[bug] on-policy rollout collects current "dones" instead of last "dones" #105
Comments
|
Thank you a ton for this! I will implement and test this out on Atari envs, which have also reached lower performance compared to stable-baselines results. My apologies that you had to debug for such a nasty mistake! I will double-check if the sb3 code is handling dones as in sb. If I include this in an update, would it be because that I include your name in the contributors? Debugging this error out counts as a good contribution, in my eyes :) |
|
Sure, that would be appreciated. Thanks for the quick response, hope it helps on the Atari envs too! |
|
Could you confirm that this is type of fix you implemented? It initializes and stores the --- a/stable_baselines3/common/base_class.py
+++ b/stable_baselines3/common/base_class.py
@@ -117,6 +117,7 @@ class BaseAlgorithm(ABC):
self.tensorboard_log = tensorboard_log
self.lr_schedule = None # type: Optional[Callable]
self._last_obs = None # type: Optional[np.ndarray]
+ self._last_dones = None # type: Optional[np.ndarray]
# When using VecNormalize:
self._last_original_obs = None # type: Optional[np.ndarray]
self._episode_num = 0
@@ -444,6 +445,7 @@ class BaseAlgorithm(ABC):
# Avoid resetting the environment when calling ``.learn()`` consecutive times
if reset_num_timesteps or self._last_obs is None:
self._last_obs = self.env.reset()
+ self._last_dones = np.zeros((self._last_obs.shape[0],), dtype=np.bool)
# Retrieve unnormalized observation for saving into the buffer
if self._vec_normalize_env is not None:
self._last_original_obs = self._vec_normalize_env.get_original_obs()
diff --git a/stable_baselines3/common/on_policy_algorithm.py b/stable_baselines3/common/on_policy_algorithm.py
index 2937b77..52d8573 100644
--- a/stable_baselines3/common/on_policy_algorithm.py
+++ b/stable_baselines3/common/on_policy_algorithm.py
@@ -153,8 +153,9 @@ class OnPolicyAlgorithm(BaseAlgorithm):
if isinstance(self.action_space, gym.spaces.Discrete):
# Reshape in case of discrete action
actions = actions.reshape(-1, 1)
- rollout_buffer.add(self._last_obs, actions, rewards, dones, values, log_probs)
+ rollout_buffer.add(self._last_obs, actions, rewards, self._last_dones, values, log_probs)
self._last_obs = new_obs
+ self._last_dones = dones
rollout_buffer.compute_returns_and_advantage(values, dones=dones) |
|
@AndyShih12 thank you for pointing out that issue.
Could you tell us from about your custom env and the hyperparameters you used for PPO?
@Miffyli I was about to ask you to push a draft PR. I think we can fix directly the GAE computation without having to add extra variable, no? |
|
I concur this effect is more pronounced in short episodes or reward-at-terminal games, but just to make sure I tested it on Atari.
