| Title | Description | DatePublished | Categories | Tags | CatalogContent | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
Web Scrape with Selenium and Beautiful Soup |
A hands-on tutorial in web scraping featuring two popular libraries, Beautiful Soup and Selenium. |
2022-02-28 |
|
|
|
Prerequisites: Python, HTML, CSS
Versions: Selenium 3.141, Beautiful Soup 4.9.3, Python 3.8
The Internet is a wondrous resource, just about anything we might hope to find lives there. If we exercise some patience and a pioneering mentality, the opportunities are limitless. However, frequently what we're looking for isn't accessible in the neat little package we'd like.
It may often be the case that we find the information we want, but in many instances it will be arrayed across a number of pages and tables, impeding our access. In these circumstances, web scraping libraries can serve as the Australian cattle dog strategically drawing together the piecemeal information we're trying to corral into one pen.
In the coverage recapping the 2020 Tokyo Olympics, FiveThirtyEight published an article, detailing the incredible success of the American women and how their participation and achievements have evolved over the history of the games. The piece includes a pair of visualizations illustrating the percentage of medals won over time and the number of athletes participating by gender. All of the data for the article was sourced from a single site, Olympedia.org.
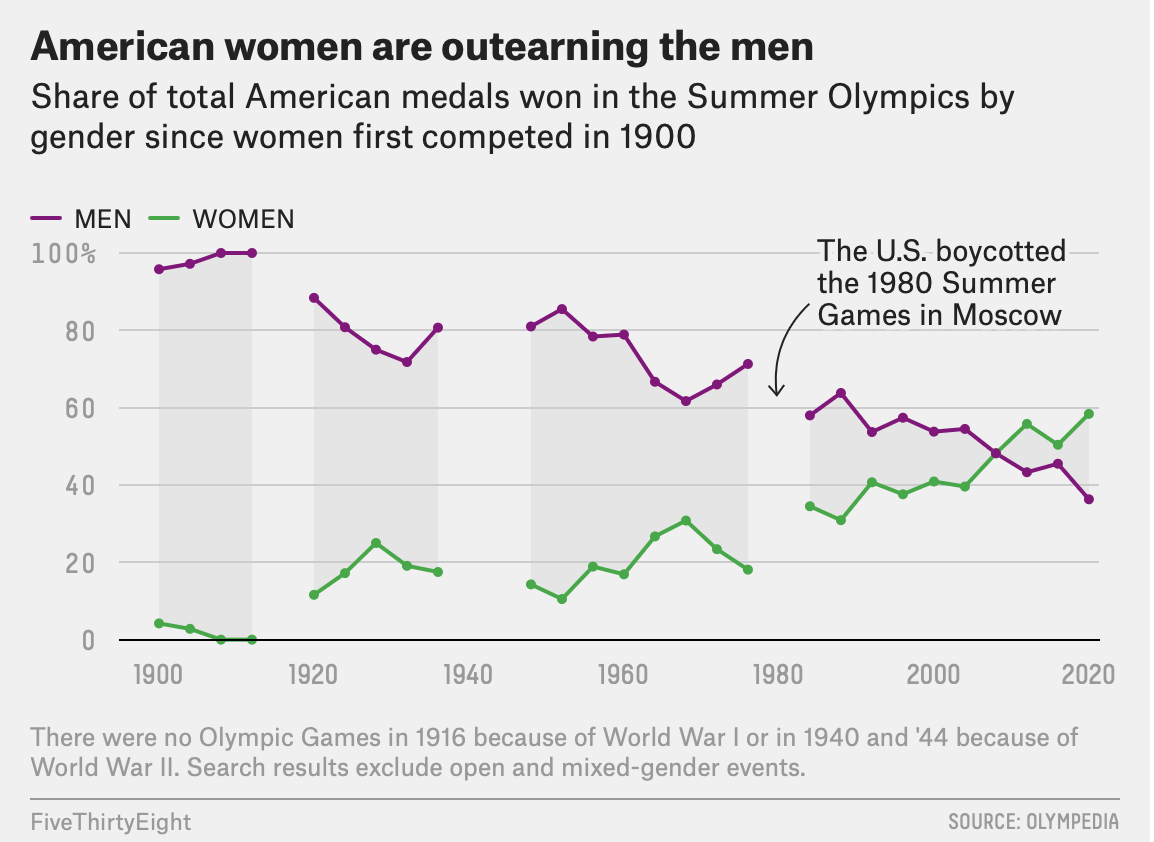 (Figure 1)
(Figure 1)
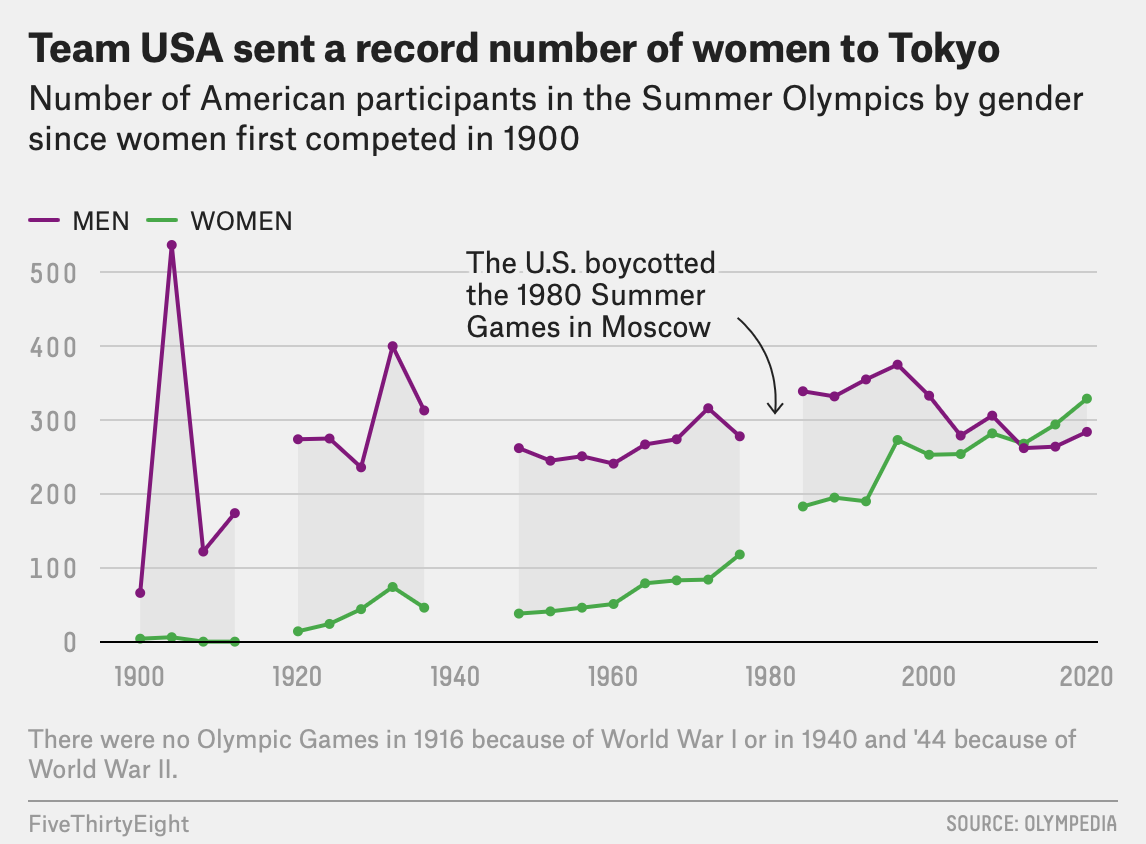 (Figure 2)
(Figure 2)
A cursory review of Olympedia reveals a comprehensive and curated view of statistics for the Olympic games. Unfortunately, all of the information is mediated through nested links and filters that reveal only narrow slices of the data. In order to recreate the FiveThirtyEight visualizations, or to create others based on that data, we must aggregate that data independently.
To meet this challenge we have a pair of tools, Selenium and Beautiful Soup, that in concert can automate the process of walking webpages and parsing HTML to cull our data into a single file. In this tutorial, we'll put together a Python script for automating our data collection, anchored by these two libraries. For the sake of brevity, the code here will be focused on the specifics of acquiring the data for figure one, similar techniques can be adapted to retrieve any other data we may wish to collect.
Our goal is to assemble data from the disparate tables of Olympedia into one concise CSV, housing all the stats we require and nothing more. In broad strokes we will need to:
- Identify the page(s) with the information we want and review the source code.
- Outline a path for navigating the pages and forms to access the data we’re targeting.
- Implement the Selenium methods to navigate the course we've chosen.
- Pass the content of each page to Beautiful Soup to parse.
- Export all the data we've collected with the
csvstandard Python library.
The Olympedia.org site has a fairly simple layout structured around a navigation bar at the top, as the main wayfinding element, with dropdowns for several categories such as "Athletes" and "Countries".
Under the "Statistics" dropdown we can select "Medals by Country", which leads us to a page with a table of medal counts by country for every Olympic games ever contested. Above the table are several dropdowns that we can use to filter the results (e.g. Olympic year, discipline, gender, etc).
By selecting the year of a given Olympics, and a gender, we can highlight the total medals won as well as the breakdown by medal type for that year. To collect the data required for our chart we must extract the values for team USA for every summer Olympics, by gender. In other words, we must select each (summer Olympic) year from the dropdown in turn to update the table with the medal information for that event, for both the men and women.
Selenium is fundamentally an automation library: it provides tools for interacting with webpages and their elements hands-free. The first step of our data collection script is to create a driver object, an instance of a browser that we can manipulate with Selenium methods.
We start with our import statements:
from selenium import webdriver
from selenium.webdriver import SafariNote: In this example, we use Safari but there are drivers available for other browsers, such as Firefox.
Next, we instantiate a driver object and assign the URL for the medals page:
driver = Safari()
driver.get('http://www.olympedia.org/statistics/medal/country')With these simple lines of code, we've launched a new Safari window, primed for automation.
Once we have our driver instantiated and pointed at our target, we must locate the elements and options necessary to update the table. The Selenium library has many tools for locating elements, circumstances may dictate a preferred path in some cases, but often there are several ways to achieve any objective. Here we've chosen to employ the .find_element_by_id() method, which allows us to identify an element by its "id" string.
We can examine the source code of the page to identify an "id", "class name" or any other feature by right-clicking the page in the browser window and selecting "inspect element".
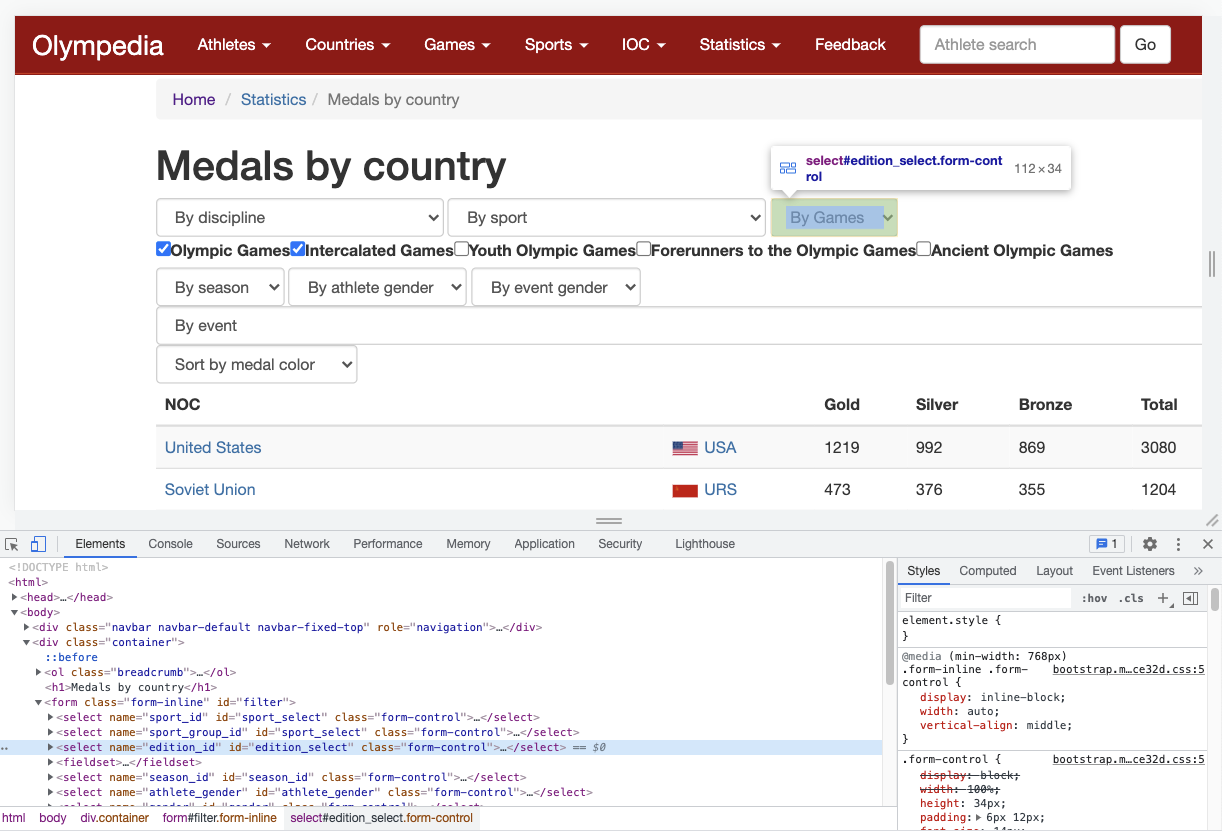
In this view, we can navigate through all the elements and identify the "id"s we need. The dropdowns for the Olympic year and gender are labeled edition_select and athlete_gender respectively. We assign those elements to variables with the following lines:
year_dd = driver.find_element_by_id('edition_select')
gender_dd = driver.find_element_by_id('athlete_gender')The next step, is to collect the options for those dropdowns, and we can do so with another locate method:
year_options = year_dd.find_elements_by_tag_name('option')
gender_options = gender_dd.find_elements_by_tag_name('option')So far we've identified the page and the form elements we need to update the tables we're targeting. We've set up our automated browser window and assigned variables to the elements in question. Now, we're in the transition phase and we're passing the baton to the Beautiful Soup library.
In the code below, we structure this handoff within a set of nested loops, cycling through men and women first, and on the interior loop, clicking through the years for every summer games. We execute each selection by simply looping each of our option lists and calling the .click() method on the option object to submit that form selection.
for gender in gender_options[1:]: # index 0 is omitted because it contains placeholder txt
gender.click()
for year in year_options[2:]: # skipping first two options to start with 1900
year.click()Once we've made our selections we can pass the page source to Beautiful Soup by calling the .page_source attribute on our driver object to parse the content of this iteration of the page:
the_soup = BeautifulSoup(driver.page_source, 'html.parser')With the page content in hand we must now locate the table elements of interest, so we can copy only those items to our output file. In order to isolate this content, we utilize two versions of Beautiful Soup's search methods. First, we can grab the start of the row containing team USA results with the .find() method. In this instance, we use a regular expression as an argument to ensure we get the correct object. Next, we can use another variation of a search method, .find_all_next(<tag><limit>) to extract the medal counts. This method allows us to pull all of the objects that follow any other, and an optional <limit> argument gives us the flexibility to specify how many elements (beyond our reference) we're interested in capturing.
head = the_soup.find(href=re.compile('USA'))
head.find_all_next('td', limit=5)At this point, we've completed the scaffolding for our browser automation and with the head.find_all_next('td', limit=5) object we have access to the medal counts for each medal type as well as the overall total for that year. Now, all that remains is to bundle our data and set up our export pipeline. First, we process the data we've sourced by calling the .string attribute on the elements we've captured and assigning the result to a variable, medals_lst. Then we supplement the medal values with the year and gender values and append the entire thing to a list.
try:
year_val = year.get_attribute('text')
head = the_soup.find(href=re.compile('USA'))
medal_values = head.find_all_next('td', limit=5)
val_lst = [x.string for x in medal_values[1:]] # the first index is the link with the country abbreviation and flag
except:
val_lst = ['0' for x in range(4)] # we address years team USA did not compete with this option
val_lst.append(gender_val)
val_lst.append(year_val)
usa_lst.append(val_lst)Having completed our data collection we can close out the browser with:
driver.quit()Finally, we can loop through all of our compiled data, usa_lst, and write it out to a CSV. A basic export can be modeled as follows:
output_f = open('output.csv', 'w', newline='')
output_writer = csv.writer(output_f)
for row in usa_lst:
output_writer.writerow(row)
output_f.close()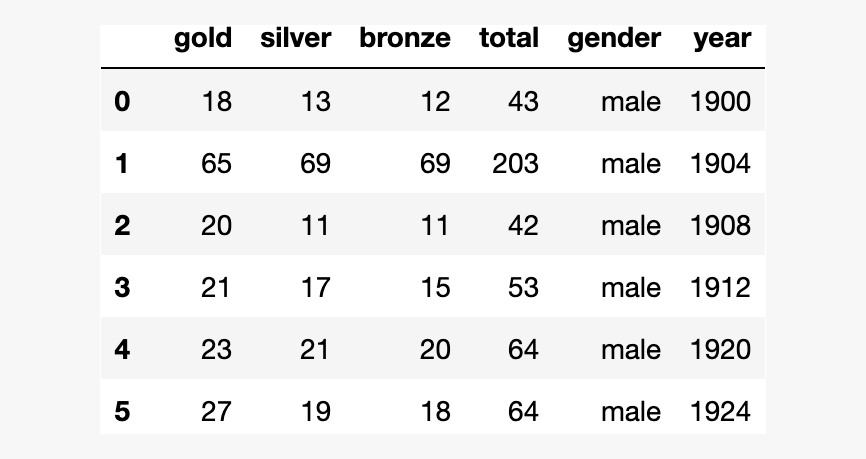
The automated actions generated with Selenium are subject to the same buffering and rendering complications that we experience in a browser first hand. Therefore, it's important to be aware of how the processing of our script may be impacted by this behavior. In this case we've added a buffer at two junctures (after each of our option selections) to ensure that the page source is current with the form information we've submitted. Without these allowances we can potentially end up capturing data that reflects an earlier state of the page.
We have chosen to use an explicit pause in our script with the time.sleep() call but we can also leverage Selenium’s wait class in these cases to set implicit and explicit pauses that can also be conditional for a range of page actions.
for gender in gender_options[1:]:
gender.click()
time.sleep(2)We've made it to the end! Now, with our tidy data in hand, we can import our CSV into our data application of choice (Excel, Power BI, Jupyter) and create a visualization. In the example below we've emulated the FiveThirtyEight figure with the Plotly Python library.

Web scraping can initially seem like an intimidating endeavor, but with a little patience and time, we can leverage powerful tools to achieve a lot. For more information on the libraries we used here please review the documentation at the links below.
- Solution code: olympic_data.py
- Selenium: https://selenium-python.readthedocs.io/index.html
- Beautiful Soup: https://www.crummy.com/software/BeautifulSoup/bs4/doc