
- "page": "ShearY: Shear vertically",
- "title": "ShearY: Shear vertically",
- "category": "section",
- "text": "ShearYIt will always perform the transformation around the center of the image. This can be particularly useful when combining the operation with CropNative.include(\"optable.jl\")\n@optable ShearY(10)It is also possible to pass some abstract vector to the constructor, in which case Augmentor will randomly sample one of its elements every time the operation is applied.include(\"optable.jl\")\n@optable 10 => ShearY(-10:10)"
-},
-
-{
- "location": "operations/scale/#",
- "page": "Scale: Relative resizing",
- "title": "Scale: Relative resizing",
- "category": "page",
- "text": ""
-},
-
-{
- "location": "operations/scale/#Augmentor.Scale",
- "page": "Scale: Relative resizing",
- "title": "Augmentor.Scale",
- "category": "type",
- "text": "Scale <: Augmentor.AffineOperation\n\nDescription\n\nMultiplies the image height and image width by the specified factors. This means that the size of the output image depends on the size of the input image.\n\nThe provided factors can either be numbers or vectors of numbers.\n\nIf numbers are provided, then the operation is deterministic and will always scale the input image with the same factors.\nIn the case vectors are provided, then each time the operation is applied a valid index is sampled and the elements corresponding to that index are used as scaling factors.\n\nThe scaling is performed relative to the image center, which can be useful when following the operation with CropNative.\n\nUsage\n\nScale(factors)\n\nScale(factors...)\n\nArguments\n\nfactors : NTuple or Vararg of Real or AbstractVector that denote the scale factor(s) for each array dimension. If only one variable is specified it is assumed that height and width should be scaled by the same factor(s).\n\nSee also\n\nZoom, Resize, augment\n\nExamples\n\nusing Augmentor\nimg = testpattern()\n\n# half the image size\naugment(img, Scale(0.5))\n\n# uniformly scale by a random factor from 1.2, 1.3, or 1.4\naugment(img, Scale([1.2, 1.3, 1.4]))\n\n# scale by either 0.5x0.7 or by 0.6x0.8\naugment(img, Scale([0.5, 0.6], [0.7, 0.8]))\n\n\n\n"
-},
-
-{
- "location": "operations/scale/#Scale-1",
- "page": "Scale: Relative resizing",
- "title": "Scale: Relative resizing",
- "category": "section",
- "text": "Scaleinclude(\"optable.jl\")\n@optable Scale(0.9,0.5)In the case that only a single scale factor is specified, the operation will assume that the intention is to scale all dimensions uniformly by that factor.include(\"optable.jl\")\n@optable Scale(1.2)It is also possible to pass some abstract vector(s) to the constructor, in which case Augmentor will randomly sample one of its elements every time the operation is applied.include(\"optable.jl\")\n@optable 10 => Scale(0.9:0.05:1.2)"
-},
-
-{
- "location": "operations/zoom/#",
- "page": "Zoom: Scale without resize",
- "title": "Zoom: Scale without resize",
- "category": "page",
- "text": ""
-},
-
-{
- "location": "operations/zoom/#Augmentor.Zoom",
- "page": "Zoom: Scale without resize",
- "title": "Augmentor.Zoom",
- "category": "type",
- "text": "Zoom <: Augmentor.ImageOperation\n\nDescription\n\nScales the image height and image width by the specified factors, but crops the image such that the original size is preserved.\n\nThe provided factors can either be numbers or vectors of numbers.\n\nIf numbers are provided, then the operation is deterministic and will always scale the input image with the same factors.\nIn the case vectors are provided, then each time the operation is applied a valid index is sampled and the elements corresponding to that index are used as scaling factors.\n\nIn contrast to Scale the size of the output image is the same as the size of the input image, while the content is scaled the same way. The same effect could be achieved by following a Scale with a CropSize, with the caveat that one would need to know the exact size of the input image before-hand.\n\nUsage\n\nZoom(factors)\n\nZoom(factors...)\n\nArguments\n\nfactors : NTuple or Vararg of Real or AbstractVector that denote the scale factor(s) for each array dimension. If only one variable is specified it is assumed that height and width should be scaled by the same factor(s).\n\nSee also\n\nScale, Resize, augment\n\nExamples\n\nusing Augmentor\nimg = testpattern()\n\n# half the image size\naugment(img, Zoom(0.5))\n\n# uniformly scale by a random factor from 1.2, 1.3, or 1.4\naugment(img, Zoom([1.2, 1.3, 1.4]))\n\n# scale by either 0.5x0.7 or by 0.6x0.8\naugment(img, Zoom([0.5, 0.6], [0.7, 0.8]))\n\n\n\n"
-},
-
-{
- "location": "operations/zoom/#Zoom-1",
- "page": "Zoom: Scale without resize",
- "title": "Zoom: Scale without resize",
- "category": "section",
- "text": "Zoominclude(\"optable.jl\")\n@optable Zoom(1.2)It is also possible to pass some abstract vector to the constructor, in which case Augmentor will randomly sample one of its elements every time the operation is applied.include(\"optable.jl\")\n@optable 10 => Zoom(0.9:0.05:1.3)"
-},
-
-{
- "location": "operations/elasticdistortion/#",
- "page": "ElasticDistortion: Smoothed random distortions",
- "title": "ElasticDistortion: Smoothed random distortions",
- "category": "page",
- "text": ""
-},
-
-{
- "location": "operations/elasticdistortion/#Augmentor.ElasticDistortion",
- "page": "ElasticDistortion: Smoothed random distortions",
- "title": "Augmentor.ElasticDistortion",
- "category": "type",
- "text": "ElasticDistortion <: Augmentor.ImageOperation\n\nDescription\n\nDistorts the given image using a randomly (uniform) generated vector field of the given grid size. This field will be stretched over the given image when applied, which in turn will morph the original image into a new image using a linear interpolation of both the image and the vector field.\n\nIn contrast to [RandomDistortion], the resulting vector field is also smoothed using a Gaussian filter with of parameter sigma. This will result in a less chaotic vector field and thus resemble a more natural distortion.\n\nUsage\n\nElasticDistortion(gridheight, gridwidth, scale, sigma, [iter=1], [border=false], [norm=true])\n\nElasticDistortion(gridheight, gridwidth, scale; [sigma=2], [iter=1], [border=false], [norm=true])\n\nElasticDistortion(gridheight, [gridwidth]; [scale=0.2], [sigma=2], [iter=1], [border=false], [norm=true])\n\nArguments\n\ngridheight : The grid height of the displacement vector field. This effectively specifies the number of vertices along the Y dimension used as landmarks, where all the positions between the grid points are interpolated.\ngridwidth : The grid width of the displacement vector field. This effectively specifies the number of vertices along the Y dimension used as landmarks, where all the positions between the grid points are interpolated.\nscale : Optional. The scaling factor applied to all displacement vectors in the field. This effectively defines the \"strength\" of the deformation. There is no theoretical upper limit to this factor, but a value somewhere between 0.01 and 1.0 seem to be the most reasonable choices. Default to 0.2.\nsigma : Optional. Sigma parameter of the Gaussian filter. This parameter effectively controls the strength of the smoothing. Defaults to 2.\niter : Optional. The number of times the smoothing operation is applied to the displacement vector field. This is especially useful if border = false because the border will be reset to zero after each pass. Thus the displacement is a little less aggressive towards the borders of the image than it is towards its center. Defaults to 1.\nborder : Optional. Specifies if the borders should be distorted as well. If false, the borders of the image will be preserved. This effectively pins the outermost vertices on their original position and the operation thus only distorts the inner content of the image. Defaults to false.\nnorm : Optional. If true, the displacement vectors of the field will be normalized by the norm of the field. This will have the effect that the scale factor should be more or less independent of the grid size. Defaults to true.\n\nSee also\n\naugment\n\nExamples\n\nusing Augmentor\nimg = testpattern()\n\n# distort with pinned borders\naugment(img, ElasticDistortion(15, 15; scale = 0.1))\n\n# distort everything more smoothly.\naugment(img, ElasticDistortion(10, 10; sigma = 4, iter=3, border=true))\n\n\n\n"
-},
-
-{
- "location": "operations/elasticdistortion/#ElasticDistortion-1",
- "page": "ElasticDistortion: Smoothed random distortions",
- "title": "ElasticDistortion: Smoothed random distortions",
- "category": "section",
- "text": "ElasticDistortioninclude(\"optable.jl\")\n@optable 10 => ElasticDistortion(15,15,0.1)include(\"optable.jl\")\n@optable 10 => ElasticDistortion(10,10,0.2,4,3,true)"
-},
-
-{
- "location": "operations/crop/#",
- "page": "Crop: Subset image",
- "title": "Crop: Subset image",
- "category": "page",
- "text": ""
-},
-
-{
- "location": "operations/crop/#Augmentor.Crop",
- "page": "Crop: Subset image",
- "title": "Augmentor.Crop",
- "category": "type",
- "text": "Crop <: Augmentor.ImageOperation\n\nDescription\n\nCrops out the area denoted by the specified pixel ranges.\n\nFor example the operation Crop(5:100, 2:10) would denote a crop for the rectangle that starts at x=2 and y=5 in the top left corner and ends at x=10 and y=100 in the bottom right corner. As we can see the y-axis is specified first, because that is how the image is stored in an array. Thus the order of the provided indices ranges needs to reflect the order of the array dimensions.\n\nUsage\n\nCrop(indices)\n\nCrop(indices...)\n\nArguments\n\nindices : NTuple or Vararg of UnitRange that denote the cropping range for each array dimension. This is very similar to how the indices for view are specified.\n\nSee also\n\nCropNative, CropSize, CropRatio, augment\n\nExamples\n\njulia> using Augmentor\n\njulia> img = testpattern()\n300×400 Array{RGBA{N0f8},2}:\n[...]\n\njulia> augment(img, Crop(1:30, 361:400)) # crop upper right corner\n30×40 Array{RGBA{N0f8},2}:\n[...]\n\n\n\n"
-},
-
-{
- "location": "operations/crop/#Crop-1",
- "page": "Crop: Subset image",
- "title": "Crop: Subset image",
- "category": "section",
- "text": "Cropinclude(\"optable.jl\")\n@optable Crop(70:140,25:155)"
-},
-
-{
- "location": "operations/cropnative/#",
- "page": "CropNative: Subset image",
- "title": "CropNative: Subset image",
- "category": "page",
- "text": ""
-},
-
-{
- "location": "operations/cropnative/#Augmentor.CropNative",
- "page": "CropNative: Subset image",
- "title": "Augmentor.CropNative",
- "category": "type",
- "text": "CropNative <: Augmentor.ImageOperation\n\nDescription\n\nCrops out the area denoted by the specified pixel ranges.\n\nFor example the operation CropNative(5:100, 2:10) would denote a crop for the rectangle that starts at x=2 and y=5 in the top left corner of native space and ends at x=10 and y=100 in the bottom right corner of native space.\n\nIn contrast to Crop, the position x=1 y=1 is not necessarily located at the top left of the current image, but instead depends on the cumulative effect of the previous transformations. The reason for this is because affine transformations are usually performed around the center of the image, which is reflected in \"native space\". This is useful for combining transformations such as Rotate or ShearX with a crop around the center area.\n\nUsage\n\nCropNative(indices)\n\nCropNative(indices...)\n\nArguments\n\nindices : NTuple or Vararg of UnitRange that denote the cropping range for each array dimension. This is very similar to how the indices for view are specified.\n\nSee also\n\nCrop, CropSize, CropRatio, augment\n\nExamples\n\nusing Augmentor\nimg = testpattern()\n\n# cropped at top left corner\naugment(img, Rotate(45) |> Crop(1:300, 1:400))\n\n# cropped around center of rotated image\naugment(img, Rotate(45) |> CropNative(1:300, 1:400))\n\n\n\n"
-},
-
-{
- "location": "operations/cropnative/#CropNative-1",
- "page": "CropNative: Subset image",
- "title": "CropNative: Subset image",
- "category": "section",
- "text": "CropNativeinclude(\"optable.jl\")\n@optable \"cropn1\" => (Rotate(45),Crop(1:210,1:280))\n@optable \"cropn2\" => (Rotate(45),CropNative(1:210,1:280))\ntbl = string(\n \"`(Rotate(45), Crop(1:210,1:280))` | `(Rotate(45), CropNative(1:210,1:280))`\\n\",\n \"-----|-----\\n\",\n \" | \\n\"\n)\nMarkdown.parse(tbl)"
-},
-
-{
- "location": "operations/cropsize/#",
- "page": "CropSize: Crop centered window",
- "title": "CropSize: Crop centered window",
- "category": "page",
- "text": ""
-},
-
-{
- "location": "operations/cropsize/#Augmentor.CropSize",
- "page": "CropSize: Crop centered window",
- "title": "Augmentor.CropSize",
- "category": "type",
- "text": "CropSize <: Augmentor.ImageOperation\n\nDescription\n\nCrops out the area of the specified pixel size around the center of the input image.\n\nFor example the operation CropSize(10, 50) would denote a crop for a rectangle of height 10 and width 50 around the center of the input image.\n\nUsage\n\nCropSize(size)\n\nCropSize(size...)\n\nArguments\n\nsize : NTuple or Vararg of Int that denote the output size in pixel for each dimension.\n\nSee also\n\nCropRatio, Crop, CropNative, augment\n\nExamples\n\nusing Augmentor\nimg = testpattern()\n\n# cropped around center of rotated image\naugment(img, Rotate(45) |> CropSize(300, 400))\n\n\n\n"
-},
-
-{
- "location": "operations/cropsize/#CropSize-1",
- "page": "CropSize: Crop centered window",
- "title": "CropSize: Crop centered window",
- "category": "section",
- "text": "CropSizeinclude(\"optable.jl\")\n@optable CropSize(45,225)"
-},
-
-{
- "location": "operations/cropratio/#",
- "page": "CropRatio: Crop centered window",
- "title": "CropRatio: Crop centered window",
- "category": "page",
- "text": ""
-},
-
-{
- "location": "operations/cropratio/#Augmentor.CropRatio",
- "page": "CropRatio: Crop centered window",
- "title": "Augmentor.CropRatio",
- "category": "type",
- "text": "CropRatio <: Augmentor.ImageOperation\n\nDescription\n\nCrops out the biggest area around the center of the given image such that the output image satisfies the specified aspect ratio (i.e. width divided by height).\n\nFor example the operation CropRatio(1) would denote a crop for the biggest square around the center of the image.\n\nFor randomly placed crops take a look at RCropRatio.\n\nUsage\n\nCropRatio(ratio)\n\nCropRatio(; ratio = 1)\n\nArguments\n\nratio::Number : Optional. A number denoting the aspect ratio. For example specifying ratio=16/9 would denote a 16:9 aspect ratio. Defaults to 1, which describes a square crop.\n\nSee also\n\nRCropRatio, CropSize, Crop, CropNative, augment\n\nExamples\n\nusing Augmentor\nimg = testpattern()\n\n# crop biggest square around the image center\naugment(img, CropRatio(1))\n\n\n\n"
-},
-
-{
- "location": "operations/cropratio/#CropRatio-1",
- "page": "CropRatio: Crop centered window",
- "title": "CropRatio: Crop centered window",
- "category": "section",
- "text": "CropRatioinclude(\"optable.jl\")\n@optable CropRatio(1)"
-},
-
-{
- "location": "operations/rcropratio/#",
- "page": "RCropRatio: Crop random window",
- "title": "RCropRatio: Crop random window",
- "category": "page",
- "text": ""
-},
-
-{
- "location": "operations/rcropratio/#Augmentor.RCropRatio",
- "page": "RCropRatio: Crop random window",
- "title": "Augmentor.RCropRatio",
- "category": "type",
- "text": "RCropRatio <: Augmentor.ImageOperation\n\nDescription\n\nCrops out the biggest possible area at some random position of the given image, such that the output image satisfies the specified aspect ratio (i.e. width divided by height).\n\nFor example the operation RCropRatio(1) would denote a crop for the biggest possible square. If there is more than one such square, then one will be selected at random.\n\nUsage\n\nRCropRatio(ratio)\n\nRCropRatio(; ratio = 1)\n\nArguments\n\nratio::Number : Optional. A number denoting the aspect ratio. For example specifying ratio=16/9 would denote a 16:9 aspect ratio. Defaults to 1, which describes a square crop.\n\nSee also\n\nCropRatio, CropSize, Crop, CropNative, augment\n\nExamples\n\nusing Augmentor\nimg = testpattern()\n\n# crop a randomly placed square of maxmimum size\naugment(img, RCropRatio(1))\n\n\n\n"
-},
-
-{
- "location": "operations/rcropratio/#RCropRatio-1",
- "page": "RCropRatio: Crop random window",
- "title": "RCropRatio: Crop random window",
- "category": "section",
- "text": "RCropRatioinclude(\"optable.jl\")\n@optable 10 => RCropRatio(1)"
-},
-
-{
- "location": "operations/resize/#",
- "page": "Resize: Set static image size",
- "title": "Resize: Set static image size",
- "category": "page",
- "text": ""
-},
-
-{
- "location": "operations/resize/#Augmentor.Resize",
- "page": "Resize: Set static image size",
- "title": "Augmentor.Resize",
- "category": "type",
- "text": "Resize <: Augmentor.ImageOperation\n\nDescription\n\nRescales the image to a fixed pre-specified pixel size.\n\nThis operation does not take any measures to preserve aspect ratio of the source image. Instead, the original image will simply be resized to the given dimensions. This is useful when one needs a set of images to all be of the exact same size.\n\nUsage\n\nResize(; height=64, width=64)\n\nResize(size)\n\nResize(size...)\n\nArguments\n\nsize : NTuple or Vararg of Int that denote the output size in pixel for each dimension.\n\nSee also\n\nCropSize, augment\n\nExamples\n\nusing Augmentor\nimg = testpattern()\n\naugment(img, Resize(30, 40))\n\n\n\n"
-},
-
-{
- "location": "operations/resize/#Resize-1",
- "page": "Resize: Set static image size",
- "title": "Resize: Set static image size",
- "category": "section",
- "text": "Resizeinclude(\"optable.jl\")\n@optable Resize(100,150)"
-},
-
-{
- "location": "operations/converteltype/#",
- "page": "ConvertEltype: Color conversion",
- "title": "ConvertEltype: Color conversion",
- "category": "page",
- "text": ""
-},
-
-{
- "location": "operations/converteltype/#Augmentor.ConvertEltype",
- "page": "ConvertEltype: Color conversion",
- "title": "Augmentor.ConvertEltype",
- "category": "type",
- "text": "ConvertEltype <: Augmentor.Operation\n\nDescription\n\nConvert the element type of the given array/image into the given eltype. This operation is especially useful for converting color images to grayscale (or the other way around). That said, the operation is not specific to color types and can also be used for numeric arrays (e.g. with separated channels).\n\nNote that this is an element-wise convert function. Thus it can not be used to combine or separate color channels. Use SplitChannels or CombineChannels for those purposes.\n\nUsage\n\nConvertEltype(eltype)\n\nArguments\n\neltype : The eltype of the resulting array/image.\n\nSee also\n\nCombineChannels, SplitChannels, augment\n\nExamples\n\njulia> using Augmentor, Colors\n\njulia> A = rand(RGB, 10, 10) # three color channels\n10×10 Array{RGB{Float64},2}:\n[...]\n\njulia> augment(A, ConvertEltype(Gray{Float32})) # convert to grayscale\n10×10 Array{Gray{Float32},2}:\n[...]\n\n\n\n"
-},
-
-{
- "location": "operations/converteltype/#ConvertEltype-1",
- "page": "ConvertEltype: Color conversion",
- "title": "ConvertEltype: Color conversion",
- "category": "section",
- "text": "ConvertEltypeinclude(\"optable.jl\")\n@optable ConvertEltype(GrayA{N0f8})"
-},
-
-{
- "location": "operations/mapfun/#",
- "page": "MapFun: Map function over Image",
- "title": "MapFun: Map function over Image",
- "category": "page",
- "text": ""
-},
-
-{
- "location": "operations/mapfun/#Augmentor.MapFun",
- "page": "MapFun: Map function over Image",
- "title": "Augmentor.MapFun",
- "category": "type",
- "text": "MapFun <: Augmentor.Operation\n\nDescription\n\nMaps the given function over all individual array elements.\n\nThis means that the given function is called with an individual elements and is expected to return a transformed element that should take the original\'s place. This further implies that the function is expected to be unary. It is encouraged that the function should be consistent with its return type and type-stable.\n\nUsage\n\nMapFun(fun)\n\nArguments\n\nfun : The unary function that should be mapped over all individual array elements.\n\nSee also\n\nAggregateThenMapFun, ConvertEltype, augment\n\nExamples\n\nusing Augmentor, ColorTypes\nimg = testpattern()\n\n# subtract the constant RGBA value from each pixel\naugment(img, MapFun(px -> px - RGBA(0.5, 0.3, 0.7, 0.0)))\n\n# separate channels to scale each numeric element by a constant value\npl = SplitChannels() |> MapFun(el -> el * 0.5) |> CombineChannels(RGBA)\naugment(img, pl)\n\n\n\n"
-},
-
-{
- "location": "operations/mapfun/#MapFun-1",
- "page": "MapFun: Map function over Image",
- "title": "MapFun: Map function over Image",
- "category": "section",
- "text": "MapFun"
-},
-
-{
- "location": "operations/aggmapfun/#",
- "page": "AggregateThenMapFun: Aggregate and Map over Image",
- "title": "AggregateThenMapFun: Aggregate and Map over Image",
- "category": "page",
- "text": ""
-},
-
-{
- "location": "operations/aggmapfun/#Augmentor.AggregateThenMapFun",
- "page": "AggregateThenMapFun: Aggregate and Map over Image",
- "title": "Augmentor.AggregateThenMapFun",
- "category": "type",
- "text": "AggregateThenMapFun <: Augmentor.Operation\n\nDescription\n\nCompute some aggregated value of the current image using the given function aggfun, and map that value over the current image using the given function mapfun.\n\nThis is particularly useful for achieving effects such as per-image normalization.\n\nUsage\n\nAggregateThenMapFun(aggfun, mapfun)\n\nArguments\n\naggfun : A function that takes the whole current image as input and which result will also be passed to mapfun. It should have a signature of img -> agg, where img will the the current image. What type and value agg should be is up to the user.\nmapfun : The binary function that should be mapped over all individual array elements. It should have a signature of (px, agg) -> new_px where px is a single element of the current image, and agg is the output of aggfun.\n\nSee also\n\nMapFun, ConvertEltype, augment\n\nExamples\n\nusing Augmentor\nimg = testpattern()\n\n# subtract the average RGB value of the current image\naugment(img, AggregateThenMapFun(img -> mean(img), (px, agg) -> px - agg))\n\n\n\n"
-},
-
-{
- "location": "operations/aggmapfun/#AggregateThenMapFun-1",
- "page": "AggregateThenMapFun: Aggregate and Map over Image",
- "title": "AggregateThenMapFun: Aggregate and Map over Image",
- "category": "section",
- "text": "AggregateThenMapFun"
-},
-
-{
- "location": "operations/splitchannels/#",
- "page": "SplitChannels: Separate color channels",
- "title": "SplitChannels: Separate color channels",
- "category": "page",
- "text": ""
-},
-
-{
- "location": "operations/splitchannels/#Augmentor.SplitChannels",
- "page": "SplitChannels: Separate color channels",
- "title": "Augmentor.SplitChannels",
- "category": "type",
- "text": "SplitChannels <: Augmentor.Operation\n\nDescription\n\nSplits out the color channels of the given image using the function ImageCore.channelview. This will effectively create a new array dimension for the colors in the front. In contrast to ImageCore.channelview it will also result in a new dimension for gray images.\n\nThis operation is mainly useful at the end of a pipeline in combination with PermuteDims in order to prepare the image for the training algorithm, which often requires the color channels to be separate.\n\nUsage\n\nSplitChannels()\n\nSee also\n\nPermuteDims, CombineChannels, augment\n\nExamples\n\njulia> using Augmentor\n\njulia> img = testpattern()\n300×400 Array{RGBA{N0f8},2}:\n[...]\n\njulia> augment(img, SplitChannels())\n4×300×400 Array{N0f8,3}:\n[...]\n\njulia> augment(img, SplitChannels() |> PermuteDims(3,2,1))\n400×300×4 Array{N0f8,3}:\n[...]\n\n\n\n"
-},
-
-{
- "location": "operations/splitchannels/#SplitChannels-1",
- "page": "SplitChannels: Separate color channels",
- "title": "SplitChannels: Separate color channels",
- "category": "section",
- "text": "SplitChannels"
-},
-
-{
- "location": "operations/combinechannels/#",
- "page": "ComineChannels: Combine color channels",
- "title": "ComineChannels: Combine color channels",
- "category": "page",
- "text": ""
-},
-
-{
- "location": "operations/combinechannels/#Augmentor.CombineChannels",
- "page": "ComineChannels: Combine color channels",
- "title": "Augmentor.CombineChannels",
- "category": "type",
- "text": "CombineChannels <: Augmentor.Operation\n\nDescription\n\nCombines the first dimension of a given array into a colorant of type colortype using the function ImageCore.colorview. The main difference is that a separate color channel is also expected for Gray images.\n\nThe shape of the input image has to be appropriate for the given colortype, which also means that the separated color channel has to be the first dimension of the array. See PermuteDims if that is not the case.\n\nUsage\n\nCombineChannels(colortype)\n\nArguments\n\ncolortype : The color type of the resulting image. Must be a subtype of ColorTypes.Colorant and match the color channel of the given image.\n\nSee also\n\nSplitChannels, PermuteDims, augment\n\nExamples\n\njulia> using Augmentor, Colors\n\njulia> A = rand(3, 10, 10) # three color channels\n3×10×10 Array{Float64,3}:\n[...]\n\njulia> augment(A, CombineChannels(RGB))\n10×10 Array{RGB{Float64},2}:\n[...]\n\njulia> B = rand(1, 10, 10) # singleton color channel\n1×10×10 Array{Float64,3}:\n[...]\n\njulia> augment(B, CombineChannels(Gray))\n10×10 Array{Gray{Float64},2}:\n[...]\n\n\n\n"
-},
-
-{
- "location": "operations/combinechannels/#CombineChannels-1",
- "page": "ComineChannels: Combine color channels",
- "title": "ComineChannels: Combine color channels",
- "category": "section",
- "text": "CombineChannels"
-},
-
-{
- "location": "operations/permutedims/#",
- "page": "PermuteDims: Change dimension order",
- "title": "PermuteDims: Change dimension order",
- "category": "page",
- "text": ""
-},
-
-{
- "location": "operations/permutedims/#Augmentor.PermuteDims",
- "page": "PermuteDims: Change dimension order",
- "title": "Augmentor.PermuteDims",
- "category": "type",
- "text": "PermuteDims <: Augmentor.Operation\n\nDescription\n\nPermute the dimensions of the given array with the predefined permutation perm. This operation is particularly useful if the order of the dimensions needs to be different than the default \"julian\" layout (described below).\n\nAugmentor expects the given images to be in vertical-major layout for which the colors are encoded in the element type itself. Many deep learning frameworks however require their input in a different order. For example it is not untypical that separate color channels are expected to be encoded in the third dimension.\n\nUsage\n\nPermuteDims(perm)\n\nPermuteDims(perm...)\n\nArguments\n\nperm : The concrete dimension permutation that should be used. Has to be specified as a Vararg{Int} or as a NTuple of Int. The length of perm has to match the number of dimensions of the expected input image to that operation.\n\nSee also\n\nSplitChannels, CombineChannels, augment\n\nExamples\n\njulia> using Augmentor, Colors\n\njulia> A = rand(10, 5, 3) # width=10, height=5, and 3 color channels\n10×5×3 Array{Float64,3}:\n[...]\n\njulia> img = augment(A, PermuteDims(3,2,1) |> CombineChannels(RGB))\n5×10 Array{RGB{Float64},2}:\n[...]\n\njulia> img2 = testpattern()\n300×400 Array{RGBA{N0f8},2}:\n[...]\n\njulia> B = augment(img2, SplitChannels() |> PermuteDims(3,2,1))\n400×300×4 Array{N0f8,3}:\n[...]\n\n\n\n"
-},
-
-{
- "location": "operations/permutedims/#PermuteDims-1",
- "page": "PermuteDims: Change dimension order",
- "title": "PermuteDims: Change dimension order",
- "category": "section",
- "text": "PermuteDims"
-},
-
-{
- "location": "operations/reshape/#",
- "page": "Reshape: Reinterpret shape",
- "title": "Reshape: Reinterpret shape",
- "category": "page",
- "text": ""
-},
-
-{
- "location": "operations/reshape/#Augmentor.Reshape",
- "page": "Reshape: Reinterpret shape",
- "title": "Augmentor.Reshape",
- "category": "type",
- "text": "Reshape <: Augmentor.Operation\n\nDescription\n\nReinterpret the shape of the given array of numbers or colorants. This is useful for example to create singleton-dimensions that deep learning frameworks may need for colorless images, or for converting an image array to a feature vector (and vice versa).\n\nUsage\n\nReshape(dims)\n\nReshape(dims...)\n\nArguments\n\ndims : The new sizes for each dimension of the output image. Has to be specified as a Vararg{Int} or as a NTuple of Int.\n\nSee also\n\nCombineChannels, augment\n\nExamples\n\njulia> using Augmentor, Colors\n\njulia> A = rand(10,10)\n10×10 Array{Float64,2}:\n[...]\n\njulia> augment(A, Reshape(10,10,1)) # add trailing singleton dimension\n10×10×1 Array{Float64,3}:\n[...]\n\n\n\n"
-},
-
-{
- "location": "operations/reshape/#Reshape-1",
- "page": "Reshape: Reinterpret shape",
- "title": "Reshape: Reinterpret shape",
- "category": "section",
- "text": "Reshape"
-},
-
-{
- "location": "operations/noop/#",
- "page": "NoOp: Identity function",
- "title": "NoOp: Identity function",
- "category": "page",
- "text": ""
-},
-
-{
- "location": "operations/noop/#Augmentor.NoOp",
- "page": "NoOp: Identity function",
- "title": "Augmentor.NoOp",
- "category": "type",
- "text": "NoOp <: Augmentor.AffineOperation\n\nIdentity transformation that does not do anything with the given image, but instead passes it along unchanged (without copying).\n\nUsually used in combination with Either to denote a \"branch\" that does not perform any computation.\n\n\n\n"
-},
-
-{
- "location": "operations/noop/#NoOp-1",
- "page": "NoOp: Identity function",
- "title": "NoOp: Identity function",
- "category": "section",
- "text": "NoOp"
-},
-
-{
- "location": "operations/cacheimage/#",
- "page": "CacheImage: Buffer current state",
- "title": "CacheImage: Buffer current state",
- "category": "page",
- "text": ""
-},
-
-{
- "location": "operations/cacheimage/#Augmentor.CacheImage",
- "page": "CacheImage: Buffer current state",
- "title": "Augmentor.CacheImage",
- "category": "type",
- "text": "CacheImage <: Augmentor.ImageOperation\n\nDescription\n\nWrite the current state of the image into the working memory. Optionally a user has the option to specify a preallocated buffer to write the image into. Note that if a buffer is provided, then it has to be of the correct size and eltype.\n\nEven without a preallocated buffer it can be beneficial in some situations to cache the image. An example for such a scenario is when chaining a number of affine transformations after an elastic distortion, because performing that lazily requires nested interpolation.\n\nUsage\n\nCacheImage()\n\nCacheImage(buffer)\n\nArguments\n\nbuffer : Optional. A preallocated AbstractArray of the appropriate size and eltype.\n\nSee also\n\naugment\n\nExamples\n\nusing Augmentor\n\n# make pipeline that forces caching after elastic distortion\npl = ElasticDistortion(3,3) |> CacheImage() |> Rotate(-10:10) |> ShearX(-5:5)\n\n# cache output of elastic distortion into the allocated\n# 20x20 Matrix{Float64}. Note that for this case this assumes that\n# the input image is also a 20x20 Matrix{Float64}\npl = ElasticDistortion(3,3) |> CacheImage(zeros(20,20)) |> Rotate(-10:10)\n\n# convenience syntax with the same effect as above.\npl = ElasticDistortion(3,3) |> zeros(20,20) |> Rotate(-10:10)\n\n\n\n"
-},
-
-{
- "location": "operations/cacheimage/#CacheImage-1",
- "page": "CacheImage: Buffer current state",
- "title": "CacheImage: Buffer current state",
- "category": "section",
- "text": "CacheImage"
-},
-
-{
- "location": "operations/either/#",
- "page": "Either: Stochastic branches",
- "title": "Either: Stochastic branches",
- "category": "page",
- "text": ""
-},
-
-{
- "location": "operations/either/#Augmentor.Either",
- "page": "Either: Stochastic branches",
- "title": "Augmentor.Either",
- "category": "type",
- "text": "Either <: Augmentor.ImageOperation\n\nDescription\n\nChooses between the given operations at random when applied. This is particularly useful if one for example wants to first either rotate the image 90 degree clockwise or anticlockwise (but never both), and then apply some other operation(s) afterwards.\n\nWhen compiling a pipeline, Either will analyze the provided operations in order to identify the preferred formalism to use when applied. The chosen formalism is chosen such that it is supported by all given operations. This way the output of applying Either will be inferable and the whole pipeline will remain type-stable (even though randomness is involved).\n\nBy default each specified image operation has the same probability of occurrence. This default behaviour can be overwritten by specifying the chance manually.\n\nUsage\n\nEither(operations, [chances])\n\nEither(operations...; [chances])\n\nEither(pairs...)\n\n*(operations...)\n\n*(pairs...)\n\nArguments\n\noperations : NTuple or Vararg of Augmentor.ImageOperation that denote the possible choices to sample from when applied.\nchances : Optional. Denotes the relative chances for an operation to be sampled. Has to contain the same number of elements as operations. Either an NTuple of numbers if specified as positional argument, or alternatively a AbstractVector of numbers if specified as a keyword argument. If omitted every operation will have equal probability of occurring.\npairs : Vararg of Pair{<:Real,<:Augmentor.ImageOperation}. A compact way to specify an operation and its chance of occurring together.\n\nSee also\n\nNoOp, augment\n\nExamples\n\nusing Augmentor\nimg = testpattern()\n\n# all three operations have equal chance of occuring\naugment(img, Either(FlipX(), FlipY(), NoOp()))\naugment(img, FlipX() * FlipY() * NoOp())\n\n# NoOp is twice as likely as either FlipX or FlipY\naugment(img, Either(1=>FlipX(), 1=>FlipY(), 2=>NoOp()))\naugment(img, Either(FlipX(), FlipY(), NoOp(), chances=[1,1,2]))\naugment(img, Either((FlipX(), FlipY(), NoOp()), (1,1,2)))\naugment(img, (1=>FlipX()) * (1=>FlipY()) * (2=>NoOp()))\n\n\n\n"
-},
-
-{
- "location": "operations/either/#Either-1",
- "page": "Either: Stochastic branches",
- "title": "Either: Stochastic branches",
- "category": "section",
- "text": "Either"
-},
-
-{
- "location": "generated/mnist_elastic/#",
- "page": "MNIST: Elastic Distortions",
- "title": "MNIST: Elastic Distortions",
- "category": "page",
- "text": ""
-},
-
-{
- "location": "generated/mnist_elastic/#elastic-1",
- "page": "MNIST: Elastic Distortions",
- "title": "MNIST: Elastic Distortions",
- "category": "section",
- "text": "In this example we are going to use Augmentor on the famous MNIST database of handwritten digits [MNIST1998] to reproduce the elastic distortions discussed in [SIMARD2003]. It may be interesting to point out, that the way Augmentor implements distortions is a little different to how it is described by the authors of the paper. This is for a couple of reasons, most notably that we want the parameters for our deformations to be independent of the size of image it is applied on. As a consequence the parameter-numbers specified in the paper are not 1-to-1 transferable to Augmentor.If the effects are sensible for the dataset, then applying elastic distortions can be a really effective way to improve the generalization ability of the network. That said, our implementation of ElasticDistortion has a lot of possible parameters to choose from. To that end, we will introduce a simple strategy for interactively exploring the parameter space on our dataset of interest.note: Note\nThis tutorial was designed to be performed in a Juypter notebook. You can find a link to the Juypter version of this tutorial in the top right corner of this page."
-},
-
-{
- "location": "generated/mnist_elastic/#Loading-the-MNIST-Trainingset-1",
- "page": "MNIST: Elastic Distortions",
- "title": "Loading the MNIST Trainingset",
- "category": "section",
- "text": "In order to access and visualize the MNIST images we employ the help of two additional Julia packages. In the interest of time and space we will not go into great detail about their functionality. Feel free to click on their respective names to find out more information about the utility they can provide.Images.jl will provide us with the necessary tools for working with image data in Julia.\nMLDatasets.jl has an MNIST submodule that offers a convenience interface to read the MNIST database.The function MNIST.traintensor returns the MNIST training images corresponding to the given indices as a multi-dimensional array. These images are stored in the native horizontal-major memory layout as a single floating point array, where all values are scaled to be between 0.0 and 1.0.using Images, MLDatasets\ntrain_tensor = MNIST.traintensor()\n@show summary(train_tensor);\nnothing # hideThis horizontal-major format is the standard way of utilizing this dataset for training machine learning models. In this tutorial, however, we are more interested in working with the MNIST images as actual Julia images in vertical-major layout, and as black digits on white background.We can convert the \"tensor\" to a Colorant array using the provided function MNIST.convert2image. This way, Julia knows we are dealing with image data and can tell programming environments such as Juypter how to visualize it. If you are working in the terminal you may want to use the package ImageInTerminal.jltrain_images = MNIST.convert2image(train_tensor)\nimg_1 = train_images[:,:,1] # show first image\nsave(\"mnist_1.png\",repeat(img_1,inner=(4,4))) # hide\nnothing # hide(Image: first image)"
-},
-
-{
- "location": "generated/mnist_elastic/#Visualizing-the-Effects-1",
- "page": "MNIST: Elastic Distortions",
- "title": "Visualizing the Effects",
- "category": "section",
- "text": "Before applying an operation (or pipeline of operations) on some dataset to train a network, we strongly recommend investing some time in selecting a decent set of hyper parameters for the operation(s). A useful tool for tasks like this is the package Interact.jl. We will use this package to define a number of widgets for controlling the parameters to our operation.Note that while the code below only focuses on configuring the parameters of a single operation, specifically ElasticDistortion, it could also be adapted to tweak a whole pipeline. Take a look at the corresponding section in High-level Interface for more information on how to define and use a pipeline.# These two package will provide us with the capabilities\n# to perform interactive visualisations in a jupyter notebook\nusing Augmentor, Interact, Reactive\n\n# The manipulate macro will turn the parameters of the\n# loop into interactive widgets.\n@manipulate for\n unpaused = true,\n ticks = fpswhen(signal(unpaused), 5.),\n image_index = 1:100,\n grid_size = 3:20,\n scale = .1:.1:.5,\n sigma = 1:5,\n iterations = 1:6,\n free_border = true\n op = ElasticDistortion(grid_size, grid_size, # equal width & height\n sigma = sigma,\n scale = scale,\n iter = iterations,\n border = free_border)\n augment(train_images[:, :, image_index], op)\nend\nnothing # hideExecuting the code above in a Juypter notebook will result in the following interactive visualisation. You can now use the sliders to investigate the effects that different parameters have on the MNIST training images.tip: Tip\nYou should always use your training set to do this kind of visualisation (not the test test!). Otherwise you are likely to achieve overly optimistic (i.e. biased) results during training.(Image: interact)Congratulations! With just a few simple lines of code, you created a simple interactive tool to visualize your image augmentation pipeline. Once you found a set of parameters that you think are appropriate for your dataset you can go ahead and train your model."
-},
-
-{
- "location": "generated/mnist_elastic/#References-1",
- "page": "MNIST: Elastic Distortions",
- "title": "References",
- "category": "section",
- "text": "[MNIST1998]: LeCun, Yan, Corinna Cortes, Christopher J.C. Burges. \"The MNIST database of handwritten digits\" Website. 1998.[SIMARD2003]: Simard, Patrice Y., David Steinkraus, and John C. Platt. \"Best practices for convolutional neural networks applied to visual document analysis.\" ICDAR. Vol. 3. 2003."
-},
-
-{
- "location": "generated/mnist_knet/#",
- "page": "MNIST: Knet.jl CNN",
- "title": "MNIST: Knet.jl CNN",
- "category": "page",
- "text": ""
-},
-
-{
- "location": "generated/mnist_knet/#MNIST:-Knet.jl-CNN-1",
- "page": "MNIST: Knet.jl CNN",
- "title": "MNIST: Knet.jl CNN",
- "category": "section",
- "text": "In this tutorial we will adapt the MNIST example from Knet.jl to utilize a custom augmentation pipeline. In order to showcase the effect that image augmentation can have on a neural network\'s ability to generalize, we will limit the training set to just the first 500 images (of the available 60,000!). For more information on the dataset see [MNIST1998].note: Note\nThis tutorial is also available as a Juypter notebook. You can find a link to the Juypter version of this tutorial in the top right corner of this page."
-},
-
-{
- "location": "generated/mnist_knet/#Preparing-the-MNIST-dataset-1",
- "page": "MNIST: Knet.jl CNN",
- "title": "Preparing the MNIST dataset",
- "category": "section",
- "text": "In order to access, prepare, and visualize the MNIST images we employ the help of three additional Julia packages. In the interest of time and space we will not go into great detail about their functionality. Feel free to click on their respective names to find out more information about the utility they can provide.MLDatasets.jl has an MNIST submodule that offers a convenience interface to read the MNIST database.\nImages.jl will provide us with the necessary tools to process and display the image data in Julia / Juypter.\nMLDataUtils.jl implements a variety of functions to convert and partition Machine Learning datasets. This will help us prepare the MNIST data to be used with Knet.jl.using Images, MLDatasets, MLDataUtils\nsrand(42);\nnothing # hideAs you may have seen previously in the elastic distortions tutorial, the function MNIST.traintensor returns the MNIST training images corresponding to the given indices as a multi-dimensional array. These images are stored in the native horizontal-major memory layout as a single array. Because we specify that the eltype of that array should be Float32, all the individual values are scaled to be between 0.0 and 1.0. Also note, how the observations are laid out along the last array dimension@show summary(MNIST.traintensor(Float32, 1:500));\nnothing # hideThe corresponding label of each image is stored as an integer value between 0 and 9. That means that if the label has the value 3, then the corresponding image is known to be a handwritten \"3\". To show a more concrete example, the following code reveals that the first training image denotes a \"5\" and the second training image a \"0\" (etc).@show summary(MNIST.trainlabels(1:500))\nprintln(\"First eight labels: \", join(MNIST.trainlabels(1:8),\", \"))For Knet we will require a slightly format for the images and also the labels. More specifically, we add an additional singleton dimension of length 1 to our image array. Think of this as our single color channel (because MNIST images are gray). Additionally we will convert our labels to proper 1-based indices. This is because some functions provided by Knet expect the labels to be in this format. We will do all this by creating a little utility function that we will name prepare_mnist.\"\"\"\n prepare_mnist(images, labels) -> (X, Y)\n\nChange the dimension layout x1×x2×N of the given array\n`images` to x1×x2×1×N and return the result as `X`.\nThe given integer vector `labels` is transformed into\nan integer vector denoting 1-based class indices.\n\"\"\"\nfunction prepare_mnist(images, labels)\n X = reshape(images, (28, 28, 1, :))\n Y = convertlabel(LabelEnc.Indices{Int8}, labels, 0:9)\n X, Y\nend\nnothing # hideWith prepare_mnist defined, we can now use it in conjunction with the functions in the MLDatasets.MNIST sub-module to load and prepare our training set. Recall that for this tutorial only the first 500 images of the training set will be used.train_x, train_y = prepare_mnist(MNIST.traintensor(Float32, 1:500), MNIST.trainlabels(1:500))\n@show summary(train_x) summary(train_y);\n[MNIST.convert2image(train_x[:,:,1,i]) for i in 1:8]\ntmp = hcat(ans...) # hide\nsave(\"mnist_knet_train.png\",repeat(tmp, inner=(4,4))) # hide\nnothing # hide(Image: training images)Similarly, we use MNIST.testtensor and MNIST.testlabels to load the full MNIST test set. We will utilize that data to measure how well the network is able to generalize with and without augmentation.test_x, test_y = prepare_mnist(MNIST.testtensor(Float32), MNIST.testlabels())\n@show summary(test_x) summary(test_y);\n[MNIST.convert2image(test_x[:,:,1,i]) for i in 1:8]\ntmp = hcat(ans...) # hide\nsave(\"mnist_knet_test.png\",repeat(tmp, inner=(4,4))) # hide\nnothing # hide(Image: test images)"
-},
-
-{
- "location": "generated/mnist_knet/#Defining-the-Network-1",
- "page": "MNIST: Knet.jl CNN",
- "title": "Defining the Network",
- "category": "section",
- "text": "With the dataset prepared, we can now define and instantiate our neural network. To keep things simple, we will use the same convolutional network as defined in the MNIST example of the Knet.jl package.using Knet\nnothing # hideThe first thing we will do is define the forward pass through the network. This will effectively outline the computation graph of the network architecture. Note how this does not define some details, such as the number of neurons per layer. We will define those later when initializing our vector of weight arrays w.\"\"\"\n forward(w, x) -> a\n\nCompute the forward pass for the given minibatch `x` by using the\nneural network parameters in `w`. The resulting (unnormalized)\nactivations of the last layer are returned as `a`.\n\"\"\"\nfunction forward(w, x)\n # conv1 (2x2 maxpool)\n a1 = pool(relu.(conv4(w[1], x) .+ w[2]))\n # conv2 (2x2 maxpool)\n a2 = pool(relu.(conv4(w[3], a1) .+ w[4]))\n # dense1 (relu)\n a3 = relu.(w[5] * mat(a2) .+ w[6])\n # dense2 (identity)\n a4 = w[7] * a3 .+ w[8]\n return a4\nend\nnothing # hideIn order to be able to train our network we need to choose a cost function. Because this is a classification problem we will use the negative log-likelihood (provided by Knet.nll). With the cost function defined we can the simply use the higher-order function grad to create a new function costgrad that computes us the corresponding gradients.\"\"\"\n cost(w, x, y) -> AbstractFloat\n\nCompute the per-instance negative log-likelihood for the data\nin the minibatch `(x, y)` given the network with the current\nparameters in `w`.\n\"\"\"\ncost(w, x, y) = nll(forward(w, x), y)\ncostgrad = grad(cost)\nnothing # hideAside from the cost function that we need for training, we would also like a more interpretable performance measurement. In this tutorial we will use \"accuracy\" for its simplicity and because we know that the class distribution for MNIST is close to uniform.\"\"\"\n acc(w, X, Y; [batchsize]) -> Float64\n\nCompute the accuracy for the data in `(X,Y)` given the network\nwith the current parameters in `w`. The resulting value is\ncomputed by iterating over the data in minibatches of size\n`batchsize`.\n\"\"\"\nfunction acc(w, X, Y; batchsize = 100)\n sum = 0; count = 0\n for (x_cpu, y) in eachbatch((X, Y), maxsize = batchsize)\n x = KnetArray{Float32}(x_cpu)\n sum += Int(accuracy(forward(w,x), y, average = false))\n count += length(y)\n end\n return sum / count\nend\nnothing # hideBefore we can train or even just use our network, we need to define how we initialize w, which is our the vector of parameter arrays. The dimensions of these individual arrays specify the filter sizes and number of neurons. It can be helpful to compare the indices here with the indices used in our forward function to see which array corresponds to which computation node of our network.function weights(atype = KnetArray{Float32})\n w = Array{Any}(8)\n # conv1\n w[1] = xavier(5,5,1,20)\n w[2] = zeros(1,1,20,1)\n # conv2\n w[3] = xavier(5,5,20,50)\n w[4] = zeros(1,1,50,1)\n # dense1\n w[5] = xavier(500,800)\n w[6] = zeros(500,1)\n # dense2\n w[7] = xavier(10,500)\n w[8] = zeros(10,1)\n return map(a->convert(atype,a), w)\nend\nnothing # hide"
-},
-
-{
- "location": "generated/mnist_knet/#Training-without-Augmentation-1",
- "page": "MNIST: Knet.jl CNN",
- "title": "Training without Augmentation",
- "category": "section",
- "text": "In order to get an intuition for how useful augmentation can be, we need a sensible baseline to compare to. To that end, we will first train the network we just defined using only the (unaltered) 500 training examples.The package ValueHistories.jl will help us record the accuracy during the training process. We will use those logs later to visualize the differences between having augmentation or no augmentation.using ValueHistoriesTo keep things simple, we will not overly optimize our training function. Thus, we will be content with using a closure. Because both, the baseline and the augmented version, will share this \"inefficiency\", we should still get a decent enough picture of their performance differences.function train_baseline(; epochs = 500, batchsize = 100, lr = .03)\n w = weights()\n log = MVHistory()\n for epoch in 1:epochs\n for (batch_x_cpu, batch_y) in eachbatch((train_x ,train_y), batchsize)\n batch_x = KnetArray{Float32}(batch_x_cpu)\n g = costgrad(w, batch_x, batch_y)\n Knet.update!(w, g, lr = lr)\n end\n\n if (epoch % 5) == 0\n train = acc(w, train_x, train_y)\n test = acc(w, test_x, test_y)\n @trace log epoch train test\n msg = \"epoch \" * lpad(epoch,4) * \": train accuracy \" * rpad(round(train,3),5,\"0\") * \", test accuracy \" * rpad(round(test,3),5,\"0\")\n println(msg)\n end\n end\n log\nend\nnothing # hideAside from the accuracy, we will also keep an eye on the training time. In particular we would like to see if and how the addition of augmentation causes our training time to increase.train_baseline(epochs=1) # warm-up\nbaseline_log = @time train_baseline(epochs=200);\nnothing # hideAs we can see, the accuracy on the training set is around a 100%, while the accuracy on the test set peaks around 90%. For a mere 500 training examples, this isn\'t actually that bad of a result."
-},
-
-{
- "location": "generated/mnist_knet/#Integrating-Augmentor-1",
- "page": "MNIST: Knet.jl CNN",
- "title": "Integrating Augmentor",
- "category": "section",
- "text": "Now that we have a network architecture with a baseline to compare to, let us finally see what it takes to add Augmentor to our experiment. First, we need to include the package to our experiment.using AugmentorThe next step, and maybe the most human-hour consuming part of adding image augmentation to a prediction problem, is to design and select a sensible augmentation pipeline. Take a look at the elastic distortions tutorial for an example of how to do just that.For this example, we already choose a quite complicated but promising augmentation pipeline for you. This pipeline was designed to yield a large variation of effects as well as to showcase how even deep pipelines are quite efficient in terms of performance.pl = Reshape(28,28) |>\n PermuteDims(2,1) |>\n ShearX(-5:5) * ShearY(-5:5) |>\n Rotate(-15:15) |>\n CropSize(28,28) |>\n Zoom(0.9:0.1:1.2) |>\n CacheImage() |>\n ElasticDistortion(10) |>\n PermuteDims(2,1) |>\n Reshape(28,28,1)Most of the used operations are quite self explanatory, but there are some details about this pipeline worth pointing out explicitly.We use the operation PermuteDims to convert the horizontal-major MNIST image to a julia-native vertical-major image. The vertical-major image is then processed and converted back to a horizontal-major array. We mainly do this here to showcase the option, but it is also to keep consistent with how the data is usually used in the literature. Alternatively, one could just work with the MNIST data in a vertical-major format all the way through without any issue.As counter-intuitive as it sounds, the operation CacheImage right before ElasticDistortion is actually used to improve performance. If we were to omit it, then the whole pipeline would be applied in one single pass. In this case, applying distortions on top of affine transformations lazily is in fact less efficient than using a temporary variable.With the pipeline now defined, let us quickly peek at what kind of effects we can achieve with it. In particular, lets apply the pipeline multiple times to the first training image and look at what kind of results it produces.[MNIST.convert2image(reshape(augment(train_x[:,:,:,1], pl), (28, 28))) for i in 1:8, j in 1:2]\ntmp = vcat(hcat(ans[:,1]...), hcat(ans[:,2]...)) # hide\nsave(\"mnist_knet_aug.png\",repeat(tmp, inner=(4,4))) # hide\nnothing # hide(Image: augmented samples)As we can see, we can achieve a wide range of effects, from more subtle to more pronounced. The important part is that all examples are still clearly representative of the true label.Next, we have to adapt the function train_baseline to make use of our augmentation pipeline. To integrate Augmentor efficiently, there are three necessary changes we have to make.Preallocate a buffer with the same size and element type that each batch has.\nbatch_x_aug = zeros(Float32, 28, 28, 1, batchsize)Add a call to augmentbatch! in the inner loop of the batch iterator using our pipeline and buffer.\naugmentbatch!(batch_x_aug, batch_x_org, pl)Replace batch_x_org with batch_x_aug in the constructor of KnetArray.\nbatch_x = KnetArray{Float32}(batch_x_aug)Applying these changes to our train_baseline function will give us something similar to the following function. Note how all the other parts of the function remain exactly the same as before.function train_augmented(; epochs = 500, batchsize = 100, lr = .03)\n w = weights()\n log = MVHistory()\n batch_x_aug = zeros(Float32, size(train_x,1), size(train_x,2), 1, batchsize)\n for epoch in 1:epochs\n for (batch_x_cpu, batch_y) in eachbatch((train_x ,train_y), batchsize)\n augmentbatch!(CPUThreads(), batch_x_aug, batch_x_cpu, pl)\n batch_x = KnetArray{Float32}(batch_x_aug)\n g = costgrad(w, batch_x, batch_y)\n Knet.update!(w, g, lr = lr)\n end\n\n if (epoch % 5) == 0\n train = acc(w, train_x, train_y)\n test = acc(w, test_x, test_y)\n @trace log epoch train test\n msg = \"epoch \" * lpad(epoch,4) * \": train accuracy \" * rpad(round(train,3),5,\"0\") * \", test accuracy \" * rpad(round(test,3),5,\"0\")\n println(msg)\n end\n end\n log\nend\nnothing # hideYou may have noticed in the code above that we also pass a CPUThreads() as the first argument to augmentbatch!. This instructs Augmentor to process the images of the batch in parallel using multi-threading. For this to work properly you will need to set the environment variable JULIA_NUM_THREADS to the number of threads you wish to use. You can check how many threads are used with the function Threads.nthreads()@show Threads.nthreads();\nnothing # hideNow that all pieces are in place, let us train our network once more. We will use the same parameters except that now instead of the original training images we will be using randomly augmented images. This will cause every epoch to be different.train_augmented(epochs=1) # warm-up\naugmented_log = @time train_augmented(epochs=200);\nnothing # hideAs we can see, our network reaches far better results on our testset than our baseline network did. However, we can also see that the training took quite a bit longer than before. This difference generally decreases as the complexity of the utilized neural network increases. Yet another way to improve performance (aside from simplifying the augmentation pipeline) would be to increase the number of available threads."
-},
-
-{
- "location": "generated/mnist_knet/#Improving-Performance-1",
- "page": "MNIST: Knet.jl CNN",
- "title": "Improving Performance",
- "category": "section",
- "text": "One of the most effective ways to make the most out of the available resources is to augment the next (couple) mini-batch while the current minibatch is being processed on the GPU. We can do this via julia\'s build in parallel computing capabilitiesFirst we need a worker process that will be responsible for augmenting our dataset each epoch. This worker also needs access to a couple of our packages# addprocs(1)\n# @everywhere using Augmentor, MLDataUtilsNext, we replace the inner eachbatch loop with a more complicated version using a RemoteChannel to exchange and queue the augmented data.function async_train_augmented(; epochs = 500, batchsize = 100, lr = .03)\n w = weights()\n log = MVHistory()\n for epoch in 1:epochs\n @sync begin\n local_ch = Channel{Tuple}(4) # prepare up to 4 minibatches in adavnce\n remote_ch = RemoteChannel(()->local_ch)\n @spawn begin\n # This block is executed on the worker process\n batch_x_aug = zeros(Float32, size(train_x,1), size(train_x,2), 1, batchsize)\n for (batch_x_cpu, batch_y) in eachbatch((train_x ,train_y), batchsize)\n # we are still using multithreading\n augmentbatch!(CPUThreads(), batch_x_aug, batch_x_cpu, pl)\n put!(remote_ch, (batch_x_aug, batch_y))\n end\n close(remote_ch)\n end\n @async begin\n # This block is executed on the main process\n for (batch_x_aug, batch_y) in local_ch\n batch_x = KnetArray{Float32}(batch_x_aug)\n g = costgrad(w, batch_x, batch_y)\n Knet.update!(w, g, lr = lr)\n end\n end\n end\n\n if (epoch % 5) == 0\n train = acc(w, train_x, train_y)\n test = acc(w, test_x, test_y)\n @trace log epoch train test\n msg = \"epoch \" * lpad(epoch,4) * \": train accuracy \" * rpad(round(train,3),5,\"0\") * \", test accuracy \" * rpad(round(test,3),5,\"0\")\n println(msg)\n end\n end\n log\nend\nnothing # hideNote that for this toy example the overhead of this approach is greater than the benefit."
-},
-
-{
- "location": "generated/mnist_knet/#Visualizing-the-Results-1",
- "page": "MNIST: Knet.jl CNN",
- "title": "Visualizing the Results",
- "category": "section",
- "text": "Before we end this tutorial, let us make use the Plots.jl package to visualize and discuss the recorded training curves. We will plot the accuracy curves of both networks side by side in order to get a good feeling about their differences.using Plots\npyplot()\nnothing # hidedefault(bg_outside=colorant\"#FFFFFF\") # hide\nplt = plot(\n plot(baseline_log, title=\"Baseline\", ylim=(.5,1)),\n plot(augmented_log, title=\"Augmented\", ylim=(.5,1)),\n size = (900, 400),\n xlab = \"Epoch\",\n ylab = \"Accuracy\",\n markersize = 1\n)\npng(plt, \"mnist_knet_curves.png\") # hide\nnothing # hide(Image: learning curves)Note how the accuracy on the (unaltered) training set increases faster for the baseline network than for the augmented one. This is to be expected, since our augmented network doesn\'t actually use the unaltered images for training, and thus has not actually seen them. Given this information, it is worth pointing out explicitly how the accuracy on training set is still greater than on the test set for the augmented network as well. This is also not a surprise, given that the augmented images are likely more similar to their original ones than to the test images.For the baseline network, the accuracy on the test set plateaus quite quickly (around 90%). For the augmented network on the other hand, it the accuracy keeps increasing for quite a while longer."
-},
-
-{
- "location": "generated/mnist_knet/#References-1",
- "page": "MNIST: Knet.jl CNN",
- "title": "References",
- "category": "section",
- "text": "[MNIST1998]: LeCun, Yan, Corinna Cortes, Christopher J.C. Burges. \"The MNIST database of handwritten digits\" Website. 1998."
-},
-
-{
- "location": "indices/#",
- "page": "Indices",
- "title": "Indices",
- "category": "page",
- "text": ""
-},
-
-{
- "location": "indices/#Functions-1",
- "page": "Indices",
- "title": "Functions",
- "category": "section",
- "text": "Order = [:function]"
-},
-
-{
- "location": "indices/#Types-1",
- "page": "Indices",
- "title": "Types",
- "category": "section",
- "text": "Order = [:type]"
-},
-
-{
- "location": "LICENSE/#",
- "page": "LICENSE",
- "title": "LICENSE",
- "category": "page",
- "text": ""
-},
-
-{
- "location": "LICENSE/#LICENSE-1",
- "page": "LICENSE",
- "title": "LICENSE",
- "category": "section",
- "text": "Markdown.parse_file(joinpath(@__DIR__, \"../LICENSE.md\"))"
-},
-
-]}