Ok, I will begin a draft on matching PPO/A2C discrete-policy performance with stable-baselines (with Atari games). We can fix it that way in GAE as well, but for that I want to make sure other code does not expect the sb2-style-dones. |
|
@Miffyli Yes your patch is the same as what I did locally. @araffin Indeed, my environment was sparse rewards and (very) short episodes. The reward only came at the last timestep of each episode, the previous code didn't receive any signal at all. Sorry to hear that it didn't close the gap for Atari games. |
|
@araffin and @Miffyli To me it seems more like an issue with It also seems to differ from how collecting samples for off-policy agents works, seen here There's also the case mentioned in this issue, where the I have created a test python file, zipped here, that highlights my concern. (Be wary of the ZeroDivisionError lol, just rerun a couple of times) The environment works as follows. Max episode time is 3 and observations are singular and represent the timestep in the environment. A There is, however, a discrepancy between how the actual TLDR:
|
|
@ryankirkpatrick97 Hey! Original motivation was to copy stable-baselines (just to get things working the same way), yes. I think that too stems from OpenAI's baselines. The discrepancy stems from the bit different ideologies of off/on-policy buffers:
Semantically, As for doing such modifications: we might have to leave things as is, because modifying this might break others' code very silently (e.g. they read dones from buffer, expect them to store in current format but suddenly it changes). PS: I was writing this at 3am so I might be talking out of my butt here. Feel free to correct and bash me for that :'). (*) With VecEnvs, |
|
@Miffyli thanks for the quick and detailed response! But hahah, hopefully you get a good nights rest! Apologies, but I seem to have some misconceptions on the ideologies between off/on-policy buffers. I would appreciate if you could help clear them up. I have read through the VecEnv code enough to understand what you mean about never returning a terminal state, and instead resetting when done is True. However, I don't understand what you mean when you say that for replay buffers, you store When a rollout buffer stores If you look at my code example, the same 9 observations are traversed for both DQN and PPO, but the resulting dones arrays are different. From what you explained earlier, I understand that the values are shifted, because in the current codebase, they are stored with their accompanied next_state returned from I believe the semantic meaning should switch to " I feel that in the long run, the discrepancy between the done arrays will become a greater source of error and confusion, than if the current code base changes and subtly breaks other's code. Again, I could totally have a misconception here, and I apologize, I wrote this a little too sassy and opinionated than necessary haha. Hopefully I explained my thoughts well. Any direction and clarification is much appreciated, and I'm looking forward to your response and future discussion. For completeness, here is pseudo-code of the current implementation for Rollout Buffers: |
|
Gah. I needed way too much coffee for this one ^^.
You are right, semantically they mean different things. This is because ideologies are bit different in on-policy (e.g. A2C, PPO) and off-policy (e.g. SAC, DQN) worlds:
Sounds like one clarifying thing would be to call I am sorry if I skipped some parts of your argument. I spent wayyyy to long pondering on this again, and do point me to arguments I might have skipped (I have to dash now). These things are kind of fun to ponder on, so I will give it another try tomorrow :') Edit: If you feel like discussing these topics more (and about the semantic meanings of data stored in different libraries) etc, RL Discord has bunch of people who I bet would be up for such discussion! |
|
What about renaming dones in on-policy, EDIT: @Miffyli i would need to check the code more carefuly, this idea came after reading your comment |
|
@Miffyli, thanks for taking the time to provide clarification! I think just personally I have spent more time reading code than I have spent looking through the literature, and that's where the confusion came from. Sounds like that simple rename might be the easiest way to go about altering things. Going to leave the big decisions up to you guys 😉 |
Took me a really long time to debug this, so hopefully this helps others out.
Describe the bug
The on-policy rollout collects last_obs, current reward, current dones. See here
In stable-baselines, the rollout collects last_obs, current reward, and last dones. See here
This messes up the returns and advantage calculations.
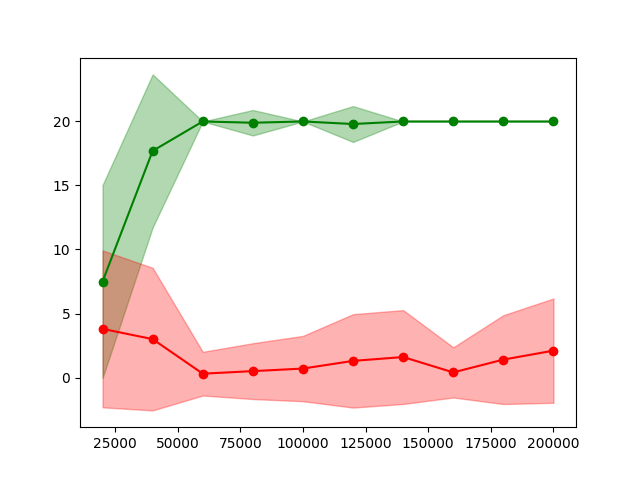
I fixed this locally, and PPO improved dramatically on my custom environment (red is before fix, green is after fix).
The text was updated successfully, but these errors were encountered: